Compare commits
1671 Commits
v2.1.2
...
invokeai-b
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
dbd2161601 | ||
|
|
1f83ac2eae | ||
|
|
f7bb68d01c | ||
|
|
8cddf9c5b3 | ||
|
|
9b546ccf06 | ||
|
|
73dbf73a95 | ||
|
|
18a1f3893f | ||
|
|
018d5dab53 | ||
|
|
96a5de30e3 | ||
|
|
4d62d5b802 | ||
|
|
17de5c7008 | ||
|
|
f95403dcda | ||
|
|
e54d060d17 | ||
|
|
a01f1d4940 | ||
|
|
1873817ac9 | ||
|
|
31333a736c | ||
|
|
03274b6da6 | ||
|
|
0646649c05 | ||
|
|
2af511c98a | ||
|
|
f0039cc70a | ||
|
|
8fa7d5ca64 | ||
|
|
d90aa42799 | ||
|
|
c5b34d21e5 | ||
|
|
40a4867143 | ||
|
|
4b25f80427 | ||
|
|
894e2e643d | ||
|
|
a38ff1a16b | ||
|
|
41f268b475 | ||
|
|
b3ae3f595f | ||
|
|
29962613d8 | ||
|
|
1170cee1d8 | ||
|
|
5983e65b22 | ||
|
|
bc724fcdc3 | ||
|
|
1faf9c5cdd | ||
|
|
6d1f8e6997 | ||
|
|
b141ab42d3 | ||
|
|
0590bd6626 | ||
|
|
35c4ff8ab0 | ||
|
|
0784e49d92 | ||
|
|
09fe21116b | ||
|
|
b185931f84 | ||
|
|
1a4d229650 | ||
|
|
e9d2205976 | ||
|
|
4b624dccf0 | ||
|
|
3dffa33097 | ||
|
|
ab9756b8d2 | ||
|
|
4b74b51ffe | ||
|
|
0a020e1c06 | ||
|
|
baf60948ee | ||
|
|
4e4fa1b71d | ||
|
|
7bd870febb | ||
|
|
b62cce20b8 | ||
|
|
6a8848b61f | ||
|
|
c8fa01908c | ||
|
|
261be4e2e5 | ||
|
|
e0695234e7 | ||
|
|
cb1d433f30 | ||
|
|
e3772f674d | ||
|
|
ad5142d6f7 | ||
|
|
fc4b76c8b9 | ||
|
|
1e6d804104 | ||
|
|
793488e90a | ||
|
|
11cd8d026f | ||
|
|
25faec8d70 | ||
|
|
a14fc3ace5 | ||
|
|
667dee7b22 | ||
|
|
f75a20b218 | ||
|
|
8246e4abf2 | ||
|
|
afcb278e66 | ||
|
|
0a0e44b51e | ||
|
|
d4d3441a52 | ||
|
|
3a0fed2fda | ||
|
|
fad6fc807b | ||
|
|
63ecdb19fe | ||
|
|
d7b2dbba66 | ||
|
|
16aeb8d640 | ||
|
|
e0bd30b98c | ||
|
|
90f77c047c | ||
|
|
941fc2297f | ||
|
|
110b067c52 | ||
|
|
71e4addd10 | ||
|
|
67435da996 | ||
|
|
8518f8c2ac | ||
|
|
d3b63ca0fe | ||
|
|
605ceb2e95 | ||
|
|
b632b35079 | ||
|
|
c9372f919c | ||
|
|
acd9838559 | ||
|
|
fd74f51384 | ||
|
|
1e5a44a474 | ||
|
|
78ea5d773d | ||
|
|
7547784e98 | ||
|
|
e82641d5f9 | ||
|
|
beff122d90 | ||
|
|
dabf56bee8 | ||
|
|
4faf902ec4 | ||
|
|
2c5c20c8a0 | ||
|
|
a8b9458de2 | ||
|
|
274d6238fa | ||
|
|
10400761f0 | ||
|
|
b598b844e4 | ||
|
|
8554f81e57 | ||
|
|
74ff73ffc8 | ||
|
|
993baadc22 | ||
|
|
ccfb0b94b9 | ||
|
|
8fbe019273 | ||
|
|
352805d607 | ||
|
|
879c80022e | ||
|
|
ea5f6b9826 | ||
|
|
4145e27ce6 | ||
|
|
3d4f4b677f | ||
|
|
249173faf5 | ||
|
|
794ef868af | ||
|
|
a1ed22517f | ||
|
|
3765ee9b59 | ||
|
|
91e4c60876 | ||
|
|
46e578e1ef | ||
|
|
3a8ef0a00c | ||
|
|
2a586f3179 | ||
|
|
6ce24846eb | ||
|
|
c2487e4330 | ||
|
|
cf262dd2ea | ||
|
|
5a8d66ab02 | ||
|
|
b0b0c48d8a | ||
|
|
8404e06d77 | ||
|
|
a91d01c27a | ||
|
|
5eeca47887 | ||
|
|
66b361294b | ||
|
|
0fb1e79a0b | ||
|
|
14f1efaf4f | ||
|
|
23aa17e387 | ||
|
|
f23cc54e1b | ||
|
|
e3d992d5d7 | ||
|
|
bb972b2e3d | ||
|
|
41a8fdea53 | ||
|
|
a78ff86e42 | ||
|
|
8e2fd4c96a | ||
|
|
2f424f29a0 | ||
|
|
90f00db032 | ||
|
|
77a63e5310 | ||
|
|
8f921741a5 | ||
|
|
071df30597 | ||
|
|
589a817952 | ||
|
|
dcb21c0f46 | ||
|
|
1cb88960fe | ||
|
|
610a1483b7 | ||
|
|
b4e7fc0d1d | ||
|
|
b792b7d68c | ||
|
|
abaa91195d | ||
|
|
1806bfb755 | ||
|
|
7377855c02 | ||
|
|
5f2a6f24cf | ||
|
|
5b8b92d957 | ||
|
|
352202a7bc | ||
|
|
82144de85f | ||
|
|
b70d713e89 | ||
|
|
e39dde4140 | ||
|
|
c151541703 | ||
|
|
29b348ece1 | ||
|
|
9f7c86c33e | ||
|
|
a79d40519c | ||
|
|
4515d52a42 | ||
|
|
2a8513eee0 | ||
|
|
b856fac713 | ||
|
|
4a3951681c | ||
|
|
ba89444e36 | ||
|
|
a044403ac3 | ||
|
|
16dea46b79 | ||
|
|
1f80b5335b | ||
|
|
eee7f13771 | ||
|
|
6db509a4ff | ||
|
|
b7965e1ee6 | ||
|
|
c3d292e8f9 | ||
|
|
206593ec99 | ||
|
|
1b62c781d7 | ||
|
|
c4de509983 | ||
|
|
8d80802a35 | ||
|
|
694925f427 | ||
|
|
61d5cb2536 | ||
|
|
c23fe4f6d2 | ||
|
|
e6e93bbb80 | ||
|
|
b5bd5240b6 | ||
|
|
827ac82d54 | ||
|
|
9c2f3259ca | ||
|
|
6abe2bfe42 | ||
|
|
acf955fc7b | ||
|
|
023db8ac41 | ||
|
|
65cf733a0c | ||
|
|
8323169864 | ||
|
|
bf5cd1bd3b | ||
|
|
c9db01e272 | ||
|
|
6d5e9161fb | ||
|
|
0636348585 | ||
|
|
4c44523ba0 | ||
|
|
5372800e60 | ||
|
|
2ae396640b | ||
|
|
252f222068 | ||
|
|
142ba8c8ea | ||
|
|
84dfd2003e | ||
|
|
5a633ba811 | ||
|
|
f207647f0f | ||
|
|
ad16581ab8 | ||
|
|
fd722ddf7d | ||
|
|
d669e69755 | ||
|
|
d912bab4c2 | ||
|
|
68c2722c02 | ||
|
|
426fea9681 | ||
|
|
62cfdb9f11 | ||
|
|
46b4d6497c | ||
|
|
757c0a5775 | ||
|
|
9c8f0b44ad | ||
|
|
21433a948c | ||
|
|
183344b878 | ||
|
|
fc164d5be2 | ||
|
|
45aa770cd1 | ||
|
|
6d0e782d71 | ||
|
|
117f70e1ec | ||
|
|
c840bd8c12 | ||
|
|
3c64fad379 | ||
|
|
bc813e4065 | ||
|
|
7c1d2422f0 | ||
|
|
a5b11e1071 | ||
|
|
c7e4daf431 | ||
|
|
4c61f3a514 | ||
|
|
2a179799d8 | ||
|
|
650f4bb58c | ||
|
|
7b92b27ceb | ||
|
|
8f1b301d01 | ||
|
|
e3a19d4f3e | ||
|
|
70283f7d8d | ||
|
|
ecbb385447 | ||
|
|
8dc56471ef | ||
|
|
282ba201d2 | ||
|
|
2394f6458f | ||
|
|
47c1be3322 | ||
|
|
741464b053 | ||
|
|
3aab5e7e20 | ||
|
|
1e7a6dc676 | ||
|
|
81fd2ee8c1 | ||
|
|
357601e2d6 | ||
|
|
71ff759692 | ||
|
|
b0657d5fde | ||
|
|
fa391c0b78 | ||
|
|
6082aace6d | ||
|
|
7ef63161ba | ||
|
|
b731b55de4 | ||
|
|
51956ba356 | ||
|
|
f494077003 | ||
|
|
317165c410 | ||
|
|
f5aadbc200 | ||
|
|
774230f7b9 | ||
|
|
72e25d99c7 | ||
|
|
7c7c1ba02d | ||
|
|
9c6af74556 | ||
|
|
57daa3e1c2 | ||
|
|
ce98fdc5c4 | ||
|
|
f901645c12 | ||
|
|
f514f17e92 | ||
|
|
8744dd0c46 | ||
|
|
f3d669319e | ||
|
|
ace7032067 | ||
|
|
d32819875a | ||
|
|
5b5898827c | ||
|
|
8a233174de | ||
|
|
bec81170b5 | ||
|
|
2f25363d76 | ||
|
|
2aa5688d90 | ||
|
|
ed06a70eca | ||
|
|
e80160f8dd | ||
|
|
bfe64b1510 | ||
|
|
bb1769abab | ||
|
|
e3f906e90d | ||
|
|
d77dc68119 | ||
|
|
ee3d695e2e | ||
|
|
0443befd2f | ||
|
|
b4fd02b910 | ||
|
|
4e0fe4ad6e | ||
|
|
3231499992 | ||
|
|
c134161a45 | ||
|
|
c3f533f20f | ||
|
|
519a9071a8 | ||
|
|
87b4663026 | ||
|
|
6c11e8ee06 | ||
|
|
2a739890a3 | ||
|
|
02e84c9565 | ||
|
|
39715017f9 | ||
|
|
35518542f8 | ||
|
|
0aa1106c96 | ||
|
|
9cf7e5f634 | ||
|
|
d9c46277ea | ||
|
|
33f832e6ab | ||
|
|
c22d529528 | ||
|
|
cd98d88fe7 | ||
|
|
281c788489 | ||
|
|
3858bef185 | ||
|
|
34e3aa1f88 | ||
|
|
f9a1afd09c | ||
|
|
251e9c0294 | ||
|
|
d8bf2e3c10 | ||
|
|
218f30b7d0 | ||
|
|
da983c7773 | ||
|
|
7012e16c43 | ||
|
|
49ffb64ef3 | ||
|
|
b1050abf7f | ||
|
|
210998081a | ||
|
|
604acb9d91 | ||
|
|
ef822902d4 | ||
|
|
5beeb1a897 | ||
|
|
de6304b729 | ||
|
|
d0be79c33d | ||
|
|
ec14e2db35 | ||
|
|
5725fcb3e0 | ||
|
|
1447b6df96 | ||
|
|
e700da23d8 | ||
|
|
b4ed8bc47a | ||
|
|
bd85e00530 | ||
|
|
4e446130d8 | ||
|
|
4c93b514bb | ||
|
|
d078941316 | ||
|
|
230d3a496d | ||
|
|
ec2890c19b | ||
|
|
036ca31282 | ||
|
|
7dbe027b18 | ||
|
|
523e44ccfe | ||
|
|
a540cc537f | ||
|
|
39c57aa358 | ||
|
|
2d990c1f54 | ||
|
|
7fb2da8741 | ||
|
|
c69fcb1c10 | ||
|
|
6a7948466e | ||
|
|
0982548e1f | ||
|
|
4ce8b1ba21 | ||
|
|
68a3132d81 | ||
|
|
b69f9d4af1 | ||
|
|
11a29fdc4d | ||
|
|
6a1129ab64 | ||
|
|
8e1fd92e7f | ||
|
|
24407048a5 | ||
|
|
a7c2333312 | ||
|
|
b5b541c747 | ||
|
|
ad6ea02c9c | ||
|
|
c22326f9f8 | ||
|
|
1a6ed85d99 | ||
|
|
a094bbd839 | ||
|
|
73dda812ea | ||
|
|
8eaf1c4033 | ||
|
|
4f44b64052 | ||
|
|
c559bf3e10 | ||
|
|
a485515bc6 | ||
|
|
2c9b29725b | ||
|
|
28612c899a | ||
|
|
f64a4db5fa | ||
|
|
88acbeaa35 | ||
|
|
46729efe95 | ||
|
|
3f477da46c | ||
|
|
71972c3709 | ||
|
|
b3d03e1146 | ||
|
|
e29c9a7d9e | ||
|
|
9b157b6532 | ||
|
|
10a1e7962b | ||
|
|
cb672d7d00 | ||
|
|
e791fb6b0b | ||
|
|
1c9001ad21 | ||
|
|
3083356cf0 | ||
|
|
179814e50a | ||
|
|
9515c07fca | ||
|
|
d4083221a6 | ||
|
|
a45e94fde7 | ||
|
|
8b6196e0a2 | ||
|
|
ee2c0ab51b | ||
|
|
ca5f129902 | ||
|
|
cf2eca7c60 | ||
|
|
16aea1e869 | ||
|
|
75ff6cd3c3 | ||
|
|
7b7b31637c | ||
|
|
fca564c18a | ||
|
|
eb8d87e185 | ||
|
|
dbadb1d7b5 | ||
|
|
a4afb69615 | ||
|
|
8b7925edf3 | ||
|
|
168a51c5a6 | ||
|
|
3f5d8c3e44 | ||
|
|
609bb19573 | ||
|
|
d561d6d3dd | ||
|
|
7ffaa17551 | ||
|
|
97eac58a50 | ||
|
|
cedbe8fcd7 | ||
|
|
5b4a241f5c | ||
|
|
cd333e414b | ||
|
|
af3543a8c7 | ||
|
|
a461875abd | ||
|
|
ab018ccdfe | ||
|
|
d41dcdfc46 | ||
|
|
686f6ef8d6 | ||
|
|
972aecc4c5 | ||
|
|
f70b7272f3 | ||
|
|
6b7be4e5dc | ||
|
|
9b1a7b553f | ||
|
|
7f99efc5df | ||
|
|
0a6d8b4855 | ||
|
|
5e41811fb5 | ||
|
|
5a4967582e | ||
|
|
1d0ba4a1a7 | ||
|
|
4878c7a2d5 | ||
|
|
9e5aa645a7 | ||
|
|
d01e23973e | ||
|
|
71bbd78574 | ||
|
|
fff41a7349 | ||
|
|
d5f524a156 | ||
|
|
3ab9d02883 | ||
|
|
27a2e27c3a | ||
|
|
da04b11a31 | ||
|
|
3795b40f63 | ||
|
|
9436f2e3d1 | ||
|
|
24d92979db | ||
|
|
c669336d6b | ||
|
|
5529309e73 | ||
|
|
49c0516602 | ||
|
|
c1c62f770f | ||
|
|
e2b6dfeeb9 | ||
|
|
8f527c2b2d | ||
|
|
3732af63e8 | ||
|
|
7fadd5e5c4 | ||
|
|
4c2a588e1f | ||
|
|
5f9de762ff | ||
|
|
91f7abb398 | ||
|
|
de89041779 | ||
|
|
488326dd95 | ||
|
|
c3edede73f | ||
|
|
6e730bd654 | ||
|
|
884a5543c7 | ||
|
|
ac972ebbe3 | ||
|
|
6420b81a5d | ||
|
|
b6ed5eafd6 | ||
|
|
3c6c18b34c | ||
|
|
694d5aa2e8 | ||
|
|
833079140b | ||
|
|
fd27948c36 | ||
|
|
1dfaaa2a57 | ||
|
|
bac6b50dd1 | ||
|
|
8f6e43d4a4 | ||
|
|
a30c91f398 | ||
|
|
17294bfa55 | ||
|
|
404000bf93 | ||
|
|
3fa1771cc9 | ||
|
|
f3bd386ff0 | ||
|
|
8486ce31de | ||
|
|
1d9845557f | ||
|
|
55dce6cfdd | ||
|
|
58be915446 | ||
|
|
dc9268f772 | ||
|
|
47ddc00c6a | ||
|
|
0d22fd59ed | ||
|
|
e744774171 | ||
|
|
d5efd57c28 | ||
|
|
b52a92da7e | ||
|
|
b949162e7e | ||
|
|
5409991256 | ||
|
|
be1bcbc173 | ||
|
|
d6196e863d | ||
|
|
63e790b79b | ||
|
|
cf53bba99e | ||
|
|
ed4c8f6a8a | ||
|
|
aab8263c31 | ||
|
|
b21bd6f428 | ||
|
|
cb6903dfd0 | ||
|
|
cd87ca8214 | ||
|
|
58e5bf5a58 | ||
|
|
f17c7ca6f7 | ||
|
|
c3dd28cff9 | ||
|
|
db4e1e8b53 | ||
|
|
3e43c3e698 | ||
|
|
cc7733af1c | ||
|
|
2a29734a56 | ||
|
|
f2e533f7c8 | ||
|
|
078f897b67 | ||
|
|
8352ab2076 | ||
|
|
1a3d47814b | ||
|
|
e852ad0a51 | ||
|
|
136cd0e868 | ||
|
|
7afe26320a | ||
|
|
702da71515 | ||
|
|
b313cf8afd | ||
|
|
852d78d9ad | ||
|
|
5570a88858 | ||
|
|
cfd897874b | ||
|
|
1249147c57 | ||
|
|
eec5c3bbb1 | ||
|
|
ca8d9fb885 | ||
|
|
096e1d3a5d | ||
|
|
7d77fb9691 | ||
|
|
a4c0dfb33c | ||
|
|
2dded68267 | ||
|
|
172ce3dc25 | ||
|
|
6c8d4b091e | ||
|
|
7beebc3659 | ||
|
|
5461318eda | ||
|
|
82e4d5aed2 | ||
|
|
d0abe13b60 | ||
|
|
aca9d74489 | ||
|
|
a0c213a158 | ||
|
|
740210fc99 | ||
|
|
ca10d0652f | ||
|
|
e1a85d8184 | ||
|
|
9d8236c59d | ||
|
|
7eafcd47a6 | ||
|
|
ded3f13a33 | ||
|
|
e5646d7241 | ||
|
|
79ac9698c1 | ||
|
|
d29f57c93d | ||
|
|
9b7cde8918 | ||
|
|
8ae71303a5 | ||
|
|
2cd7bd4a8e | ||
|
|
b813298f2a | ||
|
|
58f787f7d4 | ||
|
|
2bba543d20 | ||
|
|
d3c1b747ee | ||
|
|
b9ecf93ba3 | ||
|
|
487da8394d | ||
|
|
4c93bc56f8 | ||
|
|
727dfeae43 | ||
|
|
88d561dee7 | ||
|
|
7a379f1d4f | ||
|
|
3ad89f99d2 | ||
|
|
d76c5da514 | ||
|
|
5a7145c485 | ||
|
|
afc8639c25 | ||
|
|
da5b0673e7 | ||
|
|
d7180afe9d | ||
|
|
2e9c15711b | ||
|
|
e19b08b149 | ||
|
|
234d76a269 | ||
|
|
826d941068 | ||
|
|
34e449213c | ||
|
|
671c5943e4 | ||
|
|
16c24ec367 | ||
|
|
e8240855e0 | ||
|
|
a5e065048e | ||
|
|
a53c3269db | ||
|
|
8bf93d3a32 | ||
|
|
d42cc0fd1c | ||
|
|
d2553d783c | ||
|
|
10b747d22b | ||
|
|
1d567fa593 | ||
|
|
3a3dd39d3a | ||
|
|
f4b3d7dba2 | ||
|
|
de2c7fd372 | ||
|
|
b140e1c619 | ||
|
|
1308584289 | ||
|
|
2ac4778bcf | ||
|
|
6101d67dba | ||
|
|
3cd50fe3a1 | ||
|
|
e683b574d1 | ||
|
|
0decd05913 | ||
|
|
d01b7ea2d2 | ||
|
|
4fa91724d9 | ||
|
|
e3d1c64b77 | ||
|
|
17f35a7bba | ||
|
|
ab2f0a6fbf | ||
|
|
41cbf2f7c4 | ||
|
|
d5d2e1d7a3 | ||
|
|
587faa3e52 | ||
|
|
141be95c2c | ||
|
|
80229ab73e | ||
|
|
68b2911d2f | ||
|
|
2bf2f627e4 | ||
|
|
58676b2ce2 | ||
|
|
11f79dc1e1 | ||
|
|
2a095ddc8e | ||
|
|
dd849d2e91 | ||
|
|
8c63fac958 | ||
|
|
11a70e9764 | ||
|
|
33ce78e4a2 | ||
|
|
4f78518858 | ||
|
|
fad99ac4d2 | ||
|
|
423b592b25 | ||
|
|
8aa7d1da55 | ||
|
|
6b702c32ca | ||
|
|
767012aec0 | ||
|
|
2267057e2b | ||
|
|
b8212e4dea | ||
|
|
5b7e4a5f5d | ||
|
|
07f9fa63d0 | ||
|
|
1ae8986451 | ||
|
|
b305c240de | ||
|
|
248dc81ec3 | ||
|
|
ebe0071ed2 | ||
|
|
7a518218e5 | ||
|
|
fc14ac7faa | ||
|
|
95e2739c47 | ||
|
|
f129393a2e | ||
|
|
c55bbd1a85 | ||
|
|
ccba41cdb2 | ||
|
|
3d442bbf22 | ||
|
|
4888d0d832 | ||
|
|
47de3fb007 | ||
|
|
41bc160cb8 | ||
|
|
d0ba155c19 | ||
|
|
5f0848bf7d | ||
|
|
6551527fe2 | ||
|
|
159ce2ea08 | ||
|
|
3715570d17 | ||
|
|
65a7432b5a | ||
|
|
557e28f460 | ||
|
|
62a7f252f5 | ||
|
|
2fa14200aa | ||
|
|
0605cf94f0 | ||
|
|
d69156c616 | ||
|
|
0963bbbe78 | ||
|
|
f3351a5e47 | ||
|
|
f3f4c68acc | ||
|
|
5d617ce63d | ||
|
|
8a0d45ac5a | ||
|
|
2468ba7445 | ||
|
|
65b7d2db47 | ||
|
|
e07f1bb89c | ||
|
|
f4f813d108 | ||
|
|
6217edcb6c | ||
|
|
c5cc832304 | ||
|
|
a76038bac4 | ||
|
|
ff4942f9b4 | ||
|
|
1ccad64871 | ||
|
|
19f0022bbe | ||
|
|
ecc7b7a700 | ||
|
|
e46102124e | ||
|
|
314ed7d8f6 | ||
|
|
b1341bc611 | ||
|
|
07be605dcb | ||
|
|
fe318775c3 | ||
|
|
1bb07795d8 | ||
|
|
caf07479ec | ||
|
|
508780d07f | ||
|
|
05e67e924c | ||
|
|
fb2488314f | ||
|
|
062f58209b | ||
|
|
7cb9d6b1a6 | ||
|
|
fb721234ec | ||
|
|
92906aeb08 | ||
|
|
cab41f0538 | ||
|
|
5d0dcaf81e | ||
|
|
9591c8d4e0 | ||
|
|
bcb1fbe031 | ||
|
|
e87a2fe14b | ||
|
|
d00571b5a4 | ||
|
|
b08a514594 | ||
|
|
265ccaca4a | ||
|
|
7aa6c827f7 | ||
|
|
093174942b | ||
|
|
f299f40763 | ||
|
|
7545e38655 | ||
|
|
0bc55a0d55 | ||
|
|
d38e7170fe | ||
|
|
15a9412255 | ||
|
|
e29399e032 | ||
|
|
bc18a94d8c | ||
|
|
5d2bdd478c | ||
|
|
9cacba916b | ||
|
|
628e82fa79 | ||
|
|
fbbbba2fac | ||
|
|
9cbf9d52b4 | ||
|
|
fb35fe1a41 | ||
|
|
b60b5750af | ||
|
|
3ff40114fa | ||
|
|
71c6ae8789 | ||
|
|
d9a7536fa8 | ||
|
|
99f4417cd7 | ||
|
|
47f94bde04 | ||
|
|
197e6b95e3 | ||
|
|
8e47ca8d57 | ||
|
|
714fff39ba | ||
|
|
89239d1c54 | ||
|
|
c03d98cf46 | ||
|
|
d1ad46d6f1 | ||
|
|
6ae7560f66 | ||
|
|
e561d19206 | ||
|
|
9eed1919c2 | ||
|
|
b87f7b1129 | ||
|
|
7410a60208 | ||
|
|
7c86130a3d | ||
|
|
58a1d9aae0 | ||
|
|
24e32f6ae2 | ||
|
|
3dd7393984 | ||
|
|
f18f743d03 | ||
|
|
c660dcdfcd | ||
|
|
9e0250c0b4 | ||
|
|
08c747f1e0 | ||
|
|
04ae6fde80 | ||
|
|
b1a53c8ef0 | ||
|
|
cd64511f24 | ||
|
|
1e98e0b159 | ||
|
|
4f7af55bc3 | ||
|
|
d0e6a57e48 | ||
|
|
d28a486769 | ||
|
|
84722d92f6 | ||
|
|
8a3b5ac21d | ||
|
|
717d53a773 | ||
|
|
96926d6648 | ||
|
|
f3639de8b1 | ||
|
|
b71e675e8d | ||
|
|
d3c850104b | ||
|
|
c00155f6a4 | ||
|
|
8753070fc7 | ||
|
|
ed8f9f021d | ||
|
|
3ccc705396 | ||
|
|
11e422cf29 | ||
|
|
7f695fed39 | ||
|
|
310501cd8a | ||
|
|
106b3aea1b | ||
|
|
6e52ca3307 | ||
|
|
94c31f672f | ||
|
|
240bbb9852 | ||
|
|
8cf2ed91a9 | ||
|
|
7be5b4ca8b | ||
|
|
d589ad96aa | ||
|
|
097e41e8d2 | ||
|
|
4cf43b858d | ||
|
|
13a4666a6e | ||
|
|
9232290950 | ||
|
|
f3153d45bc | ||
|
|
d9cb6da951 | ||
|
|
17535d887f | ||
|
|
35da7f5b96 | ||
|
|
4e95a68582 | ||
|
|
9dfeb93f80 | ||
|
|
02247ffc79 | ||
|
|
48da030415 | ||
|
|
817e04bee0 | ||
|
|
e5d0b0c37d | ||
|
|
950f450665 | ||
|
|
f5d1fbd896 | ||
|
|
424cee63f1 | ||
|
|
79daf8b039 | ||
|
|
383cbca896 | ||
|
|
07c55d5e2a | ||
|
|
156151df45 | ||
|
|
03b1d71af9 | ||
|
|
da193ecd4a | ||
|
|
56fd202e21 | ||
|
|
29454a2974 | ||
|
|
c977d295f5 | ||
|
|
28eaffa188 | ||
|
|
3feff09fb3 | ||
|
|
158d1ef384 | ||
|
|
f6ad107fdd | ||
|
|
e2c392631a | ||
|
|
4a1b4d63ef | ||
|
|
83ecda977c | ||
|
|
9601febef8 | ||
|
|
0503680efa | ||
|
|
57ccec1df3 | ||
|
|
22f3634481 | ||
|
|
5590c73af2 | ||
|
|
1f76b30e54 | ||
|
|
4785a1cd05 | ||
|
|
8bd04654c7 | ||
|
|
2876c4ddec | ||
|
|
0dce3188cc | ||
|
|
106c7aa956 | ||
|
|
b04f199035 | ||
|
|
a2b992dfd1 | ||
|
|
745e253a78 | ||
|
|
2ea551d37d | ||
|
|
8d1481ca10 | ||
|
|
307e7e00c2 | ||
|
|
4bce81de26 | ||
|
|
c3ad1c8a9f | ||
|
|
05d51d7b5b | ||
|
|
09f69a4d28 | ||
|
|
a338af17c8 | ||
|
|
bc82fc0cdd | ||
|
|
418a3d6e41 | ||
|
|
fbcc52ec3d | ||
|
|
47e89f4ba1 | ||
|
|
12d15a1a3f | ||
|
|
888d3ae968 | ||
|
|
a28120abdd | ||
|
|
2aad4dab90 | ||
|
|
4493d83aea | ||
|
|
eff0fb9a69 | ||
|
|
c19107e0a8 | ||
|
|
eaf29e1751 | ||
|
|
d964374a91 | ||
|
|
9826f80d7f | ||
|
|
ec89bd19dc | ||
|
|
23aaf54f56 | ||
|
|
6d3cc25bca | ||
|
|
c9d246c4ec | ||
|
|
74406456f2 | ||
|
|
8e0cd2df18 | ||
|
|
4d4b1777db | ||
|
|
d6e5da6e37 | ||
|
|
5bb0f9bedc | ||
|
|
dec7d8b160 | ||
|
|
4ecf016ace | ||
|
|
4d74af2363 | ||
|
|
c6a2ba12e2 | ||
|
|
350b5205a3 | ||
|
|
06028e0131 | ||
|
|
c6d13e679f | ||
|
|
72357266a6 | ||
|
|
9d69843a9d | ||
|
|
0547d20b2f | ||
|
|
2af6b8fbd8 | ||
|
|
0cee72dba5 | ||
|
|
77c11a42ee | ||
|
|
bf812e6493 | ||
|
|
a3da12d867 | ||
|
|
1d62b4210f | ||
|
|
d5a3571c00 | ||
|
|
8b2ed9b8fd | ||
|
|
24792eb5da | ||
|
|
614220576f | ||
|
|
70bcbc7401 | ||
|
|
492605ac3e | ||
|
|
67f892455f | ||
|
|
ae689d1a4a | ||
|
|
10990799db | ||
|
|
c5b4397212 | ||
|
|
f62bbef9f7 | ||
|
|
6b4a06c3fc | ||
|
|
9157da8237 | ||
|
|
9c2b9af3a8 | ||
|
|
3833b28132 | ||
|
|
e3419c82e8 | ||
|
|
65f3d22649 | ||
|
|
39b0288595 | ||
|
|
13d12a0ceb | ||
|
|
b92dc8db83 | ||
|
|
b49188a39d | ||
|
|
b9c8270ee6 | ||
|
|
f0f3520bca | ||
|
|
e8f9ab82ed | ||
|
|
6ab364b16a | ||
|
|
a4dc11addc | ||
|
|
0372702eb4 | ||
|
|
aa8eeea478 | ||
|
|
e54ecc4c37 | ||
|
|
4a12c76097 | ||
|
|
be72faf78e | ||
|
|
28d44d80ed | ||
|
|
9008d9996f | ||
|
|
be2a9b78bb | ||
|
|
70003ee5b1 | ||
|
|
45a5ccba84 | ||
|
|
f80a64a0f4 | ||
|
|
511df2963b | ||
|
|
f92f62a91b | ||
|
|
3efe9899c2 | ||
|
|
bdbe4660fc | ||
|
|
8af9432f63 | ||
|
|
668d9cdb9d | ||
|
|
90f5811e59 | ||
|
|
15d21206a3 | ||
|
|
b622286f17 | ||
|
|
176add58b2 | ||
|
|
33c5f5a9c2 | ||
|
|
2b7752b72e | ||
|
|
5478d2a15e | ||
|
|
9ad76fe80c | ||
|
|
d74c4009cb | ||
|
|
ffe0e81ec9 | ||
|
|
bdf683ec41 | ||
|
|
7f41893da4 | ||
|
|
42da4f57c2 | ||
|
|
c2e11dfe83 | ||
|
|
17e1930229 | ||
|
|
bde94347d3 | ||
|
|
b1612afff4 | ||
|
|
1d10d952b2 | ||
|
|
9150f9ef3c | ||
|
|
7bc0f7cc6c | ||
|
|
c52d11b24c | ||
|
|
59486615dd | ||
|
|
f0212cd361 | ||
|
|
ee4cb5fdc9 | ||
|
|
75b919237b | ||
|
|
07a9062e1f | ||
|
|
cdb3e18b80 | ||
|
|
28a5424242 | ||
|
|
8d418af20b | ||
|
|
055badd611 | ||
|
|
944f9e98a7 | ||
|
|
fcffcf5602 | ||
|
|
f121dfe120 | ||
|
|
a7dd7b4298 | ||
|
|
d94780651c | ||
|
|
d26abd7f01 | ||
|
|
7e2b122105 | ||
|
|
8a21fc1c50 | ||
|
|
275d5040f4 | ||
|
|
1b5930dcad | ||
|
|
d5810f6270 | ||
|
|
ebc51dc535 | ||
|
|
ac6e9238f1 | ||
|
|
01eb93d664 | ||
|
|
89f69c2d94 | ||
|
|
dc6f6fcab7 | ||
|
|
6343b245ef | ||
|
|
8c80da2844 | ||
|
|
a12189e088 | ||
|
|
472c97e4e8 | ||
|
|
5baf0ae755 | ||
|
|
a56e3014a4 | ||
|
|
f3eff38f90 | ||
|
|
53d2d34b3d | ||
|
|
ede7d1a8f7 | ||
|
|
ac23a321b0 | ||
|
|
f52b233205 | ||
|
|
8242fc8bad | ||
|
|
09b6f7572b | ||
|
|
bde6e96800 | ||
|
|
13474e985b | ||
|
|
28b40bebbe | ||
|
|
1c9fd00f98 | ||
|
|
8ab66a211c | ||
|
|
bc03ff8b30 | ||
|
|
0247d63511 | ||
|
|
7604b36577 | ||
|
|
4a026bd46e | ||
|
|
6241fc19e0 | ||
|
|
25d7d71dd8 | ||
|
|
2432adb38f | ||
|
|
91acae30bf | ||
|
|
ca749b7de1 | ||
|
|
7486aa8608 | ||
|
|
0402766f4d | ||
|
|
a9ef5d1532 | ||
|
|
a485d45400 | ||
|
|
a40bdef29f | ||
|
|
fc2670b4d6 | ||
|
|
f0cd1aa736 | ||
|
|
c3807b044d | ||
|
|
b7ab025f40 | ||
|
|
633f702b39 | ||
|
|
3969637488 | ||
|
|
658ef829d4 | ||
|
|
0240656361 | ||
|
|
719a5de506 | ||
|
|
05bb9e444b | ||
|
|
0076757767 | ||
|
|
6ab03c4d08 | ||
|
|
142016827f | ||
|
|
466a82bcc2 | ||
|
|
05349f6cdc | ||
|
|
ab585aefae | ||
|
|
083ce9358b | ||
|
|
f56cf2400a | ||
|
|
5de5e659d0 | ||
|
|
fc53f6d47c | ||
|
|
2f70daef8f | ||
|
|
fc2a136eb0 | ||
|
|
ce3da40434 | ||
|
|
7933f27a72 | ||
|
|
1c197c602f | ||
|
|
90656aa7bf | ||
|
|
394b4a771e | ||
|
|
9c3f548900 | ||
|
|
5662d2daa8 | ||
|
|
fc0f966ad2 | ||
|
|
eb702a5049 | ||
|
|
1386d73302 | ||
|
|
6089f33e54 | ||
|
|
3a260cf54f | ||
|
|
9949a438f4 | ||
|
|
84c1122208 | ||
|
|
cc3d431928 | ||
|
|
c44b060a2e | ||
|
|
eff7fb89d8 | ||
|
|
cd5c112fcd | ||
|
|
563867fa99 | ||
|
|
2e230774c2 | ||
|
|
9577410be4 | ||
|
|
4ada4c9f1f | ||
|
|
9a6966924c | ||
|
|
0d62525f3d | ||
|
|
2ec864e37e | ||
|
|
9307ce3dc3 | ||
|
|
15996446e0 | ||
|
|
7a06c8fd89 | ||
|
|
4895fe8395 | ||
|
|
1e793a2dfe | ||
|
|
9c8fcaaf86 | ||
|
|
bf4344be51 | ||
|
|
f7532cdfd4 | ||
|
|
f1dd76c20b | ||
|
|
3016eeb6fb | ||
|
|
75b62d6ca8 | ||
|
|
82ae2769c8 | ||
|
|
61149abd2f | ||
|
|
eff126af6e | ||
|
|
0ca499cf96 | ||
|
|
3abf85e658 | ||
|
|
5095285854 | ||
|
|
93623a4449 | ||
|
|
0197459b02 | ||
|
|
1578bc68cc | ||
|
|
4ace397a99 | ||
|
|
d85a710211 | ||
|
|
536d534ab4 | ||
|
|
fc752a4e75 | ||
|
|
3c06d114c3 | ||
|
|
00d79c1fe3 | ||
|
|
60213893ab | ||
|
|
3b58413d9f | ||
|
|
1139884493 | ||
|
|
17e8f966d0 | ||
|
|
a42b25339f | ||
|
|
1b0731dd1a | ||
|
|
61c3886843 | ||
|
|
f76d57637e | ||
|
|
6bf73a0cf9 | ||
|
|
5145df21d9 | ||
|
|
e96ac61cb3 | ||
|
|
0e35d829c1 | ||
|
|
d08f048621 | ||
|
|
cfd453c1c7 | ||
|
|
6ca177e462 | ||
|
|
a1b1a48fb3 | ||
|
|
b5160321bf | ||
|
|
0cc2a8176e | ||
|
|
9ac81c1dc4 | ||
|
|
50191774fc | ||
|
|
fcd9b813e3 | ||
|
|
813f92a1ae | ||
|
|
0d141c1d84 | ||
|
|
2e3cd03b27 | ||
|
|
4500c8b244 | ||
|
|
d569c9dec6 | ||
|
|
01a2b8c05b | ||
|
|
b23664c794 | ||
|
|
f06fefcacc | ||
|
|
7fa3a499bb | ||
|
|
c50b64ec1d | ||
|
|
76b0bdb6f9 | ||
|
|
b0ad109886 | ||
|
|
66b312c353 | ||
|
|
fc857f9d91 | ||
|
|
d6bd0cbf61 | ||
|
|
a32f6e9ea7 | ||
|
|
b41342a779 | ||
|
|
7603c8982c | ||
|
|
d351e365d6 | ||
|
|
d453afbf6b | ||
|
|
9ae55c91cc | ||
|
|
9e46badc40 | ||
|
|
ca0f3ec0e4 | ||
|
|
4b9be6113d | ||
|
|
31964c7c4c | ||
|
|
64f9fbda2f | ||
|
|
3ece2f19f0 | ||
|
|
c38b0b906d | ||
|
|
c79678a643 | ||
|
|
2217998010 | ||
|
|
3b43f3a5a1 | ||
|
|
3f193d2b97 | ||
|
|
9fe660c515 | ||
|
|
16356d5225 | ||
|
|
e04cb70c7c | ||
|
|
ddd5137cc6 | ||
|
|
b9aef33ae8 | ||
|
|
797e2f780d | ||
|
|
0642728484 | ||
|
|
fe9b4f4a3c | ||
|
|
756e50f641 | ||
|
|
2202288eb2 | ||
|
|
fc3378bb74 | ||
|
|
96228507d2 | ||
|
|
1fe5ec32f5 | ||
|
|
6dee9051a1 | ||
|
|
d58574ca46 | ||
|
|
d282000c05 | ||
|
|
80c5322ccc | ||
|
|
da181ce64e | ||
|
|
5ef66ca237 | ||
|
|
e99e720474 | ||
|
|
7aa331af8c | ||
|
|
9e943ff7dc | ||
|
|
b5040ba8d0 | ||
|
|
07462d1d99 | ||
|
|
d273fba42c | ||
|
|
735545dca1 | ||
|
|
328f87559b | ||
|
|
6f10b06a0c | ||
|
|
fd60c8297d | ||
|
|
480064fa06 | ||
|
|
3810d6a4ce | ||
|
|
44d36a0e0b | ||
|
|
3996ee843c | ||
|
|
6d966313b9 | ||
|
|
8ce9f07223 | ||
|
|
11ac50a6ea | ||
|
|
31146eb797 | ||
|
|
99cd598334 | ||
|
|
5441be8169 | ||
|
|
3e98b50b62 | ||
|
|
5f16148dea | ||
|
|
9628d45a92 | ||
|
|
6cbdd88fe2 | ||
|
|
d423db4f82 | ||
|
|
5c8c204a1b | ||
|
|
a03471c588 | ||
|
|
6608343455 | ||
|
|
abd972f099 | ||
|
|
bd57793a65 | ||
|
|
8cdc65effc | ||
|
|
85b553c567 | ||
|
|
af74a2d1f4 | ||
|
|
6fdc9ac224 | ||
|
|
8107d354d9 | ||
|
|
7ca8abb206 | ||
|
|
28c17613c4 | ||
|
|
eeb7a4c28c | ||
|
|
0009d82a92 | ||
|
|
e6d52d7ce6 | ||
|
|
8c726d3e3e | ||
|
|
56e2d22b6e | ||
|
|
053d11fe30 | ||
|
|
0066187651 | ||
|
|
d3d24fa816 | ||
|
|
4d58fed6b0 | ||
|
|
bde5874707 | ||
|
|
eed802f5d9 | ||
|
|
c13e11a264 | ||
|
|
1c377b7995 | ||
|
|
efe8dcaae9 | ||
|
|
fc8e3dbcd3 | ||
|
|
ec1e83e912 | ||
|
|
ab9daf1241 | ||
|
|
c061c1b1b6 | ||
|
|
b9cc56593e | ||
|
|
6a0e1c8673 | ||
|
|
371edc993a | ||
|
|
d71734c90d | ||
|
|
9ad4c03277 | ||
|
|
5299324321 | ||
|
|
817e36f8bf | ||
|
|
d044d4c577 | ||
|
|
3f1120e6f2 | ||
|
|
17d73d09c0 | ||
|
|
478c379534 | ||
|
|
c5c160a788 | ||
|
|
27ee939e4b | ||
|
|
c222cf7e64 | ||
|
|
b2a3b8bbf6 | ||
|
|
11cb03f7de | ||
|
|
6b1dc34523 | ||
|
|
44786b0496 | ||
|
|
d9ed0f6005 | ||
|
|
2e7a002308 | ||
|
|
5ce62e00c9 | ||
|
|
5a8c28de97 | ||
|
|
07e03b31b7 | ||
|
|
5ee5c5a012 | ||
|
|
3075c99ed2 | ||
|
|
2c0bee2a6d | ||
|
|
8f86aa7ded | ||
|
|
34e0d7aaa8 | ||
|
|
abe4e1ea91 | ||
|
|
f1f8ce604a | ||
|
|
47dbe7bc0d | ||
|
|
ebe6daac56 | ||
|
|
d209dab881 | ||
|
|
2ff47cdecf | ||
|
|
22c34aabfe | ||
|
|
b58a80109b | ||
|
|
c5a9e70e7f | ||
|
|
c5914ce236 | ||
|
|
242abac12d | ||
|
|
4b659982b7 | ||
|
|
71733bcfa1 | ||
|
|
d047e070b8 | ||
|
|
02c530e200 | ||
|
|
d36bbb817c | ||
|
|
9997fde144 | ||
|
|
9e22ed5c12 | ||
|
|
169c56e471 | ||
|
|
b186965e77 | ||
|
|
88526b9294 | ||
|
|
071a438745 | ||
|
|
93129fde32 | ||
|
|
802b95b9d9 | ||
|
|
c279314cf5 | ||
|
|
f75b194b76 | ||
|
|
bf1996bbcf | ||
|
|
d3962ab7b5 | ||
|
|
2296f5449e | ||
|
|
b6d37a70ca | ||
|
|
71b6ddf5fb | ||
|
|
14de7ed925 | ||
|
|
6556b200b5 | ||
|
|
d627cd1865 | ||
|
|
09b6104bfd | ||
|
|
1bb5b4ab32 | ||
|
|
c18db4e47b | ||
|
|
f9c92e3576 | ||
|
|
1ceb7a60db | ||
|
|
f509650ec5 | ||
|
|
0d0f35a1e2 | ||
|
|
6dbc42fc1a | ||
|
|
f6018fe5aa | ||
|
|
e4cd66216e | ||
|
|
995fbc78c8 | ||
|
|
3083f8313d | ||
|
|
c0614ac7f3 | ||
|
|
0186630514 | ||
|
|
d53df09203 | ||
|
|
12a29bfbc0 | ||
|
|
f36114eb94 | ||
|
|
c255481c11 | ||
|
|
7f81105acf | ||
|
|
c8de679dc3 | ||
|
|
85b18fe9ee | ||
|
|
e0d8c19da6 | ||
|
|
5567808237 | ||
|
|
2817f8a428 | ||
|
|
8e4c044ca2 | ||
|
|
9dc3832b9b | ||
|
|
046abb634e | ||
|
|
d3a469d136 | ||
|
|
e79f89b619 | ||
|
|
cbd967cbc4 | ||
|
|
e090c0dc10 | ||
|
|
c381788ab9 | ||
|
|
fb312f9ed3 | ||
|
|
729752620b | ||
|
|
8ed8bf52d0 | ||
|
|
a49d546125 | ||
|
|
288e31fc60 | ||
|
|
7b2c0d12a3 | ||
|
|
2978c3eb8d | ||
|
|
5e7ed964d2 | ||
|
|
93a24445dc | ||
|
|
95d147c5df | ||
|
|
41aed57449 | ||
|
|
34a3f4a820 | ||
|
|
1f5ad1b05e | ||
|
|
87c63f1f08 | ||
|
|
5b054dd5b7 | ||
|
|
fc5c8cc800 | ||
|
|
eb2ca4970b | ||
|
|
c2b10e6461 | ||
|
|
190d266060 | ||
|
|
8c8e1a448d | ||
|
|
c52dd7e3f4 | ||
|
|
a4aea1540b | ||
|
|
3c53b46a35 | ||
|
|
65fd6cd105 | ||
|
|
61403fe306 | ||
|
|
b2f288d6ec | ||
|
|
d1d12e4f92 | ||
|
|
eaf7934d74 | ||
|
|
079ec4cb5c | ||
|
|
38d0b1e3df | ||
|
|
fc6500e819 | ||
|
|
f521f5feba | ||
|
|
ce865a8d69 | ||
|
|
00839d02ab | ||
|
|
ce52d0c42b | ||
|
|
f687d90bca | ||
|
|
7473d814f5 | ||
|
|
b2c30c2093 | ||
|
|
a7048eea5f | ||
|
|
87c9398266 | ||
|
|
63c6019f92 | ||
|
|
8eaf0d8bfe | ||
|
|
5344481809 | ||
|
|
9f32daab2d | ||
|
|
884768c39d | ||
|
|
bc2194228e | ||
|
|
10c3afef17 | ||
|
|
98e9721101 | ||
|
|
66babb2e81 | ||
|
|
31a967965b | ||
|
|
b9c9b947cd | ||
|
|
1eee08a070 | ||
|
|
aca1b61413 | ||
|
|
e18beaff9c | ||
|
|
d7554b01fd | ||
|
|
70f8793700 | ||
|
|
0d4e6cbff5 | ||
|
|
ea61bf2c94 | ||
|
|
7dead7696c | ||
|
|
ffcc5ad795 | ||
|
|
48deb3e49d | ||
|
|
6c31225d19 | ||
|
|
c0610f7cb9 | ||
|
|
313b206ff8 | ||
|
|
f0fe483915 | ||
|
|
4ee8d104f0 | ||
|
|
89791d91e8 | ||
|
|
87f3da92e9 | ||
|
|
f169bb0020 | ||
|
|
155efadec2 | ||
|
|
bffe199ad7 | ||
|
|
0c2a511671 | ||
|
|
e94c8fa285 | ||
|
|
b3363a934d | ||
|
|
599c558c87 | ||
|
|
d35ec3398d | ||
|
|
96a900d1fe | ||
|
|
f00f7095f9 | ||
|
|
d7217e3801 | ||
|
|
fc5fdae562 | ||
|
|
a491644e56 | ||
|
|
ec2a509e01 | ||
|
|
6a3a0af676 | ||
|
|
ef4b03289a | ||
|
|
963b666844 | ||
|
|
5a788f8f73 | ||
|
|
5afb63e41b | ||
|
|
279ffcfe15 | ||
|
|
9b73292fcb | ||
|
|
67d91dc550 | ||
|
|
a1c0818a08 | ||
|
|
2cf825b169 | ||
|
|
292b0d70d8 | ||
|
|
c3aa3d48a0 | ||
|
|
9e3c947cd3 | ||
|
|
4b8aebabfb | ||
|
|
080fc4b380 | ||
|
|
195294e74f | ||
|
|
da81165a4b | ||
|
|
f3ff386491 | ||
|
|
da524f159e | ||
|
|
2d1eeec063 | ||
|
|
a8bb1a1109 | ||
|
|
d9fa505412 | ||
|
|
02ce602a38 | ||
|
|
9b1843307b | ||
|
|
f0010919f2 | ||
|
|
d113b4ad41 | ||
|
|
895505976e | ||
|
|
171f4aa71b | ||
|
|
775e1a21c7 | ||
|
|
3c3d893b9d | ||
|
|
33a5c83c74 | ||
|
|
7ee0edcb9e | ||
|
|
7bd2220a24 | ||
|
|
284b432ffd | ||
|
|
ab675af264 | ||
|
|
be58a6bfbc | ||
|
|
5a40aadbee | ||
|
|
e11f15cf78 | ||
|
|
ce17051b28 | ||
|
|
a2bdc8b579 | ||
|
|
1c62ae461e | ||
|
|
c5b802b596 | ||
|
|
b9ab9ffb4a | ||
|
|
f232068ab8 | ||
|
|
4556f29359 | ||
|
|
c1521be445 | ||
|
|
f3e952ecf0 | ||
|
|
aa4e8d8cf3 | ||
|
|
a7b2074106 | ||
|
|
2282e681f7 | ||
|
|
6e2365f835 | ||
|
|
e4ea98c277 | ||
|
|
2fd5fe6c89 | ||
|
|
4a9e93463d | ||
|
|
0b5c0c374e | ||
|
|
5750f5dac2 | ||
|
|
3fb095de88 | ||
|
|
c5fecfe281 | ||
|
|
1fa6a3558e | ||
|
|
2ee68cecd9 | ||
|
|
c8d1d4d159 | ||
|
|
529b19f8f6 | ||
|
|
be4f44fafd | ||
|
|
5aec48735e | ||
|
|
3c919f0337 | ||
|
|
858ddffab6 | ||
|
|
212fec669a | ||
|
|
fc2098834d | ||
|
|
8a31e5c5e3 | ||
|
|
bcc0110c59 | ||
|
|
ce1c5e70b8 | ||
|
|
ce00c9856f | ||
|
|
7e8f364d8d | ||
|
|
088cd2c4dd | ||
|
|
9460763eff | ||
|
|
fe46d9d0f7 | ||
|
|
563196bd03 | ||
|
|
d2a038200c | ||
|
|
d6ac0eeffd | ||
|
|
3a1724652e | ||
|
|
8c073a7818 | ||
|
|
8c94f6a234 | ||
|
|
5fa8f8be43 | ||
|
|
5b35fa53a7 | ||
|
|
a2ee32f57f | ||
|
|
4486169a83 | ||
|
|
bfeafa8d5e | ||
|
|
f86c8b043c | ||
|
|
251a409087 | ||
|
|
6fdbc1978d | ||
|
|
c855d2a350 | ||
|
|
4dd74cdc68 | ||
|
|
746e97ea1d | ||
|
|
241313c4a6 | ||
|
|
b6d1a17a1e | ||
|
|
c73434c2a3 | ||
|
|
69b15024a9 | ||
|
|
26e413ae9c | ||
|
|
91eb84c5d9 | ||
|
|
5d69bd408b | ||
|
|
21bf512056 | ||
|
|
6c6e534c1a | ||
|
|
010378153f | ||
|
|
9091b6e24a | ||
|
|
64700b07a8 | ||
|
|
34f8117241 | ||
|
|
c3f82d4481 | ||
|
|
3929bd3e13 | ||
|
|
caf7caddf7 | ||
|
|
9fded69f0c | ||
|
|
9f719883c8 | ||
|
|
5d4da31dcd | ||
|
|
686640af3a | ||
|
|
edc22e06c3 | ||
|
|
409a46e2c4 | ||
|
|
e7ee4ecac7 | ||
|
|
da6c690d7b | ||
|
|
7c4544f95e | ||
|
|
f173e0a085 | ||
|
|
2a90e0c55f | ||
|
|
9d103ef030 | ||
|
|
4cc60669c1 | ||
|
|
d456aea8f3 | ||
|
|
4151883cb2 | ||
|
|
a029d90630 | ||
|
|
211d6b3831 | ||
|
|
b40faa98bd | ||
|
|
8d4ad0de4e | ||
|
|
e4b2f815e8 | ||
|
|
0dd5804949 | ||
|
|
53476af72e | ||
|
|
61ee597f4b | ||
|
|
ad0b366e47 | ||
|
|
942f029a24 | ||
|
|
e0d7c466cc | ||
|
|
16c0132a6b | ||
|
|
7cb2fcf8b4 | ||
|
|
1a65d43569 | ||
|
|
1313e31f62 | ||
|
|
aa213285bb | ||
|
|
f691353570 | ||
|
|
1c75010f29 | ||
|
|
eba8fb58ed | ||
|
|
83a7e60fe5 | ||
|
|
d4e86feeeb | ||
|
|
427614d1df | ||
|
|
ce6fb8ea29 | ||
|
|
df858eb3f9 | ||
|
|
6523fd07ab | ||
|
|
a823e37126 | ||
|
|
4eed06903c | ||
|
|
79d577bff9 | ||
|
|
3521557541 | ||
|
|
e66b1a685c | ||
|
|
c351aa19eb | ||
|
|
aa1f46820f | ||
|
|
1d34405f4f | ||
|
|
f961e865f5 | ||
|
|
9eba6acb7f | ||
|
|
e32dd1d703 | ||
|
|
bbbfea488d | ||
|
|
c8a9848ad6 | ||
|
|
e88e274bf2 | ||
|
|
cca8d14c79 | ||
|
|
464aafa862 | ||
|
|
6e98b5535d | ||
|
|
ab2972f320 | ||
|
|
1ba40db361 | ||
|
|
f69fc68e06 | ||
|
|
7d8d4bcafb | ||
|
|
4fd97ceddd | ||
|
|
ded49523cd | ||
|
|
914e5fc4f8 | ||
|
|
ab4d391a3a | ||
|
|
82f59829b8 | ||
|
|
147834e99c | ||
|
|
f41da11d66 | ||
|
|
5c5454e4a5 | ||
|
|
dedbdeeafc | ||
|
|
d1770bff37 | ||
|
|
20652620d9 | ||
|
|
51613525a4 | ||
|
|
dc39f8d6a7 | ||
|
|
f1748d7017 | ||
|
|
de7abce464 | ||
|
|
2aa5bb6aad | ||
|
|
c0c4d7ca69 | ||
|
|
7d09d9da49 | ||
|
|
ffa54f4a35 | ||
|
|
69cc0993f8 | ||
|
|
1050f2726a | ||
|
|
f7170e4156 | ||
|
|
bfa8fed568 | ||
|
|
2923dfaed1 | ||
|
|
0932b4affa | ||
|
|
0b10835269 | ||
|
|
6e0f3475b4 | ||
|
|
9b9e276491 | ||
|
|
392c0725f3 | ||
|
|
2a2f38a016 | ||
|
|
7a4e647287 | ||
|
|
b8e1151a9c | ||
|
|
f39cb668fc | ||
|
|
6c015eedb3 | ||
|
|
834e56a513 | ||
|
|
652aaa809b | ||
|
|
89880e1f72 | ||
|
|
d94f955d9d | ||
|
|
64339af2dc | ||
|
|
5d20f47993 | ||
|
|
ccf8a46320 | ||
|
|
af3d72e001 | ||
|
|
1d78e1af9c | ||
|
|
1fd605604f | ||
|
|
f0b04c5066 | ||
|
|
2836976d6d | ||
|
|
474220ce8e | ||
|
|
4074705194 | ||
|
|
e89ff01caf | ||
|
|
2187d0f31c | ||
|
|
1219c39d78 | ||
|
|
bc0b0e4752 | ||
|
|
cd3da2900d | ||
|
|
4402ca10b2 | ||
|
|
1a1625406c | ||
|
|
36e6908266 | ||
|
|
7314f1a862 | ||
|
|
5c3cbd05f1 | ||
|
|
f4e7383490 | ||
|
|
96a12099ed | ||
|
|
e159bb3dce | ||
|
|
bd0c0d77d2 | ||
|
|
f745f78cb3 | ||
|
|
7efe0f3996 | ||
|
|
9f855a358a | ||
|
|
62b80a81d3 | ||
|
|
14587c9a95 | ||
|
|
fcae5defe3 | ||
|
|
e7144055d1 | ||
|
|
c857c6cc62 | ||
|
|
7ecb11cf86 | ||
|
|
e4b61923ae | ||
|
|
aa68e4e0da | ||
|
|
09365d6d2e | ||
|
|
b77f34998c | ||
|
|
0439b51a26 | ||
|
|
ef6870c714 | ||
|
|
8cbb50c204 | ||
|
|
12a8d7fc14 | ||
|
|
3d2b497eb0 | ||
|
|
786b8878d6 | ||
|
|
55132f6463 | ||
|
|
ed9186b099 | ||
|
|
d2026d0509 | ||
|
|
0bc4ed14cd | ||
|
|
06369d07c0 | ||
|
|
4e61069821 | ||
|
|
d7ba041007 | ||
|
|
3859302f1c | ||
|
|
865439114b | ||
|
|
4d76116152 | ||
|
|
42f5bd4e12 | ||
|
|
04e77f3858 | ||
|
|
1fc1eeec38 | ||
|
|
556081695a | ||
|
|
ad7917c7aa | ||
|
|
39cca8139f | ||
|
|
1d1988683b | ||
|
|
44a0055571 | ||
|
|
0cc01143d8 | ||
|
|
1c0247d58a | ||
|
|
d335f51e5f | ||
|
|
38cd968130 | ||
|
|
0111304982 | ||
|
|
c607d4fe6c | ||
|
|
6d6076d3c7 | ||
|
|
485fcc7fcb | ||
|
|
76633f500a | ||
|
|
ed6194351c | ||
|
|
f237744ab1 | ||
|
|
678cf8519e | ||
|
|
ee9de75b8d | ||
|
|
50f3847ef8 | ||
|
|
8596e3586c | ||
|
|
5ef1e0714b | ||
|
|
be871c3ab3 | ||
|
|
dec40d9b04 | ||
|
|
fe5c008dd5 | ||
|
|
72def2ae13 | ||
|
|
31cd76a2af | ||
|
|
00c78263ce | ||
|
|
5c31feb3a1 | ||
|
|
26f129cef8 | ||
|
|
292ee06751 | ||
|
|
c00d53fcce | ||
|
|
a78a8728fe | ||
|
|
6b5d19347a | ||
|
|
26671d8eed | ||
|
|
b487fa4391 | ||
|
|
12b98ba4ec | ||
|
|
fa25a64d37 | ||
|
|
29540452f2 | ||
|
|
c7960f930a | ||
|
|
c1c8b5026a | ||
|
|
5da42e0ad2 | ||
|
|
34d6f35408 | ||
|
|
401165ba35 | ||
|
|
6d8057c84f | ||
|
|
3f23dee6f4 | ||
|
|
8cdd961ad2 | ||
|
|
470b267939 | ||
|
|
bf399e303c | ||
|
|
b3d7ad7461 | ||
|
|
cd66b2c76d | ||
|
|
6b406e2b5e | ||
|
|
6737cc1443 | ||
|
|
7fd0eeb9f9 | ||
|
|
16e3b45fa2 | ||
|
|
2f07ea03a9 | ||
|
|
b563d75c58 | ||
|
|
a7b7b20d16 | ||
|
|
a47ef3ded9 | ||
|
|
7cb9b654f3 | ||
|
|
8819e12a86 | ||
|
|
967eb60ea9 | ||
|
|
b1091ecda1 | ||
|
|
2723dd9051 | ||
|
|
8f050d992e | ||
|
|
0346095876 | ||
|
|
f9bbc55f74 | ||
|
|
878a3907e9 | ||
|
|
4cfb41d9ae | ||
|
|
6ec64ecb3c | ||
|
|
540315edaa | ||
|
|
cf10a1b736 | ||
|
|
9fb2a43780 | ||
|
|
1b743f7d9b | ||
|
|
d7bf3f7d7b | ||
|
|
eba31e7caf | ||
|
|
bde456f9fa | ||
|
|
9ee83380e6 | ||
|
|
6982e6a469 | ||
|
|
0f4d71ed63 | ||
|
|
8f3f64b22e | ||
|
|
dba0280790 | ||
|
|
19e2cff18c | ||
|
|
58f65d49b6 | ||
|
|
e5edd025d6 | ||
|
|
29e229b409 | ||
|
|
93cdb476d9 | ||
|
|
1305e7a56c | ||
|
|
58edf262e4 | ||
|
|
fd67df9447 | ||
|
|
45e5053d06 | ||
|
|
9c5999ede1 | ||
|
|
7ddf7f0b7d | ||
|
|
b8de5244b1 | ||
|
|
72e011a4e4 | ||
|
|
98db0d746c | ||
|
|
1a8e007066 | ||
|
|
8b47c82992 | ||
|
|
eab435da27 | ||
|
|
cbc029c6f9 | ||
|
|
d318968abe | ||
|
|
e71655237a | ||
|
|
6b89adfa7e |
{kind=link}
{kind=link}
{kind=link}
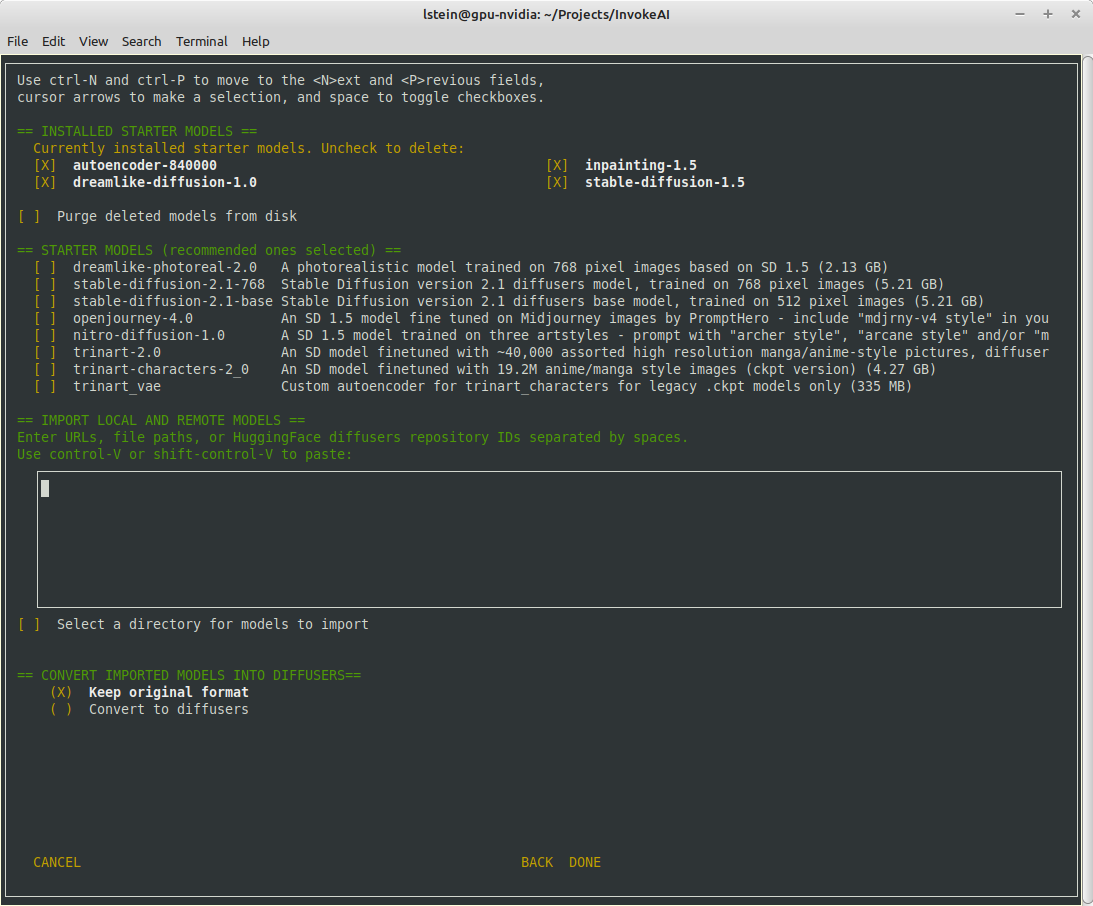{kind=link}
{kind=link}
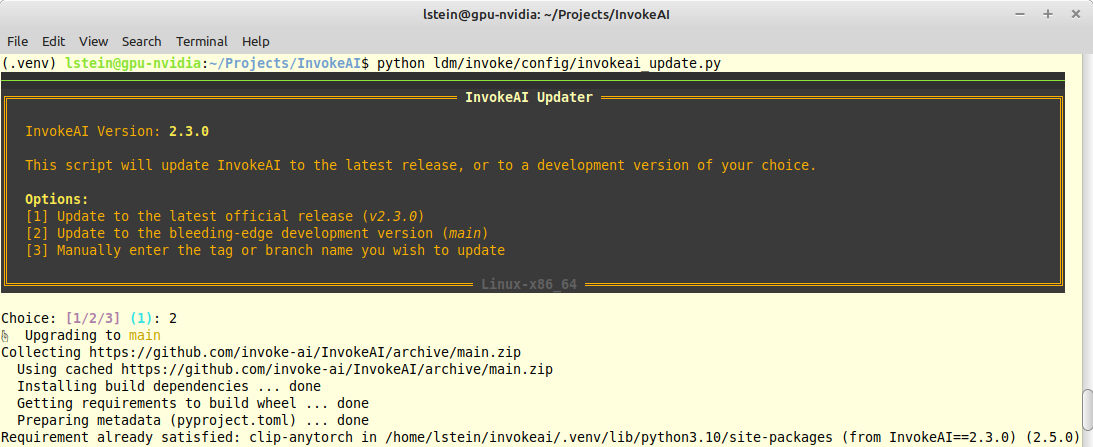
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
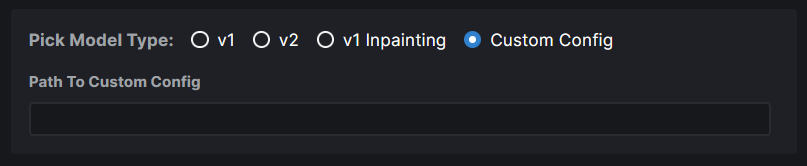{kind=link}
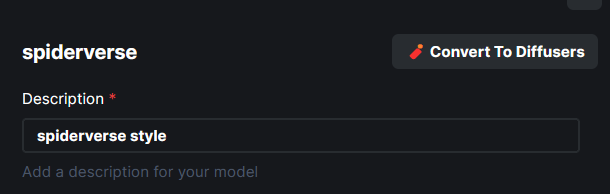{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
6
.coveragerc
Normal file
@@ -0,0 +1,6 @@
|
||||
[run]
|
||||
omit='.env/*'
|
||||
source='.'
|
||||
|
||||
[report]
|
||||
show_missing = true
|
||||
@@ -1,3 +1,25 @@
|
||||
# use this file as a whitelist
|
||||
*
|
||||
!environment*.yml
|
||||
!docker-build
|
||||
!invokeai
|
||||
!ldm
|
||||
!pyproject.toml
|
||||
|
||||
# Guard against pulling in any models that might exist in the directory tree
|
||||
**/*.pt*
|
||||
**/*.ckpt
|
||||
|
||||
# ignore frontend but whitelist dist
|
||||
invokeai/frontend/
|
||||
!invokeai/frontend/dist/
|
||||
|
||||
# ignore invokeai/assets but whitelist invokeai/assets/web
|
||||
invokeai/assets/
|
||||
!invokeai/assets/web/
|
||||
|
||||
# Byte-compiled / optimized / DLL files
|
||||
**/__pycache__/
|
||||
**/*.py[cod]
|
||||
|
||||
# Distribution / packaging
|
||||
*.egg-info/
|
||||
*.egg
|
||||
|
||||
30
.editorconfig
Normal file
@@ -0,0 +1,30 @@
|
||||
root = true
|
||||
|
||||
# All files
|
||||
[*]
|
||||
max_line_length = 80
|
||||
charset = utf-8
|
||||
end_of_line = lf
|
||||
indent_size = 2
|
||||
indent_style = space
|
||||
insert_final_newline = true
|
||||
trim_trailing_whitespace = true
|
||||
|
||||
# Python
|
||||
[*.py]
|
||||
indent_size = 4
|
||||
max_line_length = 120
|
||||
|
||||
# css
|
||||
[*.css]
|
||||
indent_size = 4
|
||||
|
||||
# flake8
|
||||
[.flake8]
|
||||
indent_size = 4
|
||||
|
||||
# Markdown MkDocs
|
||||
[docs/**/*.md]
|
||||
max_line_length = 80
|
||||
indent_size = 4
|
||||
indent_style = unset
|
||||
37
.flake8
Normal file
@@ -0,0 +1,37 @@
|
||||
[flake8]
|
||||
max-line-length = 120
|
||||
extend-ignore =
|
||||
# See https://github.com/PyCQA/pycodestyle/issues/373
|
||||
E203,
|
||||
# use Bugbear's B950 instead
|
||||
E501,
|
||||
# from black repo https://github.com/psf/black/blob/main/.flake8
|
||||
E266, W503, B907
|
||||
extend-select =
|
||||
# Bugbear line length
|
||||
B950
|
||||
extend-exclude =
|
||||
scripts/orig_scripts/*
|
||||
ldm/models/*
|
||||
ldm/modules/*
|
||||
ldm/data/*
|
||||
ldm/generate.py
|
||||
ldm/util.py
|
||||
ldm/simplet2i.py
|
||||
per-file-ignores =
|
||||
# B950 line too long
|
||||
# W605 invalid escape sequence
|
||||
# F841 assigned to but never used
|
||||
# F401 imported but unused
|
||||
tests/test_prompt_parser.py: B950, W605, F401
|
||||
tests/test_textual_inversion.py: F841, B950
|
||||
# B023 Function definition does not bind loop variable
|
||||
scripts/legacy_api.py: F401, B950, B023, F841
|
||||
ldm/invoke/__init__.py: F401
|
||||
# B010 Do not call setattr with a constant attribute value
|
||||
ldm/invoke/server_legacy.py: B010
|
||||
# =====================
|
||||
# flake-quote settings:
|
||||
# =====================
|
||||
# Set this to match black style:
|
||||
inline-quotes = double
|
||||
2
.gitattributes
vendored
@@ -1,4 +1,4 @@
|
||||
# Auto normalizes line endings on commit so devs don't need to change local settings.
|
||||
# Only affects text files and ignores other file types.
|
||||
# Only affects text files and ignores other file types.
|
||||
# For more info see: https://www.aleksandrhovhannisyan.com/blog/crlf-vs-lf-normalizing-line-endings-in-git/
|
||||
* text=auto
|
||||
|
||||
65
.github/CODEOWNERS
vendored
@@ -1,4 +1,61 @@
|
||||
ldm/invoke/pngwriter.py @CapableWeb
|
||||
ldm/invoke/server_legacy.py @CapableWeb
|
||||
scripts/legacy_api.py @CapableWeb
|
||||
tests/legacy_tests.sh @CapableWeb
|
||||
# continuous integration
|
||||
/.github/workflows/ @mauwii @lstein @blessedcoolant
|
||||
|
||||
# documentation
|
||||
/docs/ @lstein @mauwii @blessedcoolant
|
||||
mkdocs.yml @mauwii @lstein
|
||||
|
||||
# installation and configuration
|
||||
/pyproject.toml @mauwii @lstein @ebr
|
||||
/docker/ @mauwii
|
||||
/scripts/ @ebr @lstein @blessedcoolant
|
||||
/installer/ @ebr @lstein
|
||||
ldm/invoke/config @lstein @ebr
|
||||
invokeai/assets @lstein @blessedcoolant
|
||||
invokeai/configs @lstein @ebr @blessedcoolant
|
||||
/ldm/invoke/_version.py @lstein @blessedcoolant
|
||||
|
||||
# web ui
|
||||
/invokeai/frontend @blessedcoolant @psychedelicious
|
||||
/invokeai/backend @blessedcoolant @psychedelicious
|
||||
|
||||
# generation and model management
|
||||
/ldm/*.py @lstein @blessedcoolant
|
||||
/ldm/generate.py @lstein @keturn
|
||||
/ldm/invoke/args.py @lstein @blessedcoolant
|
||||
/ldm/invoke/ckpt* @lstein @blessedcoolant
|
||||
/ldm/invoke/ckpt_generator @lstein @blessedcoolant
|
||||
/ldm/invoke/CLI.py @lstein @blessedcoolant
|
||||
/ldm/invoke/config @lstein @ebr @mauwii @blessedcoolant
|
||||
/ldm/invoke/generator @keturn @damian0815
|
||||
/ldm/invoke/globals.py @lstein @blessedcoolant
|
||||
/ldm/invoke/merge_diffusers.py @lstein @blessedcoolant
|
||||
/ldm/invoke/model_manager.py @lstein @blessedcoolant
|
||||
/ldm/invoke/txt2mask.py @lstein @blessedcoolant
|
||||
/ldm/invoke/patchmatch.py @Kyle0654 @lstein
|
||||
/ldm/invoke/restoration @lstein @blessedcoolant
|
||||
|
||||
# attention, textual inversion, model configuration
|
||||
/ldm/models @damian0815 @keturn @blessedcoolant
|
||||
/ldm/modules/textual_inversion_manager.py @lstein @blessedcoolant
|
||||
/ldm/modules/attention.py @damian0815 @keturn
|
||||
/ldm/modules/diffusionmodules @damian0815 @keturn
|
||||
/ldm/modules/distributions @damian0815 @keturn
|
||||
/ldm/modules/ema.py @damian0815 @keturn
|
||||
/ldm/modules/embedding_manager.py @lstein
|
||||
/ldm/modules/encoders @damian0815 @keturn
|
||||
/ldm/modules/image_degradation @damian0815 @keturn
