mirror of
https://github.com/ROCm/ROCm.git
synced 2026-04-05 03:01:17 -04:00
# Introducing the `noinline` Parameter for Triton JIT Decorator
We're excited to introduce a new parameter, `noinline`, that can be
added to the `jit` decorator in Triton. This parameter allows developers
to specify that a particular Triton function should not be inlined into
its callers. In this post, we'll dive into the syntax, purpose, and
implementation details of this new feature.
## Syntax
To use the `noinline` parameter, simply add `noinline=True` to the `jit`
decorator for the function that you don't want to be inlined. Here's an
example:
```python
@triton.jit(noinline=True)
def device_fn(x, y, Z):
z = x + y
tl.store(Z, z)
def test_noinline():
@triton.jit
def kernel(X, Y, Z):
x = tl.load(X)
y = tl.load(Y)
device_fn(x, y, Z)
```
In this example, the `device_fn` function is decorated with
`@triton.jit(noinline=True)`, indicating that it should not be inlined
into its caller, `kernel`.
## Purpose
The `noinline` parameter serves several key purposes:
- Reducing code size: By preventing inlining, we can reduce the size of
the compiled code.
- Facilitating debugging: Keeping functions separate can make it easier
to debug the code.
- Avoiding common subexpression elimination (CSE) in certain cases: CSE
can sometimes be avoided by using the `noinline` parameter to reduce
register pressure.
- Enabling dynamic linking: This parameter makes it possible to
dynamically link Triton functions.
## Implementation
The implementation of the `noinline` parameter involves significant
changes to three analysis modules in Triton: *Allocation*, *Membar*, and
*AxisInfo*. Prior to this update, these modules assumed that all Triton
functions had been inlined into the root kernel function. With the
introduction of non-inlined functions, we've had to rework these
assumptions and make corresponding changes to the analyses.
### Call Graph and Limitations
<div style="text-align: center;">
<img
src="https://user-images.githubusercontent.com/2306281/234663904-12864247-3412-4405-987b-6991cdf053bb.png"
alt="figure 1" width="200" height="auto">
</div>
To address the changes, we build a call graph and perform all the
analyses on the call graph instead of a single function. The call graph
is constructed by traversing the call edges and storing them in an edge
map. Roots are extracted by checking nodes with no incoming edges.
The call graph has certain limitations:
- It does not support recursive function calls, although this could be
implemented in the future.
- It does not support dynamic function calls, where the function name is
unknown at compilation time.
### Allocation
<div style="text-align: center;">
<img
src="https://user-images.githubusercontent.com/2306281/234665110-bf6a2660-06fb-4648-85dc-16429439e72d.png"
alt="figure 2" width="400" height="auto">
</div>
In Triton, shared memory allocation is achieved through two operations:
`triton_gpu.convert_layout` and `triton_gpu.alloc_tensor`. The
`convert_layout` operation allocates an internal tensor, which we refer
to as a *scratch* buffer, while the `alloc_tensor` operation returns an
allocated tensor and is thus known as an *explicit* buffer.
To accommodate the introduction of function calls, we are introducing a
third type of buffer called a *virtual* buffer. Similar to scratch
buffers, virtual buffers are allocated internally within the scope of a
function call, and the buffers allocated by the called functions remain
invisible to subsequent operations in the calling function. However,
virtual buffers are distinct from scratch buffers in that the call
operation itself does not allocate memory—instead, it specifies the
total amount of memory required by all the child functions being called.
The actual allocation of buffers is performed by individual operations
within these child functions. For example, when invoking edge e1, no
memory is allocated, but the total amount of memory needed by function B
is reserved. Notably, the amount of shared memory used by function B
remains fixed across its call sites due to the consideration of dynamic
control flows within each function.
An additional challenge to address is the calculation of shared memory
offsets for functions within a call graph. While we can assume a shared
memory offset starting at 0 for a single root function, this is not the
case with a call graph, where we must determine each function's starting
offset based on the call path. Although each function has a fixed memory
consumption, the starting offset may vary. For instance, in Figure 2,
the starting offset of function C through edges e1->e2 differs from that
through edges e2->e4. To handle this, we accumulate the starting offset
at each call site and pass it as an argument to the called function.
Additionally, we amend both the function declaration and call sites by
appending an offset variable.
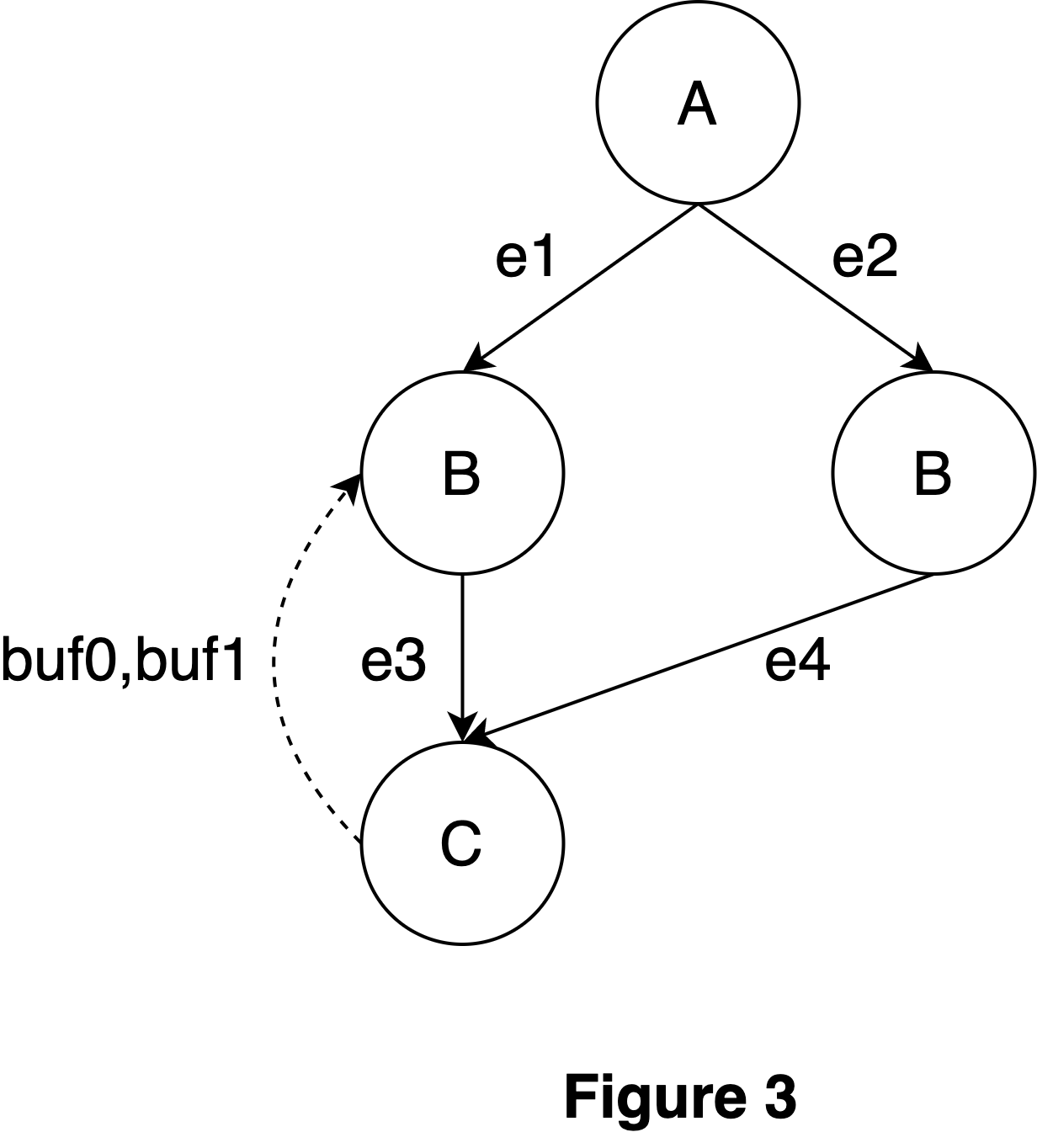
### Membar
<div style="text-align: center;">
<img
src="https://user-images.githubusercontent.com/2306281/234665157-844dd66f-5028-4ef3-bca2-4ca74b8f969d.png"
alt="figure 3" width="300" height="auto">
</div>
The membar pass is dependent on the allocation analysis. Once the offset
and size of each buffer are known, we conduct a post-order traversal of
the call graph and analyze each function on an individual basis. Unlike
previous analyses, we now return buffers that remain unsynchronized at
the end of functions, allowing the calling function to perform
synchronization in cases of overlap.
