The initial code merge of Nvidia Hopper features support. Please be
aware that the code merge is not finished yet and the trouble-shooting
is still ongoing. The new hardware features (GMMA, TMA, STMATRIX etc.)
and automatic warp-specialization are experimental for now and turned
off by default. It is recommended for a trial when version 3.0 is
released.
The work is contributed by:
ben-zhang-609, bealwang, donproc, qliu93, jsh20, allatit23, LyricZhao,
ivanyinwz, goostavz & yangjunpro
from Nvidia, in cooperation with:
ptillet, Jokeren, ThomasRaoux & zahimoud
from OpenAI.
Co-authored-by: Goostav Zhu <gzhu@nvidia.com>
* [Dot] [MFMA] Support FP16 output of MFMA dot
This PR adds cast of output tensor to requested data type.
* add tests
* fix test for FMA implementation
* loose fp16xfp16->fp16 tolerance
* enable FMA fallback for unsupported sizes of dot operation
* rework granularity check
* add constant modifier to granularity
* [WIP][FA OPTIMIZATION] Optimize chain dot
This commit optimizes chain dot operation by keeping
results of the first dot operation in registers.
* [FA OPTIMIZATION] Enable lowering pipeline for keeping result of chain dot in registers
* Move operand swapping in ttgir -> llir lowering phase
* Refactor emitMfmaOffsetForCTA function to be more readable
* Fix accidental change in 06-fused-attention.py
* Address review comments
* Fix rebase errors
0-bytes shared mem buffers don't materialize empty allocation buffers;
this could lead to unnecessary barriers.
note: reduceop code has become quite messy and will require some cleanup
Fix calculation of unique number of threads within a warp. We need to
consider the number of elements per thread in the calculation. Also
change the layout test to integer sum in order to catch bugs with unique
data as max reduction may hide those kind of problems.
This relax the restriction in the scan lowering to support layout where
we scan along a dimension which isn't the fastest moving one. This is
done by relaxing how we accesses elements during scanning and allow
elements to be strided.
Implement associative_scan in the front end and implement lowering to
LLVM for blocked layout where the scan happens on the fastest moving
dimension. This will later be generalized to support more layout.
Add a configurable parameter for the number of threads per warp for
other GPU. Like: Intel GPU.
Make it default to be 32 not change code logic on the CUDA/AMD GPU.
Note: The Intel GPU GenX ISA is explicit SIMD and can support variant
number of threads lane per HW execution unit.
* [MFMA] Activated Fused Attention Forward Pass
Patch contains following changes:
1) make_range operator now works with MFMA layout.
2) Reduce operation is forced to run in block layout:
inputs converted to block layouts, outputs returned to MFMA layout
* Use simple module walk instead of pattern rewritter.
* Remove pattern rewritter header.
* Enable basic reduce algorithm for MFMA layout
* Add TODO comment for fused attention backward pass
* Fix bug in fast codegen algorithm for reduce op
* Fix input type bug
* Increase block size to 128 since out of memory issue is not seen on MI210
* Fix block_size error
* Add mfma support in DecomposeDotOperand pattern.
Add a configurable parameter for the number of threads per warp for
other GPU. Like: Intel GPU.
Make it default to be 32 not change code logic on the CUDA/AMD GPU.
Note: The Intel GPU GenX ISA is explicit SIMD and can support variant
number of threads lane per HW execution unit.
* [MFMA] Implementation of MFMA DotOp pipeline
* Added MFMA test_dot unit tests
* Added missing ifdefs
* Update offline tests
* Removing duplicate parts
* fix build after rebase
* remove redundant stuff
* simplify MMAv3.cpp
* move reps function into operand attr description,
remove coreMatrixType type from layout conversion,
refactored type conversion
* remove duplication of mfma intruction shape computation
* move all MFMA instruction shape details into layout attribute
* fix formatting
* reenable matmul acceleration
* fix dot operator type conversion
* add offline test for dotop
* add missing ifdef wrappers
* run clang format on changes
* review and rebase fix
* add switch for MFMA instructions
* change check precision for float16 test
* disable redundant check for allowTF32
* - skip unsupported block size in matmul autotuner
- support transposed inputs of dot
* reenable matmul acceleration
* Add first part to FMA for dot operation on HW without MFMA support.
