mirror of
https://github.com/invoke-ai/InvokeAI.git
synced 2026-01-20 22:58:30 -05:00
Compare commits
63 Commits
lstein/mod
...
test/node-
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
787df67ceb | ||
|
|
4b149ab521 | ||
|
|
25ecf08962 | ||
|
|
f051daea4f | ||
|
|
143d7e03ef | ||
|
|
9d959b8cf3 | ||
|
|
1b3a6f4540 | ||
|
|
3623112807 | ||
|
|
8c65ade392 | ||
|
|
cba25766aa | ||
|
|
c2177c1778 | ||
|
|
7f2f085658 | ||
|
|
d9c816bdbb | ||
|
|
b86b72437f | ||
|
|
508c7ca9eb | ||
|
|
e7824ed176 | ||
|
|
0deb588a02 | ||
|
|
567a19e47a | ||
|
|
c572e0a6a0 | ||
|
|
c8869f543c | ||
|
|
8ec5e07011 | ||
|
|
6ba83350ff | ||
|
|
5ec405ebe6 | ||
|
|
e8ac82a492 | ||
|
|
0c5bafdeb6 | ||
|
|
507a429d42 | ||
|
|
7a6ea8a67f | ||
|
|
0738bcfe9b | ||
|
|
bdc7227b61 | ||
|
|
d93d5561b1 | ||
|
|
aab7c2c152 | ||
|
|
593d91815d | ||
|
|
cd9f0e026f | ||
|
|
7a1fe7548b | ||
|
|
e1b8874bc5 | ||
|
|
d2f102b6ab | ||
|
|
b039fb1e78 | ||
|
|
91cdccd217 | ||
|
|
968bc41bcc | ||
|
|
e44fbd0d53 | ||
|
|
bf7780079e | ||
|
|
385a8afacf | ||
|
|
fc0a2ddef3 | ||
|
|
b6dea0d3b5 | ||
|
|
e720c2cf19 | ||
|
|
68cef6d90a | ||
|
|
77150ab7cd | ||
|
|
916404745c | ||
|
|
a786615783 | ||
|
|
430e9346e6 | ||
|
|
2cd3bd8234 | ||
|
|
89c01547cb | ||
|
|
eb65c12e61 | ||
|
|
ab5c3ed189 | ||
|
|
b0e3791a80 | ||
|
|
1dd6b3a508 | ||
|
|
94e58a2254 | ||
|
|
d6aa55b965 | ||
|
|
184a6cd85f | ||
|
|
e2924067ef | ||
|
|
21d1e76ea9 | ||
|
|
bdeab50a82 | ||
|
|
40ff9ce672 |
@@ -47,9 +47,34 @@ pip install ".[dev,test]"
|
||||
These are optional groups of packages which are defined within the `pyproject.toml`
|
||||
and will be required for testing the changes you make to the code.
|
||||
|
||||
### Tests
|
||||
### Running Tests
|
||||
|
||||
We use [pytest](https://docs.pytest.org/en/7.2.x/) for our test suite. Tests can
|
||||
be found under the `./tests` folder and can be run with a single `pytest`
|
||||
command. Optionally, to review test coverage you can append `--cov`.
|
||||
|
||||
```zsh
|
||||
pytest --cov
|
||||
```
|
||||
|
||||
Test outcomes and coverage will be reported in the terminal. In addition a more
|
||||
detailed report is created in both XML and HTML format in the `./coverage`
|
||||
folder. The HTML one in particular can help identify missing statements
|
||||
requiring tests to ensure coverage. This can be run by opening
|
||||
`./coverage/html/index.html`.
|
||||
|
||||
For example.
|
||||
|
||||
```zsh
|
||||
pytest --cov; open ./coverage/html/index.html
|
||||
```
|
||||
|
||||
??? info "HTML coverage report output"
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
See the [tests documentation](./TESTS.md) for information about running and writing tests.
|
||||
### Reloading Changes
|
||||
|
||||
Experimenting with changes to the Python source code is a drag if you have to re-start the server —
|
||||
@@ -142,23 +167,6 @@ and so you'll have access to the same python environment as the InvokeAI app.
|
||||
|
||||
This is _super_ handy.
|
||||
|
||||
#### Enabling Type-Checking with Pylance
|
||||
|
||||
We use python's typing system in InvokeAI. PR reviews will include checking that types are present and correct. We don't enforce types with `mypy` at this time, but that is on the horizon.
|
||||
|
||||
Using a code analysis tool to automatically type check your code (and types) is very important when writing with types. These tools provide immediate feedback in your editor when types are incorrect, and following their suggestions lead to fewer runtime bugs.
|
||||
|
||||
Pylance, installed at the beginning of this guide, is the de-facto python LSP (language server protocol). It provides type checking in the editor (among many other features). Once installed, you do need to enable type checking manually:
|
||||
|
||||
- Open a python file
|
||||
- Look along the status bar in VSCode for `{ } Python`
|
||||
- Click the `{ }`
|
||||
- Turn type checking on - basic is fine
|
||||
|
||||
You'll now see red squiggly lines where type issues are detected. Hover your cursor over the indicated symbols to see what's wrong.
|
||||
|
||||
In 99% of cases when the type checker says there is a problem, there really is a problem, and you should take some time to understand and resolve what it is pointing out.
|
||||
|
||||
#### Debugging configs with `launch.json`
|
||||
|
||||
Debugging configs are managed in a `launch.json` file. Like most VSCode configs,
|
||||
|
||||
File diff suppressed because it is too large
Load Diff
@@ -1,89 +0,0 @@
|
||||
# InvokeAI Backend Tests
|
||||
|
||||
We use `pytest` to run the backend python tests. (See [pyproject.toml](/pyproject.toml) for the default `pytest` options.)
|
||||
|
||||
## Fast vs. Slow
|
||||
All tests are categorized as either 'fast' (no test annotation) or 'slow' (annotated with the `@pytest.mark.slow` decorator).
|
||||
|
||||
'Fast' tests are run to validate every PR, and are fast enough that they can be run routinely during development.
|
||||
|
||||
'Slow' tests are currently only run manually on an ad-hoc basis. In the future, they may be automated to run nightly. Most developers are only expected to run the 'slow' tests that directly relate to the feature(s) that they are working on.
|
||||
|
||||
As a rule of thumb, tests should be marked as 'slow' if there is a chance that they take >1s (e.g. on a CPU-only machine with slow internet connection). Common examples of slow tests are tests that depend on downloading a model, or running model inference.
|
||||
|
||||
## Running Tests
|
||||
|
||||
Below are some common test commands:
|
||||
```bash
|
||||
# Run the fast tests. (This implicitly uses the configured default option: `-m "not slow"`.)
|
||||
pytest tests/
|
||||
|
||||
# Equivalent command to run the fast tests.
|
||||
pytest tests/ -m "not slow"
|
||||
|
||||
# Run the slow tests.
|
||||
pytest tests/ -m "slow"
|
||||
|
||||
# Run the slow tests from a specific file.
|
||||
pytest tests/path/to/slow_test.py -m "slow"
|
||||
|
||||
# Run all tests (fast and slow).
|
||||
pytest tests -m ""
|
||||
```
|
||||
|
||||
## Test Organization
|
||||
|
||||
All backend tests are in the [`tests/`](/tests/) directory. This directory mirrors the organization of the `invokeai/` directory. For example, tests for `invokeai/model_management/model_manager.py` would be found in `tests/model_management/test_model_manager.py`.
|
||||
|
||||
TODO: The above statement is aspirational. A re-organization of legacy tests is required to make it true.
|
||||
|
||||
## Tests that depend on models
|
||||
|
||||
There are a few things to keep in mind when adding tests that depend on models.
|
||||
|
||||
1. If a required model is not already present, it should automatically be downloaded as part of the test setup.
|
||||
2. If a model is already downloaded, it should not be re-downloaded unnecessarily.
|
||||
3. Take reasonable care to keep the total number of models required for the tests low. Whenever possible, re-use models that are already required for other tests. If you are adding a new model, consider including a comment to explain why it is required/unique.
|
||||
|
||||
There are several utilities to help with model setup for tests. Here is a sample test that depends on a model:
|
||||
```python
|
||||
import pytest
|
||||
import torch
|
||||
|
||||
from invokeai.backend.model_management.models.base import BaseModelType, ModelType
|
||||
from invokeai.backend.util.test_utils import install_and_load_model
|
||||
|
||||
@pytest.mark.slow
|
||||
def test_model(model_installer, torch_device):
|
||||
model_info = install_and_load_model(
|
||||
model_installer=model_installer,
|
||||
model_path_id_or_url="HF/dummy_model_id",
|
||||
model_name="dummy_model",
|
||||
base_model=BaseModelType.StableDiffusion1,
|
||||
model_type=ModelType.Dummy,
|
||||
)
|
||||
|
||||
dummy_input = build_dummy_input(torch_device)
|
||||
|
||||
with torch.no_grad(), model_info as model:
|
||||
model.to(torch_device, dtype=torch.float32)
|
||||
output = model(dummy_input)
|
||||
|
||||
# Validate output...
|
||||
|
||||
```
|
||||
|
||||
## Test Coverage
|
||||
|
||||
To review test coverage, append `--cov` to your pytest command:
|
||||
```bash
|
||||
pytest tests/ --cov
|
||||
```
|
||||
|
||||
Test outcomes and coverage will be reported in the terminal. In addition, a more detailed report is created in both XML and HTML format in the `./coverage` folder. The HTML output is particularly helpful in identifying untested statements where coverage should be improved. The HTML report can be viewed by opening `./coverage/html/index.html`.
|
||||
|
||||
??? info "HTML coverage report output"
|
||||
|
||||

|
||||
|
||||

|
||||
@@ -12,9 +12,8 @@ To get started, take a look at our [new contributors checklist](newContributorCh
|
||||
Once you're setup, for more information, you can review the documentation specific to your area of interest:
|
||||
|
||||
* #### [InvokeAI Architecure](../ARCHITECTURE.md)
|
||||
* #### [Frontend Documentation](./contributingToFrontend.md)
|
||||
* #### [Frontend Documentation](development_guides/contributingToFrontend.md)
|
||||
* #### [Node Documentation](../INVOCATIONS.md)
|
||||
* #### [InvokeAI Model Manager](../MODEL_MANAGER.md)
|
||||
* #### [Local Development](../LOCAL_DEVELOPMENT.md)
|
||||
|
||||
|
||||
@@ -39,9 +38,9 @@ There are two paths to making a development contribution:
|
||||
|
||||
If you need help, you can ask questions in the [#dev-chat](https://discord.com/channels/1020123559063990373/1049495067846524939) channel of the Discord.
|
||||
|
||||
For frontend related work, **@psychedelicious** is the best person to reach out to.
|
||||
For frontend related work, **@pyschedelicious** is the best person to reach out to.
|
||||
|
||||
For backend related work, please reach out to **@blessedcoolant**, **@lstein**, **@StAlKeR7779** or **@psychedelicious**.
|
||||
For backend related work, please reach out to **@blessedcoolant**, **@lstein**, **@StAlKeR7779** or **@pyschedelicious**.
|
||||
|
||||
|
||||
## **What does the Code of Conduct mean for me?**
|
||||
|
||||
@@ -10,4 +10,4 @@ When updating or creating documentation, please keep in mind InvokeAI is a tool
|
||||
|
||||
## Help & Questions
|
||||
|
||||
Please ping @imic or @hipsterusername in the [Discord](https://discord.com/channels/1020123559063990373/1049495067846524939) if you have any questions.
|
||||
Please ping @imic1 or @hipsterusername in the [Discord](https://discord.com/channels/1020123559063990373/1049495067846524939) if you have any questions.
|
||||
@@ -159,7 +159,7 @@ groups in `invokeia.yaml`:
|
||||
| `host` | `localhost` | Name or IP address of the network interface that the web server will listen on |
|
||||
| `port` | `9090` | Network port number that the web server will listen on |
|
||||
| `allow_origins` | `[]` | A list of host names or IP addresses that are allowed to connect to the InvokeAI API in the format `['host1','host2',...]` |
|
||||
| `allow_credentials` | `true` | Require credentials for a foreign host to access the InvokeAI API (don't change this) |
|
||||
| `allow_credentials | `true` | Require credentials for a foreign host to access the InvokeAI API (don't change this) |
|
||||
| `allow_methods` | `*` | List of HTTP methods ("GET", "POST") that the web server is allowed to use when accessing the API |
|
||||
| `allow_headers` | `*` | List of HTTP headers that the web server will accept when accessing the API |
|
||||
|
||||
@@ -207,8 +207,11 @@ if INVOKEAI_ROOT is `/home/fred/invokeai` and the path is
|
||||
|
||||
| Setting | Default Value | Description |
|
||||
|----------|----------------|--------------|
|
||||
| `autoimport_dir` | `autoimport/main` | At startup time, read and import any main model files found in this directory (not recommended)|
|
||||
| `model_config_db` | `auto` | Location of the model configuration database. Specify `auto` to use the main invokeai.db database, or specify a `.yaml` or `.db` file to store the data externally.|
|
||||
| `autoimport_dir` | `autoimport/main` | At startup time, read and import any main model files found in this directory |
|
||||
| `lora_dir` | `autoimport/lora` | At startup time, read and import any LoRA/LyCORIS models found in this directory |
|
||||
| `embedding_dir` | `autoimport/embedding` | At startup time, read and import any textual inversion (embedding) models found in this directory |
|
||||
| `controlnet_dir` | `autoimport/controlnet` | At startup time, read and import any ControlNet models found in this directory |
|
||||
| `conf_path` | `configs/models.yaml` | Location of the `models.yaml` model configuration file |
|
||||
| `models_dir` | `models` | Location of the directory containing models installed by InvokeAI's model manager |
|
||||
| `legacy_conf_dir` | `configs/stable-diffusion` | Location of the directory containing the .yaml configuration files for legacy checkpoint models |
|
||||
| `db_dir` | `databases` | Location of the directory containing InvokeAI's image, schema and session database |
|
||||
@@ -231,18 +234,6 @@ Paths:
|
||||
# controlnet_dir: null
|
||||
```
|
||||
|
||||
### Model Cache
|
||||
|
||||
These options control the size of various caches that InvokeAI uses
|
||||
during the model loading and conversion process. All units are in GB
|
||||
|
||||
| Setting | Default Value | Description |
|
||||
|----------|----------------|--------------|
|
||||
| `disk` | `20.0` | Before loading a model into memory, InvokeAI converts .ckpt and .safetensors models into diffusers format and saves them to disk. This option controls the maximum size of the directory in which these converted models are stored. If set to zero, then only the most recently-used model will be cached. |
|
||||
| `ram` | `6.0` | After loading a model from disk, it is kept in system RAM until it is needed again. This option controls how much RAM is set aside for this purpose. Larger amounts allow more models to reside in RAM and for InvokeAI to quickly switch between them. |
|
||||
| `vram` | `0.25` | This allows smaller models to remain in VRAM, speeding up execution modestly. It should be a small number. |
|
||||
|
||||
|
||||
### Logging
|
||||
|
||||
These settings control the information, warning, and debugging
|
||||
|
||||
@@ -1,11 +1,13 @@
|
||||
---
|
||||
title: Control Adapters
|
||||
title: ControlNet
|
||||
---
|
||||
|
||||
# :material-loupe: Control Adapters
|
||||
# :material-loupe: ControlNet
|
||||
|
||||
## ControlNet
|
||||
|
||||
ControlNet
|
||||
|
||||
ControlNet is a powerful set of features developed by the open-source
|
||||
community (notably, Stanford researcher
|
||||
[**@ilyasviel**](https://github.com/lllyasviel)) that allows you to
|
||||
@@ -18,7 +20,7 @@ towards generating images that better fit your desired style or
|
||||
outcome.
|
||||
|
||||
|
||||
#### How it works
|
||||
### How it works
|
||||
|
||||
ControlNet works by analyzing an input image, pre-processing that
|
||||
image to identify relevant information that can be interpreted by each
|
||||
@@ -28,7 +30,7 @@ composition, or other aspects of the image to better achieve a
|
||||
specific result.
|
||||
|
||||
|
||||
#### Models
|
||||
### Models
|
||||
|
||||
InvokeAI provides access to a series of ControlNet models that provide
|
||||
different effects or styles in your generated images. Currently
|
||||
@@ -94,8 +96,6 @@ A model that generates normal maps from input images, allowing for more realisti
|
||||
**Image Segmentation**:
|
||||
A model that divides input images into segments or regions, each of which corresponds to a different object or part of the image. (More details coming soon)
|
||||
|
||||
**QR Code Monster**:
|
||||
A model that helps generate creative QR codes that still scan. Can also be used to create images with text, logos or shapes within them.
|
||||
|
||||
**Openpose**:
|
||||
The OpenPose control model allows for the identification of the general pose of a character by pre-processing an existing image with a clear human structure. With advanced options, Openpose can also detect the face or hands in the image.
|
||||
@@ -120,7 +120,7 @@ With Pix2Pix, you can input an image into the controlnet, and then "instruct" th
|
||||
Each of these models can be adjusted and combined with other ControlNet models to achieve different results, giving you even more control over your image generation process.
|
||||
|
||||
|
||||
### Using ControlNet
|
||||
## Using ControlNet
|
||||
|
||||
To use ControlNet, you can simply select the desired model and adjust both the ControlNet and Pre-processor settings to achieve the desired result. You can also use multiple ControlNet models at the same time, allowing you to achieve even more complex effects or styles in your generated images.
|
||||
|
||||
@@ -132,31 +132,3 @@ Weight - Strength of the Controlnet model applied to the generation for the sect
|
||||
Start/End - 0 represents the start of the generation, 1 represents the end. The Start/end setting controls what steps during the generation process have the ControlNet applied.
|
||||
|
||||
Additionally, each ControlNet section can be expanded in order to manipulate settings for the image pre-processor that adjusts your uploaded image before using it in when you Invoke.
|
||||
|
||||
|
||||
## IP-Adapter
|
||||
|
||||
[IP-Adapter](https://ip-adapter.github.io) is a tooling that allows for image prompt capabilities with text-to-image diffusion models. IP-Adapter works by analyzing the given image prompt to extract features, then passing those features to the UNet along with any other conditioning provided.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
#### Installation
|
||||
There are several ways to install IP-Adapter models with an existing InvokeAI installation:
|
||||
|
||||
1. Through the command line interface launched from the invoke.sh / invoke.bat scripts, option [5] to download models.
|
||||
2. Through the Model Manager UI with models from the *Tools* section of [www.models.invoke.ai](www.models.invoke.ai). To do this, copy the repo ID from the desired model page, and paste it in the Add Model field of the model manager. **Note** Both the IP-Adapter and the Image Encoder must be installed for IP-Adapter to work. For example, the [SD 1.5 IP-Adapter](https://models.invoke.ai/InvokeAI/ip_adapter_plus_sd15) and [SD1.5 Image Encoder](https://models.invoke.ai/InvokeAI/ip_adapter_sd_image_encoder) must be installed to use IP-Adapter with SD1.5 based models.
|
||||
3. **Advanced -- Not recommended ** Manually downloading the IP-Adapter and Image Encoder files - Image Encoder folders shouid be placed in the `models\any\clip_vision` folders. IP Adapter Model folders should be placed in the relevant `ip-adapter` folder of relevant base model folder of Invoke root directory. For example, for the SDXL IP-Adapter, files should be added to the `model/sdxl/ip_adapter/` folder.
|
||||
|
||||
#### Using IP-Adapter
|
||||
|
||||
IP-Adapter can be used by navigating to the *Control Adapters* options and enabling IP-Adapter.
|
||||
|
||||
IP-Adapter requires an image to be used as the Image Prompt. It can also be used in conjunction with text prompts, Image-to-Image, Inpainting, Outpainting, ControlNets and LoRAs.
|
||||
|
||||
|
||||
Each IP-Adapter has two settings that are applied to the IP-Adapter:
|
||||
|
||||
* Weight - Strength of the IP-Adapter model applied to the generation for the section, defined by start/end
|
||||
* Start/End - 0 represents the start of the generation, 1 represents the end. The Start/end setting controls what steps during the generation process have the IP-Adapter applied.
|
||||
|
||||
@@ -1,336 +0,0 @@
|
||||
---
|
||||
title: Command-line Utilities
|
||||
---
|
||||
|
||||
# :material-file-document: Utilities
|
||||
|
||||
# Command-line Utilities
|
||||
|
||||
InvokeAI comes with several scripts that are accessible via the
|
||||
command line. To access these commands, start the "developer's
|
||||
console" from the launcher (`invoke.bat` menu item [8]). Users who are
|
||||
familiar with Python can alternatively activate InvokeAI's virtual
|
||||
environment (typically, but not necessarily `invokeai/.venv`).
|
||||
|
||||
In the developer's console, type the script's name to run it. To get a
|
||||
synopsis of what a utility does and the command-line arguments it
|
||||
accepts, pass it the `-h` argument, e.g.
|
||||
|
||||
```bash
|
||||
invokeai-merge -h
|
||||
```
|
||||
## **invokeai-web**
|
||||
|
||||
This script launches the web server and is effectively identical to
|
||||
selecting option [1] in the launcher. An advantage of launching the
|
||||
server from the command line is that you can override any setting
|
||||
configuration option in `invokeai.yaml` using like-named command-line
|
||||
arguments. For example, to temporarily change the size of the RAM
|
||||
cache to 7 GB, you can launch as follows:
|
||||
|
||||
```bash
|
||||
invokeai-web --ram 7
|
||||
```
|
||||
|
||||
## **invokeai-merge**
|
||||
|
||||
This is the model merge script, the same as launcher option [4]. Call
|
||||
it with the `--gui` command-line argument to start the interactive
|
||||
console-based GUI. Alternatively, you can run it non-interactively
|
||||
using command-line arguments as illustrated in the example below which
|
||||
merges models named `stable-diffusion-1.5` and `inkdiffusion` into a new model named
|
||||
`my_new_model`:
|
||||
|
||||
```bash
|
||||
invokeai-merge --force --base-model sd-1 --models stable-diffusion-1.5 inkdiffusion --merged_model_name my_new_model
|
||||
```
|
||||
|
||||
## **invokeai-ti**
|
||||
|
||||
This is the textual inversion training script that is run by launcher
|
||||
option [3]. Call it with `--gui` to run the interactive console-based
|
||||
front end. It can also be run non-interactively. It has about a
|
||||
zillion arguments, but a typical training session can be launched
|
||||
with:
|
||||
|
||||
```bash
|
||||
invokeai-ti --model stable-diffusion-1.5 \
|
||||
--placeholder_token 'jello' \
|
||||
--learnable_property object \
|
||||
--num_train_epochs 50 \
|
||||
--train_data_dir /path/to/training/images \
|
||||
--output_dir /path/to/trained/model
|
||||
```
|
||||
|
||||
(Note that \\ is the Linux/Mac long-line continuation character. Use ^
|
||||
in Windows).
|
||||
|
||||
## **invokeai-install**
|
||||
|
||||
This is the console-based model install script that is run by launcher
|
||||
option [5]. If called without arguments, it will launch the
|
||||
interactive console-based interface. It can also be used
|
||||
non-interactively to list, add and remove models as shown by these
|
||||
examples:
|
||||
|
||||
* This will download and install three models from CivitAI, HuggingFace,
|
||||
and local disk:
|
||||
|
||||
```bash
|
||||
invokeai-install --add https://civitai.com/api/download/models/161302 ^
|
||||
gsdf/Counterfeit-V3.0 ^
|
||||
D:\Models\merge_model_two.safetensors
|
||||
```
|
||||
(Note that ^ is the Windows long-line continuation character. Use \\ on
|
||||
Linux/Mac).
|
||||
|
||||
* This will list installed models of type `main`:
|
||||
|
||||
```bash
|
||||
invokeai-model-install --list-models main
|
||||
```
|
||||
|
||||
* This will delete the models named `voxel-ish` and `realisticVision`:
|
||||
|
||||
```bash
|
||||
invokeai-model-install --delete voxel-ish realisticVision
|
||||
```
|
||||
|
||||
## **invokeai-configure**
|
||||
|
||||
This is the console-based configure script that ran when InvokeAI was
|
||||
first installed. You can run it again at any time to change the
|
||||
configuration, repair a broken install.
|
||||
|
||||
Called without any arguments, `invokeai-configure` enters interactive
|
||||
mode with two screens. The first screen is a form that provides access
|
||||
to most of InvokeAI's configuration options. The second screen lets
|
||||
you download, add, and delete models interactively. When you exit the
|
||||
second screen, the script will add any missing "support models"
|
||||
needed for core functionality, and any selected "sd weights" which are
|
||||
the model checkpoint/diffusers files.
|
||||
|
||||
This behavior can be changed via a series of command-line
|
||||
arguments. Here are some of the useful ones:
|
||||
|
||||
* `invokeai-configure --skip-sd-weights --skip-support-models`
|
||||
This will run just the configuration part of the utility, skipping
|
||||
downloading of support models and stable diffusion weights.
|
||||
|
||||
* `invokeai-configure --yes`
|
||||
This will run the configure script non-interactively. It will set the
|
||||
configuration options to their default values, install/repair support
|
||||
models, and download the "recommended" set of SD models.
|
||||
|
||||
* `invokeai-configure --yes --default_only`
|
||||
This will run the configure script non-interactively. In contrast to
|
||||
the previous command, it will only download the default SD model,
|
||||
Stable Diffusion v1.5
|
||||
|
||||
* `invokeai-configure --yes --default_only --skip-sd-weights`
|
||||
This is similar to the previous command, but will not download any
|
||||
SD models at all. It is usually used to repair a broken install.
|
||||
|
||||
By default, `invokeai-configure` runs on the currently active InvokeAI
|
||||
root folder. To run it against a different root, pass it the `--root
|
||||
</path/to/root>` argument.
|
||||
|
||||
Lastly, you can use `invokeai-configure` to create a working root
|
||||
directory entirely from scratch. Assuming you wish to make a root directory
|
||||
named `InvokeAI-New`, run this command:
|
||||
|
||||
```bash
|
||||
invokeai-configure --root InvokeAI-New --yes --default_only
|
||||
```
|
||||
This will create a minimally functional root directory. You can now
|
||||
launch the web server against it with `invokeai-web --root InvokeAI-New`.
|
||||
|
||||
## **invokeai-update**
|
||||
|
||||
This is the interactive console-based script that is run by launcher
|
||||
menu item [9] to update to a new version of InvokeAI. It takes no
|
||||
command-line arguments.
|
||||
|
||||
## **invokeai-metadata**
|
||||
|
||||
This is a script which takes a list of InvokeAI-generated images and
|
||||
outputs their metadata in the same JSON format that you get from the
|
||||
`</>` button in the Web GUI. For example:
|
||||
|
||||
```bash
|
||||
$ invokeai-metadata ffe2a115-b492-493c-afff-7679aa034b50.png
|
||||
ffe2a115-b492-493c-afff-7679aa034b50.png:
|
||||
{
|
||||
"app_version": "3.1.0",
|
||||
"cfg_scale": 8.0,
|
||||
"clip_skip": 0,
|
||||
"controlnets": [],
|
||||
"generation_mode": "sdxl_txt2img",
|
||||
"height": 1024,
|
||||
"loras": [],
|
||||
"model": {
|
||||
"base_model": "sdxl",
|
||||
"model_name": "stable-diffusion-xl-base-1.0",
|
||||
"model_type": "main"
|
||||
},
|
||||
"negative_prompt": "",
|
||||
"negative_style_prompt": "",
|
||||
"positive_prompt": "military grade sushi dinner for shock troopers",
|
||||
"positive_style_prompt": "",
|
||||
"rand_device": "cpu",
|
||||
"refiner_cfg_scale": 7.5,
|
||||
"refiner_model": {
|
||||
"base_model": "sdxl-refiner",
|
||||
"model_name": "sd_xl_refiner_1.0",
|
||||
"model_type": "main"
|
||||
},
|
||||
"refiner_negative_aesthetic_score": 2.5,
|
||||
"refiner_positive_aesthetic_score": 6.0,
|
||||
"refiner_scheduler": "euler",
|
||||
"refiner_start": 0.8,
|
||||
"refiner_steps": 20,
|
||||
"scheduler": "euler",
|
||||
"seed": 387129902,
|
||||
"steps": 25,
|
||||
"width": 1024
|
||||
}
|
||||
```
|
||||
|
||||
You may list multiple files on the command line.
|
||||
|
||||
## **invokeai-import-images**
|
||||
|
||||
InvokeAI uses a database to store information about images it
|
||||
generated, and just copying the image files from one InvokeAI root
|
||||
directory to another does not automatically import those images into
|
||||
the destination's gallery. This script allows you to bulk import
|
||||
images generated by one instance of InvokeAI into a gallery maintained
|
||||
by another. It also works on images generated by older versions of
|
||||
InvokeAI, going way back to version 1.
|
||||
|
||||
This script has an interactive mode only. The following example shows
|
||||
it in action:
|
||||
|
||||
```bash
|
||||
$ invokeai-import-images
|
||||
===============================================================================
|
||||
This script will import images generated by earlier versions of
|
||||
InvokeAI into the currently installed root directory:
|
||||
/home/XXXX/invokeai-main
|
||||
If this is not what you want to do, type ctrl-C now to cancel.
|
||||
===============================================================================
|
||||
= Configuration & Settings
|
||||
Found invokeai.yaml file at /home/XXXX/invokeai-main/invokeai.yaml:
|
||||
Database : /home/XXXX/invokeai-main/databases/invokeai.db
|
||||
Outputs : /home/XXXX/invokeai-main/outputs/images
|
||||
|
||||
Use these paths for import (yes) or choose different ones (no) [Yn]:
|
||||
Inputs: Specify absolute path containing InvokeAI .png images to import: /home/XXXX/invokeai-2.3/outputs/images/
|
||||
Include files from subfolders recursively [yN]?
|
||||
|
||||
Options for board selection for imported images:
|
||||
1) Select an existing board name. (found 4)
|
||||
2) Specify a board name to create/add to.
|
||||
3) Create/add to board named 'IMPORT'.
|
||||
4) Create/add to board named 'IMPORT' with the current datetime string appended (.e.g IMPORT_20230919T203519Z).
|
||||
5) Create/add to board named 'IMPORT' with a the original file app_version appended (.e.g IMPORT_2.2.5).
|
||||
Specify desired board option: 3
|
||||
|
||||
===============================================================================
|
||||
= Import Settings Confirmation
|
||||
|
||||
Database File Path : /home/XXXX/invokeai-main/databases/invokeai.db
|
||||
Outputs/Images Directory : /home/XXXX/invokeai-main/outputs/images
|
||||
Import Image Source Directory : /home/XXXX/invokeai-2.3/outputs/images/
|
||||
Recurse Source SubDirectories : No
|
||||
Count of .png file(s) found : 5785
|
||||
Board name option specified : IMPORT
|
||||
Database backup will be taken at : /home/XXXX/invokeai-main/databases/backup
|
||||
|
||||
Notes about the import process:
|
||||
- Source image files will not be modified, only copied to the outputs directory.
|
||||
- If the same file name already exists in the destination, the file will be skipped.
|
||||
- If the same file name already has a record in the database, the file will be skipped.
|
||||
- Invoke AI metadata tags will be updated/written into the imported copy only.
|
||||
- On the imported copy, only Invoke AI known tags (latest and legacy) will be retained (dream, sd-metadata, invokeai, invokeai_metadata)
|
||||
- A property 'imported_app_version' will be added to metadata that can be viewed in the UI's metadata viewer.
|
||||
- The new 3.x InvokeAI outputs folder structure is flat so recursively found source imges will all be placed into the single outputs/images folder.
|
||||
|
||||
Do you wish to continue with the import [Yn] ?
|
||||
|
||||
Making DB Backup at /home/lstein/invokeai-main/databases/backup/backup-20230919T203519Z-invokeai.db...Done!
|
||||
|
||||
===============================================================================
|
||||
Importing /home/XXXX/invokeai-2.3/outputs/images/17d09907-297d-4db3-a18a-60b337feac66.png
|
||||
... (5785 more lines) ...
|
||||
===============================================================================
|
||||
= Import Complete - Elpased Time: 0.28 second(s)
|
||||
|
||||
Source File(s) : 5785
|
||||
Total Imported : 5783
|
||||
Skipped b/c file already exists on disk : 1
|
||||
Skipped b/c file already exists in db : 0
|
||||
Errors during import : 1
|
||||
```
|
||||
## **invokeai-db-maintenance**
|
||||
|
||||
This script helps maintain the integrity of your InvokeAI database by
|
||||
finding and fixing three problems that can arise over time:
|
||||
|
||||
1. An image was manually deleted from the outputs directory, leaving a
|
||||
dangling image record in the InvokeAI database. This will cause a
|
||||
black image to appear in the gallery. This is an "orphaned database
|
||||
image record." The script can fix this by running a "clean"
|
||||
operation on the database, removing the orphaned entries.
|
||||
|
||||
2. An image is present in the outputs directory but there is no
|
||||
corresponding entry in the database. This can happen when the image
|
||||
is added manually to the outputs directory, or if a crash occurred
|
||||
after the image was generated but before the database was
|
||||
completely updated. The symptom is that the image is present in the
|
||||
outputs folder but doesn't appear in the InvokeAI gallery. This is
|
||||
called an "orphaned image file." The script can fix this problem by
|
||||
running an "archive" operation in which orphaned files are moved
|
||||
into a directory named `outputs/images-archive`. If you wish, you
|
||||
can then run `invokeai-image-import` to reimport these images back
|
||||
into the database.
|
||||
|
||||
3. The thumbnail for an image is missing, again causing a black
|
||||
gallery thumbnail. This is fixed by running the "thumbnaiils"
|
||||
operation, which simply regenerates and re-registers the missing
|
||||
thumbnail.
|
||||
|
||||
You can find and fix all three of these problems in a single go by
|
||||
executing this command:
|
||||
|
||||
```bash
|
||||
invokeai-db-maintenance --operation all
|
||||
```
|
||||
|
||||
Or you can run just the clean and thumbnail operations like this:
|
||||
|
||||
```bash
|
||||
invokeai-db-maintenance -operation clean, thumbnail
|
||||
```
|
||||
|
||||
If called without any arguments, the script will ask you which
|
||||
operations you wish to perform.
|
||||
|
||||
## **invokeai-migrate3**
|
||||
|
||||
This script will migrate settings and models (but not images!) from an
|
||||
InvokeAI v2.3 root folder to an InvokeAI 3.X folder. Call it with the
|
||||
source and destination root folders like this:
|
||||
|
||||
```bash
|
||||
invokeai-migrate3 --from ~/invokeai-2.3 --to invokeai-3.1.1
|
||||
```
|
||||
|
||||
Both directories must previously have been properly created and
|
||||
initialized by `invokeai-configure`. If you wish to migrate the images
|
||||
contained in the older root as well, you can use the
|
||||
`invokeai-image-migrate` script described earlier.
|
||||
|
||||
---
|
||||
|
||||
Copyright (c) 2023, Lincoln Stein and the InvokeAI Development Team
|
||||
@@ -51,9 +51,6 @@ Prevent InvokeAI from displaying unwanted racy images.
|
||||
### * [Controlling Logging](LOGGING.md)
|
||||
Control how InvokeAI logs status messages.
|
||||
|
||||
### * [Command-line Utilities](UTILITIES.md)
|
||||
A list of the command-line utilities available with InvokeAI.
|
||||
|
||||
<!-- OUT OF DATE
|
||||
### * [Miscellaneous](OTHER.md)
|
||||
Run InvokeAI on Google Colab, generate images with repeating patterns,
|
||||
|
||||
@@ -147,7 +147,6 @@ Mac and Linux machines, and runs on GPU cards with as little as 4 GB of RAM.
|
||||
|
||||
### InvokeAI Configuration
|
||||
- [Guide to InvokeAI Runtime Settings](features/CONFIGURATION.md)
|
||||
- [Database Maintenance and other Command Line Utilities](features/UTILITIES.md)
|
||||
|
||||
## :octicons-log-16: Important Changes Since Version 2.3
|
||||
|
||||
|
||||
@@ -256,10 +256,6 @@ manager, please follow these steps:
|
||||
*highly recommended** if your virtual environment is located outside of
|
||||
your runtime directory.
|
||||
|
||||
!!! tip
|
||||
|
||||
On linux, it is recommended to run invokeai with the following env var: `MALLOC_MMAP_THRESHOLD_=1048576`. For example: `MALLOC_MMAP_THRESHOLD_=1048576 invokeai --web`. This helps to prevent memory fragmentation that can lead to memory accumulation over time. This env var is set automatically when running via `invoke.sh`.
|
||||
|
||||
10. Render away!
|
||||
|
||||
Browse the [features](../features/index.md) section to learn about all the
|
||||
@@ -300,18 +296,8 @@ code for InvokeAI. For this to work, you will need to install the
|
||||
on your system, please see the [Git Installation
|
||||
Guide](https://github.com/git-guides/install-git)
|
||||
|
||||
You will also need to install the [frontend development toolchain](https://github.com/invoke-ai/InvokeAI/blob/main/docs/contributing/contribution_guides/contributingToFrontend.md).
|
||||
|
||||
If you have a "normal" installation, you should create a totally separate virtual environment for the git-based installation, else the two may interfere.
|
||||
|
||||
> **Why do I need the frontend toolchain**?
|
||||
>
|
||||
> The InvokeAI project uses trunk-based development. That means our `main` branch is the development branch, and releases are tags on that branch. Because development is very active, we don't keep an updated build of the UI in `main` - we only build it for production releases.
|
||||
>
|
||||
> That means that between releases, to have a functioning application when running directly from the repo, you will need to run the UI in dev mode or build it regularly (any time the UI code changes).
|
||||
|
||||
1. Create a fork of the InvokeAI repository through the GitHub UI or [this link](https://github.com/invoke-ai/InvokeAI/fork)
|
||||
2. From the command line, run this command:
|
||||
1. From the command line, run this command:
|
||||
```bash
|
||||
git clone https://github.com/<your_github_username>/InvokeAI.git
|
||||
```
|
||||
@@ -319,10 +305,10 @@ If you have a "normal" installation, you should create a totally separate virtua
|
||||
This will create a directory named `InvokeAI` and populate it with the
|
||||
full source code from your fork of the InvokeAI repository.
|
||||
|
||||
3. Activate the InvokeAI virtual environment as per step (4) of the manual
|
||||
2. Activate the InvokeAI virtual environment as per step (4) of the manual
|
||||
installation protocol (important!)
|
||||
|
||||
4. Enter the InvokeAI repository directory and run one of these
|
||||
3. Enter the InvokeAI repository directory and run one of these
|
||||
commands, based on your GPU:
|
||||
|
||||
=== "CUDA (NVidia)"
|
||||
@@ -348,15 +334,11 @@ installation protocol (important!)
|
||||
Be sure to pass `-e` (for an editable install) and don't forget the
|
||||
dot ("."). It is part of the command.
|
||||
|
||||
5. Install the [frontend toolchain](https://github.com/invoke-ai/InvokeAI/blob/main/docs/contributing/contribution_guides/contributingToFrontend.md) and do a production build of the UI as described.
|
||||
|
||||
6. You can now run `invokeai` and its related commands. The code will be
|
||||
You can now run `invokeai` and its related commands. The code will be
|
||||
read from the repository, so that you can edit the .py source files
|
||||
and watch the code's behavior change.
|
||||
|
||||
When you pull in new changes to the repo, be sure to re-build the UI.
|
||||
|
||||
7. If you wish to contribute to the InvokeAI project, you are
|
||||
4. If you wish to contribute to the InvokeAI project, you are
|
||||
encouraged to establish a GitHub account and "fork"
|
||||
https://github.com/invoke-ai/InvokeAI into your own copy of the
|
||||
repository. You can then use GitHub functions to create and submit
|
||||
|
||||
@@ -123,20 +123,11 @@ installation. Examples:
|
||||
# (list all controlnet models)
|
||||
invokeai-model-install --list controlnet
|
||||
|
||||
# (install the diffusers model using its hugging face repo_id)
|
||||
invokeai-model-install --add stabilityai/stable-diffusion-xl-base-1.0
|
||||
|
||||
# (install a diffusers model that lives in a subfolder)
|
||||
invokeai-model-install --add stabilityai/stable-diffusion-xl-base-1.0:vae
|
||||
|
||||
# (install the checkpoint model at the indicated URL)
|
||||
# (install the model at the indicated URL)
|
||||
invokeai-model-install --add https://civitai.com/api/download/models/128713
|
||||
|
||||
# (delete the named model if its name is unique)
|
||||
invokeai-model-install --delete analog-diffusion
|
||||
|
||||
# (delete the named model using its fully qualified name)
|
||||
invokeai-model-install --delete sd-1/main/test_model
|
||||
# (delete the named model)
|
||||
invokeai-model-install --delete sd-1/main/analog-diffusion
|
||||
```
|
||||
|
||||
### Installation via the Web GUI
|
||||
@@ -150,24 +141,6 @@ left-hand panel) and navigate to *Import Models*
|
||||
wish to install. You may use a URL, HuggingFace repo id, or a path on
|
||||
your local disk.
|
||||
|
||||
There is special scanning for CivitAI URLs which lets
|
||||
you cut-and-paste either the URL for a CivitAI model page
|
||||
(e.g. https://civitai.com/models/12345), or the direct download link
|
||||
for a model (e.g. https://civitai.com/api/download/models/12345).
|
||||
|
||||
If the desired model is a HuggingFace diffusers model that is located
|
||||
in a subfolder of the repository (e.g. vae), then append the subfolder
|
||||
to the end of the repo_id like this:
|
||||
|
||||
```
|
||||
# a VAE model located in subfolder "vae"
|
||||
stabilityai/stable-diffusion-xl-base-1.0:vae
|
||||
|
||||
# version 2 of the model located in subfolder "v2"
|
||||
monster-labs/control_v1p_sd15_qrcode_monster:v2
|
||||
|
||||
```
|
||||
|
||||
3. Alternatively, the *Scan for Models* button allows you to paste in
|
||||
the path to a folder somewhere on your machine. It will be scanned for
|
||||
importable models and prompt you to add the ones of your choice.
|
||||
@@ -198,16 +171,3 @@ subfolders and organize them as you wish.
|
||||
|
||||
The location of the autoimport directories are controlled by settings
|
||||
in `invokeai.yaml`. See [Configuration](../features/CONFIGURATION.md).
|
||||
|
||||
### Installing models that live in HuggingFace subfolders
|
||||
|
||||
On rare occasions you may need to install a diffusers-style model that
|
||||
lives in a subfolder of a HuggingFace repo id. In this event, simply
|
||||
add ":_subfolder-name_" to the end of the repo id. For example, if the
|
||||
repo id is "monster-labs/control_v1p_sd15_qrcode_monster" and the model
|
||||
you wish to fetch lives in a subfolder named "v2", then the repo id to
|
||||
pass to the various model installers should be
|
||||
|
||||
```
|
||||
monster-labs/control_v1p_sd15_qrcode_monster:v2
|
||||
```
|
||||
|
||||
@@ -4,12 +4,12 @@ The workflow editor is a blank canvas allowing for the use of individual functio
|
||||
|
||||
If you're not familiar with Diffusion, take a look at our [Diffusion Overview.](../help/diffusion.md) Understanding how diffusion works will enable you to more easily use the Workflow Editor and build workflows to suit your needs.
|
||||
|
||||
## Features
|
||||
## UI Features
|
||||
|
||||
### Linear View
|
||||
The Workflow Editor allows you to create a UI for your workflow, to make it easier to iterate on your generations.
|
||||
|
||||
To add an input to the Linear UI, right click on the input label and select "Add to Linear View".
|
||||
To add an input to the Linear UI, right click on the input and select "Add to Linear View".
|
||||
|
||||
The Linear UI View will also be part of the saved workflow, allowing you share workflows and enable other to use them, regardless of complexity.
|
||||
|
||||
@@ -25,10 +25,6 @@ Any node or input field can be renamed in the workflow editor. If the input fiel
|
||||
* Backspace/Delete to delete a node
|
||||
* Shift+Click to drag and select multiple nodes
|
||||
|
||||
### Node Caching
|
||||
|
||||
Nodes have a "Use Cache" option in their footer. This allows for performance improvements by using the previously cached values during the workflow processing.
|
||||
|
||||
|
||||
## Important Concepts
|
||||
|
||||
|
||||
@@ -8,21 +8,19 @@ To download a node, simply download the `.py` node file from the link and add it
|
||||
|
||||
To use a community workflow, download the the `.json` node graph file and load it into Invoke AI via the **Load Workflow** button in the Workflow Editor.
|
||||
|
||||
--------------------------------
|
||||
## Community Nodes
|
||||
|
||||
--------------------------------
|
||||
### Make 3D
|
||||
### FaceTools
|
||||
|
||||
**Description:** Create compelling 3D stereo images from 2D originals.
|
||||
**Description:** FaceTools is a collection of nodes created to manipulate faces as you would in Unified Canvas. It includes FaceMask, FaceOff, and FacePlace. FaceMask autodetects a face in the image using MediaPipe and creates a mask from it. FaceOff similarly detects a face, then takes the face off of the image by adding a square bounding box around it and cropping/scaling it. FacePlace puts the bounded face image from FaceOff back onto the original image. Using these nodes with other inpainting node(s), you can put new faces on existing things, put new things around existing faces, and work closer with a face as a bounded image. Additionally, you can supply X and Y offset values to scale/change the shape of the mask for finer control on FaceMask and FaceOff. See GitHub repository below for usage examples.
|
||||
|
||||
**Node Link:** [https://gitlab.com/srcrr/shift3d/-/raw/main/make3d.py](https://gitlab.com/srcrr/shift3d)
|
||||
**Node Link:** https://github.com/ymgenesis/FaceTools/
|
||||
|
||||
**Example Node Graph:** https://gitlab.com/srcrr/shift3d/-/raw/main/example-workflow.json?ref_type=heads&inline=false
|
||||
**FaceMask Output Examples**
|
||||
|
||||
**Output Examples**
|
||||
|
||||
{: style="height:512px;width:512px"}
|
||||
{: style="height:512px;width:512px"}
|
||||

|
||||

|
||||

|
||||
|
||||
--------------------------------
|
||||
### Ideal Size
|
||||
@@ -45,52 +43,6 @@ To use a community workflow, download the the `.json` node graph file and load i
|
||||
|
||||
**Node Link:** https://github.com/JPPhoto/image-picker-node
|
||||
|
||||
--------------------------------
|
||||
### Thresholding
|
||||
|
||||
**Description:** This node generates masks for highlights, midtones, and shadows given an input image. You can optionally specify a blur for the lookup table used in making those masks from the source image.
|
||||
|
||||
**Node Link:** https://github.com/JPPhoto/thresholding-node
|
||||
|
||||
**Examples**
|
||||
|
||||
Input:
|
||||
|
||||
{: style="height:512px;width:512px"}
|
||||
|
||||
Highlights/Midtones/Shadows:
|
||||
|
||||
<img src="https://github.com/invoke-ai/InvokeAI/assets/34005131/727021c1-36ff-4ec8-90c8-105e00de986d" style="width: 30%" />
|
||||
<img src="https://github.com/invoke-ai/InvokeAI/assets/34005131/0b721bfc-f051-404e-b905-2f16b824ddfe" style="width: 30%" />
|
||||
<img src="https://github.com/invoke-ai/InvokeAI/assets/34005131/04c1297f-1c88-42b6-a7df-dd090b976286" style="width: 30%" />
|
||||
|
||||
Highlights/Midtones/Shadows (with LUT blur enabled):
|
||||
|
||||
<img src="https://github.com/invoke-ai/InvokeAI/assets/34005131/19aa718a-70c1-4668-8169-d68f4bd13771" style="width: 30%" />
|
||||
<img src="https://github.com/invoke-ai/InvokeAI/assets/34005131/0a440e43-697f-4d17-82ee-f287467df0a5" style="width: 30%" />
|
||||
<img src="https://github.com/invoke-ai/InvokeAI/assets/34005131/0701fd0f-2ca7-4fe2-8613-2b52547bafce" style="width: 30%" />
|
||||
|
||||
--------------------------------
|
||||
### Halftone
|
||||
|
||||
**Description**: Halftone converts the source image to grayscale and then performs halftoning. CMYK Halftone converts the image to CMYK and applies a per-channel halftoning to make the source image look like a magazine or newspaper. For both nodes, you can specify angles and halftone dot spacing.
|
||||
|
||||
**Node Link:** https://github.com/JPPhoto/halftone-node
|
||||
|
||||
**Example**
|
||||
|
||||
Input:
|
||||
|
||||
{: style="height:512px;width:512px"}
|
||||
|
||||
Halftone Output:
|
||||
|
||||
{: style="height:512px;width:512px"}
|
||||
|
||||
CMYK Halftone Output:
|
||||
|
||||
{: style="height:512px;width:512px"}
|
||||
|
||||
--------------------------------
|
||||
### Retroize
|
||||
|
||||
@@ -125,7 +77,7 @@ Generated Prompt: An enchanted weapon will be usable by any character regardless
|
||||
**Example Node Graph:** https://github.com/helix4u/load_video_frame/blob/main/Example_Workflow.json
|
||||
|
||||
**Output Example:**
|
||||
|
||||
=======
|
||||

|
||||
[Full mp4 of Example Output test.mp4](https://github.com/helix4u/load_video_frame/blob/main/test.mp4)
|
||||
|
||||
@@ -169,6 +121,18 @@ To be imported, an .obj must use triangulated meshes, so make sure to enable tha
|
||||
**Example Usage:**
|
||||
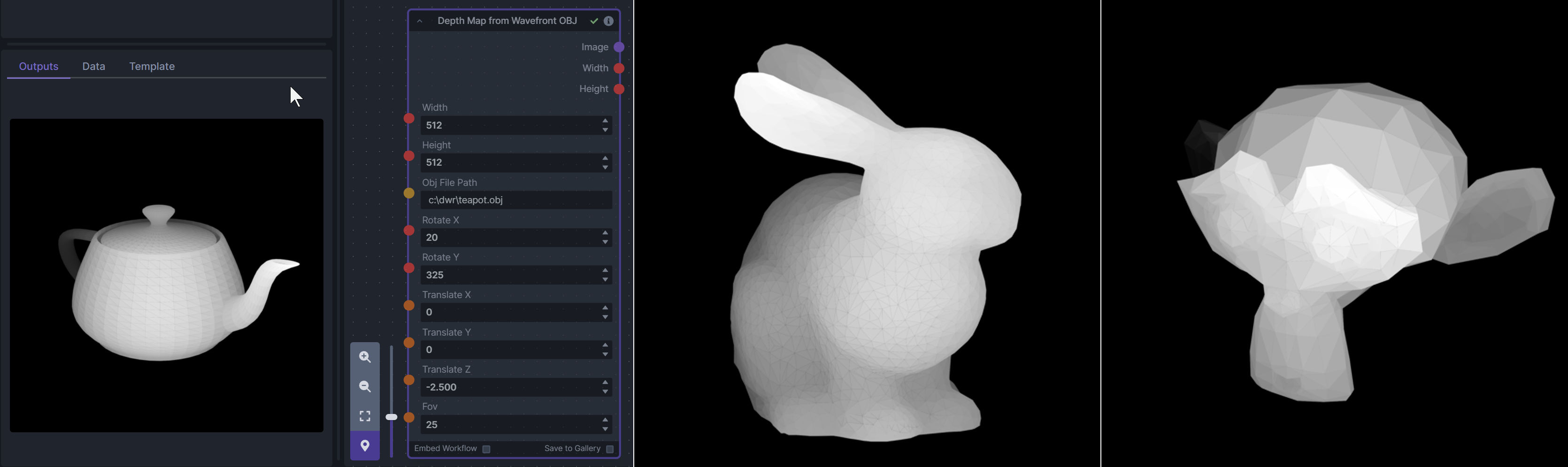
|
||||
|
||||
--------------------------------
|
||||
### Enhance Image (simple adjustments)
|
||||
|
||||
**Description:** Boost or reduce color saturation, contrast, brightness, sharpness, or invert colors of any image at any stage with this simple wrapper for pillow [PIL]'s ImageEnhance module.
|
||||
|
||||
Color inversion is toggled with a simple switch, while each of the four enhancer modes are activated by entering a value other than 1 in each corresponding input field. Values less than 1 will reduce the corresponding property, while values greater than 1 will enhance it.
|
||||
|
||||
**Node Link:** https://github.com/dwringer/image-enhance-node
|
||||
|
||||
**Example Usage:**
|
||||
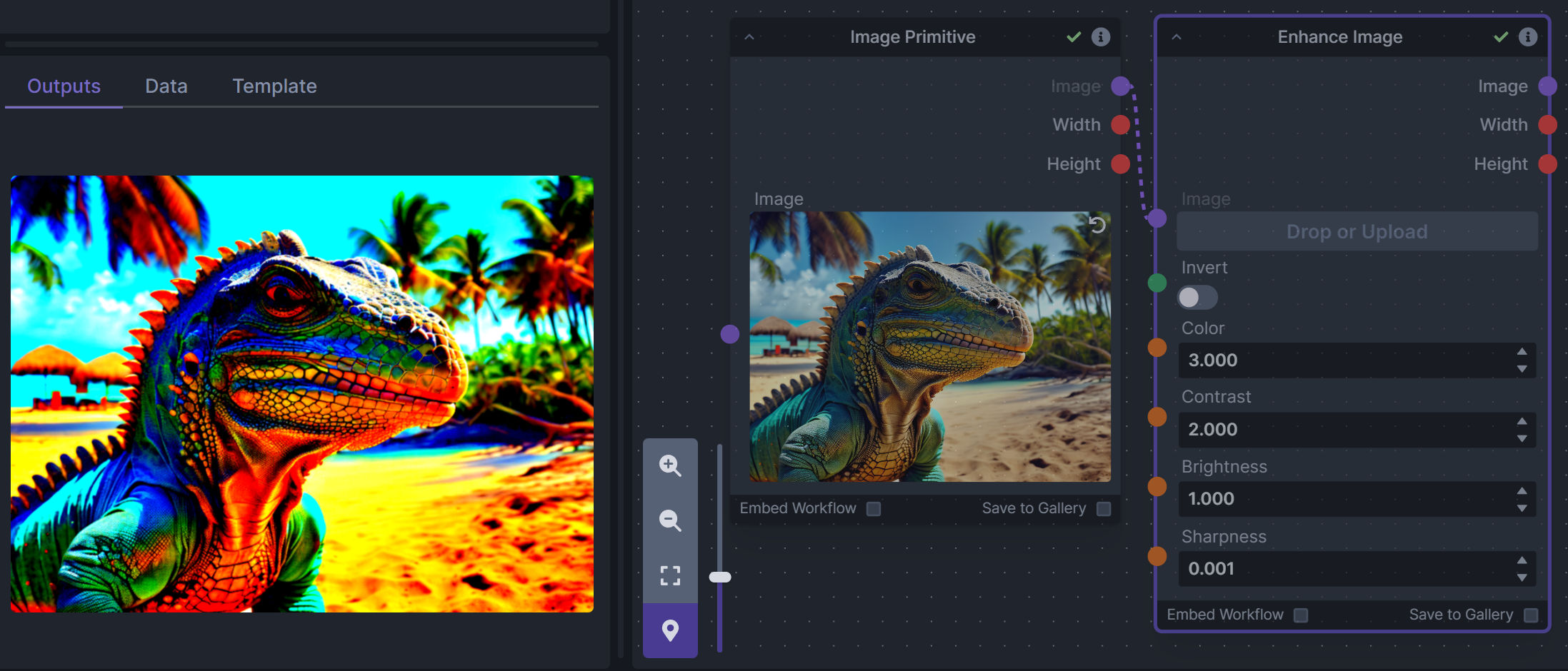
|
||||
|
||||
--------------------------------
|
||||
### Generative Grammar-Based Prompt Nodes
|
||||
|
||||
@@ -189,28 +153,16 @@ This includes 3 Nodes:
|
||||
|
||||
**Description:** This is a pack of nodes for composing masks and images, including a simple text mask creator and both image and latent offset nodes. The offsets wrap around, so these can be used in conjunction with the Seamless node to progressively generate centered on different parts of the seamless tiling.
|
||||
|
||||
This includes 15 Nodes:
|
||||
|
||||
- *Adjust Image Hue Plus* - Rotate the hue of an image in one of several different color spaces.
|
||||
- *Blend Latents/Noise (Masked)* - Use a mask to blend part of one latents tensor [including Noise outputs] into another. Can be used to "renoise" sections during a multi-stage [masked] denoising process.
|
||||
- *Enhance Image* - Boost or reduce color saturation, contrast, brightness, sharpness, or invert colors of any image at any stage with this simple wrapper for pillow [PIL]'s ImageEnhance module.
|
||||
- *Equivalent Achromatic Lightness* - Calculates image lightness accounting for Helmholtz-Kohlrausch effect based on a method described by High, Green, and Nussbaum (2023).
|
||||
- *Text to Mask (Clipseg)* - Input a prompt and an image to generate a mask representing areas of the image matched by the prompt.
|
||||
- *Text to Mask Advanced (Clipseg)* - Output up to four prompt masks combined with logical "and", logical "or", or as separate channels of an RGBA image.
|
||||
- *Image Layer Blend* - Perform a layered blend of two images using alpha compositing. Opacity of top layer is selectable, with optional mask and several different blend modes/color spaces.
|
||||
This includes 4 Nodes:
|
||||
- *Text Mask (simple 2D)* - create and position a white on black (or black on white) line of text using any font locally available to Invoke.
|
||||
- *Image Compositor* - Take a subject from an image with a flat backdrop and layer it on another image using a chroma key or flood select background removal.
|
||||
- *Image Dilate or Erode* - Dilate or expand a mask (or any image!). This is equivalent to an expand/contract operation.
|
||||
- *Image Value Thresholds* - Clip an image to pure black/white beyond specified thresholds.
|
||||
- *Offset Latents* - Offset a latents tensor in the vertical and/or horizontal dimensions, wrapping it around.
|
||||
- *Offset Image* - Offset an image in the vertical and/or horizontal dimensions, wrapping it around.
|
||||
- *Rotate/Flip Image* - Rotate an image in degrees clockwise/counterclockwise about its center, optionally resizing the image boundaries to fit, or flipping it about the vertical and/or horizontal axes.
|
||||
- *Shadows/Highlights/Midtones* - Extract three masks (with adjustable hard or soft thresholds) representing shadows, midtones, and highlights regions of an image.
|
||||
- *Text Mask (simple 2D)* - create and position a white on black (or black on white) line of text using any font locally available to Invoke.
|
||||
|
||||
**Node Link:** https://github.com/dwringer/composition-nodes
|
||||
|
||||
**Nodes and Output Examples:**
|
||||
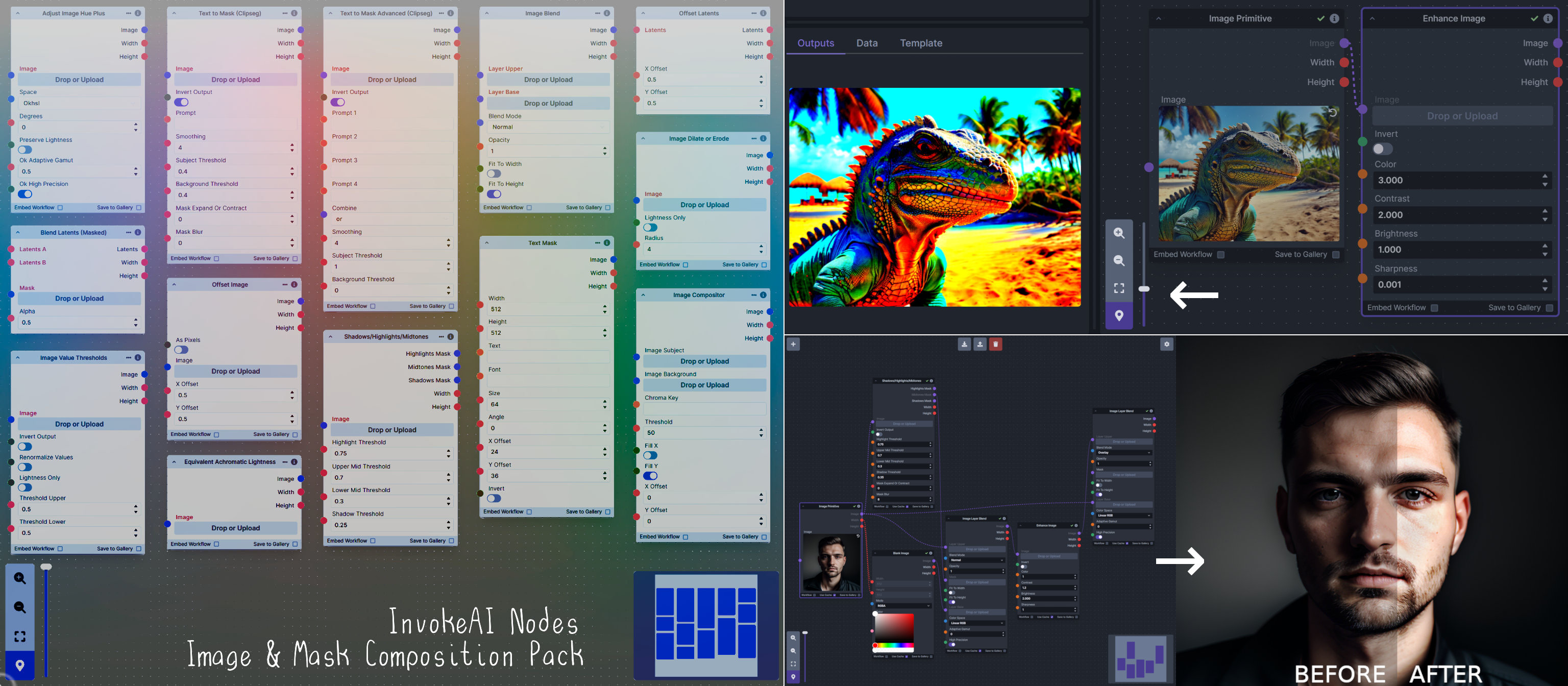
|
||||
**Example Usage:**
|
||||
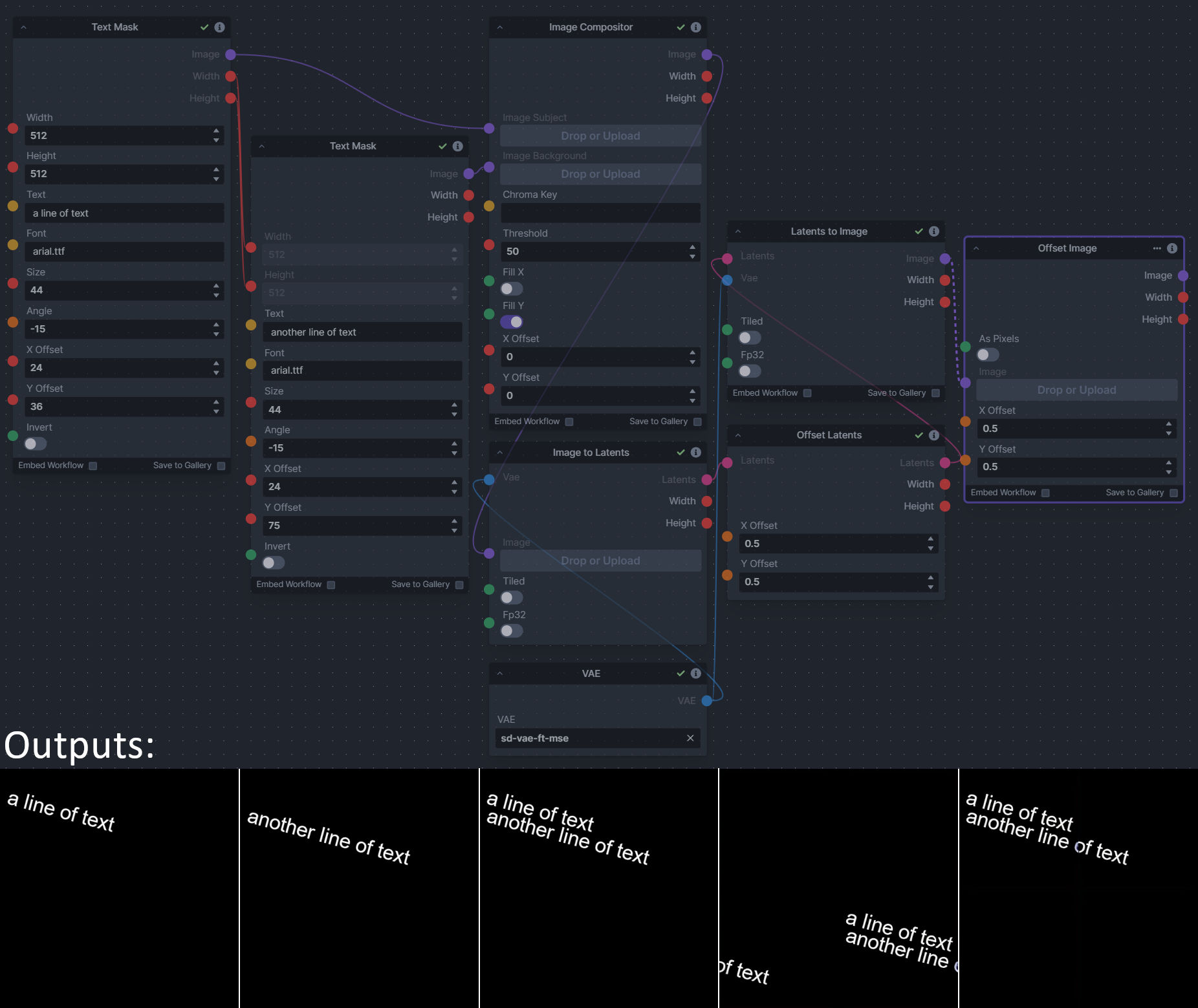
|
||||
|
||||
--------------------------------
|
||||
### Size Stepper Nodes
|
||||
@@ -244,70 +196,6 @@ Results after using the depth controlnet
|
||||
|
||||
--------------------------------
|
||||
|
||||
### Prompt Tools
|
||||
|
||||
**Description:** A set of InvokeAI nodes that add general prompt manipulation tools. These where written to accompany the PromptsFromFile node and other prompt generation nodes.
|
||||
|
||||
1. PromptJoin - Joins to prompts into one.
|
||||
2. PromptReplace - performs a search and replace on a prompt. With the option of using regex.
|
||||
3. PromptSplitNeg - splits a prompt into positive and negative using the old V2 method of [] for negative.
|
||||
4. PromptToFile - saves a prompt or collection of prompts to a file. one per line. There is an append/overwrite option.
|
||||
5. PTFieldsCollect - Converts image generation fields into a Json format string that can be passed to Prompt to file.
|
||||
6. PTFieldsExpand - Takes Json string and converts it to individual generation parameters This can be fed from the Prompts to file node.
|
||||
7. PromptJoinThree - Joins 3 prompt together.
|
||||
8. PromptStrength - This take a string and float and outputs another string in the format of (string)strength like the weighted format of compel.
|
||||
9. PromptStrengthCombine - This takes a collection of prompt strength strings and outputs a string in the .and() or .blend() format that can be fed into a proper prompt node.
|
||||
|
||||
See full docs here: https://github.com/skunkworxdark/Prompt-tools-nodes/edit/main/README.md
|
||||
|
||||
**Node Link:** https://github.com/skunkworxdark/Prompt-tools-nodes
|
||||
|
||||
--------------------------------
|
||||
|
||||
### XY Image to Grid and Images to Grids nodes
|
||||
|
||||
**Description:** Image to grid nodes and supporting tools.
|
||||
|
||||
1. "Images To Grids" node - Takes a collection of images and creates a grid(s) of images. If there are more images than the size of a single grid then mutilple grids will be created until it runs out of images.
|
||||
2. "XYImage To Grid" node - Converts a collection of XYImages into a labeled Grid of images. The XYImages collection has to be built using the supporoting nodes. See example node setups for more details.
|
||||
|
||||
|
||||
See full docs here: https://github.com/skunkworxdark/XYGrid_nodes/edit/main/README.md
|
||||
|
||||
**Node Link:** https://github.com/skunkworxdark/XYGrid_nodes
|
||||
|
||||
--------------------------------
|
||||
|
||||
### Image to Character Art Image Node's
|
||||
|
||||
**Description:** Group of nodes to convert an input image into ascii/unicode art Image
|
||||
|
||||
**Node Link:** https://github.com/mickr777/imagetoasciiimage
|
||||
|
||||
**Output Examples**
|
||||
|
||||
<img src="https://github.com/invoke-ai/InvokeAI/assets/115216705/8e061fcc-9a2c-4fa9-bcc7-c0f7b01e9056" width="300" />
|
||||
<img src="https://github.com/mickr777/imagetoasciiimage/assets/115216705/3c4990eb-2f42-46b9-90f9-0088b939dc6a" width="300" /></br>
|
||||
<img src="https://github.com/mickr777/imagetoasciiimage/assets/115216705/fee7f800-a4a8-41e2-a66b-c66e4343307e" width="300" />
|
||||
<img src="https://github.com/mickr777/imagetoasciiimage/assets/115216705/1d9c1003-a45f-45c2-aac7-46470bb89330" width="300" />
|
||||
|
||||
--------------------------------
|
||||
|
||||
### Grid to Gif
|
||||
|
||||
**Description:** One node that turns a grid image into an image colletion, one node that turns an image collection into a gif
|
||||
|
||||
**Node Link:** https://github.com/mildmisery/invokeai-GridToGifNode/blob/main/GridToGif.py
|
||||
|
||||
**Example Node Graph:** https://github.com/mildmisery/invokeai-GridToGifNode/blob/main/Grid%20to%20Gif%20Example%20Workflow.json
|
||||
|
||||
**Output Examples**
|
||||
|
||||
<img src="https://raw.githubusercontent.com/mildmisery/invokeai-GridToGifNode/main/input.png" width="300" />
|
||||
<img src="https://raw.githubusercontent.com/mildmisery/invokeai-GridToGifNode/main/output.gif" width="300" />
|
||||
|
||||
--------------------------------
|
||||
|
||||
### Example Node Template
|
||||
|
||||
**Description:** This node allows you to do super cool things with InvokeAI.
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
# List of Default Nodes
|
||||
|
||||
The table below contains a list of the default nodes shipped with InvokeAI and their descriptions.
|
||||
The table below contains a list of the default nodes shipped with InvokeAI and their descriptions.
|
||||
|
||||
| Node <img width=160 align="right"> | Function |
|
||||
|: ---------------------------------- | :--------------------------------------------------------------------------------------|
|
||||
@@ -17,12 +17,11 @@ The table below contains a list of the default nodes shipped with InvokeAI and t
|
||||
|Conditioning Primitive | A conditioning tensor primitive value|
|
||||
|Content Shuffle Processor | Applies content shuffle processing to image|
|
||||
|ControlNet | Collects ControlNet info to pass to other nodes|
|
||||
|OpenCV Inpaint | Simple inpaint using opencv.|
|
||||
|Denoise Latents | Denoises noisy latents to decodable images|
|
||||
|Divide Integers | Divides two numbers|
|
||||
|Dynamic Prompt | Parses a prompt using adieyal/dynamicprompts' random or combinatorial generator|
|
||||
|[FaceMask](./detailedNodes/faceTools.md#facemask) | Generates masks for faces in an image to use with Inpainting|
|
||||
|[FaceIdentifier](./detailedNodes/faceTools.md#faceidentifier) | Identifies and labels faces in an image|
|
||||
|[FaceOff](./detailedNodes/faceTools.md#faceoff) | Creates a new image that is a scaled bounding box with a mask on the face for Inpainting|
|
||||
|Upscale (RealESRGAN) | Upscales an image using RealESRGAN.|
|
||||
|Float Math | Perform basic math operations on two floats|
|
||||
|Float Primitive Collection | A collection of float primitive values|
|
||||
|Float Primitive | A float primitive value|
|
||||
@@ -77,7 +76,6 @@ The table below contains a list of the default nodes shipped with InvokeAI and t
|
||||
|ONNX Prompt (Raw) | A node to process inputs and produce outputs. May use dependency injection in __init__ to receive providers.|
|
||||
|ONNX Text to Latents | Generates latents from conditionings.|
|
||||
|ONNX Model Loader | Loads a main model, outputting its submodels.|
|
||||
|OpenCV Inpaint | Simple inpaint using opencv.|
|
||||
|Openpose Processor | Applies Openpose processing to image|
|
||||
|PIDI Processor | Applies PIDI processing to image|
|
||||
|Prompts from File | Loads prompts from a text file|
|
||||
@@ -99,6 +97,5 @@ The table below contains a list of the default nodes shipped with InvokeAI and t
|
||||
|String Primitive | A string primitive value|
|
||||
|Subtract Integers | Subtracts two numbers|
|
||||
|Tile Resample Processor | Tile resampler processor|
|
||||
|Upscale (RealESRGAN) | Upscales an image using RealESRGAN.|
|
||||
|VAE Loader | Loads a VAE model, outputting a VaeLoaderOutput|
|
||||
|Zoe (Depth) Processor | Applies Zoe depth processing to image|
|
||||
@@ -1,154 +0,0 @@
|
||||
# Face Nodes
|
||||
|
||||
## FaceOff
|
||||
|
||||
FaceOff mimics a user finding a face in an image and resizing the bounding box
|
||||
around the head in Canvas.
|
||||
|
||||
Enter a face ID (found with FaceIdentifier) to choose which face to mask.
|
||||
|
||||
Just as you would add more context inside the bounding box by making it larger
|
||||
in Canvas, the node gives you a padding input (in pixels) which will
|
||||
simultaneously add more context, and increase the resolution of the bounding box
|
||||
so the face remains the same size inside it.
|
||||
|
||||
The "Minimum Confidence" input defaults to 0.5 (50%), and represents a pass/fail
|
||||
threshold a detected face must reach for it to be processed. Lowering this value
|
||||
may help if detection is failing. If the detected masks are imperfect and stray
|
||||
too far outside/inside of faces, the node gives you X & Y offsets to shrink/grow
|
||||
the masks by a multiplier.
|
||||
|
||||
FaceOff will output the face in a bounded image, taking the face off of the
|
||||
original image for input into any node that accepts image inputs. The node also
|
||||
outputs a face mask with the dimensions of the bounded image. The X & Y outputs
|
||||
are for connecting to the X & Y inputs of the Paste Image node, which will place
|
||||
the bounded image back on the original image using these coordinates.
|
||||
|
||||
###### Inputs/Outputs
|
||||
|
||||
| Input | Description |
|
||||
| ------------------ | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| Image | Image for face detection |
|
||||
| Face ID | The face ID to process, numbered from 0. Multiple faces not supported. Find a face's ID with FaceIdentifier node. |
|
||||
| Minimum Confidence | Minimum confidence for face detection (lower if detection is failing) |
|
||||
| X Offset | X-axis offset of the mask |
|
||||
| Y Offset | Y-axis offset of the mask |
|
||||
| Padding | All-axis padding around the mask in pixels |
|
||||
| Chunk | Chunk (or divide) the image into sections to greatly improve face detection success. Defaults to off, but will activate if no faces are detected normally. Activate to chunk by default. |
|
||||
|
||||
| Output | Description |
|
||||
| ------------- | ------------------------------------------------ |
|
||||
| Bounded Image | Original image bound, cropped, and resized |
|
||||
| Width | The width of the bounded image in pixels |
|
||||
| Height | The height of the bounded image in pixels |
|
||||
| Mask | The output mask |
|
||||
| X | The x coordinate of the bounding box's left side |
|
||||
| Y | The y coordinate of the bounding box's top side |
|
||||
|
||||
## FaceMask
|
||||
|
||||
FaceMask mimics a user drawing masks on faces in an image in Canvas.
|
||||
|
||||
The "Face IDs" input allows the user to select specific faces to be masked.
