mirror of
https://github.com/ROCm/ROCm.git
synced 2026-04-05 03:01:17 -04:00
# Introducing the `noinline` Parameter for Triton JIT Decorator
We're excited to introduce a new parameter, `noinline`, that can be
added to the `jit` decorator in Triton. This parameter allows developers
to specify that a particular Triton function should not be inlined into
its callers. In this post, we'll dive into the syntax, purpose, and
implementation details of this new feature.
## Syntax
To use the `noinline` parameter, simply add `noinline=True` to the `jit`
decorator for the function that you don't want to be inlined. Here's an
example:
```python
@triton.jit(noinline=True)
def device_fn(x, y, Z):
z = x + y
tl.store(Z, z)
def test_noinline():
@triton.jit
def kernel(X, Y, Z):
x = tl.load(X)
y = tl.load(Y)
device_fn(x, y, Z)
```
In this example, the `device_fn` function is decorated with
`@triton.jit(noinline=True)`, indicating that it should not be inlined
into its caller, `kernel`.
## Purpose
The `noinline` parameter serves several key purposes:
- Reducing code size: By preventing inlining, we can reduce the size of
the compiled code.
- Facilitating debugging: Keeping functions separate can make it easier
to debug the code.
- Avoiding common subexpression elimination (CSE) in certain cases: CSE
can sometimes be avoided by using the `noinline` parameter to reduce
register pressure.
- Enabling dynamic linking: This parameter makes it possible to
dynamically link Triton functions.
## Implementation
The implementation of the `noinline` parameter involves significant
changes to three analysis modules in Triton: *Allocation*, *Membar*, and
*AxisInfo*. Prior to this update, these modules assumed that all Triton
functions had been inlined into the root kernel function. With the
introduction of non-inlined functions, we've had to rework these
assumptions and make corresponding changes to the analyses.
### Call Graph and Limitations
<div style="text-align: center;">
<img
src="https://user-images.githubusercontent.com/2306281/234663904-12864247-3412-4405-987b-6991cdf053bb.png"
alt="figure 1" width="200" height="auto">
</div>
To address the changes, we build a call graph and perform all the
analyses on the call graph instead of a single function. The call graph
is constructed by traversing the call edges and storing them in an edge
map. Roots are extracted by checking nodes with no incoming edges.
The call graph has certain limitations:
- It does not support recursive function calls, although this could be
implemented in the future.
- It does not support dynamic function calls, where the function name is
unknown at compilation time.
### Allocation
<div style="text-align: center;">
<img
src="https://user-images.githubusercontent.com/2306281/234665110-bf6a2660-06fb-4648-85dc-16429439e72d.png"
alt="figure 2" width="400" height="auto">
</div>
In Triton, shared memory allocation is achieved through two operations:
`triton_gpu.convert_layout` and `triton_gpu.alloc_tensor`. The
`convert_layout` operation allocates an internal tensor, which we refer
to as a *scratch* buffer, while the `alloc_tensor` operation returns an
allocated tensor and is thus known as an *explicit* buffer.
To accommodate the introduction of function calls, we are introducing a
third type of buffer called a *virtual* buffer. Similar to scratch
buffers, virtual buffers are allocated internally within the scope of a
function call, and the buffers allocated by the called functions remain
invisible to subsequent operations in the calling function. However,
virtual buffers are distinct from scratch buffers in that the call
operation itself does not allocate memory—instead, it specifies the
total amount of memory required by all the child functions being called.
The actual allocation of buffers is performed by individual operations
within these child functions. For example, when invoking edge e1, no
memory is allocated, but the total amount of memory needed by function B
is reserved. Notably, the amount of shared memory used by function B
remains fixed across its call sites due to the consideration of dynamic
control flows within each function.
An additional challenge to address is the calculation of shared memory
offsets for functions within a call graph. While we can assume a shared
memory offset starting at 0 for a single root function, this is not the
case with a call graph, where we must determine each function's starting
offset based on the call path. Although each function has a fixed memory
consumption, the starting offset may vary. For instance, in Figure 2,
the starting offset of function C through edges e1->e2 differs from that
through edges e2->e4. To handle this, we accumulate the starting offset
at each call site and pass it as an argument to the called function.
Additionally, we amend both the function declaration and call sites by
appending an offset variable.
