This PR disables following sub tests, because they are PTX specific:
- basic_async_wait
- convert_dot
- matmul_kernel_dot_operand_layout
- matmul884_kernel_dot_operand_layout
- matmul_tf32dot
Before the patch tt.load and tt.store generated incorrect bitcasts like
`%f = llvm.bitcast %i : i32 to f16` (source and destination bitcast'
types should have same bitwidth).
1, add explicit value cache in emitting indices calculation;
2, move the indices calculation emitting logics into
ConvertTritonGPUOpToLLVMPatternBase to avoid the redundant build cost by
templates. Refer to the discussion in this thread by @LyricZhao :
https://triton-lang.slack.com/archives/C042VBSQWNS/p1671336755922969
1, add explicit value cache in emitting indices calculation;
2, move the indices calculation emitting logics into
ConvertTritonGPUOpToLLVMPatternBase to avoid the redundant build cost by
templates. Refer to the discussion in this thread by @LyricZhao :
https://triton-lang.slack.com/archives/C042VBSQWNS/p1671336755922969
Most notably, this PR:
- changes the traits (and assembly format) of addptr so it can handle offsets that have arbitrary integer width.
- adds support for `cat`
1. Improve pipline's comment
2. Decompose insert_slice_async when load vector size is not supported
3. Add a test that could fail our gemm code
Copy my comments here:
There's a knob that may cause performance regression when decomposition
has been performed. We should remove this knob once we have thorough
analysis on async wait. Currently, we decompose `insert_slice_async`
into `load` and `insert_slice` without knowing which `async_wait` is
responsible for the `insert_slice_async`. To guarantee correctness, we
blindly set the `async_wait` to wait for all async ops if any `insert_slice_async` has been decomposed.
There are two options to improve this:
1. We can perform a dataflow analysis to find the `async_wait` that is
responsible for the `insert_slice_async` in the backend.
4. We can modify the pipeline to perform the decomposition before the
`async_wait` is inserted. However, it is also risky because we don't