|
||||
Leave empty to detect and mask all faces, or a comma-separated list for a
|
||||
specific combination of faces (ex: `1,2,4`). A single integer will detect and
|
||||
mask that specific face. Find face IDs with the FaceIdentifier node.
|
||||
|
||||
The "Minimum Confidence" input defaults to 0.5 (50%), and represents a pass/fail
|
||||
threshold a detected face must reach for it to be processed. Lowering this value
|
||||
may help if detection is failing.
|
||||
|
||||
If the detected masks are imperfect and stray too far outside/inside of faces,
|
||||
the node gives you X & Y offsets to shrink/grow the masks by a multiplier. All
|
||||
masks shrink/grow together by the X & Y offset values.
|
||||
|
||||
By default, masks are created to change faces. When masks are inverted, they
|
||||
change surrounding areas, protecting faces.
|
||||
|
||||
###### Inputs/Outputs
|
||||
|
||||
| Input | Description |
|
||||
| ------------------ | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| Image | Image for face detection |
|
||||
| Face IDs | Comma-separated list of face ids to mask eg '0,2,7'. Numbered from 0. Leave empty to mask all. Find face IDs with FaceIdentifier node. |
|
||||
| Minimum Confidence | Minimum confidence for face detection (lower if detection is failing) |
|
||||
| X Offset | X-axis offset of the mask |
|
||||
| Y Offset | Y-axis offset of the mask |
|
||||
| Chunk | Chunk (or divide) the image into sections to greatly improve face detection success. Defaults to off, but will activate if no faces are detected normally. Activate to chunk by default. |
|
||||
| Invert Mask | Toggle to invert the face mask |
|
||||
|
||||
| Output | Description |
|
||||
| ------ | --------------------------------- |
|
||||
| Image | The original image |
|
||||
| Width | The width of the image in pixels |
|
||||
| Height | The height of the image in pixels |
|
||||
| Mask | The output face mask |
|
||||
|
||||
## FaceIdentifier
|
||||
|
||||
FaceIdentifier outputs an image with detected face IDs printed in white numbers
|
||||
onto each face.
|
||||
|
||||
Face IDs can then be used in FaceMask and FaceOff to selectively mask all, a
|
||||
specific combination, or single faces.
|
||||
|
||||
The FaceIdentifier output image is generated for user reference, and isn't meant
|
||||
to be passed on to other image-processing nodes.
|
||||
|
||||
The "Minimum Confidence" input defaults to 0.5 (50%), and represents a pass/fail
|
||||
threshold a detected face must reach for it to be processed. Lowering this value
|
||||
may help if detection is failing. If an image is changed in the slightest, run
|
||||
it through FaceIdentifier again to get updated FaceIDs.
|
||||
|
||||
###### Inputs/Outputs
|
||||
|
||||
| Input | Description |
|
||||
| ------------------ | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| Image | Image for face detection |
|
||||
| Minimum Confidence | Minimum confidence for face detection (lower if detection is failing) |
|
||||
| Chunk | Chunk (or divide) the image into sections to greatly improve face detection success. Defaults to off, but will activate if no faces are detected normally. Activate to chunk by default. |
|
||||
|
||||
| Output | Description |
|
||||
| ------ | ------------------------------------------------------------------------------------------------ |
|
||||
| Image | The original image with small face ID numbers printed in white onto each face for user reference |
|
||||
| Width | The width of the original image in pixels |
|
||||
| Height | The height of the original image in pixels |
|
||||
|
||||
## Tips
|
||||
|
||||
- If not all target faces are being detected, activate Chunk to bypass full
|
||||
image face detection and greatly improve detection success.
|
||||
- Final results will vary between full-image detection and chunking for faces
|
||||
that are detectable by both due to the nature of the process. Try either to
|
||||
your taste.
|
||||
- Be sure Minimum Confidence is set the same when using FaceIdentifier with
|
||||
FaceOff/FaceMask.
|
||||
- For FaceOff, use the color correction node before faceplace to correct edges
|
||||
being noticeable in the final image (see example screenshot).
|
||||
- Non-inpainting models may struggle to paint/generate correctly around faces.
|
||||
- If your face won't change the way you want it to no matter what you change,
|
||||
consider that the change you're trying to make is too much at that resolution.
|
||||
For example, if an image is only 512x768 total, the face might only be 128x128
|
||||
or 256x256, much smaller than the 512x512 your SD1.5 model was probably
|
||||
trained on. Try increasing the resolution of the image by upscaling or
|
||||
resizing, add padding to increase the bounding box's resolution, or use an
|
||||
image where the face takes up more pixels.
|
||||
- If the resulting face seems out of place pasted back on the original image
|
||||
(ie. too large, not proportional), add more padding on the FaceOff node to
|
||||
give inpainting more context. Context and good prompting are important to
|
||||
keeping things proportional.
|
||||
- If you find the mask is too big/small and going too far outside/inside the
|
||||
area you want to affect, adjust the x & y offsets to shrink/grow the mask area
|
||||
- Use a higher denoise start value to resemble aspects of the original face or
|
||||
surroundings. Denoise start = 0 & denoise end = 1 will make something new,
|
||||
while denoise start = 0.50 & denoise end = 1 will be 50% old and 50% new.
|
||||
- mediapipe isn't good at detecting faces with lots of face paint, hair covering
|
||||
the face, etc. Anything that obstructs the face will likely result in no faces
|
||||
being detected.
|
||||
- If you find your face isn't being detected, try lowering the minimum
|
||||
confidence value from 0.5. This could result in false positives, however
|
||||
(random areas being detected as faces and masked).
|
||||
- After altering an image and wanting to process a different face in the newly
|
||||
altered image, run the altered image through FaceIdentifier again to see the
|
||||
new Face IDs. MediaPipe will most likely detect faces in a different order
|
||||
after an image has been changed in the slightest.
|
||||
@@ -9,6 +9,5 @@ If you're interested in finding more workflows, checkout the [#share-your-workfl
|
||||
* [SD1.5 / SD2 Text to Image](https://github.com/invoke-ai/InvokeAI/blob/main/docs/workflows/Text_to_Image.json)
|
||||
* [SDXL Text to Image](https://github.com/invoke-ai/InvokeAI/blob/main/docs/workflows/SDXL_Text_to_Image.json)
|
||||
* [SDXL (with Refiner) Text to Image](https://github.com/invoke-ai/InvokeAI/blob/main/docs/workflows/SDXL_Text_to_Image.json)
|
||||
* [Tiled Upscaling with ControlNet](https://github.com/invoke-ai/InvokeAI/blob/main/docs/workflows/ESRGAN_img2img_upscale w_Canny_ControlNet.json)
|
||||
* [FaceMask](https://github.com/invoke-ai/InvokeAI/blob/main/docs/workflows/FaceMask.json)
|
||||
* [FaceOff with 2x Face Scaling](https://github.com/invoke-ai/InvokeAI/blob/main/docs/workflows/FaceOff_FaceScale2x.json)
|
||||
* [Tiled Upscaling with ControlNet](https://github.com/invoke-ai/InvokeAI/blob/main/docs/workflows/ESRGAN_img2img_upscale w_Canny_ControlNet.json)ß
|
||||
|
||||
|
||||
File diff suppressed because it is too large
Load Diff
File diff suppressed because it is too large
Load Diff
@@ -332,7 +332,6 @@ class InvokeAiInstance:
|
||||
Configure the InvokeAI runtime directory
|
||||
"""
|
||||
|
||||
auto_install = False
|
||||
# set sys.argv to a consistent state
|
||||
new_argv = [sys.argv[0]]
|
||||
for i in range(1, len(sys.argv)):
|
||||
@@ -341,17 +340,13 @@ class InvokeAiInstance:
|
||||
new_argv.append(el)
|
||||
new_argv.append(sys.argv[i + 1])
|
||||
elif el in ["-y", "--yes", "--yes-to-all"]:
|
||||
auto_install = True
|
||||
new_argv.append(el)
|
||||
sys.argv = new_argv
|
||||
|
||||
import messages
|
||||
import requests # to catch download exceptions
|
||||
from messages import introduction
|
||||
|
||||
auto_install = auto_install or messages.user_wants_auto_configuration()
|
||||
if auto_install:
|
||||
sys.argv.append("--yes")
|
||||
else:
|
||||
messages.introduction()
|
||||
introduction()
|
||||
|
||||
from invokeai.frontend.install.invokeai_configure import invokeai_configure
|
||||
|
||||
|
||||
@@ -7,7 +7,7 @@ import os
|
||||
import platform
|
||||
from pathlib import Path
|
||||
|
||||
from prompt_toolkit import HTML, prompt
|
||||
from prompt_toolkit import prompt
|
||||
from prompt_toolkit.completion import PathCompleter
|
||||
from prompt_toolkit.validation import Validator
|
||||
from rich import box, print
|
||||
@@ -65,50 +65,17 @@ def confirm_install(dest: Path) -> bool:
|
||||
if dest.exists():
|
||||
print(f":exclamation: Directory {dest} already exists :exclamation:")
|
||||
dest_confirmed = Confirm.ask(
|
||||
":stop_sign: (re)install in this location?",
|
||||
":stop_sign: Are you sure you want to (re)install in this location?",
|
||||
default=False,
|
||||
)
|
||||
else:
|
||||
print(f"InvokeAI will be installed in {dest}")
|
||||
dest_confirmed = Confirm.ask("Use this location?", default=True)
|
||||
dest_confirmed = not Confirm.ask("Would you like to pick a different location?", default=False)
|
||||
console.line()
|
||||
|
||||
return dest_confirmed
|
||||
|
||||
|
||||
def user_wants_auto_configuration() -> bool:
|
||||
"""Prompt the user to choose between manual and auto configuration."""
|
||||
console.rule("InvokeAI Configuration Section")
|
||||
console.print(
|
||||
Panel(
|
||||
Group(
|
||||
"\n".join(
|
||||
[
|
||||
"Libraries are installed and InvokeAI will now set up its root directory and configuration. Choose between:",
|
||||
"",
|
||||
" * AUTOMATIC configuration: install reasonable defaults and a minimal set of starter models.",
|
||||
" * MANUAL configuration: manually inspect and adjust configuration options and pick from a larger set of starter models.",
|
||||
"",
|
||||
"Later you can fine tune your configuration by selecting option [6] 'Change InvokeAI startup options' from the invoke.bat/invoke.sh launcher script.",
|
||||
]
|
||||
),
|
||||
),
|
||||
box=box.MINIMAL,
|
||||
padding=(1, 1),
|
||||
)
|
||||
)
|
||||
choice = (
|
||||
prompt(
|
||||
HTML("Choose <b><a></b>utomatic or <b><m></b>anual configuration [a/m] (a): "),
|
||||
validator=Validator.from_callable(
|
||||
lambda n: n == "" or n.startswith(("a", "A", "m", "M")), error_message="Please select 'a' or 'm'"
|
||||
),
|
||||
)
|
||||
or "a"
|
||||
)
|
||||
return choice.lower().startswith("a")
|
||||
|
||||
|
||||
def dest_path(dest=None) -> Path:
|
||||
"""
|
||||
Prompt the user for the destination path and create the path
|
||||
|
||||
@@ -17,10 +17,9 @@ echo 6. Change InvokeAI startup options
|
||||
echo 7. Re-run the configure script to fix a broken install or to complete a major upgrade
|
||||
echo 8. Open the developer console
|
||||
echo 9. Update InvokeAI
|
||||
echo 10. Run the InvokeAI image database maintenance script
|
||||
echo 11. Command-line help
|
||||
echo 10. Command-line help
|
||||
echo Q - Quit
|
||||
set /P choice="Please enter 1-11, Q: [1] "
|
||||
set /P choice="Please enter 1-10, Q: [1] "
|
||||
if not defined choice set choice=1
|
||||
IF /I "%choice%" == "1" (
|
||||
echo Starting the InvokeAI browser-based UI..
|
||||
@@ -59,11 +58,8 @@ IF /I "%choice%" == "1" (
|
||||
echo Running invokeai-update...
|
||||
python -m invokeai.frontend.install.invokeai_update
|
||||
) ELSE IF /I "%choice%" == "10" (
|
||||
echo Running the db maintenance script...
|
||||
python .venv\Scripts\invokeai-db-maintenance.exe
|
||||
) ELSE IF /I "%choice%" == "11" (
|
||||
echo Displaying command line help...
|
||||
python .venv\Scripts\invokeai-web.exe --help %*
|
||||
python .venv\Scripts\invokeai.exe --help %*
|
||||
pause
|
||||
exit /b
|
||||
) ELSE IF /I "%choice%" == "q" (
|
||||
|
||||
@@ -46,9 +46,6 @@ if [ "$(uname -s)" == "Darwin" ]; then
|
||||
export PYTORCH_ENABLE_MPS_FALLBACK=1
|
||||
fi
|
||||
|
||||
# Avoid glibc memory fragmentation. See invokeai/backend/model_management/README.md for details.
|
||||
export MALLOC_MMAP_THRESHOLD_=1048576
|
||||
|
||||
# Primary function for the case statement to determine user input
|
||||
do_choice() {
|
||||
case $1 in
|
||||
@@ -100,13 +97,13 @@ do_choice() {
|
||||
;;
|
||||
10)
|
||||
clear
|
||||
printf "Running the db maintenance script\n"
|
||||
invokeai-db-maintenance --root ${INVOKEAI_ROOT}
|
||||
printf "Command-line help\n"
|
||||
invokeai --help
|
||||
;;
|
||||
11)
|
||||
"HELP 1")
|
||||
clear
|
||||
printf "Command-line help\n"
|
||||
invokeai-web --help
|
||||
invokeai --help
|
||||
;;
|
||||
*)
|
||||
clear
|
||||
@@ -128,10 +125,7 @@ do_dialog() {
|
||||
6 "Change InvokeAI startup options"
|
||||
7 "Re-run the configure script to fix a broken install or to complete a major upgrade"
|
||||
8 "Open the developer console"
|
||||
9 "Update InvokeAI"
|
||||
10 "Run the InvokeAI image database maintenance script"
|
||||
11 "Command-line help"
|
||||
)
|
||||
9 "Update InvokeAI")
|
||||
|
||||
choice=$(dialog --clear \
|
||||
--backtitle "\Zb\Zu\Z3InvokeAI" \
|
||||
@@ -163,10 +157,9 @@ do_line_input() {
|
||||
printf "7: Re-run the configure script to fix a broken install\n"
|
||||
printf "8: Open the developer console\n"
|
||||
printf "9: Update InvokeAI\n"
|
||||
printf "10: Run the InvokeAI image database maintenance script\n"
|
||||
printf "11: Command-line help\n"
|
||||
printf "10: Command-line help\n"
|
||||
printf "Q: Quit\n\n"
|
||||
read -p "Please enter 1-11, Q: [1] " yn
|
||||
read -p "Please enter 1-10, Q: [1] " yn
|
||||
choice=${yn:='1'}
|
||||
do_choice $choice
|
||||
clear
|
||||
|
||||
@@ -19,7 +19,6 @@ from invokeai.backend.util.logging import InvokeAILogger
|
||||
from invokeai.version.invokeai_version import __version__
|
||||
|
||||
from ..services.default_graphs import create_system_graphs
|
||||
from ..services.download_manager import DownloadQueueService
|
||||
from ..services.graph import GraphExecutionState, LibraryGraph
|
||||
from ..services.image_file_storage import DiskImageFileStorage
|
||||
from ..services.invocation_queue import MemoryInvocationQueue
|
||||
@@ -27,9 +26,7 @@ from ..services.invocation_services import InvocationServices
|
||||
from ..services.invocation_stats import InvocationStatsService
|
||||
from ..services.invoker import Invoker
|
||||
from ..services.latent_storage import DiskLatentsStorage, ForwardCacheLatentsStorage
|
||||
from ..services.model_install_service import ModelInstallService
|
||||
from ..services.model_loader_service import ModelLoadService
|
||||
from ..services.model_record_service import ModelRecordServiceBase
|
||||
from ..services.model_manager_service import ModelManagerService
|
||||
from ..services.processor import DefaultInvocationProcessor
|
||||
from ..services.sqlite import SqliteItemStorage
|
||||
from ..services.thread import lock
|
||||
@@ -52,7 +49,7 @@ def check_internet() -> bool:
|
||||
return False
|
||||
|
||||
|
||||
logger = InvokeAILogger.get_logger()
|
||||
logger = InvokeAILogger.getLogger()
|
||||
|
||||
|
||||
class ApiDependencies:
|
||||
@@ -130,12 +127,8 @@ class ApiDependencies:
|
||||
)
|
||||
)
|
||||
|
||||
download_queue = DownloadQueueService(event_bus=events)
|
||||
model_record_store = ModelRecordServiceBase.open(config, conn=db_conn, lock=lock)
|
||||
model_loader = ModelLoadService(config, model_record_store)
|
||||
model_installer = ModelInstallService(config, queue=download_queue, store=model_record_store, event_bus=events)
|
||||
|
||||
services = InvocationServices(
|
||||
model_manager=ModelManagerService(config, logger),
|
||||
events=events,
|
||||
latents=latents,
|
||||
images=images,
|
||||
@@ -148,10 +141,6 @@ class ApiDependencies:
|
||||
configuration=config,
|
||||
performance_statistics=InvocationStatsService(graph_execution_manager),
|
||||
logger=logger,
|
||||
download_queue=download_queue,
|
||||
model_record_store=model_record_store,
|
||||
model_loader=model_loader,
|
||||
model_installer=model_installer,
|
||||
session_queue=SqliteSessionQueue(conn=db_conn, lock=lock),
|
||||
session_processor=DefaultSessionProcessor(),
|
||||
invocation_cache=MemoryInvocationCache(max_cache_size=config.node_cache_size),
|
||||
|
||||
@@ -7,7 +7,6 @@ from fastapi.routing import APIRouter
|
||||
from pydantic import BaseModel, Field
|
||||
|
||||
from invokeai.app.invocations.upscale import ESRGAN_MODELS
|
||||
from invokeai.app.services.invocation_cache.invocation_cache_common import InvocationCacheStatus
|
||||
from invokeai.backend.image_util.invisible_watermark import InvisibleWatermark
|
||||
from invokeai.backend.image_util.patchmatch import PatchMatch
|
||||
from invokeai.backend.image_util.safety_checker import SafetyChecker
|
||||
@@ -104,43 +103,3 @@ async def set_log_level(
|
||||
"""Sets the log verbosity level"""
|
||||
ApiDependencies.invoker.services.logger.setLevel(level)
|
||||
return LogLevel(ApiDependencies.invoker.services.logger.level)
|
||||
|
||||
|
||||
@app_router.delete(
|
||||
"/invocation_cache",
|
||||
operation_id="clear_invocation_cache",
|
||||
responses={200: {"description": "The operation was successful"}},
|
||||
)
|
||||
async def clear_invocation_cache() -> None:
|
||||
"""Clears the invocation cache"""
|
||||
ApiDependencies.invoker.services.invocation_cache.clear()
|
||||
|
||||
|
||||
@app_router.put(
|
||||
"/invocation_cache/enable",
|
||||
operation_id="enable_invocation_cache",
|
||||
responses={200: {"description": "The operation was successful"}},
|
||||
)
|
||||
async def enable_invocation_cache() -> None:
|
||||
"""Clears the invocation cache"""
|
||||
ApiDependencies.invoker.services.invocation_cache.enable()
|
||||
|
||||
|
||||
@app_router.put(
|
||||
"/invocation_cache/disable",
|
||||
operation_id="disable_invocation_cache",
|
||||
responses={200: {"description": "The operation was successful"}},
|
||||
)
|
||||
async def disable_invocation_cache() -> None:
|
||||
"""Clears the invocation cache"""
|
||||
ApiDependencies.invoker.services.invocation_cache.disable()
|
||||
|
||||
|
||||
@app_router.get(
|
||||
"/invocation_cache/status",
|
||||
operation_id="get_invocation_cache_status",
|
||||
responses={200: {"model": InvocationCacheStatus}},
|
||||
)
|
||||
async def get_invocation_cache_status() -> InvocationCacheStatus:
|
||||
"""Clears the invocation cache"""
|
||||
return ApiDependencies.invoker.services.invocation_cache.get_status()
|
||||
|
||||
@@ -2,60 +2,35 @@
|
||||
|
||||
|
||||
import pathlib
|
||||
from enum import Enum
|
||||
from typing import Any, List, Literal, Optional, Union
|
||||
from typing import List, Literal, Optional, Union
|
||||
|
||||
from fastapi import Body, Path, Query, Response
|
||||
from fastapi.routing import APIRouter
|
||||
from pydantic import BaseModel, parse_obj_as
|
||||
from starlette.exceptions import HTTPException
|
||||
|
||||
from invokeai.app.api.dependencies import ApiDependencies
|
||||
from invokeai.app.services.download_manager import DownloadJobRemoteSource, DownloadJobStatus, UnknownJobIDException
|
||||
from invokeai.app.services.model_convert import MergeInterpolationMethod, ModelConvert
|
||||
from invokeai.app.services.model_install_service import ModelInstallJob
|
||||
from invokeai.backend import BaseModelType, ModelType
|
||||
from invokeai.backend.model_manager import (
|
||||
from invokeai.backend.model_management import MergeInterpolationMethod
|
||||
from invokeai.backend.model_management.models import (
|
||||
OPENAPI_MODEL_CONFIGS,
|
||||
DuplicateModelException,
|
||||
InvalidModelException,
|
||||
ModelConfigBase,
|
||||
ModelSearch,
|
||||
ModelNotFoundException,
|
||||
SchedulerPredictionType,
|
||||
UnknownModelException,
|
||||
)
|
||||
|
||||
from ..dependencies import ApiDependencies
|
||||
|
||||
models_router = APIRouter(prefix="/v1/models", tags=["models"])
|
||||
|
||||
# NOTE: The generic configuration classes defined in invokeai.backend.model_manager.config
|
||||
# such as "MainCheckpointConfig" are repackaged by code originally written by Stalker
|
||||
# into base-specific classes such as `abc.StableDiffusion1ModelCheckpointConfig`
|
||||
# This is the reason for the calls to dict() followed by pydantic.parse_obj_as()
|
||||
|
||||
# There are still numerous mypy errors here because it does not seem to like this
|
||||
# way of dynamically generating the typing hints below.
|
||||
InvokeAIModelConfig: Any = Union[tuple(OPENAPI_MODEL_CONFIGS)]
|
||||
UpdateModelResponse = Union[tuple(OPENAPI_MODEL_CONFIGS)]
|
||||
ImportModelResponse = Union[tuple(OPENAPI_MODEL_CONFIGS)]
|
||||
ConvertModelResponse = Union[tuple(OPENAPI_MODEL_CONFIGS)]
|
||||
MergeModelResponse = Union[tuple(OPENAPI_MODEL_CONFIGS)]
|
||||
ImportModelAttributes = Union[tuple(OPENAPI_MODEL_CONFIGS)]
|
||||
|
||||
|
||||
class ModelsList(BaseModel):
|
||||
models: List[InvokeAIModelConfig]
|
||||
|
||||
|
||||
class ModelDownloadStatus(BaseModel):
|
||||
"""Return information about a background installation job."""
|
||||
|
||||
job_id: int
|
||||
source: str
|
||||
priority: int
|
||||
bytes: int
|
||||
total_bytes: int
|
||||
status: DownloadJobStatus
|
||||
|
||||
|
||||
class JobControlOperation(str, Enum):
|
||||
START = "Start"
|
||||
PAUSE = "Pause"
|
||||
CANCEL = "Cancel"
|
||||
models: list[Union[tuple(OPENAPI_MODEL_CONFIGS)]]
|
||||
|
||||
|
||||
@models_router.get(
|
||||
@@ -67,22 +42,19 @@ async def list_models(
|
||||
base_models: Optional[List[BaseModelType]] = Query(default=None, description="Base models to include"),
|
||||
model_type: Optional[ModelType] = Query(default=None, description="The type of model to get"),
|
||||
) -> ModelsList:
|
||||
"""Get a list of models."""
|
||||
record_store = ApiDependencies.invoker.services.model_record_store
|
||||
"""Gets a list of models"""
|
||||
if base_models and len(base_models) > 0:
|
||||
models_raw = list()
|
||||
for base_model in base_models:
|
||||
models_raw.extend(
|
||||
[x.dict() for x in record_store.search_by_name(base_model=base_model, model_type=model_type)]
|
||||
)
|
||||
models_raw.extend(ApiDependencies.invoker.services.model_manager.list_models(base_model, model_type))
|
||||
else:
|
||||
models_raw = [x.dict() for x in record_store.search_by_name(model_type=model_type)]
|
||||
models_raw = ApiDependencies.invoker.services.model_manager.list_models(None, model_type)
|
||||
models = parse_obj_as(ModelsList, {"models": models_raw})
|
||||
return models
|
||||
|
||||
|
||||
@models_router.patch(
|
||||
"/i/{key}",
|
||||
"/{base_model}/{model_type}/{model_name}",
|
||||
operation_id="update_model",
|
||||
responses={
|
||||
200: {"description": "The model was updated successfully"},
|
||||
@@ -91,36 +63,69 @@ async def list_models(
|
||||
409: {"description": "There is already a model corresponding to the new name"},
|
||||
},
|
||||
status_code=200,
|
||||
response_model=InvokeAIModelConfig,
|
||||
response_model=UpdateModelResponse,
|
||||
)
|
||||
async def update_model(
|
||||
key: str = Path(description="Unique key of model"),
|
||||
info: InvokeAIModelConfig = Body(description="Model configuration"),
|
||||
) -> InvokeAIModelConfig:
|
||||
base_model: BaseModelType = Path(description="Base model"),
|
||||
model_type: ModelType = Path(description="The type of model"),
|
||||
model_name: str = Path(description="model name"),
|
||||
info: Union[tuple(OPENAPI_MODEL_CONFIGS)] = Body(description="Model configuration"),
|
||||
) -> UpdateModelResponse:
|
||||
"""Update model contents with a new config. If the model name or base fields are changed, then the model is renamed."""
|
||||
logger = ApiDependencies.invoker.services.logger
|
||||
info_dict = info.dict()
|
||||
record_store = ApiDependencies.invoker.services.model_record_store
|
||||
model_install = ApiDependencies.invoker.services.model_installer
|
||||
try:
|
||||
new_config = record_store.update_model(key, config=info_dict)
|
||||
except UnknownModelException as e:
|
||||
raise HTTPException(status_code=404, detail=str(e))
|
||||
except ValueError as e:
|
||||
logger.error(str(e))
|
||||
raise HTTPException(status_code=409, detail=str(e))
|
||||
|
||||
try:
|
||||
# In the event that the model's name, type or base has changed, and the model itself
|
||||
# resides in the invokeai root models directory, then the next statement will move
|
||||
# the model file into its new canonical location.
|
||||
new_config = model_install.sync_model_path(new_config.key)
|
||||
model_response = parse_obj_as(InvokeAIModelConfig, new_config.dict())
|
||||
except UnknownModelException as e:
|
||||
previous_info = ApiDependencies.invoker.services.model_manager.list_model(
|
||||
model_name=model_name,
|
||||
base_model=base_model,
|
||||
model_type=model_type,
|
||||
)
|
||||
|
||||
# rename operation requested
|
||||
if info.model_name != model_name or info.base_model != base_model:
|
||||
ApiDependencies.invoker.services.model_manager.rename_model(
|
||||
base_model=base_model,
|
||||
model_type=model_type,
|
||||
model_name=model_name,
|
||||
new_name=info.model_name,
|
||||
new_base=info.base_model,
|
||||
)
|
||||
logger.info(f"Successfully renamed {base_model.value}/{model_name}=>{info.base_model}/{info.model_name}")
|
||||
# update information to support an update of attributes
|
||||
model_name = info.model_name
|
||||
base_model = info.base_model
|
||||
new_info = ApiDependencies.invoker.services.model_manager.list_model(
|
||||
model_name=model_name,
|
||||
base_model=base_model,
|
||||
model_type=model_type,
|
||||
)
|
||||
if new_info.get("path") != previous_info.get(
|
||||
"path"
|
||||
): # model manager moved model path during rename - don't overwrite it
|
||||
info.path = new_info.get("path")
|
||||
|
||||
# replace empty string values with None/null to avoid phenomenon of vae: ''
|
||||
info_dict = info.dict()
|
||||
info_dict = {x: info_dict[x] if info_dict[x] else None for x in info_dict.keys()}
|
||||
|
||||
ApiDependencies.invoker.services.model_manager.update_model(
|
||||
model_name=model_name, base_model=base_model, model_type=model_type, model_attributes=info_dict
|
||||
)
|
||||
|
||||
model_raw = ApiDependencies.invoker.services.model_manager.list_model(
|
||||
model_name=model_name,
|
||||
base_model=base_model,
|
||||
model_type=model_type,
|
||||
)
|
||||
model_response = parse_obj_as(UpdateModelResponse, model_raw)
|
||||
except ModelNotFoundException as e:
|
||||
raise HTTPException(status_code=404, detail=str(e))
|
||||
except ValueError as e:
|
||||
logger.error(str(e))
|
||||
raise HTTPException(status_code=409, detail=str(e))
|
||||
except Exception as e:
|
||||
logger.error(str(e))
|
||||
raise HTTPException(status_code=400, detail=str(e))
|
||||
|
||||
return model_response
|
||||
|
||||
@@ -136,55 +141,37 @@ async def update_model(
|
||||
409: {"description": "There is already a model corresponding to this path or repo_id"},
|
||||
},
|
||||
status_code=201,
|
||||
response_model=ModelDownloadStatus,
|
||||
response_model=ImportModelResponse,
|
||||
)
|
||||
async def import_model(
|
||||
location: str = Body(description="A model path, repo_id or URL to import"),
|
||||
prediction_type: Optional[Literal["v_prediction", "epsilon", "sample"]] = Body(
|
||||
description="Prediction type for SDv2 checkpoints and rare SDv1 checkpoints",
|
||||
default=None,
|
||||
description="Prediction type for SDv2 checkpoint files", default="v_prediction"
|
||||
),
|
||||
priority: Optional[int] = Body(
|
||||
description="Which import jobs run first. Lower values run before higher ones.",
|
||||
default=10,
|
||||
),
|
||||
) -> ModelDownloadStatus:
|
||||
"""
|
||||
Add a model using its local path, repo_id, or remote URL.
|
||||
) -> ImportModelResponse:
|
||||
"""Add a model using its local path, repo_id, or remote URL. Model characteristics will be probed and configured automatically"""
|
||||
|
||||
Models will be downloaded, probed, configured and installed in a
|
||||
series of background threads. The return object has a `job_id` property
|
||||
that can be used to control the download job.
|
||||
|
||||
The priority controls which import jobs run first. Lower values run before
|
||||
higher ones.
|
||||
|
||||
The prediction_type applies to SDv2 models only and can be one of
|
||||
"v_prediction", "epsilon", or "sample". Default if not provided is
|
||||
"v_prediction".
|
||||
|
||||
Listen on the event bus for a series of `model_event` events with an `id`
|
||||
matching the returned job id to get the progress, completion status, errors,
|
||||
and information on the model that was installed.
|
||||
"""
|
||||
items_to_import = {location}
|
||||
prediction_types = {x.value: x for x in SchedulerPredictionType}
|
||||
logger = ApiDependencies.invoker.services.logger
|
||||
|
||||
try:
|
||||
installer = ApiDependencies.invoker.services.model_installer
|
||||
result = installer.install_model(
|
||||
location,
|
||||
probe_override={"prediction_type": SchedulerPredictionType(prediction_type) if prediction_type else None},
|
||||
priority=priority,
|
||||
installed_models = ApiDependencies.invoker.services.model_manager.heuristic_import(
|
||||
items_to_import=items_to_import, prediction_type_helper=lambda x: prediction_types.get(prediction_type)
|
||||
)
|
||||
return ModelDownloadStatus(
|
||||
job_id=result.id,
|
||||
source=result.source,
|
||||
priority=result.priority,
|
||||
bytes=result.bytes,
|
||||
total_bytes=result.total_bytes,
|
||||
status=result.status,
|
||||
info = installed_models.get(location)
|
||||
|
||||
if not info:
|
||||
logger.error("Import failed")
|
||||
raise HTTPException(status_code=415)
|
||||
|
||||
logger.info(f"Successfully imported {location}, got {info}")
|
||||
model_raw = ApiDependencies.invoker.services.model_manager.list_model(
|
||||
model_name=info.name, base_model=info.base_model, model_type=info.model_type
|
||||
)
|
||||
except UnknownModelException as e:
|
||||
return parse_obj_as(ImportModelResponse, model_raw)
|
||||
|
||||
except ModelNotFoundException as e:
|
||||
logger.error(str(e))
|
||||
raise HTTPException(status_code=404, detail=str(e))
|
||||
except InvalidModelException as e:
|
||||
@@ -201,40 +188,29 @@ async def import_model(
|
||||
responses={
|
||||
201: {"description": "The model added successfully"},
|
||||
404: {"description": "The model could not be found"},
|
||||
424: {"description": "The model appeared to add successfully, but could not be found in the model manager"},
|
||||
409: {"description": "There is already a model corresponding to this path or repo_id"},
|
||||
415: {"description": "Unrecognized file/folder format"},
|
||||
},
|
||||
status_code=201,
|
||||
response_model=InvokeAIModelConfig,
|
||||
response_model=ImportModelResponse,
|
||||
)
|
||||
async def add_model(
|
||||
info: InvokeAIModelConfig = Body(description="Model configuration"),
|
||||
) -> InvokeAIModelConfig:
|
||||
"""
|
||||
Add a model using the configuration information appropriate for its type. Only local models can be added by path.
|
||||
This call will block until the model is installed.
|
||||
"""
|
||||
info: Union[tuple(OPENAPI_MODEL_CONFIGS)] = Body(description="Model configuration"),
|
||||
) -> ImportModelResponse:
|
||||
"""Add a model using the configuration information appropriate for its type. Only local models can be added by path"""
|
||||
|
||||
logger = ApiDependencies.invoker.services.logger
|
||||
path = info.path
|
||||
installer = ApiDependencies.invoker.services.model_installer
|
||||
record_store = ApiDependencies.invoker.services.model_record_store
|
||||
try:
|
||||
key = installer.install_path(path)
|
||||
logger.info(f"Created model {key} for {path}")
|
||||
except DuplicateModelException as e:
|
||||
logger.error(str(e))
|
||||
raise HTTPException(status_code=409, detail=str(e))
|
||||
except InvalidModelException as e:
|
||||
logger.error(str(e))
|
||||
raise HTTPException(status_code=415)
|
||||
|
||||
# update with the provided info
|
||||
try:
|
||||
info_dict = info.dict()
|
||||
new_config = record_store.update_model(key, new_config=info_dict)
|
||||
return parse_obj_as(InvokeAIModelConfig, new_config.dict())
|
||||
except UnknownModelException as e:
|
||||
ApiDependencies.invoker.services.model_manager.add_model(
|
||||
info.model_name, info.base_model, info.model_type, model_attributes=info.dict()
|
||||
)
|
||||
logger.info(f"Successfully added {info.model_name}")
|
||||
model_raw = ApiDependencies.invoker.services.model_manager.list_model(
|
||||
model_name=info.model_name, base_model=info.base_model, model_type=info.model_type
|
||||
)
|
||||
return parse_obj_as(ImportModelResponse, model_raw)
|
||||
except ModelNotFoundException as e:
|
||||
logger.error(str(e))
|
||||
raise HTTPException(status_code=404, detail=str(e))
|
||||
except ValueError as e:
|
||||
@@ -243,34 +219,33 @@ async def add_model(
|
||||
|
||||
|
||||
@models_router.delete(
|
||||
"/i/{key}",
|
||||
"/{base_model}/{model_type}/{model_name}",
|
||||
operation_id="del_model",
|
||||
responses={204: {"description": "Model deleted successfully"}, 404: {"description": "Model not found"}},
|
||||
status_code=204,
|
||||
response_model=None,
|
||||
)
|
||||
async def delete_model(
|
||||
key: str = Path(description="Unique key of model to remove from model registry."),
|
||||
delete_files: Optional[bool] = Query(description="Delete underlying files and directories as well.", default=False),
|
||||
base_model: BaseModelType = Path(description="Base model"),
|
||||
model_type: ModelType = Path(description="The type of model"),
|
||||
model_name: str = Path(description="model name"),
|
||||
) -> Response:
|
||||
"""Delete Model"""
|
||||
logger = ApiDependencies.invoker.services.logger
|
||||
|
||||
try:
|
||||
installer = ApiDependencies.invoker.services.model_installer
|
||||
if delete_files:
|
||||
installer.delete(key)
|
||||
else:
|
||||
installer.unregister(key)
|
||||
logger.info(f"Deleted model: {key}")
|
||||
ApiDependencies.invoker.services.model_manager.del_model(
|
||||
model_name, base_model=base_model, model_type=model_type
|
||||
)
|
||||
logger.info(f"Deleted model: {model_name}")
|
||||
return Response(status_code=204)
|
||||
except UnknownModelException as e:
|
||||
except ModelNotFoundException as e:
|
||||
logger.error(str(e))
|
||||
raise HTTPException(status_code=404, detail=str(e))
|
||||
|
||||
|
||||
@models_router.put(
|
||||
"/convert/{key}",
|
||||
"/convert/{base_model}/{model_type}/{model_name}",
|
||||
operation_id="convert_model",
|
||||
responses={
|
||||
200: {"description": "Model converted successfully"},
|
||||
@@ -278,26 +253,33 @@ async def delete_model(
|
||||
404: {"description": "Model not found"},
|
||||
},
|
||||
status_code=200,
|
||||
response_model=InvokeAIModelConfig,
|
||||
response_model=ConvertModelResponse,
|
||||
)
|
||||
async def convert_model(
|
||||
key: str = Path(description="Unique key of model to convert from checkpoint/safetensors to diffusers format."),
|
||||
base_model: BaseModelType = Path(description="Base model"),
|
||||
model_type: ModelType = Path(description="The type of model"),
|
||||
model_name: str = Path(description="model name"),
|
||||
convert_dest_directory: Optional[str] = Query(
|
||||
default=None, description="Save the converted model to the designated directory"
|
||||
),
|
||||
) -> InvokeAIModelConfig:
|
||||
) -> ConvertModelResponse:
|
||||
"""Convert a checkpoint model into a diffusers model, optionally saving to the indicated destination directory, or `models` if none."""
|
||||
logger = ApiDependencies.invoker.services.logger
|
||||
try:
|
||||
logger.info(f"Converting model: {model_name}")
|
||||
dest = pathlib.Path(convert_dest_directory) if convert_dest_directory else None
|
||||
converter = ModelConvert(
|
||||
loader=ApiDependencies.invoker.services.model_loader,
|
||||
installer=ApiDependencies.invoker.services.model_installer,
|
||||
store=ApiDependencies.invoker.services.model_record_store,
|
||||
ApiDependencies.invoker.services.model_manager.convert_model(
|
||||
model_name,
|
||||
base_model=base_model,
|
||||
model_type=model_type,
|
||||
convert_dest_directory=dest,
|
||||
)
|
||||
model_config = converter.convert_model(key, dest_directory=dest)
|
||||
response = parse_obj_as(InvokeAIModelConfig, model_config.dict())
|
||||
except UnknownModelException as e:
|
||||
raise HTTPException(status_code=404, detail=f"Model '{key}' not found: {str(e)}")
|
||||
model_raw = ApiDependencies.invoker.services.model_manager.list_model(
|
||||
model_name, base_model=base_model, model_type=model_type
|
||||
)
|
||||
response = parse_obj_as(ConvertModelResponse, model_raw)
|
||||
except ModelNotFoundException as e:
|
||||
raise HTTPException(status_code=404, detail=f"Model '{model_name}' not found: {str(e)}")
|
||||
except ValueError as e:
|
||||
raise HTTPException(status_code=400, detail=str(e))
|
||||
return response
|
||||
@@ -316,12 +298,11 @@ async def convert_model(
|
||||
async def search_for_models(
|
||||
search_path: pathlib.Path = Query(description="Directory path to search for models"),
|
||||
) -> List[pathlib.Path]:
|
||||
"""Search for all models in a server-local path."""
|
||||
if not search_path.is_dir():
|
||||
raise HTTPException(
|
||||
status_code=404, detail=f"The search path '{search_path}' does not exist or is not directory"
|
||||
)
|
||||
return ModelSearch().search(search_path)
|
||||
return ApiDependencies.invoker.services.model_manager.search_for_models(search_path)
|
||||
|
||||
|
||||
@models_router.get(
|
||||
@@ -335,10 +316,7 @@ async def search_for_models(
|
||||
)
|
||||
async def list_ckpt_configs() -> List[pathlib.Path]:
|
||||
"""Return a list of the legacy checkpoint configuration files stored in `ROOT/configs/stable-diffusion`, relative to ROOT."""
|
||||
config = ApiDependencies.invoker.services.configuration
|
||||
conf_path = config.legacy_conf_path
|
||||
root_path = config.root_path
|
||||
return [(conf_path / x).relative_to(root_path) for x in conf_path.glob("**/*.yaml")]
|
||||
return ApiDependencies.invoker.services.model_manager.list_checkpoint_configs()
|
||||
|
||||
|
||||
@models_router.post(
|
||||
@@ -351,32 +329,27 @@ async def list_ckpt_configs() -> List[pathlib.Path]:
|
||||
response_model=bool,
|
||||
)
|
||||
async def sync_to_config() -> bool:
|
||||
"""
|
||||
Synchronize model in-memory data structures with disk.
|
||||
|
||||
Call after making changes to models.yaml, autoimport directories
|
||||
or models directory.
|
||||
"""
|
||||
installer = ApiDependencies.invoker.services.model_installer
|
||||
installer.sync_to_config()
|
||||
"""Call after making changes to models.yaml, autoimport directories or models directory to synchronize
|
||||
in-memory data structures with disk data structures."""
|
||||
ApiDependencies.invoker.services.model_manager.sync_to_config()
|
||||
return True
|
||||
|
||||
|
||||
@models_router.put(
|
||||
"/merge",
|
||||
"/merge/{base_model}",
|
||||
operation_id="merge_models",
|
||||
responses={
|
||||
200: {"description": "Model converted successfully"},
|
||||
400: {"description": "Incompatible models"},
|
||||
404: {"description": "One or more models not found"},
|
||||
409: {"description": "An identical merged model is already installed"},
|
||||
},
|
||||
status_code=200,
|
||||
response_model=InvokeAIModelConfig,
|
||||
response_model=MergeModelResponse,
|
||||
)
|
||||
async def merge_models(
|
||||
keys: List[str] = Body(description="model name", min_items=2, max_items=3),
|
||||
merged_model_name: Optional[str] = Body(description="Name of destination model", default=None),
|
||||
base_model: BaseModelType = Path(description="Base model"),
|
||||
model_names: List[str] = Body(description="model name", min_items=2, max_items=3),
|
||||
merged_model_name: Optional[str] = Body(description="Name of destination model"),
|
||||
alpha: Optional[float] = Body(description="Alpha weighting strength to apply to 2d and 3d models", default=0.5),
|
||||
interp: Optional[MergeInterpolationMethod] = Body(description="Interpolation method"),
|
||||
force: Optional[bool] = Body(
|
||||
@@ -386,147 +359,29 @@ async def merge_models(
|
||||
description="Save the merged model to the designated directory (with 'merged_model_name' appended)",
|
||||
default=None,
|
||||
),
|
||||
) -> InvokeAIModelConfig:
|
||||
"""Merge the indicated diffusers model."""
|
||||
) -> MergeModelResponse:
|
||||
"""Convert a checkpoint model into a diffusers model"""
|
||||
logger = ApiDependencies.invoker.services.logger
|
||||
try:
|
||||
logger.info(f"Merging models: {keys} into {merge_dest_directory or '<MODELS>'}/{merged_model_name}")
|
||||
logger.info(f"Merging models: {model_names} into {merge_dest_directory or '<MODELS>'}/{merged_model_name}")
|
||||
dest = pathlib.Path(merge_dest_directory) if merge_dest_directory else None
|
||||
converter = ModelConvert(
|
||||
loader=ApiDependencies.invoker.services.model_loader,
|
||||
installer=ApiDependencies.invoker.services.model_installer,
|
||||
store=ApiDependencies.invoker.services.model_record_store,
|
||||
)
|
||||
result: ModelConfigBase = converter.merge_models(
|
||||
model_keys=keys,
|
||||
merged_model_name=merged_model_name,
|
||||
result = ApiDependencies.invoker.services.model_manager.merge_models(
|
||||
model_names,
|
||||
base_model,
|
||||
merged_model_name=merged_model_name or "+".join(model_names),
|
||||
alpha=alpha,
|
||||
interp=interp,
|
||||
force=force,
|
||||
merge_dest_directory=dest,
|
||||
)
|
||||
response = parse_obj_as(InvokeAIModelConfig, result.dict())
|
||||
except DuplicateModelException as e:
|
||||
raise HTTPException(status_code=409, detail=str(e))
|
||||
except UnknownModelException:
|
||||
raise HTTPException(status_code=404, detail=f"One or more of the models '{keys}' not found")
|
||||
model_raw = ApiDependencies.invoker.services.model_manager.list_model(
|
||||
result.name,
|
||||
base_model=base_model,
|
||||
model_type=ModelType.Main,
|
||||
)
|
||||
response = parse_obj_as(ConvertModelResponse, model_raw)
|
||||
except ModelNotFoundException:
|
||||
raise HTTPException(status_code=404, detail=f"One or more of the models '{model_names}' not found")
|
||||
except ValueError as e:
|
||||
raise HTTPException(status_code=400, detail=str(e))
|
||||
return response
|
||||
|
||||
|
||||
@models_router.get(
|
||||
"/jobs",
|
||||
operation_id="list_install_jobs",
|
||||
responses={
|
||||
200: {"description": "The control job was updated successfully"},
|
||||
400: {"description": "Bad request"},
|
||||
},
|
||||
status_code=200,
|
||||
response_model=List[ModelDownloadStatus],
|
||||
)
|
||||
async def list_install_jobs() -> List[ModelDownloadStatus]:
|
||||
"""List active and pending model installation jobs."""
|
||||
job_mgr = ApiDependencies.invoker.services.download_queue
|
||||
jobs = job_mgr.list_jobs()
|
||||
return [
|
||||
ModelDownloadStatus(
|
||||
job_id=x.id,
|
||||
source=x.source,
|
||||
priority=x.priority,
|
||||
bytes=x.bytes,
|
||||
total_bytes=x.total_bytes,
|
||||
status=x.status,
|
||||
)
|
||||
for x in jobs
|
||||
if isinstance(x, ModelInstallJob)
|
||||
]
|
||||
|
||||
|
||||
@models_router.patch(
|
||||
"/jobs/control/{operation}/{job_id}",
|
||||
operation_id="control_download_jobs",
|
||||
responses={
|
||||
200: {"description": "The control job was updated successfully"},
|
||||
400: {"description": "Bad request"},
|
||||
404: {"description": "The job could not be found"},
|
||||
},
|
||||
status_code=200,
|
||||
response_model=ModelDownloadStatus,
|
||||
)
|
||||
async def control_download_jobs(
|
||||
job_id: int = Path(description="Download/install job_id for start, pause and cancel operations"),
|
||||
operation: JobControlOperation = Path(description="The operation to perform on the job."),
|
||||
priority_delta: Optional[int] = Body(
|
||||
description="Change in job priority for priority operations only. Negative numbers increase priority.",
|
||||
default=None,
|
||||
),
|
||||
) -> ModelDownloadStatus:
|
||||
"""Start, pause, cancel, or change the run priority of a running model install job."""
|
||||
logger = ApiDependencies.invoker.services.logger
|
||||
job_mgr = ApiDependencies.invoker.services.download_queue
|
||||
try:
|
||||
job = job_mgr.id_to_job(job_id)
|
||||
|
||||
if operation == JobControlOperation.START:
|
||||
job_mgr.start_job(job_id)
|
||||
|
||||
elif operation == JobControlOperation.PAUSE:
|
||||
job_mgr.pause_job(job_id)
|
||||
|
||||
elif operation == JobControlOperation.CANCEL:
|
||||
job_mgr.cancel_job(job_id)
|
||||
|
||||
else:
|
||||
raise ValueError("unknown operation {operation}")
|
||||
bytes = 0
|
||||
total_bytes = 0
|
||||
if isinstance(job, DownloadJobRemoteSource):
|
||||
bytes = job.bytes
|
||||
total_bytes = job.total_bytes
|
||||
|
||||
return ModelDownloadStatus(
|
||||
job_id=job_id,
|
||||
source=job.source,
|
||||
priority=job.priority,
|
||||
status=job.status,
|
||||
bytes=bytes,
|
||||
total_bytes=total_bytes,
|
||||
)
|
||||
except UnknownJobIDException as e:
|
||||
raise HTTPException(status_code=404, detail=str(e))
|
||||
except ValueError as e:
|
||||
logger.error(str(e))
|
||||
raise HTTPException(status_code=409, detail=str(e))
|
||||
|
||||
|
||||
@models_router.patch(
|
||||
"/jobs/cancel_all",
|
||||
operation_id="cancel_all_download_jobs",
|
||||
responses={
|
||||
204: {"description": "All jobs cancelled successfully"},
|
||||
400: {"description": "Bad request"},
|
||||
},
|
||||
)
|
||||
async def cancel_all_download_jobs():
|
||||
"""Cancel all model installation jobs."""
|
||||
logger = ApiDependencies.invoker.services.logger
|
||||
job_mgr = ApiDependencies.invoker.services.download_queue
|
||||
logger.info("Cancelling all download jobs.")
|
||||
job_mgr.cancel_all_jobs()
|
||||
return Response(status_code=204)
|
||||
|
||||
|
||||
@models_router.patch(
|
||||
"/jobs/prune",
|
||||
operation_id="prune_jobs",
|
||||
responses={
|
||||
204: {"description": "All completed jobs have been pruned"},
|
||||
400: {"description": "Bad request"},
|
||||
},
|
||||
)
|
||||
async def prune_jobs():
|
||||
"""Prune all completed and errored jobs."""
|
||||
mgr = ApiDependencies.invoker.services.download_queue
|
||||
mgr.prune_jobs()
|
||||
return Response(status_code=204)
|
||||
|
||||
@@ -84,7 +84,7 @@ async def list_queue_items(
|
||||
"""Gets all queue items (without graphs)"""
|
||||
|
||||
return ApiDependencies.invoker.services.session_queue.list_queue_items(
|
||||
queue_id=queue_id, limit=limit, status=status, cursor=cursor, priority=priority
|
||||
queue_id=queue_id, limit=limit, status=status, order_id=cursor, priority=priority
|
||||
)
|
||||
|
||||
|
||||
@@ -225,7 +225,7 @@ async def get_batch_status(
|
||||
)
|
||||
async def get_queue_item(
|
||||
queue_id: str = Path(description="The queue id to perform this operation on"),
|
||||
item_id: int = Path(description="The queue item to get"),
|
||||
item_id: str = Path(description="The queue item to get"),
|
||||
) -> SessionQueueItem:
|
||||
"""Gets a queue item"""
|
||||
return ApiDependencies.invoker.services.session_queue.get_queue_item(item_id)
|
||||
@@ -240,7 +240,7 @@ async def get_queue_item(
|
||||
)
|
||||
async def cancel_queue_item(
|
||||
queue_id: str = Path(description="The queue id to perform this operation on"),
|
||||
item_id: int = Path(description="The queue item to cancel"),
|
||||
item_id: str = Path(description="The queue item to cancel"),
|
||||
) -> SessionQueueItem:
|
||||
"""Deletes a queue item"""
|
||||
|
||||
|
||||
@@ -3,19 +3,16 @@
|
||||
from fastapi import FastAPI
|
||||
from fastapi_events.handlers.local import local_handler
|
||||
from fastapi_events.typing import Event
|
||||
from socketio import ASGIApp, AsyncServer
|
||||
from fastapi_socketio import SocketManager
|
||||
|
||||
from ..services.events import EventServiceBase
|
||||
|
||||
|
||||
class SocketIO:
|
||||
__sio: AsyncServer
|
||||
__app: ASGIApp
|
||||
__sio: SocketManager
|
||||
|
||||
def __init__(self, app: FastAPI):
|
||||
self.__sio = AsyncServer(async_mode="asgi", cors_allowed_origins="*")
|
||||
self.__app = ASGIApp(socketio_server=self.__sio, socketio_path="socket.io")
|
||||
app.mount("/ws", self.__app)
|
||||
self.__sio = SocketManager(app=app)
|
||||
|
||||
self.__sio.on("subscribe_queue", handler=self._handle_sub_queue)
|
||||
self.__sio.on("unsubscribe_queue", handler=self._handle_unsub_queue)
|
||||
|
||||
@@ -8,6 +8,7 @@ app_config.parse_args()
|
||||
|
||||
if True: # hack to make flake8 happy with imports coming after setting up the config
|
||||
import asyncio
|
||||
import logging
|
||||
import mimetypes
|
||||
import socket
|
||||
from inspect import signature
|
||||
@@ -40,9 +41,7 @@ if True: # hack to make flake8 happy with imports coming after setting up the c
|
||||
import invokeai.backend.util.mps_fixes # noqa: F401 (monkeypatching on import)
|
||||
|
||||
|
||||
app_config = InvokeAIAppConfig.get_config()
|
||||
app_config.parse_args()
|
||||
logger = InvokeAILogger.get_logger(config=app_config)
|
||||
logger = InvokeAILogger.getLogger(config=app_config)
|
||||
|
||||
# fix for windows mimetypes registry entries being borked
|
||||
# see https://github.com/invoke-ai/InvokeAI/discussions/3684#discussioncomment-6391352
|
||||
@@ -151,7 +150,7 @@ def custom_openapi():
|
||||
invoker_schema["output"] = outputs_ref
|
||||
invoker_schema["class"] = "invocation"
|
||||
|
||||
from invokeai.backend.model_manager.models import get_model_config_enums
|
||||
from invokeai.backend.model_management.models import get_model_config_enums
|
||||
|
||||
for model_config_format_enum in set(get_model_config_enums()):
|
||||
name = model_config_format_enum.__qualname__
|
||||
@@ -201,10 +200,6 @@ app.mount("/", StaticFiles(directory=Path(web_dir.__path__[0], "dist"), html=Tru
|
||||
|
||||
|
||||
def invoke_api():
|
||||
if app_config.version:
|
||||
print(f"InvokeAI version {__version__}")
|
||||
return
|
||||
|
||||
def find_port(port: int):
|
||||
"""Find a port not in use starting at given port"""
|
||||
# Taken from https://waylonwalker.com/python-find-available-port/, thanks Waylon!
|
||||
@@ -228,7 +223,7 @@ def invoke_api():
|
||||
exc_info=e,
|
||||
)
|
||||
else:
|
||||
jurigged.watch(logger=InvokeAILogger.get_logger(name="jurigged").info)
|
||||
jurigged.watch(logger=InvokeAILogger.getLogger(name="jurigged").info)
|
||||
|
||||
port = find_port(app_config.port)
|
||||
if port != app_config.port:
|
||||
@@ -247,7 +242,7 @@ def invoke_api():
|
||||
|
||||
# replace uvicorn's loggers with InvokeAI's for consistent appearance
|
||||
for logname in ["uvicorn.access", "uvicorn"]:
|
||||
log = InvokeAILogger.get_logger(logname)
|
||||
log = logging.getLogger(logname)
|
||||
log.handlers.clear()
|
||||
for ch in logger.handlers:
|
||||
log.addHandler(ch)
|
||||
@@ -256,4 +251,7 @@ def invoke_api():
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
invoke_api()
|
||||
if app_config.version:
|
||||
print(f"InvokeAI version {__version__}")
|
||||
else:
|
||||
invoke_api()
|
||||
|
||||
@@ -10,11 +10,10 @@ from pathlib import Path
|
||||
from typing import Dict, List, Literal, get_args, get_origin, get_type_hints
|
||||
|
||||
import invokeai.backend.util.logging as logger
|
||||
from invokeai.backend.model_manager import ModelType
|
||||
|
||||
from ...backend import ModelManager
|
||||
from ..invocations.baseinvocation import BaseInvocation
|
||||
from ..services.invocation_services import InvocationServices
|
||||
from ..services.model_record_service import ModelRecordServiceBase
|
||||
from .commands import BaseCommand
|
||||
|
||||
# singleton object, class variable
|
||||
@@ -22,11 +21,11 @@ completer = None
|
||||
|
||||
|
||||
class Completer(object):
|
||||
def __init__(self, model_record_store: ModelRecordServiceBase):
|
||||
def __init__(self, model_manager: ModelManager):
|
||||
self.commands = self.get_commands()
|
||||
self.matches = None
|
||||
self.linebuffer = None
|
||||
self.store = model_record_store
|
||||
self.manager = model_manager
|
||||
return
|
||||
|
||||
def complete(self, text, state):
|
||||
@@ -128,7 +127,7 @@ class Completer(object):
|
||||
if get_origin(typehint) == Literal:
|
||||
return get_args(typehint)
|
||||
if parameter == "model":
|
||||
return [x.name for x in self.store.model_info_by_name(model_type=ModelType.Main)]
|
||||
return self.manager.model_names()
|
||||
|
||||
def _pre_input_hook(self):
|
||||
if self.linebuffer:
|
||||
@@ -143,7 +142,7 @@ def set_autocompleter(services: InvocationServices) -> Completer:
|
||||
if completer:
|
||||
return completer
|
||||
|
||||
completer = Completer(services.model_record_store)
|
||||
completer = Completer(services.model_manager)
|
||||
|
||||
readline.set_completer(completer.complete)
|
||||
try:
|
||||
|
||||
@@ -7,6 +7,8 @@ from .services.config import InvokeAIAppConfig
|
||||
# parse_args() must be called before any other imports. if it is not called first, consumers of the config
|
||||
# which are imported/used before parse_args() is called will get the default config values instead of the
|
||||
# values from the command line or config file.
|
||||
config = InvokeAIAppConfig.get_config()
|
||||
config.parse_args()
|
||||
|
||||
if True: # hack to make flake8 happy with imports coming after setting up the config
|
||||
import argparse
|
||||
@@ -30,8 +32,6 @@ if True: # hack to make flake8 happy with imports coming after setting up the c
|
||||
from invokeai.app.services.images import ImageService, ImageServiceDependencies
|
||||
from invokeai.app.services.invocation_stats import InvocationStatsService
|
||||
from invokeai.app.services.resource_name import SimpleNameService
|
||||
from invokeai.app.services.session_processor.session_processor_default import DefaultSessionProcessor
|
||||
from invokeai.app.services.session_queue.session_queue_sqlite import SqliteSessionQueue
|
||||
from invokeai.app.services.urls import LocalUrlService
|
||||
from invokeai.backend.util.logging import InvokeAILogger
|
||||
from invokeai.version.invokeai_version import __version__
|
||||
@@ -40,7 +40,6 @@ if True: # hack to make flake8 happy with imports coming after setting up the c
|
||||
from .cli.completer import set_autocompleter
|
||||
from .invocations.baseinvocation import BaseInvocation
|
||||
from .services.default_graphs import create_system_graphs, default_text_to_image_graph_id
|
||||
from .services.download_manager import DownloadQueueService
|
||||
from .services.events import EventServiceBase
|
||||
from .services.graph import (
|
||||
Edge,
|
||||
@@ -55,19 +54,15 @@ if True: # hack to make flake8 happy with imports coming after setting up the c
|
||||
from .services.invocation_services import InvocationServices
|
||||
from .services.invoker import Invoker
|
||||
from .services.latent_storage import DiskLatentsStorage, ForwardCacheLatentsStorage
|
||||
from .services.model_install_service import ModelInstallService
|
||||
from .services.model_loader_service import ModelLoadService
|
||||
from .services.model_record_service import ModelRecordServiceBase
|
||||
from .services.model_manager_service import ModelManagerService
|
||||
from .services.processor import DefaultInvocationProcessor
|
||||
from .services.sqlite import SqliteItemStorage
|
||||
from .services.thread import lock
|
||||
|
||||
if torch.backends.mps.is_available():
|
||||
import invokeai.backend.util.mps_fixes # noqa: F401 (monkeypatching on import)
|
||||
|
||||
config = InvokeAIAppConfig.get_config()
|
||||
config.parse_args()
|
||||
logger = InvokeAILogger().get_logger(config=config)
|
||||
|
||||
logger = InvokeAILogger().getLogger(config=config)
|
||||
|
||||
|
||||
class CliCommand(BaseModel):
|
||||
@@ -234,12 +229,7 @@ def invoke_all(context: CliContext):
|
||||
|
||||
|
||||
def invoke_cli():
|
||||
if config.version:
|
||||
print(f"InvokeAI version {__version__}")
|
||||
return
|
||||
|
||||
logger.info(f"InvokeAI version {__version__}")
|
||||
|
||||
# get the optional list of invocations to execute on the command line
|
||||
parser = config.get_parser()
|
||||
parser.add_argument("commands", nargs="*")
|
||||
@@ -250,6 +240,8 @@ def invoke_cli():
|
||||
if infile := config.from_file:
|
||||
sys.stdin = open(infile, "r")
|
||||
|
||||
model_manager = ModelManagerService(config, logger)
|
||||
|
||||
events = EventServiceBase()
|
||||
output_folder = config.output_path
|
||||
|
||||
@@ -263,22 +255,15 @@ def invoke_cli():
|
||||
db_conn = sqlite3.connect(db_location, check_same_thread=False) # TODO: figure out a better threading solution
|
||||
logger.info(f'InvokeAI database location is "{db_location}"')
|
||||
|
||||
download_queue = DownloadQueueService(event_bus=events)
|
||||
model_record_store = ModelRecordServiceBase.open(config, conn=db_conn, lock=None)
|
||||
model_loader = ModelLoadService(config, model_record_store)
|
||||
model_installer = ModelInstallService(config, queue=download_queue, store=model_record_store, event_bus=events)
|
||||
|
||||
graph_execution_manager = SqliteItemStorage[GraphExecutionState](
|
||||
conn=db_conn, table_name="graph_executions", lock=lock
|
||||
)
|
||||
graph_execution_manager = SqliteItemStorage[GraphExecutionState](conn=db_conn, table_name="graph_executions")
|
||||
|
||||
urls = LocalUrlService()
|
||||
image_record_storage = SqliteImageRecordStorage(conn=db_conn, lock=lock)
|
||||
image_record_storage = SqliteImageRecordStorage(conn=db_conn)
|
||||
image_file_storage = DiskImageFileStorage(f"{output_folder}/images")
|
||||
names = SimpleNameService()
|
||||
|
||||
board_record_storage = SqliteBoardRecordStorage(conn=db_conn, lock=lock)
|
||||
board_image_record_storage = SqliteBoardImageRecordStorage(conn=db_conn, lock=lock)
|
||||
board_record_storage = SqliteBoardRecordStorage(conn=db_conn)
|
||||
board_image_record_storage = SqliteBoardImageRecordStorage(conn=db_conn)
|
||||
|
||||
boards = BoardService(
|
||||
services=BoardServiceDependencies(
|
||||
@@ -313,25 +298,20 @@ def invoke_cli():
|
||||
)
|
||||
|
||||
services = InvocationServices(
|
||||
model_manager=model_manager,
|
||||
events=events,
|
||||
latents=ForwardCacheLatentsStorage(DiskLatentsStorage(f"{output_folder}/latents")),
|
||||
images=images,
|
||||
boards=boards,
|
||||
board_images=board_images,
|
||||
queue=MemoryInvocationQueue(),
|
||||
graph_library=SqliteItemStorage[LibraryGraph](conn=db_conn, table_name="graphs", lock=lock),
|
||||
graph_library=SqliteItemStorage[LibraryGraph](conn=db_conn, table_name="graphs"),
|
||||
graph_execution_manager=graph_execution_manager,
|
||||
processor=DefaultInvocationProcessor(),
|
||||
performance_statistics=InvocationStatsService(graph_execution_manager),
|
||||
logger=logger,
|
||||
download_queue=download_queue,
|
||||
model_record_store=model_record_store,
|
||||
model_loader=model_loader,
|
||||
model_installer=model_installer,
|
||||
configuration=config,
|
||||
invocation_cache=MemoryInvocationCache(max_cache_size=config.node_cache_size),
|
||||
session_queue=SqliteSessionQueue(conn=db_conn, lock=lock),
|
||||
session_processor=DefaultSessionProcessor(),
|
||||
)
|
||||
|
||||
system_graphs = create_system_graphs(services.graph_library)
|
||||
@@ -499,4 +479,7 @@ def invoke_cli():
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
invoke_cli()
|
||||
if config.version:
|
||||
print(f"InvokeAI version {__version__}")
|
||||
else:
|
||||
invoke_cli()
|
||||
|
||||
@@ -67,8 +67,6 @@ class FieldDescriptions:
|
||||
width = "Width of output (px)"
|
||||
height = "Height of output (px)"
|
||||
control = "ControlNet(s) to apply"
|
||||
ip_adapter = "IP-Adapter to apply"
|
||||
t2i_adapter = "T2I-Adapter(s) to apply"
|
||||
denoised_latents = "Denoised latents tensor"
|
||||
latents = "Latents tensor"
|
||||
strength = "Strength of denoising (proportional to steps)"
|
||||
@@ -89,12 +87,6 @@ class FieldDescriptions:
|
||||
num_1 = "The first number"
|
||||
num_2 = "The second number"
|
||||
mask = "The mask to use for the operation"
|
||||
board = "The board to save the image to"
|
||||
image = "The image to process"
|
||||
tile_size = "Tile size"
|
||||
inclusive_low = "The inclusive low value"
|
||||
exclusive_high = "The exclusive high value"
|
||||
decimal_places = "The number of decimal places to round to"
|
||||
|
||||
|
||||
class Input(str, Enum):
|
||||
@@ -163,7 +155,6 @@ class UIType(str, Enum):
|
||||
VaeModel = "VaeModelField"
|
||||
LoRAModel = "LoRAModelField"
|
||||
ControlNetModel = "ControlNetModelField"
|
||||
IPAdapterModel = "IPAdapterModelField"
|
||||
UNet = "UNetField"
|
||||
Vae = "VaeField"
|
||||
CLIP = "ClipField"
|
||||
@@ -180,7 +171,6 @@ class UIType(str, Enum):
|
||||
WorkflowField = "WorkflowField"
|
||||
IsIntermediate = "IsIntermediate"
|
||||
MetadataField = "MetadataField"
|
||||
BoardField = "BoardField"
|
||||
# endregion
|
||||
|
||||
|
||||
@@ -432,22 +422,13 @@ class InvocationContext:
|
||||
services: InvocationServices
|
||||
graph_execution_state_id: str
|
||||
queue_id: str
|
||||
queue_item_id: int
|
||||
queue_batch_id: str
|
||||
queue_item_id: str
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
services: InvocationServices,
|
||||
queue_id: str,
|
||||
queue_item_id: int,
|
||||
queue_batch_id: str,
|
||||
graph_execution_state_id: str,
|
||||
):
|
||||
def __init__(self, services: InvocationServices, queue_id: str, queue_item_id: str, graph_execution_state_id: str):
|
||||
self.services = services
|
||||
self.graph_execution_state_id = graph_execution_state_id
|
||||
self.queue_id = queue_id
|
||||
self.queue_item_id = queue_item_id
|
||||
self.queue_batch_id = queue_batch_id
|
||||
|
||||
|
||||
class BaseInvocationOutput(BaseModel):
|
||||
@@ -608,7 +589,7 @@ class BaseInvocation(ABC, BaseModel):
|
||||
if cached_value is None:
|
||||
context.services.logger.debug(f'Invocation cache miss for type "{self.get_type()}": {self.id}')
|
||||
output = self.invoke(context)
|
||||
context.services.invocation_cache.save(key, output)
|
||||
context.services.invocation_cache.save(output)
|
||||
return output
|
||||
else:
|
||||
context.services.logger.debug(f'Invocation cache hit for type "{self.get_type()}": {self.id}')
|
||||
@@ -664,8 +645,6 @@ def invocation(
|
||||
:param Optional[str] title: Adds a title to the invocation. Use if the auto-generated title isn't quite right. Defaults to None.
|
||||
:param Optional[list[str]] tags: Adds tags to the invocation. Invocations may be searched for by their tags. Defaults to None.
|
||||
:param Optional[str] category: Adds a category to the invocation. Used to group the invocations in the UI. Defaults to None.
|
||||
:param Optional[str] version: Adds a version to the invocation. Must be a valid semver string. Defaults to None.
|
||||
:param Optional[bool] use_cache: Whether or not to use the invocation cache. Defaults to True. The user may override this in the workflow editor.
