mirror of
https://github.com/invoke-ai/InvokeAI.git
synced 2026-01-16 01:58:14 -05:00
Compare commits
1 Commits
test
...
psychedeli
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
ff68ae7710 |
2
.github/workflows/pypi-release.yml
vendored
2
.github/workflows/pypi-release.yml
vendored
@@ -28,7 +28,7 @@ jobs:
|
||||
run: twine check dist/*
|
||||
|
||||
- name: check PyPI versions
|
||||
if: github.ref == 'refs/heads/main' || startsWith(github.ref, 'refs/heads/release/')
|
||||
if: github.ref == 'refs/heads/main' || github.ref == 'refs/heads/v2.3'
|
||||
run: |
|
||||
pip install --upgrade requests
|
||||
python -c "\
|
||||
|
||||
@@ -47,9 +47,34 @@ pip install ".[dev,test]"
|
||||
These are optional groups of packages which are defined within the `pyproject.toml`
|
||||
and will be required for testing the changes you make to the code.
|
||||
|
||||
### Tests
|
||||
### Running Tests
|
||||
|
||||
We use [pytest](https://docs.pytest.org/en/7.2.x/) for our test suite. Tests can
|
||||
be found under the `./tests` folder and can be run with a single `pytest`
|
||||
command. Optionally, to review test coverage you can append `--cov`.
|
||||
|
||||
```zsh
|
||||
pytest --cov
|
||||
```
|
||||
|
||||
Test outcomes and coverage will be reported in the terminal. In addition a more
|
||||
detailed report is created in both XML and HTML format in the `./coverage`
|
||||
folder. The HTML one in particular can help identify missing statements
|
||||
requiring tests to ensure coverage. This can be run by opening
|
||||
`./coverage/html/index.html`.
|
||||
|
||||
For example.
|
||||
|
||||
```zsh
|
||||
pytest --cov; open ./coverage/html/index.html
|
||||
```
|
||||
|
||||
??? info "HTML coverage report output"
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
See the [tests documentation](./TESTS.md) for information about running and writing tests.
|
||||
### Reloading Changes
|
||||
|
||||
Experimenting with changes to the Python source code is a drag if you have to re-start the server —
|
||||
@@ -200,6 +225,14 @@ Now we can create the InvokeAI debugging configs:
|
||||
"program": "scripts/invokeai-cli.py",
|
||||
"justMyCode": true
|
||||
},
|
||||
{
|
||||
"type": "chrome",
|
||||
"request": "launch",
|
||||
"name": "InvokeAI UI",
|
||||
// You have to run the UI with `yarn dev` for this to work
|
||||
"url": "http://localhost:5173",
|
||||
"webRoot": "${workspaceFolder}/invokeai/frontend/web"
|
||||
},
|
||||
{
|
||||
// Run tests
|
||||
"name": "InvokeAI Test",
|
||||
@@ -235,7 +268,8 @@ Now we can create the InvokeAI debugging configs:
|
||||
|
||||
You'll see these configs in the debugging configs drop down. Running them will
|
||||
start InvokeAI with attached debugger, in the correct environment, and work just
|
||||
like the normal app.
|
||||
like the normal app, though the UI debugger requires you to run the UI in dev
|
||||
mode. See the [frontend guide](contribution_guides/contributingToFrontend.md) for setting that up.
|
||||
|
||||
Enjoy debugging InvokeAI with ease (not that we have any bugs of course).
|
||||
|
||||
|
||||
@@ -1,89 +0,0 @@
|
||||
# InvokeAI Backend Tests
|
||||
|
||||
We use `pytest` to run the backend python tests. (See [pyproject.toml](/pyproject.toml) for the default `pytest` options.)
|
||||
|
||||
## Fast vs. Slow
|
||||
All tests are categorized as either 'fast' (no test annotation) or 'slow' (annotated with the `@pytest.mark.slow` decorator).
|
||||
|
||||
'Fast' tests are run to validate every PR, and are fast enough that they can be run routinely during development.
|
||||
|
||||
'Slow' tests are currently only run manually on an ad-hoc basis. In the future, they may be automated to run nightly. Most developers are only expected to run the 'slow' tests that directly relate to the feature(s) that they are working on.
|
||||
|
||||
As a rule of thumb, tests should be marked as 'slow' if there is a chance that they take >1s (e.g. on a CPU-only machine with slow internet connection). Common examples of slow tests are tests that depend on downloading a model, or running model inference.
|
||||
|
||||
## Running Tests
|
||||
|
||||
Below are some common test commands:
|
||||
```bash
|
||||
# Run the fast tests. (This implicitly uses the configured default option: `-m "not slow"`.)
|
||||
pytest tests/
|
||||
|
||||
# Equivalent command to run the fast tests.
|
||||
pytest tests/ -m "not slow"
|
||||
|
||||
# Run the slow tests.
|
||||
pytest tests/ -m "slow"
|
||||
|
||||
# Run the slow tests from a specific file.
|
||||
pytest tests/path/to/slow_test.py -m "slow"
|
||||
|
||||
# Run all tests (fast and slow).
|
||||
pytest tests -m ""
|
||||
```
|
||||
|
||||
## Test Organization
|
||||
|
||||
All backend tests are in the [`tests/`](/tests/) directory. This directory mirrors the organization of the `invokeai/` directory. For example, tests for `invokeai/model_management/model_manager.py` would be found in `tests/model_management/test_model_manager.py`.
|
||||
|
||||
TODO: The above statement is aspirational. A re-organization of legacy tests is required to make it true.
|
||||
|
||||
## Tests that depend on models
|
||||
|
||||
There are a few things to keep in mind when adding tests that depend on models.
|
||||
|
||||
1. If a required model is not already present, it should automatically be downloaded as part of the test setup.
|
||||
2. If a model is already downloaded, it should not be re-downloaded unnecessarily.
|
||||
3. Take reasonable care to keep the total number of models required for the tests low. Whenever possible, re-use models that are already required for other tests. If you are adding a new model, consider including a comment to explain why it is required/unique.
|
||||
|
||||
There are several utilities to help with model setup for tests. Here is a sample test that depends on a model:
|
||||
```python
|
||||
import pytest
|
||||
import torch
|
||||
|
||||
from invokeai.backend.model_management.models.base import BaseModelType, ModelType
|
||||
from invokeai.backend.util.test_utils import install_and_load_model
|
||||
|
||||
@pytest.mark.slow
|
||||
def test_model(model_installer, torch_device):
|
||||
model_info = install_and_load_model(
|
||||
model_installer=model_installer,
|
||||
model_path_id_or_url="HF/dummy_model_id",
|
||||
model_name="dummy_model",
|
||||
base_model=BaseModelType.StableDiffusion1,
|
||||
model_type=ModelType.Dummy,
|
||||
)
|
||||
|
||||
dummy_input = build_dummy_input(torch_device)
|
||||
|
||||
with torch.no_grad(), model_info as model:
|
||||
model.to(torch_device, dtype=torch.float32)
|
||||
output = model(dummy_input)
|
||||
|
||||
# Validate output...
|
||||
|
||||
```
|
||||
|
||||
## Test Coverage
|
||||
|
||||
To review test coverage, append `--cov` to your pytest command:
|
||||
```bash
|
||||
pytest tests/ --cov
|
||||
```
|
||||
|
||||
Test outcomes and coverage will be reported in the terminal. In addition, a more detailed report is created in both XML and HTML format in the `./coverage` folder. The HTML output is particularly helpful in identifying untested statements where coverage should be improved. The HTML report can be viewed by opening `./coverage/html/index.html`.
|
||||
|
||||
??? info "HTML coverage report output"
|
||||
|
||||

|
||||
|
||||

|
||||
@@ -12,7 +12,7 @@ To get started, take a look at our [new contributors checklist](newContributorCh
|
||||
Once you're setup, for more information, you can review the documentation specific to your area of interest:
|
||||
|
||||
* #### [InvokeAI Architecure](../ARCHITECTURE.md)
|
||||
* #### [Frontend Documentation](./contributingToFrontend.md)
|
||||
* #### [Frontend Documentation](development_guides/contributingToFrontend.md)
|
||||
* #### [Node Documentation](../INVOCATIONS.md)
|
||||
* #### [Local Development](../LOCAL_DEVELOPMENT.md)
|
||||
|
||||
|
||||
@@ -256,10 +256,6 @@ manager, please follow these steps:
|
||||
*highly recommended** if your virtual environment is located outside of
|
||||
your runtime directory.
|
||||
|
||||
!!! tip
|
||||
|
||||
On linux, it is recommended to run invokeai with the following env var: `MALLOC_MMAP_THRESHOLD_=1048576`. For example: `MALLOC_MMAP_THRESHOLD_=1048576 invokeai --web`. This helps to prevent memory fragmentation that can lead to memory accumulation over time. This env var is set automatically when running via `invoke.sh`.
|
||||
|
||||
10. Render away!
|
||||
|
||||
Browse the [features](../features/index.md) section to learn about all the
|
||||
|
||||
@@ -8,42 +8,14 @@ To download a node, simply download the `.py` node file from the link and add it
|
||||
|
||||
To use a community workflow, download the the `.json` node graph file and load it into Invoke AI via the **Load Workflow** button in the Workflow Editor.
|
||||
|
||||
- Community Nodes
|
||||
+ [Depth Map from Wavefront OBJ](#depth-map-from-wavefront-obj)
|
||||
+ [Film Grain](#film-grain)
|
||||
+ [Generative Grammar-Based Prompt Nodes](#generative-grammar-based-prompt-nodes)
|
||||
+ [GPT2RandomPromptMaker](#gpt2randompromptmaker)
|
||||
+ [Grid to Gif](#grid-to-gif)
|
||||
+ [Halftone](#halftone)
|
||||
+ [Ideal Size](#ideal-size)
|
||||
+ [Image and Mask Composition Pack](#image-and-mask-composition-pack)
|
||||
+ [Image to Character Art Image Nodes](#image-to-character-art-image-nodes)
|
||||
+ [Image Picker](#image-picker)
|
||||
+ [Load Video Frame](#load-video-frame)
|
||||
+ [Make 3D](#make-3d)
|
||||
+ [Oobabooga](#oobabooga)
|
||||
+ [Prompt Tools](#prompt-tools)
|
||||
+ [Retroize](#retroize)
|
||||
+ [Size Stepper Nodes](#size-stepper-nodes)
|
||||
+ [Text font to Image](#text-font-to-image)
|
||||
+ [Thresholding](#thresholding)
|
||||
+ [XY Image to Grid and Images to Grids nodes](#xy-image-to-grid-and-images-to-grids-nodes)
|
||||
- [Example Node Template](#example-node-template)
|
||||
- [Disclaimer](#disclaimer)
|
||||
- [Help](#help)
|
||||
|
||||
--------------------------------
|
||||
|
||||
--------------------------------
|
||||
### Depth Map from Wavefront OBJ
|
||||
### Ideal Size
|
||||
|
||||
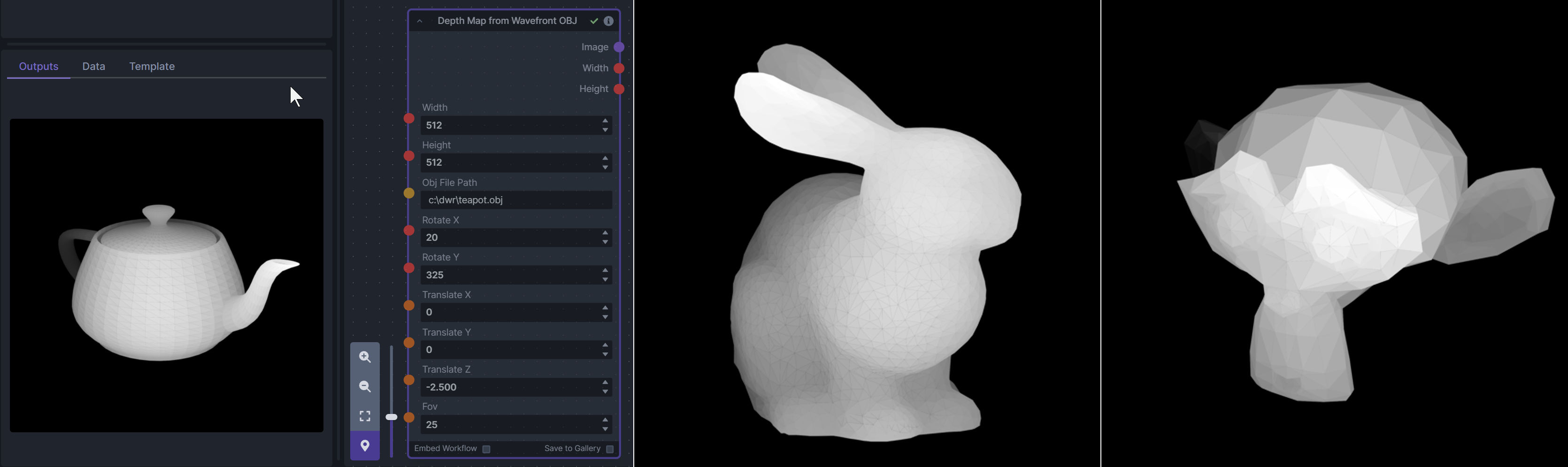
**Description:** Render depth maps from Wavefront .obj files (triangulated) using this simple 3D renderer utilizing numpy and matplotlib to compute and color the scene. There are simple parameters to change the FOV, camera position, and model orientation.
|
||||
**Description:** This node calculates an ideal image size for a first pass of a multi-pass upscaling. The aim is to avoid duplication that results from choosing a size larger than the model is capable of.
|
||||
|
||||
To be imported, an .obj must use triangulated meshes, so make sure to enable that option if exporting from a 3D modeling program. This renderer makes each triangle a solid color based on its average depth, so it will cause anomalies if your .obj has large triangles. In Blender, the Remesh modifier can be helpful to subdivide a mesh into small pieces that work well given these limitations.
|
||||
|
||||
**Node Link:** https://github.com/dwringer/depth-from-obj-node
|
||||
|
||||
**Example Usage:**
|
||||
</br><img src="https://raw.githubusercontent.com/dwringer/depth-from-obj-node/main/depth_from_obj_usage.jpg" width="500" />
|
||||
**Node Link:** https://github.com/JPPhoto/ideal-size-node
|
||||
|
||||
--------------------------------
|
||||
### Film Grain
|
||||
@@ -53,46 +25,36 @@ To be imported, an .obj must use triangulated meshes, so make sure to enable tha
|
||||
**Node Link:** https://github.com/JPPhoto/film-grain-node
|
||||
|
||||
--------------------------------
|
||||
### Generative Grammar-Based Prompt Nodes
|
||||
### Image Picker
|
||||
|
||||
**Description:** This set of 3 nodes generates prompts from simple user-defined grammar rules (loaded from custom files - examples provided below). The prompts are made by recursively expanding a special template string, replacing nonterminal "parts-of-speech" until no nonterminal terms remain in the string.
|
||||
**Description:** This InvokeAI node takes in a collection of images and randomly chooses one. This can be useful when you have a number of poses to choose from for a ControlNet node, or a number of input images for another purpose.
|
||||
|
||||
This includes 3 Nodes:
|
||||
- *Lookup Table from File* - loads a YAML file "prompt" section (or of a whole folder of YAML's) into a JSON-ified dictionary (Lookups output)
|
||||
- *Lookups Entry from Prompt* - places a single entry in a new Lookups output under the specified heading
|
||||
- *Prompt from Lookup Table* - uses a Collection of Lookups as grammar rules from which to randomly generate prompts.
|
||||
|
||||
**Node Link:** https://github.com/dwringer/generative-grammar-prompt-nodes
|
||||
|
||||
**Example Usage:**
|
||||
</br><img src="https://raw.githubusercontent.com/dwringer/generative-grammar-prompt-nodes/main/lookuptables_usage.jpg" width="500" />
|
||||
**Node Link:** https://github.com/JPPhoto/image-picker-node
|
||||
|
||||
--------------------------------
|
||||
### GPT2RandomPromptMaker
|
||||
### Thresholding
|
||||
|
||||
**Description:** A node for InvokeAI utilizes the GPT-2 language model to generate random prompts based on a provided seed and context.
|
||||
**Description:** This node generates masks for highlights, midtones, and shadows given an input image. You can optionally specify a blur for the lookup table used in making those masks from the source image.
|
||||
|
||||
**Node Link:** https://github.com/mickr777/GPT2RandomPromptMaker
|
||||
**Node Link:** https://github.com/JPPhoto/thresholding-node
|
||||
|
||||
**Output Examples**
|
||||
**Examples**
|
||||
|
||||
Generated Prompt: An enchanted weapon will be usable by any character regardless of their alignment.
|
||||
Input:
|
||||
|
||||
<img src="https://github.com/mickr777/InvokeAI/assets/115216705/8496ba09-bcdd-4ff7-8076-ff213b6a1e4c" width="200" />
|
||||
{: style="height:512px;width:512px"}
|
||||
|
||||
--------------------------------
|
||||
### Grid to Gif
|
||||
Highlights/Midtones/Shadows:
|
||||
|
||||
**Description:** One node that turns a grid image into an image collection, one node that turns an image collection into a gif.
|
||||
<img src="https://github.com/invoke-ai/InvokeAI/assets/34005131/727021c1-36ff-4ec8-90c8-105e00de986d" style="width: 30%" />
|
||||
<img src="https://github.com/invoke-ai/InvokeAI/assets/34005131/0b721bfc-f051-404e-b905-2f16b824ddfe" style="width: 30%" />
|
||||
<img src="https://github.com/invoke-ai/InvokeAI/assets/34005131/04c1297f-1c88-42b6-a7df-dd090b976286" style="width: 30%" />
|
||||
|
||||
**Node Link:** https://github.com/mildmisery/invokeai-GridToGifNode/blob/main/GridToGif.py
|
||||
Highlights/Midtones/Shadows (with LUT blur enabled):
|
||||
|
||||
**Example Node Graph:** https://github.com/mildmisery/invokeai-GridToGifNode/blob/main/Grid%20to%20Gif%20Example%20Workflow.json
|
||||
|
||||
**Output Examples**
|
||||
|
||||
<img src="https://raw.githubusercontent.com/mildmisery/invokeai-GridToGifNode/main/input.png" width="300" />
|
||||
<img src="https://raw.githubusercontent.com/mildmisery/invokeai-GridToGifNode/main/output.gif" width="300" />
|
||||
<img src="https://github.com/invoke-ai/InvokeAI/assets/34005131/19aa718a-70c1-4668-8169-d68f4bd13771" style="width: 30%" />
|
||||
<img src="https://github.com/invoke-ai/InvokeAI/assets/34005131/0a440e43-697f-4d17-82ee-f287467df0a5" style="width: 30%" />
|
||||
<img src="https://github.com/invoke-ai/InvokeAI/assets/34005131/0701fd0f-2ca7-4fe2-8613-2b52547bafce" style="width: 30%" />
|
||||
|
||||
--------------------------------
|
||||
### Halftone
|
||||
@@ -105,22 +67,108 @@ Generated Prompt: An enchanted weapon will be usable by any character regardless
|
||||
|
||||
Input:
|
||||
|
||||
<img src="https://github.com/invoke-ai/InvokeAI/assets/34005131/fd5efb9f-4355-4409-a1c2-c1ca99e0cab4" width="300" />
|
||||
{: style="height:512px;width:512px"}
|
||||
|
||||
Halftone Output:
|
||||
|
||||
<img src="https://github.com/invoke-ai/InvokeAI/assets/34005131/7e606f29-e68f-4d46-b3d5-97f799a4ec2f" width="300" />
|
||||
{: style="height:512px;width:512px"}
|
||||
|
||||
CMYK Halftone Output:
|
||||
|
||||
<img src="https://github.com/invoke-ai/InvokeAI/assets/34005131/c59c578f-db8e-4d66-8c66-2851752d75ea" width="300" />
|
||||
{: style="height:512px;width:512px"}
|
||||
|
||||
--------------------------------
|
||||
### Ideal Size
|
||||
### Retroize
|
||||
|
||||
**Description:** This node calculates an ideal image size for a first pass of a multi-pass upscaling. The aim is to avoid duplication that results from choosing a size larger than the model is capable of.
|
||||
**Description:** Retroize is a collection of nodes for InvokeAI to "Retroize" images. Any image can be given a fresh coat of retro paint with these nodes, either from your gallery or from within the graph itself. It includes nodes to pixelize, quantize, palettize, and ditherize images; as well as to retrieve palettes from existing images.
|
||||
|
||||
**Node Link:** https://github.com/JPPhoto/ideal-size-node
|
||||
**Node Link:** https://github.com/Ar7ific1al/invokeai-retroizeinode/
|
||||
|
||||
**Retroize Output Examples**
|
||||
|
||||

|
||||
|
||||
--------------------------------
|
||||
### GPT2RandomPromptMaker
|
||||
|
||||
**Description:** A node for InvokeAI utilizes the GPT-2 language model to generate random prompts based on a provided seed and context.
|
||||
|
||||
**Node Link:** https://github.com/mickr777/GPT2RandomPromptMaker
|
||||
|
||||
**Output Examples**
|
||||
|
||||
Generated Prompt: An enchanted weapon will be usable by any character regardless of their alignment.
|
||||
|
||||

|
||||
|
||||
--------------------------------
|
||||
### Load Video Frame
|
||||
|
||||
**Description:** This is a video frame image provider + indexer/video creation nodes for hooking up to iterators and ranges and ControlNets and such for invokeAI node experimentation. Think animation + ControlNet outputs.
|
||||
|
||||
**Node Link:** https://github.com/helix4u/load_video_frame
|
||||
|
||||
**Example Node Graph:** https://github.com/helix4u/load_video_frame/blob/main/Example_Workflow.json
|
||||
|
||||
**Output Example:**
|
||||
|
||||

|
||||
[Full mp4 of Example Output test.mp4](https://github.com/helix4u/load_video_frame/blob/main/test.mp4)
|
||||
|
||||
--------------------------------
|
||||
|
||||
### Oobabooga
|
||||
|
||||
**Description:** asks a local LLM running in Oobabooga's Text-Generation-Webui to write a prompt based on the user input.
|
||||
|
||||
**Link:** https://github.com/sammyf/oobabooga-node
|
||||
|
||||
|
||||
**Example:**
|
||||
|
||||
"describe a new mystical creature in its natural environment"
|
||||
|
||||
*can return*
|
||||
|
||||
"The mystical creature I am describing to you is called the "Glimmerwing". It is a majestic, iridescent being that inhabits the depths of the most enchanted forests and glimmering lakes. Its body is covered in shimmering scales that reflect every color of the rainbow, and it has delicate, translucent wings that sparkle like diamonds in the sunlight. The Glimmerwing's home is a crystal-clear lake, surrounded by towering trees with leaves that shimmer like jewels. In this serene environment, the Glimmerwing spends its days swimming gracefully through the water, chasing schools of glittering fish and playing with the gentle ripples of the lake's surface.
|
||||
As the sun sets, the Glimmerwing perches on a branch of one of the trees, spreading its wings to catch the last rays of light. The creature's scales glow softly, casting a rainbow of colors across the forest floor. The Glimmerwing sings a haunting melody, its voice echoing through the stillness of the night air. Its song is said to have the power to heal the sick and bring peace to troubled souls. Those who are lucky enough to hear the Glimmerwing's song are forever changed by its beauty and grace."
|
||||
|
||||

|
||||
|
||||
**Requirement**
|
||||
|
||||
a Text-Generation-Webui instance (might work remotely too, but I never tried it) and obviously InvokeAI 3.x
|
||||
|
||||
**Note**
|
||||
|
||||
This node works best with SDXL models, especially as the style can be described independantly of the LLM's output.
|
||||
|
||||
--------------------------------
|
||||
### Depth Map from Wavefront OBJ
|
||||
|
||||
**Description:** Render depth maps from Wavefront .obj files (triangulated) using this simple 3D renderer utilizing numpy and matplotlib to compute and color the scene. There are simple parameters to change the FOV, camera position, and model orientation.
|
||||
|
||||
To be imported, an .obj must use triangulated meshes, so make sure to enable that option if exporting from a 3D modeling program. This renderer makes each triangle a solid color based on its average depth, so it will cause anomalies if your .obj has large triangles. In Blender, the Remesh modifier can be helpful to subdivide a mesh into small pieces that work well given these limitations.
|
||||
|
||||
**Node Link:** https://github.com/dwringer/depth-from-obj-node
|
||||
|
||||
**Example Usage:**
|
||||
|
||||
|
||||
--------------------------------
|
||||
### Generative Grammar-Based Prompt Nodes
|
||||
|
||||
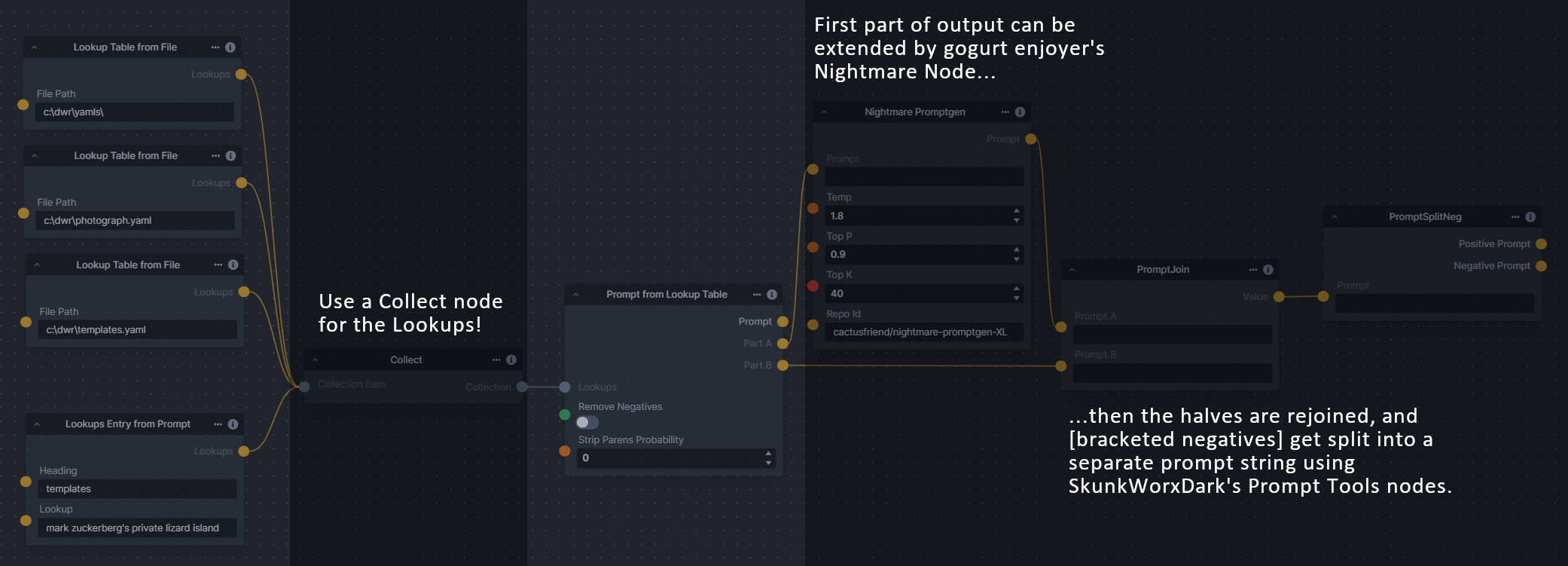
**Description:** This set of 3 nodes generates prompts from simple user-defined grammar rules (loaded from custom files - examples provided below). The prompts are made by recursively expanding a special template string, replacing nonterminal "parts-of-speech" until no more nonterminal terms remain in the string.
|
||||
|
||||
This includes 3 Nodes:
|
||||
- *Lookup Table from File* - loads a YAML file "prompt" section (or of a whole folder of YAML's) into a JSON-ified dictionary (Lookups output)
|
||||
- *Lookups Entry from Prompt* - places a single entry in a new Lookups output under the specified heading
|
||||
- *Prompt from Lookup Table* - uses a Collection of Lookups as grammar rules from which to randomly generate prompts.
|
||||
|
||||
**Node Link:** https://github.com/dwringer/generative-grammar-prompt-nodes
|
||||
|
||||
**Example Usage:**
|
||||
|
||||
|
||||
--------------------------------
|
||||
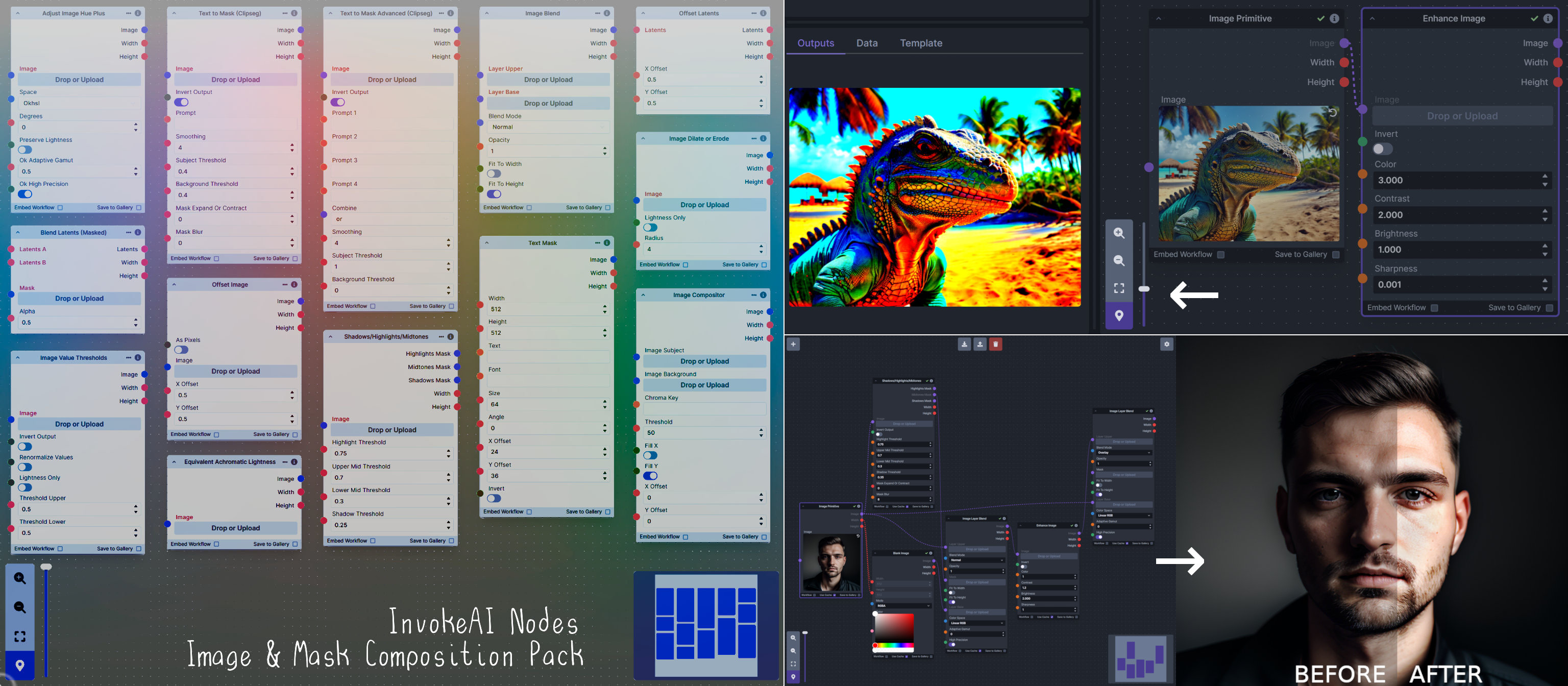
### Image and Mask Composition Pack
|
||||
@@ -146,88 +194,45 @@ This includes 15 Nodes:
|
||||
- *Text Mask (simple 2D)* - create and position a white on black (or black on white) line of text using any font locally available to Invoke.
|
||||
|
||||
**Node Link:** https://github.com/dwringer/composition-nodes
|
||||
|
||||
</br><img src="https://raw.githubusercontent.com/dwringer/composition-nodes/main/composition_pack_overview.jpg" width="500" />
|
||||
|
||||
**Nodes and Output Examples:**
|
||||
|
||||
|
||||
--------------------------------
|
||||
### Image to Character Art Image Nodes
|
||||
### Size Stepper Nodes
|
||||
|
||||
**Description:** Group of nodes to convert an input image into ascii/unicode art Image
|
||||
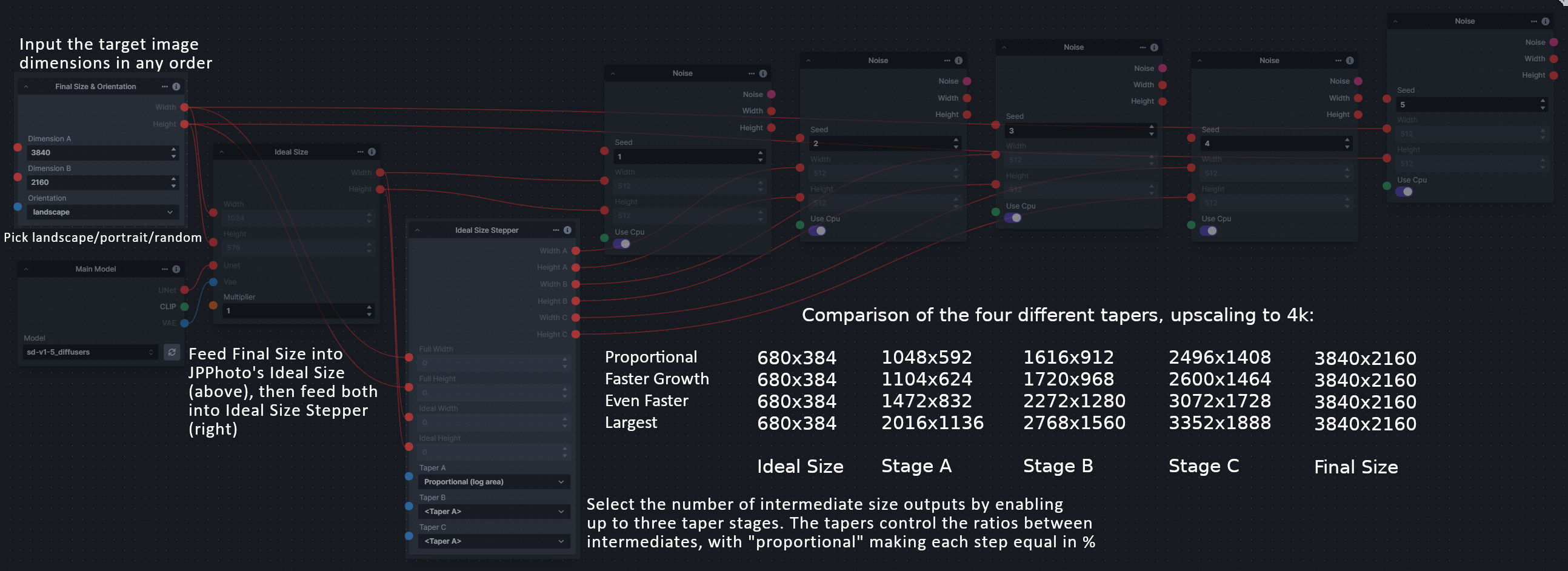
**Description:** This is a set of nodes for calculating the necessary size increments for doing upscaling workflows. Use the *Final Size & Orientation* node to enter your full size dimensions and orientation (portrait/landscape/random), then plug that and your initial generation dimensions into the *Ideal Size Stepper* and get 1, 2, or 3 intermediate pairs of dimensions for upscaling. Note this does not output the initial size or full size dimensions: the 1, 2, or 3 outputs of this node are only the intermediate sizes.
|
||||
|
||||
**Node Link:** https://github.com/mickr777/imagetoasciiimage
|
||||
A third node is included, *Random Switch (Integers)*, which is just a generic version of Final Size with no orientation selection.
|
||||
|
||||
**Node Link:** https://github.com/dwringer/size-stepper-nodes
|
||||
|
||||
**Example Usage:**
|
||||
|
||||
|
||||
--------------------------------
|
||||
|
||||
### Text font to Image
|
||||
|
||||
**Description:** text font to text image node for InvokeAI, download a font to use (or if in font cache uses it from there), the text is always resized to the image size, but can control that with padding, optional 2nd line
|
||||
|
||||
**Node Link:** https://github.com/mickr777/textfontimage
|
||||
|
||||
**Output Examples**
|
||||
|
||||
<img src="https://user-images.githubusercontent.com/115216705/271817646-8e061fcc-9a2c-4fa9-bcc7-c0f7b01e9056.png" width="300" /><img src="https://github.com/mickr777/imagetoasciiimage/assets/115216705/3c4990eb-2f42-46b9-90f9-0088b939dc6a" width="300" /></br>
|
||||
<img src="https://github.com/mickr777/imagetoasciiimage/assets/115216705/fee7f800-a4a8-41e2-a66b-c66e4343307e" width="300" />
|
||||
<img src="https://github.com/mickr777/imagetoasciiimage/assets/115216705/1d9c1003-a45f-45c2-aac7-46470bb89330" width="300" />
|
||||

|
||||
|
||||
Results after using the depth controlnet
|
||||
|
||||

|
||||

|
||||

|
||||
|
||||
--------------------------------
|
||||
|
||||
### Image Picker
|
||||
|
||||
**Description:** This InvokeAI node takes in a collection of images and randomly chooses one. This can be useful when you have a number of poses to choose from for a ControlNet node, or a number of input images for another purpose.
|
||||
|
||||
**Node Link:** https://github.com/JPPhoto/image-picker-node
|
||||
|
||||
--------------------------------
|
||||
### Load Video Frame
|
||||
|
||||
**Description:** This is a video frame image provider + indexer/video creation nodes for hooking up to iterators and ranges and ControlNets and such for invokeAI node experimentation. Think animation + ControlNet outputs.
|
||||
|
||||
**Node Link:** https://github.com/helix4u/load_video_frame
|
||||
|
||||
**Example Node Graph:** https://github.com/helix4u/load_video_frame/blob/main/Example_Workflow.json
|
||||
|
||||
**Output Example:**
|
||||
|
||||
<img src="https://github.com/helix4u/load_video_frame/blob/main/testmp4_embed_converted.gif" width="500" />
|
||||
[Full mp4 of Example Output test.mp4](https://github.com/helix4u/load_video_frame/blob/main/test.mp4)
|
||||
|
||||
--------------------------------
|
||||
### Make 3D
|
||||
|
||||
**Description:** Create compelling 3D stereo images from 2D originals.
|
||||
|
||||
**Node Link:** [https://gitlab.com/srcrr/shift3d/-/raw/main/make3d.py](https://gitlab.com/srcrr/shift3d)
|
||||
|
||||
**Example Node Graph:** https://gitlab.com/srcrr/shift3d/-/raw/main/example-workflow.json?ref_type=heads&inline=false
|
||||
|
||||
**Output Examples**
|
||||
|
||||
<img src="https://gitlab.com/srcrr/shift3d/-/raw/main/example-1.png" width="300" />
|
||||
<img src="https://gitlab.com/srcrr/shift3d/-/raw/main/example-2.png" width="300" />
|
||||
|
||||
--------------------------------
|
||||
### Oobabooga
|
||||
|
||||
**Description:** asks a local LLM running in Oobabooga's Text-Generation-Webui to write a prompt based on the user input.
|
||||
|
||||
**Link:** https://github.com/sammyf/oobabooga-node
|
||||
|
||||
**Example:**
|
||||
|
||||
"describe a new mystical creature in its natural environment"
|
||||
|
||||
*can return*
|
||||
|
||||
"The mystical creature I am describing to you is called the "Glimmerwing". It is a majestic, iridescent being that inhabits the depths of the most enchanted forests and glimmering lakes. Its body is covered in shimmering scales that reflect every color of the rainbow, and it has delicate, translucent wings that sparkle like diamonds in the sunlight. The Glimmerwing's home is a crystal-clear lake, surrounded by towering trees with leaves that shimmer like jewels. In this serene environment, the Glimmerwing spends its days swimming gracefully through the water, chasing schools of glittering fish and playing with the gentle ripples of the lake's surface.
|
||||
As the sun sets, the Glimmerwing perches on a branch of one of the trees, spreading its wings to catch the last rays of light. The creature's scales glow softly, casting a rainbow of colors across the forest floor. The Glimmerwing sings a haunting melody, its voice echoing through the stillness of the night air. Its song is said to have the power to heal the sick and bring peace to troubled souls. Those who are lucky enough to hear the Glimmerwing's song are forever changed by its beauty and grace."
|
||||
|
||||
<img src="https://github.com/sammyf/oobabooga-node/assets/42468608/cecdd820-93dd-4c35-abbf-607e001fb2ed" width="300" />
|
||||
|
||||
**Requirement**
|
||||
|
||||
a Text-Generation-Webui instance (might work remotely too, but I never tried it) and obviously InvokeAI 3.x
|
||||
|
||||
**Note**
|
||||
|
||||
This node works best with SDXL models, especially as the style can be described independently of the LLM's output.
|
||||
|
||||
--------------------------------
|
||||
### Prompt Tools
|
||||
|
||||
**Description:** A set of InvokeAI nodes that add general prompt manipulation tools. These were written to accompany the PromptsFromFile node and other prompt generation nodes.
|
||||
**Description:** A set of InvokeAI nodes that add general prompt manipulation tools. These where written to accompany the PromptsFromFile node and other prompt generation nodes.
|
||||
|
||||
1. PromptJoin - Joins to prompts into one.
|
||||
2. PromptReplace - performs a search and replace on a prompt. With the option of using regex.
|
||||
@@ -244,83 +249,51 @@ See full docs here: https://github.com/skunkworxdark/Prompt-tools-nodes/edit/mai
|
||||
**Node Link:** https://github.com/skunkworxdark/Prompt-tools-nodes
|
||||
|
||||
--------------------------------
|
||||
### Retroize
|
||||
|
||||
**Description:** Retroize is a collection of nodes for InvokeAI to "Retroize" images. Any image can be given a fresh coat of retro paint with these nodes, either from your gallery or from within the graph itself. It includes nodes to pixelize, quantize, palettize, and ditherize images; as well as to retrieve palettes from existing images.
|
||||
|
||||
**Node Link:** https://github.com/Ar7ific1al/invokeai-retroizeinode/
|
||||
|
||||
**Retroize Output Examples**
|
||||
|
||||
<img src="https://github.com/Ar7ific1al/InvokeAI_nodes_retroize/assets/2306586/de8b4fa6-324c-4c2d-b36c-297600c73974" width="500" />
|
||||
|
||||
--------------------------------
|
||||
### Size Stepper Nodes
|
||||
|
||||
**Description:** This is a set of nodes for calculating the necessary size increments for doing upscaling workflows. Use the *Final Size & Orientation* node to enter your full size dimensions and orientation (portrait/landscape/random), then plug that and your initial generation dimensions into the *Ideal Size Stepper* and get 1, 2, or 3 intermediate pairs of dimensions for upscaling. Note this does not output the initial size or full size dimensions: the 1, 2, or 3 outputs of this node are only the intermediate sizes.
|
||||
|
||||
A third node is included, *Random Switch (Integers)*, which is just a generic version of Final Size with no orientation selection.
|
||||
|
||||
**Node Link:** https://github.com/dwringer/size-stepper-nodes
|
||||
|
||||
**Example Usage:**
|
||||
</br><img src="https://raw.githubusercontent.com/dwringer/size-stepper-nodes/main/size_nodes_usage.jpg" width="500" />
|
||||
|
||||
--------------------------------
|
||||
### Text font to Image
|
||||
|
||||
**Description:** text font to text image node for InvokeAI, download a font to use (or if in font cache uses it from there), the text is always resized to the image size, but can control that with padding, optional 2nd line
|
||||
|
||||
**Node Link:** https://github.com/mickr777/textfontimage
|
||||
|
||||
**Output Examples**
|
||||
|
||||
<img src="https://github.com/mickr777/InvokeAI/assets/115216705/c21b0af3-d9c6-4c16-9152-846a23effd36" width="300" />
|
||||
|
||||
Results after using the depth controlnet
|
||||
|
||||
<img src="https://github.com/mickr777/InvokeAI/assets/115216705/915f1a53-968e-43eb-aa61-07cd8f1a733a" width="300" />
|
||||
<img src="https://github.com/mickr777/InvokeAI/assets/115216705/821ef89e-8a60-44f5-b94e-471a9d8690cc" width="300" />
|
||||
<img src="https://github.com/mickr777/InvokeAI/assets/115216705/2befcb6d-49f4-4bfd-b5fc-1fee19274f89" width="300" />
|
||||
|
||||
--------------------------------
|
||||
### Thresholding
|
||||
|
||||
**Description:** This node generates masks for highlights, midtones, and shadows given an input image. You can optionally specify a blur for the lookup table used in making those masks from the source image.
|
||||
|
||||
**Node Link:** https://github.com/JPPhoto/thresholding-node
|
||||
|
||||
**Examples**
|
||||
|
||||
Input:
|
||||
|
||||
<img src="https://github.com/invoke-ai/InvokeAI/assets/34005131/c88ada13-fb3d-484c-a4fe-947b44712632" width="300" />
|
||||
|
||||
Highlights/Midtones/Shadows:
|
||||
|
||||
<img src="https://github.com/invoke-ai/InvokeAI/assets/34005131/727021c1-36ff-4ec8-90c8-105e00de986d" width="300" />
|
||||
<img src="https://github.com/invoke-ai/InvokeAI/assets/34005131/0b721bfc-f051-404e-b905-2f16b824ddfe" width="300" />
|
||||
<img src="https://github.com/invoke-ai/InvokeAI/assets/34005131/04c1297f-1c88-42b6-a7df-dd090b976286" width="300" />
|
||||
|
||||
Highlights/Midtones/Shadows (with LUT blur enabled):
|
||||
|
||||
<img src="https://github.com/invoke-ai/InvokeAI/assets/34005131/19aa718a-70c1-4668-8169-d68f4bd13771" width="300" />
|
||||
<img src="https://github.com/invoke-ai/InvokeAI/assets/34005131/0a440e43-697f-4d17-82ee-f287467df0a5" width="300" />
|
||||
<img src="https://github.com/invoke-ai/InvokeAI/assets/34005131/0701fd0f-2ca7-4fe2-8613-2b52547bafce" width="300" />
|
||||
|
||||
--------------------------------
|
||||
### XY Image to Grid and Images to Grids nodes
|
||||
|
||||
**Description:** Image to grid nodes and supporting tools.
|
||||
|
||||
1. "Images To Grids" node - Takes a collection of images and creates a grid(s) of images. If there are more images than the size of a single grid then multiple grids will be created until it runs out of images.
|
||||
2. "XYImage To Grid" node - Converts a collection of XYImages into a labeled Grid of images. The XYImages collection has to be built using the supporting nodes. See example node setups for more details.
|
||||
1. "Images To Grids" node - Takes a collection of images and creates a grid(s) of images. If there are more images than the size of a single grid then mutilple grids will be created until it runs out of images.
|
||||
2. "XYImage To Grid" node - Converts a collection of XYImages into a labeled Grid of images. The XYImages collection has to be built using the supporoting nodes. See example node setups for more details.
|
||||
|
||||
|
||||
See full docs here: https://github.com/skunkworxdark/XYGrid_nodes/edit/main/README.md
|
||||
|
||||
**Node Link:** https://github.com/skunkworxdark/XYGrid_nodes
|
||||
|
||||
--------------------------------
|
||||
|
||||
### Image to Character Art Image Node's
|
||||
|
||||
**Description:** Group of nodes to convert an input image into ascii/unicode art Image
|
||||
|
||||
**Node Link:** https://github.com/mickr777/imagetoasciiimage
|
||||
|
||||
**Output Examples**
|
||||
|
||||
<img src="https://github.com/invoke-ai/InvokeAI/assets/115216705/8e061fcc-9a2c-4fa9-bcc7-c0f7b01e9056" width="300" />
|
||||
<img src="https://github.com/mickr777/imagetoasciiimage/assets/115216705/3c4990eb-2f42-46b9-90f9-0088b939dc6a" width="300" /></br>
|
||||
<img src="https://github.com/mickr777/imagetoasciiimage/assets/115216705/fee7f800-a4a8-41e2-a66b-c66e4343307e" width="300" />
|
||||
<img src="https://github.com/mickr777/imagetoasciiimage/assets/115216705/1d9c1003-a45f-45c2-aac7-46470bb89330" width="300" />
|
||||
|
||||
--------------------------------
|
||||
|
||||
### Grid to Gif
|
||||
|
||||
**Description:** One node that turns a grid image into an image colletion, one node that turns an image collection into a gif
|
||||
|
||||
**Node Link:** https://github.com/mildmisery/invokeai-GridToGifNode/blob/main/GridToGif.py
|
||||
|
||||
**Example Node Graph:** https://github.com/mildmisery/invokeai-GridToGifNode/blob/main/Grid%20to%20Gif%20Example%20Workflow.json
|
||||
|
||||
**Output Examples**
|
||||
|
||||
<img src="https://raw.githubusercontent.com/mildmisery/invokeai-GridToGifNode/main/input.png" width="300" />
|
||||
<img src="https://raw.githubusercontent.com/mildmisery/invokeai-GridToGifNode/main/output.gif" width="300" />
|
||||
|
||||
--------------------------------
|
||||
|
||||
### Example Node Template
|
||||
|
||||
**Description:** This node allows you to do super cool things with InvokeAI.
|
||||
@@ -331,7 +304,7 @@ See full docs here: https://github.com/skunkworxdark/XYGrid_nodes/edit/main/READ
|
||||
|
||||
**Output Examples**
|
||||
|
||||
</br><img src="https://invoke-ai.github.io/InvokeAI/assets/invoke_ai_banner.png" width="500" />
|
||||
{: style="height:115px;width:240px"}
|
||||
|
||||
|
||||
## Disclaimer
|
||||
|
||||
@@ -46,9 +46,6 @@ if [ "$(uname -s)" == "Darwin" ]; then
|
||||
export PYTORCH_ENABLE_MPS_FALLBACK=1
|
||||
fi
|
||||
|
||||
# Avoid glibc memory fragmentation. See invokeai/backend/model_management/README.md for details.
|
||||
export MALLOC_MMAP_THRESHOLD_=1048576
|
||||
|
||||
# Primary function for the case statement to determine user input
|
||||
do_choice() {
|
||||
case $1 in
|
||||
|
||||
@@ -322,20 +322,3 @@ async def unstar_images_in_list(
|
||||
return ImagesUpdatedFromListResult(updated_image_names=updated_image_names)
|
||||
except Exception:
|
||||
raise HTTPException(status_code=500, detail="Failed to unstar images")
|
||||
|
||||
|
||||
class ImagesDownloaded(BaseModel):
|
||||
response: Optional[str] = Field(
|
||||
description="If defined, the message to display to the user when images begin downloading"
|
||||
)
|
||||
|
||||
|
||||
@images_router.post("/download", operation_id="download_images_from_list", response_model=ImagesDownloaded)
|
||||
async def download_images_from_list(
|
||||
image_names: list[str] = Body(description="The list of names of images to download", embed=True),
|
||||
board_id: Optional[str] = Body(
|
||||
default=None, description="The board from which image should be downloaded from", embed=True
|
||||
),
|
||||
) -> ImagesDownloaded:
|
||||
# return ImagesDownloaded(response="Your images are downloading")
|
||||
raise HTTPException(status_code=501, detail="Endpoint is not yet implemented")
|
||||
|
||||
@@ -30,8 +30,8 @@ class SocketIO:
|
||||
|
||||
async def _handle_sub_queue(self, sid, data, *args, **kwargs):
|
||||
if "queue_id" in data:
|
||||
await self.__sio.enter_room(sid, data["queue_id"])
|
||||
self.__sio.enter_room(sid, data["queue_id"])
|
||||
|
||||
async def _handle_unsub_queue(self, sid, data, *args, **kwargs):
|
||||
if "queue_id" in data:
|
||||
await self.__sio.enter_room(sid, data["queue_id"])
|
||||
self.__sio.enter_room(sid, data["queue_id"])
|
||||
|
||||
@@ -68,7 +68,6 @@ class FieldDescriptions:
|
||||
height = "Height of output (px)"
|
||||
control = "ControlNet(s) to apply"
|
||||
ip_adapter = "IP-Adapter to apply"
|
||||
t2i_adapter = "T2I-Adapter(s) to apply"
|
||||
denoised_latents = "Denoised latents tensor"
|
||||
latents = "Latents tensor"
|
||||
strength = "Strength of denoising (proportional to steps)"
|
||||
|
||||
@@ -46,8 +46,6 @@ class FaceResultData(TypedDict):
|
||||
y_center: float
|
||||
mesh_width: int
|
||||
mesh_height: int
|
||||
chunk_x_offset: int
|
||||
chunk_y_offset: int
|
||||
|
||||
|
||||
class FaceResultDataWithId(FaceResultData):
|
||||
@@ -80,48 +78,6 @@ FONT_SIZE = 32
|
||||
FONT_STROKE_WIDTH = 4
|
||||
|
||||
|
||||
def coalesce_faces(face1: FaceResultData, face2: FaceResultData) -> FaceResultData:
|
||||
face1_x_offset = face1["chunk_x_offset"] - min(face1["chunk_x_offset"], face2["chunk_x_offset"])
|
||||
face2_x_offset = face2["chunk_x_offset"] - min(face1["chunk_x_offset"], face2["chunk_x_offset"])
|
||||
face1_y_offset = face1["chunk_y_offset"] - min(face1["chunk_y_offset"], face2["chunk_y_offset"])
|
||||
face2_y_offset = face2["chunk_y_offset"] - min(face1["chunk_y_offset"], face2["chunk_y_offset"])
|
||||
|
||||
new_im_width = (
|
||||
max(face1["image"].width, face2["image"].width)
|
||||
+ max(face1["chunk_x_offset"], face2["chunk_x_offset"])
|
||||
- min(face1["chunk_x_offset"], face2["chunk_x_offset"])
|
||||
)
|
||||
new_im_height = (
|
||||
max(face1["image"].height, face2["image"].height)
|
||||
+ max(face1["chunk_y_offset"], face2["chunk_y_offset"])
|
||||
- min(face1["chunk_y_offset"], face2["chunk_y_offset"])
|
||||
)
|
||||
pil_image = Image.new(mode=face1["image"].mode, size=(new_im_width, new_im_height))
|
||||
pil_image.paste(face1["image"], (face1_x_offset, face1_y_offset))
|
||||
pil_image.paste(face2["image"], (face2_x_offset, face2_y_offset))
|
||||
|
||||
# Mask images are always from the origin
|
||||
new_mask_im_width = max(face1["mask"].width, face2["mask"].width)
|
||||
new_mask_im_height = max(face1["mask"].height, face2["mask"].height)
|
||||
mask_pil = create_white_image(new_mask_im_width, new_mask_im_height)
|
||||
black_image = create_black_image(face1["mask"].width, face1["mask"].height)
|
||||
mask_pil.paste(black_image, (0, 0), ImageOps.invert(face1["mask"]))
|
||||
black_image = create_black_image(face2["mask"].width, face2["mask"].height)
|
||||
mask_pil.paste(black_image, (0, 0), ImageOps.invert(face2["mask"]))
|
||||
|
||||
new_face = FaceResultData(
|
||||
image=pil_image,
|
||||
mask=mask_pil,
|
||||
x_center=max(face1["x_center"], face2["x_center"]),
|
||||
y_center=max(face1["y_center"], face2["y_center"]),
|
||||
mesh_width=max(face1["mesh_width"], face2["mesh_width"]),
|
||||
mesh_height=max(face1["mesh_height"], face2["mesh_height"]),
|
||||
chunk_x_offset=max(face1["chunk_x_offset"], face2["chunk_x_offset"]),
|
||||
chunk_y_offset=max(face2["chunk_y_offset"], face2["chunk_y_offset"]),
|
||||
)
|
||||
return new_face
|
||||
|
||||
|
||||
def prepare_faces_list(
|
||||
face_result_list: list[FaceResultData],
|
||||
) -> list[FaceResultDataWithId]:
|
||||
@@ -135,7 +91,7 @@ def prepare_faces_list(
|
||||
should_add = True
|
||||
candidate_x_center = candidate["x_center"]
|
||||
candidate_y_center = candidate["y_center"]
|
||||
for idx, face in enumerate(deduped_faces):
|
||||
for face in deduped_faces:
|
||||
face_center_x = face["x_center"]
|
||||
face_center_y = face["y_center"]
|
||||
face_radius_w = face["mesh_width"] / 2
|
||||
@@ -149,7 +105,6 @@ def prepare_faces_list(
|
||||
)
|
||||
|
||||
if p < 1: # Inside of the already-added face's radius
|
||||
deduped_faces[idx] = coalesce_faces(face, candidate)
|
||||
should_add = False
|
||||
break
|
||||
|
||||
@@ -183,6 +138,7 @@ def generate_face_box_mask(
|
||||
chunk_x_offset: int = 0,
|
||||
chunk_y_offset: int = 0,
|
||||
draw_mesh: bool = True,
|
||||
check_bounds: bool = True,
|
||||
) -> list[FaceResultData]:
|
||||
result = []
|
||||
mask_pil = None
|
||||
@@ -255,20 +211,33 @@ def generate_face_box_mask(
|
||||
mask_pil = create_white_image(w + chunk_x_offset, h + chunk_y_offset)
|
||||
mask_pil.paste(init_mask_pil, (chunk_x_offset, chunk_y_offset))
|
||||
|
||||
x_center = float(x_center)
|
||||
y_center = float(y_center)
|
||||
face = FaceResultData(
|
||||
image=pil_image,
|
||||
mask=mask_pil or create_white_image(*pil_image.size),
|
||||
x_center=x_center + chunk_x_offset,
|
||||
y_center=y_center + chunk_y_offset,
|
||||
mesh_width=mesh_width,
|
||||
mesh_height=mesh_height,
|
||||
chunk_x_offset=chunk_x_offset,
|
||||
chunk_y_offset=chunk_y_offset,
|
||||
)
|
||||
left_side = x_center - mesh_width
|
||||
right_side = x_center + mesh_width
|
||||
top_side = y_center - mesh_height
|
||||
bottom_side = y_center + mesh_height
|
||||
im_width, im_height = pil_image.size
|
||||
over_w = im_width * 0.1
|
||||
over_h = im_height * 0.1
|
||||
if not check_bounds or (
|
||||
(left_side >= -over_w)
|
||||
and (right_side < im_width + over_w)
|
||||
and (top_side >= -over_h)
|
||||
and (bottom_side < im_height + over_h)
|
||||
):
|
||||
x_center = float(x_center)
|
||||
y_center = float(y_center)
|
||||
face = FaceResultData(
|
||||
image=pil_image,
|
||||
mask=mask_pil or create_white_image(*pil_image.size),
|
||||
x_center=x_center + chunk_x_offset,
|
||||
y_center=y_center + chunk_y_offset,
|
||||
mesh_width=mesh_width,
|
||||
mesh_height=mesh_height,
|
||||
)
|
||||
|
||||
result.append(face)
|
||||
result.append(face)
|
||||
else:
|
||||
context.services.logger.info("FaceTools --> Face out of bounds, ignoring.")
