mirror of
https://github.com/nod-ai/SHARK-Studio.git
synced 2026-04-20 03:00:34 -04:00
Compare commits
72 Commits
20230219.5
...
20230310.5
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
16ad7d57a3 | ||
|
|
c561ebf43c | ||
|
|
97fdff7f19 | ||
|
|
ce6d82eab2 | ||
|
|
b8f4b18951 | ||
|
|
b23d3aa584 | ||
|
|
495670d9b6 | ||
|
|
815e23a0b8 | ||
|
|
783538fe11 | ||
|
|
996c645f6a | ||
|
|
1f7d249a62 | ||
|
|
7f6c9a2dc2 | ||
|
|
93891984f3 | ||
|
|
cc0ef54e0e | ||
|
|
812152485d | ||
|
|
0816fb403a | ||
|
|
4f171772be | ||
|
|
a52331d4aa | ||
|
|
ad821a1fc8 | ||
|
|
116b128802 | ||
|
|
b118f183d1 | ||
|
|
911dff16f1 | ||
|
|
de59a66ae4 | ||
|
|
23f1468cc6 | ||
|
|
080350d311 | ||
|
|
7f3f92b9d5 | ||
|
|
be3cdec290 | ||
|
|
f09574538c | ||
|
|
b1113ab551 | ||
|
|
ef756389e3 | ||
|
|
cb17d017df | ||
|
|
798f231792 | ||
|
|
7136890da3 | ||
|
|
d567192fd3 | ||
|
|
dcc4025c78 | ||
|
|
c6c8ec36a1 | ||
|
|
1344c0659a | ||
|
|
973f6d20f4 | ||
|
|
8b5c9c51e7 | ||
|
|
bae208bcc4 | ||
|
|
b6c14ad468 | ||
|
|
0064cc2a6e | ||
|
|
0a0567e944 | ||
|
|
694b1d43a8 | ||
|
|
e7eb116bd2 | ||
|
|
596499a08c | ||
|
|
2a2e460df2 | ||
|
|
a9039b35ed | ||
|
|
a01154a507 | ||
|
|
1d9204282d | ||
|
|
5ff40a0d2d | ||
|
|
fab6d2e4e0 | ||
|
|
abab59c25f | ||
|
|
c25840b585 | ||
|
|
1b3f9125bb | ||
|
|
b5d9f5ba49 | ||
|
|
1c22aa9c8f | ||
|
|
e1d7fb879c | ||
|
|
e912c42bf0 | ||
|
|
e6841acf36 | ||
|
|
bc4459b6f4 | ||
|
|
9b544491e0 | ||
|
|
9c5415b598 | ||
|
|
040dbc317f | ||
|
|
65775046d8 | ||
|
|
b18bc36127 | ||
|
|
f01c526efd | ||
|
|
16168ab6b3 | ||
|
|
4233218629 | ||
|
|
b63fb36dc0 | ||
|
|
4e92304b89 | ||
|
|
2ae047f1a8 |
5
.flake8
Normal file
5
.flake8
Normal file
@@ -0,0 +1,5 @@
|
||||
[flake8]
|
||||
count = 1
|
||||
show-source = 1
|
||||
select = E9,F63,F7,F82
|
||||
exclude = lit.cfg.py
|
||||
11
.github/workflows/nightly.yml
vendored
11
.github/workflows/nightly.yml
vendored
@@ -44,7 +44,7 @@ jobs:
|
||||
body: |
|
||||
Automatic snapshot release of nod.ai SHARK.