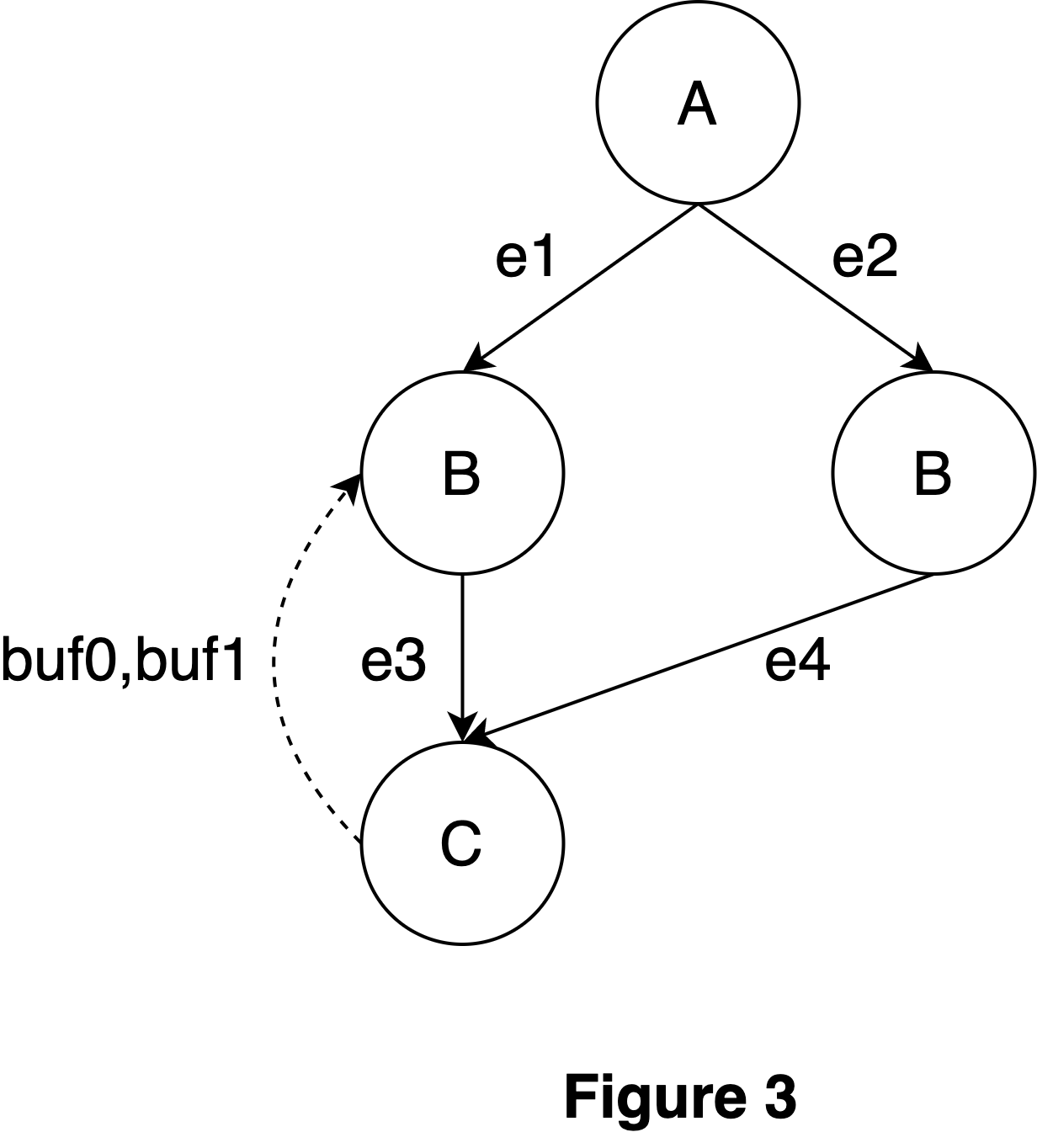
### Membar
<div style="text-align: center;">
<img
src="https://user-images.githubusercontent.com/2306281/234665157-844dd66f-5028-4ef3-bca2-4ca74b8f969d.png"
alt="figure 3" width="300" height="auto">
</div>
The membar pass is dependent on the allocation analysis. Once the offset
and size of each buffer are known, we conduct a post-order traversal of
the call graph and analyze each function on an individual basis. Unlike
previous analyses, we now return buffers that remain unsynchronized at
the end of functions, allowing the calling function to perform
synchronization in cases of overlap.