|
||||
"""
|
||||
|
||||
def wrapper(cls: Type[GenericBaseInvocation]) -> Type[GenericBaseInvocation]:
|
||||
|
||||
@@ -7,14 +7,14 @@ from compel import Compel, ReturnedEmbeddingsType
|
||||
from compel.prompt_parser import Blend, Conjunction, CrossAttentionControlSubstitute, FlattenedPrompt, Fragment
|
||||
|
||||
from invokeai.app.invocations.primitives import ConditioningField, ConditioningOutput
|
||||
from invokeai.backend.stable_diffusion.diffusion.conditioning_data import (
|
||||
from invokeai.backend.stable_diffusion.diffusion.shared_invokeai_diffusion import (
|
||||
BasicConditioningInfo,
|
||||
ExtraConditioningInfo,
|
||||
SDXLConditioningInfo,
|
||||
)
|
||||
|
||||
from ...backend.model_manager import ModelType, UnknownModelException
|
||||
from ...backend.model_manager.lora import ModelPatcher
|
||||
from ...backend.model_management.lora import ModelPatcher
|
||||
from ...backend.model_management.models import ModelNotFoundException, ModelType
|
||||
from ...backend.stable_diffusion.diffusion import InvokeAIDiffuserComponent
|
||||
from ...backend.util.devices import torch_dtype
|
||||
from .baseinvocation import (
|
||||
BaseInvocation,
|
||||
@@ -60,23 +60,23 @@ class CompelInvocation(BaseInvocation):
|
||||
|
||||
@torch.no_grad()
|
||||
def invoke(self, context: InvocationContext) -> ConditioningOutput:
|
||||
tokenizer_info = context.services.model_loader.get_model(
|
||||
tokenizer_info = context.services.model_manager.get_model(
|
||||
**self.clip.tokenizer.dict(),
|
||||
context=context,
|
||||
)
|
||||
text_encoder_info = context.services.model_loader.get_model(
|
||||
text_encoder_info = context.services.model_manager.get_model(
|
||||
**self.clip.text_encoder.dict(),
|
||||
context=context,
|
||||
)
|
||||
|
||||
def _lora_loader():
|
||||
for lora in self.clip.loras:
|
||||
lora_info = context.services.model_loader.get_model(**lora.dict(exclude={"weight"}), context=context)
|
||||
lora_info = context.services.model_manager.get_model(**lora.dict(exclude={"weight"}), context=context)
|
||||
yield (lora_info.context.model, lora.weight)
|
||||
del lora_info
|
||||
return
|
||||
|
||||
# loras = [(context.services.model_loader.get_model(**lora.dict(exclude={"weight"})).context.model, lora.weight) for lora in self.clip.loras]
|
||||
# loras = [(context.services.model_manager.get_model(**lora.dict(exclude={"weight"})).context.model, lora.weight) for lora in self.clip.loras]
|
||||
|
||||
ti_list = []
|
||||
for trigger in re.findall(r"<[a-zA-Z0-9., _-]+>", self.prompt):
|
||||
@@ -85,7 +85,7 @@ class CompelInvocation(BaseInvocation):
|
||||
ti_list.append(
|
||||
(
|
||||
name,
|
||||
context.services.model_loader.get_model(
|
||||
context.services.model_manager.get_model(
|
||||
model_name=name,
|
||||
base_model=self.clip.text_encoder.base_model,
|
||||
model_type=ModelType.TextualInversion,
|
||||
@@ -93,21 +93,20 @@ class CompelInvocation(BaseInvocation):
|
||||
).context.model,
|
||||
)
|
||||
)
|
||||
except UnknownModelException:
|
||||
except ModelNotFoundException:
|
||||
# print(e)
|
||||
# import traceback
|
||||
# print(traceback.format_exc())
|
||||
print(f'Warn: trigger: "{trigger}" not found')
|
||||
|
||||
with (
|
||||
ModelPatcher.apply_lora_text_encoder(text_encoder_info.context.model, _lora_loader()),
|
||||
ModelPatcher.apply_ti(tokenizer_info.context.model, text_encoder_info.context.model, ti_list) as (
|
||||
tokenizer,
|
||||
ti_manager,
|
||||
),
|
||||
ModelPatcher.apply_clip_skip(text_encoder_info.context.model, self.clip.skipped_layers),
|
||||
text_encoder_info as text_encoder,
|
||||
):
|
||||
with ModelPatcher.apply_lora_text_encoder(
|
||||
text_encoder_info.context.model, _lora_loader()
|
||||
), ModelPatcher.apply_ti(tokenizer_info.context.model, text_encoder_info.context.model, ti_list) as (
|
||||
tokenizer,
|
||||
ti_manager,
|
||||
), ModelPatcher.apply_clip_skip(
|
||||
text_encoder_info.context.model, self.clip.skipped_layers
|
||||
), text_encoder_info as text_encoder:
|
||||
compel = Compel(
|
||||
tokenizer=tokenizer,
|
||||
text_encoder=text_encoder,
|
||||
@@ -123,7 +122,7 @@ class CompelInvocation(BaseInvocation):
|
||||
|
||||
c, options = compel.build_conditioning_tensor_for_conjunction(conjunction)
|
||||
|
||||
ec = ExtraConditioningInfo(
|
||||
ec = InvokeAIDiffuserComponent.ExtraConditioningInfo(
|
||||
tokens_count_including_eos_bos=get_max_token_count(tokenizer, conjunction),
|
||||
cross_attention_control_args=options.get("cross_attention_control", None),
|
||||
)
|
||||
@@ -159,11 +158,11 @@ class SDXLPromptInvocationBase:
|
||||
lora_prefix: str,
|
||||
zero_on_empty: bool,
|
||||
):
|
||||
tokenizer_info = context.services.model_loader.get_model(
|
||||
tokenizer_info = context.services.model_manager.get_model(
|
||||
**clip_field.tokenizer.dict(),
|
||||
context=context,
|
||||
)
|
||||
text_encoder_info = context.services.model_loader.get_model(
|
||||
text_encoder_info = context.services.model_manager.get_model(
|
||||
**clip_field.text_encoder.dict(),
|
||||
context=context,
|
||||
)
|
||||
@@ -186,12 +185,12 @@ class SDXLPromptInvocationBase:
|
||||
|
||||
def _lora_loader():
|
||||
for lora in clip_field.loras:
|
||||
lora_info = context.services.model_loader.get_model(**lora.dict(exclude={"weight"}), context=context)
|
||||
lora_info = context.services.model_manager.get_model(**lora.dict(exclude={"weight"}), context=context)
|
||||
yield (lora_info.context.model, lora.weight)
|
||||
del lora_info
|
||||
return
|
||||
|
||||
# loras = [(context.services.model_loader.get_model(**lora.dict(exclude={"weight"})).context.model, lora.weight) for lora in self.clip.loras]
|
||||
# loras = [(context.services.model_manager.get_model(**lora.dict(exclude={"weight"})).context.model, lora.weight) for lora in self.clip.loras]
|
||||
|
||||
ti_list = []
|
||||
for trigger in re.findall(r"<[a-zA-Z0-9., _-]+>", prompt):
|
||||
@@ -200,7 +199,7 @@ class SDXLPromptInvocationBase:
|
||||
ti_list.append(
|
||||
(
|
||||
name,
|
||||
context.services.model_loader.get_model(
|
||||
context.services.model_manager.get_model(
|
||||
model_name=name,
|
||||
base_model=clip_field.text_encoder.base_model,
|
||||
model_type=ModelType.TextualInversion,
|
||||
@@ -208,21 +207,20 @@ class SDXLPromptInvocationBase:
|
||||
).context.model,
|
||||
)
|
||||
)
|
||||
except UnknownModelException:
|
||||
except ModelNotFoundException:
|
||||
# print(e)
|
||||
# import traceback
|
||||
# print(traceback.format_exc())
|
||||
print(f'Warn: trigger: "{trigger}" not found')
|
||||
|
||||
with (
|
||||
ModelPatcher.apply_lora(text_encoder_info.context.model, _lora_loader(), lora_prefix),
|
||||
ModelPatcher.apply_ti(tokenizer_info.context.model, text_encoder_info.context.model, ti_list) as (
|
||||
tokenizer,
|
||||
ti_manager,
|
||||
),
|
||||
ModelPatcher.apply_clip_skip(text_encoder_info.context.model, clip_field.skipped_layers),
|
||||
text_encoder_info as text_encoder,
|
||||
):
|
||||
with ModelPatcher.apply_lora(
|
||||
text_encoder_info.context.model, _lora_loader(), lora_prefix
|
||||
), ModelPatcher.apply_ti(tokenizer_info.context.model, text_encoder_info.context.model, ti_list) as (
|
||||
tokenizer,
|
||||
ti_manager,
|
||||
), ModelPatcher.apply_clip_skip(
|
||||
text_encoder_info.context.model, clip_field.skipped_layers
|
||||
), text_encoder_info as text_encoder:
|
||||
compel = Compel(
|
||||
tokenizer=tokenizer,
|
||||
text_encoder=text_encoder,
|
||||
@@ -246,7 +244,7 @@ class SDXLPromptInvocationBase:
|
||||
else:
|
||||
c_pooled = None
|
||||
|
||||
ec = ExtraConditioningInfo(
|
||||
ec = InvokeAIDiffuserComponent.ExtraConditioningInfo(
|
||||
tokens_count_including_eos_bos=get_max_token_count(tokenizer, conjunction),
|
||||
cross_attention_control_args=options.get("cross_attention_control", None),
|
||||
)
|
||||
@@ -438,11 +436,9 @@ def get_tokens_for_prompt_object(tokenizer, parsed_prompt: FlattenedPrompt, trun
|
||||
raise ValueError("Blend is not supported here - you need to get tokens for each of its .children")
|
||||
|
||||
text_fragments = [
|
||||
(
|
||||
x.text
|
||||
if type(x) is Fragment
|
||||
else (" ".join([f.text for f in x.original]) if type(x) is CrossAttentionControlSubstitute else str(x))
|
||||
)
|
||||
x.text
|
||||
if type(x) is Fragment
|
||||
else (" ".join([f.text for f in x.original]) if type(x) is CrossAttentionControlSubstitute else str(x))
|
||||
for x in parsed_prompt.children
|
||||
]
|
||||
text = " ".join(text_fragments)
|
||||
|
||||
@@ -28,7 +28,7 @@ from pydantic import BaseModel, Field, validator
|
||||
|
||||
from invokeai.app.invocations.primitives import ImageField, ImageOutput
|
||||
|
||||
from ...backend.model_manager import BaseModelType
|
||||
from ...backend.model_management import BaseModelType
|
||||
from ..models.image import ImageCategory, ResourceOrigin
|
||||
from .baseinvocation import (
|
||||
BaseInvocation,
|
||||
@@ -38,6 +38,7 @@ from .baseinvocation import (
|
||||
InputField,
|
||||
InvocationContext,
|
||||
OutputField,
|
||||
UIType,
|
||||
invocation,
|
||||
invocation_output,
|
||||
)
|
||||
@@ -99,7 +100,7 @@ class ControlNetInvocation(BaseInvocation):
|
||||
image: ImageField = InputField(description="The control image")
|
||||
control_model: ControlNetModelField = InputField(description=FieldDescriptions.controlnet_model, input=Input.Direct)
|
||||
control_weight: Union[float, List[float]] = InputField(
|
||||
default=1.0, description="The weight given to the ControlNet"
|
||||
default=1.0, description="The weight given to the ControlNet", ui_type=UIType.Float
|
||||
)
|
||||
begin_step_percent: float = InputField(
|
||||
default=0, ge=-1, le=2, description="When the ControlNet is first applied (% of total steps)"
|
||||
@@ -559,33 +560,3 @@ class SamDetectorReproducibleColors(SamDetector):
|
||||
img[:, :] = ann_color
|
||||
final_img.paste(Image.fromarray(img, mode="RGB"), (0, 0), Image.fromarray(np.uint8(m * 255)))
|
||||
return np.array(final_img, dtype=np.uint8)
|
||||
|
||||
|
||||
@invocation(
|
||||
"color_map_image_processor",
|
||||
title="Color Map Processor",
|
||||
tags=["controlnet"],
|
||||
category="controlnet",
|
||||
version="1.0.0",
|
||||
)
|
||||
class ColorMapImageProcessorInvocation(ImageProcessorInvocation):
|
||||
"""Generates a color map from the provided image"""
|
||||
|
||||
color_map_tile_size: int = InputField(default=64, ge=0, description=FieldDescriptions.tile_size)
|
||||
|
||||
def run_processor(self, image: Image.Image):
|
||||
image = image.convert("RGB")
|
||||
image = np.array(image, dtype=np.uint8)
|
||||
height, width = image.shape[:2]
|
||||
|
||||
width_tile_size = min(self.color_map_tile_size, width)
|
||||
height_tile_size = min(self.color_map_tile_size, height)
|
||||
|
||||
color_map = cv2.resize(
|
||||
image,
|
||||
(width // width_tile_size, height // height_tile_size),
|
||||
interpolation=cv2.INTER_CUBIC,
|
||||
)
|
||||
color_map = cv2.resize(color_map, (width, height), interpolation=cv2.INTER_NEAREST)
|
||||
color_map = Image.fromarray(color_map)
|
||||
return color_map
|
||||
|
||||
@@ -1,692 +0,0 @@
|
||||
import math
|
||||
import re
|
||||
from pathlib import Path
|
||||
from typing import Optional, TypedDict
|
||||
|
||||
import cv2
|
||||
import numpy as np
|
||||
from mediapipe.python.solutions.face_mesh import FaceMesh # type: ignore[import]
|
||||
from PIL import Image, ImageDraw, ImageFilter, ImageFont, ImageOps
|
||||
from PIL.Image import Image as ImageType
|
||||
from pydantic import validator
|
||||
|
||||
import invokeai.assets.fonts as font_assets
|
||||
from invokeai.app.invocations.baseinvocation import (
|
||||
BaseInvocation,
|
||||
InputField,
|
||||
InvocationContext,
|
||||
OutputField,
|
||||
invocation,
|
||||
invocation_output,
|
||||
)
|
||||
from invokeai.app.invocations.primitives import ImageField, ImageOutput
|
||||
from invokeai.app.models.image import ImageCategory, ResourceOrigin
|
||||
|
||||
|
||||
@invocation_output("face_mask_output")
|
||||
class FaceMaskOutput(ImageOutput):
|
||||
"""Base class for FaceMask output"""
|
||||
|
||||
mask: ImageField = OutputField(description="The output mask")
|
||||
|
||||
|
||||
@invocation_output("face_off_output")
|
||||
class FaceOffOutput(ImageOutput):
|
||||
"""Base class for FaceOff Output"""
|
||||
|
||||
mask: ImageField = OutputField(description="The output mask")
|
||||
x: int = OutputField(description="The x coordinate of the bounding box's left side")
|
||||
y: int = OutputField(description="The y coordinate of the bounding box's top side")
|
||||
|
||||
|
||||
class FaceResultData(TypedDict):
|
||||
image: ImageType
|
||||
mask: ImageType
|
||||
x_center: float
|
||||
y_center: float
|
||||
mesh_width: int
|
||||
mesh_height: int
|
||||
|
||||
|
||||
class FaceResultDataWithId(FaceResultData):
|
||||
face_id: int
|
||||
|
||||
|
||||
class ExtractFaceData(TypedDict):
|
||||
bounded_image: ImageType
|
||||
bounded_mask: ImageType
|
||||
x_min: int
|
||||
y_min: int
|
||||
x_max: int
|
||||
y_max: int
|
||||
|
||||
|
||||
class FaceMaskResult(TypedDict):
|
||||
image: ImageType
|
||||
mask: ImageType
|
||||
|
||||
|
||||
def create_white_image(w: int, h: int) -> ImageType:
|
||||
return Image.new("L", (w, h), color=255)
|
||||
|
||||
|
||||
def create_black_image(w: int, h: int) -> ImageType:
|
||||
return Image.new("L", (w, h), color=0)
|
||||
|
||||
|
||||
FONT_SIZE = 32
|
||||
FONT_STROKE_WIDTH = 4
|
||||
|
||||
|
||||
def prepare_faces_list(
|
||||
face_result_list: list[FaceResultData],
|
||||
) -> list[FaceResultDataWithId]:
|
||||
"""Deduplicates a list of faces, adding IDs to them."""
|
||||
deduped_faces: list[FaceResultData] = []
|
||||
|
||||
if len(face_result_list) == 0:
|
||||
return list()
|
||||
|
||||
for candidate in face_result_list:
|
||||
should_add = True
|
||||
candidate_x_center = candidate["x_center"]
|
||||
candidate_y_center = candidate["y_center"]
|
||||
for face in deduped_faces:
|
||||
face_center_x = face["x_center"]
|
||||
face_center_y = face["y_center"]
|
||||
face_radius_w = face["mesh_width"] / 2
|
||||
face_radius_h = face["mesh_height"] / 2
|
||||
# Determine if the center of the candidate_face is inside the ellipse of the added face
|
||||
# p < 1 -> Inside
|
||||
# p = 1 -> Exactly on the ellipse
|
||||
# p > 1 -> Outside
|
||||
p = (math.pow((candidate_x_center - face_center_x), 2) / math.pow(face_radius_w, 2)) + (
|
||||
math.pow((candidate_y_center - face_center_y), 2) / math.pow(face_radius_h, 2)
|
||||
)
|
||||
|
||||
if p < 1: # Inside of the already-added face's radius
|
||||
should_add = False
|
||||
break
|
||||
|
||||
if should_add is True:
|
||||
deduped_faces.append(candidate)
|
||||
|
||||
sorted_faces = sorted(deduped_faces, key=lambda x: x["y_center"])
|
||||
sorted_faces = sorted(sorted_faces, key=lambda x: x["x_center"])
|
||||
|
||||
# add face_id for reference
|
||||
sorted_faces_with_ids: list[FaceResultDataWithId] = []
|
||||
face_id_counter = 0
|
||||
for face in sorted_faces:
|
||||
sorted_faces_with_ids.append(
|
||||
FaceResultDataWithId(
|
||||
**face,
|
||||
face_id=face_id_counter,
|
||||
)
|
||||
)
|
||||
face_id_counter += 1
|
||||
|
||||
return sorted_faces_with_ids
|
||||
|
||||
|
||||
def generate_face_box_mask(
|
||||
context: InvocationContext,
|
||||
minimum_confidence: float,
|
||||
x_offset: float,
|
||||
y_offset: float,
|
||||
pil_image: ImageType,
|
||||
chunk_x_offset: int = 0,
|
||||
chunk_y_offset: int = 0,
|
||||
draw_mesh: bool = True,
|
||||
check_bounds: bool = True,
|
||||
) -> list[FaceResultData]:
|
||||
result = []
|
||||
mask_pil = None
|
||||
|
||||
# Convert the PIL image to a NumPy array.
|
||||
np_image = np.array(pil_image, dtype=np.uint8)
|
||||
|
||||
# Check if the input image has four channels (RGBA).
|
||||
if np_image.shape[2] == 4:
|
||||
# Convert RGBA to RGB by removing the alpha channel.
|
||||
np_image = np_image[:, :, :3]
|
||||
|
||||
# Create a FaceMesh object for face landmark detection and mesh generation.
|
||||
face_mesh = FaceMesh(
|
||||
max_num_faces=999,
|
||||
min_detection_confidence=minimum_confidence,
|
||||
min_tracking_confidence=minimum_confidence,
|
||||
)
|
||||
|
||||
# Detect the face landmarks and mesh in the input image.
|
||||
results = face_mesh.process(np_image)
|
||||
|
||||
# Check if any face is detected.
|
||||
if results.multi_face_landmarks: # type: ignore # this are via protobuf and not typed
|
||||
# Search for the face_id in the detected faces.
|
||||
for face_id, face_landmarks in enumerate(results.multi_face_landmarks): # type: ignore #this are via protobuf and not typed
|
||||
# Get the bounding box of the face mesh.
|
||||
x_coordinates = [landmark.x for landmark in face_landmarks.landmark]
|
||||
y_coordinates = [landmark.y for landmark in face_landmarks.landmark]
|
||||
x_min, x_max = min(x_coordinates), max(x_coordinates)
|
||||
y_min, y_max = min(y_coordinates), max(y_coordinates)
|
||||
|
||||
# Calculate the width and height of the face mesh.
|
||||
mesh_width = int((x_max - x_min) * np_image.shape[1])
|
||||
mesh_height = int((y_max - y_min) * np_image.shape[0])
|
||||
|
||||
# Get the center of the face.
|
||||
x_center = np.mean([landmark.x * np_image.shape[1] for landmark in face_landmarks.landmark])
|
||||
y_center = np.mean([landmark.y * np_image.shape[0] for landmark in face_landmarks.landmark])
|
||||
|
||||
face_landmark_points = np.array(
|
||||
[
|
||||
[landmark.x * np_image.shape[1], landmark.y * np_image.shape[0]]
|
||||
for landmark in face_landmarks.landmark
|
||||
]
|
||||
)
|
||||
|
||||
# Apply the scaling offsets to the face landmark points with a multiplier.
|
||||
scale_multiplier = 0.2
|
||||
x_center = np.mean(face_landmark_points[:, 0])
|
||||
y_center = np.mean(face_landmark_points[:, 1])
|
||||
|
||||
if draw_mesh:
|
||||
x_scaled = face_landmark_points[:, 0] + scale_multiplier * x_offset * (
|
||||
face_landmark_points[:, 0] - x_center
|
||||
)
|
||||
y_scaled = face_landmark_points[:, 1] + scale_multiplier * y_offset * (
|
||||
face_landmark_points[:, 1] - y_center
|
||||
)
|
||||
|
||||
convex_hull = cv2.convexHull(np.column_stack((x_scaled, y_scaled)).astype(np.int32))
|
||||
|
||||
# Generate a binary face mask using the face mesh.
|
||||
mask_image = np.ones(np_image.shape[:2], dtype=np.uint8) * 255
|
||||
cv2.fillConvexPoly(mask_image, convex_hull, 0)
|
||||
|
||||
# Convert the binary mask image to a PIL Image.
|
||||
init_mask_pil = Image.fromarray(mask_image, mode="L")
|
||||
w, h = init_mask_pil.size
|
||||
mask_pil = create_white_image(w + chunk_x_offset, h + chunk_y_offset)
|
||||
mask_pil.paste(init_mask_pil, (chunk_x_offset, chunk_y_offset))
|
||||
|
||||
left_side = x_center - mesh_width
|
||||
right_side = x_center + mesh_width
|
||||
top_side = y_center - mesh_height
|
||||
bottom_side = y_center + mesh_height
|
||||
im_width, im_height = pil_image.size
|
||||
over_w = im_width * 0.1
|
||||
over_h = im_height * 0.1
|
||||
if not check_bounds or (
|
||||
(left_side >= -over_w)
|
||||
and (right_side < im_width + over_w)
|
||||
and (top_side >= -over_h)
|
||||
and (bottom_side < im_height + over_h)
|
||||
):
|
||||
x_center = float(x_center)
|
||||
y_center = float(y_center)
|
||||
face = FaceResultData(
|
||||
image=pil_image,
|
||||
mask=mask_pil or create_white_image(*pil_image.size),
|
||||
x_center=x_center + chunk_x_offset,
|
||||
y_center=y_center + chunk_y_offset,
|
||||
mesh_width=mesh_width,
|
||||
mesh_height=mesh_height,
|
||||
)
|
||||
|
||||
result.append(face)
|
||||
else:
|
||||
context.services.logger.info("FaceTools --> Face out of bounds, ignoring.")
|
||||
|
||||
return result
|
||||
|
||||
|
||||
def extract_face(
|
||||
context: InvocationContext,
|
||||
image: ImageType,
|
||||
face: FaceResultData,
|
||||
padding: int,
|
||||
) -> ExtractFaceData:
|
||||
mask = face["mask"]
|
||||
center_x = face["x_center"]
|
||||
center_y = face["y_center"]
|
||||
mesh_width = face["mesh_width"]
|
||||
mesh_height = face["mesh_height"]
|
||||
|
||||
# Determine the minimum size of the square crop
|
||||
min_size = min(mask.width, mask.height)
|
||||
|
||||
# Calculate the crop boundaries for the output image and mask.
|
||||
mesh_width += 128 + padding # add pixels to account for mask variance
|
||||
mesh_height += 128 + padding # add pixels to account for mask variance
|
||||
crop_size = min(
|
||||
max(mesh_width, mesh_height, 128), min_size
|
||||
) # Choose the smaller of the two (given value or face mask size)
|
||||
if crop_size > 128:
|
||||
crop_size = (crop_size + 7) // 8 * 8 # Ensure crop side is multiple of 8
|
||||
|
||||
# Calculate the actual crop boundaries within the bounds of the original image.
|
||||
x_min = int(center_x - crop_size / 2)
|
||||
y_min = int(center_y - crop_size / 2)
|
||||
x_max = int(center_x + crop_size / 2)
|
||||
y_max = int(center_y + crop_size / 2)
|
||||
|
||||
# Adjust the crop boundaries to stay within the original image's dimensions
|
||||
if x_min < 0:
|
||||
context.services.logger.warning("FaceTools --> -X-axis padding reached image edge.")
|
||||
x_max -= x_min
|
||||
x_min = 0
|
||||
elif x_max > mask.width:
|
||||
context.services.logger.warning("FaceTools --> +X-axis padding reached image edge.")
|
||||
x_min -= x_max - mask.width
|
||||
x_max = mask.width
|
||||
|
||||
if y_min < 0:
|
||||
context.services.logger.warning("FaceTools --> +Y-axis padding reached image edge.")
|
||||
y_max -= y_min
|
||||
y_min = 0
|
||||
elif y_max > mask.height:
|
||||
context.services.logger.warning("FaceTools --> -Y-axis padding reached image edge.")
|
||||
y_min -= y_max - mask.height
|
||||
y_max = mask.height
|
||||
|
||||
# Ensure the crop is square and adjust the boundaries if needed
|
||||
if x_max - x_min != crop_size:
|
||||
context.services.logger.warning("FaceTools --> Limiting x-axis padding to constrain bounding box to a square.")
|
||||
diff = crop_size - (x_max - x_min)
|
||||
x_min -= diff // 2
|
||||
x_max += diff - diff // 2
|
||||
|
||||
if y_max - y_min != crop_size:
|
||||
context.services.logger.warning("FaceTools --> Limiting y-axis padding to constrain bounding box to a square.")
|
||||
diff = crop_size - (y_max - y_min)
|
||||
y_min -= diff // 2
|
||||
y_max += diff - diff // 2
|
||||
|
||||
context.services.logger.info(f"FaceTools --> Calculated bounding box (8 multiple): {crop_size}")
|
||||
|
||||
# Crop the output image to the specified size with the center of the face mesh as the center.
|
||||
mask = mask.crop((x_min, y_min, x_max, y_max))
|
||||
bounded_image = image.crop((x_min, y_min, x_max, y_max))
|
||||
|
||||
# blur mask edge by small radius
|
||||
mask = mask.filter(ImageFilter.GaussianBlur(radius=2))
|
||||
|
||||
return ExtractFaceData(
|
||||
bounded_image=bounded_image,
|
||||
bounded_mask=mask,
|
||||
x_min=x_min,
|
||||
y_min=y_min,
|
||||
x_max=x_max,
|
||||
y_max=y_max,
|
||||
)
|
||||
|
||||
|
||||
def get_faces_list(
|
||||
context: InvocationContext,
|
||||
image: ImageType,
|
||||
should_chunk: bool,
|
||||
minimum_confidence: float,
|
||||
x_offset: float,
|
||||
y_offset: float,
|
||||
draw_mesh: bool = True,
|
||||
) -> list[FaceResultDataWithId]:
|
||||
result = []
|
||||
|
||||
# Generate the face box mask and get the center of the face.
|
||||
if not should_chunk:
|
||||
context.services.logger.info("FaceTools --> Attempting full image face detection.")
|
||||
result = generate_face_box_mask(
|
||||
context=context,
|
||||
minimum_confidence=minimum_confidence,
|
||||
x_offset=x_offset,
|
||||
y_offset=y_offset,
|
||||
pil_image=image,
|
||||
chunk_x_offset=0,
|
||||
chunk_y_offset=0,
|
||||
draw_mesh=draw_mesh,
|
||||
check_bounds=False,
|
||||
)
|
||||
if should_chunk or len(result) == 0:
|
||||
context.services.logger.info("FaceTools --> Chunking image (chunk toggled on, or no face found in full image).")
|
||||
width, height = image.size
|
||||
image_chunks = []
|
||||
x_offsets = []
|
||||
y_offsets = []
|
||||
result = []
|
||||
|
||||
# If width == height, there's nothing more we can do... otherwise...
|
||||
if width > height:
|
||||
# Landscape - slice the image horizontally
|
||||
fx = 0.0
|
||||
steps = int(width * 2 / height)
|
||||
while fx <= (width - height):
|
||||
x = int(fx)
|
||||
image_chunks.append(image.crop((x, 0, x + height - 1, height - 1)))
|
||||
x_offsets.append(x)
|
||||
y_offsets.append(0)
|
||||
fx += (width - height) / steps
|
||||
context.services.logger.info(f"FaceTools --> Chunk starting at x = {x}")
|
||||
elif height > width:
|
||||
# Portrait - slice the image vertically
|
||||
fy = 0.0
|
||||
steps = int(height * 2 / width)
|
||||
while fy <= (height - width):
|
||||
y = int(fy)
|
||||
image_chunks.append(image.crop((0, y, width - 1, y + width - 1)))
|
||||
x_offsets.append(0)
|
||||
y_offsets.append(y)
|
||||
fy += (height - width) / steps
|
||||
context.services.logger.info(f"FaceTools --> Chunk starting at y = {y}")
|
||||
|
||||
for idx in range(len(image_chunks)):
|
||||
context.services.logger.info(f"FaceTools --> Evaluating faces in chunk {idx}")
|
||||
result = result + generate_face_box_mask(
|
||||
context=context,
|
||||
minimum_confidence=minimum_confidence,
|
||||
x_offset=x_offset,
|
||||
y_offset=y_offset,
|
||||
pil_image=image_chunks[idx],
|
||||
chunk_x_offset=x_offsets[idx],
|
||||
chunk_y_offset=y_offsets[idx],
|
||||
draw_mesh=draw_mesh,
|
||||
)
|
||||
|
||||
if len(result) == 0:
|
||||
# Give up
|
||||
context.services.logger.warning(
|
||||
"FaceTools --> No face detected in chunked input image. Passing through original image."
|
||||
)
|
||||
|
||||
all_faces = prepare_faces_list(result)
|
||||
|
||||
return all_faces
|
||||
|
||||
|
||||
@invocation("face_off", title="FaceOff", tags=["image", "faceoff", "face", "mask"], category="image", version="1.0.1")
|
||||
class FaceOffInvocation(BaseInvocation):
|
||||
"""Bound, extract, and mask a face from an image using MediaPipe detection"""
|
||||
|
||||
image: ImageField = InputField(description="Image for face detection")
|
||||
face_id: int = InputField(
|
||||
default=0,
|
||||
ge=0,
|
||||
description="The face ID to process, numbered from 0. Multiple faces not supported. Find a face's ID with FaceIdentifier node.",
|
||||
)
|
||||
minimum_confidence: float = InputField(
|
||||
default=0.5, description="Minimum confidence for face detection (lower if detection is failing)"
|
||||
)
|
||||
x_offset: float = InputField(default=0.0, description="X-axis offset of the mask")
|
||||
y_offset: float = InputField(default=0.0, description="Y-axis offset of the mask")
|
||||
padding: int = InputField(default=0, description="All-axis padding around the mask in pixels")
|
||||
chunk: bool = InputField(
|
||||
default=False,
|
||||
description="Whether to bypass full image face detection and default to image chunking. Chunking will occur if no faces are found in the full image.",
|
||||
)
|
||||
|
||||
def faceoff(self, context: InvocationContext, image: ImageType) -> Optional[ExtractFaceData]:
|
||||
all_faces = get_faces_list(
|
||||
context=context,
|
||||
image=image,
|
||||
should_chunk=self.chunk,
|
||||
minimum_confidence=self.minimum_confidence,
|
||||
x_offset=self.x_offset,
|
||||
y_offset=self.y_offset,
|
||||
draw_mesh=True,
|
||||
)
|
||||
|
||||
if len(all_faces) == 0:
|
||||
context.services.logger.warning("FaceOff --> No faces detected. Passing through original image.")
|
||||
return None
|
||||
|
||||
if self.face_id > len(all_faces) - 1:
|
||||
context.services.logger.warning(
|
||||
f"FaceOff --> Face ID {self.face_id} is outside of the number of faces detected ({len(all_faces)}). Passing through original image."
|
||||
)
|
||||
return None
|
||||
|
||||
face_data = extract_face(context=context, image=image, face=all_faces[self.face_id], padding=self.padding)
|
||||
# Convert the input image to RGBA mode to ensure it has an alpha channel.
|
||||
face_data["bounded_image"] = face_data["bounded_image"].convert("RGBA")
|
||||
|
||||
return face_data
|
||||
|
||||
def invoke(self, context: InvocationContext) -> FaceOffOutput:
|
||||
image = context.services.images.get_pil_image(self.image.image_name)
|
||||
result = self.faceoff(context=context, image=image)
|
||||
|
||||
if result is None:
|
||||
result_image = image
|
||||
result_mask = create_white_image(*image.size)
|
||||
x = 0
|
||||
y = 0
|
||||
else:
|
||||
result_image = result["bounded_image"]
|
||||
result_mask = result["bounded_mask"]
|
||||
x = result["x_min"]
|
||||
y = result["y_min"]
|
||||
|
||||
image_dto = context.services.images.create(
|
||||
image=result_image,
|
||||
image_origin=ResourceOrigin.INTERNAL,
|
||||
image_category=ImageCategory.GENERAL,
|
||||
node_id=self.id,
|
||||
session_id=context.graph_execution_state_id,
|
||||
is_intermediate=self.is_intermediate,
|
||||
workflow=self.workflow,
|
||||
)
|
||||
|
||||
mask_dto = context.services.images.create(
|
||||
image=result_mask,
|
||||
image_origin=ResourceOrigin.INTERNAL,
|
||||
image_category=ImageCategory.MASK,
|
||||
node_id=self.id,
|
||||
session_id=context.graph_execution_state_id,
|
||||
is_intermediate=self.is_intermediate,
|
||||
)
|
||||
|
||||
output = FaceOffOutput(
|
||||
image=ImageField(image_name=image_dto.image_name),
|
||||
width=image_dto.width,
|
||||
height=image_dto.height,
|
||||
mask=ImageField(image_name=mask_dto.image_name),
|
||||
x=x,
|
||||
y=y,
|
||||
)
|
||||
|
||||
return output
|
||||
|
||||
|
||||
@invocation("face_mask_detection", title="FaceMask", tags=["image", "face", "mask"], category="image", version="1.0.1")
|
||||
class FaceMaskInvocation(BaseInvocation):
|
||||
"""Face mask creation using mediapipe face detection"""
|
||||
|
||||
image: ImageField = InputField(description="Image to face detect")
|
||||
face_ids: str = InputField(
|
||||
default="",
|
||||
description="Comma-separated list of face ids to mask eg '0,2,7'. Numbered from 0. Leave empty to mask all. Find face IDs with FaceIdentifier node.",
|
||||
)
|
||||
minimum_confidence: float = InputField(
|
||||
default=0.5, description="Minimum confidence for face detection (lower if detection is failing)"
|
||||
)
|
||||
x_offset: float = InputField(default=0.0, description="Offset for the X-axis of the face mask")
|
||||
y_offset: float = InputField(default=0.0, description="Offset for the Y-axis of the face mask")
|
||||
chunk: bool = InputField(
|
||||
default=False,
|
||||
description="Whether to bypass full image face detection and default to image chunking. Chunking will occur if no faces are found in the full image.",
|
||||
)
|
||||
invert_mask: bool = InputField(default=False, description="Toggle to invert the mask")
|
||||
|
||||
@validator("face_ids")
|
||||
def validate_comma_separated_ints(cls, v) -> str:
|
||||
comma_separated_ints_regex = re.compile(r"^\d*(,\d+)*$")
|
||||
if comma_separated_ints_regex.match(v) is None:
|
||||
raise ValueError('Face IDs must be a comma-separated list of integers (e.g. "1,2,3")')
|
||||
return v
|
||||
|
||||
def facemask(self, context: InvocationContext, image: ImageType) -> FaceMaskResult:
|
||||
all_faces = get_faces_list(
|
||||
context=context,
|
||||
image=image,
|
||||
should_chunk=self.chunk,
|
||||
minimum_confidence=self.minimum_confidence,
|
||||
x_offset=self.x_offset,
|
||||
y_offset=self.y_offset,
|
||||
draw_mesh=True,
|
||||
)
|
||||
|
||||
mask_pil = create_white_image(*image.size)
|
||||
|
||||
id_range = list(range(0, len(all_faces)))
|
||||
ids_to_extract = id_range
|
||||
if self.face_ids != "":
|
||||
parsed_face_ids = [int(id) for id in self.face_ids.split(",")]
|
||||
# get requested face_ids that are in range
|
||||
intersected_face_ids = set(parsed_face_ids) & set(id_range)
|
||||
|
||||
if len(intersected_face_ids) == 0:
|
||||
id_range_str = ",".join([str(id) for id in id_range])
|
||||
context.services.logger.warning(
|
||||
f"Face IDs must be in range of detected faces - requested {self.face_ids}, detected {id_range_str}. Passing through original image."
|
||||
)
|
||||
return FaceMaskResult(
|
||||
image=image, # original image
|
||||
mask=mask_pil, # white mask
|
||||
)
|
||||
|
||||
ids_to_extract = list(intersected_face_ids)
|
||||
|
||||
for face_id in ids_to_extract:
|
||||
face_data = extract_face(context=context, image=image, face=all_faces[face_id], padding=0)
|
||||
face_mask_pil = face_data["bounded_mask"]
|
||||
x_min = face_data["x_min"]
|
||||
y_min = face_data["y_min"]
|
||||
x_max = face_data["x_max"]
|
||||
y_max = face_data["y_max"]
|
||||
|
||||
mask_pil.paste(
|
||||
create_black_image(x_max - x_min, y_max - y_min),
|
||||
box=(x_min, y_min),
|
||||
mask=ImageOps.invert(face_mask_pil),
|
||||
)
|
||||
|
||||
if self.invert_mask:
|
||||
mask_pil = ImageOps.invert(mask_pil)
|
||||
|
||||
# Create an RGBA image with transparency
|
||||
image = image.convert("RGBA")
|
||||
|
||||
return FaceMaskResult(
|
||||
image=image,
|
||||
mask=mask_pil,
|
||||
)
|
||||
|
||||
def invoke(self, context: InvocationContext) -> FaceMaskOutput:
|
||||
image = context.services.images.get_pil_image(self.image.image_name)
|
||||
result = self.facemask(context=context, image=image)
|
||||
|
||||
image_dto = context.services.images.create(
|
||||
image=result["image"],
|
||||
image_origin=ResourceOrigin.INTERNAL,
|
||||
image_category=ImageCategory.GENERAL,
|
||||
node_id=self.id,
|
||||
session_id=context.graph_execution_state_id,
|
||||
is_intermediate=self.is_intermediate,
|
||||
workflow=self.workflow,
|
||||
)
|
||||
|
||||
mask_dto = context.services.images.create(
|
||||
image=result["mask"],
|
||||
image_origin=ResourceOrigin.INTERNAL,
|
||||
image_category=ImageCategory.MASK,
|
||||
node_id=self.id,
|
||||
session_id=context.graph_execution_state_id,
|
||||
is_intermediate=self.is_intermediate,
|
||||
)
|
||||
|
||||
output = FaceMaskOutput(
|
||||
image=ImageField(image_name=image_dto.image_name),
|
||||
width=image_dto.width,
|
||||
height=image_dto.height,
|
||||
mask=ImageField(image_name=mask_dto.image_name),
|
||||
)
|
||||
|
||||
return output
|
||||
|
||||
|
||||
@invocation(
|
||||
"face_identifier", title="FaceIdentifier", tags=["image", "face", "identifier"], category="image", version="1.0.1"
|
||||
)
|
||||
class FaceIdentifierInvocation(BaseInvocation):
|
||||
"""Outputs an image with detected face IDs printed on each face. For use with other FaceTools."""
|
||||
|
||||
image: ImageField = InputField(description="Image to face detect")
|
||||
minimum_confidence: float = InputField(
|
||||
default=0.5, description="Minimum confidence for face detection (lower if detection is failing)"
|
||||
)
|
||||
chunk: bool = InputField(
|
||||
default=False,
|
||||
description="Whether to bypass full image face detection and default to image chunking. Chunking will occur if no faces are found in the full image.",
|
||||
)
|
||||
|
||||
def faceidentifier(self, context: InvocationContext, image: ImageType) -> ImageType:
|
||||
image = image.copy()
|
||||
|
||||
all_faces = get_faces_list(
|
||||
context=context,
|
||||
image=image,
|
||||
should_chunk=self.chunk,
|
||||
minimum_confidence=self.minimum_confidence,
|
||||
x_offset=0,
|
||||
y_offset=0,
|
||||
draw_mesh=False,
|
||||
)
|
||||
|
||||
# Note - font may be found either in the repo if running an editable install, or in the venv if running a package install
|
||||
font_path = [x for x in [Path(y, "inter/Inter-Regular.ttf") for y in font_assets.__path__] if x.exists()]
|
||||
font = ImageFont.truetype(font_path[0].as_posix(), FONT_SIZE)
|
||||
|
||||
# Paste face IDs on the output image
|
||||
draw = ImageDraw.Draw(image)
|
||||
for face in all_faces:
|
||||
x_coord = face["x_center"]
|
||||
y_coord = face["y_center"]
|
||||
text = str(face["face_id"])
|
||||
# get bbox of the text so we can center the id on the face
|
||||
_, _, bbox_w, bbox_h = draw.textbbox(xy=(0, 0), text=text, font=font, stroke_width=FONT_STROKE_WIDTH)
|
||||
x = x_coord - bbox_w / 2
|
||||
y = y_coord - bbox_h / 2
|
||||
draw.text(
|
||||
xy=(x, y),
|
||||
text=str(text),
|
||||
fill=(255, 255, 255, 255),
|
||||
font=font,
|
||||
stroke_width=FONT_STROKE_WIDTH,
|
||||
stroke_fill=(0, 0, 0, 255),
|
||||
)
|
||||
|
||||
# Create an RGBA image with transparency
|
||||
image = image.convert("RGBA")
|
||||
|
||||
return image
|
||||
|
||||
def invoke(self, context: InvocationContext) -> ImageOutput:
|
||||
image = context.services.images.get_pil_image(self.image.image_name)
|
||||
result_image = self.faceidentifier(context=context, image=image)
|
||||
|
||||
image_dto = context.services.images.create(
|
||||
image=result_image,
|
||||
image_origin=ResourceOrigin.INTERNAL,
|
||||
image_category=ImageCategory.GENERAL,
|
||||
node_id=self.id,
|
||||
session_id=context.graph_execution_state_id,
|
||||
is_intermediate=self.is_intermediate,
|
||||
workflow=self.workflow,
|
||||
)
|
||||
|
||||
return ImageOutput(
|
||||
image=ImageField(image_name=image_dto.image_name),
|
||||
width=image_dto.width,
|
||||
height=image_dto.height,
|
||||
)
|
||||
@@ -8,12 +8,12 @@ import numpy
|
||||
from PIL import Image, ImageChops, ImageFilter, ImageOps
|
||||
|
||||
from invokeai.app.invocations.metadata import CoreMetadata
|
||||
from invokeai.app.invocations.primitives import BoardField, ColorField, ImageField, ImageOutput
|
||||
from invokeai.app.invocations.primitives import ColorField, ImageField, ImageOutput
|
||||
from invokeai.backend.image_util.invisible_watermark import InvisibleWatermark
|
||||
from invokeai.backend.image_util.safety_checker import SafetyChecker
|
||||
|
||||
from ..models.image import ImageCategory, ResourceOrigin
|
||||
from .baseinvocation import BaseInvocation, FieldDescriptions, Input, InputField, InvocationContext, invocation
|
||||
from .baseinvocation import BaseInvocation, FieldDescriptions, InputField, InvocationContext, invocation
|
||||
|
||||
|
||||
@invocation("show_image", title="Show Image", tags=["image"], category="image", version="1.0.0")
|
||||
@@ -972,14 +972,13 @@ class ImageChannelMultiplyInvocation(BaseInvocation):
|
||||
title="Save Image",
|
||||
tags=["primitives", "image"],
|
||||
category="primitives",
|
||||
version="1.0.1",
|
||||
version="1.0.0",
|
||||
use_cache=False,
|
||||
)
|
||||
class SaveImageInvocation(BaseInvocation):
|
||||
"""Saves an image. Unlike an image primitive, this invocation stores a copy of the image."""
|
||||
|
||||
image: ImageField = InputField(description=FieldDescriptions.image)
|
||||
board: Optional[BoardField] = InputField(default=None, description=FieldDescriptions.board, input=Input.Direct)
|
||||
image: ImageField = InputField(description="The image to load")
|
||||
metadata: CoreMetadata = InputField(
|
||||
default=None,
|
||||
description=FieldDescriptions.core_metadata,
|
||||
@@ -993,7 +992,6 @@ class SaveImageInvocation(BaseInvocation):
|
||||
image=image,
|
||||
image_origin=ResourceOrigin.INTERNAL,
|
||||
image_category=ImageCategory.GENERAL,
|
||||
board_id=self.board.board_id if self.board else None,
|
||||
node_id=self.id,
|
||||
session_id=context.graph_execution_state_id,
|
||||
is_intermediate=self.is_intermediate,
|
||||
|
||||
@@ -269,7 +269,7 @@ class LaMaInfillInvocation(BaseInvocation):
|
||||
)
|
||||
|
||||
|
||||
@invocation("infill_cv2", title="CV2 Infill", tags=["image", "inpaint"], category="inpaint", version="1.0.0")
|
||||
@invocation("infill_cv2", title="CV2 Infill", tags=["image", "inpaint"], category="inpaint")
|
||||
class CV2InfillInvocation(BaseInvocation):
|
||||
"""Infills transparent areas of an image using OpenCV Inpainting"""
|
||||
|
||||
|
||||
@@ -1,103 +0,0 @@
|
||||
import os
|
||||
from builtins import float
|
||||
from typing import List, Union
|
||||
|
||||
from pydantic import BaseModel, Field
|
||||
|
||||
from invokeai.app.invocations.baseinvocation import (
|
||||
BaseInvocation,
|
||||
BaseInvocationOutput,
|
||||
FieldDescriptions,
|
||||
Input,
|
||||
InputField,
|
||||
InvocationContext,
|
||||
OutputField,
|
||||
UIType,
|
||||
invocation,
|
||||
invocation_output,
|
||||
)
|
||||
from invokeai.app.invocations.primitives import ImageField
|
||||
from invokeai.backend.model_manager import BaseModelType, ModelType
|
||||
from invokeai.backend.model_manager.models.ip_adapter import get_ip_adapter_image_encoder_model_id
|
||||
|
||||
|
||||
class IPAdapterModelField(BaseModel):
|
||||
model_name: str = Field(description="Name of the IP-Adapter model")
|
||||
base_model: BaseModelType = Field(description="Base model")
|
||||
|
||||
|
||||
class CLIPVisionModelField(BaseModel):
|
||||
model_name: str = Field(description="Name of the CLIP Vision image encoder model")
|
||||
base_model: BaseModelType = Field(description="Base model (usually 'Any')")
|
||||
|
||||
|
||||
class IPAdapterField(BaseModel):
|
||||
image: ImageField = Field(description="The IP-Adapter image prompt.")
|
||||
ip_adapter_model: IPAdapterModelField = Field(description="The IP-Adapter model to use.")
|
||||
image_encoder_model: CLIPVisionModelField = Field(description="The name of the CLIP image encoder model.")
|
||||
weight: Union[float, List[float]] = Field(default=1, description="The weight given to the ControlNet")
|
||||
# weight: float = Field(default=1.0, ge=0, description="The weight of the IP-Adapter.")
|
||||
begin_step_percent: float = Field(
|
||||
default=0, ge=0, le=1, description="When the IP-Adapter is first applied (% of total steps)"
|
||||
)
|
||||
end_step_percent: float = Field(
|
||||
default=1, ge=0, le=1, description="When the IP-Adapter is last applied (% of total steps)"
|
||||
)
|
||||
|
||||
|
||||
@invocation_output("ip_adapter_output")
|
||||
class IPAdapterOutput(BaseInvocationOutput):
|
||||
# Outputs
|
||||
ip_adapter: IPAdapterField = OutputField(description=FieldDescriptions.ip_adapter, title="IP-Adapter")
|
||||
|
||||
|
||||
@invocation("ip_adapter", title="IP-Adapter", tags=["ip_adapter", "control"], category="ip_adapter", version="1.0.0")
|
||||
class IPAdapterInvocation(BaseInvocation):
|
||||
"""Collects IP-Adapter info to pass to other nodes."""
|
||||
|
||||
# Inputs
|
||||
image: ImageField = InputField(description="The IP-Adapter image prompt.")
|
||||
ip_adapter_model: IPAdapterModelField = InputField(
|
||||
description="The IP-Adapter model.", title="IP-Adapter Model", input=Input.Direct, ui_order=-1
|
||||
)
|
||||
|
||||
# weight: float = InputField(default=1.0, description="The weight of the IP-Adapter.", ui_type=UIType.Float)
|
||||
weight: Union[float, List[float]] = InputField(
|
||||
default=1, ge=0, description="The weight given to the IP-Adapter", ui_type=UIType.Float, title="Weight"
|
||||
)
|
||||
|
||||
begin_step_percent: float = InputField(
|
||||
default=0, ge=-1, le=2, description="When the IP-Adapter is first applied (% of total steps)"
|
||||
)
|
||||
end_step_percent: float = InputField(
|
||||
default=1, ge=0, le=1, description="When the IP-Adapter is last applied (% of total steps)"
|
||||
)
|
||||
|
||||
def invoke(self, context: InvocationContext) -> IPAdapterOutput:
|
||||
# Lookup the CLIP Vision encoder that is intended to be used with the IP-Adapter model.
|
||||
ip_adapter_info = context.services.model_manager.model_info(
|
||||
self.ip_adapter_model.model_name, self.ip_adapter_model.base_model, ModelType.IPAdapter
|
||||
)
|
||||
# HACK(ryand): This is bad for a couple of reasons: 1) we are bypassing the model manager to read the model
|
||||
# directly, and 2) we are reading from disk every time this invocation is called without caching the result.
|
||||
# A better solution would be to store the image encoder model reference in the IP-Adapter model info, but this
|
||||
# is currently messy due to differences between how the model info is generated when installing a model from
|
||||
# disk vs. downloading the model.
|
||||
image_encoder_model_id = get_ip_adapter_image_encoder_model_id(
|
||||
os.path.join(context.services.configuration.get_config().models_path, ip_adapter_info["path"])
|
||||
)
|
||||
image_encoder_model_name = image_encoder_model_id.split("/")[-1].strip()
|
||||
image_encoder_model = CLIPVisionModelField(
|
||||
model_name=image_encoder_model_name,
|
||||
base_model=BaseModelType.Any,
|
||||
)
|
||||
return IPAdapterOutput(
|
||||
ip_adapter=IPAdapterField(
|
||||
image=self.image,
|
||||
ip_adapter_model=self.ip_adapter_model,
|
||||
image_encoder_model=image_encoder_model,
|
||||
weight=self.weight,
|
||||
begin_step_percent=self.begin_step_percent,
|
||||
end_step_percent=self.end_step_percent,
|
||||
),
|
||||
)
|
||||
@@ -1,16 +1,13 @@
|
||||
# Copyright (c) 2023 Kyle Schouviller (https://github.com/kyle0654)
|
||||
|
||||
from contextlib import ExitStack
|
||||
from functools import singledispatchmethod
|
||||
from typing import List, Literal, Optional, Union
|
||||
|
||||
import einops
|
||||
import numpy as np
|
||||
import torch
|
||||
import torchvision.transforms as T
|
||||
from diffusers import AutoencoderKL, AutoencoderTiny
|
||||
from diffusers.image_processor import VaeImageProcessor
|
||||
from diffusers.models.adapter import FullAdapterXL, T2IAdapter
|
||||
from diffusers.models.attention_processor import (
|
||||
AttnProcessor2_0,
|
||||
LoRAAttnProcessor2_0,
|
||||
@@ -22,7 +19,6 @@ from diffusers.schedulers import SchedulerMixin as Scheduler
|
||||
from pydantic import validator
|
||||
from torchvision.transforms.functional import resize as tv_resize
|
||||
|
||||
from invokeai.app.invocations.ip_adapter import IPAdapterField
|
||||
from invokeai.app.invocations.metadata import CoreMetadata
|
||||
from invokeai.app.invocations.primitives import (
|
||||
DenoiseMaskField,
|
||||
@@ -33,21 +29,18 @@ from invokeai.app.invocations.primitives import (
|
||||
LatentsOutput,
|
||||
build_latents_output,
|
||||
)
|
||||
from invokeai.app.invocations.t2i_adapter import T2IAdapterField
|
||||
from invokeai.app.util.controlnet_utils import prepare_control_image
|
||||
from invokeai.app.util.step_callback import stable_diffusion_step_callback
|
||||
from invokeai.backend.ip_adapter.ip_adapter import IPAdapter, IPAdapterPlus
|
||||
from invokeai.backend.model_manager import BaseModelType, ModelType, SilenceWarnings
|
||||
from invokeai.backend.stable_diffusion.diffusion.conditioning_data import ConditioningData, IPAdapterConditioningInfo
|
||||
from invokeai.backend.model_management.models import ModelType, SilenceWarnings
|
||||
|
||||
from ...backend.model_manager.lora import ModelPatcher
|
||||
from ...backend.model_manager.seamless import set_seamless
|
||||
from ...backend.model_management.lora import ModelPatcher
|
||||
from ...backend.model_management.models import BaseModelType
|
||||
from ...backend.model_management.seamless import set_seamless
|
||||
from ...backend.stable_diffusion import PipelineIntermediateState
|
||||
from ...backend.stable_diffusion.diffusers_pipeline import (
|
||||
ConditioningData,
|
||||
ControlNetData,
|
||||
IPAdapterData,
|
||||
StableDiffusionGeneratorPipeline,
|
||||
T2IAdapterData,
|
||||
image_resized_to_grid_as_tensor,
|
||||
)
|
||||
from ...backend.stable_diffusion.diffusion.shared_invokeai_diffusion import PostprocessingSettings
|
||||
@@ -75,6 +68,7 @@ if choose_torch_device() == torch.device("mps"):
|
||||
|
||||
DEFAULT_PRECISION = choose_precision(choose_torch_device())
|
||||
|
||||
|
||||
SAMPLER_NAME_VALUES = Literal[tuple(list(SCHEDULER_MAP.keys()))]
|
||||
|
||||
|
||||
@@ -132,7 +126,7 @@ class CreateDenoiseMaskInvocation(BaseInvocation):
|
||||
)
|
||||
|
||||
if image is not None:
|
||||
vae_info = context.services.model_loader.get_model(
|
||||
vae_info = context.services.model_manager.get_model(
|
||||
**self.vae.vae.dict(),
|
||||
context=context,
|
||||
)
|
||||
@@ -165,7 +159,7 @@ def get_scheduler(
|
||||
seed: int,
|
||||
) -> Scheduler:
|
||||
scheduler_class, scheduler_extra_config = SCHEDULER_MAP.get(scheduler_name, SCHEDULER_MAP["ddim"])
|
||||
orig_scheduler_info = context.services.model_loader.get_model(
|
||||
orig_scheduler_info = context.services.model_manager.get_model(
|
||||
**scheduler_info.dict(),
|
||||
context=context,
|
||||
)
|
||||
@@ -197,7 +191,7 @@ def get_scheduler(
|
||||
title="Denoise Latents",
|
||||
tags=["latents", "denoise", "txt2img", "t2i", "t2l", "img2img", "i2i", "l2l"],
|
||||
category="latents",
|
||||
version="1.3.0",
|
||||
version="1.0.0",
|
||||
)
|
||||
class DenoiseLatentsInvocation(BaseInvocation):
|
||||
"""Denoises noisy latents to decodable images"""
|
||||
@@ -211,7 +205,7 @@ class DenoiseLatentsInvocation(BaseInvocation):
|
||||
noise: Optional[LatentsField] = InputField(description=FieldDescriptions.noise, input=Input.Connection, ui_order=3)
|
||||
steps: int = InputField(default=10, gt=0, description=FieldDescriptions.steps)
|
||||
cfg_scale: Union[float, List[float]] = InputField(
|
||||
default=7.5, ge=1, description=FieldDescriptions.cfg_scale, title="CFG Scale"
|
||||
default=7.5, ge=1, description=FieldDescriptions.cfg_scale, ui_type=UIType.Float, title="CFG Scale"
|
||||
)
|
||||
denoising_start: float = InputField(default=0.0, ge=0, le=1, description=FieldDescriptions.denoising_start)
|
||||
denoising_end: float = InputField(default=1.0, ge=0, le=1, description=FieldDescriptions.denoising_end)
|
||||
@@ -221,18 +215,13 @@ class DenoiseLatentsInvocation(BaseInvocation):
|
||||
unet: UNetField = InputField(description=FieldDescriptions.unet, input=Input.Connection, title="UNet", ui_order=2)
|
||||
control: Union[ControlField, list[ControlField]] = InputField(
|
||||
default=None,
|
||||
description=FieldDescriptions.control,
|
||||
input=Input.Connection,
|
||||
ui_order=5,
|
||||
)
|
||||
ip_adapter: Optional[Union[IPAdapterField, list[IPAdapterField]]] = InputField(
|
||||
description=FieldDescriptions.ip_adapter, title="IP-Adapter", default=None, input=Input.Connection, ui_order=6
|
||||
)
|
||||
t2i_adapter: Union[T2IAdapterField, list[T2IAdapterField]] = InputField(
|
||||
description=FieldDescriptions.t2i_adapter, title="T2I-Adapter", default=None, input=Input.Connection, ui_order=7
|
||||
)
|
||||
latents: Optional[LatentsField] = InputField(description=FieldDescriptions.latents, input=Input.Connection)
|
||||
denoise_mask: Optional[DenoiseMaskField] = InputField(
|
||||
default=None, description=FieldDescriptions.mask, input=Input.Connection, ui_order=8
|
||||
default=None, description=FieldDescriptions.mask, input=Input.Connection, ui_order=6
|
||||
)
|
||||
|
||||
@validator("cfg_scale")
|
||||
@@ -334,6 +323,8 @@ class DenoiseLatentsInvocation(BaseInvocation):
|
||||
def prep_control_data(
|
||||
self,
|
||||
context: InvocationContext,
|
||||
# really only need model for dtype and device
|
||||
model: StableDiffusionGeneratorPipeline,
|
||||
control_input: Union[ControlField, List[ControlField]],
|
||||
latents_shape: List[int],
|
||||
exit_stack: ExitStack,
|
||||
@@ -353,205 +344,57 @@ class DenoiseLatentsInvocation(BaseInvocation):
|
||||
else:
|
||||
control_list = None
|
||||
if control_list is None:
|
||||
return None
|
||||
# After above handling, any control that is not None should now be of type list[ControlField].
|
||||
|
||||
# FIXME: add checks to skip entry if model or image is None
|
||||
# and if weight is None, populate with default 1.0?
|
||||
controlnet_data = []
|
||||
for control_info in control_list:
|
||||
control_model = exit_stack.enter_context(
|
||||
context.services.model_loader.get_model(
|
||||
model_name=control_info.control_model.model_name,
|
||||
model_type=ModelType.ControlNet,
|
||||
base_model=control_info.control_model.base_model,
|
||||
context=context,
|
||||
)
|
||||
)
|
||||
|
||||
# control_models.append(control_model)
|
||||
control_image_field = control_info.image
|
||||
input_image = context.services.images.get_pil_image(control_image_field.image_name)
|
||||
# self.image.image_type, self.image.image_name
|
||||
# FIXME: still need to test with different widths, heights, devices, dtypes
|
||||
# and add in batch_size, num_images_per_prompt?
|
||||
# and do real check for classifier_free_guidance?
|
||||
# prepare_control_image should return torch.Tensor of shape(batch_size, 3, height, width)
|
||||
control_image = prepare_control_image(
|
||||
image=input_image,
|
||||
do_classifier_free_guidance=do_classifier_free_guidance,
|
||||
width=control_width_resize,
|
||||
height=control_height_resize,
|
||||
# batch_size=batch_size * num_images_per_prompt,
|
||||
# num_images_per_prompt=num_images_per_prompt,
|
||||
device=control_model.device,
|
||||
dtype=control_model.dtype,
|
||||
control_mode=control_info.control_mode,
|
||||
resize_mode=control_info.resize_mode,
|
||||
)
|
||||
control_item = ControlNetData(
|
||||
model=control_model, # model object
|
||||
image_tensor=control_image,
|
||||
weight=control_info.control_weight,
|
||||
begin_step_percent=control_info.begin_step_percent,
|
||||
end_step_percent=control_info.end_step_percent,
|
||||
control_mode=control_info.control_mode,
|
||||
# any resizing needed should currently be happening in prepare_control_image(),
|
||||
# but adding resize_mode to ControlNetData in case needed in the future
|
||||
resize_mode=control_info.resize_mode,
|
||||
)
|
||||
controlnet_data.append(control_item)
|
||||
# MultiControlNetModel has been refactored out, just need list[ControlNetData]
|
||||
|
||||
return controlnet_data
|
||||
|
||||
def prep_ip_adapter_data(
|
||||
self,
|
||||
context: InvocationContext,
|
||||
ip_adapter: Optional[Union[IPAdapterField, list[IPAdapterField]]],
|
||||
conditioning_data: ConditioningData,
|
||||
exit_stack: ExitStack,
|
||||
) -> Optional[list[IPAdapterData]]:
|
||||
"""If IP-Adapter is enabled, then this function loads the requisite models, and adds the image prompt embeddings
|
||||
to the `conditioning_data` (in-place).
|
||||
"""
|
||||
if ip_adapter is None:
|
||||
return None
|
||||
|
||||
# ip_adapter could be a list or a single IPAdapterField. Normalize to a list here.
|
||||
if not isinstance(ip_adapter, list):
|
||||
ip_adapter = [ip_adapter]
|
||||
|
||||
if len(ip_adapter) == 0:
|
||||
return None
|
||||
|
||||
ip_adapter_data_list = []
|
||||
conditioning_data.ip_adapter_conditioning = []
|
||||
for single_ip_adapter in ip_adapter:
|
||||
ip_adapter_model: Union[IPAdapter, IPAdapterPlus] = exit_stack.enter_context(
|
||||
context.services.model_loader.get_model(
|
||||
model_name=single_ip_adapter.ip_adapter_model.model_name,
|
||||
model_type=ModelType.IPAdapter,
|
||||
base_model=single_ip_adapter.ip_adapter_model.base_model,
|
||||
context=context,
|
||||
)
|
||||
)
|
||||
|
||||
image_encoder_model_info = context.services.model_loader.get_model(
|
||||
model_name=single_ip_adapter.image_encoder_model.model_name,
|
||||
model_type=ModelType.CLIPVision,
|
||||
base_model=single_ip_adapter.image_encoder_model.base_model,
|
||||
context=context,
|
||||
)
|
||||
|
||||
input_image = context.services.images.get_pil_image(single_ip_adapter.image.image_name)
|
||||
|
||||
# TODO(ryand): With some effort, the step of running the CLIP Vision encoder could be done before any other
|
||||
# models are needed in memory. This would help to reduce peak memory utilization in low-memory environments.
|
||||
with image_encoder_model_info as image_encoder_model:
|
||||
# Get image embeddings from CLIP and ImageProjModel.
|
||||
image_prompt_embeds, uncond_image_prompt_embeds = ip_adapter_model.get_image_embeds(
|
||||
input_image, image_encoder_model
|
||||
)
|
||||
conditioning_data.ip_adapter_conditioning.append(
|
||||
IPAdapterConditioningInfo(image_prompt_embeds, uncond_image_prompt_embeds)
|
||||
control_data = None
|
||||
# from above handling, any control that is not None should now be of type list[ControlField]
|
||||
else:
|
||||
# FIXME: add checks to skip entry if model or image is None
|
||||
# and if weight is None, populate with default 1.0?
|
||||
control_data = []
|
||||
control_models = []
|
||||
for control_info in control_list:
|
||||
control_model = exit_stack.enter_context(
|
||||
context.services.model_manager.get_model(
|
||||
model_name=control_info.control_model.model_name,
|
||||
model_type=ModelType.ControlNet,
|
||||
base_model=control_info.control_model.base_model,
|
||||
context=context,
|
||||
)
|
||||
)
|
||||
|
||||
ip_adapter_data_list.append(
|
||||
IPAdapterData(
|
||||
ip_adapter_model=ip_adapter_model,
|
||||
weight=single_ip_adapter.weight,
|
||||
begin_step_percent=single_ip_adapter.begin_step_percent,
|
||||
end_step_percent=single_ip_adapter.end_step_percent,
|
||||
control_models.append(control_model)
|
||||
control_image_field = control_info.image
|
||||
input_image = context.services.images.get_pil_image(control_image_field.image_name)
|
||||
# self.image.image_type, self.image.image_name
|
||||
# FIXME: still need to test with different widths, heights, devices, dtypes
|
||||
# and add in batch_size, num_images_per_prompt?
|
||||
# and do real check for classifier_free_guidance?
|
||||
# prepare_control_image should return torch.Tensor of shape(batch_size, 3, height, width)
|
||||
control_image = prepare_control_image(
|
||||
image=input_image,
|
||||
do_classifier_free_guidance=do_classifier_free_guidance,
|
||||
width=control_width_resize,
|
||||
height=control_height_resize,
|
||||
# batch_size=batch_size * num_images_per_prompt,
|
||||
# num_images_per_prompt=num_images_per_prompt,
|
||||
device=control_model.device,
|
||||
dtype=control_model.dtype,
|
||||
control_mode=control_info.control_mode,
|
||||
resize_mode=control_info.resize_mode,
|
||||
)
|
||||
)
|
||||
|
||||
return ip_adapter_data_list
|
||||
|
||||
def run_t2i_adapters(
|
||||
self,
|
||||
context: InvocationContext,
|
||||
t2i_adapter: Optional[Union[T2IAdapterField, list[T2IAdapterField]]],
|
||||
latents_shape: list[int],
|
||||
do_classifier_free_guidance: bool,
|
||||
) -> Optional[list[T2IAdapterData]]:
|
||||
if t2i_adapter is None:
|
||||
return None
|
||||
|
||||
# Handle the possibility that t2i_adapter could be a list or a single T2IAdapterField.
|
||||
if isinstance(t2i_adapter, T2IAdapterField):
|
||||
t2i_adapter = [t2i_adapter]
|
||||
|
||||
if len(t2i_adapter) == 0:
|
||||
return None
|
||||
|
||||
t2i_adapter_data = []
|
||||
for t2i_adapter_field in t2i_adapter:
|
||||
t2i_adapter_model_info = context.services.model_loader.get_model(
|
||||
model_name=t2i_adapter_field.t2i_adapter_model.model_name,
|
||||
model_type=ModelType.T2IAdapter,
|
||||
base_model=t2i_adapter_field.t2i_adapter_model.base_model,
|
||||
context=context,
|
||||
)
|
||||
image = context.services.images.get_pil_image(t2i_adapter_field.image.image_name)
|
||||
|
||||
# The max_unet_downscale is the maximum amount that the UNet model downscales the latent image internally.
|
||||
if t2i_adapter_field.t2i_adapter_model.base_model == BaseModelType.StableDiffusion1:
|
||||
max_unet_downscale = 8
|
||||
elif t2i_adapter_field.t2i_adapter_model.base_model == BaseModelType.StableDiffusionXL:
|
||||
max_unet_downscale = 4
|
||||
else:
|
||||
raise ValueError(
|
||||
f"Unexpected T2I-Adapter base model type: '{t2i_adapter_field.t2i_adapter_model.base_model}'."
|
||||
control_item = ControlNetData(
|
||||
model=control_model,
|
||||
image_tensor=control_image,
|
||||
weight=control_info.control_weight,
|
||||
begin_step_percent=control_info.begin_step_percent,
|
||||
end_step_percent=control_info.end_step_percent,
|
||||
control_mode=control_info.control_mode,
|
||||
# any resizing needed should currently be happening in prepare_control_image(),
|
||||
# but adding resize_mode to ControlNetData in case needed in the future
|
||||
resize_mode=control_info.resize_mode,
|
||||
)
|
||||
|
||||
t2i_adapter_model: T2IAdapter
|
||||
with t2i_adapter_model_info as t2i_adapter_model:
|
||||
total_downscale_factor = t2i_adapter_model.total_downscale_factor
|
||||
if isinstance(t2i_adapter_model.adapter, FullAdapterXL):
|
||||
# HACK(ryand): Work around a bug in FullAdapterXL. This is being addressed upstream in diffusers by
|
||||
# this PR: https://github.com/huggingface/diffusers/pull/5134.
|
||||
total_downscale_factor = total_downscale_factor // 2
|
||||
|
||||
# Resize the T2I-Adapter input image.
|
||||
# We select the resize dimensions so that after the T2I-Adapter's total_downscale_factor is applied, the
|
||||
# result will match the latent image's dimensions after max_unet_downscale is applied.
|
||||
t2i_input_height = latents_shape[2] // max_unet_downscale * total_downscale_factor
|
||||
t2i_input_width = latents_shape[3] // max_unet_downscale * total_downscale_factor
|
||||
|
||||
# Note: We have hard-coded `do_classifier_free_guidance=False`. This is because we only want to prepare
|
||||
# a single image. If CFG is enabled, we will duplicate the resultant tensor after applying the
|
||||
# T2I-Adapter model.
|
||||
#
|
||||
# Note: We re-use the `prepare_control_image(...)` from ControlNet for T2I-Adapter, because it has many
|
||||
# of the same requirements (e.g. preserving binary masks during resize).
|
||||
t2i_image = prepare_control_image(
|
||||
image=image,
|
||||
do_classifier_free_guidance=False,
|
||||
width=t2i_input_width,
|
||||
height=t2i_input_height,
|
||||
num_channels=t2i_adapter_model.config.in_channels,
|
||||
device=t2i_adapter_model.device,
|
||||
dtype=t2i_adapter_model.dtype,
|
||||
resize_mode=t2i_adapter_field.resize_mode,
|
||||
)
|
||||
|
||||
adapter_state = t2i_adapter_model(t2i_image)
|
||||
|
||||
if do_classifier_free_guidance:
|
||||
for idx, value in enumerate(adapter_state):
|
||||
adapter_state[idx] = torch.cat([value] * 2, dim=0)
|
||||
|
||||
t2i_adapter_data.append(
|
||||
T2IAdapterData(
|
||||
adapter_state=adapter_state,
|
||||
weight=t2i_adapter_field.weight,
|
||||
begin_step_percent=t2i_adapter_field.begin_step_percent,
|
||||
end_step_percent=t2i_adapter_field.end_step_percent,
|
||||
)
|
||||
)
|
||||
|
||||
return t2i_adapter_data
|
||||
control_data.append(control_item)
|
||||
# MultiControlNetModel has been refactored out, just need list[ControlNetData]
|
||||
return control_data
|
||||
|
||||
# original idea by https://github.com/AmericanPresidentJimmyCarter
|
||||
# TODO: research more for second order schedulers timesteps
|
||||
@@ -624,12 +467,6 @@ class DenoiseLatentsInvocation(BaseInvocation):
|
||||
|
||||
mask, masked_latents = self.prep_inpaint_mask(context, latents)
|
||||
|
||||
# TODO(ryand): I have hard-coded `do_classifier_free_guidance=True` to mirror the behaviour of ControlNets,
|
||||
# below. Investigate whether this is appropriate.
|
||||
t2i_adapter_data = self.run_t2i_adapters(
|
||||
context, self.t2i_adapter, latents.shape, do_classifier_free_guidance=True
|
||||
)
|
||||
|
||||
# Get the source node id (we are invoking the prepared node)
|
||||
graph_execution_state = context.services.graph_execution_manager.get(context.graph_execution_state_id)
|
||||
source_node_id = graph_execution_state.prepared_source_mapping[self.id]
|
||||
@@ -639,7 +476,7 @@ class DenoiseLatentsInvocation(BaseInvocation):
|
||||
|
||||
def _lora_loader():
|
||||
for lora in self.unet.loras:
|
||||
lora_info = context.services.model_loader.get_model(
|
||||
lora_info = context.services.model_manager.get_model(
|
||||
**lora.dict(exclude={"weight"}),
|
||||
context=context,
|
||||
)
|
||||
@@ -647,16 +484,13 @@ class DenoiseLatentsInvocation(BaseInvocation):
|
||||
del lora_info
|
||||
return
|
||||
|
||||
unet_info = context.services.model_loader.get_model(
|
||||
unet_info = context.services.model_manager.get_model(
|
||||
**self.unet.unet.dict(),
|
||||
context=context,
|
||||
)
|
||||
with (
|
||||
ExitStack() as exit_stack,
|
||||
ModelPatcher.apply_lora_unet(unet_info.context.model, _lora_loader()),
|
||||
set_seamless(unet_info.context.model, self.unet.seamless_axes),
|
||||
unet_info as unet,
|
||||
):
|
||||
with ExitStack() as exit_stack, ModelPatcher.apply_lora_unet(
|
||||
unet_info.context.model, _lora_loader()
|
||||
), set_seamless(unet_info.context.model, self.unet.seamless_axes), unet_info as unet:
|
||||
latents = latents.to(device=unet.device, dtype=unet.dtype)
|
||||
if noise is not None:
|
||||
noise = noise.to(device=unet.device, dtype=unet.dtype)
|
||||
@@ -675,7 +509,8 @@ class DenoiseLatentsInvocation(BaseInvocation):
|
||||
pipeline = self.create_pipeline(unet, scheduler)
|
||||
conditioning_data = self.get_conditioning_data(context, scheduler, unet, seed)
|
||||
|
||||
controlnet_data = self.prep_control_data(
|
||||
control_data = self.prep_control_data(
|
||||
model=pipeline,
|
||||
context=context,
|
||||
control_input=self.control,
|
||||
latents_shape=latents.shape,
|
||||
@@ -684,13 +519,6 @@ class DenoiseLatentsInvocation(BaseInvocation):
|
||||
exit_stack=exit_stack,
|
||||
)
|
||||
|
||||
ip_adapter_data = self.prep_ip_adapter_data(
|
||||
context=context,
|
||||
ip_adapter=self.ip_adapter,
|
||||
conditioning_data=conditioning_data,
|
||||
exit_stack=exit_stack,
|
||||
)
|
||||
|
||||
num_inference_steps, timesteps, init_timestep = self.init_scheduler(
|
||||
scheduler,
|
||||
device=unet.device,
|
||||
@@ -709,9 +537,7 @@ class DenoiseLatentsInvocation(BaseInvocation):
|
||||
masked_latents=masked_latents,
|
||||
num_inference_steps=num_inference_steps,
|
||||
conditioning_data=conditioning_data,
|
||||
control_data=controlnet_data,
|
||||
ip_adapter_data=ip_adapter_data,
|
||||
t2i_adapter_data=t2i_adapter_data,
|
||||
control_data=control_data, # list[ControlNetData]
|
||||
callback=step_callback,
|
||||
)
|
||||
|
||||
@@ -752,7 +578,7 @@ class LatentsToImageInvocation(BaseInvocation):
|
||||
def invoke(self, context: InvocationContext) -> ImageOutput:
|
||||
latents = context.services.latents.get(self.latents.latents_name)
|
||||
|
||||
vae_info = context.services.model_loader.get_model(
|
||||
vae_info = context.services.model_manager.get_model(
|
||||
**self.vae.vae.dict(),
|
||||
context=context,
|
||||
)
|
||||
@@ -966,7 +792,8 @@ class ImageToLatentsInvocation(BaseInvocation):
|
||||
# non_noised_latents_from_image
|
||||
image_tensor = image_tensor.to(device=vae.device, dtype=vae.dtype)
|
||||
with torch.inference_mode():
|
||||
latents = ImageToLatentsInvocation._encode_to_tensor(vae, image_tensor)
|
||||
image_tensor_dist = vae.encode(image_tensor).latent_dist
|
||||
latents = image_tensor_dist.sample().to(dtype=vae.dtype) # FIXME: uses torch.randn. make reproducible!
|
||||
|
||||
latents = vae.config.scaling_factor * latents
|
||||
latents = latents.to(dtype=orig_dtype)
|
||||
@@ -977,7 +804,7 @@ class ImageToLatentsInvocation(BaseInvocation):
|
||||
def invoke(self, context: InvocationContext) -> LatentsOutput:
|
||||
image = context.services.images.get_pil_image(self.image.image_name)
|
||||
|
||||
vae_info = context.services.model_loader.get_model(
|
||||
vae_info = context.services.model_manager.get_model(
|
||||
**self.vae.vae.dict(),
|
||||
context=context,
|
||||
)
|
||||
@@ -993,18 +820,6 @@ class ImageToLatentsInvocation(BaseInvocation):
|
||||
context.services.latents.save(name, latents)
|
||||
return build_latents_output(latents_name=name, latents=latents, seed=None)
|
||||
|
||||
@singledispatchmethod
|
||||
@staticmethod
|
||||
def _encode_to_tensor(vae: AutoencoderKL, image_tensor: torch.FloatTensor) -> torch.FloatTensor:
|
||||
image_tensor_dist = vae.encode(image_tensor).latent_dist
|
||||
latents = image_tensor_dist.sample().to(dtype=vae.dtype) # FIXME: uses torch.randn. make reproducible!
|
||||
return latents
|
||||
|
||||
@_encode_to_tensor.register
|
||||
@staticmethod
|
||||
def _(vae: AutoencoderTiny, image_tensor: torch.FloatTensor) -> torch.FloatTensor:
|
||||
return vae.encode(image_tensor).latents
|
||||
|
||||
|
||||
@invocation("lblend", title="Blend Latents", tags=["latents", "blend"], category="latents", version="1.0.0")
|
||||
class BlendLatentsInvocation(BaseInvocation):
|
||||
|
||||
@@ -65,27 +65,13 @@ class DivideInvocation(BaseInvocation):
|
||||
class RandomIntInvocation(BaseInvocation):
|
||||
"""Outputs a single random integer."""
|
||||
|
||||
low: int = InputField(default=0, description=FieldDescriptions.inclusive_low)
|
||||
high: int = InputField(default=np.iinfo(np.int32).max, description=FieldDescriptions.exclusive_high)
|
||||
low: int = InputField(default=0, description="The inclusive low value")
|
||||
high: int = InputField(default=np.iinfo(np.int32).max, description="The exclusive high value")
|
||||
|
||||
def invoke(self, context: InvocationContext) -> IntegerOutput:
|
||||
return IntegerOutput(value=np.random.randint(self.low, self.high))
|
||||
|
||||
|
||||
@invocation("rand_float", title="Random Float", tags=["math", "float", "random"], category="math", version="1.0.0")
|
||||
class RandomFloatInvocation(BaseInvocation):
|
||||
"""Outputs a single random float"""
|
||||
|
||||
low: float = InputField(default=0.0, description=FieldDescriptions.inclusive_low)
|
||||
high: float = InputField(default=1.0, description=FieldDescriptions.exclusive_high)
|
||||
decimals: int = InputField(default=2, description=FieldDescriptions.decimal_places)
|
||||
|
||||
def invoke(self, context: InvocationContext) -> FloatOutput:
|
||||
random_float = np.random.uniform(self.low, self.high)
|
||||
rounded_float = round(random_float, self.decimals)
|
||||
return FloatOutput(value=rounded_float)
|
||||
|
||||
|
||||
@invocation(
|
||||
"float_to_int",
|
||||
title="Float To Integer",
|
||||
|
||||
@@ -12,10 +12,7 @@ from invokeai.app.invocations.baseinvocation import (
|
||||
invocation_output,
|
||||
)
|
||||
from invokeai.app.invocations.controlnet_image_processors import ControlField
|
||||
from invokeai.app.invocations.ip_adapter import IPAdapterModelField
|
||||
from invokeai.app.invocations.model import LoRAModelField, MainModelField, VAEModelField
|
||||
from invokeai.app.invocations.primitives import ImageField
|
||||
from invokeai.app.invocations.t2i_adapter import T2IAdapterField
|
||||
from invokeai.app.util.model_exclude_null import BaseModelExcludeNull
|
||||
|
||||
from ...version import __version__
|
||||
@@ -28,18 +25,6 @@ class LoRAMetadataField(BaseModelExcludeNull):
|
||||
weight: float = Field(description="The weight of the LoRA model")
|
||||
|
||||
|
||||
class IPAdapterMetadataField(BaseModelExcludeNull):
|
||||
image: ImageField = Field(description="The IP-Adapter image prompt.")
|
||||
ip_adapter_model: IPAdapterModelField = Field(description="The IP-Adapter model to use.")
|
||||
weight: float = Field(description="The weight of the IP-Adapter model")
|
||||
begin_step_percent: float = Field(
|
||||
default=0, ge=0, le=1, description="When the IP-Adapter is first applied (% of total steps)"
|
||||
)
|
||||
end_step_percent: float = Field(
|
||||
default=1, ge=0, le=1, description="When the IP-Adapter is last applied (% of total steps)"
|
||||
)
|
||||
|
||||
|
||||
class CoreMetadata(BaseModelExcludeNull):
|
||||
"""Core generation metadata for an image generated in InvokeAI."""