### AxisInfo
<div style="text-align: center;">
<img
src="https://user-images.githubusercontent.com/2306281/234665183-790a11ac-0ba1-47e1-98b1-e356220405a3.png"
alt="figure 4" width="400" height="auto">
</div>
The AxisInfo analysis operates differently from both membar and
allocation, as it traverses the call graph in topological order. This is
necessary because function arguments may contain axis information that
will be utilized by callee functions. As we do not implement
optimizations like function cloning, each function has a single code
base, and the axis information for an argument is determined as a
conservative result of all axis information passed by the calling
functions.
---------
Co-authored-by: Philippe Tillet <phil@openai.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
1015 lines
39 KiB
C++
1015 lines
39 KiB
C++
#include "mlir/Analysis/DataFlowFramework.h"
|
|
#include "mlir/Dialect/LLVMIR/LLVMDialect.h"
|
|
#include "llvm/Support/raw_ostream.h"
|
|
|
|
#include "triton/Analysis/AxisInfo.h"
|
|
#include "triton/Dialect/Triton/IR/Dialect.h"
|
|
#include "triton/Dialect/TritonGPU/IR/Dialect.h"
|
|
|
|
namespace mlir {
|
|
|
|
// Function for extended Euclidean Algorithm
|
|
static int64_t gcdImpl(int64_t a, int64_t b, int64_t *x, int64_t *y) {
|
|
// Base Case
|
|
if (a == 0) {
|
|
*x = 0;
|
|
*y = 1;
|
|
return b;
|
|
}
|
|
int64_t x1, y1; // To store results of recursive call
|
|
int64_t gcd = gcdImpl(b % a, a, &x1, &y1);
|
|
// Update x and y using results of
|
|
// recursive call
|
|
*x = y1 - (b / a) * x1;
|
|
*y = x1;
|
|
return gcd;
|
|
}
|
|
|
|
static int64_t gcd(int64_t a, int64_t b) {
|
|
if (a == 0)
|
|
return b;
|
|
if (b == 0)
|
|
return a;
|
|
int64_t x, y;
|
|
return gcdImpl(a, b, &x, &y);
|
|
}
|
|
|
|
static constexpr int log2Int(int64_t num) {
|
|
return (num > 1) ? 1 + log2Int(num / 2) : 0;
|
|
}
|
|
|
|
//===----------------------------------------------------------------------===//
|
|
// AxisInfo
|
|
//===----------------------------------------------------------------------===//
|
|
|
|
template <class T>
|
|
void AxisInfo::initPessimisticStateFromFunc(int argNumber, T funcOp,
|
|
DimVectorT *contiguity,
|
|
DimVectorT *divisibility,
|
|
DimVectorT *constancy) {
|
|
// liast of attributes that we care about
|
|
SmallVector<std::pair<DimVectorT *, std::string>> retVecs;
|
|
retVecs.push_back({contiguity, "tt.contiguity"});
|
|
retVecs.push_back({divisibility, "tt.divisibility"});
|
|
retVecs.push_back({constancy, "tt.constancy"});
|
|
// initialize attributes one by one
|
|
for (auto [vec, attrName] : retVecs) {
|
|
Attribute attr = funcOp.getArgAttr(argNumber, attrName);
|
|
if (auto int_attr = attr.dyn_cast_or_null<IntegerAttr>())
|
|
*vec = DimVectorT(contiguity->size(), int_attr.getValue().getZExtValue());
|
|
if (auto dense_attr = attr.dyn_cast_or_null<DenseElementsAttr>()) {
|
|
auto vals = dense_attr.getValues<int>();
|
|
*vec = DimVectorT(vals.begin(), vals.end());
|
|
}
|
|
}
|
|
}
|
|
|
|
AxisInfo AxisInfo::getPessimisticValueState(Value value) {
|
|
auto rank = 1;
|
|
if (TensorType ty = value.getType().dyn_cast<TensorType>())
|
|
rank = ty.getRank();
|
|
|
|
DimVectorT knownContiguity(rank, 1);
|
|
DimVectorT knownDivisibility(rank, 1);
|
|
DimVectorT knownConstancy(rank, 1);
|
|
|
|
BlockArgument blockArg = value.dyn_cast<BlockArgument>();
|
|
|
|
if (blockArg && blockArg.getOwner()->isEntryBlock()) {
|
|
Operation *op = blockArg.getOwner()->getParentOp();
|
|
if (auto fun = dyn_cast<FunctionOpInterface>(op))
|
|
initPessimisticStateFromFunc(blockArg.getArgNumber(), fun,
|
|
&knownContiguity, &knownDivisibility,
|
|
&knownConstancy);
|
|
// llvm codegen check alignment to generate vector load/store
|
|
// would be nice if this wasn't the case
|
|
else if (auto fun = dyn_cast<LLVM::LLVMFuncOp>(op))
|
|
initPessimisticStateFromFunc(blockArg.getArgNumber(), fun,
|
|
&knownContiguity, &knownDivisibility,
|
|
&knownConstancy);
|
|
else {
|
|
// Derive the divisibility of the induction variable only when
|
|
// the step and the lower bound are both constants
|
|
if (auto forOp = dyn_cast<scf::ForOp>(op)) {
|
|
if (blockArg == forOp.getInductionVar()) {
|
|
if (auto lowerBound =
|
|
forOp.getLowerBound().getDefiningOp<arith::ConstantOp>()) {
|
|
if (auto step =
|
|
forOp.getStep().getDefiningOp<arith::ConstantOp>()) {
|
|
auto lowerBoundVal = lowerBound.getValue()
|
|
.cast<IntegerAttr>()
|
|
.getValue()
|
|
.getZExtValue();
|
|
auto stepVal =
|
|
step.getValue().cast<IntegerAttr>().getValue().getZExtValue();
|
|
auto k = gcd(lowerBoundVal, stepVal);
|
|
if (k != 0)
|
|
knownDivisibility = DimVectorT(rank, k);
|
|
}
|
|
}
|
|
}
|
|
}
|
|
}
|
|
} else if (Operation *op = value.getDefiningOp()) {
|
|
if (Attribute attr = op->getAttr("tt.divisibility")) {
|
|
auto vals = attr.cast<DenseElementsAttr>().getValues<int>();
|
|
knownDivisibility = DimVectorT(vals.begin(), vals.end());
|
|
}
|
|
if (Attribute attr = op->getAttr("tt.contiguity")) {
|
|
auto vals = attr.cast<DenseElementsAttr>().getValues<int>();
|
|
knownContiguity = DimVectorT(vals.begin(), vals.end());
|
|
}
|
|
if (Attribute attr = op->getAttr("tt.constancy")) {
|
|
auto vals = attr.cast<DenseElementsAttr>().getValues<int>();
|
|
knownConstancy = DimVectorT(vals.begin(), vals.end());
|
|
}
|
|
}
|
|
|
|
return AxisInfo(knownContiguity, knownDivisibility, knownConstancy);
|
|
}
|
|
|
|
// The gcd of both arguments for each dimension
|
|
AxisInfo AxisInfo::join(const AxisInfo &lhs, const AxisInfo &rhs) {
|
|
// If one argument is not initialized, return the other.