* Fix offline tests.
* Fix lit tests
* refactor mmav3 to mfma
* fix rebase issues
* fix detection of mfma support and wrong assert
* remove unnecessary macros
* Add documentation for MFMA layout.
* fix line size computation for B argument
* Fix getElemsPerThread() and getSizePerThread() functions for MFMA layout.
---------
Co-authored-by: Alexander Efimov <efimov.alexander@gmail.com>
Co-authored-by: dfukalov <1671137+dfukalov@users.noreply.github.com>
Co-authored-by: weihan13 <weihan13@amd.com>
Co-authored-by: Ognjen Plavsic <ognjen.plavsic@dxc.com>
Also try to switch APIs access to the new upstream APIs that separate
explicitly the access to "discardable" and "inherent" attributes (the
latter being stored in properties now).
Generic accessors like `getAttr()` `setAttr()` `setAttrs()` are much
more expensive and to be avoided.
Conflicts:
lib/Conversion/TritonGPUToLLVM/TritonGPUToLLVMPass.cpp
lib/Target/LLVMIR/LLVMIRTranslation.cpp
python/test/unit/language/assert_helper.py
python/triton/third_party/cuda/bin/ptxas
test/Conversion/tritongpu_to_llvm.mlir
It looks like you may be committing a merge.
If this is not correct, please remove the file
.git/MERGE_HEAD
and try again.
Re-enabled reduce test after fixing the %cst stride in the ttgir, and
modifying the sweep parameters to make sure the shape per CTA to be less
than or equal to the tensor shape.
# Introducing the `noinline` Parameter for Triton JIT Decorator
We're excited to introduce a new parameter, `noinline`, that can be
added to the `jit` decorator in Triton. This parameter allows developers
to specify that a particular Triton function should not be inlined into
its callers. In this post, we'll dive into the syntax, purpose, and
implementation details of this new feature.
## Syntax
To use the `noinline` parameter, simply add `noinline=True` to the `jit`
decorator for the function that you don't want to be inlined. Here's an
example:
```python
@triton.jit(noinline=True)
def device_fn(x, y, Z):
z = x + y
tl.store(Z, z)
def test_noinline():
@triton.jit
def kernel(X, Y, Z):
x = tl.load(X)
y = tl.load(Y)
device_fn(x, y, Z)
```
In this example, the `device_fn` function is decorated with
`@triton.jit(noinline=True)`, indicating that it should not be inlined
into its caller, `kernel`.
## Purpose
The `noinline` parameter serves several key purposes:
- Reducing code size: By preventing inlining, we can reduce the size of
the compiled code.
- Facilitating debugging: Keeping functions separate can make it easier
to debug the code.
- Avoiding common subexpression elimination (CSE) in certain cases: CSE
can sometimes be avoided by using the `noinline` parameter to reduce
register pressure.
- Enabling dynamic linking: This parameter makes it possible to
dynamically link Triton functions.
## Implementation
The implementation of the `noinline` parameter involves significant
changes to three analysis modules in Triton: *Allocation*, *Membar*, and
*AxisInfo*. Prior to this update, these modules assumed that all Triton
functions had been inlined into the root kernel function. With the
introduction of non-inlined functions, we've had to rework these
assumptions and make corresponding changes to the analyses.
### Call Graph and Limitations
<div style="text-align: center;">
<img
src="https://user-images.githubusercontent.com/2306281/234663904-12864247-3412-4405-987b-6991cdf053bb.png"
alt="figure 1" width="200" height="auto">
</div>
To address the changes, we build a call graph and perform all the
analyses on the call graph instead of a single function. The call graph
is constructed by traversing the call edges and storing them in an edge
map. Roots are extracted by checking nodes with no incoming edges.
The call graph has certain limitations:
- It does not support recursive function calls, although this could be
implemented in the future.