|
||||
|
||||
@@ -57,14 +42,11 @@ class CoreMetadata(BaseModelExcludeNull):
|
||||
cfg_scale: float = Field(description="The classifier-free guidance scale parameter")
|
||||
steps: int = Field(description="The number of steps used for inference")
|
||||
scheduler: str = Field(description="The scheduler used for inference")
|
||||
clip_skip: Optional[int] = Field(
|
||||
default=None,
|
||||
clip_skip: int = Field(
|
||||
description="The number of skipped CLIP layers",
|
||||
)
|
||||
model: MainModelField = Field(description="The main model used for inference")
|
||||
controlnets: list[ControlField] = Field(description="The ControlNets used for inference")
|
||||
ipAdapters: list[IPAdapterMetadataField] = Field(description="The IP Adapters used for inference")
|
||||
t2iAdapters: list[T2IAdapterField] = Field(description="The IP Adapters used for inference")
|
||||
loras: list[LoRAMetadataField] = Field(description="The LoRAs used for inference")
|
||||
vae: Optional[VAEModelField] = Field(
|
||||
default=None,
|
||||
@@ -134,14 +116,11 @@ class MetadataAccumulatorInvocation(BaseInvocation):
|
||||
cfg_scale: float = InputField(description="The classifier-free guidance scale parameter")
|
||||
steps: int = InputField(description="The number of steps used for inference")
|
||||
scheduler: str = InputField(description="The scheduler used for inference")
|
||||
clip_skip: Optional[int] = Field(
|
||||
default=None,
|
||||
clip_skip: int = InputField(
|
||||
description="The number of skipped CLIP layers",
|
||||
)
|
||||
model: MainModelField = InputField(description="The main model used for inference")
|
||||
controlnets: list[ControlField] = InputField(description="The ControlNets used for inference")
|
||||
ipAdapters: list[IPAdapterMetadataField] = InputField(description="The IP Adapters used for inference")
|
||||
t2iAdapters: list[T2IAdapterField] = Field(description="The IP Adapters used for inference")
|
||||
loras: list[LoRAMetadataField] = InputField(description="The LoRAs used for inference")
|
||||
strength: Optional[float] = InputField(
|
||||
default=None,
|
||||
|
||||
@@ -3,8 +3,7 @@ from typing import List, Optional
|
||||
|
||||
from pydantic import BaseModel, Field
|
||||
|
||||
from invokeai.backend.model_manager import SubModelType
|
||||
|
||||
from ...backend.model_management import BaseModelType, ModelType, SubModelType
|
||||
from .baseinvocation import (
|
||||
BaseInvocation,
|
||||
BaseInvocationOutput,
|
||||
@@ -20,7 +19,9 @@ from .baseinvocation import (
|
||||
|
||||
|
||||
class ModelInfo(BaseModel):
|
||||
key: str = Field(description="Unique ID for model")
|
||||
model_name: str = Field(description="Info to load submodel")
|
||||
base_model: BaseModelType = Field(description="Base model")
|
||||
model_type: ModelType = Field(description="Info to load submodel")
|
||||
submodel: Optional[SubModelType] = Field(default=None, description="Info to load submodel")
|
||||
|
||||
|
||||
@@ -60,13 +61,16 @@ class ModelLoaderOutput(BaseInvocationOutput):
|
||||
class MainModelField(BaseModel):
|
||||
"""Main model field"""
|
||||
|
||||
key: str = Field(description="Unique ID of the model")
|
||||
model_name: str = Field(description="Name of the model")
|
||||
base_model: BaseModelType = Field(description="Base model")
|
||||
model_type: ModelType = Field(description="Model Type")
|
||||
|
||||
|
||||
class LoRAModelField(BaseModel):
|
||||
"""LoRA model field"""
|
||||
|
||||
key: str = Field(description="Unique ID for model")
|
||||
model_name: str = Field(description="Name of the LoRA model")
|
||||
base_model: BaseModelType = Field(description="Base model")
|
||||
|
||||
|
||||
@invocation("main_model_loader", title="Main Model", tags=["model"], category="model", version="1.0.0")
|
||||
@@ -77,15 +81,20 @@ class MainModelLoaderInvocation(BaseInvocation):
|
||||
# TODO: precision?
|
||||
|
||||
def invoke(self, context: InvocationContext) -> ModelLoaderOutput:
|
||||
"""Load a main model, outputting its submodels."""
|
||||
key = self.model.key
|
||||
base_model = self.model.base_model
|
||||
model_name = self.model.model_name
|
||||
model_type = ModelType.Main
|
||||
|
||||
# TODO: not found exceptions
|
||||
if not context.services.model_record_store.model_exists(key):
|
||||
raise Exception(f"Unknown model {key}")
|
||||
if not context.services.model_manager.model_exists(
|
||||
model_name=model_name,
|
||||
base_model=base_model,
|
||||
model_type=model_type,
|
||||
):
|
||||
raise Exception(f"Unknown {base_model} {model_type} model: {model_name}")
|
||||
|
||||
"""
|
||||
if not context.services.model_record_store.model_exists(
|
||||
if not context.services.model_manager.model_exists(
|
||||
model_name=self.model_name,
|
||||
model_type=SDModelType.Diffusers,
|
||||
submodel=SDModelType.Tokenizer,
|
||||
@@ -94,7 +103,7 @@ class MainModelLoaderInvocation(BaseInvocation):
|
||||
f"Failed to find tokenizer submodel in {self.model_name}! Check if model corrupted"
|
||||
)
|
||||
|
||||
if not context.services.model_record_store.model_exists(
|
||||
if not context.services.model_manager.model_exists(
|
||||
model_name=self.model_name,
|
||||
model_type=SDModelType.Diffusers,
|
||||
submodel=SDModelType.TextEncoder,
|
||||
@@ -103,7 +112,7 @@ class MainModelLoaderInvocation(BaseInvocation):
|
||||
f"Failed to find text_encoder submodel in {self.model_name}! Check if model corrupted"
|
||||
)
|
||||
|
||||
if not context.services.model_record_store.model_exists(
|
||||
if not context.services.model_manager.model_exists(
|
||||
model_name=self.model_name,
|
||||
model_type=SDModelType.Diffusers,
|
||||
submodel=SDModelType.UNet,
|
||||
@@ -116,22 +125,30 @@ class MainModelLoaderInvocation(BaseInvocation):
|
||||
return ModelLoaderOutput(
|
||||
unet=UNetField(
|
||||
unet=ModelInfo(
|
||||
key=key,
|
||||
model_name=model_name,
|
||||
base_model=base_model,
|
||||
model_type=model_type,
|
||||
submodel=SubModelType.UNet,
|
||||
),
|
||||
scheduler=ModelInfo(
|
||||
key=key,
|
||||
model_name=model_name,
|
||||
base_model=base_model,
|
||||
model_type=model_type,
|
||||
submodel=SubModelType.Scheduler,
|
||||
),
|
||||
loras=[],
|
||||
),
|
||||
clip=ClipField(
|
||||
tokenizer=ModelInfo(
|
||||
key=key,
|
||||
model_name=model_name,
|
||||
base_model=base_model,
|
||||
model_type=model_type,
|
||||
submodel=SubModelType.Tokenizer,
|
||||
),
|
||||
text_encoder=ModelInfo(
|
||||
key=key,
|
||||
model_name=model_name,
|
||||
base_model=base_model,
|
||||
model_type=model_type,
|
||||
submodel=SubModelType.TextEncoder,
|
||||
),
|
||||
loras=[],
|
||||
@@ -139,7 +156,9 @@ class MainModelLoaderInvocation(BaseInvocation):
|
||||
),
|
||||
vae=VaeField(
|
||||
vae=ModelInfo(
|
||||
key=key,
|
||||
model_name=model_name,
|
||||
base_model=base_model,
|
||||
model_type=model_type,
|
||||
submodel=SubModelType.Vae,
|
||||
),
|
||||
),
|
||||
@@ -148,7 +167,7 @@ class MainModelLoaderInvocation(BaseInvocation):
|
||||
|
||||
@invocation_output("lora_loader_output")
|
||||
class LoraLoaderOutput(BaseInvocationOutput):
|
||||
"""Model loader output."""
|
||||
"""Model loader output"""
|
||||
|
||||
unet: Optional[UNetField] = OutputField(default=None, description=FieldDescriptions.unet, title="UNet")
|
||||
clip: Optional[ClipField] = OutputField(default=None, description=FieldDescriptions.clip, title="CLIP")
|
||||
@@ -168,20 +187,24 @@ class LoraLoaderInvocation(BaseInvocation):
|
||||
)
|
||||
|
||||
def invoke(self, context: InvocationContext) -> LoraLoaderOutput:
|
||||
"""Load a LoRA model."""
|
||||
if self.lora is None:
|
||||
raise Exception("No LoRA provided")
|
||||
|
||||
key = self.lora.key
|
||||
base_model = self.lora.base_model
|
||||
lora_name = self.lora.model_name
|
||||
|
||||
if not context.services.model_record_store.model_exists(key):
|
||||
raise Exception(f"Unknown lora: {key}!")
|
||||
if not context.services.model_manager.model_exists(
|
||||
base_model=base_model,
|
||||
model_name=lora_name,
|
||||
model_type=ModelType.Lora,
|
||||
):
|
||||
raise Exception(f"Unkown lora name: {lora_name}!")
|
||||
|
||||
if self.unet is not None and any(lora.key == key for lora in self.unet.loras):
|
||||
raise Exception(f'Lora "{key}" already applied to unet')
|
||||
if self.unet is not None and any(lora.model_name == lora_name for lora in self.unet.loras):
|
||||
raise Exception(f'Lora "{lora_name}" already applied to unet')
|
||||
|
||||
if self.clip is not None and any(lora.key == key for lora in self.clip.loras):
|
||||
raise Exception(f'Lora "{key}" already applied to clip')
|
||||
if self.clip is not None and any(lora.model_name == lora_name for lora in self.clip.loras):
|
||||
raise Exception(f'Lora "{lora_name}" already applied to clip')
|
||||
|
||||
output = LoraLoaderOutput()
|
||||
|
||||
@@ -189,7 +212,9 @@ class LoraLoaderInvocation(BaseInvocation):
|
||||
output.unet = copy.deepcopy(self.unet)
|
||||
output.unet.loras.append(
|
||||
LoraInfo(
|
||||
key=key,
|
||||
base_model=base_model,
|
||||
model_name=lora_name,
|
||||
model_type=ModelType.Lora,
|
||||
submodel=None,
|
||||
weight=self.weight,
|
||||
)
|
||||
@@ -199,7 +224,9 @@ class LoraLoaderInvocation(BaseInvocation):
|
||||
output.clip = copy.deepcopy(self.clip)
|
||||
output.clip.loras.append(
|
||||
LoraInfo(
|
||||
key=key,
|
||||
base_model=base_model,
|
||||
model_name=lora_name,
|
||||
model_type=ModelType.Lora,
|
||||
submodel=None,
|
||||
weight=self.weight,
|
||||
)
|
||||
@@ -210,7 +237,7 @@ class LoraLoaderInvocation(BaseInvocation):
|
||||
|
||||
@invocation_output("sdxl_lora_loader_output")
|
||||
class SDXLLoraLoaderOutput(BaseInvocationOutput):
|
||||
"""SDXL LoRA Loader Output."""
|
||||
"""SDXL LoRA Loader Output"""
|
||||
|
||||
unet: Optional[UNetField] = OutputField(default=None, description=FieldDescriptions.unet, title="UNet")
|
||||
clip: Optional[ClipField] = OutputField(default=None, description=FieldDescriptions.clip, title="CLIP 1")
|
||||
@@ -234,22 +261,27 @@ class SDXLLoraLoaderInvocation(BaseInvocation):
|
||||
)
|
||||
|
||||
def invoke(self, context: InvocationContext) -> SDXLLoraLoaderOutput:
|
||||
"""Load an SDXL LoRA."""
|
||||
if self.lora is None:
|
||||
raise Exception("No LoRA provided")
|
||||
|
||||
key = self.lora.key
|
||||
if not context.services.model_record_store.model_exists(key):
|
||||
raise Exception(f"Unknown lora name: {key}!")
|
||||
base_model = self.lora.base_model
|
||||
lora_name = self.lora.model_name
|
||||
|
||||
if self.unet is not None and any(lora.key == key for lora in self.unet.loras):
|
||||
raise Exception(f'Lora "{key}" already applied to unet')
|
||||
if not context.services.model_manager.model_exists(
|
||||
base_model=base_model,
|
||||
model_name=lora_name,
|
||||
model_type=ModelType.Lora,
|
||||
):
|
||||
raise Exception(f"Unknown lora name: {lora_name}!")
|
||||
|
||||
if self.clip is not None and any(lora.key == key for lora in self.clip.loras):
|
||||
raise Exception(f'Lora "{key}" already applied to clip')
|
||||
if self.unet is not None and any(lora.model_name == lora_name for lora in self.unet.loras):
|
||||
raise Exception(f'Lora "{lora_name}" already applied to unet')
|
||||
|
||||
if self.clip2 is not None and any(lora.key == key for lora in self.clip2.loras):
|
||||
raise Exception(f'Lora "{key}" already applied to clip2')
|
||||
if self.clip is not None and any(lora.model_name == lora_name for lora in self.clip.loras):
|
||||
raise Exception(f'Lora "{lora_name}" already applied to clip')
|
||||
|
||||
if self.clip2 is not None and any(lora.model_name == lora_name for lora in self.clip2.loras):
|
||||
raise Exception(f'Lora "{lora_name}" already applied to clip2')
|
||||
|
||||
output = SDXLLoraLoaderOutput()
|
||||
|
||||
@@ -257,7 +289,9 @@ class SDXLLoraLoaderInvocation(BaseInvocation):
|
||||
output.unet = copy.deepcopy(self.unet)
|
||||
output.unet.loras.append(
|
||||
LoraInfo(
|
||||
key=key,
|
||||
base_model=base_model,
|
||||
model_name=lora_name,
|
||||
model_type=ModelType.Lora,
|
||||
submodel=None,
|
||||
weight=self.weight,
|
||||
)
|
||||
@@ -267,7 +301,9 @@ class SDXLLoraLoaderInvocation(BaseInvocation):
|
||||
output.clip = copy.deepcopy(self.clip)
|
||||
output.clip.loras.append(
|
||||
LoraInfo(
|
||||
key=key,
|
||||
base_model=base_model,
|
||||
model_name=lora_name,
|
||||
model_type=ModelType.Lora,
|
||||
submodel=None,
|
||||
weight=self.weight,
|
||||
)
|
||||
@@ -277,7 +313,9 @@ class SDXLLoraLoaderInvocation(BaseInvocation):
|
||||
output.clip2 = copy.deepcopy(self.clip2)
|
||||
output.clip2.loras.append(
|
||||
LoraInfo(
|
||||
key=key,
|
||||
base_model=base_model,
|
||||
model_name=lora_name,
|
||||
model_type=ModelType.Lora,
|
||||
submodel=None,
|
||||
weight=self.weight,
|
||||
)
|
||||
@@ -287,9 +325,10 @@ class SDXLLoraLoaderInvocation(BaseInvocation):
|
||||
|
||||
|
||||
class VAEModelField(BaseModel):
|
||||
"""Vae model field."""
|
||||
"""Vae model field"""
|
||||
|
||||
key: str = Field(description="Unique ID for VAE model")
|
||||
model_name: str = Field(description="Name of the model")
|
||||
base_model: BaseModelType = Field(description="Base model")
|
||||
|
||||
|
||||
@invocation_output("vae_loader_output")
|
||||
@@ -301,22 +340,29 @@ class VaeLoaderOutput(BaseInvocationOutput):
|
||||
|
||||
@invocation("vae_loader", title="VAE", tags=["vae", "model"], category="model", version="1.0.0")
|
||||
class VaeLoaderInvocation(BaseInvocation):
|
||||
"""Loads a VAE model, outputting a VaeLoaderOutput."""
|
||||
"""Loads a VAE model, outputting a VaeLoaderOutput"""
|
||||
|
||||
vae_model: VAEModelField = InputField(
|
||||
description=FieldDescriptions.vae_model, input=Input.Direct, ui_type=UIType.VaeModel, title="VAE"
|
||||
)
|
||||
|
||||
def invoke(self, context: InvocationContext) -> VaeLoaderOutput:
|
||||
"""Load a VAE model."""
|
||||
key = self.vae_model.key
|
||||
base_model = self.vae_model.base_model
|
||||
model_name = self.vae_model.model_name
|
||||
model_type = ModelType.Vae
|
||||
|
||||
if not context.services.model_record_store.model_exists(key):
|
||||
raise Exception(f"Unkown vae name: {key}!")
|
||||
if not context.services.model_manager.model_exists(
|
||||
base_model=base_model,
|
||||
model_name=model_name,
|
||||
model_type=model_type,
|
||||
):
|
||||
raise Exception(f"Unkown vae name: {model_name}!")
|
||||
return VaeLoaderOutput(
|
||||
vae=VaeField(
|
||||
vae=ModelInfo(
|
||||
key=key,
|
||||
model_name=model_name,
|
||||
base_model=base_model,
|
||||
model_type=model_type,
|
||||
)
|
||||
)
|
||||
)
|
||||
@@ -324,7 +370,7 @@ class VaeLoaderInvocation(BaseInvocation):
|
||||
|
||||
@invocation_output("seamless_output")
|
||||
class SeamlessModeOutput(BaseInvocationOutput):
|
||||
"""Modified Seamless Model output."""
|
||||
"""Modified Seamless Model output"""
|
||||
|
||||
unet: Optional[UNetField] = OutputField(description=FieldDescriptions.unet, title="UNet")
|
||||
vae: Optional[VaeField] = OutputField(description=FieldDescriptions.vae, title="VAE")
|
||||
@@ -344,7 +390,6 @@ class SeamlessModeInvocation(BaseInvocation):
|
||||
seamless_x: bool = InputField(default=True, input=Input.Any, description="Specify whether X axis is seamless")
|
||||
|
||||
def invoke(self, context: InvocationContext) -> SeamlessModeOutput:
|
||||
"""Apply seamless transformation."""
|
||||
# Conditionally append 'x' and 'y' based on seamless_x and seamless_y
|
||||
unet = copy.deepcopy(self.unet)
|
||||
vae = copy.deepcopy(self.vae)
|
||||
|
||||
@@ -17,7 +17,7 @@ from invokeai.app.invocations.primitives import ConditioningField, ConditioningO
|
||||
from invokeai.app.util.step_callback import stable_diffusion_step_callback
|
||||
from invokeai.backend import BaseModelType, ModelType, SubModelType
|
||||
|
||||
from ...backend.model_manager.lora import ONNXModelPatcher
|
||||
from ...backend.model_management import ONNXModelPatcher
|
||||
from ...backend.stable_diffusion import PipelineIntermediateState
|
||||
from ...backend.util import choose_torch_device
|
||||
from ..models.image import ImageCategory, ResourceOrigin
|
||||
@@ -62,15 +62,15 @@ class ONNXPromptInvocation(BaseInvocation):
|
||||
clip: ClipField = InputField(description=FieldDescriptions.clip, input=Input.Connection)
|
||||
|
||||
def invoke(self, context: InvocationContext) -> ConditioningOutput:
|
||||
tokenizer_info = context.services.model_loader.get_model(
|
||||
tokenizer_info = context.services.model_manager.get_model(
|
||||
**self.clip.tokenizer.dict(),
|
||||
)
|
||||
text_encoder_info = context.services.model_loader.get_model(
|
||||
text_encoder_info = context.services.model_manager.get_model(
|
||||
**self.clip.text_encoder.dict(),
|
||||
)
|
||||
with tokenizer_info as orig_tokenizer, text_encoder_info as text_encoder: # , ExitStack() as stack:
|
||||
loras = [
|
||||
(context.services.model_loader.get_model(**lora.dict(exclude={"weight"})).context.model, lora.weight)
|
||||
(context.services.model_manager.get_model(**lora.dict(exclude={"weight"})).context.model, lora.weight)
|
||||
for lora in self.clip.loras
|
||||
]
|
||||
|
||||
@@ -81,7 +81,7 @@ class ONNXPromptInvocation(BaseInvocation):
|
||||
ti_list.append(
|
||||
(
|
||||
name,
|
||||
context.services.model_loader.get_model(
|
||||
context.services.model_manager.get_model(
|
||||
model_name=name,
|
||||
base_model=self.clip.text_encoder.base_model,
|
||||
model_type=ModelType.TextualInversion,
|
||||
@@ -95,10 +95,9 @@ class ONNXPromptInvocation(BaseInvocation):
|
||||
print(f'Warn: trigger: "{trigger}" not found')
|
||||
if loras or ti_list:
|
||||
text_encoder.release_session()
|
||||
with (
|
||||
ONNXModelPatcher.apply_lora_text_encoder(text_encoder, loras),
|
||||
ONNXModelPatcher.apply_ti(orig_tokenizer, text_encoder, ti_list) as (tokenizer, ti_manager),
|
||||
):
|
||||
with ONNXModelPatcher.apply_lora_text_encoder(text_encoder, loras), ONNXModelPatcher.apply_ti(
|
||||
orig_tokenizer, text_encoder, ti_list
|
||||
) as (tokenizer, ti_manager):
|
||||
text_encoder.create_session()
|
||||
|
||||
# copy from
|
||||
@@ -166,6 +165,7 @@ class ONNXTextToLatentsInvocation(BaseInvocation):
|
||||
default=7.5,
|
||||
ge=1,
|
||||
description=FieldDescriptions.cfg_scale,
|
||||
ui_type=UIType.Float,
|
||||
)
|
||||
scheduler: SAMPLER_NAME_VALUES = InputField(
|
||||
default="euler", description=FieldDescriptions.scheduler, input=Input.Direct, ui_type=UIType.Scheduler
|
||||
@@ -178,6 +178,7 @@ class ONNXTextToLatentsInvocation(BaseInvocation):
|
||||
control: Optional[Union[ControlField, list[ControlField]]] = InputField(
|
||||
default=None,
|
||||
description=FieldDescriptions.control,
|
||||
ui_type=UIType.Control,
|
||||
)
|
||||
# seamless: bool = InputField(default=False, description="Whether or not to generate an image that can tile without seams", )
|
||||
# seamless_axes: str = InputField(default="", description="The axes to tile the image on, 'x' and/or 'y'")
|
||||
@@ -254,12 +255,12 @@ class ONNXTextToLatentsInvocation(BaseInvocation):
|
||||
eta=0.0,
|
||||
)
|
||||
|
||||
unet_info = context.services.model_loader.get_model(**self.unet.unet.dict())
|
||||
unet_info = context.services.model_manager.get_model(**self.unet.unet.dict())
|
||||
|
||||
with unet_info as unet: # , ExitStack() as stack:
|
||||
# loras = [(stack.enter_context(context.services.model_loader.get_model(**lora.dict(exclude={"weight"}))), lora.weight) for lora in self.unet.loras]
|
||||
# loras = [(stack.enter_context(context.services.model_manager.get_model(**lora.dict(exclude={"weight"}))), lora.weight) for lora in self.unet.loras]
|
||||
loras = [
|
||||
(context.services.model_loader.get_model(**lora.dict(exclude={"weight"})).context.model, lora.weight)
|
||||
(context.services.model_manager.get_model(**lora.dict(exclude={"weight"})).context.model, lora.weight)
|
||||
for lora in self.unet.loras
|
||||
]
|
||||
|
||||
@@ -345,7 +346,7 @@ class ONNXLatentsToImageInvocation(BaseInvocation):
|
||||
if self.vae.vae.submodel != SubModelType.VaeDecoder:
|
||||
raise Exception(f"Expected vae_decoder, found: {self.vae.vae.model_type}")
|
||||
|
||||
vae_info = context.services.model_loader.get_model(
|
||||
vae_info = context.services.model_manager.get_model(
|
||||
**self.vae.vae.dict(),
|
||||
)
|
||||
|
||||
@@ -418,7 +419,7 @@ class OnnxModelLoaderInvocation(BaseInvocation):
|
||||
model_type = ModelType.ONNX
|
||||
|
||||
# TODO: not found exceptions
|
||||
if not context.services.model_record_store.model_exists(
|
||||
if not context.services.model_manager.model_exists(
|
||||
model_name=model_name,
|
||||
base_model=base_model,
|
||||
model_type=model_type,
|
||||
@@ -426,7 +427,7 @@ class OnnxModelLoaderInvocation(BaseInvocation):
|
||||
raise Exception(f"Unknown {base_model} {model_type} model: {model_name}")
|
||||
|
||||
"""
|
||||
if not context.services.model_record_store.model_exists(
|
||||
if not context.services.model_manager.model_exists(
|
||||
model_name=self.model_name,
|
||||
model_type=SDModelType.Diffusers,
|
||||
submodel=SDModelType.Tokenizer,
|
||||
@@ -435,7 +436,7 @@ class OnnxModelLoaderInvocation(BaseInvocation):
|
||||
f"Failed to find tokenizer submodel in {self.model_name}! Check if model corrupted"
|
||||
)
|
||||
|
||||
if not context.services.model_record_store.model_exists(
|
||||
if not context.services.model_manager.model_exists(
|
||||
model_name=self.model_name,
|
||||
model_type=SDModelType.Diffusers,
|
||||
submodel=SDModelType.TextEncoder,
|
||||
@@ -444,7 +445,7 @@ class OnnxModelLoaderInvocation(BaseInvocation):
|
||||
f"Failed to find text_encoder submodel in {self.model_name}! Check if model corrupted"
|
||||
)
|
||||
|
||||
if not context.services.model_record_store.model_exists(
|
||||
if not context.services.model_manager.model_exists(
|
||||
model_name=self.model_name,
|
||||
model_type=SDModelType.Diffusers,
|
||||
submodel=SDModelType.UNet,
|
||||
|
||||
@@ -226,12 +226,6 @@ class ImageField(BaseModel):
|
||||
image_name: str = Field(description="The name of the image")
|
||||
|
||||
|
||||
class BoardField(BaseModel):
|
||||
"""A board primitive field"""
|
||||
|
||||
board_id: str = Field(description="The id of the board")
|
||||
|
||||
|
||||
@invocation_output("image_output")
|
||||
class ImageOutput(BaseInvocationOutput):
|
||||
"""Base class for nodes that output a single image"""
|
||||
|
||||
@@ -1,4 +1,4 @@
|
||||
from ...backend.model_manager import ModelType, SubModelType
|
||||
from ...backend.model_management import ModelType, SubModelType
|
||||
from .baseinvocation import (
|
||||
BaseInvocation,
|
||||
BaseInvocationOutput,
|
||||
@@ -48,7 +48,7 @@ class SDXLModelLoaderInvocation(BaseInvocation):
|
||||
model_type = ModelType.Main
|
||||
|
||||
# TODO: not found exceptions
|
||||
if not context.services.model_record_store.model_exists(
|
||||
if not context.services.model_manager.model_exists(
|
||||
model_name=model_name,
|
||||
base_model=base_model,
|
||||
model_type=model_type,
|
||||
@@ -137,7 +137,7 @@ class SDXLRefinerModelLoaderInvocation(BaseInvocation):
|
||||
model_type = ModelType.Main
|
||||
|
||||
# TODO: not found exceptions
|
||||
if not context.services.model_record_store.model_exists(
|
||||
if not context.services.model_manager.model_exists(
|
||||
model_name=model_name,
|
||||
base_model=base_model,
|
||||
model_type=model_type,
|
||||
|
||||
@@ -1,83 +0,0 @@
|
||||
from typing import Union
|
||||
|
||||
from pydantic import BaseModel, Field
|
||||
|
||||
from invokeai.app.invocations.baseinvocation import (
|
||||
BaseInvocation,
|
||||
BaseInvocationOutput,
|
||||
FieldDescriptions,
|
||||
Input,
|
||||
InputField,
|
||||
InvocationContext,
|
||||
OutputField,
|
||||
UIType,
|
||||
invocation,
|
||||
invocation_output,
|
||||
)
|
||||
from invokeai.app.invocations.controlnet_image_processors import CONTROLNET_RESIZE_VALUES
|
||||
from invokeai.app.invocations.primitives import ImageField
|
||||
from invokeai.backend.model_manager import BaseModelType
|
||||
|
||||
|
||||
class T2IAdapterModelField(BaseModel):
|
||||
model_name: str = Field(description="Name of the T2I-Adapter model")
|
||||
base_model: BaseModelType = Field(description="Base model")
|
||||
|
||||
|
||||
class T2IAdapterField(BaseModel):
|
||||
image: ImageField = Field(description="The T2I-Adapter image prompt.")
|
||||
t2i_adapter_model: T2IAdapterModelField = Field(description="The T2I-Adapter model to use.")
|
||||
weight: Union[float, list[float]] = Field(default=1, description="The weight given to the T2I-Adapter")
|
||||
begin_step_percent: float = Field(
|
||||
default=0, ge=0, le=1, description="When the T2I-Adapter is first applied (% of total steps)"
|
||||
)
|
||||
end_step_percent: float = Field(
|
||||
default=1, ge=0, le=1, description="When the T2I-Adapter is last applied (% of total steps)"
|
||||
)
|
||||
resize_mode: CONTROLNET_RESIZE_VALUES = Field(default="just_resize", description="The resize mode to use")
|
||||
|
||||
|
||||
@invocation_output("t2i_adapter_output")
|
||||
class T2IAdapterOutput(BaseInvocationOutput):
|
||||
t2i_adapter: T2IAdapterField = OutputField(description=FieldDescriptions.t2i_adapter, title="T2I Adapter")
|
||||
|
||||
|
||||
@invocation(
|
||||
"t2i_adapter", title="T2I-Adapter", tags=["t2i_adapter", "control"], category="t2i_adapter", version="1.0.0"
|
||||
)
|
||||
class T2IAdapterInvocation(BaseInvocation):
|
||||
"""Collects T2I-Adapter info to pass to other nodes."""
|
||||
|
||||
# Inputs
|
||||
image: ImageField = InputField(description="The IP-Adapter image prompt.")
|
||||
t2i_adapter_model: T2IAdapterModelField = InputField(
|
||||
description="The T2I-Adapter model.",
|
||||
title="T2I-Adapter Model",
|
||||
input=Input.Direct,
|
||||
ui_order=-1,
|
||||
)
|
||||
weight: Union[float, list[float]] = InputField(
|
||||
default=1, ge=0, description="The weight given to the T2I-Adapter", ui_type=UIType.Float, title="Weight"
|
||||
)
|
||||
begin_step_percent: float = InputField(
|
||||
default=0, ge=-1, le=2, description="When the T2I-Adapter is first applied (% of total steps)"
|
||||
)
|
||||
end_step_percent: float = InputField(
|
||||
default=1, ge=0, le=1, description="When the T2I-Adapter is last applied (% of total steps)"
|
||||
)
|
||||
resize_mode: CONTROLNET_RESIZE_VALUES = InputField(
|
||||
default="just_resize",
|
||||
description="The resize mode applied to the T2I-Adapter input image so that it matches the target output size.",
|
||||
)
|
||||
|
||||
def invoke(self, context: InvocationContext) -> T2IAdapterOutput:
|
||||
return T2IAdapterOutput(
|
||||
t2i_adapter=T2IAdapterField(
|
||||
image=self.image,
|
||||
t2i_adapter_model=self.t2i_adapter_model,
|
||||
weight=self.weight,
|
||||
begin_step_percent=self.begin_step_percent,
|
||||
end_step_percent=self.end_step_percent,
|
||||
resize_mode=self.resize_mode,
|
||||
)
|
||||
)
|
||||
@@ -4,14 +4,12 @@ from typing import Literal
|
||||
|
||||
import cv2 as cv
|
||||
import numpy as np
|
||||
import torch
|
||||
from basicsr.archs.rrdbnet_arch import RRDBNet
|
||||
from PIL import Image
|
||||
from realesrgan import RealESRGANer
|
||||
|
||||
from invokeai.app.invocations.primitives import ImageField, ImageOutput
|
||||
from invokeai.app.models.image import ImageCategory, ResourceOrigin
|
||||
from invokeai.backend.util.devices import choose_torch_device
|
||||
|
||||
from .baseinvocation import BaseInvocation, InputField, InvocationContext, invocation
|
||||
|
||||
@@ -24,19 +22,13 @@ ESRGAN_MODELS = Literal[
|
||||
"RealESRGAN_x2plus.pth",
|
||||
]
|
||||
|
||||
if choose_torch_device() == torch.device("mps"):
|
||||
from torch import mps
|
||||
|
||||
|
||||
@invocation("esrgan", title="Upscale (RealESRGAN)", tags=["esrgan", "upscale"], category="esrgan", version="1.1.0")
|
||||
@invocation("esrgan", title="Upscale (RealESRGAN)", tags=["esrgan", "upscale"], category="esrgan", version="1.0.0")
|
||||
class ESRGANInvocation(BaseInvocation):
|
||||
"""Upscales an image using RealESRGAN."""
|
||||
|
||||
image: ImageField = InputField(description="The input image")
|
||||
model_name: ESRGAN_MODELS = InputField(default="RealESRGAN_x4plus.pth", description="The Real-ESRGAN model to use")
|
||||
tile_size: int = InputField(
|
||||
default=400, ge=0, description="Tile size for tiled ESRGAN upscaling (0=tiling disabled)"
|
||||
)
|
||||
|
||||
def invoke(self, context: InvocationContext) -> ImageOutput:
|
||||
image = context.services.images.get_pil_image(self.image.image_name)
|
||||
@@ -94,11 +86,9 @@ class ESRGANInvocation(BaseInvocation):
|
||||
model_path=str(models_path / esrgan_model_path),
|
||||
model=rrdbnet_model,
|
||||
half=False,
|
||||
tile=self.tile_size,
|
||||
)
|
||||
|
||||
# prepare image - Real-ESRGAN uses cv2 internally, and cv2 uses BGR vs RGB for PIL
|
||||
# TODO: This strips the alpha... is that okay?
|
||||
cv_image = cv.cvtColor(np.array(image.convert("RGB")), cv.COLOR_RGB2BGR)
|
||||
|
||||
# We can pass an `outscale` value here, but it just resizes the image by that factor after
|
||||
@@ -109,10 +99,6 @@ class ESRGANInvocation(BaseInvocation):
|
||||
# back to PIL
|
||||
pil_image = Image.fromarray(cv.cvtColor(upscaled_image, cv.COLOR_BGR2RGB)).convert("RGBA")
|
||||
|
||||
torch.cuda.empty_cache()
|
||||
if choose_torch_device() == torch.device("mps"):
|
||||
mps.empty_cache()
|
||||
|
||||
image_dto = context.services.images.create(
|
||||
image=pil_image,
|
||||
image_origin=ResourceOrigin.INTERNAL,
|
||||
|
||||
@@ -25,7 +25,6 @@ from pydantic import BaseSettings
|
||||
class PagingArgumentParser(argparse.ArgumentParser):
|
||||
"""
|
||||
A custom ArgumentParser that uses pydoc to page its output.
|
||||
|
||||
It also supports reading defaults from an init file.
|
||||
"""
|
||||
|
||||
@@ -145,6 +144,16 @@ class InvokeAISettings(BaseSettings):
|
||||
return [
|
||||
"type",
|
||||
"initconf",
|
||||
"version",
|
||||
"from_file",
|
||||
"model",
|
||||
"root",
|
||||
"max_cache_size",
|
||||
"max_vram_cache_size",
|
||||
"always_use_cpu",
|
||||
"free_gpu_mem",
|
||||
"xformers_enabled",
|
||||
"tiled_decode",
|
||||
]
|
||||
|
||||
class Config:
|
||||
@@ -217,7 +226,9 @@ class InvokeAISettings(BaseSettings):
|
||||
|
||||
|
||||
def int_or_float_or_str(value: str) -> Union[int, float, str]:
|
||||
"""Workaround for argparse type checking."""
|
||||
"""
|
||||
Workaround for argparse type checking.
|
||||
"""
|
||||
try:
|
||||
return int(value)
|
||||
except Exception as e: # noqa F841
|
||||
|
||||
@@ -171,7 +171,6 @@ two configs are kept in separate sections of the config file:
|
||||
from __future__ import annotations
|
||||
|
||||
import os
|
||||
import sys
|
||||
from pathlib import Path
|
||||
from typing import ClassVar, Dict, List, Literal, Optional, Union, get_type_hints
|
||||
|
||||
@@ -183,9 +182,7 @@ from .base import InvokeAISettings
|
||||
INIT_FILE = Path("invokeai.yaml")
|
||||
DB_FILE = Path("invokeai.db")
|
||||
LEGACY_INIT_FILE = Path("invokeai.init")
|
||||
DEFAULT_MAX_DISK_CACHE = 20 # gigs, enough for three sdxl models, or 6 sd-1 models
|
||||
DEFAULT_RAM_CACHE = 7.5
|
||||
DEFAULT_VRAM_CACHE = 0.25
|
||||
DEFAULT_MAX_VRAM = 0.5
|
||||
|
||||
|
||||
class InvokeAIAppConfig(InvokeAISettings):
|
||||
@@ -220,8 +217,11 @@ class InvokeAIAppConfig(InvokeAISettings):
|
||||
|
||||
# PATHS
|
||||
root : Path = Field(default=None, description='InvokeAI runtime root directory', category='Paths')
|
||||
autoimport_dir : Optional[Path] = Field(default=None, description='Path to a directory of models files to be imported on startup.', category='Paths')
|
||||
model_config_db : Union[Path, Literal['auto'], None] = Field(default=None, description='Path to a sqlite .db file or .yaml file for storing model config records; "auto" will reuse the main sqlite db', category='Paths')
|
||||
autoimport_dir : Path = Field(default='autoimport', description='Path to a directory of models files to be imported on startup.', category='Paths')
|
||||
lora_dir : Path = Field(default=None, description='Path to a directory of LoRA/LyCORIS models to be imported on startup.', category='Paths')
|
||||
embedding_dir : Path = Field(default=None, description='Path to a directory of Textual Inversion embeddings to be imported on startup.', category='Paths')
|
||||
controlnet_dir : Path = Field(default=None, description='Path to a directory of ControlNet embeddings to be imported on startup.', category='Paths')
|
||||
conf_path : Path = Field(default='configs/models.yaml', description='Path to models definition file', category='Paths')
|
||||
models_dir : Path = Field(default='models', description='Path to the models directory', category='Paths')
|
||||
legacy_conf_dir : Path = Field(default='configs/stable-diffusion', description='Path to directory of legacy checkpoint config files', category='Paths')
|
||||
db_dir : Path = Field(default='databases', description='Path to InvokeAI databases directory', category='Paths')
|
||||
@@ -241,9 +241,8 @@ class InvokeAIAppConfig(InvokeAISettings):
|
||||
version : bool = Field(default=False, description="Show InvokeAI version and exit", category="Other")
|
||||
|
||||
# CACHE
|
||||
ram : float = Field(default=DEFAULT_RAM_CACHE, gt=0, description="Maximum memory amount used by model cache for rapid switching", category="Model Cache", )
|
||||
vram : float = Field(default=DEFAULT_VRAM_CACHE, ge=0, description="Amount of VRAM reserved for model storage", category="Model Cache", )
|
||||
disk : float = Field(default=DEFAULT_MAX_DISK_CACHE, ge=0, description="Maximum size (in GB) for the disk-based diffusers model conversion cache", category="Model Cache", )
|
||||
ram : Union[float, Literal["auto"]] = Field(default=6.0, gt=0, description="Maximum memory amount used by model cache for rapid switching (floating point number or 'auto')", category="Model Cache", )
|
||||
vram : Union[float, Literal["auto"]] = Field(default=0.25, ge=0, description="Amount of VRAM reserved for model storage (floating point number or 'auto')", category="Model Cache", )
|
||||
lazy_offload : bool = Field(default=True, description="Keep models in VRAM until their space is needed", category="Model Cache", )
|
||||
|
||||
# DEVICE
|
||||
@@ -255,7 +254,7 @@ class InvokeAIAppConfig(InvokeAISettings):
|
||||
attention_type : Literal["auto", "normal", "xformers", "sliced", "torch-sdp"] = Field(default="auto", description="Attention type", category="Generation", )
|
||||
attention_slice_size: Literal["auto", "balanced", "max", 1, 2, 3, 4, 5, 6, 7, 8] = Field(default="auto", description='Slice size, valid when attention_type=="sliced"', category="Generation", )
|
||||
force_tiled_decode : bool = Field(default=False, description="Whether to enable tiled VAE decode (reduces memory consumption with some performance penalty)", category="Generation",)
|
||||
png_compress_level : int = Field(default=6, description="The compress_level setting of PIL.Image.save(), used for PNG encoding. All settings are lossless. 0 = fastest, largest filesize, 9 = slowest, smallest filesize", category="Generation", )
|
||||
force_tiled_decode: bool = Field(default=False, description="Whether to enable tiled VAE decode (reduces memory consumption with some performance penalty)", category="Generation",)
|
||||
|
||||
# QUEUE
|
||||
max_queue_size : int = Field(default=10000, gt=0, description="Maximum number of items in the session queue", category="Queue", )
|
||||
@@ -272,17 +271,12 @@ class InvokeAIAppConfig(InvokeAISettings):
|
||||
max_vram_cache_size : Optional[float] = Field(default=None, ge=0, description="Amount of VRAM reserved for model storage", category='Memory/Performance')
|
||||
xformers_enabled : bool = Field(default=True, description="Enable/disable memory-efficient attention", category='Memory/Performance')
|
||||
tiled_decode : bool = Field(default=False, description="Whether to enable tiled VAE decode (reduces memory consumption with some performance penalty)", category='Memory/Performance')
|
||||
conf_path : Path = Field(default='configs/models.yaml', description='Path to models definition file', category='Paths')
|
||||
lora_dir : Path = Field(default=None, description='Path to a directory of LoRA/LyCORIS models to be imported on startup.', category='Paths')
|
||||
embedding_dir : Path = Field(default=None, description='Path to a directory of Textual Inversion embeddings to be imported on startup.', category='Paths')
|
||||
controlnet_dir : Path = Field(default=None, description='Path to a directory of ControlNet embeddings to be imported on startup.', category='Paths')
|
||||
|
||||
# See InvokeAIAppConfig subclass below for CACHE and DEVICE categories
|
||||
# fmt: on
|
||||
|
||||
class Config:
|
||||
validate_assignment = True
|
||||
env_prefix = "INVOKEAI"
|
||||
|
||||
def parse_args(self, argv: Optional[list[str]] = None, conf: Optional[DictConfig] = None, clobber=False):
|
||||
"""
|
||||
@@ -316,7 +310,9 @@ class InvokeAIAppConfig(InvokeAISettings):
|
||||
|
||||
@classmethod
|
||||
def get_config(cls, **kwargs) -> InvokeAIAppConfig:
|
||||
"""This returns a singleton InvokeAIAppConfig configuration object."""
|
||||
"""
|
||||
This returns a singleton InvokeAIAppConfig configuration object.
|
||||
"""
|
||||
if (
|
||||
cls.singleton_config is None
|
||||
or type(cls.singleton_config) is not cls
|
||||
@@ -326,29 +322,6 @@ class InvokeAIAppConfig(InvokeAISettings):
|
||||
cls.singleton_init = kwargs
|
||||
return cls.singleton_config
|
||||
|
||||
@classmethod
|
||||
def _excluded_from_yaml(cls) -> List[str]:
|
||||
el = super()._excluded_from_yaml()
|
||||
el.extend(
|
||||
[
|
||||
"version",
|
||||
"from_file",
|
||||
"model",
|
||||
"root",
|
||||
"max_cache_size",
|
||||
"max_vram_cache_size",
|
||||
"always_use_cpu",
|
||||
"free_gpu_mem",
|
||||
"xformers_enabled",
|
||||
"tiled_decode",
|
||||
"conf_path",
|
||||
"lora_dir",
|
||||
"embedding_dir",
|
||||
"controlnet_dir",
|
||||
]
|
||||
)
|
||||
return el
|
||||
|
||||
@property
|
||||
def root_path(self) -> Path:
|
||||
"""
|
||||
@@ -439,11 +412,7 @@ class InvokeAIAppConfig(InvokeAISettings):
|
||||
return self.max_cache_size or self.ram
|
||||
|
||||
@property
|
||||
def conversion_cache_size(self) -> float:
|
||||
return self.disk
|
||||
|
||||
@property
|
||||
def vram_cache_size(self) -> float:
|
||||
def vram_cache_size(self) -> Union[Literal["auto"], float]:
|
||||
return self.max_vram_cache_size or self.vram
|
||||
|
||||
@property
|
||||
@@ -469,7 +438,9 @@ class InvokeAIAppConfig(InvokeAISettings):
|
||||
|
||||
|
||||
def get_invokeai_config(**kwargs) -> InvokeAIAppConfig:
|
||||
"""Legacy function which returns InvokeAIAppConfig.get_config()."""
|
||||
"""
|
||||
Legacy function which returns InvokeAIAppConfig.get_config()
|
||||
"""
|
||||
return InvokeAIAppConfig.get_config(**kwargs)
|
||||
|
||||
|
||||
|
||||
@@ -1,205 +0,0 @@
|
||||
# Copyright (c) 2023 Lincoln D. Stein and the InvokeAI Development Team
|
||||
"""
|
||||
Model download service.
|
||||
"""
|
||||
|
||||
from abc import ABC, abstractmethod
|
||||
from pathlib import Path
|
||||
from typing import TYPE_CHECKING, Any, List, Optional, Union
|
||||
|
||||
from pydantic.networks import AnyHttpUrl
|
||||
|
||||
from invokeai.backend.model_manager.download import DownloadJobRemoteSource # noqa F401
|
||||
from invokeai.backend.model_manager.download import ( # noqa F401
|
||||
DownloadEventHandler,
|
||||
DownloadJobBase,
|
||||
DownloadJobPath,
|
||||
DownloadJobStatus,
|
||||
DownloadQueueBase,
|
||||
ModelDownloadQueue,
|
||||
ModelSourceMetadata,
|
||||
UnknownJobIDException,
|
||||
)
|
||||
|
||||
if TYPE_CHECKING:
|
||||
from .events import EventServiceBase
|
||||
|
||||
|
||||
class DownloadQueueServiceBase(ABC):
|
||||
"""Multithreaded queue for downloading models via URL or repo_id."""
|
||||
|
||||
@abstractmethod
|
||||
def create_download_job(
|
||||
self,
|
||||
source: Union[str, Path, AnyHttpUrl],
|
||||
destdir: Path,
|
||||
filename: Optional[Path] = None,
|
||||
start: Optional[bool] = True,
|
||||
access_token: Optional[str] = None,
|
||||
event_handlers: Optional[List[DownloadEventHandler]] = None,
|
||||
) -> DownloadJobBase:
|
||||
"""
|
||||
Create a download job.
|
||||
|
||||
:param source: Source of the download - URL, repo_id or local Path
|
||||
:param destdir: Directory to download into.
|
||||
:param filename: Optional name of file, if not provided
|
||||
will use the content-disposition field to assign the name.
|
||||
:param start: Immediately start job [True]
|
||||
:param event_handler: Callable that receives a DownloadJobBase and acts on it.
|
||||
:returns job id: The numeric ID of the DownloadJobBase object for this task.
|
||||
"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def submit_download_job(
|
||||
self,
|
||||
job: DownloadJobBase,
|
||||
start: Optional[bool] = True,
|
||||
):
|
||||
"""
|
||||
Submit a download job.
|
||||
|
||||
:param job: A DownloadJobBase
|
||||
:param start: Immediately start job [True]
|
||||
|
||||
After execution, `job.id` will be set to a non-negative value.
|
||||
"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def list_jobs(self) -> List[DownloadJobBase]:
|
||||
"""
|
||||
List active DownloadJobBases.
|
||||
|
||||
:returns List[DownloadJobBase]: List of download jobs whose state is not "completed."
|
||||
"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def id_to_job(self, id: int) -> DownloadJobBase:
|
||||
"""
|
||||
Return the DownloadJobBase corresponding to the string ID.
|
||||
|
||||
:param id: ID of the DownloadJobBase.
|
||||
|
||||
Exceptions:
|
||||
* UnknownJobIDException
|
||||
"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def start_all_jobs(self):
|
||||
"""Enqueue all idle and paused jobs."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def pause_all_jobs(self):
|
||||
"""Pause and dequeue all active jobs."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def cancel_all_jobs(self):
|
||||
"""Cancel all active and enquedjobs."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def prune_jobs(self):
|
||||
"""Prune completed and errored queue items from the job list."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def start_job(self, job: DownloadJobBase):
|
||||
"""Start the job putting it into ENQUEUED state."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def pause_job(self, job: DownloadJobBase):
|
||||
"""Pause the job, putting it into PAUSED state."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def cancel_job(self, job: DownloadJobBase):
|
||||
"""Cancel the job, clearing partial downloads and putting it into ERROR state."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def join(self):
|
||||
"""Wait until all jobs are off the queue."""
|
||||
pass
|
||||
|
||||
|
||||
class DownloadQueueService(DownloadQueueServiceBase):
|
||||
"""Multithreaded queue for downloading models via URL or repo_id."""
|
||||
|
||||
_event_bus: Optional["EventServiceBase"] = None
|
||||
_queue: DownloadQueueBase
|
||||
|
||||
def __init__(self, event_bus: Optional["EventServiceBase"] = None, **kwargs):
|
||||
"""
|
||||
Initialize new DownloadQueueService object.
|
||||
|
||||
:param event_bus: EventServiceBase object for reporting progress.
|
||||
:param **kwargs: Any of the arguments taken by invokeai.backend.model_manager.download.DownloadQueue.
|
||||
e.g. `max_parallel_dl`.
|
||||
"""
|
||||
self._event_bus = event_bus
|
||||
self._queue = ModelDownloadQueue(**kwargs)
|
||||
|
||||
def create_download_job(
|
||||
self,
|
||||
source: Union[str, Path, AnyHttpUrl],
|
||||
destdir: Path,
|
||||
filename: Optional[Path] = None,
|
||||
start: Optional[bool] = True,
|
||||
access_token: Optional[str] = None,
|
||||
event_handlers: Optional[List[DownloadEventHandler]] = None,
|
||||
) -> DownloadJobBase: # noqa D102
|
||||
event_handlers = event_handlers or []
|
||||
if self._event_bus:
|
||||
event_handlers = [*event_handlers, self._event_bus.emit_model_event]
|
||||
return self._queue.create_download_job(
|
||||
source=source,
|
||||
destdir=destdir,
|
||||
filename=filename,
|
||||
start=start,
|
||||
access_token=access_token,
|
||||
event_handlers=event_handlers,
|
||||
)
|
||||
|
||||
def submit_download_job(
|
||||
self,
|
||||
job: DownloadJobBase,
|
||||
start: bool = True,
|
||||
):
|
||||
return self._queue.submit_download_job(job, start)
|
||||
|
||||
def list_jobs(self) -> List[DownloadJobBase]: # noqa D102
|
||||
return self._queue.list_jobs()
|
||||
|
||||
def id_to_job(self, id: int) -> DownloadJobBase: # noqa D102
|
||||
return self._queue.id_to_job(id)
|
||||
|
||||
def start_all_jobs(self): # noqa D102
|
||||
return self._queue.start_all_jobs()
|
||||
|
||||
def pause_all_jobs(self): # noqa D102
|
||||
return self._queue.pause_all_jobs()
|
||||
|
||||
def cancel_all_jobs(self): # noqa D102
|
||||
return self._queue.cancel_all_jobs()
|
||||
|
||||
def prune_jobs(self): # noqa D102
|
||||
return self._queue.prune_jobs()
|
||||
|
||||
def start_job(self, job: DownloadJobBase): # noqa D102
|
||||
return self._queue.start_job(job)
|
||||
|
||||
def pause_job(self, job: DownloadJobBase): # noqa D102
|
||||
return self._queue.pause_job(job)
|
||||
|
||||
def cancel_job(self, job: DownloadJobBase): # noqa D102
|
||||
return self._queue.cancel_job(job)
|
||||
|
||||
def join(self): # noqa D102
|
||||
return self._queue.join()
|
||||
@@ -3,25 +3,17 @@
|
||||
from typing import Any, Optional
|
||||
|
||||
from invokeai.app.models.image import ProgressImage
|
||||
from invokeai.app.services.model_record_service import BaseModelType, ModelType, SubModelType
|
||||
from invokeai.app.services.session_queue.session_queue_common import (
|
||||
BatchStatus,
|
||||
EnqueueBatchResult,
|
||||
SessionQueueItem,
|
||||
SessionQueueStatus,
|
||||
)
|
||||
from invokeai.app.services.model_manager_service import BaseModelType, ModelInfo, ModelType, SubModelType
|
||||
from invokeai.app.services.session_queue.session_queue_common import EnqueueBatchResult, SessionQueueItem
|
||||
from invokeai.app.util.misc import get_timestamp
|
||||
from invokeai.backend.model_manager import SubModelType
|
||||
from invokeai.backend.model_manager.download import DownloadJobBase
|
||||
from invokeai.backend.model_manager.loader import ModelInfo
|
||||
from invokeai.backend.util.logging import InvokeAILogger
|
||||
|
||||
|
||||
class EventServiceBase:
|
||||
queue_event: str = "queue_event"
|
||||
|
||||
"""Basic event bus, to have an empty stand-in when not needed"""
|
||||
|
||||
def dispatch(self, event_name: str, payload: Any) -> None:
|
||||
"""Dispatch an event."""
|
||||
pass
|
||||
|
||||
def __emit_queue_event(self, event_name: str, payload: dict) -> None:
|
||||
@@ -37,8 +29,7 @@ class EventServiceBase:
|
||||
def emit_generator_progress(
|
||||
self,
|
||||
queue_id: str,
|
||||
queue_item_id: int,
|
||||
queue_batch_id: str,
|
||||
queue_item_id: str,
|
||||
graph_execution_state_id: str,
|
||||
node: dict,
|
||||
source_node_id: str,
|
||||
@@ -53,7 +44,6 @@ class EventServiceBase:
|
||||
payload=dict(
|
||||
queue_id=queue_id,
|
||||
queue_item_id=queue_item_id,
|
||||
queue_batch_id=queue_batch_id,
|
||||
graph_execution_state_id=graph_execution_state_id,
|
||||
node_id=node.get("id"),
|
||||
source_node_id=source_node_id,
|
||||
@@ -67,8 +57,7 @@ class EventServiceBase:
|
||||
def emit_invocation_complete(
|
||||
self,
|
||||
queue_id: str,
|
||||
queue_item_id: int,
|
||||
queue_batch_id: str,
|
||||
queue_item_id: str,
|
||||
graph_execution_state_id: str,
|
||||
result: dict,
|
||||
node: dict,
|
||||
@@ -80,7 +69,6 @@ class EventServiceBase:
|
||||
payload=dict(
|
||||
queue_id=queue_id,
|
||||
queue_item_id=queue_item_id,
|
||||
queue_batch_id=queue_batch_id,
|
||||
graph_execution_state_id=graph_execution_state_id,
|
||||
node=node,
|
||||
source_node_id=source_node_id,
|
||||
@@ -91,8 +79,7 @@ class EventServiceBase:
|
||||
def emit_invocation_error(
|
||||
self,
|
||||
queue_id: str,
|
||||
queue_item_id: int,
|
||||
queue_batch_id: str,
|
||||
queue_item_id: str,
|
||||
graph_execution_state_id: str,
|
||||
node: dict,
|
||||
source_node_id: str,
|
||||
@@ -105,7 +92,6 @@ class EventServiceBase:
|
||||
payload=dict(
|
||||
queue_id=queue_id,
|
||||
queue_item_id=queue_item_id,
|
||||
queue_batch_id=queue_batch_id,
|
||||
graph_execution_state_id=graph_execution_state_id,
|
||||
node=node,
|
||||
source_node_id=source_node_id,
|
||||
@@ -115,13 +101,7 @@ class EventServiceBase:
|
||||
)
|
||||
|
||||
def emit_invocation_started(
|
||||
self,
|
||||
queue_id: str,
|
||||
queue_item_id: int,
|
||||
queue_batch_id: str,
|
||||
graph_execution_state_id: str,
|
||||
node: dict,
|
||||
source_node_id: str,
|
||||
self, queue_id: str, queue_item_id: str, graph_execution_state_id: str, node: dict, source_node_id: str
|
||||
) -> None:
|
||||
"""Emitted when an invocation has started"""
|
||||
self.__emit_queue_event(
|
||||
@@ -129,23 +109,19 @@ class EventServiceBase:
|
||||
payload=dict(
|
||||
queue_id=queue_id,
|
||||
queue_item_id=queue_item_id,
|
||||
queue_batch_id=queue_batch_id,
|
||||
graph_execution_state_id=graph_execution_state_id,
|
||||
node=node,
|
||||
source_node_id=source_node_id,
|
||||
),
|
||||
)
|
||||
|
||||
def emit_graph_execution_complete(
|
||||
self, queue_id: str, queue_item_id: int, queue_batch_id: str, graph_execution_state_id: str
|
||||
) -> None:
|
||||
def emit_graph_execution_complete(self, queue_id: str, queue_item_id: str, graph_execution_state_id: str) -> None:
|
||||
"""Emitted when a session has completed all invocations"""
|
||||
self.__emit_queue_event(
|
||||
event_name="graph_execution_state_complete",
|
||||
payload=dict(
|
||||
queue_id=queue_id,
|
||||
queue_item_id=queue_item_id,
|
||||
queue_batch_id=queue_batch_id,
|
||||
graph_execution_state_id=graph_execution_state_id,
|
||||
),
|
||||
)
|
||||
@@ -153,10 +129,11 @@ class EventServiceBase:
|
||||
def emit_model_load_started(
|
||||
self,
|
||||
queue_id: str,
|
||||
queue_item_id: int,
|
||||
queue_batch_id: str,
|
||||
queue_item_id: str,
|
||||
graph_execution_state_id: str,
|
||||
model_key: str,
|
||||
model_name: str,
|
||||
base_model: BaseModelType,
|
||||
model_type: ModelType,
|
||||
submodel: SubModelType,
|
||||
) -> None:
|
||||
"""Emitted when a model is requested"""
|
||||
@@ -165,9 +142,10 @@ class EventServiceBase:
|
||||
payload=dict(
|
||||
queue_id=queue_id,
|
||||
queue_item_id=queue_item_id,
|
||||
queue_batch_id=queue_batch_id,
|
||||
graph_execution_state_id=graph_execution_state_id,
|
||||
model_key=model_key,
|
||||
model_name=model_name,
|
||||
base_model=base_model,
|
||||
model_type=model_type,
|
||||
submodel=submodel,
|
||||
),
|
||||
)
|
||||
@@ -175,10 +153,11 @@ class EventServiceBase:
|
||||
def emit_model_load_completed(
|
||||
self,
|
||||
queue_id: str,
|
||||
queue_item_id: int,
|
||||
queue_batch_id: str,
|
||||
queue_item_id: str,
|
||||
graph_execution_state_id: str,
|
||||
model_key: str,
|
||||
model_name: str,
|
||||
base_model: BaseModelType,
|
||||
model_type: ModelType,
|
||||
submodel: SubModelType,
|
||||
model_info: ModelInfo,
|
||||
) -> None:
|
||||
@@ -188,9 +167,10 @@ class EventServiceBase:
|
||||
payload=dict(
|
||||
queue_id=queue_id,
|
||||
queue_item_id=queue_item_id,
|
||||
queue_batch_id=queue_batch_id,
|
||||
graph_execution_state_id=graph_execution_state_id,
|
||||
model_key=model_key,
|
||||
model_name=model_name,
|
||||
base_model=base_model,
|
||||
model_type=model_type,
|
||||
submodel=submodel,
|
||||
hash=model_info.hash,
|
||||
location=str(model_info.location),
|
||||
@@ -201,8 +181,7 @@ class EventServiceBase:
|
||||
def emit_session_retrieval_error(
|
||||
self,
|
||||
queue_id: str,
|
||||
queue_item_id: int,
|
||||
queue_batch_id: str,
|
||||
queue_item_id: str,
|
||||
graph_execution_state_id: str,
|
||||
error_type: str,
|
||||
error: str,
|
||||
@@ -213,7 +192,6 @@ class EventServiceBase:
|
||||
payload=dict(
|
||||
queue_id=queue_id,
|
||||
queue_item_id=queue_item_id,
|
||||
queue_batch_id=queue_batch_id,
|
||||
graph_execution_state_id=graph_execution_state_id,
|
||||
error_type=error_type,
|
||||
error=error,
|
||||
@@ -223,8 +201,7 @@ class EventServiceBase:
|
||||
def emit_invocation_retrieval_error(
|
||||
self,
|
||||
queue_id: str,
|
||||
queue_item_id: int,
|
||||
queue_batch_id: str,
|
||||
queue_item_id: str,
|
||||
graph_execution_state_id: str,
|
||||
node_id: str,
|
||||
error_type: str,
|
||||
@@ -236,7 +213,6 @@ class EventServiceBase:
|
||||
payload=dict(
|
||||
queue_id=queue_id,
|
||||
queue_item_id=queue_item_id,
|
||||
queue_batch_id=queue_batch_id,
|
||||
graph_execution_state_id=graph_execution_state_id,
|
||||
node_id=node_id,
|
||||
error_type=error_type,
|
||||
@@ -247,8 +223,7 @@ class EventServiceBase:
|
||||
def emit_session_canceled(
|
||||
self,
|
||||
queue_id: str,
|
||||
queue_item_id: int,
|
||||
queue_batch_id: str,
|
||||
queue_item_id: str,
|
||||
graph_execution_state_id: str,
|
||||
) -> None:
|
||||
"""Emitted when a session is canceled"""
|
||||
@@ -257,36 +232,25 @@ class EventServiceBase:
|
||||
payload=dict(
|
||||
queue_id=queue_id,
|
||||
queue_item_id=queue_item_id,
|
||||
queue_batch_id=queue_batch_id,
|
||||
graph_execution_state_id=graph_execution_state_id,
|
||||
),
|
||||
)
|
||||
|
||||
def emit_queue_item_status_changed(
|
||||
self,
|
||||
session_queue_item: SessionQueueItem,
|
||||
batch_status: BatchStatus,
|
||||
queue_status: SessionQueueStatus,
|
||||
) -> None:
|
||||
def emit_queue_item_status_changed(self, session_queue_item: SessionQueueItem) -> None:
|
||||
"""Emitted when a queue item's status changes"""
|
||||
self.__emit_queue_event(
|
||||
event_name="queue_item_status_changed",
|
||||
payload=dict(
|
||||
queue_id=queue_status.queue_id,
|
||||
queue_item=dict(
|
||||
queue_id=session_queue_item.queue_id,
|
||||
item_id=session_queue_item.item_id,
|
||||
status=session_queue_item.status,
|
||||
batch_id=session_queue_item.batch_id,
|
||||
session_id=session_queue_item.session_id,
|
||||
error=session_queue_item.error,
|
||||
created_at=str(session_queue_item.created_at) if session_queue_item.created_at else None,
|
||||
updated_at=str(session_queue_item.updated_at) if session_queue_item.updated_at else None,
|
||||
started_at=str(session_queue_item.started_at) if session_queue_item.started_at else None,
|
||||
completed_at=str(session_queue_item.completed_at) if session_queue_item.completed_at else None,
|
||||
),
|
||||
batch_status=batch_status.dict(),
|
||||
queue_status=queue_status.dict(),
|
||||
queue_id=session_queue_item.queue_id,
|
||||
queue_item_id=session_queue_item.item_id,
|
||||
status=session_queue_item.status,
|
||||
batch_id=session_queue_item.batch_id,
|
||||
session_id=session_queue_item.session_id,
|
||||
error=session_queue_item.error,
|
||||
created_at=str(session_queue_item.created_at) if session_queue_item.created_at else None,
|
||||
updated_at=str(session_queue_item.updated_at) if session_queue_item.updated_at else None,
|
||||
started_at=str(session_queue_item.started_at) if session_queue_item.started_at else None,
|
||||
completed_at=str(session_queue_item.completed_at) if session_queue_item.completed_at else None,
|
||||
),
|
||||
)
|
||||
|
||||
@@ -307,9 +271,3 @@ class EventServiceBase:
|
||||
event_name="queue_cleared",
|
||||
payload=dict(queue_id=queue_id),
|
||||
)
|
||||
|
||||
def emit_model_event(self, job: DownloadJobBase) -> None:
|
||||
"""Emit event when the status of a download/install job changes."""
|
||||
self.dispatch( # use dispatch() directly here because we are not a session event.
|
||||
event_name="model_event", payload=dict(job=job)
|
||||
)
|
||||
|
||||
@@ -2,7 +2,7 @@
|
||||
|
||||
import copy
|
||||
import itertools
|
||||
from typing import Annotated, Any, Optional, Union, get_args, get_origin, get_type_hints
|
||||
from typing import Annotated, Any, Optional, Union, cast, get_args, get_origin, get_type_hints
|
||||
|
||||
import networkx as nx
|
||||
from pydantic import BaseModel, root_validator, validator
|
||||
@@ -117,10 +117,6 @@ def are_connection_types_compatible(from_type: Any, to_type: Any) -> bool:
|
||||
if from_type is int and to_type is float:
|
||||
return True
|
||||
|
||||
# allow int|float -> str, pydantic will cast for us
|
||||
if (from_type is int or from_type is float) and to_type is str:
|
||||
return True
|
||||
|
||||
# if not issubclass(from_type, to_type):
|
||||
if not is_union_subtype(from_type, to_type):
|
||||
return False
|
||||
@@ -170,18 +166,6 @@ class NodeIdMismatchError(ValueError):
|
||||
pass
|
||||
|
||||
|
||||
class InvalidSubGraphError(ValueError):
|
||||
pass
|
||||
|
||||
|
||||
class CyclicalGraphError(ValueError):
|
||||
pass
|
||||
|
||||
|
||||
class UnknownGraphValidationError(ValueError):
|
||||
pass
|
||||
|
||||
|
||||
# TODO: Create and use an Empty output?
|
||||
@invocation_output("graph_output")
|
||||
class GraphInvocationOutput(BaseInvocationOutput):
|
||||
@@ -266,6 +250,59 @@ class Graph(BaseModel):
|
||||
default_factory=list,
|
||||
)
|
||||
|
||||
@root_validator
|
||||
def validate_nodes_and_edges(cls, values):
|
||||
"""Validates that all edges match nodes in the graph"""
|
||||
nodes = cast(Optional[dict[str, BaseInvocation]], values.get("nodes"))
|
||||
edges = cast(Optional[list[Edge]], values.get("edges"))
|
||||
|
||||
if nodes is not None:
|
||||
# Validate that all node ids are unique
|
||||
node_ids = [n.id for n in nodes.values()]
|
||||
duplicate_node_ids = set([node_id for node_id in node_ids if node_ids.count(node_id) >= 2])
|
||||
if duplicate_node_ids:
|
||||
raise DuplicateNodeIdError(f"Node ids must be unique, found duplicates {duplicate_node_ids}")
|
||||
|
||||
# Validate that all node ids match the keys in the nodes dict
|
||||
for k, v in nodes.items():
|
||||
if k != v.id:
|
||||
raise NodeIdMismatchError(f"Node ids must match, got {k} and {v.id}")
|
||||
|
||||
if edges is not None and nodes is not None:
|
||||
# Validate that all edges match nodes in the graph
|
||||
node_ids = set([e.source.node_id for e in edges] + [e.destination.node_id for e in edges])
|
||||
missing_node_ids = [node_id for node_id in node_ids if node_id not in nodes]
|
||||
if missing_node_ids:
|
||||
raise NodeNotFoundError(
|
||||
f"All edges must reference nodes in the graph, missing nodes: {missing_node_ids}"
|
||||
)
|
||||
|
||||
# Validate that all edge fields match node fields in the graph
|
||||
for edge in edges:
|
||||
source_node = nodes.get(edge.source.node_id, None)
|
||||
if source_node is None:
|
||||
raise NodeFieldNotFoundError(f"Edge source node {edge.source.node_id} does not exist in the graph")
|
||||
|
||||
destination_node = nodes.get(edge.destination.node_id, None)
|
||||
if destination_node is None:
|
||||
raise NodeFieldNotFoundError(
|
||||
f"Edge destination node {edge.destination.node_id} does not exist in the graph"
|
||||
)
|
||||
|
||||
# output fields are not on the node object directly, they are on the output type
|
||||
if edge.source.field not in source_node.get_output_type().__fields__:
|
||||
raise NodeFieldNotFoundError(
|
||||
f"Edge source field {edge.source.field} does not exist in node {edge.source.node_id}"
|
||||
)
|
||||
|
||||
# input fields are on the node
|
||||
if edge.destination.field not in destination_node.__fields__:
|
||||
raise NodeFieldNotFoundError(
|
||||
f"Edge destination field {edge.destination.field} does not exist in node {edge.destination.node_id}"
|
||||
)
|
||||
|
||||
return values
|
||||
|
||||
def add_node(self, node: BaseInvocation) -> None:
|
||||
"""Adds a node to a graph
|
||||
|
||||
@@ -336,108 +373,53 @@ class Graph(BaseModel):
|
||||
except KeyError:
|
||||
pass
|
||||
|
||||
def validate_self(self) -> None:
|
||||
"""
|
||||
Validates the graph.
|
||||
|
||||
Raises an exception if the graph is invalid:
|
||||
- `DuplicateNodeIdError`
|
||||
- `NodeIdMismatchError`
|
||||
- `InvalidSubGraphError`
|
||||
- `NodeNotFoundError`
|
||||
- `NodeFieldNotFoundError`
|
||||
- `CyclicalGraphError`
|
||||
- `InvalidEdgeError`
|
||||
"""
|
||||
|
||||
# Validate that all node ids are unique
|
||||
node_ids = [n.id for n in self.nodes.values()]
|
||||
duplicate_node_ids = set([node_id for node_id in node_ids if node_ids.count(node_id) >= 2])
|
||||
if duplicate_node_ids:
|
||||
raise DuplicateNodeIdError(f"Node ids must be unique, found duplicates {duplicate_node_ids}")
|
||||
|
||||
# Validate that all node ids match the keys in the nodes dict
|
||||
for k, v in self.nodes.items():
|
||||
if k != v.id:
|
||||
raise NodeIdMismatchError(f"Node ids must match, got {k} and {v.id}")
|
||||
def is_valid(self) -> bool:
|
||||
"""Validates the graph."""
|
||||
|
||||
# Validate all subgraphs
|
||||
for gn in (n for n in self.nodes.values() if isinstance(n, GraphInvocation)):
|
||||
try:
|
||||
gn.graph.validate_self()
|
||||
except Exception as e:
|
||||
raise InvalidSubGraphError(f"Subgraph {gn.id} is invalid") from e
|
||||
if not gn.graph.is_valid():
|
||||
return False
|
||||
|
||||
# Validate that all edges match nodes and fields in the graph
|
||||
for edge in self.edges:
|
||||
source_node = self.nodes.get(edge.source.node_id, None)
|
||||
if source_node is None:
|
||||
raise NodeNotFoundError(f"Edge source node {edge.source.node_id} does not exist in the graph")
|
||||
|
||||
destination_node = self.nodes.get(edge.destination.node_id, None)
|
||||
if destination_node is None:
|
||||
raise NodeNotFoundError(f"Edge destination node {edge.destination.node_id} does not exist in the graph")
|
||||
|
||||
# output fields are not on the node object directly, they are on the output type
|
||||
if edge.source.field not in source_node.get_output_type().__fields__:
|
||||
raise NodeFieldNotFoundError(
|
||||
f"Edge source field {edge.source.field} does not exist in node {edge.source.node_id}"
|
||||
)
|
||||
|
||||
# input fields are on the node
|
||||
if edge.destination.field not in destination_node.__fields__:
|
||||
raise NodeFieldNotFoundError(
|
||||
f"Edge destination field {edge.destination.field} does not exist in node {edge.destination.node_id}"
|
||||
)
|
||||
# Validate all edges reference nodes in the graph
|
||||
node_ids = set([e.source.node_id for e in self.edges] + [e.destination.node_id for e in self.edges])
|
||||
if not all((self.has_node(node_id) for node_id in node_ids)):
|
||||
return False
|
||||
|
||||
# Validate there are no cycles
|
||||
g = self.nx_graph_flat()
|
||||
if not nx.is_directed_acyclic_graph(g):
|
||||
raise CyclicalGraphError("Graph contains cycles")
|
||||
return False
|
||||
|
||||
# Validate all edge connections are valid
|
||||
for e in self.edges:
|
||||
if not are_connections_compatible(
|
||||
self.get_node(e.source.node_id),
|
||||
e.source.field,
|
||||
self.get_node(e.destination.node_id),
|
||||
e.destination.field,
|
||||
):
|
||||
raise InvalidEdgeError(
|
||||
f"Invalid edge from {e.source.node_id}.{e.source.field} to {e.destination.node_id}.{e.destination.field}"
|
||||
if not all(
|
||||
(
|
||||
are_connections_compatible(
|
||||
self.get_node(e.source.node_id),
|
||||
e.source.field,
|
||||
self.get_node(e.destination.node_id),
|
||||
e.destination.field,
|
||||
)
|
||||
|
||||
# Validate all iterators & collectors
|
||||
# TODO: may need to validate all iterators & collectors in subgraphs so edge connections in parent graphs will be available
|
||||
for n in self.nodes.values():
|
||||
if isinstance(n, IterateInvocation) and not self._is_iterator_connection_valid(n.id):
|
||||
raise InvalidEdgeError(f"Invalid iterator node {n.id}")
|
||||
if isinstance(n, CollectInvocation) and not self._is_collector_connection_valid(n.id):
|
||||
raise InvalidEdgeError(f"Invalid collector node {n.id}")
|
||||
|
||||
return None
|
||||
|
||||
def is_valid(self) -> bool:
|
||||
"""
|
||||
Checks if the graph is valid.
|
||||
|
||||
Raises `UnknownGraphValidationError` if there is a problem validating the graph (not a validation error).
|
||||
"""
|
||||
try:
|
||||
self.validate_self()
|
||||
return True
|
||||
except (
|
||||
DuplicateNodeIdError,
|
||||
NodeIdMismatchError,
|
||||
InvalidSubGraphError,
|
||||
NodeNotFoundError,
|
||||
NodeFieldNotFoundError,
|
||||
CyclicalGraphError,
|
||||
InvalidEdgeError,
|
||||
for e in self.edges
|
||||
)
|
||||
):
|
||||
return False
|
||||
except Exception as e:
|
||||
raise UnknownGraphValidationError(f"Problem validating graph {e}") from e
|
||||
|
||||
# Validate all iterators
|
||||
# TODO: may need to validate all iterators in subgraphs so edge connections in parent graphs will be available
|
||||
if not all(
|
||||
(self._is_iterator_connection_valid(n.id) for n in self.nodes.values() if isinstance(n, IterateInvocation))
|
||||
):
|
||||
return False
|
||||
|
||||
# Validate all collectors
|
||||
# TODO: may need to validate all collectors in subgraphs so edge connections in parent graphs will be available
|
||||
if not all(
|
||||
(self._is_collector_connection_valid(n.id) for n in self.nodes.values() if isinstance(n, CollectInvocation))
|
||||
):
|
||||
return False
|
||||
|
||||
return True
|
||||
|
||||
def _validate_edge(self, edge: Edge):
|
||||
"""Validates that a new edge doesn't create a cycle in the graph"""
|
||||
@@ -818,12 +800,6 @@ class GraphExecutionState(BaseModel):
|
||||
default_factory=dict,
|
||||
)
|
||||
|
||||
@validator("graph")
|
||||
def graph_is_valid(cls, v: Graph):
|
||||
"""Validates that the graph is valid"""
|
||||
v.validate_self()
|
||||
return v
|
||||
|
||||
class Config:
|
||||
schema_extra = {
|
||||
"required": [
|
||||
|
||||
@@ -9,7 +9,6 @@ from PIL import Image, PngImagePlugin
|
||||
from PIL.Image import Image as PILImageType
|
||||
from send2trash import send2trash
|
||||
|
||||
from invokeai.app.services.config.invokeai_config import InvokeAIAppConfig
|
||||
from invokeai.app.util.thumbnails import get_thumbnail_name, make_thumbnail
|
||||
|
||||
|
||||
@@ -80,7 +79,6 @@ class DiskImageFileStorage(ImageFileStorageBase):
|
||||
__cache_ids: Queue # TODO: this is an incredibly naive cache
|
||||
__cache: Dict[Path, PILImageType]
|
||||
__max_cache_size: int
|
||||
__compress_level: int
|
||||
|
||||
def __init__(self, output_folder: Union[str, Path]):
|
||||
self.__cache = dict()
|
||||
@@ -89,7 +87,7 @@ class DiskImageFileStorage(ImageFileStorageBase):
|
||||
|
||||
self.__output_folder: Path = output_folder if isinstance(output_folder, Path) else Path(output_folder)
|
||||
self.__thumbnails_folder = self.__output_folder / "thumbnails"
|
||||
self.__compress_level = InvokeAIAppConfig.get_config().png_compress_level
|
||||
|
||||
# Validate required output folders at launch
|
||||
self.__validate_storage_folders()
|
||||
|
||||
@@ -136,7 +134,7 @@ class DiskImageFileStorage(ImageFileStorageBase):
|
||||
if original_workflow is not None:
|
||||
pnginfo.add_text("invokeai_workflow", original_workflow)
|
||||
|
||||
image.save(image_path, "PNG", pnginfo=pnginfo, compress_level=self.__compress_level)
|
||||
image.save(image_path, "PNG", pnginfo=pnginfo)
|
||||
|
||||
thumbnail_name = get_thumbnail_name(image_name)
|
||||
thumbnail_path = self.get_path(thumbnail_name, thumbnail=True)
|
||||
|
||||
@@ -584,7 +584,7 @@ class SqliteImageRecordStorage(ImageRecordStorageBase):
|
||||
FROM images
|
||||
JOIN board_images ON images.image_name = board_images.image_name
|
||||
WHERE board_images.board_id = ?
