mirror of
https://github.com/ROCm/ROCm.git
synced 2026-04-05 03:01:17 -04:00
# Introducing the `noinline` Parameter for Triton JIT Decorator
We're excited to introduce a new parameter, `noinline`, that can be
added to the `jit` decorator in Triton. This parameter allows developers
to specify that a particular Triton function should not be inlined into
its callers. In this post, we'll dive into the syntax, purpose, and
implementation details of this new feature.
## Syntax
To use the `noinline` parameter, simply add `noinline=True` to the `jit`
decorator for the function that you don't want to be inlined. Here's an
example:
```python
@triton.jit(noinline=True)
def device_fn(x, y, Z):
z = x + y
tl.store(Z, z)
def test_noinline():
@triton.jit
def kernel(X, Y, Z):
x = tl.load(X)
y = tl.load(Y)
device_fn(x, y, Z)
```
In this example, the `device_fn` function is decorated with
`@triton.jit(noinline=True)`, indicating that it should not be inlined
into its caller, `kernel`.
## Purpose
The `noinline` parameter serves several key purposes:
- Reducing code size: By preventing inlining, we can reduce the size of
the compiled code.
- Facilitating debugging: Keeping functions separate can make it easier
to debug the code.
- Avoiding common subexpression elimination (CSE) in certain cases: CSE
can sometimes be avoided by using the `noinline` parameter to reduce
register pressure.
- Enabling dynamic linking: This parameter makes it possible to
dynamically link Triton functions.
## Implementation
The implementation of the `noinline` parameter involves significant
changes to three analysis modules in Triton: *Allocation*, *Membar*, and
*AxisInfo*. Prior to this update, these modules assumed that all Triton
functions had been inlined into the root kernel function. With the
introduction of non-inlined functions, we've had to rework these
assumptions and make corresponding changes to the analyses.
### Call Graph and Limitations
<div style="text-align: center;">
<img
src="https://user-images.githubusercontent.com/2306281/234663904-12864247-3412-4405-987b-6991cdf053bb.png"
alt="figure 1" width="200" height="auto">
</div>
To address the changes, we build a call graph and perform all the
analyses on the call graph instead of a single function. The call graph
is constructed by traversing the call edges and storing them in an edge
map. Roots are extracted by checking nodes with no incoming edges.
The call graph has certain limitations:
- It does not support recursive function calls, although this could be
implemented in the future.
- It does not support dynamic function calls, where the function name is
unknown at compilation time.
### Allocation
<div style="text-align: center;">
<img
src="https://user-images.githubusercontent.com/2306281/234665110-bf6a2660-06fb-4648-85dc-16429439e72d.png"
alt="figure 2" width="400" height="auto">
</div>
In Triton, shared memory allocation is achieved through two operations:
`triton_gpu.convert_layout` and `triton_gpu.alloc_tensor`. The
`convert_layout` operation allocates an internal tensor, which we refer
to as a *scratch* buffer, while the `alloc_tensor` operation returns an
allocated tensor and is thus known as an *explicit* buffer.
To accommodate the introduction of function calls, we are introducing a
third type of buffer called a *virtual* buffer. Similar to scratch
buffers, virtual buffers are allocated internally within the scope of a
function call, and the buffers allocated by the called functions remain
invisible to subsequent operations in the calling function. However,
virtual buffers are distinct from scratch buffers in that the call
operation itself does not allocate memory—instead, it specifies the
total amount of memory required by all the child functions being called.
The actual allocation of buffers is performed by individual operations
within these child functions. For example, when invoking edge e1, no
memory is allocated, but the total amount of memory needed by function B
is reserved. Notably, the amount of shared memory used by function B
remains fixed across its call sites due to the consideration of dynamic
control flows within each function.
An additional challenge to address is the calculation of shared memory
offsets for functions within a call graph. While we can assume a shared
memory offset starting at 0 for a single root function, this is not the
case with a call graph, where we must determine each function's starting
offset based on the call path. Although each function has a fixed memory
consumption, the starting offset may vary. For instance, in Figure 2,
the starting offset of function C through edges e1->e2 differs from that
through edges e2->e4. To handle this, we accumulate the starting offset
at each call site and pass it as an argument to the called function.
Additionally, we amend both the function declaration and call sites by
appending an offset variable.
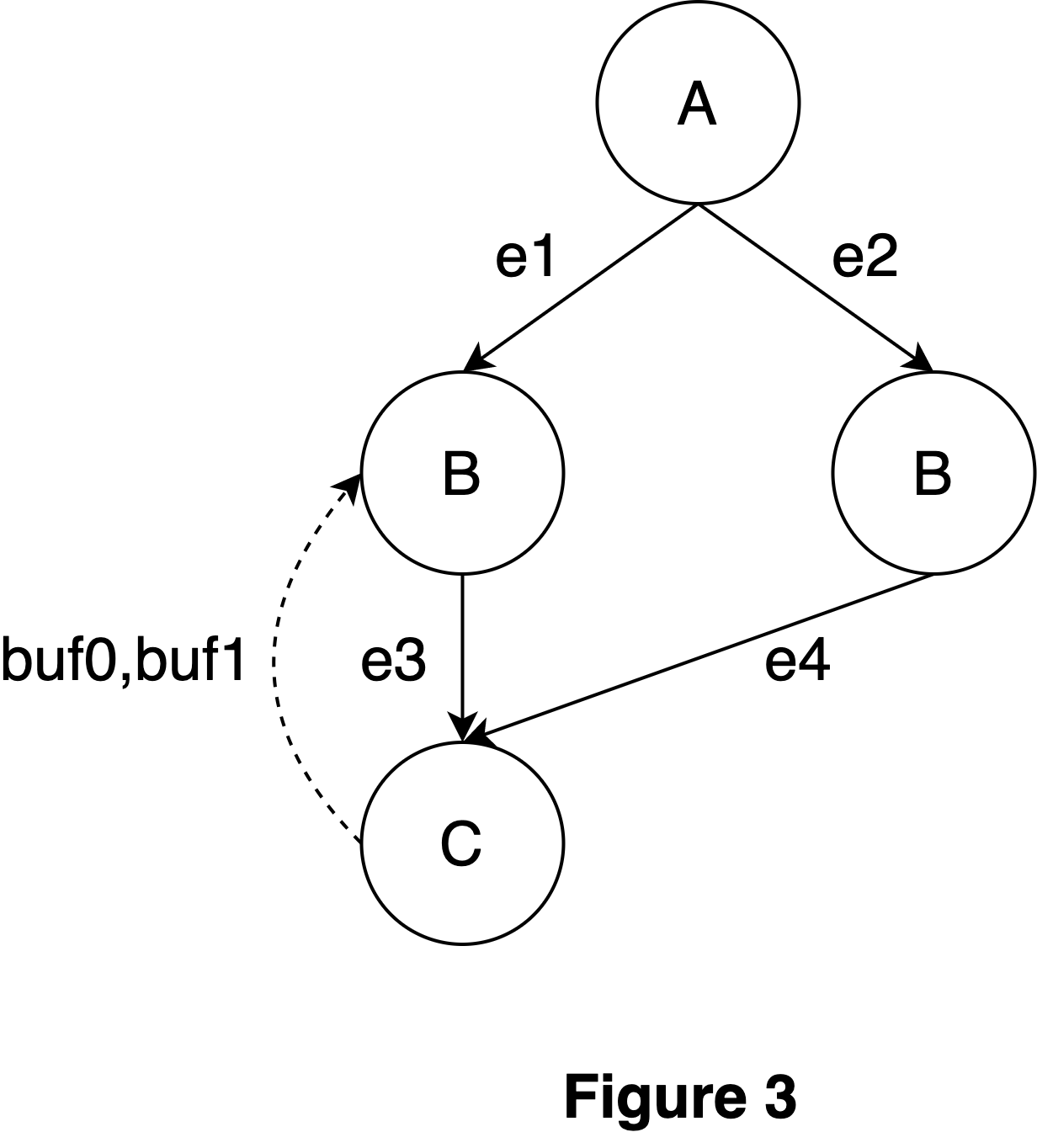
### Membar
<div style="text-align: center;">
<img
src="https://user-images.githubusercontent.com/2306281/234665157-844dd66f-5028-4ef3-bca2-4ca74b8f969d.png"
alt="figure 3" width="300" height="auto">
</div>
The membar pass is dependent on the allocation analysis. Once the offset
and size of each buffer are known, we conduct a post-order traversal of
the call graph and analyze each function on an individual basis. Unlike
previous analyses, we now return buffers that remain unsynchronized at
the end of functions, allowing the calling function to perform
synchronization in cases of overlap.
