mirror of
https://github.com/ROCm/ROCm.git
synced 2026-02-21 03:00:39 -05:00
# Introducing the `noinline` Parameter for Triton JIT Decorator
We're excited to introduce a new parameter, `noinline`, that can be
added to the `jit` decorator in Triton. This parameter allows developers
to specify that a particular Triton function should not be inlined into
its callers. In this post, we'll dive into the syntax, purpose, and
implementation details of this new feature.
## Syntax
To use the `noinline` parameter, simply add `noinline=True` to the `jit`
decorator for the function that you don't want to be inlined. Here's an
example:
```python
@triton.jit(noinline=True)
def device_fn(x, y, Z):
z = x + y
tl.store(Z, z)
def test_noinline():
@triton.jit
def kernel(X, Y, Z):
x = tl.load(X)
y = tl.load(Y)
device_fn(x, y, Z)
```
In this example, the `device_fn` function is decorated with
`@triton.jit(noinline=True)`, indicating that it should not be inlined
into its caller, `kernel`.
## Purpose
The `noinline` parameter serves several key purposes:
- Reducing code size: By preventing inlining, we can reduce the size of
the compiled code.
- Facilitating debugging: Keeping functions separate can make it easier
to debug the code.
- Avoiding common subexpression elimination (CSE) in certain cases: CSE
can sometimes be avoided by using the `noinline` parameter to reduce
register pressure.
- Enabling dynamic linking: This parameter makes it possible to
dynamically link Triton functions.
## Implementation
The implementation of the `noinline` parameter involves significant
changes to three analysis modules in Triton: *Allocation*, *Membar*, and
*AxisInfo*. Prior to this update, these modules assumed that all Triton
functions had been inlined into the root kernel function. With the
introduction of non-inlined functions, we've had to rework these
assumptions and make corresponding changes to the analyses.
### Call Graph and Limitations
<div style="text-align: center;">
<img
src="https://user-images.githubusercontent.com/2306281/234663904-12864247-3412-4405-987b-6991cdf053bb.png"
alt="figure 1" width="200" height="auto">
</div>
To address the changes, we build a call graph and perform all the
analyses on the call graph instead of a single function. The call graph
is constructed by traversing the call edges and storing them in an edge
map. Roots are extracted by checking nodes with no incoming edges.
The call graph has certain limitations:
- It does not support recursive function calls, although this could be
implemented in the future.
- It does not support dynamic function calls, where the function name is
unknown at compilation time.
### Allocation
<div style="text-align: center;">
<img
src="https://user-images.githubusercontent.com/2306281/234665110-bf6a2660-06fb-4648-85dc-16429439e72d.png"
alt="figure 2" width="400" height="auto">
</div>
In Triton, shared memory allocation is achieved through two operations:
`triton_gpu.convert_layout` and `triton_gpu.alloc_tensor`. The
`convert_layout` operation allocates an internal tensor, which we refer
to as a *scratch* buffer, while the `alloc_tensor` operation returns an
allocated tensor and is thus known as an *explicit* buffer.
To accommodate the introduction of function calls, we are introducing a
third type of buffer called a *virtual* buffer. Similar to scratch
buffers, virtual buffers are allocated internally within the scope of a
function call, and the buffers allocated by the called functions remain
invisible to subsequent operations in the calling function. However,
virtual buffers are distinct from scratch buffers in that the call
operation itself does not allocate memory—instead, it specifies the
total amount of memory required by all the child functions being called.
The actual allocation of buffers is performed by individual operations
within these child functions. For example, when invoking edge e1, no
memory is allocated, but the total amount of memory needed by function B
is reserved. Notably, the amount of shared memory used by function B
remains fixed across its call sites due to the consideration of dynamic
control flows within each function.
An additional challenge to address is the calculation of shared memory
offsets for functions within a call graph. While we can assume a shared
memory offset starting at 0 for a single root function, this is not the
case with a call graph, where we must determine each function's starting
offset based on the call path. Although each function has a fixed memory
consumption, the starting offset may vary. For instance, in Figure 2,
the starting offset of function C through edges e1->e2 differs from that
through edges e2->e4. To handle this, we accumulate the starting offset
at each call site and pass it as an argument to the called function.
Additionally, we amend both the function declaration and call sites by
appending an offset variable.
