- Added support for pyreadline3 so that Window users can benefit.
- Added the !search command to search the history for a matching string:
~~~
!search puppies
[20] puppies at the food bowl -Ak_lms
[54] house overrun by hungry puppies -C20 -s100
~~~
- Added the !clear command to clear the in-memory and on-disk
command history.
- embiggen needs to use ddim sampler due to low step count
- --hires_fix option needs to be written to log and command string
- fix call signature of _init_image_mask()
- When generating multiple images, the first seed was being used for second
and subsequent files. This should only happen when variations are being
generated. Now fixed.
- img2img confirmed working with all samplers
- inpainting working on ddim & plms. Changes to k-diffusion
module seem to be needed for inpainting support.
- switched k-diffuser noise schedule to original karras schedule,
which reduces the step number needed for good results
-if readline.set_auto_history() is not implemented, as in pyreadline3, will fall
back gracefully to automatic history saving. The only issue with this is that
-!history commands will be recorded in the history.
-!fetch on missing file no longer crashes script
-!history is now one of the autocomplete commands
-.dream_history now stored in output directory rather than ~user directory.
An important limitation of the last feature is that the history is
loaded and saved to the .dream_history file in the --outdir directory
specified at script launch time. It is not swapped around when the
--outdir is changed during the session.
Add message about interpolation size
Fix crash if sampler not set to DDIM, change parameter name to hires_fix
Hi res mode fix duplicates with img2img scaling
Add message about interpolation size
Fix crash if sampler not set to DDIM, change parameter name to hires_fix
Hi res mode fix duplicates with img2img scaling
-if readline.set_auto_history() is not implemented, as in pyreadline3, will fall
back gracefully to automatic history saving. The only issue with this is that
-!history commands will be recorded in the history.
-!fetch on missing file no longer crashes script
-!history is now one of the autocomplete commands
-.dream_history now stored in output directory rather than ~user directory.
An important limitation of the last feature is that the history is
loaded and saved to the .dream_history file in the --outdir directory
specified at script launch time. It is not swapped around when the
--outdir is changed during the session.
- When --save_orig *not* provided during image generation with
upscaling/face fixing, an extra image file was being created. This
PR fixes the problem.
- Also generalizes the tab autocomplete for image paths such that
autocomplete searches the output directory for all path-modifying
options except for --outdir.
- normalized how filenames are written out when postprocessing invoked
- various fixes of bugs encountered during testing
- updated documentation
- updated help text
- Enhance tab completion functionality
- Each of the switches that read a filepath (e.g. --init_img) will trigger file path completion. The
-S switch will display a list of recently-used seeds.
- Added new !fetch command to retrieve the metadata from a previously-generated image and populate the
readline linebuffer with the appropriate editable command to regenerate.
- Added new !history command to display previous commands and reload them for modification.
- The !fetch and !fix commands both autocomplete *and* search automatically through the current
outdir for files.
- The completer maintains a list of recently used seeds and will try to autocomplete them.
- normalized how filenames are written out when postprocessing invoked
- various fixes of bugs encountered during testing
- updated documentation
- updated help text
- Enhance tab completion functionality
- Each of the switches that read a filepath (e.g. --init_img) will trigger file path completion. The
-S switch will display a list of recently-used seeds.
- Added new !fetch command to retrieve the metadata from a previously-generated image and populate the
readline linebuffer with the appropriate editable command to regenerate.
- Added new !history command to display previous commands and reload them for modification.
- The !fetch and !fix commands both autocomplete *and* search automatically through the current
outdir for files.
- The completer maintains a list of recently used seeds and will try to autocomplete them.
- args.py will now attempt to return a metadata-containing Args
object using the following methods:
1. By looking for the 'sd-metadata' tag in the PNG info
2. By looking from the 'Dream' tag
3. As a last resort, fetch the seed from the filename and assume
defaults for all other options.
Pin `openh264` to 2.3.0 until OpenCV supports 2.3.1 or newer. Added just to `environment-mac.yml` since I know this happens on M1 / Apple Silicon Macs (running macOS 13) and that's all I can test on.
Either Huggingface's 'transformers' lib introduced a regression in v4.22, or we changed how we're using 'transformers' in such a way that we break when using v4.22.
Pin to 'transformers==4.21.*'
Signed-off-by: Ben Alkov <ben.alkov@gmail.com>
In the case of this "point", the Warp Terminal cannot be clicked directly to trigger the browser to open, and Chrome is a blank page. It should open properly once you remove it
Build the base generator in same place and way as other generators to reduce the chance of missed arguments in the future.
Fixes crash with display in-progress images, though note the feature still doesn't work for other reasons.
- For unknown reasons, conda removes the base directory from the path
on Macintoshes when pyproject.toml is present (even if the file is
empty). This commit renames pyproject.toml to pyproject.toml.hide
until the issue is understood better.
1. Add ldm/dream/restoration/__init__.py file that was inadvertently not
committed earlier.
2. Add '.' to sys.path to address weird mac problem reported in #723
- Adapted from PR #489, author Dominic Letz [https://github.com/dominicletz]
- Too many upstream changes to merge, so frankensteined it in.
- Added support for !fix syntax
- Added documentation
- The seed printed needs to be the one generated prior to the
initial noising operation. To do this, I added a new "first_seed"
argument to the image callback in dream.py.
- Closes#641
- modify strength of embiggen to reduce tiling ghosts
- normalize naming of postprocessed files (could improve more to avoid
name collisions)
- move restoration modules under ldm.dream
- supports gfpgan, esrgan, codeformer and embiggen
- To use:
dream> !fix ./outputs/img-samples/000056.292144555.png -ft gfpgan -U2 -G0.8
dream> !fix ./outputs/img-samples/000056.292144555.png -ft codeformer -G 0.8
dream> !fix ./outputs/img-samples/000056.29214455.png -U4
dream> !fix ./outputs/img-samples/000056.292144555.png -embiggen 1.5
The first example invokes gfpgan to fix faces and esrgan to upscale.
The second example invokes codeformer to fix faces, no upscaling
The third example uses esrgan to upscale 4X
The four example runs embiggen to enlarge 1.5X
- This is very preliminary work. There are some anomalies to note:
1. The syntax is non-obvious. I would prefer something like:
!fix esrgan,gfpgan
!fix esrgan
!fix embiggen,codeformer
However, this will require refactoring the gfpgan and embiggen
code.
2. Images generated using gfpgan, esrgan or codeformer all are named
"xxxxxx.xxxxxx.postprocessed.png" and the original is saved.
However, the prefix is a new one that is not related to the
original.
3. Images generated using embiggen are named "xxxxx.xxxxxxx.png",
and once again the prefix is new. I'm not sure whether the
prefix should be aligned with the original file's prefix or not.
Probably not, but opinions welcome.
Please don't make me keep having to cclean this up
1) Centering of the front matter is completely wrecked
2) We are not a billboard for Discord. We have a perfectly good badge - if the *link* needs fixing, fix it.
3) Stop putting HTML in Markdown
4) We need to state who and what we are once, clearly, not 3 times...
- <b>InvokeAI: A Stable Diffusion Toolkit</b>
- # Stable Diffusion Dream Script
- # **InvokeAI - A Stable Diffusion Toolkit**
5) Headings in Markdown SHOULD NOT HAVE additional formatting
Allowed values are 'auto', 'float32', 'autocast', 'float16'. If not specified or 'auto' a working precision is automatically selected based on the torch device.
Context: #526
Deprecated --full_precision / -F
Tested on both cuda and cpu by calling scripts/dream.py without arguments and checked the auto configuration worked. With --precision=auto/float32/autocast/float16 it performs as expected, either working or failing with a reasonable error. Also checked Img2Img.
1. let users install Rust right at the beginning in order to avoid some troubleshooting later on
2. add "conda deactivate" for troubleshooting once ldm was activated
Fix conflict
Update INSTALL_MAC.md
- modify strength of embiggen to reduce tiling ghosts
- normalize naming of postprocessed files (could improve more to avoid
name collisions)
- move restoration modules under ldm.dream
- supports gfpgan, esrgan, codeformer and embiggen
- To use:
dream> !fix ./outputs/img-samples/000056.292144555.png -ft gfpgan -U2 -G0.8
dream> !fix ./outputs/img-samples/000056.292144555.png -ft codeformer -G 0.8
dream> !fix ./outputs/img-samples/000056.29214455.png -U4
dream> !fix ./outputs/img-samples/000056.292144555.png -embiggen 1.5
The first example invokes gfpgan to fix faces and esrgan to upscale.
The second example invokes codeformer to fix faces, no upscaling
The third example uses esrgan to upscale 4X
The four example runs embiggen to enlarge 1.5X
- This is very preliminary work. There are some anomalies to note:
1. The syntax is non-obvious. I would prefer something like:
!fix esrgan,gfpgan
!fix esrgan
!fix embiggen,codeformer
However, this will require refactoring the gfpgan and embiggen
code.
2. Images generated using gfpgan, esrgan or codeformer all are named
"xxxxxx.xxxxxx.postprocessed.png" and the original is saved.
However, the prefix is a new one that is not related to the
original.
3. Images generated using embiggen are named "xxxxx.xxxxxxx.png",
and once again the prefix is new. I'm not sure whether the
prefix should be aligned with the original file's prefix or not.
Probably not, but opinions welcome.
fix double bs python path in cli.md and fix tables again
add more keys in cli.md
fix annotations in install_mac.md
remove torchaudio from pythorch-nightly installation
fix self reference
- supports gfpgan, esrgan, codeformer and embiggen
- To use:
dream> !fix ./outputs/img-samples/000056.292144555.png -ft gfpgan -U2 -G0.8
dream> !fix ./outputs/img-samples/000056.292144555.png -ft codeformer -G 0.8
dream> !fix ./outputs/img-samples/000056.29214455.png -U4
dream> !fix ./outputs/img-samples/000056.292144555.png -embiggen 1.5
The first example invokes gfpgan to fix faces and esrgan to upscale.
The second example invokes codeformer to fix faces, no upscaling
The third example uses esrgan to upscale 4X
The four example runs embiggen to enlarge 1.5X
- This is very preliminary work. There are some anomalies to note:
1. The syntax is non-obvious. I would prefer something like:
!fix esrgan,gfpgan
!fix esrgan
!fix embiggen,codeformer
However, this will require refactoring the gfpgan and embiggen
code.
2. Images generated using gfpgan, esrgan or codeformer all are named
"xxxxxx.xxxxxx.postprocessed.png" and the original is saved.
However, the prefix is a new one that is not related to the
original.
3. Images generated using embiggen are named "xxxxx.xxxxxxx.png",
and once again the prefix is new. I'm not sure whether the
prefix should be aligned with the original file's prefix or not.
Probably not, but opinions welcome.
* Support color correction for img2img and inpainting, avoiding the shift to magenta seen when running images through img2img repeatedly.
* Fix docs for color correction
* add --init_color to prompt reconstruction
* For best results, the --init_color option should point to the *very first* image used in the sequence of img2img operations. Otherwise color correction will skew towards cyan.
Co-authored-by: Lincoln Stein <lincoln.stein@gmail.com>
- use git-revision-date-localized with enabled creation date
- update requirements-mkdocs.txt and pin verisons
- add requirements
- add dev addr
- fix template
- use better icons for repo and edit button
- remove odd extension
disabled toc in order to view those large tables
added linebreaks in long cells to stop multiline arguments/shortcut
added backticks arround arguments to stop interpreting `<...>` as html
added missing identifiers to codeblocks
changed html tags to markdown to insert the png
Fixes:
File "stable-diffusion/ldm/modules/diffusionmodules/model.py", line 37, in nonlinearity
return x*torch.sigmoid(x)
RuntimeError: CUDA out of memory. Tried to allocate 1.56 GiB [..]
Now up to 1536x1280 is possible on 8GB VRAM.
Also remove unused SiLU class.
* Added linux to the workflows
- rename workflow files
Signed-off-by: Ben Alkov <ben.alkov@gmail.com>
* fixes: run on merge to 'main', 'dev';
- reduce dev merge test cases to 1 (1 takes 11 minutes 😯)
- fix model cache name
Signed-off-by: Ben Alkov <ben.alkov@gmail.com>
* add test prompts to workflows
Signed-off-by: Ben Alkov <ben.alkov@gmail.com>
Signed-off-by: Ben Alkov <ben.alkov@gmail.com>
Co-authored-by: James Reynolds <magnsuviri@me.com>
Apply ~6% speedup by moving * self.scale to earlier on a smaller tensor.
When we have enough VRAM don't make a useless zeros tensor.
Switch between cuda/mps/cpu based on q.device.type to allow cleaner per architecture future optimizations.
For cuda and cpu keep VRAM usage and faster slicing consistent.
For cpu use smaller slices. Tested ~20% faster on i7, 9.8 to 7.7 s/it.
Fix = typo to self.mem_total >= 8 in einsum_op_mps_v2 as per #582 discussion.
- fixes no closing quote in pretty-printed dream_prompt string
- removes unecessary -f switch when txt2img used
In addition, this commit does an experimental commenting-out of the
random.seed() call in the variation-generating part of ldm.dream.generator.base.
This fixes the problem of two calls that use the same seed and -v0.1
generating different images (#641). However, it does not fix the issue
of two images generated using the same seed and -VXXXXXX being
different.
- switch badge service to badgen, as I couldn't figure out shields.io
Signed-off-by: Ben Alkov <ben.alkov@gmail.com>
Signed-off-by: Ben Alkov <ben.alkov@gmail.com>
* Added linux to the workflows
- rename workflow files
Signed-off-by: Ben Alkov <ben.alkov@gmail.com>
* fixes: run on merge to 'main', 'dev';
- reduce dev merge test cases to 1 (1 takes 11 minutes 😯)
- fix model cache name
Signed-off-by: Ben Alkov <ben.alkov@gmail.com>
* add test prompts to workflows
Signed-off-by: Ben Alkov <ben.alkov@gmail.com>
Signed-off-by: Ben Alkov <ben.alkov@gmail.com>
Co-authored-by: James Reynolds <magnsuviri@me.com>
Co-authored-by: Ben Alkov <ben.alkov@gmail.com>
Co-authored-by: Lincoln Stein <lincoln.stein@gmail.com>
* due to changes in the metadata written to PNG files, web server cannot
display images
* issue is identified and will be fixed in next 24h
* Python 3.9 required for flask/react web server; environment must be
updated.
