mirror of
https://github.com/invoke-ai/InvokeAI.git
synced 2026-04-23 03:00:31 -04:00
Compare commits
940 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
7296a0c911 | ||
|
|
e38052155b | ||
|
|
644bb98476 | ||
|
|
fc10db40d0 | ||
|
|
6cea0c043e | ||
|
|
bab61fbca4 | ||
|
|
abbc96de7a | ||
|
|
bcc4735024 | ||
|
|
975d7166cd | ||
|
|
f1ba95d42e | ||
|
|
e811ffc8e2 | ||
|
|
7ff73eb75b | ||
|
|
396f739b22 | ||
|
|
ab1e15e4f5 | ||
|
|
9d9625f8ab | ||
|
|
3af42c56d2 | ||
|
|
e5935a39e4 | ||
|
|
adc332b9e3 | ||
|
|
d81a55401a | ||
|
|
db2a8306c2 | ||
|
|
a16d0b8301 | ||
|
|
2206b28576 | ||
|
|
4f20a0db2e | ||
|
|
d258af0a14 | ||
|
|
fc2175ae03 | ||
|
|
d11cb34d22 | ||
|
|
381827fd54 | ||
|
|
17c3d15488 | ||
|
|
5a681d51c9 | ||
|
|
f57ee304bc | ||
|
|
55d7d2e396 | ||
|
|
347a33f77c | ||
|
|
34cb88ef23 | ||
|
|
e676b9d075 | ||
|
|
26dc155ad8 | ||
|
|
b5aa31526f | ||
|
|
99d3f16eb4 | ||
|
|
01ca74e622 | ||
|
|
25619684c0 | ||
|
|
d336aa45f5 | ||
|
|
303acdb4ac | ||
|
|
2e5ec1c98b | ||
|
|
56e31ca4ac | ||
|
|
74e4dd4393 | ||
|
|
233b286893 | ||
|
|
07a667ad9f | ||
|
|
7437a14301 | ||
|
|
09fef01786 | ||
|
|
83fe40e7ee | ||
|
|
13b2f9d12b | ||
|
|
0214afc3d1 | ||
|
|
e23ac6d813 | ||
|
|
9faffe93f9 | ||
|
|
edfd90f2a4 | ||
|
|
e48e354bf1 | ||
|
|
4ded5b5a80 | ||
|
|
ee5808355d | ||
|
|
af305250cb | ||
|
|
c065655a1d | ||
|
|
a0a4eb9a5a | ||
|
|
c53c731371 | ||
|
|
951635fbee | ||
|
|
044648fe61 | ||
|
|
111782d6c9 | ||
|
|
f5cbf60fc0 | ||
|
|
395b7d8bbf | ||
|
|
934b3f8b87 | ||
|
|
9745c25b1b | ||
|
|
925698a688 | ||
|
|
96bbd8a26e | ||
|
|
eb1ed245fe | ||
|
|
a118700cc8 | ||
|
|
eaddd6f533 | ||
|
|
7ca0a0a0fd | ||
|
|
d185b85fb7 | ||
|
|
a35a49f585 | ||
|
|
3b606b6d63 | ||
|
|
d89472d3b1 | ||
|
|
036ab04376 | ||
|
|
e1a54badc1 | ||
|
|
bbecc86d0f | ||
|
|
d4823b6869 | ||
|
|
3488975b2b | ||
|
|
fd47da6842 | ||
|
|
8399de9c25 | ||
|
|
0fd58681a2 | ||
|
|
250163e6b7 | ||
|
|
4b1450a4ff | ||
|
|
4e2145c6c4 | ||
|
|
8a6d5f4f6a | ||
|
|
06dcd290df | ||
|
|
73b6fae00e | ||
|
|
4ae20f4876 | ||
|
|
f852c03ba5 | ||
|
|
8a14175ab2 | ||
|
|
9469bb05fe | ||
|
|
8036bb0e8f | ||
|
|
e72c78f7d4 | ||
|
|
a8009b47e9 | ||
|
|
6294c294d0 | ||
|
|
6f08a2bfb1 | ||
|
|
84e4d313a8 | ||
|
|
092cff358a | ||
|
|
ca3ccf92bc | ||
|
|
7cdc821801 | ||
|
|
08853f9be2 | ||
|
|
4897eebf5f | ||
|
|
93a170a62c | ||
|
|
facb02602c | ||
|
|
62c456a1e4 | ||
|
|
51b2297a2b | ||
|
|
64aaf9880a | ||
|
|
9e509ffb56 | ||
|
|
6e9e8d6bd2 | ||
|
|
eb6b3b8168 | ||
|
|
0f5beec657 | ||
|
|
8474fd8342 | ||
|
|
0a3e6d3f88 | ||
|
|
7cc7d06f3c | ||
|
|
b26ab0b3f1 | ||
|
|
4ae6c903e3 | ||
|
|
a7e1f06698 | ||
|
|
8dfaf7e697 | ||
|
|
f59ffbe145 | ||
|
|
bd4bb075a5 | ||
|
|
e19b7d4afb | ||
|
|
f8d0b43a9b | ||
|
|
50c77d9bf0 | ||
|
|
358cc0349e | ||
|
|
417e6ebdbc | ||
|
|
7919d659b7 | ||
|
|
ec665d2c7f | ||
|
|
020d36b234 | ||
|
|
d67272c027 | ||
|
|
82548f9e41 | ||
|
|
07a2369105 | ||
|
|
b1f7e2dfdc | ||
|
|
b2b4a35bc4 | ||
|
|
c249a25f85 | ||
|
|
25f8ab24aa | ||
|
|
c0469ef633 | ||
|
|
310e826d76 | ||
|
|
a423ead99e | ||
|
|
3707c3b034 | ||
|
|
5885db4ab5 | ||
|
|
36ed9b750d | ||
|
|
3cec06f86e | ||
|
|
28b5f7a1c5 | ||
|
|
22cbb23ae0 | ||
|
|
4d585e3eec | ||
|
|
006b4356bb | ||
|
|
da947866f2 | ||
|
|
84a2cc6fc9 | ||
|
|
b50534bb49 | ||
|
|
c305e79fee | ||
|
|
c32949d113 | ||
|
|
87a98902da | ||
|
|
2857a446c9 | ||
|
|
035d9432bd | ||
|
|
bdeb9fb1cf | ||
|
|
dadff57061 | ||
|
|
480857ae4e | ||
|
|
eaf0624004 | ||
|
|
58bca1b9f4 | ||
|
|
54aa6908fa | ||
|
|
e6d9daca96 | ||
|
|
6e5a529cb7 | ||
|
|
8c742a6e38 | ||
|
|
693373f1c1 | ||
|
|
4809080fd9 | ||
|
|
efcb1bea7f | ||
|
|
e0d7a401f3 | ||
|
|
aac979e9a4 | ||
|
|
3b0d7f076d | ||
|
|
e1acbcdbd5 | ||
|
|
7d9b81550b | ||
|
|
6a447dd1fe | ||
|
|
c2dc63ddbc | ||
|
|
1bc689d531 | ||
|
|
4829975827 | ||
|
|
49da4e00c3 | ||
|
|
89dfe5e729 | ||
|
|
6816d366df | ||
|
|
9d3d2a36c9 | ||
|
|
ed231044c8 | ||
|
|
b51a232794 | ||
|
|
4412143a6e | ||
|
|
de11cafdb3 | ||
|
|
4d9114aa7d | ||
|
|
67e2da1ebf | ||
|
|
33ecc591c3 | ||
|
|
b57459a226 | ||
|
|
01282b1c90 | ||
|
|
3f302906dc | ||
|
|
81d56596fb | ||
|
|
b536b0df0c | ||
|
|
692af1d93d | ||
|
|
bb7ef77b50 | ||
|
|
1862548573 | ||
|
|
242c1b6350 | ||
|
|
fc6e4bb04e | ||
|
|
20841abca6 | ||
|
|
e8b69d99a4 | ||
|
|
d6eaff8237 | ||
|
|
068b095956 | ||
|
|
f795a47340 | ||
|
|
df47345eb0 | ||
|
|
def04095a4 | ||
|
|
28be8f0911 | ||
|
|
b50c44bac0 | ||
|
|
b4ce0e02fc | ||
|
|
d6442d9a34 | ||
|
|
4528bcafaf | ||
|
|
8b82b81ee2 | ||
|
|
757acdd49e | ||
|
|
94b7cc583a | ||
|
|
b663a6bac4 | ||
|
|
65d40153fb | ||
|
|
c8b741a514 | ||
|
|
6d3aeffed9 | ||
|
|
203be96910 | ||
|
|
b0aa48ddb8 | ||
|
|
867dbe51e5 | ||
|
|
ff8948b6f1 | ||
|
|
fa3a6425a6 | ||
|
|
c5992ece89 | ||
|
|
12a6239929 | ||
|
|
e9238c59f4 | ||
|
|
c1cbbe51d6 | ||
|
|
4219b4a288 | ||
|
|
48c8a9c09d | ||
|
|
a67efdf4ad | ||
|
|
d6ff9c2e49 | ||
|
|
e768a3bc7b | ||
|
|
7273700f61 | ||
|
|
f909e81d91 | ||
|
|
8c85f168f6 | ||
|
|
263d86d46f | ||
|
|
0921805160 | ||
|
|
517f4811e7 | ||
|
|
0dc73c8803 | ||
|
|
26702b54c0 | ||
|
|
2d65e4543f | ||
|
|
309113956b | ||
|
|
0ac4099bc6 | ||
|
|
899dc739fa | ||
|
|
4e2439fc8e | ||
|
|
00864c24e0 | ||
|
|
b73aaa7d6f | ||
|
|
85057ae704 | ||
|
|
c3fb3a43a2 | ||
|
|
51d0a15a1b | ||
|
|
5991067fd9 | ||
|
|
32c2d3f740 | ||
|
|
c661f86b34 | ||
|
|
cc72d8eab4 | ||
|
|
e8550f9355 | ||
|
|
a1d0386ca4 | ||
|
|
495d089f85 | ||
|
|
913b91e9dd | ||
|
|
3e907f4e14 | ||
|
|
756df6ebe4 | ||
|
|
2a6be99152 | ||
|
|
3099e2bf9d | ||
|
|
6921f0412a | ||
|
|
022d5a8863 | ||
|
|
af99beedc5 | ||
|
|
f3d83dc6b7 | ||
|
|
ebc3f18a1a | ||
|
|
aeb512f8d9 | ||
|
|
a1810acb93 | ||
|
|
aa35a5083b | ||
|
|
4f17de0b32 | ||
|
|
370c3cd59b | ||
|
|
67214e16c0 | ||
|
|
4880a1d946 | ||
|
|
0f0988610f | ||
|
|
6805d28b7a | ||
|
|
9b45a24136 | ||
|
|
4e9d66a64b | ||
|
|
8fec530b0f | ||
|
|
50c66f8671 | ||
|
|
f0aa39ea81 | ||
|
|
faac814a3d | ||
|
|
fb9545bb90 | ||
|
|
8ad2ee83b6 | ||
|
|
f8ad62b5eb | ||
|
|
03ae78bc7c | ||
|
|
ec1a058dbe | ||
|
|
9e4d441e2e | ||
|
|
3770fd22f8 | ||
|
|
a0232b0e63 | ||
|
|
e1e964bf0e | ||
|
|
1b1759cffc | ||
|
|
d828502bc8 | ||
|
|
7a073b6de7 | ||
|
|
338ff8d588 | ||
|
|
a3625efd3a | ||
|
|
5efb37fe63 | ||
|
|
aef0b81d5b | ||
|
|
544edff507 | ||
|
|
42b1adab22 | ||
|
|
a2b9d12e88 | ||
|
|
7a94fb6c04 | ||
|
|
efcd159704 | ||
|
|
997e619a9d | ||
|
|
4bc184ff16 | ||
|
|
0b605a745b | ||
|
|
22b038ce3b | ||
|
|
0bb5d647b5 | ||
|
|
4a3599929b | ||
|
|
f959ce8323 | ||
|
|
74e1047870 | ||
|
|
732881c51b | ||
|
|
107be8e166 | ||
|
|
3c2f654da8 | ||
|
|
474fd44e50 | ||
|
|
0dc5f8fd65 | ||
|
|
d4215fb460 | ||
|
|
0cd05ee9fd | ||
|
|
9fcb3af1d8 | ||
|
|
c9da7e2172 | ||
|
|
9788735d6b | ||
|
|
d6139748e2 | ||
|
|
602dfb1e5d | ||
|
|
5bb3a78f56 | ||
|
|
d58df1e17b | ||
|
|
5d0e37eb2f | ||
|
|
486b333cef | ||
|
|
6fa437af03 | ||
|
|
787ef6fa27 | ||
|
|
7f0571c229 | ||
|
|
f5a58c0ceb | ||
|
|
d16eef4e66 | ||
|
|
681ff2b2b3 | ||
|
|
0d81b4ce98 | ||
|
|
99f1667ced | ||
|
|
aa5597ab4d | ||
|
|
9bbb8e8a5e | ||
|
|
f284d282c1 | ||
|
|
4231488da6 | ||
|
|
a014867e68 | ||
|
|
22654fbc9c | ||
|
|
daa4fd751c | ||
|
|
3fd265c333 | ||
|
|
26a3a9130c | ||
|
|
3dfeaab4b2 | ||
|
|
a33707cc76 | ||
|
|
21e13daf6e | ||
|
|
fa2614ee02 | ||
|
|
4be6ddb23d | ||
|
|
bba0e01926 | ||
|
|
20d57d5ccf | ||
|
|
d9121271a2 | ||
|
|
30b487c71c | ||
|
|
8a81c05caf | ||
|
|
a0dceecab9 | ||
|
|
98945a4560 | ||
|
|
9610f34dd4 | ||
|
|
8a00d855b4 | ||
|
|
25430f04c5 | ||
|
|
b2b53c4481 | ||
|
|
c6696d7913 | ||
|
|
8bcb6648f1 | ||
|
|
0ee360ba6c | ||
|
|
09bbe3eef9 | ||
|
|
d14b7a48f5 | ||
|
|
1db55b0ffa | ||
|
|
3104a1baa6 | ||
|
|
0e523ca2c1 | ||
|
|
75daef2aba | ||
|
|
b036b18986 | ||
|
|
93535fa3c2 | ||
|
|
dcafb44f8a | ||
|
|
44b1d8d1fc | ||
|
|
6f70a6bd10 | ||
|
|
0546aeed1d | ||
|
|
8933f3f5dd | ||
|
|
29cdefe873 | ||
|
|
df299bb37f | ||
|
|
481fb42371 | ||
|
|
631a04b48c | ||
|
|
547e1941f4 | ||
|
|
031d25ed63 | ||
|
|
27f4af0eb4 | ||
|
|
e0a0617093 | ||
|
|
e6a763b887 | ||
|
|
3c9c49f7d9 | ||
|
|
26690d47b7 | ||
|
|
fcaff6ce09 | ||
|
|
afd7296cb2 | ||
|
|
d6f42c76d5 | ||
|
|
68f39fe907 | ||
|
|
23a528545f | ||
|
|
c69d04a7f0 | ||
|
|
60f1e2d7ad | ||
|
|
cb386bec28 | ||
|
|
f29ceb3f12 | ||
|
|
4f51bc9421 | ||
|
|
0c41abab79 | ||
|
|
cb457c3402 | ||
|
|
606ad73814 | ||
|
|
fe70bd538a | ||
|
|
b5c7316c0a | ||
|
|
460aec03ea | ||
|
|
6730d86a13 | ||
|
|
c4bc03cb1f | ||
|
|
136ee28199 | ||
|
|
2c6d266c0a | ||
|
|
f779920eaa | ||
|
|
01bef5d165 | ||
|
|
72851d3e84 | ||
|
|
4ba85c62ca | ||
|
|
313aedb00a | ||
|
|
85bd324d74 | ||
|
|
4a04411e74 | ||
|
|
299a4db3bb | ||
|
|
390faa592c | ||
|
|
2463aeb84a | ||
|
|
ec8df163d1 | ||
|
|
a198b7da78 | ||
|
|
fb11770852 | ||
|
|
6b6f3d56f7 | ||
|
|
29d00eef9a | ||
|
|
6972cd708d | ||
|
|
82893804ff | ||
|
|
47ffe365bc | ||
|
|
f7b03b1e63 | ||
|
|
356e38e82a | ||
|
|
5ea077bb8c | ||
|
|
3c4b303555 | ||
|
|
b8651cb1a2 | ||
|
|
a6527c0ba1 | ||
|
|
6e40eca754 | ||
|
|
53fab17c33 | ||
|
|
3876d88b3c | ||
|
|
82b4526691 | ||
|
|
f56ba11394 | ||
|
|
32eb5190f2 | ||
|
|
72e378789d | ||
|
|
f10ddb0cab | ||
|
|
286127077d | ||
|
|
36278bc044 | ||
|
|
7a1c7ca43a | ||
|
|
8303d567d5 | ||
|
|
1fe19c1242 | ||
|
|
127a43865c | ||
|
|
24a48884cb | ||
|
|
47cee816fd | ||
|
|
90bacaddda | ||
|
|
c0cc9f421e | ||
|
|
dbb9032648 | ||
|
|
b9e32e59a2 | ||
|
|
545a1d8737 | ||
|
|
c4718403a2 | ||
|
|
eb308b1ff7 | ||
|
|
a277bea804 | ||
|
|
30619c0420 | ||
|
|
504d8e32be | ||
|
|
f21229cd14 | ||
|
|
640ec676c3 | ||
|
|
6370412e9c | ||
|
|
edec2c2775 | ||
|
|
bd38be31d8 | ||
|
|
b938ae0a7e | ||
|
|
6e5b1ed55f | ||
|
|
5970bd38c2 | ||
|
|
e046417cf5 | ||
|
|
27a2cd19bd | ||
|
|
0df631b802 | ||
|
|
5bb7cd168d | ||
|
|
b4ba84ad35 | ||
|
|
d1628f51c9 | ||
|
|
17c1304ce2 | ||
|
|
cc9a85f7d0 | ||
|
|
7e2999649a | ||
|
|
1473142f73 | ||
|
|
49343546e7 | ||
|
|
39d5879405 | ||
|
|
4b4ec29a09 | ||
|
|
dc6811076f | ||
|
|
0568784ee9 | ||
|
|
895eac6bcd | ||
|
|
fe0efa9bdf | ||
|
|
acabc8bd54 | ||
|
|
89f999af08 | ||
|
|
9ae76bef51 | ||
|
|
0999b43616 | ||
|
|
e6e4f58163 | ||
|
|
b371930e02 | ||
|
|
9b50e2303b | ||
|
|
49d1810991 | ||
|
|
b1b009f7b8 | ||
|
|
3431e6385c | ||
|
|
5db1027d32 | ||
|
|
579f182fe9 | ||
|
|
55bf41f63f | ||
|
|
fc32fd2d2e | ||
|
|
a2b6536078 | ||
|
|
144c54a6c8 | ||
|
|
ca40daeb97 | ||
|
|
e600cdc826 | ||
|
|
b7c52f33dc | ||
|
|
e78157fcf0 | ||
|
|
7d7b98249f | ||
|
|
f5bf84f304 | ||
|
|
c30d5bece2 | ||
|
|
27845b2f1b | ||
|
|
bad6eea077 | ||
|
|
9c26ac5ce3 | ||
|
|
b7306bb5c9 | ||
|
|
0c115177b2 | ||
|
|
5aae41b5bb | ||
|
|
7ad09a2f79 | ||
|
|
5a6d3639b7 | ||
|
|
84617d3df2 | ||
|
|
e05f30749e | ||
|
|
88a2e27338 | ||
|
|
15a6fd76c8 | ||
|
|
6adb46a86c | ||
|
|
e8a74eb79d | ||
|
|
dcd716c384 | ||
|
|
56697635dd | ||
|
|
5b5657e292 | ||
|
|
ad3dfbe1ed | ||
|
|
59ddc4f7b0 | ||
|
|
4653b79f12 | ||
|
|
778d6f167f | ||
|
|
05c71f50f1 | ||
|
|
406e0be39c | ||
|
|
0d71234a12 | ||
|
|
e38019bb70 | ||
|
|
a879880b42 | ||
|
|
71c8accbfe | ||
|
|
154fb99daf | ||
|
|
0df476ce13 | ||
|
|
e7ad830fa9 | ||
|
|
e81e0a8286 | ||
|
|
d0f7e72cbb | ||
|
|
fdead4fb8c | ||
|
|
31c9945b32 | ||
|
|
22de8a4b12 | ||
|
|
89cb3c3230 | ||
|
|
7bb99ece4e | ||
|
|
28f040123f | ||
|
|
1be3a4db64 | ||
|
|
cb44c995d2 | ||
|
|
9b9b35c315 | ||
|
|
f6edab6032 | ||
|
|
f79665b023 | ||
|
|
6b1bc7a87d | ||
|
|
c6f2994c84 | ||
|
|
0cff67ff23 | ||
|
|
e957c11c9a | ||
|
|
4baa685c7a | ||
|
|
1bd5907a12 | ||
|
|
2fd56e6029 | ||
|
|
b0548edc8c | ||
|
|
41d781176f | ||
|
|
8709de0b33 | ||
|
|
af43fe2fd4 | ||
|
|
ebbb11c3b1 | ||
|
|
0fc8c08da3 | ||
|
|
bfadcffe3c | ||
|
|
49c2332c13 | ||
|
|
dacef158c4 | ||
|
|
0c34d8201e | ||
|
|
77132075ff | ||
|
|
f008d3b0b2 | ||
|
|
4e66ccefe8 | ||
|
|
5d0ed45326 | ||
|
|
379d633ac6 | ||
|
|
93bba1b692 | ||
|
|
667e175ab7 | ||
|
|
de146aa4aa | ||
|
|
ed9c2c8208 | ||
|
|
9d984878f3 | ||
|
|
585eb8c69d | ||
|
|
c105bae127 | ||
|
|
c39f26266f | ||
|
|
47dffd123a | ||
|
|
b946ec3172 | ||
|
|
024c02329d | ||
|
|
4b43b59472 | ||
|
|
d11f115e1a | ||
|
|
92253ce854 | ||
|
|
0ebbfa90c9 | ||
|
|
fdfee11e37 | ||
|
|
6091bf4f60 | ||
|
|
07271ca468 | ||
|
|
3971382a6d | ||
|
|
0d827d8306 | ||
|
|
ec793cb636 | ||
|
|
e4f24c4dc4 | ||
|
|
a6b0581939 | ||
|
|
2a6cfde488 | ||
|
|
8c2e6a3988 | ||
|
|
0b05b24e9a | ||
|
|
842d729ec8 | ||
|
|
8642e8881d | ||
|
|
239fb86a46 | ||
|
|
269d4fe670 | ||
|
|
20813b5615 | ||
|
|
36c16d2781 | ||
|
|
3ae99df091 | ||
|
|
431fd83a43 | ||
|
|
ab41f71a36 | ||
|
|
1f526a1c27 | ||
|
|
8a60def51f | ||
|
|
4845d31857 | ||
|
|
0de5097207 | ||
|
|
505c75a5ab | ||
|
|
4c32b2a123 | ||
|
|
b2ed3c99d4 | ||
|
|
8eb3f40e1b | ||
|
|
9fcba3b876 | ||
|
|
5cabc37a87 | ||
|
|
c5a76806c1 | ||
|
|
bc6dd12083 | ||
|
|
41e1697e79 | ||
|
|
378f33bc92 | ||
|
|
1bf25fadb3 | ||
|
|
6a20271dba | ||
|
|
e36490c2ec | ||
|
|
d4378d9f2a | ||
|
|
1cc6893d0d | ||
|
|
b16d1a943d | ||
|
|
6c375b228e | ||
|
|
23cde86bc4 | ||
|
|
c6f2d127ef | ||
|
|
fb0a924918 | ||
|
|
2d9c82da85 | ||
|
|
7e031e9c01 | ||
|
|
26fe937d97 | ||
|
|
55139bb169 | ||
|
|
6a7fe6668b | ||
|
|
f5fdba795a | ||
|
|
84dc4e4ea9 | ||
|
|
24f22d539f | ||
|
|
89efe9c2b1 | ||
|
|
fbf8aa17c8 | ||
|
|
e55d39a20b | ||
|
|
3a1cedbced | ||
|
|
3d9889e272 | ||
|
|
b2026d9c00 | ||
|
|
f631b5178f | ||
|
|
8df3067599 | ||
|
|
b377b80446 | ||
|
|
7828102b67 | ||
|
|
1b0d599dc2 | ||
|
|
aa4e3adadb | ||
|
|
637d19c22b | ||
|
|
45b4432833 | ||
|
|
b71829a827 | ||
|
|
d95a698ebd | ||
|
|
49d569ec59 | ||
|
|
6ef1c2a5e1 | ||
|
|
0ec6d33086 | ||
|
|
64dfa125d2 | ||
|
|
67042e6dec | ||
|
|
a918198d4f | ||
|
|
288ac0a293 | ||
|
|
963c2ec60c | ||
|
|
79e8482b27 | ||
|
|
f98bbc32dd | ||
|
|
9380d8901c | ||
|
|
67de3f2d9b | ||
|
|
530d20c1be | ||
|
|
4d8bcad15b | ||
|
|
5c93e53195 | ||
|
|
e9c4e12454 | ||
|
|
295b5a20a8 | ||
|
|
eff9c7b92f | ||
|
|
07565d4015 | ||
|
|
94ba840948 | ||
|
|
bd251f8cce | ||
|
|
97719b0aab | ||
|
|
e89266bfe3 | ||
|
|
453ef1a220 | ||
|
|
faf8f0f291 | ||
|
|
5d36499982 | ||
|
|
151d67a0cc | ||
|
|
72431ff197 | ||
|
|
0de1feed76 | ||
|
|
7ffb626dbe | ||
|
|
79753289b1 | ||
|
|
bac4c05fd9 | ||
|
|
8a3b5d2c6f | ||
|
|
309578c19a | ||
|
|
fd58e1d0f2 | ||
|
|
04ffb979ce | ||
|
|
35c00d5a83 | ||
|
|
c2b49d58f5 | ||
|
|
6ff6b40a35 | ||
|
|
1f1beda567 | ||
|
|
91d62eb242 | ||
|
|
013e02d08b | ||
|
|
115053972c | ||
|
|
bcab754ac2 | ||
|
|
f1a542aca2 | ||
|
|
0701cc63a1 | ||
|
|
9337710b45 | ||
|
|
592ef5a9ee | ||
|
|
5fe39a3ae9 | ||
|
|
1888c586ca | ||
|
|
88922a467e | ||
|
|
84115e598c | ||
|
|
370fc67777 | ||
|
|
fa810e1d02 | ||
|
|
ec5043aa83 | ||
|
|
9a2a0cef74 | ||
|
|
c205c1d19e | ||
|
|
ae1a815453 | ||
|
|
687bc281e5 | ||
|
|
567316d753 | ||
|
|
53ac7c9d2c | ||
|
|
90be2a0cdf | ||
|
|
c7fb8f69ae | ||
|
|
7fecb8e88b | ||
|
|
ee6a2a6603 | ||
|
|
2496ac19c4 | ||
|
|
e34ed199c9 | ||
|
|
569533ef80 | ||
|
|
dfac73f9f0 | ||
|
|
f4219d5db3 | ||
|
|
04d1958e93 | ||
|
|
47d7d93e78 | ||
|
|
0e17950949 | ||
|
|
b0cfdc94b5 | ||
|
|
bb153b55d3 | ||
|
|
93ef637d59 | ||
|
|
c5689ca1a7 | ||
|
|
008e421ad4 | ||
|
|
28a77ab06c | ||
|
|
be48d3c12d | ||
|
|
518b21a49a | ||
|
|
68825ca9eb | ||
|
|
73c5f0b479 | ||
|
|
7b4e04cd7c | ||
|
|
ae4368fabe | ||
|
|
df8e39a9e1 | ||
|
|
45b43de571 | ||
|
|
6d18a72a05 | ||
|
|
af58a75e97 | ||
|
|
fd4c3bd27a | ||
|
|
1f8a60ded2 | ||
|
|
b1b677997d | ||
|
|
f17b43d736 | ||
|
|
c009a50489 | ||
|
|
97a16c455c | ||
|
|
a8a07598c8 | ||
|
|
23206e22e8 | ||
|
|
f4aba52b90 | ||
|
|
d17c273939 | ||
|
|
aeb5e7d50a | ||
|
|
580ad30832 | ||
|
|
6390f7d734 | ||
|
|
5ddbfefb6a | ||
|
|
bbf5ed7956 | ||
|
|
19cd6eed08 | ||
|
|
9c1eb263a8 | ||
|
|
75755189a7 | ||
|
|
a9ab72d27d | ||
|
|
678eb34995 | ||
|
|
ef7050f560 | ||
|
|
9787d9de74 | ||
|
|
bb4a50bab2 | ||
|
|
f3554b4e1b | ||
|
|
9dcb025241 | ||
|
|
ecf646066a | ||
|
|
3fd10b68cd | ||
|
|
6e32c7993c | ||
|
|
8329533848 | ||
|
|
fc7157b029 | ||
|
|
a1897f7490 | ||
|
|
a89b3efd14 | ||
|
|
5259693ed1 | ||
|
|
d77c24206d | ||
|
|
c5069557f3 | ||
|
|
9b220f61bd | ||
|
|
7fc3af12cc | ||
|
|
e2721b46b6 | ||
|
|
17118a04bd | ||
|
|
24788e3c83 | ||
|
|
056387c981 | ||
|
|
8a43d90273 | ||
|
|
4f9b9760db | ||
|
|
fdaddafa56 | ||
|
|
23d59abbd7 | ||
|
|
cf7fa5bce8 | ||
|
|
39e41998bb | ||
|
|
c6eff71b74 | ||
|
|
6ea4c47757 | ||
|
|
91f91aa835 | ||
|
|
ea7868d076 | ||
|
|
7d86f00d82 | ||
|
|
7785061e7d | ||
|
|
3370052e54 | ||
|
|
325dacd29c | ||
|
|
f4981a6ba9 | ||
|
|
8c159942eb | ||
|
|
deb4dc64af | ||
|
|
1a11437b6f | ||
|
|
04572c94ad | ||
|
|
1e9e78089e | ||
|
|
e65f93663d | ||
|
|
2a796fe25e | ||
|
|
61ff9ee3a7 | ||
|
|
111408c046 | ||
|
|
d7619d465e | ||
|
|
8ad4f6e56d | ||
|
|
bf4899526f | ||
|
|
6435d265c6 | ||
|
|
3163ef454d | ||
|
|
7ea636df70 | ||
|
|
1869824803 | ||
|
|
66fc8af8a6 | ||
|
|
48cb6b12f0 | ||
|
|
68e30a9864 | ||
|
|
f65dc2c081 | ||
|
|
0cd77443a7 | ||
|
|
185ed86424 | ||
|
|
fed817ab83 | ||
|
|
e0b45db69a | ||
|
|
2beac1fb04 | ||
|
|
e522de33f8 | ||
|
|
d591b50c25 | ||
|
|
b365aad6d8 | ||
|
|
65ad392361 | ||
|
|
56d75e1c77 | ||
|
|
df77a12efe | ||
|
|
faf662d12e | ||
|
|
44a7dfd486 | ||
|
|
bb15e5cf06 | ||
|
|
1a1c846be3 | ||
|
|
93c896a370 | ||
|
|
053d7c8c8e | ||
|
|
5296263954 | ||
|
|
a36b70c01c | ||
|
|
854a2a5a7a | ||
|
|
f9c64b0609 | ||
|
|
5889fa536a | ||
|
|
0e71ba892f | ||
|
|
d766a21223 | ||
|
|
5c8c54eab8 | ||
|
|
f296f4525c | ||
|
|
7c9ba4cb52 | ||
|
|
6784fd5b43 | ||
|
|
11d68cc646 | ||
|
|
ea8c877025 | ||
|
|
7a3c2332dd | ||
|
|
3835fd2f72 | ||
|
|
6f8746040c | ||
|
|
35e3940a09 | ||
|
|
415616d83f | ||
|
|
afb67efef9 | ||
|
|
1ed1fefa60 | ||
|
|
fa94a05c77 | ||
|
|
7a23d8266f | ||
|
|
a44de079dd | ||
|
|
c3c1a3edd8 | ||
|
|
ea26b5b147 | ||
|
|
4226b741b1 | ||
|
|
1424b7c254 | ||
|
|
933fb2294c | ||
|
|
5a181ee0fd | ||
|
|
3b0d59e459 | ||
|
|
fec296e41d | ||
|
|
ae4e38c6d0 | ||
|
|
a9f3f1a4b2 | ||
|
|
8a73df4fe1 | ||
|
|
ea2e1ea8f0 | ||
|
|
e8aa91931d | ||
|
|
8d22a314a6 | ||
|
|
57ce2b8aa7 | ||
|
|
6b810cb3fb | ||
|
|
4f3a5dcc43 | ||
|
|
c3ae14cf73 | ||
|
|
b9c44b92d5 | ||
|
|
5a68b4ddbc | ||
|
|
18a722839b | ||
|
|
7370cb9be6 | ||
|
|
cc4df52f82 | ||
|
|
1cb4ef05a4 | ||
|
|
7da141101c | ||
|
|
2571e199c5 | ||
|
|
79e93f905e | ||
|
|
f562e4f835 | ||
|
|
47e220aaf3 | ||
|
|
9365154bfe | ||
|
|
afc6911c96 | ||
|
|
afa1ee7ffd | ||
|
|
5a102f6b53 | ||
|
|
af345a33f3 | ||
|
|
038b110a82 | ||
|
|
f3cd49d46e | ||
|
|
ca7d7c9d93 | ||
|
|
1addeb4b59 | ||
|
|
6ea4884b0c | ||
|
|
aed9b1013e | ||
|
|
6962536b4a | ||
|
|
7e59d040aa | ||
|
|
e7c67da2c2 | ||
|
|
c44571bc36 | ||
|
|
ca257650d4 | ||
|
|
6a9962d2bb | ||
|
|
9492569a2c | ||
|
|
61e711620d | ||
|
|
3cf82505bb | ||
|
|
53bcbc58f5 | ||
|
|
42f3990f7a | ||
|
|
456205da17 | ||
|
|
ca0684700e | ||
|
|
6a702821ef | ||
|
|
682d271f6f | ||
|
|
e872c253b1 | ||
|
|
28633c9983 | ||
|
|
1cdd4b5980 | ||
|
|
89ceecc870 | ||
|
|
687cccdb99 | ||
|
|
c84f8465b8 | ||
|
|
4b5c481b7a | ||
|
|
2caa1b166d | ||
|
|
1b6ebede7b | ||
|
|
017d38eee2 | ||
|
|
78eb6b0338 | ||
|
|
3e8e0f6ddf | ||
|
|
8213f62d3b | ||
|
|
233740a40e | ||
|
|
8c5fcfd0fd | ||
|
|
6d7b231196 | ||
|
|
31ca314b02 | ||
|
|
0db304f1ee | ||
|
|
a3cb3e03f4 | ||
|
|
641a6cfdb7 | ||
|
|
f27471cea7 | ||
|
|
47508b8d6c | ||
|
|
28e0242907 | ||
|
|
96523ca01f | ||
|
|
c10a6fdab1 |
1
.gitattributes
vendored
1
.gitattributes
vendored
@@ -4,3 +4,4 @@
|
||||
* text=auto
|
||||
docker/** text eol=lf
|
||||
tests/test_model_probe/stripped_models/** filter=lfs diff=lfs merge=lfs -text
|
||||
tests/model_identification/stripped_models/** filter=lfs diff=lfs merge=lfs -text
|
||||
|
||||
1
.github/pull_request_template.md
vendored
1
.github/pull_request_template.md
vendored
@@ -18,5 +18,6 @@
|
||||
|
||||
- [ ] _The PR has a short but descriptive title, suitable for a changelog_
|
||||
- [ ] _Tests added / updated (if applicable)_
|
||||
- [ ] _❗Changes to a redux slice have a corresponding migration_
|
||||
- [ ] _Documentation added / updated (if applicable)_
|
||||
- [ ] _Updated `What's New` copy (if doing a release after this PR)_
|
||||
|
||||
8
.github/workflows/build-container.yml
vendored
8
.github/workflows/build-container.yml
vendored
@@ -45,6 +45,9 @@ jobs:
|
||||
steps:
|
||||
- name: Free up more disk space on the runner
|
||||
# https://github.com/actions/runner-images/issues/2840#issuecomment-1284059930
|
||||
# the /mnt dir has 70GBs of free space
|
||||
# /dev/sda1 74G 28K 70G 1% /mnt
|
||||
# According to some online posts the /mnt is not always there, so checking before setting docker to use it
|
||||
run: |
|
||||
echo "----- Free space before cleanup"
|
||||
df -h
|
||||
@@ -52,6 +55,11 @@ jobs:
|
||||
sudo rm -rf "$AGENT_TOOLSDIRECTORY"
|
||||
sudo swapoff /mnt/swapfile
|
||||
sudo rm -rf /mnt/swapfile
|
||||
if [ -d /mnt ]; then
|
||||
sudo chmod -R 777 /mnt
|
||||
echo '{"data-root": "/mnt/docker-root"}' | sudo tee /etc/docker/daemon.json
|
||||
sudo systemctl restart docker
|
||||
fi
|
||||
echo "----- Free space after cleanup"
|
||||
df -h
|
||||
|
||||
|
||||
30
.github/workflows/lfs-checks.yml
vendored
Normal file
30
.github/workflows/lfs-checks.yml
vendored
Normal file
@@ -0,0 +1,30 @@
|
||||
# Checks that large files and LFS-tracked files are properly checked in with pointer format.
|
||||
# Uses https://github.com/ppremk/lfs-warning to detect LFS issues.
|
||||
|
||||
name: 'lfs checks'
|
||||
|
||||
on:
|
||||
push:
|
||||
branches:
|
||||
- 'main'
|
||||
pull_request:
|
||||
types:
|
||||
- 'ready_for_review'
|
||||
- 'opened'
|
||||
- 'synchronize'
|
||||
merge_group:
|
||||
workflow_dispatch:
|
||||
|
||||
jobs:
|
||||
lfs-check:
|
||||
runs-on: ubuntu-latest
|
||||
timeout-minutes: 5
|
||||
permissions:
|
||||
# Required to label and comment on the PRs
|
||||
pull-requests: write
|
||||
steps:
|
||||
- name: checkout
|
||||
uses: actions/checkout@v4
|
||||
|
||||
- name: check lfs files
|
||||
uses: ppremk/lfs-warning@v3.3
|
||||
12
.github/workflows/typegen-checks.yml
vendored
12
.github/workflows/typegen-checks.yml
vendored
@@ -39,6 +39,18 @@ jobs:
|
||||
- name: checkout
|
||||
uses: actions/checkout@v4
|
||||
|
||||
- name: Free up more disk space on the runner
|
||||
# https://github.com/actions/runner-images/issues/2840#issuecomment-1284059930
|
||||
run: |
|
||||
echo "----- Free space before cleanup"
|
||||
df -h
|
||||
sudo rm -rf /usr/share/dotnet
|
||||
sudo rm -rf "$AGENT_TOOLSDIRECTORY"
|
||||
sudo swapoff /mnt/swapfile
|
||||
sudo rm -rf /mnt/swapfile
|
||||
echo "----- Free space after cleanup"
|
||||
df -h
|
||||
|
||||
- name: check for changed files
|
||||
if: ${{ inputs.always_run != true }}
|
||||
id: changed-files
|
||||
|
||||
@@ -22,6 +22,10 @@
|
||||
## GPU_DRIVER can be set to either `cuda` or `rocm` to enable GPU support in the container accordingly.
|
||||
# GPU_DRIVER=cuda #| rocm
|
||||
|
||||
## If you are using ROCM, you will need to ensure that the render group within the container and the host system use the same group ID.
|
||||
## To obtain the group ID of the render group on the host system, run `getent group render` and grab the number.
|
||||
# RENDER_GROUP_ID=
|
||||
|
||||
## CONTAINER_UID can be set to the UID of the user on the host system that should own the files in the container.
|
||||
## It is usually not necessary to change this. Use `id -u` on the host system to find the UID.
|
||||
# CONTAINER_UID=1000
|
||||
|
||||
@@ -43,7 +43,6 @@ ENV \
|
||||
UV_MANAGED_PYTHON=1 \
|
||||
UV_LINK_MODE=copy \
|
||||
UV_PROJECT_ENVIRONMENT=/opt/venv \
|
||||
UV_INDEX="https://download.pytorch.org/whl/cu124" \
|
||||
INVOKEAI_ROOT=/invokeai \
|
||||
INVOKEAI_HOST=0.0.0.0 \
|
||||
INVOKEAI_PORT=9090 \
|
||||
@@ -74,19 +73,17 @@ RUN --mount=type=cache,target=/root/.cache/uv \
|
||||
--mount=type=bind,source=uv.lock,target=uv.lock \
|
||||
# this is just to get the package manager to recognize that the project exists, without making changes to the docker layer
|
||||
--mount=type=bind,source=invokeai/version,target=invokeai/version \
|
||||
if [ "$TARGETPLATFORM" = "linux/arm64" ] || [ "$GPU_DRIVER" = "cpu" ]; then UV_INDEX="https://download.pytorch.org/whl/cpu"; \
|
||||
elif [ "$GPU_DRIVER" = "rocm" ]; then UV_INDEX="https://download.pytorch.org/whl/rocm6.2"; \
|
||||
fi && \
|
||||
uv sync --frozen
|
||||
|
||||
# build patchmatch
|
||||
RUN cd /usr/lib/$(uname -p)-linux-gnu/pkgconfig/ && ln -sf opencv4.pc opencv.pc
|
||||
RUN python -c "from patchmatch import patch_match"
|
||||
ulimit -n 30000 && \
|
||||
uv sync --extra $GPU_DRIVER --frozen
|
||||
|
||||
# Link amdgpu.ids for ROCm builds
|
||||
# contributed by https://github.com/Rubonnek
|
||||
RUN mkdir -p "/opt/amdgpu/share/libdrm" &&\
|
||||
ln -s "/usr/share/libdrm/amdgpu.ids" "/opt/amdgpu/share/libdrm/amdgpu.ids"
|
||||
ln -s "/usr/share/libdrm/amdgpu.ids" "/opt/amdgpu/share/libdrm/amdgpu.ids" && groupadd render
|
||||
|
||||
# build patchmatch
|
||||
RUN cd /usr/lib/$(uname -p)-linux-gnu/pkgconfig/ && ln -sf opencv4.pc opencv.pc
|
||||
RUN python -c "from patchmatch import patch_match"
|
||||
|
||||
RUN mkdir -p ${INVOKEAI_ROOT} && chown -R ${CONTAINER_UID}:${CONTAINER_GID} ${INVOKEAI_ROOT}
|
||||
|
||||
@@ -105,8 +102,6 @@ COPY invokeai ${INVOKEAI_SRC}/invokeai
|
||||
RUN --mount=type=cache,target=/root/.cache/uv \
|
||||
--mount=type=bind,source=pyproject.toml,target=pyproject.toml \
|
||||
--mount=type=bind,source=uv.lock,target=uv.lock \
|
||||
if [ "$TARGETPLATFORM" = "linux/arm64" ] || [ "$GPU_DRIVER" = "cpu" ]; then UV_INDEX="https://download.pytorch.org/whl/cpu"; \
|
||||
elif [ "$GPU_DRIVER" = "rocm" ]; then UV_INDEX="https://download.pytorch.org/whl/rocm6.2"; \
|
||||
fi && \
|
||||
uv pip install -e .