### AxisInfo
<div style="text-align: center;">
<img
src="https://user-images.githubusercontent.com/2306281/234665183-790a11ac-0ba1-47e1-98b1-e356220405a3.png"
alt="figure 4" width="400" height="auto">
</div>
The AxisInfo analysis operates differently from both membar and
allocation, as it traverses the call graph in topological order. This is
necessary because function arguments may contain axis information that
will be utilized by callee functions. As we do not implement
optimizations like function cloning, each function has a single code
base, and the axis information for an argument is determined as a
conservative result of all axis information passed by the calling
functions.
---------
Co-authored-by: Philippe Tillet <phil@openai.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
359 lines
12 KiB
C++
359 lines
12 KiB
C++
#ifndef TRITON_ANALYSIS_AXISINFO_H
|
|
#define TRITON_ANALYSIS_AXISINFO_H
|
|
|
|
#include "mlir/Analysis/DataFlow/SparseAnalysis.h"
|
|
#include "llvm/Support/raw_ostream.h"
|
|
|
|
#include "mlir/Support/LLVM.h"
|
|
#include "triton/Analysis/Utility.h"
|
|
#include "triton/Dialect/Triton/IR/Dialect.h"
|
|
#include "triton/Dialect/TritonGPU/IR/Dialect.h"
|
|
|
|
#include <optional>
|
|
#include <type_traits>
|
|
|
|
namespace mlir {
|
|
|
|
//===----------------------------------------------------------------------===//
|
|
// AxisInfo
|
|
//===----------------------------------------------------------------------===//
|
|
|
|
/// This lattice value represents known information on the axes of a lattice.
|
|
class AxisInfo {
|
|
public:
|
|
typedef SmallVector<int64_t, 4> DimVectorT;
|
|
|
|
public:
|
|
/// Default constructor
|
|
AxisInfo() : AxisInfo({}, {}, {}) {}
|
|
/// Construct contiguity info with known contiguity
|
|
AxisInfo(DimVectorT knownContiguity, DimVectorT knownDivisibility,
|
|
DimVectorT knownConstancy)
|
|
: AxisInfo(knownContiguity, knownDivisibility, knownConstancy, {}) {}
|
|
AxisInfo(DimVectorT knownContiguity, DimVectorT knownDivisibility,
|
|
DimVectorT knownConstancy, std::optional<int64_t> knownConstantValue)
|
|
: contiguity(knownContiguity), divisibility(knownDivisibility),
|
|
constancy(knownConstancy), constantValue(knownConstantValue),
|
|
rank(contiguity.size()) {
|
|
assert(knownContiguity.size() == static_cast<size_t>(rank));
|
|
assert(knownDivisibility.size() == static_cast<size_t>(rank));
|
|
assert(knownConstancy.size() == static_cast<size_t>(rank));
|
|
}
|
|
|
|
/// Accessors
|
|
int64_t getContiguity(size_t dim) const { return contiguity[dim]; }
|
|
const DimVectorT &getContiguity() const { return contiguity; }
|
|
|
|
int64_t getDivisibility(size_t dim) const { return divisibility[dim]; }
|
|
const DimVectorT &getDivisibility() const { return divisibility; }
|
|
|
|
int64_t getConstancy(size_t dim) const { return constancy[dim]; }
|
|
const DimVectorT &getConstancy() const { return constancy; }
|
|
|
|
int getRank() const { return rank; }
|
|
|
|
std::optional<int64_t> getConstantValue() const { return constantValue; }
|
|
|
|
template <class T>
|
|
static void
|
|
initPessimisticStateFromFunc(int argNumber, T funcOp, DimVectorT *contiguity,
|
|
DimVectorT *divisibility, DimVectorT *constancy);
|
|
/// Comparison
|
|
bool operator==(const AxisInfo &other) const {
|
|
return (contiguity == other.contiguity) &&
|
|
(divisibility == other.divisibility) &&
|
|
(constancy == other.constancy) &&
|
|
(constantValue == other.constantValue) && (rank == other.rank);
|
|
}
|
|
|
|
/// The pessimistic value state of the contiguity is unknown.