* Implements rudimentary api
* Fixes blocking in API
* Adds UI to monorepo > src/frontend/
* Updates frontend/README
* Reverts conda env name to `ldm`
* Fixes environment yamls
* CORS config for testing
* Fixes LogViewer position
* API WID
* Adds actions to image viewer
* Increases vite chunkSizeWarningLimit to 1500
* Implements init image
* Implements state persistence in localStorage
* Improve progress data handling
* Final build
* Fixes mimetypes error on windows
* Adds error logging
* Fixes bugged img2img strength component
* Adds sourcemaps to dev build
* Fixes missing key
* Changes connection status indicator to text
* Adds ability to serve other hosts than localhost
* Adding Flask API server
* Removes source maps from config
* Fixes prop transfer
* Add missing packages and add CORS support
* Adding API doc
* Remove defaults from openapi doc
* Adds basic error handling for server config query
* Mostly working socket.io implementation.
* Fixes bug preventing mask upload
* Fixes bug with sampler name not written to metadata
* UI Overhaul, numerous fixes
Co-authored-by: Kyle Schouviller <kyle0654@hotmail.com>
Co-authored-by: Lincoln Stein <lincoln.stein@gmail.com>
* Feature complete for #266 with exception of several small deviations:
1. initial image and model weight hashes use full sha256 hash rather than first 8 digits
2. Initialization parameters for post-processing steps not provided
3. Uses top-level "images" tags for both a single image and a grid of images. This change was suggested in a comment.
* Added scripts/sd_metadata.py to retrieve and print metadata from PNG files
* New ldm.dream.args.Args class is a namespace like object which holds all defaults and can be modified during exection to hold current settings.
* Modified dream.py and server.py to accommodate Args class.
This change makes it so any API clients can show the same error as what
happens in the terminal where you run the API. Useful for various WebUIs
to display more helpful error messages to users.
Co-authored-by: CapableWeb <capableweb@domain.com>
* Refactor generate.py and dream.py
* config file path (models.yaml) is parsed inside Generate() to simplify
API
* Better handling of keyboard interrupts in file loading mode vs
interactive
* Removed oodles of unused variables.
* move nonfunctional inpainting out of the scripts directory
* fix ugly ddim tqdm formatting
* fix embiggen breakage, formatting fixes
* fix web server handling of rel and abs outdir paths
* Can now specify either a relative or absolute path for outdir
* Outdir path does not need to be inside the stable-diffusion directory
* Closes security hole that allowed user to read any file within
stable-diffusion (eek!)
* Closes#536
* revert inadvertent change of conda env name (#528)
* Refactor generate.py and dream.py
* config file path (models.yaml) is parsed inside Generate() to simplify
API
* Better handling of keyboard interrupts in file loading mode vs
interactive
* Removed oodles of unused variables.
* move nonfunctional inpainting out of the scripts directory
* fix ugly ddim tqdm formatting
* Refactor pip requirements across the board
Signed-off-by: Ben Alkov <ben.alkov@gmail.com>
* fix name, version in setup.py
Signed-off-by: Ben Alkov <ben.alkov@gmail.com>
* Update notebooks for new requirements file changes
Signed-off-by: Ben Alkov <ben.alkov@gmail.com>
* slightly more consistent in how the different scenarios are described
* moved the stuff about `/usr/bin/python` to be adjacent to the stuff about `/usr/bin/python3`
* added an example of the 'option 1' goal state
* described a way to directly answer the question: how many snakes are living in your computer?
Code cleanup and attention.py einsum_ops update for M1 16-32GB performance.
Expected: On par with fastest ever from 8 to 128GB for 512x512. Allows large images.
When running on just cpu (intel), a call to torch.layer_norm would error with RuntimeError: expected scalar type BFloat16 but found Float
Fix buggy device handling in model.py.
Tested with scripts/dream.py --full_precision on just cpu on intel laptop. Works but slow at ~10s/it.
* Add Embiggen automation
* Make embiggen_tiles masking more intelligent and count from one (at least for the user), rewrite sections of Embiggen README, fix various typos throughout README
* drop duplicate log message
commit 1c649e4663
Author: Lincoln Stein <lincoln.stein@gmail.com>
Date: Mon Sep 12 13:29:16 2022 -0400
fix torchvision dependency version #511
commit 4d197f699e
Merge: a3e07fb190ba78
Author: Lincoln Stein <lincoln.stein@gmail.com>
Date: Mon Sep 12 07:29:19 2022 -0400
Merge branch 'development' of github.com:lstein/stable-diffusion into development
commit a3e07fb84a
Author: Lincoln Stein <lincoln.stein@gmail.com>
Date: Mon Sep 12 07:28:58 2022 -0400
fix grid crash
commit 9fa1f31bf2
Author: Lincoln Stein <lincoln.stein@gmail.com>
Date: Mon Sep 12 07:07:05 2022 -0400
fix opencv and realesrgan dependencies in mac install
commit 190ba78960
Author: Lincoln Stein <lincoln.stein@gmail.com>
Date: Mon Sep 12 01:50:58 2022 -0400
Update requirements-mac.txt
Fixed dangling dash on last line.
commit 25d9ccc509
Author: Any-Winter-4079 <50542132+Any-Winter-4079@users.noreply.github.com>
Date: Mon Sep 12 03:17:29 2022 +0200
Update model.py
commit 9cdf3aca7d
Author: Any-Winter-4079 <50542132+Any-Winter-4079@users.noreply.github.com>
Date: Mon Sep 12 02:52:36 2022 +0200
Update attention.py
Performance improvements to generate larger images in M1 #431
Update attention.py
Added dtype=r1.dtype to softmax
commit 49a96b90d8
Author: Mihai <299015+mh-dm@users.noreply.github.com>
Date: Sat Sep 10 16:58:07 2022 +0300
~7% speedup (1.57 to 1.69it/s) from switch to += in ldm.modules.attention. (#482)
Tested on 8GB eGPU nvidia setup so YMMV.
512x512 output, max VRAM stays same.
commit aba94b85e8
Author: Niek van der Maas <mail@niekvandermaas.nl>
Date: Fri Sep 9 15:01:37 2022 +0200
Fix macOS `pyenv` instructions, add code block highlight (#441)
Fix: `anaconda3-latest` does not work, specify the correct virtualenv, add missing init.
commit aac5102cf3
Author: Henry van Megen <h.vanmegen@gmail.com>
Date: Thu Sep 8 05:16:35 2022 +0200
Disabled debug output (#436)
Co-authored-by: Henry van Megen <hvanmegen@gmail.com>
commit 0ab5a36464
Author: Lincoln Stein <lincoln.stein@gmail.com>
Date: Sun Sep 11 17:19:46 2022 -0400
fix missing lines in outputs
commit 5e433728b5
Author: Lincoln Stein <lincoln.stein@gmail.com>
Date: Sun Sep 11 16:20:14 2022 -0400
upped max_steps in v1-finetune.yaml and fixed TI docs to address #493
commit 7708f4fb98
Author: Lincoln Stein <lincoln.stein@gmail.com>
Date: Sun Sep 11 16:03:37 2022 -0400
slight efficiency gain by using += in attention.py
commit b86a1deb00
Author: blessedcoolant <54517381+blessedcoolant@users.noreply.github.com>
Date: Mon Sep 12 07:47:12 2022 +1200
Remove print statement styling (#504)
Co-authored-by: Lincoln Stein <lincoln.stein@gmail.com>
commit 4951e66103
Author: chromaticist <mhostick@gmail.com>
Date: Sun Sep 11 12:44:26 2022 -0700
Adding support for .bin files from huggingface concepts (#498)
* Adding support for .bin files from huggingface concepts
* Updating documentation to include huggingface .bin info
commit 79b445b0ca
Merge: a323070 f7662c1
Author: Lincoln Stein <lincoln.stein@gmail.com>
Date: Sun Sep 11 15:39:38 2022 -0400
Merge branch 'development' of github.com:lstein/stable-diffusion into development
commit a323070a4d
Author: Lincoln Stein <lincoln.stein@gmail.com>
Date: Sun Sep 11 15:28:57 2022 -0400
update requirements for new location of gfpgan
commit f7662c1808
Author: Lincoln Stein <lincoln.stein@gmail.com>
Date: Sun Sep 11 15:00:24 2022 -0400
update requirements for changed location of gfpgan
commit 93c242c9fb
Author: Lincoln Stein <lincoln.stein@gmail.com>
Date: Sun Sep 11 14:47:58 2022 -0400
make gfpgan_model_exists flag available to web interface
commit c7c6cd7735
Author: Lincoln Stein <lincoln.stein@gmail.com>
Date: Sun Sep 11 14:43:07 2022 -0400
Update UPSCALE.md
New instructions needed to accommodate fact that the ESRGAN and GFPGAN packages are now installed by environment.yaml.
commit 77ca83e103
Author: Lincoln Stein <lincoln.stein@gmail.com>
Date: Sun Sep 11 14:31:56 2022 -0400
Update CLI.md
Final documentation tweak.
commit 0ea145d188
Author: Lincoln Stein <lincoln.stein@gmail.com>
Date: Sun Sep 11 14:29:26 2022 -0400
Update CLI.md
More doc fixes.
commit 162285ae86
Author: Lincoln Stein <lincoln.stein@gmail.com>
Date: Sun Sep 11 14:28:45 2022 -0400
Update CLI.md
Minor documentation fix
commit 37c921dfe2
Author: Lincoln Stein <lincoln.stein@gmail.com>
Date: Sun Sep 11 14:26:41 2022 -0400
documentation enhancements
commit 4f72cb44ad
Author: Lincoln Stein <lincoln.stein@gmail.com>
Date: Sun Sep 11 13:05:38 2022 -0400
moved the notebook files into their own directory
commit 878ef2e9e0
Author: Lincoln Stein <lincoln.stein@gmail.com>
Date: Sun Sep 11 12:58:06 2022 -0400
documentation tweaks
commit 4923118610
Merge: 16f6a67defafc0
Author: Lincoln Stein <lincoln.stein@gmail.com>
Date: Sun Sep 11 12:51:25 2022 -0400
Merge branch 'development' of github.com:lstein/stable-diffusion into development
commit defafc0e8e
Author: Dominic Letz <dominic@diode.io>
Date: Sun Sep 11 18:51:01 2022 +0200
Enable upscaling on m1 (#474)
commit 16f6a6731d
Author: Lincoln Stein <lincoln.stein@gmail.com>
Date: Sun Sep 11 12:47:26 2022 -0400
install GFPGAN inside SD repository in order to fix 'dark cast' issue #169
commit 0881d429f2
Author: blessedcoolant <54517381+blessedcoolant@users.noreply.github.com>
Date: Mon Sep 12 03:52:43 2022 +1200
Docs Update (#466)
Authored-by: @blessedcoolant
Co-authored-by: Lincoln Stein <lincoln.stein@gmail.com>
commit 9a29d442b4
Author: Gérald LONLAS <gerald@lonlas.com>
Date: Sun Sep 11 23:23:18 2022 +0800
Revert "Add 3x Upscale option on the Web UI (#442)" (#488)
This reverts commit f8a540881c.
commit d301836fbd
Author: Lincoln Stein <lincoln.stein@gmail.com>
Date: Sun Sep 11 10:52:19 2022 -0400
can select prior output for init_img using -1, -2, etc
commit 70aa674e9e
Author: Lincoln Stein <lincoln.stein@gmail.com>
Date: Sun Sep 11 10:34:06 2022 -0400
merge PR #495 - keep using float16 in ldm.modules.attention
commit 8748370f44
Author: Lincoln Stein <lincoln.stein@gmail.com>
Date: Sun Sep 11 10:22:32 2022 -0400
negative -S indexing recovers correct previous seed; closes issue #476
commit 839e30e4b8
Author: Lincoln Stein <lincoln.stein@gmail.com>
Date: Sun Sep 11 10:02:44 2022 -0400
improve CUDA VRAM monitoring
extra check that device==cuda before getting VRAM stats
commit bfb2781279
Author: tildebyte <337875+tildebyte@users.noreply.github.com>
Date: Sat Sep 10 10:15:56 2022 -0400
fix(readme): add note about updating env via conda (#475)
commit 5c43988862
Author: Lincoln Stein <lincoln.stein@gmail.com>
Date: Sat Sep 10 10:02:43 2022 -0400
reduce VRAM memory usage by half during model loading
* This moves the call to half() before model.to(device) to avoid GPU
copy of full model. Improves speed and reduces memory usage dramatically
* This fix contributed by @mh-dm (Mihai)
commit 99122708ca
Merge: 817c4a2ecc6b75
Author: Lincoln Stein <lincoln.stein@gmail.com>
Date: Sat Sep 10 09:54:34 2022 -0400
Merge branch 'development' of github.com:lstein/stable-diffusion into development
commit 817c4a26de
Author: Lincoln Stein <lincoln.stein@gmail.com>
Date: Sat Sep 10 09:53:27 2022 -0400
remove -F option from normalized prompt; closes#483
commit ecc6b75a3e
Author: Lincoln Stein <lincoln.stein@gmail.com>
Date: Sat Sep 10 09:53:27 2022 -0400
remove -F option from normalized prompt
commit 723d074442
Author: Lincoln Stein <lincoln.stein@gmail.com>
Date: Fri Sep 9 18:49:51 2022 -0400
Allow ctrl c when using --from_file (#472)
* added ansi escapes to highlight key parts of CLI session
* adjust exception handling so that ^C will abort when reading prompts from a file
commit 75f633cda8
Author: Lincoln Stein <lincoln.stein@gmail.com>
Date: Fri Sep 9 12:03:45 2022 -0400
re-add new logo
commit 10db192cc4
Author: Lincoln Stein <lincoln.stein@gmail.com>
Date: Fri Sep 9 09:26:10 2022 -0400
changes to dogettx optimizations to run on m1
* Author @any-winter-4079
* Author @dogettx
Thanks to many individuals who contributed time and hardware to
benchmarking and debugging these changes.
commit c85ae00b33
Author: Lincoln Stein <lincoln.stein@gmail.com>
Date: Thu Sep 8 23:57:45 2022 -0400
fix bug which caused seed to get "stuck" on previous image even when UI specified -1
commit 1b5aae3ef3
Author: Lincoln Stein <lincoln.stein@gmail.com>
Date: Thu Sep 8 22:36:47 2022 -0400
add icon to dream web server
commit 6abf739315
Author: Lincoln Stein <lincoln.stein@gmail.com>
Date: Thu Sep 8 22:25:09 2022 -0400
add favicon to web server
commit db825b8138
Merge: 33874baafee7f9
Author: Lincoln Stein <lincoln.stein@gmail.com>
Date: Thu Sep 8 22:17:37 2022 -0400
Merge branch 'deNULL-development' into development
commit 33874bae8d
Author: Lincoln Stein <lincoln.stein@gmail.com>
Date: Thu Sep 8 22:16:29 2022 -0400
Squashed commit of the following:
commit afee7f9cea
Merge: 6531446171f8db
Author: Lincoln Stein <lincoln.stein@gmail.com>
Date: Thu Sep 8 22:14:32 2022 -0400
Merge branch 'development' of github.com:deNULL/stable-diffusion into deNULL-development
commit 171f8db742
Author: Denis Olshin <me@denull.ru>
Date: Thu Sep 8 03:15:20 2022 +0300
saving full prompt to metadata when using web ui
commit d7e67b62f0
Author: Denis Olshin <me@denull.ru>
Date: Thu Sep 8 01:51:47 2022 +0300
better logic for clicking to make variations
commit afee7f9cea
Merge: 6531446171f8db
Author: Lincoln Stein <lincoln.stein@gmail.com>
Date: Thu Sep 8 22:14:32 2022 -0400
Merge branch 'development' of github.com:deNULL/stable-diffusion into deNULL-development
commit 653144694f
Author: Lincoln Stein <lincoln.stein@gmail.com>
Date: Thu Sep 8 20:41:37 2022 -0400
work around unexplained crash when timesteps=1000 (#440)
* work around unexplained crash when timesteps=1000
* this fix seems to work
commit c33a84cdfd
Author: blessedcoolant <54517381+blessedcoolant@users.noreply.github.com>
Date: Fri Sep 9 12:39:51 2022 +1200
Add New Logo (#454)
* Add instructions on how to install alongside pyenv (#393)
Like probably many others, I have a lot of different virtualenvs, one for each project. Most of them are handled by `pyenv`.
