`bool` is a subclass of `int`, so `isinstance(bool_var, int) == True`,
and a `bool` constant will be converted to an `int` constant.
In triton specifically, if a bool var is treated as an integer, it
prevents us using the `logical_and` operator which requires both
operands have the same bit length.
> Cannot bitcast data-type of size 32 to data-type of size 1
By differentiating int and bool, it allows us to make the syntax more
close to native python. We can now use `if bool_var and condition` to
check the truthiness, and `if bool_var is True` to check identity.
This depends on a [pending LLVM
release](https://github.com/ptillet/triton-llvm-releases/pull/10).
* Implement setCalleeFromCallable in CallOp.
* Cast type to ShapedType for various getters.
* Improve TritonDialect::materializeConstant due to breaking change in
constructor of arith::ConstantOp.
* Add OpaqueProperties argument in inferReturnTypes.
Co-authored-by: Philippe Tillet <phil@openai.com>
Triton runtime currently relies on KeyError to check whether a kernel
has been compiled. This results in somewhat confusing backtraces when
running the kernel crashes, as the stack traces includes not only the
actual crash, but also the stack trace for the original KeyError which
was caught.
```
at 10:18:def val_multiplier_noinline(val, i):
return val * i
^
Function val_multiplier_noinline is marked noinline, but was called with non-scalar argument val:fp32[constexpr[128]]
```
Following up on #1603, I am adding a new file meant to contain
functional regression tests to the repository.
Let me know if another folder would be a more appropriate place for
these tests.
Co-authored-by: Philippe Tillet <phil@openai.com>
Re-enabled reduce test after fixing the %cst stride in the ttgir, and
modifying the sweep parameters to make sure the shape per CTA to be less
than or equal to the tensor shape.
- Case 1: Return after static control flow is taken. Peel off
instructions after the first `return` for each basic block.
```python
if static_condition:
tl.store(...)
return
return
```
- Case 2: Return exists in both `if` and `else` branches of an inlined
`JITFunction` function
```python
def foo():
if dynamic_condition:
return a
else:
return b
```
- Case 3: Return exists in a `JITFunction` from another module
```python
import module
if cond:
a = module.func()
```
- Case 4: A chain of calls through undefined local variables
```python
import module
if cond:
a = x
a = a.to(tl.int32).to(tl.int32)
```
- Case 5: Call a function `func` without returning variables. `func` is
recognized as an `Expr` first instead of a `Call`.
```python
if cond:
foo()
else:
bar()
```
- Case 6: Call a `noinline` function. We don't need to check if the
function contains any return op.
Simple mechanism to run Triton kernels on PyTorch for debugging purpose
(upstream from Kernl).
Todo:
- random grid iteration
- support of atomic ops
- more unit tests
- cover new APIs?
This exposes `semantic.expand_dims` in the public API and builds upon it
with support for expanding multiple dimensions at once. e.g.
```python
tl.expand_dims(tl.arange(0, N), (0, -1)) # shape = [1, N, 1]
```
Compared to indexing with `None`, this API is useful because the
dimensions can be constexpr values rather than hard-coded into the
source. As a basic example
```python
@triton.jit
def max_keepdim(value, dim):
res = tl.max(value, dim)
return tl.expand_dims(res, dim)
```
Formatting of the diff is not the best. I only indented the whole
function, moved the creation of the py::bytes and the return out of the
scope and declared and assigned the cubin variable appropriately.
Everything else is unchanged.
Today it triggers the following error on CPython debug build:
```
Fatal Python error: _PyMem_DebugMalloc: Python memory allocator called without holding the GIL
Python runtime state: initialized
```
---------
Co-authored-by: Keren Zhou <kerenzhou@openai.com>
Co-authored-by: Philippe Tillet <phil@openai.com>
Closes https://github.com/openai/triton/issues/1556https://github.com/openai/triton/issues/1512
The current hash used for caching the cubin does not include the
architecture. This leads to the following error when compiling against
one arch and running against another (with no code changes to trigger a
recompilation).