### AxisInfo
<div style="text-align: center;">
<img
src="https://user-images.githubusercontent.com/2306281/234665183-790a11ac-0ba1-47e1-98b1-e356220405a3.png"
alt="figure 4" width="400" height="auto">
</div>
The AxisInfo analysis operates differently from both membar and
allocation, as it traverses the call graph in topological order. This is
necessary because function arguments may contain axis information that
will be utilized by callee functions. As we do not implement
optimizations like function cloning, each function has a single code
base, and the axis information for an argument is determined as a
conservative result of all axis information passed by the calling
functions.
---------
Co-authored-by: Philippe Tillet <phil@openai.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
869 lines
34 KiB
C++
869 lines
34 KiB
C++
#include "mlir/IR/Matchers.h"
|
|
#include "mlir/IR/TypeUtilities.h"
|
|
|
|
#include "ConvertLayoutOpToLLVM.h"
|
|
#include "LoadStoreOpToLLVM.h"
|
|
|
|
using namespace mlir;
|
|
using namespace mlir::triton;
|
|
|
|
using ::mlir::LLVM::getSharedMemoryObjectFromStruct;
|
|
using ::mlir::triton::gpu::getTotalElemsPerThread;
|
|
using ::mlir::triton::gpu::SharedEncodingAttr;
|
|
|
|
// Contains some helper functions for both Load and Store conversions.
|
|
struct LoadStoreConversionBase {
|
|
explicit LoadStoreConversionBase(ModuleAxisInfoAnalysis &axisAnalysisPass)
|
|
: axisAnalysisPass(axisAnalysisPass) {}
|
|
|
|
unsigned getContiguity(Value ptr) const {
|
|
auto tensorTy = ptr.getType().dyn_cast<RankedTensorType>();
|
|
if (!tensorTy)
|
|
return 1;
|
|
return axisAnalysisPass.getPtrContiguity(ptr);
|
|
}
|
|
|
|
unsigned getVectorSize(Value ptr) const {
|
|
auto tensorTy = ptr.getType().dyn_cast<RankedTensorType>();
|
|
if (!tensorTy)
|
|
return 1;
|
|
auto contiguity = getContiguity(ptr);
|
|
auto pointeeBitWidth = triton::getPointeeBitWidth(tensorTy);
|
|
// The maximum vector size is 128 bits on NVIDIA GPUs.
|
|
return std::min<unsigned>(128 / pointeeBitWidth, contiguity);
|
|
}
|
|
|
|
unsigned getMaskAlignment(Value mask) const {
|
|
return axisAnalysisPass.getMaskAlignment(mask);
|
|
}
|
|
|
|
protected:
|
|
ModuleAxisInfoAnalysis &axisAnalysisPass;
|
|
};
|
|
|
|
struct LoadOpConversion
|
|
: public ConvertTritonGPUOpToLLVMPattern<triton::LoadOp>,
|
|
public LoadStoreConversionBase {
|
|
using ConvertTritonGPUOpToLLVMPattern<
|
|
triton::LoadOp>::ConvertTritonGPUOpToLLVMPattern;
|
|
|
|
LoadOpConversion(TritonGPUToLLVMTypeConverter &converter,
|
|
ModuleAxisInfoAnalysis &axisAnalysisPass,
|
|
PatternBenefit benefit)
|
|
: ConvertTritonGPUOpToLLVMPattern<triton::LoadOp>(converter, benefit),
|
|
LoadStoreConversionBase(axisAnalysisPass) {}
|
|
|
|
LogicalResult
|
|
matchAndRewrite(triton::LoadOp op, OpAdaptor adaptor,
|
|
ConversionPatternRewriter &rewriter) const override {
|
|
auto loc = op->getLoc();
|
|
|
|
// original values
|
|
Value ptr = op.getPtr();
|
|
Value mask = op.getMask();
|
|
Value other = op.getOther();
|
|
|
|
// adaptor values
|
|
Value llPtr = adaptor.getPtr();
|
|
Value llMask = adaptor.getMask();
|
|
Value llOther = adaptor.getOther();
|
|
|
|
// Determine the vectorization size
|
|
Type valueTy = op.getResult().getType();
|
|
Type valueElemTy =
|
|
typeConverter->convertType(getElementTypeOrSelf(valueTy));
|
|
unsigned vec = getVectorSize(ptr);
|
|
unsigned numElems = getTotalElemsPerThread(ptr.getType());
|
|
if (llMask)
|
|
vec = std::min<size_t>(vec, getMaskAlignment(mask));
|
|
|
|
// Get the LLVM values for pointers
|
|
auto ptrElems = getTypeConverter()->unpackLLElements(loc, llPtr, rewriter,
|
|
ptr.getType());
|
|
assert(ptrElems.size() == numElems);
|
|
|
|
// Get the LLVM values for mask
|
|
SmallVector<Value> maskElems;
|
|
if (llMask) {
|
|
maskElems = getTypeConverter()->unpackLLElements(loc, llMask, rewriter,
|
|
mask.getType());
|
|
assert(maskElems.size() == numElems);
|
|
}
|
|
|
|
// Get the LLVM values for `other`
|
|
// TODO: (goostavz) handle when other is const but not splat, which
|
|
// should be rarely seen
|
|
bool otherIsSplatConstInt = false;
|
|
DenseElementsAttr constAttr;
|
|
int64_t splatVal = 0;
|
|
if (other && valueElemTy.isa<IntegerType>() &&
|
|
matchPattern(other, m_Constant(&constAttr)) && constAttr.isSplat() &&
|
|
constAttr.getElementType().isa<IntegerType>()) {
|
|
otherIsSplatConstInt = true;
|
|
splatVal = constAttr.getSplatValue<APInt>().getSExtValue();
|
|
}
|
|
SmallVector<Value> otherElems;
|
|
if (other) {
|
|
otherElems = getTypeConverter()->unpackLLElements(loc, llOther, rewriter,
|
|
other.getType());
|
|
}
|
|
|
|
// vectorized iteration through all the pointer/mask/other elements
|
|
const int valueElemNBits =
|
|
std::max(8u, valueElemTy.getIntOrFloatBitWidth());
|
|
const int numVecs = numElems / vec;
|
|
|
|
SmallVector<Value> loadedVals;
|
|
for (size_t vecStart = 0; vecStart < numElems; vecStart += vec) {
|
|
// TODO: optimization when ptr is GEP with constant offset
|
|
size_t in_off = 0;
|
|
|
|
const size_t maxWordWidth = std::max<size_t>(32, valueElemNBits);
|
|
const size_t totalWidth = valueElemNBits * vec;
|
|
const size_t width = std::min(totalWidth, maxWordWidth);
|
|
const size_t nWords = std::max<size_t>(1, totalWidth / width);
|
|
const size_t wordNElems = width / valueElemNBits;
|
|
const size_t movWidth = width < 16 ? 16 : width;
|
|
assert(wordNElems * nWords * numVecs == numElems);
|
|
|
|
// TODO(Superjomn) Add cache policy fields to StoreOp.