After installing according to these instructions I had issues with ´pyenv`and `miniconda` fighting over the $PATH of my system.
But then I stumbled upon this nice solution on SO: https://stackoverflow.com/a/73139031 , upon which I have based my suggested changes.
It runs perfectly on my M1 setup, with the anaconda setup as a virtual environment handled by pyenv.
Feel free to incorporate these instructions as you see fit.
Thanks a million for all your hard work.
* Disabled debug output (#436)
Co-authored-by: Henry van Megen <hvanmegen@gmail.com>
* Add New Logo
Co-authored-by: Håvard Gulldahl <havard@lurtgjort.no>
Co-authored-by: Henry van Megen <h.vanmegen@gmail.com>
Co-authored-by: Henry van Megen <hvanmegen@gmail.com>
Co-authored-by: Lincoln Stein <lincoln.stein@gmail.com>
commit f8a540881c
Author: Gérald LONLAS <gerald@lonlas.com>
Date: Fri Sep 9 01:45:54 2022 +0800
Add 3x Upscale option on the Web UI (#442)
commit 244239e5f6
Author: James Reynolds <magnusviri@users.noreply.github.com>
Date: Thu Sep 8 05:36:33 2022 -0600
macOS CI workflow, dream.py exits with an error, but the workflow com… (#396)
* macOS CI workflow, dream.py exits with an error, but the workflow completes.
* Files for testing
Co-authored-by: James Reynolds <magnsuviri@me.com>
Co-authored-by: Lincoln Stein <lincoln.stein@gmail.com>
commit 711d49ed30
Author: James Reynolds <magnusviri@users.noreply.github.com>
Date: Thu Sep 8 05:35:08 2022 -0600
Cache model workflow (#394)
* Add workflow that caches the model, step 1 for CI
* Change name of workflow job
Co-authored-by: James Reynolds <magnsuviri@me.com>
Co-authored-by: Lincoln Stein <lincoln.stein@gmail.com>
commit 7996a30e3a
Author: Lincoln Stein <lincoln.stein@gmail.com>
Date: Thu Sep 8 07:34:03 2022 -0400
add auto-creation of mask for inpainting (#438)
* now use a single init image for both image and mask
* turn on debugging for now to write out mask and image
* add back -M option as a fallback
commit a69ca31f34
Author: elliotsayes <elliotsayes@gmail.com>
Date: Thu Sep 8 15:30:06 2022 +1200
.gitignore WebUI temp files (#430)
* Add instructions on how to install alongside pyenv (#393)
Like probably many others, I have a lot of different virtualenvs, one for each project. Most of them are handled by `pyenv`.
After installing according to these instructions I had issues with ´pyenv`and `miniconda` fighting over the $PATH of my system.
But then I stumbled upon this nice solution on SO: https://stackoverflow.com/a/73139031 , upon which I have based my suggested changes.
It runs perfectly on my M1 setup, with the anaconda setup as a virtual environment handled by pyenv.
Feel free to incorporate these instructions as you see fit.
Thanks a million for all your hard work.
* .gitignore WebUI temp files
Co-authored-by: Håvard Gulldahl <havard@lurtgjort.no>
commit 5c6b612a72
Author: Lincoln Stein <lincoln.stein@gmail.com>
Date: Wed Sep 7 22:50:55 2022 -0400
fix bug that caused same seed to be redisplayed repeatedly
commit 56f155c590
Author: Johan Roxendal <johan@roxendal.com>
Date: Thu Sep 8 04:50:06 2022 +0200
added support for parsing run log and displaying images in the frontend init state (#410)
Co-authored-by: Johan Roxendal <johan.roxendal@litteraturbanken.se>
Co-authored-by: Lincoln Stein <lincoln.stein@gmail.com>
commit 41687746be
Author: Lincoln Stein <lincoln.stein@gmail.com>
Date: Wed Sep 7 20:24:35 2022 -0400
added missing initialization of latent_noise to None
commit 171f8db742
Author: Denis Olshin <me@denull.ru>
Date: Thu Sep 8 03:15:20 2022 +0300
saving full prompt to metadata when using web ui
commit d7e67b62f0
Author: Denis Olshin <me@denull.ru>
Date: Thu Sep 8 01:51:47 2022 +0300
better logic for clicking to make variations
commit d1d044aa87
Author: Lincoln Stein <lincoln.stein@gmail.com>
Date: Wed Sep 7 17:56:59 2022 -0400
actual image seed now written into web log rather than -1 (#428)
commit edada042b3
Author: Arturo Mendivil <60411196+artmen1516@users.noreply.github.com>
Date: Wed Sep 7 10:42:26 2022 -0700
Improve notebook and add requirements file (#422)
commit 29ab3c2028
Author: Lincoln Stein <lincoln.stein@gmail.com>
Date: Wed Sep 7 13:28:11 2022 -0400
disable neonpixel optimizations on M1 hardware (#414)
* disable neonpixel optimizations on M1 hardware
* fix typo that was causing random noise images on m1
commit 7670ecc63f
Author: cody <cnmizell@gmail.com>
Date: Wed Sep 7 12:24:41 2022 -0500
add more keyboard support on the web server (#391)
add ability to submit prompts with the "enter" key
add ability to cancel generations with the "escape" key
commit dd2aedacaf
Author: Lincoln Stein <lincoln.stein@gmail.com>
Date: Wed Sep 7 13:23:53 2022 -0400
report VRAM usage stats during initial model loading (#419)
commit f6284777e6
Author: Lincoln Stein <lincoln.stein@gmail.com>
Date: Tue Sep 6 17:12:39 2022 -0400
Squashed commit of the following:
commit 7d1344282d942a33dcecda4d5144fc154ec82915
Merge: caf4ea3ebeb556
Author: Lincoln Stein <lincoln.stein@gmail.com>
Date: Mon Sep 5 10:07:27 2022 -0400
Merge branch 'development' of github.com:WebDev9000/stable-diffusion into WebDev9000-development
commit ebeb556af9
Author: Web Dev 9000 <rirath@gmail.com>
Date: Sun Sep 4 18:05:15 2022 -0700
Fixed unintentionally removed lines
commit ff2c4b9a1b
Author: Web Dev 9000 <rirath@gmail.com>
Date: Sun Sep 4 17:50:13 2022 -0700
Add ability to recreate variations via image click
commit c012929cda
Author: Web Dev 9000 <rirath@gmail.com>
Date: Sun Sep 4 14:35:33 2022 -0700
Add files via upload
commit 02a6018992
Author: Web Dev 9000 <rirath@gmail.com>
Date: Sun Sep 4 14:35:07 2022 -0700
Add files via upload
commit eef788981c
Author: Olivier Louvignes <olivier@mg-crea.com>
Date: Tue Sep 6 12:41:08 2022 +0200
feat(txt2img): allow from_file to work with len(lines) < batch_size (#349)
commit 720e5cd651
Author: Lincoln Stein <lincoln.stein@gmail.com>
Date: Mon Sep 5 20:40:10 2022 -0400
Refactoring simplet2i (#387)
* start refactoring -not yet functional
* first phase of refactor done - not sure weighted prompts working
* Second phase of refactoring. Everything mostly working.
* The refactoring has moved all the hard-core inference work into
ldm.dream.generator.*, where there are submodules for txt2img and
img2img. inpaint will go in there as well.
* Some additional refactoring will be done soon, but relatively
minor work.
* fix -save_orig flag to actually work
* add @neonsecret attention.py memory optimization
* remove unneeded imports
* move token logging into conditioning.py
* add placeholder version of inpaint; porting in progress
* fix crash in img2img
* inpainting working; not tested on variations
* fix crashes in img2img
* ported attention.py memory optimization #117 from basujindal branch
* added @torch_no_grad() decorators to img2img, txt2img, inpaint closures
* Final commit prior to PR against development
* fixup crash when generating intermediate images in web UI
* rename ldm.simplet2i to ldm.generate
* add backward-compatibility simplet2i shell with deprecation warning
* add back in mps exception, addresses @vargol comment in #354
* replaced Conditioning class with exported functions
* fix wrong type of with_variations attribute during intialization
* changed "image_iterator()" to "get_make_image()"
* raise NotImplementedError for calling get_make_image() in parent class
* Update ldm/generate.py
better error message
Co-authored-by: Kevin Gibbons <bakkot@gmail.com>
* minor stylistic fixes and assertion checks from code review
* moved get_noise() method into img2img class
* break get_noise() into two methods, one for txt2img and the other for img2img
* inpainting works on non-square images now
* make get_noise() an abstract method in base class
* much improved inpainting
Co-authored-by: Kevin Gibbons <bakkot@gmail.com>
commit 1ad2a8e567
Author: thealanle <35761977+thealanle@users.noreply.github.com>
Date: Mon Sep 5 17:35:04 2022 -0700
Fix --outdir function for web (#373)
* Fix --outdir function for web
* Removed unnecessary hardcoded path
commit 52d8bb2836
Author: Lincoln Stein <lincoln.stein@gmail.com>
Date: Mon Sep 5 10:31:59 2022 -0400
Squashed commit of the following:
commit 0cd48e932f1326e000c46f4140f98697eb9bdc79
Author: Lincoln Stein <lincoln.stein@gmail.com>
Date: Mon Sep 5 10:27:43 2022 -0400
resolve conflicts with development
commit d7bc8c12e0
Author: Scott McMillin <scott@scottmcmillin.com>
Date: Sun Sep 4 18:52:09 2022 -0500
Add title attribute back to img tag
commit 5397c89184
Author: Scott McMillin <scott@scottmcmillin.com>
Date: Sun Sep 4 13:49:46 2022 -0500
Remove temp code
commit 1da080b509
Author: Scott McMillin <scott@scottmcmillin.com>
Date: Sun Sep 4 13:33:56 2022 -0500
Cleaned up HTML; small style changes; image click opens image; add seed to figcaption beneath image
commit caf4ea3d89
Author: Adam Rice <adam@askadam.io>
Date: Mon Sep 5 10:05:39 2022 -0400
Add a 'Remove Image' button to clear the file upload field (#382)
* added "remove image" button
* styled a new "remove image" button
* Update index.js
commit 95c088b303
Author: Kevin Gibbons <bakkot@gmail.com>
Date: Sun Sep 4 19:04:14 2022 -0700
Revert "Add CORS headers to dream server to ease integration with third-party web interfaces" (#371)
This reverts commit 91e826e5f4.
commit a20113d5a3
Author: Kevin Gibbons <bakkot@gmail.com>
Date: Sun Sep 4 18:59:12 2022 -0700
put no_grad decorator on make_image closures (#375)
commit 0f93dadd6a
Author: Lincoln Stein <lincoln.stein@gmail.com>
Date: Sun Sep 4 21:39:15 2022 -0400
fix several dangling references to --gfpgan option, which no longer exists
commit f4004f660e
Author: tildebyte <337875+tildebyte@users.noreply.github.com>
Date: Sun Sep 4 19:43:04 2022 -0400
TOIL(requirements): Split requirements to per-platform (#355)
* toil(reqs): split requirements to per-platform
Signed-off-by: Ben Alkov <ben.alkov@gmail.com>
* toil(reqs): fix for Win and Lin...
...allow pip to resolve latest torch, numpy
Signed-off-by: Ben Alkov <ben.alkov@gmail.com>
* toil(install): update reqs in Win install notebook
Signed-off-by: Ben Alkov <ben.alkov@gmail.com>
Signed-off-by: Ben Alkov <ben.alkov@gmail.com>
commit 4406fd138d
Merge: 5116c81fd7a72e
Author: Lincoln Stein <lincoln.stein@gmail.com>
Date: Sun Sep 4 08:23:53 2022 -0400
Merge branch 'SebastianAigner-main' into development
Add support for full CORS headers for dream server.
commit fd7a72e147
Author: Lincoln Stein <lincoln.stein@gmail.com>
Date: Sun Sep 4 08:23:11 2022 -0400
remove debugging message
commit 3a2be621f3
Merge: 91e826e5116c81
Author: Lincoln Stein <lincoln.stein@gmail.com>
Date: Sun Sep 4 08:15:51 2022 -0400
Merge branch 'development' into main
commit 5116c8178c
Author: Justin Wong <1584142+wongjustin99@users.noreply.github.com>
Date: Sun Sep 4 07:17:58 2022 -0400
fix save_original flag saving to the same filename (#360)
* Update README.md with new Anaconda install steps (#347)
pip3 version did not work for me and this is the recommended way to install Anaconda now it seems
* fix save_original flag saving to the same filename
Before this, the `--save_orig` flag was not working. The upscaled/GFPGAN would overwrite the original output image.
Co-authored-by: greentext2 <112735219+greentext2@users.noreply.github.com>
commit 91e826e5f4
Author: Sebastian Aigner <SebastianAigner@users.noreply.github.com>
Date: Sun Sep 4 10:22:54 2022 +0200
Add CORS headers to dream server to ease integration with third-party web interfaces
commit 6266d9e8d6
Author: Lincoln Stein <lincoln.stein@gmail.com>
Date: Sat Sep 3 15:45:20 2022 -0400
remove stray debugging message
commit 138956e516
Author: greentext2 <112735219+greentext2@users.noreply.github.com>
Date: Sat Sep 3 13:38:57 2022 -0500
Update README.md with new Anaconda install steps (#347)
pip3 version did not work for me and this is the recommended way to install Anaconda now it seems
commit 60be735e80
Author: Cora Johnson-Roberson <cora.johnson.roberson@gmail.com>
Date: Sat Sep 3 14:28:34 2022 -0400
Switch to regular pytorch channel and restore Python 3.10 for Macs. (#301)
* Switch to regular pytorch channel and restore Python 3.10 for Macs.