|
|
if (lhs.getRank() == 0)
|
|
return rhs;
|
|
if (rhs.getRank() == 0)
|
|
return lhs;
|
|
DimVectorT contiguity;
|
|
DimVectorT divisibility;
|
|
DimVectorT constancy;
|
|
for (auto d = 0; d < lhs.getRank(); ++d) {
|
|
contiguity.push_back(gcd(lhs.getContiguity(d), rhs.getContiguity(d)));
|
|
divisibility.push_back(gcd(lhs.getDivisibility(d), rhs.getDivisibility(d)));
|
|
constancy.push_back(gcd(lhs.getConstancy(d), rhs.getConstancy(d)));
|
|
}
|
|
std::optional<int64_t> constantValue;
|
|
if (lhs.getConstantValue().has_value() &&
|
|
rhs.getConstantValue().has_value() &&
|
|
lhs.getConstantValue() == rhs.getConstantValue())
|
|
constantValue = lhs.getConstantValue();
|
|
return AxisInfo(contiguity, divisibility, constancy, constantValue);
|
|
}
|
|
|
|
//===----------------------------------------------------------------------===//
|
|
// AxisInfoVisitor
|
|
//===----------------------------------------------------------------------===//
|
|
|
|
template <typename OpTy>
|
|
class CastOpAxisInfoVisitor final : public AxisInfoVisitorImpl<OpTy> {
|
|
public:
|
|
using AxisInfoVisitorImpl<OpTy>::AxisInfoVisitorImpl;
|
|
|
|
AxisInfo
|
|
getAxisInfo(OpTy op,
|
|
ArrayRef<const dataflow::Lattice<AxisInfo> *> operands) override {
|
|
return operands[0]->getValue();
|
|
}
|
|
};
|
|
|
|
class MakeRangeOpAxisInfoVisitor final
|
|
: public AxisInfoVisitorImpl<triton::MakeRangeOp> {
|
|
public:
|
|
using AxisInfoVisitorImpl<triton::MakeRangeOp>::AxisInfoVisitorImpl;
|
|
|
|
AxisInfo
|
|
getAxisInfo(triton::MakeRangeOp op,
|
|
ArrayRef<const dataflow::Lattice<AxisInfo> *> operands) override {
|
|
auto start = op.getStart();
|
|
auto end = op.getEnd();
|
|
return AxisInfo(/*contiguity=*/{end - start},
|
|
/*divisibility=*/{highestPowOf2Divisor(start)},
|
|
/*constancy=*/{1});
|
|
}
|
|
};
|
|
|
|
template <typename OpTy>
|
|
class ConstantOpAxisInfoVisitor final : public AxisInfoVisitorImpl<OpTy> {
|
|
public:
|
|
using AxisInfoVisitorImpl<OpTy>::AxisInfoVisitorImpl;
|
|
|
|
AxisInfo
|
|
getAxisInfo(OpTy op,
|
|
ArrayRef<const dataflow::Lattice<AxisInfo> *> operands) override {
|
|
auto intAttr = op.getValue().template dyn_cast<IntegerAttr>();
|
|
auto boolAttr = op.getValue().template dyn_cast<BoolAttr>();
|
|
if (intAttr || boolAttr) {
|
|
int64_t value{};
|
|
if (intAttr)
|
|
value = intAttr.getValue().getZExtValue();
|
|
else
|
|
value = boolAttr.getValue() ? 1 : 0;
|
|
return AxisInfo(/*contiguity=*/{1},
|
|
/*divisibility=*/{highestPowOf2Divisor(value)},
|
|
/*constancy=*/{1},
|
|
/*knownConstantValue=*/{value});
|
|
}
|
|
// TODO: generalize to dense attr
|
|
auto splatAttr = op.getValue().template dyn_cast<SplatElementsAttr>();
|
|
if (splatAttr && splatAttr.getElementType().isIntOrIndex()) {
|
|
int64_t value = splatAttr.template getSplatValue<APInt>().getZExtValue();
|
|
TensorType ty = splatAttr.getType().template cast<TensorType>();
|
|
return AxisInfo(
|
|
/*contiguity=*/AxisInfo::DimVectorT(ty.getRank(), 1),
|
|
/*divisibility=*/
|
|
AxisInfo::DimVectorT(ty.getRank(), highestPowOf2Divisor(value)),
|
|
/*constancy=*/
|
|
AxisInfo::DimVectorT(ty.getShape().begin(), ty.getShape().end()),
|
|
/*knownConstantValue=*/{value});
|
|
}
|
|
return AxisInfo();
|
|
}
|
|
};
|
|
|
|
template <typename OpTy>
|
|
class AddSubOpAxisInfoVisitor final : public BinaryOpVisitorImpl<OpTy> {
|
|
public:
|
|
using BinaryOpVisitorImpl<OpTy>::BinaryOpVisitorImpl;
|
|
|
|
private:
|
|
int64_t getContiguity(OpTy op, const AxisInfo &lhs, const AxisInfo &rhs,
|
|
int dim) override {
|
|
return std::max(gcd(lhs.getConstancy(dim), rhs.getContiguity(dim)),
|
|
gcd(lhs.getContiguity(dim), rhs.getConstancy(dim)));
|
|
}
|
|
|
|
int64_t getDivisibility(OpTy op, const AxisInfo &lhs, const AxisInfo &rhs,
|
|
int dim) override {
|
|
// lhs = k * d_lhs = k * k' * gcd(d_lhs, d_rhs)
|
|
// rhs = p * d_rhs = p * p' * gcd(d_lhs, d_rhs)
|
|
// lhs + rhs = k * d_lhs + p * d_rhs = (k * d_lhs + p * d_rhs) *
|
|
// gcd(d_lhs, d_rhs)
|
|
auto elemSize = 1;
|
|
if constexpr (std::is_same_v<OpTy, triton::AddPtrOp>) {
|
|
// %ptr = addptr %lhs, %rhs
|
|
// is equivalent to
|
|
// %0 = mul %lhs, %elemSize
|
|
// %ptr = add %0, %rhs
|
|
elemSize = std::max<unsigned int>(
|
|
1, triton::getPointeeBitWidth(op.getPtr().getType()) / 8);
|
|
}
|
|
return gcd(lhs.getDivisibility(dim), rhs.getDivisibility(dim) * elemSize);
|
|
}
|
|
|
|
int64_t getConstancy(OpTy op, const AxisInfo &lhs, const AxisInfo &rhs,
|
|
int dim) override {
|
|
return gcd(lhs.getConstancy(dim), rhs.getConstancy(dim));
|
|
}
|
|
|
|
std::optional<int64_t> getConstantValue(OpTy op, const AxisInfo &lhs,
|
|
const AxisInfo &rhs) override {
|
|
if (lhs.getConstantValue().has_value() &&
|
|
rhs.getConstantValue().has_value()) {
|
|
if constexpr (std::is_same_v<OpTy, arith::AddIOp> ||
|
|
std::is_same_v<OpTy, triton::AddPtrOp> ||
|
|
std::is_same_v<OpTy, LLVM::AddOp>) {
|
|
return {lhs.getConstantValue().value() +
|
|
rhs.getConstantValue().value()};
|
|
} else if constexpr (std::is_same_v<OpTy, arith::SubIOp>) {