|
||||
ORDER BY images.starred DESC, images.created_at DESC
|
||||
ORDER BY images.created_at DESC
|
||||
LIMIT 1;
|
||||
""",
|
||||
(board_id,),
|
||||
|
||||
@@ -41,25 +41,23 @@ class ImageServiceABC(ABC):
|
||||
_on_changed_callbacks: list[Callable[[ImageDTO], None]]
|
||||
_on_deleted_callbacks: list[Callable[[str], None]]
|
||||
|
||||
def __init__(self) -> None:
|
||||
self._on_changed_callbacks = list()
|
||||
self._on_deleted_callbacks = list()
|
||||
|
||||
@abstractmethod
|
||||
def on_changed(self, on_changed: Callable[[ImageDTO], None]) -> None:
|
||||
"""Register a callback for when an image is changed"""
|
||||
self._on_changed_callbacks.append(on_changed)
|
||||
"""Register a callback for when an item is changed"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def on_deleted(self, on_deleted: Callable[[str], None]) -> None:
|
||||
"""Register a callback for when an image is deleted"""
|
||||
self._on_deleted_callbacks.append(on_deleted)
|
||||
"""Register a callback for when an item is deleted"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def _on_changed(self, item: ImageDTO) -> None:
|
||||
for callback in self._on_changed_callbacks:
|
||||
callback(item)
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def _on_deleted(self, item_id: str) -> None:
|
||||
for callback in self._on_deleted_callbacks:
|
||||
callback(item_id)
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def create(
|
||||
@@ -182,9 +180,26 @@ class ImageServiceDependencies:
|
||||
|
||||
class ImageService(ImageServiceABC):
|
||||
_services: ImageServiceDependencies
|
||||
_on_changed_callbacks: list[Callable[[ImageDTO], None]] = list()
|
||||
_on_deleted_callbacks: list[Callable[[str], None]] = list()
|
||||
|
||||
def on_changed(self, on_changed: Callable[[ImageDTO], None]) -> None:
|
||||
"""Register a callback for when an item is changed"""
|
||||
self._on_changed_callbacks.append(on_changed)
|
||||
|
||||
def on_deleted(self, on_deleted: Callable[[str], None]) -> None:
|
||||
"""Register a callback for when an item is deleted"""
|
||||
self._on_deleted_callbacks.append(on_deleted)
|
||||
|
||||
def _on_changed(self, item: ImageDTO) -> None:
|
||||
for callback in self._on_changed_callbacks:
|
||||
callback(item)
|
||||
|
||||
def _on_deleted(self, item_id: str) -> None:
|
||||
for callback in self._on_deleted_callbacks:
|
||||
callback(item_id)
|
||||
|
||||
def __init__(self, services: ImageServiceDependencies):
|
||||
super().__init__()
|
||||
self._services = services
|
||||
|
||||
def create(
|
||||
|
||||
@@ -2,38 +2,24 @@ from abc import ABC, abstractmethod
|
||||
from typing import Optional, Union
|
||||
|
||||
from invokeai.app.invocations.baseinvocation import BaseInvocation, BaseInvocationOutput
|
||||
from invokeai.app.services.invocation_cache.invocation_cache_common import InvocationCacheStatus
|
||||
|
||||
|
||||
class InvocationCacheBase(ABC):
|
||||
"""
|
||||
Base class for invocation caches.
|
||||
When an invocation is executed, it is hashed and its output stored in the cache.
|
||||
When new invocations are executed, if they are flagged with `use_cache`, they
|
||||
will attempt to pull their value from the cache before executing.
|
||||
|
||||
Implementations should register for the `on_deleted` event of the `images` and `latents`
|
||||
services, and delete any cached outputs that reference the deleted image or latent.
|
||||
|
||||
See the memory implementation for an example.
|
||||
|
||||
Implementations should respect the `node_cache_size` configuration value, and skip all
|
||||
cache logic if the value is set to 0.
|
||||
"""
|
||||
"""Base class for invocation caches."""
|
||||
|
||||
@abstractmethod
|
||||
def get(self, key: Union[int, str]) -> Optional[BaseInvocationOutput]:
|
||||
"""Retrieves an invocation output from the cache"""
|
||||
"""Retrieves and invocation output from the cache"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def save(self, key: Union[int, str], invocation_output: BaseInvocationOutput) -> None:
|
||||
def save(self, value: BaseInvocationOutput) -> None:
|
||||
"""Stores an invocation output in the cache"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def delete(self, key: Union[int, str]) -> None:
|
||||
"""Deletes an invocation output from the cache"""
|
||||
"""Deleted an invocation output from the cache"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
@@ -41,22 +27,8 @@ class InvocationCacheBase(ABC):
|
||||
"""Clears the cache"""
|
||||
pass
|
||||
|
||||
@classmethod
|
||||
@abstractmethod
|
||||
def create_key(self, invocation: BaseInvocation) -> int:
|
||||
"""Gets the key for the invocation's cache item"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def disable(self) -> None:
|
||||
"""Disables the cache, overriding the max cache size"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def enable(self) -> None:
|
||||
"""Enables the cache, letting the the max cache size take effect"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def get_status(self) -> InvocationCacheStatus:
|
||||
"""Returns the status of the cache"""
|
||||
def create_key(cls, value: BaseInvocation) -> Union[int, str]:
|
||||
"""Creates the cache key for an invocation"""
|
||||
pass
|
||||
|
||||
@@ -1,9 +0,0 @@
|
||||
from pydantic import BaseModel, Field
|
||||
|
||||
|
||||
class InvocationCacheStatus(BaseModel):
|
||||
size: int = Field(description="The current size of the invocation cache")
|
||||
hits: int = Field(description="The number of cache hits")
|
||||
misses: int = Field(description="The number of cache misses")
|
||||
enabled: bool = Field(description="Whether the invocation cache is enabled")
|
||||
max_size: int = Field(description="The maximum size of the invocation cache")
|
||||
@@ -1,126 +1,70 @@
|
||||
from collections import OrderedDict
|
||||
from dataclasses import dataclass, field
|
||||
from threading import Lock
|
||||
from queue import Queue
|
||||
from typing import Optional, Union
|
||||
|
||||
|
||||
from invokeai.app.invocations.baseinvocation import BaseInvocation, BaseInvocationOutput
|
||||
from invokeai.app.services.invocation_cache.invocation_cache_base import InvocationCacheBase
|
||||
from invokeai.app.services.invocation_cache.invocation_cache_common import InvocationCacheStatus
|
||||
from invokeai.app.services.invoker import Invoker
|
||||
|
||||
|
||||
@dataclass(order=True)
|
||||
class CachedItem:
|
||||
invocation_output: BaseInvocationOutput = field(compare=False)
|
||||
invocation_output_json: str = field(compare=False)
|
||||
|
||||
|
||||
class MemoryInvocationCache(InvocationCacheBase):
|
||||
_cache: OrderedDict[Union[int, str], CachedItem]
|
||||
_max_cache_size: int
|
||||
_disabled: bool
|
||||
_hits: int
|
||||
_misses: int
|
||||
_invoker: Invoker
|
||||
_lock: Lock
|
||||
__cache: dict[Union[int, str], tuple[BaseInvocationOutput, str]]
|
||||
__max_cache_size: int
|
||||
__cache_ids: Queue
|
||||
__invoker: Invoker
|
||||
|
||||
def __init__(self, max_cache_size: int = 0) -> None:
|
||||
self._cache = OrderedDict()
|
||||
self._max_cache_size = max_cache_size
|
||||
self._disabled = False
|
||||
self._hits = 0
|
||||
self._misses = 0
|
||||
self._lock = Lock()
|
||||
def __init__(self, max_cache_size: int = 512) -> None:
|
||||
self.__cache = dict()
|
||||
self.__max_cache_size = max_cache_size
|
||||
self.__cache_ids = Queue()
|
||||
|
||||
def start(self, invoker: Invoker) -> None:
|
||||
self._invoker = invoker
|
||||
if self._max_cache_size == 0:
|
||||
return
|
||||
self._invoker.services.images.on_deleted(self._delete_by_match)
|
||||
self._invoker.services.latents.on_deleted(self._delete_by_match)
|
||||
self.__invoker = invoker
|
||||
self.__invoker.services.images.on_deleted(self.delete_by_match)
|
||||
|
||||
def get(self, key: Union[int, str]) -> Optional[BaseInvocationOutput]:
|
||||
with self._lock:
|
||||
if self._max_cache_size == 0 or self._disabled:
|
||||
return None
|
||||
item = self._cache.get(key, None)
|
||||
if item is not None:
|
||||
self._hits += 1
|
||||
self._cache.move_to_end(key)
|
||||
return item.invocation_output
|
||||
self._misses += 1
|
||||
if self.__max_cache_size == 0:
|
||||
return None
|
||||
|
||||
def save(self, key: Union[int, str], invocation_output: BaseInvocationOutput) -> None:
|
||||
with self._lock:
|
||||
if self._max_cache_size == 0 or self._disabled or key in self._cache:
|
||||
return
|
||||
# If the cache is full, we need to remove the least used
|
||||
number_to_delete = len(self._cache) + 1 - self._max_cache_size
|
||||
self._delete_oldest_access(number_to_delete)
|
||||
self._cache[key] = CachedItem(invocation_output, invocation_output.json())
|
||||
item = self.__cache.get(key, None)
|
||||
if item is not None:
|
||||
return item[0]
|
||||
|
||||
def _delete_oldest_access(self, number_to_delete: int) -> None:
|
||||
number_to_delete = min(number_to_delete, len(self._cache))
|
||||
for _ in range(number_to_delete):
|
||||
self._cache.popitem(last=False)
|
||||
def save(self, value: BaseInvocationOutput) -> None:
|
||||
if self.__max_cache_size == 0:
|
||||
return None
|
||||
|
||||
def _delete(self, key: Union[int, str]) -> None:
|
||||
if self._max_cache_size == 0:
|
||||
return
|
||||
if key in self._cache:
|
||||
del self._cache[key]
|
||||
value_json = value.json(exclude={"id"})
|
||||
key = hash(value_json)
|
||||
|
||||
if key not in self.__cache:
|
||||
self.__cache[key] = (value, value_json)
|
||||
self.__cache_ids.put(key)
|
||||
if self.__cache_ids.qsize() > self.__max_cache_size:
|
||||
try:
|
||||
self.__cache.pop(self.__cache_ids.get())
|
||||
except KeyError:
|
||||
pass
|
||||
|
||||
def delete(self, key: Union[int, str]) -> None:
|
||||
with self._lock:
|
||||
return self._delete(key)
|
||||
if self.__max_cache_size == 0:
|
||||
return None
|
||||
|
||||
if key in self.__cache:
|
||||
del self.__cache[key]
|
||||
|
||||
def delete_by_match(self, to_match: str) -> None:
|
||||
to_delete = []
|
||||
for name, item in self.__cache.items():
|
||||
if to_match in item[1]:
|
||||
to_delete.append(name)
|
||||
for key in to_delete:
|
||||
self.delete(key)
|
||||
|
||||
def clear(self, *args, **kwargs) -> None:
|
||||
with self._lock:
|
||||
if self._max_cache_size == 0:
|
||||
return
|
||||
self._cache.clear()
|
||||
self._misses = 0
|
||||
self._hits = 0
|
||||
self.__cache.clear()
|
||||
self.__cache_ids = Queue()
|
||||
|
||||
@staticmethod
|
||||
def create_key(invocation: BaseInvocation) -> int:
|
||||
return hash(invocation.json(exclude={"id"}))
|
||||
|
||||
def disable(self) -> None:
|
||||
with self._lock:
|
||||
if self._max_cache_size == 0:
|
||||
return
|
||||
self._disabled = True
|
||||
|
||||
def enable(self) -> None:
|
||||
with self._lock:
|
||||
if self._max_cache_size == 0:
|
||||
return
|
||||
self._disabled = False
|
||||
|
||||
def get_status(self) -> InvocationCacheStatus:
|
||||
with self._lock:
|
||||
return InvocationCacheStatus(
|
||||
hits=self._hits,
|
||||
misses=self._misses,
|
||||
enabled=not self._disabled and self._max_cache_size > 0,
|
||||
size=len(self._cache),
|
||||
max_size=self._max_cache_size,
|
||||
)
|
||||
|
||||
def _delete_by_match(self, to_match: str) -> None:
|
||||
with self._lock:
|
||||
if self._max_cache_size == 0:
|
||||
return
|
||||
keys_to_delete = set()
|
||||
for key, cached_item in self._cache.items():
|
||||
if to_match in cached_item.invocation_output_json:
|
||||
keys_to_delete.add(key)
|
||||
if not keys_to_delete:
|
||||
return
|
||||
for key in keys_to_delete:
|
||||
self._delete(key)
|
||||
self._invoker.services.logger.debug(
|
||||
f"Deleted {len(keys_to_delete)} cached invocation outputs for {to_match}"
|
||||
)
|
||||
@classmethod
|
||||
def create_key(cls, value: BaseInvocation) -> Union[int, str]:
|
||||
return hash(value.json(exclude={"id"}))
|
||||
|
||||
@@ -12,12 +12,9 @@ class InvocationQueueItem(BaseModel):
|
||||
graph_execution_state_id: str = Field(description="The ID of the graph execution state")
|
||||
invocation_id: str = Field(description="The ID of the node being invoked")
|
||||
session_queue_id: str = Field(description="The ID of the session queue from which this invocation queue item came")
|
||||
session_queue_item_id: int = Field(
|
||||
session_queue_item_id: str = Field(
|
||||
description="The ID of session queue item from which this invocation queue item came"
|
||||
)
|
||||
session_queue_batch_id: str = Field(
|
||||
description="The ID of the session batch from which this invocation queue item came"
|
||||
)
|
||||
invoke_all: bool = Field(default=False)
|
||||
timestamp: float = Field(default_factory=time.time)
|
||||
|
||||
|
||||
@@ -9,7 +9,6 @@ if TYPE_CHECKING:
|
||||
from invokeai.app.services.board_images import BoardImagesServiceABC
|
||||
from invokeai.app.services.boards import BoardServiceABC
|
||||
from invokeai.app.services.config import InvokeAIAppConfig
|
||||
from invokeai.app.services.download_manager import DownloadQueueServiceBase
|
||||
from invokeai.app.services.events import EventServiceBase
|
||||
from invokeai.app.services.graph import GraphExecutionState, LibraryGraph
|
||||
from invokeai.app.services.images import ImageServiceABC
|
||||
@@ -19,9 +18,7 @@ if TYPE_CHECKING:
|
||||
from invokeai.app.services.invoker import InvocationProcessorABC
|
||||
from invokeai.app.services.item_storage import ItemStorageABC
|
||||
from invokeai.app.services.latent_storage import LatentsStorageBase
|
||||
from invokeai.app.services.model_install_service import ModelInstallServiceBase
|
||||
from invokeai.app.services.model_loader_service import ModelLoadServiceBase
|
||||
from invokeai.app.services.model_record_service import ModelRecordServiceBase
|
||||
from invokeai.app.services.model_manager_service import ModelManagerServiceBase
|
||||
from invokeai.app.services.session_processor.session_processor_base import SessionProcessorBase
|
||||
from invokeai.app.services.session_queue.session_queue_base import SessionQueueBase
|
||||
|
||||
@@ -38,11 +35,8 @@ class InvocationServices:
|
||||
graph_library: "ItemStorageABC[LibraryGraph]"
|
||||
images: "ImageServiceABC"
|
||||
latents: "LatentsStorageBase"
|
||||
download_queue: "DownloadQueueServiceBase"
|
||||
model_record_store: "ModelRecordServiceBase"
|
||||
model_loader: "ModelLoadServiceBase"
|
||||
model_installer: "ModelInstallServiceBase"
|
||||
logger: "Logger"
|
||||
model_manager: "ModelManagerServiceBase"
|
||||
processor: "InvocationProcessorABC"
|
||||
performance_statistics: "InvocationStatsServiceBase"
|
||||
queue: "InvocationQueueABC"
|
||||
@@ -61,10 +55,7 @@ class InvocationServices:
|
||||
images: "ImageServiceABC",
|
||||
latents: "LatentsStorageBase",
|
||||
logger: "Logger",
|
||||
download_queue: "DownloadQueueServiceBase",
|
||||
model_record_store: "ModelRecordServiceBase",
|
||||
model_loader: "ModelLoadServiceBase",
|
||||
model_installer: "ModelInstallServiceBase",
|
||||
model_manager: "ModelManagerServiceBase",
|
||||
processor: "InvocationProcessorABC",
|
||||
performance_statistics: "InvocationStatsServiceBase",
|
||||
queue: "InvocationQueueABC",
|
||||
@@ -81,10 +72,7 @@ class InvocationServices:
|
||||
self.images = images
|
||||
self.latents = latents
|
||||
self.logger = logger
|
||||
self.download_queue = download_queue
|
||||
self.model_record_store = model_record_store
|
||||
self.model_loader = model_loader
|
||||
self.model_installer = model_installer
|
||||
self.model_manager = model_manager
|
||||
self.processor = processor
|
||||
self.performance_statistics = performance_statistics
|
||||
self.queue = queue
|
||||
|
||||
@@ -38,12 +38,12 @@ import psutil
|
||||
import torch
|
||||
|
||||
import invokeai.backend.util.logging as logger
|
||||
from invokeai.backend.model_manager.cache import CacheStats
|
||||
from invokeai.backend.model_management.model_cache import CacheStats
|
||||
|
||||
from ..invocations.baseinvocation import BaseInvocation
|
||||
from .graph import GraphExecutionState
|
||||
from .item_storage import ItemStorageABC
|
||||
from .model_loader_service import ModelLoadServiceBase
|
||||
from .model_manager_service import ModelManagerService
|
||||
|
||||
# size of GIG in bytes
|
||||
GIG = 1073741824
|
||||
@@ -174,13 +174,13 @@ class InvocationStatsService(InvocationStatsServiceBase):
|
||||
graph_id: str
|
||||
start_time: float
|
||||
ram_used: int
|
||||
model_loader: ModelLoadServiceBase
|
||||
model_manager: ModelManagerService
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
invocation: BaseInvocation,
|
||||
graph_id: str,
|
||||
model_loader: ModelLoadServiceBase,
|
||||
model_manager: ModelManagerService,
|
||||
collector: "InvocationStatsServiceBase",
|
||||
):
|
||||
"""Initialize statistics for this run."""
|
||||
@@ -189,15 +189,15 @@ class InvocationStatsService(InvocationStatsServiceBase):
|
||||
self.graph_id = graph_id
|
||||
self.start_time = 0.0
|
||||
self.ram_used = 0
|
||||
self.model_loader = model_loader
|
||||
self.model_manager = model_manager
|
||||
|
||||
def __enter__(self):
|
||||
self.start_time = time.time()
|
||||
if torch.cuda.is_available():
|
||||
torch.cuda.reset_peak_memory_stats()
|
||||
self.ram_used = psutil.Process().memory_info().rss
|
||||
if self.model_loader:
|
||||
self.model_loader.collect_cache_stats(self.collector._cache_stats[self.graph_id])
|
||||
if self.model_manager:
|
||||
self.model_manager.collect_cache_stats(self.collector._cache_stats[self.graph_id])
|
||||
|
||||
def __exit__(self, *args):
|
||||
"""Called on exit from the context."""
|
||||
@@ -208,7 +208,7 @@ class InvocationStatsService(InvocationStatsServiceBase):
|
||||
)
|
||||
self.collector.update_invocation_stats(
|
||||
graph_id=self.graph_id,
|
||||
invocation_type=self.invocation.type,
|
||||
invocation_type=self.invocation.type, # type: ignore - `type` is not on the `BaseInvocation` model, but *is* on all invocations
|
||||
time_used=time.time() - self.start_time,
|
||||
vram_used=torch.cuda.max_memory_allocated() / GIG if torch.cuda.is_available() else 0.0,
|
||||
)
|
||||
@@ -217,12 +217,12 @@ class InvocationStatsService(InvocationStatsServiceBase):
|
||||
self,
|
||||
invocation: BaseInvocation,
|
||||
graph_execution_state_id: str,
|
||||
model_loader: ModelLoadServiceBase,
|
||||
model_manager: ModelManagerService,
|
||||
) -> StatsContext:
|
||||
if not self._stats.get(graph_execution_state_id): # first time we're seeing this
|
||||
self._stats[graph_execution_state_id] = NodeLog()
|
||||
self._cache_stats[graph_execution_state_id] = CacheStats()
|
||||
return self.StatsContext(invocation, graph_execution_state_id, model_loader, self)
|
||||
return self.StatsContext(invocation, graph_execution_state_id, model_manager, self)
|
||||
|
||||
def reset_all_stats(self):
|
||||
"""Zero all statistics"""
|
||||
|
||||
@@ -18,12 +18,7 @@ class Invoker:
|
||||
self._start()
|
||||
|
||||
def invoke(
|
||||
self,
|
||||
session_queue_id: str,
|
||||
session_queue_item_id: int,
|
||||
session_queue_batch_id: str,
|
||||
graph_execution_state: GraphExecutionState,
|
||||
invoke_all: bool = False,
|
||||
self, queue_id: str, queue_item_id: str, graph_execution_state: GraphExecutionState, invoke_all: bool = False
|
||||
) -> Optional[str]:
|
||||
"""Determines the next node to invoke and enqueues it, preparing if needed.
|
||||
Returns the id of the queued node, or `None` if there are no nodes left to enqueue."""
|
||||
@@ -39,9 +34,8 @@ class Invoker:
|
||||
# Queue the invocation
|
||||
self.services.queue.put(
|
||||
InvocationQueueItem(
|
||||
session_queue_id=session_queue_id,
|
||||
session_queue_item_id=session_queue_item_id,
|
||||
session_queue_batch_id=session_queue_batch_id,
|
||||
session_queue_item_id=queue_item_id,
|
||||
session_queue_id=queue_id,
|
||||
graph_execution_state_id=graph_execution_state.id,
|
||||
invocation_id=invocation.id,
|
||||
invoke_all=invoke_all,
|
||||
|
||||
@@ -3,7 +3,7 @@
|
||||
from abc import ABC, abstractmethod
|
||||
from pathlib import Path
|
||||
from queue import Queue
|
||||
from typing import Callable, Dict, Optional, Union
|
||||
from typing import Dict, Optional, Union
|
||||
|
||||
import torch
|
||||
|
||||
@@ -11,13 +11,6 @@ import torch
|
||||
class LatentsStorageBase(ABC):
|
||||
"""Responsible for storing and retrieving latents."""
|
||||
|
||||
_on_changed_callbacks: list[Callable[[torch.Tensor], None]]
|
||||
_on_deleted_callbacks: list[Callable[[str], None]]
|
||||
|
||||
def __init__(self) -> None:
|
||||
self._on_changed_callbacks = list()
|
||||
self._on_deleted_callbacks = list()
|
||||
|
||||
@abstractmethod
|
||||
def get(self, name: str) -> torch.Tensor:
|
||||
pass
|
||||
@@ -30,22 +23,6 @@ class LatentsStorageBase(ABC):
|
||||
def delete(self, name: str) -> None:
|
||||
pass
|
||||
|
||||
def on_changed(self, on_changed: Callable[[torch.Tensor], None]) -> None:
|
||||
"""Register a callback for when an item is changed"""
|
||||
self._on_changed_callbacks.append(on_changed)
|
||||
|
||||
def on_deleted(self, on_deleted: Callable[[str], None]) -> None:
|
||||
"""Register a callback for when an item is deleted"""
|
||||
self._on_deleted_callbacks.append(on_deleted)
|
||||
|
||||
def _on_changed(self, item: torch.Tensor) -> None:
|
||||
for callback in self._on_changed_callbacks:
|
||||
callback(item)
|
||||
|
||||
def _on_deleted(self, item_id: str) -> None:
|
||||
for callback in self._on_deleted_callbacks:
|
||||
callback(item_id)
|
||||
|
||||
|
||||
class ForwardCacheLatentsStorage(LatentsStorageBase):
|
||||
"""Caches the latest N latents in memory, writing-thorugh to and reading from underlying storage"""
|
||||
@@ -56,7 +33,6 @@ class ForwardCacheLatentsStorage(LatentsStorageBase):
|
||||
__underlying_storage: LatentsStorageBase
|
||||
|
||||
def __init__(self, underlying_storage: LatentsStorageBase, max_cache_size: int = 20):
|
||||
super().__init__()
|
||||
self.__underlying_storage = underlying_storage
|
||||
self.__cache = dict()
|
||||
self.__cache_ids = Queue()
|
||||
@@ -74,13 +50,11 @@ class ForwardCacheLatentsStorage(LatentsStorageBase):
|
||||
def save(self, name: str, data: torch.Tensor) -> None:
|
||||
self.__underlying_storage.save(name, data)
|
||||
self.__set_cache(name, data)
|
||||
self._on_changed(data)
|
||||
|
||||
def delete(self, name: str) -> None:
|
||||
self.__underlying_storage.delete(name)
|
||||
if name in self.__cache:
|
||||
del self.__cache[name]
|
||||
self._on_deleted(name)
|
||||
|
||||
def __get_cache(self, name: str) -> Optional[torch.Tensor]:
|
||||
return None if name not in self.__cache else self.__cache[name]
|
||||
|
||||
@@ -1,192 +0,0 @@
|
||||
# Copyright 2023 Lincoln Stein and the InvokeAI Team
|
||||
|
||||
"""
|
||||
Convert and merge models.
|
||||
"""
|
||||
|
||||
from __future__ import annotations
|
||||
|
||||
from abc import ABC, abstractmethod
|
||||
from pathlib import Path
|
||||
from shutil import move, rmtree
|
||||
from typing import List, Optional
|
||||
|
||||
from pydantic import Field
|
||||
|
||||
from invokeai.backend.model_manager.merge import MergeInterpolationMethod, ModelMerger
|
||||
|
||||
from .config import InvokeAIAppConfig
|
||||
from .model_install_service import ModelInstallServiceBase
|
||||
from .model_loader_service import ModelInfo, ModelLoadServiceBase
|
||||
from .model_record_service import ModelConfigBase, ModelRecordServiceBase, ModelType, SubModelType
|
||||
|
||||
|
||||
class ModelConvertBase(ABC):
|
||||
"""Convert and merge models."""
|
||||
|
||||
@abstractmethod
|
||||
def __init__(
|
||||
cls,
|
||||
loader: ModelLoadServiceBase,
|
||||
installer: ModelInstallServiceBase,
|
||||
store: ModelRecordServiceBase,
|
||||
):
|
||||
"""Initialize ModelConvert with loader, installer and configuration store."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def convert_model(
|
||||
self,
|
||||
key: str,
|
||||
dest_directory: Optional[Path] = None,
|
||||
) -> ModelConfigBase:
|
||||
"""
|
||||
Convert a checkpoint file into a diffusers folder.
|
||||
|
||||
It will delete the cached version ans well as the
|
||||
original checkpoint file if it is in the models directory.
|
||||
:param key: Unique key of model.
|
||||
:dest_directory: Optional place to put converted file. If not specified,
|
||||
will be stored in the `models_dir`.
|
||||
|
||||
This will raise a ValueError unless the model is a checkpoint.
|
||||
This will raise an UnknownModelException if key is unknown.
|
||||
"""
|
||||
pass
|
||||
|
||||
def merge_models(
|
||||
self,
|
||||
model_keys: List[str] = Field(
|
||||
default=None, min_items=2, max_items=3, description="List of model keys to merge"
|
||||
),
|
||||
merged_model_name: Optional[str] = Field(default=None, description="Name of destination model after merging"),
|
||||
alpha: Optional[float] = 0.5,
|
||||
interp: Optional[MergeInterpolationMethod] = None,
|
||||
force: Optional[bool] = False,
|
||||
merge_dest_directory: Optional[Path] = None,
|
||||
) -> ModelConfigBase:
|
||||
"""
|
||||
Merge two to three diffusrs pipeline models and save as a new model.
|
||||
|
||||
:param model_keys: List of 2-3 model unique keys to merge
|
||||
:param merged_model_name: Name of destination merged model
|
||||
:param alpha: Alpha strength to apply to 2d and 3d model
|
||||
:param interp: Interpolation method. None (default)
|
||||
:param merge_dest_directory: Save the merged model to the designated directory (with 'merged_model_name' appended)
|
||||
"""
|
||||
pass
|
||||
|
||||
|
||||
class ModelConvert(ModelConvertBase):
|
||||
"""Implementation of ModelConvertBase."""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
loader: ModelLoadServiceBase,
|
||||
installer: ModelInstallServiceBase,
|
||||
store: ModelRecordServiceBase,
|
||||
):
|
||||
"""Initialize ModelConvert with loader, installer and configuration store."""
|
||||
self.loader = loader
|
||||
self.installer = installer
|
||||
self.store = store
|
||||
|
||||
def convert_model(
|
||||
self,
|
||||
key: str,
|
||||
dest_directory: Optional[Path] = None,
|
||||
) -> ModelConfigBase:
|
||||
"""
|
||||
Convert a checkpoint file into a diffusers folder.
|
||||
|
||||
It will delete the cached version as well as the
|
||||
original checkpoint file if it is in the models directory.
|
||||
:param key: Unique key of model.
|
||||
:dest_directory: Optional place to put converted file. If not specified,
|
||||
will be stored in the `models_dir`.
|
||||
|
||||
This will raise a ValueError unless the model is a checkpoint.
|
||||
This will raise an UnknownModelException if key is unknown.
|
||||
"""
|
||||
new_diffusers_path = None
|
||||
config = InvokeAIAppConfig.get_config()
|
||||
|
||||
try:
|
||||
info: ModelConfigBase = self.store.get_model(key)
|
||||
|
||||
if info.model_format != "checkpoint":
|
||||
raise ValueError(f"not a checkpoint format model: {info.name}")
|
||||
|
||||
# We are taking advantage of a side effect of get_model() that converts check points
|
||||
# into cached diffusers directories stored at `path`. It doesn't matter
|
||||
# what submodel type we request here, so we get the smallest.
|
||||
submodel = {"submodel_type": SubModelType.Scheduler} if info.model_type == ModelType.Main else {}
|
||||
converted_model: ModelInfo = self.loader.get_model(key, **submodel)
|
||||
|
||||
checkpoint_path = config.models_path / info.path
|
||||
old_diffusers_path = config.models_path / converted_model.location
|
||||
|
||||
# new values to write in
|
||||
update = info.dict()
|
||||
update.pop("config")
|
||||
update["model_format"] = "diffusers"
|
||||
update["path"] = str(converted_model.location)
|
||||
|
||||
if dest_directory:
|
||||
new_diffusers_path = Path(dest_directory) / info.name
|
||||
if new_diffusers_path.exists():
|
||||
raise ValueError(f"A diffusers model already exists at {new_diffusers_path}")
|
||||
move(old_diffusers_path, new_diffusers_path)
|
||||
update["path"] = new_diffusers_path.as_posix()
|
||||
|
||||
self.store.update_model(key, update)
|
||||
result = self.installer.sync_model_path(key, ignore_hash_change=True)
|
||||
except Exception as excp:
|
||||
# something went wrong, so don't leave dangling diffusers model in directory or it will cause a duplicate model error!
|
||||
if new_diffusers_path:
|
||||
rmtree(new_diffusers_path)
|
||||
raise excp
|
||||
|
||||
if checkpoint_path.exists() and checkpoint_path.is_relative_to(config.models_path):
|
||||
checkpoint_path.unlink()
|
||||
|
||||
return result
|
||||
|
||||
def merge_models(
|
||||
self,
|
||||
model_keys: List[str] = Field(
|
||||
default=None, min_items=2, max_items=3, description="List of model keys to merge"
|
||||
),
|
||||
merged_model_name: Optional[str] = Field(default=None, description="Name of destination model after merging"),
|
||||
alpha: Optional[float] = 0.5,
|
||||
interp: Optional[MergeInterpolationMethod] = None,
|
||||
force: Optional[bool] = False,
|
||||
merge_dest_directory: Optional[Path] = None,
|
||||
) -> ModelConfigBase:
|
||||
"""
|
||||
Merge two to three diffusrs pipeline models and save as a new model.
|
||||
|
||||
:param model_keys: List of 2-3 model unique keys to merge
|
||||
:param merged_model_name: Name of destination merged model
|
||||
:param alpha: Alpha strength to apply to 2d and 3d model
|
||||
:param interp: Interpolation method. None (default)
|
||||
:param merge_dest_directory: Save the merged model to the designated directory (with 'merged_model_name' appended)
|
||||
"""
|
||||
pass
|
||||
merger = ModelMerger(self.store)
|
||||
try:
|
||||
if not merged_model_name:
|
||||
merged_model_name = "+".join([self.store.get_model(x).name for x in model_keys])
|
||||
raise Exception("not implemented")
|
||||
|
||||
result = merger.merge_diffusion_models_and_save(
|
||||
model_keys=model_keys,
|
||||
merged_model_name=merged_model_name,
|
||||
alpha=alpha,
|
||||
interp=interp,
|
||||
force=force,
|
||||
merge_dest_directory=merge_dest_directory,
|
||||
)
|
||||
except AssertionError as e:
|
||||
raise ValueError(e)
|
||||
return result
|
||||
@@ -1,653 +0,0 @@
|
||||
# Copyright (c) 2023 Lincoln D. Stein and the InvokeAI Development Team
|
||||
|
||||
import re
|
||||
import tempfile
|
||||
from abc import ABC, abstractmethod
|
||||
from pathlib import Path
|
||||
from shutil import move, rmtree
|
||||
from typing import TYPE_CHECKING, Any, Callable, Dict, List, Literal, Optional, Set, Union
|
||||
|
||||
from pydantic import Field
|
||||
from pydantic.networks import AnyHttpUrl
|
||||
|
||||
from invokeai.app.services.config import InvokeAIAppConfig
|
||||
from invokeai.app.services.model_record_service import ModelRecordServiceBase
|
||||
from invokeai.backend import get_precision
|
||||
from invokeai.backend.model_manager.config import (
|
||||
BaseModelType,
|
||||
ModelConfigBase,
|
||||
ModelFormat,
|
||||
ModelType,
|
||||
ModelVariantType,
|
||||
SchedulerPredictionType,
|
||||
SubModelType,
|
||||
)
|
||||
from invokeai.backend.model_manager.download.model_queue import (
|
||||
HTTP_RE,
|
||||
REPO_ID_WITH_OPTIONAL_SUBFOLDER_RE,
|
||||
DownloadJobMetadataURL,
|
||||
DownloadJobRepoID,
|
||||
DownloadJobWithMetadata,
|
||||
)
|
||||
from invokeai.backend.model_manager.hash import FastModelHash
|
||||
from invokeai.backend.model_manager.models import InvalidModelException
|
||||
from invokeai.backend.model_manager.probe import ModelProbe, ModelProbeInfo
|
||||
from invokeai.backend.model_manager.search import ModelSearch
|
||||
from invokeai.backend.model_manager.storage import DuplicateModelException, ModelConfigStore
|
||||
from invokeai.backend.util import Chdir, InvokeAILogger, Logger
|
||||
|
||||
if TYPE_CHECKING:
|
||||
from .events import EventServiceBase
|
||||
|
||||
from .download_manager import (
|
||||
DownloadEventHandler,
|
||||
DownloadJobBase,
|
||||
DownloadJobPath,
|
||||
DownloadQueueService,
|
||||
DownloadQueueServiceBase,
|
||||
ModelSourceMetadata,
|
||||
)
|
||||
|
||||
|
||||
class ModelInstallJob(DownloadJobBase):
|
||||
"""This is a version of DownloadJobBase that has an additional slot for the model key and probe info."""
|
||||
|
||||
model_key: Optional[str] = Field(
|
||||
description="After model installation, this field will hold its primary key", default=None
|
||||
)
|
||||
probe_override: Optional[Dict[str, Any]] = Field(
|
||||
description="Keys in this dict will override like-named attributes in the automatic probe info",
|
||||
default=None,
|
||||
)
|
||||
|
||||
|
||||
class ModelInstallURLJob(DownloadJobMetadataURL, ModelInstallJob):
|
||||
"""Job for installing URLs."""
|
||||
|
||||
|
||||
class ModelInstallRepoIDJob(DownloadJobRepoID, ModelInstallJob):
|
||||
"""Job for installing repo ids."""
|
||||
|
||||
|
||||
class ModelInstallPathJob(DownloadJobPath, ModelInstallJob):
|
||||
"""Job for installing local paths."""
|
||||
|
||||
|
||||
ModelInstallEventHandler = Callable[["ModelInstallJob"], None]
|
||||
|
||||
|
||||
class ModelInstallServiceBase(ABC):
|
||||
"""Abstract base class for InvokeAI model installation."""
|
||||
|
||||
@abstractmethod
|
||||
def __init__(
|
||||
self,
|
||||
config: Optional[InvokeAIAppConfig] = None,
|
||||
queue: Optional[DownloadQueueServiceBase] = None,
|
||||
store: Optional[ModelRecordServiceBase] = None,
|
||||
event_bus: Optional["EventServiceBase"] = None,
|
||||
event_handlers: List[DownloadEventHandler] = [],
|
||||
):
|
||||
"""
|
||||
Create ModelInstallService object.
|
||||
|
||||
:param config: Optional InvokeAIAppConfig. If None passed,
|
||||
uses the system-wide default app config.
|
||||
:param download: Optional DownloadQueueServiceBase object. If None passed,
|
||||
a default queue object will be created.
|
||||
:param store: Optional ModelConfigStore. If None passed,
|
||||
defaults to `configs/models.yaml`.
|
||||
:param event_bus: InvokeAI event bus for reporting events to.
|
||||
:param event_handlers: List of event handlers to pass to the queue object.
|
||||
"""
|
||||
pass
|
||||
|
||||
@property
|
||||
@abstractmethod
|
||||
def queue(self) -> DownloadQueueServiceBase:
|
||||
"""Return the download queue used by the installer."""
|
||||
pass
|
||||
|
||||
@property
|
||||
@abstractmethod
|
||||
def store(self) -> ModelRecordServiceBase:
|
||||
"""Return the storage backend used by the installer."""
|
||||
pass
|
||||
|
||||
@property
|
||||
@abstractmethod
|
||||
def config(self) -> InvokeAIAppConfig:
|
||||
"""Return the app_config used by the installer."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def register_path(self, model_path: Union[Path, str], overrides: Optional[Dict[str, Any]]) -> str:
|
||||
"""
|
||||
Probe and register the model at model_path.
|
||||
|
||||
:param model_path: Filesystem Path to the model.
|
||||
:param overrides: Dict of attributes that will override probed values.
|
||||
:returns id: The string ID of the registered model.
|
||||
"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def install_path(self, model_path: Union[Path, str], overrides: Optional[Dict[str, Any]] = None) -> str:
|
||||
"""
|
||||
Probe, register and install the model in the models directory.
|
||||
|
||||
This involves moving the model from its current location into
|
||||
the models directory handled by InvokeAI.
|
||||
|
||||
:param model_path: Filesystem Path to the model.
|
||||
:param overrides: Dictionary of model probe info fields that, if present, override probed values.
|
||||
:returns id: The string ID of the installed model.
|
||||
"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def install_model(
|
||||
self,
|
||||
source: Union[str, Path, AnyHttpUrl],
|
||||
inplace: bool = True,
|
||||
priority: int = 10,
|
||||
start: Optional[bool] = True,
|
||||
variant: Optional[str] = None,
|
||||
subfolder: Optional[str] = None,
|
||||
probe_override: Optional[Dict[str, Any]] = None,
|
||||
metadata: Optional[ModelSourceMetadata] = None,
|
||||
access_token: Optional[str] = None,
|
||||
) -> ModelInstallJob:
|
||||
"""
|
||||
Download and install the indicated model.
|
||||
|
||||
This will download the model located at `source`,
|
||||
probe it, and install it into the models directory.
|
||||
This call is executed asynchronously in a separate
|
||||
thread, and the returned object is a
|
||||
invokeai.backend.model_manager.download.DownloadJobBase
|
||||
object which can be interrogated to get the status of
|
||||
the download and install process. Call our `wait_for_installs()`
|
||||
method to wait for all downloads and installations to complete.
|
||||
|
||||
:param source: Either a URL or a HuggingFace repo_id.
|
||||
:param inplace: If True, local paths will not be moved into
|
||||
the models directory, but registered in place (the default).
|
||||
:param variant: For HuggingFace models, this optional parameter
|
||||
specifies which variant to download (e.g. 'fp16')
|
||||
:param subfolder: When downloading HF repo_ids this can be used to
|
||||
specify a subfolder of the HF repository to download from.
|
||||
:param probe_override: Optional dict. Any fields in this dict
|
||||
will override corresponding probe fields. Use it to override
|
||||
`base_type`, `model_type`, `format`, `prediction_type` and `image_size`.
|
||||
:param metadata: Use this to override the fields 'description`,
|
||||
`author`, `tags`, `source` and `license`.
|
||||
|
||||
:returns ModelInstallJob object.
|
||||
|
||||
The `inplace` flag does not affect the behavior of downloaded
|
||||
models, which are always moved into the `models` directory.
|
||||
|
||||
Variants recognized by HuggingFace currently are:
|
||||
1. onnx
|
||||
2. openvino
|
||||
3. fp16
|
||||
4. None (usually returns fp32 model)
|
||||
"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def wait_for_installs(self) -> Dict[Union[str, Path, AnyHttpUrl], Optional[str]]:
|
||||
"""
|
||||
Wait for all pending installs to complete.
|
||||
|
||||
This will block until all pending downloads have
|
||||
completed, been cancelled, or errored out. It will
|
||||
block indefinitely if one or more jobs are in the
|
||||
paused state.
|
||||
|
||||
It will return a dict that maps the source model
|
||||
path, URL or repo_id to the ID of the installed model.
|
||||
"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def scan_directory(self, scan_dir: Path, install: bool = False) -> List[str]:
|
||||
"""
|
||||
Recursively scan directory for new models and register or install them.
|
||||
|
||||
:param scan_dir: Path to the directory to scan.
|
||||
:param install: Install if True, otherwise register in place.
|
||||
:returns list of IDs: Returns list of IDs of models registered/installed
|
||||
"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def sync_to_config(self):
|
||||
"""Synchronize models on disk to those in memory."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def hash(self, model_path: Union[Path, str]) -> str:
|
||||
"""
|
||||
Compute and return the fast hash of the model.
|
||||
|
||||
:param model_path: Path to the model on disk.
|
||||
:return str: FastHash of the model for use as an ID.
|
||||
"""
|
||||
pass
|
||||
|
||||
|
||||
class ModelInstallService(ModelInstallServiceBase):
|
||||
"""Model installer class handles installation from a local path."""
|
||||
|
||||
_app_config: InvokeAIAppConfig
|
||||
_logger: Logger
|
||||
_store: ModelConfigStore
|
||||
_download_queue: DownloadQueueServiceBase
|
||||
_async_installs: Dict[Union[str, Path, AnyHttpUrl], Optional[str]]
|
||||
_installed: Set[str] = Field(default=set)
|
||||
_tmpdir: Optional[tempfile.TemporaryDirectory] # used for downloads
|
||||
_cached_model_paths: Set[Path] = Field(default=set) # used to speed up directory scanning
|
||||
_precision: Literal["float16", "float32"] = Field(description="Floating point precision, string form")
|
||||
_event_bus: Optional["EventServiceBase"] = Field(description="an event bus to send install events to", default=None)
|
||||
|
||||
_legacy_configs: Dict[BaseModelType, Dict[ModelVariantType, Union[str, dict]]] = {
|
||||
BaseModelType.StableDiffusion1: {
|
||||
ModelVariantType.Normal: "v1-inference.yaml",
|
||||
ModelVariantType.Inpaint: "v1-inpainting-inference.yaml",
|
||||
},
|
||||
BaseModelType.StableDiffusion2: {
|
||||
ModelVariantType.Normal: {
|
||||
SchedulerPredictionType.Epsilon: "v2-inference.yaml",
|
||||
SchedulerPredictionType.VPrediction: "v2-inference-v.yaml",
|
||||
},
|
||||
ModelVariantType.Inpaint: {
|
||||
SchedulerPredictionType.Epsilon: "v2-inpainting-inference.yaml",
|
||||
SchedulerPredictionType.VPrediction: "v2-inpainting-inference-v.yaml",
|
||||
},
|
||||
},
|
||||
BaseModelType.StableDiffusionXL: {
|
||||
ModelVariantType.Normal: "sd_xl_base.yaml",
|
||||
},
|
||||
BaseModelType.StableDiffusionXLRefiner: {
|
||||
ModelVariantType.Normal: "sd_xl_refiner.yaml",
|
||||
},
|
||||
}
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
config: Optional[InvokeAIAppConfig] = None,
|
||||
queue: Optional[DownloadQueueServiceBase] = None,
|
||||
store: Optional[ModelRecordServiceBase] = None,
|
||||
event_bus: Optional["EventServiceBase"] = None,
|
||||
event_handlers: List[DownloadEventHandler] = [],
|
||||
): # noqa D107 - use base class docstrings
|
||||
self._app_config = config or InvokeAIAppConfig.get_config()
|
||||
self._store = store or ModelRecordServiceBase.open(self._app_config)
|
||||
self._logger = InvokeAILogger.get_logger(config=self._app_config)
|
||||
self._event_bus = event_bus
|
||||
self._precision = get_precision()
|
||||
self._handlers = event_handlers
|
||||
if self._event_bus:
|
||||
self._handlers.append(self._event_bus.emit_model_event)
|
||||
|
||||
self._download_queue = queue or DownloadQueueService(event_bus=event_bus)
|
||||
self._async_installs: Dict[Union[str, Path, AnyHttpUrl], Union[str, None]] = dict()
|
||||
self._installed = set()
|
||||
self._tmpdir = None
|
||||
|
||||
def start(self, invoker: Any): # Because .processor is giving circular import errors, declaring invoker an 'Any'
|
||||
"""Call automatically at process start."""
|
||||
self.sync_to_config()
|
||||
|
||||
@property
|
||||
def queue(self) -> DownloadQueueServiceBase:
|
||||
"""Return the queue."""
|
||||
return self._download_queue
|
||||
|
||||
@property
|
||||
def store(self) -> ModelConfigStore:
|
||||
"""Return the storage backend used by the installer."""
|
||||
return self._store
|
||||
|
||||
@property
|
||||
def config(self) -> InvokeAIAppConfig:
|
||||
"""Return the app_config used by the installer."""
|
||||
return self._app_config
|
||||
|
||||
def install_model(
|
||||
self,
|
||||
source: Union[str, Path, AnyHttpUrl],
|
||||
inplace: bool = True,
|
||||
priority: int = 10,
|
||||
start: Optional[bool] = True,
|
||||
variant: Optional[str] = None,
|
||||
subfolder: Optional[str] = None,
|
||||
probe_override: Optional[Dict[str, Any]] = None,
|
||||
metadata: Optional[ModelSourceMetadata] = None,
|
||||
access_token: Optional[str] = None,
|
||||
) -> ModelInstallJob: # noqa D102
|
||||
queue = self._download_queue
|
||||
variant = variant or ("fp16" if self._precision == "float16" else None)
|
||||
|
||||
job = self._make_download_job(
|
||||
source, variant=variant, access_token=access_token, subfolder=subfolder, priority=priority
|
||||
)
|
||||
handler = (
|
||||
self._complete_registration_handler
|
||||
if inplace and Path(source).exists()
|
||||
else self._complete_installation_handler
|
||||
)
|
||||
if isinstance(job, ModelInstallJob):
|
||||
job.probe_override = probe_override
|
||||
if metadata and isinstance(job, DownloadJobWithMetadata):
|
||||
job.metadata = metadata
|
||||
job.add_event_handler(handler)
|
||||
|
||||
self._async_installs[source] = None
|
||||
queue.submit_download_job(job, start=start)
|
||||
return job
|
||||
|
||||
def register_path(
|
||||
self, model_path: Union[Path, str], overrides: Optional[Dict[str, Any]] = None
|
||||
) -> str: # noqa D102
|
||||
model_path = Path(model_path)
|
||||
info: ModelProbeInfo = self._probe_model(model_path, overrides)
|
||||
return self._register(model_path, info)
|
||||
|
||||
def install_path(
|
||||
self,
|
||||
model_path: Union[Path, str],
|
||||
overrides: Optional[Dict[str, Any]] = None,
|
||||
) -> str: # noqa D102
|
||||
model_path = Path(model_path)
|
||||
info: ModelProbeInfo = self._probe_model(model_path, overrides)
|
||||
|
||||
dest_path = self._app_config.models_path / info.base_type.value / info.model_type.value / model_path.name
|
||||
new_path = self._move_model(model_path, dest_path)
|
||||
new_hash = self.hash(new_path)
|
||||
assert new_hash == info.hash, f"{model_path}: Model hash changed during installation, possibly corrupted."
|
||||
return self._register(
|
||||
new_path,
|
||||
info,
|
||||
)
|
||||
|
||||
def unregister(self, key: str): # noqa D102
|
||||
self._store.del_model(key)
|
||||
|
||||
def delete(self, key: str): # noqa D102
|
||||
model = self._store.get_model(key)
|
||||
path = self._app_config.models_path / model.path
|
||||
if path.is_dir():
|
||||
rmtree(path)
|
||||
else:
|
||||
path.unlink()
|
||||
self.unregister(key)
|
||||
|
||||
def conditionally_delete(self, key: str): # noqa D102
|
||||
"""Unregister the model. Delete its files only if they are within our models directory."""
|
||||
model = self._store.get_model(key)
|
||||
models_dir = self._app_config.models_path
|
||||
model_path = models_dir / model.path
|
||||
if model_path.is_relative_to(models_dir):
|
||||
self.delete(key)
|
||||
else:
|
||||
self.unregister(key)
|
||||
|
||||
def _register(self, model_path: Path, info: ModelProbeInfo) -> str:
|
||||
key: str = FastModelHash.hash(model_path)
|
||||
|
||||
model_path = model_path.absolute()
|
||||
if model_path.is_relative_to(self._app_config.models_path):
|
||||
model_path = model_path.relative_to(self._app_config.models_path)
|
||||
|
||||
registration_data = dict(
|
||||
path=model_path.as_posix(),
|
||||
name=model_path.name if model_path.is_dir() else model_path.stem,
|
||||
base_model=info.base_type,
|
||||
model_type=info.model_type,
|
||||
model_format=info.format,
|
||||
hash=key,
|
||||
)
|
||||
# add 'main' specific fields
|
||||
if info.model_type == ModelType.Main:
|
||||
if info.variant_type:
|
||||
registration_data.update(variant=info.variant_type)
|
||||
if info.format == ModelFormat.Checkpoint:
|
||||
try:
|
||||
config_file = self._legacy_configs[info.base_type][info.variant_type]
|
||||
if isinstance(config_file, dict): # need another tier for sd-2.x models
|
||||
if prediction_type := info.prediction_type:
|
||||
config_file = config_file[prediction_type]
|
||||
else:
|
||||
self._logger.warning(
|
||||
f"Could not infer prediction type for {model_path.stem}. Guessing 'v_prediction' for a SD-2 768 pixel model"
|
||||
)
|
||||
config_file = config_file[SchedulerPredictionType.VPrediction]
|
||||
registration_data.update(
|
||||
config=Path(self._app_config.legacy_conf_dir, str(config_file)).as_posix(),
|
||||
)
|
||||
except KeyError as exc:
|
||||
raise InvalidModelException(
|
||||
"Configuration file for this checkpoint could not be determined"
|
||||
) from exc
|
||||
self._store.add_model(key, registration_data)
|
||||
return key
|
||||
|
||||
def _move_model(self, old_path: Path, new_path: Path) -> Path:
|
||||
if old_path == new_path:
|
||||
return old_path
|
||||
|
||||
new_path.parent.mkdir(parents=True, exist_ok=True)
|
||||
|
||||
# if path already exists then we jigger the name to make it unique
|
||||
counter: int = 1
|
||||
while new_path.exists():
|
||||
path = new_path.with_stem(new_path.stem + f"_{counter:02d}")
|
||||
if not path.exists():
|
||||
new_path = path
|
||||
counter += 1
|
||||
return move(old_path, new_path)
|
||||
|
||||
def _probe_model(self, model_path: Union[Path, str], overrides: Optional[Dict[str, Any]] = None) -> ModelProbeInfo:
|
||||
info: ModelProbeInfo = ModelProbe.probe(Path(model_path))
|
||||
if overrides: # used to override probe fields
|
||||
for key, value in overrides.items():
|
||||
try:
|
||||
setattr(info, key, value) # skip validation errors
|
||||
except Exception:
|
||||
pass
|
||||
return info
|
||||
|
||||
def _complete_installation_handler(self, job: DownloadJobBase):
|
||||
assert isinstance(job, ModelInstallJob)
|
||||
if job.status == "completed":
|
||||
self._logger.info(f"{job.source}: Download finished with status {job.status}. Installing.")
|
||||
model_id = self.install_path(job.destination, job.probe_override)
|
||||
info = self._store.get_model(model_id)
|
||||
info.source = str(job.source)
|
||||
if isinstance(job, DownloadJobWithMetadata):
|
||||
metadata: ModelSourceMetadata = job.metadata
|
||||
info.description = metadata.description or f"Imported model {info.name}"
|
||||
info.name = metadata.name or info.name
|
||||
info.author = metadata.author
|
||||
info.tags = metadata.tags
|
||||
info.license = metadata.license
|
||||
info.thumbnail_url = metadata.thumbnail_url
|
||||
self._store.update_model(model_id, info)
|
||||
self._async_installs[job.source] = model_id
|
||||
job.model_key = model_id
|
||||
elif job.status == "error":
|
||||
self._logger.warning(f"{job.source}: Model installation error: {job.error}")
|
||||
elif job.status == "cancelled":
|
||||
self._logger.warning(f"{job.source}: Model installation cancelled at caller's request.")
|
||||
jobs = self._download_queue.list_jobs()
|
||||
if self._tmpdir and len(jobs) <= 1 and job.status in ["completed", "error", "cancelled"]:
|
||||
self._tmpdir.cleanup()
|
||||
self._tmpdir = None
|
||||
|
||||
def _complete_registration_handler(self, job: DownloadJobBase):
|
||||
assert isinstance(job, ModelInstallJob)
|
||||
if job.status == "completed":
|
||||
self._logger.info(f"{job.source}: Installing in place.")
|
||||
model_id = self.register_path(job.destination, job.probe_override)
|
||||
info = self._store.get_model(model_id)
|
||||
info.source = str(job.source)
|
||||
info.description = f"Imported model {info.name}"
|
||||
self._store.update_model(model_id, info)
|
||||
self._async_installs[job.source] = model_id
|
||||
job.model_key = model_id
|
||||
elif job.status == "error":
|
||||
self._logger.warning(f"{job.source}: Model installation error: {job.error}")
|
||||
elif job.status == "cancelled":
|
||||
self._logger.warning(f"{job.source}: Model installation cancelled at caller's request.")
|
||||
|
||||
def sync_model_path(self, key: str, ignore_hash_change: bool = False) -> ModelConfigBase:
|
||||
"""
|
||||
Move model into the location indicated by its basetype, type and name.
|
||||
|
||||
Call this after updating a model's attributes in order to move
|
||||
the model's path into the location indicated by its basetype, type and
|
||||
name. Applies only to models whose paths are within the root `models_dir`
|
||||
directory.
|
||||
|
||||
May raise an UnknownModelException.
|
||||
"""
|
||||
model = self._store.get_model(key)
|
||||
old_path = Path(model.path)
|
||||
models_dir = self._app_config.models_path
|
||||
|
||||
if not old_path.is_relative_to(models_dir):
|
||||
return model
|
||||
|
||||
new_path = models_dir / model.base_model.value / model.model_type.value / model.name
|
||||
self._logger.info(f"Moving {model.name} to {new_path}.")
|
||||
new_path = self._move_model(old_path, new_path)
|
||||
model.hash = self.hash(new_path)
|
||||
model.path = new_path.relative_to(models_dir).as_posix()
|
||||
if model.hash != key:
|
||||
assert (
|
||||
ignore_hash_change
|
||||
), f"{model.name}: Model hash changed during installation, model is possibly corrupted"
|
||||
self._logger.info(f"Model has new hash {model.hash}, but will continue to be identified by {key}")
|
||||
self._store.update_model(key, model)
|
||||
return model
|
||||
|
||||
def _make_download_job(
|
||||
self,
|
||||
source: Union[str, Path, AnyHttpUrl],
|
||||
variant: Optional[str] = None,
|
||||
subfolder: Optional[str] = None,
|
||||
access_token: Optional[str] = None,
|
||||
priority: Optional[int] = 10,
|
||||
) -> ModelInstallJob:
|
||||
# Clean up a common source of error. Doesn't work with Paths.
|
||||
if isinstance(source, str):
|
||||
source = source.strip()
|
||||
|
||||
# In the event that we are being asked to install a path that is already on disk,
|
||||
# we simply probe and register/install it. The job does not actually do anything, but we
|
||||
# create one anyway in order to have similar behavior for local files, URLs and repo_ids.
|
||||
if Path(source).exists(): # a path that is already on disk
|
||||
destdir = source
|
||||
return ModelInstallPathJob(source=source, destination=Path(destdir), event_handlers=self._handlers)
|
||||
|
||||
# choose a temporary directory inside the models directory
|
||||
models_dir = self._app_config.models_path
|
||||
self._tmpdir = self._tmpdir or tempfile.TemporaryDirectory(dir=models_dir)
|
||||
|
||||
cls = ModelInstallJob
|
||||
if match := re.match(REPO_ID_WITH_OPTIONAL_SUBFOLDER_RE, str(source)):
|
||||
cls = ModelInstallRepoIDJob
|
||||
source = match.group(1)
|
||||
subfolder = match.group(2) or subfolder
|
||||
kwargs = dict(variant=variant, subfolder=subfolder)
|
||||
elif re.match(HTTP_RE, str(source)):
|
||||
cls = ModelInstallURLJob
|
||||
kwargs = {}
|
||||
else:
|
||||
raise ValueError(f"'{source}' is not recognized as a local file, directory, repo_id or URL")
|
||||
return cls(
|
||||
source=str(source),
|
||||
destination=Path(self._tmpdir.name),
|
||||
access_token=access_token,
|
||||
priority=priority,
|
||||
event_handlers=self._handlers,
|
||||
**kwargs,
|
||||
)
|
||||
|
||||
def wait_for_installs(self) -> Dict[Union[str, Path, AnyHttpUrl], Optional[str]]:
|
||||
"""Pause until all installation jobs have completed."""
|
||||
self._download_queue.join()
|
||||
id_map = self._async_installs
|
||||
self._async_installs = dict()
|
||||
return id_map
|
||||
|
||||
def scan_directory(self, scan_dir: Path, install: bool = False) -> List[str]: # noqa D102
|
||||
self._cached_model_paths = set([Path(x.path) for x in self._store.all_models()])
|
||||
callback = self._scan_install if install else self._scan_register
|
||||
search = ModelSearch(on_model_found=callback)
|
||||
self._installed = set()
|
||||
search.search(scan_dir)
|
||||
return list(self._installed)
|
||||
|
||||
def scan_models_directory(self):
|
||||
"""
|
||||
Scan the models directory for new and missing models.
|
||||
|
||||
New models will be added to the storage backend. Missing models
|
||||
will be deleted.
|
||||
"""
|
||||
defunct_models = set()
|
||||
installed = set()
|
||||
|
||||
with Chdir(self._app_config.models_path):
|
||||
self._logger.info("Checking for models that have been moved or deleted from disk")
|
||||
for model_config in self._store.all_models():
|
||||
path = Path(model_config.path)
|
||||
if not path.exists():
|
||||
self._logger.info(f"{model_config.name}: path {path.as_posix()} no longer exists. Unregistering")
|
||||
defunct_models.add(model_config.key)
|
||||
for key in defunct_models:
|
||||
self.unregister(key)
|
||||
|
||||
self._logger.info(f"Scanning {self._app_config.models_path} for new models")
|
||||
for cur_base_model in BaseModelType:
|
||||
for cur_model_type in ModelType:
|
||||
models_dir = Path(cur_base_model.value, cur_model_type.value)
|
||||
installed.update(self.scan_directory(models_dir))
|
||||
self._logger.info(f"{len(installed)} new models registered; {len(defunct_models)} unregistered")
|
||||
|
||||
def sync_to_config(self):
|
||||
"""Synchronize models on disk to those in memory."""
|
||||
self.scan_models_directory()
|
||||
if autoimport := self._app_config.autoimport_dir:
|
||||
self._logger.info("Scanning autoimport directory for new models")
|
||||
self.scan_directory(self._app_config.root_path / autoimport)
|
||||
|
||||
def hash(self, model_path: Union[Path, str]) -> str: # noqa D102
|
||||
return FastModelHash.hash(model_path)
|
||||
|
||||
def _scan_register(self, model: Path) -> bool:
|
||||
if model in self._cached_model_paths:
|
||||
return True
|
||||
try:
|
||||
id = self.register_path(model)
|
||||
self.sync_model_path(id) # possibly move it to right place in `models`
|
||||
self._logger.info(f"Registered {model.name} with id {id}")
|
||||
self._installed.add(id)
|
||||
except DuplicateModelException:
|
||||
pass
|
||||
return True
|
||||
|
||||
def _scan_install(self, model: Path) -> bool:
|
||||
if model in self._cached_model_paths:
|
||||
return True
|
||||
try:
|
||||
id = self.install_path(model)
|
||||
self._logger.info(f"Installed {model} with id {id}")
|
||||
self._installed.add(id)
|
||||
except DuplicateModelException:
|
||||
pass
|
||||
return True
|
||||
@@ -1,140 +0,0 @@
|
||||
# Copyright (c) 2023 Lincoln D. Stein and the InvokeAI Team
|
||||
|
||||
from __future__ import annotations
|
||||
|
||||
from abc import ABC, abstractmethod
|
||||
from pathlib import Path
|
||||
from typing import TYPE_CHECKING, Any, Dict, Optional, Union
|
||||
|
||||
from pydantic import Field
|
||||
|
||||
from invokeai.app.models.exceptions import CanceledException
|
||||
from invokeai.backend.model_manager import ModelConfigStore, SubModelType
|
||||
from invokeai.backend.model_manager.cache import CacheStats
|
||||
from invokeai.backend.model_manager.loader import ModelConfigBase, ModelInfo, ModelLoad
|
||||
|
||||
from .config import InvokeAIAppConfig
|
||||
from .model_record_service import ModelRecordServiceBase
|
||||
|
||||
if TYPE_CHECKING:
|
||||
from ..invocations.baseinvocation import InvocationContext
|
||||
|
||||
|
||||
class ModelLoadServiceBase(ABC):
|
||||
"""Load models into memory."""
|
||||
|
||||
@abstractmethod
|
||||
def __init__(
|
||||
self,
|
||||
config: InvokeAIAppConfig,
|
||||
store: Union[ModelConfigStore, ModelRecordServiceBase],
|
||||
):
|
||||
"""
|
||||
Initialize a ModelLoadService
|
||||
|
||||
:param config: InvokeAIAppConfig object
|
||||
:param store: ModelConfigStore object for fetching configuration information
|
||||
installation and download events will be sent to the event bus.
|
||||
"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def get_model(
|
||||
self,
|
||||
key: str,
|
||||
submodel_type: Optional[SubModelType] = None,
|
||||
context: Optional[InvocationContext] = None,
|
||||
) -> ModelInfo:
|
||||
"""Retrieve the indicated model identified by key.
|
||||
|
||||
:param key: Unique key returned by the ModelConfigStore module.
|
||||
:param submodel_type: Submodel to return (required for main models)
|
||||
:param context" Optional InvocationContext, used in event reporting.
|
||||
"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def collect_cache_stats(self, cache_stats: CacheStats):
|
||||
"""Reset model cache statistics for graph with graph_id."""
|
||||
pass
|
||||
|
||||
|
||||
# implementation
|
||||
class ModelLoadService(ModelLoadServiceBase):
|
||||
"""Responsible for managing models on disk and in memory."""
|
||||
|
||||
_loader: ModelLoad
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
config: InvokeAIAppConfig,
|
||||
record_store: Union[ModelConfigStore, ModelRecordServiceBase],
|
||||
):
|
||||
"""
|
||||
Initialize a ModelLoadService.
|
||||
|
||||
:param config: InvokeAIAppConfig object
|
||||
:param store: ModelRecordServiceBase or ModelConfigStore object for fetching configuration information
|
||||
installation and download events will be sent to the event bus.
|
||||
"""
|
||||
self._loader = ModelLoad(config, record_store)
|
||||
|
||||
def get_model(
|
||||
self,
|
||||
key: str,
|
||||
submodel_type: Optional[SubModelType] = None,
|
||||
context: Optional[InvocationContext] = None,
|
||||
) -> ModelInfo:
|
||||
"""
|
||||
Retrieve the indicated model.
|
||||
|
||||
The submodel is required when fetching a main model.
|
||||
"""
|
||||
model_info: ModelInfo = self._loader.get_model(key, submodel_type)
|
||||
|
||||
# we can emit model loading events if we are executing with access to the invocation context
|
||||
if context:
|
||||
self._emit_load_event(
|
||||
context=context,
|
||||
model_key=key,
|
||||
submodel=submodel_type,
|
||||
model_info=model_info,
|
||||
)
|
||||
|
||||
return model_info
|
||||
|
||||
def collect_cache_stats(self, cache_stats: CacheStats):
|
||||
"""
|
||||
Reset model cache statistics. Is this used?
|
||||
"""
|
||||
self._loader.collect_cache_stats(cache_stats)
|
||||
|
||||
def _emit_load_event(
|
||||
self,
|
||||
context: InvocationContext,
|
||||
model_key: str,
|
||||
submodel: Optional[SubModelType] = None,
|
||||
model_info: Optional[ModelInfo] = None,
|
||||
):
|
||||
if context.services.queue.is_canceled(context.graph_execution_state_id):
|
||||
raise CanceledException()
|
||||
|
||||
if model_info:
|
||||
context.services.events.emit_model_load_completed(
|
||||
queue_id=context.queue_id,
|
||||
queue_item_id=context.queue_item_id,
|
||||
queue_batch_id=context.queue_batch_id,
|
||||
graph_execution_state_id=context.graph_execution_state_id,
|
||||
model_key=model_key,
|
||||
submodel=submodel,
|
||||
model_info=model_info,
|
||||
)
|
||||
else:
|
||||
context.services.events.emit_model_load_started(
|
||||
queue_id=context.queue_id,
|
||||
queue_item_id=context.queue_item_id,
|
||||
queue_batch_id=context.queue_batch_id,
|
||||
graph_execution_state_id=context.graph_execution_state_id,
|
||||
model_key=model_key,
|
||||
submodel=submodel,
|
||||
)
|
||||
673
invokeai/app/services/model_manager_service.py
Normal file
673
invokeai/app/services/model_manager_service.py
Normal file
@@ -0,0 +1,673 @@
|
||||
# Copyright (c) 2023 Lincoln D. Stein and the InvokeAI Team
|
||||
|
||||
from __future__ import annotations
|
||||
|
||||
from abc import ABC, abstractmethod
|
||||
from logging import Logger
|
||||
from pathlib import Path
|
||||
from types import ModuleType
|
||||
from typing import TYPE_CHECKING, Callable, List, Literal, Optional, Tuple, Union
|
||||
|
||||
import torch
|
||||
from pydantic import Field
|
||||
|
||||
from invokeai.app.models.exceptions import CanceledException
|
||||
from invokeai.backend.model_management import (
|
||||
AddModelResult,
|
||||
BaseModelType,
|
||||
MergeInterpolationMethod,
|
||||
ModelInfo,
|
||||
ModelManager,
|
||||
ModelMerger,
|
||||
ModelNotFoundException,
|
||||
ModelType,
|
||||
SchedulerPredictionType,
|
||||
SubModelType,
|
||||
)
|
||||
from invokeai.backend.model_management.model_cache import CacheStats
|
||||
from invokeai.backend.model_management.model_search import FindModels
|
||||
|
||||
from ...backend.util import choose_precision, choose_torch_device
|
||||
from .config import InvokeAIAppConfig
|
||||
|
||||
if TYPE_CHECKING:
|
||||
from ..invocations.baseinvocation import BaseInvocation, InvocationContext
|
||||
|
||||
|
||||
class ModelManagerServiceBase(ABC):
|
||||
"""Responsible for managing models on disk and in memory"""
|
||||
|
||||
@abstractmethod
|
||||
def __init__(
|
||||
self,
|
||||
config: InvokeAIAppConfig,
|
||||
logger: ModuleType,
|
||||
):
|
||||
"""
|
||||
Initialize with the path to the models.yaml config file.
|
||||
Optional parameters are the torch device type, precision, max_models,
|
||||
and sequential_offload boolean. Note that the default device
|
||||
type and precision are set up for a CUDA system running at half precision.
|
||||
"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def get_model(
|
||||
self,
|
||||
model_name: str,
|
||||
base_model: BaseModelType,
|
||||
model_type: ModelType,
|
||||
submodel: Optional[SubModelType] = None,
|
||||
node: Optional[BaseInvocation] = None,
|
||||
context: Optional[InvocationContext] = None,
|
||||
) -> ModelInfo:
|
||||
"""Retrieve the indicated model with name and type.
|
||||
submodel can be used to get a part (such as the vae)
|
||||
of a diffusers pipeline."""
|
||||
pass
|
||||
|
||||
@property
|
||||
@abstractmethod
|
||||
def logger(self):
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def model_exists(
|
||||
self,
|
||||
model_name: str,
|
||||
base_model: BaseModelType,
|
||||
model_type: ModelType,
|
||||
) -> bool:
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def model_info(self, model_name: str, base_model: BaseModelType, model_type: ModelType) -> dict:
|
||||
"""
|
||||
Given a model name returns a dict-like (OmegaConf) object describing it.
|
||||
Uses the exact format as the omegaconf stanza.
|
||||
"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def list_models(self, base_model: Optional[BaseModelType] = None, model_type: Optional[ModelType] = None) -> dict:
|
||||
"""
|
||||
Return a dict of models in the format:
|
||||
{ model_type1:
|
||||
{ model_name1: {'status': 'active'|'cached'|'not loaded',
|
||||
'model_name' : name,
|
||||
'model_type' : SDModelType,
|
||||
'description': description,
|
||||
'format': 'folder'|'safetensors'|'ckpt'
|
||||
},
|
||||
model_name2: { etc }
|
||||
},
|
||||
model_type2:
|
||||
{ model_name_n: etc
|
||||
}
|
||||
"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def list_model(self, model_name: str, base_model: BaseModelType, model_type: ModelType) -> dict:
|
||||
"""
|
||||
Return information about the model using the same format as list_models()
|
||||
"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def model_names(self) -> List[Tuple[str, BaseModelType, ModelType]]:
|
||||
"""
|
||||
Returns a list of all the model names known.
|
||||
"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def add_model(
|
||||
self,
|
||||
model_name: str,
|
||||
base_model: BaseModelType,
|
||||
model_type: ModelType,
|
||||
model_attributes: dict,
|
||||
clobber: bool = False,
|
||||
) -> AddModelResult:
|
||||
"""
|
||||
Update the named model with a dictionary of attributes. Will fail with an
|
||||
assertion error if the name already exists. Pass clobber=True to overwrite.
|
||||
On a successful update, the config will be changed in memory. Will fail
|
||||
with an assertion error if provided attributes are incorrect or
|
||||
the model name is missing. Call commit() to write changes to disk.
|
||||
"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def update_model(
|
||||
self,
|
||||
model_name: str,
|
||||
base_model: BaseModelType,
|
||||
model_type: ModelType,
|
||||
model_attributes: dict,
|
||||
) -> AddModelResult:
|
||||
"""
|
||||
Update the named model with a dictionary of attributes. Will fail with a
|
||||
ModelNotFoundException if the name does not already exist.
|
||||
|
||||
On a successful update, the config will be changed in memory. Will fail
|
||||
with an assertion error if provided attributes are incorrect or
|
||||
the model name is missing. Call commit() to write changes to disk.
|
||||
"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def del_model(
|
||||
self,
|
||||
model_name: str,
|
||||
base_model: BaseModelType,
|
||||
model_type: ModelType,
|
||||
):
|
||||
"""
|
||||
Delete the named model from configuration. If delete_files is true,
|
||||
then the underlying weight file or diffusers directory will be deleted
|
||||
as well. Call commit() to write to disk.
|
||||
"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def rename_model(
|
||||
self,
|
||||
model_name: str,
|
||||
base_model: BaseModelType,
|
||||
model_type: ModelType,
|
||||
new_name: str,
|
||||
):
|
||||
"""
|
||||
Rename the indicated model.
|
||||
"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def list_checkpoint_configs(self) -> List[Path]:
|
||||
"""
|
||||
List the checkpoint config paths from ROOT/configs/stable-diffusion.
|
||||
"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def convert_model(
|
||||
self,
|
||||
model_name: str,
|
||||
base_model: BaseModelType,
|
||||
model_type: Literal[ModelType.Main, ModelType.Vae],
|
||||
) -> AddModelResult:
|
||||
"""
|
||||
Convert a checkpoint file into a diffusers folder, deleting the cached
|
||||
version and deleting the original checkpoint file if it is in the models
|
||||
directory.
|
||||
:param model_name: Name of the model to convert
|
||||
:param base_model: Base model type
|
||||
:param model_type: Type of model ['vae' or 'main']
|
||||
|
||||
This will raise a ValueError unless the model is not a checkpoint. It will
|
||||
also raise a ValueError in the event that there is a similarly-named diffusers
|
||||
directory already in place.
|
||||
"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def heuristic_import(
|
||||
self,
|
||||
items_to_import: set[str],
|
||||
prediction_type_helper: Optional[Callable[[Path], SchedulerPredictionType]] = None,
|
||||
) -> dict[str, AddModelResult]:
|
||||
"""Import a list of paths, repo_ids or URLs. Returns the set of
|
||||
successfully imported items.
|
||||
:param items_to_import: Set of strings corresponding to models to be imported.
|
||||
:param prediction_type_helper: A callback that receives the Path of a Stable Diffusion 2 checkpoint model and returns a SchedulerPredictionType.
|
||||
|
||||
The prediction type helper is necessary to distinguish between
|
||||
models based on Stable Diffusion 2 Base (requiring
|
||||
SchedulerPredictionType.Epsilson) and Stable Diffusion 768
|
||||
(requiring SchedulerPredictionType.VPrediction). It is
|
||||
generally impossible to do this programmatically, so the
|
||||
prediction_type_helper usually asks the user to choose.
|
||||
|
||||
The result is a set of successfully installed models. Each element
|
||||
of the set is a dict corresponding to the newly-created OmegaConf stanza for
|
||||
that model.
|
||||
"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def merge_models(
|
||||
self,
|
||||
model_names: List[str] = Field(
|
||||
default=None, min_items=2, max_items=3, description="List of model names to merge"
|
||||
),
|
||||
base_model: Union[BaseModelType, str] = Field(
|
||||
default=None, description="Base model shared by all models to be merged"
|
||||
),
|
||||
merged_model_name: str = Field(default=None, description="Name of destination model after merging"),
|
||||
alpha: Optional[float] = 0.5,
|
||||
interp: Optional[MergeInterpolationMethod] = None,
|
||||
force: Optional[bool] = False,
|
||||
merge_dest_directory: Optional[Path] = None,
|
||||
) -> AddModelResult:
|
||||
"""
|
||||
Merge two to three diffusrs pipeline models and save as a new model.