|
||||
draft: true
|
||||
prerelease: false
|
||||
prerelease: true
|
||||
|
||||
- name: Build Package
|
||||
shell: powershell
|
||||
@@ -67,9 +67,9 @@ jobs:
|
||||
# $env:SHARK_PACKAGE_VERSION=${{ env.package_version }}
|
||||
# pip wheel -v -w dist . --pre -f https://download.pytorch.org/whl/nightly/torch -f https://llvm.github.io/torch-mlir/package-index/ -f https://nod-ai.github.io/SHARK-Runtime/pip-release-links.html
|
||||
|
||||
- uses: actions/upload-artifact@v2
|
||||
with:
|
||||
path: dist/*
|
||||
#- uses: actions/upload-artifact@v2
|
||||
# with:
|
||||
# path: dist/*
|
||||
|
||||
- name: Upload Release Assets
|
||||
id: upload-release-assets
|
||||
@@ -79,6 +79,7 @@ jobs:
|
||||
with:
|
||||
release_id: ${{ steps.create_release.outputs.id }}
|
||||
assets_path: ./dist/*
|
||||
#asset_content_type: application/vnd.microsoft.portable-executable
|
||||
|
||||
- name: Publish Release
|
||||
id: publish_release
|
||||
@@ -133,7 +134,7 @@ jobs:
|
||||
source iree.venv/bin/activate
|
||||
package_version="$(printf '%(%Y%m%d)T.${{ github.run_number }}')"
|
||||
SHARK_PACKAGE_VERSION=${package_version} \
|
||||
pip wheel -v -w wheelhouse . --pre -f https://download.pytorch.org/whl/nightly/torch -f https://llvm.github.io/torch-mlir/package-index/ -f https://iree-org.github.io/iree/pip-release-links.html
|
||||
pip wheel -v -w wheelhouse . --pre -f https://download.pytorch.org/whl/nightly/torch -f https://llvm.github.io/torch-mlir/package-index/ -f https://openxla.github.io/iree/pip-release-links.html
|
||||
# Install the built wheel
|
||||
pip install ./wheelhouse/nodai*
|
||||
# Validate the Models
|
||||
|
||||
18
.github/workflows/test-models.yml
vendored
18
.github/workflows/test-models.yml
vendored
@@ -99,11 +99,12 @@ jobs:
|
||||
run: |
|
||||
# black format check
|
||||
black --version
|
||||
black --line-length 79 --check .
|
||||
black --check .
|
||||
# stop the build if there are Python syntax errors or undefined names
|
||||
flake8 . --count --select=E9,F63,F7,F82 --show-source --statistics --exclude lit.cfg.py
|
||||
flake8 . --statistics
|
||||
# exit-zero treats all errors as warnings. The GitHub editor is 127 chars wide
|
||||
flake8 . --count --exit-zero --max-complexity=10 --max-line-length=127 --statistics --exclude lit.cfg.py
|
||||
flake8 . --isolated --count --exit-zero --max-complexity=10 --max-line-length=127 \
|
||||
--statistics --exclude lit.cfg.py
|
||||
|
||||
- name: Validate Models on CPU
|
||||
if: matrix.suite == 'cpu'
|
||||
@@ -111,7 +112,7 @@ jobs:
|
||||
cd $GITHUB_WORKSPACE
|
||||
PYTHON=python${{ matrix.python-version }} IMPORTER=1 ./setup_venv.sh
|
||||
source shark.venv/bin/activate
|
||||
pytest --forked --benchmark --ci --ci_sha=${SHORT_SHA} --update_tank -k cpu
|
||||
pytest --forked --benchmark --ci --ci_sha=${SHORT_SHA} --update_tank --tank_url="gs://shark_tank/nightly/" -k cpu
|
||||
gsutil cp ./bench_results.csv gs://shark-public/builder/bench_results/${DATE}/bench_results_cpu_${SHORT_SHA}.csv
|
||||