|
||||
/ldm/modules/losses @damian0815 @keturn
|
||||
/ldm/modules/x_transformer.py @damian0815 @keturn
|
||||
|
||||
# Nodes
|
||||
apps/ @Kyle0654 @jpphoto
|
||||
|
||||
# legacy REST API
|
||||
# these are dead code
|
||||
#/ldm/invoke/pngwriter.py @CapableWeb
|
||||
#/ldm/invoke/server_legacy.py @CapableWeb
|
||||
#/scripts/legacy_api.py @CapableWeb
|
||||
#/tests/legacy_tests.sh @CapableWeb
|
||||
|
||||
|
||||
|
||||
113
.github/workflows/build-container.yml
vendored
@@ -1,42 +1,111 @@
|
||||
# Building the Image without pushing to confirm it is still buildable
|
||||
# confirum functionality would unfortunately need way more resources
|
||||
name: build container image
|
||||
on:
|
||||
push:
|
||||
branches:
|
||||
- 'main'
|
||||
- 'development'
|
||||
pull_request:
|
||||
branches:
|
||||
- 'main'
|
||||
- 'development'
|
||||
- 'update/ci/docker/*'
|
||||
- 'update/docker/*'
|
||||
paths:
|
||||
- 'pyproject.toml'
|
||||
- 'ldm/**'
|
||||
- 'invokeai/backend/**'
|
||||
- 'invokeai/configs/**'
|
||||
- 'invokeai/frontend/dist/**'
|
||||
- 'docker/Dockerfile'
|
||||
tags:
|
||||
- 'v*.*.*'
|
||||
workflow_dispatch:
|
||||
|
||||
|
||||
jobs:
|
||||
docker:
|
||||
if: github.event.pull_request.draft == false
|
||||
strategy:
|
||||
fail-fast: false
|
||||
matrix:
|
||||
flavor:
|
||||
- amd
|
||||
- cuda
|
||||
- cpu
|
||||
include:
|
||||
- flavor: amd
|
||||
pip-extra-index-url: 'https://download.pytorch.org/whl/rocm5.2'
|
||||
- flavor: cuda
|
||||
pip-extra-index-url: ''
|
||||
- flavor: cpu
|
||||
pip-extra-index-url: 'https://download.pytorch.org/whl/cpu'
|
||||
runs-on: ubuntu-latest
|
||||
name: ${{ matrix.flavor }}
|
||||
env:
|
||||
PLATFORMS: 'linux/amd64,linux/arm64'
|
||||
DOCKERFILE: 'docker/Dockerfile'
|
||||
steps:
|
||||
- name: prepare docker-tag
|
||||
env:
|
||||
repository: ${{ github.repository }}
|
||||
run: echo "dockertag=${repository,,}" >> $GITHUB_ENV
|
||||
- name: Checkout
|
||||
uses: actions/checkout@v3
|
||||
|
||||
- name: Docker meta
|
||||
id: meta
|
||||
uses: docker/metadata-action@v4
|
||||
with:
|
||||
github-token: ${{ secrets.GITHUB_TOKEN }}
|
||||
images: |
|
||||
ghcr.io/${{ github.repository }}
|
||||
${{ vars.DOCKERHUB_REPOSITORY }}
|
||||
tags: |
|
||||
type=ref,event=branch
|
||||
type=ref,event=tag
|
||||
type=semver,pattern={{version}}
|
||||
type=semver,pattern={{major}}.{{minor}}
|
||||
type=semver,pattern={{major}}
|
||||
type=sha,enable=true,prefix=sha-,format=short
|
||||
flavor: |
|
||||
latest=${{ matrix.flavor == 'cuda' && github.ref == 'refs/heads/main' }}
|
||||
suffix=-${{ matrix.flavor }},onlatest=false
|
||||
|
||||
- name: Set up QEMU
|
||||
uses: docker/setup-qemu-action@v2
|
||||
|
||||
- name: Set up Docker Buildx
|
||||
uses: docker/setup-buildx-action@v2
|
||||
- name: Cache Docker layers
|
||||
uses: actions/cache@v2
|
||||
with:
|
||||
path: /tmp/.buildx-cache
|
||||
key: buildx-${{ hashFiles('docker-build/Dockerfile') }}
|
||||
platforms: ${{ env.PLATFORMS }}
|
||||
|
||||
- name: Login to GitHub Container Registry
|
||||
if: github.event_name != 'pull_request'
|
||||
uses: docker/login-action@v2
|
||||
with:
|
||||
registry: ghcr.io
|
||||
username: ${{ github.repository_owner }}
|
||||
password: ${{ secrets.GITHUB_TOKEN }}
|
||||
|
||||
- name: Login to Docker Hub
|
||||
if: github.event_name != 'pull_request' && vars.DOCKERHUB_REPOSITORY != ''
|
||||
uses: docker/login-action@v2
|
||||
with:
|
||||
username: ${{ secrets.DOCKERHUB_USERNAME }}
|
||||
password: ${{ secrets.DOCKERHUB_TOKEN }}
|
||||
|
||||
- name: Build container
|
||||
uses: docker/build-push-action@v3
|
||||
id: docker_build
|
||||
uses: docker/build-push-action@v4
|
||||
with:
|
||||
context: .
|
||||
file: docker-build/Dockerfile
|
||||
platforms: linux/amd64
|
||||
push: false
|
||||
tags: ${{ env.dockertag }}:latest
|
||||
cache-from: type=local,src=/tmp/.buildx-cache
|
||||
cache-to: type=local,dest=/tmp/.buildx-cache
|
||||
file: ${{ env.DOCKERFILE }}
|
||||
platforms: ${{ env.PLATFORMS }}
|
||||
push: ${{ github.ref == 'refs/heads/main' || github.ref == 'refs/tags/*' }}
|
||||
tags: ${{ steps.meta.outputs.tags }}
|
||||
labels: ${{ steps.meta.outputs.labels }}
|
||||
build-args: PIP_EXTRA_INDEX_URL=${{ matrix.pip-extra-index-url }}
|
||||
cache-from: |
|
||||
type=gha,scope=${{ github.ref_name }}-${{ matrix.flavor }}
|
||||
type=gha,scope=main-${{ matrix.flavor }}
|
||||
cache-to: type=gha,mode=max,scope=${{ github.ref_name }}-${{ matrix.flavor }}
|
||||
|
||||
- name: Docker Hub Description
|
||||
if: github.ref == 'refs/heads/main' || github.ref == 'refs/tags/*' && vars.DOCKERHUB_REPOSITORY != ''
|
||||
uses: peter-evans/dockerhub-description@v3
|
||||
with:
|
||||
username: ${{ secrets.DOCKERHUB_USERNAME }}
|
||||
password: ${{ secrets.DOCKERHUB_TOKEN }}
|
||||
repository: ${{ vars.DOCKERHUB_REPOSITORY }}
|
||||
short-description: ${{ github.event.repository.description }}
|
||||
|
||||
34
.github/workflows/clean-caches.yml
vendored
Normal file
@@ -0,0 +1,34 @@
|
||||
name: cleanup caches by a branch
|
||||
on:
|
||||
pull_request:
|
||||
types:
|
||||
- closed
|
||||
workflow_dispatch:
|
||||
|
||||
jobs:
|
||||
cleanup:
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- name: Check out code
|
||||
uses: actions/checkout@v3
|
||||
|
||||
- name: Cleanup
|
||||
run: |
|
||||
gh extension install actions/gh-actions-cache
|
||||
|
||||
REPO=${{ github.repository }}
|
||||
BRANCH=${{ github.ref }}
|
||||
|
||||
echo "Fetching list of cache key"
|
||||
cacheKeysForPR=$(gh actions-cache list -R $REPO -B $BRANCH | cut -f 1 )
|
||||
|
||||
## Setting this to not fail the workflow while deleting cache keys.
|
||||
set +e
|
||||
echo "Deleting caches..."
|
||||
for cacheKey in $cacheKeysForPR
|
||||
do
|
||||
gh actions-cache delete $cacheKey -R $REPO -B $BRANCH --confirm
|
||||
done
|
||||
echo "Done"
|
||||
env:
|
||||
GH_TOKEN: ${{ secrets.GITHUB_TOKEN }}
|
||||
80
.github/workflows/create-caches.yml
vendored
@@ -1,80 +0,0 @@
|
||||
name: Create Caches
|
||||
|
||||
on: workflow_dispatch
|
||||
|
||||
jobs:
|
||||
os_matrix:
|
||||
strategy:
|
||||
matrix:
|
||||
os: [ubuntu-latest, macos-latest]
|
||||
include:
|
||||
- os: ubuntu-latest
|
||||
environment-file: environment.yml
|
||||
default-shell: bash -l {0}
|
||||
- os: macos-latest
|
||||
environment-file: environment-mac.yml
|
||||
default-shell: bash -l {0}
|
||||
name: Test invoke.py on ${{ matrix.os }} with conda
|
||||
runs-on: ${{ matrix.os }}
|
||||
defaults:
|
||||
run:
|
||||
shell: ${{ matrix.default-shell }}
|
||||
steps:
|
||||
- name: Checkout sources
|
||||
uses: actions/checkout@v3
|
||||
|
||||
- name: setup miniconda
|
||||
uses: conda-incubator/setup-miniconda@v2
|
||||
with:
|
||||
auto-activate-base: false
|
||||
auto-update-conda: false
|
||||
miniconda-version: latest
|
||||
|
||||
- name: set environment
|
||||
run: |
|
||||
[[ "$GITHUB_REF" == 'refs/heads/main' ]] \
|
||||
&& echo "TEST_PROMPTS=tests/preflight_prompts.txt" >> $GITHUB_ENV \
|
||||
|| echo "TEST_PROMPTS=tests/dev_prompts.txt" >> $GITHUB_ENV
|
||||
echo "CONDA_ROOT=$CONDA" >> $GITHUB_ENV
|
||||
echo "CONDA_ENV_NAME=invokeai" >> $GITHUB_ENV
|
||||
|
||||
- name: Use Cached Stable Diffusion v1.4 Model
|
||||
id: cache-sd-v1-4
|
||||
uses: actions/cache@v3
|
||||
env:
|
||||
cache-name: cache-sd-v1-4
|
||||
with:
|
||||
path: models/ldm/stable-diffusion-v1/model.ckpt
|
||||
key: ${{ env.cache-name }}
|
||||
restore-keys: ${{ env.cache-name }}
|
||||
|
||||
- name: Download Stable Diffusion v1.4 Model
|
||||
if: ${{ steps.cache-sd-v1-4.outputs.cache-hit != 'true' }}
|
||||
run: |
|
||||
[[ -d models/ldm/stable-diffusion-v1 ]] \
|
||||
|| mkdir -p models/ldm/stable-diffusion-v1
|
||||
[[ -r models/ldm/stable-diffusion-v1/model.ckpt ]] \
|
||||
|| curl \
|
||||
-H "Authorization: Bearer ${{ secrets.HUGGINGFACE_TOKEN }}" \
|
||||
-o models/ldm/stable-diffusion-v1/model.ckpt \
|
||||
-L https://huggingface.co/CompVis/stable-diffusion-v-1-4-original/resolve/main/sd-v1-4.ckpt
|
||||
|
||||
- name: Activate Conda Env
|
||||
uses: conda-incubator/setup-miniconda@v2
|
||||
with:
|
||||
activate-environment: ${{ env.CONDA_ENV_NAME }}
|
||||
environment-file: ${{ matrix.environment-file }}
|
||||
|
||||
- name: Use Cached Huggingface and Torch models
|
||||
id: cache-hugginface-torch
|
||||
uses: actions/cache@v3
|
||||
env:
|
||||
cache-name: cache-hugginface-torch
|
||||
with:
|
||||
path: ~/.cache
|
||||
key: ${{ env.cache-name }}
|
||||
restore-keys: |
|
||||
${{ env.cache-name }}-${{ hashFiles('scripts/preload_models.py') }}
|
||||
|
||||
- name: run preload_models.py
|
||||
run: python scripts/preload_models.py
|
||||
29
.github/workflows/lint-frontend.yml
vendored
Normal file
@@ -0,0 +1,29 @@
|
||||
name: Lint frontend
|
||||
|
||||
on:
|
||||
pull_request:
|
||||
paths:
|
||||
- 'invokeai/frontend/**'
|
||||
push:
|
||||
paths:
|
||||
- 'invokeai/frontend/**'
|
||||
|
||||
defaults:
|
||||
run:
|
||||
working-directory: invokeai/frontend
|
||||
|
||||
jobs:
|
||||
lint-frontend:
|
||||
if: github.event.pull_request.draft == false
|
||||
runs-on: ubuntu-22.04
|
||||
steps:
|
||||
- name: Setup Node 18
|
||||
uses: actions/setup-node@v3
|
||||
with:
|
||||
node-version: '18'
|
||||
- uses: actions/checkout@v3
|
||||
- run: 'yarn install --frozen-lockfile'
|
||||
- run: 'yarn tsc'
|
||||
- run: 'yarn run madge'
|
||||
- run: 'yarn run lint --max-warnings=0'
|
||||
- run: 'yarn run prettier --check'
|
||||
11
.github/workflows/mkdocs-material.yml
vendored
@@ -7,7 +7,12 @@ on:
|
||||
|
||||
jobs:
|
||||
mkdocs-material:
|
||||
if: github.event.pull_request.draft == false
|
||||
runs-on: ubuntu-latest
|
||||
env:
|
||||
REPO_URL: '${{ github.server_url }}/${{ github.repository }}'
|
||||
REPO_NAME: '${{ github.repository }}'
|
||||
SITE_URL: 'https://${{ github.repository_owner }}.github.io/InvokeAI'
|
||||
steps:
|
||||
- name: checkout sources
|
||||
uses: actions/checkout@v3
|
||||
@@ -18,11 +23,15 @@ jobs:
|
||||
uses: actions/setup-python@v4
|
||||
with:
|
||||
python-version: '3.10'
|
||||
cache: pip
|
||||
cache-dependency-path: pyproject.toml
|
||||
|
||||
- name: install requirements
|
||||
env:
|
||||
PIP_USE_PEP517: 1
|
||||
run: |
|
||||
python -m \
|
||||
pip install -r requirements-mkdocs.txt
|
||||
pip install ".[docs]"
|
||||
|
||||
- name: confirm buildability
|
||||
run: |
|
||||
|
||||
20
.github/workflows/pyflakes.yml
vendored
Normal file
@@ -0,0 +1,20 @@
|
||||
on:
|
||||
pull_request:
|
||||
push:
|
||||
branches:
|
||||
- main
|
||||
- development
|
||||
- 'release-candidate-*'
|
||||
|
||||
jobs:
|
||||
pyflakes:
|
||||
name: runner / pyflakes
|
||||
if: github.event.pull_request.draft == false
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- uses: actions/checkout@v2
|
||||
- name: pyflakes
|
||||
uses: reviewdog/action-pyflakes@v1
|
||||
with:
|
||||
github_token: ${{ secrets.GITHUB_TOKEN }}
|
||||
reporter: github-pr-review
|
||||
41
.github/workflows/pypi-release.yml
vendored
Normal file
@@ -0,0 +1,41 @@
|
||||
name: PyPI Release
|
||||
|
||||
on:
|
||||
push:
|
||||
paths:
|
||||
- 'ldm/invoke/_version.py'
|
||||
workflow_dispatch:
|
||||
|
||||
jobs:
|
||||
release:
|
||||
if: github.repository == 'invoke-ai/InvokeAI'
|
||||
runs-on: ubuntu-22.04
|
||||
env:
|
||||
TWINE_USERNAME: __token__
|
||||
TWINE_PASSWORD: ${{ secrets.PYPI_API_TOKEN }}
|
||||
TWINE_NON_INTERACTIVE: 1
|
||||
steps:
|
||||
- name: checkout sources
|
||||
uses: actions/checkout@v3
|
||||
|
||||
- name: install deps
|
||||
run: pip install --upgrade build twine
|
||||
|
||||
- name: build package
|
||||
run: python3 -m build
|
||||
|
||||
- name: check distribution
|
||||
run: twine check dist/*
|
||||
|
||||
- name: check PyPI versions
|
||||
if: github.ref == 'refs/heads/main' || github.ref == 'refs/heads/v2.3'
|
||||
run: |
|
||||
pip install --upgrade requests
|
||||
python -c "\
|
||||
import scripts.pypi_helper; \
|
||||
EXISTS=scripts.pypi_helper.local_on_pypi(); \
|
||||
print(f'PACKAGE_EXISTS={EXISTS}')" >> $GITHUB_ENV
|
||||
|
||||
- name: upload package
|
||||
if: env.PACKAGE_EXISTS == 'False' && env.TWINE_PASSWORD != ''
|
||||
run: twine upload dist/*
|
||||
113
.github/workflows/test-invoke-conda.yml
vendored
@@ -1,113 +0,0 @@
|
||||
name: Test invoke.py
|
||||
on:
|
||||
push:
|
||||
branches:
|
||||
- 'main'
|
||||
- 'development'
|
||||
- 'fix-gh-actions-fork'
|
||||
pull_request:
|
||||
branches:
|
||||
- 'main'
|
||||
- 'development'
|
||||
|
||||
jobs:
|
||||
matrix:
|
||||
strategy:
|
||||
fail-fast: false
|
||||
matrix:
|
||||
stable-diffusion-model:
|
||||
# - 'https://huggingface.co/CompVis/stable-diffusion-v-1-4-original/resolve/main/sd-v1-4.ckpt'
|
||||
- 'https://huggingface.co/runwayml/stable-diffusion-v1-5/resolve/main/v1-5-pruned-emaonly.ckpt'
|
||||
os:
|
||||
- ubuntu-latest
|
||||
- macOS-12
|
||||
include:
|
||||
- os: ubuntu-latest
|
||||
environment-file: environment.yml
|
||||
default-shell: bash -l {0}
|
||||
- os: macOS-12
|
||||
environment-file: environment-mac.yml
|
||||
default-shell: bash -l {0}
|
||||
# - stable-diffusion-model: https://huggingface.co/CompVis/stable-diffusion-v-1-4-original/resolve/main/sd-v1-4.ckpt
|
||||
# stable-diffusion-model-dl-path: models/ldm/stable-diffusion-v1/sd-v1-4.ckpt
|
||||
# stable-diffusion-model-switch: stable-diffusion-1.4
|
||||
- stable-diffusion-model: https://huggingface.co/runwayml/stable-diffusion-v1-5/resolve/main/v1-5-pruned-emaonly.ckpt
|
||||
stable-diffusion-model-dl-path: models/ldm/stable-diffusion-v1/v1-5-pruned-emaonly.ckpt
|
||||
stable-diffusion-model-switch: stable-diffusion-1.5
|
||||
name: ${{ matrix.os }} with ${{ matrix.stable-diffusion-model-switch }}
|
||||
runs-on: ${{ matrix.os }}
|
||||
env:
|
||||
CONDA_ENV_NAME: invokeai
|
||||
defaults:
|
||||
run:
|
||||
shell: ${{ matrix.default-shell }}
|
||||
steps:
|
||||
- name: Checkout sources
|
||||
id: checkout-sources
|
||||
uses: actions/checkout@v3
|
||||
|
||||
- name: create models.yaml from example
|
||||
run: cp configs/models.yaml.example configs/models.yaml
|
||||
|
||||
- name: Use cached conda packages
|
||||
id: use-cached-conda-packages
|
||||
uses: actions/cache@v3
|
||||
with:
|
||||
path: ~/conda_pkgs_dir
|
||||
key: conda-pkgs-${{ runner.os }}-${{ runner.arch }}-${{ hashFiles(matrix.environment-file) }}
|
||||
|
||||
- name: Activate Conda Env
|
||||
id: activate-conda-env
|
||||
uses: conda-incubator/setup-miniconda@v2
|
||||
with:
|
||||
activate-environment: ${{ env.CONDA_ENV_NAME }}
|
||||
environment-file: ${{ matrix.environment-file }}
|
||||
miniconda-version: latest
|
||||
|
||||
- name: set test prompt to main branch validation
|
||||
if: ${{ github.ref == 'refs/heads/main' }}
|
||||
run: echo "TEST_PROMPTS=tests/preflight_prompts.txt" >> $GITHUB_ENV
|
||||
|
||||
- name: set test prompt to development branch validation
|
||||
if: ${{ github.ref == 'refs/heads/development' }}
|
||||
run: echo "TEST_PROMPTS=tests/dev_prompts.txt" >> $GITHUB_ENV
|
||||
|
||||
- name: set test prompt to Pull Request validation
|
||||
if: ${{ github.ref != 'refs/heads/main' && github.ref != 'refs/heads/development' }}
|
||||
run: echo "TEST_PROMPTS=tests/validate_pr_prompt.txt" >> $GITHUB_ENV
|
||||
|
||||
- name: Download ${{ matrix.stable-diffusion-model-switch }}
|
||||
id: download-stable-diffusion-model
|
||||
run: |
|
||||
[[ -d models/ldm/stable-diffusion-v1 ]] \
|
||||
|| mkdir -p models/ldm/stable-diffusion-v1
|
||||
curl \
|
||||
-H "Authorization: Bearer ${{ secrets.HUGGINGFACE_TOKEN }}" \
|
||||
-o ${{ matrix.stable-diffusion-model-dl-path }} \
|
||||
-L ${{ matrix.stable-diffusion-model }}
|
||||
|
||||
- name: run preload_models.py
|
||||
id: run-preload-models
|
||||
run: |
|
||||
python scripts/preload_models.py \
|
||||
--no-interactive
|
||||
|
||||
- name: Run the tests
|
||||
id: run-tests
|
||||
run: |
|
||||
time python scripts/invoke.py \
|
||||
--model ${{ matrix.stable-diffusion-model-switch }} \
|
||||
--from_file ${{ env.TEST_PROMPTS }}
|
||||
|
||||
- name: export conda env
|
||||
id: export-conda-env
|
||||
run: |
|
||||
mkdir -p outputs/img-samples
|
||||
conda env export --name ${{ env.CONDA_ENV_NAME }} > outputs/img-samples/environment-${{ runner.os }}-${{ runner.arch }}.yml
|
||||
|
||||
- name: Archive results
|
||||
id: archive-results
|
||||
uses: actions/upload-artifact@v3
|
||||
with:
|
||||
name: results_${{ matrix.os }}_${{ matrix.stable-diffusion-model-switch }}
|
||||
path: outputs/img-samples
|
||||
67
.github/workflows/test-invoke-pip-skip.yml
vendored
Normal file
@@ -0,0 +1,67 @@
|
||||
name: Test invoke.py pip
|
||||
on:
|
||||
pull_request:
|
||||
paths-ignore:
|
||||
- 'pyproject.toml'
|
||||
- 'ldm/**'
|
||||
- 'invokeai/backend/**'
|
||||
- 'invokeai/configs/**'
|
||||
- 'invokeai/frontend/dist/**'
|
||||
merge_group:
|
||||
workflow_dispatch:
|
||||
|
||||
concurrency:
|
||||
group: ${{ github.workflow }}-${{ github.head_ref || github.run_id }}
|
||||
cancel-in-progress: true
|
||||
|
||||
jobs:
|
||||
matrix:
|
||||
if: github.event.pull_request.draft == false
|
||||
strategy:
|
||||
matrix:
|
||||
python-version:
|
||||
# - '3.9'
|
||||
- '3.10'
|
||||
pytorch:
|
||||
# - linux-cuda-11_6
|
||||
- linux-cuda-11_7
|
||||
- linux-rocm-5_2
|
||||
- linux-cpu
|
||||
- macos-default
|
||||
- windows-cpu
|
||||
# - windows-cuda-11_6
|
||||
# - windows-cuda-11_7
|
||||
include:
|
||||
# - pytorch: linux-cuda-11_6
|
||||
# os: ubuntu-22.04
|
||||
# extra-index-url: 'https://download.pytorch.org/whl/cu116'
|
||||
# github-env: $GITHUB_ENV
|
||||
- pytorch: linux-cuda-11_7
|
||||
os: ubuntu-22.04
|
||||
github-env: $GITHUB_ENV
|
||||
- pytorch: linux-rocm-5_2
|
||||
os: ubuntu-22.04
|
||||
extra-index-url: 'https://download.pytorch.org/whl/rocm5.2'
|
||||
github-env: $GITHUB_ENV
|
||||
- pytorch: linux-cpu
|
||||
os: ubuntu-22.04
|
||||
extra-index-url: 'https://download.pytorch.org/whl/cpu'
|
||||
github-env: $GITHUB_ENV
|
||||
- pytorch: macos-default
|
||||
os: macOS-12
|
||||
github-env: $GITHUB_ENV
|
||||
- pytorch: windows-cpu
|
||||
os: windows-2022
|
||||
github-env: $env:GITHUB_ENV
|
||||
# - pytorch: windows-cuda-11_6
|
||||
# os: windows-2022
|
||||
# extra-index-url: 'https://download.pytorch.org/whl/cu116'
|
||||
# github-env: $env:GITHUB_ENV
|
||||
# - pytorch: windows-cuda-11_7
|
||||
# os: windows-2022
|
||||
# extra-index-url: 'https://download.pytorch.org/whl/cu117'
|
||||
# github-env: $env:GITHUB_ENV
|
||||
name: ${{ matrix.pytorch }} on ${{ matrix.python-version }}
|
||||
runs-on: ${{ matrix.os }}
|
||||
steps:
|
||||
- run: 'echo "No build required"'
|
||||
148
.github/workflows/test-invoke-pip.yml
vendored
Normal file
@@ -0,0 +1,148 @@
|
||||
name: Test invoke.py pip
|
||||
on:
|
||||
push:
|
||||
branches:
|
||||
- 'main'
|
||||
paths:
|
||||
- 'pyproject.toml'
|
||||
- 'ldm/**'
|
||||
- 'invokeai/backend/**'
|
||||
- 'invokeai/configs/**'
|
||||
- 'invokeai/frontend/dist/**'
|
||||
pull_request:
|
||||
paths:
|
||||
- 'pyproject.toml'
|
||||
- 'ldm/**'
|
||||
- 'invokeai/backend/**'
|
||||
- 'invokeai/configs/**'
|
||||
- 'invokeai/frontend/dist/**'
|
||||
types:
|
||||
- 'ready_for_review'
|
||||
- 'opened'
|
||||
- 'synchronize'
|
||||
merge_group:
|
||||
workflow_dispatch:
|
||||
|
||||
concurrency:
|
||||
group: ${{ github.workflow }}-${{ github.head_ref || github.run_id }}
|
||||
cancel-in-progress: true
|
||||
|
||||
jobs:
|
||||
matrix:
|
||||
if: github.event.pull_request.draft == false
|
||||
strategy:
|
||||
matrix:
|
||||
python-version:
|
||||
# - '3.9'
|
||||
- '3.10'
|
||||
pytorch:
|
||||
# - linux-cuda-11_6
|
||||
- linux-cuda-11_7
|
||||
- linux-rocm-5_2
|
||||
- linux-cpu
|
||||
- macos-default
|
||||
- windows-cpu
|
||||
# - windows-cuda-11_6
|
||||
# - windows-cuda-11_7
|
||||
include:
|
||||
# - pytorch: linux-cuda-11_6
|
||||
# os: ubuntu-22.04
|
||||
# extra-index-url: 'https://download.pytorch.org/whl/cu116'
|
||||
# github-env: $GITHUB_ENV
|
||||
- pytorch: linux-cuda-11_7
|
||||
os: ubuntu-22.04
|
||||
github-env: $GITHUB_ENV
|
||||
- pytorch: linux-rocm-5_2
|
||||
os: ubuntu-22.04
|
||||
extra-index-url: 'https://download.pytorch.org/whl/rocm5.2'
|
||||
github-env: $GITHUB_ENV
|
||||
- pytorch: linux-cpu
|
||||
os: ubuntu-22.04
|
||||
extra-index-url: 'https://download.pytorch.org/whl/cpu'
|
||||
github-env: $GITHUB_ENV
|
||||
- pytorch: macos-default
|
||||
os: macOS-12
|
||||
github-env: $GITHUB_ENV
|
||||
- pytorch: windows-cpu
|
||||
os: windows-2022
|
||||
github-env: $env:GITHUB_ENV
|
||||
# - pytorch: windows-cuda-11_6
|
||||
# os: windows-2022
|
||||
# extra-index-url: 'https://download.pytorch.org/whl/cu116'
|
||||
# github-env: $env:GITHUB_ENV
|
||||
# - pytorch: windows-cuda-11_7
|
||||
# os: windows-2022
|
||||
# extra-index-url: 'https://download.pytorch.org/whl/cu117'
|
||||
# github-env: $env:GITHUB_ENV
|
||||
name: ${{ matrix.pytorch }} on ${{ matrix.python-version }}
|
||||
runs-on: ${{ matrix.os }}
|
||||
env:
|
||||
PIP_USE_PEP517: '1'
|
||||
steps:
|
||||
- name: Checkout sources
|
||||
id: checkout-sources
|
||||
uses: actions/checkout@v3
|
||||
|
||||
- name: set test prompt to main branch validation
|
||||
if: ${{ github.ref == 'refs/heads/main' }}
|
||||
run: echo "TEST_PROMPTS=tests/preflight_prompts.txt" >> ${{ matrix.github-env }}
|
||||
|
||||
- name: set test prompt to Pull Request validation
|
||||
if: ${{ github.ref != 'refs/heads/main' }}
|
||||
run: echo "TEST_PROMPTS=tests/validate_pr_prompt.txt" >> ${{ matrix.github-env }}
|
||||
|
||||
- name: setup python
|
||||
uses: actions/setup-python@v4
|
||||
with:
|
||||
python-version: ${{ matrix.python-version }}
|
||||
cache: pip
|
||||
cache-dependency-path: pyproject.toml
|
||||
|
||||
- name: install invokeai
|
||||
env:
|
||||
PIP_EXTRA_INDEX_URL: ${{ matrix.extra-index-url }}
|
||||
run: >
|
||||
pip3 install
|
||||
--editable=".[test]"
|
||||
|
||||
- name: run pytest
|
||||
id: run-pytest
|
||||
run: pytest
|
||||
|
||||
- name: set INVOKEAI_OUTDIR
|
||||
run: >
|
||||
python -c
|
||||
"import os;from ldm.invoke.globals import Globals;OUTDIR=os.path.join(Globals.root,str('outputs'));print(f'INVOKEAI_OUTDIR={OUTDIR}')"
|
||||
>> ${{ matrix.github-env }}
|
||||
|
||||
- name: run invokeai-configure
|
||||
id: run-preload-models
|
||||
env:
|
||||
HUGGING_FACE_HUB_TOKEN: ${{ secrets.HUGGINGFACE_TOKEN }}
|
||||
run: >
|
||||
invokeai-configure
|
||||
--yes
|
||||
--default_only
|
||||
--full-precision
|
||||
# can't use fp16 weights without a GPU
|
||||
|
||||
- name: run invokeai
|
||||
id: run-invokeai
|
||||
env:
|
||||
# Set offline mode to make sure configure preloaded successfully.
|
||||
HF_HUB_OFFLINE: 1
|
||||
HF_DATASETS_OFFLINE: 1
|
||||
TRANSFORMERS_OFFLINE: 1
|
||||
run: >
|
||||
invokeai
|
||||
--no-patchmatch
|
||||
--no-nsfw_checker
|
||||
--from_file ${{ env.TEST_PROMPTS }}
|
||||
--outdir ${{ env.INVOKEAI_OUTDIR }}/${{ matrix.python-version }}/${{ matrix.pytorch }}
|
||||
|
||||
- name: Archive results
|
||||
id: archive-results
|
||||
uses: actions/upload-artifact@v3
|
||||
with:
|
||||
name: results
|
||||
path: ${{ env.INVOKEAI_OUTDIR }}
|
||||
30
.gitignore
vendored
@@ -1,4 +1,6 @@
|
||||
# ignore default image save location and model symbolic link
|
||||
.idea/
|
||||
embeddings/
|
||||
outputs/
|
||||
models/ldm/stable-diffusion-v1/model.ckpt
|
||||
**/restoration/codeformer/weights
|
||||
@@ -6,6 +8,7 @@ models/ldm/stable-diffusion-v1/model.ckpt
|
||||
# ignore user models config
|
||||
configs/models.user.yaml
|
||||
config/models.user.yml
|
||||
invokeai.init
|
||||
|
||||
# ignore the Anaconda/Miniconda installer used while building Docker image
|
||||
anaconda.sh
|
||||
@@ -65,11 +68,13 @@ htmlcov/
|
||||
.cache
|
||||
nosetests.xml
|
||||
coverage.xml
|
||||
cov.xml
|
||||
*.cover
|
||||
*.py,cover
|
||||
.hypothesis/
|
||||
.pytest_cache/
|
||||
cover/
|
||||
junit/
|
||||
|
||||
# Translations
|
||||
*.mo
|
||||
@@ -193,7 +198,7 @@ checkpoints
|
||||
.DS_Store
|
||||
|
||||
# Let the frontend manage its own gitignore
|
||||
!frontend/*
|
||||
!invokeai/frontend/*
|
||||
|
||||
# Scratch folder
|
||||
.scratch/
|
||||
@@ -201,6 +206,7 @@ checkpoints
|
||||
gfpgan/
|
||||
models/ldm/stable-diffusion-v1/*.sha256
|
||||
|
||||
|
||||
# GFPGAN model files
|
||||
gfpgan/
|
||||
|
||||
@@ -208,4 +214,24 @@ gfpgan/
|
||||
configs/models.yaml
|
||||
|
||||
# weights (will be created by installer)
|
||||
models/ldm/stable-diffusion-v1/*.ckpt
|
||||
models/ldm/stable-diffusion-v1/*.ckpt
|
||||
models/clipseg
|
||||
models/gfpgan
|
||||
|
||||
# ignore initfile
|
||||
.invokeai
|
||||
|
||||
# ignore environment.yml and requirements.txt
|
||||
# these are links to the real files in environments-and-requirements
|
||||
environment.yml
|
||||
requirements.txt
|
||||
|
||||
# source installer files
|
||||
installer/*zip
|
||||
installer/install.bat
|
||||
installer/install.sh
|
||||
installer/update.bat
|
||||
installer/update.sh
|
||||
|
||||
# no longer stored in source directory
|
||||
models
|
||||
|
||||
41
.pre-commit-config.yaml
Normal file
@@ -0,0 +1,41 @@
|
||||
# See https://pre-commit.com for more information
|
||||
# See https://pre-commit.com/hooks.html for more hooks
|
||||
repos:
|
||||
- repo: https://github.com/psf/black
|
||||
rev: 23.1.0
|
||||
hooks:
|
||||
- id: black
|
||||
|
||||
- repo: https://github.com/pycqa/isort
|
||||
rev: 5.12.0
|
||||
hooks:
|
||||
- id: isort
|
||||
|
||||
- repo: https://github.com/PyCQA/flake8
|
||||
rev: 6.0.0
|
||||
hooks:
|
||||
- id: flake8
|
||||
additional_dependencies:
|
||||
- flake8-black
|
||||
- flake8-bugbear
|
||||
- flake8-comprehensions
|
||||
- flake8-simplify
|
||||
|
||||
- repo: https://github.com/pre-commit/mirrors-prettier
|
||||
rev: 'v3.0.0-alpha.4'
|
||||
hooks:
|
||||
- id: prettier
|
||||
|
||||
- repo: https://github.com/pre-commit/pre-commit-hooks
|
||||
rev: v4.4.0
|
||||
hooks:
|
||||
- id: check-added-large-files
|
||||
- id: check-executables-have-shebangs
|
||||
- id: check-shebang-scripts-are-executable
|
||||
- id: check-merge-conflict
|
||||
- id: check-symlinks
|
||||
- id: check-toml
|
||||
- id: end-of-file-fixer
|
||||
- id: no-commit-to-branch
|
||||
args: ['--branch', 'main']
|
||||
- id: trailing-whitespace
|
||||
14
.prettierignore
Normal file
@@ -0,0 +1,14 @@
|
||||
invokeai/frontend/.husky
|
||||
invokeai/frontend/patches
|
||||
|
||||
# Ignore artifacts:
|
||||
build
|
||||
coverage
|
||||
static
|
||||
invokeai/frontend/dist
|
||||
|
||||
# Ignore all HTML files:
|
||||
*.html
|
||||
|
||||
# Ignore deprecated docs
|
||||
docs/installation/deprecated_documentation
|
||||
@@ -1,9 +1,9 @@
|
||||
endOfLine: lf
|
||||
tabWidth: 2
|
||||
useTabs: false
|
||||
singleQuote: true
|
||||
quoteProps: as-needed
|
||||
embeddedLanguageFormatting: auto
|
||||
endOfLine: lf
|
||||
singleQuote: true
|
||||
semi: true
|
||||
trailingComma: es5
|
||||
useTabs: false
|
||||
overrides:
|
||||
- files: '*.md'
|
||||
options:
|
||||
@@ -11,3 +11,9 @@ overrides:
|
||||
printWidth: 80
|
||||
parser: markdown
|
||||
cursorOffset: -1
|
||||
- files: docs/**/*.md
|
||||
options:
|
||||
tabWidth: 4
|
||||
- files: 'invokeai/frontend/public/locales/*.json'
|
||||
options:
|
||||
tabWidth: 4
|
||||
|
||||
5
.pytest.ini
Normal file
@@ -0,0 +1,5 @@
|
||||
[pytest]
|
||||
DJANGO_SETTINGS_MODULE = webtas.settings
|
||||
; python_files = tests.py test_*.py *_tests.py
|
||||
|
||||
addopts = --cov=. --cov-config=.coveragerc --cov-report xml:cov.xml
|
||||
128
CODE_OF_CONDUCT.md
Normal file
@@ -0,0 +1,128 @@
|
||||
# Contributor Covenant Code of Conduct
|
||||
|
||||
## Our Pledge
|
||||
|
||||
We as members, contributors, and leaders pledge to make participation in our
|
||||
community a harassment-free experience for everyone, regardless of age, body
|
||||
size, visible or invisible disability, ethnicity, sex characteristics, gender
|
||||
identity and expression, level of experience, education, socio-economic status,
|
||||
nationality, personal appearance, race, religion, or sexual identity
|
||||
and orientation.
|
||||
|
||||
We pledge to act and interact in ways that contribute to an open, welcoming,
|
||||
diverse, inclusive, and healthy community.
|
||||
|
||||
## Our Standards
|
||||
|
||||
Examples of behavior that contributes to a positive environment for our
|
||||
community include:
|
||||
|
||||
* Demonstrating empathy and kindness toward other people
|
||||
* Being respectful of differing opinions, viewpoints, and experiences
|
||||
* Giving and gracefully accepting constructive feedback
|
||||
* Accepting responsibility and apologizing to those affected by our mistakes,
|
||||
and learning from the experience
|
||||
* Focusing on what is best not just for us as individuals, but for the
|
||||
overall community
|
||||
|
||||
Examples of unacceptable behavior include:
|
||||
|
||||
* The use of sexualized language or imagery, and sexual attention or
|
||||
advances of any kind
|
||||
* Trolling, insulting or derogatory comments, and personal or political attacks
|
||||
* Public or private harassment
|
||||
* Publishing others' private information, such as a physical or email
|
||||
address, without their explicit permission
|
||||
* Other conduct which could reasonably be considered inappropriate in a
|
||||
professional setting
|
||||
|
||||
## Enforcement Responsibilities
|
||||
|
||||
Community leaders are responsible for clarifying and enforcing our standards of
|
||||
acceptable behavior and will take appropriate and fair corrective action in
|
||||
response to any behavior that they deem inappropriate, threatening, offensive,
|
||||
or harmful.
|
||||
|
||||
Community leaders have the right and responsibility to remove, edit, or reject
|
||||
comments, commits, code, wiki edits, issues, and other contributions that are
|
||||
not aligned to this Code of Conduct, and will communicate reasons for moderation
|
||||
decisions when appropriate.
|
||||
|
||||
## Scope
|
||||
|
||||
This Code of Conduct applies within all community spaces, and also applies when
|
||||
an individual is officially representing the community in public spaces.
|
||||
Examples of representing our community include using an official e-mail address,
|
||||
posting via an official social media account, or acting as an appointed
|
||||
representative at an online or offline event.
|
||||
|
||||
## Enforcement
|
||||
|
||||
Instances of abusive, harassing, or otherwise unacceptable behavior
|
||||
may be reported to the community leaders responsible for enforcement
|
||||
at https://github.com/invoke-ai/InvokeAI/issues. All complaints will
|
||||
be reviewed and investigated promptly and fairly.
|
||||
|
||||
All community leaders are obligated to respect the privacy and security of the
|
||||
reporter of any incident.
|
||||
|
||||
## Enforcement Guidelines
|
||||
|
||||
Community leaders will follow these Community Impact Guidelines in determining
|
||||
the consequences for any action they deem in violation of this Code of Conduct:
|
||||
|
||||
### 1. Correction
|
||||
|
||||
**Community Impact**: Use of inappropriate language or other behavior deemed
|
||||
unprofessional or unwelcome in the community.
|
||||
|
||||
**Consequence**: A private, written warning from community leaders, providing
|
||||
clarity around the nature of the violation and an explanation of why the
|
||||
behavior was inappropriate. A public apology may be requested.
|
||||
|
||||
### 2. Warning
|
||||
|
||||
**Community Impact**: A violation through a single incident or series
|
||||
of actions.
|
||||
|
||||
**Consequence**: A warning with consequences for continued behavior. No
|
||||
interaction with the people involved, including unsolicited interaction with
|
||||
those enforcing the Code of Conduct, for a specified period of time. This
|
||||
includes avoiding interactions in community spaces as well as external channels
|
||||
like social media. Violating these terms may lead to a temporary or
|
||||
permanent ban.
|
||||
|
||||
### 3. Temporary Ban
|
||||
|
||||
**Community Impact**: A serious violation of community standards, including
|
||||
sustained inappropriate behavior.
|
||||
|
||||
**Consequence**: A temporary ban from any sort of interaction or public
|
||||
communication with the community for a specified period of time. No public or
|
||||
private interaction with the people involved, including unsolicited interaction
|
||||
with those enforcing the Code of Conduct, is allowed during this period.
|
||||
Violating these terms may lead to a permanent ban.
|
||||
|
||||
### 4. Permanent Ban
|
||||
|
||||
**Community Impact**: Demonstrating a pattern of violation of community
|
||||
standards, including sustained inappropriate behavior, harassment of an
|
||||
individual, or aggression toward or disparagement of classes of individuals.
|
||||
|
||||
**Consequence**: A permanent ban from any sort of public interaction within
|
||||
the community.
|
||||
|
||||
## Attribution
|
||||
|
||||
This Code of Conduct is adapted from the [Contributor Covenant][homepage],
|
||||
version 2.0, available at
|
||||
https://www.contributor-covenant.org/version/2/0/code_of_conduct.html.
|
||||
|
||||
Community Impact Guidelines were inspired by [Mozilla's code of conduct
|
||||
enforcement ladder](https://github.com/mozilla/diversity).
|
||||
|
||||
[homepage]: https://www.contributor-covenant.org
|
||||
|
||||
For answers to common questions about this code of conduct, see the FAQ at
|
||||
https://www.contributor-covenant.org/faq. Translations are available at
|
||||
https://www.contributor-covenant.org/translations.
|
||||
84
InvokeAI_Statement_of_Values.md
Normal file
@@ -0,0 +1,84 @@
|
||||
<img src="docs/assets/invoke_ai_banner.png" align="center">
|
||||
|
||||
Invoke-AI is a community of software developers, researchers, and user
|
||||
interface experts who have come together on a voluntary basis to build
|
||||
software tools which support cutting edge AI text-to-image
|
||||
applications. This community is open to anyone who wishes to
|
||||
contribute to the effort and has the skill and time to do so.
|
||||
|
||||
# Our Values
|
||||
|
||||
The InvokeAI team is a diverse community which includes individuals
|
||||
from various parts of the world and many walks of life. Despite our
|
||||
differences, we share a number of core values which we ask prospective
|
||||
contributors to understand and respect. We believe:
|
||||
|
||||
1. That Open Source Software is a positive force in the world. We
|
||||
create software that can be used, reused, and redistributed, without
|
||||
restrictions, under a straightforward Open Source license (MIT). We
|
||||
believe that Open Source benefits society as a whole by increasing the
|
||||
availability of high quality software to all.
|
||||
|
||||
2. That those who create software should receive proper attribution
|
||||
for their creative work. While we support the exchange and reuse of
|
||||
Open Source Software, we feel strongly that the original authors of a
|
||||
piece of code should receive credit for their contribution, and we
|
||||
endeavor to do so whenever possible.
|
||||
|
||||
3. That there is moral ambiguity surrounding AI-assisted art. We are
|
||||
aware of the moral and ethical issues surrounding the release of the
|
||||
Stable Diffusion model and similar products. We are aware that, due to
|
||||
the composition of their training sets, current AI-generated image
|
||||
models are biased against certain ethnic groups, cultural concepts of
|
||||
beauty, ethnic stereotypes, and gender roles.
|
||||
|
||||
1. We recognize the potential for harm to these groups that these biases
|
||||
represent and trust that future AI models will take steps towards
|
||||
reducing or eliminating the biases noted above, respect and give due
|
||||
credit to the artists whose work is sourced, and call on developers
|
||||
and users to favor these models over the older ones as they become
|
||||
available.
|
||||
|
||||
4. We are deeply committed to ensuring that this technology benefits
|
||||
everyone, including artists. We see AI art not as a replacement for
|
||||
the artist, but rather as a tool to empower them. With that
|
||||
in mind, we are constantly debating how to build systems that put
|
||||
artists’ needs first: tools which can be readily integrated into an
|
||||
artist’s existing workflows and practices, enhancing their work and
|
||||
helping them to push it further. Every decision we take as a team,
|
||||
which includes several artists, aims to build towards that goal.
|
||||
|
||||
5. That artificial intelligence can be a force for good in the world,
|
||||
but must be used responsibly. Artificial intelligence technologies
|
||||
have the potential to improve society, in everything from cancer care,
|
||||
to customer service, to creative writing.
|
||||
|
||||
1. While we do not believe that software should arbitrarily limit what
|
||||
users can do with it, we recognize that when used irresponsibly, AI
|
||||
has the potential to do much harm. Our Discord server is actively
|
||||
moderated in order to minimize the potential of harm from
|
||||
user-contributed images. In addition, we ask users of our software to
|
||||
refrain from using it in any way that would cause mental, emotional or
|
||||
physical harm to individuals and vulnerable populations including (but
|
||||
not limited to) women; minors; ethnic minorities; religious groups;
|
||||
members of LGBTQIA communities; and people with disabilities or
|
||||
impairments.
|
||||
|
||||
2. Note that some of the image generation AI models which the Invoke-AI
|
||||
toolkit supports carry licensing agreements which impose restrictions
|
||||
on how the model is used. We ask that our users read and agree to
|
||||
these terms if they wish to make use of these models. These agreements
|
||||
are distinct from the MIT license which applies to the InvokeAI
|
||||
software and source code.
|
||||
|
||||
6. That mutual respect is key to a healthy software development
|
||||
community. Members of the InvokeAI community are expected to treat
|
||||
each other with respect, beneficence, and empathy. Each of us has a
|
||||
different background and a unique set of skills. We strive to help
|
||||
each other grow and gain new skills, and we apportion expectations in
|
||||
a way that balances the members' time, skillset, and interest
|
||||
area. Disputes are resolved by open and honest communication.
|
||||
|
||||
## Signature
|
||||
|
||||
This document has been collectively crafted and approved by the current InvokeAI team members, as of 28 Nov 2022: **lstein** (Lincoln Stein), **blessedcoolant**, **hipsterusername** (Kent Keirsey), **Kyle0654** (Kyle Schouviller), **damian0815**, **mauwii** (Matthias Wild), **Netsvetaev** (Artur Netsvetaev), **psychedelicious**, **tildebyte**, **keturn**, and **ebr** (Eugene Brodsky). Although individuals within the group may hold differing views on particular details and/or their implications, we are all in agreement about its fundamental statements, as well as their significance and importance to this project moving forward.
|
||||
331
README.md
@@ -1,23 +1,19 @@
|
||||
<div align="center">
|
||||
|
||||