|
||||
|
||||
return result
|
||||
|
||||
@@ -377,6 +346,7 @@ def get_faces_list(
|
||||
chunk_x_offset=0,
|
||||
chunk_y_offset=0,
|
||||
draw_mesh=draw_mesh,
|
||||
check_bounds=False,
|
||||
)
|
||||
if should_chunk or len(result) == 0:
|
||||
context.services.logger.info("FaceTools --> Chunking image (chunk toggled on, or no face found in full image).")
|
||||
@@ -390,26 +360,24 @@ def get_faces_list(
|
||||
if width > height:
|
||||
# Landscape - slice the image horizontally
|
||||
fx = 0.0
|
||||
steps = int(width * 2 / height) + 1
|
||||
increment = (width - height) / (steps - 1)
|
||||
steps = int(width * 2 / height)
|
||||
while fx <= (width - height):
|
||||
x = int(fx)
|
||||
image_chunks.append(image.crop((x, 0, x + height, height)))
|
||||
image_chunks.append(image.crop((x, 0, x + height - 1, height - 1)))
|
||||
x_offsets.append(x)
|
||||
y_offsets.append(0)
|
||||
fx += increment
|
||||
fx += (width - height) / steps
|
||||
context.services.logger.info(f"FaceTools --> Chunk starting at x = {x}")
|
||||
elif height > width:
|
||||
# Portrait - slice the image vertically
|
||||
fy = 0.0
|
||||
steps = int(height * 2 / width) + 1
|
||||
increment = (height - width) / (steps - 1)
|
||||
steps = int(height * 2 / width)
|
||||
while fy <= (height - width):
|
||||
y = int(fy)
|
||||
image_chunks.append(image.crop((0, y, width, y + width)))
|
||||
image_chunks.append(image.crop((0, y, width - 1, y + width - 1)))
|
||||
x_offsets.append(0)
|
||||
y_offsets.append(y)
|
||||
fy += increment
|
||||
fy += (height - width) / steps
|
||||
context.services.logger.info(f"FaceTools --> Chunk starting at y = {y}")
|
||||
|
||||
for idx in range(len(image_chunks)):
|
||||
@@ -436,7 +404,7 @@ def get_faces_list(
|
||||
return all_faces
|
||||
|
||||
|
||||
@invocation("face_off", title="FaceOff", tags=["image", "faceoff", "face", "mask"], category="image", version="1.0.2")
|
||||
@invocation("face_off", title="FaceOff", tags=["image", "faceoff", "face", "mask"], category="image", version="1.0.1")
|
||||
class FaceOffInvocation(BaseInvocation):
|
||||
"""Bound, extract, and mask a face from an image using MediaPipe detection"""
|
||||
|
||||
@@ -530,7 +498,7 @@ class FaceOffInvocation(BaseInvocation):
|
||||
return output
|
||||
|
||||
|
||||
@invocation("face_mask_detection", title="FaceMask", tags=["image", "face", "mask"], category="image", version="1.0.2")
|
||||
@invocation("face_mask_detection", title="FaceMask", tags=["image", "face", "mask"], category="image", version="1.0.1")
|
||||
class FaceMaskInvocation(BaseInvocation):
|
||||
"""Face mask creation using mediapipe face detection"""
|
||||
|
||||
@@ -648,7 +616,7 @@ class FaceMaskInvocation(BaseInvocation):
|
||||
|
||||
|
||||
@invocation(
|
||||
"face_identifier", title="FaceIdentifier", tags=["image", "face", "identifier"], category="image", version="1.0.2"
|
||||
"face_identifier", title="FaceIdentifier", tags=["image", "face", "identifier"], category="image", version="1.0.1"
|
||||
)
|
||||
class FaceIdentifierInvocation(BaseInvocation):
|
||||
"""Outputs an image with detected face IDs printed on each face. For use with other FaceTools."""
|
||||
|
||||
@@ -10,7 +10,7 @@ import torch
|
||||
import torchvision.transforms as T
|
||||
from diffusers import AutoencoderKL, AutoencoderTiny
|
||||
from diffusers.image_processor import VaeImageProcessor
|
||||
from diffusers.models.adapter import FullAdapterXL, T2IAdapter
|
||||
from diffusers.models import UNet2DConditionModel
|
||||
from diffusers.models.attention_processor import (
|
||||
AttnProcessor2_0,
|
||||
LoRAAttnProcessor2_0,
|
||||
@@ -33,7 +33,6 @@ from invokeai.app.invocations.primitives import (
|
||||
LatentsOutput,
|
||||
build_latents_output,
|
||||
)
|
||||
from invokeai.app.invocations.t2i_adapter import T2IAdapterField
|
||||
from invokeai.app.util.controlnet_utils import prepare_control_image
|
||||
from invokeai.app.util.step_callback import stable_diffusion_step_callback
|
||||
from invokeai.backend.ip_adapter.ip_adapter import IPAdapter, IPAdapterPlus
|
||||
@@ -48,7 +47,6 @@ from ...backend.stable_diffusion.diffusers_pipeline import (
|
||||
ControlNetData,
|
||||
IPAdapterData,
|
||||
StableDiffusionGeneratorPipeline,
|
||||
T2IAdapterData,
|
||||
image_resized_to_grid_as_tensor,
|
||||
)
|
||||
from ...backend.stable_diffusion.diffusion.shared_invokeai_diffusion import PostprocessingSettings
|
||||
@@ -198,7 +196,7 @@ def get_scheduler(
|
||||
title="Denoise Latents",
|
||||
tags=["latents", "denoise", "txt2img", "t2i", "t2l", "img2img", "i2i", "l2l"],
|
||||
category="latents",
|
||||
version="1.3.0",
|
||||
version="1.1.0",
|
||||
)
|
||||
class DenoiseLatentsInvocation(BaseInvocation):
|
||||
"""Denoises noisy latents to decodable images"""
|
||||
@@ -225,15 +223,12 @@ class DenoiseLatentsInvocation(BaseInvocation):
|
||||
input=Input.Connection,
|
||||
ui_order=5,
|
||||
)
|
||||
ip_adapter: Optional[Union[IPAdapterField, list[IPAdapterField]]] = InputField(
|
||||
ip_adapter: Optional[IPAdapterField] = InputField(
|
||||
description=FieldDescriptions.ip_adapter, title="IP-Adapter", default=None, input=Input.Connection, ui_order=6
|
||||
)
|
||||
t2i_adapter: Union[T2IAdapterField, list[T2IAdapterField]] = InputField(
|
||||
description=FieldDescriptions.t2i_adapter, title="T2I-Adapter", default=None, input=Input.Connection, ui_order=7
|
||||
)
|
||||
latents: Optional[LatentsField] = InputField(description=FieldDescriptions.latents, input=Input.Connection)
|
||||
denoise_mask: Optional[DenoiseMaskField] = InputField(
|
||||
default=None, description=FieldDescriptions.mask, input=Input.Connection, ui_order=8
|
||||
default=None, description=FieldDescriptions.mask, input=Input.Connection, ui_order=7
|
||||
)
|
||||
|
||||
@validator("cfg_scale")
|
||||
@@ -409,150 +404,52 @@ class DenoiseLatentsInvocation(BaseInvocation):
|
||||
def prep_ip_adapter_data(
|
||||
self,
|
||||
context: InvocationContext,
|
||||
ip_adapter: Optional[Union[IPAdapterField, list[IPAdapterField]]],
|
||||
ip_adapter: Optional[IPAdapterField],
|
||||
conditioning_data: ConditioningData,
|
||||
unet: UNet2DConditionModel,
|
||||
exit_stack: ExitStack,
|
||||
) -> Optional[list[IPAdapterData]]:
|
||||
) -> Optional[IPAdapterData]:
|
||||
"""If IP-Adapter is enabled, then this function loads the requisite models, and adds the image prompt embeddings
|
||||
to the `conditioning_data` (in-place).
|
||||
"""
|
||||
if ip_adapter is None:
|
||||
return None
|
||||
|
||||
# ip_adapter could be a list or a single IPAdapterField. Normalize to a list here.
|
||||
if not isinstance(ip_adapter, list):
|
||||
ip_adapter = [ip_adapter]
|
||||
image_encoder_model_info = context.services.model_manager.get_model(
|
||||
model_name=ip_adapter.image_encoder_model.model_name,
|
||||
model_type=ModelType.CLIPVision,
|
||||
base_model=ip_adapter.image_encoder_model.base_model,
|
||||
context=context,
|
||||
)
|
||||
|
||||
if len(ip_adapter) == 0:
|
||||
return None
|
||||
|
||||
ip_adapter_data_list = []
|
||||
conditioning_data.ip_adapter_conditioning = []
|
||||
for single_ip_adapter in ip_adapter:
|
||||
ip_adapter_model: Union[IPAdapter, IPAdapterPlus] = exit_stack.enter_context(
|
||||
context.services.model_manager.get_model(
|
||||
model_name=single_ip_adapter.ip_adapter_model.model_name,
|
||||
model_type=ModelType.IPAdapter,
|
||||
base_model=single_ip_adapter.ip_adapter_model.base_model,
|
||||
context=context,
|
||||
)
|
||||
)
|
||||
|
||||
image_encoder_model_info = context.services.model_manager.get_model(
|
||||
model_name=single_ip_adapter.image_encoder_model.model_name,
|
||||
model_type=ModelType.CLIPVision,
|
||||
base_model=single_ip_adapter.image_encoder_model.base_model,
|
||||
ip_adapter_model: Union[IPAdapter, IPAdapterPlus] = exit_stack.enter_context(
|
||||
context.services.model_manager.get_model(
|
||||
model_name=ip_adapter.ip_adapter_model.model_name,
|
||||
model_type=ModelType.IPAdapter,
|
||||
base_model=ip_adapter.ip_adapter_model.base_model,
|
||||
context=context,
|
||||
)
|
||||
)
|
||||
|
||||
input_image = context.services.images.get_pil_image(single_ip_adapter.image.image_name)
|
||||
input_image = context.services.images.get_pil_image(ip_adapter.image.image_name)
|
||||
|
||||
# TODO(ryand): With some effort, the step of running the CLIP Vision encoder could be done before any other
|
||||
# models are needed in memory. This would help to reduce peak memory utilization in low-memory environments.
|
||||
with image_encoder_model_info as image_encoder_model:
|
||||
# Get image embeddings from CLIP and ImageProjModel.
|
||||
image_prompt_embeds, uncond_image_prompt_embeds = ip_adapter_model.get_image_embeds(
|
||||
input_image, image_encoder_model
|
||||
)
|
||||
conditioning_data.ip_adapter_conditioning.append(
|
||||
IPAdapterConditioningInfo(image_prompt_embeds, uncond_image_prompt_embeds)
|
||||
)
|
||||
|
||||
ip_adapter_data_list.append(
|
||||
IPAdapterData(
|
||||
ip_adapter_model=ip_adapter_model,
|
||||
weight=single_ip_adapter.weight,
|
||||
begin_step_percent=single_ip_adapter.begin_step_percent,
|
||||
end_step_percent=single_ip_adapter.end_step_percent,
|
||||
)
|
||||
# TODO(ryand): With some effort, the step of running the CLIP Vision encoder could be done before any other
|
||||
# models are needed in memory. This would help to reduce peak memory utilization in low-memory environments.
|
||||
with image_encoder_model_info as image_encoder_model:
|
||||
# Get image embeddings from CLIP and ImageProjModel.
|
||||
image_prompt_embeds, uncond_image_prompt_embeds = ip_adapter_model.get_image_embeds(
|
||||
input_image, image_encoder_model
|
||||
)
|
||||
conditioning_data.ip_adapter_conditioning = IPAdapterConditioningInfo(
|
||||
image_prompt_embeds, uncond_image_prompt_embeds
|
||||
)
|
||||
|
||||
return ip_adapter_data_list
|
||||
|
||||
def run_t2i_adapters(
|
||||
self,
|
||||
context: InvocationContext,
|
||||
t2i_adapter: Optional[Union[T2IAdapterField, list[T2IAdapterField]]],
|
||||
latents_shape: list[int],
|
||||
do_classifier_free_guidance: bool,
|
||||
) -> Optional[list[T2IAdapterData]]:
|
||||
if t2i_adapter is None:
|
||||
return None
|
||||
|
||||
# Handle the possibility that t2i_adapter could be a list or a single T2IAdapterField.
|
||||
if isinstance(t2i_adapter, T2IAdapterField):
|
||||
t2i_adapter = [t2i_adapter]
|
||||
|
||||
if len(t2i_adapter) == 0:
|
||||
return None
|
||||
|
||||
t2i_adapter_data = []
|
||||
for t2i_adapter_field in t2i_adapter:
|
||||
t2i_adapter_model_info = context.services.model_manager.get_model(
|
||||
model_name=t2i_adapter_field.t2i_adapter_model.model_name,
|
||||
model_type=ModelType.T2IAdapter,
|
||||
base_model=t2i_adapter_field.t2i_adapter_model.base_model,
|
||||
context=context,
|
||||
)
|
||||
image = context.services.images.get_pil_image(t2i_adapter_field.image.image_name)
|
||||
|
||||
# The max_unet_downscale is the maximum amount that the UNet model downscales the latent image internally.
|
||||
if t2i_adapter_field.t2i_adapter_model.base_model == BaseModelType.StableDiffusion1:
|
||||
max_unet_downscale = 8
|
||||
elif t2i_adapter_field.t2i_adapter_model.base_model == BaseModelType.StableDiffusionXL:
|
||||
max_unet_downscale = 4
|
||||
else:
|
||||
raise ValueError(
|
||||
f"Unexpected T2I-Adapter base model type: '{t2i_adapter_field.t2i_adapter_model.base_model}'."
|
||||
)
|
||||
|
||||
t2i_adapter_model: T2IAdapter
|
||||
with t2i_adapter_model_info as t2i_adapter_model:
|
||||
total_downscale_factor = t2i_adapter_model.total_downscale_factor
|
||||
if isinstance(t2i_adapter_model.adapter, FullAdapterXL):
|
||||
# HACK(ryand): Work around a bug in FullAdapterXL. This is being addressed upstream in diffusers by
|
||||
# this PR: https://github.com/huggingface/diffusers/pull/5134.
|
||||
total_downscale_factor = total_downscale_factor // 2
|
||||
|
||||
# Resize the T2I-Adapter input image.
|
||||
# We select the resize dimensions so that after the T2I-Adapter's total_downscale_factor is applied, the
|
||||
# result will match the latent image's dimensions after max_unet_downscale is applied.
|
||||
t2i_input_height = latents_shape[2] // max_unet_downscale * total_downscale_factor
|
||||
t2i_input_width = latents_shape[3] // max_unet_downscale * total_downscale_factor
|
||||
|
||||
# Note: We have hard-coded `do_classifier_free_guidance=False`. This is because we only want to prepare
|
||||
# a single image. If CFG is enabled, we will duplicate the resultant tensor after applying the
|
||||
# T2I-Adapter model.
|
||||
#
|
||||
# Note: We re-use the `prepare_control_image(...)` from ControlNet for T2I-Adapter, because it has many
|
||||
# of the same requirements (e.g. preserving binary masks during resize).
|
||||
t2i_image = prepare_control_image(
|
||||
image=image,
|
||||
do_classifier_free_guidance=False,
|
||||
width=t2i_input_width,
|
||||
height=t2i_input_height,
|
||||
num_channels=t2i_adapter_model.config.in_channels,
|
||||
device=t2i_adapter_model.device,
|
||||
dtype=t2i_adapter_model.dtype,
|
||||
resize_mode=t2i_adapter_field.resize_mode,
|
||||
)
|
||||
|
||||
adapter_state = t2i_adapter_model(t2i_image)
|
||||
|
||||
if do_classifier_free_guidance:
|
||||
for idx, value in enumerate(adapter_state):
|
||||
adapter_state[idx] = torch.cat([value] * 2, dim=0)
|
||||
|
||||
t2i_adapter_data.append(
|
||||
T2IAdapterData(
|
||||
adapter_state=adapter_state,
|
||||
weight=t2i_adapter_field.weight,
|
||||
begin_step_percent=t2i_adapter_field.begin_step_percent,
|
||||
end_step_percent=t2i_adapter_field.end_step_percent,
|
||||
)
|
||||
)
|
||||
|
||||
return t2i_adapter_data
|
||||
return IPAdapterData(
|
||||
ip_adapter_model=ip_adapter_model,
|
||||
weight=ip_adapter.weight,
|
||||
begin_step_percent=ip_adapter.begin_step_percent,
|
||||
end_step_percent=ip_adapter.end_step_percent,
|
||||
)
|
||||
|
||||
# original idea by https://github.com/AmericanPresidentJimmyCarter
|
||||
# TODO: research more for second order schedulers timesteps
|
||||
@@ -625,12 +522,6 @@ class DenoiseLatentsInvocation(BaseInvocation):
|
||||
|
||||
mask, masked_latents = self.prep_inpaint_mask(context, latents)
|
||||
|
||||
# TODO(ryand): I have hard-coded `do_classifier_free_guidance=True` to mirror the behaviour of ControlNets,
|
||||
# below. Investigate whether this is appropriate.
|
||||
t2i_adapter_data = self.run_t2i_adapters(
|
||||
context, self.t2i_adapter, latents.shape, do_classifier_free_guidance=True
|
||||
)
|
||||
|
||||
# Get the source node id (we are invoking the prepared node)
|
||||
graph_execution_state = context.services.graph_execution_manager.get(context.graph_execution_state_id)
|
||||
source_node_id = graph_execution_state.prepared_source_mapping[self.id]
|
||||
@@ -689,6 +580,7 @@ class DenoiseLatentsInvocation(BaseInvocation):
|
||||
context=context,
|
||||
ip_adapter=self.ip_adapter,
|
||||
conditioning_data=conditioning_data,
|
||||
unet=unet,
|
||||
exit_stack=exit_stack,
|
||||
)
|
||||
|
||||
@@ -710,9 +602,8 @@ class DenoiseLatentsInvocation(BaseInvocation):
|
||||
masked_latents=masked_latents,
|
||||
num_inference_steps=num_inference_steps,
|
||||
conditioning_data=conditioning_data,
|
||||
control_data=controlnet_data,
|
||||
ip_adapter_data=ip_adapter_data,
|
||||
t2i_adapter_data=t2i_adapter_data,
|
||||
control_data=controlnet_data, # list[ControlNetData],
|
||||
ip_adapter_data=ip_adapter_data, # IPAdapterData,
|
||||
callback=step_callback,
|
||||
)
|
||||
|
||||
|
||||
@@ -15,7 +15,6 @@ from invokeai.app.invocations.controlnet_image_processors import ControlField
|
||||
from invokeai.app.invocations.ip_adapter import IPAdapterModelField
|
||||
from invokeai.app.invocations.model import LoRAModelField, MainModelField, VAEModelField
|
||||
from invokeai.app.invocations.primitives import ImageField
|
||||
from invokeai.app.invocations.t2i_adapter import T2IAdapterField
|
||||
from invokeai.app.util.model_exclude_null import BaseModelExcludeNull
|
||||
|
||||
from ...version import __version__
|
||||
@@ -44,31 +43,27 @@ class CoreMetadata(BaseModelExcludeNull):
|
||||
"""Core generation metadata for an image generated in InvokeAI."""
|
||||
|
||||
app_version: str = Field(default=__version__, description="The version of InvokeAI used to generate this image")
|
||||
generation_mode: Optional[str] = Field(
|
||||
default=None,
|
||||
generation_mode: str = Field(
|
||||
description="The generation mode that output this image",
|
||||
)
|
||||
created_by: Optional[str] = Field(description="The name of the creator of the image")
|
||||
positive_prompt: Optional[str] = Field(default=None, description="The positive prompt parameter")
|
||||
negative_prompt: Optional[str] = Field(default=None, description="The negative prompt parameter")
|
||||
width: Optional[int] = Field(default=None, description="The width parameter")
|
||||
height: Optional[int] = Field(default=None, description="The height parameter")
|
||||
seed: Optional[int] = Field(default=None, description="The seed used for noise generation")
|
||||
rand_device: Optional[str] = Field(default=None, description="The device used for random number generation")
|
||||
cfg_scale: Optional[float] = Field(default=None, description="The classifier-free guidance scale parameter")
|
||||
steps: Optional[int] = Field(default=None, description="The number of steps used for inference")
|
||||
scheduler: Optional[str] = Field(default=None, description="The scheduler used for inference")
|
||||
positive_prompt: str = Field(description="The positive prompt parameter")
|
||||
negative_prompt: str = Field(description="The negative prompt parameter")
|
||||
width: int = Field(description="The width parameter")
|
||||
height: int = Field(description="The height parameter")
|
||||
seed: int = Field(description="The seed used for noise generation")
|
||||
rand_device: str = Field(description="The device used for random number generation")
|
||||
cfg_scale: float = Field(description="The classifier-free guidance scale parameter")
|
||||
steps: int = Field(description="The number of steps used for inference")
|
||||
scheduler: str = Field(description="The scheduler used for inference")
|
||||
clip_skip: Optional[int] = Field(
|
||||
default=None,
|
||||
description="The number of skipped CLIP layers",
|
||||
)
|
||||
model: Optional[MainModelField] = Field(default=None, description="The main model used for inference")
|
||||
controlnets: Optional[list[ControlField]] = Field(default=None, description="The ControlNets used for inference")
|
||||
ipAdapters: Optional[list[IPAdapterMetadataField]] = Field(
|
||||
default=None, description="The IP Adapters used for inference"
|
||||
)
|
||||
t2iAdapters: Optional[list[T2IAdapterField]] = Field(default=None, description="The IP Adapters used for inference")
|
||||
loras: Optional[list[LoRAMetadataField]] = Field(default=None, description="The LoRAs used for inference")
|
||||
model: MainModelField = Field(description="The main model used for inference")
|
||||
controlnets: list[ControlField] = Field(description="The ControlNets used for inference")
|
||||
ipAdapters: list[IPAdapterMetadataField] = Field(description="The IP Adapters used for inference")
|
||||
loras: list[LoRAMetadataField] = Field(description="The LoRAs used for inference")
|
||||
vae: Optional[VAEModelField] = Field(
|
||||
default=None,
|
||||
description="The VAE used for decoding, if the main model's default was not used",
|
||||
@@ -125,34 +120,26 @@ class MetadataAccumulatorOutput(BaseInvocationOutput):
|
||||
class MetadataAccumulatorInvocation(BaseInvocation):
|
||||
"""Outputs a Core Metadata Object"""
|
||||
|
||||
generation_mode: Optional[str] = InputField(
|
||||
default=None,
|
||||
generation_mode: str = InputField(
|
||||
description="The generation mode that output this image",
|
||||
)
|
||||
positive_prompt: Optional[str] = InputField(default=None, description="The positive prompt parameter")
|
||||
negative_prompt: Optional[str] = InputField(default=None, description="The negative prompt parameter")
|
||||
width: Optional[int] = InputField(default=None, description="The width parameter")
|
||||
height: Optional[int] = InputField(default=None, description="The height parameter")
|
||||
seed: Optional[int] = InputField(default=None, description="The seed used for noise generation")
|
||||
rand_device: Optional[str] = InputField(default=None, description="The device used for random number generation")
|
||||
cfg_scale: Optional[float] = InputField(default=None, description="The classifier-free guidance scale parameter")
|
||||
steps: Optional[int] = InputField(default=None, description="The number of steps used for inference")
|
||||
scheduler: Optional[str] = InputField(default=None, description="The scheduler used for inference")
|
||||
clip_skip: Optional[int] = InputField(
|
||||
positive_prompt: str = InputField(description="The positive prompt parameter")
|
||||
negative_prompt: str = InputField(description="The negative prompt parameter")
|
||||
width: int = InputField(description="The width parameter")
|
||||
height: int = InputField(description="The height parameter")
|
||||
seed: int = InputField(description="The seed used for noise generation")
|
||||
rand_device: str = InputField(description="The device used for random number generation")
|
||||
cfg_scale: float = InputField(description="The classifier-free guidance scale parameter")
|
||||
steps: int = InputField(description="The number of steps used for inference")
|
||||
scheduler: str = InputField(description="The scheduler used for inference")
|
||||
clip_skip: Optional[int] = Field(
|
||||
default=None,
|
||||
description="The number of skipped CLIP layers",
|
||||
)
|
||||
model: Optional[MainModelField] = InputField(default=None, description="The main model used for inference")
|
||||
controlnets: Optional[list[ControlField]] = InputField(
|
||||
default=None, description="The ControlNets used for inference"
|
||||
)
|
||||
ipAdapters: Optional[list[IPAdapterMetadataField]] = InputField(
|
||||
default=None, description="The IP Adapters used for inference"
|
||||
)
|
||||
t2iAdapters: Optional[list[T2IAdapterField]] = InputField(
|
||||
default=None, description="The IP Adapters used for inference"
|
||||
)
|
||||
loras: Optional[list[LoRAMetadataField]] = InputField(default=None, description="The LoRAs used for inference")
|
||||
model: MainModelField = InputField(description="The main model used for inference")
|
||||
controlnets: list[ControlField] = InputField(description="The ControlNets used for inference")
|
||||
ipAdapters: list[IPAdapterMetadataField] = InputField(description="The IP Adapters used for inference")
|
||||
loras: list[LoRAMetadataField] = InputField(description="The LoRAs used for inference")
|
||||
strength: Optional[float] = InputField(
|
||||
default=None,
|
||||
description="The strength used for latents-to-latents",
|
||||
@@ -166,20 +153,6 @@ class MetadataAccumulatorInvocation(BaseInvocation):
|
||||
description="The VAE used for decoding, if the main model's default was not used",
|
||||
)
|
||||
|
||||
# High resolution fix metadata.
|
||||
hrf_width: Optional[int] = InputField(
|
||||
default=None,
|
||||
description="The high resolution fix height and width multipler.",
|
||||
)
|
||||
hrf_height: Optional[int] = InputField(
|
||||
default=None,
|
||||
description="The high resolution fix height and width multipler.",
|
||||
)
|
||||
hrf_strength: Optional[float] = InputField(
|
||||
default=None,
|
||||
description="The high resolution fix img2img strength used in the upscale pass.",
|
||||
)
|
||||
|
||||
# SDXL
|
||||
positive_style_prompt: Optional[str] = InputField(
|
||||
default=None,
|
||||
|
||||
@@ -1,83 +0,0 @@
|
||||
from typing import Union
|
||||
|
||||
from pydantic import BaseModel, Field
|
||||
|
||||
from invokeai.app.invocations.baseinvocation import (
|
||||
BaseInvocation,
|
||||
BaseInvocationOutput,
|
||||
FieldDescriptions,
|
||||
Input,
|
||||
InputField,
|
||||
InvocationContext,
|
||||
OutputField,
|
||||
UIType,
|
||||
invocation,
|
||||
invocation_output,
|
||||
)
|
||||
from invokeai.app.invocations.controlnet_image_processors import CONTROLNET_RESIZE_VALUES
|
||||
from invokeai.app.invocations.primitives import ImageField
|
||||
from invokeai.backend.model_management.models.base import BaseModelType
|
||||
|
||||
|
||||
class T2IAdapterModelField(BaseModel):
|
||||
model_name: str = Field(description="Name of the T2I-Adapter model")
|
||||
base_model: BaseModelType = Field(description="Base model")
|
||||
|
||||
|
||||
class T2IAdapterField(BaseModel):
|
||||
image: ImageField = Field(description="The T2I-Adapter image prompt.")
|
||||
t2i_adapter_model: T2IAdapterModelField = Field(description="The T2I-Adapter model to use.")
|
||||
weight: Union[float, list[float]] = Field(default=1, description="The weight given to the T2I-Adapter")
|
||||
begin_step_percent: float = Field(
|
||||
default=0, ge=0, le=1, description="When the T2I-Adapter is first applied (% of total steps)"
|
||||
)
|
||||
end_step_percent: float = Field(
|
||||
default=1, ge=0, le=1, description="When the T2I-Adapter is last applied (% of total steps)"
|
||||
)
|
||||
resize_mode: CONTROLNET_RESIZE_VALUES = Field(default="just_resize", description="The resize mode to use")
|
||||
|
||||
|
||||
@invocation_output("t2i_adapter_output")
|
||||
class T2IAdapterOutput(BaseInvocationOutput):
|
||||
t2i_adapter: T2IAdapterField = OutputField(description=FieldDescriptions.t2i_adapter, title="T2I Adapter")
|
||||
|
||||
|
||||
@invocation(
|
||||
"t2i_adapter", title="T2I-Adapter", tags=["t2i_adapter", "control"], category="t2i_adapter", version="1.0.0"
|
||||
)
|
||||
class T2IAdapterInvocation(BaseInvocation):
|
||||
"""Collects T2I-Adapter info to pass to other nodes."""
|
||||
|
||||
# Inputs
|
||||
image: ImageField = InputField(description="The IP-Adapter image prompt.")
|
||||
t2i_adapter_model: T2IAdapterModelField = InputField(
|
||||
description="The T2I-Adapter model.",
|
||||
title="T2I-Adapter Model",
|
||||
input=Input.Direct,
|
||||
ui_order=-1,
|
||||
)
|
||||
weight: Union[float, list[float]] = InputField(
|
||||
default=1, ge=0, description="The weight given to the T2I-Adapter", ui_type=UIType.Float, title="Weight"
|
||||
)
|
||||
begin_step_percent: float = InputField(
|
||||
default=0, ge=-1, le=2, description="When the T2I-Adapter is first applied (% of total steps)"
|
||||
)
|
||||
end_step_percent: float = InputField(
|
||||
default=1, ge=0, le=1, description="When the T2I-Adapter is last applied (% of total steps)"
|
||||
)
|
||||
resize_mode: CONTROLNET_RESIZE_VALUES = InputField(
|
||||
default="just_resize",
|
||||
description="The resize mode applied to the T2I-Adapter input image so that it matches the target output size.",
|
||||
)
|
||||
|
||||
def invoke(self, context: InvocationContext) -> T2IAdapterOutput:
|
||||
return T2IAdapterOutput(
|
||||
t2i_adapter=T2IAdapterField(
|
||||
image=self.image,
|
||||
t2i_adapter_model=self.t2i_adapter_model,
|
||||
weight=self.weight,
|
||||
begin_step_percent=self.begin_step_percent,
|
||||
end_step_percent=self.end_step_percent,
|
||||
resize_mode=self.resize_mode,
|
||||
)
|
||||
)
|
||||
@@ -4,14 +4,12 @@ from typing import Literal
|
||||
|
||||
import cv2 as cv
|
||||
import numpy as np
|
||||
import torch
|
||||
from basicsr.archs.rrdbnet_arch import RRDBNet
|
||||
from PIL import Image
|
||||
from realesrgan import RealESRGANer
|
||||
|
||||
from invokeai.app.invocations.primitives import ImageField, ImageOutput
|
||||
from invokeai.app.models.image import ImageCategory, ResourceOrigin
|
||||
from invokeai.backend.util.devices import choose_torch_device
|
||||
|
||||
from .baseinvocation import BaseInvocation, InputField, InvocationContext, invocation
|
||||
|
||||
@@ -24,19 +22,13 @@ ESRGAN_MODELS = Literal[
|
||||
"RealESRGAN_x2plus.pth",
|
||||
]
|
||||
|
||||
if choose_torch_device() == torch.device("mps"):
|
||||
from torch import mps
|
||||
|
||||
|
||||
@invocation("esrgan", title="Upscale (RealESRGAN)", tags=["esrgan", "upscale"], category="esrgan", version="1.1.0")
|
||||
@invocation("esrgan", title="Upscale (RealESRGAN)", tags=["esrgan", "upscale"], category="esrgan", version="1.0.0")
|
||||
class ESRGANInvocation(BaseInvocation):
|
||||
"""Upscales an image using RealESRGAN."""
|
||||
|
||||
image: ImageField = InputField(description="The input image")
|
||||
model_name: ESRGAN_MODELS = InputField(default="RealESRGAN_x4plus.pth", description="The Real-ESRGAN model to use")
|
||||
tile_size: int = InputField(
|
||||
default=400, ge=0, description="Tile size for tiled ESRGAN upscaling (0=tiling disabled)"
|
||||
)
|
||||
|
||||
def invoke(self, context: InvocationContext) -> ImageOutput:
|
||||
image = context.services.images.get_pil_image(self.image.image_name)
|
||||
@@ -94,11 +86,9 @@ class ESRGANInvocation(BaseInvocation):
|
||||
model_path=str(models_path / esrgan_model_path),
|
||||
model=rrdbnet_model,
|
||||
half=False,
|
||||
tile=self.tile_size,
|
||||
)
|
||||
|
||||
# prepare image - Real-ESRGAN uses cv2 internally, and cv2 uses BGR vs RGB for PIL
|
||||
# TODO: This strips the alpha... is that okay?
|
||||
cv_image = cv.cvtColor(np.array(image.convert("RGB")), cv.COLOR_RGB2BGR)
|
||||
|
||||
# We can pass an `outscale` value here, but it just resizes the image by that factor after
|
||||
@@ -109,10 +99,6 @@ class ESRGANInvocation(BaseInvocation):
|
||||
# back to PIL
|
||||
pil_image = Image.fromarray(cv.cvtColor(upscaled_image, cv.COLOR_BGR2RGB)).convert("RGBA")
|
||||
|
||||
torch.cuda.empty_cache()
|
||||
if choose_torch_device() == torch.device("mps"):
|
||||
mps.empty_cache()
|
||||
|
||||
image_dto = context.services.images.create(
|
||||
image=pil_image,
|
||||
image_origin=ResourceOrigin.INTERNAL,
|
||||
|
||||
@@ -55,9 +55,9 @@ class BoardImageRecordStorageBase(ABC):
|
||||
class SqliteBoardImageRecordStorage(BoardImageRecordStorageBase):
|
||||
_conn: sqlite3.Connection
|
||||
_cursor: sqlite3.Cursor
|
||||
_lock: threading.RLock
|
||||
_lock: threading.Lock
|
||||
|
||||
def __init__(self, conn: sqlite3.Connection, lock: threading.RLock) -> None:
|
||||
def __init__(self, conn: sqlite3.Connection, lock: threading.Lock) -> None:
|
||||
super().__init__()
|
||||
self._conn = conn
|
||||
# Enable row factory to get rows as dictionaries (must be done before making the cursor!)
|
||||
|
||||
@@ -89,9 +89,9 @@ class BoardRecordStorageBase(ABC):
|
||||
class SqliteBoardRecordStorage(BoardRecordStorageBase):
|
||||
_conn: sqlite3.Connection
|
||||
_cursor: sqlite3.Cursor
|
||||
_lock: threading.RLock
|
||||
_lock: threading.Lock
|
||||
|
||||
def __init__(self, conn: sqlite3.Connection, lock: threading.RLock) -> None:
|
||||
def __init__(self, conn: sqlite3.Connection, lock: threading.Lock) -> None:
|
||||
super().__init__()
|
||||
self._conn = conn
|
||||
# Enable row factory to get rows as dictionaries (must be done before making the cursor!)
|
||||
|
||||
@@ -241,8 +241,8 @@ class InvokeAIAppConfig(InvokeAISettings):
|
||||
version : bool = Field(default=False, description="Show InvokeAI version and exit", category="Other")
|
||||
|
||||
# CACHE
|
||||
ram : float = Field(default=7.5, gt=0, description="Maximum memory amount used by model cache for rapid switching (floating point number, GB)", category="Model Cache", )
|
||||
vram : float = Field(default=0.25, ge=0, description="Amount of VRAM reserved for model storage (floating point number, GB)", category="Model Cache", )
|
||||
ram : Union[float, Literal["auto"]] = Field(default=7.5, gt=0, description="Maximum memory amount used by model cache for rapid switching (floating point number or 'auto')", category="Model Cache", )
|
||||
vram : Union[float, Literal["auto"]] = Field(default=0.25, ge=0, description="Amount of VRAM reserved for model storage (floating point number or 'auto')", category="Model Cache", )
|
||||
lazy_offload : bool = Field(default=True, description="Keep models in VRAM until their space is needed", category="Model Cache", )
|
||||
|
||||
# DEVICE
|
||||
@@ -255,7 +255,6 @@ class InvokeAIAppConfig(InvokeAISettings):
|
||||
attention_slice_size: Literal["auto", "balanced", "max", 1, 2, 3, 4, 5, 6, 7, 8] = Field(default="auto", description='Slice size, valid when attention_type=="sliced"', category="Generation", )
|
||||
force_tiled_decode : bool = Field(default=False, description="Whether to enable tiled VAE decode (reduces memory consumption with some performance penalty)", category="Generation",)
|
||||
force_tiled_decode: bool = Field(default=False, description="Whether to enable tiled VAE decode (reduces memory consumption with some performance penalty)", category="Generation",)
|
||||
png_compress_level : int = Field(default=6, description="The compress_level setting of PIL.Image.save(), used for PNG encoding. All settings are lossless. 0 = fastest, largest filesize, 9 = slowest, smallest filesize", category="Generation", )
|
||||
|
||||
# QUEUE
|
||||
max_queue_size : int = Field(default=10000, gt=0, description="Maximum number of items in the session queue", category="Queue", )
|
||||
|
||||
@@ -4,12 +4,7 @@ from typing import Any, Optional
|
||||
|
||||
from invokeai.app.models.image import ProgressImage
|
||||
from invokeai.app.services.model_manager_service import BaseModelType, ModelInfo, ModelType, SubModelType
|
||||
from invokeai.app.services.session_queue.session_queue_common import (
|
||||
BatchStatus,
|
||||
EnqueueBatchResult,
|
||||
SessionQueueItem,
|
||||
SessionQueueStatus,
|
||||
)
|
||||
from invokeai.app.services.session_queue.session_queue_common import EnqueueBatchResult, SessionQueueItem
|
||||
from invokeai.app.util.misc import get_timestamp
|
||||
|
||||
|
||||
@@ -267,31 +262,21 @@ class EventServiceBase:
|
||||
),
|
||||
)
|
||||
|
||||
def emit_queue_item_status_changed(
|
||||
self,
|
||||
session_queue_item: SessionQueueItem,
|
||||
batch_status: BatchStatus,
|
||||
queue_status: SessionQueueStatus,
|
||||
) -> None:
|
||||
def emit_queue_item_status_changed(self, session_queue_item: SessionQueueItem) -> None:
|
||||
"""Emitted when a queue item's status changes"""
|
||||
self.__emit_queue_event(
|
||||
event_name="queue_item_status_changed",
|
||||
payload=dict(
|
||||
queue_id=queue_status.queue_id,
|
||||
queue_item=dict(
|
||||
queue_id=session_queue_item.queue_id,
|
||||
item_id=session_queue_item.item_id,
|
||||
status=session_queue_item.status,
|
||||
batch_id=session_queue_item.batch_id,
|
||||
session_id=session_queue_item.session_id,
|
||||
error=session_queue_item.error,
|
||||
created_at=str(session_queue_item.created_at) if session_queue_item.created_at else None,
|
||||
updated_at=str(session_queue_item.updated_at) if session_queue_item.updated_at else None,
|
||||
started_at=str(session_queue_item.started_at) if session_queue_item.started_at else None,
|
||||
completed_at=str(session_queue_item.completed_at) if session_queue_item.completed_at else None,
|
||||
),
|
||||
batch_status=batch_status.dict(),
|
||||
queue_status=queue_status.dict(),
|
||||
queue_id=session_queue_item.queue_id,
|
||||
queue_item_id=session_queue_item.item_id,
|
||||
status=session_queue_item.status,
|
||||
batch_id=session_queue_item.batch_id,
|
||||
session_id=session_queue_item.session_id,
|
||||
error=session_queue_item.error,
|
||||
created_at=str(session_queue_item.created_at) if session_queue_item.created_at else None,
|
||||
updated_at=str(session_queue_item.updated_at) if session_queue_item.updated_at else None,
|
||||
started_at=str(session_queue_item.started_at) if session_queue_item.started_at else None,
|
||||
completed_at=str(session_queue_item.completed_at) if session_queue_item.completed_at else None,
|
||||
),
|
||||
)
|
||||
|
||||
|
||||
@@ -2,7 +2,7 @@
|
||||
|
||||
import copy
|
||||
import itertools
|
||||
from typing import Annotated, Any, Optional, Union, get_args, get_origin, get_type_hints
|
||||
from typing import Annotated, Any, Optional, Union, cast, get_args, get_origin, get_type_hints
|
||||
|
||||
import networkx as nx
|
||||
from pydantic import BaseModel, root_validator, validator
|
||||
@@ -170,18 +170,6 @@ class NodeIdMismatchError(ValueError):
|
||||
pass
|
||||
|
||||
|
||||
class InvalidSubGraphError(ValueError):
|
||||
pass
|
||||
|
||||
|
||||
class CyclicalGraphError(ValueError):
|
||||
pass
|
||||
|
||||
|
||||
class UnknownGraphValidationError(ValueError):
|
||||
pass
|
||||
|
||||
|
||||
# TODO: Create and use an Empty output?
|
||||
@invocation_output("graph_output")
|
||||
class GraphInvocationOutput(BaseInvocationOutput):
|
||||
@@ -266,6 +254,59 @@ class Graph(BaseModel):
|
||||
default_factory=list,
|
||||
)
|
||||
|
||||
@root_validator
|
||||
def validate_nodes_and_edges(cls, values):
|
||||
"""Validates that all edges match nodes in the graph"""
|
||||
nodes = cast(Optional[dict[str, BaseInvocation]], values.get("nodes"))
|
||||
edges = cast(Optional[list[Edge]], values.get("edges"))
|
||||
|
||||
if nodes is not None:
|
||||
# Validate that all node ids are unique
|
||||
node_ids = [n.id for n in nodes.values()]
|
||||
duplicate_node_ids = set([node_id for node_id in node_ids if node_ids.count(node_id) >= 2])
|
||||
if duplicate_node_ids:
|
||||
raise DuplicateNodeIdError(f"Node ids must be unique, found duplicates {duplicate_node_ids}")
|
||||
|
||||
# Validate that all node ids match the keys in the nodes dict
|
||||
for k, v in nodes.items():
|
||||
if k != v.id:
|
||||
raise NodeIdMismatchError(f"Node ids must match, got {k} and {v.id}")
|
||||
|
||||
if edges is not None and nodes is not None:
|
||||
# Validate that all edges match nodes in the graph
|
||||
node_ids = set([e.source.node_id for e in edges] + [e.destination.node_id for e in edges])
|
||||
missing_node_ids = [node_id for node_id in node_ids if node_id not in nodes]
|
||||
if missing_node_ids:
|
||||
raise NodeNotFoundError(
|
||||
f"All edges must reference nodes in the graph, missing nodes: {missing_node_ids}"
|
||||
)
|
||||
|
||||
# Validate that all edge fields match node fields in the graph
|
||||
for edge in edges:
|
||||
source_node = nodes.get(edge.source.node_id, None)
|
||||
if source_node is None:
|
||||
raise NodeFieldNotFoundError(f"Edge source node {edge.source.node_id} does not exist in the graph")
|
||||
|
||||
destination_node = nodes.get(edge.destination.node_id, None)
|
||||
if destination_node is None:
|
||||
raise NodeFieldNotFoundError(
|
||||
f"Edge destination node {edge.destination.node_id} does not exist in the graph"
|
||||
)
|
||||
|
||||
# output fields are not on the node object directly, they are on the output type
|
||||
if edge.source.field not in source_node.get_output_type().__fields__:
|
||||
raise NodeFieldNotFoundError(
|
||||
f"Edge source field {edge.source.field} does not exist in node {edge.source.node_id}"
|
||||
)
|
||||
|
||||
# input fields are on the node
|
||||
if edge.destination.field not in destination_node.__fields__:
|
||||
raise NodeFieldNotFoundError(
|
||||
f"Edge destination field {edge.destination.field} does not exist in node {edge.destination.node_id}"
|
||||
)
|
||||
|
||||
return values
|
||||
|
||||
def add_node(self, node: BaseInvocation) -> None:
|
||||
"""Adds a node to a graph
|
||||
|
||||
@@ -336,108 +377,53 @@ class Graph(BaseModel):
|
||||
except KeyError:
|
||||
pass
|
||||
|
||||
def validate_self(self) -> None:
|
||||
"""
|
||||
Validates the graph.
|
||||
|
||||
Raises an exception if the graph is invalid:
|
||||
- `DuplicateNodeIdError`
|
||||
- `NodeIdMismatchError`
|
||||
- `InvalidSubGraphError`
|
||||
- `NodeNotFoundError`
|
||||
- `NodeFieldNotFoundError`
|
||||
- `CyclicalGraphError`
|
||||
- `InvalidEdgeError`
|
||||
"""
|
||||
|
||||
# Validate that all node ids are unique
|
||||
node_ids = [n.id for n in self.nodes.values()]
|
||||
duplicate_node_ids = set([node_id for node_id in node_ids if node_ids.count(node_id) >= 2])
|
||||
if duplicate_node_ids:
|
||||
raise DuplicateNodeIdError(f"Node ids must be unique, found duplicates {duplicate_node_ids}")
|
||||
|
||||
# Validate that all node ids match the keys in the nodes dict
|
||||
for k, v in self.nodes.items():
|
||||
if k != v.id:
|
||||
raise NodeIdMismatchError(f"Node ids must match, got {k} and {v.id}")
|
||||
def is_valid(self) -> bool:
|
||||
"""Validates the graph."""
|
||||
|
||||
# Validate all subgraphs
|
||||
for gn in (n for n in self.nodes.values() if isinstance(n, GraphInvocation)):
|
||||
try:
|
||||
gn.graph.validate_self()
|
||||
except Exception as e:
|
||||
raise InvalidSubGraphError(f"Subgraph {gn.id} is invalid") from e
|
||||
if not gn.graph.is_valid():
|
||||
return False
|
||||
|
||||
# Validate that all edges match nodes and fields in the graph
|
||||
for edge in self.edges:
|
||||
source_node = self.nodes.get(edge.source.node_id, None)
|
||||
if source_node is None:
|
||||
raise NodeNotFoundError(f"Edge source node {edge.source.node_id} does not exist in the graph")
|
||||
|
||||
destination_node = self.nodes.get(edge.destination.node_id, None)
|
||||
if destination_node is None:
|
||||
raise NodeNotFoundError(f"Edge destination node {edge.destination.node_id} does not exist in the graph")
|
||||
|
||||
# output fields are not on the node object directly, they are on the output type
|
||||
if edge.source.field not in source_node.get_output_type().__fields__:
|
||||
raise NodeFieldNotFoundError(
|
||||
f"Edge source field {edge.source.field} does not exist in node {edge.source.node_id}"
|
||||
)
|
||||
|
||||
# input fields are on the node
|
||||
if edge.destination.field not in destination_node.__fields__:
|
||||
raise NodeFieldNotFoundError(
|
||||
f"Edge destination field {edge.destination.field} does not exist in node {edge.destination.node_id}"
|
||||
)
|
||||
# Validate all edges reference nodes in the graph
|
||||
node_ids = set([e.source.node_id for e in self.edges] + [e.destination.node_id for e in self.edges])
|
||||
if not all((self.has_node(node_id) for node_id in node_ids)):
|
||||
return False
|
||||
|
||||
# Validate there are no cycles
|
||||
g = self.nx_graph_flat()
|
||||
if not nx.is_directed_acyclic_graph(g):
|
||||
raise CyclicalGraphError("Graph contains cycles")
|
||||
return False
|
||||
|
||||
# Validate all edge connections are valid
|
||||
for e in self.edges:
|
||||
if not are_connections_compatible(
|
||||
self.get_node(e.source.node_id),
|
||||
e.source.field,
|
||||
self.get_node(e.destination.node_id),
|
||||
e.destination.field,
|
||||
):
|
||||
raise InvalidEdgeError(
|
||||
f"Invalid edge from {e.source.node_id}.{e.source.field} to {e.destination.node_id}.{e.destination.field}"
|
||||
if not all(
|
||||
(
|
||||
are_connections_compatible(
|
||||
self.get_node(e.source.node_id),
|
||||
e.source.field,
|
||||
self.get_node(e.destination.node_id),
|
||||
e.destination.field,
|
||||
)
|
||||
|
||||
# Validate all iterators & collectors
|
||||
# TODO: may need to validate all iterators & collectors in subgraphs so edge connections in parent graphs will be available
|
||||
for n in self.nodes.values():
|
||||
if isinstance(n, IterateInvocation) and not self._is_iterator_connection_valid(n.id):
|
||||
raise InvalidEdgeError(f"Invalid iterator node {n.id}")
|
||||
if isinstance(n, CollectInvocation) and not self._is_collector_connection_valid(n.id):
|
||||
raise InvalidEdgeError(f"Invalid collector node {n.id}")
|
||||
|
||||
return None
|
||||
|
||||
def is_valid(self) -> bool:
|
||||
"""
|
||||
Checks if the graph is valid.
|
||||
|
||||
Raises `UnknownGraphValidationError` if there is a problem validating the graph (not a validation error).