|
||||
:param model_names: List of 2-3 models to merge
|
||||
:param base_model: Base model to use for all models
|
||||
:param merged_model_name: Name of destination merged model
|
||||
:param alpha: Alpha strength to apply to 2d and 3d model
|
||||
:param interp: Interpolation method. None (default)
|
||||
:param merge_dest_directory: Save the merged model to the designated directory (with 'merged_model_name' appended)
|
||||
"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def search_for_models(self, directory: Path) -> List[Path]:
|
||||
"""
|
||||
Return list of all models found in the designated directory.
|
||||
"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def sync_to_config(self):
|
||||
"""
|
||||
Re-read models.yaml, rescan the models directory, and reimport models
|
||||
in the autoimport directories. Call after making changes outside the
|
||||
model manager API.
|
||||
"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def collect_cache_stats(self, cache_stats: CacheStats):
|
||||
"""
|
||||
Reset model cache statistics for graph with graph_id.
|
||||
"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def commit(self, conf_file: Optional[Path] = None) -> None:
|
||||
"""
|
||||
Write current configuration out to the indicated file.
|
||||
If no conf_file is provided, then replaces the
|
||||
original file/database used to initialize the object.
|
||||
"""
|
||||
pass
|
||||
|
||||
|
||||
# simple implementation
|
||||
class ModelManagerService(ModelManagerServiceBase):
|
||||
"""Responsible for managing models on disk and in memory"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
config: InvokeAIAppConfig,
|
||||
logger: Logger,
|
||||
):
|
||||
"""
|
||||
Initialize with the path to the models.yaml config file.
|
||||
Optional parameters are the torch device type, precision, max_models,
|
||||
and sequential_offload boolean. Note that the default device
|
||||
type and precision are set up for a CUDA system running at half precision.
|
||||
"""
|
||||
if config.model_conf_path and config.model_conf_path.exists():
|
||||
config_file = config.model_conf_path
|
||||
else:
|
||||
config_file = config.root_dir / "configs/models.yaml"
|
||||
|
||||
logger.debug(f"Config file={config_file}")
|
||||
|
||||
device = torch.device(choose_torch_device())
|
||||
device_name = torch.cuda.get_device_name() if device == torch.device("cuda") else ""
|
||||
logger.info(f"GPU device = {device} {device_name}")
|
||||
|
||||
precision = config.precision
|
||||
if precision == "auto":
|
||||
precision = choose_precision(device)
|
||||
dtype = torch.float32 if precision == "float32" else torch.float16
|
||||
|
||||
# this is transitional backward compatibility
|
||||
# support for the deprecated `max_loaded_models`
|
||||
# configuration value. If present, then the
|
||||
# cache size is set to 2.5 GB times
|
||||
# the number of max_loaded_models. Otherwise
|
||||
# use new `ram_cache_size` config setting
|
||||
max_cache_size = config.ram_cache_size
|
||||
|
||||
logger.debug(f"Maximum RAM cache size: {max_cache_size} GiB")
|
||||
|
||||
sequential_offload = config.sequential_guidance
|
||||
|
||||
self.mgr = ModelManager(
|
||||
config=config_file,
|
||||
device_type=device,
|
||||
precision=dtype,
|
||||
max_cache_size=max_cache_size,
|
||||
sequential_offload=sequential_offload,
|
||||
logger=logger,
|
||||
)
|
||||
logger.info("Model manager service initialized")
|
||||
|
||||
def get_model(
|
||||
self,
|
||||
model_name: str,
|
||||
base_model: BaseModelType,
|
||||
model_type: ModelType,
|
||||
submodel: Optional[SubModelType] = None,
|
||||
context: Optional[InvocationContext] = None,
|
||||
) -> ModelInfo:
|
||||
"""
|
||||
Retrieve the indicated model. submodel can be used to get a
|
||||
part (such as the vae) of a diffusers mode.
|
||||
"""
|
||||
|
||||
# we can emit model loading events if we are executing with access to the invocation context
|
||||
if context:
|
||||
self._emit_load_event(
|
||||
context=context,
|
||||
model_name=model_name,
|
||||
base_model=base_model,
|
||||
model_type=model_type,
|
||||
submodel=submodel,
|
||||
)
|
||||
|
||||
model_info = self.mgr.get_model(
|
||||
model_name,
|
||||
base_model,
|
||||
model_type,
|
||||
submodel,
|
||||
)
|
||||
|
||||
if context:
|
||||
self._emit_load_event(
|
||||
context=context,
|
||||
model_name=model_name,
|
||||
base_model=base_model,
|
||||
model_type=model_type,
|
||||
submodel=submodel,
|
||||
model_info=model_info,
|
||||
)
|
||||
|
||||
return model_info
|
||||
|
||||
def model_exists(
|
||||
self,
|
||||
model_name: str,
|
||||
base_model: BaseModelType,
|
||||
model_type: ModelType,
|
||||
) -> bool:
|
||||
"""
|
||||
Given a model name, returns True if it is a valid
|
||||
identifier.
|
||||
"""
|
||||
return self.mgr.model_exists(
|
||||
model_name,
|
||||
base_model,
|
||||
model_type,
|
||||
)
|
||||
|
||||
def model_info(self, model_name: str, base_model: BaseModelType, model_type: ModelType) -> Union[dict, None]:
|
||||
"""
|
||||
Given a model name returns a dict-like (OmegaConf) object describing it.
|
||||
"""
|
||||
return self.mgr.model_info(model_name, base_model, model_type)
|
||||
|
||||
def model_names(self) -> List[Tuple[str, BaseModelType, ModelType]]:
|
||||
"""
|
||||
Returns a list of all the model names known.
|
||||
"""
|
||||
return self.mgr.model_names()
|
||||
|
||||
def list_models(
|
||||
self, base_model: Optional[BaseModelType] = None, model_type: Optional[ModelType] = None
|
||||
) -> list[dict]:
|
||||
"""
|
||||
Return a list of models.
|
||||
"""
|
||||
return self.mgr.list_models(base_model, model_type)
|
||||
|
||||
def list_model(self, model_name: str, base_model: BaseModelType, model_type: ModelType) -> Union[dict, None]:
|
||||
"""
|
||||
Return information about the model using the same format as list_models()
|
||||
"""
|
||||
return self.mgr.list_model(model_name=model_name, base_model=base_model, model_type=model_type)
|
||||
|
||||
def add_model(
|
||||
self,
|
||||
model_name: str,
|
||||
base_model: BaseModelType,
|
||||
model_type: ModelType,
|
||||
model_attributes: dict,
|
||||
clobber: bool = False,
|
||||
) -> AddModelResult:
|
||||
"""
|
||||
Update the named model with a dictionary of attributes. Will fail with an
|
||||
assertion error if the name already exists. Pass clobber=True to overwrite.
|
||||
On a successful update, the config will be changed in memory. Will fail
|
||||
with an assertion error if provided attributes are incorrect or
|
||||
the model name is missing. Call commit() to write changes to disk.
|
||||
"""
|
||||
self.logger.debug(f"add/update model {model_name}")
|
||||
return self.mgr.add_model(model_name, base_model, model_type, model_attributes, clobber)
|
||||
|
||||
def update_model(
|
||||
self,
|
||||
model_name: str,
|
||||
base_model: BaseModelType,
|
||||
model_type: ModelType,
|
||||
model_attributes: dict,
|
||||
) -> AddModelResult:
|
||||
"""
|
||||
Update the named model with a dictionary of attributes. Will fail with a
|
||||
ModelNotFoundException exception if the name does not already exist.
|
||||
On a successful update, the config will be changed in memory. Will fail
|
||||
with an assertion error if provided attributes are incorrect or
|
||||
the model name is missing. Call commit() to write changes to disk.
|
||||
"""
|
||||
self.logger.debug(f"update model {model_name}")
|
||||
if not self.model_exists(model_name, base_model, model_type):
|
||||
raise ModelNotFoundException(f"Unknown model {model_name}")
|
||||
return self.add_model(model_name, base_model, model_type, model_attributes, clobber=True)
|
||||
|
||||
def del_model(
|
||||
self,
|
||||
model_name: str,
|
||||
base_model: BaseModelType,
|
||||
model_type: ModelType,
|
||||
):
|
||||
"""
|
||||
Delete the named model from configuration. If delete_files is true,
|
||||
then the underlying weight file or diffusers directory will be deleted
|
||||
as well.
|
||||
"""
|
||||
self.logger.debug(f"delete model {model_name}")
|
||||
self.mgr.del_model(model_name, base_model, model_type)
|
||||
self.mgr.commit()
|
||||
|
||||
def convert_model(
|
||||
self,
|
||||
model_name: str,
|
||||
base_model: BaseModelType,
|
||||
model_type: Literal[ModelType.Main, ModelType.Vae],
|
||||
convert_dest_directory: Optional[Path] = Field(
|
||||
default=None, description="Optional directory location for merged model"
|
||||
),
|
||||
) -> AddModelResult:
|
||||
"""
|
||||
Convert a checkpoint file into a diffusers folder, deleting the cached
|
||||
version and deleting the original checkpoint file if it is in the models
|
||||
directory.
|
||||
:param model_name: Name of the model to convert
|
||||
:param base_model: Base model type
|
||||
:param model_type: Type of model ['vae' or 'main']
|
||||
:param convert_dest_directory: Save the converted model to the designated directory (`models/etc/etc` by default)
|
||||
|
||||
This will raise a ValueError unless the model is not a checkpoint. It will
|
||||
also raise a ValueError in the event that there is a similarly-named diffusers
|
||||
directory already in place.
|
||||
"""
|
||||
self.logger.debug(f"convert model {model_name}")
|
||||
return self.mgr.convert_model(model_name, base_model, model_type, convert_dest_directory)
|
||||
|
||||
def collect_cache_stats(self, cache_stats: CacheStats):
|
||||
"""
|
||||
Reset model cache statistics for graph with graph_id.
|
||||
"""
|
||||
self.mgr.cache.stats = cache_stats
|
||||
|
||||
def commit(self, conf_file: Optional[Path] = None):
|
||||
"""
|
||||
Write current configuration out to the indicated file.
|
||||
If no conf_file is provided, then replaces the
|
||||
original file/database used to initialize the object.
|
||||
"""
|
||||
return self.mgr.commit(conf_file)
|
||||
|
||||
def _emit_load_event(
|
||||
self,
|
||||
context: InvocationContext,
|
||||
model_name: str,
|
||||
base_model: BaseModelType,
|
||||
model_type: ModelType,
|
||||
submodel: Optional[SubModelType] = None,
|
||||
model_info: Optional[ModelInfo] = None,
|
||||
):
|
||||
if context.services.queue.is_canceled(context.graph_execution_state_id):
|
||||
raise CanceledException()
|
||||
|
||||
if model_info:
|
||||
context.services.events.emit_model_load_completed(
|
||||
queue_id=context.queue_id,
|
||||
queue_item_id=context.queue_item_id,
|
||||
graph_execution_state_id=context.graph_execution_state_id,
|
||||
model_name=model_name,
|
||||
base_model=base_model,
|
||||
model_type=model_type,
|
||||
submodel=submodel,
|
||||
model_info=model_info,
|
||||
)
|
||||
else:
|
||||
context.services.events.emit_model_load_started(
|
||||
queue_id=context.queue_id,
|
||||
queue_item_id=context.queue_item_id,
|
||||
graph_execution_state_id=context.graph_execution_state_id,
|
||||
model_name=model_name,
|
||||
base_model=base_model,
|
||||
model_type=model_type,
|
||||
submodel=submodel,
|
||||
)
|
||||
|
||||
@property
|
||||
def logger(self):
|
||||
return self.mgr.logger
|
||||
|
||||
def heuristic_import(
|
||||
self,
|
||||
items_to_import: set[str],
|
||||
prediction_type_helper: Optional[Callable[[Path], SchedulerPredictionType]] = None,
|
||||
) -> dict[str, AddModelResult]:
|
||||
"""Import a list of paths, repo_ids or URLs. Returns the set of
|
||||
successfully imported items.
|
||||
:param items_to_import: Set of strings corresponding to models to be imported.
|
||||
:param prediction_type_helper: A callback that receives the Path of a Stable Diffusion 2 checkpoint model and returns a SchedulerPredictionType.
|
||||
|
||||
The prediction type helper is necessary to distinguish between
|
||||
models based on Stable Diffusion 2 Base (requiring
|
||||
SchedulerPredictionType.Epsilson) and Stable Diffusion 768
|
||||
(requiring SchedulerPredictionType.VPrediction). It is
|
||||
generally impossible to do this programmatically, so the
|
||||
prediction_type_helper usually asks the user to choose.
|
||||
|
||||
The result is a set of successfully installed models. Each element
|
||||
of the set is a dict corresponding to the newly-created OmegaConf stanza for
|
||||
that model.
|
||||
"""
|
||||
return self.mgr.heuristic_import(items_to_import, prediction_type_helper)
|
||||
|
||||
def merge_models(
|
||||
self,
|
||||
model_names: List[str] = Field(
|
||||
default=None, min_items=2, max_items=3, description="List of model names to merge"
|
||||
),
|
||||
base_model: Union[BaseModelType, str] = Field(
|
||||
default=None, description="Base model shared by all models to be merged"
|
||||
),
|
||||
merged_model_name: str = Field(default=None, description="Name of destination model after merging"),
|
||||
alpha: float = 0.5,
|
||||
interp: Optional[MergeInterpolationMethod] = None,
|
||||
force: bool = False,
|
||||
merge_dest_directory: Optional[Path] = Field(
|
||||
default=None, description="Optional directory location for merged model"
|
||||
),
|
||||
) -> AddModelResult:
|
||||
"""
|
||||
Merge two to three diffusrs pipeline models and save as a new model.
|
||||
:param model_names: List of 2-3 models to merge
|
||||
:param base_model: Base model to use for all models
|
||||
:param merged_model_name: Name of destination merged model
|
||||
:param alpha: Alpha strength to apply to 2d and 3d model
|
||||
:param interp: Interpolation method. None (default)
|
||||
:param merge_dest_directory: Save the merged model to the designated directory (with 'merged_model_name' appended)
|
||||
"""
|
||||
merger = ModelMerger(self.mgr)
|
||||
try:
|
||||
result = merger.merge_diffusion_models_and_save(
|
||||
model_names=model_names,
|
||||
base_model=base_model,
|
||||
merged_model_name=merged_model_name,
|
||||
alpha=alpha,
|
||||
interp=interp,
|
||||
force=force,
|
||||
merge_dest_directory=merge_dest_directory,
|
||||
)
|
||||
except AssertionError as e:
|
||||
raise ValueError(e)
|
||||
return result
|
||||
|
||||
def search_for_models(self, directory: Path) -> List[Path]:
|
||||
"""
|
||||
Return list of all models found in the designated directory.
|
||||
"""
|
||||
search = FindModels([directory], self.logger)
|
||||
return search.list_models()
|
||||
|
||||
def sync_to_config(self):
|
||||
"""
|
||||
Re-read models.yaml, rescan the models directory, and reimport models
|
||||
in the autoimport directories. Call after making changes outside the
|
||||
model manager API.
|
||||
"""
|
||||
return self.mgr.sync_to_config()
|
||||
|
||||
def list_checkpoint_configs(self) -> List[Path]:
|
||||
"""
|
||||
List the checkpoint config paths from ROOT/configs/stable-diffusion.
|
||||
"""
|
||||
config = self.mgr.app_config
|
||||
conf_path = config.legacy_conf_path
|
||||
root_path = config.root_path
|
||||
return [(conf_path / x).relative_to(root_path) for x in conf_path.glob("**/*.yaml")]
|
||||
|
||||
def rename_model(
|
||||
self,
|
||||
model_name: str,
|
||||
base_model: BaseModelType,
|
||||
model_type: ModelType,
|
||||
new_name: Optional[str] = None,
|
||||
new_base: Optional[BaseModelType] = None,
|
||||
):
|
||||
"""
|
||||
Rename the indicated model. Can provide a new name and/or a new base.
|
||||
:param model_name: Current name of the model
|
||||
:param base_model: Current base of the model
|
||||
:param model_type: Model type (can't be changed)
|
||||
:param new_name: New name for the model
|
||||
:param new_base: New base for the model
|
||||
"""
|
||||
self.mgr.rename_model(
|
||||
base_model=base_model,
|
||||
model_type=model_type,
|
||||
model_name=model_name,
|
||||
new_name=new_name,
|
||||
new_base=new_base,
|
||||
)
|
||||
@@ -1,130 +0,0 @@
|
||||
# Copyright (c) 2023 Lincoln D. Stein and the InvokeAI Team
|
||||
|
||||
from __future__ import annotations
|
||||
|
||||
import sqlite3
|
||||
import threading
|
||||
from abc import abstractmethod
|
||||
from pathlib import Path
|
||||
from typing import Optional, Union
|
||||
|
||||
from invokeai.backend.model_manager import ( # noqa F401
|
||||
BaseModelType,
|
||||
ModelConfigBase,
|
||||
ModelFormat,
|
||||
ModelType,
|
||||
ModelVariantType,
|
||||
SchedulerPredictionType,
|
||||
SubModelType,
|
||||
)
|
||||
from invokeai.backend.model_manager.storage import ( # noqa F401
|
||||
ModelConfigStore,
|
||||
ModelConfigStoreSQL,
|
||||
ModelConfigStoreYAML,
|
||||
UnknownModelException,
|
||||
)
|
||||
from invokeai.backend.util.logging import InvokeAILogger
|
||||
|
||||
from .config import InvokeAIAppConfig
|
||||
|
||||
|
||||
class ModelRecordServiceBase(ModelConfigStore):
|
||||
"""
|
||||
Responsible for managing model configuration records.
|
||||
|
||||
This is an ABC that is simply a subclassing of the ModelConfigStore ABC
|
||||
in the backend.
|
||||
"""
|
||||
|
||||
@classmethod
|
||||
@abstractmethod
|
||||
def from_db_file(cls, db_file: Path) -> ModelRecordServiceBase:
|
||||
"""
|
||||
Initialize a new object from a database file.
|
||||
|
||||
If the path does not exist, a new sqlite3 db will be initialized.
|
||||
|
||||
:param db_file: Path to the database file
|
||||
"""
|
||||
pass
|
||||
|
||||
@classmethod
|
||||
def open(
|
||||
cls, config: InvokeAIAppConfig, conn: Optional[sqlite3.Connection] = None, lock: Optional[threading.Lock] = None
|
||||
) -> Union[ModelRecordServiceSQL, ModelRecordServiceFile]:
|
||||
"""
|
||||
Choose either a ModelConfigStoreSQL or a ModelConfigStoreFile backend.
|
||||
|
||||
Logic is as follows:
|
||||
1. if config.model_config_db contains a Path, then
|
||||
a. if the path looks like a .db file, open a new sqlite3 connection and return a ModelRecordServiceSQL
|
||||
b. if the path looks like a .yaml file, return a new ModelRecordServiceFile
|
||||
c. otherwise bail
|
||||
2. if config.model_config_db is the literal 'auto', then use the passed sqlite3 connection and thread lock.
|
||||
a. if either of these is missing, then we create our own connection to the invokeai.db file, which *should*
|
||||
be a safe thing to do - sqlite3 will use file-level locking.
|
||||
3. if config.model_config_db is None, then fall back to config.conf_path, using a yaml file
|
||||
"""
|
||||
logger = InvokeAILogger.get_logger()
|
||||
db = config.model_config_db
|
||||
if db is None:
|
||||
return ModelRecordServiceFile.from_db_file(config.model_conf_path)
|
||||
if str(db) == "auto":
|
||||
logger.info("Model config storage = main InvokeAI database")
|
||||
return (
|
||||
ModelRecordServiceSQL.from_connection(conn, lock)
|
||||
if (conn and lock)
|
||||
else ModelRecordServiceSQL.from_db_file(config.db_path)
|
||||
)
|
||||
assert isinstance(db, Path)
|
||||
suffix = db.suffix
|
||||
if suffix == ".yaml":
|
||||
logger.info(f"Model config storage = {str(db)}")
|
||||
return ModelRecordServiceFile.from_db_file(config.root_path / db)
|
||||
elif suffix == ".db":
|
||||
logger.info(f"Model config storage = {str(db)}")
|
||||
return ModelRecordServiceSQL.from_db_file(config.root_path / db)
|
||||
else:
|
||||
raise ValueError(
|
||||
f'Unrecognized model config record db file type {db} in "model_config_db" configuration variable.'
|
||||
)
|
||||
|
||||
|
||||
class ModelRecordServiceSQL(ModelConfigStoreSQL):
|
||||
"""
|
||||
ModelRecordService that uses Sqlite for its backend.
|
||||
Please see invokeai/backend/model_manager/storage/sql.py for
|
||||
the implementation.
|
||||
"""
|
||||
|
||||
@classmethod
|
||||
def from_connection(cls, conn: sqlite3.Connection, lock: threading.Lock) -> ModelRecordServiceSQL:
|
||||
"""
|
||||
Initialize a new object from preexisting sqlite3 connection and threading lock objects.
|
||||
|
||||
This is the same as the default __init__() constructor.
|
||||
|
||||
:param conn: sqlite3 connection object
|
||||
:param lock: threading Lock object
|
||||
"""
|
||||
return cls(conn, lock)
|
||||
|
||||
@classmethod
|
||||
def from_db_file(cls, db_file: Path) -> ModelRecordServiceSQL: # noqa D102 - docstring in ABC
|
||||
Path(db_file).parent.mkdir(parents=True, exist_ok=True)
|
||||
conn = sqlite3.connect(db_file, check_same_thread=False)
|
||||
lock = threading.Lock()
|
||||
return cls(conn, lock)
|
||||
|
||||
|
||||
class ModelRecordServiceFile(ModelConfigStoreYAML):
|
||||
"""
|
||||
ModelRecordService that uses a YAML file for its backend.
|
||||
|
||||
Please see invokeai/backend/model_manager/storage/yaml.py for
|
||||
the implementation.
|
||||
"""
|
||||
|
||||
@classmethod
|
||||
def from_db_file(cls, db_file: Path) -> ModelRecordServiceFile: # noqa D102 - docstring in ABC
|
||||
return cls(db_file)
|
||||
@@ -57,7 +57,6 @@ class DefaultInvocationProcessor(InvocationProcessorABC):
|
||||
except Exception as e:
|
||||
self.__invoker.services.logger.error("Exception while retrieving session:\n%s" % e)
|
||||
self.__invoker.services.events.emit_session_retrieval_error(
|
||||
queue_batch_id=queue_item.session_queue_batch_id,
|
||||
queue_item_id=queue_item.session_queue_item_id,
|
||||
queue_id=queue_item.session_queue_id,
|
||||
graph_execution_state_id=queue_item.graph_execution_state_id,
|
||||
@@ -71,7 +70,6 @@ class DefaultInvocationProcessor(InvocationProcessorABC):
|
||||
except Exception as e:
|
||||
self.__invoker.services.logger.error("Exception while retrieving invocation:\n%s" % e)
|
||||
self.__invoker.services.events.emit_invocation_retrieval_error(
|
||||
queue_batch_id=queue_item.session_queue_batch_id,
|
||||
queue_item_id=queue_item.session_queue_item_id,
|
||||
queue_id=queue_item.session_queue_id,
|
||||
graph_execution_state_id=queue_item.graph_execution_state_id,
|
||||
@@ -86,7 +84,6 @@ class DefaultInvocationProcessor(InvocationProcessorABC):
|
||||
|
||||
# Send starting event
|
||||
self.__invoker.services.events.emit_invocation_started(
|
||||
queue_batch_id=queue_item.session_queue_batch_id,
|
||||
queue_item_id=queue_item.session_queue_item_id,
|
||||
queue_id=queue_item.session_queue_id,
|
||||
graph_execution_state_id=graph_execution_state.id,
|
||||
@@ -97,8 +94,8 @@ class DefaultInvocationProcessor(InvocationProcessorABC):
|
||||
# Invoke
|
||||
try:
|
||||
graph_id = graph_execution_state.id
|
||||
model_loader = self.__invoker.services.model_loader
|
||||
with statistics.collect_stats(invocation, graph_id, model_loader):
|
||||
model_manager = self.__invoker.services.model_manager
|
||||
with statistics.collect_stats(invocation, graph_id, model_manager):
|
||||
# use the internal invoke_internal(), which wraps the node's invoke() method,
|
||||
# which handles a few things:
|
||||
# - nodes that require a value, but get it only from a connection
|
||||
@@ -109,7 +106,6 @@ class DefaultInvocationProcessor(InvocationProcessorABC):
|
||||
graph_execution_state_id=graph_execution_state.id,
|
||||
queue_item_id=queue_item.session_queue_item_id,
|
||||
queue_id=queue_item.session_queue_id,
|
||||
queue_batch_id=queue_item.session_queue_batch_id,
|
||||
)
|
||||
)
|
||||
|
||||
@@ -125,7 +121,6 @@ class DefaultInvocationProcessor(InvocationProcessorABC):
|
||||
|
||||
# Send complete event
|
||||
self.__invoker.services.events.emit_invocation_complete(
|
||||
queue_batch_id=queue_item.session_queue_batch_id,
|
||||
queue_item_id=queue_item.session_queue_item_id,
|
||||
queue_id=queue_item.session_queue_id,
|
||||
graph_execution_state_id=graph_execution_state.id,
|
||||
@@ -155,7 +150,6 @@ class DefaultInvocationProcessor(InvocationProcessorABC):
|
||||
self.__invoker.services.logger.error("Error while invoking:\n%s" % e)
|
||||
# Send error event
|
||||
self.__invoker.services.events.emit_invocation_error(
|
||||
queue_batch_id=queue_item.session_queue_batch_id,
|
||||
queue_item_id=queue_item.session_queue_item_id,
|
||||
queue_id=queue_item.session_queue_id,
|
||||
graph_execution_state_id=graph_execution_state.id,
|
||||
@@ -176,16 +170,14 @@ class DefaultInvocationProcessor(InvocationProcessorABC):
|
||||
if queue_item.invoke_all and not is_complete:
|
||||
try:
|
||||
self.__invoker.invoke(
|
||||
session_queue_batch_id=queue_item.session_queue_batch_id,
|
||||
session_queue_item_id=queue_item.session_queue_item_id,
|
||||
session_queue_id=queue_item.session_queue_id,
|
||||
queue_item_id=queue_item.session_queue_item_id,
|
||||
queue_id=queue_item.session_queue_id,
|
||||
graph_execution_state=graph_execution_state,
|
||||
invoke_all=True,
|
||||
)
|
||||
except Exception as e:
|
||||
self.__invoker.services.logger.error("Error while invoking:\n%s" % e)
|
||||
self.__invoker.services.events.emit_invocation_error(
|
||||
queue_batch_id=queue_item.session_queue_batch_id,
|
||||
queue_item_id=queue_item.session_queue_item_id,
|
||||
queue_id=queue_item.session_queue_id,
|
||||
graph_execution_state_id=graph_execution_state.id,
|
||||
@@ -196,7 +188,6 @@ class DefaultInvocationProcessor(InvocationProcessorABC):
|
||||
)
|
||||
elif is_complete:
|
||||
self.__invoker.services.events.emit_graph_execution_complete(
|
||||
queue_batch_id=queue_item.session_queue_batch_id,
|
||||
queue_item_id=queue_item.session_queue_item_id,
|
||||
queue_id=queue_item.session_queue_id,
|
||||
graph_execution_state_id=graph_execution_state.id,
|
||||
|
||||
@@ -1,4 +1,3 @@
|
||||
import traceback
|
||||
from threading import BoundedSemaphore
|
||||
from threading import Event as ThreadEvent
|
||||
from threading import Thread
|
||||
@@ -48,27 +47,20 @@ class DefaultSessionProcessor(SessionProcessorBase):
|
||||
async def _on_queue_event(self, event: FastAPIEvent) -> None:
|
||||
event_name = event[1]["event"]
|
||||
|
||||
# This was a match statement, but match is not supported on python 3.9
|
||||
if event_name in [
|
||||
"graph_execution_state_complete",
|
||||
"invocation_error",
|
||||
"session_retrieval_error",
|
||||
"invocation_retrieval_error",
|
||||
]:
|
||||
self.__queue_item = None
|
||||
self._poll_now()
|
||||
elif (
|
||||
event_name == "session_canceled"
|
||||
and self.__queue_item is not None
|
||||
and self.__queue_item.session_id == event[1]["data"]["graph_execution_state_id"]
|
||||
):
|
||||
self.__queue_item = None
|
||||
self._poll_now()
|
||||
elif event_name == "batch_enqueued":
|
||||
self._poll_now()
|
||||
elif event_name == "queue_cleared":
|
||||
self.__queue_item = None
|
||||
self._poll_now()
|
||||
match event_name:
|
||||
case "graph_execution_state_complete" | "invocation_error" | "session_retrieval_error" | "invocation_retrieval_error":
|
||||
self.__queue_item = None
|
||||
self._poll_now()
|
||||
case "session_canceled" if self.__queue_item is not None and self.__queue_item.session_id == event[1][
|
||||
"data"
|
||||
]["graph_execution_state_id"]:
|
||||
self.__queue_item = None
|
||||
self._poll_now()
|
||||
case "batch_enqueued":
|
||||
self._poll_now()
|
||||
case "queue_cleared":
|
||||
self.__queue_item = None
|
||||
self._poll_now()
|
||||
|
||||
def resume(self) -> SessionProcessorStatus:
|
||||
if not self.__resume_event.is_set():
|
||||
@@ -100,38 +92,29 @@ class DefaultSessionProcessor(SessionProcessorBase):
|
||||
self.__invoker.services.logger
|
||||
while not stop_event.is_set():
|
||||
poll_now_event.clear()
|
||||
try:
|
||||
# do not dequeue if there is already a session running
|
||||
if self.__queue_item is None and resume_event.is_set():
|
||||
queue_item = self.__invoker.services.session_queue.dequeue()
|
||||
|
||||
if queue_item is not None:
|
||||
self.__invoker.services.logger.debug(f"Executing queue item {queue_item.item_id}")
|
||||
self.__queue_item = queue_item
|
||||
self.__invoker.services.graph_execution_manager.set(queue_item.session)
|
||||
self.__invoker.invoke(
|
||||
session_queue_batch_id=queue_item.batch_id,
|
||||
session_queue_id=queue_item.queue_id,
|
||||
session_queue_item_id=queue_item.item_id,
|
||||
graph_execution_state=queue_item.session,
|
||||
invoke_all=True,
|
||||
)
|
||||
queue_item = None
|
||||
# do not dequeue if there is already a session running
|
||||
if self.__queue_item is None and resume_event.is_set():
|
||||
queue_item = self.__invoker.services.session_queue.dequeue()
|
||||
|
||||
if queue_item is None:
|
||||
self.__invoker.services.logger.debug("Waiting for next polling interval or event")
|
||||
poll_now_event.wait(POLLING_INTERVAL)
|
||||
continue
|
||||
except Exception as e:
|
||||
self.__invoker.services.logger.error(f"Error in session processor: {e}")
|
||||
if queue_item is not None:
|
||||
self.__invoker.services.session_queue.cancel_queue_item(
|
||||
queue_item.item_id, error=traceback.format_exc()
|
||||
self.__invoker.services.logger.debug(f"Executing queue item {queue_item.item_id}")
|
||||
self.__queue_item = queue_item
|
||||
self.__invoker.services.graph_execution_manager.set(queue_item.session)
|
||||
self.__invoker.invoke(
|
||||
queue_item_id=queue_item.item_id,
|
||||
queue_id=queue_item.queue_id,
|
||||
graph_execution_state=queue_item.session,
|
||||
invoke_all=True,
|
||||
)
|
||||
queue_item = None
|
||||
|
||||
if queue_item is None:
|
||||
self.__invoker.services.logger.debug("Waiting for next polling interval or event")
|
||||
poll_now_event.wait(POLLING_INTERVAL)
|
||||
continue
|
||||
except Exception as e:
|
||||
self.__invoker.services.logger.error(f"Fatal Error in session processor: {e}")
|
||||
self.__invoker.services.logger.error(f"Error in session processor: {e}")
|
||||
pass
|
||||
finally:
|
||||
stop_event.clear()
|
||||
|
||||
@@ -80,7 +80,7 @@ class SessionQueueBase(ABC):
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def cancel_queue_item(self, item_id: int, error: Optional[str] = None) -> SessionQueueItem:
|
||||
def cancel_queue_item(self, item_id: str) -> SessionQueueItem:
|
||||
"""Cancels a session queue item"""
|
||||
pass
|
||||
|
||||
@@ -100,13 +100,13 @@ class SessionQueueBase(ABC):
|
||||
queue_id: str,
|
||||
limit: int,
|
||||
priority: int,
|
||||
cursor: Optional[int] = None,
|
||||
order_id: Optional[int] = None,
|
||||
status: Optional[QUEUE_ITEM_STATUS] = None,
|
||||
) -> CursorPaginatedResults[SessionQueueItemDTO]:
|
||||
"""Gets a page of session queue items"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def get_queue_item(self, item_id: int) -> SessionQueueItem:
|
||||
def get_queue_item(self, item_id: str) -> SessionQueueItem:
|
||||
"""Gets a session queue item by ID"""
|
||||
pass
|
||||
|
||||
@@ -123,11 +123,6 @@ class Batch(BaseModel):
|
||||
raise NodeNotFoundError(f"Field {batch_data.field_name} not found in node {batch_data.node_path}")
|
||||
return values
|
||||
|
||||
@validator("graph")
|
||||
def validate_graph(cls, v: Graph):
|
||||
v.validate_self()
|
||||
return v
|
||||
|
||||
class Config:
|
||||
schema_extra = {
|
||||
"required": [
|
||||
@@ -160,22 +155,23 @@ def get_session(queue_item_dict: dict) -> GraphExecutionState:
|
||||
class SessionQueueItemWithoutGraph(BaseModel):
|
||||
"""Session queue item without the full graph. Used for serialization."""
|
||||
|
||||
item_id: int = Field(description="The identifier of the session queue item")
|
||||
item_id: str = Field(description="The unique identifier of the session queue item")
|
||||
order_id: int = Field(description="The auto-incrementing ID of the session queue item")
|
||||
status: QUEUE_ITEM_STATUS = Field(default="pending", description="The status of this queue item")
|
||||
priority: int = Field(default=0, description="The priority of this queue item")
|
||||
batch_id: str = Field(description="The ID of the batch associated with this queue item")
|
||||
session_id: str = Field(
|
||||
description="The ID of the session associated with this queue item. The session doesn't exist in graph_executions until the queue item is executed."
|
||||
)
|
||||
field_values: Optional[list[NodeFieldValue]] = Field(
|
||||
default=None, description="The field values that were used for this queue item"
|
||||
)
|
||||
queue_id: str = Field(description="The id of the queue with which this item is associated")
|
||||
error: Optional[str] = Field(default=None, description="The error message if this queue item errored")
|
||||
created_at: Union[datetime.datetime, str] = Field(description="When this queue item was created")
|
||||
updated_at: Union[datetime.datetime, str] = Field(description="When this queue item was updated")
|
||||
started_at: Optional[Union[datetime.datetime, str]] = Field(description="When this queue item was started")
|
||||
completed_at: Optional[Union[datetime.datetime, str]] = Field(description="When this queue item was completed")
|
||||
queue_id: str = Field(description="The id of the queue with which this item is associated")
|
||||
field_values: Optional[list[NodeFieldValue]] = Field(
|
||||
default=None, description="The field values that were used for this queue item"
|
||||
)
|
||||
|
||||
@classmethod
|
||||
def from_dict(cls, queue_item_dict: dict) -> "SessionQueueItemDTO":
|
||||
@@ -187,6 +183,7 @@ class SessionQueueItemWithoutGraph(BaseModel):
|
||||
schema_extra = {
|
||||
"required": [
|
||||
"item_id",
|
||||
"order_id",
|
||||
"status",
|
||||
"batch_id",
|
||||
"queue_id",
|
||||
@@ -217,6 +214,7 @@ class SessionQueueItem(SessionQueueItemWithoutGraph):
|
||||
schema_extra = {
|
||||
"required": [
|
||||
"item_id",
|
||||
"order_id",
|
||||
"status",
|
||||
"batch_id",
|
||||
"queue_id",
|
||||
@@ -237,7 +235,7 @@ class SessionQueueItem(SessionQueueItemWithoutGraph):
|
||||
|
||||
class SessionQueueStatus(BaseModel):
|
||||
queue_id: str = Field(..., description="The ID of the queue")
|
||||
item_id: Optional[int] = Field(description="The current queue item id")
|
||||
item_id: Optional[str] = Field(description="The current queue item id")
|
||||
batch_id: Optional[str] = Field(description="The current queue item's batch id")
|
||||
session_id: Optional[str] = Field(description="The current queue item's session id")
|
||||
pending: int = Field(..., description="Number of queue items with status 'pending'")
|
||||
@@ -390,24 +388,29 @@ def calc_session_count(batch: Batch) -> int:
|
||||
class SessionQueueValueToInsert(NamedTuple):
|
||||
"""A tuple of values to insert into the session_queue table"""
|
||||
|
||||
item_id: str # item_id
|
||||
queue_id: str # queue_id
|
||||
session: str # session json
|
||||
session_id: str # session_id
|
||||
batch_id: str # batch_id
|
||||
field_values: Optional[str] # field_values json
|
||||
priority: int # priority
|
||||
order_id: int # order_id
|
||||
|
||||
|
||||
ValuesToInsert: TypeAlias = list[SessionQueueValueToInsert]
|
||||
|
||||
|
||||
def prepare_values_to_insert(queue_id: str, batch: Batch, priority: int, max_new_queue_items: int) -> ValuesToInsert:
|
||||
def prepare_values_to_insert(
|
||||
queue_id: str, batch: Batch, priority: int, max_new_queue_items: int, order_id: int
|
||||
) -> ValuesToInsert:
|
||||
values_to_insert: ValuesToInsert = []
|
||||
for session, field_values in create_session_nfv_tuples(batch, max_new_queue_items):
|
||||
# sessions must have unique id
|
||||
session.id = uuid_string()
|
||||
values_to_insert.append(
|
||||
SessionQueueValueToInsert(
|
||||
uuid_string(), # item_id
|
||||
queue_id, # queue_id
|
||||
session.json(), # session (json)
|
||||
session.id, # session_id
|
||||
@@ -415,8 +418,10 @@ def prepare_values_to_insert(queue_id: str, batch: Batch, priority: int, max_new
|
||||
# must use pydantic_encoder bc field_values is a list of models
|
||||
json.dumps(field_values, default=pydantic_encoder) if field_values else None, # field_values (json)
|
||||
priority, # priority
|
||||
order_id,
|
||||
)
|
||||
)
|
||||
order_id += 1
|
||||
return values_to_insert
|
||||
|
||||
|
||||
|
||||
@@ -59,14 +59,13 @@ class SqliteSessionQueue(SessionQueueBase):
|
||||
|
||||
async def _on_session_event(self, event: FastAPIEvent) -> FastAPIEvent:
|
||||
event_name = event[1]["event"]
|
||||
|
||||
# This was a match statement, but match is not supported on python 3.9
|
||||
if event_name == "graph_execution_state_complete":
|
||||
await self._handle_complete_event(event)
|
||||
elif event_name in ["invocation_error", "session_retrieval_error", "invocation_retrieval_error"]:
|
||||
await self._handle_error_event(event)
|
||||
elif event_name == "session_canceled":
|
||||
await self._handle_cancel_event(event)
|
||||
match event_name:
|
||||
case "graph_execution_state_complete":
|
||||
await self._handle_complete_event(event)
|
||||
case "invocation_error" | "session_retrieval_error" | "invocation_retrieval_error":
|
||||
await self._handle_error_event(event)
|
||||
case "session_canceled":
|
||||
await self._handle_cancel_event(event)
|
||||
return event
|
||||
|
||||
async def _handle_complete_event(self, event: FastAPIEvent) -> None:
|
||||
@@ -78,6 +77,7 @@ class SqliteSessionQueue(SessionQueueBase):
|
||||
queue_item = self.get_queue_item(item_id)
|
||||
if queue_item.status not in ["completed", "failed", "canceled"]:
|
||||
queue_item = self._set_queue_item_status(item_id=queue_item.item_id, status="completed")
|
||||
self.__invoker.services.events.emit_queue_item_status_changed(queue_item)
|
||||
except SessionQueueItemNotFoundError:
|
||||
return
|
||||
|
||||
@@ -86,8 +86,8 @@ class SqliteSessionQueue(SessionQueueBase):
|
||||
item_id = event[1]["data"]["queue_item_id"]
|
||||
error = event[1]["data"]["error"]
|
||||
queue_item = self.get_queue_item(item_id)
|
||||
# always set to failed if have an error, even if previously the item was marked completed or canceled
|
||||
queue_item = self._set_queue_item_status(item_id=queue_item.item_id, status="failed", error=error)
|
||||
self.__invoker.services.events.emit_queue_item_status_changed(queue_item)
|
||||
except SessionQueueItemNotFoundError:
|
||||
return
|
||||
|
||||
@@ -95,8 +95,8 @@ class SqliteSessionQueue(SessionQueueBase):
|
||||
try:
|
||||
item_id = event[1]["data"]["queue_item_id"]
|
||||
queue_item = self.get_queue_item(item_id)
|
||||
if queue_item.status not in ["completed", "failed", "canceled"]:
|
||||
queue_item = self._set_queue_item_status(item_id=queue_item.item_id, status="canceled")
|
||||
queue_item = self._set_queue_item_status(item_id=queue_item.item_id, status="canceled")
|
||||
self.__invoker.services.events.emit_queue_item_status_changed(queue_item)
|
||||
except SessionQueueItemNotFoundError:
|
||||
return
|
||||
|
||||
@@ -107,7 +107,8 @@ class SqliteSessionQueue(SessionQueueBase):
|
||||
self.__cursor.execute(
|
||||
"""--sql
|
||||
CREATE TABLE IF NOT EXISTS session_queue (
|
||||
item_id INTEGER PRIMARY KEY AUTOINCREMENT, -- used for ordering, cursor pagination
|
||||
item_id TEXT NOT NULL PRIMARY KEY, -- the unique identifier of this queue item
|
||||
order_id INTEGER NOT NULL, -- used for ordering, cursor pagination
|
||||
batch_id TEXT NOT NULL, -- identifier of the batch this queue item belongs to
|
||||
queue_id TEXT NOT NULL, -- identifier of the queue this queue item belongs to
|
||||
session_id TEXT NOT NULL UNIQUE, -- duplicated data from the session column, for ease of access
|
||||
@@ -132,6 +133,12 @@ class SqliteSessionQueue(SessionQueueBase):
|
||||
"""
|
||||
)
|
||||
|
||||
self.__cursor.execute(
|
||||
"""--sql
|
||||
CREATE UNIQUE INDEX IF NOT EXISTS idx_session_queue_order_id ON session_queue(order_id);
|
||||
"""
|
||||
)
|
||||
|
||||
self.__cursor.execute(
|
||||
"""--sql
|
||||
CREATE UNIQUE INDEX IF NOT EXISTS idx_session_queue_session_id ON session_queue(session_id);
|
||||
@@ -295,12 +302,21 @@ class SqliteSessionQueue(SessionQueueBase):
|
||||
if prepend:
|
||||
priority = self._get_highest_priority(queue_id) + 1
|
||||
|
||||
self.__cursor.execute(
|
||||
"""--sql
|
||||
SELECT MAX(order_id)
|
||||
FROM session_queue
|
||||
"""
|
||||
)
|
||||
max_order_id = cast(Optional[int], self.__cursor.fetchone()[0]) or 0
|
||||
|
||||
requested_count = calc_session_count(batch)
|
||||
values_to_insert = prepare_values_to_insert(
|
||||
queue_id=queue_id,
|
||||
batch=batch,
|
||||
priority=priority,
|
||||
max_new_queue_items=max_new_queue_items,
|
||||
order_id=max_order_id + 1,
|
||||
)
|
||||
enqueued_count = len(values_to_insert)
|
||||
|
||||
@@ -309,8 +325,8 @@ class SqliteSessionQueue(SessionQueueBase):
|
||||
|
||||
self.__cursor.executemany(
|
||||
"""--sql
|
||||
INSERT INTO session_queue (queue_id, session, session_id, batch_id, field_values, priority)
|
||||
VALUES (?, ?, ?, ?, ?, ?)
|
||||
INSERT INTO session_queue (item_id, queue_id, session, session_id, batch_id, field_values, priority, order_id)
|
||||
VALUES (?, ?, ?, ?, ?, ?, ?, ?)
|
||||
""",
|
||||
values_to_insert,
|
||||
)
|
||||
@@ -340,7 +356,7 @@ class SqliteSessionQueue(SessionQueueBase):
|
||||
WHERE status = 'pending'
|
||||
ORDER BY
|
||||
priority DESC,
|
||||
item_id ASC
|
||||
order_id ASC
|
||||
LIMIT 1
|
||||
"""
|
||||
)
|
||||
@@ -354,6 +370,7 @@ class SqliteSessionQueue(SessionQueueBase):
|
||||
return None
|
||||
queue_item = SessionQueueItem.from_dict(dict(result))
|
||||
queue_item = self._set_queue_item_status(item_id=queue_item.item_id, status="in_progress")
|
||||
self.__invoker.services.events.emit_queue_item_status_changed(queue_item)
|
||||
return queue_item
|
||||
|
||||
def get_next(self, queue_id: str) -> Optional[SessionQueueItem]:
|
||||
@@ -408,7 +425,7 @@ class SqliteSessionQueue(SessionQueueBase):
|
||||
return SessionQueueItem.from_dict(dict(result))
|
||||
|
||||
def _set_queue_item_status(
|
||||
self, item_id: int, status: QUEUE_ITEM_STATUS, error: Optional[str] = None
|
||||
self, item_id: str, status: QUEUE_ITEM_STATUS, error: Optional[str] = None
|
||||
) -> SessionQueueItem:
|
||||
try:
|
||||
self.__lock.acquire()
|
||||
@@ -426,15 +443,7 @@ class SqliteSessionQueue(SessionQueueBase):
|
||||
raise
|
||||
finally:
|
||||
self.__lock.release()
|
||||
queue_item = self.get_queue_item(item_id)
|
||||
batch_status = self.get_batch_status(queue_id=queue_item.queue_id, batch_id=queue_item.batch_id)
|
||||
queue_status = self.get_queue_status(queue_id=queue_item.queue_id)
|
||||
self.__invoker.services.events.emit_queue_item_status_changed(
|
||||
session_queue_item=queue_item,
|
||||
batch_status=batch_status,
|
||||
queue_status=queue_status,
|
||||
)
|
||||
return queue_item
|
||||
return self.get_queue_item(item_id)
|
||||
|
||||
def is_empty(self, queue_id: str) -> IsEmptyResult:
|
||||
try:
|
||||
@@ -475,7 +484,7 @@ class SqliteSessionQueue(SessionQueueBase):
|
||||
self.__lock.release()
|
||||
return IsFullResult(is_full=is_full)
|
||||
|
||||
def delete_queue_item(self, item_id: int) -> SessionQueueItem:
|
||||
def delete_queue_item(self, item_id: str) -> SessionQueueItem:
|
||||
queue_item = self.get_queue_item(item_id=item_id)
|
||||
try:
|
||||
self.__lock.acquire()
|
||||
@@ -561,18 +570,17 @@ class SqliteSessionQueue(SessionQueueBase):
|
||||
self.__lock.release()
|
||||
return PruneResult(deleted=count)
|
||||
|
||||
def cancel_queue_item(self, item_id: int, error: Optional[str] = None) -> SessionQueueItem:
|
||||
def cancel_queue_item(self, item_id: str) -> SessionQueueItem:
|
||||
queue_item = self.get_queue_item(item_id)
|
||||
if queue_item.status not in ["canceled", "failed", "completed"]:
|
||||
status = "failed" if error is not None else "canceled"
|
||||
queue_item = self._set_queue_item_status(item_id=item_id, status=status, error=error)
|
||||
queue_item = self._set_queue_item_status(item_id=item_id, status="canceled")
|
||||
self.__invoker.services.queue.cancel(queue_item.session_id)
|
||||
self.__invoker.services.events.emit_session_canceled(
|
||||
queue_item_id=queue_item.item_id,
|
||||
queue_id=queue_item.queue_id,
|
||||
queue_batch_id=queue_item.batch_id,
|
||||
graph_execution_state_id=queue_item.session_id,
|
||||
)
|
||||
self.__invoker.services.events.emit_queue_item_status_changed(queue_item)
|
||||
return queue_item
|
||||
|
||||
def cancel_by_batch_ids(self, queue_id: str, batch_ids: list[str]) -> CancelByBatchIDsResult:
|
||||
@@ -612,16 +620,9 @@ class SqliteSessionQueue(SessionQueueBase):
|
||||
self.__invoker.services.events.emit_session_canceled(
|
||||
queue_item_id=current_queue_item.item_id,
|
||||
queue_id=current_queue_item.queue_id,
|
||||
queue_batch_id=current_queue_item.batch_id,
|
||||
graph_execution_state_id=current_queue_item.session_id,
|
||||
)
|
||||
batch_status = self.get_batch_status(queue_id=queue_id, batch_id=current_queue_item.batch_id)
|
||||
queue_status = self.get_queue_status(queue_id=queue_id)
|
||||
self.__invoker.services.events.emit_queue_item_status_changed(
|
||||
session_queue_item=current_queue_item,
|
||||
batch_status=batch_status,
|
||||
queue_status=queue_status,
|
||||
)
|
||||
self.__invoker.services.events.emit_queue_item_status_changed(current_queue_item)
|
||||
except Exception:
|
||||
self.__conn.rollback()
|
||||
raise
|
||||
@@ -664,16 +665,9 @@ class SqliteSessionQueue(SessionQueueBase):
|
||||
self.__invoker.services.events.emit_session_canceled(
|
||||
queue_item_id=current_queue_item.item_id,
|
||||
queue_id=current_queue_item.queue_id,
|
||||
queue_batch_id=current_queue_item.batch_id,
|
||||
graph_execution_state_id=current_queue_item.session_id,
|
||||
)
|
||||
batch_status = self.get_batch_status(queue_id=queue_id, batch_id=current_queue_item.batch_id)
|
||||
queue_status = self.get_queue_status(queue_id=queue_id)
|
||||
self.__invoker.services.events.emit_queue_item_status_changed(
|
||||
session_queue_item=current_queue_item,
|
||||
batch_status=batch_status,
|
||||
queue_status=queue_status,
|
||||
)
|
||||
self.__invoker.services.events.emit_queue_item_status_changed(current_queue_item)
|
||||
except Exception:
|
||||
self.__conn.rollback()
|
||||
raise
|
||||
@@ -681,7 +675,7 @@ class SqliteSessionQueue(SessionQueueBase):
|
||||
self.__lock.release()
|
||||
return CancelByQueueIDResult(canceled=count)
|
||||
|
||||
def get_queue_item(self, item_id: int) -> SessionQueueItem:
|
||||
def get_queue_item(self, item_id: str) -> SessionQueueItem:
|
||||
try:
|
||||
self.__lock.acquire()
|
||||
self.__cursor.execute(
|
||||
@@ -707,14 +701,14 @@ class SqliteSessionQueue(SessionQueueBase):
|
||||
queue_id: str,
|
||||
limit: int,
|
||||
priority: int,
|
||||
cursor: Optional[int] = None,
|
||||
order_id: Optional[int] = None,
|
||||
status: Optional[QUEUE_ITEM_STATUS] = None,
|
||||
) -> CursorPaginatedResults[SessionQueueItemDTO]:
|
||||
try:
|
||||
item_id = cursor
|
||||
self.__lock.acquire()
|
||||
query = """--sql
|
||||
SELECT item_id,
|
||||
order_id,
|
||||
status,
|
||||
priority,
|
||||
field_values,
|
||||
@@ -737,16 +731,16 @@ class SqliteSessionQueue(SessionQueueBase):
|
||||
"""
|
||||
params.append(status)
|
||||
|
||||
if item_id is not None:
|
||||
if order_id is not None:
|
||||
query += """--sql
|
||||
AND (priority < ?) OR (priority = ? AND item_id > ?)
|
||||
AND (priority < ?) OR (priority = ? AND order_id > ?)
|
||||
"""
|
||||
params.extend([priority, priority, item_id])
|
||||
params.extend([priority, priority, order_id])
|
||||
|
||||
query += """--sql
|
||||
ORDER BY
|
||||
priority DESC,
|
||||
item_id ASC
|
||||
order_id ASC
|
||||
LIMIT ?
|
||||
"""
|
||||
params.append(limit + 1)
|
||||
|
||||
@@ -265,41 +265,22 @@ def np_img_resize(np_img: np.ndarray, resize_mode: str, h: int, w: int, device:
|
||||
|
||||
|
||||
def prepare_control_image(
|
||||
# image used to be Union[PIL.Image.Image, List[PIL.Image.Image], torch.Tensor, List[torch.Tensor]]
|
||||
# but now should be able to assume that image is a single PIL.Image, which simplifies things
|
||||
image: Image,
|
||||
width: int,
|
||||
height: int,
|
||||
num_channels: int = 3,
|
||||
# FIXME: need to fix hardwiring of width and height, change to basing on latents dimensions?
|
||||
# latents_to_match_resolution, # TorchTensor of shape (batch_size, 3, height, width)
|
||||
width=512, # should be 8 * latent.shape[3]
|
||||
height=512, # should be 8 * latent height[2]
|
||||
# batch_size=1, # currently no batching
|
||||
# num_images_per_prompt=1, # currently only single image
|
||||
device="cuda",
|
||||
dtype=torch.float16,
|
||||
do_classifier_free_guidance=True,
|
||||
control_mode="balanced",
|
||||
resize_mode="just_resize_simple",
|
||||
):
|
||||
"""Pre-process images for ControlNets or T2I-Adapters.
|
||||
|
||||
Args:
|
||||
image (Image): The PIL image to pre-process.
|
||||
width (int): The target width in pixels.
|
||||
height (int): The target height in pixels.
|
||||
num_channels (int, optional): The target number of image channels. This is achieved by converting the input
|
||||
image to RGB, then naively taking the first `num_channels` channels. The primary use case is converting a
|
||||
RGB image to a single-channel grayscale image. Raises if `num_channels` cannot be achieved. Defaults to 3.
|
||||
device (str, optional): The target device for the output image. Defaults to "cuda".
|
||||
dtype (_type_, optional): The dtype for the output image. Defaults to torch.float16.
|
||||
do_classifier_free_guidance (bool, optional): If True, repeat the output image along the batch dimension.
|
||||
Defaults to True.
|
||||
control_mode (str, optional): Defaults to "balanced".
|
||||
resize_mode (str, optional): Defaults to "just_resize_simple".
|
||||
|
||||
Raises:
|
||||
NotImplementedError: If resize_mode == "crop_resize_simple".
|
||||
NotImplementedError: If resize_mode == "fill_resize_simple".
|
||||
ValueError: If `resize_mode` is not recognized.
|
||||
ValueError: If `num_channels` is out of range.
|
||||
|
||||
Returns:
|
||||
torch.Tensor: The pre-processed input tensor.
|
||||
"""
|
||||
# FIXME: implement "crop_resize_simple" and "fill_resize_simple", or pull them out
|
||||
if (
|
||||
resize_mode == "just_resize_simple"
|
||||
or resize_mode == "crop_resize_simple"
|
||||
@@ -308,10 +289,10 @@ def prepare_control_image(
|
||||
image = image.convert("RGB")
|
||||
if resize_mode == "just_resize_simple":
|
||||
image = image.resize((width, height), resample=PIL_INTERPOLATION["lanczos"])
|
||||
elif resize_mode == "crop_resize_simple":
|
||||
raise NotImplementedError(f"prepare_control_image is not implemented for resize_mode='{resize_mode}'.")
|
||||
elif resize_mode == "fill_resize_simple":
|
||||
raise NotImplementedError(f"prepare_control_image is not implemented for resize_mode='{resize_mode}'.")
|
||||
elif resize_mode == "crop_resize_simple": # not yet implemented
|
||||
pass
|
||||
elif resize_mode == "fill_resize_simple": # not yet implemented
|
||||
pass
|
||||
nimage = np.array(image)
|
||||
nimage = nimage[None, :]
|
||||
nimage = np.concatenate([nimage], axis=0)
|
||||
@@ -332,11 +313,9 @@ def prepare_control_image(
|
||||
device=device,
|
||||
)
|
||||
else:
|
||||
raise ValueError(f"Unsupported resize_mode: '{resize_mode}'.")
|
||||
|
||||
if timage.shape[1] < num_channels or num_channels <= 0:
|
||||
raise ValueError(f"Cannot achieve the target of num_channels={num_channels}.")
|
||||
timage = timage[:, :num_channels, :, :]
|
||||
pass
|
||||
print("ERROR: invalid resize_mode ==> ", resize_mode)
|
||||
exit(1)
|
||||
|
||||
timage = timage.to(device=device, dtype=dtype)
|
||||
cfg_injection = control_mode == "more_control" or control_mode == "unbalanced"
|
||||
|
||||
@@ -4,7 +4,7 @@ from PIL import Image
|
||||
from invokeai.app.models.exceptions import CanceledException
|
||||
from invokeai.app.models.image import ProgressImage
|
||||
|
||||
from ...backend.model_manager import BaseModelType
|
||||
from ...backend.model_management.models import BaseModelType
|
||||
from ...backend.stable_diffusion import PipelineIntermediateState
|
||||
from ...backend.util.util import image_to_dataURL
|
||||
from ..invocations.baseinvocation import InvocationContext
|
||||
@@ -112,7 +112,6 @@ def stable_diffusion_step_callback(
|
||||
context.services.events.emit_generator_progress(
|
||||
queue_id=context.queue_id,
|
||||
queue_item_id=context.queue_item_id,
|
||||
queue_batch_id=context.queue_batch_id,
|
||||
graph_execution_state_id=context.graph_execution_state_id,
|
||||
node=node,
|
||||
source_node_id=source_node_id,
|
||||
|
||||
Binary file not shown.
@@ -1,94 +0,0 @@
|
||||
Copyright (c) 2016-2020 The Inter Project Authors.
|
||||
"Inter" is trademark of Rasmus Andersson.
|
||||
https://github.com/rsms/inter
|
||||
|
||||
This Font Software is licensed under the SIL Open Font License, Version 1.1.
|
||||
This license is copied below, and is also available with a FAQ at:
|
||||
http://scripts.sil.org/OFL
|
||||
|
||||
-----------------------------------------------------------
|
||||
SIL OPEN FONT LICENSE Version 1.1 - 26 February 2007
|
||||
-----------------------------------------------------------
|
||||
|
||||
PREAMBLE
|
||||
The goals of the Open Font License (OFL) are to stimulate worldwide
|
||||
development of collaborative font projects, to support the font creation
|
||||
efforts of academic and linguistic communities, and to provide a free and
|
||||
open framework in which fonts may be shared and improved in partnership
|
||||
with others.
|
||||
|
||||
The OFL allows the licensed fonts to be used, studied, modified and
|
||||
redistributed freely as long as they are not sold by themselves. The
|
||||
fonts, including any derivative works, can be bundled, embedded,
|
||||
redistributed and/or sold with any software provided that any reserved
|
||||
names are not used by derivative works. The fonts and derivatives,
|
||||
however, cannot be released under any other type of license. The
|
||||
requirement for fonts to remain under this license does not apply
|
||||
to any document created using the fonts or their derivatives.
|
||||
|
||||
DEFINITIONS
|
||||
"Font Software" refers to the set of files released by the Copyright
|
||||
Holder(s) under this license and clearly marked as such. This may
|
||||
include source files, build scripts and documentation.
|
||||
|
||||
"Reserved Font Name" refers to any names specified as such after the
|
||||
copyright statement(s).
|
||||
|
||||
"Original Version" refers to the collection of Font Software components as
|
||||
distributed by the Copyright Holder(s).
|
||||
|
||||
"Modified Version" refers to any derivative made by adding to, deleting,
|
||||
or substituting -- in part or in whole -- any of the components of the
|
||||
Original Version, by changing formats or by porting the Font Software to a
|
||||
new environment.
|
||||
|
||||
"Author" refers to any designer, engineer, programmer, technical
|
||||
writer or other person who contributed to the Font Software.
|
||||
|
||||
PERMISSION AND CONDITIONS
|
||||
Permission is hereby granted, free of charge, to any person obtaining
|
||||
a copy of the Font Software, to use, study, copy, merge, embed, modify,
|
||||
redistribute, and sell modified and unmodified copies of the Font
|
||||
Software, subject to the following conditions:
|
||||
|
||||
1) Neither the Font Software nor any of its individual components,
|
||||
in Original or Modified Versions, may be sold by itself.
|
||||
|
||||
2) Original or Modified Versions of the Font Software may be bundled,
|
||||
redistributed and/or sold with any software, provided that each copy
|
||||
contains the above copyright notice and this license. These can be
|
||||
included either as stand-alone text files, human-readable headers or
|
||||
in the appropriate machine-readable metadata fields within text or
|
||||
binary files as long as those fields can be easily viewed by the user.
|
||||
|
||||
3) No Modified Version of the Font Software may use the Reserved Font
|
||||
Name(s) unless explicit written permission is granted by the corresponding
|
||||
Copyright Holder. This restriction only applies to the primary font name as
|
||||
presented to the users.
|
||||
|
||||
4) The name(s) of the Copyright Holder(s) or the Author(s) of the Font
|
||||
Software shall not be used to promote, endorse or advertise any
|
||||
Modified Version, except to acknowledge the contribution(s) of the
|
||||
Copyright Holder(s) and the Author(s) or with their explicit written
|
||||
permission.
|
||||
|
||||
5) The Font Software, modified or unmodified, in part or in whole,
|
||||
must be distributed entirely under this license, and must not be
|
||||
distributed under any other license. The requirement for fonts to
|
||||
remain under this license does not apply to any document created
|
||||
using the Font Software.
|
||||
|
||||
TERMINATION
|
||||
This license becomes null and void if any of the above conditions are
|
||||
not met.
|
||||
|
||||
DISCLAIMER
|
||||
THE FONT SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND,
|
||||
EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO ANY WARRANTIES OF
|
||||
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT
|
||||
OF COPYRIGHT, PATENT, TRADEMARK, OR OTHER RIGHT. IN NO EVENT SHALL THE
|
||||
COPYRIGHT HOLDER BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY,
|
||||
INCLUDING ANY GENERAL, SPECIAL, INDIRECT, INCIDENTAL, OR CONSEQUENTIAL
|
||||
DAMAGES, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
|
||||
FROM, OUT OF THE USE OR INABILITY TO USE THE FONT SOFTWARE OR FROM
|
||||
OTHER DEALINGS IN THE FONT SOFTWARE.
|
||||
@@ -1,15 +1,5 @@
|
||||
"""
|
||||
Initialization file for invokeai.backend
|
||||
"""
|
||||
from .model_manager import ( # noqa F401
|
||||
BaseModelType,
|
||||
DuplicateModelException,
|
||||
InvalidModelException,
|
||||
ModelConfigStore,
|
||||
ModelType,
|
||||
ModelVariantType,
|
||||
SchedulerPredictionType,
|
||||
SilenceWarnings,
|
||||
SubModelType,
|
||||
)
|
||||
from .util.devices import get_precision # noqa F401
|
||||
from .model_management import BaseModelType, ModelCache, ModelInfo, ModelManager, ModelType, SubModelType # noqa: F401
|
||||
from .model_management.models import SilenceWarnings # noqa: F401
|
||||
|
||||
@@ -1,46 +0,0 @@
|
||||
# Copyright (c) 2023 Lincoln D. Stein and the InvokeAI Development Team
|
||||
|
||||
"""Very simple functions to fetch and print metadata from InvokeAI-generated images."""
|
||||
|
||||
import json
|
||||
import sys
|
||||
from pathlib import Path
|
||||
from typing import Any, Dict
|
||||
|
||||
from PIL import Image
|
||||
|
||||
|
||||
def get_invokeai_metadata(image_path: Path) -> Dict[str, Any]:
|
||||
"""
|
||||
Retrieve "invokeai_metadata" field from png image.
|
||||
|
||||
:param image_path: Path to the image to read metadata from.
|
||||
May raise:
|
||||
OSError -- image path not found
|
||||
KeyError -- image doesn't contain the metadata field
|
||||
"""
|
||||
image: Image = Image.open(image_path)
|
||||
return json.loads(image.text["invokeai_metadata"])
|
||||
|
||||
|
||||
def print_invokeai_metadata(image_path: Path):
|
||||
"""Pretty-print the metadata."""
|
||||
try:
|
||||
metadata = get_invokeai_metadata(image_path)
|
||||
print(f"{image_path}:\n{json.dumps(metadata, sort_keys=True, indent=4)}")
|
||||
except OSError:
|
||||
print(f"{image_path}:\nNo file found.")
|
||||
except KeyError:
|
||||
print(f"{image_path}:\nNo metadata found.")
|
||||
print()
|
||||
|
||||
|
||||
def main():
|
||||
"""Run the command-line utility."""
|
||||
image_paths = sys.argv[1:]
|
||||
if not image_paths:
|
||||
print(f"Usage: {Path(sys.argv[0]).name} image1 image2 image3 ...")
|
||||
print("\nPretty-print InvokeAI image metadata from the listed png files.")
|
||||
sys.exit(-1)
|
||||
for img in image_paths:
|
||||
print_invokeai_metadata(img)
|
||||
@@ -8,7 +8,7 @@ from invokeai.app.services.config import InvokeAIAppConfig
|
||||
|
||||
def check_invokeai_root(config: InvokeAIAppConfig):
|
||||
try:
|
||||
assert config.model_conf_path.parent.exists(), f"{config.model_conf_path.parent} not found"
|
||||
assert config.model_conf_path.exists(), f"{config.model_conf_path} not found"
|
||||
assert config.db_path.parent.exists(), f"{config.db_path.parent} not found"
|
||||
assert config.models_path.exists(), f"{config.models_path} not found"
|
||||
if not config.ignore_missing_core_models:
|
||||
|
||||
@@ -1,196 +0,0 @@
|
||||
"""
|
||||
Utility (backend) functions used by model_install.py
|
||||
"""
|
||||
from pathlib import Path
|
||||
from typing import Dict, List, Optional
|
||||
|
||||
import omegaconf
|
||||
from huggingface_hub import HfFolder
|
||||
from pydantic import BaseModel, Field
|
||||
from pydantic.dataclasses import dataclass
|
||||
from tqdm import tqdm
|
||||
|
||||
import invokeai.configs as configs
|
||||
from invokeai.app.services.config import InvokeAIAppConfig
|
||||
from invokeai.app.services.model_install_service import ModelInstallJob, ModelInstallService, ModelSourceMetadata
|
||||
from invokeai.backend.model_manager import BaseModelType, ModelType
|
||||
from invokeai.backend.model_manager.download.queue import DownloadJobRemoteSource
|
||||
|
||||
# name of the starter models file
|
||||
INITIAL_MODELS = "INITIAL_MODELS.yaml"
|
||||
|
||||
|
||||
class UnifiedModelInfo(BaseModel):
|
||||
name: Optional[str] = None
|
||||
base_model: Optional[BaseModelType] = None
|
||||
model_type: Optional[ModelType] = None
|
||||
source: Optional[str] = None
|
||||
subfolder: Optional[str] = None
|
||||
description: Optional[str] = None
|
||||
recommended: bool = False
|
||||
installed: bool = False
|
||||
default: bool = False
|
||||
requires: List[str] = Field(default_factory=list)
|
||||
|
||||
|
||||
@dataclass
|
||||
class InstallSelections:
|
||||
install_models: List[UnifiedModelInfo] = Field(default_factory=list)
|
||||
remove_models: List[str] = Field(default_factory=list)
|
||||
|
||||
|
||||
class TqdmProgress(object):
|
||||
_bars: Dict[int, tqdm] # the tqdm object
|
||||
_last: Dict[int, int] # last bytes downloaded
|
||||
|
||||
def __init__(self):
|
||||
self._bars = dict()
|
||||
self._last = dict()
|
||||
|
||||
def job_update(self, job: ModelInstallJob):
|
||||
if not isinstance(job, DownloadJobRemoteSource):
|
||||
return
|
||||
job_id = job.id
|
||||
if job.status == "running" and job.total_bytes > 0: # job starts running before total bytes known
|
||||
if job_id not in self._bars:
|
||||
dest = Path(job.destination).name
|
||||
self._bars[job_id] = tqdm(
|
||||
desc=dest,
|
||||
initial=0,
|
||||
total=job.total_bytes,
|
||||
unit="iB",
|
||||
unit_scale=True,
|
||||
)
|
||||
self._last[job_id] = 0
|
||||
self._bars[job_id].update(job.bytes - self._last[job_id])
|
||||
self._last[job_id] = job.bytes
|
||||
|
||||
|
||||
class InstallHelper(object):
|
||||
"""Capture information stored jointly in INITIAL_MODELS.yaml and the installed models db."""
|
||||
|
||||
all_models: Dict[str, UnifiedModelInfo] = dict()
|
||||
_installer: ModelInstallService
|
||||
_config: InvokeAIAppConfig
|
||||
_installed_models: List[str] = []
|
||||
_starter_models: List[str] = []
|
||||
_default_model: Optional[str] = None
|
||||
_initial_models: omegaconf.DictConfig
|
||||
|
||||
def __init__(self, config: InvokeAIAppConfig):
|
||||
self._config = config
|
||||
self._installer = ModelInstallService(config=config, event_handlers=[TqdmProgress().job_update])
|
||||
self._initial_models = omegaconf.OmegaConf.load(Path(configs.__path__[0]) / INITIAL_MODELS)
|
||||
self._initialize_model_lists()
|
||||
|
||||
@property
|
||||
def installer(self) -> ModelInstallService:
|
||||
return self._installer
|
||||
|
||||
def _initialize_model_lists(self):
|
||||
"""
|
||||
Initialize our model slots.
|
||||
|
||||
Set up the following:
|
||||
installed_models -- list of installed model keys
|
||||
starter_models -- list of starter model keys from INITIAL_MODELS
|
||||
all_models -- dict of key => UnifiedModelInfo
|
||||
default_model -- key to default model
|
||||
"""
|
||||
# previously-installed models
|
||||
for model in self._installer.store.all_models():
|
||||
info = UnifiedModelInfo.parse_obj(model.dict())
|
||||
info.installed = True
|
||||
key = f"{model.base_model.value}/{model.model_type.value}/{model.name}"
|
||||
self.all_models[key] = info
|
||||
self._installed_models.append(key)
|
||||
|
||||
for key in self._initial_models.keys():
|
||||
if key in self.all_models:
|
||||
# we want to preserve the description
|
||||
description = self.all_models[key].description or self._initial_models[key].get("description")
|
||||
self.all_models[key].description = description
|
||||
else:
|
||||
base_model, model_type, model_name = key.split("/")
|
||||
info = UnifiedModelInfo(
|
||||
name=model_name,
|
||||
model_type=model_type,
|
||||
base_model=base_model,
|
||||
source=self._initial_models[key].source,
|
||||
description=self._initial_models[key].get("description"),
|
||||
recommended=self._initial_models[key].get("recommended", False),
|
||||
default=self._initial_models[key].get("default", False),
|
||||
subfolder=self._initial_models[key].get("subfolder"),
|
||||
requires=list(self._initial_models[key].get("requires", [])),
|
||||
)
|
||||
self.all_models[key] = info
|
||||
if not self.default_model:
|
||||
self._default_model = key
|
||||
elif self._initial_models[key].get("default", False):
|
||||
self._default_model = key
|
||||
self._starter_models.append(key)
|
||||
|
||||
# previously-installed models
|
||||
for model in self._installer.store.all_models():
|
||||
info = UnifiedModelInfo.parse_obj(model.dict())
|
||||
info.installed = True
|
||||
key = f"{model.base_model.value}/{model.model_type.value}/{model.name}"
|
||||
self.all_models[key] = info
|
||||
self._installed_models.append(key)
|
||||
|
||||
def recommended_models(self) -> List[UnifiedModelInfo]:
|
||||
return [self._to_model(x) for x in self._starter_models if self._to_model(x).recommended]
|
||||
|
||||
def installed_models(self) -> List[UnifiedModelInfo]:
|
||||
return [self._to_model(x) for x in self._installed_models]
|
||||
|
||||
def starter_models(self) -> List[UnifiedModelInfo]:
|
||||
return [self._to_model(x) for x in self._starter_models]
|
||||
|
||||
def default_model(self) -> UnifiedModelInfo:
|
||||
return self._to_model(self._default_model)
|
||||
|
||||
def _to_model(self, key: str) -> UnifiedModelInfo:
|
||||
return self.all_models[key]
|
||||
|
||||
def _add_required_models(self, model_list: List[UnifiedModelInfo]):
|
||||
installed = {x.source for x in self.installed_models()}
|
||||
reverse_source = {x.source: x for x in self.all_models.values()}
|
||||
additional_models = []
|
||||
for model_info in model_list:
|
||||
for requirement in model_info.requires:
|
||||
if requirement not in installed:
|
||||
additional_models.append(reverse_source.get(requirement))
|
||||
model_list.extend(additional_models)
|
||||
|
||||
def add_or_delete(self, selections: InstallSelections):
|
||||
installer = self._installer
|
||||
self._add_required_models(selections.install_models)
|
||||
for model in selections.install_models:
|
||||
metadata = ModelSourceMetadata(description=model.description, name=model.name)
|
||||
installer.install_model(
|
||||
model.source,
|
||||
subfolder=model.subfolder,
|
||||
access_token=HfFolder.get_token(),
|
||||
metadata=metadata,
|
||||
)
|
||||
|
||||
for model in selections.remove_models:
|
||||
parts = model.split("/")
|
||||
if len(parts) == 1:
|
||||
base_model, model_type, model_name = (None, None, model)
|
||||
else:
|
||||
base_model, model_type, model_name = parts
|
||||
matches = installer.store.search_by_name(
|
||||
base_model=base_model, model_type=model_type, model_name=model_name
|
||||
)
|
||||
if len(matches) > 1:
|
||||
print(f"{model} is ambiguous. Please use model_type:model_name (e.g. main:my_model) to disambiguate.")