|
||||
ulimit -n 30000 && \
|
||||
uv pip install -e .[$GPU_DRIVER]
|
||||
|
||||
|
||||
136
docker/Dockerfile-rocm-full
Normal file
136
docker/Dockerfile-rocm-full
Normal file
@@ -0,0 +1,136 @@
|
||||
# syntax=docker/dockerfile:1.4
|
||||
|
||||
#### Web UI ------------------------------------
|
||||
|
||||
FROM docker.io/node:22-slim AS web-builder
|
||||
ENV PNPM_HOME="/pnpm"
|
||||
ENV PATH="$PNPM_HOME:$PATH"
|
||||
RUN corepack use pnpm@8.x
|
||||
RUN corepack enable
|
||||
|
||||
WORKDIR /build
|
||||
COPY invokeai/frontend/web/ ./
|
||||
RUN --mount=type=cache,target=/pnpm/store \
|
||||
pnpm install --frozen-lockfile
|
||||
RUN npx vite build
|
||||
|
||||
## Backend ---------------------------------------
|
||||
|
||||
FROM library/ubuntu:24.04
|
||||
|
||||
ARG DEBIAN_FRONTEND=noninteractive
|
||||
RUN rm -f /etc/apt/apt.conf.d/docker-clean; echo 'Binary::apt::APT::Keep-Downloaded-Packages "true";' > /etc/apt/apt.conf.d/keep-cache
|
||||
RUN --mount=type=cache,target=/var/cache/apt \
|
||||
--mount=type=cache,target=/var/lib/apt \
|
||||
apt update && apt install -y --no-install-recommends \
|
||||
ca-certificates \
|
||||
git \
|
||||
gosu \
|
||||
libglib2.0-0 \
|
||||
libgl1 \
|
||||
libglx-mesa0 \
|
||||
build-essential \
|
||||
libopencv-dev \
|
||||
libstdc++-10-dev \
|
||||
wget
|
||||
|
||||
ENV \
|
||||
PYTHONUNBUFFERED=1 \
|
||||
PYTHONDONTWRITEBYTECODE=1 \
|
||||
VIRTUAL_ENV=/opt/venv \
|
||||
INVOKEAI_SRC=/opt/invokeai \
|
||||
PYTHON_VERSION=3.12 \
|
||||
UV_PYTHON=3.12 \
|
||||
UV_COMPILE_BYTECODE=1 \
|
||||
UV_MANAGED_PYTHON=1 \
|
||||
UV_LINK_MODE=copy \
|
||||
UV_PROJECT_ENVIRONMENT=/opt/venv \
|
||||
INVOKEAI_ROOT=/invokeai \
|
||||
INVOKEAI_HOST=0.0.0.0 \
|
||||
INVOKEAI_PORT=9090 \
|
||||
PATH="/opt/venv/bin:$PATH" \
|
||||
CONTAINER_UID=${CONTAINER_UID:-1000} \
|
||||
CONTAINER_GID=${CONTAINER_GID:-1000}
|
||||
|
||||
ARG GPU_DRIVER=cuda
|
||||
|
||||
# Install `uv` for package management
|
||||
COPY --from=ghcr.io/astral-sh/uv:0.6.9 /uv /uvx /bin/
|
||||
|
||||
# Install python & allow non-root user to use it by traversing the /root dir without read permissions
|
||||
RUN --mount=type=cache,target=/root/.cache/uv \
|
||||
uv python install ${PYTHON_VERSION} && \
|
||||
# chmod --recursive a+rX /root/.local/share/uv/python
|
||||
chmod 711 /root
|
||||
|
||||
WORKDIR ${INVOKEAI_SRC}
|
||||
|
||||
# Install project's dependencies as a separate layer so they aren't rebuilt every commit.
|
||||
# bind-mount instead of copy to defer adding sources to the image until next layer.
|
||||
#
|
||||
# NOTE: there are no pytorch builds for arm64 + cuda, only cpu
|
||||
# x86_64/CUDA is the default
|
||||
RUN --mount=type=cache,target=/root/.cache/uv \
|
||||
--mount=type=bind,source=pyproject.toml,target=pyproject.toml \
|
||||
--mount=type=bind,source=uv.lock,target=uv.lock \
|
||||
# this is just to get the package manager to recognize that the project exists, without making changes to the docker layer
|
||||
--mount=type=bind,source=invokeai/version,target=invokeai/version \
|
||||
ulimit -n 30000 && \
|
||||
uv sync --extra $GPU_DRIVER --frozen
|
||||
|
||||
RUN --mount=type=cache,target=/var/cache/apt \
|
||||
--mount=type=cache,target=/var/lib/apt \
|
||||
if [ "$GPU_DRIVER" = "rocm" ]; then \
|
||||
wget -O /tmp/amdgpu-install.deb \
|
||||
https://repo.radeon.com/amdgpu-install/6.3.4/ubuntu/noble/amdgpu-install_6.3.60304-1_all.deb && \
|
||||
apt install -y /tmp/amdgpu-install.deb && \
|
||||
apt update && \
|
||||
amdgpu-install --usecase=rocm -y && \
|
||||
apt-get autoclean && \
|
||||
apt clean && \
|
||||
rm -rf /tmp/* /var/tmp/* && \
|
||||
usermod -a -G render ubuntu && \
|
||||
usermod -a -G video ubuntu && \
|
||||
echo "\\n/opt/rocm/lib\\n/opt/rocm/lib64" >> /etc/ld.so.conf.d/rocm.conf && \
|
||||
ldconfig && \
|
||||
update-alternatives --auto rocm; \
|
||||
fi
|
||||
|
||||
## Heathen711: Leaving this for review input, will remove before merge
|
||||
# RUN --mount=type=cache,target=/var/cache/apt \
|
||||
# --mount=type=cache,target=/var/lib/apt \
|
||||
# if [ "$GPU_DRIVER" = "rocm" ]; then \
|
||||
# groupadd render && \
|
||||
# usermod -a -G render ubuntu && \
|
||||
# usermod -a -G video ubuntu; \
|
||||
# fi
|
||||
|
||||
## Link amdgpu.ids for ROCm builds
|
||||
## contributed by https://github.com/Rubonnek
|
||||
# RUN mkdir -p "/opt/amdgpu/share/libdrm" &&\
|
||||
# ln -s "/usr/share/libdrm/amdgpu.ids" "/opt/amdgpu/share/libdrm/amdgpu.ids"
|
||||
|
||||
# build patchmatch
|
||||
RUN cd /usr/lib/$(uname -p)-linux-gnu/pkgconfig/ && ln -sf opencv4.pc opencv.pc
|
||||
RUN python -c "from patchmatch import patch_match"
|
||||
|
||||
RUN mkdir -p ${INVOKEAI_ROOT} && chown -R ${CONTAINER_UID}:${CONTAINER_GID} ${INVOKEAI_ROOT}
|
||||
|
||||
COPY docker/docker-entrypoint.sh ./
|
||||
ENTRYPOINT ["/opt/invokeai/docker-entrypoint.sh"]
|
||||
CMD ["invokeai-web"]
|
||||
|
||||
# --link requires buldkit w/ dockerfile syntax 1.4, does not work with podman
|
||||
COPY --link --from=web-builder /build/dist ${INVOKEAI_SRC}/invokeai/frontend/web/dist
|
||||
|
||||
# add sources last to minimize image changes on code changes
|
||||
COPY invokeai ${INVOKEAI_SRC}/invokeai
|
||||
|
||||
# this should not increase image size because we've already installed dependencies
|
||||
# in a previous layer
|
||||
RUN --mount=type=cache,target=/root/.cache/uv \
|
||||
--mount=type=bind,source=pyproject.toml,target=pyproject.toml \
|
||||
--mount=type=bind,source=uv.lock,target=uv.lock \
|
||||
ulimit -n 30000 && \
|
||||
uv pip install -e .[$GPU_DRIVER]
|
||||
|
||||
@@ -47,8 +47,9 @@ services:
|
||||
|
||||
invokeai-rocm:
|
||||
<<: *invokeai
|
||||
devices:
|
||||
- /dev/kfd:/dev/kfd
|
||||
- /dev/dri:/dev/dri
|
||||
environment:
|
||||
- AMD_VISIBLE_DEVICES=all
|
||||
- RENDER_GROUP_ID=${RENDER_GROUP_ID}
|
||||
runtime: amd
|
||||
profiles:
|
||||
- rocm
|
||||
|
||||
@@ -21,6 +21,17 @@ _=$(id ${USER} 2>&1) || useradd -u ${USER_ID} ${USER}
|
||||
# ensure the UID is correct
|
||||
usermod -u ${USER_ID} ${USER} 1>/dev/null
|
||||
|
||||
## ROCM specific configuration
|
||||
# render group within the container must match the host render group
|
||||
# otherwise the container will not be able to access the host GPU.
|
||||
if [[ -v "RENDER_GROUP_ID" ]] && [[ ! -z "${RENDER_GROUP_ID}" ]]; then
|
||||
# ensure the render group exists
|
||||
groupmod -g ${RENDER_GROUP_ID} render
|
||||
usermod -a -G render ${USER}
|
||||
usermod -a -G video ${USER}
|
||||
fi
|
||||
|
||||
|
||||
### Set the $PUBLIC_KEY env var to enable SSH access.
|
||||
# We do not install openssh-server in the image by default to avoid bloat.
|
||||
# but it is useful to have the full SSH server e.g. on Runpod.
|
||||
|
||||
@@ -13,7 +13,7 @@ run() {
|
||||
|
||||
# parse .env file for build args
|
||||
build_args=$(awk '$1 ~ /=[^$]/ && $0 !~ /^#/ {print "--build-arg " $0 " "}' .env) &&
|
||||
profile="$(awk -F '=' '/GPU_DRIVER/ {print $2}' .env)"
|
||||
profile="$(awk -F '=' '/GPU_DRIVER=/ {print $2}' .env)"
|
||||
|
||||
# default to 'cuda' profile
|
||||
[[ -z "$profile" ]] && profile="cuda"
|
||||
@@ -30,7 +30,7 @@ run() {
|
||||
|
||||
printf "%s\n" "starting service $service_name"
|
||||
docker compose --profile "$profile" up -d "$service_name"
|
||||
docker compose logs -f
|
||||
docker compose --profile "$profile" logs -f
|
||||
}
|
||||
|
||||
run
|
||||
|
||||
@@ -265,7 +265,7 @@ If the key is unrecognized, this call raises an
|
||||
|
||||
#### exists(key) -> AnyModelConfig
|
||||
|
||||
Returns True if a model with the given key exists in the databsae.
|
||||
Returns True if a model with the given key exists in the database.
|
||||
|
||||
#### search_by_path(path) -> AnyModelConfig
|
||||
|
||||
@@ -718,7 +718,7 @@ When downloading remote models is implemented, additional
|
||||
configuration information, such as list of trigger terms, will be
|
||||
retrieved from the HuggingFace and Civitai model repositories.
|
||||
|
||||
The probed values can be overriden by providing a dictionary in the
|
||||
The probed values can be overridden by providing a dictionary in the
|
||||
optional `config` argument passed to `import_model()`. You may provide
|
||||
overriding values for any of the model's configuration
|
||||
attributes. Here is an example of setting the
|
||||
@@ -841,7 +841,7 @@ variable.
|
||||
|
||||
#### installer.start(invoker)
|
||||
|
||||
The `start` method is called by the API intialization routines when
|
||||
The `start` method is called by the API initialization routines when
|
||||
the API starts up. Its effect is to call `sync_to_config()` to
|
||||
synchronize the model record store database with what's currently on
|
||||
disk.
|
||||
|
||||
@@ -16,7 +16,7 @@ We thank [all contributors](https://github.com/invoke-ai/InvokeAI/graphs/contrib
|
||||
- @psychedelicious (Spencer Mabrito) - Web Team Leader
|
||||
- @joshistoast (Josh Corbett) - Web Development
|
||||
- @cheerio (Mary Rogers) - Lead Engineer & Web App Development
|
||||
- @ebr (Eugene Brodsky) - Cloud/DevOps/Sofware engineer; your friendly neighbourhood cluster-autoscaler
|
||||
- @ebr (Eugene Brodsky) - Cloud/DevOps/Software engineer; your friendly neighbourhood cluster-autoscaler
|
||||
- @sunija - Standalone version
|
||||
- @brandon (Brandon Rising) - Platform, Infrastructure, Backend Systems
|
||||
- @ryanjdick (Ryan Dick) - Machine Learning & Training
|
||||
|
||||
@@ -69,34 +69,34 @@ The following commands vary depending on the version of Invoke being installed a
|
||||
- If you have an Nvidia 20xx series GPU or older, use `invokeai[xformers]`.
|
||||
- If you have an Nvidia 30xx series GPU or newer, or do not have an Nvidia GPU, use `invokeai`.
|
||||
|
||||
7. Determine the `PyPI` index URL to use for installation, if any. This is necessary to get the right version of torch installed.
|
||||
7. Determine the torch backend to use for installation, if any. This is necessary to get the right version of torch installed. This is acheived by using [UV's built in torch support.](https://docs.astral.sh/uv/guides/integration/pytorch/#automatic-backend-selection)
|
||||
|
||||
=== "Invoke v5.12 and later"
|
||||
|
||||
- If you are on Windows or Linux with an Nvidia GPU, use `https://download.pytorch.org/whl/cu128`.
|
||||
- If you are on Linux with no GPU, use `https://download.pytorch.org/whl/cpu`.
|
||||
- If you are on Linux with an AMD GPU, use `https://download.pytorch.org/whl/rocm6.2.4`.
|
||||
- **In all other cases, do not use an index.**
|
||||
- If you are on Windows or Linux with an Nvidia GPU, use `--torch-backend=cu128`.
|
||||
- If you are on Linux with no GPU, use `--torch-backend=cpu`.
|
||||
- If you are on Linux with an AMD GPU, use `--torch-backend=rocm6.3`.
|
||||
- **In all other cases, do not use a torch backend.**
|
||||
|
||||
=== "Invoke v5.10.0 to v5.11.0"
|
||||
|
||||
- If you are on Windows or Linux with an Nvidia GPU, use `https://download.pytorch.org/whl/cu126`.
|
||||
- If you are on Linux with no GPU, use `https://download.pytorch.org/whl/cpu`.
|
||||
- If you are on Linux with an AMD GPU, use `https://download.pytorch.org/whl/rocm6.2.4`.
|
||||
- If you are on Windows or Linux with an Nvidia GPU, use `--torch-backend=cu126`.
|
||||
- If you are on Linux with no GPU, use `--torch-backend=cpu`.
|
||||
- If you are on Linux with an AMD GPU, use `--torch-backend=rocm6.2.4`.
|
||||
- **In all other cases, do not use an index.**
|
||||
|
||||
=== "Invoke v5.0.0 to v5.9.1"
|
||||
|
||||
- If you are on Windows with an Nvidia GPU, use `https://download.pytorch.org/whl/cu124`.
|
||||
- If you are on Linux with no GPU, use `https://download.pytorch.org/whl/cpu`.
|
||||
- If you are on Linux with an AMD GPU, use `https://download.pytorch.org/whl/rocm6.1`.
|
||||
- If you are on Windows with an Nvidia GPU, use `--torch-backend=cu124`.
|
||||
- If you are on Linux with no GPU, use `--torch-backend=cpu`.
|
||||
- If you are on Linux with an AMD GPU, use `--torch-backend=rocm6.1`.
|
||||
- **In all other cases, do not use an index.**
|
||||
|
||||
=== "Invoke v4"
|
||||
|
||||
- If you are on Windows with an Nvidia GPU, use `https://download.pytorch.org/whl/cu124`.
|
||||
- If you are on Linux with no GPU, use `https://download.pytorch.org/whl/cpu`.
|
||||
- If you are on Linux with an AMD GPU, use `https://download.pytorch.org/whl/rocm5.2`.
|
||||
- If you are on Windows with an Nvidia GPU, use `--torch-backend=cu124`.
|
||||
- If you are on Linux with no GPU, use `--torch-backend=cpu`.
|
||||
- If you are on Linux with an AMD GPU, use `--torch-backend=rocm5.2`.
|
||||
- **In all other cases, do not use an index.**
|
||||
|
||||
8. Install the `invokeai` package. Substitute the package specifier and version.
|
||||
@@ -105,10 +105,10 @@ The following commands vary depending on the version of Invoke being installed a
|
||||
uv pip install <PACKAGE_SPECIFIER>==<VERSION> --python 3.12 --python-preference only-managed --force-reinstall
|
||||
```
|
||||
|
||||
If you determined you needed to use a `PyPI` index URL in the previous step, you'll need to add `--index=<INDEX_URL>` like this:
|
||||
If you determined you needed to use a torch backend in the previous step, you'll need to set the backend like this:
|
||||
|
||||
```sh
|
||||
uv pip install <PACKAGE_SPECIFIER>==<VERSION> --python 3.12 --python-preference only-managed --index=<INDEX_URL> --force-reinstall
|
||||
uv pip install <PACKAGE_SPECIFIER>==<VERSION> --python 3.12 --python-preference only-managed --torch-backend=<VERSION> --force-reinstall
|
||||
```
|
||||
|
||||
9. Deactivate and reactivate your venv so that the invokeai-specific commands become available in the environment:
|
||||
|
||||
@@ -33,30 +33,45 @@ Hardware requirements vary significantly depending on model and image output siz
|
||||
|
||||
More detail on system requirements can be found [here](./requirements.md).
|
||||
|
||||
## Step 2: Download
|
||||
## Step 2: Download and Set Up the Launcher
|
||||
|
||||
Download the most recent launcher for your operating system:
|
||||
The Launcher manages your Invoke install. Follow these instructions to download and set up the Launcher.
|
||||
|
||||
- [Download for Windows](https://download.invoke.ai/Invoke%20Community%20Edition.exe)
|
||||
- [Download for macOS](https://download.invoke.ai/Invoke%20Community%20Edition.dmg)
|
||||
- [Download for Linux](https://download.invoke.ai/Invoke%20Community%20Edition.AppImage)
|
||||
!!! info "Instructions for each OS"
|
||||
|
||||
## Step 3: Install or Update
|
||||
=== "Windows"
|
||||
|
||||
Run the launcher you just downloaded, click **Install** and follow the instructions to get set up.
|
||||
- [Download for Windows](https://github.com/invoke-ai/launcher/releases/latest/download/Invoke.Community.Edition.Setup.latest.exe)
|
||||
- Run the `EXE` to install the Launcher and start it.
|
||||
- A desktop shortcut will be created; use this to run the Launcher in the future.
|
||||
- You can delete the `EXE` file you downloaded.
|
||||
|
||||
=== "macOS"
|
||||
|
||||
- [Download for macOS](https://github.com/invoke-ai/launcher/releases/latest/download/Invoke.Community.Edition-latest-arm64.dmg)
|
||||
- Open the `DMG` and drag the app into `Applications`.
|
||||
- Run the Launcher using its entry in `Applications`.
|
||||
- You can delete the `DMG` file you downloaded.
|
||||
|
||||
=== "Linux"
|
||||
|
||||
- [Download for Linux](https://github.com/invoke-ai/launcher/releases/latest/download/Invoke.Community.Edition-latest.AppImage)
|
||||
- You may need to edit the `AppImage` file properties and make it executable.
|
||||
- Optionally move the file to a location that does not require admin privileges and add a desktop shortcut for it.
|
||||
- Run the Launcher by double-clicking the `AppImage` or the shortcut you made.
|
||||
|
||||
## Step 3: Install Invoke
|
||||
|
||||
Run the Launcher you just set up if you haven't already. Click **Install** and follow the instructions to install (or update) Invoke.
|
||||
|
||||
If you have an existing Invoke installation, you can select it and let the launcher manage the install. You'll be able to update or launch the installation.
|
||||
|
||||
!!! warning "Problem running the launcher on macOS"
|
||||
!!! tip "Updating"
|
||||
|
||||
macOS may not allow you to run the launcher. We are working to resolve this by signing the launcher executable. Until that is done, you can manually flag the launcher as safe:
|
||||
The Launcher will check for updates for itself _and_ Invoke.
|
||||
|
||||
- Open the **Invoke Community Edition.dmg** file.
|
||||
- Drag the launcher to **Applications**.
|
||||
- Open a terminal.
|
||||
- Run `xattr -d 'com.apple.quarantine' /Applications/Invoke\ Community\ Edition.app`.
|
||||
|
||||
You should now be able to run the launcher.
|
||||
- When the Launcher detects an update is available for itself, you'll get a small popup window. Click through this and the Launcher will update itself.
|
||||
- When the Launcher detects an update for Invoke, you'll see a small green alert in the Launcher. Click that and follow the instructions to update Invoke.
|
||||
|
||||
## Step 4: Launch
|
||||
|
||||
|
||||
@@ -41,7 +41,7 @@ Nodes have a "Use Cache" option in their footer. This allows for performance imp
|
||||
|
||||
There are several node grouping concepts that can be examined with a narrow focus. These (and other) groupings can be pieced together to make up functional graph setups, and are important to understanding how groups of nodes work together as part of a whole. Note that the screenshots below aren't examples of complete functioning node graphs (see Examples).
|
||||
|
||||
### Noise
|
||||
### Create Latent Noise
|
||||
|
||||
An initial noise tensor is necessary for the latent diffusion process. As a result, the Denoising node requires a noise node input.
|
||||
|
||||
|
||||
@@ -4,21 +4,22 @@ These are nodes that have been developed by the community, for the community. If
|
||||
|
||||
If you'd like to submit a node for the community, please refer to the [node creation overview](contributingNodes.md).
|
||||
|
||||
To use a node, add the node to the `nodes` folder found in your InvokeAI install location.
|
||||
To use a node, add the node to the `nodes` folder found in your InvokeAI install location.
|
||||
|
||||
The suggested method is to use `git clone` to clone the repository the node is found in. This allows for easy updates of the node in the future.
|
||||
The suggested method is to use `git clone` to clone the repository the node is found in. This allows for easy updates of the node in the future.
|
||||
|
||||
If you'd prefer, you can also just download the whole node folder from the linked repository and add it to the `nodes` folder.
|
||||
If you'd prefer, you can also just download the whole node folder from the linked repository and add it to the `nodes` folder.
|
||||
|
||||
To use a community workflow, download the `.json` node graph file and load it into Invoke AI via the **Load Workflow** button in the Workflow Editor.
|
||||
To use a community workflow, download the `.json` node graph file and load it into Invoke AI via the **Load Workflow** button in the Workflow Editor.
|
||||
|
||||
- Community Nodes
|
||||
+ [Anamorphic Tools](#anamorphic-tools)
|
||||
+ [Adapters-Linked](#adapters-linked-nodes)
|
||||
+ [Autostereogram](#autostereogram-nodes)
|
||||
+ [Average Images](#average-images)
|
||||
+ [BiRefNet Background Removal](#birefnet-background-removal)
|
||||
+ [Clean Image Artifacts After Cut](#clean-image-artifacts-after-cut)
|
||||
+ [Close Color Mask](#close-color-mask)
|
||||
+ [Close Color Mask](#close-color-mask)
|
||||
+ [Clothing Mask](#clothing-mask)
|
||||
+ [Contrast Limited Adaptive Histogram Equalization](#contrast-limited-adaptive-histogram-equalization)
|
||||
+ [Curves](#curves)
|
||||
@@ -34,6 +35,7 @@ To use a community workflow, download the `.json` node graph file and load it in
|
||||
+ [Hand Refiner with MeshGraphormer](#hand-refiner-with-meshgraphormer)
|
||||
+ [Image and Mask Composition Pack](#image-and-mask-composition-pack)
|
||||
+ [Image Dominant Color](#image-dominant-color)
|
||||
+ [Image Export](#image-export)
|
||||
+ [Image to Character Art Image Nodes](#image-to-character-art-image-nodes)
|
||||
+ [Image Picker](#image-picker)
|
||||
+ [Image Resize Plus](#image-resize-plus)
|
||||
@@ -51,7 +53,7 @@ To use a community workflow, download the `.json` node graph file and load it in
|
||||
+ [Prompt Tools](#prompt-tools)
|
||||
+ [Remote Image](#remote-image)
|
||||
+ [BriaAI Background Remove](#briaai-remove-background)
|
||||
+ [Remove Background](#remove-background)
|
||||
+ [Remove Background](#remove-background)
|
||||
+ [Retroize](#retroize)
|
||||
+ [Stereogram](#stereogram-nodes)
|
||||
+ [Size Stepper Nodes](#size-stepper-nodes)
|
||||
@@ -81,7 +83,7 @@ To use a community workflow, download the `.json` node graph file and load it in
|
||||
- `IP-Adapter-Linked` - Collects IP-Adapter info to pass to other nodes.
|
||||
- `T2I-Adapter-Linked` - Collects T2I-Adapter info to pass to other nodes.
|
||||
|
||||
Note: These are inherited from the core nodes so any update to the core nodes should be reflected in these.
|
||||
Note: These are inherited from the core nodes so any update to the core nodes should be reflected in these.
|
||||
|
||||
**Node Link:** https://github.com/skunkworxdark/adapters-linked-nodes
|
||||
|
||||
@@ -103,6 +105,20 @@ Note: These are inherited from the core nodes so any update to the core nodes sh
|
||||
|
||||
**Node Link:** https://github.com/JPPhoto/average-images-node
|
||||
|
||||
--------------------------------
|
||||
### BiRefNet Background Removal
|
||||
|
||||
**Description:** Remove image backgrounds using BiRefNet (Bilateral Reference Network), a high-quality segmentation model. Supports multiple model variants including standard, high-resolution, matting, portrait, and specialized models for different use cases.
|
||||
|
||||
**Node Link:** https://github.com/veeliks/invoke_birefnet
|
||||
|
||||
**Output Examples**
|
||||
|
||||
<section>
|
||||
<img src="https://raw.githubusercontent.com/veeliks/invoke_birefnet/main/.readme/example_before_removal.png" width="49%" alt="Before background removal">
|
||||
<img src="https://raw.githubusercontent.com/veeliks/invoke_birefnet/main/.readme/example_after_removal.png" width="49%" alt="After background removal">
|
||||
</section>
|
||||
|
||||
--------------------------------
|
||||
### Clean Image Artifacts After Cut
|
||||
|
||||
@@ -216,7 +232,7 @@ This includes 3 Nodes:
|
||||
|
||||
**Node Link:** https://github.com/mickr777/GPT2RandomPromptMaker
|
||||
|
||||
**Output Examples**
|
||||
**Output Examples**
|
||||
|
||||
Generated Prompt: An enchanted weapon will be usable by any character regardless of their alignment.
|
||||
|
||||
@@ -231,7 +247,7 @@ Generated Prompt: An enchanted weapon will be usable by any character regardless
|
||||
|
||||
**Example Node Graph:** https://github.com/mildmisery/invokeai-GridToGifNode/blob/main/Grid%20to%20Gif%20Example%20Workflow.json
|
||||
|
||||
**Output Examples**
|
||||
**Output Examples**
|
||||
|
||||
<img src="https://raw.githubusercontent.com/mildmisery/invokeai-GridToGifNode/main/input.png" width="300" />
|
||||
<img src="https://raw.githubusercontent.com/mildmisery/invokeai-GridToGifNode/main/output.gif" width="300" />
|
||||
@@ -293,7 +309,7 @@ This includes 15 Nodes:
|
||||
- *Text Mask (simple 2D)* - create and position a white on black (or black on white) line of text using any font locally available to Invoke.
|
||||
|
||||
**Node Link:** https://github.com/dwringer/composition-nodes
|
||||
|
||||
|
||||
</br><img src="https://raw.githubusercontent.com/dwringer/composition-nodes/main/composition_pack_overview.jpg" width="500" />
|
||||
|
||||
--------------------------------
|
||||
@@ -306,6 +322,23 @@ Node Link: https://github.com/VeyDlin/image-dominant-color-node
|
||||
View:
|
||||
</br><img src="https://raw.githubusercontent.com/VeyDlin/image-dominant-color-node/master/.readme/node.png" width="500" />
|
||||
|
||||
--------------------------------
|
||||
### Image Export
|
||||
|
||||
**Description:** Export images in multiple formats (AVIF, JPEG, PNG, TIFF, WebP) with format-specific compression and quality options.
|
||||
|
||||
**Node Link:** https://github.com/veeliks/invoke_image_export
|
||||
|
||||
**Nodes:**
|
||||
|
||||
<section>
|
||||
<img src="https://raw.githubusercontent.com/veeliks/invoke_image_export/main/.readme/node_avif.png" width="19%" alt="Save Image as AVIF">
|
||||
<img src="https://raw.githubusercontent.com/veeliks/invoke_image_export/main/.readme/node_jpeg.png" width="19%" alt="Save Image as JPEG">
|
||||
<img src="https://raw.githubusercontent.com/veeliks/invoke_image_export/main/.readme/node_png.png" width="19%" alt="Save Image as PNG">
|
||||
<img src="https://raw.githubusercontent.com/veeliks/invoke_image_export/main/.readme/node_tiff.png" width="19%" alt="Save Image as TIFF">
|
||||
<img src="https://raw.githubusercontent.com/veeliks/invoke_image_export/main/.readme/node_webp.png" width="19%" alt="Save Image as WebP">
|
||||
</section>
|
||||
|
||||
--------------------------------
|
||||
### Image to Character Art Image Nodes
|
||||
|
||||
@@ -352,7 +385,7 @@ View:
|
||||
|
||||
**Node Link:** https://github.com/helix4u/load_video_frame
|
||||
|
||||
**Output Example:**
|
||||
**Output Example:**
|
||||
<img src="https://raw.githubusercontent.com/helix4u/load_video_frame/refs/heads/main/_git_assets/dance1736978273.gif" width="500" />
|
||||
|
||||
--------------------------------
|
||||
@@ -364,7 +397,7 @@ View:
|
||||
|
||||
**Example Node Graph:** https://gitlab.com/srcrr/shift3d/-/raw/main/example-workflow.json?ref_type=heads&inline=false
|
||||
|
||||
**Output Examples**
|
||||
**Output Examples**
|
||||
|
||||
<img src="https://gitlab.com/srcrr/shift3d/-/raw/main/example-1.png" width="300" />
|
||||
<img src="https://gitlab.com/srcrr/shift3d/-/raw/main/example-2.png" width="300" />
|
||||
@@ -386,13 +419,13 @@ View:
|
||||
- Option to only transfer luminance channel.
|
||||
- Option to save output as grayscale
|
||||
|
||||
A good use case for this node is to normalize the colors of an image that has been through the tiled scaling workflow of my XYGrid Nodes.
|
||||
A good use case for this node is to normalize the colors of an image that has been through the tiled scaling workflow of my XYGrid Nodes.
|
||||
|
||||
See full docs here: https://github.com/skunkworxdark/Prompt-tools-nodes/edit/main/README.md
|
||||
|
||||
**Node Link:** https://github.com/skunkworxdark/match_histogram
|
||||
|
||||
**Output Examples**
|
||||
**Output Examples**
|
||||
|
||||
<img src="https://github.com/skunkworxdark/match_histogram/assets/21961335/ed12f329-a0ef-444a-9bae-129ed60d6097" />
|
||||
|
||||
@@ -410,12 +443,12 @@ See full docs here: https://github.com/skunkworxdark/Prompt-tools-nodes/edit/mai
|
||||
- `Metadata To Bool` - Extracts Bool types from metadata
|
||||
- `Metadata To Model` - Extracts model types from metadata
|
||||
- `Metadata To SDXL Model` - Extracts SDXL model types from metadata
|
||||
- `Metadata To LoRAs` - Extracts Loras from metadata.
|
||||
- `Metadata To LoRAs` - Extracts Loras from metadata.
|
||||
- `Metadata To SDXL LoRAs` - Extracts SDXL Loras from metadata
|
||||
- `Metadata To ControlNets` - Extracts ControNets from metadata
|
||||
- `Metadata To IP-Adapters` - Extracts IP-Adapters from metadata
|
||||
- `Metadata To T2I-Adapters` - Extracts T2I-Adapters from metadata
|
||||
- `Denoise Latents + Metadata` - This is an inherited version of the existing `Denoise Latents` node but with a metadata input and output.
|
||||
- `Denoise Latents + Metadata` - This is an inherited version of the existing `Denoise Latents` node but with a metadata input and output.
|
||||
|
||||
**Node Link:** https://github.com/skunkworxdark/metadata-linked-nodes
|
||||
|
||||
@@ -445,7 +478,7 @@ View:
|
||||
|
||||
**Example Node Graph:** https://github.com/Jonseed/Ollama-Node/blob/main/Ollama-Node-Flux-example.json
|
||||
|
||||
**View:**
|
||||
**View:**
|
||||
|
||||
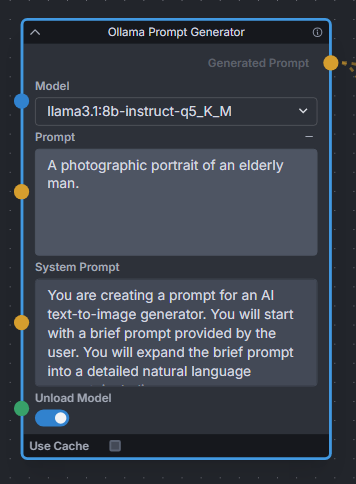
|
||||
|
||||
@@ -454,7 +487,7 @@ View:
|
||||
|
||||
<img src="https://raw.githubusercontent.com/AIrjen/OneButtonPrompt_X_InvokeAI/refs/heads/main/images/background.png" width="800" />
|
||||
|
||||
**Description:** an extensive suite of auto prompt generation and prompt helper nodes based on extensive logic. Get creative with the best prompt generator in the world.
|
||||
**Description:** an extensive suite of auto prompt generation and prompt helper nodes based on extensive logic. Get creative with the best prompt generator in the world.
|
||||
|
||||
The main node generates interesting prompts based on a set of parameters. There are also some additional nodes such as Auto Negative Prompt, One Button Artify, Create Prompt Variant and other cool prompt toys to play around with.
|
||||
|
||||
@@ -491,14 +524,14 @@ a Text-Generation-Webui instance (might work remotely too, but I never tried it)
|
||||
This node works best with SDXL models, especially as the style can be described independently of the LLM's output.
|
||||
|
||||
--------------------------------
|
||||
### Prompt Tools
|
||||
### Prompt Tools
|
||||
|
||||
**Description:** A set of InvokeAI nodes that add general prompt (string) manipulation tools. Designed to accompany the `Prompts From File` node and other prompt generation nodes.
|
||||
|
||||
1. `Prompt To File` - saves a prompt or collection of prompts to a file. one per line. There is an append/overwrite option.
|
||||
2. `PTFields Collect` - Converts image generation fields into a Json format string that can be passed to Prompt to file.
|
||||
2. `PTFields Collect` - Converts image generation fields into a Json format string that can be passed to Prompt to file.
|
||||
3. `PTFields Expand` - Takes Json string and converts it to individual generation parameters. This can be fed from the Prompts to file node.
|
||||
4. `Prompt Strength` - Formats prompt with strength like the weighted format of compel
|
||||
4. `Prompt Strength` - Formats prompt with strength like the weighted format of compel
|
||||
5. `Prompt Strength Combine` - Combines weighted prompts for .and()/.blend()
|
||||
6. `CSV To Index String` - Gets a string from a CSV by index. Includes a Random index option
|
||||
|
||||
@@ -513,7 +546,7 @@ See full docs here: https://github.com/skunkworxdark/Prompt-tools-nodes/edit/mai
|
||||
|
||||
**Node Link:** https://github.com/skunkworxdark/Prompt-tools-nodes
|
||||
|
||||
**Workflow Examples**
|
||||
**Workflow Examples**
|
||||
|
||||
<img src="https://raw.githubusercontent.com/skunkworxdark/prompt-tools/refs/heads/main/images/CSVToIndexStringNode.png"/>
|
||||
|
||||
@@ -648,7 +681,7 @@ Highlights/Midtones/Shadows (with LUT blur enabled):
|
||||
- Generate grids of images from multiple input images
|
||||
- Create XY grid images with labels from parameters
|
||||
- Split images into overlapping tiles for processing (for super-resolution workflows)
|
||||
- Recombine image tiles into a single output image blending the seams
|
||||
- Recombine image tiles into a single output image blending the seams
|
||||
|
||||
The nodes include:
|
||||
1. `Images To Grids` - Combine multiple images into a grid of images
|
||||
@@ -661,7 +694,7 @@ See full docs here: https://github.com/skunkworxdark/XYGrid_nodes/edit/main/READ
|
||||
|
||||
**Node Link:** https://github.com/skunkworxdark/XYGrid_nodes
|
||||
|
||||
**Output Examples**
|
||||
**Output Examples**
|
||||
|
||||
<img src="https://raw.githubusercontent.com/skunkworxdark/XYGrid_nodes/refs/heads/main/images/collage.png" />
|
||||
|
||||
@@ -675,7 +708,7 @@ See full docs here: https://github.com/skunkworxdark/XYGrid_nodes/edit/main/READ
|
||||
|
||||
**Example Workflow:** https://github.com/invoke-ai/InvokeAI/blob/docs/main/docs/workflows/Prompt_from_File.json
|
||||
|
||||
**Output Examples**
|
||||
**Output Examples**
|
||||
|
||||
</br><img src="https://invoke-ai.github.io/InvokeAI/assets/invoke_ai_banner.png" width="500" />
|
||||
|
||||
@@ -686,5 +719,5 @@ The nodes linked have been developed and contributed by members of the Invoke AI
|
||||
|
||||
|
||||
## Help
|
||||
If you run into any issues with a node, please post in the [InvokeAI Discord](https://discord.gg/ZmtBAhwWhy).
|
||||
If you run into any issues with a node, please post in the [InvokeAI Discord](https://discord.gg/ZmtBAhwWhy).
|
||||
|
||||
|
||||
@@ -10,6 +10,7 @@ from invokeai.app.services.board_images.board_images_default import BoardImagesS
|
||||
from invokeai.app.services.board_records.board_records_sqlite import SqliteBoardRecordStorage
|
||||
from invokeai.app.services.boards.boards_default import BoardService
|
||||
from invokeai.app.services.bulk_download.bulk_download_default import BulkDownloadService
|
||||
from invokeai.app.services.client_state_persistence.client_state_persistence_sqlite import ClientStatePersistenceSqlite
|
||||
from invokeai.app.services.config.config_default import InvokeAIAppConfig
|
||||
from invokeai.app.services.download.download_default import DownloadQueueService
|
||||
from invokeai.app.services.events.events_fastapievents import FastAPIEventService
|
||||
@@ -151,6 +152,7 @@ class ApiDependencies:
|
||||
style_preset_records = SqliteStylePresetRecordsStorage(db=db)
|
||||
style_preset_image_files = StylePresetImageFileStorageDisk(style_presets_folder / "images")
|
||||
workflow_thumbnails = WorkflowThumbnailFileStorageDisk(workflow_thumbnails_folder)
|
||||
client_state_persistence = ClientStatePersistenceSqlite(db=db)
|
||||
|
||||
services = InvocationServices(
|
||||
board_image_records=board_image_records,
|
||||
@@ -181,6 +183,7 @@ class ApiDependencies:
|
||||
style_preset_records=style_preset_records,
|
||||
style_preset_image_files=style_preset_image_files,
|
||||
workflow_thumbnails=workflow_thumbnails,
|
||||
client_state_persistence=client_state_persistence,
|
||||
)
|
||||
|
||||
ApiDependencies.invoker = Invoker(services)
|
||||
|
||||
39
invokeai/app/api/routers/board_videos.py
Normal file
39
invokeai/app/api/routers/board_videos.py
Normal file
@@ -0,0 +1,39 @@
|
||||
from fastapi import Body, HTTPException
|
||||
from fastapi.routing import APIRouter
|
||||
|
||||
from invokeai.app.services.videos_common import AddVideosToBoardResult, RemoveVideosFromBoardResult
|
||||
|
||||
board_videos_router = APIRouter(prefix="/v1/board_videos", tags=["boards"])
|
||||
|
||||
|
||||
@board_videos_router.post(
|
||||
"/batch",
|
||||
operation_id="add_videos_to_board",
|
||||
responses={
|
||||
201: {"description": "Videos were added to board successfully"},
|
||||
},
|
||||
status_code=201,
|
||||
response_model=AddVideosToBoardResult,
|
||||
)
|
||||
async def add_videos_to_board(
|
||||
board_id: str = Body(description="The id of the board to add to"),
|
||||
video_ids: list[str] = Body(description="The ids of the videos to add", embed=True),
|
||||
) -> AddVideosToBoardResult:
|
||||
"""Adds a list of videos to a board"""
|
||||
raise HTTPException(status_code=501, detail="Not implemented")
|
||||
|
||||
|
||||
@board_videos_router.post(
|
||||
"/batch/delete",
|
||||
operation_id="remove_videos_from_board",
|
||||
responses={
|
||||
201: {"description": "Videos were removed from board successfully"},
|
||||
},
|
||||
status_code=201,
|
||||
response_model=RemoveVideosFromBoardResult,
|
||||
)
|
||||
async def remove_videos_from_board(
|
||||
video_ids: list[str] = Body(description="The ids of the videos to remove", embed=True),
|
||||
) -> RemoveVideosFromBoardResult:
|
||||
"""Removes a list of videos from their board, if they had one"""
|
||||
raise HTTPException(status_code=501, detail="Not implemented")
|
||||
58
invokeai/app/api/routers/client_state.py
Normal file
58
invokeai/app/api/routers/client_state.py
Normal file
@@ -0,0 +1,58 @@
|
||||
from fastapi import Body, HTTPException, Path, Query
|
||||
from fastapi.routing import APIRouter
|
||||
|
||||
from invokeai.app.api.dependencies import ApiDependencies
|
||||
from invokeai.backend.util.logging import logging
|
||||
|
||||
client_state_router = APIRouter(prefix="/v1/client_state", tags=["client_state"])
|
||||
|
||||
|
||||
@client_state_router.get(
|
||||
"/{queue_id}/get_by_key",
|
||||
operation_id="get_client_state_by_key",
|
||||
response_model=str | None,
|
||||
)
|
||||
async def get_client_state_by_key(
|
||||
queue_id: str = Path(description="The queue id to perform this operation on"),
|
||||
key: str = Query(..., description="Key to get"),
|
||||
) -> str | None:
|
||||
"""Gets the client state"""
|
||||
try:
|
||||
return ApiDependencies.invoker.services.client_state_persistence.get_by_key(queue_id, key)
|
||||
except Exception as e:
|
||||
logging.error(f"Error getting client state: {e}")
|
||||
raise HTTPException(status_code=500, detail="Error setting client state")
|
||||
|
||||
|
||||
@client_state_router.post(
|
||||
"/{queue_id}/set_by_key",
|
||||
operation_id="set_client_state",
|
||||
response_model=str,
|
||||
)
|
||||
async def set_client_state(
|
||||
queue_id: str = Path(description="The queue id to perform this operation on"),
|
||||
key: str = Query(..., description="Key to set"),
|
||||
value: str = Body(..., description="Stringified value to set"),
|
||||
) -> str:
|
||||
"""Sets the client state"""
|
||||
try:
|
||||
return ApiDependencies.invoker.services.client_state_persistence.set_by_key(queue_id, key, value)
|
||||
except Exception as e:
|
||||
logging.error(f"Error setting client state: {e}")
|
||||
raise HTTPException(status_code=500, detail="Error setting client state")
|
||||
|
||||
|
||||
@client_state_router.post(
|
||||
"/{queue_id}/delete",
|
||||
operation_id="delete_client_state",
|
||||
responses={204: {"description": "Client state deleted"}},
|
||||
)
|
||||
async def delete_client_state(
|
||||
queue_id: str = Path(description="The queue id to perform this operation on"),
|
||||
) -> None:
|
||||
"""Deletes the client state"""
|
||||
try:
|
||||
ApiDependencies.invoker.services.client_state_persistence.delete(queue_id)
|
||||
except Exception as e:
|
||||
logging.error(f"Error deleting client state: {e}")
|
||||
raise HTTPException(status_code=500, detail="Error deleting client state")
|
||||
@@ -28,10 +28,12 @@ from invokeai.app.services.model_records import (
|
||||
UnknownModelException,
|
||||
)
|
||||
from invokeai.app.util.suppress_output import SuppressOutput
|
||||
from invokeai.backend.model_manager import BaseModelType, ModelFormat, ModelType
|
||||
from invokeai.backend.model_manager.config import (
|
||||
AnyModelConfig,
|
||||
MainCheckpointConfig,
|
||||
from invokeai.backend.model_manager.configs.factory import AnyModelConfig
|
||||
from invokeai.backend.model_manager.configs.main import (
|
||||
Main_Checkpoint_SD1_Config,
|
||||
Main_Checkpoint_SD2_Config,
|
||||
Main_Checkpoint_SDXL_Config,
|
||||
Main_Checkpoint_SDXLRefiner_Config,
|
||||
)
|
||||
from invokeai.backend.model_manager.load.model_cache.cache_stats import CacheStats
|
||||
from invokeai.backend.model_manager.metadata.fetch.huggingface import HuggingFaceMetadataFetch
|
||||
@@ -44,6 +46,7 @@ from invokeai.backend.model_manager.starter_models import (
|
||||
StarterModelBundle,
|
||||
StarterModelWithoutDependencies,
|
||||
)
|
||||
from invokeai.backend.model_manager.taxonomy import BaseModelType, ModelFormat, ModelType
|
||||
|
||||
model_manager_router = APIRouter(prefix="/v2/models", tags=["model_manager"])
|
||||
|
||||
@@ -297,10 +300,8 @@ async def update_model_record(
|
||||
"""Update a model's config."""
|
||||
logger = ApiDependencies.invoker.services.logger
|
||||
record_store = ApiDependencies.invoker.services.model_manager.store
|
||||
installer = ApiDependencies.invoker.services.model_manager.install
|
||||
try:
|
||||
record_store.update_model(key, changes=changes)
|
||||
config = installer.sync_model_path(key)
|
||||
config = record_store.update_model(key, changes=changes, allow_class_change=True)
|
||||
config = add_cover_image_to_model_config(config, ApiDependencies)
|
||||
logger.info(f"Updated model: {key}")
|
||||
except UnknownModelException as e:
|
||||
@@ -743,9 +744,18 @@ async def convert_model(
|
||||
logger.error(str(e))
|
||||
raise HTTPException(status_code=424, detail=str(e))
|
||||
|
||||
if not isinstance(model_config, MainCheckpointConfig):
|
||||
logger.error(f"The model with key {key} is not a main checkpoint model.")
|
||||
raise HTTPException(400, f"The model with key {key} is not a main checkpoint model.")
|
||||
if not isinstance(
|
||||
model_config,
|
||||
(
|
||||
Main_Checkpoint_SD1_Config,
|
||||
Main_Checkpoint_SD2_Config,
|
||||
Main_Checkpoint_SDXL_Config,
|
||||
Main_Checkpoint_SDXLRefiner_Config,
|
||||
),
|
||||
):
|
||||
msg = f"The model with key {key} is not a main SD 1/2/XL checkpoint model."