|
||||
"""
|
||||
try:
|
||||
self.validate_self()
|
||||
return True
|
||||
except (
|
||||
DuplicateNodeIdError,
|
||||
NodeIdMismatchError,
|
||||
InvalidSubGraphError,
|
||||
NodeNotFoundError,
|
||||
NodeFieldNotFoundError,
|
||||
CyclicalGraphError,
|
||||
InvalidEdgeError,
|
||||
for e in self.edges
|
||||
)
|
||||
):
|
||||
return False
|
||||
except Exception as e:
|
||||
raise UnknownGraphValidationError(f"Problem validating graph {e}") from e
|
||||
|
||||
# Validate all iterators
|
||||
# TODO: may need to validate all iterators in subgraphs so edge connections in parent graphs will be available
|
||||
if not all(
|
||||
(self._is_iterator_connection_valid(n.id) for n in self.nodes.values() if isinstance(n, IterateInvocation))
|
||||
):
|
||||
return False
|
||||
|
||||
# Validate all collectors
|
||||
# TODO: may need to validate all collectors in subgraphs so edge connections in parent graphs will be available
|
||||
if not all(
|
||||
(self._is_collector_connection_valid(n.id) for n in self.nodes.values() if isinstance(n, CollectInvocation))
|
||||
):
|
||||
return False
|
||||
|
||||
return True
|
||||
|
||||
def _validate_edge(self, edge: Edge):
|
||||
"""Validates that a new edge doesn't create a cycle in the graph"""
|
||||
@@ -818,12 +804,6 @@ class GraphExecutionState(BaseModel):
|
||||
default_factory=dict,
|
||||
)
|
||||
|
||||
@validator("graph")
|
||||
def graph_is_valid(cls, v: Graph):
|
||||
"""Validates that the graph is valid"""
|
||||
v.validate_self()
|
||||
return v
|
||||
|
||||
class Config:
|
||||
schema_extra = {
|
||||
"required": [
|
||||
|
||||
@@ -9,7 +9,6 @@ from PIL import Image, PngImagePlugin
|
||||
from PIL.Image import Image as PILImageType
|
||||
from send2trash import send2trash
|
||||
|
||||
from invokeai.app.services.config.invokeai_config import InvokeAIAppConfig
|
||||
from invokeai.app.util.thumbnails import get_thumbnail_name, make_thumbnail
|
||||
|
||||
|
||||
@@ -80,7 +79,6 @@ class DiskImageFileStorage(ImageFileStorageBase):
|
||||
__cache_ids: Queue # TODO: this is an incredibly naive cache
|
||||
__cache: Dict[Path, PILImageType]
|
||||
__max_cache_size: int
|
||||
__compress_level: int
|
||||
|
||||
def __init__(self, output_folder: Union[str, Path]):
|
||||
self.__cache = dict()
|
||||
@@ -89,7 +87,7 @@ class DiskImageFileStorage(ImageFileStorageBase):
|
||||
|
||||
self.__output_folder: Path = output_folder if isinstance(output_folder, Path) else Path(output_folder)
|
||||
self.__thumbnails_folder = self.__output_folder / "thumbnails"
|
||||
self.__compress_level = InvokeAIAppConfig.get_config().png_compress_level
|
||||
|
||||
# Validate required output folders at launch
|
||||
self.__validate_storage_folders()
|
||||
|
||||
@@ -136,7 +134,7 @@ class DiskImageFileStorage(ImageFileStorageBase):
|
||||
if original_workflow is not None:
|
||||
pnginfo.add_text("invokeai_workflow", original_workflow)
|
||||
|
||||
image.save(image_path, "PNG", pnginfo=pnginfo, compress_level=self.__compress_level)
|
||||
image.save(image_path, "PNG", pnginfo=pnginfo)
|
||||
|
||||
thumbnail_name = get_thumbnail_name(image_name)
|
||||
thumbnail_path = self.get_path(thumbnail_name, thumbnail=True)
|
||||
|
||||
@@ -150,9 +150,9 @@ class ImageRecordStorageBase(ABC):
|
||||
class SqliteImageRecordStorage(ImageRecordStorageBase):
|
||||
_conn: sqlite3.Connection
|
||||
_cursor: sqlite3.Cursor
|
||||
_lock: threading.RLock
|
||||
_lock: threading.Lock
|
||||
|
||||
def __init__(self, conn: sqlite3.Connection, lock: threading.RLock) -> None:
|
||||
def __init__(self, conn: sqlite3.Connection, lock: threading.Lock) -> None:
|
||||
super().__init__()
|
||||
self._conn = conn
|
||||
# Enable row factory to get rows as dictionaries (must be done before making the cursor!)
|
||||
|
||||
@@ -1,4 +1,3 @@
|
||||
import traceback
|
||||
from threading import BoundedSemaphore
|
||||
from threading import Event as ThreadEvent
|
||||
from threading import Thread
|
||||
@@ -124,10 +123,6 @@ class DefaultSessionProcessor(SessionProcessorBase):
|
||||
continue
|
||||
except Exception as e:
|
||||
self.__invoker.services.logger.error(f"Error in session processor: {e}")
|
||||
if queue_item is not None:
|
||||
self.__invoker.services.session_queue.cancel_queue_item(
|
||||
queue_item.item_id, error=traceback.format_exc()
|
||||
)
|
||||
poll_now_event.wait(POLLING_INTERVAL)
|
||||
continue
|
||||
except Exception as e:
|
||||
|
||||
@@ -80,7 +80,7 @@ class SessionQueueBase(ABC):
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def cancel_queue_item(self, item_id: int, error: Optional[str] = None) -> SessionQueueItem:
|
||||
def cancel_queue_item(self, item_id: int) -> SessionQueueItem:
|
||||
"""Cancels a session queue item"""
|
||||
pass
|
||||
|
||||
|
||||
@@ -123,11 +123,6 @@ class Batch(BaseModel):
|
||||
raise NodeNotFoundError(f"Field {batch_data.field_name} not found in node {batch_data.node_path}")
|
||||
return values
|
||||
|
||||
@validator("graph")
|
||||
def validate_graph(cls, v: Graph):
|
||||
v.validate_self()
|
||||
return v
|
||||
|
||||
class Config:
|
||||
schema_extra = {
|
||||
"required": [
|
||||
|
||||
@@ -36,7 +36,7 @@ class SqliteSessionQueue(SessionQueueBase):
|
||||
__invoker: Invoker
|
||||
__conn: sqlite3.Connection
|
||||
__cursor: sqlite3.Cursor
|
||||
__lock: threading.RLock
|
||||
__lock: threading.Lock
|
||||
|
||||
def start(self, invoker: Invoker) -> None:
|
||||
self.__invoker = invoker
|
||||
@@ -45,7 +45,7 @@ class SqliteSessionQueue(SessionQueueBase):
|
||||
local_handler.register(event_name=EventServiceBase.queue_event, _func=self._on_session_event)
|
||||
self.__invoker.services.logger.info(f"Pruned {prune_result.deleted} finished queue items")
|
||||
|
||||
def __init__(self, conn: sqlite3.Connection, lock: threading.RLock) -> None:
|
||||
def __init__(self, conn: sqlite3.Connection, lock: threading.Lock) -> None:
|
||||
super().__init__()
|
||||
self.__conn = conn
|
||||
# Enable row factory to get rows as dictionaries (must be done before making the cursor!)
|
||||
@@ -427,13 +427,7 @@ class SqliteSessionQueue(SessionQueueBase):
|
||||
finally:
|
||||
self.__lock.release()
|
||||
queue_item = self.get_queue_item(item_id)
|
||||
batch_status = self.get_batch_status(queue_id=queue_item.queue_id, batch_id=queue_item.batch_id)
|
||||
queue_status = self.get_queue_status(queue_id=queue_item.queue_id)
|
||||
self.__invoker.services.events.emit_queue_item_status_changed(
|
||||
session_queue_item=queue_item,
|
||||
batch_status=batch_status,
|
||||
queue_status=queue_status,
|
||||
)
|
||||
self.__invoker.services.events.emit_queue_item_status_changed(queue_item)
|
||||
return queue_item
|
||||
|
||||
def is_empty(self, queue_id: str) -> IsEmptyResult:
|
||||
@@ -561,11 +555,10 @@ class SqliteSessionQueue(SessionQueueBase):
|
||||
self.__lock.release()
|
||||
return PruneResult(deleted=count)
|
||||
|
||||
def cancel_queue_item(self, item_id: int, error: Optional[str] = None) -> SessionQueueItem:
|
||||
def cancel_queue_item(self, item_id: int) -> SessionQueueItem:
|
||||
queue_item = self.get_queue_item(item_id)
|
||||
if queue_item.status not in ["canceled", "failed", "completed"]:
|
||||
status = "failed" if error is not None else "canceled"
|
||||
queue_item = self._set_queue_item_status(item_id=item_id, status=status, error=error)
|
||||
queue_item = self._set_queue_item_status(item_id=item_id, status="canceled")
|
||||
self.__invoker.services.queue.cancel(queue_item.session_id)
|
||||
self.__invoker.services.events.emit_session_canceled(
|
||||
queue_item_id=queue_item.item_id,
|
||||
@@ -615,13 +608,7 @@ class SqliteSessionQueue(SessionQueueBase):
|
||||
queue_batch_id=current_queue_item.batch_id,
|
||||
graph_execution_state_id=current_queue_item.session_id,
|
||||
)
|
||||
batch_status = self.get_batch_status(queue_id=queue_id, batch_id=current_queue_item.batch_id)
|
||||
queue_status = self.get_queue_status(queue_id=queue_id)
|
||||
self.__invoker.services.events.emit_queue_item_status_changed(
|
||||
session_queue_item=current_queue_item,
|
||||
batch_status=batch_status,
|
||||
queue_status=queue_status,
|
||||
)
|
||||
self.__invoker.services.events.emit_queue_item_status_changed(current_queue_item)
|
||||
except Exception:
|
||||
self.__conn.rollback()
|
||||
raise
|
||||
@@ -667,13 +654,7 @@ class SqliteSessionQueue(SessionQueueBase):
|
||||
queue_batch_id=current_queue_item.batch_id,
|
||||
graph_execution_state_id=current_queue_item.session_id,
|
||||
)
|
||||
batch_status = self.get_batch_status(queue_id=queue_id, batch_id=current_queue_item.batch_id)
|
||||
queue_status = self.get_queue_status(queue_id=queue_id)
|
||||
self.__invoker.services.events.emit_queue_item_status_changed(
|
||||
session_queue_item=current_queue_item,
|
||||
batch_status=batch_status,
|
||||
queue_status=queue_status,
|
||||
)
|
||||
self.__invoker.services.events.emit_queue_item_status_changed(current_queue_item)
|
||||
except Exception:
|
||||
self.__conn.rollback()
|
||||
raise
|
||||
|
||||
@@ -16,9 +16,9 @@ class SqliteItemStorage(ItemStorageABC, Generic[T]):
|
||||
_conn: sqlite3.Connection
|
||||
_cursor: sqlite3.Cursor
|
||||
_id_field: str
|
||||
_lock: threading.RLock
|
||||
_lock: threading.Lock
|
||||
|
||||
def __init__(self, conn: sqlite3.Connection, table_name: str, lock: threading.RLock, id_field: str = "id"):
|
||||
def __init__(self, conn: sqlite3.Connection, table_name: str, lock: threading.Lock, id_field: str = "id"):
|
||||
super().__init__()
|
||||
|
||||
self._table_name = table_name
|
||||
|
||||
@@ -1,3 +1,3 @@
|
||||
import threading
|
||||
|
||||
lock = threading.RLock()
|
||||
lock = threading.Lock()
|
||||
|
||||
@@ -265,41 +265,22 @@ def np_img_resize(np_img: np.ndarray, resize_mode: str, h: int, w: int, device:
|
||||
|
||||
|
||||
def prepare_control_image(
|
||||
# image used to be Union[PIL.Image.Image, List[PIL.Image.Image], torch.Tensor, List[torch.Tensor]]
|
||||
# but now should be able to assume that image is a single PIL.Image, which simplifies things
|
||||
image: Image,
|
||||
width: int,
|
||||
height: int,
|
||||
num_channels: int = 3,
|
||||
# FIXME: need to fix hardwiring of width and height, change to basing on latents dimensions?
|
||||
# latents_to_match_resolution, # TorchTensor of shape (batch_size, 3, height, width)
|
||||
width=512, # should be 8 * latent.shape[3]
|
||||
height=512, # should be 8 * latent height[2]
|
||||
# batch_size=1, # currently no batching
|
||||
# num_images_per_prompt=1, # currently only single image
|
||||
device="cuda",
|
||||
dtype=torch.float16,
|
||||
do_classifier_free_guidance=True,
|
||||
control_mode="balanced",
|
||||
resize_mode="just_resize_simple",
|
||||
):
|
||||
"""Pre-process images for ControlNets or T2I-Adapters.
|
||||
|
||||
Args:
|
||||
image (Image): The PIL image to pre-process.
|
||||
width (int): The target width in pixels.
|
||||
height (int): The target height in pixels.
|
||||
num_channels (int, optional): The target number of image channels. This is achieved by converting the input
|
||||
image to RGB, then naively taking the first `num_channels` channels. The primary use case is converting a
|
||||
RGB image to a single-channel grayscale image. Raises if `num_channels` cannot be achieved. Defaults to 3.
|
||||
device (str, optional): The target device for the output image. Defaults to "cuda".
|
||||
dtype (_type_, optional): The dtype for the output image. Defaults to torch.float16.
|
||||
do_classifier_free_guidance (bool, optional): If True, repeat the output image along the batch dimension.
|
||||
Defaults to True.
|
||||
control_mode (str, optional): Defaults to "balanced".
|
||||
resize_mode (str, optional): Defaults to "just_resize_simple".
|
||||
|
||||
Raises:
|
||||
NotImplementedError: If resize_mode == "crop_resize_simple".
|
||||
NotImplementedError: If resize_mode == "fill_resize_simple".
|
||||
ValueError: If `resize_mode` is not recognized.
|
||||
ValueError: If `num_channels` is out of range.
|
||||
|
||||
Returns:
|
||||
torch.Tensor: The pre-processed input tensor.
|
||||
"""
|
||||
# FIXME: implement "crop_resize_simple" and "fill_resize_simple", or pull them out
|
||||
if (
|
||||
resize_mode == "just_resize_simple"
|
||||
or resize_mode == "crop_resize_simple"
|
||||
@@ -308,10 +289,10 @@ def prepare_control_image(
|
||||
image = image.convert("RGB")
|
||||
if resize_mode == "just_resize_simple":
|
||||
image = image.resize((width, height), resample=PIL_INTERPOLATION["lanczos"])
|
||||
elif resize_mode == "crop_resize_simple":
|
||||
raise NotImplementedError(f"prepare_control_image is not implemented for resize_mode='{resize_mode}'.")
|
||||
elif resize_mode == "fill_resize_simple":
|
||||
raise NotImplementedError(f"prepare_control_image is not implemented for resize_mode='{resize_mode}'.")
|
||||
elif resize_mode == "crop_resize_simple": # not yet implemented
|
||||
pass
|
||||
elif resize_mode == "fill_resize_simple": # not yet implemented
|
||||
pass
|
||||
nimage = np.array(image)
|
||||
nimage = nimage[None, :]
|
||||
nimage = np.concatenate([nimage], axis=0)
|
||||
@@ -332,11 +313,9 @@ def prepare_control_image(
|
||||
device=device,
|
||||
)
|
||||
else:
|
||||
raise ValueError(f"Unsupported resize_mode: '{resize_mode}'.")
|
||||
|
||||
if timage.shape[1] < num_channels or num_channels <= 0:
|
||||
raise ValueError(f"Cannot achieve the target of num_channels={num_channels}.")
|
||||
timage = timage[:, :num_channels, :, :]
|
||||
pass
|
||||
print("ERROR: invalid resize_mode ==> ", resize_mode)
|
||||
exit(1)
|
||||
|
||||
timage = timage.to(device=device, dtype=dtype)
|
||||
cfg_injection = control_mode == "more_control" or control_mode == "unbalanced"
|
||||
|
||||
@@ -662,7 +662,7 @@ def default_ramcache() -> float:
|
||||
|
||||
def default_startup_options(init_file: Path) -> Namespace:
|
||||
opts = InvokeAIAppConfig.get_config()
|
||||
opts.ram = opts.ram or default_ramcache()
|
||||
opts.ram = default_ramcache()
|
||||
return opts
|
||||
|
||||
|
||||
|
||||
@@ -335,7 +335,7 @@ class ModelInstall(object):
|
||||
# list all the files in the repo
|
||||
files = [x.rfilename for x in hinfo.siblings]
|
||||
if subfolder:
|
||||
files = [x for x in files if x.startswith(f"{subfolder}/")]
|
||||
files = [x for x in files if x.startswith("v2/")]
|
||||
prefix = f"{subfolder}/" if subfolder else ""
|
||||
|
||||
location = None
|
||||
|
||||
@@ -8,8 +8,6 @@ import torch.nn as nn
|
||||
import torch.nn.functional as F
|
||||
from diffusers.models.attention_processor import AttnProcessor2_0 as DiffusersAttnProcessor2_0
|
||||
|
||||
from invokeai.backend.ip_adapter.ip_attention_weights import IPAttentionProcessorWeights
|
||||
|
||||
|
||||
# Create a version of AttnProcessor2_0 that is a sub-class of nn.Module. This is required for IP-Adapter state_dict
|
||||
# loading.
|
||||
@@ -47,16 +45,18 @@ class IPAttnProcessor2_0(torch.nn.Module):
|
||||
the weight scale of image prompt.
|
||||
"""
|
||||
|
||||
def __init__(self, weights: list[IPAttentionProcessorWeights], scales: list[float]):
|
||||
def __init__(self, hidden_size, cross_attention_dim=None, scale=1.0):
|
||||
super().__init__()
|
||||
|
||||
if not hasattr(F, "scaled_dot_product_attention"):
|
||||
raise ImportError("AttnProcessor2_0 requires PyTorch 2.0, to use it, please upgrade PyTorch to 2.0.")
|
||||
|
||||
assert len(weights) == len(scales)
|
||||
self.hidden_size = hidden_size
|
||||
self.cross_attention_dim = cross_attention_dim
|
||||
self.scale = scale
|
||||
|
||||
self._weights = weights
|
||||
self._scales = scales
|
||||
self.to_k_ip = nn.Linear(cross_attention_dim or hidden_size, hidden_size, bias=False)
|
||||
self.to_v_ip = nn.Linear(cross_attention_dim or hidden_size, hidden_size, bias=False)
|
||||
|
||||
def __call__(
|
||||
self,
|
||||
@@ -67,6 +67,16 @@ class IPAttnProcessor2_0(torch.nn.Module):
|
||||
temb=None,
|
||||
ip_adapter_image_prompt_embeds=None,
|
||||
):
|
||||
if encoder_hidden_states is not None:
|
||||
# If encoder_hidden_states is not None, then we are doing cross-attention, not self-attention. In this case,
|
||||
# we will apply IP-Adapter conditioning. We validate the inputs for IP-Adapter conditioning here.
|
||||
assert ip_adapter_image_prompt_embeds is not None
|
||||
# The batch dimensions should match.
|
||||
assert ip_adapter_image_prompt_embeds.shape[0] == encoder_hidden_states.shape[0]
|
||||
# The channel dimensions should match.
|
||||
assert ip_adapter_image_prompt_embeds.shape[2] == encoder_hidden_states.shape[2]
|
||||
ip_hidden_states = ip_adapter_image_prompt_embeds
|
||||
|
||||
residual = hidden_states
|
||||
|
||||
if attn.spatial_norm is not None:
|
||||
@@ -118,36 +128,23 @@ class IPAttnProcessor2_0(torch.nn.Module):
|
||||
hidden_states = hidden_states.transpose(1, 2).reshape(batch_size, -1, attn.heads * head_dim)
|
||||
hidden_states = hidden_states.to(query.dtype)
|
||||
|
||||
if encoder_hidden_states is not None:
|
||||
# If encoder_hidden_states is not None, then we are doing cross-attention, not self-attention. In this case,
|
||||
# we will apply IP-Adapter conditioning. We validate the inputs for IP-Adapter conditioning here.
|
||||
assert ip_adapter_image_prompt_embeds is not None
|
||||
assert len(ip_adapter_image_prompt_embeds) == len(self._weights)
|
||||
if ip_hidden_states is not None:
|
||||
ip_key = self.to_k_ip(ip_hidden_states)
|
||||
ip_value = self.to_v_ip(ip_hidden_states)
|
||||
|
||||
for ipa_embed, ipa_weights, scale in zip(ip_adapter_image_prompt_embeds, self._weights, self._scales):
|
||||
# The batch dimensions should match.
|
||||
assert ipa_embed.shape[0] == encoder_hidden_states.shape[0]
|
||||
# The channel dimensions should match.
|
||||
assert ipa_embed.shape[2] == encoder_hidden_states.shape[2]
|
||||
ip_key = ip_key.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
||||
ip_value = ip_value.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
||||
|
||||
ip_hidden_states = ipa_embed
|
||||
# the output of sdp = (batch, num_heads, seq_len, head_dim)
|
||||
# TODO: add support for attn.scale when we move to Torch 2.1
|
||||
ip_hidden_states = F.scaled_dot_product_attention(
|
||||
query, ip_key, ip_value, attn_mask=None, dropout_p=0.0, is_causal=False
|
||||
)
|
||||
|
||||
ip_key = ipa_weights.to_k_ip(ip_hidden_states)
|
||||
ip_value = ipa_weights.to_v_ip(ip_hidden_states)
|
||||
ip_hidden_states = ip_hidden_states.transpose(1, 2).reshape(batch_size, -1, attn.heads * head_dim)
|
||||
ip_hidden_states = ip_hidden_states.to(query.dtype)
|
||||
|
||||
ip_key = ip_key.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
||||
ip_value = ip_value.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
||||
|
||||
# The output of sdpa has shape: (batch, num_heads, seq_len, head_dim)
|
||||
# TODO: add support for attn.scale when we move to Torch 2.1
|
||||
ip_hidden_states = F.scaled_dot_product_attention(
|
||||
query, ip_key, ip_value, attn_mask=None, dropout_p=0.0, is_causal=False
|
||||
)
|
||||
|
||||
ip_hidden_states = ip_hidden_states.transpose(1, 2).reshape(batch_size, -1, attn.heads * head_dim)
|
||||
ip_hidden_states = ip_hidden_states.to(query.dtype)
|
||||
|
||||
hidden_states = hidden_states + scale * ip_hidden_states
|
||||
hidden_states = hidden_states + self.scale * ip_hidden_states
|
||||
|
||||
# linear proj
|
||||
hidden_states = attn.to_out[0](hidden_states)
|
||||
|
||||
@@ -1,15 +1,17 @@
|
||||
# copied from https://github.com/tencent-ailab/IP-Adapter (Apache License 2.0)
|
||||
# and modified as needed
|
||||
|
||||
from contextlib import contextmanager
|
||||
from typing import Optional, Union
|
||||
|
||||
import torch
|
||||
from diffusers.models import UNet2DConditionModel
|
||||
from PIL import Image
|
||||
from transformers import CLIPImageProcessor, CLIPVisionModelWithProjection
|
||||
|
||||
from invokeai.backend.ip_adapter.ip_attention_weights import IPAttentionWeights
|
||||
from invokeai.backend.model_management.models.base import calc_model_size_by_data
|
||||
|
||||
from .attention_processor import AttnProcessor2_0, IPAttnProcessor2_0
|
||||
from .resampler import Resampler
|
||||
|
||||
|
||||
@@ -59,7 +61,7 @@ class IPAdapter:
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
state_dict: dict[str, torch.Tensor],
|
||||
state_dict: dict[torch.Tensor],
|
||||
device: torch.device,
|
||||
dtype: torch.dtype = torch.float16,
|
||||
num_tokens: int = 4,
|
||||
@@ -71,11 +73,12 @@ class IPAdapter:
|
||||
|
||||
self._clip_image_processor = CLIPImageProcessor()
|
||||
|
||||
self._image_proj_model = self._init_image_proj_model(state_dict["image_proj"])
|
||||
self._state_dict = state_dict
|
||||
|
||||
self.attn_weights = IPAttentionWeights.from_state_dict(state_dict["ip_adapter"]).to(
|
||||
self.device, dtype=self.dtype
|
||||
)
|
||||
self._image_proj_model = self._init_image_proj_model(self._state_dict["image_proj"])
|
||||
|
||||
# The _attn_processors will be initialized later when we have access to the UNet.
|
||||
self._attn_processors = None
|
||||
|
||||
def to(self, device: torch.device, dtype: Optional[torch.dtype] = None):
|
||||
self.device = device
|
||||
@@ -83,14 +86,99 @@ class IPAdapter:
|
||||
self.dtype = dtype
|
||||
|
||||
self._image_proj_model.to(device=self.device, dtype=self.dtype)
|
||||
self.attn_weights.to(device=self.device, dtype=self.dtype)
|
||||
if self._attn_processors is not None:
|
||||
torch.nn.ModuleList(self._attn_processors.values()).to(device=self.device, dtype=self.dtype)
|
||||
|
||||
def calc_size(self):
|
||||
return calc_model_size_by_data(self._image_proj_model) + calc_model_size_by_data(self.attn_weights)
|
||||
if self._state_dict is not None:
|
||||
image_proj_size = sum(
|
||||
[tensor.nelement() * tensor.element_size() for tensor in self._state_dict["image_proj"].values()]
|
||||
)
|
||||
ip_adapter_size = sum(
|
||||
[tensor.nelement() * tensor.element_size() for tensor in self._state_dict["ip_adapter"].values()]
|
||||
)
|
||||
return image_proj_size + ip_adapter_size
|
||||
else:
|
||||
return calc_model_size_by_data(self._image_proj_model) + calc_model_size_by_data(
|
||||
torch.nn.ModuleList(self._attn_processors.values())
|
||||
)
|
||||
|
||||
def _init_image_proj_model(self, state_dict):
|
||||
return ImageProjModel.from_state_dict(state_dict, self._num_tokens).to(self.device, dtype=self.dtype)
|
||||
|
||||
def _prepare_attention_processors(self, unet: UNet2DConditionModel):
|
||||
"""Prepare a dict of attention processors that can later be injected into a unet, and load the IP-Adapter
|
||||
attention weights into them.
|
||||
|
||||
Note that the `unet` param is only used to determine attention block dimensions and naming.
|
||||
TODO(ryand): As a future improvement, this could all be inferred from the state_dict when the IPAdapter is
|
||||
intialized.
|
||||
"""
|
||||
attn_procs = {}
|
||||
for name in unet.attn_processors.keys():
|
||||
cross_attention_dim = None if name.endswith("attn1.processor") else unet.config.cross_attention_dim
|
||||
if name.startswith("mid_block"):
|
||||
hidden_size = unet.config.block_out_channels[-1]
|
||||
elif name.startswith("up_blocks"):
|
||||
block_id = int(name[len("up_blocks.")])
|
||||
hidden_size = list(reversed(unet.config.block_out_channels))[block_id]
|
||||
elif name.startswith("down_blocks"):
|
||||
block_id = int(name[len("down_blocks.")])
|
||||
hidden_size = unet.config.block_out_channels[block_id]
|
||||
if cross_attention_dim is None:
|
||||
attn_procs[name] = AttnProcessor2_0()
|
||||
else:
|
||||
attn_procs[name] = IPAttnProcessor2_0(
|
||||
hidden_size=hidden_size,
|
||||
cross_attention_dim=cross_attention_dim,
|
||||
scale=1.0,
|
||||
).to(self.device, dtype=self.dtype)
|
||||
|
||||
ip_layers = torch.nn.ModuleList(attn_procs.values())
|
||||
ip_layers.load_state_dict(self._state_dict["ip_adapter"])
|
||||
self._attn_processors = attn_procs
|
||||
self._state_dict = None
|
||||
|
||||
# @genomancer: pushed scaling back out into its own method (like original Tencent implementation)
|
||||
# which makes implementing begin_step_percent and end_step_percent easier
|
||||
# but based on self._attn_processors (ala @Ryan) instead of original Tencent unet.attn_processors,
|
||||
# which should make it easier to implement multiple IPAdapters
|
||||
def set_scale(self, scale):
|
||||
if self._attn_processors is not None:
|
||||
for attn_processor in self._attn_processors.values():
|
||||
if isinstance(attn_processor, IPAttnProcessor2_0):
|
||||
attn_processor.scale = scale
|
||||
|
||||
@contextmanager
|
||||
def apply_ip_adapter_attention(self, unet: UNet2DConditionModel, scale: float):
|
||||
"""A context manager that patches `unet` with this IP-Adapter's attention processors while it is active.
|
||||
|
||||
Yields:
|
||||
None
|
||||
"""
|
||||
if self._attn_processors is None:
|
||||
# We only have to call _prepare_attention_processors(...) once, and then the result is cached and can be
|
||||
# used on any UNet model (with the same dimensions).
|
||||
self._prepare_attention_processors(unet)
|
||||
|
||||
# Set scale
|
||||
self.set_scale(scale)
|
||||
# for attn_processor in self._attn_processors.values():
|
||||
# if isinstance(attn_processor, IPAttnProcessor2_0):
|
||||
# attn_processor.scale = scale
|
||||
|
||||
orig_attn_processors = unet.attn_processors
|
||||
|
||||
# Make a (moderately-) shallow copy of the self._attn_processors dict, because unet.set_attn_processor(...)
|
||||
# actually pops elements from the passed dict.
|
||||
ip_adapter_attn_processors = {k: v for k, v in self._attn_processors.items()}
|
||||
|
||||
try:
|
||||
unet.set_attn_processor(ip_adapter_attn_processors)
|
||||
yield None
|
||||
finally:
|
||||
unet.set_attn_processor(orig_attn_processors)
|
||||
|
||||
@torch.inference_mode()
|
||||
def get_image_embeds(self, pil_image, image_encoder: CLIPVisionModelWithProjection):
|
||||
if isinstance(pil_image, Image.Image):
|
||||
@@ -130,20 +218,6 @@ class IPAdapterPlus(IPAdapter):
|
||||
return image_prompt_embeds, uncond_image_prompt_embeds
|
||||
|
||||
|
||||
class IPAdapterPlusXL(IPAdapterPlus):
|
||||
"""IP-Adapter Plus for SDXL."""
|
||||
|
||||
def _init_image_proj_model(self, state_dict):
|
||||
return Resampler.from_state_dict(
|
||||
state_dict=state_dict,
|
||||
depth=4,
|
||||
dim_head=64,
|
||||
heads=20,
|
||||
num_queries=self._num_tokens,
|
||||
ff_mult=4,
|
||||
).to(self.device, dtype=self.dtype)
|
||||
|
||||
|
||||
def build_ip_adapter(
|
||||
ip_adapter_ckpt_path: str, device: torch.device, dtype: torch.dtype = torch.float16
|
||||
) -> Union[IPAdapter, IPAdapterPlus]:
|
||||
@@ -154,14 +228,6 @@ def build_ip_adapter(
|
||||
is_plus = "proj.weight" not in state_dict["image_proj"]
|
||||
|
||||
if is_plus:
|
||||
cross_attention_dim = state_dict["ip_adapter"]["1.to_k_ip.weight"].shape[-1]
|
||||
if cross_attention_dim == 768:
|
||||
# SD1 IP-Adapter Plus
|
||||
return IPAdapterPlus(state_dict, device=device, dtype=dtype)
|
||||
elif cross_attention_dim == 2048:
|
||||
# SDXL IP-Adapter Plus
|
||||
return IPAdapterPlusXL(state_dict, device=device, dtype=dtype)
|
||||
else:
|
||||
raise Exception(f"Unsupported IP-Adapter Plus cross-attention dimension: {cross_attention_dim}.")
|
||||
return IPAdapterPlus(state_dict, device=device, dtype=dtype)
|
||||
else:
|
||||
return IPAdapter(state_dict, device=device, dtype=dtype)
|
||||
|
||||
@@ -1,46 +0,0 @@
|
||||
import torch
|
||||
|
||||
|
||||
class IPAttentionProcessorWeights(torch.nn.Module):
|
||||
"""The IP-Adapter weights for a single attention processor.
|
||||
|
||||
This class is a torch.nn.Module sub-class to facilitate loading from a state_dict. It does not have a forward(...)
|
||||
method.
|
||||
"""
|
||||
|
||||
def __init__(self, in_dim: int, out_dim: int):
|
||||
super().__init__()
|
||||
self.to_k_ip = torch.nn.Linear(in_dim, out_dim, bias=False)
|
||||
self.to_v_ip = torch.nn.Linear(in_dim, out_dim, bias=False)
|
||||
|
||||
|
||||
class IPAttentionWeights(torch.nn.Module):
|
||||
"""A collection of all the `IPAttentionProcessorWeights` objects for an IP-Adapter model.
|
||||
|
||||
This class is a torch.nn.Module sub-class so that it inherits the `.to(...)` functionality. It does not have a
|
||||
forward(...) method.
|
||||
"""
|
||||
|
||||
def __init__(self, weights: torch.nn.ModuleDict):
|
||||
super().__init__()
|
||||
self._weights = weights
|
||||
|
||||
def get_attention_processor_weights(self, idx: int) -> IPAttentionProcessorWeights:
|
||||
"""Get the `IPAttentionProcessorWeights` for the idx'th attention processor."""
|
||||
# Cast to int first, because we expect the key to represent an int. Then cast back to str, because
|
||||
# `torch.nn.ModuleDict` only supports str keys.
|
||||
return self._weights[str(int(idx))]
|
||||
|
||||
@classmethod
|
||||
def from_state_dict(cls, state_dict: dict[str, torch.Tensor]):
|
||||
attn_proc_weights: dict[str, IPAttentionProcessorWeights] = {}
|
||||
|
||||
for tensor_name, tensor in state_dict.items():
|
||||
if "to_k_ip.weight" in tensor_name:
|
||||
index = str(int(tensor_name.split(".")[0]))
|
||||
attn_proc_weights[index] = IPAttentionProcessorWeights(tensor.shape[1], tensor.shape[0])
|
||||
|
||||
attn_proc_weights_module = torch.nn.ModuleDict(attn_proc_weights)
|
||||
attn_proc_weights_module.load_state_dict(state_dict)
|
||||
|
||||
return cls(attn_proc_weights_module)
|
||||
@@ -1,53 +0,0 @@
|
||||
from contextlib import contextmanager
|
||||
|
||||
from diffusers.models import UNet2DConditionModel
|
||||
|
||||
from invokeai.backend.ip_adapter.attention_processor import AttnProcessor2_0, IPAttnProcessor2_0
|
||||
from invokeai.backend.ip_adapter.ip_adapter import IPAdapter
|
||||
|
||||
|
||||
class UNetPatcher:
|
||||
"""A class that contains multiple IP-Adapters and can apply them to a UNet."""
|
||||
|
||||
def __init__(self, ip_adapters: list[IPAdapter]):
|
||||
self._ip_adapters = ip_adapters
|
||||
self._scales = [1.0] * len(self._ip_adapters)
|
||||
|
||||
def set_scale(self, idx: int, value: float):
|
||||
self._scales[idx] = value
|
||||
|
||||
def _prepare_attention_processors(self, unet: UNet2DConditionModel):
|
||||
"""Prepare a dict of attention processors that can be injected into a unet, and load the IP-Adapter attention
|
||||
weights into them.
|
||||
|
||||
Note that the `unet` param is only used to determine attention block dimensions and naming.
|
||||
"""
|
||||
# Construct a dict of attention processors based on the UNet's architecture.
|
||||
attn_procs = {}
|
||||
for idx, name in enumerate(unet.attn_processors.keys()):
|
||||
if name.endswith("attn1.processor"):
|
||||
attn_procs[name] = AttnProcessor2_0()
|
||||
else:
|
||||
# Collect the weights from each IP Adapter for the idx'th attention processor.
|
||||
attn_procs[name] = IPAttnProcessor2_0(
|
||||
[ip_adapter.attn_weights.get_attention_processor_weights(idx) for ip_adapter in self._ip_adapters],
|
||||
self._scales,
|
||||
)
|
||||
return attn_procs
|
||||
|
||||
@contextmanager
|
||||
def apply_ip_adapter_attention(self, unet: UNet2DConditionModel):
|
||||
"""A context manager that patches `unet` with IP-Adapter attention processors."""
|
||||
|
||||
attn_procs = self._prepare_attention_processors(unet)
|
||||
|
||||
orig_attn_processors = unet.attn_processors
|
||||
|
||||
try:
|
||||
# Note to future devs: set_attn_processor(...) does something slightly unexpected - it pops elements from the
|
||||
# passed dict. So, if you wanted to keep the dict for future use, you'd have to make a moderately-shallow copy
|
||||
# of it. E.g. `attn_procs_copy = {k: v for k, v in attn_procs.items()}`.
|
||||
unet.set_attn_processor(attn_procs)
|
||||
yield None
|
||||
finally:
|
||||
unet.set_attn_processor(orig_attn_processors)
|
||||
@@ -1,27 +0,0 @@
|
||||
# Model Cache
|
||||
|
||||
## `glibc` Memory Allocator Fragmentation
|
||||
|
||||
Python (and PyTorch) relies on the memory allocator from the C Standard Library (`libc`). On linux, with the GNU C Standard Library implementation (`glibc`), our memory access patterns have been observed to cause severe memory fragmentation. This fragmentation results in large amounts of memory that has been freed but can't be released back to the OS. Loading models from disk and moving them between CPU/CUDA seem to be the operations that contribute most to the fragmentation. This memory fragmentation issue can result in OOM crashes during frequent model switching, even if `max_cache_size` is set to a reasonable value (e.g. a OOM crash with `max_cache_size=16` on a system with 32GB of RAM).
|
||||
|
||||
This problem may also exist on other OSes, and other `libc` implementations. But, at the time of writing, it has only been investigated on linux with `glibc`.
|
||||
|
||||
To better understand how the `glibc` memory allocator works, see these references:
|
||||
- Basics: https://www.gnu.org/software/libc/manual/html_node/The-GNU-Allocator.html
|
||||
- Details: https://sourceware.org/glibc/wiki/MallocInternals
|
||||
|
||||
Note the differences between memory allocated as chunks in an arena vs. memory allocated with `mmap`. Under `glibc`'s default configuration, most model tensors get allocated as chunks in an arena making them vulnerable to the problem of fragmentation.
|
||||
|
||||
We can work around this memory fragmentation issue by setting the following env var:
|
||||
|
||||
```bash
|
||||
# Force blocks >1MB to be allocated with `mmap` so that they are released to the system immediately when they are freed.
|
||||
MALLOC_MMAP_THRESHOLD_=1048576
|
||||
```
|
||||
|
||||
See the following references for more information about the `malloc` tunable parameters:
|
||||
- https://www.gnu.org/software/libc/manual/html_node/Malloc-Tunable-Parameters.html
|
||||
- https://www.gnu.org/software/libc/manual/html_node/Memory-Allocation-Tunables.html
|
||||
- https://man7.org/linux/man-pages/man3/mallopt.3.html
|
||||
|
||||
The model cache emits debug logs that provide visibility into the state of the `libc` memory allocator. See the `LibcUtil` class for more info on how these `libc` malloc stats are collected.
|
||||
@@ -1,75 +0,0 @@
|
||||
import ctypes
|
||||
|
||||
|
||||
class Struct_mallinfo2(ctypes.Structure):
|
||||
"""A ctypes Structure that matches the libc mallinfo2 struct.
|
||||
|
||||
Docs:
|
||||
- https://man7.org/linux/man-pages/man3/mallinfo.3.html
|
||||
- https://www.gnu.org/software/libc/manual/html_node/Statistics-of-Malloc.html
|
||||
|
||||
struct mallinfo2 {
|
||||
size_t arena; /* Non-mmapped space allocated (bytes) */
|
||||
size_t ordblks; /* Number of free chunks */
|
||||
size_t smblks; /* Number of free fastbin blocks */
|
||||
size_t hblks; /* Number of mmapped regions */
|
||||
size_t hblkhd; /* Space allocated in mmapped regions (bytes) */
|
||||
size_t usmblks; /* See below */
|
||||
size_t fsmblks; /* Space in freed fastbin blocks (bytes) */
|
||||
size_t uordblks; /* Total allocated space (bytes) */
|
||||
size_t fordblks; /* Total free space (bytes) */
|
||||
size_t keepcost; /* Top-most, releasable space (bytes) */
|
||||
};
|
||||
"""
|
||||
|
||||
_fields_ = [
|
||||
("arena", ctypes.c_size_t),
|
||||
("ordblks", ctypes.c_size_t),
|
||||
("smblks", ctypes.c_size_t),
|
||||
("hblks", ctypes.c_size_t),
|
||||
("hblkhd", ctypes.c_size_t),
|
||||
("usmblks", ctypes.c_size_t),
|
||||
("fsmblks", ctypes.c_size_t),
|
||||
("uordblks", ctypes.c_size_t),
|
||||
("fordblks", ctypes.c_size_t),
|
||||
("keepcost", ctypes.c_size_t),
|
||||
]
|
||||
|
||||
def __str__(self):
|
||||
s = ""
|
||||
s += f"{'arena': <10}= {(self.arena/2**30):15.5f} # Non-mmapped space allocated (GB) (uordblks + fordblks)\n"
|
||||
s += f"{'ordblks': <10}= {(self.ordblks): >15} # Number of free chunks\n"
|
||||
s += f"{'smblks': <10}= {(self.smblks): >15} # Number of free fastbin blocks \n"
|
||||
s += f"{'hblks': <10}= {(self.hblks): >15} # Number of mmapped regions \n"
|
||||
s += f"{'hblkhd': <10}= {(self.hblkhd/2**30):15.5f} # Space allocated in mmapped regions (GB)\n"
|
||||
s += f"{'usmblks': <10}= {(self.usmblks): >15} # Unused\n"
|
||||
s += f"{'fsmblks': <10}= {(self.fsmblks/2**30):15.5f} # Space in freed fastbin blocks (GB)\n"
|
||||
s += (
|
||||
f"{'uordblks': <10}= {(self.uordblks/2**30):15.5f} # Space used by in-use allocations (non-mmapped)"
|
||||
" (GB)\n"
|
||||
)
|
||||
s += f"{'fordblks': <10}= {(self.fordblks/2**30):15.5f} # Space in free blocks (non-mmapped) (GB)\n"
|
||||
s += f"{'keepcost': <10}= {(self.keepcost/2**30):15.5f} # Top-most, releasable space (GB)\n"
|
||||
return s
|
||||
|
||||
|
||||
class LibcUtil:
|
||||
"""A utility class for interacting with the C Standard Library (`libc`) via ctypes.
|
||||
|
||||
Note that this class will raise on __init__() if 'libc.so.6' can't be found. Take care to handle environments where
|
||||
this shared library is not available.
|
||||
|
||||
TODO: Improve cross-OS compatibility of this class.
|
||||
"""
|
||||
|
||||
def __init__(self):
|
||||
self._libc = ctypes.cdll.LoadLibrary("libc.so.6")
|
||||
|
||||
def mallinfo2(self) -> Struct_mallinfo2:
|
||||
"""Calls `libc` `mallinfo2`.
|
||||
|
||||
Docs: https://man7.org/linux/man-pages/man3/mallinfo.3.html
|
||||
"""
|
||||
mallinfo2 = self._libc.mallinfo2
|
||||
mallinfo2.restype = Struct_mallinfo2
|
||||
return mallinfo2()
|
||||
@@ -1,96 +0,0 @@
|
||||
import gc
|
||||
from typing import Optional
|
||||
|
||||
import psutil
|
||||
import torch
|
||||
|
||||
from invokeai.backend.model_management.libc_util import LibcUtil, Struct_mallinfo2
|
||||
|
||||
GB = 2**30 # 1 GB
|
||||
|
||||
|
||||
class MemorySnapshot:
|
||||
"""A snapshot of RAM and VRAM usage. All values are in bytes."""
|
||||
|
||||
def __init__(self, process_ram: int, vram: Optional[int], malloc_info: Optional[Struct_mallinfo2]):
|
||||
"""Initialize a MemorySnapshot.
|
||||
|
||||
Most of the time, `MemorySnapshot` will be constructed with `MemorySnapshot.capture()`.
|
||||
|
||||
Args:
|
||||
process_ram (int): CPU RAM used by the current process.
|
||||
vram (Optional[int]): VRAM used by torch.
|
||||
malloc_info (Optional[Struct_mallinfo2]): Malloc info obtained from LibcUtil.
|
||||
"""
|
||||
self.process_ram = process_ram
|
||||
self.vram = vram
|
||||
self.malloc_info = malloc_info
|
||||
|
||||
@classmethod
|
||||
def capture(cls, run_garbage_collector: bool = True):
|
||||
"""Capture and return a MemorySnapshot.
|
||||
|
||||
Note: This function has significant overhead, particularly if `run_garbage_collector == True`.
|
||||
|
||||
Args:
|
||||
run_garbage_collector (bool, optional): If true, gc.collect() will be run before checking the process RAM
|
||||
usage. Defaults to True.
|
||||
|
||||
Returns:
|
||||
MemorySnapshot
|
||||
"""
|
||||
if run_garbage_collector:
|
||||
gc.collect()
|
||||
|
||||
# According to the psutil docs (https://psutil.readthedocs.io/en/latest/#psutil.Process.memory_info), rss is
|
||||
# supported on all platforms.
|
||||
process_ram = psutil.Process().memory_info().rss
|
||||
|
||||
if torch.cuda.is_available():
|
||||
vram = torch.cuda.memory_allocated()
|
||||
else:
|
||||
# TODO: We could add support for mps.current_allocated_memory() as well. Leaving out for now until we have
|
||||
# time to test it properly.
|
||||
vram = None
|
||||
|
||||
try:
|
||||
malloc_info = LibcUtil().mallinfo2()
|
||||
except (OSError, AttributeError):
|
||||
# OSError: This is expected in environments that do not have the 'libc.so.6' shared library.
|
||||
# AttributeError: This is expected in environments that have `libc.so.6` but do not have the `mallinfo2` (e.g. glibc < 2.33)
|
||||
# TODO: Does `mallinfo` work?
|
||||
malloc_info = None
|
||||
|
||||
return cls(process_ram, vram, malloc_info)
|
||||
|
||||
|
||||
def get_pretty_snapshot_diff(snapshot_1: MemorySnapshot, snapshot_2: MemorySnapshot) -> str:
|
||||
"""Get a pretty string describing the difference between two `MemorySnapshot`s."""
|
||||
|
||||
def get_msg_line(prefix: str, val1: int, val2: int):
|
||||
diff = val2 - val1
|
||||
return f"{prefix: <30} ({(diff/GB):+5.3f}): {(val1/GB):5.3f}GB -> {(val2/GB):5.3f}GB\n"
|
||||
|
||||
msg = ""
|
||||
|
||||
msg += get_msg_line("Process RAM", snapshot_1.process_ram, snapshot_2.process_ram)
|
||||
|
||||
if snapshot_1.malloc_info is not None and snapshot_2.malloc_info is not None:
|
||||
msg += get_msg_line("libc mmap allocated", snapshot_1.malloc_info.hblkhd, snapshot_2.malloc_info.hblkhd)
|
||||
|
||||
msg += get_msg_line("libc arena used", snapshot_1.malloc_info.uordblks, snapshot_2.malloc_info.uordblks)
|
||||
|
||||
msg += get_msg_line("libc arena free", snapshot_1.malloc_info.fordblks, snapshot_2.malloc_info.fordblks)
|
||||
|
||||
libc_total_allocated_1 = snapshot_1.malloc_info.arena + snapshot_1.malloc_info.hblkhd
|
||||
libc_total_allocated_2 = snapshot_2.malloc_info.arena + snapshot_2.malloc_info.hblkhd
|
||||
msg += get_msg_line("libc total allocated", libc_total_allocated_1, libc_total_allocated_2)
|
||||
|
||||
libc_total_used_1 = snapshot_1.malloc_info.uordblks + snapshot_1.malloc_info.hblkhd
|
||||
libc_total_used_2 = snapshot_2.malloc_info.uordblks + snapshot_2.malloc_info.hblkhd
|
||||
msg += get_msg_line("libc total used", libc_total_used_1, libc_total_used_2)
|
||||
|
||||
if snapshot_1.vram is not None and snapshot_2.vram is not None:
|
||||
msg += get_msg_line("VRAM", snapshot_1.vram, snapshot_2.vram)
|
||||
|
||||
return msg
|
||||
@@ -18,10 +18,8 @@ context. Use like this:
|
||||
|
||||
import gc
|
||||
import hashlib
|
||||
import math
|
||||
import os
|
||||
import sys
|
||||
import time
|
||||
from contextlib import suppress
|
||||
from dataclasses import dataclass, field
|
||||
from pathlib import Path
|
||||
@@ -30,8 +28,6 @@ from typing import Any, Dict, Optional, Type, Union, types
|
||||
import torch
|
||||
|
||||
import invokeai.backend.util.logging as logger
|
||||
from invokeai.backend.model_management.memory_snapshot import MemorySnapshot, get_pretty_snapshot_diff
|
||||
from invokeai.backend.model_management.model_load_optimizations import skip_torch_weight_init
|
||||
|
||||
from ..util.devices import choose_torch_device
|
||||
from .models import BaseModelType, ModelBase, ModelType, SubModelType
|
||||
@@ -48,8 +44,6 @@ DEFAULT_MAX_VRAM_CACHE_SIZE = 2.75
|
||||
|
||||
# actual size of a gig
|
||||
GIG = 1073741824
|
||||
# Size of a MB in bytes.
|
||||
MB = 2**20
|
||||
|
||||
|
||||
@dataclass
|
||||
@@ -211,41 +205,22 @@ class ModelCache(object):
|
||||
cache_entry = self._cached_models.get(key, None)
|
||||
if cache_entry is None:
|
||||
self.logger.info(
|
||||
f"Loading model {model_path}, type"
|
||||
f" {base_model.value}:{model_type.value}{':'+submodel.value if submodel else ''}"
|
||||
f"Loading model {model_path}, type {base_model.value}:{model_type.value}{':'+submodel.value if submodel else ''}"
|
||||
)
|
||||
if self.stats:
|
||||
self.stats.misses += 1
|
||||
|
||||
self_reported_model_size_before_load = model_info.get_size(submodel)
|
||||
# Remove old models from the cache to make room for the new model.
|
||||
self._make_cache_room(self_reported_model_size_before_load)
|
||||
# this will remove older cached models until
|
||||
# there is sufficient room to load the requested model
|
||||
self._make_cache_room(model_info.get_size(submodel))
|
||||
|
||||
# Load the model from disk and capture a memory snapshot before/after.
|
||||
start_load_time = time.time()
|
||||
snapshot_before = MemorySnapshot.capture()
|
||||
with skip_torch_weight_init():
|
||||
model = model_info.get_model(child_type=submodel, torch_dtype=self.precision)
|
||||
snapshot_after = MemorySnapshot.capture()
|
||||
end_load_time = time.time()
|
||||
# clean memory to make MemoryUsage() more accurate
|
||||
gc.collect()
|
||||
model = model_info.get_model(child_type=submodel, torch_dtype=self.precision)
|
||||
if mem_used := model_info.get_size(submodel):
|
||||
self.logger.debug(f"CPU RAM used for load: {(mem_used/GIG):.2f} GB")
|
||||
|
||||
self_reported_model_size_after_load = model_info.get_size(submodel)
|
||||
|
||||
self.logger.debug(
|
||||
f"Moved model '{key}' from disk to cpu in {(end_load_time-start_load_time):.2f}s.\n"
|
||||
f"Self-reported size before/after load: {(self_reported_model_size_before_load/GIG):.3f}GB /"
|
||||
f" {(self_reported_model_size_after_load/GIG):.3f}GB.\n"
|
||||
f"{get_pretty_snapshot_diff(snapshot_before, snapshot_after)}"
|
||||
)
|
||||
|
||||
if abs(self_reported_model_size_after_load - self_reported_model_size_before_load) > 10 * MB:
|
||||
self.logger.debug(
|
||||
f"Model '{key}' mis-reported its size before load. Self-reported size before/after load:"
|
||||
f" {(self_reported_model_size_before_load/GIG):.2f}GB /"
|
||||
f" {(self_reported_model_size_after_load/GIG):.2f}GB."
|
||||
)
|
||||
|
||||
cache_entry = _CacheRecord(self, model, self_reported_model_size_after_load)
|
||||
cache_entry = _CacheRecord(self, model, mem_used)
|
||||
self._cached_models[key] = cache_entry
|
||||
else:
|
||||
if self.stats:
|
||||
@@ -265,45 +240,6 @@ class ModelCache(object):
|
||||
|
||||
return self.ModelLocker(self, key, cache_entry.model, gpu_load, cache_entry.size)
|
||||
|
||||
def _move_model_to_device(self, key: str, target_device: torch.device):
|
||||
cache_entry = self._cached_models[key]
|
||||
|
||||
source_device = cache_entry.model.device
|
||||
# Note: We compare device types only so that 'cuda' == 'cuda:0'. This would need to be revised to support
|
||||
# multi-GPU.
|
||||
if torch.device(source_device).type == torch.device(target_device).type:
|
||||
return
|
||||
|
||||
start_model_to_time = time.time()
|
||||
snapshot_before = MemorySnapshot.capture()
|
||||
cache_entry.model.to(target_device)
|
||||
snapshot_after = MemorySnapshot.capture()
|
||||
end_model_to_time = time.time()
|
||||
self.logger.debug(
|
||||
f"Moved model '{key}' from {source_device} to"
|
||||
f" {target_device} in {(end_model_to_time-start_model_to_time):.2f}s.\n"
|
||||
f"Estimated model size: {(cache_entry.size/GIG):.3f} GB.\n"
|
||||
f"{get_pretty_snapshot_diff(snapshot_before, snapshot_after)}"
|
||||
)
|
||||
|
||||
if snapshot_before.vram is not None and snapshot_after.vram is not None:
|
||||
vram_change = abs(snapshot_before.vram - snapshot_after.vram)
|
||||
|
||||
# If the estimated model size does not match the change in VRAM, log a warning.
|
||||
if not math.isclose(
|
||||
vram_change,
|
||||
cache_entry.size,
|
||||
rel_tol=0.1,
|
||||
abs_tol=10 * MB,
|
||||
):
|
||||
self.logger.debug(
|
||||
f"Moving model '{key}' from {source_device} to"
|
||||
f" {target_device} caused an unexpected change in VRAM usage. The model's"
|
||||
" estimated size may be incorrect. Estimated model size:"
|
||||
f" {(cache_entry.size/GIG):.3f} GB.\n"
|
||||
f"{get_pretty_snapshot_diff(snapshot_before, snapshot_after)}"
|
||||
)
|
||||
|
||||
class ModelLocker(object):
|
||||
def __init__(self, cache, key, model, gpu_load, size_needed):
|
||||
"""
|
||||
@@ -333,7 +269,11 @@ class ModelCache(object):
|
||||
if self.cache.lazy_offloading:
|
||||
self.cache._offload_unlocked_models(self.size_needed)
|
||||
|
||||
self.cache._move_model_to_device(self.key, self.cache.execution_device)
|
||||
if self.model.device != self.cache.execution_device:
|
||||
self.cache.logger.debug(f"Moving {self.key} into {self.cache.execution_device}")
|
||||
with VRAMUsage() as mem:
|
||||
self.model.to(self.cache.execution_device) # move into GPU
|
||||
self.cache.logger.debug(f"GPU VRAM used for load: {(mem.vram_used/GIG):.2f} GB")
|
||||
|
||||
self.cache.logger.debug(f"Locking {self.key} in {self.cache.execution_device}")
|
||||
self.cache._print_cuda_stats()
|
||||
@@ -346,7 +286,7 @@ class ModelCache(object):
|
||||
# in the event that the caller wants the model in RAM, we
|
||||
# move it into CPU if it is in GPU and not locked
|
||||
elif self.cache_entry.loaded and not self.cache_entry.locked:
|
||||
self.cache._move_model_to_device(self.key, self.cache.storage_device)
|
||||
self.model.to(self.cache.storage_device)
|
||||
|
||||
return self.model
|
||||
|
||||
@@ -399,8 +339,7 @@ class ModelCache(object):
|
||||
locked_models += 1
|
||||
|
||||
self.logger.debug(
|
||||
f"Current VRAM/RAM usage: {vram}/{ram}; cached_models/loaded_models/locked_models/ ="
|
||||
f" {cached_models}/{loaded_models}/{locked_models}"
|
||||
f"Current VRAM/RAM usage: {vram}/{ram}; cached_models/loaded_models/locked_models/ = {cached_models}/{loaded_models}/{locked_models}"
|
||||
)
|
||||
|
||||
def _cache_size(self) -> int:
|
||||
@@ -415,8 +354,7 @@ class ModelCache(object):
|
||||
|
||||
if current_size + bytes_needed > maximum_size:
|
||||
self.logger.debug(
|
||||
f"Max cache size exceeded: {(current_size/GIG):.2f}/{self.max_cache_size:.2f} GB, need an additional"
|
||||
f" {(bytes_needed/GIG):.2f} GB"
|
||||
f"Max cache size exceeded: {(current_size/GIG):.2f}/{self.max_cache_size:.2f} GB, need an additional {(bytes_needed/GIG):.2f} GB"
|
||||
)
|
||||
|
||||
self.logger.debug(f"Before unloading: cached_models={len(self._cached_models)}")
|
||||
@@ -449,8 +387,7 @@ class ModelCache(object):
|
||||
|
||||
device = cache_entry.model.device if hasattr(cache_entry.model, "device") else None
|
||||
self.logger.debug(
|
||||
f"Model: {model_key}, locks: {cache_entry._locks}, device: {device}, loaded: {cache_entry.loaded},"
|
||||
f" refs: {refs}"
|
||||
f"Model: {model_key}, locks: {cache_entry._locks}, device: {device}, loaded: {cache_entry.loaded}, refs: {refs}"
|
||||
)
|
||||
|
||||
# 2 refs:
|
||||
@@ -486,9 +423,11 @@ class ModelCache(object):
|
||||
if vram_in_use <= reserved:
|
||||
break
|
||||
if not cache_entry.locked and cache_entry.loaded:
|
||||
self._move_model_to_device(model_key, self.storage_device)
|
||||
|
||||
vram_in_use = torch.cuda.memory_allocated()
|
||||
self.logger.debug(f"Offloading {model_key} from {self.execution_device} into {self.storage_device}")
|
||||
with VRAMUsage() as mem:
|
||||
cache_entry.model.to(self.storage_device)
|
||||
self.logger.debug(f"GPU VRAM freed: {(mem.vram_used/GIG):.2f} GB")
|
||||
vram_in_use += mem.vram_used # note vram_used is negative
|
||||
self.logger.debug(f"{(vram_in_use/GIG):.2f}GB VRAM used for models; max allowed={(reserved/GIG):.2f}GB")
|
||||
|
||||
gc.collect()
|
||||
@@ -515,3 +454,16 @@ class ModelCache(object):
|
||||
with open(hashpath, "w") as f:
|
||||
f.write(hash)
|
||||
return hash
|
||||
|
||||
|
||||
class VRAMUsage(object):
|
||||
def __init__(self):
|
||||
self.vram = None
|
||||
self.vram_used = 0
|
||||
|
||||
def __enter__(self):
|
||||
self.vram = torch.cuda.memory_allocated()
|
||||
return self
|
||||
|
||||
def __exit__(self, *args):
|
||||
self.vram_used = torch.cuda.memory_allocated() - self.vram
|
||||
|
||||
@@ -1,30 +0,0 @@
|
||||
from contextlib import contextmanager
|
||||
|
||||
import torch
|
||||
|
||||
|
||||
def _no_op(*args, **kwargs):
|
||||
pass
|
||||
|
||||
|
||||
@contextmanager
|
||||
def skip_torch_weight_init():
|
||||
"""A context manager that monkey-patches several of the common torch layers (torch.nn.Linear, torch.nn.Conv1d, etc.)
|
||||
to skip weight initialization.
|
||||
|
||||
By default, `torch.nn.Linear` and `torch.nn.ConvNd` layers initialize their weights (according to a particular
|
||||
distribution) when __init__ is called. This weight initialization step can take a significant amount of time, and is
|
||||
completely unnecessary if the intent is to load checkpoint weights from disk for the layer. This context manager
|
||||
monkey-patches common torch layers to skip the weight initialization step.
|
||||
"""
|
||||
torch_modules = [torch.nn.Linear, torch.nn.modules.conv._ConvNd]
|
||||
saved_functions = [m.reset_parameters for m in torch_modules]
|
||||
|
||||
try:
|
||||
for torch_module in torch_modules:
|
||||
torch_module.reset_parameters = _no_op
|
||||
|
||||
yield None
|
||||
finally:
|
||||
for torch_module, saved_function in zip(torch_modules, saved_functions):
|
||||
torch_module.reset_parameters = saved_function
|
||||
@@ -57,7 +57,6 @@ class ModelProbe(object):
|
||||
"AutoencoderTiny": ModelType.Vae,
|
||||
"ControlNetModel": ModelType.ControlNet,
|
||||
"CLIPVisionModelWithProjection": ModelType.CLIPVision,
|
||||
"T2IAdapter": ModelType.T2IAdapter,
|
||||
}
|
||||
|
||||
@classmethod
|
||||
@@ -409,11 +408,6 @@ class CLIPVisionCheckpointProbe(CheckpointProbeBase):
|
||||
raise NotImplementedError()
|
||||
|
||||
|
||||
class T2IAdapterCheckpointProbe(CheckpointProbeBase):
|
||||
def get_base_type(self) -> BaseModelType:
|
||||
raise NotImplementedError()
|
||||
|
||||
|
||||
########################################################
|
||||
# classes for probing folders
|
||||
#######################################################
|
||||
@@ -601,26 +595,6 @@ class CLIPVisionFolderProbe(FolderProbeBase):
|
||||
return BaseModelType.Any
|
||||
|
||||
|
||||
class T2IAdapterFolderProbe(FolderProbeBase):
|
||||
def get_base_type(self) -> BaseModelType:
|
||||
config_file = self.folder_path / "config.json"
|
||||
if not config_file.exists():
|
||||
raise InvalidModelException(f"Cannot determine base type for {self.folder_path}")
|
||||
with open(config_file, "r") as file:
|
||||
config = json.load(file)
|
||||
|
||||
adapter_type = config.get("adapter_type", None)
|
||||
if adapter_type == "full_adapter_xl":
|
||||
return BaseModelType.StableDiffusionXL
|
||||
elif adapter_type == "full_adapter" or "light_adapter":
|
||||
# I haven't seen any T2I adapter models for SD2, so assume that this is an SD1 adapter.
|
||||
return BaseModelType.StableDiffusion1
|
||||
else:
|
||||
raise InvalidModelException(
|
||||
f"Unable to determine base model for '{self.folder_path}' (adapter_type = {adapter_type})."