gsutil cp gs://shark-public/builder/bench_results/${DATE}/bench_results_cpu_${SHORT_SHA}.csv gs://shark-public/builder/bench_results/latest/bench_results_cpu_latest.csv
|
||||
|
||||
@@ -121,7 +122,7 @@ jobs:
|
||||
cd $GITHUB_WORKSPACE
|
||||
PYTHON=python${{ matrix.python-version }} BENCHMARK=1 IMPORTER=1 ./setup_venv.sh
|
||||
source shark.venv/bin/activate
|
||||
pytest --forked --benchmark --ci --ci_sha=${SHORT_SHA} --update_tank -k cuda
|
||||
pytest --forked --benchmark --ci --ci_sha=${SHORT_SHA} --update_tank --tank_url="gs://shark_tank/nightly/" -k cuda
|
||||
gsutil cp ./bench_results.csv gs://shark-public/builder/bench_results/${DATE}/bench_results_cuda_${SHORT_SHA}.csv
|
||||
gsutil cp gs://shark-public/builder/bench_results/${DATE}/bench_results_cuda_${SHORT_SHA}.csv gs://shark-public/builder/bench_results/latest/bench_results_cuda_latest.csv
|
||||
# Disabled due to black image bug
|
||||
@@ -136,7 +137,7 @@ jobs:
|
||||
export DYLD_LIBRARY_PATH=/usr/local/lib/
|
||||
echo $PATH
|
||||
pip list | grep -E "torch|iree"
|
||||
pytest --ci --ci_sha=${SHORT_SHA} --local_tank_cache="/Volumes/builder/anush/shark_cache" -k vulkan --update_tank
|
||||
pytest --ci --ci_sha=${SHORT_SHA} --local_tank_cache="/Volumes/builder/anush/shark_cache" --tank_url="gs://shark_tank/nightly/" -k vulkan --update_tank
|
||||
|
||||
- name: Validate Vulkan Models (a100)
|
||||
if: matrix.suite == 'vulkan' && matrix.os == 'a100'
|
||||
@@ -144,15 +145,14 @@ jobs:
|
||||
cd $GITHUB_WORKSPACE
|
||||
PYTHON=python${{ matrix.python-version }} ./setup_venv.sh
|
||||
source shark.venv/bin/activate
|
||||
pytest --forked --benchmark --ci --ci_sha=${SHORT_SHA} --update_tank -k vulkan
|
||||
pytest --forked --benchmark --ci --ci_sha=${SHORT_SHA} --update_tank --tank_url="gs://shark_tank/nightly/" -k vulkan
|
||||
python build_tools/stable_diffusion_testing.py --device=vulkan
|
||||
|
||||
- name: Validate Vulkan Models (Windows)
|
||||
if: matrix.suite == 'vulkan' && matrix.os == '7950x'
|
||||
run: |
|
||||
./setup_venv.ps1
|
||||
pytest --benchmark -k vulkan -s
|
||||
type bench_results.csv
|
||||
pytest -k vulkan -s
|
||||
|
||||
- name: Validate Stable Diffusion Models (Windows)
|
||||
if: matrix.suite == 'vulkan' && matrix.os == '7950x'
|
||||
|
||||
@@ -1,3 +0,0 @@
|
||||
[style]
|
||||
based_on_style = google
|
||||
column_limit = 80
|
||||
@@ -27,7 +27,7 @@ Other users please ensure you have your latest vendor drivers and Vulkan SDK fro
|
||||
|
||||
Install the Driver from [Prerequisites](https://github.com/nod-ai/SHARK#install-your-hardware-drivers) above
|
||||
|
||||
Download the stable release [539](https://github.com/nod-ai/SHARK/releases/download/20230216.539/shark_sd_20230216_539.exe) or if you are adventurous the latest .exe from [releases page](https://github.com/nod-ai/SHARK/releases).
|
||||
Download the [stable release](https://github.com/nod-ai/shark/releases/latest)
|
||||
|
||||
Double click the .exe and you should have the [UI](http://localhost:8080/) in the browser.