Although pytorch-nightly should in theory be faster, it is currently
causing increased memory usage and slower iterations:
https://github.com/lstein/stable-diffusion/pull/283#issuecomment-1234784885
This changes the environment-mac.yaml file back to the regular pytorch
channel and moves the `transformers` dep into pip for now (since it
cannot be satisfied until tokenizers>=0.11 is built for Python 3.10).
* Specify versions for Pip packages as well.
commit d0d95d3a2a
Author: Lincoln Stein <lincoln.stein@gmail.com>
Date: Sat Sep 3 14:10:31 2022 -0400
make initimg appear in web log
commit b90a215000
Merge: 1eee8116270e31
Author: Lincoln Stein <lincoln.stein@gmail.com>
Date: Sat Sep 3 13:47:15 2022 -0400
Merge branch 'prixt-seamless' into development
commit 6270e313b8
Author: Lincoln Stein <lincoln.stein@gmail.com>
Date: Sat Sep 3 13:46:29 2022 -0400
add credit to prixt for seamless circular tiling
commit a01b7bdc40
Merge: 1eee8119d88abe
Author: Lincoln Stein <lincoln.stein@gmail.com>
Date: Sat Sep 3 13:43:04 2022 -0400
add web interface for seamless option
commit 1eee8111b9
Merge: 64eca42fb857f0
Author: Lincoln Stein <lincoln.stein@gmail.com>
Date: Sat Sep 3 12:33:39 2022 -0400
Merge branch 'development' of github.com:lstein/stable-diffusion into development
commit 64eca42610
Merge: 9130ad721a1f68
Author: Lincoln Stein <lincoln.stein@gmail.com>
Date: Sat Sep 3 12:33:05 2022 -0400
Merge branch 'main' into development
* brings in small documentation fixes that were
added directly to main during release tweaking.
commit fb857f05ba
Author: Lincoln Stein <lincoln.stein@gmail.com>
Date: Sat Sep 3 12:07:07 2022 -0400
fix typo in docs
commit 9d88abe2ea
Author: prixt <paraxite@naver.com>
Date: Sat Sep 3 22:42:16 2022 +0900
fixed typo
commit a61e49bc97
Author: prixt <paraxite@naver.com>
Date: Sat Sep 3 22:39:35 2022 +0900
* Removed unnecessary code
* Added description about --seamless
commit 02bee4fdb1
Author: prixt <paraxite@naver.com>
Date: Sat Sep 3 16:08:03 2022 +0900
added --seamless tag logging to normalize_prompt
commit d922b53c26
Author: prixt <paraxite@naver.com>
Date: Sat Sep 3 15:13:31 2022 +0900
added seamless tiling mode and commands
* This moves the call to half() before model.to(device) to avoid GPU
copy of full model. Improves speed and reduces memory usage dramatically
* This fix contributed by @mh-dm (Mihai)
* Add instructions on how to install alongside pyenv (#393)
Like probably many others, I have a lot of different virtualenvs, one for each project. Most of them are handled by `pyenv`.
After installing according to these instructions I had issues with ´pyenv`and `miniconda` fighting over the $PATH of my system.
But then I stumbled upon this nice solution on SO: https://stackoverflow.com/a/73139031 , upon which I have based my suggested changes.
It runs perfectly on my M1 setup, with the anaconda setup as a virtual environment handled by pyenv.
Feel free to incorporate these instructions as you see fit.
Thanks a million for all your hard work.
* Disabled debug output (#436)
Co-authored-by: Henry van Megen <hvanmegen@gmail.com>
* Add New Logo
Co-authored-by: Håvard Gulldahl <havard@lurtgjort.no>
Co-authored-by: Henry van Megen <h.vanmegen@gmail.com>
Co-authored-by: Henry van Megen <hvanmegen@gmail.com>
Co-authored-by: Lincoln Stein <lincoln.stein@gmail.com>
* macOS CI workflow, dream.py exits with an error, but the workflow completes.
* Files for testing
Co-authored-by: James Reynolds <magnsuviri@me.com>
Co-authored-by: Lincoln Stein <lincoln.stein@gmail.com>
* Add workflow that caches the model, step 1 for CI
* Change name of workflow job
Co-authored-by: James Reynolds <magnsuviri@me.com>
Co-authored-by: Lincoln Stein <lincoln.stein@gmail.com>
* Add instructions on how to install alongside pyenv (#393)
Like probably many others, I have a lot of different virtualenvs, one for each project. Most of them are handled by `pyenv`.
After installing according to these instructions I had issues with ´pyenv`and `miniconda` fighting over the $PATH of my system.
But then I stumbled upon this nice solution on SO: https://stackoverflow.com/a/73139031 , upon which I have based my suggested changes.
It runs perfectly on my M1 setup, with the anaconda setup as a virtual environment handled by pyenv.
Feel free to incorporate these instructions as you see fit.
Thanks a million for all your hard work.
* .gitignore WebUI temp files
Co-authored-by: Håvard Gulldahl <havard@lurtgjort.no>
Like probably many others, I have a lot of different virtualenvs, one for each project. Most of them are handled by `pyenv`.
After installing according to these instructions I had issues with ´pyenv`and `miniconda` fighting over the $PATH of my system.
But then I stumbled upon this nice solution on SO: https://stackoverflow.com/a/73139031 , upon which I have based my suggested changes.
It runs perfectly on my M1 setup, with the anaconda setup as a virtual environment handled by pyenv.
Feel free to incorporate these instructions as you see fit.
Thanks a million for all your hard work.
* start refactoring -not yet functional
* first phase of refactor done - not sure weighted prompts working
* Second phase of refactoring. Everything mostly working.
* The refactoring has moved all the hard-core inference work into
ldm.dream.generator.*, where there are submodules for txt2img and
img2img. inpaint will go in there as well.
* Some additional refactoring will be done soon, but relatively
minor work.
* fix -save_orig flag to actually work
* add @neonsecret attention.py memory optimization
* remove unneeded imports
* move token logging into conditioning.py
* add placeholder version of inpaint; porting in progress
* fix crash in img2img
* inpainting working; not tested on variations
* fix crashes in img2img
* ported attention.py memory optimization #117 from basujindal branch
* added @torch_no_grad() decorators to img2img, txt2img, inpaint closures
* Final commit prior to PR against development
* fixup crash when generating intermediate images in web UI
* rename ldm.simplet2i to ldm.generate
* add backward-compatibility simplet2i shell with deprecation warning
* add back in mps exception, addresses @vargol comment in #354
* replaced Conditioning class with exported functions
* fix wrong type of with_variations attribute during intialization
* changed "image_iterator()" to "get_make_image()"
* raise NotImplementedError for calling get_make_image() in parent class
* Update ldm/generate.py
better error message
Co-authored-by: Kevin Gibbons <bakkot@gmail.com>
* minor stylistic fixes and assertion checks from code review
* moved get_noise() method into img2img class
* break get_noise() into two methods, one for txt2img and the other for img2img
* inpainting works on non-square images now
* make get_noise() an abstract method in base class
* much improved inpainting
Co-authored-by: Kevin Gibbons <bakkot@gmail.com>
* toil(reqs): split requirements to per-platform
Signed-off-by: Ben Alkov <ben.alkov@gmail.com>
* toil(reqs): fix for Win and Lin...
...allow pip to resolve latest torch, numpy
Signed-off-by: Ben Alkov <ben.alkov@gmail.com>
* toil(install): update reqs in Win install notebook
Signed-off-by: Ben Alkov <ben.alkov@gmail.com>
Signed-off-by: Ben Alkov <ben.alkov@gmail.com>
* Update README.md with new Anaconda install steps (#347)
pip3 version did not work for me and this is the recommended way to install Anaconda now it seems
* fix save_original flag saving to the same filename
Before this, the `--save_orig` flag was not working. The upscaled/GFPGAN would overwrite the original output image.
Co-authored-by: greentext2 <112735219+greentext2@users.noreply.github.com>
* Switch to regular pytorch channel and restore Python 3.10 for Macs.
Although pytorch-nightly should in theory be faster, it is currently
causing increased memory usage and slower iterations:
https://github.com/lstein/stable-diffusion/pull/283#issuecomment-1234784885
This changes the environment-mac.yaml file back to the regular pytorch
channel and moves the `transformers` dep into pip for now (since it
cannot be satisfied until tokenizers>=0.11 is built for Python 3.10).
* Specify versions for Pip packages as well.
This merge adds the following major features:
* Support for image variations.
* Security fix for webGUI (binds to localhost by default, use
--host=0.0.0.0 to allow access from external interface.
* Scalable configs/models.yaml configuration file for adding more
models as they become available.
* More tuning and exception handling for M1 hardware running MPS.
* Various documentation fixes.
* Update README.md
Those []() link pairs get me every time.
* New issue template
* Added issue templates
* feat(install+run): add notebook for Windows for from-zero install...
...and run
Tested with JupyterLab and VSCode
Signed-off-by: Ben Alkov <ben.alkov@gmail.com>
Signed-off-by: Ben Alkov <ben.alkov@gmail.com>
Co-authored-by: Lincoln Stein <lincoln.stein@gmail.com>
Co-authored-by: James Reynolds <magnusviri@users.noreply.github.com>
Co-authored-by: James Reynolds <magnsuviri@me.com>
* check that fixed side provided when requesting variant parameter sweep
(-v)
* move _get_noise() into outer scope to improve readability -
refactoring of big method call needed
By supplying --model (defaulting to stable-diffusion-1.4) a user can specify which model to load.
Width/Height/Config Location/Weights Location are referenced from configs/models.yaml
models.yaml can serve as a base for expanding our support for other versions of Latent/Stable Diffusion.
Contained are parameters for default width/height, as well as where to find the config and weights for this model.
Adding a new model is as simple as adding to this file.
I'm using stable-diffusion on a 2022 Macbook M2 Air with 24 GB unified memory.
I see this taking about 2.0s/it.
I've moved many deps from pip to conda-forge, to take advantage of the
precompiled binaries. Some notes for Mac users, since I've seen a lot of
confusion about this:
One doesn't need the `apple` channel to run this on a Mac-- that's only
used by `tensorflow-deps`, required for running tensorflow-metal. For
that, I have an example environment.yml here:
https://developer.apple.com/forums/thread/711792?answerId=723276022#723276022
However, the `CONDA_ENV=osx-arm64` environment variable *is* needed to
ensure that you do not run any Intel-specific packages such as `mkl`,
which will fail with [cryptic errors](https://github.com/CompVis/stable-diffusion/issues/25#issuecomment-1226702274)
on the ARM architecture and cause the environment to break.
I've also added a comment in the env file about 3.10 not working yet.
When it becomes possible to update, those commands run on an osx-arm64
machine should work to determine the new version set.
Here's what a successful run of dream.py should look like:
```
$ python scripts/dream.py --full_precision SIGABRT(6) ↵ 08:42:59
* Initializing, be patient...
Loading model from models/ldm/stable-diffusion-v1/model.ckpt
LatentDiffusion: Running in eps-prediction mode
DiffusionWrapper has 859.52 M params.
making attention of type 'vanilla' with 512 in_channels
Working with z of shape (1, 4, 32, 32) = 4096 dimensions.
making attention of type 'vanilla' with 512 in_channels
Using slower but more accurate full-precision math (--full_precision)
>> Setting Sampler to k_lms
model loaded in 6.12s
* Initialization done! Awaiting your command (-h for help, 'q' to quit)
dream> "an astronaut riding a horse"
Generating: 0%| | 0/1 [00:00<?, ?it/s]/Users/corajr/Documents/lstein/ldm/modules/embedding_manager.py:152: UserWarning: The operator 'aten::nonzero' is not currently supported on the MPS backend and will fall back to run on the CPU. This may have performance implications. (Triggered internally at /Users/runner/work/_temp/anaconda/conda-bld/pytorch_1662016319283/work/aten/src/ATen/mps/MPSFallback.mm:11.)
placeholder_idx = torch.where(
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 50/50 [01:37<00:00, 1.95s/it]
Generating: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [01:38<00:00, 98.55s/it]
Usage stats:
1 image(s) generated in 98.60s
Max VRAM used for this generation: 0.00G
Outputs:
outputs/img-samples/000001.1525943180.png: "an astronaut riding a horse" -s50 -W512 -H512 -C7.5 -Ak_lms -F -S1525943180
```
- move all device init logic to T2I.__init__
- handle m1 specific edge case with autocast device type
- check torch.cuda.is_available before using cuda
* This functionality is triggered by the --fit option in the CLI (default
false), and by the "fit" checkbox in the WebGUI (default True)
* In addition, this commit contains a number of whitespace changes to
make the code more readable, as well as an attempt to unify the visual
appearance of info and warning messages.
* fix AttributeError crash when running on non-CUDA systems; closes issue #234 and issue #250
* although this prevents dream.py script from crashing immediately on MPS systems, MPS support still very much a work in progress.
* Allow configuration of which SD model to use
Closes https://github.com/lstein/stable-diffusion/issues/49 The syntax isn't quite the same (opting for --weights over --model), although --weights is more in-line with the existing naming convention.
This method also locks us into models in the models/ldm/stable-diffusion-v1/ directory. Personally, I'm not averse to this, although a secondary solution may be necessary if we wish to supply weights from an external directory.
* Fix typo
* Allow either filename OR filepath input for arg
This approach allows both
--weights SD13
--weights C:/StableDiffusion/models/ldm/stable-diffusion-v1/SD13.ckpt
Fixed merging embeddings based on the changes made in textual inversion. Tested and working. Inverted their logic to prioritize Stable Diffusion implementation over alternatives, but left the option for alternatives to still be used.
* Optimizations to the training model
Based on the changes made in
textual_inversion I carried over the relevant changes that improve model training. These changes reduce the amount of memory used, significantly improve the speed at which training runs, and improves the quality of the results.
It also fixes the problem where the model trainer wouldn't automatically stop when it hit the set number of steps.
* Update main.py
Cleaned up whitespace
Removed the changes to the index.html and .gitattributes for this PR. Will add them in separate PRs.
Applied recommended change for resolving the case issue.
Case sensitivity between os.getcwd and os.realpath can fail due to different drive letter casing. C:\ vs c:\. This change addresses that by normalizing the strings before comparing.
