mirror of
https://github.com/invoke-ai/InvokeAI.git
synced 2026-01-15 07:28:06 -05:00
Compare commits
352 Commits
v3.2.0rc2
...
fix/revert
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
97d6f207d8 | ||
|
|
dc9a9d7bec | ||
|
|
15a3e49a40 | ||
|
|
7ccfc499dc | ||
|
|
56d0d80a39 | ||
|
|
2d64ee7f9e | ||
|
|
10ada84404 | ||
|
|
7744e01e2c | ||
|
|
ce8e5f9adf | ||
|
|
fc1021b6be | ||
|
|
fadfe1dfe9 | ||
|
|
2716ae353b | ||
|
|
bf9f7271dd | ||
|
|
d3821594df | ||
|
|
631ad1596f | ||
|
|
dfe32e467d | ||
|
|
3575cf3b3b | ||
|
|
29c3f49182 | ||
|
|
d2149a8380 | ||
|
|
6532d9ffa1 | ||
|
|
89db8c83c2 | ||
|
|
fc09ab7e13 | ||
|
|
9646157ad5 | ||
|
|
b89ec2b9c3 | ||
|
|
d2fb29cf0d | ||
|
|
d1fce4b70b | ||
|
|
f50f95a81d | ||
|
|
3611029057 | ||
|
|
402cf9b0ee | ||
|
|
88bee96ca3 | ||
|
|
5048fc7c9e | ||
|
|
2a35d93a4d | ||
|
|
10fac5c085 | ||
|
|
58850ded22 | ||
|
|
f21ebdfaca | ||
|
|
c4f1e94cc4 | ||
|
|
dbbcce9f70 | ||
|
|
cc52896bd9 | ||
|
|
d12314fb8b | ||
|
|
07b88e3017 | ||
|
|
0b85f2487c | ||
|
|
5530d3fcd2 | ||
|
|
7b1b24900f | ||
|
|
f52fb45276 | ||
|
|
fb9f0339a2 | ||
|
|
ac501ee742 | ||
|
|
2182ccf8d1 | ||
|
|
fc674ff1b8 | ||
|
|
708ac6a511 | ||
|
|
d0e0b64fc8 | ||
|
|
a23580664d | ||
|
|
0edf01d927 | ||
|
|
4af5b9cbf7 | ||
|
|
1bf973d46e | ||
|
|
72252e3ff7 | ||
|
|
8d2596c288 | ||
|
|
0ffb7ecaa8 | ||
|
|
10f30fc599 | ||
|
|
136570aa1d | ||
|
|
5a30b507e0 | ||
|
|
d47fbf283c | ||
|
|
7c24312d3f | ||
|
|
905cd8c639 | ||
|
|
b13ba55c26 | ||
|
|
82747e2260 | ||
|
|
910553f49a | ||
|
|
faabd83717 | ||
|
|
5ad77ece4b | ||
|
|
6b3c413a5b | ||
|
|
2a923d1f69 | ||
|
|
c54a5ce10e | ||
|
|
14fbe41834 | ||
|
|
64ebe042b5 | ||
|
|
80d329c900 | ||
|
|
89db749d89 | ||
|
|
18164fc72a | ||
|
|
75de20af6a | ||
|
|
cb1509bf52 | ||
|
|
10cd814cf7 | ||
|
|
8ef38ecc7c | ||
|
|
69937d68d2 | ||
|
|
40f9e49b5e | ||
|
|
98fa234529 | ||
|
|
fe889235cc | ||
|
|
462c1d4c9b | ||
|
|
0ed36158c8 | ||
|
|
f3c138a208 | ||
|
|
61242bf86a | ||
|
|
d118d02df4 | ||
|
|
58b56e9b1e | ||
|
|
1f751f8c21 | ||
|
|
ca95a3bd0d | ||
|
|
55b40a9425 | ||
|
|
90083cc88d | ||
|
|
ead754432a | ||
|
|
fa9ea93477 | ||
|
|
fe0cf2c160 | ||
|
|
a681fa4b03 | ||
|
|
1cc686734b | ||
|
|
82e8b92ba0 | ||
|
|
e86658f864 | ||
|
|
ad136c2680 | ||
|
|
35374ec531 | ||
|
|
ed82bf6bb8 | ||
|
|
078c9b6964 | ||
|
|
1a9d2f1701 | ||
|
|
3e93159bce | ||
|
|
b57ebe52e4 | ||
|
|
ba4616ff89 | ||
|
|
dcfbd49e1b | ||
|
|
913fc83cbf | ||
|
|
6b8ce34eb3 | ||
|
|
9508e0c9db | ||
|
|
9c720da021 | ||
|
|
e1b576c72d | ||
|
|
971ccfb081 | ||
|
|
43a3c3c7ea | ||
|
|
4df1cdb34d | ||
|
|
3f860c3523 | ||
|
|
d8d0c9af09 | ||
|
|
9403672ac0 | ||
|
|
94591840a7 | ||
|
|
26b91a538a | ||
|
|
7ca456d674 | ||
|
|
78828b6b9c | ||
|
|
166ff9d301 | ||
|
|
4f97bd4418 | ||
|
|
e0e001758a | ||
|
|
c1887135b3 | ||
|
|
096d195d6e | ||
|
|
7870b90717 | ||
|
|
9854b244fd | ||
|
|
7d800e1ce3 | ||
|
|
1c8b1fbc53 | ||
|
|
594a3aef93 | ||
|
|
78377469db | ||
|
|
fbe6452c45 | ||
|
|
3f4ea073d1 | ||
|
|
8b7f8eaea2 | ||
|
|
88e16ce051 | ||
|
|
421440cae0 | ||
|
|
421021cede | ||
|
|
020d4302d1 | ||
|
|
8c59d2e5af | ||
|
|
17d451eaa7 | ||
|
|
23a06fd06d | ||
|
|
010c8e8038 | ||
|
|
dfc635223c | ||
|
|
37121a3a24 | ||
|
|
51b5de799a | ||
|
|
eadbe6abf7 | ||
|
|
16f48a816f | ||
|
|
95838e5559 | ||
|
|
3e8d62b1d1 | ||
|
|
2acc93eb8e | ||
|
|
fbb61f2334 | ||
|
|
be85c7972b | ||
|
|
3a586fc9c4 | ||
|
|
dedead672f | ||
|
|
67366921c0 | ||
|
|
5a1019d858 | ||
|
|
f4ba7be918 | ||
|
|
069d8b5812 | ||
|
|
24d73d484a | ||
|
|
2479a59e5e | ||
|
|
7d0ac2c36d | ||
|
|
519b892f0c | ||
|
|
763dcacfd3 | ||
|
|
3599d546e6 | ||
|
|
22a84930f6 | ||
|
|
d64e17e043 | ||
|
|
ba54277011 | ||
|
|
5915a4a51c | ||
|
|
4580ba0d87 | ||
|
|
b9fd2e9e76 | ||
|
|
75b65597af | ||
|
|
2a3c0ab5d2 | ||
|
|
7d61373b82 | ||
|
|
7d65555a5a | ||
|
|
123f2b2dbc | ||
|
|
1e4e42556e | ||
|
|
1f6699ac43 | ||
|
|
ace8665411 | ||
|
|
7fa5bae8fd | ||
|
|
f9faca7c91 | ||
|
|
594fd3ba6d | ||
|
|
44d68f5ed5 | ||
|
|
4bda7d7df5 | ||
|
|
920c5dd686 | ||
|
|
4ce00a32f4 | ||
|
|
dcbb25dfea | ||
|
|
6c8270dae2 | ||
|
|
b19572199f | ||
|
|
a673c0aa14 | ||
|
|
955ef3bc54 | ||
|
|
f002ae8da5 | ||
|
|
208bf68ba2 | ||
|
|
1aba369c83 | ||
|
|
9ac11e793c | ||
|
|
9b39888e2f | ||
|
|
c1715144f0 | ||
|
|
929557bc6f | ||
|
|
811dd93912 | ||
|
|
9a60dbd5cb | ||
|
|
637c5b0747 | ||
|
|
27164de8b8 | ||
|
|
08e40d6d16 | ||
|
|
d905c54795 | ||
|
|
dc1e804887 | ||
|
|
95fd2ee6ff | ||
|
|
5f4eb0c3b3 | ||
|
|
d464ce509b | ||
|
|
3909e68527 | ||
|
|
848e51f72b | ||
|
|
52f8c9e16f | ||
|
|
5174f382b9 | ||
|
|
c7f80cd163 | ||
|
|
309e2414ce | ||
|
|
6704f77d87 | ||
|
|
045d3f6139 | ||
|
|
a0bd8c638e | ||
|
|
de04a5f441 | ||
|
|
40ed218c26 | ||
|
|
807c6b41c5 | ||
|
|
f6bbcd0589 | ||
|
|
ada22a799e | ||
|
|
a42ef9c855 | ||
|
|
034af2d9f8 | ||
|
|
676ccd8ebb | ||
|
|
a263a4f4cc | ||
|
|
ef0754cdec | ||
|
|
8158124679 | ||
|
|
5d31df0cb7 | ||
|
|
bd63454e51 | ||
|
|
062df07de2 | ||
|
|
0fc14afcf0 | ||
|
|
4a0a1c30db | ||
|
|
3432fd72f8 | ||
|
|
05a43c41f9 | ||
|
|
bb48617101 | ||
|
|
aa2f68f608 | ||
|
|
fbccce7573 | ||
|
|
a35087ee6e | ||
|
|
03e463dc89 | ||
|
|
d467e138a4 | ||
|
|
ba4aaea45b | ||
|
|
53eb23b8b6 | ||
|
|
8b969053e7 | ||
|
|
98a076260b | ||
|
|
164877b610 | ||
|
|
b3f4f28d76 | ||
|
|
acee4bd282 | ||
|
|
fc9a7320eb | ||
|
|
7c0a083b13 | ||
|
|
50d254fdb7 | ||
|
|
0cfc1c5f86 | ||
|
|
f35dfa06bb | ||
|
|
407bca5063 | ||
|
|
1419977e89 | ||
|
|
a953944894 | ||
|
|
a4cdaa245e | ||
|
|
105a4234b0 | ||
|
|
34c563060f | ||
|
|
d45c47db81 | ||
|
|
c771a4027f | ||
|
|
3fd27b1aa9 | ||
|
|
d59e534cad | ||
|
|
0c97a1e7e7 | ||
|
|
c8b306d9f8 | ||
|
|
edd2c54b9e | ||
|
|
727cc0dafe | ||
|
|
4530bd46dc | ||
|
|
c8b109f52e | ||
|
|
a2613948d8 | ||
|
|
f8392b2f78 | ||
|
|
358116bc22 | ||
|
|
1e3590111d | ||
|
|
063b800280 | ||
|
|
3935bf92c8 | ||
|
|
066e09b517 | ||
|
|
869b4a8d49 | ||
|
|
399ebe443e | ||
|
|
13919ff300 | ||
|
|
634e5652ef | ||
|
|
9bdc718df5 | ||
|
|
73ca8ccdb3 | ||
|
|
f37ffda966 | ||
|
|
5a9777d443 | ||
|
|
8072c05ee0 | ||
|
|
75ff4f4ca3 | ||
|
|
30df123221 | ||
|
|
06193ddbe8 | ||
|
|
ce5122f87c | ||
|
|
43ebd68313 | ||
|
|
ec19fcafb1 | ||
|
|
6fcc7d4c4b | ||
|
|
912087e4dc | ||
|
|
593fb95213 | ||
|
|
6d821b32d3 | ||
|
|
297f96c16b | ||
|
|
0e53b27655 | ||
|
|
35ae9f6e71 | ||
|
|
a1d9e6b871 | ||
|
|
f05379f965 | ||
|
|
e34e6d6e80 | ||
|
|
86cb53342a | ||
|
|
e3de996525 | ||
|
|
25a71a1791 | ||
|
|
d16583ad1c | ||
|
|
46db1dd18f | ||
|
|
4c9344b0ee | ||
|
|
cba31efd78 | ||
|
|
4d01b5c0f2 | ||
|
|
e02af8f518 | ||
|
|
c485cf568b | ||
|
|
51451cbf21 | ||
|
|
0363a06963 | ||
|
|
cc280cbef1 | ||
|
|
7544eadd48 | ||
|
|
7d683b4db6 | ||
|
|
60b3c6a201 | ||
|
|
88c8cb61f0 | ||
|
|
43fbac26df | ||
|
|
627444e17c | ||
|
|
5601858f4f | ||
|
|
b152fbf72f | ||
|
|
f95111772a | ||
|
|
14ce7cf09c | ||
|
|
28a1a6939f | ||
|
|
6d2b4013f8 | ||
|
|
ca7a7b57bb | ||
|
|
c5d0e65a24 | ||
|
|
6cc7b55ec5 | ||
|
|
883e9973ec | ||
|
|
9e7d829906 | ||
|
|
456a0a59e0 | ||
|
|
4f2bf7e7e8 | ||
|
|
77e93888cf | ||
|
|
fa54974bff | ||
|
|
7ac99d6bc3 | ||
|
|
b5e1ba34b3 | ||
|
|
58aa159a50 | ||
|
|
d8f7c19030 | ||
|
|
24132a7950 | ||
|
|
45d172d5a8 | ||
|
|
3cb6d333f6 | ||
|
|
4570702dd0 | ||
|
|
1d107f30e5 | ||
|
|
79084e9e20 | ||
|
|
fc9b4539a3 | ||
|
|
09ef57718e | ||
|
|
cab8239ba8 |
2
.github/workflows/pypi-release.yml
vendored
2
.github/workflows/pypi-release.yml
vendored
@@ -28,7 +28,7 @@ jobs:
|
||||
run: twine check dist/*
|
||||
|
||||
- name: check PyPI versions
|
||||
if: github.ref == 'refs/heads/main' || github.ref == 'refs/heads/v2.3'
|
||||
if: github.ref == 'refs/heads/main' || github.ref == 'refs/heads/v2.3' || github.ref == 'refs/heads/v3.3.0post1'
|
||||
run: |
|
||||
pip install --upgrade requests
|
||||
python -c "\
|
||||
|
||||
@@ -47,34 +47,9 @@ pip install ".[dev,test]"
|
||||
These are optional groups of packages which are defined within the `pyproject.toml`
|
||||
and will be required for testing the changes you make to the code.
|
||||
|
||||
### Running Tests
|
||||
|
||||
We use [pytest](https://docs.pytest.org/en/7.2.x/) for our test suite. Tests can
|
||||
be found under the `./tests` folder and can be run with a single `pytest`
|
||||
command. Optionally, to review test coverage you can append `--cov`.
|
||||
|
||||
```zsh
|
||||
pytest --cov
|
||||
```
|
||||
|
||||
Test outcomes and coverage will be reported in the terminal. In addition a more
|
||||
detailed report is created in both XML and HTML format in the `./coverage`
|
||||
folder. The HTML one in particular can help identify missing statements
|
||||
requiring tests to ensure coverage. This can be run by opening
|
||||
`./coverage/html/index.html`.
|
||||
|
||||
For example.
|
||||
|
||||
```zsh
|
||||
pytest --cov; open ./coverage/html/index.html
|
||||
```
|
||||
|
||||
??? info "HTML coverage report output"
|
||||
|
||||

|
||||
|
||||

|
||||
### Tests
|
||||
|
||||
See the [tests documentation](./TESTS.md) for information about running and writing tests.
|
||||
### Reloading Changes
|
||||
|
||||
Experimenting with changes to the Python source code is a drag if you have to re-start the server —
|
||||
@@ -167,6 +142,23 @@ and so you'll have access to the same python environment as the InvokeAI app.
|
||||
|
||||
This is _super_ handy.
|
||||
|
||||
#### Enabling Type-Checking with Pylance
|
||||
|
||||
We use python's typing system in InvokeAI. PR reviews will include checking that types are present and correct. We don't enforce types with `mypy` at this time, but that is on the horizon.
|
||||
|
||||
Using a code analysis tool to automatically type check your code (and types) is very important when writing with types. These tools provide immediate feedback in your editor when types are incorrect, and following their suggestions lead to fewer runtime bugs.
|
||||
|
||||
Pylance, installed at the beginning of this guide, is the de-facto python LSP (language server protocol). It provides type checking in the editor (among many other features). Once installed, you do need to enable type checking manually:
|
||||
|
||||
- Open a python file
|
||||
- Look along the status bar in VSCode for `{ } Python`
|
||||
- Click the `{ }`
|
||||
- Turn type checking on - basic is fine
|
||||
|
||||
You'll now see red squiggly lines where type issues are detected. Hover your cursor over the indicated symbols to see what's wrong.
|
||||
|
||||
In 99% of cases when the type checker says there is a problem, there really is a problem, and you should take some time to understand and resolve what it is pointing out.
|
||||
|
||||
#### Debugging configs with `launch.json`
|
||||
|
||||
Debugging configs are managed in a `launch.json` file. Like most VSCode configs,
|
||||
|
||||
89
docs/contributing/TESTS.md
Normal file
89
docs/contributing/TESTS.md
Normal file
@@ -0,0 +1,89 @@
|
||||
# InvokeAI Backend Tests
|
||||
|
||||
We use `pytest` to run the backend python tests. (See [pyproject.toml](/pyproject.toml) for the default `pytest` options.)
|
||||
|
||||
## Fast vs. Slow
|
||||
All tests are categorized as either 'fast' (no test annotation) or 'slow' (annotated with the `@pytest.mark.slow` decorator).
|
||||
|
||||
'Fast' tests are run to validate every PR, and are fast enough that they can be run routinely during development.
|
||||
|
||||
'Slow' tests are currently only run manually on an ad-hoc basis. In the future, they may be automated to run nightly. Most developers are only expected to run the 'slow' tests that directly relate to the feature(s) that they are working on.
|
||||
|
||||
As a rule of thumb, tests should be marked as 'slow' if there is a chance that they take >1s (e.g. on a CPU-only machine with slow internet connection). Common examples of slow tests are tests that depend on downloading a model, or running model inference.
|
||||
|
||||
## Running Tests
|
||||
|
||||
Below are some common test commands:
|
||||
```bash
|
||||
# Run the fast tests. (This implicitly uses the configured default option: `-m "not slow"`.)
|
||||
pytest tests/
|
||||
|
||||
# Equivalent command to run the fast tests.
|
||||
pytest tests/ -m "not slow"
|
||||
|
||||
# Run the slow tests.
|
||||
pytest tests/ -m "slow"
|
||||
|
||||
# Run the slow tests from a specific file.
|
||||
pytest tests/path/to/slow_test.py -m "slow"
|
||||
|
||||
# Run all tests (fast and slow).
|
||||
pytest tests -m ""
|
||||
```
|
||||
|
||||
## Test Organization
|
||||
|
||||
All backend tests are in the [`tests/`](/tests/) directory. This directory mirrors the organization of the `invokeai/` directory. For example, tests for `invokeai/model_management/model_manager.py` would be found in `tests/model_management/test_model_manager.py`.
|
||||
|
||||
TODO: The above statement is aspirational. A re-organization of legacy tests is required to make it true.
|
||||
|
||||
## Tests that depend on models
|
||||
|
||||
There are a few things to keep in mind when adding tests that depend on models.
|
||||
|
||||
1. If a required model is not already present, it should automatically be downloaded as part of the test setup.
|
||||
2. If a model is already downloaded, it should not be re-downloaded unnecessarily.
|
||||
3. Take reasonable care to keep the total number of models required for the tests low. Whenever possible, re-use models that are already required for other tests. If you are adding a new model, consider including a comment to explain why it is required/unique.
|
||||
|
||||
There are several utilities to help with model setup for tests. Here is a sample test that depends on a model:
|
||||
```python
|
||||
import pytest
|
||||
import torch
|
||||
|
||||
from invokeai.backend.model_management.models.base import BaseModelType, ModelType
|
||||
from invokeai.backend.util.test_utils import install_and_load_model
|
||||
|
||||
@pytest.mark.slow
|
||||
def test_model(model_installer, torch_device):
|
||||
model_info = install_and_load_model(
|
||||
model_installer=model_installer,
|
||||
model_path_id_or_url="HF/dummy_model_id",
|
||||
model_name="dummy_model",
|
||||
base_model=BaseModelType.StableDiffusion1,
|
||||
model_type=ModelType.Dummy,
|
||||
)
|
||||
|
||||
dummy_input = build_dummy_input(torch_device)
|
||||
|
||||
with torch.no_grad(), model_info as model:
|
||||
model.to(torch_device, dtype=torch.float32)
|
||||
output = model(dummy_input)
|
||||
|
||||
# Validate output...
|
||||
|
||||
```
|
||||
|
||||
## Test Coverage
|
||||
|
||||
To review test coverage, append `--cov` to your pytest command:
|
||||
```bash
|
||||
pytest tests/ --cov
|
||||
```
|
||||
|
||||
Test outcomes and coverage will be reported in the terminal. In addition, a more detailed report is created in both XML and HTML format in the `./coverage` folder. The HTML output is particularly helpful in identifying untested statements where coverage should be improved. The HTML report can be viewed by opening `./coverage/html/index.html`.
|
||||
|
||||
??? info "HTML coverage report output"
|
||||
|
||||

|
||||
|
||||

|
||||
@@ -12,7 +12,7 @@ To get started, take a look at our [new contributors checklist](newContributorCh
|
||||
Once you're setup, for more information, you can review the documentation specific to your area of interest:
|
||||
|
||||
* #### [InvokeAI Architecure](../ARCHITECTURE.md)
|
||||
* #### [Frontend Documentation](development_guides/contributingToFrontend.md)
|
||||
* #### [Frontend Documentation](./contributingToFrontend.md)
|
||||
* #### [Node Documentation](../INVOCATIONS.md)
|
||||
* #### [Local Development](../LOCAL_DEVELOPMENT.md)
|
||||
|
||||
@@ -38,9 +38,9 @@ There are two paths to making a development contribution:
|
||||
|
||||
If you need help, you can ask questions in the [#dev-chat](https://discord.com/channels/1020123559063990373/1049495067846524939) channel of the Discord.
|
||||
|
||||
For frontend related work, **@pyschedelicious** is the best person to reach out to.
|
||||
For frontend related work, **@psychedelicious** is the best person to reach out to.
|
||||
|
||||
For backend related work, please reach out to **@blessedcoolant**, **@lstein**, **@StAlKeR7779** or **@pyschedelicious**.
|
||||
For backend related work, please reach out to **@blessedcoolant**, **@lstein**, **@StAlKeR7779** or **@psychedelicious**.
|
||||
|
||||
|
||||
## **What does the Code of Conduct mean for me?**
|
||||
|
||||
@@ -10,4 +10,4 @@ When updating or creating documentation, please keep in mind InvokeAI is a tool
|
||||
|
||||
## Help & Questions
|
||||
|
||||
Please ping @imic1 or @hipsterusername in the [Discord](https://discord.com/channels/1020123559063990373/1049495067846524939) if you have any questions.
|
||||
Please ping @imic or @hipsterusername in the [Discord](https://discord.com/channels/1020123559063990373/1049495067846524939) if you have any questions.
|
||||
@@ -1,13 +1,11 @@
|
||||
---
|
||||
title: ControlNet
|
||||
title: Control Adapters
|
||||
---
|
||||
|
||||
# :material-loupe: ControlNet
|
||||
# :material-loupe: Control Adapters
|
||||
|
||||
## ControlNet
|
||||
|
||||
ControlNet
|
||||
|
||||
ControlNet is a powerful set of features developed by the open-source
|
||||
community (notably, Stanford researcher
|
||||
[**@ilyasviel**](https://github.com/lllyasviel)) that allows you to
|
||||
@@ -20,7 +18,7 @@ towards generating images that better fit your desired style or
|
||||
outcome.
|
||||
|
||||
|
||||
### How it works
|
||||
#### How it works
|
||||
|
||||
ControlNet works by analyzing an input image, pre-processing that
|
||||
image to identify relevant information that can be interpreted by each
|
||||
@@ -30,7 +28,7 @@ composition, or other aspects of the image to better achieve a
|
||||
specific result.
|
||||
|
||||
|
||||
### Models
|
||||
#### Models
|
||||
|
||||
InvokeAI provides access to a series of ControlNet models that provide
|
||||
different effects or styles in your generated images. Currently
|
||||
@@ -96,6 +94,8 @@ A model that generates normal maps from input images, allowing for more realisti
|
||||
**Image Segmentation**:
|
||||
A model that divides input images into segments or regions, each of which corresponds to a different object or part of the image. (More details coming soon)
|
||||
|
||||
**QR Code Monster**:
|
||||
A model that helps generate creative QR codes that still scan. Can also be used to create images with text, logos or shapes within them.
|
||||
|
||||
**Openpose**:
|
||||
The OpenPose control model allows for the identification of the general pose of a character by pre-processing an existing image with a clear human structure. With advanced options, Openpose can also detect the face or hands in the image.
|
||||
@@ -120,7 +120,7 @@ With Pix2Pix, you can input an image into the controlnet, and then "instruct" th
|
||||
Each of these models can be adjusted and combined with other ControlNet models to achieve different results, giving you even more control over your image generation process.
|
||||
|
||||
|
||||
## Using ControlNet
|
||||
### Using ControlNet
|
||||
|
||||
To use ControlNet, you can simply select the desired model and adjust both the ControlNet and Pre-processor settings to achieve the desired result. You can also use multiple ControlNet models at the same time, allowing you to achieve even more complex effects or styles in your generated images.
|
||||
|
||||
@@ -132,3 +132,31 @@ Weight - Strength of the Controlnet model applied to the generation for the sect
|
||||
Start/End - 0 represents the start of the generation, 1 represents the end. The Start/end setting controls what steps during the generation process have the ControlNet applied.
|
||||
|
||||
Additionally, each ControlNet section can be expanded in order to manipulate settings for the image pre-processor that adjusts your uploaded image before using it in when you Invoke.
|
||||
|
||||
|
||||
## IP-Adapter
|
||||
|
||||
[IP-Adapter](https://ip-adapter.github.io) is a tooling that allows for image prompt capabilities with text-to-image diffusion models. IP-Adapter works by analyzing the given image prompt to extract features, then passing those features to the UNet along with any other conditioning provided.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
#### Installation
|
||||
There are several ways to install IP-Adapter models with an existing InvokeAI installation:
|
||||
|
||||
1. Through the command line interface launched from the invoke.sh / invoke.bat scripts, option [5] to download models.
|
||||
2. Through the Model Manager UI with models from the *Tools* section of [www.models.invoke.ai](www.models.invoke.ai). To do this, copy the repo ID from the desired model page, and paste it in the Add Model field of the model manager. **Note** Both the IP-Adapter and the Image Encoder must be installed for IP-Adapter to work. For example, the [SD 1.5 IP-Adapter](https://models.invoke.ai/InvokeAI/ip_adapter_plus_sd15) and [SD1.5 Image Encoder](https://models.invoke.ai/InvokeAI/ip_adapter_sd_image_encoder) must be installed to use IP-Adapter with SD1.5 based models.
|
||||
3. **Advanced -- Not recommended ** Manually downloading the IP-Adapter and Image Encoder files - Image Encoder folders shouid be placed in the `models\any\clip_vision` folders. IP Adapter Model folders should be placed in the relevant `ip-adapter` folder of relevant base model folder of Invoke root directory. For example, for the SDXL IP-Adapter, files should be added to the `model/sdxl/ip_adapter/` folder.
|
||||
|
||||
#### Using IP-Adapter
|
||||
|
||||
IP-Adapter can be used by navigating to the *Control Adapters* options and enabling IP-Adapter.
|
||||
|
||||
IP-Adapter requires an image to be used as the Image Prompt. It can also be used in conjunction with text prompts, Image-to-Image, Inpainting, Outpainting, ControlNets and LoRAs.
|
||||
|
||||
|
||||
Each IP-Adapter has two settings that are applied to the IP-Adapter:
|
||||
|
||||
* Weight - Strength of the IP-Adapter model applied to the generation for the section, defined by start/end
|
||||
* Start/End - 0 represents the start of the generation, 1 represents the end. The Start/end setting controls what steps during the generation process have the IP-Adapter applied.
|
||||
|
||||
@@ -256,6 +256,10 @@ manager, please follow these steps:
|
||||
*highly recommended** if your virtual environment is located outside of
|
||||
your runtime directory.
|
||||
|
||||
!!! tip
|
||||
|
||||
On linux, it is recommended to run invokeai with the following env var: `MALLOC_MMAP_THRESHOLD_=1048576`. For example: `MALLOC_MMAP_THRESHOLD_=1048576 invokeai --web`. This helps to prevent memory fragmentation that can lead to memory accumulation over time. This env var is set automatically when running via `invoke.sh`.
|
||||
|
||||
10. Render away!
|
||||
|
||||
Browse the [features](../features/index.md) section to learn about all the
|
||||
@@ -296,8 +300,18 @@ code for InvokeAI. For this to work, you will need to install the
|
||||
on your system, please see the [Git Installation
|
||||
Guide](https://github.com/git-guides/install-git)
|
||||
|
||||
You will also need to install the [frontend development toolchain](https://github.com/invoke-ai/InvokeAI/blob/main/docs/contributing/contribution_guides/contributingToFrontend.md).
|
||||
|
||||
If you have a "normal" installation, you should create a totally separate virtual environment for the git-based installation, else the two may interfere.
|
||||
|
||||
> **Why do I need the frontend toolchain**?
|
||||
>
|
||||
> The InvokeAI project uses trunk-based development. That means our `main` branch is the development branch, and releases are tags on that branch. Because development is very active, we don't keep an updated build of the UI in `main` - we only build it for production releases.
|
||||
>
|
||||
> That means that between releases, to have a functioning application when running directly from the repo, you will need to run the UI in dev mode or build it regularly (any time the UI code changes).
|
||||
|
||||
1. Create a fork of the InvokeAI repository through the GitHub UI or [this link](https://github.com/invoke-ai/InvokeAI/fork)
|
||||
1. From the command line, run this command:
|
||||
2. From the command line, run this command:
|
||||
```bash
|
||||
git clone https://github.com/<your_github_username>/InvokeAI.git
|
||||
```
|
||||
@@ -305,10 +319,10 @@ Guide](https://github.com/git-guides/install-git)
|
||||
This will create a directory named `InvokeAI` and populate it with the
|
||||
full source code from your fork of the InvokeAI repository.
|
||||
|
||||
2. Activate the InvokeAI virtual environment as per step (4) of the manual
|
||||
3. Activate the InvokeAI virtual environment as per step (4) of the manual
|
||||
installation protocol (important!)
|
||||
|
||||
3. Enter the InvokeAI repository directory and run one of these
|
||||
4. Enter the InvokeAI repository directory and run one of these
|
||||
commands, based on your GPU:
|
||||
|
||||
=== "CUDA (NVidia)"
|
||||
@@ -334,11 +348,15 @@ installation protocol (important!)
|
||||
Be sure to pass `-e` (for an editable install) and don't forget the
|
||||
dot ("."). It is part of the command.
|
||||
|
||||
You can now run `invokeai` and its related commands. The code will be
|
||||
5. Install the [frontend toolchain](https://github.com/invoke-ai/InvokeAI/blob/main/docs/contributing/contribution_guides/contributingToFrontend.md) and do a production build of the UI as described.
|
||||
|
||||
6. You can now run `invokeai` and its related commands. The code will be
|
||||
read from the repository, so that you can edit the .py source files
|
||||
and watch the code's behavior change.
|
||||
|
||||
4. If you wish to contribute to the InvokeAI project, you are
|
||||
When you pull in new changes to the repo, be sure to re-build the UI.
|
||||
|
||||
7. If you wish to contribute to the InvokeAI project, you are
|
||||
encouraged to establish a GitHub account and "fork"
|
||||
https://github.com/invoke-ai/InvokeAI into your own copy of the
|
||||
repository. You can then use GitHub functions to create and submit
|
||||
|
||||
@@ -171,3 +171,16 @@ subfolders and organize them as you wish.
|
||||
|
||||
The location of the autoimport directories are controlled by settings
|
||||
in `invokeai.yaml`. See [Configuration](../features/CONFIGURATION.md).
|
||||
|
||||
### Installing models that live in HuggingFace subfolders
|
||||
|
||||
On rare occasions you may need to install a diffusers-style model that
|
||||
lives in a subfolder of a HuggingFace repo id. In this event, simply
|
||||
add ":_subfolder-name_" to the end of the repo id. For example, if the
|
||||
repo id is "monster-labs/control_v1p_sd15_qrcode_monster" and the model
|
||||
you wish to fetch lives in a subfolder named "v2", then the repo id to
|
||||
pass to the various model installers should be
|
||||
|
||||
```
|
||||
monster-labs/control_v1p_sd15_qrcode_monster:v2
|
||||
```
|
||||
|
||||
@@ -4,12 +4,12 @@ The workflow editor is a blank canvas allowing for the use of individual functio
|
||||
|
||||
If you're not familiar with Diffusion, take a look at our [Diffusion Overview.](../help/diffusion.md) Understanding how diffusion works will enable you to more easily use the Workflow Editor and build workflows to suit your needs.
|
||||
|
||||
## UI Features
|
||||
## Features
|
||||
|
||||
### Linear View
|
||||
The Workflow Editor allows you to create a UI for your workflow, to make it easier to iterate on your generations.
|
||||
|
||||
To add an input to the Linear UI, right click on the input and select "Add to Linear View".
|
||||
To add an input to the Linear UI, right click on the input label and select "Add to Linear View".
|
||||
|
||||
The Linear UI View will also be part of the saved workflow, allowing you share workflows and enable other to use them, regardless of complexity.
|
||||
|
||||
@@ -25,6 +25,10 @@ Any node or input field can be renamed in the workflow editor. If the input fiel
|
||||
* Backspace/Delete to delete a node
|
||||
* Shift+Click to drag and select multiple nodes
|
||||
|
||||
### Node Caching
|
||||
|
||||
Nodes have a "Use Cache" option in their footer. This allows for performance improvements by using the previously cached values during the workflow processing.
|
||||
|
||||
|
||||
## Important Concepts
|
||||
|
||||
|
||||
@@ -8,19 +8,21 @@ To download a node, simply download the `.py` node file from the link and add it
|
||||
|
||||
To use a community workflow, download the the `.json` node graph file and load it into Invoke AI via the **Load Workflow** button in the Workflow Editor.
|
||||
|
||||
## Community Nodes
|
||||
--------------------------------
|
||||
|
||||
### FaceTools
|
||||
--------------------------------
|
||||
### Make 3D
|
||||
|
||||
**Description:** FaceTools is a collection of nodes created to manipulate faces as you would in Unified Canvas. It includes FaceMask, FaceOff, and FacePlace. FaceMask autodetects a face in the image using MediaPipe and creates a mask from it. FaceOff similarly detects a face, then takes the face off of the image by adding a square bounding box around it and cropping/scaling it. FacePlace puts the bounded face image from FaceOff back onto the original image. Using these nodes with other inpainting node(s), you can put new faces on existing things, put new things around existing faces, and work closer with a face as a bounded image. Additionally, you can supply X and Y offset values to scale/change the shape of the mask for finer control on FaceMask and FaceOff. See GitHub repository below for usage examples.
|
||||
**Description:** Create compelling 3D stereo images from 2D originals.
|
||||
|
||||
**Node Link:** https://github.com/ymgenesis/FaceTools/
|
||||
**Node Link:** [https://gitlab.com/srcrr/shift3d/-/raw/main/make3d.py](https://gitlab.com/srcrr/shift3d)
|
||||
|
||||
**FaceMask Output Examples**
|
||||
**Example Node Graph:** https://gitlab.com/srcrr/shift3d/-/raw/main/example-workflow.json?ref_type=heads&inline=false
|
||||
|
||||

|
||||

|
||||

|
||||
**Output Examples**
|
||||
|
||||
{: style="height:512px;width:512px"}
|
||||
{: style="height:512px;width:512px"}
|
||||
|
||||
--------------------------------
|
||||
### Ideal Size
|
||||
@@ -43,6 +45,52 @@ To use a community workflow, download the the `.json` node graph file and load i
|
||||
|
||||
**Node Link:** https://github.com/JPPhoto/image-picker-node
|
||||
|
||||
--------------------------------
|
||||
### Thresholding
|
||||
|
||||
**Description:** This node generates masks for highlights, midtones, and shadows given an input image. You can optionally specify a blur for the lookup table used in making those masks from the source image.
|
||||
|
||||
**Node Link:** https://github.com/JPPhoto/thresholding-node
|
||||
|
||||
**Examples**
|
||||
|
||||
Input:
|
||||
|
||||
{: style="height:512px;width:512px"}
|
||||
|
||||
Highlights/Midtones/Shadows:
|
||||
|
||||
<img src="https://github.com/invoke-ai/InvokeAI/assets/34005131/727021c1-36ff-4ec8-90c8-105e00de986d" style="width: 30%" />
|
||||
<img src="https://github.com/invoke-ai/InvokeAI/assets/34005131/0b721bfc-f051-404e-b905-2f16b824ddfe" style="width: 30%" />
|
||||
<img src="https://github.com/invoke-ai/InvokeAI/assets/34005131/04c1297f-1c88-42b6-a7df-dd090b976286" style="width: 30%" />
|
||||
|
||||
Highlights/Midtones/Shadows (with LUT blur enabled):
|
||||
|
||||
<img src="https://github.com/invoke-ai/InvokeAI/assets/34005131/19aa718a-70c1-4668-8169-d68f4bd13771" style="width: 30%" />
|
||||
<img src="https://github.com/invoke-ai/InvokeAI/assets/34005131/0a440e43-697f-4d17-82ee-f287467df0a5" style="width: 30%" />
|
||||
<img src="https://github.com/invoke-ai/InvokeAI/assets/34005131/0701fd0f-2ca7-4fe2-8613-2b52547bafce" style="width: 30%" />
|
||||
|
||||
--------------------------------
|
||||
### Halftone
|
||||
|
||||
**Description**: Halftone converts the source image to grayscale and then performs halftoning. CMYK Halftone converts the image to CMYK and applies a per-channel halftoning to make the source image look like a magazine or newspaper. For both nodes, you can specify angles and halftone dot spacing.
|
||||
|
||||
**Node Link:** https://github.com/JPPhoto/halftone-node
|
||||
|
||||
**Example**
|
||||
|
||||
Input:
|
||||
|
||||
{: style="height:512px;width:512px"}
|
||||
|
||||
Halftone Output:
|
||||
|
||||
{: style="height:512px;width:512px"}
|
||||
|
||||
CMYK Halftone Output:
|
||||
|
||||
{: style="height:512px;width:512px"}
|
||||
|
||||
--------------------------------
|
||||
### Retroize
|
||||
|
||||
@@ -77,7 +125,7 @@ Generated Prompt: An enchanted weapon will be usable by any character regardless
|
||||
**Example Node Graph:** https://github.com/helix4u/load_video_frame/blob/main/Example_Workflow.json
|
||||
|
||||
**Output Example:**
|
||||
=======
|
||||
|
||||

|
||||
[Full mp4 of Example Output test.mp4](https://github.com/helix4u/load_video_frame/blob/main/test.mp4)
|
||||
|
||||
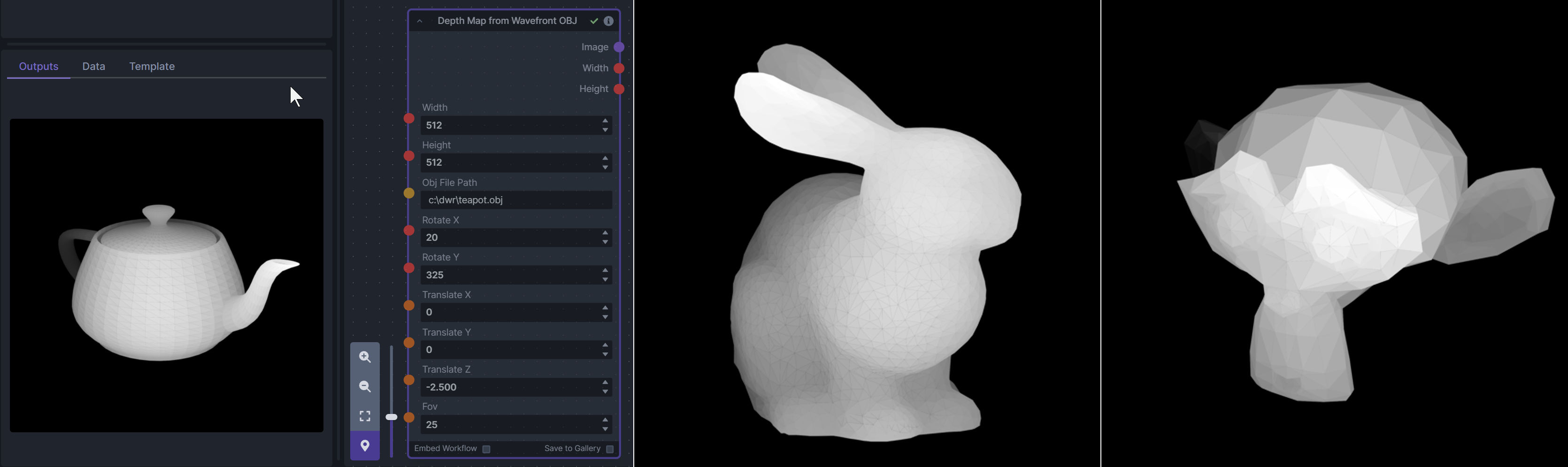
@@ -121,18 +169,6 @@ To be imported, an .obj must use triangulated meshes, so make sure to enable tha
|
||||
**Example Usage:**
|
||||
|
||||
|
||||
--------------------------------
|
||||
### Enhance Image (simple adjustments)
|
||||
|
||||
**Description:** Boost or reduce color saturation, contrast, brightness, sharpness, or invert colors of any image at any stage with this simple wrapper for pillow [PIL]'s ImageEnhance module.
|
||||
|
||||
Color inversion is toggled with a simple switch, while each of the four enhancer modes are activated by entering a value other than 1 in each corresponding input field. Values less than 1 will reduce the corresponding property, while values greater than 1 will enhance it.
|
||||
|
||||
**Node Link:** https://github.com/dwringer/image-enhance-node
|
||||
|
||||
**Example Usage:**
|
||||
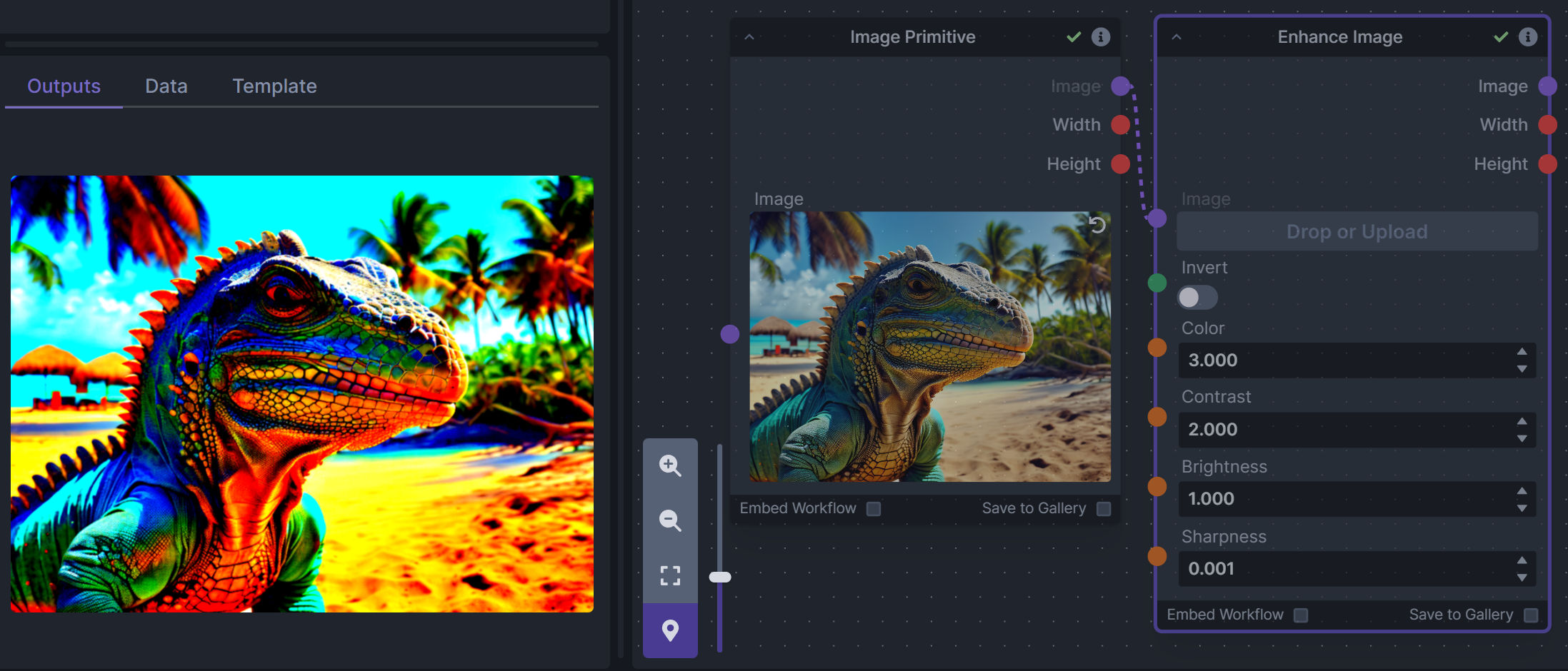
|
||||
|
||||
--------------------------------
|
||||
### Generative Grammar-Based Prompt Nodes
|
||||
|
||||
@@ -153,16 +189,28 @@ This includes 3 Nodes:
|
||||
|
||||
**Description:** This is a pack of nodes for composing masks and images, including a simple text mask creator and both image and latent offset nodes. The offsets wrap around, so these can be used in conjunction with the Seamless node to progressively generate centered on different parts of the seamless tiling.
|
||||
|
||||
This includes 4 Nodes:
|
||||
- *Text Mask (simple 2D)* - create and position a white on black (or black on white) line of text using any font locally available to Invoke.
|
||||
This includes 15 Nodes:
|
||||
|
||||
- *Adjust Image Hue Plus* - Rotate the hue of an image in one of several different color spaces.
|
||||
- *Blend Latents/Noise (Masked)* - Use a mask to blend part of one latents tensor [including Noise outputs] into another. Can be used to "renoise" sections during a multi-stage [masked] denoising process.
|
||||
- *Enhance Image* - Boost or reduce color saturation, contrast, brightness, sharpness, or invert colors of any image at any stage with this simple wrapper for pillow [PIL]'s ImageEnhance module.
|
||||
- *Equivalent Achromatic Lightness* - Calculates image lightness accounting for Helmholtz-Kohlrausch effect based on a method described by High, Green, and Nussbaum (2023).
|
||||
- *Text to Mask (Clipseg)* - Input a prompt and an image to generate a mask representing areas of the image matched by the prompt.
|
||||
- *Text to Mask Advanced (Clipseg)* - Output up to four prompt masks combined with logical "and", logical "or", or as separate channels of an RGBA image.
|
||||
- *Image Layer Blend* - Perform a layered blend of two images using alpha compositing. Opacity of top layer is selectable, with optional mask and several different blend modes/color spaces.
|
||||
- *Image Compositor* - Take a subject from an image with a flat backdrop and layer it on another image using a chroma key or flood select background removal.
|
||||
- *Image Dilate or Erode* - Dilate or expand a mask (or any image!). This is equivalent to an expand/contract operation.
|
||||
- *Image Value Thresholds* - Clip an image to pure black/white beyond specified thresholds.
|
||||
- *Offset Latents* - Offset a latents tensor in the vertical and/or horizontal dimensions, wrapping it around.
|
||||
- *Offset Image* - Offset an image in the vertical and/or horizontal dimensions, wrapping it around.
|
||||
- *Rotate/Flip Image* - Rotate an image in degrees clockwise/counterclockwise about its center, optionally resizing the image boundaries to fit, or flipping it about the vertical and/or horizontal axes.
|
||||
- *Shadows/Highlights/Midtones* - Extract three masks (with adjustable hard or soft thresholds) representing shadows, midtones, and highlights regions of an image.
|
||||
- *Text Mask (simple 2D)* - create and position a white on black (or black on white) line of text using any font locally available to Invoke.
|
||||
|
||||
**Node Link:** https://github.com/dwringer/composition-nodes
|
||||
|
||||
**Example Usage:**
|
||||
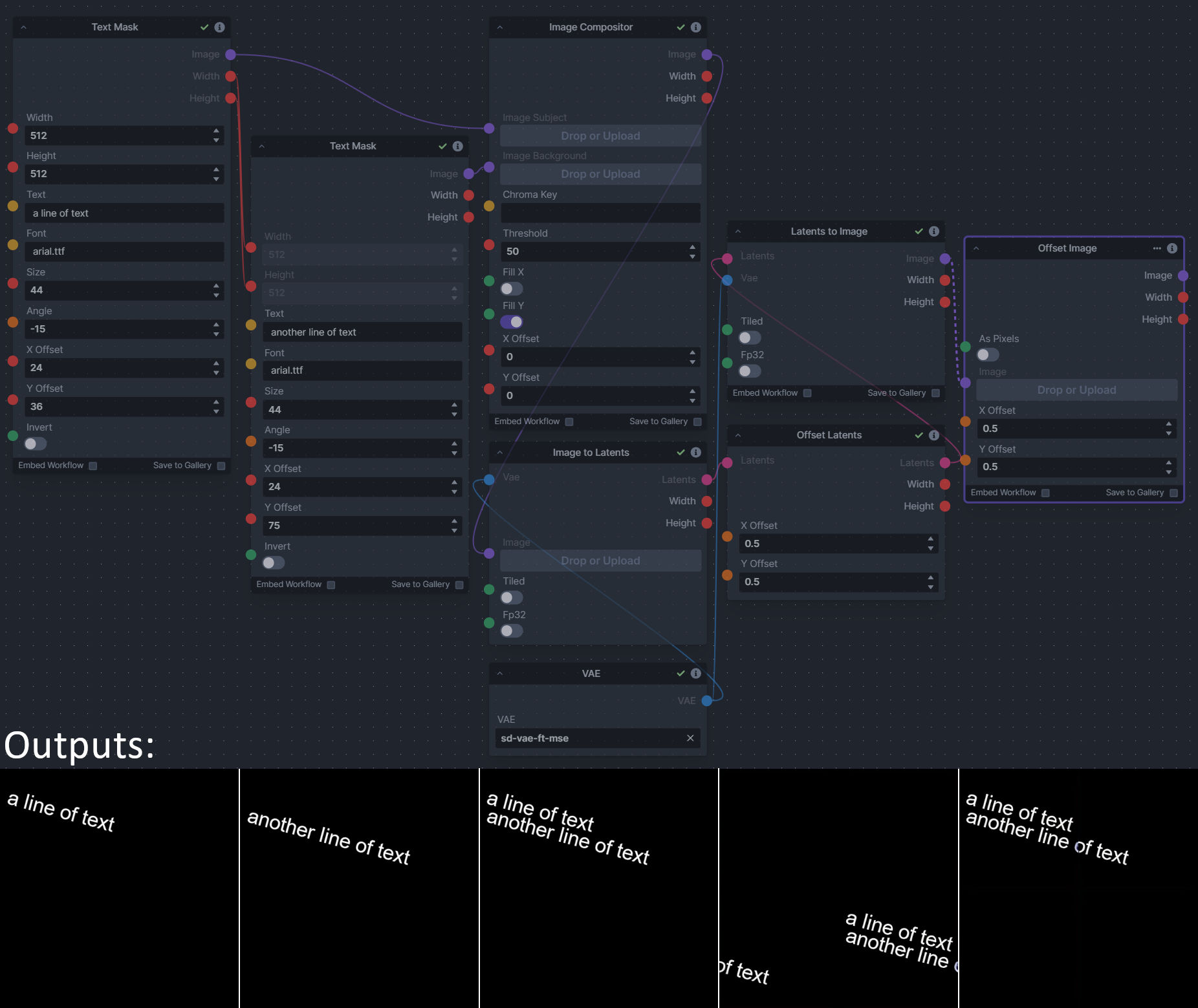
|
||||
**Nodes and Output Examples:**
|
||||
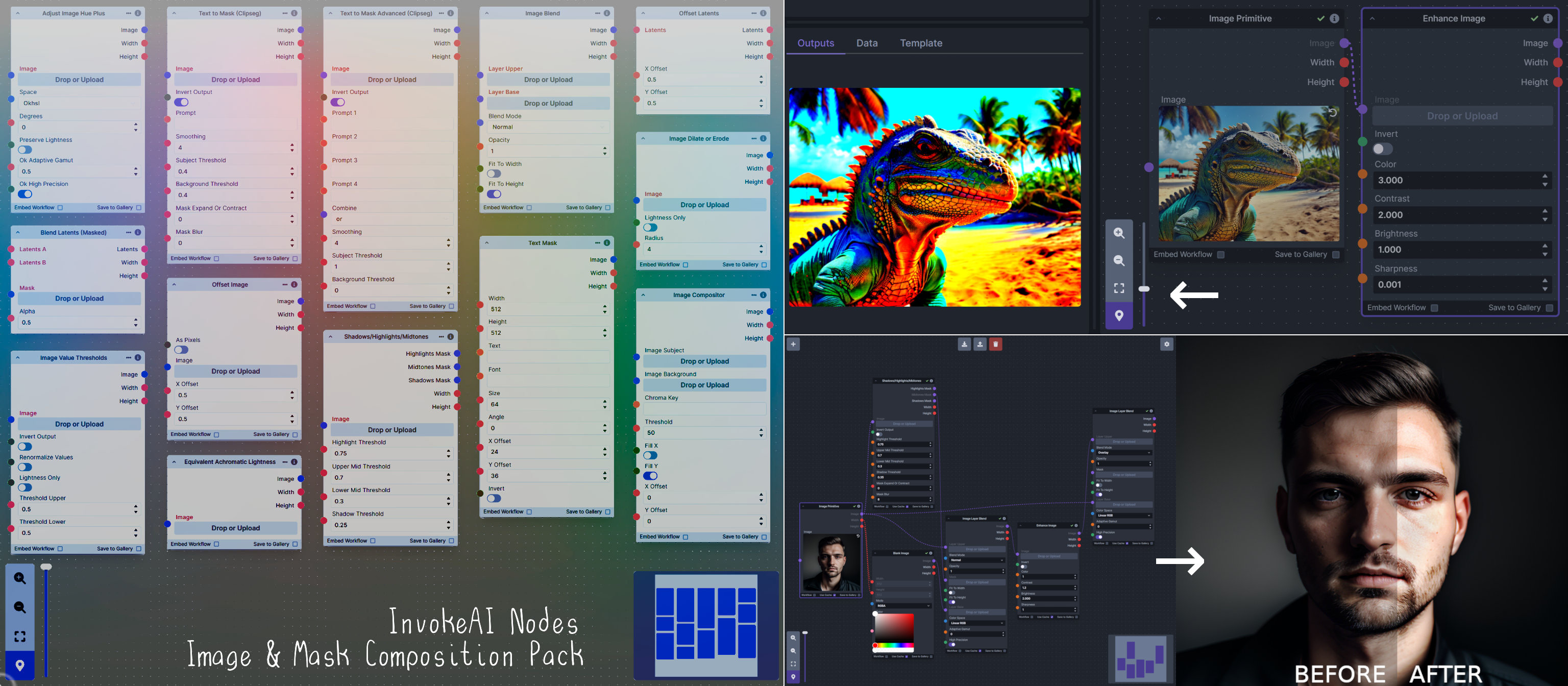
|
||||
|
||||
--------------------------------
|
||||
### Size Stepper Nodes
|
||||
@@ -230,6 +278,36 @@ See full docs here: https://github.com/skunkworxdark/XYGrid_nodes/edit/main/READ
|
||||
|
||||
--------------------------------
|
||||
|
||||
### Image to Character Art Image Node's
|
||||
|
||||
**Description:** Group of nodes to convert an input image into ascii/unicode art Image
|
||||
|
||||
**Node Link:** https://github.com/mickr777/imagetoasciiimage
|
||||
|
||||
**Output Examples**
|
||||
|
||||
<img src="https://github.com/invoke-ai/InvokeAI/assets/115216705/8e061fcc-9a2c-4fa9-bcc7-c0f7b01e9056" width="300" />
|
||||
<img src="https://github.com/mickr777/imagetoasciiimage/assets/115216705/3c4990eb-2f42-46b9-90f9-0088b939dc6a" width="300" /></br>
|
||||
<img src="https://github.com/mickr777/imagetoasciiimage/assets/115216705/fee7f800-a4a8-41e2-a66b-c66e4343307e" width="300" />
|
||||
<img src="https://github.com/mickr777/imagetoasciiimage/assets/115216705/1d9c1003-a45f-45c2-aac7-46470bb89330" width="300" />
|
||||
|
||||
--------------------------------
|
||||
|
||||
### Grid to Gif
|
||||
|
||||
**Description:** One node that turns a grid image into an image colletion, one node that turns an image collection into a gif
|
||||
|
||||
**Node Link:** https://github.com/mildmisery/invokeai-GridToGifNode/blob/main/GridToGif.py
|
||||
|
||||
**Example Node Graph:** https://github.com/mildmisery/invokeai-GridToGifNode/blob/main/Grid%20to%20Gif%20Example%20Workflow.json
|
||||
|
||||
**Output Examples**
|
||||
|
||||
<img src="https://raw.githubusercontent.com/mildmisery/invokeai-GridToGifNode/main/input.png" width="300" />
|
||||
<img src="https://raw.githubusercontent.com/mildmisery/invokeai-GridToGifNode/main/output.gif" width="300" />
|
||||
|
||||
--------------------------------
|
||||
|
||||
### Example Node Template
|
||||
|
||||
**Description:** This node allows you to do super cool things with InvokeAI.
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
# List of Default Nodes
|
||||
|
||||
The table below contains a list of the default nodes shipped with InvokeAI and their descriptions.
|
||||
The table below contains a list of the default nodes shipped with InvokeAI and their descriptions.
|
||||
|
||||
| Node <img width=160 align="right"> | Function |
|
||||
|: ---------------------------------- | :--------------------------------------------------------------------------------------|
|
||||
@@ -17,11 +17,12 @@ The table below contains a list of the default nodes shipped with InvokeAI and t
|
||||
|Conditioning Primitive | A conditioning tensor primitive value|
|
||||
|Content Shuffle Processor | Applies content shuffle processing to image|
|
||||
|ControlNet | Collects ControlNet info to pass to other nodes|
|
||||
|OpenCV Inpaint | Simple inpaint using opencv.|
|
||||
|Denoise Latents | Denoises noisy latents to decodable images|
|
||||
|Divide Integers | Divides two numbers|
|
||||
|Dynamic Prompt | Parses a prompt using adieyal/dynamicprompts' random or combinatorial generator|
|
||||
|Upscale (RealESRGAN) | Upscales an image using RealESRGAN.|
|
||||
|[FaceMask](./detailedNodes/faceTools.md#facemask) | Generates masks for faces in an image to use with Inpainting|
|
||||
|[FaceIdentifier](./detailedNodes/faceTools.md#faceidentifier) | Identifies and labels faces in an image|
|
||||
|[FaceOff](./detailedNodes/faceTools.md#faceoff) | Creates a new image that is a scaled bounding box with a mask on the face for Inpainting|
|
||||
|Float Math | Perform basic math operations on two floats|
|
||||
|Float Primitive Collection | A collection of float primitive values|
|
||||
|Float Primitive | A float primitive value|
|
||||
@@ -76,6 +77,7 @@ The table below contains a list of the default nodes shipped with InvokeAI and t
|
||||
|ONNX Prompt (Raw) | A node to process inputs and produce outputs. May use dependency injection in __init__ to receive providers.|
|
||||
|ONNX Text to Latents | Generates latents from conditionings.|
|
||||
|ONNX Model Loader | Loads a main model, outputting its submodels.|
|
||||
|OpenCV Inpaint | Simple inpaint using opencv.|
|
||||
|Openpose Processor | Applies Openpose processing to image|
|
||||
|PIDI Processor | Applies PIDI processing to image|
|
||||
|Prompts from File | Loads prompts from a text file|
|
||||
@@ -97,5 +99,6 @@ The table below contains a list of the default nodes shipped with InvokeAI and t
|
||||
|String Primitive | A string primitive value|
|
||||
|Subtract Integers | Subtracts two numbers|
|
||||
|Tile Resample Processor | Tile resampler processor|
|
||||
|Upscale (RealESRGAN) | Upscales an image using RealESRGAN.|
|
||||
|VAE Loader | Loads a VAE model, outputting a VaeLoaderOutput|
|
||||
|Zoe (Depth) Processor | Applies Zoe depth processing to image|
|
||||
154
docs/nodes/detailedNodes/faceTools.md
Normal file
154
docs/nodes/detailedNodes/faceTools.md
Normal file
@@ -0,0 +1,154 @@
|
||||
# Face Nodes
|
||||
|
||||
## FaceOff
|
||||
|
||||
FaceOff mimics a user finding a face in an image and resizing the bounding box
|
||||
around the head in Canvas.
|
||||
|
||||
Enter a face ID (found with FaceIdentifier) to choose which face to mask.
|
||||
|
||||
Just as you would add more context inside the bounding box by making it larger
|
||||
in Canvas, the node gives you a padding input (in pixels) which will
|
||||
simultaneously add more context, and increase the resolution of the bounding box
|
||||
so the face remains the same size inside it.
|
||||
|
||||
The "Minimum Confidence" input defaults to 0.5 (50%), and represents a pass/fail
|
||||
threshold a detected face must reach for it to be processed. Lowering this value
|
||||
may help if detection is failing. If the detected masks are imperfect and stray
|
||||
too far outside/inside of faces, the node gives you X & Y offsets to shrink/grow
|
||||
the masks by a multiplier.
|
||||
|
||||
FaceOff will output the face in a bounded image, taking the face off of the
|
||||
original image for input into any node that accepts image inputs. The node also
|
||||
outputs a face mask with the dimensions of the bounded image. The X & Y outputs
|
||||
are for connecting to the X & Y inputs of the Paste Image node, which will place
|
||||
the bounded image back on the original image using these coordinates.
|
||||
|
||||
###### Inputs/Outputs
|
||||
|
||||
| Input | Description |
|
||||
| ------------------ | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| Image | Image for face detection |
|
||||
| Face ID | The face ID to process, numbered from 0. Multiple faces not supported. Find a face's ID with FaceIdentifier node. |
|
||||
| Minimum Confidence | Minimum confidence for face detection (lower if detection is failing) |
|
||||
| X Offset | X-axis offset of the mask |
|
||||
| Y Offset | Y-axis offset of the mask |
|
||||
| Padding | All-axis padding around the mask in pixels |
|
||||
| Chunk | Chunk (or divide) the image into sections to greatly improve face detection success. Defaults to off, but will activate if no faces are detected normally. Activate to chunk by default. |
|
||||
|
||||
| Output | Description |
|
||||
| ------------- | ------------------------------------------------ |
|
||||
| Bounded Image | Original image bound, cropped, and resized |
|
||||
| Width | The width of the bounded image in pixels |
|
||||
| Height | The height of the bounded image in pixels |
|
||||
| Mask | The output mask |
|
||||
| X | The x coordinate of the bounding box's left side |
|
||||
| Y | The y coordinate of the bounding box's top side |
|
||||
|
||||
## FaceMask
|
||||
|
||||
FaceMask mimics a user drawing masks on faces in an image in Canvas.
|
||||
|
||||
The "Face IDs" input allows the user to select specific faces to be masked.
|
||||
Leave empty to detect and mask all faces, or a comma-separated list for a
|
||||
specific combination of faces (ex: `1,2,4`). A single integer will detect and
|
||||
mask that specific face. Find face IDs with the FaceIdentifier node.