|
||||
|
||||
# InvokeAI: A Stable Diffusion Toolkit
|
||||
|
||||
_Formerly known as lstein/stable-diffusion_
|
||||
|
||||

|
||||
|
||||
[![discord badge]][discord link]
|
||||
|
||||
[![latest release badge]][latest release link] [![github stars badge]][github stars link] [![github forks badge]][github forks link]
|
||||
|
||||
[![CI checks on main badge]][CI checks on main link] [![CI checks on dev badge]][CI checks on dev link] [![latest commit to dev badge]][latest commit to dev link]
|
||||
[![CI checks on main badge]][CI checks on main link] [![latest commit to main badge]][latest commit to main link]
|
||||
|
||||
[![github open issues badge]][github open issues link] [![github open prs badge]][github open prs link]
|
||||
[![github open issues badge]][github open issues link] [![github open prs badge]][github open prs link] [![translation status badge]][translation status link]
|
||||
|
||||
[CI checks on dev badge]: https://flat.badgen.net/github/checks/invoke-ai/InvokeAI/development?label=CI%20status%20on%20dev&cache=900&icon=github
|
||||
[CI checks on dev link]: https://github.com/invoke-ai/InvokeAI/actions?query=branch%3Adevelopment
|
||||
[CI checks on main badge]: https://flat.badgen.net/github/checks/invoke-ai/InvokeAI/main?label=CI%20status%20on%20main&cache=900&icon=github
|
||||
[CI checks on main link]: https://github.com/invoke-ai/InvokeAI/actions/workflows/test-invoke-conda.yml
|
||||
[CI checks on main link]:https://github.com/invoke-ai/InvokeAI/actions?query=branch%3Amain
|
||||
[discord badge]: https://flat.badgen.net/discord/members/ZmtBAhwWhy?icon=discord
|
||||
[discord link]: https://discord.gg/ZmtBAhwWhy
|
||||
[github forks badge]: https://flat.badgen.net/github/forks/invoke-ai/InvokeAI?icon=github
|
||||
@@ -28,161 +24,252 @@ _Formerly known as lstein/stable-diffusion_
|
||||
[github open prs link]: https://github.com/invoke-ai/InvokeAI/pulls?q=is%3Apr+is%3Aopen
|
||||
[github stars badge]: https://flat.badgen.net/github/stars/invoke-ai/InvokeAI?icon=github
|
||||
[github stars link]: https://github.com/invoke-ai/InvokeAI/stargazers
|
||||
[latest commit to dev badge]: https://flat.badgen.net/github/last-commit/invoke-ai/InvokeAI/development?icon=github&color=yellow&label=last%20dev%20commit&cache=900
|
||||
[latest commit to dev link]: https://github.com/invoke-ai/InvokeAI/commits/development
|
||||
[latest commit to main badge]: https://flat.badgen.net/github/last-commit/invoke-ai/InvokeAI/main?icon=github&color=yellow&label=last%20dev%20commit&cache=900
|
||||
[latest commit to main link]: https://github.com/invoke-ai/InvokeAI/commits/main
|
||||
[latest release badge]: https://flat.badgen.net/github/release/invoke-ai/InvokeAI/development?icon=github
|
||||
[latest release link]: https://github.com/invoke-ai/InvokeAI/releases
|
||||
[translation status badge]: https://hosted.weblate.org/widgets/invokeai/-/svg-badge.svg
|
||||
[translation status link]: https://hosted.weblate.org/engage/invokeai/
|
||||
|
||||
</div>
|
||||
|
||||
This is a fork of
|
||||
[CompVis/stable-diffusion](https://github.com/CompVis/stable-diffusion),
|
||||
the open source text-to-image generator. It provides a streamlined
|
||||
process with various new features and options to aid the image
|
||||
generation process. It runs on Windows, Mac and Linux machines, with
|
||||
GPU cards with as little as 4 GB of RAM. It provides both a polished
|
||||
Web interface (see below), and an easy-to-use command-line interface.
|
||||
InvokeAI is a leading creative engine built to empower professionals and enthusiasts alike. Generate and create stunning visual media using the latest AI-driven technologies. InvokeAI offers an industry leading Web Interface, interactive Command Line Interface, and also serves as the foundation for multiple commercial products.
|
||||
|
||||
**Quick links**: [<a href="https://discord.gg/NwVCmKwY">Discord Server</a>] [<a href="https://invoke-ai.github.io/InvokeAI/">Documentation and Tutorials</a>] [<a href="https://github.com/invoke-ai/InvokeAI/">Code and Downloads</a>] [<a href="https://github.com/invoke-ai/InvokeAI/issues">Bug Reports</a>] [<a href="https://github.com/invoke-ai/InvokeAI/discussions">Discussion, Ideas & Q&A</a>]
|
||||
**Quick links**: [[How to Install](https://invoke-ai.github.io/InvokeAI/#installation)] [<a href="https://discord.gg/ZmtBAhwWhy">Discord Server</a>] [<a href="https://invoke-ai.github.io/InvokeAI/">Documentation and Tutorials</a>] [<a href="https://github.com/invoke-ai/InvokeAI/">Code and Downloads</a>] [<a href="https://github.com/invoke-ai/InvokeAI/issues">Bug Reports</a>] [<a href="https://github.com/invoke-ai/InvokeAI/discussions">Discussion, Ideas & Q&A</a>]
|
||||
|
||||
<div align="center"><img src="docs/assets/invoke-web-server-1.png" width=640></div>
|
||||
|
||||
|
||||
_Note: This fork is rapidly evolving. Please use the
|
||||
_Note: InvokeAI is rapidly evolving. Please use the
|
||||
[Issues](https://github.com/invoke-ai/InvokeAI/issues) tab to report bugs and make feature
|
||||
requests. Be sure to use the provided templates. They will help aid diagnose issues faster._
|
||||
requests. Be sure to use the provided templates. They will help us diagnose issues faster._
|
||||
|
||||
<div align="center">
|
||||
|
||||