|
||||
)
|
||||
|
||||
|
||||
############## register probe classes ######
|
||||
ModelProbe.register_probe("diffusers", ModelType.Main, PipelineFolderProbe)
|
||||
ModelProbe.register_probe("diffusers", ModelType.Vae, VaeFolderProbe)
|
||||
@@ -629,7 +603,6 @@ ModelProbe.register_probe("diffusers", ModelType.TextualInversion, TextualInvers
|
||||
ModelProbe.register_probe("diffusers", ModelType.ControlNet, ControlNetFolderProbe)
|
||||
ModelProbe.register_probe("diffusers", ModelType.IPAdapter, IPAdapterFolderProbe)
|
||||
ModelProbe.register_probe("diffusers", ModelType.CLIPVision, CLIPVisionFolderProbe)
|
||||
ModelProbe.register_probe("diffusers", ModelType.T2IAdapter, T2IAdapterFolderProbe)
|
||||
|
||||
ModelProbe.register_probe("checkpoint", ModelType.Main, PipelineCheckpointProbe)
|
||||
ModelProbe.register_probe("checkpoint", ModelType.Vae, VaeCheckpointProbe)
|
||||
@@ -638,6 +611,5 @@ ModelProbe.register_probe("checkpoint", ModelType.TextualInversion, TextualInver
|
||||
ModelProbe.register_probe("checkpoint", ModelType.ControlNet, ControlNetCheckpointProbe)
|
||||
ModelProbe.register_probe("checkpoint", ModelType.IPAdapter, IPAdapterCheckpointProbe)
|
||||
ModelProbe.register_probe("checkpoint", ModelType.CLIPVision, CLIPVisionCheckpointProbe)
|
||||
ModelProbe.register_probe("checkpoint", ModelType.T2IAdapter, T2IAdapterCheckpointProbe)
|
||||
|
||||
ModelProbe.register_probe("onnx", ModelType.ONNX, ONNXFolderProbe)
|
||||
|
||||
@@ -25,7 +25,6 @@ from .lora import LoRAModel
|
||||
from .sdxl import StableDiffusionXLModel
|
||||
from .stable_diffusion import StableDiffusion1Model, StableDiffusion2Model
|
||||
from .stable_diffusion_onnx import ONNXStableDiffusion1Model, ONNXStableDiffusion2Model
|
||||
from .t2i_adapter import T2IAdapterModel
|
||||
from .textual_inversion import TextualInversionModel
|
||||
from .vae import VaeModel
|
||||
|
||||
@@ -39,7 +38,6 @@ MODEL_CLASSES = {
|
||||
ModelType.TextualInversion: TextualInversionModel,
|
||||
ModelType.IPAdapter: IPAdapterModel,
|
||||
ModelType.CLIPVision: CLIPVisionModel,
|
||||
ModelType.T2IAdapter: T2IAdapterModel,
|
||||
},
|
||||
BaseModelType.StableDiffusion2: {
|
||||
ModelType.ONNX: ONNXStableDiffusion2Model,
|
||||
@@ -50,7 +48,6 @@ MODEL_CLASSES = {
|
||||
ModelType.TextualInversion: TextualInversionModel,
|
||||
ModelType.IPAdapter: IPAdapterModel,
|
||||
ModelType.CLIPVision: CLIPVisionModel,
|
||||
ModelType.T2IAdapter: T2IAdapterModel,
|
||||
},
|
||||
BaseModelType.StableDiffusionXL: {
|
||||
ModelType.Main: StableDiffusionXLModel,
|
||||
@@ -62,7 +59,6 @@ MODEL_CLASSES = {
|
||||
ModelType.ONNX: ONNXStableDiffusion2Model,
|
||||
ModelType.IPAdapter: IPAdapterModel,
|
||||
ModelType.CLIPVision: CLIPVisionModel,
|
||||
ModelType.T2IAdapter: T2IAdapterModel,
|
||||
},
|
||||
BaseModelType.StableDiffusionXLRefiner: {
|
||||
ModelType.Main: StableDiffusionXLModel,
|
||||
@@ -74,7 +70,6 @@ MODEL_CLASSES = {
|
||||
ModelType.ONNX: ONNXStableDiffusion2Model,
|
||||
ModelType.IPAdapter: IPAdapterModel,
|
||||
ModelType.CLIPVision: CLIPVisionModel,
|
||||
ModelType.T2IAdapter: T2IAdapterModel,
|
||||
},
|
||||
BaseModelType.Any: {
|
||||
ModelType.CLIPVision: CLIPVisionModel,
|
||||
@@ -86,7 +81,6 @@ MODEL_CLASSES = {
|
||||
ModelType.ControlNet: ControlNetModel,
|
||||
ModelType.TextualInversion: TextualInversionModel,
|
||||
ModelType.IPAdapter: IPAdapterModel,
|
||||
ModelType.T2IAdapter: T2IAdapterModel,
|
||||
},
|
||||
# BaseModelType.Kandinsky2_1: {
|
||||
# ModelType.Main: Kandinsky2_1Model,
|
||||
|
||||
@@ -53,7 +53,6 @@ class ModelType(str, Enum):
|
||||
TextualInversion = "embedding"
|
||||
IPAdapter = "ip_adapter"
|
||||
CLIPVision = "clip_vision"
|
||||
T2IAdapter = "t2i_adapter"
|
||||
|
||||
|
||||
class SubModelType(str, Enum):
|
||||
|
||||
@@ -1,102 +0,0 @@
|
||||
import os
|
||||
from enum import Enum
|
||||
from typing import Literal, Optional
|
||||
|
||||
import torch
|
||||
from diffusers import T2IAdapter
|
||||
|
||||
from invokeai.backend.model_management.models.base import (
|
||||
BaseModelType,
|
||||
EmptyConfigLoader,
|
||||
InvalidModelException,
|
||||
ModelBase,
|
||||
ModelConfigBase,
|
||||
ModelNotFoundException,
|
||||
ModelType,
|
||||
SubModelType,
|
||||
calc_model_size_by_data,
|
||||
calc_model_size_by_fs,
|
||||
classproperty,
|
||||
)
|
||||
|
||||
|
||||
class T2IAdapterModelFormat(str, Enum):
|
||||
Diffusers = "diffusers"
|
||||
|
||||
|
||||
class T2IAdapterModel(ModelBase):
|
||||
class DiffusersConfig(ModelConfigBase):
|
||||
model_format: Literal[T2IAdapterModelFormat.Diffusers]
|
||||
|
||||
def __init__(self, model_path: str, base_model: BaseModelType, model_type: ModelType):
|
||||
assert model_type == ModelType.T2IAdapter
|
||||
super().__init__(model_path, base_model, model_type)
|
||||
|
||||
config = EmptyConfigLoader.load_config(self.model_path, config_name="config.json")
|
||||
|
||||
model_class_name = config.get("_class_name", None)
|
||||
if model_class_name not in {"T2IAdapter"}:
|
||||
raise InvalidModelException(f"Invalid T2I-Adapter model. Unknown _class_name: '{model_class_name}'.")
|
||||
|
||||
self.model_class = self._hf_definition_to_type(["diffusers", model_class_name])
|
||||
self.model_size = calc_model_size_by_fs(self.model_path)
|
||||
|
||||
def get_size(self, child_type: Optional[SubModelType] = None):
|
||||
if child_type is not None:
|
||||
raise ValueError(f"T2I-Adapters do not have child models. Invalid child type: '{child_type}'.")
|
||||
return self.model_size
|
||||
|
||||
def get_model(
|
||||
self,
|
||||
torch_dtype: Optional[torch.dtype],
|
||||
child_type: Optional[SubModelType] = None,
|
||||
) -> T2IAdapter:
|
||||
if child_type is not None:
|
||||
raise ValueError(f"T2I-Adapters do not have child models. Invalid child type: '{child_type}'.")
|
||||
|
||||
model = None
|
||||
for variant in ["fp16", None]:
|
||||
try:
|
||||
model = self.model_class.from_pretrained(
|
||||
self.model_path,
|
||||
torch_dtype=torch_dtype,
|
||||
variant=variant,
|
||||
)
|
||||
break
|
||||
except Exception:
|
||||
pass
|
||||
if not model:
|
||||
raise ModelNotFoundException()
|
||||
|
||||
# Calculate a more accurate size after loading the model into memory.
|
||||
self.model_size = calc_model_size_by_data(model)
|
||||
return model
|
||||
|
||||
@classproperty
|
||||
def save_to_config(cls) -> bool:
|
||||
return False
|
||||
|
||||
@classmethod
|
||||
def detect_format(cls, path: str):
|
||||
if not os.path.exists(path):
|
||||
raise ModelNotFoundException(f"Model not found at '{path}'.")
|
||||
|
||||
if os.path.isdir(path):
|
||||
if os.path.exists(os.path.join(path, "config.json")):
|
||||
return T2IAdapterModelFormat.Diffusers
|
||||
|
||||
raise InvalidModelException(f"Unsupported T2I-Adapter format: '{path}'.")
|
||||
|
||||
@classmethod
|
||||
def convert_if_required(
|
||||
cls,
|
||||
model_path: str,
|
||||
output_path: str,
|
||||
config: ModelConfigBase,
|
||||
base_model: BaseModelType,
|
||||
) -> str:
|
||||
format = cls.detect_format(model_path)
|
||||
if format == T2IAdapterModelFormat.Diffusers:
|
||||
return model_path
|
||||
else:
|
||||
raise ValueError(f"Unsupported format: '{format}'.")
|
||||
@@ -24,7 +24,6 @@ from transformers import CLIPFeatureExtractor, CLIPTextModel, CLIPTokenizer
|
||||
|
||||
from invokeai.app.services.config import InvokeAIAppConfig
|
||||
from invokeai.backend.ip_adapter.ip_adapter import IPAdapter
|
||||
from invokeai.backend.ip_adapter.unet_patcher import UNetPatcher
|
||||
from invokeai.backend.stable_diffusion.diffusion.conditioning_data import ConditioningData
|
||||
|
||||
from ..util import auto_detect_slice_size, normalize_device
|
||||
@@ -174,16 +173,6 @@ class IPAdapterData:
|
||||
end_step_percent: float = Field(default=1.0)
|
||||
|
||||
|
||||
@dataclass
|
||||
class T2IAdapterData:
|
||||
"""A structure containing the information required to apply conditioning from a single T2I-Adapter model."""
|
||||
|
||||
adapter_state: dict[torch.Tensor] = Field()
|
||||
weight: Union[float, list[float]] = Field(default=1.0)
|
||||
begin_step_percent: float = Field(default=0.0)
|
||||
end_step_percent: float = Field(default=1.0)
|
||||
|
||||
|
||||
@dataclass
|
||||
class InvokeAIStableDiffusionPipelineOutput(StableDiffusionPipelineOutput):
|
||||
r"""
|
||||
@@ -337,8 +326,7 @@ class StableDiffusionGeneratorPipeline(StableDiffusionPipeline):
|
||||
additional_guidance: List[Callable] = None,
|
||||
callback: Callable[[PipelineIntermediateState], None] = None,
|
||||
control_data: List[ControlNetData] = None,
|
||||
ip_adapter_data: Optional[list[IPAdapterData]] = None,
|
||||
t2i_adapter_data: Optional[list[T2IAdapterData]] = None,
|
||||
ip_adapter_data: Optional[IPAdapterData] = None,
|
||||
mask: Optional[torch.Tensor] = None,
|
||||
masked_latents: Optional[torch.Tensor] = None,
|
||||
seed: Optional[int] = None,
|
||||
@@ -391,7 +379,6 @@ class StableDiffusionGeneratorPipeline(StableDiffusionPipeline):
|
||||
additional_guidance=additional_guidance,
|
||||
control_data=control_data,
|
||||
ip_adapter_data=ip_adapter_data,
|
||||
t2i_adapter_data=t2i_adapter_data,
|
||||
callback=callback,
|
||||
)
|
||||
finally:
|
||||
@@ -411,8 +398,7 @@ class StableDiffusionGeneratorPipeline(StableDiffusionPipeline):
|
||||
*,
|
||||
additional_guidance: List[Callable] = None,
|
||||
control_data: List[ControlNetData] = None,
|
||||
ip_adapter_data: Optional[list[IPAdapterData]] = None,
|
||||
t2i_adapter_data: Optional[list[T2IAdapterData]] = None,
|
||||
ip_adapter_data: Optional[IPAdapterData] = None,
|
||||
callback: Callable[[PipelineIntermediateState], None] = None,
|
||||
):
|
||||
self._adjust_memory_efficient_attention(latents)
|
||||
@@ -425,7 +411,6 @@ class StableDiffusionGeneratorPipeline(StableDiffusionPipeline):
|
||||
if timesteps.shape[0] == 0:
|
||||
return latents, attention_map_saver
|
||||
|
||||
ip_adapter_unet_patcher = None
|
||||
if conditioning_data.extra is not None and conditioning_data.extra.wants_cross_attention_control:
|
||||
attn_ctx = self.invokeai_diffuser.custom_attention_context(
|
||||
self.invokeai_diffuser.model,
|
||||
@@ -436,8 +421,11 @@ class StableDiffusionGeneratorPipeline(StableDiffusionPipeline):
|
||||
elif ip_adapter_data is not None:
|
||||
# TODO(ryand): Should we raise an exception if both custom attention and IP-Adapter attention are active?
|
||||
# As it is now, the IP-Adapter will silently be skipped.
|
||||
ip_adapter_unet_patcher = UNetPatcher([ipa.ip_adapter_model for ipa in ip_adapter_data])
|
||||
attn_ctx = ip_adapter_unet_patcher.apply_ip_adapter_attention(self.invokeai_diffuser.model)
|
||||
weight = ip_adapter_data.weight[0] if isinstance(ip_adapter_data.weight, List) else ip_adapter_data.weight
|
||||
attn_ctx = ip_adapter_data.ip_adapter_model.apply_ip_adapter_attention(
|
||||
unet=self.invokeai_diffuser.model,
|
||||
scale=weight,
|
||||
)
|
||||
self.use_ip_adapter = True
|
||||
else:
|
||||
attn_ctx = nullcontext()
|
||||
@@ -466,8 +454,6 @@ class StableDiffusionGeneratorPipeline(StableDiffusionPipeline):
|
||||
additional_guidance=additional_guidance,
|
||||
control_data=control_data,
|
||||
ip_adapter_data=ip_adapter_data,
|
||||
t2i_adapter_data=t2i_adapter_data,
|
||||
ip_adapter_unet_patcher=ip_adapter_unet_patcher,
|
||||
)
|
||||
latents = step_output.prev_sample
|
||||
|
||||
@@ -513,9 +499,7 @@ class StableDiffusionGeneratorPipeline(StableDiffusionPipeline):
|
||||
total_step_count: int,
|
||||
additional_guidance: List[Callable] = None,
|
||||
control_data: List[ControlNetData] = None,
|
||||
ip_adapter_data: Optional[list[IPAdapterData]] = None,
|
||||
t2i_adapter_data: Optional[list[T2IAdapterData]] = None,
|
||||
ip_adapter_unet_patcher: Optional[UNetPatcher] = None,
|
||||
ip_adapter_data: Optional[IPAdapterData] = None,
|
||||
):
|
||||
# invokeai_diffuser has batched timesteps, but diffusers schedulers expect a single value
|
||||
timestep = t[0]
|
||||
@@ -528,30 +512,26 @@ class StableDiffusionGeneratorPipeline(StableDiffusionPipeline):
|
||||
|
||||
# handle IP-Adapter
|
||||
if self.use_ip_adapter and ip_adapter_data is not None: # somewhat redundant but logic is clearer
|
||||
for i, single_ip_adapter_data in enumerate(ip_adapter_data):
|
||||
first_adapter_step = math.floor(single_ip_adapter_data.begin_step_percent * total_step_count)
|
||||
last_adapter_step = math.ceil(single_ip_adapter_data.end_step_percent * total_step_count)
|
||||
weight = (
|
||||
single_ip_adapter_data.weight[step_index]
|
||||
if isinstance(single_ip_adapter_data.weight, List)
|
||||
else single_ip_adapter_data.weight
|
||||
)
|
||||
if step_index >= first_adapter_step and step_index <= last_adapter_step:
|
||||
# Only apply this IP-Adapter if the current step is within the IP-Adapter's begin/end step range.
|
||||
ip_adapter_unet_patcher.set_scale(i, weight)
|
||||
else:
|
||||
# Otherwise, set the IP-Adapter's scale to 0, so it has no effect.
|
||||
ip_adapter_unet_patcher.set_scale(i, 0.0)
|
||||
first_adapter_step = math.floor(ip_adapter_data.begin_step_percent * total_step_count)
|
||||
last_adapter_step = math.ceil(ip_adapter_data.end_step_percent * total_step_count)
|
||||
weight = (
|
||||
ip_adapter_data.weight[step_index]
|
||||
if isinstance(ip_adapter_data.weight, List)
|
||||
else ip_adapter_data.weight
|
||||
)
|
||||
if step_index >= first_adapter_step and step_index <= last_adapter_step:
|
||||
# only apply IP-Adapter if current step is within the IP-Adapter's begin/end step range
|
||||
# ip_adapter_data.ip_adapter_model.set_scale(ip_adapter_data.weight)
|
||||
ip_adapter_data.ip_adapter_model.set_scale(weight)
|
||||
else:
|
||||
# otherwise, set IP-Adapter scale to 0, so it has no effect
|
||||
ip_adapter_data.ip_adapter_model.set_scale(0.0)
|
||||
|
||||
# Handle ControlNet(s) and T2I-Adapter(s)
|
||||
down_block_additional_residuals = None
|
||||
mid_block_additional_residual = None
|
||||
if control_data is not None and t2i_adapter_data is not None:
|
||||
# TODO(ryand): This is a limitation of the UNet2DConditionModel API, not a fundamental incompatibility
|
||||
# between ControlNets and T2I-Adapters. We will try to fix this upstream in diffusers.
|
||||
raise Exception("ControlNet(s) and T2I-Adapter(s) cannot be used simultaneously (yet).")
|
||||
elif control_data is not None:
|
||||
down_block_additional_residuals, mid_block_additional_residual = self.invokeai_diffuser.do_controlnet_step(
|
||||
# handle ControlNet(s)
|
||||
# default is no controlnet, so set controlnet processing output to None
|
||||
controlnet_down_block_samples, controlnet_mid_block_sample = None, None
|
||||
if control_data is not None:
|
||||
controlnet_down_block_samples, controlnet_mid_block_sample = self.invokeai_diffuser.do_controlnet_step(
|
||||
control_data=control_data,
|
||||
sample=latent_model_input,
|
||||
timestep=timestep,
|
||||
@@ -559,32 +539,6 @@ class StableDiffusionGeneratorPipeline(StableDiffusionPipeline):
|
||||
total_step_count=total_step_count,
|
||||
conditioning_data=conditioning_data,
|
||||
)
|
||||
elif t2i_adapter_data is not None:
|
||||
accum_adapter_state = None
|
||||
for single_t2i_adapter_data in t2i_adapter_data:
|
||||
# Determine the T2I-Adapter weights for the current denoising step.
|
||||
first_t2i_adapter_step = math.floor(single_t2i_adapter_data.begin_step_percent * total_step_count)
|
||||
last_t2i_adapter_step = math.ceil(single_t2i_adapter_data.end_step_percent * total_step_count)
|
||||
t2i_adapter_weight = (
|
||||
single_t2i_adapter_data.weight[step_index]
|
||||
if isinstance(single_t2i_adapter_data.weight, list)
|
||||
else single_t2i_adapter_data.weight
|
||||
)
|
||||
if step_index < first_t2i_adapter_step or step_index > last_t2i_adapter_step:
|
||||
# If the current step is outside of the T2I-Adapter's begin/end step range, then set its weight to 0
|
||||
# so it has no effect.
|
||||
t2i_adapter_weight = 0.0
|
||||
|
||||
# Apply the t2i_adapter_weight, and accumulate.
|
||||
if accum_adapter_state is None:
|
||||
# Handle the first T2I-Adapter.
|
||||
accum_adapter_state = [val * t2i_adapter_weight for val in single_t2i_adapter_data.adapter_state]
|
||||
else:
|
||||
# Add to the previous adapter states.
|
||||
for idx, value in enumerate(single_t2i_adapter_data.adapter_state):
|
||||
accum_adapter_state[idx] += value * t2i_adapter_weight
|
||||
|
||||
down_block_additional_residuals = accum_adapter_state
|
||||
|
||||
uc_noise_pred, c_noise_pred = self.invokeai_diffuser.do_unet_step(
|
||||
sample=latent_model_input,
|
||||
@@ -593,8 +547,8 @@ class StableDiffusionGeneratorPipeline(StableDiffusionPipeline):
|
||||
total_step_count=total_step_count,
|
||||
conditioning_data=conditioning_data,
|
||||
# extra:
|
||||
down_block_additional_residuals=down_block_additional_residuals,
|
||||
mid_block_additional_residual=mid_block_additional_residual,
|
||||
down_block_additional_residuals=controlnet_down_block_samples, # from controlnet(s)
|
||||
mid_block_additional_residual=controlnet_mid_block_sample, # from controlnet(s)
|
||||
)
|
||||
|
||||
guidance_scale = conditioning_data.guidance_scale
|
||||
|
||||
@@ -81,7 +81,7 @@ class ConditioningData:
|
||||
"""
|
||||
postprocessing_settings: Optional[PostprocessingSettings] = None
|
||||
|
||||
ip_adapter_conditioning: Optional[list[IPAdapterConditioningInfo]] = None
|
||||
ip_adapter_conditioning: Optional[IPAdapterConditioningInfo] = None
|
||||
|
||||
@property
|
||||
def dtype(self):
|
||||
|
||||
@@ -346,10 +346,12 @@ class InvokeAIDiffuserComponent:
|
||||
cross_attention_kwargs = None
|
||||
if conditioning_data.ip_adapter_conditioning is not None:
|
||||
cross_attention_kwargs = {
|
||||
"ip_adapter_image_prompt_embeds": [
|
||||
torch.cat([ipa_conditioning.uncond_image_prompt_embeds, ipa_conditioning.cond_image_prompt_embeds])
|
||||
for ipa_conditioning in conditioning_data.ip_adapter_conditioning
|
||||
]
|
||||
"ip_adapter_image_prompt_embeds": torch.cat(
|
||||
[
|
||||
conditioning_data.ip_adapter_conditioning.uncond_image_prompt_embeds,
|
||||
conditioning_data.ip_adapter_conditioning.cond_image_prompt_embeds,
|
||||
]
|
||||
)
|
||||
}
|
||||
|
||||
added_cond_kwargs = None
|
||||
@@ -416,10 +418,7 @@ class InvokeAIDiffuserComponent:
|
||||
cross_attention_kwargs = None
|
||||
if conditioning_data.ip_adapter_conditioning is not None:
|
||||
cross_attention_kwargs = {
|
||||
"ip_adapter_image_prompt_embeds": [
|
||||
ipa_conditioning.uncond_image_prompt_embeds
|
||||
for ipa_conditioning in conditioning_data.ip_adapter_conditioning
|
||||
]
|
||||
"ip_adapter_image_prompt_embeds": conditioning_data.ip_adapter_conditioning.uncond_image_prompt_embeds
|
||||
}
|
||||
|
||||
added_cond_kwargs = None
|
||||
@@ -445,10 +444,7 @@ class InvokeAIDiffuserComponent:
|
||||
cross_attention_kwargs = None
|
||||
if conditioning_data.ip_adapter_conditioning is not None:
|
||||
cross_attention_kwargs = {
|
||||
"ip_adapter_image_prompt_embeds": [
|
||||
ipa_conditioning.cond_image_prompt_embeds
|
||||
for ipa_conditioning in conditioning_data.ip_adapter_conditioning
|
||||
]
|
||||
"ip_adapter_image_prompt_embeds": conditioning_data.ip_adapter_conditioning.cond_image_prompt_embeds
|
||||
}
|
||||
|
||||
added_cond_kwargs = None
|
||||
|
||||
@@ -1,67 +0,0 @@
|
||||
import contextlib
|
||||
from pathlib import Path
|
||||
from typing import Optional, Union
|
||||
|
||||
import pytest
|
||||
import torch
|
||||
|
||||
from invokeai.app.services.config.invokeai_config import InvokeAIAppConfig
|
||||
from invokeai.backend.install.model_install_backend import ModelInstall
|
||||
from invokeai.backend.model_management.model_manager import ModelInfo
|
||||
from invokeai.backend.model_management.models.base import BaseModelType, ModelNotFoundException, ModelType, SubModelType
|
||||
|
||||
|
||||
@pytest.fixture(scope="session")
|
||||
def torch_device():
|
||||
return "cuda" if torch.cuda.is_available() else "cpu"
|
||||
|
||||
|
||||
@pytest.fixture(scope="module")
|
||||
def model_installer():
|
||||
"""A global ModelInstall pytest fixture to be used by many tests."""
|
||||
# HACK(ryand): InvokeAIAppConfig.get_config() returns a singleton config object. This can lead to weird interactions
|
||||
# between tests that need to alter the config. For example, some tests change the 'root' directory in the config,
|
||||
# which can cause `install_and_load_model(...)` to re-download the model unnecessarily. As a temporary workaround,
|
||||
# we pass a kwarg to get_config, which causes the config to be re-loaded. To fix this properly, we should stop using
|
||||
# a singleton.
|
||||
return ModelInstall(InvokeAIAppConfig.get_config(log_level="info"))
|
||||
|
||||
|
||||
def install_and_load_model(
|
||||
model_installer: ModelInstall,
|
||||
model_path_id_or_url: Union[str, Path],
|
||||
model_name: str,
|
||||
base_model: BaseModelType,
|
||||
model_type: ModelType,
|
||||
submodel_type: Optional[SubModelType] = None,
|
||||
) -> ModelInfo:
|
||||
"""Install a model if it is not already installed, then get the ModelInfo for that model.
|
||||
|
||||
This is intended as a utility function for tests.
|
||||
|
||||
Args:
|
||||
model_installer (ModelInstall): The model installer.
|
||||
model_path_id_or_url (Union[str, Path]): The path, HF ID, URL, etc. where the model can be installed from if it
|
||||
is not already installed.
|
||||
model_name (str): The model name, forwarded to ModelManager.get_model(...).
|
||||
base_model (BaseModelType): The base model, forwarded to ModelManager.get_model(...).
|
||||
model_type (ModelType): The model type, forwarded to ModelManager.get_model(...).
|
||||
submodel_type (Optional[SubModelType]): The submodel type, forwarded to ModelManager.get_model(...).
|
||||
|
||||
Returns:
|
||||
ModelInfo
|
||||
"""
|
||||
# If the requested model is already installed, return its ModelInfo.
|
||||
with contextlib.suppress(ModelNotFoundException):
|
||||
return model_installer.mgr.get_model(model_name, base_model, model_type, submodel_type)
|
||||
|
||||
# Install the requested model.
|
||||
model_installer.heuristic_import(model_path_id_or_url)
|
||||
|
||||
try:
|
||||
return model_installer.mgr.get_model(model_name, base_model, model_type, submodel_type)
|
||||
except ModelNotFoundException as e:
|
||||
raise Exception(
|
||||
"Failed to get model info after installing it. There could be a mismatch between the requested model and"
|
||||
f" the installation id ('{model_path_id_or_url}'). Error: {e}"
|
||||
)
|
||||
@@ -96,22 +96,6 @@ sd-1/controlnet/tile:
|
||||
repo_id: lllyasviel/control_v11f1e_sd15_tile
|
||||
sd-1/controlnet/ip2p:
|
||||
repo_id: lllyasviel/control_v11e_sd15_ip2p
|
||||
sd-1/t2i_adapter/canny-sd15:
|
||||
repo_id: TencentARC/t2iadapter_canny_sd15v2
|
||||
sd-1/t2i_adapter/sketch-sd15:
|
||||
repo_id: TencentARC/t2iadapter_sketch_sd15v2
|
||||
sd-1/t2i_adapter/depth-sd15:
|
||||
repo_id: TencentARC/t2iadapter_depth_sd15v2
|
||||
sd-1/t2i_adapter/zoedepth-sd15:
|
||||
repo_id: TencentARC/t2iadapter_zoedepth_sd15v1
|
||||
sdxl/t2i_adapter/canny-sdxl:
|
||||
repo_id: TencentARC/t2i-adapter-canny-sdxl-1.0
|
||||
sdxl/t2i_adapter/zoedepth-sdxl:
|
||||
repo_id: TencentARC/t2i-adapter-depth-zoe-sdxl-1.0
|
||||
sdxl/t2i_adapter/lineart-sdxl:
|
||||
repo_id: TencentARC/t2i-adapter-lineart-sdxl-1.0
|
||||
sdxl/t2i_adapter/sketch-sdxl:
|
||||
repo_id: TencentARC/t2i-adapter-sketch-sdxl-1.0
|
||||
sd-1/embedding/EasyNegative:
|
||||
path: https://huggingface.co/embed/EasyNegative/resolve/main/EasyNegative.safetensors
|
||||
recommended: True
|
||||
|
||||
@@ -20,7 +20,6 @@ from multiprocessing import Process
|
||||
from multiprocessing.connection import Connection, Pipe
|
||||
from pathlib import Path
|
||||
from shutil import get_terminal_size
|
||||
from typing import Optional
|
||||
|
||||
import npyscreen
|
||||
import torch
|
||||
@@ -99,16 +98,15 @@ class addModelsForm(CyclingForm, npyscreen.FormMultiPage):
|
||||
self.tabs = self.add_widget_intelligent(
|
||||
SingleSelectColumns,
|
||||
values=[
|
||||
"STARTERS",
|
||||
"MAINS",
|
||||
"STARTER MODELS",
|
||||
"MAIN MODELS",
|
||||
"CONTROLNETS",
|
||||
"T2I-ADAPTERS",
|
||||
"IP-ADAPTERS",
|
||||
"LORAS",
|
||||
"TI EMBEDDINGS",
|
||||
"LORA/LYCORIS",
|
||||
"TEXTUAL INVERSION",
|
||||
],
|
||||
value=[self.current_tab],
|
||||
columns=7,
|
||||
columns=6,
|
||||
max_height=2,
|
||||
relx=8,
|
||||
scroll_exit=True,
|
||||
@@ -133,12 +131,6 @@ class addModelsForm(CyclingForm, npyscreen.FormMultiPage):
|
||||
)
|
||||
bottom_of_table = max(bottom_of_table, self.nextrely)
|
||||
|
||||
self.nextrely = top_of_table
|
||||
self.t2i_models = self.add_model_widgets(
|
||||
model_type=ModelType.T2IAdapter,
|
||||
window_width=window_width,
|
||||
)
|
||||
bottom_of_table = max(bottom_of_table, self.nextrely)
|
||||
self.nextrely = top_of_table
|
||||
self.ipadapter_models = self.add_model_widgets(
|
||||
model_type=ModelType.IPAdapter,
|
||||
@@ -359,7 +351,6 @@ class addModelsForm(CyclingForm, npyscreen.FormMultiPage):
|
||||
self.starter_pipelines,
|
||||
self.pipeline_models,
|
||||
self.controlnet_models,
|
||||
self.t2i_models,
|
||||
self.ipadapter_models,
|
||||
self.lora_models,
|
||||
self.ti_models,
|
||||
@@ -550,7 +541,6 @@ class addModelsForm(CyclingForm, npyscreen.FormMultiPage):
|
||||
self.starter_pipelines,
|
||||
self.pipeline_models,
|
||||
self.controlnet_models,
|
||||
self.t2i_models,
|
||||
self.ipadapter_models,
|
||||
self.lora_models,
|
||||
self.ti_models,
|
||||
@@ -631,23 +621,21 @@ def ask_user_for_prediction_type(model_path: Path, tui_conn: Connection = None)
|
||||
return _ask_user_for_pt_cmdline(model_path)
|
||||
|
||||
|
||||
def _ask_user_for_pt_cmdline(model_path: Path) -> Optional[SchedulerPredictionType]:
|
||||
def _ask_user_for_pt_cmdline(model_path: Path) -> SchedulerPredictionType:
|
||||
choices = [SchedulerPredictionType.Epsilon, SchedulerPredictionType.VPrediction, None]
|
||||
print(
|
||||
f"""
|
||||
Please select the scheduler prediction type of the checkpoint named {model_path.name}:
|
||||
[1] "epsilon" - most v1.5 models and v2 models trained on 512 pixel images
|
||||
[2] "vprediction" - v2 models trained on 768 pixel images and a few v1.5 models
|
||||
[3] Accept the best guess; you can fix it in the Web UI later
|
||||
Please select the type of the V2 checkpoint named {model_path.name}:
|
||||
[1] A model based on Stable Diffusion v2 trained on 512 pixel images (SD-2-base)
|
||||
[2] A model based on Stable Diffusion v2 trained on 768 pixel images (SD-2-768)
|
||||
[3] Skip this model and come back later.
|
||||
"""
|
||||
)
|
||||
choice = None
|
||||
ok = False
|
||||
while not ok:
|
||||
try:
|
||||
choice = input("select [3]> ").strip()
|
||||
if not choice:
|
||||
return None
|
||||
choice = input("select> ").strip()
|
||||
choice = choices[int(choice) - 1]
|
||||
ok = True
|
||||
except (ValueError, IndexError):
|
||||
@@ -658,18 +646,22 @@ Please select the scheduler prediction type of the checkpoint named {model_path.
|
||||
|
||||
|
||||
def _ask_user_for_pt_tui(model_path: Path, tui_conn: Connection) -> SchedulerPredictionType:
|
||||
tui_conn.send_bytes(f"*need v2 config for:{model_path}".encode("utf-8"))
|
||||
# note that we don't do any status checking here
|
||||
response = tui_conn.recv_bytes().decode("utf-8")
|
||||
if response is None:
|
||||
return None
|
||||
elif response == "epsilon":
|
||||
return SchedulerPredictionType.epsilon
|
||||
elif response == "v":
|
||||
return SchedulerPredictionType.VPrediction
|
||||
elif response == "guess":
|
||||
return None
|
||||
else:
|
||||
try:
|
||||
tui_conn.send_bytes(f"*need v2 config for:{model_path}".encode("utf-8"))
|
||||
# note that we don't do any status checking here
|
||||
response = tui_conn.recv_bytes().decode("utf-8")
|
||||
if response is None:
|
||||
return None
|
||||
elif response == "epsilon":
|
||||
return SchedulerPredictionType.epsilon
|
||||
elif response == "v":
|
||||
return SchedulerPredictionType.VPrediction
|
||||
elif response == "abort":
|
||||
logger.info("Conversion aborted")
|
||||
return None
|
||||
else:
|
||||
return response
|
||||
except Exception:
|
||||
return None
|
||||
|
||||
|
||||
|
||||
@@ -381,12 +381,12 @@ def select_stable_diffusion_config_file(
|
||||
wrap: bool = True,
|
||||
model_name: str = "Unknown",
|
||||
):
|
||||
message = f"Please select the correct prediction type for the checkpoint named '{model_name}'. Press <CANCEL> to skip installation."
|
||||
message = f"Please select the correct base model for the V2 checkpoint named '{model_name}'. Press <CANCEL> to skip installation."
|
||||
title = "CONFIG FILE SELECTION"
|
||||
options = [
|
||||
"'epsilon' - most v1.5 models and v2 models trained on 512 pixel images",
|
||||
"'vprediction' - v2 models trained on 768 pixel images and a few v1.5 models)",
|
||||
"Accept the best guess; you can fix it in the Web UI later",
|
||||
"An SD v2.x base model (512 pixels; no 'parameterization:' line in its yaml file)",
|
||||
"An SD v2.x v-predictive model (768 pixels; 'parameterization: \"v\"' line in its yaml file)",
|
||||
"Skip installation for now and come back later",
|
||||
]
|
||||
|
||||
F = ConfirmCancelPopup(
|
||||
@@ -410,7 +410,7 @@ def select_stable_diffusion_config_file(
|
||||
choice = F.add(
|
||||
npyscreen.SelectOne,
|
||||
values=options,
|
||||
value=[2],
|
||||
value=[0],
|
||||
max_height=len(options) + 1,
|
||||
scroll_exit=True,
|
||||
)
|
||||
@@ -420,5 +420,5 @@ def select_stable_diffusion_config_file(
|
||||
if not F.value:
|
||||
return None
|
||||
assert choice.value[0] in range(0, 3), "invalid choice"
|
||||
choices = ["epsilon", "v", "guess"]
|
||||
choices = ["epsilon", "v", "abort"]
|
||||
return choices[choice.value[0]]
|
||||
|
||||
@@ -1,5 +1,4 @@
|
||||
dist/
|
||||
public/locales/*.json
|
||||
.husky/
|
||||
node_modules/
|
||||
patches/
|
||||
|
||||
169
invokeai/frontend/web/dist/assets/App-9bf15601.js
vendored
169
invokeai/frontend/web/dist/assets/App-9bf15601.js
vendored
File diff suppressed because one or more lines are too long
169
invokeai/frontend/web/dist/assets/App-ba2d118a.js
vendored
Normal file
169
invokeai/frontend/web/dist/assets/App-ba2d118a.js
vendored
Normal file
File diff suppressed because one or more lines are too long
File diff suppressed because one or more lines are too long
@@ -1,4 +1,4 @@
|
||||
import{w as s,i6 as T,v as l,a2 as I,i7 as R,ae as V,i8 as z,i9 as j,ia as D,ib as F,ic as G,id as W,ie as K,aG as H,ig as U,ih as Y}from"./index-e8dfd0d9.js";import{M as Z}from"./MantineProvider-9228e738.js";var P=String.raw,E=P`
|
||||
import{w as s,hY as T,v as l,a2 as I,hZ as R,ae as V,h_ as z,h$ as j,i0 as D,i1 as F,i2 as G,i3 as W,i4 as K,aG as Y,i5 as Z,i6 as H}from"./index-94062f76.js";import{M as U}from"./MantineProvider-a057bfc9.js";var P=String.raw,E=P`
|
||||
:root,
|
||||
:host {
|
||||
--chakra-vh: 100vh;
|
||||
@@ -277,4 +277,4 @@ import{w as s,i6 as T,v as l,a2 as I,i7 as R,ae as V,i8 as z,i9 as j,ia as D,ib
|
||||
}
|
||||
|
||||
${E}
|
||||
`}),g={light:"chakra-ui-light",dark:"chakra-ui-dark"};function Q(e={}){const{preventTransition:o=!0}=e,n={setDataset:r=>{const t=o?n.preventTransition():void 0;document.documentElement.dataset.theme=r,document.documentElement.style.colorScheme=r,t==null||t()},setClassName(r){document.body.classList.add(r?g.dark:g.light),document.body.classList.remove(r?g.light:g.dark)},query(){return window.matchMedia("(prefers-color-scheme: dark)")},getSystemTheme(r){var t;return((t=n.query().matches)!=null?t:r==="dark")?"dark":"light"},addListener(r){const t=n.query(),i=a=>{r(a.matches?"dark":"light")};return typeof t.addListener=="function"?t.addListener(i):t.addEventListener("change",i),()=>{typeof t.removeListener=="function"?t.removeListener(i):t.removeEventListener("change",i)}},preventTransition(){const r=document.createElement("style");return r.appendChild(document.createTextNode("*{-webkit-transition:none!important;-moz-transition:none!important;-o-transition:none!important;-ms-transition:none!important;transition:none!important}")),document.head.appendChild(r),()=>{window.getComputedStyle(document.body),requestAnimationFrame(()=>{requestAnimationFrame(()=>{document.head.removeChild(r)})})}}};return n}var X="chakra-ui-color-mode";function L(e){return{ssr:!1,type:"localStorage",get(o){if(!(globalThis!=null&&globalThis.document))return o;let n;try{n=localStorage.getItem(e)||o}catch{}return n||o},set(o){try{localStorage.setItem(e,o)}catch{}}}}var ee=L(X),M=()=>{};function S(e,o){return e.type==="cookie"&&e.ssr?e.get(o):o}function O(e){const{value:o,children:n,options:{useSystemColorMode:r,initialColorMode:t,disableTransitionOnChange:i}={},colorModeManager:a=ee}=e,d=t==="dark"?"dark":"light",[u,p]=l.useState(()=>S(a,d)),[y,b]=l.useState(()=>S(a)),{getSystemTheme:w,setClassName:k,setDataset:x,addListener:$}=l.useMemo(()=>Q({preventTransition:i}),[i]),v=t==="system"&&!u?y:u,c=l.useCallback(h=>{const f=h==="system"?w():h;p(f),k(f==="dark"),x(f),a.set(f)},[a,w,k,x]);I(()=>{t==="system"&&b(w())},[]),l.useEffect(()=>{const h=a.get();if(h){c(h);return}if(t==="system"){c("system");return}c(d)},[a,d,t,c]);const C=l.useCallback(()=>{c(v==="dark"?"light":"dark")},[v,c]);l.useEffect(()=>{if(r)return $(c)},[r,$,c]);const A=l.useMemo(()=>({colorMode:o??v,toggleColorMode:o?M:C,setColorMode:o?M:c,forced:o!==void 0}),[v,C,c,o]);return s.jsx(R.Provider,{value:A,children:n})}O.displayName="ColorModeProvider";var te=["borders","breakpoints","colors","components","config","direction","fonts","fontSizes","fontWeights","letterSpacings","lineHeights","radii","shadows","sizes","space","styles","transition","zIndices"];function re(e){return V(e)?te.every(o=>Object.prototype.hasOwnProperty.call(e,o)):!1}function m(e){return typeof e=="function"}function oe(...e){return o=>e.reduce((n,r)=>r(n),o)}var ne=e=>function(...n){let r=[...n],t=n[n.length-1];return re(t)&&r.length>1?r=r.slice(0,r.length-1):t=e,oe(...r.map(i=>a=>m(i)?i(a):ae(a,i)))(t)},ie=ne(j);function ae(...e){return z({},...e,_)}function _(e,o,n,r){if((m(e)||m(o))&&Object.prototype.hasOwnProperty.call(r,n))return(...t)=>{const i=m(e)?e(...t):e,a=m(o)?o(...t):o;return z({},i,a,_)}}var q=l.createContext({getDocument(){return document},getWindow(){return window}});q.displayName="EnvironmentContext";function N(e){const{children:o,environment:n,disabled:r}=e,t=l.useRef(null),i=l.useMemo(()=>n||{getDocument:()=>{var d,u;return(u=(d=t.current)==null?void 0:d.ownerDocument)!=null?u:document},getWindow:()=>{var d,u;return(u=(d=t.current)==null?void 0:d.ownerDocument.defaultView)!=null?u:window}},[n]),a=!r||!n;return s.jsxs(q.Provider,{value:i,children:[o,a&&s.jsx("span",{id:"__chakra_env",hidden:!0,ref:t})]})}N.displayName="EnvironmentProvider";var se=e=>{const{children:o,colorModeManager:n,portalZIndex:r,resetScope:t,resetCSS:i=!0,theme:a={},environment:d,cssVarsRoot:u,disableEnvironment:p,disableGlobalStyle:y}=e,b=s.jsx(N,{environment:d,disabled:p,children:o});return s.jsx(D,{theme:a,cssVarsRoot:u,children:s.jsxs(O,{colorModeManager:n,options:a.config,children:[i?s.jsx(J,{scope:t}):s.jsx(B,{}),!y&&s.jsx(F,{}),r?s.jsx(G,{zIndex:r,children:b}):b]})})},le=e=>function({children:n,theme:r=e,toastOptions:t,...i}){return s.jsxs(se,{theme:r,...i,children:[s.jsx(W,{value:t==null?void 0:t.defaultOptions,children:n}),s.jsx(K,{...t})]})},de=le(j);const ue=()=>l.useMemo(()=>({colorScheme:"dark",fontFamily:"'Inter Variable', sans-serif",components:{ScrollArea:{defaultProps:{scrollbarSize:10},styles:{scrollbar:{"&:hover":{backgroundColor:"var(--invokeai-colors-baseAlpha-300)"}},thumb:{backgroundColor:"var(--invokeai-colors-baseAlpha-300)"}}}}}),[]),ce=L("@@invokeai-color-mode");function he({children:e}){const{i18n:o}=H(),n=o.dir(),r=l.useMemo(()=>ie({...U,direction:n}),[n]);l.useEffect(()=>{document.body.dir=n},[n]);const t=ue();return s.jsx(Z,{theme:t,children:s.jsx(de,{theme:r,colorModeManager:ce,toastOptions:Y,children:e})})}const ve=l.memo(he);export{ve as default};
|
||||
`}),g={light:"chakra-ui-light",dark:"chakra-ui-dark"};function Q(e={}){const{preventTransition:o=!0}=e,n={setDataset:r=>{const t=o?n.preventTransition():void 0;document.documentElement.dataset.theme=r,document.documentElement.style.colorScheme=r,t==null||t()},setClassName(r){document.body.classList.add(r?g.dark:g.light),document.body.classList.remove(r?g.light:g.dark)},query(){return window.matchMedia("(prefers-color-scheme: dark)")},getSystemTheme(r){var t;return((t=n.query().matches)!=null?t:r==="dark")?"dark":"light"},addListener(r){const t=n.query(),i=a=>{r(a.matches?"dark":"light")};return typeof t.addListener=="function"?t.addListener(i):t.addEventListener("change",i),()=>{typeof t.removeListener=="function"?t.removeListener(i):t.removeEventListener("change",i)}},preventTransition(){const r=document.createElement("style");return r.appendChild(document.createTextNode("*{-webkit-transition:none!important;-moz-transition:none!important;-o-transition:none!important;-ms-transition:none!important;transition:none!important}")),document.head.appendChild(r),()=>{window.getComputedStyle(document.body),requestAnimationFrame(()=>{requestAnimationFrame(()=>{document.head.removeChild(r)})})}}};return n}var X="chakra-ui-color-mode";function L(e){return{ssr:!1,type:"localStorage",get(o){if(!(globalThis!=null&&globalThis.document))return o;let n;try{n=localStorage.getItem(e)||o}catch{}return n||o},set(o){try{localStorage.setItem(e,o)}catch{}}}}var ee=L(X),M=()=>{};function S(e,o){return e.type==="cookie"&&e.ssr?e.get(o):o}function O(e){const{value:o,children:n,options:{useSystemColorMode:r,initialColorMode:t,disableTransitionOnChange:i}={},colorModeManager:a=ee}=e,d=t==="dark"?"dark":"light",[u,p]=l.useState(()=>S(a,d)),[y,b]=l.useState(()=>S(a)),{getSystemTheme:w,setClassName:k,setDataset:x,addListener:$}=l.useMemo(()=>Q({preventTransition:i}),[i]),v=t==="system"&&!u?y:u,c=l.useCallback(h=>{const f=h==="system"?w():h;p(f),k(f==="dark"),x(f),a.set(f)},[a,w,k,x]);I(()=>{t==="system"&&b(w())},[]),l.useEffect(()=>{const h=a.get();if(h){c(h);return}if(t==="system"){c("system");return}c(d)},[a,d,t,c]);const C=l.useCallback(()=>{c(v==="dark"?"light":"dark")},[v,c]);l.useEffect(()=>{if(r)return $(c)},[r,$,c]);const A=l.useMemo(()=>({colorMode:o??v,toggleColorMode:o?M:C,setColorMode:o?M:c,forced:o!==void 0}),[v,C,c,o]);return s.jsx(R.Provider,{value:A,children:n})}O.displayName="ColorModeProvider";var te=["borders","breakpoints","colors","components","config","direction","fonts","fontSizes","fontWeights","letterSpacings","lineHeights","radii","shadows","sizes","space","styles","transition","zIndices"];function re(e){return V(e)?te.every(o=>Object.prototype.hasOwnProperty.call(e,o)):!1}function m(e){return typeof e=="function"}function oe(...e){return o=>e.reduce((n,r)=>r(n),o)}var ne=e=>function(...n){let r=[...n],t=n[n.length-1];return re(t)&&r.length>1?r=r.slice(0,r.length-1):t=e,oe(...r.map(i=>a=>m(i)?i(a):ae(a,i)))(t)},ie=ne(j);function ae(...e){return z({},...e,_)}function _(e,o,n,r){if((m(e)||m(o))&&Object.prototype.hasOwnProperty.call(r,n))return(...t)=>{const i=m(e)?e(...t):e,a=m(o)?o(...t):o;return z({},i,a,_)}}var q=l.createContext({getDocument(){return document},getWindow(){return window}});q.displayName="EnvironmentContext";function N(e){const{children:o,environment:n,disabled:r}=e,t=l.useRef(null),i=l.useMemo(()=>n||{getDocument:()=>{var d,u;return(u=(d=t.current)==null?void 0:d.ownerDocument)!=null?u:document},getWindow:()=>{var d,u;return(u=(d=t.current)==null?void 0:d.ownerDocument.defaultView)!=null?u:window}},[n]),a=!r||!n;return s.jsxs(q.Provider,{value:i,children:[o,a&&s.jsx("span",{id:"__chakra_env",hidden:!0,ref:t})]})}N.displayName="EnvironmentProvider";var se=e=>{const{children:o,colorModeManager:n,portalZIndex:r,resetScope:t,resetCSS:i=!0,theme:a={},environment:d,cssVarsRoot:u,disableEnvironment:p,disableGlobalStyle:y}=e,b=s.jsx(N,{environment:d,disabled:p,children:o});return s.jsx(D,{theme:a,cssVarsRoot:u,children:s.jsxs(O,{colorModeManager:n,options:a.config,children:[i?s.jsx(J,{scope:t}):s.jsx(B,{}),!y&&s.jsx(F,{}),r?s.jsx(G,{zIndex:r,children:b}):b]})})},le=e=>function({children:n,theme:r=e,toastOptions:t,...i}){return s.jsxs(se,{theme:r,...i,children:[s.jsx(W,{value:t==null?void 0:t.defaultOptions,children:n}),s.jsx(K,{...t})]})},de=le(j);const ue=()=>l.useMemo(()=>({colorScheme:"dark",fontFamily:"'Inter Variable', sans-serif",components:{ScrollArea:{defaultProps:{scrollbarSize:10},styles:{scrollbar:{"&:hover":{backgroundColor:"var(--invokeai-colors-baseAlpha-300)"}},thumb:{backgroundColor:"var(--invokeai-colors-baseAlpha-300)"}}}}}),[]),ce=L("@@invokeai-color-mode");function he({children:e}){const{i18n:o}=Y(),n=o.dir(),r=l.useMemo(()=>ie({...Z,direction:n}),[n]);l.useEffect(()=>{document.body.dir=n},[n]);const t=ue();return s.jsx(U,{theme:t,children:s.jsx(de,{theme:r,colorModeManager:ce,toastOptions:H,children:e})})}const ve=l.memo(he);export{ve as default};