|
||||
|
||||
The "Minimum Confidence" input defaults to 0.5 (50%), and represents a pass/fail
|
||||
threshold a detected face must reach for it to be processed. Lowering this value
|
||||
may help if detection is failing.
|
||||
|
||||
If the detected masks are imperfect and stray too far outside/inside of faces,
|
||||
the node gives you X & Y offsets to shrink/grow the masks by a multiplier. All
|
||||
masks shrink/grow together by the X & Y offset values.
|
||||
|
||||
By default, masks are created to change faces. When masks are inverted, they
|
||||
change surrounding areas, protecting faces.
|
||||
|
||||
###### Inputs/Outputs
|
||||
|
||||
| Input | Description |
|
||||
| ------------------ | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| Image | Image for face detection |
|
||||
| Face IDs | Comma-separated list of face ids to mask eg '0,2,7'. Numbered from 0. Leave empty to mask all. Find face IDs with FaceIdentifier node. |
|
||||
| Minimum Confidence | Minimum confidence for face detection (lower if detection is failing) |
|
||||
| X Offset | X-axis offset of the mask |
|
||||
| Y Offset | Y-axis offset of the mask |
|
||||
| Chunk | Chunk (or divide) the image into sections to greatly improve face detection success. Defaults to off, but will activate if no faces are detected normally. Activate to chunk by default. |
|
||||
| Invert Mask | Toggle to invert the face mask |
|
||||
|
||||
| Output | Description |
|
||||
| ------ | --------------------------------- |
|
||||
| Image | The original image |
|
||||
| Width | The width of the image in pixels |
|
||||
| Height | The height of the image in pixels |
|
||||
| Mask | The output face mask |
|
||||
|
||||
## FaceIdentifier
|
||||
|
||||
FaceIdentifier outputs an image with detected face IDs printed in white numbers
|
||||
onto each face.
|
||||
|
||||
Face IDs can then be used in FaceMask and FaceOff to selectively mask all, a
|
||||
specific combination, or single faces.
|
||||
|
||||
The FaceIdentifier output image is generated for user reference, and isn't meant
|
||||
to be passed on to other image-processing nodes.
|
||||
|
||||
The "Minimum Confidence" input defaults to 0.5 (50%), and represents a pass/fail
|
||||
threshold a detected face must reach for it to be processed. Lowering this value
|
||||
may help if detection is failing. If an image is changed in the slightest, run
|
||||
it through FaceIdentifier again to get updated FaceIDs.
|
||||
|
||||
###### Inputs/Outputs
|
||||
|
||||
| Input | Description |
|
||||
| ------------------ | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| Image | Image for face detection |
|
||||
| Minimum Confidence | Minimum confidence for face detection (lower if detection is failing) |
|
||||
| Chunk | Chunk (or divide) the image into sections to greatly improve face detection success. Defaults to off, but will activate if no faces are detected normally. Activate to chunk by default. |
|
||||
|
||||
| Output | Description |
|
||||
| ------ | ------------------------------------------------------------------------------------------------ |
|
||||
| Image | The original image with small face ID numbers printed in white onto each face for user reference |
|
||||
| Width | The width of the original image in pixels |
|
||||
| Height | The height of the original image in pixels |
|
||||
|
||||
## Tips
|
||||
|
||||
- If not all target faces are being detected, activate Chunk to bypass full
|
||||
image face detection and greatly improve detection success.
|
||||
- Final results will vary between full-image detection and chunking for faces
|
||||
that are detectable by both due to the nature of the process. Try either to
|
||||
your taste.
|
||||
- Be sure Minimum Confidence is set the same when using FaceIdentifier with
|
||||
FaceOff/FaceMask.
|
||||
- For FaceOff, use the color correction node before faceplace to correct edges
|
||||
being noticeable in the final image (see example screenshot).
|
||||
- Non-inpainting models may struggle to paint/generate correctly around faces.
|
||||
- If your face won't change the way you want it to no matter what you change,
|
||||
consider that the change you're trying to make is too much at that resolution.
|
||||
For example, if an image is only 512x768 total, the face might only be 128x128
|
||||
or 256x256, much smaller than the 512x512 your SD1.5 model was probably
|
||||
trained on. Try increasing the resolution of the image by upscaling or
|
||||
resizing, add padding to increase the bounding box's resolution, or use an
|
||||
image where the face takes up more pixels.
|
||||
- If the resulting face seems out of place pasted back on the original image
|
||||
(ie. too large, not proportional), add more padding on the FaceOff node to
|
||||
give inpainting more context. Context and good prompting are important to
|
||||
keeping things proportional.
|
||||
- If you find the mask is too big/small and going too far outside/inside the
|
||||
area you want to affect, adjust the x & y offsets to shrink/grow the mask area
|
||||
- Use a higher denoise start value to resemble aspects of the original face or
|
||||
surroundings. Denoise start = 0 & denoise end = 1 will make something new,
|
||||
while denoise start = 0.50 & denoise end = 1 will be 50% old and 50% new.
|
||||
- mediapipe isn't good at detecting faces with lots of face paint, hair covering
|
||||
the face, etc. Anything that obstructs the face will likely result in no faces
|
||||
being detected.
|
||||
- If you find your face isn't being detected, try lowering the minimum
|
||||
confidence value from 0.5. This could result in false positives, however
|
||||
(random areas being detected as faces and masked).
|
||||
- After altering an image and wanting to process a different face in the newly
|
||||
altered image, run the altered image through FaceIdentifier again to see the
|
||||
new Face IDs. MediaPipe will most likely detect faces in a different order
|
||||
after an image has been changed in the slightest.
|
||||
@@ -9,5 +9,6 @@ If you're interested in finding more workflows, checkout the [#share-your-workfl
|
||||
* [SD1.5 / SD2 Text to Image](https://github.com/invoke-ai/InvokeAI/blob/main/docs/workflows/Text_to_Image.json)
|
||||
* [SDXL Text to Image](https://github.com/invoke-ai/InvokeAI/blob/main/docs/workflows/SDXL_Text_to_Image.json)
|
||||
* [SDXL (with Refiner) Text to Image](https://github.com/invoke-ai/InvokeAI/blob/main/docs/workflows/SDXL_Text_to_Image.json)
|
||||
* [Tiled Upscaling with ControlNet](https://github.com/invoke-ai/InvokeAI/blob/main/docs/workflows/ESRGAN_img2img_upscale w_Canny_ControlNet.json)ß
|
||||
|
||||
* [Tiled Upscaling with ControlNet](https://github.com/invoke-ai/InvokeAI/blob/main/docs/workflows/ESRGAN_img2img_upscale w_Canny_ControlNet.json)
|
||||
* [FaceMask](https://github.com/invoke-ai/InvokeAI/blob/main/docs/workflows/FaceMask.json)
|
||||
* [FaceOff with 2x Face Scaling](https://github.com/invoke-ai/InvokeAI/blob/main/docs/workflows/FaceOff_FaceScale2x.json)
|
||||
|
||||
1041
docs/workflows/FaceMask.json
Normal file
1041
docs/workflows/FaceMask.json
Normal file
File diff suppressed because it is too large
Load Diff
1395
docs/workflows/FaceOff_FaceScale2x.json
Normal file
1395
docs/workflows/FaceOff_FaceScale2x.json
Normal file
File diff suppressed because it is too large
Load Diff
@@ -332,6 +332,7 @@ class InvokeAiInstance:
|
||||
Configure the InvokeAI runtime directory
|
||||
"""
|
||||
|
||||
auto_install = False
|
||||
# set sys.argv to a consistent state
|
||||
new_argv = [sys.argv[0]]
|
||||
for i in range(1, len(sys.argv)):
|
||||
@@ -340,13 +341,17 @@ class InvokeAiInstance:
|
||||
new_argv.append(el)
|
||||
new_argv.append(sys.argv[i + 1])
|
||||
elif el in ["-y", "--yes", "--yes-to-all"]:
|
||||
new_argv.append(el)
|
||||
auto_install = True
|
||||
sys.argv = new_argv
|
||||
|
||||
import messages
|
||||
import requests # to catch download exceptions
|
||||
from messages import introduction
|
||||
|
||||
introduction()
|
||||
auto_install = auto_install or messages.user_wants_auto_configuration()
|
||||
if auto_install:
|
||||
sys.argv.append("--yes")
|
||||
else:
|
||||
messages.introduction()
|
||||
|
||||
from invokeai.frontend.install.invokeai_configure import invokeai_configure
|
||||
|
||||
|
||||
@@ -7,7 +7,7 @@ import os
|
||||
import platform
|
||||
from pathlib import Path
|
||||
|
||||
from prompt_toolkit import prompt
|
||||
from prompt_toolkit import HTML, prompt
|
||||
from prompt_toolkit.completion import PathCompleter
|
||||
from prompt_toolkit.validation import Validator
|
||||
from rich import box, print
|
||||
@@ -65,17 +65,50 @@ def confirm_install(dest: Path) -> bool:
|
||||
if dest.exists():
|
||||
print(f":exclamation: Directory {dest} already exists :exclamation:")
|
||||
dest_confirmed = Confirm.ask(
|
||||
":stop_sign: Are you sure you want to (re)install in this location?",
|
||||
":stop_sign: (re)install in this location?",
|
||||
default=False,
|
||||
)
|
||||
else:
|
||||
print(f"InvokeAI will be installed in {dest}")
|
||||
dest_confirmed = not Confirm.ask("Would you like to pick a different location?", default=False)
|
||||
dest_confirmed = Confirm.ask("Use this location?", default=True)
|
||||
console.line()
|
||||
|
||||
return dest_confirmed
|
||||
|
||||
|
||||
def user_wants_auto_configuration() -> bool:
|
||||
"""Prompt the user to choose between manual and auto configuration."""
|
||||
console.rule("InvokeAI Configuration Section")
|
||||
console.print(
|
||||
Panel(
|
||||
Group(
|
||||
"\n".join(
|
||||
[
|
||||
"Libraries are installed and InvokeAI will now set up its root directory and configuration. Choose between:",
|
||||
"",
|
||||
" * AUTOMATIC configuration: install reasonable defaults and a minimal set of starter models.",
|
||||
" * MANUAL configuration: manually inspect and adjust configuration options and pick from a larger set of starter models.",
|
||||
"",
|
||||
"Later you can fine tune your configuration by selecting option [6] 'Change InvokeAI startup options' from the invoke.bat/invoke.sh launcher script.",
|
||||
]
|
||||
),
|
||||
),
|
||||
box=box.MINIMAL,
|
||||
padding=(1, 1),
|
||||
)
|
||||
)
|
||||
choice = (
|
||||
prompt(
|
||||
HTML("Choose <b><a></b>utomatic or <b><m></b>anual configuration [a/m] (a): "),
|
||||
validator=Validator.from_callable(
|
||||
lambda n: n == "" or n.startswith(("a", "A", "m", "M")), error_message="Please select 'a' or 'm'"
|
||||
),
|
||||
)
|
||||
or "a"
|
||||
)
|
||||
return choice.lower().startswith("a")
|
||||
|
||||
|
||||
def dest_path(dest=None) -> Path:
|
||||
"""
|
||||
Prompt the user for the destination path and create the path
|
||||
|
||||
@@ -46,6 +46,9 @@ if [ "$(uname -s)" == "Darwin" ]; then
|
||||
export PYTORCH_ENABLE_MPS_FALLBACK=1
|
||||
fi
|
||||
|
||||
# Avoid glibc memory fragmentation. See invokeai/backend/model_management/README.md for details.
|
||||
export MALLOC_MMAP_THRESHOLD_=1048576
|
||||
|
||||
# Primary function for the case statement to determine user input
|
||||
do_choice() {
|
||||
case $1 in
|
||||
|
||||
@@ -49,7 +49,7 @@ def check_internet() -> bool:
|
||||
return False
|
||||
|
||||
|
||||
logger = InvokeAILogger.getLogger()
|
||||
logger = InvokeAILogger.get_logger()
|
||||
|
||||
|
||||
class ApiDependencies:
|
||||
|
||||
@@ -7,6 +7,7 @@ from fastapi.routing import APIRouter
|
||||
from pydantic import BaseModel, Field
|
||||
|
||||
from invokeai.app.invocations.upscale import ESRGAN_MODELS
|
||||
from invokeai.app.services.invocation_cache.invocation_cache_common import InvocationCacheStatus
|
||||
from invokeai.backend.image_util.invisible_watermark import InvisibleWatermark
|
||||
from invokeai.backend.image_util.patchmatch import PatchMatch
|
||||
from invokeai.backend.image_util.safety_checker import SafetyChecker
|
||||
@@ -113,3 +114,33 @@ async def set_log_level(
|
||||
async def clear_invocation_cache() -> None:
|
||||
"""Clears the invocation cache"""
|
||||
ApiDependencies.invoker.services.invocation_cache.clear()
|
||||
|
||||
|
||||
@app_router.put(
|
||||
"/invocation_cache/enable",
|
||||
operation_id="enable_invocation_cache",
|
||||
responses={200: {"description": "The operation was successful"}},
|
||||
)
|
||||
async def enable_invocation_cache() -> None:
|
||||
"""Clears the invocation cache"""
|
||||
ApiDependencies.invoker.services.invocation_cache.enable()
|
||||
|
||||
|
||||
@app_router.put(
|
||||
"/invocation_cache/disable",
|
||||
operation_id="disable_invocation_cache",
|
||||
responses={200: {"description": "The operation was successful"}},
|
||||
)
|
||||
async def disable_invocation_cache() -> None:
|
||||
"""Clears the invocation cache"""
|
||||
ApiDependencies.invoker.services.invocation_cache.disable()
|
||||
|
||||
|
||||
@app_router.get(
|
||||
"/invocation_cache/status",
|
||||
operation_id="get_invocation_cache_status",
|
||||
responses={200: {"model": InvocationCacheStatus}},
|
||||
)
|
||||
async def get_invocation_cache_status() -> InvocationCacheStatus:
|
||||
"""Clears the invocation cache"""
|
||||
return ApiDependencies.invoker.services.invocation_cache.get_status()
|
||||
|
||||
@@ -322,3 +322,20 @@ async def unstar_images_in_list(
|
||||
return ImagesUpdatedFromListResult(updated_image_names=updated_image_names)
|
||||
except Exception:
|
||||
raise HTTPException(status_code=500, detail="Failed to unstar images")
|
||||
|
||||
|
||||
class ImagesDownloaded(BaseModel):
|
||||
response: Optional[str] = Field(
|
||||
description="If defined, the message to display to the user when images begin downloading"
|
||||
)
|
||||
|
||||
|
||||
@images_router.post("/download", operation_id="download_images_from_list", response_model=ImagesDownloaded)
|
||||
async def download_images_from_list(
|
||||
image_names: list[str] = Body(description="The list of names of images to download", embed=True),
|
||||
board_id: Optional[str] = Body(
|
||||
default=None, description="The board from which image should be downloaded from", embed=True
|
||||
),
|
||||
) -> ImagesDownloaded:
|
||||
# return ImagesDownloaded(response="Your images are downloading")
|
||||
raise HTTPException(status_code=501, detail="Endpoint is not yet implemented")
|
||||
|
||||
@@ -146,7 +146,8 @@ async def update_model(
|
||||
async def import_model(
|
||||
location: str = Body(description="A model path, repo_id or URL to import"),
|
||||
prediction_type: Optional[Literal["v_prediction", "epsilon", "sample"]] = Body(
|
||||
description="Prediction type for SDv2 checkpoint files", default="v_prediction"
|
||||
description="Prediction type for SDv2 checkpoints and rare SDv1 checkpoints",
|
||||
default=None,
|
||||
),
|
||||
) -> ImportModelResponse:
|
||||
"""Add a model using its local path, repo_id, or remote URL. Model characteristics will be probed and configured automatically"""
|
||||
|
||||
@@ -8,7 +8,6 @@ app_config.parse_args()
|
||||
|
||||
if True: # hack to make flake8 happy with imports coming after setting up the config
|
||||
import asyncio
|
||||
import logging
|
||||
import mimetypes
|
||||
import socket
|
||||
from inspect import signature
|
||||
@@ -41,7 +40,9 @@ if True: # hack to make flake8 happy with imports coming after setting up the c
|
||||
import invokeai.backend.util.mps_fixes # noqa: F401 (monkeypatching on import)
|
||||
|
||||
|
||||
logger = InvokeAILogger.getLogger(config=app_config)
|
||||
app_config = InvokeAIAppConfig.get_config()
|
||||
app_config.parse_args()
|
||||
logger = InvokeAILogger.get_logger(config=app_config)
|
||||
|
||||
# fix for windows mimetypes registry entries being borked
|
||||
# see https://github.com/invoke-ai/InvokeAI/discussions/3684#discussioncomment-6391352
|
||||
@@ -223,7 +224,7 @@ def invoke_api():
|
||||
exc_info=e,
|
||||
)
|
||||
else:
|
||||
jurigged.watch(logger=InvokeAILogger.getLogger(name="jurigged").info)
|
||||
jurigged.watch(logger=InvokeAILogger.get_logger(name="jurigged").info)
|
||||
|
||||
port = find_port(app_config.port)
|
||||
if port != app_config.port:
|
||||
@@ -242,7 +243,7 @@ def invoke_api():
|
||||
|
||||
# replace uvicorn's loggers with InvokeAI's for consistent appearance
|
||||
for logname in ["uvicorn.access", "uvicorn"]:
|
||||
log = logging.getLogger(logname)
|
||||
log = InvokeAILogger.get_logger(logname)
|
||||
log.handlers.clear()
|
||||
for ch in logger.handlers:
|
||||
log.addHandler(ch)
|
||||
|
||||
@@ -7,8 +7,6 @@ from .services.config import InvokeAIAppConfig
|
||||
# parse_args() must be called before any other imports. if it is not called first, consumers of the config
|
||||
# which are imported/used before parse_args() is called will get the default config values instead of the
|
||||
# values from the command line or config file.
|
||||
config = InvokeAIAppConfig.get_config()
|
||||
config.parse_args()
|
||||
|
||||
if True: # hack to make flake8 happy with imports coming after setting up the config
|
||||
import argparse
|
||||
@@ -61,8 +59,9 @@ if True: # hack to make flake8 happy with imports coming after setting up the c
|
||||
if torch.backends.mps.is_available():
|
||||
import invokeai.backend.util.mps_fixes # noqa: F401 (monkeypatching on import)
|
||||
|
||||
|
||||
logger = InvokeAILogger().getLogger(config=config)
|
||||
config = InvokeAIAppConfig.get_config()
|
||||
config.parse_args()
|
||||
logger = InvokeAILogger().get_logger(config=config)
|
||||
|
||||
|
||||
class CliCommand(BaseModel):
|
||||
|
||||
@@ -68,6 +68,7 @@ class FieldDescriptions:
|
||||
height = "Height of output (px)"
|
||||
control = "ControlNet(s) to apply"
|
||||
ip_adapter = "IP-Adapter to apply"
|
||||
t2i_adapter = "T2I-Adapter(s) to apply"
|
||||
denoised_latents = "Denoised latents tensor"
|
||||
latents = "Latents tensor"
|
||||
strength = "Strength of denoising (proportional to steps)"
|
||||
@@ -88,6 +89,12 @@ class FieldDescriptions:
|
||||
num_1 = "The first number"
|
||||
num_2 = "The second number"
|
||||
mask = "The mask to use for the operation"
|
||||
board = "The board to save the image to"
|
||||
image = "The image to process"
|
||||
tile_size = "Tile size"
|
||||
inclusive_low = "The inclusive low value"
|
||||
exclusive_high = "The exclusive high value"
|
||||
decimal_places = "The number of decimal places to round to"
|
||||
|
||||
|
||||
class Input(str, Enum):
|
||||
@@ -173,6 +180,7 @@ class UIType(str, Enum):
|
||||
WorkflowField = "WorkflowField"
|
||||
IsIntermediate = "IsIntermediate"
|
||||
MetadataField = "MetadataField"
|
||||
BoardField = "BoardField"
|
||||
# endregion
|
||||
|
||||
|
||||
@@ -656,6 +664,8 @@ def invocation(
|
||||
:param Optional[str] title: Adds a title to the invocation. Use if the auto-generated title isn't quite right. Defaults to None.
|
||||
:param Optional[list[str]] tags: Adds tags to the invocation. Invocations may be searched for by their tags. Defaults to None.
|
||||
:param Optional[str] category: Adds a category to the invocation. Used to group the invocations in the UI. Defaults to None.
|
||||
:param Optional[str] version: Adds a version to the invocation. Must be a valid semver string. Defaults to None.
|
||||
:param Optional[bool] use_cache: Whether or not to use the invocation cache. Defaults to True. The user may override this in the workflow editor.
|
||||
"""
|
||||
|
||||
def wrapper(cls: Type[GenericBaseInvocation]) -> Type[GenericBaseInvocation]:
|
||||
|
||||
@@ -559,3 +559,33 @@ class SamDetectorReproducibleColors(SamDetector):
|
||||
img[:, :] = ann_color
|
||||
final_img.paste(Image.fromarray(img, mode="RGB"), (0, 0), Image.fromarray(np.uint8(m * 255)))
|
||||
return np.array(final_img, dtype=np.uint8)
|
||||
|
||||
|
||||
@invocation(
|
||||
"color_map_image_processor",
|
||||
title="Color Map Processor",
|
||||
tags=["controlnet"],
|
||||
category="controlnet",
|
||||
version="1.0.0",
|
||||
)
|
||||
class ColorMapImageProcessorInvocation(ImageProcessorInvocation):
|
||||
"""Generates a color map from the provided image"""
|
||||
|
||||
color_map_tile_size: int = InputField(default=64, ge=0, description=FieldDescriptions.tile_size)
|
||||
|
||||
def run_processor(self, image: Image.Image):
|
||||
image = image.convert("RGB")
|
||||
image = np.array(image, dtype=np.uint8)
|
||||
height, width = image.shape[:2]
|
||||
|
||||
width_tile_size = min(self.color_map_tile_size, width)
|
||||
height_tile_size = min(self.color_map_tile_size, height)
|
||||
|
||||
color_map = cv2.resize(
|
||||
image,
|
||||
(width // width_tile_size, height // height_tile_size),
|
||||
interpolation=cv2.INTER_CUBIC,
|
||||
)
|
||||
color_map = cv2.resize(color_map, (width, height), interpolation=cv2.INTER_NEAREST)
|
||||
color_map = Image.fromarray(color_map)
|
||||
return color_map
|
||||
|
||||
692
invokeai/app/invocations/facetools.py
Normal file
692
invokeai/app/invocations/facetools.py
Normal file
@@ -0,0 +1,692 @@
|
||||
import math
|
||||
import re
|
||||
from pathlib import Path
|
||||
from typing import Optional, TypedDict
|
||||
|
||||
import cv2
|
||||
import numpy as np
|
||||
from mediapipe.python.solutions.face_mesh import FaceMesh # type: ignore[import]
|
||||
from PIL import Image, ImageDraw, ImageFilter, ImageFont, ImageOps
|
||||
from PIL.Image import Image as ImageType
|
||||
from pydantic import validator
|
||||
|
||||
import invokeai.assets.fonts as font_assets
|
||||
from invokeai.app.invocations.baseinvocation import (
|
||||
BaseInvocation,
|
||||
InputField,
|
||||
InvocationContext,
|
||||
OutputField,
|
||||
invocation,
|
||||
invocation_output,
|
||||
)
|
||||
from invokeai.app.invocations.primitives import ImageField, ImageOutput
|
||||
from invokeai.app.models.image import ImageCategory, ResourceOrigin
|
||||
|
||||
|
||||
@invocation_output("face_mask_output")
|
||||
class FaceMaskOutput(ImageOutput):
|
||||
"""Base class for FaceMask output"""
|
||||
|
||||
mask: ImageField = OutputField(description="The output mask")
|
||||
|
||||
|
||||
@invocation_output("face_off_output")
|
||||
class FaceOffOutput(ImageOutput):
|
||||
"""Base class for FaceOff Output"""
|
||||
|
||||
mask: ImageField = OutputField(description="The output mask")
|
||||
x: int = OutputField(description="The x coordinate of the bounding box's left side")
|
||||
y: int = OutputField(description="The y coordinate of the bounding box's top side")
|
||||
|
||||
|
||||
class FaceResultData(TypedDict):
|
||||
image: ImageType
|
||||
mask: ImageType
|
||||
x_center: float
|
||||
y_center: float
|
||||
mesh_width: int
|
||||
mesh_height: int
|
||||
|
||||
|
||||
class FaceResultDataWithId(FaceResultData):
|
||||
face_id: int
|
||||
|
||||
|
||||
class ExtractFaceData(TypedDict):
|
||||
bounded_image: ImageType
|
||||
bounded_mask: ImageType
|
||||
x_min: int
|
||||
y_min: int
|
||||
x_max: int
|
||||
y_max: int
|
||||
|
||||
|
||||
class FaceMaskResult(TypedDict):
|
||||
image: ImageType
|
||||
mask: ImageType
|
||||
|
||||
|
||||
def create_white_image(w: int, h: int) -> ImageType:
|
||||
return Image.new("L", (w, h), color=255)
|
||||
|
||||
|
||||
def create_black_image(w: int, h: int) -> ImageType:
|
||||
return Image.new("L", (w, h), color=0)
|
||||
|
||||
|
||||
FONT_SIZE = 32
|
||||
FONT_STROKE_WIDTH = 4
|
||||
|
||||
|
||||
def prepare_faces_list(
|
||||
face_result_list: list[FaceResultData],
|
||||
) -> list[FaceResultDataWithId]:
|
||||
"""Deduplicates a list of faces, adding IDs to them."""
|
||||
deduped_faces: list[FaceResultData] = []
|
||||
|
||||
if len(face_result_list) == 0:
|
||||
return list()
|
||||
|
||||
for candidate in face_result_list:
|
||||
should_add = True
|
||||
candidate_x_center = candidate["x_center"]
|
||||
candidate_y_center = candidate["y_center"]
|
||||
for face in deduped_faces:
|
||||
face_center_x = face["x_center"]
|
||||
face_center_y = face["y_center"]
|
||||
face_radius_w = face["mesh_width"] / 2
|
||||
face_radius_h = face["mesh_height"] / 2
|
||||
# Determine if the center of the candidate_face is inside the ellipse of the added face
|
||||
# p < 1 -> Inside
|
||||
# p = 1 -> Exactly on the ellipse
|
||||
# p > 1 -> Outside
|
||||
p = (math.pow((candidate_x_center - face_center_x), 2) / math.pow(face_radius_w, 2)) + (
|
||||
math.pow((candidate_y_center - face_center_y), 2) / math.pow(face_radius_h, 2)
|
||||
)
|
||||
|
||||
if p < 1: # Inside of the already-added face's radius
|
||||
should_add = False
|
||||
break
|
||||
|
||||
if should_add is True:
|
||||
deduped_faces.append(candidate)
|
||||
|
||||
sorted_faces = sorted(deduped_faces, key=lambda x: x["y_center"])
|
||||
sorted_faces = sorted(sorted_faces, key=lambda x: x["x_center"])
|
||||
|
||||
# add face_id for reference
|
||||
sorted_faces_with_ids: list[FaceResultDataWithId] = []
|
||||
face_id_counter = 0
|
||||
for face in sorted_faces:
|
||||
sorted_faces_with_ids.append(
|
||||
FaceResultDataWithId(
|
||||
**face,
|
||||
face_id=face_id_counter,
|
||||
)
|
||||
)
|
||||
face_id_counter += 1
|
||||
|
||||
return sorted_faces_with_ids
|
||||
|
||||
|
||||
def generate_face_box_mask(
|
||||
context: InvocationContext,
|
||||
minimum_confidence: float,
|
||||
x_offset: float,
|
||||
y_offset: float,
|
||||
pil_image: ImageType,
|
||||
chunk_x_offset: int = 0,
|
||||
chunk_y_offset: int = 0,
|
||||
draw_mesh: bool = True,
|
||||
check_bounds: bool = True,
|
||||
) -> list[FaceResultData]:
|
||||
result = []
|
||||
mask_pil = None
|
||||
|
||||
# Convert the PIL image to a NumPy array.
|
||||
np_image = np.array(pil_image, dtype=np.uint8)
|
||||
|
||||
# Check if the input image has four channels (RGBA).
|
||||
if np_image.shape[2] == 4:
|
||||
# Convert RGBA to RGB by removing the alpha channel.
|
||||
np_image = np_image[:, :, :3]
|
||||
|
||||
# Create a FaceMesh object for face landmark detection and mesh generation.
|
||||
face_mesh = FaceMesh(
|
||||
max_num_faces=999,
|
||||
min_detection_confidence=minimum_confidence,
|
||||
min_tracking_confidence=minimum_confidence,
|
||||
)
|
||||
|
||||
# Detect the face landmarks and mesh in the input image.
|
||||
results = face_mesh.process(np_image)
|
||||
|
||||
# Check if any face is detected.
|
||||
if results.multi_face_landmarks: # type: ignore # this are via protobuf and not typed
|
||||
# Search for the face_id in the detected faces.
|
||||
for face_id, face_landmarks in enumerate(results.multi_face_landmarks): # type: ignore #this are via protobuf and not typed
|
||||
# Get the bounding box of the face mesh.
|
||||
x_coordinates = [landmark.x for landmark in face_landmarks.landmark]
|
||||
y_coordinates = [landmark.y for landmark in face_landmarks.landmark]
|
||||
x_min, x_max = min(x_coordinates), max(x_coordinates)
|
||||
y_min, y_max = min(y_coordinates), max(y_coordinates)
|
||||
|
||||
# Calculate the width and height of the face mesh.
|
||||
mesh_width = int((x_max - x_min) * np_image.shape[1])
|
||||
mesh_height = int((y_max - y_min) * np_image.shape[0])
|
||||
|
||||
# Get the center of the face.
|
||||
x_center = np.mean([landmark.x * np_image.shape[1] for landmark in face_landmarks.landmark])
|
||||
y_center = np.mean([landmark.y * np_image.shape[0] for landmark in face_landmarks.landmark])
|
||||
|
||||
face_landmark_points = np.array(
|
||||
[
|
||||
[landmark.x * np_image.shape[1], landmark.y * np_image.shape[0]]
|
||||
for landmark in face_landmarks.landmark
|
||||
]
|
||||
)
|
||||
|
||||
# Apply the scaling offsets to the face landmark points with a multiplier.
|
||||
scale_multiplier = 0.2
|
||||
x_center = np.mean(face_landmark_points[:, 0])
|
||||
y_center = np.mean(face_landmark_points[:, 1])
|
||||
|
||||
if draw_mesh:
|
||||
x_scaled = face_landmark_points[:, 0] + scale_multiplier * x_offset * (
|
||||
face_landmark_points[:, 0] - x_center
|
||||
)
|
||||
y_scaled = face_landmark_points[:, 1] + scale_multiplier * y_offset * (
|
||||
face_landmark_points[:, 1] - y_center
|
||||
)
|
||||
|
||||
convex_hull = cv2.convexHull(np.column_stack((x_scaled, y_scaled)).astype(np.int32))
|
||||
|
||||
# Generate a binary face mask using the face mesh.
|
||||
mask_image = np.ones(np_image.shape[:2], dtype=np.uint8) * 255
|
||||
cv2.fillConvexPoly(mask_image, convex_hull, 0)
|
||||
|
||||
# Convert the binary mask image to a PIL Image.
|
||||
init_mask_pil = Image.fromarray(mask_image, mode="L")
|
||||
w, h = init_mask_pil.size
|
||||
mask_pil = create_white_image(w + chunk_x_offset, h + chunk_y_offset)
|
||||
mask_pil.paste(init_mask_pil, (chunk_x_offset, chunk_y_offset))
|
||||
|
||||
left_side = x_center - mesh_width
|
||||
right_side = x_center + mesh_width
|
||||
top_side = y_center - mesh_height
|
||||
bottom_side = y_center + mesh_height
|
||||
im_width, im_height = pil_image.size
|
||||
over_w = im_width * 0.1
|
||||
over_h = im_height * 0.1
|
||||
if not check_bounds or (
|
||||
(left_side >= -over_w)
|
||||
and (right_side < im_width + over_w)
|
||||
and (top_side >= -over_h)
|
||||
and (bottom_side < im_height + over_h)
|
||||
):
|
||||
x_center = float(x_center)
|
||||
y_center = float(y_center)
|
||||
face = FaceResultData(
|
||||
image=pil_image,
|
||||
mask=mask_pil or create_white_image(*pil_image.size),
|
||||
x_center=x_center + chunk_x_offset,
|
||||
y_center=y_center + chunk_y_offset,
|
||||
mesh_width=mesh_width,
|
||||
mesh_height=mesh_height,
|
||||
)
|
||||
|
||||
result.append(face)
|
||||
else:
|
||||
context.services.logger.info("FaceTools --> Face out of bounds, ignoring.")
|
||||
|
||||
return result
|
||||
|
||||
|
||||
def extract_face(
|
||||
context: InvocationContext,
|
||||
image: ImageType,
|
||||
face: FaceResultData,
|
||||
padding: int,
|
||||
) -> ExtractFaceData:
|
||||
mask = face["mask"]
|
||||
center_x = face["x_center"]
|
||||
center_y = face["y_center"]
|
||||
mesh_width = face["mesh_width"]
|
||||
mesh_height = face["mesh_height"]
|
||||
|
||||
# Determine the minimum size of the square crop
|
||||
min_size = min(mask.width, mask.height)
|
||||
|
||||
# Calculate the crop boundaries for the output image and mask.
|
||||
mesh_width += 128 + padding # add pixels to account for mask variance
|
||||
mesh_height += 128 + padding # add pixels to account for mask variance
|
||||
crop_size = min(
|
||||
max(mesh_width, mesh_height, 128), min_size
|
||||
) # Choose the smaller of the two (given value or face mask size)
|
||||
if crop_size > 128:
|
||||
crop_size = (crop_size + 7) // 8 * 8 # Ensure crop side is multiple of 8
|
||||
|
||||
# Calculate the actual crop boundaries within the bounds of the original image.
|
||||
x_min = int(center_x - crop_size / 2)
|
||||
y_min = int(center_y - crop_size / 2)
|
||||
x_max = int(center_x + crop_size / 2)
|
||||
y_max = int(center_y + crop_size / 2)
|
||||
|
||||
# Adjust the crop boundaries to stay within the original image's dimensions
|
||||
if x_min < 0:
|
||||
context.services.logger.warning("FaceTools --> -X-axis padding reached image edge.")
|
||||
x_max -= x_min
|
||||
x_min = 0
|
||||
elif x_max > mask.width:
|
||||
context.services.logger.warning("FaceTools --> +X-axis padding reached image edge.")
|
||||
x_min -= x_max - mask.width
|
||||
x_max = mask.width
|
||||
|
||||
if y_min < 0:
|
||||
context.services.logger.warning("FaceTools --> +Y-axis padding reached image edge.")
|
||||
y_max -= y_min
|
||||
y_min = 0
|
||||
elif y_max > mask.height:
|
||||
context.services.logger.warning("FaceTools --> -Y-axis padding reached image edge.")
|
||||
y_min -= y_max - mask.height
|
||||
y_max = mask.height
|
||||
|
||||
# Ensure the crop is square and adjust the boundaries if needed
|
||||
if x_max - x_min != crop_size:
|
||||
context.services.logger.warning("FaceTools --> Limiting x-axis padding to constrain bounding box to a square.")
|
||||
diff = crop_size - (x_max - x_min)
|
||||
x_min -= diff // 2
|
||||
x_max += diff - diff // 2
|
||||
|
||||
if y_max - y_min != crop_size:
|
||||
context.services.logger.warning("FaceTools --> Limiting y-axis padding to constrain bounding box to a square.")
|
||||
diff = crop_size - (y_max - y_min)
|
||||
y_min -= diff // 2
|
||||
y_max += diff - diff // 2
|
||||
|
||||
context.services.logger.info(f"FaceTools --> Calculated bounding box (8 multiple): {crop_size}")
|
||||
|
||||
# Crop the output image to the specified size with the center of the face mesh as the center.
|
||||
mask = mask.crop((x_min, y_min, x_max, y_max))
|
||||
bounded_image = image.crop((x_min, y_min, x_max, y_max))
|
||||
|
||||
# blur mask edge by small radius
|
||||
mask = mask.filter(ImageFilter.GaussianBlur(radius=2))
|
||||
|
||||
return ExtractFaceData(
|
||||
bounded_image=bounded_image,
|
||||
bounded_mask=mask,
|
||||
x_min=x_min,
|
||||
y_min=y_min,
|
||||
x_max=x_max,
|
||||
y_max=y_max,
|
||||
)
|
||||
|
||||
|
||||
def get_faces_list(
|
||||
context: InvocationContext,
|
||||
image: ImageType,
|
||||
should_chunk: bool,
|
||||
minimum_confidence: float,
|
||||
x_offset: float,
|
||||
y_offset: float,
|
||||
draw_mesh: bool = True,
|
||||
) -> list[FaceResultDataWithId]:
|
||||
result = []
|
||||
|
||||
# Generate the face box mask and get the center of the face.
|
||||
if not should_chunk:
|
||||
context.services.logger.info("FaceTools --> Attempting full image face detection.")
|
||||
result = generate_face_box_mask(
|
||||
context=context,
|
||||
minimum_confidence=minimum_confidence,
|
||||
x_offset=x_offset,
|
||||
y_offset=y_offset,
|
||||
pil_image=image,
|
||||
chunk_x_offset=0,
|
||||
chunk_y_offset=0,
|
||||
draw_mesh=draw_mesh,
|
||||
check_bounds=False,
|
||||
)
|
||||
if should_chunk or len(result) == 0:
|
||||
context.services.logger.info("FaceTools --> Chunking image (chunk toggled on, or no face found in full image).")
|
||||
width, height = image.size
|
||||
image_chunks = []
|
||||
x_offsets = []
|
||||
y_offsets = []
|
||||
result = []
|
||||
|
||||
# If width == height, there's nothing more we can do... otherwise...
|
||||
if width > height:
|
||||
# Landscape - slice the image horizontally
|
||||
fx = 0.0
|
||||
steps = int(width * 2 / height)
|
||||
while fx <= (width - height):
|
||||
x = int(fx)
|
||||
image_chunks.append(image.crop((x, 0, x + height - 1, height - 1)))
|
||||
x_offsets.append(x)
|
||||
y_offsets.append(0)
|
||||
fx += (width - height) / steps
|
||||
context.services.logger.info(f"FaceTools --> Chunk starting at x = {x}")
|
||||
elif height > width:
|
||||
# Portrait - slice the image vertically
|
||||
fy = 0.0
|
||||
steps = int(height * 2 / width)
|
||||
while fy <= (height - width):
|
||||
y = int(fy)
|
||||
image_chunks.append(image.crop((0, y, width - 1, y + width - 1)))
|
||||
x_offsets.append(0)
|
||||
y_offsets.append(y)
|
||||
fy += (height - width) / steps
|
||||
context.services.logger.info(f"FaceTools --> Chunk starting at y = {y}")
|
||||
|
||||
for idx in range(len(image_chunks)):
|
||||
context.services.logger.info(f"FaceTools --> Evaluating faces in chunk {idx}")
|
||||
result = result + generate_face_box_mask(
|
||||
context=context,
|
||||
minimum_confidence=minimum_confidence,
|
||||
x_offset=x_offset,
|
||||
y_offset=y_offset,
|
||||
pil_image=image_chunks[idx],
|
||||
chunk_x_offset=x_offsets[idx],
|
||||
chunk_y_offset=y_offsets[idx],
|
||||
draw_mesh=draw_mesh,
|
||||
)
|
||||
|
||||
if len(result) == 0:
|
||||
# Give up
|
||||
context.services.logger.warning(
|
||||
"FaceTools --> No face detected in chunked input image. Passing through original image."
|
||||
)
|
||||
|
||||
all_faces = prepare_faces_list(result)
|
||||
|
||||
return all_faces
|
||||
|
||||
|
||||
@invocation("face_off", title="FaceOff", tags=["image", "faceoff", "face", "mask"], category="image", version="1.0.1")
|
||||
class FaceOffInvocation(BaseInvocation):
|
||||
"""Bound, extract, and mask a face from an image using MediaPipe detection"""
|
||||
|
||||
image: ImageField = InputField(description="Image for face detection")
|
||||
face_id: int = InputField(
|
||||
default=0,
|
||||
ge=0,
|
||||
description="The face ID to process, numbered from 0. Multiple faces not supported. Find a face's ID with FaceIdentifier node.",
|
||||
)
|
||||
minimum_confidence: float = InputField(
|
||||
default=0.5, description="Minimum confidence for face detection (lower if detection is failing)"
|
||||
)
|
||||
x_offset: float = InputField(default=0.0, description="X-axis offset of the mask")
|
||||
y_offset: float = InputField(default=0.0, description="Y-axis offset of the mask")
|
||||
padding: int = InputField(default=0, description="All-axis padding around the mask in pixels")
|
||||
chunk: bool = InputField(
|
||||
default=False,
|
||||
description="Whether to bypass full image face detection and default to image chunking. Chunking will occur if no faces are found in the full image.",
|
||||
)
|
||||
|
||||
def faceoff(self, context: InvocationContext, image: ImageType) -> Optional[ExtractFaceData]:
|
||||
all_faces = get_faces_list(
|
||||
context=context,
|
||||
image=image,
|
||||
should_chunk=self.chunk,
|
||||
minimum_confidence=self.minimum_confidence,
|
||||
x_offset=self.x_offset,
|
||||
y_offset=self.y_offset,
|
||||
draw_mesh=True,
|
||||
)
|
||||
|
||||
if len(all_faces) == 0:
|
||||
context.services.logger.warning("FaceOff --> No faces detected. Passing through original image.")
|
||||
return None
|
||||
|
||||
if self.face_id > len(all_faces) - 1:
|
||||
context.services.logger.warning(
|
||||
f"FaceOff --> Face ID {self.face_id} is outside of the number of faces detected ({len(all_faces)}). Passing through original image."
|
||||
)
|
||||
return None
|
||||
|
||||
face_data = extract_face(context=context, image=image, face=all_faces[self.face_id], padding=self.padding)
|
||||
# Convert the input image to RGBA mode to ensure it has an alpha channel.
|
||||
face_data["bounded_image"] = face_data["bounded_image"].convert("RGBA")
|
||||
|
||||
return face_data
|
||||
|
||||
def invoke(self, context: InvocationContext) -> FaceOffOutput:
|
||||
image = context.services.images.get_pil_image(self.image.image_name)
|
||||
result = self.faceoff(context=context, image=image)
|
||||
|
||||
if result is None:
|
||||
result_image = image
|
||||
result_mask = create_white_image(*image.size)
|
||||
x = 0
|
||||
y = 0
|
||||
else:
|
||||
result_image = result["bounded_image"]
|
||||
result_mask = result["bounded_mask"]
|
||||
x = result["x_min"]
|
||||
y = result["y_min"]
|
||||
|
||||
image_dto = context.services.images.create(
|
||||
image=result_image,
|
||||
image_origin=ResourceOrigin.INTERNAL,
|
||||
image_category=ImageCategory.GENERAL,
|
||||
node_id=self.id,
|
||||
session_id=context.graph_execution_state_id,
|
||||
is_intermediate=self.is_intermediate,
|
||||
workflow=self.workflow,
|
||||
)
|
||||
|
||||
mask_dto = context.services.images.create(
|
||||
image=result_mask,
|
||||
image_origin=ResourceOrigin.INTERNAL,
|
||||
image_category=ImageCategory.MASK,
|
||||
node_id=self.id,
|
||||
session_id=context.graph_execution_state_id,
|
||||
is_intermediate=self.is_intermediate,
|
||||
)
|
||||
|
||||
output = FaceOffOutput(
|
||||
image=ImageField(image_name=image_dto.image_name),
|
||||
width=image_dto.width,
|
||||
height=image_dto.height,
|
||||
mask=ImageField(image_name=mask_dto.image_name),
|
||||
x=x,
|
||||
y=y,
|
||||
)
|
||||
|
||||
return output
|
||||
|
||||
|
||||
@invocation("face_mask_detection", title="FaceMask", tags=["image", "face", "mask"], category="image", version="1.0.1")
|
||||
class FaceMaskInvocation(BaseInvocation):
|
||||
"""Face mask creation using mediapipe face detection"""
|
||||
|
||||
image: ImageField = InputField(description="Image to face detect")
|
||||
face_ids: str = InputField(
|
||||
default="",
|
||||
description="Comma-separated list of face ids to mask eg '0,2,7'. Numbered from 0. Leave empty to mask all. Find face IDs with FaceIdentifier node.",
|
||||
)
|
||||
minimum_confidence: float = InputField(
|
||||
default=0.5, description="Minimum confidence for face detection (lower if detection is failing)"
|
||||
)
|
||||
x_offset: float = InputField(default=0.0, description="Offset for the X-axis of the face mask")
|
||||
y_offset: float = InputField(default=0.0, description="Offset for the Y-axis of the face mask")
|
||||
chunk: bool = InputField(
|
||||
default=False,
|
||||
description="Whether to bypass full image face detection and default to image chunking. Chunking will occur if no faces are found in the full image.",
|
||||
)
|
||||
invert_mask: bool = InputField(default=False, description="Toggle to invert the mask")
|
||||
|
||||
@validator("face_ids")
|
||||
def validate_comma_separated_ints(cls, v) -> str:
|
||||
comma_separated_ints_regex = re.compile(r"^\d*(,\d+)*$")
|
||||
if comma_separated_ints_regex.match(v) is None:
|
||||
raise ValueError('Face IDs must be a comma-separated list of integers (e.g. "1,2,3")')
|
||||
return v
|
||||
|
||||
def facemask(self, context: InvocationContext, image: ImageType) -> FaceMaskResult:
|
||||
all_faces = get_faces_list(
|
||||
context=context,
|
||||
image=image,
|
||||
should_chunk=self.chunk,
|
||||
minimum_confidence=self.minimum_confidence,
|
||||
x_offset=self.x_offset,
|
||||
y_offset=self.y_offset,
|
||||
draw_mesh=True,
|
||||
)
|
||||
|
||||
mask_pil = create_white_image(*image.size)
|
||||
|
||||
id_range = list(range(0, len(all_faces)))
|
||||
ids_to_extract = id_range
|
||||
if self.face_ids != "":
|
||||
parsed_face_ids = [int(id) for id in self.face_ids.split(",")]
|
||||
# get requested face_ids that are in range
|
||||
intersected_face_ids = set(parsed_face_ids) & set(id_range)
|
||||
|
||||
if len(intersected_face_ids) == 0:
|
||||
id_range_str = ",".join([str(id) for id in id_range])
|
||||
context.services.logger.warning(
|
||||
f"Face IDs must be in range of detected faces - requested {self.face_ids}, detected {id_range_str}. Passing through original image."
|
||||
)
|
||||
return FaceMaskResult(
|
||||
image=image, # original image
|
||||
mask=mask_pil, # white mask
|
||||
)
|
||||
|
||||
ids_to_extract = list(intersected_face_ids)
|
||||
|
||||
for face_id in ids_to_extract:
|
||||
face_data = extract_face(context=context, image=image, face=all_faces[face_id], padding=0)
|
||||
face_mask_pil = face_data["bounded_mask"]
|
||||
x_min = face_data["x_min"]
|
||||
y_min = face_data["y_min"]
|
||||
x_max = face_data["x_max"]
|
||||
y_max = face_data["y_max"]
|
||||
|
||||
mask_pil.paste(
|
||||
create_black_image(x_max - x_min, y_max - y_min),
|
||||
box=(x_min, y_min),
|
||||
mask=ImageOps.invert(face_mask_pil),
|
||||
)
|
||||
|
||||
if self.invert_mask:
|
||||
mask_pil = ImageOps.invert(mask_pil)
|
||||
|
||||
# Create an RGBA image with transparency
|
||||
image = image.convert("RGBA")
|
||||
|
||||
return FaceMaskResult(
|
||||
image=image,
|
||||
mask=mask_pil,
|
||||
)
|
||||
|
||||
def invoke(self, context: InvocationContext) -> FaceMaskOutput:
|
||||
image = context.services.images.get_pil_image(self.image.image_name)
|
||||
result = self.facemask(context=context, image=image)
|
||||
|
||||
image_dto = context.services.images.create(
|
||||
image=result["image"],
|
||||
image_origin=ResourceOrigin.INTERNAL,
|
||||
image_category=ImageCategory.GENERAL,
|
||||
node_id=self.id,
|
||||
session_id=context.graph_execution_state_id,
|
||||
is_intermediate=self.is_intermediate,
|
||||
workflow=self.workflow,
|
||||
)
|
||||
|
||||
mask_dto = context.services.images.create(
|
||||
image=result["mask"],
|
||||
image_origin=ResourceOrigin.INTERNAL,
|
||||
image_category=ImageCategory.MASK,
|
||||
node_id=self.id,
|
||||
session_id=context.graph_execution_state_id,
|
||||
is_intermediate=self.is_intermediate,
|
||||
)
|
||||
|
||||
output = FaceMaskOutput(
|
||||
image=ImageField(image_name=image_dto.image_name),
|
||||
width=image_dto.width,
|
||||
height=image_dto.height,
|
||||
mask=ImageField(image_name=mask_dto.image_name),
|
||||
)
|
||||
|
||||
return output
|
||||
|
||||
|
||||
@invocation(
|
||||
"face_identifier", title="FaceIdentifier", tags=["image", "face", "identifier"], category="image", version="1.0.1"
|
||||
)
|
||||
class FaceIdentifierInvocation(BaseInvocation):
|
||||
"""Outputs an image with detected face IDs printed on each face. For use with other FaceTools."""
|
||||
|
||||
image: ImageField = InputField(description="Image to face detect")
|
||||
minimum_confidence: float = InputField(
|
||||
default=0.5, description="Minimum confidence for face detection (lower if detection is failing)"
|
||||
)
|
||||
chunk: bool = InputField(
|
||||
default=False,
|
||||
description="Whether to bypass full image face detection and default to image chunking. Chunking will occur if no faces are found in the full image.",
|
||||
)
|
||||
|
||||
def faceidentifier(self, context: InvocationContext, image: ImageType) -> ImageType:
|
||||
image = image.copy()
|
||||
|
||||
all_faces = get_faces_list(
|
||||
context=context,
|
||||
image=image,
|
||||
should_chunk=self.chunk,
|
||||
minimum_confidence=self.minimum_confidence,
|
||||
x_offset=0,
|
||||
y_offset=0,
|
||||
draw_mesh=False,
|
||||
)
|
||||
|
||||
# Note - font may be found either in the repo if running an editable install, or in the venv if running a package install
|
||||
font_path = [x for x in [Path(y, "inter/Inter-Regular.ttf") for y in font_assets.__path__] if x.exists()]
|
||||
font = ImageFont.truetype(font_path[0].as_posix(), FONT_SIZE)
|
||||
|
||||
# Paste face IDs on the output image
|
||||
draw = ImageDraw.Draw(image)
|
||||
for face in all_faces:
|
||||
x_coord = face["x_center"]
|
||||
y_coord = face["y_center"]
|
||||
text = str(face["face_id"])
|
||||
# get bbox of the text so we can center the id on the face
|
||||
_, _, bbox_w, bbox_h = draw.textbbox(xy=(0, 0), text=text, font=font, stroke_width=FONT_STROKE_WIDTH)
|
||||
x = x_coord - bbox_w / 2
|
||||
y = y_coord - bbox_h / 2
|
||||
draw.text(
|
||||
xy=(x, y),
|
||||
text=str(text),
|
||||
fill=(255, 255, 255, 255),
|
||||
font=font,
|
||||
stroke_width=FONT_STROKE_WIDTH,
|
||||
stroke_fill=(0, 0, 0, 255),
|
||||
)
|
||||
|
||||
# Create an RGBA image with transparency
|
||||
image = image.convert("RGBA")
|
||||
|
||||
return image
|
||||
|
||||
def invoke(self, context: InvocationContext) -> ImageOutput:
|
||||
image = context.services.images.get_pil_image(self.image.image_name)
|
||||
result_image = self.faceidentifier(context=context, image=image)
|
||||
|
||||
image_dto = context.services.images.create(
|
||||
image=result_image,
|
||||
image_origin=ResourceOrigin.INTERNAL,
|
||||
image_category=ImageCategory.GENERAL,
|
||||
node_id=self.id,
|
||||
session_id=context.graph_execution_state_id,
|
||||
is_intermediate=self.is_intermediate,
|
||||
workflow=self.workflow,
|
||||
)
|
||||
|
||||
return ImageOutput(
|
||||
image=ImageField(image_name=image_dto.image_name),
|
||||
width=image_dto.width,
|
||||
height=image_dto.height,
|
||||
)
|
||||
@@ -8,12 +8,12 @@ import numpy
|
||||
from PIL import Image, ImageChops, ImageFilter, ImageOps
|
||||
|
||||
from invokeai.app.invocations.metadata import CoreMetadata
|
||||
from invokeai.app.invocations.primitives import ColorField, ImageField, ImageOutput
|
||||
from invokeai.app.invocations.primitives import BoardField, ColorField, ImageField, ImageOutput
|
||||
from invokeai.backend.image_util.invisible_watermark import InvisibleWatermark
|
||||
from invokeai.backend.image_util.safety_checker import SafetyChecker
|
||||
|
||||
from ..models.image import ImageCategory, ResourceOrigin
|
||||
from .baseinvocation import BaseInvocation, FieldDescriptions, InputField, InvocationContext, invocation
|
||||
from .baseinvocation import BaseInvocation, FieldDescriptions, Input, InputField, InvocationContext, invocation
|
||||
|
||||
|
||||
@invocation("show_image", title="Show Image", tags=["image"], category="image", version="1.0.0")
|
||||
@@ -972,13 +972,14 @@ class ImageChannelMultiplyInvocation(BaseInvocation):
|
||||
title="Save Image",
|
||||
tags=["primitives", "image"],
|
||||
category="primitives",
|
||||
version="1.0.0",
|
||||
version="1.0.1",
|
||||
use_cache=False,
|
||||
)
|
||||
class SaveImageInvocation(BaseInvocation):
|
||||
"""Saves an image. Unlike an image primitive, this invocation stores a copy of the image."""
|
||||
|
||||
image: ImageField = InputField(description="The image to load")
|
||||
image: ImageField = InputField(description=FieldDescriptions.image)
|
||||
board: Optional[BoardField] = InputField(default=None, description=FieldDescriptions.board, input=Input.Direct)
|
||||
metadata: CoreMetadata = InputField(
|
||||
default=None,
|
||||
description=FieldDescriptions.core_metadata,
|
||||
@@ -992,6 +993,7 @@ class SaveImageInvocation(BaseInvocation):
|
||||
image=image,
|
||||
image_origin=ResourceOrigin.INTERNAL,
|
||||
image_category=ImageCategory.GENERAL,
|
||||
board_id=self.board.board_id if self.board else None,
|
||||
node_id=self.id,
|
||||
session_id=context.graph_execution_state_id,
|
||||
is_intermediate=self.is_intermediate,
|
||||
|
||||
@@ -269,7 +269,7 @@ class LaMaInfillInvocation(BaseInvocation):
|
||||
)
|
||||
|
||||
|
||||
@invocation("infill_cv2", title="CV2 Infill", tags=["image", "inpaint"], category="inpaint")
|
||||
@invocation("infill_cv2", title="CV2 Infill", tags=["image", "inpaint"], category="inpaint", version="1.0.0")
|
||||
class CV2InfillInvocation(BaseInvocation):
|
||||
"""Infills transparent areas of an image using OpenCV Inpainting"""
|
||||
|
||||
|
||||
@@ -10,7 +10,7 @@ import torch
|
||||
import torchvision.transforms as T
|
||||
from diffusers import AutoencoderKL, AutoencoderTiny
|
||||
from diffusers.image_processor import VaeImageProcessor
|
||||
from diffusers.models import UNet2DConditionModel
|
||||
from diffusers.models.adapter import FullAdapterXL, T2IAdapter
|
||||
from diffusers.models.attention_processor import (
|
||||
AttnProcessor2_0,
|
||||
LoRAAttnProcessor2_0,
|
||||
@@ -33,6 +33,7 @@ from invokeai.app.invocations.primitives import (
|
||||
LatentsOutput,
|
||||
build_latents_output,
|
||||
)
|
||||
from invokeai.app.invocations.t2i_adapter import T2IAdapterField
|
||||
from invokeai.app.util.controlnet_utils import prepare_control_image
|
||||
from invokeai.app.util.step_callback import stable_diffusion_step_callback
|
||||
from invokeai.backend.ip_adapter.ip_adapter import IPAdapter, IPAdapterPlus
|
||||
@@ -47,6 +48,7 @@ from ...backend.stable_diffusion.diffusers_pipeline import (
|
||||
ControlNetData,
|
||||
IPAdapterData,
|
||||
StableDiffusionGeneratorPipeline,
|
||||
T2IAdapterData,
|
||||
image_resized_to_grid_as_tensor,
|
||||
)
|
||||
from ...backend.stable_diffusion.diffusion.shared_invokeai_diffusion import PostprocessingSettings
|
||||
@@ -196,7 +198,7 @@ def get_scheduler(
|
||||
title="Denoise Latents",
|
||||
tags=["latents", "denoise", "txt2img", "t2i", "t2l", "img2img", "i2i", "l2l"],
|
||||
category="latents",
|
||||
version="1.1.0",
|
||||
version="1.3.0",
|
||||
)
|
||||
class DenoiseLatentsInvocation(BaseInvocation):
|
||||
"""Denoises noisy latents to decodable images"""
|
||||
@@ -223,12 +225,15 @@ class DenoiseLatentsInvocation(BaseInvocation):
|
||||
input=Input.Connection,
|
||||
ui_order=5,
|
||||
)
|
||||
ip_adapter: Optional[IPAdapterField] = InputField(
|
||||
ip_adapter: Optional[Union[IPAdapterField, list[IPAdapterField]]] = InputField(
|
||||
description=FieldDescriptions.ip_adapter, title="IP-Adapter", default=None, input=Input.Connection, ui_order=6
|
||||
)
|
||||
t2i_adapter: Union[T2IAdapterField, list[T2IAdapterField]] = InputField(
|
||||
description=FieldDescriptions.t2i_adapter, title="T2I-Adapter", default=None, input=Input.Connection, ui_order=7
|
||||
)
|
||||
latents: Optional[LatentsField] = InputField(description=FieldDescriptions.latents, input=Input.Connection)
|
||||
denoise_mask: Optional[DenoiseMaskField] = InputField(
|
||||
default=None, description=FieldDescriptions.mask, input=Input.Connection, ui_order=7
|
||||
default=None, description=FieldDescriptions.mask, input=Input.Connection, ui_order=8
|
||||
)
|
||||
|
||||
@validator("cfg_scale")
|
||||
@@ -404,52 +409,150 @@ class DenoiseLatentsInvocation(BaseInvocation):
|
||||
def prep_ip_adapter_data(
|
||||
self,
|
||||
context: InvocationContext,
|
||||
ip_adapter: Optional[IPAdapterField],
|
||||
ip_adapter: Optional[Union[IPAdapterField, list[IPAdapterField]]],
|
||||
conditioning_data: ConditioningData,
|
||||
unet: UNet2DConditionModel,
|
||||
exit_stack: ExitStack,
|
||||
) -> Optional[IPAdapterData]:
|
||||
) -> Optional[list[IPAdapterData]]:
|
||||
"""If IP-Adapter is enabled, then this function loads the requisite models, and adds the image prompt embeddings
|
||||
to the `conditioning_data` (in-place).
|
||||
"""
|
||||
if ip_adapter is None:
|
||||
return None
|
||||
|
||||
image_encoder_model_info = context.services.model_manager.get_model(
|
||||
model_name=ip_adapter.image_encoder_model.model_name,
|
||||
model_type=ModelType.CLIPVision,
|
||||
base_model=ip_adapter.image_encoder_model.base_model,
|
||||
context=context,
|
||||
)
|
||||
# ip_adapter could be a list or a single IPAdapterField. Normalize to a list here.
|
||||
if not isinstance(ip_adapter, list):
|
||||
ip_adapter = [ip_adapter]
|
||||
|
||||
ip_adapter_model: Union[IPAdapter, IPAdapterPlus] = exit_stack.enter_context(
|
||||
context.services.model_manager.get_model(
|
||||
model_name=ip_adapter.ip_adapter_model.model_name,
|
||||
model_type=ModelType.IPAdapter,
|
||||
base_model=ip_adapter.ip_adapter_model.base_model,
|
||||
if len(ip_adapter) == 0:
|
||||
return None
|
||||
|
||||
ip_adapter_data_list = []
|
||||
conditioning_data.ip_adapter_conditioning = []
|
||||
for single_ip_adapter in ip_adapter:
|
||||
ip_adapter_model: Union[IPAdapter, IPAdapterPlus] = exit_stack.enter_context(
|
||||
context.services.model_manager.get_model(
|
||||
model_name=single_ip_adapter.ip_adapter_model.model_name,
|
||||
model_type=ModelType.IPAdapter,
|
||||
base_model=single_ip_adapter.ip_adapter_model.base_model,
|
||||
context=context,
|
||||
)
|
||||
)
|
||||
|
||||
image_encoder_model_info = context.services.model_manager.get_model(
|
||||
model_name=single_ip_adapter.image_encoder_model.model_name,
|
||||
model_type=ModelType.CLIPVision,
|
||||
base_model=single_ip_adapter.image_encoder_model.base_model,
|
||||
context=context,
|
||||
)
|
||||
)
|
||||
|
||||
input_image = context.services.images.get_pil_image(ip_adapter.image.image_name)
|
||||
input_image = context.services.images.get_pil_image(single_ip_adapter.image.image_name)
|
||||
|
||||
# TODO(ryand): With some effort, the step of running the CLIP Vision encoder could be done before any other
|
||||
# models are needed in memory. This would help to reduce peak memory utilization in low-memory environments.
|
||||
with image_encoder_model_info as image_encoder_model:
|
||||
# Get image embeddings from CLIP and ImageProjModel.
|
||||
image_prompt_embeds, uncond_image_prompt_embeds = ip_adapter_model.get_image_embeds(
|
||||
input_image, image_encoder_model
|
||||
)
|
||||
conditioning_data.ip_adapter_conditioning = IPAdapterConditioningInfo(
|
||||
image_prompt_embeds, uncond_image_prompt_embeds
|
||||
# TODO(ryand): With some effort, the step of running the CLIP Vision encoder could be done before any other
|
||||
# models are needed in memory. This would help to reduce peak memory utilization in low-memory environments.
|
||||
with image_encoder_model_info as image_encoder_model:
|
||||
# Get image embeddings from CLIP and ImageProjModel.
|
||||
image_prompt_embeds, uncond_image_prompt_embeds = ip_adapter_model.get_image_embeds(
|
||||
input_image, image_encoder_model
|
||||
)
|
||||
conditioning_data.ip_adapter_conditioning.append(
|
||||
IPAdapterConditioningInfo(image_prompt_embeds, uncond_image_prompt_embeds)
|
||||
)
|
||||
|
||||
ip_adapter_data_list.append(
|
||||
IPAdapterData(
|
||||
ip_adapter_model=ip_adapter_model,
|
||||
weight=single_ip_adapter.weight,
|
||||
begin_step_percent=single_ip_adapter.begin_step_percent,
|
||||
end_step_percent=single_ip_adapter.end_step_percent,
|
||||
)
|
||||
)
|
||||
|
||||
return IPAdapterData(
|
||||
ip_adapter_model=ip_adapter_model,
|
||||
weight=ip_adapter.weight,
|
||||
begin_step_percent=ip_adapter.begin_step_percent,
|
||||
end_step_percent=ip_adapter.end_step_percent,
|
||||
)
|
||||
return ip_adapter_data_list
|
||||
|
||||
def run_t2i_adapters(
|
||||
self,
|
||||
context: InvocationContext,
|
||||
t2i_adapter: Optional[Union[T2IAdapterField, list[T2IAdapterField]]],
|
||||
latents_shape: list[int],
|
||||
do_classifier_free_guidance: bool,
|
||||
) -> Optional[list[T2IAdapterData]]:
|
||||
if t2i_adapter is None:
|
||||
return None
|
||||
|
||||
# Handle the possibility that t2i_adapter could be a list or a single T2IAdapterField.
|
||||
if isinstance(t2i_adapter, T2IAdapterField):
|
||||
t2i_adapter = [t2i_adapter]
|
||||
|
||||
if len(t2i_adapter) == 0:
|
||||
return None
|
||||
|
||||
t2i_adapter_data = []
|
||||
for t2i_adapter_field in t2i_adapter:
|
||||
t2i_adapter_model_info = context.services.model_manager.get_model(
|
||||
model_name=t2i_adapter_field.t2i_adapter_model.model_name,
|
||||
model_type=ModelType.T2IAdapter,
|
||||
base_model=t2i_adapter_field.t2i_adapter_model.base_model,
|
||||
context=context,
|
||||
)
|
||||
image = context.services.images.get_pil_image(t2i_adapter_field.image.image_name)
|
||||
|
||||
# The max_unet_downscale is the maximum amount that the UNet model downscales the latent image internally.
|
||||
if t2i_adapter_field.t2i_adapter_model.base_model == BaseModelType.StableDiffusion1:
|
||||
max_unet_downscale = 8
|
||||
elif t2i_adapter_field.t2i_adapter_model.base_model == BaseModelType.StableDiffusionXL:
|
||||
max_unet_downscale = 4
|
||||
else:
|
||||
raise ValueError(
|
||||
f"Unexpected T2I-Adapter base model type: '{t2i_adapter_field.t2i_adapter_model.base_model}'."
