mirror of
https://github.com/invoke-ai/InvokeAI.git
synced 2026-01-23 09:28:01 -05:00
Compare commits
8 Commits
v5.4.0
...
ryan/flux-
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
766c6082a3 | ||
|
|
ad5d528204 | ||
|
|
536ccf071c | ||
|
|
ca13c3b12f | ||
|
|
d54c1ef9ba | ||
|
|
e9f722aa7d | ||
|
|
139da133bd | ||
|
|
57820929d5 |
@@ -105,7 +105,7 @@ Invoke features an organized gallery system for easily storing, accessing, and r
|
||||
### Other features
|
||||
|
||||
- Support for both ckpt and diffusers models
|
||||
- SD1.5, SD2.0, SDXL, and FLUX support
|
||||
- SD1.5, SD2.0, and SDXL support
|
||||
- Upscaling Tools
|
||||
- Embedding Manager & Support
|
||||
- Model Manager & Support
|
||||
|
||||
@@ -38,9 +38,9 @@ RUN --mount=type=cache,target=/root/.cache/pip \
|
||||
if [ "$TARGETPLATFORM" = "linux/arm64" ] || [ "$GPU_DRIVER" = "cpu" ]; then \
|
||||
extra_index_url_arg="--extra-index-url https://download.pytorch.org/whl/cpu"; \
|
||||
elif [ "$GPU_DRIVER" = "rocm" ]; then \
|
||||
extra_index_url_arg="--extra-index-url https://download.pytorch.org/whl/rocm6.1"; \
|
||||
extra_index_url_arg="--extra-index-url https://download.pytorch.org/whl/rocm5.6"; \
|
||||
else \
|
||||
extra_index_url_arg="--extra-index-url https://download.pytorch.org/whl/cu124"; \
|
||||
extra_index_url_arg="--extra-index-url https://download.pytorch.org/whl/cu121"; \
|
||||
fi &&\
|
||||
|
||||
# xformers + triton fails to install on arm64
|
||||
|
||||
@@ -1,7 +1,7 @@
|
||||
# Copyright (c) 2023 Eugene Brodsky https://github.com/ebr
|
||||
|
||||
x-invokeai: &invokeai
|
||||
image: "ghcr.io/invoke-ai/invokeai:latest"
|
||||
image: "local/invokeai:latest"
|
||||
build:
|
||||
context: ..
|
||||
dockerfile: docker/Dockerfile
|
||||
|
||||
@@ -144,7 +144,7 @@ As you might have noticed, we added two new arguments to the `InputField`
|
||||
definition for `width` and `height`, called `gt` and `le`. They stand for
|
||||
_greater than or equal to_ and _less than or equal to_.
|
||||
|
||||
These impose constraints on those fields, and will raise an exception if the
|
||||
These impose contraints on those fields, and will raise an exception if the
|
||||
values do not meet the constraints. Field constraints are provided by
|
||||
**pydantic**, so anything you see in the **pydantic docs** will work.
|
||||
|
||||
|
||||
@@ -239,7 +239,7 @@ Consult the
|
||||
get it set up.
|
||||
|
||||
Suggest using VSCode's included settings sync so that your remote dev host has
|
||||
all the same app settings and extensions automatically.
|
||||
all the same app settings and extensions automagically.
|
||||
|
||||
##### One remote dev gotcha
|
||||
|
||||
|
||||
@@ -2,7 +2,7 @@
|
||||
|
||||
## **What do I need to know to help?**
|
||||
|
||||
If you are looking to help with a code contribution, InvokeAI uses several different technologies under the hood: Python (Pydantic, FastAPI, diffusers) and Typescript (React, Redux Toolkit, ChakraUI, Mantine, Konva). Familiarity with StableDiffusion and image generation concepts is helpful, but not essential.
|
||||
If you are looking to help to with a code contribution, InvokeAI uses several different technologies under the hood: Python (Pydantic, FastAPI, diffusers) and Typescript (React, Redux Toolkit, ChakraUI, Mantine, Konva). Familiarity with StableDiffusion and image generation concepts is helpful, but not essential.
|
||||
|
||||
|
||||
## **Get Started**
|
||||
|
||||
@@ -5,7 +5,7 @@ If you're a new contributor to InvokeAI or Open Source Projects, this is the gui
|
||||
## New Contributor Checklist
|
||||
|
||||
- [x] Set up your local development environment & fork of InvokAI by following [the steps outlined here](../dev-environment.md)
|
||||
- [x] Set up your local tooling with [this guide](../LOCAL_DEVELOPMENT.md). Feel free to skip this step if you already have tooling you're comfortable with.
|
||||
- [x] Set up your local tooling with [this guide](InvokeAI/contributing/LOCAL_DEVELOPMENT/#developing-invokeai-in-vscode). Feel free to skip this step if you already have tooling you're comfortable with.
|
||||
- [x] Familiarize yourself with [Git](https://www.atlassian.com/git) & our project structure by reading through the [development documentation](development.md)
|
||||
- [x] Join the [#dev-chat](https://discord.com/channels/1020123559063990373/1049495067846524939) channel of the Discord
|
||||
- [x] Choose an issue to work on! This can be achieved by asking in the #dev-chat channel, tackling a [good first issue](https://github.com/invoke-ai/InvokeAI/contribute) or finding an item on the [roadmap](https://github.com/orgs/invoke-ai/projects/7). If nothing in any of those places catches your eye, feel free to work on something of interest to you!
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
# Tutorials
|
||||
|
||||
Tutorials help new & existing users expand their ability to use InvokeAI to the full extent of our features and services.
|
||||
Tutorials help new & existing users expand their abilty to use InvokeAI to the full extent of our features and services.
|
||||
|
||||
Currently, we have a set of tutorials available on our [YouTube channel](https://www.youtube.com/@invokeai), but as InvokeAI continues to evolve with new updates, we want to ensure that we are giving our users the resources they need to succeed.
|
||||
|
||||
@@ -8,4 +8,4 @@ Tutorials can be in the form of videos or article walkthroughs on a subject of y
|
||||
|
||||
## Contributing
|
||||
|
||||
Please reach out to @imic or @hipsterusername on [Discord](https://discord.gg/ZmtBAhwWhy) to help create tutorials for InvokeAI.
|
||||
Please reach out to @imic or @hipsterusername on [Discord](https://discord.gg/ZmtBAhwWhy) to help create tutorials for InvokeAI.
|
||||
@@ -17,49 +17,46 @@ If you just want to use Invoke, you should use the [installer][installer link].
|
||||
## Setup
|
||||
|
||||
1. Run through the [requirements][requirements link].
|
||||
2. [Fork and clone][forking link] the [InvokeAI repo][repo link].
|
||||
3. Create an directory for user data (images, models, db, etc). This is typically at `~/invokeai`, but if you already have a non-dev install, you may want to create a separate directory for the dev install.
|
||||
4. Create a python virtual environment inside the directory you just created:
|
||||
1. [Fork and clone][forking link] the [InvokeAI repo][repo link].
|
||||
1. Create an directory for user data (images, models, db, etc). This is typically at `~/invokeai`, but if you already have a non-dev install, you may want to create a separate directory for the dev install.
|
||||
1. Create a python virtual environment inside the directory you just created:
|
||||
|
||||
```sh
|
||||
python3 -m venv .venv --prompt InvokeAI-Dev
|
||||
```
|
||||
```sh
|
||||
python3 -m venv .venv --prompt InvokeAI-Dev
|
||||
```
|
||||
|
||||
5. Activate the venv (you'll need to do this every time you want to run the app):
|
||||
1. Activate the venv (you'll need to do this every time you want to run the app):
|
||||
|
||||
```sh
|
||||
source .venv/bin/activate
|
||||
```
|
||||
```sh
|
||||
source .venv/bin/activate
|
||||
```
|
||||
|
||||
6. Install the repo as an [editable install][editable install link]:
|
||||
1. Install the repo as an [editable install][editable install link]:
|
||||
|
||||
```sh
|
||||
pip install -e ".[dev,test,xformers]" --use-pep517 --extra-index-url https://download.pytorch.org/whl/cu121
|
||||
```
|
||||
```sh
|
||||
pip install -e ".[dev,test,xformers]" --use-pep517 --extra-index-url https://download.pytorch.org/whl/cu121
|
||||
```
|
||||
|
||||
Refer to the [manual installation][manual install link]] instructions for more determining the correct install options. `xformers` is optional, but `dev` and `test` are not.
|
||||
Refer to the [manual installation][manual install link]] instructions for more determining the correct install options. `xformers` is optional, but `dev` and `test` are not.
|
||||
|
||||
7. Install the frontend dev toolchain:
|
||||
1. Install the frontend dev toolchain:
|
||||
|
||||
- [`nodejs`](https://nodejs.org/) (recommend v20 LTS)
|
||||
- [`pnpm`](https://pnpm.io/8.x/installation) (must be v8 - not v9!)
|
||||
- [`pnpm`](https://pnpm.io/installation#installing-a-specific-version) (must be v8 - not v9!)
|
||||
|
||||
8. Do a production build of the frontend:
|
||||
1. Do a production build of the frontend:
|
||||
|
||||
```sh
|
||||
cd PATH_TO_INVOKEAI_REPO/invokeai/frontend/web
|
||||
pnpm i
|
||||
pnpm build
|
||||
```
|
||||
```sh
|
||||
pnpm build
|
||||
```
|
||||
|
||||
9. Start the application:
|
||||
1. Start the application:
|
||||
|
||||
```sh
|
||||
cd PATH_TO_INVOKEAI_REPO
|
||||
python scripts/invokeai-web.py
|
||||
```
|
||||
```sh
|
||||
python scripts/invokeai-web.py
|
||||
```
|
||||
|
||||
10. Access the UI at `localhost:9090`.
|
||||
1. Access the UI at `localhost:9090`.
|
||||
|
||||
## Updating the UI
|
||||
|
||||
|
||||
@@ -209,7 +209,7 @@ checkpoint models.
|
||||
|
||||
To solve this, go to the Model Manager tab (the cube), select the
|
||||
checkpoint model that's giving you trouble, and press the "Convert"
|
||||
button in the upper right of your browser window. This will convert the
|
||||
button in the upper right of your browser window. This will conver the
|
||||
checkpoint into a diffusers model, after which loading should be
|
||||
faster and less memory-intensive.
|
||||
|
||||
|
||||
@@ -97,16 +97,16 @@ Prior to installing PyPatchMatch, you need to take the following steps:
|
||||
sudo pacman -S --needed base-devel
|
||||
```
|
||||
|
||||
2. Install `opencv`, `blas`, and required dependencies:
|
||||
2. Install `opencv` and `blas`:
|
||||
|
||||
```sh
|
||||
sudo pacman -S opencv blas fmt glew vtk hdf5
|
||||
sudo pacman -S opencv blas
|
||||
```
|
||||
|
||||
or for CUDA support
|
||||
|
||||
```sh
|
||||
sudo pacman -S opencv-cuda blas fmt glew vtk hdf5
|
||||
sudo pacman -S opencv-cuda blas
|
||||
```
|
||||
|
||||
3. Fix the naming of the `opencv` package configuration file:
|
||||
|
||||
@@ -21,7 +21,6 @@ To use a community workflow, download the `.json` node graph file and load it in
|
||||
+ [Clothing Mask](#clothing-mask)
|
||||
+ [Contrast Limited Adaptive Histogram Equalization](#contrast-limited-adaptive-histogram-equalization)
|
||||
+ [Depth Map from Wavefront OBJ](#depth-map-from-wavefront-obj)
|
||||
+ [Enhance Detail](#enhance-detail)
|
||||
+ [Film Grain](#film-grain)
|
||||
+ [Generative Grammar-Based Prompt Nodes](#generative-grammar-based-prompt-nodes)
|
||||
+ [GPT2RandomPromptMaker](#gpt2randompromptmaker)
|
||||
@@ -40,9 +39,7 @@ To use a community workflow, download the `.json` node graph file and load it in
|
||||
+ [Match Histogram](#match-histogram)
|
||||
+ [Metadata-Linked](#metadata-linked-nodes)
|
||||
+ [Negative Image](#negative-image)
|
||||
+ [Nightmare Promptgen](#nightmare-promptgen)
|
||||
+ [Ollama](#ollama-node)
|
||||
+ [One Button Prompt](#one-button-prompt)
|
||||
+ [Nightmare Promptgen](#nightmare-promptgen)
|
||||
+ [Oobabooga](#oobabooga)
|
||||
+ [Prompt Tools](#prompt-tools)
|
||||
+ [Remote Image](#remote-image)
|
||||
@@ -82,7 +79,7 @@ Note: These are inherited from the core nodes so any update to the core nodes sh
|
||||
|
||||
**Example Usage:**
|
||||
</br>
|
||||
<img src="https://raw.githubusercontent.com/skunkworxdark/autostereogram_nodes/refs/heads/main/images/spider.png" width="200" /> -> <img src="https://raw.githubusercontent.com/skunkworxdark/autostereogram_nodes/refs/heads/main/images/spider-depth.png" width="200" /> -> <img src="https://raw.githubusercontent.com/skunkworxdark/autostereogram_nodes/refs/heads/main/images/spider-dots.png" width="200" /> <img src="https://raw.githubusercontent.com/skunkworxdark/autostereogram_nodes/refs/heads/main/images/spider-pattern.png" width="200" />
|
||||
<img src="https://github.com/skunkworxdark/autostereogram_nodes/blob/main/images/spider.png" width="200" /> -> <img src="https://github.com/skunkworxdark/autostereogram_nodes/blob/main/images/spider-depth.png" width="200" /> -> <img src="https://github.com/skunkworxdark/autostereogram_nodes/raw/main/images/spider-dots.png" width="200" /> <img src="https://github.com/skunkworxdark/autostereogram_nodes/raw/main/images/spider-pattern.png" width="200" />
|
||||
|
||||
--------------------------------
|
||||
### Average Images
|
||||
@@ -143,17 +140,6 @@ To be imported, an .obj must use triangulated meshes, so make sure to enable tha
|
||||
**Example Usage:**
|
||||
</br><img src="https://raw.githubusercontent.com/dwringer/depth-from-obj-node/main/depth_from_obj_usage.jpg" width="500" />
|
||||
|
||||
--------------------------------
|
||||
### Enhance Detail
|
||||
|
||||
**Description:** A single node that can enhance the detail in an image. Increase or decrease details in an image using a guided filter (as opposed to the typical Gaussian blur used by most sharpening filters.) Based on the `Enhance Detail` ComfyUI node from https://github.com/spacepxl/ComfyUI-Image-Filters
|
||||
|
||||
**Node Link:** https://github.com/skunkworxdark/enhance-detail-node
|
||||
|
||||
**Example Usage:**
|
||||
</br>
|
||||
<img src="https://raw.githubusercontent.com/skunkworxdark/enhance-detail-node/refs/heads/main/images/Comparison.png" />
|
||||
|
||||
--------------------------------
|
||||
### Film Grain
|
||||
|
||||
@@ -320,7 +306,7 @@ View:
|
||||
**Node Link:** https://github.com/helix4u/load_video_frame
|
||||
|
||||
**Output Example:**
|
||||
<img src="https://raw.githubusercontent.com/helix4u/load_video_frame/refs/heads/main/_git_assets/dance1736978273.gif" width="500" />
|
||||
<img src="https://raw.githubusercontent.com/helix4u/load_video_frame/main/_git_assets/testmp4_embed_converted.gif" width="500" />
|
||||
|
||||
--------------------------------
|
||||
### Make 3D
|
||||
@@ -361,7 +347,7 @@ See full docs here: https://github.com/skunkworxdark/Prompt-tools-nodes/edit/mai
|
||||
|
||||
**Output Examples**
|
||||
|
||||
<img src="https://github.com/skunkworxdark/match_histogram/assets/21961335/ed12f329-a0ef-444a-9bae-129ed60d6097" />
|
||||
<img src="https://github.com/skunkworxdark/match_histogram/assets/21961335/ed12f329-a0ef-444a-9bae-129ed60d6097" width="300" />
|
||||
|
||||
--------------------------------
|
||||
### Metadata Linked Nodes
|
||||
@@ -403,34 +389,6 @@ View:
|
||||
|
||||
**Node Link:** [https://github.com/gogurtenjoyer/nightmare-promptgen](https://github.com/gogurtenjoyer/nightmare-promptgen)
|
||||
|
||||
--------------------------------
|
||||
### Ollama Node
|
||||
|
||||
**Description:** Uses Ollama API to expand text prompts for text-to-image generation using local LLMs. Works great for expanding basic prompts into detailed natural language prompts for Flux. Also provides a toggle to unload the LLM model immediately after expanding, to free up VRAM for Invoke to continue the image generation workflow.
|
||||
|
||||
**Node Link:** https://github.com/Jonseed/Ollama-Node
|
||||
|
||||
**Example Node Graph:** https://github.com/Jonseed/Ollama-Node/blob/main/Ollama-Node-Flux-example.json
|
||||
|
||||
**View:**
|
||||
|
||||
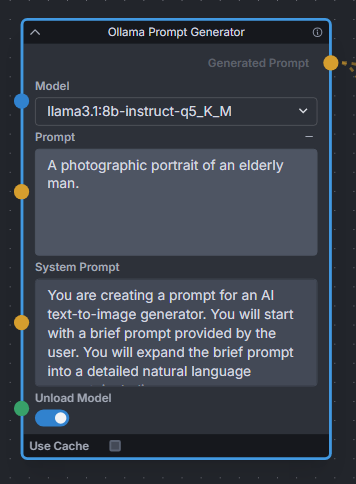
|
||||
|
||||
--------------------------------
|
||||
### One Button Prompt
|
||||
|
||||
<img src="https://raw.githubusercontent.com/AIrjen/OneButtonPrompt_X_InvokeAI/refs/heads/main/images/background.png" width="800" />
|
||||
|
||||
**Description:** an extensive suite of auto prompt generation and prompt helper nodes based on extensive logic. Get creative with the best prompt generator in the world.
|
||||
|
||||
The main node generates interesting prompts based on a set of parameters. There are also some additional nodes such as Auto Negative Prompt, One Button Artify, Create Prompt Variant and other cool prompt toys to play around with.
|
||||
|
||||
**Node Link:** [https://github.com/AIrjen/OneButtonPrompt_X_InvokeAI](https://github.com/AIrjen/OneButtonPrompt_X_InvokeAI)
|
||||
|
||||
**Nodes:**
|
||||
|
||||
<img src="https://raw.githubusercontent.com/AIrjen/OneButtonPrompt_X_InvokeAI/refs/heads/main/images/OBP_nodes_invokeai.png" width="800" />
|
||||
|
||||
--------------------------------
|
||||
### Oobabooga
|
||||
|
||||
@@ -482,7 +440,7 @@ See full docs here: https://github.com/skunkworxdark/Prompt-tools-nodes/edit/mai
|
||||
|
||||
**Workflow Examples**
|
||||
|
||||
<img src="https://raw.githubusercontent.com/skunkworxdark/prompt-tools/refs/heads/main/images/CSVToIndexStringNode.png"/>
|
||||
<img src="https://github.com/skunkworxdark/prompt-tools/blob/main/images/CSVToIndexStringNode.png" width="300" />
|
||||
|
||||
--------------------------------
|
||||
### Remote Image
|
||||
@@ -620,7 +578,7 @@ See full docs here: https://github.com/skunkworxdark/XYGrid_nodes/edit/main/READ
|
||||
|
||||
**Output Examples**
|
||||
|
||||
<img src="https://raw.githubusercontent.com/skunkworxdark/XYGrid_nodes/refs/heads/main/images/collage.png" />
|
||||
<img src="https://github.com/skunkworxdark/XYGrid_nodes/blob/main/images/collage.png" width="300" />
|
||||
|
||||
|
||||
--------------------------------
|
||||
|
||||
6
flake.lock
generated
6
flake.lock
generated
@@ -2,11 +2,11 @@
|
||||
"nodes": {
|
||||
"nixpkgs": {
|
||||
"locked": {
|
||||
"lastModified": 1727955264,
|
||||
"narHash": "sha256-lrd+7mmb5NauRoMa8+J1jFKYVa+rc8aq2qc9+CxPDKc=",
|
||||
"lastModified": 1690630721,
|
||||
"narHash": "sha256-Y04onHyBQT4Erfr2fc82dbJTfXGYrf4V0ysLUYnPOP8=",
|
||||
"owner": "NixOS",
|
||||
"repo": "nixpkgs",
|
||||
"rev": "71cd616696bd199ef18de62524f3df3ffe8b9333",
|
||||
"rev": "d2b52322f35597c62abf56de91b0236746b2a03d",
|
||||
"type": "github"
|
||||
},
|
||||
"original": {
|
||||
|
||||
@@ -34,7 +34,7 @@
|
||||
cudaPackages.cudnn
|
||||
cudaPackages.cuda_nvrtc
|
||||
cudatoolkit
|
||||
pkg-config
|
||||
pkgconfig
|
||||
libconfig
|
||||
cmake
|
||||
blas
|
||||
@@ -66,7 +66,7 @@
|
||||
black
|
||||
|
||||
# Frontend.
|
||||
pnpm_8
|
||||
yarn
|
||||
nodejs
|
||||
];
|
||||
LD_LIBRARY_PATH = pkgs.lib.makeLibraryPath buildInputs;
|
||||
|
||||
@@ -12,7 +12,7 @@ MINIMUM_PYTHON_VERSION=3.10.0
|
||||
MAXIMUM_PYTHON_VERSION=3.11.100
|
||||
PYTHON=""
|
||||
for candidate in python3.11 python3.10 python3 python ; do
|
||||
if ppath=`which $candidate 2>/dev/null`; then
|
||||
if ppath=`which $candidate`; then
|
||||
# when using `pyenv`, the executable for an inactive Python version will exist but will not be operational
|
||||
# we check that this found executable can actually run
|
||||
if [ $($candidate --version &>/dev/null; echo ${PIPESTATUS}) -gt 0 ]; then continue; fi
|
||||
@@ -30,11 +30,10 @@ done
|
||||
if [ -z "$PYTHON" ]; then
|
||||
echo "A suitable Python interpreter could not be found"
|
||||
echo "Please install Python $MINIMUM_PYTHON_VERSION or higher (maximum $MAXIMUM_PYTHON_VERSION) before running this script. See instructions at $INSTRUCTIONS for help."
|
||||
echo "For the best user experience we suggest enlarging or maximizing this window now."
|
||||
read -p "Press any key to exit"
|
||||
exit -1
|
||||
fi
|
||||
|
||||
echo "For the best user experience we suggest enlarging or maximizing this window now."
|
||||
|
||||
exec $PYTHON ./lib/main.py ${@}
|
||||
read -p "Press any key to exit"
|
||||
|
||||
@@ -245,9 +245,6 @@ class InvokeAiInstance:
|
||||
|
||||
pip = local[self.pip]
|
||||
|
||||
# Uninstall xformers if it is present; the correct version of it will be reinstalled if needed
|
||||
_ = pip["uninstall", "-yqq", "xformers"] & FG
|
||||
|
||||
pipeline = pip[
|
||||
"install",
|
||||
"--require-virtualenv",
|
||||
@@ -285,6 +282,12 @@ class InvokeAiInstance:
|
||||
shutil.copy(src, dest)
|
||||
os.chmod(dest, 0o0755)
|
||||
|
||||
def update(self):
|
||||
pass
|
||||
|
||||
def remove(self):
|
||||
pass
|
||||
|
||||
|
||||
### Utility functions ###
|
||||
|
||||
@@ -399,7 +402,7 @@ def get_torch_source() -> Tuple[str | None, str | None]:
|
||||
:rtype: list
|
||||
"""
|
||||
|
||||
from messages import GpuType, select_gpu
|
||||
from messages import select_gpu
|
||||
|
||||
# device can be one of: "cuda", "rocm", "cpu", "cuda_and_dml, autodetect"
|
||||
device = select_gpu()
|
||||
@@ -409,22 +412,16 @@ def get_torch_source() -> Tuple[str | None, str | None]:
|
||||
url = None
|
||||
optional_modules: str | None = None
|
||||
if OS == "Linux":
|
||||
if device == GpuType.ROCM:
|
||||
url = "https://download.pytorch.org/whl/rocm6.1"
|
||||
elif device == GpuType.CPU:
|
||||
if device.value == "rocm":
|
||||
url = "https://download.pytorch.org/whl/rocm5.6"
|
||||
elif device.value == "cpu":
|
||||
url = "https://download.pytorch.org/whl/cpu"
|
||||
elif device == GpuType.CUDA:
|
||||
url = "https://download.pytorch.org/whl/cu124"
|
||||
optional_modules = "[onnx-cuda]"
|
||||
elif device == GpuType.CUDA_WITH_XFORMERS:
|
||||
url = "https://download.pytorch.org/whl/cu124"
|
||||
elif device.value == "cuda":
|
||||
# CUDA uses the default PyPi index
|
||||
optional_modules = "[xformers,onnx-cuda]"
|
||||
elif OS == "Windows":
|
||||
if device == GpuType.CUDA:
|
||||
url = "https://download.pytorch.org/whl/cu124"
|
||||
optional_modules = "[onnx-cuda]"
|
||||
elif device == GpuType.CUDA_WITH_XFORMERS:
|
||||
url = "https://download.pytorch.org/whl/cu124"
|
||||
if device.value == "cuda":
|
||||
url = "https://download.pytorch.org/whl/cu121"
|
||||
optional_modules = "[xformers,onnx-cuda]"
|
||||
elif device.value == "cpu":
|
||||
# CPU uses the default PyPi index, no optional modules
|
||||
|
||||
@@ -206,7 +206,6 @@ def dest_path(dest: Optional[str | Path] = None) -> Path | None:
|
||||
|
||||
|
||||
class GpuType(Enum):
|
||||
CUDA_WITH_XFORMERS = "xformers"
|
||||
CUDA = "cuda"
|
||||
ROCM = "rocm"
|
||||
CPU = "cpu"
|
||||
@@ -222,15 +221,11 @@ def select_gpu() -> GpuType:
|
||||
return GpuType.CPU
|
||||
|
||||
nvidia = (
|
||||
"an [gold1 b]NVIDIA[/] RTX 3060 or newer GPU using CUDA",
|
||||
"an [gold1 b]NVIDIA[/] GPU (using CUDA™)",
|
||||
GpuType.CUDA,
|
||||
)
|
||||
vintage_nvidia = (
|
||||
"an [gold1 b]NVIDIA[/] RTX 20xx or older GPU using CUDA+xFormers",
|
||||
GpuType.CUDA_WITH_XFORMERS,
|
||||
)
|
||||
amd = (
|
||||
"an [gold1 b]AMD[/] GPU using ROCm",
|
||||
"an [gold1 b]AMD[/] GPU (using ROCm™)",
|
||||
GpuType.ROCM,
|
||||
)
|
||||
cpu = (
|
||||
@@ -240,13 +235,14 @@ def select_gpu() -> GpuType:
|
||||
|
||||
options = []
|
||||
if OS == "Windows":
|
||||
options = [nvidia, vintage_nvidia, cpu]
|
||||
options = [nvidia, cpu]
|
||||
if OS == "Linux":
|
||||
options = [nvidia, vintage_nvidia, amd, cpu]
|
||||
options = [nvidia, amd, cpu]
|
||||
elif OS == "Darwin":
|
||||
options = [cpu]
|
||||
|
||||
if len(options) == 1:
|
||||
print(f'Your platform [gold1]{OS}-{ARCH}[/] only supports the "{options[0][1]}" driver. Proceeding with that.')
|
||||
return options[0][1]
|
||||
|
||||
options = {str(i): opt for i, opt in enumerate(options, 1)}
|
||||
@@ -259,7 +255,7 @@ def select_gpu() -> GpuType:
|
||||
[
|
||||
f"Detected the [gold1]{OS}-{ARCH}[/] platform",
|
||||
"",
|
||||
"See [deep_sky_blue1]https://invoke-ai.github.io/InvokeAI/installation/requirements/[/] to ensure your system meets the minimum requirements.",
|
||||
"See [deep_sky_blue1]https://invoke-ai.github.io/InvokeAI/#system[/] to ensure your system meets the minimum requirements.",
|
||||
"",
|
||||
"[red3]🠶[/] [b]Your GPU drivers must be correctly installed before using InvokeAI![/] [red3]🠴[/]",
|
||||
]
|
||||
|
||||
@@ -68,7 +68,7 @@ do_line_input() {
|
||||
printf "2: Open the developer console\n"
|
||||
printf "3: Command-line help\n"
|
||||
printf "Q: Quit\n\n"
|
||||
printf "To update, download and run the installer from https://github.com/invoke-ai/InvokeAI/releases/latest\n\n"
|
||||
printf "To update, download and run the installer from https://github.com/invoke-ai/InvokeAI/releases/latest.\n\n"
|
||||
read -p "Please enter 1-4, Q: [1] " yn
|
||||
choice=${yn:='1'}
|
||||
do_choice $choice
|
||||
|
||||
@@ -5,10 +5,9 @@ from fastapi.routing import APIRouter
|
||||
from pydantic import BaseModel, Field
|
||||
|
||||
from invokeai.app.api.dependencies import ApiDependencies
|
||||
from invokeai.app.services.board_records.board_records_common import BoardChanges, BoardRecordOrderBy
|
||||
from invokeai.app.services.board_records.board_records_common import BoardChanges
|
||||
from invokeai.app.services.boards.boards_common import BoardDTO
|
||||
from invokeai.app.services.shared.pagination import OffsetPaginatedResults
|
||||
from invokeai.app.services.shared.sqlite.sqlite_common import SQLiteDirection
|
||||
|
||||
boards_router = APIRouter(prefix="/v1/boards", tags=["boards"])
|
||||
|
||||
@@ -116,8 +115,6 @@ async def delete_board(
|
||||
response_model=Union[OffsetPaginatedResults[BoardDTO], list[BoardDTO]],
|
||||
)
|
||||
async def list_boards(
|
||||
order_by: BoardRecordOrderBy = Query(default=BoardRecordOrderBy.CreatedAt, description="The attribute to order by"),
|
||||
direction: SQLiteDirection = Query(default=SQLiteDirection.Descending, description="The direction to order by"),
|
||||
all: Optional[bool] = Query(default=None, description="Whether to list all boards"),
|
||||
offset: Optional[int] = Query(default=None, description="The page offset"),
|
||||
limit: Optional[int] = Query(default=None, description="The number of boards per page"),
|
||||
@@ -125,9 +122,9 @@ async def list_boards(
|
||||
) -> Union[OffsetPaginatedResults[BoardDTO], list[BoardDTO]]:
|
||||
"""Gets a list of boards"""
|
||||
if all:
|
||||
return ApiDependencies.invoker.services.boards.get_all(order_by, direction, include_archived)
|
||||
return ApiDependencies.invoker.services.boards.get_all(include_archived)
|
||||
elif offset is not None and limit is not None:
|
||||
return ApiDependencies.invoker.services.boards.get_many(order_by, direction, offset, limit, include_archived)
|
||||
return ApiDependencies.invoker.services.boards.get_many(offset, limit, include_archived)
|
||||
else:
|
||||
raise HTTPException(
|
||||
status_code=400,
|
||||
|
||||
@@ -1,7 +1,6 @@
|
||||
# Copyright (c) 2023 Lincoln D. Stein
|
||||
"""FastAPI route for model configuration records."""
|
||||
|
||||
import contextlib
|
||||
import io
|
||||
import pathlib
|
||||
import shutil
|
||||
@@ -11,7 +10,6 @@ from enum import Enum
|
||||
from tempfile import TemporaryDirectory
|
||||
from typing import List, Optional, Type
|
||||
|
||||
import huggingface_hub
|
||||
from fastapi import Body, Path, Query, Response, UploadFile
|
||||
from fastapi.responses import FileResponse, HTMLResponse
|
||||
from fastapi.routing import APIRouter
|
||||
@@ -29,7 +27,6 @@ from invokeai.app.services.model_records import (
|
||||
ModelRecordChanges,
|
||||
UnknownModelException,
|
||||
)
|
||||
from invokeai.app.util.suppress_output import SuppressOutput
|
||||
from invokeai.backend.model_manager.config import (
|
||||
AnyModelConfig,
|
||||
BaseModelType,
|
||||
@@ -41,12 +38,7 @@ from invokeai.backend.model_manager.load.model_cache.model_cache_base import Cac
|
||||
from invokeai.backend.model_manager.metadata.fetch.huggingface import HuggingFaceMetadataFetch
|
||||
from invokeai.backend.model_manager.metadata.metadata_base import ModelMetadataWithFiles, UnknownMetadataException
|
||||
from invokeai.backend.model_manager.search import ModelSearch
|
||||
from invokeai.backend.model_manager.starter_models import (
|
||||
STARTER_BUNDLES,
|
||||
STARTER_MODELS,
|
||||
StarterModel,
|
||||
StarterModelWithoutDependencies,
|
||||
)
|
||||
from invokeai.backend.model_manager.starter_models import STARTER_MODELS, StarterModel, StarterModelWithoutDependencies
|
||||
|
||||
model_manager_router = APIRouter(prefix="/v2/models", tags=["model_manager"])
|
||||
|
||||
@@ -800,52 +792,22 @@ async def convert_model(
|
||||
return new_config
|
||||
|
||||
|
||||
class StarterModelResponse(BaseModel):
|
||||
starter_models: list[StarterModel]
|
||||
starter_bundles: dict[str, list[StarterModel]]
|
||||
|
||||
|
||||
def get_is_installed(
|
||||
starter_model: StarterModel | StarterModelWithoutDependencies, installed_models: list[AnyModelConfig]
|
||||
) -> bool:
|
||||
for model in installed_models:
|
||||
if model.source == starter_model.source:
|
||||
return True
|
||||
if (
|
||||
(model.name == starter_model.name or model.name in starter_model.previous_names)
|
||||
and model.base == starter_model.base
|
||||
and model.type == starter_model.type
|
||||
):
|
||||
return True
|
||||
return False
|
||||
|
||||
|
||||
@model_manager_router.get("/starter_models", operation_id="get_starter_models", response_model=StarterModelResponse)
|
||||
async def get_starter_models() -> StarterModelResponse:
|
||||
@model_manager_router.get("/starter_models", operation_id="get_starter_models", response_model=list[StarterModel])
|
||||
async def get_starter_models() -> list[StarterModel]:
|
||||
installed_models = ApiDependencies.invoker.services.model_manager.store.search_by_attr()
|
||||
installed_model_sources = {m.source for m in installed_models}
|
||||
starter_models = deepcopy(STARTER_MODELS)
|
||||
starter_bundles = deepcopy(STARTER_BUNDLES)
|
||||
for model in starter_models:
|
||||
model.is_installed = get_is_installed(model, installed_models)
|
||||
if model.source in installed_model_sources:
|
||||
model.is_installed = True
|
||||
# Remove already-installed dependencies
|
||||
missing_deps: list[StarterModelWithoutDependencies] = []
|
||||
|
||||
for dep in model.dependencies or []:
|
||||
if not get_is_installed(dep, installed_models):
|
||||
if dep.source not in installed_model_sources:
|
||||
missing_deps.append(dep)
|
||||
model.dependencies = missing_deps
|
||||
|
||||
for bundle in starter_bundles.values():
|
||||
for model in bundle:
|
||||
model.is_installed = get_is_installed(model, installed_models)
|
||||
# Remove already-installed dependencies
|
||||
missing_deps: list[StarterModelWithoutDependencies] = []
|
||||
for dep in model.dependencies or []:
|
||||
if not get_is_installed(dep, installed_models):
|
||||
missing_deps.append(dep)
|
||||
model.dependencies = missing_deps
|
||||
|
||||
return StarterModelResponse(starter_models=starter_models, starter_bundles=starter_bundles)
|
||||
return starter_models
|
||||
|
||||
|
||||
@model_manager_router.get(
|
||||
@@ -926,51 +888,3 @@ async def get_stats() -> Optional[CacheStats]:
|
||||
"""Return performance statistics on the model manager's RAM cache. Will return null if no models have been loaded."""
|
||||
|
||||
return ApiDependencies.invoker.services.model_manager.load.ram_cache.stats
|
||||
|
||||
|
||||
class HFTokenStatus(str, Enum):
|
||||
VALID = "valid"
|
||||
INVALID = "invalid"
|
||||
UNKNOWN = "unknown"
|
||||
|
||||
|
||||
class HFTokenHelper:
|
||||
@classmethod
|
||||
def get_status(cls) -> HFTokenStatus:
|
||||
try:
|
||||
if huggingface_hub.get_token_permission(huggingface_hub.get_token()):
|
||||
# Valid token!
|
||||
return HFTokenStatus.VALID
|
||||
# No token set
|
||||
return HFTokenStatus.INVALID
|
||||
except Exception:
|
||||
return HFTokenStatus.UNKNOWN
|
||||
|
||||
@classmethod
|
||||
def set_token(cls, token: str) -> HFTokenStatus:
|
||||
with SuppressOutput(), contextlib.suppress(Exception):
|
||||
huggingface_hub.login(token=token, add_to_git_credential=False)
|
||||
return cls.get_status()
|
||||
|
||||
|
||||
@model_manager_router.get("/hf_login", operation_id="get_hf_login_status", response_model=HFTokenStatus)
|
||||
async def get_hf_login_status() -> HFTokenStatus:
|
||||
token_status = HFTokenHelper.get_status()
|
||||
|
||||
if token_status is HFTokenStatus.UNKNOWN:
|
||||
ApiDependencies.invoker.services.logger.warning("Unable to verify HF token")
|
||||
|
||||
return token_status
|
||||
|
||||
|
||||
@model_manager_router.post("/hf_login", operation_id="do_hf_login", response_model=HFTokenStatus)
|
||||
async def do_hf_login(
|
||||
token: str = Body(description="Hugging Face token to use for login", embed=True),
|
||||
) -> HFTokenStatus:
|
||||
HFTokenHelper.set_token(token)
|
||||
token_status = HFTokenHelper.get_status()
|
||||
|
||||
if token_status is HFTokenStatus.UNKNOWN:
|
||||
ApiDependencies.invoker.services.logger.warning("Unable to verify HF token")
|
||||
|
||||
return token_status
|
||||
|
||||
@@ -83,7 +83,7 @@ async def create_workflow(
|
||||
)
|
||||
async def list_workflows(
|
||||
page: int = Query(default=0, description="The page to get"),
|
||||
per_page: Optional[int] = Query(default=None, description="The number of workflows per page"),
|
||||
per_page: int = Query(default=10, description="The number of workflows per page"),
|
||||
order_by: WorkflowRecordOrderBy = Query(
|
||||
default=WorkflowRecordOrderBy.Name, description="The attribute to order by"
|
||||
),
|
||||
@@ -93,5 +93,5 @@ async def list_workflows(
|
||||
) -> PaginatedResults[WorkflowRecordListItemDTO]:
|
||||
"""Gets a page of workflows"""
|
||||
return ApiDependencies.invoker.services.workflow_records.get_many(
|
||||
order_by=order_by, direction=direction, page=page, per_page=per_page, query=query, category=category
|
||||
page=page, per_page=per_page, order_by=order_by, direction=direction, query=query, category=category
|
||||
)
|
||||
|
||||
@@ -7,14 +7,13 @@ from pathlib import Path
|
||||
|
||||
import torch
|
||||
import uvicorn
|
||||
from fastapi import FastAPI, Request
|
||||
from fastapi import FastAPI
|
||||
from fastapi.middleware.cors import CORSMiddleware
|
||||
from fastapi.middleware.gzip import GZipMiddleware
|
||||
from fastapi.openapi.docs import get_redoc_html, get_swagger_ui_html
|
||||
from fastapi.responses import HTMLResponse, RedirectResponse
|
||||
from fastapi.responses import HTMLResponse
|
||||
from fastapi_events.handlers.local import local_handler
|
||||
from fastapi_events.middleware import EventHandlerASGIMiddleware
|
||||
from starlette.middleware.base import BaseHTTPMiddleware, RequestResponseEndpoint
|
||||
from torch.backends.mps import is_available as is_mps_available
|
||||
|
||||
# for PyCharm:
|
||||
@@ -79,29 +78,6 @@ app = FastAPI(
|
||||
lifespan=lifespan,
|
||||
)
|
||||
|
||||
|
||||
class RedirectRootWithQueryStringMiddleware(BaseHTTPMiddleware):
|
||||
"""When a request is made to the root path with a query string, redirect to the root path without the query string.
|
||||
|
||||
For example, to force a Gradio app to use dark mode, users may append `?__theme=dark` to the URL. Their browser may
|
||||
have this query string saved in history or a bookmark, so when the user navigates to `http://127.0.0.1:9090/`, the
|
||||
browser takes them to `http://127.0.0.1:9090/?__theme=dark`.
|
||||
|
||||
This breaks the static file serving in the UI, so we redirect the user to the root path without the query string.
|
||||
"""
|
||||
|
||||
async def dispatch(self, request: Request, call_next: RequestResponseEndpoint):
|
||||
if request.url.path == "/" and request.url.query:
|
||||
return RedirectResponse(url="/")
|
||||
|
||||
response = await call_next(request)
|
||||
return response
|
||||
|
||||
|
||||
# Add the middleware
|
||||
app.add_middleware(RedirectRootWithQueryStringMiddleware)
|
||||
|
||||
|
||||
# Add event handler
|
||||
event_handler_id: int = id(app)
|
||||
app.add_middleware(
|
||||
|
||||
@@ -4,7 +4,6 @@ from __future__ import annotations
|
||||
|
||||
import inspect
|
||||
import re
|
||||
import sys
|
||||
import warnings
|
||||
from abc import ABC, abstractmethod
|
||||
from enum import Enum
|
||||
@@ -193,19 +192,12 @@ class BaseInvocation(ABC, BaseModel):
|
||||
"""Gets a pydantc TypeAdapter for the union of all invocation types."""
|
||||
if not cls._typeadapter or cls._typeadapter_needs_update:
|
||||
AnyInvocation = TypeAliasType(
|
||||
"AnyInvocation", Annotated[Union[tuple(cls.get_invocations())], Field(discriminator="type")]
|
||||
"AnyInvocation", Annotated[Union[tuple(cls._invocation_classes)], Field(discriminator="type")]
|
||||
)
|
||||
cls._typeadapter = TypeAdapter(AnyInvocation)
|
||||
cls._typeadapter_needs_update = False
|
||||
return cls._typeadapter
|
||||
|
||||
@classmethod
|
||||
def invalidate_typeadapter(cls) -> None:
|
||||
"""Invalidates the typeadapter, forcing it to be rebuilt on next access. If the invocation allowlist or
|
||||
denylist is changed, this should be called to ensure the typeadapter is updated and validation respects
|
||||
the updated allowlist and denylist."""
|
||||
cls._typeadapter_needs_update = True
|
||||
|
||||
@classmethod
|
||||
def get_invocations(cls) -> Iterable[BaseInvocation]:
|
||||
"""Gets all invocations, respecting the allowlist and denylist."""
|
||||
@@ -487,26 +479,6 @@ def invocation(
|
||||
title="type", default=invocation_type, json_schema_extra={"field_kind": FieldKind.NodeAttribute}
|
||||
)
|
||||
|
||||
# Validate the `invoke()` method is implemented
|
||||
if "invoke" in cls.__abstractmethods__:
|
||||
raise ValueError(f'Invocation "{invocation_type}" must implement the "invoke" method')
|
||||
|
||||
# And validate that `invoke()` returns a subclass of `BaseInvocationOutput
|
||||
invoke_return_annotation = signature(cls.invoke).return_annotation
|
||||
|
||||
try:
|
||||
# TODO(psyche): If `invoke()` is not defined, `return_annotation` ends up as the string "BaseInvocationOutput"
|
||||
# instead of the class `BaseInvocationOutput`. This may be a pydantic bug: https://github.com/pydantic/pydantic/issues/7978
|
||||
if isinstance(invoke_return_annotation, str):
|
||||
invoke_return_annotation = getattr(sys.modules[cls.__module__], invoke_return_annotation)
|
||||
|
||||
assert invoke_return_annotation is not BaseInvocationOutput
|
||||
assert issubclass(invoke_return_annotation, BaseInvocationOutput)
|
||||
except Exception:
|
||||
raise ValueError(
|
||||
f'Invocation "{invocation_type}" must have a return annotation of a subclass of BaseInvocationOutput (got "{invoke_return_annotation}")'
|
||||
)
|
||||
|
||||
docstring = cls.__doc__
|
||||
cls = create_model(
|
||||
cls.__qualname__,
|
||||
|
||||
@@ -13,7 +13,6 @@ from diffusers.models.unets.unet_2d_condition import UNet2DConditionModel
|
||||
from diffusers.schedulers.scheduling_dpmsolver_sde import DPMSolverSDEScheduler
|
||||
from diffusers.schedulers.scheduling_tcd import TCDScheduler
|
||||
from diffusers.schedulers.scheduling_utils import SchedulerMixin as Scheduler
|
||||
from PIL import Image
|
||||
from pydantic import field_validator
|
||||
from torchvision.transforms.functional import resize as tv_resize
|
||||
from transformers import CLIPVisionModelWithProjection
|
||||
@@ -511,7 +510,6 @@ class DenoiseLatentsInvocation(BaseInvocation):
|
||||
context: InvocationContext,
|
||||
t2i_adapters: Optional[Union[T2IAdapterField, list[T2IAdapterField]]],
|
||||
ext_manager: ExtensionsManager,
|
||||
bgr_mode: bool = False,
|
||||
) -> None:
|
||||
if t2i_adapters is None:
|
||||
return
|
||||
@@ -521,10 +519,6 @@ class DenoiseLatentsInvocation(BaseInvocation):
|
||||
t2i_adapters = [t2i_adapters]
|
||||
|
||||
for t2i_adapter_field in t2i_adapters:
|
||||
image = context.images.get_pil(t2i_adapter_field.image.image_name)
|
||||
if bgr_mode: # SDXL t2i trained on cv2's BGR outputs, but PIL won't convert straight to BGR
|
||||
r, g, b = image.split()
|
||||
image = Image.merge("RGB", (b, g, r))
|
||||
ext_manager.add_extension(
|
||||
T2IAdapterExt(
|
||||
node_context=context,
|
||||
@@ -553,9 +547,7 @@ class DenoiseLatentsInvocation(BaseInvocation):
|
||||
if not isinstance(single_ipa_image_fields, list):
|
||||
single_ipa_image_fields = [single_ipa_image_fields]
|
||||
|
||||
single_ipa_images = [
|
||||
context.images.get_pil(image.image_name, mode="RGB") for image in single_ipa_image_fields
|
||||
]
|
||||
single_ipa_images = [context.images.get_pil(image.image_name) for image in single_ipa_image_fields]
|
||||
with image_encoder_model_info as image_encoder_model:
|
||||
assert isinstance(image_encoder_model, CLIPVisionModelWithProjection)
|
||||
# Get image embeddings from CLIP and ImageProjModel.
|
||||
@@ -622,17 +614,13 @@ class DenoiseLatentsInvocation(BaseInvocation):
|
||||
for t2i_adapter_field in t2i_adapter:
|
||||
t2i_adapter_model_config = context.models.get_config(t2i_adapter_field.t2i_adapter_model.key)
|
||||
t2i_adapter_loaded_model = context.models.load(t2i_adapter_field.t2i_adapter_model)
|
||||
image = context.images.get_pil(t2i_adapter_field.image.image_name, mode="RGB")
|
||||
image = context.images.get_pil(t2i_adapter_field.image.image_name)
|
||||
|
||||
# The max_unet_downscale is the maximum amount that the UNet model downscales the latent image internally.
|
||||
if t2i_adapter_model_config.base == BaseModelType.StableDiffusion1:
|
||||
max_unet_downscale = 8
|
||||
elif t2i_adapter_model_config.base == BaseModelType.StableDiffusionXL:
|
||||
max_unet_downscale = 4
|
||||
|
||||
# SDXL adapters are trained on cv2's BGR outputs
|
||||
r, g, b = image.split()
|
||||
image = Image.merge("RGB", (b, g, r))
|
||||
else:
|
||||
raise ValueError(f"Unexpected T2I-Adapter base model type: '{t2i_adapter_model_config.base}'.")
|
||||
|
||||
@@ -640,39 +628,29 @@ class DenoiseLatentsInvocation(BaseInvocation):
|
||||
with t2i_adapter_loaded_model as t2i_adapter_model:
|
||||
total_downscale_factor = t2i_adapter_model.total_downscale_factor
|
||||
|
||||
# Resize the T2I-Adapter input image.
|
||||
# We select the resize dimensions so that after the T2I-Adapter's total_downscale_factor is applied, the
|
||||
# result will match the latent image's dimensions after max_unet_downscale is applied.
|
||||
t2i_input_height = latents_shape[2] // max_unet_downscale * total_downscale_factor
|
||||
t2i_input_width = latents_shape[3] // max_unet_downscale * total_downscale_factor
|
||||
|
||||
# Note: We have hard-coded `do_classifier_free_guidance=False`. This is because we only want to prepare
|
||||
# a single image. If CFG is enabled, we will duplicate the resultant tensor after applying the
|
||||
# T2I-Adapter model.
|
||||
#
|
||||
# Note: We re-use the `prepare_control_image(...)` from ControlNet for T2I-Adapter, because it has many
|
||||
# of the same requirements (e.g. preserving binary masks during resize).
|
||||
|
||||
# Assuming fixed dimensional scaling of LATENT_SCALE_FACTOR.
|
||||
_, _, latent_height, latent_width = latents_shape
|
||||
control_height_resize = latent_height * LATENT_SCALE_FACTOR
|
||||
control_width_resize = latent_width * LATENT_SCALE_FACTOR
|
||||
t2i_image = prepare_control_image(
|
||||
image=image,
|
||||
do_classifier_free_guidance=False,
|
||||
width=control_width_resize,
|
||||
height=control_height_resize,
|
||||
width=t2i_input_width,
|
||||
height=t2i_input_height,
|
||||
num_channels=t2i_adapter_model.config["in_channels"], # mypy treats this as a FrozenDict
|
||||
device=t2i_adapter_model.device,
|
||||
dtype=t2i_adapter_model.dtype,
|
||||
resize_mode=t2i_adapter_field.resize_mode,
|
||||
)
|
||||
|
||||
# Resize the T2I-Adapter input image.
|
||||
# We select the resize dimensions so that after the T2I-Adapter's total_downscale_factor is applied, the
|
||||
# result will match the latent image's dimensions after max_unet_downscale is applied.
|
||||
# We crop the image to this size so that the positions match the input image on non-standard resolutions
|
||||
t2i_input_height = latents_shape[2] // max_unet_downscale * total_downscale_factor
|
||||
t2i_input_width = latents_shape[3] // max_unet_downscale * total_downscale_factor
|
||||
if t2i_image.shape[2] > t2i_input_height or t2i_image.shape[3] > t2i_input_width:
|
||||
t2i_image = t2i_image[
|
||||
:, :, : min(t2i_image.shape[2], t2i_input_height), : min(t2i_image.shape[3], t2i_input_width)
|
||||
]
|
||||
|
||||
adapter_state = t2i_adapter_model(t2i_image)
|
||||
|
||||
if do_classifier_free_guidance:
|
||||
@@ -920,8 +898,7 @@ class DenoiseLatentsInvocation(BaseInvocation):
|
||||
# ext = extension_field.to_extension(exit_stack, context, ext_manager)
|
||||
# ext_manager.add_extension(ext)
|
||||
self.parse_controlnet_field(exit_stack, context, self.control, ext_manager)
|
||||
bgr_mode = self.unet.unet.base == BaseModelType.StableDiffusionXL
|
||||
self.parse_t2i_adapter_field(exit_stack, context, self.t2i_adapter, ext_manager, bgr_mode)
|
||||
self.parse_t2i_adapter_field(exit_stack, context, self.t2i_adapter, ext_manager)
|
||||
|
||||
# ext: t2i/ip adapter
|
||||
ext_manager.run_callback(ExtensionCallbackType.SETUP, denoise_ctx)
|
||||
|
||||
@@ -41,7 +41,6 @@ class UIType(str, Enum, metaclass=MetaEnum):
|
||||
# region Model Field Types
|
||||
MainModel = "MainModelField"
|
||||
FluxMainModel = "FluxMainModelField"
|
||||
SD3MainModel = "SD3MainModelField"
|
||||
SDXLMainModel = "SDXLMainModelField"
|
||||
SDXLRefinerModel = "SDXLRefinerModelField"
|
||||
ONNXModel = "ONNXModelField"
|
||||
@@ -53,8 +52,6 @@ class UIType(str, Enum, metaclass=MetaEnum):
|
||||
T2IAdapterModel = "T2IAdapterModelField"
|
||||
T5EncoderModel = "T5EncoderModelField"
|
||||
CLIPEmbedModel = "CLIPEmbedModelField"
|
||||
CLIPLEmbedModel = "CLIPLEmbedModelField"
|
||||
CLIPGEmbedModel = "CLIPGEmbedModelField"
|
||||
SpandrelImageToImageModel = "SpandrelImageToImageModelField"
|
||||
# endregion
|
||||
|
||||
@@ -134,10 +131,8 @@ class FieldDescriptions:
|
||||
clip = "CLIP (tokenizer, text encoder, LoRAs) and skipped layer count"
|
||||
t5_encoder = "T5 tokenizer and text encoder"
|
||||
clip_embed_model = "CLIP Embed loader"
|
||||
clip_g_model = "CLIP-G Embed loader"
|
||||
unet = "UNet (scheduler, LoRAs)"
|
||||
transformer = "Transformer"
|
||||
mmditx = "MMDiTX"
|
||||
vae = "VAE"
|
||||
cond = "Conditioning tensor"
|
||||
controlnet_model = "ControlNet model to load"
|
||||
@@ -145,7 +140,6 @@ class FieldDescriptions:
|
||||
lora_model = "LoRA model to load"
|
||||
main_model = "Main model (UNet, VAE, CLIP) to load"
|
||||
flux_model = "Flux model (Transformer) to load"
|
||||
sd3_model = "SD3 model (MMDiTX) to load"
|
||||
sdxl_main_model = "SDXL Main model (UNet, VAE, CLIP1, CLIP2) to load"
|
||||
sdxl_refiner_model = "SDXL Refiner Main Modde (UNet, VAE, CLIP2) to load"
|
||||
onnx_main_model = "ONNX Main model (UNet, VAE, CLIP) to load"
|
||||
@@ -198,7 +192,6 @@ class FieldDescriptions:
|
||||
freeu_s2 = 'Scaling factor for stage 2 to attenuate the contributions of the skip features. This is done to mitigate the "oversmoothing effect" in the enhanced denoising process.'
|
||||
freeu_b1 = "Scaling factor for stage 1 to amplify the contributions of backbone features."
|
||||
freeu_b2 = "Scaling factor for stage 2 to amplify the contributions of backbone features."
|
||||
instantx_control_mode = "The control mode for InstantX ControlNet union models. Ignored for other ControlNet models. The standard mapping is: canny (0), tile (1), depth (2), blur (3), pose (4), gray (5), low quality (6). Negative values will be treated as 'None'."