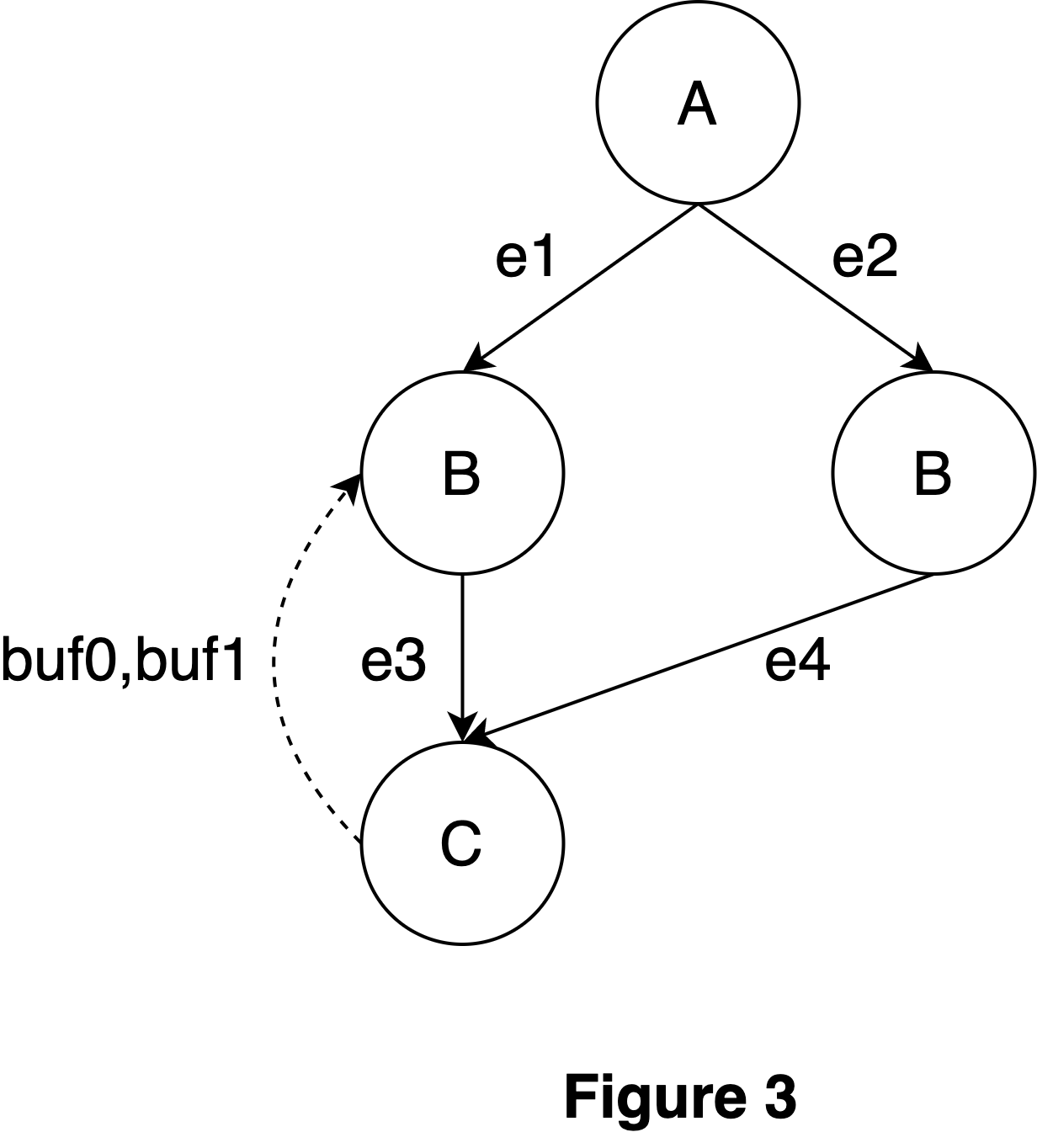
### Membar
<div style="text-align: center;">
<img
src="https://user-images.githubusercontent.com/2306281/234665157-844dd66f-5028-4ef3-bca2-4ca74b8f969d.png"
alt="figure 3" width="300" height="auto">
</div>
The membar pass is dependent on the allocation analysis. Once the offset
and size of each buffer are known, we conduct a post-order traversal of
the call graph and analyze each function on an individual basis. Unlike
previous analyses, we now return buffers that remain unsynchronized at
the end of functions, allowing the calling function to perform
synchronization in cases of overlap.
### AxisInfo
<div style="text-align: center;">
<img
src="https://user-images.githubusercontent.com/2306281/234665183-790a11ac-0ba1-47e1-98b1-e356220405a3.png"
alt="figure 4" width="400" height="auto">
</div>
The AxisInfo analysis operates differently from both membar and
allocation, as it traverses the call graph in topological order. This is
necessary because function arguments may contain axis information that
will be utilized by callee functions. As we do not implement
optimizations like function cloning, each function has a single code
base, and the axis information for an argument is determined as a
conservative result of all axis information passed by the calling
functions.
