mirror of
https://github.com/invoke-ai/InvokeAI.git
synced 2026-01-16 05:37:55 -05:00
Compare commits
320 Commits
test/node-
...
feat/contr
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
51e44d6640 | ||
|
|
44a80a4929 | ||
|
|
e625c44c73 | ||
|
|
c764e34883 | ||
|
|
5d31df0cb7 | ||
|
|
bd63454e51 | ||
|
|
062df07de2 | ||
|
|
0fc14afcf0 | ||
|
|
4a0a1c30db | ||
|
|
3432fd72f8 | ||
|
|
05a43c41f9 | ||
|
|
bb48617101 | ||
|
|
aa2f68f608 | ||
|
|
fbccce7573 | ||
|
|
a35087ee6e | ||
|
|
03e463dc89 | ||
|
|
d467e138a4 | ||
|
|
ba4aaea45b | ||
|
|
53eb23b8b6 | ||
|
|
8b969053e7 | ||
|
|
98a076260b | ||
|
|
b3f4f28d76 | ||
|
|
acee4bd282 | ||
|
|
50d254fdb7 | ||
|
|
0cfc1c5f86 | ||
|
|
1419977e89 | ||
|
|
a953944894 | ||
|
|
a4cdaa245e | ||
|
|
105a4234b0 | ||
|
|
34c563060f | ||
|
|
d45c47db81 | ||
|
|
c771a4027f | ||
|
|
3fd27b1aa9 | ||
|
|
d59e534cad | ||
|
|
0c97a1e7e7 | ||
|
|
c8b109f52e | ||
|
|
a2613948d8 | ||
|
|
f8392b2f78 | ||
|
|
358116bc22 | ||
|
|
1e3590111d | ||
|
|
063b800280 | ||
|
|
3935bf92c8 | ||
|
|
066e09b517 | ||
|
|
869b4a8d49 | ||
|
|
399ebe443e | ||
|
|
13919ff300 | ||
|
|
634e5652ef | ||
|
|
9bdc718df5 | ||
|
|
73ca8ccdb3 | ||
|
|
f37ffda966 | ||
|
|
5a9777d443 | ||
|
|
8072c05ee0 | ||
|
|
75ff4f4ca3 | ||
|
|
30df123221 | ||
|
|
06193ddbe8 | ||
|
|
ce5122f87c | ||
|
|
43ebd68313 | ||
|
|
ec19fcafb1 | ||
|
|
6fcc7d4c4b | ||
|
|
912087e4dc | ||
|
|
593fb95213 | ||
|
|
6d821b32d3 | ||
|
|
297f96c16b | ||
|
|
0e53b27655 | ||
|
|
35ae9f6e71 | ||
|
|
a1d9e6b871 | ||
|
|
f05379f965 | ||
|
|
e34e6d6e80 | ||
|
|
86cb53342a | ||
|
|
e3de996525 | ||
|
|
25a71a1791 | ||
|
|
d16583ad1c | ||
|
|
46db1dd18f | ||
|
|
4c9344b0ee | ||
|
|
cba31efd78 | ||
|
|
4d01b5c0f2 | ||
|
|
e02af8f518 | ||
|
|
c485cf568b | ||
|
|
51451cbf21 | ||
|
|
0363a06963 | ||
|
|
cc280cbef1 | ||
|
|
7544eadd48 | ||
|
|
7d683b4db6 | ||
|
|
60b3c6a201 | ||
|
|
88c8cb61f0 | ||
|
|
43fbac26df | ||
|
|
627444e17c | ||
|
|
5601858f4f | ||
|
|
b152fbf72f | ||
|
|
f95111772a | ||
|
|
14ce7cf09c | ||
|
|
28a1a6939f | ||
|
|
6d2b4013f8 | ||
|
|
ca7a7b57bb | ||
|
|
c5d0e65a24 | ||
|
|
6cc7b55ec5 | ||
|
|
883e9973ec | ||
|
|
9e7d829906 | ||
|
|
456a0a59e0 | ||
|
|
4f2bf7e7e8 | ||
|
|
77e93888cf | ||
|
|
fa54974bff | ||
|
|
7ac99d6bc3 | ||
|
|
aa82f9360c | ||
|
|
5aefa49d7d | ||
|
|
b6e9cd4fe2 | ||
|
|
6d1057c560 | ||
|
|
b4790002c7 | ||
|
|
e02700a782 | ||
|
|
83ce8ef1ec | ||
|
|
19e487b5ee | ||
|
|
aa4b56baf2 | ||
|
|
d3a2be69f1 | ||
|
|
02c087ee37 | ||
|
|
cab8d9bb20 | ||
|
|
28e6a7139b | ||
|
|
1625854eaf | ||
|
|
f87b042162 | ||
|
|
183e2c3ee0 | ||
|
|
098d506b95 | ||
|
|
7aa33c352b | ||
|
|
bf62553150 | ||
|
|
2b08d9e53b | ||
|
|
8954953eca | ||
|
|
eb2fcbe28a | ||
|
|
e78b36a9f7 | ||
|
|
144ede031e | ||
|
|
8ca37bba33 | ||
|
|
a608340c89 | ||
|
|
7fecebf7db | ||
|
|
b915d74127 | ||
|
|
6ec347bd41 | ||
|
|
e54843acc9 | ||
|
|
0960518088 | ||
|
|
21de74fac4 | ||
|
|
8ce9b6c51e | ||
|
|
b64ade586d | ||
|
|
3c44a74ba5 | ||
|
|
24d0901d8e | ||
|
|
b1b5f70ea6 | ||
|
|
6392098961 | ||
|
|
2c39aec22d | ||
|
|
d066bc6d19 | ||
|
|
e487bcd0f7 | ||
|
|
e0f8274f49 | ||
|
|
69e3513e90 | ||
|
|
7e706f02cb | ||
|
|
41dad2013a | ||
|
|
3f554d6824 | ||
|
|
202c5a48c6 | ||
|
|
2d71f6f4b8 | ||
|
|
0420874f56 | ||
|
|
f222b871e9 | ||
|
|
8b8d589033 | ||
|
|
f4c895257a | ||
|
|
10af5a26f2 | ||
|
|
1088adeb0a | ||
|
|
ad49380cd1 | ||
|
|
b2fe24c401 | ||
|
|
b128db1d58 | ||
|
|
f7f0630d97 | ||
|
|
5075e9c899 | ||
|
|
3c1549cf5c | ||
|
|
9faa53ceb1 | ||
|
|
32672cfeda | ||
|
|
b5266f89ad | ||
|
|
7a3b467ce0 | ||
|
|
bdfdf854fc | ||
|
|
1c38cce16d | ||
|
|
4cdca45228 | ||
|
|
bfed08673a | ||
|
|
c1aa2b82eb | ||
|
|
0a09f84b07 | ||
|
|
b7938d9ca9 | ||
|
|
977e348a35 | ||
|
|
864f2270c3 | ||
|
|
8b44d83859 | ||
|
|
0b6315de71 | ||
|
|
578e682562 | ||
|
|
92b49e45bb | ||
|
|
b05b8ef677 | ||
|
|
382e2139bd | ||
|
|
d7ebe3f048 | ||
|
|
5c2bdf626b | ||
|
|
390a1c9fbb | ||
|
|
c46d9b8768 | ||
|
|
ef8d9843dd | ||
|
|
dc2e1a42bc | ||
|
|
2a3909da94 | ||
|
|
e0dddbd38e | ||
|
|
231b7a5000 | ||
|
|
b7773c9962 | ||
|
|
11c501fc80 | ||
|
|
7be5743011 | ||
|
|
c48e648cbb | ||
|
|
29b4ddcc7f | ||
|
|
7ee13879e3 | ||
|
|
ced297ed21 | ||
|
|
3e813ead1f | ||
|
|
820ec08e9a | ||
|
|
4dd289b337 | ||
|
|
b60b1e359e | ||
|
|
208286e97a | ||
|
|
f7b64304ae | ||
|
|
834751e877 | ||
|
|
e7a10d310f | ||
|
|
2ce07a4730 | ||
|
|
45d5ab20ec | ||
|
|
343df03a92 | ||
|
|
b57acb7353 | ||
|
|
7bf7c16a5d | ||
|
|
56340c24c8 | ||
|
|
afe9756667 | ||
|
|
fcea65770f | ||
|
|
16664da5b6 | ||
|
|
c104807201 | ||
|
|
990ce9a1da | ||
|
|
18095ecc44 | ||
|
|
fe19f11abf | ||
|
|
c2f074dc2f | ||
|
|
e02a557454 | ||
|
|
fca60862e2 | ||
|
|
94c186bb4c | ||
|
|
a22c8cb3a1 | ||
|
|
781e8521d5 | ||
|
|
d114d0ba95 | ||
|
|
cc8b7a74da | ||
|
|
388554448a | ||
|
|
cadc0839a6 | ||
|
|
d5160648d0 | ||
|
|
6d0ea42a94 | ||
|
|
2c1100509f | ||
|
|
c34b359c36 | ||
|
|
77d135967f | ||
|
|
ebf26687cb | ||
|
|
1c8991a3df | ||
|
|
3d52656176 | ||
|
|
a2777decd4 | ||
|
|
d219167849 | ||
|
|
090db1ab3a | ||
|
|
468253aa14 | ||
|
|
3ee9a21647 | ||
|
|
0d823901ef | ||
|
|
7ee55489bb | ||
|
|
163ece9aee | ||
|
|
7b2e6deaf1 | ||
|
|
63f94579c5 | ||
|
|
3dfff278aa | ||
|
|
aa7d945b23 | ||
|
|
88db094cf2 | ||
|
|
50a0691514 | ||
|
|
a255624984 | ||
|
|
2630fe3608 | ||
|
|
dee6f86d5e | ||
|
|
6ca6cf713c | ||
|
|
3f7d5b4e0f | ||
|
|
91596d9527 | ||
|
|
d669f0855d | ||
|
|
b2d5b53b5f | ||
|
|
ddc148b70b | ||
|
|
c2d43f007b | ||
|
|
7703bf2ca1 | ||
|
|
b5e1ba34b3 | ||
|
|
23fdf0156f | ||
|
|
cdbf40c9b2 | ||
|
|
46c9dcb113 | ||
|
|
6df79045fa | ||
|
|
d776e0a0a9 | ||
|
|
94ec3da7b5 | ||
|
|
f44496a579 | ||
|
|
99fe95ab03 | ||
|
|
95ecb1a0c1 | ||
|
|
bd15874cf6 | ||
|
|
30ab81b6bb | ||
|
|
78195491bc | ||
|
|
58aa159a50 | ||
|
|
d8f7c19030 | ||
|
|
c63390f6e1 | ||
|
|
cbd451c610 | ||
|
|
b0f91f2e75 | ||
|
|
3ac68cde66 | ||
|
|
a69b1cd598 | ||
|
|
65a76a086b | ||
|
|
07381e5a26 | ||
|
|
6bb378a101 | ||
|
|
7df67d077a | ||
|
|
b761807219 | ||
|
|
fb1b03960e | ||
|
|
74bfb5e1f9 | ||
|
|
bc1bce18b0 | ||
|
|
942ecbbde4 | ||
|
|
79db0e9e93 | ||
|
|
0c17f8604f | ||
|
|
054edc4077 | ||
|
|
5a9993772d | ||
|
|
f2cd9e9ae2 | ||
|
|
9f86cfa471 | ||
|
|
8c1390166f | ||
|
|
1ad98ce999 | ||
|
|
5f4a62810e | ||
|
|
35b7ae90ae | ||
|
|
9ed4d487d2 | ||
|
|
69d37217b8 | ||
|
|
7afdefb0e5 | ||
|
|
24132a7950 | ||
|
|
dff466244d | ||
|
|
45d172d5a8 | ||
|
|
f5d95ffed5 | ||
|
|
6f9c1c6d4e | ||
|
|
811c82a677 | ||
|
|
4f0e43ec1b | ||
|
|
26a7b7b66d | ||
|
|
8611ffe32d | ||
|
|
3cb6d333f6 | ||
|
|
4570702dd0 | ||
|
|
1d107f30e5 | ||
|
|
79084e9e20 | ||
|
|
fc9b4539a3 | ||
|
|
09ef57718e | ||
|
|
cab8239ba8 |
@@ -159,7 +159,7 @@ groups in `invokeia.yaml`:
|
||||
| `host` | `localhost` | Name or IP address of the network interface that the web server will listen on |
|
||||
| `port` | `9090` | Network port number that the web server will listen on |
|
||||
| `allow_origins` | `[]` | A list of host names or IP addresses that are allowed to connect to the InvokeAI API in the format `['host1','host2',...]` |
|
||||
| `allow_credentials | `true` | Require credentials for a foreign host to access the InvokeAI API (don't change this) |
|
||||
| `allow_credentials` | `true` | Require credentials for a foreign host to access the InvokeAI API (don't change this) |
|
||||
| `allow_methods` | `*` | List of HTTP methods ("GET", "POST") that the web server is allowed to use when accessing the API |
|
||||
| `allow_headers` | `*` | List of HTTP headers that the web server will accept when accessing the API |
|
||||
|
||||
|
||||
336
docs/features/UTILITIES.md
Normal file
336
docs/features/UTILITIES.md
Normal file
@@ -0,0 +1,336 @@
|
||||
---
|
||||
title: Command-line Utilities
|
||||
---
|
||||
|
||||
# :material-file-document: Utilities
|
||||
|
||||
# Command-line Utilities
|
||||
|
||||
InvokeAI comes with several scripts that are accessible via the
|
||||
command line. To access these commands, start the "developer's
|
||||
console" from the launcher (`invoke.bat` menu item [8]). Users who are
|
||||
familiar with Python can alternatively activate InvokeAI's virtual
|
||||
environment (typically, but not necessarily `invokeai/.venv`).
|
||||
|
||||
In the developer's console, type the script's name to run it. To get a
|
||||
synopsis of what a utility does and the command-line arguments it
|
||||
accepts, pass it the `-h` argument, e.g.
|
||||
|
||||
```bash
|
||||
invokeai-merge -h
|
||||
```
|
||||
## **invokeai-web**
|
||||
|
||||
This script launches the web server and is effectively identical to
|
||||
selecting option [1] in the launcher. An advantage of launching the
|
||||
server from the command line is that you can override any setting
|
||||
configuration option in `invokeai.yaml` using like-named command-line
|
||||
arguments. For example, to temporarily change the size of the RAM
|
||||
cache to 7 GB, you can launch as follows:
|
||||
|
||||
```bash
|
||||
invokeai-web --ram 7
|
||||
```
|
||||
|
||||
## **invokeai-merge**
|
||||
|
||||
This is the model merge script, the same as launcher option [4]. Call
|
||||
it with the `--gui` command-line argument to start the interactive
|
||||
console-based GUI. Alternatively, you can run it non-interactively
|
||||
using command-line arguments as illustrated in the example below which
|
||||
merges models named `stable-diffusion-1.5` and `inkdiffusion` into a new model named
|
||||
`my_new_model`:
|
||||
|
||||
```bash
|
||||
invokeai-merge --force --base-model sd-1 --models stable-diffusion-1.5 inkdiffusion --merged_model_name my_new_model
|
||||
```
|
||||
|
||||
## **invokeai-ti**
|
||||
|
||||
This is the textual inversion training script that is run by launcher
|
||||
option [3]. Call it with `--gui` to run the interactive console-based
|
||||
front end. It can also be run non-interactively. It has about a
|
||||
zillion arguments, but a typical training session can be launched
|
||||
with:
|
||||
|
||||
```bash
|
||||
invokeai-ti --model stable-diffusion-1.5 \
|
||||
--placeholder_token 'jello' \
|
||||
--learnable_property object \
|
||||
--num_train_epochs 50 \
|
||||
--train_data_dir /path/to/training/images \
|
||||
--output_dir /path/to/trained/model
|
||||
```
|
||||
|
||||
(Note that \\ is the Linux/Mac long-line continuation character. Use ^
|
||||
in Windows).
|
||||
|
||||
## **invokeai-install**
|
||||
|
||||
This is the console-based model install script that is run by launcher
|
||||
option [5]. If called without arguments, it will launch the
|
||||
interactive console-based interface. It can also be used
|
||||
non-interactively to list, add and remove models as shown by these
|
||||
examples:
|
||||
|
||||
* This will download and install three models from CivitAI, HuggingFace,
|
||||
and local disk:
|
||||
|
||||
```bash
|
||||
invokeai-install --add https://civitai.com/api/download/models/161302 ^
|
||||
gsdf/Counterfeit-V3.0 ^
|
||||
D:\Models\merge_model_two.safetensors
|
||||
```
|
||||
(Note that ^ is the Windows long-line continuation character. Use \\ on
|
||||
Linux/Mac).
|
||||
|
||||
* This will list installed models of type `main`:
|
||||
|
||||
```bash
|
||||
invokeai-model-install --list-models main
|
||||
```
|
||||
|
||||
* This will delete the models named `voxel-ish` and `realisticVision`:
|
||||
|
||||
```bash
|
||||
invokeai-model-install --delete voxel-ish realisticVision
|
||||
```
|
||||
|
||||
## **invokeai-configure**
|
||||
|
||||
This is the console-based configure script that ran when InvokeAI was
|
||||
first installed. You can run it again at any time to change the
|
||||
configuration, repair a broken install.
|
||||
|
||||
Called without any arguments, `invokeai-configure` enters interactive
|
||||
mode with two screens. The first screen is a form that provides access
|
||||
to most of InvokeAI's configuration options. The second screen lets
|
||||
you download, add, and delete models interactively. When you exit the
|
||||
second screen, the script will add any missing "support models"
|
||||
needed for core functionality, and any selected "sd weights" which are
|
||||
the model checkpoint/diffusers files.
|
||||
|
||||
This behavior can be changed via a series of command-line
|
||||
arguments. Here are some of the useful ones:
|
||||
|
||||
* `invokeai-configure --skip-sd-weights --skip-support-models`
|
||||
This will run just the configuration part of the utility, skipping
|
||||
downloading of support models and stable diffusion weights.
|
||||
|
||||
* `invokeai-configure --yes`
|
||||
This will run the configure script non-interactively. It will set the
|
||||
configuration options to their default values, install/repair support
|
||||
models, and download the "recommended" set of SD models.
|
||||
|
||||
* `invokeai-configure --yes --default_only`
|
||||
This will run the configure script non-interactively. In contrast to
|
||||
the previous command, it will only download the default SD model,
|
||||
Stable Diffusion v1.5
|
||||
|
||||
* `invokeai-configure --yes --default_only --skip-sd-weights`
|
||||
This is similar to the previous command, but will not download any
|
||||
SD models at all. It is usually used to repair a broken install.
|
||||
|
||||
By default, `invokeai-configure` runs on the currently active InvokeAI
|
||||
root folder. To run it against a different root, pass it the `--root
|
||||
</path/to/root>` argument.
|
||||
|
||||
Lastly, you can use `invokeai-configure` to create a working root
|
||||
directory entirely from scratch. Assuming you wish to make a root directory
|
||||
named `InvokeAI-New`, run this command:
|
||||
|
||||
```bash
|
||||
invokeai-configure --root InvokeAI-New --yes --default_only
|
||||
```
|
||||
This will create a minimally functional root directory. You can now
|
||||
launch the web server against it with `invokeai-web --root InvokeAI-New`.
|
||||
|
||||
## **invokeai-update**
|
||||
|
||||
This is the interactive console-based script that is run by launcher
|
||||
menu item [9] to update to a new version of InvokeAI. It takes no
|
||||
command-line arguments.
|
||||
|
||||
## **invokeai-metadata**
|
||||
|
||||
This is a script which takes a list of InvokeAI-generated images and
|
||||
outputs their metadata in the same JSON format that you get from the
|
||||
`</>` button in the Web GUI. For example:
|
||||
|
||||
```bash
|
||||
$ invokeai-metadata ffe2a115-b492-493c-afff-7679aa034b50.png
|
||||
ffe2a115-b492-493c-afff-7679aa034b50.png:
|
||||
{
|
||||
"app_version": "3.1.0",
|
||||
"cfg_scale": 8.0,
|
||||
"clip_skip": 0,
|
||||
"controlnets": [],
|
||||
"generation_mode": "sdxl_txt2img",
|
||||
"height": 1024,
|
||||
"loras": [],
|
||||
"model": {
|
||||
"base_model": "sdxl",
|
||||
"model_name": "stable-diffusion-xl-base-1.0",
|
||||
"model_type": "main"
|
||||
},
|
||||
"negative_prompt": "",
|
||||
"negative_style_prompt": "",
|
||||
"positive_prompt": "military grade sushi dinner for shock troopers",
|
||||
"positive_style_prompt": "",
|
||||
"rand_device": "cpu",
|
||||
"refiner_cfg_scale": 7.5,
|
||||
"refiner_model": {
|
||||
"base_model": "sdxl-refiner",
|
||||
"model_name": "sd_xl_refiner_1.0",
|
||||
"model_type": "main"
|
||||
},
|
||||
"refiner_negative_aesthetic_score": 2.5,
|
||||
"refiner_positive_aesthetic_score": 6.0,
|
||||
"refiner_scheduler": "euler",
|
||||
"refiner_start": 0.8,
|
||||
"refiner_steps": 20,
|
||||
"scheduler": "euler",
|
||||
"seed": 387129902,
|
||||
"steps": 25,
|
||||
"width": 1024
|
||||
}
|
||||
```
|
||||
|
||||
You may list multiple files on the command line.
|
||||
|
||||
## **invokeai-import-images**
|
||||
|
||||
InvokeAI uses a database to store information about images it
|
||||
generated, and just copying the image files from one InvokeAI root
|
||||
directory to another does not automatically import those images into
|
||||
the destination's gallery. This script allows you to bulk import
|
||||
images generated by one instance of InvokeAI into a gallery maintained
|
||||
by another. It also works on images generated by older versions of
|
||||
InvokeAI, going way back to version 1.
|
||||
|
||||
This script has an interactive mode only. The following example shows
|
||||
it in action:
|
||||
|
||||
```bash
|
||||
$ invokeai-import-images
|
||||
===============================================================================
|
||||
This script will import images generated by earlier versions of
|
||||
InvokeAI into the currently installed root directory:
|
||||
/home/XXXX/invokeai-main
|
||||
If this is not what you want to do, type ctrl-C now to cancel.
|
||||
===============================================================================
|
||||
= Configuration & Settings
|
||||
Found invokeai.yaml file at /home/XXXX/invokeai-main/invokeai.yaml:
|
||||
Database : /home/XXXX/invokeai-main/databases/invokeai.db
|
||||
Outputs : /home/XXXX/invokeai-main/outputs/images
|
||||
|
||||
Use these paths for import (yes) or choose different ones (no) [Yn]:
|
||||
Inputs: Specify absolute path containing InvokeAI .png images to import: /home/XXXX/invokeai-2.3/outputs/images/
|
||||
Include files from subfolders recursively [yN]?
|
||||
|
||||
Options for board selection for imported images:
|
||||
1) Select an existing board name. (found 4)
|
||||
2) Specify a board name to create/add to.
|
||||
3) Create/add to board named 'IMPORT'.
|
||||
4) Create/add to board named 'IMPORT' with the current datetime string appended (.e.g IMPORT_20230919T203519Z).
|
||||
5) Create/add to board named 'IMPORT' with a the original file app_version appended (.e.g IMPORT_2.2.5).
|
||||
Specify desired board option: 3
|
||||
|
||||
===============================================================================
|
||||
= Import Settings Confirmation
|
||||
|
||||
Database File Path : /home/XXXX/invokeai-main/databases/invokeai.db
|
||||
Outputs/Images Directory : /home/XXXX/invokeai-main/outputs/images
|
||||
Import Image Source Directory : /home/XXXX/invokeai-2.3/outputs/images/
|
||||
Recurse Source SubDirectories : No
|
||||
Count of .png file(s) found : 5785
|
||||
Board name option specified : IMPORT
|
||||
Database backup will be taken at : /home/XXXX/invokeai-main/databases/backup
|
||||
|
||||
Notes about the import process:
|
||||
- Source image files will not be modified, only copied to the outputs directory.
|
||||
- If the same file name already exists in the destination, the file will be skipped.
|
||||
- If the same file name already has a record in the database, the file will be skipped.
|
||||
- Invoke AI metadata tags will be updated/written into the imported copy only.
|
||||
- On the imported copy, only Invoke AI known tags (latest and legacy) will be retained (dream, sd-metadata, invokeai, invokeai_metadata)
|
||||
- A property 'imported_app_version' will be added to metadata that can be viewed in the UI's metadata viewer.
|
||||
- The new 3.x InvokeAI outputs folder structure is flat so recursively found source imges will all be placed into the single outputs/images folder.
|
||||
|
||||
Do you wish to continue with the import [Yn] ?
|
||||
|
||||
Making DB Backup at /home/lstein/invokeai-main/databases/backup/backup-20230919T203519Z-invokeai.db...Done!
|
||||
|
||||
===============================================================================
|
||||
Importing /home/XXXX/invokeai-2.3/outputs/images/17d09907-297d-4db3-a18a-60b337feac66.png
|
||||
... (5785 more lines) ...
|
||||
===============================================================================
|
||||
= Import Complete - Elpased Time: 0.28 second(s)
|
||||
|
||||
Source File(s) : 5785
|
||||
Total Imported : 5783
|
||||
Skipped b/c file already exists on disk : 1
|
||||
Skipped b/c file already exists in db : 0
|
||||
Errors during import : 1
|
||||
```
|
||||
## **invokeai-db-maintenance**
|
||||
|
||||
This script helps maintain the integrity of your InvokeAI database by
|
||||
finding and fixing three problems that can arise over time:
|
||||
|
||||
1. An image was manually deleted from the outputs directory, leaving a
|
||||
dangling image record in the InvokeAI database. This will cause a
|
||||
black image to appear in the gallery. This is an "orphaned database
|
||||
image record." The script can fix this by running a "clean"
|
||||
operation on the database, removing the orphaned entries.
|
||||
|
||||
2. An image is present in the outputs directory but there is no
|
||||
corresponding entry in the database. This can happen when the image
|
||||
is added manually to the outputs directory, or if a crash occurred
|
||||
after the image was generated but before the database was
|
||||
completely updated. The symptom is that the image is present in the
|
||||
outputs folder but doesn't appear in the InvokeAI gallery. This is
|
||||
called an "orphaned image file." The script can fix this problem by
|
||||
running an "archive" operation in which orphaned files are moved
|
||||
into a directory named `outputs/images-archive`. If you wish, you
|
||||
can then run `invokeai-image-import` to reimport these images back
|
||||
into the database.
|
||||
|
||||
3. The thumbnail for an image is missing, again causing a black
|
||||
gallery thumbnail. This is fixed by running the "thumbnaiils"
|
||||
operation, which simply regenerates and re-registers the missing
|
||||
thumbnail.
|
||||
|
||||
You can find and fix all three of these problems in a single go by
|
||||
executing this command:
|
||||
|
||||
```bash
|
||||
invokeai-db-maintenance --operation all
|
||||
```
|
||||
|
||||
Or you can run just the clean and thumbnail operations like this:
|
||||
|
||||
```bash
|
||||
invokeai-db-maintenance -operation clean, thumbnail
|
||||
```
|
||||
|
||||
If called without any arguments, the script will ask you which
|
||||
operations you wish to perform.
|
||||
|
||||
## **invokeai-migrate3**
|
||||
|
||||
This script will migrate settings and models (but not images!) from an
|
||||
InvokeAI v2.3 root folder to an InvokeAI 3.X folder. Call it with the
|
||||
source and destination root folders like this:
|
||||
|
||||
```bash
|
||||
invokeai-migrate3 --from ~/invokeai-2.3 --to invokeai-3.1.1
|
||||
```
|
||||
|
||||
Both directories must previously have been properly created and
|
||||
initialized by `invokeai-configure`. If you wish to migrate the images
|
||||
contained in the older root as well, you can use the
|
||||
`invokeai-image-migrate` script described earlier.
|
||||
|
||||
---
|
||||
|
||||
Copyright (c) 2023, Lincoln Stein and the InvokeAI Development Team
|
||||
@@ -51,6 +51,9 @@ Prevent InvokeAI from displaying unwanted racy images.
|
||||
### * [Controlling Logging](LOGGING.md)
|
||||
Control how InvokeAI logs status messages.
|
||||
|
||||
### * [Command-line Utilities](UTILITIES.md)
|
||||
A list of the command-line utilities available with InvokeAI.
|
||||
|
||||
<!-- OUT OF DATE
|
||||
### * [Miscellaneous](OTHER.md)
|
||||
Run InvokeAI on Google Colab, generate images with repeating patterns,
|
||||
|
||||
@@ -147,6 +147,7 @@ Mac and Linux machines, and runs on GPU cards with as little as 4 GB of RAM.
|
||||
|
||||
### InvokeAI Configuration
|
||||
- [Guide to InvokeAI Runtime Settings](features/CONFIGURATION.md)
|
||||
- [Database Maintenance and other Command Line Utilities](features/UTILITIES.md)
|
||||
|
||||
## :octicons-log-16: Important Changes Since Version 2.3
|
||||
|
||||
|
||||
@@ -296,8 +296,18 @@ code for InvokeAI. For this to work, you will need to install the
|
||||
on your system, please see the [Git Installation
|
||||
Guide](https://github.com/git-guides/install-git)
|
||||
|
||||
You will also need to install the [frontend development toolchain](https://github.com/invoke-ai/InvokeAI/blob/main/docs/contributing/contribution_guides/contributingToFrontend.md).
|
||||
|
||||
If you have a "normal" installation, you should create a totally separate virtual environment for the git-based installation, else the two may interfere.
|
||||
|
||||
> **Why do I need the frontend toolchain**?
|
||||
>
|
||||
> The InvokeAI project uses trunk-based development. That means our `main` branch is the development branch, and releases are tags on that branch. Because development is very active, we don't keep an updated build of the UI in `main` - we only build it for production releases.
|
||||
>
|
||||
> That means that between releases, to have a functioning application when running directly from the repo, you will need to run the UI in dev mode or build it regularly (any time the UI code changes).
|
||||
|
||||
1. Create a fork of the InvokeAI repository through the GitHub UI or [this link](https://github.com/invoke-ai/InvokeAI/fork)
|
||||
1. From the command line, run this command:
|
||||
2. From the command line, run this command:
|
||||
```bash
|
||||
git clone https://github.com/<your_github_username>/InvokeAI.git
|
||||
```
|
||||
@@ -305,10 +315,10 @@ Guide](https://github.com/git-guides/install-git)
|
||||
This will create a directory named `InvokeAI` and populate it with the
|
||||
full source code from your fork of the InvokeAI repository.
|
||||
|
||||
2. Activate the InvokeAI virtual environment as per step (4) of the manual
|
||||
3. Activate the InvokeAI virtual environment as per step (4) of the manual
|
||||
installation protocol (important!)
|
||||
|
||||
3. Enter the InvokeAI repository directory and run one of these
|
||||
4. Enter the InvokeAI repository directory and run one of these
|
||||
commands, based on your GPU:
|
||||
|
||||
=== "CUDA (NVidia)"
|
||||
@@ -334,11 +344,15 @@ installation protocol (important!)
|
||||
Be sure to pass `-e` (for an editable install) and don't forget the
|
||||
dot ("."). It is part of the command.
|
||||
|
||||
You can now run `invokeai` and its related commands. The code will be
|
||||
5. Install the [frontend toolchain](https://github.com/invoke-ai/InvokeAI/blob/main/docs/contributing/contribution_guides/contributingToFrontend.md) and do a production build of the UI as described.
|
||||
|
||||
6. You can now run `invokeai` and its related commands. The code will be
|
||||
read from the repository, so that you can edit the .py source files
|
||||
and watch the code's behavior change.
|
||||
|
||||
4. If you wish to contribute to the InvokeAI project, you are
|
||||
When you pull in new changes to the repo, be sure to re-build the UI.
|
||||
|
||||
7. If you wish to contribute to the InvokeAI project, you are
|
||||
encouraged to establish a GitHub account and "fork"
|
||||
https://github.com/invoke-ai/InvokeAI into your own copy of the
|
||||
repository. You can then use GitHub functions to create and submit
|
||||
|
||||
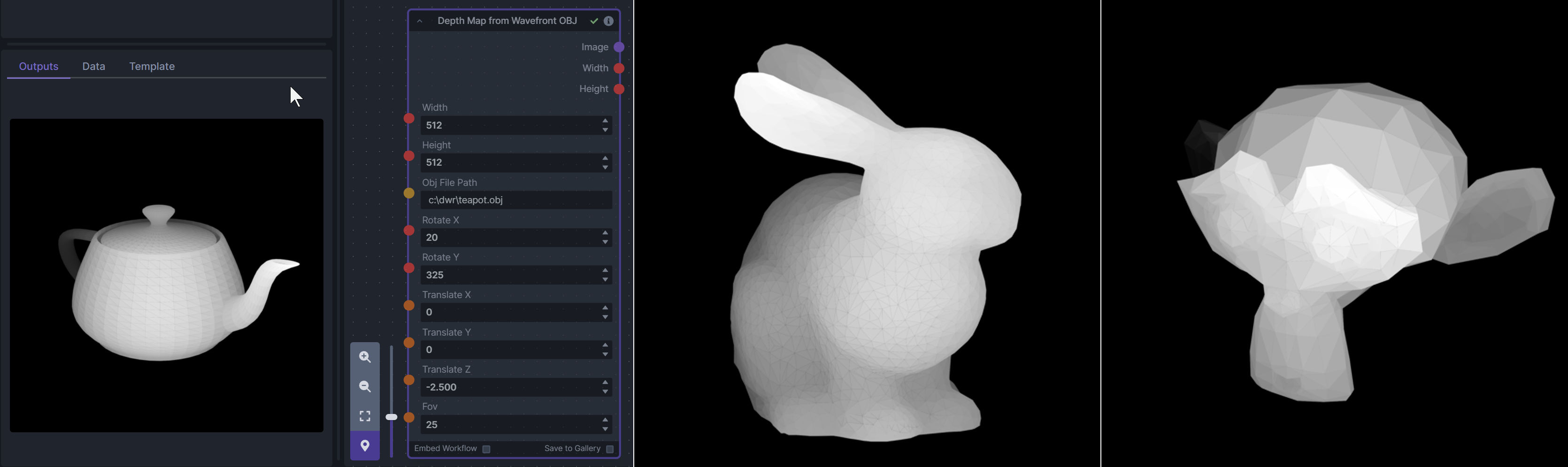
@@ -121,18 +121,6 @@ To be imported, an .obj must use triangulated meshes, so make sure to enable tha
|
||||
**Example Usage:**
|
||||
|
||||
|
||||
--------------------------------
|
||||
### Enhance Image (simple adjustments)
|
||||
|
||||
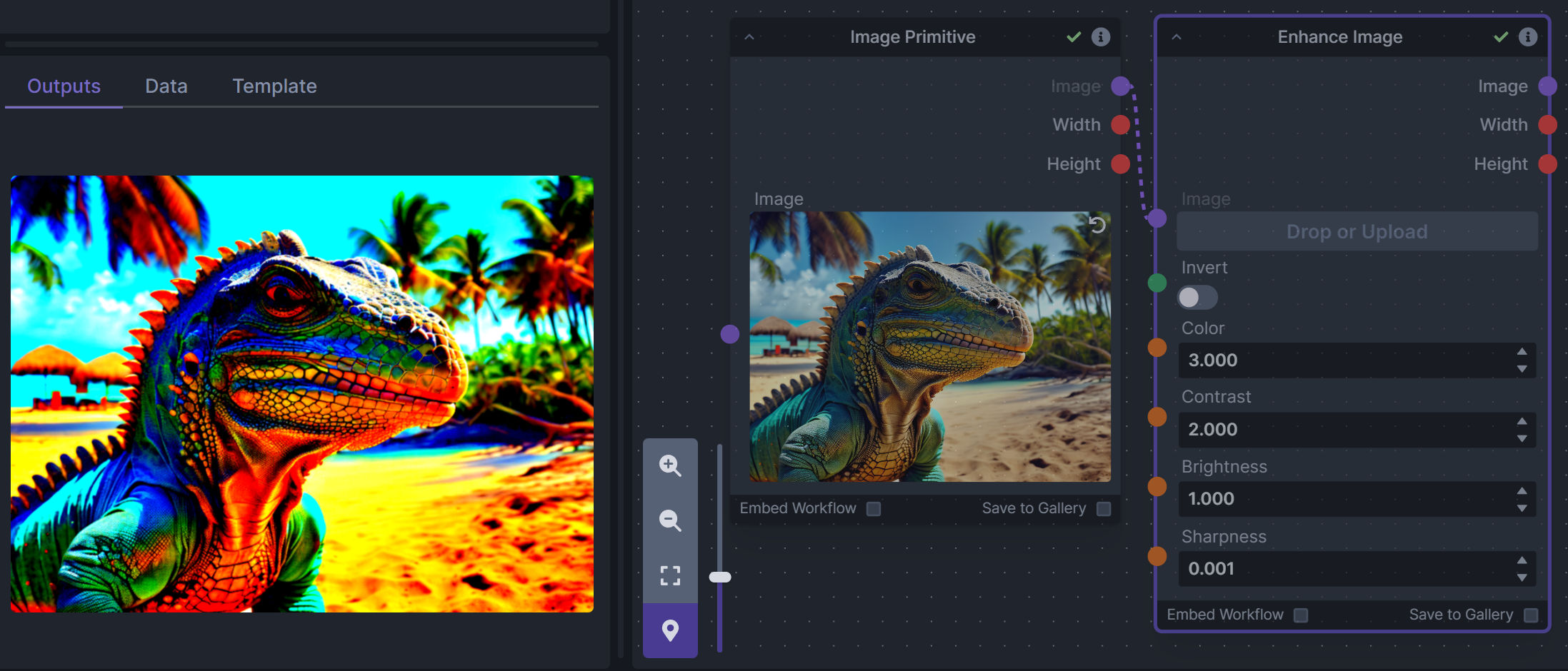
**Description:** Boost or reduce color saturation, contrast, brightness, sharpness, or invert colors of any image at any stage with this simple wrapper for pillow [PIL]'s ImageEnhance module.
|
||||
|
||||
Color inversion is toggled with a simple switch, while each of the four enhancer modes are activated by entering a value other than 1 in each corresponding input field. Values less than 1 will reduce the corresponding property, while values greater than 1 will enhance it.
|
||||
|
||||
**Node Link:** https://github.com/dwringer/image-enhance-node
|
||||
|
||||
**Example Usage:**
|
||||
|
||||
|
||||
--------------------------------
|
||||
### Generative Grammar-Based Prompt Nodes
|
||||
|
||||
@@ -153,16 +141,26 @@ This includes 3 Nodes:
|
||||
|
||||
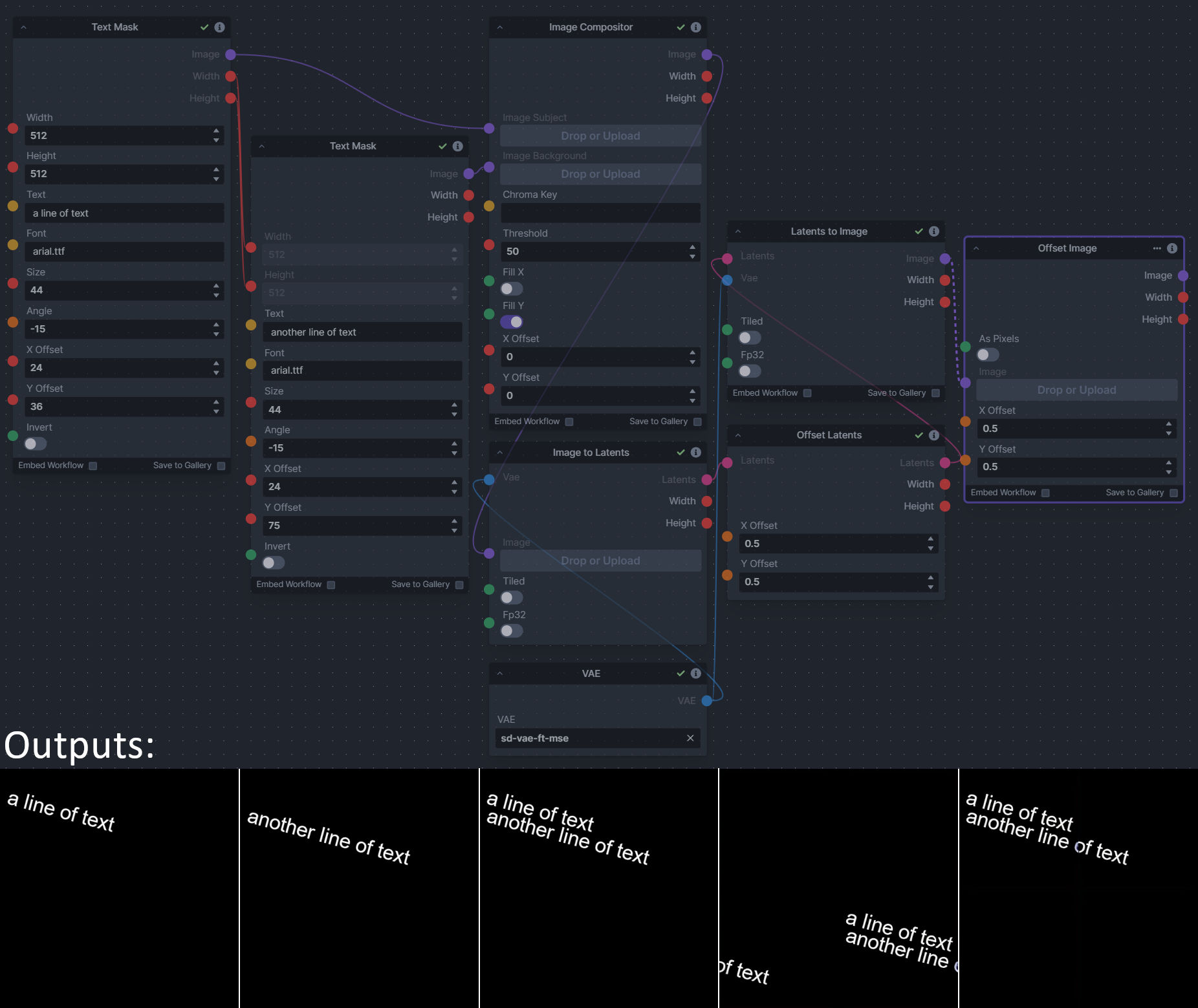
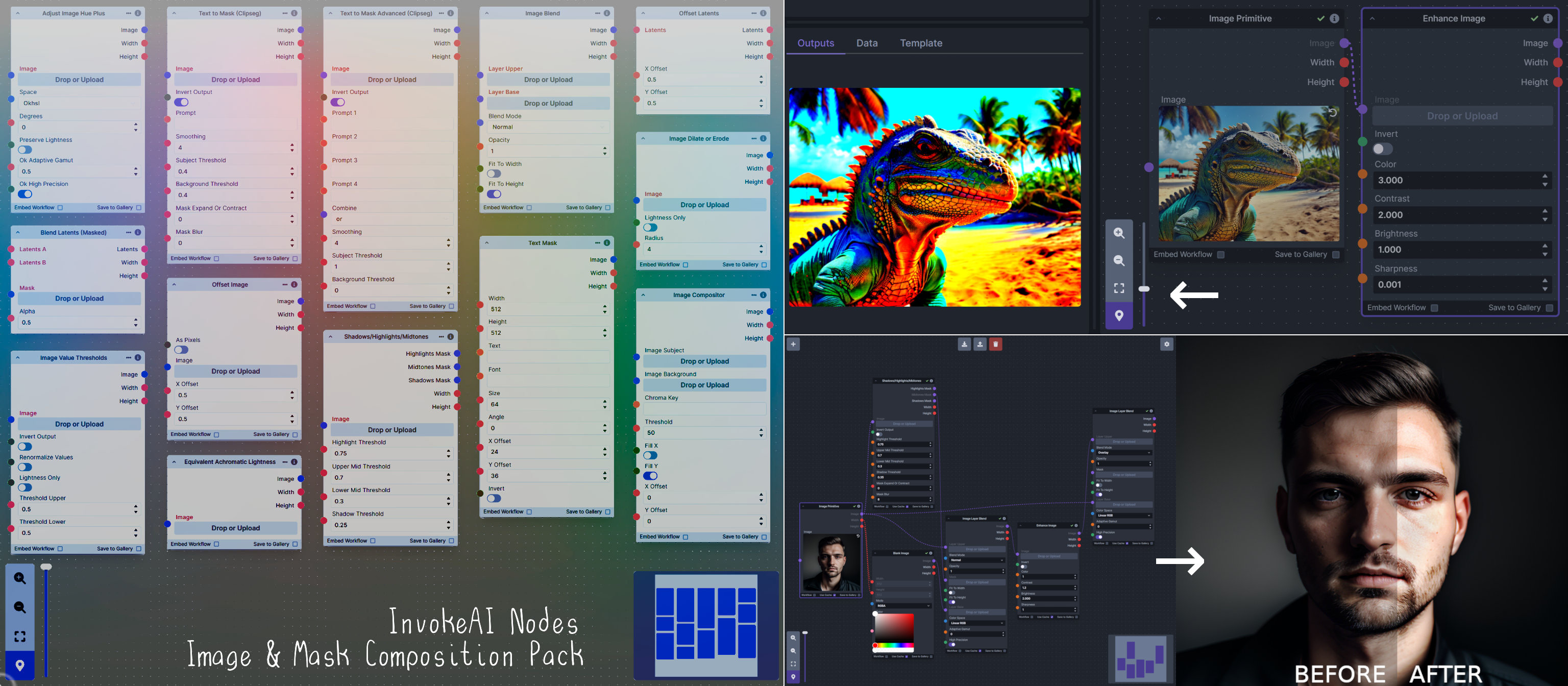
**Description:** This is a pack of nodes for composing masks and images, including a simple text mask creator and both image and latent offset nodes. The offsets wrap around, so these can be used in conjunction with the Seamless node to progressively generate centered on different parts of the seamless tiling.