|
||||
elif not matches:
|
||||
print(f"{model}: unknown model")
|
||||
else:
|
||||
for m in matches:
|
||||
print(f"Deleting {m.model_type}:{m.name}")
|
||||
installer.conditionally_delete(m.key)
|
||||
|
||||
installer.wait_for_installs()
|
||||
@@ -22,6 +22,7 @@ from typing import Any, get_args, get_type_hints
|
||||
from urllib import request
|
||||
|
||||
import npyscreen
|
||||
import omegaconf
|
||||
import psutil
|
||||
import torch
|
||||
import transformers
|
||||
@@ -37,25 +38,21 @@ from transformers import AutoFeatureExtractor, BertTokenizerFast, CLIPTextConfig
|
||||
|
||||
import invokeai.configs as configs
|
||||
from invokeai.app.services.config import InvokeAIAppConfig
|
||||
from invokeai.backend.install.install_helper import InstallHelper, InstallSelections
|
||||
from invokeai.backend.install.legacy_arg_parsing import legacy_parser
|
||||
from invokeai.backend.model_manager import BaseModelType, ModelType
|
||||
from invokeai.backend.model_manager.storage import ConfigFileVersionMismatchException, migrate_models_store
|
||||
from invokeai.backend.util import choose_precision, choose_torch_device
|
||||
from invokeai.backend.install.model_install_backend import InstallSelections, ModelInstall, hf_download_from_pretrained
|
||||
from invokeai.backend.model_management.model_probe import BaseModelType, ModelType
|
||||
from invokeai.backend.util.logging import InvokeAILogger
|
||||
from invokeai.frontend.install.model_install import addModelsForm
|
||||
from invokeai.frontend.install.model_install import addModelsForm, process_and_execute
|
||||
|
||||
# TO DO - Move all the frontend code into invokeai.frontend.install
|
||||
from invokeai.frontend.install.widgets import (
|
||||
MIN_COLS,
|
||||
MIN_LINES,
|
||||
CenteredButtonPress,
|
||||
CheckboxWithChanged,
|
||||
CyclingForm,
|
||||
FileBox,
|
||||
MultiSelectColumns,
|
||||
SingleSelectColumnsSimple,
|
||||
SingleSelectWithChanged,
|
||||
WindowTooSmallException,
|
||||
set_min_terminal_size,
|
||||
)
|
||||
@@ -73,6 +70,7 @@ def get_literal_fields(field) -> list[Any]:
|
||||
config = InvokeAIAppConfig.get_config()
|
||||
|
||||
Model_dir = "models"
|
||||
|
||||
Default_config_file = config.model_conf_path
|
||||
SD_Configs = config.legacy_conf_path
|
||||
|
||||
@@ -85,6 +83,7 @@ GB = 1073741824 # GB in bytes
|
||||
HAS_CUDA = torch.cuda.is_available()
|
||||
_, MAX_VRAM = torch.cuda.mem_get_info() if HAS_CUDA else (0, 0)
|
||||
|
||||
|
||||
MAX_VRAM /= GB
|
||||
MAX_RAM = psutil.virtual_memory().total / GB
|
||||
|
||||
@@ -94,12 +93,10 @@ INIT_FILE_PREAMBLE = """# InvokeAI initialization file
|
||||
# or renaming it and then running invokeai-configure again.
|
||||
"""
|
||||
|
||||
logger = InvokeAILogger.get_logger()
|
||||
logger = InvokeAILogger.getLogger()
|
||||
|
||||
|
||||
class DummyWidgetValue(Enum):
|
||||
"""Dummy widget values."""
|
||||
|
||||
zero = 0
|
||||
true = True
|
||||
false = False
|
||||
@@ -183,22 +180,6 @@ class ProgressBar:
|
||||
self.pbar.update(block_size)
|
||||
|
||||
|
||||
# ---------------------------------------------
|
||||
def hf_download_from_pretrained(model_class: object, model_name: str, destination: Path, **kwargs):
|
||||
filter = lambda x: "fp16 is not a valid" not in x.getMessage()
|
||||
logger.addFilter(filter)
|
||||
try:
|
||||
model = model_class.from_pretrained(
|
||||
model_name,
|
||||
resume_download=True,
|
||||
**kwargs,
|
||||
)
|
||||
model.save_pretrained(destination, safe_serialization=True)
|
||||
finally:
|
||||
logger.removeFilter(filter)
|
||||
return destination
|
||||
|
||||
|
||||
# ---------------------------------------------
|
||||
def download_with_progress_bar(model_url: str, model_dest: str, label: str = "the"):
|
||||
try:
|
||||
@@ -477,26 +458,7 @@ Use cursor arrows to make a checkbox selection, and space to toggle.
|
||||
)
|
||||
self.add_widget_intelligent(
|
||||
npyscreen.TitleFixedText,
|
||||
name="Model disk conversion cache size (GB). This is used to cache safetensors files that need to be converted to diffusers..",
|
||||
begin_entry_at=0,
|
||||
editable=False,
|
||||
color="CONTROL",
|
||||
scroll_exit=True,
|
||||
)
|
||||
self.nextrely -= 1
|
||||
self.disk = self.add_widget_intelligent(
|
||||
npyscreen.Slider,
|
||||
value=clip(old_opts.disk, range=(0, 100), step=0.5),
|
||||
out_of=100,
|
||||
lowest=0.0,
|
||||
step=0.5,
|
||||
relx=8,
|
||||
scroll_exit=True,
|
||||
)
|
||||
self.nextrely += 1
|
||||
self.add_widget_intelligent(
|
||||
npyscreen.TitleFixedText,
|
||||
name="Model RAM cache size (GB). Make this at least large enough to hold a single full model (2GB for SD-1, 6GB for SDXL).",
|
||||
name="Model RAM cache size (GB). Make this at least large enough to hold a single full model.",
|
||||
begin_entry_at=0,
|
||||
editable=False,
|
||||
color="CONTROL",
|
||||
@@ -534,45 +496,6 @@ Use cursor arrows to make a checkbox selection, and space to toggle.
|
||||
)
|
||||
else:
|
||||
self.vram = DummyWidgetValue.zero
|
||||
|
||||
self.nextrely += 1
|
||||
self.add_widget_intelligent(
|
||||
npyscreen.FixedText,
|
||||
value="Location of the database used to store model path and configuration information:",
|
||||
editable=False,
|
||||
color="CONTROL",
|
||||
)
|
||||
self.nextrely += 1
|
||||
if first_time:
|
||||
old_opts.model_config_db = "auto"
|
||||
self.model_conf_auto = self.add_widget_intelligent(
|
||||
CheckboxWithChanged,
|
||||
value=str(old_opts.model_config_db) == "auto",
|
||||
name="Main database",
|
||||
relx=2,
|
||||
max_width=25,
|
||||
scroll_exit=True,
|
||||
)
|
||||
self.nextrely -= 2
|
||||
config_db = str(old_opts.model_config_db or old_opts.conf_path)
|
||||
self.model_conf_override = self.add_widget_intelligent(
|
||||
FileBox,
|
||||
value=str(old_opts.root_path / config_db)
|
||||
if config_db != "auto"
|
||||
else str(old_opts.root_path / old_opts.conf_path),
|
||||
name="Specify models config database manually",
|
||||
select_dir=False,
|
||||
must_exist=False,
|
||||
use_two_lines=False,
|
||||
labelColor="GOOD",
|
||||
# begin_entry_at=40,
|
||||
relx=30,
|
||||
max_height=3,
|
||||
max_width=100,
|
||||
scroll_exit=True,
|
||||
hidden=str(old_opts.model_config_db) == "auto",
|
||||
)
|
||||
self.model_conf_auto.on_changed = self.show_hide_model_conf_override
|
||||
self.nextrely += 1
|
||||
self.outdir = self.add_widget_intelligent(
|
||||
FileBox,
|
||||
@@ -584,21 +507,19 @@ Use cursor arrows to make a checkbox selection, and space to toggle.
|
||||
labelColor="GOOD",
|
||||
begin_entry_at=40,
|
||||
max_height=3,
|
||||
max_width=127,
|
||||
scroll_exit=True,
|
||||
)
|
||||
self.autoimport_dirs = {}
|
||||
self.autoimport_dirs["autoimport_dir"] = self.add_widget_intelligent(
|
||||
FileBox,
|
||||
name="Optional folder to scan for new checkpoints, ControlNets, LoRAs and TI models",
|
||||
value=str(config.root_path / config.autoimport_dir) if config.autoimport_dir else "",
|
||||
name="Folder to recursively scan for new checkpoints, ControlNets, LoRAs and TI models",
|
||||
value=str(config.root_path / config.autoimport_dir),
|
||||
select_dir=True,
|
||||
must_exist=False,
|
||||
use_two_lines=False,
|
||||
labelColor="GOOD",
|
||||
begin_entry_at=32,
|
||||
max_height=3,
|
||||
max_width=127,
|
||||
scroll_exit=True,
|
||||
)
|
||||
self.nextrely += 1
|
||||
@@ -635,10 +556,6 @@ https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/blob/main/LICENS
|
||||
self.attention_slice_label.hidden = not show
|
||||
self.attention_slice_size.hidden = not show
|
||||
|
||||
def show_hide_model_conf_override(self, value):
|
||||
self.model_conf_override.hidden = value
|
||||
self.model_conf_override.display()
|
||||
|
||||
def on_ok(self):
|
||||
options = self.marshall_arguments()
|
||||
if self.validate_field_values(options):
|
||||
@@ -674,21 +591,17 @@ https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/blob/main/LICENS
|
||||
for attr in [
|
||||
"ram",
|
||||
"vram",
|
||||
"disk",
|
||||
"outdir",
|
||||
]:
|
||||
if hasattr(self, attr):
|
||||
setattr(new_opts, attr, getattr(self, attr).value)
|
||||
|
||||
for attr in self.autoimport_dirs:
|
||||
if not self.autoimport_dirs[attr].value:
|
||||
continue
|
||||
directory = Path(self.autoimport_dirs[attr].value)
|
||||
if directory.is_relative_to(config.root_path):
|
||||
directory = directory.relative_to(config.root_path)
|
||||
setattr(new_opts, attr, directory)
|
||||
|
||||
new_opts.model_config_db = "auto" if self.model_conf_auto.value else self.model_conf_override.value
|
||||
new_opts.hf_token = self.hf_token.value
|
||||
new_opts.license_acceptance = self.license_acceptance.value
|
||||
new_opts.precision = PRECISION_CHOICES[self.precision.value[0]]
|
||||
@@ -703,14 +616,13 @@ https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/blob/main/LICENS
|
||||
|
||||
|
||||
class EditOptApplication(npyscreen.NPSAppManaged):
|
||||
def __init__(self, program_opts: Namespace, invokeai_opts: Namespace, install_helper: InstallHelper):
|
||||
def __init__(self, program_opts: Namespace, invokeai_opts: Namespace):
|
||||
super().__init__()
|
||||
self.program_opts = program_opts
|
||||
self.invokeai_opts = invokeai_opts
|
||||
self.user_cancelled = False
|
||||
self.autoload_pending = True
|
||||
self.install_helper = install_helper
|
||||
self.install_selections = default_user_selections(program_opts, install_helper)
|
||||
self.install_selections = default_user_selections(program_opts)
|
||||
|
||||
def onStart(self):
|
||||
npyscreen.setTheme(npyscreen.Themes.DefaultTheme)
|
||||
@@ -733,28 +645,32 @@ class EditOptApplication(npyscreen.NPSAppManaged):
|
||||
return self.options.marshall_arguments()
|
||||
|
||||
|
||||
def default_ramcache() -> float:
|
||||
"""Run a heuristic for the default RAM cache based on installed RAM."""
|
||||
|
||||
# Note that on my 64 GB machine, psutil.virtual_memory().total gives 62 GB,
|
||||
# So we adjust everthing down a bit.
|
||||
return (
|
||||
15.0 if MAX_RAM >= 60 else 7.5 if MAX_RAM >= 30 else 4 if MAX_RAM >= 14 else 2.1
|
||||
) # 2.1 is just large enough for sd 1.5 ;-)
|
||||
def edit_opts(program_opts: Namespace, invokeai_opts: Namespace) -> argparse.Namespace:
|
||||
editApp = EditOptApplication(program_opts, invokeai_opts)
|
||||
editApp.run()
|
||||
return editApp.new_opts()
|
||||
|
||||
|
||||
def default_startup_options(init_file: Path) -> Namespace:
|
||||
opts = InvokeAIAppConfig.get_config()
|
||||
opts.ram = default_ramcache()
|
||||
return opts
|
||||
|
||||
|
||||
def default_user_selections(program_opts: Namespace, install_helper: InstallHelper) -> InstallSelections:
|
||||
default_models = (
|
||||
[install_helper.default_model()] if program_opts.default_only else install_helper.recommended_models()
|
||||
)
|
||||
def default_user_selections(program_opts: Namespace) -> InstallSelections:
|
||||
try:
|
||||
installer = ModelInstall(config)
|
||||
except omegaconf.errors.ConfigKeyError:
|
||||
logger.warning("Your models.yaml file is corrupt or out of date. Reinitializing")
|
||||
initialize_rootdir(config.root_path, True)
|
||||
installer = ModelInstall(config)
|
||||
|
||||
models = installer.all_models()
|
||||
return InstallSelections(
|
||||
install_models=default_models if program_opts.yes_to_all else list(),
|
||||
install_models=[models[installer.default_model()].path or models[installer.default_model()].repo_id]
|
||||
if program_opts.default_only
|
||||
else [models[x].path or models[x].repo_id for x in installer.recommended_models()]
|
||||
if program_opts.yes_to_all
|
||||
else list(),
|
||||
)
|
||||
|
||||
|
||||
@@ -804,7 +720,7 @@ def maybe_create_models_yaml(root: Path):
|
||||
|
||||
|
||||
# -------------------------------------
|
||||
def run_console_ui(program_opts: Namespace, initfile: Path, install_helper: InstallHelper) -> (Namespace, Namespace):
|
||||
def run_console_ui(program_opts: Namespace, initfile: Path = None) -> (Namespace, Namespace):
|
||||
invokeai_opts = default_startup_options(initfile)
|
||||
invokeai_opts.root = program_opts.root
|
||||
|
||||
@@ -813,7 +729,13 @@ def run_console_ui(program_opts: Namespace, initfile: Path, install_helper: Inst
|
||||
"Could not increase terminal size. Try running again with a larger window or smaller font size."
|
||||
)
|
||||
|
||||
editApp = EditOptApplication(program_opts, invokeai_opts, install_helper)
|
||||
# the install-models application spawns a subprocess to install
|
||||
# models, and will crash unless this is set before running.
|
||||
import torch
|
||||
|
||||
torch.multiprocessing.set_start_method("spawn")
|
||||
|
||||
editApp = EditOptApplication(program_opts, invokeai_opts)
|
||||
editApp.run()
|
||||
if editApp.user_cancelled:
|
||||
return (None, None)
|
||||
@@ -972,8 +894,7 @@ def main():
|
||||
if opt.full_precision:
|
||||
invoke_args.extend(["--precision", "float32"])
|
||||
config.parse_args(invoke_args)
|
||||
config.precision = "float32" if opt.full_precision else choose_precision(torch.device(choose_torch_device()))
|
||||
logger = InvokeAILogger().get_logger(config=config)
|
||||
logger = InvokeAILogger().getLogger(config=config)
|
||||
|
||||
errors = set()
|
||||
|
||||
@@ -986,22 +907,14 @@ def main():
|
||||
# run this unconditionally in case new directories need to be added
|
||||
initialize_rootdir(config.root_path, opt.yes_to_all)
|
||||
|
||||
# this will initialize the models.yaml file if not present
|
||||
try:
|
||||
install_helper = InstallHelper(config)
|
||||
except ConfigFileVersionMismatchException:
|
||||
config.model_config_db = migrate_models_store(config)
|
||||
install_helper = InstallHelper(config)
|
||||
|
||||
models_to_download = default_user_selections(opt, install_helper)
|
||||
models_to_download = default_user_selections(opt)
|
||||
new_init_file = config.root_path / "invokeai.yaml"
|
||||
|
||||
if opt.yes_to_all:
|
||||
write_default_options(opt, new_init_file)
|
||||
init_options = Namespace(precision="float32" if opt.full_precision else "float16")
|
||||
|
||||
else:
|
||||
init_options, models_to_download = run_console_ui(opt, new_init_file, install_helper)
|
||||
init_options, models_to_download = run_console_ui(opt, new_init_file)
|
||||
if init_options:
|
||||
write_opts(init_options, new_init_file)
|
||||
else:
|
||||
@@ -1016,12 +929,10 @@ def main():
|
||||
|
||||
if opt.skip_sd_weights:
|
||||
logger.warning("Skipping diffusion weights download per user request")
|
||||
|
||||
elif models_to_download:
|
||||
install_helper.add_or_delete(models_to_download)
|
||||
process_and_execute(opt, models_to_download)
|
||||
|
||||
postscript(errors=errors)
|
||||
|
||||
if not opt.yes_to_all:
|
||||
input("Press any key to continue...")
|
||||
except WindowTooSmallException as e:
|
||||
|
||||
@@ -3,15 +3,13 @@ Migrate the models directory and models.yaml file from an existing
|
||||
InvokeAI 2.3 installation to 3.0.0.
|
||||
"""
|
||||
|
||||
#### NOTE: THIS SCRIPT NO LONGER WORKS WITH REFACTORED MODEL MANAGER, AND WILL NOT BE UPDATED.
|
||||
|
||||
import argparse
|
||||
import os
|
||||
import shutil
|
||||
import warnings
|
||||
from dataclasses import dataclass
|
||||
from pathlib import Path
|
||||
from typing import Optional, Union
|
||||
from typing import Union
|
||||
|
||||
import diffusers
|
||||
import transformers
|
||||
@@ -23,9 +21,8 @@ from transformers import AutoFeatureExtractor, BertTokenizerFast, CLIPTextModel,
|
||||
|
||||
import invokeai.backend.util.logging as logger
|
||||
from invokeai.app.services.config import InvokeAIAppConfig
|
||||
from invokeai.app.services.model_install_service import ModelInstallService
|
||||
from invokeai.app.services.model_record_service import ModelRecordServiceBase
|
||||
from invokeai.backend.model_manager import BaseModelType, ModelProbe, ModelProbeInfo, ModelType
|
||||
from invokeai.backend.model_management import ModelManager
|
||||
from invokeai.backend.model_management.model_probe import BaseModelType, ModelProbe, ModelProbeInfo, ModelType
|
||||
|
||||
warnings.filterwarnings("ignore")
|
||||
transformers.logging.set_verbosity_error()
|
||||
@@ -46,14 +43,19 @@ class MigrateTo3(object):
|
||||
self,
|
||||
from_root: Path,
|
||||
to_models: Path,
|
||||
installer: ModelInstallService,
|
||||
model_manager: ModelManager,
|
||||
src_paths: ModelPaths,
|
||||
):
|
||||
self.root_directory = from_root
|
||||
self.dest_models = to_models
|
||||
self.installer = installer
|
||||
self.mgr = model_manager
|
||||
self.src_paths = src_paths
|
||||
|
||||
@classmethod
|
||||
def initialize_yaml(cls, yaml_file: Path):
|
||||
with open(yaml_file, "w") as file:
|
||||
file.write(yaml.dump({"__metadata__": {"version": "3.0.0"}}))
|
||||
|
||||
def create_directory_structure(self):
|
||||
"""
|
||||
Create the basic directory structure for the models folder.
|
||||
@@ -105,10 +107,44 @@ class MigrateTo3(object):
|
||||
Recursively walk through src directory, probe anything
|
||||
that looks like a model, and copy the model into the
|
||||
appropriate location within the destination models directory.
|
||||
|
||||
This is now trivially easy using the installer service.
|
||||
"""
|
||||
self.installer.scan_directory(src_dir)
|
||||
directories_scanned = set()
|
||||
for root, dirs, files in os.walk(src_dir, followlinks=True):
|
||||
for d in dirs:
|
||||
try:
|
||||
model = Path(root, d)
|
||||
info = ModelProbe().heuristic_probe(model)
|
||||
if not info:
|
||||
continue
|
||||
dest = self._model_probe_to_path(info) / model.name
|
||||
self.copy_dir(model, dest)
|
||||
directories_scanned.add(model)
|
||||
except Exception as e:
|
||||
logger.error(str(e))
|
||||
except KeyboardInterrupt:
|
||||
raise
|
||||
except Exception as e:
|
||||
logger.error(str(e))
|
||||
for f in files:
|
||||
# don't copy raw learned_embeds.bin or pytorch_lora_weights.bin
|
||||
# let them be copied as part of a tree copy operation
|
||||
try:
|
||||
if f in {"learned_embeds.bin", "pytorch_lora_weights.bin"}:
|
||||
continue
|
||||
model = Path(root, f)
|
||||
if model.parent in directories_scanned:
|
||||
continue
|
||||
info = ModelProbe().heuristic_probe(model)
|
||||
if not info:
|
||||
continue
|
||||
dest = self._model_probe_to_path(info) / f
|
||||
self.copy_file(model, dest)
|
||||
except Exception as e:
|
||||
logger.error(str(e))
|
||||
except KeyboardInterrupt:
|
||||
raise
|
||||
except Exception as e:
|
||||
logger.error(str(e))
|
||||
|
||||
def migrate_support_models(self):
|
||||
"""
|
||||
@@ -224,21 +260,23 @@ class MigrateTo3(object):
|
||||
model.save_pretrained(download_path, safe_serialization=True)
|
||||
download_path.replace(dest)
|
||||
|
||||
def _download_vae(self, repo_id: str, subfolder: str = None) -> Optional[Path]:
|
||||
self.installer.install(repo_id) # bug! We don't support subfolder yet.
|
||||
ids = self.installer.wait_for_installs()
|
||||
if key := ids.get(repo_id):
|
||||
return self.installer.store.get_model(key).path
|
||||
else:
|
||||
return None
|
||||
def _download_vae(self, repo_id: str, subfolder: str = None) -> Path:
|
||||
vae = AutoencoderKL.from_pretrained(repo_id, cache_dir=self.root_directory / "models/hub", subfolder=subfolder)
|
||||
info = ModelProbe().heuristic_probe(vae)
|
||||
_, model_name = repo_id.split("/")
|
||||
dest = self._model_probe_to_path(info) / self.unique_name(model_name, info)
|
||||
vae.save_pretrained(dest, safe_serialization=True)
|
||||
return dest
|
||||
|
||||
def _vae_path(self, vae: Union[str, dict]) -> Optional[Path]:
|
||||
"""Convert 2.3 VAE stanza to a straight path."""
|
||||
vae_path: Optional[Path] = None
|
||||
def _vae_path(self, vae: Union[str, dict]) -> Path:
|
||||
"""
|
||||
Convert 2.3 VAE stanza to a straight path.
|
||||
"""
|
||||
vae_path = None
|
||||
|
||||
# First get a path
|
||||
if isinstance(vae, str):
|
||||
vae_path = Path(vae)
|
||||
vae_path = vae
|
||||
|
||||
elif isinstance(vae, DictConfig):
|
||||
if p := vae.get("path"):
|
||||
@@ -246,21 +284,28 @@ class MigrateTo3(object):
|
||||
elif repo_id := vae.get("repo_id"):
|
||||
if repo_id == "stabilityai/sd-vae-ft-mse": # this guy is already downloaded
|
||||
vae_path = "models/core/convert/sd-vae-ft-mse"
|
||||
return Path(vae_path)
|
||||
return vae_path
|
||||
else:
|
||||
vae_path = self._download_vae(repo_id, vae.get("subfolder"))
|
||||
|
||||
if vae_path is None:
|
||||
return None
|
||||
assert vae_path is not None, "Couldn't find VAE for this model"
|
||||
|
||||
# if the VAE is in the old models directory, then we must move it into the new
|
||||
# one. VAEs outside of this directory can stay where they are.
|
||||
vae_path = Path(vae_path)
|
||||
if vae_path.is_relative_to(self.src_paths.models):
|
||||
key = self.installer.install_path(vae_path) # this will move the model
|
||||
return self.installer.store.get_model(key).path
|
||||
elif vae_path.is_relative_to(self.dest_models):
|
||||
key = self.installer.register_path(vae_path) # this will keep the model in place
|
||||
return self.installer.store.get_model(key).path
|
||||
info = ModelProbe().heuristic_probe(vae_path)
|
||||
dest = self._model_probe_to_path(info) / vae_path.name
|
||||
if not dest.exists():
|
||||
if vae_path.is_dir():
|
||||
self.copy_dir(vae_path, dest)
|
||||
else:
|
||||
self.copy_file(vae_path, dest)
|
||||
vae_path = dest
|
||||
|
||||
if vae_path.is_relative_to(self.dest_models):
|
||||
rel_path = vae_path.relative_to(self.dest_models)
|
||||
return Path("models", rel_path)
|
||||
else:
|
||||
return vae_path
|
||||
|
||||
@@ -456,27 +501,44 @@ def get_legacy_embeddings(root: Path) -> ModelPaths:
|
||||
return _parse_legacy_yamlfile(root, path)
|
||||
|
||||
|
||||
def do_migrate(config: InvokeAIAppConfig, src_directory: Path, dest_directory: Path):
|
||||
def do_migrate(src_directory: Path, dest_directory: Path):
|
||||
"""
|
||||
Migrate models from src to dest InvokeAI root directories
|
||||
"""
|
||||
config_file = dest_directory / "configs" / "models.yaml.3"
|
||||
dest_models = dest_directory / "models.3"
|
||||
mm_store = ModelRecordServiceBase.open(config)
|
||||
mm_install = ModelInstallService(config=config, store=mm_store)
|
||||
|
||||
version_3 = (dest_directory / "models" / "core").exists()
|
||||
if not version_3:
|
||||
src_directory = (dest_directory / "models").replace(src_directory / "models.orig")
|
||||
print(f"Original models directory moved to {dest_directory}/models.orig")
|
||||
|
||||
# Here we create the destination models.yaml file.
|
||||
# If we are writing into a version 3 directory and the
|
||||
# file already exists, then we write into a copy of it to
|
||||
# avoid deleting its previous customizations. Otherwise we
|
||||
# create a new empty one.
|
||||
if version_3: # write into the dest directory
|
||||
try:
|
||||
shutil.copy(dest_directory / "configs" / "models.yaml", config_file)
|
||||
except Exception:
|
||||
MigrateTo3.initialize_yaml(config_file)
|
||||
mgr = ModelManager(config_file) # important to initialize BEFORE moving the models directory
|
||||
(dest_directory / "models").replace(dest_models)
|
||||
else:
|
||||
MigrateTo3.initialize_yaml(config_file)
|
||||
mgr = ModelManager(config_file)
|
||||
|
||||
paths = get_legacy_embeddings(src_directory)
|
||||
migrator = MigrateTo3(from_root=src_directory, to_models=dest_models, installer=mm_install, src_paths=paths)
|
||||
migrator = MigrateTo3(from_root=src_directory, to_models=dest_models, model_manager=mgr, src_paths=paths)
|
||||
migrator.migrate()
|
||||
print("Migration successful.")
|
||||
|
||||
if not version_3:
|
||||
(dest_directory / "models").replace(src_directory / "models.orig")
|
||||
print(f"Original models directory moved to {dest_directory}/models.orig")
|
||||
|
||||
(dest_directory / "configs" / "models.yaml").replace(src_directory / "configs" / "models.yaml.orig")
|
||||
print(f"Original models.yaml file moved to {dest_directory}/configs/models.yaml.orig")
|
||||
|
||||
config_file.replace(config_file.with_suffix(""))
|
||||
dest_models.replace(dest_models.with_suffix(""))
|
||||
|
||||
|
||||
@@ -526,7 +588,7 @@ script, which will perform a full upgrade in place.""",
|
||||
|
||||
initialize_rootdir(dest_root, True)
|
||||
|
||||
do_migrate(config, src_root, dest_root)
|
||||
do_migrate(src_root, dest_root)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
|
||||
551
invokeai/backend/install/model_install_backend.py
Normal file
551
invokeai/backend/install/model_install_backend.py
Normal file
@@ -0,0 +1,551 @@
|
||||
"""
|
||||
Utility (backend) functions used by model_install.py
|
||||
"""
|
||||
import os
|
||||
import shutil
|
||||
import warnings
|
||||
from dataclasses import dataclass, field
|
||||
from pathlib import Path
|
||||
from tempfile import TemporaryDirectory
|
||||
from typing import Callable, Dict, List, Optional, Set, Union
|
||||
|
||||
import requests
|
||||
import torch
|
||||
from diffusers import DiffusionPipeline
|
||||
from diffusers import logging as dlogging
|
||||
from huggingface_hub import HfApi, HfFolder, hf_hub_url
|
||||
from omegaconf import OmegaConf
|
||||
from tqdm import tqdm
|
||||
|
||||
import invokeai.configs as configs
|
||||
from invokeai.app.services.config import InvokeAIAppConfig
|
||||
from invokeai.backend.model_management import AddModelResult, BaseModelType, ModelManager, ModelType, ModelVariantType
|
||||
from invokeai.backend.model_management.model_probe import ModelProbe, ModelProbeInfo, SchedulerPredictionType
|
||||
from invokeai.backend.util import download_with_resume
|
||||
from invokeai.backend.util.devices import choose_torch_device, torch_dtype
|
||||
|
||||
from ..util.logging import InvokeAILogger
|
||||
|
||||
warnings.filterwarnings("ignore")
|
||||
|
||||
# --------------------------globals-----------------------
|
||||
config = InvokeAIAppConfig.get_config()
|
||||
logger = InvokeAILogger.getLogger(name="InvokeAI")
|
||||
|
||||
# the initial "configs" dir is now bundled in the `invokeai.configs` package
|
||||
Dataset_path = Path(configs.__path__[0]) / "INITIAL_MODELS.yaml"
|
||||
|
||||
Config_preamble = """
|
||||
# This file describes the alternative machine learning models
|
||||
# available to InvokeAI script.
|
||||
#
|
||||
# To add a new model, follow the examples below. Each
|
||||
# model requires a model config file, a weights file,
|
||||
# and the width and height of the images it
|
||||
# was trained on.
|
||||
"""
|
||||
|
||||
LEGACY_CONFIGS = {
|
||||
BaseModelType.StableDiffusion1: {
|
||||
ModelVariantType.Normal: "v1-inference.yaml",
|
||||
ModelVariantType.Inpaint: "v1-inpainting-inference.yaml",
|
||||
},
|
||||
BaseModelType.StableDiffusion2: {
|
||||
ModelVariantType.Normal: {
|
||||
SchedulerPredictionType.Epsilon: "v2-inference.yaml",
|
||||
SchedulerPredictionType.VPrediction: "v2-inference-v.yaml",
|
||||
},
|
||||
ModelVariantType.Inpaint: {
|
||||
SchedulerPredictionType.Epsilon: "v2-inpainting-inference.yaml",
|
||||
SchedulerPredictionType.VPrediction: "v2-inpainting-inference-v.yaml",
|
||||
},
|
||||
},
|
||||
BaseModelType.StableDiffusionXL: {
|
||||
ModelVariantType.Normal: "sd_xl_base.yaml",
|
||||
},
|
||||
BaseModelType.StableDiffusionXLRefiner: {
|
||||
ModelVariantType.Normal: "sd_xl_refiner.yaml",
|
||||
},
|
||||
}
|
||||
|
||||
|
||||
@dataclass
|
||||
class ModelInstallList:
|
||||
"""Class for listing models to be installed/removed"""
|
||||
|
||||
install_models: List[str] = field(default_factory=list)
|
||||
remove_models: List[str] = field(default_factory=list)
|
||||
|
||||
|
||||
@dataclass
|
||||
class InstallSelections:
|
||||
install_models: List[str] = field(default_factory=list)
|
||||
remove_models: List[str] = field(default_factory=list)
|
||||
|
||||
|
||||
@dataclass
|
||||
class ModelLoadInfo:
|
||||
name: str
|
||||
model_type: ModelType
|
||||
base_type: BaseModelType
|
||||
path: Optional[Path] = None
|
||||
repo_id: Optional[str] = None
|
||||
description: str = ""
|
||||
installed: bool = False
|
||||
recommended: bool = False
|
||||
default: bool = False
|
||||
|
||||
|
||||
class ModelInstall(object):
|
||||
def __init__(
|
||||
self,
|
||||
config: InvokeAIAppConfig,
|
||||
prediction_type_helper: Optional[Callable[[Path], SchedulerPredictionType]] = None,
|
||||
model_manager: Optional[ModelManager] = None,
|
||||
access_token: Optional[str] = None,
|
||||
):
|
||||
self.config = config
|
||||
self.mgr = model_manager or ModelManager(config.model_conf_path)
|
||||
self.datasets = OmegaConf.load(Dataset_path)
|
||||
self.prediction_helper = prediction_type_helper
|
||||
self.access_token = access_token or HfFolder.get_token()
|
||||
self.reverse_paths = self._reverse_paths(self.datasets)
|
||||
|
||||
def all_models(self) -> Dict[str, ModelLoadInfo]:
|
||||
"""
|
||||
Return dict of model_key=>ModelLoadInfo objects.
|
||||
This method consolidates and simplifies the entries in both
|
||||
models.yaml and INITIAL_MODELS.yaml so that they can
|
||||
be treated uniformly. It also sorts the models alphabetically
|
||||
by their name, to improve the display somewhat.
|
||||
"""
|
||||
model_dict = dict()
|
||||
|
||||
# first populate with the entries in INITIAL_MODELS.yaml
|
||||
for key, value in self.datasets.items():
|
||||
name, base, model_type = ModelManager.parse_key(key)
|
||||
value["name"] = name
|
||||
value["base_type"] = base
|
||||
value["model_type"] = model_type
|
||||
model_dict[key] = ModelLoadInfo(**value)
|
||||
|
||||
# supplement with entries in models.yaml
|
||||
installed_models = [x for x in self.mgr.list_models()]
|
||||
# suppresses autoloaded models
|
||||
# installed_models = [x for x in self.mgr.list_models() if not self._is_autoloaded(x)]
|
||||
|
||||
for md in installed_models:
|
||||
base = md["base_model"]
|
||||
model_type = md["model_type"]
|
||||
name = md["model_name"]
|
||||
key = ModelManager.create_key(name, base, model_type)
|
||||
if key in model_dict:
|
||||
model_dict[key].installed = True
|
||||
else:
|
||||
model_dict[key] = ModelLoadInfo(
|
||||
name=name,
|
||||
base_type=base,
|
||||
model_type=model_type,
|
||||
path=value.get("path"),
|
||||
installed=True,
|
||||
)
|
||||
return {x: model_dict[x] for x in sorted(model_dict.keys(), key=lambda y: model_dict[y].name.lower())}
|
||||
|
||||
def _is_autoloaded(self, model_info: dict) -> bool:
|
||||
path = model_info.get("path")
|
||||
if not path:
|
||||
return False
|
||||
for autodir in ["autoimport_dir", "lora_dir", "embedding_dir", "controlnet_dir"]:
|
||||
if autodir_path := getattr(self.config, autodir):
|
||||
autodir_path = self.config.root_path / autodir_path
|
||||
if Path(path).is_relative_to(autodir_path):
|
||||
return True
|
||||
return False
|
||||
|
||||
def list_models(self, model_type):
|
||||
installed = self.mgr.list_models(model_type=model_type)
|
||||
print(f"Installed models of type `{model_type}`:")
|
||||
for i in installed:
|
||||
print(f"{i['model_name']}\t{i['base_model']}\t{i['path']}")
|
||||
|
||||
# logic here a little reversed to maintain backward compatibility
|
||||
def starter_models(self, all_models: bool = False) -> Set[str]:
|
||||
models = set()
|
||||
for key, value in self.datasets.items():
|
||||
name, base, model_type = ModelManager.parse_key(key)
|
||||
if all_models or model_type in [ModelType.Main, ModelType.Vae]:
|
||||
models.add(key)
|
||||
return models
|
||||
|
||||
def recommended_models(self) -> Set[str]:
|
||||
starters = self.starter_models(all_models=True)
|
||||
return set([x for x in starters if self.datasets[x].get("recommended", False)])
|
||||
|
||||
def default_model(self) -> str:
|
||||
starters = self.starter_models()
|
||||
defaults = [x for x in starters if self.datasets[x].get("default", False)]
|
||||
return defaults[0]
|
||||
|
||||
def install(self, selections: InstallSelections):
|
||||
verbosity = dlogging.get_verbosity() # quench NSFW nags
|
||||
dlogging.set_verbosity_error()
|
||||
|
||||
job = 1
|
||||
jobs = len(selections.remove_models) + len(selections.install_models)
|
||||
|
||||
# remove requested models
|
||||
for key in selections.remove_models:
|
||||
name, base, mtype = self.mgr.parse_key(key)
|
||||
logger.info(f"Deleting {mtype} model {name} [{job}/{jobs}]")
|
||||
try:
|
||||
self.mgr.del_model(name, base, mtype)
|
||||
except FileNotFoundError as e:
|
||||
logger.warning(e)
|
||||
job += 1
|
||||
|
||||
# add requested models
|
||||
for path in selections.install_models:
|
||||
logger.info(f"Installing {path} [{job}/{jobs}]")
|
||||
try:
|
||||
self.heuristic_import(path)
|
||||
except (ValueError, KeyError) as e:
|
||||
logger.error(str(e))
|
||||
job += 1
|
||||
|
||||
dlogging.set_verbosity(verbosity)
|
||||
self.mgr.commit()
|
||||
|
||||
def heuristic_import(
|
||||
self,
|
||||
model_path_id_or_url: Union[str, Path],
|
||||
models_installed: Set[Path] = None,
|
||||
) -> Dict[str, AddModelResult]:
|
||||
"""
|
||||
:param model_path_id_or_url: A Path to a local model to import, or a string representing its repo_id or URL
|
||||
:param models_installed: Set of installed models, used for recursive invocation
|
||||
Returns a set of dict objects corresponding to newly-created stanzas in models.yaml.
|
||||
"""
|
||||
|
||||
if not models_installed:
|
||||
models_installed = dict()
|
||||
|
||||
# A little hack to allow nested routines to retrieve info on the requested ID
|
||||
self.current_id = model_path_id_or_url
|
||||
path = Path(model_path_id_or_url)
|
||||
# checkpoint file, or similar
|
||||
if path.is_file():
|
||||
models_installed.update({str(path): self._install_path(path)})
|
||||
|
||||
# folders style or similar
|
||||
elif path.is_dir() and any(
|
||||
[
|
||||
(path / x).exists()
|
||||
for x in {"config.json", "model_index.json", "learned_embeds.bin", "pytorch_lora_weights.bin"}
|
||||
]
|
||||
):
|
||||
models_installed.update({str(model_path_id_or_url): self._install_path(path)})
|
||||
|
||||
# recursive scan
|
||||
elif path.is_dir():
|
||||
for child in path.iterdir():
|
||||
self.heuristic_import(child, models_installed=models_installed)
|
||||
|
||||
# huggingface repo
|
||||
elif len(str(model_path_id_or_url).split("/")) == 2:
|
||||
models_installed.update({str(model_path_id_or_url): self._install_repo(str(model_path_id_or_url))})
|
||||
|
||||
# a URL
|
||||
elif str(model_path_id_or_url).startswith(("http:", "https:", "ftp:")):
|
||||
models_installed.update({str(model_path_id_or_url): self._install_url(model_path_id_or_url)})
|
||||
|
||||
else:
|
||||
raise KeyError(f"{str(model_path_id_or_url)} is not recognized as a local path, repo ID or URL. Skipping")
|
||||
|
||||
return models_installed
|
||||
|
||||
# install a model from a local path. The optional info parameter is there to prevent
|
||||
# the model from being probed twice in the event that it has already been probed.
|
||||
def _install_path(self, path: Path, info: ModelProbeInfo = None) -> AddModelResult:
|
||||
info = info or ModelProbe().heuristic_probe(path, self.prediction_helper)
|
||||
if not info:
|
||||
logger.warning(f"Unable to parse format of {path}")
|
||||
return None
|
||||
model_name = path.stem if path.is_file() else path.name
|
||||
if self.mgr.model_exists(model_name, info.base_type, info.model_type):
|
||||
raise ValueError(f'A model named "{model_name}" is already installed.')
|
||||
attributes = self._make_attributes(path, info)
|
||||
return self.mgr.add_model(
|
||||
model_name=model_name,
|
||||
base_model=info.base_type,
|
||||
model_type=info.model_type,
|
||||
model_attributes=attributes,
|
||||
)
|
||||
|
||||
def _install_url(self, url: str) -> AddModelResult:
|
||||
with TemporaryDirectory(dir=self.config.models_path) as staging:
|
||||
location = download_with_resume(url, Path(staging))
|
||||
if not location:
|
||||
logger.error(f"Unable to download {url}. Skipping.")
|
||||
info = ModelProbe().heuristic_probe(location)
|
||||
dest = self.config.models_path / info.base_type.value / info.model_type.value / location.name
|
||||
dest.parent.mkdir(parents=True, exist_ok=True)
|
||||
models_path = shutil.move(location, dest)
|
||||
|
||||
# staged version will be garbage-collected at this time
|
||||
return self._install_path(Path(models_path), info)
|
||||
|
||||
def _install_repo(self, repo_id: str) -> AddModelResult:
|
||||
hinfo = HfApi().model_info(repo_id)
|
||||
|
||||
# we try to figure out how to download this most economically
|
||||
# list all the files in the repo
|
||||
files = [x.rfilename for x in hinfo.siblings]
|
||||
location = None
|
||||
|
||||
with TemporaryDirectory(dir=self.config.models_path) as staging:
|
||||
staging = Path(staging)
|
||||
if "model_index.json" in files:
|
||||
location = self._download_hf_pipeline(repo_id, staging) # pipeline
|
||||
elif "unet/model.onnx" in files:
|
||||
location = self._download_hf_model(repo_id, files, staging)
|
||||
else:
|
||||
for suffix in ["safetensors", "bin"]:
|
||||
if f"pytorch_lora_weights.{suffix}" in files:
|
||||
location = self._download_hf_model(repo_id, ["pytorch_lora_weights.bin"], staging) # LoRA
|
||||
break
|
||||
elif (
|
||||
self.config.precision == "float16" and f"diffusion_pytorch_model.fp16.{suffix}" in files
|
||||
): # vae, controlnet or some other standalone
|
||||
files = ["config.json", f"diffusion_pytorch_model.fp16.{suffix}"]
|
||||
location = self._download_hf_model(repo_id, files, staging)
|
||||
break
|
||||
elif f"diffusion_pytorch_model.{suffix}" in files:
|
||||
files = ["config.json", f"diffusion_pytorch_model.{suffix}"]
|
||||
location = self._download_hf_model(repo_id, files, staging)
|
||||
break
|
||||
elif f"learned_embeds.{suffix}" in files:
|
||||
location = self._download_hf_model(repo_id, [f"learned_embeds.{suffix}"], staging)
|
||||
break
|
||||
if not location:
|
||||
logger.warning(f"Could not determine type of repo {repo_id}. Skipping install.")
|
||||
return {}
|
||||
|
||||
info = ModelProbe().heuristic_probe(location, self.prediction_helper)
|
||||
if not info:
|
||||
logger.warning(f"Could not probe {location}. Skipping install.")
|
||||
return {}
|
||||
dest = (
|
||||
self.config.models_path
|
||||
/ info.base_type.value
|
||||
/ info.model_type.value
|
||||
/ self._get_model_name(repo_id, location)
|
||||
)
|
||||
if dest.exists():
|
||||
shutil.rmtree(dest)
|
||||
shutil.copytree(location, dest)
|
||||
return self._install_path(dest, info)
|
||||
|
||||
def _get_model_name(self, path_name: str, location: Path) -> str:
|
||||
"""
|
||||
Calculate a name for the model - primitive implementation.
|
||||
"""
|
||||
if key := self.reverse_paths.get(path_name):
|
||||
(name, base, mtype) = ModelManager.parse_key(key)
|
||||
return name
|
||||
elif location.is_dir():
|
||||
return location.name
|
||||
else:
|
||||
return location.stem
|
||||
|
||||
def _make_attributes(self, path: Path, info: ModelProbeInfo) -> dict:
|
||||
model_name = path.name if path.is_dir() else path.stem
|
||||
description = f"{info.base_type.value} {info.model_type.value} model {model_name}"
|
||||
if key := self.reverse_paths.get(self.current_id):
|
||||
if key in self.datasets:
|
||||
description = self.datasets[key].get("description") or description
|
||||
|
||||
rel_path = self.relative_to_root(path, self.config.models_path)
|
||||
|
||||
attributes = dict(
|
||||
path=str(rel_path),
|
||||
description=str(description),
|
||||
model_format=info.format,
|
||||
)
|
||||
legacy_conf = None
|
||||
if info.model_type == ModelType.Main or info.model_type == ModelType.ONNX:
|
||||
attributes.update(
|
||||
dict(
|
||||
variant=info.variant_type,
|
||||
)
|
||||
)
|
||||
if info.format == "checkpoint":
|
||||
try:
|
||||
possible_conf = path.with_suffix(".yaml")
|
||||
if possible_conf.exists():
|
||||
legacy_conf = str(self.relative_to_root(possible_conf))
|
||||
elif info.base_type == BaseModelType.StableDiffusion2:
|
||||
legacy_conf = Path(
|
||||
self.config.legacy_conf_dir,
|
||||
LEGACY_CONFIGS[info.base_type][info.variant_type][info.prediction_type],
|
||||
)
|
||||
else:
|
||||
legacy_conf = Path(
|
||||
self.config.legacy_conf_dir, LEGACY_CONFIGS[info.base_type][info.variant_type]
|
||||
)
|
||||
except KeyError:
|
||||
legacy_conf = Path(self.config.legacy_conf_dir, "v1-inference.yaml") # best guess
|
||||
|
||||
if info.model_type == ModelType.ControlNet and info.format == "checkpoint":
|
||||
possible_conf = path.with_suffix(".yaml")
|
||||
if possible_conf.exists():
|
||||
legacy_conf = str(self.relative_to_root(possible_conf))
|
||||
|
||||
if legacy_conf:
|
||||
attributes.update(dict(config=str(legacy_conf)))
|
||||
return attributes
|
||||
|
||||
def relative_to_root(self, path: Path, root: Optional[Path] = None) -> Path:
|
||||
root = root or self.config.root_path
|
||||
if path.is_relative_to(root):
|
||||
return path.relative_to(root)
|
||||
else:
|
||||
return path
|
||||
|
||||
def _download_hf_pipeline(self, repo_id: str, staging: Path) -> Path:
|
||||
"""
|
||||
This retrieves a StableDiffusion model from cache or remote and then
|
||||
does a save_pretrained() to the indicated staging area.
|
||||
"""
|
||||
_, name = repo_id.split("/")
|
||||
precision = torch_dtype(choose_torch_device())
|
||||
variants = ["fp16", None] if precision == torch.float16 else [None, "fp16"]
|
||||
|
||||
model = None
|
||||
for variant in variants:
|
||||
try:
|
||||
model = DiffusionPipeline.from_pretrained(
|
||||
repo_id,
|
||||
variant=variant,
|
||||
torch_dtype=precision,
|
||||
safety_checker=None,
|
||||
)
|
||||
except Exception as e: # most errors are due to fp16 not being present. Fix this to catch other errors
|
||||
if "fp16" not in str(e):
|
||||
print(e)
|
||||
|
||||
if model:
|
||||
break
|
||||
|
||||
if not model:
|
||||
logger.error(f"Diffusers model {repo_id} could not be downloaded. Skipping.")
|
||||
return None
|
||||
model.save_pretrained(staging / name, safe_serialization=True)
|
||||
return staging / name
|
||||
|
||||
def _download_hf_model(self, repo_id: str, files: List[str], staging: Path) -> Path:
|
||||
_, name = repo_id.split("/")
|
||||
location = staging / name
|
||||
paths = list()
|
||||
for filename in files:
|
||||
filePath = Path(filename)
|
||||
p = hf_download_with_resume(
|
||||
repo_id,
|
||||
model_dir=location / filePath.parent,
|
||||
model_name=filePath.name,
|
||||
access_token=self.access_token,
|
||||
subfolder=filePath.parent,
|
||||
)
|
||||
if p:
|
||||
paths.append(p)
|
||||
else:
|
||||
logger.warning(f"Could not download {filename} from {repo_id}.")
|
||||
|
||||
return location if len(paths) > 0 else None
|
||||
|
||||
@classmethod
|
||||
def _reverse_paths(cls, datasets) -> dict:
|
||||
"""
|
||||
Reverse mapping from repo_id/path to destination name.
|
||||
"""
|
||||
return {v.get("path") or v.get("repo_id"): k for k, v in datasets.items()}
|
||||
|
||||
|
||||
# -------------------------------------
|
||||
def yes_or_no(prompt: str, default_yes=True):
|
||||
default = "y" if default_yes else "n"
|
||||
response = input(f"{prompt} [{default}] ") or default
|
||||
if default_yes:
|
||||
return response[0] not in ("n", "N")
|
||||
else:
|
||||
return response[0] in ("y", "Y")
|
||||
|
||||
|
||||
# ---------------------------------------------
|
||||
def hf_download_from_pretrained(model_class: object, model_name: str, destination: Path, **kwargs):
|
||||
logger = InvokeAILogger.getLogger("InvokeAI")
|
||||
logger.addFilter(lambda x: "fp16 is not a valid" not in x.getMessage())
|
||||
|
||||
model = model_class.from_pretrained(
|
||||
model_name,
|
||||
resume_download=True,
|
||||
**kwargs,
|
||||
)
|
||||
model.save_pretrained(destination, safe_serialization=True)
|
||||
return destination
|
||||
|
||||
|
||||
# ---------------------------------------------
|
||||
def hf_download_with_resume(
|
||||
repo_id: str,
|
||||
model_dir: str,
|
||||
model_name: str,
|
||||
model_dest: Path = None,
|
||||
access_token: str = None,
|
||||
subfolder: str = None,
|
||||
) -> Path:
|
||||
model_dest = model_dest or Path(os.path.join(model_dir, model_name))
|
||||
os.makedirs(model_dir, exist_ok=True)
|
||||
|
||||
url = hf_hub_url(repo_id, model_name, subfolder=subfolder)
|
||||
|
||||
header = {"Authorization": f"Bearer {access_token}"} if access_token else {}
|
||||
open_mode = "wb"
|
||||
exist_size = 0
|
||||
|
||||
if os.path.exists(model_dest):
|
||||
exist_size = os.path.getsize(model_dest)
|
||||
header["Range"] = f"bytes={exist_size}-"
|
||||
open_mode = "ab"
|
||||
|
||||
resp = requests.get(url, headers=header, stream=True)
|
||||
total = int(resp.headers.get("content-length", 0))
|
||||
|
||||
if resp.status_code == 416: # "range not satisfiable", which means nothing to return
|
||||
logger.info(f"{model_name}: complete file found. Skipping.")
|
||||
return model_dest
|
||||
elif resp.status_code == 404:
|
||||
logger.warning("File not found")
|
||||
return None
|
||||
elif resp.status_code != 200:
|
||||
logger.warning(f"{model_name}: {resp.reason}")
|
||||
elif exist_size > 0:
|
||||
logger.info(f"{model_name}: partial file found. Resuming...")
|
||||
else:
|
||||
logger.info(f"{model_name}: Downloading...")
|
||||
|
||||
try:
|
||||
with open(model_dest, open_mode) as file, tqdm(
|
||||
desc=model_name,
|
||||
initial=exist_size,
|
||||
total=total + exist_size,
|
||||
unit="iB",
|
||||
unit_scale=True,
|
||||
unit_divisor=1000,
|
||||
) as bar:
|
||||
for data in resp.iter_content(chunk_size=1024):
|
||||
size = file.write(data)
|
||||
bar.update(size)
|
||||
except Exception as e:
|
||||
logger.error(f"An error occurred while downloading {model_name}: {str(e)}")
|
||||
return None
|
||||
return model_dest
|
||||
@@ -1,45 +0,0 @@
|
||||
# IP-Adapter Model Formats
|
||||
|
||||
The official IP-Adapter models are released here: [h94/IP-Adapter](https://huggingface.co/h94/IP-Adapter)
|
||||
|
||||
This official model repo does not integrate well with InvokeAI's current approach to model management, so we have defined a new file structure for IP-Adapter models. The InvokeAI format is described below.
|
||||
|
||||
## CLIP Vision Models
|
||||
|
||||
CLIP Vision models are organized in `diffusers`` format. The expected directory structure is:
|
||||
|
||||
```bash
|
||||
ip_adapter_sd_image_encoder/
|
||||
├── config.json
|
||||
└── model.safetensors
|
||||
```
|
||||
|
||||
## IP-Adapter Models
|
||||
|
||||
IP-Adapter models are stored in a directory containing two files
|
||||
- `image_encoder.txt`: A text file containing the model identifier for the CLIP Vision encoder that is intended to be used with this IP-Adapter model.
|
||||
- `ip_adapter.bin`: The IP-Adapter weights.
|
||||
|
||||
Sample directory structure:
|
||||
```bash
|
||||
ip_adapter_sd15/
|
||||
├── image_encoder.txt
|
||||
└── ip_adapter.bin
|
||||
```
|
||||
|
||||
### Why save the weights in a .safetensors file?
|
||||
|
||||
The weights in `ip_adapter.bin` are stored in a nested dict, which is not supported by `safetensors`. This could be solved by splitting `ip_adapter.bin` into multiple files, but for now we have decided to maintain consistency with the checkpoint structure used in the official [h94/IP-Adapter](https://huggingface.co/h94/IP-Adapter) repo.
|
||||
|
||||
## InvokeAI Hosted IP-Adapters
|
||||
|
||||
Image Encoders:
|
||||
- [InvokeAI/ip_adapter_sd_image_encoder](https://huggingface.co/InvokeAI/ip_adapter_sd_image_encoder)
|
||||
- [InvokeAI/ip_adapter_sdxl_image_encoder](https://huggingface.co/InvokeAI/ip_adapter_sdxl_image_encoder)
|
||||
|
||||
IP-Adapters:
|
||||
- [InvokeAI/ip_adapter_sd15](https://huggingface.co/InvokeAI/ip_adapter_sd15)
|
||||
- [InvokeAI/ip_adapter_plus_sd15](https://huggingface.co/InvokeAI/ip_adapter_plus_sd15)
|
||||
- [InvokeAI/ip_adapter_plus_face_sd15](https://huggingface.co/InvokeAI/ip_adapter_plus_face_sd15)
|
||||
- [InvokeAI/ip_adapter_sdxl](https://huggingface.co/InvokeAI/ip_adapter_sdxl)
|
||||
- [InvokeAI/ip_adapter_sdxl_vit_h](https://huggingface.co/InvokeAI/ip_adapter_sdxl_vit_h)
|
||||
@@ -1,165 +0,0 @@
|
||||
# copied from https://github.com/tencent-ailab/IP-Adapter (Apache License 2.0)
|
||||
# and modified as needed
|
||||
|
||||
# tencent-ailab comment:
|
||||
# modified from https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import torch.nn.functional as F
|
||||
from diffusers.models.attention_processor import AttnProcessor2_0 as DiffusersAttnProcessor2_0
|
||||
|
||||
from invokeai.backend.ip_adapter.ip_attention_weights import IPAttentionProcessorWeights
|
||||
|
||||
|
||||
# Create a version of AttnProcessor2_0 that is a sub-class of nn.Module. This is required for IP-Adapter state_dict
|
||||
# loading.
|
||||
class AttnProcessor2_0(DiffusersAttnProcessor2_0, nn.Module):
|
||||
def __init__(self):
|
||||
DiffusersAttnProcessor2_0.__init__(self)
|
||||
nn.Module.__init__(self)
|
||||
|
||||
def __call__(
|
||||
self,
|
||||
attn,
|
||||
hidden_states,
|
||||
encoder_hidden_states=None,
|
||||
attention_mask=None,
|
||||
temb=None,
|
||||
ip_adapter_image_prompt_embeds=None,
|
||||
):
|
||||
"""Re-definition of DiffusersAttnProcessor2_0.__call__(...) that accepts and ignores the
|
||||
ip_adapter_image_prompt_embeds parameter.
|
||||
"""
|
||||
return DiffusersAttnProcessor2_0.__call__(
|
||||
self, attn, hidden_states, encoder_hidden_states, attention_mask, temb
|
||||
)
|
||||
|
||||
|
||||
class IPAttnProcessor2_0(torch.nn.Module):
|
||||
r"""
|
||||
Attention processor for IP-Adapater for PyTorch 2.0.
|
||||
Args:
|
||||
hidden_size (`int`):
|
||||
The hidden size of the attention layer.
|
||||
cross_attention_dim (`int`):
|
||||
The number of channels in the `encoder_hidden_states`.
|
||||
scale (`float`, defaults to 1.0):
|
||||
the weight scale of image prompt.
|
||||
"""
|
||||
|
||||
def __init__(self, weights: list[IPAttentionProcessorWeights], scales: list[float]):
|
||||
super().__init__()
|
||||
|
||||
if not hasattr(F, "scaled_dot_product_attention"):
|
||||
raise ImportError("AttnProcessor2_0 requires PyTorch 2.0, to use it, please upgrade PyTorch to 2.0.")
|
||||
|
||||
assert len(weights) == len(scales)
|
||||
|
||||
self._weights = weights
|
||||
self._scales = scales
|
||||
|
||||
def __call__(
|
||||
self,
|
||||
attn,
|
||||
hidden_states,
|
||||
encoder_hidden_states=None,
|
||||
attention_mask=None,
|
||||
temb=None,
|
||||
ip_adapter_image_prompt_embeds=None,
|
||||
):
|
||||
residual = hidden_states
|
||||
|
||||
if attn.spatial_norm is not None:
|
||||
hidden_states = attn.spatial_norm(hidden_states, temb)
|
||||
|
||||
input_ndim = hidden_states.ndim
|
||||
|
||||
if input_ndim == 4:
|
||||
batch_size, channel, height, width = hidden_states.shape
|
||||
hidden_states = hidden_states.view(batch_size, channel, height * width).transpose(1, 2)
|
||||
|
||||
batch_size, sequence_length, _ = (
|
||||
hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape
|
||||
)
|
||||
|
||||
if attention_mask is not None:
|
||||
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
|
||||
# scaled_dot_product_attention expects attention_mask shape to be
|
||||
# (batch, heads, source_length, target_length)
|
||||
attention_mask = attention_mask.view(batch_size, attn.heads, -1, attention_mask.shape[-1])
|
||||
|
||||
if attn.group_norm is not None:
|
||||
hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
|
||||
|
||||
query = attn.to_q(hidden_states)
|
||||
|
||||
if encoder_hidden_states is None:
|
||||
encoder_hidden_states = hidden_states
|
||||
elif attn.norm_cross:
|
||||
encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
|
||||
|
||||
key = attn.to_k(encoder_hidden_states)
|
||||
value = attn.to_v(encoder_hidden_states)
|
||||
|
||||
inner_dim = key.shape[-1]
|
||||
head_dim = inner_dim // attn.heads
|
||||
|
||||
query = query.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
||||
|
||||
key = key.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
||||
value = value.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
||||
|
||||
# the output of sdp = (batch, num_heads, seq_len, head_dim)
|
||||
# TODO: add support for attn.scale when we move to Torch 2.1
|
||||
hidden_states = F.scaled_dot_product_attention(
|
||||
query, key, value, attn_mask=attention_mask, dropout_p=0.0, is_causal=False
|
||||
)
|
||||
|
||||
hidden_states = hidden_states.transpose(1, 2).reshape(batch_size, -1, attn.heads * head_dim)
|
||||
hidden_states = hidden_states.to(query.dtype)
|
||||
|
||||
if encoder_hidden_states is not None:
|
||||
# If encoder_hidden_states is not None, then we are doing cross-attention, not self-attention. In this case,
|
||||
# we will apply IP-Adapter conditioning. We validate the inputs for IP-Adapter conditioning here.
|
||||
assert ip_adapter_image_prompt_embeds is not None
|
||||
assert len(ip_adapter_image_prompt_embeds) == len(self._weights)
|
||||
|
||||
for ipa_embed, ipa_weights, scale in zip(ip_adapter_image_prompt_embeds, self._weights, self._scales):
|
||||
# The batch dimensions should match.
|
||||
assert ipa_embed.shape[0] == encoder_hidden_states.shape[0]
|
||||
# The channel dimensions should match.
|
||||
assert ipa_embed.shape[2] == encoder_hidden_states.shape[2]
|
||||
|
||||
ip_hidden_states = ipa_embed
|
||||
|
||||
ip_key = ipa_weights.to_k_ip(ip_hidden_states)
|
||||
ip_value = ipa_weights.to_v_ip(ip_hidden_states)
|
||||
|
||||
ip_key = ip_key.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
||||
ip_value = ip_value.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
||||
|
||||
# The output of sdpa has shape: (batch, num_heads, seq_len, head_dim)
|
||||
# TODO: add support for attn.scale when we move to Torch 2.1
|
||||
ip_hidden_states = F.scaled_dot_product_attention(
|
||||
query, ip_key, ip_value, attn_mask=None, dropout_p=0.0, is_causal=False
|
||||
)
|
||||
|
||||
ip_hidden_states = ip_hidden_states.transpose(1, 2).reshape(batch_size, -1, attn.heads * head_dim)
|
||||
ip_hidden_states = ip_hidden_states.to(query.dtype)
|
||||
|
||||
hidden_states = hidden_states + scale * ip_hidden_states
|
||||
|
||||
# linear proj
|
||||
hidden_states = attn.to_out[0](hidden_states)
|
||||
# dropout
|
||||
hidden_states = attn.to_out[1](hidden_states)
|
||||
|
||||
if input_ndim == 4:
|
||||
hidden_states = hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width)
|
||||
|
||||
if attn.residual_connection:
|
||||
hidden_states = hidden_states + residual
|
||||
|
||||
hidden_states = hidden_states / attn.rescale_output_factor
|
||||
|
||||
return hidden_states
|
||||
@@ -1,167 +0,0 @@
|
||||
# copied from https://github.com/tencent-ailab/IP-Adapter (Apache License 2.0)
|
||||
# and modified as needed
|
||||
|
||||
from typing import Optional, Union
|
||||
|
||||
import torch
|
||||
from PIL import Image
|
||||
from transformers import CLIPImageProcessor, CLIPVisionModelWithProjection
|
||||
|
||||
from invokeai.backend.ip_adapter.ip_attention_weights import IPAttentionWeights
|
||||
from invokeai.backend.model_manager.models.base import calc_model_size_by_data
|
||||
|
||||
from .resampler import Resampler
|
||||
|
||||
|
||||
class ImageProjModel(torch.nn.Module):
|
||||
"""Image Projection Model"""
|
||||
|
||||
def __init__(self, cross_attention_dim=1024, clip_embeddings_dim=1024, clip_extra_context_tokens=4):
|
||||
super().__init__()
|
||||
|
||||
self.cross_attention_dim = cross_attention_dim
|
||||
self.clip_extra_context_tokens = clip_extra_context_tokens
|
||||
self.proj = torch.nn.Linear(clip_embeddings_dim, self.clip_extra_context_tokens * cross_attention_dim)
|
||||
self.norm = torch.nn.LayerNorm(cross_attention_dim)
|
||||
|
||||
@classmethod
|
||||
def from_state_dict(cls, state_dict: dict[torch.Tensor], clip_extra_context_tokens=4):
|
||||
"""Initialize an ImageProjModel from a state_dict.
|
||||
|
||||
The cross_attention_dim and clip_embeddings_dim are inferred from the shape of the tensors in the state_dict.
|
||||
|
||||
Args:
|
||||
state_dict (dict[torch.Tensor]): The state_dict of model weights.
|
||||
clip_extra_context_tokens (int, optional): Defaults to 4.
|
||||
|
||||
Returns:
|
||||
ImageProjModel
|
||||
"""
|
||||
cross_attention_dim = state_dict["norm.weight"].shape[0]
|
||||
clip_embeddings_dim = state_dict["proj.weight"].shape[-1]
|
||||
|
||||
model = cls(cross_attention_dim, clip_embeddings_dim, clip_extra_context_tokens)
|
||||
|
||||
model.load_state_dict(state_dict)
|
||||
return model
|
||||
|
||||
def forward(self, image_embeds):
|
||||
embeds = image_embeds
|
||||
clip_extra_context_tokens = self.proj(embeds).reshape(
|
||||
-1, self.clip_extra_context_tokens, self.cross_attention_dim
|
||||
)
|
||||
clip_extra_context_tokens = self.norm(clip_extra_context_tokens)
|
||||
return clip_extra_context_tokens
|
||||
|
||||
|
||||
class IPAdapter:
|
||||
"""IP-Adapter: https://arxiv.org/pdf/2308.06721.pdf"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
state_dict: dict[str, torch.Tensor],
|
||||
device: torch.device,
|
||||
dtype: torch.dtype = torch.float16,
|
||||
num_tokens: int = 4,
|
||||
):
|
||||
self.device = device
|
||||
self.dtype = dtype
|
||||
|
||||
self._num_tokens = num_tokens
|
||||
|
||||
self._clip_image_processor = CLIPImageProcessor()
|
||||
|
||||
self._image_proj_model = self._init_image_proj_model(state_dict["image_proj"])
|
||||
|
||||
self.attn_weights = IPAttentionWeights.from_state_dict(state_dict["ip_adapter"]).to(
|
||||
self.device, dtype=self.dtype
|
||||
)
|
||||
|
||||
def to(self, device: torch.device, dtype: Optional[torch.dtype] = None):
|
||||
self.device = device
|
||||
if dtype is not None:
|
||||
self.dtype = dtype
|
||||
|
||||
self._image_proj_model.to(device=self.device, dtype=self.dtype)
|
||||
self.attn_weights.to(device=self.device, dtype=self.dtype)
|
||||
|
||||
def calc_size(self):
|
||||
return calc_model_size_by_data(self._image_proj_model) + calc_model_size_by_data(self.attn_weights)
|
||||
|
||||
def _init_image_proj_model(self, state_dict):
|
||||
return ImageProjModel.from_state_dict(state_dict, self._num_tokens).to(self.device, dtype=self.dtype)
|
||||
|
||||
@torch.inference_mode()
|
||||
def get_image_embeds(self, pil_image, image_encoder: CLIPVisionModelWithProjection):
|
||||
if isinstance(pil_image, Image.Image):
|
||||
pil_image = [pil_image]
|
||||
clip_image = self._clip_image_processor(images=pil_image, return_tensors="pt").pixel_values
|
||||
clip_image_embeds = image_encoder(clip_image.to(self.device, dtype=self.dtype)).image_embeds
|
||||
image_prompt_embeds = self._image_proj_model(clip_image_embeds)
|
||||
uncond_image_prompt_embeds = self._image_proj_model(torch.zeros_like(clip_image_embeds))
|
||||
return image_prompt_embeds, uncond_image_prompt_embeds
|
||||
|
||||
|
||||
class IPAdapterPlus(IPAdapter):
|
||||
"""IP-Adapter with fine-grained features"""
|
||||
|
||||
def _init_image_proj_model(self, state_dict):
|
||||
return Resampler.from_state_dict(
|
||||
state_dict=state_dict,
|
||||
depth=4,
|
||||
dim_head=64,
|
||||
heads=12,
|
||||
num_queries=self._num_tokens,
|
||||
ff_mult=4,
|
||||
).to(self.device, dtype=self.dtype)
|
||||
|
||||
@torch.inference_mode()
|
||||
def get_image_embeds(self, pil_image, image_encoder: CLIPVisionModelWithProjection):
|
||||
if isinstance(pil_image, Image.Image):
|
||||
pil_image = [pil_image]
|
||||
clip_image = self._clip_image_processor(images=pil_image, return_tensors="pt").pixel_values
|
||||
clip_image = clip_image.to(self.device, dtype=self.dtype)
|
||||
clip_image_embeds = image_encoder(clip_image, output_hidden_states=True).hidden_states[-2]
|
||||
image_prompt_embeds = self._image_proj_model(clip_image_embeds)
|
||||
uncond_clip_image_embeds = image_encoder(torch.zeros_like(clip_image), output_hidden_states=True).hidden_states[
|
||||
-2
|
||||
]
|
||||
uncond_image_prompt_embeds = self._image_proj_model(uncond_clip_image_embeds)
|
||||
return image_prompt_embeds, uncond_image_prompt_embeds
|
||||
|
||||
|
||||
class IPAdapterPlusXL(IPAdapterPlus):
|
||||
"""IP-Adapter Plus for SDXL."""
|
||||
|
||||
def _init_image_proj_model(self, state_dict):
|
||||
return Resampler.from_state_dict(
|
||||
state_dict=state_dict,
|
||||
depth=4,
|
||||
dim_head=64,
|
||||
heads=20,
|
||||
num_queries=self._num_tokens,
|
||||
ff_mult=4,
|
||||
).to(self.device, dtype=self.dtype)
|
||||
|
||||
|
||||
def build_ip_adapter(
|
||||
ip_adapter_ckpt_path: str, device: torch.device, dtype: torch.dtype = torch.float16
|
||||
) -> Union[IPAdapter, IPAdapterPlus]:
|
||||
state_dict = torch.load(ip_adapter_ckpt_path, map_location="cpu")
|
||||
|
||||
# Determine if the state_dict is from an IPAdapter or IPAdapterPlus based on the image_proj weights that it
|
||||
# contains.
|
||||
is_plus = "proj.weight" not in state_dict["image_proj"]
|
||||
|
||||
if is_plus:
|
||||
cross_attention_dim = state_dict["ip_adapter"]["1.to_k_ip.weight"].shape[-1]
|
||||
if cross_attention_dim == 768:
|
||||
# SD1 IP-Adapter Plus
|
||||
return IPAdapterPlus(state_dict, device=device, dtype=dtype)
|
||||
elif cross_attention_dim == 2048:
|
||||
# SDXL IP-Adapter Plus
|
||||
return IPAdapterPlusXL(state_dict, device=device, dtype=dtype)
|
||||
else:
|
||||
raise Exception(f"Unsupported IP-Adapter Plus cross-attention dimension: {cross_attention_dim}.")
|
||||
else:
|
||||
return IPAdapter(state_dict, device=device, dtype=dtype)
|
||||
@@ -1,46 +0,0 @@
|
||||
import torch
|
||||
|
||||
|
||||
class IPAttentionProcessorWeights(torch.nn.Module):
|
||||
"""The IP-Adapter weights for a single attention processor.
|
||||
|
||||
This class is a torch.nn.Module sub-class to facilitate loading from a state_dict. It does not have a forward(...)
|
||||
method.
|
||||
"""
|
||||
|
||||
def __init__(self, in_dim: int, out_dim: int):
|
||||
super().__init__()
|
||||
self.to_k_ip = torch.nn.Linear(in_dim, out_dim, bias=False)
|
||||
self.to_v_ip = torch.nn.Linear(in_dim, out_dim, bias=False)
|
||||
|
||||
|
||||
class IPAttentionWeights(torch.nn.Module):
|
||||
"""A collection of all the `IPAttentionProcessorWeights` objects for an IP-Adapter model.
|
||||
|
||||
This class is a torch.nn.Module sub-class so that it inherits the `.to(...)` functionality. It does not have a
|
||||
forward(...) method.
|
||||
"""
|
||||
|
||||
def __init__(self, weights: torch.nn.ModuleDict):
|
||||
super().__init__()
|
||||
self._weights = weights
|
||||
|
||||
def get_attention_processor_weights(self, idx: int) -> IPAttentionProcessorWeights:
|
||||
"""Get the `IPAttentionProcessorWeights` for the idx'th attention processor."""
|
||||
# Cast to int first, because we expect the key to represent an int. Then cast back to str, because
|
||||
# `torch.nn.ModuleDict` only supports str keys.
|
||||
return self._weights[str(int(idx))]
|
||||
|
||||
@classmethod
|
||||
def from_state_dict(cls, state_dict: dict[str, torch.Tensor]):
|
||||
attn_proc_weights: dict[str, IPAttentionProcessorWeights] = {}
|
||||
|
||||
for tensor_name, tensor in state_dict.items():
|
||||
if "to_k_ip.weight" in tensor_name:
|
||||
index = str(int(tensor_name.split(".")[0]))
|
||||
attn_proc_weights[index] = IPAttentionProcessorWeights(tensor.shape[1], tensor.shape[0])
|
||||
|
||||
attn_proc_weights_module = torch.nn.ModuleDict(attn_proc_weights)
|
||||
attn_proc_weights_module.load_state_dict(state_dict)
|
||||
|
||||
return cls(attn_proc_weights_module)
|
||||
@@ -1,158 +0,0 @@
|
||||
# copied from https://github.com/tencent-ailab/IP-Adapter (Apache License 2.0)
|
||||
|
||||
# tencent ailab comment: modified from
|
||||
# https://github.com/mlfoundations/open_flamingo/blob/main/open_flamingo/src/helpers.py
|
||||
import math
|
||||
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
|
||||
|
||||
# FFN
|
||||
def FeedForward(dim, mult=4):
|
||||
inner_dim = int(dim * mult)
|
||||
return nn.Sequential(
|
||||
nn.LayerNorm(dim),
|
||||
nn.Linear(dim, inner_dim, bias=False),
|
||||
nn.GELU(),
|
||||
nn.Linear(inner_dim, dim, bias=False),
|
||||
)
|
||||
|
||||
|
||||
def reshape_tensor(x, heads):
|
||||
bs, length, width = x.shape
|
||||
# (bs, length, width) --> (bs, length, n_heads, dim_per_head)
|
||||
x = x.view(bs, length, heads, -1)
|
||||
# (bs, length, n_heads, dim_per_head) --> (bs, n_heads, length, dim_per_head)
|
||||
x = x.transpose(1, 2)
|
||||
# (bs, n_heads, length, dim_per_head) --> (bs*n_heads, length, dim_per_head)
|
||||
x = x.reshape(bs, heads, length, -1)
|
||||
return x
|
||||
|
||||
|
||||
class PerceiverAttention(nn.Module):
|
||||
def __init__(self, *, dim, dim_head=64, heads=8):
|
||||
super().__init__()
|
||||
self.scale = dim_head**-0.5
|
||||
self.dim_head = dim_head
|
||||
self.heads = heads
|
||||
inner_dim = dim_head * heads
|
||||
|
||||
self.norm1 = nn.LayerNorm(dim)
|
||||
self.norm2 = nn.LayerNorm(dim)
|
||||
|
||||
self.to_q = nn.Linear(dim, inner_dim, bias=False)
|
||||
self.to_kv = nn.Linear(dim, inner_dim * 2, bias=False)
|
||||
self.to_out = nn.Linear(inner_dim, dim, bias=False)
|
||||
|
||||
def forward(self, x, latents):
|
||||
"""
|
||||
Args:
|
||||
x (torch.Tensor): image features
|
||||
shape (b, n1, D)
|
||||
latent (torch.Tensor): latent features
|
||||
shape (b, n2, D)
|
||||
"""
|
||||
x = self.norm1(x)
|
||||
latents = self.norm2(latents)
|
||||
|
||||
b, l, _ = latents.shape
|
||||
|
||||
q = self.to_q(latents)
|
||||
kv_input = torch.cat((x, latents), dim=-2)
|
||||
k, v = self.to_kv(kv_input).chunk(2, dim=-1)
|
||||
|
||||
q = reshape_tensor(q, self.heads)
|
||||
k = reshape_tensor(k, self.heads)
|
||||
v = reshape_tensor(v, self.heads)
|
||||
|
||||
# attention
|
||||
scale = 1 / math.sqrt(math.sqrt(self.dim_head))
|
||||
weight = (q * scale) @ (k * scale).transpose(-2, -1) # More stable with f16 than dividing afterwards
|
||||
weight = torch.softmax(weight.float(), dim=-1).type(weight.dtype)
|
||||
out = weight @ v
|
||||
|
||||
out = out.permute(0, 2, 1, 3).reshape(b, l, -1)
|
||||
|
||||
return self.to_out(out)
|
||||
|
||||
|
||||
class Resampler(nn.Module):
|
||||
def __init__(
|
||||
self,
|
||||
dim=1024,
|
||||
depth=8,
|
||||
dim_head=64,
|
||||
heads=16,
|
||||
num_queries=8,
|
||||
embedding_dim=768,
|
||||
output_dim=1024,
|
||||
ff_mult=4,
|
||||
):
|
||||
super().__init__()
|
||||
|
||||
self.latents = nn.Parameter(torch.randn(1, num_queries, dim) / dim**0.5)
|
||||
|
||||
self.proj_in = nn.Linear(embedding_dim, dim)
|
||||
|
||||
self.proj_out = nn.Linear(dim, output_dim)
|
||||
self.norm_out = nn.LayerNorm(output_dim)
|
||||
|
||||
self.layers = nn.ModuleList([])
|
||||
for _ in range(depth):
|
||||
self.layers.append(
|
||||
nn.ModuleList(
|
||||
[
|
||||
PerceiverAttention(dim=dim, dim_head=dim_head, heads=heads),
|
||||
FeedForward(dim=dim, mult=ff_mult),
|
||||
]
|
||||
)
|
||||
)
|
||||
|
||||
@classmethod
|
||||
def from_state_dict(cls, state_dict: dict[torch.Tensor], depth=8, dim_head=64, heads=16, num_queries=8, ff_mult=4):
|
||||
"""A convenience function that initializes a Resampler from a state_dict.