|
|
return {lhs.getConstantValue().value() -
|
|
rhs.getConstantValue().value()};
|
|
}
|
|
}
|
|
return {};
|
|
}
|
|
};
|
|
|
|
class MulIOpAxisInfoVisitor final : public BinaryOpVisitorImpl<arith::MulIOp> {
|
|
public:
|
|
using BinaryOpVisitorImpl<arith::MulIOp>::BinaryOpVisitorImpl;
|
|
|
|
private:
|
|
int64_t getContiguity(arith::MulIOp op, const AxisInfo &lhs,
|
|
const AxisInfo &rhs, int dim) override {
|
|
// lhs * 1 = lhs
|
|
auto lhsContiguity =
|
|
rhs.getConstantValue().has_value() && rhs.getConstantValue() == 1
|
|
? lhs.getContiguity(dim)
|
|
: 1;
|
|
// 1 * rhs = rhs
|
|
auto rhsContiguity =
|
|
lhs.getConstantValue().has_value() && lhs.getConstantValue() == 1
|
|
? rhs.getContiguity(dim)
|
|
: 1;
|
|
return std::max(lhsContiguity, rhsContiguity);
|
|
}
|
|
|
|
int64_t getConstancy(arith::MulIOp op, const AxisInfo &lhs,
|
|
const AxisInfo &rhs, int dim) override {
|
|
return gcd(lhs.getConstancy(dim), rhs.getConstancy(dim));
|
|
}
|
|
|
|
int64_t getDivisibility(arith::MulIOp op, const AxisInfo &lhs,
|
|
const AxisInfo &rhs, int dim) override {
|
|
// lhs = k * d_lhs
|
|
// rhs = p * d_rhs
|
|
// lhs * rhs = k * d_lhs * p * d_rhs = k * p * d_lhs * d_rhs
|
|
return lhs.getDivisibility(dim) * rhs.getDivisibility(dim);
|
|
}
|
|
|
|
std::optional<int64_t> getConstantValue(arith::MulIOp op, const AxisInfo &lhs,
|
|
const AxisInfo &rhs) override {
|
|
if (lhs.getConstantValue().has_value() &&
|
|
rhs.getConstantValue().has_value())
|
|
return {lhs.getConstantValue().value() * rhs.getConstantValue().value()};
|
|
return {};
|
|
}
|
|
};
|
|
|
|
template <typename OpTy>
|
|
class DivOpAxisInfoVisitor final : public BinaryOpVisitorImpl<OpTy> {
|
|
public:
|
|
using BinaryOpVisitorImpl<OpTy>::BinaryOpVisitorImpl;
|
|
|
|
private:
|
|
int64_t getContiguity(OpTy op, const AxisInfo &lhs, const AxisInfo &rhs,
|
|
int dim) override {
|
|
// lhs / 1 = lhs
|
|
return rhs.getConstantValue().has_value() &&
|
|
rhs.getConstantValue().value() == 1
|
|
? lhs.getContiguity(dim)
|
|
: 1;
|
|
}
|
|
|
|
int64_t getConstancy(OpTy op, const AxisInfo &lhs, const AxisInfo &rhs,
|
|
int dim) override {
|
|
auto resTy = op.getResult().getType().template dyn_cast<RankedTensorType>();
|
|
if (!resTy)
|
|
return BinaryOpVisitorImpl<OpTy>::getConstancy(op, lhs, rhs, dim);
|
|
auto shape = resTy.getShape();
|
|
// Case 1: both lhs and rhs are constants.
|
|
auto constancy = gcd(lhs.getConstancy(dim), rhs.getConstancy(dim));
|
|
// Case 2: lhs contiguous, rhs constant.
|
|
// lhs: d_lhs * k, d_lhs * k + 1, ..., d_lhs * k + n
|
|
// rhs: d_rhs * p, d_rhs * p, ..., d_rhs * p
|
|
// lhs / rhs = d_lhs * k / (d_rhs * p), (d_lhs * k + 1) / (d_rhs * p),
|
|
// ..., (d_lhs * k + n) / (d_rhs * p)
|
|
// Because d_lhs % d_rhs = 0 || d_rhs % d_lhs = 0,
|
|
// the minimal constancy is gcd(d_lhs, d_rhs).
|
|
// Since gcd(d_lhs, d_rhs) maybe > len(lhs),
|
|
// we need to use another gcd to get the actual constancy.
|
|
if (AxisInfoVisitor::isContiguousDim(lhs, shape, dim) &&
|
|
AxisInfoVisitor::isConstantDim(rhs, shape, dim)) {
|
|
constancy = std::max(constancy, gcd(lhs.getContiguity(dim),
|
|
gcd(lhs.getDivisibility(dim),
|
|
rhs.getDivisibility(dim))));
|
|
}
|
|
return constancy;
|
|
}
|
|
|
|
int64_t getDivisibility(OpTy op, const AxisInfo &lhs, const AxisInfo &rhs,
|
|
int dim) override {
|
|
// Case 1: lhs is 0
|
|
if (lhs.getConstantValue().has_value() &&
|
|
lhs.getConstantValue().value() == 0)
|
|
return lhs.getDivisibility(dim);
|
|
// Case 2: rhs is 1
|
|
if (rhs.getConstantValue().has_value() &&
|
|
rhs.getConstantValue().value() == 1)
|
|
return lhs.getDivisibility(dim);
|
|
// otherwise: return 1
|
|
return 1;
|
|
}
|
|
|
|
std::optional<int64_t> getConstantValue(OpTy op, const AxisInfo &lhs,
|
|
const AxisInfo &rhs) override {
|
|
if (lhs.getConstantValue().has_value() &&
|
|
rhs.getConstantValue().has_value())
|
|
return {lhs.getConstantValue().value() / rhs.getConstantValue().value()};
|
|
return {};
|
|
}
|
|
};
|
|
|
|
template <typename OpTy>
|
|
class RemOpAxisInfoVisitor final : public BinaryOpVisitorImpl<OpTy> {
|
|
public:
|
|
using BinaryOpVisitorImpl<OpTy>::BinaryOpVisitorImpl;
|
|
|
|
private:
|
|
int64_t getContiguity(OpTy op, const AxisInfo &lhs, const AxisInfo &rhs,
|
|
int dim) override {
|
|
auto resTy = op.getResult().getType().template dyn_cast<RankedTensorType>();
|
|
if (!resTy)
|
|
return BinaryOpVisitorImpl<OpTy>::getContiguity(op, lhs, rhs, dim);
|
|
auto shape = resTy.getShape();
|
|
int64_t contiguity = 1;
|
|
// lhs contiguous, rhs constant
|
|
// lhs: d_lhs * k, d_lhs * k + 1, ..., d_lhs * k + n
|
|
// rhs: d_rhs * p, d_rhs * p, ..., d_rhs * p
|
|
// lhs % rhs = d_lhs * k % (d_rhs * p), (d_lhs * k + 1) % (d_rhs * p),
|
|
// ..., (d_lhs * k + n) % (d_rhs * p)
|
|
// Because d_lhs % d_rhs = 0 || d_rhs % d_lhs = 0,
|
|
// The minimal contiguity is gcd(d_lhs, d_rhs).
|
|
// Since gcd(d_lhs, d_rhs) maybe > len(lhs),
|
|
// we need to use another gcd to get the actual contiguity.