|
||||
|
||||
This includes 4 Nodes:
|
||||
- *Text Mask (simple 2D)* - create and position a white on black (or black on white) line of text using any font locally available to Invoke.
|
||||
This includes 14 Nodes:
|
||||
- *Adjust Image Hue Plus* - Rotate the hue of an image in one of several different color spaces.
|
||||
- *Blend Latents/Noise (Masked)* - Use a mask to blend part of one latents tensor [including Noise outputs] into another. Can be used to "renoise" sections during a multi-stage [masked] denoising process.
|
||||
- *Enhance Image* - Boost or reduce color saturation, contrast, brightness, sharpness, or invert colors of any image at any stage with this simple wrapper for pillow [PIL]'s ImageEnhance module.
|
||||
- *Equivalent Achromatic Lightness* - Calculates image lightness accounting for Helmholtz-Kohlrausch effect based on a method described by High, Green, and Nussbaum (2023).
|
||||
- *Text to Mask (Clipseg)* - Input a prompt and an image to generate a mask representing areas of the image matched by the prompt.
|
||||
- *Text to Mask Advanced (Clipseg)* - Output up to four prompt masks combined with logical "and", logical "or", or as separate channels of an RGBA image.
|
||||
- *Image Layer Blend* - Perform a layered blend of two images using alpha compositing. Opacity of top layer is selectable, with optional mask and several different blend modes/color spaces.
|
||||
- *Image Compositor* - Take a subject from an image with a flat backdrop and layer it on another image using a chroma key or flood select background removal.
|
||||
- *Image Dilate or Erode* - Dilate or expand a mask (or any image!). This is equivalent to an expand/contract operation.
|
||||
- *Image Value Thresholds* - Clip an image to pure black/white beyond specified thresholds.
|
||||
- *Offset Latents* - Offset a latents tensor in the vertical and/or horizontal dimensions, wrapping it around.
|
||||
- *Offset Image* - Offset an image in the vertical and/or horizontal dimensions, wrapping it around.
|
||||
- *Shadows/Highlights/Midtones* - Extract three masks (with adjustable hard or soft thresholds) representing shadows, midtones, and highlights regions of an image.
|
||||
- *Text Mask (simple 2D)* - create and position a white on black (or black on white) line of text using any font locally available to Invoke.
|
||||
|
||||
**Node Link:** https://github.com/dwringer/composition-nodes
|
||||
|
||||
**Example Usage:**
|
||||
|
||||
**Nodes and Output Examples:**
|
||||
|
||||
|
||||
--------------------------------
|
||||
### Size Stepper Nodes
|
||||
@@ -196,6 +194,40 @@ Results after using the depth controlnet
|
||||
|
||||
--------------------------------
|
||||
|
||||
### Prompt Tools
|
||||
|
||||
**Description:** A set of InvokeAI nodes that add general prompt manipulation tools. These where written to accompany the PromptsFromFile node and other prompt generation nodes.
|
||||
|
||||
1. PromptJoin - Joins to prompts into one.
|
||||
2. PromptReplace - performs a search and replace on a prompt. With the option of using regex.
|
||||
3. PromptSplitNeg - splits a prompt into positive and negative using the old V2 method of [] for negative.
|
||||
4. PromptToFile - saves a prompt or collection of prompts to a file. one per line. There is an append/overwrite option.
|
||||
5. PTFieldsCollect - Converts image generation fields into a Json format string that can be passed to Prompt to file.
|
||||
6. PTFieldsExpand - Takes Json string and converts it to individual generation parameters This can be fed from the Prompts to file node.
|
||||
7. PromptJoinThree - Joins 3 prompt together.
|
||||
8. PromptStrength - This take a string and float and outputs another string in the format of (string)strength like the weighted format of compel.
|
||||
9. PromptStrengthCombine - This takes a collection of prompt strength strings and outputs a string in the .and() or .blend() format that can be fed into a proper prompt node.
|
||||
|
||||
See full docs here: https://github.com/skunkworxdark/Prompt-tools-nodes/edit/main/README.md
|
||||
|
||||
**Node Link:** https://github.com/skunkworxdark/Prompt-tools-nodes
|
||||
|
||||
--------------------------------
|
||||
|
||||
### XY Image to Grid and Images to Grids nodes
|
||||
|
||||
**Description:** Image to grid nodes and supporting tools.
|
||||
|
||||
1. "Images To Grids" node - Takes a collection of images and creates a grid(s) of images. If there are more images than the size of a single grid then mutilple grids will be created until it runs out of images.
|
||||
2. "XYImage To Grid" node - Converts a collection of XYImages into a labeled Grid of images. The XYImages collection has to be built using the supporoting nodes. See example node setups for more details.
|
||||
|
||||
|
||||
See full docs here: https://github.com/skunkworxdark/XYGrid_nodes/edit/main/README.md
|
||||
|
||||
**Node Link:** https://github.com/skunkworxdark/XYGrid_nodes
|
||||
|
||||
--------------------------------
|
||||
|
||||
### Example Node Template
|
||||
|
||||
**Description:** This node allows you to do super cool things with InvokeAI.
|
||||
|
||||
@@ -332,6 +332,7 @@ class InvokeAiInstance:
|
||||
Configure the InvokeAI runtime directory
|
||||
"""
|
||||
|
||||
auto_install = False
|
||||
# set sys.argv to a consistent state
|
||||
new_argv = [sys.argv[0]]
|
||||
for i in range(1, len(sys.argv)):
|
||||
@@ -340,13 +341,17 @@ class InvokeAiInstance:
|
||||
new_argv.append(el)
|
||||
new_argv.append(sys.argv[i + 1])
|
||||
elif el in ["-y", "--yes", "--yes-to-all"]:
|
||||
new_argv.append(el)
|
||||
auto_install = True
|
||||
sys.argv = new_argv
|
||||
|
||||
import messages
|
||||
import requests # to catch download exceptions
|
||||
from messages import introduction
|
||||
|
||||
introduction()
|
||||
auto_install = auto_install or messages.user_wants_auto_configuration()
|
||||
if auto_install:
|
||||
sys.argv.append("--yes")
|
||||
else:
|
||||
messages.introduction()
|
||||
|
||||
from invokeai.frontend.install.invokeai_configure import invokeai_configure
|
||||
|
||||
|
||||
@@ -7,7 +7,7 @@ import os
|
||||
import platform
|
||||
from pathlib import Path
|
||||
|
||||
from prompt_toolkit import prompt
|
||||
from prompt_toolkit import HTML, prompt
|
||||
from prompt_toolkit.completion import PathCompleter
|
||||
from prompt_toolkit.validation import Validator
|
||||
from rich import box, print
|
||||
@@ -65,17 +65,50 @@ def confirm_install(dest: Path) -> bool:
|
||||
if dest.exists():
|
||||
print(f":exclamation: Directory {dest} already exists :exclamation:")
|
||||
dest_confirmed = Confirm.ask(
|
||||
":stop_sign: Are you sure you want to (re)install in this location?",
|
||||
":stop_sign: (re)install in this location?",
|
||||
default=False,
|
||||
)
|
||||
else:
|
||||
print(f"InvokeAI will be installed in {dest}")
|
||||
dest_confirmed = not Confirm.ask("Would you like to pick a different location?", default=False)
|
||||
dest_confirmed = Confirm.ask("Use this location?", default=True)
|
||||
console.line()
|
||||
|
||||
return dest_confirmed
|
||||
|
||||
|
||||
def user_wants_auto_configuration() -> bool:
|
||||
"""Prompt the user to choose between manual and auto configuration."""
|
||||
console.rule("InvokeAI Configuration Section")
|
||||
console.print(
|
||||
Panel(
|
||||
Group(
|
||||
"\n".join(
|
||||
[
|
||||
"Libraries are installed and InvokeAI will now set up its root directory and configuration. Choose between:",
|
||||
"",
|
||||
" * AUTOMATIC configuration: install reasonable defaults and a minimal set of starter models.",
|
||||
" * MANUAL configuration: manually inspect and adjust configuration options and pick from a larger set of starter models.",
|
||||
"",
|
||||
"Later you can fine tune your configuration by selecting option [6] 'Change InvokeAI startup options' from the invoke.bat/invoke.sh launcher script.",
|
||||
]
|
||||
),
|
||||
),
|
||||
box=box.MINIMAL,
|
||||
padding=(1, 1),
|
||||
)
|
||||
)
|
||||
choice = (
|
||||
prompt(
|
||||
HTML("Choose <b><a></b>utomatic or <b><m></b>anual configuration [a/m] (a): "),
|
||||
validator=Validator.from_callable(
|
||||
lambda n: n == "" or n.startswith(("a", "A", "m", "M")), error_message="Please select 'a' or 'm'"
|
||||
),
|
||||
)
|
||||
or "a"
|
||||
)
|
||||
return choice.lower().startswith("a")
|
||||
|
||||
|
||||
def dest_path(dest=None) -> Path:
|
||||
"""
|
||||
Prompt the user for the destination path and create the path
|
||||
|
||||
@@ -17,9 +17,10 @@ echo 6. Change InvokeAI startup options
|
||||
echo 7. Re-run the configure script to fix a broken install or to complete a major upgrade
|
||||
echo 8. Open the developer console
|
||||
echo 9. Update InvokeAI
|
||||
echo 10. Command-line help
|
||||
echo 10. Run the InvokeAI image database maintenance script
|
||||
echo 11. Command-line help
|
||||
echo Q - Quit
|
||||
set /P choice="Please enter 1-10, Q: [1] "
|
||||
set /P choice="Please enter 1-11, Q: [1] "
|
||||
if not defined choice set choice=1
|
||||
IF /I "%choice%" == "1" (
|
||||
echo Starting the InvokeAI browser-based UI..
|
||||
@@ -58,8 +59,11 @@ IF /I "%choice%" == "1" (
|
||||
echo Running invokeai-update...
|
||||
python -m invokeai.frontend.install.invokeai_update
|
||||
) ELSE IF /I "%choice%" == "10" (
|
||||
echo Running the db maintenance script...
|
||||
python .venv\Scripts\invokeai-db-maintenance.exe
|
||||
) ELSE IF /I "%choice%" == "11" (
|
||||
echo Displaying command line help...
|
||||
python .venv\Scripts\invokeai.exe --help %*
|
||||
python .venv\Scripts\invokeai-web.exe --help %*
|
||||
pause
|
||||
exit /b
|
||||
) ELSE IF /I "%choice%" == "q" (
|
||||
|
||||
@@ -97,13 +97,13 @@ do_choice() {
|
||||
;;
|
||||
10)
|
||||
clear
|
||||
printf "Command-line help\n"
|
||||
invokeai --help
|
||||
printf "Running the db maintenance script\n"
|
||||
invokeai-db-maintenance --root ${INVOKEAI_ROOT}
|
||||
;;
|
||||
"HELP 1")
|
||||
11)
|
||||
clear
|
||||
printf "Command-line help\n"
|
||||
invokeai --help
|
||||
invokeai-web --help
|
||||
;;
|
||||
*)
|
||||
clear
|
||||
@@ -125,7 +125,10 @@ do_dialog() {
|
||||
6 "Change InvokeAI startup options"
|
||||
7 "Re-run the configure script to fix a broken install or to complete a major upgrade"
|
||||
8 "Open the developer console"
|
||||
9 "Update InvokeAI")
|
||||
9 "Update InvokeAI"
|
||||
10 "Run the InvokeAI image database maintenance script"
|
||||
11 "Command-line help"
|
||||
)
|
||||
|
||||
choice=$(dialog --clear \
|
||||
--backtitle "\Zb\Zu\Z3InvokeAI" \
|
||||
@@ -157,9 +160,10 @@ do_line_input() {
|
||||
printf "7: Re-run the configure script to fix a broken install\n"
|
||||
printf "8: Open the developer console\n"
|
||||
printf "9: Update InvokeAI\n"
|
||||
printf "10: Command-line help\n"
|
||||
printf "10: Run the InvokeAI image database maintenance script\n"
|
||||
printf "11: Command-line help\n"
|
||||
printf "Q: Quit\n\n"
|
||||
read -p "Please enter 1-10, Q: [1] " yn
|
||||
read -p "Please enter 1-11, Q: [1] " yn
|
||||
choice=${yn:='1'}
|
||||
do_choice $choice
|
||||
clear
|
||||
|
||||
@@ -49,7 +49,7 @@ def check_internet() -> bool:
|
||||
return False
|
||||
|
||||
|
||||
logger = InvokeAILogger.getLogger()
|
||||
logger = InvokeAILogger.get_logger()
|
||||
|
||||
|
||||
class ApiDependencies:
|
||||
|
||||
@@ -7,6 +7,7 @@ from fastapi.routing import APIRouter
|
||||
from pydantic import BaseModel, Field
|
||||
|
||||
from invokeai.app.invocations.upscale import ESRGAN_MODELS
|
||||
from invokeai.app.services.invocation_cache.invocation_cache_common import InvocationCacheStatus
|
||||
from invokeai.backend.image_util.invisible_watermark import InvisibleWatermark
|
||||
from invokeai.backend.image_util.patchmatch import PatchMatch
|
||||
from invokeai.backend.image_util.safety_checker import SafetyChecker
|
||||
@@ -103,3 +104,43 @@ async def set_log_level(
|
||||
"""Sets the log verbosity level"""
|
||||
ApiDependencies.invoker.services.logger.setLevel(level)
|
||||
return LogLevel(ApiDependencies.invoker.services.logger.level)
|
||||
|
||||
|
||||
@app_router.delete(
|
||||
"/invocation_cache",
|
||||
operation_id="clear_invocation_cache",
|
||||
responses={200: {"description": "The operation was successful"}},
|
||||
)
|
||||
async def clear_invocation_cache() -> None:
|
||||
"""Clears the invocation cache"""
|
||||
ApiDependencies.invoker.services.invocation_cache.clear()
|
||||
|
||||
|
||||
@app_router.put(
|
||||
"/invocation_cache/enable",
|
||||
operation_id="enable_invocation_cache",
|
||||
responses={200: {"description": "The operation was successful"}},
|
||||
)
|
||||
async def enable_invocation_cache() -> None:
|
||||
"""Clears the invocation cache"""
|
||||
ApiDependencies.invoker.services.invocation_cache.enable()
|
||||
|
||||
|
||||
@app_router.put(
|
||||
"/invocation_cache/disable",
|
||||
operation_id="disable_invocation_cache",
|
||||
responses={200: {"description": "The operation was successful"}},
|
||||
)
|
||||
async def disable_invocation_cache() -> None:
|
||||
"""Clears the invocation cache"""
|
||||
ApiDependencies.invoker.services.invocation_cache.disable()
|
||||
|
||||
|
||||
@app_router.get(
|
||||
"/invocation_cache/status",
|
||||
operation_id="get_invocation_cache_status",
|
||||
responses={200: {"model": InvocationCacheStatus}},
|
||||
)
|
||||
async def get_invocation_cache_status() -> InvocationCacheStatus:
|
||||
"""Clears the invocation cache"""
|
||||
return ApiDependencies.invoker.services.invocation_cache.get_status()
|
||||
|
||||
@@ -146,7 +146,8 @@ async def update_model(
|
||||
async def import_model(
|
||||
location: str = Body(description="A model path, repo_id or URL to import"),
|
||||
prediction_type: Optional[Literal["v_prediction", "epsilon", "sample"]] = Body(
|
||||
description="Prediction type for SDv2 checkpoint files", default="v_prediction"
|
||||
description="Prediction type for SDv2 checkpoints and rare SDv1 checkpoints",
|
||||
default=None,
|
||||
),
|
||||
) -> ImportModelResponse:
|
||||
"""Add a model using its local path, repo_id, or remote URL. Model characteristics will be probed and configured automatically"""
|
||||
|
||||
@@ -84,7 +84,7 @@ async def list_queue_items(
|
||||
"""Gets all queue items (without graphs)"""
|
||||
|
||||
return ApiDependencies.invoker.services.session_queue.list_queue_items(
|
||||
queue_id=queue_id, limit=limit, status=status, order_id=cursor, priority=priority
|
||||
queue_id=queue_id, limit=limit, status=status, cursor=cursor, priority=priority
|
||||
)
|
||||
|
||||
|
||||
@@ -225,7 +225,7 @@ async def get_batch_status(
|
||||
)
|
||||
async def get_queue_item(
|
||||
queue_id: str = Path(description="The queue id to perform this operation on"),
|
||||
item_id: str = Path(description="The queue item to get"),
|
||||
item_id: int = Path(description="The queue item to get"),
|
||||
) -> SessionQueueItem:
|
||||
"""Gets a queue item"""
|
||||
return ApiDependencies.invoker.services.session_queue.get_queue_item(item_id)
|
||||
@@ -240,7 +240,7 @@ async def get_queue_item(
|
||||
)
|
||||
async def cancel_queue_item(
|
||||
queue_id: str = Path(description="The queue id to perform this operation on"),
|
||||
item_id: str = Path(description="The queue item to cancel"),
|
||||
item_id: int = Path(description="The queue item to cancel"),
|
||||
) -> SessionQueueItem:
|
||||
"""Deletes a queue item"""
|
||||
|
||||
|
||||
@@ -3,16 +3,19 @@
|
||||
from fastapi import FastAPI
|
||||
from fastapi_events.handlers.local import local_handler
|
||||
from fastapi_events.typing import Event
|
||||
from fastapi_socketio import SocketManager
|
||||
from socketio import ASGIApp, AsyncServer
|
||||
|
||||
from ..services.events import EventServiceBase
|
||||
|
||||
|
||||
class SocketIO:
|
||||
__sio: SocketManager
|
||||
__sio: AsyncServer
|
||||
__app: ASGIApp
|
||||
|
||||
def __init__(self, app: FastAPI):
|
||||
self.__sio = SocketManager(app=app)
|
||||
self.__sio = AsyncServer(async_mode="asgi", cors_allowed_origins="*")
|
||||
self.__app = ASGIApp(socketio_server=self.__sio, socketio_path="socket.io")
|
||||
app.mount("/ws", self.__app)
|
||||
|
||||
self.__sio.on("subscribe_queue", handler=self._handle_sub_queue)
|
||||
self.__sio.on("unsubscribe_queue", handler=self._handle_unsub_queue)
|
||||
|
||||
@@ -8,7 +8,6 @@ app_config.parse_args()
|
||||
|
||||
if True: # hack to make flake8 happy with imports coming after setting up the config
|
||||
import asyncio
|
||||
import logging
|
||||
import mimetypes
|
||||
import socket
|
||||
from inspect import signature
|
||||
@@ -41,7 +40,9 @@ if True: # hack to make flake8 happy with imports coming after setting up the c
|
||||
import invokeai.backend.util.mps_fixes # noqa: F401 (monkeypatching on import)
|
||||
|
||||
|
||||
logger = InvokeAILogger.getLogger(config=app_config)
|
||||
app_config = InvokeAIAppConfig.get_config()
|
||||
app_config.parse_args()
|
||||
logger = InvokeAILogger.get_logger(config=app_config)
|
||||
|
||||
# fix for windows mimetypes registry entries being borked
|
||||
# see https://github.com/invoke-ai/InvokeAI/discussions/3684#discussioncomment-6391352
|
||||
@@ -223,7 +224,7 @@ def invoke_api():
|
||||
exc_info=e,
|
||||
)
|
||||
else:
|
||||
jurigged.watch(logger=InvokeAILogger.getLogger(name="jurigged").info)
|
||||
jurigged.watch(logger=InvokeAILogger.get_logger(name="jurigged").info)
|
||||
|
||||
port = find_port(app_config.port)
|
||||
if port != app_config.port:
|
||||
@@ -242,7 +243,7 @@ def invoke_api():
|
||||
|
||||
# replace uvicorn's loggers with InvokeAI's for consistent appearance
|
||||
for logname in ["uvicorn.access", "uvicorn"]:
|
||||
log = logging.getLogger(logname)
|
||||
log = InvokeAILogger.get_logger(logname)
|
||||
log.handlers.clear()
|
||||
for ch in logger.handlers:
|
||||
log.addHandler(ch)
|
||||
|
||||
@@ -7,8 +7,6 @@ from .services.config import InvokeAIAppConfig
|
||||
# parse_args() must be called before any other imports. if it is not called first, consumers of the config
|
||||
# which are imported/used before parse_args() is called will get the default config values instead of the
|
||||
# values from the command line or config file.
|
||||
config = InvokeAIAppConfig.get_config()
|
||||
config.parse_args()
|
||||
|
||||
if True: # hack to make flake8 happy with imports coming after setting up the config
|
||||
import argparse
|
||||
@@ -61,8 +59,9 @@ if True: # hack to make flake8 happy with imports coming after setting up the c
|
||||
if torch.backends.mps.is_available():
|
||||
import invokeai.backend.util.mps_fixes # noqa: F401 (monkeypatching on import)
|
||||
|
||||
|
||||
logger = InvokeAILogger().getLogger(config=config)
|
||||
config = InvokeAIAppConfig.get_config()
|
||||
config.parse_args()
|
||||
logger = InvokeAILogger().get_logger(config=config)
|
||||
|
||||
|
||||
class CliCommand(BaseModel):
|
||||
|
||||
@@ -67,6 +67,7 @@ class FieldDescriptions:
|
||||
width = "Width of output (px)"
|
||||
height = "Height of output (px)"
|
||||
control = "ControlNet(s) to apply"
|
||||
ip_adapter = "IP-Adapter to apply"
|
||||
denoised_latents = "Denoised latents tensor"
|
||||
latents = "Latents tensor"
|
||||
strength = "Strength of denoising (proportional to steps)"
|
||||
@@ -87,6 +88,12 @@ class FieldDescriptions:
|
||||
num_1 = "The first number"
|
||||
num_2 = "The second number"
|
||||
mask = "The mask to use for the operation"
|
||||
board = "The board to save the image to"
|
||||
image = "The image to process"
|
||||
tile_size = "Tile size"
|
||||
inclusive_low = "The inclusive low value"
|
||||
exclusive_high = "The exclusive high value"
|
||||
decimal_places = "The number of decimal places to round to"
|
||||
|
||||
|
||||
class Input(str, Enum):
|
||||
@@ -155,6 +162,7 @@ class UIType(str, Enum):
|
||||
VaeModel = "VaeModelField"
|
||||
LoRAModel = "LoRAModelField"
|
||||
ControlNetModel = "ControlNetModelField"
|
||||
IPAdapterModel = "IPAdapterModelField"
|
||||
UNet = "UNetField"
|
||||
Vae = "VaeField"
|
||||
CLIP = "ClipField"
|
||||
@@ -171,6 +179,7 @@ class UIType(str, Enum):
|
||||
WorkflowField = "WorkflowField"
|
||||
IsIntermediate = "IsIntermediate"
|
||||
MetadataField = "MetadataField"
|
||||
BoardField = "BoardField"
|
||||
# endregion
|
||||
|
||||
|
||||
@@ -422,13 +431,22 @@ class InvocationContext:
|
||||
services: InvocationServices
|
||||
graph_execution_state_id: str
|
||||
queue_id: str
|
||||
queue_item_id: str
|
||||
queue_item_id: int
|
||||
queue_batch_id: str
|
||||
|
||||
def __init__(self, services: InvocationServices, queue_id: str, queue_item_id: str, graph_execution_state_id: str):
|
||||
def __init__(
|
||||
self,
|
||||
services: InvocationServices,
|
||||
queue_id: str,
|
||||
queue_item_id: int,
|
||||
queue_batch_id: str,
|
||||
graph_execution_state_id: str,
|
||||
):
|
||||
self.services = services
|
||||
self.graph_execution_state_id = graph_execution_state_id
|
||||
self.queue_id = queue_id
|
||||
self.queue_item_id = queue_item_id
|
||||
self.queue_batch_id = queue_batch_id
|
||||
|
||||
|
||||
class BaseInvocationOutput(BaseModel):
|
||||
@@ -589,7 +607,7 @@ class BaseInvocation(ABC, BaseModel):
|
||||
if cached_value is None:
|
||||
context.services.logger.debug(f'Invocation cache miss for type "{self.get_type()}": {self.id}')
|
||||
output = self.invoke(context)
|
||||
context.services.invocation_cache.save(output)
|
||||
context.services.invocation_cache.save(key, output)
|
||||
return output
|
||||
else:
|
||||
context.services.logger.debug(f'Invocation cache hit for type "{self.get_type()}": {self.id}')
|
||||
@@ -645,6 +663,8 @@ def invocation(
|
||||
:param Optional[str] title: Adds a title to the invocation. Use if the auto-generated title isn't quite right. Defaults to None.
|
||||
:param Optional[list[str]] tags: Adds tags to the invocation. Invocations may be searched for by their tags. Defaults to None.
|
||||
:param Optional[str] category: Adds a category to the invocation. Used to group the invocations in the UI. Defaults to None.
|
||||
:param Optional[str] version: Adds a version to the invocation. Must be a valid semver string. Defaults to None.
|
||||
:param Optional[bool] use_cache: Whether or not to use the invocation cache. Defaults to True. The user may override this in the workflow editor.
|
||||
"""
|
||||
|
||||
def wrapper(cls: Type[GenericBaseInvocation]) -> Type[GenericBaseInvocation]:
|
||||
|
||||
@@ -7,14 +7,14 @@ from compel import Compel, ReturnedEmbeddingsType
|
||||
from compel.prompt_parser import Blend, Conjunction, CrossAttentionControlSubstitute, FlattenedPrompt, Fragment
|
||||
|
||||
from invokeai.app.invocations.primitives import ConditioningField, ConditioningOutput
|
||||
from invokeai.backend.stable_diffusion.diffusion.shared_invokeai_diffusion import (
|
||||
from invokeai.backend.stable_diffusion.diffusion.conditioning_data import (
|
||||
BasicConditioningInfo,
|
||||
ExtraConditioningInfo,
|
||||
SDXLConditioningInfo,
|
||||
)
|
||||
|
||||
from ...backend.model_management.lora import ModelPatcher
|
||||
from ...backend.model_management.models import ModelNotFoundException, ModelType
|
||||
from ...backend.stable_diffusion.diffusion import InvokeAIDiffuserComponent
|
||||
from ...backend.util.devices import torch_dtype
|
||||
from .baseinvocation import (
|
||||
BaseInvocation,
|
||||
@@ -99,14 +99,15 @@ class CompelInvocation(BaseInvocation):
|
||||
# print(traceback.format_exc())
|
||||
print(f'Warn: trigger: "{trigger}" not found')
|
||||
|
||||
with ModelPatcher.apply_lora_text_encoder(
|
||||
text_encoder_info.context.model, _lora_loader()
|
||||
), ModelPatcher.apply_ti(tokenizer_info.context.model, text_encoder_info.context.model, ti_list) as (
|
||||
tokenizer,
|
||||
ti_manager,
|
||||
), ModelPatcher.apply_clip_skip(
|
||||
text_encoder_info.context.model, self.clip.skipped_layers
|
||||
), text_encoder_info as text_encoder:
|
||||
with (
|
||||
ModelPatcher.apply_lora_text_encoder(text_encoder_info.context.model, _lora_loader()),
|
||||
ModelPatcher.apply_ti(tokenizer_info.context.model, text_encoder_info.context.model, ti_list) as (
|
||||
tokenizer,
|
||||
ti_manager,
|
||||
),
|
||||
ModelPatcher.apply_clip_skip(text_encoder_info.context.model, self.clip.skipped_layers),
|
||||
text_encoder_info as text_encoder,
|
||||
):
|
||||
compel = Compel(
|
||||
tokenizer=tokenizer,
|
||||
text_encoder=text_encoder,
|
||||
@@ -122,7 +123,7 @@ class CompelInvocation(BaseInvocation):
|
||||
|
||||
c, options = compel.build_conditioning_tensor_for_conjunction(conjunction)
|
||||
|
||||
ec = InvokeAIDiffuserComponent.ExtraConditioningInfo(
|
||||
ec = ExtraConditioningInfo(
|
||||
tokens_count_including_eos_bos=get_max_token_count(tokenizer, conjunction),
|
||||
cross_attention_control_args=options.get("cross_attention_control", None),
|
||||
)
|
||||
@@ -213,14 +214,15 @@ class SDXLPromptInvocationBase:
|
||||
# print(traceback.format_exc())
|
||||
print(f'Warn: trigger: "{trigger}" not found')
|
||||
|
||||
with ModelPatcher.apply_lora(
|
||||
text_encoder_info.context.model, _lora_loader(), lora_prefix
|
||||
), ModelPatcher.apply_ti(tokenizer_info.context.model, text_encoder_info.context.model, ti_list) as (
|
||||
tokenizer,
|
||||
ti_manager,
|
||||
), ModelPatcher.apply_clip_skip(
|
||||
text_encoder_info.context.model, clip_field.skipped_layers
|
||||
), text_encoder_info as text_encoder:
|
||||
with (
|
||||
ModelPatcher.apply_lora(text_encoder_info.context.model, _lora_loader(), lora_prefix),
|
||||
ModelPatcher.apply_ti(tokenizer_info.context.model, text_encoder_info.context.model, ti_list) as (
|
||||
tokenizer,
|
||||
ti_manager,
|
||||
),
|
||||
ModelPatcher.apply_clip_skip(text_encoder_info.context.model, clip_field.skipped_layers),
|
||||
text_encoder_info as text_encoder,
|
||||
):
|
||||
compel = Compel(
|
||||
tokenizer=tokenizer,
|
||||
text_encoder=text_encoder,
|
||||
@@ -244,7 +246,7 @@ class SDXLPromptInvocationBase:
|
||||
else:
|
||||
c_pooled = None
|
||||
|
||||
ec = InvokeAIDiffuserComponent.ExtraConditioningInfo(
|
||||
ec = ExtraConditioningInfo(
|
||||
tokens_count_including_eos_bos=get_max_token_count(tokenizer, conjunction),
|
||||
cross_attention_control_args=options.get("cross_attention_control", None),
|
||||
)
|
||||
@@ -436,9 +438,11 @@ def get_tokens_for_prompt_object(tokenizer, parsed_prompt: FlattenedPrompt, trun
|
||||
raise ValueError("Blend is not supported here - you need to get tokens for each of its .children")
|
||||
|
||||
text_fragments = [
|
||||
x.text
|
||||
if type(x) is Fragment
|
||||
else (" ".join([f.text for f in x.original]) if type(x) is CrossAttentionControlSubstitute else str(x))
|
||||
(
|
||||
x.text
|
||||
if type(x) is Fragment
|
||||
else (" ".join([f.text for f in x.original]) if type(x) is CrossAttentionControlSubstitute else str(x))
|
||||
)
|
||||
for x in parsed_prompt.children
|
||||
]
|
||||
text = " ".join(text_fragments)
|
||||
|
||||
@@ -6,9 +6,11 @@ from typing import Dict, List, Literal, Optional, Union
|
||||
|
||||
import cv2
|
||||
import numpy as np
|
||||
import torch
|
||||
from controlnet_aux import (
|
||||
CannyDetector,
|
||||
ContentShuffleDetector,
|
||||
DWposeDetector,
|
||||
HEDdetector,
|
||||
LeresDetector,
|
||||
LineartAnimeDetector,
|
||||
@@ -38,7 +40,6 @@ from .baseinvocation import (
|
||||
InputField,
|
||||
InvocationContext,
|
||||
OutputField,
|
||||
UIType,
|
||||
invocation,
|
||||
invocation_output,
|
||||
)
|
||||
@@ -100,7 +101,7 @@ class ControlNetInvocation(BaseInvocation):
|
||||
image: ImageField = InputField(description="The control image")
|
||||
control_model: ControlNetModelField = InputField(description=FieldDescriptions.controlnet_model, input=Input.Direct)
|
||||
control_weight: Union[float, List[float]] = InputField(
|
||||
default=1.0, description="The weight given to the ControlNet", ui_type=UIType.Float
|
||||
default=1.0, description="The weight given to the ControlNet"
|
||||
)
|
||||
begin_step_percent: float = InputField(
|
||||
default=0, ge=-1, le=2, description="When the ControlNet is first applied (% of total steps)"
|
||||
@@ -126,7 +127,7 @@ class ControlNetInvocation(BaseInvocation):
|
||||
|
||||
|
||||
@invocation(
|
||||
"image_processor", title="Base Image Processor", tags=["controlnet"], category="controlnet", version="1.0.0"
|
||||
"image_processor", title="Base Image Processorwp", tags=["controlnet"], category="controlnet", version="1.0.0"
|
||||
)
|
||||
class ImageProcessorInvocation(BaseInvocation):
|
||||
"""Base class for invocations that preprocess images for ControlNet"""
|
||||
@@ -560,3 +561,59 @@ class SamDetectorReproducibleColors(SamDetector):
|
||||
img[:, :] = ann_color
|
||||
final_img.paste(Image.fromarray(img, mode="RGB"), (0, 0), Image.fromarray(np.uint8(m * 255)))
|
||||
return np.array(final_img, dtype=np.uint8)
|
||||
|
||||
|
||||
@invocation(
|
||||
"color_map_image_processor",
|
||||
title="Color Map Processor",
|
||||
tags=["controlnet"],
|
||||
category="controlnet",
|
||||
version="1.0.0",
|
||||
)
|
||||
class ColorMapImageProcessorInvocation(ImageProcessorInvocation):
|
||||
"""Generates a color map from the provided image"""
|
||||
|
||||
color_map_tile_size: int = InputField(default=64, ge=0, description=FieldDescriptions.tile_size)
|
||||
|
||||
def run_processor(self, image: Image.Image):
|
||||
image = image.convert("RGB")
|
||||
image = np.array(image, dtype=np.uint8)
|
||||
height, width = image.shape[:2]
|
||||
|
||||
width_tile_size = min(self.color_map_tile_size, width)
|
||||
height_tile_size = min(self.color_map_tile_size, height)
|
||||
|
||||
color_map = cv2.resize(
|
||||
image,
|
||||
(width // width_tile_size, height // height_tile_size),
|
||||
interpolation=cv2.INTER_CUBIC,
|
||||
)
|
||||
color_map = cv2.resize(color_map, (width, height), interpolation=cv2.INTER_NEAREST)
|
||||
color_map = Image.fromarray(color_map)
|
||||
return color_map
|
||||
|
||||
|
||||
@invocation(
|
||||
"dwpose_image_processor",
|
||||
title="DWPose Processor",
|
||||
tags=["controlnet", "dwpose", "pose"],
|
||||
category="controlnet",
|
||||
version="1.0.0",
|
||||
)
|
||||
class DWPoseImageProcessorInvocation(ImageProcessorInvocation):
|
||||
"""Applies DW-Pose processing to image"""
|
||||
|
||||
detect_resolution: int = InputField(default=512, ge=0, description=FieldDescriptions.detect_res)
|
||||
image_resolution: int = InputField(default=512, ge=0, description=FieldDescriptions.image_res)
|
||||
|
||||
def run_processor(self, image):
|
||||
# device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
|
||||
# for now, executing DWPose processing on CPU only
|
||||
device = "cpu"
|
||||
dwpose_processor = DWposeDetector(device=device)
|
||||
processed_image = dwpose_processor(
|
||||
image,
|
||||
detect_resolution=self.detect_resolution,
|
||||
image_resolution=self.image_resolution,
|
||||
)
|
||||
return processed_image
|
||||
|
||||
@@ -8,12 +8,12 @@ import numpy
|
||||
from PIL import Image, ImageChops, ImageFilter, ImageOps
|
||||
|
||||
from invokeai.app.invocations.metadata import CoreMetadata
|
||||
from invokeai.app.invocations.primitives import ColorField, ImageField, ImageOutput
|
||||
from invokeai.app.invocations.primitives import BoardField, ColorField, ImageField, ImageOutput
|
||||
from invokeai.backend.image_util.invisible_watermark import InvisibleWatermark
|
||||
from invokeai.backend.image_util.safety_checker import SafetyChecker
|
||||
|
||||
from ..models.image import ImageCategory, ResourceOrigin
|
||||
from .baseinvocation import BaseInvocation, FieldDescriptions, InputField, InvocationContext, invocation
|
||||
from .baseinvocation import BaseInvocation, FieldDescriptions, Input, InputField, InvocationContext, invocation
|
||||
|
||||
|
||||
@invocation("show_image", title="Show Image", tags=["image"], category="image", version="1.0.0")
|
||||
@@ -972,13 +972,14 @@ class ImageChannelMultiplyInvocation(BaseInvocation):
|
||||
title="Save Image",
|
||||
tags=["primitives", "image"],
|
||||
category="primitives",
|
||||
version="1.0.0",
|
||||
version="1.0.1",
|
||||
use_cache=False,
|
||||
)
|
||||
class SaveImageInvocation(BaseInvocation):
|
||||
"""Saves an image. Unlike an image primitive, this invocation stores a copy of the image."""
|
||||
|
||||
image: ImageField = InputField(description="The image to load")
|
||||
image: ImageField = InputField(description=FieldDescriptions.image)
|
||||
board: Optional[BoardField] = InputField(default=None, description=FieldDescriptions.board, input=Input.Direct)
|
||||
metadata: CoreMetadata = InputField(
|
||||
default=None,
|
||||
description=FieldDescriptions.core_metadata,
|
||||
@@ -992,6 +993,7 @@ class SaveImageInvocation(BaseInvocation):
|
||||
image=image,
|
||||
image_origin=ResourceOrigin.INTERNAL,
|
||||
image_category=ImageCategory.GENERAL,
|
||||
board_id=self.board.board_id if self.board else None,
|
||||
node_id=self.id,
|
||||
session_id=context.graph_execution_state_id,
|
||||
is_intermediate=self.is_intermediate,
|
||||
|
||||
103
invokeai/app/invocations/ip_adapter.py
Normal file
103
invokeai/app/invocations/ip_adapter.py
Normal file
@@ -0,0 +1,103 @@
|
||||
import os
|
||||
from builtins import float
|
||||
from typing import List, Union
|
||||
|
||||
from pydantic import BaseModel, Field
|
||||
|
||||
from invokeai.app.invocations.baseinvocation import (
|
||||
BaseInvocation,
|
||||
BaseInvocationOutput,
|
||||
FieldDescriptions,
|
||||
Input,
|
||||
InputField,
|
||||
InvocationContext,
|
||||
OutputField,
|
||||
UIType,
|
||||
invocation,
|
||||
invocation_output,
|
||||
)
|
||||
from invokeai.app.invocations.primitives import ImageField
|
||||
from invokeai.backend.model_management.models.base import BaseModelType, ModelType
|
||||
from invokeai.backend.model_management.models.ip_adapter import get_ip_adapter_image_encoder_model_id
|
||||
|
||||
|
||||
class IPAdapterModelField(BaseModel):
|
||||
model_name: str = Field(description="Name of the IP-Adapter model")
|
||||
base_model: BaseModelType = Field(description="Base model")
|
||||
|
||||
|
||||
class CLIPVisionModelField(BaseModel):
|
||||
model_name: str = Field(description="Name of the CLIP Vision image encoder model")
|
||||
base_model: BaseModelType = Field(description="Base model (usually 'Any')")
|
||||
|
||||
|
||||
class IPAdapterField(BaseModel):
|
||||
image: ImageField = Field(description="The IP-Adapter image prompt.")
|
||||
ip_adapter_model: IPAdapterModelField = Field(description="The IP-Adapter model to use.")
|
||||
image_encoder_model: CLIPVisionModelField = Field(description="The name of the CLIP image encoder model.")
|
||||
weight: Union[float, List[float]] = Field(default=1, description="The weight given to the ControlNet")
|
||||
# weight: float = Field(default=1.0, ge=0, description="The weight of the IP-Adapter.")
|
||||
begin_step_percent: float = Field(
|
||||
default=0, ge=0, le=1, description="When the IP-Adapter is first applied (% of total steps)"
|
||||
)
|
||||
end_step_percent: float = Field(
|
||||
default=1, ge=0, le=1, description="When the IP-Adapter is last applied (% of total steps)"
|
||||
)
|
||||
|
||||
|
||||
@invocation_output("ip_adapter_output")
|
||||
class IPAdapterOutput(BaseInvocationOutput):
|
||||
# Outputs
|
||||
ip_adapter: IPAdapterField = OutputField(description=FieldDescriptions.ip_adapter, title="IP-Adapter")
|
||||
|
||||
|
||||
@invocation("ip_adapter", title="IP-Adapter", tags=["ip_adapter", "control"], category="ip_adapter", version="1.0.0")
|
||||
class IPAdapterInvocation(BaseInvocation):
|
||||
"""Collects IP-Adapter info to pass to other nodes."""
|
||||
|
||||
# Inputs
|
||||
image: ImageField = InputField(description="The IP-Adapter image prompt.")