|
|
// TODO(Superjomn) Deal with cache policy here.
|
|
const bool hasL2EvictPolicy = false;
|
|
|
|
PTXBuilder ptxBuilder;
|
|
|
|
Value pred = mask ? maskElems[vecStart] : int_val(1, 1);
|
|
|
|
const std::string readConstraint =
|
|
(width == 64) ? "l" : ((width == 32) ? "r" : "c");
|
|
const std::string writeConstraint =
|
|
(width == 64) ? "=l" : ((width == 32) ? "=r" : "=c");
|
|
|
|
// prepare asm operands
|
|
auto *dstsOpr = ptxBuilder.newListOperand();
|
|
for (size_t wordIdx = 0; wordIdx < nWords; ++wordIdx) {
|
|
auto *opr = ptxBuilder.newOperand(writeConstraint,
|
|
/*init=*/true); // =r operations
|
|
dstsOpr->listAppend(opr);
|
|
}
|
|
|
|
auto *addrOpr =
|
|
ptxBuilder.newAddrOperand(ptrElems[vecStart], "l", in_off);
|
|
|
|
// Define the instruction opcode
|
|
auto &ld = ptxBuilder.create<>("ld")
|
|
->o("volatile", op.getIsVolatile())
|
|
.global()
|
|
.o("ca", op.getCache() == triton::CacheModifier::CA)
|
|
.o("cg", op.getCache() == triton::CacheModifier::CG)
|
|
.o("L1::evict_first",
|
|
op.getEvict() == triton::EvictionPolicy::EVICT_FIRST)
|
|
.o("L1::evict_last",
|
|
op.getEvict() == triton::EvictionPolicy::EVICT_LAST)
|
|
.o("L1::cache_hint", hasL2EvictPolicy)
|
|
.v(nWords)
|
|
.b(width);
|
|
|
|
PTXBuilder::Operand *evictOpr{};
|
|
|
|
// Here lack a mlir::Value to bind to this operation, so disabled.
|
|
// if (has_l2_evict_policy)
|
|
// evictOpr = ptxBuilder.newOperand(l2Evict, "l");
|
|
|
|
if (!evictOpr)
|
|
ld(dstsOpr, addrOpr).predicate(pred, "b");
|
|
else
|
|
ld(dstsOpr, addrOpr, evictOpr).predicate(pred, "b");
|
|
|
|
if (other) {
|
|
for (size_t ii = 0; ii < nWords; ++ii) {
|
|
// PTX doesn't support mov.u8, so we need to use mov.u16
|
|
PTXInstr &mov =
|
|
ptxBuilder.create<>("mov")->o("u" + std::to_string(movWidth));
|
|
|
|
size_t size = width / valueElemNBits;
|
|
|
|
auto vecTy = LLVM::getFixedVectorType(valueElemTy, size);
|
|
Value v = undef(vecTy);
|
|
for (size_t s = 0; s < size; ++s) {
|
|
Value falseVal = otherElems[vecStart + ii * size + s];
|
|
Value sVal = createIndexAttrConstant(
|
|
rewriter, loc, this->getTypeConverter()->getIndexType(), s);
|
|
v = insert_element(vecTy, v, falseVal, sVal);
|
|
}
|
|
v = bitcast(v, IntegerType::get(getContext(), width));
|
|
|
|
PTXInstr::Operand *opr{};
|
|
|
|
if (otherIsSplatConstInt) {
|
|
for (size_t s = 0; s < 32; s += valueElemNBits)
|
|
splatVal |= splatVal << valueElemNBits;
|
|
opr = ptxBuilder.newConstantOperand(splatVal);
|
|
} else
|
|
opr = ptxBuilder.newOperand(v, readConstraint);
|
|
|
|
mov(dstsOpr->listGet(ii), opr).predicateNot(pred, "b");
|
|
}
|
|
}
|
|
|
|
// Create inline ASM signature
|
|
SmallVector<Type> retTys(nWords, IntegerType::get(getContext(), width));
|
|
Type retTy = retTys.size() > 1
|
|
? LLVM::LLVMStructType::getLiteral(getContext(), retTys)
|
|
: retTys[0];
|
|
|
|
// TODO: if (has_l2_evict_policy)
|
|
// auto asmDialectAttr =
|
|
// LLVM::AsmDialectAttr::get(rewriter.getContext(),
|
|
// LLVM::AsmDialect::AD_ATT);
|
|
Value ret = ptxBuilder.launch(rewriter, loc, retTy);
|
|
|
|
// Extract and store return values
|
|
SmallVector<Value> rets;
|
|
for (unsigned int ii = 0; ii < nWords; ++ii) {
|
|
Value curr;
|
|
if (retTy.isa<LLVM::LLVMStructType>()) {
|
|
curr = extract_val(IntegerType::get(getContext(), width), ret, ii);
|
|
} else {
|
|
curr = ret;
|
|
}
|
|
curr = bitcast(curr, LLVM::getFixedVectorType(valueElemTy,
|
|
width / valueElemNBits));
|
|
rets.push_back(curr);
|
|
}
|
|
int tmp = width / valueElemNBits;
|
|
for (size_t ii = 0; ii < vec; ++ii) {
|
|
Value vecIdx = createIndexAttrConstant(
|
|
rewriter, loc, this->getTypeConverter()->getIndexType(), ii % tmp);
|
|
Value loaded = extract_element(valueElemTy, rets[ii / tmp], vecIdx);
|
|
loadedVals.push_back(loaded);
|
|
}
|
|
} // end vec
|
|
|
|
Type llvmResultStructTy = getTypeConverter()->convertType(valueTy);
|
|
Value resultStruct = getTypeConverter()->packLLElements(
|
|
loc, loadedVals, rewriter, llvmResultStructTy);