This adds correct treatment of upscaling/face-fixing within the WebUI.
Also adds a basic status message so that the user knows what's happening
during the post-processing steps.
This adds an option -t argument that will print out color-coded tokenization, SD has a maximum of 77 tokens, it silently discards tokens over the limit if your prompt is too long.
By using -t you can see how your prompt is being tokenized which helps prompt crafting.
- Quenched tokenizer warnings during model initialization.
- Changed "batch" to "iterations" for generating multiple images in
order to conserve vram.
- Updated README.
- Moved static folder from under scripts to top level. Can store other
static content there in future.
- Added screenshot of web server in action (to static folder).
example: "an apple: a banana:0 a watermelon:0.5"
the above example turns into 3 sub-prompts:
"an apple" 1.0 (default if no value)
"a banana" 0.0
"a watermelon" 0.5
The weights are added and normalized
The resulting image will be: apple 66%, banana 0%, watermelon 33%
This allows users with 6 & 8gb cards to run 512x512 and for even larger resolutions for bigger GPUs
I compared the output in Beyond Compare and there are minor differences detected at tolerance 3, but side by side the differences are not perceptible.
You must not distribute the weights provided to you directly or indirectly without explicit consent of the authors.
You must not distribute harmful, offensive, dehumanizing content or otherwise harmful representations of people or their environments, cultures, religions, etc. produced with the model weights
or other generated content described in the "Misuse and Malicious Use" section in the model card.
The model weights are provided for research purposes only.
MIT License
Copyright (c) 2022 Lincoln D. Stein (https://github.com/lstein)
This software is derived from a fork of the source code available from
https://github.com/pesser/stable-diffusion and
https://github.com/CompViz/stable-diffusion. They carry the following
copyrights:
Copyright (c) 2022 Machine Vision and Learning Group, LMU Munich
Copyright (c) 2022 Robin Rombach and Patrick Esser and contributors
Please see individual source code files for copyright and authorship
attributions.
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
@@ -11,4 +29,4 @@ FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
There is now a command-line script, located in scripts/dream.py, which
provides an interactive interface to image generation similar to
the "dream mothership" bot that Stable AI provided on its Discord
server. The advantage of this is that the lengthy model
initialization only happens once. After that image generation is
fast.
[![CI checks on main badge]][CI checks on main link] [![CI checks on dev badge]][CI checks on dev link] [![latest commit to dev badge]][latest commit to dev link]
Note that this has only been tested in the Linux environment!
[![github open issues badge]][github open issues link] [![github open prs badge]][github open prs link]
~~~~
(ldm) ~/stable-diffusion$ ./scripts/dream.py
* Initializing, be patient...
Loading model from models/ldm/text2img-large/model.ckpt
LatentDiffusion: Running in eps-prediction mode
DiffusionWrapper has 872.30 M params.
making attention of type 'vanilla' with 512 in_channels
Working with z of shape (1, 4, 32, 32) = 4096 dimensions.
making attention of type 'vanilla' with 512 in_channels
Loading Bert tokenizer from "models/bert"
setting sampler to plms
[CI checks on dev badge]: https://flat.badgen.net/github/checks/invoke-ai/InvokeAI/development?label=CI%20status%20on%20dev&cache=900&icon=github
[CI checks on dev link]: https://github.com/invoke-ai/InvokeAI/actions?query=branch%3Adevelopment
[CI checks on main badge]: https://flat.badgen.net/github/checks/invoke-ai/InvokeAI/main?label=CI%20status%20on%20main&cache=900&icon=github
[CI checks on main link]: https://github.com/invoke-ai/InvokeAI/actions/workflows/test-dream-conda.yml
[latest commit to dev badge]: https://flat.badgen.net/github/last-commit/invoke-ai/InvokeAI/development?icon=github&color=yellow&label=last%20dev%20commit&cache=900
[latest commit to dev link]: https://github.com/invoke-ai/InvokeAI/commits/development
Downloading: "https://github.com/DagnyT/hardnet/raw/master/pretrained/train_liberty_with_aug/checkpoint_liberty_with_aug.pth" to /u/lstein/.cache/torch/hub/checkpoints/checkpoint_liberty_with_aug.pth
I added the requirement for torchmetrics to environment.yaml.
### Hardware Requirements
## Installation and support
#### System
Follow the directions from the original README, which starts below, to
configure the environment and install requirements. For support,
please use this repository's GitHub Issues tracking service. Feel free
to send me an email if you use and like the script.
You wil need one of the following:
*Author:* Lincoln D. Stein <lincoln.stein@gmail.com>
- An NVIDIA-based graphics card with 4 GB or more VRAM memory.
- An Apple computer with an M1 chip.
# Original README from CompViz/stable-diffusion
*Stable Diffusion was made possible thanks to a collaboration with [Stability AI](https://stability.ai/) and [Runway](https://runwayml.com/) and builds upon our previous work:*
#### Memory
[**High-Resolution Image Synthesis with Latent Diffusion Models**](https://arxiv.org/abs/2112.10752)<br/>
[Stable Diffusion](#stable-diffusion-v1) is a latent text-to-image diffusion
model.
Thanks to a generous compute donation from [Stability AI](https://stability.ai/) and support from [LAION](https://laion.ai/), we were able to train a Latent Diffusion Model on 512x512 images from a subset of the [LAION-5B](https://laion.ai/blog/laion-5b/) database.
Similar to Google's [Imagen](https://arxiv.org/abs/2205.11487),
this model uses a frozen CLIP ViT-L/14 text encoder to condition the model on text prompts.
With its 860M UNet and 123M text encoder, the model is relatively lightweight and runs on a GPU with at least 10GB VRAM.
See [this section](#stable-diffusion-v1) below and the [model card](https://huggingface.co/CompVis/stable-diffusion).
- At least 6 GB of free disk space for the machine learning model, Python, and all its dependencies.
## Requirements
A suitable [conda](https://conda.io/) environment named `ldm` can be created
and activated with:
#### Note
```
conda env create -f environment.yaml
conda activate ldm
Precision is auto configured based on the device. If however you encounter
errors like 'expected type Float but found Half' or 'not implemented for Half'
you can try starting `dream.py` with the `--precision=float32` flag:
*Note: Stable Diffusion v1 is a general text-to-image diffusion model and therefore mirrors biases and (mis-)conceptions that are present
in its training data.
Details on the training procedure and data, as well as the intended use of the model can be found in the corresponding [model card](https://huggingface.co/CompVis/stable-diffusion).
Research into the safe deployment of general text-to-image models is an ongoing effort. To prevent misuse and harm, we currently provide access to the checkpoints only for [academic research purposes upon request](https://stability.ai/academia-access-form).
**This is an experiment in safe and community-driven publication of a capable and general text-to-image model. We are working on a public release with a more permissive license that also incorporates ethical considerations.***
### Latest Changes
[Request access to Stable Diffusion v1 checkpoints for academic research](https://stability.ai/academia-access-form)
- vNEXT (TODO 2022)
### Weights
- Deprecated `--full_precision` / `-F`. Simply omit it and `dream.py` will auto
configure. To switch away from auto use the new flag like `--precision=float32`.
We currently provide three checkpoints, `sd-v1-1.ckpt`, `sd-v1-2.ckpt` and `sd-v1-3.ckpt`,
which were trained as follows,
- v1.14 (11 September 2022)
- `sd-v1-1.ckpt`: 237k steps at resolution `256x256` on [laion2B-en](https://huggingface.co/datasets/laion/laion2B-en).
194k steps at resolution `512x512` on [laion-high-resolution](https://huggingface.co/datasets/laion/laion-high-resolution) (170M examples from LAION-5B with resolution `>= 1024x1024`).
- `sd-v1-2.ckpt`: Resumed from `sd-v1-1.ckpt`.
515k steps at resolution `512x512` on "laion-improved-aesthetics" (a subset of laion2B-en,
filtered to images with an original size `>= 512x512`, estimated aesthetics score `> 5.0`, and an estimated watermark probability `< 0.5`. The watermark estimate is from the LAION-5B metadata, the aesthetics score is estimated using an [improved aesthetics estimator](https://github.com/christophschuhmann/improved-aesthetic-predictor)).
- `sd-v1-3.ckpt`: Resumed from `sd-v1-2.ckpt`. 195k steps at resolution `512x512` on "laion-improved-aesthetics" and 10\% dropping of the text-conditioning to improve [classifier-free guidance sampling](https://arxiv.org/abs/2207.12598).
- Memory optimizations for small-RAM cards. 512x512 now possible on 4 GB GPUs.
- Full support for Apple hardware with M1 or M2 chips.
- Add "seamless mode" for circular tiling of image. Generates beautiful effects.
([prixt](https://github.com/prixt)).
- Inpainting support.
- Improved web server GUI.
- Lots of code and documentation cleanups.
Evaluations with different classifier-free guidance scales (1.5, 2.0, 3.0, 4.0,
5.0, 6.0, 7.0, 8.0) and 50 PLMS sampling
steps show the relative improvements of the checkpoints:
python scripts/txt2img.py --prompt "a photograph of an astronaut riding a horse" --plms
```
A full set of contribution guidelines, along with templates, are in progress, but for now the most
important thing is to **make your pull request against the "development" branch**, and not against
"main". This will help keep public breakage to a minimum and will allow you to propose more radical
changes.
By default, this uses a guidance scale of `--scale 7.5`, [Katherine Crowson's implementation](https://github.com/CompVis/latent-diffusion/pull/51) of the [PLMS](https://arxiv.org/abs/2202.09778) sampler,
and renders images of size 512x512 (which it was trained on) in 50 steps. All supported arguments are listed below (type `python scripts/txt2img.py --help`).
--config CONFIG path to config which constructs model
--ckpt CKPT path to checkpoint of model
--seed SEED the seed (for reproducible sampling)
--precision {full,autocast}
evaluate at this precision
### Support
```
Note: The inference config for all v1 versions is designed to be used with EMA-only checkpoints.
For this reason `use_ema=False` is set in the configuration, otherwise the code will try to switch from
non-EMA to EMA weights. If you want to examine the effect of EMA vs no EMA, we provide "full" checkpoints
which contain both types of weights. For these, `use_ema=False` will load and use the non-EMA weights.
For support, please use this repository's GitHub Issues tracking service. Feel free to send me an
email if you use and like the script.
Original portions of the software are Copyright (c) 2020
[Lincoln D. Stein](https://github.com/lstein)
#### Diffusers Integration
Another way to download and sample Stable Diffusion is by using the [diffusers library](https://github.com/huggingface/diffusers/tree/main#new--stable-diffusion-is-now-fully-compatible-with-diffusers)
```py
# make sure you're logged in with `huggingface-cli login`
prompt="a photo of an astronaut riding a horse on mars"
withautocast("cuda"):
image=pipe(prompt)["sample"][0]
image.save("astronaut_rides_horse.png")
```
### Image Modification with Stable Diffusion
By using a diffusion-denoising mechanism as first proposed by [SDEdit](https://arxiv.org/abs/2108.01073), the model can be used for different
tasks such as text-guided image-to-image translation and upscaling. Similar to the txt2img sampling script,
we provide a script to perform image modification with Stable Diffusion.
The following describes an example where a rough sketch made in [Pinta](https://www.pinta-project.com/) is converted into a detailed artwork.
```
python scripts/img2img.py --prompt "A fantasy landscape, trending on artstation" --init-img <path-to-img.jpg> --strength 0.8
```
Here, strength is a value between 0.0 and 1.0, that controls the amount of noise that is added to the input image.
Values that approach 1.0 allow for lots of variations but will also produce images that are not semantically consistent with the input. See the following example.
This procedure can, for example, also be used to upscale samples from the base model.
## Comments
- Our codebase for the diffusion models builds heavily on [OpenAI's ADM codebase](https://github.com/openai/guided-diffusion)
and [https://github.com/lucidrains/denoising-diffusion-pytorch](https://github.com/lucidrains/denoising-diffusion-pytorch).
Thanks for open-sourcing!
- The implementation of the transformer encoder is from [x-transformers](https://github.com/lucidrains/x-transformers) by [lucidrains](https://github.com/lucidrains?tab=repositories).
## BibTeX
```
@misc{rombach2021highresolution,
title={High-Resolution Image Synthesis with Latent Diffusion Models},
author={Robin Rombach and Andreas Blattmann and Dominik Lorenz and Patrick Esser and Björn Ommer},
year={2021},
eprint={2112.10752},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
### Further Reading
Please see the original README for more information on this software and underlying algorithm,
located in the file [README-CompViz.md](docs/other/README-CompViz.md).
- Supports a Google Colab notebook for a standalone server running on Google hardware [Arturo Mendivil](https://github.com/artmen1516)
- WebUI supports GFPGAN/ESRGAN facial reconstruction and upscaling [Kevin Gibbons](https://github.com/bakkot)
- WebUI supports incremental display of in-progress images during generation [Kevin Gibbons](https://github.com/bakkot)
- Output directory can be specified on the dream> command line.
- The grid was displaying duplicated images when not enough images to fill the final row [Muhammad Usama](https://github.com/SMUsamaShah)
- Can specify --grid on dream.py command line as the default.
- Miscellaneous internal bug and stability fixes.
---
## v1.12 (28 August 2022)
- Improved file handling, including ability to read prompts from standard input.
(kudos to [Yunsaki](https://github.com/yunsaki)
- The web server is now integrated with the dream.py script. Invoke by adding --web to
the dream.py command arguments.
- Face restoration and upscaling via GFPGAN and Real-ESGAN are now automatically
enabled if the GFPGAN directory is located as a sibling to Stable Diffusion.
VRAM requirements are modestly reduced. Thanks to both [Blessedcoolant](https://github.com/blessedcoolant) and
[Oceanswave](https://github.com/oceanswave) for their work on this.
- You can now swap samplers on the dream> command line. [Blessedcoolant](https://github.com/blessedcoolant)
---
## v1.11 (26 August 2022)
- NEW FEATURE: Support upscaling and face enhancement using the GFPGAN module. (kudos to [Oceanswave](https://github.com/Oceanswave)
- You now can specify a seed of -1 to use the previous image's seed, -2 to use the seed for the image generated before that, etc.
Seed memory only extends back to the previous command, but will work on all images generated with the -n# switch.
- Variant generation support temporarily disabled pending more general solution.
- Created a feature branch named **yunsaki-morphing-dream** which adds experimental support for
iteratively modifying the prompt and its parameters. Please see[ Pull Request #86](https://github.com/lstein/stable-diffusion/pull/86)
for a synopsis of how this works. Note that when this feature is eventually added to the main branch, it will may be modified
significantly.