|
||||
|
||||
|
||||
class ImageField(BaseModel):
|
||||
@@ -252,12 +245,6 @@ class FluxConditioningField(BaseModel):
|
||||
conditioning_name: str = Field(description="The name of conditioning tensor")
|
||||
|
||||
|
||||
class SD3ConditioningField(BaseModel):
|
||||
"""A conditioning tensor primitive value"""
|
||||
|
||||
conditioning_name: str = Field(description="The name of conditioning tensor")
|
||||
|
||||
|
||||
class ConditioningField(BaseModel):
|
||||
"""A conditioning tensor primitive value"""
|
||||
|
||||
|
||||
@@ -1,99 +0,0 @@
|
||||
from pydantic import BaseModel, Field, field_validator, model_validator
|
||||
|
||||
from invokeai.app.invocations.baseinvocation import (
|
||||
BaseInvocation,
|
||||
BaseInvocationOutput,
|
||||
Classification,
|
||||
invocation,
|
||||
invocation_output,
|
||||
)
|
||||
from invokeai.app.invocations.fields import FieldDescriptions, ImageField, InputField, OutputField, UIType
|
||||
from invokeai.app.invocations.model import ModelIdentifierField
|
||||
from invokeai.app.invocations.util import validate_begin_end_step, validate_weights
|
||||
from invokeai.app.services.shared.invocation_context import InvocationContext
|
||||
from invokeai.app.util.controlnet_utils import CONTROLNET_RESIZE_VALUES
|
||||
|
||||
|
||||
class FluxControlNetField(BaseModel):
|
||||
image: ImageField = Field(description="The control image")
|
||||
control_model: ModelIdentifierField = Field(description="The ControlNet model to use")
|
||||
control_weight: float | list[float] = Field(default=1, description="The weight given to the ControlNet")
|
||||
begin_step_percent: float = Field(
|
||||
default=0, ge=0, le=1, description="When the ControlNet is first applied (% of total steps)"
|
||||
)
|
||||
end_step_percent: float = Field(
|
||||
default=1, ge=0, le=1, description="When the ControlNet is last applied (% of total steps)"
|
||||
)
|
||||
resize_mode: CONTROLNET_RESIZE_VALUES = Field(default="just_resize", description="The resize mode to use")
|
||||
instantx_control_mode: int | None = Field(default=-1, description=FieldDescriptions.instantx_control_mode)
|
||||
|
||||
@field_validator("control_weight")
|
||||
@classmethod
|
||||
def validate_control_weight(cls, v: float | list[float]) -> float | list[float]:
|
||||
validate_weights(v)
|
||||
return v
|
||||
|
||||
@model_validator(mode="after")
|
||||
def validate_begin_end_step_percent(self):
|
||||
validate_begin_end_step(self.begin_step_percent, self.end_step_percent)
|
||||
return self
|
||||
|
||||
|
||||
@invocation_output("flux_controlnet_output")
|
||||
class FluxControlNetOutput(BaseInvocationOutput):
|
||||
"""FLUX ControlNet info"""
|
||||
|
||||
control: FluxControlNetField = OutputField(description=FieldDescriptions.control)
|
||||
|
||||
|
||||
@invocation(
|
||||
"flux_controlnet",
|
||||
title="FLUX ControlNet",
|
||||
tags=["controlnet", "flux"],
|
||||
category="controlnet",
|
||||
version="1.0.0",
|
||||
classification=Classification.Prototype,
|
||||
)
|
||||
class FluxControlNetInvocation(BaseInvocation):
|
||||
"""Collect FLUX ControlNet info to pass to other nodes."""
|
||||
|
||||
image: ImageField = InputField(description="The control image")
|
||||
control_model: ModelIdentifierField = InputField(
|
||||
description=FieldDescriptions.controlnet_model, ui_type=UIType.ControlNetModel
|
||||
)
|
||||
control_weight: float | list[float] = InputField(
|
||||
default=1.0, ge=-1, le=2, description="The weight given to the ControlNet"
|
||||
)
|
||||
begin_step_percent: float = InputField(
|
||||
default=0, ge=0, le=1, description="When the ControlNet is first applied (% of total steps)"
|
||||
)
|
||||
end_step_percent: float = InputField(
|
||||
default=1, ge=0, le=1, description="When the ControlNet is last applied (% of total steps)"
|
||||
)
|
||||
resize_mode: CONTROLNET_RESIZE_VALUES = InputField(default="just_resize", description="The resize mode used")
|
||||
# Note: We default to -1 instead of None, because in the workflow editor UI None is not currently supported.
|
||||
instantx_control_mode: int | None = InputField(default=-1, description=FieldDescriptions.instantx_control_mode)
|
||||
|
||||
@field_validator("control_weight")
|
||||
@classmethod
|
||||
def validate_control_weight(cls, v: float | list[float]) -> float | list[float]:
|
||||
validate_weights(v)
|
||||
return v
|
||||
|
||||
@model_validator(mode="after")
|
||||
def validate_begin_end_step_percent(self):
|
||||
validate_begin_end_step(self.begin_step_percent, self.end_step_percent)
|
||||
return self
|
||||
|
||||
def invoke(self, context: InvocationContext) -> FluxControlNetOutput:
|
||||
return FluxControlNetOutput(
|
||||
control=FluxControlNetField(
|
||||
image=self.image,
|
||||
control_model=self.control_model,
|
||||
control_weight=self.control_weight,
|
||||
begin_step_percent=self.begin_step_percent,
|
||||
end_step_percent=self.end_step_percent,
|
||||
resize_mode=self.resize_mode,
|
||||
instantx_control_mode=self.instantx_control_mode,
|
||||
),
|
||||
)
|
||||
@@ -1,38 +1,26 @@
|
||||
from contextlib import ExitStack
|
||||
from typing import Callable, Iterator, Optional, Tuple
|
||||
|
||||
import numpy as np
|
||||
import numpy.typing as npt
|
||||
import torch
|
||||
import torchvision.transforms as tv_transforms
|
||||
from torchvision.transforms.functional import resize as tv_resize
|
||||
from transformers import CLIPImageProcessor, CLIPVisionModelWithProjection
|
||||
|
||||
from invokeai.app.invocations.baseinvocation import BaseInvocation, Classification, invocation
|
||||
from invokeai.app.invocations.fields import (
|
||||
DenoiseMaskField,
|
||||
FieldDescriptions,
|
||||
FluxConditioningField,
|
||||
ImageField,
|
||||
Input,
|
||||
InputField,
|
||||
LatentsField,
|
||||
WithBoard,
|
||||
WithMetadata,
|
||||
)
|
||||
from invokeai.app.invocations.flux_controlnet import FluxControlNetField
|
||||
from invokeai.app.invocations.ip_adapter import IPAdapterField
|
||||
from invokeai.app.invocations.model import TransformerField, VAEField
|
||||
from invokeai.app.invocations.model import TransformerField
|
||||
from invokeai.app.invocations.primitives import LatentsOutput
|
||||
from invokeai.app.services.shared.invocation_context import InvocationContext
|
||||
from invokeai.backend.flux.controlnet.instantx_controlnet_flux import InstantXControlNetFlux
|
||||
from invokeai.backend.flux.controlnet.xlabs_controlnet_flux import XLabsControlNetFlux
|
||||
from invokeai.backend.flux.denoise import denoise
|
||||
from invokeai.backend.flux.extensions.inpaint_extension import InpaintExtension
|
||||
from invokeai.backend.flux.extensions.instantx_controlnet_extension import InstantXControlNetExtension
|
||||
from invokeai.backend.flux.extensions.xlabs_controlnet_extension import XLabsControlNetExtension
|
||||
from invokeai.backend.flux.extensions.xlabs_ip_adapter_extension import XLabsIPAdapterExtension
|
||||
from invokeai.backend.flux.ip_adapter.xlabs_ip_adapter_flux import XlabsIpAdapterFlux
|
||||
from invokeai.backend.flux.inpaint_extension import InpaintExtension
|
||||
from invokeai.backend.flux.model import Flux
|
||||
from invokeai.backend.flux.sampling_utils import (
|
||||
clip_timestep_schedule_fractional,
|
||||
@@ -42,7 +30,7 @@ from invokeai.backend.flux.sampling_utils import (
|
||||
pack,
|
||||
unpack,
|
||||
)
|
||||
from invokeai.backend.lora.conversions.flux_lora_constants import FLUX_LORA_TRANSFORMER_PREFIX
|
||||
from invokeai.backend.lora.conversions.flux_kohya_lora_conversion_utils import FLUX_KOHYA_TRANFORMER_PREFIX
|
||||
from invokeai.backend.lora.lora_model_raw import LoRAModelRaw
|
||||
from invokeai.backend.lora.lora_patcher import LoRAPatcher
|
||||
from invokeai.backend.model_manager.config import ModelFormat
|
||||
@@ -56,7 +44,7 @@ from invokeai.backend.util.devices import TorchDevice
|
||||
title="FLUX Denoise",
|
||||
tags=["image", "flux"],
|
||||
category="image",
|
||||
version="3.2.0",
|
||||
version="3.0.0",
|
||||
classification=Classification.Prototype,
|
||||
)
|
||||
class FluxDenoiseInvocation(BaseInvocation, WithMetadata, WithBoard):
|
||||
@@ -89,24 +77,6 @@ class FluxDenoiseInvocation(BaseInvocation, WithMetadata, WithBoard):
|
||||
positive_text_conditioning: FluxConditioningField = InputField(
|
||||
description=FieldDescriptions.positive_cond, input=Input.Connection
|
||||
)
|
||||
negative_text_conditioning: FluxConditioningField | None = InputField(
|
||||
default=None,
|
||||
description="Negative conditioning tensor. Can be None if cfg_scale is 1.0.",
|
||||
input=Input.Connection,
|
||||
)
|
||||
cfg_scale: float | list[float] = InputField(default=1.0, description=FieldDescriptions.cfg_scale, title="CFG Scale")
|
||||
cfg_scale_start_step: int = InputField(
|
||||
default=0,
|
||||
title="CFG Scale Start Step",
|
||||
description="Index of the first step to apply cfg_scale. Negative indices count backwards from the "
|
||||
+ "the last step (e.g. a value of -1 refers to the final step).",
|
||||
)
|
||||
cfg_scale_end_step: int = InputField(
|
||||
default=-1,
|
||||
title="CFG Scale End Step",
|
||||
description="Index of the last step to apply cfg_scale. Negative indices count backwards from the "
|
||||
+ "last step (e.g. a value of -1 refers to the final step).",
|
||||
)
|
||||
width: int = InputField(default=1024, multiple_of=16, description="Width of the generated image.")
|
||||
height: int = InputField(default=1024, multiple_of=16, description="Height of the generated image.")
|
||||
num_steps: int = InputField(
|
||||
@@ -117,18 +87,6 @@ class FluxDenoiseInvocation(BaseInvocation, WithMetadata, WithBoard):
|
||||
description="The guidance strength. Higher values adhere more strictly to the prompt, and will produce less diverse images. FLUX dev only, ignored for schnell.",
|
||||
)
|
||||
seed: int = InputField(default=0, description="Randomness seed for reproducibility.")
|
||||
control: FluxControlNetField | list[FluxControlNetField] | None = InputField(
|
||||
default=None, input=Input.Connection, description="ControlNet models."
|
||||
)
|
||||
controlnet_vae: VAEField | None = InputField(
|
||||
default=None,
|
||||
description=FieldDescriptions.vae,
|
||||
input=Input.Connection,
|
||||
)
|
||||
|
||||
ip_adapter: IPAdapterField | list[IPAdapterField] | None = InputField(
|
||||
description=FieldDescriptions.ip_adapter, title="IP-Adapter", default=None, input=Input.Connection
|
||||
)
|
||||
|
||||
@torch.no_grad()
|
||||
def invoke(self, context: InvocationContext) -> LatentsOutput:
|
||||
@@ -138,19 +96,6 @@ class FluxDenoiseInvocation(BaseInvocation, WithMetadata, WithBoard):
|
||||
name = context.tensors.save(tensor=latents)
|
||||
return LatentsOutput.build(latents_name=name, latents=latents, seed=None)
|
||||
|
||||
def _load_text_conditioning(
|
||||
self, context: InvocationContext, conditioning_name: str, dtype: torch.dtype
|
||||
) -> Tuple[torch.Tensor, torch.Tensor]:
|
||||
# Load the conditioning data.
|
||||
cond_data = context.conditioning.load(conditioning_name)
|
||||
assert len(cond_data.conditionings) == 1
|
||||
flux_conditioning = cond_data.conditionings[0]
|
||||
assert isinstance(flux_conditioning, FLUXConditioningInfo)
|
||||
flux_conditioning = flux_conditioning.to(dtype=dtype)
|
||||
t5_embeddings = flux_conditioning.t5_embeds
|
||||
clip_embeddings = flux_conditioning.clip_embeds
|
||||
return t5_embeddings, clip_embeddings
|
||||
|
||||
def _run_diffusion(
|
||||
self,
|
||||
context: InvocationContext,
|
||||
@@ -158,15 +103,13 @@ class FluxDenoiseInvocation(BaseInvocation, WithMetadata, WithBoard):
|
||||
inference_dtype = torch.bfloat16
|
||||
|
||||
# Load the conditioning data.
|
||||
pos_t5_embeddings, pos_clip_embeddings = self._load_text_conditioning(
|
||||
context, self.positive_text_conditioning.conditioning_name, inference_dtype
|
||||
)
|
||||
neg_t5_embeddings: torch.Tensor | None = None
|
||||
neg_clip_embeddings: torch.Tensor | None = None
|
||||
if self.negative_text_conditioning is not None:
|
||||
neg_t5_embeddings, neg_clip_embeddings = self._load_text_conditioning(
|
||||
context, self.negative_text_conditioning.conditioning_name, inference_dtype
|
||||
)
|
||||
cond_data = context.conditioning.load(self.positive_text_conditioning.conditioning_name)
|
||||
assert len(cond_data.conditionings) == 1
|
||||
flux_conditioning = cond_data.conditionings[0]
|
||||
assert isinstance(flux_conditioning, FLUXConditioningInfo)
|
||||
flux_conditioning = flux_conditioning.to(dtype=inference_dtype)
|
||||
t5_embeddings = flux_conditioning.t5_embeds
|
||||
clip_embeddings = flux_conditioning.clip_embeds
|
||||
|
||||
# Load the input latents, if provided.
|
||||
init_latents = context.tensors.load(self.latents.latents_name) if self.latents else None
|
||||
@@ -224,19 +167,11 @@ class FluxDenoiseInvocation(BaseInvocation, WithMetadata, WithBoard):
|
||||
|
||||
inpaint_mask = self._prep_inpaint_mask(context, x)
|
||||
|
||||
b, _c, latent_h, latent_w = x.shape
|
||||
img_ids = generate_img_ids(h=latent_h, w=latent_w, batch_size=b, device=x.device, dtype=x.dtype)
|
||||
b, _c, h, w = x.shape
|
||||
img_ids = generate_img_ids(h=h, w=w, batch_size=b, device=x.device, dtype=x.dtype)
|
||||
|
||||
pos_bs, pos_t5_seq_len, _ = pos_t5_embeddings.shape
|
||||
pos_txt_ids = torch.zeros(
|
||||
pos_bs, pos_t5_seq_len, 3, dtype=inference_dtype, device=TorchDevice.choose_torch_device()
|
||||
)
|
||||
neg_txt_ids: torch.Tensor | None = None
|
||||
if neg_t5_embeddings is not None:
|
||||
neg_bs, neg_t5_seq_len, _ = neg_t5_embeddings.shape
|
||||
neg_txt_ids = torch.zeros(
|
||||
neg_bs, neg_t5_seq_len, 3, dtype=inference_dtype, device=TorchDevice.choose_torch_device()
|
||||
)
|
||||
bs, t5_seq_len, _ = t5_embeddings.shape
|
||||
txt_ids = torch.zeros(bs, t5_seq_len, 3, dtype=inference_dtype, device=TorchDevice.choose_torch_device())
|
||||
|
||||
# Pack all latent tensors.
|
||||
init_latents = pack(init_latents) if init_latents is not None else None
|
||||
@@ -257,36 +192,12 @@ class FluxDenoiseInvocation(BaseInvocation, WithMetadata, WithBoard):
|
||||
noise=noise,
|
||||
)
|
||||
|
||||
# Compute the IP-Adapter image prompt clip embeddings.
|
||||
# We do this before loading other models to minimize peak memory.
|
||||
# TODO(ryand): We should really do this in a separate invocation to benefit from caching.
|
||||
ip_adapter_fields = self._normalize_ip_adapter_fields()
|
||||
pos_image_prompt_clip_embeds, neg_image_prompt_clip_embeds = self._prep_ip_adapter_image_prompt_clip_embeds(
|
||||
ip_adapter_fields, context
|
||||
)
|
||||
|
||||
cfg_scale = self.prep_cfg_scale(
|
||||
cfg_scale=self.cfg_scale,
|
||||
timesteps=timesteps,
|
||||
cfg_scale_start_step=self.cfg_scale_start_step,
|
||||
cfg_scale_end_step=self.cfg_scale_end_step,
|
||||
)
|
||||
|
||||
with ExitStack() as exit_stack:
|
||||
# Prepare ControlNet extensions.
|
||||
# Note: We do this before loading the transformer model to minimize peak memory (see implementation).
|
||||
controlnet_extensions = self._prep_controlnet_extensions(
|
||||
context=context,
|
||||
exit_stack=exit_stack,
|
||||
latent_height=latent_h,
|
||||
latent_width=latent_w,
|
||||
dtype=inference_dtype,
|
||||
device=x.device,
|
||||
)
|
||||
|
||||
# Load the transformer model.
|
||||
(cached_weights, transformer) = exit_stack.enter_context(transformer_info.model_on_device())
|
||||
with (
|
||||
transformer_info.model_on_device() as (cached_weights, transformer),
|
||||
ExitStack() as exit_stack,
|
||||
):
|
||||
assert isinstance(transformer, Flux)
|
||||
|
||||
config = transformer_info.config
|
||||
assert config is not None
|
||||
|
||||
@@ -298,110 +209,40 @@ class FluxDenoiseInvocation(BaseInvocation, WithMetadata, WithBoard):
|
||||
LoRAPatcher.apply_lora_patches(
|
||||
model=transformer,
|
||||
patches=self._lora_iterator(context),
|
||||
prefix=FLUX_LORA_TRANSFORMER_PREFIX,
|
||||
prefix=FLUX_KOHYA_TRANFORMER_PREFIX,
|
||||
cached_weights=cached_weights,
|
||||
)
|
||||
)
|
||||
elif config.format in [
|
||||
ModelFormat.BnbQuantizedLlmInt8b,
|
||||
ModelFormat.BnbQuantizednf4b,
|
||||
ModelFormat.GGUFQuantized,
|
||||
]:
|
||||
elif config.format in [ModelFormat.BnbQuantizedLlmInt8b, ModelFormat.BnbQuantizednf4b]:
|
||||
# The model is quantized, so apply the LoRA weights as sidecar layers. This results in slower inference,
|
||||
# than directly patching the weights, but is agnostic to the quantization format.
|
||||
exit_stack.enter_context(
|
||||
LoRAPatcher.apply_lora_sidecar_patches(
|
||||
model=transformer,
|
||||
patches=self._lora_iterator(context),
|
||||
prefix=FLUX_LORA_TRANSFORMER_PREFIX,
|
||||
prefix=FLUX_KOHYA_TRANFORMER_PREFIX,
|
||||
dtype=inference_dtype,
|
||||
)
|
||||
)
|
||||
else:
|
||||
raise ValueError(f"Unsupported model format: {config.format}")
|
||||
|
||||
# Prepare IP-Adapter extensions.
|
||||
pos_ip_adapter_extensions, neg_ip_adapter_extensions = self._prep_ip_adapter_extensions(
|
||||
pos_image_prompt_clip_embeds=pos_image_prompt_clip_embeds,
|
||||
neg_image_prompt_clip_embeds=neg_image_prompt_clip_embeds,
|
||||
ip_adapter_fields=ip_adapter_fields,
|
||||
context=context,
|
||||
exit_stack=exit_stack,
|
||||
dtype=inference_dtype,
|
||||
)
|
||||
|
||||
x = denoise(
|
||||
model=transformer,
|
||||
img=x,
|
||||
img_ids=img_ids,
|
||||
txt=pos_t5_embeddings,
|
||||
txt_ids=pos_txt_ids,
|
||||
vec=pos_clip_embeddings,
|
||||
neg_txt=neg_t5_embeddings,
|
||||
neg_txt_ids=neg_txt_ids,
|
||||
neg_vec=neg_clip_embeddings,
|
||||
txt=t5_embeddings,
|
||||
txt_ids=txt_ids,
|
||||
vec=clip_embeddings,
|
||||
timesteps=timesteps,
|
||||
step_callback=self._build_step_callback(context),
|
||||
guidance=self.guidance,
|
||||
cfg_scale=cfg_scale,
|
||||
inpaint_extension=inpaint_extension,
|
||||
controlnet_extensions=controlnet_extensions,
|
||||
pos_ip_adapter_extensions=pos_ip_adapter_extensions,
|
||||
neg_ip_adapter_extensions=neg_ip_adapter_extensions,
|
||||
)
|
||||
|
||||
x = unpack(x.float(), self.height, self.width)
|
||||
return x
|
||||
|
||||
@classmethod
|
||||
def prep_cfg_scale(
|
||||
cls, cfg_scale: float | list[float], timesteps: list[float], cfg_scale_start_step: int, cfg_scale_end_step: int
|
||||
) -> list[float]:
|
||||
"""Prepare the cfg_scale schedule.
|
||||
|
||||
- Clips the cfg_scale schedule based on cfg_scale_start_step and cfg_scale_end_step.
|
||||
- If cfg_scale is a list, then it is assumed to be a schedule and is returned as-is.
|
||||
- If cfg_scale is a scalar, then a linear schedule is created from cfg_scale_start_step to cfg_scale_end_step.
|
||||
"""
|
||||
# num_steps is the number of denoising steps, which is one less than the number of timesteps.
|
||||
num_steps = len(timesteps) - 1
|
||||
|
||||
# Normalize cfg_scale to a list if it is a scalar.
|
||||
cfg_scale_list: list[float]
|
||||
if isinstance(cfg_scale, float):
|
||||
cfg_scale_list = [cfg_scale] * num_steps
|
||||
elif isinstance(cfg_scale, list):
|
||||
cfg_scale_list = cfg_scale
|
||||
else:
|
||||
raise ValueError(f"Unsupported cfg_scale type: {type(cfg_scale)}")
|
||||
assert len(cfg_scale_list) == num_steps
|
||||
|
||||
# Handle negative indices for cfg_scale_start_step and cfg_scale_end_step.
|
||||
start_step_index = cfg_scale_start_step
|
||||
if start_step_index < 0:
|
||||
start_step_index = num_steps + start_step_index
|
||||
end_step_index = cfg_scale_end_step
|
||||
if end_step_index < 0:
|
||||
end_step_index = num_steps + end_step_index
|
||||
|
||||
# Validate the start and end step indices.
|
||||
if not (0 <= start_step_index < num_steps):
|
||||
raise ValueError(f"Invalid cfg_scale_start_step. Out of range: {cfg_scale_start_step}.")
|
||||
if not (0 <= end_step_index < num_steps):
|
||||
raise ValueError(f"Invalid cfg_scale_end_step. Out of range: {cfg_scale_end_step}.")
|
||||
if start_step_index > end_step_index:
|
||||
raise ValueError(
|
||||
f"cfg_scale_start_step ({cfg_scale_start_step}) must be before cfg_scale_end_step "
|
||||
+ f"({cfg_scale_end_step})."
|
||||
)
|
||||
|
||||
# Set values outside the start and end step indices to 1.0. This is equivalent to disabling cfg_scale for those
|
||||
# steps.
|
||||
clipped_cfg_scale = [1.0] * num_steps
|
||||
clipped_cfg_scale[start_step_index : end_step_index + 1] = cfg_scale_list[start_step_index : end_step_index + 1]
|
||||
|
||||
return clipped_cfg_scale
|
||||
|
||||
def _prep_inpaint_mask(self, context: InvocationContext, latents: torch.Tensor) -> torch.Tensor | None:
|
||||
"""Prepare the inpaint mask.
|
||||
|
||||
@@ -443,210 +284,6 @@ class FluxDenoiseInvocation(BaseInvocation, WithMetadata, WithBoard):
|
||||
# `latents`.
|
||||
return mask.expand_as(latents)
|
||||
|
||||
def _prep_controlnet_extensions(
|
||||
self,
|
||||
context: InvocationContext,
|
||||
exit_stack: ExitStack,
|
||||
latent_height: int,
|
||||
latent_width: int,
|
||||
dtype: torch.dtype,
|
||||
device: torch.device,
|
||||
) -> list[XLabsControlNetExtension | InstantXControlNetExtension]:
|
||||
# Normalize the controlnet input to list[ControlField].
|
||||
controlnets: list[FluxControlNetField]
|
||||
if self.control is None:
|
||||
controlnets = []
|
||||
elif isinstance(self.control, FluxControlNetField):
|
||||
controlnets = [self.control]
|
||||
elif isinstance(self.control, list):
|
||||
controlnets = self.control
|
||||
else:
|
||||
raise ValueError(f"Unsupported controlnet type: {type(self.control)}")
|
||||
|
||||
# TODO(ryand): Add a field to the model config so that we can distinguish between XLabs and InstantX ControlNets
|
||||
# before loading the models. Then make sure that all VAE encoding is done before loading the ControlNets to
|
||||
# minimize peak memory.
|
||||
|
||||
# First, load the ControlNet models so that we can determine the ControlNet types.
|
||||
controlnet_models = [context.models.load(controlnet.control_model) for controlnet in controlnets]
|
||||
|
||||
# Calculate the controlnet conditioning tensors.
|
||||
# We do this before loading the ControlNet models because it may require running the VAE, and we are trying to
|
||||
# keep peak memory down.
|
||||
controlnet_conds: list[torch.Tensor] = []
|
||||
for controlnet, controlnet_model in zip(controlnets, controlnet_models, strict=True):
|
||||
image = context.images.get_pil(controlnet.image.image_name)
|
||||
if isinstance(controlnet_model.model, InstantXControlNetFlux):
|
||||
if self.controlnet_vae is None:
|
||||
raise ValueError("A ControlNet VAE is required when using an InstantX FLUX ControlNet.")
|
||||
vae_info = context.models.load(self.controlnet_vae.vae)
|
||||
controlnet_conds.append(
|
||||
InstantXControlNetExtension.prepare_controlnet_cond(
|
||||
controlnet_image=image,
|
||||
vae_info=vae_info,
|
||||
latent_height=latent_height,
|
||||
latent_width=latent_width,
|
||||
dtype=dtype,
|
||||
device=device,
|
||||
resize_mode=controlnet.resize_mode,
|
||||
)
|
||||
)
|
||||
elif isinstance(controlnet_model.model, XLabsControlNetFlux):
|
||||
controlnet_conds.append(
|
||||
XLabsControlNetExtension.prepare_controlnet_cond(
|
||||
controlnet_image=image,
|
||||
latent_height=latent_height,
|
||||
latent_width=latent_width,
|
||||
dtype=dtype,
|
||||
device=device,
|
||||
resize_mode=controlnet.resize_mode,
|
||||
)
|
||||
)
|
||||
|
||||
# Finally, load the ControlNet models and initialize the ControlNet extensions.
|
||||
controlnet_extensions: list[XLabsControlNetExtension | InstantXControlNetExtension] = []
|
||||
for controlnet, controlnet_cond, controlnet_model in zip(
|
||||
controlnets, controlnet_conds, controlnet_models, strict=True
|
||||
):
|
||||
model = exit_stack.enter_context(controlnet_model)
|
||||
|
||||
if isinstance(model, XLabsControlNetFlux):
|
||||
controlnet_extensions.append(
|
||||
XLabsControlNetExtension(
|
||||
model=model,
|
||||
controlnet_cond=controlnet_cond,
|
||||
weight=controlnet.control_weight,
|
||||
begin_step_percent=controlnet.begin_step_percent,
|
||||
end_step_percent=controlnet.end_step_percent,
|
||||
)
|
||||
)
|
||||
elif isinstance(model, InstantXControlNetFlux):
|
||||
instantx_control_mode: torch.Tensor | None = None
|
||||
if controlnet.instantx_control_mode is not None and controlnet.instantx_control_mode >= 0:
|
||||
instantx_control_mode = torch.tensor(controlnet.instantx_control_mode, dtype=torch.long)
|
||||
instantx_control_mode = instantx_control_mode.reshape([-1, 1])
|
||||
|
||||
controlnet_extensions.append(
|
||||
InstantXControlNetExtension(
|
||||
model=model,
|
||||
controlnet_cond=controlnet_cond,
|
||||
instantx_control_mode=instantx_control_mode,
|
||||
weight=controlnet.control_weight,
|
||||
begin_step_percent=controlnet.begin_step_percent,
|
||||
end_step_percent=controlnet.end_step_percent,
|
||||
)
|
||||
)
|
||||
else:
|
||||
raise ValueError(f"Unsupported ControlNet model type: {type(model)}")
|
||||
|
||||
return controlnet_extensions
|
||||
|
||||
def _normalize_ip_adapter_fields(self) -> list[IPAdapterField]:
|
||||
if self.ip_adapter is None:
|
||||
return []
|
||||
elif isinstance(self.ip_adapter, IPAdapterField):
|
||||
return [self.ip_adapter]
|
||||
elif isinstance(self.ip_adapter, list):
|
||||
return self.ip_adapter
|
||||
else:
|
||||
raise ValueError(f"Unsupported IP-Adapter type: {type(self.ip_adapter)}")
|
||||
|
||||
def _prep_ip_adapter_image_prompt_clip_embeds(
|
||||
self,
|
||||
ip_adapter_fields: list[IPAdapterField],
|
||||
context: InvocationContext,
|
||||
) -> tuple[list[torch.Tensor], list[torch.Tensor]]:
|
||||
"""Run the IPAdapter CLIPVisionModel, returning image prompt embeddings."""
|
||||
clip_image_processor = CLIPImageProcessor()
|
||||
|
||||
pos_image_prompt_clip_embeds: list[torch.Tensor] = []
|
||||
neg_image_prompt_clip_embeds: list[torch.Tensor] = []
|
||||
for ip_adapter_field in ip_adapter_fields:
|
||||
# `ip_adapter_field.image` could be a list or a single ImageField. Normalize to a list here.
|
||||
ipa_image_fields: list[ImageField]
|
||||
if isinstance(ip_adapter_field.image, ImageField):
|
||||
ipa_image_fields = [ip_adapter_field.image]
|
||||
elif isinstance(ip_adapter_field.image, list):
|
||||
ipa_image_fields = ip_adapter_field.image
|
||||
else:
|
||||
raise ValueError(f"Unsupported IP-Adapter image type: {type(ip_adapter_field.image)}")
|
||||
|
||||
if len(ipa_image_fields) != 1:
|
||||
raise ValueError(
|
||||
f"FLUX IP-Adapter only supports a single image prompt (received {len(ipa_image_fields)})."
|
||||
)
|
||||
|
||||
ipa_images = [context.images.get_pil(image.image_name, mode="RGB") for image in ipa_image_fields]
|
||||
|
||||
pos_images: list[npt.NDArray[np.uint8]] = []
|
||||
neg_images: list[npt.NDArray[np.uint8]] = []
|
||||
for ipa_image in ipa_images:
|
||||
assert ipa_image.mode == "RGB"
|
||||
pos_image = np.array(ipa_image)
|
||||
# We use a black image as the negative image prompt for parity with
|
||||
# https://github.com/XLabs-AI/x-flux-comfyui/blob/45c834727dd2141aebc505ae4b01f193a8414e38/nodes.py#L592-L593
|
||||
# An alternative scheme would be to apply zeros_like() after calling the clip_image_processor.
|
||||
neg_image = np.zeros_like(pos_image)
|
||||
pos_images.append(pos_image)
|
||||
neg_images.append(neg_image)
|
||||
|
||||
with context.models.load(ip_adapter_field.image_encoder_model) as image_encoder_model:
|
||||
assert isinstance(image_encoder_model, CLIPVisionModelWithProjection)
|
||||
|
||||
clip_image: torch.Tensor = clip_image_processor(images=pos_images, return_tensors="pt").pixel_values
|
||||
clip_image = clip_image.to(device=image_encoder_model.device, dtype=image_encoder_model.dtype)
|
||||
pos_clip_image_embeds = image_encoder_model(clip_image).image_embeds
|
||||
|
||||
clip_image = clip_image_processor(images=neg_images, return_tensors="pt").pixel_values
|
||||
clip_image = clip_image.to(device=image_encoder_model.device, dtype=image_encoder_model.dtype)
|
||||
neg_clip_image_embeds = image_encoder_model(clip_image).image_embeds
|
||||
|
||||
pos_image_prompt_clip_embeds.append(pos_clip_image_embeds)
|
||||
neg_image_prompt_clip_embeds.append(neg_clip_image_embeds)
|
||||
|
||||
return pos_image_prompt_clip_embeds, neg_image_prompt_clip_embeds
|
||||
|
||||
def _prep_ip_adapter_extensions(
|
||||
self,
|
||||
ip_adapter_fields: list[IPAdapterField],
|
||||
pos_image_prompt_clip_embeds: list[torch.Tensor],
|
||||
neg_image_prompt_clip_embeds: list[torch.Tensor],
|
||||
context: InvocationContext,
|
||||
exit_stack: ExitStack,
|
||||
dtype: torch.dtype,
|
||||
) -> tuple[list[XLabsIPAdapterExtension], list[XLabsIPAdapterExtension]]:
|
||||
pos_ip_adapter_extensions: list[XLabsIPAdapterExtension] = []
|
||||
neg_ip_adapter_extensions: list[XLabsIPAdapterExtension] = []
|
||||
for ip_adapter_field, pos_image_prompt_clip_embed, neg_image_prompt_clip_embed in zip(
|
||||
ip_adapter_fields, pos_image_prompt_clip_embeds, neg_image_prompt_clip_embeds, strict=True
|
||||
):
|
||||
ip_adapter_model = exit_stack.enter_context(context.models.load(ip_adapter_field.ip_adapter_model))
|
||||
assert isinstance(ip_adapter_model, XlabsIpAdapterFlux)
|
||||
ip_adapter_model = ip_adapter_model.to(dtype=dtype)
|
||||
if ip_adapter_field.mask is not None:
|
||||
raise ValueError("IP-Adapter masks are not yet supported in Flux.")
|
||||
ip_adapter_extension = XLabsIPAdapterExtension(
|
||||
model=ip_adapter_model,
|
||||
image_prompt_clip_embed=pos_image_prompt_clip_embed,
|
||||
weight=ip_adapter_field.weight,
|
||||
begin_step_percent=ip_adapter_field.begin_step_percent,
|
||||
end_step_percent=ip_adapter_field.end_step_percent,
|
||||
)
|
||||
ip_adapter_extension.run_image_proj(dtype=dtype)
|
||||
pos_ip_adapter_extensions.append(ip_adapter_extension)
|
||||
|
||||
ip_adapter_extension = XLabsIPAdapterExtension(
|
||||
model=ip_adapter_model,
|
||||
image_prompt_clip_embed=neg_image_prompt_clip_embed,
|
||||
weight=ip_adapter_field.weight,
|
||||
begin_step_percent=ip_adapter_field.begin_step_percent,
|
||||
end_step_percent=ip_adapter_field.end_step_percent,
|
||||
)
|
||||
ip_adapter_extension.run_image_proj(dtype=dtype)
|
||||
neg_ip_adapter_extensions.append(ip_adapter_extension)
|
||||
|
||||
return pos_ip_adapter_extensions, neg_ip_adapter_extensions
|
||||
|
||||
def _lora_iterator(self, context: InvocationContext) -> Iterator[Tuple[LoRAModelRaw, float]]:
|
||||
for lora in self.transformer.loras:
|
||||
lora_info = context.models.load(lora.lora)
|
||||
|
||||
@@ -1,89 +0,0 @@
|
||||
from builtins import float
|
||||
from typing import List, Literal, Union
|
||||
|
||||
from pydantic import field_validator, model_validator
|
||||
from typing_extensions import Self
|
||||
|
||||
from invokeai.app.invocations.baseinvocation import BaseInvocation, Classification, invocation
|
||||
from invokeai.app.invocations.fields import InputField, UIType
|
||||
from invokeai.app.invocations.ip_adapter import (
|
||||
CLIP_VISION_MODEL_MAP,
|
||||
IPAdapterField,
|
||||
IPAdapterInvocation,
|
||||
IPAdapterOutput,
|
||||
)
|
||||
from invokeai.app.invocations.model import ModelIdentifierField
|
||||
from invokeai.app.invocations.primitives import ImageField
|
||||
from invokeai.app.invocations.util import validate_begin_end_step, validate_weights
|
||||
from invokeai.app.services.shared.invocation_context import InvocationContext
|
||||
from invokeai.backend.model_manager.config import (
|
||||
IPAdapterCheckpointConfig,
|
||||
IPAdapterInvokeAIConfig,
|
||||
)
|
||||
|
||||
|
||||
@invocation(
|
||||
"flux_ip_adapter",
|
||||
title="FLUX IP-Adapter",
|
||||
tags=["ip_adapter", "control"],
|
||||
category="ip_adapter",
|
||||
version="1.0.0",
|
||||
classification=Classification.Prototype,
|
||||
)
|
||||
class FluxIPAdapterInvocation(BaseInvocation):
|
||||
"""Collects FLUX IP-Adapter info to pass to other nodes."""
|
||||
|
||||
# FLUXIPAdapterInvocation is based closely on IPAdapterInvocation, but with some unsupported features removed.
|
||||
|
||||
image: ImageField = InputField(description="The IP-Adapter image prompt(s).")
|
||||
ip_adapter_model: ModelIdentifierField = InputField(
|
||||
description="The IP-Adapter model.", title="IP-Adapter Model", ui_type=UIType.IPAdapterModel
|
||||
)
|
||||
# Currently, the only known ViT model used by FLUX IP-Adapters is ViT-L.
|
||||
clip_vision_model: Literal["ViT-L"] = InputField(description="CLIP Vision model to use.", default="ViT-L")
|
||||
weight: Union[float, List[float]] = InputField(
|
||||
default=1, description="The weight given to the IP-Adapter", title="Weight"
|
||||
)
|
||||
begin_step_percent: float = InputField(
|
||||
default=0, ge=0, le=1, description="When the IP-Adapter is first applied (% of total steps)"
|
||||
)
|
||||
end_step_percent: float = InputField(
|
||||
default=1, ge=0, le=1, description="When the IP-Adapter is last applied (% of total steps)"
|
||||
)
|
||||
|
||||
@field_validator("weight")
|
||||
@classmethod
|
||||
def validate_ip_adapter_weight(cls, v: float) -> float:
|
||||
validate_weights(v)
|
||||
return v
|
||||
|
||||
@model_validator(mode="after")
|
||||
def validate_begin_end_step_percent(self) -> Self:
|
||||
validate_begin_end_step(self.begin_step_percent, self.end_step_percent)
|
||||
return self
|
||||
|
||||
def invoke(self, context: InvocationContext) -> IPAdapterOutput:
|
||||
# Lookup the CLIP Vision encoder that is intended to be used with the IP-Adapter model.
|
||||
ip_adapter_info = context.models.get_config(self.ip_adapter_model.key)
|
||||
assert isinstance(ip_adapter_info, (IPAdapterInvokeAIConfig, IPAdapterCheckpointConfig))
|
||||
|
||||
# Note: There is a IPAdapterInvokeAIConfig.image_encoder_model_id field, but it isn't trustworthy.
|
||||
image_encoder_starter_model = CLIP_VISION_MODEL_MAP[self.clip_vision_model]
|
||||
image_encoder_model_id = image_encoder_starter_model.source
|
||||
image_encoder_model_name = image_encoder_starter_model.name
|
||||
image_encoder_model = IPAdapterInvocation.get_clip_image_encoder(
|
||||
context, image_encoder_model_id, image_encoder_model_name
|
||||
)
|
||||
|
||||
return IPAdapterOutput(
|
||||
ip_adapter=IPAdapterField(
|
||||
image=self.image,
|
||||
ip_adapter_model=self.ip_adapter_model,
|
||||
image_encoder_model=ModelIdentifierField.from_config(image_encoder_model),
|
||||
weight=self.weight,
|
||||
target_blocks=[], # target_blocks is currently unused for FLUX IP-Adapters.
|
||||
begin_step_percent=self.begin_step_percent,
|
||||
end_step_percent=self.end_step_percent,
|
||||
mask=None, # mask is currently unused for FLUX IP-Adapters.
|
||||
),
|
||||
)
|
||||
@@ -1,89 +0,0 @@
|
||||
from typing import Literal
|
||||
|
||||
from invokeai.app.invocations.baseinvocation import (
|
||||
BaseInvocation,
|
||||
BaseInvocationOutput,
|
||||
Classification,
|
||||
invocation,
|
||||
invocation_output,
|
||||
)
|
||||
from invokeai.app.invocations.fields import FieldDescriptions, Input, InputField, OutputField, UIType
|
||||
from invokeai.app.invocations.model import CLIPField, ModelIdentifierField, T5EncoderField, TransformerField, VAEField
|
||||
from invokeai.app.services.shared.invocation_context import InvocationContext
|
||||
from invokeai.backend.flux.util import max_seq_lengths
|
||||
from invokeai.backend.model_manager.config import (
|
||||
CheckpointConfigBase,
|
||||
SubModelType,
|
||||
)
|
||||
|
||||
|
||||
@invocation_output("flux_model_loader_output")
|
||||
class FluxModelLoaderOutput(BaseInvocationOutput):
|
||||
"""Flux base model loader output"""
|
||||
|
||||
transformer: TransformerField = OutputField(description=FieldDescriptions.transformer, title="Transformer")
|
||||
clip: CLIPField = OutputField(description=FieldDescriptions.clip, title="CLIP")
|
||||
t5_encoder: T5EncoderField = OutputField(description=FieldDescriptions.t5_encoder, title="T5 Encoder")
|
||||
vae: VAEField = OutputField(description=FieldDescriptions.vae, title="VAE")
|
||||
max_seq_len: Literal[256, 512] = OutputField(
|
||||
description="The max sequence length to used for the T5 encoder. (256 for schnell transformer, 512 for dev transformer)",
|
||||
title="Max Seq Length",
|
||||
)
|
||||
|
||||
|
||||
@invocation(
|
||||
"flux_model_loader",
|
||||
title="Flux Main Model",
|
||||
tags=["model", "flux"],
|
||||
category="model",
|
||||
version="1.0.4",
|
||||
classification=Classification.Prototype,
|
||||
)
|
||||
class FluxModelLoaderInvocation(BaseInvocation):
|
||||
"""Loads a flux base model, outputting its submodels."""
|
||||
|
||||
model: ModelIdentifierField = InputField(
|
||||
description=FieldDescriptions.flux_model,
|
||||
ui_type=UIType.FluxMainModel,
|
||||
input=Input.Direct,
|
||||
)
|
||||
|
||||
t5_encoder_model: ModelIdentifierField = InputField(
|
||||
description=FieldDescriptions.t5_encoder, ui_type=UIType.T5EncoderModel, input=Input.Direct, title="T5 Encoder"
|
||||
)
|
||||
|
||||
clip_embed_model: ModelIdentifierField = InputField(
|
||||
description=FieldDescriptions.clip_embed_model,
|
||||
ui_type=UIType.CLIPEmbedModel,
|
||||
input=Input.Direct,
|
||||
title="CLIP Embed",
|
||||
)
|
||||
|
||||
vae_model: ModelIdentifierField = InputField(
|
||||
description=FieldDescriptions.vae_model, ui_type=UIType.FluxVAEModel, title="VAE"
|
||||
)
|
||||
|
||||
def invoke(self, context: InvocationContext) -> FluxModelLoaderOutput:
|
||||
for key in [self.model.key, self.t5_encoder_model.key, self.clip_embed_model.key, self.vae_model.key]:
|
||||
if not context.models.exists(key):
|
||||
raise ValueError(f"Unknown model: {key}")
|
||||
|
||||
transformer = self.model.model_copy(update={"submodel_type": SubModelType.Transformer})
|
||||
vae = self.vae_model.model_copy(update={"submodel_type": SubModelType.VAE})
|
||||
|
||||
tokenizer = self.clip_embed_model.model_copy(update={"submodel_type": SubModelType.Tokenizer})
|
||||
clip_encoder = self.clip_embed_model.model_copy(update={"submodel_type": SubModelType.TextEncoder})
|
||||
|
||||
tokenizer2 = self.t5_encoder_model.model_copy(update={"submodel_type": SubModelType.Tokenizer2})
|
||||
t5_encoder = self.t5_encoder_model.model_copy(update={"submodel_type": SubModelType.TextEncoder2})
|
||||
|
||||
transformer_config = context.models.get_config(transformer)
|
||||
assert isinstance(transformer_config, CheckpointConfigBase)
|
||||
|
||||
return FluxModelLoaderOutput(
|
||||
transformer=TransformerField(transformer=transformer, loras=[]),
|
||||
clip=CLIPField(tokenizer=tokenizer, text_encoder=clip_encoder, loras=[], skipped_layers=0),
|
||||
t5_encoder=T5EncoderField(tokenizer=tokenizer2, text_encoder=t5_encoder),
|
||||
vae=VAEField(vae=vae),
|
||||
max_seq_len=max_seq_lengths[transformer_config.config_path],
|
||||
)
|
||||
@@ -10,7 +10,7 @@ from invokeai.app.invocations.model import CLIPField, T5EncoderField
|
||||
from invokeai.app.invocations.primitives import FluxConditioningOutput
|
||||
from invokeai.app.services.shared.invocation_context import InvocationContext
|
||||
from invokeai.backend.flux.modules.conditioner import HFEncoder
|
||||
from invokeai.backend.lora.conversions.flux_lora_constants import FLUX_LORA_CLIP_PREFIX
|
||||
from invokeai.backend.lora.conversions.flux_kohya_lora_conversion_utils import FLUX_KOHYA_CLIP_PREFIX
|
||||
from invokeai.backend.lora.lora_model_raw import LoRAModelRaw
|
||||
from invokeai.backend.lora.lora_patcher import LoRAPatcher
|
||||
from invokeai.backend.model_manager.config import ModelFormat
|
||||
@@ -101,7 +101,7 @@ class FluxTextEncoderInvocation(BaseInvocation):
|
||||
LoRAPatcher.apply_lora_patches(
|
||||
model=clip_text_encoder,
|
||||
patches=self._clip_lora_iterator(context),
|
||||
prefix=FLUX_LORA_CLIP_PREFIX,
|
||||
prefix=FLUX_KOHYA_CLIP_PREFIX,
|
||||
cached_weights=cached_weights,
|
||||
)
|
||||
)
|
||||
|
||||
@@ -9,7 +9,6 @@ from invokeai.app.invocations.fields import FieldDescriptions, InputField, Outpu
|
||||
from invokeai.app.invocations.model import ModelIdentifierField
|
||||
from invokeai.app.invocations.primitives import ImageField
|
||||
from invokeai.app.invocations.util import validate_begin_end_step, validate_weights
|
||||
from invokeai.app.services.model_records.model_records_base import ModelRecordChanges
|
||||
from invokeai.app.services.shared.invocation_context import InvocationContext
|
||||
from invokeai.backend.model_manager.config import (
|
||||
AnyModelConfig,
|
||||
@@ -18,12 +17,6 @@ from invokeai.backend.model_manager.config import (
|
||||
IPAdapterInvokeAIConfig,
|
||||
ModelType,
|
||||
)
|
||||
from invokeai.backend.model_manager.starter_models import (
|
||||
StarterModel,
|
||||
clip_vit_l_image_encoder,
|
||||
ip_adapter_sd_image_encoder,
|
||||
ip_adapter_sdxl_image_encoder,
|
||||
)
|
||||
|
||||
|
||||
class IPAdapterField(BaseModel):
|
||||
@@ -62,14 +55,10 @@ class IPAdapterOutput(BaseInvocationOutput):
|
||||
ip_adapter: IPAdapterField = OutputField(description=FieldDescriptions.ip_adapter, title="IP-Adapter")
|
||||
|
||||
|
||||
CLIP_VISION_MODEL_MAP: dict[Literal["ViT-L", "ViT-H", "ViT-G"], StarterModel] = {
|
||||
"ViT-L": clip_vit_l_image_encoder,
|
||||
"ViT-H": ip_adapter_sd_image_encoder,
|
||||
"ViT-G": ip_adapter_sdxl_image_encoder,
|
||||
}
|
||||
CLIP_VISION_MODEL_MAP = {"ViT-H": "ip_adapter_sd_image_encoder", "ViT-G": "ip_adapter_sdxl_image_encoder"}
|
||||
|
||||
|
||||
@invocation("ip_adapter", title="IP-Adapter", tags=["ip_adapter", "control"], category="ip_adapter", version="1.5.0")
|
||||
@invocation("ip_adapter", title="IP-Adapter", tags=["ip_adapter", "control"], category="ip_adapter", version="1.4.1")
|
||||
class IPAdapterInvocation(BaseInvocation):
|
||||
"""Collects IP-Adapter info to pass to other nodes."""
|
||||
|
||||
@@ -81,7 +70,7 @@ class IPAdapterInvocation(BaseInvocation):
|
||||
ui_order=-1,
|
||||
ui_type=UIType.IPAdapterModel,
|
||||
)
|
||||
clip_vision_model: Literal["ViT-H", "ViT-G", "ViT-L"] = InputField(
|
||||
clip_vision_model: Literal["ViT-H", "ViT-G"] = InputField(
|
||||
description="CLIP Vision model to use. Overrides model settings. Mandatory for checkpoint models.",
|
||||
default="ViT-H",
|
||||
ui_order=2,
|
||||
@@ -122,11 +111,9 @@ class IPAdapterInvocation(BaseInvocation):
|
||||
image_encoder_model_id = ip_adapter_info.image_encoder_model_id
|
||||
image_encoder_model_name = image_encoder_model_id.split("/")[-1].strip()
|
||||
else:
|
||||
image_encoder_starter_model = CLIP_VISION_MODEL_MAP[self.clip_vision_model]
|
||||
image_encoder_model_id = image_encoder_starter_model.source
|
||||
image_encoder_model_name = image_encoder_starter_model.name
|
||||
image_encoder_model_name = CLIP_VISION_MODEL_MAP[self.clip_vision_model]
|
||||
|
||||
image_encoder_model = self.get_clip_image_encoder(context, image_encoder_model_id, image_encoder_model_name)
|
||||
image_encoder_model = self._get_image_encoder(context, image_encoder_model_name)
|
||||
|
||||
if self.method == "style":
|
||||
if ip_adapter_info.base == "sd-1":
|
||||
@@ -160,10 +147,7 @@ class IPAdapterInvocation(BaseInvocation):
|
||||
),
|
||||
)
|
||||
|
||||
@classmethod
|
||||
def get_clip_image_encoder(
|
||||
cls, context: InvocationContext, image_encoder_model_id: str, image_encoder_model_name: str
|
||||
) -> AnyModelConfig:
|
||||
def _get_image_encoder(self, context: InvocationContext, image_encoder_model_name: str) -> AnyModelConfig:
|
||||
image_encoder_models = context.models.search_by_attrs(
|
||||
name=image_encoder_model_name, base=BaseModelType.Any, type=ModelType.CLIPVision
|
||||
)
|
||||
@@ -175,11 +159,7 @@ class IPAdapterInvocation(BaseInvocation):
|
||||
)
|
||||
|
||||
installer = context._services.model_manager.install
|
||||
# Note: We hard-code the type to CLIPVision here because if the model contains both a CLIPVision and a
|
||||
# CLIPText model, the probe may treat it as a CLIPText model.
|
||||
job = installer.heuristic_import(
|
||||
image_encoder_model_id, ModelRecordChanges(name=image_encoder_model_name, type=ModelType.CLIPVision)
|
||||
)
|
||||
job = installer.heuristic_import(f"InvokeAI/{image_encoder_model_name}")
|
||||
installer.wait_for_job(job, timeout=600) # Wait for up to 10 minutes
|
||||
image_encoder_models = context.models.search_by_attrs(
|
||||
name=image_encoder_model_name, base=BaseModelType.Any, type=ModelType.CLIPVision
|
||||
|
||||
@@ -5,7 +5,6 @@ from PIL import Image
|
||||
from invokeai.app.invocations.baseinvocation import BaseInvocation, Classification, InvocationContext, invocation
|
||||
from invokeai.app.invocations.fields import ImageField, InputField, TensorField, WithBoard, WithMetadata
|
||||
from invokeai.app.invocations.primitives import ImageOutput, MaskOutput
|
||||
from invokeai.backend.image_util.util import pil_to_np
|
||||
|
||||
|
||||
@invocation(
|
||||
@@ -149,55 +148,3 @@ class MaskTensorToImageInvocation(BaseInvocation, WithMetadata, WithBoard):
|
||||
mask_pil = Image.fromarray(mask_np, mode="L")
|
||||
image_dto = context.images.save(image=mask_pil)
|
||||
return ImageOutput.build(image_dto)
|
||||
|
||||
|
||||
@invocation(
|
||||
"apply_tensor_mask_to_image",
|
||||
title="Apply Tensor Mask to Image",
|
||||
tags=["mask"],
|
||||
category="mask",
|
||||
version="1.0.0",
|
||||
)
|
||||
class ApplyMaskTensorToImageInvocation(BaseInvocation, WithMetadata, WithBoard):
|
||||
"""Applies a tensor mask to an image.
|
||||
|
||||
The image is converted to RGBA and the mask is applied to the alpha channel."""
|
||||
|
||||
mask: TensorField = InputField(description="The mask tensor to apply.")
|
||||
image: ImageField = InputField(description="The image to apply the mask to.")
|
||||
invert: bool = InputField(default=False, description="Whether to invert the mask.")
|
||||
|
||||
def invoke(self, context: InvocationContext) -> ImageOutput:
|
||||
image = context.images.get_pil(self.image.image_name, mode="RGBA")
|
||||
mask = context.tensors.load(self.mask.tensor_name)
|
||||
|
||||
# Squeeze the channel dimension if it exists.
|
||||
if mask.dim() == 3:
|
||||
mask = mask.squeeze(0)
|
||||
|
||||
# Ensure that the mask is binary.
|
||||
if mask.dtype != torch.bool:
|
||||
mask = mask > 0.5
|
||||
mask_np = (mask.float() * 255).byte().cpu().numpy().astype(np.uint8)
|
||||
|
||||
if self.invert:
|
||||
mask_np = 255 - mask_np
|
||||
|
||||
# Apply the mask only to the alpha channel where the original alpha is non-zero. This preserves the original
|
||||
# image's transparency - else the transparent regions would end up as opaque black.
|
||||
|
||||
# Separate the image into R, G, B, and A channels
|
||||
image_np = pil_to_np(image)
|
||||
r, g, b, a = np.split(image_np, 4, axis=-1)
|
||||
|
||||
# Apply the mask to the alpha channel
|
||||
new_alpha = np.where(a.squeeze() > 0, mask_np, a.squeeze())
|
||||
|
||||
# Stack the RGB channels with the modified alpha
|
||||
masked_image_np = np.dstack([r.squeeze(), g.squeeze(), b.squeeze(), new_alpha])
|
||||
|
||||
# Convert back to an image (RGBA)
|
||||
masked_image = Image.fromarray(masked_image_np.astype(np.uint8), "RGBA")
|
||||
image_dto = context.images.save(image=masked_image)
|
||||
|
||||
return ImageOutput.build(image_dto)
|
||||
|
||||
@@ -40,7 +40,7 @@ class IPAdapterMetadataField(BaseModel):
|
||||
|
||||
image: ImageField = Field(description="The IP-Adapter image prompt.")