---------
Co-authored-by: Philippe Tillet <phil@openai.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
527 lines
21 KiB
C++
527 lines
21 KiB
C++
#include "triton/Analysis/Allocation.h"
|
|
#include "mlir/Analysis/DataFlowFramework.h"
|
|
#include "mlir/Analysis/Liveness.h"
|
|
#include "mlir/Analysis/SliceAnalysis.h"
|
|
#include "mlir/Dialect/Tensor/IR/Tensor.h"
|
|
#include "triton/Analysis/Alias.h"
|
|
#include "triton/Analysis/Utility.h"
|
|
#include "triton/Dialect/TritonGPU/IR/Dialect.h"
|
|
#include "llvm/ADT/SmallVector.h"
|
|
|
|
#include <algorithm>
|
|
#include <limits>
|
|
#include <numeric>
|
|
|
|
using ::mlir::triton::gpu::BlockedEncodingAttr;
|
|
using ::mlir::triton::gpu::DotOperandEncodingAttr;
|
|
using ::mlir::triton::gpu::getContigPerThread;
|
|
using ::mlir::triton::gpu::getOrder;
|
|
using ::mlir::triton::gpu::getShapePerCTA;
|
|
using ::mlir::triton::gpu::getSizePerThread;
|
|
using ::mlir::triton::gpu::MmaEncodingAttr;
|
|
using ::mlir::triton::gpu::SharedEncodingAttr;
|
|
using ::mlir::triton::gpu::SliceEncodingAttr;
|
|
|
|
namespace mlir {
|
|
|
|
//===----------------------------------------------------------------------===//
|
|
// Shared Memory Allocation Analysis
|
|
//===----------------------------------------------------------------------===//
|
|
namespace triton {
|
|
|
|
// Bitwidth of pointers
|
|
constexpr int kPtrBitWidth = 64;
|
|
|
|
static std::pair<SmallVector<unsigned>, SmallVector<unsigned>>
|
|
getCvtOrder(Attribute srcLayout, Attribute dstLayout) {
|
|
auto srcMmaLayout = srcLayout.dyn_cast<MmaEncodingAttr>();
|
|
auto srcDotLayout = srcLayout.dyn_cast<DotOperandEncodingAttr>();
|
|
auto dstMmaLayout = dstLayout.dyn_cast<MmaEncodingAttr>();
|
|
auto dstDotLayout = dstLayout.dyn_cast<DotOperandEncodingAttr>();
|
|
assert(!(srcMmaLayout && dstMmaLayout) &&
|
|
"Unexpected mma -> mma layout conversion");
|
|
// mma or dot layout does not have an order, so the order depends on the
|
|
// layout of the other operand.
|
|
auto inOrd = (srcMmaLayout || srcDotLayout) ? getOrder(dstLayout)
|
|
: getOrder(srcLayout);
|
|
auto outOrd = (dstMmaLayout || dstDotLayout) ? getOrder(srcLayout)
|
|
: getOrder(dstLayout);
|
|
|
|
return {inOrd, outOrd};
|
|
}
|
|
|
|
SmallVector<unsigned>
|
|
getScratchConfigForCvtLayout(triton::gpu::ConvertLayoutOp op, unsigned &inVec,
|
|
unsigned &outVec) {
|
|
auto srcTy = op.getSrc().getType().cast<RankedTensorType>();
|
|
auto dstTy = op.getResult().getType().cast<RankedTensorType>();
|
|
Attribute srcLayout = srcTy.getEncoding();
|
|
Attribute dstLayout = dstTy.getEncoding();
|
|
|
|
// MmaToDotShortcut doesn't use shared mem
|
|
if (srcLayout.isa<MmaEncodingAttr>() &&
|
|
dstLayout.isa<DotOperandEncodingAttr>())
|
|
if (isMmaToDotShortcut(srcTy, dstTy))
|
|
return {};
|
|
|
|
assert(srcLayout && dstLayout &&
|
|
"Unexpected layout in getScratchConfigForCvtLayout()");
|
|
auto [inOrd, outOrd] = getCvtOrder(srcLayout, dstLayout);
|
|
unsigned srcContigPerThread = getContigPerThread(srcLayout)[inOrd[0]];
|
|
unsigned dstContigPerThread = getContigPerThread(dstLayout)[outOrd[0]];
|
|
// TODO: Fix the legacy issue that ourOrd[0] == 0 always means
|
|
// that we cannot do vectorization.