|
||||
|
||||
Some of the shape parameters are inferred from the state_dict (e.g. dim, embedding_dim, etc.). At the time of
|
||||
writing, we did not have a need for inferring ALL of the shape parameters from the state_dict, but this would be
|
||||
possible if needed in the future.
|
||||
|
||||
Args:
|
||||
state_dict (dict[torch.Tensor]): The state_dict to load.
|
||||
depth (int, optional):
|
||||
dim_head (int, optional):
|
||||
heads (int, optional):
|
||||
ff_mult (int, optional):
|
||||
|
||||
Returns:
|
||||
Resampler
|
||||
"""
|
||||
dim = state_dict["latents"].shape[2]
|
||||
num_queries = state_dict["latents"].shape[1]
|
||||
embedding_dim = state_dict["proj_in.weight"].shape[-1]
|
||||
output_dim = state_dict["norm_out.weight"].shape[0]
|
||||
|
||||
model = cls(
|
||||
dim=dim,
|
||||
depth=depth,
|
||||
dim_head=dim_head,
|
||||
heads=heads,
|
||||
num_queries=num_queries,
|
||||
embedding_dim=embedding_dim,
|
||||
output_dim=output_dim,
|
||||
ff_mult=ff_mult,
|
||||
)
|
||||
model.load_state_dict(state_dict)
|
||||
return model
|
||||
|
||||
def forward(self, x):
|
||||
latents = self.latents.repeat(x.size(0), 1, 1)
|
||||
|
||||
x = self.proj_in(x)
|
||||
|
||||
for attn, ff in self.layers:
|
||||
latents = attn(x, latents) + latents
|
||||
latents = ff(latents) + latents
|
||||
|
||||
latents = self.proj_out(latents)
|
||||
return self.norm_out(latents)
|
||||
@@ -1,53 +0,0 @@
|
||||
from contextlib import contextmanager
|
||||
|
||||
from diffusers.models import UNet2DConditionModel
|
||||
|
||||
from invokeai.backend.ip_adapter.attention_processor import AttnProcessor2_0, IPAttnProcessor2_0
|
||||
from invokeai.backend.ip_adapter.ip_adapter import IPAdapter
|
||||
|
||||
|
||||
class UNetPatcher:
|
||||
"""A class that contains multiple IP-Adapters and can apply them to a UNet."""
|
||||
|
||||
def __init__(self, ip_adapters: list[IPAdapter]):
|
||||
self._ip_adapters = ip_adapters
|
||||
self._scales = [1.0] * len(self._ip_adapters)
|
||||
|
||||
def set_scale(self, idx: int, value: float):
|
||||
self._scales[idx] = value
|
||||
|
||||
def _prepare_attention_processors(self, unet: UNet2DConditionModel):
|
||||
"""Prepare a dict of attention processors that can be injected into a unet, and load the IP-Adapter attention
|
||||
weights into them.
|
||||
|
||||
Note that the `unet` param is only used to determine attention block dimensions and naming.
|
||||
"""
|
||||
# Construct a dict of attention processors based on the UNet's architecture.
|
||||
attn_procs = {}
|
||||
for idx, name in enumerate(unet.attn_processors.keys()):
|
||||
if name.endswith("attn1.processor"):
|
||||
attn_procs[name] = AttnProcessor2_0()
|
||||
else:
|
||||
# Collect the weights from each IP Adapter for the idx'th attention processor.
|
||||
attn_procs[name] = IPAttnProcessor2_0(
|
||||
[ip_adapter.attn_weights.get_attention_processor_weights(idx) for ip_adapter in self._ip_adapters],
|
||||
self._scales,
|
||||
)
|
||||
return attn_procs
|
||||
|
||||
@contextmanager
|
||||
def apply_ip_adapter_attention(self, unet: UNet2DConditionModel):
|
||||
"""A context manager that patches `unet` with IP-Adapter attention processors."""
|
||||
|
||||
attn_procs = self._prepare_attention_processors(unet)
|
||||
|
||||
orig_attn_processors = unet.attn_processors
|
||||
|
||||
try:
|
||||
# Note to future devs: set_attn_processor(...) does something slightly unexpected - it pops elements from the
|
||||
# passed dict. So, if you wanted to keep the dict for future use, you'd have to make a moderately-shallow copy
|
||||
# of it. E.g. `attn_procs_copy = {k: v for k, v in attn_procs.items()}`.
|
||||
unet.set_attn_processor(attn_procs)
|
||||
yield None
|
||||
finally:
|
||||
unet.set_attn_processor(orig_attn_processors)
|
||||
@@ -1 +0,0 @@
|
||||
The contents of this directory are deprecated. model_manager.py is here only for reference.
|
||||
@@ -1,27 +0,0 @@
|
||||
# Model Cache
|
||||
|
||||
## `glibc` Memory Allocator Fragmentation
|
||||
|
||||
Python (and PyTorch) relies on the memory allocator from the C Standard Library (`libc`). On linux, with the GNU C Standard Library implementation (`glibc`), our memory access patterns have been observed to cause severe memory fragmentation. This fragmentation results in large amounts of memory that has been freed but can't be released back to the OS. Loading models from disk and moving them between CPU/CUDA seem to be the operations that contribute most to the fragmentation. This memory fragmentation issue can result in OOM crashes during frequent model switching, even if `max_cache_size` is set to a reasonable value (e.g. a OOM crash with `max_cache_size=16` on a system with 32GB of RAM).
|
||||
|
||||
This problem may also exist on other OSes, and other `libc` implementations. But, at the time of writing, it has only been investigated on linux with `glibc`.
|
||||
|
||||
To better understand how the `glibc` memory allocator works, see these references:
|
||||
- Basics: https://www.gnu.org/software/libc/manual/html_node/The-GNU-Allocator.html
|
||||
- Details: https://sourceware.org/glibc/wiki/MallocInternals
|
||||
|
||||
Note the differences between memory allocated as chunks in an arena vs. memory allocated with `mmap`. Under `glibc`'s default configuration, most model tensors get allocated as chunks in an arena making them vulnerable to the problem of fragmentation.
|
||||
|
||||
We can work around this memory fragmentation issue by setting the following env var:
|
||||
|
||||
```bash
|
||||
# Force blocks >1MB to be allocated with `mmap` so that they are released to the system immediately when they are freed.
|
||||
MALLOC_MMAP_THRESHOLD_=1048576
|
||||
```
|
||||
|
||||
See the following references for more information about the `malloc` tunable parameters:
|
||||
- https://www.gnu.org/software/libc/manual/html_node/Malloc-Tunable-Parameters.html
|
||||
- https://www.gnu.org/software/libc/manual/html_node/Memory-Allocation-Tunables.html
|
||||
- https://man7.org/linux/man-pages/man3/mallopt.3.html
|
||||
|
||||
The model cache emits debug logs that provide visibility into the state of the `libc` memory allocator. See the `LibcUtil` class for more info on how these `libc` malloc stats are collected.
|
||||
@@ -19,8 +19,9 @@
|
||||
|
||||
import re
|
||||
from contextlib import nullcontext
|
||||
from io import BytesIO
|
||||
from pathlib import Path
|
||||
from typing import Dict, Optional, Union
|
||||
from typing import Optional, Union
|
||||
|
||||
import requests
|
||||
import torch
|
||||
@@ -73,7 +74,7 @@ if is_accelerate_available():
|
||||
from accelerate import init_empty_weights
|
||||
from accelerate.utils import set_module_tensor_to_device
|
||||
|
||||
logger = InvokeAILogger.get_logger(__name__)
|
||||
logger = InvokeAILogger.getLogger(__name__)
|
||||
CONVERT_MODEL_ROOT = InvokeAIAppConfig.get_config().models_path / "core/convert"
|
||||
|
||||
|
||||
@@ -1222,7 +1223,7 @@ def download_from_original_stable_diffusion_ckpt(
|
||||
# scan model
|
||||
scan_result = scan_file_path(checkpoint_path)
|
||||
if scan_result.infected_files != 0:
|
||||
raise Exception("The model {checkpoint_path} is potentially infected by malware. Aborting import.")
|
||||
raise "The model {checkpoint_path} is potentially infected by malware. Aborting import."
|
||||
if device is None:
|
||||
device = "cuda" if torch.cuda.is_available() else "cpu"
|
||||
checkpoint = torch.load(checkpoint_path, map_location=device)
|
||||
@@ -1271,19 +1272,19 @@ def download_from_original_stable_diffusion_ckpt(
|
||||
# only refiner xl has embedder and one text embedders
|
||||
config_url = "https://raw.githubusercontent.com/Stability-AI/generative-models/main/configs/inference/sd_xl_refiner.yaml"
|
||||
|
||||
original_config_file = requests.get(config_url).text
|
||||
original_config_file = BytesIO(requests.get(config_url).content)
|
||||
|
||||
original_config = OmegaConf.load(original_config_file)
|
||||
if original_config.model["params"].get("use_ema") is not None:
|
||||
extract_ema = original_config.model["params"]["use_ema"]
|
||||
if original_config["model"]["params"].get("use_ema") is not None:
|
||||
extract_ema = original_config["model"]["params"]["use_ema"]
|
||||
|
||||
if (
|
||||
model_version in [BaseModelType.StableDiffusion2, BaseModelType.StableDiffusion1]
|
||||
and original_config.model["params"].get("parameterization") == "v"
|
||||
model_version == BaseModelType.StableDiffusion2
|
||||
and original_config["model"]["params"].get("parameterization") == "v"
|
||||
):
|
||||
prediction_type = "v_prediction"
|
||||
upcast_attention = True
|
||||
image_size = 768 if model_version == BaseModelType.StableDiffusion2 else 512
|
||||
image_size = 768
|
||||
else:
|
||||
prediction_type = "epsilon"
|
||||
upcast_attention = False
|
||||
@@ -1311,11 +1312,11 @@ def download_from_original_stable_diffusion_ckpt(
|
||||
num_in_channels = 4
|
||||
|
||||
if "unet_config" in original_config.model.params:
|
||||
original_config.model["params"]["unet_config"]["params"]["in_channels"] = num_in_channels
|
||||
original_config["model"]["params"]["unet_config"]["params"]["in_channels"] = num_in_channels
|
||||
|
||||
if (
|
||||
"parameterization" in original_config.model["params"]
|
||||
and original_config.model["params"]["parameterization"] == "v"
|
||||
"parameterization" in original_config["model"]["params"]
|
||||
and original_config["model"]["params"]["parameterization"] == "v"
|
||||
):
|
||||
if prediction_type is None:
|
||||
# NOTE: For stable diffusion 2 base it is recommended to pass `prediction_type=="epsilon"`
|
||||
@@ -1436,7 +1437,7 @@ def download_from_original_stable_diffusion_ckpt(
|
||||
|
||||
if model_type == "FrozenOpenCLIPEmbedder":
|
||||
config_name = "stabilityai/stable-diffusion-2"
|
||||
config_kwargs: Dict[str, Union[str, int]] = {"subfolder": "text_encoder"}
|
||||
config_kwargs = {"subfolder": "text_encoder"}
|
||||
|
||||
text_model = convert_open_clip_checkpoint(checkpoint, config_name, **config_kwargs)
|
||||
tokenizer = CLIPTokenizer.from_pretrained(CONVERT_MODEL_ROOT / "stable-diffusion-2-clip", subfolder="tokenizer")
|
||||
@@ -1663,7 +1664,7 @@ def download_controlnet_from_original_ckpt(
|
||||
# scan model
|
||||
scan_result = scan_file_path(checkpoint_path)
|
||||
if scan_result.infected_files != 0:
|
||||
raise Exception("The model {checkpoint_path} is potentially infected by malware. Aborting import.")
|
||||
raise "The model {checkpoint_path} is potentially infected by malware. Aborting import."
|
||||
if device is None:
|
||||
device = "cuda" if torch.cuda.is_available() else "cpu"
|
||||
checkpoint = torch.load(checkpoint_path, map_location=device)
|
||||
@@ -1684,7 +1685,7 @@ def download_controlnet_from_original_ckpt(
|
||||
original_config = OmegaConf.load(original_config_file)
|
||||
|
||||
if num_in_channels is not None:
|
||||
original_config.model["params"]["unet_config"]["params"]["in_channels"] = num_in_channels
|
||||
original_config["model"]["params"]["unet_config"]["params"]["in_channels"] = num_in_channels
|
||||
|
||||
if "control_stage_config" not in original_config.model.params:
|
||||
raise ValueError("`control_stage_config` not present in original config")
|
||||
@@ -1724,7 +1725,7 @@ def convert_ckpt_to_diffusers(
|
||||
and in addition a path-like object indicating the location of the desired diffusers
|
||||
model to be written.
|
||||
"""
|
||||
pipe = download_from_original_stable_diffusion_ckpt(str(checkpoint_path), **kwargs)
|
||||
pipe = download_from_original_stable_diffusion_ckpt(checkpoint_path, **kwargs)
|
||||
|
||||
pipe.save_pretrained(
|
||||
dump_path,
|
||||
@@ -1742,6 +1743,6 @@ def convert_controlnet_to_diffusers(
|
||||
and in addition a path-like object indicating the location of the desired diffusers
|
||||
model to be written.
|
||||
"""
|
||||
pipe = download_controlnet_from_original_ckpt(str(checkpoint_path), **kwargs)
|
||||
pipe = download_controlnet_from_original_ckpt(checkpoint_path, **kwargs)
|
||||
|
||||
pipe.save_pretrained(dump_path, safe_serialization=True)
|
||||
@@ -12,7 +12,7 @@ from diffusers.models import UNet2DConditionModel
|
||||
from safetensors.torch import load_file
|
||||
from transformers import CLIPTextModel, CLIPTokenizer
|
||||
|
||||
from .models.lora import LoRALayerBase, LoRAModel, LoRAModelRaw
|
||||
from .models.lora import LoRAModel
|
||||
|
||||
"""
|
||||
loras = [
|
||||
@@ -87,7 +87,7 @@ class ModelPatcher:
|
||||
def apply_lora_text_encoder(
|
||||
cls,
|
||||
text_encoder: CLIPTextModel,
|
||||
loras: List[Tuple[LoRAModelRaw, float]],
|
||||
loras: List[Tuple[LoRAModel, float]],
|
||||
):
|
||||
with cls.apply_lora(text_encoder, loras, "lora_te_"):
|
||||
yield
|
||||
@@ -97,7 +97,7 @@ class ModelPatcher:
|
||||
def apply_sdxl_lora_text_encoder(
|
||||
cls,
|
||||
text_encoder: CLIPTextModel,
|
||||
loras: List[Tuple[LoRAModelRaw, float]],
|
||||
loras: List[Tuple[LoRAModel, float]],
|
||||
):
|
||||
with cls.apply_lora(text_encoder, loras, "lora_te1_"):
|
||||
yield
|
||||
@@ -107,7 +107,7 @@ class ModelPatcher:
|
||||
def apply_sdxl_lora_text_encoder2(
|
||||
cls,
|
||||
text_encoder: CLIPTextModel,
|
||||
loras: List[Tuple[LoRAModelRaw, float]],
|
||||
loras: List[Tuple[LoRAModel, float]],
|
||||
):
|
||||
with cls.apply_lora(text_encoder, loras, "lora_te2_"):
|
||||
yield
|
||||
@@ -117,7 +117,7 @@ class ModelPatcher:
|
||||
def apply_lora(
|
||||
cls,
|
||||
model: torch.nn.Module,
|
||||
loras: List[Tuple[LoRAModelRaw, float]],
|
||||
loras: List[Tuple[LoRAModel, float]],
|
||||
prefix: str,
|
||||
):
|
||||
original_weights = dict()
|
||||
@@ -337,7 +337,7 @@ class ONNXModelPatcher:
|
||||
def apply_lora(
|
||||
cls,
|
||||
model: IAIOnnxRuntimeModel,
|
||||
loras: List[Tuple[LoRAModelRaw, torch.Tensor]],
|
||||
loras: List[Tuple[LoRAModel, float]],
|
||||
prefix: str,
|
||||
):
|
||||
from .models.base import IAIOnnxRuntimeModel
|
||||
@@ -348,7 +348,7 @@ class ONNXModelPatcher:
|
||||
orig_weights = dict()
|
||||
|
||||
try:
|
||||
blended_loras: Dict[str, torch.Tensor] = dict()
|
||||
blended_loras = dict()
|
||||
|
||||
for lora, lora_weight in loras:
|
||||
for layer_key, layer in lora.layers.items():
|
||||
@@ -1,6 +1,5 @@
|
||||
"""
|
||||
Manage a RAM cache of diffusion/transformer models for fast switching.
|
||||
|
||||
They are moved between GPU VRAM and CPU RAM as necessary. If the cache
|
||||
grows larger than a preset maximum, then the least recently used
|
||||
model will be cleared and (re)loaded from disk when next needed.
|
||||
@@ -19,21 +18,17 @@ context. Use like this:
|
||||
|
||||
import gc
|
||||
import hashlib
|
||||
import math
|
||||
import os
|
||||
import sys
|
||||
import time
|
||||
from contextlib import suppress
|
||||
from dataclasses import dataclass, field
|
||||
from pathlib import Path
|
||||
from typing import Any, Dict, List, Optional, Type, Union
|
||||
from typing import Any, Dict, Optional, Type, Union, types
|
||||
|
||||
import torch
|
||||
|
||||
from invokeai.backend.model_manager.memory_snapshot import MemorySnapshot, get_pretty_snapshot_diff
|
||||
from invokeai.backend.util import InvokeAILogger, Logger
|
||||
import invokeai.backend.util.logging as logger
|
||||
|
||||
from ..util import GIG
|
||||
from ..util.devices import choose_torch_device
|
||||
from .models import BaseModelType, ModelBase, ModelType, SubModelType
|
||||
|
||||
@@ -49,8 +44,6 @@ DEFAULT_MAX_VRAM_CACHE_SIZE = 2.75
|
||||
|
||||
# actual size of a gig
|
||||
GIG = 1073741824
|
||||
# Size of a MB in bytes.
|
||||
MB = 2**20
|
||||
|
||||
|
||||
@dataclass
|
||||
@@ -65,10 +58,20 @@ class CacheStats(object):
|
||||
loaded_model_sizes: Dict[str, int] = field(default_factory=dict)
|
||||
|
||||
|
||||
class ModelLocker(object):
|
||||
"Forward declaration"
|
||||
pass
|
||||
|
||||
|
||||
class ModelCache(object):
|
||||
"Forward declaration"
|
||||
pass
|
||||
|
||||
|
||||
class _CacheRecord:
|
||||
size: int
|
||||
model: Any
|
||||
cache: "ModelCache"
|
||||
cache: ModelCache
|
||||
_locks: int
|
||||
|
||||
def __init__(self, cache, model: Any, size: int):
|
||||
@@ -104,9 +107,10 @@ class ModelCache(object):
|
||||
execution_device: torch.device = torch.device("cuda"),
|
||||
storage_device: torch.device = torch.device("cpu"),
|
||||
precision: torch.dtype = torch.float16,
|
||||
sequential_offload: bool = False,
|
||||
lazy_offloading: bool = True,
|
||||
sha_chunksize: int = 16777216,
|
||||
logger: Logger = InvokeAILogger.get_logger(),
|
||||
logger: types.ModuleType = logger,
|
||||
):
|
||||
"""
|
||||
:param max_cache_size: Maximum size of the RAM cache [6.0 GB]
|
||||
@@ -114,6 +118,7 @@ class ModelCache(object):
|
||||
:param storage_device: Torch device to save inactive model in [torch.device('cpu')]
|
||||
:param precision: Precision for loaded models [torch.float16]
|
||||
:param lazy_offloading: Keep model in VRAM until another model needs to be loaded
|
||||
:param sequential_offload: Conserve VRAM by loading and unloading each stage of the pipeline sequentially
|
||||
:param sha_chunksize: Chunksize to use when calculating sha256 model hash
|
||||
"""
|
||||
self.model_infos: Dict[str, ModelBase] = dict()
|
||||
@@ -128,37 +133,40 @@ class ModelCache(object):
|
||||
self.logger = logger
|
||||
|
||||
# used for stats collection
|
||||
self.stats: Optional[CacheStats] = None
|
||||
self.stats = None
|
||||
|
||||
self._cached_models: Dict[str, _CacheRecord] = dict()
|
||||
self._cache_stack: List[str] = list()
|
||||
self._cached_models = dict()
|
||||
self._cache_stack = list()
|
||||
|
||||
# Note that the combination of model_path and submodel_type
|
||||
# are sufficient to generate a unique cache key. This key
|
||||
# is not the same as the unique hash used to identify models
|
||||
# in invokeai.backend.model_manager.storage
|
||||
def get_key(
|
||||
self,
|
||||
model_path: Path,
|
||||
model_path: str,
|
||||
base_model: BaseModelType,
|
||||
model_type: ModelType,
|
||||
submodel_type: Optional[SubModelType] = None,
|
||||
):
|
||||
key = model_path.as_posix()
|
||||
key = f"{model_path}:{base_model}:{model_type}"
|
||||
if submodel_type:
|
||||
key += f":{submodel_type}"
|
||||
return key
|
||||
|
||||
def _get_model_info(
|
||||
self,
|
||||
model_path: Path,
|
||||
model_path: str,
|
||||
model_class: Type[ModelBase],
|
||||
base_model: BaseModelType,
|
||||
model_type: ModelType,
|
||||
):
|
||||
model_info_key = self.get_key(model_path=model_path)
|
||||
model_info_key = self.get_key(
|
||||
model_path=model_path,
|
||||
base_model=base_model,
|
||||
model_type=model_type,
|
||||
submodel_type=None,
|
||||
)
|
||||
|
||||
if model_info_key not in self.model_infos:
|
||||
self.model_infos[model_info_key] = model_class(
|
||||
model_path.as_posix(),
|
||||
model_path,
|
||||
base_model,
|
||||
model_type,
|
||||
)
|
||||
@@ -187,56 +195,39 @@ class ModelCache(object):
|
||||
base_model=base_model,
|
||||
model_type=model_type,
|
||||
)
|
||||
key = self.get_key(model_path, submodel)
|
||||
|
||||
key = self.get_key(
|
||||
model_path=model_path,
|
||||
base_model=base_model,
|
||||
model_type=model_type,
|
||||
submodel_type=submodel,
|
||||
)
|
||||
# TODO: lock for no copies on simultaneous calls?
|
||||
cache_entry = self._cached_models.get(key, None)
|
||||
if cache_entry is None:
|
||||
self.logger.info(
|
||||
f"Loading model {model_path}, type"
|
||||
f" {base_model.value}:{model_type.value}{':'+submodel.value if submodel else ''}"
|
||||
f"Loading model {model_path}, type {base_model.value}:{model_type.value}{':'+submodel.value if submodel else ''}"
|
||||
)
|
||||
if self.stats:
|
||||
self.stats.misses += 1
|
||||
|
||||
self_reported_model_size_before_load = model_info.get_size(submodel)
|
||||
# Remove old models from the cache to make room for the new model.
|
||||
self._make_cache_room(self_reported_model_size_before_load)
|
||||
# this will remove older cached models until
|
||||
# there is sufficient room to load the requested model
|
||||
self._make_cache_room(model_info.get_size(submodel))
|
||||
|
||||
# Load the model from disk and capture a memory snapshot before/after.
|
||||
start_load_time = time.time()
|
||||
snapshot_before = MemorySnapshot.capture()
|
||||
# clean memory to make MemoryUsage() more accurate
|
||||
gc.collect()
|
||||
model = model_info.get_model(child_type=submodel, torch_dtype=self.precision)
|
||||
snapshot_after = MemorySnapshot.capture()
|
||||
end_load_time = time.time()
|
||||
if mem_used := model_info.get_size(submodel):
|
||||
self.logger.debug(f"CPU RAM used for load: {(mem_used/GIG):.2f} GB")
|
||||
|
||||
self_reported_model_size_after_load = model_info.get_size(submodel)
|
||||
|
||||
self.logger.debug(
|
||||
f"Moved model '{key}' from disk to cpu in {(end_load_time-start_load_time):.2f}s.\n"
|
||||
f"Self-reported size before/after load: {(self_reported_model_size_before_load/GIG):.3f}GB /"
|
||||
f" {(self_reported_model_size_after_load/GIG):.3f}GB.\n"
|
||||
f"{get_pretty_snapshot_diff(snapshot_before, snapshot_after)}"
|
||||
)
|
||||
|
||||
# We only log a warning for over-reported (not under-reported) model sizes before load. There is a known
|
||||
# issue where models report their fp32 size before load, and are then loaded as fp16. Once this issue is
|
||||
# addressed, it would make sense to log a warning for both over-reported and under-reported model sizes.
|
||||
if (self_reported_model_size_after_load - self_reported_model_size_before_load) > 10 * MB:
|
||||
self.logger.warning(
|
||||
f"Model '{key}' mis-reported its size before load. Self-reported size before/after load:"
|
||||
f" {(self_reported_model_size_before_load/GIG):.2f}GB /"
|
||||
f" {(self_reported_model_size_after_load/GIG):.2f}GB."
|
||||
)
|
||||
|
||||
cache_entry = _CacheRecord(self, model, self_reported_model_size_after_load)
|
||||
cache_entry = _CacheRecord(self, model, mem_used)
|
||||
self._cached_models[key] = cache_entry
|
||||
else:
|
||||
if self.stats:
|
||||
self.stats.hits += 1
|
||||
|
||||
if self.stats:
|
||||
self.stats.cache_size = int(self.max_cache_size * GIG)
|
||||
self.stats.cache_size = self.max_cache_size * GIG
|
||||
self.stats.high_watermark = max(self.stats.high_watermark, self._cache_size())
|
||||
self.stats.in_cache = len(self._cached_models)
|
||||
self.stats.loaded_model_sizes[key] = max(
|
||||
@@ -249,52 +240,9 @@ class ModelCache(object):
|
||||
|
||||
return self.ModelLocker(self, key, cache_entry.model, gpu_load, cache_entry.size)
|
||||
|
||||
def _move_model_to_device(self, key: str, target_device: torch.device):
|
||||
cache_entry = self._cached_models[key]
|
||||
|
||||
source_device = cache_entry.model.device
|
||||
# Note: We compare device types only so that 'cuda' == 'cuda:0'. This would need to be revised to support
|
||||
# multi-GPU.
|
||||
if torch.device(source_device).type == torch.device(target_device).type:
|
||||
return
|
||||
|
||||
start_model_to_time = time.time()
|
||||
snapshot_before = MemorySnapshot.capture()
|
||||
cache_entry.model.to(target_device)
|
||||
snapshot_after = MemorySnapshot.capture()
|
||||
end_model_to_time = time.time()
|
||||
self.logger.debug(
|
||||
f"Moved model '{key}' from {source_device} to"
|
||||
f" {target_device} in {(end_model_to_time-start_model_to_time):.2f}s.\n"
|
||||
f"Estimated model size: {(cache_entry.size/GIG):.3f} GB.\n"
|
||||
f"{get_pretty_snapshot_diff(snapshot_before, snapshot_after)}"
|
||||
)
|
||||
|
||||
if snapshot_before.vram is not None and snapshot_after.vram is not None:
|
||||
vram_change = abs(snapshot_before.vram - snapshot_after.vram)
|
||||
|
||||
# If the estimated model size does not match the change in VRAM, log a warning.
|
||||
if not math.isclose(
|
||||
vram_change,
|
||||
cache_entry.size,
|
||||
rel_tol=0.1,
|
||||
abs_tol=10 * MB,
|
||||
):
|
||||
self.logger.warning(
|
||||
f"Moving model '{key}' from {source_device} to"
|
||||
f" {target_device} caused an unexpected change in VRAM usage. The model's"
|
||||
" estimated size may be incorrect. Estimated model size:"
|
||||
f" {(cache_entry.size/GIG):.3f} GB.\n"
|
||||
f"{get_pretty_snapshot_diff(snapshot_before, snapshot_after)}"
|
||||
)
|
||||
|
||||
class ModelLocker(object):
|
||||
"""Context manager that locks models into VRAM."""
|
||||
|
||||
def __init__(self, cache, key, model, gpu_load, size_needed):
|
||||
"""
|
||||
Initialize a context manager object that locks models into VRAM.
|
||||
|
||||
:param cache: The model_cache object
|
||||
:param key: The key of the model to lock in GPU
|
||||
:param model: The model to lock
|
||||
@@ -321,7 +269,11 @@ class ModelCache(object):
|
||||
if self.cache.lazy_offloading:
|
||||
self.cache._offload_unlocked_models(self.size_needed)
|
||||
|
||||
self.cache._move_model_to_device(self.key, self.cache.execution_device)
|
||||
if self.model.device != self.cache.execution_device:
|
||||
self.cache.logger.debug(f"Moving {self.key} into {self.cache.execution_device}")
|
||||
with VRAMUsage() as mem:
|
||||
self.model.to(self.cache.execution_device) # move into GPU
|
||||
self.cache.logger.debug(f"GPU VRAM used for load: {(mem.vram_used/GIG):.2f} GB")
|
||||
|
||||
self.cache.logger.debug(f"Locking {self.key} in {self.cache.execution_device}")
|
||||
self.cache._print_cuda_stats()
|
||||
@@ -334,7 +286,7 @@ class ModelCache(object):
|
||||
# in the event that the caller wants the model in RAM, we
|
||||
# move it into CPU if it is in GPU and not locked
|
||||
elif self.cache_entry.loaded and not self.cache_entry.locked:
|
||||
self.cache._move_model_to_device(self.key, self.cache.storage_device)
|
||||
self.model.to(self.cache.storage_device)
|
||||
|
||||
return self.model
|
||||
|
||||
@@ -353,6 +305,18 @@ class ModelCache(object):
|
||||
self._cache_stack.remove(cache_id)
|
||||
self._cached_models.pop(cache_id, None)
|
||||
|
||||
def model_hash(
|
||||
self,
|
||||
model_path: Union[str, Path],
|
||||
) -> str:
|
||||
"""
|
||||
Given the HF repo id or path to a model on disk, returns a unique
|
||||
hash. Works for legacy checkpoint files, HF models on disk, and HF repo IDs
|
||||
|
||||
:param model_path: Path to model file/directory on disk.
|
||||
"""
|
||||
return self._local_model_hash(model_path)
|
||||
|
||||
def cache_size(self) -> float:
|
||||
"""Return the current size of the cache, in GB."""
|
||||
return self._cache_size() / GIG
|
||||
@@ -375,8 +339,7 @@ class ModelCache(object):
|
||||
locked_models += 1
|
||||
|
||||
self.logger.debug(
|
||||
f"Current VRAM/RAM usage: {vram}/{ram}; cached_models/loaded_models/locked_models/ ="
|
||||
f" {cached_models}/{loaded_models}/{locked_models}"
|
||||
f"Current VRAM/RAM usage: {vram}/{ram}; cached_models/loaded_models/locked_models/ = {cached_models}/{loaded_models}/{locked_models}"
|
||||
)
|
||||
|
||||
def _cache_size(self) -> int:
|
||||
@@ -391,8 +354,7 @@ class ModelCache(object):
|
||||
|
||||
if current_size + bytes_needed > maximum_size:
|
||||
self.logger.debug(
|
||||
f"Max cache size exceeded: {(current_size/GIG):.2f}/{self.max_cache_size:.2f} GB, need an additional"
|
||||
f" {(bytes_needed/GIG):.2f} GB"
|
||||
f"Max cache size exceeded: {(current_size/GIG):.2f}/{self.max_cache_size:.2f} GB, need an additional {(bytes_needed/GIG):.2f} GB"
|
||||
)
|
||||
|
||||
self.logger.debug(f"Before unloading: cached_models={len(self._cached_models)}")
|
||||
@@ -404,8 +366,8 @@ class ModelCache(object):
|
||||
|
||||
refs = sys.getrefcount(cache_entry.model)
|
||||
|
||||
# Manually clear local variable references of just finished function calls.
|
||||
# For some reason python doesn't want to garbage collect it even when gc.collect() is called
|
||||
# manualy clear local variable references of just finished function calls
|
||||
# for some reason python don't want to collect it even by gc.collect() immidiately
|
||||
if refs > 2:
|
||||
while True:
|
||||
cleared = False
|
||||
@@ -425,8 +387,7 @@ class ModelCache(object):
|
||||
|
||||
device = cache_entry.model.device if hasattr(cache_entry.model, "device") else None
|
||||
self.logger.debug(
|
||||
f"Model: {model_key}, locks: {cache_entry._locks}, device: {device}, loaded: {cache_entry.loaded},"
|
||||
f" refs: {refs}"
|
||||
f"Model: {model_key}, locks: {cache_entry._locks}, device: {device}, loaded: {cache_entry.loaded}, refs: {refs}"
|
||||
)
|
||||
|
||||
# 2 refs:
|
||||
@@ -462,9 +423,11 @@ class ModelCache(object):
|
||||
if vram_in_use <= reserved:
|
||||
break
|
||||
if not cache_entry.locked and cache_entry.loaded:
|
||||
self._move_model_to_device(model_key, self.storage_device)
|
||||
|
||||
vram_in_use = torch.cuda.memory_allocated()
|
||||
self.logger.debug(f"Offloading {model_key} from {self.execution_device} into {self.storage_device}")
|
||||
with VRAMUsage() as mem:
|
||||
cache_entry.model.to(self.storage_device)
|
||||
self.logger.debug(f"GPU VRAM freed: {(mem.vram_used/GIG):.2f} GB")
|
||||
vram_in_use += mem.vram_used # note vram_used is negative
|
||||
self.logger.debug(f"{(vram_in_use/GIG):.2f}GB VRAM used for models; max allowed={(reserved/GIG):.2f}GB")
|
||||
|
||||
gc.collect()
|
||||
@@ -491,3 +454,16 @@ class ModelCache(object):
|
||||
with open(hashpath, "w") as f:
|
||||
f.write(hash)
|
||||
return hash
|
||||
|
||||
|
||||
class VRAMUsage(object):
|
||||
def __init__(self):
|
||||
self.vram = None
|
||||
self.vram_used = 0
|
||||
|
||||
def __enter__(self):
|
||||
self.vram = torch.cuda.memory_allocated()
|
||||
return self
|
||||
|
||||
def __exit__(self, *args):
|
||||
self.vram_used = torch.cuda.memory_allocated() - self.vram
|
||||
@@ -25,7 +25,6 @@ Models are described using four attributes:
|
||||
ModelType.Lora -- a LoRA or LyCORIS fine-tune
|
||||
ModelType.TextualInversion -- a textual inversion embedding
|
||||
ModelType.ControlNet -- a ControlNet model
|
||||
ModelType.IPAdapter -- an IPAdapter model
|
||||
|
||||
3) BaseModelType -- an enum indicating the stable diffusion base model, one of:
|
||||
BaseModelType.StableDiffusion1
|
||||
@@ -1001,8 +1000,8 @@ class ModelManager(object):
|
||||
new_models_found = True
|
||||
except DuplicateModelException as e:
|
||||
self.logger.warning(e)
|
||||
except InvalidModelException as e:
|
||||
self.logger.warning(f"Not a valid model: {model_path}. {e}")
|
||||
except InvalidModelException:
|
||||
self.logger.warning(f"Not a valid model: {model_path}")
|
||||
except NotImplementedError as e:
|
||||
self.logger.warning(e)
|
||||
|
||||
|
||||
@@ -1,5 +1,5 @@
|
||||
"""
|
||||
invokeai.backend.model_manager.merge exports:
|
||||
invokeai.backend.model_management.model_merge exports:
|
||||
merge_diffusion_models() -- combine multiple models by location and return a pipeline object
|
||||
merge_diffusion_models_and_commit() -- combine multiple models by ModelManager ID and write to models.yaml
|
||||
|
||||
@@ -9,17 +9,14 @@ Copyright (c) 2023 Lincoln Stein and the InvokeAI Development Team
|
||||
import warnings
|
||||
from enum import Enum
|
||||
from pathlib import Path
|
||||
from typing import List, Optional, Set
|
||||
from typing import List, Optional, Union
|
||||
|
||||
from diffusers import DiffusionPipeline
|
||||
from diffusers import logging as dlogging
|
||||
|
||||
import invokeai.backend.util.logging as logger
|
||||
from invokeai.app.services.config import InvokeAIAppConfig
|
||||
from invokeai.app.services.model_install_service import ModelInstallService
|
||||
|
||||
from . import BaseModelType, ModelConfigBase, ModelConfigStore, ModelType
|
||||
from .config import MainConfig
|
||||
from ...backend.model_management import AddModelResult, BaseModelType, ModelManager, ModelType, ModelVariantType
|
||||
|
||||
|
||||
class MergeInterpolationMethod(str, Enum):
|
||||
@@ -30,18 +27,8 @@ class MergeInterpolationMethod(str, Enum):
|
||||
|
||||
|
||||
class ModelMerger(object):
|
||||
_store: ModelConfigStore
|
||||
_config: InvokeAIAppConfig
|
||||
|
||||
def __init__(self, store: ModelConfigStore, config: Optional[InvokeAIAppConfig] = None):
|
||||
"""
|
||||
Initialize a ModelMerger object.
|
||||
|
||||
:param store: Underlying storage manager for the running process.
|
||||
:param config: InvokeAIAppConfig object (if not provided, default will be selected).
|
||||
"""
|
||||
self._store = store
|
||||
self._config = config or InvokeAIAppConfig.get_config()
|
||||
def __init__(self, manager: ModelManager):
|
||||
self.manager = manager
|
||||
|
||||
def merge_diffusion_models(
|
||||
self,
|
||||
@@ -83,14 +70,15 @@ class ModelMerger(object):
|
||||
|
||||
def merge_diffusion_models_and_save(
|
||||
self,
|
||||
model_keys: List[str],
|
||||
model_names: List[str],
|
||||
base_model: Union[BaseModelType, str],
|
||||
merged_model_name: str,
|
||||
alpha: Optional[float] = 0.5,
|
||||
alpha: float = 0.5,
|
||||
interp: Optional[MergeInterpolationMethod] = None,
|
||||
force: Optional[bool] = False,
|
||||
force: bool = False,
|
||||
merge_dest_directory: Optional[Path] = None,
|
||||
**kwargs,
|
||||
) -> ModelConfigBase:
|
||||
) -> AddModelResult:
|
||||
"""
|
||||
:param models: up to three models, designated by their InvokeAI models.yaml model name
|
||||
:param base_model: base model (must be the same for all merged models!)
|
||||
@@ -104,38 +92,25 @@ class ModelMerger(object):
|
||||
**kwargs - the default DiffusionPipeline.get_config_dict kwargs:
|
||||
cache_dir, resume_download, force_download, proxies, local_files_only, use_auth_token, revision, torch_dtype, device_map
|
||||
"""
|
||||
model_paths: List[Path] = list()
|
||||
model_names = list()
|
||||
config = self._config
|
||||
store = self._store
|
||||
base_models: Set[BaseModelType] = set()
|
||||
model_paths = list()
|
||||
config = self.manager.app_config
|
||||
base_model = BaseModelType(base_model)
|
||||
vae = None
|
||||
|
||||
assert (
|
||||
len(model_keys) <= 2 or interp == MergeInterpolationMethod.AddDifference
|
||||
), "When merging three models, only the 'add_difference' merge method is supported"
|
||||
|
||||
for key in model_keys:
|
||||
info = store.get_model(key)
|
||||
assert isinstance(info, MainConfig)
|
||||
model_names.append(info.name)
|
||||
for mod in model_names:
|
||||
info = self.manager.list_model(mod, base_model=base_model, model_type=ModelType.Main)
|
||||
assert info, f"model {mod}, base_model {base_model}, is unknown"
|
||||
assert (
|
||||
info.model_format == "diffusers"
|
||||
), f"{info.name} ({info.key}) is not a diffusers model. It must be optimized before merging"
|
||||
info["model_format"] == "diffusers"
|
||||
), f"{mod} is not a diffusers model. It must be optimized before merging"
|
||||
assert info["variant"] == "normal", f"{mod} is a {info['variant']} model, which cannot currently be merged"
|
||||
assert (
|
||||
info.variant == "normal"
|
||||
), f"{info.name} ({info.key}) is a {info.variant} model, which cannot currently be merged"
|
||||
|
||||
len(model_names) <= 2 or interp == MergeInterpolationMethod.AddDifference
|
||||
), "When merging three models, only the 'add_difference' merge method is supported"
|
||||
# pick up the first model's vae
|
||||
if key == model_keys[0]:
|
||||
vae = info.vae
|
||||
|
||||
# tally base models used
|
||||
base_models.add(info.base_model)
|
||||
model_paths.extend([(config.models_path / info.path).as_posix()])
|
||||
|
||||
assert len(base_models) == 1, f"All models to merge must have same base model, but found bases {base_models}"
|
||||
base_model = base_models.pop()
|
||||
if mod == model_names[0]:
|
||||
vae = info.get("vae")
|
||||
model_paths.extend([(config.root_path / info["path"]).as_posix()])
|
||||
|
||||
merge_method = None if interp == "weighted_sum" else MergeInterpolationMethod(interp)
|
||||
logger.debug(f"interp = {interp}, merge_method={merge_method}")
|
||||
@@ -149,19 +124,17 @@ class ModelMerger(object):
|
||||
dump_path = (dump_path / merged_model_name).as_posix()
|
||||
|
||||
merged_pipe.save_pretrained(dump_path, safe_serialization=True)
|
||||
|
||||
# register model and get its unique key
|
||||
installer = ModelInstallService(store=self._store, config=self._config)
|
||||
key = installer.register_path(dump_path)
|
||||
|
||||
# update model's config
|
||||
model_config = self._store.get_model(key)
|
||||
model_config.update(
|
||||
dict(
|
||||
name=merged_model_name,
|
||||
description=f"Merge of models {', '.join(model_names)}",
|
||||
vae=vae,
|
||||
)
|
||||
attributes = dict(
|
||||
path=dump_path,
|
||||
description=f"Merge of models {', '.join(model_names)}",
|
||||
model_format="diffusers",
|
||||
variant=ModelVariantType.Normal.value,
|
||||
vae=vae,
|
||||
)
|
||||
return self.manager.add_model(
|
||||
merged_model_name,
|
||||
base_model=base_model,
|
||||
model_type=ModelType.Main,
|
||||
model_attributes=attributes,
|
||||
clobber=True,
|
||||
)
|
||||
self._store.update_model(key, model_config)
|
||||
return model_config
|
||||
523
invokeai/backend/model_management/model_probe.py
Normal file
523
invokeai/backend/model_management/model_probe.py
Normal file
@@ -0,0 +1,523 @@
|
||||
import json
|
||||
from dataclasses import dataclass
|
||||
from pathlib import Path
|
||||
from typing import Callable, Dict, Literal, Optional, Union
|
||||
|
||||
import safetensors.torch
|
||||
import torch
|
||||
from diffusers import ConfigMixin, ModelMixin
|
||||
from picklescan.scanner import scan_file_path
|
||||
|
||||
from .models import (
|
||||
BaseModelType,
|
||||
InvalidModelException,
|
||||
ModelType,
|
||||
ModelVariantType,
|
||||
SchedulerPredictionType,
|
||||
SilenceWarnings,
|
||||
)
|
||||
from .models.base import read_checkpoint_meta
|
||||
from .util import lora_token_vector_length
|
||||
|
||||
|
||||
@dataclass
|
||||
class ModelProbeInfo(object):
|
||||
model_type: ModelType
|
||||
base_type: BaseModelType
|
||||
variant_type: ModelVariantType
|
||||
prediction_type: SchedulerPredictionType
|
||||
upcast_attention: bool
|
||||
format: Literal["diffusers", "checkpoint", "lycoris", "olive", "onnx"]
|
||||
image_size: int
|
||||
|
||||
|
||||
class ProbeBase(object):
|
||||
"""forward declaration"""
|
||||
|
||||
pass
|
||||
|
||||
|
||||
class ModelProbe(object):
|
||||
PROBES = {
|
||||
"diffusers": {},
|
||||
"checkpoint": {},
|
||||
"onnx": {},
|
||||
}
|
||||
|
||||
CLASS2TYPE = {
|
||||
"StableDiffusionPipeline": ModelType.Main,
|
||||
"StableDiffusionInpaintPipeline": ModelType.Main,
|
||||
"StableDiffusionXLPipeline": ModelType.Main,
|
||||
"StableDiffusionXLImg2ImgPipeline": ModelType.Main,
|
||||
"StableDiffusionXLInpaintPipeline": ModelType.Main,
|
||||
"AutoencoderKL": ModelType.Vae,
|
||||
"ControlNetModel": ModelType.ControlNet,
|
||||
}
|
||||
|
||||
@classmethod
|
||||
def register_probe(
|
||||
cls, format: Literal["diffusers", "checkpoint", "onnx"], model_type: ModelType, probe_class: ProbeBase
|
||||
):
|
||||
cls.PROBES[format][model_type] = probe_class
|
||||
|
||||
@classmethod
|
||||
def heuristic_probe(
|
||||
cls,
|
||||
model: Union[Dict, ModelMixin, Path],
|
||||
prediction_type_helper: Callable[[Path], SchedulerPredictionType] = None,
|
||||
) -> ModelProbeInfo:
|
||||
if isinstance(model, Path):
|
||||
return cls.probe(model_path=model, prediction_type_helper=prediction_type_helper)
|
||||
elif isinstance(model, (dict, ModelMixin, ConfigMixin)):
|
||||
return cls.probe(model_path=None, model=model, prediction_type_helper=prediction_type_helper)
|
||||
else:
|
||||
raise InvalidModelException("model parameter {model} is neither a Path, nor a model")
|
||||
|
||||
@classmethod
|
||||
def probe(
|
||||
cls,
|
||||
model_path: Path,
|
||||
model: Optional[Union[Dict, ModelMixin]] = None,
|
||||
prediction_type_helper: Optional[Callable[[Path], SchedulerPredictionType]] = None,
|
||||
) -> ModelProbeInfo:
|
||||
"""
|
||||
Probe the model at model_path and return sufficient information about it
|
||||
to place it somewhere in the models directory hierarchy. If the model is
|
||||
already loaded into memory, you may provide it as model in order to avoid
|
||||
opening it a second time. The prediction_type_helper callable is a function that receives
|
||||
the path to the model and returns the BaseModelType. It is called to distinguish
|
||||
between V2-Base and V2-768 SD models.
|
||||
"""
|
||||
if model_path:
|
||||
format_type = "diffusers" if model_path.is_dir() else "checkpoint"
|
||||
else:
|
||||
format_type = "diffusers" if isinstance(model, (ConfigMixin, ModelMixin)) else "checkpoint"
|
||||
model_info = None
|
||||
try:
|
||||
model_type = (
|
||||
cls.get_model_type_from_folder(model_path, model)
|
||||
if format_type == "diffusers"
|
||||
else cls.get_model_type_from_checkpoint(model_path, model)
|
||||
)
|
||||
format_type = "onnx" if model_type == ModelType.ONNX else format_type
|
||||
probe_class = cls.PROBES[format_type].get(model_type)
|
||||
if not probe_class:
|
||||
return None
|
||||
probe = probe_class(model_path, model, prediction_type_helper)
|
||||
base_type = probe.get_base_type()
|
||||
variant_type = probe.get_variant_type()
|
||||
prediction_type = probe.get_scheduler_prediction_type()
|
||||
format = probe.get_format()
|
||||
model_info = ModelProbeInfo(
|
||||
model_type=model_type,
|
||||
base_type=base_type,
|
||||
variant_type=variant_type,
|
||||
prediction_type=prediction_type,
|
||||
upcast_attention=(
|
||||
base_type == BaseModelType.StableDiffusion2
|
||||
and prediction_type == SchedulerPredictionType.VPrediction
|
||||
),
|
||||
format=format,
|
||||
image_size=1024
|
||||
if (base_type in {BaseModelType.StableDiffusionXL, BaseModelType.StableDiffusionXLRefiner})
|
||||
else 768
|
||||
if (
|
||||
base_type == BaseModelType.StableDiffusion2
|
||||
and prediction_type == SchedulerPredictionType.VPrediction
|
||||
)
|
||||
else 512,
|
||||
)
|
||||
except Exception:
|
||||
raise
|
||||
|
||||
return model_info
|
||||
|
||||
@classmethod
|
||||
def get_model_type_from_checkpoint(cls, model_path: Path, checkpoint: dict) -> ModelType:
|
||||
if model_path.suffix not in (".bin", ".pt", ".ckpt", ".safetensors", ".pth"):
|
||||
return None
|
||||
|
||||
if model_path.name == "learned_embeds.bin":
|
||||
return ModelType.TextualInversion
|
||||
|
||||
ckpt = checkpoint if checkpoint else read_checkpoint_meta(model_path, scan=True)
|
||||
ckpt = ckpt.get("state_dict", ckpt)
|
||||
|
||||
for key in ckpt.keys():
|
||||
if any(key.startswith(v) for v in {"cond_stage_model.", "first_stage_model.", "model.diffusion_model."}):
|
||||
return ModelType.Main
|
||||
elif any(key.startswith(v) for v in {"encoder.conv_in", "decoder.conv_in"}):
|
||||
return ModelType.Vae
|
||||
elif any(key.startswith(v) for v in {"lora_te_", "lora_unet_"}):
|
||||
return ModelType.Lora
|
||||
elif any(key.endswith(v) for v in {"to_k_lora.up.weight", "to_q_lora.down.weight"}):
|
||||
return ModelType.Lora
|
||||
elif any(key.startswith(v) for v in {"control_model", "input_blocks"}):
|
||||
return ModelType.ControlNet
|
||||
elif key in {"emb_params", "string_to_param"}:
|
||||
return ModelType.TextualInversion
|
||||
|
||||
else:
|
||||
# diffusers-ti
|
||||
if len(ckpt) < 10 and all(isinstance(v, torch.Tensor) for v in ckpt.values()):
|
||||
return ModelType.TextualInversion
|
||||
|
||||
raise InvalidModelException(f"Unable to determine model type for {model_path}")
|
||||
|
||||
@classmethod
|
||||
def get_model_type_from_folder(cls, folder_path: Path, model: ModelMixin) -> ModelType:
|
||||
"""
|
||||
Get the model type of a hugging-face style folder.
|
||||
"""
|
||||
class_name = None
|
||||
if model:
|
||||
class_name = model.__class__.__name__
|
||||
else:
|
||||
if (folder_path / "unet/model.onnx").exists():
|
||||
return ModelType.ONNX
|
||||
if (folder_path / "learned_embeds.bin").exists():
|
||||
return ModelType.TextualInversion
|
||||
|
||||
if (folder_path / "pytorch_lora_weights.bin").exists():
|
||||
return ModelType.Lora
|
||||
|
||||
i = folder_path / "model_index.json"
|
||||
c = folder_path / "config.json"
|
||||
config_path = i if i.exists() else c if c.exists() else None
|
||||
|
||||
if config_path:
|
||||
with open(config_path, "r") as file:
|
||||
conf = json.load(file)
|
||||
class_name = conf["_class_name"]
|
||||
|
||||
if class_name and (type := cls.CLASS2TYPE.get(class_name)):
|
||||
return type
|
||||
|
||||
# give up
|
||||
raise InvalidModelException(f"Unable to determine model type for {folder_path}")
|
||||
|
||||
@classmethod
|
||||
def _scan_and_load_checkpoint(cls, model_path: Path) -> dict:
|
||||
with SilenceWarnings():
|
||||
if model_path.suffix.endswith((".ckpt", ".pt", ".bin")):
|
||||
cls._scan_model(model_path, model_path)
|
||||
return torch.load(model_path)
|
||||
else:
|
||||
return safetensors.torch.load_file(model_path)
|
||||
|
||||
@classmethod
|
||||
def _scan_model(cls, model_name, checkpoint):
|
||||
"""
|
||||
Apply picklescanner to the indicated checkpoint and issue a warning
|
||||
and option to exit if an infected file is identified.
|
||||
"""
|
||||
# scan model
|
||||
scan_result = scan_file_path(checkpoint)
|
||||
if scan_result.infected_files != 0:
|
||||
raise "The model {model_name} is potentially infected by malware. Aborting import."
|
||||
|
||||
|
||||
# ##################################################3
|
||||
# Checkpoint probing
|
||||
# ##################################################3
|
||||
class ProbeBase(object):
|
||||
def get_base_type(self) -> BaseModelType:
|
||||
pass
|
||||
|
||||
def get_variant_type(self) -> ModelVariantType:
|
||||
pass
|
||||
|
||||
def get_scheduler_prediction_type(self) -> SchedulerPredictionType:
|
||||
pass
|
||||
|
||||
def get_format(self) -> str:
|
||||
pass
|
||||
|
||||
|
||||
class CheckpointProbeBase(ProbeBase):
|
||||
def __init__(
|
||||
self, checkpoint_path: Path, checkpoint: dict, helper: Callable[[Path], SchedulerPredictionType] = None
|
||||
) -> BaseModelType:
|
||||
self.checkpoint = checkpoint or ModelProbe._scan_and_load_checkpoint(checkpoint_path)
|
||||
self.checkpoint_path = checkpoint_path
|
||||
self.helper = helper
|
||||
|
||||
def get_base_type(self) -> BaseModelType:
|
||||
pass
|
||||
|
||||
def get_format(self) -> str:
|
||||
return "checkpoint"
|
||||
|
||||
def get_variant_type(self) -> ModelVariantType:
|
||||
model_type = ModelProbe.get_model_type_from_checkpoint(self.checkpoint_path, self.checkpoint)
|
||||
if model_type != ModelType.Main:
|
||||
return ModelVariantType.Normal
|
||||
state_dict = self.checkpoint.get("state_dict") or self.checkpoint
|
||||
in_channels = state_dict["model.diffusion_model.input_blocks.0.0.weight"].shape[1]
|
||||
if in_channels == 9:
|
||||
return ModelVariantType.Inpaint
|
||||
elif in_channels == 5:
|
||||
return ModelVariantType.Depth
|
||||
elif in_channels == 4:
|
||||
return ModelVariantType.Normal
|
||||
else:
|
||||
raise InvalidModelException(
|
||||
f"Cannot determine variant type (in_channels={in_channels}) at {self.checkpoint_path}"
|
||||
)
|
||||
|
||||
|
||||
class PipelineCheckpointProbe(CheckpointProbeBase):
|
||||
def get_base_type(self) -> BaseModelType:
|
||||
checkpoint = self.checkpoint
|
||||
state_dict = self.checkpoint.get("state_dict") or checkpoint
|
||||
key_name = "model.diffusion_model.input_blocks.2.1.transformer_blocks.0.attn2.to_k.weight"
|
||||
if key_name in state_dict and state_dict[key_name].shape[-1] == 768:
|
||||
return BaseModelType.StableDiffusion1
|
||||
if key_name in state_dict and state_dict[key_name].shape[-1] == 1024:
|
||||
return BaseModelType.StableDiffusion2
|
||||
key_name = "model.diffusion_model.input_blocks.4.1.transformer_blocks.0.attn2.to_k.weight"
|
||||
if key_name in state_dict and state_dict[key_name].shape[-1] == 2048:
|
||||
return BaseModelType.StableDiffusionXL
|
||||
elif key_name in state_dict and state_dict[key_name].shape[-1] == 1280:
|
||||
return BaseModelType.StableDiffusionXLRefiner
|
||||
else:
|
||||
raise InvalidModelException("Cannot determine base type")
|
||||
|
||||
def get_scheduler_prediction_type(self) -> SchedulerPredictionType:
|
||||
type = self.get_base_type()
|
||||
if type == BaseModelType.StableDiffusion1:
|
||||
return SchedulerPredictionType.Epsilon
|
||||
checkpoint = self.checkpoint
|
||||
state_dict = self.checkpoint.get("state_dict") or checkpoint
|
||||
key_name = "model.diffusion_model.input_blocks.2.1.transformer_blocks.0.attn2.to_k.weight"
|
||||
if key_name in state_dict and state_dict[key_name].shape[-1] == 1024:
|
||||
if "global_step" in checkpoint:
|
||||
if checkpoint["global_step"] == 220000:
|
||||
return SchedulerPredictionType.Epsilon
|
||||
elif checkpoint["global_step"] == 110000:
|
||||
return SchedulerPredictionType.VPrediction
|
||||
if (
|
||||
self.checkpoint_path and self.helper and not self.checkpoint_path.with_suffix(".yaml").exists()
|
||||
): # if a .yaml config file exists, then this step not needed
|
||||
return self.helper(self.checkpoint_path)
|
||||
else:
|
||||
return None
|
||||
|
||||
|
||||
class VaeCheckpointProbe(CheckpointProbeBase):
|
||||
def get_base_type(self) -> BaseModelType:
|
||||
# I can't find any standalone 2.X VAEs to test with!
|
||||
return BaseModelType.StableDiffusion1
|
||||
|
||||
|
||||
class LoRACheckpointProbe(CheckpointProbeBase):
|
||||
def get_format(self) -> str:
|
||||
return "lycoris"
|
||||
|
||||
def get_base_type(self) -> BaseModelType:
|
||||
checkpoint = self.checkpoint
|
||||
token_vector_length = lora_token_vector_length(checkpoint)
|
||||
|
||||
if token_vector_length == 768:
|
||||
return BaseModelType.StableDiffusion1
|
||||
elif token_vector_length == 1024:
|
||||
return BaseModelType.StableDiffusion2
|
||||
elif token_vector_length == 2048:
|
||||
return BaseModelType.StableDiffusionXL
|
||||
else:
|
||||
raise InvalidModelException(f"Unknown LoRA type: {self.checkpoint_path}")
|
||||
|
||||
|
||||
class TextualInversionCheckpointProbe(CheckpointProbeBase):
|
||||
def get_format(self) -> str:
|
||||
return None
|
||||
|
||||
def get_base_type(self) -> BaseModelType:
|
||||
checkpoint = self.checkpoint
|
||||
if "string_to_token" in checkpoint:
|
||||
token_dim = list(checkpoint["string_to_param"].values())[0].shape[-1]
|
||||
elif "emb_params" in checkpoint:
|
||||
token_dim = checkpoint["emb_params"].shape[-1]
|
||||
else:
|
||||
token_dim = list(checkpoint.values())[0].shape[0]
|
||||
if token_dim == 768:
|
||||
return BaseModelType.StableDiffusion1
|
||||
elif token_dim == 1024:
|
||||
return BaseModelType.StableDiffusion2
|
||||
else:
|
||||
return None
|
||||
|
||||
|
||||
class ControlNetCheckpointProbe(CheckpointProbeBase):
|
||||
def get_base_type(self) -> BaseModelType:
|
||||
checkpoint = self.checkpoint
|
||||
for key_name in (
|
||||
"control_model.input_blocks.2.1.transformer_blocks.0.attn2.to_k.weight",
|
||||
"input_blocks.2.1.transformer_blocks.0.attn2.to_k.weight",
|
||||
):
|
||||
if key_name not in checkpoint:
|
||||
continue
|
||||
if checkpoint[key_name].shape[-1] == 768:
|
||||
return BaseModelType.StableDiffusion1
|
||||
elif checkpoint[key_name].shape[-1] == 1024:
|
||||
return BaseModelType.StableDiffusion2
|
||||
elif self.checkpoint_path and self.helper:
|
||||
return self.helper(self.checkpoint_path)
|
||||
raise InvalidModelException("Unable to determine base type for {self.checkpoint_path}")
|
||||
|
||||
|
||||
########################################################
|
||||
# classes for probing folders
|
||||
#######################################################
|
||||
class FolderProbeBase(ProbeBase):
|
||||
def __init__(self, folder_path: Path, model: ModelMixin = None, helper: Callable = None): # not used
|
||||
self.model = model
|
||||
self.folder_path = folder_path
|
||||
|
||||
def get_variant_type(self) -> ModelVariantType:
|
||||
return ModelVariantType.Normal
|
||||
|
||||
def get_format(self) -> str:
|
||||
return "diffusers"
|
||||
|
||||
|
||||
class PipelineFolderProbe(FolderProbeBase):
|
||||
def get_base_type(self) -> BaseModelType:
|
||||
if self.model:
|
||||
unet_conf = self.model.unet.config
|
||||
else:
|
||||
with open(self.folder_path / "unet" / "config.json", "r") as file:
|
||||
unet_conf = json.load(file)
|
||||
if unet_conf["cross_attention_dim"] == 768:
|
||||
return BaseModelType.StableDiffusion1
|
||||
elif unet_conf["cross_attention_dim"] == 1024:
|
||||
return BaseModelType.StableDiffusion2
|
||||
elif unet_conf["cross_attention_dim"] == 1280:
|
||||
return BaseModelType.StableDiffusionXLRefiner
|
||||
elif unet_conf["cross_attention_dim"] == 2048:
|
||||
return BaseModelType.StableDiffusionXL
|
||||
else:
|
||||
raise InvalidModelException(f"Unknown base model for {self.folder_path}")
|
||||
|
||||
def get_scheduler_prediction_type(self) -> SchedulerPredictionType:
|
||||
if self.model:
|
||||
scheduler_conf = self.model.scheduler.config
|
||||
else:
|
||||
with open(self.folder_path / "scheduler" / "scheduler_config.json", "r") as file:
|
||||
scheduler_conf = json.load(file)
|
||||
if scheduler_conf["prediction_type"] == "v_prediction":
|
||||
return SchedulerPredictionType.VPrediction
|
||||
elif scheduler_conf["prediction_type"] == "epsilon":
|
||||
return SchedulerPredictionType.Epsilon
|
||||
else:
|
||||
return None
|
||||
|
||||
def get_variant_type(self) -> ModelVariantType:
|
||||
# This only works for pipelines! Any kind of
|
||||
# exception results in our returning the
|
||||
# "normal" variant type
|
||||
try:
|
||||
if self.model:
|
||||
conf = self.model.unet.config
|
||||
else:
|
||||
config_file = self.folder_path / "unet" / "config.json"
|
||||
with open(config_file, "r") as file:
|
||||
conf = json.load(file)
|
||||
|
||||
in_channels = conf["in_channels"]
|
||||
if in_channels == 9:
|
||||
return ModelVariantType.Inpaint
|
||||
elif in_channels == 5:
|
||||
return ModelVariantType.Depth
|
||||
elif in_channels == 4:
|
||||
return ModelVariantType.Normal
|
||||
except Exception:
|
||||
pass
|
||||
return ModelVariantType.Normal
|
||||
|
||||
|
||||
class VaeFolderProbe(FolderProbeBase):
|
||||
def get_base_type(self) -> BaseModelType:
|
||||
config_file = self.folder_path / "config.json"
|
||||
if not config_file.exists():
|
||||
raise InvalidModelException(f"Cannot determine base type for {self.folder_path}")
|
||||
with open(config_file, "r") as file:
|
||||
config = json.load(file)
|
||||
return (
|
||||
BaseModelType.StableDiffusionXL
|
||||
if config.get("scaling_factor", 0) == 0.13025 and config.get("sample_size") in [512, 1024]
|
||||
else BaseModelType.StableDiffusion1
|
||||
)
|
||||
|
||||
|
||||
class TextualInversionFolderProbe(FolderProbeBase):
|
||||
def get_format(self) -> str:
|
||||
return None
|
||||
|
||||
def get_base_type(self) -> BaseModelType:
|
||||
path = self.folder_path / "learned_embeds.bin"
|
||||
if not path.exists():
|
||||
return None
|
||||
checkpoint = ModelProbe._scan_and_load_checkpoint(path)
|
||||
return TextualInversionCheckpointProbe(None, checkpoint=checkpoint).get_base_type()
|
||||
|
||||
|
||||
class ONNXFolderProbe(FolderProbeBase):
|
||||
def get_format(self) -> str:
|
||||
return "onnx"
|
||||
|
||||
def get_base_type(self) -> BaseModelType:
|
||||
return BaseModelType.StableDiffusion1
|
||||
|
||||
def get_variant_type(self) -> ModelVariantType:
|
||||
return ModelVariantType.Normal
|
||||
|
||||
|
||||
class ControlNetFolderProbe(FolderProbeBase):
|
||||
def get_base_type(self) -> BaseModelType:
|
||||
config_file = self.folder_path / "config.json"
|
||||
if not config_file.exists():
|
||||
raise InvalidModelException(f"Cannot determine base type for {self.folder_path}")
|
||||
with open(config_file, "r") as file:
|
||||
config = json.load(file)
|
||||
# no obvious way to distinguish between sd2-base and sd2-768
|
||||
dimension = config["cross_attention_dim"]
|
||||
base_model = (
|
||||
BaseModelType.StableDiffusion1
|
||||
if dimension == 768
|
||||
else BaseModelType.StableDiffusion2
|
||||
if dimension == 1024
|
||||
else BaseModelType.StableDiffusionXL
|
||||
if dimension == 2048
|
||||
else None
|
||||
)
|
||||
if not base_model:
|
||||
raise InvalidModelException(f"Unable to determine model base for {self.folder_path}")
|
||||
return base_model
|
||||
|
||||
|
||||
class LoRAFolderProbe(FolderProbeBase):
|
||||
def get_base_type(self) -> BaseModelType:
|
||||
model_file = None
|
||||
for suffix in ["safetensors", "bin"]:
|
||||
base_file = self.folder_path / f"pytorch_lora_weights.{suffix}"
|
||||
if base_file.exists():
|
||||
model_file = base_file
|
||||
break
|
||||
if not model_file:
|
||||
raise InvalidModelException("Unknown LoRA format encountered")
|
||||
return LoRACheckpointProbe(model_file, None).get_base_type()
|
||||
|
||||
|
||||
############## register probe classes ######
|
||||
ModelProbe.register_probe("diffusers", ModelType.Main, PipelineFolderProbe)
|
||||
ModelProbe.register_probe("diffusers", ModelType.Vae, VaeFolderProbe)
|
||||
ModelProbe.register_probe("diffusers", ModelType.Lora, LoRAFolderProbe)
|
||||
ModelProbe.register_probe("diffusers", ModelType.TextualInversion, TextualInversionFolderProbe)
|
||||
ModelProbe.register_probe("diffusers", ModelType.ControlNet, ControlNetFolderProbe)
|
||||
ModelProbe.register_probe("checkpoint", ModelType.Main, PipelineCheckpointProbe)
|
||||
ModelProbe.register_probe("checkpoint", ModelType.Vae, VaeCheckpointProbe)
|
||||
ModelProbe.register_probe("checkpoint", ModelType.Lora, LoRACheckpointProbe)
|
||||
ModelProbe.register_probe("checkpoint", ModelType.TextualInversion, TextualInversionCheckpointProbe)
|
||||
ModelProbe.register_probe("checkpoint", ModelType.ControlNet, ControlNetCheckpointProbe)
|
||||
ModelProbe.register_probe("onnx", ModelType.ONNX, ONNXFolderProbe)
|
||||
108
invokeai/backend/model_management/model_search.py
Normal file
108
invokeai/backend/model_management/model_search.py
Normal file
@@ -0,0 +1,108 @@
|
||||
# Copyright 2023, Lincoln D. Stein and the InvokeAI Team
|
||||
"""
|
||||
Abstract base class for recursive directory search for models.
|
||||
"""
|
||||
|
||||
import os
|
||||
from abc import ABC, abstractmethod
|
||||
from pathlib import Path
|
||||
from typing import List, Set, types
|
||||
|
||||
import invokeai.backend.util.logging as logger
|
||||
|
||||
|
||||
class ModelSearch(ABC):
|
||||
def __init__(self, directories: List[Path], logger: types.ModuleType = logger):
|
||||
"""
|
||||
Initialize a recursive model directory search.
|
||||
:param directories: List of directory Paths to recurse through
|
||||
:param logger: Logger to use
|
||||
"""
|
||||
self.directories = directories
|
||||
self.logger = logger
|
||||
self._items_scanned = 0
|
||||
self._models_found = 0
|
||||
self._scanned_dirs = set()
|
||||
self._scanned_paths = set()
|
||||
self._pruned_paths = set()
|
||||
|
||||
@abstractmethod
|
||||
def on_search_started(self):
|
||||
"""
|
||||
Called before the scan starts.
|
||||
"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def on_model_found(self, model: Path):
|
||||
"""
|
||||
Process a found model. Raise an exception if something goes wrong.
|
||||
:param model: Model to process - could be a directory or checkpoint.
|
||||
"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def on_search_completed(self):
|
||||
"""
|
||||
Perform some activity when the scan is completed. May use instance
|
||||
variables, items_scanned and models_found
|
||||
"""
|
||||
pass
|
||||
|
||||
def search(self):
|
||||
self.on_search_started()
|
||||
for dir in self.directories:
|
||||
self.walk_directory(dir)
|
||||
self.on_search_completed()
|
||||
|
||||
def walk_directory(self, path: Path):
|
||||
for root, dirs, files in os.walk(path, followlinks=True):
|
||||
if str(Path(root).name).startswith("."):
|
||||
self._pruned_paths.add(root)
|
||||
if any([Path(root).is_relative_to(x) for x in self._pruned_paths]):
|
||||
continue
|
||||
|
||||
self._items_scanned += len(dirs) + len(files)
|
||||
for d in dirs:
|
||||
path = Path(root) / d
|
||||
if path in self._scanned_paths or path.parent in self._scanned_dirs:
|
||||
self._scanned_dirs.add(path)
|
||||
continue
|
||||
if any(
|
||||
[
|
||||
(path / x).exists()
|
||||
for x in {"config.json", "model_index.json", "learned_embeds.bin", "pytorch_lora_weights.bin"}
|
||||
]
|
||||
):
|
||||
try:
|
||||
self.on_model_found(path)
|
||||
self._models_found += 1
|
||||
self._scanned_dirs.add(path)
|
||||
except Exception as e:
|
||||
self.logger.warning(str(e))
|
||||
|
||||
for f in files:
|
||||
path = Path(root) / f
|
||||
if path.parent in self._scanned_dirs:
|
||||
continue
|
||||
if path.suffix in {".ckpt", ".bin", ".pth", ".safetensors", ".pt"}:
|
||||
try:
|
||||
self.on_model_found(path)
|
||||
self._models_found += 1
|
||||
except Exception as e:
|
||||
self.logger.warning(str(e))
|
||||
|
||||
|
||||
class FindModels(ModelSearch):
|
||||
def on_search_started(self):
|
||||
self.models_found: Set[Path] = set()
|
||||
|
||||
def on_model_found(self, model: Path):
|
||||
self.models_found.add(model)
|
||||
|
||||
def on_search_completed(self):
|
||||
pass
|
||||
|
||||
def list_models(self) -> List[Path]:
|
||||
self.search()
|
||||
return list(self.models_found)
|
||||
@@ -1,29 +1,28 @@
|
||||
import inspect
|
||||
from enum import Enum
|
||||
from typing import Any, Literal, get_origin
|
||||
from typing import Literal, get_origin
|
||||
|
||||
from pydantic import BaseModel
|
||||
|
||||
from .base import ( # noqa: F401
|
||||
BaseModelType,
|
||||
DuplicateModelException,
|
||||
InvalidModelException,
|
||||
ModelBase,
|
||||
ModelConfigBase,
|
||||
ModelError,
|
||||
ModelNotFoundException,
|
||||
ModelType,
|
||||
ModelVariantType,
|
||||
SchedulerPredictionType,
|
||||
SilenceWarnings,
|
||||
SubModelType,
|
||||
read_checkpoint_meta,
|
||||
)
|
||||
from .clip_vision import CLIPVisionModel
|
||||
from .controlnet import ControlNetModel # TODO:
|
||||
from .ip_adapter import IPAdapterModel
|
||||
from .lora import LoRAModel
|
||||
from .sdxl import StableDiffusionXLModel
|
||||
from .stable_diffusion import StableDiffusion1Model, StableDiffusion2Model
|
||||
from .stable_diffusion_onnx import ONNXStableDiffusion1Model, ONNXStableDiffusion2Model
|
||||
from .t2i_adapter import T2IAdapterModel
|
||||
from .textual_inversion import TextualInversionModel
|
||||
from .vae import VaeModel
|
||||
|
||||
@@ -35,9 +34,6 @@ MODEL_CLASSES = {
|
||||
ModelType.Lora: LoRAModel,
|
||||
ModelType.ControlNet: ControlNetModel,
|
||||
ModelType.TextualInversion: TextualInversionModel,
|
||||
ModelType.IPAdapter: IPAdapterModel,
|
||||
ModelType.CLIPVision: CLIPVisionModel,
|
||||
ModelType.T2IAdapter: T2IAdapterModel,
|
||||
},
|
||||
BaseModelType.StableDiffusion2: {
|
||||
ModelType.ONNX: ONNXStableDiffusion2Model,
|
||||
@@ -46,9 +42,6 @@ MODEL_CLASSES = {
|
||||
ModelType.Lora: LoRAModel,
|
||||
ModelType.ControlNet: ControlNetModel,
|
||||
ModelType.TextualInversion: TextualInversionModel,
|
||||
ModelType.IPAdapter: IPAdapterModel,
|
||||
ModelType.CLIPVision: CLIPVisionModel,
|
||||
ModelType.T2IAdapter: T2IAdapterModel,
|
||||
},
|
||||
BaseModelType.StableDiffusionXL: {
|
||||
ModelType.Main: StableDiffusionXLModel,
|
||||
@@ -58,9 +51,6 @@ MODEL_CLASSES = {
|
||||
ModelType.ControlNet: ControlNetModel,
|
||||
ModelType.TextualInversion: TextualInversionModel,
|
||||
ModelType.ONNX: ONNXStableDiffusion2Model,
|
||||
ModelType.IPAdapter: IPAdapterModel,
|
||||
ModelType.CLIPVision: CLIPVisionModel,
|
||||
ModelType.T2IAdapter: T2IAdapterModel,
|
||||
},
|
||||
BaseModelType.StableDiffusionXLRefiner: {
|
||||
ModelType.Main: StableDiffusionXLModel,
|
||||
@@ -70,21 +60,6 @@ MODEL_CLASSES = {
|
||||
ModelType.ControlNet: ControlNetModel,
|
||||
ModelType.TextualInversion: TextualInversionModel,
|
||||
ModelType.ONNX: ONNXStableDiffusion2Model,
|
||||
ModelType.IPAdapter: IPAdapterModel,
|
||||
ModelType.CLIPVision: CLIPVisionModel,
|
||||
ModelType.T2IAdapter: T2IAdapterModel,
|
||||
},
|
||||
BaseModelType.Any: {
|
||||
ModelType.CLIPVision: CLIPVisionModel,
|
||||
# The following model types are not expected to be used with BaseModelType.Any.
|
||||
ModelType.ONNX: ONNXStableDiffusion2Model,
|
||||
ModelType.Main: StableDiffusion2Model,
|
||||
ModelType.Vae: VaeModel,
|
||||
ModelType.Lora: LoRAModel,
|
||||
ModelType.ControlNet: ControlNetModel,
|
||||
ModelType.TextualInversion: TextualInversionModel,
|
||||
ModelType.IPAdapter: IPAdapterModel,
|
||||
ModelType.T2IAdapter: T2IAdapterModel,
|
||||
},
|
||||
# BaseModelType.Kandinsky2_1: {
|
||||
# ModelType.Main: Kandinsky2_1Model,
|
||||
@@ -95,12 +70,14 @@ MODEL_CLASSES = {
|
||||
# },
|
||||
}
|
||||
|
||||
MODEL_CONFIGS: Any = list()
|
||||
OPENAPI_MODEL_CONFIGS: Any = list()
|
||||
MODEL_CONFIGS = list()
|
||||
OPENAPI_MODEL_CONFIGS = list()
|
||||
|
||||
|
||||
class OpenAPIModelInfoBase(BaseModel):
|
||||
key: str
|
||||
model_name: str
|
||||
base_model: BaseModelType
|
||||
model_type: ModelType
|
||||
|
||||
|
||||
for base_model, models in MODEL_CLASSES.items():
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user