|
||||
ip_adapter_model: ModelIdentifierField = Field(description="The IP-Adapter model.")
|
||||
clip_vision_model: Literal["ViT-L", "ViT-H", "ViT-G"] = Field(description="The CLIP Vision model")
|
||||
clip_vision_model: Literal["ViT-H", "ViT-G"] = Field(description="The CLIP Vision model")
|
||||
method: Literal["full", "style", "composition"] = Field(description="Method to apply IP Weights with")
|
||||
weight: Union[float, list[float]] = Field(description="The weight given to the IP-Adapter")
|
||||
begin_step_percent: float = Field(description="When the IP-Adapter is first applied (% of total steps)")
|
||||
|
||||
@@ -1,5 +1,5 @@
|
||||
import copy
|
||||
from typing import List, Optional
|
||||
from typing import List, Literal, Optional
|
||||
|
||||
from pydantic import BaseModel, Field
|
||||
|
||||
@@ -13,9 +13,11 @@ from invokeai.app.invocations.baseinvocation import (
|
||||
from invokeai.app.invocations.fields import FieldDescriptions, Input, InputField, OutputField, UIType
|
||||
from invokeai.app.services.shared.invocation_context import InvocationContext
|
||||
from invokeai.app.shared.models import FreeUConfig
|
||||
from invokeai.backend.flux.util import max_seq_lengths
|
||||
from invokeai.backend.model_manager.config import (
|
||||
AnyModelConfig,
|
||||
BaseModelType,
|
||||
CheckpointConfigBase,
|
||||
ModelType,
|
||||
SubModelType,
|
||||
)
|
||||
@@ -137,6 +139,78 @@ class ModelIdentifierInvocation(BaseInvocation):
|
||||
return ModelIdentifierOutput(model=self.model)
|
||||
|
||||
|
||||
@invocation_output("flux_model_loader_output")
|
||||
class FluxModelLoaderOutput(BaseInvocationOutput):
|
||||
"""Flux base model loader output"""
|
||||
|
||||
transformer: TransformerField = OutputField(description=FieldDescriptions.transformer, title="Transformer")
|
||||
clip: CLIPField = OutputField(description=FieldDescriptions.clip, title="CLIP")
|
||||
t5_encoder: T5EncoderField = OutputField(description=FieldDescriptions.t5_encoder, title="T5 Encoder")
|
||||
vae: VAEField = OutputField(description=FieldDescriptions.vae, title="VAE")
|
||||
max_seq_len: Literal[256, 512] = OutputField(
|
||||
description="The max sequence length to used for the T5 encoder. (256 for schnell transformer, 512 for dev transformer)",
|
||||
title="Max Seq Length",
|
||||
)
|
||||
|
||||
|
||||
@invocation(
|
||||
"flux_model_loader",
|
||||
title="Flux Main Model",
|
||||
tags=["model", "flux"],
|
||||
category="model",
|
||||
version="1.0.4",
|
||||
classification=Classification.Prototype,
|
||||
)
|
||||
class FluxModelLoaderInvocation(BaseInvocation):
|
||||
"""Loads a flux base model, outputting its submodels."""
|
||||
|
||||
model: ModelIdentifierField = InputField(
|
||||
description=FieldDescriptions.flux_model,
|
||||
ui_type=UIType.FluxMainModel,
|
||||
input=Input.Direct,
|
||||
)
|
||||
|
||||
t5_encoder_model: ModelIdentifierField = InputField(
|
||||
description=FieldDescriptions.t5_encoder, ui_type=UIType.T5EncoderModel, input=Input.Direct, title="T5 Encoder"
|
||||
)
|
||||
|
||||
clip_embed_model: ModelIdentifierField = InputField(
|
||||
description=FieldDescriptions.clip_embed_model,
|
||||
ui_type=UIType.CLIPEmbedModel,
|
||||
input=Input.Direct,
|
||||
title="CLIP Embed",
|
||||
)
|
||||
|
||||
vae_model: ModelIdentifierField = InputField(
|
||||
description=FieldDescriptions.vae_model, ui_type=UIType.FluxVAEModel, title="VAE"
|
||||
)
|
||||
|
||||
def invoke(self, context: InvocationContext) -> FluxModelLoaderOutput:
|
||||
for key in [self.model.key, self.t5_encoder_model.key, self.clip_embed_model.key, self.vae_model.key]:
|
||||
if not context.models.exists(key):
|
||||
raise ValueError(f"Unknown model: {key}")
|
||||
|
||||
transformer = self.model.model_copy(update={"submodel_type": SubModelType.Transformer})
|
||||
vae = self.vae_model.model_copy(update={"submodel_type": SubModelType.VAE})
|
||||
|
||||
tokenizer = self.clip_embed_model.model_copy(update={"submodel_type": SubModelType.Tokenizer})
|
||||
clip_encoder = self.clip_embed_model.model_copy(update={"submodel_type": SubModelType.TextEncoder})
|
||||
|
||||
tokenizer2 = self.t5_encoder_model.model_copy(update={"submodel_type": SubModelType.Tokenizer2})
|
||||
t5_encoder = self.t5_encoder_model.model_copy(update={"submodel_type": SubModelType.TextEncoder2})
|
||||
|
||||
transformer_config = context.models.get_config(transformer)
|
||||
assert isinstance(transformer_config, CheckpointConfigBase)
|
||||
|
||||
return FluxModelLoaderOutput(
|
||||
transformer=TransformerField(transformer=transformer, loras=[]),
|
||||
clip=CLIPField(tokenizer=tokenizer, text_encoder=clip_encoder, loras=[], skipped_layers=0),
|
||||
t5_encoder=T5EncoderField(tokenizer=tokenizer2, text_encoder=t5_encoder),
|
||||
vae=VAEField(vae=vae),
|
||||
max_seq_len=max_seq_lengths[transformer_config.config_path],
|
||||
)
|
||||
|
||||
|
||||
@invocation(
|
||||
"main_model_loader",
|
||||
title="Main Model",
|
||||
|
||||
@@ -18,7 +18,6 @@ from invokeai.app.invocations.fields import (
|
||||
InputField,
|
||||
LatentsField,
|
||||
OutputField,
|
||||
SD3ConditioningField,
|
||||
TensorField,
|
||||
UIComponent,
|
||||
)
|
||||
@@ -427,17 +426,6 @@ class FluxConditioningOutput(BaseInvocationOutput):
|
||||
return cls(conditioning=FluxConditioningField(conditioning_name=conditioning_name))
|
||||
|
||||
|
||||
@invocation_output("sd3_conditioning_output")
|
||||
class SD3ConditioningOutput(BaseInvocationOutput):
|
||||
"""Base class for nodes that output a single SD3 conditioning tensor"""
|
||||
|
||||
conditioning: SD3ConditioningField = OutputField(description=FieldDescriptions.cond)
|
||||
|
||||
@classmethod
|
||||
def build(cls, conditioning_name: str) -> "SD3ConditioningOutput":
|
||||
return cls(conditioning=SD3ConditioningField(conditioning_name=conditioning_name))
|
||||
|
||||
|
||||
@invocation_output("conditioning_output")
|
||||
class ConditioningOutput(BaseInvocationOutput):
|
||||
"""Base class for nodes that output a single conditioning tensor"""
|
||||
|
||||
@@ -1,260 +0,0 @@
|
||||
from typing import Callable, Tuple
|
||||
|
||||
import torch
|
||||
from diffusers.models.transformers.transformer_sd3 import SD3Transformer2DModel
|
||||
from diffusers.schedulers.scheduling_flow_match_euler_discrete import FlowMatchEulerDiscreteScheduler
|
||||
from tqdm import tqdm
|
||||
|
||||
from invokeai.app.invocations.baseinvocation import BaseInvocation, Classification, invocation
|
||||
from invokeai.app.invocations.constants import LATENT_SCALE_FACTOR
|
||||
from invokeai.app.invocations.fields import (
|
||||
FieldDescriptions,
|
||||
Input,
|
||||
InputField,
|
||||
SD3ConditioningField,
|
||||
WithBoard,
|
||||
WithMetadata,
|
||||
)
|
||||
from invokeai.app.invocations.model import TransformerField
|
||||
from invokeai.app.invocations.primitives import LatentsOutput
|
||||
from invokeai.app.invocations.sd3_text_encoder import SD3_T5_MAX_SEQ_LEN
|
||||
from invokeai.app.services.shared.invocation_context import InvocationContext
|
||||
from invokeai.backend.model_manager.config import BaseModelType
|
||||
from invokeai.backend.stable_diffusion.diffusers_pipeline import PipelineIntermediateState
|
||||
from invokeai.backend.stable_diffusion.diffusion.conditioning_data import SD3ConditioningInfo
|
||||
from invokeai.backend.util.devices import TorchDevice
|
||||
|
||||
|
||||
@invocation(
|
||||
"sd3_denoise",
|
||||
title="SD3 Denoise",
|
||||
tags=["image", "sd3"],
|
||||
category="image",
|
||||
version="1.0.0",
|
||||
classification=Classification.Prototype,
|
||||
)
|
||||
class SD3DenoiseInvocation(BaseInvocation, WithMetadata, WithBoard):
|
||||
"""Run denoising process with a SD3 model."""
|
||||
|
||||
transformer: TransformerField = InputField(
|
||||
description=FieldDescriptions.sd3_model,
|
||||
input=Input.Connection,
|
||||
title="Transformer",
|
||||
)
|
||||
positive_conditioning: SD3ConditioningField = InputField(
|
||||
description=FieldDescriptions.positive_cond, input=Input.Connection
|
||||
)
|
||||
negative_conditioning: SD3ConditioningField = InputField(
|
||||
description=FieldDescriptions.negative_cond, input=Input.Connection
|
||||
)
|
||||
cfg_scale: float | list[float] = InputField(default=3.5, description=FieldDescriptions.cfg_scale, title="CFG Scale")
|
||||
width: int = InputField(default=1024, multiple_of=16, description="Width of the generated image.")
|
||||
height: int = InputField(default=1024, multiple_of=16, description="Height of the generated image.")
|
||||
steps: int = InputField(default=10, gt=0, description=FieldDescriptions.steps)
|
||||
seed: int = InputField(default=0, description="Randomness seed for reproducibility.")
|
||||
|
||||
@torch.no_grad()
|
||||
def invoke(self, context: InvocationContext) -> LatentsOutput:
|
||||
latents = self._run_diffusion(context)
|
||||
latents = latents.detach().to("cpu")
|
||||
|
||||
name = context.tensors.save(tensor=latents)
|
||||
return LatentsOutput.build(latents_name=name, latents=latents, seed=None)
|
||||
|
||||
def _load_text_conditioning(
|
||||
self,
|
||||
context: InvocationContext,
|
||||
conditioning_name: str,
|
||||
joint_attention_dim: int,
|
||||
dtype: torch.dtype,
|
||||
device: torch.device,
|
||||
) -> Tuple[torch.Tensor, torch.Tensor]:
|
||||
# Load the conditioning data.
|
||||
cond_data = context.conditioning.load(conditioning_name)
|
||||
assert len(cond_data.conditionings) == 1
|
||||
sd3_conditioning = cond_data.conditionings[0]
|
||||
assert isinstance(sd3_conditioning, SD3ConditioningInfo)
|
||||
sd3_conditioning = sd3_conditioning.to(dtype=dtype, device=device)
|
||||
|
||||
t5_embeds = sd3_conditioning.t5_embeds
|
||||
if t5_embeds is None:
|
||||
t5_embeds = torch.zeros(
|
||||
(1, SD3_T5_MAX_SEQ_LEN, joint_attention_dim),
|
||||
device=device,
|
||||
dtype=dtype,
|
||||
)
|
||||
|
||||
clip_prompt_embeds = torch.cat([sd3_conditioning.clip_l_embeds, sd3_conditioning.clip_g_embeds], dim=-1)
|
||||
clip_prompt_embeds = torch.nn.functional.pad(
|
||||
clip_prompt_embeds, (0, t5_embeds.shape[-1] - clip_prompt_embeds.shape[-1])
|
||||
)
|
||||
|
||||
prompt_embeds = torch.cat([clip_prompt_embeds, t5_embeds], dim=-2)
|
||||
pooled_prompt_embeds = torch.cat(
|
||||
[sd3_conditioning.clip_l_pooled_embeds, sd3_conditioning.clip_g_pooled_embeds], dim=-1
|
||||
)
|
||||
|
||||
return prompt_embeds, pooled_prompt_embeds
|
||||
|
||||
def _get_noise(
|
||||
self,
|
||||
num_samples: int,
|
||||
num_channels_latents: int,
|
||||
height: int,
|
||||
width: int,
|
||||
dtype: torch.dtype,
|
||||
device: torch.device,
|
||||
seed: int,
|
||||
) -> torch.Tensor:
|
||||
# We always generate noise on the same device and dtype then cast to ensure consistency across devices/dtypes.
|
||||
rand_device = "cpu"
|
||||
rand_dtype = torch.float16
|
||||
|
||||
return torch.randn(
|
||||
num_samples,
|
||||
num_channels_latents,
|
||||
int(height) // LATENT_SCALE_FACTOR,
|
||||
int(width) // LATENT_SCALE_FACTOR,
|
||||
device=rand_device,
|
||||
dtype=rand_dtype,
|
||||
generator=torch.Generator(device=rand_device).manual_seed(seed),
|
||||
).to(device=device, dtype=dtype)
|
||||
|
||||
def _prepare_cfg_scale(self, num_timesteps: int) -> list[float]:
|
||||
"""Prepare the CFG scale list.
|
||||
|
||||
Args:
|
||||
num_timesteps (int): The number of timesteps in the scheduler. Could be different from num_steps depending
|
||||
on the scheduler used (e.g. higher order schedulers).
|
||||
|
||||
Returns:
|
||||
list[float]: _description_
|
||||
"""
|
||||
if isinstance(self.cfg_scale, float):
|
||||
cfg_scale = [self.cfg_scale] * num_timesteps
|
||||
elif isinstance(self.cfg_scale, list):
|
||||
assert len(self.cfg_scale) == num_timesteps
|
||||
cfg_scale = self.cfg_scale
|
||||
else:
|
||||
raise ValueError(f"Invalid CFG scale type: {type(self.cfg_scale)}")
|
||||
|
||||
return cfg_scale
|
||||
|
||||
def _run_diffusion(
|
||||
self,
|
||||
context: InvocationContext,
|
||||
):
|
||||
inference_dtype = TorchDevice.choose_torch_dtype()
|
||||
device = TorchDevice.choose_torch_device()
|
||||
|
||||
transformer_info = context.models.load(self.transformer.transformer)
|
||||
|
||||
# Load/process the conditioning data.
|
||||
# TODO(ryand): Make CFG optional.
|
||||
do_classifier_free_guidance = True
|
||||
pos_prompt_embeds, pos_pooled_prompt_embeds = self._load_text_conditioning(
|
||||
context=context,
|
||||
conditioning_name=self.positive_conditioning.conditioning_name,
|
||||
joint_attention_dim=transformer_info.model.config.joint_attention_dim,
|
||||
dtype=inference_dtype,
|
||||
device=device,
|
||||
)
|
||||
neg_prompt_embeds, neg_pooled_prompt_embeds = self._load_text_conditioning(
|
||||
context=context,
|
||||
conditioning_name=self.negative_conditioning.conditioning_name,
|
||||
joint_attention_dim=transformer_info.model.config.joint_attention_dim,
|
||||
dtype=inference_dtype,
|
||||
device=device,
|
||||
)
|
||||
# TODO(ryand): Support both sequential and batched CFG inference.
|
||||
prompt_embeds = torch.cat([neg_prompt_embeds, pos_prompt_embeds], dim=0)
|
||||
pooled_prompt_embeds = torch.cat([neg_pooled_prompt_embeds, pos_pooled_prompt_embeds], dim=0)
|
||||
|
||||
# Prepare the scheduler.
|
||||
scheduler = FlowMatchEulerDiscreteScheduler()
|
||||
scheduler.set_timesteps(num_inference_steps=self.steps, device=device)
|
||||
timesteps = scheduler.timesteps
|
||||
assert isinstance(timesteps, torch.Tensor)
|
||||
|
||||
# Prepare the CFG scale list.
|
||||
cfg_scale = self._prepare_cfg_scale(len(timesteps))
|
||||
|
||||
# Generate initial latent noise.
|
||||
num_channels_latents = transformer_info.model.config.in_channels
|
||||
assert isinstance(num_channels_latents, int)
|
||||
noise = self._get_noise(
|
||||
num_samples=1,
|
||||
num_channels_latents=num_channels_latents,
|
||||
height=self.height,
|
||||
width=self.width,
|
||||
dtype=inference_dtype,
|
||||
device=device,
|
||||
seed=self.seed,
|
||||
)
|
||||
latents: torch.Tensor = noise
|
||||
|
||||
total_steps = len(timesteps)
|
||||
step_callback = self._build_step_callback(context)
|
||||
|
||||
step_callback(
|
||||
PipelineIntermediateState(
|
||||
step=0,
|
||||
order=1,
|
||||
total_steps=total_steps,
|
||||
timestep=int(timesteps[0]),
|
||||
latents=latents,
|
||||
),
|
||||
)
|
||||
|
||||
with transformer_info.model_on_device() as (cached_weights, transformer):
|
||||
assert isinstance(transformer, SD3Transformer2DModel)
|
||||
|
||||
# 6. Denoising loop
|
||||
for step_idx, t in tqdm(list(enumerate(timesteps))):
|
||||
# Expand the latents if we are doing CFG.
|
||||
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
|
||||
# Expand the timestep to match the latent model input.
|
||||
timestep = t.expand(latent_model_input.shape[0])
|
||||
|
||||
noise_pred = transformer(
|
||||
hidden_states=latent_model_input,
|
||||
timestep=timestep,
|
||||
encoder_hidden_states=prompt_embeds,
|
||||
pooled_projections=pooled_prompt_embeds,
|
||||
joint_attention_kwargs=None,
|
||||
return_dict=False,
|
||||
)[0]
|
||||
|
||||
# Apply CFG.
|
||||
if do_classifier_free_guidance:
|
||||
noise_pred_uncond, noise_pred_cond = noise_pred.chunk(2)
|
||||
noise_pred = noise_pred_uncond + cfg_scale[step_idx] * (noise_pred_cond - noise_pred_uncond)
|
||||
|
||||
# Compute the previous noisy sample x_t -> x_t-1.
|
||||
latents_dtype = latents.dtype
|
||||
latents = scheduler.step(model_output=noise_pred, timestep=t, sample=latents, return_dict=False)[0]
|
||||
|
||||
# TODO(ryand): This MPS dtype handling was copied from diffusers, I haven't tested to see if it's
|
||||
# needed.
|
||||
if latents.dtype != latents_dtype:
|
||||
if torch.backends.mps.is_available():
|
||||
# some platforms (eg. apple mps) misbehave due to a pytorch bug: https://github.com/pytorch/pytorch/pull/99272
|
||||
latents = latents.to(latents_dtype)
|
||||
|
||||
step_callback(
|
||||
PipelineIntermediateState(
|
||||
step=step_idx + 1,
|
||||
order=1,
|
||||
total_steps=total_steps,
|
||||
timestep=int(t),
|
||||
latents=latents,
|
||||
),
|
||||
)
|
||||
|
||||
return latents
|
||||
|
||||
def _build_step_callback(self, context: InvocationContext) -> Callable[[PipelineIntermediateState], None]:
|
||||
def step_callback(state: PipelineIntermediateState) -> None:
|
||||
context.util.sd_step_callback(state, BaseModelType.StableDiffusion3)
|
||||
|
||||
return step_callback
|
||||
@@ -1,73 +0,0 @@
|
||||
from contextlib import nullcontext
|
||||
|
||||
import torch
|
||||
from diffusers.models.autoencoders.autoencoder_kl import AutoencoderKL
|
||||
from einops import rearrange
|
||||
from PIL import Image
|
||||
|
||||
from invokeai.app.invocations.baseinvocation import BaseInvocation, invocation
|
||||
from invokeai.app.invocations.fields import (
|
||||
FieldDescriptions,
|
||||
Input,
|
||||
InputField,
|
||||
LatentsField,
|
||||
WithBoard,
|
||||
WithMetadata,
|
||||
)
|
||||
from invokeai.app.invocations.model import VAEField
|
||||
from invokeai.app.invocations.primitives import ImageOutput
|
||||
from invokeai.app.services.shared.invocation_context import InvocationContext
|
||||
from invokeai.backend.stable_diffusion.extensions.seamless import SeamlessExt
|
||||
from invokeai.backend.util.devices import TorchDevice
|
||||
|
||||
|
||||
@invocation(
|
||||
"sd3_l2i",
|
||||
title="SD3 Latents to Image",
|
||||
tags=["latents", "image", "vae", "l2i", "sd3"],
|
||||
category="latents",
|
||||
version="1.3.0",
|
||||
)
|
||||
class SD3LatentsToImageInvocation(BaseInvocation, WithMetadata, WithBoard):
|
||||
"""Generates an image from latents."""
|
||||
|
||||
latents: LatentsField = InputField(
|
||||
description=FieldDescriptions.latents,
|
||||
input=Input.Connection,
|
||||
)
|
||||
vae: VAEField = InputField(
|
||||
description=FieldDescriptions.vae,
|
||||
input=Input.Connection,
|
||||
)
|
||||
|
||||
@torch.no_grad()
|
||||
def invoke(self, context: InvocationContext) -> ImageOutput:
|
||||
latents = context.tensors.load(self.latents.latents_name)
|
||||
|
||||
vae_info = context.models.load(self.vae.vae)
|
||||
assert isinstance(vae_info.model, (AutoencoderKL))
|
||||
with SeamlessExt.static_patch_model(vae_info.model, self.vae.seamless_axes), vae_info as vae:
|
||||
assert isinstance(vae, (AutoencoderKL))
|
||||
latents = latents.to(vae.device)
|
||||
|
||||
vae.disable_tiling()
|
||||
|
||||
tiling_context = nullcontext()
|
||||
|
||||
# clear memory as vae decode can request a lot
|
||||
TorchDevice.empty_cache()
|
||||
|
||||
with torch.inference_mode(), tiling_context:
|
||||
# copied from diffusers pipeline
|
||||
latents = latents / vae.config.scaling_factor
|
||||
img = vae.decode(latents, return_dict=False)[0]
|
||||
|
||||
img = img.clamp(-1, 1)
|
||||
img = rearrange(img[0], "c h w -> h w c") # noqa: F821
|
||||
img_pil = Image.fromarray((127.5 * (img + 1.0)).byte().cpu().numpy())
|
||||
|
||||
TorchDevice.empty_cache()
|
||||
|
||||
image_dto = context.images.save(image=img_pil)
|
||||
|
||||
return ImageOutput.build(image_dto)
|
||||
@@ -1,108 +0,0 @@
|
||||
from typing import Optional
|
||||
|
||||
from invokeai.app.invocations.baseinvocation import (
|
||||
BaseInvocation,
|
||||
BaseInvocationOutput,
|
||||
Classification,
|
||||
invocation,
|
||||
invocation_output,
|
||||
)
|
||||
from invokeai.app.invocations.fields import FieldDescriptions, Input, InputField, OutputField, UIType
|
||||
from invokeai.app.invocations.model import CLIPField, ModelIdentifierField, T5EncoderField, TransformerField, VAEField
|
||||
from invokeai.app.services.shared.invocation_context import InvocationContext
|
||||
from invokeai.backend.model_manager.config import SubModelType
|
||||
|
||||
|
||||
@invocation_output("sd3_model_loader_output")
|
||||
class Sd3ModelLoaderOutput(BaseInvocationOutput):
|
||||
"""SD3 base model loader output."""
|
||||
|
||||
transformer: TransformerField = OutputField(description=FieldDescriptions.transformer, title="Transformer")
|
||||
clip_l: CLIPField = OutputField(description=FieldDescriptions.clip, title="CLIP L")
|
||||
clip_g: CLIPField = OutputField(description=FieldDescriptions.clip, title="CLIP G")
|
||||
t5_encoder: T5EncoderField = OutputField(description=FieldDescriptions.t5_encoder, title="T5 Encoder")
|
||||
vae: VAEField = OutputField(description=FieldDescriptions.vae, title="VAE")
|
||||
|
||||
|
||||
@invocation(
|
||||
"sd3_model_loader",
|
||||
title="SD3 Main Model",
|
||||
tags=["model", "sd3"],
|
||||
category="model",
|
||||
version="1.0.0",
|
||||
classification=Classification.Prototype,
|
||||
)
|
||||
class Sd3ModelLoaderInvocation(BaseInvocation):
|
||||
"""Loads a SD3 base model, outputting its submodels."""
|
||||
|
||||
model: ModelIdentifierField = InputField(
|
||||
description=FieldDescriptions.sd3_model,
|
||||
ui_type=UIType.SD3MainModel,
|
||||
input=Input.Direct,
|
||||
)
|
||||
|
||||
t5_encoder_model: Optional[ModelIdentifierField] = InputField(
|
||||
description=FieldDescriptions.t5_encoder,
|
||||
ui_type=UIType.T5EncoderModel,
|
||||
input=Input.Direct,
|
||||
title="T5 Encoder",
|
||||
default=None,
|
||||
)
|
||||
|
||||
clip_l_model: Optional[ModelIdentifierField] = InputField(
|
||||
description=FieldDescriptions.clip_embed_model,
|
||||
ui_type=UIType.CLIPLEmbedModel,
|
||||
input=Input.Direct,
|
||||
title="CLIP L Encoder",
|
||||
default=None,
|
||||
)
|
||||
|
||||
clip_g_model: Optional[ModelIdentifierField] = InputField(
|
||||
description=FieldDescriptions.clip_g_model,
|
||||
ui_type=UIType.CLIPGEmbedModel,
|
||||
input=Input.Direct,
|
||||
title="CLIP G Encoder",
|
||||
default=None,
|
||||
)
|
||||
|
||||
vae_model: Optional[ModelIdentifierField] = InputField(
|
||||
description=FieldDescriptions.vae_model, ui_type=UIType.VAEModel, title="VAE", default=None
|
||||
)
|
||||
|
||||
def invoke(self, context: InvocationContext) -> Sd3ModelLoaderOutput:
|
||||
transformer = self.model.model_copy(update={"submodel_type": SubModelType.Transformer})
|
||||
vae = (
|
||||
self.vae_model.model_copy(update={"submodel_type": SubModelType.VAE})
|
||||
if self.vae_model
|
||||
else self.model.model_copy(update={"submodel_type": SubModelType.VAE})
|
||||
)
|
||||
tokenizer_l = self.model.model_copy(update={"submodel_type": SubModelType.Tokenizer})
|
||||
clip_encoder_l = (
|
||||
self.clip_l_model.model_copy(update={"submodel_type": SubModelType.TextEncoder})
|
||||
if self.clip_l_model
|
||||
else self.model.model_copy(update={"submodel_type": SubModelType.TextEncoder})
|
||||
)
|
||||
tokenizer_g = self.model.model_copy(update={"submodel_type": SubModelType.Tokenizer2})
|
||||
clip_encoder_g = (
|
||||
self.clip_g_model.model_copy(update={"submodel_type": SubModelType.TextEncoder2})
|
||||
if self.clip_g_model
|
||||
else self.model.model_copy(update={"submodel_type": SubModelType.TextEncoder2})
|
||||
)
|
||||
tokenizer_t5 = (
|
||||
self.t5_encoder_model.model_copy(update={"submodel_type": SubModelType.Tokenizer3})
|
||||
if self.t5_encoder_model
|
||||
else self.model.model_copy(update={"submodel_type": SubModelType.Tokenizer3})
|
||||
)
|
||||
t5_encoder = (
|
||||
self.t5_encoder_model.model_copy(update={"submodel_type": SubModelType.TextEncoder3})
|
||||
if self.t5_encoder_model
|
||||
else self.model.model_copy(update={"submodel_type": SubModelType.TextEncoder3})
|
||||
)
|
||||
|
||||
return Sd3ModelLoaderOutput(
|
||||
transformer=TransformerField(transformer=transformer, loras=[]),
|
||||
clip_l=CLIPField(tokenizer=tokenizer_l, text_encoder=clip_encoder_l, loras=[], skipped_layers=0),
|
||||
clip_g=CLIPField(tokenizer=tokenizer_g, text_encoder=clip_encoder_g, loras=[], skipped_layers=0),
|
||||
t5_encoder=T5EncoderField(tokenizer=tokenizer_t5, text_encoder=t5_encoder),
|
||||
vae=VAEField(vae=vae),
|
||||
)
|
||||
@@ -1,199 +0,0 @@
|
||||
from contextlib import ExitStack
|
||||
from typing import Iterator, Tuple
|
||||
|
||||
import torch
|
||||
from transformers import (
|
||||
CLIPTextModel,
|
||||
CLIPTextModelWithProjection,
|
||||
CLIPTokenizer,
|
||||
T5EncoderModel,
|
||||
T5Tokenizer,
|
||||
T5TokenizerFast,
|
||||
)
|
||||
|
||||
from invokeai.app.invocations.baseinvocation import BaseInvocation, Classification, invocation
|
||||
from invokeai.app.invocations.fields import FieldDescriptions, Input, InputField
|
||||
from invokeai.app.invocations.model import CLIPField, T5EncoderField
|
||||
from invokeai.app.invocations.primitives import SD3ConditioningOutput
|
||||
from invokeai.app.services.shared.invocation_context import InvocationContext
|
||||
from invokeai.backend.lora.conversions.flux_lora_constants import FLUX_LORA_CLIP_PREFIX
|
||||
from invokeai.backend.lora.lora_model_raw import LoRAModelRaw
|
||||
from invokeai.backend.lora.lora_patcher import LoRAPatcher
|
||||
from invokeai.backend.model_manager.config import ModelFormat
|
||||
from invokeai.backend.stable_diffusion.diffusion.conditioning_data import ConditioningFieldData, SD3ConditioningInfo
|
||||
|
||||
# The SD3 T5 Max Sequence Length set based on the default in diffusers.
|
||||
SD3_T5_MAX_SEQ_LEN = 256
|
||||
|
||||
|
||||
@invocation(
|
||||
"sd3_text_encoder",
|
||||
title="SD3 Text Encoding",
|
||||
tags=["prompt", "conditioning", "sd3"],
|
||||
category="conditioning",
|
||||
version="1.0.0",
|
||||
classification=Classification.Prototype,
|
||||
)
|
||||
class Sd3TextEncoderInvocation(BaseInvocation):
|
||||
"""Encodes and preps a prompt for a SD3 image."""
|
||||
|
||||
clip_l: CLIPField = InputField(
|
||||
title="CLIP L",
|
||||
description=FieldDescriptions.clip,
|
||||
input=Input.Connection,
|
||||
)
|
||||
clip_g: CLIPField = InputField(
|
||||
title="CLIP G",
|
||||
description=FieldDescriptions.clip,
|
||||
input=Input.Connection,
|
||||
)
|
||||
|
||||
# The SD3 models were trained with text encoder dropout, so the T5 encoder can be omitted to save time/memory.
|
||||
t5_encoder: T5EncoderField | None = InputField(
|
||||
title="T5Encoder",
|
||||
default=None,
|
||||
description=FieldDescriptions.t5_encoder,
|
||||
input=Input.Connection,
|
||||
)
|
||||
prompt: str = InputField(description="Text prompt to encode.")
|
||||
|
||||
@torch.no_grad()
|
||||
def invoke(self, context: InvocationContext) -> SD3ConditioningOutput:
|
||||
# Note: The text encoding model are run in separate functions to ensure that all model references are locally
|
||||
# scoped. This ensures that earlier models can be freed and gc'd before loading later models (if necessary).
|
||||
|
||||
clip_l_embeddings, clip_l_pooled_embeddings = self._clip_encode(context, self.clip_l)
|
||||
clip_g_embeddings, clip_g_pooled_embeddings = self._clip_encode(context, self.clip_g)
|
||||
|
||||
t5_embeddings: torch.Tensor | None = None
|
||||
if self.t5_encoder is not None:
|
||||
t5_embeddings = self._t5_encode(context, SD3_T5_MAX_SEQ_LEN)
|
||||
|
||||
conditioning_data = ConditioningFieldData(
|
||||
conditionings=[
|
||||
SD3ConditioningInfo(
|
||||
clip_l_embeds=clip_l_embeddings,
|
||||
clip_l_pooled_embeds=clip_l_pooled_embeddings,
|
||||
clip_g_embeds=clip_g_embeddings,
|
||||
clip_g_pooled_embeds=clip_g_pooled_embeddings,
|
||||
t5_embeds=t5_embeddings,
|
||||
)
|
||||
]
|
||||
)
|
||||
|
||||
conditioning_name = context.conditioning.save(conditioning_data)
|
||||
return SD3ConditioningOutput.build(conditioning_name)
|
||||
|
||||
def _t5_encode(self, context: InvocationContext, max_seq_len: int) -> torch.Tensor:
|
||||
assert self.t5_encoder is not None
|
||||
t5_tokenizer_info = context.models.load(self.t5_encoder.tokenizer)
|
||||
t5_text_encoder_info = context.models.load(self.t5_encoder.text_encoder)
|
||||
|
||||
prompt = [self.prompt]
|
||||
|
||||
with (
|
||||
t5_text_encoder_info as t5_text_encoder,
|
||||
t5_tokenizer_info as t5_tokenizer,
|
||||
):
|
||||
assert isinstance(t5_text_encoder, T5EncoderModel)
|
||||
assert isinstance(t5_tokenizer, (T5Tokenizer, T5TokenizerFast))
|
||||
|
||||
text_inputs = t5_tokenizer(
|
||||
prompt,
|
||||
padding="max_length",
|
||||
max_length=max_seq_len,
|
||||
truncation=True,
|
||||
add_special_tokens=True,
|
||||
return_tensors="pt",
|
||||
)
|
||||
text_input_ids = text_inputs.input_ids
|
||||
untruncated_ids = t5_tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
|
||||
assert isinstance(text_input_ids, torch.Tensor)
|
||||
assert isinstance(untruncated_ids, torch.Tensor)
|
||||
if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
|
||||
text_input_ids, untruncated_ids
|
||||
):
|
||||
removed_text = t5_tokenizer.batch_decode(untruncated_ids[:, max_seq_len - 1 : -1])
|
||||
context.logger.warning(
|
||||
"The following part of your input was truncated because `max_sequence_length` is set to "
|
||||
f" {max_seq_len} tokens: {removed_text}"
|
||||
)
|
||||
|
||||
prompt_embeds = t5_text_encoder(text_input_ids.to(t5_text_encoder.device))[0]
|
||||
|
||||
assert isinstance(prompt_embeds, torch.Tensor)
|
||||
return prompt_embeds
|
||||
|
||||
def _clip_encode(
|
||||
self, context: InvocationContext, clip_model: CLIPField, tokenizer_max_length: int = 77
|
||||
) -> Tuple[torch.Tensor, torch.Tensor]:
|
||||
clip_tokenizer_info = context.models.load(clip_model.tokenizer)
|
||||
clip_text_encoder_info = context.models.load(clip_model.text_encoder)
|
||||
|
||||
prompt = [self.prompt]
|
||||
|
||||
with (
|
||||
clip_text_encoder_info.model_on_device() as (cached_weights, clip_text_encoder),
|
||||
clip_tokenizer_info as clip_tokenizer,
|
||||
ExitStack() as exit_stack,
|
||||
):
|
||||
assert isinstance(clip_text_encoder, (CLIPTextModel, CLIPTextModelWithProjection))
|
||||
assert isinstance(clip_tokenizer, CLIPTokenizer)
|
||||
|
||||
clip_text_encoder_config = clip_text_encoder_info.config
|
||||
assert clip_text_encoder_config is not None
|
||||
|
||||
# Apply LoRA models to the CLIP encoder.
|
||||
# Note: We apply the LoRA after the transformer has been moved to its target device for faster patching.
|
||||
if clip_text_encoder_config.format in [ModelFormat.Diffusers]:
|
||||
# The model is non-quantized, so we can apply the LoRA weights directly into the model.
|
||||
exit_stack.enter_context(
|
||||
LoRAPatcher.apply_lora_patches(
|
||||
model=clip_text_encoder,
|
||||
patches=self._clip_lora_iterator(context, clip_model),
|
||||
prefix=FLUX_LORA_CLIP_PREFIX,
|
||||
cached_weights=cached_weights,
|
||||
)
|
||||
)
|
||||
else:
|
||||
# There are currently no supported CLIP quantized models. Add support here if needed.
|
||||
raise ValueError(f"Unsupported model format: {clip_text_encoder_config.format}")
|
||||
|
||||
clip_text_encoder = clip_text_encoder.eval().requires_grad_(False)
|
||||
|
||||
text_inputs = clip_tokenizer(
|
||||
prompt,
|
||||
padding="max_length",
|
||||
max_length=tokenizer_max_length,
|
||||
truncation=True,
|
||||
return_tensors="pt",
|
||||
)
|
||||
|
||||
text_input_ids = text_inputs.input_ids
|
||||
untruncated_ids = clip_tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
|
||||
assert isinstance(text_input_ids, torch.Tensor)
|
||||
assert isinstance(untruncated_ids, torch.Tensor)
|
||||
if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
|
||||
text_input_ids, untruncated_ids
|
||||
):
|
||||
removed_text = clip_tokenizer.batch_decode(untruncated_ids[:, tokenizer_max_length - 1 : -1])
|
||||
context.logger.warning(
|
||||
"The following part of your input was truncated because CLIP can only handle sequences up to"
|
||||
f" {tokenizer_max_length} tokens: {removed_text}"
|
||||
)
|
||||
prompt_embeds = clip_text_encoder(
|
||||
input_ids=text_input_ids.to(clip_text_encoder.device), output_hidden_states=True
|
||||
)
|
||||
pooled_prompt_embeds = prompt_embeds[0]
|
||||
prompt_embeds = prompt_embeds.hidden_states[-2]
|
||||
|
||||
return prompt_embeds, pooled_prompt_embeds
|
||||
|
||||
def _clip_lora_iterator(
|
||||
self, context: InvocationContext, clip_model: CLIPField
|
||||
) -> Iterator[Tuple[LoRAModelRaw, float]]:
|
||||
for lora in clip_model.loras:
|
||||
lora_info = context.models.load(lora.lora)
|
||||
assert isinstance(lora_info.model, LoRAModelRaw)
|
||||
yield (lora_info.model, lora.weight)
|
||||
del lora_info
|
||||
@@ -1,11 +1,9 @@
|
||||
from enum import Enum
|
||||
from pathlib import Path
|
||||
from typing import Literal
|
||||
|
||||
import numpy as np
|
||||
import torch
|
||||
from PIL import Image
|
||||
from pydantic import BaseModel, Field
|
||||
from transformers import AutoModelForMaskGeneration, AutoProcessor
|
||||
from transformers.models.sam import SamModel
|
||||
from transformers.models.sam.processing_sam import SamProcessor
|
||||
@@ -25,31 +23,12 @@ SEGMENT_ANYTHING_MODEL_IDS: dict[SegmentAnythingModelKey, str] = {
|
||||
}
|
||||
|
||||
|
||||
class SAMPointLabel(Enum):
|
||||
negative = -1
|
||||
neutral = 0
|
||||
positive = 1
|
||||
|
||||
|
||||
class SAMPoint(BaseModel):
|
||||
x: int = Field(..., description="The x-coordinate of the point")
|
||||
y: int = Field(..., description="The y-coordinate of the point")
|
||||
label: SAMPointLabel = Field(..., description="The label of the point")
|
||||
|
||||
|
||||
class SAMPointsField(BaseModel):
|
||||
points: list[SAMPoint] = Field(..., description="The points of the object")
|
||||
|
||||
def to_list(self) -> list[list[int]]:
|
||||
return [[point.x, point.y, point.label.value] for point in self.points]
|
||||
|
||||
|
||||
@invocation(
|
||||
"segment_anything",
|
||||
title="Segment Anything",
|
||||
tags=["prompt", "segmentation"],
|
||||
category="segmentation",
|
||||
version="1.1.0",
|
||||
version="1.0.0",
|
||||
)
|
||||
class SegmentAnythingInvocation(BaseInvocation):
|
||||
"""Runs a Segment Anything Model."""
|
||||
@@ -61,13 +40,7 @@ class SegmentAnythingInvocation(BaseInvocation):
|
||||
|
||||
model: SegmentAnythingModelKey = InputField(description="The Segment Anything model to use.")
|
||||
image: ImageField = InputField(description="The image to segment.")
|
||||
bounding_boxes: list[BoundingBoxField] | None = InputField(
|
||||
default=None, description="The bounding boxes to prompt the SAM model with."
|
||||
)
|
||||
point_lists: list[SAMPointsField] | None = InputField(
|
||||
default=None,
|
||||
description="The list of point lists to prompt the SAM model with. Each list of points represents a single object.",
|
||||
)
|
||||
bounding_boxes: list[BoundingBoxField] = InputField(description="The bounding boxes to prompt the SAM model with.")
|
||||
apply_polygon_refinement: bool = InputField(
|
||||
description="Whether to apply polygon refinement to the masks. This will smooth the edges of the masks slightly and ensure that each mask consists of a single closed polygon (before merging).",
|
||||
default=True,
|
||||
@@ -82,12 +55,7 @@ class SegmentAnythingInvocation(BaseInvocation):
|
||||
# The models expect a 3-channel RGB image.
|
||||
image_pil = context.images.get_pil(self.image.image_name, mode="RGB")
|
||||
|
||||
if self.point_lists is not None and self.bounding_boxes is not None:
|
||||
raise ValueError("Only one of point_lists or bounding_box can be provided.")
|
||||
|
||||
if (not self.bounding_boxes or len(self.bounding_boxes) == 0) and (
|
||||
not self.point_lists or len(self.point_lists) == 0
|
||||
):
|
||||
if len(self.bounding_boxes) == 0:
|
||||
combined_mask = torch.zeros(image_pil.size[::-1], dtype=torch.bool)
|
||||
else:
|
||||
masks = self._segment(context=context, image=image_pil)
|
||||
@@ -115,13 +83,14 @@ class SegmentAnythingInvocation(BaseInvocation):
|
||||
assert isinstance(sam_processor, SamProcessor)
|
||||
return SegmentAnythingPipeline(sam_model=sam_model, sam_processor=sam_processor)
|
||||
|
||||
def _segment(self, context: InvocationContext, image: Image.Image) -> list[torch.Tensor]:
|
||||
def _segment(
|
||||
self,
|
||||
context: InvocationContext,
|
||||
image: Image.Image,
|
||||
) -> list[torch.Tensor]:
|
||||
"""Use Segment Anything (SAM) to generate masks given an image + a set of bounding boxes."""
|
||||
# Convert the bounding boxes to the SAM input format.
|
||||
sam_bounding_boxes = (
|
||||
[[bb.x_min, bb.y_min, bb.x_max, bb.y_max] for bb in self.bounding_boxes] if self.bounding_boxes else None
|
||||
)
|
||||
sam_points = [p.to_list() for p in self.point_lists] if self.point_lists else None
|
||||
sam_bounding_boxes = [[bb.x_min, bb.y_min, bb.x_max, bb.y_max] for bb in self.bounding_boxes]
|
||||
|
||||
with (
|
||||
context.models.load_remote_model(
|
||||
@@ -129,7 +98,7 @@ class SegmentAnythingInvocation(BaseInvocation):
|
||||
) as sam_pipeline,
|
||||
):
|
||||
assert isinstance(sam_pipeline, SegmentAnythingPipeline)
|
||||
masks = sam_pipeline.segment(image=image, bounding_boxes=sam_bounding_boxes, point_lists=sam_points)
|
||||
masks = sam_pipeline.segment(image=image, bounding_boxes=sam_bounding_boxes)
|
||||
|
||||
masks = self._process_masks(masks)
|
||||
if self.apply_polygon_refinement:
|
||||
@@ -172,10 +141,9 @@ class SegmentAnythingInvocation(BaseInvocation):
|
||||
|
||||
return masks
|
||||
|
||||
def _filter_masks(
|
||||
self, masks: list[torch.Tensor], bounding_boxes: list[BoundingBoxField] | None
|
||||
) -> list[torch.Tensor]:
|
||||
def _filter_masks(self, masks: list[torch.Tensor], bounding_boxes: list[BoundingBoxField]) -> list[torch.Tensor]:
|
||||
"""Filter the detected masks based on the specified mask filter."""
|
||||
assert len(masks) == len(bounding_boxes)
|
||||
|
||||
if self.mask_filter == "all":
|
||||
return masks
|
||||
@@ -183,10 +151,6 @@ class SegmentAnythingInvocation(BaseInvocation):
|
||||
# Find the largest mask.
|
||||
return [max(masks, key=lambda x: float(x.sum()))]
|
||||
elif self.mask_filter == "highest_box_score":
|
||||
assert (
|
||||
bounding_boxes is not None
|
||||
), "Bounding boxes must be provided to use the 'highest_box_score' mask filter."
|
||||
assert len(masks) == len(bounding_boxes)
|
||||
# Find the index of the bounding box with the highest score.
|
||||
# Note that we fallback to -1.0 if the score is None. This is mainly to satisfy the type checker. In most
|
||||
# cases the scores should all be non-None when using this filtering mode. That being said, -1.0 is a
|
||||
|
||||
@@ -1,8 +1,7 @@
|
||||
from abc import ABC, abstractmethod
|
||||
|
||||
from invokeai.app.services.board_records.board_records_common import BoardChanges, BoardRecord, BoardRecordOrderBy
|
||||
from invokeai.app.services.board_records.board_records_common import BoardChanges, BoardRecord
|
||||
from invokeai.app.services.shared.pagination import OffsetPaginatedResults
|
||||
from invokeai.app.services.shared.sqlite.sqlite_common import SQLiteDirection
|
||||
|
||||
|
||||
class BoardRecordStorageBase(ABC):
|
||||
@@ -40,19 +39,12 @@ class BoardRecordStorageBase(ABC):
|
||||
|
||||
@abstractmethod
|
||||
def get_many(
|
||||
self,
|
||||
order_by: BoardRecordOrderBy,
|
||||
direction: SQLiteDirection,
|
||||
offset: int = 0,
|
||||
limit: int = 10,
|
||||
include_archived: bool = False,
|
||||
self, offset: int = 0, limit: int = 10, include_archived: bool = False
|
||||
) -> OffsetPaginatedResults[BoardRecord]:
|
||||
"""Gets many board records."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def get_all(
|
||||
self, order_by: BoardRecordOrderBy, direction: SQLiteDirection, include_archived: bool = False
|
||||
) -> list[BoardRecord]:
|
||||
def get_all(self, include_archived: bool = False) -> list[BoardRecord]:
|
||||
"""Gets all board records."""
|
||||
pass
|
||||
|
||||
@@ -1,10 +1,8 @@
|
||||
from datetime import datetime
|
||||
from enum import Enum
|
||||
from typing import Optional, Union
|
||||
|
||||
from pydantic import BaseModel, Field
|
||||
|
||||
from invokeai.app.util.metaenum import MetaEnum
|
||||
from invokeai.app.util.misc import get_iso_timestamp
|
||||
from invokeai.app.util.model_exclude_null import BaseModelExcludeNull
|
||||
|
||||
@@ -62,13 +60,6 @@ class BoardChanges(BaseModel, extra="forbid"):
|
||||
archived: Optional[bool] = Field(default=None, description="Whether or not the board is archived")
|
||||
|
||||
|
||||
class BoardRecordOrderBy(str, Enum, metaclass=MetaEnum):
|
||||
"""The order by options for board records"""
|
||||
|
||||
CreatedAt = "created_at"
|
||||
Name = "board_name"
|
||||
|
||||
|
||||
class BoardRecordNotFoundException(Exception):
|
||||
"""Raised when an board record is not found."""
|
||||
|
||||
|
||||
@@ -8,12 +8,10 @@ from invokeai.app.services.board_records.board_records_common import (
|
||||
BoardRecord,
|
||||
BoardRecordDeleteException,
|
||||
BoardRecordNotFoundException,
|
||||
BoardRecordOrderBy,
|
||||
BoardRecordSaveException,
|
||||
deserialize_board_record,
|
||||
)
|
||||
from invokeai.app.services.shared.pagination import OffsetPaginatedResults
|
||||
from invokeai.app.services.shared.sqlite.sqlite_common import SQLiteDirection
|
||||
from invokeai.app.services.shared.sqlite.sqlite_database import SqliteDatabase
|
||||
from invokeai.app.util.misc import uuid_string
|
||||
|
||||
@@ -146,12 +144,7 @@ class SqliteBoardRecordStorage(BoardRecordStorageBase):
|
||||
return self.get(board_id)
|
||||
|
||||
def get_many(
|
||||
self,
|
||||
order_by: BoardRecordOrderBy,
|
||||
direction: SQLiteDirection,
|
||||
offset: int = 0,
|
||||
limit: int = 10,
|
||||
include_archived: bool = False,
|
||||
self, offset: int = 0, limit: int = 10, include_archived: bool = False
|
||||
) -> OffsetPaginatedResults[BoardRecord]:
|
||||
try:
|
||||
self._lock.acquire()
|
||||
@@ -161,16 +154,17 @@ class SqliteBoardRecordStorage(BoardRecordStorageBase):
|
||||
SELECT *
|
||||
FROM boards
|
||||
{archived_filter}
|
||||
ORDER BY {order_by} {direction}
|
||||
ORDER BY created_at DESC
|
||||
LIMIT ? OFFSET ?;
|
||||
"""
|
||||
|
||||
# Determine archived filter condition
|
||||
archived_filter = "" if include_archived else "WHERE archived = 0"
|
||||
if include_archived:
|
||||
archived_filter = ""
|
||||
else:
|
||||
archived_filter = "WHERE archived = 0"
|
||||
|
||||
final_query = base_query.format(
|
||||
archived_filter=archived_filter, order_by=order_by.value, direction=direction.value
|
||||
)
|
||||
final_query = base_query.format(archived_filter=archived_filter)
|
||||
|
||||
# Execute query to fetch boards
|
||||
self._cursor.execute(final_query, (limit, offset))
|
||||
@@ -204,32 +198,23 @@ class SqliteBoardRecordStorage(BoardRecordStorageBase):
|
||||
finally:
|
||||
self._lock.release()
|
||||
|
||||
def get_all(
|
||||
self, order_by: BoardRecordOrderBy, direction: SQLiteDirection, include_archived: bool = False
|
||||
) -> list[BoardRecord]:
|
||||
def get_all(self, include_archived: bool = False) -> list[BoardRecord]:
|
||||
try:
|
||||
self._lock.acquire()
|
||||
|
||||
if order_by == BoardRecordOrderBy.Name:
|
||||
base_query = """
|
||||
SELECT *
|
||||
FROM boards
|
||||
{archived_filter}
|
||||
ORDER BY LOWER(board_name) {direction}
|
||||
"""
|
||||
base_query = """
|
||||
SELECT *
|
||||
FROM boards
|
||||
{archived_filter}
|
||||
ORDER BY created_at DESC
|
||||
"""
|
||||
|
||||
if include_archived:
|
||||
archived_filter = ""
|
||||
else:
|
||||
base_query = """
|
||||
SELECT *
|
||||
FROM boards
|
||||
{archived_filter}
|
||||
ORDER BY {order_by} {direction}
|
||||
"""
|
||||
archived_filter = "WHERE archived = 0"
|
||||
|
||||
archived_filter = "" if include_archived else "WHERE archived = 0"
|
||||
|
||||
final_query = base_query.format(
|
||||
archived_filter=archived_filter, order_by=order_by.value, direction=direction.value
|
||||
)
|
||||
final_query = base_query.format(archived_filter=archived_filter)
|
||||
|
||||
self._cursor.execute(final_query)
|
||||
|
||||
|
||||
@@ -1,9 +1,8 @@
|
||||
from abc import ABC, abstractmethod
|
||||
|
||||
from invokeai.app.services.board_records.board_records_common import BoardChanges, BoardRecordOrderBy
|
||||
from invokeai.app.services.board_records.board_records_common import BoardChanges
|
||||
from invokeai.app.services.boards.boards_common import BoardDTO
|
||||
from invokeai.app.services.shared.pagination import OffsetPaginatedResults
|
||||
from invokeai.app.services.shared.sqlite.sqlite_common import SQLiteDirection
|
||||
|
||||
|
||||
class BoardServiceABC(ABC):
|
||||
@@ -44,19 +43,12 @@ class BoardServiceABC(ABC):
|
||||
|
||||
@abstractmethod
|
||||
def get_many(
|
||||
self,
|
||||
order_by: BoardRecordOrderBy,
|
||||
direction: SQLiteDirection,
|
||||
offset: int = 0,
|
||||
limit: int = 10,
|
||||
include_archived: bool = False,
|
||||
self, offset: int = 0, limit: int = 10, include_archived: bool = False
|
||||
) -> OffsetPaginatedResults[BoardDTO]:
|
||||
"""Gets many boards."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def get_all(
|
||||
self, order_by: BoardRecordOrderBy, direction: SQLiteDirection, include_archived: bool = False
|
||||
) -> list[BoardDTO]:
|
||||
def get_all(self, include_archived: bool = False) -> list[BoardDTO]:
|
||||
"""Gets all boards."""