|
|
inVec = outOrd[0] == 0 ? 1 : inOrd[0] == 0 ? 1 : srcContigPerThread;
|
|
outVec = outOrd[0] == 0 ? 1 : dstContigPerThread;
|
|
|
|
auto srcShape = srcTy.getShape();
|
|
auto dstShape = dstTy.getShape();
|
|
auto srcShapePerCTA = getShapePerCTA(srcLayout, srcShape);
|
|
auto dstShapePerCTA = getShapePerCTA(dstLayout, dstShape);
|
|
|
|
unsigned rank = dstTy.getRank();
|
|
SmallVector<unsigned> paddedRepShape(rank);
|
|
unsigned pad = std::max(inVec, outVec);
|
|
for (unsigned d = 0; d < rank; ++d) {
|
|
paddedRepShape[d] =
|
|
std::max(std::min<unsigned>(srcTy.getShape()[d], srcShapePerCTA[d]),
|
|
std::min<unsigned>(dstTy.getShape()[d], dstShapePerCTA[d]));
|
|
}
|
|
if (rank == 1)
|
|
return paddedRepShape;
|
|
unsigned paddedDim = 1;
|
|
if (auto dstBlockedLayout = dstLayout.dyn_cast<BlockedEncodingAttr>()) {
|
|
paddedDim = dstBlockedLayout.getOrder()[0];
|
|
}
|
|
paddedRepShape[paddedDim] += pad;
|
|
return paddedRepShape;
|
|
}
|
|
|
|
// TODO: extend beyond scalars
|
|
SmallVector<unsigned> getScratchConfigForAtomicRMW(triton::AtomicRMWOp op) {
|
|
SmallVector<unsigned> smemShape;
|
|
if (op.getPtr().getType().isa<RankedTensorType>()) {
|
|
// do nothing or just assert because shared memory is not used in tensor up
|
|
// to now
|
|
} else {
|
|
// need only bytes for scalar
|
|
// always vec = 1 and elemsPerThread = 1 for scalar?
|
|
smemShape.push_back(1);
|
|
}
|
|
return smemShape;
|
|
}
|
|
|
|
SmallVector<unsigned> getScratchConfigForAtomicCAS(triton::AtomicCASOp op) {
|
|
return SmallVector<unsigned>{1};
|
|
}
|
|
|
|
class AllocationAnalysis {
|
|
public:
|
|
AllocationAnalysis(Operation *operation,
|
|
Allocation::FuncAllocMapT *funcAllocMap,
|
|
Allocation *allocation)
|
|
: operation(operation), funcAllocMap(funcAllocMap),
|
|
allocation(allocation) {
|
|
run();
|
|
}
|
|
|
|
private:
|
|
using BufferT = Allocation::BufferT;
|
|
|
|
/// Value -> Liveness Range
|
|
/// Use MapVector to ensure determinism.
|
|
using BufferRangeMapT = llvm::MapVector<BufferT *, Interval<size_t>>;
|
|
/// Nodes -> Nodes
|
|
using GraphT = DenseMap<BufferT *, DenseSet<BufferT *>>;
|
|
|
|
void run() {
|
|
getValuesAndSizes();
|
|
resolveLiveness();
|
|
computeOffsets();
|
|
}
|
|
|
|
/// Initializes explicitly defined shared memory values for a given operation.
|
|
void getExplicitValueSize(Operation *op) {
|
|
// Values returned from scf.yield will not be allocated even though they
|
|
// have the shared encoding.
|
|
// For example: %a = scf.if -> yield
|
|
// %a must be allocated elsewhere by other operations.
|
|
// FIXME(Keren): extract and insert are always alias for now
|
|
if (!maybeSharedAllocationOp(op) || maybeAliasOp(op)) {
|
|
return;
|
|
}
|
|
|
|
for (Value result : op->getResults()) {
|
|
if (isSharedEncoding(result)) {
|
|
// Bytes could be a different value once we support padding or other
|
|
// allocation policies.
|
|
auto tensorType = result.getType().dyn_cast<RankedTensorType>();
|
|
auto bytes = tensorType.getNumElements() *
|
|
tensorType.getElementTypeBitWidth() / 8;
|
|
allocation->addBuffer<BufferT::BufferKind::Explicit>(result, bytes);
|
|
}
|
|
}
|
|
}
|
|
|
|
/// Initializes temporary shared memory for a given operation.