|
||||
|
||||
</div>
|
||||
|
||||
## Table of Contents
|
||||
|
||||
1. [Installation](#installation)
|
||||
2. [Hardware Requirements](#hardware-requirements)
|
||||
3. [Features](#features)
|
||||
4. [Latest Changes](#latest-changes)
|
||||
5. [Troubleshooting](#troubleshooting)
|
||||
6. [Contributing](#contributing)
|
||||
7. [Contributors](#contributors)
|
||||
8. [Support](#support)
|
||||
9. [Further Reading](#further-reading)
|
||||
1. [Quick Start](#getting-started-with-invokeai)
|
||||
2. [Installation](#detailed-installation-instructions)
|
||||
3. [Hardware Requirements](#hardware-requirements)
|
||||
4. [Features](#features)
|
||||
5. [Latest Changes](#latest-changes)
|
||||
6. [Troubleshooting](#troubleshooting)
|
||||
7. [Contributing](#contributing)
|
||||
8. [Contributors](#contributors)
|
||||
9. [Support](#support)
|
||||
10. [Further Reading](#further-reading)
|
||||
|
||||
### Installation
|
||||
## Getting Started with InvokeAI
|
||||
|
||||
This fork is supported across multiple platforms. You can find individual installation instructions
|
||||
below.
|
||||
For full installation and upgrade instructions, please see:
|
||||
[InvokeAI Installation Overview](https://invoke-ai.github.io/InvokeAI/installation/)
|
||||
|
||||
- #### [Linux](https://invoke-ai.github.io/InvokeAI/installation/INSTALL_LINUX/)
|
||||
### Automatic Installer (suggested for 1st time users)
|
||||
|
||||
- #### [Windows](https://invoke-ai.github.io/InvokeAI/installation/INSTALL_WINDOWS/)
|
||||
1. Go to the bottom of the [Latest Release Page](https://github.com/invoke-ai/InvokeAI/releases/latest)
|
||||
|
||||
- #### [Macintosh](https://invoke-ai.github.io/InvokeAI/installation/INSTALL_MAC/)
|
||||
2. Download the .zip file for your OS (Windows/macOS/Linux).
|
||||
|
||||
### Hardware Requirements
|
||||
3. Unzip the file.
|
||||
|
||||
#### System
|
||||
4. If you are on Windows, double-click on the `install.bat` script. On
|
||||
macOS, open a Terminal window, drag the file `install.sh` from Finder
|
||||
into the Terminal, and press return. On Linux, run `install.sh`.
|
||||
|
||||
You wil need one of the following:
|
||||
5. You'll be asked to confirm the location of the folder in which
|
||||
to install InvokeAI and its image generation model files. Pick a
|
||||
location with at least 15 GB of free memory. More if you plan on
|
||||
installing lots of models.
|
||||
|
||||
6. Wait while the installer does its thing. After installing the software,
|
||||
the installer will launch a script that lets you configure InvokeAI and
|
||||
select a set of starting image generaiton models.
|
||||
|
||||
7. Find the folder that InvokeAI was installed into (it is not the
|
||||
same as the unpacked zip file directory!) The default location of this
|
||||
folder (if you didn't change it in step 5) is `~/invokeai` on
|
||||
Linux/Mac systems, and `C:\Users\YourName\invokeai` on Windows. This directory will contain launcher scripts named `invoke.sh` and `invoke.bat`.
|
||||
|
||||
8. On Windows systems, double-click on the `invoke.bat` file. On
|
||||
macOS, open a Terminal window, drag `invoke.sh` from the folder into
|
||||
the Terminal, and press return. On Linux, run `invoke.sh`
|
||||
|
||||
9. Press 2 to open the "browser-based UI", press enter/return, wait a
|
||||
minute or two for Stable Diffusion to start up, then open your browser
|
||||
and go to http://localhost:9090.
|
||||
|
||||
10. Type `banana sushi` in the box on the top left and click `Invoke`
|
||||
|
||||
### Command-Line Installation (for users familiar with Terminals)
|
||||
|
||||
You must have Python 3.9 or 3.10 installed on your machine. Earlier or later versions are
|
||||
not supported.
|
||||
|
||||
1. Open a command-line window on your machine. The PowerShell is recommended for Windows.
|
||||
2. Create a directory to install InvokeAI into. You'll need at least 15 GB of free space:
|
||||
|
||||
```terminal
|
||||
mkdir invokeai
|
||||
````
|
||||
|
||||
3. Create a virtual environment named `.venv` inside this directory and activate it:
|
||||
|
||||
```terminal
|
||||
cd invokeai
|
||||
python -m venv .venv --prompt InvokeAI
|
||||
```
|
||||
|
||||
4. Activate the virtual environment (do it every time you run InvokeAI)
|
||||
|
||||
_For Linux/Mac users:_
|
||||
|
||||
```sh
|
||||
source .venv/bin/activate
|
||||
```
|
||||
|
||||
_For Windows users:_
|
||||
|
||||
```ps
|
||||
.venv\Scripts\activate
|
||||
```
|
||||
|
||||
5. Install the InvokeAI module and its dependencies. Choose the command suited for your platform & GPU.
|
||||
|
||||
_For Windows/Linux with an NVIDIA GPU:_
|
||||
|
||||
```terminal
|
||||
pip install InvokeAI[xformers] --use-pep517 --extra-index-url https://download.pytorch.org/whl/cu117
|
||||
```
|
||||
|
||||
_For Linux with an AMD GPU:_
|
||||
|
||||
```sh
|
||||
pip install InvokeAI --use-pep517 --extra-index-url https://download.pytorch.org/whl/rocm5.4.2
|
||||
```
|
||||
|
||||
_For Macintoshes, either Intel or M1/M2:_
|
||||
|
||||
```sh
|
||||
pip install InvokeAI --use-pep517
|
||||
```
|
||||
|
||||
6. Configure InvokeAI and install a starting set of image generation models (you only need to do this once):
|
||||
|
||||
```terminal
|
||||
invokeai-configure
|
||||
```
|
||||
|
||||
7. Launch the web server (do it every time you run InvokeAI):
|
||||
|
||||
```terminal
|
||||
invokeai --web
|
||||
```
|
||||
|
||||
8. Point your browser to http://localhost:9090 to bring up the web interface.
|
||||
9. Type `banana sushi` in the box on the top left and click `Invoke`.
|
||||
|
||||
Be sure to activate the virtual environment each time before re-launching InvokeAI,
|
||||
using `source .venv/bin/activate` or `.venv\Scripts\activate`.
|
||||
|
||||
### Detailed Installation Instructions
|
||||
|
||||
This fork is supported across Linux, Windows and Macintosh. Linux
|
||||
users can use either an Nvidia-based card (with CUDA support) or an
|
||||
AMD card (using the ROCm driver). For full installation and upgrade
|
||||
instructions, please see:
|
||||
[InvokeAI Installation Overview](https://invoke-ai.github.io/InvokeAI/installation/INSTALL_SOURCE/)
|
||||
|
||||
## Hardware Requirements
|
||||
|
||||
InvokeAI is supported across Linux, Windows and macOS. Linux
|
||||
users can use either an Nvidia-based card (with CUDA support) or an
|
||||
AMD card (using the ROCm driver).
|
||||
|
||||
### System
|
||||
|
||||
You will need one of the following:
|
||||
|
||||
- An NVIDIA-based graphics card with 4 GB or more VRAM memory.
|
||||
- An Apple computer with an M1 chip.
|
||||
- An AMD-based graphics card with 4GB or more VRAM memory. (Linux only)
|
||||
|
||||
#### Memory
|
||||
We do not recommend the GTX 1650 or 1660 series video cards. They are
|
||||
unable to run in half-precision mode and do not have sufficient VRAM
|
||||
to render 512x512 images.
|
||||
|
||||
### Memory
|
||||
|
||||
- At least 12 GB Main Memory RAM.
|
||||
|
||||
#### Disk
|
||||
### Disk
|
||||
|
||||
- At least 12 GB of free disk space for the machine learning model, Python, and all its dependencies.
|
||||
|
||||
**Note**
|
||||
## Features
|
||||
|
||||
If you have a Nvidia 10xx series card (e.g. the 1080ti), please
|
||||
run the dream script in full-precision mode as shown below.
|
||||
Feature documentation can be reviewed by navigating to [the InvokeAI Documentation page](https://invoke-ai.github.io/InvokeAI/features/)
|
||||
|
||||
Similarly, specify full-precision mode on Apple M1 hardware.
|
||||
### *Web Server & UI*
|
||||
|
||||
Precision is auto configured based on the device. If however you encounter
|
||||
errors like 'expected type Float but found Half' or 'not implemented for Half'
|
||||
you can try starting `invoke.py` with the `--precision=float32` flag:
|
||||
InvokeAI offers a locally hosted Web Server & React Frontend, with an industry leading user experience. The Web-based UI allows for simple and intuitive workflows, and is responsive for use on mobile devices and tablets accessing the web server.
|
||||
|
||||
```bash
|
||||
(invokeai) ~/InvokeAI$ python scripts/invoke.py --precision=float32
|
||||
```
|
||||
### *Unified Canvas*
|
||||
|
||||
### Features
|
||||
The Unified Canvas is a fully integrated canvas implementation with support for all core generation capabilities, in/outpainting, brush tools, and more. This creative tool unlocks the capability for artists to create with AI as a creative collaborator, and can be used to augment AI-generated imagery, sketches, photography, renders, and more.
|
||||
|
||||
#### Major Features
|
||||
### *Advanced Prompt Syntax*
|
||||
|
||||
- [Web Server](https://invoke-ai.github.io/InvokeAI/features/WEB/)
|
||||
- [Interactive Command Line Interface](https://invoke-ai.github.io/InvokeAI/features/CLI/)
|
||||
- [Image To Image](https://invoke-ai.github.io/InvokeAI/features/IMG2IMG/)
|
||||
- [Inpainting Support](https://invoke-ai.github.io/InvokeAI/features/INPAINTING/)
|
||||
- [Outpainting Support](https://invoke-ai.github.io/InvokeAI/features/OUTPAINTING/)
|
||||
- [Upscaling, face-restoration and outpainting](https://invoke-ai.github.io/InvokeAI/features/POSTPROCESS/)
|
||||
- [Reading Prompts From File](https://invoke-ai.github.io/InvokeAI/features/PROMPTS/#reading-prompts-from-a-file)
|
||||
- [Prompt Blending](https://invoke-ai.github.io/InvokeAI/features/PROMPTS/#prompt-blending)
|
||||
- [Thresholding and Perlin Noise Initialization Options](https://invoke-ai.github.io/InvokeAI/features/OTHER/#thresholding-and-perlin-noise-initialization-options)
|
||||
- [Negative/Unconditioned Prompts](https://invoke-ai.github.io/InvokeAI/features/PROMPTS/#negative-and-unconditioned-prompts)
|
||||
- [Variations](https://invoke-ai.github.io/InvokeAI/features/VARIATIONS/)
|
||||
- [Personalizing Text-to-Image Generation](https://invoke-ai.github.io/InvokeAI/features/TEXTUAL_INVERSION/)
|
||||
- [Simplified API for text to image generation](https://invoke-ai.github.io/InvokeAI/features/OTHER/#simplified-api)
|
||||
InvokeAI's advanced prompt syntax allows for token weighting, cross-attention control, and prompt blending, allowing for fine-tuned tweaking of your invocations and exploration of the latent space.
|
||||
|
||||
#### Other Features
|
||||
### *Command Line Interface*
|
||||
|
||||
- [Google Colab](https://invoke-ai.github.io/InvokeAI/features/OTHER/#google-colab)
|
||||
- [Seamless Tiling](https://invoke-ai.github.io/InvokeAI/features/OTHER/#seamless-tiling)
|
||||
- [Shortcut: Reusing Seeds](https://invoke-ai.github.io/InvokeAI/features/OTHER/#shortcuts-reusing-seeds)
|
||||
- [Preload Models](https://invoke-ai.github.io/InvokeAI/features/OTHER/#preload-models)
|
||||
For users utilizing a terminal-based environment, or who want to take advantage of CLI features, InvokeAI offers an extensive and actively supported command-line interface that provides the full suite of generation functionality available in the tool.
|
||||
|
||||
### Other features
|
||||
|
||||
- *Support for both ckpt and diffusers models*
|
||||
- *SD 2.0, 2.1 support*
|
||||
- *Noise Control & Tresholding*
|
||||
- *Popular Sampler Support*
|
||||
- *Upscaling & Face Restoration Tools*
|
||||
- *Embedding Manager & Support*
|
||||
- *Model Manager & Support*
|
||||
|
||||
### Coming Soon
|
||||
|
||||
- *Node-Based Architecture & UI*
|
||||
- And more...
|
||||
|
||||
### Latest Changes
|
||||
|
||||
- v2.0.1 (13 October 2022)
|
||||
- fix noisy images at high step count when using k* samplers
|
||||
- dream.py script now calls invoke.py module directly rather than
|
||||
via a new python process (which could break the environment)
|
||||
For our latest changes, view our [Release
|
||||
Notes](https://github.com/invoke-ai/InvokeAI/releases) and the
|
||||
[CHANGELOG](docs/CHANGELOG.md).
|
||||
|
||||
- v2.0.0 (9 October 2022)
|
||||
|
||||
- `dream.py` script renamed `invoke.py`. A `dream.py` script wrapper remains
|
||||
for backward compatibility.
|
||||
- Completely new WebGUI - launch with `python3 scripts/invoke.py --web`
|
||||
- Support for <a href="https://invoke-ai.github.io/InvokeAI/features/INPAINTING/">inpainting</a> and <a href="https://invoke-ai.github.io/InvokeAI/features/OUTPAINTING/">outpainting</a>
|
||||
- img2img runs on all k* samplers
|
||||
- Support for <a href="https://invoke-ai.github.io/InvokeAI/features/PROMPTS/#negative-and-unconditioned-prompts">negative prompts</a>
|
||||
- Support for CodeFormer face reconstruction
|
||||
- Support for Textual Inversion on Macintoshes
|
||||
- Support in both WebGUI and CLI for <a href="https://invoke-ai.github.io/InvokeAI/features/POSTPROCESS/">post-processing of previously-generated images</a>
|
||||
using facial reconstruction, ESRGAN upscaling, outcropping (similar to DALL-E infinite canvas),
|
||||
and "embiggen" upscaling. See the `!fix` command.
|
||||
- New `--hires` option on `invoke>` line allows <a href="https://invoke-ai.github.io/InvokeAI/features/CLI/#txt2img">larger images to be created without duplicating elements</a>, at the cost of some performance.
|
||||
- New `--perlin` and `--threshold` options allow you to add and control variation
|
||||
during image generation (see <a href="https://github.com/invoke-ai/InvokeAI/blob/main/docs/features/OTHER.md#thresholding-and-perlin-noise-initialization-options">Thresholding and Perlin Noise Initialization</a>
|
||||
- Extensive metadata now written into PNG files, allowing reliable regeneration of images
|
||||
and tweaking of previous settings.
|
||||
- Command-line completion in `invoke.py` now works on Windows, Linux and Mac platforms.
|
||||
- Improved <a href="https://invoke-ai.github.io/InvokeAI/features/CLI/">command-line completion behavior</a>.
|
||||
New commands added:
|
||||
- List command-line history with `!history`
|
||||
- Search command-line history with `!search`
|
||||
- Clear history with `!clear`
|
||||
- Deprecated `--full_precision` / `-F`. Simply omit it and `invoke.py` will auto
|
||||
configure. To switch away from auto use the new flag like `--precision=float32`.
|
||||
|
||||
For older changelogs, please visit the **[CHANGELOG](https://invoke-ai.github.io/InvokeAI/CHANGELOG#v114-11-september-2022)**.
|
||||
|
||||
### Troubleshooting
|
||||
## Troubleshooting
|
||||
|
||||
Please check out our **[Q&A](https://invoke-ai.github.io/InvokeAI/help/TROUBLESHOOT/#faq)** to get solutions for common installation
|
||||
problems and other issues.
|
||||
|
||||
# Contributing
|
||||
## Contributing
|
||||
|
||||
Anyone who wishes to contribute to this project, whether documentation, features, bug fixes, code
|
||||
cleanup, testing, or code reviews, is very much encouraged to do so. If you are unfamiliar with how
|
||||
to contribute to GitHub projects, here is a
|
||||
[Getting Started Guide](https://opensource.com/article/19/7/create-pull-request-github).
|
||||
cleanup, testing, or code reviews, is very much encouraged to do so.
|
||||
|
||||
A full set of contribution guidelines, along with templates, are in progress, but for now the most
|
||||
important thing is to **make your pull request against the "development" branch**, and not against
|
||||
"main". This will help keep public breakage to a minimum and will allow you to propose more radical
|
||||
changes.
|
||||
To join, just raise your hand on the InvokeAI Discord server (#dev-chat) or the GitHub discussion board.
|
||||
|
||||
If you'd like to help with translation, please see our [translation guide](docs/other/TRANSLATION.md).
|
||||
|
||||
If you are unfamiliar with how
|
||||
to contribute to GitHub projects, here is a
|
||||
[Getting Started Guide](https://opensource.com/article/19/7/create-pull-request-github). A full set of contribution guidelines, along with templates, are in progress. You can **make your pull request against the "main" branch**.
|
||||
|
||||
We hope you enjoy using our software as much as we enjoy creating it,
|
||||
and we hope that some of those of you who are reading this will elect
|
||||
to become part of our community.
|
||||
|
||||
Welcome to InvokeAI!
|
||||
|
||||
### Contributors
|
||||
|
||||
@@ -190,15 +277,11 @@ This fork is a combined effort of various people from across the world.
|
||||
[Check out the list of all these amazing people](https://invoke-ai.github.io/InvokeAI/other/CONTRIBUTORS/). We thank them for
|
||||
their time, hard work and effort.
|
||||
|
||||
Thanks to [Weblate](https://weblate.org/) for generously providing translation services to this project.
|
||||
|
||||
### Support
|
||||
|
||||
For support, please use this repository's GitHub Issues tracking service. Feel free to send me an
|
||||
email if you use and like the script.
|
||||
For support, please use this repository's GitHub Issues tracking service, or join the Discord.
|
||||
|
||||
Original portions of the software are Copyright (c) 2020
|
||||
[Lincoln D. Stein](https://github.com/lstein)
|
||||
Original portions of the software are Copyright (c) 2023 by respective contributors.
|
||||
|
||||
### Further Reading
|
||||
|
||||
Please see the original README for more information on this software and underlying algorithm,
|
||||
located in the file [README-CompViz.md](https://invoke-ai.github.io/InvokeAI/other/README-CompViz/).
|
||||
|
||||
@@ -21,7 +21,7 @@ This model card focuses on the model associated with the Stable Diffusion model,
|
||||
|
||||
# Uses
|
||||
|
||||
## Direct Use
|
||||
## Direct Use
|
||||
The model is intended for research purposes only. Possible research areas and
|
||||
tasks include
|
||||
|
||||
@@ -68,11 +68,11 @@ Using the model to generate content that is cruel to individuals is a misuse of
|
||||
considerations.
|
||||
|
||||
### Bias
|
||||
While the capabilities of image generation models are impressive, they can also reinforce or exacerbate social biases.
|
||||
Stable Diffusion v1 was trained on subsets of [LAION-2B(en)](https://laion.ai/blog/laion-5b/),
|
||||
which consists of images that are primarily limited to English descriptions.
|
||||
Texts and images from communities and cultures that use other languages are likely to be insufficiently accounted for.
|
||||
This affects the overall output of the model, as white and western cultures are often set as the default. Further, the
|
||||
While the capabilities of image generation models are impressive, they can also reinforce or exacerbate social biases.
|
||||
Stable Diffusion v1 was trained on subsets of [LAION-2B(en)](https://laion.ai/blog/laion-5b/),
|
||||
which consists of images that are primarily limited to English descriptions.
|
||||
Texts and images from communities and cultures that use other languages are likely to be insufficiently accounted for.
|
||||
This affects the overall output of the model, as white and western cultures are often set as the default. Further, the
|
||||
ability of the model to generate content with non-English prompts is significantly worse than with English-language prompts.
|
||||
|
||||
|
||||
@@ -84,7 +84,7 @@ The model developers used the following dataset for training the model:
|
||||
- LAION-2B (en) and subsets thereof (see next section)
|
||||
|
||||
**Training Procedure**
|
||||
Stable Diffusion v1 is a latent diffusion model which combines an autoencoder with a diffusion model that is trained in the latent space of the autoencoder. During training,
|
||||
Stable Diffusion v1 is a latent diffusion model which combines an autoencoder with a diffusion model that is trained in the latent space of the autoencoder. During training,
|
||||
|
||||
- Images are encoded through an encoder, which turns images into latent representations. The autoencoder uses a relative downsampling factor of 8 and maps images of shape H x W x 3 to latents of shape H/f x W/f x 4
|
||||
- Text prompts are encoded through a ViT-L/14 text-encoder.
|
||||
@@ -108,12 +108,12 @@ filtered to images with an original size `>= 512x512`, estimated aesthetics scor
|
||||
- **Batch:** 32 x 8 x 2 x 4 = 2048
|
||||
- **Learning rate:** warmup to 0.0001 for 10,000 steps and then kept constant
|
||||
|
||||
## Evaluation Results
|
||||
## Evaluation Results
|
||||
Evaluations with different classifier-free guidance scales (1.5, 2.0, 3.0, 4.0,
|
||||
5.0, 6.0, 7.0, 8.0) and 50 PLMS sampling
|
||||
steps show the relative improvements of the checkpoints:
|
||||
|
||||