|
||||
pass
|
||||
|
||||
@@ -1,9 +1,8 @@
|
||||
from invokeai.app.services.board_records.board_records_common import BoardChanges, BoardRecordOrderBy
|
||||
from invokeai.app.services.board_records.board_records_common import BoardChanges
|
||||
from invokeai.app.services.boards.boards_base import BoardServiceABC
|
||||
from invokeai.app.services.boards.boards_common import BoardDTO, board_record_to_dto
|
||||
from invokeai.app.services.invoker import Invoker
|
||||
from invokeai.app.services.shared.pagination import OffsetPaginatedResults
|
||||
from invokeai.app.services.shared.sqlite.sqlite_common import SQLiteDirection
|
||||
|
||||
|
||||
class BoardService(BoardServiceABC):
|
||||
@@ -48,16 +47,9 @@ class BoardService(BoardServiceABC):
|
||||
self.__invoker.services.board_records.delete(board_id)
|
||||
|
||||
def get_many(
|
||||
self,
|
||||
order_by: BoardRecordOrderBy,
|
||||
direction: SQLiteDirection,
|
||||
offset: int = 0,
|
||||
limit: int = 10,
|
||||
include_archived: bool = False,
|
||||
self, offset: int = 0, limit: int = 10, include_archived: bool = False
|
||||
) -> OffsetPaginatedResults[BoardDTO]:
|
||||
board_records = self.__invoker.services.board_records.get_many(
|
||||
order_by, direction, offset, limit, include_archived
|
||||
)
|
||||
board_records = self.__invoker.services.board_records.get_many(offset, limit, include_archived)
|
||||
board_dtos = []
|
||||
for r in board_records.items:
|
||||
cover_image = self.__invoker.services.image_records.get_most_recent_image_for_board(r.board_id)
|
||||
@@ -71,10 +63,8 @@ class BoardService(BoardServiceABC):
|
||||
|
||||
return OffsetPaginatedResults[BoardDTO](items=board_dtos, offset=offset, limit=limit, total=len(board_dtos))
|
||||
|
||||
def get_all(
|
||||
self, order_by: BoardRecordOrderBy, direction: SQLiteDirection, include_archived: bool = False
|
||||
) -> list[BoardDTO]:
|
||||
board_records = self.__invoker.services.board_records.get_all(order_by, direction, include_archived)
|
||||
def get_all(self, include_archived: bool = False) -> list[BoardDTO]:
|
||||
board_records = self.__invoker.services.board_records.get_all(include_archived)
|
||||
board_dtos = []
|
||||
for r in board_records:
|
||||
cover_image = self.__invoker.services.image_records.get_most_recent_image_for_board(r.board_id)
|
||||
|
||||
@@ -250,9 +250,9 @@ class InvokeAIAppConfig(BaseSettings):
|
||||
)
|
||||
|
||||
if as_example:
|
||||
file.write("# This is an example file with default and example settings.\n")
|
||||
file.write("# You should not copy this whole file into your config.\n")
|
||||
file.write("# Only add the settings you need to change to your config file.\n\n")
|
||||
file.write(
|
||||
"# This is an example file with default and example settings. Use the values here as a baseline.\n\n"
|
||||
)
|
||||
file.write("# Internal metadata - do not edit:\n")
|
||||
file.write(yaml.dump(meta_dict, sort_keys=False))
|
||||
file.write("\n")
|
||||
|
||||
@@ -110,26 +110,15 @@ class DiskImageFileStorage(ImageFileStorageBase):
|
||||
except Exception as e:
|
||||
raise ImageFileDeleteException from e
|
||||
|
||||
# TODO: make this a bit more flexible for e.g. cloud storage
|
||||
def get_path(self, image_name: str, thumbnail: bool = False) -> Path:
|
||||
base_folder = self.__thumbnails_folder if thumbnail else self.__output_folder
|
||||
filename = get_thumbnail_name(image_name) if thumbnail else image_name
|
||||
path = self.__output_folder / image_name
|
||||
|
||||
# Strip any path information from the filename
|
||||
basename = Path(filename).name
|
||||
if thumbnail:
|
||||
thumbnail_name = get_thumbnail_name(image_name)
|
||||
path = self.__thumbnails_folder / thumbnail_name
|
||||
|
||||
if basename != filename:
|
||||
raise ValueError("Invalid image name, potential directory traversal detected")
|
||||
|
||||
image_path = base_folder / basename
|
||||
|
||||
# Ensure the image path is within the base folder to prevent directory traversal
|
||||
resolved_base = base_folder.resolve()
|
||||
resolved_image_path = image_path.resolve()
|
||||
|
||||
if not resolved_image_path.is_relative_to(resolved_base):
|
||||
raise ValueError("Image path outside outputs folder, potential directory traversal detected")
|
||||
|
||||
return resolved_image_path
|
||||
return path
|
||||
|
||||
def validate_path(self, path: Union[str, Path]) -> bool:
|
||||
"""Validates the path given for an image or thumbnail."""
|
||||
|
||||
@@ -15,7 +15,6 @@ from invokeai.app.util.model_exclude_null import BaseModelExcludeNull
|
||||
from invokeai.backend.model_manager.config import (
|
||||
AnyModelConfig,
|
||||
BaseModelType,
|
||||
ClipVariantType,
|
||||
ControlAdapterDefaultSettings,
|
||||
MainModelDefaultSettings,
|
||||
ModelFormat,
|
||||
@@ -86,7 +85,7 @@ class ModelRecordChanges(BaseModelExcludeNull):
|
||||
|
||||
# Checkpoint-specific changes
|
||||
# TODO(MM2): Should we expose these? Feels footgun-y...
|
||||
variant: Optional[ModelVariantType | ClipVariantType] = Field(description="The variant of the model.", default=None)
|
||||
variant: Optional[ModelVariantType] = Field(description="The variant of the model.", default=None)
|
||||
prediction_type: Optional[SchedulerPredictionType] = Field(
|
||||
description="The prediction type of the model.", default=None
|
||||
)
|
||||
|
||||
@@ -1,4 +1,3 @@
|
||||
from copy import deepcopy
|
||||
from dataclasses import dataclass
|
||||
from pathlib import Path
|
||||
from typing import TYPE_CHECKING, Callable, Optional, Union
|
||||
@@ -222,7 +221,7 @@ class ImagesInterface(InvocationContextInterface):
|
||||
)
|
||||
|
||||
def get_pil(self, image_name: str, mode: IMAGE_MODES | None = None) -> Image:
|
||||
"""Gets an image as a PIL Image object. This method returns a copy of the image.
|
||||
"""Gets an image as a PIL Image object.
|
||||
|
||||
Args:
|
||||
image_name: The name of the image to get.
|
||||
@@ -234,15 +233,11 @@ class ImagesInterface(InvocationContextInterface):
|
||||
image = self._services.images.get_pil_image(image_name)
|
||||
if mode and mode != image.mode:
|
||||
try:
|
||||
# convert makes a copy!
|
||||
image = image.convert(mode)
|
||||
except ValueError:
|
||||
self._services.logger.warning(
|
||||
f"Could not convert image from {image.mode} to {mode}. Using original mode instead."
|
||||
)
|
||||
else:
|
||||
# copy the image to prevent the user from modifying the original
|
||||
image = image.copy()
|
||||
return image
|
||||
|
||||
def get_metadata(self, image_name: str) -> Optional[MetadataField]:
|
||||
@@ -295,15 +290,15 @@ class TensorsInterface(InvocationContextInterface):
|
||||
return name
|
||||
|
||||
def load(self, name: str) -> Tensor:
|
||||
"""Loads a tensor by name. This method returns a copy of the tensor.
|
||||
"""Loads a tensor by name.
|
||||
|
||||
Args:
|
||||
name: The name of the tensor to load.
|
||||
|
||||
Returns:
|
||||
The tensor.
|
||||
The loaded tensor.
|
||||
"""
|
||||
return self._services.tensors.load(name).clone()
|
||||
return self._services.tensors.load(name)
|
||||
|
||||
|
||||
class ConditioningInterface(InvocationContextInterface):
|
||||
@@ -321,16 +316,16 @@ class ConditioningInterface(InvocationContextInterface):
|
||||
return name
|
||||
|
||||
def load(self, name: str) -> ConditioningFieldData:
|
||||
"""Loads conditioning data by name. This method returns a copy of the conditioning data.
|
||||
"""Loads conditioning data by name.
|
||||
|
||||
Args:
|
||||
name: The name of the conditioning data to load.
|
||||
|
||||
Returns:
|
||||
The conditioning data.
|
||||
The loaded conditioning data.
|
||||
"""
|
||||
|
||||
return deepcopy(self._services.conditioning.load(name))
|
||||
return self._services.conditioning.load(name)
|
||||
|
||||
|
||||
class ModelsInterface(InvocationContextInterface):
|
||||
|
||||
@@ -1,382 +0,0 @@
|
||||
{
|
||||
"name": "SD3.5 Text to Image",
|
||||
"author": "InvokeAI",
|
||||
"description": "Sample text to image workflow for Stable Diffusion 3.5",
|
||||
"version": "1.0.0",
|
||||
"contact": "invoke@invoke.ai",
|
||||
"tags": "text2image, SD3.5, default",
|
||||
"notes": "",
|
||||
"exposedFields": [
|
||||
{
|
||||
"nodeId": "3f22f668-0e02-4fde-a2bb-c339586ceb4c",
|
||||
"fieldName": "model"
|
||||
},
|
||||
{
|
||||
"nodeId": "e17d34e7-6ed1-493c-9a85-4fcd291cb084",
|
||||
"fieldName": "prompt"
|
||||
}
|
||||
],
|
||||
"meta": {
|
||||
"version": "3.0.0",
|
||||
"category": "default"
|
||||
},
|
||||
"id": "e3a51d6b-8208-4d6d-b187-fcfe8b32934c",
|
||||
"nodes": [
|
||||
{
|
||||
"id": "3f22f668-0e02-4fde-a2bb-c339586ceb4c",
|
||||
"type": "invocation",
|
||||
"data": {
|
||||
"id": "3f22f668-0e02-4fde-a2bb-c339586ceb4c",
|
||||
"type": "sd3_model_loader",
|
||||
"version": "1.0.0",
|
||||
"label": "",
|
||||
"notes": "",
|
||||
"isOpen": true,
|
||||
"isIntermediate": true,
|
||||
"useCache": true,
|
||||
"nodePack": "invokeai",
|
||||
"inputs": {
|
||||
"model": {
|
||||
"name": "model",
|
||||
"label": "",
|
||||
"value": {
|
||||
"key": "f7b20be9-92a8-4cfb-bca4-6c3b5535c10b",
|
||||
"hash": "placeholder",
|
||||
"name": "stable-diffusion-3.5-medium",
|
||||
"base": "sd-3",
|
||||
"type": "main"
|
||||
}
|
||||
},
|
||||
"t5_encoder_model": {
|
||||
"name": "t5_encoder_model",
|
||||
"label": ""
|
||||
},
|
||||
"clip_l_model": {
|
||||
"name": "clip_l_model",
|
||||
"label": ""
|
||||
},
|
||||
"clip_g_model": {
|
||||
"name": "clip_g_model",
|
||||
"label": ""
|
||||
},
|
||||
"vae_model": {
|
||||
"name": "vae_model",
|
||||
"label": ""
|
||||
}
|
||||
}
|
||||
},
|
||||
"position": {
|
||||
"x": -55.58689609637031,
|
||||
"y": -111.53602444662268
|
||||
}
|
||||
},
|
||||
{
|
||||
"id": "f7e394ac-6394-4096-abcb-de0d346506b3",
|
||||
"type": "invocation",
|
||||
"data": {
|
||||
"id": "f7e394ac-6394-4096-abcb-de0d346506b3",
|
||||
"type": "rand_int",
|
||||
"version": "1.0.1",
|
||||
"label": "",
|
||||
"notes": "",
|
||||
"isOpen": true,
|
||||
"isIntermediate": true,
|
||||
"useCache": false,
|
||||
"nodePack": "invokeai",
|
||||
"inputs": {
|
||||
"low": {
|
||||
"name": "low",
|
||||
"label": "",
|
||||
"value": 0
|
||||
},
|
||||
"high": {
|
||||
"name": "high",
|
||||
"label": "",
|
||||
"value": 2147483647
|
||||
}
|
||||
}
|
||||
},
|
||||
"position": {
|
||||
"x": 470.45870147220353,
|
||||
"y": 350.3141781644303
|
||||
}
|
||||
},
|
||||
{
|
||||
"id": "9eb72af0-dd9e-4ec5-ad87-d65e3c01f48b",
|
||||
"type": "invocation",
|
||||
"data": {
|
||||
"id": "9eb72af0-dd9e-4ec5-ad87-d65e3c01f48b",
|
||||
"type": "sd3_l2i",
|
||||
"version": "1.3.0",
|
||||
"label": "",
|
||||
"notes": "",
|
||||
"isOpen": true,
|
||||
"isIntermediate": false,
|
||||
"useCache": true,
|
||||
"nodePack": "invokeai",
|
||||
"inputs": {
|
||||
"board": {
|
||||
"name": "board",
|
||||
"label": ""
|
||||
},
|
||||
"metadata": {
|
||||
"name": "metadata",
|
||||
"label": ""
|
||||
},
|
||||
"latents": {
|
||||
"name": "latents",
|
||||
"label": ""
|
||||
},
|
||||
"vae": {
|
||||
"name": "vae",
|
||||
"label": ""
|
||||
}
|
||||
}
|
||||
},
|
||||
"position": {
|
||||
"x": 1192.3097009334897,
|
||||
"y": -366.0994675072209
|
||||
}
|
||||
},
|
||||
{
|
||||
"id": "3b4f7f27-cfc0-4373-a009-99c5290d0cd6",
|
||||
"type": "invocation",
|
||||
"data": {
|
||||
"id": "3b4f7f27-cfc0-4373-a009-99c5290d0cd6",
|
||||
"type": "sd3_text_encoder",
|
||||
"version": "1.0.0",
|
||||
"label": "",
|
||||
"notes": "",
|
||||
"isOpen": true,
|
||||
"isIntermediate": true,
|
||||
"useCache": true,
|
||||
"nodePack": "invokeai",
|
||||
"inputs": {
|
||||
"clip_l": {
|
||||
"name": "clip_l",
|
||||
"label": ""
|
||||
},
|
||||
"clip_g": {
|
||||
"name": "clip_g",
|
||||
"label": ""
|
||||
},
|
||||
"t5_encoder": {
|
||||
"name": "t5_encoder",
|
||||
"label": ""
|
||||
},
|
||||
"prompt": {
|
||||
"name": "prompt",
|
||||
"label": "",
|
||||
"value": ""
|
||||
}
|
||||
}
|
||||
},
|
||||
"position": {
|
||||
"x": 408.16054647924784,
|
||||
"y": 65.06415352118786
|
||||
}
|
||||
},
|
||||
{
|
||||
"id": "e17d34e7-6ed1-493c-9a85-4fcd291cb084",
|
||||
"type": "invocation",
|
||||
"data": {
|
||||
"id": "e17d34e7-6ed1-493c-9a85-4fcd291cb084",
|
||||
"type": "sd3_text_encoder",
|
||||
"version": "1.0.0",
|
||||
"label": "",
|
||||
"notes": "",
|
||||
"isOpen": true,
|
||||
"isIntermediate": true,
|
||||
"useCache": true,
|
||||
"nodePack": "invokeai",
|
||||
"inputs": {
|
||||
"clip_l": {
|
||||
"name": "clip_l",
|
||||
"label": ""
|
||||
},
|
||||
"clip_g": {
|
||||
"name": "clip_g",
|
||||
"label": ""
|
||||
},
|
||||
"t5_encoder": {
|
||||
"name": "t5_encoder",
|
||||
"label": ""
|
||||
},
|
||||
"prompt": {
|
||||
"name": "prompt",
|
||||
"label": "",
|
||||
"value": ""
|
||||
}
|
||||
}
|
||||
},
|
||||
"position": {
|
||||
"x": 378.9283412440941,
|
||||
"y": -302.65777497352553
|
||||
}
|
||||
},
|
||||
{
|
||||
"id": "c7539f7b-7ac5-49b9-93eb-87ede611409f",
|
||||
"type": "invocation",
|
||||
"data": {
|
||||
"id": "c7539f7b-7ac5-49b9-93eb-87ede611409f",
|
||||
"type": "sd3_denoise",
|
||||
"version": "1.0.0",
|
||||
"label": "",
|
||||
"notes": "",
|
||||
"isOpen": true,
|
||||
"isIntermediate": true,
|
||||
"useCache": true,
|
||||
"nodePack": "invokeai",
|
||||
"inputs": {
|
||||
"board": {
|
||||
"name": "board",
|
||||
"label": ""
|
||||
},
|
||||
"metadata": {
|
||||
"name": "metadata",
|
||||
"label": ""
|
||||
},
|
||||
"transformer": {
|
||||
"name": "transformer",
|
||||
"label": ""
|
||||
},
|
||||
"positive_conditioning": {
|
||||
"name": "positive_conditioning",
|
||||
"label": ""
|
||||
},
|
||||
"negative_conditioning": {
|
||||
"name": "negative_conditioning",
|
||||
"label": ""
|
||||
},
|
||||
"cfg_scale": {
|
||||
"name": "cfg_scale",
|
||||
"label": "",
|
||||
"value": 3.5
|
||||
},
|
||||
"width": {
|
||||
"name": "width",
|
||||
"label": "",
|
||||
"value": 1024
|
||||
},
|
||||
"height": {
|
||||
"name": "height",
|
||||
"label": "",
|
||||
"value": 1024
|
||||
},
|
||||
"steps": {
|
||||
"name": "steps",
|
||||
"label": "",
|
||||
"value": 30
|
||||
},
|
||||
"seed": {
|
||||
"name": "seed",
|
||||
"label": "",
|
||||
"value": 0
|
||||
}
|
||||
}
|
||||
},
|
||||
"position": {
|
||||
"x": 813.7814762740603,
|
||||
"y": -142.20529727605867
|
||||
}
|
||||
}
|
||||
],
|
||||
"edges": [
|
||||
{
|
||||
"id": "reactflow__edge-3f22f668-0e02-4fde-a2bb-c339586ceb4cvae-9eb72af0-dd9e-4ec5-ad87-d65e3c01f48bvae",
|
||||
"type": "default",
|
||||
"source": "3f22f668-0e02-4fde-a2bb-c339586ceb4c",
|
||||
"target": "9eb72af0-dd9e-4ec5-ad87-d65e3c01f48b",
|
||||
"sourceHandle": "vae",
|
||||
"targetHandle": "vae"
|
||||
},
|
||||
{
|
||||
"id": "reactflow__edge-3f22f668-0e02-4fde-a2bb-c339586ceb4ct5_encoder-3b4f7f27-cfc0-4373-a009-99c5290d0cd6t5_encoder",
|
||||
"type": "default",
|
||||
"source": "3f22f668-0e02-4fde-a2bb-c339586ceb4c",
|
||||
"target": "3b4f7f27-cfc0-4373-a009-99c5290d0cd6",
|
||||
"sourceHandle": "t5_encoder",
|
||||
"targetHandle": "t5_encoder"
|
||||
},
|
||||
{
|
||||
"id": "reactflow__edge-3f22f668-0e02-4fde-a2bb-c339586ceb4ct5_encoder-e17d34e7-6ed1-493c-9a85-4fcd291cb084t5_encoder",
|
||||
"type": "default",
|
||||
"source": "3f22f668-0e02-4fde-a2bb-c339586ceb4c",
|
||||
"target": "e17d34e7-6ed1-493c-9a85-4fcd291cb084",
|
||||
"sourceHandle": "t5_encoder",
|
||||
"targetHandle": "t5_encoder"
|
||||
},
|
||||
{
|
||||
"id": "reactflow__edge-3f22f668-0e02-4fde-a2bb-c339586ceb4cclip_g-3b4f7f27-cfc0-4373-a009-99c5290d0cd6clip_g",
|
||||
"type": "default",
|
||||
"source": "3f22f668-0e02-4fde-a2bb-c339586ceb4c",
|
||||
"target": "3b4f7f27-cfc0-4373-a009-99c5290d0cd6",
|
||||
"sourceHandle": "clip_g",
|
||||
"targetHandle": "clip_g"
|
||||
},
|
||||
{
|
||||
"id": "reactflow__edge-3f22f668-0e02-4fde-a2bb-c339586ceb4cclip_g-e17d34e7-6ed1-493c-9a85-4fcd291cb084clip_g",
|
||||
"type": "default",
|
||||
"source": "3f22f668-0e02-4fde-a2bb-c339586ceb4c",
|
||||
"target": "e17d34e7-6ed1-493c-9a85-4fcd291cb084",
|
||||
"sourceHandle": "clip_g",
|
||||
"targetHandle": "clip_g"
|
||||
},
|
||||
{
|
||||
"id": "reactflow__edge-3f22f668-0e02-4fde-a2bb-c339586ceb4cclip_l-3b4f7f27-cfc0-4373-a009-99c5290d0cd6clip_l",
|
||||
"type": "default",
|
||||
"source": "3f22f668-0e02-4fde-a2bb-c339586ceb4c",
|
||||
"target": "3b4f7f27-cfc0-4373-a009-99c5290d0cd6",
|
||||
"sourceHandle": "clip_l",
|
||||
"targetHandle": "clip_l"
|
||||
},
|
||||
{
|
||||
"id": "reactflow__edge-3f22f668-0e02-4fde-a2bb-c339586ceb4cclip_l-e17d34e7-6ed1-493c-9a85-4fcd291cb084clip_l",
|
||||
"type": "default",
|
||||
"source": "3f22f668-0e02-4fde-a2bb-c339586ceb4c",
|
||||
"target": "e17d34e7-6ed1-493c-9a85-4fcd291cb084",
|
||||
"sourceHandle": "clip_l",
|
||||
"targetHandle": "clip_l"
|
||||
},
|
||||
{
|
||||
"id": "reactflow__edge-3f22f668-0e02-4fde-a2bb-c339586ceb4ctransformer-c7539f7b-7ac5-49b9-93eb-87ede611409ftransformer",
|
||||
"type": "default",
|
||||
"source": "3f22f668-0e02-4fde-a2bb-c339586ceb4c",
|
||||
"target": "c7539f7b-7ac5-49b9-93eb-87ede611409f",
|
||||
"sourceHandle": "transformer",
|
||||
"targetHandle": "transformer"
|
||||
},
|
||||
{
|
||||
"id": "reactflow__edge-f7e394ac-6394-4096-abcb-de0d346506b3value-c7539f7b-7ac5-49b9-93eb-87ede611409fseed",
|
||||
"type": "default",
|
||||
"source": "f7e394ac-6394-4096-abcb-de0d346506b3",
|
||||
"target": "c7539f7b-7ac5-49b9-93eb-87ede611409f",
|
||||
"sourceHandle": "value",
|
||||
"targetHandle": "seed"
|
||||
},
|
||||
{
|
||||
"id": "reactflow__edge-c7539f7b-7ac5-49b9-93eb-87ede611409flatents-9eb72af0-dd9e-4ec5-ad87-d65e3c01f48blatents",
|
||||
"type": "default",
|
||||
"source": "c7539f7b-7ac5-49b9-93eb-87ede611409f",
|
||||
"target": "9eb72af0-dd9e-4ec5-ad87-d65e3c01f48b",
|
||||
"sourceHandle": "latents",
|
||||
"targetHandle": "latents"
|
||||
},
|
||||
{
|
||||
"id": "reactflow__edge-e17d34e7-6ed1-493c-9a85-4fcd291cb084conditioning-c7539f7b-7ac5-49b9-93eb-87ede611409fpositive_conditioning",
|
||||
"type": "default",
|
||||
"source": "e17d34e7-6ed1-493c-9a85-4fcd291cb084",
|
||||
"target": "c7539f7b-7ac5-49b9-93eb-87ede611409f",
|
||||
"sourceHandle": "conditioning",
|
||||
"targetHandle": "positive_conditioning"
|
||||
},
|
||||
{
|
||||
"id": "reactflow__edge-3b4f7f27-cfc0-4373-a009-99c5290d0cd6conditioning-c7539f7b-7ac5-49b9-93eb-87ede611409fnegative_conditioning",
|
||||
"type": "default",
|
||||
"source": "3b4f7f27-cfc0-4373-a009-99c5290d0cd6",
|
||||
"target": "c7539f7b-7ac5-49b9-93eb-87ede611409f",
|
||||
"sourceHandle": "conditioning",
|
||||
"targetHandle": "negative_conditioning"
|
||||
}
|
||||
]
|
||||
}
|
||||
@@ -39,11 +39,11 @@ class WorkflowRecordsStorageBase(ABC):
|
||||
@abstractmethod
|
||||
def get_many(
|
||||
self,
|
||||
page: int,
|
||||
per_page: int,
|
||||
order_by: WorkflowRecordOrderBy,
|
||||
direction: SQLiteDirection,
|
||||
category: WorkflowCategory,
|
||||
page: int,
|
||||
per_page: Optional[int],
|
||||
query: Optional[str],
|
||||
) -> PaginatedResults[WorkflowRecordListItemDTO]:
|
||||
"""Gets many workflows."""
|
||||
|
||||
@@ -125,11 +125,11 @@ class SqliteWorkflowRecordsStorage(WorkflowRecordsStorageBase):
|
||||
|
||||
def get_many(
|
||||
self,
|
||||
page: int,
|
||||
per_page: int,
|
||||
order_by: WorkflowRecordOrderBy,
|
||||
direction: SQLiteDirection,
|
||||
category: WorkflowCategory,
|
||||
page: int = 0,
|
||||
per_page: Optional[int] = None,
|
||||
query: Optional[str] = None,
|
||||
) -> PaginatedResults[WorkflowRecordListItemDTO]:
|
||||
try:
|
||||
@@ -153,7 +153,6 @@ class SqliteWorkflowRecordsStorage(WorkflowRecordsStorageBase):
|
||||
"""
|
||||
main_params: list[int | str] = [category.value]
|
||||
count_params: list[int | str] = [category.value]
|
||||
|
||||
stripped_query = query.strip() if query else None
|
||||
if stripped_query:
|
||||
wildcard_query = "%" + stripped_query + "%"
|
||||
@@ -162,28 +161,20 @@ class SqliteWorkflowRecordsStorage(WorkflowRecordsStorageBase):
|
||||
main_params.extend([wildcard_query, wildcard_query])
|
||||
count_params.extend([wildcard_query, wildcard_query])
|
||||
|
||||
main_query += f" ORDER BY {order_by.value} {direction.value}"
|
||||
|
||||
if per_page:
|
||||
main_query += " LIMIT ? OFFSET ?"
|
||||
main_params.extend([per_page, page * per_page])
|
||||
|
||||
main_query += f" ORDER BY {order_by.value} {direction.value} LIMIT ? OFFSET ?;"
|
||||
main_params.extend([per_page, page * per_page])
|
||||
self._cursor.execute(main_query, main_params)
|
||||
rows = self._cursor.fetchall()
|
||||
workflows = [WorkflowRecordListItemDTOValidator.validate_python(dict(row)) for row in rows]
|
||||
|
||||
self._cursor.execute(count_query, count_params)
|
||||
total = self._cursor.fetchone()[0]
|
||||
|
||||
if per_page:
|
||||
pages = total // per_page + (total % per_page > 0)
|
||||
else:
|
||||
pages = 1 # If no pagination, there is only one page
|
||||
pages = total // per_page + (total % per_page > 0)
|
||||
|
||||
return PaginatedResults(
|
||||
items=workflows,
|
||||
page=page,
|
||||
per_page=per_page if per_page else total,
|
||||
per_page=per_page,
|
||||
pages=pages,
|
||||
total=total,
|
||||
)
|
||||
|
||||
@@ -34,25 +34,6 @@ SD1_5_LATENT_RGB_FACTORS = [
|
||||
[-0.1307, -0.1874, -0.7445], # L4
|
||||
]
|
||||
|
||||
SD3_5_LATENT_RGB_FACTORS = [
|
||||
[-0.05240681, 0.03251581, 0.0749016],
|
||||
[-0.0580572, 0.00759826, 0.05729818],
|
||||
[0.16144888, 0.01270368, -0.03768577],
|
||||
[0.14418615, 0.08460266, 0.15941818],
|
||||
[0.04894035, 0.0056485, -0.06686988],
|
||||
[0.05187166, 0.19222395, 0.06261094],
|
||||
[0.1539433, 0.04818359, 0.07103094],
|
||||
[-0.08601796, 0.09013458, 0.10893912],
|
||||
[-0.12398469, -0.06766567, 0.0033688],
|
||||
[-0.0439737, 0.07825329, 0.02258823],
|
||||
[0.03101129, 0.06382551, 0.07753657],
|
||||
[-0.01315361, 0.08554491, -0.08772475],
|
||||
[0.06464487, 0.05914605, 0.13262741],
|
||||
[-0.07863674, -0.02261737, -0.12761454],
|
||||
[-0.09923835, -0.08010759, -0.06264447],
|
||||
[-0.03392309, -0.0804029, -0.06078822],
|
||||
]
|
||||
|
||||
FLUX_LATENT_RGB_FACTORS = [
|
||||
[-0.0412, 0.0149, 0.0521],
|
||||
[0.0056, 0.0291, 0.0768],
|
||||
@@ -129,9 +110,6 @@ def stable_diffusion_step_callback(
|
||||
sdxl_latent_rgb_factors = torch.tensor(SDXL_LATENT_RGB_FACTORS, dtype=sample.dtype, device=sample.device)
|
||||
sdxl_smooth_matrix = torch.tensor(SDXL_SMOOTH_MATRIX, dtype=sample.dtype, device=sample.device)
|
||||
image = sample_to_lowres_estimated_image(sample, sdxl_latent_rgb_factors, sdxl_smooth_matrix)
|
||||
elif base_model == BaseModelType.StableDiffusion3:
|
||||
sd3_latent_rgb_factors = torch.tensor(SD3_5_LATENT_RGB_FACTORS, dtype=sample.dtype, device=sample.device)
|
||||
image = sample_to_lowres_estimated_image(sample, sd3_latent_rgb_factors)
|
||||
else:
|
||||
v1_5_latent_rgb_factors = torch.tensor(SD1_5_LATENT_RGB_FACTORS, dtype=sample.dtype, device=sample.device)
|
||||
image = sample_to_lowres_estimated_image(sample, v1_5_latent_rgb_factors)
|
||||
|
||||
@@ -1,58 +0,0 @@
|
||||
from dataclasses import dataclass
|
||||
|
||||
import torch
|
||||
|
||||
|
||||
@dataclass
|
||||
class ControlNetFluxOutput:
|
||||
single_block_residuals: list[torch.Tensor] | None
|
||||
double_block_residuals: list[torch.Tensor] | None
|
||||
|
||||
def apply_weight(self, weight: float):
|
||||
if self.single_block_residuals is not None:
|
||||
for i in range(len(self.single_block_residuals)):
|
||||
self.single_block_residuals[i] = self.single_block_residuals[i] * weight
|
||||
if self.double_block_residuals is not None:
|
||||
for i in range(len(self.double_block_residuals)):
|
||||
self.double_block_residuals[i] = self.double_block_residuals[i] * weight
|
||||
|
||||
|
||||
def add_tensor_lists_elementwise(
|
||||
list1: list[torch.Tensor] | None, list2: list[torch.Tensor] | None
|
||||
) -> list[torch.Tensor] | None:
|
||||
"""Add two tensor lists elementwise that could be None."""
|
||||
if list1 is None and list2 is None:
|
||||
return None
|
||||
if list1 is None:
|
||||
return list2
|
||||
if list2 is None:
|
||||
return list1
|
||||
|
||||
new_list: list[torch.Tensor] = []
|
||||
for list1_tensor, list2_tensor in zip(list1, list2, strict=True):
|
||||
new_list.append(list1_tensor + list2_tensor)
|
||||
return new_list
|
||||
|
||||
|
||||
def add_controlnet_flux_outputs(
|
||||
controlnet_output_1: ControlNetFluxOutput, controlnet_output_2: ControlNetFluxOutput
|
||||
) -> ControlNetFluxOutput:
|
||||
return ControlNetFluxOutput(
|
||||
single_block_residuals=add_tensor_lists_elementwise(
|
||||
controlnet_output_1.single_block_residuals, controlnet_output_2.single_block_residuals
|
||||
),
|
||||
double_block_residuals=add_tensor_lists_elementwise(
|
||||
controlnet_output_1.double_block_residuals, controlnet_output_2.double_block_residuals
|
||||
),
|
||||
)
|
||||
|
||||
|
||||
def sum_controlnet_flux_outputs(
|
||||
controlnet_outputs: list[ControlNetFluxOutput],
|
||||
) -> ControlNetFluxOutput:
|
||||
controlnet_output_sum = ControlNetFluxOutput(single_block_residuals=None, double_block_residuals=None)
|
||||
|
||||
for controlnet_output in controlnet_outputs:
|
||||
controlnet_output_sum = add_controlnet_flux_outputs(controlnet_output_sum, controlnet_output)
|
||||
|
||||
return controlnet_output_sum
|
||||
@@ -1,180 +0,0 @@
|
||||
# This file was initially copied from:
|
||||
# https://github.com/huggingface/diffusers/blob/99f608218caa069a2f16dcf9efab46959b15aec0/src/diffusers/models/controlnet_flux.py
|
||||
|
||||
|
||||
from dataclasses import dataclass
|
||||
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
|
||||
from invokeai.backend.flux.controlnet.zero_module import zero_module
|
||||
from invokeai.backend.flux.model import FluxParams
|
||||
from invokeai.backend.flux.modules.layers import (
|
||||
DoubleStreamBlock,
|
||||
EmbedND,
|
||||
MLPEmbedder,
|
||||
SingleStreamBlock,
|
||||
timestep_embedding,
|
||||
)
|
||||
|
||||
|
||||
@dataclass
|
||||
class InstantXControlNetFluxOutput:
|
||||
controlnet_block_samples: list[torch.Tensor] | None
|
||||
controlnet_single_block_samples: list[torch.Tensor] | None
|
||||
|
||||
|
||||
# NOTE(ryand): Mapping between diffusers FLUX transformer params and BFL FLUX transformer params:
|
||||
# - Diffusers: BFL
|
||||
# - in_channels: in_channels
|
||||
# - num_layers: depth
|
||||
# - num_single_layers: depth_single_blocks
|
||||
# - attention_head_dim: hidden_size // num_heads
|
||||
# - num_attention_heads: num_heads
|
||||
# - joint_attention_dim: context_in_dim
|
||||
# - pooled_projection_dim: vec_in_dim
|
||||
# - guidance_embeds: guidance_embed
|
||||
# - axes_dims_rope: axes_dim
|
||||
|
||||
|
||||
class InstantXControlNetFlux(torch.nn.Module):
|
||||
def __init__(self, params: FluxParams, num_control_modes: int | None = None):
|
||||
"""
|
||||
Args:
|
||||
params (FluxParams): The parameters for the FLUX model.
|
||||
num_control_modes (int | None, optional): The number of controlnet modes. If non-None, then the model is a
|
||||
'union controlnet' model and expects a mode conditioning input at runtime.
|
||||
"""
|
||||
super().__init__()
|
||||
|
||||
# The following modules mirror the base FLUX transformer model.
|
||||
# -------------------------------------------------------------
|
||||
self.params = params
|
||||
self.in_channels = params.in_channels
|
||||
self.out_channels = self.in_channels
|
||||
if params.hidden_size % params.num_heads != 0:
|
||||
raise ValueError(f"Hidden size {params.hidden_size} must be divisible by num_heads {params.num_heads}")
|
||||
pe_dim = params.hidden_size // params.num_heads
|
||||
if sum(params.axes_dim) != pe_dim:
|
||||
raise ValueError(f"Got {params.axes_dim} but expected positional dim {pe_dim}")
|
||||
self.hidden_size = params.hidden_size
|
||||
self.num_heads = params.num_heads
|
||||
self.pe_embedder = EmbedND(dim=pe_dim, theta=params.theta, axes_dim=params.axes_dim)
|
||||
self.img_in = nn.Linear(self.in_channels, self.hidden_size, bias=True)
|
||||
self.time_in = MLPEmbedder(in_dim=256, hidden_dim=self.hidden_size)
|
||||
self.vector_in = MLPEmbedder(params.vec_in_dim, self.hidden_size)
|
||||
self.guidance_in = (
|
||||
MLPEmbedder(in_dim=256, hidden_dim=self.hidden_size) if params.guidance_embed else nn.Identity()
|
||||
)
|
||||
self.txt_in = nn.Linear(params.context_in_dim, self.hidden_size)
|
||||
|
||||
self.double_blocks = nn.ModuleList(
|
||||
[
|
||||
DoubleStreamBlock(
|
||||
self.hidden_size,
|
||||
self.num_heads,
|
||||
mlp_ratio=params.mlp_ratio,
|
||||
qkv_bias=params.qkv_bias,
|
||||
)
|
||||
for _ in range(params.depth)
|
||||
]
|
||||
)
|
||||
|
||||
self.single_blocks = nn.ModuleList(
|
||||
[
|
||||
SingleStreamBlock(self.hidden_size, self.num_heads, mlp_ratio=params.mlp_ratio)
|
||||
for _ in range(params.depth_single_blocks)
|
||||
]
|
||||
)
|
||||
|
||||
# The following modules are specific to the ControlNet model.
|
||||
# -----------------------------------------------------------
|
||||
self.controlnet_blocks = nn.ModuleList([])
|
||||
for _ in range(len(self.double_blocks)):
|
||||
self.controlnet_blocks.append(zero_module(nn.Linear(self.hidden_size, self.hidden_size)))
|
||||
|
||||
self.controlnet_single_blocks = nn.ModuleList([])
|
||||
for _ in range(len(self.single_blocks)):
|
||||
self.controlnet_single_blocks.append(zero_module(nn.Linear(self.hidden_size, self.hidden_size)))
|
||||
|
||||
self.is_union = False
|
||||
if num_control_modes is not None:
|
||||
self.is_union = True
|
||||
self.controlnet_mode_embedder = nn.Embedding(num_control_modes, self.hidden_size)
|
||||
|
||||
self.controlnet_x_embedder = zero_module(torch.nn.Linear(self.in_channels, self.hidden_size))
|
||||
|
||||
def forward(
|
||||
self,
|
||||
controlnet_cond: torch.Tensor,
|
||||
controlnet_mode: torch.Tensor | None,
|
||||
img: torch.Tensor,
|
||||
img_ids: torch.Tensor,
|
||||
txt: torch.Tensor,
|
||||
txt_ids: torch.Tensor,
|
||||
timesteps: torch.Tensor,
|
||||
y: torch.Tensor,
|
||||
guidance: torch.Tensor | None = None,
|
||||
) -> InstantXControlNetFluxOutput:
|
||||
if img.ndim != 3 or txt.ndim != 3:
|
||||
raise ValueError("Input img and txt tensors must have 3 dimensions.")
|
||||
|
||||
img = self.img_in(img)
|
||||
|
||||
# Add controlnet_cond embedding.
|
||||
img = img + self.controlnet_x_embedder(controlnet_cond)
|
||||
|
||||
vec = self.time_in(timestep_embedding(timesteps, 256))
|
||||
if self.params.guidance_embed:
|
||||
if guidance is None:
|
||||
raise ValueError("Didn't get guidance strength for guidance distilled model.")
|
||||
vec = vec + self.guidance_in(timestep_embedding(guidance, 256))
|
||||
vec = vec + self.vector_in(y)
|
||||
txt = self.txt_in(txt)
|
||||
|
||||
# If this is a union ControlNet, then concat the control mode embedding to the T5 text embedding.
|
||||
if self.is_union:
|
||||
if controlnet_mode is None:
|
||||
# We allow users to enter 'None' as the controlnet_mode if they don't want to worry about this input.
|
||||
# We've chosen to use a zero-embedding in this case.
|
||||
zero_index = torch.zeros([1, 1], dtype=torch.long, device=txt.device)
|
||||
controlnet_mode_emb = torch.zeros_like(self.controlnet_mode_embedder(zero_index))
|
||||
else:
|
||||
controlnet_mode_emb = self.controlnet_mode_embedder(controlnet_mode)
|
||||
txt = torch.cat([controlnet_mode_emb, txt], dim=1)
|
||||
txt_ids = torch.cat([txt_ids[:, :1, :], txt_ids], dim=1)
|
||||
else:
|
||||
assert controlnet_mode is None
|
||||
|
||||
ids = torch.cat((txt_ids, img_ids), dim=1)
|
||||
pe = self.pe_embedder(ids)
|
||||
|
||||
double_block_samples: list[torch.Tensor] = []
|
||||
for block in self.double_blocks:
|
||||
img, txt = block(img=img, txt=txt, vec=vec, pe=pe)
|
||||
double_block_samples.append(img)
|
||||
|
||||
img = torch.cat((txt, img), 1)
|
||||
|
||||
single_block_samples: list[torch.Tensor] = []
|
||||
for block in self.single_blocks:
|
||||
img = block(img, vec=vec, pe=pe)
|
||||
single_block_samples.append(img[:, txt.shape[1] :])
|
||||
|
||||
# ControlNet Block
|
||||
controlnet_double_block_samples: list[torch.Tensor] = []
|
||||
for double_block_sample, controlnet_block in zip(double_block_samples, self.controlnet_blocks, strict=True):
|
||||
double_block_sample = controlnet_block(double_block_sample)
|
||||
controlnet_double_block_samples.append(double_block_sample)
|
||||
|
||||
controlnet_single_block_samples: list[torch.Tensor] = []
|
||||
for single_block_sample, controlnet_block in zip(
|
||||
single_block_samples, self.controlnet_single_blocks, strict=True
|
||||
):
|
||||
single_block_sample = controlnet_block(single_block_sample)
|
||||
controlnet_single_block_samples.append(single_block_sample)
|
||||
|
||||
return InstantXControlNetFluxOutput(
|
||||
controlnet_block_samples=controlnet_double_block_samples or None,
|
||||
controlnet_single_block_samples=controlnet_single_block_samples or None,
|
||||
)
|
||||
@@ -1,295 +0,0 @@
|
||||
from typing import Any, Dict
|
||||
|
||||
import torch
|
||||
|
||||
from invokeai.backend.flux.model import FluxParams
|
||||
|
||||
|
||||
def is_state_dict_xlabs_controlnet(sd: Dict[str, Any]) -> bool:
|
||||
"""Is the state dict for an XLabs ControlNet model?
|
||||
|
||||
This is intended to be a reasonably high-precision detector, but it is not guaranteed to have perfect precision.
|
||||
"""
|
||||
# If all of the expected keys are present, then this is very likely an XLabs ControlNet model.
|
||||
expected_keys = {
|
||||
"controlnet_blocks.0.bias",
|
||||
"controlnet_blocks.0.weight",
|
||||
"input_hint_block.0.bias",
|
||||
"input_hint_block.0.weight",
|
||||
"pos_embed_input.bias",
|
||||
"pos_embed_input.weight",
|
||||
}
|
||||
|
||||
if expected_keys.issubset(sd.keys()):
|
||||
return True
|
||||
return False
|
||||
|
||||
|
||||
def is_state_dict_instantx_controlnet(sd: Dict[str, Any]) -> bool:
|
||||
"""Is the state dict for an InstantX ControlNet model?
|
||||
|
||||
This is intended to be a reasonably high-precision detector, but it is not guaranteed to have perfect precision.
|
||||
"""
|
||||
# If all of the expected keys are present, then this is very likely an InstantX ControlNet model.
|
||||
expected_keys = {
|
||||
"controlnet_blocks.0.bias",
|
||||
"controlnet_blocks.0.weight",
|
||||
"controlnet_x_embedder.bias",
|
||||
"controlnet_x_embedder.weight",
|
||||
}
|
||||
|
||||
if expected_keys.issubset(sd.keys()):
|
||||
return True
|
||||
return False
|
||||
|
||||
|
||||
def _fuse_weights(*t: torch.Tensor) -> torch.Tensor:
|
||||
"""Fuse weights along dimension 0.
|
||||
|
||||
Used to fuse q, k, v attention weights into a single qkv tensor when converting from diffusers to BFL format.
|
||||
"""
|
||||
# TODO(ryand): Double check dim=0 is correct.
|
||||
return torch.cat(t, dim=0)
|
||||
|
||||
|
||||
def _convert_flux_double_block_sd_from_diffusers_to_bfl_format(
|
||||
sd: Dict[str, torch.Tensor], double_block_index: int
|
||||
) -> Dict[str, torch.Tensor]:
|
||||
"""Convert the state dict for a double block from diffusers format to BFL format."""
|
||||
to_prefix = f"double_blocks.{double_block_index}"
|
||||
from_prefix = f"transformer_blocks.{double_block_index}"
|
||||
|
||||
new_sd: dict[str, torch.Tensor] = {}
|
||||
|
||||
# Check one key to determine if this block exists.
|
||||
if f"{from_prefix}.attn.add_q_proj.bias" not in sd:
|
||||
return new_sd
|
||||
|
||||
# txt_attn.qkv
|
||||
new_sd[f"{to_prefix}.txt_attn.qkv.bias"] = _fuse_weights(
|
||||
sd.pop(f"{from_prefix}.attn.add_q_proj.bias"),
|
||||
sd.pop(f"{from_prefix}.attn.add_k_proj.bias"),
|
||||
sd.pop(f"{from_prefix}.attn.add_v_proj.bias"),
|
||||
)
|
||||
new_sd[f"{to_prefix}.txt_attn.qkv.weight"] = _fuse_weights(
|
||||
sd.pop(f"{from_prefix}.attn.add_q_proj.weight"),
|
||||
sd.pop(f"{from_prefix}.attn.add_k_proj.weight"),
|
||||
sd.pop(f"{from_prefix}.attn.add_v_proj.weight"),
|
||||
)
|
||||
|
||||
# img_attn.qkv
|
||||
new_sd[f"{to_prefix}.img_attn.qkv.bias"] = _fuse_weights(
|
||||
sd.pop(f"{from_prefix}.attn.to_q.bias"),
|
||||
sd.pop(f"{from_prefix}.attn.to_k.bias"),
|
||||
sd.pop(f"{from_prefix}.attn.to_v.bias"),
|
||||
)
|
||||
new_sd[f"{to_prefix}.img_attn.qkv.weight"] = _fuse_weights(
|
||||
sd.pop(f"{from_prefix}.attn.to_q.weight"),
|
||||
sd.pop(f"{from_prefix}.attn.to_k.weight"),
|
||||
sd.pop(f"{from_prefix}.attn.to_v.weight"),
|
||||
)
|
||||
|
||||
# Handle basic 1-to-1 key conversions.
|
||||
key_map = {
|
||||
# img_attn
|
||||
"attn.norm_k.weight": "img_attn.norm.key_norm.scale",
|
||||
"attn.norm_q.weight": "img_attn.norm.query_norm.scale",
|
||||
"attn.to_out.0.weight": "img_attn.proj.weight",
|
||||
"attn.to_out.0.bias": "img_attn.proj.bias",
|
||||
# img_mlp
|
||||
"ff.net.0.proj.weight": "img_mlp.0.weight",
|
||||
"ff.net.0.proj.bias": "img_mlp.0.bias",
|
||||
"ff.net.2.weight": "img_mlp.2.weight",
|
||||
"ff.net.2.bias": "img_mlp.2.bias",
|
||||
# img_mod
|
||||
"norm1.linear.weight": "img_mod.lin.weight",
|
||||
"norm1.linear.bias": "img_mod.lin.bias",
|
||||
# txt_attn
|
||||
"attn.norm_added_q.weight": "txt_attn.norm.query_norm.scale",
|
||||
"attn.norm_added_k.weight": "txt_attn.norm.key_norm.scale",
|
||||
"attn.to_add_out.weight": "txt_attn.proj.weight",
|
||||
"attn.to_add_out.bias": "txt_attn.proj.bias",
|
||||
# txt_mlp
|
||||
"ff_context.net.0.proj.weight": "txt_mlp.0.weight",
|
||||
"ff_context.net.0.proj.bias": "txt_mlp.0.bias",
|
||||
"ff_context.net.2.weight": "txt_mlp.2.weight",
|
||||
"ff_context.net.2.bias": "txt_mlp.2.bias",
|
||||
# txt_mod
|
||||
"norm1_context.linear.weight": "txt_mod.lin.weight",
|
||||
"norm1_context.linear.bias": "txt_mod.lin.bias",
|
||||
}
|
||||
for from_key, to_key in key_map.items():
|
||||
new_sd[f"{to_prefix}.{to_key}"] = sd.pop(f"{from_prefix}.{from_key}")
|
||||
|
||||
return new_sd
|
||||
|
||||
|
||||
def _convert_flux_single_block_sd_from_diffusers_to_bfl_format(
|
||||
sd: Dict[str, torch.Tensor], single_block_index: int
|
||||
) -> Dict[str, torch.Tensor]:
|
||||
"""Convert the state dict for a single block from diffusers format to BFL format."""
|
||||
to_prefix = f"single_blocks.{single_block_index}"
|
||||
from_prefix = f"single_transformer_blocks.{single_block_index}"
|
||||
|
||||
new_sd: dict[str, torch.Tensor] = {}
|
||||
|
||||
# Check one key to determine if this block exists.
|
||||
if f"{from_prefix}.attn.to_q.bias" not in sd:
|
||||
return new_sd
|
||||
|
||||
# linear1 (qkv)
|
||||
new_sd[f"{to_prefix}.linear1.bias"] = _fuse_weights(
|
||||
sd.pop(f"{from_prefix}.attn.to_q.bias"),
|
||||
sd.pop(f"{from_prefix}.attn.to_k.bias"),
|
||||
sd.pop(f"{from_prefix}.attn.to_v.bias"),
|
||||
sd.pop(f"{from_prefix}.proj_mlp.bias"),
|
||||
)
|
||||
new_sd[f"{to_prefix}.linear1.weight"] = _fuse_weights(
|
||||
sd.pop(f"{from_prefix}.attn.to_q.weight"),
|
||||
sd.pop(f"{from_prefix}.attn.to_k.weight"),
|
||||
sd.pop(f"{from_prefix}.attn.to_v.weight"),
|
||||
sd.pop(f"{from_prefix}.proj_mlp.weight"),
|
||||
)
|
||||
|
||||
# Handle basic 1-to-1 key conversions.
|
||||
key_map = {
|
||||
# linear2
|
||||
"proj_out.weight": "linear2.weight",
|
||||
"proj_out.bias": "linear2.bias",
|
||||
# modulation
|
||||
"norm.linear.weight": "modulation.lin.weight",
|
||||
"norm.linear.bias": "modulation.lin.bias",
|
||||
# norm
|
||||
"attn.norm_k.weight": "norm.key_norm.scale",
|
||||
"attn.norm_q.weight": "norm.query_norm.scale",
|
||||
}
|
||||
for from_key, to_key in key_map.items():
|
||||
new_sd[f"{to_prefix}.{to_key}"] = sd.pop(f"{from_prefix}.{from_key}")
|
||||
|
||||
return new_sd
|
||||
|
||||
|
||||
def convert_diffusers_instantx_state_dict_to_bfl_format(sd: Dict[str, torch.Tensor]) -> Dict[str, torch.Tensor]:
|
||||
"""Convert an InstantX ControlNet state dict to the format that can be loaded by our internal
|
||||
InstantXControlNetFlux model.
|
||||
|
||||
The original InstantX ControlNet model was developed to be used in diffusers. We have ported the original
|
||||
implementation to InstantXControlNetFlux to make it compatible with BFL-style models. This function converts the
|
||||
original state dict to the format expected by InstantXControlNetFlux.
|
||||
"""
|
||||
# Shallow copy sd so that we can pop keys from it without modifying the original.
|
||||
sd = sd.copy()
|
||||
|
||||
new_sd: dict[str, torch.Tensor] = {}
|
||||
|
||||
# Handle basic 1-to-1 key conversions.
|
||||
basic_key_map = {
|
||||
# Base model keys.
|
||||
# ----------------
|
||||
# txt_in keys.
|
||||
"context_embedder.bias": "txt_in.bias",
|
||||
"context_embedder.weight": "txt_in.weight",
|
||||
# guidance_in MLPEmbedder keys.
|
||||
"time_text_embed.guidance_embedder.linear_1.bias": "guidance_in.in_layer.bias",
|
||||
"time_text_embed.guidance_embedder.linear_1.weight": "guidance_in.in_layer.weight",
|
||||
"time_text_embed.guidance_embedder.linear_2.bias": "guidance_in.out_layer.bias",
|
||||
"time_text_embed.guidance_embedder.linear_2.weight": "guidance_in.out_layer.weight",
|
||||
# vector_in MLPEmbedder keys.
|
||||
"time_text_embed.text_embedder.linear_1.bias": "vector_in.in_layer.bias",
|
||||
"time_text_embed.text_embedder.linear_1.weight": "vector_in.in_layer.weight",
|
||||
"time_text_embed.text_embedder.linear_2.bias": "vector_in.out_layer.bias",
|
||||
"time_text_embed.text_embedder.linear_2.weight": "vector_in.out_layer.weight",
|
||||
# time_in MLPEmbedder keys.
|
||||
"time_text_embed.timestep_embedder.linear_1.bias": "time_in.in_layer.bias",
|
||||
"time_text_embed.timestep_embedder.linear_1.weight": "time_in.in_layer.weight",
|
||||
"time_text_embed.timestep_embedder.linear_2.bias": "time_in.out_layer.bias",
|
||||
"time_text_embed.timestep_embedder.linear_2.weight": "time_in.out_layer.weight",
|
||||
# img_in keys.
|
||||
"x_embedder.bias": "img_in.bias",
|
||||
"x_embedder.weight": "img_in.weight",
|
||||
}
|
||||
for old_key, new_key in basic_key_map.items():
|
||||
v = sd.pop(old_key, None)
|
||||
if v is not None:
|
||||
new_sd[new_key] = v
|
||||
|
||||
# Handle the double_blocks.
|
||||
block_index = 0
|
||||
while True:
|
||||
converted_double_block_sd = _convert_flux_double_block_sd_from_diffusers_to_bfl_format(sd, block_index)
|
||||
if len(converted_double_block_sd) == 0:
|
||||
break
|
||||
new_sd.update(converted_double_block_sd)
|
||||
block_index += 1
|
||||
|
||||
# Handle the single_blocks.
|
||||
block_index = 0
|
||||
while True:
|
||||
converted_singe_block_sd = _convert_flux_single_block_sd_from_diffusers_to_bfl_format(sd, block_index)
|
||||
if len(converted_singe_block_sd) == 0:
|
||||
break
|
||||
new_sd.update(converted_singe_block_sd)
|
||||
block_index += 1
|
||||
|
||||
# Transfer controlnet keys as-is.
|
||||
for k in list(sd.keys()):
|
||||
if k.startswith("controlnet_"):
|
||||
new_sd[k] = sd.pop(k)
|
||||
|
||||
# Assert that all keys have been handled.
|
||||
assert len(sd) == 0
|
||||
return new_sd
|
||||
|
||||
|
||||
def infer_flux_params_from_state_dict(sd: Dict[str, torch.Tensor]) -> FluxParams:
|
||||
"""Infer the FluxParams from the shape of a FLUX state dict. When a model is distributed in diffusers format, this
|
||||
information is all contained in the config.json file that accompanies the model. However, being apple to infer the
|
||||
params from the state dict enables us to load models (e.g. an InstantX ControlNet) from a single weight file.
|
||||
"""
|
||||
hidden_size = sd["img_in.weight"].shape[0]
|
||||
mlp_hidden_dim = sd["double_blocks.0.img_mlp.0.weight"].shape[0]
|
||||
# mlp_ratio is a float, but we treat it as an int here to avoid having to think about possible float precision
|
||||
# issues. In practice, mlp_ratio is usually 4.
|
||||
mlp_ratio = mlp_hidden_dim // hidden_size
|
||||
|
||||
head_dim = sd["double_blocks.0.img_attn.norm.query_norm.scale"].shape[0]
|
||||
num_heads = hidden_size // head_dim
|
||||
|
||||
# Count the number of double blocks.
|
||||
double_block_index = 0
|
||||
while f"double_blocks.{double_block_index}.img_attn.qkv.weight" in sd:
|
||||
double_block_index += 1
|
||||
|
||||
# Count the number of single blocks.
|
||||
single_block_index = 0
|
||||
while f"single_blocks.{single_block_index}.linear1.weight" in sd:
|
||||
single_block_index += 1
|
||||
|
||||
return FluxParams(
|
||||
in_channels=sd["img_in.weight"].shape[1],
|
||||
vec_in_dim=sd["vector_in.in_layer.weight"].shape[1],
|
||||
context_in_dim=sd["txt_in.weight"].shape[1],
|
||||
hidden_size=hidden_size,
|
||||
mlp_ratio=mlp_ratio,
|
||||
num_heads=num_heads,
|
||||
depth=double_block_index,
|
||||
depth_single_blocks=single_block_index,
|
||||
# axes_dim cannot be inferred from the state dict. The hard-coded value is correct for dev/schnell models.
|
||||
axes_dim=[16, 56, 56],
|
||||
# theta cannot be inferred from the state dict. The hard-coded value is correct for dev/schnell models.
|
||||
theta=10_000,
|
||||
qkv_bias="double_blocks.0.img_attn.qkv.bias" in sd,
|
||||
guidance_embed="guidance_in.in_layer.weight" in sd,
|
||||
)
|
||||
|
||||
|
||||
def infer_instantx_num_control_modes_from_state_dict(sd: Dict[str, torch.Tensor]) -> int | None:
|
||||
"""Infer the number of ControlNet Union modes from the shape of a InstantX ControlNet state dict.
