# Introducing the `noinline` Parameter for Triton JIT Decorator
We're excited to introduce a new parameter, `noinline`, that can be
added to the `jit` decorator in Triton. This parameter allows developers
to specify that a particular Triton function should not be inlined into
its callers. In this post, we'll dive into the syntax, purpose, and
implementation details of this new feature.
## Syntax
To use the `noinline` parameter, simply add `noinline=True` to the `jit`
decorator for the function that you don't want to be inlined. Here's an
example:
```python
@triton.jit(noinline=True)
def device_fn(x, y, Z):
z = x + y
tl.store(Z, z)
def test_noinline():
@triton.jit
def kernel(X, Y, Z):
x = tl.load(X)
y = tl.load(Y)
device_fn(x, y, Z)
```
In this example, the `device_fn` function is decorated with
`@triton.jit(noinline=True)`, indicating that it should not be inlined
into its caller, `kernel`.
## Purpose
The `noinline` parameter serves several key purposes:
- Reducing code size: By preventing inlining, we can reduce the size of
the compiled code.
- Facilitating debugging: Keeping functions separate can make it easier
to debug the code.
- Avoiding common subexpression elimination (CSE) in certain cases: CSE
can sometimes be avoided by using the `noinline` parameter to reduce
register pressure.
- Enabling dynamic linking: This parameter makes it possible to
dynamically link Triton functions.
## Implementation
The implementation of the `noinline` parameter involves significant
changes to three analysis modules in Triton: *Allocation*, *Membar*, and
*AxisInfo*. Prior to this update, these modules assumed that all Triton
functions had been inlined into the root kernel function. With the
introduction of non-inlined functions, we've had to rework these
assumptions and make corresponding changes to the analyses.
### Call Graph and Limitations
<div style="text-align: center;">
<img
src="https://user-images.githubusercontent.com/2306281/234663904-12864247-3412-4405-987b-6991cdf053bb.png"
alt="figure 1" width="200" height="auto">
</div>
To address the changes, we build a call graph and perform all the
analyses on the call graph instead of a single function. The call graph
is constructed by traversing the call edges and storing them in an edge
map. Roots are extracted by checking nodes with no incoming edges.
The call graph has certain limitations:
- It does not support recursive function calls, although this could be
implemented in the future.
- It does not support dynamic function calls, where the function name is
unknown at compilation time.
### Allocation
<div style="text-align: center;">
<img
src="https://user-images.githubusercontent.com/2306281/234665110-bf6a2660-06fb-4648-85dc-16429439e72d.png"
alt="figure 2" width="400" height="auto">
</div>
In Triton, shared memory allocation is achieved through two operations:
`triton_gpu.convert_layout` and `triton_gpu.alloc_tensor`. The
`convert_layout` operation allocates an internal tensor, which we refer
to as a *scratch* buffer, while the `alloc_tensor` operation returns an
allocated tensor and is thus known as an *explicit* buffer.
To accommodate the introduction of function calls, we are introducing a
third type of buffer called a *virtual* buffer. Similar to scratch
buffers, virtual buffers are allocated internally within the scope of a
function call, and the buffers allocated by the called functions remain
invisible to subsequent operations in the calling function. However,
virtual buffers are distinct from scratch buffers in that the call
operation itself does not allocate memory—instead, it specifies the
total amount of memory required by all the child functions being called.
The actual allocation of buffers is performed by individual operations
within these child functions. For example, when invoking edge e1, no
memory is allocated, but the total amount of memory needed by function B
is reserved. Notably, the amount of shared memory used by function B
remains fixed across its call sites due to the consideration of dynamic
control flows within each function.
An additional challenge to address is the calculation of shared memory
offsets for functions within a call graph. While we can assume a shared
memory offset starting at 0 for a single root function, this is not the
case with a call graph, where we must determine each function's starting
offset based on the call path. Although each function has a fixed memory
consumption, the starting offset may vary. For instance, in Figure 2,
the starting offset of function C through edges e1->e2 differs from that
through edges e2->e4. To handle this, we accumulate the starting offset
at each call site and pass it as an argument to the called function.
Additionally, we amend both the function declaration and call sites by
appending an offset variable.