- It does not support dynamic function calls, where the function name is
unknown at compilation time.
### Allocation
<div style="text-align: center;">
<img
src="https://user-images.githubusercontent.com/2306281/234665110-bf6a2660-06fb-4648-85dc-16429439e72d.png"
alt="figure 2" width="400" height="auto">
</div>
In Triton, shared memory allocation is achieved through two operations:
`triton_gpu.convert_layout` and `triton_gpu.alloc_tensor`. The
`convert_layout` operation allocates an internal tensor, which we refer
to as a *scratch* buffer, while the `alloc_tensor` operation returns an
allocated tensor and is thus known as an *explicit* buffer.
To accommodate the introduction of function calls, we are introducing a
third type of buffer called a *virtual* buffer. Similar to scratch
buffers, virtual buffers are allocated internally within the scope of a
function call, and the buffers allocated by the called functions remain
invisible to subsequent operations in the calling function. However,
virtual buffers are distinct from scratch buffers in that the call
operation itself does not allocate memory—instead, it specifies the
total amount of memory required by all the child functions being called.
The actual allocation of buffers is performed by individual operations
within these child functions. For example, when invoking edge e1, no
memory is allocated, but the total amount of memory needed by function B
is reserved. Notably, the amount of shared memory used by function B
remains fixed across its call sites due to the consideration of dynamic
control flows within each function.
An additional challenge to address is the calculation of shared memory
offsets for functions within a call graph. While we can assume a shared
memory offset starting at 0 for a single root function, this is not the
case with a call graph, where we must determine each function's starting
offset based on the call path. Although each function has a fixed memory
consumption, the starting offset may vary. For instance, in Figure 2,
the starting offset of function C through edges e1->e2 differs from that
through edges e2->e4. To handle this, we accumulate the starting offset
at each call site and pass it as an argument to the called function.
Additionally, we amend both the function declaration and call sites by
appending an offset variable.