|
||||
|
||||
Returns None if the model is not a ControlNet Union model. Otherwise returns the number of modes.
|
||||
"""
|
||||
mode_embedder_key = "controlnet_mode_embedder.weight"
|
||||
if mode_embedder_key not in sd:
|
||||
return None
|
||||
|
||||
return sd[mode_embedder_key].shape[0]
|
||||
@@ -1,130 +0,0 @@
|
||||
# This file was initially based on:
|
||||
# https://github.com/XLabs-AI/x-flux/blob/47495425dbed499be1e8e5a6e52628b07349cba2/src/flux/controlnet.py
|
||||
|
||||
|
||||
from dataclasses import dataclass
|
||||
|
||||
import torch
|
||||
from einops import rearrange
|
||||
|
||||
from invokeai.backend.flux.controlnet.zero_module import zero_module
|
||||
from invokeai.backend.flux.model import FluxParams
|
||||
from invokeai.backend.flux.modules.layers import DoubleStreamBlock, EmbedND, MLPEmbedder, timestep_embedding
|
||||
|
||||
|
||||
@dataclass
|
||||
class XLabsControlNetFluxOutput:
|
||||
controlnet_double_block_residuals: list[torch.Tensor] | None
|
||||
|
||||
|
||||
class XLabsControlNetFlux(torch.nn.Module):
|
||||
"""A ControlNet model for FLUX.
|
||||
|
||||
The architecture is very similar to the base FLUX model, with the following differences:
|
||||
- A `controlnet_depth` parameter is passed to control the number of double_blocks that the ControlNet is applied to.
|
||||
In order to keep the ControlNet small, this is typically much less than the depth of the base FLUX model.
|
||||
- There is a set of `controlnet_blocks` that are applied to the output of each double_block.
|
||||
"""
|
||||
|
||||
def __init__(self, params: FluxParams, controlnet_depth: int = 2):
|
||||
super().__init__()
|
||||
|
||||
self.params = params
|
||||
self.in_channels = params.in_channels
|
||||
self.out_channels = self.in_channels
|
||||
if params.hidden_size % params.num_heads != 0:
|
||||
raise ValueError(f"Hidden size {params.hidden_size} must be divisible by num_heads {params.num_heads}")
|
||||
pe_dim = params.hidden_size // params.num_heads
|
||||
if sum(params.axes_dim) != pe_dim:
|
||||
raise ValueError(f"Got {params.axes_dim} but expected positional dim {pe_dim}")
|
||||
self.hidden_size = params.hidden_size
|
||||
self.num_heads = params.num_heads
|
||||
self.pe_embedder = EmbedND(dim=pe_dim, theta=params.theta, axes_dim=params.axes_dim)
|
||||
self.img_in = torch.nn.Linear(self.in_channels, self.hidden_size, bias=True)
|
||||
self.time_in = MLPEmbedder(in_dim=256, hidden_dim=self.hidden_size)
|
||||
self.vector_in = MLPEmbedder(params.vec_in_dim, self.hidden_size)
|
||||
self.guidance_in = (
|
||||
MLPEmbedder(in_dim=256, hidden_dim=self.hidden_size) if params.guidance_embed else torch.nn.Identity()
|
||||
)
|
||||
self.txt_in = torch.nn.Linear(params.context_in_dim, self.hidden_size)
|
||||
|
||||
self.double_blocks = torch.nn.ModuleList(
|
||||
[
|
||||
DoubleStreamBlock(
|
||||
self.hidden_size,
|
||||
self.num_heads,
|
||||
mlp_ratio=params.mlp_ratio,
|
||||
qkv_bias=params.qkv_bias,
|
||||
)
|
||||
for _ in range(controlnet_depth)
|
||||
]
|
||||
)
|
||||
|
||||
# Add ControlNet blocks.
|
||||
self.controlnet_blocks = torch.nn.ModuleList([])
|
||||
for _ in range(controlnet_depth):
|
||||
controlnet_block = torch.nn.Linear(self.hidden_size, self.hidden_size)
|
||||
controlnet_block = zero_module(controlnet_block)
|
||||
self.controlnet_blocks.append(controlnet_block)
|
||||
self.pos_embed_input = torch.nn.Linear(self.in_channels, self.hidden_size, bias=True)
|
||||
self.input_hint_block = torch.nn.Sequential(
|
||||
torch.nn.Conv2d(3, 16, 3, padding=1),
|
||||
torch.nn.SiLU(),
|
||||
torch.nn.Conv2d(16, 16, 3, padding=1),
|
||||
torch.nn.SiLU(),
|
||||
torch.nn.Conv2d(16, 16, 3, padding=1, stride=2),
|
||||
torch.nn.SiLU(),
|
||||
torch.nn.Conv2d(16, 16, 3, padding=1),
|
||||
torch.nn.SiLU(),
|
||||
torch.nn.Conv2d(16, 16, 3, padding=1, stride=2),
|
||||
torch.nn.SiLU(),
|
||||
torch.nn.Conv2d(16, 16, 3, padding=1),
|
||||
torch.nn.SiLU(),
|
||||
torch.nn.Conv2d(16, 16, 3, padding=1, stride=2),
|
||||
torch.nn.SiLU(),
|
||||
zero_module(torch.nn.Conv2d(16, 16, 3, padding=1)),
|
||||
)
|
||||
|
||||
def forward(
|
||||
self,
|
||||
img: torch.Tensor,
|
||||
img_ids: torch.Tensor,
|
||||
controlnet_cond: torch.Tensor,
|
||||
txt: torch.Tensor,
|
||||
txt_ids: torch.Tensor,
|
||||
timesteps: torch.Tensor,
|
||||
y: torch.Tensor,
|
||||
guidance: torch.Tensor | None = None,
|
||||
) -> XLabsControlNetFluxOutput:
|
||||
if img.ndim != 3 or txt.ndim != 3:
|
||||
raise ValueError("Input img and txt tensors must have 3 dimensions.")
|
||||
|
||||
# running on sequences img
|
||||
img = self.img_in(img)
|
||||
controlnet_cond = self.input_hint_block(controlnet_cond)
|
||||
controlnet_cond = rearrange(controlnet_cond, "b c (h ph) (w pw) -> b (h w) (c ph pw)", ph=2, pw=2)
|
||||
controlnet_cond = self.pos_embed_input(controlnet_cond)
|
||||
img = img + controlnet_cond
|
||||
vec = self.time_in(timestep_embedding(timesteps, 256))
|
||||
if self.params.guidance_embed:
|
||||
if guidance is None:
|
||||
raise ValueError("Didn't get guidance strength for guidance distilled model.")
|
||||
vec = vec + self.guidance_in(timestep_embedding(guidance, 256))
|
||||
vec = vec + self.vector_in(y)
|
||||
txt = self.txt_in(txt)
|
||||
|
||||
ids = torch.cat((txt_ids, img_ids), dim=1)
|
||||
pe = self.pe_embedder(ids)
|
||||
|
||||
block_res_samples: list[torch.Tensor] = []
|
||||
|
||||
for block in self.double_blocks:
|
||||
img, txt = block(img=img, txt=txt, vec=vec, pe=pe)
|
||||
block_res_samples.append(img)
|
||||
|
||||
controlnet_block_res_samples: list[torch.Tensor] = []
|
||||
for block_res_sample, controlnet_block in zip(block_res_samples, self.controlnet_blocks, strict=True):
|
||||
block_res_sample = controlnet_block(block_res_sample)
|
||||
controlnet_block_res_samples.append(block_res_sample)
|
||||
|
||||
return XLabsControlNetFluxOutput(controlnet_double_block_residuals=controlnet_block_res_samples)
|
||||
@@ -1,12 +0,0 @@
|
||||
from typing import TypeVar
|
||||
|
||||
import torch
|
||||
|
||||
T = TypeVar("T", bound=torch.nn.Module)
|
||||
|
||||
|
||||
def zero_module(module: T) -> T:
|
||||
"""Initialize the parameters of a module to zero."""
|
||||
for p in module.parameters():
|
||||
torch.nn.init.zeros_(p)
|
||||
return module
|
||||
@@ -1,83 +0,0 @@
|
||||
import einops
|
||||
import torch
|
||||
|
||||
from invokeai.backend.flux.extensions.xlabs_ip_adapter_extension import XLabsIPAdapterExtension
|
||||
from invokeai.backend.flux.math import attention
|
||||
from invokeai.backend.flux.modules.layers import DoubleStreamBlock
|
||||
|
||||
|
||||
class CustomDoubleStreamBlockProcessor:
|
||||
"""A class containing a custom implementation of DoubleStreamBlock.forward() with additional features
|
||||
(IP-Adapter, etc.).
|
||||
"""
|
||||
|
||||
@staticmethod
|
||||
def _double_stream_block_forward(
|
||||
block: DoubleStreamBlock, img: torch.Tensor, txt: torch.Tensor, vec: torch.Tensor, pe: torch.Tensor
|
||||
) -> tuple[torch.Tensor, torch.Tensor, torch.Tensor]:
|
||||
"""This function is a direct copy of DoubleStreamBlock.forward(), but it returns some of the intermediate
|
||||
values.
|
||||
"""
|
||||
img_mod1, img_mod2 = block.img_mod(vec)
|
||||
txt_mod1, txt_mod2 = block.txt_mod(vec)
|
||||
|
||||
# prepare image for attention
|
||||
img_modulated = block.img_norm1(img)
|
||||
img_modulated = (1 + img_mod1.scale) * img_modulated + img_mod1.shift
|
||||
img_qkv = block.img_attn.qkv(img_modulated)
|
||||
img_q, img_k, img_v = einops.rearrange(img_qkv, "B L (K H D) -> K B H L D", K=3, H=block.num_heads)
|
||||
img_q, img_k = block.img_attn.norm(img_q, img_k, img_v)
|
||||
|
||||
# prepare txt for attention
|
||||
txt_modulated = block.txt_norm1(txt)
|
||||
txt_modulated = (1 + txt_mod1.scale) * txt_modulated + txt_mod1.shift
|
||||
txt_qkv = block.txt_attn.qkv(txt_modulated)
|
||||
txt_q, txt_k, txt_v = einops.rearrange(txt_qkv, "B L (K H D) -> K B H L D", K=3, H=block.num_heads)
|
||||
txt_q, txt_k = block.txt_attn.norm(txt_q, txt_k, txt_v)
|
||||
|
||||
# run actual attention
|
||||
q = torch.cat((txt_q, img_q), dim=2)
|
||||
k = torch.cat((txt_k, img_k), dim=2)
|
||||
v = torch.cat((txt_v, img_v), dim=2)
|
||||
|
||||
attn = attention(q, k, v, pe=pe)
|
||||
txt_attn, img_attn = attn[:, : txt.shape[1]], attn[:, txt.shape[1] :]
|
||||
|
||||
# calculate the img bloks
|
||||
img = img + img_mod1.gate * block.img_attn.proj(img_attn)
|
||||
img = img + img_mod2.gate * block.img_mlp((1 + img_mod2.scale) * block.img_norm2(img) + img_mod2.shift)
|
||||
|
||||
# calculate the txt bloks
|
||||
txt = txt + txt_mod1.gate * block.txt_attn.proj(txt_attn)
|
||||
txt = txt + txt_mod2.gate * block.txt_mlp((1 + txt_mod2.scale) * block.txt_norm2(txt) + txt_mod2.shift)
|
||||
return img, txt, img_q
|
||||
|
||||
@staticmethod
|
||||
def custom_double_block_forward(
|
||||
timestep_index: int,
|
||||
total_num_timesteps: int,
|
||||
block_index: int,
|
||||
block: DoubleStreamBlock,
|
||||
img: torch.Tensor,
|
||||
txt: torch.Tensor,
|
||||
vec: torch.Tensor,
|
||||
pe: torch.Tensor,
|
||||
ip_adapter_extensions: list[XLabsIPAdapterExtension],
|
||||
) -> tuple[torch.Tensor, torch.Tensor]:
|
||||
"""A custom implementation of DoubleStreamBlock.forward() with additional features:
|
||||
- IP-Adapter support
|
||||
"""
|
||||
img, txt, img_q = CustomDoubleStreamBlockProcessor._double_stream_block_forward(block, img, txt, vec, pe)
|
||||
|
||||
# Apply IP-Adapter conditioning.
|
||||
for ip_adapter_extension in ip_adapter_extensions:
|
||||
img = ip_adapter_extension.run_ip_adapter(
|
||||
timestep_index=timestep_index,
|
||||
total_num_timesteps=total_num_timesteps,
|
||||
block_index=block_index,
|
||||
block=block,
|
||||
img_q=img_q,
|
||||
img=img,
|
||||
)
|
||||
|
||||
return img, txt
|
||||
@@ -1,14 +1,9 @@
|
||||
import math
|
||||
from typing import Callable
|
||||
|
||||
import torch
|
||||
from tqdm import tqdm
|
||||
|
||||
from invokeai.backend.flux.controlnet.controlnet_flux_output import ControlNetFluxOutput, sum_controlnet_flux_outputs
|
||||
from invokeai.backend.flux.extensions.inpaint_extension import InpaintExtension
|
||||
from invokeai.backend.flux.extensions.instantx_controlnet_extension import InstantXControlNetExtension
|
||||
from invokeai.backend.flux.extensions.xlabs_controlnet_extension import XLabsControlNetExtension
|
||||
from invokeai.backend.flux.extensions.xlabs_ip_adapter_extension import XLabsIPAdapterExtension
|
||||
from invokeai.backend.flux.inpaint_extension import InpaintExtension
|
||||
from invokeai.backend.flux.model import Flux
|
||||
from invokeai.backend.stable_diffusion.diffusers_pipeline import PipelineIntermediateState
|
||||
|
||||
@@ -18,23 +13,14 @@ def denoise(
|
||||
# model input
|
||||
img: torch.Tensor,
|
||||
img_ids: torch.Tensor,
|
||||
# positive text conditioning
|
||||
txt: torch.Tensor,
|
||||
txt_ids: torch.Tensor,
|
||||
vec: torch.Tensor,
|
||||
# negative text conditioning
|
||||
neg_txt: torch.Tensor | None,
|
||||
neg_txt_ids: torch.Tensor | None,
|
||||
neg_vec: torch.Tensor | None,
|
||||
# sampling parameters
|
||||
timesteps: list[float],
|
||||
step_callback: Callable[[PipelineIntermediateState], None],
|
||||
guidance: float,
|
||||
cfg_scale: list[float],
|
||||
inpaint_extension: InpaintExtension | None,
|
||||
controlnet_extensions: list[XLabsControlNetExtension | InstantXControlNetExtension],
|
||||
pos_ip_adapter_extensions: list[XLabsIPAdapterExtension],
|
||||
neg_ip_adapter_extensions: list[XLabsIPAdapterExtension],
|
||||
):
|
||||
# step 0 is the initial state
|
||||
total_steps = len(timesteps) - 1
|
||||
@@ -47,34 +33,11 @@ def denoise(
|
||||
latents=img,
|
||||
),
|
||||
)
|
||||
step = 1
|
||||
# guidance_vec is ignored for schnell.
|
||||
guidance_vec = torch.full((img.shape[0],), guidance, device=img.device, dtype=img.dtype)
|
||||
for step_index, (t_curr, t_prev) in tqdm(list(enumerate(zip(timesteps[:-1], timesteps[1:], strict=True)))):
|
||||
for t_curr, t_prev in tqdm(list(zip(timesteps[:-1], timesteps[1:], strict=True))):
|
||||
t_vec = torch.full((img.shape[0],), t_curr, dtype=img.dtype, device=img.device)
|
||||
|
||||
# Run ControlNet models.
|
||||
controlnet_residuals: list[ControlNetFluxOutput] = []
|
||||
for controlnet_extension in controlnet_extensions:
|
||||
controlnet_residuals.append(
|
||||
controlnet_extension.run_controlnet(
|
||||
timestep_index=step_index,
|
||||
total_num_timesteps=total_steps,
|
||||
img=img,
|
||||
img_ids=img_ids,
|
||||
txt=txt,
|
||||
txt_ids=txt_ids,
|
||||
y=vec,
|
||||
timesteps=t_vec,
|
||||
guidance=guidance_vec,
|
||||
)
|
||||
)
|
||||
|
||||
# Merge the ControlNet residuals from multiple ControlNets.
|
||||
# TODO(ryand): We may want to calculate the sum just-in-time to keep peak memory low. Keep in mind, that the
|
||||
# controlnet_residuals datastructure is efficient in that it likely contains multiple references to the same
|
||||
# tensors. Calculating the sum materializes each tensor into its own instance.
|
||||
merged_controlnet_residuals = sum_controlnet_flux_outputs(controlnet_residuals)
|
||||
|
||||
pred = model(
|
||||
img=img,
|
||||
img_ids=img_ids,
|
||||
@@ -83,39 +46,8 @@ def denoise(
|
||||
y=vec,
|
||||
timesteps=t_vec,
|
||||
guidance=guidance_vec,
|
||||
timestep_index=step_index,
|
||||
total_num_timesteps=total_steps,
|
||||
controlnet_double_block_residuals=merged_controlnet_residuals.double_block_residuals,
|
||||
controlnet_single_block_residuals=merged_controlnet_residuals.single_block_residuals,
|
||||
ip_adapter_extensions=pos_ip_adapter_extensions,
|
||||
)
|
||||
|
||||
step_cfg_scale = cfg_scale[step_index]
|
||||
|
||||
# If step_cfg_scale, is 1.0, then we don't need to run the negative prediction.
|
||||
if not math.isclose(step_cfg_scale, 1.0):
|
||||
# TODO(ryand): Add option to run positive and negative predictions in a single batch for better performance
|
||||
# on systems with sufficient VRAM.
|
||||
|
||||
if neg_txt is None or neg_txt_ids is None or neg_vec is None:
|
||||
raise ValueError("Negative text conditioning is required when cfg_scale is not 1.0.")
|
||||
|
||||
neg_pred = model(
|
||||
img=img,
|
||||
img_ids=img_ids,
|
||||
txt=neg_txt,
|
||||
txt_ids=neg_txt_ids,
|
||||
y=neg_vec,
|
||||
timesteps=t_vec,
|
||||
guidance=guidance_vec,
|
||||
timestep_index=step_index,
|
||||
total_num_timesteps=total_steps,
|
||||
controlnet_double_block_residuals=None,
|
||||
controlnet_single_block_residuals=None,
|
||||
ip_adapter_extensions=neg_ip_adapter_extensions,
|
||||
)
|
||||
pred = neg_pred + step_cfg_scale * (pred - neg_pred)
|
||||
|
||||
preview_img = img - t_curr * pred
|
||||
img = img + (t_prev - t_curr) * pred
|
||||
|
||||
@@ -125,12 +57,13 @@ def denoise(
|
||||
|
||||
step_callback(
|
||||
PipelineIntermediateState(
|
||||
step=step_index + 1,
|
||||
step=step,
|
||||
order=1,
|
||||
total_steps=total_steps,
|
||||
timestep=int(t_curr),
|
||||
latents=preview_img,
|
||||
),
|
||||
)
|
||||
step += 1
|
||||
|
||||
return img
|
||||
|
||||
@@ -1,45 +0,0 @@
|
||||
import math
|
||||
from abc import ABC, abstractmethod
|
||||
from typing import List, Union
|
||||
|
||||
import torch
|
||||
|
||||
from invokeai.backend.flux.controlnet.controlnet_flux_output import ControlNetFluxOutput
|
||||
|
||||
|
||||
class BaseControlNetExtension(ABC):
|
||||
def __init__(
|
||||
self,
|
||||
weight: Union[float, List[float]],
|
||||
begin_step_percent: float,
|
||||
end_step_percent: float,
|
||||
):
|
||||
self._weight = weight
|
||||
self._begin_step_percent = begin_step_percent
|
||||
self._end_step_percent = end_step_percent
|
||||
|
||||
def _get_weight(self, timestep_index: int, total_num_timesteps: int) -> float:
|
||||
first_step = math.floor(self._begin_step_percent * total_num_timesteps)
|
||||
last_step = math.ceil(self._end_step_percent * total_num_timesteps)
|
||||
|
||||
if timestep_index < first_step or timestep_index > last_step:
|
||||
return 0.0
|
||||
|
||||
if isinstance(self._weight, list):
|
||||
return self._weight[timestep_index]
|
||||
|
||||
return self._weight
|
||||
|
||||
@abstractmethod
|
||||
def run_controlnet(
|
||||
self,
|
||||
timestep_index: int,
|
||||
total_num_timesteps: int,
|
||||
img: torch.Tensor,
|
||||
img_ids: torch.Tensor,
|
||||
txt: torch.Tensor,
|
||||
txt_ids: torch.Tensor,
|
||||
y: torch.Tensor,
|
||||
timesteps: torch.Tensor,
|
||||
guidance: torch.Tensor | None,
|
||||
) -> ControlNetFluxOutput: ...
|
||||
@@ -1,194 +0,0 @@
|
||||
import math
|
||||
from typing import List, Union
|
||||
|
||||
import torch
|
||||
from PIL.Image import Image
|
||||
|
||||
from invokeai.app.invocations.constants import LATENT_SCALE_FACTOR
|
||||
from invokeai.app.invocations.flux_vae_encode import FluxVaeEncodeInvocation
|
||||
from invokeai.app.util.controlnet_utils import CONTROLNET_RESIZE_VALUES, prepare_control_image
|
||||
from invokeai.backend.flux.controlnet.controlnet_flux_output import ControlNetFluxOutput
|
||||
from invokeai.backend.flux.controlnet.instantx_controlnet_flux import (
|
||||
InstantXControlNetFlux,
|
||||
InstantXControlNetFluxOutput,
|
||||
)
|
||||
from invokeai.backend.flux.extensions.base_controlnet_extension import BaseControlNetExtension
|
||||
from invokeai.backend.flux.sampling_utils import pack
|
||||
from invokeai.backend.model_manager.load.load_base import LoadedModel
|
||||
|
||||
|
||||
class InstantXControlNetExtension(BaseControlNetExtension):
|
||||
def __init__(
|
||||
self,
|
||||
model: InstantXControlNetFlux,
|
||||
controlnet_cond: torch.Tensor,
|
||||
instantx_control_mode: torch.Tensor | None,
|
||||
weight: Union[float, List[float]],
|
||||
begin_step_percent: float,
|
||||
end_step_percent: float,
|
||||
):
|
||||
super().__init__(
|
||||
weight=weight,
|
||||
begin_step_percent=begin_step_percent,
|
||||
end_step_percent=end_step_percent,
|
||||
)
|
||||
self._model = model
|
||||
# The VAE-encoded and 'packed' control image to pass to the ControlNet model.
|
||||
self._controlnet_cond = controlnet_cond
|
||||
# TODO(ryand): Should we define an enum for the instantx_control_mode? Is it likely to change for future models?
|
||||
# The control mode for InstantX ControlNet union models.
|
||||
# See the values defined here: https://huggingface.co/InstantX/FLUX.1-dev-Controlnet-Union#control-mode
|
||||
# Expected shape: (batch_size, 1), Expected dtype: torch.long
|
||||
# If None, a zero-embedding will be used.
|
||||
self._instantx_control_mode = instantx_control_mode
|
||||
|
||||
# TODO(ryand): Pass in these params if a new base transformer / InstantX ControlNet pair get released.
|
||||
self._flux_transformer_num_double_blocks = 19
|
||||
self._flux_transformer_num_single_blocks = 38
|
||||
|
||||
@classmethod
|
||||
def prepare_controlnet_cond(
|
||||
cls,
|
||||
controlnet_image: Image,
|
||||
vae_info: LoadedModel,
|
||||
latent_height: int,
|
||||
latent_width: int,
|
||||
dtype: torch.dtype,
|
||||
device: torch.device,
|
||||
resize_mode: CONTROLNET_RESIZE_VALUES,
|
||||
):
|
||||
image_height = latent_height * LATENT_SCALE_FACTOR
|
||||
image_width = latent_width * LATENT_SCALE_FACTOR
|
||||
|
||||
resized_controlnet_image = prepare_control_image(
|
||||
image=controlnet_image,
|
||||
do_classifier_free_guidance=False,
|
||||
width=image_width,
|
||||
height=image_height,
|
||||
device=device,
|
||||
dtype=dtype,
|
||||
control_mode="balanced",
|
||||
resize_mode=resize_mode,
|
||||
)
|
||||
|
||||
# Shift the image from [0, 1] to [-1, 1].
|
||||
resized_controlnet_image = resized_controlnet_image * 2 - 1
|
||||
|
||||
# Run VAE encoder.
|
||||
controlnet_cond = FluxVaeEncodeInvocation.vae_encode(vae_info=vae_info, image_tensor=resized_controlnet_image)
|
||||
controlnet_cond = pack(controlnet_cond)
|
||||
|
||||
return controlnet_cond
|
||||
|
||||
@classmethod
|
||||
def from_controlnet_image(
|
||||
cls,
|
||||
model: InstantXControlNetFlux,
|
||||
controlnet_image: Image,
|
||||
instantx_control_mode: torch.Tensor | None,
|
||||
vae_info: LoadedModel,
|
||||
latent_height: int,
|
||||
latent_width: int,
|
||||
dtype: torch.dtype,
|
||||
device: torch.device,
|
||||
resize_mode: CONTROLNET_RESIZE_VALUES,
|
||||
weight: Union[float, List[float]],
|
||||
begin_step_percent: float,
|
||||
end_step_percent: float,
|
||||
):
|
||||
image_height = latent_height * LATENT_SCALE_FACTOR
|
||||
image_width = latent_width * LATENT_SCALE_FACTOR
|
||||
|
||||
resized_controlnet_image = prepare_control_image(
|
||||
image=controlnet_image,
|
||||
do_classifier_free_guidance=False,
|
||||
width=image_width,
|
||||
height=image_height,
|
||||
device=device,
|
||||
dtype=dtype,
|
||||
control_mode="balanced",
|
||||
resize_mode=resize_mode,
|
||||
)
|
||||
|
||||
# Shift the image from [0, 1] to [-1, 1].
|
||||
resized_controlnet_image = resized_controlnet_image * 2 - 1
|
||||
|
||||
# Run VAE encoder.
|
||||
controlnet_cond = FluxVaeEncodeInvocation.vae_encode(vae_info=vae_info, image_tensor=resized_controlnet_image)
|
||||
controlnet_cond = pack(controlnet_cond)
|
||||
|
||||
return cls(
|
||||
model=model,
|
||||
controlnet_cond=controlnet_cond,
|
||||
instantx_control_mode=instantx_control_mode,
|
||||
weight=weight,
|
||||
begin_step_percent=begin_step_percent,
|
||||
end_step_percent=end_step_percent,
|
||||
)
|
||||
|
||||
def _instantx_output_to_controlnet_output(
|
||||
self, instantx_output: InstantXControlNetFluxOutput
|
||||
) -> ControlNetFluxOutput:
|
||||
# The `interval_control` logic here is based on
|
||||
# https://github.com/huggingface/diffusers/blob/31058cdaef63ca660a1a045281d156239fba8192/src/diffusers/models/transformers/transformer_flux.py#L507-L511
|
||||
|
||||
# Handle double block residuals.
|
||||
double_block_residuals: list[torch.Tensor] = []
|
||||
double_block_samples = instantx_output.controlnet_block_samples
|
||||
if double_block_samples:
|
||||
interval_control = self._flux_transformer_num_double_blocks / len(double_block_samples)
|
||||
interval_control = int(math.ceil(interval_control))
|
||||
for i in range(self._flux_transformer_num_double_blocks):
|
||||
double_block_residuals.append(double_block_samples[i // interval_control])
|
||||
|
||||
# Handle single block residuals.
|
||||
single_block_residuals: list[torch.Tensor] = []
|
||||
single_block_samples = instantx_output.controlnet_single_block_samples
|
||||
if single_block_samples:
|
||||
interval_control = self._flux_transformer_num_single_blocks / len(single_block_samples)
|
||||
interval_control = int(math.ceil(interval_control))
|
||||
for i in range(self._flux_transformer_num_single_blocks):
|
||||
single_block_residuals.append(single_block_samples[i // interval_control])
|
||||
|
||||
return ControlNetFluxOutput(
|
||||
double_block_residuals=double_block_residuals or None,
|
||||
single_block_residuals=single_block_residuals or None,
|
||||
)
|
||||
|
||||
def run_controlnet(
|
||||
self,
|
||||
timestep_index: int,
|
||||
total_num_timesteps: int,
|
||||
img: torch.Tensor,
|
||||
img_ids: torch.Tensor,
|
||||
txt: torch.Tensor,
|
||||
txt_ids: torch.Tensor,
|
||||
y: torch.Tensor,
|
||||
timesteps: torch.Tensor,
|
||||
guidance: torch.Tensor | None,
|
||||
) -> ControlNetFluxOutput:
|
||||
weight = self._get_weight(timestep_index=timestep_index, total_num_timesteps=total_num_timesteps)
|
||||
if weight < 1e-6:
|
||||
return ControlNetFluxOutput(single_block_residuals=None, double_block_residuals=None)
|
||||
|
||||
# Make sure inputs have correct device and dtype.
|
||||
self._controlnet_cond = self._controlnet_cond.to(device=img.device, dtype=img.dtype)
|
||||
self._instantx_control_mode = (
|
||||
self._instantx_control_mode.to(device=img.device) if self._instantx_control_mode is not None else None
|
||||
)
|
||||
|
||||
instantx_output: InstantXControlNetFluxOutput = self._model(
|
||||
controlnet_cond=self._controlnet_cond,
|
||||
controlnet_mode=self._instantx_control_mode,
|
||||
img=img,
|
||||
img_ids=img_ids,
|
||||
txt=txt,
|
||||
txt_ids=txt_ids,
|
||||
timesteps=timesteps,
|
||||
y=y,
|
||||
guidance=guidance,
|
||||
)
|
||||
|
||||
controlnet_output = self._instantx_output_to_controlnet_output(instantx_output)
|
||||
controlnet_output.apply_weight(weight)
|
||||
return controlnet_output
|
||||
@@ -1,150 +0,0 @@
|
||||
from typing import List, Union
|
||||
|
||||
import torch
|
||||
from PIL.Image import Image
|
||||
|
||||
from invokeai.app.invocations.constants import LATENT_SCALE_FACTOR
|
||||
from invokeai.app.util.controlnet_utils import CONTROLNET_RESIZE_VALUES, prepare_control_image
|
||||
from invokeai.backend.flux.controlnet.controlnet_flux_output import ControlNetFluxOutput
|
||||
from invokeai.backend.flux.controlnet.xlabs_controlnet_flux import XLabsControlNetFlux, XLabsControlNetFluxOutput
|
||||
from invokeai.backend.flux.extensions.base_controlnet_extension import BaseControlNetExtension
|
||||
|
||||
|
||||
class XLabsControlNetExtension(BaseControlNetExtension):
|
||||
def __init__(
|
||||
self,
|
||||
model: XLabsControlNetFlux,
|
||||
controlnet_cond: torch.Tensor,
|
||||
weight: Union[float, List[float]],
|
||||
begin_step_percent: float,
|
||||
end_step_percent: float,
|
||||
):
|
||||
super().__init__(
|
||||
weight=weight,
|
||||
begin_step_percent=begin_step_percent,
|
||||
end_step_percent=end_step_percent,
|
||||
)
|
||||
|
||||
self._model = model
|
||||
# _controlnet_cond is the control image passed to the ControlNet model.
|
||||
# Pixel values are in the range [-1, 1]. Shape: (batch_size, 3, height, width).
|
||||
self._controlnet_cond = controlnet_cond
|
||||
|
||||
# TODO(ryand): Pass in these params if a new base transformer / XLabs ControlNet pair get released.
|
||||
self._flux_transformer_num_double_blocks = 19
|
||||
self._flux_transformer_num_single_blocks = 38
|
||||
|
||||
@classmethod
|
||||
def prepare_controlnet_cond(
|
||||
cls,
|
||||
controlnet_image: Image,
|
||||
latent_height: int,
|
||||
latent_width: int,
|
||||
dtype: torch.dtype,
|
||||
device: torch.device,
|
||||
resize_mode: CONTROLNET_RESIZE_VALUES,
|
||||
):
|
||||
image_height = latent_height * LATENT_SCALE_FACTOR
|
||||
image_width = latent_width * LATENT_SCALE_FACTOR
|
||||
|
||||
controlnet_cond = prepare_control_image(
|
||||
image=controlnet_image,
|
||||
do_classifier_free_guidance=False,
|
||||
width=image_width,
|
||||
height=image_height,
|
||||
device=device,
|
||||
dtype=dtype,
|
||||
control_mode="balanced",
|
||||
resize_mode=resize_mode,
|
||||
)
|
||||
|
||||
# Map pixel values from [0, 1] to [-1, 1].
|
||||
controlnet_cond = controlnet_cond * 2 - 1
|
||||
|
||||
return controlnet_cond
|
||||
|
||||
@classmethod
|
||||
def from_controlnet_image(
|
||||
cls,
|
||||
model: XLabsControlNetFlux,
|
||||
controlnet_image: Image,
|
||||
latent_height: int,
|
||||
latent_width: int,
|
||||
dtype: torch.dtype,
|
||||
device: torch.device,
|
||||
resize_mode: CONTROLNET_RESIZE_VALUES,
|
||||
weight: Union[float, List[float]],
|
||||
begin_step_percent: float,
|
||||
end_step_percent: float,
|
||||
):
|
||||
image_height = latent_height * LATENT_SCALE_FACTOR
|
||||
image_width = latent_width * LATENT_SCALE_FACTOR
|
||||
|
||||
controlnet_cond = prepare_control_image(
|
||||
image=controlnet_image,
|
||||
do_classifier_free_guidance=False,
|
||||
width=image_width,
|
||||
height=image_height,
|
||||
device=device,
|
||||
dtype=dtype,
|
||||
control_mode="balanced",
|
||||
resize_mode=resize_mode,
|
||||
)
|
||||
|
||||
# Map pixel values from [0, 1] to [-1, 1].
|
||||
controlnet_cond = controlnet_cond * 2 - 1
|
||||
|
||||
return cls(
|
||||
model=model,
|
||||
controlnet_cond=controlnet_cond,
|
||||
weight=weight,
|
||||
begin_step_percent=begin_step_percent,
|
||||
end_step_percent=end_step_percent,
|
||||
)
|
||||
|
||||
def _xlabs_output_to_controlnet_output(self, xlabs_output: XLabsControlNetFluxOutput) -> ControlNetFluxOutput:
|
||||
# The modulo index logic used here is based on:
|
||||
# https://github.com/XLabs-AI/x-flux/blob/47495425dbed499be1e8e5a6e52628b07349cba2/src/flux/model.py#L198-L200
|
||||
|
||||
# Handle double block residuals.
|
||||
double_block_residuals: list[torch.Tensor] = []
|
||||
xlabs_double_block_residuals = xlabs_output.controlnet_double_block_residuals
|
||||
if xlabs_double_block_residuals is not None:
|
||||
for i in range(self._flux_transformer_num_double_blocks):
|
||||
double_block_residuals.append(xlabs_double_block_residuals[i % len(xlabs_double_block_residuals)])
|
||||
|
||||
return ControlNetFluxOutput(
|
||||
double_block_residuals=double_block_residuals,
|
||||
single_block_residuals=None,
|
||||
)
|
||||
|
||||
def run_controlnet(
|
||||
self,
|
||||
timestep_index: int,
|
||||
total_num_timesteps: int,
|
||||
img: torch.Tensor,
|
||||
img_ids: torch.Tensor,
|
||||
txt: torch.Tensor,
|
||||
txt_ids: torch.Tensor,
|
||||
y: torch.Tensor,
|
||||
timesteps: torch.Tensor,
|
||||
guidance: torch.Tensor | None,
|
||||
) -> ControlNetFluxOutput:
|
||||
weight = self._get_weight(timestep_index=timestep_index, total_num_timesteps=total_num_timesteps)
|
||||
if weight < 1e-6:
|
||||
return ControlNetFluxOutput(single_block_residuals=None, double_block_residuals=None)
|
||||
|
||||
xlabs_output: XLabsControlNetFluxOutput = self._model(
|
||||
img=img,
|
||||
img_ids=img_ids,
|
||||
controlnet_cond=self._controlnet_cond,
|
||||
txt=txt,
|
||||
txt_ids=txt_ids,
|
||||
timesteps=timesteps,
|
||||
y=y,
|
||||
guidance=guidance,
|
||||
)
|
||||
|
||||
controlnet_output = self._xlabs_output_to_controlnet_output(xlabs_output)
|
||||
controlnet_output.apply_weight(weight)
|
||||
return controlnet_output
|
||||
@@ -1,89 +0,0 @@
|
||||
import math
|
||||
from typing import List, Union
|
||||
|
||||
import einops
|
||||
import torch
|
||||
from PIL import Image
|
||||
from transformers import CLIPImageProcessor, CLIPVisionModelWithProjection
|
||||
|
||||
from invokeai.backend.flux.ip_adapter.xlabs_ip_adapter_flux import XlabsIpAdapterFlux
|
||||
from invokeai.backend.flux.modules.layers import DoubleStreamBlock
|
||||
|
||||
|
||||
class XLabsIPAdapterExtension:
|
||||
def __init__(
|
||||
self,
|
||||
model: XlabsIpAdapterFlux,
|
||||
image_prompt_clip_embed: torch.Tensor,
|
||||
weight: Union[float, List[float]],
|
||||
begin_step_percent: float,
|
||||
end_step_percent: float,
|
||||
):
|
||||
self._model = model
|
||||
self._image_prompt_clip_embed = image_prompt_clip_embed
|
||||
self._weight = weight
|
||||
self._begin_step_percent = begin_step_percent
|
||||
self._end_step_percent = end_step_percent
|
||||
|
||||
self._image_proj: torch.Tensor | None = None
|
||||
|
||||
def _get_weight(self, timestep_index: int, total_num_timesteps: int) -> float:
|
||||
first_step = math.floor(self._begin_step_percent * total_num_timesteps)
|
||||
last_step = math.ceil(self._end_step_percent * total_num_timesteps)
|
||||
|
||||
if timestep_index < first_step or timestep_index > last_step:
|
||||
return 0.0
|
||||
|
||||
if isinstance(self._weight, list):
|
||||
return self._weight[timestep_index]
|
||||
|
||||
return self._weight
|
||||
|
||||
@staticmethod
|
||||
def run_clip_image_encoder(
|
||||
pil_image: List[Image.Image], image_encoder: CLIPVisionModelWithProjection
|
||||
) -> torch.Tensor:
|
||||
clip_image_processor = CLIPImageProcessor()
|
||||
clip_image: torch.Tensor = clip_image_processor(images=pil_image, return_tensors="pt").pixel_values
|
||||
clip_image = clip_image.to(device=image_encoder.device, dtype=image_encoder.dtype)
|
||||
clip_image_embeds = image_encoder(clip_image).image_embeds
|
||||
return clip_image_embeds
|
||||
|
||||
def run_image_proj(self, dtype: torch.dtype):
|
||||
image_prompt_clip_embed = self._image_prompt_clip_embed.to(dtype=dtype)
|
||||
self._image_proj = self._model.image_proj(image_prompt_clip_embed)
|
||||
|
||||
def run_ip_adapter(
|
||||
self,
|
||||
timestep_index: int,
|
||||
total_num_timesteps: int,
|
||||
block_index: int,
|
||||
block: DoubleStreamBlock,
|
||||
img_q: torch.Tensor,
|
||||
img: torch.Tensor,
|
||||
) -> torch.Tensor:
|
||||
"""The logic in this function is based on:
|
||||
https://github.com/XLabs-AI/x-flux/blob/47495425dbed499be1e8e5a6e52628b07349cba2/src/flux/modules/layers.py#L245-L301
|
||||
"""
|
||||
weight = self._get_weight(timestep_index=timestep_index, total_num_timesteps=total_num_timesteps)
|
||||
if weight < 1e-6:
|
||||
return img
|
||||
|
||||
ip_adapter_block = self._model.ip_adapter_double_blocks.double_blocks[block_index]
|
||||
|
||||
ip_key = ip_adapter_block.ip_adapter_double_stream_k_proj(self._image_proj)
|
||||
ip_value = ip_adapter_block.ip_adapter_double_stream_v_proj(self._image_proj)
|
||||
|
||||
# Reshape projections for multi-head attention.
|
||||
ip_key = einops.rearrange(ip_key, "B L (H D) -> B H L D", H=block.num_heads)
|
||||
ip_value = einops.rearrange(ip_value, "B L (H D) -> B H L D", H=block.num_heads)
|
||||
|
||||
# Compute attention between IP projections and the latent query.
|
||||
ip_attn = torch.nn.functional.scaled_dot_product_attention(
|
||||
img_q, ip_key, ip_value, dropout_p=0.0, is_causal=False
|
||||
)
|
||||
ip_attn = einops.rearrange(ip_attn, "B H L D -> B L (H D)", H=block.num_heads)
|
||||
|
||||
img = img + weight * ip_attn
|
||||
|
||||
return img
|
||||
@@ -1,93 +0,0 @@
|
||||
# This file is based on:
|
||||
# https://github.com/XLabs-AI/x-flux/blob/47495425dbed499be1e8e5a6e52628b07349cba2/src/flux/modules/layers.py#L221
|
||||
import einops
|
||||
import torch
|
||||
|
||||
from invokeai.backend.flux.math import attention
|
||||
from invokeai.backend.flux.modules.layers import DoubleStreamBlock
|
||||
|
||||
|
||||
class IPDoubleStreamBlockProcessor(torch.nn.Module):
|
||||
"""Attention processor for handling IP-adapter with double stream block."""
|
||||
|
||||
def __init__(self, context_dim: int, hidden_dim: int):
|
||||
super().__init__()
|
||||
|
||||
# Ensure context_dim matches the dimension of image_proj
|
||||
self.context_dim = context_dim
|
||||
self.hidden_dim = hidden_dim
|
||||
|
||||
# Initialize projections for IP-adapter
|
||||
self.ip_adapter_double_stream_k_proj = torch.nn.Linear(context_dim, hidden_dim, bias=True)
|
||||
self.ip_adapter_double_stream_v_proj = torch.nn.Linear(context_dim, hidden_dim, bias=True)
|
||||
|
||||
torch.nn.init.zeros_(self.ip_adapter_double_stream_k_proj.weight)
|
||||
torch.nn.init.zeros_(self.ip_adapter_double_stream_k_proj.bias)
|
||||
|
||||
torch.nn.init.zeros_(self.ip_adapter_double_stream_v_proj.weight)
|
||||
torch.nn.init.zeros_(self.ip_adapter_double_stream_v_proj.bias)
|
||||
|
||||
def __call__(
|
||||
self,
|
||||
attn: DoubleStreamBlock,
|
||||
img: torch.Tensor,
|
||||
txt: torch.Tensor,
|
||||
vec: torch.Tensor,
|
||||
pe: torch.Tensor,
|
||||
image_proj: torch.Tensor,
|
||||
ip_scale: float = 1.0,
|
||||
):
|
||||
# Prepare image for attention
|
||||
img_mod1, img_mod2 = attn.img_mod(vec)
|
||||
txt_mod1, txt_mod2 = attn.txt_mod(vec)
|
||||
|
||||
img_modulated = attn.img_norm1(img)
|
||||
img_modulated = (1 + img_mod1.scale) * img_modulated + img_mod1.shift
|
||||
img_qkv = attn.img_attn.qkv(img_modulated)
|
||||
img_q, img_k, img_v = einops.rearrange(
|
||||
img_qkv, "B L (K H D) -> K B H L D", K=3, H=attn.num_heads, D=attn.head_dim
|
||||
)
|
||||
img_q, img_k = attn.img_attn.norm(img_q, img_k, img_v)
|
||||
|
||||
txt_modulated = attn.txt_norm1(txt)
|
||||
txt_modulated = (1 + txt_mod1.scale) * txt_modulated + txt_mod1.shift
|
||||
txt_qkv = attn.txt_attn.qkv(txt_modulated)
|
||||
txt_q, txt_k, txt_v = einops.rearrange(
|
||||
txt_qkv, "B L (K H D) -> K B H L D", K=3, H=attn.num_heads, D=attn.head_dim
|
||||
)
|
||||
txt_q, txt_k = attn.txt_attn.norm(txt_q, txt_k, txt_v)
|
||||
|
||||
q = torch.cat((txt_q, img_q), dim=2)
|
||||
k = torch.cat((txt_k, img_k), dim=2)
|
||||
v = torch.cat((txt_v, img_v), dim=2)
|
||||
|
||||
attn1 = attention(q, k, v, pe=pe)
|
||||
txt_attn, img_attn = attn1[:, : txt.shape[1]], attn1[:, txt.shape[1] :]
|
||||
|
||||
# print(f"txt_attn shape: {txt_attn.size()}")
|
||||
# print(f"img_attn shape: {img_attn.size()}")
|
||||
|
||||
img = img + img_mod1.gate * attn.img_attn.proj(img_attn)
|
||||
img = img + img_mod2.gate * attn.img_mlp((1 + img_mod2.scale) * attn.img_norm2(img) + img_mod2.shift)
|
||||
|
||||
txt = txt + txt_mod1.gate * attn.txt_attn.proj(txt_attn)
|
||||
txt = txt + txt_mod2.gate * attn.txt_mlp((1 + txt_mod2.scale) * attn.txt_norm2(txt) + txt_mod2.shift)
|
||||
|
||||
# IP-adapter processing
|
||||
ip_query = img_q # latent sample query
|
||||
ip_key = self.ip_adapter_double_stream_k_proj(image_proj)
|
||||
ip_value = self.ip_adapter_double_stream_v_proj(image_proj)
|
||||
|
||||
# Reshape projections for multi-head attention
|
||||
ip_key = einops.rearrange(ip_key, "B L (H D) -> B H L D", H=attn.num_heads, D=attn.head_dim)
|
||||
ip_value = einops.rearrange(ip_value, "B L (H D) -> B H L D", H=attn.num_heads, D=attn.head_dim)
|
||||
|
||||
# Compute attention between IP projections and the latent query
|
||||
ip_attention = torch.nn.functional.scaled_dot_product_attention(
|
||||
ip_query, ip_key, ip_value, dropout_p=0.0, is_causal=False
|
||||
)
|
||||
ip_attention = einops.rearrange(ip_attention, "B H L D -> B L (H D)", H=attn.num_heads, D=attn.head_dim)
|
||||
|
||||
img = img + ip_scale * ip_attention
|
||||
|
||||
return img, txt
|
||||
@@ -1,50 +0,0 @@
|
||||
from typing import Any, Dict
|
||||
|
||||
import torch
|
||||
|
||||
from invokeai.backend.flux.ip_adapter.xlabs_ip_adapter_flux import XlabsIpAdapterParams
|
||||
|
||||
|
||||
def is_state_dict_xlabs_ip_adapter(sd: Dict[str, Any]) -> bool:
|
||||
"""Is the state dict for an XLabs FLUX IP-Adapter model?
|
||||
|
||||
This is intended to be a reasonably high-precision detector, but it is not guaranteed to have perfect precision.
|
||||
"""
|
||||
# If all of the expected keys are present, then this is very likely an XLabs IP-Adapter model.
|
||||
expected_keys = {
|
||||
"double_blocks.0.processor.ip_adapter_double_stream_k_proj.bias",
|
||||
"double_blocks.0.processor.ip_adapter_double_stream_k_proj.weight",
|
||||
"double_blocks.0.processor.ip_adapter_double_stream_v_proj.bias",
|
||||
"double_blocks.0.processor.ip_adapter_double_stream_v_proj.weight",
|
||||
"ip_adapter_proj_model.norm.bias",
|
||||
"ip_adapter_proj_model.norm.weight",
|
||||
"ip_adapter_proj_model.proj.bias",
|
||||
"ip_adapter_proj_model.proj.weight",
|
||||
}
|
||||
|
||||
if expected_keys.issubset(sd.keys()):
|
||||
return True
|
||||
return False
|
||||
|
||||
|
||||
def infer_xlabs_ip_adapter_params_from_state_dict(state_dict: dict[str, torch.Tensor]) -> XlabsIpAdapterParams:
|
||||
num_double_blocks = 0
|
||||
context_dim = 0
|
||||
hidden_dim = 0
|
||||
|
||||
# Count the number of double blocks.
|
||||
double_block_index = 0
|
||||
while f"double_blocks.{double_block_index}.processor.ip_adapter_double_stream_k_proj.weight" in state_dict:
|
||||
double_block_index += 1
|
||||
num_double_blocks = double_block_index
|
||||
|
||||
hidden_dim = state_dict["double_blocks.0.processor.ip_adapter_double_stream_k_proj.weight"].shape[0]
|
||||
context_dim = state_dict["double_blocks.0.processor.ip_adapter_double_stream_k_proj.weight"].shape[1]
|
||||
clip_embeddings_dim = state_dict["ip_adapter_proj_model.proj.weight"].shape[1]
|
||||
|
||||
return XlabsIpAdapterParams(
|
||||
num_double_blocks=num_double_blocks,
|
||||
context_dim=context_dim,
|
||||
hidden_dim=hidden_dim,
|
||||
clip_embeddings_dim=clip_embeddings_dim,
|
||||
)
|
||||
@@ -1,67 +0,0 @@
|
||||
from dataclasses import dataclass
|
||||
|
||||
import torch
|
||||
|
||||
from invokeai.backend.ip_adapter.ip_adapter import ImageProjModel
|
||||
|
||||
|
||||
class IPDoubleStreamBlock(torch.nn.Module):
|
||||
def __init__(self, context_dim: int, hidden_dim: int):
|
||||
super().__init__()
|
||||
|
||||
self.context_dim = context_dim
|
||||
self.hidden_dim = hidden_dim
|
||||
|
||||
self.ip_adapter_double_stream_k_proj = torch.nn.Linear(context_dim, hidden_dim, bias=True)
|
||||
self.ip_adapter_double_stream_v_proj = torch.nn.Linear(context_dim, hidden_dim, bias=True)
|
||||
|
||||
|
||||
class IPAdapterDoubleBlocks(torch.nn.Module):
|
||||
def __init__(self, num_double_blocks: int, context_dim: int, hidden_dim: int):
|
||||
super().__init__()
|
||||
self.double_blocks = torch.nn.ModuleList(
|
||||
[IPDoubleStreamBlock(context_dim, hidden_dim) for _ in range(num_double_blocks)]
|
||||
)
|
||||
|
||||
|
||||
@dataclass
|
||||
class XlabsIpAdapterParams:
|
||||
num_double_blocks: int
|
||||
context_dim: int
|
||||
hidden_dim: int
|
||||
|
||||
clip_embeddings_dim: int
|
||||
|
||||
|
||||
class XlabsIpAdapterFlux(torch.nn.Module):
|
||||
def __init__(self, params: XlabsIpAdapterParams):
|
||||
super().__init__()
|
||||
self.image_proj = ImageProjModel(
|
||||
cross_attention_dim=params.context_dim, clip_embeddings_dim=params.clip_embeddings_dim
|
||||
)
|
||||
self.ip_adapter_double_blocks = IPAdapterDoubleBlocks(
|
||||
num_double_blocks=params.num_double_blocks, context_dim=params.context_dim, hidden_dim=params.hidden_dim
|
||||
)
|
||||
|
||||
def load_xlabs_state_dict(self, state_dict: dict[str, torch.Tensor], assign: bool = False):
|
||||
"""We need this custom function to load state dicts rather than using .load_state_dict(...) because the model
|
||||
structure does not match the state_dict structure.
|
||||
"""
|
||||
# Split the state_dict into the image projection model and the double blocks.
|
||||
image_proj_sd: dict[str, torch.Tensor] = {}
|
||||
double_blocks_sd: dict[str, torch.Tensor] = {}
|
||||
for k, v in state_dict.items():
|
||||
if k.startswith("ip_adapter_proj_model."):
|
||||
image_proj_sd[k] = v
|
||||
elif k.startswith("double_blocks."):
|
||||
double_blocks_sd[k] = v
|
||||
else:
|
||||
raise ValueError(f"Unexpected key: {k}")
|
||||
|
||||
# Initialize the image projection model.
|
||||
image_proj_sd = {k.replace("ip_adapter_proj_model.", ""): v for k, v in image_proj_sd.items()}
|
||||
self.image_proj.load_state_dict(image_proj_sd, assign=assign)
|
||||
|
||||
# Initialize the double blocks.
|
||||
double_blocks_sd = {k.replace("processor.", ""): v for k, v in double_blocks_sd.items()}
|
||||
self.ip_adapter_double_blocks.load_state_dict(double_blocks_sd, assign=assign)
|
||||
@@ -16,10 +16,7 @@ def attention(q: Tensor, k: Tensor, v: Tensor, pe: Tensor) -> Tensor:
|
||||
|
||||
def rope(pos: Tensor, dim: int, theta: int) -> Tensor:
|
||||
assert dim % 2 == 0
|
||||
scale = (
|
||||
torch.arange(0, dim, 2, dtype=torch.float32 if pos.device.type == "mps" else torch.float64, device=pos.device)
|
||||
/ dim
|
||||
)
|
||||
scale = torch.arange(0, dim, 2, dtype=torch.float64, device=pos.device) / dim
|
||||
omega = 1.0 / (theta**scale)
|
||||
out = torch.einsum("...n,d->...nd", pos, omega)
|
||||
out = torch.stack([torch.cos(out), -torch.sin(out), torch.sin(out), torch.cos(out)], dim=-1)
|
||||
|
||||
@@ -5,8 +5,6 @@ from dataclasses import dataclass
|
||||
import torch
|
||||
from torch import Tensor, nn
|
||||
|
||||
from invokeai.backend.flux.custom_block_processor import CustomDoubleStreamBlockProcessor
|
||||
from invokeai.backend.flux.extensions.xlabs_ip_adapter_extension import XLabsIPAdapterExtension
|
||||
from invokeai.backend.flux.modules.layers import (
|
||||
DoubleStreamBlock,
|
||||
EmbedND,
|
||||
@@ -89,12 +87,7 @@ class Flux(nn.Module):
|
||||
txt_ids: Tensor,
|
||||
timesteps: Tensor,
|
||||
y: Tensor,
|
||||
guidance: Tensor | None,
|
||||
timestep_index: int,
|
||||
total_num_timesteps: int,
|
||||
controlnet_double_block_residuals: list[Tensor] | None,
|
||||
controlnet_single_block_residuals: list[Tensor] | None,
|
||||
ip_adapter_extensions: list[XLabsIPAdapterExtension],
|
||||
guidance: Tensor | None = None,
|
||||
) -> Tensor:
|
||||
if img.ndim != 3 or txt.ndim != 3:
|
||||
raise ValueError("Input img and txt tensors must have 3 dimensions.")