|
|
if (AxisInfoVisitor::isContiguousDim(lhs, shape, dim) &&
|
|
AxisInfoVisitor::isConstantDim(rhs, shape, dim)) {
|
|
contiguity = std::max(contiguity, gcd(lhs.getContiguity(dim),
|
|
gcd(lhs.getDivisibility(dim),
|
|
rhs.getDivisibility(dim))));
|
|
}
|
|
return contiguity;
|
|
}
|
|
|
|
int64_t getDivisibility(OpTy op, const AxisInfo &lhs, const AxisInfo &rhs,
|
|
int dim) override {
|
|
// lhs: d_lhs * k = gcd(d_lhs, d_rhs) * k' * k = gcd(d_lhs, d_rhs) * k''
|
|
// rhs: d_rhs * p = gcd(d_lhs, d_rhs) * p' * p = gcd(d_lhs, d_rhs) * p''
|
|
// lhs = gcd(d_lhs, d_rhs) * k'' = gcd(d_lhs, d_rhs) * d + r
|
|
// r must be divisible by gcd(d_lhs, d_rhs)
|
|
return gcd(lhs.getDivisibility(dim), rhs.getDivisibility(dim));
|
|
};
|
|
|
|
int64_t getConstancy(OpTy op, const AxisInfo &lhs, const AxisInfo &rhs,
|
|
int dim) override {
|
|
auto resTy = op.getResult().getType().template dyn_cast<RankedTensorType>();
|
|
if (!resTy)
|
|
return BinaryOpVisitorImpl<OpTy>::getConstancy(op, lhs, rhs, dim);
|
|
auto shape = resTy.getShape();
|
|
// lhs % 1 = 0
|
|
return rhs.getConstantValue().has_value() &&
|
|
rhs.getConstantValue().value() == 1
|
|
? shape[dim]
|
|
: gcd(lhs.getConstancy(dim), rhs.getConstancy(dim));
|
|
}
|
|
|
|
std::optional<int64_t> getConstantValue(OpTy op, const AxisInfo &lhs,
|
|
const AxisInfo &rhs) override {
|
|
if (lhs.getConstantValue().has_value() &&
|
|
rhs.getConstantValue().has_value())
|
|
return {lhs.getConstantValue().value() % rhs.getConstantValue().value()};
|
|
else if (rhs.getConstantValue().has_value() &&
|
|
rhs.getConstantValue().value() == 1)
|
|
return {0};
|
|
return {};
|
|
}
|
|
};
|
|
|
|
class SplatOpAxisInfoVisitor final
|
|
: public AxisInfoVisitorImpl<triton::SplatOp> {
|
|
public:
|
|
using AxisInfoVisitorImpl<triton::SplatOp>::AxisInfoVisitorImpl;
|
|
|
|
AxisInfo
|
|
getAxisInfo(triton::SplatOp op,
|
|
ArrayRef<const dataflow::Lattice<AxisInfo> *> operands) override {
|
|
Type _retTy = *op->result_type_begin();
|
|
TensorType retTy = _retTy.cast<TensorType>();
|
|
AxisInfo opInfo = operands[0]->getValue();
|
|
AxisInfo::DimVectorT contiguity;
|
|
AxisInfo::DimVectorT divisibility;
|
|
AxisInfo::DimVectorT constancy;
|
|
for (int d = 0; d < retTy.getRank(); ++d) {
|
|
contiguity.push_back(1);
|
|
divisibility.push_back(opInfo.getDivisibility(0));
|
|
constancy.push_back(retTy.getShape()[d]);
|
|
}
|
|
return AxisInfo(contiguity, divisibility, constancy,
|
|
operands[0]->getValue().getConstantValue());
|
|
}
|
|
};
|
|
|
|
class ExpandDimsOpAxisInfoVisitor final
|
|
: public AxisInfoVisitorImpl<triton::ExpandDimsOp> {
|
|
public:
|
|
using AxisInfoVisitorImpl<triton::ExpandDimsOp>::AxisInfoVisitorImpl;
|
|
|
|
AxisInfo
|
|
getAxisInfo(triton::ExpandDimsOp op,
|
|
ArrayRef<const dataflow::Lattice<AxisInfo> *> operands) override {
|
|
AxisInfo opInfo = operands[0]->getValue();
|
|
AxisInfo::DimVectorT contiguity = opInfo.getContiguity();
|
|
AxisInfo::DimVectorT divisibility = opInfo.getDivisibility();
|
|
AxisInfo::DimVectorT constancy = opInfo.getConstancy();
|
|
contiguity.insert(contiguity.begin() + op.getAxis(), 1);
|
|
divisibility.insert(divisibility.begin() + op.getAxis(), 1);
|
|
constancy.insert(constancy.begin() + op.getAxis(), 1);
|
|
return AxisInfo(contiguity, divisibility, constancy,
|
|
operands[0]->getValue().getConstantValue());
|
|
}
|
|
};
|
|
|
|
class BroadcastOpAxisInfoVisitor final
|
|
: public AxisInfoVisitorImpl<triton::BroadcastOp> {
|
|
public:
|
|
using AxisInfoVisitorImpl<triton::BroadcastOp>::AxisInfoVisitorImpl;
|
|
|
|
AxisInfo
|
|
getAxisInfo(triton::BroadcastOp op,
|
|
ArrayRef<const dataflow::Lattice<AxisInfo> *> operands) override {
|
|
Type _retTy = *op->result_type_begin();
|
|
Type _opTy = *op->operand_type_begin();
|
|
TensorType retTy = _retTy.cast<TensorType>();
|
|
TensorType opTy = _opTy.cast<TensorType>();
|
|
ArrayRef<int64_t> retShape = retTy.getShape();
|
|
ArrayRef<int64_t> opShape = opTy.getShape();
|
|
AxisInfo opInfo = operands[0]->getValue();
|
|
AxisInfo::DimVectorT contiguity;
|
|
AxisInfo::DimVectorT divisibility;
|
|
AxisInfo::DimVectorT constancy;
|
|
for (int d = 0; d < retTy.getRank(); ++d) {
|
|
contiguity.push_back(opShape[d] == 1 ? 1 : opInfo.getContiguity(d));
|
|
divisibility.push_back(opInfo.getDivisibility(d));
|
|
constancy.push_back(opShape[d] == 1 ? retShape[d]
|
|
: opInfo.getConstancy(d));
|
|
}
|
|
return AxisInfo(contiguity, divisibility, constancy,
|
|
operands[0]->getValue().getConstantValue());
|
|
}
|
|
};
|
|
|
|
template <typename OpTy>
|
|
class CmpOpAxisInfoVisitor final : public AxisInfoVisitorImpl<OpTy> {
|
|
public:
|
|
using AxisInfoVisitorImpl<OpTy>::AxisInfoVisitorImpl;
|
|
|
|
AxisInfo
|
|
getAxisInfo(OpTy op,
|
|
ArrayRef<const dataflow::Lattice<AxisInfo> *> operands) override {
|
|
auto resTy = op.getResult().getType().template dyn_cast<RankedTensorType>();
|
|
if (!resTy)
|
|
return AxisInfo();
|
|
auto shape = resTy.getShape();
|
|
short rank = resTy.getRank();
|
|
auto lhsInfo = operands[0]->getValue();
|
|
auto rhsInfo = operands[1]->getValue();
|
|
|
|
AxisInfo::DimVectorT contiguity, divisibility, constancy;
|
|
std::optional<int64_t> constantValue;
|
|
for (short d = 0; d < rank; ++d) {
|
|
int64_t constHint = 1;
|
|
if (lhsInfo.getConstantValue().has_value() &&
|
|
rhsInfo.getConstantValue().has_value()) {
|
|
constHint = lhsInfo.getConstancy(d);
|
|
constantValue =
|
|
compare(getPredicate(op), lhsInfo.getConstantValue().value(),
|
|
rhsInfo.getConstantValue().value())
|
|
? 1
|
|
: 0;
|
|
} else {
|
|
// Case 1: lhs and rhs are both partial constants
|
|
constHint = gcd(lhsInfo.getConstancy(d), rhsInfo.getConstancy(d));
|
|
// Case 2: lhs all constant, rhs all contiguous
|
|
// NOTE:
|
|
// lhs: 4 4 4 4
|
|
// rhs: 4 5 6 7
|
|
// lhs ge rhs: 1, 0, 0, 0
|
|
// Case 3: lhs all contiguous, rhs all constant
|
|
// NOTE
|
|
// lhs: 4 5 6 7
|
|
// rhs: 4 4 4 4
|
|
// lhs sle rhs: 1, 0, 0, 0
|
|
if (/*Case 2=*/(
|
|
notGePredicate(getPredicate(op)) &&
|