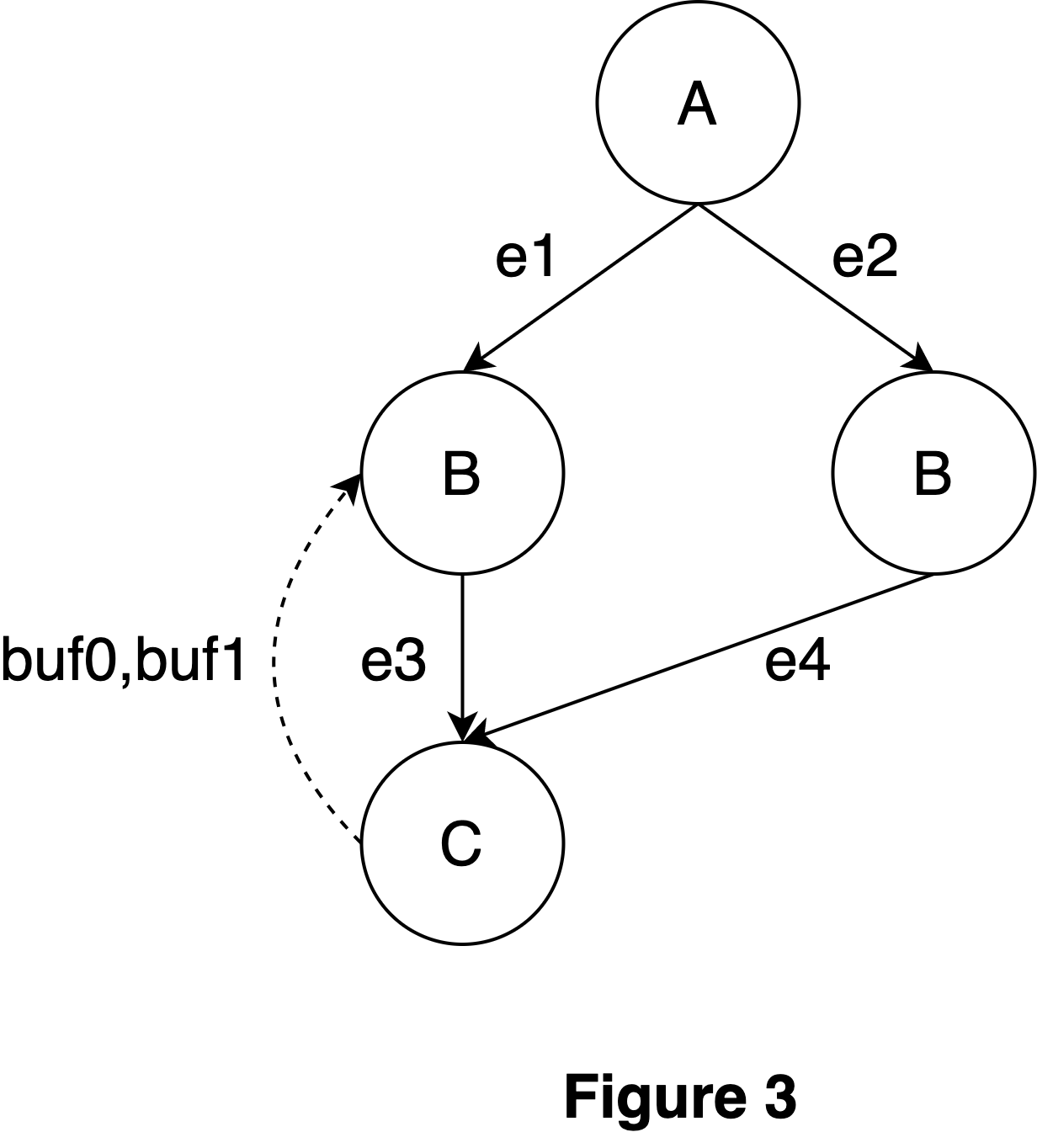
### Membar
<div style="text-align: center;">
<img
src="https://user-images.githubusercontent.com/2306281/234665157-844dd66f-5028-4ef3-bca2-4ca74b8f969d.png"
alt="figure 3" width="300" height="auto">
</div>
The membar pass is dependent on the allocation analysis. Once the offset
and size of each buffer are known, we conduct a post-order traversal of
the call graph and analyze each function on an individual basis. Unlike
previous analyses, we now return buffers that remain unsynchronized at
the end of functions, allowing the calling function to perform
synchronization in cases of overlap.
### AxisInfo
<div style="text-align: center;">
<img
src="https://user-images.githubusercontent.com/2306281/234665183-790a11ac-0ba1-47e1-98b1-e356220405a3.png"
alt="figure 4" width="400" height="auto">
</div>
The AxisInfo analysis operates differently from both membar and
allocation, as it traverses the call graph in topological order. This is
necessary because function arguments may contain axis information that
will be utilized by callee functions. As we do not implement
optimizations like function cloning, each function has a single code
base, and the axis information for an argument is determined as a
conservative result of all axis information passed by the calling
functions.
---------
Co-authored-by: Philippe Tillet <phil@openai.com>
MLIR current only supports a custom inlining interface per dialect, so
we cannot change the inlining decision of `func.func`.
https://discourse.llvm.org/t/avoid-inlining-some-functions-using-the-func-dialect/69830/3
Could revert it back once they've designed a better inliner interface.