|
|
static AxisInfo getPessimisticValueState(MLIRContext *context = nullptr) {
|
|
return AxisInfo();
|
|
}
|
|
static AxisInfo getPessimisticValueState(Value value);
|
|
|
|
/// The gcd of both arguments for each dimension
|
|
static AxisInfo join(const AxisInfo &lhs, const AxisInfo &rhs);
|
|
|
|
void print(raw_ostream &os) const {
|
|
auto print = [&](StringRef name, DimVectorT vec) {
|
|
os << name << " = [";
|
|
llvm::interleaveComma(vec, os);
|
|
os << "]";
|
|
};
|
|
print("contiguity", contiguity);
|
|
print(", divisibility", divisibility);
|
|
print(", constancy", constancy);
|
|
os << ", constant_value = ";
|
|
if (constantValue)
|
|
os << *constantValue;
|
|
else
|
|
os << "<none>";
|
|
}
|
|
|
|
private:
|
|
/// The _contiguity_ information maps the `d`-th
|
|
/// dimension to the length of the shortest
|
|
/// sequence of contiguous integers along it.
|
|
/// Suppose we have an array of N elements,
|
|
/// with a contiguity value C,
|
|
/// the array can be divided into a list of
|
|
/// N/C sequences of C contiguous elements.
|
|
/// Since we have N = 2^k, C must be a power of two.
|
|
/// For example:
|
|
/// [10, 11, 12, 13, 18, 19, 20, 21]
|
|
/// [20, 21, 22, 23, 28, 29, 30, 31]
|
|
/// Would have contiguity [1, 4].
|
|
/// and
|
|
/// [12, 16, 20, 24]
|
|
/// [13, 17, 21, 25]
|
|
/// [14, 18, 22, 26]
|
|
/// [15, 19, 23, 27]
|
|
/// [18, 22, 26, 30]
|
|
/// [19, 23, 27, 31]
|
|
/// Would have contiguity [2, 1].
|
|
DimVectorT contiguity;
|
|
|
|
/// The _divisibility_ information maps the `d`-th
|
|
/// dimension to the largest power-of-two that
|
|
/// divides the first element of all groups of
|
|
// _contiguity_ values along it
|
|
/// For example:
|
|
/// [10, 11, 12, 13, 18, 19, 20, 21]
|
|
/// [20, 21, 22, 23, 28, 29, 30, 31]
|
|
// would have divisibility [1, 2]
|
|
// and
|
|
/// [12, 16, 20, 24]
|
|
/// [13, 17, 21, 25]
|
|
/// [14, 18, 22, 26]
|
|
/// [15, 19, 23, 27]
|
|
// would have divisibility [4, 1]
|
|
// On the other hand:
|
|
// [0, 1, 2, 0, 4, 5, 6, 7]
|
|
// would have divisibility 1 because
|
|
// _contiguity_=1
|
|
DimVectorT divisibility;
|
|
|
|
/// The _constancy_ information maps the `d`-th
|
|
/// dimension to the length of the shortest
|
|
/// sequence of constant integer along it. This is
|
|
/// particularly useful to infer the contiguity
|
|
/// of operations (e.g., add) involving a constant.
|
|
/// Suppose we have an array of N elements,
|
|
/// with a constancy value C,
|
|
/// the array can be divided into a list of
|
|
/// N/C sequences of C elements with the same value.
|
|
/// Since we have N = 2^k, C must be a power of two.
|
|
/// For example
|
|
/// [8, 8, 8, 8, 12, 12, 12, 12]
|
|
/// [16, 16, 16, 16, 20, 20, 20, 20]
|
|
/// would have constancy [1, 4]
|
|
DimVectorT constancy;
|
|
|
|
/// The constant value of the lattice if we can infer it.