|
|
rewriter.replaceOp(op, {resultStruct});
|
|
return success();
|
|
}
|
|
};
|
|
|
|
struct StoreOpConversion
|
|
: public ConvertTritonGPUOpToLLVMPattern<triton::StoreOp>,
|
|
public LoadStoreConversionBase {
|
|
using ConvertTritonGPUOpToLLVMPattern<
|
|
triton::StoreOp>::ConvertTritonGPUOpToLLVMPattern;
|
|
|
|
StoreOpConversion(TritonGPUToLLVMTypeConverter &converter,
|
|
ModuleAxisInfoAnalysis &axisAnalysisPass,
|
|
PatternBenefit benefit)
|
|
: ConvertTritonGPUOpToLLVMPattern<triton::StoreOp>(converter, benefit),
|
|
LoadStoreConversionBase(axisAnalysisPass) {}
|
|
|
|
LogicalResult
|
|
matchAndRewrite(triton::StoreOp op, OpAdaptor adaptor,
|
|
ConversionPatternRewriter &rewriter) const override {
|
|
Value ptr = op.getPtr();
|
|
Value value = op.getValue();
|
|
|
|
Value llPtr = adaptor.getPtr();
|
|
Value llMask = adaptor.getMask();
|
|
Value llValue = adaptor.getValue();
|
|
|
|
auto loc = op->getLoc();
|
|
MLIRContext *ctx = rewriter.getContext();
|
|
|
|
auto valueTy = value.getType();
|
|
Type valueElemTy =
|
|
typeConverter->convertType(getElementTypeOrSelf(valueTy));
|
|
|
|
unsigned vec = getVectorSize(ptr);
|
|
unsigned elemsPerThread = getTotalElemsPerThread(ptr.getType());
|
|
|
|
auto ptrElems = getTypeConverter()->unpackLLElements(loc, llPtr, rewriter,
|
|
ptr.getType());
|
|
auto valueElems = getTypeConverter()->unpackLLElements(
|
|
loc, llValue, rewriter, value.getType());
|
|
assert(ptrElems.size() == valueElems.size());
|
|
|
|
// Determine the vectorization size
|
|
SmallVector<Value> maskElems;
|
|
if (llMask) {
|
|
Value mask = op.getMask();
|
|
maskElems = getTypeConverter()->unpackLLElements(loc, llMask, rewriter,
|
|
mask.getType());
|
|
assert(valueElems.size() == maskElems.size());
|
|
|
|
unsigned maskAlign = getMaskAlignment(mask);
|
|
vec = std::min(vec, maskAlign);
|
|
}
|
|
|
|
// numElements = 1 for scalar
|
|
auto tensorTy = valueTy.dyn_cast<RankedTensorType>();
|
|
auto numElems = tensorTy ? tensorTy.getNumElements() : 1;
|
|
Value mask = int_val(1, 1);
|
|
auto tid = tid_val();
|
|
mask = and_(mask,
|
|
icmp_slt(mul(tid, i32_val(elemsPerThread)), i32_val(numElems)));
|
|
|
|
const size_t dtsize =
|
|
std::max<int>(1, valueElemTy.getIntOrFloatBitWidth() / 8);
|
|
const size_t valueElemNBits = dtsize * 8;
|
|
|
|
const int numVecs = elemsPerThread / vec;
|
|
for (size_t vecStart = 0; vecStart < elemsPerThread; vecStart += vec) {
|
|
// TODO: optimization when ptr is AddPtr with constant offset
|
|
size_t in_off = 0;
|
|
|
|
const size_t maxWordWidth = std::max<size_t>(32, valueElemNBits);
|
|
const size_t totalWidth = valueElemNBits * vec;
|
|
const size_t width = std::min(totalWidth, maxWordWidth);
|
|
const size_t nWords = std::max<size_t>(1, totalWidth / width);
|
|
const size_t wordNElems = width / valueElemNBits;
|
|
assert(wordNElems * nWords * numVecs == elemsPerThread);
|
|
|
|
// TODO(Superjomn) Add cache policy fields to StoreOp.
|
|
// TODO(Superjomn) Deal with cache policy here.
|
|
|
|
Type valArgTy = IntegerType::get(ctx, width);
|
|
auto wordTy = vec_ty(valueElemTy, wordNElems);
|
|
|
|
SmallVector<std::pair<Value, std::string>> asmArgs;
|
|
for (size_t wordIdx = 0; wordIdx < nWords; ++wordIdx) {
|
|
// llWord is a width-len composition
|
|
Value llWord = undef(wordTy);
|
|
// Insert each value element to the composition
|
|
for (size_t elemIdx = 0; elemIdx < wordNElems; ++elemIdx) {
|
|
const size_t elemOffset = vecStart + wordIdx * wordNElems + elemIdx;
|
|
assert(elemOffset < valueElems.size());
|
|
Value elem = valueElems[elemOffset];
|
|
if (elem.getType().isInteger(1))
|
|
elem = sext(i8_ty, elem);
|
|
elem = bitcast(elem, valueElemTy);
|
|
|
|
llWord = insert_element(wordTy, llWord, elem, i32_val(elemIdx));
|
|
}
|
|
llWord = bitcast(llWord, valArgTy);
|
|
std::string constraint =
|
|
(width == 64) ? "l" : ((width == 32) ? "r" : "c");
|
|
asmArgs.emplace_back(llWord, constraint);
|
|
}
|
|
|
|
// Prepare the PTX inline asm.