|
(AxisInfoVisitor::isConstantDim(lhsInfo, shape, d) &&
|
|
AxisInfoVisitor::isContiguousDim(rhsInfo, shape, d))) ||
|
|
/*Case 3=*/(notLePredicate(getPredicate(op)) &&
|
|
(AxisInfoVisitor::isContiguousDim(lhsInfo, shape, d) &&
|
|
AxisInfoVisitor::isConstantDim(rhsInfo, shape, d)))) {
|
|
constHint = std::max(constHint, gcd(lhsInfo.getContiguity(d),
|
|
gcd(lhsInfo.getDivisibility(d),
|
|
rhsInfo.getDivisibility(d))));
|
|
}
|
|
}
|
|
|
|
constancy.push_back(constHint);
|
|
divisibility.push_back(1);
|
|
contiguity.push_back(1);
|
|
}
|
|
|
|
return AxisInfo(contiguity, divisibility, constancy, constantValue);
|
|
}
|
|
|
|
private:
|
|
static arith::CmpIPredicate getPredicate(triton::gpu::CmpIOp op) {
|
|
return op.getPredicate();
|
|
}
|
|
|
|
static arith::CmpIPredicate getPredicate(arith::CmpIOp op) {
|
|
return op.getPredicate();
|
|
}
|
|
|
|
static bool notGePredicate(arith::CmpIPredicate predicate) {
|
|
return predicate != arith::CmpIPredicate::sge &&
|
|
predicate != arith::CmpIPredicate::uge;
|
|
}
|
|
|
|
static bool notLePredicate(arith::CmpIPredicate predicate) {
|
|
return predicate != arith::CmpIPredicate::sle &&
|
|
predicate != arith::CmpIPredicate::ule;
|
|
}
|
|
|
|
static bool compare(arith::CmpIPredicate predicate, int64_t lhs,
|
|
int64_t rhs) {
|
|
switch (predicate) {
|
|
case arith::CmpIPredicate::eq:
|
|
return lhs == rhs;
|
|
case arith::CmpIPredicate::ne:
|
|
return lhs != rhs;
|
|
case arith::CmpIPredicate::slt:
|
|
return lhs < rhs;
|
|
case arith::CmpIPredicate::sle:
|
|
return lhs <= rhs;
|
|
case arith::CmpIPredicate::sgt:
|
|
return lhs > rhs;
|
|
case arith::CmpIPredicate::sge:
|
|
return lhs >= rhs;
|
|
case arith::CmpIPredicate::ult:
|
|
return (uint64_t)lhs < (uint64_t)rhs;
|
|
case arith::CmpIPredicate::ule:
|
|
return (uint64_t)lhs <= (uint64_t)rhs;
|
|
case arith::CmpIPredicate::ugt:
|
|
return (uint64_t)lhs > (uint64_t)rhs;
|
|
case arith::CmpIPredicate::uge:
|
|
return (uint64_t)lhs >= (uint64_t)rhs;
|
|
default:
|
|
break;
|
|
}
|
|
llvm_unreachable("unknown comparison predicate");
|
|
}
|
|
};
|
|
|
|
template <typename OpTy>
|
|
class SelectOpAxisInfoVisitor final : public AxisInfoVisitorImpl<OpTy> {
|
|
public:
|
|
using AxisInfoVisitorImpl<OpTy>::AxisInfoVisitorImpl;
|
|
|
|
AxisInfo
|
|
getAxisInfo(OpTy op,
|
|
ArrayRef<const dataflow::Lattice<AxisInfo> *> operands) override {
|
|
auto resTy = op.getResult().getType().template dyn_cast<RankedTensorType>();
|
|
if (!resTy)
|
|
return AxisInfo();
|
|
auto shape = resTy.getShape();
|
|
auto rank = shape.size();
|
|
auto condConstancy = operands[0]->getValue().getConstancy();
|
|
auto lhsInfo = operands[1]->getValue();
|
|
auto rhsInfo = operands[2]->getValue();
|
|
|
|
AxisInfo::DimVectorT contiguity, divisibility, constancy;
|
|
std::optional<int64_t> constantValue;
|
|
if (operands[0]->getValue().getConstantValue().has_value()) {
|
|
if (operands[0]->getValue().getConstantValue() == 0) {
|
|
contiguity = rhsInfo.getContiguity();
|
|
divisibility = rhsInfo.getDivisibility();
|
|
constancy = rhsInfo.getConstancy();
|
|
constantValue = rhsInfo.getConstantValue();
|
|
} else {
|
|
contiguity = lhsInfo.getContiguity();
|
|
divisibility = lhsInfo.getDivisibility();
|
|
constancy = lhsInfo.getConstancy();
|
|
constantValue = lhsInfo.getConstantValue();
|
|
}
|
|
} else {
|
|
for (auto d = 0; d < rank; ++d) {
|
|
constancy.push_back(
|
|
std::min(gcd(lhsInfo.getConstancy(d), condConstancy[d]),
|
|
gcd(rhsInfo.getConstancy(d), condConstancy[d])));
|
|
divisibility.push_back(
|
|
std::min(lhsInfo.getDivisibility(d), rhsInfo.getDivisibility(d)));
|
|
contiguity.push_back(
|
|
std::min(gcd(lhsInfo.getContiguity(d), condConstancy[d]),
|
|
gcd(rhsInfo.getContiguity(d), condConstancy[d])));
|
|
}
|
|
if (lhsInfo.getConstantValue().has_value() &&
|
|
rhsInfo.getConstantValue().has_value() &&
|
|
lhsInfo.getConstantValue() == rhsInfo.getConstantValue())
|
|
constantValue = lhsInfo.getConstantValue();
|
|
}
|
|
|
|
return AxisInfo(contiguity, divisibility, constancy, constantValue);
|
|
}
|
|
};
|
|
|
|
template <typename OpTy>
|
|
class LogicalOpAxisInfoVisitor final : public BinaryOpVisitorImpl<OpTy> {
|
|
public:
|
|
using BinaryOpVisitorImpl<OpTy>::BinaryOpVisitorImpl;
|
|
|
|
private:
|
|
int64_t getConstancy(OpTy op, const AxisInfo &lhs, const AxisInfo &rhs,
|
|
int dim) override {
|
|
return gcd(lhs.getConstancy(dim), rhs.getConstancy(dim));
|
|
}
|
|
|
|
std::optional<int64_t> getConstantValue(OpTy op, const AxisInfo &lhs,
|
|
const AxisInfo &rhs) override {
|
|
if (lhs.getConstantValue().has_value() &&
|
|
rhs.getConstantValue().has_value()) {
|
|
if constexpr (std::is_same_v<OpTy, arith::AndIOp>) {
|
|
return {lhs.getConstantValue().value() &
|
|
rhs.getConstantValue().value()};
|
|
} else if constexpr (std::is_same_v<OpTy, arith::OrIOp>) {
|
|
return {lhs.getConstantValue().value() |
|
|
rhs.getConstantValue().value()};
|
|
} else if constexpr (std::is_same_v<OpTy, arith::XOrIOp>) {
|
|
return {lhs.getConstantValue().value() ^
|
|
rhs.getConstantValue().value()};
|
|
}
|
|
}
|
|
return {};
|
|
}
|
|
};
|
|
|
|
class ShLIOpAxisInfoVisitor final : public BinaryOpVisitorImpl<arith::ShLIOp> {
|
|
public:
|
|
using BinaryOpVisitorImpl<arith::ShLIOp>::BinaryOpVisitorImpl;
|
|
|
|
private:
|
|
int64_t getContiguity(arith::ShLIOp op, const AxisInfo &lhs,
|
|
const AxisInfo &rhs, int dim) override {
|
|
if (rhs.getConstantValue().has_value() &&
|
|
rhs.getConstantValue().value() == 0)
|
|
return lhs.getContiguity(dim);
|
|
else
|
|
return 1;
|
|
}
|
|
|
|
int64_t getDivisibility(arith::ShLIOp op, const AxisInfo &lhs,
|
|
const AxisInfo &rhs, int dim) override {
|
|
auto shift = rhs.getConstantValue().has_value()
|
|
? rhs.getConstantValue().value()
|
|
: rhs.getDivisibility(dim);
|
|
auto numBits = log2Int(lhs.getDivisibility(dim));
|
|
auto maxBits = log2Int(highestPowOf2Divisor<int64_t>(0));
|
|
// Make sure the return value doesn't exceed highestPowOf2Divisor<int64>(0)
|
|
if (shift + numBits > maxBits)