|
|
std::optional<int64_t> constantValue;
|
|
|
|
// number of dimensions of the lattice
|
|
int rank{};
|
|
};
|
|
|
|
class AxisInfoVisitor {
|
|
public:
|
|
AxisInfoVisitor() = default;
|
|
virtual ~AxisInfoVisitor() = default;
|
|
|
|
static bool isContiguousDim(const AxisInfo &info, ArrayRef<int64_t> shape,
|
|
int dim) {
|
|
return info.getContiguity(dim) == shape[dim];
|
|
}
|
|
|
|
static bool isConstantDim(const AxisInfo &info, ArrayRef<int64_t> shape,
|
|
int dim) {
|
|
return info.getConstancy(dim) == shape[dim];
|
|
}
|
|
|
|
virtual AxisInfo
|
|
getAxisInfo(Operation *op,
|
|
ArrayRef<const dataflow::Lattice<AxisInfo> *> operands) = 0;
|
|
|
|
virtual bool match(Operation *op) = 0;
|
|
};
|
|
|
|
/// Base class for all operations
|
|
template <typename OpTy> class AxisInfoVisitorImpl : public AxisInfoVisitor {
|
|
public:
|
|
using AxisInfoVisitor::AxisInfoVisitor;
|
|
|
|
AxisInfo
|
|
getAxisInfo(Operation *op,
|
|
ArrayRef<const dataflow::Lattice<AxisInfo> *> operands) final {
|
|
return getAxisInfo(cast<OpTy>(op), operands);
|
|
}
|
|
|
|
bool match(Operation *op) final { return isa<OpTy>(op); }
|
|
|
|
virtual AxisInfo
|
|
getAxisInfo(OpTy op, ArrayRef<const dataflow::Lattice<AxisInfo> *> operands) {
|
|
llvm_unreachable("Unimplemented getAxisInfo");
|
|
}
|
|
};
|
|
|
|
/// Binary operations
|
|
template <typename OpTy>
|
|
class BinaryOpVisitorImpl : public AxisInfoVisitorImpl<OpTy> {
|
|
public:
|
|
using AxisInfoVisitorImpl<OpTy>::AxisInfoVisitorImpl;
|
|
|
|
AxisInfo
|
|
getAxisInfo(OpTy op,
|
|
ArrayRef<const dataflow::Lattice<AxisInfo> *> operands) override {
|
|
auto lhsInfo = operands[0]->getValue();
|
|
auto rhsInfo = operands[1]->getValue();
|
|
auto rank = lhsInfo.getRank();
|
|
assert(operands.size() == 2 && "Expected two operands");
|
|
AxisInfo::DimVectorT contiguity;
|
|
AxisInfo::DimVectorT divisibility;
|
|
AxisInfo::DimVectorT constancy;
|
|
auto constantValue = getConstantValue(op, lhsInfo, rhsInfo);
|
|
for (auto d = 0; d < rank; ++d) {
|
|
if (constantValue.has_value()) {
|
|
contiguity.push_back(1);
|
|
constancy.push_back(
|
|
std::max(lhsInfo.getConstancy(d), rhsInfo.getConstancy(d)));
|
|
divisibility.push_back(highestPowOf2Divisor(constantValue.value()));
|
|
} else {
|
|
contiguity.push_back(getContiguity(op, lhsInfo, rhsInfo, d));
|
|
constancy.push_back(getConstancy(op, lhsInfo, rhsInfo, d));
|
|
divisibility.push_back(getDivisibility(op, lhsInfo, rhsInfo, d));
|
|
}
|
|
}
|
|
return AxisInfo(contiguity, divisibility, constancy, constantValue);
|
|
}
|
|
|
|
protected:
|
|
virtual int64_t getContiguity(OpTy op, const AxisInfo &lhs,
|
|
const AxisInfo &rhs, int dim) {
|
|
return 1;
|
|
}
|
|
|
|
virtual int64_t getDivisibility(OpTy op, const AxisInfo &lhs,
|
|
const AxisInfo &rhs, int dim) {
|
|
return 1;
|
|
}
|
|
|
|
virtual int64_t getConstancy(OpTy op, const AxisInfo &lhs,
|
|
const AxisInfo &rhs, int dim) {
|
|
return 1;
|
|
}
|
|
|
|
virtual std::optional<int64_t> getConstantValue(OpTy op, const AxisInfo &lhs,
|
|
const AxisInfo &rhs) {
|
|
return {};
|
|
}
|
|
};
|
|
|
|
class AxisInfoVisitorList {
|
|
public:
|
|
template <typename... Ts, typename = std::enable_if_t<sizeof...(Ts) != 0>>
|
|
void append() {
|
|