|
|
PTXBuilder ptxBuilder;
|
|
auto *asmArgList = ptxBuilder.newListOperand(asmArgs);
|
|
|
|
Value maskVal = llMask ? and_(mask, maskElems[vecStart]) : mask;
|
|
|
|
auto *asmAddr =
|
|
ptxBuilder.newAddrOperand(ptrElems[vecStart], "l", in_off);
|
|
|
|
auto &ptxStoreInstr =
|
|
ptxBuilder.create<>("st")->global().v(nWords).b(width);
|
|
ptxStoreInstr(asmAddr, asmArgList).predicate(maskVal, "b");
|
|
|
|
Type boolTy = getTypeConverter()->convertType(rewriter.getIntegerType(1));
|
|
llvm::SmallVector<Type> argTys({boolTy, ptr.getType()});
|
|
argTys.insert(argTys.end(), nWords, valArgTy);
|
|
|
|
auto asmReturnTy = void_ty(ctx);
|
|
|
|
ptxBuilder.launch(rewriter, loc, asmReturnTy);
|
|
}
|
|
rewriter.eraseOp(op);
|
|
return success();
|
|
}
|
|
};
|
|
|
|
struct AtomicCASOpConversion
|
|
: public ConvertTritonGPUOpToLLVMPattern<triton::AtomicCASOp>,
|
|
public LoadStoreConversionBase {
|
|
using ConvertTritonGPUOpToLLVMPattern<
|
|
triton::AtomicCASOp>::ConvertTritonGPUOpToLLVMPattern;
|
|
|
|
AtomicCASOpConversion(TritonGPUToLLVMTypeConverter &converter,
|
|
ModuleAllocation &allocation,
|
|
ModuleAxisInfoAnalysis &axisAnalysisPass,
|
|
PatternBenefit benefit)
|
|
: ConvertTritonGPUOpToLLVMPattern<triton::AtomicCASOp>(
|
|
converter, allocation, benefit),
|
|
LoadStoreConversionBase(axisAnalysisPass) {}
|
|
|
|
LogicalResult
|
|
matchAndRewrite(triton::AtomicCASOp op, OpAdaptor adaptor,
|
|
ConversionPatternRewriter &rewriter) const override {
|
|
auto loc = op.getLoc();
|
|
MLIRContext *ctx = rewriter.getContext();
|
|
|
|
Value llPtr = adaptor.getPtr();
|
|
Value llCmp = adaptor.getCmp();
|
|
Value llVal = adaptor.getVal();
|
|
|
|
auto ptrElements = getTypeConverter()->unpackLLElements(
|
|
loc, llPtr, rewriter, op.getPtr().getType());
|
|
auto cmpElements = getTypeConverter()->unpackLLElements(
|
|
loc, llCmp, rewriter, op.getCmp().getType());
|
|
auto valElements = getTypeConverter()->unpackLLElements(
|
|
loc, llVal, rewriter, op.getVal().getType());
|
|
|
|
auto TensorTy = op.getResult().getType().dyn_cast<RankedTensorType>();
|
|
Type valueElemTy =
|
|
TensorTy ? getTypeConverter()->convertType(TensorTy.getElementType())
|
|
: op.getResult().getType();
|
|
auto valueElemNBits = valueElemTy.getIntOrFloatBitWidth();
|
|
auto tid = tid_val();
|
|
Value pred = icmp_eq(tid, i32_val(0));
|
|
PTXBuilder ptxBuilderMemfence;
|
|
auto memfence = ptxBuilderMemfence.create<PTXInstr>("membar")->o("gl");
|
|
memfence();
|
|
auto ASMReturnTy = void_ty(ctx);
|
|
ptxBuilderMemfence.launch(rewriter, loc, ASMReturnTy);
|
|
|
|
Value atomPtr = getSharedMemoryBase(loc, rewriter, op.getOperation());
|
|
atomPtr = bitcast(atomPtr, ptr_ty(valueElemTy, 3));
|
|
Value casPtr = ptrElements[0];
|
|
Value casCmp = cmpElements[0];
|
|
Value casVal = valElements[0];
|
|
|
|
PTXBuilder ptxBuilderAtomicCAS;
|
|
auto *dstOpr = ptxBuilderAtomicCAS.newOperand("=r", /*init=*/true);
|
|
auto *ptrOpr = ptxBuilderAtomicCAS.newAddrOperand(casPtr, "l");
|
|
auto *cmpOpr = ptxBuilderAtomicCAS.newOperand(casCmp, "r");
|
|
auto *valOpr = ptxBuilderAtomicCAS.newOperand(casVal, "r");
|
|
auto &atom = *ptxBuilderAtomicCAS.create<PTXInstr>("atom");
|
|
atom.global().o("cas").o("b32");
|
|
atom(dstOpr, ptrOpr, cmpOpr, valOpr).predicate(pred);
|
|
auto old = ptxBuilderAtomicCAS.launch(rewriter, loc, valueElemTy);
|
|
barrier();
|
|
|
|
PTXBuilder ptxBuilderStore;
|
|
auto *dstOprStore = ptxBuilderStore.newAddrOperand(atomPtr, "r");
|
|
auto *valOprStore = ptxBuilderStore.newOperand(old, "r");
|
|
auto &st = *ptxBuilderStore.create<PTXInstr>("st");
|
|
st.shared().o("b32");
|
|
st(dstOprStore, valOprStore).predicate(pred);
|
|
ptxBuilderStore.launch(rewriter, loc, ASMReturnTy);
|
|
ptxBuilderMemfence.launch(rewriter, loc, ASMReturnTy);
|
|
barrier();
|
|
Value ret = load(atomPtr);
|
|
barrier();
|
|
rewriter.replaceOp(op, {ret});
|
|
return success();
|
|
}
|
|
};
|
|
|
|
struct AtomicRMWOpConversion
|
|
: public ConvertTritonGPUOpToLLVMPattern<triton::AtomicRMWOp>,
|
|
public LoadStoreConversionBase {
|
|
using ConvertTritonGPUOpToLLVMPattern<
|
|
triton::AtomicRMWOp>::ConvertTritonGPUOpToLLVMPattern;
|
|
|
|
AtomicRMWOpConversion(TritonGPUToLLVMTypeConverter &converter,
|
|
ModuleAllocation &allocation,
|
|
ModuleAxisInfoAnalysis &axisAnalysisPass,
|
|
PatternBenefit benefit)
|
|
: ConvertTritonGPUOpToLLVMPattern<triton::AtomicRMWOp>(
|
|
converter, allocation, benefit),
|
|
LoadStoreConversionBase(axisAnalysisPass) {}
|
|
|
|
LogicalResult
|
|
matchAndRewrite(triton::AtomicRMWOp op, OpAdaptor adaptor,
|
|
ConversionPatternRewriter &rewriter) const override {
|
|
auto loc = op.getLoc();
|
|
MLIRContext *ctx = rewriter.getContext();
|
|
|
|
auto atomicRmwAttr = op.getAtomicRmwOp();
|
|
|
|
Value val = op.getVal();
|
|
Value ptr = op.getPtr();
|
|
|
|
Value llPtr = adaptor.getPtr();
|
|
Value llVal = adaptor.getVal();
|
|
Value llMask = adaptor.getMask();
|
|
|
|
auto valElements = getTypeConverter()->unpackLLElements(
|
|
loc, llVal, rewriter, val.getType());
|
|
auto ptrElements = getTypeConverter()->unpackLLElements(
|
|
loc, llPtr, rewriter, ptr.getType());
|
|
SmallVector<Value> maskElements;
|
|
if (llMask)
|
|
maskElements = getTypeConverter()->unpackLLElements(
|
|
loc, llMask, rewriter, op.getMask().getType());
|
|
|
|