|
||||
158
invokeai/frontend/web/dist/assets/index-94062f76.js
vendored
Normal file
158
invokeai/frontend/web/dist/assets/index-94062f76.js
vendored
Normal file
File diff suppressed because one or more lines are too long
158
invokeai/frontend/web/dist/assets/index-e8dfd0d9.js
vendored
158
invokeai/frontend/web/dist/assets/index-e8dfd0d9.js
vendored
File diff suppressed because one or more lines are too long
5
invokeai/frontend/web/dist/index.html
vendored
5
invokeai/frontend/web/dist/index.html
vendored
@@ -3,9 +3,6 @@
|
||||
<head>
|
||||
<meta charset="UTF-8" />
|
||||
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
|
||||
<meta http-equiv="Cache-Control" content="no-cache, no-store, must-revalidate">
|
||||
<meta http-equiv="Pragma" content="no-cache">
|
||||
<meta http-equiv="Expires" content="0">
|
||||
<title>InvokeAI - A Stable Diffusion Toolkit</title>
|
||||
<link rel="shortcut icon" type="icon" href="./assets/favicon-0d253ced.ico" />
|
||||
<style>
|
||||
@@ -15,7 +12,7 @@
|
||||
margin: 0;
|
||||
}
|
||||
</style>
|
||||
<script type="module" crossorigin src="./assets/index-e8dfd0d9.js"></script>
|
||||
<script type="module" crossorigin src="./assets/index-94062f76.js"></script>
|
||||
</head>
|
||||
|
||||
<body dir="ltr">
|
||||
|
||||
15
invokeai/frontend/web/dist/locales/ar.json
vendored
15
invokeai/frontend/web/dist/locales/ar.json
vendored
@@ -1,9 +1,13 @@
|
||||
{
|
||||
"common": {
|
||||
"hotkeysLabel": "مفاتيح الأختصار",
|
||||
"themeLabel": "الموضوع",
|
||||
"languagePickerLabel": "منتقي اللغة",
|
||||
"reportBugLabel": "بلغ عن خطأ",
|
||||
"settingsLabel": "إعدادات",
|
||||
"darkTheme": "داكن",
|
||||
"lightTheme": "فاتح",
|
||||
"greenTheme": "أخضر",
|
||||
"img2img": "صورة إلى صورة",
|
||||
"unifiedCanvas": "لوحة موحدة",
|
||||
"nodes": "عقد",
|
||||
@@ -53,6 +57,7 @@
|
||||
"maintainAspectRatio": "الحفاظ على نسبة الأبعاد",
|
||||
"autoSwitchNewImages": "التبديل التلقائي إلى الصور الجديدة",
|
||||
"singleColumnLayout": "تخطيط عمود واحد",
|
||||
"pinGallery": "تثبيت المعرض",
|
||||
"allImagesLoaded": "تم تحميل جميع الصور",
|
||||
"loadMore": "تحميل المزيد",
|
||||
"noImagesInGallery": "لا توجد صور في المعرض"
|
||||
@@ -337,6 +342,7 @@
|
||||
"cfgScale": "مقياس الإعداد الذاتي للجملة",
|
||||
"width": "عرض",
|
||||
"height": "ارتفاع",
|
||||
"sampler": "مزج",
|
||||
"seed": "بذرة",
|
||||
"randomizeSeed": "تبديل بذرة",
|
||||
"shuffle": "تشغيل",
|
||||
@@ -358,6 +364,10 @@
|
||||
"hiresOptim": "تحسين الدقة العالية",
|
||||
"imageFit": "ملائمة الصورة الأولية لحجم الخرج",
|
||||
"codeformerFidelity": "الوثوقية",
|
||||
"seamSize": "حجم التشقق",
|
||||
"seamBlur": "ضباب التشقق",
|
||||
"seamStrength": "قوة التشقق",
|
||||
"seamSteps": "خطوات التشقق",
|
||||
"scaleBeforeProcessing": "تحجيم قبل المعالجة",
|
||||
"scaledWidth": "العرض المحجوب",
|
||||
"scaledHeight": "الارتفاع المحجوب",
|
||||
@@ -368,6 +378,8 @@
|
||||
"infillScalingHeader": "التعبئة والتحجيم",
|
||||
"img2imgStrength": "قوة صورة إلى صورة",
|
||||
"toggleLoopback": "تبديل الإعادة",
|
||||
"invoke": "إطلاق",
|
||||
"promptPlaceholder": "اكتب المحث هنا. [العلامات السلبية], (زيادة الوزن) ++, (نقص الوزن)--, التبديل و الخلط متاحة (انظر الوثائق)",
|
||||
"sendTo": "أرسل إلى",
|
||||
"sendToImg2Img": "أرسل إلى صورة إلى صورة",
|
||||
"sendToUnifiedCanvas": "أرسل إلى الخطوط الموحدة",
|
||||
@@ -381,6 +393,7 @@
|
||||
"useAll": "استخدام الكل",
|
||||
"useInitImg": "استخدام الصورة الأولية",
|
||||
"info": "معلومات",
|
||||
"deleteImage": "حذف الصورة",
|
||||
"initialImage": "الصورة الأولية",
|
||||
"showOptionsPanel": "إظهار لوحة الخيارات"
|
||||
},
|
||||
@@ -390,6 +403,7 @@
|
||||
"saveSteps": "حفظ الصور كل n خطوات",
|
||||
"confirmOnDelete": "تأكيد عند الحذف",
|
||||
"displayHelpIcons": "عرض أيقونات المساعدة",
|
||||
"useCanvasBeta": "استخدام مخطط الأزرار بيتا",
|
||||
"enableImageDebugging": "تمكين التصحيح عند التصوير",
|
||||
"resetWebUI": "إعادة تعيين واجهة الويب",
|
||||
"resetWebUIDesc1": "إعادة تعيين واجهة الويب يعيد فقط ذاكرة التخزين المؤقت للمتصفح لصورك وإعداداتك المذكورة. لا يحذف أي صور من القرص.",
|
||||
@@ -399,6 +413,7 @@
|
||||
"toast": {
|
||||
"tempFoldersEmptied": "تم تفريغ مجلد المؤقت",
|
||||
"uploadFailed": "فشل التحميل",
|
||||
"uploadFailedMultipleImagesDesc": "تم الصق صور متعددة، قد يتم تحميل صورة واحدة فقط في الوقت الحالي",
|
||||
"uploadFailedUnableToLoadDesc": "تعذر تحميل الملف",
|
||||
"downloadImageStarted": "بدأ تنزيل الصورة",
|
||||
"imageCopied": "تم نسخ الصورة",
|
||||
|
||||
17
invokeai/frontend/web/dist/locales/de.json
vendored
17
invokeai/frontend/web/dist/locales/de.json
vendored
@@ -1,8 +1,12 @@
|
||||
{
|
||||
"common": {
|
||||
"themeLabel": "Thema",
|
||||
"languagePickerLabel": "Sprachauswahl",
|
||||
"reportBugLabel": "Fehler melden",
|
||||
"settingsLabel": "Einstellungen",
|
||||
"darkTheme": "Dunkel",
|
||||
"lightTheme": "Hell",
|
||||
"greenTheme": "Grün",
|
||||
"img2img": "Bild zu Bild",
|
||||
"nodes": "Knoten",
|
||||
"langGerman": "Deutsch",
|
||||
@@ -44,6 +48,7 @@
|
||||
"langEnglish": "Englisch",
|
||||
"langDutch": "Niederländisch",
|
||||
"langFrench": "Französisch",
|
||||
"oceanTheme": "Ozean",
|
||||
"langItalian": "Italienisch",
|
||||
"langPortuguese": "Portogisisch",
|
||||
"langRussian": "Russisch",
|
||||
@@ -71,6 +76,7 @@
|
||||
"maintainAspectRatio": "Seitenverhältnis beibehalten",
|
||||
"autoSwitchNewImages": "Automatisch zu neuen Bildern wechseln",
|
||||
"singleColumnLayout": "Einspaltiges Layout",
|
||||
"pinGallery": "Galerie anpinnen",
|
||||
"allImagesLoaded": "Alle Bilder geladen",
|
||||
"loadMore": "Mehr laden",
|
||||
"noImagesInGallery": "Keine Bilder in der Galerie"
|
||||
@@ -340,6 +346,7 @@
|
||||
"cfgScale": "CFG-Skala",
|
||||
"width": "Breite",
|
||||
"height": "Höhe",
|
||||
"sampler": "Sampler",
|
||||
"randomizeSeed": "Zufälliger Seed",
|
||||
"shuffle": "Mischen",
|
||||
"noiseThreshold": "Rausch-Schwellenwert",
|
||||
@@ -360,6 +367,10 @@
|
||||
"hiresOptim": "High-Res-Optimierung",
|
||||
"imageFit": "Ausgangsbild an Ausgabegröße anpassen",
|
||||
"codeformerFidelity": "Glaubwürdigkeit",
|
||||
"seamSize": "Nahtgröße",
|
||||
"seamBlur": "Nahtunschärfe",
|
||||
"seamStrength": "Stärke der Naht",
|
||||
"seamSteps": "Nahtstufen",
|
||||
"scaleBeforeProcessing": "Skalieren vor der Verarbeitung",
|
||||
"scaledWidth": "Skaliert W",
|
||||
"scaledHeight": "Skaliert H",
|
||||
@@ -370,6 +381,8 @@
|
||||
"infillScalingHeader": "Infill und Skalierung",
|
||||
"img2imgStrength": "Bild-zu-Bild-Stärke",
|
||||
"toggleLoopback": "Toggle Loopback",
|
||||
"invoke": "Invoke",
|
||||
"promptPlaceholder": "Prompt hier eingeben. [negative Token], (mehr Gewicht)++, (geringeres Gewicht)--, Tausch und Überblendung sind verfügbar (siehe Dokumente)",
|
||||
"sendTo": "Senden an",
|
||||
"sendToImg2Img": "Senden an Bild zu Bild",
|
||||
"sendToUnifiedCanvas": "Senden an Unified Canvas",
|
||||
@@ -381,6 +394,7 @@
|
||||
"useSeed": "Seed verwenden",
|
||||
"useAll": "Alle verwenden",
|
||||
"useInitImg": "Ausgangsbild verwenden",
|
||||
"deleteImage": "Bild löschen",
|
||||
"initialImage": "Ursprüngliches Bild",
|
||||
"showOptionsPanel": "Optionsleiste zeigen",
|
||||
"cancel": {
|
||||
@@ -392,6 +406,7 @@
|
||||
"saveSteps": "Speichern der Bilder alle n Schritte",
|
||||
"confirmOnDelete": "Bestätigen beim Löschen",
|
||||
"displayHelpIcons": "Hilfesymbole anzeigen",
|
||||
"useCanvasBeta": "Canvas Beta Layout verwenden",
|
||||
"enableImageDebugging": "Bild-Debugging aktivieren",
|
||||
"resetWebUI": "Web-Oberfläche zurücksetzen",
|
||||
"resetWebUIDesc1": "Das Zurücksetzen der Web-Oberfläche setzt nur den lokalen Cache des Browsers mit Ihren Bildern und gespeicherten Einstellungen zurück. Es werden keine Bilder von der Festplatte gelöscht.",
|
||||
@@ -401,6 +416,7 @@
|
||||
"toast": {
|
||||
"tempFoldersEmptied": "Temp-Ordner geleert",
|
||||
"uploadFailed": "Hochladen fehlgeschlagen",
|
||||
"uploadFailedMultipleImagesDesc": "Mehrere Bilder eingefügt, es kann nur ein Bild auf einmal hochgeladen werden",
|
||||
"uploadFailedUnableToLoadDesc": "Datei kann nicht geladen werden",
|
||||
"downloadImageStarted": "Bild wird heruntergeladen",
|
||||
"imageCopied": "Bild kopiert",
|
||||
@@ -516,6 +532,7 @@
|
||||
"modifyConfig": "Optionen einstellen",
|
||||
"toggleAutoscroll": "Auroscroll ein/ausschalten",
|
||||
"toggleLogViewer": "Log Betrachter ein/ausschalten",
|
||||
"showGallery": "Zeige Galerie",
|
||||
"showOptionsPanel": "Zeige Optionen",
|
||||
"reset": "Zurücksetzen",
|
||||
"nextImage": "Nächstes Bild",
|
||||
|
||||
64
invokeai/frontend/web/dist/locales/en.json
vendored
64
invokeai/frontend/web/dist/locales/en.json
vendored
@@ -38,24 +38,19 @@
|
||||
"searchBoard": "Search Boards...",
|
||||
"selectBoard": "Select a Board",
|
||||
"topMessage": "This board contains images used in the following features:",
|
||||
"uncategorized": "Uncategorized",
|
||||
"downloadBoard": "Download Board"
|
||||
"uncategorized": "Uncategorized"
|
||||
},
|
||||
"common": {
|
||||
"accept": "Accept",
|
||||
"advanced": "Advanced",
|
||||
"areYouSure": "Are you sure?",
|
||||
"auto": "Auto",
|
||||
"back": "Back",
|
||||
"batch": "Batch Manager",
|
||||
"cancel": "Cancel",
|
||||
"close": "Close",
|
||||
"on": "On",
|
||||
"communityLabel": "Community",
|
||||
"controlNet": "ControlNet",
|
||||
"controlAdapter": "Control Adapter",
|
||||
"controlNet": "Controlnet",
|
||||
"ipAdapter": "IP Adapter",
|
||||
"t2iAdapter": "T2I Adapter",
|
||||
"darkMode": "Dark Mode",
|
||||
"discordLabel": "Discord",
|
||||
"dontAskMeAgain": "Don't ask me again",
|
||||
@@ -135,17 +130,6 @@
|
||||
"upload": "Upload"
|
||||
},
|
||||
"controlnet": {
|
||||
"controlAdapter_one": "Control Adapter",
|
||||
"controlAdapter_other": "Control Adapters",
|
||||
"controlnet": "$t(controlnet.controlAdapter_one) #{{number}} ($t(common.controlNet))",
|
||||
"ip_adapter": "$t(controlnet.controlAdapter_one) #{{number}} ($t(common.ipAdapter))",
|
||||
"t2i_adapter": "$t(controlnet.controlAdapter_one) #{{number}} ($t(common.t2iAdapter))",
|
||||
"addControlNet": "Add $t(common.controlNet)",
|
||||
"addIPAdapter": "Add $t(common.ipAdapter)",
|
||||
"addT2IAdapter": "Add $t(common.t2iAdapter)",
|
||||
"controlNetEnabledT2IDisabled": "$t(common.controlNet) enabled, $t(common.t2iAdapter)s disabled",
|
||||
"t2iEnabledControlNetDisabled": "$t(common.t2iAdapter) enabled, $t(common.controlNet)s disabled",
|
||||
"controlNetT2IMutexDesc": "$t(common.controlNet) and $t(common.t2iAdapter) at same time is currently unsupported.",
|
||||
"amult": "a_mult",
|
||||
"autoConfigure": "Auto configure processor",
|
||||
"balanced": "Balanced",
|
||||
@@ -278,8 +262,7 @@
|
||||
"batchValues": "Batch Values",
|
||||
"notReady": "Unable to Queue",
|
||||
"batchQueued": "Batch Queued",
|
||||
"batchQueuedDesc_one": "Added {{count}} sessions to {{direction}} of queue",
|
||||
"batchQueuedDesc_other": "Added {{count}} sessions to {{direction}} of queue",
|
||||
"batchQueuedDesc": "Added {{item_count}} sessions to {{direction}} of queue",
|
||||
"front": "front",
|
||||
"back": "back",
|
||||
"batchFailedToQueue": "Failed to Queue Batch",
|
||||
@@ -328,10 +311,7 @@
|
||||
"showUploads": "Show Uploads",
|
||||
"singleColumnLayout": "Single Column Layout",
|
||||
"unableToLoad": "Unable to load Gallery",
|
||||
"uploads": "Uploads",
|
||||
"downloadSelection": "Download Selection",
|
||||
"preparingDownload": "Preparing Download",
|
||||
"preparingDownloadFailed": "Problem Preparing Download"
|
||||
"uploads": "Uploads"
|
||||
},
|
||||
"hotkeys": {
|
||||
"acceptStagingImage": {
|
||||
@@ -559,10 +539,8 @@
|
||||
"negativePrompt": "Negative Prompt",
|
||||
"noImageDetails": "No image details found",
|
||||
"noMetaData": "No metadata found",
|
||||
"noRecallParameters": "No parameters to recall found",
|
||||
"perlin": "Perlin Noise",
|
||||
"positivePrompt": "Positive Prompt",
|
||||
"recallParameters": "Recall Parameters",
|
||||
"scheduler": "Scheduler",
|
||||
"seamless": "Seamless",
|
||||
"seed": "Seed",
|
||||
@@ -707,7 +685,6 @@
|
||||
"vae": "VAE",
|
||||
"vaeLocation": "VAE Location",
|
||||
"vaeLocationValidationMsg": "Path to where your VAE is located.",
|
||||
"vaePrecision": "VAE Precision",
|
||||
"vaeRepoID": "VAE Repo ID",
|
||||
"vaeRepoIDValidationMsg": "Online repository of your VAE",
|
||||
"variant": "Variant",
|
||||
@@ -720,7 +697,7 @@
|
||||
"noLoRAsAvailable": "No LoRAs available",
|
||||
"noMatchingLoRAs": "No matching LoRAs",
|
||||
"noMatchingModels": "No matching Models",
|
||||
"noModelsAvailable": "No models available",
|
||||
"noModelsAvailable": "No Modelss available",
|
||||
"selectLoRA": "Select a LoRA",
|
||||
"selectModel": "Select a Model"
|
||||
},
|
||||
@@ -808,14 +785,6 @@
|
||||
"integerPolymorphic": "Integer Polymorphic",
|
||||
"integerPolymorphicDescription": "A collection of integers.",
|
||||
"invalidOutputSchema": "Invalid output schema",
|
||||
"ipAdapter": "IP-Adapter",
|
||||
"ipAdapterCollection": "IP-Adapters Collection",
|
||||
"ipAdapterCollectionDescription": "A collection of IP-Adapters.",
|
||||
"ipAdapterDescription": "An Image Prompt Adapter (IP-Adapter).",
|
||||
"ipAdapterModel": "IP-Adapter Model",
|
||||
"ipAdapterModelDescription": "IP-Adapter Model Field",
|
||||
"ipAdapterPolymorphic": "IP-Adapter Polymorphic",
|
||||
"ipAdapterPolymorphicDescription": "A collection of IP-Adapters.",
|
||||
"latentsCollection": "Latents Collection",
|
||||
"latentsCollectionDescription": "Latents may be passed between nodes.",
|
||||
"latentsField": "Latents",
|
||||
@@ -928,7 +897,6 @@
|
||||
},
|
||||
"parameters": {
|
||||
"aspectRatio": "Aspect Ratio",
|
||||
"aspectRatioFree": "Free",
|
||||
"boundingBoxHeader": "Bounding Box",
|
||||
"boundingBoxHeight": "Bounding Box Height",
|
||||
"boundingBoxWidth": "Bounding Box Width",
|
||||
@@ -976,10 +944,9 @@
|
||||
"missingFieldTemplate": "Missing field template",
|
||||
"missingInputForField": "{{nodeLabel}} -> {{fieldLabel}} missing input",
|
||||
"missingNodeTemplate": "Missing node template",
|
||||
"noControlImageForControlAdapter": "Control Adapter #{{number}} has no control image",
|
||||
"noControlImageForControlNet": "ControlNet {{index}} has no control image",
|
||||
"noInitialImageSelected": "No initial image selected",
|
||||
"noModelForControlAdapter": "Control Adapter #{{number}} has no model selected.",
|
||||
"incompatibleBaseModelForControlAdapter": "Control Adapter #{{number}} model is invalid with main model.",
|
||||
"noModelForControlNet": "ControlNet {{index}} has no model selected.",
|
||||
"noModelSelected": "No model selected",
|
||||
"noPrompts": "No prompts generated",
|
||||
"noNodesInGraph": "No nodes in graph",
|
||||
@@ -1114,23 +1081,11 @@
|
||||
"showAdvancedOptions": "Show Advanced Options",
|
||||
"showProgressInViewer": "Show Progress Images in Viewer",
|
||||
"ui": "User Interface",
|
||||
"useSlidersForAll": "Use Sliders For All Options",
|
||||
"clearIntermediatesDisabled": "Queue must be empty to clear intermediates",
|
||||
"clearIntermediatesDesc1": "Clearing intermediates will reset your Canvas and ControlNet state.",
|
||||
"clearIntermediatesDesc2": "Intermediate images are byproducts of generation, different from the result images in the gallery. Clearing intermediates will free disk space.",
|
||||
"clearIntermediatesDesc3": "Your gallery images will not be deleted.",
|
||||
"clearIntermediates": "Clear Intermediates",
|
||||
"clearIntermediatesWithCount_one": "Clear {{count}} Intermediate",
|
||||
"clearIntermediatesWithCount_other": "Clear {{count}} Intermediates",
|
||||
"clearIntermediatesWithCount_zero": "No Intermediates to Clear",
|
||||
"intermediatesCleared_one": "Cleared {{count}} Intermediate",
|
||||
"intermediatesCleared_other": "Cleared {{count}} Intermediates",
|
||||
"intermediatesClearedFailed": "Problem Clearing Intermediates"
|
||||
"useSlidersForAll": "Use Sliders For All Options"
|
||||
},
|
||||
"toast": {
|
||||
"addedToBoard": "Added to board",
|
||||
"baseModelChangedCleared_one": "Base model changed, cleared or disabled {{count}} incompatible submodel",
|
||||
"baseModelChangedCleared_other": "Base model changed, cleared or disabled {{count}} incompatible submodels",
|
||||
"baseModelChangedCleared": "Base model changed, cleared",
|
||||
"canceled": "Processing Canceled",
|
||||
"canvasCopiedClipboard": "Canvas Copied to Clipboard",
|
||||
"canvasDownloaded": "Canvas Downloaded",
|
||||
@@ -1150,6 +1105,7 @@
|
||||
"imageSavingFailed": "Image Saving Failed",
|
||||
"imageUploaded": "Image Uploaded",
|
||||
"imageUploadFailed": "Image Upload Failed",
|
||||
"incompatibleSubmodel": "incompatible submodel",
|
||||
"initialImageNotSet": "Initial Image Not Set",
|
||||
"initialImageNotSetDesc": "Could not load initial image",
|
||||
"initialImageSet": "Initial Image Set",
|
||||
|
||||
175
invokeai/frontend/web/dist/locales/es.json
vendored
175
invokeai/frontend/web/dist/locales/es.json
vendored
@@ -1,12 +1,16 @@
|
||||
{
|
||||
"common": {
|
||||
"hotkeysLabel": "Atajos de teclado",
|
||||
"themeLabel": "Tema",
|
||||
"languagePickerLabel": "Selector de idioma",
|
||||
"reportBugLabel": "Reportar errores",
|
||||
"settingsLabel": "Ajustes",
|
||||
"darkTheme": "Oscuro",
|
||||
"lightTheme": "Claro",
|
||||
"greenTheme": "Verde",
|
||||
"img2img": "Imagen a Imagen",
|
||||
"unifiedCanvas": "Lienzo Unificado",
|
||||
"nodes": "Editor del flujo de trabajo",
|
||||
"nodes": "Nodos",
|
||||
"langSpanish": "Español",
|
||||
"nodesDesc": "Un sistema de generación de imágenes basado en nodos, actualmente se encuentra en desarrollo. Mantente pendiente a nuestras actualizaciones acerca de esta fabulosa funcionalidad.",
|
||||
"postProcessing": "Post-procesamiento",
|
||||
@@ -15,7 +19,7 @@
|
||||
"postProcessDesc3": "La Interfaz de Línea de Comandos de Invoke AI ofrece muchas otras características, incluyendo -Embiggen-.",
|
||||
"training": "Entrenamiento",
|
||||
"trainingDesc1": "Un flujo de trabajo dedicado para el entrenamiento de sus propios -embeddings- y puntos de control utilizando Inversión Textual y Dreambooth desde la interfaz web.",
|
||||
"trainingDesc2": "InvokeAI ya admite el entrenamiento de incrustaciones personalizadas mediante la inversión textual mediante el script principal.",
|
||||
"trainingDesc2": "InvokeAI ya soporta el entrenamiento de -embeddings- personalizados utilizando la Inversión Textual mediante el script principal.",
|
||||
"upload": "Subir imagen",
|
||||
"close": "Cerrar",
|
||||
"load": "Cargar",
|
||||
@@ -59,27 +63,18 @@
|
||||
"statusConvertingModel": "Convertir el modelo",
|
||||
"statusModelConverted": "Modelo adaptado",
|
||||
"statusMergingModels": "Fusionar modelos",
|
||||
"oceanTheme": "Océano",
|
||||
"langPortuguese": "Portugués",
|
||||
"langKorean": "Coreano",
|
||||
"langHebrew": "Hebreo",
|
||||
"pinOptionsPanel": "Pin del panel de opciones",
|
||||
"loading": "Cargando",
|
||||
"loadingInvokeAI": "Cargando invocar a la IA",
|
||||
"postprocessing": "Tratamiento posterior",
|
||||
"txt2img": "De texto a imagen",
|
||||
"accept": "Aceptar",
|
||||
"cancel": "Cancelar",
|
||||
"linear": "Lineal",
|
||||
"random": "Aleatorio",
|
||||
"generate": "Generar",
|
||||
"openInNewTab": "Abrir en una nueva pestaña",
|
||||
"dontAskMeAgain": "No me preguntes de nuevo",
|
||||
"areYouSure": "¿Estas seguro?",
|
||||
"imagePrompt": "Indicación de imagen",
|
||||
"batch": "Administrador de lotes",
|
||||
"darkMode": "Modo oscuro",
|
||||
"lightMode": "Modo claro",
|
||||
"modelManager": "Administrador de modelos",
|
||||
"communityLabel": "Comunidad"
|
||||
"linear": "Lineal"
|
||||
},
|
||||
"gallery": {
|
||||
"generations": "Generaciones",
|
||||
@@ -92,15 +87,10 @@
|
||||
"maintainAspectRatio": "Mantener relación de aspecto",
|
||||
"autoSwitchNewImages": "Auto seleccionar Imágenes nuevas",
|
||||
"singleColumnLayout": "Diseño de una columna",
|
||||
"pinGallery": "Fijar galería",
|
||||
"allImagesLoaded": "Todas las imágenes cargadas",
|
||||
"loadMore": "Cargar más",
|
||||
"noImagesInGallery": "No hay imágenes para mostrar",
|
||||
"deleteImage": "Eliminar Imagen",
|
||||
"deleteImageBin": "Las imágenes eliminadas se enviarán a la papelera de tu sistema operativo.",
|
||||
"deleteImagePermanent": "Las imágenes eliminadas no se pueden restaurar.",
|
||||
"images": "Imágenes",
|
||||
"assets": "Activos",
|
||||
"autoAssignBoardOnClick": "Asignación automática de tableros al hacer clic"
|
||||
"noImagesInGallery": "Sin imágenes en la galería"
|
||||
},
|
||||
"hotkeys": {
|
||||
"keyboardShortcuts": "Atajos de teclado",
|
||||
@@ -307,12 +297,7 @@
|
||||
"acceptStagingImage": {
|
||||
"title": "Aceptar imagen",
|
||||
"desc": "Aceptar la imagen actual en el área de preparación"
|
||||
},
|
||||
"addNodes": {
|
||||
"title": "Añadir Nodos",
|
||||
"desc": "Abre el menú para añadir nodos"
|
||||
},
|
||||
"nodesHotkeys": "Teclas de acceso rápido a los nodos"
|
||||
}
|
||||
},
|
||||
"modelManager": {
|
||||
"modelManager": "Gestor de Modelos",
|
||||
@@ -364,8 +349,8 @@
|
||||
"delete": "Eliminar",
|
||||
"deleteModel": "Eliminar Modelo",
|
||||
"deleteConfig": "Eliminar Configuración",
|
||||
"deleteMsg1": "¿Estás seguro de que deseas eliminar este modelo de InvokeAI?",
|
||||
"deleteMsg2": "Esto eliminará el modelo del disco si está en la carpeta raíz de InvokeAI. Si está utilizando una ubicación personalizada, el modelo NO se eliminará del disco.",
|
||||
"deleteMsg1": "¿Estás seguro de querer eliminar esta entrada de modelo de InvokeAI?",
|
||||
"deleteMsg2": "El checkpoint del modelo no se eliminará de tu disco. Puedes volver a añadirlo si lo deseas.",
|
||||
"safetensorModels": "SafeTensors",
|
||||
"addDiffuserModel": "Añadir difusores",
|
||||
"inpainting": "v1 Repintado",
|
||||
@@ -384,8 +369,8 @@
|
||||
"convertToDiffusers": "Convertir en difusores",
|
||||
"convertToDiffusersHelpText1": "Este modelo se convertirá al formato 🧨 Difusores.",
|
||||
"convertToDiffusersHelpText2": "Este proceso sustituirá su entrada del Gestor de Modelos por la versión de Difusores del mismo modelo.",
|
||||
"convertToDiffusersHelpText3": "Tu archivo del punto de control en el disco se eliminará si está en la carpeta raíz de InvokeAI. Si está en una ubicación personalizada, NO se eliminará.",
|
||||
"convertToDiffusersHelpText5": "Por favor, asegúrate de tener suficiente espacio en el disco. Los modelos generalmente varían entre 2 GB y 7 GB de tamaño.",
|
||||
"convertToDiffusersHelpText3": "Su archivo de puntos de control en el disco NO será borrado ni modificado de ninguna manera. Puede volver a añadir su punto de control al Gestor de Modelos si lo desea.",
|
||||
"convertToDiffusersHelpText5": "Asegúrese de que dispone de suficiente espacio en disco. Los modelos suelen variar entre 4 GB y 7 GB de tamaño.",
|
||||
"convertToDiffusersHelpText6": "¿Desea transformar este modelo?",
|
||||
"convertToDiffusersSaveLocation": "Guardar ubicación",
|
||||
"v1": "v1",
|
||||
@@ -424,27 +409,7 @@
|
||||
"pickModelType": "Elige el tipo de modelo",
|
||||
"v2_768": "v2 (768px)",
|
||||
"addDifference": "Añadir una diferencia",
|
||||
"scanForModels": "Buscar modelos",
|
||||
"vae": "VAE",
|
||||
"variant": "Variante",
|
||||
"baseModel": "Modelo básico",
|
||||
"modelConversionFailed": "Conversión al modelo fallida",
|
||||
"selectModel": "Seleccionar un modelo",
|
||||
"modelUpdateFailed": "Error al actualizar el modelo",
|
||||
"modelsMergeFailed": "Fusión del modelo fallida",
|
||||
"convertingModelBegin": "Convirtiendo el modelo. Por favor, espere.",
|
||||
"modelDeleted": "Modelo eliminado",
|
||||
"modelDeleteFailed": "Error al borrar el modelo",
|
||||
"noCustomLocationProvided": "‐No se proporcionó una ubicación personalizada",
|
||||
"importModels": "Importar los modelos",
|
||||
"settings": "Ajustes",
|
||||
"syncModels": "Sincronizar las plantillas",
|
||||
"syncModelsDesc": "Si tus plantillas no están sincronizados con el backend, puedes actualizarlas usando esta opción. Esto suele ser útil en los casos en los que actualizas manualmente tu archivo models.yaml o añades plantillas a la carpeta raíz de InvokeAI después de que la aplicación haya arrancado.",
|
||||
"modelsSynced": "Plantillas sincronizadas",
|
||||
"modelSyncFailed": "La sincronización de la plantilla falló",
|
||||
"loraModels": "LoRA",
|
||||
"onnxModels": "Onnx",
|
||||
"oliveModels": "Olives"
|
||||
"scanForModels": "Buscar modelos"
|
||||
},
|
||||
"parameters": {
|
||||
"images": "Imágenes",
|
||||
@@ -452,9 +417,10 @@
|
||||
"cfgScale": "Escala CFG",
|
||||
"width": "Ancho",
|
||||
"height": "Alto",
|
||||
"sampler": "Muestreo",
|
||||
"seed": "Semilla",
|
||||
"randomizeSeed": "Semilla aleatoria",
|
||||
"shuffle": "Semilla aleatoria",
|
||||
"shuffle": "Aleatorizar",
|
||||
"noiseThreshold": "Umbral de Ruido",
|
||||
"perlinNoise": "Ruido Perlin",
|
||||
"variations": "Variaciones",
|
||||
@@ -473,6 +439,10 @@
|
||||
"hiresOptim": "Optimización de Alta Resolución",
|
||||
"imageFit": "Ajuste tamaño de imagen inicial al tamaño objetivo",
|
||||
"codeformerFidelity": "Fidelidad",
|
||||
"seamSize": "Tamaño del parche",
|
||||
"seamBlur": "Desenfoque del parche",
|
||||
"seamStrength": "Fuerza del parche",
|
||||
"seamSteps": "Pasos del parche",
|
||||
"scaleBeforeProcessing": "Redimensionar antes de procesar",
|
||||
"scaledWidth": "Ancho escalado",
|
||||
"scaledHeight": "Alto escalado",
|
||||
@@ -483,6 +453,8 @@
|
||||
"infillScalingHeader": "Remplazo y escalado",
|
||||
"img2imgStrength": "Peso de Imagen a Imagen",
|
||||
"toggleLoopback": "Alternar Retroalimentación",
|
||||
"invoke": "Invocar",
|
||||
"promptPlaceholder": "Ingrese la entrada aquí. [símbolos negativos], (subir peso)++, (bajar peso)--, también disponible alternado y mezclado (ver documentación)",
|
||||
"sendTo": "Enviar a",
|
||||
"sendToImg2Img": "Enviar a Imagen a Imagen",
|
||||
"sendToUnifiedCanvas": "Enviar a Lienzo Unificado",
|
||||
@@ -495,6 +467,7 @@
|
||||
"useAll": "Usar Todo",
|
||||
"useInitImg": "Usar Imagen Inicial",
|
||||
"info": "Información",
|
||||
"deleteImage": "Eliminar Imagen",
|
||||
"initialImage": "Imagen Inicial",
|
||||
"showOptionsPanel": "Mostrar panel de opciones",
|
||||
"symmetry": "Simetría",
|
||||
@@ -508,72 +481,37 @@
|
||||
},
|
||||
"copyImage": "Copiar la imagen",
|
||||
"general": "General",
|
||||
"negativePrompts": "Preguntas negativas",
|
||||
"imageToImage": "Imagen a imagen",
|
||||
"denoisingStrength": "Intensidad de la eliminación del ruido",
|
||||
"hiresStrength": "Alta resistencia",
|
||||
"showPreview": "Mostrar la vista previa",
|
||||
"hidePreview": "Ocultar la vista previa",
|
||||
"noiseSettings": "Ruido",
|
||||
"seamlessXAxis": "Eje x",
|
||||
"seamlessYAxis": "Eje y",
|
||||
"scheduler": "Programador",
|
||||
"boundingBoxWidth": "Anchura del recuadro",
|
||||
"boundingBoxHeight": "Altura del recuadro",
|
||||
"positivePromptPlaceholder": "Prompt Positivo",
|
||||
"negativePromptPlaceholder": "Prompt Negativo",
|
||||
"controlNetControlMode": "Modo de control",
|
||||
"clipSkip": "Omitir el CLIP",
|
||||
"aspectRatio": "Relación",
|
||||
"maskAdjustmentsHeader": "Ajustes de la máscara",
|
||||
"maskBlur": "Difuminar",
|
||||
"maskBlurMethod": "Método del desenfoque",
|
||||
"seamHighThreshold": "Alto",
|
||||
"seamLowThreshold": "Bajo",
|
||||
"coherencePassHeader": "Parámetros de la coherencia",
|
||||
"compositingSettingsHeader": "Ajustes de la composición",
|
||||
"coherenceSteps": "Pasos",
|
||||
"coherenceStrength": "Fuerza",
|
||||
"patchmatchDownScaleSize": "Reducir a escala",
|
||||
"coherenceMode": "Modo"
|
||||
"hidePreview": "Ocultar la vista previa"
|
||||
},
|
||||
"settings": {
|
||||
"models": "Modelos",
|
||||
"displayInProgress": "Mostrar las imágenes del progreso",
|
||||
"displayInProgress": "Mostrar imágenes en progreso",
|
||||
"saveSteps": "Guardar imágenes cada n pasos",
|
||||
"confirmOnDelete": "Confirmar antes de eliminar",
|
||||
"displayHelpIcons": "Mostrar iconos de ayuda",
|
||||
"useCanvasBeta": "Usar versión beta del Lienzo",
|
||||
"enableImageDebugging": "Habilitar depuración de imágenes",
|
||||
"resetWebUI": "Restablecer interfaz web",
|
||||
"resetWebUIDesc1": "Al restablecer la interfaz web, solo se restablece la caché local del navegador de sus imágenes y la configuración guardada. No se elimina ninguna imagen de su disco duro.",
|
||||
"resetWebUIDesc2": "Si las imágenes no se muestran en la galería o algo más no funciona, intente restablecer antes de reportar un incidente en GitHub.",
|
||||
"resetComplete": "Se ha restablecido la interfaz web.",
|
||||
"useSlidersForAll": "Utilice controles deslizantes para todas las opciones",
|
||||
"general": "General",
|
||||
"consoleLogLevel": "Nivel del registro",
|
||||
"shouldLogToConsole": "Registro de la consola",
|
||||
"developer": "Desarrollador",
|
||||
"antialiasProgressImages": "Imágenes del progreso de Antialias",
|
||||
"showProgressInViewer": "Mostrar las imágenes del progreso en el visor",
|
||||
"ui": "Interfaz del usuario",
|
||||
"generation": "Generación",
|
||||
"favoriteSchedulers": "Programadores favoritos",
|
||||
"favoriteSchedulersPlaceholder": "No hay programadores favoritos",
|
||||
"showAdvancedOptions": "Mostrar las opciones avanzadas",
|
||||
"alternateCanvasLayout": "Diseño alternativo del lienzo",
|
||||
"beta": "Beta",
|
||||
"enableNodesEditor": "Activar el editor de nodos",
|
||||
"experimental": "Experimental",
|
||||
"autoChangeDimensions": "Actualiza W/H a los valores predeterminados del modelo cuando se modifica"
|
||||
"resetComplete": "La interfaz web se ha restablecido. Actualice la página para recargarla.",
|
||||
"useSlidersForAll": "Utilice controles deslizantes para todas las opciones"
|
||||
},
|
||||
"toast": {
|
||||
"tempFoldersEmptied": "Directorio temporal vaciado",
|
||||
"uploadFailed": "Error al subir archivo",
|
||||
"uploadFailedMultipleImagesDesc": "Únicamente se puede subir una imágen a la vez",
|
||||
"uploadFailedUnableToLoadDesc": "No se pudo cargar la imágen",
|
||||
"downloadImageStarted": "Descargando imágen",
|
||||
"imageCopied": "Imágen copiada",
|
||||
"imageLinkCopied": "Enlace de imágen copiado",
|
||||
"imageNotLoaded": "No se cargó la imágen",
|
||||
"imageNotLoadedDesc": "No se pudo encontrar la imagen",
|
||||
"imageNotLoadedDesc": "No se encontró imagen para enviar al módulo Imagen a Imagen",
|
||||
"imageSavedToGallery": "Imágen guardada en la galería",
|
||||
"canvasMerged": "Lienzo consolidado",
|
||||
"sentToImageToImage": "Enviar hacia Imagen a Imagen",
|
||||
@@ -598,21 +536,7 @@
|
||||
"serverError": "Error en el servidor",
|
||||
"disconnected": "Desconectado del servidor",
|
||||
"canceled": "Procesando la cancelación",
|
||||
"connected": "Conectado al servidor",
|
||||
"problemCopyingImageLink": "No se puede copiar el enlace de la imagen",
|
||||
"uploadFailedInvalidUploadDesc": "Debe ser una sola imagen PNG o JPEG",
|
||||
"parameterSet": "Conjunto de parámetros",
|
||||
"parameterNotSet": "Parámetro no configurado",
|
||||
"nodesSaved": "Nodos guardados",
|
||||
"nodesLoadedFailed": "Error al cargar los nodos",
|
||||
"nodesLoaded": "Nodos cargados",
|
||||
"nodesCleared": "Nodos borrados",
|
||||
"problemCopyingImage": "No se puede copiar la imagen",
|
||||
"nodesNotValidJSON": "JSON no válido",
|
||||
"nodesCorruptedGraph": "No se puede cargar. El gráfico parece estar dañado.",
|
||||
"nodesUnrecognizedTypes": "No se puede cargar. El gráfico tiene tipos no reconocidos",
|
||||
"nodesNotValidGraph": "Gráfico del nodo InvokeAI no válido",
|
||||
"nodesBrokenConnections": "No se puede cargar. Algunas conexiones están rotas."
|
||||
"connected": "Conectado al servidor"
|
||||
},
|
||||
"tooltip": {
|
||||
"feature": {
|
||||
@@ -686,8 +610,7 @@
|
||||
"betaClear": "Limpiar",
|
||||
"betaDarkenOutside": "Oscurecer fuera",
|
||||
"betaLimitToBox": "Limitar a caja",
|
||||
"betaPreserveMasked": "Preservar área enmascarada",
|
||||
"antialiasing": "Suavizado"
|
||||
"betaPreserveMasked": "Preservar área enmascarada"
|
||||
},
|
||||
"accessibility": {
|
||||
"invokeProgressBar": "Activar la barra de progreso",
|
||||
@@ -708,30 +631,8 @@
|
||||
"modifyConfig": "Modificar la configuración",
|
||||
"toggleAutoscroll": "Activar el autodesplazamiento",
|
||||
"toggleLogViewer": "Alternar el visor de registros",
|
||||
"showOptionsPanel": "Mostrar el panel lateral",
|
||||
"showGallery": "Mostrar galería",
|
||||
"showOptionsPanel": "Mostrar el panel de opciones",
|
||||
"menu": "Menú"
|
||||
},
|
||||
"ui": {
|
||||
"hideProgressImages": "Ocultar el progreso de la imagen",
|
||||
"showProgressImages": "Mostrar el progreso de la imagen",
|
||||
"swapSizes": "Cambiar los tamaños",
|
||||
"lockRatio": "Proporción del bloqueo"
|
||||
},
|
||||
"nodes": {
|
||||
"showGraphNodes": "Mostrar la superposición de los gráficos",
|
||||
"zoomInNodes": "Acercar",
|
||||
"hideMinimapnodes": "Ocultar el minimapa",
|
||||
"fitViewportNodes": "Ajustar la vista",
|
||||
"zoomOutNodes": "Alejar",
|
||||
"hideGraphNodes": "Ocultar la superposición de los gráficos",
|
||||
"hideLegendNodes": "Ocultar la leyenda del tipo de campo",
|
||||
"showLegendNodes": "Mostrar la leyenda del tipo de campo",
|
||||
"showMinimapnodes": "Mostrar el minimapa",
|
||||
"reloadNodeTemplates": "Recargar las plantillas de nodos",
|
||||
"loadWorkflow": "Cargar el flujo de trabajo",
|
||||
"resetWorkflow": "Reiniciar e flujo de trabajo",
|
||||
"resetWorkflowDesc": "¿Está seguro de que deseas restablecer este flujo de trabajo?",
|
||||
"resetWorkflowDesc2": "Al reiniciar el flujo de trabajo se borrarán todos los nodos, aristas y detalles del flujo de trabajo.",
|
||||
"downloadWorkflow": "Descargar el flujo de trabajo en un archivo JSON"
|
||||
}
|
||||
}
|
||||
|
||||
8
invokeai/frontend/web/dist/locales/fi.json
vendored
8
invokeai/frontend/web/dist/locales/fi.json
vendored
@@ -15,6 +15,7 @@
|
||||
"rotateCounterClockwise": "Kierrä vastapäivään",
|
||||
"rotateClockwise": "Kierrä myötäpäivään",
|
||||
"flipVertically": "Käännä pystysuoraan",
|
||||
"showGallery": "Näytä galleria",
|
||||
"modifyConfig": "Muokkaa konfiguraatiota",
|
||||
"toggleAutoscroll": "Kytke automaattinen vieritys",
|
||||
"toggleLogViewer": "Kytke lokin katselutila",
|
||||
@@ -33,13 +34,18 @@
|
||||
"hotkeysLabel": "Pikanäppäimet",
|
||||
"reportBugLabel": "Raportoi Bugista",
|
||||
"langPolish": "Puola",
|
||||
"themeLabel": "Teema",
|
||||
"langDutch": "Hollanti",
|
||||
"settingsLabel": "Asetukset",
|
||||
"githubLabel": "Github",
|
||||
"darkTheme": "Tumma",
|
||||
"lightTheme": "Vaalea",
|
||||
"greenTheme": "Vihreä",
|
||||
"langGerman": "Saksa",
|
||||
"langPortuguese": "Portugali",
|
||||
"discordLabel": "Discord",
|
||||
"langEnglish": "Englanti",
|
||||
"oceanTheme": "Meren sininen",
|
||||
"langRussian": "Venäjä",
|
||||
"langUkranian": "Ukraina",
|
||||
"langSpanish": "Espanja",
|
||||
@@ -73,6 +79,7 @@
|
||||
"statusGeneratingInpainting": "Generoidaan sisällemaalausta",
|
||||
"statusGeneratingOutpainting": "Generoidaan ulosmaalausta",
|
||||
"statusRestoringFaces": "Korjataan kasvoja",
|
||||
"pinOptionsPanel": "Kiinnitä asetukset -paneeli",
|
||||
"loadingInvokeAI": "Ladataan Invoke AI:ta",
|
||||
"loading": "Ladataan",
|
||||
"statusGenerating": "Generoidaan",
|
||||
@@ -88,6 +95,7 @@
|
||||
"galleryImageResetSize": "Resetoi koko",
|
||||
"maintainAspectRatio": "Säilytä kuvasuhde",
|
||||
"galleryImageSize": "Kuvan koko",
|
||||
"pinGallery": "Kiinnitä galleria",
|
||||
"showGenerations": "Näytä generaatiot",
|
||||
"singleColumnLayout": "Yhden sarakkeen asettelu",
|
||||
"generations": "Generoinnit",
|
||||
|
||||
22
invokeai/frontend/web/dist/locales/fr.json
vendored
22
invokeai/frontend/web/dist/locales/fr.json
vendored
@@ -1,9 +1,13 @@
|
||||
{
|
||||
"common": {
|
||||
"hotkeysLabel": "Raccourcis clavier",
|
||||
"themeLabel": "Thème",
|
||||
"languagePickerLabel": "Sélecteur de langue",
|
||||
"reportBugLabel": "Signaler un bug",
|
||||
"settingsLabel": "Paramètres",
|
||||
"darkTheme": "Sombre",
|
||||
"lightTheme": "Clair",
|
||||
"greenTheme": "Vert",
|
||||
"img2img": "Image en image",
|
||||
"unifiedCanvas": "Canvas unifié",
|
||||
"nodes": "Nœuds",
|
||||
@@ -51,6 +55,7 @@
|
||||
"statusConvertingModel": "Conversion du modèle",
|
||||
"statusModelConverted": "Modèle converti",
|
||||
"loading": "Chargement",
|
||||
"pinOptionsPanel": "Épingler la page d'options",
|
||||
"statusMergedModels": "Modèles mélangés",
|
||||
"txt2img": "Texte vers image",
|
||||
"postprocessing": "Post-Traitement"
|
||||
@@ -66,6 +71,7 @@
|
||||
"maintainAspectRatio": "Maintenir le rapport d'aspect",
|
||||
"autoSwitchNewImages": "Basculer automatiquement vers de nouvelles images",
|
||||
"singleColumnLayout": "Mise en page en colonne unique",
|
||||
"pinGallery": "Épingler la galerie",
|
||||
"allImagesLoaded": "Toutes les images chargées",
|
||||
"loadMore": "Charger plus",
|
||||
"noImagesInGallery": "Aucune image dans la galerie"
|
||||
@@ -350,6 +356,7 @@
|
||||
"cfgScale": "CFG Echelle",
|
||||
"width": "Largeur",
|
||||
"height": "Hauteur",
|
||||
"sampler": "Echantillonneur",
|
||||
"seed": "Graine",
|
||||
"randomizeSeed": "Graine Aléatoire",
|
||||
"shuffle": "Mélanger",
|
||||
@@ -371,6 +378,10 @@
|
||||
"hiresOptim": "Optimisation Haute Résolution",
|
||||
"imageFit": "Ajuster Image Initiale à la Taille de Sortie",
|
||||
"codeformerFidelity": "Fidélité",
|
||||
"seamSize": "Taille des Joints",
|
||||
"seamBlur": "Flou des Joints",
|
||||
"seamStrength": "Force des Joints",
|
||||
"seamSteps": "Etapes des Joints",
|
||||
"scaleBeforeProcessing": "Echelle Avant Traitement",
|
||||
"scaledWidth": "Larg. Échelle",
|
||||
"scaledHeight": "Haut. Échelle",
|
||||
@@ -381,6 +392,8 @@
|
||||
"infillScalingHeader": "Remplissage et Mise à l'Échelle",
|
||||
"img2imgStrength": "Force de l'Image à l'Image",
|
||||
"toggleLoopback": "Activer/Désactiver la Boucle",
|
||||
"invoke": "Invoker",
|
||||
"promptPlaceholder": "Tapez le prompt ici. [tokens négatifs], (poids positif)++, (poids négatif)--, swap et blend sont disponibles (voir les docs)",
|
||||
"sendTo": "Envoyer à",
|
||||
"sendToImg2Img": "Envoyer à Image à Image",
|
||||
"sendToUnifiedCanvas": "Envoyer au Canvas Unifié",
|
||||
@@ -394,6 +407,7 @@
|
||||
"useAll": "Tout utiliser",
|
||||
"useInitImg": "Utiliser l'image initiale",
|
||||
"info": "Info",
|
||||
"deleteImage": "Supprimer l'image",
|
||||
"initialImage": "Image initiale",
|
||||
"showOptionsPanel": "Afficher le panneau d'options"
|
||||
},
|
||||
@@ -403,6 +417,7 @@
|
||||
"saveSteps": "Enregistrer les images tous les n étapes",
|
||||
"confirmOnDelete": "Confirmer la suppression",
|
||||
"displayHelpIcons": "Afficher les icônes d'aide",
|
||||
"useCanvasBeta": "Utiliser la mise en page bêta de Canvas",
|
||||
"enableImageDebugging": "Activer le débogage d'image",
|
||||
"resetWebUI": "Réinitialiser l'interface Web",
|
||||
"resetWebUIDesc1": "Réinitialiser l'interface Web ne réinitialise que le cache local du navigateur de vos images et de vos paramètres enregistrés. Cela n'efface pas les images du disque.",
|
||||
@@ -412,6 +427,7 @@
|
||||
"toast": {
|
||||
"tempFoldersEmptied": "Dossiers temporaires vidés",
|
||||
"uploadFailed": "Téléchargement échoué",
|
||||
"uploadFailedMultipleImagesDesc": "Plusieurs images collées, peut uniquement télécharger une image à la fois",
|
||||
"uploadFailedUnableToLoadDesc": "Impossible de charger le fichier",
|
||||
"downloadImageStarted": "Téléchargement de l'image démarré",
|
||||
"imageCopied": "Image copiée",
|
||||
@@ -522,10 +538,6 @@
|
||||
"useThisParameter": "Utiliser ce paramètre",
|
||||
"zoomIn": "Zoom avant",
|
||||
"zoomOut": "Zoom arrière",
|
||||
"showOptionsPanel": "Montrer la page d'options",
|
||||
"modelSelect": "Choix du modèle",
|
||||
"invokeProgressBar": "Barre de Progression Invoke",
|
||||
"copyMetadataJson": "Copie des métadonnées JSON",
|
||||
"menu": "Menu"
|
||||
"showOptionsPanel": "Montrer la page d'options"
|
||||
}
|
||||
}
|
||||
|
||||
18
invokeai/frontend/web/dist/locales/he.json
vendored
18
invokeai/frontend/web/dist/locales/he.json
vendored
@@ -107,10 +107,13 @@
|
||||
},
|
||||
"common": {
|
||||
"nodesDesc": "מערכת מבוססת צמתים עבור יצירת תמונות עדיין תחת פיתוח. השארו קשובים לעדכונים עבור הפיצ׳ר המדהים הזה.",
|
||||
"themeLabel": "ערכת נושא",
|
||||
"languagePickerLabel": "בחירת שפה",
|
||||
"githubLabel": "גיטהאב",
|
||||
"discordLabel": "דיסקורד",
|
||||
"settingsLabel": "הגדרות",
|
||||
"darkTheme": "חשוך",