|
|
return highestPowOf2Divisor<int64_t>(0);
|
|
return lhs.getDivisibility(dim) << shift;
|
|
}
|
|
|
|
int64_t getConstancy(arith::ShLIOp op, const AxisInfo &lhs,
|
|
const AxisInfo &rhs, int dim) override {
|
|
return gcd(lhs.getConstancy(dim), rhs.getConstancy(dim));
|
|
}
|
|
|
|
std::optional<int64_t> getConstantValue(arith::ShLIOp op, const AxisInfo &lhs,
|
|
const AxisInfo &rhs) override {
|
|
if (lhs.getConstantValue().has_value() &&
|
|
rhs.getConstantValue().has_value())
|
|
return {lhs.getConstantValue().value() << rhs.getConstantValue().value()};
|
|
return {};
|
|
}
|
|
};
|
|
|
|
template <typename OpTy>
|
|
class ShROpAxisInfoVisitor final : public BinaryOpVisitorImpl<OpTy> {
|
|
public:
|
|
using BinaryOpVisitorImpl<OpTy>::BinaryOpVisitorImpl;
|
|
|
|
private:
|
|
int64_t getContiguity(OpTy op, const AxisInfo &lhs, const AxisInfo &rhs,
|
|
int dim) override {
|
|
if (rhs.getConstantValue().has_value() &&
|
|
rhs.getConstantValue().value() == 0)
|
|
return lhs.getContiguity(dim);
|
|
else
|
|
return 1;
|
|
}
|
|
|
|
int64_t getDivisibility(OpTy op, const AxisInfo &lhs, const AxisInfo &rhs,
|
|
int dim) override {
|
|
if (rhs.getConstantValue().has_value())
|
|
return std::max<int64_t>(1, lhs.getDivisibility(dim) /
|
|
(1 << rhs.getConstantValue().value()));
|
|
else
|
|
return std::max<int64_t>(1, lhs.getDivisibility(dim) /
|
|
(1 << rhs.getDivisibility(dim)));
|
|
}
|
|
|
|
int64_t getConstancy(OpTy op, const AxisInfo &lhs, const AxisInfo &rhs,
|
|
int dim) override {
|
|
return gcd(lhs.getConstancy(dim), rhs.getConstancy(dim));
|
|
}
|
|
|
|
std::optional<int64_t> getConstantValue(OpTy op, const AxisInfo &lhs,
|
|
const AxisInfo &rhs) override {
|
|
if (lhs.getConstantValue().has_value() &&
|
|
rhs.getConstantValue().has_value())
|
|
return {lhs.getConstantValue().value() >> rhs.getConstantValue().value()};
|
|
return {};
|
|
}
|
|
};
|
|
|
|
template <typename OpTy>
|
|
class MaxMinOpAxisInfoVisitor final : public AxisInfoVisitorImpl<OpTy> {
|
|
public:
|
|
using AxisInfoVisitorImpl<OpTy>::AxisInfoVisitorImpl;
|
|
|
|
AxisInfo
|
|
getAxisInfo(OpTy op,
|
|
ArrayRef<const dataflow::Lattice<AxisInfo> *> operands) override {
|
|
auto lhsInfo = operands[0]->getValue();
|
|
auto rhsInfo = operands[1]->getValue();
|
|
std::optional<int64_t> constantValue;
|
|
if (lhsInfo.getConstantValue().has_value() &&
|
|
rhsInfo.getConstantValue().has_value()) {
|
|
if constexpr (std::is_same_v<OpTy, arith::MaxSIOp> ||
|
|
std::is_same_v<OpTy, arith::MaxUIOp>) {
|
|
constantValue = {std::max(lhsInfo.getConstantValue().value(),
|
|
rhsInfo.getConstantValue().value())};
|
|
} else if constexpr (std::is_same_v<OpTy, arith::MinSIOp> ||
|
|
std::is_same_v<OpTy, arith::MinUIOp>) {
|
|
constantValue = {std::min(lhsInfo.getConstantValue().value(),
|
|
rhsInfo.getConstantValue().value())};
|
|
}
|
|
}
|
|
auto rank = lhsInfo.getRank();
|
|
return AxisInfo(/*knownContiguity=*/AxisInfo::DimVectorT(rank, 1),
|
|
/*knownDivisibility=*/AxisInfo::DimVectorT(rank, 1),
|
|
/*knownConstancy=*/AxisInfo::DimVectorT(rank, 1),
|
|
/*constantValue=*/constantValue);
|
|
}
|
|
};
|
|
|
|
//===----------------------------------------------------------------------===//
|
|
// AxisInfoAnalysis
|
|
//===----------------------------------------------------------------------===//
|
|
|
|
AxisInfoAnalysis::AxisInfoAnalysis(DataFlowSolver &solver)
|
|
: dataflow::SparseDataFlowAnalysis<dataflow::Lattice<AxisInfo>>(solver) {
|
|
// UnrealizedConversionCast:
|
|
// This is needed by TritonGPUToLLVM, to get AxisInfo when the graph is
|
|
// in the process of a PartialConversion, where UnrealizedConversionCast
|
|
// may exist
|
|
visitors.append<CastOpAxisInfoVisitor<arith::ExtSIOp>,
|
|
CastOpAxisInfoVisitor<arith::ExtUIOp>,
|
|
CastOpAxisInfoVisitor<arith::TruncIOp>,
|
|
CastOpAxisInfoVisitor<arith::IndexCastOp>,
|
|
CastOpAxisInfoVisitor<triton::PtrToIntOp>,
|
|
CastOpAxisInfoVisitor<triton::IntToPtrOp>,
|
|
CastOpAxisInfoVisitor<triton::gpu::ConvertLayoutOp>,
|
|
CastOpAxisInfoVisitor<mlir::UnrealizedConversionCastOp>,
|
|
CastOpAxisInfoVisitor<triton::BitcastOp>>();
|
|
// TODO: Remove rules for LLVM::ConstantOp, LLVM::AddOp
|
|
// when scf.for supports integers induction variable
|
|
visitors.append<MakeRangeOpAxisInfoVisitor>();
|
|
visitors.append<ConstantOpAxisInfoVisitor<arith::ConstantOp>,
|
|
ConstantOpAxisInfoVisitor<LLVM::ConstantOp>>();
|
|
visitors.append<AddSubOpAxisInfoVisitor<triton::AddPtrOp>,
|
|
AddSubOpAxisInfoVisitor<arith::AddIOp>,
|
|
AddSubOpAxisInfoVisitor<arith::SubIOp>,
|
|
AddSubOpAxisInfoVisitor<LLVM::AddOp>>();
|
|
visitors.append<MulIOpAxisInfoVisitor>();
|
|
visitors.append<DivOpAxisInfoVisitor<arith::DivSIOp>,
|
|
DivOpAxisInfoVisitor<arith::DivUIOp>>();
|
|
visitors.append<RemOpAxisInfoVisitor<arith::RemSIOp>,
|
|
RemOpAxisInfoVisitor<arith::RemUIOp>>();
|
|
visitors.append<BroadcastOpAxisInfoVisitor>();
|
|
visitors.append<SplatOpAxisInfoVisitor>();
|
|
visitors.append<ExpandDimsOpAxisInfoVisitor>();
|
|
visitors.append<CmpOpAxisInfoVisitor<arith::CmpIOp>,
|
|
CmpOpAxisInfoVisitor<triton::gpu::CmpIOp>>();
|
|
visitors.append<LogicalOpAxisInfoVisitor<arith::AndIOp>,
|
|
LogicalOpAxisInfoVisitor<arith::OrIOp>,
|
|
LogicalOpAxisInfoVisitor<arith::XOrIOp>>();
|
|
visitors.append<SelectOpAxisInfoVisitor<mlir::arith::SelectOp>,
|
|
SelectOpAxisInfoVisitor<triton::gpu::SelectOp>>();
|
|
visitors.append<ShLIOpAxisInfoVisitor, ShROpAxisInfoVisitor<arith::ShRUIOp>,
|
|
ShROpAxisInfoVisitor<arith::ShRSIOp>>();
|
|
visitors.append<MaxMinOpAxisInfoVisitor<arith::MaxSIOp>,
|
|
MaxMinOpAxisInfoVisitor<arith::MaxUIOp>,
|
|
MaxMinOpAxisInfoVisitor<arith::MinSIOp>,
|
|
MaxMinOpAxisInfoVisitor<arith::MinUIOp>>();
|
|
}
|
|
|
|
void AxisInfoAnalysis::visitOperation(
|
|
Operation *op, ArrayRef<const dataflow::Lattice<AxisInfo> *> operands,
|
|
ArrayRef<dataflow::Lattice<AxisInfo> *> results) {
|
|
// TODO: For sure not the right way to do this
|
|
// but why is scf.if not initialized otherwise?