auto tensorTy = op.getResult().getType().dyn_cast<RankedTensorType>();
|
|
Type valueElemTy =
|
|
tensorTy ? getTypeConverter()->convertType(tensorTy.getElementType())
|
|
: op.getResult().getType();
|
|
const size_t valueElemNBits = valueElemTy.getIntOrFloatBitWidth();
|
|
auto elemsPerThread = getTotalElemsPerThread(val.getType());
|
|
// vec = 1, numElements = 1 for scalar
|
|
auto vec = getVectorSize(ptr);
|
|
int numElems = 1;
|
|
// tensor
|
|
if (tensorTy) {
|
|
auto valTy = val.getType().cast<RankedTensorType>();
|
|
vec = std::min<unsigned>(vec, valTy.getElementType().isF16() ? 2 : 1);
|
|
// mask
|
|
numElems = tensorTy.getNumElements();
|
|
}
|
|
Value mask = int_val(1, 1);
|
|
auto tid = tid_val();
|
|
mask = and_(mask,
|
|
icmp_slt(mul(tid, i32_val(elemsPerThread)), i32_val(numElems)));
|
|
|
|
auto vecTy = vec_ty(valueElemTy, vec);
|
|
SmallVector<Value> resultVals(elemsPerThread);
|
|
for (size_t i = 0; i < elemsPerThread; i += vec) {
|
|
Value rmwVal = undef(vecTy);
|
|
for (int ii = 0; ii < vec; ++ii) {
|
|
Value iiVal = createIndexAttrConstant(
|
|
rewriter, loc, getTypeConverter()->getIndexType(), ii);
|
|
rmwVal = insert_element(vecTy, rmwVal, valElements[i + ii], iiVal);
|
|
}
|
|
|
|
Value rmwPtr = ptrElements[i];
|
|
Value rmwMask = llMask ? and_(mask, maskElements[i]) : mask;
|
|
std::string sTy;
|
|
PTXBuilder ptxBuilderAtomicRMW;
|
|
std::string tyId = valueElemNBits * vec == 64
|
|
? "l"
|
|
: (valueElemNBits * vec == 32 ? "r" : "h");
|
|
auto *dstOpr = ptxBuilderAtomicRMW.newOperand("=" + tyId, /*init=*/true);
|
|
auto *ptrOpr = ptxBuilderAtomicRMW.newAddrOperand(rmwPtr, "l");
|
|
auto *valOpr = ptxBuilderAtomicRMW.newOperand(rmwVal, tyId);
|
|
|
|
auto &atom = ptxBuilderAtomicRMW.create<>("atom")->global().o("gpu");
|
|
auto rmwOp = stringifyRMWOp(atomicRmwAttr).str();
|
|
auto sBits = std::to_string(valueElemNBits);
|
|
switch (atomicRmwAttr) {
|
|
case RMWOp::AND:
|
|
sTy = "b" + sBits;
|
|
break;
|
|
case RMWOp::OR:
|
|
sTy = "b" + sBits;
|
|
break;
|
|
case RMWOp::XOR:
|
|
sTy = "b" + sBits;
|
|
break;
|
|
case RMWOp::ADD:
|
|
sTy = "s" + sBits;
|
|
break;
|
|
case RMWOp::FADD:
|
|
rmwOp = "add";
|
|
rmwOp += (valueElemNBits == 16 ? ".noftz" : "");
|
|
sTy = "f" + sBits;
|
|
sTy += (vec == 2 && valueElemNBits == 16) ? "x2" : "";
|
|
break;
|
|
case RMWOp::MAX:
|
|
sTy = "s" + sBits;
|
|
break;
|
|
case RMWOp::MIN:
|
|
sTy = "s" + sBits;
|
|
break;
|
|
case RMWOp::UMAX:
|
|
rmwOp = "max";
|
|
sTy = "u" + sBits;
|
|
break;
|
|
case RMWOp::UMIN:
|
|
rmwOp = "min";
|
|
sTy = "u" + sBits;
|
|
break;
|
|
case RMWOp::XCHG:
|
|
sTy = "b" + sBits;
|
|
break;
|
|
default:
|
|
return failure();
|
|
}
|
|
atom.o(rmwOp).o(sTy);
|
|
if (tensorTy) {
|
|
atom(dstOpr, ptrOpr, valOpr).predicate(rmwMask);
|
|
auto retType = vec == 1 ? valueElemTy : vecTy;
|
|
auto ret = ptxBuilderAtomicRMW.launch(rewriter, loc, retType);
|
|
for (int ii = 0; ii < vec; ++ii) {
|
|
resultVals[i + ii] =
|
|
vec == 1 ? ret : extract_element(valueElemTy, ret, i32_val(ii));
|
|
}
|
|
} else {
|
|
PTXBuilder ptxBuilderMemfence;
|
|
auto memfenc = ptxBuilderMemfence.create<PTXInstr>("membar")->o("gl");
|
|
memfenc();
|
|
auto ASMReturnTy = void_ty(ctx);
|
|
ptxBuilderMemfence.launch(rewriter, loc, ASMReturnTy);
|
|
rmwMask = and_(rmwMask, icmp_eq(tid, i32_val(0)));
|
|
atom(dstOpr, ptrOpr, valOpr).predicate(rmwMask);
|
|
auto old = ptxBuilderAtomicRMW.launch(rewriter, loc, valueElemTy);
|
|
Value atomPtr = getSharedMemoryBase(loc, rewriter, op.getOperation());
|
|
atomPtr = bitcast(atomPtr, ptr_ty(valueElemTy, 3));
|
|
// Only threads with rmwMask = True store the result
|
|
PTXBuilder ptxBuilderStore;
|
|
auto &storeShared =
|
|
ptxBuilderStore.create<>("st")->shared().o("b" + sBits);
|
|
auto *ptrOpr = ptxBuilderStore.newAddrOperand(atomPtr, "r");
|
|
auto *valOpr = ptxBuilderStore.newOperand(old, tyId);
|
|
storeShared(ptrOpr, valOpr).predicate(rmwMask);
|
|
ptxBuilderStore.launch(rewriter, loc, void_ty(ctx));
|
|
barrier();
|
|
Value ret = load(atomPtr);
|
|
barrier();
|
|
rewriter.replaceOp(op, {ret});
|
|
}
|
|
}
|
|
if (tensorTy) {
|
|
Type structTy = getTypeConverter()->convertType(tensorTy);
|
|
Value resultStruct = getTypeConverter()->packLLElements(
|
|
loc, resultVals, rewriter, structTy);
|
|
rewriter.replaceOp(op, {resultStruct});
|
|
}
|
|
return success();
|
|
}
|
|
};
|
|
|
|
struct InsertSliceOpConversion
|
|
: public ConvertTritonGPUOpToLLVMPattern<tensor::InsertSliceOp> {
|
|
using ConvertTritonGPUOpToLLVMPattern<
|
|
tensor::InsertSliceOp>::ConvertTritonGPUOpToLLVMPattern;
|
|
|
|
LogicalResult
|
|
matchAndRewrite(tensor::InsertSliceOp op, OpAdaptor adaptor,
|
|
ConversionPatternRewriter &rewriter) const override {
|
|
// %dst = insert_slice %src into %dst[%offsets]
|
|
Location loc = op->getLoc();
|
|
Value dst = op.getDest();
|
|
Value src = op.getSource();
|
|
Value res = op.getResult();
|
|
auto funcOp = op->getParentOfType<FunctionOpInterface>();
|
|
auto *funcAllocation = allocation->getFuncData(funcOp);
|
|
assert(funcAllocation->getBufferId(res) == Allocation::InvalidBufferId &&
|
|
"Only support in-place insert_slice for now");
|
|
|
|
auto srcTy = src.getType().dyn_cast<RankedTensorType>();
|
|
auto srcLayout = srcTy.getEncoding().dyn_cast<BlockedEncodingAttr>();
|
|
auto srcShape = srcTy.getShape();
|
|