|
||||
@@ -112,39 +105,12 @@ class Flux(nn.Module):
|
||||
ids = torch.cat((txt_ids, img_ids), dim=1)
|
||||
pe = self.pe_embedder(ids)
|
||||
|
||||
# Validate double_block_residuals shape.
|
||||
if controlnet_double_block_residuals is not None:
|
||||
assert len(controlnet_double_block_residuals) == len(self.double_blocks)
|
||||
for block_index, block in enumerate(self.double_blocks):
|
||||
assert isinstance(block, DoubleStreamBlock)
|
||||
|
||||
img, txt = CustomDoubleStreamBlockProcessor.custom_double_block_forward(
|
||||
timestep_index=timestep_index,
|
||||
total_num_timesteps=total_num_timesteps,
|
||||
block_index=block_index,
|
||||
block=block,
|
||||
img=img,
|
||||
txt=txt,
|
||||
vec=vec,
|
||||
pe=pe,
|
||||
ip_adapter_extensions=ip_adapter_extensions,
|
||||
)
|
||||
|
||||
if controlnet_double_block_residuals is not None:
|
||||
img += controlnet_double_block_residuals[block_index]
|
||||
for block in self.double_blocks:
|
||||
img, txt = block(img=img, txt=txt, vec=vec, pe=pe)
|
||||
|
||||
img = torch.cat((txt, img), 1)
|
||||
|
||||
# Validate single_block_residuals shape.
|
||||
if controlnet_single_block_residuals is not None:
|
||||
assert len(controlnet_single_block_residuals) == len(self.single_blocks)
|
||||
|
||||
for block_index, block in enumerate(self.single_blocks):
|
||||
for block in self.single_blocks:
|
||||
img = block(img, vec=vec, pe=pe)
|
||||
|
||||
if controlnet_single_block_residuals is not None:
|
||||
img[:, txt.shape[1] :, ...] += controlnet_single_block_residuals[block_index]
|
||||
|
||||
img = img[:, txt.shape[1] :, ...]
|
||||
|
||||
img = self.final_layer(img, vec) # (N, T, patch_size ** 2 * out_channels)
|
||||
|
||||
@@ -168,17 +168,8 @@ def generate_img_ids(h: int, w: int, batch_size: int, device: torch.device, dtyp
|
||||
Returns:
|
||||
torch.Tensor: Image position ids.
|
||||
"""
|
||||
|
||||
if device.type == "mps":
|
||||
orig_dtype = dtype
|
||||
dtype = torch.float16
|
||||
|
||||
img_ids = torch.zeros(h // 2, w // 2, 3, device=device, dtype=dtype)
|
||||
img_ids[..., 1] = img_ids[..., 1] + torch.arange(h // 2, device=device, dtype=dtype)[:, None]
|
||||
img_ids[..., 2] = img_ids[..., 2] + torch.arange(w // 2, device=device, dtype=dtype)[None, :]
|
||||
img_ids = repeat(img_ids, "h w c -> b (h w) c", b=batch_size)
|
||||
|
||||
if device.type == "mps":
|
||||
img_ids.to(orig_dtype)
|
||||
|
||||
return img_ids
|
||||
|
||||
@@ -1,4 +1,4 @@
|
||||
from typing import Optional, TypeAlias
|
||||
from typing import Optional
|
||||
|
||||
import torch
|
||||
from PIL import Image
|
||||
@@ -7,14 +7,6 @@ from transformers.models.sam.processing_sam import SamProcessor
|
||||
|
||||
from invokeai.backend.raw_model import RawModel
|
||||
|
||||
# Type aliases for the inputs to the SAM model.
|
||||
ListOfBoundingBoxes: TypeAlias = list[list[int]]
|
||||
"""A list of bounding boxes. Each bounding box is in the format [xmin, ymin, xmax, ymax]."""
|
||||
ListOfPoints: TypeAlias = list[list[int]]
|
||||
"""A list of points. Each point is in the format [x, y]."""
|
||||
ListOfPointLabels: TypeAlias = list[int]
|
||||
"""A list of SAM point labels. Each label is an integer where -1 is background, 0 is neutral, and 1 is foreground."""
|
||||
|
||||
|
||||
class SegmentAnythingPipeline(RawModel):
|
||||
"""A wrapper class for the transformers SAM model and processor that makes it compatible with the model manager."""
|
||||
@@ -35,53 +27,20 @@ class SegmentAnythingPipeline(RawModel):
|
||||
|
||||
return calc_module_size(self._sam_model)
|
||||
|
||||
def segment(
|
||||
self,
|
||||
image: Image.Image,
|
||||
bounding_boxes: list[list[int]] | None = None,
|
||||
point_lists: list[list[list[int]]] | None = None,
|
||||
) -> torch.Tensor:
|
||||
def segment(self, image: Image.Image, bounding_boxes: list[list[int]]) -> torch.Tensor:
|
||||
"""Run the SAM model.
|
||||
|
||||
Either bounding_boxes or point_lists must be provided. If both are provided, bounding_boxes will be used and
|
||||
point_lists will be ignored.
|
||||
|
||||
Args:
|
||||
image (Image.Image): The image to segment.
|
||||
bounding_boxes (list[list[int]]): The bounding box prompts. Each bounding box is in the format
|
||||
[xmin, ymin, xmax, ymax].
|
||||
point_lists (list[list[list[int]]]): The points prompts. Each point is in the format [x, y, label].
|
||||
`label` is an integer where -1 is background, 0 is neutral, and 1 is foreground.
|
||||
|
||||
Returns:
|
||||
torch.Tensor: The segmentation masks. dtype: torch.bool. shape: [num_masks, channels, height, width].
|
||||
"""
|
||||
|
||||
# Prep the inputs:
|
||||
# - Create a list of bounding boxes or points and labels.
|
||||
# - Add a batch dimension of 1 to the inputs.
|
||||
if bounding_boxes:
|
||||
input_boxes: list[ListOfBoundingBoxes] | None = [bounding_boxes]
|
||||
input_points: list[ListOfPoints] | None = None
|
||||
input_labels: list[ListOfPointLabels] | None = None
|
||||
elif point_lists:
|
||||
input_boxes: list[ListOfBoundingBoxes] | None = None
|
||||
input_points: list[ListOfPoints] | None = []
|
||||
input_labels: list[ListOfPointLabels] | None = []
|
||||
for point_list in point_lists:
|
||||
input_points.append([[p[0], p[1]] for p in point_list])
|
||||
input_labels.append([p[2] for p in point_list])
|
||||
|
||||
else:
|
||||
raise ValueError("Either bounding_boxes or points and labels must be provided.")
|
||||
|
||||
inputs = self._sam_processor(
|
||||
images=image,
|
||||
input_boxes=input_boxes,
|
||||
input_points=input_points,
|
||||
input_labels=input_labels,
|
||||
return_tensors="pt",
|
||||
).to(self._sam_model.device)
|
||||
# Add batch dimension of 1 to the bounding boxes.
|
||||
boxes = [bounding_boxes]
|
||||
inputs = self._sam_processor(images=image, input_boxes=boxes, return_tensors="pt").to(self._sam_model.device)
|
||||
outputs = self._sam_model(**inputs)
|
||||
masks = self._sam_processor.post_process_masks(
|
||||
masks=outputs.pred_masks,
|
||||
|
||||
@@ -2,7 +2,6 @@ from typing import Dict
|
||||
|
||||
import torch
|
||||
|
||||
from invokeai.backend.lora.conversions.flux_lora_constants import FLUX_LORA_TRANSFORMER_PREFIX
|
||||
from invokeai.backend.lora.layers.any_lora_layer import AnyLoRALayer
|
||||
from invokeai.backend.lora.layers.concatenated_lora_layer import ConcatenatedLoRALayer
|
||||
from invokeai.backend.lora.layers.lora_layer import LoRALayer
|
||||
@@ -190,9 +189,7 @@ def lora_model_from_flux_diffusers_state_dict(state_dict: Dict[str, torch.Tensor
|
||||
# Assert that all keys were processed.
|
||||
assert len(grouped_state_dict) == 0
|
||||
|
||||
layers_with_prefix = {f"{FLUX_LORA_TRANSFORMER_PREFIX}{k}": v for k, v in layers.items()}
|
||||
|
||||
return LoRAModelRaw(layers=layers_with_prefix)
|
||||
return LoRAModelRaw(layers=layers)
|
||||
|
||||
|
||||
def _group_by_layer(state_dict: Dict[str, torch.Tensor]) -> dict[str, dict[str, torch.Tensor]]:
|
||||
|
||||
@@ -3,7 +3,6 @@ from typing import Any, Dict, TypeVar
|
||||
|
||||
import torch
|
||||
|
||||
from invokeai.backend.lora.conversions.flux_lora_constants import FLUX_LORA_CLIP_PREFIX, FLUX_LORA_TRANSFORMER_PREFIX
|
||||
from invokeai.backend.lora.layers.any_lora_layer import AnyLoRALayer
|
||||
from invokeai.backend.lora.layers.utils import any_lora_layer_from_state_dict
|
||||
from invokeai.backend.lora.lora_model_raw import LoRAModelRaw
|
||||
@@ -24,6 +23,11 @@ FLUX_KOHYA_TRANSFORMER_KEY_REGEX = (
|
||||
FLUX_KOHYA_CLIP_KEY_REGEX = r"lora_te1_text_model_encoder_layers_(\d+)_(mlp|self_attn)_(\w+)\.?.*"
|
||||
|
||||
|
||||
# Prefixes used to distinguish between transformer and CLIP text encoder keys in the InvokeAI LoRA format.
|
||||
FLUX_KOHYA_TRANFORMER_PREFIX = "lora_transformer-"
|
||||
FLUX_KOHYA_CLIP_PREFIX = "lora_clip-"
|
||||
|
||||
|
||||
def is_state_dict_likely_in_flux_kohya_format(state_dict: Dict[str, Any]) -> bool:
|
||||
"""Checks if the provided state dict is likely in the Kohya FLUX LoRA format.
|
||||
|
||||
@@ -63,9 +67,9 @@ def lora_model_from_flux_kohya_state_dict(state_dict: Dict[str, torch.Tensor]) -
|
||||
# Create LoRA layers.
|
||||
layers: dict[str, AnyLoRALayer] = {}
|
||||
for layer_key, layer_state_dict in transformer_grouped_sd.items():
|
||||
layers[FLUX_LORA_TRANSFORMER_PREFIX + layer_key] = any_lora_layer_from_state_dict(layer_state_dict)
|
||||
layers[FLUX_KOHYA_TRANFORMER_PREFIX + layer_key] = any_lora_layer_from_state_dict(layer_state_dict)
|
||||
for layer_key, layer_state_dict in clip_grouped_sd.items():
|
||||
layers[FLUX_LORA_CLIP_PREFIX + layer_key] = any_lora_layer_from_state_dict(layer_state_dict)
|
||||
layers[FLUX_KOHYA_CLIP_PREFIX + layer_key] = any_lora_layer_from_state_dict(layer_state_dict)
|
||||
|
||||
# Create and return the LoRAModelRaw.
|
||||
return LoRAModelRaw(layers=layers)
|
||||
|
||||
@@ -1,3 +0,0 @@
|
||||
# Prefixes used to distinguish between transformer and CLIP text encoder keys in the FLUX InvokeAI LoRA format.
|
||||
FLUX_LORA_TRANSFORMER_PREFIX = "lora_transformer-"
|
||||
FLUX_LORA_CLIP_PREFIX = "lora_clip-"
|
||||
@@ -53,7 +53,6 @@ class BaseModelType(str, Enum):
|
||||
Any = "any"
|
||||
StableDiffusion1 = "sd-1"
|
||||
StableDiffusion2 = "sd-2"
|
||||
StableDiffusion3 = "sd-3"
|
||||
StableDiffusionXL = "sdxl"
|
||||
StableDiffusionXLRefiner = "sdxl-refiner"
|
||||
Flux = "flux"
|
||||
@@ -84,10 +83,8 @@ class SubModelType(str, Enum):
|
||||
Transformer = "transformer"
|
||||
TextEncoder = "text_encoder"
|
||||
TextEncoder2 = "text_encoder_2"
|
||||
TextEncoder3 = "text_encoder_3"
|
||||
Tokenizer = "tokenizer"
|
||||
Tokenizer2 = "tokenizer_2"
|
||||
Tokenizer3 = "tokenizer_3"
|
||||
VAE = "vae"
|
||||
VAEDecoder = "vae_decoder"
|
||||
VAEEncoder = "vae_encoder"
|
||||
@@ -95,13 +92,6 @@ class SubModelType(str, Enum):
|
||||
SafetyChecker = "safety_checker"
|
||||
|
||||
|
||||
class ClipVariantType(str, Enum):
|
||||
"""Variant type."""
|
||||
|
||||
L = "large"
|
||||
G = "gigantic"
|
||||
|
||||
|
||||
class ModelVariantType(str, Enum):
|
||||
"""Variant type."""
|
||||
|
||||
@@ -124,7 +114,6 @@ class ModelFormat(str, Enum):
|
||||
T5Encoder = "t5_encoder"
|
||||
BnbQuantizedLlmInt8b = "bnb_quantized_int8b"
|
||||
BnbQuantizednf4b = "bnb_quantized_nf4b"
|
||||
GGUFQuantized = "gguf_quantized"
|
||||
|
||||
|
||||
class SchedulerPredictionType(str, Enum):
|
||||
@@ -157,15 +146,6 @@ class ModelSourceType(str, Enum):
|
||||
DEFAULTS_PRECISION = Literal["fp16", "fp32"]
|
||||
|
||||
|
||||
AnyVariant: TypeAlias = Union[ModelVariantType, ClipVariantType, None]
|
||||
|
||||
|
||||
class SubmodelDefinition(BaseModel):
|
||||
path_or_prefix: str
|
||||
model_type: ModelType
|
||||
variant: AnyVariant = None
|
||||
|
||||
|
||||
class MainModelDefaultSettings(BaseModel):
|
||||
vae: str | None = Field(default=None, description="Default VAE for this model (model key)")
|
||||
vae_precision: DEFAULTS_PRECISION | None = Field(default=None, description="Default VAE precision for this model")
|
||||
@@ -177,7 +157,6 @@ class MainModelDefaultSettings(BaseModel):
|
||||
)
|
||||
width: int | None = Field(default=None, multiple_of=8, ge=64, description="Default width for this model")
|
||||
height: int | None = Field(default=None, multiple_of=8, ge=64, description="Default height for this model")
|
||||
guidance: float | None = Field(default=None, ge=1, description="Default Guidance for this model")
|
||||
|
||||
model_config = ConfigDict(extra="forbid")
|
||||
|
||||
@@ -212,15 +191,12 @@ class ModelConfigBase(BaseModel):
|
||||
schema["required"].extend(["key", "type", "format"])
|
||||
|
||||
model_config = ConfigDict(validate_assignment=True, json_schema_extra=json_schema_extra)
|
||||
submodels: Optional[Dict[SubModelType, SubmodelDefinition]] = Field(
|
||||
description="Loadable submodels in this model", default=None
|
||||
)
|
||||
|
||||
|
||||
class CheckpointConfigBase(ModelConfigBase):
|
||||
"""Model config for checkpoint-style models."""
|
||||
|
||||
format: Literal[ModelFormat.Checkpoint, ModelFormat.BnbQuantizednf4b, ModelFormat.GGUFQuantized] = Field(
|
||||
format: Literal[ModelFormat.Checkpoint, ModelFormat.BnbQuantizednf4b] = Field(
|
||||
description="Format of the provided checkpoint model", default=ModelFormat.Checkpoint
|
||||
)
|
||||
config_path: str = Field(description="path to the checkpoint model config file")
|
||||
@@ -357,7 +333,7 @@ class MainConfigBase(ModelConfigBase):
|
||||
default_settings: Optional[MainModelDefaultSettings] = Field(
|
||||
description="Default settings for this model", default=None
|
||||
)
|
||||
variant: AnyVariant = ModelVariantType.Normal
|
||||
variant: ModelVariantType = ModelVariantType.Normal
|
||||
|
||||
|
||||
class MainCheckpointConfig(CheckpointConfigBase, MainConfigBase):
|
||||
@@ -386,21 +362,6 @@ class MainBnbQuantized4bCheckpointConfig(CheckpointConfigBase, MainConfigBase):
|
||||
return Tag(f"{ModelType.Main.value}.{ModelFormat.BnbQuantizednf4b.value}")
|
||||
|
||||
|
||||
class MainGGUFCheckpointConfig(CheckpointConfigBase, MainConfigBase):
|
||||
"""Model config for main checkpoint models."""
|
||||
|
||||
prediction_type: SchedulerPredictionType = SchedulerPredictionType.Epsilon
|
||||
upcast_attention: bool = False
|
||||
|
||||
def __init__(self, *args, **kwargs):
|
||||
super().__init__(*args, **kwargs)
|
||||
self.format = ModelFormat.GGUFQuantized
|
||||
|
||||
@staticmethod
|
||||
def get_tag() -> Tag:
|
||||
return Tag(f"{ModelType.Main.value}.{ModelFormat.GGUFQuantized.value}")
|
||||
|
||||
|
||||
class MainDiffusersConfig(DiffusersConfigBase, MainConfigBase):
|
||||
"""Model config for main diffusers models."""
|
||||
|
||||
@@ -416,8 +377,6 @@ class IPAdapterBaseConfig(ModelConfigBase):
|
||||
class IPAdapterInvokeAIConfig(IPAdapterBaseConfig):
|
||||
"""Model config for IP Adapter diffusers format models."""
|
||||
|
||||
# TODO(ryand): Should we deprecate this field? From what I can tell, it hasn't been probed correctly for a long
|
||||
# time. Need to go through the history to make sure I'm understanding this fully.
|
||||
image_encoder_model_id: str
|
||||
format: Literal[ModelFormat.InvokeAI]
|
||||
|
||||
@@ -441,33 +400,12 @@ class CLIPEmbedDiffusersConfig(DiffusersConfigBase):
|
||||
|
||||
type: Literal[ModelType.CLIPEmbed] = ModelType.CLIPEmbed
|
||||
format: Literal[ModelFormat.Diffusers] = ModelFormat.Diffusers
|
||||
variant: ClipVariantType = ClipVariantType.L
|
||||
|
||||
@staticmethod
|
||||
def get_tag() -> Tag:
|
||||
return Tag(f"{ModelType.CLIPEmbed.value}.{ModelFormat.Diffusers.value}")
|
||||
|
||||
|
||||
class CLIPGEmbedDiffusersConfig(CLIPEmbedDiffusersConfig):
|
||||
"""Model config for CLIP-G Embeddings."""
|
||||
|
||||
variant: ClipVariantType = ClipVariantType.G
|
||||
|
||||
@staticmethod
|
||||
def get_tag() -> Tag:
|
||||
return Tag(f"{ModelType.CLIPEmbed.value}.{ModelFormat.Diffusers.value}.{ClipVariantType.G}")
|
||||
|
||||
|
||||
class CLIPLEmbedDiffusersConfig(CLIPEmbedDiffusersConfig):
|
||||
"""Model config for CLIP-L Embeddings."""
|
||||
|
||||
variant: ClipVariantType = ClipVariantType.L
|
||||
|
||||
@staticmethod
|
||||
def get_tag() -> Tag:
|
||||
return Tag(f"{ModelType.CLIPEmbed.value}.{ModelFormat.Diffusers.value}.{ClipVariantType.L}")
|
||||
|
||||
|
||||
class CLIPVisionDiffusersConfig(DiffusersConfigBase):
|
||||
"""Model config for CLIPVision."""
|
||||
|
||||
@@ -527,7 +465,6 @@ AnyModelConfig = Annotated[
|
||||
Annotated[MainDiffusersConfig, MainDiffusersConfig.get_tag()],
|
||||
Annotated[MainCheckpointConfig, MainCheckpointConfig.get_tag()],
|
||||
Annotated[MainBnbQuantized4bCheckpointConfig, MainBnbQuantized4bCheckpointConfig.get_tag()],
|
||||
Annotated[MainGGUFCheckpointConfig, MainGGUFCheckpointConfig.get_tag()],
|
||||
Annotated[VAEDiffusersConfig, VAEDiffusersConfig.get_tag()],
|
||||
Annotated[VAECheckpointConfig, VAECheckpointConfig.get_tag()],
|
||||
Annotated[ControlNetDiffusersConfig, ControlNetDiffusersConfig.get_tag()],
|
||||
@@ -544,8 +481,6 @@ AnyModelConfig = Annotated[
|
||||
Annotated[SpandrelImageToImageConfig, SpandrelImageToImageConfig.get_tag()],
|
||||
Annotated[CLIPVisionDiffusersConfig, CLIPVisionDiffusersConfig.get_tag()],
|
||||
Annotated[CLIPEmbedDiffusersConfig, CLIPEmbedDiffusersConfig.get_tag()],
|
||||
Annotated[CLIPLEmbedDiffusersConfig, CLIPLEmbedDiffusersConfig.get_tag()],
|
||||
Annotated[CLIPGEmbedDiffusersConfig, CLIPGEmbedDiffusersConfig.get_tag()],
|
||||
],
|
||||
Discriminator(get_model_discriminator_value),
|
||||
]
|
||||
|
||||
@@ -1,41 +0,0 @@
|
||||
from pathlib import Path
|
||||
from typing import Optional
|
||||
|
||||
from transformers import CLIPVisionModelWithProjection
|
||||
|
||||
from invokeai.backend.model_manager.config import (
|
||||
AnyModel,
|
||||
AnyModelConfig,
|
||||
BaseModelType,
|
||||
DiffusersConfigBase,
|
||||
ModelFormat,
|
||||
ModelType,
|
||||
SubModelType,
|
||||
)
|
||||
from invokeai.backend.model_manager.load.load_default import ModelLoader
|
||||
from invokeai.backend.model_manager.load.model_loader_registry import ModelLoaderRegistry
|
||||
|
||||
|
||||
@ModelLoaderRegistry.register(base=BaseModelType.Any, type=ModelType.CLIPVision, format=ModelFormat.Diffusers)
|
||||
class ClipVisionLoader(ModelLoader):
|
||||
"""Class to load CLIPVision models."""
|
||||
|
||||
def _load_model(
|
||||
self,
|
||||
config: AnyModelConfig,
|
||||
submodel_type: Optional[SubModelType] = None,
|
||||
) -> AnyModel:
|
||||
if not isinstance(config, DiffusersConfigBase):
|
||||
raise ValueError("Only DiffusersConfigBase models are currently supported here.")
|
||||
|
||||
if submodel_type is not None:
|
||||
raise Exception("There are no submodels in CLIP Vision models.")
|
||||
|
||||
model_path = Path(config.path)
|
||||
|
||||
model = CLIPVisionModelWithProjection.from_pretrained(
|
||||
model_path, torch_dtype=self._torch_dtype, local_files_only=True
|
||||
)
|
||||
assert isinstance(model, CLIPVisionModelWithProjection)
|
||||
|
||||
return model
|
||||
@@ -8,36 +8,17 @@ from diffusers import ControlNetModel
|
||||
from invokeai.backend.model_manager import (
|
||||
AnyModel,
|
||||
AnyModelConfig,
|
||||
)
|
||||
from invokeai.backend.model_manager.config import (
|
||||
BaseModelType,
|
||||
ControlNetCheckpointConfig,
|
||||
ModelFormat,
|
||||
ModelType,
|
||||
SubModelType,
|
||||
)
|
||||
from invokeai.backend.model_manager.config import ControlNetCheckpointConfig, SubModelType
|
||||
from invokeai.backend.model_manager.load.model_loader_registry import ModelLoaderRegistry
|
||||
from invokeai.backend.model_manager.load.model_loaders.generic_diffusers import GenericDiffusersLoader
|
||||
|
||||
|
||||
@ModelLoaderRegistry.register(
|
||||
base=BaseModelType.StableDiffusion1, type=ModelType.ControlNet, format=ModelFormat.Diffusers
|
||||
)
|
||||
@ModelLoaderRegistry.register(
|
||||
base=BaseModelType.StableDiffusion1, type=ModelType.ControlNet, format=ModelFormat.Checkpoint
|
||||
)
|
||||
@ModelLoaderRegistry.register(
|
||||
base=BaseModelType.StableDiffusion2, type=ModelType.ControlNet, format=ModelFormat.Diffusers
|
||||
)
|
||||
@ModelLoaderRegistry.register(
|
||||
base=BaseModelType.StableDiffusion2, type=ModelType.ControlNet, format=ModelFormat.Checkpoint
|
||||
)
|
||||
@ModelLoaderRegistry.register(
|
||||
base=BaseModelType.StableDiffusionXL, type=ModelType.ControlNet, format=ModelFormat.Diffusers
|
||||
)
|
||||
@ModelLoaderRegistry.register(
|
||||
base=BaseModelType.StableDiffusionXL, type=ModelType.ControlNet, format=ModelFormat.Checkpoint
|
||||
)
|
||||
@ModelLoaderRegistry.register(base=BaseModelType.Any, type=ModelType.ControlNet, format=ModelFormat.Diffusers)
|
||||
@ModelLoaderRegistry.register(base=BaseModelType.Any, type=ModelType.ControlNet, format=ModelFormat.Checkpoint)
|
||||
class ControlNetLoader(GenericDiffusersLoader):
|
||||
"""Class to load ControlNet models."""
|
||||
|
||||
|
||||
@@ -10,19 +10,6 @@ from safetensors.torch import load_file
|
||||
from transformers import AutoConfig, AutoModelForTextEncoding, CLIPTextModel, CLIPTokenizer, T5EncoderModel, T5Tokenizer
|
||||
|
||||
from invokeai.app.services.config.config_default import get_config
|
||||
from invokeai.backend.flux.controlnet.instantx_controlnet_flux import InstantXControlNetFlux
|
||||
from invokeai.backend.flux.controlnet.state_dict_utils import (
|
||||
convert_diffusers_instantx_state_dict_to_bfl_format,
|
||||
infer_flux_params_from_state_dict,
|
||||
infer_instantx_num_control_modes_from_state_dict,
|
||||
is_state_dict_instantx_controlnet,
|
||||
is_state_dict_xlabs_controlnet,
|
||||
)
|
||||
from invokeai.backend.flux.controlnet.xlabs_controlnet_flux import XLabsControlNetFlux
|
||||
from invokeai.backend.flux.ip_adapter.state_dict_utils import infer_xlabs_ip_adapter_params_from_state_dict
|
||||
from invokeai.backend.flux.ip_adapter.xlabs_ip_adapter_flux import (
|
||||
XlabsIpAdapterFlux,
|
||||
)
|
||||
from invokeai.backend.flux.model import Flux
|
||||
from invokeai.backend.flux.modules.autoencoder import AutoEncoder
|
||||
from invokeai.backend.flux.util import ae_params, params
|
||||
@@ -37,12 +24,8 @@ from invokeai.backend.model_manager import (
|
||||
from invokeai.backend.model_manager.config import (
|
||||
CheckpointConfigBase,
|
||||
CLIPEmbedDiffusersConfig,
|
||||
ControlNetCheckpointConfig,
|
||||
ControlNetDiffusersConfig,
|
||||
IPAdapterCheckpointConfig,
|
||||
MainBnbQuantized4bCheckpointConfig,
|
||||
MainCheckpointConfig,
|
||||
MainGGUFCheckpointConfig,
|
||||
T5EncoderBnbQuantizedLlmInt8bConfig,
|
||||
T5EncoderConfig,
|
||||
VAECheckpointConfig,
|
||||
@@ -52,8 +35,6 @@ from invokeai.backend.model_manager.load.model_loader_registry import ModelLoade
|
||||
from invokeai.backend.model_manager.util.model_util import (
|
||||
convert_bundle_to_flux_transformer_checkpoint,
|
||||
)
|
||||
from invokeai.backend.quantization.gguf.loaders import gguf_sd_loader
|
||||
from invokeai.backend.quantization.gguf.utils import TORCH_COMPATIBLE_QTYPES
|
||||
from invokeai.backend.util.silence_warnings import SilenceWarnings
|
||||
|
||||
try:
|
||||
@@ -128,9 +109,9 @@ class BnbQuantizedLlmInt8bCheckpointModel(ModelLoader):
|
||||
"The bnb modules are not available. Please install bitsandbytes if available on your platform."
|
||||
)
|
||||
match submodel_type:
|
||||
case SubModelType.Tokenizer2 | SubModelType.Tokenizer3:
|
||||
case SubModelType.Tokenizer2:
|
||||
return T5Tokenizer.from_pretrained(Path(config.path) / "tokenizer_2", max_length=512)
|
||||
case SubModelType.TextEncoder2 | SubModelType.TextEncoder3:
|
||||
case SubModelType.TextEncoder2:
|
||||
te2_model_path = Path(config.path) / "text_encoder_2"
|
||||
model_config = AutoConfig.from_pretrained(te2_model_path)
|
||||
with accelerate.init_empty_weights():
|
||||
@@ -172,10 +153,10 @@ class T5EncoderCheckpointModel(ModelLoader):
|
||||
raise ValueError("Only T5EncoderConfig models are currently supported here.")
|
||||
|
||||
match submodel_type:
|
||||
case SubModelType.Tokenizer2 | SubModelType.Tokenizer3:
|
||||
case SubModelType.Tokenizer2:
|
||||
return T5Tokenizer.from_pretrained(Path(config.path) / "tokenizer_2", max_length=512)
|
||||
case SubModelType.TextEncoder2 | SubModelType.TextEncoder3:
|
||||
return T5EncoderModel.from_pretrained(Path(config.path) / "text_encoder_2", torch_dtype="auto")
|
||||
case SubModelType.TextEncoder2:
|
||||
return T5EncoderModel.from_pretrained(Path(config.path) / "text_encoder_2")
|
||||
|
||||
raise ValueError(
|
||||
f"Only Tokenizer and TextEncoder submodels are currently supported. Received: {submodel_type.value if submodel_type else 'None'}"
|
||||
@@ -223,52 +204,6 @@ class FluxCheckpointModel(ModelLoader):
|
||||
return model
|
||||
|
||||
|
||||
@ModelLoaderRegistry.register(base=BaseModelType.Flux, type=ModelType.Main, format=ModelFormat.GGUFQuantized)
|
||||
class FluxGGUFCheckpointModel(ModelLoader):
|
||||
"""Class to load GGUF main models."""
|
||||
|
||||
def _load_model(
|
||||
self,
|
||||
config: AnyModelConfig,
|
||||
submodel_type: Optional[SubModelType] = None,
|
||||
) -> AnyModel:
|
||||
if not isinstance(config, CheckpointConfigBase):
|
||||
raise ValueError("Only CheckpointConfigBase models are currently supported here.")
|
||||
|
||||
match submodel_type:
|
||||
case SubModelType.Transformer:
|
||||
return self._load_from_singlefile(config)
|
||||
|
||||
raise ValueError(
|
||||
f"Only Transformer submodels are currently supported. Received: {submodel_type.value if submodel_type else 'None'}"
|
||||
)
|
||||
|
||||
def _load_from_singlefile(
|
||||
self,
|
||||
config: AnyModelConfig,
|
||||
) -> AnyModel:
|
||||
assert isinstance(config, MainGGUFCheckpointConfig)
|
||||
model_path = Path(config.path)
|
||||
|
||||
with SilenceWarnings():
|
||||
model = Flux(params[config.config_path])
|
||||
|
||||
# HACK(ryand): We shouldn't be hard-coding the compute_dtype here.
|
||||
sd = gguf_sd_loader(model_path, compute_dtype=torch.bfloat16)
|
||||
|
||||
# HACK(ryand): There are some broken GGUF models in circulation that have the wrong shape for img_in.weight.
|
||||
# We override the shape here to fix the issue.
|
||||
# Example model with this issue (Q4_K_M): https://civitai.com/models/705823/ggufk-flux-unchained-km-quants
|
||||
img_in_weight = sd.get("img_in.weight", None)
|
||||
if img_in_weight is not None and img_in_weight._ggml_quantization_type in TORCH_COMPATIBLE_QTYPES:
|
||||
expected_img_in_weight_shape = model.img_in.weight.shape
|
||||
img_in_weight.quantized_data = img_in_weight.quantized_data.view(expected_img_in_weight_shape)
|
||||
img_in_weight.tensor_shape = expected_img_in_weight_shape
|
||||
|
||||
model.load_state_dict(sd, assign=True)
|
||||
return model
|
||||
|
||||
|
||||
@ModelLoaderRegistry.register(base=BaseModelType.Flux, type=ModelType.Main, format=ModelFormat.BnbQuantizednf4b)
|
||||
class FluxBnbQuantizednf4bCheckpointModel(ModelLoader):
|
||||
"""Class to load main models."""
|
||||
@@ -309,74 +244,3 @@ class FluxBnbQuantizednf4bCheckpointModel(ModelLoader):
|
||||
sd = convert_bundle_to_flux_transformer_checkpoint(sd)
|
||||
model.load_state_dict(sd, assign=True)
|
||||
return model
|
||||
|
||||
|
||||
@ModelLoaderRegistry.register(base=BaseModelType.Flux, type=ModelType.ControlNet, format=ModelFormat.Checkpoint)
|
||||
@ModelLoaderRegistry.register(base=BaseModelType.Flux, type=ModelType.ControlNet, format=ModelFormat.Diffusers)
|
||||
class FluxControlnetModel(ModelLoader):
|
||||
"""Class to load FLUX ControlNet models."""
|
||||
|
||||
def _load_model(
|
||||
self,
|
||||
config: AnyModelConfig,
|
||||
submodel_type: Optional[SubModelType] = None,
|
||||
) -> AnyModel:
|
||||
if isinstance(config, ControlNetCheckpointConfig):
|
||||
model_path = Path(config.path)
|
||||
elif isinstance(config, ControlNetDiffusersConfig):
|
||||
# If this is a diffusers directory, we simply ignore the config file and load from the weight file.
|
||||
model_path = Path(config.path) / "diffusion_pytorch_model.safetensors"
|
||||
else:
|
||||
raise ValueError(f"Unexpected ControlNet model config type: {type(config)}")
|
||||
|
||||
sd = load_file(model_path)
|
||||
|
||||
# Detect the FLUX ControlNet model type from the state dict.
|
||||
if is_state_dict_xlabs_controlnet(sd):
|
||||
return self._load_xlabs_controlnet(sd)
|
||||
elif is_state_dict_instantx_controlnet(sd):
|
||||
return self._load_instantx_controlnet(sd)
|
||||
else:
|
||||
raise ValueError("Do not recognize the state dict as an XLabs or InstantX ControlNet model.")
|
||||
|
||||
def _load_xlabs_controlnet(self, sd: dict[str, torch.Tensor]) -> AnyModel:
|
||||
with accelerate.init_empty_weights():
|
||||
# HACK(ryand): Is it safe to assume dev here?
|
||||
model = XLabsControlNetFlux(params["flux-dev"])
|
||||
|
||||
model.load_state_dict(sd, assign=True)
|
||||
return model
|
||||
|
||||
def _load_instantx_controlnet(self, sd: dict[str, torch.Tensor]) -> AnyModel:
|
||||
sd = convert_diffusers_instantx_state_dict_to_bfl_format(sd)
|
||||
flux_params = infer_flux_params_from_state_dict(sd)
|
||||
num_control_modes = infer_instantx_num_control_modes_from_state_dict(sd)
|
||||
|
||||
with accelerate.init_empty_weights():
|
||||
model = InstantXControlNetFlux(flux_params, num_control_modes)
|
||||
|
||||
model.load_state_dict(sd, assign=True)
|
||||
return model
|
||||
|
||||
|
||||
@ModelLoaderRegistry.register(base=BaseModelType.Flux, type=ModelType.IPAdapter, format=ModelFormat.Checkpoint)
|
||||
class FluxIpAdapterModel(ModelLoader):
|
||||
"""Class to load FLUX IP-Adapter models."""
|
||||
|
||||
def _load_model(
|
||||
self,
|
||||
config: AnyModelConfig,
|
||||
submodel_type: Optional[SubModelType] = None,
|
||||
) -> AnyModel:
|
||||
if not isinstance(config, IPAdapterCheckpointConfig):
|
||||
raise ValueError(f"Unexpected model config type: {type(config)}.")
|
||||
|
||||
sd = load_file(Path(config.path))
|
||||
|
||||
params = infer_xlabs_ip_adapter_params_from_state_dict(sd)
|
||||
|
||||
with accelerate.init_empty_weights():
|
||||
model = XlabsIpAdapterFlux(params=params)
|
||||
|
||||
model.load_xlabs_state_dict(sd, assign=True)
|
||||
return model
|
||||
|
||||
@@ -22,6 +22,7 @@ from invokeai.backend.model_manager.load.load_default import ModelLoader
|
||||
from invokeai.backend.model_manager.load.model_loader_registry import ModelLoaderRegistry
|
||||
|
||||
|
||||
@ModelLoaderRegistry.register(base=BaseModelType.Any, type=ModelType.CLIPVision, format=ModelFormat.Diffusers)
|
||||
@ModelLoaderRegistry.register(base=BaseModelType.Any, type=ModelType.T2IAdapter, format=ModelFormat.Diffusers)
|
||||
class GenericDiffusersLoader(ModelLoader):
|
||||
"""Class to load simple diffusers models."""
|
||||
|
||||
@@ -42,7 +42,6 @@ VARIANT_TO_IN_CHANNEL_MAP = {
|
||||
@ModelLoaderRegistry.register(
|
||||
base=BaseModelType.StableDiffusionXLRefiner, type=ModelType.Main, format=ModelFormat.Diffusers
|
||||
)
|
||||
@ModelLoaderRegistry.register(base=BaseModelType.StableDiffusion3, type=ModelType.Main, format=ModelFormat.Diffusers)
|
||||
@ModelLoaderRegistry.register(base=BaseModelType.StableDiffusion1, type=ModelType.Main, format=ModelFormat.Checkpoint)
|
||||
@ModelLoaderRegistry.register(base=BaseModelType.StableDiffusion2, type=ModelType.Main, format=ModelFormat.Checkpoint)
|
||||
@ModelLoaderRegistry.register(base=BaseModelType.StableDiffusionXL, type=ModelType.Main, format=ModelFormat.Checkpoint)
|
||||
@@ -52,6 +51,13 @@ VARIANT_TO_IN_CHANNEL_MAP = {
|
||||
class StableDiffusionDiffusersModel(GenericDiffusersLoader):
|
||||
"""Class to load main models."""
|
||||
|
||||
model_base_to_model_type = {
|
||||
BaseModelType.StableDiffusion1: "FrozenCLIPEmbedder",
|
||||
BaseModelType.StableDiffusion2: "FrozenOpenCLIPEmbedder",
|
||||
BaseModelType.StableDiffusionXL: "SDXL",
|
||||
BaseModelType.StableDiffusionXLRefiner: "SDXL-Refiner",
|
||||
}
|
||||
|
||||
def _load_model(
|
||||
self,
|
||||
config: AnyModelConfig,
|
||||
@@ -111,6 +117,8 @@ class StableDiffusionDiffusersModel(GenericDiffusersLoader):
|
||||
load_class = load_classes[config.base][config.variant]
|
||||
except KeyError as e:
|
||||
raise Exception(f"No diffusers pipeline known for base={config.base}, variant={config.variant}") from e
|
||||
prediction_type = config.prediction_type.value
|
||||
upcast_attention = config.upcast_attention
|
||||
|
||||
# Without SilenceWarnings we get log messages like this:
|
||||
# site-packages/huggingface_hub/file_download.py:1132: FutureWarning: `resume_download` is deprecated and will be removed in version 1.0.0. Downloads always resume when possible. If you want to force a new download, use `force_download=True`.
|
||||
@@ -121,7 +129,13 @@ class StableDiffusionDiffusersModel(GenericDiffusersLoader):
|
||||
# ['text_model.embeddings.position_ids']
|
||||
|
||||
with SilenceWarnings():
|
||||
pipeline = load_class.from_single_file(config.path, torch_dtype=self._torch_dtype)
|
||||
pipeline = load_class.from_single_file(
|
||||
config.path,
|
||||
torch_dtype=self._torch_dtype,
|
||||
prediction_type=prediction_type,
|
||||
upcast_attention=upcast_attention,
|
||||
load_safety_checker=False,
|
||||
)
|
||||
|
||||
if not submodel_type:
|
||||
return pipeline
|
||||
|
||||
@@ -20,7 +20,7 @@ from typing import Optional
|
||||
|
||||
import requests
|
||||
from huggingface_hub import HfApi, configure_http_backend, hf_hub_url
|
||||
from huggingface_hub.errors import RepositoryNotFoundError, RevisionNotFoundError
|
||||
from huggingface_hub.utils._errors import RepositoryNotFoundError, RevisionNotFoundError
|
||||
from pydantic.networks import AnyHttpUrl
|
||||
from requests.sessions import Session
|
||||
|
||||
|
||||
@@ -1,7 +1,7 @@
|
||||
import json
|
||||
import re
|
||||
from pathlib import Path
|
||||
from typing import Any, Callable, Dict, Literal, Optional, Union
|
||||
from typing import Any, Dict, Literal, Optional, Union
|
||||
|
||||
import safetensors.torch
|
||||
import spandrel
|
||||
@@ -10,11 +10,6 @@ from picklescan.scanner import scan_file_path
|
||||
|
||||
import invokeai.backend.util.logging as logger
|
||||
from invokeai.app.util.misc import uuid_string
|
||||
from invokeai.backend.flux.controlnet.state_dict_utils import (
|
||||
is_state_dict_instantx_controlnet,
|
||||
is_state_dict_xlabs_controlnet,
|
||||
)
|
||||
from invokeai.backend.flux.ip_adapter.state_dict_utils import is_state_dict_xlabs_ip_adapter
|
||||
from invokeai.backend.lora.conversions.flux_diffusers_lora_conversion_utils import (
|
||||
is_state_dict_likely_in_flux_diffusers_format,
|
||||
)
|
||||
@@ -22,7 +17,6 @@ from invokeai.backend.lora.conversions.flux_kohya_lora_conversion_utils import i
|
||||
from invokeai.backend.model_hash.model_hash import HASHING_ALGORITHMS, ModelHash
|
||||
from invokeai.backend.model_manager.config import (
|
||||
AnyModelConfig,
|
||||
AnyVariant,
|
||||
BaseModelType,
|
||||
ControlAdapterDefaultSettings,
|
||||
InvalidModelConfigException,
|
||||
@@ -34,17 +28,8 @@ from invokeai.backend.model_manager.config import (
|
||||
ModelType,
|
||||
ModelVariantType,
|
||||
SchedulerPredictionType,
|
||||
SubmodelDefinition,
|
||||
SubModelType,
|
||||
)
|
||||
from invokeai.backend.model_manager.load.model_loaders.generic_diffusers import ConfigLoader
|
||||
from invokeai.backend.model_manager.util.model_util import (
|
||||
get_clip_variant_type,
|
||||
lora_token_vector_length,
|
||||
read_checkpoint_meta,
|
||||
)
|
||||
from invokeai.backend.quantization.gguf.ggml_tensor import GGMLTensor
|
||||
from invokeai.backend.quantization.gguf.loaders import gguf_sd_loader
|
||||
from invokeai.backend.model_manager.util.model_util import lora_token_vector_length, read_checkpoint_meta
|
||||
from invokeai.backend.spandrel_image_to_image_model import SpandrelImageToImageModel
|
||||
from invokeai.backend.util.silence_warnings import SilenceWarnings
|
||||
|
||||
@@ -120,7 +105,6 @@ class ModelProbe(object):
|
||||
"StableDiffusionXLPipeline": ModelType.Main,
|
||||
"StableDiffusionXLImg2ImgPipeline": ModelType.Main,
|
||||
"StableDiffusionXLInpaintPipeline": ModelType.Main,
|
||||
"StableDiffusion3Pipeline": ModelType.Main,
|
||||
"LatentConsistencyModelPipeline": ModelType.Main,
|
||||
"AutoencoderKL": ModelType.VAE,
|
||||
"AutoencoderTiny": ModelType.VAE,
|
||||
@@ -130,13 +114,8 @@ class ModelProbe(object):
|
||||
"CLIPModel": ModelType.CLIPEmbed,
|
||||
"CLIPTextModel": ModelType.CLIPEmbed,
|
||||
"T5EncoderModel": ModelType.T5Encoder,
|
||||
"FluxControlNetModel": ModelType.ControlNet,
|
||||
"SD3Transformer2DModel": ModelType.Main,
|
||||
"CLIPTextModelWithProjection": ModelType.CLIPEmbed,
|
||||
}
|
||||
|
||||
TYPE2VARIANT: Dict[ModelType, Callable[[str], Optional[AnyVariant]]] = {ModelType.CLIPEmbed: get_clip_variant_type}
|
||||
|
||||
@classmethod
|
||||
def register_probe(
|
||||
cls, format: Literal["diffusers", "checkpoint", "onnx"], model_type: ModelType, probe_class: type[ProbeBase]
|
||||
@@ -183,10 +162,7 @@ class ModelProbe(object):
|
||||
fields["path"] = model_path.as_posix()
|
||||
fields["type"] = fields.get("type") or model_type
|
||||
fields["base"] = fields.get("base") or probe.get_base_type()
|
||||
variant_func = cls.TYPE2VARIANT.get(fields["type"], None)
|
||||
fields["variant"] = (
|
||||
fields.get("variant") or (variant_func and variant_func(model_path.as_posix())) or probe.get_variant_type()
|
||||
)
|
||||
fields["variant"] = fields.get("variant") or probe.get_variant_type()
|
||||
fields["prediction_type"] = fields.get("prediction_type") or probe.get_scheduler_prediction_type()
|
||||
fields["image_encoder_model_id"] = fields.get("image_encoder_model_id") or probe.get_image_encoder_model_id()
|
||||
fields["name"] = fields.get("name") or cls.get_model_name(model_path)
|
||||
@@ -211,7 +187,6 @@ class ModelProbe(object):
|
||||
if fields["type"] in [ModelType.Main, ModelType.ControlNet, ModelType.VAE] and fields["format"] in [
|
||||
ModelFormat.Checkpoint,
|
||||
ModelFormat.BnbQuantizednf4b,
|
||||
ModelFormat.GGUFQuantized,
|
||||
]:
|
||||
ckpt_config_path = cls._get_checkpoint_config_path(
|
||||
model_path,
|
||||
@@ -233,10 +208,6 @@ class ModelProbe(object):
|
||||
and fields["prediction_type"] == SchedulerPredictionType.VPrediction
|
||||
)
|
||||
|
||||
get_submodels = getattr(probe, "get_submodels", None)
|
||||
if fields["base"] == BaseModelType.StableDiffusion3 and callable(get_submodels):
|
||||
fields["submodels"] = get_submodels()
|
||||
|
||||
model_info = ModelConfigFactory.make_config(fields) # , key=fields.get("key", None))
|
||||
return model_info
|
||||
|
||||
@@ -249,7 +220,7 @@ class ModelProbe(object):
|
||||
|
||||
@classmethod
|
||||
def get_model_type_from_checkpoint(cls, model_path: Path, checkpoint: Optional[CkptType] = None) -> ModelType:
|
||||
if model_path.suffix not in (".bin", ".pt", ".ckpt", ".safetensors", ".pth", ".gguf"):
|
||||
if model_path.suffix not in (".bin", ".pt", ".ckpt", ".safetensors", ".pth"):
|
||||
raise InvalidModelConfigException(f"{model_path}: unrecognized suffix")
|
||||
|
||||
if model_path.name == "learned_embeds.bin":
|
||||
@@ -264,6 +235,8 @@ class ModelProbe(object):
|
||||
"cond_stage_model.",
|
||||
"first_stage_model.",
|
||||
"model.diffusion_model.",
|
||||
# FLUX models in the official BFL format contain keys with the "double_blocks." prefix.
|
||||
"double_blocks.",
|
||||
# Some FLUX checkpoint files contain transformer keys prefixed with "model.diffusion_model".
|
||||
# This prefix is typically used to distinguish between multiple models bundled in a single file.
|
||||
"model.diffusion_model.double_blocks.",
|
||||
@@ -271,10 +244,6 @@ class ModelProbe(object):
|
||||
):
|
||||
# Keys starting with double_blocks are associated with Flux models
|
||||
return ModelType.Main
|
||||
# FLUX models in the official BFL format contain keys with the "double_blocks." prefix, but we must be
|
||||
# careful to avoid false positives on XLabs FLUX IP-Adapter models.
|
||||
elif key.startswith("double_blocks.") and "ip_adapter" not in key:
|
||||
return ModelType.Main
|
||||
elif key.startswith(("encoder.conv_in", "decoder.conv_in")):
|
||||
return ModelType.VAE
|
||||
elif key.startswith(("lora_te_", "lora_unet_")):
|
||||
@@ -283,28 +252,9 @@ class ModelProbe(object):
|
||||
# LoRA models, but as of the time of writing, we support Diffusers FLUX PEFT LoRA models.
|
||||
elif key.endswith(("to_k_lora.up.weight", "to_q_lora.down.weight", "lora_A.weight", "lora_B.weight")):
|
||||
return ModelType.LoRA
|
||||
elif key.startswith(
|
||||
(
|
||||
"controlnet",
|
||||
"control_model",
|
||||
"input_blocks",
|
||||
# XLabs FLUX ControlNet models have keys starting with "controlnet_blocks."
|
||||
# For example: https://huggingface.co/XLabs-AI/flux-controlnet-collections/blob/86ab1e915a389d5857135c00e0d350e9e38a9048/flux-canny-controlnet_v2.safetensors
|
||||
# TODO(ryand): This is very fragile. XLabs FLUX ControlNet models also contain keys starting with
|
||||
# "double_blocks.", which we check for above. But, I'm afraid to modify this logic because it is so
|
||||
# delicate.
|
||||
"controlnet_blocks",
|
||||
)
|
||||
):
|
||||
elif key.startswith(("controlnet", "control_model", "input_blocks")):
|
||||
return ModelType.ControlNet
|
||||
elif key.startswith(
|
||||
(
|
||||
"image_proj.",
|
||||
"ip_adapter.",
|
||||
# XLabs FLUX IP-Adapter models have keys startinh with "ip_adapter_proj_model.".
|
||||
"ip_adapter_proj_model.",
|
||||
)
|
||||
):
|
||||
elif key.startswith(("image_proj.", "ip_adapter.")):
|
||||
return ModelType.IPAdapter
|
||||
elif key in {"emb_params", "string_to_param"}:
|
||||
return ModelType.TextualInversion
|
||||
@@ -328,10 +278,12 @@ class ModelProbe(object):
|
||||
return ModelType.SpandrelImageToImage
|
||||
except spandrel.UnsupportedModelError:
|
||||
pass
|
||||
except Exception as e:
|
||||
logger.warning(
|
||||
f"Encountered error while probing to determine if {model_path} is a Spandrel model. Ignoring. Error: {e}"
|
||||
)
|
||||
except RuntimeError as e:
|
||||
if "No such file or directory" in str(e):
|
||||
# This error is expected if the model_path does not exist (which is the case in some unit tests).
|
||||
pass
|
||||
else:
|
||||
raise e
|
||||
|
||||
raise InvalidModelConfigException(f"Unable to determine model type for {model_path}")
|
||||
|
||||
@@ -456,8 +408,6 @@ class ModelProbe(object):
|
||||
model = torch.load(model_path, map_location="cpu")
|
||||
assert isinstance(model, dict)
|
||||
return model
|
||||
elif model_path.suffix.endswith(".gguf"):
|
||||
return gguf_sd_loader(model_path, compute_dtype=torch.float32)
|
||||
else:
|
||||
return safetensors.torch.load_file(model_path)
|
||||
|
||||
@@ -482,11 +432,9 @@ MODEL_NAME_TO_PREPROCESSOR = {
|
||||
"normal": "normalbae_image_processor",
|
||||
"sketch": "pidi_image_processor",
|
||||
"scribble": "lineart_image_processor",
|
||||
"lineart anime": "lineart_anime_image_processor",
|
||||
"lineart_anime": "lineart_anime_image_processor",
|
||||
"lineart": "lineart_image_processor",
|
||||
"lineart_anime": "lineart_anime_image_processor",
|
||||
"softedge": "hed_image_processor",
|
||||
"hed": "hed_image_processor",
|
||||
"shuffle": "content_shuffle_image_processor",
|
||||
"pose": "dw_openpose_image_processor",
|
||||
"mediapipe": "mediapipe_face_processor",
|
||||
@@ -498,8 +446,7 @@ MODEL_NAME_TO_PREPROCESSOR = {
|
||||
|
||||
def get_default_settings_controlnet_t2i_adapter(model_name: str) -> Optional[ControlAdapterDefaultSettings]:
|
||||
for k, v in MODEL_NAME_TO_PREPROCESSOR.items():
|
||||
model_name_lower = model_name.lower()
|
||||
if k in model_name_lower:
|
||||
if k in model_name:
|
||||
return ControlAdapterDefaultSettings(preprocessor=v)
|
||||
return None
|
||||
|
||||
@@ -530,8 +477,6 @@ class CheckpointProbeBase(ProbeBase):
|
||||
or "model.diffusion_model.double_blocks.0.img_attn.proj.weight.quant_state.bitsandbytes__nf4" in state_dict
|
||||
):
|
||||
return ModelFormat.BnbQuantizednf4b
|
||||
elif any(isinstance(v, GGMLTensor) for v in state_dict.values()):
|
||||
return ModelFormat.GGUFQuantized
|
||||
return ModelFormat("checkpoint")
|
||||
|
||||
def get_variant_type(self) -> ModelVariantType:
|
||||
@@ -673,11 +618,6 @@ class ControlNetCheckpointProbe(CheckpointProbeBase):
|
||||
|
||||
def get_base_type(self) -> BaseModelType:
|
||||
checkpoint = self.checkpoint
|
||||
if is_state_dict_xlabs_controlnet(checkpoint) or is_state_dict_instantx_controlnet(checkpoint):
|
||||
# TODO(ryand): Should I distinguish between XLabs, InstantX and other ControlNet models by implementing
|
||||
# get_format()?
|
||||
return BaseModelType.Flux
|
||||
|
||||
for key_name in (
|
||||
"control_model.input_blocks.2.1.transformer_blocks.0.attn2.to_k.weight",
|
||||
"controlnet_mid_block.bias",
|
||||
@@ -703,10 +643,6 @@ class IPAdapterCheckpointProbe(CheckpointProbeBase):
|
||||
|
||||
def get_base_type(self) -> BaseModelType:
|
||||
checkpoint = self.checkpoint
|
||||
|
||||
if is_state_dict_xlabs_ip_adapter(checkpoint):
|
||||
return BaseModelType.Flux
|
||||
|
||||
for key in checkpoint.keys():
|
||||
if not key.startswith(("image_proj.", "ip_adapter.")):
|
||||
continue
|
||||
@@ -767,33 +703,18 @@ class FolderProbeBase(ProbeBase):
|
||||
|
||||
class PipelineFolderProbe(FolderProbeBase):
|
||||
def get_base_type(self) -> BaseModelType:
|
||||
# Handle pipelines with a UNet (i.e SD 1.x, SD2, SDXL).
|
||||
config_path = self.model_path / "unet" / "config.json"
|
||||
if config_path.exists():
|
||||
with open(config_path) as file:
|
||||
unet_conf = json.load(file)
|
||||
if unet_conf["cross_attention_dim"] == 768:
|
||||
return BaseModelType.StableDiffusion1
|
||||
elif unet_conf["cross_attention_dim"] == 1024:
|
||||
return BaseModelType.StableDiffusion2
|
||||
elif unet_conf["cross_attention_dim"] == 1280:
|
||||
return BaseModelType.StableDiffusionXLRefiner
|
||||
elif unet_conf["cross_attention_dim"] == 2048:
|
||||
return BaseModelType.StableDiffusionXL
|
||||
else:
|
||||
raise InvalidModelConfigException(f"Unknown base model for {self.model_path}")
|
||||
|
||||
# Handle pipelines with a transformer (i.e. SD3).
|
||||
config_path = self.model_path / "transformer" / "config.json"
|
||||
if config_path.exists():
|
||||
with open(config_path) as file:
|
||||
transformer_conf = json.load(file)
|
||||
if transformer_conf["_class_name"] == "SD3Transformer2DModel":
|
||||
return BaseModelType.StableDiffusion3
|
||||
else:
|
||||
raise InvalidModelConfigException(f"Unknown base model for {self.model_path}")
|
||||
|
||||
raise InvalidModelConfigException(f"Unknown base model for {self.model_path}")
|
||||
with open(self.model_path / "unet" / "config.json", "r") as file:
|
||||
unet_conf = json.load(file)
|
||||
if unet_conf["cross_attention_dim"] == 768:
|
||||
return BaseModelType.StableDiffusion1
|
||||
elif unet_conf["cross_attention_dim"] == 1024:
|
||||
return BaseModelType.StableDiffusion2
|
||||
elif unet_conf["cross_attention_dim"] == 1280:
|
||||
return BaseModelType.StableDiffusionXLRefiner
|
||||
elif unet_conf["cross_attention_dim"] == 2048:
|
||||
return BaseModelType.StableDiffusionXL
|
||||
else:
|
||||
raise InvalidModelConfigException(f"Unknown base model for {self.model_path}")
|
||||
|
||||
def get_scheduler_prediction_type(self) -> SchedulerPredictionType:
|
||||
with open(self.model_path / "scheduler" / "scheduler_config.json", "r") as file:
|
||||
@@ -805,23 +726,6 @@ class PipelineFolderProbe(FolderProbeBase):
|
||||
else:
|
||||
raise InvalidModelConfigException("Unknown scheduler prediction type: {scheduler_conf['prediction_type']}")
|
||||
|
||||
def get_submodels(self) -> Dict[SubModelType, SubmodelDefinition]:
|
||||
config = ConfigLoader.load_config(self.model_path, config_name="model_index.json")
|
||||
submodels: Dict[SubModelType, SubmodelDefinition] = {}
|
||||
for key, value in config.items():
|
||||
if key.startswith("_") or not (isinstance(value, list) and len(value) == 2):
|
||||
continue
|
||||
model_loader = str(value[1])
|
||||
if model_type := ModelProbe.CLASS2TYPE.get(model_loader):
|
||||
variant_func = ModelProbe.TYPE2VARIANT.get(model_type, None)
|
||||
submodels[SubModelType(key)] = SubmodelDefinition(
|
||||
path_or_prefix=(self.model_path / key).resolve().as_posix(),
|
||||
model_type=model_type,
|
||||
variant=variant_func and variant_func((self.model_path / key).as_posix()),
|
||||
)
|
||||
|
||||
return submodels
|
||||
|
||||
def get_variant_type(self) -> ModelVariantType:
|
||||
# This only works for pipelines! Any kind of
|
||||
# exception results in our returning the
|
||||
@@ -935,19 +839,22 @@ class ControlNetFolderProbe(FolderProbeBase):
|
||||
raise InvalidModelConfigException(f"Cannot determine base type for {self.model_path}")
|
||||
with open(config_file, "r") as file:
|
||||
config = json.load(file)
|
||||
|
||||
if config.get("_class_name", None) == "FluxControlNetModel":
|
||||
return BaseModelType.Flux
|
||||
|
||||
# no obvious way to distinguish between sd2-base and sd2-768
|
||||
dimension = config["cross_attention_dim"]
|
||||
if dimension == 768:
|
||||
return BaseModelType.StableDiffusion1
|
||||
if dimension == 1024:
|
||||
return BaseModelType.StableDiffusion2
|
||||
if dimension == 2048:
|
||||
return BaseModelType.StableDiffusionXL
|
||||
raise InvalidModelConfigException(f"Unable to determine model base for {self.model_path}")
|
||||
base_model = (
|
||||
BaseModelType.StableDiffusion1
|
||||
if dimension == 768
|
||||
else (
|
||||
BaseModelType.StableDiffusion2
|
||||
if dimension == 1024
|
||||
else BaseModelType.StableDiffusionXL
|
||||
if dimension == 2048
|
||||
else None
|
||||
)
|
||||
)
|
||||
if not base_model:
|
||||
raise InvalidModelConfigException(f"Unable to determine model base for {self.model_path}")
|
||||
return base_model
|
||||
|
||||
|
||||
class LoRAFolderProbe(FolderProbeBase):
|
||||
|
||||
@@ -130,7 +130,7 @@ class ModelSearch:
|
||||
return
|
||||
|
||||
for n in file_names:
|
||||
if n.endswith((".ckpt", ".bin", ".pth", ".safetensors", ".pt", ".gguf")):
|
||||
if n.endswith((".ckpt", ".bin", ".pth", ".safetensors", ".pt")):
|
||||
try:
|
||||
self.model_found(absolute_path / n)
|
||||
except KeyboardInterrupt:
|
||||
|
||||
File diff suppressed because it is too large
Load Diff
@@ -8,9 +8,6 @@ import safetensors
|
||||
import torch
|
||||
from picklescan.scanner import scan_file_path
|
||||
|
||||
from invokeai.backend.model_manager.config import ClipVariantType
|
||||
from invokeai.backend.quantization.gguf.loaders import gguf_sd_loader
|
||||
|
||||
|
||||
def _fast_safetensors_reader(path: str) -> Dict[str, torch.Tensor]:
|
||||
checkpoint = {}
|
||||
@@ -57,11 +54,7 @@ def read_checkpoint_meta(path: Union[str, Path], scan: bool = False) -> Dict[str
|
||||
scan_result = scan_file_path(path)
|
||||
if scan_result.infected_files != 0:
|
||||
raise Exception(f'The model file "{path}" is potentially infected by malware. Aborting import.')