|
||||
|
||||
|
||||
@@ -1,2 +1,4 @@
|
||||
from apps.stable_diffusion.scripts.txt2img import txt2img_inf
|
||||
from apps.stable_diffusion.scripts.img2img import img2img_inf
|
||||
from apps.stable_diffusion.scripts.inpaint import inpaint_inf
|
||||
from apps.stable_diffusion.scripts.outpaint import outpaint_inf
|
||||
|
||||
@@ -6,6 +6,7 @@ from dataclasses import dataclass
|
||||
from apps.stable_diffusion.src import (
|
||||
args,
|
||||
Image2ImagePipeline,
|
||||
StencilPipeline,
|
||||
get_schedulers,
|
||||
set_init_device_flags,
|
||||
utils,
|
||||
@@ -24,18 +25,24 @@ class Config:
|
||||
height: int
|
||||
width: int
|
||||
device: str
|
||||
use_stencil: str
|
||||
|
||||
|
||||
img2img_obj = None
|
||||
config_obj = None
|
||||
schedulers = None
|
||||
|
||||
# set initial values of iree_vulkan_target_triple, use_tuned and import_mlir.
|
||||
init_iree_vulkan_target_triple = args.iree_vulkan_target_triple
|
||||
init_use_tuned = args.use_tuned
|
||||
init_import_mlir = args.import_mlir
|
||||
|
||||
|
||||
# Exposed to UI.
|
||||
def img2img_inf(
|
||||
prompt: str,
|
||||
negative_prompt: str,
|
||||
init_image: str,
|
||||
init_image: Image,
|
||||
height: int,
|
||||
width: int,
|
||||
steps: int,
|
||||
@@ -50,6 +57,7 @@ def img2img_inf(
|
||||
precision: str,
|
||||
device: str,
|
||||
max_length: int,
|
||||
use_stencil: str,
|
||||
save_metadata_to_json: bool,
|
||||
save_metadata_to_png: bool,
|
||||
):
|
||||
@@ -64,8 +72,11 @@ def img2img_inf(
|
||||
args.steps = steps
|
||||
args.strength = strength
|
||||
args.scheduler = scheduler
|
||||
args.img_path = init_image
|
||||
image = Image.open(args.img_path).convert("RGB")
|
||||
args.img_path = "not none"
|
||||
|
||||
if init_image is None:
|
||||
return None, "An Initial Image is required"
|
||||
image = init_image.convert("RGB")
|
||||
|
||||
# set ckpt_loc and hf_model_id.
|
||||
types = (
|
||||
@@ -86,14 +97,27 @@ def img2img_inf(
|
||||
else:
|
||||
args.hf_model_id = custom_model
|
||||
|
||||
if image is None:
|
||||
return None, "An Initial Image is required"
|
||||
|
||||
args.save_metadata_to_json = save_metadata_to_json
|
||||
args.write_metadata_to_png = save_metadata_to_png
|
||||
|
||||
use_stencil = None if use_stencil == "None" else use_stencil
|
||||
args.use_stencil = use_stencil
|
||||
if use_stencil is not None:
|
||||
args.scheduler = "DDIM"
|
||||
args.hf_model_id = "runwayml/stable-diffusion-v1-5"
|
||||
elif args.scheduler != "PNDM":
|
||||
if "Shark" in args.scheduler:
|
||||
print(
|
||||
f"SharkEulerDiscrete scheduler not supported. Switching to PNDM scheduler"
|
||||
)
|
||||
args.scheduler = "PNDM"
|
||||
else:
|
||||
sys.exit(
|
||||
"Img2Img works best with PNDM scheduler. Other schedulers are not supported yet."