|
||||

|
||||
|
||||
Evaluated using 50 PLMS steps and 10000 random prompts from the COCO2017 validation set, evaluated at 512x512 resolution. Not optimized for FID scores.
|
||||
## Environmental Impact
|
||||
|
||||
@@ -1,74 +0,0 @@
|
||||
FROM ubuntu AS get_miniconda
|
||||
|
||||
SHELL ["/bin/bash", "-c"]
|
||||
|
||||
# install wget
|
||||
RUN apt-get update \
|
||||
&& apt-get install -y \
|
||||
wget \
|
||||
&& apt-get clean \
|
||||
&& rm -rf /var/lib/apt/lists/*
|
||||
|
||||
# download and install miniconda
|
||||
ARG conda_version=py39_4.12.0-Linux-x86_64
|
||||
ARG conda_prefix=/opt/conda
|
||||
RUN wget --progress=dot:giga -O /miniconda.sh \
|
||||
https://repo.anaconda.com/miniconda/Miniconda3-${conda_version}.sh \
|
||||
&& bash /miniconda.sh -b -p ${conda_prefix} \
|
||||
&& rm -f /miniconda.sh
|
||||
|
||||
FROM ubuntu AS invokeai
|
||||
|
||||
# use bash
|
||||
SHELL [ "/bin/bash", "-c" ]
|
||||
|
||||
# clean bashrc
|
||||
RUN echo "" > ~/.bashrc
|
||||
|
||||
# Install necesarry packages
|
||||
RUN apt-get update \
|
||||
&& apt-get install -y \
|
||||
--no-install-recommends \
|
||||
gcc \
|
||||
git \
|
||||
libgl1-mesa-glx \
|
||||
libglib2.0-0 \
|
||||
pip \
|
||||
python3 \
|
||||
python3-dev \
|
||||
&& apt-get clean \
|
||||
&& rm -rf /var/lib/apt/lists/*
|
||||
|
||||
# clone repository and create symlinks
|
||||
ARG invokeai_git=https://github.com/invoke-ai/InvokeAI.git
|
||||
ARG project_name=invokeai
|
||||
RUN git clone ${invokeai_git} /${project_name} \
|
||||
&& mkdir /${project_name}/models/ldm/stable-diffusion-v1 \
|
||||
&& ln -s /data/models/sd-v1-4.ckpt /${project_name}/models/ldm/stable-diffusion-v1/model.ckpt \
|
||||
&& ln -s /data/outputs/ /${project_name}/outputs
|
||||
|
||||
# set workdir
|
||||
WORKDIR /${project_name}
|
||||
|
||||
# install conda env and preload models
|
||||
ARG conda_prefix=/opt/conda
|
||||
ARG conda_env_file=environment.yml
|
||||
COPY --from=get_miniconda ${conda_prefix} ${conda_prefix}
|
||||
RUN source ${conda_prefix}/etc/profile.d/conda.sh \
|
||||
&& conda init bash \
|
||||
&& source ~/.bashrc \
|
||||
&& conda env create \
|
||||
--name ${project_name} \
|
||||
--file ${conda_env_file} \
|
||||
&& rm -Rf ~/.cache \
|
||||
&& conda clean -afy \
|
||||
&& echo "conda activate ${project_name}" >> ~/.bashrc \
|
||||
&& ln -s /data/models/GFPGANv1.4.pth ./src/gfpgan/experiments/pretrained_models/GFPGANv1.4.pth \
|
||||
&& conda activate ${project_name} \
|
||||
&& python scripts/preload_models.py
|
||||
|
||||
# Copy entrypoint and set env
|
||||
ENV CONDA_PREFIX=${conda_prefix}
|
||||
ENV PROJECT_NAME=${project_name}
|
||||
COPY docker-build/entrypoint.sh /
|
||||
ENTRYPOINT [ "/entrypoint.sh" ]
|
||||
@@ -1,81 +0,0 @@
|
||||
#!/usr/bin/env bash
|
||||
set -e
|
||||
# IMPORTANT: You need to have a token on huggingface.co to be able to download the checkpoint!!!
|
||||
# configure values by using env when executing build.sh
|
||||
# f.e. env ARCH=aarch64 GITHUB_INVOKE_AI=https://github.com/yourname/yourfork.git ./build.sh
|
||||
|
||||
source ./docker-build/env.sh || echo "please run from repository root" || exit 1
|
||||
|
||||
invokeai_conda_version=${INVOKEAI_CONDA_VERSION:-py39_4.12.0-${platform/\//-}}
|
||||
invokeai_conda_prefix=${INVOKEAI_CONDA_PREFIX:-\/opt\/conda}
|
||||
invokeai_conda_env_file=${INVOKEAI_CONDA_ENV_FILE:-environment.yml}
|
||||
invokeai_git=${INVOKEAI_GIT:-https://github.com/invoke-ai/InvokeAI.git}
|
||||
huggingface_token=${HUGGINGFACE_TOKEN?}
|
||||
|
||||
# print the settings
|
||||
echo "You are using these values:"
|
||||
echo -e "project_name:\t\t ${project_name}"
|
||||
echo -e "volumename:\t\t ${volumename}"
|
||||
echo -e "arch:\t\t\t ${arch}"
|
||||
echo -e "platform:\t\t ${platform}"
|
||||
echo -e "invokeai_conda_version:\t ${invokeai_conda_version}"
|
||||
echo -e "invokeai_conda_prefix:\t ${invokeai_conda_prefix}"
|
||||
echo -e "invokeai_conda_env_file: ${invokeai_conda_env_file}"
|
||||
echo -e "invokeai_git:\t\t ${invokeai_git}"
|
||||
echo -e "invokeai_tag:\t\t ${invokeai_tag}\n"
|
||||
|
||||
_runAlpine() {
|
||||
docker run \
|
||||
--rm \
|
||||
--interactive \
|
||||
--tty \
|
||||
--mount source="$volumename",target=/data \
|
||||
--workdir /data \
|
||||
alpine "$@"
|
||||
}
|
||||
|
||||
_copyCheckpoints() {
|
||||
echo "creating subfolders for models and outputs"
|
||||
_runAlpine mkdir models
|
||||
_runAlpine mkdir outputs
|
||||
echo -n "downloading sd-v1-4.ckpt"
|
||||
_runAlpine wget --header="Authorization: Bearer ${huggingface_token}" -O models/sd-v1-4.ckpt https://huggingface.co/CompVis/stable-diffusion-v-1-4-original/resolve/main/sd-v1-4.ckpt
|
||||
echo "done"
|
||||
echo "downloading GFPGANv1.4.pth"
|
||||
_runAlpine wget -O models/GFPGANv1.4.pth https://github.com/TencentARC/GFPGAN/releases/download/v1.3.0/GFPGANv1.4.pth
|
||||
}
|
||||
|
||||
_checkVolumeContent() {
|
||||
_runAlpine ls -lhA /data/models
|
||||
}
|
||||
|
||||
_getModelMd5s() {
|
||||
_runAlpine \
|
||||
alpine sh -c "md5sum /data/models/*"
|
||||
}
|
||||
|
||||
if [[ -n "$(docker volume ls -f name="${volumename}" -q)" ]]; then
|
||||
echo "Volume already exists"
|
||||
if [[ -z "$(_checkVolumeContent)" ]]; then
|
||||
echo "looks empty, copying checkpoint"
|
||||
_copyCheckpoints
|
||||
fi
|
||||
echo "Models in ${volumename}:"
|
||||
_checkVolumeContent
|
||||
else
|
||||
echo -n "createing docker volume "
|
||||
docker volume create "${volumename}"
|
||||
_copyCheckpoints
|
||||
fi
|
||||
|
||||
# Build Container
|
||||
docker build \
|
||||
--platform="${platform}" \
|
||||
--tag "${invokeai_tag}" \
|
||||
--build-arg project_name="${project_name}" \
|
||||
--build-arg conda_version="${invokeai_conda_version}" \
|
||||
--build-arg conda_prefix="${invokeai_conda_prefix}" \
|
||||
--build-arg conda_env_file="${invokeai_conda_env_file}" \
|
||||
--build-arg invokeai_git="${invokeai_git}" \
|
||||
--file ./docker-build/Dockerfile \
|
||||
.
|
||||
@@ -1,8 +0,0 @@
|
||||
#!/bin/bash
|
||||
set -e
|
||||
|
||||
source "${CONDA_PREFIX}/etc/profile.d/conda.sh"
|
||||
conda activate "${PROJECT_NAME}"
|
||||
|
||||
python scripts/invoke.py \
|
||||
${@:---web --host=0.0.0.0}
|
||||
@@ -1,13 +0,0 @@
|
||||
#!/usr/bin/env bash
|
||||
|
||||
project_name=${PROJECT_NAME:-invokeai}
|
||||
volumename=${VOLUMENAME:-${project_name}_data}
|
||||
arch=${ARCH:-x86_64}
|
||||
platform=${PLATFORM:-Linux/${arch}}
|
||||
invokeai_tag=${INVOKEAI_TAG:-${project_name}-${arch}}
|
||||
|
||||
export project_name
|
||||
export volumename
|
||||
export arch
|
||||
export platform
|
||||
export invokeai_tag
|
||||
@@ -1,15 +0,0 @@
|
||||
#!/usr/bin/env bash
|
||||
set -e
|
||||
|
||||
source ./docker-build/env.sh || echo "please run from repository root" || exit 1
|
||||
|
||||
docker run \
|
||||
--interactive \
|
||||
--tty \
|
||||
--rm \
|
||||
--platform "$platform" \
|
||||
--name "$project_name" \
|
||||
--hostname "$project_name" \
|
||||
--mount source="$volumename",target=/data \
|
||||
--publish 9090:9090 \
|
||||
"$invokeai_tag" ${1:+$@}
|
||||
103
docker/Dockerfile
Normal file
@@ -0,0 +1,103 @@
|
||||
# syntax=docker/dockerfile:1
|
||||
|
||||
ARG PYTHON_VERSION=3.9
|
||||
##################
|
||||
## base image ##
|
||||
##################
|
||||
FROM python:${PYTHON_VERSION}-slim AS python-base
|
||||
|
||||
LABEL org.opencontainers.image.authors="mauwii@outlook.de"
|
||||
|
||||
# prepare for buildkit cache
|
||||
RUN rm -f /etc/apt/apt.conf.d/docker-clean \
|
||||
&& echo 'Binary::apt::APT::Keep-Downloaded-Packages "true";' >/etc/apt/apt.conf.d/keep-cache
|
||||
|
||||
# Install necessary packages
|
||||
RUN \
|
||||
--mount=type=cache,target=/var/cache/apt,sharing=locked \
|
||||
--mount=type=cache,target=/var/lib/apt,sharing=locked \
|
||||
apt-get update \
|
||||
&& apt-get install -y \
|
||||
--no-install-recommends \
|
||||
libgl1-mesa-glx=20.3.* \
|
||||
libglib2.0-0=2.66.* \
|
||||
libopencv-dev=4.5.*
|
||||
|
||||
# set working directory and env
|
||||
ARG APPDIR=/usr/src
|
||||
ARG APPNAME=InvokeAI
|
||||
WORKDIR ${APPDIR}
|
||||
ENV PATH ${APPDIR}/${APPNAME}/bin:$PATH
|
||||
# Keeps Python from generating .pyc files in the container
|
||||
ENV PYTHONDONTWRITEBYTECODE 1
|
||||
# Turns off buffering for easier container logging
|
||||
ENV PYTHONUNBUFFERED 1
|
||||
# don't fall back to legacy build system
|
||||
ENV PIP_USE_PEP517=1
|
||||
|
||||
#######################
|
||||
## build pyproject ##
|
||||
#######################
|
||||
FROM python-base AS pyproject-builder
|
||||
|
||||
# Install dependencies
|
||||
RUN \
|
||||
--mount=type=cache,target=/var/cache/apt,sharing=locked \
|
||||
--mount=type=cache,target=/var/lib/apt,sharing=locked \
|
||||
apt-get update \
|
||||
&& apt-get install -y \
|
||||
--no-install-recommends \
|
||||
build-essential=12.9 \
|
||||
gcc=4:10.2.* \
|
||||
python3-dev=3.9.*
|
||||
|
||||
# prepare pip for buildkit cache
|
||||
ARG PIP_CACHE_DIR=/var/cache/buildkit/pip
|
||||
ENV PIP_CACHE_DIR ${PIP_CACHE_DIR}
|
||||
RUN mkdir -p ${PIP_CACHE_DIR}
|
||||
|
||||
# create virtual environment
|
||||
RUN --mount=type=cache,target=${PIP_CACHE_DIR},sharing=locked \
|
||||
python3 -m venv "${APPNAME}" \
|
||||
--upgrade-deps
|
||||
|
||||
# copy sources
|
||||
COPY --link . .
|
||||
|
||||
# install pyproject.toml
|
||||
ARG PIP_EXTRA_INDEX_URL
|
||||
ENV PIP_EXTRA_INDEX_URL ${PIP_EXTRA_INDEX_URL}
|
||||
RUN --mount=type=cache,target=${PIP_CACHE_DIR},sharing=locked \
|
||||
"${APPNAME}/bin/pip" install .
|
||||
|
||||
# build patchmatch
|
||||
RUN python3 -c "from patchmatch import patch_match"
|
||||
|
||||
#####################
|
||||
## runtime image ##
|
||||
#####################
|
||||
FROM python-base AS runtime
|
||||
|
||||
# Create a new user
|
||||
ARG UNAME=appuser
|
||||
RUN useradd \
|
||||
--no-log-init \
|
||||
-m \
|
||||
-U \
|
||||
"${UNAME}"
|
||||
|
||||
# create volume directory
|
||||
ARG VOLUME_DIR=/data
|
||||
RUN mkdir -p "${VOLUME_DIR}" \
|
||||
&& chown -R "${UNAME}" "${VOLUME_DIR}"
|
||||
|
||||
# setup runtime environment
|
||||
USER ${UNAME}
|
||||
COPY --chown=${UNAME} --from=pyproject-builder ${APPDIR}/${APPNAME} ${APPNAME}
|
||||
ENV INVOKEAI_ROOT ${VOLUME_DIR}
|
||||
ENV TRANSFORMERS_CACHE ${VOLUME_DIR}/.cache
|
||||
ENV INVOKE_MODEL_RECONFIGURE "--yes --default_only"
|
||||
EXPOSE 9090
|
||||
ENTRYPOINT [ "invokeai" ]
|
||||
CMD [ "--web", "--host", "0.0.0.0", "--port", "9090" ]
|
||||
VOLUME [ "${VOLUME_DIR}" ]
|
||||
51
docker/build.sh
Executable file
@@ -0,0 +1,51 @@
|
||||
#!/usr/bin/env bash
|
||||
set -e
|
||||
|
||||
# If you want to build a specific flavor, set the CONTAINER_FLAVOR environment variable
|
||||
# e.g. CONTAINER_FLAVOR=cpu ./build.sh
|
||||
# Possible Values are:
|
||||
# - cpu
|
||||
# - cuda
|
||||
# - rocm
|
||||
# Don't forget to also set it when executing run.sh
|
||||
# if it is not set, the script will try to detect the flavor by itself.
|
||||
#
|
||||
# Doc can be found here:
|
||||
# https://invoke-ai.github.io/InvokeAI/installation/040_INSTALL_DOCKER/
|
||||
|
||||
SCRIPTDIR=$(dirname "${BASH_SOURCE[0]}")
|
||||
cd "$SCRIPTDIR" || exit 1
|
||||
|
||||
source ./env.sh
|
||||
|
||||
DOCKERFILE=${INVOKE_DOCKERFILE:-./Dockerfile}
|
||||
|
||||
# print the settings
|
||||
echo -e "You are using these values:\n"
|
||||
echo -e "Dockerfile:\t\t${DOCKERFILE}"
|
||||
echo -e "index-url:\t\t${PIP_EXTRA_INDEX_URL:-none}"
|
||||
echo -e "Volumename:\t\t${VOLUMENAME}"
|
||||
echo -e "Platform:\t\t${PLATFORM}"
|
||||
echo -e "Container Registry:\t${CONTAINER_REGISTRY}"
|
||||
echo -e "Container Repository:\t${CONTAINER_REPOSITORY}"
|
||||
echo -e "Container Tag:\t\t${CONTAINER_TAG}"
|
||||
echo -e "Container Flavor:\t${CONTAINER_FLAVOR}"
|
||||
echo -e "Container Image:\t${CONTAINER_IMAGE}\n"
|
||||
|
||||
# Create docker volume
|
||||
if [[ -n "$(docker volume ls -f name="${VOLUMENAME}" -q)" ]]; then
|
||||
echo -e "Volume already exists\n"
|
||||
else
|
||||
echo -n "creating docker volume "
|
||||
docker volume create "${VOLUMENAME}"
|
||||
fi
|
||||
|
||||
# Build Container
|
||||
DOCKER_BUILDKIT=1 docker build \
|
||||
--platform="${PLATFORM:-linux/amd64}" \
|
||||
--tag="${CONTAINER_IMAGE:-invokeai}" \
|
||||
${CONTAINER_FLAVOR:+--build-arg="CONTAINER_FLAVOR=${CONTAINER_FLAVOR}"} \
|
||||
${PIP_EXTRA_INDEX_URL:+--build-arg="PIP_EXTRA_INDEX_URL=${PIP_EXTRA_INDEX_URL}"} \
|
||||
${PIP_PACKAGE:+--build-arg="PIP_PACKAGE=${PIP_PACKAGE}"} \
|
||||
--file="${DOCKERFILE}" \
|
||||
..
|
||||
51
docker/env.sh
Normal file
@@ -0,0 +1,51 @@
|
||||
#!/usr/bin/env bash
|
||||
|
||||
# This file is used to set environment variables for the build.sh and run.sh scripts.
|
||||
|
||||
# Try to detect the container flavor if no PIP_EXTRA_INDEX_URL got specified
|
||||
if [[ -z "$PIP_EXTRA_INDEX_URL" ]]; then
|
||||
|
||||
# Activate virtual environment if not already activated and exists
|
||||
if [[ -z $VIRTUAL_ENV ]]; then
|
||||
[[ -e "$(dirname "${BASH_SOURCE[0]}")/../.venv/bin/activate" ]] \
|
||||
&& source "$(dirname "${BASH_SOURCE[0]}")/../.venv/bin/activate" \
|
||||
&& echo "Activated virtual environment: $VIRTUAL_ENV"
|
||||
fi
|
||||
|
||||
# Decide which container flavor to build if not specified
|
||||
if [[ -z "$CONTAINER_FLAVOR" ]] && python -c "import torch" &>/dev/null; then
|
||||
# Check for CUDA and ROCm
|
||||
CUDA_AVAILABLE=$(python -c "import torch;print(torch.cuda.is_available())")
|
||||
ROCM_AVAILABLE=$(python -c "import torch;print(torch.version.hip is not None)")
|
||||
if [[ "${CUDA_AVAILABLE}" == "True" ]]; then
|
||||
CONTAINER_FLAVOR="cuda"
|
||||
elif [[ "${ROCM_AVAILABLE}" == "True" ]]; then
|
||||
CONTAINER_FLAVOR="rocm"
|
||||
else
|
||||
CONTAINER_FLAVOR="cpu"
|
||||
fi
|
||||
fi
|
||||
|
||||
# Set PIP_EXTRA_INDEX_URL based on container flavor
|
||||
if [[ "$CONTAINER_FLAVOR" == "rocm" ]]; then
|
||||
PIP_EXTRA_INDEX_URL="https://download.pytorch.org/whl/rocm"
|
||||
elif [[ "$CONTAINER_FLAVOR" == "cpu" ]]; then
|
||||
PIP_EXTRA_INDEX_URL="https://download.pytorch.org/whl/cpu"
|
||||
# elif [[ -z "$CONTAINER_FLAVOR" || "$CONTAINER_FLAVOR" == "cuda" ]]; then
|
||||
# PIP_PACKAGE=${PIP_PACKAGE-".[xformers]"}
|
||||
fi
|
||||
fi
|
||||
|
||||
# Variables shared by build.sh and run.sh
|
||||
REPOSITORY_NAME="${REPOSITORY_NAME-$(basename "$(git rev-parse --show-toplevel)")}"
|
||||
REPOSITORY_NAME="${REPOSITORY_NAME,,}"
|
||||
VOLUMENAME="${VOLUMENAME-"${REPOSITORY_NAME}_data"}"
|
||||
ARCH="${ARCH-$(uname -m)}"
|
||||
PLATFORM="${PLATFORM-linux/${ARCH}}"
|
||||
INVOKEAI_BRANCH="${INVOKEAI_BRANCH-$(git branch --show)}"
|
||||
CONTAINER_REGISTRY="${CONTAINER_REGISTRY-"ghcr.io"}"
|
||||
CONTAINER_REPOSITORY="${CONTAINER_REPOSITORY-"$(whoami)/${REPOSITORY_NAME}"}"
|
||||
CONTAINER_FLAVOR="${CONTAINER_FLAVOR-cuda}"
|
||||
CONTAINER_TAG="${CONTAINER_TAG-"${INVOKEAI_BRANCH##*/}-${CONTAINER_FLAVOR}"}"
|
||||
CONTAINER_IMAGE="${CONTAINER_REGISTRY}/${CONTAINER_REPOSITORY}:${CONTAINER_TAG}"
|
||||
CONTAINER_IMAGE="${CONTAINER_IMAGE,,}"
|
||||
41
docker/run.sh
Executable file
@@ -0,0 +1,41 @@
|
||||
#!/usr/bin/env bash
|
||||
set -e
|
||||
|
||||
# How to use: https://invoke-ai.github.io/InvokeAI/installation/040_INSTALL_DOCKER/
|
||||
|
||||
SCRIPTDIR=$(dirname "${BASH_SOURCE[0]}")
|
||||
cd "$SCRIPTDIR" || exit 1
|
||||
|
||||
source ./env.sh
|
||||
|
||||
# Create outputs directory if it does not exist
|
||||
[[ -d ./outputs ]] || mkdir ./outputs
|
||||
|
||||
echo -e "You are using these values:\n"
|
||||
echo -e "Volumename:\t${VOLUMENAME}"
|
||||
echo -e "Invokeai_tag:\t${CONTAINER_IMAGE}"
|
||||
echo -e "local Models:\t${MODELSPATH:-unset}\n"
|
||||
|
||||
docker run \
|
||||
--interactive \
|
||||
--tty \
|
||||
--rm \
|
||||
--platform="${PLATFORM}" \
|
||||
--name="${REPOSITORY_NAME,,}" \
|
||||
--hostname="${REPOSITORY_NAME,,}" \
|
||||
--mount=source="${VOLUMENAME}",target=/data \
|
||||
--mount type=bind,source="$(pwd)"/outputs,target=/data/outputs \
|
||||
${MODELSPATH:+--mount="type=bind,source=${MODELSPATH},target=/data/models"} \
|
||||
${HUGGING_FACE_HUB_TOKEN:+--env="HUGGING_FACE_HUB_TOKEN=${HUGGING_FACE_HUB_TOKEN}"} \
|
||||
--publish=9090:9090 \
|
||||
--cap-add=sys_nice \
|
||||
${GPU_FLAGS:+--gpus="${GPU_FLAGS}"} \
|
||||
"${CONTAINER_IMAGE}" ${@:+$@}
|
||||
|
||||
# Remove Trash folder
|
||||
for f in outputs/.Trash*; do
|
||||
if [ -e "$f" ]; then
|
||||
rm -Rf "$f"
|
||||
break
|
||||
fi
|
||||
done
|
||||
5
docs/.markdownlint.jsonc
Normal file
@@ -0,0 +1,5 @@
|
||||
{
|
||||
"MD046": false,
|
||||
"MD007": false,
|
||||
"MD030": false
|
||||
}
|
||||
@@ -4,45 +4,425 @@ title: Changelog
|
||||
|
||||
# :octicons-log-16: **Changelog**
|
||||
|
||||
## v2.0.1 (13 October 2022)
|
||||
## v2.3.0 <small>(15 January 2023)</small>
|
||||
|
||||
- fix noisy images at high step count when using k* samplers
|
||||
- dream.py script now calls invoke.py module directly rather than
|
||||
via a new python process (which could break the environment)
|
||||
**Transition to diffusers
|
||||
|
||||
Version 2.3 provides support for both the traditional `.ckpt` weight
|
||||
checkpoint files as well as the HuggingFace `diffusers` format. This
|
||||
introduces several changes you should know about.
|
||||
|
||||
1. The models.yaml format has been updated. There are now two
|
||||
different type of configuration stanza. The traditional ckpt
|
||||
one will look like this, with a `format` of `ckpt` and a
|
||||
`weights` field that points to the absolute or ROOTDIR-relative
|
||||
location of the ckpt file.
|
||||
|
||||
```
|
||||
inpainting-1.5:
|
||||
description: RunwayML SD 1.5 model optimized for inpainting (4.27 GB)
|
||||
repo_id: runwayml/stable-diffusion-inpainting
|
||||
format: ckpt
|
||||
width: 512
|
||||
height: 512
|
||||
weights: models/ldm/stable-diffusion-v1/sd-v1-5-inpainting.ckpt
|
||||
config: configs/stable-diffusion/v1-inpainting-inference.yaml
|
||||
vae: models/ldm/stable-diffusion-v1/vae-ft-mse-840000-ema-pruned.ckpt
|
||||
```
|
||||
|
||||
A configuration stanza for a diffusers model hosted at HuggingFace will look like this,
|
||||
with a `format` of `diffusers` and a `repo_id` that points to the
|
||||
repository ID of the model on HuggingFace:
|
||||
|
||||
```
|
||||
stable-diffusion-2.1:
|
||||
description: Stable Diffusion version 2.1 diffusers model (5.21 GB)
|
||||
repo_id: stabilityai/stable-diffusion-2-1
|
||||
format: diffusers
|
||||
```
|
||||
|
||||
A configuration stanza for a diffuers model stored locally should
|
||||
look like this, with a `format` of `diffusers`, but a `path` field
|
||||
that points at the directory that contains `model_index.json`:
|
||||
|
||||
```
|
||||
waifu-diffusion:
|
||||
description: Latest waifu diffusion 1.4
|
||||
format: diffusers
|
||||
path: models/diffusers/hakurei-haifu-diffusion-1.4
|
||||
```
|
||||
|
||||
2. In order of precedence, InvokeAI will now use HF_HOME, then
|
||||
XDG_CACHE_HOME, then finally default to `ROOTDIR/models` to
|
||||
store HuggingFace diffusers models.
|
||||
|
||||
Consequently, the format of the models directory has changed to
|
||||
mimic the HuggingFace cache directory. When HF_HOME and XDG_HOME
|
||||
are not set, diffusers models are now automatically downloaded
|
||||
and retrieved from the directory `ROOTDIR/models/diffusers`,
|
||||
while other models are stored in the directory
|
||||
`ROOTDIR/models/hub`. This organization is the same as that used
|
||||
by HuggingFace for its cache management.
|
||||
|
||||
This allows you to share diffusers and ckpt model files easily with
|
||||
other machine learning applications that use the HuggingFace
|
||||
libraries. To do this, set the environment variable HF_HOME
|
||||
before starting up InvokeAI to tell it what directory to
|
||||
cache models in. To tell InvokeAI to use the standard HuggingFace
|
||||
cache directory, you would set HF_HOME like this (Linux/Mac):
|
||||
|
||||
`export HF_HOME=~/.cache/huggingface`
|
||||
|
||||
Both HuggingFace and InvokeAI will fall back to the XDG_CACHE_HOME
|
||||
environment variable if HF_HOME is not set; this path
|
||||
takes precedence over `ROOTDIR/models` to allow for the same sharing
|
||||
with other machine learning applications that use HuggingFace
|
||||
libraries.
|
||||
|
||||
3. If you upgrade to InvokeAI 2.3.* from an earlier version, there
|
||||
will be a one-time migration from the old models directory format
|
||||
to the new one. You will see a message about this the first time
|
||||
you start `invoke.py`.
|
||||
|
||||
4. Both the front end back ends of the model manager have been
|
||||
rewritten to accommodate diffusers. You can import models using
|
||||
their local file path, using their URLs, or their HuggingFace
|
||||
repo_ids. On the command line, all these syntaxes work:
|
||||
|
||||
```
|
||||
!import_model stabilityai/stable-diffusion-2-1-base
|
||||
!import_model /opt/sd-models/sd-1.4.ckpt
|
||||
!import_model https://huggingface.co/Fictiverse/Stable_Diffusion_PaperCut_Model/blob/main/PaperCut_v1.ckpt
|
||||
```
|
||||
|
||||
**KNOWN BUGS (15 January 2023)
|
||||
|
||||
1. On CUDA systems, the 768 pixel stable-diffusion-2.0 and
|
||||
stable-diffusion-2.1 models can only be run as `diffusers` models
|
||||
when the `xformer` library is installed and configured. Without
|
||||
`xformers`, InvokeAI returns black images.
|
||||
|
||||
2. Inpainting and outpainting have regressed in quality.
|
||||
|
||||
Both these issues are being actively worked on.
|
||||
|
||||
## v2.2.4 <small>(11 December 2022)</small>
|
||||
|
||||
**the `invokeai` directory**
|
||||
|
||||
Previously there were two directories to worry about, the directory that
|
||||
contained the InvokeAI source code and the launcher scripts, and the `invokeai`
|
||||
directory that contained the models files, embeddings, configuration and
|
||||
outputs. With the 2.2.4 release, this dual system is done away with, and
|
||||
everything, including the `invoke.bat` and `invoke.sh` launcher scripts, now
|
||||
live in a directory named `invokeai`. By default this directory is located in
|
||||
your home directory (e.g. `\Users\yourname` on Windows), but you can select
|
||||
where it goes at install time.
|
||||
|
||||
After installation, you can delete the install directory (the one that the zip
|
||||
file creates when it unpacks). Do **not** delete or move the `invokeai`
|
||||
directory!
|
||||
|
||||
**Initialization file `invokeai/invokeai.init`**
|
||||
|
||||
You can place frequently-used startup options in this file, such as the default
|
||||
number of steps or your preferred sampler. To keep everything in one place, this
|
||||
file has now been moved into the `invokeai` directory and is named
|
||||
`invokeai.init`.
|
||||
|
||||
**To update from Version 2.2.3**
|
||||
|
||||
The easiest route is to download and unpack one of the 2.2.4 installer files.
|
||||
When it asks you for the location of the `invokeai` runtime directory, respond
|
||||
with the path to the directory that contains your 2.2.3 `invokeai`. That is, if
|
||||
`invokeai` lives at `C:\Users\fred\invokeai`, then answer with `C:\Users\fred`
|
||||
and answer "Y" when asked if you want to reuse the directory.
|
||||
|
||||
The `update.sh` (`update.bat`) script that came with the 2.2.3 source installer
|
||||
does not know about the new directory layout and won't be fully functional.
|
||||
|
||||
**To update to 2.2.5 (and beyond) there's now an update path**
|
||||
|
||||
As they become available, you can update to more recent versions of InvokeAI
|
||||
using an `update.sh` (`update.bat`) script located in the `invokeai` directory.
|
||||
Running it without any arguments will install the most recent version of
|
||||
InvokeAI. Alternatively, you can get set releases by running the `update.sh`
|
||||
script with an argument in the command shell. This syntax accepts the path to
|
||||
the desired release's zip file, which you can find by clicking on the green
|
||||
"Code" button on this repository's home page.
|
||||
|
||||
**Other 2.2.4 Improvements**
|
||||
|
||||
- Fix InvokeAI GUI initialization by @addianto in #1687
|
||||
- fix link in documentation by @lstein in #1728
|
||||
- Fix broken link by @ShawnZhong in #1736
|
||||
- Remove reference to binary installer by @lstein in #1731
|
||||
- documentation fixes for 2.2.3 by @lstein in #1740
|
||||
- Modify installer links to point closer to the source installer by @ebr in
|
||||
#1745
|
||||
- add documentation warning about 1650/60 cards by @lstein in #1753
|
||||
- Fix Linux source URL in installation docs by @andybearman in #1756
|
||||
- Make install instructions discoverable in readme by @damian0815 in #1752
|
||||
- typo fix by @ofirkris in #1755
|
||||
- Non-interactive model download (support HUGGINGFACE_TOKEN) by @ebr in #1578
|
||||
- fix(srcinstall): shell installer - cp scripts instead of linking by @tildebyte
|
||||
in #1765
|
||||
- stability and usage improvements to binary & source installers by @lstein in
|
||||
#1760
|
||||
- fix off-by-one bug in cross-attention-control by @damian0815 in #1774
|
||||
- Eventually update APP_VERSION to 2.2.3 by @spezialspezial in #1768
|
||||
- invoke script cds to its location before running by @lstein in #1805
|
||||
- Make PaperCut and VoxelArt models load again by @lstein in #1730
|
||||
- Fix --embedding_directory / --embedding_path not working by @blessedcoolant in
|
||||
#1817
|
||||
- Clean up readme by @hipsterusername in #1820
|
||||
- Optimized Docker build with support for external working directory by @ebr in
|
||||
#1544
|
||||
- disable pushing the cloud container by @mauwii in #1831
|
||||
- Fix docker push github action and expand with additional metadata by @ebr in
|
||||
#1837
|
||||
- Fix Broken Link To Notebook by @VedantMadane in #1821
|
||||
- Account for flat models by @spezialspezial in #1766
|
||||
- Update invoke.bat.in isolate environment variables by @lynnewu in #1833
|
||||
- Arch Linux Specific PatchMatch Instructions & fixing conda install on linux by
|
||||
@SammCheese in #1848
|
||||
- Make force free GPU memory work in img2img by @addianto in #1844
|
||||
- New installer by @lstein
|
||||
|
||||
## v2.2.3 <small>(2 December 2022)</small>
|
||||
|
||||
!!! Note
|
||||
|
||||
This point release removes references to the binary installer from the
|
||||
installation guide. The binary installer is not stable at the current
|
||||
time. First time users are encouraged to use the "source" installer as
|
||||
described in [Installing InvokeAI with the Source Installer](installation/deprecated_documentation/INSTALL_SOURCE.md)
|
||||
|
||||
With InvokeAI 2.2, this project now provides enthusiasts and professionals a
|
||||
robust workflow solution for creating AI-generated and human facilitated
|
||||
compositions. Additional enhancements have been made as well, improving safety,
|
||||
ease of use, and installation.
|
||||
|
||||
Optimized for efficiency, InvokeAI needs only ~3.5GB of VRAM to generate a
|
||||
512x768 image (and less for smaller images), and is compatible with
|
||||
Windows/Linux/Mac (M1 & M2).
|
||||
|
||||
You can see the [release video](https://youtu.be/hIYBfDtKaus) here, which
|
||||
introduces the main WebUI enhancement for version 2.2 -
|
||||
[The Unified Canvas](features/UNIFIED_CANVAS.md). This new workflow is the
|
||||
biggest enhancement added to the WebUI to date, and unlocks a stunning amount of
|
||||
potential for users to create and iterate on their creations. The following
|
||||
sections describe what's new for InvokeAI.
|
||||
|
||||
## v2.2.2 <small>(30 November 2022)</small>
|
||||
|
||||
!!! note
|
||||
|
||||
The binary installer is not ready for prime time. First time users are recommended to install via the "source" installer accessible through the links at the bottom of this page.****
|
||||
|
||||
With InvokeAI 2.2, this project now provides enthusiasts and professionals a
|
||||
robust workflow solution for creating AI-generated and human facilitated
|
||||
compositions. Additional enhancements have been made as well, improving safety,
|
||||
ease of use, and installation.
|
||||
|
||||
Optimized for efficiency, InvokeAI needs only ~3.5GB of VRAM to generate a
|
||||
512x768 image (and less for smaller images), and is compatible with
|
||||
Windows/Linux/Mac (M1 & M2).
|
||||
|
||||
You can see the [release video](https://youtu.be/hIYBfDtKaus) here, which
|
||||
introduces the main WebUI enhancement for version 2.2 -
|
||||
[The Unified Canvas](https://invoke-ai.github.io/InvokeAI/features/UNIFIED_CANVAS/).
|
||||
This new workflow is the biggest enhancement added to the WebUI to date, and
|
||||
unlocks a stunning amount of potential for users to create and iterate on their
|
||||
creations. The following sections describe what's new for InvokeAI.
|
||||
|
||||
## v2.2.0 <small>(2 December 2022)</small>
|
||||
|
||||
With InvokeAI 2.2, this project now provides enthusiasts and professionals a
|
||||
robust workflow solution for creating AI-generated and human facilitated
|
||||
compositions. Additional enhancements have been made as well, improving safety,
|
||||
ease of use, and installation.
|
||||
|
||||
Optimized for efficiency, InvokeAI needs only ~3.5GB of VRAM to generate a
|
||||
512x768 image (and less for smaller images), and is compatible with
|
||||
Windows/Linux/Mac (M1 & M2).
|
||||
|
||||
You can see the [release video](https://youtu.be/hIYBfDtKaus) here, which
|
||||
introduces the main WebUI enhancement for version 2.2 -
|
||||
[The Unified Canvas](features/UNIFIED_CANVAS.md). This new workflow is the
|
||||
biggest enhancement added to the WebUI to date, and unlocks a stunning amount of
|
||||
potential for users to create and iterate on their creations. The following
|
||||
sections describe what's new for InvokeAI.
|
||||
|
||||
## v2.1.3 <small>(13 November 2022)</small>
|
||||
|
||||
- A choice of installer scripts that automate installation and configuration.
|
||||
See
|
||||
[Installation](installation/index.md).
|
||||
- A streamlined manual installation process that works for both Conda and
|
||||
PIP-only installs. See
|
||||
[Manual Installation](installation/020_INSTALL_MANUAL.md).
|
||||
- The ability to save frequently-used startup options (model to load, steps,
|
||||
sampler, etc) in a `.invokeai` file. See
|
||||
[Client](features/CLI.md)
|
||||
- Support for AMD GPU cards (non-CUDA) on Linux machines.
|
||||
- Multiple bugs and edge cases squashed.
|
||||
|
||||
## v2.1.0 <small>(2 November 2022)</small>
|
||||
|
||||
- update mac instructions to use invokeai for env name by @willwillems in #1030
|
||||
- Update .gitignore by @blessedcoolant in #1040
|
||||
- reintroduce fix for m1 from #579 missing after merge by @skurovec in #1056
|
||||
- Update Stable_Diffusion_AI_Notebook.ipynb (Take 2) by @ChloeL19 in #1060
|
||||
- Print out the device type which is used by @manzke in #1073
|
||||
- Hires Addition by @hipsterusername in #1063
|
||||
- fix for "1 leaked semaphore objects to clean up at shutdown" on M1 by
|
||||
@skurovec in #1081
|
||||
- Forward dream.py to invoke.py using the same interpreter, add deprecation
|
||||
warning by @db3000 in #1077
|
||||
- fix noisy images at high step counts by @lstein in #1086
|
||||
- Generalize facetool strength argument by @db3000 in #1078
|
||||
- Enable fast switching among models at the invoke> command line by @lstein in
|
||||
#1066
|
||||
- Fix Typo, committed changing ldm environment to invokeai by @jdries3 in #1095
|
||||
- Update generate.py by @unreleased in #1109
|
||||
- Update 'ldm' env to 'invokeai' in troubleshooting steps by @19wolf in #1125
|
||||
- Fixed documentation typos and resolved merge conflicts by @rupeshs in #1123
|
||||
- Fix broken doc links, fix malaprop in the project subtitle by @majick in #1131
|
||||
- Only output facetool parameters if enhancing faces by @db3000 in #1119
|
||||
- Update gitignore to ignore codeformer weights at new location by
|
||||
@spezialspezial in #1136
|
||||
- fix links to point to invoke-ai.github.io #1117 by @mauwii in #1143
|
||||
- Rework-mkdocs by @mauwii in #1144
|
||||
- add option to CLI and pngwriter that allows user to set PNG compression level
|
||||
by @lstein in #1127
|
||||
- Fix img2img DDIM index out of bound by @wfng92 in #1137
|
||||
- Fix gh actions by @mauwii in #1128
|
||||
- update mac instructions to use invokeai for env name by @willwillems in #1030
|
||||
- Update .gitignore by @blessedcoolant in #1040
|
||||
- reintroduce fix for m1 from #579 missing after merge by @skurovec in #1056
|
||||
- Update Stable_Diffusion_AI_Notebook.ipynb (Take 2) by @ChloeL19 in #1060
|
||||
- Print out the device type which is used by @manzke in #1073
|
||||
- Hires Addition by @hipsterusername in #1063
|
||||
- fix for "1 leaked semaphore objects to clean up at shutdown" on M1 by
|
||||
@skurovec in #1081
|
||||
- Forward dream.py to invoke.py using the same interpreter, add deprecation
|
||||
warning by @db3000 in #1077
|
||||
- fix noisy images at high step counts by @lstein in #1086
|
||||
- Generalize facetool strength argument by @db3000 in #1078
|
||||
- Enable fast switching among models at the invoke> command line by @lstein in
|
||||
#1066
|
||||
- Fix Typo, committed changing ldm environment to invokeai by @jdries3 in #1095
|
||||
- Fixed documentation typos and resolved merge conflicts by @rupeshs in #1123
|
||||
- Only output facetool parameters if enhancing faces by @db3000 in #1119
|
||||
- add option to CLI and pngwriter that allows user to set PNG compression level
|
||||
by @lstein in #1127
|
||||
- Fix img2img DDIM index out of bound by @wfng92 in #1137
|
||||
- Add text prompt to inpaint mask support by @lstein in #1133
|
||||
- Respect http[s] protocol when making socket.io middleware by @damian0815 in
|
||||
#976
|
||||
- WebUI: Adds Codeformer support by @psychedelicious in #1151
|
||||
- Skips normalizing prompts for web UI metadata by @psychedelicious in #1165
|
||||
- Add Asymmetric Tiling by @carson-katri in #1132
|
||||
- Web UI: Increases max CFG Scale to 200 by @psychedelicious in #1172
|
||||
- Corrects color channels in face restoration; Fixes #1167 by @psychedelicious
|
||||
in #1175
|
||||
- Flips channels using array slicing instead of using OpenCV by @psychedelicious
|
||||
in #1178
|
||||
- Fix typo in docs: s/Formally/Formerly by @noodlebox in #1176
|
||||
- fix clipseg loading problems by @lstein in #1177
|
||||
- Correct color channels in upscale using array slicing by @wfng92 in #1181
|
||||
- Web UI: Filters existing images when adding new images; Fixes #1085 by
|
||||
@psychedelicious in #1171
|
||||
- fix a number of bugs in textual inversion by @lstein in #1190
|
||||
- Improve !fetch, add !replay command by @ArDiouscuros in #882
|
||||
- Fix generation of image with s>1000 by @holstvoogd in #951
|
||||
- Web UI: Gallery improvements by @psychedelicious in #1198
|
||||
- Update CLI.md by @krummrey in #1211
|
||||
- outcropping improvements by @lstein in #1207
|
||||
- add support for loading VAE autoencoders by @lstein in #1216
|
||||
- remove duplicate fix_func for MPS by @wfng92 in #1210
|
||||
- Metadata storage and retrieval fixes by @lstein in #1204
|
||||
- nix: add shell.nix file by @Cloudef in #1170
|
||||
- Web UI: Changes vite dist asset paths to relative by @psychedelicious in #1185
|
||||
- Web UI: Removes isDisabled from PromptInput by @psychedelicious in #1187
|
||||
- Allow user to generate images with initial noise as on M1 / mps system by
|
||||
@ArDiouscuros in #981
|
||||
- feat: adding filename format template by @plucked in #968
|
||||
- Web UI: Fixes broken bundle by @psychedelicious in #1242
|
||||
- Support runwayML custom inpainting model by @lstein in #1243
|
||||
- Update IMG2IMG.md by @talitore in #1262
|
||||
- New dockerfile - including a build- and a run- script as well as a GH-Action
|
||||
by @mauwii in #1233
|
||||
- cut over from karras to model noise schedule for higher steps by @lstein in
|
||||
#1222
|
||||
- Prompt tweaks by @lstein in #1268
|
||||
- Outpainting implementation by @Kyle0654 in #1251
|
||||
- fixing aspect ratio on hires by @tjennings in #1249
|
||||
- Fix-build-container-action by @mauwii in #1274
|
||||
- handle all unicode characters by @damian0815 in #1276
|
||||
- adds models.user.yml to .gitignore by @JakeHL in #1281
|
||||
- remove debug branch, set fail-fast to false by @mauwii in #1284
|
||||
- Protect-secrets-on-pr by @mauwii in #1285
|
||||
- Web UI: Adds initial inpainting implementation by @psychedelicious in #1225
|
||||
- fix environment-mac.yml - tested on x64 and arm64 by @mauwii in #1289
|
||||
- Use proper authentication to download model by @mauwii in #1287
|
||||
- Prevent indexing error for mode RGB by @spezialspezial in #1294
|
||||
- Integrate sd-v1-5 model into test matrix (easily expandable), remove
|
||||
unecesarry caches by @mauwii in #1293
|
||||
- add --no-interactive to configure_invokeai step by @mauwii in #1302
|
||||
- 1-click installer and updater. Uses micromamba to install git and conda into a
|
||||
contained environment (if necessary) before running the normal installation
|
||||
script by @cmdr2 in #1253
|
||||
- configure_invokeai.py script downloads the weight files by @lstein in #1290
|
||||
|
||||
## v2.0.1 <small>(13 October 2022)</small>
|
||||
|
||||
- fix noisy images at high step count when using k\* samplers
|
||||
- dream.py script now calls invoke.py module directly rather than via a new
|
||||
python process (which could break the environment)
|
||||
|
||||
## v2.0.0 <small>(9 October 2022)</small>
|
||||
|
||||
- `dream.py` script renamed `invoke.py`. A `dream.py` script wrapper remains
|
||||
for backward compatibility.
|
||||
- `dream.py` script renamed `invoke.py`. A `dream.py` script wrapper remains for
|
||||
backward compatibility.
|
||||
- Completely new WebGUI - launch with `python3 scripts/invoke.py --web`
|
||||
- Support for [inpainting](features/INPAINTING.md) and [outpainting](features/OUTPAINTING.md)
|
||||
- img2img runs on all k* samplers
|
||||
- Support for [negative prompts](features/PROMPTS.md#negative-and-unconditioned-prompts)
|
||||
- Support for [inpainting](features/INPAINTING.md) and
|
||||
[outpainting](features/OUTPAINTING.md)
|
||||
- img2img runs on all k\* samplers
|
||||
- Support for
|
||||
[negative prompts](features/PROMPTS.md#negative-and-unconditioned-prompts)
|
||||
- Support for CodeFormer face reconstruction
|
||||
- Support for Textual Inversion on Macintoshes
|
||||
- Support in both WebGUI and CLI for [post-processing of previously-generated images](features/POSTPROCESS.md)
|
||||
using facial reconstruction, ESRGAN upscaling, outcropping (similar to DALL-E infinite canvas),
|
||||
and "embiggen" upscaling. See the `!fix` command.
|
||||
- New `--hires` option on `invoke>` line allows [larger images to be created without duplicating elements](features/CLI.md#this-is-an-example-of-txt2img), at the cost of some performance.
|
||||
- New `--perlin` and `--threshold` options allow you to add and control variation
|
||||
during image generation (see [Thresholding and Perlin Noise Initialization](features/OTHER.md#thresholding-and-perlin-noise-initialization-options))
|
||||
- Extensive metadata now written into PNG files, allowing reliable regeneration of images
|
||||
and tweaking of previous settings.
|
||||
- Command-line completion in `invoke.py` now works on Windows, Linux and Mac platforms.
|
||||
- Improved [command-line completion behavior](features/CLI.md)
|
||||
New commands added:
|
||||
- Support in both WebGUI and CLI for
|
||||
[post-processing of previously-generated images](features/POSTPROCESS.md)
|
||||
using facial reconstruction, ESRGAN upscaling, outcropping (similar to DALL-E
|
||||
infinite canvas), and "embiggen" upscaling. See the `!fix` command.
|
||||
- New `--hires` option on `invoke>` line allows
|
||||
[larger images to be created without duplicating elements](features/CLI.md#this-is-an-example-of-txt2img),
|
||||
at the cost of some performance.
|
||||
- New `--perlin` and `--threshold` options allow you to add and control
|
||||
variation during image generation (see
|
||||
[Thresholding and Perlin Noise Initialization](features/OTHER.md#thresholding-and-perlin-noise-initialization-options))
|
||||
- Extensive metadata now written into PNG files, allowing reliable regeneration
|
||||
of images and tweaking of previous settings.
|
||||
- Command-line completion in `invoke.py` now works on Windows, Linux and Mac
|
||||
platforms.
|
||||
- Improved [command-line completion behavior](features/CLI.md) New commands
|
||||
added:
|
||||
- List command-line history with `!history`
|
||||
- Search command-line history with `!search`
|
||||
- Clear history with `!clear`
|
||||
- Deprecated `--full_precision` / `-F`. Simply omit it and `invoke.py` will auto
|
||||
configure. To switch away from auto use the new flag like `--precision=float32`.
|
||||
configure. To switch away from auto use the new flag like
|
||||
`--precision=float32`.
|
||||
|
||||
## v1.14 <small>(11 September 2022)</small>
|
||||
|
||||
- Memory optimizations for small-RAM cards. 512x512 now possible on 4 GB GPUs.
|
||||
- Full support for Apple hardware with M1 or M2 chips.
|
||||
- Add "seamless mode" for circular tiling of image. Generates beautiful effects.
|
||||
([prixt](https://github.com/prixt)).
|
||||
([prixt](https://github.com/prixt)).
|
||||
- Inpainting support.
|
||||
- Improved web server GUI.
|
||||
- Lots of code and documentation cleanups.
|
||||
@@ -50,16 +430,17 @@ title: Changelog
|
||||
## v1.13 <small>(3 September 2022)</small>
|
||||
|
||||
- Support image variations (see [VARIATIONS](features/VARIATIONS.md)
|
||||
([Kevin Gibbons](https://github.com/bakkot) and many contributors and reviewers)
|
||||
- Supports a Google Colab notebook for a standalone server running on Google hardware
|
||||
[Arturo Mendivil](https://github.com/artmen1516)
|
||||
([Kevin Gibbons](https://github.com/bakkot) and many contributors and
|
||||
reviewers)
|
||||
- Supports a Google Colab notebook for a standalone server running on Google
|
||||
hardware [Arturo Mendivil](https://github.com/artmen1516)
|
||||
- WebUI supports GFPGAN/ESRGAN facial reconstruction and upscaling
|
||||
[Kevin Gibbons](https://github.com/bakkot)
|
||||
[Kevin Gibbons](https://github.com/bakkot)
|
||||
- WebUI supports incremental display of in-progress images during generation
|
||||
[Kevin Gibbons](https://github.com/bakkot)
|
||||
[Kevin Gibbons](https://github.com/bakkot)
|
||||
- A new configuration file scheme that allows new models (including upcoming
|
||||
stable-diffusion-v1.5) to be added without altering the code.
|
||||
([David Wager](https://github.com/maddavid12))
|
||||
stable-diffusion-v1.5) to be added without altering the code.
|
||||
([David Wager](https://github.com/maddavid12))
|
||||
- Can specify --grid on invoke.py command line as the default.
|
||||
- Miscellaneous internal bug and stability fixes.
|
||||
- Works on M1 Apple hardware.
|
||||
@@ -71,49 +452,59 @@ title: Changelog
|
||||
|
||||
- Improved file handling, including ability to read prompts from standard input.
|
||||
(kudos to [Yunsaki](https://github.com/yunsaki)
|
||||
- The web server is now integrated with the invoke.py script. Invoke by adding --web to
|
||||
the invoke.py command arguments.
|
||||
- The web server is now integrated with the invoke.py script. Invoke by adding
|
||||
--web to the invoke.py command arguments.
|
||||
- Face restoration and upscaling via GFPGAN and Real-ESGAN are now automatically
|
||||
enabled if the GFPGAN directory is located as a sibling to Stable Diffusion.
|
||||
VRAM requirements are modestly reduced. Thanks to both [Blessedcoolant](https://github.com/blessedcoolant) and
|
||||
VRAM requirements are modestly reduced. Thanks to both
|
||||
[Blessedcoolant](https://github.com/blessedcoolant) and
|
||||
[Oceanswave](https://github.com/oceanswave) for their work on this.
|
||||
- You can now swap samplers on the invoke> command line. [Blessedcoolant](https://github.com/blessedcoolant)
|
||||
- You can now swap samplers on the invoke> command line.
|
||||
[Blessedcoolant](https://github.com/blessedcoolant)
|
||||
|
||||
---
|
||||
|
||||
## v1.11 <small>(26 August 2022)</small>
|
||||
|
||||
- NEW FEATURE: Support upscaling and face enhancement using the GFPGAN module. (kudos to [Oceanswave](https://github.com/Oceanswave)
|
||||
- You now can specify a seed of -1 to use the previous image's seed, -2 to use the seed for the image generated before that, etc.
|
||||
Seed memory only extends back to the previous command, but will work on all images generated with the -n# switch.
|
||||
- NEW FEATURE: Support upscaling and face enhancement using the GFPGAN module.
|
||||
(kudos to [Oceanswave](https://github.com/Oceanswave)
|
||||
- You now can specify a seed of -1 to use the previous image's seed, -2 to use
|
||||
the seed for the image generated before that, etc. Seed memory only extends
|
||||
back to the previous command, but will work on all images generated with the
|
||||
-n# switch.
|
||||
- Variant generation support temporarily disabled pending more general solution.
|
||||
- Created a feature branch named **yunsaki-morphing-invoke** which adds experimental support for
|
||||
iteratively modifying the prompt and its parameters. Please see[Pull Request #86](https://github.com/lstein/stable-diffusion/pull/86)
|
||||
for a synopsis of how this works. Note that when this feature is eventually added to the main branch, it will may be modified
|
||||
significantly.
|
||||
- Created a feature branch named **yunsaki-morphing-invoke** which adds
|
||||
experimental support for iteratively modifying the prompt and its parameters.
|
||||
Please
|
||||
see[Pull Request #86](https://github.com/lstein/stable-diffusion/pull/86) for
|
||||
a synopsis of how this works. Note that when this feature is eventually added
|
||||
to the main branch, it will may be modified significantly.
|
||||
|
||||
---
|
||||
|
||||
## v1.10 <small>(25 August 2022)</small>
|
||||
|
||||
- A barebones but fully functional interactive web server for online generation of txt2img and img2img.
|
||||
- A barebones but fully functional interactive web server for online generation
|
||||
of txt2img and img2img.
|
||||
|
||||
---
|
||||
|
||||
## v1.09 <small>(24 August 2022)</small>
|
||||
|
||||
- A new -v option allows you to generate multiple variants of an initial image
|
||||
in img2img mode. (kudos to [Oceanswave](https://github.com/Oceanswave). [
|
||||
See this discussion in the PR for examples and details on use](https://github.com/lstein/stable-diffusion/pull/71#issuecomment-1226700810))
|
||||
- Added ability to personalize text to image generation (kudos to [Oceanswave](https://github.com/Oceanswave) and [nicolai256](https://github.com/nicolai256))
|
||||
in img2img mode. (kudos to [Oceanswave](https://github.com/Oceanswave).
|
||||
[ See this discussion in the PR for examples and details on use](https://github.com/lstein/stable-diffusion/pull/71#issuecomment-1226700810))
|
||||
- Added ability to personalize text to image generation (kudos to
|
||||
[Oceanswave](https://github.com/Oceanswave) and
|
||||
[nicolai256](https://github.com/nicolai256))
|
||||
- Enabled all of the samplers from k_diffusion
|
||||
|
||||
---
|
||||
|
||||
## v1.08 <small>(24 August 2022)</small>
|
||||
|
||||
- Escape single quotes on the invoke> command before trying to parse. This avoids
|
||||
parse errors.
|
||||
- Escape single quotes on the invoke> command before trying to parse. This
|
||||
avoids parse errors.
|
||||
- Removed instruction to get Python3.8 as first step in Windows install.
|
||||
Anaconda3 does it for you.
|
||||
- Added bounds checks for numeric arguments that could cause crashes.
|
||||
@@ -123,34 +514,36 @@ title: Changelog
|
||||
|
||||
## v1.07 <small>(23 August 2022)</small>
|
||||
|
||||
- Image filenames will now never fill gaps in the sequence, but will be assigned the
|
||||
next higher name in the chosen directory. This ensures that the alphabetic and chronological
|
||||
sort orders are the same.
|
||||
- Image filenames will now never fill gaps in the sequence, but will be assigned
|
||||
the next higher name in the chosen directory. This ensures that the alphabetic
|
||||
and chronological sort orders are the same.
|
||||
|
||||
---
|
||||
|
||||
## v1.06 <small>(23 August 2022)</small>
|
||||
|
||||
- Added weighted prompt support contributed by [xraxra](https://github.com/xraxra)
|
||||
- Example of using weighted prompts to tweak a demonic figure contributed by [bmaltais](https://github.com/bmaltais)
|
||||
- Added weighted prompt support contributed by
|
||||
[xraxra](https://github.com/xraxra)
|
||||
- Example of using weighted prompts to tweak a demonic figure contributed by
|
||||
[bmaltais](https://github.com/bmaltais)
|
||||
|
||||
---
|
||||
|
||||
## v1.05 <small>(22 August 2022 - after the drop)</small>
|
||||
|
||||
- Filenames now use the following formats:
|
||||
000010.95183149.png -- Two files produced by the same command (e.g. -n2),
|
||||
000010.26742632.png -- distinguished by a different seed.
|
||||
- Filenames now use the following formats: 000010.95183149.png -- Two files
|
||||
produced by the same command (e.g. -n2), 000010.26742632.png -- distinguished
|
||||
by a different seed.
|
||||
|
||||
000011.455191342.01.png -- Two files produced by the same command using
|
||||
000011.455191342.02.png -- a batch size>1 (e.g. -b2). They have the same seed.
|
||||
|
||||
000011.4160627868.grid#1-4.png -- a grid of four images (-g); the whole grid can
|
||||
be regenerated with the indicated key
|
||||
000011.4160627868.grid#1-4.png -- a grid of four images (-g); the whole grid
|
||||
can be regenerated with the indicated key
|
||||
|
||||
- It should no longer be possible for one image to overwrite another
|
||||
- You can use the "cd" and "pwd" commands at the invoke> prompt to set and retrieve
|
||||
the path of the output directory.
|
||||
- You can use the "cd" and "pwd" commands at the invoke> prompt to set and
|
||||
retrieve the path of the output directory.
|
||||
|
||||
---
|
||||
|
||||
@@ -164,26 +557,28 @@ title: Changelog
|
||||
|
||||
## v1.03 <small>(22 August 2022)</small>
|
||||
|
||||
- The original txt2img and img2img scripts from the CompViz repository have been moved into
|
||||
a subfolder named "orig_scripts", to reduce confusion.
|
||||
- The original txt2img and img2img scripts from the CompViz repository have been
|
||||
moved into a subfolder named "orig_scripts", to reduce confusion.
|
||||
|
||||
---
|
||||
|
||||
## v1.02 <small>(21 August 2022)</small>
|
||||
|
||||
- A copy of the prompt and all of its switches and options is now stored in the corresponding
|
||||
image in a tEXt metadata field named "Dream". You can read the prompt using scripts/images2prompt.py,
|
||||
or an image editor that allows you to explore the full metadata.
|
||||
**Please run "conda env update" to load the k_lms dependencies!!**
|
||||
- A copy of the prompt and all of its switches and options is now stored in the
|
||||
corresponding image in a tEXt metadata field named "Dream". You can read the
|
||||
prompt using scripts/images2prompt.py, or an image editor that allows you to
|
||||
explore the full metadata. **Please run "conda env update" to load the k_lms
|
||||
dependencies!!**
|
||||
|
||||
---
|
||||
|
||||
## v1.01 <small>(21 August 2022)</small>
|
||||
|
||||
- added k_lms sampling.
|
||||
**Please run "conda env update" to load the k_lms dependencies!!**
|
||||
- use half precision arithmetic by default, resulting in faster execution and lower memory requirements
|
||||
Pass argument --full_precision to invoke.py to get slower but more accurate image generation
|
||||
- added k_lms sampling. **Please run "conda env update" to load the k_lms
|
||||
dependencies!!**
|
||||
- use half precision arithmetic by default, resulting in faster execution and
|
||||
lower memory requirements Pass argument --full_precision to invoke.py to get
|
||||
slower but more accurate image generation
|
||||
|
||||
---
|
||||
|
||||
|
||||
BIN
docs/assets/canvas/biker_granny.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 359 KiB |
BIN
docs/assets/canvas/biker_jacket_granny.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 528 KiB |
BIN
docs/assets/canvas/mask_granny.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 601 KiB |
BIN
docs/assets/canvas/staging_area.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 59 KiB |
BIN
docs/assets/canvas_preview.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 142 KiB |
BIN
docs/assets/concepts/image1.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 122 KiB |
BIN
docs/assets/concepts/image2.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 128 KiB |
BIN
docs/assets/concepts/image3.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 99 KiB |
BIN
docs/assets/concepts/image4.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 112 KiB |
BIN
docs/assets/concepts/image5.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 107 KiB |
BIN
docs/assets/installer-walkthrough/choose-gpu.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 26 KiB |
BIN
docs/assets/installer-walkthrough/confirm-directory.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 84 KiB |
BIN
docs/assets/installer-walkthrough/downloading-models.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 37 KiB |
BIN
docs/assets/installer-walkthrough/installing-models.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 128 KiB |
BIN
docs/assets/installer-walkthrough/settings-form.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 114 KiB |
BIN
docs/assets/installer-walkthrough/unpacked-zipfile.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 56 KiB |
BIN
docs/assets/installing-models/webui-models-1.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 98 KiB |
BIN
docs/assets/installing-models/webui-models-2.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 94 KiB |
BIN
docs/assets/installing-models/webui-models-3.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 99 KiB |
BIN
docs/assets/installing-models/webui-models-4.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 98 KiB |
BIN
docs/assets/invoke_ai_banner.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 169 KiB |
{kind=link}
|
Before Width: | Height: | Size: 284 KiB |
{kind=link}
|
Before Width: | Height: | Size: 252 KiB |
{kind=link}
|
Before Width: | Height: | Size: 428 KiB |
{kind=link}
|
Before Width: | Height: | Size: 331 KiB |
{kind=link}
|
Before Width: | Height: | Size: 369 KiB |
{kind=link}
|
Before Width: | Height: | Size: 362 KiB |
{kind=link}
|
Before Width: | Height: | Size: 329 KiB |
{kind=link}
|
Before Width: | Height: | Size: 329 KiB |
{kind=link}
|
Before Width: | Height: | Size: 377 KiB |
{kind=link}
|
Before Width: | Height: | Size: 328 KiB |
{kind=link}
|
Before Width: | Height: | Size: 380 KiB |
{kind=link}
|
Before Width: | Height: | Size: 372 KiB |
{kind=link}
|
Before Width: | Height: | Size: 401 KiB |
{kind=link}
|
Before Width: | Height: | Size: 441 KiB |
{kind=link}
|
Before Width: | Height: | Size: 451 KiB |
{kind=link}
|
Before Width: | Height: | Size: 1.3 MiB |
{kind=link}
|
Before Width: | Height: | Size: 338 KiB |
{kind=link}
|
Before Width: | Height: | Size: 271 KiB |
{kind=link}
|
Before Width: | Height: | Size: 353 KiB |
{kind=link}
|
Before Width: | Height: | Size: 330 KiB |
{kind=link}
|
Before Width: | Height: | Size: 439 KiB |
{kind=link}
|
Before Width: | Height: | Size: 463 KiB |
{kind=link}
|
Before Width: | Height: | Size: 444 KiB |
{kind=link}
|
Before Width: | Height: | Size: 468 KiB |
{kind=link}
|
Before Width: | Height: | Size: 466 KiB |
{kind=link}
|
Before Width: | Height: | Size: 475 KiB |
{kind=link}
|
Before Width: | Height: | Size: 429 KiB |
{kind=link}
|
Before Width: | Height: | Size: 429 KiB |
{kind=link}
|
Before Width: | Height: | Size: 1.3 MiB |
{kind=link}
|
Before Width: | Height: | Size: 477 KiB |
{kind=link}
|
Before Width: | Height: | Size: 476 KiB |
{kind=link}
|
Before Width: | Height: | Size: 434 KiB |
@@ -1,116 +0,0 @@
|
||||
## 000001.1863159593.png
|
||||