---
## v1.10 (25 August 2022)
- A barebones but fully functional interactive web server for online generation of txt2img and img2img.
---
## v1.09 (24 August 2022)
- A new -v option allows you to generate multiple variants of an initial image
in img2img mode. (kudos to [Oceanswave](https://github.com/Oceanswave). [
See this discussion in the PR for examples and details on use](https://github.com/lstein/stable-diffusion/pull/71#issuecomment-1226700810))
- Added ability to personalize text to image generation (kudos to [Oceanswave](https://github.com/Oceanswave) and [nicolai256](https://github.com/nicolai256))
- Enabled all of the samplers from k_diffusion
---
## v1.08 (24 August 2022)
- Escape single quotes on the dream> command before trying to parse. This avoids
parse errors.
- Removed instruction to get Python3.8 as first step in Windows install.
Anaconda3 does it for you.
- Added bounds checks for numeric arguments that could cause crashes.
- Cleaned up the copyright and license agreement files.
---
## v1.07 (23 August 2022)
- Image filenames will now never fill gaps in the sequence, but will be assigned the
next higher name in the chosen directory. This ensures that the alphabetic and chronological
sort orders are the same.
---
## v1.06 (23 August 2022)
- Added weighted prompt support contributed by [xraxra](https://github.com/xraxra)
- Example of using weighted prompts to tweak a demonic figure contributed by [bmaltais](https://github.com/bmaltais)
---
## v1.05 (22 August 2022 - after the drop)
- Filenames now use the following formats:
000010.95183149.png -- Two files produced by the same command (e.g. -n2),
000010.26742632.png -- distinguished by a different seed.
000011.455191342.01.png -- Two files produced by the same command using
000011.455191342.02.png -- a batch size>1 (e.g. -b2). They have the same seed.
000011.4160627868.grid#1-4.png -- a grid of four images (-g); the whole grid can
be regenerated with the indicated key
- It should no longer be possible for one image to overwrite another
- You can use the "cd" and "pwd" commands at the dream> prompt to set and retrieve
the path of the output directory.
---
## v1.04 (22 August 2022 - after the drop)
- Updated README to reflect installation of the released weights.
- Suppressed very noisy and inconsequential warning when loading the frozen CLIP
tokenizer.
---
## v1.03 (22 August 2022)
- The original txt2img and img2img scripts from the CompViz repository have been moved into
a subfolder named "orig_scripts", to reduce confusion.
---
## v1.02 (21 August 2022)
- A copy of the prompt and all of its switches and options is now stored in the corresponding
image in a tEXt metadata field named "Dream". You can read the prompt using scripts/images2prompt.py,
or an image editor that allows you to explore the full metadata.
**Please run "conda env update" to load the k_lms dependencies!!**
---
## v1.01 (21 August 2022)
- added k_lms sampling.
**Please run "conda env update" to load the k_lms dependencies!!**
- use half precision arithmetic by default, resulting in faster execution and lower memory requirements
Pass argument --full_precision to dream.py to get slower but more accurate image generation
| `--prompt_as_dir` | `-p` | `False` | Name output directories using the prompt text. |
| `--from_file <path>` | | `None` | Read list of prompts from a file. Use `-` to read from standard input |
| `--model <modelname>` | | `stable-diffusion-1.4` | Loads model specified in configs/models.yaml. Currently one of "stable-diffusion-1.4" or "laion400m" |
| `--full_precision` | `-F` | `False` | Run in slower full-precision mode. Needed for Macintosh M1/M2 hardware and some older video cards. |
| `--web` | | `False` | Start in web server mode |
| `--host <ip addr>` | | `localhost` | Which network interface web server should listen on. Set to 0.0.0.0 to listen on any. |
| `--port <port>` | | `9090` | Which port web server should listen for requests on. |
| `--config <path>` | | `configs/models.yaml` | Configuration file for models and their weights. |
| `--iterations <int>` | `-n<int>` | `1` | How many images to generate per prompt. |
| `--grid` | `-g` | `False` | Save all image series as a grid rather than individually. |
| `--sampler <sampler>` | `-A<sampler>` | `k_lms` | Sampler to use. Use `-h` to get list of available samplers. |
| `--seamless` | | `False` | Create interesting effects by tiling elements of the image. |
| `--embedding_path <path>` | | `None` | Path to pre-trained embedding manager checkpoints, for custom models |
| `--gfpgan_dir` | | `src/gfpgan` | Path to where GFPGAN is installed. |
| `--gfpgan_model_path` | | `experiments/pretrained_models/GFPGANv1.4.pth` | Path to GFPGAN model file, relative to `--gfpgan_dir`. |
| `--device <device>` | `-d<device>` | `torch.cuda.current_device()` | Device to run SD on, e.g. "cuda:0" |
| `--free_gpu_mem` | | `False` | Free GPU memory after sampling, to allow image decoding and saving in low VRAM conditions |
| `--precision` | | `auto` | Set model precision, default is selected by device. Options: auto, float32, float16, autocast |
| --iterations <int> | -n<int> | 1 | How many images to generate from this prompt |
| --steps <int> | -s<int> | 50 | How many steps of refinement to apply |
| --cfg_scale <float>| -C<float> | 7.5 | How hard to try to match the prompt to the generated image; any number greater than 1.0 works, but the useful range is roughly 5.0 to 20.0 |
| --seed <int> | -S<int> | None | Set the random seed for the next series of images. This can be used to recreate an image generated previously.|
| --sampler <sampler>| -A<sampler>| k_lms | Sampler to use. Use -h to get list of available samplers. |
| --hires_fix | | | Larger images often have duplication artefacts. This option suppresses duplicates by generating the image at low res, and then using img2img to increase the resolution |
| --grid | -g | False | Turn on grid mode to return a single image combining all the images generated by this prompt |
| --individual | -i | True | Turn off grid mode (deprecated; leave off --grid instead) |
| --outdir <path> | -o<path> | outputs/img_samples | Temporarily change the location of these images |
| --log_tokenization | -t | False | Display a color-coded list of the parsed tokens derived from the prompt |
| --skip_normalization| -x | False | Weighted subprompts will not be normalized. See [Weighted Prompts](./OTHER.md#weighted-prompts) |
| --upscale <int> <float> | -U <int> <float> | -U 1 0.75| Upscale image by magnification factor (2, 4), and set strength of upscaling (0.0-1.0). If strength not set, will default to 0.75. |
| --gfpgan_strength <float> | -G <float> | -G0 | Fix faces using the GFPGAN algorithm; argument indicates how hard the algorithm should try (0.0-1.0) |
| --save_original | -save_orig| False | When upscaling or fixing faces, this will cause the original image to be saved rather than replaced. |
| --variation <float> |-v<float>| 0.0 | Add a bit of noise (0.0=none, 1.0=high) to the image in order to generate a series of variations. Usually used in combination with -S<seed> and -n<int> to generate a series a riffs on a starting image. See [Variations](./VARIATIONS.md). |
| --with_variations <pattern> | -V<pattern>| None | Combine two or more variations. See [Variations](./VARIATIONS.md) for now to use this. |
Note that the width and height of the image must be multiples of
64. You can provide different values, but they will be rounded down to
the nearest multiple of 64.
### This is an example of img2img:
~~~~
dream> waterfall and rainbow -I./vacation-photo.png -W640 -H480 --fit
~~~~
This will modify the indicated vacation photograph by making it more
like the prompt. Results will vary greatly depending on what is in the
image. We also ask to --fit the image into a box no bigger than
640x480. Otherwise the image size will be identical to the provided
photo and you may run out of memory if it is large.
In addition to the command-line options recognized by txt2img, img2img
| --init_img <path> | -I<path> | None | Path to the initialization image |
| --fit | -F | False | Scale the image to fit into the specified -H and -W dimensions |
| --strength <float> | -s<float> | 0.75 | How hard to try to match the prompt to the initial image. Ranges from 0.0-0.99, with higher values replacing the initial image completely.|
### This is an example of inpainting:
~~~~
dream> waterfall and rainbow -I./vacation-photo.png -M./vacation-mask.png -W640 -H480 --fit
~~~~
This will do the same thing as img2img, but image alterations will
only occur within transparent areas defined by the mask file specified
by -M. You may also supply just a single initial image with the areas
to overpaint made transparent, but you must be careful not to destroy
the pixels underneath when you create the transparent areas. See
[Inpainting](./INPAINTING.md) for details.
inpainting accepts all the arguments used for txt2img and img2img, as
## **Creating Transparent Regions for Inpainting**
Inpainting is really cool. To do it, you start with an initial image and use a photoeditor to make
one or more regions transparent (i.e. they have a "hole" in them). You then provide the path to this
image at the dream> command line using the `-I` switch. Stable Diffusion will only paint within the
transparent region.
There's a catch. In the current implementation, you have to prepare the initial image correctly so
that the underlying colors are preserved under the transparent area. Many imaging editing
applications will by default erase the color information under the transparent pixels and replace
them with white or black, which will lead to suboptimal inpainting. You also must take care to
export the PNG file in such a way that the color information is preserved.
If your photoeditor is erasing the underlying color information, `dream.py` will give you a big fat
warning. If you can't find a way to coax your photoeditor to retain color values under transparent
areas, then you can combine the `-I` and `-M` switches to provide both the original unedited image
and the masked (partially transparent) image:
```bash
dream> "man with cat on shoulder" -I./images/man.png -M./images/man-transparent.png
```
We are hoping to get rid of the need for this workaround in an upcoming release.
---
## Recipe for GIMP
[GIMP](https://www.gimp.org/) is a popular Linux photoediting tool.
1. Open image in GIMP.
2. Layer->Transparency->Add Alpha Channel
3. Use lasoo tool to select region to mask
4. Choose Select -> Float to create a floating selection
5. Open the Layers toolbar (++ctrl+l++) and select "Floating Selection"
6. Set opacity to 0%
7. Export as PNG
8. In the export dialogue, Make sure the "Save colour values from
transparent pixels" checkbox is selected.
## Recipe for Adobe Photoshop
1. Open image in Photoshop

2. Use any of the selection tools (Marquee, Lasso, or Wand) to select the area you desire to inpaint.

3. Because we'll be applying a mask over the area we want to preserve, you should now select the inverse by using the ++shift+ctrl+i++ shortcut, or right clicking and using the "Select Inverse" option.
4. You'll now create a mask by selecting the image layer, and Masking the selection. Make sure that you don't delete any of the undrlying image, or your inpainting results will be dramatically impacted.

5. Make sure to hide any background layers that are present. You should see the mask applied to your image layer, and the image on your canvas should display the checkered background.

6. Save the image as a transparent PNG by using the "Save a Copy" option in the File menu, or using the Alt + Ctrl + S keyboard shortcut

7. After following the inpainting instructions above (either through the CLI or the Web UI), marvel at your newfound ability to selectively dream. Lookin' good!

8. In the export dialogue, Make sure the "Save colour values from transparent pixels" checkbox is selected.
The seamless tiling mode causes generated images to seamlessly tile with itself. To use it, add the
`--seamless` option when starting the script which will result in all generated images to tile, or
for each `dream>` prompt as shown here:
```python
dream>"pond garden with lotus by claude monet"--seamless-s100-n4
```
---
## **Shortcuts: Reusing Seeds**
Since it is so common to reuse seeds while refining a prompt, there is now a shortcut as of version
1.11. Provide a `**-S**` (or `**--seed**`) switch of `-1` to use the seed of the most recent image
generated. If you produced multiple images with the `**-n**` switch, then you can go back further
using -2, -3, etc. up to the first image generated by the previous command. Sorry, but you can't go
back further than one command.
Here's an example of using this to do a quick refinement. It also illustrates using the new `**-G**`
switch to turn on upscaling and face enhancement (see previous section):
```bash
dream> a cute child playing hopscotch -G0.5
[...]
outputs/img-samples/000039.3498014304.png: "a cute child playing hopscotch" -s50 -W512 -H512 -C7.5 -mk_lms -S3498014304
# I wonder what it will look like if I bump up the steps and set facial enhancement to full strength?
dream> a cute child playing hopscotch -G1.0 -s100 -S -1
reusing previous seed 3498014304
[...]
outputs/img-samples/000040.3498014304.png: "a cute child playing hopscotch" -G1.0 -s100 -W512 -H512 -C7.5 -mk_lms -S3498014304
```
---
## **Weighted Prompts**
You may weight different sections of the prompt to tell the sampler to attach different levels of
priority to them, by adding `:(number)` to the end of the section you wish to up- or downweight. For
example consider this prompt:
```bash
tabby cat:0.25 white duck:0.75 hybrid
```
This will tell the sampler to invest 25% of its effort on the tabby cat aspect of the image and 75%
on the white duck aspect (surprisingly, this example actually works). The prompt weights can use any
combination of integers and floating point numbers, and they do not need to add up to 1.
---
## Thresholding and Perlin Noise Initialization Options
Two new options are the thresholding (`--threshold`) and the perlin noise initialization (`--perlin`) options. Thresholding limits the range of the latent values during optimization, which helps combat oversaturation with higher CFG scale values. Perlin noise initialization starts with a percentage (a value ranging from 0 to 1) of perlin noise mixed into the initial noise. Both features allow for more variations and options in the course of generating images.
For better intuition into what these options do in practice, [here is a graphic demonstrating them both](static/truncation_comparison.jpg) in use. In generating this graphic, perlin noise at initialization was programmatically varied going across on the diagram by values 0.0, 0.1, 0.2, 0.4, 0.5, 0.6, 0.8, 0.9, 1.0; and the threshold was varied going down from
0, 1, 2, 3, 4, 5, 10, 20, 100. The other options are fixed, so the initial prompt is as follows (no thresholding or perlin noise):
```
a portrait of a beautiful young lady -S 1950357039 -s 100 -C 20 -A k_euler_a --threshold 0 --perlin 0
```
Here's an example of another prompt used when setting the threshold to 5 and perlin noise to 0.2:
```
a portrait of a beautiful young lady -S 1950357039 -s 100 -C 20 -A k_euler_a --threshold 5 --perlin 0.2
```
Note: currently the thresholding feature is only implemented for the k-diffusion style samplers, and empirically appears to work best with `k_euler_a` and `k_dpm_2_a`. Using 0 disables thresholding. Using 0 for perlin noise disables using perlin noise for initialization. Finally, using 1 for perlin noise uses only perlin noise for initialization.
---
## **Simplified API**
For programmers who wish to incorporate stable-diffusion into other products, this repository
includes a simplified API for text to image generation, which lets you create images from a prompt
in just three lines of code:
```bash
from ldm.generate import Generate
g= Generate()
outputs= g.txt2img("a unicorn in manhattan")
```
Outputs is a list of lists in the format [filename1,seed1],[filename2,seed2]...].