|
|
for (auto op : operands)
|
|
if (op->getValue().getRank() == 0)
|
|
setToEntryState((dataflow::Lattice<AxisInfo> *)op);
|
|
AxisInfo curr = visitors.apply(op, operands);
|
|
if (curr.getRank() == 0)
|
|
return setAllToEntryStates(results);
|
|
// override with hint
|
|
auto newContiguity = curr.getContiguity();
|
|
auto newDivisibility = curr.getDivisibility();
|
|
auto newConstancy = curr.getConstancy();
|
|
if (Attribute attr = op->getAttr("tt.contiguity")) {
|
|
auto vals = attr.cast<DenseElementsAttr>().getValues<int>();
|
|
newContiguity = AxisInfo::DimVectorT(vals.begin(), vals.end());
|
|
}
|
|
if (Attribute attr = op->getAttr("tt.divisibility")) {
|
|
auto vals = attr.cast<DenseElementsAttr>().getValues<int>();
|
|
newDivisibility = AxisInfo::DimVectorT(vals.begin(), vals.end());
|
|
}
|
|
if (Attribute attr = op->getAttr("tt.constancy")) {
|
|
auto vals = attr.cast<DenseElementsAttr>().getValues<int>();
|
|
newConstancy = AxisInfo::DimVectorT(vals.begin(), vals.end());
|
|
}
|
|
curr = mlir::AxisInfo(newContiguity, newDivisibility, newConstancy,
|
|
curr.getConstantValue());
|
|
// join all lattice elements
|
|
for (auto *result : results)
|
|
propagateIfChanged(result, result->join(curr));
|
|
}
|
|
|
|
unsigned ModuleAxisInfoAnalysis::getPtrContiguity(Value ptr) {
|
|
auto tensorTy = ptr.getType().dyn_cast<RankedTensorType>();
|
|
if (!tensorTy)
|
|
return 1;
|
|
auto layout = tensorTy.getEncoding();
|
|
auto shape = tensorTy.getShape();
|
|
|
|
// Here order should be ordered by contiguous first, so the first element
|
|
// should have the largest contiguous.
|
|
auto order = triton::gpu::getOrder(layout);
|
|
unsigned align = getPtrAlignment(ptr);
|
|
|
|
auto uniqueContigPerThread = triton::gpu::getUniqueContigPerThread(tensorTy);
|
|
assert(order[0] < uniqueContigPerThread.size() &&
|
|
"Unxpected uniqueContigPerThread size");
|
|
unsigned contiguity = uniqueContigPerThread[order[0]];
|
|
contiguity = std::min(align, contiguity);
|
|
|
|
return contiguity;
|
|
}
|
|
|
|
unsigned ModuleAxisInfoAnalysis::getPtrAlignment(Value ptr) {
|
|
auto tensorTy = ptr.getType().dyn_cast<RankedTensorType>();
|
|
if (!tensorTy)
|
|
return 1;
|
|
auto *axisInfo = getAxisInfo(ptr);
|
|
if (!axisInfo)
|
|
return 1;
|
|
auto layout = tensorTy.getEncoding();
|
|
auto order = triton::gpu::getOrder(layout);
|
|
auto maxMultipleBytes = axisInfo->getDivisibility(order[0]);
|
|
auto maxContig = axisInfo->getContiguity(order[0]);
|
|
auto elemNumBits = triton::getPointeeBitWidth(tensorTy);
|
|
auto elemNumBytes = std::max<unsigned>(elemNumBits / 8, 1);
|
|
auto maxMultiple = std::max<int64_t>(maxMultipleBytes / elemNumBytes, 1);
|
|
unsigned alignment = std::min(maxMultiple, maxContig);
|
|
return alignment;
|
|
}
|
|
|
|
unsigned ModuleAxisInfoAnalysis::getMaskAlignment(Value mask) {
|
|
auto tensorTy = mask.getType().dyn_cast<RankedTensorType>();
|
|
if (!tensorTy)
|
|
return 1;
|
|
auto *axisInfo = getAxisInfo(mask);
|
|
if (!axisInfo)
|
|
return 1;
|
|
auto maskOrder = triton::gpu::getOrder(tensorTy.getEncoding());
|
|
auto alignment = std::max<unsigned>(axisInfo->getConstancy(maskOrder[0]), 1);
|
|
return alignment;
|
|
}
|
|
|
|
void ModuleAxisInfoAnalysis::initialize(FunctionOpInterface funcOp) {
|
|
std::unique_ptr<DataFlowSolver> solver = createDataFlowSolver();
|
|
AxisInfoAnalysis *analysis = solver->load<AxisInfoAnalysis>();
|
|
if (failed(solver->initializeAndRun(funcOp)))
|
|
return;
|
|
auto *axisInfoMap = getFuncData(funcOp);
|
|
auto updateAxisInfoMap = [&](Value value) {
|
|
auto axisInfo = analysis->getLatticeElement(value)->getValue();
|
|
AxisInfo curAxisInfo;
|
|
if (axisInfoMap->count(value)) {
|
|
curAxisInfo = AxisInfo::join(axisInfo, axisInfoMap->lookup(value));
|
|
} else {
|
|
curAxisInfo = axisInfo;
|
|
}
|
|
(*axisInfoMap)[value] = curAxisInfo;
|
|
};
|
|
funcOp.walk([&](Operation *op) {
|
|
for (auto value : op->getResults()) {
|
|
updateAxisInfoMap(value);
|
|
}
|
|
});
|
|
funcOp.walk([&](Block *block) {
|
|
for (auto value : block->getArguments()) {
|
|
updateAxisInfoMap(value);
|
|
}
|
|
});
|
|
}
|
|
|
|
void ModuleAxisInfoAnalysis::update(CallOpInterface callOp,
|
|
FunctionOpInterface callee) {
|
|
auto caller = callOp->getParentOfType<FunctionOpInterface>();
|
|
auto *axisInfoMap = getFuncData(caller);
|
|
for (auto entry : llvm::enumerate(callOp->getOperands())) {
|
|
auto index = entry.index();
|
|
auto value = entry.value();
|
|
auto setAttrFn = [&](StringRef attrName, int64_t prevValue) {
|
|
auto curValue = highestPowOf2Divisor<int64_t>(0);
|
|
if (callee.getArgAttrOfType<IntegerAttr>(index, attrName)) {
|
|
curValue =
|
|
callee.getArgAttrOfType<IntegerAttr>(index, attrName).getInt();
|
|
}
|
|
auto attr = IntegerAttr::get(IntegerType::get(callee.getContext(), 64),
|
|
gcd(prevValue, curValue));
|
|
callee.setArgAttr(index, attrName, attr);
|
|
};
|
|
auto axisInfo = axisInfoMap->lookup(value);
|
|
assert(axisInfo.getRank() == 1 && "only scalar arguments are supported");
|
|
setAttrFn("tt.contiguity", axisInfo.getContiguity(0));
|
|
setAttrFn("tt.divisibility", axisInfo.getDivisibility(0));
|
|
setAttrFn("tt.constancy", axisInfo.getConstancy(0));
|
|
}
|
|
}
|
|
|
|
} // namespace mlir
|