|
||||
|
||||
banana sushi -s 50 -S 1863159593 -W 512 -H 512 -C 7.5 -A k_lms
|
||||
## 000002.1151955949.png
|
||||

|
||||
|
||||
banana sushi -s 50 -S 1151955949 -W 512 -H 512 -C 7.5 -A plms
|
||||
## 000003.2736230502.png
|
||||

|
||||
|
||||
banana sushi -s 50 -S 2736230502 -W 512 -H 512 -C 7.5 -A ddim
|
||||
## 000004.42.png
|
||||

|
||||
|
||||
banana sushi -s 50 -S 42 -W 512 -H 512 -C 7.5 -A k_lms
|
||||
## 000005.42.png
|
||||

|
||||
|
||||
banana sushi -s 50 -S 42 -W 512 -H 512 -C 7.5 -A k_lms
|
||||
## 000006.478163327.png
|
||||

|
||||
|
||||
banana sushi -s 50 -S 478163327 -W 640 -H 448 -C 7.5 -A k_lms
|
||||
## 000007.2407640369.png
|
||||

|
||||
|
||||
banana sushi -s 50 -S 42 -W 512 -H 512 -C 7.5 -A k_lms -V 2407640369:0.1
|
||||
## 000008.2772421987.png
|
||||

|
||||
|
||||
banana sushi -s 50 -S 42 -W 512 -H 512 -C 7.5 -A k_lms -V 2772421987:0.1
|
||||
## 000009.3532317557.png
|
||||

|
||||
|
||||
banana sushi -s 50 -S 42 -W 512 -H 512 -C 7.5 -A k_lms -V 3532317557:0.1
|
||||
## 000010.2028635318.png
|
||||

|
||||
|
||||
banana sushi -s 50 -S 2028635318 -W 512 -H 512 -C 7.5 -A k_lms
|
||||
## 000011.1111168647.png
|
||||

|
||||
|
||||
pond with waterlillies -s 50 -S 1111168647 -W 512 -H 512 -C 7.5 -A k_lms
|
||||
## 000012.1476370516.png
|
||||

|
||||
|
||||
pond with waterlillies -s 50 -S 1476370516 -W 512 -H 512 -C 7.5 -A k_lms
|
||||
## 000013.4281108706.png
|
||||

|
||||
|
||||
banana sushi -s 50 -S 4281108706 -W 960 -H 960 -C 7.5 -A k_lms
|
||||
## 000014.2396987386.png
|
||||

|
||||
|
||||
old sea captain with crow on shoulder -s 50 -S 2396987386 -W 512 -H 512 -C 7.5 -I docs/assets/preflight-checks/inputs/Lincoln-and-Parrot-512.png -A k_lms -f 0.75
|
||||
## 000015.1252923272.png
|
||||

|
||||
|
||||
old sea captain with crow on shoulder -s 50 -S 1252923272 -W 512 -H 512 -C 7.5 -I docs/assets/preflight-checks/inputs/Lincoln-and-Parrot-512-transparent.png -A k_lms -f 0.75
|
||||
## 000016.2633891320.png
|
||||

|
||||
|
||||
old sea captain with crow on shoulder -s 50 -S 2633891320 -W 512 -H 512 -C 7.5 -I docs/assets/preflight-checks/inputs/Lincoln-and-Parrot-512.png -A plms -f 0.75
|
||||
## 000017.1134411920.png
|
||||

|
||||
|
||||
old sea captain with crow on shoulder -s 50 -S 1134411920 -W 512 -H 512 -C 7.5 -I docs/assets/preflight-checks/inputs/Lincoln-and-Parrot-512.png -A k_euler_a -f 0.75
|
||||
## 000018.47.png
|
||||

|
||||
|
||||
big red dog playing with cat -s 50 -S 47 -W 512 -H 512 -C 7.5 -A k_lms
|
||||
## 000019.47.png
|
||||

|
||||
|
||||
big red++++ dog playing with cat -s 50 -S 47 -W 512 -H 512 -C 7.5 -A k_lms
|
||||
## 000020.47.png
|
||||

|
||||
|
||||
big red dog playing with cat+++ -s 50 -S 47 -W 512 -H 512 -C 7.5 -A k_lms
|
||||
## 000021.47.png
|
||||

|
||||
|
||||
big (red dog).swap(tiger) playing with cat -s 50 -S 47 -W 512 -H 512 -C 7.5 -A k_lms
|
||||
## 000022.47.png
|
||||

|
||||
|
||||
dog:1,cat:2 -s 50 -S 47 -W 512 -H 512 -C 7.5 -A k_lms
|
||||
## 000023.47.png
|
||||

|
||||
|
||||
dog:2,cat:1 -s 50 -S 47 -W 512 -H 512 -C 7.5 -A k_lms
|
||||
## 000024.1029061431.png
|
||||

|
||||
|
||||
medusa with cobras -s 50 -S 1029061431 -W 512 -H 512 -C 7.5 -I docs/assets/preflight-checks/inputs/curly.png -A k_lms -f 0.75 -tm hair
|
||||
## 000025.1284519352.png
|
||||

|
||||
|
||||
bearded man -s 50 -S 1284519352 -W 512 -H 512 -C 7.5 -I docs/assets/preflight-checks/inputs/curly.png -A k_lms -f 0.75 -tm face
|
||||
## curly.942491079.gfpgan.png
|
||||

|
||||
|
||||
!fix ./docs/assets/preflight-checks/inputs/curly.png -s 50 -S 942491079 -W 512 -H 512 -C 7.5 -A k_lms -G 0.8 -ft gfpgan -U 2.0 0.75
|
||||
## curly.942491079.outcrop.png
|
||||

|
||||
|
||||
!fix ./docs/assets/preflight-checks/inputs/curly.png -s 50 -S 942491079 -W 512 -H 512 -C 7.5 -A k_lms -c top 64
|
||||
## curly.942491079.outpaint.png
|
||||

|
||||
|
||||
!fix ./docs/assets/preflight-checks/inputs/curly.png -s 50 -S 942491079 -W 512 -H 512 -C 7.5 -A k_lms -D top 64
|
||||
## curly.942491079.outcrop-01.png
|
||||

|
||||
|
||||
!fix ./docs/assets/preflight-checks/inputs/curly.png -s 50 -S 942491079 -W 512 -H 512 -C 7.5 -A k_lms -c top 64
|
||||
@@ -1,29 +0,0 @@
|
||||
outputs/preflight/000001.1863159593.png: banana sushi -s 50 -S 1863159593 -W 512 -H 512 -C 7.5 -A k_lms
|
||||
outputs/preflight/000002.1151955949.png: banana sushi -s 50 -S 1151955949 -W 512 -H 512 -C 7.5 -A plms
|
||||
outputs/preflight/000003.2736230502.png: banana sushi -s 50 -S 2736230502 -W 512 -H 512 -C 7.5 -A ddim
|
||||
outputs/preflight/000004.42.png: banana sushi -s 50 -S 42 -W 512 -H 512 -C 7.5 -A k_lms
|
||||
outputs/preflight/000005.42.png: banana sushi -s 50 -S 42 -W 512 -H 512 -C 7.5 -A k_lms
|
||||
outputs/preflight/000006.478163327.png: banana sushi -s 50 -S 478163327 -W 640 -H 448 -C 7.5 -A k_lms
|
||||
outputs/preflight/000007.2407640369.png: banana sushi -s 50 -S 42 -W 512 -H 512 -C 7.5 -A k_lms -V 2407640369:0.1
|
||||
outputs/preflight/000008.2772421987.png: banana sushi -s 50 -S 42 -W 512 -H 512 -C 7.5 -A k_lms -V 2772421987:0.1
|
||||
outputs/preflight/000009.3532317557.png: banana sushi -s 50 -S 42 -W 512 -H 512 -C 7.5 -A k_lms -V 3532317557:0.1
|
||||
outputs/preflight/000010.2028635318.png: banana sushi -s 50 -S 2028635318 -W 512 -H 512 -C 7.5 -A k_lms
|
||||
outputs/preflight/000011.1111168647.png: pond with waterlillies -s 50 -S 1111168647 -W 512 -H 512 -C 7.5 -A k_lms
|
||||
outputs/preflight/000012.1476370516.png: pond with waterlillies -s 50 -S 1476370516 -W 512 -H 512 -C 7.5 -A k_lms
|
||||
outputs/preflight/000013.4281108706.png: banana sushi -s 50 -S 4281108706 -W 960 -H 960 -C 7.5 -A k_lms
|
||||
outputs/preflight/000014.2396987386.png: old sea captain with crow on shoulder -s 50 -S 2396987386 -W 512 -H 512 -C 7.5 -I docs/assets/preflight-checks/inputs/Lincoln-and-Parrot-512.png -A k_lms -f 0.75
|
||||
outputs/preflight/000015.1252923272.png: old sea captain with crow on shoulder -s 50 -S 1252923272 -W 512 -H 512 -C 7.5 -I docs/assets/preflight-checks/inputs/Lincoln-and-Parrot-512-transparent.png -A k_lms -f 0.75
|
||||
outputs/preflight/000016.2633891320.png: old sea captain with crow on shoulder -s 50 -S 2633891320 -W 512 -H 512 -C 7.5 -I docs/assets/preflight-checks/inputs/Lincoln-and-Parrot-512.png -A plms -f 0.75
|
||||
outputs/preflight/000017.1134411920.png: old sea captain with crow on shoulder -s 50 -S 1134411920 -W 512 -H 512 -C 7.5 -I docs/assets/preflight-checks/inputs/Lincoln-and-Parrot-512.png -A k_euler_a -f 0.75
|
||||
outputs/preflight/000018.47.png: big red dog playing with cat -s 50 -S 47 -W 512 -H 512 -C 7.5 -A k_lms
|
||||
outputs/preflight/000019.47.png: big red++++ dog playing with cat -s 50 -S 47 -W 512 -H 512 -C 7.5 -A k_lms
|
||||
outputs/preflight/000020.47.png: big red dog playing with cat+++ -s 50 -S 47 -W 512 -H 512 -C 7.5 -A k_lms
|
||||
outputs/preflight/000021.47.png: big (red dog).swap(tiger) playing with cat -s 50 -S 47 -W 512 -H 512 -C 7.5 -A k_lms
|
||||
outputs/preflight/000022.47.png: dog:1,cat:2 -s 50 -S 47 -W 512 -H 512 -C 7.5 -A k_lms
|
||||
outputs/preflight/000023.47.png: dog:2,cat:1 -s 50 -S 47 -W 512 -H 512 -C 7.5 -A k_lms
|
||||
outputs/preflight/000024.1029061431.png: medusa with cobras -s 50 -S 1029061431 -W 512 -H 512 -C 7.5 -I docs/assets/preflight-checks/inputs/curly.png -A k_lms -f 0.75 -tm hair
|
||||
outputs/preflight/000025.1284519352.png: bearded man -s 50 -S 1284519352 -W 512 -H 512 -C 7.5 -I docs/assets/preflight-checks/inputs/curly.png -A k_lms -f 0.75 -tm face
|
||||
outputs/preflight/curly.942491079.gfpgan.png: !fix ./docs/assets/preflight-checks/inputs/curly.png -s 50 -S 942491079 -W 512 -H 512 -C 7.5 -A k_lms -G 0.8 -ft gfpgan -U 2.0 0.75
|
||||
outputs/preflight/curly.942491079.outcrop.png: !fix ./docs/assets/preflight-checks/inputs/curly.png -s 50 -S 942491079 -W 512 -H 512 -C 7.5 -A k_lms -c top 64
|
||||
outputs/preflight/curly.942491079.outpaint.png: !fix ./docs/assets/preflight-checks/inputs/curly.png -s 50 -S 942491079 -W 512 -H 512 -C 7.5 -A k_lms -D top 64
|
||||
outputs/preflight/curly.942491079.outcrop-01.png: !fix ./docs/assets/preflight-checks/inputs/curly.png -s 50 -S 942491079 -W 512 -H 512 -C 7.5 -A k_lms -c top 64
|
||||
@@ -1,61 +0,0 @@
|
||||
# outputs/preflight/000001.1863159593.png
|
||||
banana sushi -s 50 -S 1863159593 -W 512 -H 512 -C 7.5 -A k_lms
|
||||
# outputs/preflight/000002.1151955949.png
|
||||
banana sushi -s 50 -S 1151955949 -W 512 -H 512 -C 7.5 -A plms
|
||||
# outputs/preflight/000003.2736230502.png
|
||||
banana sushi -s 50 -S 2736230502 -W 512 -H 512 -C 7.5 -A ddim
|
||||
# outputs/preflight/000004.42.png
|
||||
banana sushi -s 50 -S 42 -W 512 -H 512 -C 7.5 -A k_lms
|
||||
# outputs/preflight/000005.42.png
|
||||
banana sushi -s 50 -S 42 -W 512 -H 512 -C 7.5 -A k_lms
|
||||
# outputs/preflight/000006.478163327.png
|
||||
banana sushi -s 50 -S 478163327 -W 640 -H 448 -C 7.5 -A k_lms
|
||||
# outputs/preflight/000007.2407640369.png
|
||||
banana sushi -s 50 -S 42 -W 512 -H 512 -C 7.5 -A k_lms -V 2407640369:0.1
|
||||
# outputs/preflight/000007.2772421987.png
|
||||
banana sushi -s 50 -S 42 -W 512 -H 512 -C 7.5 -A k_lms -V 2772421987:0.1
|
||||
# outputs/preflight/000007.3532317557.png
|
||||
banana sushi -s 50 -S 42 -W 512 -H 512 -C 7.5 -A k_lms -V 3532317557:0.1
|
||||
# outputs/preflight/000008.2028635318.png
|
||||
banana sushi -s 50 -S 2028635318 -W 512 -H 512 -C 7.5 -A k_lms
|
||||
# outputs/preflight/000009.1111168647.png
|
||||
pond with waterlillies -s 50 -S 1111168647 -W 512 -H 512 -C 7.5 -A k_lms
|
||||
# outputs/preflight/000010.1476370516.png
|
||||
pond with waterlillies -s 50 -S 1476370516 -W 512 -H 512 -C 7.5 -A k_lms --seamless
|
||||
# outputs/preflight/000011.4281108706.png
|
||||
banana sushi -s 50 -S 4281108706 -W 960 -H 960 -C 7.5 -A k_lms
|
||||
# outputs/preflight/000012.2396987386.png
|
||||
old sea captain with crow on shoulder -s 50 -S 2396987386 -W 512 -H 512 -C 7.5 -I docs/assets/preflight-checks/inputs/Lincoln-and-Parrot-512.png -A k_lms -f 0.75
|
||||
# outputs/preflight/000013.1252923272.png
|
||||
old sea captain with crow on shoulder -s 50 -S 1252923272 -W 512 -H 512 -C 7.5 -I docs/assets/preflight-checks/inputs/Lincoln-and-Parrot-512-transparent.png -A k_lms -f 0.75
|
||||
# outputs/preflight/000014.2633891320.png
|
||||
old sea captain with crow on shoulder -s 50 -S 2633891320 -W 512 -H 512 -C 7.5 -I docs/assets/preflight-checks/inputs/Lincoln-and-Parrot-512.png -A plms -f 0.75
|
||||
# outputs/preflight/000015.1134411920.png
|
||||
old sea captain with crow on shoulder -s 50 -S 1134411920 -W 512 -H 512 -C 7.5 -I docs/assets/preflight-checks/inputs/Lincoln-and-Parrot-512.png -A k_euler_a -f 0.75
|
||||
# outputs/preflight/000016.42.png
|
||||
big red dog playing with cat -s 50 -S 47 -W 512 -H 512 -C 7.5 -A k_lms
|
||||
# outputs/preflight/000017.42.png
|
||||
big red++++ dog playing with cat -s 50 -S 47 -W 512 -H 512 -C 7.5 -A k_lms
|
||||
# outputs/preflight/000018.42.png
|
||||
big red dog playing with cat+++ -s 50 -S 47 -W 512 -H 512 -C 7.5 -A k_lms
|
||||
# outputs/preflight/000019.42.png
|
||||
big (red dog).swap(tiger) playing with cat -s 50 -S 47 -W 512 -H 512 -C 7.5 -A k_lms
|
||||
# outputs/preflight/000020.42.png
|
||||
dog:1,cat:2 -s 50 -S 47 -W 512 -H 512 -C 7.5 -A k_lms
|
||||
# outputs/preflight/000021.42.png
|
||||
dog:2,cat:1 -s 50 -S 47 -W 512 -H 512 -C 7.5 -A k_lms
|
||||
# outputs/preflight/000022.1029061431.png
|
||||
medusa with cobras -s 50 -S 1029061431 -W 512 -H 512 -C 7.5 -I docs/assets/preflight-checks/inputs/curly.png -A k_lms -f 0.75 -tm hair
|
||||
# outputs/preflight/000023.1284519352.png
|
||||
bearded man -s 50 -S 1284519352 -W 512 -H 512 -C 7.5 -I docs/assets/preflight-checks/inputs/curly.png -A k_lms -f 0.75 -tm face
|
||||
# outputs/preflight/000024.curly.hair.deselected.png
|
||||
!mask -I docs/assets/preflight-checks/inputs/curly.png -tm hair
|
||||
# outputs/preflight/curly.942491079.gfpgan.png
|
||||
!fix ./docs/assets/preflight-checks/inputs/curly.png -U2 -G0.8
|
||||
# outputs/preflight/curly.942491079.outcrop.png
|
||||
!fix ./docs/assets/preflight-checks/inputs/curly.png -c top 64
|
||||
# outputs/preflight/curly.942491079.outpaint.png
|
||||
!fix ./docs/assets/preflight-checks/inputs/curly.png -D top 64
|
||||
# outputs/preflight/curly.942491079.outcrop-01.png
|
||||
!switch inpainting-1.5
|
||||
!fix ./docs/assets/preflight-checks/inputs/curly.png -c top 64
|
||||
BIN
docs/assets/textual-inversion/ti-frontend.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 124 KiB |
93
docs/contributing/ARCHITECTURE.md
Normal file
@@ -0,0 +1,93 @@
|
||||
# Invoke.AI Architecture
|
||||
|
||||
```mermaid
|
||||
flowchart TB
|
||||
|
||||
subgraph apps[Applications]
|
||||
webui[WebUI]
|
||||
cli[CLI]
|
||||
|
||||
subgraph webapi[Web API]
|
||||
api[HTTP API]
|
||||
sio[Socket.IO]
|
||||
end
|
||||
|
||||
end
|
||||
|
||||
subgraph invoke[Invoke]
|
||||
direction LR
|
||||
invoker
|
||||
services
|
||||
sessions
|
||||
invocations
|
||||
end
|
||||
|
||||
subgraph core[AI Core]
|
||||
Generate
|
||||
end
|
||||
|
||||
webui --> webapi
|
||||
webapi --> invoke
|
||||
cli --> invoke
|
||||
|
||||
invoker --> services & sessions
|
||||
invocations --> services
|
||||
sessions --> invocations
|
||||
|
||||
services --> core
|
||||
|
||||
%% Styles
|
||||
classDef sg fill:#5028C8,font-weight:bold,stroke-width:2,color:#fff,stroke:#14141A
|
||||
classDef default stroke-width:2px,stroke:#F6B314,color:#fff,fill:#14141A
|
||||
|
||||
class apps,webapi,invoke,core sg
|
||||
|
||||
```
|
||||
|
||||
## Applications
|
||||
|
||||
Applications are built on top of the invoke framework. They should construct `invoker` and then interact through it. They should avoid interacting directly with core code in order to support a variety of configurations.
|
||||
|
||||
### Web UI
|
||||
|
||||
The Web UI is built on top of an HTTP API built with [FastAPI](https://fastapi.tiangolo.com/) and [Socket.IO](https://socket.io/). The frontend code is found in `/frontend` and the backend code is found in `/ldm/invoke/app/api_app.py` and `/ldm/invoke/app/api/`. The code is further organized as such:
|
||||
|
||||
| Component | Description |
|
||||
| --- | --- |
|
||||
| api_app.py | Sets up the API app, annotates the OpenAPI spec with additional data, and runs the API |
|
||||
| dependencies | Creates all invoker services and the invoker, and provides them to the API |
|
||||
| events | An eventing system that could in the future be adapted to support horizontal scale-out |
|
||||
| sockets | The Socket.IO interface - handles listening to and emitting session events (events are defined in the events service module) |
|
||||
| routers | API definitions for different areas of API functionality |
|
||||
|
||||
### CLI
|
||||
|
||||
The CLI is built automatically from invocation metadata, and also supports invocation piping and auto-linking. Code is available in `/ldm/invoke/app/cli_app.py`.
|
||||
|
||||
## Invoke
|
||||
|
||||
The Invoke framework provides the interface to the underlying AI systems and is built with flexibility and extensibility in mind. There are four major concepts: invoker, sessions, invocations, and services.
|
||||
|
||||
### Invoker
|
||||
|
||||
The invoker (`/ldm/invoke/app/services/invoker.py`) is the primary interface through which applications interact with the framework. Its primary purpose is to create, manage, and invoke sessions. It also maintains two sets of services:
|
||||
- **invocation services**, which are used by invocations to interact with core functionality.
|
||||
- **invoker services**, which are used by the invoker to manage sessions and manage the invocation queue.
|
||||
|
||||
### Sessions
|
||||
|
||||
Invocations and links between them form a graph, which is maintained in a session. Sessions can be queued for invocation, which will execute their graph (either the next ready invocation, or all invocations). Sessions also maintain execution history for the graph (including storage of any outputs). An invocation may be added to a session at any time, and there is capability to add and entire graph at once, as well as to automatically link new invocations to previous invocations. Invocations can not be deleted or modified once added.
|
||||
|
||||
The session graph does not support looping. This is left as an application problem to prevent additional complexity in the graph.
|
||||
|
||||
### Invocations
|
||||
|
||||
Invocations represent individual units of execution, with inputs and outputs. All invocations are located in `/ldm/invoke/app/invocations`, and are all automatically discovered and made available in the applications. These are the primary way to expose new functionality in Invoke.AI, and the [implementation guide](INVOCATIONS.md) explains how to add new invocations.
|
||||
|
||||
### Services
|
||||
|
||||
Services provide invocations access AI Core functionality and other necessary functionality (e.g. image storage). These are available in `/ldm/invoke/app/services`. As a general rule, new services should provide an interface as an abstract base class, and may provide a lightweight local implementation by default in their module. The goal for all services should be to enable the usage of different implementations (e.g. using cloud storage for image storage), but should not load any module dependencies unless that implementation has been used (i.e. don't import anything that won't be used, especially if it's expensive to import).
|
||||
|
||||
## AI Core
|
||||
|
||||
The AI Core is represented by the rest of the code base (i.e. the code outside of `/ldm/invoke/app/`).
|
||||
105
docs/contributing/INVOCATIONS.md
Normal file
@@ -0,0 +1,105 @@
|
||||
# Invocations
|
||||
|
||||
Invocations represent a single operation, its inputs, and its outputs. These operations and their outputs can be chained together to generate and modify images.
|
||||
|
||||
## Creating a new invocation
|
||||
|
||||
To create a new invocation, either find the appropriate module file in `/ldm/invoke/app/invocations` to add your invocation to, or create a new one in that folder. All invocations in that folder will be discovered and made available to the CLI and API automatically. Invocations make use of [typing](https://docs.python.org/3/library/typing.html) and [pydantic](https://pydantic-docs.helpmanual.io/) for validation and integration into the CLI and API.
|
||||
|
||||
An invocation looks like this:
|
||||
|
||||
```py
|
||||
class UpscaleInvocation(BaseInvocation):
|
||||
"""Upscales an image."""
|
||||
type: Literal['upscale'] = 'upscale'
|
||||
|
||||
# Inputs
|
||||
image: Union[ImageField,None] = Field(description="The input image")
|
||||
strength: float = Field(default=0.75, gt=0, le=1, description="The strength")
|
||||
level: Literal[2,4] = Field(default=2, description = "The upscale level")
|
||||
|
||||
def invoke(self, context: InvocationContext) -> ImageOutput:
|
||||
image = context.services.images.get(self.image.image_type, self.image.image_name)
|
||||
results = context.services.generate.upscale_and_reconstruct(
|
||||
image_list = [[image, 0]],
|
||||
upscale = (self.level, self.strength),
|
||||
strength = 0.0, # GFPGAN strength
|
||||
save_original = False,
|
||||
image_callback = None,
|
||||
)
|
||||
|
||||
# Results are image and seed, unwrap for now
|
||||
# TODO: can this return multiple results?
|
||||
image_type = ImageType.RESULT
|
||||
image_name = context.services.images.create_name(context.graph_execution_state_id, self.id)
|
||||
context.services.images.save(image_type, image_name, results[0][0])
|
||||
return ImageOutput(
|
||||
image = ImageField(image_type = image_type, image_name = image_name)
|
||||
)
|
||||
```
|
||||
|
||||
Each portion is important to implement correctly.
|
||||
|
||||
### Class definition and type
|
||||
```py
|
||||
class UpscaleInvocation(BaseInvocation):
|
||||
"""Upscales an image."""
|
||||
type: Literal['upscale'] = 'upscale'
|
||||
```
|
||||
All invocations must derive from `BaseInvocation`. They should have a docstring that declares what they do in a single, short line. They should also have a `type` with a type hint that's `Literal["command_name"]`, where `command_name` is what the user will type on the CLI or use in the API to create this invocation. The `command_name` must be unique. The `type` must be assigned to the value of the literal in the type hint.
|
||||
|
||||
### Inputs
|
||||
```py
|
||||
# Inputs
|
||||
image: Union[ImageField,None] = Field(description="The input image")
|
||||
strength: float = Field(default=0.75, gt=0, le=1, description="The strength")
|
||||
level: Literal[2,4] = Field(default=2, description="The upscale level")
|
||||
```
|
||||
Inputs consist of three parts: a name, a type hint, and a `Field` with default, description, and validation information. For example:
|
||||
| Part | Value | Description |
|
||||
| ---- | ----- | ----------- |
|
||||
| Name | `strength` | This field is referred to as `strength` |
|
||||
| Type Hint | `float` | This field must be of type `float` |
|
||||
| Field | `Field(default=0.75, gt=0, le=1, description="The strength")` | The default value is `0.75`, the value must be in the range (0,1], and help text will show "The strength" for this field. |
|
||||
|
||||
Notice that `image` has type `Union[ImageField,None]`. The `Union` allows this field to be parsed with `None` as a value, which enables linking to previous invocations. All fields should either provide a default value or allow `None` as a value, so that they can be overwritten with a linked output from another invocation.
|
||||
|
||||
The special type `ImageField` is also used here. All images are passed as `ImageField`, which protects them from pydantic validation errors (since images only ever come from links).
|
||||
|
||||
Finally, note that for all linking, the `type` of the linked fields must match. If the `name` also matches, then the field can be **automatically linked** to a previous invocation by name and matching.
|
||||
|
||||
### Invoke Function
|
||||
```py
|
||||
def invoke(self, context: InvocationContext) -> ImageOutput:
|
||||
image = context.services.images.get(self.image.image_type, self.image.image_name)
|
||||
results = context.services.generate.upscale_and_reconstruct(
|
||||
image_list = [[image, 0]],
|
||||
upscale = (self.level, self.strength),
|
||||
strength = 0.0, # GFPGAN strength
|
||||
save_original = False,
|
||||
image_callback = None,
|
||||
)
|
||||
|
||||
# Results are image and seed, unwrap for now
|
||||
image_type = ImageType.RESULT
|
||||
image_name = context.services.images.create_name(context.graph_execution_state_id, self.id)
|
||||
context.services.images.save(image_type, image_name, results[0][0])
|
||||
return ImageOutput(
|
||||
image = ImageField(image_type = image_type, image_name = image_name)
|
||||
)
|
||||
```
|
||||
The `invoke` function is the last portion of an invocation. It is provided an `InvocationContext` which contains services to perform work as well as a `session_id` for use as needed. It should return a class with output values that derives from `BaseInvocationOutput`.
|
||||
|
||||
Before being called, the invocation will have all of its fields set from defaults, inputs, and finally links (overriding in that order).
|
||||
|
||||
Assume that this invocation may be running simultaneously with other invocations, may be running on another machine, or in other interesting scenarios. If you need functionality, please provide it as a service in the `InvocationServices` class, and make sure it can be overridden.
|
||||
|
||||
### Outputs
|
||||
```py
|
||||
class ImageOutput(BaseInvocationOutput):
|
||||
"""Base class for invocations that output an image"""
|
||||
type: Literal['image'] = 'image'
|
||||
|
||||
image: ImageField = Field(default=None, description="The output image")
|
||||
```
|
||||
Output classes look like an invocation class without the invoke method. Prefer to use an existing output class if available, and prefer to name inputs the same as outputs when possible, to promote automatic invocation linking.
|
||||
@@ -1,45 +1,56 @@
|
||||
---
|
||||
title: CLI
|
||||
hide:
|
||||
- toc
|
||||
title: Command-Line Interface
|
||||
---
|
||||
|
||||
# :material-bash: CLI
|
||||
|
||||
## **Interactive Command Line Interface**
|
||||
|
||||
The `invoke.py` script, located in `scripts/`, provides an interactive
|
||||
interface to image generation similar to the "invoke mothership" bot that Stable
|
||||
AI provided on its Discord server.
|
||||
The InvokeAI command line interface (CLI) provides scriptable access
|
||||
to InvokeAI's features.Some advanced features are only available
|
||||
through the CLI, though they eventually find their way into the WebUI.
|
||||
|
||||
Unlike the `txt2img.py` and `img2img.py` scripts provided in the original
|
||||
[CompVis/stable-diffusion](https://github.com/CompVis/stable-diffusion) source
|
||||
code repository, the time-consuming initialization of the AI model
|
||||
initialization only happens once. After that image generation from the
|
||||
command-line interface is very fast.
|
||||
The CLI is accessible from the `invoke.sh`/`invoke.bat` launcher by
|
||||
selecting option (1). Alternatively, it can be launched directly from
|
||||
the command line by activating the InvokeAI environment and giving the
|
||||
command:
|
||||
|
||||
```bash
|
||||
invokeai
|
||||
```
|
||||
|
||||
After some startup messages, you will be presented with the `invoke> `
|
||||
prompt. Here you can type prompts to generate images and issue other
|
||||
commands to load and manipulate generative models. The CLI has a large
|
||||
number of command-line options that control its behavior. To get a
|
||||
concise summary of the options, call `invokeai` with the `--help` argument:
|
||||
|
||||
```bash
|
||||
invokeai --help
|
||||
```
|
||||
|
||||
The script uses the readline library to allow for in-line editing, command
|
||||
history (++up++ and ++down++), autocompletion, and more. To help keep track of
|
||||
which prompts generated which images, the script writes a log file of image
|
||||
names and prompts to the selected output directory.
|
||||
|
||||
In addition, as of version 1.02, it also writes the prompt into the PNG file's
|
||||
metadata where it can be retrieved using `scripts/images2prompt.py`
|
||||
|
||||
The script is confirmed to work on Linux, Windows and Mac systems.
|
||||
|
||||
!!! note
|
||||
|
||||
This script runs from the command-line or can be used as a Web application. The Web GUI is
|
||||
currently rudimentary, but a much better replacement is on its way.
|
||||
Here is a typical session
|
||||
|
||||
```bash
|
||||
(invokeai) ~/stable-diffusion$ python3 ./scripts/invoke.py
|
||||
PS1:C:\Users\fred> invokeai
|
||||
* Initializing, be patient...
|
||||
Loading model from models/ldm/text2img-large/model.ckpt
|
||||
(...more initialization messages...)
|
||||
|
||||
* Initialization done! Awaiting your command...
|
||||
* Initializing, be patient...
|
||||
>> Initialization file /home/lstein/invokeai/invokeai.init found. Loading...
|
||||
>> Internet connectivity is True
|
||||
>> InvokeAI, version 2.3.0-rc5
|
||||
>> InvokeAI runtime directory is "/home/lstein/invokeai"
|
||||
>> GFPGAN Initialized
|
||||
>> CodeFormer Initialized
|
||||
>> ESRGAN Initialized
|
||||
>> Using device_type cuda
|
||||
>> xformers memory-efficient attention is available and enabled
|
||||
(...more initialization messages...)
|
||||
* Initialization done! Awaiting your command (-h for help, 'q' to quit)
|
||||
invoke> ashley judd riding a camel -n2 -s150
|
||||
Outputs:
|
||||
outputs/img-samples/00009.png: "ashley judd riding a camel" -n2 -s150 -S 416354203
|
||||
@@ -49,33 +60,22 @@ invoke> "there's a fly in my soup" -n6 -g
|
||||
outputs/img-samples/00011.png: "there's a fly in my soup" -n6 -g -S 2685670268
|
||||
seeds for individual rows: [2685670268, 1216708065, 2335773498, 822223658, 714542046, 3395302430]
|
||||
invoke> q
|
||||
|
||||
# this shows how to retrieve the prompt stored in the saved image's metadata
|
||||
(invokeai) ~/stable-diffusion$ python ./scripts/images2prompt.py outputs/img_samples/*.png
|
||||
00009.png: "ashley judd riding a camel" -s150 -S 416354203
|
||||
00010.png: "ashley judd riding a camel" -s150 -S 1362479620
|
||||
00011.png: "there's a fly in my soup" -n6 -g -S 2685670268
|
||||
```
|
||||
|
||||