|
||||
ip_adapter_model: IPAdapterModelField = InputField(
|
||||
description="The IP-Adapter model.", title="IP-Adapter Model", input=Input.Direct, ui_order=-1
|
||||
)
|
||||
|
||||
# weight: float = InputField(default=1.0, description="The weight of the IP-Adapter.", ui_type=UIType.Float)
|
||||
weight: Union[float, List[float]] = InputField(
|
||||
default=1, ge=0, description="The weight given to the IP-Adapter", ui_type=UIType.Float, title="Weight"
|
||||
)
|
||||
|
||||
begin_step_percent: float = InputField(
|
||||
default=0, ge=-1, le=2, description="When the IP-Adapter is first applied (% of total steps)"
|
||||
)
|
||||
end_step_percent: float = InputField(
|
||||
default=1, ge=0, le=1, description="When the IP-Adapter is last applied (% of total steps)"
|
||||
)
|
||||
|
||||
def invoke(self, context: InvocationContext) -> IPAdapterOutput:
|
||||
# Lookup the CLIP Vision encoder that is intended to be used with the IP-Adapter model.
|
||||
ip_adapter_info = context.services.model_manager.model_info(
|
||||
self.ip_adapter_model.model_name, self.ip_adapter_model.base_model, ModelType.IPAdapter
|
||||
)
|
||||
# HACK(ryand): This is bad for a couple of reasons: 1) we are bypassing the model manager to read the model
|
||||
# directly, and 2) we are reading from disk every time this invocation is called without caching the result.
|
||||
# A better solution would be to store the image encoder model reference in the IP-Adapter model info, but this
|
||||
# is currently messy due to differences between how the model info is generated when installing a model from
|
||||
# disk vs. downloading the model.
|
||||
image_encoder_model_id = get_ip_adapter_image_encoder_model_id(
|
||||
os.path.join(context.services.configuration.get_config().models_path, ip_adapter_info["path"])
|
||||
)
|
||||
image_encoder_model_name = image_encoder_model_id.split("/")[-1].strip()
|
||||
image_encoder_model = CLIPVisionModelField(
|
||||
model_name=image_encoder_model_name,
|
||||
base_model=BaseModelType.Any,
|
||||
)
|
||||
return IPAdapterOutput(
|
||||
ip_adapter=IPAdapterField(
|
||||
image=self.image,
|
||||
ip_adapter_model=self.ip_adapter_model,
|
||||
image_encoder_model=image_encoder_model,
|
||||
weight=self.weight,
|
||||
begin_step_percent=self.begin_step_percent,
|
||||
end_step_percent=self.end_step_percent,
|
||||
),
|
||||
)
|
||||
@@ -1,13 +1,16 @@
|
||||
# Copyright (c) 2023 Kyle Schouviller (https://github.com/kyle0654)
|
||||
|
||||
from contextlib import ExitStack
|
||||
from functools import singledispatchmethod
|
||||
from typing import List, Literal, Optional, Union
|
||||
|
||||
import einops
|
||||
import numpy as np
|
||||
import torch
|
||||
import torchvision.transforms as T
|
||||
from diffusers import AutoencoderKL, AutoencoderTiny
|
||||
from diffusers.image_processor import VaeImageProcessor
|
||||
from diffusers.models import UNet2DConditionModel
|
||||
from diffusers.models.attention_processor import (
|
||||
AttnProcessor2_0,
|
||||
LoRAAttnProcessor2_0,
|
||||
@@ -19,6 +22,7 @@ from diffusers.schedulers import SchedulerMixin as Scheduler
|
||||
from pydantic import validator
|
||||
from torchvision.transforms.functional import resize as tv_resize
|
||||
|
||||
from invokeai.app.invocations.ip_adapter import IPAdapterField
|
||||
from invokeai.app.invocations.metadata import CoreMetadata
|
||||
from invokeai.app.invocations.primitives import (
|
||||
DenoiseMaskField,
|
||||
@@ -31,15 +35,17 @@ from invokeai.app.invocations.primitives import (
|
||||
)
|
||||
from invokeai.app.util.controlnet_utils import prepare_control_image
|
||||
from invokeai.app.util.step_callback import stable_diffusion_step_callback
|
||||
from invokeai.backend.ip_adapter.ip_adapter import IPAdapter, IPAdapterPlus
|
||||
from invokeai.backend.model_management.models import ModelType, SilenceWarnings
|
||||
from invokeai.backend.stable_diffusion.diffusion.conditioning_data import ConditioningData, IPAdapterConditioningInfo
|
||||
|
||||
from ...backend.model_management.lora import ModelPatcher
|
||||
from ...backend.model_management.models import BaseModelType
|
||||
from ...backend.model_management.seamless import set_seamless
|
||||
from ...backend.stable_diffusion import PipelineIntermediateState
|
||||
from ...backend.stable_diffusion.diffusers_pipeline import (
|
||||
ConditioningData,
|
||||
ControlNetData,
|
||||
IPAdapterData,
|
||||
StableDiffusionGeneratorPipeline,
|
||||
image_resized_to_grid_as_tensor,
|
||||
)
|
||||
@@ -68,7 +74,6 @@ if choose_torch_device() == torch.device("mps"):
|
||||
|
||||
DEFAULT_PRECISION = choose_precision(choose_torch_device())
|
||||
|
||||
|
||||
SAMPLER_NAME_VALUES = Literal[tuple(list(SCHEDULER_MAP.keys()))]
|
||||
|
||||
|
||||
@@ -191,7 +196,7 @@ def get_scheduler(
|
||||
title="Denoise Latents",
|
||||
tags=["latents", "denoise", "txt2img", "t2i", "t2l", "img2img", "i2i", "l2l"],
|
||||
category="latents",
|
||||
version="1.0.0",
|
||||
version="1.1.0",
|
||||
)
|
||||
class DenoiseLatentsInvocation(BaseInvocation):
|
||||
"""Denoises noisy latents to decodable images"""
|
||||
@@ -205,7 +210,7 @@ class DenoiseLatentsInvocation(BaseInvocation):
|
||||
noise: Optional[LatentsField] = InputField(description=FieldDescriptions.noise, input=Input.Connection, ui_order=3)
|
||||
steps: int = InputField(default=10, gt=0, description=FieldDescriptions.steps)
|
||||
cfg_scale: Union[float, List[float]] = InputField(
|
||||
default=7.5, ge=1, description=FieldDescriptions.cfg_scale, ui_type=UIType.Float, title="CFG Scale"
|
||||
default=7.5, ge=1, description=FieldDescriptions.cfg_scale, title="CFG Scale"
|
||||
)
|
||||
denoising_start: float = InputField(default=0.0, ge=0, le=1, description=FieldDescriptions.denoising_start)
|
||||
denoising_end: float = InputField(default=1.0, ge=0, le=1, description=FieldDescriptions.denoising_end)
|
||||
@@ -215,13 +220,15 @@ class DenoiseLatentsInvocation(BaseInvocation):
|
||||
unet: UNetField = InputField(description=FieldDescriptions.unet, input=Input.Connection, title="UNet", ui_order=2)
|
||||
control: Union[ControlField, list[ControlField]] = InputField(
|
||||
default=None,
|
||||
description=FieldDescriptions.control,
|
||||
input=Input.Connection,
|
||||
ui_order=5,
|
||||
)
|
||||
ip_adapter: Optional[IPAdapterField] = InputField(
|
||||
description=FieldDescriptions.ip_adapter, title="IP-Adapter", default=None, input=Input.Connection, ui_order=6
|
||||
)
|
||||
latents: Optional[LatentsField] = InputField(description=FieldDescriptions.latents, input=Input.Connection)
|
||||
denoise_mask: Optional[DenoiseMaskField] = InputField(
|
||||
default=None, description=FieldDescriptions.mask, input=Input.Connection, ui_order=6
|
||||
default=None, description=FieldDescriptions.mask, input=Input.Connection, ui_order=7
|
||||
)
|
||||
|
||||
@validator("cfg_scale")
|
||||
@@ -323,8 +330,6 @@ class DenoiseLatentsInvocation(BaseInvocation):
|
||||
def prep_control_data(
|
||||
self,
|
||||
context: InvocationContext,
|
||||
# really only need model for dtype and device
|
||||
model: StableDiffusionGeneratorPipeline,
|
||||
control_input: Union[ControlField, List[ControlField]],
|
||||
latents_shape: List[int],
|
||||
exit_stack: ExitStack,
|
||||
@@ -344,57 +349,107 @@ class DenoiseLatentsInvocation(BaseInvocation):
|
||||
else:
|
||||
control_list = None
|
||||
if control_list is None:
|
||||
control_data = None
|
||||
# from above handling, any control that is not None should now be of type list[ControlField]
|
||||
else:
|
||||
# FIXME: add checks to skip entry if model or image is None
|
||||
# and if weight is None, populate with default 1.0?
|
||||
control_data = []
|
||||
control_models = []
|
||||
for control_info in control_list:
|
||||
control_model = exit_stack.enter_context(
|
||||
context.services.model_manager.get_model(
|
||||
model_name=control_info.control_model.model_name,
|
||||
model_type=ModelType.ControlNet,
|
||||
base_model=control_info.control_model.base_model,
|
||||
context=context,
|
||||
)
|
||||
)
|
||||
return None
|
||||
# After above handling, any control that is not None should now be of type list[ControlField].
|
||||
|
||||
control_models.append(control_model)
|
||||
control_image_field = control_info.image
|
||||
input_image = context.services.images.get_pil_image(control_image_field.image_name)
|
||||
# self.image.image_type, self.image.image_name
|
||||
# FIXME: still need to test with different widths, heights, devices, dtypes
|
||||
# and add in batch_size, num_images_per_prompt?
|
||||
# and do real check for classifier_free_guidance?
|
||||
# prepare_control_image should return torch.Tensor of shape(batch_size, 3, height, width)
|
||||
control_image = prepare_control_image(
|
||||
image=input_image,
|
||||
do_classifier_free_guidance=do_classifier_free_guidance,
|
||||
width=control_width_resize,
|
||||
height=control_height_resize,
|
||||
# batch_size=batch_size * num_images_per_prompt,
|
||||
# num_images_per_prompt=num_images_per_prompt,
|
||||
device=control_model.device,
|
||||
dtype=control_model.dtype,
|
||||
control_mode=control_info.control_mode,
|
||||
resize_mode=control_info.resize_mode,
|
||||
# FIXME: add checks to skip entry if model or image is None
|
||||
# and if weight is None, populate with default 1.0?
|
||||
controlnet_data = []
|
||||
for control_info in control_list:
|
||||
control_model = exit_stack.enter_context(
|
||||
context.services.model_manager.get_model(
|
||||
model_name=control_info.control_model.model_name,
|
||||
model_type=ModelType.ControlNet,
|
||||
base_model=control_info.control_model.base_model,
|
||||
context=context,
|
||||
)
|
||||
control_item = ControlNetData(
|
||||
model=control_model,
|
||||
image_tensor=control_image,
|
||||
weight=control_info.control_weight,
|
||||
begin_step_percent=control_info.begin_step_percent,
|
||||
end_step_percent=control_info.end_step_percent,
|
||||
control_mode=control_info.control_mode,
|
||||
# any resizing needed should currently be happening in prepare_control_image(),
|
||||
# but adding resize_mode to ControlNetData in case needed in the future
|
||||
resize_mode=control_info.resize_mode,
|
||||
)
|
||||
control_data.append(control_item)
|
||||
# MultiControlNetModel has been refactored out, just need list[ControlNetData]
|
||||
return control_data
|
||||
)
|
||||
|
||||
# control_models.append(control_model)
|
||||
control_image_field = control_info.image
|
||||
input_image = context.services.images.get_pil_image(control_image_field.image_name)
|
||||
# self.image.image_type, self.image.image_name
|
||||
# FIXME: still need to test with different widths, heights, devices, dtypes
|
||||
# and add in batch_size, num_images_per_prompt?
|
||||
# and do real check for classifier_free_guidance?
|
||||
# prepare_control_image should return torch.Tensor of shape(batch_size, 3, height, width)
|
||||
control_image = prepare_control_image(
|
||||
image=input_image,
|
||||
do_classifier_free_guidance=do_classifier_free_guidance,
|
||||
width=control_width_resize,
|
||||
height=control_height_resize,
|
||||
# batch_size=batch_size * num_images_per_prompt,
|
||||
# num_images_per_prompt=num_images_per_prompt,
|
||||
device=control_model.device,
|
||||
dtype=control_model.dtype,
|
||||
control_mode=control_info.control_mode,
|
||||
resize_mode=control_info.resize_mode,
|
||||
)
|
||||
control_item = ControlNetData(
|
||||
model=control_model, # model object
|
||||
image_tensor=control_image,
|
||||
weight=control_info.control_weight,
|
||||
begin_step_percent=control_info.begin_step_percent,
|
||||
end_step_percent=control_info.end_step_percent,
|
||||
control_mode=control_info.control_mode,
|
||||
# any resizing needed should currently be happening in prepare_control_image(),
|
||||
# but adding resize_mode to ControlNetData in case needed in the future
|
||||
resize_mode=control_info.resize_mode,
|
||||
)
|
||||
controlnet_data.append(control_item)
|
||||
# MultiControlNetModel has been refactored out, just need list[ControlNetData]
|
||||
|
||||
return controlnet_data
|
||||
|
||||
def prep_ip_adapter_data(
|
||||
self,
|
||||
context: InvocationContext,
|
||||
ip_adapter: Optional[IPAdapterField],
|
||||
conditioning_data: ConditioningData,
|
||||
unet: UNet2DConditionModel,
|
||||
exit_stack: ExitStack,
|
||||
) -> Optional[IPAdapterData]:
|
||||
"""If IP-Adapter is enabled, then this function loads the requisite models, and adds the image prompt embeddings
|
||||
to the `conditioning_data` (in-place).
|
||||
"""
|
||||
if ip_adapter is None:
|
||||
return None
|
||||
|
||||
image_encoder_model_info = context.services.model_manager.get_model(
|
||||
model_name=ip_adapter.image_encoder_model.model_name,
|
||||
model_type=ModelType.CLIPVision,
|
||||
base_model=ip_adapter.image_encoder_model.base_model,
|
||||
context=context,
|
||||
)
|
||||
|
||||
ip_adapter_model: Union[IPAdapter, IPAdapterPlus] = exit_stack.enter_context(
|
||||
context.services.model_manager.get_model(
|
||||
model_name=ip_adapter.ip_adapter_model.model_name,
|
||||
model_type=ModelType.IPAdapter,
|
||||
base_model=ip_adapter.ip_adapter_model.base_model,
|
||||
context=context,
|
||||
)
|
||||
)
|
||||
|
||||
input_image = context.services.images.get_pil_image(ip_adapter.image.image_name)
|
||||
|
||||
# TODO(ryand): With some effort, the step of running the CLIP Vision encoder could be done before any other
|
||||
# models are needed in memory. This would help to reduce peak memory utilization in low-memory environments.
|
||||
with image_encoder_model_info as image_encoder_model:
|
||||
# Get image embeddings from CLIP and ImageProjModel.
|
||||
image_prompt_embeds, uncond_image_prompt_embeds = ip_adapter_model.get_image_embeds(
|
||||
input_image, image_encoder_model
|
||||
)
|
||||
conditioning_data.ip_adapter_conditioning = IPAdapterConditioningInfo(
|
||||
image_prompt_embeds, uncond_image_prompt_embeds
|
||||
)
|
||||
|
||||
return IPAdapterData(
|
||||
ip_adapter_model=ip_adapter_model,
|
||||
weight=ip_adapter.weight,
|
||||
begin_step_percent=ip_adapter.begin_step_percent,
|
||||
end_step_percent=ip_adapter.end_step_percent,
|
||||
)
|
||||
|
||||
# original idea by https://github.com/AmericanPresidentJimmyCarter
|
||||
# TODO: research more for second order schedulers timesteps
|
||||
@@ -488,9 +543,12 @@ class DenoiseLatentsInvocation(BaseInvocation):
|
||||
**self.unet.unet.dict(),
|
||||
context=context,
|
||||
)
|
||||
with ExitStack() as exit_stack, ModelPatcher.apply_lora_unet(
|
||||
unet_info.context.model, _lora_loader()
|
||||
), set_seamless(unet_info.context.model, self.unet.seamless_axes), unet_info as unet:
|
||||
with (
|
||||
ExitStack() as exit_stack,
|
||||
ModelPatcher.apply_lora_unet(unet_info.context.model, _lora_loader()),
|
||||
set_seamless(unet_info.context.model, self.unet.seamless_axes),
|
||||
unet_info as unet,
|
||||
):
|
||||
latents = latents.to(device=unet.device, dtype=unet.dtype)
|
||||
if noise is not None:
|
||||
noise = noise.to(device=unet.device, dtype=unet.dtype)
|
||||
@@ -509,8 +567,7 @@ class DenoiseLatentsInvocation(BaseInvocation):
|
||||
pipeline = self.create_pipeline(unet, scheduler)
|
||||
conditioning_data = self.get_conditioning_data(context, scheduler, unet, seed)
|
||||
|
||||
control_data = self.prep_control_data(
|
||||
model=pipeline,
|
||||
controlnet_data = self.prep_control_data(
|
||||
context=context,
|
||||
control_input=self.control,
|
||||
latents_shape=latents.shape,
|
||||
@@ -519,6 +576,14 @@ class DenoiseLatentsInvocation(BaseInvocation):
|
||||
exit_stack=exit_stack,
|
||||
)
|
||||
|
||||
ip_adapter_data = self.prep_ip_adapter_data(
|
||||
context=context,
|
||||
ip_adapter=self.ip_adapter,
|
||||
conditioning_data=conditioning_data,
|
||||
unet=unet,
|
||||
exit_stack=exit_stack,
|
||||
)
|
||||
|
||||
num_inference_steps, timesteps, init_timestep = self.init_scheduler(
|
||||
scheduler,
|
||||
device=unet.device,
|
||||
@@ -537,7 +602,8 @@ class DenoiseLatentsInvocation(BaseInvocation):
|
||||
masked_latents=masked_latents,
|
||||
num_inference_steps=num_inference_steps,
|
||||
conditioning_data=conditioning_data,
|
||||
control_data=control_data, # list[ControlNetData]
|
||||
control_data=controlnet_data, # list[ControlNetData],
|
||||
ip_adapter_data=ip_adapter_data, # IPAdapterData,
|
||||
callback=step_callback,
|
||||
)
|
||||
|
||||
@@ -792,8 +858,7 @@ class ImageToLatentsInvocation(BaseInvocation):
|
||||
# non_noised_latents_from_image
|
||||
image_tensor = image_tensor.to(device=vae.device, dtype=vae.dtype)
|
||||
with torch.inference_mode():
|
||||
image_tensor_dist = vae.encode(image_tensor).latent_dist
|
||||
latents = image_tensor_dist.sample().to(dtype=vae.dtype) # FIXME: uses torch.randn. make reproducible!
|
||||
latents = ImageToLatentsInvocation._encode_to_tensor(vae, image_tensor)
|
||||
|
||||
latents = vae.config.scaling_factor * latents
|
||||
latents = latents.to(dtype=orig_dtype)
|
||||
@@ -820,6 +885,18 @@ class ImageToLatentsInvocation(BaseInvocation):
|
||||
context.services.latents.save(name, latents)
|
||||
return build_latents_output(latents_name=name, latents=latents, seed=None)
|
||||
|
||||
@singledispatchmethod
|
||||
@staticmethod
|
||||
def _encode_to_tensor(vae: AutoencoderKL, image_tensor: torch.FloatTensor) -> torch.FloatTensor:
|
||||
image_tensor_dist = vae.encode(image_tensor).latent_dist
|
||||
latents = image_tensor_dist.sample().to(dtype=vae.dtype) # FIXME: uses torch.randn. make reproducible!
|
||||
return latents
|
||||
|
||||
@_encode_to_tensor.register
|
||||
@staticmethod
|
||||
def _(vae: AutoencoderTiny, image_tensor: torch.FloatTensor) -> torch.FloatTensor:
|
||||
return vae.encode(image_tensor).latents
|
||||
|
||||
|
||||
@invocation("lblend", title="Blend Latents", tags=["latents", "blend"], category="latents", version="1.0.0")
|
||||
class BlendLatentsInvocation(BaseInvocation):
|
||||
|
||||
@@ -65,13 +65,27 @@ class DivideInvocation(BaseInvocation):
|
||||
class RandomIntInvocation(BaseInvocation):
|
||||
"""Outputs a single random integer."""
|
||||
|
||||
low: int = InputField(default=0, description="The inclusive low value")
|
||||
high: int = InputField(default=np.iinfo(np.int32).max, description="The exclusive high value")
|
||||
low: int = InputField(default=0, description=FieldDescriptions.inclusive_low)
|
||||
high: int = InputField(default=np.iinfo(np.int32).max, description=FieldDescriptions.exclusive_high)
|
||||
|
||||
def invoke(self, context: InvocationContext) -> IntegerOutput:
|
||||
return IntegerOutput(value=np.random.randint(self.low, self.high))
|
||||
|
||||
|
||||
@invocation("rand_float", title="Random Float", tags=["math", "float", "random"], category="math", version="1.0.0")
|
||||
class RandomFloatInvocation(BaseInvocation):
|
||||
"""Outputs a single random float"""
|
||||
|
||||
low: float = InputField(default=0.0, description=FieldDescriptions.inclusive_low)
|
||||
high: float = InputField(default=1.0, description=FieldDescriptions.exclusive_high)
|
||||
decimals: int = InputField(default=2, description=FieldDescriptions.decimal_places)
|
||||
|
||||
def invoke(self, context: InvocationContext) -> FloatOutput:
|
||||
random_float = np.random.uniform(self.low, self.high)
|
||||
rounded_float = round(random_float, self.decimals)
|
||||
return FloatOutput(value=rounded_float)
|
||||
|
||||
|
||||
@invocation(
|
||||
"float_to_int",
|
||||
title="Float To Integer",
|
||||
|
||||
@@ -42,7 +42,8 @@ class CoreMetadata(BaseModelExcludeNull):
|
||||
cfg_scale: float = Field(description="The classifier-free guidance scale parameter")
|
||||
steps: int = Field(description="The number of steps used for inference")
|
||||
scheduler: str = Field(description="The scheduler used for inference")
|
||||
clip_skip: int = Field(
|
||||
clip_skip: Optional[int] = Field(
|
||||
default=None,
|
||||
description="The number of skipped CLIP layers",
|
||||
)
|
||||
model: MainModelField = Field(description="The main model used for inference")
|
||||
@@ -116,7 +117,8 @@ class MetadataAccumulatorInvocation(BaseInvocation):
|
||||
cfg_scale: float = InputField(description="The classifier-free guidance scale parameter")
|
||||
steps: int = InputField(description="The number of steps used for inference")
|
||||
scheduler: str = InputField(description="The scheduler used for inference")
|
||||
clip_skip: int = InputField(
|
||||
clip_skip: Optional[int] = Field(
|
||||
default=None,
|
||||
description="The number of skipped CLIP layers",
|
||||
)
|
||||
model: MainModelField = InputField(description="The main model used for inference")
|
||||
|
||||
@@ -95,9 +95,10 @@ class ONNXPromptInvocation(BaseInvocation):
|
||||
print(f'Warn: trigger: "{trigger}" not found')
|
||||
if loras or ti_list:
|
||||
text_encoder.release_session()
|
||||
with ONNXModelPatcher.apply_lora_text_encoder(text_encoder, loras), ONNXModelPatcher.apply_ti(
|
||||
orig_tokenizer, text_encoder, ti_list
|
||||
) as (tokenizer, ti_manager):
|
||||
with (
|
||||
ONNXModelPatcher.apply_lora_text_encoder(text_encoder, loras),
|
||||
ONNXModelPatcher.apply_ti(orig_tokenizer, text_encoder, ti_list) as (tokenizer, ti_manager),
|
||||
):
|
||||
text_encoder.create_session()
|
||||
|
||||
# copy from
|
||||
@@ -165,7 +166,6 @@ class ONNXTextToLatentsInvocation(BaseInvocation):
|
||||
default=7.5,
|
||||
ge=1,
|
||||
description=FieldDescriptions.cfg_scale,
|
||||
ui_type=UIType.Float,
|
||||
)
|
||||
scheduler: SAMPLER_NAME_VALUES = InputField(
|
||||
default="euler", description=FieldDescriptions.scheduler, input=Input.Direct, ui_type=UIType.Scheduler
|
||||
@@ -178,7 +178,6 @@ class ONNXTextToLatentsInvocation(BaseInvocation):
|
||||
control: Optional[Union[ControlField, list[ControlField]]] = InputField(
|
||||
default=None,
|
||||
description=FieldDescriptions.control,
|
||||
ui_type=UIType.Control,
|
||||
)
|
||||
# seamless: bool = InputField(default=False, description="Whether or not to generate an image that can tile without seams", )
|
||||
# seamless_axes: str = InputField(default="", description="The axes to tile the image on, 'x' and/or 'y'")
|
||||
|
||||
@@ -226,6 +226,12 @@ class ImageField(BaseModel):
|
||||
image_name: str = Field(description="The name of the image")
|
||||
|
||||
|
||||
class BoardField(BaseModel):
|
||||
"""A board primitive field"""
|
||||
|
||||
board_id: str = Field(description="The id of the board")
|
||||
|
||||
|
||||
@invocation_output("image_output")
|
||||
class ImageOutput(BaseInvocationOutput):
|
||||
"""Base class for nodes that output a single image"""
|
||||
|
||||
@@ -241,7 +241,7 @@ class InvokeAIAppConfig(InvokeAISettings):
|
||||
version : bool = Field(default=False, description="Show InvokeAI version and exit", category="Other")
|
||||
|
||||
# CACHE
|
||||
ram : Union[float, Literal["auto"]] = Field(default=6.0, gt=0, description="Maximum memory amount used by model cache for rapid switching (floating point number or 'auto')", category="Model Cache", )
|
||||
ram : Union[float, Literal["auto"]] = Field(default=7.5, gt=0, description="Maximum memory amount used by model cache for rapid switching (floating point number or 'auto')", category="Model Cache", )
|
||||
vram : Union[float, Literal["auto"]] = Field(default=0.25, ge=0, description="Amount of VRAM reserved for model storage (floating point number or 'auto')", category="Model Cache", )
|
||||
lazy_offload : bool = Field(default=True, description="Keep models in VRAM until their space is needed", category="Model Cache", )
|
||||
|
||||
@@ -277,6 +277,7 @@ class InvokeAIAppConfig(InvokeAISettings):
|
||||
|
||||
class Config:
|
||||
validate_assignment = True
|
||||
env_prefix = "INVOKEAI"
|
||||
|
||||
def parse_args(self, argv: Optional[list[str]] = None, conf: Optional[DictConfig] = None, clobber=False):
|
||||
"""
|
||||
|
||||
@@ -29,7 +29,8 @@ class EventServiceBase:
|
||||
def emit_generator_progress(
|
||||
self,
|
||||
queue_id: str,
|
||||
queue_item_id: str,
|
||||
queue_item_id: int,
|
||||
queue_batch_id: str,
|
||||
graph_execution_state_id: str,
|
||||
node: dict,
|
||||
source_node_id: str,
|
||||
@@ -44,6 +45,7 @@ class EventServiceBase:
|
||||
payload=dict(
|
||||
queue_id=queue_id,
|
||||
queue_item_id=queue_item_id,
|
||||
queue_batch_id=queue_batch_id,
|
||||
graph_execution_state_id=graph_execution_state_id,
|
||||
node_id=node.get("id"),
|
||||
source_node_id=source_node_id,
|
||||
@@ -57,7 +59,8 @@ class EventServiceBase:
|
||||
def emit_invocation_complete(
|
||||
self,
|
||||
queue_id: str,
|
||||
queue_item_id: str,
|
||||
queue_item_id: int,
|
||||
queue_batch_id: str,
|
||||
graph_execution_state_id: str,
|
||||
result: dict,
|
||||
node: dict,
|
||||
@@ -69,6 +72,7 @@ class EventServiceBase:
|
||||
payload=dict(
|
||||
queue_id=queue_id,
|
||||
queue_item_id=queue_item_id,
|
||||
queue_batch_id=queue_batch_id,
|
||||
graph_execution_state_id=graph_execution_state_id,
|
||||
node=node,
|
||||
source_node_id=source_node_id,
|
||||
@@ -79,7 +83,8 @@ class EventServiceBase:
|
||||
def emit_invocation_error(
|
||||
self,
|
||||
queue_id: str,
|
||||
queue_item_id: str,
|
||||
queue_item_id: int,
|
||||
queue_batch_id: str,
|
||||
graph_execution_state_id: str,
|
||||
node: dict,
|
||||
source_node_id: str,
|
||||
@@ -92,6 +97,7 @@ class EventServiceBase:
|
||||
payload=dict(
|
||||
queue_id=queue_id,
|
||||
queue_item_id=queue_item_id,
|
||||
queue_batch_id=queue_batch_id,
|
||||
graph_execution_state_id=graph_execution_state_id,
|
||||
node=node,
|
||||
source_node_id=source_node_id,
|
||||
@@ -101,7 +107,13 @@ class EventServiceBase:
|
||||
)
|
||||
|
||||
def emit_invocation_started(
|
||||
self, queue_id: str, queue_item_id: str, graph_execution_state_id: str, node: dict, source_node_id: str
|
||||
self,
|
||||
queue_id: str,
|
||||
queue_item_id: int,
|
||||
queue_batch_id: str,
|
||||
graph_execution_state_id: str,
|
||||
node: dict,
|
||||
source_node_id: str,
|
||||
) -> None:
|
||||
"""Emitted when an invocation has started"""
|
||||
self.__emit_queue_event(
|
||||
@@ -109,19 +121,23 @@ class EventServiceBase:
|
||||
payload=dict(
|
||||
queue_id=queue_id,
|
||||
queue_item_id=queue_item_id,
|
||||
queue_batch_id=queue_batch_id,
|
||||
graph_execution_state_id=graph_execution_state_id,
|
||||
node=node,
|
||||
source_node_id=source_node_id,
|
||||
),
|
||||
)
|
||||
|
||||
def emit_graph_execution_complete(self, queue_id: str, queue_item_id: str, graph_execution_state_id: str) -> None:
|
||||
def emit_graph_execution_complete(
|
||||
self, queue_id: str, queue_item_id: int, queue_batch_id: str, graph_execution_state_id: str
|
||||
) -> None:
|
||||
"""Emitted when a session has completed all invocations"""
|
||||
self.__emit_queue_event(
|
||||
event_name="graph_execution_state_complete",
|
||||
payload=dict(
|
||||
queue_id=queue_id,
|
||||
queue_item_id=queue_item_id,
|
||||
queue_batch_id=queue_batch_id,
|
||||
graph_execution_state_id=graph_execution_state_id,
|
||||
),
|
||||
)
|
||||
@@ -129,7 +145,8 @@ class EventServiceBase:
|
||||
def emit_model_load_started(
|
||||
self,
|
||||
queue_id: str,
|
||||
queue_item_id: str,
|
||||
queue_item_id: int,
|
||||
queue_batch_id: str,
|
||||
graph_execution_state_id: str,
|
||||
model_name: str,
|
||||
base_model: BaseModelType,
|
||||
@@ -142,6 +159,7 @@ class EventServiceBase:
|
||||
payload=dict(
|
||||
queue_id=queue_id,
|
||||
queue_item_id=queue_item_id,
|
||||
queue_batch_id=queue_batch_id,
|
||||
graph_execution_state_id=graph_execution_state_id,
|
||||
model_name=model_name,
|
||||
base_model=base_model,
|
||||
@@ -153,7 +171,8 @@ class EventServiceBase:
|
||||
def emit_model_load_completed(
|
||||
self,
|
||||
queue_id: str,
|
||||
queue_item_id: str,
|
||||
queue_item_id: int,
|
||||
queue_batch_id: str,
|
||||
graph_execution_state_id: str,
|
||||
model_name: str,
|
||||
base_model: BaseModelType,
|
||||
@@ -167,6 +186,7 @@ class EventServiceBase:
|
||||
payload=dict(
|
||||
queue_id=queue_id,
|
||||
queue_item_id=queue_item_id,
|
||||
queue_batch_id=queue_batch_id,
|
||||
graph_execution_state_id=graph_execution_state_id,
|
||||
model_name=model_name,
|
||||
base_model=base_model,
|
||||
@@ -181,7 +201,8 @@ class EventServiceBase:
|
||||
def emit_session_retrieval_error(
|
||||
self,
|
||||
queue_id: str,
|
||||
queue_item_id: str,
|
||||
queue_item_id: int,
|
||||
queue_batch_id: str,
|
||||
graph_execution_state_id: str,
|
||||
error_type: str,
|
||||
error: str,
|
||||
@@ -192,6 +213,7 @@ class EventServiceBase:
|
||||
payload=dict(
|
||||
queue_id=queue_id,
|
||||
queue_item_id=queue_item_id,
|
||||
queue_batch_id=queue_batch_id,
|
||||
graph_execution_state_id=graph_execution_state_id,
|
||||
error_type=error_type,
|
||||
error=error,
|
||||
@@ -201,7 +223,8 @@ class EventServiceBase:
|
||||
def emit_invocation_retrieval_error(
|
||||
self,
|
||||
queue_id: str,
|
||||
queue_item_id: str,
|
||||
queue_item_id: int,
|
||||
queue_batch_id: str,
|
||||
graph_execution_state_id: str,
|
||||
node_id: str,
|
||||
error_type: str,
|
||||
@@ -213,6 +236,7 @@ class EventServiceBase:
|
||||
payload=dict(
|
||||
queue_id=queue_id,
|
||||
queue_item_id=queue_item_id,
|
||||
queue_batch_id=queue_batch_id,
|
||||
graph_execution_state_id=graph_execution_state_id,
|
||||
node_id=node_id,
|
||||
error_type=error_type,
|
||||
@@ -223,7 +247,8 @@ class EventServiceBase:
|
||||
def emit_session_canceled(
|
||||
self,
|
||||
queue_id: str,
|
||||
queue_item_id: str,
|
||||
queue_item_id: int,
|
||||
queue_batch_id: str,
|
||||
graph_execution_state_id: str,
|
||||
) -> None:
|
||||
"""Emitted when a session is canceled"""
|
||||
@@ -232,6 +257,7 @@ class EventServiceBase:
|
||||
payload=dict(
|
||||
queue_id=queue_id,
|
||||
queue_item_id=queue_item_id,
|
||||
queue_batch_id=queue_batch_id,
|
||||
graph_execution_state_id=graph_execution_state_id,
|
||||
),
|
||||
)
|
||||
|
||||
@@ -117,6 +117,10 @@ def are_connection_types_compatible(from_type: Any, to_type: Any) -> bool:
|
||||
if from_type is int and to_type is float:
|
||||
return True
|
||||
|
||||
# allow int|float -> str, pydantic will cast for us
|
||||
if (from_type is int or from_type is float) and to_type is str:
|
||||
return True
|
||||
|
||||
# if not issubclass(from_type, to_type):
|
||||
if not is_union_subtype(from_type, to_type):
|
||||
return False
|
||||
|
||||
@@ -41,23 +41,25 @@ class ImageServiceABC(ABC):
|
||||
_on_changed_callbacks: list[Callable[[ImageDTO], None]]
|
||||
_on_deleted_callbacks: list[Callable[[str], None]]
|
||||
|
||||
@abstractmethod
|
||||
def __init__(self) -> None:
|
||||
self._on_changed_callbacks = list()
|
||||
self._on_deleted_callbacks = list()
|
||||
|
||||
def on_changed(self, on_changed: Callable[[ImageDTO], None]) -> None:
|
||||
"""Register a callback for when an item is changed"""
|
||||
pass
|
||||
"""Register a callback for when an image is changed"""
|
||||
self._on_changed_callbacks.append(on_changed)
|
||||
|
||||
@abstractmethod
|
||||
def on_deleted(self, on_deleted: Callable[[str], None]) -> None:
|
||||
"""Register a callback for when an item is deleted"""
|
||||
pass
|
||||
"""Register a callback for when an image is deleted"""
|
||||
self._on_deleted_callbacks.append(on_deleted)
|
||||
|
||||
@abstractmethod
|
||||
def _on_changed(self, item: ImageDTO) -> None:
|
||||
pass
|
||||
for callback in self._on_changed_callbacks:
|
||||
callback(item)
|
||||
|
||||
@abstractmethod
|
||||
def _on_deleted(self, item_id: str) -> None:
|
||||
pass
|
||||
for callback in self._on_deleted_callbacks:
|
||||
callback(item_id)
|
||||
|
||||
@abstractmethod
|
||||
def create(
|
||||
@@ -180,26 +182,9 @@ class ImageServiceDependencies:
|
||||
|
||||
class ImageService(ImageServiceABC):
|
||||
_services: ImageServiceDependencies
|
||||
_on_changed_callbacks: list[Callable[[ImageDTO], None]] = list()
|
||||
_on_deleted_callbacks: list[Callable[[str], None]] = list()
|
||||
|
||||
def on_changed(self, on_changed: Callable[[ImageDTO], None]) -> None:
|
||||
"""Register a callback for when an item is changed"""
|
||||
self._on_changed_callbacks.append(on_changed)
|
||||
|
||||
def on_deleted(self, on_deleted: Callable[[str], None]) -> None:
|
||||
"""Register a callback for when an item is deleted"""
|
||||
self._on_deleted_callbacks.append(on_deleted)
|
||||
|
||||
def _on_changed(self, item: ImageDTO) -> None:
|
||||
for callback in self._on_changed_callbacks:
|
||||
callback(item)
|
||||
|
||||
def _on_deleted(self, item_id: str) -> None:
|
||||
for callback in self._on_deleted_callbacks:
|
||||
callback(item_id)
|
||||
|
||||
def __init__(self, services: ImageServiceDependencies):
|
||||
super().__init__()
|
||||
self._services = services
|
||||
|
||||
def create(
|
||||
|
||||
@@ -2,24 +2,38 @@ from abc import ABC, abstractmethod
|
||||
from typing import Optional, Union
|
||||
|
||||
from invokeai.app.invocations.baseinvocation import BaseInvocation, BaseInvocationOutput
|
||||
from invokeai.app.services.invocation_cache.invocation_cache_common import InvocationCacheStatus
|
||||
|
||||
|
||||
class InvocationCacheBase(ABC):
|
||||
"""Base class for invocation caches."""
|
||||
"""
|
||||
Base class for invocation caches.
|
||||
When an invocation is executed, it is hashed and its output stored in the cache.
|
||||
When new invocations are executed, if they are flagged with `use_cache`, they
|
||||
will attempt to pull their value from the cache before executing.
|
||||
|
||||
Implementations should register for the `on_deleted` event of the `images` and `latents`
|
||||
services, and delete any cached outputs that reference the deleted image or latent.
|
||||
|
||||
See the memory implementation for an example.
|
||||
|
||||
Implementations should respect the `node_cache_size` configuration value, and skip all
|
||||
cache logic if the value is set to 0.
|
||||
"""
|
||||
|
||||
@abstractmethod
|
||||
def get(self, key: Union[int, str]) -> Optional[BaseInvocationOutput]:
|
||||
"""Retrieves and invocation output from the cache"""
|
||||
"""Retrieves an invocation output from the cache"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def save(self, value: BaseInvocationOutput) -> None:
|
||||
def save(self, key: Union[int, str], invocation_output: BaseInvocationOutput) -> None:
|
||||
"""Stores an invocation output in the cache"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def delete(self, key: Union[int, str]) -> None:
|
||||
"""Deleted an invocation output from the cache"""
|
||||
"""Deletes an invocation output from the cache"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
@@ -27,8 +41,22 @@ class InvocationCacheBase(ABC):
|
||||
"""Clears the cache"""
|
||||
pass
|
||||
|
||||
@classmethod
|
||||
@abstractmethod
|
||||
def create_key(cls, value: BaseInvocation) -> Union[int, str]:
|
||||
"""Creates the cache key for an invocation"""
|
||||
def create_key(self, invocation: BaseInvocation) -> int:
|
||||
"""Gets the key for the invocation's cache item"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def disable(self) -> None:
|
||||
"""Disables the cache, overriding the max cache size"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def enable(self) -> None:
|
||||
"""Enables the cache, letting the the max cache size take effect"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def get_status(self) -> InvocationCacheStatus:
|
||||
"""Returns the status of the cache"""
|
||||
pass
|
||||
|
||||
@@ -0,0 +1,9 @@
|
||||
from pydantic import BaseModel, Field
|
||||
|
||||
|
||||
class InvocationCacheStatus(BaseModel):
|
||||
size: int = Field(description="The current size of the invocation cache")
|
||||
hits: int = Field(description="The number of cache hits")
|
||||
misses: int = Field(description="The number of cache misses")
|
||||
enabled: bool = Field(description="Whether the invocation cache is enabled")
|
||||
max_size: int = Field(description="The maximum size of the invocation cache")
|
||||
@@ -1,70 +1,126 @@
|
||||
from queue import Queue
|
||||
from collections import OrderedDict
|
||||
from dataclasses import dataclass, field
|
||||
from threading import Lock
|
||||
from typing import Optional, Union
|
||||
|
||||
|
||||
from invokeai.app.invocations.baseinvocation import BaseInvocation, BaseInvocationOutput
|
||||
from invokeai.app.services.invocation_cache.invocation_cache_base import InvocationCacheBase
|
||||
from invokeai.app.services.invocation_cache.invocation_cache_common import InvocationCacheStatus
|
||||
from invokeai.app.services.invoker import Invoker
|
||||
|
||||
|
||||
class MemoryInvocationCache(InvocationCacheBase):
|
||||
__cache: dict[Union[int, str], tuple[BaseInvocationOutput, str]]
|
||||
__max_cache_size: int
|
||||
__cache_ids: Queue
|
||||
__invoker: Invoker
|
||||
@dataclass(order=True)
|
||||
class CachedItem:
|
||||
invocation_output: BaseInvocationOutput = field(compare=False)
|
||||
invocation_output_json: str = field(compare=False)
|
||||
|
||||
def __init__(self, max_cache_size: int = 512) -> None:
|
||||
self.__cache = dict()
|
||||
self.__max_cache_size = max_cache_size
|
||||
self.__cache_ids = Queue()
|
||||
|
||||
class MemoryInvocationCache(InvocationCacheBase):
|
||||
_cache: OrderedDict[Union[int, str], CachedItem]
|
||||
_max_cache_size: int
|
||||
_disabled: bool
|
||||
_hits: int
|
||||
_misses: int
|
||||
_invoker: Invoker
|
||||
_lock: Lock
|
||||
|
||||
def __init__(self, max_cache_size: int = 0) -> None:
|
||||
self._cache = OrderedDict()
|
||||
self._max_cache_size = max_cache_size
|
||||
self._disabled = False
|
||||
self._hits = 0
|
||||
self._misses = 0
|
||||
self._lock = Lock()
|
||||
|
||||
def start(self, invoker: Invoker) -> None:
|
||||
self.__invoker = invoker
|
||||
self.__invoker.services.images.on_deleted(self.delete_by_match)
|
||||
self._invoker = invoker
|
||||
if self._max_cache_size == 0:
|
||||
return
|
||||
self._invoker.services.images.on_deleted(self._delete_by_match)
|
||||
self._invoker.services.latents.on_deleted(self._delete_by_match)
|
||||
|
||||
def get(self, key: Union[int, str]) -> Optional[BaseInvocationOutput]:
|
||||
if self.__max_cache_size == 0:
|
||||
with self._lock:
|
||||
if self._max_cache_size == 0 or self._disabled:
|
||||
return None
|
||||
item = self._cache.get(key, None)
|
||||
if item is not None:
|
||||
self._hits += 1
|
||||
self._cache.move_to_end(key)
|
||||
return item.invocation_output
|
||||
self._misses += 1
|
||||
return None
|
||||
|
||||
item = self.__cache.get(key, None)
|
||||
if item is not None:
|
||||
return item[0]
|
||||
def save(self, key: Union[int, str], invocation_output: BaseInvocationOutput) -> None:
|
||||
with self._lock:
|
||||
if self._max_cache_size == 0 or self._disabled or key in self._cache:
|
||||
return
|
||||
# If the cache is full, we need to remove the least used
|
||||
number_to_delete = len(self._cache) + 1 - self._max_cache_size
|
||||
self._delete_oldest_access(number_to_delete)
|
||||
self._cache[key] = CachedItem(invocation_output, invocation_output.json())
|
||||
|
||||
def save(self, value: BaseInvocationOutput) -> None:
|
||||
if self.__max_cache_size == 0:
|
||||
return None
|
||||
def _delete_oldest_access(self, number_to_delete: int) -> None:
|
||||
number_to_delete = min(number_to_delete, len(self._cache))
|
||||
for _ in range(number_to_delete):
|
||||
self._cache.popitem(last=False)
|
||||
|
||||
value_json = value.json(exclude={"id"})
|
||||
key = hash(value_json)
|
||||
|
||||
if key not in self.__cache:
|
||||
self.__cache[key] = (value, value_json)
|
||||
self.__cache_ids.put(key)
|
||||
if self.__cache_ids.qsize() > self.__max_cache_size:
|
||||
try:
|
||||
self.__cache.pop(self.__cache_ids.get())
|
||||
except KeyError:
|
||||
pass
|
||||
def _delete(self, key: Union[int, str]) -> None:
|
||||
if self._max_cache_size == 0:
|
||||
return
|
||||
if key in self._cache:
|
||||
del self._cache[key]
|
||||
|
||||
def delete(self, key: Union[int, str]) -> None:
|
||||
if self.__max_cache_size == 0:
|
||||
return None
|
||||
|
||||
if key in self.__cache:
|
||||
del self.__cache[key]
|
||||
|
||||
def delete_by_match(self, to_match: str) -> None:
|
||||
to_delete = []
|
||||
for name, item in self.__cache.items():
|
||||
if to_match in item[1]:
|
||||
to_delete.append(name)
|
||||
for key in to_delete:
|
||||
self.delete(key)
|
||||
with self._lock:
|
||||
return self._delete(key)
|
||||
|
||||
def clear(self, *args, **kwargs) -> None:
|
||||
self.__cache.clear()
|
||||
self.__cache_ids = Queue()
|
||||
with self._lock:
|
||||
if self._max_cache_size == 0:
|
||||
return
|
||||
self._cache.clear()
|
||||
self._misses = 0
|
||||
self._hits = 0
|
||||
|
||||
@classmethod
|
||||
def create_key(cls, value: BaseInvocation) -> Union[int, str]:
|
||||
return hash(value.json(exclude={"id"}))
|
||||
@staticmethod
|
||||
def create_key(invocation: BaseInvocation) -> int:
|
||||
return hash(invocation.json(exclude={"id"}))
|
||||
|
||||
def disable(self) -> None:
|
||||
with self._lock:
|
||||
if self._max_cache_size == 0:
|
||||
return
|
||||
self._disabled = True
|
||||
|
||||
def enable(self) -> None:
|
||||
with self._lock:
|
||||
if self._max_cache_size == 0:
|
||||
return
|
||||
self._disabled = False
|
||||
|
||||
def get_status(self) -> InvocationCacheStatus:
|
||||
with self._lock:
|
||||
return InvocationCacheStatus(
|
||||
hits=self._hits,
|
||||
misses=self._misses,
|
||||
enabled=not self._disabled and self._max_cache_size > 0,
|
||||
size=len(self._cache),
|
||||
max_size=self._max_cache_size,
|
||||
)
|
||||
|
||||
def _delete_by_match(self, to_match: str) -> None:
|
||||
with self._lock:
|
||||
if self._max_cache_size == 0:
|
||||
return
|
||||
keys_to_delete = set()
|
||||
for key, cached_item in self._cache.items():
|
||||
if to_match in cached_item.invocation_output_json:
|
||||
keys_to_delete.add(key)
|
||||
if not keys_to_delete:
|
||||
return
|
||||
for key in keys_to_delete:
|
||||
self._delete(key)
|
||||
self._invoker.services.logger.debug(
|
||||
f"Deleted {len(keys_to_delete)} cached invocation outputs for {to_match}"
|
||||
)
|
||||
|
||||
@@ -12,9 +12,12 @@ class InvocationQueueItem(BaseModel):
|
||||
graph_execution_state_id: str = Field(description="The ID of the graph execution state")
|
||||
invocation_id: str = Field(description="The ID of the node being invoked")
|
||||
session_queue_id: str = Field(description="The ID of the session queue from which this invocation queue item came")
|
||||
session_queue_item_id: str = Field(
|
||||
session_queue_item_id: int = Field(
|
||||
description="The ID of session queue item from which this invocation queue item came"
|
||||
)
|
||||
session_queue_batch_id: str = Field(
|
||||
description="The ID of the session batch from which this invocation queue item came"
|
||||
)
|
||||
invoke_all: bool = Field(default=False)
|
||||
timestamp: float = Field(default_factory=time.time)
|
||||
|
||||
|
||||
@@ -18,7 +18,12 @@ class Invoker:
|
||||
self._start()
|
||||
|
||||
def invoke(
|
||||
self, queue_id: str, queue_item_id: str, graph_execution_state: GraphExecutionState, invoke_all: bool = False
|
||||
self,
|
||||
session_queue_id: str,
|
||||
session_queue_item_id: int,
|
||||
session_queue_batch_id: str,
|
||||
graph_execution_state: GraphExecutionState,
|
||||
invoke_all: bool = False,
|
||||
) -> Optional[str]:
|
||||
"""Determines the next node to invoke and enqueues it, preparing if needed.
|
||||
Returns the id of the queued node, or `None` if there are no nodes left to enqueue."""
|
||||
@@ -34,8 +39,9 @@ class Invoker:
|
||||
# Queue the invocation
|
||||
self.services.queue.put(
|
||||
InvocationQueueItem(
|
||||
session_queue_item_id=queue_item_id,
|
||||
session_queue_id=queue_id,
|
||||
session_queue_id=session_queue_id,
|
||||
session_queue_item_id=session_queue_item_id,
|
||||
session_queue_batch_id=session_queue_batch_id,
|
||||
graph_execution_state_id=graph_execution_state.id,
|
||||
invocation_id=invocation.id,
|
||||
invoke_all=invoke_all,
|
||||
|
||||
@@ -3,7 +3,7 @@
|
||||
from abc import ABC, abstractmethod
|
||||
from pathlib import Path
|
||||
from queue import Queue
|
||||
from typing import Dict, Optional, Union
|
||||
from typing import Callable, Dict, Optional, Union
|
||||
|
||||
import torch
|
||||
|
||||
@@ -11,6 +11,13 @@ import torch
|
||||
class LatentsStorageBase(ABC):
|
||||
"""Responsible for storing and retrieving latents."""