|
||||
)
|
||||
|
||||
t2i_adapter_model: T2IAdapter
|
||||
with t2i_adapter_model_info as t2i_adapter_model:
|
||||
total_downscale_factor = t2i_adapter_model.total_downscale_factor
|
||||
if isinstance(t2i_adapter_model.adapter, FullAdapterXL):
|
||||
# HACK(ryand): Work around a bug in FullAdapterXL. This is being addressed upstream in diffusers by
|
||||
# this PR: https://github.com/huggingface/diffusers/pull/5134.
|
||||
total_downscale_factor = total_downscale_factor // 2
|
||||
|
||||
# Resize the T2I-Adapter input image.
|
||||
# We select the resize dimensions so that after the T2I-Adapter's total_downscale_factor is applied, the
|
||||
# result will match the latent image's dimensions after max_unet_downscale is applied.
|
||||
t2i_input_height = latents_shape[2] // max_unet_downscale * total_downscale_factor
|
||||
t2i_input_width = latents_shape[3] // max_unet_downscale * total_downscale_factor
|
||||
|
||||
# Note: We have hard-coded `do_classifier_free_guidance=False`. This is because we only want to prepare
|
||||
# a single image. If CFG is enabled, we will duplicate the resultant tensor after applying the
|
||||
# T2I-Adapter model.
|
||||
#
|
||||
# Note: We re-use the `prepare_control_image(...)` from ControlNet for T2I-Adapter, because it has many
|
||||
# of the same requirements (e.g. preserving binary masks during resize).
|
||||
t2i_image = prepare_control_image(
|
||||
image=image,
|
||||
do_classifier_free_guidance=False,
|
||||
width=t2i_input_width,
|
||||
height=t2i_input_height,
|
||||
num_channels=t2i_adapter_model.config.in_channels,
|
||||
device=t2i_adapter_model.device,
|
||||
dtype=t2i_adapter_model.dtype,
|
||||
resize_mode=t2i_adapter_field.resize_mode,
|
||||
)
|
||||
|
||||
adapter_state = t2i_adapter_model(t2i_image)
|
||||
|
||||
if do_classifier_free_guidance:
|
||||
for idx, value in enumerate(adapter_state):
|
||||
adapter_state[idx] = torch.cat([value] * 2, dim=0)
|
||||
|
||||
t2i_adapter_data.append(
|
||||
T2IAdapterData(
|
||||
adapter_state=adapter_state,
|
||||
weight=t2i_adapter_field.weight,
|
||||
begin_step_percent=t2i_adapter_field.begin_step_percent,
|
||||
end_step_percent=t2i_adapter_field.end_step_percent,
|
||||
)
|
||||
)
|
||||
|
||||
return t2i_adapter_data
|
||||
|
||||
# original idea by https://github.com/AmericanPresidentJimmyCarter
|
||||
# TODO: research more for second order schedulers timesteps
|
||||
@@ -522,6 +625,12 @@ class DenoiseLatentsInvocation(BaseInvocation):
|
||||
|
||||
mask, masked_latents = self.prep_inpaint_mask(context, latents)
|
||||
|
||||
# TODO(ryand): I have hard-coded `do_classifier_free_guidance=True` to mirror the behaviour of ControlNets,
|
||||
# below. Investigate whether this is appropriate.
|
||||
t2i_adapter_data = self.run_t2i_adapters(
|
||||
context, self.t2i_adapter, latents.shape, do_classifier_free_guidance=True
|
||||
)
|
||||
|
||||
# Get the source node id (we are invoking the prepared node)
|
||||
graph_execution_state = context.services.graph_execution_manager.get(context.graph_execution_state_id)
|
||||
source_node_id = graph_execution_state.prepared_source_mapping[self.id]
|
||||
@@ -580,7 +689,6 @@ class DenoiseLatentsInvocation(BaseInvocation):
|
||||
context=context,
|
||||
ip_adapter=self.ip_adapter,
|
||||
conditioning_data=conditioning_data,
|
||||
unet=unet,
|
||||
exit_stack=exit_stack,
|
||||
)
|
||||
|
||||
@@ -602,8 +710,9 @@ class DenoiseLatentsInvocation(BaseInvocation):
|
||||
masked_latents=masked_latents,
|
||||
num_inference_steps=num_inference_steps,
|
||||
conditioning_data=conditioning_data,
|
||||
control_data=controlnet_data, # list[ControlNetData],
|
||||
ip_adapter_data=ip_adapter_data, # IPAdapterData,
|
||||
control_data=controlnet_data,
|
||||
ip_adapter_data=ip_adapter_data,
|
||||
t2i_adapter_data=t2i_adapter_data,
|
||||
callback=step_callback,
|
||||
)
|
||||
|
||||
|
||||
@@ -65,13 +65,27 @@ class DivideInvocation(BaseInvocation):
|
||||
class RandomIntInvocation(BaseInvocation):
|
||||
"""Outputs a single random integer."""
|
||||
|
||||
low: int = InputField(default=0, description="The inclusive low value")
|
||||
high: int = InputField(default=np.iinfo(np.int32).max, description="The exclusive high value")
|
||||
low: int = InputField(default=0, description=FieldDescriptions.inclusive_low)
|
||||
high: int = InputField(default=np.iinfo(np.int32).max, description=FieldDescriptions.exclusive_high)
|
||||
|
||||
def invoke(self, context: InvocationContext) -> IntegerOutput:
|
||||
return IntegerOutput(value=np.random.randint(self.low, self.high))
|
||||
|
||||
|
||||
@invocation("rand_float", title="Random Float", tags=["math", "float", "random"], category="math", version="1.0.0")
|
||||
class RandomFloatInvocation(BaseInvocation):
|
||||
"""Outputs a single random float"""
|
||||
|
||||
low: float = InputField(default=0.0, description=FieldDescriptions.inclusive_low)
|
||||
high: float = InputField(default=1.0, description=FieldDescriptions.exclusive_high)
|
||||
decimals: int = InputField(default=2, description=FieldDescriptions.decimal_places)
|
||||
|
||||
def invoke(self, context: InvocationContext) -> FloatOutput:
|
||||
random_float = np.random.uniform(self.low, self.high)
|
||||
rounded_float = round(random_float, self.decimals)
|
||||
return FloatOutput(value=rounded_float)
|
||||
|
||||
|
||||
@invocation(
|
||||
"float_to_int",
|
||||
title="Float To Integer",
|
||||
|
||||
@@ -12,7 +12,10 @@ from invokeai.app.invocations.baseinvocation import (
|
||||
invocation_output,
|
||||
)
|
||||
from invokeai.app.invocations.controlnet_image_processors import ControlField
|
||||
from invokeai.app.invocations.ip_adapter import IPAdapterModelField
|
||||
from invokeai.app.invocations.model import LoRAModelField, MainModelField, VAEModelField
|
||||
from invokeai.app.invocations.primitives import ImageField
|
||||
from invokeai.app.invocations.t2i_adapter import T2IAdapterField
|
||||
from invokeai.app.util.model_exclude_null import BaseModelExcludeNull
|
||||
|
||||
from ...version import __version__
|
||||
@@ -25,6 +28,18 @@ class LoRAMetadataField(BaseModelExcludeNull):
|
||||
weight: float = Field(description="The weight of the LoRA model")
|
||||
|
||||
|
||||
class IPAdapterMetadataField(BaseModelExcludeNull):
|
||||
image: ImageField = Field(description="The IP-Adapter image prompt.")
|
||||
ip_adapter_model: IPAdapterModelField = Field(description="The IP-Adapter model to use.")
|
||||
weight: float = Field(description="The weight of the IP-Adapter model")
|
||||
begin_step_percent: float = Field(
|
||||
default=0, ge=0, le=1, description="When the IP-Adapter is first applied (% of total steps)"
|
||||
)
|
||||
end_step_percent: float = Field(
|
||||
default=1, ge=0, le=1, description="When the IP-Adapter is last applied (% of total steps)"
|
||||
)
|
||||
|
||||
|
||||
class CoreMetadata(BaseModelExcludeNull):
|
||||
"""Core generation metadata for an image generated in InvokeAI."""
|
||||
|
||||
@@ -48,6 +63,8 @@ class CoreMetadata(BaseModelExcludeNull):
|
||||
)
|
||||
model: MainModelField = Field(description="The main model used for inference")
|
||||
controlnets: list[ControlField] = Field(description="The ControlNets used for inference")
|
||||
ipAdapters: list[IPAdapterMetadataField] = Field(description="The IP Adapters used for inference")
|
||||
t2iAdapters: list[T2IAdapterField] = Field(description="The IP Adapters used for inference")
|
||||
loras: list[LoRAMetadataField] = Field(description="The LoRAs used for inference")
|
||||
vae: Optional[VAEModelField] = Field(
|
||||
default=None,
|
||||
@@ -123,6 +140,8 @@ class MetadataAccumulatorInvocation(BaseInvocation):
|
||||
)
|
||||
model: MainModelField = InputField(description="The main model used for inference")
|
||||
controlnets: list[ControlField] = InputField(description="The ControlNets used for inference")
|
||||
ipAdapters: list[IPAdapterMetadataField] = InputField(description="The IP Adapters used for inference")
|
||||
t2iAdapters: list[T2IAdapterField] = Field(description="The IP Adapters used for inference")
|
||||
loras: list[LoRAMetadataField] = InputField(description="The LoRAs used for inference")
|
||||
strength: Optional[float] = InputField(
|
||||
default=None,
|
||||
|
||||
@@ -226,6 +226,12 @@ class ImageField(BaseModel):
|
||||
image_name: str = Field(description="The name of the image")
|
||||
|
||||
|
||||
class BoardField(BaseModel):
|
||||
"""A board primitive field"""
|
||||
|
||||
board_id: str = Field(description="The id of the board")
|
||||
|
||||
|
||||
@invocation_output("image_output")
|
||||
class ImageOutput(BaseInvocationOutput):
|
||||
"""Base class for nodes that output a single image"""
|
||||
|
||||
83
invokeai/app/invocations/t2i_adapter.py
Normal file
83
invokeai/app/invocations/t2i_adapter.py
Normal file
@@ -0,0 +1,83 @@
|
||||
from typing import Union
|
||||
|
||||
from pydantic import BaseModel, Field
|
||||
|
||||
from invokeai.app.invocations.baseinvocation import (
|
||||
BaseInvocation,
|
||||
BaseInvocationOutput,
|
||||
FieldDescriptions,
|
||||
Input,
|
||||
InputField,
|
||||
InvocationContext,
|
||||
OutputField,
|
||||
UIType,
|
||||
invocation,
|
||||
invocation_output,
|
||||
)
|
||||
from invokeai.app.invocations.controlnet_image_processors import CONTROLNET_RESIZE_VALUES
|
||||
from invokeai.app.invocations.primitives import ImageField
|
||||
from invokeai.backend.model_management.models.base import BaseModelType
|
||||
|
||||
|
||||
class T2IAdapterModelField(BaseModel):
|
||||
model_name: str = Field(description="Name of the T2I-Adapter model")
|
||||
base_model: BaseModelType = Field(description="Base model")
|
||||
|
||||
|
||||
class T2IAdapterField(BaseModel):
|
||||
image: ImageField = Field(description="The T2I-Adapter image prompt.")
|
||||
t2i_adapter_model: T2IAdapterModelField = Field(description="The T2I-Adapter model to use.")
|
||||
weight: Union[float, list[float]] = Field(default=1, description="The weight given to the T2I-Adapter")
|
||||
begin_step_percent: float = Field(
|
||||
default=0, ge=0, le=1, description="When the T2I-Adapter is first applied (% of total steps)"
|
||||
)
|
||||
end_step_percent: float = Field(
|
||||
default=1, ge=0, le=1, description="When the T2I-Adapter is last applied (% of total steps)"
|
||||
)
|
||||
resize_mode: CONTROLNET_RESIZE_VALUES = Field(default="just_resize", description="The resize mode to use")
|
||||
|
||||
|
||||
@invocation_output("t2i_adapter_output")
|
||||
class T2IAdapterOutput(BaseInvocationOutput):
|
||||
t2i_adapter: T2IAdapterField = OutputField(description=FieldDescriptions.t2i_adapter, title="T2I Adapter")
|
||||
|
||||
|
||||
@invocation(
|
||||
"t2i_adapter", title="T2I-Adapter", tags=["t2i_adapter", "control"], category="t2i_adapter", version="1.0.0"
|
||||
)
|
||||
class T2IAdapterInvocation(BaseInvocation):
|
||||
"""Collects T2I-Adapter info to pass to other nodes."""
|
||||
|
||||
# Inputs
|
||||
image: ImageField = InputField(description="The IP-Adapter image prompt.")
|
||||
t2i_adapter_model: T2IAdapterModelField = InputField(
|
||||
description="The T2I-Adapter model.",
|
||||
title="T2I-Adapter Model",
|
||||
input=Input.Direct,
|
||||
ui_order=-1,
|
||||
)
|
||||
weight: Union[float, list[float]] = InputField(
|
||||
default=1, ge=0, description="The weight given to the T2I-Adapter", ui_type=UIType.Float, title="Weight"
|
||||
)
|
||||
begin_step_percent: float = InputField(
|
||||
default=0, ge=-1, le=2, description="When the T2I-Adapter is first applied (% of total steps)"
|
||||
)
|
||||
end_step_percent: float = InputField(
|
||||
default=1, ge=0, le=1, description="When the T2I-Adapter is last applied (% of total steps)"
|
||||
)
|
||||
resize_mode: CONTROLNET_RESIZE_VALUES = InputField(
|
||||
default="just_resize",
|
||||
description="The resize mode applied to the T2I-Adapter input image so that it matches the target output size.",
|
||||
)
|
||||
|
||||
def invoke(self, context: InvocationContext) -> T2IAdapterOutput:
|
||||
return T2IAdapterOutput(
|
||||
t2i_adapter=T2IAdapterField(
|
||||
image=self.image,
|
||||
t2i_adapter_model=self.t2i_adapter_model,
|
||||
weight=self.weight,
|
||||
begin_step_percent=self.begin_step_percent,
|
||||
end_step_percent=self.end_step_percent,
|
||||
resize_mode=self.resize_mode,
|
||||
)
|
||||
)
|
||||
@@ -4,12 +4,14 @@ from typing import Literal
|
||||
|
||||
import cv2 as cv
|
||||
import numpy as np
|
||||
import torch
|
||||
from basicsr.archs.rrdbnet_arch import RRDBNet
|
||||
from PIL import Image
|
||||
from realesrgan import RealESRGANer
|
||||
|
||||
from invokeai.app.invocations.primitives import ImageField, ImageOutput
|
||||
from invokeai.app.models.image import ImageCategory, ResourceOrigin
|
||||
from invokeai.backend.util.devices import choose_torch_device
|
||||
|
||||
from .baseinvocation import BaseInvocation, InputField, InvocationContext, invocation
|
||||
|
||||
@@ -22,13 +24,19 @@ ESRGAN_MODELS = Literal[
|
||||
"RealESRGAN_x2plus.pth",
|
||||
]
|
||||
|
||||
if choose_torch_device() == torch.device("mps"):
|
||||
from torch import mps
|
||||
|
||||
@invocation("esrgan", title="Upscale (RealESRGAN)", tags=["esrgan", "upscale"], category="esrgan", version="1.0.0")
|
||||
|
||||
@invocation("esrgan", title="Upscale (RealESRGAN)", tags=["esrgan", "upscale"], category="esrgan", version="1.1.0")
|
||||
class ESRGANInvocation(BaseInvocation):
|
||||
"""Upscales an image using RealESRGAN."""
|
||||
|
||||
image: ImageField = InputField(description="The input image")
|
||||
model_name: ESRGAN_MODELS = InputField(default="RealESRGAN_x4plus.pth", description="The Real-ESRGAN model to use")
|
||||
tile_size: int = InputField(
|
||||
default=400, ge=0, description="Tile size for tiled ESRGAN upscaling (0=tiling disabled)"
|
||||
)
|
||||
|
||||
def invoke(self, context: InvocationContext) -> ImageOutput:
|
||||
image = context.services.images.get_pil_image(self.image.image_name)
|
||||
@@ -86,9 +94,11 @@ class ESRGANInvocation(BaseInvocation):
|
||||
model_path=str(models_path / esrgan_model_path),
|
||||
model=rrdbnet_model,
|
||||
half=False,
|
||||
tile=self.tile_size,
|
||||
)
|
||||
|
||||
# prepare image - Real-ESRGAN uses cv2 internally, and cv2 uses BGR vs RGB for PIL
|
||||
# TODO: This strips the alpha... is that okay?
|
||||
cv_image = cv.cvtColor(np.array(image.convert("RGB")), cv.COLOR_RGB2BGR)
|
||||
|
||||
# We can pass an `outscale` value here, but it just resizes the image by that factor after
|
||||
@@ -99,6 +109,10 @@ class ESRGANInvocation(BaseInvocation):
|
||||
# back to PIL
|
||||
pil_image = Image.fromarray(cv.cvtColor(upscaled_image, cv.COLOR_BGR2RGB)).convert("RGBA")
|
||||
|
||||
torch.cuda.empty_cache()
|
||||
if choose_torch_device() == torch.device("mps"):
|
||||
mps.empty_cache()
|
||||
|
||||
image_dto = context.services.images.create(
|
||||
image=pil_image,
|
||||
image_origin=ResourceOrigin.INTERNAL,
|
||||
|
||||
@@ -241,8 +241,8 @@ class InvokeAIAppConfig(InvokeAISettings):
|
||||
version : bool = Field(default=False, description="Show InvokeAI version and exit", category="Other")
|
||||
|
||||
# CACHE
|
||||
ram : Union[float, Literal["auto"]] = Field(default=6.0, gt=0, description="Maximum memory amount used by model cache for rapid switching (floating point number or 'auto')", category="Model Cache", )
|
||||
vram : Union[float, Literal["auto"]] = Field(default=0.25, ge=0, description="Amount of VRAM reserved for model storage (floating point number or 'auto')", category="Model Cache", )
|
||||
ram : float = Field(default=7.5, gt=0, description="Maximum memory amount used by model cache for rapid switching (floating point number, GB)", category="Model Cache", )
|
||||
vram : float = Field(default=0.25, ge=0, description="Amount of VRAM reserved for model storage (floating point number, GB)", category="Model Cache", )
|
||||
lazy_offload : bool = Field(default=True, description="Keep models in VRAM until their space is needed", category="Model Cache", )
|
||||
|
||||
# DEVICE
|
||||
@@ -255,6 +255,7 @@ class InvokeAIAppConfig(InvokeAISettings):
|
||||
attention_slice_size: Literal["auto", "balanced", "max", 1, 2, 3, 4, 5, 6, 7, 8] = Field(default="auto", description='Slice size, valid when attention_type=="sliced"', category="Generation", )
|
||||
force_tiled_decode : bool = Field(default=False, description="Whether to enable tiled VAE decode (reduces memory consumption with some performance penalty)", category="Generation",)
|
||||
force_tiled_decode: bool = Field(default=False, description="Whether to enable tiled VAE decode (reduces memory consumption with some performance penalty)", category="Generation",)
|
||||
png_compress_level : int = Field(default=6, description="The compress_level setting of PIL.Image.save(), used for PNG encoding. All settings are lossless. 0 = fastest, largest filesize, 9 = slowest, smallest filesize", category="Generation", )
|
||||
|
||||
# QUEUE
|
||||
max_queue_size : int = Field(default=10000, gt=0, description="Maximum number of items in the session queue", category="Queue", )
|
||||
@@ -277,6 +278,7 @@ class InvokeAIAppConfig(InvokeAISettings):
|
||||
|
||||
class Config:
|
||||
validate_assignment = True
|
||||
env_prefix = "INVOKEAI"
|
||||
|
||||
def parse_args(self, argv: Optional[list[str]] = None, conf: Optional[DictConfig] = None, clobber=False):
|
||||
"""
|
||||
|
||||
@@ -4,7 +4,12 @@ from typing import Any, Optional
|
||||
|
||||
from invokeai.app.models.image import ProgressImage
|
||||
from invokeai.app.services.model_manager_service import BaseModelType, ModelInfo, ModelType, SubModelType
|
||||
from invokeai.app.services.session_queue.session_queue_common import EnqueueBatchResult, SessionQueueItem
|
||||
from invokeai.app.services.session_queue.session_queue_common import (
|
||||
BatchStatus,
|
||||
EnqueueBatchResult,
|
||||
SessionQueueItem,
|
||||
SessionQueueStatus,
|
||||
)
|
||||
from invokeai.app.util.misc import get_timestamp
|
||||
|
||||
|
||||
@@ -262,21 +267,31 @@ class EventServiceBase:
|
||||
),
|
||||
)
|
||||
|
||||
def emit_queue_item_status_changed(self, session_queue_item: SessionQueueItem) -> None:
|
||||
def emit_queue_item_status_changed(
|
||||
self,
|
||||
session_queue_item: SessionQueueItem,
|
||||
batch_status: BatchStatus,
|
||||
queue_status: SessionQueueStatus,
|
||||
) -> None:
|
||||
"""Emitted when a queue item's status changes"""
|
||||
self.__emit_queue_event(
|
||||
event_name="queue_item_status_changed",
|
||||
payload=dict(
|
||||
queue_id=session_queue_item.queue_id,
|
||||
queue_item_id=session_queue_item.item_id,
|
||||
status=session_queue_item.status,
|
||||
batch_id=session_queue_item.batch_id,
|
||||
session_id=session_queue_item.session_id,
|
||||
error=session_queue_item.error,
|
||||
created_at=str(session_queue_item.created_at) if session_queue_item.created_at else None,
|
||||
updated_at=str(session_queue_item.updated_at) if session_queue_item.updated_at else None,
|
||||
started_at=str(session_queue_item.started_at) if session_queue_item.started_at else None,
|
||||
completed_at=str(session_queue_item.completed_at) if session_queue_item.completed_at else None,
|
||||
queue_id=queue_status.queue_id,
|
||||
queue_item=dict(
|
||||
queue_id=session_queue_item.queue_id,
|
||||
item_id=session_queue_item.item_id,
|
||||
status=session_queue_item.status,
|
||||
batch_id=session_queue_item.batch_id,
|
||||
session_id=session_queue_item.session_id,
|
||||
error=session_queue_item.error,
|
||||
created_at=str(session_queue_item.created_at) if session_queue_item.created_at else None,
|
||||
updated_at=str(session_queue_item.updated_at) if session_queue_item.updated_at else None,
|
||||
started_at=str(session_queue_item.started_at) if session_queue_item.started_at else None,
|
||||
completed_at=str(session_queue_item.completed_at) if session_queue_item.completed_at else None,
|
||||
),
|
||||
batch_status=batch_status.dict(),
|
||||
queue_status=queue_status.dict(),
|
||||
),
|
||||
)
|
||||
|
||||
|
||||
@@ -2,7 +2,7 @@
|
||||
|
||||
import copy
|
||||
import itertools
|
||||
from typing import Annotated, Any, Optional, Union, cast, get_args, get_origin, get_type_hints
|
||||
from typing import Annotated, Any, Optional, Union, get_args, get_origin, get_type_hints
|
||||
|
||||
import networkx as nx
|
||||
from pydantic import BaseModel, root_validator, validator
|
||||
@@ -117,6 +117,10 @@ def are_connection_types_compatible(from_type: Any, to_type: Any) -> bool:
|
||||
if from_type is int and to_type is float:
|
||||
return True
|
||||
|
||||
# allow int|float -> str, pydantic will cast for us
|
||||
if (from_type is int or from_type is float) and to_type is str:
|
||||
return True
|
||||
|
||||
# if not issubclass(from_type, to_type):
|
||||
if not is_union_subtype(from_type, to_type):
|
||||
return False
|
||||
@@ -166,6 +170,18 @@ class NodeIdMismatchError(ValueError):
|
||||
pass
|
||||
|
||||
|
||||
class InvalidSubGraphError(ValueError):
|
||||
pass
|
||||
|
||||
|
||||
class CyclicalGraphError(ValueError):
|
||||
pass
|
||||
|
||||
|
||||
class UnknownGraphValidationError(ValueError):
|
||||
pass
|
||||
|
||||
|
||||
# TODO: Create and use an Empty output?
|
||||
@invocation_output("graph_output")
|
||||
class GraphInvocationOutput(BaseInvocationOutput):
|
||||
@@ -250,59 +266,6 @@ class Graph(BaseModel):
|
||||
default_factory=list,
|
||||
)
|
||||
|
||||
@root_validator
|
||||
def validate_nodes_and_edges(cls, values):
|
||||
"""Validates that all edges match nodes in the graph"""
|
||||
nodes = cast(Optional[dict[str, BaseInvocation]], values.get("nodes"))
|
||||
edges = cast(Optional[list[Edge]], values.get("edges"))
|
||||
|
||||
if nodes is not None:
|
||||
# Validate that all node ids are unique
|
||||
node_ids = [n.id for n in nodes.values()]
|
||||
duplicate_node_ids = set([node_id for node_id in node_ids if node_ids.count(node_id) >= 2])
|
||||
if duplicate_node_ids:
|
||||
raise DuplicateNodeIdError(f"Node ids must be unique, found duplicates {duplicate_node_ids}")
|
||||
|
||||
# Validate that all node ids match the keys in the nodes dict
|
||||
for k, v in nodes.items():
|
||||
if k != v.id:
|
||||
raise NodeIdMismatchError(f"Node ids must match, got {k} and {v.id}")
|
||||
|
||||
if edges is not None and nodes is not None:
|
||||
# Validate that all edges match nodes in the graph
|
||||
node_ids = set([e.source.node_id for e in edges] + [e.destination.node_id for e in edges])
|
||||
missing_node_ids = [node_id for node_id in node_ids if node_id not in nodes]
|
||||
if missing_node_ids:
|
||||
raise NodeNotFoundError(
|
||||
f"All edges must reference nodes in the graph, missing nodes: {missing_node_ids}"
|
||||
)
|
||||
|
||||
# Validate that all edge fields match node fields in the graph
|
||||
for edge in edges:
|
||||
source_node = nodes.get(edge.source.node_id, None)
|
||||
if source_node is None:
|
||||
raise NodeFieldNotFoundError(f"Edge source node {edge.source.node_id} does not exist in the graph")
|
||||
|
||||
destination_node = nodes.get(edge.destination.node_id, None)
|
||||
if destination_node is None:
|
||||
raise NodeFieldNotFoundError(
|
||||
f"Edge destination node {edge.destination.node_id} does not exist in the graph"
|
||||
)
|
||||
|
||||
# output fields are not on the node object directly, they are on the output type
|
||||
if edge.source.field not in source_node.get_output_type().__fields__:
|
||||
raise NodeFieldNotFoundError(
|
||||
f"Edge source field {edge.source.field} does not exist in node {edge.source.node_id}"
|
||||
)
|
||||
|
||||
# input fields are on the node
|
||||
if edge.destination.field not in destination_node.__fields__:
|
||||
raise NodeFieldNotFoundError(
|
||||
f"Edge destination field {edge.destination.field} does not exist in node {edge.destination.node_id}"
|
||||
)
|
||||
|
||||
return values
|
||||
|
||||
def add_node(self, node: BaseInvocation) -> None:
|
||||
"""Adds a node to a graph
|
||||
|
||||
@@ -373,53 +336,108 @@ class Graph(BaseModel):
|
||||
except KeyError:
|
||||
pass
|
||||
|
||||
def is_valid(self) -> bool:
|
||||
"""Validates the graph."""
|
||||
def validate_self(self) -> None:
|
||||
"""
|
||||
Validates the graph.
|
||||
|
||||
Raises an exception if the graph is invalid:
|
||||
- `DuplicateNodeIdError`
|
||||
- `NodeIdMismatchError`
|
||||
- `InvalidSubGraphError`
|
||||
- `NodeNotFoundError`
|
||||
- `NodeFieldNotFoundError`
|
||||
- `CyclicalGraphError`
|
||||
- `InvalidEdgeError`
|
||||
"""
|
||||
|
||||
# Validate that all node ids are unique
|
||||
node_ids = [n.id for n in self.nodes.values()]
|
||||
duplicate_node_ids = set([node_id for node_id in node_ids if node_ids.count(node_id) >= 2])
|
||||
if duplicate_node_ids:
|
||||
raise DuplicateNodeIdError(f"Node ids must be unique, found duplicates {duplicate_node_ids}")
|
||||
|
||||
# Validate that all node ids match the keys in the nodes dict
|
||||
for k, v in self.nodes.items():
|
||||
if k != v.id:
|
||||
raise NodeIdMismatchError(f"Node ids must match, got {k} and {v.id}")
|
||||
|
||||
# Validate all subgraphs
|
||||
for gn in (n for n in self.nodes.values() if isinstance(n, GraphInvocation)):
|
||||
if not gn.graph.is_valid():
|
||||
return False
|
||||
try:
|
||||
gn.graph.validate_self()
|
||||
except Exception as e:
|
||||
raise InvalidSubGraphError(f"Subgraph {gn.id} is invalid") from e
|
||||
|
||||
# Validate all edges reference nodes in the graph
|
||||
node_ids = set([e.source.node_id for e in self.edges] + [e.destination.node_id for e in self.edges])
|
||||
if not all((self.has_node(node_id) for node_id in node_ids)):
|
||||
return False
|
||||
# Validate that all edges match nodes and fields in the graph
|
||||
for edge in self.edges:
|
||||
source_node = self.nodes.get(edge.source.node_id, None)
|
||||
if source_node is None:
|
||||
raise NodeNotFoundError(f"Edge source node {edge.source.node_id} does not exist in the graph")
|
||||
|
||||
destination_node = self.nodes.get(edge.destination.node_id, None)
|
||||
if destination_node is None:
|
||||
raise NodeNotFoundError(f"Edge destination node {edge.destination.node_id} does not exist in the graph")
|
||||
|
||||
# output fields are not on the node object directly, they are on the output type
|
||||
if edge.source.field not in source_node.get_output_type().__fields__:
|
||||
raise NodeFieldNotFoundError(
|
||||
f"Edge source field {edge.source.field} does not exist in node {edge.source.node_id}"
|
||||
)
|
||||
|
||||
# input fields are on the node
|
||||
if edge.destination.field not in destination_node.__fields__:
|
||||
raise NodeFieldNotFoundError(
|
||||
f"Edge destination field {edge.destination.field} does not exist in node {edge.destination.node_id}"
|
||||
)
|
||||
|
||||
# Validate there are no cycles
|
||||
g = self.nx_graph_flat()
|
||||
if not nx.is_directed_acyclic_graph(g):
|
||||
return False
|
||||
raise CyclicalGraphError("Graph contains cycles")
|
||||
|
||||
# Validate all edge connections are valid
|
||||
if not all(
|
||||
(
|
||||
are_connections_compatible(
|
||||
self.get_node(e.source.node_id),
|
||||
e.source.field,
|
||||
self.get_node(e.destination.node_id),
|
||||
e.destination.field,
|
||||
for e in self.edges:
|
||||
if not are_connections_compatible(
|
||||
self.get_node(e.source.node_id),
|
||||
e.source.field,
|
||||
self.get_node(e.destination.node_id),
|
||||
e.destination.field,
|
||||
):
|
||||
raise InvalidEdgeError(
|
||||
f"Invalid edge from {e.source.node_id}.{e.source.field} to {e.destination.node_id}.{e.destination.field}"
|
||||
)
|
||||
for e in self.edges
|
||||
)
|
||||
|
||||
# Validate all iterators & collectors
|
||||
# TODO: may need to validate all iterators & collectors in subgraphs so edge connections in parent graphs will be available
|
||||
for n in self.nodes.values():
|
||||
if isinstance(n, IterateInvocation) and not self._is_iterator_connection_valid(n.id):
|
||||
raise InvalidEdgeError(f"Invalid iterator node {n.id}")
|
||||
if isinstance(n, CollectInvocation) and not self._is_collector_connection_valid(n.id):
|
||||
raise InvalidEdgeError(f"Invalid collector node {n.id}")
|
||||
|
||||
return None
|
||||
|
||||
def is_valid(self) -> bool:
|
||||
"""
|
||||
Checks if the graph is valid.
|
||||
|
||||
Raises `UnknownGraphValidationError` if there is a problem validating the graph (not a validation error).
|
||||
"""
|
||||
try:
|
||||
self.validate_self()
|
||||
return True
|
||||
except (
|
||||
DuplicateNodeIdError,
|
||||
NodeIdMismatchError,
|
||||
InvalidSubGraphError,
|
||||
NodeNotFoundError,
|
||||
NodeFieldNotFoundError,
|
||||
CyclicalGraphError,
|
||||
InvalidEdgeError,
|
||||
):
|
||||
return False
|
||||
|
||||
# Validate all iterators
|
||||
# TODO: may need to validate all iterators in subgraphs so edge connections in parent graphs will be available
|
||||
if not all(
|
||||
(self._is_iterator_connection_valid(n.id) for n in self.nodes.values() if isinstance(n, IterateInvocation))
|
||||
):
|
||||
return False
|
||||
|
||||
# Validate all collectors
|
||||
# TODO: may need to validate all collectors in subgraphs so edge connections in parent graphs will be available
|
||||
if not all(
|
||||
(self._is_collector_connection_valid(n.id) for n in self.nodes.values() if isinstance(n, CollectInvocation))
|
||||
):
|
||||
return False
|
||||
|
||||
return True
|
||||
except Exception as e:
|
||||
raise UnknownGraphValidationError(f"Problem validating graph {e}") from e
|
||||
|
||||
def _validate_edge(self, edge: Edge):
|
||||
"""Validates that a new edge doesn't create a cycle in the graph"""
|
||||
@@ -800,6 +818,12 @@ class GraphExecutionState(BaseModel):
|
||||
default_factory=dict,
|
||||
)
|
||||
|
||||
@validator("graph")
|
||||
def graph_is_valid(cls, v: Graph):
|
||||
"""Validates that the graph is valid"""
|
||||
v.validate_self()
|
||||
return v
|
||||
|
||||
class Config:
|
||||
schema_extra = {
|
||||
"required": [
|
||||
|
||||
@@ -9,6 +9,7 @@ from PIL import Image, PngImagePlugin
|
||||
from PIL.Image import Image as PILImageType
|
||||
from send2trash import send2trash
|
||||
|
||||
from invokeai.app.services.config.invokeai_config import InvokeAIAppConfig
|
||||
from invokeai.app.util.thumbnails import get_thumbnail_name, make_thumbnail
|
||||
|
||||
|
||||
@@ -79,6 +80,7 @@ class DiskImageFileStorage(ImageFileStorageBase):
|
||||
__cache_ids: Queue # TODO: this is an incredibly naive cache
|
||||
__cache: Dict[Path, PILImageType]
|
||||
__max_cache_size: int
|
||||
__compress_level: int
|
||||
|
||||
def __init__(self, output_folder: Union[str, Path]):
|
||||
self.__cache = dict()
|
||||
@@ -87,7 +89,7 @@ class DiskImageFileStorage(ImageFileStorageBase):
|
||||
|
||||
self.__output_folder: Path = output_folder if isinstance(output_folder, Path) else Path(output_folder)
|
||||
self.__thumbnails_folder = self.__output_folder / "thumbnails"
|
||||
|
||||
self.__compress_level = InvokeAIAppConfig.get_config().png_compress_level
|
||||
# Validate required output folders at launch
|
||||
self.__validate_storage_folders()
|
||||
|
||||
@@ -134,7 +136,7 @@ class DiskImageFileStorage(ImageFileStorageBase):
|
||||
if original_workflow is not None:
|
||||
pnginfo.add_text("invokeai_workflow", original_workflow)
|
||||
|
||||
image.save(image_path, "PNG", pnginfo=pnginfo)
|
||||
image.save(image_path, "PNG", pnginfo=pnginfo, compress_level=self.__compress_level)
|
||||
|
||||
thumbnail_name = get_thumbnail_name(image_name)
|
||||
thumbnail_path = self.get_path(thumbnail_name, thumbnail=True)
|
||||
|
||||
@@ -584,7 +584,7 @@ class SqliteImageRecordStorage(ImageRecordStorageBase):
|
||||
FROM images
|
||||
JOIN board_images ON images.image_name = board_images.image_name
|
||||
WHERE board_images.board_id = ?
|
||||
ORDER BY images.created_at DESC
|
||||
ORDER BY images.starred DESC, images.created_at DESC
|
||||
LIMIT 1;
|
||||
""",
|
||||
(board_id,),
|
||||
|
||||
@@ -2,6 +2,7 @@ from abc import ABC, abstractmethod
|
||||
from typing import Optional, Union
|
||||
|
||||
from invokeai.app.invocations.baseinvocation import BaseInvocation, BaseInvocationOutput
|
||||
from invokeai.app.services.invocation_cache.invocation_cache_common import InvocationCacheStatus
|
||||
|
||||
|
||||
class InvocationCacheBase(ABC):
|
||||
@@ -32,7 +33,7 @@ class InvocationCacheBase(ABC):
|
||||
|
||||
@abstractmethod
|
||||
def delete(self, key: Union[int, str]) -> None:
|
||||
"""Deleteds an invocation output from the cache"""
|
||||
"""Deletes an invocation output from the cache"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
@@ -44,3 +45,18 @@ class InvocationCacheBase(ABC):
|
||||
def create_key(self, invocation: BaseInvocation) -> int:
|
||||
"""Gets the key for the invocation's cache item"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def disable(self) -> None:
|
||||
"""Disables the cache, overriding the max cache size"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def enable(self) -> None:
|
||||
"""Enables the cache, letting the the max cache size take effect"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def get_status(self) -> InvocationCacheStatus:
|
||||
"""Returns the status of the cache"""
|
||||
pass
|
||||
|
||||
@@ -0,0 +1,9 @@
|
||||
from pydantic import BaseModel, Field
|
||||
|
||||
|
||||
class InvocationCacheStatus(BaseModel):
|
||||
size: int = Field(description="The current size of the invocation cache")
|
||||
hits: int = Field(description="The number of cache hits")
|
||||
misses: int = Field(description="The number of cache misses")
|
||||
enabled: bool = Field(description="Whether the invocation cache is enabled")
|
||||
max_size: int = Field(description="The maximum size of the invocation cache")
|
||||
@@ -1,81 +1,126 @@
|
||||
from queue import Queue
|
||||
from collections import OrderedDict
|
||||
from dataclasses import dataclass, field
|
||||
from threading import Lock
|
||||
from typing import Optional, Union
|
||||
|
||||
from invokeai.app.invocations.baseinvocation import BaseInvocation, BaseInvocationOutput
|
||||
from invokeai.app.services.invocation_cache.invocation_cache_base import InvocationCacheBase
|
||||
from invokeai.app.services.invocation_cache.invocation_cache_common import InvocationCacheStatus
|
||||
from invokeai.app.services.invoker import Invoker
|
||||
|
||||
|
||||
@dataclass(order=True)
|
||||
class CachedItem:
|
||||
invocation_output: BaseInvocationOutput = field(compare=False)
|
||||
invocation_output_json: str = field(compare=False)
|
||||
|
||||
|
||||
class MemoryInvocationCache(InvocationCacheBase):
|
||||
__cache: dict[Union[int, str], tuple[BaseInvocationOutput, str]]
|
||||
__max_cache_size: int
|
||||
__cache_ids: Queue
|
||||
__invoker: Invoker
|
||||
_cache: OrderedDict[Union[int, str], CachedItem]
|
||||
_max_cache_size: int
|
||||
_disabled: bool
|
||||
_hits: int
|
||||
_misses: int
|
||||
_invoker: Invoker
|
||||
_lock: Lock
|
||||
|
||||
def __init__(self, max_cache_size: int = 0) -> None:
|
||||
self.__cache = dict()
|
||||
self.__max_cache_size = max_cache_size
|
||||
self.__cache_ids = Queue()
|
||||
self._cache = OrderedDict()
|
||||
self._max_cache_size = max_cache_size
|
||||
self._disabled = False
|
||||
self._hits = 0
|
||||
self._misses = 0
|
||||
self._lock = Lock()
|
||||
|
||||
def start(self, invoker: Invoker) -> None:
|
||||
self.__invoker = invoker
|
||||
if self.__max_cache_size == 0:
|
||||
self._invoker = invoker
|
||||
if self._max_cache_size == 0:
|
||||
return
|
||||
self.__invoker.services.images.on_deleted(self._delete_by_match)
|
||||
self.__invoker.services.latents.on_deleted(self._delete_by_match)
|
||||
self._invoker.services.images.on_deleted(self._delete_by_match)
|
||||
self._invoker.services.latents.on_deleted(self._delete_by_match)
|
||||
|
||||
def get(self, key: Union[int, str]) -> Optional[BaseInvocationOutput]:
|
||||
if self.__max_cache_size == 0:
|
||||
return
|
||||
|
||||
item = self.__cache.get(key, None)
|
||||
if item is not None:
|
||||
return item[0]
|
||||
with self._lock:
|
||||
if self._max_cache_size == 0 or self._disabled:
|
||||
return None
|
||||
item = self._cache.get(key, None)
|
||||
if item is not None:
|
||||
self._hits += 1
|
||||
self._cache.move_to_end(key)
|
||||
return item.invocation_output
|
||||
self._misses += 1
|
||||
return None
|
||||
|
||||
def save(self, key: Union[int, str], invocation_output: BaseInvocationOutput) -> None:
|
||||
if self.__max_cache_size == 0:
|
||||
return
|
||||
with self._lock:
|
||||
if self._max_cache_size == 0 or self._disabled or key in self._cache:
|
||||
return
|
||||
# If the cache is full, we need to remove the least used
|
||||
number_to_delete = len(self._cache) + 1 - self._max_cache_size
|
||||
self._delete_oldest_access(number_to_delete)
|
||||
self._cache[key] = CachedItem(invocation_output, invocation_output.json())
|
||||
|
||||
if key not in self.__cache:
|
||||
self.__cache[key] = (invocation_output, invocation_output.json())
|
||||
self.__cache_ids.put(key)
|
||||
if self.__cache_ids.qsize() > self.__max_cache_size:
|
||||
try:
|
||||
self.__cache.pop(self.__cache_ids.get())
|
||||
except KeyError:
|
||||
# this means the cache_ids are somehow out of sync w/ the cache
|
||||
pass
|
||||
def _delete_oldest_access(self, number_to_delete: int) -> None:
|
||||
number_to_delete = min(number_to_delete, len(self._cache))
|
||||
for _ in range(number_to_delete):
|
||||
self._cache.popitem(last=False)
|
||||
|
||||
def _delete(self, key: Union[int, str]) -> None:
|
||||
if self._max_cache_size == 0:
|
||||
return
|
||||
if key in self._cache:
|
||||
del self._cache[key]
|
||||
|
||||
def delete(self, key: Union[int, str]) -> None:
|
||||
if self.__max_cache_size == 0:
|
||||
return
|
||||
|
||||
if key in self.__cache:
|
||||
del self.__cache[key]
|
||||
with self._lock:
|
||||
return self._delete(key)
|
||||
|
||||
def clear(self, *args, **kwargs) -> None:
|
||||
if self.__max_cache_size == 0:
|
||||
return
|
||||
with self._lock:
|
||||
if self._max_cache_size == 0:
|
||||
return
|
||||
self._cache.clear()
|
||||
self._misses = 0
|
||||
self._hits = 0
|
||||
|
||||
self.__cache.clear()
|
||||
self.__cache_ids = Queue()
|
||||
|
||||
def create_key(self, invocation: BaseInvocation) -> int:
|
||||
@staticmethod
|
||||
def create_key(invocation: BaseInvocation) -> int:
|
||||
return hash(invocation.json(exclude={"id"}))
|
||||
|
||||
def disable(self) -> None:
|
||||
with self._lock:
|
||||
if self._max_cache_size == 0:
|
||||
return
|
||||
self._disabled = True
|
||||
|
||||
def enable(self) -> None:
|
||||
with self._lock:
|
||||
if self._max_cache_size == 0:
|
||||
return
|
||||
self._disabled = False
|
||||
|
||||
def get_status(self) -> InvocationCacheStatus:
|
||||
with self._lock:
|
||||
return InvocationCacheStatus(
|
||||
hits=self._hits,
|
||||
misses=self._misses,
|
||||
enabled=not self._disabled and self._max_cache_size > 0,
|
||||
size=len(self._cache),
|
||||
max_size=self._max_cache_size,
|
||||
)
|
||||
|
||||
def _delete_by_match(self, to_match: str) -> None:
|
||||
if self.__max_cache_size == 0:
|
||||
return
|
||||
|
||||
keys_to_delete = set()
|
||||
for key, value_tuple in self.__cache.items():
|
||||
if to_match in value_tuple[1]:
|
||||
keys_to_delete.add(key)
|
||||
|
||||
if not keys_to_delete:
|
||||
return
|
||||
|
||||
for key in keys_to_delete:
|
||||
self.delete(key)
|
||||
|
||||
self.__invoker.services.logger.debug(f"Deleted {len(keys_to_delete)} cached invocation outputs for {to_match}")
|
||||
with self._lock:
|
||||
if self._max_cache_size == 0:
|
||||
return
|
||||
keys_to_delete = set()
|
||||
for key, cached_item in self._cache.items():
|
||||
if to_match in cached_item.invocation_output_json:
|
||||
keys_to_delete.add(key)
|
||||
if not keys_to_delete:
|
||||
return
|
||||
for key in keys_to_delete:
|
||||
self._delete(key)
|
||||
self._invoker.services.logger.debug(
|
||||
f"Deleted {len(keys_to_delete)} cached invocation outputs for {to_match}"
|
||||
)
|
||||
|
||||
@@ -1,3 +1,4 @@
|
||||
import traceback
|
||||
from threading import BoundedSemaphore
|
||||
from threading import Event as ThreadEvent
|
||||
from threading import Thread
|
||||
@@ -47,20 +48,27 @@ class DefaultSessionProcessor(SessionProcessorBase):
|
||||
async def _on_queue_event(self, event: FastAPIEvent) -> None:
|
||||
event_name = event[1]["event"]
|
||||
|
||||
match event_name:
|
||||
case "graph_execution_state_complete" | "invocation_error" | "session_retrieval_error" | "invocation_retrieval_error":
|
||||
self.__queue_item = None
|
||||
self._poll_now()
|
||||
case "session_canceled" if self.__queue_item is not None and self.__queue_item.session_id == event[1][
|
||||
"data"
|
||||
]["graph_execution_state_id"]:
|
||||
self.__queue_item = None
|
||||
self._poll_now()
|
||||
case "batch_enqueued":
|
||||
self._poll_now()
|
||||
case "queue_cleared":
|
||||
self.__queue_item = None
|
||||
self._poll_now()
|
||||
# This was a match statement, but match is not supported on python 3.9
|
||||
if event_name in [
|
||||
"graph_execution_state_complete",
|
||||
"invocation_error",
|
||||
"session_retrieval_error",
|
||||
"invocation_retrieval_error",
|
||||
]:
|
||||
self.__queue_item = None
|
||||
self._poll_now()
|
||||
elif (
|
||||
event_name == "session_canceled"
|
||||
and self.__queue_item is not None
|
||||
and self.__queue_item.session_id == event[1]["data"]["graph_execution_state_id"]
|
||||
):
|
||||
self.__queue_item = None
|
||||
self._poll_now()
|
||||
elif event_name == "batch_enqueued":
|
||||
self._poll_now()
|
||||
elif event_name == "queue_cleared":
|
||||
self.__queue_item = None
|
||||
self._poll_now()
|
||||
|
||||
def resume(self) -> SessionProcessorStatus:
|
||||
if not self.__resume_event.is_set():
|
||||
@@ -92,30 +100,38 @@ class DefaultSessionProcessor(SessionProcessorBase):
|
||||
self.__invoker.services.logger
|
||||
while not stop_event.is_set():
|
||||
poll_now_event.clear()
|
||||
try:
|
||||
# do not dequeue if there is already a session running
|
||||
if self.__queue_item is None and resume_event.is_set():
|
||||
queue_item = self.__invoker.services.session_queue.dequeue()
|
||||
|
||||
# do not dequeue if there is already a session running
|
||||
if self.__queue_item is None and resume_event.is_set():
|
||||
queue_item = self.__invoker.services.session_queue.dequeue()
|
||||
if queue_item is not None:
|
||||
self.__invoker.services.logger.debug(f"Executing queue item {queue_item.item_id}")
|
||||
self.__queue_item = queue_item
|
||||
self.__invoker.services.graph_execution_manager.set(queue_item.session)
|
||||
self.__invoker.invoke(
|
||||
session_queue_batch_id=queue_item.batch_id,
|
||||
session_queue_id=queue_item.queue_id,
|
||||
session_queue_item_id=queue_item.item_id,
|
||||
graph_execution_state=queue_item.session,
|
||||
invoke_all=True,
|
||||
)
|
||||
queue_item = None
|
||||
|
||||
if queue_item is None:
|
||||
self.__invoker.services.logger.debug("Waiting for next polling interval or event")
|
||||
poll_now_event.wait(POLLING_INTERVAL)
|
||||
continue
|
||||
except Exception as e:
|
||||
self.__invoker.services.logger.error(f"Error in session processor: {e}")
|
||||
if queue_item is not None:
|
||||
self.__invoker.services.logger.debug(f"Executing queue item {queue_item.item_id}")
|
||||
self.__queue_item = queue_item
|
||||
self.__invoker.services.graph_execution_manager.set(queue_item.session)
|
||||
self.__invoker.invoke(
|
||||
session_queue_batch_id=queue_item.batch_id,
|
||||
session_queue_id=queue_item.queue_id,
|
||||
session_queue_item_id=queue_item.item_id,
|
||||
graph_execution_state=queue_item.session,
|
||||
invoke_all=True,
|
||||
self.__invoker.services.session_queue.cancel_queue_item(
|
||||
queue_item.item_id, error=traceback.format_exc()
|
||||
)
|
||||
queue_item = None
|
||||
|
||||
if queue_item is None:
|
||||
self.__invoker.services.logger.debug("Waiting for next polling interval or event")
|
||||
poll_now_event.wait(POLLING_INTERVAL)
|
||||
continue
|
||||
except Exception as e:
|
||||
self.__invoker.services.logger.error(f"Error in session processor: {e}")
|
||||
self.__invoker.services.logger.error(f"Fatal Error in session processor: {e}")
|
||||
pass
|
||||
finally:
|
||||
stop_event.clear()
|
||||
|
||||
@@ -80,7 +80,7 @@ class SessionQueueBase(ABC):
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def cancel_queue_item(self, item_id: int) -> SessionQueueItem:
|
||||
def cancel_queue_item(self, item_id: int, error: Optional[str] = None) -> SessionQueueItem:
|
||||
"""Cancels a session queue item"""
|
||||
pass
|
||||
|
||||
|
||||
@@ -123,6 +123,11 @@ class Batch(BaseModel):
|
||||
raise NodeNotFoundError(f"Field {batch_data.field_name} not found in node {batch_data.node_path}")
|
||||
return values
|
||||
|
||||
@validator("graph")
|
||||
def validate_graph(cls, v: Graph):
|
||||
v.validate_self()
|
||||
return v
|
||||
|
||||
class Config:
|
||||
schema_extra = {
|
||||
"required": [
|
||||
@@ -162,15 +167,15 @@ class SessionQueueItemWithoutGraph(BaseModel):
|
||||
session_id: str = Field(
|
||||
description="The ID of the session associated with this queue item. The session doesn't exist in graph_executions until the queue item is executed."
|
||||
)
|
||||
field_values: Optional[list[NodeFieldValue]] = Field(
|
||||
default=None, description="The field values that were used for this queue item"
|
||||
)
|
||||
queue_id: str = Field(description="The id of the queue with which this item is associated")
|
||||
error: Optional[str] = Field(default=None, description="The error message if this queue item errored")
|
||||
created_at: Union[datetime.datetime, str] = Field(description="When this queue item was created")
|
||||
updated_at: Union[datetime.datetime, str] = Field(description="When this queue item was updated")
|
||||
started_at: Optional[Union[datetime.datetime, str]] = Field(description="When this queue item was started")
|
||||
completed_at: Optional[Union[datetime.datetime, str]] = Field(description="When this queue item was completed")
|
||||
queue_id: str = Field(description="The id of the queue with which this item is associated")
|
||||
field_values: Optional[list[NodeFieldValue]] = Field(
|
||||
default=None, description="The field values that were used for this queue item"
|
||||
)
|
||||
|
||||
@classmethod
|
||||
def from_dict(cls, queue_item_dict: dict) -> "SessionQueueItemDTO":
|
||||
|
||||
@@ -59,13 +59,14 @@ class SqliteSessionQueue(SessionQueueBase):
|
||||
|
||||
async def _on_session_event(self, event: FastAPIEvent) -> FastAPIEvent:
|
||||
event_name = event[1]["event"]
|
||||
match event_name:
|
||||
case "graph_execution_state_complete":
|
||||
await self._handle_complete_event(event)
|
||||
case "invocation_error" | "session_retrieval_error" | "invocation_retrieval_error":
|
||||
await self._handle_error_event(event)
|
||||
case "session_canceled":
|
||||
await self._handle_cancel_event(event)
|
||||
|
||||
# This was a match statement, but match is not supported on python 3.9
|
||||
if event_name == "graph_execution_state_complete":
|
||||
await self._handle_complete_event(event)
|
||||
elif event_name in ["invocation_error", "session_retrieval_error", "invocation_retrieval_error"]:
|
||||
await self._handle_error_event(event)
|
||||
elif event_name == "session_canceled":
|
||||
await self._handle_cancel_event(event)
|
||||
return event
|
||||
|
||||
async def _handle_complete_event(self, event: FastAPIEvent) -> None:
|
||||
@@ -426,7 +427,13 @@ class SqliteSessionQueue(SessionQueueBase):
|
||||
finally:
|
||||
self.__lock.release()
|
||||
queue_item = self.get_queue_item(item_id)
|
||||
self.__invoker.services.events.emit_queue_item_status_changed(queue_item)
|
||||
batch_status = self.get_batch_status(queue_id=queue_item.queue_id, batch_id=queue_item.batch_id)
|
||||
queue_status = self.get_queue_status(queue_id=queue_item.queue_id)
|
||||
self.__invoker.services.events.emit_queue_item_status_changed(
|
||||
session_queue_item=queue_item,
|
||||
batch_status=batch_status,
|
||||
queue_status=queue_status,
|
||||
)
|
||||
return queue_item
|
||||
|
||||
def is_empty(self, queue_id: str) -> IsEmptyResult:
|
||||
@@ -554,10 +561,11 @@ class SqliteSessionQueue(SessionQueueBase):
|
||||
self.__lock.release()
|
||||
return PruneResult(deleted=count)
|
||||
|
||||
def cancel_queue_item(self, item_id: int) -> SessionQueueItem:
|
||||
def cancel_queue_item(self, item_id: int, error: Optional[str] = None) -> SessionQueueItem:
|
||||
queue_item = self.get_queue_item(item_id)
|
||||
if queue_item.status not in ["canceled", "failed", "completed"]:
|
||||
queue_item = self._set_queue_item_status(item_id=item_id, status="canceled")
|
||||
status = "failed" if error is not None else "canceled"
|
||||
queue_item = self._set_queue_item_status(item_id=item_id, status=status, error=error)
|
||||
self.__invoker.services.queue.cancel(queue_item.session_id)
|
||||
self.__invoker.services.events.emit_session_canceled(
|
||||
queue_item_id=queue_item.item_id,
|
||||
@@ -607,7 +615,13 @@ class SqliteSessionQueue(SessionQueueBase):
|
||||
queue_batch_id=current_queue_item.batch_id,
|
||||
graph_execution_state_id=current_queue_item.session_id,
|
||||
)
|
||||
self.__invoker.services.events.emit_queue_item_status_changed(current_queue_item)
|
||||
batch_status = self.get_batch_status(queue_id=queue_id, batch_id=current_queue_item.batch_id)
|
||||
queue_status = self.get_queue_status(queue_id=queue_id)
|
||||
self.__invoker.services.events.emit_queue_item_status_changed(
|
||||
session_queue_item=current_queue_item,
|
||||
batch_status=batch_status,
|
||||
queue_status=queue_status,
|
||||
)
|
||||
except Exception:
|
||||
self.__conn.rollback()
|
||||
raise
|
||||
@@ -653,7 +667,13 @@ class SqliteSessionQueue(SessionQueueBase):
|
||||
queue_batch_id=current_queue_item.batch_id,
|
||||
graph_execution_state_id=current_queue_item.session_id,
|
||||
)
|
||||
self.__invoker.services.events.emit_queue_item_status_changed(current_queue_item)
|
||||
batch_status = self.get_batch_status(queue_id=queue_id, batch_id=current_queue_item.batch_id)
|
||||
queue_status = self.get_queue_status(queue_id=queue_id)
|
||||
self.__invoker.services.events.emit_queue_item_status_changed(
|
||||
session_queue_item=current_queue_item,
|
||||
batch_status=batch_status,
|
||||
queue_status=queue_status,
|
||||
)
|
||||
except Exception:
|
||||
self.__conn.rollback()
|
||||
raise
|
||||
|
||||
@@ -265,22 +265,41 @@ def np_img_resize(np_img: np.ndarray, resize_mode: str, h: int, w: int, device:
|
||||
|
||||
|
||||
def prepare_control_image(
|
||||
# image used to be Union[PIL.Image.Image, List[PIL.Image.Image], torch.Tensor, List[torch.Tensor]]
|
||||
# but now should be able to assume that image is a single PIL.Image, which simplifies things
|
||||
image: Image,
|
||||
# FIXME: need to fix hardwiring of width and height, change to basing on latents dimensions?
|
||||
# latents_to_match_resolution, # TorchTensor of shape (batch_size, 3, height, width)
|
||||
width=512, # should be 8 * latent.shape[3]
|
||||
height=512, # should be 8 * latent height[2]
|
||||
# batch_size=1, # currently no batching
|
||||
# num_images_per_prompt=1, # currently only single image
|
||||
width: int,
|
||||
height: int,
|
||||
num_channels: int = 3,
|
||||
device="cuda",
|
||||
dtype=torch.float16,
|
||||
do_classifier_free_guidance=True,
|
||||
control_mode="balanced",
|
||||
resize_mode="just_resize_simple",
|
||||
):
|
||||
# FIXME: implement "crop_resize_simple" and "fill_resize_simple", or pull them out
|
||||
"""Pre-process images for ControlNets or T2I-Adapters.
|
||||
|
||||
Args:
|
||||
image (Image): The PIL image to pre-process.
|
||||
width (int): The target width in pixels.
|
||||
height (int): The target height in pixels.
|
||||
num_channels (int, optional): The target number of image channels. This is achieved by converting the input
|
||||
image to RGB, then naively taking the first `num_channels` channels. The primary use case is converting a
|
||||
RGB image to a single-channel grayscale image. Raises if `num_channels` cannot be achieved. Defaults to 3.
|
||||
device (str, optional): The target device for the output image. Defaults to "cuda".
|
||||
dtype (_type_, optional): The dtype for the output image. Defaults to torch.float16.
|
||||
do_classifier_free_guidance (bool, optional): If True, repeat the output image along the batch dimension.
|
||||
Defaults to True.
|
||||
control_mode (str, optional): Defaults to "balanced".
|
||||
resize_mode (str, optional): Defaults to "just_resize_simple".
|
||||
|
||||
Raises:
|
||||
NotImplementedError: If resize_mode == "crop_resize_simple".
|
||||
NotImplementedError: If resize_mode == "fill_resize_simple".
|
||||
ValueError: If `resize_mode` is not recognized.
|
||||
ValueError: If `num_channels` is out of range.
|
||||
|
||||
Returns:
|
||||
torch.Tensor: The pre-processed input tensor.
|
||||
"""
|
||||
if (
|
||||
resize_mode == "just_resize_simple"
|
||||
or resize_mode == "crop_resize_simple"
|
||||
@@ -289,10 +308,10 @@ def prepare_control_image(
|
||||
image = image.convert("RGB")
|
||||
if resize_mode == "just_resize_simple":
|
||||
image = image.resize((width, height), resample=PIL_INTERPOLATION["lanczos"])
|
||||
elif resize_mode == "crop_resize_simple": # not yet implemented
|
||||
pass
|
||||
elif resize_mode == "fill_resize_simple": # not yet implemented
|
||||
pass
|
||||
elif resize_mode == "crop_resize_simple":
|
||||
raise NotImplementedError(f"prepare_control_image is not implemented for resize_mode='{resize_mode}'.")
|
||||
elif resize_mode == "fill_resize_simple":
|
||||
raise NotImplementedError(f"prepare_control_image is not implemented for resize_mode='{resize_mode}'.")
|
||||
nimage = np.array(image)
|
||||
nimage = nimage[None, :]
|
||||
nimage = np.concatenate([nimage], axis=0)
|
||||
@@ -313,9 +332,11 @@ def prepare_control_image(
|
||||
device=device,
|
||||
)
|
||||
else:
|
||||
pass
|
||||
print("ERROR: invalid resize_mode ==> ", resize_mode)
|
||||
exit(1)
|
||||
raise ValueError(f"Unsupported resize_mode: '{resize_mode}'.")
|
||||
|
||||
if timage.shape[1] < num_channels or num_channels <= 0:
|
||||
raise ValueError(f"Cannot achieve the target of num_channels={num_channels}.")
|
||||
timage = timage[:, :num_channels, :, :]
|
||||
|
||||
timage = timage.to(device=device, dtype=dtype)
|
||||
cfg_injection = control_mode == "more_control" or control_mode == "unbalanced"
|
||||
|
||||
BIN
invokeai/assets/fonts/inter/Inter-Regular.ttf
Executable file
BIN
invokeai/assets/fonts/inter/Inter-Regular.ttf
Executable file
Binary file not shown.