|
|
void getScratchValueSize(Operation *op) {
|
|
if (auto reduceOp = dyn_cast<triton::ReduceOp>(op)) {
|
|
ReduceOpHelper helper(reduceOp);
|
|
unsigned bytes = helper.getScratchSizeInBytes();
|
|
allocation->addBuffer<BufferT::BufferKind::Scratch>(op, bytes);
|
|
} else if (auto cvtLayout = dyn_cast<triton::gpu::ConvertLayoutOp>(op)) {
|
|
auto srcTy = cvtLayout.getSrc().getType().cast<RankedTensorType>();
|
|
auto dstTy = cvtLayout.getResult().getType().cast<RankedTensorType>();
|
|
auto srcEncoding = srcTy.getEncoding();
|
|
auto dstEncoding = dstTy.getEncoding();
|
|
if (srcEncoding.isa<SharedEncodingAttr>() ||
|
|
dstEncoding.isa<SharedEncodingAttr>()) {
|
|
// Conversions from/to shared memory do not need scratch memory.
|
|
return;
|
|
}
|
|
// ConvertLayoutOp with both input/output non-shared_layout
|
|
// TODO: Besides of implementing ConvertLayoutOp via shared memory, it's
|
|
// also possible to realize it with other approaches in restricted
|
|
// conditions, such as warp-shuffle
|
|
unsigned inVec = 0;
|
|
unsigned outVec = 0;
|
|
auto smemShape = getScratchConfigForCvtLayout(cvtLayout, inVec, outVec);
|
|
unsigned elems = std::accumulate(smemShape.begin(), smemShape.end(), 1,
|
|
std::multiplies{});
|
|
auto bytes =
|
|
srcTy.getElementType().isa<triton::PointerType>()
|
|
? elems * kPtrBitWidth / 8
|
|
: elems * std::max<int>(8, srcTy.getElementTypeBitWidth()) / 8;
|
|
allocation->addBuffer<BufferT::BufferKind::Scratch>(op, bytes);
|
|
} else if (auto atomicRMWOp = dyn_cast<triton::AtomicRMWOp>(op)) {
|
|
auto value = op->getOperand(0);
|
|
// only scalar requires scratch memory
|
|
// make it explicit for readability
|
|
if (value.getType().dyn_cast<RankedTensorType>()) {
|
|
// nothing to do
|
|
} else {
|
|
auto smemShape = getScratchConfigForAtomicRMW(atomicRMWOp);
|
|
unsigned elems = std::accumulate(smemShape.begin(), smemShape.end(), 1,
|
|
std::multiplies{});
|
|
auto elemTy =
|
|
value.getType().cast<triton::PointerType>().getPointeeType();
|
|
auto bytes =
|
|
elemTy.isa<triton::PointerType>()
|
|
? elems * kPtrBitWidth / 8
|
|
: elems * std::max<int>(8, elemTy.getIntOrFloatBitWidth()) / 8;
|
|
allocation->addBuffer<BufferT::BufferKind::Scratch>(op, bytes);
|
|
}
|
|
} else if (auto atomicCASOp = dyn_cast<triton::AtomicCASOp>(op)) {
|
|
auto value = op->getOperand(0);
|
|
auto smemShape = getScratchConfigForAtomicCAS(atomicCASOp);
|
|
unsigned elems = std::accumulate(smemShape.begin(), smemShape.end(), 1,
|
|
std::multiplies{});
|
|
auto elemTy =
|
|
value.getType().cast<triton::PointerType>().getPointeeType();
|
|
auto bytes = elemTy.isa<triton::PointerType>()
|
|
? elems * kPtrBitWidth / 8
|
|
: elems * elemTy.getIntOrFloatBitWidth() / 8;
|
|
allocation->addBuffer<BufferT::BufferKind::Scratch>(op, bytes);
|
|
} else if (auto callOp = dyn_cast<CallOpInterface>(op)) {
|
|
auto callable = callOp.resolveCallable();
|
|
auto funcOp = dyn_cast<FunctionOpInterface>(callable);
|
|
auto *funcAlloc = &(*funcAllocMap)[funcOp];
|
|
auto bytes = funcAlloc->getSharedMemorySize();
|
|
allocation->addBuffer<BufferT::BufferKind::Virtual>(op, bytes);
|
|
}
|
|
}
|
|
|
|
void getValueAlias(Value value, SharedMemoryAliasAnalysis &analysis) {
|
|
dataflow::Lattice<AliasInfo> *latticeElement =
|
|
analysis.getLatticeElement(value);
|
|
if (latticeElement) {
|
|
AliasInfo &info = latticeElement->getValue();
|
|
if (!info.getAllocs().empty()) {
|
|
for (auto alloc : info.getAllocs()) {
|
|
allocation->addAlias(value, alloc);
|
|
}
|
|
}
|
|
}
|
|
}
|
|
|
|
/// Extract all shared memory values and their sizes
|
|
void getValuesAndSizes() {
|
|
// Get the alloc values
|
|
operation->walk<WalkOrder::PreOrder>([&](Operation *op) {
|
|
getExplicitValueSize(op);
|
|
getScratchValueSize(op);
|
|
});
|
|
// Get the alias values
|
|
std::unique_ptr<DataFlowSolver> solver = createDataFlowSolver();
|
|
SharedMemoryAliasAnalysis *aliasAnalysis =
|
|
solver->load<SharedMemoryAliasAnalysis>();
|
|
if (failed(solver->initializeAndRun(operation))) {
|
|
// TODO: return error instead of bailing out..