Inlining attributes will be implemented in the next PR since this PR is
already huge.
This PR introduces a new semantics: **block pointer**, which makes users
easier & faster to load a block from a parent tensor.
Below is a detailed API change by an example:
```
# Make a block pointer, which points to a block in the parent shape
# `base`: the parent tensor
# `shape`: the shape of the parent tensor
# `strides`: the strides of the parent tensor
# `offsets`: the offsets of the block in the parent tensor
# `order`: the order of the data arrangement in memory
# Below is an example loading a 2D column-major matrix
block_ptr = tl.make_block_ptr(base=ptr, shape=(M, N), strides=(stride_m, stride_n), offsets=(0, 0), block_shape=(BLOCK_M, BLOCK_N), order=(1, 0))
# Advance the offsets; note that the striding information is already saved in `block_ptr`
# `base`: the block pointer to be advanced
# `offsets`: the offsets for each dimension
block_ptr = tl.advance(base=block_ptr, offsets=(BLOCK_M, -BLOCK_N))
block_ptr = tl.advance(base=block_ptr, offsets=(-BLOCK_M, BLOCK_N))
# Load from a block pointer, the output type is the dereferenced type of `block_ptr`, e.g. ptr<tensor<32x32xf32>> -> tensor<32x32xf32>
# `ptr`: the block pointer to be loaded
# `boundary_check`: a tuple of dimensions to check the boundary
# `padding`: padding strategy for elements out of bound
val = tl.load(ptr=block_ptr, boundary_check=(0, 1), padding="zero")
# Store by a block pointer, in which the pointer and the value tensor should have the same shape
# `ptr`: the block pointer to be stored
# `boundary_check`: a tuple of dimensions to check the boundary (no-write if out of bound)
tl.store(ptr=block_ptr, value=val, boundary_check=(0, 1))
```
---------
Co-authored-by: Philippe Tillet <phil@openai.com>
https://github.com/openai/triton/issues/1328
Match the convert_layout operation in SimplifyReduceCvt
(convert_layout->reduce). This way we don't miss higher priority rewrite
patterns like RematerializeBackward and SimplifyConversion. We also need
to set SimplifyConversion's benefit = 4, RematerializeBackward's benefit
= 3, and RematerializeForward's benefit = 2.
Differentiate between immediate and non-immediate block arguments.
If we have a load that immediately depends on a block argument in the
current iteration, it is an immediate dependency. Otherwise, it is a
non-immediate dependency, which means the load depends on a block
argument in the previous iterations.
For example:
```
scf.for (%arg0, %arg1, %arg2) {
%0 = load %arg0 <--- immediate dep, this address is initialized at numStages-2
%1 = load %arg1
%2 = add %1, %arg2
%3 = load %2 <--- non-immediate dep, %arg1 must be an update-to-date value
}
```
The above code pattern is commonly seen in cases where we have indirect
memory accesses using a lookup table, such as PyTorch's `bsr_dense_bmm`.
This PR improves `bsr_dense_bmm` for about ~20% on the unit test cases.
This PR;
- Fixes syntax errors like `.type values: dict[str,
Callable[[list[Any]], Any]]` to `:type values: dict[str,
Callable[[list[Any]], Any]]`,
- Fixes typos,
- Fixes formatting like `k ++` to ` k++`,
- Increases consistency (e.g. by transforming the minority `cd dir/` to
the majority `cd dir`).
- Significant simplification of the optimizer pipeline. Right mma
version is now set directly after the coalescing pass. DotOperand layout
no longer hold a state to `isRow` argument, and instead query it from
their parent
- Moved a bunch of things from TritonGPUToLLVM/DotOpHelpers to
TritonGPUAttrDefs. All MMAv1 state is now queried from attributes.
- logic for getELemsPerThread is no longer duplicated in TypeConverter
* Cleaned up pipeline pass. Now works when there are element-wise ops
between the load and the dot
* Made `splat` compatible with varibales that have DotOperandLayout
* Moves rematerialization utils to separate Transforms/Utility.cpp file.
* Frontend:
- `int` kernel arguments are always signed
- Loop induction variable is now determine by integer promotion on
lb/ub/step
* Optimizer:
- Added new ExtractSliceOp that enforces 32-bit offsets
* Backend:
- Use 64-bit indices when lowering functions and control flow
- Removed `idx_val` macro and replaced it with `i32_val`
- Cleaned up comments
- Added new ArithToIndex pass to make sure operations on indices are
done with the `index` dialect, that gets converted to LLVM separately
using a 64-bit target
This PR disables following sub tests, because they are PTX specific:
- basic_async_wait
- convert_dot
- matmul_kernel_dot_operand_layout
- matmul884_kernel_dot_operand_layout
- matmul_tf32dot
{kind=link}
{kind=link}
{kind=link}
{kind=link}