|
||||
"lightTheme": "מואר",
|
||||
"langEnglish": "אנגלית",
|
||||
"langDutch": "הולנדית",
|
||||
"langArabic": "ערבית",
|
||||
@@ -152,6 +155,7 @@
|
||||
"statusMergedModels": "מודלים מוזגו",
|
||||
"hotkeysLabel": "מקשים חמים",
|
||||
"reportBugLabel": "דווח באג",
|
||||
"greenTheme": "ירוק",
|
||||
"langItalian": "איטלקית",
|
||||
"upload": "העלאה",
|
||||
"langPolish": "פולנית",
|
||||
@@ -380,6 +384,7 @@
|
||||
"maintainAspectRatio": "שמור על יחס רוחב-גובה",
|
||||
"autoSwitchNewImages": "החלף אוטומטית לתמונות חדשות",
|
||||
"singleColumnLayout": "תצוגת עמודה אחת",
|
||||
"pinGallery": "הצמד גלריה",
|
||||
"allImagesLoaded": "כל התמונות נטענו",
|
||||
"loadMore": "טען עוד",
|
||||
"noImagesInGallery": "אין תמונות בגלריה",
|
||||
@@ -394,6 +399,7 @@
|
||||
"cfgScale": "סולם CFG",
|
||||
"width": "רוחב",
|
||||
"height": "גובה",
|
||||
"sampler": "דוגם",
|
||||
"seed": "זרע",
|
||||
"imageToImage": "תמונה לתמונה",
|
||||
"randomizeSeed": "זרע אקראי",
|
||||
@@ -410,6 +416,10 @@
|
||||
"hiresOptim": "אופטימיזצית רזולוציה גבוהה",
|
||||
"hiresStrength": "חוזק רזולוציה גבוהה",
|
||||
"codeformerFidelity": "דבקות",
|
||||
"seamSize": "גודל תפר",
|
||||
"seamBlur": "טשטוש תפר",
|
||||
"seamStrength": "חוזק תפר",
|
||||
"seamSteps": "שלבי תפר",
|
||||
"scaleBeforeProcessing": "שנה קנה מידה לפני עיבוד",
|
||||
"scaledWidth": "קנה מידה לאחר שינוי W",
|
||||
"scaledHeight": "קנה מידה לאחר שינוי H",
|
||||
@@ -422,12 +432,14 @@
|
||||
"symmetry": "סימטריה",
|
||||
"vSymmetryStep": "צעד סימטריה V",
|
||||
"hSymmetryStep": "צעד סימטריה H",
|
||||
"invoke": "הפעלה",
|
||||
"cancel": {
|
||||
"schedule": "ביטול לאחר האיטרציה הנוכחית",
|
||||
"isScheduled": "מבטל",
|
||||
"immediate": "ביטול מיידי",
|
||||
"setType": "הגדר סוג ביטול"
|
||||
},
|
||||
"negativePrompts": "בקשות שליליות",
|
||||
"sendTo": "שליחה אל",
|
||||
"copyImage": "העתקת תמונה",
|
||||
"downloadImage": "הורדת תמונה",
|
||||
@@ -452,12 +464,15 @@
|
||||
"seamlessTiling": "ריצוף חלק",
|
||||
"img2imgStrength": "חוזק תמונה לתמונה",
|
||||
"initialImage": "תמונה ראשונית",
|
||||
"copyImageToLink": "העתקת תמונה לקישור"
|
||||
"copyImageToLink": "העתקת תמונה לקישור",
|
||||
"deleteImage": "מחיקת תמונה",
|
||||
"promptPlaceholder": "הקלד בקשה כאן. [אסימונים שליליים], (העלאת משקל)++ , (הורדת משקל)--, החלפה ומיזוג זמינים (ראה מסמכים)"
|
||||
},
|
||||
"settings": {
|
||||
"models": "מודלים",
|
||||
"displayInProgress": "הצגת תמונות בתהליך",
|
||||
"confirmOnDelete": "אישור בעת המחיקה",
|
||||
"useCanvasBeta": "שימוש בגרסת ביתא של תצוגת הקנבס",
|
||||
"useSlidersForAll": "שימוש במחוונים לכל האפשרויות",
|
||||
"resetWebUI": "איפוס ממשק משתמש",
|
||||
"resetWebUIDesc1": "איפוס ממשק המשתמש האינטרנטי מאפס רק את המטמון המקומי של הדפדפן של התמונות וההגדרות שנשמרו. זה לא מוחק תמונות מהדיסק.",
|
||||
@@ -469,6 +484,7 @@
|
||||
},
|
||||
"toast": {
|
||||
"uploadFailed": "העלאה נכשלה",
|
||||
"uploadFailedMultipleImagesDesc": "תמונות מרובות הודבקו, ניתן להעלות תמונה אחת בלבד בכל פעם",
|
||||
"imageCopied": "התמונה הועתקה",
|
||||
"imageLinkCopied": "קישור תמונה הועתק",
|
||||
"imageNotLoadedDesc": "לא נמצאה תמונה לשליחה למודול תמונה לתמונה",
|
||||
|
||||
959
invokeai/frontend/web/dist/locales/it.json
vendored
959
invokeai/frontend/web/dist/locales/it.json
vendored
File diff suppressed because it is too large
Load Diff
11
invokeai/frontend/web/dist/locales/ja.json
vendored
11
invokeai/frontend/web/dist/locales/ja.json
vendored
@@ -1,8 +1,12 @@
|
||||
{
|
||||
"common": {
|
||||
"themeLabel": "テーマ",
|
||||
"languagePickerLabel": "言語選択",
|
||||
"reportBugLabel": "バグ報告",
|
||||
"settingsLabel": "設定",
|
||||
"darkTheme": "ダーク",
|
||||
"lightTheme": "ライト",
|
||||
"greenTheme": "緑",
|
||||
"langJapanese": "日本語",
|
||||
"nodesDesc": "現在、画像生成のためのノードベースシステムを開発中です。機能についてのアップデートにご期待ください。",
|
||||
"postProcessing": "後処理",
|
||||
@@ -52,12 +56,14 @@
|
||||
"loadingInvokeAI": "Invoke AIをロード中",
|
||||
"statusConvertingModel": "モデルの変換",
|
||||
"statusMergedModels": "マージ済モデル",
|
||||
"pinOptionsPanel": "オプションパネルを固定",
|
||||
"githubLabel": "Github",
|
||||
"hotkeysLabel": "ホットキー",
|
||||
"langHebrew": "עברית",
|
||||
"discordLabel": "Discord",
|
||||
"langItalian": "Italiano",
|
||||
"langEnglish": "English",
|
||||
"oceanTheme": "オーシャン",
|
||||
"langArabic": "アラビア語",
|
||||
"langDutch": "Nederlands",
|
||||
"langFrench": "Français",
|
||||
@@ -77,6 +83,7 @@
|
||||
"gallerySettings": "ギャラリーの設定",
|
||||
"maintainAspectRatio": "アスペクト比を維持",
|
||||
"singleColumnLayout": "1カラムレイアウト",
|
||||
"pinGallery": "ギャラリーにピン留め",
|
||||
"allImagesLoaded": "すべての画像を読み込む",
|
||||
"loadMore": "さらに読み込む",
|
||||
"noImagesInGallery": "ギャラリーに画像がありません",
|
||||
@@ -348,6 +355,7 @@
|
||||
"useSeed": "シード値を使用",
|
||||
"useAll": "すべてを使用",
|
||||
"info": "情報",
|
||||
"deleteImage": "画像を削除",
|
||||
"showOptionsPanel": "オプションパネルを表示"
|
||||
},
|
||||
"settings": {
|
||||
@@ -356,6 +364,7 @@
|
||||
"saveSteps": "nステップごとに画像を保存",
|
||||
"confirmOnDelete": "削除時に確認",
|
||||
"displayHelpIcons": "ヘルプアイコンを表示",
|
||||
"useCanvasBeta": "キャンバスレイアウト(Beta)を使用する",
|
||||
"enableImageDebugging": "画像のデバッグを有効化",
|
||||
"resetWebUI": "WebUIをリセット",
|
||||
"resetWebUIDesc1": "WebUIのリセットは、画像と保存された設定のキャッシュをリセットするだけです。画像を削除するわけではありません。",
|
||||
@@ -364,6 +373,7 @@
|
||||
},
|
||||
"toast": {
|
||||
"uploadFailed": "アップロード失敗",
|
||||
"uploadFailedMultipleImagesDesc": "一度にアップロードできる画像は1枚のみです。",
|
||||
"uploadFailedUnableToLoadDesc": "ファイルを読み込むことができません。",
|
||||
"downloadImageStarted": "画像ダウンロード開始",
|
||||
"imageCopied": "画像をコピー",
|
||||
@@ -461,6 +471,7 @@
|
||||
"toggleAutoscroll": "自動スクロールの切替",
|
||||
"modifyConfig": "Modify Config",
|
||||
"toggleLogViewer": "Log Viewerの切替",
|
||||
"showGallery": "ギャラリーを表示",
|
||||
"showOptionsPanel": "オプションパネルを表示"
|
||||
}
|
||||
}
|
||||
|
||||
4
invokeai/frontend/web/dist/locales/ko.json
vendored
4
invokeai/frontend/web/dist/locales/ko.json
vendored
@@ -1,9 +1,13 @@
|
||||
{
|
||||
"common": {
|
||||
"themeLabel": "테마 설정",
|
||||
"languagePickerLabel": "언어 설정",
|
||||
"reportBugLabel": "버그 리포트",
|
||||
"githubLabel": "Github",
|
||||
"settingsLabel": "설정",
|
||||
"darkTheme": "다크 모드",
|
||||
"lightTheme": "라이트 모드",
|
||||
"greenTheme": "그린 모드",
|
||||
"langArabic": "العربية",
|
||||
"langEnglish": "English",
|
||||
"langDutch": "Nederlands",
|
||||
|
||||
965
invokeai/frontend/web/dist/locales/nl.json
vendored
965
invokeai/frontend/web/dist/locales/nl.json
vendored
File diff suppressed because it is too large
Load Diff
43
invokeai/frontend/web/dist/locales/pl.json
vendored
43
invokeai/frontend/web/dist/locales/pl.json
vendored
@@ -1,9 +1,13 @@
|
||||
{
|
||||
"common": {
|
||||
"hotkeysLabel": "Skróty klawiszowe",
|
||||
"themeLabel": "Motyw",
|
||||
"languagePickerLabel": "Wybór języka",
|
||||
"reportBugLabel": "Zgłoś błąd",
|
||||
"settingsLabel": "Ustawienia",
|
||||
"darkTheme": "Ciemny",
|
||||
"lightTheme": "Jasny",
|
||||
"greenTheme": "Zielony",
|
||||
"img2img": "Obraz na obraz",
|
||||
"unifiedCanvas": "Tryb uniwersalny",
|
||||
"nodes": "Węzły",
|
||||
@@ -39,11 +43,7 @@
|
||||
"statusUpscaling": "Powiększanie obrazu",
|
||||
"statusUpscalingESRGAN": "Powiększanie (ESRGAN)",
|
||||
"statusLoadingModel": "Wczytywanie modelu",
|
||||
"statusModelChanged": "Zmieniono model",
|
||||
"githubLabel": "GitHub",
|
||||
"discordLabel": "Discord",
|
||||
"darkMode": "Tryb ciemny",
|
||||
"lightMode": "Tryb jasny"
|
||||
"statusModelChanged": "Zmieniono model"
|
||||
},
|
||||
"gallery": {
|
||||
"generations": "Wygenerowane",
|
||||
@@ -56,6 +56,7 @@
|
||||
"maintainAspectRatio": "Zachowaj proporcje",
|
||||
"autoSwitchNewImages": "Przełączaj na nowe obrazy",
|
||||
"singleColumnLayout": "Układ jednokolumnowy",
|
||||
"pinGallery": "Przypnij galerię",
|
||||
"allImagesLoaded": "Koniec listy",
|
||||
"loadMore": "Wczytaj więcej",
|
||||
"noImagesInGallery": "Brak obrazów w galerii"
|
||||
@@ -273,6 +274,7 @@
|
||||
"cfgScale": "Skala CFG",
|
||||
"width": "Szerokość",
|
||||
"height": "Wysokość",
|
||||
"sampler": "Próbkowanie",
|
||||
"seed": "Inicjator",
|
||||
"randomizeSeed": "Losowy inicjator",
|
||||
"shuffle": "Losuj",
|
||||
@@ -294,6 +296,10 @@
|
||||
"hiresOptim": "Optymalizacja wys. rozdzielczości",
|
||||
"imageFit": "Przeskaluj oryginalny obraz",
|
||||
"codeformerFidelity": "Dokładność",
|
||||
"seamSize": "Rozmiar",
|
||||
"seamBlur": "Rozmycie",
|
||||
"seamStrength": "Siła",
|
||||
"seamSteps": "Kroki",
|
||||
"scaleBeforeProcessing": "Tryb skalowania",
|
||||
"scaledWidth": "Sk. do szer.",
|
||||
"scaledHeight": "Sk. do wys.",
|
||||
@@ -304,6 +310,8 @@
|
||||
"infillScalingHeader": "Wypełnienie i skalowanie",
|
||||
"img2imgStrength": "Wpływ sugestii na obraz",
|
||||
"toggleLoopback": "Wł/wył sprzężenie zwrotne",
|
||||
"invoke": "Wywołaj",
|
||||
"promptPlaceholder": "W tym miejscu wprowadź swoje sugestie. [negatywne sugestie], (wzmocnienie), (osłabienie)--, po więcej opcji (np. swap lub blend) zajrzyj do dokumentacji",
|
||||
"sendTo": "Wyślij do",
|
||||
"sendToImg2Img": "Użyj w trybie \"Obraz na obraz\"",
|
||||
"sendToUnifiedCanvas": "Użyj w trybie uniwersalnym",
|
||||
@@ -316,6 +324,7 @@
|
||||
"useAll": "Skopiuj wszystko",
|
||||
"useInitImg": "Użyj oryginalnego obrazu",
|
||||
"info": "Informacje",
|
||||
"deleteImage": "Usuń obraz",
|
||||
"initialImage": "Oryginalny obraz",
|
||||
"showOptionsPanel": "Pokaż panel ustawień"
|
||||
},
|
||||
@@ -325,6 +334,7 @@
|
||||
"saveSteps": "Zapisuj obrazy co X kroków",
|
||||
"confirmOnDelete": "Potwierdzaj usuwanie",
|
||||
"displayHelpIcons": "Wyświetlaj ikony pomocy",
|
||||
"useCanvasBeta": "Nowy układ trybu uniwersalnego",
|
||||
"enableImageDebugging": "Włącz debugowanie obrazu",
|
||||
"resetWebUI": "Zresetuj interfejs",
|
||||
"resetWebUIDesc1": "Resetowanie interfejsu wyczyści jedynie dane i ustawienia zapisane w pamięci przeglądarki. Nie usunie żadnych obrazów z dysku.",
|
||||
@@ -334,6 +344,7 @@
|
||||
"toast": {
|
||||
"tempFoldersEmptied": "Wyczyszczono folder tymczasowy",
|
||||
"uploadFailed": "Błąd przesyłania obrazu",
|
||||
"uploadFailedMultipleImagesDesc": "Możliwe jest przesłanie tylko jednego obrazu na raz",
|
||||
"uploadFailedUnableToLoadDesc": "Błąd wczytywania obrazu",
|
||||
"downloadImageStarted": "Rozpoczęto pobieranie",
|
||||
"imageCopied": "Skopiowano obraz",
|
||||
@@ -435,27 +446,5 @@
|
||||
"betaDarkenOutside": "Przyciemnienie",
|
||||
"betaLimitToBox": "Ogranicz do zaznaczenia",
|
||||
"betaPreserveMasked": "Zachowaj obszar"
|
||||
},
|
||||
"accessibility": {
|
||||
"zoomIn": "Przybliż",
|
||||
"exitViewer": "Wyjdź z podglądu",
|
||||
"modelSelect": "Wybór modelu",
|
||||
"invokeProgressBar": "Pasek postępu",
|
||||
"reset": "Zerowanie",
|
||||
"useThisParameter": "Użyj tego parametru",
|
||||
"copyMetadataJson": "Kopiuj metadane JSON",
|
||||
"uploadImage": "Wgrywanie obrazu",
|
||||
"previousImage": "Poprzedni obraz",
|
||||
"nextImage": "Następny obraz",
|
||||
"zoomOut": "Oddal",
|
||||
"rotateClockwise": "Obróć zgodnie ze wskazówkami zegara",
|
||||
"rotateCounterClockwise": "Obróć przeciwnie do wskazówek zegara",
|
||||
"flipHorizontally": "Odwróć horyzontalnie",
|
||||
"flipVertically": "Odwróć wertykalnie",
|
||||
"modifyConfig": "Modyfikuj ustawienia",
|
||||
"toggleAutoscroll": "Przełącz autoprzewijanie",
|
||||
"toggleLogViewer": "Przełącz podgląd logów",
|
||||
"showOptionsPanel": "Pokaż panel opcji",
|
||||
"menu": "Menu"
|
||||
}
|
||||
}
|
||||
|
||||
19
invokeai/frontend/web/dist/locales/pt.json
vendored
19
invokeai/frontend/web/dist/locales/pt.json
vendored
@@ -1,8 +1,11 @@
|
||||
{
|
||||
"common": {
|
||||
"greenTheme": "Verde",
|
||||
"langArabic": "العربية",
|
||||
"themeLabel": "Tema",
|
||||
"reportBugLabel": "Reportar Bug",
|
||||
"settingsLabel": "Configurações",
|
||||
"lightTheme": "Claro",
|
||||
"langBrPortuguese": "Português do Brasil",
|
||||
"languagePickerLabel": "Seletor de Idioma",
|
||||
"langDutch": "Nederlands",
|
||||
@@ -54,11 +57,14 @@
|
||||
"statusModelChanged": "Modelo Alterado",
|
||||
"githubLabel": "Github",
|
||||
"discordLabel": "Discord",
|
||||
"darkTheme": "Escuro",
|
||||
"training": "Treinando",
|
||||
"statusGeneratingOutpainting": "Geração de Ampliação",
|
||||
"statusGenerationComplete": "Geração Completa",
|
||||
"statusMergingModels": "Mesclando Modelos",
|
||||
"statusMergedModels": "Modelos Mesclados",
|
||||
"oceanTheme": "Oceano",
|
||||
"pinOptionsPanel": "Fixar painel de opções",
|
||||
"loading": "A carregar",
|
||||
"loadingInvokeAI": "A carregar Invoke AI",
|
||||
"langPortuguese": "Português"
|
||||
@@ -68,6 +74,7 @@
|
||||
"gallerySettings": "Configurações de Galeria",
|
||||
"maintainAspectRatio": "Mater Proporções",
|
||||
"autoSwitchNewImages": "Trocar para Novas Imagens Automaticamente",
|
||||
"pinGallery": "Fixar Galeria",
|
||||
"singleColumnLayout": "Disposição em Coluna Única",
|
||||
"allImagesLoaded": "Todas as Imagens Carregadas",
|
||||
"loadMore": "Carregar Mais",
|
||||
@@ -400,6 +407,7 @@
|
||||
"width": "Largura",
|
||||
"seed": "Seed",
|
||||
"hiresStrength": "Força da Alta Resolução",
|
||||
"negativePrompts": "Indicações negativas",
|
||||
"general": "Geral",
|
||||
"randomizeSeed": "Seed Aleatório",
|
||||
"shuffle": "Embaralhar",
|
||||
@@ -417,6 +425,10 @@
|
||||
"hiresOptim": "Otimização de Alta Res",
|
||||
"imageFit": "Caber Imagem Inicial No Tamanho de Saída",
|
||||
"codeformerFidelity": "Fidelidade",
|
||||
"seamSize": "Tamanho da Fronteira",
|
||||
"seamBlur": "Desfoque da Fronteira",
|
||||
"seamStrength": "Força da Fronteira",
|
||||
"seamSteps": "Passos da Fronteira",
|
||||
"tileSize": "Tamanho do Ladrilho",
|
||||
"boundingBoxHeader": "Caixa Delimitadora",
|
||||
"seamCorrectionHeader": "Correção de Fronteira",
|
||||
@@ -424,10 +436,12 @@
|
||||
"img2imgStrength": "Força de Imagem Para Imagem",
|
||||
"toggleLoopback": "Ativar Loopback",
|
||||
"symmetry": "Simetria",
|
||||
"promptPlaceholder": "Digite o prompt aqui. [tokens negativos], (upweight)++, (downweight)--, trocar e misturar estão disponíveis (veja docs)",
|
||||
"sendTo": "Mandar para",
|
||||
"openInViewer": "Abrir No Visualizador",
|
||||
"closeViewer": "Fechar Visualizador",
|
||||
"usePrompt": "Usar Prompt",
|
||||
"deleteImage": "Apagar Imagem",
|
||||
"initialImage": "Imagem inicial",
|
||||
"showOptionsPanel": "Mostrar Painel de Opções",
|
||||
"strength": "Força",
|
||||
@@ -435,10 +449,12 @@
|
||||
"upscale": "Redimensionar",
|
||||
"upscaleImage": "Redimensionar Imagem",
|
||||
"scaleBeforeProcessing": "Escala Antes do Processamento",
|
||||
"invoke": "Invocar",
|
||||
"images": "Imagems",
|
||||
"steps": "Passos",
|
||||
"cfgScale": "Escala CFG",
|
||||
"height": "Altura",
|
||||
"sampler": "Amostrador",
|
||||
"imageToImage": "Imagem para Imagem",
|
||||
"variationAmount": "Quntidade de Variatções",
|
||||
"scaledWidth": "L Escalada",
|
||||
@@ -465,6 +481,7 @@
|
||||
"settings": {
|
||||
"confirmOnDelete": "Confirmar Antes de Apagar",
|
||||
"displayHelpIcons": "Mostrar Ícones de Ajuda",
|
||||
"useCanvasBeta": "Usar Layout de Telas Beta",
|
||||
"enableImageDebugging": "Ativar Depuração de Imagem",
|
||||
"useSlidersForAll": "Usar deslizadores para todas as opções",
|
||||
"resetWebUIDesc1": "Reiniciar a interface apenas reinicia o cache local do broswer para imagens e configurações lembradas. Não apaga nenhuma imagem do disco.",
|
||||
@@ -477,6 +494,7 @@
|
||||
},
|
||||
"toast": {
|
||||
"uploadFailed": "Envio Falhou",
|
||||
"uploadFailedMultipleImagesDesc": "Várias imagens copiadas, só é permitido uma imagem de cada vez",
|
||||
"uploadFailedUnableToLoadDesc": "Não foj possível carregar o ficheiro",
|
||||
"downloadImageStarted": "Download de Imagem Começou",
|
||||
"imageNotLoadedDesc": "Nenhuma imagem encontrada a enviar para o módulo de imagem para imagem",
|
||||
@@ -593,6 +611,7 @@
|
||||
"flipVertically": "Espelhar verticalmente",
|
||||
"modifyConfig": "Modificar config",
|
||||
"toggleAutoscroll": "Alternar rolagem automática",
|
||||
"showGallery": "Mostrar galeria",
|
||||
"showOptionsPanel": "Mostrar painel de opções",
|
||||
"uploadImage": "Enviar imagem",
|
||||
"previousImage": "Imagem anterior",
|
||||
|
||||
17
invokeai/frontend/web/dist/locales/pt_BR.json
vendored
17
invokeai/frontend/web/dist/locales/pt_BR.json
vendored
@@ -1,9 +1,13 @@
|
||||
{
|
||||
"common": {
|
||||
"hotkeysLabel": "Teclas de atalho",
|
||||
"themeLabel": "Tema",
|
||||
"languagePickerLabel": "Seletor de Idioma",
|
||||
"reportBugLabel": "Relatar Bug",
|
||||
"settingsLabel": "Configurações",
|
||||
"darkTheme": "Noite",
|
||||
"lightTheme": "Dia",
|
||||
"greenTheme": "Verde",
|
||||
"img2img": "Imagem Para Imagem",
|
||||
"unifiedCanvas": "Tela Unificada",
|
||||
"nodes": "Nódulos",
|
||||
@@ -59,6 +63,7 @@
|
||||
"statusMergedModels": "Modelos Mesclados",
|
||||
"langRussian": "Russo",
|
||||
"langSpanish": "Espanhol",
|
||||
"pinOptionsPanel": "Fixar painel de opções",
|
||||
"loadingInvokeAI": "Carregando Invoke AI",
|
||||
"loading": "Carregando"
|
||||
},
|
||||
@@ -73,6 +78,7 @@
|
||||
"maintainAspectRatio": "Mater Proporções",
|
||||
"autoSwitchNewImages": "Trocar para Novas Imagens Automaticamente",
|
||||
"singleColumnLayout": "Disposição em Coluna Única",
|
||||
"pinGallery": "Fixar Galeria",
|
||||
"allImagesLoaded": "Todas as Imagens Carregadas",
|
||||
"loadMore": "Carregar Mais",
|
||||
"noImagesInGallery": "Sem Imagens na Galeria"
|
||||
@@ -396,6 +402,7 @@
|
||||
"cfgScale": "Escala CFG",
|
||||
"width": "Largura",
|
||||
"height": "Altura",
|
||||
"sampler": "Amostrador",
|
||||
"seed": "Seed",
|
||||
"randomizeSeed": "Seed Aleatório",
|
||||
"shuffle": "Embaralhar",
|
||||
@@ -417,6 +424,10 @@
|
||||
"hiresOptim": "Otimização de Alta Res",
|
||||
"imageFit": "Caber Imagem Inicial No Tamanho de Saída",
|
||||
"codeformerFidelity": "Fidelidade",
|
||||
"seamSize": "Tamanho da Fronteira",
|
||||
"seamBlur": "Desfoque da Fronteira",
|
||||
"seamStrength": "Força da Fronteira",
|
||||
"seamSteps": "Passos da Fronteira",
|
||||
"scaleBeforeProcessing": "Escala Antes do Processamento",
|
||||
"scaledWidth": "L Escalada",
|
||||
"scaledHeight": "A Escalada",
|
||||
@@ -427,6 +438,8 @@
|
||||
"infillScalingHeader": "Preencimento e Escala",
|
||||
"img2imgStrength": "Força de Imagem Para Imagem",
|
||||
"toggleLoopback": "Ativar Loopback",
|
||||
"invoke": "Invoke",
|
||||
"promptPlaceholder": "Digite o prompt aqui. [tokens negativos], (upweight)++, (downweight)--, trocar e misturar estão disponíveis (veja docs)",
|
||||
"sendTo": "Mandar para",
|
||||
"sendToImg2Img": "Mandar para Imagem Para Imagem",
|
||||
"sendToUnifiedCanvas": "Mandar para Tela Unificada",
|
||||
@@ -439,12 +452,14 @@
|
||||
"useAll": "Usar Todos",
|
||||
"useInitImg": "Usar Imagem Inicial",
|
||||
"info": "Informações",
|
||||
"deleteImage": "Apagar Imagem",
|
||||
"initialImage": "Imagem inicial",
|
||||
"showOptionsPanel": "Mostrar Painel de Opções",
|
||||
"vSymmetryStep": "V Passo de Simetria",
|
||||
"hSymmetryStep": "H Passo de Simetria",
|
||||
"symmetry": "Simetria",
|
||||
"copyImage": "Copiar imagem",
|
||||
"negativePrompts": "Indicações negativas",
|
||||
"hiresStrength": "Força da Alta Resolução",
|
||||
"denoisingStrength": "A força de remoção de ruído",
|
||||
"imageToImage": "Imagem para Imagem",
|
||||
@@ -462,6 +477,7 @@
|
||||
"saveSteps": "Salvar imagens a cada n passos",
|
||||
"confirmOnDelete": "Confirmar Antes de Apagar",
|
||||
"displayHelpIcons": "Mostrar Ícones de Ajuda",
|
||||
"useCanvasBeta": "Usar Layout de Telas Beta",
|
||||
"enableImageDebugging": "Ativar Depuração de Imagem",
|
||||
"resetWebUI": "Reiniciar Interface",
|
||||
"resetWebUIDesc1": "Reiniciar a interface apenas reinicia o cache local do broswer para imagens e configurações lembradas. Não apaga nenhuma imagem do disco.",
|
||||
@@ -472,6 +488,7 @@
|
||||
"toast": {
|
||||
"tempFoldersEmptied": "Pasta de Arquivos Temporários Esvaziada",
|
||||
"uploadFailed": "Envio Falhou",
|
||||
"uploadFailedMultipleImagesDesc": "Várias imagens copiadas, só é permitido uma imagem de cada vez",
|
||||
"uploadFailedUnableToLoadDesc": "Não foj possível carregar o arquivo",
|
||||
"downloadImageStarted": "Download de Imagem Começou",
|
||||
"imageCopied": "Imagem Copiada",
|
||||
|
||||
211
invokeai/frontend/web/dist/locales/ru.json
vendored
211
invokeai/frontend/web/dist/locales/ru.json
vendored
@@ -1,12 +1,16 @@
|
||||
{
|
||||
"common": {
|
||||
"hotkeysLabel": "Горячие клавиши",
|
||||
"themeLabel": "Тема",
|
||||
"languagePickerLabel": "Язык",
|
||||
"reportBugLabel": "Сообщить об ошибке",
|
||||
"settingsLabel": "Настройки",
|
||||
"darkTheme": "Темная",
|
||||
"lightTheme": "Светлая",
|
||||
"greenTheme": "Зеленая",
|
||||
"img2img": "Изображение в изображение (img2img)",
|
||||
"unifiedCanvas": "Единый холст",
|
||||
"nodes": "Редактор рабочего процесса",
|
||||
"nodes": "Ноды",
|
||||
"langRussian": "Русский",
|
||||
"nodesDesc": "Cистема генерации изображений на основе нодов (узлов) уже разрабатывается. Следите за новостями об этой замечательной функции.",
|
||||
"postProcessing": "Постобработка",
|
||||
@@ -45,12 +49,14 @@
|
||||
"statusMergingModels": "Слияние моделей",
|
||||
"statusModelConverted": "Модель сконвертирована",
|
||||
"statusMergedModels": "Модели объединены",
|
||||
"pinOptionsPanel": "Закрепить панель настроек",
|
||||
"loading": "Загрузка",
|
||||
"loadingInvokeAI": "Загрузка Invoke AI",
|
||||
"back": "Назад",
|
||||
"statusConvertingModel": "Конвертация модели",
|
||||
"cancel": "Отменить",
|
||||
"accept": "Принять",
|
||||
"oceanTheme": "Океан",
|
||||
"langUkranian": "Украинский",
|
||||
"langEnglish": "Английский",
|
||||
"postprocessing": "Постобработка",
|
||||
@@ -68,21 +74,7 @@
|
||||
"langPortuguese": "Португальский",
|
||||
"txt2img": "Текст в изображение (txt2img)",
|
||||
"langBrPortuguese": "Португальский (Бразилия)",
|
||||
"linear": "Линейная обработка",
|
||||
"dontAskMeAgain": "Больше не спрашивать",
|
||||
"areYouSure": "Вы уверены?",
|
||||
"random": "Случайное",
|
||||
"generate": "Сгенерировать",
|
||||
"openInNewTab": "Открыть в новой вкладке",
|
||||
"imagePrompt": "Запрос",
|
||||
"communityLabel": "Сообщество",
|
||||
"lightMode": "Светлая тема",
|
||||
"batch": "Пакетный менеджер",
|
||||
"modelManager": "Менеджер моделей",
|
||||
"darkMode": "Темная тема",
|
||||
"nodeEditor": "Редактор Нодов (Узлов)",
|
||||
"controlNet": "Controlnet",
|
||||
"advanced": "Расширенные"
|
||||
"linear": "Линейная обработка"
|
||||
},
|
||||
"gallery": {
|
||||
"generations": "Генерации",
|
||||
@@ -95,15 +87,10 @@
|
||||
"maintainAspectRatio": "Сохранять пропорции",
|
||||
"autoSwitchNewImages": "Автоматически выбирать новые",
|
||||
"singleColumnLayout": "Одна колонка",
|
||||
"pinGallery": "Закрепить галерею",
|
||||
"allImagesLoaded": "Все изображения загружены",
|
||||
"loadMore": "Показать больше",
|
||||
"noImagesInGallery": "Изображений нет",
|
||||
"deleteImagePermanent": "Удаленные изображения невозможно восстановить.",
|
||||
"deleteImageBin": "Удаленные изображения будут отправлены в корзину вашей операционной системы.",
|
||||
"deleteImage": "Удалить изображение",
|
||||
"images": "Изображения",
|
||||
"assets": "Ресурсы",
|
||||
"autoAssignBoardOnClick": "Авто-назначение доски по клику"
|
||||
"noImagesInGallery": "Изображений нет"
|
||||
},
|
||||
"hotkeys": {
|
||||
"keyboardShortcuts": "Горячие клавиши",
|
||||
@@ -310,12 +297,7 @@
|
||||
"acceptStagingImage": {
|
||||
"title": "Принять изображение",
|
||||
"desc": "Принять текущее изображение"
|
||||
},
|
||||
"addNodes": {
|
||||
"desc": "Открывает меню добавления узла",
|
||||
"title": "Добавление узлов"
|
||||
},
|
||||
"nodesHotkeys": "Горячие клавиши узлов"
|
||||
}
|
||||
},
|
||||
"modelManager": {
|
||||
"modelManager": "Менеджер моделей",
|
||||
@@ -368,14 +350,14 @@
|
||||
"deleteModel": "Удалить модель",
|
||||
"deleteConfig": "Удалить конфигурацию",
|
||||
"deleteMsg1": "Вы точно хотите удалить модель из InvokeAI?",
|
||||
"deleteMsg2": "Это приведет К УДАЛЕНИЮ модели С ДИСКА, если она находится в корневой папке Invoke. Если вы используете пользовательское расположение, то модель НЕ будет удалена с диска.",
|
||||
"deleteMsg2": "Это не удалит файл модели с диска. Позже вы можете добавить его снова.",
|
||||
"repoIDValidationMsg": "Онлайн-репозиторий модели",
|
||||
"convertToDiffusersHelpText5": "Пожалуйста, убедитесь, что у вас достаточно места на диске. Модели обычно занимают 2–7 Гб.",
|
||||
"convertToDiffusersHelpText5": "Пожалуйста, убедитесь, что у вас достаточно места на диске. Модели обычно занимают 4 – 7 Гб.",
|
||||
"invokeAIFolder": "Каталог InvokeAI",
|
||||
"ignoreMismatch": "Игнорировать несоответствия между выбранными моделями",
|
||||
"addCheckpointModel": "Добавить модель Checkpoint/Safetensor",
|
||||
"formMessageDiffusersModelLocationDesc": "Укажите хотя бы одно.",
|
||||
"convertToDiffusersHelpText3": "Ваш файл контрольной точки НА ДИСКЕ будет УДАЛЕН, если он находится в корневой папке InvokeAI. Если он находится в пользовательском расположении, то он НЕ будет удален.",
|
||||
"convertToDiffusersHelpText3": "Файл модели на диске НЕ будет удалён или изменён. Вы сможете заново добавить его в Model Manager при необходимости.",
|
||||
"vaeRepoID": "ID репозитория VAE",
|
||||
"mergedModelName": "Название объединенной модели",
|
||||
"checkpointModels": "Checkpoints",
|
||||
@@ -427,27 +409,7 @@
|
||||
"weightedSum": "Взвешенная сумма",
|
||||
"safetensorModels": "SafeTensors",
|
||||
"v2_768": "v2 (768px)",
|
||||
"v2_base": "v2 (512px)",
|
||||
"modelDeleted": "Модель удалена",
|
||||
"importModels": "Импорт Моделей",
|
||||
"variant": "Вариант",
|
||||
"baseModel": "Базовая модель",
|
||||
"modelsSynced": "Модели синхронизированы",
|
||||
"modelSyncFailed": "Не удалось синхронизировать модели",
|
||||
"vae": "VAE",
|
||||
"modelDeleteFailed": "Не удалось удалить модель",
|
||||
"noCustomLocationProvided": "Пользовательское местоположение не указано",
|
||||
"convertingModelBegin": "Конвертация модели. Пожалуйста, подождите.",
|
||||
"settings": "Настройки",
|
||||
"selectModel": "Выберите модель",
|
||||
"syncModels": "Синхронизация моделей",
|
||||
"syncModelsDesc": "Если ваши модели не синхронизированы с серверной частью, вы можете обновить их, используя эту опцию. Обычно это удобно в тех случаях, когда вы вручную обновляете свой файл \"models.yaml\" или добавляете модели в корневую папку InvokeAI после загрузки приложения.",
|
||||
"modelUpdateFailed": "Не удалось обновить модель",
|
||||
"modelConversionFailed": "Не удалось сконвертировать модель",
|
||||
"modelsMergeFailed": "Не удалось выполнить слияние моделей",
|
||||
"loraModels": "LoRAs",
|
||||
"onnxModels": "Onnx",
|
||||
"oliveModels": "Olives"
|
||||
"v2_base": "v2 (512px)"
|
||||
},
|
||||
"parameters": {
|
||||
"images": "Изображения",
|
||||
@@ -455,9 +417,10 @@
|
||||
"cfgScale": "Уровень CFG",
|
||||
"width": "Ширина",
|
||||
"height": "Высота",
|
||||
"sampler": "Семплер",
|
||||
"seed": "Сид",
|
||||
"randomizeSeed": "Случайный сид",
|
||||
"shuffle": "Обновить сид",
|
||||
"shuffle": "Обновить",
|
||||
"noiseThreshold": "Порог шума",
|
||||
"perlinNoise": "Шум Перлина",
|
||||
"variations": "Вариации",
|
||||
@@ -476,6 +439,10 @@
|
||||
"hiresOptim": "Оптимизация High Res",
|
||||
"imageFit": "Уместить изображение",
|
||||
"codeformerFidelity": "Точность",
|
||||
"seamSize": "Размер шва",
|
||||
"seamBlur": "Размытие шва",
|
||||
"seamStrength": "Сила шва",
|
||||
"seamSteps": "Шаги шва",
|
||||
"scaleBeforeProcessing": "Масштабировать",
|
||||
"scaledWidth": "Масштаб Ш",
|
||||
"scaledHeight": "Масштаб В",
|
||||
@@ -486,6 +453,8 @@
|
||||
"infillScalingHeader": "Заполнение и масштабирование",
|
||||
"img2imgStrength": "Сила обработки img2img",
|
||||
"toggleLoopback": "Зациклить обработку",
|
||||
"invoke": "Invoke",
|
||||
"promptPlaceholder": "Введите запрос здесь (на английском). [исключенные токены], (более значимые)++, (менее значимые)--, swap и blend тоже доступны (смотрите Github)",
|
||||
"sendTo": "Отправить",
|
||||
"sendToImg2Img": "Отправить в img2img",
|
||||
"sendToUnifiedCanvas": "Отправить на Единый холст",
|
||||
@@ -498,6 +467,7 @@
|
||||
"useAll": "Использовать все",
|
||||
"useInitImg": "Использовать как исходное",
|
||||
"info": "Метаданные",
|
||||
"deleteImage": "Удалить изображение",
|
||||
"initialImage": "Исходное изображение",
|
||||
"showOptionsPanel": "Показать панель настроек",
|
||||
"vSymmetryStep": "Шаг верт. симметрии",
|
||||
@@ -515,27 +485,8 @@
|
||||
"imageToImage": "Изображение в изображение",
|
||||
"denoisingStrength": "Сила шумоподавления",
|
||||
"copyImage": "Скопировать изображение",
|
||||
"showPreview": "Показать предпросмотр",
|
||||
"noiseSettings": "Шум",
|
||||
"seamlessXAxis": "Ось X",
|
||||
"seamlessYAxis": "Ось Y",
|
||||
"scheduler": "Планировщик",
|
||||
"boundingBoxWidth": "Ширина ограничивающей рамки",
|
||||
"boundingBoxHeight": "Высота ограничивающей рамки",
|
||||
"positivePromptPlaceholder": "Запрос",
|
||||
"negativePromptPlaceholder": "Исключающий запрос",
|
||||
"controlNetControlMode": "Режим управления",
|
||||
"clipSkip": "CLIP Пропуск",
|
||||
"aspectRatio": "Соотношение",
|
||||
"maskAdjustmentsHeader": "Настройка маски",
|
||||
"maskBlur": "Размытие",
|
||||
"maskBlurMethod": "Метод размытия",
|
||||
"seamLowThreshold": "Низкий",
|
||||
"seamHighThreshold": "Высокий",
|
||||
"coherenceSteps": "Шагов",
|
||||
"coherencePassHeader": "Порог Coherence",
|
||||
"coherenceStrength": "Сила",
|
||||
"compositingSettingsHeader": "Настройки компоновки"
|
||||
"negativePrompts": "Исключающий запрос",
|
||||
"showPreview": "Показать предпросмотр"
|
||||
},
|
||||
"settings": {
|
||||
"models": "Модели",
|
||||
@@ -543,38 +494,24 @@
|
||||
"saveSteps": "Сохранять каждые n щагов",
|
||||
"confirmOnDelete": "Подтверждать удаление",
|
||||
"displayHelpIcons": "Показывать значки подсказок",
|
||||
"useCanvasBeta": "Показывать инструменты слева (Beta UI)",
|
||||
"enableImageDebugging": "Включить отладку",
|
||||
"resetWebUI": "Сброс настроек Web UI",
|
||||
"resetWebUIDesc1": "Сброс настроек веб-интерфейса удаляет только локальный кэш браузера с вашими изображениями и настройками. Он не удаляет изображения с диска.",
|
||||
"resetWebUIDesc2": "Если изображения не отображаются в галерее или не работает что-то еще, пожалуйста, попробуйте сбросить настройки, прежде чем сообщать о проблеме на GitHub.",
|
||||
"resetComplete": "Настройки веб-интерфейса были сброшены.",
|
||||
"useSlidersForAll": "Использовать ползунки для всех параметров",
|
||||
"consoleLogLevel": "Уровень логирования",
|
||||
"shouldLogToConsole": "Логи в консоль",
|
||||
"developer": "Разработчик",
|
||||
"general": "Основное",
|
||||
"showProgressInViewer": "Показывать процесс генерации в Просмотрщике",
|
||||
"antialiasProgressImages": "Сглаживать предпоказ процесса генерации",
|
||||
"generation": "Поколение",
|
||||
"ui": "Пользовательский интерфейс",
|
||||
"favoriteSchedulers": "Избранные планировщики",
|
||||
"favoriteSchedulersPlaceholder": "Нет избранных планировщиков",
|
||||
"enableNodesEditor": "Включить редактор узлов",
|
||||
"experimental": "Экспериментальные",
|
||||
"beta": "Бета",
|
||||
"alternateCanvasLayout": "Альтернативный слой холста",
|
||||
"showAdvancedOptions": "Показать доп. параметры",
|
||||
"autoChangeDimensions": "Обновить Ш/В на стандартные для модели при изменении"
|
||||
"resetComplete": "Интерфейс сброшен. Обновите эту страницу.",
|
||||
"useSlidersForAll": "Использовать ползунки для всех параметров"
|
||||
},
|
||||
"toast": {
|
||||
"tempFoldersEmptied": "Временная папка очищена",
|
||||
"uploadFailed": "Загрузка не удалась",
|
||||
"uploadFailedMultipleImagesDesc": "Можно вставить только одно изображение (вы попробовали вставить несколько)",
|
||||
"uploadFailedUnableToLoadDesc": "Невозможно загрузить файл",
|
||||
"downloadImageStarted": "Скачивание изображения началось",
|
||||
"imageCopied": "Изображение скопировано",
|
||||
"imageLinkCopied": "Ссылка на изображение скопирована",
|
||||
"imageNotLoaded": "Изображение не загружено",
|
||||
"imageNotLoadedDesc": "Не удалось найти изображение",
|
||||
"imageNotLoadedDesc": "Не найдены изображения для отправки в img2img",
|
||||
"imageSavedToGallery": "Изображение сохранено в галерею",
|
||||
"canvasMerged": "Холст объединен",
|
||||
"sentToImageToImage": "Отправить в img2img",
|
||||
@@ -599,21 +536,7 @@
|
||||
"serverError": "Ошибка сервера",
|
||||
"disconnected": "Отключено от сервера",
|
||||
"connected": "Подключено к серверу",
|
||||
"canceled": "Обработка отменена",
|
||||
"problemCopyingImageLink": "Не удалось скопировать ссылку на изображение",
|
||||
"uploadFailedInvalidUploadDesc": "Должно быть одно изображение в формате PNG или JPEG",
|
||||
"parameterNotSet": "Параметр не задан",
|
||||
"parameterSet": "Параметр задан",
|
||||
"nodesLoaded": "Узлы загружены",
|
||||
"problemCopyingImage": "Не удается скопировать изображение",
|
||||
"nodesLoadedFailed": "Не удалось загрузить Узлы",
|
||||
"nodesCleared": "Узлы очищены",
|
||||
"nodesBrokenConnections": "Не удается загрузить. Некоторые соединения повреждены.",
|
||||
"nodesUnrecognizedTypes": "Не удается загрузить. Граф имеет нераспознанные типы",
|
||||
"nodesNotValidJSON": "Недопустимый JSON",
|
||||
"nodesCorruptedGraph": "Не удается загрузить. Граф, похоже, поврежден.",
|
||||
"nodesSaved": "Узлы сохранены",
|
||||
"nodesNotValidGraph": "Недопустимый граф узлов InvokeAI"
|
||||
"canceled": "Обработка отменена"
|
||||
},
|
||||
"tooltip": {
|
||||
"feature": {
|
||||
@@ -687,8 +610,7 @@
|
||||
"betaClear": "Очистить",
|
||||
"betaDarkenOutside": "Затемнить снаружи",
|
||||
"betaLimitToBox": "Ограничить выделением",
|
||||
"betaPreserveMasked": "Сохранять маскируемую область",
|
||||
"antialiasing": "Не удалось скопировать ссылку на изображение"
|
||||
"betaPreserveMasked": "Сохранять маскируемую область"
|
||||
},
|
||||
"accessibility": {
|
||||
"modelSelect": "Выбор модели",
|
||||
@@ -703,7 +625,8 @@
|
||||
"flipHorizontally": "Отразить горизонтально",
|
||||
"toggleAutoscroll": "Включить автопрокрутку",
|
||||
"toggleLogViewer": "Показать или скрыть просмотрщик логов",
|
||||
"showOptionsPanel": "Показать боковую панель",
|
||||
"showOptionsPanel": "Показать опции",
|
||||
"showGallery": "Показать галерею",
|
||||
"invokeProgressBar": "Индикатор выполнения",
|
||||
"reset": "Сброс",
|
||||
"modifyConfig": "Изменить конфиг",
|
||||
@@ -711,69 +634,5 @@
|
||||
"copyMetadataJson": "Скопировать метаданные JSON",
|
||||
"exitViewer": "Закрыть просмотрщик",
|
||||
"menu": "Меню"
|
||||
},
|
||||
"ui": {
|
||||
"showProgressImages": "Показывать промежуточный итог",
|
||||
"hideProgressImages": "Не показывать промежуточный итог",
|
||||
"swapSizes": "Поменять местами размеры",
|
||||
"lockRatio": "Зафиксировать пропорции"
|
||||
},
|
||||
"nodes": {
|
||||
"zoomInNodes": "Увеличьте масштаб",
|
||||
"zoomOutNodes": "Уменьшите масштаб",
|
||||
"fitViewportNodes": "Уместить вид",
|
||||
"hideGraphNodes": "Скрыть оверлей графа",
|
||||
"showGraphNodes": "Показать оверлей графа",
|
||||
"showLegendNodes": "Показать тип поля",
|
||||
"hideMinimapnodes": "Скрыть миникарту",
|
||||
"hideLegendNodes": "Скрыть тип поля",
|
||||
"showMinimapnodes": "Показать миникарту",
|
||||
"loadWorkflow": "Загрузить рабочий процесс",
|
||||
"resetWorkflowDesc2": "Сброс рабочего процесса очистит все узлы, ребра и детали рабочего процесса.",
|
||||
"resetWorkflow": "Сбросить рабочий процесс",
|
||||
"resetWorkflowDesc": "Вы уверены, что хотите сбросить этот рабочий процесс?",
|
||||
"reloadNodeTemplates": "Перезагрузить шаблоны узлов",
|
||||
"downloadWorkflow": "Скачать JSON рабочего процесса"
|
||||
},
|
||||
"controlnet": {
|
||||
"amult": "a_mult",
|
||||
"contentShuffleDescription": "Перетасовывает содержимое изображения",
|
||||
"bgth": "bg_th",
|
||||
"contentShuffle": "Перетасовка содержимого",
|
||||
"beginEndStepPercent": "Процент начала/конца шага",
|
||||
"duplicate": "Дублировать",
|
||||
"balanced": "Сбалансированный",
|
||||
"f": "F",
|
||||
"depthMidasDescription": "Генерация карты глубины с использованием Midas",
|
||||
"control": "Контроль",
|
||||
"coarse": "Грубость обработки",
|
||||
"crop": "Обрезка",
|
||||
"depthMidas": "Глубина (Midas)",
|
||||
"enableControlnet": "Включить ControlNet",
|
||||
"detectResolution": "Определить разрешение",
|
||||
"controlMode": "Режим контроля",
|
||||
"cannyDescription": "Детектор границ Canny",
|
||||
"depthZoe": "Глубина (Zoe)",
|
||||
"autoConfigure": "Автонастройка процессора",
|
||||
"delete": "Удалить",
|
||||
"canny": "Canny",
|
||||
"depthZoeDescription": "Генерация карты глубины с использованием Zoe"
|
||||
},
|
||||
"boards": {
|
||||
"autoAddBoard": "Авто добавление Доски",
|
||||
"topMessage": "Эта доска содержит изображения, используемые в следующих функциях:",
|
||||
"move": "Перемещение",
|
||||
"menuItemAutoAdd": "Авто добавление на эту доску",
|
||||
"myBoard": "Моя Доска",
|
||||
"searchBoard": "Поиск Доски...",
|
||||
"noMatching": "Нет подходящих Досок",
|
||||
"selectBoard": "Выбрать Доску",
|
||||
"cancel": "Отменить",
|
||||
"addBoard": "Добавить Доску",
|
||||
"bottomMessage": "Удаление этой доски и ее изображений приведет к сбросу всех функций, использующихся их в данный момент.",
|
||||
"uncategorized": "Без категории",
|
||||
"changeBoard": "Изменить Доску",
|
||||
"loading": "Загрузка...",
|
||||
"clearSearch": "Очистить поиск"
|
||||
}
|
||||
}
|
||||
|
||||
8
invokeai/frontend/web/dist/locales/sv.json
vendored
8
invokeai/frontend/web/dist/locales/sv.json
vendored
@@ -15,6 +15,7 @@
|
||||
"reset": "Starta om",
|
||||
"previousImage": "Föregående bild",
|
||||
"useThisParameter": "Använd denna parametern",
|
||||
"showGallery": "Visa galleri",
|
||||
"rotateCounterClockwise": "Rotera moturs",
|
||||
"rotateClockwise": "Rotera medurs",
|
||||
"modifyConfig": "Ändra konfiguration",
|
||||
@@ -26,6 +27,10 @@
|
||||
"githubLabel": "Github",
|
||||
"discordLabel": "Discord",
|
||||
"settingsLabel": "Inställningar",
|
||||
"darkTheme": "Mörk",
|
||||
"lightTheme": "Ljus",
|
||||
"greenTheme": "Grön",
|
||||
"oceanTheme": "Hav",
|
||||
"langEnglish": "Engelska",
|
||||
"langDutch": "Nederländska",
|
||||
"langFrench": "Franska",
|
||||
@@ -58,10 +63,12 @@
|
||||
"statusGenerationComplete": "Generering klar",
|
||||
"statusModelConverted": "Modell konverterad",
|
||||
"statusMergingModels": "Sammanfogar modeller",
|
||||
"pinOptionsPanel": "Nåla fast inställningspanelen",
|
||||
"loading": "Laddar",
|
||||
"loadingInvokeAI": "Laddar Invoke AI",
|
||||
"statusRestoringFaces": "Återskapar ansikten",
|
||||
"languagePickerLabel": "Språkväljare",
|
||||
"themeLabel": "Tema",
|
||||
"txt2img": "Text till bild",
|
||||
"nodes": "Noder",
|
||||
"img2img": "Bild till bild",
|
||||
@@ -101,6 +108,7 @@
|
||||
"galleryImageResetSize": "Återställ storlek",
|
||||
"gallerySettings": "Galleriinställningar",
|
||||
"maintainAspectRatio": "Behåll bildförhållande",
|
||||
"pinGallery": "Nåla fast galleri",
|
||||
"noImagesInGallery": "Inga bilder i galleriet",
|
||||
"autoSwitchNewImages": "Ändra automatiskt till nya bilder",
|
||||
"singleColumnLayout": "Enkolumnslayout"
|
||||
|
||||
8
invokeai/frontend/web/dist/locales/tr.json
vendored
8
invokeai/frontend/web/dist/locales/tr.json
vendored
@@ -19,15 +19,21 @@
|
||||
"reset": "Sıfırla",
|
||||
"uploadImage": "Resim Yükle",
|
||||
"previousImage": "Önceki Resim",
|
||||
"menu": "Menü"
|
||||
"menu": "Menü",
|
||||
"showGallery": "Galeriyi Göster"
|
||||
},
|
||||
"common": {
|
||||
"hotkeysLabel": "Kısayol Tuşları",
|
||||
"themeLabel": "Tema",
|
||||
"languagePickerLabel": "Dil Seçimi",
|
||||
"reportBugLabel": "Hata Bildir",
|
||||
"githubLabel": "Github",
|
||||
"discordLabel": "Discord",
|
||||
"settingsLabel": "Ayarlar",
|
||||
"darkTheme": "Karanlık Tema",
|
||||
"lightTheme": "Aydınlık Tema",
|
||||
"greenTheme": "Yeşil Tema",
|
||||
"oceanTheme": "Okyanus Tema",
|
||||
"langArabic": "Arapça",
|
||||
"langEnglish": "İngilizce",
|
||||
"langDutch": "Hollandaca",
|
||||
|
||||
21
invokeai/frontend/web/dist/locales/uk.json
vendored
21
invokeai/frontend/web/dist/locales/uk.json
vendored
@@ -1,9 +1,13 @@
|
||||
{
|
||||
"common": {
|
||||
"hotkeysLabel": "Гарячi клавіші",
|
||||
"themeLabel": "Тема",
|
||||
"languagePickerLabel": "Мова",
|
||||
"reportBugLabel": "Повідомити про помилку",
|
||||
"settingsLabel": "Налаштування",
|
||||
"darkTheme": "Темна",
|
||||
"lightTheme": "Світла",
|
||||
"greenTheme": "Зелена",
|
||||
"img2img": "Зображення із зображення (img2img)",
|
||||
"unifiedCanvas": "Універсальне полотно",
|
||||
"nodes": "Вузли",
|
||||
@@ -51,6 +55,8 @@
|
||||
"langHebrew": "Іврит",
|
||||
"langKorean": "Корейська",
|
||||
"langPortuguese": "Португальська",
|