94
invokeai/assets/fonts/inter/LICENSE.txt
Executable file
94
invokeai/assets/fonts/inter/LICENSE.txt
Executable file
@@ -0,0 +1,94 @@
|
||||
Copyright (c) 2016-2020 The Inter Project Authors.
|
||||
"Inter" is trademark of Rasmus Andersson.
|
||||
https://github.com/rsms/inter
|
||||
|
||||
This Font Software is licensed under the SIL Open Font License, Version 1.1.
|
||||
This license is copied below, and is also available with a FAQ at:
|
||||
http://scripts.sil.org/OFL
|
||||
|
||||
-----------------------------------------------------------
|
||||
SIL OPEN FONT LICENSE Version 1.1 - 26 February 2007
|
||||
-----------------------------------------------------------
|
||||
|
||||
PREAMBLE
|
||||
The goals of the Open Font License (OFL) are to stimulate worldwide
|
||||
development of collaborative font projects, to support the font creation
|
||||
efforts of academic and linguistic communities, and to provide a free and
|
||||
open framework in which fonts may be shared and improved in partnership
|
||||
with others.
|
||||
|
||||
The OFL allows the licensed fonts to be used, studied, modified and
|
||||
redistributed freely as long as they are not sold by themselves. The
|
||||
fonts, including any derivative works, can be bundled, embedded,
|
||||
redistributed and/or sold with any software provided that any reserved
|
||||
names are not used by derivative works. The fonts and derivatives,
|
||||
however, cannot be released under any other type of license. The
|
||||
requirement for fonts to remain under this license does not apply
|
||||
to any document created using the fonts or their derivatives.
|
||||
|
||||
DEFINITIONS
|
||||
"Font Software" refers to the set of files released by the Copyright
|
||||
Holder(s) under this license and clearly marked as such. This may
|
||||
include source files, build scripts and documentation.
|
||||
|
||||
"Reserved Font Name" refers to any names specified as such after the
|
||||
copyright statement(s).
|
||||
|
||||
"Original Version" refers to the collection of Font Software components as
|
||||
distributed by the Copyright Holder(s).
|
||||
|
||||
"Modified Version" refers to any derivative made by adding to, deleting,
|
||||
or substituting -- in part or in whole -- any of the components of the
|
||||
Original Version, by changing formats or by porting the Font Software to a
|
||||
new environment.
|
||||
|
||||
"Author" refers to any designer, engineer, programmer, technical
|
||||
writer or other person who contributed to the Font Software.
|
||||
|
||||
PERMISSION AND CONDITIONS
|
||||
Permission is hereby granted, free of charge, to any person obtaining
|
||||
a copy of the Font Software, to use, study, copy, merge, embed, modify,
|
||||
redistribute, and sell modified and unmodified copies of the Font
|
||||
Software, subject to the following conditions:
|
||||
|
||||
1) Neither the Font Software nor any of its individual components,
|
||||
in Original or Modified Versions, may be sold by itself.
|
||||
|
||||
2) Original or Modified Versions of the Font Software may be bundled,
|
||||
redistributed and/or sold with any software, provided that each copy
|
||||
contains the above copyright notice and this license. These can be
|
||||
included either as stand-alone text files, human-readable headers or
|
||||
in the appropriate machine-readable metadata fields within text or
|
||||
binary files as long as those fields can be easily viewed by the user.
|
||||
|
||||
3) No Modified Version of the Font Software may use the Reserved Font
|
||||
Name(s) unless explicit written permission is granted by the corresponding
|
||||
Copyright Holder. This restriction only applies to the primary font name as
|
||||
presented to the users.
|
||||
|
||||
4) The name(s) of the Copyright Holder(s) or the Author(s) of the Font
|
||||
Software shall not be used to promote, endorse or advertise any
|
||||
Modified Version, except to acknowledge the contribution(s) of the
|
||||
Copyright Holder(s) and the Author(s) or with their explicit written
|
||||
permission.
|
||||
|
||||
5) The Font Software, modified or unmodified, in part or in whole,
|
||||
must be distributed entirely under this license, and must not be
|
||||
distributed under any other license. The requirement for fonts to
|
||||
remain under this license does not apply to any document created
|
||||
using the Font Software.
|
||||
|
||||
TERMINATION
|
||||
This license becomes null and void if any of the above conditions are
|
||||
not met.
|
||||
|
||||
DISCLAIMER
|
||||
THE FONT SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND,
|
||||
EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO ANY WARRANTIES OF
|
||||
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT
|
||||
OF COPYRIGHT, PATENT, TRADEMARK, OR OTHER RIGHT. IN NO EVENT SHALL THE
|
||||
COPYRIGHT HOLDER BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY,
|
||||
INCLUDING ANY GENERAL, SPECIAL, INDIRECT, INCIDENTAL, OR CONSEQUENTIAL
|
||||
DAMAGES, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
|
||||
FROM, OUT OF THE USE OR INABILITY TO USE THE FONT SOFTWARE OR FROM
|
||||
OTHER DEALINGS IN THE FONT SOFTWARE.
|
||||
@@ -70,7 +70,6 @@ def get_literal_fields(field) -> list[Any]:
|
||||
config = InvokeAIAppConfig.get_config()
|
||||
|
||||
Model_dir = "models"
|
||||
|
||||
Default_config_file = config.model_conf_path
|
||||
SD_Configs = config.legacy_conf_path
|
||||
|
||||
@@ -93,7 +92,7 @@ INIT_FILE_PREAMBLE = """# InvokeAI initialization file
|
||||
# or renaming it and then running invokeai-configure again.
|
||||
"""
|
||||
|
||||
logger = InvokeAILogger.getLogger()
|
||||
logger = InvokeAILogger.get_logger()
|
||||
|
||||
|
||||
class DummyWidgetValue(Enum):
|
||||
@@ -458,7 +457,7 @@ Use cursor arrows to make a checkbox selection, and space to toggle.
|
||||
)
|
||||
self.add_widget_intelligent(
|
||||
npyscreen.TitleFixedText,
|
||||
name="Model RAM cache size (GB). Make this at least large enough to hold a single full model.",
|
||||
name="Model RAM cache size (GB). Make this at least large enough to hold a single full model (2GB for SD-1, 6GB for SDXL).",
|
||||
begin_entry_at=0,
|
||||
editable=False,
|
||||
color="CONTROL",
|
||||
@@ -651,8 +650,19 @@ def edit_opts(program_opts: Namespace, invokeai_opts: Namespace) -> argparse.Nam
|
||||
return editApp.new_opts()
|
||||
|
||||
|
||||
def default_ramcache() -> float:
|
||||
"""Run a heuristic for the default RAM cache based on installed RAM."""
|
||||
|
||||
# Note that on my 64 GB machine, psutil.virtual_memory().total gives 62 GB,
|
||||
# So we adjust everthing down a bit.
|
||||
return (
|
||||
15.0 if MAX_RAM >= 60 else 7.5 if MAX_RAM >= 30 else 4 if MAX_RAM >= 14 else 2.1
|
||||
) # 2.1 is just large enough for sd 1.5 ;-)
|
||||
|
||||
|
||||
def default_startup_options(init_file: Path) -> Namespace:
|
||||
opts = InvokeAIAppConfig.get_config()
|
||||
opts.ram = opts.ram or default_ramcache()
|
||||
return opts
|
||||
|
||||
|
||||
@@ -894,7 +904,7 @@ def main():
|
||||
if opt.full_precision:
|
||||
invoke_args.extend(["--precision", "float32"])
|
||||
config.parse_args(invoke_args)
|
||||
logger = InvokeAILogger().getLogger(config=config)
|
||||
logger = InvokeAILogger().get_logger(config=config)
|
||||
|
||||
errors = set()
|
||||
|
||||
|
||||
@@ -2,6 +2,7 @@
|
||||
Utility (backend) functions used by model_install.py
|
||||
"""
|
||||
import os
|
||||
import re
|
||||
import shutil
|
||||
import warnings
|
||||
from dataclasses import dataclass, field
|
||||
@@ -30,7 +31,7 @@ warnings.filterwarnings("ignore")
|
||||
|
||||
# --------------------------globals-----------------------
|
||||
config = InvokeAIAppConfig.get_config()
|
||||
logger = InvokeAILogger.getLogger(name="InvokeAI")
|
||||
logger = InvokeAILogger.get_logger(name="InvokeAI")
|
||||
|
||||
# the initial "configs" dir is now bundled in the `invokeai.configs` package
|
||||
Dataset_path = Path(configs.__path__[0]) / "INITIAL_MODELS.yaml"
|
||||
@@ -47,8 +48,14 @@ Config_preamble = """
|
||||
|
||||
LEGACY_CONFIGS = {
|
||||
BaseModelType.StableDiffusion1: {
|
||||
ModelVariantType.Normal: "v1-inference.yaml",
|
||||
ModelVariantType.Inpaint: "v1-inpainting-inference.yaml",
|
||||
ModelVariantType.Normal: {
|
||||
SchedulerPredictionType.Epsilon: "v1-inference.yaml",
|
||||
SchedulerPredictionType.VPrediction: "v1-inference-v.yaml",
|
||||
},
|
||||
ModelVariantType.Inpaint: {
|
||||
SchedulerPredictionType.Epsilon: "v1-inpainting-inference.yaml",
|
||||
SchedulerPredictionType.VPrediction: "v1-inpainting-inference-v.yaml",
|
||||
},
|
||||
},
|
||||
BaseModelType.StableDiffusion2: {
|
||||
ModelVariantType.Normal: {
|
||||
@@ -69,14 +76,6 @@ LEGACY_CONFIGS = {
|
||||
}
|
||||
|
||||
|
||||
@dataclass
|
||||
class ModelInstallList:
|
||||
"""Class for listing models to be installed/removed"""
|
||||
|
||||
install_models: List[str] = field(default_factory=list)
|
||||
remove_models: List[str] = field(default_factory=list)
|
||||
|
||||
|
||||
@dataclass
|
||||
class InstallSelections:
|
||||
install_models: List[str] = field(default_factory=list)
|
||||
@@ -90,10 +89,12 @@ class ModelLoadInfo:
|
||||
base_type: BaseModelType
|
||||
path: Optional[Path] = None
|
||||
repo_id: Optional[str] = None
|
||||
subfolder: Optional[str] = None
|
||||
description: str = ""
|
||||
installed: bool = False
|
||||
recommended: bool = False
|
||||
default: bool = False
|
||||
requires: Optional[List[str]] = field(default_factory=list)
|
||||
|
||||
|
||||
class ModelInstall(object):
|
||||
@@ -127,12 +128,13 @@ class ModelInstall(object):
|
||||
value["name"] = name
|
||||
value["base_type"] = base
|
||||
value["model_type"] = model_type
|
||||
model_dict[key] = ModelLoadInfo(**value)
|
||||
model_info = ModelLoadInfo(**value)
|
||||
if model_info.subfolder and model_info.repo_id:
|
||||
model_info.repo_id += f":{model_info.subfolder}"
|
||||
model_dict[key] = model_info
|
||||
|
||||
# supplement with entries in models.yaml
|
||||
installed_models = [x for x in self.mgr.list_models()]
|
||||
# suppresses autoloaded models
|
||||
# installed_models = [x for x in self.mgr.list_models() if not self._is_autoloaded(x)]
|
||||
|
||||
for md in installed_models:
|
||||
base = md["base_model"]
|
||||
@@ -164,9 +166,12 @@ class ModelInstall(object):
|
||||
|
||||
def list_models(self, model_type):
|
||||
installed = self.mgr.list_models(model_type=model_type)
|
||||
print()
|
||||
print(f"Installed models of type `{model_type}`:")
|
||||
print(f"{'Model Key':50} Model Path")
|
||||
for i in installed:
|
||||
print(f"{i['model_name']}\t{i['base_model']}\t{i['path']}")
|
||||
print(f"{'/'.join([i['base_model'],i['model_type'],i['model_name']]):50} {i['path']}")
|
||||
print()
|
||||
|
||||
# logic here a little reversed to maintain backward compatibility
|
||||
def starter_models(self, all_models: bool = False) -> Set[str]:
|
||||
@@ -204,6 +209,8 @@ class ModelInstall(object):
|
||||
job += 1
|
||||
|
||||
# add requested models
|
||||
self._remove_installed(selections.install_models)
|
||||
self._add_required_models(selections.install_models)
|
||||
for path in selections.install_models:
|
||||
logger.info(f"Installing {path} [{job}/{jobs}]")
|
||||
try:
|
||||
@@ -263,6 +270,26 @@ class ModelInstall(object):
|
||||
|
||||
return models_installed
|
||||
|
||||
def _remove_installed(self, model_list: List[str]):
|
||||
all_models = self.all_models()
|
||||
for path in model_list:
|
||||
key = self.reverse_paths.get(path)
|
||||
if key and all_models[key].installed:
|
||||
logger.warning(f"{path} already installed. Skipping.")
|
||||
model_list.remove(path)
|
||||
|
||||
def _add_required_models(self, model_list: List[str]):
|
||||
additional_models = []
|
||||
all_models = self.all_models()
|
||||
for path in model_list:
|
||||
if not (key := self.reverse_paths.get(path)):
|
||||
continue
|
||||
for requirement in all_models[key].requires:
|
||||
requirement_key = self.reverse_paths.get(requirement)
|
||||
if not all_models[requirement_key].installed:
|
||||
additional_models.append(requirement)
|
||||
model_list.extend(additional_models)
|
||||
|
||||
# install a model from a local path. The optional info parameter is there to prevent
|
||||
# the model from being probed twice in the event that it has already been probed.
|
||||
def _install_path(self, path: Path, info: ModelProbeInfo = None) -> AddModelResult:
|
||||
@@ -286,7 +313,7 @@ class ModelInstall(object):
|
||||
location = download_with_resume(url, Path(staging))
|
||||
if not location:
|
||||
logger.error(f"Unable to download {url}. Skipping.")
|
||||
info = ModelProbe().heuristic_probe(location)
|
||||
info = ModelProbe().heuristic_probe(location, self.prediction_helper)
|
||||
dest = self.config.models_path / info.base_type.value / info.model_type.value / location.name
|
||||
dest.parent.mkdir(parents=True, exist_ok=True)
|
||||
models_path = shutil.move(location, dest)
|
||||
@@ -295,46 +322,63 @@ class ModelInstall(object):
|
||||
return self._install_path(Path(models_path), info)
|
||||
|
||||
def _install_repo(self, repo_id: str) -> AddModelResult:
|
||||
# hack to recover models stored in subfolders --
|
||||
# Required to get the "v2" model of monster-labs/control_v1p_sd15_qrcode_monster
|
||||
subfolder = None
|
||||
if match := re.match(r"^([^/]+/[^/]+):(\w+)$", repo_id):
|
||||
repo_id = match.group(1)
|
||||
subfolder = match.group(2)
|
||||
|
||||
hinfo = HfApi().model_info(repo_id)
|
||||
|
||||
# we try to figure out how to download this most economically
|
||||
# list all the files in the repo
|
||||
files = [x.rfilename for x in hinfo.siblings]
|
||||
if subfolder:
|
||||
files = [x for x in files if x.startswith(f"{subfolder}/")]
|
||||
prefix = f"{subfolder}/" if subfolder else ""
|
||||
|
||||
location = None
|
||||
|
||||
with TemporaryDirectory(dir=self.config.models_path) as staging:
|
||||
staging = Path(staging)
|
||||
if "model_index.json" in files:
|
||||
location = self._download_hf_pipeline(repo_id, staging) # pipeline
|
||||
elif "unet/model.onnx" in files:
|
||||
if f"{prefix}model_index.json" in files:
|
||||
location = self._download_hf_pipeline(repo_id, staging, subfolder=subfolder) # pipeline
|
||||
elif f"{prefix}unet/model.onnx" in files:
|
||||
location = self._download_hf_model(repo_id, files, staging)
|
||||
else:
|
||||
for suffix in ["safetensors", "bin"]:
|
||||
if f"pytorch_lora_weights.{suffix}" in files:
|
||||
location = self._download_hf_model(repo_id, ["pytorch_lora_weights.bin"], staging) # LoRA
|
||||
if f"{prefix}pytorch_lora_weights.{suffix}" in files:
|
||||
location = self._download_hf_model(
|
||||
repo_id, ["pytorch_lora_weights.bin"], staging, subfolder=subfolder
|
||||
) # LoRA
|
||||
break
|
||||
elif (
|
||||
self.config.precision == "float16" and f"diffusion_pytorch_model.fp16.{suffix}" in files
|
||||
self.config.precision == "float16" and f"{prefix}diffusion_pytorch_model.fp16.{suffix}" in files
|
||||
): # vae, controlnet or some other standalone
|
||||
files = ["config.json", f"diffusion_pytorch_model.fp16.{suffix}"]
|
||||
location = self._download_hf_model(repo_id, files, staging)
|
||||
location = self._download_hf_model(repo_id, files, staging, subfolder=subfolder)
|
||||
break
|
||||
elif f"diffusion_pytorch_model.{suffix}" in files:
|
||||
elif f"{prefix}diffusion_pytorch_model.{suffix}" in files:
|
||||
files = ["config.json", f"diffusion_pytorch_model.{suffix}"]
|
||||
location = self._download_hf_model(repo_id, files, staging)
|
||||
location = self._download_hf_model(repo_id, files, staging, subfolder=subfolder)
|
||||
break
|
||||
elif f"learned_embeds.{suffix}" in files:
|
||||
location = self._download_hf_model(repo_id, [f"learned_embeds.{suffix}"], staging)
|
||||
elif f"{prefix}learned_embeds.{suffix}" in files:
|
||||
location = self._download_hf_model(
|
||||
repo_id, [f"learned_embeds.{suffix}"], staging, subfolder=subfolder
|
||||
)
|
||||
break
|
||||
elif "image_encoder.txt" in files and f"ip_adapter.{suffix}" in files: # IP-Adapter
|
||||
elif (
|
||||
f"{prefix}image_encoder.txt" in files and f"{prefix}ip_adapter.{suffix}" in files
|
||||
): # IP-Adapter
|
||||
files = ["image_encoder.txt", f"ip_adapter.{suffix}"]
|
||||
location = self._download_hf_model(repo_id, files, staging)
|
||||
location = self._download_hf_model(repo_id, files, staging, subfolder=subfolder)
|
||||
break
|
||||
elif f"model.{suffix}" in files and "config.json" in files:
|
||||
elif f"{prefix}model.{suffix}" in files and f"{prefix}config.json" in files:
|
||||
# This elif-condition is pretty fragile, but it is intended to handle CLIP Vision models hosted
|
||||
# by InvokeAI for use with IP-Adapters.
|
||||
files = ["config.json", f"model.{suffix}"]
|
||||
location = self._download_hf_model(repo_id, files, staging)
|
||||
location = self._download_hf_model(repo_id, files, staging, subfolder=subfolder)
|
||||
break
|
||||
if not location:
|
||||
logger.warning(f"Could not determine type of repo {repo_id}. Skipping install.")
|
||||
@@ -393,7 +437,7 @@ class ModelInstall(object):
|
||||
possible_conf = path.with_suffix(".yaml")
|
||||
if possible_conf.exists():
|
||||
legacy_conf = str(self.relative_to_root(possible_conf))
|
||||
elif info.base_type == BaseModelType.StableDiffusion2:
|
||||
elif info.base_type in [BaseModelType.StableDiffusion1, BaseModelType.StableDiffusion2]:
|
||||
legacy_conf = Path(
|
||||
self.config.legacy_conf_dir,
|
||||
LEGACY_CONFIGS[info.base_type][info.variant_type][info.prediction_type],
|
||||
@@ -421,9 +465,9 @@ class ModelInstall(object):
|
||||
else:
|
||||
return path
|
||||
|
||||
def _download_hf_pipeline(self, repo_id: str, staging: Path) -> Path:
|
||||
def _download_hf_pipeline(self, repo_id: str, staging: Path, subfolder: str = None) -> Path:
|
||||
"""
|
||||
This retrieves a StableDiffusion model from cache or remote and then
|
||||
Retrieve a StableDiffusion model from cache or remote and then
|
||||
does a save_pretrained() to the indicated staging area.
|
||||
"""
|
||||
_, name = repo_id.split("/")
|
||||
@@ -438,6 +482,7 @@ class ModelInstall(object):
|
||||
variant=variant,
|
||||
torch_dtype=precision,
|
||||
safety_checker=None,
|
||||
subfolder=subfolder,
|
||||
)
|
||||
except Exception as e: # most errors are due to fp16 not being present. Fix this to catch other errors
|
||||
if "fp16" not in str(e):
|
||||
@@ -452,7 +497,7 @@ class ModelInstall(object):
|
||||
model.save_pretrained(staging / name, safe_serialization=True)
|
||||
return staging / name
|
||||
|
||||
def _download_hf_model(self, repo_id: str, files: List[str], staging: Path) -> Path:
|
||||
def _download_hf_model(self, repo_id: str, files: List[str], staging: Path, subfolder: None) -> Path:
|
||||
_, name = repo_id.split("/")
|
||||
location = staging / name
|
||||
paths = list()
|
||||
@@ -463,7 +508,7 @@ class ModelInstall(object):
|
||||
model_dir=location / filePath.parent,
|
||||
model_name=filePath.name,
|
||||
access_token=self.access_token,
|
||||
subfolder=filePath.parent,
|
||||
subfolder=filePath.parent / subfolder if subfolder else filePath.parent,
|
||||
)
|
||||
if p:
|
||||
paths.append(p)
|
||||
@@ -492,7 +537,7 @@ def yes_or_no(prompt: str, default_yes=True):
|
||||
|
||||
# ---------------------------------------------
|
||||
def hf_download_from_pretrained(model_class: object, model_name: str, destination: Path, **kwargs):
|
||||
logger = InvokeAILogger.getLogger("InvokeAI")
|
||||
logger = InvokeAILogger.get_logger("InvokeAI")
|
||||
logger.addFilter(lambda x: "fp16 is not a valid" not in x.getMessage())
|
||||
|
||||
model = model_class.from_pretrained(
|
||||
|
||||
@@ -8,6 +8,8 @@ import torch.nn as nn
|
||||
import torch.nn.functional as F
|
||||
from diffusers.models.attention_processor import AttnProcessor2_0 as DiffusersAttnProcessor2_0
|
||||
|
||||
from invokeai.backend.ip_adapter.ip_attention_weights import IPAttentionProcessorWeights
|
||||
|
||||
|
||||
# Create a version of AttnProcessor2_0 that is a sub-class of nn.Module. This is required for IP-Adapter state_dict
|
||||
# loading.
|
||||
@@ -45,18 +47,16 @@ class IPAttnProcessor2_0(torch.nn.Module):
|
||||
the weight scale of image prompt.
|
||||
"""
|
||||
|
||||
def __init__(self, hidden_size, cross_attention_dim=None, scale=1.0):
|
||||
def __init__(self, weights: list[IPAttentionProcessorWeights], scales: list[float]):
|
||||
super().__init__()
|
||||
|
||||
if not hasattr(F, "scaled_dot_product_attention"):
|
||||
raise ImportError("AttnProcessor2_0 requires PyTorch 2.0, to use it, please upgrade PyTorch to 2.0.")
|
||||
|
||||
self.hidden_size = hidden_size
|
||||
self.cross_attention_dim = cross_attention_dim
|
||||
self.scale = scale
|
||||
assert len(weights) == len(scales)
|
||||
|
||||
self.to_k_ip = nn.Linear(cross_attention_dim or hidden_size, hidden_size, bias=False)
|
||||
self.to_v_ip = nn.Linear(cross_attention_dim or hidden_size, hidden_size, bias=False)
|
||||
self._weights = weights
|
||||
self._scales = scales
|
||||
|
||||
def __call__(
|
||||
self,
|
||||
@@ -67,16 +67,6 @@ class IPAttnProcessor2_0(torch.nn.Module):
|
||||
temb=None,
|
||||
ip_adapter_image_prompt_embeds=None,
|
||||
):
|
||||
if encoder_hidden_states is not None:
|
||||
# If encoder_hidden_states is not None, then we are doing cross-attention, not self-attention. In this case,
|
||||
# we will apply IP-Adapter conditioning. We validate the inputs for IP-Adapter conditioning here.
|
||||
assert ip_adapter_image_prompt_embeds is not None
|
||||
# The batch dimensions should match.
|
||||
assert ip_adapter_image_prompt_embeds.shape[0] == encoder_hidden_states.shape[0]
|
||||
# The channel dimensions should match.
|
||||
assert ip_adapter_image_prompt_embeds.shape[2] == encoder_hidden_states.shape[2]
|
||||
ip_hidden_states = ip_adapter_image_prompt_embeds
|
||||
|
||||
residual = hidden_states
|
||||
|
||||
if attn.spatial_norm is not None:
|
||||
@@ -128,23 +118,36 @@ class IPAttnProcessor2_0(torch.nn.Module):
|
||||
hidden_states = hidden_states.transpose(1, 2).reshape(batch_size, -1, attn.heads * head_dim)
|
||||
hidden_states = hidden_states.to(query.dtype)
|
||||
|
||||
if ip_hidden_states is not None:
|
||||
ip_key = self.to_k_ip(ip_hidden_states)
|
||||
ip_value = self.to_v_ip(ip_hidden_states)
|
||||
if encoder_hidden_states is not None:
|
||||
# If encoder_hidden_states is not None, then we are doing cross-attention, not self-attention. In this case,
|
||||
# we will apply IP-Adapter conditioning. We validate the inputs for IP-Adapter conditioning here.
|
||||
assert ip_adapter_image_prompt_embeds is not None
|
||||
assert len(ip_adapter_image_prompt_embeds) == len(self._weights)
|
||||
|
||||
ip_key = ip_key.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
||||
ip_value = ip_value.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
||||
for ipa_embed, ipa_weights, scale in zip(ip_adapter_image_prompt_embeds, self._weights, self._scales):
|
||||
# The batch dimensions should match.
|
||||
assert ipa_embed.shape[0] == encoder_hidden_states.shape[0]
|
||||
# The channel dimensions should match.
|
||||
assert ipa_embed.shape[2] == encoder_hidden_states.shape[2]
|
||||
|
||||
# the output of sdp = (batch, num_heads, seq_len, head_dim)
|
||||
# TODO: add support for attn.scale when we move to Torch 2.1
|
||||
ip_hidden_states = F.scaled_dot_product_attention(
|
||||
query, ip_key, ip_value, attn_mask=None, dropout_p=0.0, is_causal=False
|
||||
)
|
||||
ip_hidden_states = ipa_embed
|
||||
|
||||
ip_hidden_states = ip_hidden_states.transpose(1, 2).reshape(batch_size, -1, attn.heads * head_dim)
|
||||
ip_hidden_states = ip_hidden_states.to(query.dtype)
|
||||
ip_key = ipa_weights.to_k_ip(ip_hidden_states)
|
||||
ip_value = ipa_weights.to_v_ip(ip_hidden_states)
|
||||
|
||||
hidden_states = hidden_states + self.scale * ip_hidden_states
|
||||
ip_key = ip_key.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
||||
ip_value = ip_value.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
||||
|
||||
# The output of sdpa has shape: (batch, num_heads, seq_len, head_dim)
|
||||
# TODO: add support for attn.scale when we move to Torch 2.1
|
||||
ip_hidden_states = F.scaled_dot_product_attention(
|
||||
query, ip_key, ip_value, attn_mask=None, dropout_p=0.0, is_causal=False
|
||||
)
|
||||
|
||||
ip_hidden_states = ip_hidden_states.transpose(1, 2).reshape(batch_size, -1, attn.heads * head_dim)
|
||||
ip_hidden_states = ip_hidden_states.to(query.dtype)
|
||||
|
||||
hidden_states = hidden_states + scale * ip_hidden_states
|
||||
|
||||
# linear proj
|
||||
hidden_states = attn.to_out[0](hidden_states)
|
||||
|
||||
@@ -1,15 +1,15 @@
|
||||
# copied from https://github.com/tencent-ailab/IP-Adapter (Apache License 2.0)
|
||||
# and modified as needed
|
||||
|
||||
from contextlib import contextmanager
|
||||
from typing import Optional, Union
|
||||
|
||||
import torch
|
||||
from diffusers.models import UNet2DConditionModel
|
||||
from PIL import Image
|
||||
from transformers import CLIPImageProcessor, CLIPVisionModelWithProjection
|
||||
|
||||
from .attention_processor import AttnProcessor2_0, IPAttnProcessor2_0
|
||||
from invokeai.backend.ip_adapter.ip_attention_weights import IPAttentionWeights
|
||||
from invokeai.backend.model_management.models.base import calc_model_size_by_data
|
||||
|
||||
from .resampler import Resampler
|
||||
|
||||
|
||||
@@ -59,7 +59,7 @@ class IPAdapter:
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
state_dict: dict[torch.Tensor],
|
||||
state_dict: dict[str, torch.Tensor],
|
||||
device: torch.device,
|
||||
dtype: torch.dtype = torch.float16,
|
||||
num_tokens: int = 4,
|
||||
@@ -71,12 +71,11 @@ class IPAdapter:
|
||||
|
||||
self._clip_image_processor = CLIPImageProcessor()
|
||||
|
||||
self._state_dict = state_dict
|
||||
self._image_proj_model = self._init_image_proj_model(state_dict["image_proj"])
|
||||
|
||||
self._image_proj_model = self._init_image_proj_model(self._state_dict["image_proj"])
|
||||
|
||||
# The _attn_processors will be initialized later when we have access to the UNet.
|
||||
self._attn_processors = None
|
||||
self.attn_weights = IPAttentionWeights.from_state_dict(state_dict["ip_adapter"]).to(
|
||||
self.device, dtype=self.dtype
|
||||
)
|
||||
|
||||
def to(self, device: torch.device, dtype: Optional[torch.dtype] = None):
|
||||
self.device = device
|
||||
@@ -84,85 +83,14 @@ class IPAdapter:
|
||||
self.dtype = dtype
|
||||
|
||||
self._image_proj_model.to(device=self.device, dtype=self.dtype)
|
||||
if self._attn_processors is not None:
|
||||
torch.nn.ModuleList(self._attn_processors.values()).to(device=self.device, dtype=self.dtype)
|
||||
self.attn_weights.to(device=self.device, dtype=self.dtype)
|
||||
|
||||
def calc_size(self):
|
||||
return calc_model_size_by_data(self._image_proj_model) + calc_model_size_by_data(self.attn_weights)
|
||||
|
||||
def _init_image_proj_model(self, state_dict):
|
||||
return ImageProjModel.from_state_dict(state_dict, self._num_tokens).to(self.device, dtype=self.dtype)
|
||||
|
||||
def _prepare_attention_processors(self, unet: UNet2DConditionModel):
|
||||
"""Prepare a dict of attention processors that can later be injected into a unet, and load the IP-Adapter
|
||||
attention weights into them.
|
||||
|
||||
Note that the `unet` param is only used to determine attention block dimensions and naming.
|
||||
TODO(ryand): As a future improvement, this could all be inferred from the state_dict when the IPAdapter is
|
||||
intialized.
|
||||
"""
|
||||
attn_procs = {}
|
||||
for name in unet.attn_processors.keys():
|
||||
cross_attention_dim = None if name.endswith("attn1.processor") else unet.config.cross_attention_dim
|
||||
if name.startswith("mid_block"):
|
||||
hidden_size = unet.config.block_out_channels[-1]
|
||||
elif name.startswith("up_blocks"):
|
||||
block_id = int(name[len("up_blocks.")])
|
||||
hidden_size = list(reversed(unet.config.block_out_channels))[block_id]
|
||||
elif name.startswith("down_blocks"):
|
||||
block_id = int(name[len("down_blocks.")])
|
||||
hidden_size = unet.config.block_out_channels[block_id]
|
||||
if cross_attention_dim is None:
|
||||
attn_procs[name] = AttnProcessor2_0()
|
||||
else:
|
||||
attn_procs[name] = IPAttnProcessor2_0(
|
||||
hidden_size=hidden_size,
|
||||
cross_attention_dim=cross_attention_dim,
|
||||
scale=1.0,
|
||||
).to(self.device, dtype=self.dtype)
|
||||
|
||||
ip_layers = torch.nn.ModuleList(attn_procs.values())
|
||||
ip_layers.load_state_dict(self._state_dict["ip_adapter"])
|
||||
self._attn_processors = attn_procs
|
||||
self._state_dict = None
|
||||
|
||||
# @genomancer: pushed scaling back out into its own method (like original Tencent implementation)
|
||||
# which makes implementing begin_step_percent and end_step_percent easier
|
||||
# but based on self._attn_processors (ala @Ryan) instead of original Tencent unet.attn_processors,
|
||||
# which should make it easier to implement multiple IPAdapters
|
||||
def set_scale(self, scale):
|
||||
if self._attn_processors is not None:
|
||||
for attn_processor in self._attn_processors.values():
|
||||
if isinstance(attn_processor, IPAttnProcessor2_0):
|
||||
attn_processor.scale = scale
|
||||
|
||||
@contextmanager
|
||||
def apply_ip_adapter_attention(self, unet: UNet2DConditionModel, scale: float):
|
||||
"""A context manager that patches `unet` with this IP-Adapter's attention processors while it is active.
|
||||
|
||||
Yields:
|
||||
None
|
||||
"""
|
||||
if self._attn_processors is None:
|
||||
# We only have to call _prepare_attention_processors(...) once, and then the result is cached and can be
|
||||
# used on any UNet model (with the same dimensions).
|
||||
self._prepare_attention_processors(unet)
|
||||
|
||||
# Set scale
|
||||
self.set_scale(scale)
|
||||
# for attn_processor in self._attn_processors.values():
|
||||
# if isinstance(attn_processor, IPAttnProcessor2_0):
|
||||
# attn_processor.scale = scale
|
||||
|
||||
orig_attn_processors = unet.attn_processors
|
||||
|
||||
# Make a (moderately-) shallow copy of the self._attn_processors dict, because unet.set_attn_processor(...)
|
||||
# actually pops elements from the passed dict.
|
||||
ip_adapter_attn_processors = {k: v for k, v in self._attn_processors.items()}
|
||||
|
||||
try:
|
||||
unet.set_attn_processor(ip_adapter_attn_processors)
|
||||
yield None
|
||||
finally:
|
||||
unet.set_attn_processor(orig_attn_processors)
|
||||
|
||||
@torch.inference_mode()
|
||||
def get_image_embeds(self, pil_image, image_encoder: CLIPVisionModelWithProjection):
|
||||
if isinstance(pil_image, Image.Image):
|
||||
@@ -202,6 +130,20 @@ class IPAdapterPlus(IPAdapter):
|
||||
return image_prompt_embeds, uncond_image_prompt_embeds
|
||||
|
||||
|
||||
class IPAdapterPlusXL(IPAdapterPlus):
|
||||
"""IP-Adapter Plus for SDXL."""
|
||||
|
||||
def _init_image_proj_model(self, state_dict):
|
||||
return Resampler.from_state_dict(
|
||||
state_dict=state_dict,
|
||||
depth=4,
|
||||
dim_head=64,
|
||||
heads=20,
|
||||
num_queries=self._num_tokens,
|
||||
ff_mult=4,
|
||||
).to(self.device, dtype=self.dtype)
|
||||
|
||||
|
||||
def build_ip_adapter(
|
||||
ip_adapter_ckpt_path: str, device: torch.device, dtype: torch.dtype = torch.float16
|
||||
) -> Union[IPAdapter, IPAdapterPlus]:
|
||||
@@ -212,6 +154,14 @@ def build_ip_adapter(
|
||||
is_plus = "proj.weight" not in state_dict["image_proj"]
|
||||
|
||||
if is_plus:
|
||||
return IPAdapterPlus(state_dict, device=device, dtype=dtype)
|
||||
cross_attention_dim = state_dict["ip_adapter"]["1.to_k_ip.weight"].shape[-1]
|
||||
if cross_attention_dim == 768:
|
||||
# SD1 IP-Adapter Plus
|
||||
return IPAdapterPlus(state_dict, device=device, dtype=dtype)
|
||||
elif cross_attention_dim == 2048:
|
||||
# SDXL IP-Adapter Plus
|
||||
return IPAdapterPlusXL(state_dict, device=device, dtype=dtype)
|
||||
else:
|
||||
raise Exception(f"Unsupported IP-Adapter Plus cross-attention dimension: {cross_attention_dim}.")
|
||||
else:
|
||||
return IPAdapter(state_dict, device=device, dtype=dtype)
|
||||
|
||||
46
invokeai/backend/ip_adapter/ip_attention_weights.py
Normal file
46
invokeai/backend/ip_adapter/ip_attention_weights.py
Normal file
@@ -0,0 +1,46 @@
|
||||
import torch
|
||||
|
||||
|
||||
class IPAttentionProcessorWeights(torch.nn.Module):
|
||||
"""The IP-Adapter weights for a single attention processor.
|
||||
|
||||
This class is a torch.nn.Module sub-class to facilitate loading from a state_dict. It does not have a forward(...)
|
||||
method.
|
||||
"""
|
||||
|
||||
def __init__(self, in_dim: int, out_dim: int):
|
||||
super().__init__()
|
||||
self.to_k_ip = torch.nn.Linear(in_dim, out_dim, bias=False)
|
||||
self.to_v_ip = torch.nn.Linear(in_dim, out_dim, bias=False)
|
||||
|
||||
|
||||
class IPAttentionWeights(torch.nn.Module):
|
||||
"""A collection of all the `IPAttentionProcessorWeights` objects for an IP-Adapter model.
|
||||
|
||||
This class is a torch.nn.Module sub-class so that it inherits the `.to(...)` functionality. It does not have a
|
||||
forward(...) method.
|
||||
"""
|
||||
|
||||
def __init__(self, weights: torch.nn.ModuleDict):
|
||||
super().__init__()
|
||||
self._weights = weights
|
||||
|
||||
def get_attention_processor_weights(self, idx: int) -> IPAttentionProcessorWeights:
|
||||
"""Get the `IPAttentionProcessorWeights` for the idx'th attention processor."""
|
||||
# Cast to int first, because we expect the key to represent an int. Then cast back to str, because
|
||||
# `torch.nn.ModuleDict` only supports str keys.
|
||||
return self._weights[str(int(idx))]
|
||||
|
||||
@classmethod
|
||||
def from_state_dict(cls, state_dict: dict[str, torch.Tensor]):
|
||||
attn_proc_weights: dict[str, IPAttentionProcessorWeights] = {}
|
||||
|
||||
for tensor_name, tensor in state_dict.items():
|
||||
if "to_k_ip.weight" in tensor_name:
|
||||
index = str(int(tensor_name.split(".")[0]))
|
||||
attn_proc_weights[index] = IPAttentionProcessorWeights(tensor.shape[1], tensor.shape[0])
|
||||
|
||||
attn_proc_weights_module = torch.nn.ModuleDict(attn_proc_weights)
|
||||
attn_proc_weights_module.load_state_dict(state_dict)
|
||||
|
||||
return cls(attn_proc_weights_module)
|
||||
53
invokeai/backend/ip_adapter/unet_patcher.py
Normal file
53
invokeai/backend/ip_adapter/unet_patcher.py
Normal file
@@ -0,0 +1,53 @@
|
||||
from contextlib import contextmanager
|
||||
|
||||
from diffusers.models import UNet2DConditionModel
|
||||
|
||||
from invokeai.backend.ip_adapter.attention_processor import AttnProcessor2_0, IPAttnProcessor2_0
|
||||
from invokeai.backend.ip_adapter.ip_adapter import IPAdapter
|
||||
|
||||
|
||||
class UNetPatcher:
|
||||
"""A class that contains multiple IP-Adapters and can apply them to a UNet."""
|
||||
|
||||
def __init__(self, ip_adapters: list[IPAdapter]):
|
||||
self._ip_adapters = ip_adapters
|
||||
self._scales = [1.0] * len(self._ip_adapters)
|
||||
|
||||
def set_scale(self, idx: int, value: float):
|
||||
self._scales[idx] = value
|
||||
|
||||
def _prepare_attention_processors(self, unet: UNet2DConditionModel):
|
||||
"""Prepare a dict of attention processors that can be injected into a unet, and load the IP-Adapter attention
|
||||
weights into them.
|
||||
|
||||
Note that the `unet` param is only used to determine attention block dimensions and naming.
|
||||
"""
|
||||
# Construct a dict of attention processors based on the UNet's architecture.
|
||||
attn_procs = {}
|
||||
for idx, name in enumerate(unet.attn_processors.keys()):
|
||||
if name.endswith("attn1.processor"):
|
||||
attn_procs[name] = AttnProcessor2_0()
|
||||
else:
|
||||
# Collect the weights from each IP Adapter for the idx'th attention processor.
|
||||
attn_procs[name] = IPAttnProcessor2_0(
|
||||
[ip_adapter.attn_weights.get_attention_processor_weights(idx) for ip_adapter in self._ip_adapters],
|
||||
self._scales,
|
||||
)
|
||||
return attn_procs
|
||||
|
||||
@contextmanager
|
||||
def apply_ip_adapter_attention(self, unet: UNet2DConditionModel):
|
||||
"""A context manager that patches `unet` with IP-Adapter attention processors."""
|
||||
|
||||
attn_procs = self._prepare_attention_processors(unet)
|
||||
|
||||
orig_attn_processors = unet.attn_processors
|
||||
|
||||
try:
|
||||
# Note to future devs: set_attn_processor(...) does something slightly unexpected - it pops elements from the
|
||||
# passed dict. So, if you wanted to keep the dict for future use, you'd have to make a moderately-shallow copy
|
||||
# of it. E.g. `attn_procs_copy = {k: v for k, v in attn_procs.items()}`.
|
||||
unet.set_attn_processor(attn_procs)
|
||||
yield None
|
||||
finally:
|
||||
unet.set_attn_processor(orig_attn_processors)
|
||||
27
invokeai/backend/model_management/README.md
Normal file
27
invokeai/backend/model_management/README.md
Normal file
@@ -0,0 +1,27 @@
|
||||
# Model Cache
|
||||
|
||||
## `glibc` Memory Allocator Fragmentation
|
||||
|
||||
Python (and PyTorch) relies on the memory allocator from the C Standard Library (`libc`). On linux, with the GNU C Standard Library implementation (`glibc`), our memory access patterns have been observed to cause severe memory fragmentation. This fragmentation results in large amounts of memory that has been freed but can't be released back to the OS. Loading models from disk and moving them between CPU/CUDA seem to be the operations that contribute most to the fragmentation. This memory fragmentation issue can result in OOM crashes during frequent model switching, even if `max_cache_size` is set to a reasonable value (e.g. a OOM crash with `max_cache_size=16` on a system with 32GB of RAM).
|
||||
|
||||
This problem may also exist on other OSes, and other `libc` implementations. But, at the time of writing, it has only been investigated on linux with `glibc`.
|
||||
|
||||
To better understand how the `glibc` memory allocator works, see these references:
|
||||
- Basics: https://www.gnu.org/software/libc/manual/html_node/The-GNU-Allocator.html
|
||||
- Details: https://sourceware.org/glibc/wiki/MallocInternals
|
||||
|
||||
Note the differences between memory allocated as chunks in an arena vs. memory allocated with `mmap`. Under `glibc`'s default configuration, most model tensors get allocated as chunks in an arena making them vulnerable to the problem of fragmentation.
|
||||
|
||||
We can work around this memory fragmentation issue by setting the following env var:
|
||||
|
||||
```bash
|
||||
# Force blocks >1MB to be allocated with `mmap` so that they are released to the system immediately when they are freed.
|
||||
MALLOC_MMAP_THRESHOLD_=1048576
|
||||
```
|
||||
|
||||
See the following references for more information about the `malloc` tunable parameters:
|
||||
- https://www.gnu.org/software/libc/manual/html_node/Malloc-Tunable-Parameters.html
|
||||
- https://www.gnu.org/software/libc/manual/html_node/Memory-Allocation-Tunables.html
|
||||
- https://man7.org/linux/man-pages/man3/mallopt.3.html
|
||||
|
||||
The model cache emits debug logs that provide visibility into the state of the `libc` memory allocator. See the `LibcUtil` class for more info on how these `libc` malloc stats are collected.
|
||||
@@ -74,7 +74,7 @@ if is_accelerate_available():
|
||||
from accelerate import init_empty_weights
|
||||
from accelerate.utils import set_module_tensor_to_device
|
||||
|
||||
logger = InvokeAILogger.getLogger(__name__)
|
||||
logger = InvokeAILogger.get_logger(__name__)
|
||||
CONVERT_MODEL_ROOT = InvokeAIAppConfig.get_config().models_path / "core/convert"
|
||||
|
||||
|
||||
@@ -1279,12 +1279,12 @@ def download_from_original_stable_diffusion_ckpt(
|
||||
extract_ema = original_config["model"]["params"]["use_ema"]
|
||||
|
||||
if (
|
||||
model_version == BaseModelType.StableDiffusion2
|
||||
model_version in [BaseModelType.StableDiffusion2, BaseModelType.StableDiffusion1]
|
||||
and original_config["model"]["params"].get("parameterization") == "v"
|
||||
):
|
||||
prediction_type = "v_prediction"
|
||||
upcast_attention = True
|
||||
image_size = 768
|
||||
image_size = 768 if model_version == BaseModelType.StableDiffusion2 else 512
|
||||
else:
|
||||
prediction_type = "epsilon"
|
||||
upcast_attention = False
|
||||
|
||||
75
invokeai/backend/model_management/libc_util.py
Normal file
75
invokeai/backend/model_management/libc_util.py
Normal file
@@ -0,0 +1,75 @@
|
||||
import ctypes
|
||||
|
||||
|
||||
class Struct_mallinfo2(ctypes.Structure):
|
||||
"""A ctypes Structure that matches the libc mallinfo2 struct.
|
||||
|
||||
Docs:
|
||||
- https://man7.org/linux/man-pages/man3/mallinfo.3.html
|
||||
- https://www.gnu.org/software/libc/manual/html_node/Statistics-of-Malloc.html
|
||||
|
||||
struct mallinfo2 {
|
||||
size_t arena; /* Non-mmapped space allocated (bytes) */
|
||||
size_t ordblks; /* Number of free chunks */
|
||||
size_t smblks; /* Number of free fastbin blocks */
|
||||
size_t hblks; /* Number of mmapped regions */
|
||||
size_t hblkhd; /* Space allocated in mmapped regions (bytes) */
|
||||
size_t usmblks; /* See below */
|
||||
size_t fsmblks; /* Space in freed fastbin blocks (bytes) */
|
||||
size_t uordblks; /* Total allocated space (bytes) */
|
||||
size_t fordblks; /* Total free space (bytes) */
|
||||
size_t keepcost; /* Top-most, releasable space (bytes) */
|
||||
};
|
||||
"""
|
||||
|
||||
_fields_ = [
|
||||
("arena", ctypes.c_size_t),
|
||||
("ordblks", ctypes.c_size_t),
|
||||
("smblks", ctypes.c_size_t),
|
||||
("hblks", ctypes.c_size_t),
|
||||
("hblkhd", ctypes.c_size_t),
|
||||
("usmblks", ctypes.c_size_t),
|
||||
("fsmblks", ctypes.c_size_t),
|
||||
("uordblks", ctypes.c_size_t),
|
||||
("fordblks", ctypes.c_size_t),
|
||||
("keepcost", ctypes.c_size_t),
|
||||
]
|
||||
|
||||
def __str__(self):
|
||||
s = ""
|
||||
s += f"{'arena': <10}= {(self.arena/2**30):15.5f} # Non-mmapped space allocated (GB) (uordblks + fordblks)\n"
|
||||
s += f"{'ordblks': <10}= {(self.ordblks): >15} # Number of free chunks\n"
|
||||
s += f"{'smblks': <10}= {(self.smblks): >15} # Number of free fastbin blocks \n"
|
||||
s += f"{'hblks': <10}= {(self.hblks): >15} # Number of mmapped regions \n"
|
||||
s += f"{'hblkhd': <10}= {(self.hblkhd/2**30):15.5f} # Space allocated in mmapped regions (GB)\n"
|
||||
s += f"{'usmblks': <10}= {(self.usmblks): >15} # Unused\n"
|
||||
s += f"{'fsmblks': <10}= {(self.fsmblks/2**30):15.5f} # Space in freed fastbin blocks (GB)\n"
|
||||
s += (
|
||||
f"{'uordblks': <10}= {(self.uordblks/2**30):15.5f} # Space used by in-use allocations (non-mmapped)"
|
||||
" (GB)\n"
|
||||
)
|
||||
s += f"{'fordblks': <10}= {(self.fordblks/2**30):15.5f} # Space in free blocks (non-mmapped) (GB)\n"
|
||||
s += f"{'keepcost': <10}= {(self.keepcost/2**30):15.5f} # Top-most, releasable space (GB)\n"
|
||||
return s
|
||||
|
||||
|
||||
class LibcUtil:
|
||||
"""A utility class for interacting with the C Standard Library (`libc`) via ctypes.
|
||||
|
||||
Note that this class will raise on __init__() if 'libc.so.6' can't be found. Take care to handle environments where
|
||||
this shared library is not available.
|
||||
|
||||
TODO: Improve cross-OS compatibility of this class.
|
||||
"""
|
||||
|
||||
def __init__(self):
|
||||
self._libc = ctypes.cdll.LoadLibrary("libc.so.6")
|
||||
|
||||
def mallinfo2(self) -> Struct_mallinfo2:
|
||||
"""Calls `libc` `mallinfo2`.
|
||||
|
||||
Docs: https://man7.org/linux/man-pages/man3/mallinfo.3.html
|
||||
"""
|
||||
mallinfo2 = self._libc.mallinfo2
|
||||
mallinfo2.restype = Struct_mallinfo2
|
||||
return mallinfo2()
|
||||
94
invokeai/backend/model_management/memory_snapshot.py
Normal file
94
invokeai/backend/model_management/memory_snapshot.py
Normal file
@@ -0,0 +1,94 @@
|
||||
import gc
|
||||
from typing import Optional
|
||||
|
||||
import psutil
|
||||
import torch
|
||||
|
||||
from invokeai.backend.model_management.libc_util import LibcUtil, Struct_mallinfo2
|
||||
|
||||
GB = 2**30 # 1 GB
|
||||
|
||||
|
||||
class MemorySnapshot:
|
||||
"""A snapshot of RAM and VRAM usage. All values are in bytes."""
|
||||
|
||||
def __init__(self, process_ram: int, vram: Optional[int], malloc_info: Optional[Struct_mallinfo2]):
|
||||
"""Initialize a MemorySnapshot.
|
||||
|
||||
Most of the time, `MemorySnapshot` will be constructed with `MemorySnapshot.capture()`.
|
||||
|
||||
Args:
|
||||
process_ram (int): CPU RAM used by the current process.
|
||||
vram (Optional[int]): VRAM used by torch.
|
||||
malloc_info (Optional[Struct_mallinfo2]): Malloc info obtained from LibcUtil.
|
||||
"""
|
||||
self.process_ram = process_ram
|
||||
self.vram = vram
|
||||
self.malloc_info = malloc_info
|
||||
|
||||
@classmethod
|
||||
def capture(cls, run_garbage_collector: bool = True):
|
||||
"""Capture and return a MemorySnapshot.
|
||||
|
||||
Note: This function has significant overhead, particularly if `run_garbage_collector == True`.
|
||||
|
||||
Args:
|
||||
run_garbage_collector (bool, optional): If true, gc.collect() will be run before checking the process RAM
|
||||
usage. Defaults to True.
|
||||
|
||||
Returns:
|
||||
MemorySnapshot
|
||||
"""
|
||||
if run_garbage_collector:
|
||||
gc.collect()
|
||||
|
||||
# According to the psutil docs (https://psutil.readthedocs.io/en/latest/#psutil.Process.memory_info), rss is
|
||||
# supported on all platforms.
|
||||
process_ram = psutil.Process().memory_info().rss
|
||||
|
||||
if torch.cuda.is_available():
|
||||
vram = torch.cuda.memory_allocated()
|
||||
else:
|
||||
# TODO: We could add support for mps.current_allocated_memory() as well. Leaving out for now until we have
|
||||
# time to test it properly.
|
||||
vram = None
|
||||
|
||||
try:
|
||||
malloc_info = LibcUtil().mallinfo2()
|
||||
except OSError:
|
||||
# This is expected in environments that do not have the 'libc.so.6' shared library.
|
||||
malloc_info = None
|
||||
|
||||
return cls(process_ram, vram, malloc_info)
|
||||
|
||||
|
||||
def get_pretty_snapshot_diff(snapshot_1: MemorySnapshot, snapshot_2: MemorySnapshot) -> str:
|
||||
"""Get a pretty string describing the difference between two `MemorySnapshot`s."""
|
||||
|
||||
def get_msg_line(prefix: str, val1: int, val2: int):
|
||||
diff = val2 - val1
|
||||
return f"{prefix: <30} ({(diff/GB):+5.3f}): {(val1/GB):5.3f}GB -> {(val2/GB):5.3f}GB\n"
|
||||
|
||||
msg = ""
|
||||
|
||||
msg += get_msg_line("Process RAM", snapshot_1.process_ram, snapshot_2.process_ram)
|
||||
|
||||
if snapshot_1.malloc_info is not None and snapshot_2.malloc_info is not None:
|
||||
msg += get_msg_line("libc mmap allocated", snapshot_1.malloc_info.hblkhd, snapshot_2.malloc_info.hblkhd)
|
||||
|
||||
msg += get_msg_line("libc arena used", snapshot_1.malloc_info.uordblks, snapshot_2.malloc_info.uordblks)
|
||||
|
||||
msg += get_msg_line("libc arena free", snapshot_1.malloc_info.fordblks, snapshot_2.malloc_info.fordblks)
|
||||
|
||||
libc_total_allocated_1 = snapshot_1.malloc_info.arena + snapshot_1.malloc_info.hblkhd
|
||||
libc_total_allocated_2 = snapshot_2.malloc_info.arena + snapshot_2.malloc_info.hblkhd
|
||||
msg += get_msg_line("libc total allocated", libc_total_allocated_1, libc_total_allocated_2)
|
||||
|
||||
libc_total_used_1 = snapshot_1.malloc_info.uordblks + snapshot_1.malloc_info.hblkhd
|
||||
libc_total_used_2 = snapshot_2.malloc_info.uordblks + snapshot_2.malloc_info.hblkhd
|
||||
msg += get_msg_line("libc total used", libc_total_used_1, libc_total_used_2)
|
||||
|
||||
if snapshot_1.vram is not None and snapshot_2.vram is not None:
|
||||
msg += get_msg_line("VRAM", snapshot_1.vram, snapshot_2.vram)
|
||||
|
||||
return msg
|
||||
@@ -18,8 +18,10 @@ context. Use like this:
|
||||
|
||||
import gc
|
||||
import hashlib
|
||||
import math
|
||||
import os
|
||||
import sys
|
||||
import time
|
||||
from contextlib import suppress
|
||||
from dataclasses import dataclass, field
|
||||
from pathlib import Path
|
||||
@@ -28,6 +30,8 @@ from typing import Any, Dict, Optional, Type, Union, types
|
||||
import torch
|
||||
|
||||
import invokeai.backend.util.logging as logger
|
||||
from invokeai.backend.model_management.memory_snapshot import MemorySnapshot, get_pretty_snapshot_diff
|
||||
from invokeai.backend.model_management.model_load_optimizations import skip_torch_weight_init
|
||||
|
||||
from ..util.devices import choose_torch_device
|
||||
from .models import BaseModelType, ModelBase, ModelType, SubModelType
|
||||
@@ -44,6 +48,8 @@ DEFAULT_MAX_VRAM_CACHE_SIZE = 2.75
|
||||
|
||||
# actual size of a gig
|
||||
GIG = 1073741824
|
||||
# Size of a MB in bytes.
|
||||
MB = 2**20
|
||||
|
||||
|
||||
@dataclass
|
||||
@@ -205,22 +211,41 @@ class ModelCache(object):
|
||||
cache_entry = self._cached_models.get(key, None)
|
||||
if cache_entry is None:
|
||||
self.logger.info(
|
||||
f"Loading model {model_path}, type {base_model.value}:{model_type.value}{':'+submodel.value if submodel else ''}"
|
||||
f"Loading model {model_path}, type"
|
||||
f" {base_model.value}:{model_type.value}{':'+submodel.value if submodel else ''}"
|
||||
)
|
||||
if self.stats:
|
||||
self.stats.misses += 1
|
||||
|
||||
# this will remove older cached models until
|
||||
# there is sufficient room to load the requested model
|
||||
self._make_cache_room(model_info.get_size(submodel))
|
||||
self_reported_model_size_before_load = model_info.get_size(submodel)
|
||||
# Remove old models from the cache to make room for the new model.
|
||||
self._make_cache_room(self_reported_model_size_before_load)
|
||||
|
||||
# clean memory to make MemoryUsage() more accurate
|
||||
gc.collect()
|
||||
model = model_info.get_model(child_type=submodel, torch_dtype=self.precision)
|
||||
if mem_used := model_info.get_size(submodel):
|
||||
self.logger.debug(f"CPU RAM used for load: {(mem_used/GIG):.2f} GB")
|
||||
# Load the model from disk and capture a memory snapshot before/after.
|
||||
start_load_time = time.time()
|
||||
snapshot_before = MemorySnapshot.capture()
|
||||
with skip_torch_weight_init():
|
||||
model = model_info.get_model(child_type=submodel, torch_dtype=self.precision)
|
||||
snapshot_after = MemorySnapshot.capture()
|
||||
end_load_time = time.time()
|
||||
|
||||
cache_entry = _CacheRecord(self, model, mem_used)
|
||||
self_reported_model_size_after_load = model_info.get_size(submodel)
|
||||
|
||||
self.logger.debug(
|
||||
f"Moved model '{key}' from disk to cpu in {(end_load_time-start_load_time):.2f}s.\n"
|
||||
f"Self-reported size before/after load: {(self_reported_model_size_before_load/GIG):.3f}GB /"
|
||||
f" {(self_reported_model_size_after_load/GIG):.3f}GB.\n"
|
||||
f"{get_pretty_snapshot_diff(snapshot_before, snapshot_after)}"
|
||||
)
|
||||
|
||||
if abs(self_reported_model_size_after_load - self_reported_model_size_before_load) > 10 * MB:
|
||||
self.logger.debug(
|
||||
f"Model '{key}' mis-reported its size before load. Self-reported size before/after load:"
|
||||
f" {(self_reported_model_size_before_load/GIG):.2f}GB /"
|
||||
f" {(self_reported_model_size_after_load/GIG):.2f}GB."
|
||||
)
|
||||
|
||||
cache_entry = _CacheRecord(self, model, self_reported_model_size_after_load)
|
||||
self._cached_models[key] = cache_entry
|
||||
else:
|
||||
if self.stats:
|
||||
@@ -240,6 +265,45 @@ class ModelCache(object):
|
||||
|
||||
return self.ModelLocker(self, key, cache_entry.model, gpu_load, cache_entry.size)
|
||||
|
||||
def _move_model_to_device(self, key: str, target_device: torch.device):
|
||||
cache_entry = self._cached_models[key]
|
||||
|
||||
source_device = cache_entry.model.device
|
||||
# Note: We compare device types only so that 'cuda' == 'cuda:0'. This would need to be revised to support
|
||||
# multi-GPU.
|
||||
if torch.device(source_device).type == torch.device(target_device).type:
|
||||
return
|
||||
|
||||
start_model_to_time = time.time()
|
||||
snapshot_before = MemorySnapshot.capture()
|
||||
cache_entry.model.to(target_device)
|
||||
snapshot_after = MemorySnapshot.capture()
|
||||
end_model_to_time = time.time()
|
||||
self.logger.debug(
|
||||
f"Moved model '{key}' from {source_device} to"
|
||||
f" {target_device} in {(end_model_to_time-start_model_to_time):.2f}s.\n"
|
||||
f"Estimated model size: {(cache_entry.size/GIG):.3f} GB.\n"
|
||||
f"{get_pretty_snapshot_diff(snapshot_before, snapshot_after)}"
|
||||
)
|
||||
|
||||
if snapshot_before.vram is not None and snapshot_after.vram is not None:
|
||||
vram_change = abs(snapshot_before.vram - snapshot_after.vram)
|
||||
|
||||
# If the estimated model size does not match the change in VRAM, log a warning.
|
||||
if not math.isclose(
|
||||
vram_change,
|
||||
cache_entry.size,
|
||||
rel_tol=0.1,
|
||||
abs_tol=10 * MB,
|
||||
):
|
||||
self.logger.debug(
|
||||
f"Moving model '{key}' from {source_device} to"
|
||||
f" {target_device} caused an unexpected change in VRAM usage. The model's"
|
||||
" estimated size may be incorrect. Estimated model size:"
|
||||
f" {(cache_entry.size/GIG):.3f} GB.\n"
|
||||
f"{get_pretty_snapshot_diff(snapshot_before, snapshot_after)}"
|
||||
)
|
||||
|
||||
class ModelLocker(object):
|
||||
def __init__(self, cache, key, model, gpu_load, size_needed):
|
||||
"""
|
||||
@@ -269,11 +333,7 @@ class ModelCache(object):
|
||||
if self.cache.lazy_offloading:
|
||||
self.cache._offload_unlocked_models(self.size_needed)
|
||||
|
||||
if self.model.device != self.cache.execution_device:
|
||||
self.cache.logger.debug(f"Moving {self.key} into {self.cache.execution_device}")
|
||||
with VRAMUsage() as mem:
|
||||
self.model.to(self.cache.execution_device) # move into GPU
|
||||
self.cache.logger.debug(f"GPU VRAM used for load: {(mem.vram_used/GIG):.2f} GB")
|
||||
self.cache._move_model_to_device(self.key, self.cache.execution_device)
|
||||
|
||||
self.cache.logger.debug(f"Locking {self.key} in {self.cache.execution_device}")
|
||||
self.cache._print_cuda_stats()
|
||||
@@ -286,7 +346,7 @@ class ModelCache(object):
|
||||
# in the event that the caller wants the model in RAM, we
|
||||
# move it into CPU if it is in GPU and not locked
|
||||
elif self.cache_entry.loaded and not self.cache_entry.locked:
|
||||
self.model.to(self.cache.storage_device)
|
||||
self.cache._move_model_to_device(self.key, self.cache.storage_device)
|
||||
|
||||
return self.model
|
||||
|
||||
@@ -339,7 +399,8 @@ class ModelCache(object):
|
||||
locked_models += 1
|
||||
|
||||
self.logger.debug(
|
||||
f"Current VRAM/RAM usage: {vram}/{ram}; cached_models/loaded_models/locked_models/ = {cached_models}/{loaded_models}/{locked_models}"
|
||||
f"Current VRAM/RAM usage: {vram}/{ram}; cached_models/loaded_models/locked_models/ ="
|
||||
f" {cached_models}/{loaded_models}/{locked_models}"
|
||||
)
|
||||
|
||||
def _cache_size(self) -> int:
|
||||
@@ -354,7 +415,8 @@ class ModelCache(object):
|
||||
|
||||
if current_size + bytes_needed > maximum_size:
|
||||
self.logger.debug(
|
||||
f"Max cache size exceeded: {(current_size/GIG):.2f}/{self.max_cache_size:.2f} GB, need an additional {(bytes_needed/GIG):.2f} GB"
|
||||
f"Max cache size exceeded: {(current_size/GIG):.2f}/{self.max_cache_size:.2f} GB, need an additional"
|
||||
f" {(bytes_needed/GIG):.2f} GB"
|
||||
)
|
||||
|
||||
self.logger.debug(f"Before unloading: cached_models={len(self._cached_models)}")
|
||||
@@ -387,7 +449,8 @@ class ModelCache(object):
|
||||
|
||||
device = cache_entry.model.device if hasattr(cache_entry.model, "device") else None
|
||||
self.logger.debug(
|
||||
f"Model: {model_key}, locks: {cache_entry._locks}, device: {device}, loaded: {cache_entry.loaded}, refs: {refs}"
|
||||
f"Model: {model_key}, locks: {cache_entry._locks}, device: {device}, loaded: {cache_entry.loaded},"
|
||||
f" refs: {refs}"
|
||||
)
|
||||
|
||||
# 2 refs:
|
||||
@@ -423,11 +486,9 @@ class ModelCache(object):
|
||||
if vram_in_use <= reserved:
|
||||
break
|
||||
if not cache_entry.locked and cache_entry.loaded:
|
||||
self.logger.debug(f"Offloading {model_key} from {self.execution_device} into {self.storage_device}")
|
||||
with VRAMUsage() as mem:
|
||||
cache_entry.model.to(self.storage_device)
|
||||
self.logger.debug(f"GPU VRAM freed: {(mem.vram_used/GIG):.2f} GB")
|
||||
vram_in_use += mem.vram_used # note vram_used is negative
|
||||
self._move_model_to_device(model_key, self.storage_device)
|
||||
|
||||
vram_in_use = torch.cuda.memory_allocated()
|
||||
self.logger.debug(f"{(vram_in_use/GIG):.2f}GB VRAM used for models; max allowed={(reserved/GIG):.2f}GB")
|
||||
|
||||
gc.collect()
|
||||
@@ -454,16 +515,3 @@ class ModelCache(object):
|
||||
with open(hashpath, "w") as f:
|
||||
f.write(hash)
|
||||
return hash
|
||||
|
||||
|
||||
class VRAMUsage(object):
|
||||
def __init__(self):
|
||||
self.vram = None
|
||||
self.vram_used = 0
|
||||
|
||||
def __enter__(self):
|
||||
self.vram = torch.cuda.memory_allocated()
|
||||
return self
|
||||
|
||||
def __exit__(self, *args):
|
||||
self.vram_used = torch.cuda.memory_allocated() - self.vram
|
||||
|
||||
@@ -0,0 +1,30 @@
|
||||
from contextlib import contextmanager
|
||||
|
||||
import torch
|
||||
|
||||
|
||||
def _no_op(*args, **kwargs):
|
||||
pass
|
||||
|
||||
|
||||
@contextmanager
|
||||
def skip_torch_weight_init():
|
||||
"""A context manager that monkey-patches several of the common torch layers (torch.nn.Linear, torch.nn.Conv1d, etc.)