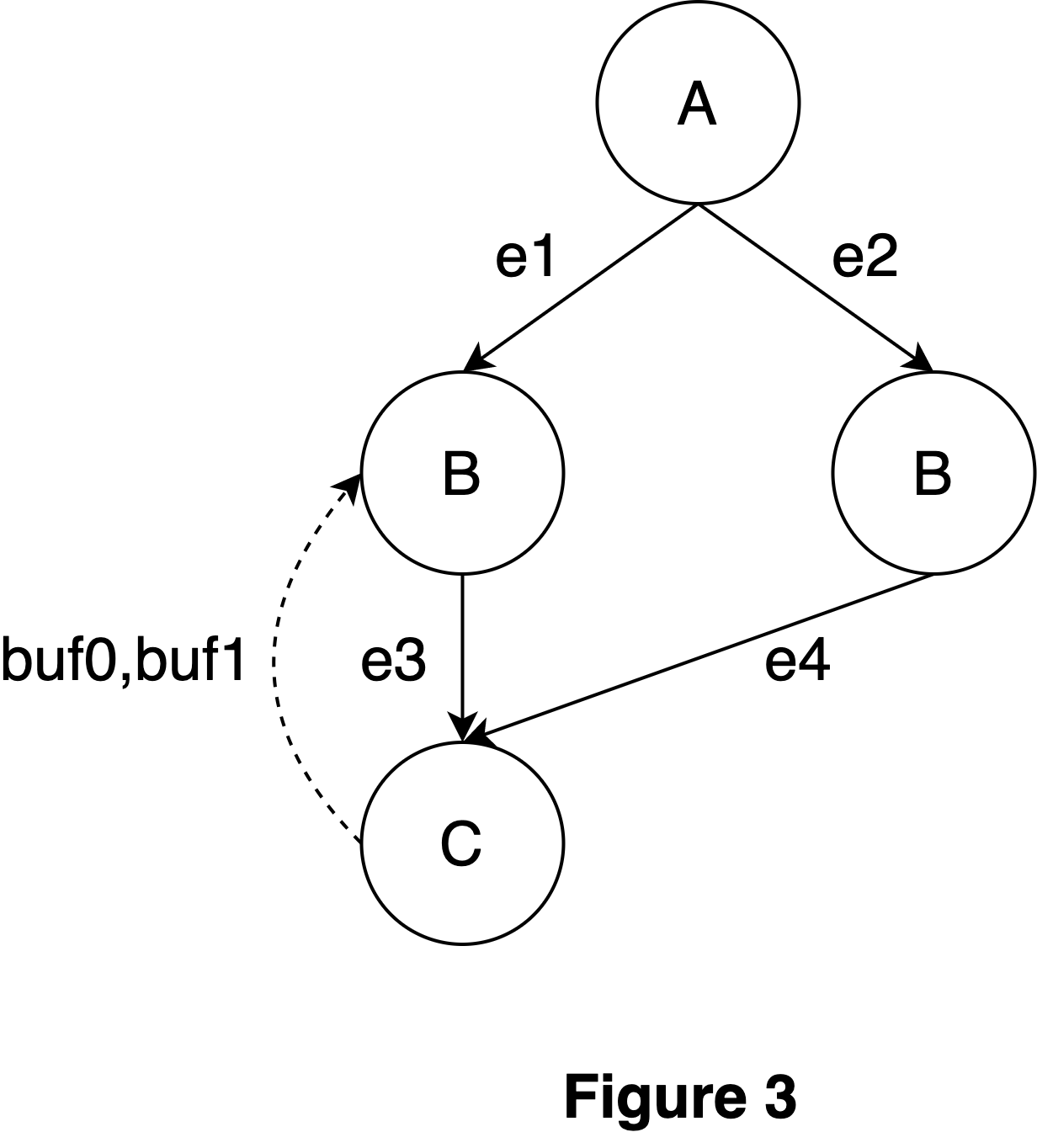
### Membar
<div style="text-align: center;">
<img
src="https://user-images.githubusercontent.com/2306281/234665157-844dd66f-5028-4ef3-bca2-4ca74b8f969d.png"
alt="figure 3" width="300" height="auto">
</div>
The membar pass is dependent on the allocation analysis. Once the offset
and size of each buffer are known, we conduct a post-order traversal of
the call graph and analyze each function on an individual basis. Unlike
previous analyses, we now return buffers that remain unsynchronized at
the end of functions, allowing the calling function to perform
synchronization in cases of overlap.
### AxisInfo
<div style="text-align: center;">
<img
src="https://user-images.githubusercontent.com/2306281/234665183-790a11ac-0ba1-47e1-98b1-e356220405a3.png"
alt="figure 4" width="400" height="auto">
</div>
The AxisInfo analysis operates differently from both membar and
allocation, as it traverses the call graph in topological order. This is
necessary because function arguments may contain axis information that
will be utilized by callee functions. As we do not implement
optimizations like function cloning, each function has a single code
base, and the axis information for an argument is determined as a
conservative result of all axis information passed by the calling
functions.
---------
Co-authored-by: Philippe Tillet <phil@openai.com>
MLIR current only supports a custom inlining interface per dialect, so
we cannot change the inlining decision of `func.func`.
https://discourse.llvm.org/t/avoid-inlining-some-functions-using-the-func-dialect/69830/3
Could revert it back once they've designed a better inliner interface.
Inlining attributes will be implemented in the next PR since this PR is
already huge.
This PR;
- Fixes syntax errors like `.type values: dict[str,
Callable[[list[Any]], Any]]` to `:type values: dict[str,
Callable[[list[Any]], Any]]`,
- Fixes typos,
- Fixes formatting like `k ++` to ` k++`,
- Increases consistency (e.g. by transforming the minority `cd dir/` to
the majority `cd dir`).
Before this PR, loops' induction variables' (IV) alignment info is lost.
For example:
```
for n in range(0, K, BLOCK):
x = base + n
^-- Triton doesn't know n is always a multiple of BLOCK
```
This PR fixes this.
---------
Co-authored-by: Philippe Tillet <phil@openai.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}