|
||||
|
||||
_on_changed_callbacks: list[Callable[[torch.Tensor], None]]
|
||||
_on_deleted_callbacks: list[Callable[[str], None]]
|
||||
|
||||
def __init__(self) -> None:
|
||||
self._on_changed_callbacks = list()
|
||||
self._on_deleted_callbacks = list()
|
||||
|
||||
@abstractmethod
|
||||
def get(self, name: str) -> torch.Tensor:
|
||||
pass
|
||||
@@ -23,6 +30,22 @@ class LatentsStorageBase(ABC):
|
||||
def delete(self, name: str) -> None:
|
||||
pass
|
||||
|
||||
def on_changed(self, on_changed: Callable[[torch.Tensor], None]) -> None:
|
||||
"""Register a callback for when an item is changed"""
|
||||
self._on_changed_callbacks.append(on_changed)
|
||||
|
||||
def on_deleted(self, on_deleted: Callable[[str], None]) -> None:
|
||||
"""Register a callback for when an item is deleted"""
|
||||
self._on_deleted_callbacks.append(on_deleted)
|
||||
|
||||
def _on_changed(self, item: torch.Tensor) -> None:
|
||||
for callback in self._on_changed_callbacks:
|
||||
callback(item)
|
||||
|
||||
def _on_deleted(self, item_id: str) -> None:
|
||||
for callback in self._on_deleted_callbacks:
|
||||
callback(item_id)
|
||||
|
||||
|
||||
class ForwardCacheLatentsStorage(LatentsStorageBase):
|
||||
"""Caches the latest N latents in memory, writing-thorugh to and reading from underlying storage"""
|
||||
@@ -33,6 +56,7 @@ class ForwardCacheLatentsStorage(LatentsStorageBase):
|
||||
__underlying_storage: LatentsStorageBase
|
||||
|
||||
def __init__(self, underlying_storage: LatentsStorageBase, max_cache_size: int = 20):
|
||||
super().__init__()
|
||||
self.__underlying_storage = underlying_storage
|
||||
self.__cache = dict()
|
||||
self.__cache_ids = Queue()
|
||||
@@ -50,11 +74,13 @@ class ForwardCacheLatentsStorage(LatentsStorageBase):
|
||||
def save(self, name: str, data: torch.Tensor) -> None:
|
||||
self.__underlying_storage.save(name, data)
|
||||
self.__set_cache(name, data)
|
||||
self._on_changed(data)
|
||||
|
||||
def delete(self, name: str) -> None:
|
||||
self.__underlying_storage.delete(name)
|
||||
if name in self.__cache:
|
||||
del self.__cache[name]
|
||||
self._on_deleted(name)
|
||||
|
||||
def __get_cache(self, name: str) -> Optional[torch.Tensor]:
|
||||
return None if name not in self.__cache else self.__cache[name]
|
||||
|
||||
@@ -539,6 +539,7 @@ class ModelManagerService(ModelManagerServiceBase):
|
||||
context.services.events.emit_model_load_completed(
|
||||
queue_id=context.queue_id,
|
||||
queue_item_id=context.queue_item_id,
|
||||
queue_batch_id=context.queue_batch_id,
|
||||
graph_execution_state_id=context.graph_execution_state_id,
|
||||
model_name=model_name,
|
||||
base_model=base_model,
|
||||
@@ -550,6 +551,7 @@ class ModelManagerService(ModelManagerServiceBase):
|
||||
context.services.events.emit_model_load_started(
|
||||
queue_id=context.queue_id,
|
||||
queue_item_id=context.queue_item_id,
|
||||
queue_batch_id=context.queue_batch_id,
|
||||
graph_execution_state_id=context.graph_execution_state_id,
|
||||
model_name=model_name,
|
||||
base_model=base_model,
|
||||
|
||||
@@ -57,6 +57,7 @@ class DefaultInvocationProcessor(InvocationProcessorABC):
|
||||
except Exception as e:
|
||||
self.__invoker.services.logger.error("Exception while retrieving session:\n%s" % e)
|
||||
self.__invoker.services.events.emit_session_retrieval_error(
|
||||
queue_batch_id=queue_item.session_queue_batch_id,
|
||||
queue_item_id=queue_item.session_queue_item_id,
|
||||
queue_id=queue_item.session_queue_id,
|
||||
graph_execution_state_id=queue_item.graph_execution_state_id,
|
||||
@@ -70,6 +71,7 @@ class DefaultInvocationProcessor(InvocationProcessorABC):
|
||||
except Exception as e:
|
||||
self.__invoker.services.logger.error("Exception while retrieving invocation:\n%s" % e)
|
||||
self.__invoker.services.events.emit_invocation_retrieval_error(
|
||||
queue_batch_id=queue_item.session_queue_batch_id,
|
||||
queue_item_id=queue_item.session_queue_item_id,
|
||||
queue_id=queue_item.session_queue_id,
|
||||
graph_execution_state_id=queue_item.graph_execution_state_id,
|
||||
@@ -84,6 +86,7 @@ class DefaultInvocationProcessor(InvocationProcessorABC):
|
||||
|
||||
# Send starting event
|
||||
self.__invoker.services.events.emit_invocation_started(
|
||||
queue_batch_id=queue_item.session_queue_batch_id,
|
||||
queue_item_id=queue_item.session_queue_item_id,
|
||||
queue_id=queue_item.session_queue_id,
|
||||
graph_execution_state_id=graph_execution_state.id,
|
||||
@@ -106,6 +109,7 @@ class DefaultInvocationProcessor(InvocationProcessorABC):
|
||||
graph_execution_state_id=graph_execution_state.id,
|
||||
queue_item_id=queue_item.session_queue_item_id,
|
||||
queue_id=queue_item.session_queue_id,
|
||||
queue_batch_id=queue_item.session_queue_batch_id,
|
||||
)
|
||||
)
|
||||
|
||||
@@ -121,6 +125,7 @@ class DefaultInvocationProcessor(InvocationProcessorABC):
|
||||
|
||||
# Send complete event
|
||||
self.__invoker.services.events.emit_invocation_complete(
|
||||
queue_batch_id=queue_item.session_queue_batch_id,
|
||||
queue_item_id=queue_item.session_queue_item_id,
|
||||
queue_id=queue_item.session_queue_id,
|
||||
graph_execution_state_id=graph_execution_state.id,
|
||||
@@ -150,6 +155,7 @@ class DefaultInvocationProcessor(InvocationProcessorABC):
|
||||
self.__invoker.services.logger.error("Error while invoking:\n%s" % e)
|
||||
# Send error event
|
||||
self.__invoker.services.events.emit_invocation_error(
|
||||
queue_batch_id=queue_item.session_queue_batch_id,
|
||||
queue_item_id=queue_item.session_queue_item_id,
|
||||
queue_id=queue_item.session_queue_id,
|
||||
graph_execution_state_id=graph_execution_state.id,
|
||||
@@ -170,14 +176,16 @@ class DefaultInvocationProcessor(InvocationProcessorABC):
|
||||
if queue_item.invoke_all and not is_complete:
|
||||
try:
|
||||
self.__invoker.invoke(
|
||||
queue_item_id=queue_item.session_queue_item_id,
|
||||
queue_id=queue_item.session_queue_id,
|
||||
session_queue_batch_id=queue_item.session_queue_batch_id,
|
||||
session_queue_item_id=queue_item.session_queue_item_id,
|
||||
session_queue_id=queue_item.session_queue_id,
|
||||
graph_execution_state=graph_execution_state,
|
||||
invoke_all=True,
|
||||
)
|
||||
except Exception as e:
|
||||
self.__invoker.services.logger.error("Error while invoking:\n%s" % e)
|
||||
self.__invoker.services.events.emit_invocation_error(
|
||||
queue_batch_id=queue_item.session_queue_batch_id,
|
||||
queue_item_id=queue_item.session_queue_item_id,
|
||||
queue_id=queue_item.session_queue_id,
|
||||
graph_execution_state_id=graph_execution_state.id,
|
||||
@@ -188,6 +196,7 @@ class DefaultInvocationProcessor(InvocationProcessorABC):
|
||||
)
|
||||
elif is_complete:
|
||||
self.__invoker.services.events.emit_graph_execution_complete(
|
||||
queue_batch_id=queue_item.session_queue_batch_id,
|
||||
queue_item_id=queue_item.session_queue_item_id,
|
||||
queue_id=queue_item.session_queue_id,
|
||||
graph_execution_state_id=graph_execution_state.id,
|
||||
|
||||
@@ -47,20 +47,27 @@ class DefaultSessionProcessor(SessionProcessorBase):
|
||||
async def _on_queue_event(self, event: FastAPIEvent) -> None:
|
||||
event_name = event[1]["event"]
|
||||
|
||||
match event_name:
|
||||
case "graph_execution_state_complete" | "invocation_error" | "session_retrieval_error" | "invocation_retrieval_error":
|
||||
self.__queue_item = None
|
||||
self._poll_now()
|
||||
case "session_canceled" if self.__queue_item is not None and self.__queue_item.session_id == event[1][
|
||||
"data"
|
||||
]["graph_execution_state_id"]:
|
||||
self.__queue_item = None
|
||||
self._poll_now()
|
||||
case "batch_enqueued":
|
||||
self._poll_now()
|
||||
case "queue_cleared":
|
||||
self.__queue_item = None
|
||||
self._poll_now()
|
||||
# This was a match statement, but match is not supported on python 3.9
|
||||
if event_name in [
|
||||
"graph_execution_state_complete",
|
||||
"invocation_error",
|
||||
"session_retrieval_error",
|
||||
"invocation_retrieval_error",
|
||||
]:
|
||||
self.__queue_item = None
|
||||
self._poll_now()
|
||||
elif (
|
||||
event_name == "session_canceled"
|
||||
and self.__queue_item is not None
|
||||
and self.__queue_item.session_id == event[1]["data"]["graph_execution_state_id"]
|
||||
):
|
||||
self.__queue_item = None
|
||||
self._poll_now()
|
||||
elif event_name == "batch_enqueued":
|
||||
self._poll_now()
|
||||
elif event_name == "queue_cleared":
|
||||
self.__queue_item = None
|
||||
self._poll_now()
|
||||
|
||||
def resume(self) -> SessionProcessorStatus:
|
||||
if not self.__resume_event.is_set():
|
||||
@@ -92,29 +99,34 @@ class DefaultSessionProcessor(SessionProcessorBase):
|
||||
self.__invoker.services.logger
|
||||
while not stop_event.is_set():
|
||||
poll_now_event.clear()
|
||||
try:
|
||||
# do not dequeue if there is already a session running
|
||||
if self.__queue_item is None and resume_event.is_set():
|
||||
queue_item = self.__invoker.services.session_queue.dequeue()
|
||||
|
||||
# do not dequeue if there is already a session running
|
||||
if self.__queue_item is None and resume_event.is_set():
|
||||
queue_item = self.__invoker.services.session_queue.dequeue()
|
||||
if queue_item is not None:
|
||||
self.__invoker.services.logger.debug(f"Executing queue item {queue_item.item_id}")
|
||||
self.__queue_item = queue_item
|
||||
self.__invoker.services.graph_execution_manager.set(queue_item.session)
|
||||
self.__invoker.invoke(
|
||||
session_queue_batch_id=queue_item.batch_id,
|
||||
session_queue_id=queue_item.queue_id,
|
||||
session_queue_item_id=queue_item.item_id,
|
||||
graph_execution_state=queue_item.session,
|
||||
invoke_all=True,
|
||||
)
|
||||
queue_item = None
|
||||
|
||||
if queue_item is not None:
|
||||
self.__invoker.services.logger.debug(f"Executing queue item {queue_item.item_id}")
|
||||
self.__queue_item = queue_item
|
||||
self.__invoker.services.graph_execution_manager.set(queue_item.session)
|
||||
self.__invoker.invoke(
|
||||
queue_item_id=queue_item.item_id,
|
||||
queue_id=queue_item.queue_id,
|
||||
graph_execution_state=queue_item.session,
|
||||
invoke_all=True,
|
||||
)
|
||||
queue_item = None
|
||||
|
||||
if queue_item is None:
|
||||
self.__invoker.services.logger.debug("Waiting for next polling interval or event")
|
||||
if queue_item is None:
|
||||
self.__invoker.services.logger.debug("Waiting for next polling interval or event")
|
||||
poll_now_event.wait(POLLING_INTERVAL)
|
||||
continue
|
||||
except Exception as e:
|
||||
self.__invoker.services.logger.error(f"Error in session processor: {e}")
|
||||
poll_now_event.wait(POLLING_INTERVAL)
|
||||
continue
|
||||
except Exception as e:
|
||||
self.__invoker.services.logger.error(f"Error in session processor: {e}")
|
||||
self.__invoker.services.logger.error(f"Fatal Error in session processor: {e}")
|
||||
pass
|
||||
finally:
|
||||
stop_event.clear()
|
||||
|
||||
@@ -80,7 +80,7 @@ class SessionQueueBase(ABC):
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def cancel_queue_item(self, item_id: str) -> SessionQueueItem:
|
||||
def cancel_queue_item(self, item_id: int) -> SessionQueueItem:
|
||||
"""Cancels a session queue item"""
|
||||
pass
|
||||
|
||||
@@ -100,13 +100,13 @@ class SessionQueueBase(ABC):
|
||||
queue_id: str,
|
||||
limit: int,
|
||||
priority: int,
|
||||
order_id: Optional[int] = None,
|
||||
cursor: Optional[int] = None,
|
||||
status: Optional[QUEUE_ITEM_STATUS] = None,
|
||||
) -> CursorPaginatedResults[SessionQueueItemDTO]:
|
||||
"""Gets a page of session queue items"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def get_queue_item(self, item_id: str) -> SessionQueueItem:
|
||||
def get_queue_item(self, item_id: int) -> SessionQueueItem:
|
||||
"""Gets a session queue item by ID"""
|
||||
pass
|
||||
|
||||
@@ -155,23 +155,22 @@ def get_session(queue_item_dict: dict) -> GraphExecutionState:
|
||||
class SessionQueueItemWithoutGraph(BaseModel):
|
||||
"""Session queue item without the full graph. Used for serialization."""
|
||||
|
||||
item_id: str = Field(description="The unique identifier of the session queue item")
|
||||
order_id: int = Field(description="The auto-incrementing ID of the session queue item")
|
||||
item_id: int = Field(description="The identifier of the session queue item")
|
||||
status: QUEUE_ITEM_STATUS = Field(default="pending", description="The status of this queue item")
|
||||
priority: int = Field(default=0, description="The priority of this queue item")
|
||||
batch_id: str = Field(description="The ID of the batch associated with this queue item")
|
||||
session_id: str = Field(
|
||||
description="The ID of the session associated with this queue item. The session doesn't exist in graph_executions until the queue item is executed."
|
||||
)
|
||||
field_values: Optional[list[NodeFieldValue]] = Field(
|
||||
default=None, description="The field values that were used for this queue item"
|
||||
)
|
||||
queue_id: str = Field(description="The id of the queue with which this item is associated")
|
||||
error: Optional[str] = Field(default=None, description="The error message if this queue item errored")
|
||||
created_at: Union[datetime.datetime, str] = Field(description="When this queue item was created")
|
||||
updated_at: Union[datetime.datetime, str] = Field(description="When this queue item was updated")
|
||||
started_at: Optional[Union[datetime.datetime, str]] = Field(description="When this queue item was started")
|
||||
completed_at: Optional[Union[datetime.datetime, str]] = Field(description="When this queue item was completed")
|
||||
queue_id: str = Field(description="The id of the queue with which this item is associated")
|
||||
field_values: Optional[list[NodeFieldValue]] = Field(
|
||||
default=None, description="The field values that were used for this queue item"
|
||||
)
|
||||
|
||||
@classmethod
|
||||
def from_dict(cls, queue_item_dict: dict) -> "SessionQueueItemDTO":
|
||||
@@ -183,7 +182,6 @@ class SessionQueueItemWithoutGraph(BaseModel):
|
||||
schema_extra = {
|
||||
"required": [
|
||||
"item_id",
|
||||
"order_id",
|
||||
"status",
|
||||
"batch_id",
|
||||
"queue_id",
|
||||
@@ -214,7 +212,6 @@ class SessionQueueItem(SessionQueueItemWithoutGraph):
|
||||
schema_extra = {
|
||||
"required": [
|
||||
"item_id",
|
||||
"order_id",
|
||||
"status",
|
||||
"batch_id",
|
||||
"queue_id",
|
||||
@@ -235,7 +232,7 @@ class SessionQueueItem(SessionQueueItemWithoutGraph):
|
||||
|
||||
class SessionQueueStatus(BaseModel):
|
||||
queue_id: str = Field(..., description="The ID of the queue")
|
||||
item_id: Optional[str] = Field(description="The current queue item id")
|
||||
item_id: Optional[int] = Field(description="The current queue item id")
|
||||
batch_id: Optional[str] = Field(description="The current queue item's batch id")
|
||||
session_id: Optional[str] = Field(description="The current queue item's session id")
|
||||
pending: int = Field(..., description="Number of queue items with status 'pending'")
|
||||
@@ -388,29 +385,24 @@ def calc_session_count(batch: Batch) -> int:
|
||||
class SessionQueueValueToInsert(NamedTuple):
|
||||
"""A tuple of values to insert into the session_queue table"""
|
||||
|
||||
item_id: str # item_id
|
||||
queue_id: str # queue_id
|
||||
session: str # session json
|
||||
session_id: str # session_id
|
||||
batch_id: str # batch_id
|
||||
field_values: Optional[str] # field_values json
|
||||
priority: int # priority
|
||||
order_id: int # order_id
|
||||
|
||||
|
||||
ValuesToInsert: TypeAlias = list[SessionQueueValueToInsert]
|
||||
|
||||
|
||||
def prepare_values_to_insert(
|
||||
queue_id: str, batch: Batch, priority: int, max_new_queue_items: int, order_id: int
|
||||
) -> ValuesToInsert:
|
||||
def prepare_values_to_insert(queue_id: str, batch: Batch, priority: int, max_new_queue_items: int) -> ValuesToInsert:
|
||||
values_to_insert: ValuesToInsert = []
|
||||
for session, field_values in create_session_nfv_tuples(batch, max_new_queue_items):
|
||||
# sessions must have unique id
|
||||
session.id = uuid_string()
|
||||
values_to_insert.append(
|
||||
SessionQueueValueToInsert(
|
||||
uuid_string(), # item_id
|
||||
queue_id, # queue_id
|
||||
session.json(), # session (json)
|
||||
session.id, # session_id
|
||||
@@ -418,10 +410,8 @@ def prepare_values_to_insert(
|
||||
# must use pydantic_encoder bc field_values is a list of models
|
||||
json.dumps(field_values, default=pydantic_encoder) if field_values else None, # field_values (json)
|
||||
priority, # priority
|
||||
order_id,
|
||||
)
|
||||
)
|
||||
order_id += 1
|
||||
return values_to_insert
|
||||
|
||||
|
||||
|
||||
@@ -59,13 +59,14 @@ class SqliteSessionQueue(SessionQueueBase):
|
||||
|
||||
async def _on_session_event(self, event: FastAPIEvent) -> FastAPIEvent:
|
||||
event_name = event[1]["event"]
|
||||
match event_name:
|
||||
case "graph_execution_state_complete":
|
||||
await self._handle_complete_event(event)
|
||||
case "invocation_error" | "session_retrieval_error" | "invocation_retrieval_error":
|
||||
await self._handle_error_event(event)
|
||||
case "session_canceled":
|
||||
await self._handle_cancel_event(event)
|
||||
|
||||
# This was a match statement, but match is not supported on python 3.9
|
||||
if event_name == "graph_execution_state_complete":
|
||||
await self._handle_complete_event(event)
|
||||
elif event_name in ["invocation_error", "session_retrieval_error", "invocation_retrieval_error"]:
|
||||
await self._handle_error_event(event)
|
||||
elif event_name == "session_canceled":
|
||||
await self._handle_cancel_event(event)
|
||||
return event
|
||||
|
||||
async def _handle_complete_event(self, event: FastAPIEvent) -> None:
|
||||
@@ -77,7 +78,6 @@ class SqliteSessionQueue(SessionQueueBase):
|
||||
queue_item = self.get_queue_item(item_id)
|
||||
if queue_item.status not in ["completed", "failed", "canceled"]:
|
||||
queue_item = self._set_queue_item_status(item_id=queue_item.item_id, status="completed")
|
||||
self.__invoker.services.events.emit_queue_item_status_changed(queue_item)
|
||||
except SessionQueueItemNotFoundError:
|
||||
return
|
||||
|
||||
@@ -86,8 +86,8 @@ class SqliteSessionQueue(SessionQueueBase):
|
||||
item_id = event[1]["data"]["queue_item_id"]
|
||||
error = event[1]["data"]["error"]
|
||||
queue_item = self.get_queue_item(item_id)
|
||||
# always set to failed if have an error, even if previously the item was marked completed or canceled
|
||||
queue_item = self._set_queue_item_status(item_id=queue_item.item_id, status="failed", error=error)
|
||||
self.__invoker.services.events.emit_queue_item_status_changed(queue_item)
|
||||
except SessionQueueItemNotFoundError:
|
||||
return
|
||||
|
||||
@@ -95,8 +95,8 @@ class SqliteSessionQueue(SessionQueueBase):
|
||||
try:
|
||||
item_id = event[1]["data"]["queue_item_id"]
|
||||
queue_item = self.get_queue_item(item_id)
|
||||
queue_item = self._set_queue_item_status(item_id=queue_item.item_id, status="canceled")
|
||||
self.__invoker.services.events.emit_queue_item_status_changed(queue_item)
|
||||
if queue_item.status not in ["completed", "failed", "canceled"]:
|
||||
queue_item = self._set_queue_item_status(item_id=queue_item.item_id, status="canceled")
|
||||
except SessionQueueItemNotFoundError:
|
||||
return
|
||||
|
||||
@@ -107,8 +107,7 @@ class SqliteSessionQueue(SessionQueueBase):
|
||||
self.__cursor.execute(
|
||||
"""--sql
|
||||
CREATE TABLE IF NOT EXISTS session_queue (
|
||||
item_id TEXT NOT NULL PRIMARY KEY, -- the unique identifier of this queue item
|
||||
order_id INTEGER NOT NULL, -- used for ordering, cursor pagination
|
||||
item_id INTEGER PRIMARY KEY AUTOINCREMENT, -- used for ordering, cursor pagination
|
||||
batch_id TEXT NOT NULL, -- identifier of the batch this queue item belongs to
|
||||
queue_id TEXT NOT NULL, -- identifier of the queue this queue item belongs to
|
||||
session_id TEXT NOT NULL UNIQUE, -- duplicated data from the session column, for ease of access
|
||||
@@ -133,12 +132,6 @@ class SqliteSessionQueue(SessionQueueBase):
|
||||
"""
|
||||
)
|
||||
|
||||
self.__cursor.execute(
|
||||
"""--sql
|
||||
CREATE UNIQUE INDEX IF NOT EXISTS idx_session_queue_order_id ON session_queue(order_id);
|
||||
"""
|
||||
)
|
||||
|
||||
self.__cursor.execute(
|
||||
"""--sql
|
||||
CREATE UNIQUE INDEX IF NOT EXISTS idx_session_queue_session_id ON session_queue(session_id);
|
||||
@@ -302,21 +295,12 @@ class SqliteSessionQueue(SessionQueueBase):
|
||||
if prepend:
|
||||
priority = self._get_highest_priority(queue_id) + 1
|
||||
|
||||
self.__cursor.execute(
|
||||
"""--sql
|
||||
SELECT MAX(order_id)
|
||||
FROM session_queue
|
||||
"""
|
||||
)
|
||||
max_order_id = cast(Optional[int], self.__cursor.fetchone()[0]) or 0
|
||||
|
||||
requested_count = calc_session_count(batch)
|
||||
values_to_insert = prepare_values_to_insert(
|
||||
queue_id=queue_id,
|
||||
batch=batch,
|
||||
priority=priority,
|
||||
max_new_queue_items=max_new_queue_items,
|
||||
order_id=max_order_id + 1,
|
||||
)
|
||||
enqueued_count = len(values_to_insert)
|
||||
|
||||
@@ -325,8 +309,8 @@ class SqliteSessionQueue(SessionQueueBase):
|
||||
|
||||
self.__cursor.executemany(
|
||||
"""--sql
|
||||
INSERT INTO session_queue (item_id, queue_id, session, session_id, batch_id, field_values, priority, order_id)
|
||||
VALUES (?, ?, ?, ?, ?, ?, ?, ?)
|
||||
INSERT INTO session_queue (queue_id, session, session_id, batch_id, field_values, priority)
|
||||
VALUES (?, ?, ?, ?, ?, ?)
|
||||
""",
|
||||
values_to_insert,
|
||||
)
|
||||
@@ -356,7 +340,7 @@ class SqliteSessionQueue(SessionQueueBase):
|
||||
WHERE status = 'pending'
|
||||
ORDER BY
|
||||
priority DESC,
|
||||
order_id ASC
|
||||
item_id ASC
|
||||
LIMIT 1
|
||||
"""
|
||||
)
|
||||
@@ -370,7 +354,6 @@ class SqliteSessionQueue(SessionQueueBase):
|
||||
return None
|
||||
queue_item = SessionQueueItem.from_dict(dict(result))
|
||||
queue_item = self._set_queue_item_status(item_id=queue_item.item_id, status="in_progress")
|
||||
self.__invoker.services.events.emit_queue_item_status_changed(queue_item)
|
||||
return queue_item
|
||||
|
||||
def get_next(self, queue_id: str) -> Optional[SessionQueueItem]:
|
||||
@@ -425,7 +408,7 @@ class SqliteSessionQueue(SessionQueueBase):
|
||||
return SessionQueueItem.from_dict(dict(result))
|
||||
|
||||
def _set_queue_item_status(
|
||||
self, item_id: str, status: QUEUE_ITEM_STATUS, error: Optional[str] = None
|
||||
self, item_id: int, status: QUEUE_ITEM_STATUS, error: Optional[str] = None
|
||||
) -> SessionQueueItem:
|
||||
try:
|
||||
self.__lock.acquire()
|
||||
@@ -443,7 +426,9 @@ class SqliteSessionQueue(SessionQueueBase):
|
||||
raise
|
||||
finally:
|
||||
self.__lock.release()
|
||||
return self.get_queue_item(item_id)
|
||||
queue_item = self.get_queue_item(item_id)
|
||||
self.__invoker.services.events.emit_queue_item_status_changed(queue_item)
|
||||
return queue_item
|
||||
|
||||
def is_empty(self, queue_id: str) -> IsEmptyResult:
|
||||
try:
|
||||
@@ -484,7 +469,7 @@ class SqliteSessionQueue(SessionQueueBase):
|
||||
self.__lock.release()
|
||||
return IsFullResult(is_full=is_full)
|
||||
|
||||
def delete_queue_item(self, item_id: str) -> SessionQueueItem:
|
||||
def delete_queue_item(self, item_id: int) -> SessionQueueItem:
|
||||
queue_item = self.get_queue_item(item_id=item_id)
|
||||
try:
|
||||
self.__lock.acquire()
|
||||
@@ -570,7 +555,7 @@ class SqliteSessionQueue(SessionQueueBase):
|
||||
self.__lock.release()
|
||||
return PruneResult(deleted=count)
|
||||
|
||||
def cancel_queue_item(self, item_id: str) -> SessionQueueItem:
|
||||
def cancel_queue_item(self, item_id: int) -> SessionQueueItem:
|
||||
queue_item = self.get_queue_item(item_id)
|
||||
if queue_item.status not in ["canceled", "failed", "completed"]:
|
||||
queue_item = self._set_queue_item_status(item_id=item_id, status="canceled")
|
||||
@@ -578,9 +563,9 @@ class SqliteSessionQueue(SessionQueueBase):
|
||||
self.__invoker.services.events.emit_session_canceled(
|
||||
queue_item_id=queue_item.item_id,
|
||||
queue_id=queue_item.queue_id,
|
||||
queue_batch_id=queue_item.batch_id,
|
||||
graph_execution_state_id=queue_item.session_id,
|
||||
)
|
||||
self.__invoker.services.events.emit_queue_item_status_changed(queue_item)
|
||||
return queue_item
|
||||
|
||||
def cancel_by_batch_ids(self, queue_id: str, batch_ids: list[str]) -> CancelByBatchIDsResult:
|
||||
@@ -620,6 +605,7 @@ class SqliteSessionQueue(SessionQueueBase):
|
||||
self.__invoker.services.events.emit_session_canceled(
|
||||
queue_item_id=current_queue_item.item_id,
|
||||
queue_id=current_queue_item.queue_id,
|
||||
queue_batch_id=current_queue_item.batch_id,
|
||||
graph_execution_state_id=current_queue_item.session_id,
|
||||
)
|
||||
self.__invoker.services.events.emit_queue_item_status_changed(current_queue_item)
|
||||
@@ -665,6 +651,7 @@ class SqliteSessionQueue(SessionQueueBase):
|
||||
self.__invoker.services.events.emit_session_canceled(
|
||||
queue_item_id=current_queue_item.item_id,
|
||||
queue_id=current_queue_item.queue_id,
|
||||
queue_batch_id=current_queue_item.batch_id,
|
||||
graph_execution_state_id=current_queue_item.session_id,
|
||||
)
|
||||
self.__invoker.services.events.emit_queue_item_status_changed(current_queue_item)
|
||||
@@ -675,7 +662,7 @@ class SqliteSessionQueue(SessionQueueBase):
|
||||
self.__lock.release()
|
||||
return CancelByQueueIDResult(canceled=count)
|
||||
|
||||
def get_queue_item(self, item_id: str) -> SessionQueueItem:
|
||||
def get_queue_item(self, item_id: int) -> SessionQueueItem:
|
||||
try:
|
||||
self.__lock.acquire()
|
||||
self.__cursor.execute(
|
||||
@@ -701,14 +688,14 @@ class SqliteSessionQueue(SessionQueueBase):
|
||||
queue_id: str,
|
||||
limit: int,
|
||||
priority: int,
|
||||
order_id: Optional[int] = None,
|
||||
cursor: Optional[int] = None,
|
||||
status: Optional[QUEUE_ITEM_STATUS] = None,
|
||||
) -> CursorPaginatedResults[SessionQueueItemDTO]:
|
||||
try:
|
||||
item_id = cursor
|
||||
self.__lock.acquire()
|
||||
query = """--sql
|
||||
SELECT item_id,
|
||||
order_id,
|
||||
status,
|
||||
priority,
|
||||
field_values,
|
||||
@@ -731,16 +718,16 @@ class SqliteSessionQueue(SessionQueueBase):
|
||||
"""
|
||||
params.append(status)
|
||||
|
||||
if order_id is not None:
|
||||
if item_id is not None:
|
||||
query += """--sql
|
||||
AND (priority < ?) OR (priority = ? AND order_id > ?)
|
||||
AND (priority < ?) OR (priority = ? AND item_id > ?)
|
||||
"""
|
||||
params.extend([priority, priority, order_id])
|
||||
params.extend([priority, priority, item_id])
|
||||
|
||||
query += """--sql
|
||||
ORDER BY
|
||||
priority DESC,
|
||||
order_id ASC
|
||||
item_id ASC
|
||||
LIMIT ?
|
||||
"""
|
||||
params.append(limit + 1)
|
||||
|
||||
@@ -112,6 +112,7 @@ def stable_diffusion_step_callback(
|
||||
context.services.events.emit_generator_progress(
|
||||
queue_id=context.queue_id,
|
||||
queue_item_id=context.queue_item_id,
|
||||
queue_batch_id=context.queue_batch_id,
|
||||
graph_execution_state_id=context.graph_execution_state_id,
|
||||
node=node,
|
||||
source_node_id=source_node_id,
|
||||
|
||||
46
invokeai/backend/image_util/invoke_metadata.py
Normal file
46
invokeai/backend/image_util/invoke_metadata.py
Normal file
@@ -0,0 +1,46 @@
|
||||
# Copyright (c) 2023 Lincoln D. Stein and the InvokeAI Development Team
|
||||
|
||||
"""Very simple functions to fetch and print metadata from InvokeAI-generated images."""
|
||||
|
||||
import json
|
||||
import sys
|
||||
from pathlib import Path
|
||||
from typing import Any, Dict
|
||||
|
||||
from PIL import Image
|
||||
|
||||
|
||||
def get_invokeai_metadata(image_path: Path) -> Dict[str, Any]:
|
||||
"""
|
||||
Retrieve "invokeai_metadata" field from png image.
|
||||
|
||||
:param image_path: Path to the image to read metadata from.
|
||||
May raise:
|
||||
OSError -- image path not found
|
||||
KeyError -- image doesn't contain the metadata field
|
||||
"""
|
||||
image: Image = Image.open(image_path)
|
||||
return json.loads(image.text["invokeai_metadata"])
|
||||
|
||||
|
||||
def print_invokeai_metadata(image_path: Path):
|
||||
"""Pretty-print the metadata."""
|
||||
try:
|
||||
metadata = get_invokeai_metadata(image_path)
|
||||
print(f"{image_path}:\n{json.dumps(metadata, sort_keys=True, indent=4)}")
|
||||
except OSError:
|
||||
print(f"{image_path}:\nNo file found.")
|
||||
except KeyError:
|
||||
print(f"{image_path}:\nNo metadata found.")
|
||||
print()
|
||||
|
||||
|
||||
def main():
|
||||
"""Run the command-line utility."""
|
||||
image_paths = sys.argv[1:]
|
||||
if not image_paths:
|
||||
print(f"Usage: {Path(sys.argv[0]).name} image1 image2 image3 ...")
|
||||
print("\nPretty-print InvokeAI image metadata from the listed png files.")
|
||||
sys.exit(-1)
|
||||
for img in image_paths:
|
||||
print_invokeai_metadata(img)
|
||||
@@ -70,7 +70,6 @@ def get_literal_fields(field) -> list[Any]:
|
||||
config = InvokeAIAppConfig.get_config()
|
||||
|
||||
Model_dir = "models"
|
||||
|
||||
Default_config_file = config.model_conf_path
|
||||
SD_Configs = config.legacy_conf_path
|
||||
|
||||
@@ -93,7 +92,7 @@ INIT_FILE_PREAMBLE = """# InvokeAI initialization file
|
||||
# or renaming it and then running invokeai-configure again.
|
||||
"""
|
||||
|
||||
logger = InvokeAILogger.getLogger()
|
||||
logger = InvokeAILogger.get_logger()
|
||||
|
||||
|
||||
class DummyWidgetValue(Enum):
|
||||
@@ -458,7 +457,7 @@ Use cursor arrows to make a checkbox selection, and space to toggle.
|
||||
)
|
||||
self.add_widget_intelligent(
|
||||
npyscreen.TitleFixedText,
|
||||
name="Model RAM cache size (GB). Make this at least large enough to hold a single full model.",
|
||||
name="Model RAM cache size (GB). Make this at least large enough to hold a single full model (2GB for SD-1, 6GB for SDXL).",
|
||||
begin_entry_at=0,
|
||||
editable=False,
|
||||
color="CONTROL",
|
||||
@@ -651,8 +650,19 @@ def edit_opts(program_opts: Namespace, invokeai_opts: Namespace) -> argparse.Nam
|
||||
return editApp.new_opts()
|
||||
|
||||
|
||||
def default_ramcache() -> float:
|
||||
"""Run a heuristic for the default RAM cache based on installed RAM."""
|
||||
|
||||
# Note that on my 64 GB machine, psutil.virtual_memory().total gives 62 GB,
|
||||
# So we adjust everthing down a bit.
|
||||
return (
|
||||
15.0 if MAX_RAM >= 60 else 7.5 if MAX_RAM >= 30 else 4 if MAX_RAM >= 14 else 2.1
|
||||
) # 2.1 is just large enough for sd 1.5 ;-)
|
||||
|
||||
|
||||
def default_startup_options(init_file: Path) -> Namespace:
|
||||
opts = InvokeAIAppConfig.get_config()
|
||||
opts.ram = default_ramcache()
|
||||
return opts
|
||||
|
||||
|
||||
@@ -894,7 +904,7 @@ def main():
|
||||
if opt.full_precision:
|
||||
invoke_args.extend(["--precision", "float32"])
|
||||
config.parse_args(invoke_args)
|
||||
logger = InvokeAILogger().getLogger(config=config)
|
||||
logger = InvokeAILogger().get_logger(config=config)
|
||||
|
||||
errors = set()
|
||||
|
||||
|
||||
@@ -30,7 +30,7 @@ warnings.filterwarnings("ignore")
|
||||
|
||||
# --------------------------globals-----------------------
|
||||
config = InvokeAIAppConfig.get_config()
|
||||
logger = InvokeAILogger.getLogger(name="InvokeAI")
|
||||
logger = InvokeAILogger.get_logger(name="InvokeAI")
|
||||
|
||||
# the initial "configs" dir is now bundled in the `invokeai.configs` package
|
||||
Dataset_path = Path(configs.__path__[0]) / "INITIAL_MODELS.yaml"
|
||||
@@ -47,8 +47,14 @@ Config_preamble = """
|
||||
|
||||
LEGACY_CONFIGS = {
|
||||
BaseModelType.StableDiffusion1: {
|
||||
ModelVariantType.Normal: "v1-inference.yaml",
|
||||
ModelVariantType.Inpaint: "v1-inpainting-inference.yaml",
|
||||
ModelVariantType.Normal: {
|
||||
SchedulerPredictionType.Epsilon: "v1-inference.yaml",
|
||||
SchedulerPredictionType.VPrediction: "v1-inference-v.yaml",
|
||||
},
|
||||
ModelVariantType.Inpaint: {
|
||||
SchedulerPredictionType.Epsilon: "v1-inpainting-inference.yaml",
|
||||
SchedulerPredictionType.VPrediction: "v1-inpainting-inference-v.yaml",
|
||||
},
|
||||
},
|
||||
BaseModelType.StableDiffusion2: {
|
||||
ModelVariantType.Normal: {
|
||||
@@ -69,14 +75,6 @@ LEGACY_CONFIGS = {
|
||||
}
|
||||
|
||||
|
||||
@dataclass
|
||||
class ModelInstallList:
|
||||
"""Class for listing models to be installed/removed"""
|
||||
|
||||
install_models: List[str] = field(default_factory=list)
|
||||
remove_models: List[str] = field(default_factory=list)
|
||||
|
||||
|
||||
@dataclass
|
||||
class InstallSelections:
|
||||
install_models: List[str] = field(default_factory=list)
|
||||
@@ -94,6 +92,7 @@ class ModelLoadInfo:
|
||||
installed: bool = False
|
||||
recommended: bool = False
|
||||
default: bool = False
|
||||
requires: Optional[List[str]] = field(default_factory=list)
|
||||
|
||||
|
||||
class ModelInstall(object):
|
||||
@@ -131,8 +130,6 @@ class ModelInstall(object):
|
||||
|
||||
# supplement with entries in models.yaml
|
||||
installed_models = [x for x in self.mgr.list_models()]
|
||||
# suppresses autoloaded models
|
||||
# installed_models = [x for x in self.mgr.list_models() if not self._is_autoloaded(x)]
|
||||
|
||||
for md in installed_models:
|
||||
base = md["base_model"]
|
||||
@@ -164,9 +161,12 @@ class ModelInstall(object):
|
||||
|
||||
def list_models(self, model_type):
|
||||
installed = self.mgr.list_models(model_type=model_type)
|
||||
print()
|
||||
print(f"Installed models of type `{model_type}`:")
|
||||
print(f"{'Model Key':50} Model Path")
|
||||
for i in installed:
|
||||
print(f"{i['model_name']}\t{i['base_model']}\t{i['path']}")
|
||||
print(f"{'/'.join([i['base_model'],i['model_type'],i['model_name']]):50} {i['path']}")
|
||||
print()
|
||||
|
||||
# logic here a little reversed to maintain backward compatibility
|
||||
def starter_models(self, all_models: bool = False) -> Set[str]:
|
||||
@@ -204,6 +204,8 @@ class ModelInstall(object):
|
||||
job += 1
|
||||
|
||||
# add requested models
|
||||
self._remove_installed(selections.install_models)
|
||||
self._add_required_models(selections.install_models)
|
||||
for path in selections.install_models:
|
||||
logger.info(f"Installing {path} [{job}/{jobs}]")
|
||||
try:
|
||||
@@ -263,6 +265,26 @@ class ModelInstall(object):
|
||||
|
||||
return models_installed
|
||||
|
||||
def _remove_installed(self, model_list: List[str]):
|
||||
all_models = self.all_models()
|
||||
for path in model_list:
|
||||
key = self.reverse_paths.get(path)
|
||||
if key and all_models[key].installed:
|
||||
logger.warning(f"{path} already installed. Skipping.")
|
||||
model_list.remove(path)
|
||||
|
||||
def _add_required_models(self, model_list: List[str]):
|
||||
additional_models = []
|
||||
all_models = self.all_models()
|
||||
for path in model_list:
|
||||
if not (key := self.reverse_paths.get(path)):
|
||||
continue
|
||||
for requirement in all_models[key].requires:
|
||||
requirement_key = self.reverse_paths.get(requirement)
|
||||
if not all_models[requirement_key].installed:
|
||||
additional_models.append(requirement)
|
||||
model_list.extend(additional_models)
|
||||
|
||||
# install a model from a local path. The optional info parameter is there to prevent
|
||||
# the model from being probed twice in the event that it has already been probed.
|
||||
def _install_path(self, path: Path, info: ModelProbeInfo = None) -> AddModelResult:
|
||||
@@ -286,7 +308,7 @@ class ModelInstall(object):
|
||||
location = download_with_resume(url, Path(staging))
|
||||
if not location:
|
||||
logger.error(f"Unable to download {url}. Skipping.")
|
||||
info = ModelProbe().heuristic_probe(location)
|
||||
info = ModelProbe().heuristic_probe(location, self.prediction_helper)
|
||||
dest = self.config.models_path / info.base_type.value / info.model_type.value / location.name
|
||||
dest.parent.mkdir(parents=True, exist_ok=True)
|
||||
models_path = shutil.move(location, dest)
|
||||
@@ -326,6 +348,16 @@ class ModelInstall(object):
|
||||
elif f"learned_embeds.{suffix}" in files:
|
||||
location = self._download_hf_model(repo_id, [f"learned_embeds.{suffix}"], staging)
|
||||
break
|
||||
elif "image_encoder.txt" in files and f"ip_adapter.{suffix}" in files: # IP-Adapter
|
||||
files = ["image_encoder.txt", f"ip_adapter.{suffix}"]
|
||||
location = self._download_hf_model(repo_id, files, staging)
|
||||
break
|
||||
elif f"model.{suffix}" in files and "config.json" in files:
|
||||
# This elif-condition is pretty fragile, but it is intended to handle CLIP Vision models hosted
|
||||
# by InvokeAI for use with IP-Adapters.
|
||||
files = ["config.json", f"model.{suffix}"]
|
||||
location = self._download_hf_model(repo_id, files, staging)
|
||||
break
|
||||
if not location:
|
||||
logger.warning(f"Could not determine type of repo {repo_id}. Skipping install.")
|
||||
return {}
|
||||
@@ -383,7 +415,7 @@ class ModelInstall(object):
|
||||
possible_conf = path.with_suffix(".yaml")
|
||||
if possible_conf.exists():
|
||||
legacy_conf = str(self.relative_to_root(possible_conf))
|
||||
elif info.base_type == BaseModelType.StableDiffusion2:
|
||||
elif info.base_type in [BaseModelType.StableDiffusion1, BaseModelType.StableDiffusion2]:
|
||||
legacy_conf = Path(
|
||||
self.config.legacy_conf_dir,
|
||||
LEGACY_CONFIGS[info.base_type][info.variant_type][info.prediction_type],
|
||||
@@ -482,7 +514,7 @@ def yes_or_no(prompt: str, default_yes=True):
|
||||
|
||||
# ---------------------------------------------
|
||||
def hf_download_from_pretrained(model_class: object, model_name: str, destination: Path, **kwargs):
|
||||
logger = InvokeAILogger.getLogger("InvokeAI")
|
||||
logger = InvokeAILogger.get_logger("InvokeAI")
|
||||
logger.addFilter(lambda x: "fp16 is not a valid" not in x.getMessage())
|
||||
|
||||
model = model_class.from_pretrained(
|
||||
@@ -534,14 +566,17 @@ def hf_download_with_resume(
|
||||
logger.info(f"{model_name}: Downloading...")
|
||||
|
||||
try:
|
||||
with open(model_dest, open_mode) as file, tqdm(
|
||||
desc=model_name,
|
||||
initial=exist_size,
|
||||
total=total + exist_size,
|
||||
unit="iB",
|
||||
unit_scale=True,
|
||||
unit_divisor=1000,
|
||||
) as bar:
|
||||
with (
|
||||
open(model_dest, open_mode) as file,
|
||||
tqdm(
|
||||
desc=model_name,
|
||||
initial=exist_size,
|
||||
total=total + exist_size,
|
||||
unit="iB",
|
||||
unit_scale=True,
|
||||
unit_divisor=1000,
|
||||
) as bar,
|
||||
):
|
||||
for data in resp.iter_content(chunk_size=1024):
|
||||
size = file.write(data)
|
||||
bar.update(size)
|
||||
|
||||
45
invokeai/backend/ip_adapter/README.md
Normal file
45
invokeai/backend/ip_adapter/README.md
Normal file
@@ -0,0 +1,45 @@
|
||||
# IP-Adapter Model Formats
|
||||
|
||||
The official IP-Adapter models are released here: [h94/IP-Adapter](https://huggingface.co/h94/IP-Adapter)
|
||||
|
||||
This official model repo does not integrate well with InvokeAI's current approach to model management, so we have defined a new file structure for IP-Adapter models. The InvokeAI format is described below.