|
||||
to skip weight initialization.
|
||||
|
||||
By default, `torch.nn.Linear` and `torch.nn.ConvNd` layers initialize their weights (according to a particular
|
||||
distribution) when __init__ is called. This weight initialization step can take a significant amount of time, and is
|
||||
completely unnecessary if the intent is to load checkpoint weights from disk for the layer. This context manager
|
||||
monkey-patches common torch layers to skip the weight initialization step.
|
||||
"""
|
||||
torch_modules = [torch.nn.Linear, torch.nn.modules.conv._ConvNd]
|
||||
saved_functions = [m.reset_parameters for m in torch_modules]
|
||||
|
||||
try:
|
||||
for torch_module in torch_modules:
|
||||
torch_module.reset_parameters = _no_op
|
||||
|
||||
yield None
|
||||
finally:
|
||||
for torch_module, saved_function in zip(torch_modules, saved_functions):
|
||||
torch_module.reset_parameters = saved_function
|
||||
@@ -57,6 +57,7 @@ class ModelProbe(object):
|
||||
"AutoencoderTiny": ModelType.Vae,
|
||||
"ControlNetModel": ModelType.ControlNet,
|
||||
"CLIPVisionModelWithProjection": ModelType.CLIPVision,
|
||||
"T2IAdapter": ModelType.T2IAdapter,
|
||||
}
|
||||
|
||||
@classmethod
|
||||
@@ -90,8 +91,7 @@ class ModelProbe(object):
|
||||
to place it somewhere in the models directory hierarchy. If the model is
|
||||
already loaded into memory, you may provide it as model in order to avoid
|
||||
opening it a second time. The prediction_type_helper callable is a function that receives
|
||||
the path to the model and returns the BaseModelType. It is called to distinguish
|
||||
between V2-Base and V2-768 SD models.
|
||||
the path to the model and returns the SchedulerPredictionType.
|
||||
"""
|
||||
if model_path:
|
||||
format_type = "diffusers" if model_path.is_dir() else "checkpoint"
|
||||
@@ -305,25 +305,36 @@ class PipelineCheckpointProbe(CheckpointProbeBase):
|
||||
else:
|
||||
raise InvalidModelException("Cannot determine base type")
|
||||
|
||||
def get_scheduler_prediction_type(self) -> SchedulerPredictionType:
|
||||
def get_scheduler_prediction_type(self) -> Optional[SchedulerPredictionType]:
|
||||
"""Return model prediction type."""
|
||||
# if there is a .yaml associated with this checkpoint, then we do not need
|
||||
# to probe for the prediction type as it will be ignored.
|
||||
if self.checkpoint_path and self.checkpoint_path.with_suffix(".yaml").exists():
|
||||
return None
|
||||
|
||||
type = self.get_base_type()
|
||||
if type == BaseModelType.StableDiffusion1:
|
||||
return SchedulerPredictionType.Epsilon
|
||||
checkpoint = self.checkpoint
|
||||
state_dict = self.checkpoint.get("state_dict") or checkpoint
|
||||
key_name = "model.diffusion_model.input_blocks.2.1.transformer_blocks.0.attn2.to_k.weight"
|
||||
if key_name in state_dict and state_dict[key_name].shape[-1] == 1024:
|
||||
if "global_step" in checkpoint:
|
||||
if checkpoint["global_step"] == 220000:
|
||||
return SchedulerPredictionType.Epsilon
|
||||
elif checkpoint["global_step"] == 110000:
|
||||
return SchedulerPredictionType.VPrediction
|
||||
if (
|
||||
self.checkpoint_path and self.helper and not self.checkpoint_path.with_suffix(".yaml").exists()
|
||||
): # if a .yaml config file exists, then this step not needed
|
||||
return self.helper(self.checkpoint_path)
|
||||
else:
|
||||
return None
|
||||
if type == BaseModelType.StableDiffusion2:
|
||||
checkpoint = self.checkpoint
|
||||
state_dict = self.checkpoint.get("state_dict") or checkpoint
|
||||
key_name = "model.diffusion_model.input_blocks.2.1.transformer_blocks.0.attn2.to_k.weight"
|
||||
if key_name in state_dict and state_dict[key_name].shape[-1] == 1024:
|
||||
if "global_step" in checkpoint:
|
||||
if checkpoint["global_step"] == 220000:
|
||||
return SchedulerPredictionType.Epsilon
|
||||
elif checkpoint["global_step"] == 110000:
|
||||
return SchedulerPredictionType.VPrediction
|
||||
if self.helper and self.checkpoint_path:
|
||||
if helper_guess := self.helper(self.checkpoint_path):
|
||||
return helper_guess
|
||||
return SchedulerPredictionType.VPrediction # a guess for sd2 ckpts
|
||||
|
||||
elif type == BaseModelType.StableDiffusion1:
|
||||
if self.helper and self.checkpoint_path:
|
||||
if helper_guess := self.helper(self.checkpoint_path):
|
||||
return helper_guess
|
||||
return SchedulerPredictionType.Epsilon # a reasonable guess for sd1 ckpts
|
||||
else:
|
||||
return None
|
||||
|
||||
|
||||
class VaeCheckpointProbe(CheckpointProbeBase):
|
||||
@@ -398,6 +409,11 @@ class CLIPVisionCheckpointProbe(CheckpointProbeBase):
|
||||
raise NotImplementedError()
|
||||
|
||||
|
||||
class T2IAdapterCheckpointProbe(CheckpointProbeBase):
|
||||
def get_base_type(self) -> BaseModelType:
|
||||
raise NotImplementedError()
|
||||
|
||||
|
||||
########################################################
|
||||
# classes for probing folders
|
||||
#######################################################
|
||||
@@ -585,6 +601,26 @@ class CLIPVisionFolderProbe(FolderProbeBase):
|
||||
return BaseModelType.Any
|
||||
|
||||
|
||||
class T2IAdapterFolderProbe(FolderProbeBase):
|
||||
def get_base_type(self) -> BaseModelType:
|
||||
config_file = self.folder_path / "config.json"
|
||||
if not config_file.exists():
|
||||
raise InvalidModelException(f"Cannot determine base type for {self.folder_path}")
|
||||
with open(config_file, "r") as file:
|
||||
config = json.load(file)
|
||||
|
||||
adapter_type = config.get("adapter_type", None)
|
||||
if adapter_type == "full_adapter_xl":
|
||||
return BaseModelType.StableDiffusionXL
|
||||
elif adapter_type == "full_adapter" or "light_adapter":
|
||||
# I haven't seen any T2I adapter models for SD2, so assume that this is an SD1 adapter.
|
||||
return BaseModelType.StableDiffusion1
|
||||
else:
|
||||
raise InvalidModelException(
|
||||
f"Unable to determine base model for '{self.folder_path}' (adapter_type = {adapter_type})."
|
||||
)
|
||||
|
||||
|
||||
############## register probe classes ######
|
||||
ModelProbe.register_probe("diffusers", ModelType.Main, PipelineFolderProbe)
|
||||
ModelProbe.register_probe("diffusers", ModelType.Vae, VaeFolderProbe)
|
||||
@@ -593,6 +629,7 @@ ModelProbe.register_probe("diffusers", ModelType.TextualInversion, TextualInvers
|
||||
ModelProbe.register_probe("diffusers", ModelType.ControlNet, ControlNetFolderProbe)
|
||||
ModelProbe.register_probe("diffusers", ModelType.IPAdapter, IPAdapterFolderProbe)
|
||||
ModelProbe.register_probe("diffusers", ModelType.CLIPVision, CLIPVisionFolderProbe)
|
||||
ModelProbe.register_probe("diffusers", ModelType.T2IAdapter, T2IAdapterFolderProbe)
|
||||
|
||||
ModelProbe.register_probe("checkpoint", ModelType.Main, PipelineCheckpointProbe)
|
||||
ModelProbe.register_probe("checkpoint", ModelType.Vae, VaeCheckpointProbe)
|
||||
@@ -601,5 +638,6 @@ ModelProbe.register_probe("checkpoint", ModelType.TextualInversion, TextualInver
|
||||
ModelProbe.register_probe("checkpoint", ModelType.ControlNet, ControlNetCheckpointProbe)
|
||||
ModelProbe.register_probe("checkpoint", ModelType.IPAdapter, IPAdapterCheckpointProbe)
|
||||
ModelProbe.register_probe("checkpoint", ModelType.CLIPVision, CLIPVisionCheckpointProbe)
|
||||
ModelProbe.register_probe("checkpoint", ModelType.T2IAdapter, T2IAdapterCheckpointProbe)
|
||||
|
||||
ModelProbe.register_probe("onnx", ModelType.ONNX, ONNXFolderProbe)
|
||||
|
||||
@@ -71,7 +71,13 @@ class ModelSearch(ABC):
|
||||
if any(
|
||||
[
|
||||
(path / x).exists()
|
||||
for x in {"config.json", "model_index.json", "learned_embeds.bin", "pytorch_lora_weights.bin"}
|
||||
for x in {
|
||||
"config.json",
|
||||
"model_index.json",
|
||||
"learned_embeds.bin",
|
||||
"pytorch_lora_weights.bin",
|
||||
"image_encoder.txt",
|
||||
}
|
||||
]
|
||||
):
|
||||
try:
|
||||
|
||||
@@ -25,6 +25,7 @@ from .lora import LoRAModel
|
||||
from .sdxl import StableDiffusionXLModel
|
||||
from .stable_diffusion import StableDiffusion1Model, StableDiffusion2Model
|
||||
from .stable_diffusion_onnx import ONNXStableDiffusion1Model, ONNXStableDiffusion2Model
|
||||
from .t2i_adapter import T2IAdapterModel
|
||||
from .textual_inversion import TextualInversionModel
|
||||
from .vae import VaeModel
|
||||
|
||||
@@ -38,6 +39,7 @@ MODEL_CLASSES = {
|
||||
ModelType.TextualInversion: TextualInversionModel,
|
||||
ModelType.IPAdapter: IPAdapterModel,
|
||||
ModelType.CLIPVision: CLIPVisionModel,
|
||||
ModelType.T2IAdapter: T2IAdapterModel,
|
||||
},
|
||||
BaseModelType.StableDiffusion2: {
|
||||
ModelType.ONNX: ONNXStableDiffusion2Model,
|
||||
@@ -48,6 +50,7 @@ MODEL_CLASSES = {
|
||||
ModelType.TextualInversion: TextualInversionModel,
|
||||
ModelType.IPAdapter: IPAdapterModel,
|
||||
ModelType.CLIPVision: CLIPVisionModel,
|
||||
ModelType.T2IAdapter: T2IAdapterModel,
|
||||
},
|
||||
BaseModelType.StableDiffusionXL: {
|
||||
ModelType.Main: StableDiffusionXLModel,
|
||||
@@ -59,6 +62,7 @@ MODEL_CLASSES = {
|
||||
ModelType.ONNX: ONNXStableDiffusion2Model,
|
||||
ModelType.IPAdapter: IPAdapterModel,
|
||||
ModelType.CLIPVision: CLIPVisionModel,
|
||||
ModelType.T2IAdapter: T2IAdapterModel,
|
||||
},
|
||||
BaseModelType.StableDiffusionXLRefiner: {
|
||||
ModelType.Main: StableDiffusionXLModel,
|
||||
@@ -70,6 +74,7 @@ MODEL_CLASSES = {
|
||||
ModelType.ONNX: ONNXStableDiffusion2Model,
|
||||
ModelType.IPAdapter: IPAdapterModel,
|
||||
ModelType.CLIPVision: CLIPVisionModel,
|
||||
ModelType.T2IAdapter: T2IAdapterModel,
|
||||
},
|
||||
BaseModelType.Any: {
|
||||
ModelType.CLIPVision: CLIPVisionModel,
|
||||
@@ -81,6 +86,7 @@ MODEL_CLASSES = {
|
||||
ModelType.ControlNet: ControlNetModel,
|
||||
ModelType.TextualInversion: TextualInversionModel,
|
||||
ModelType.IPAdapter: IPAdapterModel,
|
||||
ModelType.T2IAdapter: T2IAdapterModel,
|
||||
},
|
||||
# BaseModelType.Kandinsky2_1: {
|
||||
# ModelType.Main: Kandinsky2_1Model,
|
||||
|
||||
@@ -53,6 +53,7 @@ class ModelType(str, Enum):
|
||||
TextualInversion = "embedding"
|
||||
IPAdapter = "ip_adapter"
|
||||
CLIPVision = "clip_vision"
|
||||
T2IAdapter = "t2i_adapter"
|
||||
|
||||
|
||||
class SubModelType(str, Enum):
|
||||
|
||||
@@ -13,6 +13,7 @@ from invokeai.backend.model_management.models.base import (
|
||||
ModelConfigBase,
|
||||
ModelType,
|
||||
SubModelType,
|
||||
calc_model_size_by_fs,
|
||||
classproperty,
|
||||
)
|
||||
|
||||
@@ -30,7 +31,7 @@ class IPAdapterModel(ModelBase):
|
||||
assert model_type == ModelType.IPAdapter
|
||||
super().__init__(model_path, base_model, model_type)
|
||||
|
||||
self.model_size = os.path.getsize(self.model_path)
|
||||
self.model_size = calc_model_size_by_fs(self.model_path)
|
||||
|
||||
@classmethod
|
||||
def detect_format(cls, path: str) -> str:
|
||||
@@ -63,10 +64,13 @@ class IPAdapterModel(ModelBase):
|
||||
if child_type is not None:
|
||||
raise ValueError("There are no child models in an IP-Adapter model.")
|
||||
|
||||
return build_ip_adapter(
|
||||
model = build_ip_adapter(
|
||||
ip_adapter_ckpt_path=os.path.join(self.model_path, "ip_adapter.bin"), device="cpu", dtype=torch_dtype
|
||||
)
|
||||
|
||||
self.model_size = model.calc_size()
|
||||
return model
|
||||
|
||||
@classmethod
|
||||
def convert_if_required(
|
||||
cls,
|
||||
|
||||
102
invokeai/backend/model_management/models/t2i_adapter.py
Normal file
102
invokeai/backend/model_management/models/t2i_adapter.py
Normal file
@@ -0,0 +1,102 @@
|
||||
import os
|
||||
from enum import Enum
|
||||
from typing import Literal, Optional
|
||||
|
||||
import torch
|
||||
from diffusers import T2IAdapter
|
||||
|
||||
from invokeai.backend.model_management.models.base import (
|
||||
BaseModelType,
|
||||
EmptyConfigLoader,
|
||||
InvalidModelException,
|
||||
ModelBase,
|
||||
ModelConfigBase,
|
||||
ModelNotFoundException,
|
||||
ModelType,
|
||||
SubModelType,
|
||||
calc_model_size_by_data,
|
||||
calc_model_size_by_fs,
|
||||
classproperty,
|
||||
)
|
||||
|
||||
|
||||
class T2IAdapterModelFormat(str, Enum):
|
||||
Diffusers = "diffusers"
|
||||
|
||||
|
||||
class T2IAdapterModel(ModelBase):
|
||||
class DiffusersConfig(ModelConfigBase):
|
||||
model_format: Literal[T2IAdapterModelFormat.Diffusers]
|
||||
|
||||
def __init__(self, model_path: str, base_model: BaseModelType, model_type: ModelType):
|
||||
assert model_type == ModelType.T2IAdapter
|
||||
super().__init__(model_path, base_model, model_type)
|
||||
|
||||
config = EmptyConfigLoader.load_config(self.model_path, config_name="config.json")
|
||||
|
||||
model_class_name = config.get("_class_name", None)
|
||||
if model_class_name not in {"T2IAdapter"}:
|
||||
raise InvalidModelException(f"Invalid T2I-Adapter model. Unknown _class_name: '{model_class_name}'.")
|
||||
|
||||
self.model_class = self._hf_definition_to_type(["diffusers", model_class_name])
|
||||
self.model_size = calc_model_size_by_fs(self.model_path)
|
||||
|
||||
def get_size(self, child_type: Optional[SubModelType] = None):
|
||||
if child_type is not None:
|
||||
raise ValueError(f"T2I-Adapters do not have child models. Invalid child type: '{child_type}'.")
|
||||
return self.model_size
|
||||
|
||||
def get_model(
|
||||
self,
|
||||
torch_dtype: Optional[torch.dtype],
|
||||
child_type: Optional[SubModelType] = None,
|
||||
) -> T2IAdapter:
|
||||
if child_type is not None:
|
||||
raise ValueError(f"T2I-Adapters do not have child models. Invalid child type: '{child_type}'.")
|
||||
|
||||
model = None
|
||||
for variant in ["fp16", None]:
|
||||
try:
|
||||
model = self.model_class.from_pretrained(
|
||||
self.model_path,
|
||||
torch_dtype=torch_dtype,
|
||||
variant=variant,
|
||||
)
|
||||
break
|
||||
except Exception:
|
||||
pass
|
||||
if not model:
|
||||
raise ModelNotFoundException()
|
||||
|
||||
# Calculate a more accurate size after loading the model into memory.
|
||||
self.model_size = calc_model_size_by_data(model)
|
||||
return model
|
||||
|
||||
@classproperty
|
||||
def save_to_config(cls) -> bool:
|
||||
return False
|
||||
|
||||
@classmethod
|
||||
def detect_format(cls, path: str):
|
||||
if not os.path.exists(path):
|
||||
raise ModelNotFoundException(f"Model not found at '{path}'.")
|
||||
|
||||
if os.path.isdir(path):
|
||||
if os.path.exists(os.path.join(path, "config.json")):
|
||||
return T2IAdapterModelFormat.Diffusers
|
||||
|
||||
raise InvalidModelException(f"Unsupported T2I-Adapter format: '{path}'.")
|
||||
|
||||
@classmethod
|
||||
def convert_if_required(
|
||||
cls,
|
||||
model_path: str,
|
||||
output_path: str,
|
||||
config: ModelConfigBase,
|
||||
base_model: BaseModelType,
|
||||
) -> str:
|
||||
format = cls.detect_format(model_path)
|
||||
if format == T2IAdapterModelFormat.Diffusers:
|
||||
return model_path
|
||||
else:
|
||||
raise ValueError(f"Unsupported format: '{format}'.")
|
||||
@@ -24,6 +24,7 @@ from transformers import CLIPFeatureExtractor, CLIPTextModel, CLIPTokenizer
|
||||
|
||||
from invokeai.app.services.config import InvokeAIAppConfig
|
||||
from invokeai.backend.ip_adapter.ip_adapter import IPAdapter
|
||||
from invokeai.backend.ip_adapter.unet_patcher import UNetPatcher
|
||||
from invokeai.backend.stable_diffusion.diffusion.conditioning_data import ConditioningData
|
||||
|
||||
from ..util import auto_detect_slice_size, normalize_device
|
||||
@@ -173,6 +174,16 @@ class IPAdapterData:
|
||||
end_step_percent: float = Field(default=1.0)
|
||||
|
||||
|
||||
@dataclass
|
||||
class T2IAdapterData:
|
||||
"""A structure containing the information required to apply conditioning from a single T2I-Adapter model."""
|
||||
|
||||
adapter_state: dict[torch.Tensor] = Field()
|
||||
weight: Union[float, list[float]] = Field(default=1.0)
|
||||
begin_step_percent: float = Field(default=0.0)
|
||||
end_step_percent: float = Field(default=1.0)
|
||||
|
||||
|
||||
@dataclass
|
||||
class InvokeAIStableDiffusionPipelineOutput(StableDiffusionPipelineOutput):
|
||||
r"""
|
||||
@@ -326,7 +337,8 @@ class StableDiffusionGeneratorPipeline(StableDiffusionPipeline):
|
||||
additional_guidance: List[Callable] = None,
|
||||
callback: Callable[[PipelineIntermediateState], None] = None,
|
||||
control_data: List[ControlNetData] = None,
|
||||
ip_adapter_data: Optional[IPAdapterData] = None,
|
||||
ip_adapter_data: Optional[list[IPAdapterData]] = None,
|
||||
t2i_adapter_data: Optional[list[T2IAdapterData]] = None,
|
||||
mask: Optional[torch.Tensor] = None,
|
||||
masked_latents: Optional[torch.Tensor] = None,
|
||||
seed: Optional[int] = None,
|
||||
@@ -379,6 +391,7 @@ class StableDiffusionGeneratorPipeline(StableDiffusionPipeline):
|
||||
additional_guidance=additional_guidance,
|
||||
control_data=control_data,
|
||||
ip_adapter_data=ip_adapter_data,
|
||||
t2i_adapter_data=t2i_adapter_data,
|
||||
callback=callback,
|
||||
)
|
||||
finally:
|
||||
@@ -398,7 +411,8 @@ class StableDiffusionGeneratorPipeline(StableDiffusionPipeline):
|
||||
*,
|
||||
additional_guidance: List[Callable] = None,
|
||||
control_data: List[ControlNetData] = None,
|
||||
ip_adapter_data: Optional[IPAdapterData] = None,
|
||||
ip_adapter_data: Optional[list[IPAdapterData]] = None,
|
||||
t2i_adapter_data: Optional[list[T2IAdapterData]] = None,
|
||||
callback: Callable[[PipelineIntermediateState], None] = None,
|
||||
):
|
||||
self._adjust_memory_efficient_attention(latents)
|
||||
@@ -411,6 +425,7 @@ class StableDiffusionGeneratorPipeline(StableDiffusionPipeline):
|
||||
if timesteps.shape[0] == 0:
|
||||
return latents, attention_map_saver
|
||||
|
||||
ip_adapter_unet_patcher = None
|
||||
if conditioning_data.extra is not None and conditioning_data.extra.wants_cross_attention_control:
|
||||
attn_ctx = self.invokeai_diffuser.custom_attention_context(
|
||||
self.invokeai_diffuser.model,
|
||||
@@ -421,11 +436,8 @@ class StableDiffusionGeneratorPipeline(StableDiffusionPipeline):
|
||||
elif ip_adapter_data is not None:
|
||||
# TODO(ryand): Should we raise an exception if both custom attention and IP-Adapter attention are active?
|
||||
# As it is now, the IP-Adapter will silently be skipped.
|
||||
weight = ip_adapter_data.weight[0] if isinstance(ip_adapter_data.weight, List) else ip_adapter_data.weight
|
||||
attn_ctx = ip_adapter_data.ip_adapter_model.apply_ip_adapter_attention(
|
||||
unet=self.invokeai_diffuser.model,
|
||||
scale=weight,
|
||||
)
|
||||
ip_adapter_unet_patcher = UNetPatcher([ipa.ip_adapter_model for ipa in ip_adapter_data])
|
||||
attn_ctx = ip_adapter_unet_patcher.apply_ip_adapter_attention(self.invokeai_diffuser.model)
|
||||
self.use_ip_adapter = True
|
||||
else:
|
||||
attn_ctx = nullcontext()
|
||||
@@ -454,6 +466,8 @@ class StableDiffusionGeneratorPipeline(StableDiffusionPipeline):
|
||||
additional_guidance=additional_guidance,
|
||||
control_data=control_data,
|
||||
ip_adapter_data=ip_adapter_data,
|
||||
t2i_adapter_data=t2i_adapter_data,
|
||||
ip_adapter_unet_patcher=ip_adapter_unet_patcher,
|
||||
)
|
||||
latents = step_output.prev_sample
|
||||
|
||||
@@ -499,7 +513,9 @@ class StableDiffusionGeneratorPipeline(StableDiffusionPipeline):
|
||||
total_step_count: int,
|
||||
additional_guidance: List[Callable] = None,
|
||||
control_data: List[ControlNetData] = None,
|
||||
ip_adapter_data: Optional[IPAdapterData] = None,
|
||||
ip_adapter_data: Optional[list[IPAdapterData]] = None,
|
||||
t2i_adapter_data: Optional[list[T2IAdapterData]] = None,
|
||||
ip_adapter_unet_patcher: Optional[UNetPatcher] = None,
|
||||
):
|
||||
# invokeai_diffuser has batched timesteps, but diffusers schedulers expect a single value
|
||||
timestep = t[0]
|
||||
@@ -512,26 +528,30 @@ class StableDiffusionGeneratorPipeline(StableDiffusionPipeline):
|
||||
|
||||
# handle IP-Adapter
|
||||
if self.use_ip_adapter and ip_adapter_data is not None: # somewhat redundant but logic is clearer
|
||||
first_adapter_step = math.floor(ip_adapter_data.begin_step_percent * total_step_count)
|
||||
last_adapter_step = math.ceil(ip_adapter_data.end_step_percent * total_step_count)
|
||||
weight = (
|
||||
ip_adapter_data.weight[step_index]
|
||||
if isinstance(ip_adapter_data.weight, List)
|
||||
else ip_adapter_data.weight
|
||||
)
|
||||
if step_index >= first_adapter_step and step_index <= last_adapter_step:
|
||||
# only apply IP-Adapter if current step is within the IP-Adapter's begin/end step range
|
||||
# ip_adapter_data.ip_adapter_model.set_scale(ip_adapter_data.weight)
|
||||
ip_adapter_data.ip_adapter_model.set_scale(weight)
|
||||
else:
|
||||
# otherwise, set IP-Adapter scale to 0, so it has no effect
|
||||
ip_adapter_data.ip_adapter_model.set_scale(0.0)
|
||||
for i, single_ip_adapter_data in enumerate(ip_adapter_data):
|
||||
first_adapter_step = math.floor(single_ip_adapter_data.begin_step_percent * total_step_count)
|
||||
last_adapter_step = math.ceil(single_ip_adapter_data.end_step_percent * total_step_count)
|
||||
weight = (
|
||||
single_ip_adapter_data.weight[step_index]
|
||||
if isinstance(single_ip_adapter_data.weight, List)
|
||||
else single_ip_adapter_data.weight
|
||||
)
|
||||
if step_index >= first_adapter_step and step_index <= last_adapter_step:
|
||||
# Only apply this IP-Adapter if the current step is within the IP-Adapter's begin/end step range.
|
||||
ip_adapter_unet_patcher.set_scale(i, weight)
|
||||
else:
|
||||
# Otherwise, set the IP-Adapter's scale to 0, so it has no effect.
|
||||
ip_adapter_unet_patcher.set_scale(i, 0.0)
|
||||
|
||||
# handle ControlNet(s)
|
||||
# default is no controlnet, so set controlnet processing output to None
|
||||
controlnet_down_block_samples, controlnet_mid_block_sample = None, None
|
||||
if control_data is not None:
|
||||
controlnet_down_block_samples, controlnet_mid_block_sample = self.invokeai_diffuser.do_controlnet_step(
|
||||
# Handle ControlNet(s) and T2I-Adapter(s)
|
||||
down_block_additional_residuals = None
|
||||
mid_block_additional_residual = None
|
||||
if control_data is not None and t2i_adapter_data is not None:
|
||||
# TODO(ryand): This is a limitation of the UNet2DConditionModel API, not a fundamental incompatibility
|
||||
# between ControlNets and T2I-Adapters. We will try to fix this upstream in diffusers.
|
||||
raise Exception("ControlNet(s) and T2I-Adapter(s) cannot be used simultaneously (yet).")
|
||||
elif control_data is not None:
|
||||
down_block_additional_residuals, mid_block_additional_residual = self.invokeai_diffuser.do_controlnet_step(
|
||||
control_data=control_data,
|
||||
sample=latent_model_input,
|
||||
timestep=timestep,
|
||||
@@ -539,6 +559,32 @@ class StableDiffusionGeneratorPipeline(StableDiffusionPipeline):
|
||||
total_step_count=total_step_count,
|
||||
conditioning_data=conditioning_data,
|
||||
)
|
||||
elif t2i_adapter_data is not None:
|
||||
accum_adapter_state = None
|
||||
for single_t2i_adapter_data in t2i_adapter_data:
|
||||
# Determine the T2I-Adapter weights for the current denoising step.
|
||||
first_t2i_adapter_step = math.floor(single_t2i_adapter_data.begin_step_percent * total_step_count)
|
||||
last_t2i_adapter_step = math.ceil(single_t2i_adapter_data.end_step_percent * total_step_count)
|
||||
t2i_adapter_weight = (
|
||||
single_t2i_adapter_data.weight[step_index]
|
||||
if isinstance(single_t2i_adapter_data.weight, list)
|
||||
else single_t2i_adapter_data.weight
|
||||
)
|
||||
if step_index < first_t2i_adapter_step or step_index > last_t2i_adapter_step:
|
||||
# If the current step is outside of the T2I-Adapter's begin/end step range, then set its weight to 0
|
||||
# so it has no effect.
|
||||
t2i_adapter_weight = 0.0
|
||||
|
||||
# Apply the t2i_adapter_weight, and accumulate.
|
||||
if accum_adapter_state is None:
|
||||
# Handle the first T2I-Adapter.
|
||||
accum_adapter_state = [val * t2i_adapter_weight for val in single_t2i_adapter_data.adapter_state]
|
||||
else:
|
||||
# Add to the previous adapter states.
|
||||
for idx, value in enumerate(single_t2i_adapter_data.adapter_state):
|
||||
accum_adapter_state[idx] += value * t2i_adapter_weight
|
||||
|
||||
down_block_additional_residuals = accum_adapter_state
|
||||
|
||||
uc_noise_pred, c_noise_pred = self.invokeai_diffuser.do_unet_step(
|
||||
sample=latent_model_input,
|
||||
@@ -547,8 +593,8 @@ class StableDiffusionGeneratorPipeline(StableDiffusionPipeline):
|
||||
total_step_count=total_step_count,
|
||||
conditioning_data=conditioning_data,
|
||||
# extra:
|
||||
down_block_additional_residuals=controlnet_down_block_samples, # from controlnet(s)
|
||||
mid_block_additional_residual=controlnet_mid_block_sample, # from controlnet(s)
|
||||
down_block_additional_residuals=down_block_additional_residuals,
|
||||
mid_block_additional_residual=mid_block_additional_residual,
|
||||
)
|
||||
|
||||
guidance_scale = conditioning_data.guidance_scale
|
||||
|
||||
@@ -81,7 +81,7 @@ class ConditioningData:
|
||||
"""
|
||||
postprocessing_settings: Optional[PostprocessingSettings] = None
|
||||
|
||||
ip_adapter_conditioning: Optional[IPAdapterConditioningInfo] = None
|
||||
ip_adapter_conditioning: Optional[list[IPAdapterConditioningInfo]] = None
|
||||
|
||||
@property
|
||||
def dtype(self):
|
||||
|
||||
@@ -346,12 +346,10 @@ class InvokeAIDiffuserComponent:
|
||||
cross_attention_kwargs = None
|
||||
if conditioning_data.ip_adapter_conditioning is not None:
|
||||
cross_attention_kwargs = {
|
||||
"ip_adapter_image_prompt_embeds": torch.cat(
|
||||
[
|
||||
conditioning_data.ip_adapter_conditioning.uncond_image_prompt_embeds,
|
||||
conditioning_data.ip_adapter_conditioning.cond_image_prompt_embeds,
|
||||
]
|
||||
)
|
||||
"ip_adapter_image_prompt_embeds": [
|
||||
torch.cat([ipa_conditioning.uncond_image_prompt_embeds, ipa_conditioning.cond_image_prompt_embeds])
|
||||
for ipa_conditioning in conditioning_data.ip_adapter_conditioning
|
||||
]
|
||||
}
|
||||
|
||||
added_cond_kwargs = None
|
||||
@@ -418,7 +416,10 @@ class InvokeAIDiffuserComponent:
|
||||
cross_attention_kwargs = None
|
||||
if conditioning_data.ip_adapter_conditioning is not None:
|
||||
cross_attention_kwargs = {
|
||||
"ip_adapter_image_prompt_embeds": conditioning_data.ip_adapter_conditioning.uncond_image_prompt_embeds
|
||||
"ip_adapter_image_prompt_embeds": [
|
||||
ipa_conditioning.uncond_image_prompt_embeds
|
||||
for ipa_conditioning in conditioning_data.ip_adapter_conditioning
|
||||
]
|
||||
}
|
||||
|
||||
added_cond_kwargs = None
|
||||
@@ -444,7 +445,10 @@ class InvokeAIDiffuserComponent:
|
||||
cross_attention_kwargs = None
|
||||
if conditioning_data.ip_adapter_conditioning is not None:
|
||||
cross_attention_kwargs = {
|
||||
"ip_adapter_image_prompt_embeds": conditioning_data.ip_adapter_conditioning.cond_image_prompt_embeds
|
||||
"ip_adapter_image_prompt_embeds": [
|
||||
ipa_conditioning.cond_image_prompt_embeds
|
||||
for ipa_conditioning in conditioning_data.ip_adapter_conditioning
|
||||
]
|
||||
}
|
||||
|
||||
added_cond_kwargs = None
|
||||
|
||||
@@ -24,7 +24,7 @@ from invokeai.backend.util.logging import InvokeAILogger
|
||||
# Modified ControlNetModel with encoder_attention_mask argument added
|
||||
|
||||
|
||||
logger = InvokeAILogger.getLogger(__name__)
|
||||
logger = InvokeAILogger.get_logger(__name__)
|
||||
|
||||
|
||||
class ControlNetModel(ModelMixin, ConfigMixin, FromOriginalControlnetMixin):
|
||||
|
||||
@@ -1,7 +1,6 @@
|
||||
# Copyright (c) 2023 Lincoln D. Stein and The InvokeAI Development Team
|
||||
|
||||
"""
|
||||
invokeai.backend.util.logging
|
||||
"""invokeai.backend.util.logging
|
||||
|
||||
Logging class for InvokeAI that produces console messages
|
||||
|
||||
@@ -9,9 +8,9 @@ Usage:
|
||||
|
||||
from invokeai.backend.util.logging import InvokeAILogger
|
||||
|
||||
logger = InvokeAILogger.getLogger(name='InvokeAI') // Initialization
|
||||
logger = InvokeAILogger.get_logger(name='InvokeAI') // Initialization
|
||||
(or)
|
||||
logger = InvokeAILogger.getLogger(__name__) // To use the filename
|
||||
logger = InvokeAILogger.get_logger(__name__) // To use the filename
|
||||
logger.configure()
|
||||
|
||||
logger.critical('this is critical') // Critical Message
|
||||
@@ -34,13 +33,13 @@ IAILogger.debug('this is a debugging message')
|
||||
## Configuration
|
||||
|
||||
The default configuration will print to stderr on the console. To add
|
||||
additional logging handlers, call getLogger with an initialized InvokeAIAppConfig
|
||||
additional logging handlers, call get_logger with an initialized InvokeAIAppConfig
|
||||
object:
|
||||
|
||||
|
||||
config = InvokeAIAppConfig.get_config()
|
||||
config.parse_args()
|
||||
logger = InvokeAILogger.getLogger(config=config)
|
||||
logger = InvokeAILogger.get_logger(config=config)
|
||||
|
||||
### Three command-line options control logging:
|
||||
|
||||
@@ -173,6 +172,7 @@ InvokeAI:
|
||||
log_level: info
|
||||
log_format: color
|
||||
```
|
||||
|
||||
"""
|
||||
|
||||
import logging.handlers
|
||||
@@ -193,39 +193,35 @@ except ImportError:
|
||||
|
||||
# module level functions
|
||||
def debug(msg, *args, **kwargs):
|
||||
InvokeAILogger.getLogger().debug(msg, *args, **kwargs)
|
||||
InvokeAILogger.get_logger().debug(msg, *args, **kwargs)
|
||||
|
||||
|
||||
def info(msg, *args, **kwargs):
|
||||
InvokeAILogger.getLogger().info(msg, *args, **kwargs)
|
||||
InvokeAILogger.get_logger().info(msg, *args, **kwargs)
|
||||
|
||||
|
||||
def warning(msg, *args, **kwargs):
|
||||
InvokeAILogger.getLogger().warning(msg, *args, **kwargs)
|
||||
InvokeAILogger.get_logger().warning(msg, *args, **kwargs)
|
||||
|
||||
|
||||
def error(msg, *args, **kwargs):
|
||||
InvokeAILogger.getLogger().error(msg, *args, **kwargs)
|
||||
InvokeAILogger.get_logger().error(msg, *args, **kwargs)
|
||||
|
||||
|
||||
def critical(msg, *args, **kwargs):
|
||||
InvokeAILogger.getLogger().critical(msg, *args, **kwargs)
|
||||
InvokeAILogger.get_logger().critical(msg, *args, **kwargs)
|
||||
|
||||
|
||||
def log(level, msg, *args, **kwargs):
|
||||
InvokeAILogger.getLogger().log(level, msg, *args, **kwargs)
|
||||
InvokeAILogger.get_logger().log(level, msg, *args, **kwargs)
|
||||
|
||||
|
||||
def disable(level=logging.CRITICAL):
|
||||
InvokeAILogger.getLogger().disable(level)
|
||||
InvokeAILogger.get_logger().disable(level)
|
||||
|
||||
|
||||
def basicConfig(**kwargs):
|
||||
InvokeAILogger.getLogger().basicConfig(**kwargs)
|
||||
|
||||
|
||||
def getLogger(name: str = None) -> logging.Logger:
|
||||
return InvokeAILogger.getLogger(name)
|
||||
InvokeAILogger.get_logger().basicConfig(**kwargs)
|
||||
|
||||
|
||||
_FACILITY_MAP = (
|
||||
@@ -351,7 +347,7 @@ class InvokeAILogger(object):
|
||||
loggers = dict()
|
||||
|
||||
@classmethod
|
||||
def getLogger(
|
||||
def get_logger(
|
||||
cls, name: str = "InvokeAI", config: InvokeAIAppConfig = InvokeAIAppConfig.get_config()
|
||||
) -> logging.Logger:
|
||||
if name in cls.loggers:
|
||||
@@ -360,13 +356,13 @@ class InvokeAILogger(object):
|
||||
else:
|
||||
logger = logging.getLogger(name)
|
||||
logger.setLevel(config.log_level.upper()) # yes, strings work here
|
||||
for ch in cls.getLoggers(config):
|
||||
for ch in cls.get_loggers(config):
|
||||
logger.addHandler(ch)
|
||||
cls.loggers[name] = logger
|
||||
return cls.loggers[name]
|
||||
|
||||
@classmethod
|
||||
def getLoggers(cls, config: InvokeAIAppConfig) -> list[logging.Handler]:
|
||||
def get_loggers(cls, config: InvokeAIAppConfig) -> list[logging.Handler]:
|
||||
handler_strs = config.log_handlers
|
||||
handlers = list()
|
||||
for handler in handler_strs:
|
||||
|
||||
67
invokeai/backend/util/test_utils.py
Normal file
67
invokeai/backend/util/test_utils.py
Normal file
@@ -0,0 +1,67 @@
|
||||
import contextlib
|
||||
from pathlib import Path
|
||||
from typing import Optional, Union
|
||||
|
||||
import pytest
|
||||
import torch
|
||||
|
||||
from invokeai.app.services.config.invokeai_config import InvokeAIAppConfig
|
||||
from invokeai.backend.install.model_install_backend import ModelInstall
|
||||
from invokeai.backend.model_management.model_manager import ModelInfo
|
||||
from invokeai.backend.model_management.models.base import BaseModelType, ModelNotFoundException, ModelType, SubModelType
|
||||
|
||||
|
||||
@pytest.fixture(scope="session")
|
||||
def torch_device():
|
||||
return "cuda" if torch.cuda.is_available() else "cpu"
|
||||
|
||||
|
||||
@pytest.fixture(scope="module")
|
||||
def model_installer():
|
||||
"""A global ModelInstall pytest fixture to be used by many tests."""
|
||||
# HACK(ryand): InvokeAIAppConfig.get_config() returns a singleton config object. This can lead to weird interactions
|
||||
# between tests that need to alter the config. For example, some tests change the 'root' directory in the config,
|
||||
# which can cause `install_and_load_model(...)` to re-download the model unnecessarily. As a temporary workaround,
|
||||
# we pass a kwarg to get_config, which causes the config to be re-loaded. To fix this properly, we should stop using
|
||||
# a singleton.
|
||||
return ModelInstall(InvokeAIAppConfig.get_config(log_level="info"))
|
||||
|
||||
|
||||
def install_and_load_model(
|
||||
model_installer: ModelInstall,
|
||||
model_path_id_or_url: Union[str, Path],
|
||||
model_name: str,
|
||||
base_model: BaseModelType,
|
||||
model_type: ModelType,
|
||||
submodel_type: Optional[SubModelType] = None,
|
||||
) -> ModelInfo:
|
||||
"""Install a model if it is not already installed, then get the ModelInfo for that model.
|
||||
|
||||
This is intended as a utility function for tests.
|
||||
|
||||
Args:
|
||||
model_installer (ModelInstall): The model installer.
|
||||
model_path_id_or_url (Union[str, Path]): The path, HF ID, URL, etc. where the model can be installed from if it
|
||||
is not already installed.
|
||||
model_name (str): The model name, forwarded to ModelManager.get_model(...).
|
||||
base_model (BaseModelType): The base model, forwarded to ModelManager.get_model(...).
|
||||
model_type (ModelType): The model type, forwarded to ModelManager.get_model(...).
|
||||
submodel_type (Optional[SubModelType]): The submodel type, forwarded to ModelManager.get_model(...).
|
||||
|
||||
Returns:
|
||||
ModelInfo
|
||||
"""
|
||||
# If the requested model is already installed, return its ModelInfo.
|
||||
with contextlib.suppress(ModelNotFoundException):
|
||||
return model_installer.mgr.get_model(model_name, base_model, model_type, submodel_type)
|
||||
|
||||
# Install the requested model.
|
||||
model_installer.heuristic_import(model_path_id_or_url)
|
||||
|
||||
try:
|
||||
return model_installer.mgr.get_model(model_name, base_model, model_type, submodel_type)
|
||||
except ModelNotFoundException as e:
|
||||
raise Exception(
|
||||
"Failed to get model info after installing it. There could be a mismatch between the requested model and"
|
||||
f" the installation id ('{model_path_id_or_url}'). Error: {e}"
|
||||
)
|
||||
@@ -60,6 +60,9 @@ sd-1/main/trinart_stable_diffusion_v2:
|
||||
description: An SD-1.5 model finetuned with ~40K assorted high resolution manga/anime-style images (2.13 GB)
|
||||
repo_id: naclbit/trinart_stable_diffusion_v2
|
||||
recommended: False
|
||||
sd-1/controlnet/qrcode_monster:
|
||||
repo_id: monster-labs/control_v1p_sd15_qrcode_monster
|
||||
subfolder: v2
|
||||
sd-1/controlnet/canny:
|
||||
repo_id: lllyasviel/control_v11p_sd15_canny
|
||||
recommended: True
|
||||
@@ -93,6 +96,22 @@ sd-1/controlnet/tile:
|
||||
repo_id: lllyasviel/control_v11f1e_sd15_tile
|
||||
sd-1/controlnet/ip2p:
|
||||
repo_id: lllyasviel/control_v11e_sd15_ip2p
|
||||
sd-1/t2i_adapter/canny-sd15:
|
||||
repo_id: TencentARC/t2iadapter_canny_sd15v2
|
||||
sd-1/t2i_adapter/sketch-sd15:
|
||||
repo_id: TencentARC/t2iadapter_sketch_sd15v2
|
||||
sd-1/t2i_adapter/depth-sd15:
|
||||
repo_id: TencentARC/t2iadapter_depth_sd15v2
|
||||
sd-1/t2i_adapter/zoedepth-sd15:
|
||||
repo_id: TencentARC/t2iadapter_zoedepth_sd15v1
|
||||
sdxl/t2i_adapter/canny-sdxl:
|
||||
repo_id: TencentARC/t2i-adapter-canny-sdxl-1.0
|
||||
sdxl/t2i_adapter/zoedepth-sdxl:
|
||||
repo_id: TencentARC/t2i-adapter-depth-zoe-sdxl-1.0
|
||||
sdxl/t2i_adapter/lineart-sdxl:
|
||||
repo_id: TencentARC/t2i-adapter-lineart-sdxl-1.0
|
||||
sdxl/t2i_adapter/sketch-sdxl:
|
||||
repo_id: TencentARC/t2i-adapter-sketch-sdxl-1.0
|
||||
sd-1/embedding/EasyNegative:
|
||||
path: https://huggingface.co/embed/EasyNegative/resolve/main/EasyNegative.safetensors
|
||||
recommended: True
|
||||
@@ -103,3 +122,35 @@ sd-1/lora/LowRA:
|
||||
recommended: True
|
||||
sd-1/lora/Ink scenery:
|
||||
path: https://civitai.com/api/download/models/83390
|
||||
sd-1/ip_adapter/ip_adapter_sd15:
|
||||
repo_id: InvokeAI/ip_adapter_sd15
|
||||
recommended: True
|
||||
requires:
|
||||
- InvokeAI/ip_adapter_sd_image_encoder
|
||||
description: IP-Adapter for SD 1.5 models
|
||||
sd-1/ip_adapter/ip_adapter_plus_sd15:
|
||||
repo_id: InvokeAI/ip_adapter_plus_sd15
|
||||
recommended: False
|
||||
requires:
|
||||
- InvokeAI/ip_adapter_sd_image_encoder
|
||||
description: Refined IP-Adapter for SD 1.5 models
|
||||
sd-1/ip_adapter/ip_adapter_plus_face_sd15:
|
||||
repo_id: InvokeAI/ip_adapter_plus_face_sd15
|
||||
recommended: False
|
||||
requires:
|
||||
- InvokeAI/ip_adapter_sd_image_encoder
|
||||
description: Refined IP-Adapter for SD 1.5 models, adapted for faces
|
||||
sdxl/ip_adapter/ip_adapter_sdxl:
|
||||
repo_id: InvokeAI/ip_adapter_sdxl
|
||||
recommended: False
|
||||
requires:
|
||||
- InvokeAI/ip_adapter_sdxl_image_encoder
|
||||
description: IP-Adapter for SDXL models
|
||||
any/clip_vision/ip_adapter_sd_image_encoder:
|
||||
repo_id: InvokeAI/ip_adapter_sd_image_encoder
|
||||
recommended: False
|
||||
description: Required model for using IP-Adapters with SD-1/2 models
|
||||
any/clip_vision/ip_adapter_sdxl_image_encoder:
|
||||
repo_id: InvokeAI/ip_adapter_sdxl_image_encoder
|
||||
recommended: False
|
||||
description: Required model for using IP-Adapters with SDXL models
|
||||
|
||||
80
invokeai/configs/stable-diffusion/v1-inference-v.yaml
Normal file
80
invokeai/configs/stable-diffusion/v1-inference-v.yaml
Normal file
@@ -0,0 +1,80 @@
|
||||
model:
|
||||
base_learning_rate: 1.0e-04
|
||||
target: invokeai.backend.models.diffusion.ddpm.LatentDiffusion
|
||||
params:
|
||||
parameterization: "v"
|
||||
linear_start: 0.00085
|
||||
linear_end: 0.0120
|
||||
num_timesteps_cond: 1
|
||||
log_every_t: 200
|
||||
timesteps: 1000
|
||||
first_stage_key: "jpg"
|
||||
cond_stage_key: "txt"
|
||||
image_size: 64
|
||||
channels: 4
|
||||
cond_stage_trainable: false # Note: different from the one we trained before
|
||||
conditioning_key: crossattn
|
||||
monitor: val/loss_simple_ema
|
||||
scale_factor: 0.18215
|
||||
use_ema: False
|
||||
|
||||
scheduler_config: # 10000 warmup steps
|
||||
target: invokeai.backend.stable_diffusion.lr_scheduler.LambdaLinearScheduler
|
||||
params:
|
||||
warm_up_steps: [ 10000 ]
|
||||
cycle_lengths: [ 10000000000000 ] # incredibly large number to prevent corner cases
|
||||
f_start: [ 1.e-6 ]
|
||||
f_max: [ 1. ]
|
||||
f_min: [ 1. ]
|
||||
|
||||
personalization_config:
|
||||
target: invokeai.backend.stable_diffusion.embedding_manager.EmbeddingManager
|
||||
params:
|
||||
placeholder_strings: ["*"]
|
||||
initializer_words: ['sculpture']
|
||||
per_image_tokens: false
|
||||
num_vectors_per_token: 1
|
||||
progressive_words: False
|
||||
|
||||
unet_config:
|
||||
target: invokeai.backend.stable_diffusion.diffusionmodules.openaimodel.UNetModel
|
||||
params:
|
||||
image_size: 32 # unused
|
||||
in_channels: 4
|
||||
out_channels: 4
|
||||
model_channels: 320
|
||||
attention_resolutions: [ 4, 2, 1 ]
|
||||
num_res_blocks: 2
|
||||
channel_mult: [ 1, 2, 4, 4 ]
|
||||
num_heads: 8
|
||||
use_spatial_transformer: True
|
||||
transformer_depth: 1
|
||||
context_dim: 768
|
||||
use_checkpoint: True
|
||||
legacy: False
|
||||
|
||||
first_stage_config:
|
||||
target: invokeai.backend.stable_diffusion.autoencoder.AutoencoderKL
|
||||
params:
|
||||
embed_dim: 4
|
||||
monitor: val/rec_loss
|
||||
ddconfig:
|
||||
double_z: true
|
||||
z_channels: 4
|
||||
resolution: 256
|
||||
in_channels: 3
|
||||
out_ch: 3
|
||||
ch: 128
|
||||
ch_mult:
|
||||
- 1
|
||||
- 2
|
||||
- 4
|
||||
- 4
|
||||
num_res_blocks: 2
|
||||
attn_resolutions: []
|
||||
dropout: 0.0
|
||||
lossconfig:
|
||||
target: torch.nn.Identity
|
||||
|
||||
cond_stage_config:
|
||||
target: invokeai.backend.stable_diffusion.encoders.modules.WeightedFrozenCLIPEmbedder
|
||||
@@ -20,6 +20,7 @@ from multiprocessing import Process
|
||||
from multiprocessing.connection import Connection, Pipe
|
||||
from pathlib import Path
|
||||
from shutil import get_terminal_size
|
||||
from typing import Optional
|
||||
|
||||
import npyscreen
|
||||
import torch
|
||||
@@ -45,7 +46,7 @@ from invokeai.frontend.install.widgets import (
|
||||
)
|
||||
|
||||
config = InvokeAIAppConfig.get_config()
|
||||
logger = InvokeAILogger.getLogger()
|
||||
logger = InvokeAILogger.get_logger()
|
||||
|
||||
# build a table mapping all non-printable characters to None
|
||||
# for stripping control characters
|
||||
@@ -98,14 +99,16 @@ class addModelsForm(CyclingForm, npyscreen.FormMultiPage):
|
||||
self.tabs = self.add_widget_intelligent(
|
||||
SingleSelectColumns,
|
||||
values=[
|
||||
"STARTER MODELS",
|
||||
"MAIN MODELS",
|
||||
"STARTERS",
|
||||
"MAINS",
|
||||
"CONTROLNETS",
|
||||
"LORA/LYCORIS",
|
||||
"TEXTUAL INVERSION",
|
||||
"T2I-ADAPTERS",
|
||||
"IP-ADAPTERS",
|
||||
"LORAS",
|
||||
"TI EMBEDDINGS",
|
||||
],
|
||||
value=[self.current_tab],
|
||||
columns=5,
|
||||
columns=7,
|
||||
max_height=2,
|
||||
relx=8,
|
||||
scroll_exit=True,
|
||||
@@ -130,6 +133,19 @@ class addModelsForm(CyclingForm, npyscreen.FormMultiPage):
|
||||
)
|
||||
bottom_of_table = max(bottom_of_table, self.nextrely)
|
||||
|
||||
self.nextrely = top_of_table
|
||||
self.t2i_models = self.add_model_widgets(
|
||||
model_type=ModelType.T2IAdapter,
|
||||
window_width=window_width,
|
||||
)
|
||||
bottom_of_table = max(bottom_of_table, self.nextrely)
|
||||
self.nextrely = top_of_table
|
||||
self.ipadapter_models = self.add_model_widgets(
|
||||
model_type=ModelType.IPAdapter,
|
||||
window_width=window_width,
|
||||
)
|
||||
bottom_of_table = max(bottom_of_table, self.nextrely)
|
||||
|
||||
self.nextrely = top_of_table
|
||||
self.lora_models = self.add_model_widgets(
|
||||
model_type=ModelType.Lora,
|
||||
@@ -343,6 +359,8 @@ class addModelsForm(CyclingForm, npyscreen.FormMultiPage):
|
||||
self.starter_pipelines,
|
||||
self.pipeline_models,
|
||||
self.controlnet_models,
|
||||
self.t2i_models,
|
||||
self.ipadapter_models,
|
||||
self.lora_models,
|
||||
self.ti_models,
|
||||
]
|
||||
@@ -532,6 +550,8 @@ class addModelsForm(CyclingForm, npyscreen.FormMultiPage):
|
||||
self.starter_pipelines,
|
||||
self.pipeline_models,
|
||||
self.controlnet_models,
|
||||
self.t2i_models,
|
||||
self.ipadapter_models,
|
||||
self.lora_models,
|
||||
self.ti_models,
|
||||
]
|
||||
@@ -553,6 +573,25 @@ class addModelsForm(CyclingForm, npyscreen.FormMultiPage):
|
||||
if downloads := section.get("download_ids"):
|
||||
selections.install_models.extend(downloads.value.split())
|
||||
|
||||
# NOT NEEDED - DONE IN BACKEND NOW
|
||||
# # special case for the ipadapter_models. If any of the adapters are
|
||||
# # chosen, then we add the corresponding encoder(s) to the install list.
|
||||
# section = self.ipadapter_models
|
||||
# if section.get("models_selected"):
|
||||
# selected_adapters = [
|
||||
# self.all_models[section["models"][x]].name for x in section.get("models_selected").value
|
||||
# ]
|
||||
# encoders = []
|
||||
# if any(["sdxl" in x for x in selected_adapters]):
|
||||
# encoders.append("ip_adapter_sdxl_image_encoder")
|
||||
# if any(["sd15" in x for x in selected_adapters]):
|
||||
# encoders.append("ip_adapter_sd_image_encoder")
|
||||
# for encoder in encoders:
|
||||
# key = f"any/clip_vision/{encoder}"
|
||||
# repo_id = f"InvokeAI/{encoder}"
|
||||
# if key not in self.all_models:
|
||||
# selections.install_models.append(repo_id)
|
||||
|
||||
|
||||
class AddModelApplication(npyscreen.NPSAppManaged):
|
||||
def __init__(self, opt):
|
||||
@@ -592,21 +631,23 @@ def ask_user_for_prediction_type(model_path: Path, tui_conn: Connection = None)
|
||||
return _ask_user_for_pt_cmdline(model_path)
|
||||
|
||||
|
||||
def _ask_user_for_pt_cmdline(model_path: Path) -> SchedulerPredictionType:
|
||||
def _ask_user_for_pt_cmdline(model_path: Path) -> Optional[SchedulerPredictionType]:
|
||||
choices = [SchedulerPredictionType.Epsilon, SchedulerPredictionType.VPrediction, None]
|
||||
print(
|
||||
f"""
|
||||
Please select the type of the V2 checkpoint named {model_path.name}:
|
||||
[1] A model based on Stable Diffusion v2 trained on 512 pixel images (SD-2-base)
|
||||
[2] A model based on Stable Diffusion v2 trained on 768 pixel images (SD-2-768)
|
||||
[3] Skip this model and come back later.
|
||||
Please select the scheduler prediction type of the checkpoint named {model_path.name}:
|
||||
[1] "epsilon" - most v1.5 models and v2 models trained on 512 pixel images
|
||||
[2] "vprediction" - v2 models trained on 768 pixel images and a few v1.5 models
|
||||
[3] Accept the best guess; you can fix it in the Web UI later
|
||||
"""
|
||||
)
|
||||
choice = None
|
||||
ok = False
|
||||
while not ok:
|
||||
try:
|
||||
choice = input("select> ").strip()
|
||||
choice = input("select [3]> ").strip()
|
||||
if not choice:
|
||||
return None
|
||||
choice = choices[int(choice) - 1]
|
||||
ok = True
|
||||
except (ValueError, IndexError):
|
||||
@@ -617,22 +658,18 @@ Please select the type of the V2 checkpoint named {model_path.name}:
|
||||
|
||||
|
||||
def _ask_user_for_pt_tui(model_path: Path, tui_conn: Connection) -> SchedulerPredictionType:
|
||||
try:
|
||||
tui_conn.send_bytes(f"*need v2 config for:{model_path}".encode("utf-8"))
|
||||
# note that we don't do any status checking here
|
||||
response = tui_conn.recv_bytes().decode("utf-8")
|
||||
if response is None:
|
||||
return None
|
||||
elif response == "epsilon":
|
||||
return SchedulerPredictionType.epsilon
|
||||
elif response == "v":
|
||||
return SchedulerPredictionType.VPrediction
|
||||
elif response == "abort":
|
||||
logger.info("Conversion aborted")
|
||||
return None
|
||||
else:
|
||||
return response
|
||||
except Exception:
|
||||
tui_conn.send_bytes(f"*need v2 config for:{model_path}".encode("utf-8"))
|
||||
# note that we don't do any status checking here
|
||||
response = tui_conn.recv_bytes().decode("utf-8")
|
||||
if response is None:
|
||||
return None
|
||||
elif response == "epsilon":
|
||||
return SchedulerPredictionType.epsilon
|
||||
elif response == "v":
|
||||
return SchedulerPredictionType.VPrediction
|
||||
elif response == "guess":
|
||||
return None
|
||||
else:
|
||||
return None
|
||||
|
||||
|
||||
@@ -652,7 +689,7 @@ def process_and_execute(
|
||||
translator = StderrToMessage(conn_out)
|
||||
sys.stderr = translator
|
||||
sys.stdout = translator
|
||||
logger = InvokeAILogger.getLogger()
|
||||
logger = InvokeAILogger.get_logger()
|
||||
logger.handlers.clear()
|
||||
logger.addHandler(logging.StreamHandler(translator))
|
||||
|
||||
@@ -765,7 +802,7 @@ def main():
|
||||
if opt.full_precision:
|
||||
invoke_args.extend(["--precision", "float32"])
|
||||
config.parse_args(invoke_args)
|
||||
logger = InvokeAILogger().getLogger(config=config)
|
||||
logger = InvokeAILogger().get_logger(config=config)
|
||||
|
||||
if not config.model_conf_path.exists():
|
||||
logger.info("Your InvokeAI root directory is not set up. Calling invokeai-configure.")
|
||||
|
||||
@@ -381,12 +381,12 @@ def select_stable_diffusion_config_file(
|
||||
wrap: bool = True,
|
||||
model_name: str = "Unknown",
|
||||
):
|
||||
message = f"Please select the correct base model for the V2 checkpoint named '{model_name}'. Press <CANCEL> to skip installation."
|
||||
message = f"Please select the correct prediction type for the checkpoint named '{model_name}'. Press <CANCEL> to skip installation."