||||
"pinOptionsPanel": "Закріпити панель налаштувань",
|
||||
"oceanTheme": "Океан",
|
||||
"langArabic": "Арабська",
|
||||
"langSimplifiedChinese": "Китайська (спрощена)",
|
||||
"langSpanish": "Іспанська",
|
||||
@@ -81,6 +87,7 @@
|
||||
"maintainAspectRatio": "Зберігати пропорції",
|
||||
"autoSwitchNewImages": "Автоматично вибирати нові",
|
||||
"singleColumnLayout": "Одна колонка",
|
||||
"pinGallery": "Закріпити галерею",
|
||||
"allImagesLoaded": "Всі зображення завантажені",
|
||||
"loadMore": "Завантажити більше",
|
||||
"noImagesInGallery": "Зображень немає"
|
||||
@@ -410,6 +417,7 @@
|
||||
"cfgScale": "Рівень CFG",
|
||||
"width": "Ширина",
|
||||
"height": "Висота",
|
||||
"sampler": "Семплер",
|
||||
"seed": "Сід",
|
||||
"randomizeSeed": "Випадковий сид",
|
||||
"shuffle": "Оновити",
|
||||
@@ -431,6 +439,10 @@
|
||||
"hiresOptim": "Оптимізація High Res",
|
||||
"imageFit": "Вмістити зображення",
|
||||
"codeformerFidelity": "Точність",
|
||||
"seamSize": "Размір шву",
|
||||
"seamBlur": "Розмиття шву",
|
||||
"seamStrength": "Сила шву",
|
||||
"seamSteps": "Кроки шву",
|
||||
"scaleBeforeProcessing": "Масштабувати",
|
||||
"scaledWidth": "Масштаб Ш",
|
||||
"scaledHeight": "Масштаб В",
|
||||
@@ -441,6 +453,8 @@
|
||||
"infillScalingHeader": "Заповнення і масштабування",
|
||||
"img2imgStrength": "Сила обробки img2img",
|
||||
"toggleLoopback": "Зациклити обробку",
|
||||
"invoke": "Викликати",
|
||||
"promptPlaceholder": "Введіть запит тут (англійською). [видалені токени], (більш вагомі)++, (менш вагомі)--, swap и blend також доступні (дивіться Github)",
|
||||
"sendTo": "Надіслати",
|
||||
"sendToImg2Img": "Надіслати у img2img",
|
||||
"sendToUnifiedCanvas": "Надіслати на полотно",
|
||||
@@ -453,6 +467,7 @@
|
||||
"useAll": "Використати все",
|
||||
"useInitImg": "Використати як початкове",
|
||||
"info": "Метадані",
|
||||
"deleteImage": "Видалити зображення",
|
||||
"initialImage": "Початкове зображення",
|
||||
"showOptionsPanel": "Показати панель налаштувань",
|
||||
"general": "Основне",
|
||||
@@ -470,7 +485,8 @@
|
||||
"denoisingStrength": "Сила шумоподавлення",
|
||||
"copyImage": "Копіювати зображення",
|
||||
"symmetry": "Симетрія",
|
||||
"hSymmetryStep": "Крок гор. симетрії"
|
||||
"hSymmetryStep": "Крок гор. симетрії",
|
||||
"negativePrompts": "Виключний запит"
|
||||
},
|
||||
"settings": {
|
||||
"models": "Моделі",
|
||||
@@ -478,6 +494,7 @@
|
||||
"saveSteps": "Зберігати кожні n кроків",
|
||||
"confirmOnDelete": "Підтверджувати видалення",
|
||||
"displayHelpIcons": "Показувати значки підказок",
|
||||
"useCanvasBeta": "Показувати інструменты зліва (Beta UI)",
|
||||
"enableImageDebugging": "Увімкнути налагодження",
|
||||
"resetWebUI": "Повернути початкові",
|
||||
"resetWebUIDesc1": "Скидання настройок веб-інтерфейсу видаляє лише локальний кеш браузера з вашими зображеннями та налаштуваннями. Це не призводить до видалення зображень з диску.",
|
||||
@@ -488,6 +505,7 @@
|
||||
"toast": {
|
||||
"tempFoldersEmptied": "Тимчасова папка очищена",
|
||||
"uploadFailed": "Не вдалося завантажити",
|
||||
"uploadFailedMultipleImagesDesc": "Можна вставити лише одне зображення (ви спробували вставити декілька)",
|
||||
"uploadFailedUnableToLoadDesc": "Неможливо завантажити файл",
|
||||
"downloadImageStarted": "Завантаження зображення почалося",
|
||||
"imageCopied": "Зображення скопійоване",
|
||||
@@ -608,6 +626,7 @@
|
||||
"rotateClockwise": "Обертати за годинниковою стрілкою",
|
||||
"toggleAutoscroll": "Увімкнути автопрокручування",
|
||||
"toggleLogViewer": "Показати або приховати переглядач журналів",
|
||||
"showGallery": "Показати галерею",
|
||||
"previousImage": "Попереднє зображення",
|
||||
"copyMetadataJson": "Скопіювати метадані JSON",
|
||||
"flipVertically": "Перевернути по вертикалі",
|
||||
|
||||
1237
invokeai/frontend/web/dist/locales/zh_CN.json
vendored
1237
invokeai/frontend/web/dist/locales/zh_CN.json
vendored
File diff suppressed because it is too large
Load Diff
23
invokeai/frontend/web/dist/locales/zh_Hant.json
vendored
23
invokeai/frontend/web/dist/locales/zh_Hant.json
vendored
@@ -13,6 +13,9 @@
|
||||
"settingsLabel": "設定",
|
||||
"upload": "上傳",
|
||||
"langArabic": "阿拉伯語",
|
||||
"greenTheme": "綠色",
|
||||
"lightTheme": "淺色",
|
||||
"darkTheme": "深色",
|
||||
"discordLabel": "Discord",
|
||||
"nodesDesc": "使用Node生成圖像的系統正在開發中。敬請期待有關於這項功能的更新。",
|
||||
"reportBugLabel": "回報錯誤",
|
||||
@@ -30,24 +33,6 @@
|
||||
"langBrPortuguese": "巴西葡萄牙語",
|
||||
"langRussian": "俄語",
|
||||
"langSpanish": "西班牙語",
|
||||
"unifiedCanvas": "統一畫布",
|
||||
"cancel": "取消",
|
||||
"langHebrew": "希伯來語",
|
||||
"txt2img": "文字轉圖片"
|
||||
},
|
||||
"accessibility": {
|
||||
"modelSelect": "選擇模型",
|
||||
"invokeProgressBar": "Invoke 進度條",
|
||||
"uploadImage": "上傳圖片",
|
||||
"reset": "重設",
|
||||
"nextImage": "下一張圖片",
|
||||
"previousImage": "上一張圖片",
|
||||
"flipHorizontally": "水平翻轉",
|
||||
"useThisParameter": "使用此參數",
|
||||
"zoomIn": "放大",
|
||||
"zoomOut": "縮小",
|
||||
"flipVertically": "垂直翻轉",
|
||||
"modifyConfig": "修改配置",
|
||||
"menu": "選單"
|
||||
"unifiedCanvas": "統一畫布"
|
||||
}
|
||||
}
|
||||
|
||||
@@ -3,9 +3,6 @@
|
||||
<head>
|
||||
<meta charset="UTF-8" />
|
||||
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
|
||||
<meta http-equiv="Cache-Control" content="no-cache, no-store, must-revalidate">
|
||||
<meta http-equiv="Pragma" content="no-cache">
|
||||
<meta http-equiv="Expires" content="0">
|
||||
<title>InvokeAI - A Stable Diffusion Toolkit</title>
|
||||
<link rel="shortcut icon" type="icon" href="favicon.ico" />
|
||||
<style>
|
||||
|
||||
@@ -54,42 +54,42 @@
|
||||
]
|
||||
},
|
||||
"dependencies": {
|
||||
"@chakra-ui/anatomy": "^2.2.1",
|
||||
"@chakra-ui/icons": "^2.1.1",
|
||||
"@chakra-ui/react": "^2.8.1",
|
||||
"@chakra-ui/anatomy": "^2.2.0",
|
||||
"@chakra-ui/icons": "^2.1.0",
|
||||
"@chakra-ui/react": "^2.8.0",
|
||||
"@chakra-ui/styled-system": "^2.9.1",
|
||||
"@chakra-ui/theme-tools": "^2.1.1",
|
||||
"@chakra-ui/theme-tools": "^2.1.0",
|
||||
"@dagrejs/graphlib": "^2.1.13",
|
||||
"@dnd-kit/core": "^6.0.8",
|
||||
"@dnd-kit/modifiers": "^6.0.1",
|
||||
"@dnd-kit/utilities": "^3.2.1",
|
||||
"@emotion/react": "^11.11.1",
|
||||
"@emotion/styled": "^11.11.0",
|
||||
"@floating-ui/react-dom": "^2.0.2",
|
||||
"@fontsource-variable/inter": "^5.0.13",
|
||||
"@fontsource/inter": "^5.0.13",
|
||||
"@floating-ui/react-dom": "^2.0.1",
|
||||
"@fontsource-variable/inter": "^5.0.8",
|
||||
"@fontsource/inter": "^5.0.8",
|
||||
"@mantine/core": "^6.0.19",
|
||||
"@mantine/form": "^6.0.19",
|
||||
"@mantine/hooks": "^6.0.19",
|
||||
"@nanostores/react": "^0.7.1",
|
||||
"@reduxjs/toolkit": "^1.9.7",
|
||||
"@roarr/browser-log-writer": "^1.3.0",
|
||||
"@reduxjs/toolkit": "^1.9.5",
|
||||
"@roarr/browser-log-writer": "^1.1.5",
|
||||
"@stevebel/png": "^1.5.1",
|
||||
"compare-versions": "^6.1.0",
|
||||
"dateformat": "^5.0.3",
|
||||
"formik": "^2.4.5",
|
||||
"framer-motion": "^10.16.4",
|
||||
"formik": "^2.4.3",
|
||||
"framer-motion": "^10.16.1",
|
||||
"fuse.js": "^6.6.2",
|
||||
"i18next": "^23.5.1",
|
||||
"i18next": "^23.4.4",
|
||||
"i18next-browser-languagedetector": "^7.0.2",
|
||||
"i18next-http-backend": "^2.2.2",
|
||||
"konva": "^9.2.2",
|
||||
"i18next-http-backend": "^2.2.1",
|
||||
"konva": "^9.2.0",
|
||||
"lodash-es": "^4.17.21",
|
||||
"nanostores": "^0.9.2",
|
||||
"new-github-issue-url": "^1.0.0",
|
||||
"openapi-fetch": "^0.7.10",
|
||||
"overlayscrollbars": "^2.3.2",
|
||||
"overlayscrollbars-react": "^0.5.2",
|
||||
"openapi-fetch": "^0.7.4",
|
||||
"overlayscrollbars": "^2.2.0",
|
||||
"overlayscrollbars-react": "^0.5.0",
|
||||
"patch-package": "^8.0.0",
|
||||
"query-string": "^8.1.0",
|
||||
"react": "^18.2.0",
|
||||
@@ -98,25 +98,25 @@
|
||||
"react-dropzone": "^14.2.3",
|
||||
"react-error-boundary": "^4.0.11",
|
||||
"react-hotkeys-hook": "4.4.1",
|
||||
"react-i18next": "^13.3.0",
|
||||
"react-icons": "^4.11.0",
|
||||
"react-i18next": "^13.1.2",
|
||||
"react-icons": "^4.10.1",
|
||||
"react-konva": "^18.2.10",
|
||||
"react-redux": "^8.1.3",
|
||||
"react-redux": "^8.1.2",
|
||||
"react-resizable-panels": "^0.0.55",
|
||||
"react-use": "^17.4.0",
|
||||
"react-virtuoso": "^4.6.1",
|
||||
"react-zoom-pan-pinch": "^3.2.0",
|
||||
"reactflow": "^11.9.3",
|
||||
"react-virtuoso": "^4.5.0",
|
||||
"react-zoom-pan-pinch": "^3.0.8",
|
||||
"reactflow": "^11.8.3",
|
||||
"redux-dynamic-middlewares": "^2.2.0",
|
||||
"redux-remember": "^4.0.4",
|
||||
"redux-remember": "^4.0.1",
|
||||
"roarr": "^7.15.1",
|
||||
"serialize-error": "^11.0.2",
|
||||
"serialize-error": "^11.0.1",
|
||||
"socket.io-client": "^4.7.2",
|
||||
"type-fest": "^4.4.0",
|
||||
"type-fest": "^4.2.0",
|
||||
"use-debounce": "^9.0.4",
|
||||
"use-image": "^1.1.1",
|
||||
"uuid": "^9.0.1",
|
||||
"zod": "^3.22.4",
|
||||
"uuid": "^9.0.0",
|
||||
"zod": "^3.22.2",
|
||||
"zod-validation-error": "^1.5.0"
|
||||
},
|
||||
"peerDependencies": {
|
||||
@@ -129,40 +129,39 @@
|
||||
"devDependencies": {
|
||||
"@chakra-ui/cli": "^2.4.1",
|
||||
"@types/dateformat": "^5.0.0",
|
||||
"@types/lodash-es": "^4.17.9",
|
||||
"@types/node": "^20.8.6",
|
||||
"@types/react": "^18.2.28",
|
||||
"@types/react-dom": "^18.2.13",
|
||||
"@types/react-redux": "^7.1.27",
|
||||
"@types/react-transition-group": "^4.4.7",
|
||||
"@types/uuid": "^9.0.5",
|
||||
"@typescript-eslint/eslint-plugin": "^6.7.5",
|
||||
"@typescript-eslint/parser": "^6.7.5",
|
||||
"@vitejs/plugin-react-swc": "^3.4.0",
|
||||
"axios": "^1.5.1",
|
||||
"@types/lodash-es": "^4.14.194",
|
||||
"@types/node": "^20.5.1",
|
||||
"@types/react": "^18.2.20",
|
||||
"@types/react-dom": "^18.2.6",
|
||||
"@types/react-redux": "^7.1.25",
|
||||
"@types/react-transition-group": "^4.4.6",
|
||||
"@types/uuid": "^9.0.2",
|
||||
"@typescript-eslint/eslint-plugin": "^6.4.1",
|
||||
"@typescript-eslint/parser": "^6.4.1",
|
||||
"@vitejs/plugin-react-swc": "^3.3.2",
|
||||
"axios": "^1.4.0",
|
||||
"babel-plugin-transform-imports": "^2.0.0",
|
||||
"concurrently": "^8.2.1",
|
||||
"eslint": "^8.51.0",
|
||||
"concurrently": "^8.2.0",
|
||||
"eslint": "^8.47.0",
|
||||
"eslint-config-prettier": "^9.0.0",
|
||||
"eslint-plugin-prettier": "^5.0.1",
|
||||
"eslint-plugin-prettier": "^5.0.0",
|
||||
"eslint-plugin-react": "^7.33.2",
|
||||
"eslint-plugin-react-hooks": "^4.6.0",
|
||||
"form-data": "^4.0.0",
|
||||
"husky": "^8.0.3",
|
||||
"lint-staged": "^15.0.1",
|
||||
"lint-staged": "^14.0.1",
|
||||
"madge": "^6.1.0",
|
||||
"openapi-types": "^12.1.3",
|
||||
"openapi-typescript": "^6.7.0",
|
||||
"openapi-typescript": "^6.5.2",
|
||||
"postinstall-postinstall": "^2.1.0",
|
||||
"prettier": "^3.0.3",
|
||||
"prettier": "^3.0.2",
|
||||
"rollup-plugin-visualizer": "^5.9.2",
|
||||
"ts-toolbelt": "^9.6.0",
|
||||
"typescript": "^5.2.2",
|
||||
"vite": "^4.4.11",
|
||||
"vite": "^4.4.9",
|
||||
"vite-plugin-css-injected-by-js": "^3.3.0",
|
||||
"vite-plugin-dts": "^3.6.0",
|
||||
"vite-plugin-dts": "^3.5.2",
|
||||
"vite-plugin-eslint": "^1.8.1",
|
||||
"vite-tsconfig-paths": "^4.2.1",
|
||||
"vite-tsconfig-paths": "^4.2.0",
|
||||
"yarn": "^1.22.19"
|
||||
}
|
||||
}
|
||||
|
||||
@@ -1,9 +1,13 @@
|
||||
{
|
||||
"common": {
|
||||
"hotkeysLabel": "مفاتيح الأختصار",
|
||||
"themeLabel": "الموضوع",
|
||||
"languagePickerLabel": "منتقي اللغة",
|
||||
"reportBugLabel": "بلغ عن خطأ",
|
||||
"settingsLabel": "إعدادات",
|
||||
"darkTheme": "داكن",
|
||||
"lightTheme": "فاتح",
|
||||
"greenTheme": "أخضر",
|
||||
"img2img": "صورة إلى صورة",
|
||||
"unifiedCanvas": "لوحة موحدة",
|
||||
"nodes": "عقد",
|
||||
@@ -53,6 +57,7 @@
|
||||
"maintainAspectRatio": "الحفاظ على نسبة الأبعاد",
|
||||
"autoSwitchNewImages": "التبديل التلقائي إلى الصور الجديدة",
|
||||
"singleColumnLayout": "تخطيط عمود واحد",
|
||||
"pinGallery": "تثبيت المعرض",
|
||||
"allImagesLoaded": "تم تحميل جميع الصور",
|
||||
"loadMore": "تحميل المزيد",
|
||||
"noImagesInGallery": "لا توجد صور في المعرض"
|
||||
@@ -337,6 +342,7 @@
|
||||
"cfgScale": "مقياس الإعداد الذاتي للجملة",
|
||||
"width": "عرض",
|
||||
"height": "ارتفاع",
|
||||
"sampler": "مزج",
|
||||
"seed": "بذرة",
|
||||
"randomizeSeed": "تبديل بذرة",
|
||||
"shuffle": "تشغيل",
|
||||
@@ -358,6 +364,10 @@
|
||||
"hiresOptim": "تحسين الدقة العالية",
|
||||
"imageFit": "ملائمة الصورة الأولية لحجم الخرج",
|
||||
"codeformerFidelity": "الوثوقية",
|
||||
"seamSize": "حجم التشقق",
|
||||
"seamBlur": "ضباب التشقق",
|
||||
"seamStrength": "قوة التشقق",
|
||||
"seamSteps": "خطوات التشقق",
|
||||
"scaleBeforeProcessing": "تحجيم قبل المعالجة",
|
||||
"scaledWidth": "العرض المحجوب",
|
||||
"scaledHeight": "الارتفاع المحجوب",
|
||||
@@ -368,6 +378,8 @@
|
||||
"infillScalingHeader": "التعبئة والتحجيم",
|
||||
"img2imgStrength": "قوة صورة إلى صورة",
|
||||
"toggleLoopback": "تبديل الإعادة",
|
||||
"invoke": "إطلاق",
|
||||
"promptPlaceholder": "اكتب المحث هنا. [العلامات السلبية], (زيادة الوزن) ++, (نقص الوزن)--, التبديل و الخلط متاحة (انظر الوثائق)",
|
||||
"sendTo": "أرسل إلى",
|
||||
"sendToImg2Img": "أرسل إلى صورة إلى صورة",
|
||||
"sendToUnifiedCanvas": "أرسل إلى الخطوط الموحدة",
|
||||
@@ -381,6 +393,7 @@
|
||||
"useAll": "استخدام الكل",
|
||||
"useInitImg": "استخدام الصورة الأولية",
|
||||
"info": "معلومات",
|
||||
"deleteImage": "حذف الصورة",
|
||||
"initialImage": "الصورة الأولية",
|
||||
"showOptionsPanel": "إظهار لوحة الخيارات"
|
||||
},
|
||||
@@ -390,6 +403,7 @@
|
||||
"saveSteps": "حفظ الصور كل n خطوات",
|
||||
"confirmOnDelete": "تأكيد عند الحذف",
|
||||
"displayHelpIcons": "عرض أيقونات المساعدة",
|
||||
"useCanvasBeta": "استخدام مخطط الأزرار بيتا",
|
||||
"enableImageDebugging": "تمكين التصحيح عند التصوير",
|
||||
"resetWebUI": "إعادة تعيين واجهة الويب",
|
||||
"resetWebUIDesc1": "إعادة تعيين واجهة الويب يعيد فقط ذاكرة التخزين المؤقت للمتصفح لصورك وإعداداتك المذكورة. لا يحذف أي صور من القرص.",
|
||||
@@ -399,6 +413,7 @@
|
||||
"toast": {
|
||||
"tempFoldersEmptied": "تم تفريغ مجلد المؤقت",
|
||||
"uploadFailed": "فشل التحميل",
|
||||
"uploadFailedMultipleImagesDesc": "تم الصق صور متعددة، قد يتم تحميل صورة واحدة فقط في الوقت الحالي",
|
||||
"uploadFailedUnableToLoadDesc": "تعذر تحميل الملف",
|
||||
"downloadImageStarted": "بدأ تنزيل الصورة",
|
||||
"imageCopied": "تم نسخ الصورة",
|
||||
|
||||
@@ -1,8 +1,12 @@
|
||||
{
|
||||
"common": {
|
||||
"themeLabel": "Thema",
|
||||
"languagePickerLabel": "Sprachauswahl",
|
||||
"reportBugLabel": "Fehler melden",
|
||||
"settingsLabel": "Einstellungen",
|
||||
"darkTheme": "Dunkel",
|
||||
"lightTheme": "Hell",
|
||||
"greenTheme": "Grün",
|
||||
"img2img": "Bild zu Bild",
|
||||
"nodes": "Knoten",
|
||||
"langGerman": "Deutsch",
|
||||
@@ -44,6 +48,7 @@
|
||||
"langEnglish": "Englisch",
|
||||
"langDutch": "Niederländisch",
|
||||
"langFrench": "Französisch",
|
||||
"oceanTheme": "Ozean",
|
||||
"langItalian": "Italienisch",
|
||||
"langPortuguese": "Portogisisch",
|
||||
"langRussian": "Russisch",
|
||||
@@ -71,6 +76,7 @@
|
||||
"maintainAspectRatio": "Seitenverhältnis beibehalten",
|
||||
"autoSwitchNewImages": "Automatisch zu neuen Bildern wechseln",
|
||||
"singleColumnLayout": "Einspaltiges Layout",
|
||||
"pinGallery": "Galerie anpinnen",
|
||||
"allImagesLoaded": "Alle Bilder geladen",
|
||||
"loadMore": "Mehr laden",
|
||||
"noImagesInGallery": "Keine Bilder in der Galerie"
|
||||
@@ -340,6 +346,7 @@
|
||||
"cfgScale": "CFG-Skala",
|
||||
"width": "Breite",
|
||||
"height": "Höhe",
|
||||
"sampler": "Sampler",
|
||||
"randomizeSeed": "Zufälliger Seed",
|
||||
"shuffle": "Mischen",
|
||||
"noiseThreshold": "Rausch-Schwellenwert",
|
||||
@@ -360,6 +367,10 @@
|
||||
"hiresOptim": "High-Res-Optimierung",
|
||||
"imageFit": "Ausgangsbild an Ausgabegröße anpassen",
|
||||
"codeformerFidelity": "Glaubwürdigkeit",
|
||||
"seamSize": "Nahtgröße",
|
||||
"seamBlur": "Nahtunschärfe",
|
||||
"seamStrength": "Stärke der Naht",
|
||||
"seamSteps": "Nahtstufen",
|
||||
"scaleBeforeProcessing": "Skalieren vor der Verarbeitung",
|
||||
"scaledWidth": "Skaliert W",
|
||||
"scaledHeight": "Skaliert H",
|
||||
@@ -370,6 +381,8 @@
|
||||
"infillScalingHeader": "Infill und Skalierung",
|
||||
"img2imgStrength": "Bild-zu-Bild-Stärke",
|
||||
"toggleLoopback": "Toggle Loopback",
|
||||
"invoke": "Invoke",
|
||||
"promptPlaceholder": "Prompt hier eingeben. [negative Token], (mehr Gewicht)++, (geringeres Gewicht)--, Tausch und Überblendung sind verfügbar (siehe Dokumente)",
|
||||
"sendTo": "Senden an",
|
||||
"sendToImg2Img": "Senden an Bild zu Bild",
|
||||
"sendToUnifiedCanvas": "Senden an Unified Canvas",
|
||||
@@ -381,6 +394,7 @@
|
||||
"useSeed": "Seed verwenden",
|
||||
"useAll": "Alle verwenden",
|
||||
"useInitImg": "Ausgangsbild verwenden",
|
||||
"deleteImage": "Bild löschen",
|
||||
"initialImage": "Ursprüngliches Bild",
|
||||
"showOptionsPanel": "Optionsleiste zeigen",
|
||||
"cancel": {
|
||||
@@ -392,6 +406,7 @@
|
||||
"saveSteps": "Speichern der Bilder alle n Schritte",
|
||||
"confirmOnDelete": "Bestätigen beim Löschen",
|
||||
"displayHelpIcons": "Hilfesymbole anzeigen",
|
||||
"useCanvasBeta": "Canvas Beta Layout verwenden",
|
||||
"enableImageDebugging": "Bild-Debugging aktivieren",
|
||||
"resetWebUI": "Web-Oberfläche zurücksetzen",
|
||||
"resetWebUIDesc1": "Das Zurücksetzen der Web-Oberfläche setzt nur den lokalen Cache des Browsers mit Ihren Bildern und gespeicherten Einstellungen zurück. Es werden keine Bilder von der Festplatte gelöscht.",
|
||||
@@ -401,6 +416,7 @@
|
||||
"toast": {
|
||||
"tempFoldersEmptied": "Temp-Ordner geleert",
|
||||
"uploadFailed": "Hochladen fehlgeschlagen",
|
||||
"uploadFailedMultipleImagesDesc": "Mehrere Bilder eingefügt, es kann nur ein Bild auf einmal hochgeladen werden",
|
||||
"uploadFailedUnableToLoadDesc": "Datei kann nicht geladen werden",
|
||||
"downloadImageStarted": "Bild wird heruntergeladen",
|
||||
"imageCopied": "Bild kopiert",
|
||||
@@ -516,6 +532,7 @@
|
||||
"modifyConfig": "Optionen einstellen",
|
||||
"toggleAutoscroll": "Auroscroll ein/ausschalten",
|
||||
"toggleLogViewer": "Log Betrachter ein/ausschalten",
|
||||
"showGallery": "Zeige Galerie",
|
||||
"showOptionsPanel": "Zeige Optionen",
|
||||
"reset": "Zurücksetzen",
|
||||
"nextImage": "Nächstes Bild",
|
||||
|
||||
@@ -38,24 +38,19 @@
|
||||
"searchBoard": "Search Boards...",
|
||||
"selectBoard": "Select a Board",
|
||||
"topMessage": "This board contains images used in the following features:",
|
||||
"uncategorized": "Uncategorized",
|
||||
"downloadBoard": "Download Board"
|
||||
"uncategorized": "Uncategorized"
|
||||
},
|
||||
"common": {
|
||||
"accept": "Accept",
|
||||
"advanced": "Advanced",
|
||||
"areYouSure": "Are you sure?",
|
||||
"auto": "Auto",
|
||||
"back": "Back",
|
||||
"batch": "Batch Manager",
|
||||
"cancel": "Cancel",
|
||||
"close": "Close",
|
||||
"on": "On",
|
||||
"communityLabel": "Community",
|
||||
"controlNet": "ControlNet",
|
||||
"controlAdapter": "Control Adapter",
|
||||
"controlNet": "Controlnet",
|
||||
"ipAdapter": "IP Adapter",
|
||||
"t2iAdapter": "T2I Adapter",
|
||||
"darkMode": "Dark Mode",
|
||||
"discordLabel": "Discord",
|
||||
"dontAskMeAgain": "Don't ask me again",
|
||||
@@ -135,17 +130,6 @@
|
||||
"upload": "Upload"
|
||||
},
|
||||
"controlnet": {
|
||||
"controlAdapter_one": "Control Adapter",
|
||||
"controlAdapter_other": "Control Adapters",
|
||||
"controlnet": "$t(controlnet.controlAdapter_one) #{{number}} ($t(common.controlNet))",
|
||||
"ip_adapter": "$t(controlnet.controlAdapter_one) #{{number}} ($t(common.ipAdapter))",
|
||||
"t2i_adapter": "$t(controlnet.controlAdapter_one) #{{number}} ($t(common.t2iAdapter))",
|
||||
"addControlNet": "Add $t(common.controlNet)",
|
||||
"addIPAdapter": "Add $t(common.ipAdapter)",
|
||||
"addT2IAdapter": "Add $t(common.t2iAdapter)",
|
||||
"controlNetEnabledT2IDisabled": "$t(common.controlNet) enabled, $t(common.t2iAdapter)s disabled",
|
||||
"t2iEnabledControlNetDisabled": "$t(common.t2iAdapter) enabled, $t(common.controlNet)s disabled",
|
||||
"controlNetT2IMutexDesc": "$t(common.controlNet) and $t(common.t2iAdapter) at same time is currently unsupported.",
|
||||
"amult": "a_mult",
|
||||
"autoConfigure": "Auto configure processor",
|
||||
"balanced": "Balanced",
|
||||
@@ -278,8 +262,7 @@
|
||||
"batchValues": "Batch Values",
|
||||
"notReady": "Unable to Queue",
|
||||
"batchQueued": "Batch Queued",
|
||||
"batchQueuedDesc_one": "Added {{count}} sessions to {{direction}} of queue",
|
||||
"batchQueuedDesc_other": "Added {{count}} sessions to {{direction}} of queue",
|
||||
"batchQueuedDesc": "Added {{item_count}} sessions to {{direction}} of queue",
|
||||
"front": "front",
|
||||
"back": "back",
|
||||
"batchFailedToQueue": "Failed to Queue Batch",
|
||||
@@ -328,10 +311,7 @@
|
||||
"showUploads": "Show Uploads",
|
||||
"singleColumnLayout": "Single Column Layout",
|
||||
"unableToLoad": "Unable to load Gallery",
|
||||
"uploads": "Uploads",
|
||||
"downloadSelection": "Download Selection",
|
||||
"preparingDownload": "Preparing Download",
|
||||
"preparingDownloadFailed": "Problem Preparing Download"
|
||||
"uploads": "Uploads"
|
||||
},
|
||||
"hotkeys": {
|
||||
"acceptStagingImage": {
|
||||
@@ -559,10 +539,8 @@
|
||||
"negativePrompt": "Negative Prompt",
|
||||
"noImageDetails": "No image details found",
|
||||
"noMetaData": "No metadata found",
|
||||
"noRecallParameters": "No parameters to recall found",
|
||||
"perlin": "Perlin Noise",
|
||||
"positivePrompt": "Positive Prompt",
|
||||
"recallParameters": "Recall Parameters",
|
||||
"scheduler": "Scheduler",
|
||||
"seamless": "Seamless",
|
||||
"seed": "Seed",
|
||||
@@ -707,7 +685,6 @@
|
||||
"vae": "VAE",
|
||||
"vaeLocation": "VAE Location",
|
||||
"vaeLocationValidationMsg": "Path to where your VAE is located.",
|
||||
"vaePrecision": "VAE Precision",
|
||||
"vaeRepoID": "VAE Repo ID",
|
||||
"vaeRepoIDValidationMsg": "Online repository of your VAE",
|
||||
"variant": "Variant",
|
||||
@@ -808,14 +785,6 @@
|
||||
"integerPolymorphic": "Integer Polymorphic",
|
||||
"integerPolymorphicDescription": "A collection of integers.",
|
||||
"invalidOutputSchema": "Invalid output schema",
|
||||
"ipAdapter": "IP-Adapter",
|
||||
"ipAdapterCollection": "IP-Adapters Collection",
|
||||
"ipAdapterCollectionDescription": "A collection of IP-Adapters.",
|
||||
"ipAdapterDescription": "An Image Prompt Adapter (IP-Adapter).",
|
||||
"ipAdapterModel": "IP-Adapter Model",
|
||||
"ipAdapterModelDescription": "IP-Adapter Model Field",
|
||||
"ipAdapterPolymorphic": "IP-Adapter Polymorphic",
|
||||
"ipAdapterPolymorphicDescription": "A collection of IP-Adapters.",
|
||||
"latentsCollection": "Latents Collection",
|
||||
"latentsCollectionDescription": "Latents may be passed between nodes.",
|
||||
"latentsField": "Latents",
|
||||
@@ -928,7 +897,6 @@
|
||||
},
|
||||
"parameters": {
|
||||
"aspectRatio": "Aspect Ratio",
|
||||
"aspectRatioFree": "Free",
|
||||
"boundingBoxHeader": "Bounding Box",
|
||||
"boundingBoxHeight": "Bounding Box Height",
|
||||
"boundingBoxWidth": "Bounding Box Width",
|
||||
@@ -976,10 +944,9 @@
|
||||
"missingFieldTemplate": "Missing field template",
|
||||
"missingInputForField": "{{nodeLabel}} -> {{fieldLabel}} missing input",
|
||||
"missingNodeTemplate": "Missing node template",
|
||||
"noControlImageForControlAdapter": "Control Adapter #{{number}} has no control image",
|
||||
"noControlImageForControlNet": "ControlNet {{index}} has no control image",
|
||||
"noInitialImageSelected": "No initial image selected",
|
||||
"noModelForControlAdapter": "Control Adapter #{{number}} has no model selected.",
|
||||
"incompatibleBaseModelForControlAdapter": "Control Adapter #{{number}} model is invalid with main model.",
|
||||
"noModelForControlNet": "ControlNet {{index}} has no model selected.",
|
||||
"noModelSelected": "No model selected",
|
||||
"noPrompts": "No prompts generated",
|
||||
"noNodesInGraph": "No nodes in graph",
|
||||
@@ -1114,23 +1081,11 @@
|
||||
"showAdvancedOptions": "Show Advanced Options",
|
||||
"showProgressInViewer": "Show Progress Images in Viewer",
|
||||
"ui": "User Interface",
|
||||
"useSlidersForAll": "Use Sliders For All Options",
|
||||
"clearIntermediatesDisabled": "Queue must be empty to clear intermediates",
|
||||
"clearIntermediatesDesc1": "Clearing intermediates will reset your Canvas and ControlNet state.",
|
||||
"clearIntermediatesDesc2": "Intermediate images are byproducts of generation, different from the result images in the gallery. Clearing intermediates will free disk space.",
|
||||
"clearIntermediatesDesc3": "Your gallery images will not be deleted.",
|
||||
"clearIntermediates": "Clear Intermediates",
|
||||
"clearIntermediatesWithCount_one": "Clear {{count}} Intermediate",
|
||||
"clearIntermediatesWithCount_other": "Clear {{count}} Intermediates",
|
||||
"clearIntermediatesWithCount_zero": "No Intermediates to Clear",
|
||||
"intermediatesCleared_one": "Cleared {{count}} Intermediate",
|
||||
"intermediatesCleared_other": "Cleared {{count}} Intermediates",
|
||||
"intermediatesClearedFailed": "Problem Clearing Intermediates"
|
||||
"useSlidersForAll": "Use Sliders For All Options"
|
||||
},
|
||||
"toast": {
|
||||
"addedToBoard": "Added to board",
|
||||
"baseModelChangedCleared_one": "Base model changed, cleared or disabled {{count}} incompatible submodel",
|
||||
"baseModelChangedCleared_other": "Base model changed, cleared or disabled {{count}} incompatible submodels",
|
||||
"baseModelChangedCleared": "Base model changed, cleared",
|
||||
"canceled": "Processing Canceled",
|
||||
"canvasCopiedClipboard": "Canvas Copied to Clipboard",
|
||||
"canvasDownloaded": "Canvas Downloaded",
|
||||
@@ -1150,6 +1105,7 @@
|
||||
"imageSavingFailed": "Image Saving Failed",
|
||||
"imageUploaded": "Image Uploaded",
|
||||
"imageUploadFailed": "Image Upload Failed",
|
||||
"incompatibleSubmodel": "incompatible submodel",
|
||||
"initialImageNotSet": "Initial Image Not Set",
|
||||
"initialImageNotSetDesc": "Could not load initial image",
|
||||
"initialImageSet": "Initial Image Set",
|
||||
|
||||
@@ -1,12 +1,16 @@
|
||||
{
|
||||
"common": {
|
||||
"hotkeysLabel": "Atajos de teclado",
|
||||
"themeLabel": "Tema",
|
||||
"languagePickerLabel": "Selector de idioma",
|
||||
"reportBugLabel": "Reportar errores",
|
||||
"settingsLabel": "Ajustes",
|
||||
"darkTheme": "Oscuro",
|
||||
"lightTheme": "Claro",
|
||||
"greenTheme": "Verde",
|
||||
"img2img": "Imagen a Imagen",
|
||||
"unifiedCanvas": "Lienzo Unificado",
|
||||
"nodes": "Editor del flujo de trabajo",
|
||||
"nodes": "Nodos",
|
||||
"langSpanish": "Español",
|
||||
"nodesDesc": "Un sistema de generación de imágenes basado en nodos, actualmente se encuentra en desarrollo. Mantente pendiente a nuestras actualizaciones acerca de esta fabulosa funcionalidad.",
|
||||
"postProcessing": "Post-procesamiento",
|
||||
@@ -15,7 +19,7 @@
|
||||
"postProcessDesc3": "La Interfaz de Línea de Comandos de Invoke AI ofrece muchas otras características, incluyendo -Embiggen-.",
|
||||
"training": "Entrenamiento",
|
||||
"trainingDesc1": "Un flujo de trabajo dedicado para el entrenamiento de sus propios -embeddings- y puntos de control utilizando Inversión Textual y Dreambooth desde la interfaz web.",
|
||||
"trainingDesc2": "InvokeAI ya admite el entrenamiento de incrustaciones personalizadas mediante la inversión textual mediante el script principal.",
|
||||
"trainingDesc2": "InvokeAI ya soporta el entrenamiento de -embeddings- personalizados utilizando la Inversión Textual mediante el script principal.",
|
||||
"upload": "Subir imagen",
|
||||
"close": "Cerrar",
|
||||
"load": "Cargar",
|
||||
@@ -59,27 +63,18 @@
|
||||
"statusConvertingModel": "Convertir el modelo",
|
||||
"statusModelConverted": "Modelo adaptado",
|
||||
"statusMergingModels": "Fusionar modelos",
|
||||
"oceanTheme": "Océano",
|
||||
"langPortuguese": "Portugués",
|
||||
"langKorean": "Coreano",
|
||||
"langHebrew": "Hebreo",
|
||||
"pinOptionsPanel": "Pin del panel de opciones",
|
||||
"loading": "Cargando",
|
||||
"loadingInvokeAI": "Cargando invocar a la IA",
|
||||
"postprocessing": "Tratamiento posterior",
|
||||
"txt2img": "De texto a imagen",
|
||||
"accept": "Aceptar",
|
||||
"cancel": "Cancelar",
|
||||
"linear": "Lineal",
|
||||
"random": "Aleatorio",
|
||||
"generate": "Generar",
|
||||
"openInNewTab": "Abrir en una nueva pestaña",
|
||||
"dontAskMeAgain": "No me preguntes de nuevo",
|
||||
"areYouSure": "¿Estas seguro?",
|
||||
"imagePrompt": "Indicación de imagen",
|
||||
"batch": "Administrador de lotes",
|
||||
"darkMode": "Modo oscuro",
|
||||
"lightMode": "Modo claro",
|
||||
"modelManager": "Administrador de modelos",
|
||||
"communityLabel": "Comunidad"
|
||||
"linear": "Lineal"
|
||||
},
|
||||
"gallery": {
|
||||
"generations": "Generaciones",
|
||||
@@ -92,15 +87,10 @@
|
||||
"maintainAspectRatio": "Mantener relación de aspecto",
|
||||
"autoSwitchNewImages": "Auto seleccionar Imágenes nuevas",
|
||||
"singleColumnLayout": "Diseño de una columna",
|
||||
"pinGallery": "Fijar galería",
|
||||
"allImagesLoaded": "Todas las imágenes cargadas",
|
||||
"loadMore": "Cargar más",
|
||||
"noImagesInGallery": "No hay imágenes para mostrar",
|
||||
"deleteImage": "Eliminar Imagen",
|
||||
"deleteImageBin": "Las imágenes eliminadas se enviarán a la papelera de tu sistema operativo.",
|
||||
"deleteImagePermanent": "Las imágenes eliminadas no se pueden restaurar.",
|
||||
"images": "Imágenes",
|
||||
"assets": "Activos",
|
||||
"autoAssignBoardOnClick": "Asignación automática de tableros al hacer clic"
|
||||
"noImagesInGallery": "Sin imágenes en la galería"
|
||||
},
|
||||
"hotkeys": {
|
||||
"keyboardShortcuts": "Atajos de teclado",
|
||||
@@ -307,12 +297,7 @@
|
||||
"acceptStagingImage": {
|
||||
"title": "Aceptar imagen",
|
||||
"desc": "Aceptar la imagen actual en el área de preparación"
|
||||
},
|
||||
"addNodes": {
|
||||
"title": "Añadir Nodos",
|
||||
"desc": "Abre el menú para añadir nodos"
|
||||
},
|
||||
"nodesHotkeys": "Teclas de acceso rápido a los nodos"
|
||||
}
|
||||
},
|
||||
"modelManager": {
|
||||
"modelManager": "Gestor de Modelos",
|
||||
@@ -364,8 +349,8 @@
|
||||
"delete": "Eliminar",
|
||||
"deleteModel": "Eliminar Modelo",
|
||||
"deleteConfig": "Eliminar Configuración",
|
||||
"deleteMsg1": "¿Estás seguro de que deseas eliminar este modelo de InvokeAI?",
|
||||
"deleteMsg2": "Esto eliminará el modelo del disco si está en la carpeta raíz de InvokeAI. Si está utilizando una ubicación personalizada, el modelo NO se eliminará del disco.",
|
||||
"deleteMsg1": "¿Estás seguro de querer eliminar esta entrada de modelo de InvokeAI?",
|
||||
"deleteMsg2": "El checkpoint del modelo no se eliminará de tu disco. Puedes volver a añadirlo si lo deseas.",
|
||||
"safetensorModels": "SafeTensors",
|
||||
"addDiffuserModel": "Añadir difusores",
|
||||
"inpainting": "v1 Repintado",
|
||||
@@ -384,8 +369,8 @@
|
||||
"convertToDiffusers": "Convertir en difusores",
|
||||
"convertToDiffusersHelpText1": "Este modelo se convertirá al formato 🧨 Difusores.",
|
||||
"convertToDiffusersHelpText2": "Este proceso sustituirá su entrada del Gestor de Modelos por la versión de Difusores del mismo modelo.",
|
||||
"convertToDiffusersHelpText3": "Tu archivo del punto de control en el disco se eliminará si está en la carpeta raíz de InvokeAI. Si está en una ubicación personalizada, NO se eliminará.",
|
||||
"convertToDiffusersHelpText5": "Por favor, asegúrate de tener suficiente espacio en el disco. Los modelos generalmente varían entre 2 GB y 7 GB de tamaño.",
|
||||
"convertToDiffusersHelpText3": "Su archivo de puntos de control en el disco NO será borrado ni modificado de ninguna manera. Puede volver a añadir su punto de control al Gestor de Modelos si lo desea.",
|
||||
"convertToDiffusersHelpText5": "Asegúrese de que dispone de suficiente espacio en disco. Los modelos suelen variar entre 4 GB y 7 GB de tamaño.",
|
||||
"convertToDiffusersHelpText6": "¿Desea transformar este modelo?",
|
||||
"convertToDiffusersSaveLocation": "Guardar ubicación",
|
||||
"v1": "v1",
|
||||
@@ -424,27 +409,7 @@
|
||||
"pickModelType": "Elige el tipo de modelo",
|
||||
"v2_768": "v2 (768px)",
|
||||
"addDifference": "Añadir una diferencia",
|
||||
"scanForModels": "Buscar modelos",
|
||||
"vae": "VAE",
|
||||
"variant": "Variante",
|
||||
"baseModel": "Modelo básico",
|
||||
"modelConversionFailed": "Conversión al modelo fallida",
|
||||
"selectModel": "Seleccionar un modelo",
|
||||
"modelUpdateFailed": "Error al actualizar el modelo",
|
||||
"modelsMergeFailed": "Fusión del modelo fallida",
|
||||
"convertingModelBegin": "Convirtiendo el modelo. Por favor, espere.",
|
||||
"modelDeleted": "Modelo eliminado",
|
||||
"modelDeleteFailed": "Error al borrar el modelo",
|
||||
"noCustomLocationProvided": "‐No se proporcionó una ubicación personalizada",
|
||||
"importModels": "Importar los modelos",
|
||||
"settings": "Ajustes",
|
||||
"syncModels": "Sincronizar las plantillas",
|
||||
"syncModelsDesc": "Si tus plantillas no están sincronizados con el backend, puedes actualizarlas usando esta opción. Esto suele ser útil en los casos en los que actualizas manualmente tu archivo models.yaml o añades plantillas a la carpeta raíz de InvokeAI después de que la aplicación haya arrancado.",
|
||||
"modelsSynced": "Plantillas sincronizadas",
|
||||
"modelSyncFailed": "La sincronización de la plantilla falló",
|
||||
"loraModels": "LoRA",
|
||||
"onnxModels": "Onnx",
|
||||
"oliveModels": "Olives"
|
||||
"scanForModels": "Buscar modelos"
|
||||
},
|
||||
"parameters": {
|
||||
"images": "Imágenes",
|
||||
@@ -452,9 +417,10 @@
|
||||
"cfgScale": "Escala CFG",
|
||||
"width": "Ancho",
|
||||
"height": "Alto",
|
||||
"sampler": "Muestreo",
|
||||
"seed": "Semilla",
|
||||
"randomizeSeed": "Semilla aleatoria",
|
||||
"shuffle": "Semilla aleatoria",
|
||||
"shuffle": "Aleatorizar",
|
||||
"noiseThreshold": "Umbral de Ruido",
|
||||
"perlinNoise": "Ruido Perlin",
|
||||
"variations": "Variaciones",
|
||||
@@ -473,6 +439,10 @@
|
||||
"hiresOptim": "Optimización de Alta Resolución",
|
||||
"imageFit": "Ajuste tamaño de imagen inicial al tamaño objetivo",
|
||||
"codeformerFidelity": "Fidelidad",
|
||||
"seamSize": "Tamaño del parche",
|
||||
"seamBlur": "Desenfoque del parche",
|
||||
"seamStrength": "Fuerza del parche",
|
||||
"seamSteps": "Pasos del parche",
|
||||
"scaleBeforeProcessing": "Redimensionar antes de procesar",
|
||||
"scaledWidth": "Ancho escalado",
|
||||
"scaledHeight": "Alto escalado",
|
||||
@@ -483,6 +453,8 @@
|
||||
"infillScalingHeader": "Remplazo y escalado",
|
||||
"img2imgStrength": "Peso de Imagen a Imagen",
|
||||
"toggleLoopback": "Alternar Retroalimentación",
|
||||
"invoke": "Invocar",
|
||||
"promptPlaceholder": "Ingrese la entrada aquí. [símbolos negativos], (subir peso)++, (bajar peso)--, también disponible alternado y mezclado (ver documentación)",
|
||||
"sendTo": "Enviar a",
|
||||
"sendToImg2Img": "Enviar a Imagen a Imagen",
|
||||
"sendToUnifiedCanvas": "Enviar a Lienzo Unificado",
|
||||
@@ -495,6 +467,7 @@
|
||||
"useAll": "Usar Todo",
|
||||
"useInitImg": "Usar Imagen Inicial",
|
||||
"info": "Información",
|
||||
"deleteImage": "Eliminar Imagen",
|
||||
"initialImage": "Imagen Inicial",
|
||||
"showOptionsPanel": "Mostrar panel de opciones",
|
||||
"symmetry": "Simetría",
|
||||
@@ -508,72 +481,37 @@
|
||||
},
|
||||
"copyImage": "Copiar la imagen",
|
||||
"general": "General",
|
||||
"negativePrompts": "Preguntas negativas",
|
||||
"imageToImage": "Imagen a imagen",
|
||||
"denoisingStrength": "Intensidad de la eliminación del ruido",
|
||||
"hiresStrength": "Alta resistencia",
|
||||
"showPreview": "Mostrar la vista previa",
|
||||
"hidePreview": "Ocultar la vista previa",
|
||||
"noiseSettings": "Ruido",
|
||||
"seamlessXAxis": "Eje x",
|
||||
"seamlessYAxis": "Eje y",
|
||||
"scheduler": "Programador",
|
||||
"boundingBoxWidth": "Anchura del recuadro",
|
||||
"boundingBoxHeight": "Altura del recuadro",
|
||||
"positivePromptPlaceholder": "Prompt Positivo",
|
||||
"negativePromptPlaceholder": "Prompt Negativo",
|
||||
"controlNetControlMode": "Modo de control",
|
||||
"clipSkip": "Omitir el CLIP",
|
||||
"aspectRatio": "Relación",
|
||||
"maskAdjustmentsHeader": "Ajustes de la máscara",
|
||||
"maskBlur": "Difuminar",
|
||||
"maskBlurMethod": "Método del desenfoque",
|
||||
"seamHighThreshold": "Alto",
|
||||
"seamLowThreshold": "Bajo",
|
||||
"coherencePassHeader": "Parámetros de la coherencia",
|
||||
"compositingSettingsHeader": "Ajustes de la composición",
|
||||
"coherenceSteps": "Pasos",
|
||||
"coherenceStrength": "Fuerza",
|
||||
"patchmatchDownScaleSize": "Reducir a escala",
|
||||
"coherenceMode": "Modo"
|
||||
"hidePreview": "Ocultar la vista previa"
|
||||
},
|
||||
"settings": {
|
||||
"models": "Modelos",
|
||||
"displayInProgress": "Mostrar las imágenes del progreso",
|
||||
"displayInProgress": "Mostrar imágenes en progreso",
|
||||
"saveSteps": "Guardar imágenes cada n pasos",
|
||||
"confirmOnDelete": "Confirmar antes de eliminar",
|
||||
"displayHelpIcons": "Mostrar iconos de ayuda",
|
||||
"useCanvasBeta": "Usar versión beta del Lienzo",
|
||||
"enableImageDebugging": "Habilitar depuración de imágenes",
|
||||
"resetWebUI": "Restablecer interfaz web",
|
||||
"resetWebUIDesc1": "Al restablecer la interfaz web, solo se restablece la caché local del navegador de sus imágenes y la configuración guardada. No se elimina ninguna imagen de su disco duro.",
|
||||
"resetWebUIDesc2": "Si las imágenes no se muestran en la galería o algo más no funciona, intente restablecer antes de reportar un incidente en GitHub.",
|
||||
"resetComplete": "Se ha restablecido la interfaz web.",
|
||||
"useSlidersForAll": "Utilice controles deslizantes para todas las opciones",
|
||||
"general": "General",
|
||||
"consoleLogLevel": "Nivel del registro",
|
||||
"shouldLogToConsole": "Registro de la consola",
|
||||
"developer": "Desarrollador",
|
||||
"antialiasProgressImages": "Imágenes del progreso de Antialias",
|
||||
"showProgressInViewer": "Mostrar las imágenes del progreso en el visor",
|
||||
"ui": "Interfaz del usuario",
|
||||
"generation": "Generación",
|
||||
"favoriteSchedulers": "Programadores favoritos",
|
||||
"favoriteSchedulersPlaceholder": "No hay programadores favoritos",
|
||||
"showAdvancedOptions": "Mostrar las opciones avanzadas",
|
||||
"alternateCanvasLayout": "Diseño alternativo del lienzo",
|
||||
"beta": "Beta",
|
||||
"enableNodesEditor": "Activar el editor de nodos",
|
||||
"experimental": "Experimental",
|
||||
"autoChangeDimensions": "Actualiza W/H a los valores predeterminados del modelo cuando se modifica"
|
||||
"resetComplete": "La interfaz web se ha restablecido. Actualice la página para recargarla.",
|
||||
"useSlidersForAll": "Utilice controles deslizantes para todas las opciones"
|
||||
},
|
||||
"toast": {
|
||||
"tempFoldersEmptied": "Directorio temporal vaciado",
|
||||
"uploadFailed": "Error al subir archivo",
|
||||
"uploadFailedMultipleImagesDesc": "Únicamente se puede subir una imágen a la vez",
|
||||
"uploadFailedUnableToLoadDesc": "No se pudo cargar la imágen",
|
||||
"downloadImageStarted": "Descargando imágen",
|
||||
"imageCopied": "Imágen copiada",
|
||||
"imageLinkCopied": "Enlace de imágen copiado",
|
||||
"imageNotLoaded": "No se cargó la imágen",
|
||||
"imageNotLoadedDesc": "No se pudo encontrar la imagen",
|
||||
"imageNotLoadedDesc": "No se encontró imagen para enviar al módulo Imagen a Imagen",
|
||||
"imageSavedToGallery": "Imágen guardada en la galería",
|
||||
"canvasMerged": "Lienzo consolidado",
|
||||
"sentToImageToImage": "Enviar hacia Imagen a Imagen",
|
||||
@@ -598,21 +536,7 @@
|
||||
"serverError": "Error en el servidor",
|
||||
"disconnected": "Desconectado del servidor",
|
||||
"canceled": "Procesando la cancelación",
|
||||
"connected": "Conectado al servidor",
|
||||
"problemCopyingImageLink": "No se puede copiar el enlace de la imagen",
|
||||
"uploadFailedInvalidUploadDesc": "Debe ser una sola imagen PNG o JPEG",
|
||||
"parameterSet": "Conjunto de parámetros",
|
||||
"parameterNotSet": "Parámetro no configurado",
|
||||
"nodesSaved": "Nodos guardados",
|
||||
"nodesLoadedFailed": "Error al cargar los nodos",
|
||||
"nodesLoaded": "Nodos cargados",
|
||||
"nodesCleared": "Nodos borrados",
|
||||
"problemCopyingImage": "No se puede copiar la imagen",
|
||||
"nodesNotValidJSON": "JSON no válido",
|
||||
"nodesCorruptedGraph": "No se puede cargar. El gráfico parece estar dañado.",
|
||||
"nodesUnrecognizedTypes": "No se puede cargar. El gráfico tiene tipos no reconocidos",
|
||||
"nodesNotValidGraph": "Gráfico del nodo InvokeAI no válido",
|
||||
"nodesBrokenConnections": "No se puede cargar. Algunas conexiones están rotas."