|
||||
logger.error(msg)
|
||||
raise HTTPException(400, msg)
|
||||
|
||||
with TemporaryDirectory(dir=ApiDependencies.invoker.services.configuration.models_path) as tmpdir:
|
||||
convert_path = pathlib.Path(tmpdir) / pathlib.Path(model_config.path).stem
|
||||
|
||||
@@ -7,7 +7,6 @@ from pydantic import BaseModel, Field
|
||||
from invokeai.app.api.dependencies import ApiDependencies
|
||||
from invokeai.app.services.session_processor.session_processor_common import SessionProcessorStatus
|
||||
from invokeai.app.services.session_queue.session_queue_common import (
|
||||
QUEUE_ITEM_STATUS,
|
||||
Batch,
|
||||
BatchStatus,
|
||||
CancelAllExceptCurrentResult,
|
||||
@@ -18,6 +17,7 @@ from invokeai.app.services.session_queue.session_queue_common import (
|
||||
DeleteByDestinationResult,
|
||||
EnqueueBatchResult,
|
||||
FieldIdentifier,
|
||||
ItemIdsResult,
|
||||
PruneResult,
|
||||
RetryItemsResult,
|
||||
SessionQueueCountsByDestination,
|
||||
@@ -25,7 +25,7 @@ from invokeai.app.services.session_queue.session_queue_common import (
|
||||
SessionQueueItemNotFoundError,
|
||||
SessionQueueStatus,
|
||||
)
|
||||
from invokeai.app.services.shared.pagination import CursorPaginatedResults
|
||||
from invokeai.app.services.shared.sqlite.sqlite_common import SQLiteDirection
|
||||
|
||||
session_queue_router = APIRouter(prefix="/v1/queue", tags=["queue"])
|
||||
|
||||
@@ -68,36 +68,6 @@ async def enqueue_batch(
|
||||
raise HTTPException(status_code=500, detail=f"Unexpected error while enqueuing batch: {e}")
|
||||
|
||||
|
||||
@session_queue_router.get(
|
||||
"/{queue_id}/list",
|
||||
operation_id="list_queue_items",
|
||||
responses={
|
||||
200: {"model": CursorPaginatedResults[SessionQueueItem]},
|
||||
},
|
||||
)
|
||||
async def list_queue_items(
|
||||
queue_id: str = Path(description="The queue id to perform this operation on"),
|
||||
limit: int = Query(default=50, description="The number of items to fetch"),
|
||||
status: Optional[QUEUE_ITEM_STATUS] = Query(default=None, description="The status of items to fetch"),
|
||||
cursor: Optional[int] = Query(default=None, description="The pagination cursor"),
|
||||
priority: int = Query(default=0, description="The pagination cursor priority"),
|
||||
destination: Optional[str] = Query(default=None, description="The destination of queue items to fetch"),
|
||||
) -> CursorPaginatedResults[SessionQueueItem]:
|
||||
"""Gets cursor-paginated queue items"""
|
||||
|
||||
try:
|
||||
return ApiDependencies.invoker.services.session_queue.list_queue_items(
|
||||
queue_id=queue_id,
|
||||
limit=limit,
|
||||
status=status,
|
||||
cursor=cursor,
|
||||
priority=priority,
|
||||
destination=destination,
|
||||
)
|
||||
except Exception as e:
|
||||
raise HTTPException(status_code=500, detail=f"Unexpected error while listing all items: {e}")
|
||||
|
||||
|
||||
@session_queue_router.get(
|
||||
"/{queue_id}/list_all",
|
||||
operation_id="list_all_queue_items",
|
||||
@@ -119,6 +89,56 @@ async def list_all_queue_items(
|
||||
raise HTTPException(status_code=500, detail=f"Unexpected error while listing all queue items: {e}")
|
||||
|
||||
|
||||
@session_queue_router.get(
|
||||
"/{queue_id}/item_ids",
|
||||
operation_id="get_queue_item_ids",
|
||||
responses={
|
||||
200: {"model": ItemIdsResult},
|
||||
},
|
||||
)
|
||||
async def get_queue_item_ids(
|
||||
queue_id: str = Path(description="The queue id to perform this operation on"),
|
||||
order_dir: SQLiteDirection = Query(default=SQLiteDirection.Descending, description="The order of sort"),
|
||||
) -> ItemIdsResult:
|
||||
"""Gets all queue item ids that match the given parameters"""
|
||||
try:
|
||||
return ApiDependencies.invoker.services.session_queue.get_queue_item_ids(queue_id=queue_id, order_dir=order_dir)
|
||||
except Exception as e:
|
||||
raise HTTPException(status_code=500, detail=f"Unexpected error while listing all queue item ids: {e}")
|
||||
|
||||
|
||||
@session_queue_router.post(
|
||||
"/{queue_id}/items_by_ids",
|
||||
operation_id="get_queue_items_by_item_ids",
|
||||
responses={200: {"model": list[SessionQueueItem]}},
|
||||
)
|
||||
async def get_queue_items_by_item_ids(
|
||||
queue_id: str = Path(description="The queue id to perform this operation on"),
|
||||
item_ids: list[int] = Body(
|
||||
embed=True, description="Object containing list of queue item ids to fetch queue items for"
|
||||
),
|
||||
) -> list[SessionQueueItem]:
|
||||
"""Gets queue items for the specified queue item ids. Maintains order of item ids."""
|
||||
try:
|
||||
session_queue_service = ApiDependencies.invoker.services.session_queue
|
||||
|
||||
# Fetch queue items preserving the order of requested item ids
|
||||
queue_items: list[SessionQueueItem] = []
|
||||
for item_id in item_ids:
|
||||
try:
|
||||
queue_item = session_queue_service.get_queue_item(item_id=item_id)
|
||||
if queue_item.queue_id != queue_id: # Auth protection for items from other queues
|
||||
continue
|
||||
queue_items.append(queue_item)
|
||||
except Exception:
|
||||
# Skip missing queue items - they may have been deleted between item id fetch and queue item fetch
|
||||
continue
|
||||
|
||||
return queue_items
|
||||
except Exception:
|
||||
raise HTTPException(status_code=500, detail="Failed to get queue items")
|
||||
|
||||
|
||||
@session_queue_router.put(
|
||||
"/{queue_id}/processor/resume",
|
||||
operation_id="resume",
|
||||
@@ -354,7 +374,10 @@ async def get_queue_item(
|
||||
) -> SessionQueueItem:
|
||||
"""Gets a queue item"""
|
||||
try:
|
||||
return ApiDependencies.invoker.services.session_queue.get_queue_item(item_id)
|
||||
queue_item = ApiDependencies.invoker.services.session_queue.get_queue_item(item_id=item_id)
|
||||
if queue_item.queue_id != queue_id:
|
||||
raise HTTPException(status_code=404, detail=f"Queue item with id {item_id} not found in queue {queue_id}")
|
||||
return queue_item
|
||||
except SessionQueueItemNotFoundError:
|
||||
raise HTTPException(status_code=404, detail=f"Queue item with id {item_id} not found in queue {queue_id}")
|
||||
except Exception as e:
|
||||
|
||||
119
invokeai/app/api/routers/videos.py
Normal file
119
invokeai/app/api/routers/videos.py
Normal file
@@ -0,0 +1,119 @@
|
||||
from typing import Optional
|
||||
|
||||
from fastapi import Body, HTTPException, Path, Query
|
||||
from fastapi.routing import APIRouter
|
||||
|
||||
from invokeai.app.services.shared.pagination import OffsetPaginatedResults
|
||||
from invokeai.app.services.shared.sqlite.sqlite_common import SQLiteDirection
|
||||
from invokeai.app.services.videos_common import (
|
||||
DeleteVideosResult,
|
||||
StarredVideosResult,
|
||||
UnstarredVideosResult,
|
||||
VideoDTO,
|
||||
VideoIdsResult,
|
||||
VideoRecordChanges,
|
||||
)
|
||||
|
||||
videos_router = APIRouter(prefix="/v1/videos", tags=["videos"])
|
||||
|
||||
|
||||
@videos_router.patch(
|
||||
"/i/{video_id}",
|
||||
operation_id="update_video",
|
||||
response_model=VideoDTO,
|
||||
)
|
||||
async def update_video(
|
||||
video_id: str = Path(description="The id of the video to update"),
|
||||
video_changes: VideoRecordChanges = Body(description="The changes to apply to the video"),
|
||||
) -> VideoDTO:
|
||||
"""Updates a video"""
|
||||
|
||||
raise HTTPException(status_code=501, detail="Not implemented")
|
||||
|
||||
|
||||
@videos_router.get(
|
||||
"/i/{video_id}",
|
||||
operation_id="get_video_dto",
|
||||
response_model=VideoDTO,
|
||||
)
|
||||
async def get_video_dto(
|
||||
video_id: str = Path(description="The id of the video to get"),
|
||||
) -> VideoDTO:
|
||||
"""Gets a video's DTO"""
|
||||
|
||||
raise HTTPException(status_code=501, detail="Not implemented")
|
||||
|
||||
|
||||
@videos_router.post("/delete", operation_id="delete_videos_from_list", response_model=DeleteVideosResult)
|
||||
async def delete_videos_from_list(
|
||||
video_ids: list[str] = Body(description="The list of ids of videos to delete", embed=True),
|
||||
) -> DeleteVideosResult:
|
||||
raise HTTPException(status_code=501, detail="Not implemented")
|
||||
|
||||
|
||||
@videos_router.post("/star", operation_id="star_videos_in_list", response_model=StarredVideosResult)
|
||||
async def star_videos_in_list(
|
||||
video_ids: list[str] = Body(description="The list of ids of videos to star", embed=True),
|
||||
) -> StarredVideosResult:
|
||||
raise HTTPException(status_code=501, detail="Not implemented")
|
||||
|
||||
|
||||
@videos_router.post("/unstar", operation_id="unstar_videos_in_list", response_model=UnstarredVideosResult)
|
||||
async def unstar_videos_in_list(
|
||||
video_ids: list[str] = Body(description="The list of ids of videos to unstar", embed=True),
|
||||
) -> UnstarredVideosResult:
|
||||
raise HTTPException(status_code=501, detail="Not implemented")
|
||||
|
||||
|
||||
@videos_router.delete("/uncategorized", operation_id="delete_uncategorized_videos", response_model=DeleteVideosResult)
|
||||
async def delete_uncategorized_videos() -> DeleteVideosResult:
|
||||
"""Deletes all videos that are uncategorized"""
|
||||
|
||||
raise HTTPException(status_code=501, detail="Not implemented")
|
||||
|
||||
|
||||
@videos_router.get("/", operation_id="list_video_dtos", response_model=OffsetPaginatedResults[VideoDTO])
|
||||
async def list_video_dtos(
|
||||
is_intermediate: Optional[bool] = Query(default=None, description="Whether to list intermediate videos."),
|
||||
board_id: Optional[str] = Query(
|
||||
default=None,
|
||||
description="The board id to filter by. Use 'none' to find videos without a board.",
|
||||
),
|
||||
offset: int = Query(default=0, description="The page offset"),
|
||||
limit: int = Query(default=10, description="The number of videos per page"),
|
||||
order_dir: SQLiteDirection = Query(default=SQLiteDirection.Descending, description="The order of sort"),
|
||||
starred_first: bool = Query(default=True, description="Whether to sort by starred videos first"),
|
||||
search_term: Optional[str] = Query(default=None, description="The term to search for"),
|
||||
) -> OffsetPaginatedResults[VideoDTO]:
|
||||
"""Lists video DTOs"""
|
||||
|
||||
raise HTTPException(status_code=501, detail="Not implemented")
|
||||
|
||||
|
||||
@videos_router.get("/ids", operation_id="get_video_ids")
|
||||
async def get_video_ids(
|
||||
is_intermediate: Optional[bool] = Query(default=None, description="Whether to list intermediate videos."),
|
||||
board_id: Optional[str] = Query(
|
||||
default=None,
|
||||
description="The board id to filter by. Use 'none' to find videos without a board.",
|
||||
),
|
||||
order_dir: SQLiteDirection = Query(default=SQLiteDirection.Descending, description="The order of sort"),
|
||||
starred_first: bool = Query(default=True, description="Whether to sort by starred videos first"),
|
||||
search_term: Optional[str] = Query(default=None, description="The term to search for"),
|
||||
) -> VideoIdsResult:
|
||||
"""Gets ordered list of video ids with metadata for optimistic updates"""
|
||||
|
||||
raise HTTPException(status_code=501, detail="Not implemented")
|
||||
|
||||
|
||||
@videos_router.post(
|
||||
"/videos_by_ids",
|
||||
operation_id="get_videos_by_ids",
|
||||
responses={200: {"model": list[VideoDTO]}},
|
||||
)
|
||||
async def get_videos_by_ids(
|
||||
video_ids: list[str] = Body(embed=True, description="Object containing list of video ids to fetch DTOs for"),
|
||||
) -> list[VideoDTO]:
|
||||
"""Gets video DTOs for the specified video ids. Maintains order of input ids."""
|
||||
|
||||
raise HTTPException(status_code=501, detail="Not implemented")
|
||||
@@ -18,7 +18,9 @@ from invokeai.app.api.no_cache_staticfiles import NoCacheStaticFiles
|
||||
from invokeai.app.api.routers import (
|
||||
app_info,
|
||||
board_images,
|
||||
board_videos,
|
||||
boards,
|
||||
client_state,
|
||||
download_queue,
|
||||
images,
|
||||
model_manager,
|
||||
@@ -26,6 +28,7 @@ from invokeai.app.api.routers import (
|
||||
session_queue,
|
||||
style_presets,
|
||||
utilities,
|
||||
videos,
|
||||
workflows,
|
||||
)
|
||||
from invokeai.app.api.sockets import SocketIO
|
||||
@@ -124,13 +127,16 @@ app.include_router(utilities.utilities_router, prefix="/api")
|
||||
app.include_router(model_manager.model_manager_router, prefix="/api")
|
||||
app.include_router(download_queue.download_queue_router, prefix="/api")
|
||||
app.include_router(images.images_router, prefix="/api")
|
||||
app.include_router(videos.videos_router, prefix="/api")
|
||||
app.include_router(boards.boards_router, prefix="/api")
|
||||
app.include_router(board_images.board_images_router, prefix="/api")
|
||||
app.include_router(board_videos.board_videos_router, prefix="/api")
|
||||
app.include_router(model_relationships.model_relationships_router, prefix="/api")
|
||||
app.include_router(app_info.app_router, prefix="/api")
|
||||
app.include_router(session_queue.session_queue_router, prefix="/api")
|
||||
app.include_router(workflows.workflows_router, prefix="/api")
|
||||
app.include_router(style_presets.style_presets_router, prefix="/api")
|
||||
app.include_router(client_state.client_state_router, prefix="/api")
|
||||
|
||||
app.openapi = get_openapi_func(app)
|
||||
|
||||
@@ -155,6 +161,12 @@ def overridden_redoc() -> HTMLResponse:
|
||||
|
||||
web_root_path = Path(list(web_dir.__path__)[0])
|
||||
|
||||
if app_config.unsafe_disable_picklescan:
|
||||
logger.warning(
|
||||
"The unsafe_disable_picklescan option is enabled. This disables malware scanning while installing and"
|
||||
"loading models, which may allow malicious code to be executed. Use at your own risk."
|
||||
)
|
||||
|
||||
try:
|
||||
app.mount("/", NoCacheStaticFiles(directory=Path(web_root_path, "dist"), html=True), name="ui")
|
||||
except RuntimeError:
|
||||
|
||||
@@ -36,6 +36,9 @@ from pydantic_core import PydanticUndefined
|
||||
from invokeai.app.invocations.fields import (
|
||||
FieldKind,
|
||||
Input,
|
||||
InputFieldJSONSchemaExtra,
|
||||
UIType,
|
||||
migrate_model_ui_type,
|
||||
)
|
||||
from invokeai.app.services.config.config_default import get_config
|
||||
from invokeai.app.services.shared.invocation_context import InvocationContext
|
||||
@@ -256,7 +259,9 @@ class BaseInvocation(ABC, BaseModel):
|
||||
is_intermediate: bool = Field(
|
||||
default=False,
|
||||
description="Whether or not this is an intermediate invocation.",
|
||||
json_schema_extra={"ui_type": "IsIntermediate", "field_kind": FieldKind.NodeAttribute},
|
||||
json_schema_extra=InputFieldJSONSchemaExtra(
|
||||
input=Input.Direct, field_kind=FieldKind.NodeAttribute, ui_type=UIType._IsIntermediate
|
||||
).model_dump(exclude_none=True),
|
||||
)
|
||||
use_cache: bool = Field(
|
||||
default=True,
|
||||
@@ -445,6 +450,15 @@ with warnings.catch_warnings():
|
||||
RESERVED_PYDANTIC_FIELD_NAMES = {m[0] for m in inspect.getmembers(_Model())}
|
||||
|
||||
|
||||
def is_enum_member(value: Any, enum_class: type[Enum]) -> bool:
|
||||
"""Checks if a value is a member of an enum class."""
|
||||
try:
|
||||
enum_class(value)
|
||||
return True
|
||||
except ValueError:
|
||||
return False
|
||||
|
||||
|
||||
def validate_fields(model_fields: dict[str, FieldInfo], model_type: str) -> None:
|
||||
"""
|
||||
Validates the fields of an invocation or invocation output:
|
||||
@@ -456,51 +470,99 @@ def validate_fields(model_fields: dict[str, FieldInfo], model_type: str) -> None
|
||||
"""
|
||||
for name, field in model_fields.items():
|
||||
if name in RESERVED_PYDANTIC_FIELD_NAMES:
|
||||
raise InvalidFieldError(f'Invalid field name "{name}" on "{model_type}" (reserved by pydantic)')
|
||||
raise InvalidFieldError(f"{model_type}.{name}: Invalid field name (reserved by pydantic)")
|
||||
|
||||
if not field.annotation:
|
||||
raise InvalidFieldError(f'Invalid field type "{name}" on "{model_type}" (missing annotation)')
|
||||
raise InvalidFieldError(f"{model_type}.{name}: Invalid field type (missing annotation)")
|
||||
|
||||
if not isinstance(field.json_schema_extra, dict):
|
||||
raise InvalidFieldError(
|
||||
f'Invalid field definition for "{name}" on "{model_type}" (missing json_schema_extra dict)'
|
||||
)
|
||||
raise InvalidFieldError(f"{model_type}.{name}: Invalid field definition (missing json_schema_extra dict)")
|
||||
|
||||
field_kind = field.json_schema_extra.get("field_kind", None)
|
||||
|
||||
# must have a field_kind
|
||||
if not isinstance(field_kind, FieldKind):
|
||||
if not is_enum_member(field_kind, FieldKind):
|
||||
raise InvalidFieldError(
|
||||
f'Invalid field definition for "{name}" on "{model_type}" (maybe it\'s not an InputField or OutputField?)'
|
||||
f"{model_type}.{name}: Invalid field definition for (maybe it's not an InputField or OutputField?)"
|
||||
)
|
||||
|
||||
if field_kind is FieldKind.Input and (
|
||||
if field_kind == FieldKind.Input.value and (
|
||||
name in RESERVED_NODE_ATTRIBUTE_FIELD_NAMES or name in RESERVED_INPUT_FIELD_NAMES
|
||||
):
|
||||
raise InvalidFieldError(f'Invalid field name "{name}" on "{model_type}" (reserved input field name)')
|
||||
raise InvalidFieldError(f"{model_type}.{name}: Invalid field name (reserved input field name)")
|
||||
|
||||
if field_kind is FieldKind.Output and name in RESERVED_OUTPUT_FIELD_NAMES:
|
||||
raise InvalidFieldError(f'Invalid field name "{name}" on "{model_type}" (reserved output field name)')
|
||||
if field_kind == FieldKind.Output.value and name in RESERVED_OUTPUT_FIELD_NAMES:
|
||||
raise InvalidFieldError(f"{model_type}.{name}: Invalid field name (reserved output field name)")
|
||||
|
||||
if (field_kind is FieldKind.Internal) and name not in RESERVED_INPUT_FIELD_NAMES:
|
||||
raise InvalidFieldError(
|
||||
f'Invalid field name "{name}" on "{model_type}" (internal field without reserved name)'
|
||||
)
|
||||
if field_kind == FieldKind.Internal.value and name not in RESERVED_INPUT_FIELD_NAMES:
|
||||
raise InvalidFieldError(f"{model_type}.{name}: Invalid field name (internal field without reserved name)")
|
||||
|
||||
# node attribute fields *must* be in the reserved list
|
||||
if (
|
||||
field_kind is FieldKind.NodeAttribute
|
||||
field_kind == FieldKind.NodeAttribute.value
|
||||
and name not in RESERVED_NODE_ATTRIBUTE_FIELD_NAMES
|
||||
and name not in RESERVED_OUTPUT_FIELD_NAMES
|
||||
):
|
||||
raise InvalidFieldError(
|
||||
f'Invalid field name "{name}" on "{model_type}" (node attribute field without reserved name)'
|
||||
f"{model_type}.{name}: Invalid field name (node attribute field without reserved name)"
|
||||
)
|
||||
|
||||
ui_type = field.json_schema_extra.get("ui_type", None)
|
||||
if isinstance(ui_type, str) and ui_type.startswith("DEPRECATED_"):
|
||||
logger.warning(f'"UIType.{ui_type.split("_")[-1]}" is deprecated, ignoring')
|
||||
field.json_schema_extra.pop("ui_type")
|
||||
ui_model_base = field.json_schema_extra.get("ui_model_base", None)
|
||||
ui_model_type = field.json_schema_extra.get("ui_model_type", None)
|
||||
ui_model_variant = field.json_schema_extra.get("ui_model_variant", None)
|
||||
ui_model_format = field.json_schema_extra.get("ui_model_format", None)
|
||||
|
||||
if ui_type is not None:
|
||||
# There are 3 cases where we may need to take action:
|
||||
#
|
||||
# 1. The ui_type is a migratable, deprecated value. For example, ui_type=UIType.MainModel value is
|
||||
# deprecated and should be migrated to:
|
||||
# - ui_model_base=[BaseModelType.StableDiffusion1, BaseModelType.StableDiffusion2]
|
||||
# - ui_model_type=[ModelType.Main]
|
||||
#
|
||||
# 2. ui_type was set in conjunction with any of the new ui_model_[base|type|variant|format] fields, which
|
||||
# is not allowed (they are mutually exclusive). In this case, we ignore ui_type and log a warning.
|
||||
#
|
||||
# 3. ui_type is a deprecated value that is not migratable. For example, ui_type=UIType.Image is deprecated;
|
||||
# Image fields are now automatically detected based on the field's type annotation. In this case, we
|
||||
# ignore ui_type and log a warning.
|
||||
#
|
||||
# The cases must be checked in this order to ensure proper handling.
|
||||
|
||||
# Easier to work with as an enum
|
||||
ui_type = UIType(ui_type)
|
||||
|
||||
# The enum member values are not always the same as their names - we want to log the name so the user can
|
||||
# easily review their code and see where the deprecated enum member is used.
|
||||
human_readable_name = f"UIType.{ui_type.name}"
|
||||
|
||||
# Case 1: migratable deprecated value
|
||||
did_migrate = migrate_model_ui_type(ui_type, field.json_schema_extra)
|
||||
|
||||
if did_migrate:
|
||||
logger.warning(
|
||||
f'{model_type}.{name}: Migrated deprecated "ui_type" "{human_readable_name}" to new ui_model_[base|type|variant|format] fields'
|
||||
)
|
||||
field.json_schema_extra.pop("ui_type")
|
||||
|
||||
# Case 2: mutually exclusive with new fields
|
||||
elif (
|
||||
ui_model_base is not None
|
||||
or ui_model_type is not None
|
||||
or ui_model_variant is not None
|
||||
or ui_model_format is not None
|
||||
):
|
||||
logger.warning(
|
||||
f'{model_type}.{name}: "ui_type" is mutually exclusive with "ui_model_[base|type|format|variant]", ignoring "ui_type"'
|
||||
)
|
||||
field.json_schema_extra.pop("ui_type")
|
||||
|
||||
# Case 3: deprecated value that is not migratable
|
||||
elif ui_type.startswith("DEPRECATED_"):
|
||||
logger.warning(f'{model_type}.{name}: Deprecated "ui_type" "{human_readable_name}", ignoring')
|
||||
field.json_schema_extra.pop("ui_type")
|
||||
|
||||
return None
|
||||
|
||||
|
||||
|
||||
@@ -22,7 +22,7 @@ from invokeai.app.invocations.model import TransformerField
|
||||
from invokeai.app.invocations.primitives import LatentsOutput
|
||||
from invokeai.app.services.shared.invocation_context import InvocationContext
|
||||
from invokeai.backend.flux.sampling_utils import clip_timestep_schedule_fractional
|
||||
from invokeai.backend.model_manager.config import BaseModelType
|
||||
from invokeai.backend.model_manager.taxonomy import BaseModelType
|
||||
from invokeai.backend.rectified_flow.rectified_flow_inpaint_extension import RectifiedFlowInpaintExtension
|
||||
from invokeai.backend.stable_diffusion.diffusers_pipeline import PipelineIntermediateState
|
||||
from invokeai.backend.stable_diffusion.diffusion.conditioning_data import CogView4ConditioningInfo
|
||||
|
||||
@@ -17,6 +17,7 @@ from invokeai.app.services.shared.invocation_context import InvocationContext
|
||||
from invokeai.backend.model_manager.load.load_base import LoadedModel
|
||||
from invokeai.backend.stable_diffusion.diffusers_pipeline import image_resized_to_grid_as_tensor
|
||||
from invokeai.backend.util.devices import TorchDevice
|
||||
from invokeai.backend.util.vae_working_memory import estimate_vae_working_memory_cogview4
|
||||
|
||||
# TODO(ryand): This is effectively a copy of SD3ImageToLatentsInvocation and a subset of ImageToLatentsInvocation. We
|
||||
# should refactor to avoid this duplication.
|
||||
@@ -38,7 +39,11 @@ class CogView4ImageToLatentsInvocation(BaseInvocation, WithMetadata, WithBoard):
|
||||
|
||||
@staticmethod
|
||||
def vae_encode(vae_info: LoadedModel, image_tensor: torch.Tensor) -> torch.Tensor:
|
||||
with vae_info as vae:
|
||||
assert isinstance(vae_info.model, AutoencoderKL)
|
||||
estimated_working_memory = estimate_vae_working_memory_cogview4(
|
||||
operation="encode", image_tensor=image_tensor, vae=vae_info.model
|
||||
)
|
||||
with vae_info.model_on_device(working_mem_bytes=estimated_working_memory) as (_, vae):
|
||||
assert isinstance(vae, AutoencoderKL)
|
||||
|
||||
vae.disable_tiling()
|
||||
@@ -62,6 +67,8 @@ class CogView4ImageToLatentsInvocation(BaseInvocation, WithMetadata, WithBoard):
|
||||
image_tensor = einops.rearrange(image_tensor, "c h w -> 1 c h w")
|
||||
|
||||
vae_info = context.models.load(self.vae.vae)
|
||||
assert isinstance(vae_info.model, AutoencoderKL)
|
||||
|
||||
latents = self.vae_encode(vae_info=vae_info, image_tensor=image_tensor)
|
||||
|
||||
latents = latents.to("cpu")
|
||||
|
||||
@@ -6,7 +6,6 @@ from einops import rearrange
|
||||
from PIL import Image
|
||||
|
||||
from invokeai.app.invocations.baseinvocation import BaseInvocation, Classification, invocation
|
||||
from invokeai.app.invocations.constants import LATENT_SCALE_FACTOR
|
||||
from invokeai.app.invocations.fields import (
|
||||
FieldDescriptions,
|
||||
Input,
|
||||
@@ -20,6 +19,7 @@ from invokeai.app.invocations.primitives import ImageOutput
|
||||
from invokeai.app.services.shared.invocation_context import InvocationContext
|
||||
from invokeai.backend.stable_diffusion.extensions.seamless import SeamlessExt
|
||||
from invokeai.backend.util.devices import TorchDevice
|
||||
from invokeai.backend.util.vae_working_memory import estimate_vae_working_memory_cogview4
|
||||
|
||||
# TODO(ryand): This is effectively a copy of SD3LatentsToImageInvocation and a subset of LatentsToImageInvocation. We
|
||||
# should refactor to avoid this duplication.
|
||||
@@ -39,22 +39,15 @@ class CogView4LatentsToImageInvocation(BaseInvocation, WithMetadata, WithBoard):
|
||||
latents: LatentsField = InputField(description=FieldDescriptions.latents, input=Input.Connection)
|
||||
vae: VAEField = InputField(description=FieldDescriptions.vae, input=Input.Connection)
|
||||
|
||||
def _estimate_working_memory(self, latents: torch.Tensor, vae: AutoencoderKL) -> int:
|
||||
"""Estimate the working memory required by the invocation in bytes."""
|
||||
out_h = LATENT_SCALE_FACTOR * latents.shape[-2]
|
||||
out_w = LATENT_SCALE_FACTOR * latents.shape[-1]
|
||||
element_size = next(vae.parameters()).element_size()
|
||||
scaling_constant = 2200 # Determined experimentally.
|
||||
working_memory = out_h * out_w * element_size * scaling_constant
|
||||
return int(working_memory)
|
||||
|
||||
@torch.no_grad()
|
||||
def invoke(self, context: InvocationContext) -> ImageOutput:
|
||||
latents = context.tensors.load(self.latents.latents_name)
|
||||
|
||||
vae_info = context.models.load(self.vae.vae)
|
||||
assert isinstance(vae_info.model, (AutoencoderKL))
|
||||
estimated_working_memory = self._estimate_working_memory(latents, vae_info.model)
|
||||
estimated_working_memory = estimate_vae_working_memory_cogview4(
|
||||
operation="decode", image_tensor=latents, vae=vae_info.model
|
||||
)
|
||||
with (
|
||||
SeamlessExt.static_patch_model(vae_info.model, self.vae.seamless_axes),
|
||||
vae_info.model_on_device(working_mem_bytes=estimated_working_memory) as (_, vae),
|
||||
|
||||
@@ -5,7 +5,7 @@ from invokeai.app.invocations.baseinvocation import (
|
||||
invocation,
|
||||
invocation_output,
|
||||
)
|
||||
from invokeai.app.invocations.fields import FieldDescriptions, Input, InputField, OutputField, UIType
|
||||
from invokeai.app.invocations.fields import FieldDescriptions, Input, InputField, OutputField
|
||||
from invokeai.app.invocations.model import (
|
||||
GlmEncoderField,
|
||||
ModelIdentifierField,
|
||||
@@ -13,7 +13,7 @@ from invokeai.app.invocations.model import (
|
||||
VAEField,
|
||||
)
|
||||
from invokeai.app.services.shared.invocation_context import InvocationContext
|
||||
from invokeai.backend.model_manager.config import SubModelType
|
||||
from invokeai.backend.model_manager.taxonomy import BaseModelType, ModelType, SubModelType
|
||||
|
||||
|
||||
@invocation_output("cogview4_model_loader_output")
|
||||
@@ -38,8 +38,9 @@ class CogView4ModelLoaderInvocation(BaseInvocation):
|
||||
|
||||
model: ModelIdentifierField = InputField(
|
||||
description=FieldDescriptions.cogview4_model,
|
||||
ui_type=UIType.CogView4MainModel,
|
||||
input=Input.Direct,
|
||||
ui_model_base=BaseModelType.CogView4,
|
||||
ui_model_type=ModelType.Main,
|
||||
)
|
||||
|
||||
def invoke(self, context: InvocationContext) -> CogView4ModelLoaderOutput:
|
||||
|
||||
@@ -16,7 +16,6 @@ from invokeai.app.invocations.fields import (
|
||||
ImageField,
|
||||
InputField,
|
||||
OutputField,
|
||||
UIType,
|
||||
)
|
||||
from invokeai.app.invocations.model import ModelIdentifierField
|
||||
from invokeai.app.invocations.primitives import ImageOutput
|
||||
@@ -28,6 +27,7 @@ from invokeai.app.util.controlnet_utils import (
|
||||
heuristic_resize_fast,
|
||||
)
|
||||
from invokeai.backend.image_util.util import np_to_pil, pil_to_np
|
||||
from invokeai.backend.model_manager.taxonomy import BaseModelType, ModelType
|
||||
|
||||
|
||||
class ControlField(BaseModel):
|
||||
@@ -63,13 +63,17 @@ class ControlOutput(BaseInvocationOutput):
|
||||
control: ControlField = OutputField(description=FieldDescriptions.control)
|
||||
|
||||
|
||||
@invocation("controlnet", title="ControlNet - SD1.5, SDXL", tags=["controlnet"], category="controlnet", version="1.1.3")
|
||||
@invocation(
|
||||
"controlnet", title="ControlNet - SD1.5, SD2, SDXL", tags=["controlnet"], category="controlnet", version="1.1.3"
|
||||
)
|
||||
class ControlNetInvocation(BaseInvocation):
|
||||
"""Collects ControlNet info to pass to other nodes"""
|
||||
|
||||
image: ImageField = InputField(description="The control image")
|
||||
control_model: ModelIdentifierField = InputField(
|
||||
description=FieldDescriptions.controlnet_model, ui_type=UIType.ControlNetModel
|
||||
description=FieldDescriptions.controlnet_model,
|
||||
ui_model_base=[BaseModelType.StableDiffusion1, BaseModelType.StableDiffusion2, BaseModelType.StableDiffusionXL],
|
||||
ui_model_type=ModelType.ControlNet,
|
||||
)
|
||||
control_weight: Union[float, List[float]] = InputField(
|
||||
default=1.0, ge=-1, le=2, description="The weight given to the ControlNet"
|
||||
|
||||
@@ -20,9 +20,7 @@ from invokeai.app.invocations.fields import (
|
||||
from invokeai.app.invocations.image_to_latents import ImageToLatentsInvocation
|
||||
from invokeai.app.invocations.model import UNetField, VAEField
|
||||
from invokeai.app.services.shared.invocation_context import InvocationContext
|
||||
from invokeai.backend.model_manager import LoadedModel
|
||||
from invokeai.backend.model_manager.config import MainConfigBase
|
||||
from invokeai.backend.model_manager.taxonomy import ModelVariantType
|
||||
from invokeai.backend.model_manager.taxonomy import FluxVariantType, ModelType, ModelVariantType
|
||||
from invokeai.backend.stable_diffusion.diffusers_pipeline import image_resized_to_grid_as_tensor
|
||||
|
||||
|
||||
@@ -182,10 +180,11 @@ class CreateGradientMaskInvocation(BaseInvocation):
|
||||
if self.unet is not None and self.vae is not None and self.image is not None:
|
||||
# all three fields must be present at the same time
|
||||
main_model_config = context.models.get_config(self.unet.unet.key)
|
||||
assert isinstance(main_model_config, MainConfigBase)
|
||||
if main_model_config.variant is ModelVariantType.Inpaint:
|
||||
assert main_model_config.type is ModelType.Main
|
||||
variant = getattr(main_model_config, "variant", None)
|
||||
if variant is ModelVariantType.Inpaint or variant is FluxVariantType.DevFill:
|
||||
mask = dilated_mask_tensor
|
||||
vae_info: LoadedModel = context.models.load(self.vae.vae)
|
||||
vae_info = context.models.load(self.vae.vae)
|
||||
image = context.images.get_pil(self.image.image_name)
|
||||
image_tensor = image_resized_to_grid_as_tensor(image.convert("RGB"))
|
||||
if image_tensor.dim() == 3:
|
||||
|
||||
@@ -39,7 +39,7 @@ from invokeai.app.invocations.t2i_adapter import T2IAdapterField
|
||||
from invokeai.app.services.shared.invocation_context import InvocationContext
|
||||
from invokeai.app.util.controlnet_utils import prepare_control_image
|
||||
from invokeai.backend.ip_adapter.ip_adapter import IPAdapter
|
||||
from invokeai.backend.model_manager.config import AnyModelConfig
|
||||
from invokeai.backend.model_manager.configs.factory import AnyModelConfig
|
||||
from invokeai.backend.model_manager.taxonomy import BaseModelType, ModelVariantType
|
||||
from invokeai.backend.model_patcher import ModelPatcher
|
||||
from invokeai.backend.patches.layer_patcher import LayerPatcher
|
||||
|
||||
@@ -1,11 +1,19 @@
|
||||
from enum import Enum
|
||||
from typing import Any, Callable, Optional, Tuple
|
||||
|
||||
from pydantic import BaseModel, ConfigDict, Field, RootModel, TypeAdapter, model_validator
|
||||
from pydantic import BaseModel, ConfigDict, Field, RootModel, TypeAdapter
|
||||
from pydantic.fields import _Unset
|
||||
from pydantic_core import PydanticUndefined
|
||||
|
||||
from invokeai.app.util.metaenum import MetaEnum
|
||||
from invokeai.backend.image_util.segment_anything.shared import BoundingBox
|
||||
from invokeai.backend.model_manager.taxonomy import (
|
||||
BaseModelType,
|
||||
ClipVariantType,
|
||||
ModelFormat,
|
||||
ModelType,
|
||||
ModelVariantType,
|
||||
)
|
||||
from invokeai.backend.util.logging import InvokeAILogger
|
||||
|
||||
logger = InvokeAILogger.get_logger()
|
||||
@@ -38,35 +46,6 @@ class UIType(str, Enum, metaclass=MetaEnum):
|
||||
used, and the type will be ignored. They are included here for backwards compatibility.
|
||||
"""
|
||||
|
||||
# region Model Field Types
|
||||
MainModel = "MainModelField"
|
||||
CogView4MainModel = "CogView4MainModelField"
|
||||
FluxMainModel = "FluxMainModelField"
|
||||
SD3MainModel = "SD3MainModelField"
|
||||
SDXLMainModel = "SDXLMainModelField"
|
||||
SDXLRefinerModel = "SDXLRefinerModelField"
|
||||
ONNXModel = "ONNXModelField"
|
||||
VAEModel = "VAEModelField"
|
||||
FluxVAEModel = "FluxVAEModelField"
|
||||
LoRAModel = "LoRAModelField"
|
||||
ControlNetModel = "ControlNetModelField"
|
||||
IPAdapterModel = "IPAdapterModelField"
|
||||
T2IAdapterModel = "T2IAdapterModelField"
|
||||
T5EncoderModel = "T5EncoderModelField"
|
||||
CLIPEmbedModel = "CLIPEmbedModelField"
|
||||
CLIPLEmbedModel = "CLIPLEmbedModelField"
|
||||
CLIPGEmbedModel = "CLIPGEmbedModelField"
|
||||
SpandrelImageToImageModel = "SpandrelImageToImageModelField"
|
||||
ControlLoRAModel = "ControlLoRAModelField"
|
||||
SigLipModel = "SigLipModelField"
|
||||
FluxReduxModel = "FluxReduxModelField"
|
||||
LlavaOnevisionModel = "LLaVAModelField"
|
||||
Imagen3Model = "Imagen3ModelField"
|
||||
Imagen4Model = "Imagen4ModelField"
|
||||
ChatGPT4oModel = "ChatGPT4oModelField"
|
||||
FluxKontextModel = "FluxKontextModelField"
|
||||
# endregion
|
||||
|
||||
# region Misc Field Types
|
||||
Scheduler = "SchedulerField"
|
||||
Any = "AnyField"
|
||||
@@ -75,6 +54,7 @@ class UIType(str, Enum, metaclass=MetaEnum):
|
||||
# region Internal Field Types
|
||||
_Collection = "CollectionField"
|
||||
_CollectionItem = "CollectionItemField"
|
||||
_IsIntermediate = "IsIntermediate"
|
||||
# endregion
|
||||
|
||||
# region DEPRECATED
|
||||
@@ -112,13 +92,44 @@ class UIType(str, Enum, metaclass=MetaEnum):
|
||||
CollectionItem = "DEPRECATED_CollectionItem"
|
||||
Enum = "DEPRECATED_Enum"
|
||||
WorkflowField = "DEPRECATED_WorkflowField"
|
||||
IsIntermediate = "DEPRECATED_IsIntermediate"
|
||||
BoardField = "DEPRECATED_BoardField"
|
||||
MetadataItem = "DEPRECATED_MetadataItem"
|
||||
MetadataItemCollection = "DEPRECATED_MetadataItemCollection"
|
||||
MetadataItemPolymorphic = "DEPRECATED_MetadataItemPolymorphic"
|
||||
MetadataDict = "DEPRECATED_MetadataDict"
|
||||
|
||||
# Deprecated Model Field Types - use ui_model_[base|type|variant|format] instead
|
||||
MainModel = "DEPRECATED_MainModelField"
|
||||
CogView4MainModel = "DEPRECATED_CogView4MainModelField"
|
||||
FluxMainModel = "DEPRECATED_FluxMainModelField"
|
||||
SD3MainModel = "DEPRECATED_SD3MainModelField"
|
||||
SDXLMainModel = "DEPRECATED_SDXLMainModelField"
|
||||
SDXLRefinerModel = "DEPRECATED_SDXLRefinerModelField"
|
||||
ONNXModel = "DEPRECATED_ONNXModelField"
|
||||
VAEModel = "DEPRECATED_VAEModelField"
|
||||
FluxVAEModel = "DEPRECATED_FluxVAEModelField"
|
||||
LoRAModel = "DEPRECATED_LoRAModelField"
|
||||
ControlNetModel = "DEPRECATED_ControlNetModelField"
|
||||
IPAdapterModel = "DEPRECATED_IPAdapterModelField"
|
||||
T2IAdapterModel = "DEPRECATED_T2IAdapterModelField"
|
||||
T5EncoderModel = "DEPRECATED_T5EncoderModelField"
|
||||
CLIPEmbedModel = "DEPRECATED_CLIPEmbedModelField"
|
||||
CLIPLEmbedModel = "DEPRECATED_CLIPLEmbedModelField"
|
||||
CLIPGEmbedModel = "DEPRECATED_CLIPGEmbedModelField"
|
||||
SpandrelImageToImageModel = "DEPRECATED_SpandrelImageToImageModelField"
|
||||
ControlLoRAModel = "DEPRECATED_ControlLoRAModelField"
|
||||
SigLipModel = "DEPRECATED_SigLipModelField"
|
||||
FluxReduxModel = "DEPRECATED_FluxReduxModelField"
|
||||
LlavaOnevisionModel = "DEPRECATED_LLaVAModelField"
|
||||
Imagen3Model = "DEPRECATED_Imagen3ModelField"
|
||||
Imagen4Model = "DEPRECATED_Imagen4ModelField"
|
||||
ChatGPT4oModel = "DEPRECATED_ChatGPT4oModelField"
|
||||
Gemini2_5Model = "DEPRECATED_Gemini2_5ModelField"
|
||||
FluxKontextModel = "DEPRECATED_FluxKontextModelField"
|
||||
Veo3Model = "DEPRECATED_Veo3ModelField"
|
||||
RunwayModel = "DEPRECATED_RunwayModelField"
|
||||
# endregion
|
||||
|
||||
|
||||
class UIComponent(str, Enum, metaclass=MetaEnum):
|
||||
"""
|
||||
@@ -224,6 +235,12 @@ class ImageField(BaseModel):
|
||||
image_name: str = Field(description="The name of the image")
|
||||
|
||||
|
||||
class VideoField(BaseModel):
|
||||
"""A video primitive field"""
|
||||
|
||||
video_id: str = Field(description="The id of the video")
|
||||
|
||||
|
||||
class BoardField(BaseModel):
|
||||
"""A board primitive field"""
|
||||
|
||||
@@ -321,14 +338,9 @@ class ConditioningField(BaseModel):
|
||||
)
|
||||
|
||||
|
||||
class BoundingBoxField(BaseModel):
|
||||
class BoundingBoxField(BoundingBox):
|
||||
"""A bounding box primitive value."""
|
||||
|
||||
x_min: int = Field(ge=0, description="The minimum x-coordinate of the bounding box (inclusive).")
|
||||
x_max: int = Field(ge=0, description="The maximum x-coordinate of the bounding box (exclusive).")
|
||||
y_min: int = Field(ge=0, description="The minimum y-coordinate of the bounding box (inclusive).")
|
||||
y_max: int = Field(ge=0, description="The maximum y-coordinate of the bounding box (exclusive).")
|
||||
|
||||
score: Optional[float] = Field(
|
||||
default=None,
|
||||
ge=0.0,
|
||||
@@ -337,21 +349,6 @@ class BoundingBoxField(BaseModel):
|
||||
"when the bounding box was produced by a detector and has an associated confidence score.",
|
||||
)
|
||||
|
||||
@model_validator(mode="after")
|
||||
def check_coords(self):
|
||||
if self.x_min > self.x_max:
|
||||
raise ValueError(f"x_min ({self.x_min}) is greater than x_max ({self.x_max}).")
|
||||
if self.y_min > self.y_max:
|
||||
raise ValueError(f"y_min ({self.y_min}) is greater than y_max ({self.y_max}).")
|
||||
return self
|
||||
|
||||
def tuple(self) -> Tuple[int, int, int, int]:
|
||||
"""
|
||||
Returns the bounding box as a tuple suitable for use with PIL's `Image.crop()` method.
|
||||
This method returns a tuple of the form (left, upper, right, lower) == (x_min, y_min, x_max, y_max).
|
||||
"""
|
||||
return (self.x_min, self.y_min, self.x_max, self.y_max)
|
||||
|
||||
|
||||
class MetadataField(RootModel[dict[str, Any]]):
|
||||
"""
|
||||
@@ -418,10 +415,15 @@ class InputFieldJSONSchemaExtra(BaseModel):
|
||||
ui_component: Optional[UIComponent] = None
|
||||
ui_order: Optional[int] = None
|
||||
ui_choice_labels: Optional[dict[str, str]] = None
|
||||
ui_model_base: Optional[list[BaseModelType]] = None
|
||||
ui_model_type: Optional[list[ModelType]] = None
|
||||
ui_model_variant: Optional[list[ClipVariantType | ModelVariantType]] = None
|
||||
ui_model_format: Optional[list[ModelFormat]] = None
|
||||
|
||||
model_config = ConfigDict(
|
||||
validate_assignment=True,
|
||||
json_schema_serialization_defaults_required=True,
|
||||
use_enum_values=True,
|
||||
)
|
||||
|
||||
|
||||
@@ -474,16 +476,121 @@ class OutputFieldJSONSchemaExtra(BaseModel):
|
||||
"""
|
||||
|
||||
field_kind: FieldKind
|
||||
ui_hidden: bool
|
||||
ui_type: Optional[UIType]
|
||||
ui_order: Optional[int]
|
||||
ui_hidden: bool = False
|
||||
ui_order: Optional[int] = None
|
||||
ui_type: Optional[UIType] = None
|
||||
|
||||
model_config = ConfigDict(
|
||||
validate_assignment=True,
|
||||
json_schema_serialization_defaults_required=True,
|
||||
use_enum_values=True,
|
||||
)
|
||||
|
||||
|
||||
def migrate_model_ui_type(ui_type: UIType | str, json_schema_extra: dict[str, Any]) -> bool:
|
||||
"""Migrate deprecated model-specifier ui_type values to new-style ui_model_[base|type|variant|format] in json_schema_extra."""