|
||||
|
||||
## CLIP Vision Models
|
||||
|
||||
CLIP Vision models are organized in `diffusers`` format. The expected directory structure is:
|
||||
|
||||
```bash
|
||||
ip_adapter_sd_image_encoder/
|
||||
├── config.json
|
||||
└── model.safetensors
|
||||
```
|
||||
|
||||
## IP-Adapter Models
|
||||
|
||||
IP-Adapter models are stored in a directory containing two files
|
||||
- `image_encoder.txt`: A text file containing the model identifier for the CLIP Vision encoder that is intended to be used with this IP-Adapter model.
|
||||
- `ip_adapter.bin`: The IP-Adapter weights.
|
||||
|
||||
Sample directory structure:
|
||||
```bash
|
||||
ip_adapter_sd15/
|
||||
├── image_encoder.txt
|
||||
└── ip_adapter.bin
|
||||
```
|
||||
|
||||
### Why save the weights in a .safetensors file?
|
||||
|
||||
The weights in `ip_adapter.bin` are stored in a nested dict, which is not supported by `safetensors`. This could be solved by splitting `ip_adapter.bin` into multiple files, but for now we have decided to maintain consistency with the checkpoint structure used in the official [h94/IP-Adapter](https://huggingface.co/h94/IP-Adapter) repo.
|
||||
|
||||
## InvokeAI Hosted IP-Adapters
|
||||
|
||||
Image Encoders:
|
||||
- [InvokeAI/ip_adapter_sd_image_encoder](https://huggingface.co/InvokeAI/ip_adapter_sd_image_encoder)
|
||||
- [InvokeAI/ip_adapter_sdxl_image_encoder](https://huggingface.co/InvokeAI/ip_adapter_sdxl_image_encoder)
|
||||
|
||||
IP-Adapters:
|
||||
- [InvokeAI/ip_adapter_sd15](https://huggingface.co/InvokeAI/ip_adapter_sd15)
|
||||
- [InvokeAI/ip_adapter_plus_sd15](https://huggingface.co/InvokeAI/ip_adapter_plus_sd15)
|
||||
- [InvokeAI/ip_adapter_plus_face_sd15](https://huggingface.co/InvokeAI/ip_adapter_plus_face_sd15)
|
||||
- [InvokeAI/ip_adapter_sdxl](https://huggingface.co/InvokeAI/ip_adapter_sdxl)
|
||||
- [InvokeAI/ip_adapter_sdxl_vit_h](https://huggingface.co/InvokeAI/ip_adapter_sdxl_vit_h)
|
||||
0
invokeai/backend/ip_adapter/__init__.py
Normal file
0
invokeai/backend/ip_adapter/__init__.py
Normal file
162
invokeai/backend/ip_adapter/attention_processor.py
Normal file
162
invokeai/backend/ip_adapter/attention_processor.py
Normal file
@@ -0,0 +1,162 @@
|
||||
# copied from https://github.com/tencent-ailab/IP-Adapter (Apache License 2.0)
|
||||
# and modified as needed
|
||||
|
||||
# tencent-ailab comment:
|
||||
# modified from https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import torch.nn.functional as F
|
||||
from diffusers.models.attention_processor import AttnProcessor2_0 as DiffusersAttnProcessor2_0
|
||||
|
||||
|
||||
# Create a version of AttnProcessor2_0 that is a sub-class of nn.Module. This is required for IP-Adapter state_dict
|
||||
# loading.
|
||||
class AttnProcessor2_0(DiffusersAttnProcessor2_0, nn.Module):
|
||||
def __init__(self):
|
||||
DiffusersAttnProcessor2_0.__init__(self)
|
||||
nn.Module.__init__(self)
|
||||
|
||||
def __call__(
|
||||
self,
|
||||
attn,
|
||||
hidden_states,
|
||||
encoder_hidden_states=None,
|
||||
attention_mask=None,
|
||||
temb=None,
|
||||
ip_adapter_image_prompt_embeds=None,
|
||||
):
|
||||
"""Re-definition of DiffusersAttnProcessor2_0.__call__(...) that accepts and ignores the
|
||||
ip_adapter_image_prompt_embeds parameter.
|
||||
"""
|
||||
return DiffusersAttnProcessor2_0.__call__(
|
||||
self, attn, hidden_states, encoder_hidden_states, attention_mask, temb
|
||||
)
|
||||
|
||||
|
||||
class IPAttnProcessor2_0(torch.nn.Module):
|
||||
r"""
|
||||
Attention processor for IP-Adapater for PyTorch 2.0.
|
||||
Args:
|
||||
hidden_size (`int`):
|
||||
The hidden size of the attention layer.
|
||||
cross_attention_dim (`int`):
|
||||
The number of channels in the `encoder_hidden_states`.
|
||||
scale (`float`, defaults to 1.0):
|
||||
the weight scale of image prompt.
|
||||
"""
|
||||
|
||||
def __init__(self, hidden_size, cross_attention_dim=None, scale=1.0):
|
||||
super().__init__()
|
||||
|
||||
if not hasattr(F, "scaled_dot_product_attention"):
|
||||
raise ImportError("AttnProcessor2_0 requires PyTorch 2.0, to use it, please upgrade PyTorch to 2.0.")
|
||||
|
||||
self.hidden_size = hidden_size
|
||||
self.cross_attention_dim = cross_attention_dim
|
||||
self.scale = scale
|
||||
|
||||
self.to_k_ip = nn.Linear(cross_attention_dim or hidden_size, hidden_size, bias=False)
|
||||
self.to_v_ip = nn.Linear(cross_attention_dim or hidden_size, hidden_size, bias=False)
|
||||
|
||||
def __call__(
|
||||
self,
|
||||
attn,
|
||||
hidden_states,
|
||||
encoder_hidden_states=None,
|
||||
attention_mask=None,
|
||||
temb=None,
|
||||
ip_adapter_image_prompt_embeds=None,
|
||||
):
|
||||
if encoder_hidden_states is not None:
|
||||
# If encoder_hidden_states is not None, then we are doing cross-attention, not self-attention. In this case,
|
||||
# we will apply IP-Adapter conditioning. We validate the inputs for IP-Adapter conditioning here.
|
||||
assert ip_adapter_image_prompt_embeds is not None
|
||||
# The batch dimensions should match.
|
||||
assert ip_adapter_image_prompt_embeds.shape[0] == encoder_hidden_states.shape[0]
|
||||
# The channel dimensions should match.
|
||||
assert ip_adapter_image_prompt_embeds.shape[2] == encoder_hidden_states.shape[2]
|
||||
ip_hidden_states = ip_adapter_image_prompt_embeds
|
||||
|
||||
residual = hidden_states
|
||||
|
||||
if attn.spatial_norm is not None:
|
||||
hidden_states = attn.spatial_norm(hidden_states, temb)
|
||||
|
||||
input_ndim = hidden_states.ndim
|
||||
|
||||
if input_ndim == 4:
|
||||
batch_size, channel, height, width = hidden_states.shape
|
||||
hidden_states = hidden_states.view(batch_size, channel, height * width).transpose(1, 2)
|
||||
|
||||
batch_size, sequence_length, _ = (
|
||||
hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape
|
||||
)
|
||||
|
||||
if attention_mask is not None:
|
||||
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
|
||||
# scaled_dot_product_attention expects attention_mask shape to be
|
||||
# (batch, heads, source_length, target_length)
|
||||
attention_mask = attention_mask.view(batch_size, attn.heads, -1, attention_mask.shape[-1])
|
||||
|
||||
if attn.group_norm is not None:
|
||||
hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
|
||||
|
||||
query = attn.to_q(hidden_states)
|
||||
|
||||
if encoder_hidden_states is None:
|
||||
encoder_hidden_states = hidden_states
|
||||
elif attn.norm_cross:
|
||||
encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
|
||||
|
||||
key = attn.to_k(encoder_hidden_states)
|
||||
value = attn.to_v(encoder_hidden_states)
|
||||
|
||||
inner_dim = key.shape[-1]
|
||||
head_dim = inner_dim // attn.heads
|
||||
|
||||
query = query.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
||||
|
||||
key = key.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
||||
value = value.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
||||
|
||||
# the output of sdp = (batch, num_heads, seq_len, head_dim)
|
||||
# TODO: add support for attn.scale when we move to Torch 2.1
|
||||
hidden_states = F.scaled_dot_product_attention(
|
||||
query, key, value, attn_mask=attention_mask, dropout_p=0.0, is_causal=False
|
||||
)
|
||||
|
||||
hidden_states = hidden_states.transpose(1, 2).reshape(batch_size, -1, attn.heads * head_dim)
|
||||
hidden_states = hidden_states.to(query.dtype)
|
||||
|
||||
if ip_hidden_states is not None:
|
||||
ip_key = self.to_k_ip(ip_hidden_states)
|
||||
ip_value = self.to_v_ip(ip_hidden_states)
|
||||
|
||||
ip_key = ip_key.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
||||
ip_value = ip_value.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
||||
|
||||
# the output of sdp = (batch, num_heads, seq_len, head_dim)
|
||||
# TODO: add support for attn.scale when we move to Torch 2.1
|
||||
ip_hidden_states = F.scaled_dot_product_attention(
|
||||
query, ip_key, ip_value, attn_mask=None, dropout_p=0.0, is_causal=False
|
||||
)
|
||||
|
||||
ip_hidden_states = ip_hidden_states.transpose(1, 2).reshape(batch_size, -1, attn.heads * head_dim)
|
||||
ip_hidden_states = ip_hidden_states.to(query.dtype)
|
||||
|
||||
hidden_states = hidden_states + self.scale * ip_hidden_states
|
||||
|
||||
# linear proj
|
||||
hidden_states = attn.to_out[0](hidden_states)
|
||||
# dropout
|
||||
hidden_states = attn.to_out[1](hidden_states)
|
||||
|
||||
if input_ndim == 4:
|
||||
hidden_states = hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width)
|
||||
|
||||
if attn.residual_connection:
|
||||
hidden_states = hidden_states + residual
|
||||
|
||||
hidden_states = hidden_states / attn.rescale_output_factor
|
||||
|
||||
return hidden_states
|
||||
233
invokeai/backend/ip_adapter/ip_adapter.py
Normal file
233
invokeai/backend/ip_adapter/ip_adapter.py
Normal file
@@ -0,0 +1,233 @@
|
||||
# copied from https://github.com/tencent-ailab/IP-Adapter (Apache License 2.0)
|
||||
# and modified as needed
|
||||
|
||||
from contextlib import contextmanager
|
||||
from typing import Optional, Union
|
||||
|
||||
import torch
|
||||
from diffusers.models import UNet2DConditionModel
|
||||
from PIL import Image
|
||||
from transformers import CLIPImageProcessor, CLIPVisionModelWithProjection
|
||||
|
||||
from invokeai.backend.model_management.models.base import calc_model_size_by_data
|
||||
|
||||
from .attention_processor import AttnProcessor2_0, IPAttnProcessor2_0
|
||||
from .resampler import Resampler
|
||||
|
||||
|
||||
class ImageProjModel(torch.nn.Module):
|
||||
"""Image Projection Model"""
|
||||
|
||||
def __init__(self, cross_attention_dim=1024, clip_embeddings_dim=1024, clip_extra_context_tokens=4):
|
||||
super().__init__()
|
||||
|
||||
self.cross_attention_dim = cross_attention_dim
|
||||
self.clip_extra_context_tokens = clip_extra_context_tokens
|
||||
self.proj = torch.nn.Linear(clip_embeddings_dim, self.clip_extra_context_tokens * cross_attention_dim)
|
||||
self.norm = torch.nn.LayerNorm(cross_attention_dim)
|
||||
|
||||
@classmethod
|
||||
def from_state_dict(cls, state_dict: dict[torch.Tensor], clip_extra_context_tokens=4):
|
||||
"""Initialize an ImageProjModel from a state_dict.
|
||||
|
||||
The cross_attention_dim and clip_embeddings_dim are inferred from the shape of the tensors in the state_dict.
|
||||
|
||||
Args:
|
||||
state_dict (dict[torch.Tensor]): The state_dict of model weights.
|
||||
clip_extra_context_tokens (int, optional): Defaults to 4.
|
||||
|
||||
Returns:
|
||||
ImageProjModel
|
||||
"""
|
||||
cross_attention_dim = state_dict["norm.weight"].shape[0]
|
||||
clip_embeddings_dim = state_dict["proj.weight"].shape[-1]
|
||||
|
||||
model = cls(cross_attention_dim, clip_embeddings_dim, clip_extra_context_tokens)
|
||||
|
||||
model.load_state_dict(state_dict)
|
||||
return model
|
||||
|
||||
def forward(self, image_embeds):
|
||||
embeds = image_embeds
|
||||
clip_extra_context_tokens = self.proj(embeds).reshape(
|
||||
-1, self.clip_extra_context_tokens, self.cross_attention_dim
|
||||
)
|
||||
clip_extra_context_tokens = self.norm(clip_extra_context_tokens)
|
||||
return clip_extra_context_tokens
|
||||
|
||||
|
||||
class IPAdapter:
|
||||
"""IP-Adapter: https://arxiv.org/pdf/2308.06721.pdf"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
state_dict: dict[torch.Tensor],
|
||||
device: torch.device,
|
||||
dtype: torch.dtype = torch.float16,
|
||||
num_tokens: int = 4,
|
||||
):
|
||||
self.device = device
|
||||
self.dtype = dtype
|
||||
|
||||
self._num_tokens = num_tokens
|
||||
|
||||
self._clip_image_processor = CLIPImageProcessor()
|
||||
|
||||
self._state_dict = state_dict
|
||||
|
||||
self._image_proj_model = self._init_image_proj_model(self._state_dict["image_proj"])
|
||||
|
||||
# The _attn_processors will be initialized later when we have access to the UNet.
|
||||
self._attn_processors = None
|
||||
|
||||
def to(self, device: torch.device, dtype: Optional[torch.dtype] = None):
|
||||
self.device = device
|
||||
if dtype is not None:
|
||||
self.dtype = dtype
|
||||
|
||||
self._image_proj_model.to(device=self.device, dtype=self.dtype)
|
||||
if self._attn_processors is not None:
|
||||
torch.nn.ModuleList(self._attn_processors.values()).to(device=self.device, dtype=self.dtype)
|
||||
|
||||
def calc_size(self):
|
||||
if self._state_dict is not None:
|
||||
image_proj_size = sum(
|
||||
[tensor.nelement() * tensor.element_size() for tensor in self._state_dict["image_proj"].values()]
|
||||
)
|
||||
ip_adapter_size = sum(
|
||||
[tensor.nelement() * tensor.element_size() for tensor in self._state_dict["ip_adapter"].values()]
|
||||
)
|
||||
return image_proj_size + ip_adapter_size
|
||||
else:
|
||||
return calc_model_size_by_data(self._image_proj_model) + calc_model_size_by_data(
|
||||
torch.nn.ModuleList(self._attn_processors.values())
|
||||
)
|
||||
|
||||
def _init_image_proj_model(self, state_dict):
|
||||
return ImageProjModel.from_state_dict(state_dict, self._num_tokens).to(self.device, dtype=self.dtype)
|
||||
|
||||
def _prepare_attention_processors(self, unet: UNet2DConditionModel):
|
||||
"""Prepare a dict of attention processors that can later be injected into a unet, and load the IP-Adapter
|
||||
attention weights into them.
|
||||
|
||||
Note that the `unet` param is only used to determine attention block dimensions and naming.
|
||||
TODO(ryand): As a future improvement, this could all be inferred from the state_dict when the IPAdapter is
|
||||
intialized.
|
||||
"""
|
||||
attn_procs = {}
|
||||
for name in unet.attn_processors.keys():
|
||||
cross_attention_dim = None if name.endswith("attn1.processor") else unet.config.cross_attention_dim
|
||||
if name.startswith("mid_block"):
|
||||
hidden_size = unet.config.block_out_channels[-1]
|
||||
elif name.startswith("up_blocks"):
|
||||
block_id = int(name[len("up_blocks.")])
|
||||
hidden_size = list(reversed(unet.config.block_out_channels))[block_id]
|
||||
elif name.startswith("down_blocks"):
|
||||
block_id = int(name[len("down_blocks.")])
|
||||
hidden_size = unet.config.block_out_channels[block_id]
|
||||
if cross_attention_dim is None:
|
||||
attn_procs[name] = AttnProcessor2_0()
|
||||
else:
|
||||
attn_procs[name] = IPAttnProcessor2_0(
|
||||
hidden_size=hidden_size,
|
||||
cross_attention_dim=cross_attention_dim,
|
||||
scale=1.0,
|
||||
).to(self.device, dtype=self.dtype)
|
||||
|
||||
ip_layers = torch.nn.ModuleList(attn_procs.values())
|
||||
ip_layers.load_state_dict(self._state_dict["ip_adapter"])
|
||||
self._attn_processors = attn_procs
|
||||
self._state_dict = None
|
||||
|
||||
# @genomancer: pushed scaling back out into its own method (like original Tencent implementation)
|
||||
# which makes implementing begin_step_percent and end_step_percent easier
|
||||
# but based on self._attn_processors (ala @Ryan) instead of original Tencent unet.attn_processors,
|
||||
# which should make it easier to implement multiple IPAdapters
|
||||
def set_scale(self, scale):
|
||||
if self._attn_processors is not None:
|
||||
for attn_processor in self._attn_processors.values():
|
||||
if isinstance(attn_processor, IPAttnProcessor2_0):
|
||||
attn_processor.scale = scale
|
||||
|
||||
@contextmanager
|
||||
def apply_ip_adapter_attention(self, unet: UNet2DConditionModel, scale: float):
|
||||
"""A context manager that patches `unet` with this IP-Adapter's attention processors while it is active.
|
||||
|
||||
Yields:
|
||||
None
|
||||
"""
|
||||
if self._attn_processors is None:
|
||||
# We only have to call _prepare_attention_processors(...) once, and then the result is cached and can be
|
||||
# used on any UNet model (with the same dimensions).
|
||||
self._prepare_attention_processors(unet)
|
||||
|
||||
# Set scale
|
||||
self.set_scale(scale)
|
||||
# for attn_processor in self._attn_processors.values():
|
||||
# if isinstance(attn_processor, IPAttnProcessor2_0):
|
||||
# attn_processor.scale = scale
|
||||
|
||||
orig_attn_processors = unet.attn_processors
|
||||
|
||||
# Make a (moderately-) shallow copy of the self._attn_processors dict, because unet.set_attn_processor(...)
|
||||
# actually pops elements from the passed dict.
|
||||
ip_adapter_attn_processors = {k: v for k, v in self._attn_processors.items()}
|
||||
|
||||
try:
|
||||
unet.set_attn_processor(ip_adapter_attn_processors)
|
||||
yield None
|
||||
finally:
|
||||
unet.set_attn_processor(orig_attn_processors)
|
||||
|
||||
@torch.inference_mode()
|
||||
def get_image_embeds(self, pil_image, image_encoder: CLIPVisionModelWithProjection):
|
||||
if isinstance(pil_image, Image.Image):
|
||||
pil_image = [pil_image]
|
||||
clip_image = self._clip_image_processor(images=pil_image, return_tensors="pt").pixel_values
|
||||
clip_image_embeds = image_encoder(clip_image.to(self.device, dtype=self.dtype)).image_embeds
|
||||
image_prompt_embeds = self._image_proj_model(clip_image_embeds)
|
||||
uncond_image_prompt_embeds = self._image_proj_model(torch.zeros_like(clip_image_embeds))
|
||||
return image_prompt_embeds, uncond_image_prompt_embeds
|
||||
|
||||
|
||||
class IPAdapterPlus(IPAdapter):
|
||||
"""IP-Adapter with fine-grained features"""
|
||||
|
||||
def _init_image_proj_model(self, state_dict):
|
||||
return Resampler.from_state_dict(
|
||||
state_dict=state_dict,
|
||||
depth=4,
|
||||
dim_head=64,
|
||||
heads=12,
|
||||
num_queries=self._num_tokens,
|
||||
ff_mult=4,
|
||||
).to(self.device, dtype=self.dtype)
|
||||
|
||||
@torch.inference_mode()
|
||||
def get_image_embeds(self, pil_image, image_encoder: CLIPVisionModelWithProjection):
|
||||
if isinstance(pil_image, Image.Image):
|
||||
pil_image = [pil_image]
|
||||
clip_image = self._clip_image_processor(images=pil_image, return_tensors="pt").pixel_values
|
||||
clip_image = clip_image.to(self.device, dtype=self.dtype)
|
||||
clip_image_embeds = image_encoder(clip_image, output_hidden_states=True).hidden_states[-2]
|
||||
image_prompt_embeds = self._image_proj_model(clip_image_embeds)
|
||||
uncond_clip_image_embeds = image_encoder(torch.zeros_like(clip_image), output_hidden_states=True).hidden_states[
|
||||
-2
|
||||
]
|
||||
uncond_image_prompt_embeds = self._image_proj_model(uncond_clip_image_embeds)
|
||||
return image_prompt_embeds, uncond_image_prompt_embeds
|
||||
|
||||
|
||||
def build_ip_adapter(
|
||||
ip_adapter_ckpt_path: str, device: torch.device, dtype: torch.dtype = torch.float16
|
||||
) -> Union[IPAdapter, IPAdapterPlus]:
|
||||
state_dict = torch.load(ip_adapter_ckpt_path, map_location="cpu")
|
||||
|
||||
# Determine if the state_dict is from an IPAdapter or IPAdapterPlus based on the image_proj weights that it
|
||||
# contains.
|
||||
is_plus = "proj.weight" not in state_dict["image_proj"]
|
||||
|
||||
if is_plus:
|
||||
return IPAdapterPlus(state_dict, device=device, dtype=dtype)
|
||||
else:
|
||||
return IPAdapter(state_dict, device=device, dtype=dtype)
|
||||
158
invokeai/backend/ip_adapter/resampler.py
Normal file
158
invokeai/backend/ip_adapter/resampler.py
Normal file
@@ -0,0 +1,158 @@
|
||||
# copied from https://github.com/tencent-ailab/IP-Adapter (Apache License 2.0)
|
||||
|
||||
# tencent ailab comment: modified from
|
||||
# https://github.com/mlfoundations/open_flamingo/blob/main/open_flamingo/src/helpers.py
|
||||
import math
|
||||
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
|
||||
|
||||
# FFN
|
||||
def FeedForward(dim, mult=4):
|
||||
inner_dim = int(dim * mult)
|
||||
return nn.Sequential(
|
||||
nn.LayerNorm(dim),
|
||||
nn.Linear(dim, inner_dim, bias=False),
|
||||
nn.GELU(),
|
||||
nn.Linear(inner_dim, dim, bias=False),
|
||||
)
|
||||
|
||||
|
||||
def reshape_tensor(x, heads):
|
||||
bs, length, width = x.shape
|
||||
# (bs, length, width) --> (bs, length, n_heads, dim_per_head)
|
||||
x = x.view(bs, length, heads, -1)
|
||||
# (bs, length, n_heads, dim_per_head) --> (bs, n_heads, length, dim_per_head)
|
||||
x = x.transpose(1, 2)
|
||||
# (bs, n_heads, length, dim_per_head) --> (bs*n_heads, length, dim_per_head)
|
||||
x = x.reshape(bs, heads, length, -1)
|
||||
return x
|
||||
|
||||
|
||||
class PerceiverAttention(nn.Module):
|
||||
def __init__(self, *, dim, dim_head=64, heads=8):
|
||||
super().__init__()
|
||||
self.scale = dim_head**-0.5
|
||||
self.dim_head = dim_head
|
||||
self.heads = heads
|
||||
inner_dim = dim_head * heads
|
||||
|
||||
self.norm1 = nn.LayerNorm(dim)
|
||||
self.norm2 = nn.LayerNorm(dim)
|
||||
|
||||
self.to_q = nn.Linear(dim, inner_dim, bias=False)
|
||||
self.to_kv = nn.Linear(dim, inner_dim * 2, bias=False)
|
||||
self.to_out = nn.Linear(inner_dim, dim, bias=False)
|
||||
|
||||
def forward(self, x, latents):
|
||||
"""
|
||||
Args:
|
||||
x (torch.Tensor): image features
|
||||
shape (b, n1, D)
|
||||
latent (torch.Tensor): latent features
|
||||
shape (b, n2, D)
|
||||
"""
|
||||
x = self.norm1(x)
|
||||
latents = self.norm2(latents)
|
||||
|
||||
b, l, _ = latents.shape
|
||||
|
||||
q = self.to_q(latents)
|
||||
kv_input = torch.cat((x, latents), dim=-2)
|
||||
k, v = self.to_kv(kv_input).chunk(2, dim=-1)
|
||||
|
||||
q = reshape_tensor(q, self.heads)
|
||||
k = reshape_tensor(k, self.heads)
|
||||
v = reshape_tensor(v, self.heads)
|
||||
|
||||
# attention
|
||||
scale = 1 / math.sqrt(math.sqrt(self.dim_head))
|
||||
weight = (q * scale) @ (k * scale).transpose(-2, -1) # More stable with f16 than dividing afterwards
|
||||
weight = torch.softmax(weight.float(), dim=-1).type(weight.dtype)
|
||||
out = weight @ v
|
||||
|
||||
out = out.permute(0, 2, 1, 3).reshape(b, l, -1)
|
||||
|
||||
return self.to_out(out)
|
||||
|
||||
|
||||
class Resampler(nn.Module):
|
||||
def __init__(
|
||||
self,
|
||||
dim=1024,
|
||||
depth=8,
|
||||
dim_head=64,
|
||||
heads=16,
|
||||
num_queries=8,
|
||||
embedding_dim=768,
|
||||
output_dim=1024,
|
||||
ff_mult=4,
|
||||
):
|
||||
super().__init__()
|
||||
|
||||
self.latents = nn.Parameter(torch.randn(1, num_queries, dim) / dim**0.5)
|
||||
|
||||
self.proj_in = nn.Linear(embedding_dim, dim)
|
||||
|
||||
self.proj_out = nn.Linear(dim, output_dim)
|
||||
self.norm_out = nn.LayerNorm(output_dim)
|
||||
|
||||
self.layers = nn.ModuleList([])
|
||||
for _ in range(depth):
|
||||
self.layers.append(
|
||||
nn.ModuleList(
|
||||
[
|
||||
PerceiverAttention(dim=dim, dim_head=dim_head, heads=heads),
|
||||
FeedForward(dim=dim, mult=ff_mult),
|
||||
]
|
||||
)
|
||||
)
|
||||
|
||||
@classmethod
|
||||
def from_state_dict(cls, state_dict: dict[torch.Tensor], depth=8, dim_head=64, heads=16, num_queries=8, ff_mult=4):
|
||||
"""A convenience function that initializes a Resampler from a state_dict.
|
||||
|
||||
Some of the shape parameters are inferred from the state_dict (e.g. dim, embedding_dim, etc.). At the time of
|
||||
writing, we did not have a need for inferring ALL of the shape parameters from the state_dict, but this would be
|
||||
possible if needed in the future.
|
||||
|
||||
Args:
|
||||
state_dict (dict[torch.Tensor]): The state_dict to load.
|
||||
depth (int, optional):
|
||||
dim_head (int, optional):
|
||||
heads (int, optional):
|
||||
ff_mult (int, optional):
|
||||
|
||||
Returns:
|
||||
Resampler
|
||||
"""
|
||||
dim = state_dict["latents"].shape[2]
|
||||
num_queries = state_dict["latents"].shape[1]
|
||||
embedding_dim = state_dict["proj_in.weight"].shape[-1]
|
||||
output_dim = state_dict["norm_out.weight"].shape[0]
|
||||
|
||||
model = cls(
|
||||
dim=dim,
|
||||
depth=depth,
|
||||
dim_head=dim_head,
|
||||
heads=heads,
|
||||
num_queries=num_queries,
|
||||
embedding_dim=embedding_dim,
|
||||
output_dim=output_dim,
|
||||
ff_mult=ff_mult,
|
||||
)
|
||||
model.load_state_dict(state_dict)
|
||||
return model
|
||||
|
||||
def forward(self, x):
|
||||
latents = self.latents.repeat(x.size(0), 1, 1)
|
||||
|
||||
x = self.proj_in(x)
|
||||
|
||||
for attn, ff in self.layers:
|
||||
latents = attn(x, latents) + latents
|
||||
latents = ff(latents) + latents
|
||||
|
||||
latents = self.proj_out(latents)
|
||||
return self.norm_out(latents)
|
||||
@@ -74,7 +74,7 @@ if is_accelerate_available():
|
||||
from accelerate import init_empty_weights
|
||||
from accelerate.utils import set_module_tensor_to_device
|
||||
|
||||
logger = InvokeAILogger.getLogger(__name__)
|
||||
logger = InvokeAILogger.get_logger(__name__)
|
||||
CONVERT_MODEL_ROOT = InvokeAIAppConfig.get_config().models_path / "core/convert"
|
||||
|
||||
|
||||
@@ -1279,12 +1279,12 @@ def download_from_original_stable_diffusion_ckpt(
|
||||
extract_ema = original_config["model"]["params"]["use_ema"]
|
||||
|
||||
if (
|
||||
model_version == BaseModelType.StableDiffusion2
|
||||
model_version in [BaseModelType.StableDiffusion2, BaseModelType.StableDiffusion1]
|
||||
and original_config["model"]["params"].get("parameterization") == "v"
|
||||
):
|
||||
prediction_type = "v_prediction"
|
||||
upcast_attention = True
|
||||
image_size = 768
|
||||
image_size = 768 if model_version == BaseModelType.StableDiffusion2 else 512
|
||||
else:
|
||||
prediction_type = "epsilon"
|
||||
upcast_attention = False
|
||||
|
||||
@@ -25,6 +25,7 @@ Models are described using four attributes:
|
||||
ModelType.Lora -- a LoRA or LyCORIS fine-tune
|
||||
ModelType.TextualInversion -- a textual inversion embedding
|
||||
ModelType.ControlNet -- a ControlNet model
|
||||
ModelType.IPAdapter -- an IPAdapter model
|
||||
|
||||
3) BaseModelType -- an enum indicating the stable diffusion base model, one of:
|
||||
BaseModelType.StableDiffusion1
|
||||
@@ -1000,8 +1001,8 @@ class ModelManager(object):
|
||||
new_models_found = True
|
||||
except DuplicateModelException as e:
|
||||
self.logger.warning(e)
|
||||
except InvalidModelException:
|
||||
self.logger.warning(f"Not a valid model: {model_path}")
|
||||
except InvalidModelException as e:
|
||||
self.logger.warning(f"Not a valid model: {model_path}. {e}")
|
||||
except NotImplementedError as e:
|
||||
self.logger.warning(e)
|
||||
|
||||
|
||||
@@ -1,4 +1,5 @@
|
||||
import json
|
||||
import re
|
||||
from dataclasses import dataclass
|
||||
from pathlib import Path
|
||||
from typing import Callable, Dict, Literal, Optional, Union
|
||||
@@ -8,6 +9,8 @@ import torch
|
||||
from diffusers import ConfigMixin, ModelMixin
|
||||
from picklescan.scanner import scan_file_path
|
||||
|
||||
from invokeai.backend.model_management.models.ip_adapter import IPAdapterModelFormat
|
||||
|
||||
from .models import (
|
||||
BaseModelType,
|
||||
InvalidModelException,
|
||||
@@ -51,7 +54,9 @@ class ModelProbe(object):
|
||||
"StableDiffusionXLImg2ImgPipeline": ModelType.Main,
|
||||
"StableDiffusionXLInpaintPipeline": ModelType.Main,
|
||||
"AutoencoderKL": ModelType.Vae,
|
||||
"AutoencoderTiny": ModelType.Vae,
|
||||
"ControlNetModel": ModelType.ControlNet,
|
||||
"CLIPVisionModelWithProjection": ModelType.CLIPVision,
|
||||
}
|
||||
|
||||
@classmethod
|
||||
@@ -85,8 +90,7 @@ class ModelProbe(object):
|
||||
to place it somewhere in the models directory hierarchy. If the model is
|
||||
already loaded into memory, you may provide it as model in order to avoid
|
||||
opening it a second time. The prediction_type_helper callable is a function that receives
|
||||
the path to the model and returns the BaseModelType. It is called to distinguish
|
||||
between V2-Base and V2-768 SD models.
|
||||
the path to the model and returns the SchedulerPredictionType.
|
||||
"""
|
||||
if model_path:
|
||||
format_type = "diffusers" if model_path.is_dir() else "checkpoint"
|
||||
@@ -118,14 +122,18 @@ class ModelProbe(object):
|
||||
and prediction_type == SchedulerPredictionType.VPrediction
|
||||
),
|
||||
format=format,
|
||||
image_size=1024
|
||||
if (base_type in {BaseModelType.StableDiffusionXL, BaseModelType.StableDiffusionXLRefiner})
|
||||
else 768
|
||||
if (
|
||||
base_type == BaseModelType.StableDiffusion2
|
||||
and prediction_type == SchedulerPredictionType.VPrediction
|
||||
)
|
||||
else 512,
|
||||
image_size=(
|
||||
1024
|
||||
if (base_type in {BaseModelType.StableDiffusionXL, BaseModelType.StableDiffusionXLRefiner})
|
||||
else (
|
||||
768
|
||||
if (
|
||||
base_type == BaseModelType.StableDiffusion2
|
||||
and prediction_type == SchedulerPredictionType.VPrediction
|
||||
)
|
||||
else 512
|
||||
)
|
||||
),
|
||||
)
|
||||
except Exception:
|
||||
raise
|
||||
@@ -170,6 +178,7 @@ class ModelProbe(object):
|
||||
Get the model type of a hugging-face style folder.
|
||||
"""
|
||||
class_name = None
|
||||
error_hint = None
|
||||
if model:
|
||||
class_name = model.__class__.__name__
|
||||
else:
|
||||
@@ -177,9 +186,10 @@ class ModelProbe(object):
|
||||
return ModelType.ONNX
|
||||
if (folder_path / "learned_embeds.bin").exists():
|
||||
return ModelType.TextualInversion
|
||||
|
||||
if (folder_path / "pytorch_lora_weights.bin").exists():
|
||||
return ModelType.Lora
|
||||
if (folder_path / "image_encoder.txt").exists():
|
||||
return ModelType.IPAdapter
|
||||
|
||||
i = folder_path / "model_index.json"
|
||||
c = folder_path / "config.json"
|
||||
@@ -188,13 +198,24 @@ class ModelProbe(object):
|
||||
if config_path:
|
||||
with open(config_path, "r") as file:
|
||||
conf = json.load(file)
|
||||
class_name = conf["_class_name"]
|
||||
if "_class_name" in conf:
|
||||
class_name = conf["_class_name"]
|
||||
elif "architectures" in conf:
|
||||
class_name = conf["architectures"][0]
|
||||
else:
|
||||
class_name = None
|
||||
else:
|
||||
error_hint = f"No model_index.json or config.json found in {folder_path}."
|
||||
|
||||
if class_name and (type := cls.CLASS2TYPE.get(class_name)):
|
||||
return type
|
||||
else:
|
||||
error_hint = f"class {class_name} is not one of the supported classes [{', '.join(cls.CLASS2TYPE.keys())}]"
|
||||
|
||||
# give up
|
||||
raise InvalidModelException(f"Unable to determine model type for {folder_path}")
|
||||
raise InvalidModelException(
|
||||
f"Unable to determine model type for {folder_path}" + (f"; {error_hint}" if error_hint else "")
|
||||
)
|
||||
|
||||
@classmethod
|
||||
def _scan_and_load_checkpoint(cls, model_path: Path) -> dict:
|
||||
@@ -283,25 +304,36 @@ class PipelineCheckpointProbe(CheckpointProbeBase):
|
||||
else:
|
||||
raise InvalidModelException("Cannot determine base type")
|
||||
|
||||
def get_scheduler_prediction_type(self) -> SchedulerPredictionType:
|
||||
def get_scheduler_prediction_type(self) -> Optional[SchedulerPredictionType]:
|
||||
"""Return model prediction type."""
|
||||
# if there is a .yaml associated with this checkpoint, then we do not need
|
||||
# to probe for the prediction type as it will be ignored.
|
||||
if self.checkpoint_path and self.checkpoint_path.with_suffix(".yaml").exists():
|
||||
return None
|
||||
|
||||
type = self.get_base_type()
|
||||
if type == BaseModelType.StableDiffusion1:
|
||||
return SchedulerPredictionType.Epsilon
|
||||
checkpoint = self.checkpoint
|
||||
state_dict = self.checkpoint.get("state_dict") or checkpoint
|
||||
key_name = "model.diffusion_model.input_blocks.2.1.transformer_blocks.0.attn2.to_k.weight"
|
||||
if key_name in state_dict and state_dict[key_name].shape[-1] == 1024:
|
||||
if "global_step" in checkpoint:
|
||||
if checkpoint["global_step"] == 220000:
|
||||
return SchedulerPredictionType.Epsilon
|
||||
elif checkpoint["global_step"] == 110000:
|
||||
return SchedulerPredictionType.VPrediction
|
||||
if (
|
||||
self.checkpoint_path and self.helper and not self.checkpoint_path.with_suffix(".yaml").exists()
|
||||
): # if a .yaml config file exists, then this step not needed
|
||||
return self.helper(self.checkpoint_path)
|
||||
else:
|
||||
return None
|
||||
if type == BaseModelType.StableDiffusion2:
|
||||
checkpoint = self.checkpoint
|
||||
state_dict = self.checkpoint.get("state_dict") or checkpoint
|
||||
key_name = "model.diffusion_model.input_blocks.2.1.transformer_blocks.0.attn2.to_k.weight"
|
||||
if key_name in state_dict and state_dict[key_name].shape[-1] == 1024:
|
||||
if "global_step" in checkpoint:
|
||||
if checkpoint["global_step"] == 220000:
|
||||
return SchedulerPredictionType.Epsilon
|
||||
elif checkpoint["global_step"] == 110000:
|
||||
return SchedulerPredictionType.VPrediction
|
||||
if self.helper and self.checkpoint_path:
|
||||
if helper_guess := self.helper(self.checkpoint_path):
|
||||
return helper_guess
|
||||
return SchedulerPredictionType.VPrediction # a guess for sd2 ckpts
|
||||
|
||||
elif type == BaseModelType.StableDiffusion1:
|
||||
if self.helper and self.checkpoint_path:
|
||||
if helper_guess := self.helper(self.checkpoint_path):
|
||||
return helper_guess
|
||||
return SchedulerPredictionType.Epsilon # a reasonable guess for sd1 ckpts
|
||||
else:
|
||||
return None
|
||||
|
||||
|
||||
class VaeCheckpointProbe(CheckpointProbeBase):
|
||||
@@ -366,6 +398,16 @@ class ControlNetCheckpointProbe(CheckpointProbeBase):
|
||||
raise InvalidModelException("Unable to determine base type for {self.checkpoint_path}")
|
||||
|
||||
|
||||
class IPAdapterCheckpointProbe(CheckpointProbeBase):
|
||||
def get_base_type(self) -> BaseModelType:
|
||||
raise NotImplementedError()
|
||||
|
||||
|
||||
class CLIPVisionCheckpointProbe(CheckpointProbeBase):
|
||||
def get_base_type(self) -> BaseModelType:
|
||||
raise NotImplementedError()
|
||||
|
||||
|
||||
########################################################
|
||||
# classes for probing folders
|
||||
#######################################################
|
||||
@@ -438,16 +480,32 @@ class PipelineFolderProbe(FolderProbeBase):
|
||||
|
||||
class VaeFolderProbe(FolderProbeBase):
|
||||
def get_base_type(self) -> BaseModelType:
|
||||
if self._config_looks_like_sdxl():
|
||||
return BaseModelType.StableDiffusionXL
|
||||
elif self._name_looks_like_sdxl():
|
||||
# but SD and SDXL VAE are the same shape (3-channel RGB to 4-channel float scaled down
|
||||
# by a factor of 8), we can't necessarily tell them apart by config hyperparameters.
|
||||
return BaseModelType.StableDiffusionXL
|
||||
else:
|
||||
return BaseModelType.StableDiffusion1
|
||||
|
||||
def _config_looks_like_sdxl(self) -> bool:
|
||||
# config values that distinguish Stability's SD 1.x VAE from their SDXL VAE.
|
||||
config_file = self.folder_path / "config.json"
|
||||
if not config_file.exists():
|
||||
raise InvalidModelException(f"Cannot determine base type for {self.folder_path}")
|
||||
with open(config_file, "r") as file:
|
||||
config = json.load(file)
|
||||
return (
|
||||
BaseModelType.StableDiffusionXL
|
||||
if config.get("scaling_factor", 0) == 0.13025 and config.get("sample_size") in [512, 1024]
|
||||
else BaseModelType.StableDiffusion1
|
||||
)
|
||||
return config.get("scaling_factor", 0) == 0.13025 and config.get("sample_size") in [512, 1024]
|
||||
|
||||
def _name_looks_like_sdxl(self) -> bool:
|
||||
return bool(re.search(r"xl\b", self._guess_name(), re.IGNORECASE))
|
||||
|
||||
def _guess_name(self) -> str:
|
||||
name = self.folder_path.name
|
||||
if name == "vae":
|
||||
name = self.folder_path.parent.name
|
||||
return name
|
||||
|
||||
|
||||
class TextualInversionFolderProbe(FolderProbeBase):
|
||||
@@ -485,11 +543,13 @@ class ControlNetFolderProbe(FolderProbeBase):
|
||||
base_model = (
|
||||
BaseModelType.StableDiffusion1
|
||||
if dimension == 768
|
||||
else BaseModelType.StableDiffusion2
|
||||
if dimension == 1024
|
||||
else BaseModelType.StableDiffusionXL
|
||||
if dimension == 2048
|
||||
else None
|
||||
else (
|
||||
BaseModelType.StableDiffusion2
|
||||
if dimension == 1024
|
||||
else BaseModelType.StableDiffusionXL
|
||||
if dimension == 2048
|
||||
else None
|
||||
)
|
||||
)
|
||||
if not base_model:
|
||||
raise InvalidModelException(f"Unable to determine model base for {self.folder_path}")
|
||||
@@ -509,15 +569,47 @@ class LoRAFolderProbe(FolderProbeBase):
|
||||
return LoRACheckpointProbe(model_file, None).get_base_type()
|
||||
|
||||
|
||||
class IPAdapterFolderProbe(FolderProbeBase):
|
||||
def get_format(self) -> str:
|
||||
return IPAdapterModelFormat.InvokeAI.value
|
||||
|
||||
def get_base_type(self) -> BaseModelType:
|
||||
model_file = self.folder_path / "ip_adapter.bin"
|
||||
if not model_file.exists():
|
||||
raise InvalidModelException("Unknown IP-Adapter model format.")
|
||||
|
||||
state_dict = torch.load(model_file, map_location="cpu")
|
||||
cross_attention_dim = state_dict["ip_adapter"]["1.to_k_ip.weight"].shape[-1]
|
||||
if cross_attention_dim == 768:
|
||||
return BaseModelType.StableDiffusion1
|
||||
elif cross_attention_dim == 1024:
|
||||
return BaseModelType.StableDiffusion2
|
||||
elif cross_attention_dim == 2048:
|
||||
return BaseModelType.StableDiffusionXL
|
||||
else:
|
||||
raise InvalidModelException(f"IP-Adapter had unexpected cross-attention dimension: {cross_attention_dim}.")