assert(srcLayout && "Unexpected srcLayout in InsertSliceOpConversion");
|
|
|
|
auto dstTy = dst.getType().dyn_cast<RankedTensorType>();
|
|
auto dstLayout = dstTy.getEncoding().dyn_cast<SharedEncodingAttr>();
|
|
auto llDst = adaptor.getDest();
|
|
assert(dstLayout && "Unexpected dstLayout in InsertSliceOpConversion");
|
|
assert(op.hasUnitStride() &&
|
|
"Only unit stride supported by InsertSliceOpConversion");
|
|
|
|
// newBase = base + offset
|
|
// Triton support either static and dynamic offsets
|
|
auto smemObj = getSharedMemoryObjectFromStruct(loc, llDst, rewriter);
|
|
SmallVector<Value, 4> offsets;
|
|
SmallVector<Value, 4> srcStrides;
|
|
auto mixedOffsets = op.getMixedOffsets();
|
|
for (auto i = 0; i < mixedOffsets.size(); ++i) {
|
|
if (op.isDynamicOffset(i)) {
|
|
offsets.emplace_back(adaptor.getOffsets()[i]);
|
|
} else {
|
|
offsets.emplace_back(i32_val(op.getStaticOffset(i)));
|
|
}
|
|
// Like insert_slice_async, we only support slice from one dimension,
|
|
// which has a slice size of 1
|
|
if (op.getStaticSize(i) != 1) {
|
|
srcStrides.emplace_back(smemObj.strides[i]);
|
|
}
|
|
}
|
|
|
|
// Compute the offset based on the original strides of the shared memory
|
|
// object
|
|
auto offset = dot(rewriter, loc, offsets, smemObj.strides);
|
|
auto elemTy = getTypeConverter()->convertType(dstTy.getElementType());
|
|
auto elemPtrTy = ptr_ty(elemTy, 3);
|
|
auto smemBase = gep(elemPtrTy, smemObj.base, offset);
|
|
|
|
auto llSrc = adaptor.getSource();
|
|
auto srcIndices = emitIndices(loc, rewriter, srcLayout, srcTy);
|
|
storeDistributedToShared(src, llSrc, srcStrides, srcIndices, dst, smemBase,
|
|
elemTy, loc, rewriter);
|
|
// Barrier is not necessary.
|
|
// The membar pass knows that it writes to shared memory and will handle it
|
|
// properly.
|
|
rewriter.replaceOp(op, llDst);
|
|
return success();
|
|
}
|
|
};
|
|
|
|
struct InsertSliceAsyncOpConversion
|
|
: public ConvertTritonGPUOpToLLVMPattern<triton::gpu::InsertSliceAsyncOp>,
|
|
public LoadStoreConversionBase {
|
|
using ConvertTritonGPUOpToLLVMPattern<
|
|
triton::gpu::InsertSliceAsyncOp>::ConvertTritonGPUOpToLLVMPattern;
|
|
|
|
InsertSliceAsyncOpConversion(
|
|
TritonGPUToLLVMTypeConverter &converter, ModuleAllocation &allocation,
|
|
ConvertTritonGPUOpToLLVMPatternBase::IndexCacheInfo &indexCacheInfo,
|
|
ModuleAxisInfoAnalysis &axisAnalysisPass, PatternBenefit benefit)
|
|
: ConvertTritonGPUOpToLLVMPattern<triton::gpu::InsertSliceAsyncOp>(
|
|
converter, allocation, indexCacheInfo, benefit),
|
|
LoadStoreConversionBase(axisAnalysisPass) {}
|
|
|
|
LogicalResult
|
|
matchAndRewrite(triton::gpu::InsertSliceAsyncOp op, OpAdaptor adaptor,
|
|
ConversionPatternRewriter &rewriter) const override {
|
|
// insert_slice_async %src, %dst, %index, %mask, %other
|
|
auto loc = op.getLoc();
|
|
Value src = op.getSrc();
|
|
Value dst = op.getDst();
|
|
Value res = op.getResult();
|
|
Value mask = op.getMask();
|
|
Value other = op.getOther();
|
|
auto funcOp = op->getParentOfType<FunctionOpInterface>();
|
|
auto *funcAllocation = allocation->getFuncData(funcOp);
|
|
assert(funcAllocation->getBufferId(res) == Allocation::InvalidBufferId &&
|
|
"Only support in-place insert_slice_async for now");
|
|
|
|
auto srcTy = src.getType().cast<RankedTensorType>();
|
|
auto resTy = dst.getType().cast<RankedTensorType>();
|
|
auto resElemTy = getTypeConverter()->convertType(resTy.getElementType());
|
|
auto srcBlockedLayout = srcTy.getEncoding().cast<BlockedEncodingAttr>();
|
|
auto resSharedLayout = resTy.getEncoding().cast<SharedEncodingAttr>();
|
|
auto srcShape = srcTy.getShape();
|
|
assert(srcShape.size() == 2 &&
|
|
"insert_slice_async: Unexpected rank of %src");
|
|
|
|
Value llDst = adaptor.getDst();
|
|
Value llSrc = adaptor.getSrc();
|
|
Value llMask = adaptor.getMask();
|
|
Value llOther = adaptor.getOther();
|
|
Value llIndex = adaptor.getIndex();
|
|
|
|
// %src
|
|
auto srcElems = getTypeConverter()->unpackLLElements(loc, llSrc, rewriter,
|
|
src.getType());
|
|
|
|
// %dst
|
|
auto dstTy = dst.getType().cast<RankedTensorType>();
|
|
auto dstShape = dstTy.getShape();
|
|
auto smemObj = getSharedMemoryObjectFromStruct(loc, llDst, rewriter);
|
|
auto axis = op->getAttrOfType<IntegerAttr>("axis").getInt();
|
|
SmallVector<Value, 4> offsetVals;
|
|
SmallVector<Value, 4> srcStrides;
|
|
for (auto i = 0; i < dstShape.size(); ++i) {
|
|
if (i == axis) {
|
|
offsetVals.emplace_back(llIndex);
|
|
} else {
|
|
offsetVals.emplace_back(i32_val(0));
|
|
srcStrides.emplace_back(smemObj.strides[i]);
|
|
}
|
|
}
|
|
// Compute the offset based on the original dimensions of the shared
|
|
// memory object
|
|
auto dstOffset = dot(rewriter, loc, offsetVals, smemObj.strides);
|
|
auto dstPtrTy = ptr_ty(resElemTy, 3);
|
|
Value dstPtrBase = gep(dstPtrTy, smemObj.base, dstOffset);
|
|
|
|
// %mask
|
|
SmallVector<Value> maskElems;
|
|
if (llMask) {
|
|
maskElems = getTypeConverter()->unpackLLElements(loc, llMask, rewriter,
|
|
mask.getType());
|
|
assert(srcElems.size() == maskElems.size());
|
|
}
|
|
|
|
// %other
|
|
SmallVector<Value> otherElems;
|
|
if (llOther) {
|
|
// FIXME(Keren): always assume other is 0 for now
|
|
// It's not necessary for now because the pipeline pass will skip
|
|
// generating insert_slice_async if the load op has any "other" tensor.