|
||||
if not isinstance(ui_type, UIType):
|
||||
ui_type = UIType(ui_type)
|
||||
|
||||
ui_model_type: list[ModelType] | None = None
|
||||
ui_model_base: list[BaseModelType] | None = None
|
||||
ui_model_format: list[ModelFormat] | None = None
|
||||
ui_model_variant: list[ClipVariantType | ModelVariantType] | None = None
|
||||
|
||||
match ui_type:
|
||||
case UIType.MainModel:
|
||||
ui_model_base = [BaseModelType.StableDiffusion1, BaseModelType.StableDiffusion2]
|
||||
ui_model_type = [ModelType.Main]
|
||||
case UIType.CogView4MainModel:
|
||||
ui_model_base = [BaseModelType.CogView4]
|
||||
ui_model_type = [ModelType.Main]
|
||||
case UIType.FluxMainModel:
|
||||
ui_model_base = [BaseModelType.Flux]
|
||||
ui_model_type = [ModelType.Main]
|
||||
case UIType.SD3MainModel:
|
||||
ui_model_base = [BaseModelType.StableDiffusion3]
|
||||
ui_model_type = [ModelType.Main]
|
||||
case UIType.SDXLMainModel:
|
||||
ui_model_base = [BaseModelType.StableDiffusionXL]
|
||||
ui_model_type = [ModelType.Main]
|
||||
case UIType.SDXLRefinerModel:
|
||||
ui_model_base = [BaseModelType.StableDiffusionXLRefiner]
|
||||
ui_model_type = [ModelType.Main]
|
||||
case UIType.VAEModel:
|
||||
ui_model_type = [ModelType.VAE]
|
||||
case UIType.FluxVAEModel:
|
||||
ui_model_base = [BaseModelType.Flux]
|
||||
ui_model_type = [ModelType.VAE]
|
||||
case UIType.LoRAModel:
|
||||
ui_model_type = [ModelType.LoRA]
|
||||
case UIType.ControlNetModel:
|
||||
ui_model_type = [ModelType.ControlNet]
|
||||
case UIType.IPAdapterModel:
|
||||
ui_model_type = [ModelType.IPAdapter]
|
||||
case UIType.T2IAdapterModel:
|
||||
ui_model_type = [ModelType.T2IAdapter]
|
||||
case UIType.T5EncoderModel:
|
||||
ui_model_type = [ModelType.T5Encoder]
|
||||
case UIType.CLIPEmbedModel:
|
||||
ui_model_type = [ModelType.CLIPEmbed]
|
||||
case UIType.CLIPLEmbedModel:
|
||||
ui_model_type = [ModelType.CLIPEmbed]
|
||||
ui_model_variant = [ClipVariantType.L]
|
||||
case UIType.CLIPGEmbedModel:
|
||||
ui_model_type = [ModelType.CLIPEmbed]
|
||||
ui_model_variant = [ClipVariantType.G]
|
||||
case UIType.SpandrelImageToImageModel:
|
||||
ui_model_type = [ModelType.SpandrelImageToImage]
|
||||
case UIType.ControlLoRAModel:
|
||||
ui_model_type = [ModelType.ControlLoRa]
|
||||
case UIType.SigLipModel:
|
||||
ui_model_type = [ModelType.SigLIP]
|
||||
case UIType.FluxReduxModel:
|
||||
ui_model_type = [ModelType.FluxRedux]
|
||||
case UIType.LlavaOnevisionModel:
|
||||
ui_model_type = [ModelType.LlavaOnevision]
|
||||
case UIType.Imagen3Model:
|
||||
ui_model_base = [BaseModelType.Imagen3]
|
||||
ui_model_type = [ModelType.Main]
|
||||
case UIType.Imagen4Model:
|
||||
ui_model_base = [BaseModelType.Imagen4]
|
||||
ui_model_type = [ModelType.Main]
|
||||
case UIType.ChatGPT4oModel:
|
||||
ui_model_base = [BaseModelType.ChatGPT4o]
|
||||
ui_model_type = [ModelType.Main]
|
||||
case UIType.Gemini2_5Model:
|
||||
ui_model_base = [BaseModelType.Gemini2_5]
|
||||
ui_model_type = [ModelType.Main]
|
||||
case UIType.FluxKontextModel:
|
||||
ui_model_base = [BaseModelType.FluxKontext]
|
||||
ui_model_type = [ModelType.Main]
|
||||
case UIType.Veo3Model:
|
||||
ui_model_base = [BaseModelType.Veo3]
|
||||
ui_model_type = [ModelType.Video]
|
||||
case UIType.RunwayModel:
|
||||
ui_model_base = [BaseModelType.Runway]
|
||||
ui_model_type = [ModelType.Video]
|
||||
case _:
|
||||
pass
|
||||
|
||||
did_migrate = False
|
||||
|
||||
if ui_model_type is not None:
|
||||
json_schema_extra["ui_model_type"] = [m.value for m in ui_model_type]
|
||||
did_migrate = True
|
||||
if ui_model_base is not None:
|
||||
json_schema_extra["ui_model_base"] = [m.value for m in ui_model_base]
|
||||
did_migrate = True
|
||||
if ui_model_format is not None:
|
||||
json_schema_extra["ui_model_format"] = [m.value for m in ui_model_format]
|
||||
did_migrate = True
|
||||
if ui_model_variant is not None:
|
||||
json_schema_extra["ui_model_variant"] = [m.value for m in ui_model_variant]
|
||||
did_migrate = True
|
||||
|
||||
return did_migrate
|
||||
|
||||
|
||||
def InputField(
|
||||
# copied from pydantic's Field
|
||||
# TODO: Can we support default_factory?
|
||||
@@ -510,35 +617,63 @@ def InputField(
|
||||
ui_hidden: Optional[bool] = None,
|
||||
ui_order: Optional[int] = None,
|
||||
ui_choice_labels: Optional[dict[str, str]] = None,
|
||||
ui_model_base: Optional[BaseModelType | list[BaseModelType]] = None,
|
||||
ui_model_type: Optional[ModelType | list[ModelType]] = None,
|
||||
ui_model_variant: Optional[ClipVariantType | ModelVariantType | list[ClipVariantType | ModelVariantType]] = None,
|
||||
ui_model_format: Optional[ModelFormat | list[ModelFormat]] = None,
|
||||
) -> Any:
|
||||
"""
|
||||
Creates an input field for an invocation.
|
||||
|
||||
This is a wrapper for Pydantic's [Field](https://docs.pydantic.dev/latest/api/fields/#pydantic.fields.Field) \
|
||||
This is a wrapper for Pydantic's [Field](https://docs.pydantic.dev/latest/api/fields/#pydantic.fields.Field)
|
||||
that adds a few extra parameters to support graph execution and the node editor UI.
|
||||
|
||||
:param Input input: [Input.Any] The kind of input this field requires. \
|
||||
`Input.Direct` means a value must be provided on instantiation. \
|
||||
`Input.Connection` means the value must be provided by a connection. \
|
||||
`Input.Any` means either will do.
|
||||
If the field is a `ModelIdentifierField`, use the `ui_model_[base|type|variant|format]` args to filter the model list
|
||||
in the Workflow Editor. Otherwise, use `ui_type` to provide extra type hints for the UI.
|
||||
|
||||
:param UIType ui_type: [None] Optionally provides an extra type hint for the UI. \
|
||||
In some situations, the field's type is not enough to infer the correct UI type. \
|
||||
For example, model selection fields should render a dropdown UI component to select a model. \
|
||||
Internally, there is no difference between SD-1, SD-2 and SDXL model fields, they all use \
|
||||
`MainModelField`. So to ensure the base-model-specific UI is rendered, you can use \
|
||||
`UIType.SDXLMainModelField` to indicate that the field is an SDXL main model field.
|
||||
Don't use both `ui_type` and `ui_model_[base|type|variant|format]` - if both are provided, a warning will be
|
||||
logged and `ui_type` will be ignored.
|
||||
|
||||
:param UIComponent ui_component: [None] Optionally specifies a specific component to use in the UI. \
|
||||
The UI will always render a suitable component, but sometimes you want something different than the default. \
|
||||
For example, a `string` field will default to a single-line input, but you may want a multi-line textarea instead. \
|
||||
For this case, you could provide `UIComponent.Textarea`.
|
||||
Args:
|
||||
input: The kind of input this field requires.
|
||||
- `Input.Direct` means a value must be provided on instantiation.
|
||||
- `Input.Connection` means the value must be provided by a connection.
|
||||
- `Input.Any` means either will do.
|
||||
|
||||
:param bool ui_hidden: [False] Specifies whether or not this field should be hidden in the UI.
|
||||
ui_type: Optionally provides an extra type hint for the UI. In some situations, the field's type is not enough
|
||||
to infer the correct UI type. For example, Scheduler fields are enums, but we want to render a special scheduler
|
||||
dropdown in the UI. Use `UIType.Scheduler` to indicate this.
|
||||
|
||||
:param int ui_order: [None] Specifies the order in which this field should be rendered in the UI.
|
||||
ui_component: Optionally specifies a specific component to use in the UI. The UI will always render a suitable
|
||||
component, but sometimes you want something different than the default. For example, a `string` field will
|
||||
default to a single-line input, but you may want a multi-line textarea instead. In this case, you could use
|
||||
`UIComponent.Textarea`.
|
||||
|
||||
:param dict[str, str] ui_choice_labels: [None] Specifies the labels to use for the choices in an enum field.
|
||||
ui_hidden: Specifies whether or not this field should be hidden in the UI.
|
||||
|
||||
ui_order: Specifies the order in which this field should be rendered in the UI. If omitted, the field will be
|
||||
rendered after all fields with an explicit order, in the order they are defined in the Invocation class.
|
||||
|
||||
ui_model_base: Specifies the base model architectures to filter the model list by in the Workflow Editor. For
|
||||
example, `ui_model_base=BaseModelType.StableDiffusionXL` will show only SDXL architecture models. This arg is
|
||||
only valid if this Input field is annotated as a `ModelIdentifierField`.
|
||||
|
||||
ui_model_type: Specifies the model type(s) to filter the model list by in the Workflow Editor. For example,
|
||||
`ui_model_type=ModelType.VAE` will show only VAE models. This arg is only valid if this Input field is
|
||||
annotated as a `ModelIdentifierField`.
|
||||
|
||||
ui_model_variant: Specifies the model variant(s) to filter the model list by in the Workflow Editor. For example,
|
||||
`ui_model_variant=ModelVariantType.Inpainting` will show only inpainting models. This arg is only valid if this
|
||||
Input field is annotated as a `ModelIdentifierField`.
|
||||
|
||||
ui_model_format: Specifies the model format(s) to filter the model list by in the Workflow Editor. For example,
|
||||
`ui_model_format=ModelFormat.Diffusers` will show only models in the diffusers format. This arg is only valid
|
||||
if this Input field is annotated as a `ModelIdentifierField`.
|
||||
|
||||
ui_choice_labels: Specifies the labels to use for the choices in an enum field. If omitted, the enum values
|
||||
will be used. This arg is only valid if the field is annotated with as a `Literal`. For example,
|
||||
`Literal["choice1", "choice2", "choice3"]` with `ui_choice_labels={"choice1": "Choice 1", "choice2": "Choice 2",
|
||||
"choice3": "Choice 3"}` will render a dropdown with the labels "Choice 1", "Choice 2" and "Choice 3".
|
||||
"""
|
||||
|
||||
json_schema_extra_ = InputFieldJSONSchemaExtra(
|
||||
@@ -546,8 +681,6 @@ def InputField(
|
||||
field_kind=FieldKind.Input,
|
||||
)
|
||||
|
||||
if ui_type is not None:
|
||||
json_schema_extra_.ui_type = ui_type
|
||||
if ui_component is not None:
|
||||
json_schema_extra_.ui_component = ui_component
|
||||
if ui_hidden is not None:
|
||||
@@ -556,6 +689,28 @@ def InputField(
|
||||
json_schema_extra_.ui_order = ui_order
|
||||
if ui_choice_labels is not None:
|
||||
json_schema_extra_.ui_choice_labels = ui_choice_labels
|
||||
if ui_model_base is not None:
|
||||
if isinstance(ui_model_base, list):
|
||||
json_schema_extra_.ui_model_base = ui_model_base
|
||||
else:
|
||||
json_schema_extra_.ui_model_base = [ui_model_base]
|
||||
if ui_model_type is not None:
|
||||
if isinstance(ui_model_type, list):
|
||||
json_schema_extra_.ui_model_type = ui_model_type
|
||||
else:
|
||||
json_schema_extra_.ui_model_type = [ui_model_type]
|
||||
if ui_model_variant is not None:
|
||||
if isinstance(ui_model_variant, list):
|
||||
json_schema_extra_.ui_model_variant = ui_model_variant
|
||||
else:
|
||||
json_schema_extra_.ui_model_variant = [ui_model_variant]
|
||||
if ui_model_format is not None:
|
||||
if isinstance(ui_model_format, list):
|
||||
json_schema_extra_.ui_model_format = ui_model_format
|
||||
else:
|
||||
json_schema_extra_.ui_model_format = [ui_model_format]
|
||||
if ui_type is not None:
|
||||
json_schema_extra_.ui_type = ui_type
|
||||
|
||||
"""
|
||||
There is a conflict between the typing of invocation definitions and the typing of an invocation's
|
||||
@@ -657,20 +812,20 @@ def OutputField(
|
||||
"""
|
||||
Creates an output field for an invocation output.
|
||||
|
||||
This is a wrapper for Pydantic's [Field](https://docs.pydantic.dev/1.10/usage/schema/#field-customization) \
|
||||
This is a wrapper for Pydantic's [Field](https://docs.pydantic.dev/1.10/usage/schema/#field-customization)
|
||||
that adds a few extra parameters to support graph execution and the node editor UI.
|
||||
|
||||
:param UIType ui_type: [None] Optionally provides an extra type hint for the UI. \
|
||||
In some situations, the field's type is not enough to infer the correct UI type. \
|
||||
For example, model selection fields should render a dropdown UI component to select a model. \
|
||||
Internally, there is no difference between SD-1, SD-2 and SDXL model fields, they all use \
|
||||
`MainModelField`. So to ensure the base-model-specific UI is rendered, you can use \
|
||||
`UIType.SDXLMainModelField` to indicate that the field is an SDXL main model field.
|
||||
Args:
|
||||
ui_type: Optionally provides an extra type hint for the UI. In some situations, the field's type is not enough
|
||||
to infer the correct UI type. For example, Scheduler fields are enums, but we want to render a special scheduler
|
||||
dropdown in the UI. Use `UIType.Scheduler` to indicate this.
|
||||
|
||||
:param bool ui_hidden: [False] Specifies whether or not this field should be hidden in the UI. \
|
||||
ui_hidden: Specifies whether or not this field should be hidden in the UI.
|
||||
|
||||
:param int ui_order: [None] Specifies the order in which this field should be rendered in the UI. \
|
||||
ui_order: Specifies the order in which this field should be rendered in the UI. If omitted, the field will be
|
||||
rendered after all fields with an explicit order, in the order they are defined in the Invocation class.
|
||||
"""
|
||||
|
||||
return Field(
|
||||
default=default,
|
||||
title=title,
|
||||
@@ -688,9 +843,9 @@ def OutputField(
|
||||
min_length=min_length,
|
||||
max_length=max_length,
|
||||
json_schema_extra=OutputFieldJSONSchemaExtra(
|
||||
ui_type=ui_type,
|
||||
ui_hidden=ui_hidden,
|
||||
ui_order=ui_order,
|
||||
ui_type=ui_type,
|
||||
field_kind=FieldKind.Output,
|
||||
).model_dump(exclude_none=True),
|
||||
)
|
||||
|
||||
@@ -4,9 +4,10 @@ from invokeai.app.invocations.baseinvocation import (
|
||||
invocation,
|
||||
invocation_output,
|
||||
)
|
||||
from invokeai.app.invocations.fields import FieldDescriptions, ImageField, InputField, OutputField, UIType
|
||||
from invokeai.app.invocations.fields import FieldDescriptions, ImageField, InputField, OutputField
|
||||
from invokeai.app.invocations.model import ControlLoRAField, ModelIdentifierField
|
||||
from invokeai.app.services.shared.invocation_context import InvocationContext
|
||||
from invokeai.backend.model_manager.taxonomy import BaseModelType, ModelType
|
||||
|
||||
|
||||
@invocation_output("flux_control_lora_loader_output")
|
||||
@@ -29,7 +30,10 @@ class FluxControlLoRALoaderInvocation(BaseInvocation):
|
||||
"""LoRA model and Image to use with FLUX transformer generation."""
|
||||
|
||||
lora: ModelIdentifierField = InputField(
|
||||
description=FieldDescriptions.control_lora_model, title="Control LoRA", ui_type=UIType.ControlLoRAModel
|
||||
description=FieldDescriptions.control_lora_model,
|
||||
title="Control LoRA",
|
||||
ui_model_base=BaseModelType.Flux,
|
||||
ui_model_type=ModelType.ControlLoRa,
|
||||
)
|
||||
image: ImageField = InputField(description="The image to encode.")
|
||||
weight: float = InputField(description="The weight of the LoRA.", default=1.0)
|
||||
|
||||
@@ -6,11 +6,12 @@ from invokeai.app.invocations.baseinvocation import (
|
||||
invocation,
|
||||
invocation_output,
|
||||
)
|
||||
from invokeai.app.invocations.fields import FieldDescriptions, ImageField, InputField, OutputField, UIType
|
||||
from invokeai.app.invocations.fields import FieldDescriptions, ImageField, InputField, OutputField
|
||||
from invokeai.app.invocations.model import ModelIdentifierField
|
||||
from invokeai.app.invocations.util import validate_begin_end_step, validate_weights
|
||||
from invokeai.app.services.shared.invocation_context import InvocationContext
|
||||
from invokeai.app.util.controlnet_utils import CONTROLNET_RESIZE_VALUES
|
||||
from invokeai.backend.model_manager.taxonomy import BaseModelType, ModelType
|
||||
|
||||
|
||||
class FluxControlNetField(BaseModel):
|
||||
@@ -57,7 +58,9 @@ class FluxControlNetInvocation(BaseInvocation):
|
||||
|
||||
image: ImageField = InputField(description="The control image")
|
||||
control_model: ModelIdentifierField = InputField(
|
||||
description=FieldDescriptions.controlnet_model, ui_type=UIType.ControlNetModel
|
||||
description=FieldDescriptions.controlnet_model,
|
||||
ui_model_base=BaseModelType.Flux,
|
||||
ui_model_type=ModelType.ControlNet,
|
||||
)
|
||||
control_weight: float | list[float] = InputField(
|
||||
default=1.0, ge=-1, le=2, description="The weight given to the ControlNet"
|
||||
|
||||
@@ -48,7 +48,7 @@ from invokeai.backend.flux.sampling_utils import (
|
||||
unpack,
|
||||
)
|
||||
from invokeai.backend.flux.text_conditioning import FluxReduxConditioning, FluxTextConditioning
|
||||
from invokeai.backend.model_manager.taxonomy import ModelFormat, ModelVariantType
|
||||
from invokeai.backend.model_manager.taxonomy import BaseModelType, FluxVariantType, ModelFormat, ModelType
|
||||
from invokeai.backend.patches.layer_patcher import LayerPatcher
|
||||
from invokeai.backend.patches.lora_conversions.flux_lora_constants import FLUX_LORA_TRANSFORMER_PREFIX
|
||||
from invokeai.backend.patches.model_patch_raw import ModelPatchRaw
|
||||
@@ -63,7 +63,7 @@ from invokeai.backend.util.devices import TorchDevice
|
||||
title="FLUX Denoise",
|
||||
tags=["image", "flux"],
|
||||
category="image",
|
||||
version="4.0.0",
|
||||
version="4.1.0",
|
||||
)
|
||||
class FluxDenoiseInvocation(BaseInvocation):
|
||||
"""Run denoising process with a FLUX transformer model."""
|
||||
@@ -153,7 +153,7 @@ class FluxDenoiseInvocation(BaseInvocation):
|
||||
description=FieldDescriptions.ip_adapter, title="IP-Adapter", default=None, input=Input.Connection
|
||||
)
|
||||
|
||||
kontext_conditioning: Optional[FluxKontextConditioningField] = InputField(
|
||||
kontext_conditioning: FluxKontextConditioningField | list[FluxKontextConditioningField] | None = InputField(
|
||||
default=None,
|
||||
description="FLUX Kontext conditioning (reference image).",
|
||||
input=Input.Connection,
|
||||
@@ -232,7 +232,8 @@ class FluxDenoiseInvocation(BaseInvocation):
|
||||
)
|
||||
|
||||
transformer_config = context.models.get_config(self.transformer.transformer)
|
||||
is_schnell = "schnell" in getattr(transformer_config, "config_path", "")
|
||||
assert transformer_config.base is BaseModelType.Flux and transformer_config.type is ModelType.Main
|
||||
is_schnell = transformer_config.variant is FluxVariantType.Schnell
|
||||
|
||||
# Calculate the timestep schedule.
|
||||
timesteps = get_schedule(
|
||||
@@ -277,7 +278,7 @@ class FluxDenoiseInvocation(BaseInvocation):
|
||||
|
||||
# Prepare the extra image conditioning tensor (img_cond) for either FLUX structural control or FLUX Fill.
|
||||
img_cond: torch.Tensor | None = None
|
||||
is_flux_fill = transformer_config.variant == ModelVariantType.Inpaint # type: ignore
|
||||
is_flux_fill = transformer_config.variant is FluxVariantType.DevFill
|
||||
if is_flux_fill:
|
||||
img_cond = self._prep_flux_fill_img_cond(
|
||||
context, device=TorchDevice.choose_torch_device(), dtype=inference_dtype
|
||||
@@ -328,6 +329,21 @@ class FluxDenoiseInvocation(BaseInvocation):
|
||||
cfg_scale_end_step=self.cfg_scale_end_step,
|
||||
)
|
||||
|
||||
kontext_extension = None
|
||||
if self.kontext_conditioning:
|
||||
if not self.controlnet_vae:
|
||||
raise ValueError("A VAE (e.g., controlnet_vae) must be provided to use Kontext conditioning.")
|
||||
|
||||
kontext_extension = KontextExtension(
|
||||
context=context,
|
||||
kontext_conditioning=self.kontext_conditioning
|
||||
if isinstance(self.kontext_conditioning, list)
|
||||
else [self.kontext_conditioning],
|
||||
vae_field=self.controlnet_vae,
|
||||
device=TorchDevice.choose_torch_device(),
|
||||
dtype=inference_dtype,
|
||||
)
|
||||
|
||||
with ExitStack() as exit_stack:
|
||||
# Prepare ControlNet extensions.
|
||||
# Note: We do this before loading the transformer model to minimize peak memory (see implementation).
|
||||
@@ -385,19 +401,6 @@ class FluxDenoiseInvocation(BaseInvocation):
|
||||
dtype=inference_dtype,
|
||||
)
|
||||
|
||||
kontext_extension = None
|
||||
if self.kontext_conditioning is not None:
|
||||
if not self.controlnet_vae:
|
||||
raise ValueError("A VAE (e.g., controlnet_vae) must be provided to use Kontext conditioning.")
|
||||
|
||||
kontext_extension = KontextExtension(
|
||||
context=context,
|
||||
kontext_conditioning=self.kontext_conditioning,
|
||||
vae_field=self.controlnet_vae,
|
||||
device=TorchDevice.choose_torch_device(),
|
||||
dtype=inference_dtype,
|
||||
)
|
||||
|
||||
# Prepare Kontext conditioning if provided
|
||||
img_cond_seq = None
|
||||
img_cond_seq_ids = None
|
||||
|
||||
@@ -5,7 +5,7 @@ from pydantic import field_validator, model_validator
|
||||
from typing_extensions import Self
|
||||
|
||||
from invokeai.app.invocations.baseinvocation import BaseInvocation, invocation
|
||||
from invokeai.app.invocations.fields import InputField, UIType
|
||||
from invokeai.app.invocations.fields import InputField
|
||||
from invokeai.app.invocations.ip_adapter import (
|
||||
CLIP_VISION_MODEL_MAP,
|
||||
IPAdapterField,
|
||||
@@ -16,10 +16,8 @@ from invokeai.app.invocations.model import ModelIdentifierField
|
||||
from invokeai.app.invocations.primitives import ImageField
|
||||
from invokeai.app.invocations.util import validate_begin_end_step, validate_weights
|
||||
from invokeai.app.services.shared.invocation_context import InvocationContext
|
||||
from invokeai.backend.model_manager.config import (
|
||||
IPAdapterCheckpointConfig,
|
||||
IPAdapterInvokeAIConfig,
|
||||
)
|
||||
from invokeai.backend.model_manager.configs.ip_adapter import IPAdapter_Checkpoint_FLUX_Config
|
||||
from invokeai.backend.model_manager.taxonomy import BaseModelType, ModelType
|
||||
|
||||
|
||||
@invocation(
|
||||
@@ -36,7 +34,10 @@ class FluxIPAdapterInvocation(BaseInvocation):
|
||||
|
||||
image: ImageField = InputField(description="The IP-Adapter image prompt(s).")
|
||||
ip_adapter_model: ModelIdentifierField = InputField(
|
||||
description="The IP-Adapter model.", title="IP-Adapter Model", ui_type=UIType.IPAdapterModel
|
||||
description="The IP-Adapter model.",
|
||||
title="IP-Adapter Model",
|
||||
ui_model_base=BaseModelType.Flux,
|
||||
ui_model_type=ModelType.IPAdapter,
|
||||
)
|
||||
# Currently, the only known ViT model used by FLUX IP-Adapters is ViT-L.
|
||||
clip_vision_model: Literal["ViT-L"] = InputField(description="CLIP Vision model to use.", default="ViT-L")
|
||||
@@ -64,7 +65,7 @@ class FluxIPAdapterInvocation(BaseInvocation):
|
||||
def invoke(self, context: InvocationContext) -> IPAdapterOutput:
|
||||
# Lookup the CLIP Vision encoder that is intended to be used with the IP-Adapter model.
|
||||
ip_adapter_info = context.models.get_config(self.ip_adapter_model.key)
|
||||
assert isinstance(ip_adapter_info, (IPAdapterInvokeAIConfig, IPAdapterCheckpointConfig))
|
||||
assert isinstance(ip_adapter_info, IPAdapter_Checkpoint_FLUX_Config)
|
||||
|
||||
# Note: There is a IPAdapterInvokeAIConfig.image_encoder_model_id field, but it isn't trustworthy.
|
||||
image_encoder_starter_model = CLIP_VISION_MODEL_MAP[self.clip_vision_model]
|
||||
|
||||
@@ -6,10 +6,10 @@ from invokeai.app.invocations.baseinvocation import (
|
||||
invocation,
|
||||
invocation_output,
|
||||
)
|
||||
from invokeai.app.invocations.fields import FieldDescriptions, Input, InputField, OutputField, UIType
|
||||
from invokeai.app.invocations.fields import FieldDescriptions, Input, InputField, OutputField
|
||||
from invokeai.app.invocations.model import CLIPField, LoRAField, ModelIdentifierField, T5EncoderField, TransformerField
|
||||
from invokeai.app.services.shared.invocation_context import InvocationContext
|
||||
from invokeai.backend.model_manager.taxonomy import BaseModelType
|
||||
from invokeai.backend.model_manager.taxonomy import BaseModelType, ModelType
|
||||
|
||||
|
||||
@invocation_output("flux_lora_loader_output")
|
||||
@@ -36,7 +36,10 @@ class FluxLoRALoaderInvocation(BaseInvocation):
|
||||
"""Apply a LoRA model to a FLUX transformer and/or text encoder."""
|
||||
|
||||
lora: ModelIdentifierField = InputField(
|
||||
description=FieldDescriptions.lora_model, title="LoRA", ui_type=UIType.LoRAModel
|
||||
description=FieldDescriptions.lora_model,
|
||||
title="LoRA",
|
||||
ui_model_base=BaseModelType.Flux,
|
||||
ui_model_type=ModelType.LoRA,
|
||||
)
|
||||
weight: float = InputField(default=0.75, description=FieldDescriptions.lora_weight)
|
||||
transformer: TransformerField | None = InputField(
|
||||
|
||||
@@ -6,18 +6,16 @@ from invokeai.app.invocations.baseinvocation import (
|
||||
invocation,
|
||||
invocation_output,
|
||||
)
|
||||
from invokeai.app.invocations.fields import FieldDescriptions, Input, InputField, OutputField, UIType
|
||||
from invokeai.app.invocations.fields import FieldDescriptions, Input, InputField, OutputField
|
||||
from invokeai.app.invocations.model import CLIPField, ModelIdentifierField, T5EncoderField, TransformerField, VAEField
|
||||
from invokeai.app.services.shared.invocation_context import InvocationContext
|
||||
from invokeai.app.util.t5_model_identifier import (
|
||||
preprocess_t5_encoder_model_identifier,
|
||||
preprocess_t5_tokenizer_model_identifier,
|
||||
)
|
||||
from invokeai.backend.flux.util import max_seq_lengths
|
||||
from invokeai.backend.model_manager.config import (
|
||||
CheckpointConfigBase,
|
||||
)
|
||||
from invokeai.backend.model_manager.taxonomy import SubModelType
|
||||
from invokeai.backend.flux.util import get_flux_max_seq_length
|
||||
from invokeai.backend.model_manager.configs.base import Checkpoint_Config_Base
|
||||
from invokeai.backend.model_manager.taxonomy import BaseModelType, ModelType, SubModelType
|
||||
|
||||
|
||||
@invocation_output("flux_model_loader_output")
|
||||
@@ -46,23 +44,30 @@ class FluxModelLoaderInvocation(BaseInvocation):
|
||||
|
||||
model: ModelIdentifierField = InputField(
|
||||
description=FieldDescriptions.flux_model,
|
||||
ui_type=UIType.FluxMainModel,
|
||||
input=Input.Direct,
|
||||
ui_model_base=BaseModelType.Flux,
|
||||
ui_model_type=ModelType.Main,
|
||||
)
|
||||
|
||||
t5_encoder_model: ModelIdentifierField = InputField(
|
||||
description=FieldDescriptions.t5_encoder, ui_type=UIType.T5EncoderModel, input=Input.Direct, title="T5 Encoder"
|
||||
description=FieldDescriptions.t5_encoder,
|
||||
input=Input.Direct,
|
||||
title="T5 Encoder",
|
||||
ui_model_type=ModelType.T5Encoder,
|
||||
)
|
||||
|
||||
clip_embed_model: ModelIdentifierField = InputField(
|
||||
description=FieldDescriptions.clip_embed_model,
|
||||
ui_type=UIType.CLIPEmbedModel,
|
||||
input=Input.Direct,
|
||||
title="CLIP Embed",
|
||||
ui_model_type=ModelType.CLIPEmbed,
|
||||
)
|
||||
|
||||
vae_model: ModelIdentifierField = InputField(
|
||||
description=FieldDescriptions.vae_model, ui_type=UIType.FluxVAEModel, title="VAE"
|
||||
description=FieldDescriptions.vae_model,
|
||||
title="VAE",
|
||||
ui_model_base=BaseModelType.Flux,
|
||||
ui_model_type=ModelType.VAE,
|
||||
)
|
||||
|
||||
def invoke(self, context: InvocationContext) -> FluxModelLoaderOutput:
|
||||
@@ -80,12 +85,12 @@ class FluxModelLoaderInvocation(BaseInvocation):
|
||||
t5_encoder = preprocess_t5_encoder_model_identifier(self.t5_encoder_model)
|
||||
|
||||
transformer_config = context.models.get_config(transformer)
|
||||
assert isinstance(transformer_config, CheckpointConfigBase)
|
||||
assert isinstance(transformer_config, Checkpoint_Config_Base)
|
||||
|
||||
return FluxModelLoaderOutput(
|
||||
transformer=TransformerField(transformer=transformer, loras=[]),
|
||||
clip=CLIPField(tokenizer=tokenizer, text_encoder=clip_encoder, loras=[], skipped_layers=0),
|
||||
t5_encoder=T5EncoderField(tokenizer=tokenizer2, text_encoder=t5_encoder, loras=[]),
|
||||
vae=VAEField(vae=vae),
|
||||
max_seq_len=max_seq_lengths[transformer_config.config_path],
|
||||
max_seq_len=get_flux_max_seq_length(transformer_config.variant),
|
||||
)
|
||||
|
||||
@@ -18,16 +18,15 @@ from invokeai.app.invocations.fields import (
|
||||
InputField,
|
||||
OutputField,
|
||||
TensorField,
|
||||
UIType,
|
||||
)
|
||||
from invokeai.app.invocations.model import ModelIdentifierField
|
||||
from invokeai.app.invocations.primitives import ImageField
|
||||
from invokeai.app.services.model_records.model_records_base import ModelRecordChanges
|
||||
from invokeai.app.services.shared.invocation_context import InvocationContext
|
||||
from invokeai.backend.flux.redux.flux_redux_model import FluxReduxModel
|
||||
from invokeai.backend.model_manager import BaseModelType, ModelType
|
||||
from invokeai.backend.model_manager.config import AnyModelConfig
|
||||
from invokeai.backend.model_manager.configs.factory import AnyModelConfig
|
||||
from invokeai.backend.model_manager.starter_models import siglip
|
||||
from invokeai.backend.model_manager.taxonomy import BaseModelType, ModelType
|
||||
from invokeai.backend.sig_lip.sig_lip_pipeline import SigLipPipeline
|
||||
from invokeai.backend.util.devices import TorchDevice
|
||||
|
||||
@@ -64,7 +63,8 @@ class FluxReduxInvocation(BaseInvocation):
|
||||
redux_model: ModelIdentifierField = InputField(
|
||||
description="The FLUX Redux model to use.",
|
||||
title="FLUX Redux Model",
|
||||
ui_type=UIType.FluxReduxModel,
|
||||
ui_model_base=BaseModelType.Flux,
|
||||
ui_model_type=ModelType.FluxRedux,
|
||||
)
|
||||
downsampling_factor: int = InputField(
|
||||
ge=1,
|
||||
|
||||
@@ -17,7 +17,7 @@ from invokeai.app.invocations.model import CLIPField, T5EncoderField
|
||||
from invokeai.app.invocations.primitives import FluxConditioningOutput
|
||||
from invokeai.app.services.shared.invocation_context import InvocationContext
|
||||
from invokeai.backend.flux.modules.conditioner import HFEncoder
|
||||
from invokeai.backend.model_manager import ModelFormat
|
||||
from invokeai.backend.model_manager.taxonomy import ModelFormat
|
||||
from invokeai.backend.patches.layer_patcher import LayerPatcher
|
||||
from invokeai.backend.patches.lora_conversions.flux_lora_constants import FLUX_LORA_CLIP_PREFIX, FLUX_LORA_T5_PREFIX
|
||||
from invokeai.backend.patches.model_patch_raw import ModelPatchRaw
|
||||
|
||||
@@ -3,7 +3,6 @@ from einops import rearrange
|
||||
from PIL import Image
|
||||
|
||||
from invokeai.app.invocations.baseinvocation import BaseInvocation, invocation
|
||||
from invokeai.app.invocations.constants import LATENT_SCALE_FACTOR
|
||||
from invokeai.app.invocations.fields import (
|
||||
FieldDescriptions,
|
||||
Input,
|
||||
@@ -18,6 +17,7 @@ from invokeai.app.services.shared.invocation_context import InvocationContext
|
||||
from invokeai.backend.flux.modules.autoencoder import AutoEncoder
|
||||
from invokeai.backend.model_manager.load.load_base import LoadedModel
|
||||
from invokeai.backend.util.devices import TorchDevice
|
||||
from invokeai.backend.util.vae_working_memory import estimate_vae_working_memory_flux
|
||||
|
||||
|
||||
@invocation(
|
||||
@@ -39,17 +39,11 @@ class FluxVaeDecodeInvocation(BaseInvocation, WithMetadata, WithBoard):
|
||||
input=Input.Connection,
|
||||
)
|
||||
|
||||
def _estimate_working_memory(self, latents: torch.Tensor, vae: AutoEncoder) -> int:
|
||||
"""Estimate the working memory required by the invocation in bytes."""
|
||||
out_h = LATENT_SCALE_FACTOR * latents.shape[-2]
|
||||
out_w = LATENT_SCALE_FACTOR * latents.shape[-1]
|
||||
element_size = next(vae.parameters()).element_size()
|
||||
scaling_constant = 2200 # Determined experimentally.
|
||||
working_memory = out_h * out_w * element_size * scaling_constant
|
||||
return int(working_memory)
|
||||
|
||||
def _vae_decode(self, vae_info: LoadedModel, latents: torch.Tensor) -> Image.Image:
|
||||
estimated_working_memory = self._estimate_working_memory(latents, vae_info.model)
|
||||
assert isinstance(vae_info.model, AutoEncoder)
|
||||
estimated_working_memory = estimate_vae_working_memory_flux(
|
||||
operation="decode", image_tensor=latents, vae=vae_info.model
|
||||
)
|
||||
with vae_info.model_on_device(working_mem_bytes=estimated_working_memory) as (_, vae):
|
||||
assert isinstance(vae, AutoEncoder)
|
||||
vae_dtype = next(iter(vae.parameters())).dtype
|
||||
|
||||
@@ -12,9 +12,10 @@ from invokeai.app.invocations.model import VAEField
|
||||
from invokeai.app.invocations.primitives import LatentsOutput
|
||||
from invokeai.app.services.shared.invocation_context import InvocationContext
|
||||
from invokeai.backend.flux.modules.autoencoder import AutoEncoder
|
||||
from invokeai.backend.model_manager import LoadedModel
|
||||
from invokeai.backend.model_manager.load.load_base import LoadedModel
|
||||
from invokeai.backend.stable_diffusion.diffusers_pipeline import image_resized_to_grid_as_tensor
|
||||
from invokeai.backend.util.devices import TorchDevice
|
||||
from invokeai.backend.util.vae_working_memory import estimate_vae_working_memory_flux
|
||||
|
||||
|
||||
@invocation(
|
||||
@@ -41,8 +42,12 @@ class FluxVaeEncodeInvocation(BaseInvocation):
|
||||
# TODO(ryand): Write a util function for generating random tensors that is consistent across devices / dtypes.
|
||||
# There's a starting point in get_noise(...), but it needs to be extracted and generalized. This function
|
||||
# should be used for VAE encode sampling.
|
||||
assert isinstance(vae_info.model, AutoEncoder)
|
||||
estimated_working_memory = estimate_vae_working_memory_flux(
|
||||
operation="encode", image_tensor=image_tensor, vae=vae_info.model
|
||||
)
|
||||
generator = torch.Generator(device=TorchDevice.choose_torch_device()).manual_seed(0)
|
||||
with vae_info as vae:
|
||||
with vae_info.model_on_device(working_mem_bytes=estimated_working_memory) as (_, vae):
|
||||
assert isinstance(vae, AutoEncoder)
|
||||
vae_dtype = next(iter(vae.parameters())).dtype
|
||||
image_tensor = image_tensor.to(device=TorchDevice.choose_torch_device(), dtype=vae_dtype)
|
||||
|
||||
@@ -649,102 +649,104 @@ class MaskCombineInvocation(BaseInvocation, WithMetadata, WithBoard):
|
||||
title="Color Correct",
|
||||
tags=["image", "color"],
|
||||
category="image",
|
||||
version="1.2.2",
|
||||
version="2.0.0",
|
||||
)
|
||||
class ColorCorrectInvocation(BaseInvocation, WithMetadata, WithBoard):
|
||||
"""
|
||||
Shifts the colors of a target image to match the reference image, optionally
|
||||
using a mask to only color-correct certain regions of the target image.
|
||||
Matches the color histogram of a base image to a reference image, optionally
|
||||
using a mask to only color-correct certain regions of the base image.
|
||||
"""
|
||||
|
||||
image: ImageField = InputField(description="The image to color-correct")
|
||||
reference: ImageField = InputField(description="Reference image for color-correction")
|
||||
mask: Optional[ImageField] = InputField(default=None, description="Mask to use when applying color-correction")
|
||||
mask_blur_radius: float = InputField(default=8, description="Mask blur radius")
|
||||
base_image: ImageField = InputField(description="The image to color-correct")
|
||||
color_reference: ImageField = InputField(description="Reference image for color-correction")
|
||||
mask: Optional[ImageField] = InputField(default=None, description="Optional mask to limit color correction area")
|
||||
colorspace: Literal["RGB", "YCbCr", "YCbCr-Chroma", "YCbCr-Luma"] = InputField(
|
||||
default="RGB", description="Colorspace in which to apply histogram matching", title="Color Space"
|
||||
)
|
||||
|
||||
def _match_histogram_channel(self, source: numpy.ndarray, reference: numpy.ndarray) -> numpy.ndarray:
|
||||
"""Match histogram of source channel to reference channel using cumulative distribution functions."""
|
||||
# Compute histograms
|
||||
source_hist, _ = numpy.histogram(source.flatten(), bins=256, range=(0, 256))
|
||||
reference_hist, _ = numpy.histogram(reference.flatten(), bins=256, range=(0, 256))
|
||||
|
||||
# Compute cumulative distribution functions
|
||||
source_cdf = source_hist.cumsum()
|
||||
reference_cdf = reference_hist.cumsum()
|
||||
|
||||
# Normalize CDFs (avoid division by zero)
|
||||
if source_cdf[-1] > 0:
|
||||
source_cdf = source_cdf / source_cdf[-1]
|
||||
if reference_cdf[-1] > 0:
|
||||
reference_cdf = reference_cdf / reference_cdf[-1]
|
||||
|
||||
# Create lookup table using linear interpolation
|
||||
lookup_table = numpy.interp(source_cdf, reference_cdf, numpy.arange(256))
|
||||
|
||||
# Apply lookup table to source image
|
||||
return lookup_table[source].astype(numpy.uint8)
|
||||
|
||||
def invoke(self, context: InvocationContext) -> ImageOutput:
|
||||
pil_init_mask = None
|
||||
# Load images as RGBA
|
||||
base_image = context.images.get_pil(self.base_image.image_name, "RGBA")
|
||||
|
||||
# Store original alpha channel
|
||||
original_alpha = base_image.getchannel("A")
|
||||
|
||||
# Convert to working colorspace
|
||||
if self.colorspace == "RGB":
|
||||
base_array = numpy.asarray(base_image.convert("RGB"), dtype=numpy.uint8)
|
||||
ref_rgb = context.images.get_pil(self.color_reference.image_name, "RGB")
|
||||
ref_array = numpy.asarray(ref_rgb, dtype=numpy.uint8)
|
||||
channels_to_match = [0, 1, 2] # R, G, B
|
||||
else:
|
||||
# Convert to YCbCr colorspace
|
||||
base_ycbcr = base_image.convert("YCbCr")
|
||||
ref_ycbcr = context.images.get_pil(self.color_reference.image_name, "YCbCr")
|
||||
|
||||
base_array = numpy.asarray(base_ycbcr, dtype=numpy.uint8)
|
||||
ref_array = numpy.asarray(ref_ycbcr, dtype=numpy.uint8)
|
||||
|
||||
# Determine which channels to match based on mode
|
||||
if self.colorspace == "YCbCr":
|
||||
channels_to_match = [0, 1, 2] # Y, Cb, Cr
|
||||
elif self.colorspace == "YCbCr-Chroma":
|
||||
channels_to_match = [1, 2] # Cb, Cr only
|
||||
else: # YCbCr-Luma
|
||||
channels_to_match = [0] # Y only
|
||||
|
||||
# Apply histogram matching to selected channels
|
||||
corrected_array = base_array.copy()
|
||||
for channel_idx in channels_to_match:
|
||||
corrected_array[:, :, channel_idx] = self._match_histogram_channel(
|
||||
base_array[:, :, channel_idx], ref_array[:, :, channel_idx]
|
||||
)
|
||||
|
||||
# Convert back to RGB if we were in YCbCr
|
||||
if self.colorspace != "RGB":
|
||||
corrected_image = Image.fromarray(corrected_array, mode="YCbCr").convert("RGB")
|
||||
else:
|
||||
corrected_image = Image.fromarray(corrected_array, mode="RGB")
|
||||
|
||||
# Apply mask if provided (white = original, black = result)
|
||||
if self.mask is not None:
|
||||
pil_init_mask = context.images.get_pil(self.mask.image_name).convert("L")
|
||||
|
||||
init_image = context.images.get_pil(self.reference.image_name)
|
||||
|
||||
result = context.images.get_pil(self.image.image_name).convert("RGBA")
|
||||
|
||||
# if init_image is None or init_mask is None:
|
||||
# return result
|
||||
|
||||
# Get the original alpha channel of the mask if there is one.
|
||||
# Otherwise it is some other black/white image format ('1', 'L' or 'RGB')
|
||||
# pil_init_mask = (
|
||||
# init_mask.getchannel("A")
|
||||
# if init_mask.mode == "RGBA"
|
||||
# else init_mask.convert("L")
|
||||
# )
|
||||
pil_init_image = init_image.convert("RGBA") # Add an alpha channel if one doesn't exist
|
||||
|
||||
# Build an image with only visible pixels from source to use as reference for color-matching.
|
||||
init_rgb_pixels = numpy.asarray(init_image.convert("RGB"), dtype=numpy.uint8)
|
||||
init_a_pixels = numpy.asarray(pil_init_image.getchannel("A"), dtype=numpy.uint8)
|
||||
init_mask_pixels = numpy.asarray(pil_init_mask, dtype=numpy.uint8)
|
||||
|
||||
# Get numpy version of result
|
||||
np_image = numpy.asarray(result.convert("RGB"), dtype=numpy.uint8)
|
||||
|
||||
# Mask and calculate mean and standard deviation
|
||||
mask_pixels = init_a_pixels * init_mask_pixels > 0
|
||||
np_init_rgb_pixels_masked = init_rgb_pixels[mask_pixels, :]
|
||||
np_image_masked = np_image[mask_pixels, :]
|
||||
|
||||
if np_init_rgb_pixels_masked.size > 0:
|
||||
init_means = np_init_rgb_pixels_masked.mean(axis=0)
|
||||
init_std = np_init_rgb_pixels_masked.std(axis=0)
|
||||
gen_means = np_image_masked.mean(axis=0)
|
||||
gen_std = np_image_masked.std(axis=0)
|
||||
|
||||
# Color correct
|
||||
np_matched_result = np_image.copy()
|
||||
np_matched_result[:, :, :] = (
|
||||
(
|
||||
(
|
||||
(np_matched_result[:, :, :].astype(numpy.float32) - gen_means[None, None, :])
|
||||
/ gen_std[None, None, :]
|
||||
)
|
||||
* init_std[None, None, :]
|
||||
+ init_means[None, None, :]
|
||||
)
|
||||
.clip(0, 255)
|
||||
.astype(numpy.uint8)
|
||||
)
|
||||
matched_result = Image.fromarray(np_matched_result, mode="RGB")
|
||||
# Load mask as grayscale
|
||||
mask_image = context.images.get_pil(self.mask.image_name, "L")
|
||||
# Start with corrected image, paste base image where mask is white
|
||||
result = corrected_image.copy()
|
||||
if mask_image.size != result.size:
|
||||
raise ValueError("Mask size must match base image size.")