know the correct vectorized shape yet in the pipeline pass. Making the
pipeline pass aware of the vectorization could introduce additional
dependencies on the AxisInfoAnalysis and the Coalesce analysis.
Cross operation barriers are taken care of by the Membar pass.
Explicit barriers are only required if there's any synchronization
necessary within each operation.
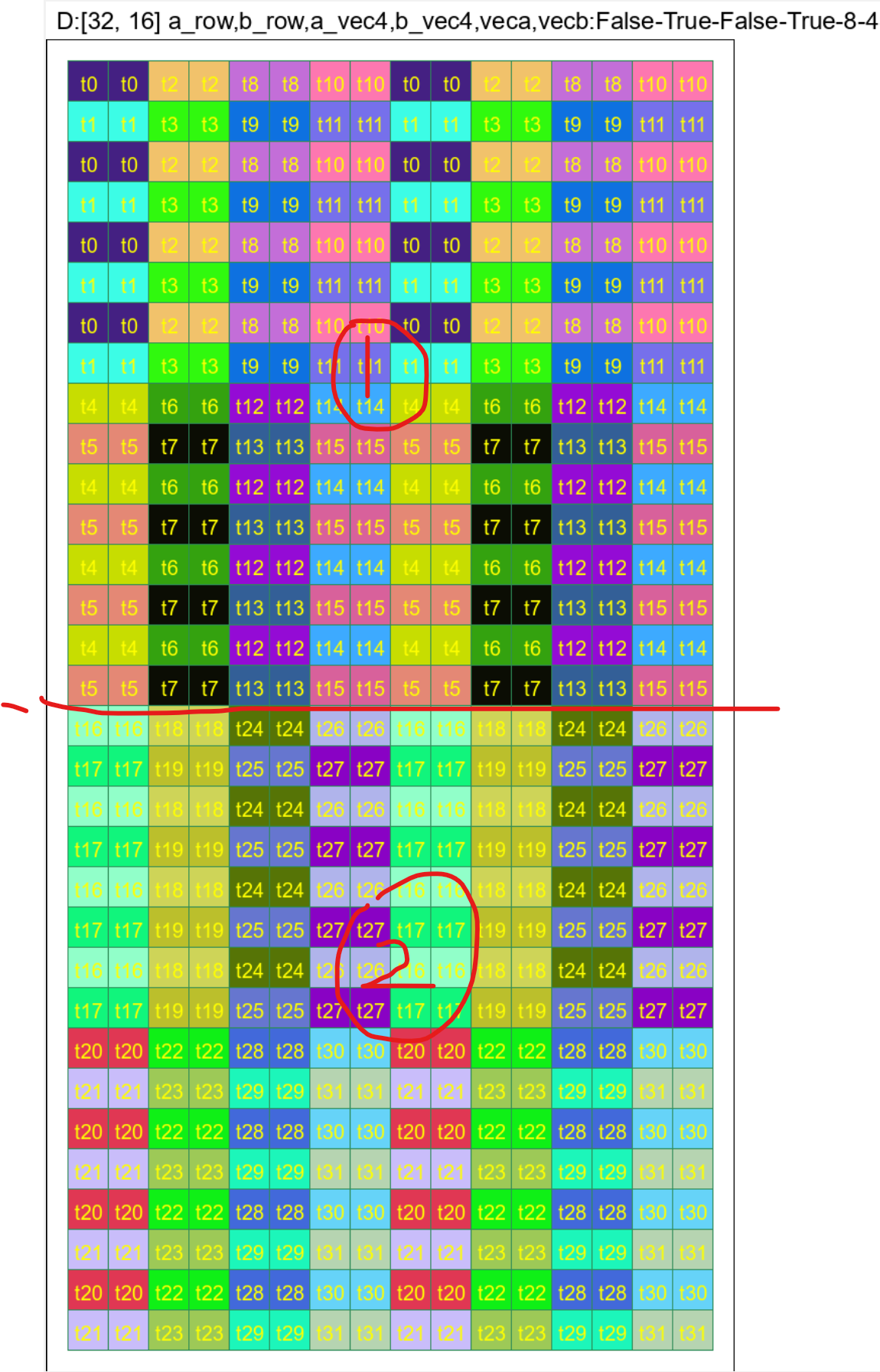
A (potential) problem by directly adopting `tensor.extract_slice`.
Long story short, `tensor.extract_slice` is not aware of swizzling.
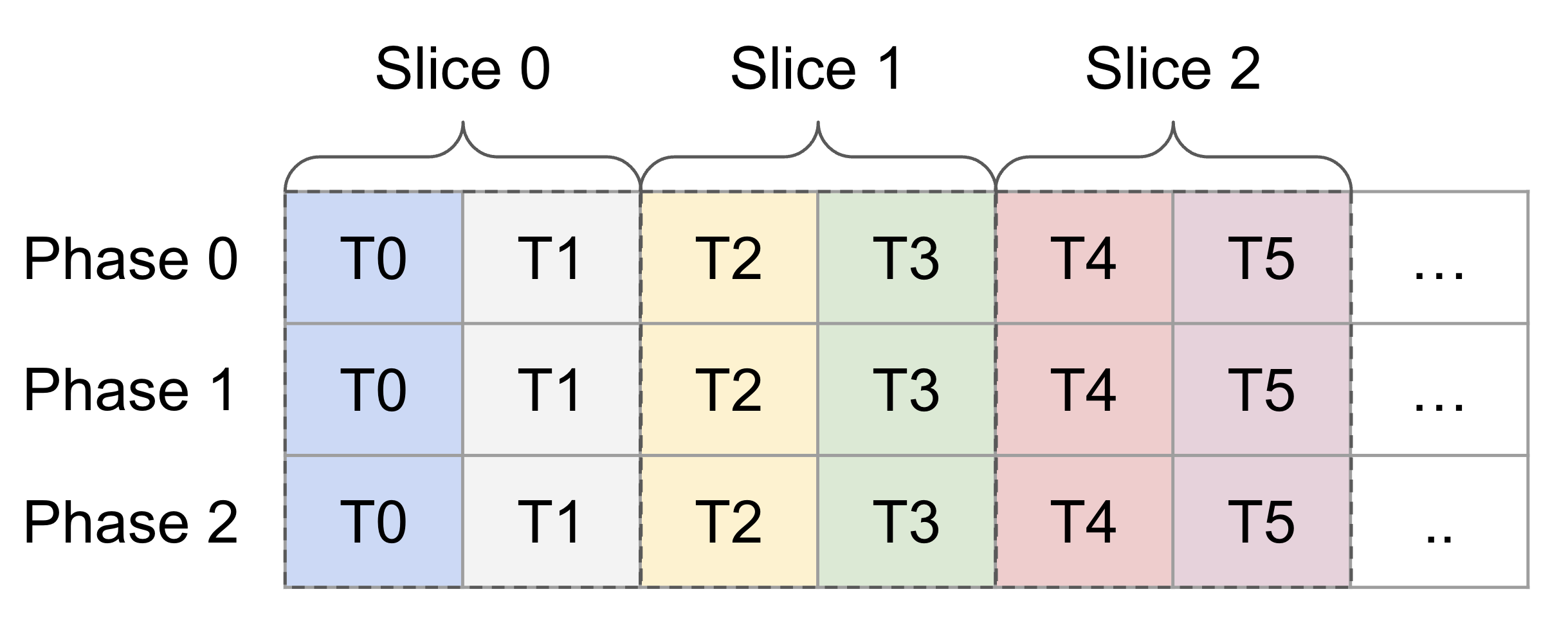
Consider the following shared memory tensor and its first three slices,
where each slice includes two tile (the loading unit of LDGSTS) of
elements. Currently, the tiles haven't been swizzled yet, so slicing
seems to work.
<img width="1219" alt="image"
src="https://user-images.githubusercontent.com/2306281/201833023-a7950705-2d50-4c0a-8527-7505261c3a3c.png">
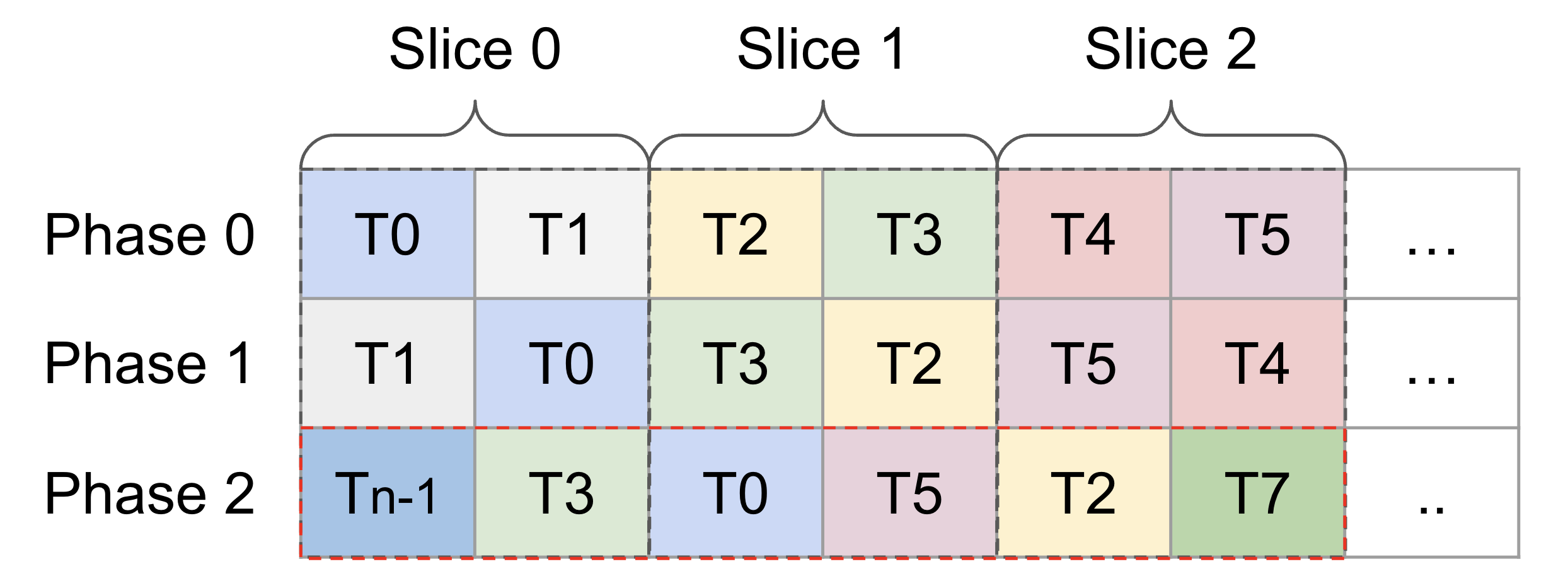
However, now consider the following figure, which is the layout after
applying swizzling on the first figure.