|
||||
"connected": "Conectado al servidor"
|
||||
},
|
||||
"tooltip": {
|
||||
"feature": {
|
||||
@@ -686,8 +610,7 @@
|
||||
"betaClear": "Limpiar",
|
||||
"betaDarkenOutside": "Oscurecer fuera",
|
||||
"betaLimitToBox": "Limitar a caja",
|
||||
"betaPreserveMasked": "Preservar área enmascarada",
|
||||
"antialiasing": "Suavizado"
|
||||
"betaPreserveMasked": "Preservar área enmascarada"
|
||||
},
|
||||
"accessibility": {
|
||||
"invokeProgressBar": "Activar la barra de progreso",
|
||||
@@ -708,30 +631,8 @@
|
||||
"modifyConfig": "Modificar la configuración",
|
||||
"toggleAutoscroll": "Activar el autodesplazamiento",
|
||||
"toggleLogViewer": "Alternar el visor de registros",
|
||||
"showOptionsPanel": "Mostrar el panel lateral",
|
||||
"showGallery": "Mostrar galería",
|
||||
"showOptionsPanel": "Mostrar el panel de opciones",
|
||||
"menu": "Menú"
|
||||
},
|
||||
"ui": {
|
||||
"hideProgressImages": "Ocultar el progreso de la imagen",
|
||||
"showProgressImages": "Mostrar el progreso de la imagen",
|
||||
"swapSizes": "Cambiar los tamaños",
|
||||
"lockRatio": "Proporción del bloqueo"
|
||||
},
|
||||
"nodes": {
|
||||
"showGraphNodes": "Mostrar la superposición de los gráficos",
|
||||
"zoomInNodes": "Acercar",
|
||||
"hideMinimapnodes": "Ocultar el minimapa",
|
||||
"fitViewportNodes": "Ajustar la vista",
|
||||
"zoomOutNodes": "Alejar",
|
||||
"hideGraphNodes": "Ocultar la superposición de los gráficos",
|
||||
"hideLegendNodes": "Ocultar la leyenda del tipo de campo",
|
||||
"showLegendNodes": "Mostrar la leyenda del tipo de campo",
|
||||
"showMinimapnodes": "Mostrar el minimapa",
|
||||
"reloadNodeTemplates": "Recargar las plantillas de nodos",
|
||||
"loadWorkflow": "Cargar el flujo de trabajo",
|
||||
"resetWorkflow": "Reiniciar e flujo de trabajo",
|
||||
"resetWorkflowDesc": "¿Está seguro de que deseas restablecer este flujo de trabajo?",
|
||||
"resetWorkflowDesc2": "Al reiniciar el flujo de trabajo se borrarán todos los nodos, aristas y detalles del flujo de trabajo.",
|
||||
"downloadWorkflow": "Descargar el flujo de trabajo en un archivo JSON"
|
||||
}
|
||||
}
|
||||
|
||||
@@ -15,6 +15,7 @@
|
||||
"rotateCounterClockwise": "Kierrä vastapäivään",
|
||||
"rotateClockwise": "Kierrä myötäpäivään",
|
||||
"flipVertically": "Käännä pystysuoraan",
|
||||
"showGallery": "Näytä galleria",
|
||||
"modifyConfig": "Muokkaa konfiguraatiota",
|
||||
"toggleAutoscroll": "Kytke automaattinen vieritys",
|
||||
"toggleLogViewer": "Kytke lokin katselutila",
|
||||
@@ -33,13 +34,18 @@
|
||||
"hotkeysLabel": "Pikanäppäimet",
|
||||
"reportBugLabel": "Raportoi Bugista",
|
||||
"langPolish": "Puola",
|
||||
"themeLabel": "Teema",
|
||||
"langDutch": "Hollanti",
|
||||
"settingsLabel": "Asetukset",
|
||||
"githubLabel": "Github",
|
||||
"darkTheme": "Tumma",
|
||||
"lightTheme": "Vaalea",
|
||||
"greenTheme": "Vihreä",
|
||||
"langGerman": "Saksa",
|
||||
"langPortuguese": "Portugali",
|
||||
"discordLabel": "Discord",
|
||||
"langEnglish": "Englanti",
|
||||
"oceanTheme": "Meren sininen",
|
||||
"langRussian": "Venäjä",
|
||||
"langUkranian": "Ukraina",
|
||||
"langSpanish": "Espanja",
|
||||
@@ -73,6 +79,7 @@
|
||||
"statusGeneratingInpainting": "Generoidaan sisällemaalausta",
|
||||
"statusGeneratingOutpainting": "Generoidaan ulosmaalausta",
|
||||
"statusRestoringFaces": "Korjataan kasvoja",
|
||||
"pinOptionsPanel": "Kiinnitä asetukset -paneeli",
|
||||
"loadingInvokeAI": "Ladataan Invoke AI:ta",
|
||||
"loading": "Ladataan",
|
||||
"statusGenerating": "Generoidaan",
|
||||
@@ -88,6 +95,7 @@
|
||||
"galleryImageResetSize": "Resetoi koko",
|
||||
"maintainAspectRatio": "Säilytä kuvasuhde",
|
||||
"galleryImageSize": "Kuvan koko",
|
||||
"pinGallery": "Kiinnitä galleria",
|
||||
"showGenerations": "Näytä generaatiot",
|
||||
"singleColumnLayout": "Yhden sarakkeen asettelu",
|
||||
"generations": "Generoinnit",
|
||||
|
||||
@@ -1,9 +1,13 @@
|
||||
{
|
||||
"common": {
|
||||
"hotkeysLabel": "Raccourcis clavier",
|
||||
"themeLabel": "Thème",
|
||||
"languagePickerLabel": "Sélecteur de langue",
|
||||
"reportBugLabel": "Signaler un bug",
|
||||
"settingsLabel": "Paramètres",
|
||||
"darkTheme": "Sombre",
|
||||
"lightTheme": "Clair",
|
||||
"greenTheme": "Vert",
|
||||
"img2img": "Image en image",
|
||||
"unifiedCanvas": "Canvas unifié",
|
||||
"nodes": "Nœuds",
|
||||
@@ -51,6 +55,7 @@
|
||||
"statusConvertingModel": "Conversion du modèle",
|
||||
"statusModelConverted": "Modèle converti",
|
||||
"loading": "Chargement",
|
||||
"pinOptionsPanel": "Épingler la page d'options",
|
||||
"statusMergedModels": "Modèles mélangés",
|
||||
"txt2img": "Texte vers image",
|
||||
"postprocessing": "Post-Traitement"
|
||||
@@ -66,6 +71,7 @@
|
||||
"maintainAspectRatio": "Maintenir le rapport d'aspect",
|
||||
"autoSwitchNewImages": "Basculer automatiquement vers de nouvelles images",
|
||||
"singleColumnLayout": "Mise en page en colonne unique",
|
||||
"pinGallery": "Épingler la galerie",
|
||||
"allImagesLoaded": "Toutes les images chargées",
|
||||
"loadMore": "Charger plus",
|
||||
"noImagesInGallery": "Aucune image dans la galerie"
|
||||
@@ -350,6 +356,7 @@
|
||||
"cfgScale": "CFG Echelle",
|
||||
"width": "Largeur",
|
||||
"height": "Hauteur",
|
||||
"sampler": "Echantillonneur",
|
||||
"seed": "Graine",
|
||||
"randomizeSeed": "Graine Aléatoire",
|
||||
"shuffle": "Mélanger",
|
||||
@@ -371,6 +378,10 @@
|
||||
"hiresOptim": "Optimisation Haute Résolution",
|
||||
"imageFit": "Ajuster Image Initiale à la Taille de Sortie",
|
||||
"codeformerFidelity": "Fidélité",
|
||||
"seamSize": "Taille des Joints",
|
||||
"seamBlur": "Flou des Joints",
|
||||
"seamStrength": "Force des Joints",
|
||||
"seamSteps": "Etapes des Joints",
|
||||
"scaleBeforeProcessing": "Echelle Avant Traitement",
|
||||
"scaledWidth": "Larg. Échelle",
|
||||
"scaledHeight": "Haut. Échelle",
|
||||
@@ -381,6 +392,8 @@
|
||||
"infillScalingHeader": "Remplissage et Mise à l'Échelle",
|
||||
"img2imgStrength": "Force de l'Image à l'Image",
|
||||
"toggleLoopback": "Activer/Désactiver la Boucle",
|
||||
"invoke": "Invoker",
|
||||
"promptPlaceholder": "Tapez le prompt ici. [tokens négatifs], (poids positif)++, (poids négatif)--, swap et blend sont disponibles (voir les docs)",
|
||||
"sendTo": "Envoyer à",
|
||||
"sendToImg2Img": "Envoyer à Image à Image",
|
||||
"sendToUnifiedCanvas": "Envoyer au Canvas Unifié",
|
||||
@@ -394,6 +407,7 @@
|
||||
"useAll": "Tout utiliser",
|
||||
"useInitImg": "Utiliser l'image initiale",
|
||||
"info": "Info",
|
||||
"deleteImage": "Supprimer l'image",
|
||||
"initialImage": "Image initiale",
|
||||
"showOptionsPanel": "Afficher le panneau d'options"
|
||||
},
|
||||
@@ -403,6 +417,7 @@
|
||||
"saveSteps": "Enregistrer les images tous les n étapes",
|
||||
"confirmOnDelete": "Confirmer la suppression",
|
||||
"displayHelpIcons": "Afficher les icônes d'aide",
|
||||
"useCanvasBeta": "Utiliser la mise en page bêta de Canvas",
|
||||
"enableImageDebugging": "Activer le débogage d'image",
|
||||
"resetWebUI": "Réinitialiser l'interface Web",
|
||||
"resetWebUIDesc1": "Réinitialiser l'interface Web ne réinitialise que le cache local du navigateur de vos images et de vos paramètres enregistrés. Cela n'efface pas les images du disque.",
|
||||
@@ -412,6 +427,7 @@
|
||||
"toast": {
|
||||
"tempFoldersEmptied": "Dossiers temporaires vidés",
|
||||
"uploadFailed": "Téléchargement échoué",
|
||||
"uploadFailedMultipleImagesDesc": "Plusieurs images collées, peut uniquement télécharger une image à la fois",
|
||||
"uploadFailedUnableToLoadDesc": "Impossible de charger le fichier",
|
||||
"downloadImageStarted": "Téléchargement de l'image démarré",
|
||||
"imageCopied": "Image copiée",
|
||||
@@ -522,10 +538,6 @@
|
||||
"useThisParameter": "Utiliser ce paramètre",
|
||||
"zoomIn": "Zoom avant",
|
||||
"zoomOut": "Zoom arrière",
|
||||
"showOptionsPanel": "Montrer la page d'options",
|
||||
"modelSelect": "Choix du modèle",
|
||||
"invokeProgressBar": "Barre de Progression Invoke",
|
||||
"copyMetadataJson": "Copie des métadonnées JSON",
|
||||
"menu": "Menu"
|
||||
"showOptionsPanel": "Montrer la page d'options"
|
||||
}
|
||||
}
|
||||
|
||||
@@ -107,10 +107,13 @@
|
||||
},
|
||||
"common": {
|
||||
"nodesDesc": "מערכת מבוססת צמתים עבור יצירת תמונות עדיין תחת פיתוח. השארו קשובים לעדכונים עבור הפיצ׳ר המדהים הזה.",
|
||||
"themeLabel": "ערכת נושא",
|
||||
"languagePickerLabel": "בחירת שפה",
|
||||
"githubLabel": "גיטהאב",
|
||||
"discordLabel": "דיסקורד",
|
||||
"settingsLabel": "הגדרות",
|
||||
"darkTheme": "חשוך",
|
||||
"lightTheme": "מואר",
|
||||
"langEnglish": "אנגלית",
|
||||
"langDutch": "הולנדית",
|
||||
"langArabic": "ערבית",
|
||||
@@ -152,6 +155,7 @@
|
||||
"statusMergedModels": "מודלים מוזגו",
|
||||
"hotkeysLabel": "מקשים חמים",
|
||||
"reportBugLabel": "דווח באג",
|
||||
"greenTheme": "ירוק",
|
||||
"langItalian": "איטלקית",
|
||||
"upload": "העלאה",
|
||||
"langPolish": "פולנית",
|
||||
@@ -380,6 +384,7 @@
|
||||
"maintainAspectRatio": "שמור על יחס רוחב-גובה",
|
||||
"autoSwitchNewImages": "החלף אוטומטית לתמונות חדשות",
|
||||
"singleColumnLayout": "תצוגת עמודה אחת",
|
||||
"pinGallery": "הצמד גלריה",
|
||||
"allImagesLoaded": "כל התמונות נטענו",
|
||||
"loadMore": "טען עוד",
|
||||
"noImagesInGallery": "אין תמונות בגלריה",
|
||||
@@ -394,6 +399,7 @@
|
||||
"cfgScale": "סולם CFG",
|
||||
"width": "רוחב",
|
||||
"height": "גובה",
|
||||
"sampler": "דוגם",
|
||||
"seed": "זרע",
|
||||
"imageToImage": "תמונה לתמונה",
|
||||
"randomizeSeed": "זרע אקראי",
|
||||
@@ -410,6 +416,10 @@
|
||||
"hiresOptim": "אופטימיזצית רזולוציה גבוהה",
|
||||
"hiresStrength": "חוזק רזולוציה גבוהה",
|
||||
"codeformerFidelity": "דבקות",
|
||||
"seamSize": "גודל תפר",
|
||||
"seamBlur": "טשטוש תפר",
|
||||
"seamStrength": "חוזק תפר",
|
||||
"seamSteps": "שלבי תפר",
|
||||
"scaleBeforeProcessing": "שנה קנה מידה לפני עיבוד",
|
||||
"scaledWidth": "קנה מידה לאחר שינוי W",
|
||||
"scaledHeight": "קנה מידה לאחר שינוי H",
|
||||
@@ -422,12 +432,14 @@
|
||||
"symmetry": "סימטריה",
|
||||
"vSymmetryStep": "צעד סימטריה V",
|
||||
"hSymmetryStep": "צעד סימטריה H",
|
||||
"invoke": "הפעלה",
|
||||
"cancel": {
|
||||
"schedule": "ביטול לאחר האיטרציה הנוכחית",
|
||||
"isScheduled": "מבטל",
|
||||
"immediate": "ביטול מיידי",
|
||||
"setType": "הגדר סוג ביטול"
|
||||
},
|
||||
"negativePrompts": "בקשות שליליות",
|
||||
"sendTo": "שליחה אל",
|
||||
"copyImage": "העתקת תמונה",
|
||||
"downloadImage": "הורדת תמונה",
|
||||
@@ -452,12 +464,15 @@
|
||||
"seamlessTiling": "ריצוף חלק",
|
||||
"img2imgStrength": "חוזק תמונה לתמונה",
|
||||
"initialImage": "תמונה ראשונית",
|
||||
"copyImageToLink": "העתקת תמונה לקישור"
|
||||
"copyImageToLink": "העתקת תמונה לקישור",
|
||||
"deleteImage": "מחיקת תמונה",
|
||||
"promptPlaceholder": "הקלד בקשה כאן. [אסימונים שליליים], (העלאת משקל)++ , (הורדת משקל)--, החלפה ומיזוג זמינים (ראה מסמכים)"
|
||||
},
|
||||
"settings": {
|
||||
"models": "מודלים",
|
||||
"displayInProgress": "הצגת תמונות בתהליך",
|
||||
"confirmOnDelete": "אישור בעת המחיקה",
|
||||
"useCanvasBeta": "שימוש בגרסת ביתא של תצוגת הקנבס",
|
||||
"useSlidersForAll": "שימוש במחוונים לכל האפשרויות",
|
||||
"resetWebUI": "איפוס ממשק משתמש",
|
||||
"resetWebUIDesc1": "איפוס ממשק המשתמש האינטרנטי מאפס רק את המטמון המקומי של הדפדפן של התמונות וההגדרות שנשמרו. זה לא מוחק תמונות מהדיסק.",
|
||||
@@ -469,6 +484,7 @@
|
||||
},
|
||||
"toast": {
|
||||
"uploadFailed": "העלאה נכשלה",
|
||||
"uploadFailedMultipleImagesDesc": "תמונות מרובות הודבקו, ניתן להעלות תמונה אחת בלבד בכל פעם",
|
||||
"imageCopied": "התמונה הועתקה",
|
||||
"imageLinkCopied": "קישור תמונה הועתק",
|
||||
"imageNotLoadedDesc": "לא נמצאה תמונה לשליחה למודול תמונה לתמונה",
|
||||
|
||||
File diff suppressed because it is too large
Load Diff
@@ -1,8 +1,12 @@
|
||||
{
|
||||
"common": {
|
||||
"themeLabel": "テーマ",
|
||||
"languagePickerLabel": "言語選択",
|
||||
"reportBugLabel": "バグ報告",
|
||||
"settingsLabel": "設定",
|
||||
"darkTheme": "ダーク",
|
||||
"lightTheme": "ライト",
|
||||
"greenTheme": "緑",
|
||||
"langJapanese": "日本語",
|
||||
"nodesDesc": "現在、画像生成のためのノードベースシステムを開発中です。機能についてのアップデートにご期待ください。",
|
||||
"postProcessing": "後処理",
|
||||
@@ -52,12 +56,14 @@
|
||||
"loadingInvokeAI": "Invoke AIをロード中",
|
||||
"statusConvertingModel": "モデルの変換",
|
||||
"statusMergedModels": "マージ済モデル",
|
||||
"pinOptionsPanel": "オプションパネルを固定",
|
||||
"githubLabel": "Github",
|
||||
"hotkeysLabel": "ホットキー",
|
||||
"langHebrew": "עברית",
|
||||
"discordLabel": "Discord",
|
||||
"langItalian": "Italiano",
|
||||
"langEnglish": "English",
|
||||
"oceanTheme": "オーシャン",
|
||||
"langArabic": "アラビア語",
|
||||
"langDutch": "Nederlands",
|
||||
"langFrench": "Français",
|
||||
@@ -77,6 +83,7 @@
|
||||
"gallerySettings": "ギャラリーの設定",
|
||||
"maintainAspectRatio": "アスペクト比を維持",
|
||||
"singleColumnLayout": "1カラムレイアウト",
|
||||
"pinGallery": "ギャラリーにピン留め",
|
||||
"allImagesLoaded": "すべての画像を読み込む",
|
||||
"loadMore": "さらに読み込む",
|
||||
"noImagesInGallery": "ギャラリーに画像がありません",
|
||||
@@ -348,6 +355,7 @@
|
||||
"useSeed": "シード値を使用",
|
||||
"useAll": "すべてを使用",
|
||||
"info": "情報",
|
||||
"deleteImage": "画像を削除",
|
||||
"showOptionsPanel": "オプションパネルを表示"
|
||||
},
|
||||
"settings": {
|
||||
@@ -356,6 +364,7 @@
|
||||
"saveSteps": "nステップごとに画像を保存",
|
||||
"confirmOnDelete": "削除時に確認",
|
||||
"displayHelpIcons": "ヘルプアイコンを表示",
|
||||
"useCanvasBeta": "キャンバスレイアウト(Beta)を使用する",
|
||||
"enableImageDebugging": "画像のデバッグを有効化",
|
||||
"resetWebUI": "WebUIをリセット",
|
||||
"resetWebUIDesc1": "WebUIのリセットは、画像と保存された設定のキャッシュをリセットするだけです。画像を削除するわけではありません。",
|
||||
@@ -364,6 +373,7 @@
|
||||
},
|
||||
"toast": {
|
||||
"uploadFailed": "アップロード失敗",
|
||||
"uploadFailedMultipleImagesDesc": "一度にアップロードできる画像は1枚のみです。",
|
||||
"uploadFailedUnableToLoadDesc": "ファイルを読み込むことができません。",
|
||||
"downloadImageStarted": "画像ダウンロード開始",
|
||||
"imageCopied": "画像をコピー",
|
||||
@@ -461,6 +471,7 @@
|
||||
"toggleAutoscroll": "自動スクロールの切替",
|
||||
"modifyConfig": "Modify Config",
|
||||
"toggleLogViewer": "Log Viewerの切替",
|
||||
"showGallery": "ギャラリーを表示",
|
||||
"showOptionsPanel": "オプションパネルを表示"
|
||||
}
|
||||
}
|
||||
|
||||
@@ -1,9 +1,13 @@
|
||||
{
|
||||
"common": {
|
||||
"themeLabel": "테마 설정",
|
||||
"languagePickerLabel": "언어 설정",
|
||||
"reportBugLabel": "버그 리포트",
|
||||
"githubLabel": "Github",
|
||||
"settingsLabel": "설정",
|
||||
"darkTheme": "다크 모드",
|
||||
"lightTheme": "라이트 모드",
|
||||
"greenTheme": "그린 모드",
|
||||
"langArabic": "العربية",
|
||||
"langEnglish": "English",
|
||||
"langDutch": "Nederlands",
|
||||
|
||||
File diff suppressed because it is too large
Load Diff
@@ -1,9 +1,13 @@
|
||||
{
|
||||
"common": {
|
||||
"hotkeysLabel": "Skróty klawiszowe",
|
||||
"themeLabel": "Motyw",
|
||||
"languagePickerLabel": "Wybór języka",
|
||||
"reportBugLabel": "Zgłoś błąd",
|
||||
"settingsLabel": "Ustawienia",
|
||||
"darkTheme": "Ciemny",
|
||||
"lightTheme": "Jasny",
|
||||
"greenTheme": "Zielony",
|
||||
"img2img": "Obraz na obraz",
|
||||
"unifiedCanvas": "Tryb uniwersalny",
|
||||
"nodes": "Węzły",
|
||||
@@ -39,11 +43,7 @@
|
||||
"statusUpscaling": "Powiększanie obrazu",
|
||||
"statusUpscalingESRGAN": "Powiększanie (ESRGAN)",
|
||||
"statusLoadingModel": "Wczytywanie modelu",
|
||||
"statusModelChanged": "Zmieniono model",
|
||||
"githubLabel": "GitHub",
|
||||
"discordLabel": "Discord",
|
||||
"darkMode": "Tryb ciemny",
|
||||
"lightMode": "Tryb jasny"
|
||||
"statusModelChanged": "Zmieniono model"
|
||||
},
|
||||
"gallery": {
|
||||
"generations": "Wygenerowane",
|
||||
@@ -56,6 +56,7 @@
|
||||
"maintainAspectRatio": "Zachowaj proporcje",
|
||||
"autoSwitchNewImages": "Przełączaj na nowe obrazy",
|
||||
"singleColumnLayout": "Układ jednokolumnowy",
|
||||
"pinGallery": "Przypnij galerię",
|
||||
"allImagesLoaded": "Koniec listy",
|
||||
"loadMore": "Wczytaj więcej",
|
||||
"noImagesInGallery": "Brak obrazów w galerii"
|
||||
@@ -273,6 +274,7 @@
|
||||
"cfgScale": "Skala CFG",
|
||||
"width": "Szerokość",
|
||||
"height": "Wysokość",
|
||||
"sampler": "Próbkowanie",
|
||||
"seed": "Inicjator",
|
||||
"randomizeSeed": "Losowy inicjator",
|
||||
"shuffle": "Losuj",
|
||||
@@ -294,6 +296,10 @@
|
||||
"hiresOptim": "Optymalizacja wys. rozdzielczości",
|
||||
"imageFit": "Przeskaluj oryginalny obraz",
|
||||
"codeformerFidelity": "Dokładność",
|
||||
"seamSize": "Rozmiar",
|
||||
"seamBlur": "Rozmycie",
|
||||
"seamStrength": "Siła",
|
||||
"seamSteps": "Kroki",
|
||||
"scaleBeforeProcessing": "Tryb skalowania",
|
||||
"scaledWidth": "Sk. do szer.",
|
||||
"scaledHeight": "Sk. do wys.",
|
||||
@@ -304,6 +310,8 @@
|
||||
"infillScalingHeader": "Wypełnienie i skalowanie",
|
||||
"img2imgStrength": "Wpływ sugestii na obraz",
|
||||
"toggleLoopback": "Wł/wył sprzężenie zwrotne",
|
||||
"invoke": "Wywołaj",
|
||||
"promptPlaceholder": "W tym miejscu wprowadź swoje sugestie. [negatywne sugestie], (wzmocnienie), (osłabienie)--, po więcej opcji (np. swap lub blend) zajrzyj do dokumentacji",
|
||||
"sendTo": "Wyślij do",
|
||||
"sendToImg2Img": "Użyj w trybie \"Obraz na obraz\"",
|
||||
"sendToUnifiedCanvas": "Użyj w trybie uniwersalnym",
|
||||
@@ -316,6 +324,7 @@
|
||||
"useAll": "Skopiuj wszystko",
|
||||
"useInitImg": "Użyj oryginalnego obrazu",
|
||||
"info": "Informacje",
|
||||
"deleteImage": "Usuń obraz",
|
||||
"initialImage": "Oryginalny obraz",
|
||||
"showOptionsPanel": "Pokaż panel ustawień"
|
||||
},
|
||||
@@ -325,6 +334,7 @@
|
||||
"saveSteps": "Zapisuj obrazy co X kroków",
|
||||
"confirmOnDelete": "Potwierdzaj usuwanie",
|
||||
"displayHelpIcons": "Wyświetlaj ikony pomocy",
|
||||
"useCanvasBeta": "Nowy układ trybu uniwersalnego",
|
||||
"enableImageDebugging": "Włącz debugowanie obrazu",
|
||||
"resetWebUI": "Zresetuj interfejs",
|
||||
"resetWebUIDesc1": "Resetowanie interfejsu wyczyści jedynie dane i ustawienia zapisane w pamięci przeglądarki. Nie usunie żadnych obrazów z dysku.",
|
||||
@@ -334,6 +344,7 @@
|
||||
"toast": {
|
||||
"tempFoldersEmptied": "Wyczyszczono folder tymczasowy",
|
||||
"uploadFailed": "Błąd przesyłania obrazu",
|
||||
"uploadFailedMultipleImagesDesc": "Możliwe jest przesłanie tylko jednego obrazu na raz",
|
||||
"uploadFailedUnableToLoadDesc": "Błąd wczytywania obrazu",
|
||||
"downloadImageStarted": "Rozpoczęto pobieranie",
|
||||
"imageCopied": "Skopiowano obraz",
|
||||
@@ -435,27 +446,5 @@
|
||||
"betaDarkenOutside": "Przyciemnienie",
|
||||
"betaLimitToBox": "Ogranicz do zaznaczenia",
|
||||
"betaPreserveMasked": "Zachowaj obszar"
|
||||
},
|
||||
"accessibility": {
|
||||
"zoomIn": "Przybliż",
|
||||
"exitViewer": "Wyjdź z podglądu",
|
||||
"modelSelect": "Wybór modelu",
|
||||
"invokeProgressBar": "Pasek postępu",
|
||||
"reset": "Zerowanie",
|
||||
"useThisParameter": "Użyj tego parametru",
|
||||
"copyMetadataJson": "Kopiuj metadane JSON",
|
||||
"uploadImage": "Wgrywanie obrazu",
|
||||
"previousImage": "Poprzedni obraz",
|
||||
"nextImage": "Następny obraz",
|
||||
"zoomOut": "Oddal",
|
||||
"rotateClockwise": "Obróć zgodnie ze wskazówkami zegara",
|
||||
"rotateCounterClockwise": "Obróć przeciwnie do wskazówek zegara",
|
||||
"flipHorizontally": "Odwróć horyzontalnie",
|
||||
"flipVertically": "Odwróć wertykalnie",
|
||||
"modifyConfig": "Modyfikuj ustawienia",
|
||||
"toggleAutoscroll": "Przełącz autoprzewijanie",
|
||||
"toggleLogViewer": "Przełącz podgląd logów",
|
||||
"showOptionsPanel": "Pokaż panel opcji",
|
||||
"menu": "Menu"
|
||||
}
|
||||
}
|
||||
|
||||
@@ -1,8 +1,11 @@
|
||||
{
|
||||
"common": {
|
||||
"greenTheme": "Verde",
|
||||
"langArabic": "العربية",
|
||||
"themeLabel": "Tema",
|
||||
"reportBugLabel": "Reportar Bug",
|
||||
"settingsLabel": "Configurações",
|
||||
"lightTheme": "Claro",
|
||||
"langBrPortuguese": "Português do Brasil",
|
||||
"languagePickerLabel": "Seletor de Idioma",
|
||||
"langDutch": "Nederlands",
|
||||
@@ -54,11 +57,14 @@
|
||||
"statusModelChanged": "Modelo Alterado",
|
||||
"githubLabel": "Github",
|
||||
"discordLabel": "Discord",
|
||||
"darkTheme": "Escuro",
|
||||
"training": "Treinando",
|
||||
"statusGeneratingOutpainting": "Geração de Ampliação",
|
||||
"statusGenerationComplete": "Geração Completa",
|
||||
"statusMergingModels": "Mesclando Modelos",
|
||||
"statusMergedModels": "Modelos Mesclados",
|
||||
"oceanTheme": "Oceano",
|
||||
"pinOptionsPanel": "Fixar painel de opções",
|
||||
"loading": "A carregar",
|
||||
"loadingInvokeAI": "A carregar Invoke AI",
|
||||
"langPortuguese": "Português"
|
||||
@@ -68,6 +74,7 @@
|
||||
"gallerySettings": "Configurações de Galeria",
|
||||
"maintainAspectRatio": "Mater Proporções",
|
||||
"autoSwitchNewImages": "Trocar para Novas Imagens Automaticamente",
|
||||
"pinGallery": "Fixar Galeria",
|
||||
"singleColumnLayout": "Disposição em Coluna Única",
|
||||
"allImagesLoaded": "Todas as Imagens Carregadas",
|
||||
"loadMore": "Carregar Mais",
|
||||
@@ -400,6 +407,7 @@
|
||||
"width": "Largura",
|
||||
"seed": "Seed",
|
||||
"hiresStrength": "Força da Alta Resolução",
|
||||
"negativePrompts": "Indicações negativas",
|
||||
"general": "Geral",
|
||||
"randomizeSeed": "Seed Aleatório",
|
||||
"shuffle": "Embaralhar",
|
||||
@@ -417,6 +425,10 @@
|
||||
"hiresOptim": "Otimização de Alta Res",
|
||||
"imageFit": "Caber Imagem Inicial No Tamanho de Saída",
|
||||
"codeformerFidelity": "Fidelidade",
|
||||
"seamSize": "Tamanho da Fronteira",
|
||||
"seamBlur": "Desfoque da Fronteira",
|
||||
"seamStrength": "Força da Fronteira",
|
||||
"seamSteps": "Passos da Fronteira",
|
||||
"tileSize": "Tamanho do Ladrilho",
|
||||
"boundingBoxHeader": "Caixa Delimitadora",
|
||||
"seamCorrectionHeader": "Correção de Fronteira",
|
||||
@@ -424,10 +436,12 @@
|
||||
"img2imgStrength": "Força de Imagem Para Imagem",
|
||||
"toggleLoopback": "Ativar Loopback",
|
||||
"symmetry": "Simetria",
|
||||
"promptPlaceholder": "Digite o prompt aqui. [tokens negativos], (upweight)++, (downweight)--, trocar e misturar estão disponíveis (veja docs)",
|
||||
"sendTo": "Mandar para",
|
||||
"openInViewer": "Abrir No Visualizador",
|
||||
"closeViewer": "Fechar Visualizador",
|
||||
"usePrompt": "Usar Prompt",
|
||||
"deleteImage": "Apagar Imagem",
|
||||
"initialImage": "Imagem inicial",
|
||||
"showOptionsPanel": "Mostrar Painel de Opções",
|
||||
"strength": "Força",
|
||||
@@ -435,10 +449,12 @@
|
||||
"upscale": "Redimensionar",
|
||||
"upscaleImage": "Redimensionar Imagem",
|
||||
"scaleBeforeProcessing": "Escala Antes do Processamento",
|
||||
"invoke": "Invocar",
|
||||
"images": "Imagems",
|
||||
"steps": "Passos",
|
||||
"cfgScale": "Escala CFG",
|
||||
"height": "Altura",
|
||||
"sampler": "Amostrador",
|
||||
"imageToImage": "Imagem para Imagem",
|
||||
"variationAmount": "Quntidade de Variatções",
|
||||
"scaledWidth": "L Escalada",
|
||||
@@ -465,6 +481,7 @@
|
||||
"settings": {
|
||||
"confirmOnDelete": "Confirmar Antes de Apagar",
|
||||
"displayHelpIcons": "Mostrar Ícones de Ajuda",
|
||||
"useCanvasBeta": "Usar Layout de Telas Beta",
|
||||
"enableImageDebugging": "Ativar Depuração de Imagem",
|
||||
"useSlidersForAll": "Usar deslizadores para todas as opções",
|
||||
"resetWebUIDesc1": "Reiniciar a interface apenas reinicia o cache local do broswer para imagens e configurações lembradas. Não apaga nenhuma imagem do disco.",
|
||||
@@ -477,6 +494,7 @@
|
||||
},
|
||||
"toast": {
|
||||
"uploadFailed": "Envio Falhou",
|
||||
"uploadFailedMultipleImagesDesc": "Várias imagens copiadas, só é permitido uma imagem de cada vez",
|
||||
"uploadFailedUnableToLoadDesc": "Não foj possível carregar o ficheiro",
|
||||
"downloadImageStarted": "Download de Imagem Começou",
|
||||
"imageNotLoadedDesc": "Nenhuma imagem encontrada a enviar para o módulo de imagem para imagem",
|
||||
@@ -593,6 +611,7 @@
|
||||
"flipVertically": "Espelhar verticalmente",
|
||||
"modifyConfig": "Modificar config",
|
||||
"toggleAutoscroll": "Alternar rolagem automática",
|
||||
"showGallery": "Mostrar galeria",
|
||||
"showOptionsPanel": "Mostrar painel de opções",
|
||||
"uploadImage": "Enviar imagem",
|
||||
"previousImage": "Imagem anterior",
|
||||
|
||||
@@ -1,9 +1,13 @@
|
||||
{
|
||||
"common": {
|
||||
"hotkeysLabel": "Teclas de atalho",
|
||||
"themeLabel": "Tema",
|
||||
"languagePickerLabel": "Seletor de Idioma",
|
||||
"reportBugLabel": "Relatar Bug",
|
||||
"settingsLabel": "Configurações",
|
||||
"darkTheme": "Noite",
|
||||
"lightTheme": "Dia",
|
||||
"greenTheme": "Verde",
|
||||
"img2img": "Imagem Para Imagem",
|
||||
"unifiedCanvas": "Tela Unificada",
|
||||
"nodes": "Nódulos",
|
||||
@@ -59,6 +63,7 @@
|
||||
"statusMergedModels": "Modelos Mesclados",
|
||||
"langRussian": "Russo",
|
||||
"langSpanish": "Espanhol",
|
||||
"pinOptionsPanel": "Fixar painel de opções",
|
||||
"loadingInvokeAI": "Carregando Invoke AI",
|
||||
"loading": "Carregando"
|
||||
},
|
||||
@@ -73,6 +78,7 @@
|
||||
"maintainAspectRatio": "Mater Proporções",
|
||||
"autoSwitchNewImages": "Trocar para Novas Imagens Automaticamente",
|
||||
"singleColumnLayout": "Disposição em Coluna Única",
|
||||
"pinGallery": "Fixar Galeria",
|
||||
"allImagesLoaded": "Todas as Imagens Carregadas",
|
||||
"loadMore": "Carregar Mais",
|
||||
"noImagesInGallery": "Sem Imagens na Galeria"
|
||||
@@ -396,6 +402,7 @@
|
||||
"cfgScale": "Escala CFG",
|
||||
"width": "Largura",
|
||||
"height": "Altura",
|
||||
"sampler": "Amostrador",
|
||||
"seed": "Seed",
|
||||
"randomizeSeed": "Seed Aleatório",
|
||||
"shuffle": "Embaralhar",
|
||||
@@ -417,6 +424,10 @@
|
||||
"hiresOptim": "Otimização de Alta Res",
|
||||
"imageFit": "Caber Imagem Inicial No Tamanho de Saída",
|
||||
"codeformerFidelity": "Fidelidade",
|
||||
"seamSize": "Tamanho da Fronteira",
|
||||
"seamBlur": "Desfoque da Fronteira",
|
||||
"seamStrength": "Força da Fronteira",
|
||||
"seamSteps": "Passos da Fronteira",
|
||||
"scaleBeforeProcessing": "Escala Antes do Processamento",
|
||||
"scaledWidth": "L Escalada",
|
||||
"scaledHeight": "A Escalada",
|
||||
@@ -427,6 +438,8 @@
|
||||
"infillScalingHeader": "Preencimento e Escala",
|
||||
"img2imgStrength": "Força de Imagem Para Imagem",
|
||||
"toggleLoopback": "Ativar Loopback",
|
||||
"invoke": "Invoke",
|
||||
"promptPlaceholder": "Digite o prompt aqui. [tokens negativos], (upweight)++, (downweight)--, trocar e misturar estão disponíveis (veja docs)",
|
||||
"sendTo": "Mandar para",
|
||||
"sendToImg2Img": "Mandar para Imagem Para Imagem",
|
||||
"sendToUnifiedCanvas": "Mandar para Tela Unificada",
|
||||
@@ -439,12 +452,14 @@
|
||||
"useAll": "Usar Todos",
|
||||
"useInitImg": "Usar Imagem Inicial",
|
||||
"info": "Informações",
|
||||
"deleteImage": "Apagar Imagem",
|
||||
"initialImage": "Imagem inicial",
|
||||
"showOptionsPanel": "Mostrar Painel de Opções",
|
||||
"vSymmetryStep": "V Passo de Simetria",
|
||||
"hSymmetryStep": "H Passo de Simetria",
|
||||
"symmetry": "Simetria",
|
||||
"copyImage": "Copiar imagem",
|
||||
"negativePrompts": "Indicações negativas",
|
||||
"hiresStrength": "Força da Alta Resolução",
|
||||
"denoisingStrength": "A força de remoção de ruído",
|
||||
"imageToImage": "Imagem para Imagem",
|
||||
@@ -462,6 +477,7 @@
|
||||
"saveSteps": "Salvar imagens a cada n passos",
|
||||
"confirmOnDelete": "Confirmar Antes de Apagar",
|
||||
"displayHelpIcons": "Mostrar Ícones de Ajuda",
|
||||
"useCanvasBeta": "Usar Layout de Telas Beta",
|
||||
"enableImageDebugging": "Ativar Depuração de Imagem",
|
||||
"resetWebUI": "Reiniciar Interface",
|
||||
"resetWebUIDesc1": "Reiniciar a interface apenas reinicia o cache local do broswer para imagens e configurações lembradas. Não apaga nenhuma imagem do disco.",
|
||||
@@ -472,6 +488,7 @@
|
||||
"toast": {
|
||||
"tempFoldersEmptied": "Pasta de Arquivos Temporários Esvaziada",
|
||||
"uploadFailed": "Envio Falhou",
|
||||
"uploadFailedMultipleImagesDesc": "Várias imagens copiadas, só é permitido uma imagem de cada vez",
|
||||
"uploadFailedUnableToLoadDesc": "Não foj possível carregar o arquivo",
|
||||
"downloadImageStarted": "Download de Imagem Começou",
|
||||
"imageCopied": "Imagem Copiada",
|
||||
|
||||
@@ -1,12 +1,16 @@
|
||||
{
|
||||
"common": {
|
||||
"hotkeysLabel": "Горячие клавиши",
|
||||
"themeLabel": "Тема",
|
||||
"languagePickerLabel": "Язык",
|
||||
"reportBugLabel": "Сообщить об ошибке",
|
||||
"settingsLabel": "Настройки",
|
||||
"darkTheme": "Темная",
|
||||
"lightTheme": "Светлая",
|
||||
"greenTheme": "Зеленая",
|
||||
"img2img": "Изображение в изображение (img2img)",
|
||||
"unifiedCanvas": "Единый холст",
|
||||
"nodes": "Редактор рабочего процесса",
|
||||
"nodes": "Ноды",
|
||||
"langRussian": "Русский",
|
||||
"nodesDesc": "Cистема генерации изображений на основе нодов (узлов) уже разрабатывается. Следите за новостями об этой замечательной функции.",
|
||||
"postProcessing": "Постобработка",
|
||||
@@ -45,12 +49,14 @@
|
||||
"statusMergingModels": "Слияние моделей",
|
||||
"statusModelConverted": "Модель сконвертирована",
|
||||
"statusMergedModels": "Модели объединены",
|
||||
"pinOptionsPanel": "Закрепить панель настроек",
|
||||
"loading": "Загрузка",
|
||||
"loadingInvokeAI": "Загрузка Invoke AI",
|
||||
"back": "Назад",
|
||||
"statusConvertingModel": "Конвертация модели",
|
||||
"cancel": "Отменить",
|
||||
"accept": "Принять",
|
||||
"oceanTheme": "Океан",
|
||||
"langUkranian": "Украинский",
|
||||
"langEnglish": "Английский",
|
||||
"postprocessing": "Постобработка",
|
||||
@@ -68,21 +74,7 @@
|
||||
"langPortuguese": "Португальский",
|
||||
"txt2img": "Текст в изображение (txt2img)",
|
||||
"langBrPortuguese": "Португальский (Бразилия)",
|
||||
"linear": "Линейная обработка",
|
||||
"dontAskMeAgain": "Больше не спрашивать",
|
||||
"areYouSure": "Вы уверены?",
|
||||
"random": "Случайное",
|
||||
"generate": "Сгенерировать",
|
||||
"openInNewTab": "Открыть в новой вкладке",
|
||||
"imagePrompt": "Запрос",
|
||||
"communityLabel": "Сообщество",
|
||||
"lightMode": "Светлая тема",
|
||||
"batch": "Пакетный менеджер",
|
||||
"modelManager": "Менеджер моделей",
|
||||
"darkMode": "Темная тема",
|
||||
"nodeEditor": "Редактор Нодов (Узлов)",
|
||||
"controlNet": "Controlnet",
|
||||
"advanced": "Расширенные"
|
||||
"linear": "Линейная обработка"
|
||||
},
|
||||
"gallery": {
|
||||
"generations": "Генерации",
|
||||
@@ -95,15 +87,10 @@
|
||||
"maintainAspectRatio": "Сохранять пропорции",
|
||||
"autoSwitchNewImages": "Автоматически выбирать новые",
|
||||
"singleColumnLayout": "Одна колонка",
|
||||
"pinGallery": "Закрепить галерею",
|
||||
"allImagesLoaded": "Все изображения загружены",
|
||||
"loadMore": "Показать больше",
|
||||
"noImagesInGallery": "Изображений нет",
|
||||
"deleteImagePermanent": "Удаленные изображения невозможно восстановить.",
|
||||
"deleteImageBin": "Удаленные изображения будут отправлены в корзину вашей операционной системы.",
|
||||
"deleteImage": "Удалить изображение",
|
||||
"images": "Изображения",
|
||||
"assets": "Ресурсы",
|
||||
"autoAssignBoardOnClick": "Авто-назначение доски по клику"
|
||||
"noImagesInGallery": "Изображений нет"
|
||||
},
|
||||
"hotkeys": {
|
||||
"keyboardShortcuts": "Горячие клавиши",
|
||||
@@ -310,12 +297,7 @@
|
||||
"acceptStagingImage": {
|
||||
"title": "Принять изображение",
|
||||
"desc": "Принять текущее изображение"
|
||||
},
|
||||
"addNodes": {
|
||||
"desc": "Открывает меню добавления узла",
|
||||
"title": "Добавление узлов"
|
||||
},
|
||||
"nodesHotkeys": "Горячие клавиши узлов"
|
||||
}
|
||||
},
|
||||
"modelManager": {
|
||||
"modelManager": "Менеджер моделей",
|
||||
@@ -368,14 +350,14 @@
|
||||
"deleteModel": "Удалить модель",
|
||||
"deleteConfig": "Удалить конфигурацию",
|
||||
"deleteMsg1": "Вы точно хотите удалить модель из InvokeAI?",
|
||||
"deleteMsg2": "Это приведет К УДАЛЕНИЮ модели С ДИСКА, если она находится в корневой папке Invoke. Если вы используете пользовательское расположение, то модель НЕ будет удалена с диска.",
|
||||
"deleteMsg2": "Это не удалит файл модели с диска. Позже вы можете добавить его снова.",
|
||||
"repoIDValidationMsg": "Онлайн-репозиторий модели",
|
||||
"convertToDiffusersHelpText5": "Пожалуйста, убедитесь, что у вас достаточно места на диске. Модели обычно занимают 2–7 Гб.",
|
||||
"convertToDiffusersHelpText5": "Пожалуйста, убедитесь, что у вас достаточно места на диске. Модели обычно занимают 4 – 7 Гб.",
|
||||
"invokeAIFolder": "Каталог InvokeAI",
|
||||
"ignoreMismatch": "Игнорировать несоответствия между выбранными моделями",
|
||||
"addCheckpointModel": "Добавить модель Checkpoint/Safetensor",
|
||||
"formMessageDiffusersModelLocationDesc": "Укажите хотя бы одно.",
|
||||
"convertToDiffusersHelpText3": "Ваш файл контрольной точки НА ДИСКЕ будет УДАЛЕН, если он находится в корневой папке InvokeAI. Если он находится в пользовательском расположении, то он НЕ будет удален.",
|
||||
"convertToDiffusersHelpText3": "Файл модели на диске НЕ будет удалён или изменён. Вы сможете заново добавить его в Model Manager при необходимости.",
|
||||
"vaeRepoID": "ID репозитория VAE",
|
||||
"mergedModelName": "Название объединенной модели",
|
||||
"checkpointModels": "Checkpoints",
|
||||
@@ -427,27 +409,7 @@
|
||||
"weightedSum": "Взвешенная сумма",
|
||||
"safetensorModels": "SafeTensors",
|
||||
"v2_768": "v2 (768px)",
|
||||
"v2_base": "v2 (512px)",
|
||||
"modelDeleted": "Модель удалена",
|
||||
"importModels": "Импорт Моделей",
|
||||
"variant": "Вариант",
|
||||
"baseModel": "Базовая модель",
|
||||
"modelsSynced": "Модели синхронизированы",
|
||||
"modelSyncFailed": "Не удалось синхронизировать модели",
|
||||
"vae": "VAE",
|
||||
"modelDeleteFailed": "Не удалось удалить модель",
|
||||
"noCustomLocationProvided": "Пользовательское местоположение не указано",
|
||||
"convertingModelBegin": "Конвертация модели. Пожалуйста, подождите.",
|
||||
"settings": "Настройки",
|
||||
"selectModel": "Выберите модель",
|
||||
"syncModels": "Синхронизация моделей",
|
||||
"syncModelsDesc": "Если ваши модели не синхронизированы с серверной частью, вы можете обновить их, используя эту опцию. Обычно это удобно в тех случаях, когда вы вручную обновляете свой файл \"models.yaml\" или добавляете модели в корневую папку InvokeAI после загрузки приложения.",
|
||||
"modelUpdateFailed": "Не удалось обновить модель",
|
||||
"modelConversionFailed": "Не удалось сконвертировать модель",
|
||||
"modelsMergeFailed": "Не удалось выполнить слияние моделей",
|
||||
"loraModels": "LoRAs",
|
||||
"onnxModels": "Onnx",
|
||||
"oliveModels": "Olives"
|
||||
"v2_base": "v2 (512px)"
|
||||
},
|
||||
"parameters": {
|
||||
"images": "Изображения",
|
||||
@@ -455,9 +417,10 @@
|
||||
"cfgScale": "Уровень CFG",
|
||||
"width": "Ширина",
|
||||
"height": "Высота",
|
||||
"sampler": "Семплер",
|
||||
"seed": "Сид",
|
||||
"randomizeSeed": "Случайный сид",
|
||||
"shuffle": "Обновить сид",
|
||||
"shuffle": "Обновить",
|
||||
"noiseThreshold": "Порог шума",
|
||||
"perlinNoise": "Шум Перлина",
|
||||
"variations": "Вариации",
|
||||
@@ -476,6 +439,10 @@
|
||||
"hiresOptim": "Оптимизация High Res",
|
||||
"imageFit": "Уместить изображение",
|
||||
"codeformerFidelity": "Точность",
|
||||
"seamSize": "Размер шва",
|
||||
"seamBlur": "Размытие шва",
|
||||
"seamStrength": "Сила шва",
|
||||
"seamSteps": "Шаги шва",
|
||||
"scaleBeforeProcessing": "Масштабировать",
|
||||
"scaledWidth": "Масштаб Ш",
|
||||
"scaledHeight": "Масштаб В",
|
||||
@@ -486,6 +453,8 @@
|
||||
"infillScalingHeader": "Заполнение и масштабирование",
|
||||
"img2imgStrength": "Сила обработки img2img",
|
||||
"toggleLoopback": "Зациклить обработку",
|
||||
"invoke": "Invoke",
|
||||
"promptPlaceholder": "Введите запрос здесь (на английском). [исключенные токены], (более значимые)++, (менее значимые)--, swap и blend тоже доступны (смотрите Github)",
|
||||
"sendTo": "Отправить",
|
||||
"sendToImg2Img": "Отправить в img2img",
|
||||
"sendToUnifiedCanvas": "Отправить на Единый холст",
|
||||
@@ -498,6 +467,7 @@
|
||||
"useAll": "Использовать все",
|
||||
"useInitImg": "Использовать как исходное",
|
||||
"info": "Метаданные",
|
||||
"deleteImage": "Удалить изображение",
|
||||
"initialImage": "Исходное изображение",
|
||||
"showOptionsPanel": "Показать панель настроек",
|
||||
"vSymmetryStep": "Шаг верт. симметрии",
|
||||
@@ -515,27 +485,8 @@
|
||||
"imageToImage": "Изображение в изображение",
|
||||
"denoisingStrength": "Сила шумоподавления",
|
||||
"copyImage": "Скопировать изображение",
|
||||
"showPreview": "Показать предпросмотр",
|
||||
"noiseSettings": "Шум",
|
||||
"seamlessXAxis": "Ось X",
|
||||
"seamlessYAxis": "Ось Y",
|
||||
"scheduler": "Планировщик",
|
||||
"boundingBoxWidth": "Ширина ограничивающей рамки",
|
||||
"boundingBoxHeight": "Высота ограничивающей рамки",
|
||||
"positivePromptPlaceholder": "Запрос",
|
||||
"negativePromptPlaceholder": "Исключающий запрос",
|
||||
"controlNetControlMode": "Режим управления",
|
||||
"clipSkip": "CLIP Пропуск",
|
||||
"aspectRatio": "Соотношение",
|
||||
"maskAdjustmentsHeader": "Настройка маски",
|
||||
"maskBlur": "Размытие",
|
||||
"maskBlurMethod": "Метод размытия",
|
||||
"seamLowThreshold": "Низкий",
|
||||
"seamHighThreshold": "Высокий",
|
||||
"coherenceSteps": "Шагов",
|
||||
"coherencePassHeader": "Порог Coherence",
|
||||
"coherenceStrength": "Сила",
|
||||
"compositingSettingsHeader": "Настройки компоновки"
|
||||
"negativePrompts": "Исключающий запрос",
|
||||
"showPreview": "Показать предпросмотр"
|
||||
},
|
||||
"settings": {
|
||||
"models": "Модели",
|
||||
@@ -543,38 +494,24 @@
|
||||
"saveSteps": "Сохранять каждые n щагов",
|
||||
"confirmOnDelete": "Подтверждать удаление",
|
||||
"displayHelpIcons": "Показывать значки подсказок",
|
||||
"useCanvasBeta": "Показывать инструменты слева (Beta UI)",
|
||||
"enableImageDebugging": "Включить отладку",
|
||||
"resetWebUI": "Сброс настроек Web UI",
|
||||
"resetWebUIDesc1": "Сброс настроек веб-интерфейса удаляет только локальный кэш браузера с вашими изображениями и настройками. Он не удаляет изображения с диска.",
|
||||
"resetWebUIDesc2": "Если изображения не отображаются в галерее или не работает что-то еще, пожалуйста, попробуйте сбросить настройки, прежде чем сообщать о проблеме на GitHub.",
|
||||
"resetComplete": "Настройки веб-интерфейса были сброшены.",
|
||||
"useSlidersForAll": "Использовать ползунки для всех параметров",
|
||||
"consoleLogLevel": "Уровень логирования",
|
||||
"shouldLogToConsole": "Логи в консоль",
|
||||
"developer": "Разработчик",
|
||||
"general": "Основное",
|
||||
"showProgressInViewer": "Показывать процесс генерации в Просмотрщике",
|
||||
"antialiasProgressImages": "Сглаживать предпоказ процесса генерации",
|
||||
"generation": "Поколение",
|
||||
"ui": "Пользовательский интерфейс",
|
||||
"favoriteSchedulers": "Избранные планировщики",
|
||||
"favoriteSchedulersPlaceholder": "Нет избранных планировщиков",
|
||||
"enableNodesEditor": "Включить редактор узлов",
|
||||
"experimental": "Экспериментальные",
|
||||
"beta": "Бета",
|
||||
"alternateCanvasLayout": "Альтернативный слой холста",
|
||||
"showAdvancedOptions": "Показать доп. параметры",
|
||||
"autoChangeDimensions": "Обновить Ш/В на стандартные для модели при изменении"
|
||||
"resetComplete": "Интерфейс сброшен. Обновите эту страницу.",
|
||||
"useSlidersForAll": "Использовать ползунки для всех параметров"
|
||||
},
|
||||
"toast": {
|
||||
"tempFoldersEmptied": "Временная папка очищена",
|
||||
"uploadFailed": "Загрузка не удалась",
|
||||
"uploadFailedMultipleImagesDesc": "Можно вставить только одно изображение (вы попробовали вставить несколько)",
|
||||
"uploadFailedUnableToLoadDesc": "Невозможно загрузить файл",
|
||||
"downloadImageStarted": "Скачивание изображения началось",
|
||||
"imageCopied": "Изображение скопировано",
|
||||
"imageLinkCopied": "Ссылка на изображение скопирована",
|
||||
"imageNotLoaded": "Изображение не загружено",
|
||||
"imageNotLoadedDesc": "Не удалось найти изображение",
|
||||
"imageNotLoadedDesc": "Не найдены изображения для отправки в img2img",
|
||||
"imageSavedToGallery": "Изображение сохранено в галерею",
|
||||
"canvasMerged": "Холст объединен",
|
||||
"sentToImageToImage": "Отправить в img2img",
|
||||
@@ -599,21 +536,7 @@
|
||||
"serverError": "Ошибка сервера",
|
||||
"disconnected": "Отключено от сервера",
|
||||
"connected": "Подключено к серверу",
|
||||
"canceled": "Обработка отменена",
|
||||
"problemCopyingImageLink": "Не удалось скопировать ссылку на изображение",
|
||||
"uploadFailedInvalidUploadDesc": "Должно быть одно изображение в формате PNG или JPEG",
|
||||
"parameterNotSet": "Параметр не задан",
|
||||
"parameterSet": "Параметр задан",
|
||||
"nodesLoaded": "Узлы загружены",
|
||||
"problemCopyingImage": "Не удается скопировать изображение",
|
||||
"nodesLoadedFailed": "Не удалось загрузить Узлы",
|
||||
"nodesCleared": "Узлы очищены",
|
||||
"nodesBrokenConnections": "Не удается загрузить. Некоторые соединения повреждены.",
|
||||
"nodesUnrecognizedTypes": "Не удается загрузить. Граф имеет нераспознанные типы",
|
||||
"nodesNotValidJSON": "Недопустимый JSON",
|
||||
"nodesCorruptedGraph": "Не удается загрузить. Граф, похоже, поврежден.",
|
||||
"nodesSaved": "Узлы сохранены",
|
||||
"nodesNotValidGraph": "Недопустимый граф узлов InvokeAI"
|
||||
"canceled": "Обработка отменена"
|
||||
},
|
||||
"tooltip": {
|
||||
"feature": {
|
||||
@@ -687,8 +610,7 @@
|
||||
"betaClear": "Очистить",
|
||||
"betaDarkenOutside": "Затемнить снаружи",
|
||||
"betaLimitToBox": "Ограничить выделением",
|
||||
"betaPreserveMasked": "Сохранять маскируемую область",
|
||||
"antialiasing": "Не удалось скопировать ссылку на изображение"
|
||||
"betaPreserveMasked": "Сохранять маскируемую область"
|
||||
},
|
||||
"accessibility": {
|
||||
"modelSelect": "Выбор модели",
|
||||
@@ -703,7 +625,8 @@
|
||||
"flipHorizontally": "Отразить горизонтально",
|
||||
"toggleAutoscroll": "Включить автопрокрутку",
|
||||
"toggleLogViewer": "Показать или скрыть просмотрщик логов",
|
||||
"showOptionsPanel": "Показать боковую панель",
|
||||
"showOptionsPanel": "Показать опции",
|
||||
"showGallery": "Показать галерею",
|
||||
"invokeProgressBar": "Индикатор выполнения",
|
||||
"reset": "Сброс",
|
||||
"modifyConfig": "Изменить конфиг",
|
||||
@@ -711,69 +634,5 @@
|
||||
"copyMetadataJson": "Скопировать метаданные JSON",
|
||||
"exitViewer": "Закрыть просмотрщик",
|
||||
"menu": "Меню"
|
||||
},
|
||||
"ui": {
|
||||
"showProgressImages": "Показывать промежуточный итог",
|
||||
"hideProgressImages": "Не показывать промежуточный итог",
|
||||
"swapSizes": "Поменять местами размеры",
|
||||
"lockRatio": "Зафиксировать пропорции"
|
||||
},
|
||||
"nodes": {
|
||||
"zoomInNodes": "Увеличьте масштаб",
|
||||
"zoomOutNodes": "Уменьшите масштаб",
|
||||
"fitViewportNodes": "Уместить вид",
|
||||
"hideGraphNodes": "Скрыть оверлей графа",
|
||||
"showGraphNodes": "Показать оверлей графа",
|
||||
"showLegendNodes": "Показать тип поля",
|
||||
"hideMinimapnodes": "Скрыть миникарту",
|
||||
"hideLegendNodes": "Скрыть тип поля",
|
||||
"showMinimapnodes": "Показать миникарту",
|
||||
"loadWorkflow": "Загрузить рабочий процесс",
|
||||
"resetWorkflowDesc2": "Сброс рабочего процесса очистит все узлы, ребра и детали рабочего процесса.",
|
||||
"resetWorkflow": "Сбросить рабочий процесс",
|
||||
"resetWorkflowDesc": "Вы уверены, что хотите сбросить этот рабочий процесс?",
|
||||
"reloadNodeTemplates": "Перезагрузить шаблоны узлов",
|
||||
"downloadWorkflow": "Скачать JSON рабочего процесса"
|
||||
},
|
||||
"controlnet": {
|
||||
"amult": "a_mult",
|
||||
"contentShuffleDescription": "Перетасовывает содержимое изображения",
|
||||
"bgth": "bg_th",
|
||||
"contentShuffle": "Перетасовка содержимого",
|
||||
"beginEndStepPercent": "Процент начала/конца шага",
|
||||
"duplicate": "Дублировать",
|
||||
"balanced": "Сбалансированный",
|
||||
"f": "F",
|
||||
"depthMidasDescription": "Генерация карты глубины с использованием Midas",
|
||||
"control": "Контроль",
|
||||
"coarse": "Грубость обработки",
|
||||
"crop": "Обрезка",
|
||||
"depthMidas": "Глубина (Midas)",
|
||||
"enableControlnet": "Включить ControlNet",
|
||||
"detectResolution": "Определить разрешение",
|
||||
"controlMode": "Режим контроля",
|
||||
"cannyDescription": "Детектор границ Canny",
|
||||
"depthZoe": "Глубина (Zoe)",
|
||||
"autoConfigure": "Автонастройка процессора",
|
||||
"delete": "Удалить",
|
||||
"canny": "Canny",
|
||||
"depthZoeDescription": "Генерация карты глубины с использованием Zoe"
|
||||
},
|
||||
"boards": {
|
||||
"autoAddBoard": "Авто добавление Доски",
|
||||
"topMessage": "Эта доска содержит изображения, используемые в следующих функциях:",
|
||||
"move": "Перемещение",
|
||||
"menuItemAutoAdd": "Авто добавление на эту доску",
|
||||
"myBoard": "Моя Доска",
|
||||
"searchBoard": "Поиск Доски...",
|
||||
"noMatching": "Нет подходящих Досок",
|
||||
"selectBoard": "Выбрать Доску",
|
||||
"cancel": "Отменить",
|
||||
"addBoard": "Добавить Доску",
|
||||
"bottomMessage": "Удаление этой доски и ее изображений приведет к сбросу всех функций, использующихся их в данный момент.",
|
||||
"uncategorized": "Без категории",
|
||||
"changeBoard": "Изменить Доску",
|
||||
"loading": "Загрузка...",
|
||||
"clearSearch": "Очистить поиск"
|
||||
}
|
||||
}
|
||||
|
||||
@@ -15,6 +15,7 @@
|
||||
"reset": "Starta om",
|
||||
"previousImage": "Föregående bild",
|
||||
"useThisParameter": "Använd denna parametern",
|
||||
"showGallery": "Visa galleri",
|
||||
"rotateCounterClockwise": "Rotera moturs",
|
||||
"rotateClockwise": "Rotera medurs",
|
||||
"modifyConfig": "Ändra konfiguration",
|
||||
@@ -26,6 +27,10 @@
|
||||
"githubLabel": "Github",
|
||||
"discordLabel": "Discord",
|
||||
"settingsLabel": "Inställningar",
|
||||
"darkTheme": "Mörk",
|
||||
"lightTheme": "Ljus",
|
||||
"greenTheme": "Grön",
|
||||
"oceanTheme": "Hav",
|
||||
"langEnglish": "Engelska",
|
||||
"langDutch": "Nederländska",
|
||||
"langFrench": "Franska",
|
||||
@@ -58,10 +63,12 @@
|
||||
"statusGenerationComplete": "Generering klar",
|
||||
"statusModelConverted": "Modell konverterad",
|
||||
"statusMergingModels": "Sammanfogar modeller",
|
||||
"pinOptionsPanel": "Nåla fast inställningspanelen",
|
||||
"loading": "Laddar",
|
||||
"loadingInvokeAI": "Laddar Invoke AI",
|
||||
"statusRestoringFaces": "Återskapar ansikten",
|
||||
"languagePickerLabel": "Språkväljare",
|
||||
"themeLabel": "Tema",
|
||||
"txt2img": "Text till bild",
|
||||
"nodes": "Noder",
|
||||
"img2img": "Bild till bild",
|
||||
@@ -101,6 +108,7 @@
|
||||
"galleryImageResetSize": "Återställ storlek",
|
||||
"gallerySettings": "Galleriinställningar",
|
||||
"maintainAspectRatio": "Behåll bildförhållande",
|
||||
"pinGallery": "Nåla fast galleri",
|
||||
"noImagesInGallery": "Inga bilder i galleriet",
|
||||
"autoSwitchNewImages": "Ändra automatiskt till nya bilder",
|
||||
"singleColumnLayout": "Enkolumnslayout"
|
||||
|
||||
@@ -19,15 +19,21 @@
|
||||
"reset": "Sıfırla",
|
||||
"uploadImage": "Resim Yükle",
|
||||
"previousImage": "Önceki Resim",
|
||||
"menu": "Menü"
|
||||
"menu": "Menü",
|
||||
"showGallery": "Galeriyi Göster"
|
||||
},
|
||||
"common": {
|
||||
"hotkeysLabel": "Kısayol Tuşları",
|
||||
"themeLabel": "Tema",
|
||||
"languagePickerLabel": "Dil Seçimi",
|
||||
"reportBugLabel": "Hata Bildir",
|
||||
"githubLabel": "Github",
|
||||
"discordLabel": "Discord",
|
||||
"settingsLabel": "Ayarlar",
|
||||
"darkTheme": "Karanlık Tema",
|
||||
"lightTheme": "Aydınlık Tema",
|
||||
"greenTheme": "Yeşil Tema",
|
||||
"oceanTheme": "Okyanus Tema",
|
||||
"langArabic": "Arapça",
|
||||
"langEnglish": "İngilizce",
|
||||
"langDutch": "Hollandaca",
|
||||
|
||||
@@ -1,9 +1,13 @@
|
||||
{
|
||||
"common": {
|
||||
"hotkeysLabel": "Гарячi клавіші",
|
||||
"themeLabel": "Тема",
|
||||
"languagePickerLabel": "Мова",
|
||||
"reportBugLabel": "Повідомити про помилку",
|
||||
"settingsLabel": "Налаштування",
|
||||
"darkTheme": "Темна",
|
||||
"lightTheme": "Світла",
|
||||
"greenTheme": "Зелена",
|
||||
"img2img": "Зображення із зображення (img2img)",
|
||||
"unifiedCanvas": "Універсальне полотно",
|
||||
"nodes": "Вузли",
|
||||
@@ -51,6 +55,8 @@
|
||||
"langHebrew": "Іврит",
|
||||
"langKorean": "Корейська",
|
||||
"langPortuguese": "Португальська",
|
||||
"pinOptionsPanel": "Закріпити панель налаштувань",
|
||||
"oceanTheme": "Океан",
|
||||
"langArabic": "Арабська",
|
||||
"langSimplifiedChinese": "Китайська (спрощена)",
|
||||
"langSpanish": "Іспанська",
|
||||
@@ -81,6 +87,7 @@
|
||||
"maintainAspectRatio": "Зберігати пропорції",
|
||||
"autoSwitchNewImages": "Автоматично вибирати нові",
|
||||
"singleColumnLayout": "Одна колонка",
|
||||
"pinGallery": "Закріпити галерею",
|
||||
"allImagesLoaded": "Всі зображення завантажені",
|
||||
"loadMore": "Завантажити більше",
|
||||
"noImagesInGallery": "Зображень немає"
|
||||
@@ -410,6 +417,7 @@
|
||||
"cfgScale": "Рівень CFG",
|
||||
"width": "Ширина",
|
||||
"height": "Висота",
|
||||
"sampler": "Семплер",
|
||||
"seed": "Сід",
|
||||
"randomizeSeed": "Випадковий сид",
|
||||
"shuffle": "Оновити",
|
||||
@@ -431,6 +439,10 @@
|
||||
"hiresOptim": "Оптимізація High Res",
|
||||
"imageFit": "Вмістити зображення",
|
||||
"codeformerFidelity": "Точність",
|
||||
"seamSize": "Размір шву",
|
||||
"seamBlur": "Розмиття шву",
|
||||
"seamStrength": "Сила шву",
|
||||
"seamSteps": "Кроки шву",
|
||||
"scaleBeforeProcessing": "Масштабувати",
|
||||
"scaledWidth": "Масштаб Ш",
|
||||
"scaledHeight": "Масштаб В",
|
||||
@@ -441,6 +453,8 @@
|
||||
"infillScalingHeader": "Заповнення і масштабування",
|
||||
"img2imgStrength": "Сила обробки img2img",
|
||||
"toggleLoopback": "Зациклити обробку",
|
||||
"invoke": "Викликати",
|
||||
"promptPlaceholder": "Введіть запит тут (англійською). [видалені токени], (більш вагомі)++, (менш вагомі)--, swap и blend також доступні (дивіться Github)",
|
||||
"sendTo": "Надіслати",
|
||||
"sendToImg2Img": "Надіслати у img2img",
|
||||
"sendToUnifiedCanvas": "Надіслати на полотно",
|
||||
@@ -453,6 +467,7 @@
|
||||
"useAll": "Використати все",
|
||||
"useInitImg": "Використати як початкове",
|
||||
"info": "Метадані",
|
||||
"deleteImage": "Видалити зображення",
|
||||
"initialImage": "Початкове зображення",
|
||||
"showOptionsPanel": "Показати панель налаштувань",
|
||||
"general": "Основне",
|
||||
@@ -470,7 +485,8 @@
|
||||
"denoisingStrength": "Сила шумоподавлення",
|
||||
"copyImage": "Копіювати зображення",
|
||||
"symmetry": "Симетрія",
|
||||
"hSymmetryStep": "Крок гор. симетрії"
|
||||
"hSymmetryStep": "Крок гор. симетрії",
|
||||
"negativePrompts": "Виключний запит"
|
||||
},
|
||||
"settings": {
|
||||
"models": "Моделі",
|
||||
@@ -478,6 +494,7 @@
|
||||
"saveSteps": "Зберігати кожні n кроків",
|
||||
"confirmOnDelete": "Підтверджувати видалення",
|
||||
"displayHelpIcons": "Показувати значки підказок",
|
||||
"useCanvasBeta": "Показувати інструменты зліва (Beta UI)",
|
||||
"enableImageDebugging": "Увімкнути налагодження",
|
||||
"resetWebUI": "Повернути початкові",
|
||||
"resetWebUIDesc1": "Скидання настройок веб-інтерфейсу видаляє лише локальний кеш браузера з вашими зображеннями та налаштуваннями. Це не призводить до видалення зображень з диску.",
|
||||
@@ -488,6 +505,7 @@
|
||||
"toast": {
|
||||
"tempFoldersEmptied": "Тимчасова папка очищена",
|
||||
"uploadFailed": "Не вдалося завантажити",
|
||||
"uploadFailedMultipleImagesDesc": "Можна вставити лише одне зображення (ви спробували вставити декілька)",
|
||||
"uploadFailedUnableToLoadDesc": "Неможливо завантажити файл",
|
||||
"downloadImageStarted": "Завантаження зображення почалося",
|
||||
"imageCopied": "Зображення скопійоване",
|
||||
@@ -608,6 +626,7 @@
|
||||
"rotateClockwise": "Обертати за годинниковою стрілкою",
|
||||
"toggleAutoscroll": "Увімкнути автопрокручування",
|
||||
"toggleLogViewer": "Показати або приховати переглядач журналів",
|
||||
"showGallery": "Показати галерею",
|
||||
"previousImage": "Попереднє зображення",
|
||||
"copyMetadataJson": "Скопіювати метадані JSON",
|
||||
"flipVertically": "Перевернути по вертикалі",
|
||||
|
||||
File diff suppressed because it is too large
Load Diff
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user