|
|
llvm_unreachable("failed to run SharedMemoryAliasAnalysis");
|
|
}
|
|
operation->walk<WalkOrder::PreOrder>([&](Operation *op) {
|
|
for (auto operand : op->getOperands()) {
|
|
getValueAlias(operand, *aliasAnalysis);
|
|
}
|
|
for (auto value : op->getResults()) {
|
|
getValueAlias(value, *aliasAnalysis);
|
|
}
|
|
});
|
|
}
|
|
|
|
/// Computes the liveness range of the allocated value.
|
|
/// Each buffer is allocated only once.
|
|
void resolveExplicitBufferLiveness(
|
|
function_ref<Interval<size_t>(Value value)> getLiveness) {
|
|
for (auto valueBufferIter : allocation->valueBuffer) {
|
|
auto value = valueBufferIter.first;
|
|
auto *buffer = valueBufferIter.second;
|
|
bufferRange[buffer] = getLiveness(value);
|
|
}
|
|
}
|
|
|
|
/// Extends the liveness range by unionizing the liveness range of the aliased
|
|
/// values because each allocated buffer could be an alias of others, if block
|
|
/// arguments are involved.
|
|
void resolveAliasBufferLiveness(
|
|
function_ref<Interval<size_t>(Value value)> getLiveness) {
|
|
for (auto aliasBufferIter : allocation->aliasBuffer) {
|
|
auto value = aliasBufferIter.first;
|
|
auto buffers = aliasBufferIter.second;
|
|
auto range = getLiveness(value);
|
|
for (auto *buffer : buffers) {
|
|
auto minId = range.start();
|
|
auto maxId = range.end();
|
|
if (bufferRange.count(buffer)) {
|
|
// Extend the allocated buffer's range
|
|
minId = std::min(minId, bufferRange[buffer].start());
|
|
maxId = std::max(maxId, bufferRange[buffer].end());
|
|
}
|
|
bufferRange[buffer] = Interval(minId, maxId);
|
|
}
|
|
}
|
|
}
|
|
|
|
/// Computes the liveness range of scratched buffers.
|
|
/// Some operations may have a temporary buffer that is not explicitly
|
|
/// allocated, but is used to store intermediate results.
|
|
void resolveScratchBufferLiveness(
|
|
const DenseMap<Operation *, size_t> &operationId) {
|
|
// Analyze liveness of scratch buffers and vritual buffers.
|
|
auto processScratchMemory = [&](const auto &container) {
|
|
for (auto opScratchIter : container) {
|
|
// Any scratch memory's live range is the current operation's live
|
|
// range.
|
|
auto *op = opScratchIter.first;
|
|
auto *buffer = opScratchIter.second;
|
|
bufferRange.insert({buffer, Interval(operationId.lookup(op),
|
|
operationId.lookup(op) + 1)});
|
|
}
|
|
};
|
|
processScratchMemory(allocation->opScratch);
|
|
processScratchMemory(allocation->opVirtual);
|
|
}
|
|
|
|
/// Resolves liveness of all values involved under the root operation.
|
|
void resolveLiveness() {
|
|
// Assign an ID to each operation using post-order traversal.
|
|
// To achieve the correct liveness range, the parent operation's ID
|
|
// should be greater than each of its child operation's ID .
|
|
// Example:
|
|
// ...
|
|
// %5 = triton.convert_layout %4
|
|
// %6 = scf.for ... iter_args(%arg0 = %0) -> (i32) {
|
|
// %2 = triton.convert_layout %5
|
|
// ...