<img width="1244" alt="image"
src="https://user-images.githubusercontent.com/2306281/201834824-7daae360-f5bc-4e6b-a921-20be3f294b78.png">
Note that on phase 2, all tiles have been swizzled out of their
originally slices. This implies that if we use the tile index after
slicing, we can no longer locate the correct tiles. For example, T3 was
in slice 1 but got swapped to slice 0 after swizzling.
Here's a more detailed explanation. In the current `triton-mlir` branch,
we only compute the relative offset of each tile. So T3's index in Slice
1 is *1*, and it will be swizzled using *1* and *phase id*. Whereas the
correct index of T3 should be *3*, which is the relative offset to the
beginning of the shared memory tensor being swizzled, and T3 should be
swizzled using *3* and *phase id*.
This PR proposes a hacky solution for this problem. We restore the
"correct" offset of each tile by **assuming that slicing on a specific
dim only happens at most once on the output of insert_slice_async**. I
admit it's risky and fragile.
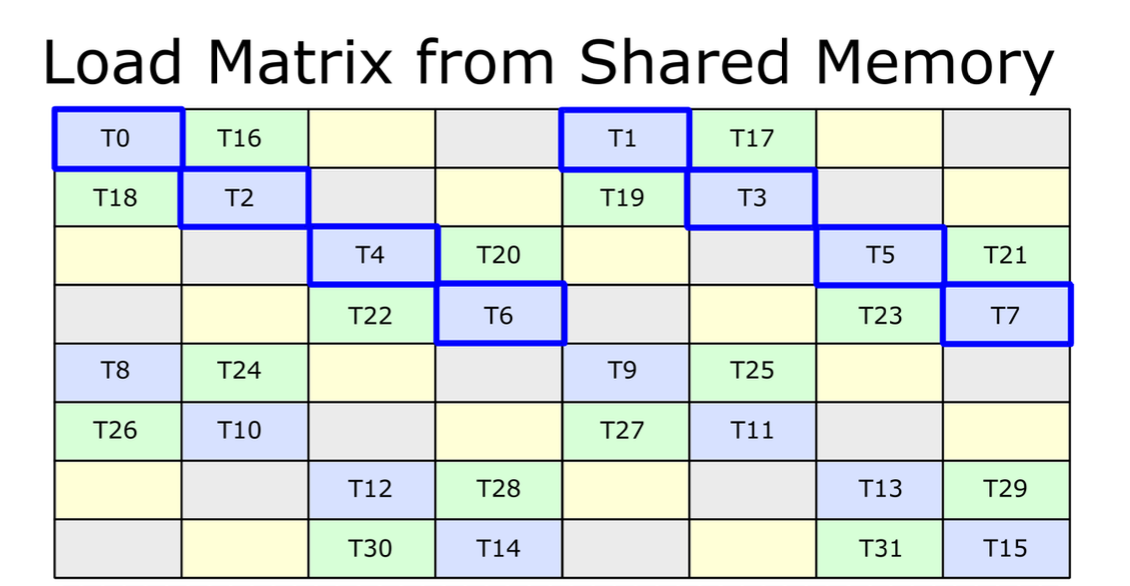
The other possible solution is adopting cutlass' swizzling logic that
limits the indices being swizzled in a "bounding box" that matches the
mma instruction executes. For example, in the following tensor layout,
each 4x4 submatrix is a minimum swizzling unit, and the entire tensor
represents the tensor layout of operand A in `mma.16816`.
<img width="565" alt="image"
src="https://user-images.githubusercontent.com/2306281/201836879-4ca7824b-530c-4a06-a3d5-1e74a2de1b42.png">
Co-authored-by: Phil Tillet <phil@openai.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}