|
||||
else:
|
||||
result.paste(base_image.convert("RGB"), mask=mask_image)
|
||||
else:
|
||||
matched_result = Image.fromarray(np_image, mode="RGB")
|
||||
result = corrected_image
|
||||
|
||||
# Blur the mask out (into init image) by specified amount
|
||||
if self.mask_blur_radius > 0:
|
||||
nm = numpy.asarray(pil_init_mask, dtype=numpy.uint8)
|
||||
inverted_nm = 255 - nm
|
||||
dilation_size = int(round(self.mask_blur_radius) + 20)
|
||||
dilating_kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (dilation_size, dilation_size))
|
||||
inverted_dilated_nm = cv2.dilate(inverted_nm, dilating_kernel)
|
||||
dilated_nm = 255 - inverted_dilated_nm
|
||||
nmd = cv2.erode(
|
||||
dilated_nm,
|
||||
kernel=numpy.ones((3, 3), dtype=numpy.uint8),
|
||||
iterations=int(self.mask_blur_radius / 2),
|
||||
)
|
||||
pmd = Image.fromarray(nmd, mode="L")
|
||||
blurred_init_mask = pmd.filter(ImageFilter.BoxBlur(self.mask_blur_radius))
|
||||
else:
|
||||
blurred_init_mask = pil_init_mask
|
||||
|
||||
multiplied_blurred_init_mask = ImageChops.multiply(blurred_init_mask, result.split()[-1])
|
||||
|
||||
# Paste original on color-corrected generation (using blurred mask)
|
||||
matched_result.paste(init_image, (0, 0), mask=multiplied_blurred_init_mask)
|
||||
|
||||
image_dto = context.images.save(image=matched_result)
|
||||
# Convert to RGBA and restore original alpha
|
||||
result = result.convert("RGBA")
|
||||
result.putalpha(original_alpha)
|
||||
|
||||
# Save and return
|
||||
image_dto = context.images.save(image=result)
|
||||
return ImageOutput.build(image_dto)
|
||||
|
||||
|
||||
@@ -1347,3 +1349,96 @@ class PasteImageIntoBoundingBoxInvocation(BaseInvocation, WithMetadata, WithBoar
|
||||
|
||||
image_dto = context.images.save(image=target_image)
|
||||
return ImageOutput.build(image_dto)
|
||||
|
||||
|
||||
@invocation(
|
||||
"flux_kontext_image_prep",
|
||||
title="FLUX Kontext Image Prep",
|
||||
tags=["image", "concatenate", "flux", "kontext"],
|
||||
category="image",
|
||||
version="1.0.0",
|
||||
)
|
||||
class FluxKontextConcatenateImagesInvocation(BaseInvocation, WithMetadata, WithBoard):
|
||||
"""Prepares an image or images for use with FLUX Kontext. The first/single image is resized to the nearest
|
||||
preferred Kontext resolution. All other images are concatenated horizontally, maintaining their aspect ratio."""
|
||||
|
||||
images: list[ImageField] = InputField(
|
||||
description="The images to concatenate",
|
||||
min_length=1,
|
||||
max_length=10,
|
||||
)
|
||||
|
||||
use_preferred_resolution: bool = InputField(
|
||||
default=True, description="Use FLUX preferred resolutions for the first image"
|
||||
)
|
||||
|
||||
def invoke(self, context: InvocationContext) -> ImageOutput:
|
||||
from invokeai.backend.flux.util import PREFERED_KONTEXT_RESOLUTIONS
|
||||
|
||||
# Step 1: Load all images
|
||||
pil_images = []
|
||||
for image_field in self.images:
|
||||
image = context.images.get_pil(image_field.image_name, mode="RGBA")
|
||||
pil_images.append(image)
|
||||
|
||||
# Step 2: Determine target resolution for the first image
|
||||
first_image = pil_images[0]
|
||||
width, height = first_image.size
|
||||
|
||||
if self.use_preferred_resolution:
|
||||
aspect_ratio = width / height
|
||||
|
||||
# Find the closest preferred resolution for the first image
|
||||
_, target_width, target_height = min(
|
||||
((abs(aspect_ratio - w / h), w, h) for w, h in PREFERED_KONTEXT_RESOLUTIONS), key=lambda x: x[0]
|
||||
)
|
||||
|
||||
# Apply BFL's scaling formula
|
||||
scaled_height = 2 * int(target_height / 16)
|
||||
final_height = 8 * scaled_height # This will be consistent for all images
|
||||
scaled_width = 2 * int(target_width / 16)
|
||||
first_width = 8 * scaled_width
|
||||
else:
|
||||
# Use original dimensions of first image, ensuring divisibility by 16
|
||||
final_height = 16 * (height // 16)
|
||||
first_width = 16 * (width // 16)
|
||||
# Ensure minimum dimensions
|
||||
if final_height < 16:
|
||||
final_height = 16
|
||||
if first_width < 16:
|
||||
first_width = 16
|
||||
|
||||
# Step 3: Process and resize all images with consistent height
|
||||
processed_images = []
|
||||
total_width = 0
|
||||
|
||||
for i, image in enumerate(pil_images):
|
||||
if i == 0:
|
||||
# First image uses the calculated dimensions
|
||||
final_width = first_width
|
||||
else:
|
||||
# Subsequent images maintain aspect ratio with the same height
|
||||
img_aspect_ratio = image.width / image.height
|
||||
# Calculate width that maintains aspect ratio at the target height
|
||||
calculated_width = int(final_height * img_aspect_ratio)
|
||||
# Ensure width is divisible by 16 for proper VAE encoding
|
||||
final_width = 16 * (calculated_width // 16)
|
||||
# Ensure minimum width
|
||||
if final_width < 16:
|
||||
final_width = 16
|
||||
|
||||
# Resize image to calculated dimensions
|
||||
resized_image = image.resize((final_width, final_height), Image.Resampling.LANCZOS)
|
||||
processed_images.append(resized_image)
|
||||
total_width += final_width
|
||||
|
||||
# Step 4: Concatenate images horizontally
|
||||
concatenated_image = Image.new("RGB", (total_width, final_height))
|
||||
x_offset = 0
|
||||
for img in processed_images:
|
||||
concatenated_image.paste(img, (x_offset, 0))
|
||||
x_offset += img.width
|
||||
|
||||
# Save the concatenated image
|
||||
image_dto = context.images.save(image=concatenated_image)
|
||||
return ImageOutput.build(image_dto)
|
||||
|
||||
@@ -23,10 +23,11 @@ from invokeai.app.invocations.fields import (
|
||||
from invokeai.app.invocations.model import VAEField
|
||||
from invokeai.app.invocations.primitives import LatentsOutput
|
||||
from invokeai.app.services.shared.invocation_context import InvocationContext
|
||||
from invokeai.backend.model_manager import LoadedModel
|
||||
from invokeai.backend.model_manager.load.load_base import LoadedModel
|
||||
from invokeai.backend.stable_diffusion.diffusers_pipeline import image_resized_to_grid_as_tensor
|
||||
from invokeai.backend.stable_diffusion.vae_tiling import patch_vae_tiling_params
|
||||
from invokeai.backend.util.devices import TorchDevice
|
||||
from invokeai.backend.util.vae_working_memory import estimate_vae_working_memory_sd15_sdxl
|
||||
|
||||
|
||||
@invocation(
|
||||
@@ -52,11 +53,24 @@ class ImageToLatentsInvocation(BaseInvocation):
|
||||
tile_size: int = InputField(default=0, multiple_of=8, description=FieldDescriptions.vae_tile_size)
|
||||
fp32: bool = InputField(default=False, description=FieldDescriptions.fp32)
|
||||
|
||||
@staticmethod
|
||||
@classmethod
|
||||
def vae_encode(
|
||||
vae_info: LoadedModel, upcast: bool, tiled: bool, image_tensor: torch.Tensor, tile_size: int = 0
|
||||
cls,
|
||||
vae_info: LoadedModel,
|
||||
upcast: bool,
|
||||
tiled: bool,
|
||||
image_tensor: torch.Tensor,
|
||||
tile_size: int = 0,
|
||||
) -> torch.Tensor:
|
||||
with vae_info as vae:
|
||||
assert isinstance(vae_info.model, (AutoencoderKL, AutoencoderTiny))
|
||||
estimated_working_memory = estimate_vae_working_memory_sd15_sdxl(
|
||||
operation="encode",
|
||||
image_tensor=image_tensor,
|
||||
vae=vae_info.model,
|
||||
tile_size=tile_size if tiled else None,
|
||||
fp32=upcast,
|
||||
)
|
||||
with vae_info.model_on_device(working_mem_bytes=estimated_working_memory) as (_, vae):
|
||||
assert isinstance(vae, (AutoencoderKL, AutoencoderTiny))
|
||||
orig_dtype = vae.dtype
|
||||
if upcast:
|
||||
@@ -113,6 +127,7 @@ class ImageToLatentsInvocation(BaseInvocation):
|
||||
image = context.images.get_pil(self.image.image_name)
|
||||
|
||||
vae_info = context.models.load(self.vae.vae)
|
||||
assert isinstance(vae_info.model, (AutoencoderKL, AutoencoderTiny))
|
||||
|
||||
image_tensor = image_resized_to_grid_as_tensor(image.convert("RGB"))
|
||||
if image_tensor.dim() == 3:
|
||||
@@ -120,7 +135,11 @@ class ImageToLatentsInvocation(BaseInvocation):
|
||||
|
||||
context.util.signal_progress("Running VAE encoder")
|
||||
latents = self.vae_encode(
|
||||
vae_info=vae_info, upcast=self.fp32, tiled=self.tiled, image_tensor=image_tensor, tile_size=self.tile_size
|
||||
vae_info=vae_info,
|
||||
upcast=self.fp32,
|
||||
tiled=self.tiled or context.config.get().force_tiled_decode,
|
||||
image_tensor=image_tensor,
|
||||
tile_size=self.tile_size,
|
||||
)
|
||||
|
||||
latents = latents.to("cpu")
|
||||
|
||||
@@ -5,16 +5,16 @@ from pydantic import BaseModel, Field, field_validator, model_validator
|
||||
from typing_extensions import Self
|
||||
|
||||
from invokeai.app.invocations.baseinvocation import BaseInvocation, BaseInvocationOutput, invocation, invocation_output
|
||||
from invokeai.app.invocations.fields import FieldDescriptions, InputField, OutputField, TensorField, UIType
|
||||
from invokeai.app.invocations.fields import FieldDescriptions, InputField, OutputField, TensorField
|
||||
from invokeai.app.invocations.model import ModelIdentifierField
|
||||
from invokeai.app.invocations.primitives import ImageField
|
||||
from invokeai.app.invocations.util import validate_begin_end_step, validate_weights
|
||||
from invokeai.app.services.model_records.model_records_base import ModelRecordChanges
|
||||
from invokeai.app.services.shared.invocation_context import InvocationContext
|
||||
from invokeai.backend.model_manager.config import (
|
||||
AnyModelConfig,
|
||||
IPAdapterCheckpointConfig,
|
||||
IPAdapterInvokeAIConfig,
|
||||
from invokeai.backend.model_manager.configs.factory import AnyModelConfig
|
||||
from invokeai.backend.model_manager.configs.ip_adapter import (
|
||||
IPAdapter_Checkpoint_Config_Base,
|
||||
IPAdapter_InvokeAI_Config_Base,
|
||||
)
|
||||
from invokeai.backend.model_manager.starter_models import (
|
||||
StarterModel,
|
||||
@@ -85,7 +85,8 @@ class IPAdapterInvocation(BaseInvocation):
|
||||
description="The IP-Adapter model.",
|
||||
title="IP-Adapter Model",
|
||||
ui_order=-1,
|
||||
ui_type=UIType.IPAdapterModel,
|
||||
ui_model_base=[BaseModelType.StableDiffusion1, BaseModelType.StableDiffusionXL],
|
||||
ui_model_type=ModelType.IPAdapter,
|
||||
)
|
||||
clip_vision_model: Literal["ViT-H", "ViT-G", "ViT-L"] = InputField(
|
||||
description="CLIP Vision model to use. Overrides model settings. Mandatory for checkpoint models.",
|
||||
@@ -122,9 +123,9 @@ class IPAdapterInvocation(BaseInvocation):
|
||||
def invoke(self, context: InvocationContext) -> IPAdapterOutput:
|
||||
# Lookup the CLIP Vision encoder that is intended to be used with the IP-Adapter model.
|
||||
ip_adapter_info = context.models.get_config(self.ip_adapter_model.key)
|
||||
assert isinstance(ip_adapter_info, (IPAdapterInvokeAIConfig, IPAdapterCheckpointConfig))
|
||||
assert isinstance(ip_adapter_info, (IPAdapter_InvokeAI_Config_Base, IPAdapter_Checkpoint_Config_Base))
|
||||
|
||||
if isinstance(ip_adapter_info, IPAdapterInvokeAIConfig):
|
||||
if isinstance(ip_adapter_info, IPAdapter_InvokeAI_Config_Base):
|
||||
image_encoder_model_id = ip_adapter_info.image_encoder_model_id
|
||||
image_encoder_model_name = image_encoder_model_id.split("/")[-1].strip()
|
||||
else:
|
||||
|
||||
@@ -27,6 +27,7 @@ from invokeai.app.services.shared.invocation_context import InvocationContext
|
||||
from invokeai.backend.stable_diffusion.extensions.seamless import SeamlessExt
|
||||
from invokeai.backend.stable_diffusion.vae_tiling import patch_vae_tiling_params
|
||||
from invokeai.backend.util.devices import TorchDevice
|
||||
from invokeai.backend.util.vae_working_memory import estimate_vae_working_memory_sd15_sdxl
|
||||
|
||||
|
||||
@invocation(
|
||||
@@ -53,39 +54,6 @@ class LatentsToImageInvocation(BaseInvocation, WithMetadata, WithBoard):
|
||||
tile_size: int = InputField(default=0, multiple_of=8, description=FieldDescriptions.vae_tile_size)
|
||||
fp32: bool = InputField(default=False, description=FieldDescriptions.fp32)
|
||||
|
||||
def _estimate_working_memory(
|
||||
self, latents: torch.Tensor, use_tiling: bool, vae: AutoencoderKL | AutoencoderTiny
|
||||
) -> int:
|
||||
"""Estimate the working memory required by the invocation in bytes."""
|
||||
# It was found experimentally that the peak working memory scales linearly with the number of pixels and the
|
||||
# element size (precision). This estimate is accurate for both SD1 and SDXL.
|
||||
element_size = 4 if self.fp32 else 2
|
||||
scaling_constant = 2200 # Determined experimentally.
|
||||
|
||||
if use_tiling:
|
||||
tile_size = self.tile_size
|
||||
if tile_size == 0:
|
||||
tile_size = vae.tile_sample_min_size
|
||||
assert isinstance(tile_size, int)
|
||||
out_h = tile_size
|
||||
out_w = tile_size
|
||||
working_memory = out_h * out_w * element_size * scaling_constant
|
||||
|
||||
# We add 25% to the working memory estimate when tiling is enabled to account for factors like tile overlap
|
||||
# and number of tiles. We could make this more precise in the future, but this should be good enough for
|
||||
# most use cases.
|
||||
working_memory = working_memory * 1.25
|
||||
else:
|
||||
out_h = LATENT_SCALE_FACTOR * latents.shape[-2]
|
||||
out_w = LATENT_SCALE_FACTOR * latents.shape[-1]
|
||||
working_memory = out_h * out_w * element_size * scaling_constant
|
||||
|
||||
if self.fp32:
|
||||
# If we are running in FP32, then we should account for the likely increase in model size (~250MB).
|
||||
working_memory += 250 * 2**20
|
||||
|
||||
return int(working_memory)
|
||||
|
||||
@torch.no_grad()
|
||||
def invoke(self, context: InvocationContext) -> ImageOutput:
|
||||
latents = context.tensors.load(self.latents.latents_name)
|
||||
@@ -94,8 +62,13 @@ class LatentsToImageInvocation(BaseInvocation, WithMetadata, WithBoard):
|
||||
|
||||
vae_info = context.models.load(self.vae.vae)
|
||||
assert isinstance(vae_info.model, (AutoencoderKL, AutoencoderTiny))
|
||||
|
||||
estimated_working_memory = self._estimate_working_memory(latents, use_tiling, vae_info.model)
|
||||
estimated_working_memory = estimate_vae_working_memory_sd15_sdxl(
|
||||
operation="decode",
|
||||
image_tensor=latents,
|
||||
vae=vae_info.model,
|
||||
tile_size=self.tile_size if use_tiling else None,
|
||||
fp32=self.fp32,
|
||||
)
|
||||
with (
|
||||
SeamlessExt.static_patch_model(vae_info.model, self.vae.seamless_axes),
|
||||
vae_info.model_on_device(working_mem_bytes=estimated_working_memory) as (_, vae),
|
||||
|
||||
@@ -6,11 +6,12 @@ from pydantic import field_validator
|
||||
from transformers import AutoProcessor, LlavaOnevisionForConditionalGeneration, LlavaOnevisionProcessor
|
||||
|
||||
from invokeai.app.invocations.baseinvocation import BaseInvocation, Classification, invocation
|
||||
from invokeai.app.invocations.fields import FieldDescriptions, ImageField, InputField, UIComponent, UIType
|
||||
from invokeai.app.invocations.fields import FieldDescriptions, ImageField, InputField, UIComponent
|
||||
from invokeai.app.invocations.model import ModelIdentifierField
|
||||
from invokeai.app.invocations.primitives import StringOutput
|
||||
from invokeai.app.services.shared.invocation_context import InvocationContext
|
||||
from invokeai.backend.llava_onevision_pipeline import LlavaOnevisionPipeline
|
||||
from invokeai.backend.model_manager.taxonomy import ModelType
|
||||
from invokeai.backend.util.devices import TorchDevice
|
||||
|
||||
|
||||
@@ -34,7 +35,7 @@ class LlavaOnevisionVllmInvocation(BaseInvocation):
|
||||
vllm_model: ModelIdentifierField = InputField(
|
||||
title="LLaVA Model Type",
|
||||
description=FieldDescriptions.vllm_model,
|
||||
ui_type=UIType.LlavaOnevisionModel,
|
||||
ui_model_type=ModelType.LlavaOnevision,
|
||||
)
|
||||
|
||||
@field_validator("images", mode="before")
|
||||
|
||||
@@ -53,7 +53,7 @@ from invokeai.app.invocations.primitives import (
|
||||
from invokeai.app.invocations.scheduler import SchedulerOutput
|
||||
from invokeai.app.invocations.t2i_adapter import T2IAdapterField, T2IAdapterInvocation
|
||||
from invokeai.app.services.shared.invocation_context import InvocationContext
|
||||
from invokeai.backend.model_manager.taxonomy import ModelType, SubModelType
|
||||
from invokeai.backend.model_manager.taxonomy import BaseModelType, ModelType, SubModelType
|
||||
from invokeai.backend.stable_diffusion.schedulers.schedulers import SCHEDULER_NAME_VALUES
|
||||
from invokeai.version import __version__
|
||||
|
||||
@@ -473,7 +473,6 @@ class MetadataToModelOutput(BaseInvocationOutput):
|
||||
model: ModelIdentifierField = OutputField(
|
||||
description=FieldDescriptions.main_model,
|
||||
title="Model",
|
||||
ui_type=UIType.MainModel,
|
||||
)
|
||||
name: str = OutputField(description="Model Name", title="Name")
|
||||
unet: UNetField = OutputField(description=FieldDescriptions.unet, title="UNet")
|
||||
@@ -488,7 +487,6 @@ class MetadataToSDXLModelOutput(BaseInvocationOutput):
|
||||
model: ModelIdentifierField = OutputField(
|
||||
description=FieldDescriptions.main_model,
|
||||
title="Model",
|
||||
ui_type=UIType.SDXLMainModel,
|
||||
)
|
||||
name: str = OutputField(description="Model Name", title="Name")
|
||||
unet: UNetField = OutputField(description=FieldDescriptions.unet, title="UNet")
|
||||
@@ -519,8 +517,7 @@ class MetadataToModelInvocation(BaseInvocation, WithMetadata):
|
||||
input=Input.Direct,
|
||||
)
|
||||
default_value: ModelIdentifierField = InputField(
|
||||
description="The default model to use if not found in the metadata",
|
||||
ui_type=UIType.MainModel,
|
||||
description="The default model to use if not found in the metadata", ui_model_type=ModelType.Main
|
||||
)
|
||||
|
||||
_validate_custom_label = model_validator(mode="after")(validate_custom_label)
|
||||
@@ -575,7 +572,8 @@ class MetadataToSDXLModelInvocation(BaseInvocation, WithMetadata):
|
||||
)
|
||||
default_value: ModelIdentifierField = InputField(
|
||||
description="The default SDXL Model to use if not found in the metadata",
|
||||
ui_type=UIType.SDXLMainModel,
|
||||
ui_model_type=ModelType.Main,
|
||||
ui_model_base=BaseModelType.StableDiffusionXL,
|
||||
)
|
||||
|
||||
_validate_custom_label = model_validator(mode="after")(validate_custom_label)
|
||||
|
||||
@@ -9,12 +9,10 @@ from invokeai.app.invocations.baseinvocation import (
|
||||
invocation,
|
||||
invocation_output,
|
||||
)
|
||||
from invokeai.app.invocations.fields import FieldDescriptions, ImageField, Input, InputField, OutputField, UIType
|
||||
from invokeai.app.invocations.fields import FieldDescriptions, ImageField, Input, InputField, OutputField
|
||||
from invokeai.app.services.shared.invocation_context import InvocationContext
|
||||
from invokeai.app.shared.models import FreeUConfig
|
||||
from invokeai.backend.model_manager.config import (
|
||||
AnyModelConfig,
|
||||
)
|
||||
from invokeai.backend.model_manager.configs.factory import AnyModelConfig
|
||||
from invokeai.backend.model_manager.taxonomy import BaseModelType, ModelType, SubModelType
|
||||
|
||||
|
||||
@@ -24,8 +22,9 @@ class ModelIdentifierField(BaseModel):
|
||||
name: str = Field(description="The model's name")
|
||||
base: BaseModelType = Field(description="The model's base model type")
|
||||
type: ModelType = Field(description="The model's type")
|
||||
submodel_type: Optional[SubModelType] = Field(
|
||||
description="The submodel to load, if this is a main model", default=None
|
||||
submodel_type: SubModelType | None = Field(
|
||||
description="The submodel to load, if this is a main model",
|
||||
default=None,
|
||||
)
|
||||
|
||||
@classmethod
|
||||
@@ -145,7 +144,7 @@ class ModelIdentifierInvocation(BaseInvocation):
|
||||
|
||||
@invocation(
|
||||
"main_model_loader",
|
||||
title="Main Model - SD1.5",
|
||||
title="Main Model - SD1.5, SD2",
|
||||
tags=["model"],
|
||||
category="model",
|
||||
version="1.0.4",
|
||||
@@ -153,7 +152,11 @@ class ModelIdentifierInvocation(BaseInvocation):
|
||||
class MainModelLoaderInvocation(BaseInvocation):
|
||||
"""Loads a main model, outputting its submodels."""
|
||||
|
||||
model: ModelIdentifierField = InputField(description=FieldDescriptions.main_model, ui_type=UIType.MainModel)
|
||||
model: ModelIdentifierField = InputField(
|
||||
description=FieldDescriptions.main_model,
|
||||
ui_model_base=[BaseModelType.StableDiffusion1, BaseModelType.StableDiffusion2],
|
||||
ui_model_type=ModelType.Main,
|
||||
)
|
||||
# TODO: precision?
|
||||
|
||||
def invoke(self, context: InvocationContext) -> ModelLoaderOutput:
|
||||
@@ -187,7 +190,10 @@ class LoRALoaderInvocation(BaseInvocation):
|
||||
"""Apply selected lora to unet and text_encoder."""
|
||||
|
||||
lora: ModelIdentifierField = InputField(
|
||||
description=FieldDescriptions.lora_model, title="LoRA", ui_type=UIType.LoRAModel
|
||||
description=FieldDescriptions.lora_model,
|
||||
title="LoRA",
|
||||
ui_model_base=BaseModelType.StableDiffusion1,
|
||||
ui_model_type=ModelType.LoRA,
|
||||
)
|
||||
weight: float = InputField(default=0.75, description=FieldDescriptions.lora_weight)
|
||||
unet: Optional[UNetField] = InputField(
|
||||
@@ -250,7 +256,9 @@ class LoRASelectorInvocation(BaseInvocation):
|
||||
"""Selects a LoRA model and weight."""
|
||||
|
||||
lora: ModelIdentifierField = InputField(
|
||||
description=FieldDescriptions.lora_model, title="LoRA", ui_type=UIType.LoRAModel
|
||||
description=FieldDescriptions.lora_model,
|
||||
title="LoRA",
|
||||
ui_model_type=ModelType.LoRA,
|
||||
)
|
||||
weight: float = InputField(default=0.75, description=FieldDescriptions.lora_weight)
|
||||
|
||||
@@ -332,7 +340,10 @@ class SDXLLoRALoaderInvocation(BaseInvocation):
|
||||
"""Apply selected lora to unet and text_encoder."""
|
||||
|
||||
lora: ModelIdentifierField = InputField(
|
||||
description=FieldDescriptions.lora_model, title="LoRA", ui_type=UIType.LoRAModel
|
||||
description=FieldDescriptions.lora_model,
|
||||
title="LoRA",
|
||||
ui_model_base=BaseModelType.StableDiffusionXL,
|
||||
ui_model_type=ModelType.LoRA,
|
||||
)
|
||||
weight: float = InputField(default=0.75, description=FieldDescriptions.lora_weight)
|
||||
unet: Optional[UNetField] = InputField(
|
||||
@@ -473,13 +484,26 @@ class SDXLLoRACollectionLoader(BaseInvocation):
|
||||
|
||||
|
||||
@invocation(
|
||||
"vae_loader", title="VAE Model - SD1.5, SDXL, SD3, FLUX", tags=["vae", "model"], category="model", version="1.0.4"
|
||||
"vae_loader",
|
||||
title="VAE Model - SD1.5, SD2, SDXL, SD3, FLUX",
|
||||
tags=["vae", "model"],
|
||||
category="model",
|
||||
version="1.0.4",
|
||||
)
|
||||
class VAELoaderInvocation(BaseInvocation):
|
||||
"""Loads a VAE model, outputting a VaeLoaderOutput"""
|
||||
|
||||
vae_model: ModelIdentifierField = InputField(
|
||||
description=FieldDescriptions.vae_model, title="VAE", ui_type=UIType.VAEModel
|
||||
description=FieldDescriptions.vae_model,
|
||||
title="VAE",
|
||||
ui_model_base=[
|
||||
BaseModelType.StableDiffusion1,
|
||||
BaseModelType.StableDiffusion2,
|
||||
BaseModelType.StableDiffusionXL,
|
||||
BaseModelType.StableDiffusion3,
|
||||
BaseModelType.Flux,
|
||||
],
|
||||
ui_model_type=ModelType.VAE,
|
||||
)
|
||||
|
||||
def invoke(self, context: InvocationContext) -> VAEOutput:
|
||||
|
||||
@@ -27,6 +27,7 @@ from invokeai.app.invocations.fields import (
|
||||
SD3ConditioningField,
|
||||
TensorField,
|
||||
UIComponent,
|
||||
VideoField,
|
||||
)
|
||||
from invokeai.app.services.images.images_common import ImageDTO
|
||||
from invokeai.app.services.shared.invocation_context import InvocationContext
|
||||
@@ -287,6 +288,30 @@ class ImageCollectionInvocation(BaseInvocation):
|
||||
return ImageCollectionOutput(collection=self.collection)
|
||||
|
||||
|
||||
# endregion
|
||||
|
||||
# region Video
|
||||
|
||||
|
||||
@invocation_output("video_output")
|
||||
class VideoOutput(BaseInvocationOutput):
|
||||
"""Base class for nodes that output a video"""
|
||||
|
||||
video: VideoField = OutputField(description="The output video")
|
||||
width: int = OutputField(description="The width of the video in pixels")
|
||||
height: int = OutputField(description="The height of the video in pixels")
|
||||
duration_seconds: float = OutputField(description="The duration of the video in seconds")
|
||||
|
||||
@classmethod
|
||||
def build(cls, video_id: str, width: int, height: int, duration_seconds: float) -> "VideoOutput":
|
||||
return cls(
|
||||
video=VideoField(video_id=video_id),
|
||||
width=width,
|
||||
height=height,
|
||||
duration_seconds=duration_seconds,
|
||||
)
|
||||
|
||||
|
||||
# endregion
|
||||
|
||||
# region DenoiseMask
|
||||
|
||||
@@ -23,7 +23,7 @@ from invokeai.app.invocations.primitives import LatentsOutput
|
||||
from invokeai.app.invocations.sd3_text_encoder import SD3_T5_MAX_SEQ_LEN
|
||||
from invokeai.app.services.shared.invocation_context import InvocationContext
|
||||
from invokeai.backend.flux.sampling_utils import clip_timestep_schedule_fractional
|
||||
from invokeai.backend.model_manager import BaseModelType
|
||||
from invokeai.backend.model_manager.taxonomy import BaseModelType
|
||||
from invokeai.backend.rectified_flow.rectified_flow_inpaint_extension import RectifiedFlowInpaintExtension
|
||||
from invokeai.backend.stable_diffusion.diffusers_pipeline import PipelineIntermediateState
|
||||
from invokeai.backend.stable_diffusion.diffusion.conditioning_data import SD3ConditioningInfo
|
||||
|
||||
@@ -17,6 +17,7 @@ from invokeai.app.services.shared.invocation_context import InvocationContext
|
||||
from invokeai.backend.model_manager.load.load_base import LoadedModel
|
||||
from invokeai.backend.stable_diffusion.diffusers_pipeline import image_resized_to_grid_as_tensor
|
||||
from invokeai.backend.util.devices import TorchDevice
|
||||
from invokeai.backend.util.vae_working_memory import estimate_vae_working_memory_sd3
|
||||
|
||||
|
||||
@invocation(
|
||||
@@ -34,7 +35,11 @@ class SD3ImageToLatentsInvocation(BaseInvocation, WithMetadata, WithBoard):
|
||||
|
||||
@staticmethod
|
||||
def vae_encode(vae_info: LoadedModel, image_tensor: torch.Tensor) -> torch.Tensor:
|
||||
with vae_info as vae:
|
||||
assert isinstance(vae_info.model, AutoencoderKL)
|
||||
estimated_working_memory = estimate_vae_working_memory_sd3(
|
||||
operation="encode", image_tensor=image_tensor, vae=vae_info.model
|
||||
)
|
||||
with vae_info.model_on_device(working_mem_bytes=estimated_working_memory) as (_, vae):
|
||||
assert isinstance(vae, AutoencoderKL)
|
||||
|
||||
vae.disable_tiling()
|
||||
@@ -58,6 +63,8 @@ class SD3ImageToLatentsInvocation(BaseInvocation, WithMetadata, WithBoard):
|
||||
image_tensor = einops.rearrange(image_tensor, "c h w -> 1 c h w")
|
||||
|
||||
vae_info = context.models.load(self.vae.vae)
|
||||
assert isinstance(vae_info.model, AutoencoderKL)
|
||||
|
||||
latents = self.vae_encode(vae_info=vae_info, image_tensor=image_tensor)
|
||||
|
||||
latents = latents.to("cpu")
|
||||
|
||||
@@ -6,7 +6,6 @@ from einops import rearrange
|
||||
from PIL import Image
|
||||
|
||||
from invokeai.app.invocations.baseinvocation import BaseInvocation, invocation
|
||||
from invokeai.app.invocations.constants import LATENT_SCALE_FACTOR
|
||||
from invokeai.app.invocations.fields import (
|
||||
FieldDescriptions,
|
||||
Input,
|
||||
@@ -20,6 +19,7 @@ from invokeai.app.invocations.primitives import ImageOutput
|
||||
from invokeai.app.services.shared.invocation_context import InvocationContext
|
||||
from invokeai.backend.stable_diffusion.extensions.seamless import SeamlessExt
|
||||
from invokeai.backend.util.devices import TorchDevice
|
||||
from invokeai.backend.util.vae_working_memory import estimate_vae_working_memory_sd3
|
||||
|
||||
|
||||
@invocation(
|
||||
@@ -41,22 +41,15 @@ class SD3LatentsToImageInvocation(BaseInvocation, WithMetadata, WithBoard):
|
||||
input=Input.Connection,
|
||||
)
|
||||
|
||||
def _estimate_working_memory(self, latents: torch.Tensor, vae: AutoencoderKL) -> int:
|
||||
"""Estimate the working memory required by the invocation in bytes."""
|
||||
out_h = LATENT_SCALE_FACTOR * latents.shape[-2]
|
||||
out_w = LATENT_SCALE_FACTOR * latents.shape[-1]
|
||||
element_size = next(vae.parameters()).element_size()
|
||||
scaling_constant = 2200 # Determined experimentally.
|
||||
working_memory = out_h * out_w * element_size * scaling_constant
|
||||
return int(working_memory)
|
||||
|
||||
@torch.no_grad()
|
||||
def invoke(self, context: InvocationContext) -> ImageOutput:
|
||||
latents = context.tensors.load(self.latents.latents_name)
|
||||
|
||||
vae_info = context.models.load(self.vae.vae)
|
||||
assert isinstance(vae_info.model, (AutoencoderKL))
|
||||
estimated_working_memory = self._estimate_working_memory(latents, vae_info.model)
|
||||
estimated_working_memory = estimate_vae_working_memory_sd3(
|
||||
operation="decode", image_tensor=latents, vae=vae_info.model
|
||||
)
|
||||
with (
|
||||
SeamlessExt.static_patch_model(vae_info.model, self.vae.seamless_axes),
|
||||
vae_info.model_on_device(working_mem_bytes=estimated_working_memory) as (_, vae),
|
||||
|
||||
@@ -6,14 +6,14 @@ from invokeai.app.invocations.baseinvocation import (
|
||||
invocation,
|
||||
invocation_output,
|
||||
)
|
||||
from invokeai.app.invocations.fields import FieldDescriptions, Input, InputField, OutputField, UIType
|
||||
from invokeai.app.invocations.fields import FieldDescriptions, Input, InputField, OutputField
|
||||
from invokeai.app.invocations.model import CLIPField, ModelIdentifierField, T5EncoderField, TransformerField, VAEField
|
||||
from invokeai.app.services.shared.invocation_context import InvocationContext
|
||||
from invokeai.app.util.t5_model_identifier import (
|
||||
preprocess_t5_encoder_model_identifier,
|
||||
preprocess_t5_tokenizer_model_identifier,
|
||||
)
|
||||
from invokeai.backend.model_manager.taxonomy import SubModelType
|
||||
from invokeai.backend.model_manager.taxonomy import BaseModelType, ClipVariantType, ModelType, SubModelType
|
||||
|
||||
|
||||
@invocation_output("sd3_model_loader_output")
|
||||
@@ -39,36 +39,43 @@ class Sd3ModelLoaderInvocation(BaseInvocation):
|
||||
|
||||
model: ModelIdentifierField = InputField(
|
||||
description=FieldDescriptions.sd3_model,
|
||||
ui_type=UIType.SD3MainModel,
|
||||
input=Input.Direct,
|
||||
ui_model_base=BaseModelType.StableDiffusion3,
|
||||
ui_model_type=ModelType.Main,
|
||||
)
|
||||
|
||||
t5_encoder_model: Optional[ModelIdentifierField] = InputField(
|
||||
description=FieldDescriptions.t5_encoder,
|
||||
ui_type=UIType.T5EncoderModel,
|
||||
input=Input.Direct,
|
||||
title="T5 Encoder",
|
||||
default=None,
|
||||
ui_model_type=ModelType.T5Encoder,
|
||||
)
|
||||
|
||||
clip_l_model: Optional[ModelIdentifierField] = InputField(
|
||||
description=FieldDescriptions.clip_embed_model,
|
||||
ui_type=UIType.CLIPLEmbedModel,
|
||||
input=Input.Direct,
|
||||
title="CLIP L Encoder",
|
||||
default=None,
|
||||
ui_model_type=ModelType.CLIPEmbed,
|
||||
ui_model_variant=ClipVariantType.L,
|
||||
)
|
||||
|
||||
clip_g_model: Optional[ModelIdentifierField] = InputField(
|
||||
description=FieldDescriptions.clip_g_model,
|
||||
ui_type=UIType.CLIPGEmbedModel,
|
||||
input=Input.Direct,
|
||||
title="CLIP G Encoder",
|
||||
default=None,
|
||||
ui_model_type=ModelType.CLIPEmbed,
|
||||
ui_model_variant=ClipVariantType.G,
|
||||
)
|
||||
|
||||
vae_model: Optional[ModelIdentifierField] = InputField(
|
||||
description=FieldDescriptions.vae_model, ui_type=UIType.VAEModel, title="VAE", default=None
|
||||
description=FieldDescriptions.vae_model,
|
||||
title="VAE",
|
||||
default=None,
|
||||
ui_model_base=BaseModelType.StableDiffusion3,
|
||||
ui_model_type=ModelType.VAE,
|
||||
)
|
||||
|
||||
def invoke(self, context: InvocationContext) -> Sd3ModelLoaderOutput:
|
||||
|
||||
@@ -1,8 +1,8 @@
|
||||
from invokeai.app.invocations.baseinvocation import BaseInvocation, BaseInvocationOutput, invocation, invocation_output
|
||||
from invokeai.app.invocations.fields import FieldDescriptions, InputField, OutputField, UIType
|
||||
from invokeai.app.invocations.fields import FieldDescriptions, InputField, OutputField
|
||||
from invokeai.app.invocations.model import CLIPField, ModelIdentifierField, UNetField, VAEField
|
||||
from invokeai.app.services.shared.invocation_context import InvocationContext
|
||||
from invokeai.backend.model_manager.taxonomy import SubModelType
|
||||
from invokeai.backend.model_manager.taxonomy import BaseModelType, ModelType, SubModelType
|
||||
|
||||
|
||||
@invocation_output("sdxl_model_loader_output")
|
||||
@@ -29,7 +29,9 @@ class SDXLModelLoaderInvocation(BaseInvocation):
|
||||
"""Loads an sdxl base model, outputting its submodels."""
|
||||
|
||||
model: ModelIdentifierField = InputField(
|
||||
description=FieldDescriptions.sdxl_main_model, ui_type=UIType.SDXLMainModel
|
||||
description=FieldDescriptions.sdxl_main_model,
|
||||
ui_model_base=BaseModelType.StableDiffusionXL,
|
||||
ui_model_type=ModelType.Main,
|
||||
)
|
||||
# TODO: precision?
|
||||
|
||||
@@ -67,7 +69,9 @@ class SDXLRefinerModelLoaderInvocation(BaseInvocation):
|
||||
"""Loads an sdxl refiner model, outputting its submodels."""
|
||||
|
||||
model: ModelIdentifierField = InputField(
|
||||
description=FieldDescriptions.sdxl_refiner_model, ui_type=UIType.SDXLRefinerModel
|
||||
description=FieldDescriptions.sdxl_refiner_model,
|
||||
ui_model_base=BaseModelType.StableDiffusionXLRefiner,
|
||||
ui_model_type=ModelType.Main,
|
||||
)
|
||||
# TODO: precision?
|
||||
|
||||
|
||||
@@ -1,72 +1,75 @@
|
||||
from enum import Enum
|
||||
from itertools import zip_longest
|
||||
from pathlib import Path
|
||||
from typing import Literal
|
||||
|
||||
import numpy as np
|
||||
import torch
|
||||
from PIL import Image
|
||||
from pydantic import BaseModel, Field
|
||||
from transformers import AutoProcessor
|
||||
from pydantic import BaseModel, Field, model_validator
|
||||
from transformers.models.sam import SamModel
|
||||
from transformers.models.sam.processing_sam import SamProcessor
|
||||
from transformers.models.sam2 import Sam2Model
|
||||
from transformers.models.sam2.processing_sam2 import Sam2Processor
|
||||
|
||||
from invokeai.app.invocations.baseinvocation import BaseInvocation, invocation
|
||||
from invokeai.app.invocations.fields import BoundingBoxField, ImageField, InputField, TensorField
|
||||
from invokeai.app.invocations.primitives import MaskOutput
|
||||
from invokeai.app.services.shared.invocation_context import InvocationContext
|
||||
from invokeai.backend.image_util.segment_anything.mask_refinement import mask_to_polygon, polygon_to_mask
|
||||
from invokeai.backend.image_util.segment_anything.segment_anything_2_pipeline import SegmentAnything2Pipeline
|
||||
from invokeai.backend.image_util.segment_anything.segment_anything_pipeline import SegmentAnythingPipeline
|
||||
from invokeai.backend.image_util.segment_anything.shared import SAMInput, SAMPoint
|
||||
|
||||
SegmentAnythingModelKey = Literal["segment-anything-base", "segment-anything-large", "segment-anything-huge"]
|
||||
SegmentAnythingModelKey = Literal[
|
||||
"segment-anything-base",
|
||||
"segment-anything-large",
|
||||
"segment-anything-huge",
|
||||
"segment-anything-2-tiny",
|
||||
"segment-anything-2-small",
|
||||
"segment-anything-2-base",
|
||||
"segment-anything-2-large",
|
||||
]
|
||||
SEGMENT_ANYTHING_MODEL_IDS: dict[SegmentAnythingModelKey, str] = {
|
||||
"segment-anything-base": "facebook/sam-vit-base",
|
||||
"segment-anything-large": "facebook/sam-vit-large",
|
||||
"segment-anything-huge": "facebook/sam-vit-huge",
|
||||
"segment-anything-2-tiny": "facebook/sam2.1-hiera-tiny",
|
||||
"segment-anything-2-small": "facebook/sam2.1-hiera-small",
|
||||
"segment-anything-2-base": "facebook/sam2.1-hiera-base-plus",
|
||||
"segment-anything-2-large": "facebook/sam2.1-hiera-large",
|
||||
}
|
||||
|
||||
|
||||
class SAMPointLabel(Enum):
|
||||
negative = -1
|
||||
neutral = 0
|
||||
positive = 1
|
||||
|
||||
|
||||
class SAMPoint(BaseModel):
|
||||
x: int = Field(..., description="The x-coordinate of the point")
|
||||
y: int = Field(..., description="The y-coordinate of the point")
|
||||
label: SAMPointLabel = Field(..., description="The label of the point")
|
||||
|
||||
|
||||
class SAMPointsField(BaseModel):
|
||||
points: list[SAMPoint] = Field(..., description="The points of the object")
|
||||
points: list[SAMPoint] = Field(..., description="The points of the object", min_length=1)
|
||||
|
||||
def to_list(self) -> list[list[int]]:
|
||||
def to_list(self) -> list[list[float]]:
|
||||
return [[point.x, point.y, point.label.value] for point in self.points]
|
||||
|
||||
|
||||
@invocation(
|
||||
"segment_anything",
|
||||
title="Segment Anything",
|
||||
tags=["prompt", "segmentation"],
|
||||
tags=["prompt", "segmentation", "sam", "sam2"],
|
||||
category="segmentation",
|
||||
version="1.2.0",
|
||||
version="1.3.0",
|
||||
)
|
||||
class SegmentAnythingInvocation(BaseInvocation):
|
||||
"""Runs a Segment Anything Model."""
|
||||
"""Runs a Segment Anything Model (SAM or SAM2)."""
|
||||
|
||||
# Reference:
|
||||
# - https://arxiv.org/pdf/2304.02643
|
||||
# - https://huggingface.co/docs/transformers/v4.43.3/en/model_doc/grounding-dino#grounded-sam
|
||||
# - https://github.com/NielsRogge/Transformers-Tutorials/blob/a39f33ac1557b02ebfb191ea7753e332b5ca933f/Grounding%20DINO/GroundingDINO_with_Segment_Anything.ipynb
|
||||
|
||||
model: SegmentAnythingModelKey = InputField(description="The Segment Anything model to use.")
|
||||
model: SegmentAnythingModelKey = InputField(description="The Segment Anything model to use (SAM or SAM2).")
|
||||
image: ImageField = InputField(description="The image to segment.")
|
||||
bounding_boxes: list[BoundingBoxField] | None = InputField(
|
||||
default=None, description="The bounding boxes to prompt the SAM model with."
|
||||
default=None, description="The bounding boxes to prompt the model with."
|
||||
)
|
||||
point_lists: list[SAMPointsField] | None = InputField(
|
||||
default=None,
|
||||
description="The list of point lists to prompt the SAM model with. Each list of points represents a single object.",
|
||||
description="The list of point lists to prompt the model with. Each list of points represents a single object.",
|
||||
)
|
||||
apply_polygon_refinement: bool = InputField(
|
||||
description="Whether to apply polygon refinement to the masks. This will smooth the edges of the masks slightly and ensure that each mask consists of a single closed polygon (before merging).",
|
||||
@@ -77,14 +80,18 @@ class SegmentAnythingInvocation(BaseInvocation):
|
||||
default="all",
|
||||
)
|
||||
|
||||
@model_validator(mode="after")
|
||||
def validate_points_and_boxes_len(self):
|
||||
if self.point_lists is not None and self.bounding_boxes is not None:
|
||||
if len(self.point_lists) != len(self.bounding_boxes):
|
||||
raise ValueError("If both point_lists and bounding_boxes are provided, they must have the same length.")
|
||||
return self
|
||||
|
||||
@torch.no_grad()
|
||||
def invoke(self, context: InvocationContext) -> MaskOutput:
|
||||
# The models expect a 3-channel RGB image.
|
||||
image_pil = context.images.get_pil(self.image.image_name, mode="RGB")
|
||||
|
||||
if self.point_lists is not None and self.bounding_boxes is not None:
|
||||
raise ValueError("Only one of point_lists or bounding_box can be provided.")