|
||||
if str(path).endswith(".gguf"):
|
||||
# The GGUF reader used here uses numpy memmap, so these tensors are not loaded into memory during this function
|
||||
checkpoint = gguf_sd_loader(Path(path), compute_dtype=torch.float32)
|
||||
else:
|
||||
checkpoint = torch.load(path, map_location=torch.device("meta"))
|
||||
checkpoint = torch.load(path, map_location=torch.device("meta"))
|
||||
return checkpoint
|
||||
|
||||
|
||||
@@ -166,20 +159,3 @@ def convert_bundle_to_flux_transformer_checkpoint(
|
||||
del transformer_state_dict[k]
|
||||
|
||||
return original_state_dict
|
||||
|
||||
|
||||
def get_clip_variant_type(location: str) -> Optional[ClipVariantType]:
|
||||
path = Path(location)
|
||||
config_path = path / "config.json"
|
||||
if not config_path.exists():
|
||||
return None
|
||||
with open(config_path) as file:
|
||||
clip_conf = json.load(file)
|
||||
hidden_size = clip_conf.get("hidden_size", -1)
|
||||
match hidden_size:
|
||||
case 1280:
|
||||
return ClipVariantType.G
|
||||
case 768:
|
||||
return ClipVariantType.L
|
||||
case _:
|
||||
return None
|
||||
|
||||
@@ -129,11 +129,9 @@ def _filter_by_variant(files: List[Path], variant: ModelRepoVariant) -> Set[Path
|
||||
|
||||
# Some special handling is needed here if there is not an exact match and if we cannot infer the variant
|
||||
# from the file name. In this case, we only give this file a point if the requested variant is FP32 or DEFAULT.
|
||||
if (
|
||||
variant is not ModelRepoVariant.Default
|
||||
and candidate_variant_label
|
||||
and candidate_variant_label.startswith(f".{variant.value}")
|
||||
) or (not candidate_variant_label and variant in [ModelRepoVariant.FP32, ModelRepoVariant.Default]):
|
||||
if candidate_variant_label == f".{variant}" or (
|
||||
not candidate_variant_label and variant in [ModelRepoVariant.FP32, ModelRepoVariant.Default]
|
||||
):
|
||||
score += 1
|
||||
|
||||
if parent not in subfolder_weights:
|
||||
@@ -148,7 +146,7 @@ def _filter_by_variant(files: List[Path], variant: ModelRepoVariant) -> Set[Path
|
||||
# Check if at least one of the files has the explicit fp16 variant.
|
||||
at_least_one_fp16 = False
|
||||
for candidate in candidate_list:
|
||||
if len(candidate.path.suffixes) == 2 and candidate.path.suffixes[0].startswith(".fp16"):
|
||||
if len(candidate.path.suffixes) == 2 and candidate.path.suffixes[0] == ".fp16":
|
||||
at_least_one_fp16 = True
|
||||
break
|
||||
|
||||
@@ -164,16 +162,7 @@ def _filter_by_variant(files: List[Path], variant: ModelRepoVariant) -> Set[Path
|
||||
# candidate.
|
||||
highest_score_candidate = max(candidate_list, key=lambda candidate: candidate.score)
|
||||
if highest_score_candidate:
|
||||
pattern = r"^(.*?)-\d+-of-\d+(\.\w+)$"
|
||||
match = re.match(pattern, highest_score_candidate.path.as_posix())
|
||||
if match:
|
||||
for candidate in candidate_list:
|
||||
if candidate.path.as_posix().startswith(match.group(1)) and candidate.path.as_posix().endswith(
|
||||
match.group(2)
|
||||
):
|
||||
result.add(candidate.path)
|
||||
else:
|
||||
result.add(highest_score_candidate.path)
|
||||
result.add(highest_score_candidate.path)
|
||||
|
||||
# If one of the architecture-related variants was specified and no files matched other than
|
||||
# config and text files then we return an empty list
|
||||
|
||||
@@ -1,157 +0,0 @@
|
||||
from typing import overload
|
||||
|
||||
import gguf
|
||||
import torch
|
||||
|
||||
from invokeai.backend.quantization.gguf.utils import (
|
||||
DEQUANTIZE_FUNCTIONS,
|
||||
TORCH_COMPATIBLE_QTYPES,
|
||||
dequantize,
|
||||
)
|
||||
|
||||
|
||||
def dequantize_and_run(func, args, kwargs):
|
||||
"""A helper function for running math ops on GGMLTensor inputs.
|
||||
|
||||
Dequantizes the inputs, and runs the function.
|
||||
"""
|
||||
dequantized_args = [a.get_dequantized_tensor() if hasattr(a, "get_dequantized_tensor") else a for a in args]
|
||||
dequantized_kwargs = {
|
||||
k: v.get_dequantized_tensor() if hasattr(v, "get_dequantized_tensor") else v for k, v in kwargs.items()
|
||||
}
|
||||
return func(*dequantized_args, **dequantized_kwargs)
|
||||
|
||||
|
||||
def apply_to_quantized_tensor(func, args, kwargs):
|
||||
"""A helper function to apply a function to a quantized GGML tensor, and re-wrap the result in a GGMLTensor.
|
||||
|
||||
Assumes that the first argument is a GGMLTensor.
|
||||
"""
|
||||
# We expect the first argument to be a GGMLTensor, and all other arguments to be non-GGMLTensors.
|
||||
ggml_tensor = args[0]
|
||||
assert isinstance(ggml_tensor, GGMLTensor)
|
||||
assert all(not isinstance(a, GGMLTensor) for a in args[1:])
|
||||
assert all(not isinstance(v, GGMLTensor) for v in kwargs.values())
|
||||
|
||||
new_data = func(ggml_tensor.quantized_data, *args[1:], **kwargs)
|
||||
|
||||
if new_data.dtype != ggml_tensor.quantized_data.dtype:
|
||||
# This is intended to catch calls such as `.to(dtype-torch.float32)`, which are not supported on GGMLTensors.
|
||||
raise ValueError("Operation changed the dtype of GGMLTensor unexpectedly.")
|
||||
|
||||
return GGMLTensor(
|
||||
new_data, ggml_tensor._ggml_quantization_type, ggml_tensor.tensor_shape, ggml_tensor.compute_dtype
|
||||
)
|
||||
|
||||
|
||||
GGML_TENSOR_OP_TABLE = {
|
||||
# Ops to run on the quantized tensor.
|
||||
torch.ops.aten.detach.default: apply_to_quantized_tensor, # pyright: ignore
|
||||
torch.ops.aten._to_copy.default: apply_to_quantized_tensor, # pyright: ignore
|
||||
# Ops to run on dequantized tensors.
|
||||
torch.ops.aten.t.default: dequantize_and_run, # pyright: ignore
|
||||
torch.ops.aten.addmm.default: dequantize_and_run, # pyright: ignore
|
||||
torch.ops.aten.mul.Tensor: dequantize_and_run, # pyright: ignore
|
||||
}
|
||||
|
||||
if torch.backends.mps.is_available():
|
||||
GGML_TENSOR_OP_TABLE.update(
|
||||
{torch.ops.aten.linear.default: dequantize_and_run} # pyright: ignore
|
||||
)
|
||||
|
||||
|
||||
class GGMLTensor(torch.Tensor):
|
||||
"""A torch.Tensor sub-class holding a quantized GGML tensor.
|
||||
|
||||
The underlying tensor is quantized, but the GGMLTensor class provides a dequantized view of the tensor on-the-fly
|
||||
when it is used in operations.
|
||||
"""
|
||||
|
||||
@staticmethod
|
||||
def __new__(
|
||||
cls,
|
||||
data: torch.Tensor,
|
||||
ggml_quantization_type: gguf.GGMLQuantizationType,
|
||||
tensor_shape: torch.Size,
|
||||
compute_dtype: torch.dtype,
|
||||
):
|
||||
# Type hinting is not supported for torch.Tensor._make_wrapper_subclass, so we ignore the errors.
|
||||
return torch.Tensor._make_wrapper_subclass( # pyright: ignore
|
||||
cls,
|
||||
data.shape,
|
||||
dtype=data.dtype,
|
||||
layout=data.layout,
|
||||
device=data.device,
|
||||
strides=data.stride(),
|
||||
storage_offset=data.storage_offset(),
|
||||
)
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
data: torch.Tensor,
|
||||
ggml_quantization_type: gguf.GGMLQuantizationType,
|
||||
tensor_shape: torch.Size,
|
||||
compute_dtype: torch.dtype,
|
||||
):
|
||||
self.quantized_data = data
|
||||
self._ggml_quantization_type = ggml_quantization_type
|
||||
# The dequantized shape of the tensor.
|
||||
self.tensor_shape = tensor_shape
|
||||
self.compute_dtype = compute_dtype
|
||||
|
||||
def __repr__(self, *, tensor_contents=None):
|
||||
return f"GGMLTensor(type={self._ggml_quantization_type.name}, dequantized_shape=({self.tensor_shape})"
|
||||
|
||||
@overload
|
||||
def size(self, dim: None = None) -> torch.Size: ...
|
||||
|
||||
@overload
|
||||
def size(self, dim: int) -> int: ...
|
||||
|
||||
def size(self, dim: int | None = None):
|
||||
"""Return the size of the tensor after dequantization. I.e. the shape that will be used in any math ops."""
|
||||
if dim is not None:
|
||||
return self.tensor_shape[dim]
|
||||
return self.tensor_shape
|
||||
|
||||
@property
|
||||
def shape(self) -> torch.Size: # pyright: ignore[reportIncompatibleVariableOverride] pyright doesn't understand this for some reason.
|
||||
"""The shape of the tensor after dequantization. I.e. the shape that will be used in any math ops."""
|
||||
return self.size()
|
||||
|
||||
@property
|
||||
def quantized_shape(self) -> torch.Size:
|
||||
"""The shape of the quantized tensor."""
|
||||
return self.quantized_data.shape
|
||||
|
||||
def requires_grad_(self, mode: bool = True) -> torch.Tensor:
|
||||
"""The GGMLTensor class is currently only designed for inference (not training). Setting requires_grad to True
|
||||
is not supported. This method is a no-op.
|
||||
"""
|
||||
return self
|
||||
|
||||
def get_dequantized_tensor(self):
|
||||
"""Return the dequantized tensor.
|
||||
|
||||
Args:
|
||||
dtype: The dtype of the dequantized tensor.
|
||||
"""
|
||||
if self._ggml_quantization_type in TORCH_COMPATIBLE_QTYPES:
|
||||
return self.quantized_data.to(self.compute_dtype)
|
||||
elif self._ggml_quantization_type in DEQUANTIZE_FUNCTIONS:
|
||||
# TODO(ryand): Look into how the dtype param is intended to be used.
|
||||
return dequantize(
|
||||
data=self.quantized_data, qtype=self._ggml_quantization_type, oshape=self.tensor_shape, dtype=None
|
||||
).to(self.compute_dtype)
|
||||
else:
|
||||
# There is no GPU implementation for this quantization type, so fallback to the numpy implementation.
|
||||
new = gguf.quants.dequantize(self.quantized_data.cpu().numpy(), self._ggml_quantization_type)
|
||||
return torch.from_numpy(new).to(self.quantized_data.device, dtype=self.compute_dtype)
|
||||
|
||||
@classmethod
|
||||
def __torch_dispatch__(cls, func, types, args, kwargs):
|
||||
# We will likely hit cases here in the future where a new op is encountered that is not yet supported.
|
||||
# The new op simply needs to be added to the GGML_TENSOR_OP_TABLE.
|
||||
if func in GGML_TENSOR_OP_TABLE:
|
||||
return GGML_TENSOR_OP_TABLE[func](func, args, kwargs)
|
||||
return NotImplemented
|
||||
@@ -1,22 +0,0 @@
|
||||
from pathlib import Path
|
||||
|
||||
import gguf
|
||||
import torch
|
||||
|
||||
from invokeai.backend.quantization.gguf.ggml_tensor import GGMLTensor
|
||||
from invokeai.backend.quantization.gguf.utils import TORCH_COMPATIBLE_QTYPES
|
||||
|
||||
|
||||
def gguf_sd_loader(path: Path, compute_dtype: torch.dtype) -> dict[str, GGMLTensor]:
|
||||
reader = gguf.GGUFReader(path)
|
||||
|
||||
sd: dict[str, GGMLTensor] = {}
|
||||
for tensor in reader.tensors:
|
||||
torch_tensor = torch.from_numpy(tensor.data)
|
||||
shape = torch.Size(tuple(int(v) for v in reversed(tensor.shape)))
|
||||
if tensor.tensor_type in TORCH_COMPATIBLE_QTYPES:
|
||||
torch_tensor = torch_tensor.view(*shape)
|
||||
sd[tensor.name] = GGMLTensor(
|
||||
torch_tensor, ggml_quantization_type=tensor.tensor_type, tensor_shape=shape, compute_dtype=compute_dtype
|
||||
)
|
||||
return sd
|
||||
@@ -1,308 +0,0 @@
|
||||
# Largely based on https://github.com/city96/ComfyUI-GGUF
|
||||
|
||||
from typing import Callable, Optional, Union
|
||||
|
||||
import gguf
|
||||
import torch
|
||||
|
||||
TORCH_COMPATIBLE_QTYPES = {None, gguf.GGMLQuantizationType.F32, gguf.GGMLQuantizationType.F16}
|
||||
|
||||
# K Quants #
|
||||
QK_K = 256
|
||||
K_SCALE_SIZE = 12
|
||||
|
||||
|
||||
def get_scale_min(scales: torch.Tensor):
|
||||
n_blocks = scales.shape[0]
|
||||
scales = scales.view(torch.uint8)
|
||||
scales = scales.reshape((n_blocks, 3, 4))
|
||||
|
||||
d, m, m_d = torch.split(scales, scales.shape[-2] // 3, dim=-2)
|
||||
|
||||
sc = torch.cat([d & 0x3F, (m_d & 0x0F) | ((d >> 2) & 0x30)], dim=-1)
|
||||
min = torch.cat([m & 0x3F, (m_d >> 4) | ((m >> 2) & 0x30)], dim=-1)
|
||||
|
||||
return (sc.reshape((n_blocks, 8)), min.reshape((n_blocks, 8)))
|
||||
|
||||
|
||||
# Legacy Quants #
|
||||
def dequantize_blocks_Q8_0(
|
||||
blocks: torch.Tensor, block_size: int, type_size: int, dtype: Optional[torch.dtype] = None
|
||||
) -> torch.Tensor:
|
||||
d, x = split_block_dims(blocks, 2)
|
||||
d = d.view(torch.float16).to(dtype)
|
||||
x = x.view(torch.int8)
|
||||
return d * x
|
||||
|
||||
|
||||
def dequantize_blocks_Q5_1(
|
||||
blocks: torch.Tensor, block_size: int, type_size: int, dtype: Optional[torch.dtype] = None
|
||||
) -> torch.Tensor:
|
||||
n_blocks = blocks.shape[0]
|
||||
|
||||
d, m, qh, qs = split_block_dims(blocks, 2, 2, 4)
|
||||
d = d.view(torch.float16).to(dtype)
|
||||
m = m.view(torch.float16).to(dtype)
|
||||
qh = to_uint32(qh)
|
||||
|
||||
qh = qh.reshape((n_blocks, 1)) >> torch.arange(32, device=d.device, dtype=torch.int32).reshape(1, 32)
|
||||
ql = qs.reshape((n_blocks, -1, 1, block_size // 2)) >> torch.tensor(
|
||||
[0, 4], device=d.device, dtype=torch.uint8
|
||||
).reshape(1, 1, 2, 1)
|
||||
qh = (qh & 1).to(torch.uint8)
|
||||
ql = (ql & 0x0F).reshape((n_blocks, -1))
|
||||
|
||||
qs = ql | (qh << 4)
|
||||
return (d * qs) + m
|
||||
|
||||
|
||||
def dequantize_blocks_Q5_0(
|
||||
blocks: torch.Tensor, block_size: int, type_size: int, dtype: Optional[torch.dtype] = None
|
||||
) -> torch.Tensor:
|
||||
n_blocks = blocks.shape[0]
|
||||
|
||||
d, qh, qs = split_block_dims(blocks, 2, 4)
|
||||
d = d.view(torch.float16).to(dtype)
|
||||
qh = to_uint32(qh)
|
||||
|
||||
qh = qh.reshape(n_blocks, 1) >> torch.arange(32, device=d.device, dtype=torch.int32).reshape(1, 32)
|
||||
ql = qs.reshape(n_blocks, -1, 1, block_size // 2) >> torch.tensor(
|
||||
[0, 4], device=d.device, dtype=torch.uint8
|
||||
).reshape(1, 1, 2, 1)
|
||||
|
||||
qh = (qh & 1).to(torch.uint8)
|
||||
ql = (ql & 0x0F).reshape(n_blocks, -1)
|
||||
|
||||
qs = (ql | (qh << 4)).to(torch.int8) - 16
|
||||
return d * qs
|
||||
|
||||
|
||||
def dequantize_blocks_Q4_1(
|
||||
blocks: torch.Tensor, block_size: int, type_size: int, dtype: Optional[torch.dtype] = None
|
||||
) -> torch.Tensor:
|
||||
n_blocks = blocks.shape[0]
|
||||
|
||||
d, m, qs = split_block_dims(blocks, 2, 2)
|
||||
d = d.view(torch.float16).to(dtype)
|
||||
m = m.view(torch.float16).to(dtype)
|
||||
|
||||
qs = qs.reshape((n_blocks, -1, 1, block_size // 2)) >> torch.tensor(
|
||||
[0, 4], device=d.device, dtype=torch.uint8
|
||||
).reshape(1, 1, 2, 1)
|
||||
qs = (qs & 0x0F).reshape(n_blocks, -1)
|
||||
|
||||
return (d * qs) + m
|
||||
|
||||
|
||||
def dequantize_blocks_Q4_0(
|
||||
blocks: torch.Tensor, block_size: int, type_size: int, dtype: Optional[torch.dtype] = None
|
||||
) -> torch.Tensor:
|
||||
n_blocks = blocks.shape[0]
|
||||
|
||||
d, qs = split_block_dims(blocks, 2)
|
||||
d = d.view(torch.float16).to(dtype)
|
||||
|
||||
qs = qs.reshape((n_blocks, -1, 1, block_size // 2)) >> torch.tensor(
|
||||
[0, 4], device=d.device, dtype=torch.uint8
|
||||
).reshape((1, 1, 2, 1))
|
||||
qs = (qs & 0x0F).reshape((n_blocks, -1)).to(torch.int8) - 8
|
||||
return d * qs
|
||||
|
||||
|
||||
def dequantize_blocks_BF16(
|
||||
blocks: torch.Tensor, block_size: int, type_size: int, dtype: Optional[torch.dtype] = None
|
||||
) -> torch.Tensor:
|
||||
return (blocks.view(torch.int16).to(torch.int32) << 16).view(torch.float32)
|
||||
|
||||
|
||||
def dequantize_blocks_Q6_K(
|
||||
blocks: torch.Tensor, block_size: int, type_size: int, dtype: Optional[torch.dtype] = None
|
||||
) -> torch.Tensor:
|
||||
n_blocks = blocks.shape[0]
|
||||
|
||||
(
|
||||
ql,
|
||||
qh,
|
||||
scales,
|
||||
d,
|
||||
) = split_block_dims(blocks, QK_K // 2, QK_K // 4, QK_K // 16)
|
||||
|
||||
scales = scales.view(torch.int8).to(dtype)
|
||||
d = d.view(torch.float16).to(dtype)
|
||||
d = (d * scales).reshape((n_blocks, QK_K // 16, 1))
|
||||
|
||||
ql = ql.reshape((n_blocks, -1, 1, 64)) >> torch.tensor([0, 4], device=d.device, dtype=torch.uint8).reshape(
|
||||
(1, 1, 2, 1)
|
||||
)
|
||||
ql = (ql & 0x0F).reshape((n_blocks, -1, 32))
|
||||
qh = qh.reshape((n_blocks, -1, 1, 32)) >> torch.tensor([0, 2, 4, 6], device=d.device, dtype=torch.uint8).reshape(
|
||||
(1, 1, 4, 1)
|
||||
)
|
||||
qh = (qh & 0x03).reshape((n_blocks, -1, 32))
|
||||
q = (ql | (qh << 4)).to(torch.int8) - 32
|
||||
q = q.reshape((n_blocks, QK_K // 16, -1))
|
||||
|
||||
return (d * q).reshape((n_blocks, QK_K))
|
||||
|
||||
|
||||
def dequantize_blocks_Q5_K(
|
||||
blocks: torch.Tensor, block_size: int, type_size: int, dtype: Optional[torch.dtype] = None
|
||||
) -> torch.Tensor:
|
||||
n_blocks = blocks.shape[0]
|
||||
|
||||
d, dmin, scales, qh, qs = split_block_dims(blocks, 2, 2, K_SCALE_SIZE, QK_K // 8)
|
||||
|
||||
d = d.view(torch.float16).to(dtype)
|
||||
dmin = dmin.view(torch.float16).to(dtype)
|
||||
|
||||
sc, m = get_scale_min(scales)
|
||||
|
||||
d = (d * sc).reshape((n_blocks, -1, 1))
|
||||
dm = (dmin * m).reshape((n_blocks, -1, 1))
|
||||
|
||||
ql = qs.reshape((n_blocks, -1, 1, 32)) >> torch.tensor([0, 4], device=d.device, dtype=torch.uint8).reshape(
|
||||
(1, 1, 2, 1)
|
||||
)
|
||||
qh = qh.reshape((n_blocks, -1, 1, 32)) >> torch.tensor(list(range(8)), device=d.device, dtype=torch.uint8).reshape(
|
||||
(1, 1, 8, 1)
|
||||
)
|
||||
ql = (ql & 0x0F).reshape((n_blocks, -1, 32))
|
||||
qh = (qh & 0x01).reshape((n_blocks, -1, 32))
|
||||
q = ql | (qh << 4)
|
||||
|
||||
return (d * q - dm).reshape((n_blocks, QK_K))
|
||||
|
||||
|
||||
def dequantize_blocks_Q4_K(
|
||||
blocks: torch.Tensor, block_size: int, type_size: int, dtype: Optional[torch.dtype] = None
|
||||
) -> torch.Tensor:
|
||||
n_blocks = blocks.shape[0]
|
||||
|
||||
d, dmin, scales, qs = split_block_dims(blocks, 2, 2, K_SCALE_SIZE)
|
||||
d = d.view(torch.float16).to(dtype)
|
||||
dmin = dmin.view(torch.float16).to(dtype)
|
||||
|
||||
sc, m = get_scale_min(scales)
|
||||
|
||||
d = (d * sc).reshape((n_blocks, -1, 1))
|
||||
dm = (dmin * m).reshape((n_blocks, -1, 1))
|
||||
|
||||
qs = qs.reshape((n_blocks, -1, 1, 32)) >> torch.tensor([0, 4], device=d.device, dtype=torch.uint8).reshape(
|
||||
(1, 1, 2, 1)
|
||||
)
|
||||
qs = (qs & 0x0F).reshape((n_blocks, -1, 32))
|
||||
|
||||
return (d * qs - dm).reshape((n_blocks, QK_K))
|
||||
|
||||
|
||||
def dequantize_blocks_Q3_K(
|
||||
blocks: torch.Tensor, block_size: int, type_size: int, dtype: Optional[torch.dtype] = None
|
||||
) -> torch.Tensor:
|
||||
n_blocks = blocks.shape[0]
|
||||
|
||||
hmask, qs, scales, d = split_block_dims(blocks, QK_K // 8, QK_K // 4, 12)
|
||||
d = d.view(torch.float16).to(dtype)
|
||||
|
||||
lscales, hscales = scales[:, :8], scales[:, 8:]
|
||||
lscales = lscales.reshape((n_blocks, 1, 8)) >> torch.tensor([0, 4], device=d.device, dtype=torch.uint8).reshape(
|
||||
(1, 2, 1)
|
||||
)
|
||||
lscales = lscales.reshape((n_blocks, 16))
|
||||
hscales = hscales.reshape((n_blocks, 1, 4)) >> torch.tensor(
|
||||
[0, 2, 4, 6], device=d.device, dtype=torch.uint8
|
||||
).reshape((1, 4, 1))
|
||||
hscales = hscales.reshape((n_blocks, 16))
|
||||
scales = (lscales & 0x0F) | ((hscales & 0x03) << 4)
|
||||
scales = scales.to(torch.int8) - 32
|
||||
|
||||
dl = (d * scales).reshape((n_blocks, 16, 1))
|
||||
|
||||
ql = qs.reshape((n_blocks, -1, 1, 32)) >> torch.tensor([0, 2, 4, 6], device=d.device, dtype=torch.uint8).reshape(
|
||||
(1, 1, 4, 1)
|
||||
)
|
||||
qh = hmask.reshape(n_blocks, -1, 1, 32) >> torch.tensor(list(range(8)), device=d.device, dtype=torch.uint8).reshape(
|
||||
(1, 1, 8, 1)
|
||||
)
|
||||
ql = ql.reshape((n_blocks, 16, QK_K // 16)) & 3
|
||||
qh = (qh.reshape((n_blocks, 16, QK_K // 16)) & 1) ^ 1
|
||||
q = ql.to(torch.int8) - (qh << 2).to(torch.int8)
|
||||
|
||||
return (dl * q).reshape((n_blocks, QK_K))
|
||||
|
||||
|
||||
def dequantize_blocks_Q2_K(
|
||||
blocks: torch.Tensor, block_size: int, type_size: int, dtype: Optional[torch.dtype] = None
|
||||
) -> torch.Tensor:
|
||||
n_blocks = blocks.shape[0]
|
||||
|
||||
scales, qs, d, dmin = split_block_dims(blocks, QK_K // 16, QK_K // 4, 2)
|
||||
d = d.view(torch.float16).to(dtype)
|
||||
dmin = dmin.view(torch.float16).to(dtype)
|
||||
|
||||
# (n_blocks, 16, 1)
|
||||
dl = (d * (scales & 0xF)).reshape((n_blocks, QK_K // 16, 1))
|
||||
ml = (dmin * (scales >> 4)).reshape((n_blocks, QK_K // 16, 1))
|
||||
|
||||
shift = torch.tensor([0, 2, 4, 6], device=d.device, dtype=torch.uint8).reshape((1, 1, 4, 1))
|
||||
|
||||
qs = (qs.reshape((n_blocks, -1, 1, 32)) >> shift) & 3
|
||||
qs = qs.reshape((n_blocks, QK_K // 16, 16))
|
||||
qs = dl * qs - ml
|
||||
|
||||
return qs.reshape((n_blocks, -1))
|
||||
|
||||
|
||||
DEQUANTIZE_FUNCTIONS: dict[
|
||||
gguf.GGMLQuantizationType, Callable[[torch.Tensor, int, int, Optional[torch.dtype]], torch.Tensor]
|
||||
] = {
|
||||
gguf.GGMLQuantizationType.BF16: dequantize_blocks_BF16,
|
||||
gguf.GGMLQuantizationType.Q8_0: dequantize_blocks_Q8_0,
|
||||
gguf.GGMLQuantizationType.Q5_1: dequantize_blocks_Q5_1,
|
||||
gguf.GGMLQuantizationType.Q5_0: dequantize_blocks_Q5_0,
|
||||
gguf.GGMLQuantizationType.Q4_1: dequantize_blocks_Q4_1,
|
||||
gguf.GGMLQuantizationType.Q4_0: dequantize_blocks_Q4_0,
|
||||
gguf.GGMLQuantizationType.Q6_K: dequantize_blocks_Q6_K,
|
||||
gguf.GGMLQuantizationType.Q5_K: dequantize_blocks_Q5_K,
|
||||
gguf.GGMLQuantizationType.Q4_K: dequantize_blocks_Q4_K,
|
||||
gguf.GGMLQuantizationType.Q3_K: dequantize_blocks_Q3_K,
|
||||
gguf.GGMLQuantizationType.Q2_K: dequantize_blocks_Q2_K,
|
||||
}
|
||||
|
||||
|
||||
def is_torch_compatible(tensor: Optional[torch.Tensor]):
|
||||
return getattr(tensor, "tensor_type", None) in TORCH_COMPATIBLE_QTYPES
|
||||
|
||||
|
||||
def is_quantized(tensor: torch.Tensor):
|
||||
return not is_torch_compatible(tensor)
|
||||
|
||||
|
||||
def dequantize(
|
||||
data: torch.Tensor, qtype: gguf.GGMLQuantizationType, oshape: torch.Size, dtype: Optional[torch.dtype] = None
|
||||
):
|
||||
"""
|
||||
Dequantize tensor back to usable shape/dtype
|
||||
"""
|
||||
block_size, type_size = gguf.GGML_QUANT_SIZES[qtype]
|
||||
dequantize_blocks = DEQUANTIZE_FUNCTIONS[qtype]
|
||||
|
||||
rows = data.reshape((-1, data.shape[-1])).view(torch.uint8)
|
||||
|
||||
n_blocks = rows.numel() // type_size
|
||||
blocks = rows.reshape((n_blocks, type_size))
|
||||
blocks = dequantize_blocks(blocks, block_size, type_size, dtype)
|
||||
return blocks.reshape(oshape)
|
||||
|
||||
|
||||
def to_uint32(x: torch.Tensor) -> torch.Tensor:
|
||||
x = x.view(torch.uint8).to(torch.int32)
|
||||
return (x[:, 0] | x[:, 1] << 8 | x[:, 2] << 16 | x[:, 3] << 24).unsqueeze(1)
|
||||
|
||||
|
||||
def split_block_dims(blocks: torch.Tensor, *args):
|
||||
n_max = blocks.shape[1]
|
||||
dims = list(args) + [n_max - sum(args)]
|
||||
return torch.split(blocks, dims, dim=1)
|
||||
|
||||
|
||||
PATCH_TYPES = Union[torch.Tensor, list[torch.Tensor], tuple[torch.Tensor]]
|
||||
@@ -171,19 +171,8 @@ class StableDiffusionGeneratorPipeline(StableDiffusionPipeline):
|
||||
"""
|
||||
if xformers is available, use it, otherwise use sliced attention.
|
||||
"""
|
||||
|
||||
# On 30xx and 40xx series GPUs, `torch-sdp` is faster than `xformers`. This corresponds to a CUDA major
|
||||
# version of 8 or higher. So, for major version 7 or below, we prefer `xformers`.
|
||||
# See:
|
||||
# - https://developer.nvidia.com/cuda-gpus
|
||||
# - https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#compute-capabilities
|
||||
try:
|
||||
prefer_xformers = torch.cuda.is_available() and torch.cuda.get_device_properties("cuda").major <= 7 # type: ignore # Type of "get_device_properties" is partially unknown
|
||||
except Exception:
|
||||
prefer_xformers = False
|
||||
|
||||
config = get_config()
|
||||
if config.attention_type == "xformers" and is_xformers_available() and prefer_xformers:
|
||||
if config.attention_type == "xformers":
|
||||
self.enable_xformers_memory_efficient_attention()
|
||||
return
|
||||
elif config.attention_type == "sliced":
|
||||
@@ -198,24 +187,20 @@ class StableDiffusionGeneratorPipeline(StableDiffusionPipeline):
|
||||
self.disable_attention_slicing()
|
||||
return
|
||||
elif config.attention_type == "torch-sdp":
|
||||
# torch-sdp is the default in diffusers.
|
||||
return
|
||||
if hasattr(torch.nn.functional, "scaled_dot_product_attention"):
|
||||
# diffusers enables sdp automatically
|
||||
return
|
||||
else:
|
||||
raise Exception("torch-sdp attention slicing not available")
|
||||
|
||||
# See https://github.com/invoke-ai/InvokeAI/issues/7049 for context.
|
||||
# Bumping torch from 2.2.2 to 2.4.1 caused the sliced attention implementation to produce incorrect results.
|
||||
# For now, if a user is on an MPS device and has not explicitly set the attention_type, then we select the
|
||||
# non-sliced torch-sdp implementation. This keeps things working on MPS at the cost of increased peak memory
|
||||
# utilization.
|
||||
if torch.backends.mps.is_available():
|
||||
return
|
||||
|
||||
# The remainder if this code is called when attention_type=='auto'.
|
||||
# the remainder if this code is called when attention_type=='auto'
|
||||
if self.unet.device.type == "cuda":
|
||||
if is_xformers_available() and prefer_xformers:
|
||||
if is_xformers_available():
|
||||
self.enable_xformers_memory_efficient_attention()
|
||||
return
|
||||
# torch-sdp is the default in diffusers.
|
||||
return
|
||||
elif hasattr(torch.nn.functional, "scaled_dot_product_attention"):
|
||||
# diffusers enables sdp automatically
|
||||
return
|
||||
|
||||
if self.unet.device.type == "cpu" or self.unet.device.type == "mps":
|
||||
mem_free = psutil.virtual_memory().free
|
||||
@@ -499,22 +484,6 @@ class StableDiffusionGeneratorPipeline(StableDiffusionPipeline):
|
||||
for idx, value in enumerate(single_t2i_adapter_data.adapter_state):
|
||||
accum_adapter_state[idx] += value * t2i_adapter_weight
|
||||
|
||||
# Hack: force compatibility with irregular resolutions by padding the feature map with zeros
|
||||
for idx, tensor in enumerate(accum_adapter_state):
|
||||
# The tensor size is supposed to be some integer downscale factor of the latents size.
|
||||
# Internally, the unet will pad the latents before downscaling between levels when it is no longer divisible by its downscale factor.
|
||||
# If the latent size does not scale down evenly, we need to pad the tensor so that it matches the the downscaled padded latents later on.
|
||||
scale_factor = latents.size()[-1] // tensor.size()[-1]
|
||||
required_padding_width = math.ceil(latents.size()[-1] / scale_factor) - tensor.size()[-1]
|
||||
required_padding_height = math.ceil(latents.size()[-2] / scale_factor) - tensor.size()[-2]
|
||||
tensor = torch.nn.functional.pad(
|
||||
tensor,
|
||||
(0, required_padding_width, 0, required_padding_height, 0, 0, 0, 0),
|
||||
mode="constant",
|
||||
value=0,
|
||||
)
|
||||
accum_adapter_state[idx] = tensor
|
||||
|
||||
down_intrablock_additional_residuals = accum_adapter_state
|
||||
|
||||
# Handle inpainting models.
|
||||
|
||||
@@ -49,32 +49,9 @@ class FLUXConditioningInfo:
|
||||
return self
|
||||
|
||||
|
||||
@dataclass
|
||||
class SD3ConditioningInfo:
|
||||
clip_l_pooled_embeds: torch.Tensor
|
||||
clip_l_embeds: torch.Tensor
|
||||
clip_g_pooled_embeds: torch.Tensor
|
||||
clip_g_embeds: torch.Tensor
|
||||
t5_embeds: torch.Tensor | None
|
||||
|
||||
def to(self, device: torch.device | None = None, dtype: torch.dtype | None = None):
|
||||
self.clip_l_pooled_embeds = self.clip_l_pooled_embeds.to(device=device, dtype=dtype)
|
||||
self.clip_l_embeds = self.clip_l_embeds.to(device=device, dtype=dtype)
|
||||
self.clip_g_pooled_embeds = self.clip_g_pooled_embeds.to(device=device, dtype=dtype)
|
||||
self.clip_g_embeds = self.clip_g_embeds.to(device=device, dtype=dtype)
|
||||
if self.t5_embeds is not None:
|
||||
self.t5_embeds = self.t5_embeds.to(device=device, dtype=dtype)
|
||||
return self
|
||||
|
||||
|
||||
@dataclass
|
||||
class ConditioningFieldData:
|
||||
conditionings: (
|
||||
List[BasicConditioningInfo]
|
||||
| List[SDXLConditioningInfo]
|
||||
| List[FLUXConditioningInfo]
|
||||
| List[SD3ConditioningInfo]
|
||||
)
|
||||
conditionings: List[BasicConditioningInfo] | List[SDXLConditioningInfo] | List[FLUXConditioningInfo]
|
||||
|
||||
|
||||
@dataclass
|
||||
|
||||
@@ -33,7 +33,7 @@ class PreviewExt(ExtensionBase):
|
||||
def initial_preview(self, ctx: DenoiseContext):
|
||||
self.callback(
|
||||
PipelineIntermediateState(
|
||||
step=0,
|
||||
step=-1,
|
||||
order=ctx.scheduler.order,
|
||||
total_steps=len(ctx.inputs.timesteps),
|
||||
timestep=int(ctx.scheduler.config.num_train_timesteps), # TODO: is there any code which uses it?
|
||||
|
||||
@@ -3,7 +3,7 @@ from typing import Any, Dict, List, Optional, Tuple, Union
|
||||
import diffusers
|
||||
import torch
|
||||
from diffusers.configuration_utils import ConfigMixin, register_to_config
|
||||
from diffusers.loaders.single_file_model import FromOriginalModelMixin
|
||||
from diffusers.loaders import FromOriginalControlNetMixin
|
||||
from diffusers.models.attention_processor import AttentionProcessor, AttnProcessor
|
||||
from diffusers.models.controlnet import ControlNetConditioningEmbedding, ControlNetOutput, zero_module
|
||||
from diffusers.models.embeddings import (
|
||||
@@ -32,9 +32,7 @@ from invokeai.backend.util.logging import InvokeAILogger
|
||||
logger = InvokeAILogger.get_logger(__name__)
|
||||
|
||||
|
||||
# NOTE(ryand): I'm not the origina author of this code, but for future reference, it appears that this class was copied
|
||||
# from diffusers in order to add support for the encoder_attention_mask argument.
|
||||
class ControlNetModel(ModelMixin, ConfigMixin, FromOriginalModelMixin):
|
||||
class ControlNetModel(ModelMixin, ConfigMixin, FromOriginalControlNetMixin):
|
||||
"""
|
||||
A ControlNet model.
|
||||
|
||||
|
||||
@@ -52,51 +52,49 @@
|
||||
}
|
||||
},
|
||||
"dependencies": {
|
||||
"@dagrejs/dagre": "^1.1.4",
|
||||
"@dagrejs/graphlib": "^2.2.4",
|
||||
"@dagrejs/dagre": "^1.1.3",
|
||||
"@dagrejs/graphlib": "^2.2.3",
|
||||
"@dnd-kit/core": "^6.1.0",
|
||||
"@dnd-kit/sortable": "^8.0.0",
|
||||
"@dnd-kit/utilities": "^3.2.2",
|
||||
"@fontsource-variable/inter": "^5.1.0",
|
||||
"@invoke-ai/ui-library": "^0.0.43",
|
||||
"@fontsource-variable/inter": "^5.0.20",
|
||||
"@invoke-ai/ui-library": "^0.0.37",
|
||||
"@nanostores/react": "^0.7.3",
|
||||
"@reduxjs/toolkit": "2.2.3",
|
||||
"@roarr/browser-log-writer": "^1.3.0",
|
||||
"async-mutex": "^0.5.0",
|
||||
"chakra-react-select": "^4.9.2",
|
||||
"chakra-react-select": "^4.9.1",
|
||||
"cmdk": "^1.0.0",
|
||||
"compare-versions": "^6.1.1",
|
||||
"dateformat": "^5.0.3",
|
||||
"fracturedjsonjs": "^4.0.2",
|
||||
"framer-motion": "^11.10.0",
|
||||
"i18next": "^23.15.1",
|
||||
"i18next-http-backend": "^2.6.1",
|
||||
"framer-motion": "^11.3.24",
|
||||
"i18next": "^23.12.2",
|
||||
"i18next-http-backend": "^2.5.2",
|
||||
"idb-keyval": "^6.2.1",
|
||||
"jsondiffpatch": "^0.6.0",
|
||||
"konva": "^9.3.15",
|
||||
"konva": "^9.3.14",
|
||||
"lodash-es": "^4.17.21",
|
||||
"lru-cache": "^11.0.1",
|
||||
"lru-cache": "^11.0.0",
|
||||
"nanoid": "^5.0.7",
|
||||
"nanostores": "^0.11.3",
|
||||
"nanostores": "^0.11.2",
|
||||
"new-github-issue-url": "^1.0.0",
|
||||
"overlayscrollbars": "^2.10.0",
|
||||
"overlayscrollbars-react": "^0.5.6",
|
||||
"perfect-freehand": "^1.2.2",
|
||||
"query-string": "^9.1.0",
|
||||
"raf-throttle": "^2.0.6",
|
||||
"react": "^18.3.1",
|
||||
"react-colorful": "^5.6.1",
|
||||
"react-dom": "^18.3.1",
|
||||
"react-dropzone": "^14.2.9",
|
||||
"react-dropzone": "^14.2.3",
|
||||
"react-error-boundary": "^4.0.13",
|
||||
"react-hook-form": "^7.53.0",
|
||||
"react-hook-form": "^7.52.2",
|
||||
"react-hotkeys-hook": "4.5.0",
|
||||
"react-i18next": "^15.0.2",
|
||||
"react-icons": "^5.3.0",
|
||||
"react-i18next": "^14.1.3",
|
||||
"react-icons": "^5.2.1",
|
||||
"react-redux": "9.1.2",
|
||||
"react-resizable-panels": "^2.1.4",
|
||||
"react-resizable-panels": "^2.1.2",
|
||||
"react-use": "^17.5.1",
|
||||
"react-virtuoso": "^4.10.4",
|
||||
"react-virtuoso": "^4.9.0",
|
||||
"reactflow": "^11.11.4",
|
||||
"redux-dynamic-middlewares": "^2.2.0",
|
||||
"redux-remember": "^5.1.0",
|
||||
@@ -104,55 +102,56 @@
|
||||
"rfdc": "^1.4.1",
|
||||
"roarr": "^7.21.1",
|
||||
"serialize-error": "^11.0.3",
|
||||
"socket.io-client": "^4.8.0",
|
||||
"socket.io-client": "^4.7.5",
|
||||
"stable-hash": "^0.0.4",
|
||||
"use-debounce": "^10.0.3",
|
||||
"use-debounce": "^10.0.2",
|
||||
"use-device-pixel-ratio": "^1.1.2",
|
||||
"uuid": "^10.0.0",
|
||||
"zod": "^3.23.8",
|
||||
"zod-validation-error": "^3.4.0"
|
||||
"zod-validation-error": "^3.3.1"
|
||||
},
|
||||
"peerDependencies": {
|
||||
"react": "^18.2.0",
|
||||
"react-dom": "^18.2.0"
|
||||
"react-dom": "^18.2.0",
|
||||
"ts-toolbelt": "^9.6.0"
|
||||
},
|
||||
"devDependencies": {
|
||||
"@invoke-ai/eslint-config-react": "^0.0.14",
|
||||
"@invoke-ai/prettier-config-react": "^0.0.7",
|
||||
"@storybook/addon-essentials": "^8.3.4",
|
||||
"@storybook/addon-interactions": "^8.3.4",
|
||||
"@storybook/addon-links": "^8.3.4",
|
||||
"@storybook/addon-storysource": "^8.3.4",
|
||||
"@storybook/manager-api": "^8.3.4",
|
||||
"@storybook/react": "^8.3.4",
|
||||
"@storybook/react-vite": "^8.3.4",
|
||||
"@storybook/theming": "^8.3.4",
|
||||
"@storybook/addon-essentials": "^8.2.8",
|
||||
"@storybook/addon-interactions": "^8.2.8",
|
||||
"@storybook/addon-links": "^8.2.8",
|
||||
"@storybook/addon-storysource": "^8.2.8",
|
||||
"@storybook/manager-api": "^8.2.8",
|
||||
"@storybook/react": "^8.2.8",
|
||||
"@storybook/react-vite": "^8.2.8",
|
||||
"@storybook/theming": "^8.2.8",
|
||||
"@types/dateformat": "^5.0.2",
|
||||
"@types/lodash-es": "^4.17.12",
|
||||
"@types/node": "^20.16.10",
|
||||
"@types/react": "^18.3.11",
|
||||
"@types/node": "^20.14.15",
|
||||
"@types/react": "^18.3.3",
|
||||
"@types/react-dom": "^18.3.0",
|
||||
"@types/uuid": "^10.0.0",
|
||||
"@vitejs/plugin-react-swc": "^3.7.1",
|
||||
"@vitest/coverage-v8": "^1.6.0",
|
||||
"@vitest/ui": "^1.6.0",
|
||||
"@vitejs/plugin-react-swc": "^3.7.0",
|
||||
"@vitest/coverage-v8": "^1.5.0",
|
||||
"@vitest/ui": "^1.5.0",
|
||||
"concurrently": "^8.2.2",
|
||||
"csstype": "^3.1.3",
|
||||
"dpdm": "^3.14.0",
|
||||
"eslint": "^8.57.1",
|
||||
"eslint-plugin-i18next": "^6.1.0",
|
||||
"eslint": "^8.57.0",
|
||||
"eslint-plugin-i18next": "^6.0.9",
|
||||
"eslint-plugin-path": "^1.3.0",
|
||||
"knip": "^5.31.0",
|
||||
"knip": "^5.27.2",
|
||||
"openapi-types": "^12.1.3",
|
||||
"openapi-typescript": "^7.4.1",
|
||||
"openapi-typescript": "^7.3.0",
|
||||
"prettier": "^3.3.3",
|
||||
"rollup-plugin-visualizer": "^5.12.0",
|
||||
"storybook": "^8.3.4",
|
||||
"tsafe": "^1.7.5",
|
||||
"type-fest": "^4.26.1",
|
||||
"typescript": "^5.6.2",
|
||||
"vite": "^5.4.8",
|
||||
"vite-plugin-css-injected-by-js": "^3.5.2",
|
||||
"storybook": "^8.2.8",
|
||||
"ts-toolbelt": "^9.6.0",
|
||||
"tsafe": "^1.7.2",
|
||||
"typescript": "^5.5.4",
|
||||
"vite": "^5.4.0",
|
||||
"vite-plugin-css-injected-by-js": "^3.5.1",
|
||||
"vite-plugin-dts": "^3.9.1",
|
||||
"vite-plugin-eslint": "^1.8.1",
|
||||
"vite-tsconfig-paths": "^4.3.2",
|
||||
|
||||
6069
invokeai/frontend/web/pnpm-lock.yaml
generated
6069
invokeai/frontend/web/pnpm-lock.yaml
generated
File diff suppressed because it is too large
Load Diff
@@ -4,7 +4,7 @@
|
||||
"reportBugLabel": "Fehler melden",
|
||||
"settingsLabel": "Einstellungen",
|
||||
"img2img": "Bild zu Bild",
|
||||
"nodes": "Arbeitsabläufe",
|
||||
"nodes": "Workflows",
|
||||
"upload": "Hochladen",
|
||||
"load": "Laden",
|
||||
"statusDisconnected": "Getrennt",
|
||||
@@ -83,20 +83,7 @@
|
||||
"tab": "Tabulator",
|
||||
"enabled": "Aktiviert",
|
||||
"disabled": "Ausgeschaltet",
|
||||
"dontShowMeThese": "Zeig mir diese nicht",
|
||||
"apply": "Anwenden",
|
||||
"edit": "Ändern",
|
||||
"openInViewer": "Im Viewer öffnen",
|
||||
"loadingImage": "Lade Bild",
|
||||
"off": "Aus",
|
||||
"view": "Anzeigen",
|
||||
"placeholderSelectAModel": "Modell auswählen",
|
||||
"reset": "Zurücksetzen",
|
||||
"none": "Keine",
|
||||
"new": "Neu",
|
||||
"ok": "OK",
|
||||
"close": "Schließen",
|
||||
"clipboard": "Zwischenablage"
|
||||
"dontShowMeThese": "Zeig mir diese nicht"
|
||||
},
|
||||
"gallery": {
|
||||
"galleryImageSize": "Bildgröße",
|
||||
@@ -130,353 +117,16 @@
|
||||
"alwaysShowImageSizeBadge": "Zeige immer Bilder Größe Abzeichen",
|
||||
"selectForCompare": "Zum Vergleichen auswählen",
|
||||
"compareImage": "Bilder vergleichen",
|
||||
"exitSearch": "Bildsuche beenden",
|
||||
"exitSearch": "Suche beenden",
|
||||
"newestFirst": "Neueste zuerst",
|
||||
"oldestFirst": "Älteste zuerst",
|
||||
"openInViewer": "Im Viewer öffnen",
|
||||
"swapImages": "Bilder tauschen",
|
||||
"slider": "Slider",
|
||||
"showStarredImagesFirst": "Mit * markierte Bilder zuerst zeigen",
|
||||
"compareHelp1": "Halten Sie <Kbd>Alt</Kbd> gedrückt, während Sie auf ein Galeriebild klicken oder die Pfeiltasten verwenden, um das Vergleichsbild zu ändern.",
|
||||
"compareHelp4": "Drücken Sie <Kbd>Z</Kbd> oder <Kbd>Esc</Kbd> zum Beenden.",
|
||||
"move": "Bewegen",
|
||||
"exitBoardSearch": "Suchen beenden",
|
||||
"searchImages": "Suche mit Metadaten",
|
||||
"selectAllOnPage": "Alle auf Seite auswählen",
|
||||
"showArchivedBoards": "Archivierte Boards anzeigen",
|
||||
"hover": "Schweben",
|
||||
"compareHelp2": "Drücken Sie <Kbd>M</Kbd>, um durch alle Vergleichsmodi zu wechseln.",
|
||||
"compareHelp3": "Drücken Sie <Kbd>C</Kbd>, um die verglichenen Bilder zu wechseln.",
|
||||
"gallery": "Galerie",
|
||||
"sortDirection": "Sortierreihenfolge",
|
||||
"sideBySide": "Nebeneinander",
|
||||
"openViewer": "Viewer öffnen",
|
||||
"viewerImage": "Viewer-Bild",
|
||||
"exitCompare": "Vergleichen beenden",
|
||||
"closeViewer": "Viewer schließen",
|
||||
"selectAnImageToCompare": "Wählen Sie ein Bild zum Vergleichen",
|
||||
"stretchToFit": "Strecken bis es passt",
|
||||
"displayBoardSearch": "Board durchsuchen",
|
||||
"displaySearch": "Bild suchen",
|
||||
"go": "Los",
|
||||
"jump": "Springen",
|
||||
"assetsTab": "Dateien, die Sie zur Verwendung in Ihren Projekten hochgeladen haben.",
|
||||
"imagesTab": "Bilder, die Sie in Invoke erstellt und gespeichert haben.",
|
||||
"boardsSettings": "Ordnereinstellungen",
|
||||
"imagesSettings": "Galeriebildereinstellungen"
|
||||
"swapImages": "Bilder tauschen"
|
||||
},
|
||||
"hotkeys": {
|
||||
"noHotkeysFound": "Kein Hotkey gefunden",
|
||||
"searchHotkeys": "Hotkeys durchsuchen",
|
||||
"clearSearch": "Suche leeren",
|
||||
"canvas": {
|
||||
"fitBboxToCanvas": {
|
||||
"desc": "Skalierung und Positionierung der Ansicht auf Bbox-Größe.",
|
||||
"title": "Bbox auf Arbeitsfläche skalieren"
|
||||
},
|
||||
"selectBboxTool": {
|
||||
"title": "Bbox Werkzeug",
|
||||
"desc": "Bbox Werkzeug auswählen."