|
||||
title = "CONFIG FILE SELECTION"
|
||||
options = [
|
||||
"An SD v2.x base model (512 pixels; no 'parameterization:' line in its yaml file)",
|
||||
"An SD v2.x v-predictive model (768 pixels; 'parameterization: \"v\"' line in its yaml file)",
|
||||
"Skip installation for now and come back later",
|
||||
"'epsilon' - most v1.5 models and v2 models trained on 512 pixel images",
|
||||
"'vprediction' - v2 models trained on 768 pixel images and a few v1.5 models)",
|
||||
"Accept the best guess; you can fix it in the Web UI later",
|
||||
]
|
||||
|
||||
F = ConfirmCancelPopup(
|
||||
@@ -410,7 +410,7 @@ def select_stable_diffusion_config_file(
|
||||
choice = F.add(
|
||||
npyscreen.SelectOne,
|
||||
values=options,
|
||||
value=[0],
|
||||
value=[2],
|
||||
max_height=len(options) + 1,
|
||||
scroll_exit=True,
|
||||
)
|
||||
@@ -420,5 +420,5 @@ def select_stable_diffusion_config_file(
|
||||
if not F.value:
|
||||
return None
|
||||
assert choice.value[0] in range(0, 3), "invalid choice"
|
||||
choices = ["epsilon", "v", "abort"]
|
||||
choices = ["epsilon", "v", "guess"]
|
||||
return choices[choice.value[0]]
|
||||
|
||||
@@ -1,4 +1,5 @@
|
||||
dist/
|
||||
public/locales/*.json
|
||||
.husky/
|
||||
node_modules/
|
||||
patches/
|
||||
|
||||
169
invokeai/frontend/web/dist/assets/App-8c45baef.js
vendored
Normal file
169
invokeai/frontend/web/dist/assets/App-8c45baef.js
vendored
Normal file
File diff suppressed because one or more lines are too long
169
invokeai/frontend/web/dist/assets/App-dbf8f111.js
vendored
169
invokeai/frontend/web/dist/assets/App-dbf8f111.js
vendored
File diff suppressed because one or more lines are too long
1
invokeai/frontend/web/dist/assets/MantineProvider-70b4f32d.js
vendored
Normal file
1
invokeai/frontend/web/dist/assets/MantineProvider-70b4f32d.js
vendored
Normal file
File diff suppressed because one or more lines are too long
File diff suppressed because one or more lines are too long
280
invokeai/frontend/web/dist/assets/ThemeLocaleProvider-b6697945.js
vendored
Normal file
280
invokeai/frontend/web/dist/assets/ThemeLocaleProvider-b6697945.js
vendored
Normal file
@@ -0,0 +1,280 @@
|
||||
import{w as s,i2 as T,v as l,a2 as I,i3 as R,ae as V,i4 as z,i5 as j,i6 as D,i7 as F,i8 as G,i9 as W,ia as K,aG as H,ib as U,ic as Y}from"./index-27e8922c.js";import{M as Z}from"./MantineProvider-70b4f32d.js";var P=String.raw,E=P`
|
||||
:root,
|
||||
:host {
|
||||
--chakra-vh: 100vh;
|
||||
}
|
||||
|
||||
@supports (height: -webkit-fill-available) {
|
||||
:root,
|
||||
:host {
|
||||
--chakra-vh: -webkit-fill-available;
|
||||
}
|
||||
}
|
||||
|
||||
@supports (height: -moz-fill-available) {
|
||||
:root,
|
||||
:host {
|
||||
--chakra-vh: -moz-fill-available;
|
||||
}
|
||||
}
|
||||
|
||||
@supports (height: 100dvh) {
|
||||
:root,
|
||||
:host {
|
||||
--chakra-vh: 100dvh;
|
||||
}
|
||||
}
|
||||
`,B=()=>s.jsx(T,{styles:E}),J=({scope:e=""})=>s.jsx(T,{styles:P`
|
||||
html {
|
||||
line-height: 1.5;
|
||||
-webkit-text-size-adjust: 100%;
|
||||
font-family: system-ui, sans-serif;
|
||||
-webkit-font-smoothing: antialiased;
|
||||
text-rendering: optimizeLegibility;
|
||||
-moz-osx-font-smoothing: grayscale;
|
||||
touch-action: manipulation;
|
||||
}
|
||||
|
||||
body {
|
||||
position: relative;
|
||||
min-height: 100%;
|
||||
margin: 0;
|
||||
font-feature-settings: "kern";
|
||||
}
|
||||
|
||||
${e} :where(*, *::before, *::after) {
|
||||
border-width: 0;
|
||||
border-style: solid;
|
||||
box-sizing: border-box;
|
||||
word-wrap: break-word;
|
||||
}
|
||||
|
||||
main {
|
||||
display: block;
|
||||
}
|
||||
|
||||
${e} hr {
|
||||
border-top-width: 1px;
|
||||
box-sizing: content-box;
|
||||
height: 0;
|
||||
overflow: visible;
|
||||
}
|
||||
|
||||
${e} :where(pre, code, kbd,samp) {
|
||||
font-family: SFMono-Regular, Menlo, Monaco, Consolas, monospace;
|
||||
font-size: 1em;
|
||||
}
|
||||
|
||||
${e} a {
|
||||
background-color: transparent;
|
||||
color: inherit;
|
||||
text-decoration: inherit;
|
||||
}
|
||||
|
||||
${e} abbr[title] {
|
||||
border-bottom: none;
|
||||
text-decoration: underline;
|
||||
-webkit-text-decoration: underline dotted;
|
||||
text-decoration: underline dotted;
|
||||
}
|
||||
|
||||
${e} :where(b, strong) {
|
||||
font-weight: bold;
|
||||
}
|
||||
|
||||
${e} small {
|
||||
font-size: 80%;
|
||||
}
|
||||
|
||||
${e} :where(sub,sup) {
|
||||
font-size: 75%;
|
||||
line-height: 0;
|
||||
position: relative;
|
||||
vertical-align: baseline;
|
||||
}
|
||||
|
||||
${e} sub {
|
||||
bottom: -0.25em;
|
||||
}
|
||||
|
||||
${e} sup {
|
||||
top: -0.5em;
|
||||
}
|
||||
|
||||
${e} img {
|
||||
border-style: none;
|
||||
}
|
||||
|
||||
${e} :where(button, input, optgroup, select, textarea) {
|
||||
font-family: inherit;
|
||||
font-size: 100%;
|
||||
line-height: 1.15;
|
||||
margin: 0;
|
||||
}
|
||||
|
||||
${e} :where(button, input) {
|
||||
overflow: visible;
|
||||
}
|
||||
|
||||
${e} :where(button, select) {
|
||||
text-transform: none;
|
||||
}
|
||||
|
||||
${e} :where(
|
||||
button::-moz-focus-inner,
|
||||
[type="button"]::-moz-focus-inner,
|
||||
[type="reset"]::-moz-focus-inner,
|
||||
[type="submit"]::-moz-focus-inner
|
||||
) {
|
||||
border-style: none;
|
||||
padding: 0;
|
||||
}
|
||||
|
||||
${e} fieldset {
|
||||
padding: 0.35em 0.75em 0.625em;
|
||||
}
|
||||
|
||||
${e} legend {
|
||||
box-sizing: border-box;
|
||||
color: inherit;
|
||||
display: table;
|
||||
max-width: 100%;
|
||||
padding: 0;
|
||||
white-space: normal;
|
||||
}
|
||||
|
||||
${e} progress {
|
||||
vertical-align: baseline;
|
||||
}
|
||||
|
||||
${e} textarea {
|
||||
overflow: auto;
|
||||
}
|
||||
|
||||
${e} :where([type="checkbox"], [type="radio"]) {
|
||||
box-sizing: border-box;
|
||||
padding: 0;
|
||||
}
|
||||
|
||||
${e} input[type="number"]::-webkit-inner-spin-button,
|
||||
${e} input[type="number"]::-webkit-outer-spin-button {
|
||||
-webkit-appearance: none !important;
|
||||
}
|
||||
|
||||
${e} input[type="number"] {
|
||||
-moz-appearance: textfield;
|
||||
}
|
||||
|
||||
${e} input[type="search"] {
|
||||
-webkit-appearance: textfield;
|
||||
outline-offset: -2px;
|
||||
}
|
||||
|
||||
${e} input[type="search"]::-webkit-search-decoration {
|
||||
-webkit-appearance: none !important;
|
||||
}
|
||||
|
||||
${e} ::-webkit-file-upload-button {
|
||||
-webkit-appearance: button;
|
||||
font: inherit;
|
||||
}
|
||||
|
||||
${e} details {
|
||||
display: block;
|
||||
}
|
||||
|
||||
${e} summary {
|
||||
display: list-item;
|
||||
}
|
||||
|
||||
template {
|
||||
display: none;
|
||||
}
|
||||
|
||||
[hidden] {
|
||||
display: none !important;
|
||||
}
|
||||
|
||||
${e} :where(
|
||||
blockquote,
|
||||
dl,
|
||||
dd,
|
||||
h1,
|
||||
h2,
|
||||
h3,
|
||||
h4,
|
||||
h5,
|
||||
h6,
|
||||
hr,
|
||||
figure,
|
||||
p,
|
||||
pre
|
||||
) {
|
||||
margin: 0;
|
||||
}
|
||||
|
||||
${e} button {
|
||||
background: transparent;
|
||||
padding: 0;
|
||||
}
|
||||
|
||||
${e} fieldset {
|
||||
margin: 0;
|
||||
padding: 0;
|
||||
}
|
||||
|
||||
${e} :where(ol, ul) {
|
||||
margin: 0;
|
||||
padding: 0;
|
||||
}
|
||||
|
||||
${e} textarea {
|
||||
resize: vertical;
|
||||
}
|
||||
|
||||
${e} :where(button, [role="button"]) {
|
||||
cursor: pointer;
|
||||
}
|
||||
|
||||
${e} button::-moz-focus-inner {
|
||||
border: 0 !important;
|
||||
}
|
||||
|
||||
${e} table {
|
||||
border-collapse: collapse;
|
||||
}
|
||||
|
||||
${e} :where(h1, h2, h3, h4, h5, h6) {
|
||||
font-size: inherit;
|
||||
font-weight: inherit;
|
||||
}
|
||||
|
||||
${e} :where(button, input, optgroup, select, textarea) {
|
||||
padding: 0;
|
||||
line-height: inherit;
|
||||
color: inherit;
|
||||
}
|
||||
|
||||
${e} :where(img, svg, video, canvas, audio, iframe, embed, object) {
|
||||
display: block;
|
||||
}
|
||||
|
||||
${e} :where(img, video) {
|
||||
max-width: 100%;
|
||||
height: auto;
|
||||
}
|
||||
|
||||
[data-js-focus-visible]
|
||||
:focus:not([data-focus-visible-added]):not(
|
||||
[data-focus-visible-disabled]
|
||||
) {
|
||||
outline: none;
|
||||
box-shadow: none;
|
||||
}
|
||||
|
||||
${e} select::-ms-expand {
|
||||
display: none;
|
||||
}
|
||||
|
||||
${E}
|
||||
`}),g={light:"chakra-ui-light",dark:"chakra-ui-dark"};function Q(e={}){const{preventTransition:o=!0}=e,n={setDataset:r=>{const t=o?n.preventTransition():void 0;document.documentElement.dataset.theme=r,document.documentElement.style.colorScheme=r,t==null||t()},setClassName(r){document.body.classList.add(r?g.dark:g.light),document.body.classList.remove(r?g.light:g.dark)},query(){return window.matchMedia("(prefers-color-scheme: dark)")},getSystemTheme(r){var t;return((t=n.query().matches)!=null?t:r==="dark")?"dark":"light"},addListener(r){const t=n.query(),i=a=>{r(a.matches?"dark":"light")};return typeof t.addListener=="function"?t.addListener(i):t.addEventListener("change",i),()=>{typeof t.removeListener=="function"?t.removeListener(i):t.removeEventListener("change",i)}},preventTransition(){const r=document.createElement("style");return r.appendChild(document.createTextNode("*{-webkit-transition:none!important;-moz-transition:none!important;-o-transition:none!important;-ms-transition:none!important;transition:none!important}")),document.head.appendChild(r),()=>{window.getComputedStyle(document.body),requestAnimationFrame(()=>{requestAnimationFrame(()=>{document.head.removeChild(r)})})}}};return n}var X="chakra-ui-color-mode";function L(e){return{ssr:!1,type:"localStorage",get(o){if(!(globalThis!=null&&globalThis.document))return o;let n;try{n=localStorage.getItem(e)||o}catch{}return n||o},set(o){try{localStorage.setItem(e,o)}catch{}}}}var ee=L(X),M=()=>{};function S(e,o){return e.type==="cookie"&&e.ssr?e.get(o):o}function O(e){const{value:o,children:n,options:{useSystemColorMode:r,initialColorMode:t,disableTransitionOnChange:i}={},colorModeManager:a=ee}=e,d=t==="dark"?"dark":"light",[u,p]=l.useState(()=>S(a,d)),[y,b]=l.useState(()=>S(a)),{getSystemTheme:w,setClassName:k,setDataset:x,addListener:$}=l.useMemo(()=>Q({preventTransition:i}),[i]),v=t==="system"&&!u?y:u,c=l.useCallback(m=>{const f=m==="system"?w():m;p(f),k(f==="dark"),x(f),a.set(f)},[a,w,k,x]);I(()=>{t==="system"&&b(w())},[]),l.useEffect(()=>{const m=a.get();if(m){c(m);return}if(t==="system"){c("system");return}c(d)},[a,d,t,c]);const C=l.useCallback(()=>{c(v==="dark"?"light":"dark")},[v,c]);l.useEffect(()=>{if(r)return $(c)},[r,$,c]);const A=l.useMemo(()=>({colorMode:o??v,toggleColorMode:o?M:C,setColorMode:o?M:c,forced:o!==void 0}),[v,C,c,o]);return s.jsx(R.Provider,{value:A,children:n})}O.displayName="ColorModeProvider";var te=["borders","breakpoints","colors","components","config","direction","fonts","fontSizes","fontWeights","letterSpacings","lineHeights","radii","shadows","sizes","space","styles","transition","zIndices"];function re(e){return V(e)?te.every(o=>Object.prototype.hasOwnProperty.call(e,o)):!1}function h(e){return typeof e=="function"}function oe(...e){return o=>e.reduce((n,r)=>r(n),o)}var ne=e=>function(...n){let r=[...n],t=n[n.length-1];return re(t)&&r.length>1?r=r.slice(0,r.length-1):t=e,oe(...r.map(i=>a=>h(i)?i(a):ae(a,i)))(t)},ie=ne(j);function ae(...e){return z({},...e,_)}function _(e,o,n,r){if((h(e)||h(o))&&Object.prototype.hasOwnProperty.call(r,n))return(...t)=>{const i=h(e)?e(...t):e,a=h(o)?o(...t):o;return z({},i,a,_)}}var q=l.createContext({getDocument(){return document},getWindow(){return window}});q.displayName="EnvironmentContext";function N(e){const{children:o,environment:n,disabled:r}=e,t=l.useRef(null),i=l.useMemo(()=>n||{getDocument:()=>{var d,u;return(u=(d=t.current)==null?void 0:d.ownerDocument)!=null?u:document},getWindow:()=>{var d,u;return(u=(d=t.current)==null?void 0:d.ownerDocument.defaultView)!=null?u:window}},[n]),a=!r||!n;return s.jsxs(q.Provider,{value:i,children:[o,a&&s.jsx("span",{id:"__chakra_env",hidden:!0,ref:t})]})}N.displayName="EnvironmentProvider";var se=e=>{const{children:o,colorModeManager:n,portalZIndex:r,resetScope:t,resetCSS:i=!0,theme:a={},environment:d,cssVarsRoot:u,disableEnvironment:p,disableGlobalStyle:y}=e,b=s.jsx(N,{environment:d,disabled:p,children:o});return s.jsx(D,{theme:a,cssVarsRoot:u,children:s.jsxs(O,{colorModeManager:n,options:a.config,children:[i?s.jsx(J,{scope:t}):s.jsx(B,{}),!y&&s.jsx(F,{}),r?s.jsx(G,{zIndex:r,children:b}):b]})})},le=e=>function({children:n,theme:r=e,toastOptions:t,...i}){return s.jsxs(se,{theme:r,...i,children:[s.jsx(W,{value:t==null?void 0:t.defaultOptions,children:n}),s.jsx(K,{...t})]})},de=le(j);const ue=()=>l.useMemo(()=>({colorScheme:"dark",fontFamily:"'Inter Variable', sans-serif",components:{ScrollArea:{defaultProps:{scrollbarSize:10},styles:{scrollbar:{"&:hover":{backgroundColor:"var(--invokeai-colors-baseAlpha-300)"}},thumb:{backgroundColor:"var(--invokeai-colors-baseAlpha-300)"}}}}}),[]),ce=L("@@invokeai-color-mode");function me({children:e}){const{i18n:o}=H(),n=o.dir(),r=l.useMemo(()=>ie({...U,direction:n}),[n]);l.useEffect(()=>{document.body.dir=n},[n]);const t=ue();return s.jsx(Z,{theme:t,children:s.jsx(de,{theme:r,colorModeManager:ce,toastOptions:Y,children:e})})}const ve=l.memo(me);export{ve as default};
|
||||
158
invokeai/frontend/web/dist/assets/index-27e8922c.js
vendored
Normal file
158
invokeai/frontend/web/dist/assets/index-27e8922c.js
vendored
Normal file
File diff suppressed because one or more lines are too long
128
invokeai/frontend/web/dist/assets/index-f6c3f475.js
vendored
128
invokeai/frontend/web/dist/assets/index-f6c3f475.js
vendored
File diff suppressed because one or more lines are too long
File diff suppressed because one or more lines are too long
5
invokeai/frontend/web/dist/index.html
vendored
5
invokeai/frontend/web/dist/index.html
vendored
@@ -3,6 +3,9 @@
|
||||
<head>
|
||||
<meta charset="UTF-8" />
|
||||
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
|
||||
<meta http-equiv="Cache-Control" content="no-cache, no-store, must-revalidate">
|
||||
<meta http-equiv="Pragma" content="no-cache">
|
||||
<meta http-equiv="Expires" content="0">
|
||||
<title>InvokeAI - A Stable Diffusion Toolkit</title>
|
||||
<link rel="shortcut icon" type="icon" href="./assets/favicon-0d253ced.ico" />
|
||||
<style>
|
||||
@@ -12,7 +15,7 @@
|
||||
margin: 0;
|
||||
}
|
||||
</style>
|
||||
<script type="module" crossorigin src="./assets/index-f6c3f475.js"></script>
|
||||
<script type="module" crossorigin src="./assets/index-27e8922c.js"></script>
|
||||
</head>
|
||||
|
||||
<body dir="ltr">
|
||||
|
||||
15
invokeai/frontend/web/dist/locales/ar.json
vendored
15
invokeai/frontend/web/dist/locales/ar.json
vendored
@@ -1,13 +1,9 @@
|
||||
{
|
||||
"common": {
|
||||
"hotkeysLabel": "مفاتيح الأختصار",
|
||||
"themeLabel": "الموضوع",
|
||||
"languagePickerLabel": "منتقي اللغة",
|
||||
"reportBugLabel": "بلغ عن خطأ",
|
||||
"settingsLabel": "إعدادات",
|
||||
"darkTheme": "داكن",
|
||||
"lightTheme": "فاتح",
|
||||
"greenTheme": "أخضر",
|
||||
"img2img": "صورة إلى صورة",
|
||||
"unifiedCanvas": "لوحة موحدة",
|
||||
"nodes": "عقد",
|
||||
@@ -57,7 +53,6 @@
|
||||
"maintainAspectRatio": "الحفاظ على نسبة الأبعاد",
|
||||
"autoSwitchNewImages": "التبديل التلقائي إلى الصور الجديدة",
|
||||
"singleColumnLayout": "تخطيط عمود واحد",
|
||||
"pinGallery": "تثبيت المعرض",
|
||||
"allImagesLoaded": "تم تحميل جميع الصور",
|
||||
"loadMore": "تحميل المزيد",
|
||||
"noImagesInGallery": "لا توجد صور في المعرض"
|
||||
@@ -342,7 +337,6 @@
|
||||
"cfgScale": "مقياس الإعداد الذاتي للجملة",
|
||||
"width": "عرض",
|
||||
"height": "ارتفاع",
|
||||
"sampler": "مزج",
|
||||
"seed": "بذرة",
|
||||
"randomizeSeed": "تبديل بذرة",
|
||||
"shuffle": "تشغيل",
|
||||
@@ -364,10 +358,6 @@
|
||||
"hiresOptim": "تحسين الدقة العالية",
|
||||
"imageFit": "ملائمة الصورة الأولية لحجم الخرج",
|
||||
"codeformerFidelity": "الوثوقية",
|
||||
"seamSize": "حجم التشقق",
|
||||
"seamBlur": "ضباب التشقق",
|
||||
"seamStrength": "قوة التشقق",
|
||||
"seamSteps": "خطوات التشقق",
|
||||
"scaleBeforeProcessing": "تحجيم قبل المعالجة",
|
||||
"scaledWidth": "العرض المحجوب",
|
||||
"scaledHeight": "الارتفاع المحجوب",
|
||||
@@ -378,8 +368,6 @@
|
||||
"infillScalingHeader": "التعبئة والتحجيم",
|
||||
"img2imgStrength": "قوة صورة إلى صورة",
|
||||
"toggleLoopback": "تبديل الإعادة",
|
||||
"invoke": "إطلاق",
|
||||
"promptPlaceholder": "اكتب المحث هنا. [العلامات السلبية], (زيادة الوزن) ++, (نقص الوزن)--, التبديل و الخلط متاحة (انظر الوثائق)",
|
||||
"sendTo": "أرسل إلى",
|
||||
"sendToImg2Img": "أرسل إلى صورة إلى صورة",
|
||||
"sendToUnifiedCanvas": "أرسل إلى الخطوط الموحدة",
|
||||
@@ -393,7 +381,6 @@
|
||||
"useAll": "استخدام الكل",
|
||||
"useInitImg": "استخدام الصورة الأولية",
|
||||
"info": "معلومات",
|
||||
"deleteImage": "حذف الصورة",
|
||||
"initialImage": "الصورة الأولية",
|
||||
"showOptionsPanel": "إظهار لوحة الخيارات"
|
||||
},
|
||||
@@ -403,7 +390,6 @@
|
||||
"saveSteps": "حفظ الصور كل n خطوات",
|
||||
"confirmOnDelete": "تأكيد عند الحذف",
|
||||
"displayHelpIcons": "عرض أيقونات المساعدة",
|
||||
"useCanvasBeta": "استخدام مخطط الأزرار بيتا",
|
||||
"enableImageDebugging": "تمكين التصحيح عند التصوير",
|
||||
"resetWebUI": "إعادة تعيين واجهة الويب",
|
||||
"resetWebUIDesc1": "إعادة تعيين واجهة الويب يعيد فقط ذاكرة التخزين المؤقت للمتصفح لصورك وإعداداتك المذكورة. لا يحذف أي صور من القرص.",
|
||||
@@ -413,7 +399,6 @@
|
||||
"toast": {
|
||||
"tempFoldersEmptied": "تم تفريغ مجلد المؤقت",
|
||||
"uploadFailed": "فشل التحميل",
|
||||
"uploadFailedMultipleImagesDesc": "تم الصق صور متعددة، قد يتم تحميل صورة واحدة فقط في الوقت الحالي",
|
||||
"uploadFailedUnableToLoadDesc": "تعذر تحميل الملف",
|
||||
"downloadImageStarted": "بدأ تنزيل الصورة",
|
||||
"imageCopied": "تم نسخ الصورة",
|
||||
|
||||
17
invokeai/frontend/web/dist/locales/de.json
vendored
17
invokeai/frontend/web/dist/locales/de.json
vendored
@@ -1,12 +1,8 @@
|
||||
{
|
||||
"common": {
|
||||
"themeLabel": "Thema",
|
||||
"languagePickerLabel": "Sprachauswahl",
|
||||
"reportBugLabel": "Fehler melden",
|
||||
"settingsLabel": "Einstellungen",
|
||||
"darkTheme": "Dunkel",
|
||||
"lightTheme": "Hell",
|
||||
"greenTheme": "Grün",
|
||||
"img2img": "Bild zu Bild",
|
||||
"nodes": "Knoten",
|
||||
"langGerman": "Deutsch",
|
||||
@@ -48,7 +44,6 @@
|
||||
"langEnglish": "Englisch",
|
||||
"langDutch": "Niederländisch",
|
||||
"langFrench": "Französisch",
|
||||
"oceanTheme": "Ozean",
|
||||
"langItalian": "Italienisch",
|
||||
"langPortuguese": "Portogisisch",
|
||||
"langRussian": "Russisch",
|
||||
@@ -76,7 +71,6 @@
|
||||
"maintainAspectRatio": "Seitenverhältnis beibehalten",
|
||||
"autoSwitchNewImages": "Automatisch zu neuen Bildern wechseln",
|
||||
"singleColumnLayout": "Einspaltiges Layout",
|
||||
"pinGallery": "Galerie anpinnen",
|
||||
"allImagesLoaded": "Alle Bilder geladen",
|
||||
"loadMore": "Mehr laden",
|
||||
"noImagesInGallery": "Keine Bilder in der Galerie"
|
||||
@@ -346,7 +340,6 @@
|
||||
"cfgScale": "CFG-Skala",
|
||||
"width": "Breite",
|
||||
"height": "Höhe",
|
||||
"sampler": "Sampler",
|
||||
"randomizeSeed": "Zufälliger Seed",
|
||||
"shuffle": "Mischen",
|
||||
"noiseThreshold": "Rausch-Schwellenwert",
|
||||
@@ -367,10 +360,6 @@
|
||||
"hiresOptim": "High-Res-Optimierung",
|
||||
"imageFit": "Ausgangsbild an Ausgabegröße anpassen",
|
||||
"codeformerFidelity": "Glaubwürdigkeit",
|
||||
"seamSize": "Nahtgröße",
|
||||
"seamBlur": "Nahtunschärfe",
|
||||
"seamStrength": "Stärke der Naht",
|
||||
"seamSteps": "Nahtstufen",
|
||||
"scaleBeforeProcessing": "Skalieren vor der Verarbeitung",
|
||||
"scaledWidth": "Skaliert W",
|
||||
"scaledHeight": "Skaliert H",
|
||||
@@ -381,8 +370,6 @@
|
||||
"infillScalingHeader": "Infill und Skalierung",
|
||||
"img2imgStrength": "Bild-zu-Bild-Stärke",
|
||||
"toggleLoopback": "Toggle Loopback",
|
||||
"invoke": "Invoke",
|
||||
"promptPlaceholder": "Prompt hier eingeben. [negative Token], (mehr Gewicht)++, (geringeres Gewicht)--, Tausch und Überblendung sind verfügbar (siehe Dokumente)",
|
||||
"sendTo": "Senden an",
|
||||
"sendToImg2Img": "Senden an Bild zu Bild",
|
||||
"sendToUnifiedCanvas": "Senden an Unified Canvas",
|
||||
@@ -394,7 +381,6 @@
|
||||
"useSeed": "Seed verwenden",
|
||||
"useAll": "Alle verwenden",
|
||||
"useInitImg": "Ausgangsbild verwenden",
|
||||
"deleteImage": "Bild löschen",
|
||||
"initialImage": "Ursprüngliches Bild",
|
||||
"showOptionsPanel": "Optionsleiste zeigen",
|
||||
"cancel": {
|
||||
@@ -406,7 +392,6 @@
|
||||
"saveSteps": "Speichern der Bilder alle n Schritte",
|
||||
"confirmOnDelete": "Bestätigen beim Löschen",
|
||||
"displayHelpIcons": "Hilfesymbole anzeigen",
|
||||
"useCanvasBeta": "Canvas Beta Layout verwenden",
|
||||
"enableImageDebugging": "Bild-Debugging aktivieren",
|
||||
"resetWebUI": "Web-Oberfläche zurücksetzen",
|
||||
"resetWebUIDesc1": "Das Zurücksetzen der Web-Oberfläche setzt nur den lokalen Cache des Browsers mit Ihren Bildern und gespeicherten Einstellungen zurück. Es werden keine Bilder von der Festplatte gelöscht.",
|
||||
@@ -416,7 +401,6 @@
|
||||
"toast": {
|
||||
"tempFoldersEmptied": "Temp-Ordner geleert",
|
||||
"uploadFailed": "Hochladen fehlgeschlagen",
|
||||
"uploadFailedMultipleImagesDesc": "Mehrere Bilder eingefügt, es kann nur ein Bild auf einmal hochgeladen werden",
|
||||
"uploadFailedUnableToLoadDesc": "Datei kann nicht geladen werden",
|
||||
"downloadImageStarted": "Bild wird heruntergeladen",
|
||||
"imageCopied": "Bild kopiert",
|
||||
@@ -532,7 +516,6 @@
|
||||
"modifyConfig": "Optionen einstellen",
|
||||
"toggleAutoscroll": "Auroscroll ein/ausschalten",
|
||||
"toggleLogViewer": "Log Betrachter ein/ausschalten",
|
||||
"showGallery": "Zeige Galerie",
|
||||
"showOptionsPanel": "Zeige Optionen",
|
||||
"reset": "Zurücksetzen",
|
||||
"nextImage": "Nächstes Bild",
|
||||
|
||||
407
invokeai/frontend/web/dist/locales/en.json
vendored
407
invokeai/frontend/web/dist/locales/en.json
vendored
@@ -13,14 +13,15 @@
|
||||
"reset": "Reset",
|
||||
"rotateClockwise": "Rotate Clockwise",
|
||||
"rotateCounterClockwise": "Rotate Counter-Clockwise",
|
||||
"showGallery": "Show Gallery",
|
||||
"showGalleryPanel": "Show Gallery Panel",
|
||||
"showOptionsPanel": "Show Side Panel",
|
||||
"toggleAutoscroll": "Toggle autoscroll",
|
||||
"toggleLogViewer": "Toggle Log Viewer",
|
||||
"uploadImage": "Upload Image",
|
||||
"useThisParameter": "Use this parameter",
|
||||
"zoomIn": "Zoom In",
|
||||
"zoomOut": "Zoom Out"
|
||||
"zoomOut": "Zoom Out",
|
||||
"loadMore": "Load More"
|
||||
},
|
||||
"boards": {
|
||||
"addBoard": "Add Board",
|
||||
@@ -37,19 +38,24 @@
|
||||
"searchBoard": "Search Boards...",
|
||||
"selectBoard": "Select a Board",
|
||||
"topMessage": "This board contains images used in the following features:",
|
||||
"uncategorized": "Uncategorized"
|
||||
"uncategorized": "Uncategorized",
|
||||
"downloadBoard": "Download Board"
|
||||
},
|
||||
"common": {
|
||||
"accept": "Accept",
|
||||
"advanced": "Advanced",
|
||||
"areYouSure": "Are you sure?",
|
||||
"auto": "Auto",
|
||||
"back": "Back",
|
||||
"batch": "Batch Manager",
|
||||
"cancel": "Cancel",
|
||||
"close": "Close",
|
||||
"on": "On",
|
||||
"communityLabel": "Community",
|
||||
"controlNet": "Controlnet",
|
||||
"controlNet": "ControlNet",
|
||||
"controlAdapter": "Control Adapter",
|
||||
"ipAdapter": "IP Adapter",
|
||||
"t2iAdapter": "T2I Adapter",
|
||||
"darkMode": "Dark Mode",
|
||||
"discordLabel": "Discord",
|
||||
"dontAskMeAgain": "Don't ask me again",
|
||||
@@ -57,6 +63,7 @@
|
||||
"githubLabel": "Github",
|
||||
"hotkeysLabel": "Hotkeys",
|
||||
"imagePrompt": "Image Prompt",
|
||||
"imageFailedToLoad": "Unable to Load Image",
|
||||
"img2img": "Image To Image",
|
||||
"langArabic": "العربية",
|
||||
"langBrPortuguese": "Português do Brasil",
|
||||
@@ -80,6 +87,7 @@
|
||||
"load": "Load",
|
||||
"loading": "Loading",
|
||||
"loadingInvokeAI": "Loading Invoke AI",
|
||||
"learnMore": "Learn More",
|
||||
"modelManager": "Model Manager",
|
||||
"nodeEditor": "Node Editor",
|
||||
"nodes": "Workflow Editor",
|
||||
@@ -110,6 +118,7 @@
|
||||
"statusModelChanged": "Model Changed",
|
||||
"statusModelConverted": "Model Converted",
|
||||
"statusPreparing": "Preparing",
|
||||
"statusProcessing": "Processing",
|
||||
"statusProcessingCanceled": "Processing Canceled",
|
||||
"statusProcessingComplete": "Processing Complete",
|
||||
"statusRestoringFaces": "Restoring Faces",
|
||||
@@ -126,6 +135,17 @@
|
||||
"upload": "Upload"
|
||||
},
|
||||
"controlnet": {
|
||||
"controlAdapter_one": "Control Adapter",
|
||||
"controlAdapter_other": "Control Adapters",
|
||||
"controlnet": "$t(controlnet.controlAdapter) #{{number}} ($t(common.controlNet))",
|
||||
"ip_adapter": "$t(controlnet.controlAdapter) #{{number}} ($t(common.ipAdapter))",
|
||||
"t2i_adapter": "$t(controlnet.controlAdapter) #{{number}} ($t(common.t2iAdapter))",
|
||||
"addControlNet": "Add $t(common.controlNet)",
|
||||
"addIPAdapter": "Add $t(common.ipAdapter)",
|
||||
"addT2IAdapter": "Add $t(common.t2iAdapter)",
|
||||
"controlNetEnabledT2IDisabled": "$t(common.controlNet) enabled, $t(common.t2iAdapter)s disabled",
|
||||
"t2iEnabledControlNetDisabled": "$t(common.t2iAdapter) enabled, $t(common.controlNet)s disabled",
|
||||
"controlNetT2IMutexDesc": "$t(common.controlNet) and $t(common.t2iAdapter) at same time is currently unsupported.",
|
||||
"amult": "a_mult",
|
||||
"autoConfigure": "Auto configure processor",
|
||||
"balanced": "Balanced",
|
||||
@@ -133,6 +153,8 @@
|
||||
"bgth": "bg_th",
|
||||
"canny": "Canny",
|
||||
"cannyDescription": "Canny edge detection",
|
||||
"colorMap": "Color",
|
||||
"colorMapDescription": "Generates a color map from the image",
|
||||
"coarse": "Coarse",
|
||||
"contentShuffle": "Content Shuffle",
|
||||
"contentShuffleDescription": "Shuffles the content in an image",
|
||||
@@ -156,6 +178,7 @@
|
||||
"hideAdvanced": "Hide Advanced",
|
||||
"highThreshold": "High Threshold",
|
||||
"imageResolution": "Image Resolution",
|
||||
"colorMapTileSize": "Tile Size",
|
||||
"importImageFromCanvas": "Import Image From Canvas",
|
||||
"importMaskFromCanvas": "Import Mask From Canvas",
|
||||
"incompatibleBaseModel": "Incompatible base model:",
|
||||
@@ -203,6 +226,82 @@
|
||||
"incompatibleModel": "Incompatible base model:",
|
||||
"noMatchingEmbedding": "No matching Embeddings"
|
||||
},
|
||||
"queue": {
|
||||
"queue": "Queue",
|
||||
"queueFront": "Add to Front of Queue",
|
||||
"queueBack": "Add to Queue",
|
||||
"queueCountPrediction": "Add {{predicted}} to Queue",
|
||||
"queueMaxExceeded": "Max of {{max_queue_size}} exceeded, would skip {{skip}}",
|
||||
"queuedCount": "{{pending}} Pending",
|
||||
"queueTotal": "{{total}} Total",
|
||||
"queueEmpty": "Queue Empty",
|
||||
"enqueueing": "Queueing Batch",
|
||||
"resume": "Resume",
|
||||
"resumeTooltip": "Resume Processor",
|
||||
"resumeSucceeded": "Processor Resumed",
|
||||
"resumeFailed": "Problem Resuming Processor",
|
||||
"pause": "Pause",
|
||||
"pauseTooltip": "Pause Processor",
|
||||
"pauseSucceeded": "Processor Paused",
|
||||
"pauseFailed": "Problem Pausing Processor",
|
||||
"cancel": "Cancel",
|
||||
"cancelTooltip": "Cancel Current Item",
|
||||
"cancelSucceeded": "Item Canceled",
|
||||
"cancelFailed": "Problem Canceling Item",
|
||||
"prune": "Prune",
|
||||
"pruneTooltip": "Prune {{item_count}} Completed Items",
|
||||
"pruneSucceeded": "Pruned {{item_count}} Completed Items from Queue",
|
||||
"pruneFailed": "Problem Pruning Queue",
|
||||
"clear": "Clear",
|
||||
"clearTooltip": "Cancel and Clear All Items",
|
||||
"clearSucceeded": "Queue Cleared",
|
||||
"clearFailed": "Problem Clearing Queue",
|
||||
"cancelBatch": "Cancel Batch",
|
||||
"cancelItem": "Cancel Item",
|
||||
"cancelBatchSucceeded": "Batch Canceled",
|
||||
"cancelBatchFailed": "Problem Canceling Batch",
|
||||
"clearQueueAlertDialog": "Clearing the queue immediately cancels any processing items and clears the queue entirely.",
|
||||
"clearQueueAlertDialog2": "Are you sure you want to clear the queue?",
|
||||
"current": "Current",
|
||||
"next": "Next",
|
||||
"status": "Status",
|
||||
"total": "Total",
|
||||
"pending": "Pending",
|
||||
"in_progress": "In Progress",
|
||||
"completed": "Completed",
|
||||
"failed": "Failed",
|
||||
"canceled": "Canceled",
|
||||
"completedIn": "Completed in",
|
||||
"batch": "Batch",
|
||||
"item": "Item",
|
||||
"session": "Session",
|
||||
"batchValues": "Batch Values",
|
||||
"notReady": "Unable to Queue",
|
||||
"batchQueued": "Batch Queued",
|
||||
"batchQueuedDesc_one": "Added {{count}} sessions to {{direction}} of queue",
|
||||
"batchQueuedDesc_other": "Added {{count}} sessions to {{direction}} of queue",
|
||||
"front": "front",
|
||||
"back": "back",
|
||||
"batchFailedToQueue": "Failed to Queue Batch",
|
||||
"graphQueued": "Graph queued",
|
||||
"graphFailedToQueue": "Failed to queue graph"
|
||||
},
|
||||
"invocationCache": {
|
||||
"invocationCache": "Invocation Cache",
|
||||
"cacheSize": "Cache Size",
|
||||
"maxCacheSize": "Max Cache Size",
|
||||
"hits": "Cache Hits",
|
||||
"misses": "Cache Misses",
|
||||
"clear": "Clear",
|
||||
"clearSucceeded": "Invocation Cache Cleared",
|
||||
"clearFailed": "Problem Clearing Invocation Cache",
|
||||
"enable": "Enable",
|
||||
"enableSucceeded": "Invocation Cache Enabled",
|
||||
"enableFailed": "Problem Enabling Invocation Cache",
|
||||
"disable": "Disable",
|
||||
"disableSucceeded": "Invocation Cache Disabled",
|
||||
"disableFailed": "Problem Disabling Invocation Cache"
|
||||
},
|
||||
"gallery": {
|
||||
"allImagesLoaded": "All Images Loaded",
|
||||
"assets": "Assets",
|
||||
@@ -229,7 +328,10 @@
|
||||
"showUploads": "Show Uploads",
|
||||
"singleColumnLayout": "Single Column Layout",
|
||||
"unableToLoad": "Unable to load Gallery",
|
||||
"uploads": "Uploads"
|
||||
"uploads": "Uploads",
|
||||
"downloadSelection": "Download Selection",
|
||||
"preparingDownload": "Preparing Download",
|
||||
"preparingDownloadFailed": "Problem Preparing Download"
|
||||
},
|
||||
"hotkeys": {
|
||||
"acceptStagingImage": {
|
||||
@@ -574,7 +676,7 @@
|
||||
"onnxModels": "Onnx",
|
||||
"pathToCustomConfig": "Path To Custom Config",
|
||||
"pickModelType": "Pick Model Type",
|
||||
"predictionType": "Prediction Type (for Stable Diffusion 2.x Models only)",
|
||||
"predictionType": "Prediction Type (for Stable Diffusion 2.x Models and occasional Stable Diffusion 1.x Models)",
|
||||
"quickAdd": "Quick Add",
|
||||
"repo_id": "Repo ID",
|
||||
"repoIDValidationMsg": "Online repository of your model",
|
||||
@@ -603,6 +705,7 @@
|
||||
"vae": "VAE",
|
||||
"vaeLocation": "VAE Location",
|
||||
"vaeLocationValidationMsg": "Path to where your VAE is located.",
|
||||
"vaePrecision": "VAE Precision",
|
||||
"vaeRepoID": "VAE Repo ID",
|
||||
"vaeRepoIDValidationMsg": "Online repository of your VAE",
|
||||
"variant": "Variant",
|
||||
@@ -615,7 +718,7 @@
|
||||
"noLoRAsAvailable": "No LoRAs available",
|
||||
"noMatchingLoRAs": "No matching LoRAs",
|
||||
"noMatchingModels": "No matching Models",
|
||||
"noModelsAvailable": "No Modelss available",
|
||||
"noModelsAvailable": "No models available",
|
||||
"selectLoRA": "Select a LoRA",
|
||||
"selectModel": "Select a Model"
|
||||
},
|
||||
@@ -624,6 +727,8 @@
|
||||
"addNodeToolTip": "Add Node (Shift+A, Space)",
|
||||
"animatedEdges": "Animated Edges",
|
||||
"animatedEdgesHelp": "Animate selected edges and edges connected to selected nodes",
|
||||
"boardField": "Board",
|
||||
"boardFieldDescription": "A gallery board",
|
||||
"boolean": "Booleans",
|
||||
"booleanCollection": "Boolean Collection",
|
||||
"booleanCollectionDescription": "A collection of booleans.",
|
||||
@@ -633,6 +738,7 @@
|
||||
"cannotConnectInputToInput": "Cannot connect input to input",
|
||||
"cannotConnectOutputToOutput": "Cannot connect output to output",
|
||||
"cannotConnectToSelf": "Cannot connect to self",
|
||||
"cannotDuplicateConnection": "Cannot create duplicate connections",
|
||||
"clipField": "Clip",
|
||||
"clipFieldDescription": "Tokenizer and text_encoder submodels.",
|
||||
"collection": "Collection",
|
||||
@@ -641,7 +747,8 @@
|
||||
"collectionItemDescription": "TODO",
|
||||
"colorCodeEdges": "Color-Code Edges",
|
||||
"colorCodeEdgesHelp": "Color-code edges according to their connected fields",
|
||||
"colorCollectionDescription": "A collection of colors.",
|
||||
"colorCollection": "A collection of colors.",
|
||||
"colorCollectionDescription": "TODO",
|
||||
"colorField": "Color",
|
||||
"colorFieldDescription": "A RGBA color.",
|
||||
"colorPolymorphic": "Color Polymorphic",
|
||||
@@ -688,7 +795,8 @@
|
||||
"imageFieldDescription": "Images may be passed between nodes.",
|
||||
"imagePolymorphic": "Image Polymorphic",
|
||||
"imagePolymorphicDescription": "A collection of images.",
|
||||
"inputFields": "Input Feilds",
|
||||
"inputField": "Input Field",
|
||||
"inputFields": "Input Fields",
|
||||
"inputMayOnlyHaveOneConnection": "Input may only have one connection",
|
||||
"inputNode": "Input Node",
|
||||
"integer": "Integer",
|
||||
@@ -698,6 +806,14 @@
|
||||
"integerPolymorphic": "Integer Polymorphic",
|
||||
"integerPolymorphicDescription": "A collection of integers.",
|
||||
"invalidOutputSchema": "Invalid output schema",
|
||||
"ipAdapter": "IP-Adapter",
|
||||
"ipAdapterCollection": "IP-Adapters Collection",
|
||||
"ipAdapterCollectionDescription": "A collection of IP-Adapters.",
|
||||
"ipAdapterDescription": "An Image Prompt Adapter (IP-Adapter).",
|
||||
"ipAdapterModel": "IP-Adapter Model",
|
||||
"ipAdapterModelDescription": "IP-Adapter Model Field",
|
||||
"ipAdapterPolymorphic": "IP-Adapter Polymorphic",
|
||||
"ipAdapterPolymorphicDescription": "A collection of IP-Adapters.",
|
||||
"latentsCollection": "Latents Collection",
|
||||
"latentsCollectionDescription": "Latents may be passed between nodes.",
|
||||
"latentsField": "Latents",
|
||||
@@ -706,6 +822,7 @@
|
||||
"latentsPolymorphicDescription": "Latents may be passed between nodes.",
|
||||
"loadingNodes": "Loading Nodes...",
|
||||
"loadWorkflow": "Load Workflow",
|
||||
"noWorkflow": "No Workflow",
|
||||
"loRAModelField": "LoRA",
|
||||
"loRAModelFieldDescription": "TODO",
|
||||
"mainModelField": "Model",
|
||||
@@ -727,14 +844,15 @@
|
||||
"noImageFoundState": "No initial image found in state",
|
||||
"noMatchingNodes": "No matching nodes",
|
||||
"noNodeSelected": "No node selected",
|
||||
"noOpacity": "Node Opacity",
|
||||
"nodeOpacity": "Node Opacity",
|
||||
"noOutputRecorded": "No outputs recorded",
|
||||
"noOutputSchemaName": "No output schema name found in ref object",
|
||||
"notes": "Notes",
|
||||
"notesDescription": "Add notes about your workflow",
|
||||
"oNNXModelField": "ONNX Model",
|
||||
"oNNXModelFieldDescription": "ONNX model field.",
|
||||
"outputFields": "Output Feilds",
|
||||
"outputField": "Output Field",
|
||||
"outputFields": "Output Fields",
|
||||
"outputNode": "Output node",
|
||||
"outputSchemaNotFound": "Output schema not found",
|
||||
"pickOne": "Pick One",
|
||||
@@ -783,6 +901,7 @@
|
||||
"unknownNode": "Unknown Node",
|
||||
"unknownTemplate": "Unknown Template",
|
||||
"unkownInvocation": "Unknown Invocation type",
|
||||
"updateNode": "Update Node",
|
||||
"updateApp": "Update App",
|
||||
"vaeField": "Vae",
|
||||
"vaeFieldDescription": "Vae submodel.",
|
||||
@@ -806,7 +925,8 @@
|
||||
"zoomOutNodes": "Zoom Out"
|
||||
},
|
||||
"parameters": {
|
||||
"aspectRatio": "Ratio",
|
||||
"aspectRatio": "Aspect Ratio",
|
||||
"aspectRatioFree": "Free",
|
||||
"boundingBoxHeader": "Bounding Box",
|
||||
"boundingBoxHeight": "Bounding Box Height",
|
||||
"boundingBoxWidth": "Bounding Box Width",
|
||||
@@ -819,6 +939,7 @@
|
||||
},
|
||||
"cfgScale": "CFG Scale",
|
||||
"clipSkip": "CLIP Skip",
|
||||
"clipSkipWithLayerCount": "CLIP Skip {{layerCount}}",
|
||||
"closeViewer": "Close Viewer",
|
||||
"codeformerFidelity": "Fidelity",
|
||||
"coherenceMode": "Mode",
|
||||
@@ -853,10 +974,12 @@
|
||||
"missingFieldTemplate": "Missing field template",
|
||||
"missingInputForField": "{{nodeLabel}} -> {{fieldLabel}} missing input",
|
||||
"missingNodeTemplate": "Missing node template",
|
||||
"noControlImageForControlNet": "ControlNet {{index}} has no control image",
|
||||
"noControlImageForControlAdapter": "Control Adapter #{{number}} has no control image",
|
||||
"noInitialImageSelected": "No initial image selected",
|
||||
"noModelForControlNet": "ControlNet {{index}} has no model selected.",
|
||||
"noModelForControlAdapter": "Control Adapter #{{number}} has no model selected.",
|
||||
"incompatibleBaseModelForControlAdapter": "Control Adapter #{{number}} model is invalid with main model.",
|
||||
"noModelSelected": "No model selected",
|
||||
"noPrompts": "No prompts generated",
|
||||
"noNodesInGraph": "No nodes in graph",
|
||||
"readyToInvoke": "Ready to Invoke",
|
||||
"systemBusy": "System busy",
|
||||
@@ -875,7 +998,12 @@
|
||||
"perlinNoise": "Perlin Noise",
|
||||
"positivePromptPlaceholder": "Positive Prompt",
|
||||
"randomizeSeed": "Randomize Seed",
|
||||
"manualSeed": "Manual Seed",
|
||||
"randomSeed": "Random Seed",
|
||||
"restoreFaces": "Restore Faces",
|
||||
"iterations": "Iterations",
|
||||
"iterationsWithCount_one": "{{count}} Iteration",
|
||||
"iterationsWithCount_other": "{{count}} Iterations",
|
||||
"scale": "Scale",
|
||||
"scaleBeforeProcessing": "Scale Before Processing",
|
||||
"scaledHeight": "Scaled H",
|
||||
@@ -886,13 +1014,17 @@
|
||||
"seamlessTiling": "Seamless Tiling",
|
||||
"seamlessXAxis": "X Axis",
|
||||
"seamlessYAxis": "Y Axis",
|
||||
"seamlessX": "Seamless X",
|
||||
"seamlessY": "Seamless Y",
|
||||
"seamlessX&Y": "Seamless X & Y",
|
||||
"seamLowThreshold": "Low",
|
||||
"seed": "Seed",
|
||||
"seedWeights": "Seed Weights",
|
||||
"imageActions": "Image Actions",
|
||||
"sendTo": "Send to",
|
||||
"sendToImg2Img": "Send to Image to Image",
|
||||
"sendToUnifiedCanvas": "Send To Unified Canvas",
|
||||
"showOptionsPanel": "Show Options Panel",
|
||||
"showOptionsPanel": "Show Side Panel (O or T)",
|
||||
"showPreview": "Show Preview",
|
||||
"shuffle": "Shuffle Seed",
|
||||
"steps": "Steps",
|
||||
@@ -901,24 +1033,39 @@
|
||||
"tileSize": "Tile Size",
|
||||
"toggleLoopback": "Toggle Loopback",
|
||||
"type": "Type",
|
||||
"upscale": "Upscale",
|
||||
"upscale": "Upscale (Shift + U)",
|
||||
"upscaleImage": "Upscale Image",
|
||||
"upscaling": "Upscaling",
|
||||
"useAll": "Use All",
|
||||
"useCpuNoise": "Use CPU Noise",
|
||||
"cpuNoise": "CPU Noise",
|
||||
"gpuNoise": "GPU Noise",
|
||||
"useInitImg": "Use Initial Image",
|
||||
"usePrompt": "Use Prompt",
|
||||
"useSeed": "Use Seed",
|
||||
"variationAmount": "Variation Amount",
|
||||
"variations": "Variations",
|
||||
"vSymmetryStep": "V Symmetry Step",
|
||||
"width": "Width"
|
||||
"width": "Width",
|
||||
"isAllowedToUpscale": {
|
||||
"useX2Model": "Image is too large to upscale with x4 model, use x2 model",
|
||||
"tooLarge": "Image is too large to upscale, select smaller image"
|
||||
}
|
||||
},
|
||||
"prompt": {
|
||||
"dynamicPrompts": {
|
||||
"combinatorial": "Combinatorial Generation",
|
||||
"dynamicPrompts": "Dynamic Prompts",
|
||||
"enableDynamicPrompts": "Enable Dynamic Prompts",
|
||||
"maxPrompts": "Max Prompts"
|
||||
"maxPrompts": "Max Prompts",
|
||||
"promptsWithCount_one": "{{count}} Prompt",
|
||||
"promptsWithCount_other": "{{count}} Prompts",
|
||||
"seedBehaviour": {
|
||||
"label": "Seed Behaviour",
|
||||
"perIterationLabel": "Seed per Iteration",
|
||||
"perIterationDesc": "Use a different seed for each iteration",
|
||||
"perPromptLabel": "Seed per Image",
|
||||
"perPromptDesc": "Use a different seed for each image"
|
||||
}
|
||||
},
|
||||
"sdxl": {
|
||||
"cfgScale": "CFG Scale",
|
||||
@@ -965,11 +1112,22 @@
|
||||
"showAdvancedOptions": "Show Advanced Options",
|
||||
"showProgressInViewer": "Show Progress Images in Viewer",
|
||||
"ui": "User Interface",
|
||||
"useSlidersForAll": "Use Sliders For All Options"
|
||||
"useSlidersForAll": "Use Sliders For All Options",
|
||||
"clearIntermediatesDesc1": "Clearing intermediates will reset your Canvas and ControlNet state.",
|
||||
"clearIntermediatesDesc2": "Intermediate images are byproducts of generation, different from the result images in the gallery. Clearing intermediates will free disk space.",
|
||||
"clearIntermediatesDesc3": "Your gallery images will not be deleted.",
|
||||
"clearIntermediates": "Clear Intermediates",
|
||||
"clearIntermediatesWithCount_one": "Clear {{count}} Intermediate",
|
||||
"clearIntermediatesWithCount_other": "Clear {{count}} Intermediates",
|
||||
"clearIntermediatesWithCount_zero": "No Intermediates to Clear",
|
||||
"intermediatesCleared_one": "Cleared {{count}} Intermediate",
|
||||
"intermediatesCleared_other": "Cleared {{count}} Intermediates",
|
||||
"intermediatesClearedFailed": "Problem Clearing Intermediates"
|
||||
},
|
||||
"toast": {
|
||||
"addedToBoard": "Added to board",
|
||||
"baseModelChangedCleared": "Base model changed, cleared",
|
||||
"baseModelChangedCleared_one": "Base model changed, cleared or disabled {{count}} incompatible submodel",
|
||||
"baseModelChangedCleared_other": "Base model changed, cleared or disabled {{count}} incompatible submodels",
|
||||
"canceled": "Processing Canceled",
|
||||
"canvasCopiedClipboard": "Canvas Copied to Clipboard",
|
||||
"canvasDownloaded": "Canvas Downloaded",
|
||||
@@ -989,7 +1147,6 @@
|
||||
"imageSavingFailed": "Image Saving Failed",
|
||||
"imageUploaded": "Image Uploaded",
|
||||
"imageUploadFailed": "Image Upload Failed",
|
||||
"incompatibleSubmodel": "incompatible submodel",
|
||||
"initialImageNotSet": "Initial Image Not Set",
|
||||
"initialImageNotSetDesc": "Could not load initial image",
|
||||
"initialImageSet": "Initial Image Set",
|
||||
@@ -1066,6 +1223,210 @@
|
||||
"variations": "Try a variation with a value between 0.1 and 1.0 to change the result for a given seed. Interesting variations of the seed are between 0.1 and 0.3."
|
||||
}
|
||||
},
|
||||
"popovers": {
|
||||
"clipSkip": {
|
||||
"heading": "CLIP Skip",
|
||||
"paragraphs": [
|
||||
"Choose how many layers of the CLIP model to skip.",
|
||||
"Some models work better with certain CLIP Skip settings.",
|
||||
"A higher value typically results in a less detailed image."
|
||||
]
|
||||
},
|
||||
"paramNegativeConditioning": {
|
||||
"heading": "Negative Prompt",
|
||||
"paragraphs": [
|
||||
"The generation process avoids the concepts in the negative prompt. Use this to exclude qualities or objects from the output.",
|
||||
"Supports Compel syntax and embeddings."
|
||||
]
|
||||
},
|
||||
"paramPositiveConditioning": {
|
||||
"heading": "Positive Prompt",
|
||||
"paragraphs": [
|
||||
"Guides the generation process. You may use any words or phrases.",
|
||||
"Compel and Dynamic Prompts syntaxes and embeddings."
|
||||
]
|
||||
},
|
||||
"paramScheduler": {
|
||||
"heading": "Scheduler",
|
||||
"paragraphs": [
|
||||
"Scheduler defines how to iteratively add noise to an image or how to update a sample based on a model's output."
|
||||
]
|
||||
},
|
||||
"compositingBlur": {
|
||||
"heading": "Blur",
|
||||
"paragraphs": ["The blur radius of the mask."]
|
||||
},
|
||||
"compositingBlurMethod": {
|
||||
"heading": "Blur Method",
|
||||
"paragraphs": ["The method of blur applied to the masked area."]
|
||||
},
|
||||
"compositingCoherencePass": {
|
||||
"heading": "Coherence Pass",
|
||||
"paragraphs": [
|
||||
"A second round of denoising helps to composite the Inpainted/Outpainted image."
|
||||
]
|
||||
},
|
||||
"compositingCoherenceMode": {
|
||||
"heading": "Mode",
|
||||
"paragraphs": ["The mode of the Coherence Pass."]
|
||||
},
|
||||
"compositingCoherenceSteps": {
|
||||
"heading": "Steps",
|
||||
"paragraphs": [
|
||||
"Number of denoising steps used in the Coherence Pass.",
|
||||
"Same as the main Steps parameter."
|
||||
]
|
||||
},
|
||||
"compositingStrength": {
|
||||
"heading": "Strength",
|
||||
"paragraphs": [
|
||||
"Denoising strength for the Coherence Pass.",
|
||||
"Same as the Image to Image Denoising Strength parameter."
|
||||
]
|
||||
},
|
||||
"compositingMaskAdjustments": {
|
||||
"heading": "Mask Adjustments",
|
||||
"paragraphs": ["Adjust the mask."]
|
||||
},
|
||||
"controlNetBeginEnd": {
|
||||
"heading": "Begin / End Step Percentage",
|
||||
"paragraphs": [
|
||||
"Which steps of the denoising process will have the ControlNet applied.",
|
||||
"ControlNets applied at the beginning of the process guide composition, and ControlNets applied at the end guide details."
|
||||
]
|
||||
},
|
||||
"controlNetControlMode": {
|
||||
"heading": "Control Mode",
|
||||
"paragraphs": [
|
||||
"Lends more weight to either the prompt or ControlNet."
|
||||
]
|
||||
},
|
||||
"controlNetResizeMode": {
|
||||
"heading": "Resize Mode",
|
||||
"paragraphs": [
|
||||
"How the ControlNet image will be fit to the image output size."
|
||||
]
|
||||
},
|
||||
"controlNet": {
|
||||
"heading": "ControlNet",
|
||||
"paragraphs": [
|
||||
"ControlNets provide guidance to the generation process, helping create images with controlled composition, structure, or style, depending on the model selected."
|
||||
]
|
||||
},
|
||||
"controlNetWeight": {
|
||||
"heading": "Weight",
|
||||
"paragraphs": [
|
||||
"How strongly the ControlNet will impact the generated image."
|
||||
]
|
||||
},
|
||||
"dynamicPrompts": {
|
||||
"heading": "Dynamic Prompts",
|
||||
"paragraphs": [
|
||||
"Dynamic Prompts parses a single prompt into many.",
|
||||
"The basic syntax is \"a {red|green|blue} ball\". This will produce three prompts: \"a red ball\", \"a green ball\" and \"a blue ball\".",
|
||||
"You can use the syntax as many times as you like in a single prompt, but be sure to keep the number of prompts generated in check with the Max Prompts setting."
|
||||
]
|
||||
},
|
||||
"dynamicPromptsMaxPrompts": {
|
||||
"heading": "Max Prompts",
|
||||
"paragraphs": [
|
||||
"Limits the number of prompts that can be generated by Dynamic Prompts."
|
||||
]
|
||||
},
|
||||
"dynamicPromptsSeedBehaviour": {
|
||||
"heading": "Seed Behaviour",
|
||||
"paragraphs": [
|
||||
"Controls how the seed is used when generating prompts.",
|
||||
"Per Iteration will use a unique seed for each iteration. Use this to explore prompt variations on a single seed.",
|
||||
"For example, if you have 5 prompts, each image will use the same seed.",
|
||||
"Per Image will use a unique seed for each image. This provides more variation."
|
||||
]
|
||||
},
|
||||
"infillMethod": {
|
||||
"heading": "Infill Method",
|
||||
"paragraphs": ["Method to infill the selected area."]
|
||||
},
|
||||
"lora": {
|
||||
"heading": "LoRA Weight",
|
||||
"paragraphs": [
|
||||
"Higher LoRA weight will lead to larger impacts on the final image."
|
||||
]
|
||||
},
|
||||
"noiseUseCPU": {
|
||||
"heading": "Use CPU Noise",
|
||||
"paragraphs": [
|
||||
"Controls whether noise is generated on the CPU or GPU.",
|
||||
"With CPU Noise enabled, a particular seed will produce the same image on any machine.",
|
||||
"There is no performance impact to enabling CPU Noise."
|
||||
]
|
||||
},
|
||||
"paramCFGScale": {
|
||||
"heading": "CFG Scale",
|
||||
"paragraphs": [
|
||||
"Controls how much your prompt influences the generation process."
|
||||
]
|
||||
},
|
||||
"paramDenoisingStrength": {
|
||||
"heading": "Denoising Strength",
|
||||
"paragraphs": [
|
||||
"How much noise is added to the input image.",
|
||||
"0 will result in an identical image, while 1 will result in a completely new image."
|
||||
]
|
||||
},
|
||||
"paramIterations": {
|
||||
"heading": "Iterations",
|
||||
"paragraphs": [
|
||||
"The number of images to generate.",
|
||||
"If Dynamic Prompts is enabled, each of the prompts will be generated this many times."
|
||||
]
|
||||
},
|
||||
"paramModel": {
|
||||
"heading": "Model",
|
||||
"paragraphs": [
|
||||
"Model used for the denoising steps.",
|
||||
"Different models are typically trained to specialize in producing particular aesthetic results and content."
|
||||
]
|
||||
},
|
||||
"paramRatio": {
|
||||
"heading": "Aspect Ratio",
|
||||
"paragraphs": [
|
||||
"The aspect ratio of the dimensions of the image generated.",
|
||||
"An image size (in number of pixels) equivalent to 512x512 is recommended for SD1.5 models and a size equivalent to 1024x1024 is recommended for SDXL models."
|
||||
]
|
||||
},
|
||||
"paramSeed": {
|
||||
"heading": "Seed",
|
||||
"paragraphs": [
|
||||
"Controls the starting noise used for generation.",
|
||||
"Disable “Random Seed” to produce identical results with the same generation settings."
|
||||
]
|
||||
},
|
||||
"paramSteps": {
|
||||
"heading": "Steps",
|
||||
"paragraphs": [
|
||||
"Number of steps that will be performed in each generation.",
|
||||
"Higher step counts will typically create better images but will require more generation time."
|
||||
]
|
||||
},
|
||||
"paramVAE": {
|
||||
"heading": "VAE",
|
||||
"paragraphs": [
|
||||
"Model used for translating AI output into the final image."
|
||||
]
|
||||
},
|
||||
"paramVAEPrecision": {
|
||||
"heading": "VAE Precision",
|
||||
"paragraphs": [
|
||||
"The precision used during VAE encoding and decoding. FP16/half precision is more efficient, at the expense of minor image variations."
|
||||
]
|
||||
},
|
||||
"scaleBeforeProcessing": {
|
||||
"heading": "Scale Before Processing",
|
||||
"paragraphs": [
|
||||
"Scales the selected area to the size best suited for the model before the image generation process."