|
||||
|
||||
if (not self.bounding_boxes or len(self.bounding_boxes) == 0) and (
|
||||
not self.point_lists or len(self.point_lists) == 0
|
||||
):
|
||||
@@ -111,26 +118,38 @@ class SegmentAnythingInvocation(BaseInvocation):
|
||||
# model, and figure out how to make it work in the pipeline.
|
||||
# torch_dtype=TorchDevice.choose_torch_dtype(),
|
||||
)
|
||||
|
||||
sam_processor = AutoProcessor.from_pretrained(model_path, local_files_only=True)
|
||||
assert isinstance(sam_processor, SamProcessor)
|
||||
sam_processor = SamProcessor.from_pretrained(model_path, local_files_only=True)
|
||||
return SegmentAnythingPipeline(sam_model=sam_model, sam_processor=sam_processor)
|
||||
|
||||
def _segment(self, context: InvocationContext, image: Image.Image) -> list[torch.Tensor]:
|
||||
"""Use Segment Anything (SAM) to generate masks given an image + a set of bounding boxes."""
|
||||
# Convert the bounding boxes to the SAM input format.
|
||||
sam_bounding_boxes = (
|
||||
[[bb.x_min, bb.y_min, bb.x_max, bb.y_max] for bb in self.bounding_boxes] if self.bounding_boxes else None
|
||||
)
|
||||
sam_points = [p.to_list() for p in self.point_lists] if self.point_lists else None
|
||||
@staticmethod
|
||||
def _load_sam_2_model(model_path: Path):
|
||||
sam2_model = Sam2Model.from_pretrained(model_path, local_files_only=True)
|
||||
sam2_processor = Sam2Processor.from_pretrained(model_path, local_files_only=True)
|
||||
return SegmentAnything2Pipeline(sam2_model=sam2_model, sam2_processor=sam2_processor)
|
||||
|
||||
with (
|
||||
context.models.load_remote_model(
|
||||
source=SEGMENT_ANYTHING_MODEL_IDS[self.model], loader=SegmentAnythingInvocation._load_sam_model
|
||||
) as sam_pipeline,
|
||||
):
|
||||
assert isinstance(sam_pipeline, SegmentAnythingPipeline)
|
||||
masks = sam_pipeline.segment(image=image, bounding_boxes=sam_bounding_boxes, point_lists=sam_points)
|
||||
def _segment(self, context: InvocationContext, image: Image.Image) -> list[torch.Tensor]:
|
||||
"""Use Segment Anything (SAM or SAM2) to generate masks given an image + a set of bounding boxes."""
|
||||
|
||||
source = SEGMENT_ANYTHING_MODEL_IDS[self.model]
|
||||
inputs: list[SAMInput] = []
|
||||
for bbox_field, point_field in zip_longest(self.bounding_boxes or [], self.point_lists or [], fillvalue=None):
|
||||
inputs.append(
|
||||
SAMInput(
|
||||
bounding_box=bbox_field,
|
||||
points=point_field.points if point_field else None,
|
||||
)
|
||||
)
|
||||
|
||||
if "sam2" in source:
|
||||
loader = SegmentAnythingInvocation._load_sam_2_model
|
||||
with context.models.load_remote_model(source=source, loader=loader) as pipeline:
|
||||
assert isinstance(pipeline, SegmentAnything2Pipeline)
|
||||
masks = pipeline.segment(image=image, inputs=inputs)
|
||||
else:
|
||||
loader = SegmentAnythingInvocation._load_sam_model
|
||||
with context.models.load_remote_model(source=source, loader=loader) as pipeline:
|
||||
assert isinstance(pipeline, SegmentAnythingPipeline)
|
||||
masks = pipeline.segment(image=image, inputs=inputs)
|
||||
|
||||
masks = self._process_masks(masks)
|
||||
if self.apply_polygon_refinement:
|
||||
|
||||
@@ -11,7 +11,6 @@ from invokeai.app.invocations.fields import (
|
||||
FieldDescriptions,
|
||||
ImageField,
|
||||
InputField,
|
||||
UIType,
|
||||
WithBoard,
|
||||
WithMetadata,
|
||||
)
|
||||
@@ -19,6 +18,7 @@ from invokeai.app.invocations.model import ModelIdentifierField
|
||||
from invokeai.app.invocations.primitives import ImageOutput
|
||||
from invokeai.app.services.session_processor.session_processor_common import CanceledException
|
||||
from invokeai.app.services.shared.invocation_context import InvocationContext
|
||||
from invokeai.backend.model_manager.taxonomy import ModelType
|
||||
from invokeai.backend.spandrel_image_to_image_model import SpandrelImageToImageModel
|
||||
from invokeai.backend.tiles.tiles import calc_tiles_min_overlap
|
||||
from invokeai.backend.tiles.utils import TBLR, Tile
|
||||
@@ -33,7 +33,7 @@ class SpandrelImageToImageInvocation(BaseInvocation, WithMetadata, WithBoard):
|
||||
image_to_image_model: ModelIdentifierField = InputField(
|
||||
title="Image-to-Image Model",
|
||||
description=FieldDescriptions.spandrel_image_to_image_model,
|
||||
ui_type=UIType.SpandrelImageToImageModel,
|
||||
ui_model_type=ModelType.SpandrelImageToImage,
|
||||
)
|
||||
tile_size: int = InputField(
|
||||
default=512, description="The tile size for tiled image-to-image. Set to 0 to disable tiling."
|
||||
|
||||
@@ -8,11 +8,12 @@ from invokeai.app.invocations.baseinvocation import (
|
||||
invocation,
|
||||
invocation_output,
|
||||
)
|
||||
from invokeai.app.invocations.fields import FieldDescriptions, ImageField, InputField, OutputField, UIType
|
||||
from invokeai.app.invocations.fields import FieldDescriptions, ImageField, InputField, OutputField
|
||||
from invokeai.app.invocations.model import ModelIdentifierField
|
||||
from invokeai.app.invocations.util import validate_begin_end_step, validate_weights
|
||||
from invokeai.app.services.shared.invocation_context import InvocationContext
|
||||
from invokeai.app.util.controlnet_utils import CONTROLNET_RESIZE_VALUES
|
||||
from invokeai.backend.model_manager.taxonomy import BaseModelType, ModelType
|
||||
|
||||
|
||||
class T2IAdapterField(BaseModel):
|
||||
@@ -60,7 +61,8 @@ class T2IAdapterInvocation(BaseInvocation):
|
||||
description="The T2I-Adapter model.",
|
||||
title="T2I-Adapter Model",
|
||||
ui_order=-1,
|
||||
ui_type=UIType.T2IAdapterModel,
|
||||
ui_model_base=[BaseModelType.StableDiffusion1, BaseModelType.StableDiffusionXL],
|
||||
ui_model_type=ModelType.T2IAdapter,
|
||||
)
|
||||
weight: Union[float, list[float]] = InputField(
|
||||
default=1, ge=0, description="The weight given to the T2I-Adapter", title="Weight"
|
||||
|
||||
@@ -49,3 +49,11 @@ class BoardImageRecordStorageBase(ABC):
|
||||
) -> int:
|
||||
"""Gets the number of images for a board."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def get_asset_count_for_board(
|
||||
self,
|
||||
board_id: str,
|
||||
) -> int:
|
||||
"""Gets the number of assets for a board."""
|
||||
pass
|
||||
|
||||
@@ -3,6 +3,8 @@ from typing import Optional, cast
|
||||
|
||||
from invokeai.app.services.board_image_records.board_image_records_base import BoardImageRecordStorageBase
|
||||
from invokeai.app.services.image_records.image_records_common import (
|
||||
ASSETS_CATEGORIES,
|
||||
IMAGE_CATEGORIES,
|
||||
ImageCategory,
|
||||
ImageRecord,
|
||||
deserialize_image_record,
|
||||
@@ -151,15 +153,38 @@ class SqliteBoardImageRecordStorage(BoardImageRecordStorageBase):
|
||||
|
||||
def get_image_count_for_board(self, board_id: str) -> int:
|
||||
with self._db.transaction() as cursor:
|
||||
# Convert the enum values to unique list of strings
|
||||
category_strings = [c.value for c in set(IMAGE_CATEGORIES)]
|
||||
# Create the correct length of placeholders
|
||||
placeholders = ",".join("?" * len(category_strings))
|
||||
cursor.execute(
|
||||
"""--sql
|
||||
f"""--sql
|
||||
SELECT COUNT(*)
|
||||
FROM board_images
|
||||
INNER JOIN images ON board_images.image_name = images.image_name
|
||||
WHERE images.is_intermediate = FALSE
|
||||
WHERE images.is_intermediate = FALSE AND images.image_category IN ( {placeholders} )
|
||||
AND board_images.board_id = ?;
|
||||
""",
|
||||
(board_id,),
|
||||
(*category_strings, board_id),
|
||||
)
|
||||
count = cast(int, cursor.fetchone()[0])
|
||||
return count
|
||||
|
||||
def get_asset_count_for_board(self, board_id: str) -> int:
|
||||
with self._db.transaction() as cursor:
|
||||
# Convert the enum values to unique list of strings
|
||||
category_strings = [c.value for c in set(ASSETS_CATEGORIES)]
|
||||
# Create the correct length of placeholders
|
||||
placeholders = ",".join("?" * len(category_strings))
|
||||
cursor.execute(
|
||||
f"""--sql
|
||||
SELECT COUNT(*)
|
||||
FROM board_images
|
||||
INNER JOIN images ON board_images.image_name = images.image_name
|
||||
WHERE images.is_intermediate = FALSE AND images.image_category IN ( {placeholders} )
|
||||
AND board_images.board_id = ?;
|
||||
""",
|
||||
(*category_strings, board_id),
|
||||
)
|
||||
count = cast(int, cursor.fetchone()[0])
|
||||
return count
|
||||
|
||||
@@ -12,12 +12,20 @@ class BoardDTO(BoardRecord):
|
||||
"""The URL of the thumbnail of the most recent image in the board."""
|
||||
image_count: int = Field(description="The number of images in the board.")
|
||||
"""The number of images in the board."""
|
||||
asset_count: int = Field(description="The number of assets in the board.")
|
||||
"""The number of assets in the board."""
|
||||
video_count: int = Field(description="The number of videos in the board.")
|
||||
"""The number of videos in the board."""
|
||||
|
||||
|
||||
def board_record_to_dto(board_record: BoardRecord, cover_image_name: Optional[str], image_count: int) -> BoardDTO:
|
||||
def board_record_to_dto(
|
||||
board_record: BoardRecord, cover_image_name: Optional[str], image_count: int, asset_count: int, video_count: int
|
||||
) -> BoardDTO:
|
||||
"""Converts a board record to a board DTO."""
|
||||
return BoardDTO(
|
||||
**board_record.model_dump(exclude={"cover_image_name"}),
|
||||
cover_image_name=cover_image_name,
|
||||
image_count=image_count,
|
||||
asset_count=asset_count,
|
||||
video_count=video_count,
|
||||
)
|
||||
|
||||
@@ -17,7 +17,7 @@ class BoardService(BoardServiceABC):
|
||||
board_name: str,
|
||||
) -> BoardDTO:
|
||||
board_record = self.__invoker.services.board_records.save(board_name)
|
||||
return board_record_to_dto(board_record, None, 0)
|
||||
return board_record_to_dto(board_record, None, 0, 0, 0)
|
||||
|
||||
def get_dto(self, board_id: str) -> BoardDTO:
|
||||
board_record = self.__invoker.services.board_records.get(board_id)
|
||||
@@ -27,7 +27,9 @@ class BoardService(BoardServiceABC):
|
||||
else:
|
||||
cover_image_name = None
|
||||
image_count = self.__invoker.services.board_image_records.get_image_count_for_board(board_id)
|
||||
return board_record_to_dto(board_record, cover_image_name, image_count)
|
||||
asset_count = self.__invoker.services.board_image_records.get_asset_count_for_board(board_id)
|
||||
video_count = 0 # noop for OSS
|
||||
return board_record_to_dto(board_record, cover_image_name, image_count, asset_count, video_count)
|
||||
|
||||
def update(
|
||||
self,
|
||||
@@ -42,7 +44,9 @@ class BoardService(BoardServiceABC):
|
||||
cover_image_name = None
|
||||
|
||||
image_count = self.__invoker.services.board_image_records.get_image_count_for_board(board_id)
|
||||
return board_record_to_dto(board_record, cover_image_name, image_count)
|
||||
asset_count = self.__invoker.services.board_image_records.get_asset_count_for_board(board_id)
|
||||
video_count = 0 # noop for OSS
|
||||
return board_record_to_dto(board_record, cover_image_name, image_count, asset_count, video_count)
|
||||
|
||||
def delete(self, board_id: str) -> None:
|
||||
self.__invoker.services.board_records.delete(board_id)
|
||||
@@ -67,7 +71,9 @@ class BoardService(BoardServiceABC):
|
||||
cover_image_name = None
|
||||
|
||||
image_count = self.__invoker.services.board_image_records.get_image_count_for_board(r.board_id)
|
||||
board_dtos.append(board_record_to_dto(r, cover_image_name, image_count))
|
||||
asset_count = self.__invoker.services.board_image_records.get_asset_count_for_board(r.board_id)
|
||||
video_count = 0 # noop for OSS
|
||||
board_dtos.append(board_record_to_dto(r, cover_image_name, image_count, asset_count, video_count))
|
||||
|
||||
return OffsetPaginatedResults[BoardDTO](items=board_dtos, offset=offset, limit=limit, total=len(board_dtos))
|
||||
|
||||
@@ -84,6 +90,8 @@ class BoardService(BoardServiceABC):
|
||||
cover_image_name = None
|
||||
|
||||
image_count = self.__invoker.services.board_image_records.get_image_count_for_board(r.board_id)
|
||||
board_dtos.append(board_record_to_dto(r, cover_image_name, image_count))
|
||||
asset_count = self.__invoker.services.board_image_records.get_asset_count_for_board(r.board_id)
|
||||
video_count = 0 # noop for OSS
|
||||
board_dtos.append(board_record_to_dto(r, cover_image_name, image_count, asset_count, video_count))
|
||||
|
||||
return board_dtos
|
||||
|
||||
@@ -150,4 +150,15 @@ class BulkDownloadService(BulkDownloadBase):
|
||||
def _is_valid_path(self, path: Union[str, Path]) -> bool:
|
||||
"""Validates the path given for a bulk download."""
|
||||
path = path if isinstance(path, Path) else Path(path)
|
||||
return path.exists()
|
||||
|
||||
# Resolve the path to handle any path traversal attempts (e.g., ../)
|
||||
resolved_path = path.resolve()
|
||||
|
||||
# The path may not traverse out of the bulk downloads folder or its subfolders
|
||||
does_not_traverse = resolved_path.parent == self._bulk_downloads_folder.resolve()
|
||||
|
||||
# The path must exist and be a .zip file
|
||||
does_exist = resolved_path.exists()
|
||||
is_zip_file = resolved_path.suffix == ".zip"
|
||||
|
||||
return does_exist and is_zip_file and does_not_traverse
|
||||
|
||||
@@ -0,0 +1,42 @@
|
||||
from abc import ABC, abstractmethod
|
||||
|
||||
|
||||
class ClientStatePersistenceABC(ABC):
|
||||
"""
|
||||
Base class for client persistence implementations.
|
||||
This class defines the interface for persisting client data.
|
||||
"""
|
||||
|
||||
@abstractmethod
|
||||
def set_by_key(self, queue_id: str, key: str, value: str) -> str:
|
||||
"""
|
||||
Set a key-value pair for the client.
|
||||
|
||||
Args:
|
||||
key (str): The key to set.
|
||||
value (str): The value to set for the key.
|
||||
|
||||
Returns:
|
||||
str: The value that was set.
|
||||
"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def get_by_key(self, queue_id: str, key: str) -> str | None:
|
||||
"""
|
||||
Get the value for a specific key of the client.
|
||||
|
||||
Args:
|
||||
key (str): The key to retrieve the value for.
|
||||
|
||||
Returns:
|
||||
str | None: The value associated with the key, or None if the key does not exist.
|
||||
"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def delete(self, queue_id: str) -> None:
|
||||
"""
|
||||
Delete all client state.
|
||||
"""
|
||||
pass
|
||||
@@ -0,0 +1,65 @@
|
||||
import json
|
||||
|
||||
from invokeai.app.services.client_state_persistence.client_state_persistence_base import ClientStatePersistenceABC
|
||||
from invokeai.app.services.invoker import Invoker
|
||||
from invokeai.app.services.shared.sqlite.sqlite_database import SqliteDatabase
|
||||
|
||||
|
||||
class ClientStatePersistenceSqlite(ClientStatePersistenceABC):
|
||||
"""
|
||||
Base class for client persistence implementations.
|
||||
This class defines the interface for persisting client data.
|
||||
"""
|
||||
|
||||
def __init__(self, db: SqliteDatabase) -> None:
|
||||
super().__init__()
|
||||
self._db = db
|
||||
self._default_row_id = 1
|
||||
|
||||
def start(self, invoker: Invoker) -> None:
|
||||
self._invoker = invoker
|
||||
|
||||
def _get(self) -> dict[str, str] | None:
|
||||
with self._db.transaction() as cursor:
|
||||
cursor.execute(
|
||||
f"""
|
||||
SELECT data FROM client_state
|
||||
WHERE id = {self._default_row_id}
|
||||
"""
|
||||
)
|
||||
row = cursor.fetchone()
|
||||
if row is None:
|
||||
return None
|
||||
return json.loads(row[0])
|
||||
|
||||
def set_by_key(self, queue_id: str, key: str, value: str) -> str:
|
||||
state = self._get() or {}
|
||||
state.update({key: value})
|
||||
|
||||
with self._db.transaction() as cursor:
|
||||
cursor.execute(
|
||||
f"""
|
||||
INSERT INTO client_state (id, data)
|
||||
VALUES ({self._default_row_id}, ?)
|
||||
ON CONFLICT(id) DO UPDATE
|
||||
SET data = excluded.data;
|
||||
""",
|
||||
(json.dumps(state),),
|
||||
)
|
||||
|
||||
return value
|
||||
|
||||
def get_by_key(self, queue_id: str, key: str) -> str | None:
|
||||
state = self._get()
|
||||
if state is None:
|
||||
return None
|
||||
return state.get(key, None)
|
||||
|
||||
def delete(self, queue_id: str) -> None:
|
||||
with self._db.transaction() as cursor:
|
||||
cursor.execute(
|
||||
f"""
|
||||
DELETE FROM client_state
|
||||
WHERE id = {self._default_row_id}
|
||||
"""
|
||||
)
|
||||
@@ -107,6 +107,8 @@ class InvokeAIAppConfig(BaseSettings):
|
||||
hashing_algorithm: Model hashing algorthim for model installs. 'blake3_multi' is best for SSDs. 'blake3_single' is best for spinning disk HDDs. 'random' disables hashing, instead assigning a UUID to models. Useful when using a memory db to reduce model installation time, or if you don't care about storing stable hashes for models. Alternatively, any other hashlib algorithm is accepted, though these are not nearly as performant as blake3.<br>Valid values: `blake3_multi`, `blake3_single`, `random`, `md5`, `sha1`, `sha224`, `sha256`, `sha384`, `sha512`, `blake2b`, `blake2s`, `sha3_224`, `sha3_256`, `sha3_384`, `sha3_512`, `shake_128`, `shake_256`
|
||||
remote_api_tokens: List of regular expression and token pairs used when downloading models from URLs. The download URL is tested against the regex, and if it matches, the token is provided in as a Bearer token.
|
||||
scan_models_on_startup: Scan the models directory on startup, registering orphaned models. This is typically only used in conjunction with `use_memory_db` for testing purposes.
|
||||
unsafe_disable_picklescan: UNSAFE. Disable the picklescan security check during model installation. Recommended only for development and testing purposes. This will allow arbitrary code execution during model installation, so should never be used in production.
|
||||
allow_unknown_models: Allow installation of models that we are unable to identify. If enabled, models will be marked as `unknown` in the database, and will not have any metadata associated with them. If disabled, unknown models will be rejected during installation.
|
||||
"""
|
||||
|
||||
_root: Optional[Path] = PrivateAttr(default=None)
|
||||
@@ -196,6 +198,8 @@ class InvokeAIAppConfig(BaseSettings):
|
||||
hashing_algorithm: HASHING_ALGORITHMS = Field(default="blake3_single", description="Model hashing algorthim for model installs. 'blake3_multi' is best for SSDs. 'blake3_single' is best for spinning disk HDDs. 'random' disables hashing, instead assigning a UUID to models. Useful when using a memory db to reduce model installation time, or if you don't care about storing stable hashes for models. Alternatively, any other hashlib algorithm is accepted, though these are not nearly as performant as blake3.")
|
||||
remote_api_tokens: Optional[list[URLRegexTokenPair]] = Field(default=None, description="List of regular expression and token pairs used when downloading models from URLs. The download URL is tested against the regex, and if it matches, the token is provided in as a Bearer token.")
|
||||
scan_models_on_startup: bool = Field(default=False, description="Scan the models directory on startup, registering orphaned models. This is typically only used in conjunction with `use_memory_db` for testing purposes.")
|
||||
unsafe_disable_picklescan: bool = Field(default=False, description="UNSAFE. Disable the picklescan security check during model installation. Recommended only for development and testing purposes. This will allow arbitrary code execution during model installation, so should never be used in production.")
|
||||
allow_unknown_models: bool = Field(default=True, description="Allow installation of models that we are unable to identify. If enabled, models will be marked as `unknown` in the database, and will not have any metadata associated with them. If disabled, unknown models will be rejected during installation.")
|
||||
|
||||
# fmt: on
|
||||
|
||||
|
||||
@@ -44,8 +44,8 @@ if TYPE_CHECKING:
|
||||
SessionQueueItem,
|
||||
SessionQueueStatus,
|
||||
)
|
||||
from invokeai.backend.model_manager import SubModelType
|
||||
from invokeai.backend.model_manager.config import AnyModelConfig
|
||||
from invokeai.backend.model_manager.configs.factory import AnyModelConfig
|
||||
from invokeai.backend.model_manager.taxonomy import SubModelType
|
||||
|
||||
|
||||
class EventServiceBase:
|
||||
|
||||
@@ -16,8 +16,8 @@ from invokeai.app.services.session_queue.session_queue_common import (
|
||||
)
|
||||
from invokeai.app.services.shared.graph import AnyInvocation, AnyInvocationOutput
|
||||
from invokeai.app.util.misc import get_timestamp
|
||||
from invokeai.backend.model_manager import SubModelType
|
||||
from invokeai.backend.model_manager.config import AnyModelConfig
|
||||
from invokeai.backend.model_manager.configs.factory import AnyModelConfig
|
||||
from invokeai.backend.model_manager.taxonomy import SubModelType
|
||||
|
||||
if TYPE_CHECKING:
|
||||
from invokeai.app.services.download.download_base import DownloadJob
|
||||
@@ -234,8 +234,8 @@ class QueueItemStatusChangedEvent(QueueItemEventBase):
|
||||
error_type: Optional[str] = Field(default=None, description="The error type, if any")
|
||||
error_message: Optional[str] = Field(default=None, description="The error message, if any")
|
||||
error_traceback: Optional[str] = Field(default=None, description="The error traceback, if any")
|
||||
created_at: Optional[str] = Field(default=None, description="The timestamp when the queue item was created")
|
||||
updated_at: Optional[str] = Field(default=None, description="The timestamp when the queue item was last updated")
|
||||
created_at: str = Field(description="The timestamp when the queue item was created")
|
||||
updated_at: str = Field(description="The timestamp when the queue item was last updated")
|
||||
started_at: Optional[str] = Field(default=None, description="The timestamp when the queue item was started")
|
||||
completed_at: Optional[str] = Field(default=None, description="The timestamp when the queue item was completed")
|
||||
batch_status: BatchStatus = Field(description="The status of the batch")
|
||||
@@ -258,8 +258,8 @@ class QueueItemStatusChangedEvent(QueueItemEventBase):
|
||||
error_type=queue_item.error_type,
|
||||
error_message=queue_item.error_message,
|
||||
error_traceback=queue_item.error_traceback,
|
||||
created_at=str(queue_item.created_at) if queue_item.created_at else None,
|
||||
updated_at=str(queue_item.updated_at) if queue_item.updated_at else None,
|
||||
created_at=str(queue_item.created_at),
|
||||
updated_at=str(queue_item.updated_at),
|
||||
started_at=str(queue_item.started_at) if queue_item.started_at else None,
|
||||
completed_at=str(queue_item.completed_at) if queue_item.completed_at else None,
|
||||
batch_status=batch_status,
|
||||
@@ -546,11 +546,18 @@ class ModelInstallCompleteEvent(ModelEventBase):
|
||||
source: ModelSource = Field(description="Source of the model; local path, repo_id or url")
|
||||
key: str = Field(description="Model config record key")
|
||||
total_bytes: Optional[int] = Field(description="Size of the model (may be None for installation of a local path)")
|
||||
config: AnyModelConfig = Field(description="The installed model's config")
|
||||
|
||||
@classmethod
|
||||
def build(cls, job: "ModelInstallJob") -> "ModelInstallCompleteEvent":
|
||||
assert job.config_out is not None
|
||||
return cls(id=job.id, source=job.source, key=(job.config_out.key), total_bytes=job.total_bytes)
|
||||
return cls(
|
||||
id=job.id,
|
||||
source=job.source,
|
||||
key=(job.config_out.key),
|
||||
total_bytes=job.total_bytes,
|
||||
config=job.config_out,
|
||||
)
|
||||
|
||||
|
||||
@payload_schema.register
|
||||
|
||||
@@ -58,6 +58,15 @@ class ImageCategory(str, Enum, metaclass=MetaEnum):
|
||||
"""OTHER: The image is some other type of image with a specialized purpose. To be used by external nodes."""
|
||||
|
||||
|
||||
IMAGE_CATEGORIES: list[ImageCategory] = [ImageCategory.GENERAL]
|
||||
ASSETS_CATEGORIES: list[ImageCategory] = [
|
||||
ImageCategory.CONTROL,
|
||||
ImageCategory.MASK,
|
||||
ImageCategory.USER,
|
||||
ImageCategory.OTHER,
|
||||
]
|
||||
|
||||
|
||||
class InvalidImageCategoryException(ValueError):
|
||||
"""Raised when a provided value is not a valid ImageCategory.
|
||||
|
||||
|
||||
@@ -17,6 +17,7 @@ if TYPE_CHECKING:
|
||||
from invokeai.app.services.board_records.board_records_base import BoardRecordStorageBase
|
||||
from invokeai.app.services.boards.boards_base import BoardServiceABC
|
||||
from invokeai.app.services.bulk_download.bulk_download_base import BulkDownloadBase
|
||||
from invokeai.app.services.client_state_persistence.client_state_persistence_base import ClientStatePersistenceABC
|
||||
from invokeai.app.services.config import InvokeAIAppConfig
|
||||
from invokeai.app.services.download import DownloadQueueServiceBase
|
||||
from invokeai.app.services.events.events_base import EventServiceBase
|
||||
@@ -73,6 +74,7 @@ class InvocationServices:
|
||||
style_preset_records: "StylePresetRecordsStorageBase",
|
||||
style_preset_image_files: "StylePresetImageFileStorageBase",
|
||||
workflow_thumbnails: "WorkflowThumbnailServiceBase",
|
||||
client_state_persistence: "ClientStatePersistenceABC",
|
||||
):
|
||||
self.board_images = board_images
|
||||
self.board_image_records = board_image_records
|
||||
@@ -102,3 +104,4 @@ class InvocationServices:
|
||||
self.style_preset_records = style_preset_records
|
||||
self.style_preset_image_files = style_preset_image_files
|
||||
self.workflow_thumbnails = workflow_thumbnails
|
||||
self.client_state_persistence = client_state_persistence
|
||||
|
||||
@@ -12,7 +12,6 @@ from invokeai.app.services.download import DownloadQueueServiceBase
|
||||
from invokeai.app.services.invoker import Invoker
|
||||
from invokeai.app.services.model_install.model_install_common import ModelInstallJob, ModelSource
|
||||
from invokeai.app.services.model_records import ModelRecordChanges, ModelRecordServiceBase
|
||||
from invokeai.backend.model_manager import AnyModelConfig
|
||||
|
||||
if TYPE_CHECKING:
|
||||
from invokeai.app.services.events.events_base import EventServiceBase
|
||||
@@ -231,19 +230,6 @@ class ModelInstallServiceBase(ABC):
|
||||
will block indefinitely until the installs complete.
|
||||
"""
|
||||
|
||||
@abstractmethod
|
||||
def sync_model_path(self, key: str) -> AnyModelConfig:
|
||||
"""
|
||||
Move model into the location indicated by its basetype, type and name.
|
||||
|
||||
Call this after updating a model's attributes in order to move
|
||||
the model's path into the location indicated by its basetype, type and
|
||||
name. Applies only to models whose paths are within the root `models_dir`
|
||||
directory.
|
||||
|
||||
May raise an UnknownModelException.
|
||||
"""
|
||||
|
||||
@abstractmethod
|
||||
def download_and_cache_model(self, source: str | AnyHttpUrl) -> Path:
|
||||
"""
|
||||
|
||||
@@ -10,11 +10,17 @@ from typing_extensions import Annotated
|
||||
|
||||
from invokeai.app.services.download import DownloadJob, MultiFileDownloadJob
|
||||
from invokeai.app.services.model_records import ModelRecordChanges
|
||||
from invokeai.backend.model_manager.config import AnyModelConfig
|
||||
from invokeai.backend.model_manager.configs.factory import AnyModelConfig
|
||||
from invokeai.backend.model_manager.metadata import AnyModelRepoMetadata
|
||||
from invokeai.backend.model_manager.taxonomy import ModelRepoVariant, ModelSourceType
|
||||
|
||||
|
||||
class InvalidModelConfigException(Exception):
|
||||
"""Raised when a model configuration is invalid."""
|
||||
|
||||
pass
|
||||
|
||||
|
||||
class InstallStatus(str, Enum):
|
||||
"""State of an install job running in the background."""
|
||||
|
||||
|
||||
@@ -5,9 +5,10 @@ import os
|
||||
import re
|
||||
import threading
|
||||
import time
|
||||
from copy import deepcopy
|
||||
from pathlib import Path
|
||||
from queue import Empty, Queue
|
||||
from shutil import copyfile, copytree, move, rmtree
|
||||
from shutil import move, rmtree
|
||||
from tempfile import mkdtemp
|
||||
from typing import TYPE_CHECKING, Any, Dict, List, Optional, Tuple, Type, Union
|
||||
|
||||
@@ -26,6 +27,7 @@ from invokeai.app.services.model_install.model_install_common import (
|
||||
MODEL_SOURCE_TO_TYPE_MAP,
|
||||
HFModelSource,
|
||||
InstallStatus,
|
||||
InvalidModelConfigException,
|
||||
LocalModelSource,
|
||||
ModelInstallJob,
|
||||
ModelSource,
|
||||
@@ -34,13 +36,12 @@ from invokeai.app.services.model_install.model_install_common import (
|
||||
)
|
||||
from invokeai.app.services.model_records import DuplicateModelException, ModelRecordServiceBase
|
||||
from invokeai.app.services.model_records.model_records_base import ModelRecordChanges
|
||||
from invokeai.backend.model_manager.config import (
|
||||
from invokeai.backend.model_manager.configs.base import Checkpoint_Config_Base
|
||||
from invokeai.backend.model_manager.configs.factory import (
|
||||
AnyModelConfig,
|
||||
CheckpointConfigBase,
|
||||
InvalidModelConfigException,
|
||||
ModelConfigBase,
|
||||
ModelConfigFactory,
|
||||
)
|
||||
from invokeai.backend.model_manager.legacy_probe import ModelProbe
|
||||
from invokeai.backend.model_manager.configs.unknown import Unknown_Config
|
||||
from invokeai.backend.model_manager.metadata import (
|
||||
AnyModelRepoMetadata,
|
||||
HuggingFaceMetadataFetch,
|
||||
@@ -180,26 +181,32 @@ class ModelInstallService(ModelInstallServiceBase):
|
||||
self,
|
||||
model_path: Union[Path, str],
|
||||
config: Optional[ModelRecordChanges] = None,
|
||||
) -> str: # noqa D102
|
||||
) -> str:
|
||||
model_path = Path(model_path)
|
||||
config = config or ModelRecordChanges()
|
||||
info: AnyModelConfig = self._probe(Path(model_path), config) # type: ignore
|
||||
|
||||
if preferred_name := config.name:
|
||||
preferred_name = Path(preferred_name).with_suffix(model_path.suffix)
|
||||
|
||||
dest_path = (
|
||||
self.app_config.models_path / info.base.value / info.type.value / (preferred_name or model_path.name)
|
||||
)
|
||||
dest_dir = self.app_config.models_path / info.key
|
||||
try:
|
||||
new_path = self._copy_model(model_path, dest_path)
|
||||
except FileExistsError as excp:
|
||||
if dest_dir.exists():
|
||||
raise FileExistsError(
|
||||
f"Cannot install model {model_path.name} to {dest_dir}: destination already exists"
|
||||
)
|
||||
dest_dir.mkdir(parents=True)
|
||||
dest_path = dest_dir / model_path.name if model_path.is_file() else dest_dir
|
||||
if model_path.is_file():
|
||||
move(model_path, dest_path)
|
||||
elif model_path.is_dir():
|
||||
# Move the contents of the directory, not the directory itself
|
||||
for item in model_path.iterdir():
|
||||
move(item, dest_dir / item.name)
|
||||
except FileExistsError as e:
|
||||
raise DuplicateModelException(
|
||||
f"A model named {model_path.name} is already installed at {dest_path.as_posix()}"
|
||||
) from excp
|
||||
f"A model named {model_path.name} is already installed at {dest_dir.as_posix()}"
|
||||
) from e
|
||||
|
||||
return self._register(
|
||||
new_path,
|
||||
dest_path,
|
||||
config,
|
||||
info,
|
||||
)
|
||||
@@ -362,9 +369,18 @@ class ModelInstallService(ModelInstallServiceBase):
|
||||
def unconditionally_delete(self, key: str) -> None: # noqa D102
|
||||
model = self.record_store.get_model(key)
|
||||
model_path = self.app_config.models_path / model.path
|
||||
# Models are stored in a directory named by their key. To delete the model on disk, we delete the entire
|
||||
# directory. However, the path we store in the model record may be either a file within the key directory,
|
||||
# or the directory itself. So we have to handle both cases.
|
||||
if model_path.is_file() or model_path.is_symlink():
|
||||
model_path.unlink()
|
||||
# Sanity check - file models should be in their own directory under the models dir. The parent of the
|
||||
# file should be the model's directory, not the Invoke models dir!
|
||||
assert model_path.parent != self.app_config.models_path
|
||||
rmtree(model_path.parent)
|
||||
elif model_path.is_dir():
|
||||
# Sanity check - folder models should be in their own directory under the models dir. The path should
|
||||
# not be the Invoke models dir itself!
|
||||
assert model_path != self.app_config.models_path
|
||||
rmtree(model_path)
|
||||
self.unregister(key)
|
||||
|
||||
@@ -524,7 +540,7 @@ class ModelInstallService(ModelInstallServiceBase):
|
||||
x.content_type is not None and "text/html" in x.content_type for x in multifile_download_job.download_parts
|
||||
):
|
||||
install_job.set_error(
|
||||
InvalidModelConfigException(
|
||||
ValueError(
|
||||
f"At least one file in {install_job.local_path} is an HTML page, not a model. This can happen when an access token is required to download."
|
||||
)
|
||||
)
|
||||
@@ -587,79 +603,25 @@ class ModelInstallService(ModelInstallServiceBase):
|
||||
found_models = search.search(self._app_config.models_path)
|
||||
self._logger.info(f"{len(found_models)} new models registered")
|
||||
|
||||
def sync_model_path(self, key: str) -> AnyModelConfig:
|
||||
"""
|
||||
Move model into the location indicated by its basetype, type and name.
|
||||
|
||||
Call this after updating a model's attributes in order to move
|
||||
the model's path into the location indicated by its basetype, type and
|
||||
name. Applies only to models whose paths are within the root `models_dir`
|
||||
directory.
|
||||
|
||||
May raise an UnknownModelException.
|
||||
"""
|
||||
model = self.record_store.get_model(key)
|
||||
models_dir = self.app_config.models_path
|
||||
old_path = self.app_config.models_path / model.path
|
||||
|
||||
if not old_path.is_relative_to(models_dir):
|
||||
# The model is not in the models directory - we don't need to move it.
|
||||
return model
|
||||
|
||||
new_path = models_dir / model.base.value / model.type.value / old_path.name
|
||||
|
||||
if old_path == new_path or new_path.exists() and old_path == new_path.resolve():
|
||||
return model
|
||||
|
||||
self._logger.info(f"Moving {model.name} to {new_path}.")
|
||||
new_path = self._move_model(old_path, new_path)
|
||||
model.path = new_path.relative_to(models_dir).as_posix()
|
||||
self.record_store.update_model(key, ModelRecordChanges(path=model.path))
|
||||
return model
|
||||
|
||||
def _copy_model(self, old_path: Path, new_path: Path) -> Path:
|
||||
if old_path == new_path:
|
||||
return old_path
|
||||
new_path.parent.mkdir(parents=True, exist_ok=True)
|
||||
if old_path.is_dir():
|
||||
copytree(old_path, new_path)
|
||||
else:
|
||||
copyfile(old_path, new_path)
|
||||
return new_path
|
||||
|
||||
def _move_model(self, old_path: Path, new_path: Path) -> Path:
|
||||
if old_path == new_path:
|
||||
return old_path
|
||||
|
||||
new_path.parent.mkdir(parents=True, exist_ok=True)
|
||||
|
||||
# if path already exists then we jigger the name to make it unique
|
||||
counter: int = 1
|
||||
while new_path.exists():
|
||||
path = new_path.with_stem(new_path.stem + f"_{counter:02d}")
|
||||
if not path.exists():
|
||||
new_path = path
|
||||
counter += 1
|
||||
move(old_path, new_path)
|
||||
return new_path
|
||||
|
||||
def _probe(self, model_path: Path, config: Optional[ModelRecordChanges] = None):
|
||||
config = config or ModelRecordChanges()
|
||||
hash_algo = self._app_config.hashing_algorithm
|
||||
fields = config.model_dump()
|
||||
|
||||
# WARNING!
|
||||
# The legacy probe relies on the implicit order of tests to determine model classification.
|
||||
# This can lead to regressions between the legacy and new probes.
|
||||
# Do NOT change the order of `probe` and `classify` without implementing one of the following fixes:
|
||||
# Short-term fix: `classify` tests `matches` in the same order as the legacy probe.
|
||||
# Long-term fix: Improve `matches` to be more specific so that only one config matches
|
||||
# any given model - eliminating ambiguity and removing reliance on order.
|
||||
# After implementing either of these fixes, remove @pytest.mark.xfail from `test_regression_against_model_probe`
|
||||
try:
|
||||
return ModelProbe.probe(model_path=model_path, fields=fields, hash_algo=hash_algo) # type: ignore
|
||||
except InvalidModelConfigException:
|
||||
return ModelConfigBase.classify(model_path, hash_algo, **fields)
|
||||
result = ModelConfigFactory.from_model_on_disk(
|
||||
mod=model_path,
|
||||
override_fields=deepcopy(fields),
|
||||
hash_algo=hash_algo,
|
||||
allow_unknown=self.app_config.allow_unknown_models,
|
||||
)
|
||||
|
||||
if result.config is None:
|
||||
self._logger.error(f"Could not identify model for {model_path}, detailed results: {result.details}")
|
||||
raise InvalidModelConfigException(f"Could not identify model for {model_path}")
|
||||
elif isinstance(result.config, Unknown_Config):
|
||||
self._logger.error(f"Could not identify model for {model_path}, detailed results: {result.details}")
|
||||
|
||||
return result.config
|
||||
|
||||
def _register(
|
||||
self, model_path: Path, config: Optional[ModelRecordChanges] = None, info: Optional[AnyModelConfig] = None
|
||||
@@ -680,7 +642,7 @@ class ModelInstallService(ModelInstallServiceBase):
|
||||
|
||||
info.path = model_path.as_posix()
|
||||
|
||||
if isinstance(info, CheckpointConfigBase):
|
||||
if isinstance(info, Checkpoint_Config_Base) and info.config_path is not None:
|
||||
# Checkpoints have a config file needed for conversion. Same handling as the model weights - if it's in the
|
||||
# invoke-managed legacy config dir, we use a relative path.
|
||||
legacy_config_path = self.app_config.legacy_conf_path / info.config_path
|
||||
|
||||
@@ -5,7 +5,7 @@ from abc import ABC, abstractmethod
|
||||
from pathlib import Path
|
||||
from typing import Callable, Optional
|
||||
|
||||
from invokeai.backend.model_manager.config import AnyModelConfig
|
||||
from invokeai.backend.model_manager.configs.factory import AnyModelConfig
|
||||
from invokeai.backend.model_manager.load import LoadedModel, LoadedModelWithoutConfig
|
||||
from invokeai.backend.model_manager.load.model_cache.model_cache import ModelCache
|
||||
from invokeai.backend.model_manager.taxonomy import AnyModel, SubModelType
|
||||
|
||||
@@ -11,7 +11,7 @@ from torch import load as torch_load
|
||||
from invokeai.app.services.config import InvokeAIAppConfig
|
||||
from invokeai.app.services.invoker import Invoker
|
||||
from invokeai.app.services.model_load.model_load_base import ModelLoadServiceBase
|
||||
from invokeai.backend.model_manager.config import AnyModelConfig
|
||||
from invokeai.backend.model_manager.configs.factory import AnyModelConfig
|
||||
from invokeai.backend.model_manager.load import (
|
||||
LoadedModel,
|
||||
LoadedModelWithoutConfig,
|
||||
@@ -87,9 +87,21 @@ class ModelLoadService(ModelLoadServiceBase):
|
||||
def torch_load_file(checkpoint: Path) -> AnyModel:
|
||||
scan_result = scan_file_path(checkpoint)
|
||||
if scan_result.infected_files != 0:
|
||||
raise Exception(f"The model at {checkpoint} is potentially infected by malware. Aborting load.")
|
||||
if self._app_config.unsafe_disable_picklescan:
|
||||
self._logger.warning(
|
||||
f"Model at {checkpoint} is potentially infected by malware, but picklescan is disabled. "
|
||||
"Proceeding with caution."
|
||||
)
|
||||
else:
|
||||
raise Exception(f"The model at {checkpoint} is potentially infected by malware. Aborting load.")
|
||||
if scan_result.scan_err:
|
||||
raise Exception(f"Error scanning model at {checkpoint} for malware. Aborting load.")
|
||||
if self._app_config.unsafe_disable_picklescan:
|
||||
self._logger.warning(
|
||||
f"Error scanning model at {checkpoint} for malware, but picklescan is disabled. "
|
||||
"Proceeding with caution."
|
||||
)
|
||||
else:
|
||||
raise Exception(f"Error scanning model at {checkpoint} for malware. Aborting load.")
|
||||
|
||||
result = torch_load(checkpoint, map_location="cpu")
|
||||
return result
|
||||
|
||||
@@ -1,12 +1,10 @@
|
||||
"""Initialization file for model manager service."""
|
||||
|
||||
from invokeai.app.services.model_manager.model_manager_default import ModelManagerService, ModelManagerServiceBase
|
||||
from invokeai.backend.model_manager import AnyModelConfig
|
||||
from invokeai.backend.model_manager.load import LoadedModel
|
||||
|
||||
__all__ = [
|
||||
"ModelManagerServiceBase",
|
||||
"ModelManagerService",
|
||||
"AnyModelConfig",
|
||||
"LoadedModel",
|
||||
]
|
||||
|
||||
@@ -12,14 +12,14 @@ from pydantic import BaseModel, Field
|
||||
|
||||
from invokeai.app.services.shared.pagination import PaginatedResults
|
||||
from invokeai.app.util.model_exclude_null import BaseModelExcludeNull
|
||||
from invokeai.backend.model_manager.config import (
|
||||
AnyModelConfig,
|
||||
ControlAdapterDefaultSettings,
|
||||
MainModelDefaultSettings,
|
||||
)
|
||||
from invokeai.backend.model_manager.configs.controlnet import ControlAdapterDefaultSettings
|
||||
from invokeai.backend.model_manager.configs.factory import AnyModelConfig
|
||||
from invokeai.backend.model_manager.configs.lora import LoraModelDefaultSettings
|
||||
from invokeai.backend.model_manager.configs.main import MainModelDefaultSettings
|
||||
from invokeai.backend.model_manager.taxonomy import (
|
||||
BaseModelType,
|
||||
ClipVariantType,
|
||||
FluxVariantType,
|
||||
ModelFormat,
|
||||
ModelSourceType,
|
||||
ModelType,
|
||||
@@ -83,13 +83,15 @@ class ModelRecordChanges(BaseModelExcludeNull):
|
||||
file_size: Optional[int] = Field(description="Size of model file", default=None)
|
||||
format: Optional[str] = Field(description="format of model file", default=None)
|
||||
trigger_phrases: Optional[set[str]] = Field(description="Set of trigger phrases for this model", default=None)
|
||||
default_settings: Optional[MainModelDefaultSettings | ControlAdapterDefaultSettings] = Field(
|
||||
description="Default settings for this model", default=None
|
||||
default_settings: Optional[MainModelDefaultSettings | LoraModelDefaultSettings | ControlAdapterDefaultSettings] = (
|
||||
Field(description="Default settings for this model", default=None)
|
||||
)
|
||||
|
||||
# Checkpoint-specific changes
|
||||
# TODO(MM2): Should we expose these? Feels footgun-y...
|
||||
variant: Optional[ModelVariantType | ClipVariantType] = Field(description="The variant of the model.", default=None)
|
||||
variant: Optional[ModelVariantType | ClipVariantType | FluxVariantType] = Field(
|
||||
description="The variant of the model.", default=None
|
||||
)
|
||||
prediction_type: Optional[SchedulerPredictionType] = Field(
|
||||
description="The prediction type of the model.", default=None
|
||||
)
|
||||
@@ -125,12 +127,14 @@ class ModelRecordServiceBase(ABC):
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def update_model(self, key: str, changes: ModelRecordChanges) -> AnyModelConfig:
|
||||
def update_model(self, key: str, changes: ModelRecordChanges, allow_class_change: bool = False) -> AnyModelConfig:
|
||||
"""
|
||||
Update the model, returning the updated version.