|
||||
|
||||
The `invoke>` prompt's arguments are pretty much identical to those used in the
|
||||
Discord bot, except you don't need to type `!invoke` (it doesn't hurt if you do).
|
||||
A significant change is that creation of individual images is now the default
|
||||
unless `--grid` (`-g`) is given. A full list is given in
|
||||
[List of prompt arguments](#list-of-prompt-arguments).
|
||||
|
||||
## Arguments
|
||||
|
||||
The script itself also recognizes a series of command-line switches that will
|
||||
change important global defaults, such as the directory for image outputs and
|
||||
the location of the model weight files.
|
||||
The script recognizes a series of command-line switches that will
|
||||
change important global defaults, such as the directory for image
|
||||
outputs and the location of the model weight files.
|
||||
|
||||
### List of arguments recognized at the command line
|
||||
|
||||
These command-line arguments can be passed to `invoke.py` when you first run it
|
||||
from the Windows, Mac or Linux command line. Some set defaults that can be
|
||||
overridden on a per-prompt basis (see [List of prompt arguments](#list-of-prompt-arguments). Others
|
||||
overridden on a per-prompt basis (see
|
||||
[List of prompt arguments](#list-of-prompt-arguments). Others
|
||||
|
||||
| Argument <img width="240" align="right"/> | Shortcut <img width="100" align="right"/> | Default <img width="320" align="right"/> | Description |
|
||||
| ----------------------------------------- | ----------------------------------------- | ---------------------------------------------- | ---------------------------------------------------------------------------------------------------- |
|
||||
@@ -83,21 +83,28 @@ overridden on a per-prompt basis (see [List of prompt arguments](#list-of-prompt
|
||||
| `--outdir <path>` | `-o<path>` | `outputs/img_samples` | Location for generated images. |
|
||||
| `--prompt_as_dir` | `-p` | `False` | Name output directories using the prompt text. |
|
||||
| `--from_file <path>` | | `None` | Read list of prompts from a file. Use `-` to read from standard input |
|
||||
| `--model <modelname>` | | `stable-diffusion-1.4` | Loads model specified in configs/models.yaml. Currently one of "stable-diffusion-1.4" or "laion400m" |
|
||||
| `--full_precision` | `-F` | `False` | Run in slower full-precision mode. Needed for Macintosh M1/M2 hardware and some older video cards. |
|
||||
| `--png_compression <0-9>` | `-z<0-9>` | 6 | Select level of compression for output files, from 0 (no compression) to 9 (max compression) |
|
||||
| `--safety-checker` | | False | Activate safety checker for NSFW and other potentially disturbing imagery |
|
||||
| `--model <modelname>` | | `stable-diffusion-1.5` | Loads the initial model specified in configs/models.yaml. |
|
||||
| `--ckpt_convert ` | | `False` | If provided both .ckpt and .safetensors files will be auto-converted into diffusers format in memory |
|
||||
| `--autoconvert <path>` | | `None` | On startup, scan the indicated directory for new .ckpt/.safetensor files and automatically convert and import them |
|
||||
| `--precision` | | `fp16` | Provide `fp32` for full precision mode, `fp16` for half-precision. `fp32` needed for Macintoshes and some NVidia cards. |
|
||||
| `--png_compression <0-9>` | `-z<0-9>` | `6` | Select level of compression for output files, from 0 (no compression) to 9 (max compression) |
|
||||
| `--safety-checker` | | `False` | Activate safety checker for NSFW and other potentially disturbing imagery |
|
||||
| `--patchmatch`, `--no-patchmatch` | | `--patchmatch` | Load/Don't load the PatchMatch inpainting extension |
|
||||
| `--xformers`, `--no-xformers` | | `--xformers` | Load/Don't load the Xformers memory-efficient attention module (CUDA only) |
|
||||
| `--web` | | `False` | Start in web server mode |
|
||||
| `--host <ip addr>` | | `localhost` | Which network interface web server should listen on. Set to 0.0.0.0 to listen on any. |
|
||||
| `--port <port>` | | `9090` | Which port web server should listen for requests on. |
|
||||
| `--config <path>` | | `configs/models.yaml` | Configuration file for models and their weights. |
|
||||
| `--iterations <int>` | `-n<int>` | `1` | How many images to generate per prompt. |
|
||||
| `--width <int>` | `-W<int>` | `512` | Width of generated image |
|
||||
| `--height <int>` | `-H<int>` | `512` | Height of generated image | `--steps <int>` | `-s<int>` | `50` | How many steps of refinement to apply |
|
||||
| `--strength <float>` | `-s<float>` | `0.75` | For img2img: how hard to try to match the prompt to the initial image. Ranges from 0.0-0.99, with higher values replacing the initial image completely. |
|
||||
| `--fit` | `-F` | `False` | For img2img: scale the init image to fit into the specified -H and -W dimensions |
|
||||
| `--grid` | `-g` | `False` | Save all image series as a grid rather than individually. |
|
||||
| `--sampler <sampler>` | `-A<sampler>` | `k_lms` | Sampler to use. Use `-h` to get list of available samplers. |
|
||||
| `--seamless` | | `False` | Create interesting effects by tiling elements of the image. |
|
||||
| `--embedding_path <path>` | | `None` | Path to pre-trained embedding manager checkpoints, for custom models |
|
||||
| `--gfpgan_dir` | | `src/gfpgan` | Path to where GFPGAN is installed. |
|
||||
| `--gfpgan_model_path` | | `experiments/pretrained_models/GFPGANv1.4.pth` | Path to GFPGAN model file, relative to `--gfpgan_dir`. |
|
||||
| `--gfpgan_model_path` | | `experiments/pretrained_models/GFPGANv1.4.pth` | Path to GFPGAN model file. |
|
||||
| `--free_gpu_mem` | | `False` | Free GPU memory after sampling, to allow image decoding and saving in low VRAM conditions |
|
||||
| `--precision` | | `auto` | Set model precision, default is selected by device. Options: auto, float32, float16, autocast |
|
||||
|
||||
@@ -107,7 +114,8 @@ overridden on a per-prompt basis (see [List of prompt arguments](#list-of-prompt
|
||||
|
||||
| Argument | Shortcut | Default | Description |
|
||||
|--------------------|------------|---------------------|--------------|
|
||||
| `--weights <path>` | | `None` | Pth to weights file; use `--model stable-diffusion-1.4` instead |
|
||||
| `--full_precision` | | `False` | Same as `--precision=fp32`|
|
||||
| `--weights <path>` | | `None` | Path to weights file; use `--model stable-diffusion-1.4` instead |
|
||||
| `--laion400m` | `-l` | `False` | Use older LAION400m weights; use `--model=laion400m` instead |
|
||||
|
||||
</div>
|
||||
@@ -120,11 +128,48 @@ overridden on a per-prompt basis (see [List of prompt arguments](#list-of-prompt
|
||||
You can either double your slashes (ick): `C:\\path\\to\\my\\file`, or
|
||||
use Linux/Mac style forward slashes (better): `C:/path/to/my/file`.
|
||||
|
||||
## The .invokeai initialization file
|
||||
|
||||
To start up invoke.py with your preferred settings, place your desired
|
||||
startup options in a file in your home directory named `.invokeai` The
|
||||
file should contain the startup options as you would type them on the
|
||||
command line (`--steps=10 --grid`), one argument per line, or a
|
||||
mixture of both using any of the accepted command switch formats:
|
||||
|
||||
!!! example "my unmodified initialization file"
|
||||
|
||||
```bash title="~/.invokeai" linenums="1"
|
||||
# InvokeAI initialization file
|
||||
# This is the InvokeAI initialization file, which contains command-line default values.
|
||||
# Feel free to edit. If anything goes wrong, you can re-initialize this file by deleting
|
||||
# or renaming it and then running invokeai-configure again.
|
||||
|
||||
# The --root option below points to the folder in which InvokeAI stores its models, configs and outputs.
|
||||
--root="/Users/mauwii/invokeai"
|
||||
|
||||
# the --outdir option controls the default location of image files.
|
||||
--outdir="/Users/mauwii/invokeai/outputs"
|
||||
|
||||
# You may place other frequently-used startup commands here, one or more per line.
|
||||
# Examples:
|
||||
# --web --host=0.0.0.0
|
||||
# --steps=20
|
||||
# -Ak_euler_a -C10.0
|
||||
```
|
||||
|
||||
!!! note
|
||||
|
||||
The initialization file only accepts the command line arguments.
|
||||
There are additional arguments that you can provide on the `invoke>` command
|
||||
line (such as `-n` or `--iterations`) that cannot be entered into this file.
|
||||
Also be alert for empty blank lines at the end of the file, which will cause
|
||||
an arguments error at startup time.
|
||||
|
||||
## List of prompt arguments
|
||||
|
||||
After the invoke.py script initializes, it will present you with a
|
||||
`invoke>` prompt. Here you can enter information to generate images
|
||||
from text ([txt2img](#txt2img)), to embellish an existing image or sketch
|
||||
After the invoke.py script initializes, it will present you with a `invoke>`
|
||||
prompt. Here you can enter information to generate images from text
|
||||
([txt2img](#txt2img)), to embellish an existing image or sketch
|
||||
([img2img](#img2img)), or to selectively alter chosen regions of the image
|
||||
([inpainting](#inpainting)).
|
||||
|
||||
@@ -141,60 +186,63 @@ from text ([txt2img](#txt2img)), to embellish an existing image or sketch
|
||||
|
||||
Here are the invoke> command that apply to txt2img:
|
||||
|
||||
| Argument <img width="680" align="right"/> | Shortcut <img width="420" align="right"/> | Default <img width="480" align="right"/> | Description |
|
||||
|--------------------|------------|---------------------|--------------|
|
||||
| "my prompt" | | | Text prompt to use. The quotation marks are optional. |
|
||||
| --width <int> | -W<int> | 512 | Width of generated image |
|
||||
| --height <int> | -H<int> | 512 | Height of generated image |
|
||||
| --iterations <int> | -n<int> | 1 | How many images to generate from this prompt |
|
||||
| --steps <int> | -s<int> | 50 | How many steps of refinement to apply |
|
||||
| --cfg_scale <float>| -C<float> | 7.5 | How hard to try to match the prompt to the generated image; any number greater than 1.0 works, but the useful range is roughly 5.0 to 20.0 |
|
||||
| --seed <int> | -S<int> | None | Set the random seed for the next series of images. This can be used to recreate an image generated previously.|
|
||||
| --sampler <sampler>| -A<sampler>| k_lms | Sampler to use. Use -h to get list of available samplers. |
|
||||
| --karras_max <int> | | 29 | When using k_* samplers, set the maximum number of steps before shifting from using the Karras noise schedule (good for low step counts) to the LatentDiffusion noise schedule (good for high step counts) This value is sticky. [29] |
|
||||
| --hires_fix | | | Larger images often have duplication artefacts. This option suppresses duplicates by generating the image at low res, and then using img2img to increase the resolution |
|
||||
| --png_compression <0-9> | -z<0-9> | 6 | Select level of compression for output files, from 0 (no compression) to 9 (max compression) |
|
||||
| --grid | -g | False | Turn on grid mode to return a single image combining all the images generated by this prompt |
|
||||
| --individual | -i | True | Turn off grid mode (deprecated; leave off --grid instead) |
|
||||
| --outdir <path> | -o<path> | outputs/img_samples | Temporarily change the location of these images |
|
||||
| --seamless | | False | Activate seamless tiling for interesting effects |
|
||||
| --seamless_axes | | x,y | Specify which axes to use circular convolution on. |
|
||||
| --log_tokenization | -t | False | Display a color-coded list of the parsed tokens derived from the prompt |
|
||||
| --skip_normalization| -x | False | Weighted subprompts will not be normalized. See [Weighted Prompts](./OTHER.md#weighted-prompts) |
|
||||
| --upscale <int> <float> | -U <int> <float> | -U 1 0.75| Upscale image by magnification factor (2, 4), and set strength of upscaling (0.0-1.0). If strength not set, will default to 0.75. |
|
||||
| --facetool_strength <float> | -G <float> | -G0 | Fix faces (defaults to using the GFPGAN algorithm); argument indicates how hard the algorithm should try (0.0-1.0) |
|
||||
| --facetool <name> | -ft <name> | -ft gfpgan | Select face restoration algorithm to use: gfpgan, codeformer |
|
||||
| --codeformer_fidelity | -cf <float> | 0.75 | Used along with CodeFormer. Takes values between 0 and 1. 0 produces high quality but low accuracy. 1 produces high accuracy but low quality |
|
||||
| --save_original | -save_orig| False | When upscaling or fixing faces, this will cause the original image to be saved rather than replaced. |
|
||||
| --variation <float> |-v<float>| 0.0 | Add a bit of noise (0.0=none, 1.0=high) to the image in order to generate a series of variations. Usually used in combination with -S<seed> and -n<int> to generate a series a riffs on a starting image. See [Variations](./VARIATIONS.md). |
|
||||
| --with_variations <pattern> | | None | Combine two or more variations. See [Variations](./VARIATIONS.md) for now to use this. |
|
||||
| --save_intermediates <n> | | None | Save the image from every nth step into an "intermediates" folder inside the output directory |
|
||||
| Argument <img width="680" align="right"/> | Shortcut <img width="420" align="right"/> | Default <img width="480" align="right"/> | Description |
|
||||
| ----------------------------------------- | ----------------------------------------- | ---------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ |
|
||||
| "my prompt" | | | Text prompt to use. The quotation marks are optional. |
|
||||
| `--width <int>` | `-W<int>` | `512` | Width of generated image |
|
||||
| `--height <int>` | `-H<int>` | `512` | Height of generated image |
|
||||
| `--iterations <int>` | `-n<int>` | `1` | How many images to generate from this prompt |
|
||||
| `--steps <int>` | `-s<int>` | `50` | How many steps of refinement to apply |
|
||||
| `--cfg_scale <float>` | `-C<float>` | `7.5` | How hard to try to match the prompt to the generated image; any number greater than 1.0 works, but the useful range is roughly 5.0 to 20.0 |
|
||||
| `--seed <int>` | `-S<int>` | `None` | Set the random seed for the next series of images. This can be used to recreate an image generated previously. |
|
||||
| `--sampler <sampler>` | `-A<sampler>` | `k_lms` | Sampler to use. Use -h to get list of available samplers. |
|
||||
| `--karras_max <int>` | | `29` | When using k\_\* samplers, set the maximum number of steps before shifting from using the Karras noise schedule (good for low step counts) to the LatentDiffusion noise schedule (good for high step counts) This value is sticky. [29] |
|
||||
| `--hires_fix` | | | Larger images often have duplication artefacts. This option suppresses duplicates by generating the image at low res, and then using img2img to increase the resolution |
|
||||
| `--png_compression <0-9>` | `-z<0-9>` | `6` | Select level of compression for output files, from 0 (no compression) to 9 (max compression) |
|
||||
| `--grid` | `-g` | `False` | Turn on grid mode to return a single image combining all the images generated by this prompt |
|
||||
| `--individual` | `-i` | `True` | Turn off grid mode (deprecated; leave off --grid instead) |
|
||||
| `--outdir <path>` | `-o<path>` | `outputs/img_samples` | Temporarily change the location of these images |
|
||||
| `--seamless` | | `False` | Activate seamless tiling for interesting effects |
|
||||
| `--seamless_axes` | | `x,y` | Specify which axes to use circular convolution on. |
|
||||
| `--log_tokenization` | `-t` | `False` | Display a color-coded list of the parsed tokens derived from the prompt |
|
||||
| `--skip_normalization` | `-x` | `False` | Weighted subprompts will not be normalized. See [Weighted Prompts](./OTHER.md#weighted-prompts) |
|
||||
| `--upscale <int> <float>` | `-U <int> <float>` | `-U 1 0.75` | Upscale image by magnification factor (2, 4), and set strength of upscaling (0.0-1.0). If strength not set, will default to 0.75. |
|
||||
| `--facetool_strength <float>` | `-G <float> ` | `-G0` | Fix faces (defaults to using the GFPGAN algorithm); argument indicates how hard the algorithm should try (0.0-1.0) |
|
||||
| `--facetool <name>` | `-ft <name>` | `-ft gfpgan` | Select face restoration algorithm to use: gfpgan, codeformer |
|
||||
| `--codeformer_fidelity` | `-cf <float>` | `0.75` | Used along with CodeFormer. Takes values between 0 and 1. 0 produces high quality but low accuracy. 1 produces high accuracy but low quality |
|
||||
| `--save_original` | `-save_orig` | `False` | When upscaling or fixing faces, this will cause the original image to be saved rather than replaced. |
|
||||
| `--variation <float>` | `-v<float>` | `0.0` | Add a bit of noise (0.0=none, 1.0=high) to the image in order to generate a series of variations. Usually used in combination with `-S<seed>` and `-n<int>` to generate a series a riffs on a starting image. See [Variations](./VARIATIONS.md). |
|
||||
| `--with_variations <pattern>` | | `None` | Combine two or more variations. See [Variations](./VARIATIONS.md) for now to use this. |
|
||||
| `--save_intermediates <n>` | | `None` | Save the image from every nth step into an "intermediates" folder inside the output directory |
|
||||
| `--h_symmetry_time_pct <float>` | | `None` | Create symmetry along the X axis at the desired percent complete of the generation process. (Must be between 0.0 and 1.0; set to a very small number like 0.0001 for just after the first step of generation.) |
|
||||
| `--v_symmetry_time_pct <float>` | | `None` | Create symmetry along the Y axis at the desired percent complete of the generation process. (Must be between 0.0 and 1.0; set to a very small number like 0.0001 for just after the first step of generation.) |
|
||||
|
||||
Note that the width and height of the image must be multiples of
|
||||
64. You can provide different values, but they will be rounded down to
|
||||
the nearest multiple of 64.
|
||||
!!! note
|
||||
|
||||
the width and height of the image must be multiples of 64. You can
|
||||
provide different values, but they will be rounded down to the nearest multiple
|
||||
of 64.
|
||||
|
||||
### This is an example of img2img:
|
||||
!!! example "This is a example of img2img"
|
||||
|
||||
~~~~
|
||||
invoke> waterfall and rainbow -I./vacation-photo.png -W640 -H480 --fit
|
||||
~~~~
|
||||
```bash
|
||||
invoke> waterfall and rainbow -I./vacation-photo.png -W640 -H480 --fit
|
||||
```
|
||||
|
||||
This will modify the indicated vacation photograph by making it more
|
||||
like the prompt. Results will vary greatly depending on what is in the
|
||||
image. We also ask to --fit the image into a box no bigger than
|
||||
640x480. Otherwise the image size will be identical to the provided
|
||||
photo and you may run out of memory if it is large.
|
||||
This will modify the indicated vacation photograph by making it more like the
|
||||
prompt. Results will vary greatly depending on what is in the image. We also ask
|
||||
to --fit the image into a box no bigger than 640x480. Otherwise the image size
|
||||
will be identical to the provided photo and you may run out of memory if it is
|
||||
large.
|
||||
|
||||
In addition to the command-line options recognized by txt2img, img2img
|
||||
accepts additional options:
|
||||
In addition to the command-line options recognized by txt2img, img2img accepts
|
||||
additional options:
|
||||
|
||||
| Argument <img width="160" align="right"/> | Shortcut | Default | Description |
|
||||
|----------------------|-------------|-----------------|--------------|
|
||||
| `--init_img <path>` | `-I<path>` | `None` | Path to the initialization image |
|
||||
| `--fit` | `-F` | `False` | Scale the image to fit into the specified -H and -W dimensions |
|
||||
| `--strength <float>` | `-s<float>` | `0.75` | How hard to try to match the prompt to the initial image. Ranges from 0.0-0.99, with higher values replacing the initial image completely.|
|
||||
| Argument <img width="160" align="right"/> | Shortcut | Default | Description |
|
||||
| ----------------------------------------- | ----------- | ------- | ------------------------------------------------------------------------------------------------------------------------------------------ |
|
||||
| `--init_img <path>` | `-I<path>` | `None` | Path to the initialization image |
|
||||
| `--fit` | `-F` | `False` | Scale the image to fit into the specified -H and -W dimensions |
|
||||
| `--strength <float>` | `-s<float>` | `0.75` | How hard to try to match the prompt to the initial image. Ranges from 0.0-0.99, with higher values replacing the initial image completely. |
|
||||
|
||||
### inpainting
|
||||
|
||||
@@ -211,73 +259,72 @@ accepts additional options:
|
||||
the pixels underneath when you create the transparent areas. See
|
||||
[Inpainting](./INPAINTING.md) for details.
|
||||
|
||||
inpainting accepts all the arguments used for txt2img and img2img, as
|
||||
well as the --mask (-M) and --text_mask (-tm) arguments:
|
||||
inpainting accepts all the arguments used for txt2img and img2img, as well as
|
||||
the --mask (-M) and --text_mask (-tm) arguments:
|
||||
|
||||
| Argument <img width="100" align="right"/> | Shortcut | Default | Description |
|
||||
|--------------------|------------|---------------------|--------------|
|
||||
| `--init_mask <path>` | `-M<path>` | `None` |Path to an image the same size as the initial_image, with areas for inpainting made transparent.|
|
||||
| `--invert_mask ` | | False |If true, invert the mask so that transparent areas are opaque and vice versa.|
|
||||
| `--text_mask <prompt> [<float>]` | `-tm <prompt> [<float>]` | <none> | Create a mask from a text prompt describing part of the image|
|
||||
| Argument <img width="100" align="right"/> | Shortcut | Default | Description |
|
||||
| ----------------------------------------- | ------------------------ | ------- | ------------------------------------------------------------------------------------------------ |
|
||||
| `--init_mask <path>` | `-M<path>` | `None` | Path to an image the same size as the initial_image, with areas for inpainting made transparent. |
|
||||
| `--invert_mask ` | | False | If true, invert the mask so that transparent areas are opaque and vice versa. |
|
||||
| `--text_mask <prompt> [<float>]` | `-tm <prompt> [<float>]` | <none> | Create a mask from a text prompt describing part of the image |
|
||||
|
||||
The mask may either be an image with transparent areas, in which case
|
||||
the inpainting will occur in the transparent areas only, or a black
|
||||
and white image, in which case all black areas will be painted into.
|
||||
The mask may either be an image with transparent areas, in which case the
|
||||
inpainting will occur in the transparent areas only, or a black and white image,
|
||||
in which case all black areas will be painted into.
|
||||
|
||||
`--text_mask` (short form `-tm`) is a way to generate a mask using a
|
||||
text description of the part of the image to replace. For example, if
|
||||
you have an image of a breakfast plate with a bagel, toast and
|
||||
scrambled eggs, you can selectively mask the bagel and replace it with
|
||||
a piece of cake this way:
|
||||
`--text_mask` (short form `-tm`) is a way to generate a mask using a text
|
||||
description of the part of the image to replace. For example, if you have an
|
||||
image of a breakfast plate with a bagel, toast and scrambled eggs, you can
|
||||
selectively mask the bagel and replace it with a piece of cake this way:
|
||||
|
||||
~~~
|
||||
```bash
|
||||
invoke> a piece of cake -I /path/to/breakfast.png -tm bagel
|
||||
~~~
|
||||
```
|
||||
|
||||
The algorithm uses <a
|
||||
href="https://github.com/timojl/clipseg">clipseg</a> to classify
|
||||
different regions of the image. The classifier puts out a confidence
|
||||
score for each region it identifies. Generally regions that score
|
||||
above 0.5 are reliable, but if you are getting too much or too little
|
||||
masking you can adjust the threshold down (to get more mask), or up
|
||||
(to get less). In this example, by passing `-tm` a higher value, we
|
||||
are insisting on a more stringent classification.
|
||||
href="https://github.com/timojl/clipseg">clipseg</a> to classify different
|
||||
regions of the image. The classifier puts out a confidence score for each region
|
||||
it identifies. Generally regions that score above 0.5 are reliable, but if you
|
||||
are getting too much or too little masking you can adjust the threshold down (to
|
||||
get more mask), or up (to get less). In this example, by passing `-tm` a higher
|
||||
value, we are insisting on a more stringent classification.
|
||||
|
||||
~~~
|
||||
```bash
|
||||
invoke> a piece of cake -I /path/to/breakfast.png -tm bagel 0.6
|
||||
~~~
|
||||
```
|
||||
|
||||
# Other Commands
|
||||
### Custom Styles and Subjects
|
||||
|
||||
You can load and use hundreds of community-contributed Textual
|
||||
Inversion models just by typing the appropriate trigger phrase. Please
|
||||
see [Concepts Library](CONCEPTS.md) for more details.
|
||||
|
||||
## Other Commands
|
||||
|
||||
The CLI offers a number of commands that begin with "!".
|
||||
|
||||
## Postprocessing images
|
||||
### Postprocessing images
|
||||
|
||||
To postprocess a file using face restoration or upscaling, use the
|
||||
`!fix` command.
|
||||
To postprocess a file using face restoration or upscaling, use the `!fix`
|
||||
command.
|
||||
|
||||
### `!fix`
|
||||
#### `!fix`
|
||||
|
||||
This command runs a post-processor on a previously-generated image. It
|
||||
takes a PNG filename or path and applies your choice of the `-U`, `-G`, or
|
||||
`--embiggen` switches in order to fix faces or upscale. If you provide a
|
||||
filename, the script will look for it in the current output
|
||||
directory. Otherwise you can provide a full or partial path to the
|
||||
desired file.
|
||||
This command runs a post-processor on a previously-generated image. It takes a
|
||||
PNG filename or path and applies your choice of the `-U`, `-G`, or `--embiggen`
|
||||
switches in order to fix faces or upscale. If you provide a filename, the script
|
||||
will look for it in the current output directory. Otherwise you can provide a
|
||||
full or partial path to the desired file.
|
||||
|
||||
Some examples:
|
||||
|
||||
!!! example ""
|
||||
|
||||
Upscale to 4X its original size and fix faces using codeformer:
|
||||
!!! example "Upscale to 4X its original size and fix faces using codeformer"
|
||||
|
||||
```bash
|
||||
invoke> !fix 0000045.4829112.png -G1 -U4 -ft codeformer
|
||||
```
|
||||
|
||||
!!! example ""
|
||||
|
||||
Use the GFPGAN algorithm to fix faces, then upscale to 3X using --embiggen:
|
||||
!!! example "Use the GFPGAN algorithm to fix faces, then upscale to 3X using --embiggen"
|
||||
|
||||
```bash
|
||||
invoke> !fix 0000045.4829112.png -G0.8 -ft gfpgan
|
||||
@@ -286,138 +333,103 @@ Some examples:
|
||||
>> GFPGAN - Restoring Faces for image seed:4829112
|
||||
Outputs:
|
||||
[1] outputs/img-samples/000017.4829112.gfpgan-00.png: !fix "outputs/img-samples/0000045.4829112.png" -s 50 -S -W 512 -H 512 -C 7.5 -A k_lms -G 0.8
|
||||
```
|
||||
|
||||
### !mask
|
||||
#### `!mask`
|
||||
|
||||
This command takes an image, a text prompt, and uses the `clipseg`
|
||||
algorithm to automatically generate a mask of the area that matches
|
||||
the text prompt. It is useful for debugging the text masking process
|
||||
prior to inpainting with the `--text_mask` argument. See
|
||||
[INPAINTING.md] for details.
|
||||
This command takes an image, a text prompt, and uses the `clipseg` algorithm to
|
||||
automatically generate a mask of the area that matches the text prompt. It is
|
||||
useful for debugging the text masking process prior to inpainting with the
|
||||
`--text_mask` argument. See [INPAINTING.md] for details.
|
||||
|
||||
## Model selection and importation
|
||||
### Model selection and importation
|
||||
|
||||
The CLI allows you to add new models on the fly, as well as to switch
|
||||
among them rapidly without leaving the script.
|
||||
among them rapidly without leaving the script. There are several
|
||||
different model formats, each described in the [Model Installation
|
||||
Guide](../installation/050_INSTALLING_MODELS.md).
|
||||
|
||||
### !models
|
||||
#### `!models`
|
||||
|
||||
This prints out a list of the models defined in `config/models.yaml'.
|
||||
The active model is bold-faced
|
||||
This prints out a list of the models defined in `config/models.yaml'. The active
|
||||
model is bold-faced
|
||||
|
||||
Example:
|
||||
<pre>
|
||||
laion400m not loaded <no description>
|
||||
<b>stable-diffusion-1.4 active Stable Diffusion v1.4</b>
|
||||
waifu-diffusion not loaded Waifu Diffusion v1.3
|
||||
</pre>
|
||||
|
||||
### !switch <model>
|
||||
|
||||
This quickly switches from one model to another without leaving the
|
||||
CLI script. `invoke.py` uses a memory caching system; once a model
|
||||
has been loaded, switching back and forth is quick. The following
|
||||
example shows this in action. Note how the second column of the
|
||||
`!models` table changes to `cached` after a model is first loaded,
|
||||
and that the long initialization step is not needed when loading
|
||||
a cached model.
|
||||
|
||||
<pre>
|
||||
invoke> !models
|
||||
laion400m not loaded <no description>
|
||||
<b>stable-diffusion-1.4 cached Stable Diffusion v1.4</b>
|
||||
waifu-diffusion active Waifu Diffusion v1.3
|
||||
|
||||
invoke> !switch waifu-diffusion
|
||||
>> Caching model stable-diffusion-1.4 in system RAM
|
||||
>> Loading waifu-diffusion from models/ldm/stable-diffusion-v1/model-epoch08-float16.ckpt
|
||||
| LatentDiffusion: Running in eps-prediction mode
|
||||
| DiffusionWrapper has 859.52 M params.
|
||||
| Making attention of type 'vanilla' with 512 in_channels
|
||||
| Working with z of shape (1, 4, 32, 32) = 4096 dimensions.
|
||||
| Making attention of type 'vanilla' with 512 in_channels
|
||||
| Using faster float16 precision
|
||||
>> Model loaded in 18.24s
|
||||
>> Max VRAM used to load the model: 2.17G
|
||||
>> Current VRAM usage:2.17G
|
||||
>> Setting Sampler to k_lms
|
||||
|
||||
invoke> !models
|
||||
laion400m not loaded <no description>
|
||||
stable-diffusion-1.4 cached Stable Diffusion v1.4
|
||||
<b>waifu-diffusion active Waifu Diffusion v1.3</b>
|
||||
|
||||
invoke> !switch stable-diffusion-1.4
|
||||
>> Caching model waifu-diffusion in system RAM
|
||||
>> Retrieving model stable-diffusion-1.4 from system RAM cache
|
||||
>> Setting Sampler to k_lms
|
||||
|
||||
invoke> !models
|
||||
laion400m not loaded <no description>
|
||||
<b>stable-diffusion-1.4 active Stable Diffusion v1.4</b>
|
||||
waifu-diffusion cached Waifu Diffusion v1.3
|
||||
inpainting-1.5 not loaded Stable Diffusion inpainting model
|
||||
<b>stable-diffusion-1.5 active Stable Diffusion v1.5</b>
|
||||
waifu-diffusion not loaded Waifu Diffusion v1.4
|
||||
</pre>
|
||||
|
||||
### !import_model <path/to/model/weights>
|
||||
#### `!switch <model>`
|
||||
|
||||
This command imports a new model weights file into InvokeAI, makes it
|
||||
available for image generation within the script, and writes out the
|
||||
configuration for the model into `config/models.yaml` for use in
|
||||
subsequent sessions.
|
||||
This quickly switches from one model to another without leaving the CLI script.
|
||||
`invoke.py` uses a memory caching system; once a model has been loaded,
|
||||
switching back and forth is quick. The following example shows this in action.
|
||||
Note how the second column of the `!models` table changes to `cached` after a
|
||||
model is first loaded, and that the long initialization step is not needed when
|
||||
loading a cached model.
|
||||
|
||||
Provide `!import_model` with the path to a weights file ending in
|
||||
`.ckpt`. If you type a partial path and press tab, the CLI will
|
||||
autocomplete. Although it will also autocomplete to `.vae` files,
|
||||
these are not currenty supported (but will be soon).
|
||||
#### `!import_model <hugging_face_repo_ID>`
|
||||
|
||||
When you hit return, the CLI will prompt you to fill in additional
|
||||
information about the model, including the short name you wish to use
|
||||
for it with the `!switch` command, a brief description of the model,
|
||||
the default image width and height to use with this model, and the
|
||||
model's configuration file. The latter three fields are automatically
|
||||
filled with reasonable defaults. In the example below, the bold-faced
|
||||
text shows what the user typed in with the exception of the width,
|
||||
height and configuration file paths, which were filled in
|
||||
This imports and installs a `diffusers`-style model that is stored on
|
||||
the [HuggingFace Web Site](https://huggingface.co). You can look up
|
||||
any [Stable Diffusion diffusers
|
||||
model](https://huggingface.co/models?library=diffusers) and install it
|
||||
with a command like the following:
|
||||
|
||||
```bash
|
||||
!import_model prompthero/openjourney
|
||||
```
|
||||
|
||||
#### `!import_model <path/to/diffusers/directory>`
|
||||
|
||||
If you have a copy of a `diffusers`-style model saved to disk, you can
|
||||
import it by passing the path to model's top-level directory.
|
||||
|
||||
#### `!import_model <url>`
|
||||
|
||||
For a `.ckpt` or `.safetensors` file, if you have a direct download
|
||||
URL for the file, you can provide it to `!import_model` and the file
|
||||
will be downloaded and installed for you.
|
||||
|
||||
#### `!import_model <path/to/model/weights.ckpt>`
|
||||
|
||||
This command imports a new model weights file into InvokeAI, makes it available
|
||||
for image generation within the script, and writes out the configuration for the
|
||||
model into `config/models.yaml` for use in subsequent sessions.
|
||||
|
||||
Provide `!import_model` with the path to a weights file ending in `.ckpt`. If
|
||||
you type a partial path and press tab, the CLI will autocomplete. Although it
|
||||
will also autocomplete to `.vae` files, these are not currenty supported (but
|
||||
will be soon).
|
||||
|
||||
When you hit return, the CLI will prompt you to fill in additional information
|
||||
about the model, including the short name you wish to use for it with the
|
||||
`!switch` command, a brief description of the model, the default image width and
|
||||
height to use with this model, and the model's configuration file. The latter
|
||||
three fields are automatically filled with reasonable defaults. In the example
|
||||
below, the bold-faced text shows what the user typed in with the exception of
|
||||
the width, height and configuration file paths, which were filled in
|
||||
automatically.
|
||||
|
||||
Example:
|
||||
#### `!import_model <path/to/directory_of_models>`
|
||||
|
||||
<pre>
|
||||
invoke> <b>!import_model models/ldm/stable-diffusion-v1/model-epoch08-float16.ckpt</b>
|
||||
>> Model import in process. Please enter the values needed to configure this model:
|
||||
If you provide the path of a directory that contains one or more
|
||||
`.ckpt` or `.safetensors` files, the CLI will scan the directory and
|
||||
interactively offer to import the models it finds there. Also see the
|
||||
`--autoconvert` command-line option.
|
||||
|
||||
Name for this model: <b>waifu-diffusion</b>
|
||||
Description of this model: <b>Waifu Diffusion v1.3</b>
|
||||
Configuration file for this model: <b>configs/stable-diffusion/v1-inference.yaml</b>
|
||||
Default image width: <b>512</b>
|
||||
Default image height: <b>512</b>
|
||||
>> New configuration:
|
||||
waifu-diffusion:
|
||||
config: configs/stable-diffusion/v1-inference.yaml
|
||||
description: Waifu Diffusion v1.3
|
||||
height: 512
|
||||
weights: models/ldm/stable-diffusion-v1/model-epoch08-float16.ckpt
|
||||
width: 512
|
||||
OK to import [n]? <b>y</b>
|
||||
>> Caching model stable-diffusion-1.4 in system RAM
|
||||
>> Loading waifu-diffusion from models/ldm/stable-diffusion-v1/model-epoch08-float16.ckpt
|
||||
| LatentDiffusion: Running in eps-prediction mode
|
||||
| DiffusionWrapper has 859.52 M params.
|
||||
| Making attention of type 'vanilla' with 512 in_channels
|
||||
| Working with z of shape (1, 4, 32, 32) = 4096 dimensions.
|
||||
| Making attention of type 'vanilla' with 512 in_channels
|
||||
| Using faster float16 precision
|
||||
invoke>
|
||||
</pre>
|
||||
#### `!edit_model <name_of_model>`
|
||||
|
||||
###!edit_model <name_of_model>
|
||||
|
||||
The `!edit_model` command can be used to modify a model that is
|
||||
already defined in `config/models.yaml`. Call it with the short
|
||||
name of the model you wish to modify, and it will allow you to
|
||||
modify the model's `description`, `weights` and other fields.
|
||||
The `!edit_model` command can be used to modify a model that is already defined
|
||||
in `config/models.yaml`. Call it with the short name of the model you wish to
|
||||
modify, and it will allow you to modify the model's `description`, `weights` and
|
||||
other fields.
|
||||
|
||||
Example:
|
||||
|
||||
<pre>
|
||||
invoke> <b>!edit_model waifu-diffusion</b>
|
||||
>> Editing model waifu-diffusion from configuration file ./configs/models.yaml
|
||||
@@ -440,80 +452,79 @@ OK to import [n]? y
|
||||
>> Loading waifu-diffusion from models/ldm/stable-diffusion-v1/model-epoch10-float16.ckpt
|
||||
...
|
||||
</pre>
|
||||
=======
|
||||
invoke> !fix 000017.4829112.gfpgan-00.png --embiggen 3
|
||||
...lots of text...
|
||||
Outputs:
|
||||
[2] outputs/img-samples/000018.2273800735.embiggen-00.png: !fix "outputs/img-samples/000017.243781548.gfpgan-00.png" -s 50 -S 2273800735 -W 512 -H 512 -C 7.5 -A k_lms --embiggen 3.0 0.75 0.25
|
||||
|
||||
### History processing
|
||||
|
||||
The CLI provides a series of convenient commands for reviewing previous actions,
|
||||
retrieving them, modifying them, and re-running them.
|
||||
|
||||
#### `!history`
|
||||
|
||||
The invoke script keeps track of all the commands you issue during a session,
|
||||
allowing you to re-run them. On Mac and Linux systems, it also writes the
|
||||
command-line history out to disk, giving you access to the most recent 1000
|
||||
commands issued.
|
||||
|
||||
The `!history` command will return a numbered list of all the commands issued
|
||||
during the session (Windows), or the most recent 1000 commands (Mac|Linux). You
|
||||
can then repeat a command by using the command `!NNN`, where "NNN" is the
|
||||
history line number. For example:
|
||||
|
||||
!!! example ""
|
||||
|
||||
```bash
|
||||
invoke> !history
|
||||
...
|
||||
[14] happy woman sitting under tree wearing broad hat and flowing garment
|
||||
[15] beautiful woman sitting under tree wearing broad hat and flowing garment
|
||||
[18] beautiful woman sitting under tree wearing broad hat and flowing garment -v0.2 -n6
|
||||
[20] watercolor of beautiful woman sitting under tree wearing broad hat and flowing garment -v0.2 -n6 -S2878767194
|
||||
[21] surrealist painting of beautiful woman sitting under tree wearing broad hat and flowing garment -v0.2 -n6 -S2878767194
|
||||
...
|
||||
invoke> !20
|
||||
invoke> watercolor of beautiful woman sitting under tree wearing broad hat and flowing garment -v0.2 -n6 -S2878767194
|
||||
```
|
||||
## History processing
|
||||
|
||||
The CLI provides a series of convenient commands for reviewing previous
|
||||
actions, retrieving them, modifying them, and re-running them.
|
||||
####`!fetch`
|
||||
|
||||
### !history
|
||||
This command retrieves the generation parameters from a previously generated
|
||||
image and either loads them into the command line (Linux|Mac), or prints them
|
||||
out in a comment for copy-and-paste (Windows). You may provide either the name
|
||||
of a file in the current output directory, or a full file path. Specify path to
|
||||
a folder with image png files, and wildcard \*.png to retrieve the dream command
|
||||
used to generate the images, and save them to a file commands.txt for further
|
||||
processing.
|
||||
|
||||
The invoke script keeps track of all the commands you issue during a
|
||||
session, allowing you to re-run them. On Mac and Linux systems, it
|
||||
also writes the command-line history out to disk, giving you access to
|
||||
the most recent 1000 commands issued.
|
||||
!!! example "load the generation command for a single png file"
|
||||
|
||||
The `!history` command will return a numbered list of all the commands
|
||||
issued during the session (Windows), or the most recent 1000 commands
|
||||
(Mac|Linux). You can then repeat a command by using the command `!NNN`,
|
||||
where "NNN" is the history line number. For example:
|
||||
```bash
|
||||
invoke> !fetch 0000015.8929913.png
|
||||
# the script returns the next line, ready for editing and running:
|
||||
invoke> a fantastic alien landscape -W 576 -H 512 -s 60 -A plms -C 7.5
|
||||
```
|
||||
|
||||
```bash
|
||||
invoke> !history
|
||||
...
|
||||
[14] happy woman sitting under tree wearing broad hat and flowing garment
|
||||
[15] beautiful woman sitting under tree wearing broad hat and flowing garment
|
||||
[18] beautiful woman sitting under tree wearing broad hat and flowing garment -v0.2 -n6
|
||||
[20] watercolor of beautiful woman sitting under tree wearing broad hat and flowing garment -v0.2 -n6 -S2878767194
|
||||
[21] surrealist painting of beautiful woman sitting under tree wearing broad hat and flowing garment -v0.2 -n6 -S2878767194
|
||||
...
|
||||
invoke> !20
|
||||
invoke> watercolor of beautiful woman sitting under tree wearing broad hat and flowing garment -v0.2 -n6 -S2878767194
|
||||
```
|
||||
!!! example "fetch the generation commands from a batch of files and store them into `selected.txt`"
|
||||
|
||||
### !fetch
|
||||
```bash
|
||||
invoke> !fetch outputs\selected-imgs\*.png selected.txt
|
||||
```
|
||||
|
||||
This command retrieves the generation parameters from a previously
|
||||
generated image and either loads them into the command line
|
||||
(Linux|Mac), or prints them out in a comment for copy-and-paste
|
||||
(Windows). You may provide either the name of a file in the current
|
||||
output directory, or a full file path. Specify path to a folder with
|
||||
image png files, and wildcard *.png to retrieve the dream command used
|
||||
to generate the images, and save them to a file commands.txt for
|
||||
further processing.
|
||||
|
||||
This example loads the generation command for a single png file:
|
||||
|
||||
```bash
|
||||
invoke> !fetch 0000015.8929913.png
|
||||
# the script returns the next line, ready for editing and running:
|
||||
invoke> a fantastic alien landscape -W 576 -H 512 -s 60 -A plms -C 7.5
|
||||
```
|
||||
|
||||
This one fetches the generation commands from a batch of files and
|
||||
stores them into `selected.txt`:
|
||||
|
||||
```bash
|
||||
invoke> !fetch outputs\selected-imgs\*.png selected.txt
|
||||
```
|
||||
|
||||
### !replay
|
||||
#### `!replay`
|
||||
|
||||
This command replays a text file generated by !fetch or created manually
|
||||
|
||||
~~~
|
||||
invoke> !replay outputs\selected-imgs\selected.txt
|
||||
~~~
|
||||
!!! example
|
||||
|
||||
Note that these commands may behave unexpectedly if given a PNG file that
|
||||
was not generated by InvokeAI.
|
||||
```bash
|
||||
invoke> !replay outputs\selected-imgs\selected.txt
|
||||
```
|
||||
|
||||
### !search <search string>
|
||||
!!! note
|
||||
|
||||
These commands may behave unexpectedly if given a PNG file that was
|
||||
not generated by InvokeAI.
|
||||
|
||||
#### `!search <search string>`
|
||||
|
||||
This is similar to !history but it only returns lines that contain
|
||||
`search string`. For example:
|
||||
@@ -523,44 +534,49 @@ invoke> !search surreal
|
||||
[21] surrealist painting of beautiful woman sitting under tree wearing broad hat and flowing garment -v0.2 -n6 -S2878767194
|
||||
```
|
||||
|
||||
### `!clear`
|
||||
#### `!clear`
|
||||
|
||||
This clears the search history from memory and disk. Be advised that
|
||||
this operation is irreversible and does not issue any warnings!
|
||||
This clears the search history from memory and disk. Be advised that this
|
||||
operation is irreversible and does not issue any warnings!
|
||||
|
||||
## Command-line editing and completion
|
||||
|
||||
The command-line offers convenient history tracking, editing, and
|
||||
command completion.
|
||||
The command-line offers convenient history tracking, editing, and command
|
||||
completion.
|
||||
|
||||
- To scroll through previous commands and potentially edit/reuse them, use the ++up++ and ++down++ keys.
|
||||
- To edit the current command, use the ++left++ and ++right++ keys to position the cursor, and then ++backspace++, ++delete++ or insert characters.
|
||||
- To move to the very beginning of the command, type ++ctrl+a++ (or ++command+a++ on the Mac)
|
||||
- To scroll through previous commands and potentially edit/reuse them, use the
|
||||
++up++ and ++down++ keys.
|
||||
- To edit the current command, use the ++left++ and ++right++ keys to position
|
||||
the cursor, and then ++backspace++, ++delete++ or insert characters.
|
||||
- To move to the very beginning of the command, type ++ctrl+a++ (or
|
||||
++command+a++ on the Mac)
|
||||
- To move to the end of the command, type ++ctrl+e++.
|
||||
- To cut a section of the command, position the cursor where you want to start cutting and type ++ctrl+k++
|
||||
- To paste a cut section back in, position the cursor where you want to paste, and type ++ctrl+y++
|
||||
- To cut a section of the command, position the cursor where you want to start
|
||||
cutting and type ++ctrl+k++
|
||||
- To paste a cut section back in, position the cursor where you want to paste,
|
||||
and type ++ctrl+y++
|
||||
|
||||
Windows users can get similar, but more limited, functionality if they
|
||||
launch `invoke.py` with the `winpty` program and have the `pyreadline3`
|
||||
library installed:
|
||||
Windows users can get similar, but more limited, functionality if they launch
|
||||
`invoke.py` with the `winpty` program and have the `pyreadline3` library
|
||||
installed:
|
||||
|
||||
```batch
|
||||
> winpty python scripts\invoke.py
|
||||
```
|
||||
|
||||
On the Mac and Linux platforms, when you exit invoke.py, the last 1000
|
||||
lines of your command-line history will be saved. When you restart
|
||||
`invoke.py`, you can access the saved history using the ++up++ key.
|
||||
On the Mac and Linux platforms, when you exit invoke.py, the last 1000 lines of
|
||||
your command-line history will be saved. When you restart `invoke.py`, you can
|
||||
access the saved history using the ++up++ key.
|
||||
|
||||
In addition, limited command-line completion is installed. In various
|
||||
contexts, you can start typing your command and press ++tab++. A list of
|
||||
potential completions will be presented to you. You can then type a
|
||||
little more, hit ++tab++ again, and eventually autocomplete what you want.
|
||||
In addition, limited command-line completion is installed. In various contexts,
|
||||
you can start typing your command and press ++tab++. A list of potential
|
||||
completions will be presented to you. You can then type a little more, hit
|
||||
++tab++ again, and eventually autocomplete what you want.
|
||||
|
||||
When specifying file paths using the one-letter shortcuts, the CLI
|
||||
will attempt to complete pathnames for you. This is most handy for the
|
||||
`-I` (init image) and `-M` (init mask) paths. To initiate completion, start
|
||||
the path with a slash (`/`) or `./`. For example:
|
||||
When specifying file paths using the one-letter shortcuts, the CLI will attempt
|
||||
to complete pathnames for you. This is most handy for the `-I` (init image) and
|
||||
`-M` (init mask) paths. To initiate completion, start the path with a slash
|
||||
(`/`) or `./`. For example:
|
||||
|
||||
```bash
|
||||
invoke> zebra with a mustache -I./test-pictures<TAB>
|
||||
|
||||
164
docs/features/CONCEPTS.md
Normal file
@@ -0,0 +1,164 @@
|
||||
---
|
||||
title: Styles and Subjects
|
||||
---
|
||||
|
||||
# :material-library-shelves: The Hugging Face Concepts Library and Importing Textual Inversion files
|
||||
|
||||
## Using Textual Inversion Files
|
||||
|
||||
Textual inversion (TI) files are small models that customize the output of
|
||||
Stable Diffusion image generation. They can augment SD with specialized subjects
|
||||
and artistic styles. They are also known as "embeds" in the machine learning
|
||||
world.
|
||||
|
||||
Each TI file introduces one or more vocabulary terms to the SD model. These are
|
||||
known in InvokeAI as "triggers." Triggers are often, but not always, denoted
|
||||
using angle brackets as in "<trigger-phrase>". The two most common type of
|
||||
TI files that you'll encounter are `.pt` and `.bin` files, which are produced by
|
||||
different TI training packages. InvokeAI supports both formats, but its
|
||||
[built-in TI training system](TEXTUAL_INVERSION.md) produces `.pt`.
|
||||
|
||||
The [Hugging Face company](https://huggingface.co/sd-concepts-library) has
|
||||
amassed a large ligrary of >800 community-contributed TI files covering a
|
||||
broad range of subjects and styles. InvokeAI has built-in support for this
|
||||
library which downloads and merges TI files automatically upon request. You can
|
||||
also install your own or others' TI files by placing them in a designated
|
||||
directory.
|
||||
|
||||
You may also be interested in using [LoRA Models](LORAS.md) to
|
||||
generate images with specialized styles and subjects.
|
||||
|
||||
### An Example
|
||||
|
||||
Here are a few examples to illustrate how Textual Inversion works. All
|
||||
these images were generated using the command-line client and the
|
||||
Stable Diffusion 1.5 model:
|
||||
|
||||
| Japanese gardener | Japanese gardener <ghibli-face> | Japanese gardener <hoi4-leaders> | Japanese gardener <cartoona-animals> |
|
||||
| :--------------------------------: | :-----------------------------------: | :------------------------------------: | :----------------------------------------: |
|
||||
|  |  |  |  |
|
||||
|
||||
You can also combine styles and concepts:
|
||||
|
||||
<figure markdown>
|
||||
| A portrait of <alf> in <cartoona-animal> style |
|
||||
| :--------------------------------------------------------: |
|
||||
|  |
|
||||
</figure>
|
||||
## Using a Hugging Face Concept
|
||||
|
||||
!!! warning "Authenticating to HuggingFace"
|
||||
|
||||
Some concepts require valid authentication to HuggingFace. Without it, they will not be downloaded
|
||||
and will be silently ignored.
|
||||
|
||||
If you used an installer to install InvokeAI, you may have already set a HuggingFace token.
|
||||
If you skipped this step, you can:
|
||||
|
||||
- run the InvokeAI configuration script again (if you used a manual installer): `invokeai-configure`
|
||||
- set one of the `HUGGINGFACE_TOKEN` or `HUGGING_FACE_HUB_TOKEN` environment variables to contain your token
|
||||
|
||||
Finally, if you already used any HuggingFace library on your computer, you might already have a token
|
||||
in your local cache. Check for a hidden `.huggingface` directory in your home folder. If it
|
||||
contains a `token` file, then you are all set.
|
||||
|
||||
|
||||
Hugging Face TI concepts are downloaded and installed automatically as you
|
||||
require them. This requires your machine to be connected to the Internet. To
|
||||
find out what each concept is for, you can browse the
|
||||
[Hugging Face concepts library](https://huggingface.co/sd-concepts-library) and
|
||||
look at examples of what each concept produces.
|
||||
|
||||
When you have an idea of a concept you wish to try, go to the command-line
|
||||
client (CLI) and type a `<` character and the beginning of the Hugging Face
|
||||
concept name you wish to load. Press ++tab++, and the CLI will show you all
|
||||
matching concepts. You can also type `<` and hit ++tab++ to get a listing of all
|
||||
~800 concepts, but be prepared to scroll up to see them all! If there is more
|
||||
than one match you can continue to type and ++tab++ until the concept is
|
||||
completed.
|
||||
|
||||
!!! example
|
||||
|
||||
if you type in `<x` and hit ++tab++, you'll be prompted with the completions:
|
||||
|
||||
```py
|
||||
<xatu2> <xatu> <xbh> <xi> <xidiversity> <xioboma> <xuna> <xyz>
|
||||
```
|
||||
|
||||
Now type `id` and press ++tab++. It will be autocompleted to `<xidiversity>`
|
||||
because this is a unique match.
|
||||
|
||||
Finish your prompt and generate as usual. You may include multiple concept terms
|
||||
in the prompt.
|
||||
|
||||
If you have never used this concept before, you will see a message that the TI
|
||||
model is being downloaded and installed. After this, the concept will be saved
|
||||
locally (in the `models/sd-concepts-library` directory) for future use.
|
||||
|
||||
Several steps happen during downloading and installation, including a scan of
|
||||
the file for malicious code. Should any errors occur, you will be warned and the
|
||||
concept will fail to load. Generation will then continue treating the trigger
|
||||
term as a normal string of characters (e.g. as literal `<ghibli-face>`).
|
||||
|
||||
You can also use `<concept-names>` in the WebGUI's prompt textbox. There is no
|
||||
autocompletion at this time.
|
||||
|
||||
## Installing your Own TI Files
|
||||
|
||||
You may install any number of `.pt` and `.bin` files simply by copying them into
|
||||
the `embeddings` directory of the InvokeAI runtime directory (usually `invokeai`
|
||||
in your home directory). You may create subdirectories in order to organize the
|
||||
files in any way you wish. Be careful not to overwrite one file with another.
|
||||
For example, TI files generated by the Hugging Face toolkit share the named
|
||||
`learned_embedding.bin`. You can use subdirectories to keep them distinct.
|
||||
|
||||
At startup time, InvokeAI will scan the `embeddings` directory and load any TI
|
||||
files it finds there. At startup you will see messages similar to these:
|
||||
|
||||
```bash
|
||||
>> Loading embeddings from /data/lstein/invokeai-2.3/embeddings
|
||||
| Loading v1 embedding file: style-hamunaptra
|
||||
| Loading v4 embedding file: embeddings/learned_embeds-steps-500.bin
|
||||
| Loading v2 embedding file: lfa
|
||||
| Loading v3 embedding file: easynegative
|
||||
| Loading v1 embedding file: rem_rezero
|
||||
| Loading v2 embedding file: midj-strong
|
||||
| Loading v4 embedding file: anime-background-style-v2/learned_embeds.bin
|
||||
| Loading v4 embedding file: kamon-style/learned_embeds.bin
|
||||
** Notice: kamon-style/learned_embeds.bin was trained on a model with an incompatible token dimension: 768 vs 1024.
|
||||
>> Textual inversion triggers: <anime-background-style-v2>, <easynegative>, <lfa>, <midj-strong>, <milo>, Rem3-2600, Style-Hamunaptra
|
||||
```
|
||||
|
||||
Textual Inversion embeddings trained on version 1.X stable diffusion
|
||||
models are incompatible with version 2.X models and vice-versa.
|
||||
|
||||
After the embeddings load, InvokeAI will print out a list of all the
|
||||
recognized trigger terms. To trigger the term, include it in the
|
||||
prompt exactly as written, including angle brackets if any and
|
||||
respecting the capitalization.
|
||||
|
||||
There are at least four different embedding file formats, and each uses
|
||||
a different convention for the trigger terms. In some cases, the
|
||||
trigger term is specified in the file contents and may or may not be
|
||||
surrounded by angle brackets. In the example above, `Rem3-2600`,
|
||||
`Style-Hamunaptra`, and `<midj-strong>` were specified this way and
|
||||
there is no easy way to change the term.
|
||||
|
||||
In other cases the trigger term is not contained within the embedding
|
||||
file. In this case, InvokeAI constructs a trigger term consisting of
|
||||
the base name of the file (without the file extension) surrounded by
|
||||
angle brackets. In the example above `<easynegative`> is such a file
|
||||
(the filename was `easynegative.safetensors`). In such cases, you can
|
||||
change the trigger term simply by renaming the file.
|
||||
|
||||
## Training your own Textual Inversion models
|
||||
|
||||
InvokeAI provides a script that lets you train your own Textual
|
||||
Inversion embeddings using a small number (about a half-dozen) images
|
||||
of your desired style or subject. Please see [Textual
|
||||
Inversion](TEXTUAL_INVERSION.md) for details.
|
||||
|
||||
## Further Reading
|
||||
|
||||
Please see [the repository](https://github.com/rinongal/textual_inversion) and
|
||||
associated paper for details and limitations.
|
||||
@@ -85,7 +85,7 @@ increasing size, every tile after the first in a row or column
|
||||
effectively only covers an extra `1 - overlap_ratio` on each axis. If
|
||||
the input/`--init_img` is same size as a tile, the ideal (for time)
|
||||
scaling factors with the default overlap (0.25) are 1.75, 2.5, 3.25,
|
||||
4.0 etc..
|
||||
4.0, etc.
|
||||
|
||||
`-embiggen_tiles <spaced list of tiles>`
|
||||
|
||||
@@ -100,6 +100,15 @@ Tiles are numbered starting with one, and left-to-right,
|
||||
top-to-bottom. So, if you are generating a 3x3 tiled image, the
|
||||
middle row would be `4 5 6`.
|
||||
|
||||
`-embiggen_strength <strength>`
|
||||
|
||||
Another advanced option if you want to experiment with the strength parameter
|
||||
that embiggen uses when it calls Img2Img. Values range from 0.0 to 1.0
|
||||
and lower values preserve more of the character of the initial image.
|
||||
Values that are too high will result in a completely different end image,
|
||||
while values that are too low will result in an image not dissimilar to one
|
||||
you would get with ESRGAN upscaling alone. The default value is 0.4.
|
||||
|
||||
### Examples
|
||||
|
||||
!!! example ""
|
||||
|
||||
@@ -4,135 +4,183 @@ title: Image-to-Image
|
||||
|
||||
# :material-image-multiple: Image-to-Image
|
||||
|
||||
## `img2img`
|
||||
Both the Web and command-line interfaces provide an "img2img" feature
|
||||
that lets you seed your creations with an initial drawing or
|
||||
photo. This is a really cool feature that tells stable diffusion to
|
||||
build the prompt on top of the image you provide, preserving the
|
||||
original's basic shape and layout.
|
||||
|
||||
This script also provides an `img2img` feature that lets you seed your creations with an initial
|
||||
drawing or photo. This is a really cool feature that tells stable diffusion to build the prompt on
|
||||
top of the image you provide, preserving the original's basic shape and layout. To use it, provide
|
||||
the `--init_img` option as shown here:
|
||||
See the [WebUI Guide](WEB.md) for a walkthrough of the img2img feature
|
||||
in the InvokeAI web server. This document describes how to use img2img
|
||||
in the command-line tool.
|
||||
|
||||
```commandline
|
||||
tree on a hill with a river, nature photograph, national geographic -I./test-pictures/tree-and-river-sketch.png -f 0.85
|
||||
```
|
||||
## Basic Usage
|
||||
|
||||
This will take the original image shown here:
|
||||
Launch the command-line client by launching `invoke.sh`/`invoke.bat`
|
||||
and choosing option (1). Alternative, activate the InvokeAI
|
||||
environment and issue the command `invokeai`.
|
||||
|
||||
<figure markdown>
|
||||
<img src="https://user-images.githubusercontent.com/50542132/193946000-c42a96d8-5a74-4f8a-b4c3-5213e6cadcce.png" width=350>
|
||||
</figure>
|
||||
Once the `invoke> ` prompt appears, you can start an img2img render by
|
||||
pointing to a seed file with the `-I` option as shown here:
|
||||
|
||||
and generate a new image based on it as shown here:
|
||||
!!! example ""
|
||||
|
||||
<figure markdown>
|
||||
<img src="https://user-images.githubusercontent.com/111189/194135515-53d4c060-e994-4016-8121-7c685e281ac9.png" width=350>
|
||||
</figure>
|
||||
```commandline
|
||||
tree on a hill with a river, nature photograph, national geographic -I./test-pictures/tree-and-river-sketch.png -f 0.85
|
||||
```
|
||||
|
||||
The `--init_img` (`-I`) option gives the path to the seed picture. `--strength` (`-f`) controls how much
|
||||
the original will be modified, ranging from `0.0` (keep the original intact), to `1.0` (ignore the
|
||||
original completely). The default is `0.75`, and ranges from `0.25-0.90` give interesting results.
|
||||
Other relevant options include `-C` (classification free guidance scale), and `-s` (steps). Unlike `txt2img`,
|
||||
adding steps will continuously change the resulting image and it will not converge.
|
||||
<figure markdown>
|
||||
|
||||
You may also pass a `-v<variation_amount>` option to generate `-n<iterations>` count variants on
|
||||
the original image. This is done by passing the first generated image
|
||||
back into img2img the requested number of times. It generates
|
||||
| original image | generated image |
|
||||
| :------------: | :-------------: |
|
||||
| { width=320 } | { width=320 } |
|
||||
|
||||
</figure>
|
||||
|
||||
The `--init_img` (`-I`) option gives the path to the seed picture. `--strength`
|
||||
(`-f`) controls how much the original will be modified, ranging from `0.0` (keep
|
||||
the original intact), to `1.0` (ignore the original completely). The default is
|
||||
`0.75`, and ranges from `0.25-0.90` give interesting results. Other relevant
|
||||
options include `-C` (classification free guidance scale), and `-s` (steps).
|
||||
Unlike `txt2img`, adding steps will continuously change the resulting image and
|
||||
it will not converge.
|
||||
|
||||
You may also pass a `-v<variation_amount>` option to generate `-n<iterations>`
|
||||
count variants on the original image. This is done by passing the first
|
||||
generated image back into img2img the requested number of times. It generates
|
||||
interesting variants.
|
||||
|
||||
Note that the prompt makes a big difference. For example, this slight variation on the prompt produces
|
||||
a very different image:
|
||||
Note that the prompt makes a big difference. For example, this slight variation
|
||||
on the prompt produces a very different image:
|
||||
|
||||
<figure markdown>
|
||||
<img src="https://user-images.githubusercontent.com/111189/194135220-16b62181-b60c-4248-8989-4834a8fd7fbd.png" width=350>
|
||||
{ width=320 }
|
||||
<caption markdown>photograph of a tree on a hill with a river</caption>
|
||||
</figure>
|
||||
|
||||
!!! tip
|
||||
|
||||
When designing prompts, think about how the images scraped from the internet were captioned. Very few photographs will
|
||||
be labeled "photograph" or "photorealistic." They will, however, be captioned with the publication, photographer, camera
|
||||
model, or film settings.
|
||||
When designing prompts, think about how the images scraped from the internet were
|
||||
captioned. Very few photographs will be labeled "photograph" or "photorealistic."
|
||||
They will, however, be captioned with the publication, photographer, camera model,
|
||||
or film settings.
|
||||
|
||||
If the initial image contains transparent regions, then Stable Diffusion will only draw within the
|
||||
transparent regions, a process called [`inpainting`](./INPAINTING.md#creating-transparent-regions-for-inpainting). However, for this to work correctly, the color
|
||||
information underneath the transparent needs to be preserved, not erased.
|
||||
If the initial image contains transparent regions, then Stable Diffusion will
|
||||
only draw within the transparent regions, a process called
|
||||
[`inpainting`](./INPAINTING.md#creating-transparent-regions-for-inpainting).
|
||||
However, for this to work correctly, the color information underneath the
|
||||
transparent needs to be preserved, not erased.
|
||||
|
||||
!!! warning
|
||||
!!! warning "**IMPORTANT ISSUE** "
|
||||
|
||||
**IMPORTANT ISSUE** `img2img` does not work properly on initial images smaller than 512x512. Please scale your
|
||||
image to at least 512x512 before using it. Larger images are not a problem, but may run out of VRAM on your
|
||||
GPU card. To fix this, use the --fit option, which downscales the initial image to fit within the box specified
|
||||
by width x height:
|
||||
~~~
|
||||
tree on a hill with a river, national geographic -I./test-pictures/big-sketch.png -H512 -W512 --fit
|
||||
~~~
|
||||
`img2img` does not work properly on initial images smaller
|
||||
than 512x512. Please scale your image to at least 512x512 before using it.
|
||||
Larger images are not a problem, but may run out of VRAM on your GPU card. To
|
||||
fix this, use the --fit option, which downscales the initial image to fit within
|
||||
the box specified by width x height:
|
||||
|
||||
```
|
||||
tree on a hill with a river, national geographic -I./test-pictures/big-sketch.png -H512 -W512 --fit
|
||||
```
|
||||
|
||||
## How does it actually work, though?
|
||||
|
||||
The main difference between `img2img` and `prompt2img` is the starting point. While `prompt2img` always starts with pure
|
||||
gaussian noise and progressively refines it over the requested number of steps, `img2img` skips some of these earlier steps
|
||||
(how many it skips is indirectly controlled by the `--strength` parameter), and uses instead your initial image mixed with gaussian noise as the starting image.
|
||||
The main difference between `img2img` and `prompt2img` is the starting point.
|
||||
While `prompt2img` always starts with pure gaussian noise and progressively
|
||||
refines it over the requested number of steps, `img2img` skips some of these
|
||||
earlier steps (how many it skips is indirectly controlled by the `--strength`
|
||||
parameter), and uses instead your initial image mixed with gaussian noise as the
|
||||
starting image.
|
||||
|
||||
**Let's start** by thinking about vanilla `prompt2img`, just generating an image from a prompt. If the step count is 10, then the "latent space" (Stable Diffusion's internal representation of the image) for the prompt "fire" with seed `1592514025` develops something like this:
|
||||
**Let's start** by thinking about vanilla `prompt2img`, just generating an image
|
||||
from a prompt. If the step count is 10, then the "latent space" (Stable
|
||||
Diffusion's internal representation of the image) for the prompt "fire" with
|
||||
seed `1592514025` develops something like this:
|
||||
|
||||
```commandline
|
||||
invoke> "fire" -s10 -W384 -H384 -S1592514025
|
||||
```
|
||||
!!! example ""
|
||||
|
||||
<figure markdown>
|
||||