|
||||
},
|
||||
"setFillToWhite": {
|
||||
"title": "Farbe auf Weiß einstellen",
|
||||
"desc": "Setzt die aktuelle Werkzeugfarbe auf weiß."
|
||||
},
|
||||
"title": "Leinwand",
|
||||
"selectBrushTool": {
|
||||
"title": "Pinselwerkzeug",
|
||||
"desc": "Wählen Sie das Pinselwerkzeug aus."
|
||||
},
|
||||
"decrementToolWidth": {
|
||||
"title": "Werkzeugbreite verringern",
|
||||
"desc": "Verringern Sie die Breite des Pinsels oder Radiergummis, je nachdem, welches ausgewählt ist."
|
||||
},
|
||||
"incrementToolWidth": {
|
||||
"title": "Werkzeugbreite erhöhen",
|
||||
"desc": "Vergrößern Sie die Breite des Pinsels oder Radiergummis, je nachdem, welches ausgewählt ist."
|
||||
},
|
||||
"selectColorPickerTool": {
|
||||
"title": "Farbwähler-Werkzeug",
|
||||
"desc": "Farbwähler-Werkzeug auswählen."
|
||||
},
|
||||
"selectEraserTool": {
|
||||
"title": "Radiergummi-Werkzeug",
|
||||
"desc": "Radiergummi-Werkzeug auswählen."
|
||||
},
|
||||
"fitLayersToCanvas": {
|
||||
"title": "Ebenen an die Leinwand anpassen",
|
||||
"desc": "Alle sichtbaren Ebenen in der Ansicht einpassen."
|
||||
},
|
||||
"filterSelected": {
|
||||
"title": "Filter",
|
||||
"desc": "Gewählte Ebene filtern. Nur bei \"Raster\" und Kontroll-Ebenen."
|
||||
},
|
||||
"transformSelected": {
|
||||
"title": "Umwandeln",
|
||||
"desc": "Transformieren Sie die ausgewählte Ebene."
|
||||
},
|
||||
"setZoomTo100Percent": {
|
||||
"title": "Auf 100 % zoomen",
|
||||
"desc": "Leinwand-Zoom auf 100 % setzen."
|
||||
},
|
||||
"setZoomTo200Percent": {
|
||||
"title": "Auf 200 % zoomen",
|
||||
"desc": "Leinwand-Zoom auf 200 % setzen."
|
||||
},
|
||||
"setZoomTo400Percent": {
|
||||
"title": "Auf 400 % zoomen",
|
||||
"desc": "Leinwand-Zoom auf 400 % setzen."
|
||||
},
|
||||
"setZoomTo800Percent": {
|
||||
"title": "Auf 800 % zoomen",
|
||||
"desc": "Leinwand-Zoom auf 800 % setzen."
|
||||
},
|
||||
"deleteSelected": {
|
||||
"title": "Ebene löschen",
|
||||
"desc": "Ausgewählte Ebene löschen."
|
||||
},
|
||||
"undo": {
|
||||
"title": "Rückgängig",
|
||||
"desc": "Letzte Aktion rückgängig machen."
|
||||
},
|
||||
"redo": {
|
||||
"title": "Wiederholen",
|
||||
"desc": "Letzte Aktion wiederholen."
|
||||
},
|
||||
"nextEntity": {
|
||||
"title": "Nächste Ebene",
|
||||
"desc": "Nächste Ebene in der Liste auswählen."
|
||||
},
|
||||
"resetSelected": {
|
||||
"title": "Ebene zurücksetzen",
|
||||
"desc": "Ausgewählte Ebene zurücksetzen. Gilt nur für Malmaske bei \"Inpaint\" und \"Regionaler Führung\"."
|
||||
},
|
||||
"prevEntity": {
|
||||
"title": "Vorherige Ebene",
|
||||
"desc": "Vorherige Ebene in der Liste auswählen."
|
||||
},
|
||||
"selectMoveTool": {
|
||||
"title": "Verschieben-Werkzeug",
|
||||
"desc": "Verschieben-Werkzeug auswählen."
|
||||
},
|
||||
"selectRectTool": {
|
||||
"title": "Rechteck-Werkzeug",
|
||||
"desc": "Rechteck-Werkzeug auswählen."
|
||||
},
|
||||
"selectViewTool": {
|
||||
"desc": "Wählen Sie das Ansichts-Tool.",
|
||||
"title": "Ansichts-Tool"
|
||||
},
|
||||
"quickSwitch": {
|
||||
"title": "Ebenen schnell umschalten",
|
||||
"desc": "Wechseln Sie zwischen den beiden zuletzt gewählten Ebenen. Wenn eine Ebene mit einem Lesezeichen versehen ist, wird zwischen ihr und der letzten nicht markierten Ebene gewechselt."
|
||||
},
|
||||
"applyFilter": {
|
||||
"title": "Filter anwenden",
|
||||
"desc": "Wende den ausstehenden Filter auf die ausgewählte Ebene an."
|
||||
},
|
||||
"cancelFilter": {
|
||||
"title": "Filter abbrechen",
|
||||
"desc": "Den ausstehenden Filter abbrechen."
|
||||
},
|
||||
"applyTransform": {
|
||||
"desc": "Die ausstehende Transformation auf die ausgewählte Ebene anwenden.",
|
||||
"title": "Transformation anwenden"
|
||||
},
|
||||
"cancelTransform": {
|
||||
"title": "Transformation abbrechen",
|
||||
"desc": "Die ausstehende Transformation abbrechen."
|
||||
}
|
||||
},
|
||||
"viewer": {
|
||||
"useSize": {
|
||||
"desc": "Aktuelle Bildgröße als Bbox-Größe verwenden.",
|
||||
"title": "Maße übernehmen"
|
||||
},
|
||||
"title": "Bildbetrachter",
|
||||
"toggleViewer": {
|
||||
"title": "Bildbetrachter anzeigen/ausblenden",
|
||||
"desc": "Zeigen oder verbergen Sie den Bildbetrachter. Nur auf der Arbeitsflächen-Registerkarte."
|
||||
},
|
||||
"nextComparisonMode": {
|
||||
"title": "Nächster Vergleichsmodus",
|
||||
"desc": "Alle Vergleichsmodi durchlaufen."
|
||||
},
|
||||
"swapImages": {
|
||||
"title": "Vergleichsbilder tauschen",
|
||||
"desc": "Vergleichs-Bilder tauschen."
|
||||
},
|
||||
"runPostprocessing": {
|
||||
"title": "Nachbearbeitung ausführen",
|
||||
"desc": "Ausgewählte Nachbearbeitung/en auf aktuelles Bild anwenden."
|
||||
},
|
||||
"toggleMetadata": {
|
||||
"title": "Metadaten anzeigen/ausblenden",
|
||||
"desc": "Zeigen oder verbergen der Metadaten des Bildes."
|
||||
},
|
||||
"recallPrompts": {
|
||||
"title": "Prompts abrufen",
|
||||
"desc": "Rufen Sie die positiven und negativen Prompts für das aktuelle Bild ab."
|
||||
},
|
||||
"recallSeed": {
|
||||
"desc": "Seed für aktuelles Bild abrufen.",
|
||||
"title": "Seed abrufen"
|
||||
},
|
||||
"loadWorkflow": {
|
||||
"title": "Lade Arbeitsablauf/Workflow",
|
||||
"desc": "Laden Sie den gespeicherten Workflow des aktuellen Bildes (falls es einen hat)."
|
||||
},
|
||||
"recallAll": {
|
||||
"title": "Alle Metadaten abrufen",
|
||||
"desc": "Alle Metadaten für das aktuelle Bild abrufen."
|
||||
},
|
||||
"remix": {
|
||||
"desc": "Rufen Sie alle Metadaten außer dem Seed für das aktuelle Bild ab.",
|
||||
"title": "Remixen"
|
||||
}
|
||||
},
|
||||
"app": {
|
||||
"invoke": {
|
||||
"title": "Invoke",
|
||||
"desc": "Stellt eine Generierung in die Warteschlange und fügt sie am Ende hinzu."
|
||||
},
|
||||
"invokeFront": {
|
||||
"title": "Invoke (Front)",
|
||||
"desc": "Stellt eine Generierung in die Warteschlange und fügt sie am Anfang hinzu."
|
||||
},
|
||||
"cancelQueueItem": {
|
||||
"title": "Abbrechen",
|
||||
"desc": "Aktuelles Warteschlangenelement abbrechen."
|
||||
},
|
||||
"clearQueue": {
|
||||
"title": "Warteschlange löschen",
|
||||
"desc": "Warteschlange abbrechen und komplett löschen."
|
||||
},
|
||||
"selectUpscalingTab": {
|
||||
"title": "Wählen Sie die Registerkarte Hochskalieren",
|
||||
"desc": "Wählt die Registerkarte Hochskalieren."
|
||||
},
|
||||
"selectCanvasTab": {
|
||||
"desc": "Wählt die Arbeitsflächen-Registerkarte.",
|
||||
"title": "Wählen Sie die Arbeitsflächen-Registerkarte"
|
||||
},
|
||||
"selectWorkflowsTab": {
|
||||
"title": "Wählt die Registerkarte Arbeitsabläufe",
|
||||
"desc": "Wählt die Registerkarte Arbeitsabläufe."
|
||||
},
|
||||
"selectModelsTab": {
|
||||
"title": "Wählt die Registerkarte Modelle",
|
||||
"desc": "Wählt die Registerkarte Modelle."
|
||||
},
|
||||
"selectQueueTab": {
|
||||
"title": "Wählt die Registerkarte Warteschlange",
|
||||
"desc": "Wählt die Registerkarte Warteschlange."
|
||||
},
|
||||
"focusPrompt": {
|
||||
"desc": "Bewegt den Cursor-Fokus auf den positiven Prompt.",
|
||||
"title": "Fokus-Prompt"
|
||||
},
|
||||
"toggleLeftPanel": {
|
||||
"title": "Linkes Panel ein-/ausblenden",
|
||||
"desc": "Linke Seite zeigen/verbergen."
|
||||
},
|
||||
"toggleRightPanel": {
|
||||
"title": "Rechte Seite umschalten",
|
||||
"desc": "Rechte Seite zeigen/verbergen."
|
||||
},
|
||||
"resetPanelLayout": {
|
||||
"title": "Layout zurücksetzen",
|
||||
"desc": "Beide Seiten auf Standard zurücksetzen."
|
||||
},
|
||||
"title": "Anwendung",
|
||||
"togglePanels": {
|
||||
"title": "Seiten umschalten",
|
||||
"desc": "Zeigen oder verbergen Sie beide Panels auf einmal."
|
||||
}
|
||||
},
|
||||
"hotkeys": "Tastaturbefehle",
|
||||
"gallery": {
|
||||
"title": "Galerie",
|
||||
"selectAllOnPage": {
|
||||
"title": "Alle auf der Seite auswählen",
|
||||
"desc": "Alle Bilder auf der aktuellen Seite auswählen."
|
||||
},
|
||||
"galleryNavRight": {
|
||||
"title": "Nach rechts navigieren",
|
||||
"desc": "Navigieren Sie im Galerieraster nach rechts, und wählen Sie das Bild aus. Wenn es sich um das letzte Bild in der Reihe handelt, gehen Sie zur nächsten Reihe. Wenn Sie sich beim letzten Bild der Seite befinden, gehen Sie zur nächsten Seite."
|
||||
},
|
||||
"galleryNavDownAlt": {
|
||||
"title": "Nach unten navigieren (Bild vergleichen)",
|
||||
"desc": "Wie \"Abwärts navigieren\", wählt aber das Vergleichsbild aus und öffnet den Vergleichsmodus, falls er nicht bereits geöffnet ist."
|
||||
},
|
||||
"galleryNavUp": {
|
||||
"title": "Nach oben navigieren",
|
||||
"desc": "Navigieren Sie im Galerieraster nach oben, und wählen Sie das Bild aus. Wenn Sie sich oben auf der Seite befinden, gehen Sie zur vorherigen Seite."
|
||||
},
|
||||
"galleryNavDown": {
|
||||
"title": "Nach unten navigieren",
|
||||
"desc": "Navigieren Sie im Galerieraster nach unten, und wählen Sie das Bild aus. Wenn Sie sich am Ende der Seite befinden, gehen Sie zur nächsten Seite."
|
||||
},
|
||||
"galleryNavLeft": {
|
||||
"title": "Nach links navigieren",
|
||||
"desc": "Navigieren Sie im Galerieraster nach links, und wählen Sie das Bild aus. Wenn Sie sich im ersten Bild der Reihe befinden, gehen Sie zur vorherigen Reihe. Wenn Sie sich beim ersten Bild der Seite befinden, gehen Sie zur vorherigen Seite."
|
||||
},
|
||||
"galleryNavUpAlt": {
|
||||
"title": "Nach oben navigieren (Bild vergleichen)",
|
||||
"desc": "Wie „Nach oben navigieren“, wählt aber das Vergleichsbild aus und öffnet den Vergleichsmodus, falls er nicht bereits geöffnet ist."
|
||||
},
|
||||
"galleryNavRightAlt": {
|
||||
"title": "Nach rechts navigieren (Bild vergleichen)",
|
||||
"desc": "Wie \"Navigieren nach rechts\", wählt aber das Vergleichsbild aus und öffnet den Vergleichsmodus, falls er nicht bereits geöffnet ist."
|
||||
},
|
||||
"clearSelection": {
|
||||
"title": "Auswahl aufheben",
|
||||
"desc": "Aktuelle Auswahl aufheben, falls vorhanden."
|
||||
},
|
||||
"galleryNavLeftAlt": {
|
||||
"title": "Nach links navigieren (Bild vergleichen)",
|
||||
"desc": "Wie „Nach links navigieren“, wählt aber das Vergleichsbild aus und öffnet den Vergleichsmodus, falls er nicht bereits geöffnet ist."
|
||||
},
|
||||
"deleteSelection": {
|
||||
"title": "Löschen",
|
||||
"desc": "Alle ausgewählten Bilder löschen. Standardmäßig werden Sie aufgefordert, den Löschvorgang zu bestätigen. Wenn die Bilder derzeit in der App verwendet werden, werden Sie gewarnt."
|
||||
}
|
||||
},
|
||||
"workflows": {
|
||||
"redo": {
|
||||
"title": "Wiederholen",
|
||||
"desc": "Letzte Workflow-Aktion wiederherstellen."
|
||||
},
|
||||
"copySelection": {
|
||||
"title": "Kopieren",
|
||||
"desc": "Ausgewählte Knoten und Kanten kopieren."
|
||||
},
|
||||
"title": "Arbeitsabläufe",
|
||||
"addNode": {
|
||||
"title": "Knoten hinzufügen",
|
||||
"desc": "Öffnen Sie das \"Knoten zufügen\"-Menü."
|
||||
},
|
||||
"pasteSelection": {
|
||||
"title": "Einfügen",
|
||||
"desc": "Kopierte Knoten und Kanten einfügen."
|
||||
},
|
||||
"selectAll": {
|
||||
"title": "Alles auswählen",
|
||||
"desc": "Alle Knoten und Kanten auswählen."
|
||||
},
|
||||
"deleteSelection": {
|
||||
"title": "Löschen",
|
||||
"desc": "Lösche ausgewählte Knoten und Kanten."
|
||||
},
|
||||
"undo": {
|
||||
"title": "Rückgängig",
|
||||
"desc": "Letzte Workflow-Aktion rückgängig machen."
|
||||
},
|
||||
"pasteSelectionWithEdges": {
|
||||
"desc": "Kopierte Knoten, Kanten und alle mit den kopierten Knoten verbundenen Kanten einfügen.",
|
||||
"title": "Einfügen mit Kanten"
|
||||
}
|
||||
}
|
||||
"clearSearch": "Suche leeren"
|
||||
},
|
||||
"modelManager": {
|
||||
"modelUpdated": "Model aktualisiert",
|
||||
@@ -514,7 +164,7 @@
|
||||
"baseModel": "Basis Modell",
|
||||
"convertToDiffusers": "Konvertiere zu Diffusers",
|
||||
"vae": "VAE",
|
||||
"predictionType": "Vorhersagetyp",
|
||||
"predictionType": "Vorhersagetyp (für Stable Diffusion 2.x-Modelle und gelegentliche Stable Diffusion 1.x-Modelle)",
|
||||
"selectModel": "Wählen Sie Modell aus",
|
||||
"repo_id": "Repo-ID",
|
||||
"modelDeleted": "Modell gelöscht",
|
||||
@@ -536,62 +186,8 @@
|
||||
"addModels": "Model hinzufügen",
|
||||
"deleteModelImage": "Lösche Model Bild",
|
||||
"huggingFaceRepoID": "HuggingFace Repo ID",
|
||||
"huggingFacePlaceholder": "besitzer/model-name",
|
||||
"modelSettings": "Modelleinstellungen",
|
||||
"typePhraseHere": "Phrase hier eingeben",
|
||||
"spandrelImageToImage": "Bild zu Bild (Spandrel)",
|
||||
"starterModels": "Einstiegsmodelle",
|
||||
"t5Encoder": "T5-Kodierer",
|
||||
"uploadImage": "Bild hochladen",
|
||||
"urlOrLocalPath": "URL oder lokaler Pfad",
|
||||
"install": "Installieren",
|
||||
"textualInversions": "Textuelle Inversionen",
|
||||
"ipAdapters": "IP-Adapter",
|
||||
"modelImageUpdated": "Modellbild aktualisiert",
|
||||
"path": "Pfad",
|
||||
"pathToConfig": "Pfad zur Konfiguration",
|
||||
"scanPlaceholder": "Pfad zu einem lokalen Ordner",
|
||||
"noMatchingModels": "Keine passenden Modelle",
|
||||
"localOnly": "nur lokal",
|
||||
"installAll": "Alles installieren",
|
||||
"main": "Haupt",
|
||||
"metadata": "Metadaten",
|
||||
"modelImageDeleted": "Modellbild gelöscht",
|
||||
"modelName": "Modellname",
|
||||
"noModelsInstalled": "Keine Modelle installiert",
|
||||
"source": "Quelle",
|
||||
"simpleModelPlaceholder": "URL oder Pfad zu einem lokalen Datei- oder Diffusers-Ordner",
|
||||
"imageEncoderModelId": "Bild Encoder Modell ID",
|
||||
"installRepo": "Repo installieren",
|
||||
"huggingFaceHelper": "Wenn mehrere Modelle in diesem Repo gefunden werden, werden Sie aufgefordert, eines für die Installation auszuwählen.",
|
||||
"inplaceInstall": "In-place-Installation",
|
||||
"modelImageDeleteFailed": "Modellbild konnte nicht gelöscht werden",
|
||||
"repoVariant": "Repo Variante",
|
||||
"learnMoreAboutSupportedModels": "Erfahren Sie mehr über die Modelle, die wir unterstützen",
|
||||
"clipEmbed": "CLIP einbetten",
|
||||
"starterModelsInModelManager": "Modelle für Ihren Start finden Sie im Modell-Manager",
|
||||
"noModelsInstalledDesc1": "Installiere Modelle mit dem",
|
||||
"modelImageUpdateFailed": "Modellbild-Update fehlgeschlagen",
|
||||
"prune": "Bereinigen",
|
||||
"loraModels": "LoRAs",
|
||||
"scanFolder": "Ordner scannen",
|
||||
"installQueue": "Installations-Warteschlange",
|
||||
"pruneTooltip": "Abgeschlossene Importe aus Warteschlange entfernen",
|
||||
"scanResults": "Ergebnisse des Scans",
|
||||
"urlOrLocalPathHelper": "URLs sollten auf eine einzelne Datei deuten. Lokale Pfade können zusätzlich auch auf einen Ordner für ein einzelnes Diffusers-Modell hinweisen.",
|
||||
"inplaceInstallDesc": "Installieren Sie Modelle, ohne die Dateien zu kopieren. Wenn Sie das Modell verwenden, wird es direkt von seinem Speicherort geladen. Wenn deaktiviert, werden die Dateien während der Installation in das von Invoke verwaltete Modellverzeichnis kopiert.",
|
||||
"scanFolderHelper": "Der Ordner wird rekursiv nach Modellen durchsucht. Dies kann bei sehr großen Ordnern etwas dauern.",
|
||||
"includesNModels": "Enthält {{n}} Modelle und deren Abhängigkeiten",
|
||||
"starterBundles": "Starterpakete",
|
||||
"installingXModels_one": "{{count}} Modell wird installiert",
|
||||
"installingXModels_other": "{{count}} Modelle werden installiert",
|
||||
"skippingXDuplicates_one": ", überspringe {{count}} Duplikat",
|
||||
"skippingXDuplicates_other": ", überspringe {{count}} Duplikate",
|
||||
"installingModel": "Modell wird installiert",
|
||||
"loraTriggerPhrases": "LoRA-Auslösephrasen",
|
||||
"installingBundle": "Bündel wird installiert",
|
||||
"triggerPhrases": "Auslösephrasen",
|
||||
"mainModelTriggerPhrases": "Hauptmodell-Auslösephrasen"
|
||||
"hfToken": "HuggingFace Schlüssel",
|
||||
"huggingFacePlaceholder": "besitzer/model-name"
|
||||
},
|
||||
"parameters": {
|
||||
"images": "Bilder",
|
||||
@@ -630,19 +226,7 @@
|
||||
"setToOptimalSize": "Optimiere Größe für Modell",
|
||||
"useSize": "Maße übernehmen",
|
||||
"remixImage": "Remix des Bilds erstellen",
|
||||
"imageActions": "Weitere Bildaktionen",
|
||||
"invoke": {
|
||||
"layer": {
|
||||
"t2iAdapterIncompatibleBboxWidth": "$t(parameters.invoke.layer.t2iAdapterRequiresDimensionsToBeMultipleOf) {{multiple}}, Bbox-Breite ist {{width}}",
|
||||
"t2iAdapterIncompatibleScaledBboxWidth": "$t(parameters.invoke.layer.t2iAdapterRequiresDimensionsToBeMultipleOf) {{multiple}}, Skalierte Bbox-Breite ist {{width}}",
|
||||
"t2iAdapterIncompatibleScaledBboxHeight": "$t(parameters.invoke.layer.t2iAdapterRequiresDimensionsToBeMultipleOf) {{multiple}}, Skalierte Bbox-Höhe ist {{height}}",
|
||||
"t2iAdapterIncompatibleBboxHeight": "$t(parameters.invoke.layer.t2iAdapterRequiresDimensionsToBeMultipleOf) {{multiple}}, Bbox-Höhe ist {{height}}"
|
||||
},
|
||||
"fluxModelIncompatibleScaledBboxWidth": "$t(parameters.invoke.fluxRequiresDimensionsToBeMultipleOf16), Skalierte Bbox-Breite ist {{width}}",
|
||||
"fluxModelIncompatibleScaledBboxHeight": "$t(parameters.invoke.fluxRequiresDimensionsToBeMultipleOf16), Skalierte Bbox-Höhe ist {{height}}",
|
||||
"fluxModelIncompatibleBboxWidth": "$t(parameters.invoke.fluxRequiresDimensionsToBeMultipleOf16), Bbox-Breite ist {{width}}",
|
||||
"fluxModelIncompatibleBboxHeight": "$t(parameters.invoke.fluxRequiresDimensionsToBeMultipleOf16), Bbox-Höhe ist {{height}}"
|
||||
}
|
||||
"imageActions": "Weitere Bildaktionen"
|
||||
},
|
||||
"settings": {
|
||||
"displayInProgress": "Zwischenbilder anzeigen",
|
||||
@@ -677,57 +261,24 @@
|
||||
"toast": {
|
||||
"uploadFailed": "Hochladen fehlgeschlagen",
|
||||
"imageCopied": "Bild kopiert",
|
||||
"parametersNotSet": "Parameter nicht zurückgerufen",
|
||||
"parametersNotSet": "Parameter nicht festgelegt",
|
||||
"addedToBoard": "Dem Board hinzugefügt",
|
||||
"loadedWithWarnings": "Workflow mit Warnungen geladen",
|
||||
"imageSaved": "Bild gespeichert",
|
||||
"linkCopied": "Link kopiert",
|
||||
"problemCopyingLayer": "Ebene kann nicht kopiert werden",
|
||||
"problemSavingLayer": "Ebene kann nicht gespeichert werden",
|
||||
"parameterSetDesc": "{{parameter}} zurückgerufen",
|
||||
"imageUploaded": "Bild hochgeladen",
|
||||
"problemCopyingImage": "Bild kann nicht kopiert werden",
|
||||
"parameterNotSetDesc": "{{parameter}} kann nicht zurückgerufen werden",
|
||||
"prunedQueue": "Warteschlange bereinigt",
|
||||
"modelAddedSimple": "Modell zur Warteschlange hinzugefügt",
|
||||
"parametersSet": "Parameter zurückgerufen",
|
||||
"imageNotLoadedDesc": "Bild konnte nicht gefunden werden",
|
||||
"setControlImage": "Als Kontrollbild festlegen",
|
||||
"sentToUpscale": "An Vergrößerung gesendet",
|
||||
"parameterNotSetDescWithMessage": "{{parameter}} kann nicht zurückgerufen werden: {{message}}",
|
||||
"unableToLoadImageMetadata": "Bildmetadaten können nicht geladen werden",
|
||||
"unableToLoadImage": "Bild kann nicht geladen werden",
|
||||
"serverError": "Serverfehler",
|
||||
"parameterNotSet": "Parameter nicht zurückgerufen",
|
||||
"sessionRef": "Sitzung: {{sessionId}}",
|
||||
"problemDownloadingImage": "Bild kann nicht heruntergeladen werden",
|
||||
"parameters": "Parameter",
|
||||
"parameterSet": "Parameter zurückgerufen",
|
||||
"importFailed": "Import fehlgeschlagen",
|
||||
"importSuccessful": "Import erfolgreich",
|
||||
"setNodeField": "Als Knotenfeld festlegen",
|
||||
"somethingWentWrong": "Etwas ist schief gelaufen",
|
||||
"workflowLoaded": "Arbeitsablauf geladen",
|
||||
"workflowDeleted": "Arbeitsablauf gelöscht",
|
||||
"errorCopied": "Fehler kopiert",
|
||||
"layerCopiedToClipboard": "Ebene in die Zwischenablage kopiert",
|
||||
"sentToCanvas": "An Leinwand gesendet"
|
||||
"loadedWithWarnings": "Workflow mit Warnungen geladen"
|
||||
},
|
||||
"accessibility": {
|
||||
"uploadImage": "Bild hochladen",
|
||||
"previousImage": "Vorheriges Bild",
|
||||
"showOptionsPanel": "Seitenpanel anzeigen",
|
||||
"reset": "Zurücksetzten",
|
||||
"nextImage": "Nächstes Bild",
|
||||
"showGalleryPanel": "Galerie-Panel anzeigen",
|
||||
"menu": "Menü",
|
||||
"invokeProgressBar": "Invoke Fortschrittsanzeige",
|
||||
"mode": "Modus",
|
||||
"resetUI": "$t(accessibility.reset) von UI",
|
||||
"createIssue": "Ticket erstellen",
|
||||
"about": "Über",
|
||||
"submitSupportTicket": "Support-Ticket senden",
|
||||
"toggleRightPanel": "Rechtes Bedienfeld umschalten (G)",
|
||||
"toggleLeftPanel": "Linkes Bedienfeld umschalten (T)",
|
||||
"uploadImages": "Bild(er) hochladen"
|
||||
"submitSupportTicket": "Support-Ticket senden"
|
||||
},
|
||||
"boards": {
|
||||
"autoAddBoard": "Board automatisch erstellen",
|
||||
@@ -749,6 +300,7 @@
|
||||
"deleteBoardOnly": "Nur Ordner löschen",
|
||||
"deleteBoard": "Lösche Ordner",
|
||||
"deleteBoardAndImages": "Lösche Ordner und Bilder",
|
||||
"deletedBoardsCannotbeRestored": "Gelöschte Ordner können nicht wiederhergestellt werden",
|
||||
"movingImagesToBoard_one": "Verschiebe {{count}} Bild in Ordner:",
|
||||
"movingImagesToBoard_other": "Verschiebe {{count}} Bilder in Ordner:",
|
||||
"selectedForAutoAdd": "Ausgewählt für Automatisches hinzufügen",
|
||||
@@ -762,13 +314,10 @@
|
||||
"shared": "Geteilte Ordner",
|
||||
"archiveBoard": "Ordner archivieren",
|
||||
"archived": "Archiviert",
|
||||
"noBoards": "Kein {{boardType}} Ordner",
|
||||
"noBoards": "Kein {boardType}} Ordner",
|
||||
"hideBoards": "Ordner verstecken",
|
||||
"viewBoards": "Ordner ansehen",
|
||||
"deletedPrivateBoardsCannotbeRestored": "Gelöschte Boards können nicht wiederhergestellt werden. Wenn Sie „Nur Board löschen“ wählen, werden die Bilder in einen privaten, nicht kategorisierten Status für den Ersteller des Bildes versetzt.",
|
||||
"assetsWithCount_one": "{{count}} in der Sammlung",
|
||||
"assetsWithCount_other": "{{count}} in der Sammlung",
|
||||
"deletedBoardsCannotbeRestored": "Gelöschte Ordner können nicht wiederhergestellt werden. Die Auswahl von \"Nur Ordner löschen\" verschiebt Bilder in einen unkategorisierten Zustand."
|
||||
"deletedPrivateBoardsCannotbeRestored": "Gelöschte Boards können nicht wiederhergestellt werden. Wenn Sie „Nur Board löschen“ wählen, werden die Bilder in einen privaten, nicht kategorisierten Status für den Ersteller des Bildes versetzt."
|
||||
},
|
||||
"queue": {
|
||||
"status": "Status",
|
||||
@@ -828,19 +377,7 @@
|
||||
"graphQueued": "Graph eingereiht",
|
||||
"graphFailedToQueue": "Fehler beim Einreihen des Graphen",
|
||||
"generations_one": "Generation",
|
||||
"generations_other": "Generationen",
|
||||
"iterations_one": "Iteration",
|
||||
"iterations_other": "Iterationen",
|
||||
"gallery": "Galerie",
|
||||
"generation": "Erstellung",
|
||||
"workflows": "Arbeitsabläufe",
|
||||
"other": "Sonstige",
|
||||
"origin": "Ursprung",
|
||||
"destination": "Ziel",
|
||||
"upscaling": "Hochskalierung",
|
||||
"canvas": "Leinwand",
|
||||
"prompts_one": "Prompt",
|
||||
"prompts_other": "Prompts"
|
||||
"generations_other": "Generationen"
|
||||
},
|
||||
"metadata": {
|
||||
"negativePrompt": "Negativ Beschreibung",
|
||||
@@ -855,6 +392,7 @@
|
||||
"width": "Breite",
|
||||
"createdBy": "Erstellt von",
|
||||
"steps": "Schritte",
|
||||
"seamless": "Nahtlos",
|
||||
"positivePrompt": "Positiver Prompt",
|
||||
"generationMode": "Generierungsmodus",
|
||||
"Threshold": "Rauschen-Schwelle",
|
||||
@@ -869,9 +407,7 @@
|
||||
"imageDimensions": "Bilder Auslösungen",
|
||||
"parameterSet": "Parameter {{parameter}} setzen",
|
||||
"recallParameter": "{{label}} Abrufen",
|
||||
"parsingFailed": "Parsing Fehlgeschlagen",
|
||||
"canvasV2Metadata": "Leinwand",
|
||||
"guidance": "Führung"
|
||||
"parsingFailed": "Parsing Fehlgeschlagen"
|
||||
},
|
||||
"popovers": {
|
||||
"noiseUseCPU": {
|
||||
@@ -996,8 +532,7 @@
|
||||
},
|
||||
"paramScheduler": {
|
||||
"paragraphs": [
|
||||
"Verwendeter Planer währende des Generierungsprozesses.",
|
||||
"Jeder Planer definiert, wie einem Bild iterativ Rauschen hinzugefügt wird, oder wie ein Sample basierend auf der Ausgabe eines Modells aktualisiert wird."
|
||||
"\"Planer\" definiert, wie iterativ Rauschen zu einem Bild hinzugefügt wird, oder wie ein Sample bei der Ausgabe eines Modells aktualisiert wird."
|
||||
],
|
||||
"heading": "Planer"
|
||||
},
|
||||
@@ -1020,64 +555,6 @@
|
||||
"paragraphs": [
|
||||
"Die Skalierung steuert die Größe des Ausgabebildes und basiert auf einem Vielfachen der Auflösung des Originalbildes. So würde z. B. eine 2-fache Hochskalierung eines 1024x1024px Bildes eine 2048x2048px große Ausgabe erzeugen."
|
||||
]
|
||||
},
|
||||
"ipAdapterMethod": {
|
||||
"heading": "Methode"
|
||||
},
|
||||
"refinerScheduler": {
|
||||
"heading": "Planer",
|
||||
"paragraphs": [
|
||||
"Planer, der während der Veredelungsphase des Generierungsprozesses verwendet wird.",
|
||||
"Ähnlich wie der Generierungsplaner."
|
||||
]
|
||||
},
|
||||
"compositingCoherenceMode": {
|
||||
"paragraphs": [
|
||||
"Verwendete Methode zur Erstellung eines kohärenten Bildes mit dem neu generierten maskierten Bereich."
|
||||
],
|
||||
"heading": "Modus"
|
||||
},
|
||||
"compositingCoherencePass": {
|
||||
"heading": "Kohärenzdurchlauf"
|
||||
},
|
||||
"controlNet": {
|
||||
"heading": "ControlNet"
|
||||
},
|
||||
"compositingMaskAdjustments": {
|
||||
"paragraphs": [
|
||||
"Die Maske anpassen."
|
||||
],
|
||||
"heading": "Maskenanpassungen"
|
||||
},
|
||||
"compositingMaskBlur": {
|
||||
"paragraphs": [
|
||||
"Der Unschärferadius der Maske."
|
||||
],
|
||||
"heading": "Maskenunschärfe"
|
||||
},
|
||||
"compositingBlurMethod": {
|
||||
"paragraphs": [
|
||||
"Die auf den maskierten Bereich angewendete Unschärfemethode."
|
||||
],
|
||||
"heading": "Unschärfemethode"
|
||||
},
|
||||
"controlNetResizeMode": {
|
||||
"heading": "Größenänderungsmodus"
|
||||
},
|
||||
"paramWidth": {
|
||||
"heading": "Breite",
|
||||
"paragraphs": [
|
||||
"Breite des generierten Bildes. Muss ein Vielfaches von 8 sein."
|
||||
]
|
||||
},
|
||||
"controlNetControlMode": {
|
||||
"heading": "Kontrollmodus"
|
||||
},
|
||||
"controlNetProcessor": {
|
||||
"heading": "Prozessor"
|
||||
},
|
||||
"patchmatchDownScaleSize": {
|
||||
"heading": "Herunterskalieren"
|
||||
}
|
||||
},
|
||||
"invocationCache": {
|
||||
@@ -1111,7 +588,7 @@
|
||||
"cannotConnectToSelf": "Es kann keine Verbindung zu sich selbst hergestellt werden",
|
||||
"colorCodeEdges": "Farbkodierte Kanten",
|
||||
"addNodeToolTip": "Knoten hinzufügen (Umschalt+A, Leertaste)",
|
||||
"collectionFieldType": "{{name}} (Sammlung)",
|
||||
"collectionFieldType": "{{name}} Sammlung",
|
||||
"connectionWouldCreateCycle": "Verbindung würde einen Kreislauf/cycle schaffen",
|
||||
"inputMayOnlyHaveOneConnection": "Eingang darf nur eine Verbindung haben",
|
||||
"hideLegendNodes": "Feldtyp-Legende ausblenden",
|
||||
@@ -1175,43 +652,7 @@
|
||||
"enum": "Aufzählung",
|
||||
"fullyContainNodes": "Vollständig ausgewählte Nodes auswählen",
|
||||
"editMode": "Im Workflow-Editor bearbeiten",
|
||||
"resetToDefaultValue": "Auf Standardwert zurücksetzen",
|
||||
"singleFieldType": "{{name}} (Einzeln)",
|
||||
"collectionOrScalarFieldType": "{{name}} (Einzeln oder Sammlung)",
|
||||
"missingFieldTemplate": "Fehlende Feldvorlage",
|
||||
"missingNode": "Fehlender Aufrufknoten",
|
||||
"missingInvocationTemplate": "Fehlende Aufrufvorlage",
|
||||
"edit": "Bearbeiten",
|
||||
"workflowAuthor": "Autor",
|
||||
"graph": "Graph",
|
||||
"workflowDescription": "Kurze Beschreibung",
|
||||
"versionUnknown": " Version unbekannt",
|
||||
"workflow": "Arbeitsablauf",
|
||||
"noGraph": "Kein Graph",
|
||||
"version": "Version",
|
||||
"zoomInNodes": "Hineinzoomen",
|
||||
"zoomOutNodes": "Herauszoomen",
|
||||
"workflowName": "Name",
|
||||
"unknownNode": "Unbekannter Knoten",
|
||||
"workflowContact": "Kontaktdaten",
|
||||
"workflowNotes": "Notizen",
|
||||
"workflowTags": "Tags",
|
||||
"workflowVersion": "Version",
|
||||
"saveToGallery": "In Galerie speichern",
|
||||
"noWorkflows": "Keine Arbeitsabläufe",
|
||||
"noMatchingWorkflows": "Keine passenden Arbeitsabläufe",
|
||||
"unknownErrorValidatingWorkflow": "Unbekannter Fehler beim Validieren des Arbeitsablaufes",
|
||||
"inputFieldTypeParseError": "Typ des Eingabefelds {{node}}.{{field}} kann nicht analysiert werden ({{message}})",
|
||||
"workflowSettings": "Arbeitsablauf Editor Einstellungen",
|
||||
"unableToLoadWorkflow": "Arbeitsablauf kann nicht geladen werden",
|
||||
"viewMode": "In linearen Ansicht verwenden",
|
||||
"unableToValidateWorkflow": "Arbeitsablauf kann nicht validiert werden",
|
||||
"outputFieldTypeParseError": "Typ des Ausgabefelds {{node}}.{{field}} kann nicht analysiert werden ({{message}})",
|
||||
"unableToGetWorkflowVersion": "Version des Arbeitsablaufschemas kann nicht bestimmt werden",
|
||||
"unknownFieldType": "$t(nodes.unknownField) Typ: {{type}}",
|
||||
"unknownField": "Unbekanntes Feld",
|
||||
"unableToUpdateNodes_one": "{{count}} Knoten kann nicht aktualisiert werden",
|
||||
"unableToUpdateNodes_other": "{{count}} Knoten können nicht aktualisiert werden"
|
||||
"resetToDefaultValue": "Auf Standardwert zurücksetzen"
|
||||
},
|
||||
"hrf": {
|
||||
"enableHrf": "Korrektur für hohe Auflösungen",
|
||||
@@ -1233,8 +674,7 @@
|
||||
"noLoRAsInstalled": "Keine LoRAs installiert",
|
||||
"addLora": "LoRA hinzufügen",
|
||||
"defaultVAE": "Standard VAE",
|
||||
"lora": "LoRA",
|
||||
"concepts": "Konzepte"
|
||||
"lora": "LoRA"
|
||||
},
|
||||
"accordions": {
|
||||
"generation": {
|
||||
@@ -1279,17 +719,7 @@
|
||||
"openWorkflow": "Arbeitsablauf öffnen",
|
||||
"saveWorkflowToProject": "Arbeitsablauf in Projekt speichern",
|
||||
"workflowCleared": "Arbeitsablauf gelöscht",
|
||||
"loading": "Lade Arbeitsabläufe",
|
||||
"name": "Name",
|
||||
"ascending": "Aufsteigend",
|
||||
"defaultWorkflows": "Standard Arbeitsabläufe",
|
||||
"userWorkflows": "Benutzer Arbeitsabläufe",
|
||||
"projectWorkflows": "Projekt Arbeitsabläufe",
|
||||
"opened": "Geöffnet",
|
||||
"loadWorkflow": "Arbeitsablauf $t(common.load)",
|
||||
"updated": "Aktualisiert",
|
||||
"created": "Erstellt",
|
||||
"descending": "Absteigend"
|
||||
"loading": "Lade Arbeitsabläufe"
|
||||
},
|
||||
"sdxl": {
|
||||
"concatPromptStyle": "Verknüpfen von Prompt & Stil",
|
||||
@@ -1306,222 +736,7 @@
|
||||
},
|
||||
"ui": {
|
||||
"tabs": {
|
||||
"queue": "Warteschlange",
|
||||
"generation": "Erzeugung",
|
||||
"gallery": "Galerie",
|
||||
"models": "Modelle",
|
||||
"upscaling": "Hochskalierung",
|
||||
"workflows": "Arbeitsabläufe",
|
||||
"canvas": "Leinwand"
|
||||
"queue": "Warteschlange"
|
||||
}
|
||||
},
|
||||
"system": {
|
||||
"logNamespaces": {
|
||||
"logNamespaces": "Namespaces loggen",
|
||||
"models": "Modelle",
|
||||
"gallery": "Galerie",
|
||||
"events": "Ereignisse",
|
||||
"queue": "Warteschlange",
|
||||
"system": "System",
|
||||
"workflows": "Arbeitsabläufe",
|
||||
"generation": "Erstellung",
|
||||
"metadata": "Metadaten",
|
||||
"config": "Konfiguration",
|
||||
"canvas": "Leinwand"
|
||||
},
|
||||
"logLevel": {
|
||||
"fatal": "Fatal",
|
||||
"trace": "Trace",
|
||||
"logLevel": "Protokollierungsstufe",
|
||||
"error": "Fehler",
|
||||
"info": "Infos",
|
||||
"warn": "Warnung",
|
||||
"debug": "Fehlerdiagnose"
|
||||
},
|
||||
"enableLogging": "Protokollierung aktivieren"
|
||||
},
|
||||
"whatsNew": {
|
||||
"whatsNewInInvoke": "Was gibt's Neues"
|
||||
},
|
||||
"stylePresets": {
|
||||
"name": "Name",
|
||||
"acceptedColumnsKeys": "Akzeptierte Spalten/Schlüssel:",
|
||||
"noTemplates": "Keine Vorlagen",
|
||||
"promptTemplatesDesc2": "Verwenden Sie die Platzhalterzeichenfolge<Pre>{{placeholder}}</Pre>, um anzugeben, wo Ihre Eingabeaufforderung in die Vorlage aufgenommen werden soll.",
|
||||
"noMatchingTemplates": "Keine passenden Vorlagen",
|
||||
"myTemplates": "Meine Vorlagen",
|
||||
"toggleViewMode": "Ansicht umschalten",
|
||||
"viewModeTooltip": "So sieht Ihr Prompt mit der aktuell ausgewählten Vorlage aus. Um Ihren Prompt zu bearbeiten, klicken Sie irgendwo in das Textfeld.",
|
||||
"templateDeleted": "Promptvorlage gelöscht",
|
||||
"unableToDeleteTemplate": "Promptvorlage kann nicht gelöscht werden",
|
||||
"insertPlaceholder": "Platzhalter einfügen",
|
||||
"type": "Typ",
|
||||
"uploadImage": "Bild hochladen",
|
||||
"updatePromptTemplate": "Promptvorlage aktualisieren",
|
||||
"exportFailed": "CSV kann nicht generiert und heruntergeladen werden",
|
||||
"viewList": "Vorlagenliste anzeigen",
|
||||
"useForTemplate": "Für Promptvorlage nutzen",
|
||||
"shared": "Geteilt",
|
||||
"private": "Privat",
|
||||
"promptTemplatesDesc1": "Promptvorlagen fügen den Prompts, die Sie in das Prompt-Feld schreiben, Text hinzu.",
|
||||
"negativePrompt": "Negativ-Prompt",
|
||||
"positivePromptColumn": "'prompt' oder 'positive_prompt'",
|
||||
"promptTemplatesDesc3": "Wenn Sie den Platzhalter weglassen, wird die Vorlage an das Ende Ihres Prompts angehängt.",
|
||||
"sharedTemplates": "Geteilte Vorlagen",
|
||||
"importTemplates": "Promptvorlagen importieren (CSV/JSON)",
|
||||
"flatten": "Ausgewählte Vorlage in aktuelle Eingabeaufforderung einblenden",
|
||||
"searchByName": "Nach Name suchen",
|
||||
"promptTemplateCleared": "Promptvorlage gelöscht",
|
||||
"preview": "Vorschau",
|
||||
"positivePrompt": "Positiv-Prompt",
|
||||
"active": "Aktiv",
|
||||
"deleteTemplate2": "Sind Sie sicher, dass Sie diese Vorlage löschen möchten? Dies kann nicht rückgängig gemacht werden.",
|
||||
"deleteTemplate": "Vorlage löschen",
|
||||
"copyTemplate": "Vorlage kopieren",
|
||||
"editTemplate": "Vorlage bearbeiten",
|
||||
"deleteImage": "Bild löschen",
|
||||
"defaultTemplates": "Standardvorlagen",
|
||||
"nameColumn": "'name'",
|
||||
"exportDownloaded": "Export heruntergeladen"
|
||||
},
|
||||
"newUserExperience": {
|
||||
"gettingStartedSeries": "Wünschen Sie weitere Anleitungen? In unserer <LinkComponent>Einführungsserie</LinkComponent> finden Sie Tipps, wie Sie das Potenzial von Invoke Studio voll ausschöpfen können.",
|
||||
"toGetStarted": "Um zu beginnen, geben Sie einen Prompt in das Feld ein und klicken Sie auf <StrongComponent>Invoke</StrongComponent>, um Ihr erstes Bild zu erzeugen. Sie können Ihre Bilder direkt in der <StrongComponent>Galerie</StrongComponent> speichern oder sie auf der <StrongComponent>Leinwand</StrongComponent> bearbeiten."
|
||||
},
|
||||
"controlLayers": {
|
||||
"pullBboxIntoLayerOk": "Bbox in die Ebene gezogen",
|
||||
"saveBboxToGallery": "Bbox in Galerie speichern",
|
||||
"tool": {
|
||||
"bbox": "Bbox"
|
||||
},
|
||||
"transform": {
|
||||
"fitToBbox": "An Bbox anpassen",
|
||||
"reset": "Zurücksetzen",
|
||||
"apply": "Anwenden",
|
||||
"cancel": "Abbrechen"
|
||||
},
|
||||
"pullBboxIntoLayerError": "Problem, Bbox in die Ebene zu ziehen",
|
||||
"pullBboxIntoLayer": "Bbox in Ebene ziehen",
|
||||
"HUD": {
|
||||
"bbox": "Bbox",
|
||||
"scaledBbox": "Skalierte Bbox",
|
||||
"entityStatus": {
|
||||
"isHidden": "{{title}} ist ausgeblendet",
|
||||
"isDisabled": "{{title}} ist deaktiviert",
|
||||
"isLocked": "{{title}} ist gesperrt",
|
||||
"isEmpty": "{{title}} ist leer"
|
||||
}
|
||||
},
|
||||
"fitBboxToLayers": "Bbox an Ebenen anpassen",
|
||||
"pullBboxIntoReferenceImage": "Bbox ins Referenzbild ziehen",
|
||||
"pullBboxIntoReferenceImageOk": "Bbox in Referenzbild gezogen",
|
||||
"pullBboxIntoReferenceImageError": "Problem, Bbox ins Referenzbild zu ziehen",
|
||||
"bboxOverlay": "Bbox Overlay anzeigen",
|
||||
"clipToBbox": "Pinselstriche auf Bbox beschränken",
|
||||
"canvasContextMenu": {
|
||||
"saveBboxToGallery": "Bbox in Galerie speichern",
|
||||
"bboxGroup": "Aus Bbox erstellen",
|
||||
"canvasGroup": "Leinwand",
|
||||
"newGlobalReferenceImage": "Neues globales Referenzbild",
|
||||
"newRegionalReferenceImage": "Neues regionales Referenzbild",
|
||||
"newControlLayer": "Neue Kontroll-Ebene",
|
||||
"newRasterLayer": "Neue Raster-Ebene"
|
||||
},
|
||||
"rectangle": "Rechteck",
|
||||
"saveCanvasToGallery": "Leinwand in Galerie speichern",
|
||||
"newRasterLayerError": "Problem beim Erstellen einer Raster-Ebene",
|
||||
"saveLayerToAssets": "Ebene in Galerie speichern",
|
||||
"deleteReferenceImage": "Referenzbild löschen",
|
||||
"referenceImage": "Referenzbild",
|
||||
"opacity": "Opazität",
|
||||
"resetCanvas": "Leinwand zurücksetzen",
|
||||
"removeBookmark": "Lesezeichen entfernen",
|
||||
"rasterLayer": "Raster-Ebene",
|
||||
"rasterLayers_withCount_visible": "Raster-Ebenen ({{count}})",
|
||||
"controlLayers_withCount_visible": "Kontroll-Ebenen ({{count}})",
|
||||
"deleteSelected": "Ausgewählte löschen",
|
||||
"newRegionalReferenceImageError": "Problem beim Erstellen eines regionalen Referenzbilds",
|
||||
"newControlLayerOk": "Kontroll-Ebene erstellt",
|
||||
"newControlLayerError": "Problem beim Erstellen einer Kontroll-Ebene",
|
||||
"newRasterLayerOk": "Raster-Layer erstellt",
|
||||
"moveToFront": "Nach vorne bringen",
|
||||
"copyToClipboard": "In die Zwischenablage kopieren",
|
||||
"controlLayers_withCount_hidden": "Kontroll-Ebenen ({{count}} ausgeblendet)",
|
||||
"clearCaches": "Cache leeren",
|
||||
"controlLayer": "Kontroll-Ebene",
|
||||
"rasterLayers_withCount_hidden": "Raster-Ebenen ({{count}} ausgeblendet)",
|
||||
"transparency": "Transparenz",
|
||||
"canvas": "Leinwand",
|
||||
"global": "Global",
|
||||
"regional": "Regional",
|
||||
"newGlobalReferenceImageOk": "Globales Referenzbild erstellt",
|
||||
"savedToGalleryError": "Fehler beim Speichern in der Galerie",
|
||||
"savedToGalleryOk": "In Galerie gespeichert",
|
||||
"newGlobalReferenceImageError": "Problem beim Erstellen eines globalen Referenzbilds",
|
||||
"newRegionalReferenceImageOk": "Regionales Referenzbild erstellt",
|
||||
"duplicate": "Duplizieren",
|
||||
"regionalReferenceImage": "Regionales Referenzbild",
|
||||
"globalReferenceImage": "Globales Referenzbild",
|
||||
"regionIsEmpty": "Ausgewählte Region is leer",
|
||||
"mergeVisible": "Sichtbare vereinen",
|
||||
"mergeVisibleOk": "Sichtbare Ebenen vereinen",
|
||||
"mergeVisibleError": "Fehler beim Vereinen sichtbarer Ebenen",
|
||||
"clearHistory": "Verlauf leeren",
|
||||
"addLayer": "Ebene hinzufügen",
|
||||
"width": "Breite",
|
||||
"weight": "Gewichtung",
|
||||
"addReferenceImage": "$t(controlLayers.referenceImage) hinzufügen",
|
||||
"addInpaintMask": "$t(controlLayers.inpaintMask) hinzufügen",
|
||||
"addGlobalReferenceImage": "$t(controlLayers.globalReferenceImage) hinzufügen",
|
||||
"regionalGuidance": "Regionale Führung",
|
||||
"globalReferenceImages_withCount_visible": "Globale Referenzbilder ({{count}})",
|
||||
"addPositivePrompt": "$t(controlLayers.prompt) hinzufügen",
|
||||
"locked": "Gesperrt",
|
||||
"showHUD": "HUD anzeigen",
|
||||
"addNegativePrompt": "$t(controlLayers.negativePrompt) hinzufügen",
|
||||
"addRasterLayer": "$t(controlLayers.rasterLayer) hinzufügen",
|
||||
"addRegionalGuidance": "$t(controlLayers.regionalGuidance) hinzufügen",
|
||||
"addControlLayer": "$t(controlLayers.controlLayer) hinzufügen",
|
||||
"newCanvasSession": "Neue Leinwand-Sitzung",
|
||||
"replaceLayer": "Ebene ersetzen",
|
||||
"newGallerySession": "Neue Galerie-Sitzung",
|
||||
"unlocked": "Entsperrt",
|
||||
"showProgressOnCanvas": "Fortschritt auf Leinwand anzeigen",
|
||||
"controlMode": {
|
||||
"balanced": "Ausgewogen"
|
||||
},
|
||||
"globalReferenceImages_withCount_hidden": "Globale Referenzbilder ({{count}} ausgeblendet)",
|
||||
"sendToGallery": "An Galerie senden",
|
||||
"stagingArea": {
|
||||
"accept": "Annehmen",
|
||||
"next": "Nächste",
|
||||
"discardAll": "Alle verwerfen",
|
||||
"discard": "Verwerfen",
|
||||
"previous": "Vorherige"
|
||||
},
|
||||
"regionalGuidance_withCount_visible": "Regionale Führung ({{count}})",
|
||||
"regionalGuidance_withCount_hidden": "Regionale Führung ({{count}} ausgeblendet)",
|
||||
"settings": {
|
||||
"snapToGrid": {
|
||||
"on": "Ein",
|
||||
"off": "Aus",
|
||||
"label": "Am Raster ausrichten"
|
||||
}
|
||||
},
|
||||
"layer_one": "Ebene",
|
||||
"layer_other": "Ebenen",
|
||||
"layer_withCount_one": "Ebene ({{count}})",
|
||||
"layer_withCount_other": "Ebenen ({{count}})"
|
||||
},
|
||||
"upsell": {
|
||||
"shareAccess": "Zugang teilen",
|
||||
"professional": "Professionell",
|
||||
"inviteTeammates": "Teamkollegen einladen",
|
||||
"professionalUpsell": "Verfügbar in der Professional Edition von Invoke. Klicken Sie hier oder besuchen Sie invoke.com/pricing für weitere Details."
|
||||
},
|
||||
"upscaling": {
|
||||
"creativity": "Kreativität",
|
||||
"structure": "Struktur",
|
||||
"scale": "Maßstab"
|
||||
}
|
||||
}
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user