Please see ldm/generate.py for more information. A set of example scripts is coming RSN.
---
## **Preload Models**
In situations where you have limited internet connectivity or are blocked behind a firewall, you can
use the preload script to preload the required files for Stable Diffusion to run.
The preload script `scripts/preload_models.py` needs to be run once at least while connected to the
internet. In the following runs, it will load up the cached versions of the required files from the
Downloading: "https://github.com/DagnyT/hardnet/raw/master/pretrained/train_liberty_with_aug/checkpoint_liberty_with_aug.pth" to /u/lstein/.cache/torch/hub/checkpoints/checkpoint_liberty_with_aug.pth
You may weight different sections of the prompt to tell the sampler to attach different levels of
priority to them, by adding `:(number)` to the end of the section you wish to up- or downweight. For
example consider this prompt:
```bash
tabby cat:0.25 white duck:0.75 hybrid
```
This will tell the sampler to invest 25% of its effort on the tabby cat aspect of the image and 75%
on the white duck aspect (surprisingly, this example actually works). The prompt weights can use any
combination of integers and floating point numbers, and they do not need to add up to 1.
---
## **Negative and Unconditioned Prompts**
Any words between a pair of square brackets will try and be ignored by Stable Diffusion's model during generation of images.
```bash
this is a test prompt [not really] to make you understand [cool] how this works.
```
In the above statement, the words 'not really cool` will be ignored by Stable Diffusion.
Here's a prompt that depicts what it does.
original prompt:
`#!bash "A fantastical translucent poney made of water and foam, ethereal, radiant, hyperalism, scottish folklore, digital painting, artstation, concept art, smooth, 8 k frostbite 3 engine, ultra detailed, art by artgerm and greg rutkowski and magali villeneuve" -s 20 -W 512 -H 768 -C 7.5 -A k_euler_a -S 1654590180`
That image has a woman, so if we want the horse without a rider, we can influence the image not to have a woman by putting [woman] in the prompt, like this:
`#!bash "A fantastical translucent poney made of water and foam, ethereal, radiant, hyperalism, scottish folklore, digital painting, artstation, concept art, smooth, 8 k frostbite 3 engine, ultra detailed, art by artgerm and greg rutkowski and magali villeneuve [woman]" -s 20 -W 512 -H 768 -C 7.5 -A k_euler_a -S 1654590180`
That's nice - but say we also don't want the image to be quite so blue. We can add "blue" to the list of negative prompts, so it's now [woman blue]:
`#!bash "A fantastical translucent poney made of water and foam, ethereal, radiant, hyperalism, scottish folklore, digital painting, artstation, concept art, smooth, 8 k frostbite 3 engine, ultra detailed, art by artgerm and greg rutkowski and magali villeneuve [woman blue]" -s 20 -W 512 -H 768 -C 7.5 -A k_euler_a -S 1654590180`
Getting close - but there's no sense in having a saddle when our horse doesn't have a rider, so we'll add one more negative prompt: [woman blue saddle].
`#!bash "A fantastical translucent poney made of water and foam, ethereal, radiant, hyperalism, scottish folklore, digital painting, artstation, concept art, smooth, 8 k frostbite 3 engine, ultra detailed, art by artgerm and greg rutkowski and magali villeneuve [woman blue saddle]" -s 20 -W 512 -H 768 -C 7.5 -A k_euler_a -S 1654590180`
* The only requirement for words to be ignored is that they are in between a pair of square brackets.
* You can provide multiple words within the same bracket.
* You can provide multiple brackets with multiple words in different places of your prompt. That works just fine.
* To improve typical anatomy problems, you can add negative prompts like `[bad anatomy, extra legs, extra arms, extra fingers, poorly drawn hands, poorly drawn feet, disfigured, out of frame, tiling, bad art, deformed, mutated]`.
As features keep increasing, making the right choices for your needs can become increasingly difficult. What sampler to use? And for how many steps? Do you change the CFG value? Do you use prompt weighting? Do you allow variations?
Even once you have a result, do you blend it with other images? Pass it through `img2img`? With what strength? Do you use inpainting to correct small details? Outpainting to extend cropped sections?
The purpose of this series of documents is to help you better understand these tools, so you can make the best out of them. Feel free to contribute with your own findings!
In this document, we will talk about sampler convergence.
Looking for a short version? Here's a TL;DR in 3 tables.
| Remember |
|:---|
| Results converge as steps (`-s`) are increased (except for `K_DPM_2_A` and `K_EULER_A`). Often at ≥ `-s100`, but may require ≥ `-s700`). |
| Producing a batch of candidate images at low (`-s8` to `-s30`) step counts can save you hours of computation. |
| `K_HEUN` and `K_DPM_2` converge in less steps (but are slower). |
| `K_DPM_2_A` and `K_EULER_A` incorporate a lot of creativity/variability. |
| For most use cases, `K_LMS`, `K_HEUN` and `K_DPM_2` are the best choices (the latter 2 run 0.5x as quick, but tend to converge 2x as quick as `K_LMS`). At very low steps (≤ `-s8`), `K_HEUN` and `K_DPM_2` are not recommended. Use `K_LMS` instead.|
| For variability, use `K_EULER_A` (runs 2x as quick as `K_DPM_2_A`). |
---
### *Sampler results*
Let's start by choosing a prompt and using it with each of our 8 samplers, running it for 10, 20, 30, 40, 50 and 100 steps.
Immediately, you can notice results tend to converge -that is, as `-s` (step) values increase, images look more and more similar until there comes a point where the image no longer changes.
You can also notice how `DDIM` and `PLMS` eventually tend to converge to K-sampler results as steps are increased.
Among K-samplers, `K_HEUN` and `K_DPM_2` seem to require the fewest steps to converge, and even at low step counts they are good indicators of the final result. And finally, `K_DPM_2_A` and `K_EULER_A` seem to do a bit of their own thing and don't keep much similarity with the rest of the samplers.
### *Batch generation speedup*
This realization is very useful because it means you don't need to create a batch of 100 images (`-n100`) at `-s100` to choose your favorite 2 or 3 images.
You can produce the same 100 images at `-s10` to `-s30` using a K-sampler (since they converge faster), get a rough idea of the final result, choose your 2 or 3 favorite ones, and then run `-s100` on those images to polish some details.
The latter technique is 3-8x as quick.
Example:
At 60s per 100 steps.
(Option A) 60s * 100 images = 6000s (100 images at `-s100`, manually picking 3 favorites)
(Option B) 6s * 100 images + 60s * 3 images = 780s (100 images at `-s10`, manually picking 3 favorites, and running those 3 at `-s100` to polish details)
The result is 1 hour and 40 minutes (Option A) vs 13 minutes (Option B).
### *Topic convergance*
Now, these results seem interesting, but do they hold for other topics? How about nature? Food? People? Animals? Let's try!
With nature, you can see how initial results are even more indicative of final result -more so than with characters/people. `K_HEUN` and `K_DPM_2` are again the quickest indicators, almost right from the start. Results also converge faster (e.g. `K_HEUN` converged at `-s21`).
Food. `"a hamburger with a bowl of french fries" -W512 -H512 -C7.5 -S4053222918`
Again, `K_HEUN` and `K_DPM_2` take the fewest number of steps to be good indicators of the final result. `K_DPM_2_A` and `K_EULER_A` seem to incorporate a lot of creativity/variability, capable of producing rotten hamburgers, but also of adding lettuce to the mix. And they're the only samplers that produced an actual 'bowl of fries'!
Animals. `"grown tiger, full body" -W512 -H512 -C7.5 -S3721629802`
`K_HEUN` and `K_DPM_2` once again require the least number of steps to be indicative of the final result (around `-s30`), while other samplers are still struggling with several tails or malformed back legs.
It also takes longer to converge (for comparison, `K_HEUN` required around 150 steps to converge). This is normal, as producing human/animal faces/bodies is one of the things the model struggles the most with. For these topics, running for more steps will often increase coherence within the composition.
People. `"Ultra realistic photo, (Miranda Bloom-Kerr), young, stunning model, blue eyes, blond hair, beautiful face, intricate, highly detailed, smooth, art by artgerm and greg rutkowski and alphonse mucha, stained glass" -W512 -H512 -C7.5 -S2131956332`. This time, we will go up to 300 steps.
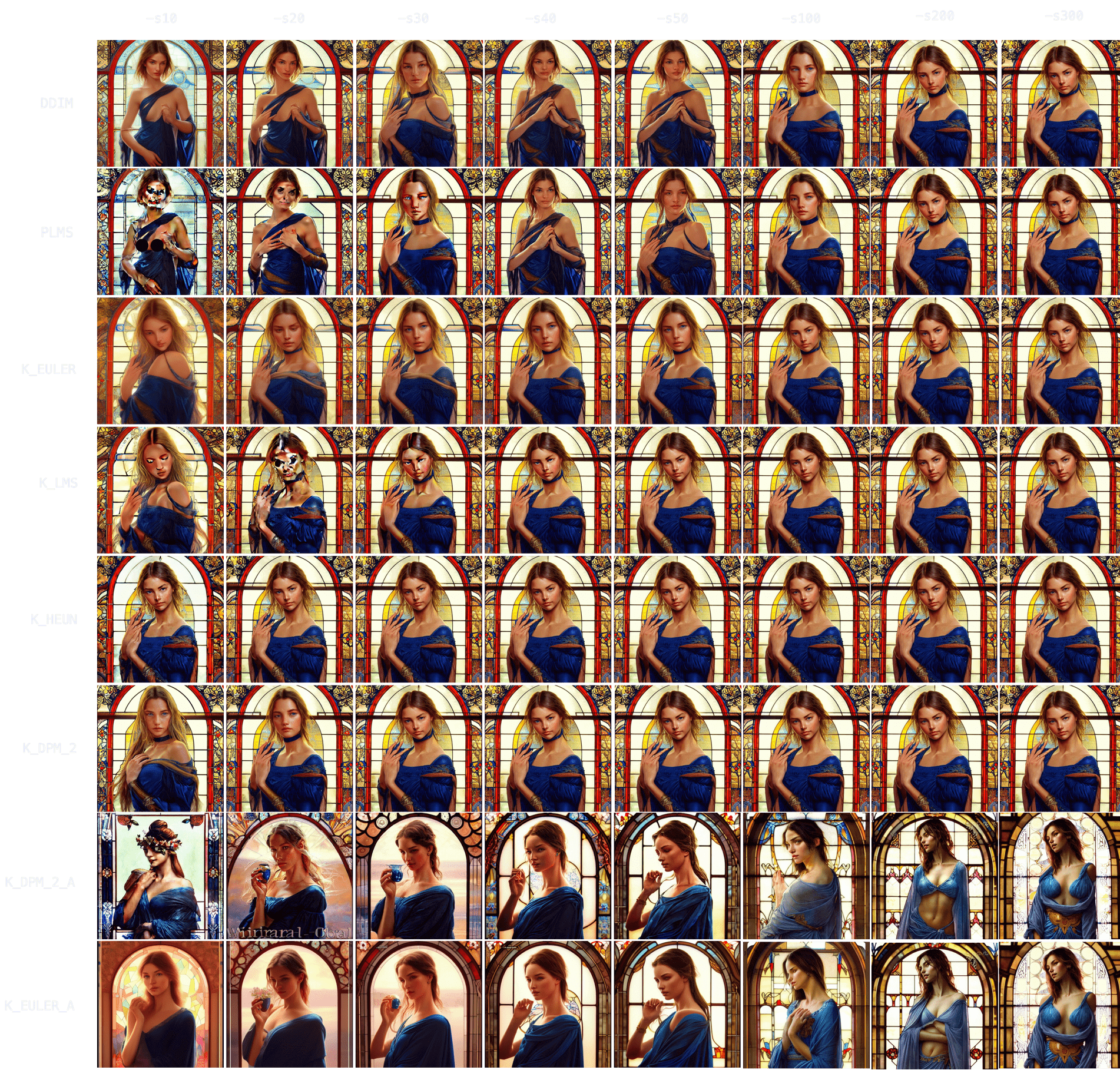
Observing the results, it again takes longer for all samplers to converge (`K_HEUN` took around 150 steps), but we can observe good indicative results much earlier (see: `K_HEUN`). Conversely, `DDIM` and `PLMS` are still undergoing moderate changes (see: lace around her neck), even at `-s300`.
In fact, as we can see in this other experiment, some samplers can take 700+ steps to converge when generating people.
Note also the point of convergence may not be the most desirable state (e.g. I prefer an earlier version of the face, more rounded), but it will probably be the most coherent arms/hands/face attributes-wise. You can always merge different images with a photo editing tool and pass it through `img2img` to smoothen the composition.
### *Sampler generation times*
Once we understand the concept of sampler convergence, we must look into the performance of each sampler in terms of steps (iterations) per second, as not all samplers run at the same speed.
On my M1 Max with 64GB of RAM, for a 512x512 image:
| Sampler | (3 sample average) it/s |
|---|---|
| `DDIM` | 1.89 |
| `PLMS` | 1.86 |
| `K_EULER` | 1.86 |
| `K_LMS` | 1.91 |
| `K_HEUN` | 0.95 (slower) |
| `K_DPM_2` | 0.95 (slower) |
| `K_DPM_2_A` | 0.95 (slower) |
| `K_EULER_A` | 1.86 |
Combining our results with the steps per second of each sampler, three choices come out on top: `K_LMS`, `K_HEUN` and `K_DPM_2` (where the latter two run 0.5x as quick but tend to converge 2x as quick as `K_LMS`). For creativity and a lot of variation between iterations, `K_EULER_A` can be a good choice (which runs 2x as quick as `K_DPM_2_A`).
Additionally, image generation at very low steps (≤ `-s8`) is not recommended for `K_HEUN` and `K_DPM_2`. Use `K_LMS` instead.
Finally, it is relevant to mention that, in general, there are 3 important moments in the process of image formation as steps increase:
* The (earliest) point at which an image becomes a good indicator of the final result (useful for batch generation at low step values, to then improve the quality/coherence of the chosen images via running the same prompt and seed for more steps).
* The (earliest) point at which an image becomes coherent, even if different from the result if steps are increased (useful for batch generation at low step values, where quality/coherence is improved via techniques other than increasing the steps -e.g. via inpainting).
* The point at which an image fully converges.
Hence, remember that your workflow/strategy should define your optimal number of steps, even for the same prompt and seed (for example, if you seek full convergence, you may run `K_LMS` for `-s200` in the case of the red-haired girl, but `K_LMS` and `-s20`-taking one tenth the time- may do as well if your workflow includes adding small details, such as the missing shoulder strap, via `img2img`).