|
||||
]
|
||||
}
|
||||
},
|
||||
"ui": {
|
||||
"hideProgressImages": "Hide Progress Images",
|
||||
"lockRatio": "Lock Ratio",
|
||||
@@ -1128,6 +1489,8 @@
|
||||
"showCanvasDebugInfo": "Show Additional Canvas Info",
|
||||
"showGrid": "Show Grid",
|
||||
"showHide": "Show/Hide",
|
||||
"showResultsOn": "Show Results (On)",
|
||||
"showResultsOff": "Show Results (Off)",
|
||||
"showIntermediates": "Show Intermediates",
|
||||
"snapToGrid": "Snap to Grid",
|
||||
"undo": "Undo"
|
||||
|
||||
175
invokeai/frontend/web/dist/locales/es.json
vendored
175
invokeai/frontend/web/dist/locales/es.json
vendored
@@ -1,16 +1,12 @@
|
||||
{
|
||||
"common": {
|
||||
"hotkeysLabel": "Atajos de teclado",
|
||||
"themeLabel": "Tema",
|
||||
"languagePickerLabel": "Selector de idioma",
|
||||
"reportBugLabel": "Reportar errores",
|
||||
"settingsLabel": "Ajustes",
|
||||
"darkTheme": "Oscuro",
|
||||
"lightTheme": "Claro",
|
||||
"greenTheme": "Verde",
|
||||
"img2img": "Imagen a Imagen",
|
||||
"unifiedCanvas": "Lienzo Unificado",
|
||||
"nodes": "Nodos",
|
||||
"nodes": "Editor del flujo de trabajo",
|
||||
"langSpanish": "Español",
|
||||
"nodesDesc": "Un sistema de generación de imágenes basado en nodos, actualmente se encuentra en desarrollo. Mantente pendiente a nuestras actualizaciones acerca de esta fabulosa funcionalidad.",
|
||||
"postProcessing": "Post-procesamiento",
|
||||
@@ -19,7 +15,7 @@
|
||||
"postProcessDesc3": "La Interfaz de Línea de Comandos de Invoke AI ofrece muchas otras características, incluyendo -Embiggen-.",
|
||||
"training": "Entrenamiento",
|
||||
"trainingDesc1": "Un flujo de trabajo dedicado para el entrenamiento de sus propios -embeddings- y puntos de control utilizando Inversión Textual y Dreambooth desde la interfaz web.",
|
||||
"trainingDesc2": "InvokeAI ya soporta el entrenamiento de -embeddings- personalizados utilizando la Inversión Textual mediante el script principal.",
|
||||
"trainingDesc2": "InvokeAI ya admite el entrenamiento de incrustaciones personalizadas mediante la inversión textual mediante el script principal.",
|
||||
"upload": "Subir imagen",
|
||||
"close": "Cerrar",
|
||||
"load": "Cargar",
|
||||
@@ -63,18 +59,27 @@
|
||||
"statusConvertingModel": "Convertir el modelo",
|
||||
"statusModelConverted": "Modelo adaptado",
|
||||
"statusMergingModels": "Fusionar modelos",
|
||||
"oceanTheme": "Océano",
|
||||
"langPortuguese": "Portugués",
|
||||
"langKorean": "Coreano",
|
||||
"langHebrew": "Hebreo",
|
||||
"pinOptionsPanel": "Pin del panel de opciones",
|
||||
"loading": "Cargando",
|
||||
"loadingInvokeAI": "Cargando invocar a la IA",
|
||||
"postprocessing": "Tratamiento posterior",
|
||||
"txt2img": "De texto a imagen",
|
||||
"accept": "Aceptar",
|
||||
"cancel": "Cancelar",
|
||||
"linear": "Lineal"
|
||||
"linear": "Lineal",
|
||||
"random": "Aleatorio",
|
||||
"generate": "Generar",
|
||||
"openInNewTab": "Abrir en una nueva pestaña",
|
||||
"dontAskMeAgain": "No me preguntes de nuevo",
|
||||
"areYouSure": "¿Estas seguro?",
|
||||
"imagePrompt": "Indicación de imagen",
|
||||
"batch": "Administrador de lotes",
|
||||
"darkMode": "Modo oscuro",
|
||||
"lightMode": "Modo claro",
|
||||
"modelManager": "Administrador de modelos",
|
||||
"communityLabel": "Comunidad"
|
||||
},
|
||||
"gallery": {
|
||||
"generations": "Generaciones",
|
||||
@@ -87,10 +92,15 @@
|
||||
"maintainAspectRatio": "Mantener relación de aspecto",
|
||||
"autoSwitchNewImages": "Auto seleccionar Imágenes nuevas",
|
||||
"singleColumnLayout": "Diseño de una columna",
|
||||
"pinGallery": "Fijar galería",
|
||||
"allImagesLoaded": "Todas las imágenes cargadas",
|
||||
"loadMore": "Cargar más",
|
||||
"noImagesInGallery": "Sin imágenes en la galería"
|
||||
"noImagesInGallery": "No hay imágenes para mostrar",
|
||||
"deleteImage": "Eliminar Imagen",
|
||||
"deleteImageBin": "Las imágenes eliminadas se enviarán a la papelera de tu sistema operativo.",
|
||||
"deleteImagePermanent": "Las imágenes eliminadas no se pueden restaurar.",
|
||||
"images": "Imágenes",
|
||||
"assets": "Activos",
|
||||
"autoAssignBoardOnClick": "Asignación automática de tableros al hacer clic"
|
||||
},
|
||||
"hotkeys": {
|
||||
"keyboardShortcuts": "Atajos de teclado",
|
||||
@@ -297,7 +307,12 @@
|
||||
"acceptStagingImage": {
|
||||
"title": "Aceptar imagen",
|
||||
"desc": "Aceptar la imagen actual en el área de preparación"
|
||||
}
|
||||
},
|
||||
"addNodes": {
|
||||
"title": "Añadir Nodos",
|
||||
"desc": "Abre el menú para añadir nodos"
|
||||
},
|
||||
"nodesHotkeys": "Teclas de acceso rápido a los nodos"
|
||||
},
|
||||
"modelManager": {
|
||||
"modelManager": "Gestor de Modelos",
|
||||
@@ -349,8 +364,8 @@
|
||||
"delete": "Eliminar",
|
||||
"deleteModel": "Eliminar Modelo",
|
||||
"deleteConfig": "Eliminar Configuración",
|
||||
"deleteMsg1": "¿Estás seguro de querer eliminar esta entrada de modelo de InvokeAI?",
|
||||
"deleteMsg2": "El checkpoint del modelo no se eliminará de tu disco. Puedes volver a añadirlo si lo deseas.",
|
||||
"deleteMsg1": "¿Estás seguro de que deseas eliminar este modelo de InvokeAI?",
|
||||
"deleteMsg2": "Esto eliminará el modelo del disco si está en la carpeta raíz de InvokeAI. Si está utilizando una ubicación personalizada, el modelo NO se eliminará del disco.",
|
||||
"safetensorModels": "SafeTensors",
|
||||
"addDiffuserModel": "Añadir difusores",
|
||||
"inpainting": "v1 Repintado",
|
||||
@@ -369,8 +384,8 @@
|
||||
"convertToDiffusers": "Convertir en difusores",
|
||||
"convertToDiffusersHelpText1": "Este modelo se convertirá al formato 🧨 Difusores.",
|
||||
"convertToDiffusersHelpText2": "Este proceso sustituirá su entrada del Gestor de Modelos por la versión de Difusores del mismo modelo.",
|
||||
"convertToDiffusersHelpText3": "Su archivo de puntos de control en el disco NO será borrado ni modificado de ninguna manera. Puede volver a añadir su punto de control al Gestor de Modelos si lo desea.",
|
||||
"convertToDiffusersHelpText5": "Asegúrese de que dispone de suficiente espacio en disco. Los modelos suelen variar entre 4 GB y 7 GB de tamaño.",
|
||||
"convertToDiffusersHelpText3": "Tu archivo del punto de control en el disco se eliminará si está en la carpeta raíz de InvokeAI. Si está en una ubicación personalizada, NO se eliminará.",
|
||||
"convertToDiffusersHelpText5": "Por favor, asegúrate de tener suficiente espacio en el disco. Los modelos generalmente varían entre 2 GB y 7 GB de tamaño.",
|
||||
"convertToDiffusersHelpText6": "¿Desea transformar este modelo?",
|
||||
"convertToDiffusersSaveLocation": "Guardar ubicación",
|
||||
"v1": "v1",
|
||||
@@ -409,7 +424,27 @@
|
||||
"pickModelType": "Elige el tipo de modelo",
|
||||
"v2_768": "v2 (768px)",
|
||||
"addDifference": "Añadir una diferencia",
|
||||
"scanForModels": "Buscar modelos"
|
||||
"scanForModels": "Buscar modelos",
|
||||
"vae": "VAE",
|
||||
"variant": "Variante",
|
||||
"baseModel": "Modelo básico",
|
||||
"modelConversionFailed": "Conversión al modelo fallida",
|
||||
"selectModel": "Seleccionar un modelo",
|
||||
"modelUpdateFailed": "Error al actualizar el modelo",
|
||||
"modelsMergeFailed": "Fusión del modelo fallida",
|
||||
"convertingModelBegin": "Convirtiendo el modelo. Por favor, espere.",
|
||||
"modelDeleted": "Modelo eliminado",
|
||||
"modelDeleteFailed": "Error al borrar el modelo",
|
||||
"noCustomLocationProvided": "‐No se proporcionó una ubicación personalizada",
|
||||
"importModels": "Importar los modelos",
|
||||
"settings": "Ajustes",
|
||||
"syncModels": "Sincronizar las plantillas",
|
||||
"syncModelsDesc": "Si tus plantillas no están sincronizados con el backend, puedes actualizarlas usando esta opción. Esto suele ser útil en los casos en los que actualizas manualmente tu archivo models.yaml o añades plantillas a la carpeta raíz de InvokeAI después de que la aplicación haya arrancado.",
|
||||
"modelsSynced": "Plantillas sincronizadas",
|
||||
"modelSyncFailed": "La sincronización de la plantilla falló",
|
||||
"loraModels": "LoRA",
|
||||
"onnxModels": "Onnx",
|
||||
"oliveModels": "Olives"
|
||||
},
|
||||
"parameters": {
|
||||
"images": "Imágenes",
|
||||
@@ -417,10 +452,9 @@
|
||||
"cfgScale": "Escala CFG",
|
||||
"width": "Ancho",
|
||||
"height": "Alto",
|
||||
"sampler": "Muestreo",
|
||||
"seed": "Semilla",
|
||||
"randomizeSeed": "Semilla aleatoria",
|
||||
"shuffle": "Aleatorizar",
|
||||
"shuffle": "Semilla aleatoria",
|
||||
"noiseThreshold": "Umbral de Ruido",
|
||||
"perlinNoise": "Ruido Perlin",
|
||||
"variations": "Variaciones",
|
||||
@@ -439,10 +473,6 @@
|
||||
"hiresOptim": "Optimización de Alta Resolución",
|
||||
"imageFit": "Ajuste tamaño de imagen inicial al tamaño objetivo",
|
||||
"codeformerFidelity": "Fidelidad",
|
||||
"seamSize": "Tamaño del parche",
|
||||
"seamBlur": "Desenfoque del parche",
|
||||
"seamStrength": "Fuerza del parche",
|
||||
"seamSteps": "Pasos del parche",
|
||||
"scaleBeforeProcessing": "Redimensionar antes de procesar",
|
||||
"scaledWidth": "Ancho escalado",
|
||||
"scaledHeight": "Alto escalado",
|
||||
@@ -453,8 +483,6 @@
|
||||
"infillScalingHeader": "Remplazo y escalado",
|
||||
"img2imgStrength": "Peso de Imagen a Imagen",
|
||||
"toggleLoopback": "Alternar Retroalimentación",
|
||||
"invoke": "Invocar",
|
||||
"promptPlaceholder": "Ingrese la entrada aquí. [símbolos negativos], (subir peso)++, (bajar peso)--, también disponible alternado y mezclado (ver documentación)",
|
||||
"sendTo": "Enviar a",
|
||||
"sendToImg2Img": "Enviar a Imagen a Imagen",
|
||||
"sendToUnifiedCanvas": "Enviar a Lienzo Unificado",
|
||||
@@ -467,7 +495,6 @@
|
||||
"useAll": "Usar Todo",
|
||||
"useInitImg": "Usar Imagen Inicial",
|
||||
"info": "Información",
|
||||
"deleteImage": "Eliminar Imagen",
|
||||
"initialImage": "Imagen Inicial",
|
||||
"showOptionsPanel": "Mostrar panel de opciones",
|
||||
"symmetry": "Simetría",
|
||||
@@ -481,37 +508,72 @@
|
||||
},
|
||||
"copyImage": "Copiar la imagen",
|
||||
"general": "General",
|
||||
"negativePrompts": "Preguntas negativas",
|
||||
"imageToImage": "Imagen a imagen",
|
||||
"denoisingStrength": "Intensidad de la eliminación del ruido",
|
||||
"hiresStrength": "Alta resistencia",
|
||||
"showPreview": "Mostrar la vista previa",
|
||||
"hidePreview": "Ocultar la vista previa"
|
||||
"hidePreview": "Ocultar la vista previa",
|
||||
"noiseSettings": "Ruido",
|
||||
"seamlessXAxis": "Eje x",
|
||||
"seamlessYAxis": "Eje y",
|
||||
"scheduler": "Programador",
|
||||
"boundingBoxWidth": "Anchura del recuadro",
|
||||
"boundingBoxHeight": "Altura del recuadro",
|
||||
"positivePromptPlaceholder": "Prompt Positivo",
|
||||
"negativePromptPlaceholder": "Prompt Negativo",
|
||||
"controlNetControlMode": "Modo de control",
|
||||
"clipSkip": "Omitir el CLIP",
|
||||
"aspectRatio": "Relación",
|
||||
"maskAdjustmentsHeader": "Ajustes de la máscara",
|
||||
"maskBlur": "Difuminar",
|
||||
"maskBlurMethod": "Método del desenfoque",
|
||||
"seamHighThreshold": "Alto",
|
||||
"seamLowThreshold": "Bajo",
|
||||
"coherencePassHeader": "Parámetros de la coherencia",
|
||||
"compositingSettingsHeader": "Ajustes de la composición",
|
||||
"coherenceSteps": "Pasos",
|
||||
"coherenceStrength": "Fuerza",
|
||||
"patchmatchDownScaleSize": "Reducir a escala",
|
||||
"coherenceMode": "Modo"
|
||||
},
|
||||
"settings": {
|
||||
"models": "Modelos",
|
||||
"displayInProgress": "Mostrar imágenes en progreso",
|
||||
"displayInProgress": "Mostrar las imágenes del progreso",
|
||||
"saveSteps": "Guardar imágenes cada n pasos",
|
||||
"confirmOnDelete": "Confirmar antes de eliminar",
|
||||
"displayHelpIcons": "Mostrar iconos de ayuda",
|
||||
"useCanvasBeta": "Usar versión beta del Lienzo",
|
||||
"enableImageDebugging": "Habilitar depuración de imágenes",
|
||||
"resetWebUI": "Restablecer interfaz web",
|
||||
"resetWebUIDesc1": "Al restablecer la interfaz web, solo se restablece la caché local del navegador de sus imágenes y la configuración guardada. No se elimina ninguna imagen de su disco duro.",
|
||||
"resetWebUIDesc2": "Si las imágenes no se muestran en la galería o algo más no funciona, intente restablecer antes de reportar un incidente en GitHub.",
|
||||
"resetComplete": "La interfaz web se ha restablecido. Actualice la página para recargarla.",
|
||||
"useSlidersForAll": "Utilice controles deslizantes para todas las opciones"
|
||||
"resetComplete": "Se ha restablecido la interfaz web.",
|
||||
"useSlidersForAll": "Utilice controles deslizantes para todas las opciones",
|
||||
"general": "General",
|
||||
"consoleLogLevel": "Nivel del registro",
|
||||
"shouldLogToConsole": "Registro de la consola",
|
||||
"developer": "Desarrollador",
|
||||
"antialiasProgressImages": "Imágenes del progreso de Antialias",
|
||||
"showProgressInViewer": "Mostrar las imágenes del progreso en el visor",
|
||||
"ui": "Interfaz del usuario",
|
||||
"generation": "Generación",
|
||||
"favoriteSchedulers": "Programadores favoritos",
|
||||
"favoriteSchedulersPlaceholder": "No hay programadores favoritos",
|
||||
"showAdvancedOptions": "Mostrar las opciones avanzadas",
|
||||
"alternateCanvasLayout": "Diseño alternativo del lienzo",
|
||||
"beta": "Beta",
|
||||
"enableNodesEditor": "Activar el editor de nodos",
|
||||
"experimental": "Experimental",
|
||||
"autoChangeDimensions": "Actualiza W/H a los valores predeterminados del modelo cuando se modifica"
|
||||
},
|
||||
"toast": {
|
||||
"tempFoldersEmptied": "Directorio temporal vaciado",
|
||||
"uploadFailed": "Error al subir archivo",
|
||||
"uploadFailedMultipleImagesDesc": "Únicamente se puede subir una imágen a la vez",
|
||||
"uploadFailedUnableToLoadDesc": "No se pudo cargar la imágen",
|
||||
"downloadImageStarted": "Descargando imágen",
|
||||
"imageCopied": "Imágen copiada",
|
||||
"imageLinkCopied": "Enlace de imágen copiado",
|
||||
"imageNotLoaded": "No se cargó la imágen",
|
||||
"imageNotLoadedDesc": "No se encontró imagen para enviar al módulo Imagen a Imagen",
|
||||
"imageNotLoadedDesc": "No se pudo encontrar la imagen",
|
||||
"imageSavedToGallery": "Imágen guardada en la galería",
|
||||
"canvasMerged": "Lienzo consolidado",
|
||||
"sentToImageToImage": "Enviar hacia Imagen a Imagen",
|
||||
@@ -536,7 +598,21 @@
|
||||
"serverError": "Error en el servidor",
|
||||
"disconnected": "Desconectado del servidor",
|
||||
"canceled": "Procesando la cancelación",
|
||||
"connected": "Conectado al servidor"
|
||||
"connected": "Conectado al servidor",
|
||||
"problemCopyingImageLink": "No se puede copiar el enlace de la imagen",
|
||||
"uploadFailedInvalidUploadDesc": "Debe ser una sola imagen PNG o JPEG",
|
||||
"parameterSet": "Conjunto de parámetros",
|
||||
"parameterNotSet": "Parámetro no configurado",
|
||||
"nodesSaved": "Nodos guardados",
|
||||
"nodesLoadedFailed": "Error al cargar los nodos",
|
||||
"nodesLoaded": "Nodos cargados",
|
||||
"nodesCleared": "Nodos borrados",
|
||||
"problemCopyingImage": "No se puede copiar la imagen",
|
||||
"nodesNotValidJSON": "JSON no válido",
|
||||
"nodesCorruptedGraph": "No se puede cargar. El gráfico parece estar dañado.",
|
||||
"nodesUnrecognizedTypes": "No se puede cargar. El gráfico tiene tipos no reconocidos",
|
||||
"nodesNotValidGraph": "Gráfico del nodo InvokeAI no válido",
|
||||
"nodesBrokenConnections": "No se puede cargar. Algunas conexiones están rotas."
|
||||
},
|
||||
"tooltip": {
|
||||
"feature": {
|
||||
@@ -610,7 +686,8 @@
|
||||
"betaClear": "Limpiar",
|
||||
"betaDarkenOutside": "Oscurecer fuera",
|
||||
"betaLimitToBox": "Limitar a caja",
|
||||
"betaPreserveMasked": "Preservar área enmascarada"
|
||||
"betaPreserveMasked": "Preservar área enmascarada",
|
||||
"antialiasing": "Suavizado"
|
||||
},
|
||||
"accessibility": {
|
||||
"invokeProgressBar": "Activar la barra de progreso",
|
||||
@@ -631,8 +708,30 @@
|
||||
"modifyConfig": "Modificar la configuración",
|
||||
"toggleAutoscroll": "Activar el autodesplazamiento",
|
||||
"toggleLogViewer": "Alternar el visor de registros",
|
||||
"showGallery": "Mostrar galería",
|
||||
"showOptionsPanel": "Mostrar el panel de opciones",
|
||||
"showOptionsPanel": "Mostrar el panel lateral",
|
||||
"menu": "Menú"
|
||||
},
|
||||
"ui": {
|
||||
"hideProgressImages": "Ocultar el progreso de la imagen",
|
||||
"showProgressImages": "Mostrar el progreso de la imagen",
|
||||
"swapSizes": "Cambiar los tamaños",
|
||||
"lockRatio": "Proporción del bloqueo"
|
||||
},
|
||||
"nodes": {
|
||||
"showGraphNodes": "Mostrar la superposición de los gráficos",
|
||||
"zoomInNodes": "Acercar",
|
||||
"hideMinimapnodes": "Ocultar el minimapa",
|
||||
"fitViewportNodes": "Ajustar la vista",
|
||||
"zoomOutNodes": "Alejar",
|
||||
"hideGraphNodes": "Ocultar la superposición de los gráficos",
|
||||
"hideLegendNodes": "Ocultar la leyenda del tipo de campo",
|
||||
"showLegendNodes": "Mostrar la leyenda del tipo de campo",
|
||||
"showMinimapnodes": "Mostrar el minimapa",
|
||||
"reloadNodeTemplates": "Recargar las plantillas de nodos",
|
||||
"loadWorkflow": "Cargar el flujo de trabajo",
|
||||
"resetWorkflow": "Reiniciar e flujo de trabajo",
|
||||
"resetWorkflowDesc": "¿Está seguro de que deseas restablecer este flujo de trabajo?",
|
||||
"resetWorkflowDesc2": "Al reiniciar el flujo de trabajo se borrarán todos los nodos, aristas y detalles del flujo de trabajo.",
|
||||
"downloadWorkflow": "Descargar el flujo de trabajo en un archivo JSON"
|
||||
}
|
||||
}
|
||||
|
||||
8
invokeai/frontend/web/dist/locales/fi.json
vendored
8
invokeai/frontend/web/dist/locales/fi.json
vendored
@@ -15,7 +15,6 @@
|
||||
"rotateCounterClockwise": "Kierrä vastapäivään",
|
||||
"rotateClockwise": "Kierrä myötäpäivään",
|
||||
"flipVertically": "Käännä pystysuoraan",
|
||||
"showGallery": "Näytä galleria",
|
||||
"modifyConfig": "Muokkaa konfiguraatiota",
|
||||
"toggleAutoscroll": "Kytke automaattinen vieritys",
|
||||
"toggleLogViewer": "Kytke lokin katselutila",
|
||||
@@ -34,18 +33,13 @@
|
||||
"hotkeysLabel": "Pikanäppäimet",
|
||||
"reportBugLabel": "Raportoi Bugista",
|
||||
"langPolish": "Puola",
|
||||
"themeLabel": "Teema",
|
||||
"langDutch": "Hollanti",
|
||||
"settingsLabel": "Asetukset",
|
||||
"githubLabel": "Github",
|
||||
"darkTheme": "Tumma",
|
||||
"lightTheme": "Vaalea",
|
||||
"greenTheme": "Vihreä",
|
||||
"langGerman": "Saksa",
|
||||
"langPortuguese": "Portugali",
|
||||
"discordLabel": "Discord",
|
||||
"langEnglish": "Englanti",
|
||||
"oceanTheme": "Meren sininen",
|
||||
"langRussian": "Venäjä",
|
||||
"langUkranian": "Ukraina",
|
||||
"langSpanish": "Espanja",
|
||||
@@ -79,7 +73,6 @@
|
||||
"statusGeneratingInpainting": "Generoidaan sisällemaalausta",
|
||||
"statusGeneratingOutpainting": "Generoidaan ulosmaalausta",
|
||||
"statusRestoringFaces": "Korjataan kasvoja",
|
||||
"pinOptionsPanel": "Kiinnitä asetukset -paneeli",
|
||||
"loadingInvokeAI": "Ladataan Invoke AI:ta",
|
||||
"loading": "Ladataan",
|
||||
"statusGenerating": "Generoidaan",
|
||||
@@ -95,7 +88,6 @@
|
||||
"galleryImageResetSize": "Resetoi koko",
|
||||
"maintainAspectRatio": "Säilytä kuvasuhde",
|
||||
"galleryImageSize": "Kuvan koko",
|
||||
"pinGallery": "Kiinnitä galleria",
|
||||
"showGenerations": "Näytä generaatiot",
|
||||
"singleColumnLayout": "Yhden sarakkeen asettelu",
|
||||
"generations": "Generoinnit",
|
||||
|
||||
22
invokeai/frontend/web/dist/locales/fr.json
vendored
22
invokeai/frontend/web/dist/locales/fr.json
vendored
@@ -1,13 +1,9 @@
|
||||
{
|
||||
"common": {
|
||||
"hotkeysLabel": "Raccourcis clavier",
|
||||
"themeLabel": "Thème",
|
||||
"languagePickerLabel": "Sélecteur de langue",
|
||||
"reportBugLabel": "Signaler un bug",
|
||||
"settingsLabel": "Paramètres",
|
||||
"darkTheme": "Sombre",
|
||||
"lightTheme": "Clair",
|
||||
"greenTheme": "Vert",
|
||||
"img2img": "Image en image",
|
||||
"unifiedCanvas": "Canvas unifié",
|
||||
"nodes": "Nœuds",
|
||||
@@ -55,7 +51,6 @@
|
||||
"statusConvertingModel": "Conversion du modèle",
|
||||
"statusModelConverted": "Modèle converti",
|
||||
"loading": "Chargement",
|
||||
"pinOptionsPanel": "Épingler la page d'options",
|
||||
"statusMergedModels": "Modèles mélangés",
|
||||
"txt2img": "Texte vers image",
|
||||
"postprocessing": "Post-Traitement"
|
||||
@@ -71,7 +66,6 @@
|
||||
"maintainAspectRatio": "Maintenir le rapport d'aspect",
|
||||
"autoSwitchNewImages": "Basculer automatiquement vers de nouvelles images",
|
||||
"singleColumnLayout": "Mise en page en colonne unique",
|
||||
"pinGallery": "Épingler la galerie",
|
||||
"allImagesLoaded": "Toutes les images chargées",
|
||||
"loadMore": "Charger plus",
|
||||
"noImagesInGallery": "Aucune image dans la galerie"
|
||||
@@ -356,7 +350,6 @@
|
||||
"cfgScale": "CFG Echelle",
|
||||
"width": "Largeur",
|
||||
"height": "Hauteur",
|
||||
"sampler": "Echantillonneur",
|
||||
"seed": "Graine",
|
||||
"randomizeSeed": "Graine Aléatoire",
|
||||
"shuffle": "Mélanger",
|
||||
@@ -378,10 +371,6 @@
|
||||
"hiresOptim": "Optimisation Haute Résolution",
|
||||
"imageFit": "Ajuster Image Initiale à la Taille de Sortie",
|
||||
"codeformerFidelity": "Fidélité",
|
||||
"seamSize": "Taille des Joints",
|
||||
"seamBlur": "Flou des Joints",
|
||||
"seamStrength": "Force des Joints",
|
||||
"seamSteps": "Etapes des Joints",
|
||||
"scaleBeforeProcessing": "Echelle Avant Traitement",
|
||||
"scaledWidth": "Larg. Échelle",
|
||||
"scaledHeight": "Haut. Échelle",
|
||||
@@ -392,8 +381,6 @@
|
||||
"infillScalingHeader": "Remplissage et Mise à l'Échelle",
|
||||
"img2imgStrength": "Force de l'Image à l'Image",
|
||||
"toggleLoopback": "Activer/Désactiver la Boucle",
|
||||
"invoke": "Invoker",
|
||||
"promptPlaceholder": "Tapez le prompt ici. [tokens négatifs], (poids positif)++, (poids négatif)--, swap et blend sont disponibles (voir les docs)",
|
||||
"sendTo": "Envoyer à",
|
||||
"sendToImg2Img": "Envoyer à Image à Image",
|
||||
"sendToUnifiedCanvas": "Envoyer au Canvas Unifié",
|
||||
@@ -407,7 +394,6 @@
|
||||
"useAll": "Tout utiliser",
|
||||
"useInitImg": "Utiliser l'image initiale",
|
||||
"info": "Info",
|
||||
"deleteImage": "Supprimer l'image",
|
||||
"initialImage": "Image initiale",
|
||||
"showOptionsPanel": "Afficher le panneau d'options"
|
||||
},
|
||||
@@ -417,7 +403,6 @@
|
||||
"saveSteps": "Enregistrer les images tous les n étapes",
|
||||
"confirmOnDelete": "Confirmer la suppression",
|
||||
"displayHelpIcons": "Afficher les icônes d'aide",
|
||||
"useCanvasBeta": "Utiliser la mise en page bêta de Canvas",
|
||||
"enableImageDebugging": "Activer le débogage d'image",
|
||||
"resetWebUI": "Réinitialiser l'interface Web",
|
||||
"resetWebUIDesc1": "Réinitialiser l'interface Web ne réinitialise que le cache local du navigateur de vos images et de vos paramètres enregistrés. Cela n'efface pas les images du disque.",
|
||||
@@ -427,7 +412,6 @@
|
||||
"toast": {
|
||||
"tempFoldersEmptied": "Dossiers temporaires vidés",
|
||||
"uploadFailed": "Téléchargement échoué",
|
||||
"uploadFailedMultipleImagesDesc": "Plusieurs images collées, peut uniquement télécharger une image à la fois",
|
||||
"uploadFailedUnableToLoadDesc": "Impossible de charger le fichier",
|
||||
"downloadImageStarted": "Téléchargement de l'image démarré",
|
||||
"imageCopied": "Image copiée",
|
||||
@@ -538,6 +522,10 @@
|
||||
"useThisParameter": "Utiliser ce paramètre",
|
||||
"zoomIn": "Zoom avant",
|
||||
"zoomOut": "Zoom arrière",
|
||||
"showOptionsPanel": "Montrer la page d'options"
|
||||
"showOptionsPanel": "Montrer la page d'options",
|
||||
"modelSelect": "Choix du modèle",
|
||||
"invokeProgressBar": "Barre de Progression Invoke",
|
||||
"copyMetadataJson": "Copie des métadonnées JSON",
|
||||
"menu": "Menu"
|
||||
}
|
||||
}
|
||||
|
||||
18
invokeai/frontend/web/dist/locales/he.json
vendored
18
invokeai/frontend/web/dist/locales/he.json
vendored
@@ -107,13 +107,10 @@
|
||||
},
|
||||
"common": {
|
||||
"nodesDesc": "מערכת מבוססת צמתים עבור יצירת תמונות עדיין תחת פיתוח. השארו קשובים לעדכונים עבור הפיצ׳ר המדהים הזה.",
|
||||
"themeLabel": "ערכת נושא",
|
||||
"languagePickerLabel": "בחירת שפה",
|
||||
"githubLabel": "גיטהאב",
|
||||
"discordLabel": "דיסקורד",
|
||||
"settingsLabel": "הגדרות",
|
||||
"darkTheme": "חשוך",
|
||||
"lightTheme": "מואר",
|
||||
"langEnglish": "אנגלית",
|
||||
"langDutch": "הולנדית",
|
||||
"langArabic": "ערבית",
|
||||
@@ -155,7 +152,6 @@
|
||||
"statusMergedModels": "מודלים מוזגו",
|
||||
"hotkeysLabel": "מקשים חמים",
|
||||
"reportBugLabel": "דווח באג",
|
||||
"greenTheme": "ירוק",
|
||||
"langItalian": "איטלקית",
|
||||
"upload": "העלאה",
|
||||
"langPolish": "פולנית",
|
||||
@@ -384,7 +380,6 @@
|
||||
"maintainAspectRatio": "שמור על יחס רוחב-גובה",
|
||||
"autoSwitchNewImages": "החלף אוטומטית לתמונות חדשות",
|
||||
"singleColumnLayout": "תצוגת עמודה אחת",
|
||||
"pinGallery": "הצמד גלריה",
|
||||
"allImagesLoaded": "כל התמונות נטענו",
|
||||
"loadMore": "טען עוד",
|
||||
"noImagesInGallery": "אין תמונות בגלריה",
|
||||
@@ -399,7 +394,6 @@
|
||||
"cfgScale": "סולם CFG",
|
||||
"width": "רוחב",
|
||||
"height": "גובה",
|
||||
"sampler": "דוגם",
|
||||
"seed": "זרע",
|
||||
"imageToImage": "תמונה לתמונה",
|
||||
"randomizeSeed": "זרע אקראי",
|
||||
@@ -416,10 +410,6 @@
|
||||
"hiresOptim": "אופטימיזצית רזולוציה גבוהה",
|
||||
"hiresStrength": "חוזק רזולוציה גבוהה",
|
||||
"codeformerFidelity": "דבקות",
|
||||
"seamSize": "גודל תפר",
|
||||
"seamBlur": "טשטוש תפר",
|
||||
"seamStrength": "חוזק תפר",
|
||||
"seamSteps": "שלבי תפר",
|
||||
"scaleBeforeProcessing": "שנה קנה מידה לפני עיבוד",
|
||||
"scaledWidth": "קנה מידה לאחר שינוי W",
|
||||
"scaledHeight": "קנה מידה לאחר שינוי H",
|
||||
@@ -432,14 +422,12 @@
|
||||
"symmetry": "סימטריה",
|
||||
"vSymmetryStep": "צעד סימטריה V",
|
||||
"hSymmetryStep": "צעד סימטריה H",
|
||||
"invoke": "הפעלה",
|
||||
"cancel": {
|
||||
"schedule": "ביטול לאחר האיטרציה הנוכחית",
|
||||
"isScheduled": "מבטל",
|
||||
"immediate": "ביטול מיידי",
|
||||
"setType": "הגדר סוג ביטול"
|
||||
},
|
||||
"negativePrompts": "בקשות שליליות",
|
||||
"sendTo": "שליחה אל",
|
||||
"copyImage": "העתקת תמונה",
|
||||
"downloadImage": "הורדת תמונה",
|
||||
@@ -464,15 +452,12 @@
|
||||
"seamlessTiling": "ריצוף חלק",
|
||||
"img2imgStrength": "חוזק תמונה לתמונה",
|
||||
"initialImage": "תמונה ראשונית",
|
||||
"copyImageToLink": "העתקת תמונה לקישור",
|
||||
"deleteImage": "מחיקת תמונה",
|
||||
"promptPlaceholder": "הקלד בקשה כאן. [אסימונים שליליים], (העלאת משקל)++ , (הורדת משקל)--, החלפה ומיזוג זמינים (ראה מסמכים)"
|
||||
"copyImageToLink": "העתקת תמונה לקישור"
|
||||
},
|
||||
"settings": {
|
||||
"models": "מודלים",
|
||||
"displayInProgress": "הצגת תמונות בתהליך",
|
||||
"confirmOnDelete": "אישור בעת המחיקה",
|
||||
"useCanvasBeta": "שימוש בגרסת ביתא של תצוגת הקנבס",
|
||||
"useSlidersForAll": "שימוש במחוונים לכל האפשרויות",
|
||||
"resetWebUI": "איפוס ממשק משתמש",
|
||||
"resetWebUIDesc1": "איפוס ממשק המשתמש האינטרנטי מאפס רק את המטמון המקומי של הדפדפן של התמונות וההגדרות שנשמרו. זה לא מוחק תמונות מהדיסק.",
|
||||
@@ -484,7 +469,6 @@
|
||||
},
|
||||
"toast": {
|
||||
"uploadFailed": "העלאה נכשלה",
|
||||
"uploadFailedMultipleImagesDesc": "תמונות מרובות הודבקו, ניתן להעלות תמונה אחת בלבד בכל פעם",
|
||||
"imageCopied": "התמונה הועתקה",
|
||||
"imageLinkCopied": "קישור תמונה הועתק",
|
||||
"imageNotLoadedDesc": "לא נמצאה תמונה לשליחה למודול תמונה לתמונה",
|
||||
|
||||
790
invokeai/frontend/web/dist/locales/it.json
vendored
790
invokeai/frontend/web/dist/locales/it.json
vendored
@@ -1,16 +1,12 @@
|
||||
{
|
||||
"common": {
|
||||
"hotkeysLabel": "Tasti di scelta rapida",
|
||||
"themeLabel": "Tema",
|
||||
"languagePickerLabel": "Seleziona lingua",
|
||||
"languagePickerLabel": "Lingua",
|
||||
"reportBugLabel": "Segnala un errore",
|
||||
"settingsLabel": "Impostazioni",
|
||||
"darkTheme": "Scuro",
|
||||
"lightTheme": "Chiaro",
|
||||
"greenTheme": "Verde",
|
||||
"img2img": "Immagine a Immagine",
|
||||
"unifiedCanvas": "Tela unificata",
|
||||
"nodes": "Nodi",
|
||||
"nodes": "Editor del flusso di lavoro",
|
||||
"langItalian": "Italiano",
|
||||
"nodesDesc": "Attualmente è in fase di sviluppo un sistema basato su nodi per la generazione di immagini. Resta sintonizzato per gli aggiornamenti su questa fantastica funzionalità.",
|
||||
"postProcessing": "Post-elaborazione",
|
||||
@@ -19,7 +15,7 @@
|
||||
"postProcessDesc3": "L'interfaccia da riga di comando di 'Invoke AI' offre varie altre funzionalità tra cui Embiggen.",
|
||||
"training": "Addestramento",
|
||||
"trainingDesc1": "Un flusso di lavoro dedicato per addestrare i tuoi Incorporamenti e Checkpoint utilizzando Inversione Testuale e Dreambooth dall'interfaccia web.",
|
||||
"trainingDesc2": "InvokeAI supporta già l'addestramento di incorporamenti personalizzati utilizzando l'inversione testuale utilizzando lo script principale.",
|
||||
"trainingDesc2": "InvokeAI supporta già l'addestramento di incorporamenti personalizzati utilizzando l'inversione testuale tramite lo script principale.",
|
||||
"upload": "Caricamento",
|
||||
"close": "Chiudi",
|
||||
"load": "Carica",
|
||||
@@ -31,14 +27,14 @@
|
||||
"statusProcessingCanceled": "Elaborazione annullata",
|
||||
"statusProcessingComplete": "Elaborazione completata",
|
||||
"statusGenerating": "Generazione in corso",
|
||||
"statusGeneratingTextToImage": "Generazione da Testo a Immagine",
|
||||
"statusGeneratingTextToImage": "Generazione Testo a Immagine",
|
||||
"statusGeneratingImageToImage": "Generazione da Immagine a Immagine",
|
||||
"statusGeneratingInpainting": "Generazione Inpainting",
|
||||
"statusGeneratingOutpainting": "Generazione Outpainting",
|
||||
"statusGenerationComplete": "Generazione completata",
|
||||
"statusIterationComplete": "Iterazione completata",
|
||||
"statusSavingImage": "Salvataggio dell'immagine",
|
||||
"statusRestoringFaces": "Restaura i volti",
|
||||
"statusRestoringFaces": "Restaura volti",
|
||||
"statusRestoringFacesGFPGAN": "Restaura volti (GFPGAN)",
|
||||
"statusRestoringFacesCodeFormer": "Restaura volti (CodeFormer)",
|
||||
"statusUpscaling": "Ampliamento",
|
||||
@@ -65,16 +61,33 @@
|
||||
"statusConvertingModel": "Conversione Modello",
|
||||
"langKorean": "Coreano",
|
||||
"langPortuguese": "Portoghese",
|
||||
"pinOptionsPanel": "Blocca il pannello Opzioni",
|
||||
"loading": "Caricamento in corso",
|
||||
"oceanTheme": "Oceano",
|
||||
"langHebrew": "Ebraico",
|
||||
"loadingInvokeAI": "Caricamento Invoke AI",
|
||||
"postprocessing": "Post Elaborazione",
|
||||
"txt2img": "Testo a Immagine",
|
||||
"accept": "Accetta",
|
||||
"cancel": "Annulla",
|
||||
"linear": "Lineare"
|
||||
"linear": "Lineare",
|
||||
"generate": "Genera",
|
||||
"random": "Casuale",
|
||||
"openInNewTab": "Apri in una nuova scheda",
|
||||
"areYouSure": "Sei sicuro?",
|
||||
"dontAskMeAgain": "Non chiedermelo più",
|
||||
"imagePrompt": "Prompt Immagine",
|
||||
"darkMode": "Modalità scura",
|
||||
"lightMode": "Modalità chiara",
|
||||
"batch": "Gestione Lotto",
|
||||
"modelManager": "Gestore modello",
|
||||
"communityLabel": "Comunità",
|
||||
"nodeEditor": "Editor dei nodi",
|
||||
"statusProcessing": "Elaborazione in corso",
|
||||
"advanced": "Avanzate",
|
||||
"imageFailedToLoad": "Impossibile caricare l'immagine",
|
||||
"learnMore": "Per saperne di più",
|
||||
"ipAdapter": "Adattatore IP",
|
||||
"t2iAdapter": "Adattatore T2I",
|
||||
"controlAdapter": "Adattatore di Controllo"
|
||||
},
|
||||
"gallery": {
|
||||
"generations": "Generazioni",
|
||||
@@ -87,10 +100,22 @@
|
||||
"maintainAspectRatio": "Mantenere le proporzioni",
|
||||
"autoSwitchNewImages": "Passaggio automatico a nuove immagini",
|
||||
"singleColumnLayout": "Layout a colonna singola",
|
||||
"pinGallery": "Blocca la galleria",
|
||||
"allImagesLoaded": "Tutte le immagini caricate",
|
||||
"loadMore": "Carica di più",
|
||||
"noImagesInGallery": "Nessuna immagine nella galleria"
|
||||
"loadMore": "Carica altro",
|
||||
"noImagesInGallery": "Nessuna immagine da visualizzare",
|
||||
"deleteImage": "Elimina l'immagine",
|
||||
"deleteImagePermanent": "Le immagini eliminate non possono essere ripristinate.",
|
||||
"deleteImageBin": "Le immagini eliminate verranno spostate nel Cestino del tuo sistema operativo.",
|
||||
"images": "Immagini",
|
||||
"assets": "Risorse",
|
||||
"autoAssignBoardOnClick": "Assegna automaticamente la bacheca al clic",
|
||||
"featuresWillReset": "Se elimini questa immagine, quelle funzionalità verranno immediatamente ripristinate.",
|
||||
"loading": "Caricamento in corso",
|
||||
"unableToLoad": "Impossibile caricare la Galleria",
|
||||
"currentlyInUse": "Questa immagine è attualmente utilizzata nelle seguenti funzionalità:",
|
||||
"copy": "Copia",
|
||||
"download": "Scarica",
|
||||
"setCurrentImage": "Imposta come immagine corrente"
|
||||
},
|
||||
"hotkeys": {
|
||||
"keyboardShortcuts": "Tasti rapidi",
|
||||
@@ -163,7 +188,7 @@
|
||||
"desc": "Mostra le informazioni sui metadati dell'immagine corrente"
|
||||
},
|
||||
"sendToImageToImage": {
|
||||
"title": "Invia a da Immagine a Immagine",
|
||||
"title": "Invia a Immagine a Immagine",
|
||||
"desc": "Invia l'immagine corrente a da Immagine a Immagine"
|
||||
},
|
||||
"deleteImage": {
|
||||
@@ -297,6 +322,11 @@
|
||||
"acceptStagingImage": {
|
||||
"title": "Accetta l'immagine della sessione",
|
||||
"desc": "Accetta l'immagine dell'area della sessione corrente"
|
||||
},
|
||||
"nodesHotkeys": "Tasti di scelta rapida dei Nodi",
|
||||
"addNodes": {
|
||||
"title": "Aggiungi Nodi",
|
||||
"desc": "Apre il menu Aggiungi Nodi"
|
||||
}
|
||||
},
|
||||
"modelManager": {
|
||||
@@ -308,7 +338,7 @@
|
||||
"safetensorModels": "SafeTensor",
|
||||
"modelAdded": "Modello Aggiunto",
|
||||
"modelUpdated": "Modello Aggiornato",
|
||||
"modelEntryDeleted": "Modello Rimosso",
|
||||
"modelEntryDeleted": "Voce del modello eliminata",
|
||||
"cannotUseSpaces": "Impossibile utilizzare gli spazi",
|
||||
"addNew": "Aggiungi nuovo",
|
||||
"addNewModel": "Aggiungi nuovo Modello",
|
||||
@@ -323,7 +353,7 @@
|
||||
"config": "Configurazione",
|
||||
"configValidationMsg": "Percorso del file di configurazione del modello.",
|
||||
"modelLocation": "Posizione del modello",
|
||||
"modelLocationValidationMsg": "Percorso dove si trova il modello.",
|
||||
"modelLocationValidationMsg": "Fornisci il percorso di una cartella locale in cui è archiviato il tuo modello di diffusori",
|
||||
"repo_id": "Repo ID",
|
||||
"repoIDValidationMsg": "Repository online del modello",
|
||||
"vaeLocation": "Posizione file VAE",
|
||||
@@ -360,7 +390,7 @@
|
||||
"deleteModel": "Elimina modello",
|
||||
"deleteConfig": "Elimina configurazione",
|
||||
"deleteMsg1": "Sei sicuro di voler eliminare questo modello da InvokeAI?",
|
||||
"deleteMsg2": "Questo non eliminerà il file Checkpoint del modello dal tuo disco. Puoi aggiungerlo nuovamente se lo desideri.",
|
||||
"deleteMsg2": "Questo eliminerà il modello dal disco se si trova nella cartella principale di InvokeAI. Se utilizzi una cartella personalizzata, il modello NON verrà eliminato dal disco.",
|
||||
"formMessageDiffusersModelLocation": "Ubicazione modelli diffusori",
|
||||
"formMessageDiffusersModelLocationDesc": "Inseriscine almeno uno.",
|
||||
"formMessageDiffusersVAELocation": "Ubicazione file VAE",
|
||||
@@ -369,7 +399,7 @@
|
||||
"convertToDiffusers": "Converti in Diffusori",
|
||||
"convertToDiffusersHelpText2": "Questo processo sostituirà la voce in Gestione Modelli con la versione Diffusori dello stesso modello.",
|
||||
"convertToDiffusersHelpText4": "Questo è un processo una tantum. Potrebbero essere necessari circa 30-60 secondi a seconda delle specifiche del tuo computer.",
|
||||
"convertToDiffusersHelpText5": "Assicurati di avere spazio su disco sufficiente. I modelli generalmente variano tra 4 GB e 7 GB di dimensioni.",
|
||||
"convertToDiffusersHelpText5": "Assicurati di avere spazio su disco sufficiente. I modelli generalmente variano tra 2 GB e 7 GB di dimensioni.",
|
||||
"convertToDiffusersHelpText6": "Vuoi convertire questo modello?",
|
||||
"convertToDiffusersSaveLocation": "Ubicazione salvataggio",
|
||||
"inpainting": "v1 Inpainting",
|
||||
@@ -378,12 +408,12 @@
|
||||
"modelConverted": "Modello convertito",
|
||||
"sameFolder": "Stessa cartella",
|
||||
"invokeRoot": "Cartella InvokeAI",
|
||||
"merge": "Fondere",
|
||||
"modelsMerged": "Modelli fusi",
|
||||
"mergeModels": "Fondi Modelli",
|
||||
"merge": "Unisci",
|
||||
"modelsMerged": "Modelli uniti",
|
||||
"mergeModels": "Unisci Modelli",
|
||||
"modelOne": "Modello 1",
|
||||
"modelTwo": "Modello 2",
|
||||
"mergedModelName": "Nome del modello fuso",
|
||||
"mergedModelName": "Nome del modello unito",
|
||||
"alpha": "Alpha",
|
||||
"interpolationType": "Tipo di interpolazione",
|
||||
"mergedModelCustomSaveLocation": "Percorso personalizzato",
|
||||
@@ -394,7 +424,7 @@
|
||||
"mergedModelSaveLocation": "Ubicazione salvataggio",
|
||||
"convertToDiffusersHelpText1": "Questo modello verrà convertito nel formato 🧨 Diffusore.",
|
||||
"custom": "Personalizzata",
|
||||
"convertToDiffusersHelpText3": "Il tuo file checkpoint sul disco NON verrà comunque cancellato o modificato. Se lo desideri, puoi aggiungerlo di nuovo in Gestione Modelli.",
|
||||
"convertToDiffusersHelpText3": "Il file checkpoint su disco SARÀ eliminato se si trova nella cartella principale di InvokeAI. Se si trova in una posizione personalizzata, NON verrà eliminato.",
|
||||
"v1": "v1",
|
||||
"pathToCustomConfig": "Percorso alla configurazione personalizzata",
|
||||
"modelThree": "Modello 3",
|
||||
@@ -406,10 +436,39 @@
|
||||
"inverseSigmoid": "Sigmoide inverso",
|
||||
"v2_base": "v2 (512px)",
|
||||
"v2_768": "v2 (768px)",
|
||||
"none": "niente",
|
||||
"none": "nessuno",
|
||||
"addDifference": "Aggiungi differenza",
|
||||
"pickModelType": "Scegli il tipo di modello",
|
||||
"scanForModels": "Cerca modelli"
|
||||
"scanForModels": "Cerca modelli",
|
||||
"variant": "Variante",
|
||||
"baseModel": "Modello Base",
|
||||
"vae": "VAE",
|
||||
"modelUpdateFailed": "Aggiornamento del modello non riuscito",
|
||||
"modelConversionFailed": "Conversione del modello non riuscita",
|
||||
"modelsMergeFailed": "Unione modelli non riuscita",
|
||||
"selectModel": "Seleziona Modello",
|
||||
"modelDeleted": "Modello eliminato",
|
||||
"modelDeleteFailed": "Impossibile eliminare il modello",
|
||||
"noCustomLocationProvided": "Nessuna posizione personalizzata fornita",
|
||||
"convertingModelBegin": "Conversione del modello. Attendere prego.",
|
||||
"importModels": "Importa modelli",
|
||||
"modelsSynced": "Modelli sincronizzati",
|
||||
"modelSyncFailed": "Sincronizzazione modello non riuscita",
|
||||
"settings": "Impostazioni",
|
||||
"syncModels": "Sincronizza Modelli",
|
||||
"syncModelsDesc": "Se i tuoi modelli non sono sincronizzati con il back-end, puoi aggiornarli utilizzando questa opzione. Questo è generalmente utile nei casi in cui aggiorni manualmente il tuo file models.yaml o aggiungi modelli alla cartella principale di InvokeAI dopo l'avvio dell'applicazione.",
|
||||
"loraModels": "LoRA",
|
||||
"oliveModels": "Olive",
|
||||
"onnxModels": "ONNX",
|
||||
"noModels": "Nessun modello trovato",
|
||||
"predictionType": "Tipo di previsione (per modelli Stable Diffusion 2.x ed alcuni modelli Stable Diffusion 1.x)",
|
||||
"quickAdd": "Aggiunta rapida",
|
||||
"simpleModelDesc": "Fornire un percorso a un modello diffusori locale, un modello checkpoint/safetensor locale, un ID repository HuggingFace o un URL del modello checkpoint/diffusori.",
|
||||
"advanced": "Avanzate",
|
||||
"useCustomConfig": "Utilizza configurazione personalizzata",
|
||||
"closeAdvanced": "Chiudi Avanzate",
|
||||
"modelType": "Tipo di modello",
|
||||
"customConfigFileLocation": "Posizione del file di configurazione personalizzato"
|
||||
},
|
||||
"parameters": {
|
||||
"images": "Immagini",
|
||||
@@ -417,10 +476,9 @@
|
||||
"cfgScale": "Scala CFG",
|
||||
"width": "Larghezza",
|
||||
"height": "Altezza",
|
||||
"sampler": "Campionatore",
|
||||
"seed": "Seme",
|
||||
"randomizeSeed": "Seme randomizzato",
|
||||
"shuffle": "Casuale",
|
||||
"shuffle": "Mescola il seme",
|
||||
"noiseThreshold": "Soglia del rumore",
|
||||
"perlinNoise": "Rumore Perlin",
|
||||
"variations": "Variazioni",
|
||||
@@ -431,7 +489,7 @@
|
||||
"type": "Tipo",
|
||||
"strength": "Forza",
|
||||
"upscaling": "Ampliamento",
|
||||
"upscale": "Amplia",
|
||||
"upscale": "Amplia (Shift + U)",
|
||||
"upscaleImage": "Amplia Immagine",
|
||||
"scale": "Scala",
|
||||
"otherOptions": "Altre opzioni",
|
||||
@@ -439,10 +497,6 @@
|
||||
"hiresOptim": "Ottimizzazione alta risoluzione",
|
||||
"imageFit": "Adatta l'immagine iniziale alle dimensioni di output",
|
||||
"codeformerFidelity": "Fedeltà",
|
||||
"seamSize": "Dimensione della cucitura",
|
||||
"seamBlur": "Sfocatura cucitura",
|
||||
"seamStrength": "Forza della cucitura",
|
||||
"seamSteps": "Passaggi di cucitura",
|
||||
"scaleBeforeProcessing": "Scala prima dell'elaborazione",
|
||||
"scaledWidth": "Larghezza ridimensionata",
|
||||
"scaledHeight": "Altezza ridimensionata",
|
||||
@@ -453,10 +507,8 @@
|
||||
"infillScalingHeader": "Riempimento e ridimensionamento",
|
||||
"img2imgStrength": "Forza da Immagine a Immagine",
|
||||
"toggleLoopback": "Attiva/disattiva elaborazione ricorsiva",
|
||||
"invoke": "Invoke",
|
||||
"promptPlaceholder": "Digita qui il prompt usando termini in lingua inglese. [token negativi], (aumenta il peso)++, (diminuisci il peso)--, scambia e fondi sono disponibili (consulta la documentazione)",
|
||||
"sendTo": "Invia a",
|
||||
"sendToImg2Img": "Invia a da Immagine a Immagine",
|
||||
"sendToImg2Img": "Invia a Immagine a Immagine",
|
||||
"sendToUnifiedCanvas": "Invia a Tela Unificata",
|
||||
"copyImageToLink": "Copia l'immagine nel collegamento",
|
||||
"downloadImage": "Scarica l'immagine",
|
||||
@@ -467,54 +519,121 @@
|
||||
"useAll": "Usa Tutto",
|
||||
"useInitImg": "Usa l'immagine iniziale",
|
||||
"info": "Informazioni",
|
||||
"deleteImage": "Elimina immagine",
|
||||
"initialImage": "Immagine iniziale",
|
||||
"showOptionsPanel": "Mostra pannello opzioni",
|
||||
"showOptionsPanel": "Mostra il pannello laterale (O o T)",
|
||||
"general": "Generale",
|
||||
"denoisingStrength": "Forza riduzione rumore",
|
||||
"denoisingStrength": "Forza di riduzione del rumore",
|
||||
"copyImage": "Copia immagine",
|
||||
"hiresStrength": "Forza Alta Risoluzione",
|
||||
"negativePrompts": "Prompt Negativi",
|
||||
"imageToImage": "Immagine a Immagine",
|
||||
"cancel": {
|
||||
"schedule": "Annulla dopo l'iterazione corrente",
|
||||
"isScheduled": "Annullamento",
|
||||
"setType": "Imposta il tipo di annullamento",
|
||||
"immediate": "Annulla immediatamente"
|
||||
"immediate": "Annulla immediatamente",
|
||||
"cancel": "Annulla"
|
||||
},
|
||||
"hSymmetryStep": "Passi Simmetria Orizzontale",
|
||||
"vSymmetryStep": "Passi Simmetria Verticale",
|
||||
"symmetry": "Simmetria",
|
||||
"hidePreview": "Nascondi l'anteprima",
|
||||
"showPreview": "Mostra l'anteprima"
|
||||
"showPreview": "Mostra l'anteprima",
|
||||
"noiseSettings": "Rumore",
|
||||
"seamlessXAxis": "Asse X",
|
||||
"seamlessYAxis": "Asse Y",
|
||||
"scheduler": "Campionatore",
|
||||
"boundingBoxWidth": "Larghezza riquadro di delimitazione",
|
||||
"boundingBoxHeight": "Altezza riquadro di delimitazione",
|
||||
"positivePromptPlaceholder": "Prompt Positivo",
|
||||
"negativePromptPlaceholder": "Prompt Negativo",
|
||||
"controlNetControlMode": "Modalità di controllo",
|
||||
"clipSkip": "CLIP Skip",
|
||||
"aspectRatio": "Proporzioni",
|
||||
"maskAdjustmentsHeader": "Regolazioni della maschera",
|
||||
"maskBlur": "Sfocatura",
|
||||
"maskBlurMethod": "Metodo di sfocatura",
|
||||
"seamLowThreshold": "Basso",
|
||||
"seamHighThreshold": "Alto",
|
||||
"coherencePassHeader": "Passaggio di coerenza",
|
||||
"coherenceSteps": "Passi",
|
||||
"coherenceStrength": "Forza",
|
||||
"compositingSettingsHeader": "Impostazioni di composizione",
|
||||
"patchmatchDownScaleSize": "Ridimensiona",
|
||||
"coherenceMode": "Modalità",
|
||||
"invoke": {
|
||||
"noNodesInGraph": "Nessun nodo nel grafico",
|
||||
"noModelSelected": "Nessun modello selezionato",
|
||||
"noPrompts": "Nessun prompt generato",
|
||||
"noInitialImageSelected": "Nessuna immagine iniziale selezionata",
|
||||
"readyToInvoke": "Pronto per invocare",
|
||||
"addingImagesTo": "Aggiungi immagini a",
|
||||
"systemBusy": "Sistema occupato",
|
||||
"unableToInvoke": "Impossibile invocare",
|
||||
"systemDisconnected": "Sistema disconnesso",
|
||||
"noControlImageForControlAdapter": "L'adattatore di controllo {{number}} non ha un'immagine di controllo",
|
||||
"noModelForControlAdapter": "Nessun modello selezionato per l'adattatore di controllo {{number}}.",
|
||||
"incompatibleBaseModelForControlAdapter": "Il modello dell'adattatore di controllo {{number}} non è compatibile con il modello principale."