|
|
// scf.yield %arg0
|
|
// }
|
|
// For example, %5 is defined in the parent region and used in
|
|
// the child region, and is not passed as a block argument.
|
|
// %6 should should have an ID greater than its child operations,
|
|
// otherwise %5 liveness range ends before the child operation's liveness
|
|
// range ends.
|
|
DenseMap<Operation *, size_t> operationId;
|
|
operation->walk<WalkOrder::PostOrder>(
|
|
[&](Operation *op) { operationId[op] = operationId.size(); });
|
|
|
|
// Analyze liveness of explicit buffers
|
|
Liveness liveness(operation);
|
|
auto getValueLivenessRange = [&](Value value) {
|
|
auto liveOperations = liveness.resolveLiveness(value);
|
|
auto minId = std::numeric_limits<size_t>::max();
|
|
auto maxId = std::numeric_limits<size_t>::min();
|
|
std::for_each(liveOperations.begin(), liveOperations.end(),
|
|
[&](Operation *liveOp) {
|
|
if (operationId[liveOp] < minId) {
|
|
minId = operationId[liveOp];
|
|
}
|
|
if ((operationId[liveOp] + 1) > maxId) {
|
|
maxId = operationId[liveOp] + 1;
|
|
}
|
|
});
|
|
return Interval(minId, maxId);
|
|
};
|
|
|
|
resolveExplicitBufferLiveness(getValueLivenessRange);
|
|
resolveAliasBufferLiveness(getValueLivenessRange);
|
|
resolveScratchBufferLiveness(operationId);
|
|
}
|
|
|
|
/// Computes the shared memory offsets for all related values.
|
|
/// Paper: Algorithms for Compile-Time Memory Optimization
|
|
/// (https://www.cs.utexas.edu/users/harrison/papers/compile-time.pdf)
|
|
void computeOffsets() {
|
|
SmallVector<BufferT *> buffers;
|
|
for (auto bufferIter : bufferRange) {
|
|
buffers.emplace_back(bufferIter.first);
|
|
}
|
|
|
|
DenseMap<BufferT *, size_t> bufferStart;
|
|
calculateStarts(buffers, bufferStart);
|
|
|
|
GraphT interference;
|
|
buildInterferenceGraph(buffers, bufferStart, interference);
|
|
|
|
allocate(buffers, bufferStart, interference);
|
|
}
|
|
|
|
/// Computes the initial shared memory offsets.
|
|
void calculateStarts(const SmallVector<BufferT *> &buffers,
|
|
DenseMap<BufferT *, size_t> &bufferStart) {
|
|
// v = values in shared memory
|
|
// t = triplet of (size, start, end)
|
|
// shared memory space
|
|
// -
|
|
// | *******t4
|
|
// | /|\ v2 inserts t4, t5, and t6
|
|
// | |
|
|
// | ******t5 ************t6
|
|
// | ^^^^^v2^^^^^^
|
|
// | | *********************t2
|
|
// | \|/ v2 erases t1
|
|
// | ******t1 ^^^^^^^^^v1^^^^^^^^^ ************t3
|
|
// |---------------------------------------------| liveness range
|
|
// 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 ...
|
|
// If the available triple's range is less than a given buffer range,
|
|
// we won't know if there has been an overlap without using graph coloring.
|
|
// Start -> Liveness Range
|
|
using TripleMapT = std::multimap<size_t, Interval<size_t>>;
|
|
TripleMapT tripleMap;
|
|
tripleMap.insert(std::make_pair(0, Interval<size_t>()));
|
|
SmallVector<BufferT *> xBuffers = buffers;
|
|
while (!xBuffers.empty()) {
|
|
auto tripleIt = tripleMap.begin();
|
|
auto size = tripleIt->first;
|
|
auto range = tripleIt->second;
|
|
tripleMap.erase(tripleIt);
|
|
auto bufferIt =
|
|
std::find_if(xBuffers.begin(), xBuffers.end(), [&](auto *buffer) {
|
|
auto xRange = bufferRange[buffer];
|
|
bool res = xRange.intersects(range);
|
|
for (auto val : tripleMap)
|
|
res = res && !val.second.intersects(xRange);
|
|
return res;
|
|
});
|
|
if (bufferIt != xBuffers.end()) {
|
|
auto buffer = *bufferIt;
|
|
auto xSize = buffer->size;
|
|
auto xRange = bufferRange.lookup(buffer);
|
|
bufferStart[buffer] = size;
|
|
tripleMap.insert(
|
|
{size + xSize, Interval{std::max(range.start(), xRange.start()),
|
|
std::min(range.end(), xRange.end())}});
|
|
// We could either insert (range.start, xRange.start) or (range.start,
|
|
// xRange.end), both are correct and determine the potential buffer
|
|
// offset, and the graph coloring algorithm will solve the interference,
|
|
// if any
|
|
if (range.start() < xRange.start())
|
|
tripleMap.insert({size, Interval{range.start(), xRange.end()}});
|
|
if (xRange.end() < range.end())
|
|
tripleMap.insert({size, Interval{xRange.start(), range.end()}});
|
|
xBuffers.erase(bufferIt);
|
|
}
|
|
}
|
|
}
|
|
|
|
/// Builds a graph of all shared memory values. Edges are created between
|
|
/// shared memory values that are overlapping.