|
||||
</figure>
|
||||
```bash
|
||||
invoke> "fire" -s10 -W384 -H384 -S1592514025
|
||||
```
|
||||
|
||||
Put simply: starting from a frame of fuzz/static, SD finds details in each frame that it thinks look like "fire" and brings them a little bit more into focus, gradually scrubbing out the fuzz until a clear image remains.
|
||||
<figure markdown>
|
||||
{ width=720 }
|
||||
</figure>
|
||||
|
||||
**When you use `img2img`** some of the earlier steps are cut, and instead an initial image of your choice is used. But because of how the maths behind Stable Diffusion works, this image needs to be mixed with just the right amount of noise (fuzz/static) for where it is being inserted. This is where the strength parameter comes in. Depending on the set strength, your image will be inserted into the sequence at the appropriate point, with just the right amount of noise.
|
||||
Put simply: starting from a frame of fuzz/static, SD finds details in each frame
|
||||
that it thinks look like "fire" and brings them a little bit more into focus,
|
||||
gradually scrubbing out the fuzz until a clear image remains.
|
||||
|
||||
**When you use `img2img`** some of the earlier steps are cut, and instead an
|
||||
initial image of your choice is used. But because of how the maths behind Stable
|
||||
Diffusion works, this image needs to be mixed with just the right amount of
|
||||
noise (fuzz/static) for where it is being inserted. This is where the strength
|
||||
parameter comes in. Depending on the set strength, your image will be inserted
|
||||
into the sequence at the appropriate point, with just the right amount of noise.
|
||||
|
||||
### A concrete example
|
||||
|
||||
I want SD to draw a fire based on this hand-drawn image:
|
||||
!!! example "I want SD to draw a fire based on this hand-drawn image"
|
||||
|
||||
<figure markdown>
|
||||

|
||||
</figure>
|
||||
{ align=left }
|
||||
|
||||
Let's only do 10 steps, to make it easier to see what's happening. If strength is `0.7`, this is what the internal steps the algorithm has to take will look like:
|
||||
Let's only do 10 steps, to make it easier to see what's happening. If strength
|
||||
is `0.7`, this is what the internal steps the algorithm has to take will look
|
||||
like:
|
||||
|
||||
<figure markdown>
|
||||

|
||||
</figure>
|
||||
<figure markdown>
|
||||

|
||||
</figure>
|
||||
|
||||
With strength `0.4`, the steps look more like this:
|
||||
With strength `0.4`, the steps look more like this:
|
||||
|
||||
<figure markdown>
|
||||

|
||||
</figure>
|
||||
<figure markdown>
|
||||

|
||||
</figure>
|
||||
|
||||
Notice how much more fuzzy the starting image is for strength `0.7` compared to `0.4`, and notice also how much longer the sequence is with `0.7`:
|
||||
Notice how much more fuzzy the starting image is for strength `0.7` compared to
|
||||
`0.4`, and notice also how much longer the sequence is with `0.7`:
|
||||
|
||||
| | strength = 0.7 | strength = 0.4 |
|
||||
| -- | -- | -- |
|
||||
| initial image that SD sees |  |  |
|
||||
| steps argument to `invoke>` | `-S10` | `-S10` |
|
||||
| steps actually taken | 7 | 4 |
|
||||
| latent space at each step |  |  |
|
||||
| output |  |  |
|
||||
| | strength = 0.7 | strength = 0.4 |
|
||||
| --------------------------- | ------------------------------------------------------------- | ------------------------------------------------------------- |
|
||||
| initial image that SD sees |  |  |
|
||||
| steps argument to `invoke>` | `-S10` | `-S10` |
|
||||
| steps actually taken | `7` | `4` |
|
||||
| latent space at each step |  |  |
|
||||
| output |  |  |
|
||||
|
||||
Both of the outputs look kind of like what I was thinking of. With the strength higher, my input becomes more vague, *and* Stable Diffusion has more steps to refine its output. But it's not really making what I want, which is a picture of cheery open fire. With the strength lower, my input is more clear, *but* Stable Diffusion has less chance to refine itself, so the result ends up inheriting all the problems of my bad drawing.
|
||||
Both of the outputs look kind of like what I was thinking of. With the strength
|
||||
higher, my input becomes more vague, _and_ Stable Diffusion has more steps to
|
||||
refine its output. But it's not really making what I want, which is a picture of
|
||||
cheery open fire. With the strength lower, my input is more clear, _but_ Stable
|
||||
Diffusion has less chance to refine itself, so the result ends up inheriting all
|
||||
the problems of my bad drawing.
|
||||
|
||||
If you want to try this out yourself, all of these are using a seed of `1592514025` with a width/height of `384`, step count `10`, the default sampler (`k_lms`), and the single-word prompt `"fire"`:
|
||||
If you want to try this out yourself, all of these are using a seed of
|
||||
`1592514025` with a width/height of `384`, step count `10`, the default sampler
|
||||
(`k_lms`), and the single-word prompt `"fire"`:
|
||||
|
||||
```commandline
|
||||
```bash
|
||||
invoke> "fire" -s10 -W384 -H384 -S1592514025 -I /tmp/fire-drawing.png --strength 0.7
|
||||
```
|
||||
|
||||
The code for rendering intermediates is on my (damian0815's) branch [document-img2img](https://github.com/damian0815/InvokeAI/tree/document-img2img) - run `invoke.py` and check your `outputs/img-samples/intermediates` folder while generating an image.
|
||||
The code for rendering intermediates is on my (damian0815's) branch
|
||||
[document-img2img](https://github.com/damian0815/InvokeAI/tree/document-img2img) -
|
||||
run `invoke.py` and check your `outputs/img-samples/intermediates` folder while
|
||||
generating an image.
|
||||
|
||||
### Compensating for the reduced step count
|
||||
|
||||
After putting this guide together I was curious to see how the difference would be if I increased the step count to compensate, so that SD could have the same amount of steps to develop the image regardless of the strength. So I ran the generation again using the same seed, but this time adapting the step count to give each generation 20 steps.
|
||||
After putting this guide together I was curious to see how the difference would
|
||||
be if I increased the step count to compensate, so that SD could have the same
|
||||
amount of steps to develop the image regardless of the strength. So I ran the
|
||||
generation again using the same seed, but this time adapting the step count to
|
||||
give each generation 20 steps.
|
||||
|
||||
Here's strength `0.4` (note step count `50`, which is `20 ÷ 0.4` to make sure SD does `20` steps from my image):
|
||||
Here's strength `0.4` (note step count `50`, which is `20 ÷ 0.4` to make sure SD
|
||||
does `20` steps from my image):
|
||||
|
||||
```commandline
|
||||
```bash
|
||||
invoke> "fire" -s50 -W384 -H384 -S1592514025 -I /tmp/fire-drawing.png -f 0.4
|
||||
```
|
||||
|
||||
@@ -140,7 +188,8 @@ invoke> "fire" -s50 -W384 -H384 -S1592514025 -I /tmp/fire-drawing.png -f 0.4
|
||||

|
||||
</figure>
|
||||
|
||||
and here is strength `0.7` (note step count `30`, which is roughly `20 ÷ 0.7` to make sure SD does `20` steps from my image):
|
||||
and here is strength `0.7` (note step count `30`, which is roughly `20 ÷ 0.7` to
|
||||
make sure SD does `20` steps from my image):
|
||||
|
||||
```commandline
|
||||
invoke> "fire" -s30 -W384 -H384 -S1592514025 -I /tmp/fire-drawing.png -f 0.7
|
||||
@@ -150,7 +199,11 @@ invoke> "fire" -s30 -W384 -H384 -S1592514025 -I /tmp/fire-drawing.png -f 0.7
|
||||

|
||||
</figure>
|
||||
|
||||
In both cases the image is nice and clean and "finished", but because at strength `0.7` Stable Diffusion has been give so much more freedom to improve on my badly-drawn flames, they've come out looking much better. You can really see the difference when looking at the latent steps. There's more noise on the first image with strength `0.7`:
|
||||
In both cases the image is nice and clean and "finished", but because at
|
||||
strength `0.7` Stable Diffusion has been give so much more freedom to improve on
|
||||
my badly-drawn flames, they've come out looking much better. You can really see
|
||||
the difference when looking at the latent steps. There's more noise on the first
|
||||
image with strength `0.7`:
|
||||
|
||||
<figure markdown>
|
||||

|
||||
@@ -162,15 +215,19 @@ than there is for strength `0.4`:
|
||||

|
||||
</figure>
|
||||
|
||||
and that extra noise gives the algorithm more choices when it is evaluating how to denoise any particular pixel in the image.
|
||||
and that extra noise gives the algorithm more choices when it is evaluating how
|
||||
to denoise any particular pixel in the image.
|
||||
|
||||
Unfortunately, it seems that `img2img` is very sensitive to the step count. Here's strength `0.7` with a step count of `29` (SD did 19 steps from my image):
|
||||
Unfortunately, it seems that `img2img` is very sensitive to the step count.
|
||||
Here's strength `0.7` with a step count of `29` (SD did 19 steps from my image):
|
||||
|
||||
<figure markdown>
|
||||

|
||||
</figure>
|
||||
|
||||
By comparing the latents we can sort of see that something got interpreted differently enough on the third or fourth step to lead to a rather different interpretation of the flames.
|
||||
By comparing the latents we can sort of see that something got interpreted
|
||||
differently enough on the third or fourth step to lead to a rather different
|
||||
interpretation of the flames.
|
||||
|
||||
<figure markdown>
|
||||

|
||||
@@ -180,4 +237,9 @@ By comparing the latents we can sort of see that something got interpreted diffe
|
||||

|
||||
</figure>
|
||||
|
||||
This is the result of a difference in the de-noising "schedule" - basically the noise has to be cleaned by a certain degree each step or the model won't "converge" on the image properly (see [stable diffusion blog](https://huggingface.co/blog/stable_diffusion) for more about that). A different step count means a different schedule, which means things get interpreted slightly differently at every step.
|
||||
This is the result of a difference in the de-noising "schedule" - basically the
|
||||
noise has to be cleaned by a certain degree each step or the model won't
|
||||
"converge" on the image properly (see
|
||||
[stable diffusion blog](https://huggingface.co/blog/stable_diffusion) for more
|
||||
about that). A different step count means a different schedule, which means
|
||||
things get interpreted slightly differently at every step.
|
||||
|
||||