(visitors.emplace_back(std::make_unique<Ts>()), ...);
|
|
}
|
|
|
|
AxisInfo apply(Operation *op,
|
|
ArrayRef<const dataflow::Lattice<AxisInfo> *> operands) {
|
|
for (auto &visitor : visitors)
|
|
if (visitor->match(op))
|
|
return visitor->getAxisInfo(op, operands);
|
|
return AxisInfo();
|
|
}
|
|
|
|
private:
|
|
std::vector<std::unique_ptr<AxisInfoVisitor>> visitors;
|
|
};
|
|
|
|
class AxisInfoAnalysis
|
|
: public dataflow::SparseDataFlowAnalysis<dataflow::Lattice<AxisInfo>> {
|
|
private:
|
|
AxisInfoVisitorList visitors;
|
|
|
|
void setToEntryState(dataflow::Lattice<AxisInfo> *lattice) override {
|
|
propagateIfChanged(
|
|
lattice,
|
|
lattice->join(AxisInfo::getPessimisticValueState(lattice->getPoint())));
|
|
}
|
|
|
|
public:
|
|
AxisInfoAnalysis(DataFlowSolver &solver);
|
|
using dataflow::SparseDataFlowAnalysis<
|
|
dataflow::Lattice<AxisInfo>>::getLatticeElement;
|
|
using FuncAxisInfoMapT = DenseMap<FunctionOpInterface, AxisInfo>;
|
|
|
|
void visitOperation(Operation *op,
|
|
ArrayRef<const dataflow::Lattice<AxisInfo> *> operands,
|
|
ArrayRef<dataflow::Lattice<AxisInfo> *> results) override;
|
|
};
|
|
|
|
/// Module level axis info analysis based on the call graph, assuming that we
|
|
/// do not have recursive functions.
|
|
/// Since each function will be called multiple times, we need to
|
|
/// calculate the axis info based on the axis info of all the callers.
|
|
/// In the future, we can perform optimization using function cloning so that
|
|
/// each call site will have unique axis info.
|
|
using AxisInfoMapT = DenseMap<Value, AxisInfo>;
|
|
class ModuleAxisInfoAnalysis : public CallGraph<AxisInfoMapT> {
|
|
public:
|
|
explicit ModuleAxisInfoAnalysis(ModuleOp moduleOp)
|
|
: CallGraph<AxisInfoMapT>(moduleOp) {
|
|
SmallVector<FunctionOpInterface> funcs;
|
|
for (auto root : getRoots()) {
|
|
walk<WalkOrder::PreOrder, WalkOrder::PostOrder>(
|
|
// Pre-order edge walk callback
|
|
[](CallOpInterface callOp, FunctionOpInterface funcOp) {},
|
|
// Post-order node walk callback
|
|
[&](FunctionOpInterface funcOp) {
|
|
funcs.push_back(funcOp);
|
|
funcMap.try_emplace(funcOp, AxisInfoMapT{});
|
|
});
|
|
}
|
|
SetVector<FunctionOpInterface> sortedFuncs(funcs.begin(), funcs.end());
|
|
SymbolTableCollection symbolTable;
|
|
for (auto funcOp : llvm::reverse(sortedFuncs)) {
|
|
initialize(funcOp);
|
|
funcOp.walk([&](CallOpInterface callOp) {
|
|
auto callee =
|
|
dyn_cast<FunctionOpInterface>(callOp.resolveCallable(&symbolTable));
|
|
update(callOp, callee);
|
|
});
|
|
}
|
|
}
|
|
|
|
AxisInfo *getAxisInfo(Value value) {
|
|
auto funcOp =
|
|
value.getParentRegion()->getParentOfType<FunctionOpInterface>();
|
|
auto *axisInfoMap = getFuncData(funcOp);
|
|
if (!axisInfoMap) {
|
|
return nullptr;
|
|
}
|
|
auto it = axisInfoMap->find(value);
|
|
if (it == axisInfoMap->end()) {
|
|
return nullptr;
|
|
}
|
|
return &(it->second);
|
|
}
|
|
|
|
unsigned getPtrContiguity(Value ptr);
|
|
|
|
unsigned getPtrAlignment(Value ptr);
|
|
|
|
unsigned getMaskAlignment(Value mask);
|
|
|
|
private:
|
|
void initialize(FunctionOpInterface funcOp);
|
|
|
|
void update(CallOpInterface callOp, FunctionOpInterface funcOp);
|
|
};
|
|
|
|
} // namespace mlir
|
|
|
|
#endif
|