[![CI checks on main badge]][CI checks on main link] [![CI checks on dev badge]][CI checks on dev link] [![latest commit to dev badge]][latest commit to dev link]
[![github open issues badge]][github open issues link] [![github open prs badge]][github open prs link]
[CI checks on dev badge]: https://flat.badgen.net/github/checks/lstein/stable-diffusion/development?label=CI%20status%20on%20dev&cache=900&icon=github
[CI checks on dev link]: https://github.com/lstein/stable-diffusion/actions?query=branch%3Adevelopment
[CI checks on main badge]: https://flat.badgen.net/github/checks/lstein/stable-diffusion/main?label=CI%20status%20on%20main&cache=900&icon=github
[CI checks on main link]: https://github.com/lstein/stable-diffusion/actions/workflows/test-dream-conda.yml
[latest commit to dev badge]: https://flat.badgen.net/github/last-commit/lstein/stable-diffusion/development?icon=github&color=yellow&label=last%20dev%20commit&cache=900
[latest commit to dev link]: https://github.com/lstein/stable-diffusion/commits/development
You can also do text-guided image-to-image translation. For example, turning a
sketch into a detailed drawing.
`strength` is a value between 0.0 and 1.0 that controls the amount of noise that
is added to the input image. Values that approach 1.0 allow for lots of
variations but will also produce images that are not semantically consistent
with the input. 0.0 preserves image exactly, 1.0 replaces it completely.
Make sure your input image size dimensions are multiples of 64 e.g. 512x512.
Otherwise you'll get `Error: product of dimension sizes > 2**31'`. If you still
get the error
[try a different size](https://support.apple.com/guide/preview/resize-rotate-or-flip-an-image-prvw2015/mac#:~:text=image's%20file%20size-,In%20the%20Preview%20app%20on%20your%20Mac%2C%20open%20the%20file,is%20shown%20at%20the%20bottom.)
like 512x256.
If you're on a Docker container, copy your input image into the Docker volume
# for the pre-release weights use the -l or --liaon400m switch
(ldm) ~/InvokeAI$ python3 scripts/dream.py -l
# for the post-release weights do not use the switch
(ldm) ~/InvokeAI$ python3 scripts/dream.py
# for additional configuration switches and arguments, use -h or --help
(ldm) ~/InvokeAI$ python3 scripts/dream.py -h
```
9. Subsequently, to relaunch the script, be sure to run "conda activate ldm" (step 5, second command), enter the `InvokeAI` directory, and then launch the dream script (step 8). If you forget to activate the ldm environment, the script will fail with multiple `ModuleNotFound` errors.
## Updating to newer versions of the script
This distribution is changing rapidly. If you used the `git clone` method (step 5) to download the InvokeAI directory, then to update to the latest and greatest version, launch the Anaconda window, enter `InvokeAI` and type:
```
(ldm) ~/InvokeAI$ git pull
```
This will bring your local copy into sync with the remote one.
# wait until the checkpoint file has downloaded, then proceed
# create symlink to checkpoint
mkdir -p models/ldm/stable-diffusion-v1/
PATH_TO_CKPT="$HOME/Downloads" # (1)!
ln -s "$PATH_TO_CKPT/sd-v1-4.ckpt" \
models/ldm/stable-diffusion-v1/model.ckpt
```
1. or wherever you saved sd-v1-4.ckpt
!!! todo "create Conda Environment"
=== "M1 arm64"
```bash
PIP_EXISTS_ACTION=w CONDA_SUBDIR=osx-arm64 \
conda env create \
-f environment-mac.yml \
&& conda activate ldm
```
=== "Intel x86_64"
```bash
PIP_EXISTS_ACTION=w CONDA_SUBDIR=osx-64 \
conda env create \
-f environment-mac.yml \
&& conda activate ldm
```
```{.bash .annotate title="preload models and run script"}
# only need to do this once
python scripts/preload_models.py
# now you can run SD in CLI mode
python scripts/dream.py --full_precision # (1)!
# or run the web interface!
python scripts/dream.py --web
# The original scripts should work as well.
python scripts/orig_scripts/txt2img.py \
--prompt "a photograph of an astronaut riding a horse" \
--plms
```
Note, `export PIP_EXISTS_ACTION=w` is a precaution to fix `conda env
create -f environment-mac.yml` never finishing in some situations. So
it isn't required but wont hurt.
---
## Common problems
After you followed all the instructions and try to run dream.py, you might
get several errors. Here's the errors I've seen and found solutions for.
### Is it slow?
```bash title="Be sure to specify 1 sample and 1 iteration."
python ./scripts/orig_scripts/txt2img.py \
--prompt "ocean" \
--ddim_steps 5 \
--n_samples 1 \
--n_iter 1
```
---
### Doesn't work anymore?
PyTorch nightly includes support for MPS. Because of this, this setup is
inherently unstable. One morning I woke up and it no longer worked no matter
what I did until I switched to miniforge. However, I have another Mac that works
just fine with Anaconda. If you can't get it to work, please search a little
first because many of the errors will get posted and solved. If you can't find a
solution please
[create an issue](https://github.com/invoke-ai/InvokeAI/issues).
One debugging step is to update to the latest version of PyTorch nightly.
```bash
conda install \
pytorch \
torchvision \
-c pytorch-nightly \
-n ldm
```
If it takes forever to run `conda env create -f environment-mac.yml`, try this:
```bash
git clean -f
conda clean \
--yes \
--all
```
Or you could try to completley reset Anaconda:
```bash
conda update \
--force-reinstall \
-y \
-n base \
-c defaults conda
```
---
### "No module named cv2", torch, 'ldm', 'transformers', 'taming', etc
There are several causes of these errors:
1. Did you remember to `conda activate ldm`? If your terminal prompt begins with
"(ldm)" then you activated it. If it begins with "(base)" or something else
you haven't.
2. You might've run `./scripts/preload_models.py` or `./scripts/dream.py`
instead of `python ./scripts/preload_models.py` or
`python ./scripts/dream.py`. The cause of this error is long so it's below.
<!-- I could not find out where the error is, otherwise would have marked it as a footnote -->
3. if it says you're missing taming you need to rebuild your virtual
environment.
```bash
conda deactivate
conda env remove -n ldm
conda env create -f environment-mac.yml
```
4. If you have activated the ldm virtual environment and tried rebuilding it,
maybe the problem could be that I have something installed that you don't and
you'll just need to manually install it. Make sure you activate the virtual
environment so it installs there instead of globally.
```bash
conda activate ldm
pip install <package name>
```
You might also need to install Rust (I mention this again below).
---
### How many snakes are living in your computer?
You might have multiple Python installations on your system, in which case it's
important to be explicit and consistent about which one to use for a given
project. This is because virtual environments are coupled to the Python that
created it (and all the associated 'system-level' modules).
When you run `python` or `python3`, your shell searches the colon-delimited
locations in the `PATH` environment variable (`echo $PATH` to see that list) in
that order - first match wins. You can ask for the location of the first
`python3` found in your `PATH` with the `which` command like this:
```bash
% which python3
/usr/bin/python3
```
Anything in `/usr/bin` is
[part of the OS](https://developer.apple.com/library/archive/documentation/FileManagement/Conceptual/FileSystemProgrammingGuide/FileSystemOverview/FileSystemOverview.html#//apple_ref/doc/uid/TP40010672-CH2-SW6).
However, `/usr/bin/python3` is not actually python3, but rather a stub that
offers to install Xcode (which includes python 3). If you have Xcode installed
already, `/usr/bin/python3` will execute
`/Library/Developer/CommandLineTools/usr/bin/python3` or
`/Applications/Xcode.app/Contents/Developer/usr/bin/python3` (depending on which
Xcode you've selected with `xcode-select`).
Note that `/usr/bin/python` is an entirely different python - specifically,
python 2. Note: starting in macOS 12.3, `/usr/bin/python` no longer exists.
```bash
% which python3
/opt/homebrew/bin/python3
```
If you installed python3 with Homebrew and you've modified your path to search
for Homebrew binaries before system ones, you'll see the above path.
```bash
% which python
/opt/anaconda3/bin/python
```
If you have Anaconda installed, you will see the above path. There is a
`/opt/anaconda3/bin/python3` also.
We expect that `/opt/anaconda3/bin/python` and `/opt/anaconda3/bin/python3`
should actually be the _same python_, which you can verify by comparing the
output of `python3 -V` and `python -V`.
```bash
(ldm) % which python
/Users/name/miniforge3/envs/ldm/bin/python
```
The above is what you'll see if you have miniforge and correctly activated the
ldm environment, while usingd the standalone setup instructions above.
If you otherwise installed via pyenv, you will get this result:
```bash
(anaconda3-2022.05) % which python
/Users/name/.pyenv/shims/python
```
It's all a mess and you should know
[how to modify the path environment variable](https://support.apple.com/guide/terminal/use-environment-variables-apd382cc5fa-4f58-4449-b20a-41c53c006f8f/mac)
if you want to fix it. Here's a brief hint of the most common ways you can
modify it (don't really have the time to explain it all here).
- ~/.zshrc
- ~/.bash_profile
- ~/.bashrc
- /etc/paths.d
- /etc/path
Which one you use will depend on what you have installed, except putting a file
in /etc/paths.d - which also is the way I prefer to do.
Finally, to answer the question posed by this section's title, it may help to
list all of the `python` / `python3` things found in `$PATH` instead of just the
first hit. To do so, add the `-a` switch to `which`:
```bash
% which -a python3
...
```
This will show a list of all binaries which are actually available in your PATH.
---
### Debugging?
Tired of waiting for your renders to finish before you can see if it works?
Reduce the steps! The image quality will be horrible but at least you'll get
quick feedback.
```bash
python ./scripts/txt2img.py \
--prompt "ocean" \
--ddim_steps 5 \
--n_samples 1 \
--n_iter 1
```
---
### OSError: Can't load tokenizer for 'openai/clip-vit-large-patch14'
```bash
python scripts/preload_models.py
```
---
### "The operator [name] is not current implemented for the MPS device." (sic)
!!! example "example error"
```bash
... NotImplementedError: The operator 'aten::_index_put_impl_' is not current
implemented for the MPS device. If you want this op to be added in priority
during the prototype phase of this feature, please comment on
https://github.com/pytorch/pytorch/issues/77764.
As a temporary fix, you can set the environment variable
`PYTORCH_ENABLE_MPS_FALLBACK=1` to use the CPU as a fallback for this op.
WARNING: this will be slower than running natively on MPS.
RuntimeError: view size is not compatible with input tensor's size and stride (at least one dimension spans across two contiguous subspaces). Use .reshape(...) instead.
```
Update to the latest version of invoke-ai/InvokeAI. We were patching
pytorch but we found a file in stable-diffusion that we could change instead.
This is a 32-bit vs 16-bit problem.
---
### The processor must support the Intel bla bla bla
What? Intel? On an Apple Silicon?
```bash
Intel MKL FATAL ERROR: This system does not meet the minimum requirements for use of the Intel(R) Math Kernel Library. The processor must support the Intel(R) Supplemental Streaming SIMD Extensions 3 (Intel(R) SSSE3) instructions. The processor must support the Intel(R) Streaming SIMD Extensions 4.2 (Intel(R) SSE4.2) instructions. The processor must support the Intel(R) Advanced Vector Extensions (Intel(R) AVX) instructions.
```
This is due to the Intel `mkl` package getting picked up when you try to install
something that depends on it-- Rosetta can translate some Intel instructions but
not the specialized ones here. To avoid this, make sure to use the environment
variable `CONDA_SUBDIR=osx-arm64`, which restricts the Conda environment to only
use ARM packages, and use `nomkl` as described above.
---
### input types 'tensor<2x1280xf32>' and 'tensor<\*xf16>' are not broadcast compatible
May appear when just starting to generate, e.g.:
```bash
dream> clouds
Generating: 0%| | 0/1 [00:00<?, ?it/s]/Users/[...]/dev/stable-diffusion/ldm/modules/embedding_manager.py:152: UserWarning: The operator 'aten::nonzero' is not currently supported on the MPS backend and will fall back to run on the CPU. This may have performance implications. (Triggered internally at /Users/runner/work/_temp/anaconda/conda-bld/pytorch_1662016319283/work/aten/src/ATen/mps/MPSFallback.mm:11.)
placeholder_idx = torch.where(
loc("mps_add"("(mpsFileLoc): /AppleInternal/Library/BuildRoots/20d6c351-ee94-11ec-bcaf-7247572f23b4/Library/Caches/com.apple.xbs/Sources/MetalPerformanceShadersGraph/mpsgraph/MetalPerformanceShadersGraph/Core/Files/MPSGraphUtilities.mm":219:0)): error: input types 'tensor<2x1280xf32>' and 'tensor<*xf16>' are not broadcast compatible
LLVM ERROR: Failed to infer result type(s).
Abort trap: 6
/Users/[...]/opt/anaconda3/envs/ldm/lib/python3.9/multiprocessing/resource_tracker.py:216: UserWarning: resource_tracker: There appear to be 1 leaked semaphore objects to clean up at shutdown
warnings.warn('resource_tracker: There appear to be %d '
Please replace `C:\path\to\sd-v1.4.ckpt` with the correct path to wherever you stashed this file. If you prefer not to copy or move the .ckpt file,
you may instead create a shortcut to it from within `models\ldm\stable-diffusion-v1\`.
9. Start generating images!
```bash
# for the pre-release weights
python scripts\dream.py -l
# for the post-release weights
python scripts\dream.py
```
10. Subsequently, to relaunch the script, first activate the Anaconda command window (step 3),enter the InvokeAI directory (step 5, `cd \path\to\InvokeAI`), run `conda activate ldm` (step 6b), and then launch the dream script (step 9).
**Note:** Tildebyte has written an alternative
["Easy peasy Windows install"](https://github.com/invoke-ai/InvokeAI/wiki/Easy-peasy-Windows-install)
which uses the Windows Powershell and pew. If you are having trouble with
Anaconda on Windows, give this a try (or try it first!)
---
This distribution is changing rapidly. If you used the `git clone` method (step 5) to download the InvokeAI directory, then to update to the latest and greatest version, launch the Anaconda window, enter `InvokeAI`, and type:
This distribution is changing rapidly. If you used the `git clone` method
(step 5) to download the stable-diffusion directory, then to update to the
latest and greatest version, launch the Anaconda window, enter
`stable-diffusion`, and type:
```bash
git pull
conda env update
```
This will bring your local copy into sync with the remote one.
File diff suppressed because one or more lines are too long
Some files were not shown because too many files have changed in this diff
Show More
Reference in New Issue
Block a user
Blocking a user prevents them from interacting with repositories, such as opening or commenting on pull requests or issues. Learn more about blocking a user.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}