```
RuntimeError: Triton Error [CUDA]: device kernel image is invalid
```
Was not sure what unit tests would be appropriate here (if any)
Co-authored-by: davidma <davidma@speechmatics.com>
# Introducing the `noinline` Parameter for Triton JIT Decorator
We're excited to introduce a new parameter, `noinline`, that can be
added to the `jit` decorator in Triton. This parameter allows developers
to specify that a particular Triton function should not be inlined into
its callers. In this post, we'll dive into the syntax, purpose, and
implementation details of this new feature.
## Syntax
To use the `noinline` parameter, simply add `noinline=True` to the `jit`
decorator for the function that you don't want to be inlined. Here's an
example:
```python
@triton.jit(noinline=True)
def device_fn(x, y, Z):
z = x + y
tl.store(Z, z)
def test_noinline():
@triton.jit
def kernel(X, Y, Z):
x = tl.load(X)
y = tl.load(Y)
device_fn(x, y, Z)
```
In this example, the `device_fn` function is decorated with
`@triton.jit(noinline=True)`, indicating that it should not be inlined
into its caller, `kernel`.
## Purpose
The `noinline` parameter serves several key purposes:
- Reducing code size: By preventing inlining, we can reduce the size of
the compiled code.
- Facilitating debugging: Keeping functions separate can make it easier
to debug the code.
- Avoiding common subexpression elimination (CSE) in certain cases: CSE
can sometimes be avoided by using the `noinline` parameter to reduce
register pressure.
- Enabling dynamic linking: This parameter makes it possible to
dynamically link Triton functions.
## Implementation
The implementation of the `noinline` parameter involves significant
changes to three analysis modules in Triton: *Allocation*, *Membar*, and
*AxisInfo*. Prior to this update, these modules assumed that all Triton
functions had been inlined into the root kernel function. With the
introduction of non-inlined functions, we've had to rework these
assumptions and make corresponding changes to the analyses.
### Call Graph and Limitations
<div style="text-align: center;">
<img
src="https://user-images.githubusercontent.com/2306281/234663904-12864247-3412-4405-987b-6991cdf053bb.png"
alt="figure 1" width="200" height="auto">
</div>
To address the changes, we build a call graph and perform all the
analyses on the call graph instead of a single function. The call graph
is constructed by traversing the call edges and storing them in an edge
map. Roots are extracted by checking nodes with no incoming edges.
The call graph has certain limitations:
- It does not support recursive function calls, although this could be
implemented in the future.
- It does not support dynamic function calls, where the function name is
unknown at compilation time.
### Allocation
<div style="text-align: center;">
<img
src="https://user-images.githubusercontent.com/2306281/234665110-bf6a2660-06fb-4648-85dc-16429439e72d.png"
alt="figure 2" width="400" height="auto">
</div>
In Triton, shared memory allocation is achieved through two operations:
`triton_gpu.convert_layout` and `triton_gpu.alloc_tensor`. The
`convert_layout` operation allocates an internal tensor, which we refer
to as a *scratch* buffer, while the `alloc_tensor` operation returns an
allocated tensor and is thus known as an *explicit* buffer.
To accommodate the introduction of function calls, we are introducing a
third type of buffer called a *virtual* buffer. Similar to scratch
buffers, virtual buffers are allocated internally within the scope of a
function call, and the buffers allocated by the called functions remain
invisible to subsequent operations in the calling function. However,
virtual buffers are distinct from scratch buffers in that the call
operation itself does not allocate memory—instead, it specifies the
total amount of memory required by all the child functions being called.
The actual allocation of buffers is performed by individual operations
within these child functions. For example, when invoking edge e1, no
memory is allocated, but the total amount of memory needed by function B
is reserved. Notably, the amount of shared memory used by function B
remains fixed across its call sites due to the consideration of dynamic
control flows within each function.