|
|
void buildInterferenceGraph(const SmallVector<BufferT *> &buffers,
|
|
const DenseMap<BufferT *, size_t> &bufferStart,
|
|
GraphT &interference) {
|
|
for (auto x : buffers) {
|
|
for (auto y : buffers) {
|
|
if (x == y)
|
|
continue;
|
|
auto xStart = bufferStart.lookup(x);
|
|
auto yStart = bufferStart.lookup(y);
|
|
auto xSize = x->size;
|
|
auto ySize = y->size;
|
|
Interval xSizeRange = {xStart, xStart + xSize};
|
|
Interval ySizeRange = {yStart, yStart + ySize};
|
|
auto xOpRange = bufferRange.lookup(x);
|
|
auto yOpRange = bufferRange.lookup(y);
|
|
if (xOpRange.intersects(yOpRange) &&
|
|
xSizeRange.intersects(ySizeRange)) {
|
|
interference[x].insert(y);
|
|
}
|
|
}
|
|
}
|
|
}
|
|
|
|
/// Finalizes shared memory offsets considering interference.
|
|
void allocate(const SmallVector<BufferT *> &buffers,
|
|
const DenseMap<BufferT *, size_t> &bufferStart,
|
|
const GraphT &interference) {
|
|
// First-fit graph coloring
|
|
// Neighbors are nodes that interfere with each other.
|
|
// We color a node by finding the index of the first available
|
|
// non-neighboring node or the first neighboring node without any color.
|
|
// Nodes with the same color do not interfere with each other.
|
|
DenseMap<BufferT *, int> colors;
|
|
for (auto value : buffers) {
|
|
colors[value] = (value == buffers[0]) ? 0 : -1;
|
|
}
|
|
SmallVector<bool> available(buffers.size());
|
|
for (auto x : buffers) {
|
|
std::fill(available.begin(), available.end(), true);
|
|
for (auto y : interference.lookup(x)) {
|
|
int color = colors[y];
|
|
if (color >= 0) {
|
|
available[color] = false;
|
|
}
|
|
}
|
|
auto it = std::find(available.begin(), available.end(), true);
|
|
colors[x] = std::distance(available.begin(), it);
|
|
}
|
|
// Finalize allocation
|
|
// color0: [0, 7), [0, 8), [0, 15) -> [0, 7), [0, 8), [0, 15)
|
|
// color1: [7, 9) -> [0 + 1 * 15, 9 + 1 * 15) -> [15, 24)
|
|
// color2: [8, 12) -> [8 + 2 * 15, 12 + 2 * 15) -> [38, 42)
|
|
// TODO(Keren): We are wasting memory here.
|
|
// Nodes with color2 can actually start with 24.
|
|
for (auto x : buffers) {
|
|
size_t adj = 0;
|
|
for (auto y : interference.lookup(x)) {
|
|
adj = std::max(adj, bufferStart.lookup(y) + y->size);
|
|
}
|
|
x->offset = bufferStart.lookup(x) + colors.lookup(x) * adj;
|
|
allocation->sharedMemorySize =
|
|
std::max(allocation->sharedMemorySize, x->offset + x->size);
|
|
}
|
|
}
|
|
|
|
private:
|
|
Operation *operation;
|
|
Allocation::FuncAllocMapT *funcAllocMap;
|
|
Allocation *allocation;
|
|
BufferRangeMapT bufferRange;
|
|
};
|
|
|
|
} // namespace triton
|
|
|
|
void Allocation::run(FuncAllocMapT &funcAllocMap) {
|
|
triton::AllocationAnalysis(getOperation(), &funcAllocMap, this);
|
|
}
|
|
|
|
} // namespace mlir
|