|
||||
|
||||
:param key: Unique key for the model to be updated.
|
||||
:param changes: A set of changes to apply to this model. Changes are validated before being written.
|
||||
:param allow_class_change: If True, allows changes that would change the model config class. For example,
|
||||
changing a LoRA into a Main model. This does not disable validation, so the changes must still be valid.
|
||||
"""
|
||||
pass
|
||||
|
||||
|
||||
@@ -58,10 +58,7 @@ from invokeai.app.services.model_records.model_records_base import (
|
||||
)
|
||||
from invokeai.app.services.shared.pagination import PaginatedResults
|
||||
from invokeai.app.services.shared.sqlite.sqlite_database import SqliteDatabase
|
||||
from invokeai.backend.model_manager.config import (
|
||||
AnyModelConfig,
|
||||
ModelConfigFactory,
|
||||
)
|
||||
from invokeai.backend.model_manager.configs.factory import AnyModelConfig, ModelConfigFactory
|
||||
from invokeai.backend.model_manager.taxonomy import BaseModelType, ModelFormat, ModelType
|
||||
|
||||
|
||||
@@ -137,15 +134,36 @@ class ModelRecordServiceSQL(ModelRecordServiceBase):
|
||||
if cursor.rowcount == 0:
|
||||
raise UnknownModelException("model not found")
|
||||
|
||||
def update_model(self, key: str, changes: ModelRecordChanges) -> AnyModelConfig:
|
||||
def update_model(self, key: str, changes: ModelRecordChanges, allow_class_change: bool = False) -> AnyModelConfig:
|
||||
with self._db.transaction() as cursor:
|
||||
record = self.get_model(key)
|
||||
|
||||
# Model configs use pydantic's `validate_assignment`, so each change is validated by pydantic.
|
||||
for field_name in changes.model_fields_set:
|
||||
setattr(record, field_name, getattr(changes, field_name))
|
||||
if allow_class_change:
|
||||
# The changes may cause the model config class to change. To handle this, we need to construct the new
|
||||
# class from scratch rather than trying to modify the existing instance in place.
|
||||
#
|
||||
# 1. Convert the existing record to a dict
|
||||
# 2. Apply the changes to the dict
|
||||
# 3. Attempt to create a new model config from the updated dict
|
||||
|
||||
json_serialized = record.model_dump_json()
|
||||
# 1. Convert the existing record to a dict
|
||||
record_as_dict = record.model_dump()
|
||||
|
||||
# 2. Apply the changes to the dict
|
||||
for field_name in changes.model_fields_set:
|
||||
record_as_dict[field_name] = getattr(changes, field_name)
|
||||
|
||||
# 3. Attempt to create a new model config from the updated dict
|
||||
record = ModelConfigFactory.from_dict(record_as_dict)
|
||||
|
||||
# If we get this far, the updated model config is valid, so we can save it to the database.
|
||||
json_serialized = record.model_dump_json()
|
||||
else:
|
||||
# We are not allowing the model config class to change, so we can just update the existing instance in
|
||||
# place. If the changes are invalid for the existing class, an exception will be raised by pydantic.
|
||||
for field_name in changes.model_fields_set:
|
||||
setattr(record, field_name, getattr(changes, field_name))
|
||||
json_serialized = record.model_dump_json()
|
||||
|
||||
cursor.execute(
|
||||
"""--sql
|
||||
@@ -172,7 +190,7 @@ class ModelRecordServiceSQL(ModelRecordServiceBase):
|
||||
with self._db.transaction() as cursor:
|
||||
cursor.execute(
|
||||
"""--sql
|
||||
SELECT config, strftime('%s',updated_at) FROM models
|
||||
SELECT config FROM models
|
||||
WHERE id=?;
|
||||
""",
|
||||
(key,),
|
||||
@@ -180,14 +198,14 @@ class ModelRecordServiceSQL(ModelRecordServiceBase):
|
||||
rows = cursor.fetchone()
|
||||
if not rows:
|
||||
raise UnknownModelException("model not found")
|
||||
model = ModelConfigFactory.make_config(json.loads(rows[0]), timestamp=rows[1])
|
||||
model = ModelConfigFactory.from_dict(json.loads(rows[0]))
|
||||
return model
|
||||
|
||||
def get_model_by_hash(self, hash: str) -> AnyModelConfig:
|
||||
with self._db.transaction() as cursor:
|
||||
cursor.execute(
|
||||
"""--sql
|
||||
SELECT config, strftime('%s',updated_at) FROM models
|
||||
SELECT config FROM models
|
||||
WHERE hash=?;
|
||||
""",
|
||||
(hash,),
|
||||
@@ -195,7 +213,7 @@ class ModelRecordServiceSQL(ModelRecordServiceBase):
|
||||
rows = cursor.fetchone()
|
||||
if not rows:
|
||||
raise UnknownModelException("model not found")
|
||||
model = ModelConfigFactory.make_config(json.loads(rows[0]), timestamp=rows[1])
|
||||
model = ModelConfigFactory.from_dict(json.loads(rows[0]))
|
||||
return model
|
||||
|
||||
def exists(self, key: str) -> bool:
|
||||
@@ -263,7 +281,7 @@ class ModelRecordServiceSQL(ModelRecordServiceBase):
|
||||
|
||||
cursor.execute(
|
||||
f"""--sql
|
||||
SELECT config, strftime('%s',updated_at)
|
||||
SELECT config
|
||||
FROM models
|
||||
{where}
|
||||
ORDER BY {ordering[order_by]} -- using ? to bind doesn't work here for some reason;
|
||||
@@ -276,15 +294,20 @@ class ModelRecordServiceSQL(ModelRecordServiceBase):
|
||||
results: list[AnyModelConfig] = []
|
||||
for row in result:
|
||||
try:
|
||||
model_config = ModelConfigFactory.make_config(json.loads(row[0]), timestamp=row[1])
|
||||
except pydantic.ValidationError:
|
||||
model_config = ModelConfigFactory.from_dict(json.loads(row[0]))
|
||||
except pydantic.ValidationError as e:
|
||||
# We catch this error so that the app can still run if there are invalid model configs in the database.
|
||||
# One reason that an invalid model config might be in the database is if someone had to rollback from a
|
||||
# newer version of the app that added a new model type.
|
||||
row_data = f"{row[0][:64]}..." if len(row[0]) > 64 else row[0]
|
||||
try:
|
||||
name = json.loads(row[0]).get("name", "<unknown>")
|
||||
except Exception:
|
||||
name = "<unknown>"
|
||||
self._logger.warning(
|
||||
f"Found an invalid model config in the database. Ignoring this model. ({row_data})"
|
||||
f"Skipping invalid model config in the database with name {name}. Ignoring this model. ({row_data})"
|
||||
)
|
||||
self._logger.warning(f"Validation error: {e}")
|
||||
else:
|
||||
results.append(model_config)
|
||||
|
||||
@@ -295,12 +318,12 @@ class ModelRecordServiceSQL(ModelRecordServiceBase):
|
||||
with self._db.transaction() as cursor:
|
||||
cursor.execute(
|
||||
"""--sql
|
||||
SELECT config, strftime('%s',updated_at) FROM models
|
||||
SELECT config FROM models
|
||||
WHERE path=?;
|
||||
""",
|
||||
(str(path),),
|
||||
)
|
||||
results = [ModelConfigFactory.make_config(json.loads(x[0]), timestamp=x[1]) for x in cursor.fetchall()]
|
||||
results = [ModelConfigFactory.from_dict(json.loads(x[0])) for x in cursor.fetchall()]
|
||||
return results
|
||||
|
||||
def search_by_hash(self, hash: str) -> List[AnyModelConfig]:
|
||||
@@ -308,12 +331,12 @@ class ModelRecordServiceSQL(ModelRecordServiceBase):
|
||||
with self._db.transaction() as cursor:
|
||||
cursor.execute(
|
||||
"""--sql
|
||||
SELECT config, strftime('%s',updated_at) FROM models
|
||||
SELECT config FROM models
|
||||
WHERE hash=?;
|
||||
""",
|
||||
(hash,),
|
||||
)
|
||||
results = [ModelConfigFactory.make_config(json.loads(x[0]), timestamp=x[1]) for x in cursor.fetchall()]
|
||||
results = [ModelConfigFactory.from_dict(json.loads(x[0])) for x in cursor.fetchall()]
|
||||
return results
|
||||
|
||||
def list_models(
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
from invokeai.app.services.invoker import Invoker
|
||||
from invokeai.app.services.model_relationships.model_relationships_base import ModelRelationshipsServiceABC
|
||||
from invokeai.backend.model_manager.config import AnyModelConfig
|
||||
from invokeai.backend.model_manager.configs.factory import AnyModelConfig
|
||||
|
||||
|
||||
class ModelRelationshipsService(ModelRelationshipsServiceABC):
|
||||
|
||||
@@ -15,6 +15,7 @@ from invokeai.app.services.session_queue.session_queue_common import (
|
||||
EnqueueBatchResult,
|
||||
IsEmptyResult,
|
||||
IsFullResult,
|
||||
ItemIdsResult,
|
||||
PruneResult,
|
||||
RetryItemsResult,
|
||||
SessionQueueCountsByDestination,
|
||||
@@ -23,6 +24,7 @@ from invokeai.app.services.session_queue.session_queue_common import (
|
||||
)
|
||||
from invokeai.app.services.shared.graph import GraphExecutionState
|
||||
from invokeai.app.services.shared.pagination import CursorPaginatedResults
|
||||
from invokeai.app.services.shared.sqlite.sqlite_common import SQLiteDirection
|
||||
|
||||
|
||||
class SessionQueueBase(ABC):
|
||||
@@ -145,7 +147,7 @@ class SessionQueueBase(ABC):
|
||||
status: Optional[QUEUE_ITEM_STATUS] = None,
|
||||
destination: Optional[str] = None,
|
||||
) -> CursorPaginatedResults[SessionQueueItem]:
|
||||
"""Gets a page of session queue items"""
|
||||
"""Gets a page of session queue items. Do not remove."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
@@ -157,9 +159,18 @@ class SessionQueueBase(ABC):
|
||||
"""Gets all queue items that match the given parameters"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def get_queue_item_ids(
|
||||
self,
|
||||
queue_id: str,
|
||||
order_dir: SQLiteDirection = SQLiteDirection.Descending,
|
||||
) -> ItemIdsResult:
|
||||
"""Gets all queue item ids that match the given parameters"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def get_queue_item(self, item_id: int) -> SessionQueueItem:
|
||||
"""Gets a session queue item by ID"""
|
||||
"""Gets a session queue item by ID for a given queue"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
|
||||
@@ -1,7 +1,7 @@
|
||||
import datetime
|
||||
import json
|
||||
from itertools import chain, product
|
||||
from typing import Generator, Literal, Optional, TypeAlias, Union, cast
|
||||
from typing import Generator, Literal, Optional, TypeAlias, Union
|
||||
|
||||
from pydantic import (
|
||||
AliasChoices,
|
||||
@@ -15,7 +15,6 @@ from pydantic import (
|
||||
)
|
||||
from pydantic_core import to_jsonable_python
|
||||
|
||||
from invokeai.app.invocations.baseinvocation import BaseInvocation
|
||||
from invokeai.app.invocations.fields import ImageField
|
||||
from invokeai.app.services.shared.graph import Graph, GraphExecutionState, NodeNotFoundError
|
||||
from invokeai.app.services.workflow_records.workflow_records_common import (
|
||||
@@ -137,20 +136,18 @@ class Batch(BaseModel):
|
||||
return v
|
||||
|
||||
@model_validator(mode="after")
|
||||
def validate_batch_nodes_and_edges(cls, values):
|
||||
batch_data_collection = cast(Optional[BatchDataCollection], values.data)
|
||||
if batch_data_collection is None:
|
||||
return values
|
||||
graph = cast(Graph, values.graph)
|
||||
for batch_data_list in batch_data_collection:
|
||||
def validate_batch_nodes_and_edges(self):
|
||||
if self.data is None:
|
||||
return self
|
||||
for batch_data_list in self.data:
|
||||
for batch_data in batch_data_list:
|
||||
try:
|
||||
node = cast(BaseInvocation, graph.get_node(batch_data.node_path))
|
||||
node = self.graph.get_node(batch_data.node_path)
|
||||
except NodeNotFoundError:
|
||||
raise NodeNotFoundError(f"Node {batch_data.node_path} not found in graph")
|
||||
if batch_data.field_name not in type(node).model_fields:
|
||||
raise NodeNotFoundError(f"Field {batch_data.field_name} not found in node {batch_data.node_path}")
|
||||
return values
|
||||
return self
|
||||
|
||||
@field_validator("graph")
|
||||
def validate_graph(cls, v: Graph):
|
||||
@@ -176,6 +173,14 @@ DEFAULT_QUEUE_ID = "default"
|
||||
|
||||
QUEUE_ITEM_STATUS = Literal["pending", "in_progress", "completed", "failed", "canceled"]
|
||||
|
||||
|
||||
class ItemIdsResult(BaseModel):
|
||||
"""Response containing ordered item ids with metadata for optimistic updates."""
|
||||
|
||||
item_ids: list[int] = Field(description="Ordered list of item ids")
|
||||
total_count: int = Field(description="Total number of queue items matching the query")
|
||||
|
||||
|
||||
NodeFieldValueValidator = TypeAdapter(list[NodeFieldValue])
|
||||
|
||||
|
||||
|
||||
@@ -22,6 +22,7 @@ from invokeai.app.services.session_queue.session_queue_common import (
|
||||
EnqueueBatchResult,
|
||||
IsEmptyResult,
|
||||
IsFullResult,
|
||||
ItemIdsResult,
|
||||
PruneResult,
|
||||
RetryItemsResult,
|
||||
SessionQueueCountsByDestination,
|
||||
@@ -34,6 +35,7 @@ from invokeai.app.services.session_queue.session_queue_common import (
|
||||
)
|
||||
from invokeai.app.services.shared.graph import GraphExecutionState
|
||||
from invokeai.app.services.shared.pagination import CursorPaginatedResults
|
||||
from invokeai.app.services.shared.sqlite.sqlite_common import SQLiteDirection
|
||||
from invokeai.app.services.shared.sqlite.sqlite_database import SqliteDatabase
|
||||
|
||||
|
||||
@@ -671,6 +673,26 @@ class SqliteSessionQueue(SessionQueueBase):
|
||||
items = [SessionQueueItem.queue_item_from_dict(dict(result)) for result in results]
|
||||
return items
|
||||
|
||||
def get_queue_item_ids(
|
||||
self,
|
||||
queue_id: str,
|
||||
order_dir: SQLiteDirection = SQLiteDirection.Descending,
|
||||
) -> ItemIdsResult:
|
||||
with self._db.transaction() as cursor_:
|
||||
query = f"""--sql
|
||||
SELECT item_id
|
||||
FROM session_queue
|
||||
WHERE queue_id = ?
|
||||
ORDER BY created_at {order_dir.value}
|
||||
"""
|
||||
query_params = [queue_id]
|
||||
|
||||
cursor_.execute(query, query_params)
|
||||
result = cast(list[sqlite3.Row], cursor_.fetchall())
|
||||
item_ids = [row[0] for row in result]
|
||||
|
||||
return ItemIdsResult(item_ids=item_ids, total_count=len(item_ids))
|
||||
|
||||
def get_queue_status(self, queue_id: str) -> SessionQueueStatus:
|
||||
with self._db.transaction() as cursor:
|
||||
cursor.execute(
|
||||
|
||||
@@ -19,10 +19,8 @@ from invokeai.app.services.model_records.model_records_base import UnknownModelE
|
||||
from invokeai.app.services.session_processor.session_processor_common import ProgressImage
|
||||
from invokeai.app.services.shared.sqlite.sqlite_common import SQLiteDirection
|
||||
from invokeai.app.util.step_callback import diffusion_step_callback
|
||||
from invokeai.backend.model_manager.config import (
|
||||
AnyModelConfig,
|
||||
ModelConfigBase,
|
||||
)
|
||||
from invokeai.backend.model_manager.configs.base import Config_Base
|
||||
from invokeai.backend.model_manager.configs.factory import AnyModelConfig
|
||||
from invokeai.backend.model_manager.load.load_base import LoadedModel, LoadedModelWithoutConfig
|
||||
from invokeai.backend.model_manager.taxonomy import AnyModel, BaseModelType, ModelFormat, ModelType, SubModelType
|
||||
from invokeai.backend.stable_diffusion.diffusers_pipeline import PipelineIntermediateState
|
||||
@@ -558,7 +556,7 @@ class ModelsInterface(InvocationContextInterface):
|
||||
The absolute path to the model.
|
||||
"""
|
||||
|
||||
model_path = Path(config_or_path.path) if isinstance(config_or_path, ModelConfigBase) else Path(config_or_path)
|
||||
model_path = Path(config_or_path.path) if isinstance(config_or_path, Config_Base) else Path(config_or_path)
|
||||
|
||||
if model_path.is_absolute():
|
||||
return model_path.resolve()
|
||||
|
||||
@@ -23,6 +23,10 @@ from invokeai.app.services.shared.sqlite_migrator.migrations.migration_17 import
|
||||
from invokeai.app.services.shared.sqlite_migrator.migrations.migration_18 import build_migration_18
|
||||
from invokeai.app.services.shared.sqlite_migrator.migrations.migration_19 import build_migration_19
|
||||
from invokeai.app.services.shared.sqlite_migrator.migrations.migration_20 import build_migration_20
|
||||
from invokeai.app.services.shared.sqlite_migrator.migrations.migration_21 import build_migration_21
|
||||
from invokeai.app.services.shared.sqlite_migrator.migrations.migration_22 import build_migration_22
|
||||
from invokeai.app.services.shared.sqlite_migrator.migrations.migration_23 import build_migration_23
|
||||
from invokeai.app.services.shared.sqlite_migrator.migrations.migration_24 import build_migration_24
|
||||
from invokeai.app.services.shared.sqlite_migrator.sqlite_migrator_impl import SqliteMigrator
|
||||
|
||||
|
||||
@@ -63,6 +67,10 @@ def init_db(config: InvokeAIAppConfig, logger: Logger, image_files: ImageFileSto
|
||||
migrator.register_migration(build_migration_18())
|
||||
migrator.register_migration(build_migration_19(app_config=config))
|
||||
migrator.register_migration(build_migration_20())
|
||||
migrator.register_migration(build_migration_21())
|
||||
migrator.register_migration(build_migration_22(app_config=config, logger=logger))
|
||||
migrator.register_migration(build_migration_23(app_config=config, logger=logger))
|
||||
migrator.register_migration(build_migration_24(app_config=config, logger=logger))
|
||||
migrator.run_migrations()
|
||||
|
||||
return db
|
||||
|
||||
@@ -0,0 +1,40 @@
|
||||
import sqlite3
|
||||
|
||||
from invokeai.app.services.shared.sqlite_migrator.sqlite_migrator_common import Migration
|
||||
|
||||
|
||||
class Migration21Callback:
|
||||
def __call__(self, cursor: sqlite3.Cursor) -> None:
|
||||
cursor.execute(
|
||||
"""
|
||||
CREATE TABLE client_state (
|
||||
id INTEGER PRIMARY KEY CHECK(id = 1),
|
||||
data TEXT NOT NULL, -- Frontend will handle the shape of this data
|
||||
updated_at DATETIME NOT NULL DEFAULT (CURRENT_TIMESTAMP)
|
||||
);
|
||||
"""
|
||||
)
|
||||
cursor.execute(
|
||||
"""
|
||||
CREATE TRIGGER tg_client_state_updated_at
|
||||
AFTER UPDATE ON client_state
|
||||
FOR EACH ROW
|
||||
BEGIN
|
||||
UPDATE client_state
|
||||
SET updated_at = CURRENT_TIMESTAMP
|
||||
WHERE id = OLD.id;
|
||||
END;
|
||||
"""
|
||||
)
|
||||
|
||||
|
||||
def build_migration_21() -> Migration:
|
||||
"""Builds the migration object for migrating from version 20 to version 21. This includes:
|
||||
- Creating the `client_state` table.
|
||||
- Adding a trigger to update the `updated_at` field on updates.
|
||||
"""
|
||||
return Migration(
|
||||
from_version=20,
|
||||
to_version=21,
|
||||
callback=Migration21Callback(),
|
||||
)
|
||||
@@ -0,0 +1,89 @@
|
||||
import sqlite3
|
||||
from logging import Logger
|
||||
|
||||
from invokeai.app.services.config import InvokeAIAppConfig
|
||||
from invokeai.app.services.shared.sqlite_migrator.sqlite_migrator_common import Migration
|
||||
|
||||
|
||||
class Migration22Callback:
|
||||
def __init__(self, app_config: InvokeAIAppConfig, logger: Logger) -> None:
|
||||
self._app_config = app_config
|
||||
self._logger = logger
|
||||
self._models_dir = app_config.models_path.resolve()
|
||||
|
||||
def __call__(self, cursor: sqlite3.Cursor) -> None:
|
||||
self._logger.info("Removing UNIQUE(name, base, type) constraint from models table")
|
||||
|
||||
# Step 1: Rename the existing models table
|
||||
cursor.execute("ALTER TABLE models RENAME TO models_old;")
|
||||
|
||||
# Step 2: Create the new models table without the UNIQUE(name, base, type) constraint
|
||||
cursor.execute(
|
||||
"""--sql
|
||||
CREATE TABLE models (
|
||||
id TEXT NOT NULL PRIMARY KEY,
|
||||
hash TEXT GENERATED ALWAYS as (json_extract(config, '$.hash')) VIRTUAL NOT NULL,
|
||||
base TEXT GENERATED ALWAYS as (json_extract(config, '$.base')) VIRTUAL NOT NULL,
|
||||
type TEXT GENERATED ALWAYS as (json_extract(config, '$.type')) VIRTUAL NOT NULL,
|
||||
path TEXT GENERATED ALWAYS as (json_extract(config, '$.path')) VIRTUAL NOT NULL,
|
||||
format TEXT GENERATED ALWAYS as (json_extract(config, '$.format')) VIRTUAL NOT NULL,
|
||||
name TEXT GENERATED ALWAYS as (json_extract(config, '$.name')) VIRTUAL NOT NULL,
|
||||
description TEXT GENERATED ALWAYS as (json_extract(config, '$.description')) VIRTUAL,
|
||||
source TEXT GENERATED ALWAYS as (json_extract(config, '$.source')) VIRTUAL NOT NULL,
|
||||
source_type TEXT GENERATED ALWAYS as (json_extract(config, '$.source_type')) VIRTUAL NOT NULL,
|
||||
source_api_response TEXT GENERATED ALWAYS as (json_extract(config, '$.source_api_response')) VIRTUAL,
|
||||
trigger_phrases TEXT GENERATED ALWAYS as (json_extract(config, '$.trigger_phrases')) VIRTUAL,
|
||||
file_size INTEGER GENERATED ALWAYS as (json_extract(config, '$.file_size')) VIRTUAL NOT NULL,
|
||||
-- Serialized JSON representation of the whole config object, which will contain additional fields from subclasses
|
||||
config TEXT NOT NULL,
|
||||
created_at DATETIME NOT NULL DEFAULT(STRFTIME('%Y-%m-%d %H:%M:%f', 'NOW')),
|
||||
-- Updated via trigger
|
||||
updated_at DATETIME NOT NULL DEFAULT(STRFTIME('%Y-%m-%d %H:%M:%f', 'NOW')),
|
||||
-- Explicit unique constraint on path
|
||||
UNIQUE(path)
|
||||
);
|
||||
"""
|
||||
)
|
||||
|
||||
# Step 3: Copy all data from the old table to the new table
|
||||
# Only copy the stored columns (id, config, created_at, updated_at), not the virtual columns
|
||||
cursor.execute(
|
||||
"INSERT INTO models (id, config, created_at, updated_at) "
|
||||
"SELECT id, config, created_at, updated_at FROM models_old;"
|
||||
)
|
||||
|
||||
# Step 4: Drop the old table
|
||||
cursor.execute("DROP TABLE models_old;")
|
||||
|
||||
# Step 5: Recreate indexes
|
||||
cursor.execute("CREATE INDEX IF NOT EXISTS base_index ON models(base);")
|
||||
cursor.execute("CREATE INDEX IF NOT EXISTS type_index ON models(type);")
|
||||
cursor.execute("CREATE INDEX IF NOT EXISTS name_index ON models(name);")
|
||||
|
||||
# Step 6: Recreate the updated_at trigger
|
||||
cursor.execute(
|
||||
"""--sql
|
||||
CREATE TRIGGER models_updated_at
|
||||
AFTER UPDATE
|
||||
ON models FOR EACH ROW
|
||||
BEGIN
|
||||
UPDATE models SET updated_at = STRFTIME('%Y-%m-%d %H:%M:%f', 'NOW')
|
||||
WHERE id = old.id;
|
||||
END;
|
||||
"""
|
||||
)
|
||||
|
||||
|
||||
def build_migration_22(app_config: InvokeAIAppConfig, logger: Logger) -> Migration:
|
||||
"""Builds the migration object for migrating from version 21 to version 22.
|
||||
|
||||
This migration:
|
||||
- Removes the UNIQUE constraint on the combination of (base, name, type) columns in the models table
|
||||
- Adds an explicit UNIQUE contraint on the path column
|
||||
"""
|
||||
|
||||
return Migration(
|
||||
from_version=21,
|
||||
to_version=22,
|
||||
callback=Migration22Callback(app_config=app_config, logger=logger),
|
||||
)
|
||||
@@ -0,0 +1,193 @@
|
||||
import json
|
||||
import sqlite3
|
||||
from copy import deepcopy
|
||||
from logging import Logger
|
||||
from typing import Any
|
||||
|
||||
from pydantic import ValidationError
|
||||
|
||||
from invokeai.app.services.config import InvokeAIAppConfig
|
||||
from invokeai.app.services.shared.sqlite_migrator.sqlite_migrator_common import Migration
|
||||
from invokeai.backend.model_manager.configs.factory import AnyModelConfig, AnyModelConfigValidator
|
||||
from invokeai.backend.model_manager.configs.unknown import Unknown_Config
|
||||
from invokeai.backend.model_manager.taxonomy import (
|
||||
BaseModelType,
|
||||
ClipVariantType,
|
||||
FluxVariantType,
|
||||
ModelFormat,
|
||||
ModelType,
|
||||
ModelVariantType,
|
||||
SchedulerPredictionType,
|
||||
)
|
||||
|
||||
|
||||
class Migration23Callback:
|
||||
def __init__(self, app_config: InvokeAIAppConfig, logger: Logger) -> None:
|
||||
self._app_config = app_config
|
||||
self._logger = logger
|
||||
self._models_dir = app_config.models_path.resolve()
|
||||
|
||||
def __call__(self, cursor: sqlite3.Cursor) -> None:
|
||||
# Grab all model records
|
||||
cursor.execute("SELECT id, config FROM models;")
|
||||
rows = cursor.fetchall()
|
||||
|
||||
migrated_count = 0
|
||||
fallback_count = 0
|
||||
|
||||
for model_id, config_json in rows:
|
||||
try:
|
||||
# Migrate the config JSON to the latest schema
|
||||
config_dict: dict[str, Any] = json.loads(config_json)
|
||||
migrated_config = self._parse_and_migrate_config(config_dict)
|
||||
|
||||
if isinstance(migrated_config, Unknown_Config):
|
||||
fallback_count += 1
|
||||
else:
|
||||
migrated_count += 1
|
||||
|
||||
# Write the migrated config back to the database
|
||||
cursor.execute(
|
||||
"UPDATE models SET config = ? WHERE id = ?;",
|
||||
(migrated_config.model_dump_json(), model_id),
|
||||
)
|
||||
except ValidationError as e:
|
||||
self._logger.error("Invalid config schema for model %s: %s", model_id, e)
|
||||
raise
|
||||
except json.JSONDecodeError as e:
|
||||
self._logger.error("Invalid config JSON for model %s: %s", model_id, e)
|
||||
raise
|
||||
|
||||
if migrated_count > 0 and fallback_count == 0:
|
||||
self._logger.info(f"Migration complete: {migrated_count} model configs migrated")
|
||||
elif migrated_count > 0 and fallback_count > 0:
|
||||
self._logger.warning(
|
||||
f"Migration complete: {migrated_count} model configs migrated, "
|
||||
f"{fallback_count} model configs could not be migrated and were saved as unknown models",
|
||||
)
|
||||
elif migrated_count == 0 and fallback_count > 0:
|
||||
self._logger.warning(
|
||||
f"Migration complete: all {fallback_count} model configs could not be migrated and were saved as unknown models",
|
||||
)
|
||||
else:
|
||||
self._logger.info("Migration complete: no model configs needed migration")
|
||||
|
||||
def _parse_and_migrate_config(self, config_dict: dict[str, Any]) -> AnyModelConfig:
|
||||
# In v6.9.0 we made some improvements to the model taxonomy and the model config schemas. There are a changes
|
||||
# we need to make to old configs to bring them up to date.
|
||||
|
||||
type = config_dict.get("type")
|
||||
format = config_dict.get("format")
|
||||
base = config_dict.get("base")
|
||||
|
||||
if base == BaseModelType.Flux.value and type == ModelType.Main.value:
|
||||
# Prior to v6.9.0, we used an awkward combination of `config_path` and `variant` to distinguish between FLUX
|
||||
# variants.
|
||||
#
|
||||
# `config_path` was set to one of:
|
||||
# - flux-dev
|
||||
# - flux-dev-fill
|
||||
# - flux-schnell
|
||||
#
|
||||
# `variant` was set to ModelVariantType.Inpaint for FLUX Fill models and ModelVariantType.Normal for all other FLUX
|
||||
# models.
|
||||
#
|
||||
# We now use the `variant` field to directly represent the FLUX variant type, and `config_path` is no longer used.
|
||||
|
||||
# Extract and remove `config_path` if present.
|
||||
config_path = config_dict.pop("config_path", None)
|
||||
|
||||
match config_path:
|
||||
case "flux-dev":
|
||||
config_dict["variant"] = FluxVariantType.Dev.value
|
||||
case "flux-dev-fill":
|
||||
config_dict["variant"] = FluxVariantType.DevFill.value
|
||||
case "flux-schnell":
|
||||
config_dict["variant"] = FluxVariantType.Schnell.value
|
||||
case _:
|
||||
# Unknown config_path - default to Dev variant
|
||||
config_dict["variant"] = FluxVariantType.Dev.value
|
||||
|
||||
if (
|
||||
base
|
||||
in {
|
||||
BaseModelType.StableDiffusion1.value,
|
||||
BaseModelType.StableDiffusion2.value,
|
||||
BaseModelType.StableDiffusionXL.value,
|
||||
BaseModelType.StableDiffusionXLRefiner.value,
|
||||
}
|
||||
and type == ModelType.Main.value
|
||||
):
|
||||
# Prior to v6.9.0, the prediction_type field was optional and would default to Epsilon if not present.
|
||||
# We now make it explicit and always present. Use the existing value if present, otherwise default to
|
||||
# Epsilon, matching the probe logic.
|
||||
#
|
||||
# It's only on SD1.x, SD2.x, and SDXL main models.
|
||||
config_dict["prediction_type"] = config_dict.get("prediction_type", SchedulerPredictionType.Epsilon.value)
|
||||
|
||||
# Prior to v6.9.0, the variant field was optional and would default to Normal if not present.
|
||||
# We now make it explicit and always present. Use the existing value if present, otherwise default to
|
||||
# Normal. It's only on SD main models.
|
||||
config_dict["variant"] = config_dict.get("variant", ModelVariantType.Normal.value)
|
||||
|
||||
if base == BaseModelType.Flux.value and type == ModelType.LoRA.value and format == ModelFormat.Diffusers.value:
|
||||
# Prior to v6.9.0, we used the Diffusers format for FLUX LoRA models that used the diffusers _key_
|
||||
# structure. This was misleading, as everywhere else in the application, we used the Diffusers format
|
||||
# to indicate that the model files were in the Diffusers _file_ format (i.e. a directory containing
|
||||
# the weights and config files).
|
||||
#
|
||||
# At runtime, we check the LoRA's state dict directly to determine the key structure, so we do not need
|
||||
# to rely on the format field for this purpose. As of v6.9.0, we always use the LyCORIS format for single-
|
||||
# file LoRAs, regardless of the key structure.
|
||||
#
|
||||
# This change allows LoRA model identification to not need a special case for FLUX LoRAs in the diffusers
|
||||
# key format.
|
||||
config_dict["format"] = ModelFormat.LyCORIS.value
|
||||
|
||||
if type == ModelType.CLIPVision.value:
|
||||
# Prior to v6.9.0, some CLIP Vision models were associated with a specific base model architecture:
|
||||
# - CLIP-ViT-bigG-14-laion2B-39B-b160k is the image encoder for SDXL IP Adapter and was associated with SDXL
|
||||
# - CLIP-ViT-H-14-laion2B-s32B-b79K is the image encoder for SD1.5 IP Adapter and was associated with SD1.5
|
||||
#
|
||||
# While this made some sense at the time, it is more correct and flexible to treat CLIP Vision models
|
||||
# as independent of any specific base model architecture.
|
||||
config_dict["base"] = BaseModelType.Any.value
|
||||
|
||||
if type == ModelType.CLIPEmbed.value:
|
||||
# Prior to v6.9.0, some CLIP Embed models did not have a variant set. The default was the L variant.
|
||||
# We now make it explicit and always present. Use the existing value if present, otherwise default to
|
||||
# L variant. Also, treat CLIP Embed models as independent of any specific base model architecture.
|
||||
config_dict["base"] = BaseModelType.Any.value
|
||||
config_dict["variant"] = config_dict.get("variant", ClipVariantType.L.value)
|
||||
|
||||
try:
|
||||
migrated_config = AnyModelConfigValidator.validate_python(config_dict)
|
||||
# This could be a ValidationError or any other error that occurs during validation. A failure to generate a
|
||||
# union discriminator could raise a ValueError, for example. Who knows what else could fail - catch all.
|
||||
except Exception as e:
|
||||
self._logger.error("Failed to validate migrated config, attempting to save as unknown model: %s", e)
|
||||
cloned_config_dict = deepcopy(config_dict)
|
||||
cloned_config_dict.pop("base", None)
|
||||
cloned_config_dict.pop("type", None)
|
||||
cloned_config_dict.pop("format", None)
|
||||
|
||||
migrated_config = Unknown_Config(
|
||||
**cloned_config_dict,
|
||||
base=BaseModelType.Unknown,
|
||||
type=ModelType.Unknown,
|
||||
format=ModelFormat.Unknown,
|
||||
)
|
||||
return migrated_config
|
||||
|
||||
|
||||
def build_migration_23(app_config: InvokeAIAppConfig, logger: Logger) -> Migration:
|
||||
"""Builds the migration object for migrating from version 22 to version 23.
|
||||
|
||||
This migration updates model configurations to the latest config schemas for v6.9.0.
|
||||
"""
|
||||
|
||||
return Migration(
|
||||
from_version=22,
|
||||
to_version=23,
|
||||
callback=Migration23Callback(app_config=app_config, logger=logger),
|
||||
)
|
||||
@@ -0,0 +1,240 @@
|
||||
import json
|
||||
import sqlite3
|
||||
from logging import Logger
|
||||
from pathlib import Path
|
||||
from typing import NamedTuple
|
||||
|
||||
from pydantic import ValidationError
|
||||
|
||||
from invokeai.app.services.config import InvokeAIAppConfig
|
||||
from invokeai.app.services.shared.sqlite_migrator.sqlite_migrator_common import Migration
|
||||
from invokeai.backend.model_manager.configs.factory import AnyModelConfigValidator
|
||||
|
||||
|
||||
class NormalizeResult(NamedTuple):
|
||||
new_relative_path: str | None
|
||||
rollback_ops: list[tuple[Path, Path]]
|
||||
|
||||
|
||||
class Migration24Callback:
|
||||
def __init__(self, app_config: InvokeAIAppConfig, logger: Logger) -> None:
|
||||
self._app_config = app_config
|
||||
self._logger = logger
|
||||
self._models_dir = app_config.models_path.resolve()
|
||||
|
||||
def __call__(self, cursor: sqlite3.Cursor) -> None:
|
||||
# Grab all model records
|
||||
cursor.execute("SELECT id, config FROM models;")
|
||||
rows = cursor.fetchall()
|
||||
|
||||
for model_id, config_json in rows:
|
||||
try:
|
||||
config = AnyModelConfigValidator.validate_json(config_json)
|
||||
except ValidationError:
|
||||
# This could happen if the config schema changed in a way that makes old configs invalid. Unlikely
|
||||
# for users, more likely for devs testing out migration paths.
|
||||
self._logger.warning("Skipping model %s: invalid config schema", model_id)
|
||||
continue
|
||||
except json.JSONDecodeError:
|
||||
# This should never happen, as we use pydantic to serialize the config to JSON.
|
||||
self._logger.warning("Skipping model %s: invalid config JSON", model_id)
|
||||
continue
|
||||
|
||||
# We'll use a savepoint so we can roll back the database update if something goes wrong, and a simple
|
||||
# rollback of file operations if needed.
|
||||
cursor.execute("SAVEPOINT migrate_model")
|
||||
try:
|
||||
new_relative_path, rollback_ops = self._normalize_model_storage(
|
||||
key=config.key,
|
||||
path_value=config.path,
|
||||
)
|
||||
except Exception as err:
|
||||
self._logger.error("Error normalizing model %s: %s", config.key, err)
|
||||
cursor.execute("ROLLBACK TO SAVEPOINT migrate_model")
|
||||
cursor.execute("RELEASE SAVEPOINT migrate_model")
|
||||
continue
|
||||
|
||||
if new_relative_path is None:
|
||||
cursor.execute("RELEASE SAVEPOINT migrate_model")
|
||||
continue
|
||||
|
||||
config.path = new_relative_path
|
||||
try:
|
||||
cursor.execute(
|
||||
"UPDATE models SET config = ? WHERE id = ?;",
|
||||
(config.model_dump_json(), model_id),
|
||||
)
|
||||
except Exception as err:
|
||||
self._logger.error("Database update failed for model %s: %s", config.key, err)
|
||||
cursor.execute("ROLLBACK TO SAVEPOINT migrate_model")
|
||||
cursor.execute("RELEASE SAVEPOINT migrate_model")
|
||||
self._rollback_file_ops(rollback_ops)
|
||||
continue
|
||||
|
||||
cursor.execute("RELEASE SAVEPOINT migrate_model")
|
||||
|
||||
self._prune_empty_directories()
|
||||
|
||||
def _normalize_model_storage(self, key: str, path_value: str) -> NormalizeResult:
|
||||
models_dir = self._models_dir
|
||||
stored_path = Path(path_value)
|
||||
|
||||
relative_path: Path | None
|
||||
if stored_path.is_absolute():
|
||||
# If the stored path is absolute, we need to check if it's inside the models directory, which means it is
|
||||
# an Invoke-managed model. If it's outside, it is user-managed we leave it alone.
|
||||
try:
|
||||
relative_path = stored_path.resolve().relative_to(models_dir)
|
||||
except ValueError:
|
||||
self._logger.info("Leaving user-managed model %s at %s", key, stored_path)
|
||||
return NormalizeResult(new_relative_path=None, rollback_ops=[])
|
||||
else:
|
||||
# Relative paths are always relative to the models directory and thus Invoke-managed.
|
||||
relative_path = stored_path
|
||||
|
||||
# If the relative path is empty, assume something is wrong. Warn and skip.
|
||||
if not relative_path.parts:
|
||||
self._logger.warning("Skipping model %s: empty relative path", key)
|
||||
return NormalizeResult(new_relative_path=None, rollback_ops=[])
|
||||
|
||||
# Sanity check: the path is relative. It should be present in the models directory.
|
||||
absolute_path = (models_dir / relative_path).resolve()
|
||||
if not absolute_path.exists():
|
||||
self._logger.warning(
|
||||
"Skipping model %s: expected model files at %s but nothing was found",
|
||||
key,
|
||||
absolute_path,
|
||||
)
|
||||
return NormalizeResult(new_relative_path=None, rollback_ops=[])
|
||||
|
||||
if relative_path.parts[0] == key:
|
||||
# Already normalized. Still ensure the stored path is relative.
|
||||
normalized_path = relative_path.as_posix()
|
||||
# If the stored path is already the normalized path, no change is needed.
|
||||
new_relative_path = normalized_path if stored_path.as_posix() != normalized_path else None
|
||||
return NormalizeResult(new_relative_path=new_relative_path, rollback_ops=[])
|
||||
|
||||
# We'll store the file operations we perform so we can roll them back if needed.
|
||||
rollback_ops: list[tuple[Path, Path]] = []
|
||||
|
||||
# Destination directory is models_dir/<key> - a flat directory structure.
|
||||
destination_dir = models_dir / key
|
||||
|
||||
try:
|
||||
if absolute_path.is_file():
|
||||
destination_dir.mkdir(parents=True, exist_ok=True)
|
||||
dest_file = destination_dir / absolute_path.name
|
||||
# This really shouldn't happen.
|
||||
if dest_file.exists():
|
||||
self._logger.warning(
|
||||
"Destination for model %s already exists at %s; skipping move",
|
||||
key,
|
||||
dest_file,
|
||||
)
|
||||
return NormalizeResult(new_relative_path=None, rollback_ops=[])
|
||||
|
||||
self._logger.info("Moving model file %s -> %s", absolute_path, dest_file)
|
||||
|
||||
# `Path.rename()` effectively moves the file or directory.
|
||||
absolute_path.rename(dest_file)
|
||||
rollback_ops.append((dest_file, absolute_path))
|
||||
|
||||
return NormalizeResult(
|
||||
new_relative_path=(Path(key) / dest_file.name).as_posix(),
|
||||
rollback_ops=rollback_ops,
|
||||
)
|
||||
|
||||
if absolute_path.is_dir():
|
||||
dest_path = destination_dir
|
||||
# This really shouldn't happen.
|
||||
if dest_path.exists():
|
||||
self._logger.warning(
|
||||
"Destination directory %s already exists for model %s; skipping",
|
||||
dest_path,
|
||||
key,
|
||||
)
|
||||
return NormalizeResult(new_relative_path=None, rollback_ops=[])
|
||||
|
||||
self._logger.info("Moving model directory %s -> %s", absolute_path, dest_path)
|
||||
|
||||
# `Path.rename()` effectively moves the file or directory.
|
||||
absolute_path.rename(dest_path)
|
||||
rollback_ops.append((dest_path, absolute_path))
|
||||
|
||||
return NormalizeResult(
|
||||
new_relative_path=Path(key).as_posix(),
|
||||
rollback_ops=rollback_ops,
|
||||
)
|
||||
|
||||
# Maybe a broken symlink or something else weird?
|
||||
self._logger.warning("Skipping model %s: path %s is neither a file nor directory", key, absolute_path)
|
||||
return NormalizeResult(new_relative_path=None, rollback_ops=[])
|
||||
except Exception:
|
||||
self._rollback_file_ops(rollback_ops)
|
||||
raise
|
||||
|
||||
def _rollback_file_ops(self, rollback_ops: list[tuple[Path, Path]]) -> None:
|
||||
# This is a super-simple rollback that just reverses the move operations we performed.
|
||||
for source, destination in reversed(rollback_ops):
|
||||
try:
|
||||
if source.exists():
|
||||
source.rename(destination)
|
||||
except Exception as err:
|
||||
self._logger.error("Failed to rollback move %s -> %s: %s", source, destination, err)
|
||||
|
||||
def _prune_empty_directories(self) -> None:
|
||||
# These directories are system directories we want to keep even if empty. Technically, the app should not
|
||||
# have any problems if these are removed, creating them as needed, but it's cleaner to just leave them alone.
|
||||
keep_names = {"model_images", ".download_cache"}
|
||||
keep_dirs = {self._models_dir / name for name in keep_names}
|
||||
removed_dirs: set[Path] = set()
|
||||
|
||||
# Walk the models directory tree from the bottom up, removing empty directories. We sort by path length
|
||||
# descending to ensure we visit children before parents.
|
||||
for directory in sorted(self._models_dir.rglob("*"), key=lambda p: len(p.parts), reverse=True):
|
||||
if not directory.is_dir():
|
||||
continue
|
||||
if directory == self._models_dir:
|
||||
continue
|
||||
if any(directory == keep or keep in directory.parents for keep in keep_dirs):
|
||||
continue
|
||||
|
||||
try:
|
||||
next(directory.iterdir())
|
||||
except StopIteration:
|
||||
try:
|
||||
directory.rmdir()
|
||||
removed_dirs.add(directory)
|
||||
self._logger.debug("Removed empty directory %s", directory)
|
||||
except OSError:
|
||||
# Directory not empty (or some other error) - bail out.
|
||||
self._logger.warning("Failed to prune directory %s - not empty?", directory)
|
||||
continue
|
||||
except OSError:
|
||||
continue
|
||||
|
||||
self._logger.info("Pruned %d empty directories under %s", len(removed_dirs), self._models_dir)
|
||||
|
||||
|
||||
def build_migration_24(app_config: InvokeAIAppConfig, logger: Logger) -> Migration:
|
||||
"""Builds the migration object for migrating from version 23 to version 24.
|
||||
|
||||
This migration normalizes on-disk model storage so that each model lives within
|
||||
a directory named by its key inside the Invoke-managed models directory, and
|
||||
updates database records to reference the new relative paths.
|
||||
|
||||
This migration behaves a bit differently than others. Because it involves FS operations, if we rolled the
|
||||
DB back on any failure, we could leave the FS out of sync with the DB. Instead, we use savepoints
|
||||
to roll back individual model updates on failure, and we roll back any FS operations we performed
|
||||
for that model.
|
||||
|
||||
If a model cannot be migrated for any reason (invalid config, missing files, FS errors, DB errors), we log a
|
||||
warning and skip it, leaving it in its original state and location. The model will still work, but it will be in
|
||||
the "wrong" location on disk.