|
||||
|
||||
|
||||
class CLIPVisionFolderProbe(FolderProbeBase):
|
||||
def get_base_type(self) -> BaseModelType:
|
||||
return BaseModelType.Any
|
||||
|
||||
|
||||
############## register probe classes ######
|
||||
ModelProbe.register_probe("diffusers", ModelType.Main, PipelineFolderProbe)
|
||||
ModelProbe.register_probe("diffusers", ModelType.Vae, VaeFolderProbe)
|
||||
ModelProbe.register_probe("diffusers", ModelType.Lora, LoRAFolderProbe)
|
||||
ModelProbe.register_probe("diffusers", ModelType.TextualInversion, TextualInversionFolderProbe)
|
||||
ModelProbe.register_probe("diffusers", ModelType.ControlNet, ControlNetFolderProbe)
|
||||
ModelProbe.register_probe("diffusers", ModelType.IPAdapter, IPAdapterFolderProbe)
|
||||
ModelProbe.register_probe("diffusers", ModelType.CLIPVision, CLIPVisionFolderProbe)
|
||||
|
||||
ModelProbe.register_probe("checkpoint", ModelType.Main, PipelineCheckpointProbe)
|
||||
ModelProbe.register_probe("checkpoint", ModelType.Vae, VaeCheckpointProbe)
|
||||
ModelProbe.register_probe("checkpoint", ModelType.Lora, LoRACheckpointProbe)
|
||||
ModelProbe.register_probe("checkpoint", ModelType.TextualInversion, TextualInversionCheckpointProbe)
|
||||
ModelProbe.register_probe("checkpoint", ModelType.ControlNet, ControlNetCheckpointProbe)
|
||||
ModelProbe.register_probe("checkpoint", ModelType.IPAdapter, IPAdapterCheckpointProbe)
|
||||
ModelProbe.register_probe("checkpoint", ModelType.CLIPVision, CLIPVisionCheckpointProbe)
|
||||
|
||||
ModelProbe.register_probe("onnx", ModelType.ONNX, ONNXFolderProbe)
|
||||
|
||||
@@ -71,7 +71,13 @@ class ModelSearch(ABC):
|
||||
if any(
|
||||
[
|
||||
(path / x).exists()
|
||||
for x in {"config.json", "model_index.json", "learned_embeds.bin", "pytorch_lora_weights.bin"}
|
||||
for x in {
|
||||
"config.json",
|
||||
"model_index.json",
|
||||
"learned_embeds.bin",
|
||||
"pytorch_lora_weights.bin",
|
||||
"image_encoder.txt",
|
||||
}
|
||||
]
|
||||
):
|
||||
try:
|
||||
@@ -79,7 +85,7 @@ class ModelSearch(ABC):
|
||||
self._models_found += 1
|
||||
self._scanned_dirs.add(path)
|
||||
except Exception as e:
|
||||
self.logger.warning(str(e))
|
||||
self.logger.warning(f"Failed to process '{path}': {e}")
|
||||
|
||||
for f in files:
|
||||
path = Path(root) / f
|
||||
@@ -90,7 +96,7 @@ class ModelSearch(ABC):
|
||||
self.on_model_found(path)
|
||||
self._models_found += 1
|
||||
except Exception as e:
|
||||
self.logger.warning(str(e))
|
||||
self.logger.warning(f"Failed to process '{path}': {e}")
|
||||
|
||||
|
||||
class FindModels(ModelSearch):
|
||||
|
||||
@@ -18,7 +18,9 @@ from .base import ( # noqa: F401
|
||||
SilenceWarnings,
|
||||
SubModelType,
|
||||
)
|
||||
from .clip_vision import CLIPVisionModel
|
||||
from .controlnet import ControlNetModel # TODO:
|
||||
from .ip_adapter import IPAdapterModel
|
||||
from .lora import LoRAModel
|
||||
from .sdxl import StableDiffusionXLModel
|
||||
from .stable_diffusion import StableDiffusion1Model, StableDiffusion2Model
|
||||
@@ -34,6 +36,8 @@ MODEL_CLASSES = {
|
||||
ModelType.Lora: LoRAModel,
|
||||
ModelType.ControlNet: ControlNetModel,
|
||||
ModelType.TextualInversion: TextualInversionModel,
|
||||
ModelType.IPAdapter: IPAdapterModel,
|
||||
ModelType.CLIPVision: CLIPVisionModel,
|
||||
},
|
||||
BaseModelType.StableDiffusion2: {
|
||||
ModelType.ONNX: ONNXStableDiffusion2Model,
|
||||
@@ -42,6 +46,8 @@ MODEL_CLASSES = {
|
||||
ModelType.Lora: LoRAModel,
|
||||
ModelType.ControlNet: ControlNetModel,
|
||||
ModelType.TextualInversion: TextualInversionModel,
|
||||
ModelType.IPAdapter: IPAdapterModel,
|
||||
ModelType.CLIPVision: CLIPVisionModel,
|
||||
},
|
||||
BaseModelType.StableDiffusionXL: {
|
||||
ModelType.Main: StableDiffusionXLModel,
|
||||
@@ -51,6 +57,8 @@ MODEL_CLASSES = {
|
||||
ModelType.ControlNet: ControlNetModel,
|
||||
ModelType.TextualInversion: TextualInversionModel,
|
||||
ModelType.ONNX: ONNXStableDiffusion2Model,
|
||||
ModelType.IPAdapter: IPAdapterModel,
|
||||
ModelType.CLIPVision: CLIPVisionModel,
|
||||
},
|
||||
BaseModelType.StableDiffusionXLRefiner: {
|
||||
ModelType.Main: StableDiffusionXLModel,
|
||||
@@ -60,6 +68,19 @@ MODEL_CLASSES = {
|
||||
ModelType.ControlNet: ControlNetModel,
|
||||
ModelType.TextualInversion: TextualInversionModel,
|
||||
ModelType.ONNX: ONNXStableDiffusion2Model,
|
||||
ModelType.IPAdapter: IPAdapterModel,
|
||||
ModelType.CLIPVision: CLIPVisionModel,
|
||||
},
|
||||
BaseModelType.Any: {
|
||||
ModelType.CLIPVision: CLIPVisionModel,
|
||||
# The following model types are not expected to be used with BaseModelType.Any.
|
||||
ModelType.ONNX: ONNXStableDiffusion2Model,
|
||||
ModelType.Main: StableDiffusion2Model,
|
||||
ModelType.Vae: VaeModel,
|
||||
ModelType.Lora: LoRAModel,
|
||||
ModelType.ControlNet: ControlNetModel,
|
||||
ModelType.TextualInversion: TextualInversionModel,
|
||||
ModelType.IPAdapter: IPAdapterModel,
|
||||
},
|
||||
# BaseModelType.Kandinsky2_1: {
|
||||
# ModelType.Main: Kandinsky2_1Model,
|
||||
|
||||
@@ -36,6 +36,7 @@ class ModelNotFoundException(Exception):
|
||||
|
||||
|
||||
class BaseModelType(str, Enum):
|
||||
Any = "any" # For models that are not associated with any particular base model.
|
||||
StableDiffusion1 = "sd-1"
|
||||
StableDiffusion2 = "sd-2"
|
||||
StableDiffusionXL = "sdxl"
|
||||
@@ -50,6 +51,8 @@ class ModelType(str, Enum):
|
||||
Lora = "lora"
|
||||
ControlNet = "controlnet" # used by model_probe
|
||||
TextualInversion = "embedding"
|
||||
IPAdapter = "ip_adapter"
|
||||
CLIPVision = "clip_vision"
|
||||
|
||||
|
||||
class SubModelType(str, Enum):
|
||||
|
||||
82
invokeai/backend/model_management/models/clip_vision.py
Normal file
82
invokeai/backend/model_management/models/clip_vision.py
Normal file
@@ -0,0 +1,82 @@
|
||||
import os
|
||||
from enum import Enum
|
||||
from typing import Literal, Optional
|
||||
|
||||
import torch
|
||||
from transformers import CLIPVisionModelWithProjection
|
||||
|
||||
from invokeai.backend.model_management.models.base import (
|
||||
BaseModelType,
|
||||
InvalidModelException,
|
||||
ModelBase,
|
||||
ModelConfigBase,
|
||||
ModelType,
|
||||
SubModelType,
|
||||
calc_model_size_by_data,
|
||||
calc_model_size_by_fs,
|
||||
classproperty,
|
||||
)
|
||||
|
||||
|
||||
class CLIPVisionModelFormat(str, Enum):
|
||||
Diffusers = "diffusers"
|
||||
|
||||
|
||||
class CLIPVisionModel(ModelBase):
|
||||
class DiffusersConfig(ModelConfigBase):
|
||||
model_format: Literal[CLIPVisionModelFormat.Diffusers]
|
||||
|
||||
def __init__(self, model_path: str, base_model: BaseModelType, model_type: ModelType):
|
||||
assert model_type == ModelType.CLIPVision
|
||||
super().__init__(model_path, base_model, model_type)
|
||||
|
||||
self.model_size = calc_model_size_by_fs(self.model_path)
|
||||
|
||||
@classmethod
|
||||
def detect_format(cls, path: str) -> str:
|
||||
if not os.path.exists(path):
|
||||
raise ModuleNotFoundError(f"No CLIP Vision model at path '{path}'.")
|
||||
|
||||
if os.path.isdir(path) and os.path.exists(os.path.join(path, "config.json")):
|
||||
return CLIPVisionModelFormat.Diffusers
|
||||
|
||||
raise InvalidModelException(f"Unexpected CLIP Vision model format: {path}")
|
||||
|
||||
@classproperty
|
||||
def save_to_config(cls) -> bool:
|
||||
return True
|
||||
|
||||
def get_size(self, child_type: Optional[SubModelType] = None) -> int:
|
||||
if child_type is not None:
|
||||
raise ValueError("There are no child models in a CLIP Vision model.")
|
||||
|
||||
return self.model_size
|
||||
|
||||
def get_model(
|
||||
self,
|
||||
torch_dtype: Optional[torch.dtype],
|
||||
child_type: Optional[SubModelType] = None,
|
||||
) -> CLIPVisionModelWithProjection:
|
||||
if child_type is not None:
|
||||
raise ValueError("There are no child models in a CLIP Vision model.")
|
||||
|
||||
model = CLIPVisionModelWithProjection.from_pretrained(self.model_path, torch_dtype=torch_dtype)
|
||||
|
||||
# Calculate a more accurate model size.
|
||||
self.model_size = calc_model_size_by_data(model)
|
||||
|
||||
return model
|
||||
|
||||
@classmethod
|
||||
def convert_if_required(
|
||||
cls,
|
||||
model_path: str,
|
||||
output_path: str,
|
||||
config: ModelConfigBase,
|
||||
base_model: BaseModelType,
|
||||
) -> str:
|
||||
format = cls.detect_format(model_path)
|
||||
if format == CLIPVisionModelFormat.Diffusers:
|
||||
return model_path
|
||||
else:
|
||||
raise ValueError(f"Unsupported format: '{format}'.")
|
||||
96
invokeai/backend/model_management/models/ip_adapter.py
Normal file
96
invokeai/backend/model_management/models/ip_adapter.py
Normal file
@@ -0,0 +1,96 @@
|
||||
import os
|
||||
import typing
|
||||
from enum import Enum
|
||||
from typing import Literal, Optional
|
||||
|
||||
import torch
|
||||
|
||||
from invokeai.backend.ip_adapter.ip_adapter import IPAdapter, IPAdapterPlus, build_ip_adapter
|
||||
from invokeai.backend.model_management.models.base import (
|
||||
BaseModelType,
|
||||
InvalidModelException,
|
||||
ModelBase,
|
||||
ModelConfigBase,
|
||||
ModelType,
|
||||
SubModelType,
|
||||
calc_model_size_by_fs,
|
||||
classproperty,
|
||||
)
|
||||
|
||||
|
||||
class IPAdapterModelFormat(str, Enum):
|
||||
# The custom IP-Adapter model format defined by InvokeAI.
|
||||
InvokeAI = "invokeai"
|
||||
|
||||
|
||||
class IPAdapterModel(ModelBase):
|
||||
class InvokeAIConfig(ModelConfigBase):
|
||||
model_format: Literal[IPAdapterModelFormat.InvokeAI]
|
||||
|
||||
def __init__(self, model_path: str, base_model: BaseModelType, model_type: ModelType):
|
||||
assert model_type == ModelType.IPAdapter
|
||||
super().__init__(model_path, base_model, model_type)
|
||||
|
||||
self.model_size = calc_model_size_by_fs(self.model_path)
|
||||
|
||||
@classmethod
|
||||
def detect_format(cls, path: str) -> str:
|
||||
if not os.path.exists(path):
|
||||
raise ModuleNotFoundError(f"No IP-Adapter model at path '{path}'.")
|
||||
|
||||
if os.path.isdir(path):
|
||||
model_file = os.path.join(path, "ip_adapter.bin")
|
||||
image_encoder_config_file = os.path.join(path, "image_encoder.txt")
|
||||
if os.path.exists(model_file) and os.path.exists(image_encoder_config_file):
|
||||
return IPAdapterModelFormat.InvokeAI
|
||||
|
||||
raise InvalidModelException(f"Unexpected IP-Adapter model format: {path}")
|
||||
|
||||
@classproperty
|
||||
def save_to_config(cls) -> bool:
|
||||
return True
|
||||
|
||||
def get_size(self, child_type: Optional[SubModelType] = None) -> int:
|
||||
if child_type is not None:
|
||||
raise ValueError("There are no child models in an IP-Adapter model.")
|
||||
|
||||
return self.model_size
|
||||
|
||||
def get_model(
|
||||
self,
|
||||
torch_dtype: Optional[torch.dtype],
|
||||
child_type: Optional[SubModelType] = None,
|
||||
) -> typing.Union[IPAdapter, IPAdapterPlus]:
|
||||
if child_type is not None:
|
||||
raise ValueError("There are no child models in an IP-Adapter model.")
|
||||
|
||||
model = build_ip_adapter(
|
||||
ip_adapter_ckpt_path=os.path.join(self.model_path, "ip_adapter.bin"), device="cpu", dtype=torch_dtype
|
||||
)
|
||||
|
||||
self.model_size = model.calc_size()
|
||||
return model
|
||||
|
||||
@classmethod
|
||||
def convert_if_required(
|
||||
cls,
|
||||
model_path: str,
|
||||
output_path: str,
|
||||
config: ModelConfigBase,
|
||||
base_model: BaseModelType,
|
||||
) -> str:
|
||||
format = cls.detect_format(model_path)
|
||||
if format == IPAdapterModelFormat.InvokeAI:
|
||||
return model_path
|
||||
else:
|
||||
raise ValueError(f"Unsupported format: '{format}'.")
|
||||
|
||||
|
||||
def get_ip_adapter_image_encoder_model_id(model_path: str):
|
||||
"""Read the ID of the image encoder associated with the IP-Adapter at `model_path`."""
|
||||
image_encoder_config_file = os.path.join(model_path, "image_encoder.txt")
|
||||
|
||||
with open(image_encoder_config_file, "r") as f:
|
||||
image_encoder_model = f.readline().strip()
|
||||
|
||||
return image_encoder_model
|
||||
@@ -1,15 +1,6 @@
|
||||
"""
|
||||
Initialization file for the invokeai.backend.stable_diffusion package
|
||||
"""
|
||||
from .diffusers_pipeline import ( # noqa: F401
|
||||
ConditioningData,
|
||||
PipelineIntermediateState,
|
||||
StableDiffusionGeneratorPipeline,
|
||||
)
|
||||
from .diffusers_pipeline import PipelineIntermediateState, StableDiffusionGeneratorPipeline # noqa: F401
|
||||
from .diffusion import InvokeAIDiffuserComponent # noqa: F401
|
||||
from .diffusion.cross_attention_map_saving import AttentionMapSaver # noqa: F401
|
||||
from .diffusion.shared_invokeai_diffusion import ( # noqa: F401
|
||||
BasicConditioningInfo,
|
||||
PostprocessingSettings,
|
||||
SDXLConditioningInfo,
|
||||
)
|
||||
|
||||
@@ -1,8 +1,8 @@
|
||||
from __future__ import annotations
|
||||
|
||||
import dataclasses
|
||||
import inspect
|
||||
from dataclasses import dataclass, field
|
||||
import math
|
||||
from contextlib import nullcontext
|
||||
from dataclasses import dataclass
|
||||
from typing import Any, Callable, List, Optional, Union
|
||||
|
||||
import einops
|
||||
@@ -23,9 +23,11 @@ from pydantic import Field
|
||||
from transformers import CLIPFeatureExtractor, CLIPTextModel, CLIPTokenizer
|
||||
|
||||
from invokeai.app.services.config import InvokeAIAppConfig
|
||||
from invokeai.backend.ip_adapter.ip_adapter import IPAdapter
|
||||
from invokeai.backend.stable_diffusion.diffusion.conditioning_data import ConditioningData
|
||||
|
||||
from ..util import auto_detect_slice_size, normalize_device
|
||||
from .diffusion import AttentionMapSaver, BasicConditioningInfo, InvokeAIDiffuserComponent, PostprocessingSettings
|
||||
from .diffusion import AttentionMapSaver, InvokeAIDiffuserComponent
|
||||
|
||||
|
||||
@dataclass
|
||||
@@ -95,7 +97,7 @@ class AddsMaskGuidance:
|
||||
# Mask anything that has the same shape as prev_sample, return others as-is.
|
||||
return output_class(
|
||||
{
|
||||
k: (self.apply_mask(v, self._t_for_field(k, t)) if are_like_tensors(prev_sample, v) else v)
|
||||
k: self.apply_mask(v, self._t_for_field(k, t)) if are_like_tensors(prev_sample, v) else v
|
||||
for k, v in step_output.items()
|
||||
}
|
||||
)
|
||||
@@ -162,39 +164,13 @@ class ControlNetData:
|
||||
|
||||
|
||||
@dataclass
|
||||
class ConditioningData:
|
||||
unconditioned_embeddings: BasicConditioningInfo
|
||||
text_embeddings: BasicConditioningInfo
|
||||
guidance_scale: Union[float, List[float]]
|
||||
"""
|
||||
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
|
||||
`guidance_scale` is defined as `w` of equation 2. of [Imagen Paper](https://arxiv.org/pdf/2205.11487.pdf).
|
||||
Guidance scale is enabled by setting `guidance_scale > 1`. Higher guidance scale encourages to generate
|
||||
images that are closely linked to the text `prompt`, usually at the expense of lower image quality.
|
||||
"""
|
||||
extra: Optional[InvokeAIDiffuserComponent.ExtraConditioningInfo] = None
|
||||
scheduler_args: dict[str, Any] = field(default_factory=dict)
|
||||
"""
|
||||
Additional arguments to pass to invokeai_diffuser.do_latent_postprocessing().
|
||||
"""
|
||||
postprocessing_settings: Optional[PostprocessingSettings] = None
|
||||
|
||||
@property
|
||||
def dtype(self):
|
||||
return self.text_embeddings.dtype
|
||||
|
||||
def add_scheduler_args_if_applicable(self, scheduler, **kwargs):
|
||||
scheduler_args = dict(self.scheduler_args)
|
||||
step_method = inspect.signature(scheduler.step)
|
||||
for name, value in kwargs.items():
|
||||
try:
|
||||
step_method.bind_partial(**{name: value})
|
||||
except TypeError:
|
||||
# FIXME: don't silently discard arguments
|
||||
pass # debug("%s does not accept argument named %r", scheduler, name)
|
||||
else:
|
||||
scheduler_args[name] = value
|
||||
return dataclasses.replace(self, scheduler_args=scheduler_args)
|
||||
class IPAdapterData:
|
||||
ip_adapter_model: IPAdapter = Field(default=None)
|
||||
# TODO: change to polymorphic so can do different weights per step (once implemented...)
|
||||
weight: Union[float, List[float]] = Field(default=1.0)
|
||||
# weight: float = Field(default=1.0)
|
||||
begin_step_percent: float = Field(default=0.0)
|
||||
end_step_percent: float = Field(default=1.0)
|
||||
|
||||
|
||||
@dataclass
|
||||
@@ -277,6 +253,7 @@ class StableDiffusionGeneratorPipeline(StableDiffusionPipeline):
|
||||
)
|
||||
self.invokeai_diffuser = InvokeAIDiffuserComponent(self.unet, self._unet_forward)
|
||||
self.control_model = control_model
|
||||
self.use_ip_adapter = False
|
||||
|
||||
def _adjust_memory_efficient_attention(self, latents: torch.Tensor):
|
||||
"""
|
||||
@@ -349,6 +326,7 @@ class StableDiffusionGeneratorPipeline(StableDiffusionPipeline):
|
||||
additional_guidance: List[Callable] = None,
|
||||
callback: Callable[[PipelineIntermediateState], None] = None,
|
||||
control_data: List[ControlNetData] = None,
|
||||
ip_adapter_data: Optional[IPAdapterData] = None,
|
||||
mask: Optional[torch.Tensor] = None,
|
||||
masked_latents: Optional[torch.Tensor] = None,
|
||||
seed: Optional[int] = None,
|
||||
@@ -400,6 +378,7 @@ class StableDiffusionGeneratorPipeline(StableDiffusionPipeline):
|
||||
conditioning_data,
|
||||
additional_guidance=additional_guidance,
|
||||
control_data=control_data,
|
||||
ip_adapter_data=ip_adapter_data,
|
||||
callback=callback,
|
||||
)
|
||||
finally:
|
||||
@@ -419,6 +398,7 @@ class StableDiffusionGeneratorPipeline(StableDiffusionPipeline):
|
||||
*,
|
||||
additional_guidance: List[Callable] = None,
|
||||
control_data: List[ControlNetData] = None,
|
||||
ip_adapter_data: Optional[IPAdapterData] = None,
|
||||
callback: Callable[[PipelineIntermediateState], None] = None,
|
||||
):
|
||||
self._adjust_memory_efficient_attention(latents)
|
||||
@@ -431,12 +411,26 @@ class StableDiffusionGeneratorPipeline(StableDiffusionPipeline):
|
||||
if timesteps.shape[0] == 0:
|
||||
return latents, attention_map_saver
|
||||
|
||||
extra_conditioning_info = conditioning_data.extra
|
||||
with self.invokeai_diffuser.custom_attention_context(
|
||||
self.invokeai_diffuser.model,
|
||||
extra_conditioning_info=extra_conditioning_info,
|
||||
step_count=len(self.scheduler.timesteps),
|
||||
):
|
||||
if conditioning_data.extra is not None and conditioning_data.extra.wants_cross_attention_control:
|
||||
attn_ctx = self.invokeai_diffuser.custom_attention_context(
|
||||
self.invokeai_diffuser.model,
|
||||
extra_conditioning_info=conditioning_data.extra,
|
||||
step_count=len(self.scheduler.timesteps),
|
||||
)
|
||||
self.use_ip_adapter = False
|
||||
elif ip_adapter_data is not None:
|
||||
# TODO(ryand): Should we raise an exception if both custom attention and IP-Adapter attention are active?
|
||||
# As it is now, the IP-Adapter will silently be skipped.
|
||||
weight = ip_adapter_data.weight[0] if isinstance(ip_adapter_data.weight, List) else ip_adapter_data.weight
|
||||
attn_ctx = ip_adapter_data.ip_adapter_model.apply_ip_adapter_attention(
|
||||
unet=self.invokeai_diffuser.model,
|
||||
scale=weight,
|
||||
)
|
||||
self.use_ip_adapter = True
|
||||
else:
|
||||
attn_ctx = nullcontext()
|
||||
|
||||
with attn_ctx:
|
||||
if callback is not None:
|
||||
callback(
|
||||
PipelineIntermediateState(
|
||||
@@ -459,6 +453,7 @@ class StableDiffusionGeneratorPipeline(StableDiffusionPipeline):
|
||||
total_step_count=len(timesteps),
|
||||
additional_guidance=additional_guidance,
|
||||
control_data=control_data,
|
||||
ip_adapter_data=ip_adapter_data,
|
||||
)
|
||||
latents = step_output.prev_sample
|
||||
|
||||
@@ -504,6 +499,7 @@ class StableDiffusionGeneratorPipeline(StableDiffusionPipeline):
|
||||
total_step_count: int,
|
||||
additional_guidance: List[Callable] = None,
|
||||
control_data: List[ControlNetData] = None,
|
||||
ip_adapter_data: Optional[IPAdapterData] = None,
|
||||
):
|
||||
# invokeai_diffuser has batched timesteps, but diffusers schedulers expect a single value
|
||||
timestep = t[0]
|
||||
@@ -514,6 +510,24 @@ class StableDiffusionGeneratorPipeline(StableDiffusionPipeline):
|
||||
# i.e. before or after passing it to InvokeAIDiffuserComponent
|
||||
latent_model_input = self.scheduler.scale_model_input(latents, timestep)
|
||||
|
||||
# handle IP-Adapter
|
||||
if self.use_ip_adapter and ip_adapter_data is not None: # somewhat redundant but logic is clearer
|
||||
first_adapter_step = math.floor(ip_adapter_data.begin_step_percent * total_step_count)
|
||||
last_adapter_step = math.ceil(ip_adapter_data.end_step_percent * total_step_count)
|
||||
weight = (
|
||||
ip_adapter_data.weight[step_index]
|
||||
if isinstance(ip_adapter_data.weight, List)
|
||||
else ip_adapter_data.weight
|
||||
)
|
||||
if step_index >= first_adapter_step and step_index <= last_adapter_step:
|
||||
# only apply IP-Adapter if current step is within the IP-Adapter's begin/end step range
|
||||
# ip_adapter_data.ip_adapter_model.set_scale(ip_adapter_data.weight)
|
||||
ip_adapter_data.ip_adapter_model.set_scale(weight)
|
||||
else:
|
||||
# otherwise, set IP-Adapter scale to 0, so it has no effect
|
||||
ip_adapter_data.ip_adapter_model.set_scale(0.0)
|
||||
|
||||
# handle ControlNet(s)
|
||||
# default is no controlnet, so set controlnet processing output to None
|
||||
controlnet_down_block_samples, controlnet_mid_block_sample = None, None
|
||||
if control_data is not None:
|
||||
|
||||
@@ -3,9 +3,4 @@ Initialization file for invokeai.models.diffusion
|
||||
"""
|
||||
from .cross_attention_control import InvokeAICrossAttentionMixin # noqa: F401
|
||||
from .cross_attention_map_saving import AttentionMapSaver # noqa: F401
|
||||
from .shared_invokeai_diffusion import ( # noqa: F401
|
||||
BasicConditioningInfo,
|
||||
InvokeAIDiffuserComponent,
|
||||
PostprocessingSettings,
|
||||
SDXLConditioningInfo,
|
||||
)
|
||||
from .shared_invokeai_diffusion import InvokeAIDiffuserComponent # noqa: F401
|
||||
|
||||
101
invokeai/backend/stable_diffusion/diffusion/conditioning_data.py
Normal file
101
invokeai/backend/stable_diffusion/diffusion/conditioning_data.py
Normal file
@@ -0,0 +1,101 @@
|
||||
import dataclasses
|
||||
import inspect
|
||||
from dataclasses import dataclass, field
|
||||
from typing import Any, List, Optional, Union
|
||||
|
||||
import torch
|
||||
|
||||
from .cross_attention_control import Arguments
|
||||
|
||||
|
||||
@dataclass
|
||||
class ExtraConditioningInfo:
|
||||
tokens_count_including_eos_bos: int
|
||||
cross_attention_control_args: Optional[Arguments] = None
|
||||
|
||||
@property
|
||||
def wants_cross_attention_control(self):
|
||||
return self.cross_attention_control_args is not None
|
||||
|
||||
|
||||
@dataclass
|
||||
class BasicConditioningInfo:
|
||||
embeds: torch.Tensor
|
||||
# TODO(ryand): Right now we awkwardly copy the extra conditioning info from here up to `ConditioningData`. This
|
||||
# should only be stored in one place.
|
||||
extra_conditioning: Optional[ExtraConditioningInfo]
|
||||
# weight: float
|
||||
# mode: ConditioningAlgo
|
||||
|
||||
def to(self, device, dtype=None):
|
||||
self.embeds = self.embeds.to(device=device, dtype=dtype)
|
||||
return self
|
||||
|
||||
|
||||
@dataclass
|
||||
class SDXLConditioningInfo(BasicConditioningInfo):
|
||||
pooled_embeds: torch.Tensor
|
||||
add_time_ids: torch.Tensor
|
||||
|
||||
def to(self, device, dtype=None):
|
||||
self.pooled_embeds = self.pooled_embeds.to(device=device, dtype=dtype)
|
||||
self.add_time_ids = self.add_time_ids.to(device=device, dtype=dtype)
|
||||
return super().to(device=device, dtype=dtype)
|
||||
|
||||
|
||||
@dataclass(frozen=True)
|
||||
class PostprocessingSettings:
|
||||
threshold: float
|
||||
warmup: float
|
||||
h_symmetry_time_pct: Optional[float]
|
||||
v_symmetry_time_pct: Optional[float]
|
||||
|
||||
|
||||
@dataclass
|
||||
class IPAdapterConditioningInfo:
|
||||
cond_image_prompt_embeds: torch.Tensor
|
||||
"""IP-Adapter image encoder conditioning embeddings.
|
||||
Shape: (batch_size, num_tokens, encoding_dim).
|
||||
"""
|
||||
uncond_image_prompt_embeds: torch.Tensor
|
||||
"""IP-Adapter image encoding embeddings to use for unconditional generation.
|
||||
Shape: (batch_size, num_tokens, encoding_dim).
|
||||
"""
|
||||
|
||||
|
||||
@dataclass
|
||||
class ConditioningData:
|
||||
unconditioned_embeddings: BasicConditioningInfo
|
||||
text_embeddings: BasicConditioningInfo
|
||||
guidance_scale: Union[float, List[float]]
|
||||
"""
|
||||
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
|
||||
`guidance_scale` is defined as `w` of equation 2. of [Imagen Paper](https://arxiv.org/pdf/2205.11487.pdf).
|
||||
Guidance scale is enabled by setting `guidance_scale > 1`. Higher guidance scale encourages to generate
|
||||
images that are closely linked to the text `prompt`, usually at the expense of lower image quality.
|
||||
"""
|
||||
extra: Optional[ExtraConditioningInfo] = None
|
||||
scheduler_args: dict[str, Any] = field(default_factory=dict)
|
||||
"""
|
||||
Additional arguments to pass to invokeai_diffuser.do_latent_postprocessing().
|
||||
"""
|
||||
postprocessing_settings: Optional[PostprocessingSettings] = None
|
||||
|
||||
ip_adapter_conditioning: Optional[IPAdapterConditioningInfo] = None
|
||||
|
||||
@property
|
||||
def dtype(self):
|
||||
return self.text_embeddings.dtype
|
||||
|
||||
def add_scheduler_args_if_applicable(self, scheduler, **kwargs):
|
||||
scheduler_args = dict(self.scheduler_args)
|
||||
step_method = inspect.signature(scheduler.step)
|
||||
for name, value in kwargs.items():
|
||||
try:
|
||||
step_method.bind_partial(**{name: value})
|
||||
except TypeError:
|
||||
# FIXME: don't silently discard arguments
|
||||
pass # debug("%s does not accept argument named %r", scheduler, name)
|
||||
else:
|
||||
scheduler_args[name] = value
|
||||
return dataclasses.replace(self, scheduler_args=scheduler_args)
|
||||
@@ -376,11 +376,11 @@ def get_cross_attention_modules(model, which: CrossAttentionType) -> list[tuple[
|
||||
# non-fatal error but .swap() won't work.
|
||||
logger.error(
|
||||
f"Error! CrossAttentionControl found an unexpected number of {cross_attention_class} modules in the model "
|
||||
+ f"(expected {expected_count}, found {cross_attention_modules_in_model_count}). Either monkey-patching failed "
|
||||
+ "or some assumption has changed about the structure of the model itself. Please fix the monkey-patching, "
|
||||
+ f"and/or update the {expected_count} above to an appropriate number, and/or find and inform someone who knows "
|
||||
+ "what it means. This error is non-fatal, but it is likely that .swap() and attention map display will not "
|
||||
+ "work properly until it is fixed."
|
||||
f"(expected {expected_count}, found {cross_attention_modules_in_model_count}). Either monkey-patching "
|
||||
"failed or some assumption has changed about the structure of the model itself. Please fix the "
|
||||
f"monkey-patching, and/or update the {expected_count} above to an appropriate number, and/or find and "
|
||||
"inform someone who knows what it means. This error is non-fatal, but it is likely that .swap() and "
|
||||
"attention map display will not work properly until it is fixed."
|
||||
)
|
||||
return attention_module_tuples
|
||||
|
||||
@@ -577,6 +577,7 @@ class SlicedSwapCrossAttnProcesser(SlicedAttnProcessor):
|
||||
attention_mask=None,
|
||||
# kwargs
|
||||
swap_cross_attn_context: SwapCrossAttnContext = None,
|
||||
**kwargs,
|
||||
):
|
||||
attention_type = CrossAttentionType.SELF if encoder_hidden_states is None else CrossAttentionType.TOKENS
|
||||
|
||||
|
||||
@@ -2,7 +2,6 @@ from __future__ import annotations
|
||||
|
||||
import math
|
||||
from contextlib import contextmanager
|
||||
from dataclasses import dataclass
|
||||
from typing import Any, Callable, Optional, Union
|
||||
|
||||
import torch
|
||||
@@ -10,9 +9,14 @@ from diffusers import UNet2DConditionModel
|
||||
from typing_extensions import TypeAlias
|
||||
|
||||
from invokeai.app.services.config import InvokeAIAppConfig
|
||||
from invokeai.backend.stable_diffusion.diffusion.conditioning_data import (
|
||||
ConditioningData,
|
||||
ExtraConditioningInfo,
|
||||
PostprocessingSettings,
|
||||
SDXLConditioningInfo,
|
||||
)
|
||||
|
||||
from .cross_attention_control import (
|
||||
Arguments,
|
||||
Context,
|
||||
CrossAttentionType,
|
||||
SwapCrossAttnContext,
|
||||
@@ -31,37 +35,6 @@ ModelForwardCallback: TypeAlias = Union[
|
||||
]
|
||||
|
||||
|
||||
@dataclass
|
||||
class BasicConditioningInfo:
|
||||
embeds: torch.Tensor
|
||||
extra_conditioning: Optional[InvokeAIDiffuserComponent.ExtraConditioningInfo]
|
||||
# weight: float
|
||||
# mode: ConditioningAlgo
|
||||
|
||||
def to(self, device, dtype=None):
|
||||
self.embeds = self.embeds.to(device=device, dtype=dtype)
|
||||
return self
|
||||
|
||||
|
||||
@dataclass
|
||||
class SDXLConditioningInfo(BasicConditioningInfo):
|
||||
pooled_embeds: torch.Tensor
|
||||
add_time_ids: torch.Tensor
|
||||
|
||||
def to(self, device, dtype=None):
|
||||
self.pooled_embeds = self.pooled_embeds.to(device=device, dtype=dtype)
|
||||
self.add_time_ids = self.add_time_ids.to(device=device, dtype=dtype)
|
||||
return super().to(device=device, dtype=dtype)
|
||||
|
||||
|
||||
@dataclass(frozen=True)
|
||||
class PostprocessingSettings:
|
||||
threshold: float
|
||||
warmup: float
|
||||
h_symmetry_time_pct: Optional[float]
|
||||
v_symmetry_time_pct: Optional[float]
|
||||
|
||||
|
||||
class InvokeAIDiffuserComponent:
|
||||
"""
|
||||
The aim of this component is to provide a single place for code that can be applied identically to
|
||||
@@ -75,15 +48,6 @@ class InvokeAIDiffuserComponent:
|
||||
debug_thresholding = False
|
||||
sequential_guidance = False
|
||||
|
||||
@dataclass
|
||||
class ExtraConditioningInfo:
|
||||
tokens_count_including_eos_bos: int
|
||||
cross_attention_control_args: Optional[Arguments] = None
|
||||
|
||||
@property
|
||||
def wants_cross_attention_control(self):
|
||||
return self.cross_attention_control_args is not None
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
model,
|
||||
@@ -103,30 +67,26 @@ class InvokeAIDiffuserComponent:
|
||||
@contextmanager
|
||||
def custom_attention_context(
|
||||
self,
|
||||
unet: UNet2DConditionModel, # note: also may futz with the text encoder depending on requested LoRAs
|
||||
unet: UNet2DConditionModel,
|
||||
extra_conditioning_info: Optional[ExtraConditioningInfo],
|
||||
step_count: int,
|
||||
):
|
||||
old_attn_processors = None
|
||||
if extra_conditioning_info and (extra_conditioning_info.wants_cross_attention_control):
|
||||
old_attn_processors = unet.attn_processors
|
||||
# Load lora conditions into the model
|
||||
if extra_conditioning_info.wants_cross_attention_control:
|
||||
self.cross_attention_control_context = Context(
|
||||
arguments=extra_conditioning_info.cross_attention_control_args,
|
||||
step_count=step_count,
|
||||
)
|
||||
setup_cross_attention_control_attention_processors(
|
||||
unet,
|
||||
self.cross_attention_control_context,
|
||||
)
|
||||
old_attn_processors = unet.attn_processors
|
||||
|
||||
try:
|
||||
self.cross_attention_control_context = Context(
|
||||
arguments=extra_conditioning_info.cross_attention_control_args,
|
||||
step_count=step_count,
|
||||
)
|
||||
setup_cross_attention_control_attention_processors(
|
||||
unet,
|
||||
self.cross_attention_control_context,
|
||||
)
|
||||
|
||||
yield None
|
||||
finally:
|
||||
self.cross_attention_control_context = None
|
||||
if old_attn_processors is not None:
|
||||
unet.set_attn_processor(old_attn_processors)
|
||||
unet.set_attn_processor(old_attn_processors)
|
||||
# TODO resuscitate attention map saving
|
||||
# self.remove_attention_map_saving()
|
||||
|
||||
@@ -376,11 +336,24 @@ class InvokeAIDiffuserComponent:
|
||||
|
||||
# methods below are called from do_diffusion_step and should be considered private to this class.
|
||||
|
||||
def _apply_standard_conditioning(self, x, sigma, conditioning_data, **kwargs):
|
||||
# fast batched path
|
||||
def _apply_standard_conditioning(self, x, sigma, conditioning_data: ConditioningData, **kwargs):
|
||||
"""Runs the conditioned and unconditioned UNet forward passes in a single batch for faster inference speed at
|
||||
the cost of higher memory usage.
|
||||
"""
|
||||
x_twice = torch.cat([x] * 2)
|
||||
sigma_twice = torch.cat([sigma] * 2)
|
||||
|
||||
cross_attention_kwargs = None
|
||||
if conditioning_data.ip_adapter_conditioning is not None:
|
||||
cross_attention_kwargs = {
|
||||
"ip_adapter_image_prompt_embeds": torch.cat(
|
||||
[
|
||||
conditioning_data.ip_adapter_conditioning.uncond_image_prompt_embeds,
|
||||
conditioning_data.ip_adapter_conditioning.cond_image_prompt_embeds,
|
||||
]
|
||||
)
|
||||
}
|
||||
|
||||
added_cond_kwargs = None
|
||||
if type(conditioning_data.text_embeddings) is SDXLConditioningInfo:
|
||||
added_cond_kwargs = {
|
||||
@@ -408,6 +381,7 @@ class InvokeAIDiffuserComponent:
|
||||
x_twice,
|
||||
sigma_twice,
|
||||
both_conditionings,
|
||||
cross_attention_kwargs=cross_attention_kwargs,
|
||||
encoder_attention_mask=encoder_attention_mask,
|
||||
added_cond_kwargs=added_cond_kwargs,
|
||||
**kwargs,
|
||||
@@ -419,9 +393,12 @@ class InvokeAIDiffuserComponent:
|
||||
self,
|
||||
x: torch.Tensor,
|
||||
sigma,
|
||||
conditioning_data,
|
||||
conditioning_data: ConditioningData,
|
||||
**kwargs,
|
||||
):
|
||||
"""Runs the conditioned and unconditioned UNet forward passes sequentially for lower memory usage at the cost of
|
||||
slower execution speed.
|
||||
"""
|
||||
# low-memory sequential path
|
||||
uncond_down_block, cond_down_block = None, None
|
||||
down_block_additional_residuals = kwargs.pop("down_block_additional_residuals", None)
|
||||
@@ -437,6 +414,13 @@ class InvokeAIDiffuserComponent:
|
||||
if mid_block_additional_residual is not None:
|
||||
uncond_mid_block, cond_mid_block = mid_block_additional_residual.chunk(2)
|
||||
|
||||
# Run unconditional UNet denoising.
|
||||
cross_attention_kwargs = None
|
||||
if conditioning_data.ip_adapter_conditioning is not None:
|
||||
cross_attention_kwargs = {
|
||||
"ip_adapter_image_prompt_embeds": conditioning_data.ip_adapter_conditioning.uncond_image_prompt_embeds
|
||||
}
|
||||
|
||||
added_cond_kwargs = None
|
||||
is_sdxl = type(conditioning_data.text_embeddings) is SDXLConditioningInfo
|
||||
if is_sdxl:
|
||||
@@ -449,12 +433,21 @@ class InvokeAIDiffuserComponent:
|
||||
x,
|
||||
sigma,
|
||||
conditioning_data.unconditioned_embeddings.embeds,
|
||||
cross_attention_kwargs=cross_attention_kwargs,
|
||||
down_block_additional_residuals=uncond_down_block,
|
||||
mid_block_additional_residual=uncond_mid_block,
|
||||
added_cond_kwargs=added_cond_kwargs,
|
||||
**kwargs,
|
||||
)
|
||||
|
||||
# Run conditional UNet denoising.
|
||||
cross_attention_kwargs = None
|
||||
if conditioning_data.ip_adapter_conditioning is not None:
|
||||
cross_attention_kwargs = {
|
||||
"ip_adapter_image_prompt_embeds": conditioning_data.ip_adapter_conditioning.cond_image_prompt_embeds
|
||||
}
|
||||
|
||||
added_cond_kwargs = None
|
||||
if is_sdxl:
|
||||
added_cond_kwargs = {
|
||||
"text_embeds": conditioning_data.text_embeddings.pooled_embeds,
|
||||
@@ -465,6 +458,7 @@ class InvokeAIDiffuserComponent:
|
||||
x,
|
||||
sigma,
|
||||
conditioning_data.text_embeddings.embeds,
|
||||
cross_attention_kwargs=cross_attention_kwargs,
|
||||
down_block_additional_residuals=cond_down_block,
|
||||
mid_block_additional_residual=cond_mid_block,
|
||||
added_cond_kwargs=added_cond_kwargs,
|
||||
|
||||
568
invokeai/backend/util/db_maintenance.py
Normal file
568
invokeai/backend/util/db_maintenance.py
Normal file
@@ -0,0 +1,568 @@
|
||||
# pylint: disable=line-too-long
|
||||
# pylint: disable=broad-exception-caught
|
||||
# pylint: disable=missing-function-docstring
|
||||
"""Script to peform db maintenance and outputs directory management."""
|
||||
|
||||
import argparse
|
||||
import datetime
|
||||
import enum
|
||||
import glob
|
||||
import locale
|
||||
import os
|
||||
import shutil
|
||||
import sqlite3
|
||||
from pathlib import Path
|
||||
|
||||
import PIL
|
||||
import PIL.ImageOps
|
||||
import PIL.PngImagePlugin
|
||||
import yaml
|
||||
|
||||
|
||||
class ConfigMapper:
|
||||
"""Configuration loader."""
|
||||
|
||||
def __init__(self): # noqa D107
|
||||
pass
|
||||
|
||||
TIMESTAMP_STRING = datetime.datetime.utcnow().strftime("%Y%m%dT%H%M%SZ")
|
||||
|
||||
INVOKE_DIRNAME = "invokeai"
|
||||
YAML_FILENAME = "invokeai.yaml"
|
||||
DATABASE_FILENAME = "invokeai.db"
|
||||
|
||||
database_path = None
|
||||
database_backup_dir = None
|
||||
outputs_path = None
|
||||
archive_path = None
|
||||
thumbnails_path = None
|
||||
thumbnails_archive_path = None
|
||||
|
||||
def load(self):
|
||||
"""Read paths from yaml config and validate."""
|
||||
root = "."
|
||||
|
||||
if not self.__load_from_root_config(os.path.abspath(root)):
|
||||
return False
|
||||
|
||||
return True
|
||||
|
||||
def __load_from_root_config(self, invoke_root):
|
||||
"""Validate a yaml path exists, confirm the user wants to use it and load config."""
|
||||
yaml_path = os.path.join(invoke_root, self.YAML_FILENAME)
|
||||
if os.path.exists(yaml_path):
|
||||
db_dir, outdir = self.__load_paths_from_yaml_file(yaml_path)
|
||||
|
||||
if db_dir is None or outdir is None:
|
||||
print("The invokeai.yaml file was found but is missing the db_dir and/or outdir setting!")
|
||||
return False
|
||||
|
||||
if os.path.isabs(db_dir):
|
||||
self.database_path = os.path.join(db_dir, self.DATABASE_FILENAME)
|
||||
else:
|
||||
self.database_path = os.path.join(invoke_root, db_dir, self.DATABASE_FILENAME)
|
||||
|
||||
self.database_backup_dir = os.path.join(os.path.dirname(self.database_path), "backup")
|
||||
|
||||
if os.path.isabs(outdir):
|
||||
self.outputs_path = os.path.join(outdir, "images")
|
||||
self.archive_path = os.path.join(outdir, "images-archive")
|
||||
else:
|
||||
self.outputs_path = os.path.join(invoke_root, outdir, "images")
|
||||
self.archive_path = os.path.join(invoke_root, outdir, "images-archive")
|
||||
|
||||
self.thumbnails_path = os.path.join(self.outputs_path, "thumbnails")
|
||||
self.thumbnails_archive_path = os.path.join(self.archive_path, "thumbnails")
|
||||
|
||||
db_exists = os.path.exists(self.database_path)
|
||||
outdir_exists = os.path.exists(self.outputs_path)
|
||||
|
||||
text = f"Found {self.YAML_FILENAME} file at {yaml_path}:"
|
||||
text += f"\n Database : {self.database_path} - {'Exists!' if db_exists else 'Not Found!'}"
|
||||
text += f"\n Outputs : {self.outputs_path}- {'Exists!' if outdir_exists else 'Not Found!'}"
|
||||
print(text)
|
||||
|
||||
if db_exists and outdir_exists:
|
||||
return True
|
||||
else:
|
||||
print(
|
||||
"\nOne or more paths specified in invoke.yaml do not exist. Please inspect/correct the configuration and ensure the script is run in the developer console mode (option 8) from an Invoke AI root directory."
|
||||
)
|
||||
return False
|
||||
else:
|
||||
print(
|
||||
f"Auto-discovery of configuration failed! Could not find ({yaml_path})!\n\nPlease ensure the script is run in the developer console mode (option 8) from an Invoke AI root directory."
|
||||
)
|
||||
return False
|
||||
|
||||
def __load_paths_from_yaml_file(self, yaml_path):
|
||||
"""Load an Invoke AI yaml file and get the database and outputs paths."""
|
||||
try:
|
||||
with open(yaml_path, "rt", encoding=locale.getpreferredencoding()) as file:
|
||||
yamlinfo = yaml.safe_load(file)
|
||||
db_dir = yamlinfo.get("InvokeAI", {}).get("Paths", {}).get("db_dir", None)
|
||||
outdir = yamlinfo.get("InvokeAI", {}).get("Paths", {}).get("outdir", None)
|
||||
return db_dir, outdir
|
||||
except Exception:
|
||||
print(f"Failed to load paths from yaml file! {yaml_path}!")
|
||||
return None, None
|
||||
|
||||
|
||||
class MaintenanceStats:
|
||||
"""DTO for tracking work progress."""
|
||||
|
||||
def __init__(self): # noqa D107
|
||||
pass
|
||||
|
||||
time_start = datetime.datetime.utcnow()
|
||||
count_orphaned_db_entries_cleaned = 0
|
||||
count_orphaned_disk_files_cleaned = 0
|
||||
count_orphaned_thumbnails_cleaned = 0
|
||||
count_thumbnails_regenerated = 0
|
||||
count_errors = 0
|
||||
|
||||
@staticmethod
|
||||
def get_elapsed_time_string():
|
||||
"""Get a friendly time string for the time elapsed since processing start."""