|
||||
)
|
||||
cpu_scheduling = not args.scheduler.startswith("Shark")
|
||||
args.precision = precision
|
||||
dtype = torch.float32 if precision == "fp32" else torch.half
|
||||
cpu_scheduling = not scheduler.startswith("Shark")
|
||||
new_config_obj = Config(
|
||||
args.hf_model_id,
|
||||
args.ckpt_loc,
|
||||
@@ -103,43 +127,60 @@ def img2img_inf(
|
||||
height,
|
||||
width,
|
||||
device,
|
||||
use_stencil,
|
||||
)
|
||||
if config_obj != new_config_obj:
|
||||
if not img2img_obj or config_obj != new_config_obj:
|
||||
config_obj = new_config_obj
|
||||
args.precision = precision
|
||||
args.batch_size = batch_size
|
||||
args.max_length = max_length
|
||||
args.height = height
|
||||
args.width = width
|
||||
args.device = device.split("=>", 1)[1].strip()
|
||||
args.iree_vulkan_target_triple = ""
|
||||
args.use_tuned = True
|
||||
args.import_mlir = True
|
||||
args.iree_vulkan_target_triple = init_iree_vulkan_target_triple
|
||||
args.use_tuned = init_use_tuned
|
||||
args.import_mlir = init_import_mlir
|
||||
set_init_device_flags()
|
||||
model_id = (
|
||||
args.hf_model_id
|
||||
if args.hf_model_id
|
||||
else "runwayml/stable-diffusion-inpainting"
|
||||
else "stabilityai/stable-diffusion-2-1-base"
|
||||
)
|
||||
schedulers = get_schedulers(model_id)
|
||||
scheduler_obj = schedulers[scheduler]
|
||||
img2img_obj = Image2ImagePipeline.from_pretrained(
|
||||
scheduler_obj,
|
||||
args.import_mlir,
|
||||
args.hf_model_id,
|
||||
args.ckpt_loc,
|
||||
args.custom_vae,
|
||||
args.precision,
|
||||
args.max_length,
|
||||
args.batch_size,
|
||||
args.height,
|
||||
args.width,
|
||||
args.use_base_vae,
|
||||
args.use_tuned,
|
||||
)
|
||||
|
||||
if not img2img_obj:
|
||||
sys.exit("text to image pipeline must not return a null value")
|
||||
if use_stencil is not None:
|
||||
args.use_tuned = False
|
||||
img2img_obj = StencilPipeline.from_pretrained(
|
||||
scheduler_obj,
|
||||
args.import_mlir,
|
||||
args.hf_model_id,
|
||||
args.ckpt_loc,
|
||||
args.custom_vae,
|
||||
args.precision,
|
||||
args.max_length,
|
||||
args.batch_size,
|
||||
args.height,
|
||||
args.width,
|
||||
args.use_base_vae,
|
||||
args.use_tuned,
|
||||
low_cpu_mem_usage=args.low_cpu_mem_usage,
|
||||
use_stencil=use_stencil,
|
||||
)
|
||||
else:
|
||||
img2img_obj = Image2ImagePipeline.from_pretrained(
|
||||
scheduler_obj,
|
||||
args.import_mlir,
|
||||
args.hf_model_id,
|
||||
args.ckpt_loc,
|
||||
args.custom_vae,
|
||||
args.precision,
|
||||
args.max_length,
|
||||
args.batch_size,
|
||||
args.height,
|
||||
args.width,
|
||||
args.use_base_vae,
|
||||
args.use_tuned,
|
||||
low_cpu_mem_usage=args.low_cpu_mem_usage,
|
||||
)
|
||||
|
||||
img2img_obj.scheduler = schedulers[scheduler]
|
||||
|
||||
@@ -148,6 +189,7 @@ def img2img_inf(
|
||||
generated_imgs = []
|
||||
seeds = []
|
||||
img_seed = utils.sanitize_seed(seed)
|
||||
extra_info = {"STRENGTH": strength}
|
||||
for current_batch in range(batch_count):
|
||||
if current_batch > 0:
|
||||
img_seed = utils.sanitize_seed(-1)
|
||||
@@ -166,8 +208,9 @@ def img2img_inf(
|
||||
dtype,
|
||||
args.use_base_vae,
|
||||
cpu_scheduling,
|
||||
use_stencil=use_stencil,
|
||||
)
|
||||
save_output_img(out_imgs[0], img_seed)
|
||||
save_output_img(out_imgs[0], img_seed, extra_info)
|
||||
generated_imgs.extend(out_imgs)
|
||||
seeds.append(img_seed)
|
||||
img2img_obj.log += "\n"
|
||||
@@ -196,11 +239,11 @@ if __name__ == "__main__":