|
|
// assert(false && "insert_slice_async: Other value not supported yet");
|
|
otherElems = getTypeConverter()->unpackLLElements(loc, llOther, rewriter,
|
|
other.getType());
|
|
assert(srcElems.size() == otherElems.size());
|
|
}
|
|
|
|
// We don't use getVec() here because we are copying from memory to memory.
|
|
// If contiguity > vector size, we can have one pointer maintaining the
|
|
// start of the vector and the other pointer moving to the next vector.
|
|
unsigned inVec = getContiguity(src);
|
|
unsigned outVec = resSharedLayout.getVec();
|
|
unsigned minVec = std::min(outVec, inVec);
|
|
unsigned numElems = getTotalElemsPerThread(srcTy);
|
|
unsigned perPhase = resSharedLayout.getPerPhase();
|
|
unsigned maxPhase = resSharedLayout.getMaxPhase();
|
|
auto sizePerThread = srcBlockedLayout.getSizePerThread();
|
|
auto threadsPerCTA = getThreadsPerCTA(srcBlockedLayout);
|
|
auto inOrder = srcBlockedLayout.getOrder();
|
|
DenseMap<unsigned, Value> sharedPtrs =
|
|
getSwizzledSharedPtrs(loc, inVec, srcTy, resSharedLayout, resElemTy,
|
|
smemObj, rewriter, offsetVals, srcStrides);
|
|
|
|
// If perPhase * maxPhase > threadsPerCTA, we will have elements
|
|
// that share the same tile indices. The index calculation will
|
|
// be cached.
|
|
auto numSwizzleRows = std::max<unsigned>(
|
|
(perPhase * maxPhase) / threadsPerCTA[inOrder[1]], 1);
|
|
// A sharedLayout encoding has a "vec" parameter.
|
|
// On the column dimension, if inVec > outVec, it means we have to divide
|
|
// single vector read into multiple ones
|
|
auto numVecCols = std::max<unsigned>(inVec / outVec, 1);
|
|
|
|
auto srcIndices = emitIndices(loc, rewriter, srcBlockedLayout, srcTy);
|
|
|
|
for (unsigned elemIdx = 0; elemIdx < numElems; elemIdx += minVec) {
|
|
// 16 * 8 = 128bits
|
|
auto maxBitWidth =
|
|
std::max<unsigned>(128, resElemTy.getIntOrFloatBitWidth());
|
|
auto vecBitWidth = resElemTy.getIntOrFloatBitWidth() * minVec;
|
|
auto bitWidth = std::min<unsigned>(maxBitWidth, vecBitWidth);
|
|
auto numWords = vecBitWidth / bitWidth;
|
|
auto numWordElems = bitWidth / resElemTy.getIntOrFloatBitWidth();
|
|
|
|
// Tune CG and CA here.
|
|
auto byteWidth = bitWidth / 8;
|
|
CacheModifier srcCacheModifier =
|
|
byteWidth == 16 ? CacheModifier::CG : CacheModifier::CA;
|
|
assert(byteWidth == 16 || byteWidth == 8 || byteWidth == 4);
|
|
auto resByteWidth = resElemTy.getIntOrFloatBitWidth() / 8;
|
|
|
|
Value basePtr = sharedPtrs[elemIdx];
|
|
for (size_t wordIdx = 0; wordIdx < numWords; ++wordIdx) {
|
|
PTXBuilder ptxBuilder;
|
|
auto wordElemIdx = wordIdx * numWordElems;
|
|
auto ©AsyncOp =
|
|
*ptxBuilder.create<PTXCpAsyncLoadInstr>(srcCacheModifier);
|
|
auto *dstOperand =
|
|
ptxBuilder.newAddrOperand(basePtr, "r", wordElemIdx * resByteWidth);
|
|
auto *srcOperand =
|
|
ptxBuilder.newAddrOperand(srcElems[elemIdx + wordElemIdx], "l");
|
|
auto *copySize = ptxBuilder.newConstantOperand(byteWidth);
|
|
auto *srcSize = copySize;
|
|
if (op.getMask()) {
|
|
// We don't use predicate in this case, setting src-size to 0
|
|
// if there's any mask. cp.async will automatically fill the
|
|
// remaining slots with 0 if cp-size > src-size.
|
|
// XXX(Keren): Always assume other = 0 for now.
|
|
auto selectOp = select(maskElems[elemIdx + wordElemIdx],
|
|
i32_val(byteWidth), i32_val(0));
|
|
srcSize = ptxBuilder.newOperand(selectOp, "r");
|
|
}
|
|
copyAsyncOp(dstOperand, srcOperand, copySize, srcSize);
|
|
ptxBuilder.launch(rewriter, loc, void_ty(getContext()));
|
|
}
|
|
}
|
|
|
|
rewriter.replaceOp(op, llDst);
|
|
return success();
|
|
}
|
|
};
|
|
|
|
void populateLoadStoreOpToLLVMPatterns(
|
|
TritonGPUToLLVMTypeConverter &typeConverter, RewritePatternSet &patterns,
|
|
ModuleAxisInfoAnalysis &axisInfoAnalysis, ModuleAllocation &allocation,
|
|
ConvertTritonGPUOpToLLVMPatternBase::IndexCacheInfo &indexCacheInfo,
|
|
PatternBenefit benefit) {
|
|
patterns.add<LoadOpConversion>(typeConverter, axisInfoAnalysis, benefit);
|
|
patterns.add<StoreOpConversion>(typeConverter, axisInfoAnalysis, benefit);
|
|
patterns.add<AtomicCASOpConversion>(typeConverter, allocation,
|
|
axisInfoAnalysis, benefit);
|
|
patterns.add<AtomicRMWOpConversion>(typeConverter, allocation,
|
|
axisInfoAnalysis, benefit);
|
|
patterns.add<InsertSliceOpConversion>(typeConverter, allocation,
|
|
indexCacheInfo, benefit);
|
|
patterns.add<InsertSliceAsyncOpConversion>(
|
|
typeConverter, allocation, indexCacheInfo, axisInfoAnalysis, benefit);
|
|
}
|