An additional challenge to address is the calculation of shared memory
offsets for functions within a call graph. While we can assume a shared
memory offset starting at 0 for a single root function, this is not the
case with a call graph, where we must determine each function's starting
offset based on the call path. Although each function has a fixed memory
consumption, the starting offset may vary. For instance, in Figure 2,
the starting offset of function C through edges e1->e2 differs from that
through edges e2->e4. To handle this, we accumulate the starting offset
at each call site and pass it as an argument to the called function.
Additionally, we amend both the function declaration and call sites by
appending an offset variable.
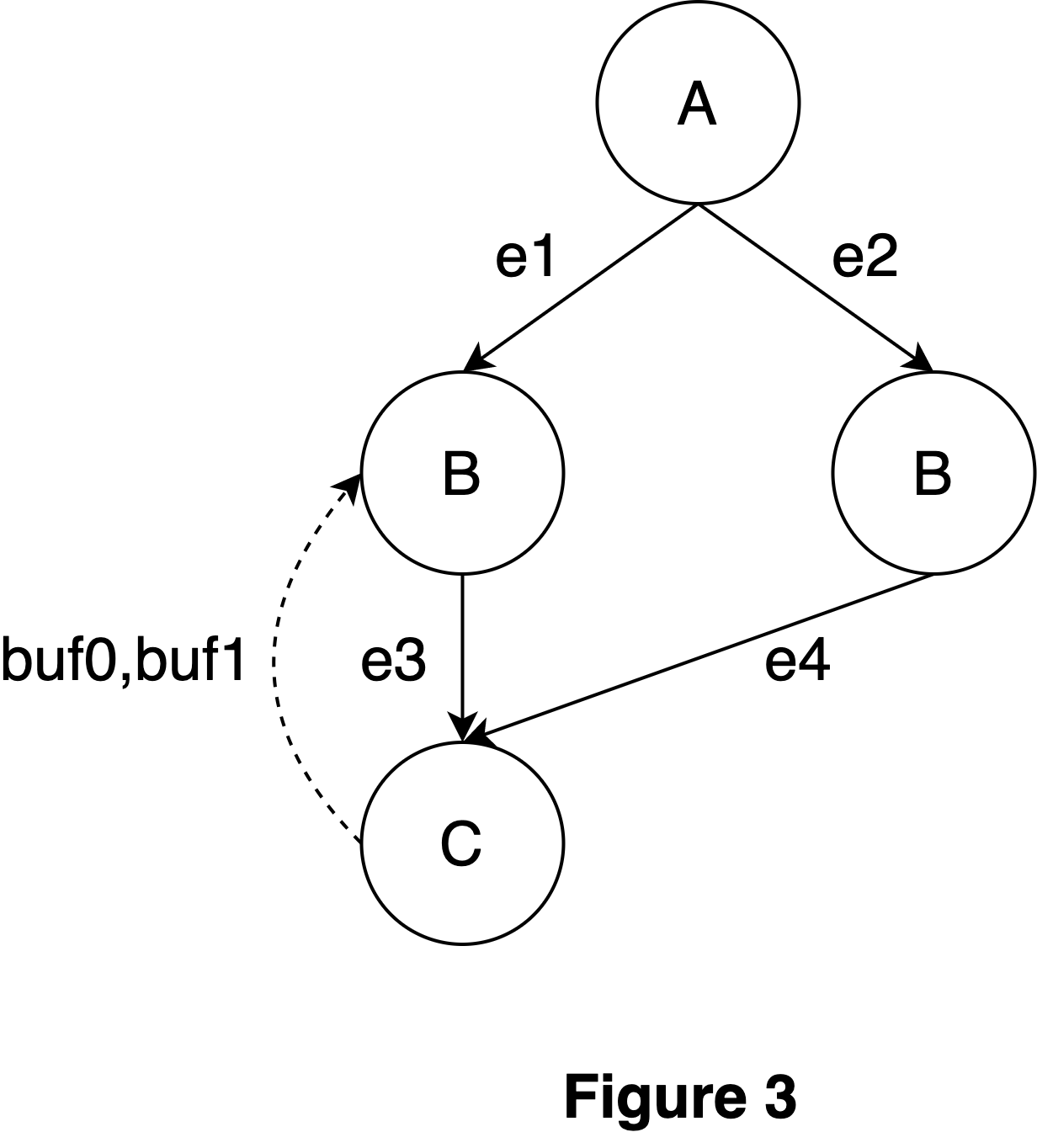
### Membar
<div style="text-align: center;">
<img
src="https://user-images.githubusercontent.com/2306281/234665157-844dd66f-5028-4ef3-bca2-4ca74b8f969d.png"
alt="figure 3" width="300" height="auto">
</div>
The membar pass is dependent on the allocation analysis. Once the offset
and size of each buffer are known, we conduct a post-order traversal of
the call graph and analyze each function on an individual basis. Unlike
previous analyses, we now return buffers that remain unsynchronized at
the end of functions, allowing the calling function to perform
synchronization in cases of overlap.