|
||||
# When the models get uploaded, it should be default to False.
|
||||
args.import_mlir = True
|
||||
|
||||
dtype = torch.float32 if args.precision == "fp32" else torch.half
|
||||
cpu_scheduling = not args.scheduler.startswith("Shark")
|
||||
set_init_device_flags()
|
||||
schedulers = get_schedulers(args.hf_model_id)
|
||||
if args.scheduler != "PNDM":
|
||||
use_stencil = args.use_stencil
|
||||
if use_stencil:
|
||||
args.scheduler = "DDIM"
|
||||
args.hf_model_id = "runwayml/stable-diffusion-v1-5"
|
||||
elif args.scheduler != "PNDM":
|
||||
if "Shark" in args.scheduler:
|
||||
print(
|
||||
f"SharkEulerDiscrete scheduler not supported. Switching to PNDM scheduler"
|
||||
@@ -210,27 +253,49 @@ if __name__ == "__main__":
|
||||
sys.exit(
|
||||
"Img2Img works best with PNDM scheduler. Other schedulers are not supported yet."
|
||||
)
|
||||
cpu_scheduling = not args.scheduler.startswith("Shark")
|
||||
dtype = torch.float32 if args.precision == "fp32" else torch.half
|
||||
set_init_device_flags()
|
||||
schedulers = get_schedulers(args.hf_model_id)
|
||||
|
||||
scheduler_obj = schedulers[args.scheduler]
|
||||
image = Image.open(args.img_path).convert("RGB")
|
||||
seed = utils.sanitize_seed(args.seed)
|
||||
|
||||
# Adjust for height and width based on model
|
||||
|
||||
img2img_obj = Image2ImagePipeline.from_pretrained(
|
||||
scheduler_obj,
|
||||
args.import_mlir,
|
||||
args.hf_model_id,
|
||||
args.ckpt_loc,
|
||||
args.custom_vae,
|
||||
args.precision,
|
||||
args.max_length,
|
||||
args.batch_size,
|
||||
args.height,
|
||||
args.width,
|
||||
args.use_base_vae,
|
||||
args.use_tuned,
|
||||
)
|
||||
if use_stencil:
|
||||
img2img_obj = StencilPipeline.from_pretrained(
|
||||
scheduler_obj,
|
||||
args.import_mlir,
|
||||
args.hf_model_id,
|
||||
args.ckpt_loc,
|
||||
args.custom_vae,
|
||||
args.precision,
|
||||
args.max_length,
|
||||
args.batch_size,
|
||||
args.height,
|
||||
args.width,
|
||||
args.use_base_vae,
|
||||
args.use_tuned,
|
||||
low_cpu_mem_usage=args.low_cpu_mem_usage,
|
||||
use_stencil=use_stencil,
|
||||
)
|
||||
else:
|
||||
img2img_obj = Image2ImagePipeline.from_pretrained(
|
||||
scheduler_obj,
|
||||
args.import_mlir,
|
||||
args.hf_model_id,
|
||||
args.ckpt_loc,
|
||||
args.custom_vae,
|
||||
args.precision,
|
||||
args.max_length,
|
||||
args.batch_size,
|
||||
args.height,
|
||||
args.width,
|
||||
args.use_base_vae,
|
||||
args.use_tuned,
|
||||
low_cpu_mem_usage=args.low_cpu_mem_usage,
|
||||
)
|
||||
|
||||
start_time = time.time()
|
||||
generated_imgs = img2img_obj.generate_images(
|
||||
@@ -248,6 +313,7 @@ if __name__ == "__main__":
|
||||
dtype,
|
||||
args.use_base_vae,
|
||||
cpu_scheduling,
|
||||
use_stencil=use_stencil,
|
||||
)
|
||||
total_time = time.time() - start_time
|
||||
text_output = f"prompt={args.prompts}"
|
||||
@@ -261,5 +327,6 @@ if __name__ == "__main__":
|
||||
text_output += img2img_obj.log
|
||||
text_output += f"\nTotal image generation time: {total_time:.4f}sec"
|
||||
|
||||
save_output_img(generated_imgs[0], seed)
|
||||
extra_info = {"STRENGTH": args.strength}
|
||||
save_output_img(generated_imgs[0], seed, extra_info)
|
||||
print(text_output)