|
||||
},
|
||||
"enableNoiseSettings": "Abilita le impostazioni del rumore",
|
||||
"cpuNoise": "Rumore CPU",
|
||||
"gpuNoise": "Rumore GPU",
|
||||
"useCpuNoise": "Usa la CPU per generare rumore",
|
||||
"manualSeed": "Seme manuale",
|
||||
"randomSeed": "Seme casuale",
|
||||
"iterations": "Iterazioni",
|
||||
"iterationsWithCount_one": "{{count}} Iterazione",
|
||||
"iterationsWithCount_many": "{{count}} Iterazioni",
|
||||
"iterationsWithCount_other": "",
|
||||
"seamlessX&Y": "Senza cuciture X & Y",
|
||||
"isAllowedToUpscale": {
|
||||
"useX2Model": "L'immagine è troppo grande per l'ampliamento con il modello x4, utilizza il modello x2",
|
||||
"tooLarge": "L'immagine è troppo grande per l'ampliamento, seleziona un'immagine più piccola"
|
||||
},
|
||||
"seamlessX": "Senza cuciture X",
|
||||
"seamlessY": "Senza cuciture Y",
|
||||
"imageActions": "Azioni Immagine"
|
||||
},
|
||||
"settings": {
|
||||
"models": "Modelli",
|
||||
"displayInProgress": "Visualizza immagini in corso",
|
||||
"displayInProgress": "Visualizza le immagini di avanzamento",
|
||||
"saveSteps": "Salva le immagini ogni n passaggi",
|
||||
"confirmOnDelete": "Conferma l'eliminazione",
|
||||
"displayHelpIcons": "Visualizza le icone della Guida",
|
||||
"useCanvasBeta": "Utilizza il layout beta di Canvas",
|
||||
"enableImageDebugging": "Abilita il debug dell'immagine",
|
||||
"resetWebUI": "Reimposta l'interfaccia utente Web",
|
||||
"resetWebUIDesc1": "Il ripristino dell'interfaccia utente Web reimposta solo la cache locale del browser delle immagini e le impostazioni memorizzate. Non cancella alcuna immagine dal disco.",
|
||||
"resetWebUIDesc2": "Se le immagini non vengono visualizzate nella galleria o qualcos'altro non funziona, prova a reimpostare prima di segnalare un problema su GitHub.",
|
||||
"resetComplete": "L'interfaccia utente Web è stata reimpostata. Aggiorna la pagina per ricaricarla.",
|
||||
"useSlidersForAll": "Usa i cursori per tutte le opzioni"
|
||||
"resetComplete": "L'interfaccia utente Web è stata reimpostata.",
|
||||
"useSlidersForAll": "Usa i cursori per tutte le opzioni",
|
||||
"general": "Generale",
|
||||
"consoleLogLevel": "Livello del registro",
|
||||
"shouldLogToConsole": "Registrazione della console",
|
||||
"developer": "Sviluppatore",
|
||||
"antialiasProgressImages": "Anti aliasing delle immagini di avanzamento",
|
||||
"showProgressInViewer": "Mostra le immagini di avanzamento nel visualizzatore",
|
||||
"generation": "Generazione",
|
||||
"ui": "Interfaccia Utente",
|
||||
"favoriteSchedulersPlaceholder": "Nessun campionatore preferito",
|
||||
"favoriteSchedulers": "Campionatori preferiti",
|
||||
"showAdvancedOptions": "Mostra Opzioni Avanzate",
|
||||
"alternateCanvasLayout": "Layout alternativo della tela",
|
||||
"beta": "Beta",
|
||||
"enableNodesEditor": "Abilita l'editor dei nodi",
|
||||
"experimental": "Sperimentale",
|
||||
"autoChangeDimensions": "Aggiorna L/A alle impostazioni predefinite del modello in caso di modifica"
|
||||
},
|
||||
"toast": {
|
||||
"tempFoldersEmptied": "Cartella temporanea svuotata",
|
||||
"uploadFailed": "Caricamento fallito",
|
||||
"uploadFailedMultipleImagesDesc": "Più immagini incollate, si può caricare solo un'immagine alla volta",
|
||||
"uploadFailedUnableToLoadDesc": "Impossibile caricare il file",
|
||||
"downloadImageStarted": "Download dell'immagine avviato",
|
||||
"imageCopied": "Immagine copiata",
|
||||
"imageLinkCopied": "Collegamento immagine copiato",
|
||||
"imageNotLoaded": "Nessuna immagine caricata",
|
||||
"imageNotLoadedDesc": "Nessuna immagine trovata da inviare al modulo da Immagine a Immagine",
|
||||
"imageNotLoadedDesc": "Impossibile trovare l'immagine",
|
||||
"imageSavedToGallery": "Immagine salvata nella Galleria",
|
||||
"canvasMerged": "Tela unita",
|
||||
"sentToImageToImage": "Inviato a da Immagine a Immagine",
|
||||
"sentToImageToImage": "Inviato a Immagine a Immagine",
|
||||
"sentToUnifiedCanvas": "Inviato a Tela Unificata",
|
||||
"parametersSet": "Parametri impostati",
|
||||
"parametersNotSet": "Parametri non impostati",
|
||||
@@ -536,7 +655,57 @@
|
||||
"serverError": "Errore del Server",
|
||||
"disconnected": "Disconnesso dal Server",
|
||||
"connected": "Connesso al Server",
|
||||
"canceled": "Elaborazione annullata"
|
||||
"canceled": "Elaborazione annullata",
|
||||
"problemCopyingImageLink": "Impossibile copiare il collegamento dell'immagine",
|
||||
"uploadFailedInvalidUploadDesc": "Deve essere una singola immagine PNG o JPEG",
|
||||
"parameterSet": "Parametro impostato",
|
||||
"parameterNotSet": "Parametro non impostato",
|
||||
"nodesLoadedFailed": "Impossibile caricare i nodi",
|
||||
"nodesSaved": "Nodi salvati",
|
||||
"nodesLoaded": "Nodi caricati",
|
||||
"nodesCleared": "Nodi cancellati",
|
||||
"problemCopyingImage": "Impossibile copiare l'immagine",
|
||||
"nodesNotValidGraph": "Grafico del nodo InvokeAI non valido",
|
||||
"nodesCorruptedGraph": "Impossibile caricare. Il grafico sembra essere danneggiato.",
|
||||
"nodesUnrecognizedTypes": "Impossibile caricare. Il grafico ha tipi di dati non riconosciuti",
|
||||
"nodesNotValidJSON": "JSON non valido",
|
||||
"nodesBrokenConnections": "Impossibile caricare. Alcune connessioni sono interrotte.",
|
||||
"baseModelChangedCleared_one": "Il modello base è stato modificato, cancellato o disabilitato {{number}} sotto-modello incompatibile",
|
||||
"baseModelChangedCleared_many": "",
|
||||
"baseModelChangedCleared_other": "",
|
||||
"imageSavingFailed": "Salvataggio dell'immagine non riuscito",
|
||||
"canvasSentControlnetAssets": "Tela inviata a ControlNet & Risorse",
|
||||
"problemCopyingCanvasDesc": "Impossibile copiare la tela",
|
||||
"loadedWithWarnings": "Flusso di lavoro caricato con avvisi",
|
||||
"canvasCopiedClipboard": "Tela copiata negli appunti",
|
||||
"maskSavedAssets": "Maschera salvata nelle risorse",
|
||||
"modelAddFailed": "Aggiunta del modello non riuscita",
|
||||
"problemDownloadingCanvas": "Problema durante il download della tela",
|
||||
"problemMergingCanvas": "Problema nell'unione delle tele",
|
||||
"imageUploaded": "Immagine caricata",
|
||||
"addedToBoard": "Aggiunto alla bacheca",
|
||||
"modelAddedSimple": "Modello aggiunto",
|
||||
"problemImportingMaskDesc": "Impossibile importare la maschera",
|
||||
"problemCopyingCanvas": "Problema durante la copia della tela",
|
||||
"problemSavingCanvas": "Problema nel salvataggio della tela",
|
||||
"canvasDownloaded": "Tela scaricata",
|
||||
"problemMergingCanvasDesc": "Impossibile unire le tele",
|
||||
"problemDownloadingCanvasDesc": "Impossibile scaricare la tela",
|
||||
"imageSaved": "Immagine salvata",
|
||||
"maskSentControlnetAssets": "Maschera inviata a ControlNet & Risorse",
|
||||
"canvasSavedGallery": "Tela salvata nella Galleria",
|
||||
"imageUploadFailed": "Caricamento immagine non riuscito",
|
||||
"modelAdded": "Modello aggiunto: {{modelName}}",
|
||||
"problemImportingMask": "Problema durante l'importazione della maschera",
|
||||
"setInitialImage": "Imposta come immagine iniziale",
|
||||
"setControlImage": "Imposta come immagine di controllo",
|
||||
"setNodeField": "Imposta come campo nodo",
|
||||
"problemSavingMask": "Problema nel salvataggio della maschera",
|
||||
"problemSavingCanvasDesc": "Impossibile salvare la tela",
|
||||
"setCanvasInitialImage": "Imposta come immagine iniziale della tela",
|
||||
"workflowLoaded": "Flusso di lavoro caricato",
|
||||
"setIPAdapterImage": "Imposta come immagine per l'Adattatore IP",
|
||||
"problemSavingMaskDesc": "Impossibile salvare la maschera"
|
||||
},
|
||||
"tooltip": {
|
||||
"feature": {
|
||||
@@ -610,7 +779,10 @@
|
||||
"betaClear": "Svuota",
|
||||
"betaDarkenOutside": "Oscura all'esterno",
|
||||
"betaLimitToBox": "Limita al rettangolo",
|
||||
"betaPreserveMasked": "Conserva quanto mascherato"
|
||||
"betaPreserveMasked": "Conserva quanto mascherato",
|
||||
"antialiasing": "Anti aliasing",
|
||||
"showResultsOn": "Mostra i risultati (attivato)",
|
||||
"showResultsOff": "Mostra i risultati (disattivato)"
|
||||
},
|
||||
"accessibility": {
|
||||
"modelSelect": "Seleziona modello",
|
||||
@@ -628,11 +800,519 @@
|
||||
"rotateClockwise": "Ruotare in senso orario",
|
||||
"flipHorizontally": "Capovolgi orizzontalmente",
|
||||
"toggleLogViewer": "Attiva/disattiva visualizzatore registro",
|
||||
"showGallery": "Mostra la galleria immagini",
|
||||
"showOptionsPanel": "Mostra il pannello opzioni",
|
||||
"showOptionsPanel": "Mostra il pannello laterale",
|
||||
"flipVertically": "Capovolgi verticalmente",
|
||||
"toggleAutoscroll": "Attiva/disattiva lo scorrimento automatico",
|
||||
"modifyConfig": "Modifica configurazione",
|
||||
"menu": "Menu"
|
||||
"menu": "Menu",
|
||||
"showGalleryPanel": "Mostra il pannello Galleria",
|
||||
"loadMore": "Carica altro"
|
||||
},
|
||||
"ui": {
|
||||
"hideProgressImages": "Nascondi avanzamento immagini",
|
||||
"showProgressImages": "Mostra avanzamento immagini",
|
||||
"swapSizes": "Scambia dimensioni",
|
||||
"lockRatio": "Blocca le proporzioni"
|
||||
},
|
||||
"nodes": {
|
||||
"zoomOutNodes": "Rimpicciolire",
|
||||
"hideGraphNodes": "Nascondi sovrapposizione grafico",
|
||||
"hideLegendNodes": "Nascondi la legenda del tipo di campo",
|
||||
"showLegendNodes": "Mostra legenda del tipo di campo",
|
||||
"hideMinimapnodes": "Nascondi minimappa",
|
||||
"showMinimapnodes": "Mostra minimappa",
|
||||
"zoomInNodes": "Ingrandire",
|
||||
"fitViewportNodes": "Adatta vista",
|
||||
"showGraphNodes": "Mostra sovrapposizione grafico",
|
||||
"resetWorkflowDesc2": "Reimpostare il flusso di lavoro cancellerà tutti i nodi, i bordi e i dettagli del flusso di lavoro.",
|
||||
"reloadNodeTemplates": "Ricarica i modelli di nodo",
|
||||
"loadWorkflow": "Importa flusso di lavoro JSON",
|
||||
"resetWorkflow": "Reimposta flusso di lavoro",
|
||||
"resetWorkflowDesc": "Sei sicuro di voler reimpostare questo flusso di lavoro?",
|
||||
"downloadWorkflow": "Esporta flusso di lavoro JSON",
|
||||
"scheduler": "Campionatore",
|
||||
"addNode": "Aggiungi nodo",
|
||||
"sDXLMainModelFieldDescription": "Campo del modello SDXL.",
|
||||
"boardField": "Bacheca",
|
||||
"animatedEdgesHelp": "Anima i bordi selezionati e i bordi collegati ai nodi selezionati",
|
||||
"sDXLMainModelField": "Modello SDXL",
|
||||
"executionStateInProgress": "In corso",
|
||||
"executionStateError": "Errore",
|
||||
"executionStateCompleted": "Completato",
|
||||
"boardFieldDescription": "Una bacheca della galleria",
|
||||
"addNodeToolTip": "Aggiungi nodo (Shift+A, Space)",
|
||||
"sDXLRefinerModelField": "Modello Refiner",
|
||||
"problemReadingMetadata": "Problema durante la lettura dei metadati dall'immagine",
|
||||
"colorCodeEdgesHelp": "Bordi con codice colore in base ai campi collegati",
|
||||
"animatedEdges": "Bordi animati",
|
||||
"snapToGrid": "Aggancia alla griglia",
|
||||
"validateConnections": "Convalida connessioni e grafico",
|
||||
"validateConnectionsHelp": "Impedisce che vengano effettuate connessioni non valide e che vengano \"invocati\" grafici non validi",
|
||||
"fullyContainNodesHelp": "I nodi devono essere completamente all'interno della casella di selezione per essere selezionati",
|
||||
"fullyContainNodes": "Contenere completamente i nodi da selezionare",
|
||||
"snapToGridHelp": "Aggancia i nodi alla griglia quando vengono spostati",
|
||||
"workflowSettings": "Impostazioni Editor del flusso di lavoro",
|
||||
"colorCodeEdges": "Bordi con codice colore",
|
||||
"mainModelField": "Modello",
|
||||
"noOutputRecorded": "Nessun output registrato",
|
||||
"noFieldsLinearview": "Nessun campo aggiunto alla vista lineare",
|
||||
"removeLinearView": "Rimuovi dalla vista lineare",
|
||||
"workflowDescription": "Breve descrizione",
|
||||
"workflowContact": "Contatto",
|
||||
"workflowVersion": "Versione",
|
||||
"workflow": "Flusso di lavoro",
|
||||
"noWorkflow": "Nessun flusso di lavoro",
|
||||
"workflowTags": "Tag",
|
||||
"workflowValidation": "Errore di convalida del flusso di lavoro",
|
||||
"workflowAuthor": "Autore",
|
||||
"workflowName": "Nome",
|
||||
"workflowNotes": "Note"
|
||||
},
|
||||
"boards": {
|
||||
"autoAddBoard": "Aggiungi automaticamente bacheca",
|
||||
"menuItemAutoAdd": "Aggiungi automaticamente a questa Bacheca",
|
||||
"cancel": "Annulla",
|
||||
"addBoard": "Aggiungi Bacheca",
|
||||
"bottomMessage": "L'eliminazione di questa bacheca e delle sue immagini ripristinerà tutte le funzionalità che le stanno attualmente utilizzando.",
|
||||
"changeBoard": "Cambia Bacheca",
|
||||
"loading": "Caricamento in corso ...",
|
||||
"clearSearch": "Cancella Ricerca",
|
||||
"topMessage": "Questa bacheca contiene immagini utilizzate nelle seguenti funzionalità:",
|
||||
"move": "Sposta",
|
||||
"myBoard": "Bacheca",
|
||||
"searchBoard": "Cerca bacheche ...",
|
||||
"noMatching": "Nessuna bacheca corrispondente",
|
||||
"selectBoard": "Seleziona una Bacheca",
|
||||
"uncategorized": "Non categorizzato"
|
||||
},
|
||||
"controlnet": {
|
||||
"contentShuffleDescription": "Rimescola il contenuto di un'immagine",
|
||||
"contentShuffle": "Rimescola contenuto",
|
||||
"beginEndStepPercent": "Percentuale passi Inizio / Fine",
|
||||
"duplicate": "Duplica",
|
||||
"balanced": "Bilanciato",
|
||||
"depthMidasDescription": "Generazione di mappe di profondità usando Midas",
|
||||
"control": "ControlNet",
|
||||
"crop": "Ritaglia",
|
||||
"depthMidas": "Profondità (Midas)",
|
||||
"enableControlnet": "Abilita ControlNet",
|
||||
"detectResolution": "Rileva risoluzione",
|
||||
"controlMode": "Modalità Controllo",
|
||||
"cannyDescription": "Canny rilevamento bordi",
|
||||
"depthZoe": "Profondità (Zoe)",
|
||||
"autoConfigure": "Configura automaticamente il processore",
|
||||
"delete": "Elimina",
|
||||
"depthZoeDescription": "Generazione di mappe di profondità usando Zoe",
|
||||
"resize": "Ridimensiona",
|
||||
"showAdvanced": "Mostra opzioni Avanzate",
|
||||
"bgth": "Soglia rimozione sfondo",
|
||||
"importImageFromCanvas": "Importa immagine dalla Tela",
|
||||
"lineartDescription": "Converte l'immagine in lineart",
|
||||
"importMaskFromCanvas": "Importa maschera dalla Tela",
|
||||
"hideAdvanced": "Nascondi opzioni avanzate",
|
||||
"ipAdapterModel": "Modello Adattatore",
|
||||
"resetControlImage": "Reimposta immagine di controllo",
|
||||
"f": "F",
|
||||
"h": "H",
|
||||
"prompt": "Prompt",
|
||||
"openPoseDescription": "Stima della posa umana utilizzando Openpose",
|
||||
"resizeMode": "Modalità ridimensionamento",
|
||||
"weight": "Peso",
|
||||
"selectModel": "Seleziona un modello",
|
||||
"w": "W",
|
||||
"processor": "Processore",
|
||||
"none": "Nessuno",
|
||||
"incompatibleBaseModel": "Modello base incompatibile:",
|
||||
"pidiDescription": "Elaborazione immagini PIDI",
|
||||
"fill": "Riempire",
|
||||
"colorMapDescription": "Genera una mappa dei colori dall'immagine",
|
||||
"lineartAnimeDescription": "Elaborazione lineart in stile anime",
|
||||
"imageResolution": "Risoluzione dell'immagine",
|
||||
"colorMap": "Colore",
|
||||
"lowThreshold": "Soglia inferiore",
|
||||
"highThreshold": "Soglia superiore",
|
||||
"normalBaeDescription": "Elaborazione BAE normale",
|
||||
"noneDescription": "Nessuna elaborazione applicata",
|
||||
"saveControlImage": "Salva immagine di controllo",
|
||||
"toggleControlNet": "Attiva/disattiva questo ControlNet",
|
||||
"safe": "Sicuro",
|
||||
"colorMapTileSize": "Dimensione piastrella",
|
||||
"ipAdapterImageFallback": "Nessuna immagine dell'Adattatore IP selezionata",
|
||||
"mediapipeFaceDescription": "Rilevamento dei volti tramite Mediapipe",
|
||||
"hedDescription": "Rilevamento dei bordi nidificati olisticamente",
|
||||
"setControlImageDimensions": "Imposta le dimensioni dell'immagine di controllo su L/A",
|
||||
"resetIPAdapterImage": "Reimposta immagine Adattatore IP",
|
||||
"handAndFace": "Mano e faccia",
|
||||
"enableIPAdapter": "Abilita Adattatore IP",
|
||||
"maxFaces": "Numero massimo di volti",
|
||||
"addT2IAdapter": "Aggiungi $t(common.t2iAdapter)",
|
||||
"controlNetEnabledT2IDisabled": "$t(common.controlNet) abilitato, $t(common.t2iAdapter) disabilitati",
|
||||
"t2iEnabledControlNetDisabled": "$t(common.t2iAdapter) abilitato, $t(common.controlNet) disabilitati",
|
||||
"addControlNet": "Aggiungi $t(common.controlNet)",
|
||||
"controlNetT2IMutexDesc": "$t(common.controlNet) e $t(common.t2iAdapter) contemporaneamente non sono attualmente supportati.",
|
||||
"addIPAdapter": "Aggiungi $t(common.ipAdapter)",
|
||||
"controlAdapter": "Adattatore di Controllo",
|
||||
"megaControl": "Mega ControlNet"
|
||||
},
|
||||
"queue": {
|
||||
"queueFront": "Aggiungi all'inizio della coda",
|
||||
"queueBack": "Aggiungi alla coda",
|
||||
"queueCountPrediction": "Aggiungi {{predicted}} alla coda",
|
||||
"queue": "Coda",
|
||||
"status": "Stato",
|
||||
"pruneSucceeded": "Rimossi {{item_count}} elementi completati dalla coda",
|
||||
"cancelTooltip": "Annulla l'elemento corrente",
|
||||
"queueEmpty": "Coda vuota",
|
||||
"pauseSucceeded": "Elaborazione sospesa",
|
||||
"in_progress": "In corso",
|
||||
"notReady": "Impossibile mettere in coda",
|
||||
"batchFailedToQueue": "Impossibile mettere in coda il lotto",
|
||||
"completed": "Completati",
|
||||
"batchValues": "Valori del lotto",
|
||||
"cancelFailed": "Problema durante l'annullamento dell'elemento",
|
||||
"batchQueued": "Lotto aggiunto alla coda",
|
||||
"pauseFailed": "Problema durante la sospensione dell'elaborazione",
|
||||
"clearFailed": "Problema nella cancellazione della coda",
|
||||
"queuedCount": "{{pending}} In attesa",
|
||||
"front": "inizio",
|
||||
"clearSucceeded": "Coda cancellata",
|
||||
"pause": "Sospendi",
|
||||
"pruneTooltip": "Rimuovi {{item_count}} elementi completati",
|
||||
"cancelSucceeded": "Elemento annullato",
|
||||
"batchQueuedDesc": "Aggiunte {{item_count}} sessioni a {{direction}} della coda",
|
||||
"graphQueued": "Grafico in coda",
|
||||
"batch": "Lotto",
|
||||
"clearQueueAlertDialog": "Lo svuotamento della coda annulla immediatamente tutti gli elementi in elaborazione e cancella completamente la coda.",
|
||||
"pending": "In attesa",
|
||||
"completedIn": "Completato in",
|
||||
"resumeFailed": "Problema nel riavvio dell'elaborazione",
|
||||
"clear": "Cancella",
|
||||
"prune": "Rimuovi",
|
||||
"total": "Totale",
|
||||
"canceled": "Annullati",
|
||||
"pruneFailed": "Problema nel rimuovere la coda",
|
||||
"cancelBatchSucceeded": "Lotto annullato",
|
||||
"clearTooltip": "Annulla e cancella tutti gli elementi",
|
||||
"current": "Attuale",
|
||||
"pauseTooltip": "Sospende l'elaborazione",
|
||||
"failed": "Falliti",
|
||||
"cancelItem": "Annulla l'elemento",
|
||||
"next": "Prossimo",
|
||||
"cancelBatch": "Annulla lotto",
|
||||
"back": "fine",
|
||||
"cancel": "Annulla",
|
||||
"session": "Sessione",
|
||||
"queueTotal": "{{total}} Totale",
|
||||
"resumeSucceeded": "Elaborazione ripresa",
|
||||
"enqueueing": "Lotto in coda",
|
||||
"resumeTooltip": "Riprendi l'elaborazione",
|
||||
"resume": "Riprendi",
|
||||
"cancelBatchFailed": "Problema durante l'annullamento del lotto",
|
||||
"clearQueueAlertDialog2": "Sei sicuro di voler cancellare la coda?",
|
||||
"item": "Elemento",
|
||||
"graphFailedToQueue": "Impossibile mettere in coda il grafico",
|
||||
"queueMaxExceeded": "È stato superato il limite massimo di {{max_queue_size}} e {{skip}} elementi verrebbero saltati"
|
||||
},
|
||||
"embedding": {
|
||||
"noMatchingEmbedding": "Nessun Incorporamento corrispondente",
|
||||
"addEmbedding": "Aggiungi Incorporamento",
|
||||
"incompatibleModel": "Modello base incompatibile:"
|
||||
},
|
||||
"models": {
|
||||
"noMatchingModels": "Nessun modello corrispondente",
|
||||
"loading": "caricamento",
|
||||
"noMatchingLoRAs": "Nessun LoRA corrispondente",
|
||||
"noLoRAsAvailable": "Nessun LoRA disponibile",
|
||||
"noModelsAvailable": "Nessun modello disponibile",
|
||||
"selectModel": "Seleziona un modello",
|
||||
"selectLoRA": "Seleziona un LoRA"
|
||||
},
|
||||
"invocationCache": {
|
||||
"disable": "Disabilita",
|
||||
"misses": "Non trovati in cache",
|
||||
"enableFailed": "Problema nell'abilitazione della cache delle invocazioni",
|
||||
"invocationCache": "Cache delle invocazioni",
|
||||
"clearSucceeded": "Cache delle invocazioni svuotata",
|
||||
"enableSucceeded": "Cache delle invocazioni abilitata",
|
||||
"clearFailed": "Problema durante lo svuotamento della cache delle invocazioni",
|
||||
"hits": "Trovati in cache",
|
||||
"disableSucceeded": "Cache delle invocazioni disabilitata",
|
||||
"disableFailed": "Problema durante la disabilitazione della cache delle invocazioni",
|
||||
"enable": "Abilita",
|
||||
"clear": "Svuota",
|
||||
"maxCacheSize": "Dimensione max cache",
|
||||
"cacheSize": "Dimensione cache"
|
||||
},
|
||||
"dynamicPrompts": {
|
||||
"seedBehaviour": {
|
||||
"perPromptDesc": "Utilizza un seme diverso per ogni immagine",
|
||||
"perIterationLabel": "Per iterazione",
|
||||
"perIterationDesc": "Utilizza un seme diverso per ogni iterazione",
|
||||
"perPromptLabel": "Per immagine",
|
||||
"label": "Comportamento del seme"
|
||||
},
|
||||
"enableDynamicPrompts": "Abilita prompt dinamici",
|
||||
"combinatorial": "Generazione combinatoria",
|
||||
"maxPrompts": "Numero massimo di prompt",
|
||||
"promptsWithCount_one": "{{count}} Prompt",
|
||||
"promptsWithCount_many": "{{count}} Prompt",
|
||||
"promptsWithCount_other": "",
|
||||
"dynamicPrompts": "Prompt dinamici"
|
||||
},
|
||||
"popovers": {
|
||||
"paramScheduler": {
|
||||
"paragraphs": [
|
||||
"Il campionatore definisce come aggiungere in modo iterativo il rumore a un'immagine o come aggiornare un campione in base all'output di un modello."
|
||||
],
|
||||
"heading": "Campionatore"
|
||||
},
|
||||
"compositingMaskAdjustments": {
|
||||
"heading": "Regolazioni della maschera",
|
||||
"paragraphs": [
|
||||
"Regola la maschera."
|
||||
]
|
||||
},
|
||||
"compositingCoherenceSteps": {
|
||||
"heading": "Passi",
|
||||
"paragraphs": [
|
||||
"Numero di passi di riduzione del rumore utilizzati nel Passaggio di Coerenza.",
|
||||
"Uguale al parametro principale Passi."
|
||||
]
|
||||
},
|
||||
"compositingBlur": {
|
||||
"heading": "Sfocatura",
|
||||
"paragraphs": [
|
||||
"Il raggio di sfocatura della maschera."
|
||||
]
|
||||
},
|
||||
"compositingCoherenceMode": {
|
||||
"heading": "Modalità",
|
||||
"paragraphs": [
|
||||
"La modalità del Passaggio di Coerenza."
|
||||
]
|
||||
},
|
||||
"clipSkip": {
|
||||
"paragraphs": [
|
||||
"Scegli quanti livelli del modello CLIP saltare.",
|
||||
"Alcuni modelli funzionano meglio con determinate impostazioni di CLIP Skip.",
|
||||
"Un valore più alto in genere produce un'immagine meno dettagliata."
|
||||
]
|
||||
},
|
||||
"compositingCoherencePass": {
|
||||
"heading": "Passaggio di Coerenza",
|
||||
"paragraphs": [
|
||||
"Un secondo ciclo di riduzione del rumore aiuta a comporre l'immagine Inpaint/Outpaint."
|
||||
]
|
||||
},
|
||||
"compositingStrength": {
|
||||
"heading": "Forza",
|
||||
"paragraphs": [
|
||||
"Intensità di riduzione del rumore per il passaggio di coerenza.",
|
||||
"Uguale al parametro intensità di riduzione del rumore da immagine a immagine."
|
||||
]
|
||||
},
|
||||
"paramNegativeConditioning": {
|
||||
"paragraphs": [
|
||||
"Il processo di generazione evita i concetti nel prompt negativo. Utilizzatelo per escludere qualità o oggetti dall'output.",
|
||||
"Supporta la sintassi e gli incorporamenti di Compel."
|
||||
],
|
||||
"heading": "Prompt negativo"
|
||||
},
|
||||
"compositingBlurMethod": {
|
||||
"heading": "Metodo di sfocatura",
|
||||
"paragraphs": [
|
||||
"Il metodo di sfocatura applicato all'area mascherata."
|
||||
]
|
||||
},
|
||||
"paramPositiveConditioning": {
|
||||
"heading": "Prompt positivo",
|
||||
"paragraphs": [
|
||||
"Guida il processo di generazione. Puoi usare qualsiasi parola o frase.",
|
||||
"Supporta sintassi e incorporamenti di Compel e Prompt Dinamici."
|
||||
]
|
||||
},
|
||||
"controlNetBeginEnd": {
|
||||
"heading": "Percentuale passi Inizio / Fine",
|
||||
"paragraphs": [
|
||||
"A quali passi del processo di rimozione del rumore verrà applicato ControlNet.",
|
||||
"I ControlNet applicati all'inizio del processo guidano la composizione, mentre i ControlNet applicati alla fine guidano i dettagli."
|
||||
]
|
||||
},
|
||||
"noiseUseCPU": {
|
||||
"paragraphs": [
|
||||
"Controlla se viene generato rumore sulla CPU o sulla GPU.",
|
||||
"Con il rumore della CPU abilitato, un seme particolare produrrà la stessa immagine su qualsiasi macchina.",
|
||||
"Non vi è alcun impatto sulle prestazioni nell'abilitare il rumore della CPU."
|
||||
],
|
||||
"heading": "Usa la CPU per generare rumore"
|
||||
},
|
||||
"scaleBeforeProcessing": {
|
||||
"paragraphs": [
|
||||
"Ridimensiona l'area selezionata alla dimensione più adatta al modello prima del processo di generazione dell'immagine."
|
||||
],
|
||||
"heading": "Scala prima dell'elaborazione"
|
||||
},
|
||||
"paramRatio": {
|
||||
"heading": "Proporzioni",
|
||||
"paragraphs": [
|
||||
"Le proporzioni delle dimensioni dell'immagine generata.",
|
||||
"Per i modelli SD1.5 si consiglia una dimensione dell'immagine (in numero di pixel) equivalente a 512x512 mentre per i modelli SDXL si consiglia una dimensione equivalente a 1024x1024."
|
||||
]
|
||||
},
|
||||
"dynamicPrompts": {
|
||||
"paragraphs": [
|
||||
"Prompt Dinamici crea molte variazioni a partire da un singolo prompt.",
|
||||
"La sintassi di base è \"a {red|green|blue} ball\". Ciò produrrà tre prompt: \"a red ball\", \"a green ball\" e \"a blue ball\".",
|
||||
"Puoi utilizzare la sintassi quante volte vuoi in un singolo prompt, ma assicurati di tenere sotto controllo il numero di prompt generati con l'impostazione \"Numero massimo di prompt\"."
|
||||
],
|
||||
"heading": "Prompt Dinamici"
|
||||
},
|
||||
"paramVAE": {
|
||||
"paragraphs": [
|
||||
"Modello utilizzato per tradurre l'output dell'intelligenza artificiale nell'immagine finale."
|
||||
],
|
||||
"heading": "VAE"
|
||||
},
|
||||
"paramIterations": {
|
||||
"paragraphs": [
|
||||
"Il numero di immagini da generare.",
|
||||
"Se i prompt dinamici sono abilitati, ciascuno dei prompt verrà generato questo numero di volte."
|
||||
],
|
||||
"heading": "Iterazioni"
|
||||
},
|
||||
"paramVAEPrecision": {
|
||||
"heading": "Precisione VAE",
|
||||
"paragraphs": [
|
||||
"La precisione utilizzata durante la codifica e decodifica VAE. FP16/mezza precisione è più efficiente, a scapito di minori variazioni dell'immagine."
|
||||
]
|
||||
},
|
||||
"paramSeed": {
|
||||
"paragraphs": [
|
||||
"Controlla il rumore iniziale utilizzato per la generazione.",
|
||||
"Disabilita seme \"Casuale\" per produrre risultati identici con le stesse impostazioni di generazione."
|
||||
],
|
||||
"heading": "Seme"
|
||||
},
|
||||
"controlNetResizeMode": {
|
||||
"heading": "Modalità ridimensionamento",
|
||||
"paragraphs": [
|
||||
"Come l'immagine ControlNet verrà adattata alle dimensioni di output dell'immagine."
|
||||
]
|
||||
},
|
||||
"dynamicPromptsSeedBehaviour": {
|
||||
"paragraphs": [
|
||||
"Controlla il modo in cui viene utilizzato il seme durante la generazione dei prompt.",
|
||||
"Per iterazione utilizzerà un seme univoco per ogni iterazione. Usalo per esplorare variazioni del prompt su un singolo seme.",
|
||||
"Ad esempio, se hai 5 prompt, ogni immagine utilizzerà lo stesso seme.",
|
||||
"Per immagine utilizzerà un seme univoco per ogni immagine. Ciò fornisce più variazione."
|
||||
],
|
||||
"heading": "Comportamento del seme"
|
||||
},
|
||||
"paramModel": {
|
||||
"heading": "Modello",
|
||||
"paragraphs": [
|
||||
"Modello utilizzato per i passaggi di riduzione del rumore.",
|
||||
"Diversi modelli sono generalmente addestrati per specializzarsi nella produzione di particolari risultati e contenuti estetici."
|
||||
]
|
||||
},
|
||||
"paramDenoisingStrength": {
|
||||
"paragraphs": [
|
||||
"Quanto rumore viene aggiunto all'immagine in ingresso.",
|
||||
"0 risulterà in un'immagine identica, mentre 1 risulterà in un'immagine completamente nuova."
|
||||
],
|
||||
"heading": "Forza di riduzione del rumore"
|
||||
},
|
||||
"dynamicPromptsMaxPrompts": {
|
||||
"heading": "Numero massimo di prompt",
|
||||
"paragraphs": [
|
||||
"Limita il numero di prompt che possono essere generati da Prompt Dinamici."
|
||||
]
|
||||
},
|
||||
"infillMethod": {
|
||||
"paragraphs": [
|
||||
"Metodo per riempire l'area selezionata."
|
||||
],
|
||||
"heading": "Metodo di riempimento"
|
||||
},
|
||||
"controlNetWeight": {
|
||||
"heading": "Peso",
|
||||
"paragraphs": [
|
||||
"Quanto forte sarà l'impatto di ControlNet sull'immagine generata."
|
||||
]
|
||||
},
|
||||
"paramCFGScale": {
|
||||
"heading": "Scala CFG",
|
||||
"paragraphs": [
|
||||
"Controlla quanto il tuo prompt influenza il processo di generazione."
|
||||
]
|
||||
},
|
||||
"controlNetControlMode": {
|
||||
"paragraphs": [
|
||||
"Attribuisce più peso al prompt o a ControlNet."
|
||||
],
|
||||
"heading": "Modalità di controllo"
|
||||
},
|
||||
"paramSteps": {
|
||||
"heading": "Passi",
|
||||
"paragraphs": [
|
||||
"Numero di passi che verranno eseguiti in ogni generazione.",
|
||||
"Un numero di passi più elevato generalmente creerà immagini migliori ma richiederà più tempo di generazione."
|
||||
]
|
||||
},
|
||||
"lora": {
|
||||
"heading": "Peso LoRA",
|
||||
"paragraphs": [
|
||||
"Un peso LoRA più elevato porterà a impatti maggiori sull'immagine finale."
|
||||
]
|
||||
},
|
||||
"controlNet": {
|
||||
"paragraphs": [
|
||||
"ControlNet fornisce una guida al processo di generazione, aiutando a creare immagini con composizione, struttura o stile controllati, a seconda del modello selezionato."
|
||||
]
|
||||
}
|
||||
},
|
||||
"sdxl": {
|
||||
"selectAModel": "Seleziona un modello",
|
||||
"scheduler": "Campionatore",
|
||||
"noModelsAvailable": "Nessun modello disponibile",
|
||||
"denoisingStrength": "Forza di riduzione del rumore",
|
||||
"concatPromptStyle": "Concatena Prompt & Stile",
|
||||
"loading": "Caricamento...",
|
||||
"steps": "Passi",
|
||||
"refinerStart": "Inizio Affinamento",
|
||||
"cfgScale": "Scala CFG",
|
||||
"negStylePrompt": "Prompt Stile negativo",
|
||||
"refiner": "Affinatore",
|
||||
"negAestheticScore": "Punteggio estetico negativo",
|
||||
"useRefiner": "Utilizza l'affinatore",
|
||||
"refinermodel": "Modello Affinatore",
|
||||
"posAestheticScore": "Punteggio estetico positivo",
|
||||
"posStylePrompt": "Prompt Stile positivo"
|
||||
},
|
||||
"metadata": {
|
||||
"initImage": "Immagine iniziale",
|
||||
"seamless": "Senza giunture",
|
||||
"positivePrompt": "Prompt positivo",
|
||||
"negativePrompt": "Prompt negativo",
|
||||
"generationMode": "Modalità generazione",
|
||||
"Threshold": "Livello di soglia del rumore",
|
||||
"metadata": "Metadati",
|
||||
"strength": "Forza Immagine a Immagine",
|
||||
"seed": "Seme",
|
||||
"imageDetails": "Dettagli dell'immagine",
|
||||
"perlin": "Rumore Perlin",
|
||||
"model": "Modello",
|
||||
"noImageDetails": "Nessun dettaglio dell'immagine trovato",
|
||||
"hiresFix": "Ottimizzazione Alta Risoluzione",
|
||||
"cfgScale": "Scala CFG",
|
||||
"fit": "Adatta Immagine a Immagine",
|
||||
"height": "Altezza",
|
||||
"variations": "Coppie Peso-Seme",
|
||||
"noMetaData": "Nessun metadato trovato",
|
||||
"width": "Larghezza",
|
||||
"createdBy": "Creato da",
|
||||
"workflow": "Flusso di lavoro",
|
||||
"steps": "Passi",
|
||||
"scheduler": "Campionatore"
|
||||
}
|
||||
}
|
||||
|
||||
11
invokeai/frontend/web/dist/locales/ja.json
vendored
11
invokeai/frontend/web/dist/locales/ja.json
vendored
@@ -1,12 +1,8 @@
|
||||
{
|
||||
"common": {
|
||||
"themeLabel": "テーマ",
|
||||
"languagePickerLabel": "言語選択",
|
||||
"reportBugLabel": "バグ報告",
|
||||
"settingsLabel": "設定",
|
||||
"darkTheme": "ダーク",
|
||||
"lightTheme": "ライト",
|
||||
"greenTheme": "緑",
|
||||
"langJapanese": "日本語",
|
||||
"nodesDesc": "現在、画像生成のためのノードベースシステムを開発中です。機能についてのアップデートにご期待ください。",
|
||||
"postProcessing": "後処理",
|
||||
@@ -56,14 +52,12 @@
|
||||
"loadingInvokeAI": "Invoke AIをロード中",
|
||||
"statusConvertingModel": "モデルの変換",
|
||||
"statusMergedModels": "マージ済モデル",
|
||||
"pinOptionsPanel": "オプションパネルを固定",
|
||||
"githubLabel": "Github",
|
||||
"hotkeysLabel": "ホットキー",
|
||||
"langHebrew": "עברית",
|
||||
"discordLabel": "Discord",
|
||||
"langItalian": "Italiano",
|
||||
"langEnglish": "English",
|
||||
"oceanTheme": "オーシャン",
|
||||
"langArabic": "アラビア語",
|
||||
"langDutch": "Nederlands",
|
||||
"langFrench": "Français",
|
||||
@@ -83,7 +77,6 @@
|
||||
"gallerySettings": "ギャラリーの設定",
|
||||
"maintainAspectRatio": "アスペクト比を維持",
|
||||
"singleColumnLayout": "1カラムレイアウト",
|
||||
"pinGallery": "ギャラリーにピン留め",
|
||||
"allImagesLoaded": "すべての画像を読み込む",
|
||||
"loadMore": "さらに読み込む",
|
||||
"noImagesInGallery": "ギャラリーに画像がありません",
|
||||
@@ -355,7 +348,6 @@
|
||||
"useSeed": "シード値を使用",
|
||||
"useAll": "すべてを使用",
|
||||
"info": "情報",
|
||||
"deleteImage": "画像を削除",
|
||||
"showOptionsPanel": "オプションパネルを表示"
|
||||
},
|
||||
"settings": {
|
||||
@@ -364,7 +356,6 @@
|
||||
"saveSteps": "nステップごとに画像を保存",
|
||||
"confirmOnDelete": "削除時に確認",
|
||||
"displayHelpIcons": "ヘルプアイコンを表示",
|
||||
"useCanvasBeta": "キャンバスレイアウト(Beta)を使用する",
|
||||
"enableImageDebugging": "画像のデバッグを有効化",
|
||||
"resetWebUI": "WebUIをリセット",
|
||||
"resetWebUIDesc1": "WebUIのリセットは、画像と保存された設定のキャッシュをリセットするだけです。画像を削除するわけではありません。",
|
||||
@@ -373,7 +364,6 @@
|
||||
},
|
||||
"toast": {
|
||||
"uploadFailed": "アップロード失敗",
|
||||
"uploadFailedMultipleImagesDesc": "一度にアップロードできる画像は1枚のみです。",
|
||||
"uploadFailedUnableToLoadDesc": "ファイルを読み込むことができません。",
|
||||
"downloadImageStarted": "画像ダウンロード開始",
|
||||
"imageCopied": "画像をコピー",
|
||||
@@ -471,7 +461,6 @@
|
||||
"toggleAutoscroll": "自動スクロールの切替",
|
||||
"modifyConfig": "Modify Config",
|
||||
"toggleLogViewer": "Log Viewerの切替",
|
||||
"showGallery": "ギャラリーを表示",
|
||||
"showOptionsPanel": "オプションパネルを表示"
|
||||
}
|
||||
}
|
||||
|
||||
4
invokeai/frontend/web/dist/locales/ko.json
vendored
4
invokeai/frontend/web/dist/locales/ko.json
vendored
@@ -1,13 +1,9 @@
|
||||
{
|
||||
"common": {
|
||||
"themeLabel": "테마 설정",
|
||||
"languagePickerLabel": "언어 설정",
|
||||
"reportBugLabel": "버그 리포트",
|
||||
"githubLabel": "Github",
|
||||
"settingsLabel": "설정",
|
||||
"darkTheme": "다크 모드",
|
||||
"lightTheme": "라이트 모드",
|
||||
"greenTheme": "그린 모드",
|
||||
"langArabic": "العربية",
|
||||
"langEnglish": "English",
|
||||
"langDutch": "Nederlands",
|
||||
|
||||
183
invokeai/frontend/web/dist/locales/nl.json
vendored
183
invokeai/frontend/web/dist/locales/nl.json
vendored
@@ -1,16 +1,12 @@
|
||||
{
|
||||
"common": {
|
||||
"hotkeysLabel": "Sneltoetsen",
|
||||
"themeLabel": "Thema",
|
||||
"languagePickerLabel": "Taalkeuze",
|
||||
"languagePickerLabel": "Taal",
|
||||
"reportBugLabel": "Meld bug",
|
||||
"settingsLabel": "Instellingen",
|
||||
"darkTheme": "Donker",
|
||||
"lightTheme": "Licht",
|
||||
"greenTheme": "Groen",
|
||||
"img2img": "Afbeelding naar afbeelding",
|
||||
"unifiedCanvas": "Centraal canvas",
|
||||
"nodes": "Knooppunten",
|
||||
"nodes": "Werkstroom-editor",
|
||||
"langDutch": "Nederlands",
|
||||
"nodesDesc": "Een op knooppunten gebaseerd systeem voor het genereren van afbeeldingen is momenteel in ontwikkeling. Blijf op de hoogte voor nieuws over deze verbluffende functie.",
|
||||
"postProcessing": "Naverwerking",
|
||||
@@ -65,15 +61,25 @@
|
||||
"statusMergedModels": "Modellen samengevoegd",
|
||||
"cancel": "Annuleer",
|
||||
"accept": "Akkoord",
|
||||
"langPortuguese": "Português",
|
||||
"pinOptionsPanel": "Zet deelscherm Opties vast",
|
||||
"langPortuguese": "Portugees",
|
||||
"loading": "Bezig met laden",
|
||||
"loadingInvokeAI": "Bezig met laden van Invoke AI",
|
||||
"oceanTheme": "Oceaan",
|
||||
"langHebrew": "עברית",
|
||||
"langKorean": "한국어",
|
||||
"txt2img": "Tekst naar afbeelding",
|
||||
"postprocessing": "Nabewerking"
|
||||
"postprocessing": "Naverwerking",
|
||||
"dontAskMeAgain": "Vraag niet opnieuw",
|
||||
"imagePrompt": "Afbeeldingsprompt",
|
||||
"random": "Willekeurig",
|
||||
"generate": "Genereer",
|
||||
"openInNewTab": "Open in nieuw tabblad",
|
||||
"areYouSure": "Weet je het zeker?",
|
||||
"linear": "Lineair",
|
||||
"batch": "Seriebeheer",
|
||||
"modelManager": "Modelbeheer",
|
||||
"darkMode": "Donkere modus",
|
||||
"lightMode": "Lichte modus",
|
||||
"communityLabel": "Gemeenschap"
|
||||
},
|
||||
"gallery": {
|
||||
"generations": "Gegenereerde afbeeldingen",
|
||||
@@ -86,10 +92,15 @@
|
||||
"maintainAspectRatio": "Behoud beeldverhoiding",
|
||||
"autoSwitchNewImages": "Wissel autom. naar nieuwe afbeeldingen",
|
||||
"singleColumnLayout": "Eenkolomsindeling",
|
||||
"pinGallery": "Zet galerij vast",
|
||||
"allImagesLoaded": "Alle afbeeldingen geladen",
|
||||
"loadMore": "Laad meer",
|
||||
"noImagesInGallery": "Geen afbeeldingen in galerij"
|
||||
"noImagesInGallery": "Geen afbeeldingen om te tonen",
|
||||
"deleteImage": "Wis afbeelding",
|
||||
"deleteImageBin": "Gewiste afbeeldingen worden naar de prullenbak van je besturingssysteem gestuurd.",
|
||||
"deleteImagePermanent": "Gewiste afbeeldingen kunnen niet worden hersteld.",
|
||||
"assets": "Eigen onderdelen",
|
||||
"images": "Afbeeldingen",
|
||||
"autoAssignBoardOnClick": "Ken automatisch bord toe bij klikken"
|
||||
},
|
||||
"hotkeys": {
|
||||
"keyboardShortcuts": "Sneltoetsen",
|
||||
@@ -296,7 +307,12 @@
|
||||
"acceptStagingImage": {
|
||||
"title": "Accepteer sessie-afbeelding",
|
||||
"desc": "Accepteert de huidige sessie-afbeelding"
|
||||
}
|
||||
},
|
||||
"addNodes": {
|
||||
"title": "Voeg knooppunten toe",
|
||||
"desc": "Opent het menu Voeg knooppunt toe"
|
||||
},
|
||||
"nodesHotkeys": "Sneltoetsen knooppunten"
|
||||
},
|
||||
"modelManager": {
|
||||
"modelManager": "Modelonderhoud",
|
||||
@@ -348,12 +364,12 @@
|
||||
"delete": "Verwijder",
|
||||
"deleteModel": "Verwijder model",
|
||||
"deleteConfig": "Verwijder configuratie",
|
||||
"deleteMsg1": "Weet je zeker dat je deze modelregel wilt verwijderen uit InvokeAI?",
|
||||
"deleteMsg2": "Hiermee wordt het checkpointbestand niet van je schijf verwijderd. Je kunt deze opnieuw toevoegen als je dat wilt.",
|
||||
"deleteMsg1": "Weet je zeker dat je dit model wilt verwijderen uit InvokeAI?",
|
||||
"deleteMsg2": "Hiermee ZAL het model van schijf worden verwijderd als het zich bevindt in de InvokeAI-beginmap. Als je het model vanaf een eigen locatie gebruikt, dan ZAL het model NIET van schijf worden verwijderd.",
|
||||
"formMessageDiffusersVAELocationDesc": "Indien niet opgegeven, dan zal InvokeAI kijken naar het VAE-bestand in de hierboven gegeven modellocatie.",
|
||||
"repoIDValidationMsg": "Online repository van je model",
|
||||
"formMessageDiffusersModelLocation": "Locatie Diffusers-model",
|
||||
"convertToDiffusersHelpText3": "Je Checkpoint-bestand op schijf zal NIET worden verwijderd of gewijzigd. Je kunt je Checkpoint opnieuw toevoegen aan Modelonderhoud als je dat wilt.",
|
||||
"convertToDiffusersHelpText3": "Je checkpoint-bestand op schijf ZAL worden verwijderd als het zich in de InvokeAI root map bevindt. Het zal NIET worden verwijderd als het zich in een andere locatie bevindt.",
|
||||
"convertToDiffusersHelpText6": "Wil je dit model omzetten?",
|
||||
"allModels": "Alle modellen",
|
||||
"checkpointModels": "Checkpoints",
|
||||
@@ -371,7 +387,7 @@
|
||||
"convertToDiffusersHelpText1": "Dit model wordt omgezet naar de🧨 Diffusers-indeling.",
|
||||
"convertToDiffusersHelpText2": "Dit proces vervangt het onderdeel in Modelonderhoud met de Diffusers-versie van hetzelfde model.",
|
||||
"convertToDiffusersHelpText4": "Dit is een eenmalig proces. Dit neemt ongeveer 30 tot 60 sec. in beslag, afhankelijk van de specificaties van je computer.",
|
||||
"convertToDiffusersHelpText5": "Zorg ervoor dat je genoeg schijfruimte hebt. Modellen nemen gewoonlijk ongeveer 4 - 7 GB ruimte in beslag.",
|
||||
"convertToDiffusersHelpText5": "Zorg ervoor dat je genoeg schijfruimte hebt. Modellen nemen gewoonlijk ongeveer 2 tot 7 GB ruimte in beslag.",
|
||||
"convertToDiffusersSaveLocation": "Bewaarlocatie",
|
||||
"v1": "v1",
|
||||
"inpainting": "v1-inpainting",
|
||||
@@ -408,7 +424,27 @@
|
||||
"none": "geen",
|
||||
"addDifference": "Voeg verschil toe",
|
||||
"scanForModels": "Scan naar modellen",
|
||||
"pickModelType": "Kies modelsoort"
|
||||
"pickModelType": "Kies modelsoort",
|
||||
"baseModel": "Basismodel",
|
||||
"vae": "VAE",
|
||||
"variant": "Variant",
|
||||
"modelConversionFailed": "Omzetten model mislukt",
|
||||
"modelUpdateFailed": "Bijwerken model mislukt",
|
||||
"modelsMergeFailed": "Samenvoegen model mislukt",
|
||||
"selectModel": "Kies model",
|
||||
"settings": "Instellingen",
|
||||
"modelDeleted": "Model verwijderd",
|
||||
"noCustomLocationProvided": "Geen Aangepaste Locatie Opgegeven",
|
||||
"syncModels": "Synchroniseer Modellen",
|
||||
"modelsSynced": "Modellen Gesynchroniseerd",
|
||||
"modelSyncFailed": "Synchronisatie Modellen Gefaald",
|
||||
"modelDeleteFailed": "Model kon niet verwijderd worden",
|
||||
"convertingModelBegin": "Model aan het converteren. Even geduld.",
|
||||
"importModels": "Importeer Modellen",
|
||||
"syncModelsDesc": "Als je modellen niet meer synchroon zijn met de backend, kan je ze met deze optie verversen. Dit wordt typisch gebruikt in het geval je het models.yaml bestand met de hand bewerkt of als je modellen aan de InvokeAI root map toevoegt nadat de applicatie gestart werd.",
|
||||
"loraModels": "LoRA's",
|
||||
"onnxModels": "Onnx",
|
||||
"oliveModels": "Olives"
|
||||
},
|
||||
"parameters": {
|
||||
"images": "Afbeeldingen",
|
||||
@@ -416,10 +452,9 @@
|
||||
"cfgScale": "CFG-schaal",
|
||||
"width": "Breedte",
|
||||
"height": "Hoogte",
|
||||
"sampler": "Sampler",
|
||||
"seed": "Seed",
|
||||
"randomizeSeed": "Willekeurige seed",
|
||||
"shuffle": "Meng",
|
||||
"shuffle": "Mengseed",
|
||||
"noiseThreshold": "Drempelwaarde ruis",
|
||||
"perlinNoise": "Perlinruis",
|
||||
"variations": "Variaties",
|
||||
@@ -438,10 +473,6 @@
|
||||
"hiresOptim": "Hogeresolutie-optimalisatie",
|
||||
"imageFit": "Pas initiële afbeelding in uitvoergrootte",
|
||||
"codeformerFidelity": "Getrouwheid",
|
||||
"seamSize": "Grootte naad",
|
||||
"seamBlur": "Vervaging naad",
|
||||
"seamStrength": "Sterkte naad",
|
||||
"seamSteps": "Stappen naad",
|
||||
"scaleBeforeProcessing": "Schalen voor verwerking",
|
||||
"scaledWidth": "Geschaalde B",
|
||||
"scaledHeight": "Geschaalde H",
|
||||
@@ -452,8 +483,6 @@
|
||||
"infillScalingHeader": "Infill en schaling",
|
||||
"img2imgStrength": "Sterkte Afbeelding naar afbeelding",
|
||||
"toggleLoopback": "Zet recursieve verwerking aan/uit",
|
||||
"invoke": "Genereer",
|
||||
"promptPlaceholder": "Voer invoertekst hier in. [negatieve trefwoorden], (verhoogdgewicht)++, (verlaagdgewicht)--, swap (wisselen) en blend (mengen) zijn beschikbaar (zie documentatie)",
|
||||
"sendTo": "Stuur naar",
|
||||
"sendToImg2Img": "Stuur naar Afbeelding naar afbeelding",
|
||||
"sendToUnifiedCanvas": "Stuur naar Centraal canvas",
|
||||
@@ -466,7 +495,6 @@
|
||||
"useAll": "Hergebruik alles",
|
||||
"useInitImg": "Gebruik initiële afbeelding",
|
||||
"info": "Info",
|
||||
"deleteImage": "Verwijder afbeelding",
|
||||
"initialImage": "Initiële afbeelding",
|
||||
"showOptionsPanel": "Toon deelscherm Opties",
|
||||
"symmetry": "Symmetrie",
|
||||
@@ -478,37 +506,72 @@
|
||||
"setType": "Stel annuleervorm in",
|
||||
"schedule": "Annuleer na huidige iteratie"
|
||||
},
|
||||
"negativePrompts": "Negatieve invoer",
|
||||
"general": "Algemeen",
|
||||
"copyImage": "Kopieer afbeelding",
|
||||
"imageToImage": "Afbeelding naar afbeelding",
|
||||
"denoisingStrength": "Sterkte ontruisen",
|
||||
"hiresStrength": "Sterkte hogere resolutie"
|
||||
"hiresStrength": "Sterkte hogere resolutie",
|
||||
"scheduler": "Planner",
|
||||
"noiseSettings": "Ruis",
|
||||
"seamlessXAxis": "X-as",
|
||||
"seamlessYAxis": "Y-as",
|
||||
"hidePreview": "Verberg voorvertoning",
|
||||
"showPreview": "Toon voorvertoning",
|
||||
"boundingBoxWidth": "Tekenvak breedte",
|
||||
"boundingBoxHeight": "Tekenvak hoogte",
|
||||
"clipSkip": "Overslaan CLIP",
|
||||
"aspectRatio": "Verhouding",
|
||||
"negativePromptPlaceholder": "Negatieve prompt",
|
||||
"controlNetControlMode": "Aansturingsmodus",
|
||||
"positivePromptPlaceholder": "Positieve prompt",
|
||||
"maskAdjustmentsHeader": "Maskeraanpassingen",
|
||||
"compositingSettingsHeader": "Instellingen afbeeldingsopbouw",
|
||||
"coherencePassHeader": "Coherentiestap",
|
||||
"maskBlur": "Vervaag",
|
||||
"maskBlurMethod": "Vervagingsmethode",
|
||||
"coherenceSteps": "Stappen",
|
||||
"coherenceStrength": "Sterkte",
|
||||
"seamHighThreshold": "Hoog",
|
||||
"seamLowThreshold": "Laag"
|
||||
},
|
||||
"settings": {
|
||||
"models": "Modellen",
|
||||
"displayInProgress": "Toon afbeeldingen gedurende verwerking",
|
||||
"displayInProgress": "Toon voortgangsafbeeldingen",
|
||||
"saveSteps": "Bewaar afbeeldingen elke n stappen",
|
||||
"confirmOnDelete": "Bevestig bij verwijderen",
|
||||
"displayHelpIcons": "Toon hulppictogrammen",
|
||||
"useCanvasBeta": "Gebruik bètavormgeving van canvas",
|
||||
"enableImageDebugging": "Schakel foutopsporing afbeelding in",
|
||||
"resetWebUI": "Herstel web-UI",
|
||||
"resetWebUIDesc1": "Herstel web-UI herstelt alleen de lokale afbeeldingscache en de onthouden instellingen van je browser. Het verwijdert geen afbeeldingen van schijf.",
|
||||
"resetWebUIDesc2": "Als afbeeldingen niet getoond worden in de galerij of iets anders werkt niet, probeer dan eerst deze herstelfunctie voordat je een fout aanmeldt op GitHub.",
|
||||
"resetComplete": "Webgebruikersinterface is hersteld. Vernieuw de pasgina om opnieuw te laden.",
|
||||
"useSlidersForAll": "Gebruik schuifbalken voor alle opties"
|
||||
"resetComplete": "Webgebruikersinterface is hersteld.",
|
||||
"useSlidersForAll": "Gebruik schuifbalken voor alle opties",
|
||||
"consoleLogLevel": "Logboekniveau",
|
||||
"shouldLogToConsole": "Schrijf logboek naar console",
|
||||
"developer": "Ontwikkelaar",
|
||||
"general": "Algemeen",
|
||||
"showProgressInViewer": "Toon voortgangsafbeeldingen in viewer",
|
||||
"generation": "Generatie",
|
||||
"ui": "Gebruikersinterface",
|
||||
"antialiasProgressImages": "Voer anti-aliasing uit op voortgangsafbeeldingen",
|
||||
"showAdvancedOptions": "Toon uitgebreide opties",
|
||||
"favoriteSchedulers": "Favoriete planners",
|
||||
"favoriteSchedulersPlaceholder": "Geen favoriete planners ingesteld",
|
||||
"beta": "Bèta",
|
||||
"experimental": "Experimenteel",
|
||||
"alternateCanvasLayout": "Omwisselen Canvas Layout",
|
||||
"enableNodesEditor": "Knopen Editor Inschakelen",
|
||||
"autoChangeDimensions": "Werk bij wijziging afmetingen bij naar modelstandaard"
|
||||
},
|
||||
"toast": {
|
||||
"tempFoldersEmptied": "Tijdelijke map geleegd",
|
||||
"uploadFailed": "Upload mislukt",
|
||||
"uploadFailedMultipleImagesDesc": "Meerdere afbeeldingen geplakt, slechts een afbeelding per keer toegestaan",
|
||||
"uploadFailedUnableToLoadDesc": "Kan bestand niet laden",
|
||||
"downloadImageStarted": "Afbeeldingsdownload gestart",
|
||||
"imageCopied": "Afbeelding gekopieerd",
|
||||
"imageLinkCopied": "Afbeeldingskoppeling gekopieerd",
|
||||
"imageNotLoaded": "Geen afbeelding geladen",
|
||||
"imageNotLoadedDesc": "Geen afbeelding gevonden om te sturen naar de module Afbeelding naar afbeelding",
|
||||
"imageNotLoadedDesc": "Geen afbeeldingen gevonden",
|
||||
"imageSavedToGallery": "Afbeelding opgeslagen naar galerij",
|
||||
"canvasMerged": "Canvas samengevoegd",
|
||||
"sentToImageToImage": "Gestuurd naar Afbeelding naar afbeelding",
|
||||
@@ -529,7 +592,25 @@
|
||||
"metadataLoadFailed": "Fout bij laden metagegevens",
|
||||
"initialImageSet": "Initiële afbeelding ingesteld",
|
||||
"initialImageNotSet": "Initiële afbeelding niet ingesteld",
|
||||
"initialImageNotSetDesc": "Kan initiële afbeelding niet laden"
|
||||
"initialImageNotSetDesc": "Kan initiële afbeelding niet laden",
|
||||
"serverError": "Serverfout",
|
||||
"disconnected": "Verbinding met server verbroken",
|
||||
"connected": "Verbonden met server",
|
||||
"canceled": "Verwerking geannuleerd",
|
||||
"uploadFailedInvalidUploadDesc": "Moet een enkele PNG- of JPEG-afbeelding zijn",
|
||||
"problemCopyingImageLink": "Kan afbeeldingslink niet kopiëren",
|
||||
"parameterNotSet": "Parameter niet ingesteld",
|
||||
"parameterSet": "Instellen parameters",
|
||||
"nodesSaved": "Knooppunten bewaard",
|
||||
"nodesLoaded": "Knooppunten geladen",
|
||||
"nodesCleared": "Knooppunten weggehaald",
|
||||
"nodesLoadedFailed": "Laden knooppunten mislukt",
|
||||
"problemCopyingImage": "Kan Afbeelding Niet Kopiëren",
|
||||
"nodesNotValidJSON": "Ongeldige JSON",
|
||||
"nodesCorruptedGraph": "Kan niet laden. Graph lijkt corrupt.",
|
||||
"nodesUnrecognizedTypes": "Laden mislukt. Graph heeft onherkenbare types",
|
||||
"nodesBrokenConnections": "Laden mislukt. Sommige verbindingen zijn verbroken.",
|
||||
"nodesNotValidGraph": "Geen geldige knooppunten graph"
|
||||
},
|
||||
"tooltip": {
|
||||
"feature": {
|
||||
@@ -603,7 +684,8 @@
|
||||
"betaClear": "Wis",
|
||||
"betaDarkenOutside": "Verduister buiten tekenvak",
|
||||
"betaLimitToBox": "Beperk tot tekenvak",
|
||||
"betaPreserveMasked": "Behoud masker"
|
||||
"betaPreserveMasked": "Behoud masker",
|
||||
"antialiasing": "Anti-aliasing"
|
||||
},
|
||||
"accessibility": {
|
||||
"exitViewer": "Stop viewer",
|
||||
@@ -624,7 +706,30 @@
|
||||
"modifyConfig": "Wijzig configuratie",
|
||||
"toggleAutoscroll": "Autom. scrollen aan/uit",
|
||||
"toggleLogViewer": "Logboekviewer aan/uit",
|
||||
"showGallery": "Toon galerij",
|
||||
"showOptionsPanel": "Toon deelscherm Opties"
|
||||
"showOptionsPanel": "Toon zijscherm",
|
||||
"menu": "Menu"
|
||||
},
|
||||
"ui": {
|
||||
"showProgressImages": "Toon voortgangsafbeeldingen",
|
||||
"hideProgressImages": "Verberg voortgangsafbeeldingen",
|
||||
"swapSizes": "Wissel afmetingen om",
|
||||
"lockRatio": "Zet verhouding vast"
|
||||
},
|
||||
"nodes": {
|
||||
"zoomOutNodes": "Uitzoomen",
|
||||
"fitViewportNodes": "Aanpassen aan beeld",
|
||||
"hideMinimapnodes": "Minimap verbergen",
|
||||
"showLegendNodes": "Typelegende veld tonen",
|
||||
"zoomInNodes": "Inzoomen",
|
||||
"hideGraphNodes": "Graph overlay verbergen",
|
||||
"showGraphNodes": "Graph overlay tonen",
|
||||
"showMinimapnodes": "Minimap tonen",
|
||||
"hideLegendNodes": "Typelegende veld verbergen",
|
||||
"reloadNodeTemplates": "Herlaad knooppuntsjablonen",
|
||||
"loadWorkflow": "Laad werkstroom",
|
||||
"resetWorkflow": "Herstel werkstroom",
|
||||
"resetWorkflowDesc": "Weet je zeker dat je deze werkstroom wilt herstellen?",
|
||||
"resetWorkflowDesc2": "Herstel van een werkstroom haalt alle knooppunten, randen en werkstroomdetails weg.",
|
||||
"downloadWorkflow": "Download JSON van werkstroom"
|
||||
}
|
||||
}
|
||||
|
||||
43
invokeai/frontend/web/dist/locales/pl.json
vendored
43
invokeai/frontend/web/dist/locales/pl.json
vendored
@@ -1,13 +1,9 @@
|
||||
{
|
||||
"common": {
|
||||
"hotkeysLabel": "Skróty klawiszowe",
|
||||
"themeLabel": "Motyw",
|
||||
"languagePickerLabel": "Wybór języka",
|
||||
"reportBugLabel": "Zgłoś błąd",
|
||||
"settingsLabel": "Ustawienia",
|
||||
"darkTheme": "Ciemny",
|
||||
"lightTheme": "Jasny",
|
||||
"greenTheme": "Zielony",
|
||||
"img2img": "Obraz na obraz",
|
||||
"unifiedCanvas": "Tryb uniwersalny",
|
||||
"nodes": "Węzły",
|
||||
@@ -43,7 +39,11 @@
|
||||
"statusUpscaling": "Powiększanie obrazu",
|
||||
"statusUpscalingESRGAN": "Powiększanie (ESRGAN)",
|
||||
"statusLoadingModel": "Wczytywanie modelu",
|
||||
"statusModelChanged": "Zmieniono model"
|
||||
"statusModelChanged": "Zmieniono model",
|
||||
"githubLabel": "GitHub",
|
||||
"discordLabel": "Discord",
|
||||
"darkMode": "Tryb ciemny",
|
||||
"lightMode": "Tryb jasny"
|
||||
},
|
||||
"gallery": {
|
||||
"generations": "Wygenerowane",
|
||||
@@ -56,7 +56,6 @@
|
||||
"maintainAspectRatio": "Zachowaj proporcje",
|
||||
"autoSwitchNewImages": "Przełączaj na nowe obrazy",
|
||||
"singleColumnLayout": "Układ jednokolumnowy",
|
||||
"pinGallery": "Przypnij galerię",
|
||||
"allImagesLoaded": "Koniec listy",
|
||||
"loadMore": "Wczytaj więcej",
|
||||
"noImagesInGallery": "Brak obrazów w galerii"
|
||||
@@ -274,7 +273,6 @@
|
||||
"cfgScale": "Skala CFG",
|
||||
"width": "Szerokość",
|
||||
"height": "Wysokość",
|
||||
"sampler": "Próbkowanie",
|
||||
"seed": "Inicjator",
|
||||
"randomizeSeed": "Losowy inicjator",
|
||||
"shuffle": "Losuj",
|
||||
@@ -296,10 +294,6 @@
|
||||
"hiresOptim": "Optymalizacja wys. rozdzielczości",
|
||||
"imageFit": "Przeskaluj oryginalny obraz",
|
||||
"codeformerFidelity": "Dokładność",
|
||||
"seamSize": "Rozmiar",
|
||||
"seamBlur": "Rozmycie",
|
||||
"seamStrength": "Siła",
|
||||
"seamSteps": "Kroki",
|
||||
"scaleBeforeProcessing": "Tryb skalowania",
|
||||
"scaledWidth": "Sk. do szer.",
|
||||
"scaledHeight": "Sk. do wys.",
|
||||
@@ -310,8 +304,6 @@
|
||||
"infillScalingHeader": "Wypełnienie i skalowanie",
|
||||
"img2imgStrength": "Wpływ sugestii na obraz",
|
||||
"toggleLoopback": "Wł/wył sprzężenie zwrotne",
|
||||
"invoke": "Wywołaj",
|
||||
"promptPlaceholder": "W tym miejscu wprowadź swoje sugestie. [negatywne sugestie], (wzmocnienie), (osłabienie)--, po więcej opcji (np. swap lub blend) zajrzyj do dokumentacji",
|
||||
"sendTo": "Wyślij do",
|
||||
"sendToImg2Img": "Użyj w trybie \"Obraz na obraz\"",
|
||||
"sendToUnifiedCanvas": "Użyj w trybie uniwersalnym",
|
||||
@@ -324,7 +316,6 @@
|
||||
"useAll": "Skopiuj wszystko",
|
||||
"useInitImg": "Użyj oryginalnego obrazu",
|
||||
"info": "Informacje",
|
||||
"deleteImage": "Usuń obraz",
|
||||
"initialImage": "Oryginalny obraz",
|
||||
"showOptionsPanel": "Pokaż panel ustawień"
|
||||
},
|
||||
@@ -334,7 +325,6 @@
|
||||
"saveSteps": "Zapisuj obrazy co X kroków",
|
||||
"confirmOnDelete": "Potwierdzaj usuwanie",
|
||||
"displayHelpIcons": "Wyświetlaj ikony pomocy",
|
||||
"useCanvasBeta": "Nowy układ trybu uniwersalnego",
|
||||
"enableImageDebugging": "Włącz debugowanie obrazu",
|
||||
"resetWebUI": "Zresetuj interfejs",
|
||||
"resetWebUIDesc1": "Resetowanie interfejsu wyczyści jedynie dane i ustawienia zapisane w pamięci przeglądarki. Nie usunie żadnych obrazów z dysku.",
|
||||
@@ -344,7 +334,6 @@
|
||||
"toast": {
|
||||
"tempFoldersEmptied": "Wyczyszczono folder tymczasowy",
|
||||
"uploadFailed": "Błąd przesyłania obrazu",
|
||||
"uploadFailedMultipleImagesDesc": "Możliwe jest przesłanie tylko jednego obrazu na raz",
|
||||
"uploadFailedUnableToLoadDesc": "Błąd wczytywania obrazu",
|
||||
"downloadImageStarted": "Rozpoczęto pobieranie",
|
||||
"imageCopied": "Skopiowano obraz",
|
||||
@@ -446,5 +435,27 @@
|
||||
"betaDarkenOutside": "Przyciemnienie",
|
||||
"betaLimitToBox": "Ogranicz do zaznaczenia",
|
||||
"betaPreserveMasked": "Zachowaj obszar"
|
||||
},
|
||||
"accessibility": {
|
||||
"zoomIn": "Przybliż",
|
||||
"exitViewer": "Wyjdź z podglądu",
|
||||
"modelSelect": "Wybór modelu",
|
||||
"invokeProgressBar": "Pasek postępu",
|
||||
"reset": "Zerowanie",
|
||||
"useThisParameter": "Użyj tego parametru",
|
||||
"copyMetadataJson": "Kopiuj metadane JSON",
|
||||
"uploadImage": "Wgrywanie obrazu",
|
||||
"previousImage": "Poprzedni obraz",
|
||||
"nextImage": "Następny obraz",
|
||||
"zoomOut": "Oddal",
|
||||
"rotateClockwise": "Obróć zgodnie ze wskazówkami zegara",
|
||||
"rotateCounterClockwise": "Obróć przeciwnie do wskazówek zegara",
|
||||
"flipHorizontally": "Odwróć horyzontalnie",
|
||||
"flipVertically": "Odwróć wertykalnie",
|
||||
"modifyConfig": "Modyfikuj ustawienia",
|
||||
"toggleAutoscroll": "Przełącz autoprzewijanie",
|
||||
"toggleLogViewer": "Przełącz podgląd logów",
|
||||
"showOptionsPanel": "Pokaż panel opcji",
|
||||
"menu": "Menu"
|
||||
}
|
||||
}
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user