### AxisInfo
<div style="text-align: center;">
<img
src="https://user-images.githubusercontent.com/2306281/234665183-790a11ac-0ba1-47e1-98b1-e356220405a3.png"
alt="figure 4" width="400" height="auto">
</div>
The AxisInfo analysis operates differently from both membar and
allocation, as it traverses the call graph in topological order. This is
necessary because function arguments may contain axis information that
will be utilized by callee functions. As we do not implement
optimizations like function cloning, each function has a single code
base, and the axis information for an argument is determined as a
conservative result of all axis information passed by the calling
functions.
---------
Co-authored-by: Philippe Tillet <phil@openai.com>
To avoid puzzling segment fault problems caused by multiprocessing, this
PR:
- Uses "spawn" instead of "fork".
- Define the `instance_descriptor` namedtuple globally.
- Make the `kernel_sub` JITFunction defined by the child process only.
The current main would fail on `math.scalbn` because we implicitly cast
the first argument from `int32` to `float32`, while the function only
accepts `int32` as the first argument and `float32` as the second
argument.
So we update the type matching logic as follows:
1. Check if there's a type tuple that matches the types of the input
arguments
2. If yes, we don't allow arithmetic check.
3. If not, we will do arithmetic check to implicitly cast types among
arguments.
4. If we still don't find a corresponding function that accepts the
casted types, throwing an error.
---------
Co-authored-by: Philippe Tillet <phil@openai.com>
Related to #1271 . I am currently working on adding support for
Pre-volta GPUs in Triton.
---------
Co-authored-by: Himanshu Pathak <himanshu@mtatva.com>
Co-authored-by: Philippe Tillet <phil@openai.com>
We have had complaints/issues randomly where a zombie python process is
holding this lock. We don't need it since renames are atomic on posix.
So refactor this to make temp files unique and then use replace
(https://docs.python.org/3/library/os.html#os.replace )
Fixes#1545
`build_temp` is a temporary directory which `distutils` used to keep in
the `./build` directory, but when `pyproject.toml` is present `pip` now
puts it in `/tmp` and removes it at the end of the build.
Instead, this creates a new permanent directory like
`python/build/cmake.linux_x86_64-cpython-3.8` (the old name but with
cmake instead of temp).
While I was looking at the verbose pip output, I also noticed a bunch of
warnings like
```
Python recognizes 'triton/runtime.backends' as an importable package,
but it is not listed in the `packages` configuration of setuptools.
'triton/runtime.backends' has been automatically added to the distribution only
because it may contain data files, but this behavior is likely to change
in future versions of setuptools (and therefore is considered deprecated).
```
So I've also added these to the packages list.
---------
Co-authored-by: Keren Zhou <kerenzhou@openai.com>
Change the usage of LRU cache decorator from @functools.lru_cache to
@functools.lru_cache().
The former raises an error TypeError('Expected maxsize to be an integer
or None' for Python 3.7 or older.
This way reduces build time with assertions enabled LLVM and
dramatically speeds up triton's build with a "debug" LLVM.
Co-authored-by: Philippe Tillet <phil@openai.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}