|
||||
|
||||
@@ -30,15 +30,21 @@ inpaint_obj = None
|
||||
config_obj = None
|
||||
schedulers = None
|
||||
|
||||
# set initial values of iree_vulkan_target_triple, use_tuned and import_mlir.
|
||||
init_iree_vulkan_target_triple = args.iree_vulkan_target_triple
|
||||
init_use_tuned = args.use_tuned
|
||||
init_import_mlir = args.import_mlir
|
||||
|
||||
|
||||
# Exposed to UI.
|
||||
def inpaint_inf(
|
||||
prompt: str,
|
||||
negative_prompt: str,
|
||||
image: Image,
|
||||
mask_image: Image,
|
||||
image_dict,
|
||||
height: int,
|
||||
width: int,
|
||||
inpaint_full_res: bool,
|
||||
inpaint_full_res_padding: int,
|
||||
steps: int,
|
||||
guidance_scale: float,
|
||||
seed: int,
|
||||
@@ -62,6 +68,8 @@ def inpaint_inf(
|
||||
args.guidance_scale = guidance_scale
|
||||
args.steps = steps
|
||||
args.scheduler = scheduler
|
||||
args.img_path = "not none"
|
||||
args.mask_path = "not none"
|
||||
|
||||
# set ckpt_loc and hf_model_id.
|
||||
types = (
|
||||
@@ -97,7 +105,7 @@ def inpaint_inf(
|
||||
width,
|
||||
device,
|
||||
)
|
||||
if config_obj != new_config_obj:
|
||||
if not inpaint_obj or config_obj != new_config_obj:
|
||||
config_obj = new_config_obj
|
||||
args.precision = precision
|
||||
args.batch_size = batch_size
|
||||
@@ -105,9 +113,9 @@ def inpaint_inf(
|
||||
args.height = height
|
||||
args.width = width
|
||||
args.device = device.split("=>", 1)[1].strip()
|
||||
args.iree_vulkan_target_triple = ""
|
||||
args.use_tuned = True
|
||||
args.import_mlir = False
|
||||
args.iree_vulkan_target_triple = init_iree_vulkan_target_triple
|
||||
args.use_tuned = init_use_tuned
|
||||
args.import_mlir = init_import_mlir
|
||||
set_init_device_flags()
|
||||
model_id = (
|
||||
args.hf_model_id
|
||||
@@ -131,9 +139,6 @@ def inpaint_inf(
|
||||
args.use_tuned,
|
||||
)
|
||||
|
||||
if not inpaint_obj:
|
||||
sys.exit("text to image pipeline must not return a null value")
|
||||
|
||||
inpaint_obj.scheduler = schedulers[scheduler]
|
||||
|
||||
start_time = time.time()
|
||||
@@ -141,6 +146,8 @@ def inpaint_inf(
|
||||
generated_imgs = []
|
||||
seeds = []
|
||||
img_seed = utils.sanitize_seed(seed)
|
||||
image = image_dict["image"]
|
||||
mask_image = image_dict["mask"]
|
||||
for i in range(batch_count):
|
||||
if i > 0:
|
||||
img_seed = utils.sanitize_seed(-1)
|
||||
@@ -152,6 +159,8 @@ def inpaint_inf(
|
||||
batch_size,
|
||||
height,
|
||||
width,
|
||||
inpaint_full_res,
|
||||
inpaint_full_res_padding,
|
||||
steps,
|
||||
guidance_scale,
|
||||
img_seed,
|
||||
@@ -188,14 +197,16 @@ if __name__ == "__main__":
|
||||
if args.mask_path is None:
|
||||
print("Flag --mask_path is required.")