|
||||
"""
|
||||
|
||||
return Migration(
|
||||
from_version=23,
|
||||
to_version=24,
|
||||
callback=Migration24Callback(app_config=app_config, logger=logger),
|
||||
)
|
||||
179
invokeai/app/services/videos_common.py
Normal file
179
invokeai/app/services/videos_common.py
Normal file
@@ -0,0 +1,179 @@
|
||||
import datetime
|
||||
from typing import Optional, Union
|
||||
|
||||
from pydantic import BaseModel, Field, StrictBool, StrictStr
|
||||
|
||||
from invokeai.app.util.misc import get_iso_timestamp
|
||||
from invokeai.app.util.model_exclude_null import BaseModelExcludeNull
|
||||
|
||||
VIDEO_DTO_COLS = ", ".join(
|
||||
[
|
||||
"videos." + c
|
||||
for c in [
|
||||
"video_id",
|
||||
"width",
|
||||
"height",
|
||||
"session_id",
|
||||
"node_id",
|
||||
"is_intermediate",
|
||||
"created_at",
|
||||
"updated_at",
|
||||
"deleted_at",
|
||||
"starred",
|
||||
]
|
||||
]
|
||||
)
|
||||
|
||||
|
||||
class VideoRecord(BaseModelExcludeNull):
|
||||
"""Deserialized video record without metadata."""
|
||||
|
||||
video_id: str = Field(description="The unique id of the video.")
|
||||
"""The unique id of the video."""
|
||||
width: int = Field(description="The width of the video in px.")
|
||||
"""The actual width of the video in px. This may be different from the width in metadata."""
|
||||
height: int = Field(description="The height of the video in px.")
|
||||
"""The actual height of the video in px. This may be different from the height in metadata."""
|
||||
created_at: Union[datetime.datetime, str] = Field(description="The created timestamp of the video.")
|
||||
"""The created timestamp of the video."""
|
||||
updated_at: Union[datetime.datetime, str] = Field(description="The updated timestamp of the video.")
|
||||
"""The updated timestamp of the video."""
|
||||
deleted_at: Optional[Union[datetime.datetime, str]] = Field(
|
||||
default=None, description="The deleted timestamp of the video."
|
||||
)
|
||||
"""The deleted timestamp of the video."""
|
||||
is_intermediate: bool = Field(description="Whether this is an intermediate video.")
|
||||
"""Whether this is an intermediate video."""
|
||||
session_id: Optional[str] = Field(
|
||||
default=None,
|
||||
description="The session ID that generated this video, if it is a generated video.",
|
||||
)
|
||||
"""The session ID that generated this video, if it is a generated video."""
|
||||
node_id: Optional[str] = Field(
|
||||
default=None,
|
||||
description="The node ID that generated this video, if it is a generated video.",
|
||||
)
|
||||
"""The node ID that generated this video, if it is a generated video."""
|
||||
starred: bool = Field(description="Whether this video is starred.")
|
||||
"""Whether this video is starred."""
|
||||
|
||||
|
||||
class VideoRecordChanges(BaseModelExcludeNull):
|
||||
"""A set of changes to apply to a video record.
|
||||
|
||||
Only limited changes are valid:
|
||||
- `session_id`: change the session associated with a video
|
||||
- `is_intermediate`: change the video's `is_intermediate` flag
|
||||
- `starred`: change whether the video is starred
|
||||
"""
|
||||
|
||||
session_id: Optional[StrictStr] = Field(
|
||||
default=None,
|
||||
description="The video's new session ID.",
|
||||
)
|
||||
"""The video's new session ID."""
|
||||
is_intermediate: Optional[StrictBool] = Field(default=None, description="The video's new `is_intermediate` flag.")
|
||||
"""The video's new `is_intermediate` flag."""
|
||||
starred: Optional[StrictBool] = Field(default=None, description="The video's new `starred` state")
|
||||
"""The video's new `starred` state."""
|
||||
|
||||
|
||||
def deserialize_video_record(video_dict: dict) -> VideoRecord:
|
||||
"""Deserializes a video record."""
|
||||
|
||||
# Retrieve all the values, setting "reasonable" defaults if they are not present.
|
||||
video_id = video_dict.get("video_id", "unknown")
|
||||
width = video_dict.get("width", 0)
|
||||
height = video_dict.get("height", 0)
|
||||
session_id = video_dict.get("session_id", None)
|
||||
node_id = video_dict.get("node_id", None)
|
||||
created_at = video_dict.get("created_at", get_iso_timestamp())
|
||||
updated_at = video_dict.get("updated_at", get_iso_timestamp())
|
||||
deleted_at = video_dict.get("deleted_at", get_iso_timestamp())
|
||||
is_intermediate = video_dict.get("is_intermediate", False)
|
||||
starred = video_dict.get("starred", False)
|
||||
|
||||
return VideoRecord(
|
||||
video_id=video_id,
|
||||
width=width,
|
||||
height=height,
|
||||
session_id=session_id,
|
||||
node_id=node_id,
|
||||
created_at=created_at,
|
||||
updated_at=updated_at,
|
||||
deleted_at=deleted_at,
|
||||
is_intermediate=is_intermediate,
|
||||
starred=starred,
|
||||
)
|
||||
|
||||
|
||||
class VideoCollectionCounts(BaseModel):
|
||||
starred_count: int = Field(description="The number of starred videos in the collection.")
|
||||
unstarred_count: int = Field(description="The number of unstarred videos in the collection.")
|
||||
|
||||
|
||||
class VideoIdsResult(BaseModel):
|
||||
"""Response containing ordered video ids with metadata for optimistic updates."""
|
||||
|
||||
video_ids: list[str] = Field(description="Ordered list of video ids")
|
||||
starred_count: int = Field(description="Number of starred videos (when starred_first=True)")
|
||||
total_count: int = Field(description="Total number of videos matching the query")
|
||||
|
||||
|
||||
class VideoUrlsDTO(BaseModelExcludeNull):
|
||||
"""The URLs for an image and its thumbnail."""
|
||||
|
||||
video_id: str = Field(description="The unique id of the video.")
|
||||
"""The unique id of the video."""
|
||||
video_url: str = Field(description="The URL of the video.")
|
||||
"""The URL of the video."""
|
||||
thumbnail_url: str = Field(description="The URL of the video's thumbnail.")
|
||||
"""The URL of the video's thumbnail."""
|
||||
|
||||
|
||||
class VideoDTO(VideoRecord, VideoUrlsDTO):
|
||||
"""Deserialized video record, enriched for the frontend."""
|
||||
|
||||
board_id: Optional[str] = Field(
|
||||
default=None, description="The id of the board the image belongs to, if one exists."
|
||||
)
|
||||
"""The id of the board the image belongs to, if one exists."""
|
||||
|
||||
|
||||
def video_record_to_dto(
|
||||
video_record: VideoRecord,
|
||||
video_url: str,
|
||||
thumbnail_url: str,
|
||||
board_id: Optional[str],
|
||||
) -> VideoDTO:
|
||||
"""Converts a video record to a video DTO."""
|
||||
return VideoDTO(
|
||||
**video_record.model_dump(),
|
||||
video_url=video_url,
|
||||
thumbnail_url=thumbnail_url,
|
||||
board_id=board_id,
|
||||
)
|
||||
|
||||
|
||||
class ResultWithAffectedBoards(BaseModel):
|
||||
affected_boards: list[str] = Field(description="The ids of boards affected by the delete operation")
|
||||
|
||||
|
||||
class DeleteVideosResult(ResultWithAffectedBoards):
|
||||
deleted_videos: list[str] = Field(description="The ids of the videos that were deleted")
|
||||
|
||||
|
||||
class StarredVideosResult(ResultWithAffectedBoards):
|
||||
starred_videos: list[str] = Field(description="The ids of the videos that were starred")
|
||||
|
||||
|
||||
class UnstarredVideosResult(ResultWithAffectedBoards):
|
||||
unstarred_videos: list[str] = Field(description="The ids of the videos that were unstarred")
|
||||
|
||||
|
||||
class AddVideosToBoardResult(ResultWithAffectedBoards):
|
||||
added_videos: list[str] = Field(description="The video ids that were added to the board")
|
||||
|
||||
|
||||
class RemoveVideosFromBoardResult(ResultWithAffectedBoards):
|
||||
removed_videos: list[str] = Field(description="The video ids that were removed from their board")
|
||||
@@ -12,6 +12,7 @@ from invokeai.app.invocations.fields import InputFieldJSONSchemaExtra, OutputFie
|
||||
from invokeai.app.invocations.model import ModelIdentifierField
|
||||
from invokeai.app.services.events.events_common import EventBase
|
||||
from invokeai.app.services.session_processor.session_processor_common import ProgressImage
|
||||
from invokeai.backend.model_manager.configs.factory import AnyModelConfigValidator
|
||||
from invokeai.backend.util.logging import InvokeAILogger
|
||||
|
||||
logger = InvokeAILogger.get_logger()
|
||||
@@ -115,6 +116,13 @@ def get_openapi_func(
|
||||
# additional_schemas[1] is a dict of $defs that we need to add to the top level of the schema
|
||||
move_defs_to_top_level(openapi_schema, additional_schemas[1])
|
||||
|
||||
any_model_config_schema = AnyModelConfigValidator.json_schema(
|
||||
mode="serialization",
|
||||
ref_template="#/components/schemas/{model}",
|
||||
)
|
||||
move_defs_to_top_level(openapi_schema, any_model_config_schema)
|
||||
openapi_schema["components"]["schemas"]["AnyModelConfig"] = any_model_config_schema
|
||||
|
||||
if post_transform is not None:
|
||||
openapi_schema = post_transform(openapi_schema)
|
||||
|
||||
|
||||
@@ -5,7 +5,7 @@ import torch
|
||||
from invokeai.backend.flux.model import FluxParams
|
||||
|
||||
|
||||
def is_state_dict_xlabs_controlnet(sd: Dict[str, Any]) -> bool:
|
||||
def is_state_dict_xlabs_controlnet(sd: dict[str | int, Any]) -> bool:
|
||||
"""Is the state dict for an XLabs ControlNet model?
|
||||
|
||||
This is intended to be a reasonably high-precision detector, but it is not guaranteed to have perfect precision.
|
||||
@@ -25,7 +25,7 @@ def is_state_dict_xlabs_controlnet(sd: Dict[str, Any]) -> bool:
|
||||
return False
|
||||
|
||||
|
||||
def is_state_dict_instantx_controlnet(sd: Dict[str, Any]) -> bool:
|
||||
def is_state_dict_instantx_controlnet(sd: dict[str | int, Any]) -> bool:
|
||||
"""Is the state dict for an InstantX ControlNet model?
|
||||
|
||||
This is intended to be a reasonably high-precision detector, but it is not guaranteed to have perfect precision.
|
||||
|
||||
@@ -112,7 +112,7 @@ def denoise(
|
||||
)
|
||||
|
||||
# Slice prediction to only include the main image tokens
|
||||
if img_input_ids is not None:
|
||||
if img_cond_seq is not None:
|
||||
pred = pred[:, :original_seq_len]
|
||||
|
||||
step_cfg_scale = cfg_scale[step_index]
|
||||
@@ -125,9 +125,26 @@ def denoise(
|
||||
if neg_regional_prompting_extension is None:
|
||||
raise ValueError("Negative text conditioning is required when cfg_scale is not 1.0.")
|
||||
|
||||
# For negative prediction with Kontext, we need to include the reference images
|
||||
# to maintain consistency between positive and negative passes. Without this,
|
||||
# CFG would create artifacts as the attention mechanism would see different
|
||||
# spatial structures in each pass
|
||||
neg_img_input = img
|
||||
neg_img_input_ids = img_ids
|
||||
|
||||
# Add channel-wise conditioning for negative pass if present
|
||||
if img_cond is not None:
|
||||
neg_img_input = torch.cat((neg_img_input, img_cond), dim=-1)
|
||||
|
||||
# Add sequence-wise conditioning (Kontext) for negative pass
|
||||
# This ensures reference images are processed consistently
|
||||
if img_cond_seq is not None:
|
||||
neg_img_input = torch.cat((neg_img_input, img_cond_seq), dim=1)
|
||||
neg_img_input_ids = torch.cat((neg_img_input_ids, img_cond_seq_ids), dim=1)
|
||||
|
||||
neg_pred = model(
|
||||
img=img,
|
||||
img_ids=img_ids,
|
||||
img=neg_img_input,
|
||||
img_ids=neg_img_input_ids,
|
||||
txt=neg_regional_prompting_extension.regional_text_conditioning.t5_embeddings,
|
||||
txt_ids=neg_regional_prompting_extension.regional_text_conditioning.t5_txt_ids,
|
||||
y=neg_regional_prompting_extension.regional_text_conditioning.clip_embeddings,
|
||||
@@ -140,6 +157,10 @@ def denoise(
|
||||
ip_adapter_extensions=neg_ip_adapter_extensions,
|
||||
regional_prompting_extension=neg_regional_prompting_extension,
|
||||
)
|
||||
|
||||
# Slice negative prediction to match main image tokens
|
||||
if img_cond_seq is not None:
|
||||
neg_pred = neg_pred[:, :original_seq_len]
|
||||
pred = neg_pred + step_cfg_scale * (pred - neg_pred)
|
||||
|
||||
preview_img = img - t_curr * pred
|
||||
|
||||
@@ -1,15 +1,14 @@
|
||||
import einops
|
||||
import numpy as np
|
||||
import torch
|
||||
import torch.nn.functional as F
|
||||
import torchvision.transforms as T
|
||||
from einops import repeat
|
||||
from PIL import Image
|
||||
|
||||
from invokeai.app.invocations.fields import FluxKontextConditioningField
|
||||
from invokeai.app.invocations.flux_vae_encode import FluxVaeEncodeInvocation
|
||||
from invokeai.app.invocations.model import VAEField
|
||||
from invokeai.app.services.shared.invocation_context import InvocationContext
|
||||
from invokeai.backend.flux.modules.autoencoder import AutoEncoder
|
||||
from invokeai.backend.flux.sampling_utils import pack
|
||||
from invokeai.backend.flux.util import PREFERED_KONTEXT_RESOLUTIONS
|
||||
from invokeai.backend.util.devices import TorchDevice
|
||||
|
||||
|
||||
def generate_img_ids_with_offset(
|
||||
@@ -19,8 +18,10 @@ def generate_img_ids_with_offset(
|
||||
device: torch.device,
|
||||
dtype: torch.dtype,
|
||||
idx_offset: int = 0,
|
||||
h_offset: int = 0,
|
||||
w_offset: int = 0,
|
||||
) -> torch.Tensor:
|
||||
"""Generate tensor of image position ids with an optional offset.
|
||||
"""Generate tensor of image position ids with optional index and spatial offsets.
|
||||
|
||||
Args:
|
||||
latent_height (int): Height of image in latent space (after packing, this becomes h//2).
|
||||
@@ -28,7 +29,9 @@ def generate_img_ids_with_offset(
|
||||
batch_size (int): Number of images in the batch.
|
||||
device (torch.device): Device to create tensors on.
|
||||
dtype (torch.dtype): Data type for the tensors.
|
||||
idx_offset (int): Offset to add to the first dimension of the image ids.
|
||||
idx_offset (int): Offset to add to the first dimension of the image ids (default: 0).
|
||||
h_offset (int): Spatial offset for height/y-coordinates in latent space (default: 0).
|
||||
w_offset (int): Spatial offset for width/x-coordinates in latent space (default: 0).
|
||||
|
||||
Returns:
|
||||
torch.Tensor: Image position ids with shape [batch_size, (latent_height//2 * latent_width//2), 3].
|
||||
@@ -42,6 +45,10 @@ def generate_img_ids_with_offset(
|
||||
packed_height = latent_height // 2
|
||||
packed_width = latent_width // 2
|
||||
|
||||
# Convert spatial offsets from latent space to packed space
|
||||
packed_h_offset = h_offset // 2
|
||||
packed_w_offset = w_offset // 2
|
||||
|
||||
# Create base tensor for position IDs with shape [packed_height, packed_width, 3]
|
||||
# The 3 channels represent: [batch_offset, y_position, x_position]
|
||||
img_ids = torch.zeros(packed_height, packed_width, 3, device=device, dtype=dtype)
|
||||
@@ -49,13 +56,13 @@ def generate_img_ids_with_offset(
|
||||
# Set the batch offset for all positions
|
||||
img_ids[..., 0] = idx_offset
|
||||
|
||||
# Create y-coordinate indices (vertical positions)
|
||||
y_indices = torch.arange(packed_height, device=device, dtype=dtype)
|
||||
# Create y-coordinate indices (vertical positions) with spatial offset
|
||||
y_indices = torch.arange(packed_height, device=device, dtype=dtype) + packed_h_offset
|
||||
# Broadcast y_indices to match the spatial dimensions [packed_height, 1]
|
||||
img_ids[..., 1] = y_indices[:, None]
|
||||
|
||||
# Create x-coordinate indices (horizontal positions)
|
||||
x_indices = torch.arange(packed_width, device=device, dtype=dtype)
|
||||
# Create x-coordinate indices (horizontal positions) with spatial offset
|
||||
x_indices = torch.arange(packed_width, device=device, dtype=dtype) + packed_w_offset
|
||||
# Broadcast x_indices to match the spatial dimensions [1, packed_width]
|
||||
img_ids[..., 2] = x_indices[None, :]
|
||||
|
||||
@@ -73,14 +80,14 @@ class KontextExtension:
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
kontext_conditioning: FluxKontextConditioningField,
|
||||
kontext_conditioning: list[FluxKontextConditioningField],
|
||||
context: InvocationContext,
|
||||
vae_field: VAEField,
|
||||
device: torch.device,
|
||||
dtype: torch.dtype,
|
||||
):
|
||||
"""
|
||||
Initializes the KontextExtension, pre-processing the reference image
|
||||
Initializes the KontextExtension, pre-processing the reference images
|
||||
into latents and positional IDs.
|
||||
"""
|
||||
self._context = context
|
||||
@@ -93,54 +100,116 @@ class KontextExtension:
|
||||
self.kontext_latents, self.kontext_ids = self._prepare_kontext()
|
||||
|
||||
def _prepare_kontext(self) -> tuple[torch.Tensor, torch.Tensor]:
|
||||
"""Encodes the reference image and prepares its latents and IDs."""
|
||||
image = self._context.images.get_pil(self.kontext_conditioning.image.image_name)
|
||||
"""Encodes the reference images and prepares their concatenated latents and IDs with spatial tiling."""
|
||||
all_latents = []
|
||||
all_ids = []
|
||||
|
||||
# Calculate aspect ratio of input image
|
||||
width, height = image.size
|
||||
aspect_ratio = width / height
|
||||
# Track cumulative dimensions for spatial tiling
|
||||
# These track the running extent of the virtual canvas in latent space
|
||||
canvas_h = 0 # Running canvas height
|
||||
canvas_w = 0 # Running canvas width
|
||||
|
||||
# Find the closest preferred resolution by aspect ratio
|
||||
_, target_width, target_height = min(
|
||||
((abs(aspect_ratio - w / h), w, h) for w, h in PREFERED_KONTEXT_RESOLUTIONS), key=lambda x: x[0]
|
||||
)
|
||||
|
||||
# Apply BFL's scaling formula
|
||||
# This ensures compatibility with the model's training
|
||||
scaled_width = 2 * int(target_width / 16)
|
||||
scaled_height = 2 * int(target_height / 16)
|
||||
|
||||
# Resize to the exact resolution used during training
|
||||
image = image.convert("RGB")
|
||||
final_width = 8 * scaled_width
|
||||
final_height = 8 * scaled_height
|
||||
image = image.resize((final_width, final_height), Image.Resampling.LANCZOS)
|
||||
|
||||
# Convert to tensor with same normalization as BFL
|
||||
image_np = np.array(image)
|
||||
image_tensor = torch.from_numpy(image_np).float() / 127.5 - 1.0
|
||||
image_tensor = einops.rearrange(image_tensor, "h w c -> 1 c h w")
|
||||
image_tensor = image_tensor.to(self._device)
|
||||
|
||||
# Continue with VAE encoding
|
||||
vae_info = self._context.models.load(self._vae_field.vae)
|
||||
kontext_latents_unpacked = FluxVaeEncodeInvocation.vae_encode(vae_info=vae_info, image_tensor=image_tensor)
|
||||
|
||||
# Extract tensor dimensions
|
||||
batch_size, _, latent_height, latent_width = kontext_latents_unpacked.shape
|
||||
for idx, kontext_field in enumerate(self.kontext_conditioning):
|
||||
image = self._context.images.get_pil(kontext_field.image.image_name)
|
||||
|
||||
# Pack the latents and generate IDs
|
||||
kontext_latents_packed = pack(kontext_latents_unpacked).to(self._device, self._dtype)
|
||||
kontext_ids = generate_img_ids_with_offset(
|
||||
latent_height=latent_height,
|
||||
latent_width=latent_width,
|
||||
batch_size=batch_size,
|
||||
device=self._device,
|
||||
dtype=self._dtype,
|
||||
idx_offset=1,
|
||||
)
|
||||
# Convert to RGB
|
||||
image = image.convert("RGB")
|
||||
|
||||
return kontext_latents_packed, kontext_ids
|
||||
# Convert to tensor using torchvision transforms for consistency
|
||||
transformation = T.Compose(
|
||||
[
|
||||
T.ToTensor(), # Converts PIL image to tensor and scales to [0, 1]
|
||||
]
|
||||
)
|
||||
image_tensor = transformation(image)
|
||||
# Convert from [0, 1] to [-1, 1] range expected by VAE
|
||||
image_tensor = image_tensor * 2.0 - 1.0
|
||||
image_tensor = image_tensor.unsqueeze(0) # Add batch dimension
|
||||
image_tensor = image_tensor.to(self._device)
|
||||
|
||||
# Continue with VAE encoding
|
||||
# Don't sample from the distribution for reference images - use the mean (matching ComfyUI)
|
||||
# Estimate working memory for encode operation (50% of decode memory requirements)
|
||||
img_h = image_tensor.shape[-2]
|
||||
img_w = image_tensor.shape[-1]
|
||||
element_size = next(vae_info.model.parameters()).element_size()
|
||||
scaling_constant = 1100 # 50% of decode scaling constant (2200)
|
||||
estimated_working_memory = int(img_h * img_w * element_size * scaling_constant)
|
||||
|
||||
with vae_info.model_on_device(working_mem_bytes=estimated_working_memory) as (_, vae):
|
||||
assert isinstance(vae, AutoEncoder)
|
||||
vae_dtype = next(iter(vae.parameters())).dtype
|
||||
image_tensor = image_tensor.to(device=TorchDevice.choose_torch_device(), dtype=vae_dtype)
|
||||
# Use sample=False to get the distribution mean without noise
|
||||
kontext_latents_unpacked = vae.encode(image_tensor, sample=False)
|
||||
TorchDevice.empty_cache()
|
||||
|
||||
# Extract tensor dimensions
|
||||
batch_size, _, latent_height, latent_width = kontext_latents_unpacked.shape
|
||||
|
||||
# Pad latents to be compatible with patch_size=2
|
||||
# This ensures dimensions are even for the pack() function
|
||||
pad_h = (2 - latent_height % 2) % 2
|
||||
pad_w = (2 - latent_width % 2) % 2
|
||||
if pad_h > 0 or pad_w > 0:
|
||||
kontext_latents_unpacked = F.pad(kontext_latents_unpacked, (0, pad_w, 0, pad_h), mode="circular")
|
||||
# Update dimensions after padding
|
||||
_, _, latent_height, latent_width = kontext_latents_unpacked.shape
|
||||
|
||||
# Pack the latents
|
||||
kontext_latents_packed = pack(kontext_latents_unpacked).to(self._device, self._dtype)
|
||||
|
||||
# Determine spatial offsets for this reference image
|
||||
h_offset = 0
|
||||
w_offset = 0
|
||||
|
||||
if idx > 0: # First image starts at (0, 0)
|
||||
# Calculate potential canvas dimensions for each tiling option
|
||||
# Option 1: Tile vertically (below existing content)
|
||||
potential_h_vertical = canvas_h + latent_height
|
||||
|
||||
# Option 2: Tile horizontally (to the right of existing content)
|
||||
potential_w_horizontal = canvas_w + latent_width
|
||||
|
||||
# Choose arrangement that minimizes the maximum dimension
|
||||
# This keeps the canvas closer to square, optimizing attention computation
|
||||
if potential_h_vertical > potential_w_horizontal:
|
||||
# Tile horizontally (to the right of existing images)
|
||||
w_offset = canvas_w
|
||||
canvas_w = canvas_w + latent_width
|
||||
canvas_h = max(canvas_h, latent_height)
|
||||
else:
|
||||
# Tile vertically (below existing images)
|
||||
h_offset = canvas_h
|
||||
canvas_h = canvas_h + latent_height
|
||||
canvas_w = max(canvas_w, latent_width)
|
||||
else:
|
||||
# First image - just set canvas dimensions
|
||||
canvas_h = latent_height
|
||||
canvas_w = latent_width
|
||||
|
||||
# Generate IDs with both index offset and spatial offsets
|
||||
kontext_ids = generate_img_ids_with_offset(
|
||||
latent_height=latent_height,
|
||||
latent_width=latent_width,
|
||||
batch_size=batch_size,
|
||||
device=self._device,
|
||||
dtype=self._dtype,
|
||||
idx_offset=1, # All reference images use index=1 (matching ComfyUI implementation)
|
||||
h_offset=h_offset,
|
||||
w_offset=w_offset,
|
||||
)
|
||||
|
||||
all_latents.append(kontext_latents_packed)
|
||||
all_ids.append(kontext_ids)
|
||||
|
||||
# Concatenate all latents and IDs along the sequence dimension
|
||||
concatenated_latents = torch.cat(all_latents, dim=1) # Concatenate along sequence dimension
|
||||
concatenated_ids = torch.cat(all_ids, dim=1) # Concatenate along sequence dimension
|
||||
|
||||
return concatenated_latents, concatenated_ids
|
||||
|
||||
def ensure_batch_size(self, target_batch_size: int) -> None:
|
||||
"""Ensures the kontext latents and IDs match the target batch size by repeating if necessary."""
|
||||
|
||||
@@ -1,10 +1,7 @@
|
||||
from typing import TYPE_CHECKING
|
||||
|
||||
if TYPE_CHECKING:
|
||||
from invokeai.backend.model_manager.legacy_probe import CkptType
|
||||
from typing import Any
|
||||
|
||||
|
||||
def get_flux_in_channels_from_state_dict(state_dict: "CkptType") -> int | None:
|
||||
def get_flux_in_channels_from_state_dict(state_dict: dict[str | int, Any]) -> int | None:
|
||||
"""Gets the in channels from the state dict."""
|
||||
|
||||
# "Standard" FLUX models use "img_in.weight", but some community fine tunes use
|
||||
|
||||
@@ -1,11 +1,11 @@
|
||||
from typing import Any, Dict
|
||||
from typing import Any
|
||||
|
||||
import torch
|
||||
|
||||
from invokeai.backend.flux.ip_adapter.xlabs_ip_adapter_flux import XlabsIpAdapterParams
|
||||
|
||||
|
||||
def is_state_dict_xlabs_ip_adapter(sd: Dict[str, Any]) -> bool:
|
||||
def is_state_dict_xlabs_ip_adapter(sd: dict[str | int, Any]) -> bool:
|
||||
"""Is the state dict for an XLabs FLUX IP-Adapter model?
|
||||
|
||||
This is intended to be a reasonably high-precision detector, but it is not guaranteed to have perfect precision.
|
||||
@@ -27,7 +27,7 @@ def is_state_dict_xlabs_ip_adapter(sd: Dict[str, Any]) -> bool:
|
||||
return False
|
||||
|
||||
|
||||
def infer_xlabs_ip_adapter_params_from_state_dict(state_dict: dict[str, torch.Tensor]) -> XlabsIpAdapterParams:
|
||||
def infer_xlabs_ip_adapter_params_from_state_dict(state_dict: dict[str | int, torch.Tensor]) -> XlabsIpAdapterParams:
|
||||
num_double_blocks = 0
|
||||
context_dim = 0
|
||||
hidden_dim = 0
|
||||
|
||||
@@ -1,7 +1,7 @@
|
||||
from typing import Any, Dict
|
||||
from typing import Any
|
||||
|
||||
|
||||
def is_state_dict_likely_flux_redux(state_dict: Dict[str, Any]) -> bool:
|
||||
def is_state_dict_likely_flux_redux(state_dict: dict[str | int, Any]) -> bool:
|
||||
"""Checks if the provided state dict is likely a FLUX Redux model."""
|
||||
|
||||
expected_keys = {"redux_down.bias", "redux_down.weight", "redux_up.bias", "redux_up.weight"}
|
||||
|
||||
@@ -1,10 +1,11 @@
|
||||
# Initially pulled from https://github.com/black-forest-labs/flux
|
||||
|
||||
from dataclasses import dataclass
|
||||
from typing import Dict, Literal
|
||||
from typing import Literal
|
||||
|
||||
from invokeai.backend.flux.model import FluxParams
|
||||
from invokeai.backend.flux.modules.autoencoder import AutoEncoderParams
|
||||
from invokeai.backend.model_manager.taxonomy import AnyVariant, FluxVariantType
|
||||
|
||||
|
||||
@dataclass
|
||||
@@ -41,30 +42,39 @@ PREFERED_KONTEXT_RESOLUTIONS = [
|
||||
]
|
||||
|
||||
|
||||
max_seq_lengths: Dict[str, Literal[256, 512]] = {
|
||||
"flux-dev": 512,
|
||||
"flux-dev-fill": 512,
|
||||
"flux-schnell": 256,
|
||||
_flux_max_seq_lengths: dict[AnyVariant, Literal[256, 512]] = {
|
||||
FluxVariantType.Dev: 512,
|
||||
FluxVariantType.DevFill: 512,
|
||||
FluxVariantType.Schnell: 256,
|
||||
}
|
||||
|
||||
|
||||
ae_params = {
|
||||
"flux": AutoEncoderParams(
|
||||
resolution=256,
|
||||
in_channels=3,
|
||||
ch=128,
|
||||
out_ch=3,
|
||||
ch_mult=[1, 2, 4, 4],
|
||||
num_res_blocks=2,
|
||||
z_channels=16,
|
||||
scale_factor=0.3611,
|
||||
shift_factor=0.1159,
|
||||
)
|
||||
}
|
||||
def get_flux_max_seq_length(variant: AnyVariant):
|
||||
try:
|
||||
return _flux_max_seq_lengths[variant]
|
||||
except KeyError:
|
||||
raise ValueError(f"Unknown variant for FLUX max seq len: {variant}")
|
||||
|
||||
|
||||
params = {
|
||||
"flux-dev": FluxParams(
|
||||
_flux_ae_params = AutoEncoderParams(
|
||||
resolution=256,
|
||||
in_channels=3,
|
||||
ch=128,
|
||||
out_ch=3,
|
||||
ch_mult=[1, 2, 4, 4],
|
||||
num_res_blocks=2,
|
||||
z_channels=16,
|
||||
scale_factor=0.3611,
|
||||
shift_factor=0.1159,
|
||||
)
|
||||
|
||||
|
||||
def get_flux_ae_params() -> AutoEncoderParams:
|
||||
return _flux_ae_params
|
||||
|
||||
|
||||
_flux_transformer_params: dict[AnyVariant, FluxParams] = {
|
||||
FluxVariantType.Dev: FluxParams(
|
||||
in_channels=64,
|
||||
vec_in_dim=768,
|
||||
context_in_dim=4096,
|
||||
@@ -78,7 +88,7 @@ params = {
|
||||
qkv_bias=True,
|
||||
guidance_embed=True,
|
||||
),
|
||||
"flux-schnell": FluxParams(
|
||||
FluxVariantType.Schnell: FluxParams(
|
||||
in_channels=64,
|
||||
vec_in_dim=768,
|
||||
context_in_dim=4096,
|
||||
@@ -92,7 +102,7 @@ params = {
|
||||
qkv_bias=True,
|
||||
guidance_embed=False,
|
||||
),
|
||||
"flux-dev-fill": FluxParams(
|
||||
FluxVariantType.DevFill: FluxParams(
|
||||
in_channels=384,
|
||||
out_channels=64,
|
||||
vec_in_dim=768,
|
||||
@@ -108,3 +118,10 @@ params = {
|
||||
guidance_embed=True,
|
||||
),
|
||||
}
|
||||
|
||||
|
||||
def get_flux_transformers_params(variant: AnyVariant):
|
||||
try:
|
||||
return _flux_transformer_params[variant]
|
||||
except KeyError:
|
||||
raise ValueError(f"Unknown variant for FLUX transformer params: {variant}")
|
||||
|
||||
304
invokeai/backend/image_util/imwatermark/vendor.py
Normal file
304
invokeai/backend/image_util/imwatermark/vendor.py
Normal file
@@ -0,0 +1,304 @@
|
||||
# This file is vendored from https://github.com/ShieldMnt/invisible-watermark
|
||||
#
|
||||
# `invisible-watermark` is MIT licensed as of August 23, 2025, when the code was copied into this repo.
|
||||
#
|
||||
# Why we vendored it in:
|
||||
# `invisible-watermark` has a dependency on `opencv-python`, which conflicts with Invoke's dependency on
|
||||
# `opencv-contrib-python`. It's easier to copy the code over than complicate the installation process by
|
||||
# requiring an extra post-install step of removing `opencv-python` and installing `opencv-contrib-python`.
|
||||
|
||||
import struct
|
||||
import uuid
|
||||
import base64
|
||||
import cv2
|
||||
import numpy as np
|
||||
import pywt
|
||||
|
||||
|
||||
class WatermarkEncoder(object):
|
||||
def __init__(self, content=b""):
|
||||
seq = np.array([n for n in content], dtype=np.uint8)
|
||||
self._watermarks = list(np.unpackbits(seq))
|
||||
self._wmLen = len(self._watermarks)
|
||||
self._wmType = "bytes"
|
||||
|
||||
def set_by_ipv4(self, addr):
|
||||
bits = []
|
||||
ips = addr.split(".")
|
||||
for ip in ips:
|
||||
bits += list(np.unpackbits(np.array([ip % 255], dtype=np.uint8)))
|
||||
self._watermarks = bits
|
||||
self._wmLen = len(self._watermarks)
|
||||
self._wmType = "ipv4"
|
||||
assert self._wmLen == 32
|
||||
|
||||
def set_by_uuid(self, uid):
|
||||
u = uuid.UUID(uid)
|
||||
self._wmType = "uuid"
|
||||
seq = np.array([n for n in u.bytes], dtype=np.uint8)
|
||||
self._watermarks = list(np.unpackbits(seq))
|
||||
self._wmLen = len(self._watermarks)
|
||||
|
||||
def set_by_bytes(self, content):
|
||||
self._wmType = "bytes"
|
||||
seq = np.array([n for n in content], dtype=np.uint8)
|
||||
self._watermarks = list(np.unpackbits(seq))
|
||||
self._wmLen = len(self._watermarks)
|
||||
|
||||
def set_by_b16(self, b16):
|
||||
content = base64.b16decode(b16)
|
||||
self.set_by_bytes(content)
|
||||
self._wmType = "b16"
|
||||
|
||||
def set_by_bits(self, bits=[]):
|
||||
self._watermarks = [int(bit) % 2 for bit in bits]
|
||||
self._wmLen = len(self._watermarks)
|
||||
self._wmType = "bits"
|
||||
|
||||
def set_watermark(self, wmType="bytes", content=""):
|
||||
if wmType == "ipv4":
|
||||
self.set_by_ipv4(content)
|
||||
elif wmType == "uuid":
|
||||
self.set_by_uuid(content)
|
||||
elif wmType == "bits":
|
||||
self.set_by_bits(content)
|
||||
elif wmType == "bytes":
|
||||
self.set_by_bytes(content)
|
||||
elif wmType == "b16":
|
||||
self.set_by_b16(content)
|
||||
else:
|
||||
raise NameError("%s is not supported" % wmType)
|
||||
|
||||
def get_length(self):
|
||||
return self._wmLen
|
||||
|
||||
# @classmethod
|
||||
# def loadModel(cls):
|
||||
# RivaWatermark.loadModel()
|
||||
|
||||
def encode(self, cv2Image, method="dwtDct", **configs):
|
||||
(r, c, channels) = cv2Image.shape
|
||||
if r * c < 256 * 256:
|
||||
raise RuntimeError("image too small, should be larger than 256x256")
|
||||
|
||||
if method == "dwtDct":
|
||||
embed = EmbedMaxDct(self._watermarks, wmLen=self._wmLen, **configs)
|
||||
return embed.encode(cv2Image)
|
||||
# elif method == 'dwtDctSvd':
|
||||
# embed = EmbedDwtDctSvd(self._watermarks, wmLen=self._wmLen, **configs)
|
||||
# return embed.encode(cv2Image)
|
||||
# elif method == 'rivaGan':
|
||||
# embed = RivaWatermark(self._watermarks, self._wmLen)
|
||||
# return embed.encode(cv2Image)
|
||||
else:
|
||||
raise NameError("%s is not supported" % method)
|
||||
|
||||
|
||||
class WatermarkDecoder(object):
|
||||
def __init__(self, wm_type="bytes", length=0):
|
||||
self._wmType = wm_type
|
||||
if wm_type == "ipv4":
|
||||
self._wmLen = 32
|
||||
elif wm_type == "uuid":
|
||||
self._wmLen = 128
|
||||
elif wm_type == "bytes":
|
||||
self._wmLen = length
|
||||
elif wm_type == "bits":
|
||||
self._wmLen = length
|
||||
elif wm_type == "b16":
|
||||
self._wmLen = length
|
||||
else:
|
||||
raise NameError("%s is unsupported" % wm_type)
|
||||
|
||||
def reconstruct_ipv4(self, bits):
|
||||
ips = [str(ip) for ip in list(np.packbits(bits))]
|
||||
return ".".join(ips)
|
||||
|
||||
def reconstruct_uuid(self, bits):
|
||||
nums = np.packbits(bits)
|
||||
bstr = b""
|
||||
for i in range(16):
|
||||
bstr += struct.pack(">B", nums[i])
|
||||
|
||||
return str(uuid.UUID(bytes=bstr))
|
||||
|
||||
def reconstruct_bits(self, bits):
|
||||
# return ''.join([str(b) for b in bits])
|
||||
return bits
|
||||
|
||||
def reconstruct_b16(self, bits):
|
||||
bstr = self.reconstruct_bytes(bits)
|
||||
return base64.b16encode(bstr)
|
||||
|
||||
def reconstruct_bytes(self, bits):
|
||||
nums = np.packbits(bits)
|
||||
bstr = b""
|
||||
for i in range(self._wmLen // 8):
|
||||
bstr += struct.pack(">B", nums[i])
|
||||
return bstr
|
||||
|
||||
def reconstruct(self, bits):
|
||||
if len(bits) != self._wmLen:
|
||||
raise RuntimeError("bits are not matched with watermark length")
|
||||
|
||||
if self._wmType == "ipv4":
|
||||
return self.reconstruct_ipv4(bits)
|
||||
elif self._wmType == "uuid":
|
||||
return self.reconstruct_uuid(bits)
|
||||
elif self._wmType == "bits":
|
||||
return self.reconstruct_bits(bits)
|
||||
elif self._wmType == "b16":
|
||||
return self.reconstruct_b16(bits)
|
||||
else:
|
||||
return self.reconstruct_bytes(bits)
|
||||
|
||||
def decode(self, cv2Image, method="dwtDct", **configs):
|
||||
(r, c, channels) = cv2Image.shape
|
||||
if r * c < 256 * 256:
|
||||
raise RuntimeError("image too small, should be larger than 256x256")
|
||||
|
||||
bits = []
|
||||
if method == "dwtDct":
|
||||
embed = EmbedMaxDct(watermarks=[], wmLen=self._wmLen, **configs)
|
||||
bits = embed.decode(cv2Image)
|
||||
# elif method == 'dwtDctSvd':
|
||||
# embed = EmbedDwtDctSvd(watermarks=[], wmLen=self._wmLen, **configs)
|
||||
# bits = embed.decode(cv2Image)
|
||||
# elif method == 'rivaGan':
|
||||
# embed = RivaWatermark(watermarks=[], wmLen=self._wmLen, **configs)
|
||||
# bits = embed.decode(cv2Image)
|
||||
else:
|
||||
raise NameError("%s is not supported" % method)
|
||||
return self.reconstruct(bits)
|
||||
|
||||
# @classmethod
|
||||
# def loadModel(cls):
|
||||
# RivaWatermark.loadModel()
|
||||
|
||||
|
||||
class EmbedMaxDct(object):
|
||||
def __init__(self, watermarks=[], wmLen=8, scales=[0, 36, 36], block=4):
|
||||
self._watermarks = watermarks
|
||||
self._wmLen = wmLen
|
||||
self._scales = scales
|
||||
self._block = block
|
||||
|
||||
def encode(self, bgr):
|
||||
(row, col, channels) = bgr.shape
|
||||
|
||||
yuv = cv2.cvtColor(bgr, cv2.COLOR_BGR2YUV)
|
||||
|
||||
for channel in range(2):
|
||||
if self._scales[channel] <= 0:
|
||||
continue
|
||||
|
||||
ca1, (h1, v1, d1) = pywt.dwt2(yuv[: row // 4 * 4, : col // 4 * 4, channel], "haar")
|
||||
self.encode_frame(ca1, self._scales[channel])
|
||||
|
||||
yuv[: row // 4 * 4, : col // 4 * 4, channel] = pywt.idwt2((ca1, (v1, h1, d1)), "haar")
|
||||
|
||||
bgr_encoded = cv2.cvtColor(yuv, cv2.COLOR_YUV2BGR)
|
||||
return bgr_encoded
|
||||
|
||||
def decode(self, bgr):
|
||||
(row, col, channels) = bgr.shape
|
||||
|
||||
yuv = cv2.cvtColor(bgr, cv2.COLOR_BGR2YUV)
|
||||
|
||||
scores = [[] for i in range(self._wmLen)]
|
||||
for channel in range(2):
|
||||
if self._scales[channel] <= 0:
|
||||
continue
|
||||
|
||||
ca1, (h1, v1, d1) = pywt.dwt2(yuv[: row // 4 * 4, : col // 4 * 4, channel], "haar")
|
||||
|
||||
scores = self.decode_frame(ca1, self._scales[channel], scores)
|
||||
|
||||
avgScores = list(map(lambda l: np.array(l).mean(), scores))
|
||||
|
||||
bits = np.array(avgScores) * 255 > 127
|
||||
return bits
|
||||
|
||||
def decode_frame(self, frame, scale, scores):
|
||||
(row, col) = frame.shape
|
||||
num = 0
|
||||
|
||||
for i in range(row // self._block):
|
||||
for j in range(col // self._block):
|
||||
block = frame[
|
||||
i * self._block : i * self._block + self._block, j * self._block : j * self._block + self._block
|
||||
]
|
||||
|
||||
score = self.infer_dct_matrix(block, scale)
|
||||
# score = self.infer_dct_svd(block, scale)
|
||||
wmBit = num % self._wmLen
|
||||
scores[wmBit].append(score)
|
||||
num = num + 1
|
||||
|
||||
return scores
|
||||
|
||||
def diffuse_dct_svd(self, block, wmBit, scale):
|
||||
u, s, v = np.linalg.svd(cv2.dct(block))
|
||||
|
||||
s[0] = (s[0] // scale + 0.25 + 0.5 * wmBit) * scale
|
||||
return cv2.idct(np.dot(u, np.dot(np.diag(s), v)))
|
||||
|
||||
def infer_dct_svd(self, block, scale):
|
||||
u, s, v = np.linalg.svd(cv2.dct(block))
|
||||
|
||||
score = 0
|
||||
score = int((s[0] % scale) > scale * 0.5)
|
||||
return score
|
||||
if score >= 0.5:
|
||||
return 1.0
|
||||
else:
|
||||
return 0.0
|
||||
|
||||
def diffuse_dct_matrix(self, block, wmBit, scale):
|
||||
pos = np.argmax(abs(block.flatten()[1:])) + 1
|
||||
i, j = pos // self._block, pos % self._block
|
||||
val = block[i][j]
|
||||
if val >= 0.0:
|
||||
block[i][j] = (val // scale + 0.25 + 0.5 * wmBit) * scale
|
||||
else:
|
||||
val = abs(val)
|
||||
block[i][j] = -1.0 * (val // scale + 0.25 + 0.5 * wmBit) * scale
|
||||
return block
|
||||
|
||||
def infer_dct_matrix(self, block, scale):
|
||||
pos = np.argmax(abs(block.flatten()[1:])) + 1
|
||||
i, j = pos // self._block, pos % self._block
|
||||
|
||||
val = block[i][j]
|
||||
if val < 0:
|
||||
val = abs(val)
|
||||
|
||||
if (val % scale) > 0.5 * scale:
|
||||
return 1
|
||||
else:
|
||||
return 0
|
||||
|
||||
def encode_frame(self, frame, scale):
|
||||
"""
|
||||
frame is a matrix (M, N)
|
||||
|
||||
we get K (watermark bits size) blocks (self._block x self._block)
|
||||
|
||||
For i-th block, we encode watermark[i] bit into it
|
||||
"""
|
||||
(row, col) = frame.shape
|
||||
num = 0
|
||||
for i in range(row // self._block):
|
||||
for j in range(col // self._block):
|
||||
block = frame[
|
||||
i * self._block : i * self._block + self._block, j * self._block : j * self._block + self._block
|
||||
]
|
||||
wmBit = self._watermarks[(num % self._wmLen)]
|
||||
|
||||
diffusedBlock = self.diffuse_dct_matrix(block, wmBit, scale)
|
||||
# diffusedBlock = self.diffuse_dct_svd(block, wmBit, scale)
|
||||
frame[
|
||||
i * self._block : i * self._block + self._block, j * self._block : j * self._block + self._block
|
||||
] = diffusedBlock
|
||||
|
||||
num = num + 1
|
||||
@@ -6,13 +6,10 @@ configuration variable, that allows the watermarking to be supressed.
|
||||
|
||||
import cv2
|
||||
import numpy as np
|
||||
from imwatermark import WatermarkEncoder
|
||||
from PIL import Image
|
||||
|
||||
import invokeai.backend.util.logging as logger
|
||||
from invokeai.app.services.config.config_default import get_config
|
||||
|
||||
config = get_config()
|
||||
from invokeai.backend.image_util.imwatermark.vendor import WatermarkEncoder
|
||||
|
||||
|
||||
class InvisibleWatermark:
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user