|
||||
time_now = datetime.datetime.utcnow()
|
||||
total_seconds = (time_now - MaintenanceStats.time_start).total_seconds()
|
||||
hours = int((total_seconds) / 3600)
|
||||
minutes = int(((total_seconds) % 3600) / 60)
|
||||
seconds = total_seconds % 60
|
||||
out_str = f"{hours} hour(s) -" if hours > 0 else ""
|
||||
out_str += f"{minutes} minute(s) -" if minutes > 0 else ""
|
||||
out_str += f"{seconds:.2f} second(s)"
|
||||
return out_str
|
||||
|
||||
|
||||
class DatabaseMapper:
|
||||
"""Class to abstract database functionality."""
|
||||
|
||||
def __init__(self, database_path, database_backup_dir): # noqa D107
|
||||
self.database_path = database_path
|
||||
self.database_backup_dir = database_backup_dir
|
||||
self.connection = None
|
||||
self.cursor = None
|
||||
|
||||
def backup(self, timestamp_string):
|
||||
"""Take a backup of the database."""
|
||||
if not os.path.exists(self.database_backup_dir):
|
||||
print(f"Database backup directory {self.database_backup_dir} does not exist -> creating...", end="")
|
||||
os.makedirs(self.database_backup_dir)
|
||||
print("Done!")
|
||||
database_backup_path = os.path.join(self.database_backup_dir, f"backup-{timestamp_string}-invokeai.db")
|
||||
print(f"Making DB Backup at {database_backup_path}...", end="")
|
||||
shutil.copy2(self.database_path, database_backup_path)
|
||||
print("Done!")
|
||||
|
||||
def connect(self):
|
||||
"""Open connection to the database."""
|
||||
self.connection = sqlite3.connect(self.database_path)
|
||||
self.cursor = self.connection.cursor()
|
||||
|
||||
def get_all_image_files(self):
|
||||
"""Get the full list of image file names from the database."""
|
||||
sql_get_image_by_name = "SELECT image_name FROM images"
|
||||
self.cursor.execute(sql_get_image_by_name)
|
||||
rows = self.cursor.fetchall()
|
||||
db_files = []
|
||||
for row in rows:
|
||||
db_files.append(row[0])
|
||||
return db_files
|
||||
|
||||
def remove_image_file_record(self, filename: str):
|
||||
"""Remove an image file reference from the database by filename."""
|
||||
sanitized_filename = str.replace(filename, "'", "''") # prevent injection
|
||||
sql_command = f"DELETE FROM images WHERE image_name='{sanitized_filename}'"
|
||||
self.cursor.execute(sql_command)
|
||||
self.connection.commit()
|
||||
|
||||
def does_image_exist(self, image_filename):
|
||||
"""Check database if a image name already exists and return a boolean."""
|
||||
sanitized_filename = str.replace(image_filename, "'", "''") # prevent injection
|
||||
sql_get_image_by_name = f"SELECT image_name FROM images WHERE image_name='{sanitized_filename}'"
|
||||
self.cursor.execute(sql_get_image_by_name)
|
||||
rows = self.cursor.fetchall()
|
||||
return True if len(rows) > 0 else False
|
||||
|
||||
def disconnect(self):
|
||||
"""Disconnect from the db, cleaning up connections and cursors."""
|
||||
if self.cursor is not None:
|
||||
self.cursor.close()
|
||||
if self.connection is not None:
|
||||
self.connection.close()
|
||||
|
||||
|
||||
class PhysicalFileMapper:
|
||||
"""Containing class for script functionality."""
|
||||
|
||||
def __init__(self, outputs_path, thumbnails_path, archive_path, thumbnails_archive_path): # noqa D107
|
||||
self.outputs_path = outputs_path
|
||||
self.archive_path = archive_path
|
||||
self.thumbnails_path = thumbnails_path
|
||||
self.thumbnails_archive_path = thumbnails_archive_path
|
||||
|
||||
def create_archive_directories(self):
|
||||
"""Create the directory for archiving orphaned image files."""
|
||||
if not os.path.exists(self.archive_path):
|
||||
print(f"Image archive directory ({self.archive_path}) does not exist -> creating...", end="")
|
||||
os.makedirs(self.archive_path)
|
||||
print("Created!")
|
||||
if not os.path.exists(self.thumbnails_archive_path):
|
||||
print(
|
||||
f"Image thumbnails archive directory ({self.thumbnails_archive_path}) does not exist -> creating...",
|
||||
end="",
|
||||
)
|
||||
os.makedirs(self.thumbnails_archive_path)
|
||||
print("Created!")
|
||||
|
||||
def get_image_path_for_image_name(self, image_filename): # noqa D102
|
||||
return os.path.join(self.outputs_path, image_filename)
|
||||
|
||||
def image_file_exists(self, image_filename): # noqa D102
|
||||
return os.path.exists(self.get_image_path_for_image_name(image_filename))
|
||||
|
||||
def get_thumbnail_path_for_image(self, image_filename): # noqa D102
|
||||
return os.path.join(self.thumbnails_path, os.path.splitext(image_filename)[0]) + ".webp"
|
||||
|
||||
def get_image_name_from_thumbnail_path(self, thumbnail_path): # noqa D102
|
||||
return os.path.splitext(os.path.basename(thumbnail_path))[0] + ".png"
|
||||
|
||||
def thumbnail_exists_for_filename(self, image_filename): # noqa D102
|
||||
return os.path.exists(self.get_thumbnail_path_for_image(image_filename))
|
||||
|
||||
def archive_image(self, image_filename): # noqa D102
|
||||
if self.image_file_exists(image_filename):
|
||||
image_path = self.get_image_path_for_image_name(image_filename)
|
||||
shutil.move(image_path, self.archive_path)
|
||||
|
||||
def archive_thumbnail_by_image_filename(self, image_filename): # noqa D102
|
||||
if self.thumbnail_exists_for_filename(image_filename):
|
||||
thumbnail_path = self.get_thumbnail_path_for_image(image_filename)
|
||||
shutil.move(thumbnail_path, self.thumbnails_archive_path)
|
||||
|
||||
def get_all_png_filenames_in_directory(self, directory_path): # noqa D102
|
||||
filepaths = glob.glob(directory_path + "/*.png", recursive=False)
|
||||
filenames = []
|
||||
for filepath in filepaths:
|
||||
filenames.append(os.path.basename(filepath))
|
||||
return filenames
|
||||
|
||||
def get_all_thumbnails_with_full_path(self, thumbnails_directory): # noqa D102
|
||||
return glob.glob(thumbnails_directory + "/*.webp", recursive=False)
|
||||
|
||||
def generate_thumbnail_for_image_name(self, image_filename): # noqa D102
|
||||
# create thumbnail
|
||||
file_path = self.get_image_path_for_image_name(image_filename)
|
||||
thumb_path = self.get_thumbnail_path_for_image(image_filename)
|
||||
thumb_size = 256, 256
|
||||
with PIL.Image.open(file_path) as source_image:
|
||||
source_image.thumbnail(thumb_size)
|
||||
source_image.save(thumb_path, "webp")
|
||||
|
||||
|
||||
class MaintenanceOperation(str, enum.Enum):
|
||||
"""Enum class for operations."""
|
||||
|
||||
Ask = "ask"
|
||||
CleanOrphanedDbEntries = "clean"
|
||||
CleanOrphanedDiskFiles = "archive"
|
||||
ReGenerateThumbnails = "thumbnails"
|
||||
All = "all"
|
||||
|
||||
|
||||
class InvokeAIDatabaseMaintenanceApp:
|
||||
"""Main processor class for the application."""
|
||||
|
||||
_operation: MaintenanceOperation
|
||||
_headless: bool = False
|
||||
__stats: MaintenanceStats = MaintenanceStats()
|
||||
|
||||
def __init__(self, operation: MaintenanceOperation = MaintenanceOperation.Ask):
|
||||
"""Initialize maintenance app."""
|
||||
self._operation = MaintenanceOperation(operation)
|
||||
self._headless = operation != MaintenanceOperation.Ask
|
||||
|
||||
def ask_for_operation(self) -> MaintenanceOperation:
|
||||
"""Ask user to choose the operation to perform."""
|
||||
while True:
|
||||
print()
|
||||
print("It is recommennded to run these operations as ordered below to avoid additional")
|
||||
print("work being performed that will be discarded in a subsequent step.")
|
||||
print()
|
||||
print("Select maintenance operation:")
|
||||
print()
|
||||
print("1) Clean Orphaned Database Image Entries")
|
||||
print(" Cleans entries in the database where the matching file was removed from")
|
||||
print(" the outputs directory.")
|
||||
print("2) Archive Orphaned Image Files")
|
||||
print(" Files found in the outputs directory without an entry in the database are")
|
||||
print(" moved to an archive directory.")
|
||||
print("3) Re-Generate Missing Thumbnail Files")
|
||||
print(" For files found in the outputs directory, re-generate a thumbnail if it")
|
||||
print(" not found in the thumbnails directory.")
|
||||
print()
|
||||
print("(CTRL-C to quit)")
|
||||
|
||||
try:
|
||||
input_option = int(input("Specify desired operation number (1-3): "))
|
||||
|
||||
operations = [
|
||||
MaintenanceOperation.CleanOrphanedDbEntries,
|
||||
MaintenanceOperation.CleanOrphanedDiskFiles,
|
||||
MaintenanceOperation.ReGenerateThumbnails,
|
||||
]
|
||||
return operations[input_option - 1]
|
||||
except (IndexError, ValueError):
|
||||
print("\nInvalid selection!")
|
||||
|
||||
def ask_to_continue(self) -> bool:
|
||||
"""Ask user whether they want to continue with the operation."""
|
||||
while True:
|
||||
input_choice = input("Do you wish to continue? (Y or N)? ")
|
||||
if str.lower(input_choice) == "y":
|
||||
return True
|
||||
if str.lower(input_choice) == "n":
|
||||
return False
|
||||
|
||||
def clean_orphaned_db_entries(
|
||||
self, config: ConfigMapper, file_mapper: PhysicalFileMapper, db_mapper: DatabaseMapper
|
||||
):
|
||||
"""Clean dangling database entries that no longer point to a file in outputs."""
|
||||
if self._headless:
|
||||
print(f"Removing database references to images that no longer exist in {config.outputs_path}...")
|
||||
else:
|
||||
print()
|
||||
print("===============================================================================")
|
||||
print("= Clean Orphaned Database Entries")
|
||||
print()
|
||||
print("Perform this operation if you have removed files from the outputs/images")
|
||||
print("directory but the database was never updated. You may see this as empty imaages")
|
||||
print("in the app gallery, or images that only show an enlarged version of the")
|
||||
print("thumbnail.")
|
||||
print()
|
||||
print(f"Database File Path : {config.database_path}")
|
||||
print(f"Database backup will be taken at : {config.database_backup_dir}")
|
||||
print(f"Outputs/Images Directory : {config.outputs_path}")
|
||||
print(f"Outputs/Images Archive Directory : {config.archive_path}")
|
||||
|
||||
print("\nNotes about this operation:")
|
||||
print("- This operation will find database image file entries that do not exist in the")
|
||||
print(" outputs/images dir and remove those entries from the database.")
|
||||
print("- This operation will target all image types including intermediate files.")
|
||||
print("- If a thumbnail still exists in outputs/images/thumbnails matching the")
|
||||
print(" orphaned entry, it will be moved to the archive directory.")
|
||||
print()
|
||||
|
||||
if not self.ask_to_continue():
|
||||
raise KeyboardInterrupt
|
||||
|
||||
file_mapper.create_archive_directories()
|
||||
db_mapper.backup(config.TIMESTAMP_STRING)
|
||||
db_mapper.connect()
|
||||
db_files = db_mapper.get_all_image_files()
|
||||
for db_file in db_files:
|
||||
try:
|
||||
if not file_mapper.image_file_exists(db_file):
|
||||
print(f"Found orphaned image db entry {db_file}. Cleaning ...", end="")
|
||||
db_mapper.remove_image_file_record(db_file)
|
||||
print("Cleaned!")
|
||||
if file_mapper.thumbnail_exists_for_filename(db_file):
|
||||
print("A thumbnail was found, archiving ...", end="")
|
||||
file_mapper.archive_thumbnail_by_image_filename(db_file)
|
||||
print("Archived!")
|
||||
self.__stats.count_orphaned_db_entries_cleaned += 1
|
||||
except Exception as ex:
|
||||
print("An error occurred cleaning db entry, error was:")
|
||||
print(ex)
|
||||
self.__stats.count_errors += 1
|
||||
|
||||
def clean_orphaned_disk_files(
|
||||
self, config: ConfigMapper, file_mapper: PhysicalFileMapper, db_mapper: DatabaseMapper
|
||||
):
|
||||
"""Archive image files that no longer have entries in the database."""
|
||||
if self._headless:
|
||||
print(f"Archiving orphaned image files to {config.archive_path}...")
|
||||
else:
|
||||
print()
|
||||
print("===============================================================================")
|
||||
print("= Clean Orphaned Disk Files")
|
||||
print()
|
||||
print("Perform this operation if you have files that were copied into the outputs")
|
||||
print("directory which are not referenced by the database. This can happen if you")
|
||||
print("upgraded to a version with a fresh database, but re-used the outputs directory")
|
||||
print("and now new images are mixed with the files not in the db. The script will")
|
||||
print("archive these files so you can choose to delete them or re-import using the")
|
||||
print("official import script.")
|
||||
print()
|
||||
print(f"Database File Path : {config.database_path}")
|
||||
print(f"Database backup will be taken at : {config.database_backup_dir}")
|
||||
print(f"Outputs/Images Directory : {config.outputs_path}")
|
||||
print(f"Outputs/Images Archive Directory : {config.archive_path}")
|
||||
|
||||
print("\nNotes about this operation:")
|
||||
print("- This operation will find image files not referenced by the database and move to an")
|
||||
print(" archive directory.")
|
||||
print("- This operation will target all image types including intermediate references.")
|
||||
print("- The matching thumbnail will also be archived.")
|
||||
print("- Any remaining orphaned thumbnails will also be archived.")
|
||||
|
||||
if not self.ask_to_continue():
|
||||
raise KeyboardInterrupt
|
||||
|
||||
print()
|
||||
|
||||
file_mapper.create_archive_directories()
|
||||
db_mapper.backup(config.TIMESTAMP_STRING)
|
||||
db_mapper.connect()
|
||||
phys_files = file_mapper.get_all_png_filenames_in_directory(config.outputs_path)
|
||||
for phys_file in phys_files:
|
||||
try:
|
||||
if not db_mapper.does_image_exist(phys_file):
|
||||
print(f"Found orphaned file {phys_file}, archiving...", end="")
|
||||
file_mapper.archive_image(phys_file)
|
||||
print("Archived!")
|
||||
if file_mapper.thumbnail_exists_for_filename(phys_file):
|
||||
print("Related thumbnail exists, archiving...", end="")
|
||||
file_mapper.archive_thumbnail_by_image_filename(phys_file)
|
||||
print("Archived!")
|
||||
else:
|
||||
print("No matching thumbnail existed to be cleaned.")
|
||||
self.__stats.count_orphaned_disk_files_cleaned += 1
|
||||
except Exception as ex:
|
||||
print("Error found trying to archive file or thumbnail, error was:")
|
||||
print(ex)
|
||||
self.__stats.count_errors += 1
|
||||
|
||||
thumb_filepaths = file_mapper.get_all_thumbnails_with_full_path(config.thumbnails_path)
|
||||
# archive any remaining orphaned thumbnails
|
||||
for thumb_filepath in thumb_filepaths:
|
||||
try:
|
||||
thumb_src_image_name = file_mapper.get_image_name_from_thumbnail_path(thumb_filepath)
|
||||
if not file_mapper.image_file_exists(thumb_src_image_name):
|
||||
print(f"Found orphaned thumbnail {thumb_filepath}, archiving...", end="")
|
||||
file_mapper.archive_thumbnail_by_image_filename(thumb_src_image_name)
|
||||
print("Archived!")
|
||||
self.__stats.count_orphaned_thumbnails_cleaned += 1
|
||||
except Exception as ex:
|
||||
print("Error found trying to archive thumbnail, error was:")
|
||||
print(ex)
|
||||
self.__stats.count_errors += 1
|
||||
|
||||
def regenerate_thumbnails(self, config: ConfigMapper, file_mapper: PhysicalFileMapper, *args):
|
||||
"""Create missing thumbnails for any valid general images both in the db and on disk."""
|
||||
if self._headless:
|
||||
print("Regenerating missing image thumbnails...")
|
||||
else:
|
||||
print()
|
||||
print("===============================================================================")
|
||||
print("= Regenerate Thumbnails")
|
||||
print()
|
||||
print("This operation will find files that have no matching thumbnail on disk")
|
||||
print("and regenerate those thumbnail files.")
|
||||
print("NOTE: It is STRONGLY recommended that the user first clean/archive orphaned")
|
||||
print(" disk files from the previous menu to avoid wasting time regenerating")
|
||||
print(" thumbnails for orphaned files.")
|
||||
|
||||
print()
|
||||
print(f"Outputs/Images Directory : {config.outputs_path}")
|
||||
print(f"Outputs/Images Directory : {config.thumbnails_path}")
|
||||
|
||||
print("\nNotes about this operation:")
|
||||
print("- This operation will find image files both referenced in the db and on disk")
|
||||
print(" that do not have a matching thumbnail on disk and re-generate the thumbnail")
|
||||
print(" file.")
|
||||
|
||||
if not self.ask_to_continue():
|
||||
raise KeyboardInterrupt
|
||||
|
||||
print()
|
||||
|
||||
phys_files = file_mapper.get_all_png_filenames_in_directory(config.outputs_path)
|
||||
for phys_file in phys_files:
|
||||
try:
|
||||
if not file_mapper.thumbnail_exists_for_filename(phys_file):
|
||||
print(f"Found file without thumbnail {phys_file}...Regenerating Thumbnail...", end="")
|
||||
file_mapper.generate_thumbnail_for_image_name(phys_file)
|
||||
print("Done!")
|
||||
self.__stats.count_thumbnails_regenerated += 1
|
||||
except Exception as ex:
|
||||
print("Error found trying to regenerate thumbnail, error was:")
|
||||
print(ex)
|
||||
self.__stats.count_errors += 1
|
||||
|
||||
def main(self): # noqa D107
|
||||
print("\n===============================================================================")
|
||||
print("Database and outputs Maintenance for Invoke AI 3.0.0 +")
|
||||
print("===============================================================================\n")
|
||||
|
||||
config_mapper = ConfigMapper()
|
||||
if not config_mapper.load():
|
||||
print("\nInvalid configuration...exiting.\n")
|
||||
return
|
||||
|
||||
file_mapper = PhysicalFileMapper(
|
||||
config_mapper.outputs_path,
|
||||
config_mapper.thumbnails_path,
|
||||
config_mapper.archive_path,
|
||||
config_mapper.thumbnails_archive_path,
|
||||
)
|
||||
db_mapper = DatabaseMapper(config_mapper.database_path, config_mapper.database_backup_dir)
|
||||
|
||||
op = self._operation
|
||||
operations_to_perform = []
|
||||
|
||||
if op == MaintenanceOperation.Ask:
|
||||
op = self.ask_for_operation()
|
||||
|
||||
if op in [MaintenanceOperation.CleanOrphanedDbEntries, MaintenanceOperation.All]:
|
||||
operations_to_perform.append(self.clean_orphaned_db_entries)
|
||||
if op in [MaintenanceOperation.CleanOrphanedDiskFiles, MaintenanceOperation.All]:
|
||||
operations_to_perform.append(self.clean_orphaned_disk_files)
|
||||
if op in [MaintenanceOperation.ReGenerateThumbnails, MaintenanceOperation.All]:
|
||||
operations_to_perform.append(self.regenerate_thumbnails)
|
||||
|
||||
for operation in operations_to_perform:
|
||||
operation(config_mapper, file_mapper, db_mapper)
|
||||
|
||||
print("\n===============================================================================")
|
||||
print(f"= Maintenance Complete - Elapsed Time: {MaintenanceStats.get_elapsed_time_string()}")
|
||||
print()
|
||||
print(f"Orphaned db entries cleaned : {self.__stats.count_orphaned_db_entries_cleaned}")
|
||||
print(f"Orphaned disk files archived : {self.__stats.count_orphaned_disk_files_cleaned}")
|
||||
print(f"Orphaned thumbnail files archived : {self.__stats.count_orphaned_thumbnails_cleaned}")
|
||||
print(f"Thumbnails regenerated : {self.__stats.count_thumbnails_regenerated}")
|
||||
print(f"Errors during operation : {self.__stats.count_errors}")
|
||||
|
||||
print()
|
||||
|
||||
|
||||
def main(): # noqa D107
|
||||
parser = argparse.ArgumentParser(
|
||||
description="InvokeAI image database maintenance utility",
|
||||
formatter_class=argparse.RawDescriptionHelpFormatter,
|
||||
epilog="""Operations:
|
||||
ask Choose operation from a menu [default]
|
||||
all Run all maintenance operations
|
||||
clean Clean database of dangling entries
|
||||
archive Archive orphaned image files
|
||||
thumbnails Regenerate missing image thumbnails
|
||||
""",
|
||||
)
|
||||
parser.add_argument("--root", default=".", type=Path, help="InvokeAI root directory")
|
||||
parser.add_argument(
|
||||
"--operation", default="ask", choices=[x.value for x in MaintenanceOperation], help="Operation to perform."
|
||||
)
|
||||
args = parser.parse_args()
|
||||
try:
|
||||
os.chdir(args.root)
|
||||
app = InvokeAIDatabaseMaintenanceApp(args.operation)
|
||||
app.main()
|
||||
except KeyboardInterrupt:
|
||||
print("\n\nUser cancelled execution.")
|
||||
except FileNotFoundError:
|
||||
print(f"Invalid root directory '{args.root}'.")
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
@@ -24,7 +24,7 @@ from invokeai.backend.util.logging import InvokeAILogger
|
||||
# Modified ControlNetModel with encoder_attention_mask argument added
|
||||
|
||||
|
||||
logger = InvokeAILogger.getLogger(__name__)
|
||||
logger = InvokeAILogger.get_logger(__name__)
|
||||
|
||||
|
||||
class ControlNetModel(ModelMixin, ConfigMixin, FromOriginalControlnetMixin):
|
||||
|
||||
@@ -1,7 +1,6 @@
|
||||
# Copyright (c) 2023 Lincoln D. Stein and The InvokeAI Development Team
|
||||
|
||||
"""
|
||||
invokeai.backend.util.logging
|
||||
"""invokeai.backend.util.logging
|
||||
|
||||
Logging class for InvokeAI that produces console messages
|
||||
|
||||
@@ -9,9 +8,9 @@ Usage:
|
||||
|
||||
from invokeai.backend.util.logging import InvokeAILogger
|
||||
|
||||
logger = InvokeAILogger.getLogger(name='InvokeAI') // Initialization
|
||||
logger = InvokeAILogger.get_logger(name='InvokeAI') // Initialization
|
||||
(or)
|
||||
logger = InvokeAILogger.getLogger(__name__) // To use the filename
|
||||
logger = InvokeAILogger.get_logger(__name__) // To use the filename
|
||||
logger.configure()
|
||||
|
||||
logger.critical('this is critical') // Critical Message
|
||||
@@ -34,13 +33,13 @@ IAILogger.debug('this is a debugging message')
|
||||
## Configuration
|
||||
|
||||
The default configuration will print to stderr on the console. To add
|
||||
additional logging handlers, call getLogger with an initialized InvokeAIAppConfig
|
||||
additional logging handlers, call get_logger with an initialized InvokeAIAppConfig
|
||||
object:
|
||||
|
||||
|
||||
config = InvokeAIAppConfig.get_config()
|
||||
config.parse_args()
|
||||
logger = InvokeAILogger.getLogger(config=config)
|
||||
logger = InvokeAILogger.get_logger(config=config)
|
||||
|
||||
### Three command-line options control logging:
|
||||
|
||||
@@ -173,6 +172,7 @@ InvokeAI:
|
||||
log_level: info
|
||||
log_format: color
|
||||
```
|
||||
|
||||
"""
|
||||
|
||||
import logging.handlers
|
||||
@@ -193,39 +193,35 @@ except ImportError:
|
||||
|
||||
# module level functions
|
||||
def debug(msg, *args, **kwargs):
|
||||
InvokeAILogger.getLogger().debug(msg, *args, **kwargs)
|
||||
InvokeAILogger.get_logger().debug(msg, *args, **kwargs)
|
||||
|
||||
|
||||
def info(msg, *args, **kwargs):
|
||||
InvokeAILogger.getLogger().info(msg, *args, **kwargs)
|
||||
InvokeAILogger.get_logger().info(msg, *args, **kwargs)
|
||||
|
||||
|
||||
def warning(msg, *args, **kwargs):
|
||||
InvokeAILogger.getLogger().warning(msg, *args, **kwargs)
|
||||
InvokeAILogger.get_logger().warning(msg, *args, **kwargs)
|
||||
|
||||
|
||||
def error(msg, *args, **kwargs):
|
||||
InvokeAILogger.getLogger().error(msg, *args, **kwargs)
|
||||
InvokeAILogger.get_logger().error(msg, *args, **kwargs)
|
||||
|
||||
|
||||
def critical(msg, *args, **kwargs):
|
||||
InvokeAILogger.getLogger().critical(msg, *args, **kwargs)
|
||||
InvokeAILogger.get_logger().critical(msg, *args, **kwargs)
|
||||
|
||||
|
||||
def log(level, msg, *args, **kwargs):
|
||||
InvokeAILogger.getLogger().log(level, msg, *args, **kwargs)
|
||||
InvokeAILogger.get_logger().log(level, msg, *args, **kwargs)
|
||||
|
||||
|
||||
def disable(level=logging.CRITICAL):
|
||||
InvokeAILogger.getLogger().disable(level)
|
||||
InvokeAILogger.get_logger().disable(level)
|
||||
|
||||
|
||||
def basicConfig(**kwargs):
|
||||
InvokeAILogger.getLogger().basicConfig(**kwargs)
|
||||
|
||||
|
||||
def getLogger(name: str = None) -> logging.Logger:
|
||||
return InvokeAILogger.getLogger(name)
|
||||
InvokeAILogger.get_logger().basicConfig(**kwargs)
|
||||
|
||||
|
||||
_FACILITY_MAP = (
|
||||
@@ -351,7 +347,7 @@ class InvokeAILogger(object):
|
||||
loggers = dict()
|
||||
|
||||
@classmethod
|
||||
def getLogger(
|
||||
def get_logger(
|
||||
cls, name: str = "InvokeAI", config: InvokeAIAppConfig = InvokeAIAppConfig.get_config()
|
||||
) -> logging.Logger:
|
||||
if name in cls.loggers:
|
||||
@@ -360,13 +356,13 @@ class InvokeAILogger(object):
|
||||
else:
|
||||
logger = logging.getLogger(name)
|
||||
logger.setLevel(config.log_level.upper()) # yes, strings work here
|
||||
for ch in cls.getLoggers(config):
|
||||
for ch in cls.get_loggers(config):
|
||||
logger.addHandler(ch)
|
||||
cls.loggers[name] = logger
|
||||
return cls.loggers[name]
|
||||
|
||||
@classmethod
|
||||
def getLoggers(cls, config: InvokeAIAppConfig) -> list[logging.Handler]:
|
||||
def get_loggers(cls, config: InvokeAIAppConfig) -> list[logging.Handler]:
|
||||
handler_strs = config.log_handlers
|
||||
handlers = list()
|
||||
for handler in handler_strs:
|
||||
|
||||
@@ -103,3 +103,35 @@ sd-1/lora/LowRA:
|
||||
recommended: True
|
||||
sd-1/lora/Ink scenery:
|
||||
path: https://civitai.com/api/download/models/83390
|
||||
sd-1/ip_adapter/ip_adapter_sd15:
|
||||
repo_id: InvokeAI/ip_adapter_sd15
|
||||
recommended: True
|
||||
requires:
|
||||
- InvokeAI/ip_adapter_sd_image_encoder
|
||||
description: IP-Adapter for SD 1.5 models
|
||||
sd-1/ip_adapter/ip_adapter_plus_sd15:
|
||||
repo_id: InvokeAI/ip_adapter_plus_sd15
|
||||
recommended: False
|
||||
requires:
|
||||
- InvokeAI/ip_adapter_sd_image_encoder
|
||||
description: Refined IP-Adapter for SD 1.5 models
|
||||
sd-1/ip_adapter/ip_adapter_plus_face_sd15:
|
||||
repo_id: InvokeAI/ip_adapter_plus_face_sd15
|
||||
recommended: False
|
||||
requires:
|
||||
- InvokeAI/ip_adapter_sd_image_encoder
|
||||
description: Refined IP-Adapter for SD 1.5 models, adapted for faces
|
||||
sdxl/ip_adapter/ip_adapter_sdxl:
|
||||
repo_id: InvokeAI/ip_adapter_sdxl
|
||||
recommended: False
|
||||
requires:
|
||||
- InvokeAI/ip_adapter_sdxl_image_encoder
|
||||
description: IP-Adapter for SDXL models
|
||||
any/clip_vision/ip_adapter_sd_image_encoder:
|
||||
repo_id: InvokeAI/ip_adapter_sd_image_encoder
|
||||
recommended: False
|
||||
description: Required model for using IP-Adapters with SD-1/2 models
|
||||
any/clip_vision/ip_adapter_sdxl_image_encoder:
|
||||
repo_id: InvokeAI/ip_adapter_sdxl_image_encoder
|
||||
recommended: False
|
||||
description: Required model for using IP-Adapters with SDXL models
|
||||
|
||||
80
invokeai/configs/stable-diffusion/v1-inference-v.yaml
Normal file
80
invokeai/configs/stable-diffusion/v1-inference-v.yaml
Normal file
@@ -0,0 +1,80 @@
|
||||
model:
|
||||
base_learning_rate: 1.0e-04
|
||||
target: invokeai.backend.models.diffusion.ddpm.LatentDiffusion
|
||||
params:
|
||||
parameterization: "v"
|
||||
linear_start: 0.00085
|
||||
linear_end: 0.0120
|
||||
num_timesteps_cond: 1
|
||||
log_every_t: 200
|
||||
timesteps: 1000
|
||||
first_stage_key: "jpg"
|
||||
cond_stage_key: "txt"
|
||||
image_size: 64
|
||||
channels: 4
|
||||
cond_stage_trainable: false # Note: different from the one we trained before
|
||||
conditioning_key: crossattn
|
||||
monitor: val/loss_simple_ema
|
||||
scale_factor: 0.18215
|
||||
use_ema: False
|
||||
|
||||
scheduler_config: # 10000 warmup steps
|
||||
target: invokeai.backend.stable_diffusion.lr_scheduler.LambdaLinearScheduler
|
||||
params:
|
||||
warm_up_steps: [ 10000 ]
|
||||
cycle_lengths: [ 10000000000000 ] # incredibly large number to prevent corner cases
|
||||
f_start: [ 1.e-6 ]
|
||||
f_max: [ 1. ]
|
||||
f_min: [ 1. ]
|
||||
|
||||
personalization_config:
|
||||
target: invokeai.backend.stable_diffusion.embedding_manager.EmbeddingManager
|
||||
params:
|
||||
placeholder_strings: ["*"]
|
||||
initializer_words: ['sculpture']
|
||||
per_image_tokens: false
|
||||
num_vectors_per_token: 1
|
||||
progressive_words: False
|
||||
|
||||
unet_config:
|
||||
target: invokeai.backend.stable_diffusion.diffusionmodules.openaimodel.UNetModel
|
||||
params:
|
||||
image_size: 32 # unused
|
||||
in_channels: 4
|
||||
out_channels: 4
|
||||
model_channels: 320
|
||||
attention_resolutions: [ 4, 2, 1 ]
|
||||
num_res_blocks: 2
|
||||
channel_mult: [ 1, 2, 4, 4 ]
|
||||
num_heads: 8
|
||||
use_spatial_transformer: True
|
||||
transformer_depth: 1
|
||||
context_dim: 768
|
||||
use_checkpoint: True
|
||||
legacy: False
|
||||
|
||||
first_stage_config:
|
||||
target: invokeai.backend.stable_diffusion.autoencoder.AutoencoderKL
|
||||
params:
|
||||
embed_dim: 4
|
||||
monitor: val/rec_loss
|
||||
ddconfig:
|
||||
double_z: true
|
||||
z_channels: 4
|
||||
resolution: 256
|
||||
in_channels: 3
|
||||
out_ch: 3
|
||||
ch: 128
|
||||
ch_mult:
|
||||
- 1
|
||||
- 2
|
||||
- 4
|
||||
- 4
|
||||
num_res_blocks: 2
|
||||
attn_resolutions: []
|
||||
dropout: 0.0
|
||||
lossconfig:
|
||||
target: torch.nn.Identity
|
||||
|
||||
cond_stage_config:
|
||||
target: invokeai.backend.stable_diffusion.encoders.modules.WeightedFrozenCLIPEmbedder
|
||||
@@ -45,7 +45,7 @@ from invokeai.frontend.install.widgets import (
|
||||
)
|
||||
|
||||
config = InvokeAIAppConfig.get_config()
|
||||
logger = InvokeAILogger.getLogger()
|
||||
logger = InvokeAILogger.get_logger()
|
||||
|
||||
# build a table mapping all non-printable characters to None
|
||||
# for stripping control characters
|
||||
@@ -101,11 +101,12 @@ class addModelsForm(CyclingForm, npyscreen.FormMultiPage):
|
||||
"STARTER MODELS",
|
||||
"MAIN MODELS",
|
||||
"CONTROLNETS",
|
||||
"IP-ADAPTERS",
|
||||
"LORA/LYCORIS",
|
||||
"TEXTUAL INVERSION",
|
||||
],
|
||||
value=[self.current_tab],
|
||||
columns=5,
|
||||
columns=6,
|
||||
max_height=2,
|
||||
relx=8,
|
||||
scroll_exit=True,
|
||||
@@ -130,6 +131,13 @@ class addModelsForm(CyclingForm, npyscreen.FormMultiPage):
|
||||
)
|
||||
bottom_of_table = max(bottom_of_table, self.nextrely)
|
||||
|
||||
self.nextrely = top_of_table
|
||||
self.ipadapter_models = self.add_model_widgets(
|
||||
model_type=ModelType.IPAdapter,
|
||||
window_width=window_width,
|
||||
)
|
||||
bottom_of_table = max(bottom_of_table, self.nextrely)
|
||||
|
||||
self.nextrely = top_of_table
|
||||
self.lora_models = self.add_model_widgets(
|
||||
model_type=ModelType.Lora,
|
||||
@@ -343,6 +351,7 @@ class addModelsForm(CyclingForm, npyscreen.FormMultiPage):
|
||||
self.starter_pipelines,
|
||||
self.pipeline_models,
|
||||
self.controlnet_models,
|
||||
self.ipadapter_models,
|
||||
self.lora_models,
|
||||
self.ti_models,
|
||||
]
|
||||
@@ -532,6 +541,7 @@ class addModelsForm(CyclingForm, npyscreen.FormMultiPage):
|
||||
self.starter_pipelines,
|
||||
self.pipeline_models,
|
||||
self.controlnet_models,
|
||||
self.ipadapter_models,
|
||||
self.lora_models,
|
||||
self.ti_models,
|
||||
]
|
||||
@@ -553,6 +563,25 @@ class addModelsForm(CyclingForm, npyscreen.FormMultiPage):
|
||||
if downloads := section.get("download_ids"):
|
||||
selections.install_models.extend(downloads.value.split())
|
||||
|
||||
# NOT NEEDED - DONE IN BACKEND NOW
|
||||
# # special case for the ipadapter_models. If any of the adapters are
|
||||
# # chosen, then we add the corresponding encoder(s) to the install list.
|
||||
# section = self.ipadapter_models
|
||||
# if section.get("models_selected"):
|
||||
# selected_adapters = [
|
||||
# self.all_models[section["models"][x]].name for x in section.get("models_selected").value
|
||||
# ]
|
||||
# encoders = []
|
||||
# if any(["sdxl" in x for x in selected_adapters]):
|
||||
# encoders.append("ip_adapter_sdxl_image_encoder")
|
||||
# if any(["sd15" in x for x in selected_adapters]):
|
||||
# encoders.append("ip_adapter_sd_image_encoder")
|
||||
# for encoder in encoders:
|
||||
# key = f"any/clip_vision/{encoder}"
|
||||
# repo_id = f"InvokeAI/{encoder}"
|
||||
# if key not in self.all_models:
|
||||
# selections.install_models.append(repo_id)
|
||||
|
||||
|
||||
class AddModelApplication(npyscreen.NPSAppManaged):
|
||||
def __init__(self, opt):
|
||||
@@ -652,7 +681,7 @@ def process_and_execute(
|
||||
translator = StderrToMessage(conn_out)
|
||||
sys.stderr = translator
|
||||
sys.stdout = translator
|
||||
logger = InvokeAILogger.getLogger()
|
||||
logger = InvokeAILogger.get_logger()
|
||||
logger.handlers.clear()
|
||||
logger.addHandler(logging.StreamHandler(translator))
|
||||
|
||||
@@ -765,7 +794,7 @@ def main():
|
||||
if opt.full_precision:
|
||||
invoke_args.extend(["--precision", "float32"])
|
||||
config.parse_args(invoke_args)
|
||||
logger = InvokeAILogger().getLogger(config=config)
|
||||
logger = InvokeAILogger().get_logger(config=config)
|
||||
|
||||
if not config.model_conf_path.exists():
|
||||
logger.info("Your InvokeAI root directory is not set up. Calling invokeai-configure.")
|
||||
|
||||
169
invokeai/frontend/web/dist/assets/App-d1567775.js
vendored
169
invokeai/frontend/web/dist/assets/App-d1567775.js
vendored
File diff suppressed because one or more lines are too long
169
invokeai/frontend/web/dist/assets/App-dbf8f111.js
vendored
Normal file
169
invokeai/frontend/web/dist/assets/App-dbf8f111.js
vendored
Normal file
File diff suppressed because one or more lines are too long
@@ -1,4 +1,4 @@
|
||||
import{v as m,h5 as Je,u as y,Y as Xa,h6 as Ja,a7 as ua,ab as d,h7 as b,h8 as o,h9 as Qa,ha as h,hb as fa,hc as Za,hd as eo,aE as ro,he as ao,a4 as oo,hf as to}from"./index-f83c2c5c.js";import{s as ha,n as t,t as io,o as ma,p as no,q as ga,v as ya,w as pa,x as lo,y as Sa,z as xa,A as xr,B as so,D as co,E as bo,F as $a,G as ka,H as _a,J as vo,K as wa,L as uo,M as fo,N as ho,O as mo,Q as za,R as go,S as yo,T as po,U as So,V as xo,W as $o,e as ko,X as _o}from"./menu-31376327.js";var Ca=String.raw,Aa=Ca`
|
||||
import{v as m,hj as Je,u as y,Y as Xa,hk as Ja,a7 as ua,ab as d,hl as b,hm as o,hn as Qa,ho as h,hp as fa,hq as Za,hr as eo,aE as ro,hs as ao,a4 as oo,ht as to}from"./index-f6c3f475.js";import{s as ha,n as t,t as io,o as ma,p as no,q as ga,v as ya,w as pa,x as lo,y as Sa,z as xa,A as xr,B as so,D as co,E as bo,F as $a,G as ka,H as _a,J as vo,K as wa,L as uo,M as fo,N as ho,O as mo,Q as za,R as go,S as yo,T as po,U as So,V as xo,W as $o,e as ko,X as _o}from"./menu-c9cc8c3d.js";var Ca=String.raw,Aa=Ca`
|
||||
:root,
|
||||
:host {
|
||||
--chakra-vh: 100vh;
|
||||
128
invokeai/frontend/web/dist/assets/index-f6c3f475.js
vendored
Normal file
128
invokeai/frontend/web/dist/assets/index-f6c3f475.js
vendored
Normal file
File diff suppressed because one or more lines are too long
128
invokeai/frontend/web/dist/assets/index-f83c2c5c.js
vendored
128
invokeai/frontend/web/dist/assets/index-f83c2c5c.js
vendored
File diff suppressed because one or more lines are too long
File diff suppressed because one or more lines are too long
2
invokeai/frontend/web/dist/index.html
vendored
2
invokeai/frontend/web/dist/index.html
vendored
@@ -12,7 +12,7 @@
|
||||
margin: 0;
|
||||
}
|
||||
</style>
|
||||
<script type="module" crossorigin src="./assets/index-f83c2c5c.js"></script>
|
||||
<script type="module" crossorigin src="./assets/index-f6c3f475.js"></script>
|
||||
</head>
|
||||
|
||||
<body dir="ltr">
|
||||
|
||||
1588
invokeai/frontend/web/dist/locales/en.json
vendored
1588
invokeai/frontend/web/dist/locales/en.json
vendored
File diff suppressed because it is too large
Load Diff
@@ -50,6 +50,7 @@
|
||||
"close": "Close",
|
||||
"communityLabel": "Community",
|
||||
"controlNet": "Controlnet",
|
||||
"ipAdapter": "IP Adapter",
|
||||
"darkMode": "Dark Mode",
|
||||
"discordLabel": "Discord",
|
||||
"dontAskMeAgain": "Don't ask me again",
|
||||
@@ -57,6 +58,7 @@
|
||||
"githubLabel": "Github",
|
||||
"hotkeysLabel": "Hotkeys",
|
||||
"imagePrompt": "Image Prompt",
|
||||
"imageFailedToLoad": "Unable to Load Image",
|
||||
"img2img": "Image To Image",
|
||||
"langArabic": "العربية",
|
||||
"langBrPortuguese": "Português do Brasil",
|
||||
@@ -80,6 +82,7 @@
|
||||
"load": "Load",
|
||||
"loading": "Loading",
|
||||
"loadingInvokeAI": "Loading Invoke AI",
|
||||
"learnMore": "Learn More",
|
||||
"modelManager": "Model Manager",
|
||||
"nodeEditor": "Node Editor",
|
||||
"nodes": "Workflow Editor",
|
||||
@@ -134,6 +137,8 @@
|
||||
"bgth": "bg_th",
|
||||
"canny": "Canny",
|
||||
"cannyDescription": "Canny edge detection",
|
||||
"colorMap": "Color",
|
||||
"colorMapDescription": "Generates a color map from the image",
|
||||
"coarse": "Coarse",
|
||||
"contentShuffle": "Content Shuffle",
|
||||
"contentShuffleDescription": "Shuffles the content in an image",
|
||||
@@ -157,6 +162,7 @@
|
||||
"hideAdvanced": "Hide Advanced",
|
||||
"highThreshold": "High Threshold",
|
||||
"imageResolution": "Image Resolution",
|
||||
"colorMapTileSize": "Tile Size",
|
||||
"importImageFromCanvas": "Import Image From Canvas",
|
||||
"importMaskFromCanvas": "Import Mask From Canvas",
|
||||
"incompatibleBaseModel": "Incompatible base model:",
|
||||
@@ -193,7 +199,11 @@
|
||||
"showAdvanced": "Show Advanced",
|
||||
"toggleControlNet": "Toggle this ControlNet",
|
||||
"w": "W",
|
||||
"weight": "Weight"
|
||||
"weight": "Weight",
|
||||
"enableIPAdapter": "Enable IP Adapter",
|
||||
"ipAdapterModel": "Adapter Model",
|
||||
"resetIPAdapterImage": "Reset IP Adapter Image",
|
||||
"ipAdapterImageFallback": "No IP Adapter Image Selected"
|
||||
},
|
||||
"embedding": {
|
||||
"addEmbedding": "Add Embedding",
|
||||
@@ -234,6 +244,8 @@
|
||||
"cancelItem": "Cancel Item",
|
||||
"cancelBatchSucceeded": "Batch Canceled",
|
||||
"cancelBatchFailed": "Problem Canceling Batch",
|
||||
"clearQueueAlertDialog": "Clearing the queue immediately cancels any processing items and clears the queue entirely.",
|
||||
"clearQueueAlertDialog2": "Are you sure you want to clear the queue?",
|
||||
"current": "Current",
|
||||
"next": "Next",
|
||||
"status": "Status",
|
||||
@@ -257,6 +269,22 @@
|
||||
"graphQueued": "Graph queued",
|
||||
"graphFailedToQueue": "Failed to queue graph"
|
||||
},
|
||||
"invocationCache": {
|
||||
"invocationCache": "Invocation Cache",
|
||||
"cacheSize": "Cache Size",
|
||||
"maxCacheSize": "Max Cache Size",
|
||||
"hits": "Cache Hits",
|
||||
"misses": "Cache Misses",
|
||||
"clear": "Clear",
|
||||
"clearSucceeded": "Invocation Cache Cleared",
|
||||
"clearFailed": "Problem Clearing Invocation Cache",
|
||||
"enable": "Enable",
|
||||
"enableSucceeded": "Invocation Cache Enabled",
|
||||
"enableFailed": "Problem Enabling Invocation Cache",
|
||||
"disable": "Disable",
|
||||
"disableSucceeded": "Invocation Cache Disabled",
|
||||
"disableFailed": "Problem Disabling Invocation Cache"
|
||||
},
|
||||
"gallery": {
|
||||
"allImagesLoaded": "All Images Loaded",
|
||||
"assets": "Assets",
|
||||
@@ -628,7 +656,7 @@
|
||||
"onnxModels": "Onnx",
|
||||
"pathToCustomConfig": "Path To Custom Config",
|
||||
"pickModelType": "Pick Model Type",
|
||||
"predictionType": "Prediction Type (for Stable Diffusion 2.x Models only)",
|
||||
"predictionType": "Prediction Type (for Stable Diffusion 2.x Models and occasional Stable Diffusion 1.x Models)",
|
||||
"quickAdd": "Quick Add",
|
||||
"repo_id": "Repo ID",
|
||||
"repoIDValidationMsg": "Online repository of your model",
|
||||
@@ -678,6 +706,8 @@
|
||||
"addNodeToolTip": "Add Node (Shift+A, Space)",
|
||||
"animatedEdges": "Animated Edges",
|
||||
"animatedEdgesHelp": "Animate selected edges and edges connected to selected nodes",
|
||||
"boardField": "Board",
|
||||
"boardFieldDescription": "A gallery board",
|
||||
"boolean": "Booleans",
|
||||
"booleanCollection": "Boolean Collection",
|
||||
"booleanCollectionDescription": "A collection of booleans.",
|
||||
@@ -687,6 +717,7 @@
|
||||
"cannotConnectInputToInput": "Cannot connect input to input",
|
||||
"cannotConnectOutputToOutput": "Cannot connect output to output",
|
||||
"cannotConnectToSelf": "Cannot connect to self",
|
||||
"cannotDuplicateConnection": "Cannot create duplicate connections",
|
||||
"clipField": "Clip",
|
||||
"clipFieldDescription": "Tokenizer and text_encoder submodels.",
|
||||
"collection": "Collection",
|
||||
@@ -865,7 +896,7 @@
|
||||
"zoomOutNodes": "Zoom Out"
|
||||
},
|
||||
"parameters": {
|
||||
"aspectRatio": "Ratio",
|
||||
"aspectRatio": "Aspect Ratio",
|
||||
"boundingBoxHeader": "Bounding Box",
|
||||
"boundingBoxHeight": "Bounding Box Height",
|
||||
"boundingBoxWidth": "Bounding Box Width",
|
||||
@@ -878,6 +909,7 @@
|
||||
},
|
||||
"cfgScale": "CFG Scale",
|
||||
"clipSkip": "CLIP Skip",
|
||||
"clipSkipWithLayerCount": "CLIP Skip {{layerCount}}",
|
||||
"closeViewer": "Close Viewer",
|
||||
"codeformerFidelity": "Fidelity",
|
||||
"coherenceMode": "Mode",
|
||||
@@ -951,6 +983,9 @@
|
||||
"seamlessTiling": "Seamless Tiling",
|
||||
"seamlessXAxis": "X Axis",
|
||||
"seamlessYAxis": "Y Axis",
|
||||
"seamlessX": "Seamless X",
|
||||
"seamlessY": "Seamless Y",
|
||||
"seamlessX&Y": "Seamless X & Y",
|
||||
"seamLowThreshold": "Low",
|
||||
"seed": "Seed",
|
||||
"seedWeights": "Seed Weights",
|
||||
@@ -972,6 +1007,8 @@
|
||||
"upscaling": "Upscaling",
|
||||
"useAll": "Use All",
|
||||
"useCpuNoise": "Use CPU Noise",
|
||||
"cpuNoise": "CPU Noise",
|
||||
"gpuNoise": "GPU Noise",
|
||||
"useInitImg": "Use Initial Image",
|
||||
"usePrompt": "Use Prompt",
|
||||
"useSeed": "Use Seed",
|
||||
@@ -991,8 +1028,8 @@
|
||||
"label": "Seed Behaviour",
|
||||
"perIterationLabel": "Seed per Iteration",
|
||||
"perIterationDesc": "Use a different seed for each iteration",
|
||||
"perPromptLabel": "Seed per Prompt",
|
||||
"perPromptDesc": "Use a different seed for each prompt"
|
||||
"perPromptLabel": "Seed per Image",
|
||||
"perPromptDesc": "Use a different seed for each image"
|
||||
}
|
||||
},
|
||||
"sdxl": {
|
||||
@@ -1116,6 +1153,7 @@
|
||||
"serverError": "Server Error",
|
||||
"setCanvasInitialImage": "Set as canvas initial image",
|
||||
"setControlImage": "Set as control image",
|
||||
"setIPAdapterImage": "Set as IP Adapter Image",
|
||||
"setInitialImage": "Set as initial image",
|
||||
"setNodeField": "Set as node field",
|
||||
"tempFoldersEmptied": "Temp Folder Emptied",
|
||||
@@ -1140,6 +1178,210 @@
|
||||
"variations": "Try a variation with a value between 0.1 and 1.0 to change the result for a given seed. Interesting variations of the seed are between 0.1 and 0.3."
|
||||
}
|
||||
},
|
||||
"popovers": {
|
||||
"clipSkip": {
|
||||
"heading": "CLIP Skip",
|
||||
"paragraphs": [
|
||||
"Choose how many layers of the CLIP model to skip.",
|
||||
"Some models work better with certain CLIP Skip settings.",
|
||||
"A higher value typically results in a less detailed image."
|
||||
]
|
||||
},
|
||||
"paramNegativeConditioning": {
|
||||
"heading": "Negative Prompt",
|
||||
"paragraphs": [
|
||||
"The generation process avoids the concepts in the negative prompt. Use this to exclude qualities or objects from the output.",
|
||||
"Supports Compel syntax and embeddings."
|
||||
]
|
||||
},
|
||||
"paramPositiveConditioning": {
|
||||
"heading": "Positive Prompt",
|
||||
"paragraphs": [
|
||||
"Guides the generation process. You may use any words or phrases.",
|
||||
"Compel and Dynamic Prompts syntaxes and embeddings."
|
||||
]
|
||||
},
|
||||
"paramScheduler": {
|
||||
"heading": "Scheduler",
|
||||
"paragraphs": [
|
||||
"Scheduler defines how to iteratively add noise to an image or how to update a sample based on a model's output."
|
||||
]
|
||||
},
|
||||
"compositingBlur": {
|
||||
"heading": "Blur",
|
||||
"paragraphs": ["The blur radius of the mask."]
|
||||
},
|
||||
"compositingBlurMethod": {
|
||||
"heading": "Blur Method",
|
||||
"paragraphs": ["The method of blur applied to the masked area."]
|
||||
},
|
||||
"compositingCoherencePass": {
|
||||
"heading": "Coherence Pass",
|
||||
"paragraphs": [
|
||||
"A second round of denoising helps to composite the Inpainted/Outpainted image."
|
||||
]
|
||||
},
|
||||
"compositingCoherenceMode": {
|
||||
"heading": "Mode",
|
||||
"paragraphs": ["The mode of the Coherence Pass."]
|
||||
},
|
||||
"compositingCoherenceSteps": {
|
||||
"heading": "Steps",
|
||||
"paragraphs": [
|
||||
"Number of denoising steps used in the Coherence Pass.",
|
||||
"Same as the main Steps parameter."
|
||||
]
|
||||
},
|
||||
"compositingStrength": {
|
||||
"heading": "Strength",
|
||||
"paragraphs": [
|
||||
"Denoising strength for the Coherence Pass.",
|
||||
"Same as the Image to Image Denoising Strength parameter."
|
||||
]
|
||||
},
|
||||
"compositingMaskAdjustments": {
|
||||
"heading": "Mask Adjustments",
|
||||
"paragraphs": ["Adjust the mask."]
|
||||
},
|
||||
"controlNetBeginEnd": {
|
||||
"heading": "Begin / End Step Percentage",
|
||||
"paragraphs": [
|
||||
"Which steps of the denoising process will have the ControlNet applied.",
|
||||
"ControlNets applied at the beginning of the process guide composition, and ControlNets applied at the end guide details."
|
||||
]
|
||||
},
|
||||
"controlNetControlMode": {
|
||||
"heading": "Control Mode",
|
||||
"paragraphs": [
|
||||
"Lends more weight to either the prompt or ControlNet."
|
||||
]
|
||||
},
|
||||
"controlNetResizeMode": {
|
||||
"heading": "Resize Mode",
|
||||
"paragraphs": [
|
||||
"How the ControlNet image will be fit to the image output size."
|
||||
]
|
||||
},
|
||||
"controlNet": {
|
||||
"heading": "ControlNet",
|
||||
"paragraphs": [
|
||||
"ControlNets provide guidance to the generation process, helping create images with controlled composition, structure, or style, depending on the model selected."
|
||||
]
|
||||
},
|
||||
"controlNetWeight": {
|
||||
"heading": "Weight",
|
||||
"paragraphs": [
|
||||
"How strongly the ControlNet will impact the generated image."
|
||||
]
|
||||
},
|
||||
"dynamicPrompts": {
|
||||
"heading": "Dynamic Prompts",
|
||||
"paragraphs": [
|
||||
"Dynamic Prompts parses a single prompt into many.",
|
||||
"The basic syntax is \"a {red|green|blue} ball\". This will produce three prompts: \"a red ball\", \"a green ball\" and \"a blue ball\".",
|
||||
"You can use the syntax as many times as you like in a single prompt, but be sure to keep the number of prompts generated in check with the Max Prompts setting."
|
||||
]
|
||||
},
|
||||
"dynamicPromptsMaxPrompts": {
|
||||
"heading": "Max Prompts",
|
||||
"paragraphs": [
|
||||
"Limits the number of prompts that can be generated by Dynamic Prompts."
|
||||
]
|
||||
},
|
||||
"dynamicPromptsSeedBehaviour": {
|
||||
"heading": "Seed Behaviour",
|
||||
"paragraphs": [
|
||||
"Controls how the seed is used when generating prompts.",
|
||||
"Per Iteration will use a unique seed for each iteration. Use this to explore prompt variations on a single seed.",
|
||||
"For example, if you have 5 prompts, each image will use the same seed.",
|
||||
"Per Image will use a unique seed for each image. This provides more variation."
|
||||
]
|
||||
},
|
||||
"infillMethod": {
|
||||
"heading": "Infill Method",
|
||||
"paragraphs": ["Method to infill the selected area."]
|
||||
},
|
||||
"lora": {
|
||||
"heading": "LoRA Weight",
|
||||
"paragraphs": [
|
||||
"Higher LoRA weight will lead to larger impacts on the final image."
|
||||
]
|
||||
},
|
||||
"noiseUseCPU": {
|
||||
"heading": "Use CPU Noise",
|
||||
"paragraphs": [
|
||||
"Controls whether noise is generated on the CPU or GPU.",
|
||||
"With CPU Noise enabled, a particular seed will produce the same image on any machine.",
|
||||
"There is no performance impact to enabling CPU Noise."
|
||||
]
|
||||
},
|
||||
"paramCFGScale": {
|
||||
"heading": "CFG Scale",
|
||||
"paragraphs": [
|
||||
"Controls how much your prompt influences the generation process."
|
||||
]
|
||||
},
|
||||
"paramDenoisingStrength": {
|
||||
"heading": "Denoising Strength",
|
||||
"paragraphs": [
|
||||
"How much noise is added to the input image.",
|
||||
"0 will result in an identical image, while 1 will result in a completely new image."
|
||||
]
|
||||
},
|
||||
"paramIterations": {
|
||||
"heading": "Iterations",
|
||||
"paragraphs": [
|
||||
"The number of images to generate.",
|
||||
"If Dynamic Prompts is enabled, each of the prompts will be generated this many times."
|
||||
]
|
||||
},
|
||||
"paramModel": {
|
||||
"heading": "Model",
|
||||
"paragraphs": [
|
||||
"Model used for the denoising steps.",
|
||||
"Different models are typically trained to specialize in producing particular aesthetic results and content."
|
||||
]
|
||||
},
|
||||
"paramRatio": {
|
||||
"heading": "Aspect Ratio",
|
||||
"paragraphs": [
|
||||
"The aspect ratio of the dimensions of the image generated.",
|
||||
"An image size (in number of pixels) equivalent to 512x512 is recommended for SD1.5 models and a size equivalent to 1024x1024 is recommended for SDXL models."
|
||||
]
|
||||
},
|
||||
"paramSeed": {
|
||||
"heading": "Seed",
|
||||
"paragraphs": [
|
||||
"Controls the starting noise used for generation.",
|
||||
"Disable “Random Seed” to produce identical results with the same generation settings."
|
||||
]
|
||||
},
|
||||
"paramSteps": {
|
||||
"heading": "Steps",
|
||||
"paragraphs": [
|
||||
"Number of steps that will be performed in each generation.",
|
||||
"Higher step counts will typically create better images but will require more generation time."
|
||||
]
|
||||
},
|
||||
"paramVAE": {
|
||||
"heading": "VAE",
|
||||
"paragraphs": [
|
||||
"Model used for translating AI output into the final image."
|
||||
]
|
||||
},
|
||||
"paramVAEPrecision": {
|
||||
"heading": "VAE Precision",
|
||||
"paragraphs": [
|
||||
"The precision used during VAE encoding and decoding. FP16/half precision is more efficient, at the expense of minor image variations."
|
||||
]
|
||||
},
|
||||
"scaleBeforeProcessing": {
|
||||
"heading": "Scale Before Processing",
|
||||
"paragraphs": [
|
||||
"Scales the selected area to the size best suited for the model before the image generation process."
|
||||
]
|
||||
}
|
||||
},
|
||||
"ui": {
|
||||
"hideProgressImages": "Hide Progress Images",
|
||||
"lockRatio": "Lock Ratio",
|
||||
@@ -1202,6 +1444,8 @@
|
||||
"showCanvasDebugInfo": "Show Additional Canvas Info",
|
||||
"showGrid": "Show Grid",
|
||||
"showHide": "Show/Hide",
|
||||
"showResultsOn": "Show Results (On)",
|
||||
"showResultsOff": "Show Results (Off)",
|
||||
"showIntermediates": "Show Intermediates",
|
||||
"snapToGrid": "Snap to Grid",
|
||||
"undo": "Undo"
|
||||
|
||||
@@ -36,7 +36,8 @@ const App = ({ config = DEFAULT_CONFIG, selectedImage }: Props) => {
|
||||
|
||||
const logger = useLogger('system');
|
||||
const dispatch = useAppDispatch();
|
||||
const { handlePreselectedImage } = usePreselectedImage();
|
||||
const { handleSendToCanvas, handleSendToImg2Img, handleUseAllMetadata } =
|
||||
usePreselectedImage(selectedImage?.imageName);
|
||||
const handleReset = useCallback(() => {
|
||||
localStorage.clear();
|
||||
location.reload();
|
||||
@@ -59,8 +60,22 @@ const App = ({ config = DEFAULT_CONFIG, selectedImage }: Props) => {
|
||||
}, [dispatch]);
|
||||
|
||||
useEffect(() => {
|
||||
handlePreselectedImage(selectedImage);
|
||||
}, [handlePreselectedImage, selectedImage]);
|
||||
if (selectedImage && selectedImage.action === 'sendToCanvas') {
|
||||
handleSendToCanvas();
|
||||
}
|
||||
}, [selectedImage, handleSendToCanvas]);
|
||||
|
||||
useEffect(() => {
|
||||
if (selectedImage && selectedImage.action === 'sendToImg2Img') {
|
||||
handleSendToImg2Img();
|
||||
}
|
||||
}, [selectedImage, handleSendToImg2Img]);
|
||||
|
||||
useEffect(() => {
|
||||
if (selectedImage && selectedImage.action === 'useAllParameters') {
|
||||
handleUseAllMetadata();
|
||||
}
|
||||
}, [selectedImage, handleUseAllMetadata]);
|
||||
|
||||
const headerComponent = useStore($headerComponent);
|
||||
|
||||
|
||||
@@ -17,7 +17,10 @@ import '../../i18n';
|
||||
import AppDndContext from '../../features/dnd/components/AppDndContext';
|
||||
import { $customStarUI, CustomStarUi } from 'app/store/nanostores/customStarUI';
|
||||
import { $headerComponent } from 'app/store/nanostores/headerComponent';
|
||||
import { $queueId, DEFAULT_QUEUE_ID } from 'features/queue/store/nanoStores';
|
||||
import {
|
||||
$queueId,
|
||||
DEFAULT_QUEUE_ID,
|
||||
} from 'features/queue/store/queueNanoStore';
|
||||
|
||||
const App = lazy(() => import('./App'));
|
||||
const ThemeLocaleProvider = lazy(() => import('./ThemeLocaleProvider'));
|
||||
|
||||
@@ -5,7 +5,7 @@ import {
|
||||
} from '@chakra-ui/react';
|
||||
import { ReactNode, memo, useEffect, useMemo } from 'react';
|
||||
import { useTranslation } from 'react-i18next';
|
||||
import { theme as invokeAITheme } from 'theme/theme';
|
||||
import { TOAST_OPTIONS, theme as invokeAITheme } from 'theme/theme';
|
||||
|
||||
import '@fontsource-variable/inter';
|
||||
import { MantineProvider } from '@mantine/core';
|
||||
@@ -39,7 +39,11 @@ function ThemeLocaleProvider({ children }: ThemeLocaleProviderProps) {
|
||||
|
||||
return (
|
||||
<MantineProvider theme={mantineTheme}>
|
||||
<ChakraProvider theme={theme} colorModeManager={manager}>
|
||||
<ChakraProvider
|
||||
theme={theme}
|
||||
colorModeManager={manager}
|
||||
toastOptions={TOAST_OPTIONS}
|
||||
>
|
||||
{children}
|
||||
</ChakraProvider>
|
||||
</MantineProvider>
|
||||
|
||||
@@ -54,21 +54,6 @@ import { addModelSelectedListener } from './listeners/modelSelected';
|
||||
import { addModelsLoadedListener } from './listeners/modelsLoaded';
|
||||
import { addDynamicPromptsListener } from './listeners/promptChanged';
|
||||
import { addReceivedOpenAPISchemaListener } from './listeners/receivedOpenAPISchema';
|
||||
import {
|
||||
addSessionCanceledFulfilledListener,
|
||||
addSessionCanceledPendingListener,
|
||||
addSessionCanceledRejectedListener,
|
||||
} from './listeners/sessionCanceled';
|
||||
import {
|
||||
addSessionCreatedFulfilledListener,
|
||||
addSessionCreatedPendingListener,
|
||||
addSessionCreatedRejectedListener,
|
||||
} from './listeners/sessionCreated';
|
||||
import {
|
||||
addSessionInvokedFulfilledListener,
|
||||
addSessionInvokedPendingListener,
|
||||
addSessionInvokedRejectedListener,
|
||||
} from './listeners/sessionInvoked';
|
||||
import { addSocketConnectedEventListener as addSocketConnectedListener } from './listeners/socketio/socketConnected';
|
||||
import { addSocketDisconnectedEventListener as addSocketDisconnectedListener } from './listeners/socketio/socketDisconnected';
|
||||
import { addGeneratorProgressEventListener as addGeneratorProgressListener } from './listeners/socketio/socketGeneratorProgress';
|
||||
@@ -86,6 +71,7 @@ import { addStagingAreaImageSavedListener } from './listeners/stagingAreaImageSa
|
||||
import { addTabChangedListener } from './listeners/tabChanged';
|
||||
import { addUpscaleRequestedListener } from './listeners/upscaleRequested';
|
||||
import { addWorkflowLoadedListener } from './listeners/workflowLoaded';
|
||||
import { addBatchEnqueuedListener } from './listeners/batchEnqueued';
|
||||
|
||||
export const listenerMiddleware = createListenerMiddleware();
|
||||
|
||||
@@ -136,6 +122,7 @@ addEnqueueRequestedCanvasListener();
|
||||
addEnqueueRequestedNodes();
|
||||
addEnqueueRequestedLinear();
|
||||
addAnyEnqueuedListener();
|
||||
addBatchEnqueuedListener();
|
||||
|
||||
// Canvas actions
|
||||
addCanvasSavedToGalleryListener();
|
||||
@@ -175,21 +162,6 @@ addSessionRetrievalErrorEventListener();
|
||||
addInvocationRetrievalErrorEventListener();
|
||||
addSocketQueueItemStatusChangedEventListener();
|
||||
|
||||
// Session Created
|
||||
addSessionCreatedPendingListener();
|
||||
addSessionCreatedFulfilledListener();
|
||||
addSessionCreatedRejectedListener();
|
||||
|
||||
// Session Invoked
|
||||
addSessionInvokedPendingListener();
|
||||
addSessionInvokedFulfilledListener();
|
||||
addSessionInvokedRejectedListener();
|
||||
|
||||
// Session Canceled
|
||||
addSessionCanceledPendingListener();
|
||||
addSessionCanceledFulfilledListener();
|
||||
addSessionCanceledRejectedListener();
|
||||
|
||||
// ControlNet
|
||||
addControlNetImageProcessedListener();
|
||||
addControlNetAutoProcessListener();
|
||||
|
||||
@@ -1,7 +1,7 @@
|
||||
import { isAnyOf } from '@reduxjs/toolkit';
|
||||
import { logger } from 'app/logging/logger';
|
||||
import {
|
||||
canvasBatchesAndSessionsReset,
|
||||
canvasBatchIdsReset,
|
||||
commitStagingAreaImage,
|
||||
discardStagedImages,
|
||||
} from 'features/canvas/store/canvasSlice';
|
||||
@@ -38,7 +38,7 @@ export const addCommitStagingAreaImageListener = () => {
|
||||
})
|
||||
);
|
||||
}
|
||||
dispatch(canvasBatchesAndSessionsReset());
|
||||
dispatch(canvasBatchIdsReset());
|
||||
} catch {
|
||||
log.error('Failed to cancel canvas batches');
|
||||
dispatch(
|
||||
|
||||
@@ -0,0 +1,96 @@
|
||||
import { createStandaloneToast } from '@chakra-ui/react';
|
||||
import { logger } from 'app/logging/logger';
|
||||
import { parseify } from 'common/util/serialize';
|
||||
import { zPydanticValidationError } from 'features/system/store/zodSchemas';
|
||||
import { t } from 'i18next';
|
||||
import { get, truncate, upperFirst } from 'lodash-es';
|
||||
import { queueApi } from 'services/api/endpoints/queue';
|
||||
import { TOAST_OPTIONS, theme } from 'theme/theme';
|
||||
import { startAppListening } from '..';
|
||||
|
||||
const { toast } = createStandaloneToast({
|
||||
theme: theme,
|
||||
defaultOptions: TOAST_OPTIONS.defaultOptions,
|
||||
});
|
||||
|
||||
export const addBatchEnqueuedListener = () => {
|
||||
// success
|
||||
startAppListening({
|
||||
matcher: queueApi.endpoints.enqueueBatch.matchFulfilled,
|
||||
effect: async (action) => {
|
||||
const response = action.payload;
|
||||
const arg = action.meta.arg.originalArgs;
|
||||
logger('queue').debug(
|
||||
{ enqueueResult: parseify(response) },
|
||||
'Batch enqueued'
|
||||
);
|
||||
|
||||
if (!toast.isActive('batch-queued')) {
|
||||
toast({
|
||||
id: 'batch-queued',
|
||||
title: t('queue.batchQueued'),
|
||||
description: t('queue.batchQueuedDesc', {
|
||||
item_count: response.enqueued,
|
||||
direction: arg.prepend ? t('queue.front') : t('queue.back'),
|
||||
}),
|
||||
duration: 1000,
|
||||
status: 'success',
|
||||
});
|
||||
}
|
||||
},
|
||||
});
|
||||
|
||||
// error
|
||||
startAppListening({
|
||||
matcher: queueApi.endpoints.enqueueBatch.matchRejected,
|
||||
effect: async (action) => {
|
||||
const response = action.payload;
|
||||
const arg = action.meta.arg.originalArgs;
|
||||
|
||||
if (!response) {
|
||||
toast({
|
||||
title: t('queue.batchFailedToQueue'),
|
||||
status: 'error',
|
||||
description: 'Unknown Error',
|
||||
});
|
||||
logger('queue').error(
|
||||
{ batchConfig: parseify(arg), error: parseify(response) },
|
||||
t('queue.batchFailedToQueue')
|
||||
);
|
||||
return;
|
||||
}
|
||||
|
||||
const result = zPydanticValidationError.safeParse(response);
|
||||
if (result.success) {
|
||||
result.data.data.detail.map((e) => {
|
||||
toast({
|
||||
id: 'batch-failed-to-queue',
|
||||
title: truncate(upperFirst(e.msg), { length: 128 }),
|
||||
status: 'error',
|
||||
description: truncate(
|
||||
`Path:
|
||||
${e.loc.join('.')}`,
|
||||
{ length: 128 }
|
||||
),
|
||||
});
|
||||
});
|
||||
} else {
|
||||
let detail = 'Unknown Error';
|
||||
if (response.status === 403 && 'body' in response) {
|
||||
detail = get(response, 'body.detail', 'Unknown Error');
|
||||
} else if (response.status === 403 && 'error' in response) {
|
||||
detail = get(response, 'error.detail', 'Unknown Error');
|
||||
}
|
||||
toast({
|
||||
title: t('queue.batchFailedToQueue'),
|
||||
status: 'error',
|
||||
description: detail,
|
||||
});
|
||||
}
|
||||
logger('queue').error(
|
||||
{ batchConfig: parseify(arg), error: parseify(response) },
|
||||
t('queue.batchFailedToQueue')
|
||||
);
|
||||
},
|
||||
});
|
||||
};
|
||||
@@ -1,5 +1,8 @@
|
||||
import { resetCanvas } from 'features/canvas/store/canvasSlice';
|
||||
import { controlNetReset } from 'features/controlNet/store/controlNetSlice';
|
||||
import {
|
||||
controlNetReset,
|
||||
ipAdapterStateReset,
|
||||
} from 'features/controlNet/store/controlNetSlice';
|
||||
import { getImageUsage } from 'features/deleteImageModal/store/selectors';
|
||||
import { nodeEditorReset } from 'features/nodes/store/nodesSlice';
|
||||
import { clearInitialImage } from 'features/parameters/store/generationSlice';
|
||||
@@ -18,6 +21,7 @@ export const addDeleteBoardAndImagesFulfilledListener = () => {
|
||||
let wasCanvasReset = false;
|
||||
let wasNodeEditorReset = false;
|
||||
let wasControlNetReset = false;
|
||||
let wasIPAdapterReset = false;
|
||||
|
||||
const state = getState();
|
||||
deleted_images.forEach((image_name) => {
|
||||
@@ -42,6 +46,11 @@ export const addDeleteBoardAndImagesFulfilledListener = () => {
|
||||
dispatch(controlNetReset());
|
||||
wasControlNetReset = true;
|
||||
}
|
||||
|
||||
if (imageUsage.isIPAdapterImage && !wasIPAdapterReset) {
|
||||
dispatch(ipAdapterStateReset());
|
||||
wasIPAdapterReset = true;
|
||||
}
|
||||
});
|
||||
},
|
||||
});
|
||||
|
||||
@@ -25,7 +25,7 @@ export const addBoardIdSelectedListener = () => {
|
||||
const state = getState();
|
||||
|
||||
const board_id = boardIdSelected.match(action)
|
||||
? action.payload
|
||||
? action.payload.boardId
|
||||
: state.gallery.selectedBoardId;
|
||||
|
||||
const galleryView = galleryViewChanged.match(action)
|
||||
@@ -55,7 +55,12 @@ export const addBoardIdSelectedListener = () => {
|
||||
|
||||
if (boardImagesData) {
|
||||
const firstImage = imagesSelectors.selectAll(boardImagesData)[0];
|
||||
dispatch(imageSelected(firstImage ?? null));
|
||||
const selectedImage = imagesSelectors.selectById(
|
||||
boardImagesData,
|
||||
action.payload.selectedImageName
|
||||
);
|
||||
|
||||
dispatch(imageSelected(selectedImage || firstImage || null));
|
||||
} else {
|
||||
// board has no images - deselect
|
||||
dispatch(imageSelected(null));
|
||||
|
||||
@@ -3,7 +3,7 @@ import { startAppListening } from '..';
|
||||
import { $logger } from 'app/logging/logger';
|
||||
import { getBaseLayerBlob } from 'features/canvas/util/getBaseLayerBlob';
|
||||
import { addToast } from 'features/system/store/systemSlice';
|
||||
import { copyBlobToClipboard } from 'features/canvas/util/copyBlobToClipboard';
|
||||
import { copyBlobToClipboard } from 'features/system/util/copyBlobToClipboard';
|
||||
import { t } from 'i18next';
|
||||
|
||||
export const addCanvasCopiedToClipboardListener = () => {
|
||||
@@ -15,10 +15,12 @@ export const addCanvasCopiedToClipboardListener = () => {
|
||||
.child({ namespace: 'canvasCopiedToClipboardListener' });
|
||||
const state = getState();
|
||||
|
||||
const blob = await getBaseLayerBlob(state);
|
||||
try {
|
||||
const blob = getBaseLayerBlob(state);
|
||||
|
||||
if (!blob) {
|
||||
moduleLog.error('Problem getting base layer blob');
|
||||
copyBlobToClipboard(blob);
|
||||
} catch (err) {
|
||||
moduleLog.error(String(err));
|
||||
dispatch(
|
||||
addToast({
|
||||
title: t('toast.problemCopyingCanvas'),
|
||||
@@ -29,8 +31,6 @@ export const addCanvasCopiedToClipboardListener = () => {
|
||||
return;
|
||||
}
|
||||
|
||||
copyBlobToClipboard(blob);
|
||||
|
||||
dispatch(
|
||||
addToast({
|
||||
title: t('toast.canvasCopiedClipboard'),
|
||||
|
||||
@@ -15,10 +15,11 @@ export const addCanvasDownloadedAsImageListener = () => {
|
||||
.child({ namespace: 'canvasSavedToGalleryListener' });
|
||||
const state = getState();
|
||||
|
||||
const blob = await getBaseLayerBlob(state);
|
||||
|
||||
if (!blob) {
|
||||
moduleLog.error('Problem getting base layer blob');
|
||||
let blob;
|
||||
try {
|
||||
blob = await getBaseLayerBlob(state);
|
||||
} catch (err) {
|
||||
moduleLog.error(String(err));
|
||||
dispatch(
|
||||
addToast({
|
||||
title: t('toast.problemDownloadingCanvas'),
|
||||
|
||||
@@ -3,9 +3,9 @@ import { canvasImageToControlNet } from 'features/canvas/store/actions';
|
||||
import { getBaseLayerBlob } from 'features/canvas/util/getBaseLayerBlob';
|
||||
import { controlNetImageChanged } from 'features/controlNet/store/controlNetSlice';
|
||||
import { addToast } from 'features/system/store/systemSlice';
|
||||
import { t } from 'i18next';
|
||||
import { imagesApi } from 'services/api/endpoints/images';
|
||||
import { startAppListening } from '..';
|
||||
import { t } from 'i18next';
|
||||
|
||||
export const addCanvasImageToControlNetListener = () => {
|
||||
startAppListening({
|
||||
@@ -14,10 +14,11 @@ export const addCanvasImageToControlNetListener = () => {
|
||||
const log = logger('canvas');
|
||||
const state = getState();
|
||||
|
||||
const blob = await getBaseLayerBlob(state);
|
||||
|
||||
if (!blob) {
|
||||
log.error('Problem getting base layer blob');
|
||||
let blob;
|
||||
try {
|
||||
blob = await getBaseLayerBlob(state, true);
|
||||
} catch (err) {
|
||||
log.error(String(err));
|
||||
dispatch(
|
||||
addToast({
|
||||
title: t('toast.problemSavingCanvas'),
|
||||
@@ -35,10 +36,10 @@ export const addCanvasImageToControlNetListener = () => {
|
||||
file: new File([blob], 'savedCanvas.png', {
|
||||
type: 'image/png',
|
||||
}),
|
||||
image_category: 'mask',
|
||||
image_category: 'control',
|
||||
is_intermediate: false,
|
||||
board_id: autoAddBoardId === 'none' ? undefined : autoAddBoardId,
|
||||
crop_visible: true,
|
||||
crop_visible: false,
|
||||
postUploadAction: {
|
||||
type: 'TOAST',
|
||||
toastOptions: { title: t('toast.canvasSentControlnetAssets') },
|
||||
|
||||
@@ -3,9 +3,9 @@ import { canvasMaskToControlNet } from 'features/canvas/store/actions';
|
||||
import { getCanvasData } from 'features/canvas/util/getCanvasData';
|
||||
import { controlNetImageChanged } from 'features/controlNet/store/controlNetSlice';
|
||||
import { addToast } from 'features/system/store/systemSlice';
|
||||
import { t } from 'i18next';
|
||||
import { imagesApi } from 'services/api/endpoints/images';
|
||||
import { startAppListening } from '..';
|
||||
import { t } from 'i18next';
|
||||
|
||||
export const addCanvasMaskToControlNetListener = () => {
|
||||
startAppListening({
|
||||
@@ -50,7 +50,7 @@ export const addCanvasMaskToControlNetListener = () => {
|
||||
image_category: 'mask',
|
||||
is_intermediate: false,
|
||||
board_id: autoAddBoardId === 'none' ? undefined : autoAddBoardId,
|
||||
crop_visible: true,
|
||||
crop_visible: false,
|
||||
postUploadAction: {
|
||||
type: 'TOAST',
|
||||
toastOptions: { title: t('toast.maskSentControlnetAssets') },
|
||||
|
||||
@@ -13,10 +13,11 @@ export const addCanvasSavedToGalleryListener = () => {
|
||||
const log = logger('canvas');
|
||||
const state = getState();
|
||||
|
||||
const blob = await getBaseLayerBlob(state);
|
||||
|
||||
if (!blob) {
|
||||
log.error('Problem getting base layer blob');
|
||||
let blob;
|
||||
try {
|
||||
blob = await getBaseLayerBlob(state);
|
||||
} catch (err) {
|
||||
log.error(String(err));
|
||||
dispatch(
|
||||
addToast({
|
||||
title: t('toast.problemSavingCanvas'),
|
||||
|
||||
@@ -65,7 +65,6 @@ export const addControlNetImageProcessedListener = () => {
|
||||
);
|
||||
const enqueueResult = await req.unwrap();
|
||||
req.reset();
|
||||
console.log(enqueueResult.queue_item.session_id);
|
||||
log.debug(
|
||||
{ enqueueResult: parseify(enqueueResult) },
|
||||
t('queue.graphQueued')
|
||||
|
||||
@@ -12,8 +12,6 @@ import { getCanvasGenerationMode } from 'features/canvas/util/getCanvasGeneratio
|
||||
import { canvasGraphBuilt } from 'features/nodes/store/actions';
|
||||
import { buildCanvasGraph } from 'features/nodes/util/graphBuilders/buildCanvasGraph';
|
||||
import { prepareLinearUIBatch } from 'features/nodes/util/graphBuilders/buildLinearBatchConfig';
|
||||
import { addToast } from 'features/system/store/systemSlice';
|
||||
import { t } from 'i18next';
|
||||
import { imagesApi } from 'services/api/endpoints/images';
|
||||
import { queueApi } from 'services/api/endpoints/queue';
|
||||
import { ImageDTO } from 'services/api/types';
|
||||
@@ -140,8 +138,6 @@ export const addEnqueueRequestedCanvasListener = () => {
|
||||
const enqueueResult = await req.unwrap();
|
||||
req.reset();
|
||||
|
||||
log.debug({ enqueueResult: parseify(enqueueResult) }, 'Batch enqueued');
|
||||
|
||||
const batchId = enqueueResult.batch.batch_id as string; // we know the is a string, backend provides it
|
||||
|
||||
// Prep the canvas staging area if it is not yet initialized
|
||||
@@ -158,28 +154,8 @@ export const addEnqueueRequestedCanvasListener = () => {
|
||||
|
||||
// Associate the session with the canvas session ID
|
||||
dispatch(canvasBatchIdAdded(batchId));
|
||||
|
||||
dispatch(
|
||||
addToast({
|
||||
title: t('queue.batchQueued'),
|
||||
description: t('queue.batchQueuedDesc', {
|
||||
item_count: enqueueResult.enqueued,
|
||||
direction: prepend ? t('queue.front') : t('queue.back'),
|
||||
}),
|
||||
status: 'success',
|
||||
})
|
||||
);
|
||||
} catch {
|
||||
log.error(
|
||||
{ batchConfig: parseify(batchConfig) },
|
||||
t('queue.batchFailedToQueue')
|
||||
);
|
||||
dispatch(
|
||||
addToast({
|
||||
title: t('queue.batchFailedToQueue'),
|
||||
status: 'error',
|
||||
})
|
||||
);
|
||||
// no-op
|
||||
}
|
||||
},
|
||||
});
|
||||
|
||||
@@ -1,13 +1,9 @@
|
||||
import { logger } from 'app/logging/logger';
|
||||
import { enqueueRequested } from 'app/store/actions';
|
||||
import { parseify } from 'common/util/serialize';
|
||||
import { prepareLinearUIBatch } from 'features/nodes/util/graphBuilders/buildLinearBatchConfig';
|
||||
import { buildLinearImageToImageGraph } from 'features/nodes/util/graphBuilders/buildLinearImageToImageGraph';
|
||||
import { buildLinearSDXLImageToImageGraph } from 'features/nodes/util/graphBuilders/buildLinearSDXLImageToImageGraph';
|
||||
import { buildLinearSDXLTextToImageGraph } from 'features/nodes/util/graphBuilders/buildLinearSDXLTextToImageGraph';
|
||||
import { buildLinearTextToImageGraph } from 'features/nodes/util/graphBuilders/buildLinearTextToImageGraph';
|
||||
import { addToast } from 'features/system/store/systemSlice';
|
||||
import { t } from 'i18next';
|
||||
import { queueApi } from 'services/api/endpoints/queue';
|
||||
import { startAppListening } from '..';
|
||||
|
||||
@@ -18,7 +14,6 @@ export const addEnqueueRequestedLinear = () => {
|
||||
(action.payload.tabName === 'txt2img' ||
|
||||
action.payload.tabName === 'img2img'),
|
||||
effect: async (action, { getState, dispatch }) => {
|
||||
const log = logger('queue');
|
||||
const state = getState();
|
||||
const model = state.generation.model;
|
||||
const { prepend } = action.payload;
|
||||
@@ -41,38 +36,12 @@ export const addEnqueueRequestedLinear = () => {
|
||||
|
||||
const batchConfig = prepareLinearUIBatch(state, graph, prepend);
|
||||
|
||||
try {
|
||||
const req = dispatch(
|
||||
queueApi.endpoints.enqueueBatch.initiate(batchConfig, {
|
||||
fixedCacheKey: 'enqueueBatch',
|
||||
})
|
||||
);
|
||||
const enqueueResult = await req.unwrap();
|
||||
req.reset();
|
||||
|
||||
log.debug({ enqueueResult: parseify(enqueueResult) }, 'Batch enqueued');
|
||||
dispatch(
|
||||
addToast({
|
||||
title: t('queue.batchQueued'),
|
||||
description: t('queue.batchQueuedDesc', {
|
||||
item_count: enqueueResult.enqueued,
|
||||
direction: prepend ? t('queue.front') : t('queue.back'),
|
||||
}),
|
||||
status: 'success',
|
||||
})
|
||||
);
|
||||
} catch {
|
||||
log.error(
|
||||
{ batchConfig: parseify(batchConfig) },
|
||||
t('queue.batchFailedToQueue')
|
||||
);
|
||||
dispatch(
|
||||
addToast({
|
||||
title: t('queue.batchFailedToQueue'),
|
||||
status: 'error',
|
||||
})
|
||||
);
|
||||
}
|
||||
const req = dispatch(
|
||||
queueApi.endpoints.enqueueBatch.initiate(batchConfig, {
|
||||
fixedCacheKey: 'enqueueBatch',
|
||||
})
|
||||
);
|
||||
req.reset();
|
||||
},
|
||||
});
|
||||
};
|
||||
|
||||
@@ -1,9 +1,5 @@
|
||||
import { logger } from 'app/logging/logger';
|
||||
import { enqueueRequested } from 'app/store/actions';
|
||||
import { parseify } from 'common/util/serialize';
|
||||
import { buildNodesGraph } from 'features/nodes/util/graphBuilders/buildNodesGraph';
|
||||
import { addToast } from 'features/system/store/systemSlice';
|
||||
import { t } from 'i18next';
|
||||
import { queueApi } from 'services/api/endpoints/queue';
|
||||
import { BatchConfig } from 'services/api/types';
|
||||
import { startAppListening } from '..';
|
||||
@@ -13,9 +9,7 @@ export const addEnqueueRequestedNodes = () => {
|
||||
predicate: (action): action is ReturnType<typeof enqueueRequested> =>
|
||||
enqueueRequested.match(action) && action.payload.tabName === 'nodes',
|
||||
effect: async (action, { getState, dispatch }) => {
|
||||
const log = logger('queue');
|
||||
const state = getState();
|
||||
const { prepend } = action.payload;
|
||||
const graph = buildNodesGraph(state.nodes);
|
||||
const batchConfig: BatchConfig = {
|
||||
batch: {
|
||||
@@ -25,38 +19,12 @@ export const addEnqueueRequestedNodes = () => {
|
||||
prepend: action.payload.prepend,
|
||||
};
|
||||
|
||||
try {
|
||||
const req = dispatch(
|
||||
queueApi.endpoints.enqueueBatch.initiate(batchConfig, {
|
||||
fixedCacheKey: 'enqueueBatch',
|
||||
})
|
||||
);
|
||||
const enqueueResult = await req.unwrap();
|
||||
req.reset();
|
||||
|
||||
log.debug({ enqueueResult: parseify(enqueueResult) }, 'Batch enqueued');
|
||||
dispatch(
|
||||
addToast({
|
||||
title: t('queue.batchQueued'),
|
||||
description: t('queue.batchQueuedDesc', {
|
||||
item_count: enqueueResult.enqueued,
|
||||
direction: prepend ? t('queue.front') : t('queue.back'),
|
||||
}),
|
||||
status: 'success',
|
||||
})
|
||||
);
|
||||
} catch {
|
||||
log.error(
|
||||
{ batchConfig: parseify(batchConfig) },
|
||||
'Failed to enqueue batch'
|
||||
);
|
||||
dispatch(
|
||||
addToast({
|
||||
title: t('queue.batchFailedToQueue'),
|
||||
status: 'error',
|
||||
})
|
||||
);
|
||||
}
|
||||
const req = dispatch(
|
||||
queueApi.endpoints.enqueueBatch.initiate(batchConfig, {
|
||||
fixedCacheKey: 'enqueueBatch',
|
||||
})
|
||||
);
|
||||
req.reset();
|
||||
},
|
||||
});
|
||||
};
|
||||
|
||||
@@ -3,6 +3,7 @@ import { resetCanvas } from 'features/canvas/store/canvasSlice';
|
||||
import {
|
||||
controlNetImageChanged,
|
||||
controlNetProcessedImageChanged,
|
||||
ipAdapterImageChanged,
|
||||
} from 'features/controlNet/store/controlNetSlice';
|
||||
import { imageDeletionConfirmed } from 'features/deleteImageModal/store/actions';
|
||||
import { isModalOpenChanged } from 'features/deleteImageModal/store/slice';
|
||||
@@ -110,6 +111,14 @@ export const addRequestedSingleImageDeletionListener = () => {
|
||||
}
|
||||
});
|
||||
|
||||
// Remove IP Adapter Set Image if image is deleted.
|
||||
if (
|
||||
getState().controlNet.ipAdapterInfo.adapterImage?.image_name ===
|
||||
imageDTO.image_name
|
||||
) {
|
||||
dispatch(ipAdapterImageChanged(null));
|
||||
}
|
||||
|
||||
// reset nodes that use the deleted images
|
||||
getState().nodes.nodes.forEach((node) => {
|
||||
if (!isInvocationNode(node)) {
|
||||
@@ -227,6 +236,14 @@ export const addRequestedMultipleImageDeletionListener = () => {
|
||||
}
|
||||
});
|
||||
|
||||
// Remove IP Adapter Set Image if image is deleted.
|
||||
if (
|
||||
getState().controlNet.ipAdapterInfo.adapterImage?.image_name ===
|
||||
imageDTO.image_name
|
||||
) {
|
||||
dispatch(ipAdapterImageChanged(null));
|
||||
}
|
||||
|
||||
// reset nodes that use the deleted images
|
||||
getState().nodes.nodes.forEach((node) => {
|
||||
if (!isInvocationNode(node)) {
|
||||
|
||||
@@ -1,7 +1,13 @@
|
||||
import { createAction } from '@reduxjs/toolkit';
|
||||
import { logger } from 'app/logging/logger';
|
||||
import { parseify } from 'common/util/serialize';
|
||||
import { setInitialCanvasImage } from 'features/canvas/store/canvasSlice';
|
||||
import { controlNetImageChanged } from 'features/controlNet/store/controlNetSlice';
|
||||
import {
|
||||
controlNetImageChanged,
|
||||
controlNetIsEnabledChanged,
|
||||
ipAdapterImageChanged,
|
||||
isIPAdapterEnabledChanged,
|
||||
} from 'features/controlNet/store/controlNetSlice';
|
||||
import {
|
||||
TypesafeDraggableData,
|
||||
TypesafeDroppableData,
|
||||
@@ -14,7 +20,6 @@ import {
|
||||
import { initialImageChanged } from 'features/parameters/store/generationSlice';
|
||||
import { imagesApi } from 'services/api/endpoints/images';
|
||||
import { startAppListening } from '../';
|
||||
import { parseify } from 'common/util/serialize';
|
||||
|
||||
export const dndDropped = createAction<{
|
||||
overData: TypesafeDroppableData;
|
||||
@@ -96,6 +101,25 @@ export const addImageDroppedListener = () => {
|
||||
controlNetId,
|
||||
})
|
||||
);
|
||||
dispatch(
|
||||
controlNetIsEnabledChanged({
|
||||
controlNetId,
|
||||
isEnabled: true,
|
||||
})
|
||||
);
|
||||
return;
|
||||
}
|
||||
|
||||
/**
|
||||
* Image dropped on IP Adapter image
|
||||
*/
|
||||
if (
|
||||
overData.actionType === 'SET_IP_ADAPTER_IMAGE' &&
|
||||
activeData.payloadType === 'IMAGE_DTO' &&
|
||||
activeData.payload.imageDTO
|
||||
) {
|
||||
dispatch(ipAdapterImageChanged(activeData.payload.imageDTO));
|
||||
dispatch(isIPAdapterEnabledChanged(true));
|
||||
return;
|
||||
}
|
||||
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user