|
||||
exit()
|
||||
if "inpaint" not in args.hf_model_id:
|
||||
print("Please use inpainting model with --hf_model_id.")
|
||||
exit()
|
||||
|
||||
dtype = torch.float32 if args.precision == "fp32" else torch.half
|
||||
cpu_scheduling = not args.scheduler.startswith("Shark")
|
||||
set_init_device_flags()
|
||||
schedulers = get_schedulers(args.hf_model_id)
|
||||
model_id = (
|
||||
args.hf_model_id
|
||||
if "inpaint" in args.hf_model_id
|
||||
else "stabilityai/stable-diffusion-2-inpainting"
|
||||
)
|
||||
schedulers = get_schedulers(model_id)
|
||||
scheduler_obj = schedulers[args.scheduler]
|
||||
seed = args.seed
|
||||
image = Image.open(args.img_path)
|
||||
@@ -230,6 +241,8 @@ if __name__ == "__main__":
|
||||
args.batch_size,
|
||||
args.height,
|
||||
args.width,
|
||||
args.inpaint_full_res,
|
||||
args.inpaint_full_res_padding,
|
||||
args.steps,
|
||||
args.guidance_scale,
|
||||
seed,
|
||||
|
||||
298
apps/stable_diffusion/scripts/outpaint.py
Normal file
298
apps/stable_diffusion/scripts/outpaint.py
Normal file
@@ -0,0 +1,298 @@
|
||||
import sys
|
||||
import torch
|
||||
import time
|
||||
from PIL import Image
|
||||
from dataclasses import dataclass
|
||||
from apps.stable_diffusion.src import (
|
||||
args,
|
||||
OutpaintPipeline,
|
||||
get_schedulers,
|
||||
set_init_device_flags,
|
||||
utils,
|
||||
clear_all,
|
||||
save_output_img,
|
||||
)
|
||||
|
||||
|
||||
@dataclass
|
||||
class Config:
|
||||
model_id: str
|
||||
ckpt_loc: str
|
||||
precision: str
|
||||
batch_size: int
|
||||
max_length: int
|
||||
height: int
|
||||
width: int
|
||||
device: str
|
||||
|
||||
|
||||
outpaint_obj = None
|
||||
config_obj = None
|
||||
schedulers = None
|
||||
|
||||
# set initial values of iree_vulkan_target_triple, use_tuned and import_mlir.
|
||||
init_iree_vulkan_target_triple = args.iree_vulkan_target_triple
|
||||
init_use_tuned = args.use_tuned
|
||||
init_import_mlir = args.import_mlir
|
||||
|
||||
|
||||
# Exposed to UI.
|
||||
def outpaint_inf(
|
||||
prompt: str,
|
||||
negative_prompt: str,
|
||||
init_image: Image,
|
||||
pixels: int,
|
||||
mask_blur: int,
|
||||
directions: list,
|
||||
noise_q: float,
|
||||
color_variation: float,
|
||||
height: int,
|
||||
width: int,
|
||||
steps: int,
|
||||
guidance_scale: float,
|
||||
seed: int,
|
||||
batch_count: int,
|
||||
batch_size: int,
|
||||
scheduler: str,
|
||||
custom_model: str,
|
||||
hf_model_id: str,
|
||||
precision: str,
|
||||
device: str,
|
||||
max_length: int,
|
||||
save_metadata_to_json: bool,
|
||||
save_metadata_to_png: bool,
|
||||
):
|
||||
global outpaint_obj
|
||||
global config_obj
|
||||
global schedulers
|
||||
|
||||
args.prompts = [prompt]
|
||||
args.negative_prompts = [negative_prompt]
|
||||
args.guidance_scale = guidance_scale
|
||||
args.steps = steps
|
||||
args.scheduler = scheduler
|
||||
args.img_path = "not none"
|
||||
|
||||
# set ckpt_loc and hf_model_id.
|
||||
types = (
|
||||
".ckpt",
|
||||
".safetensors",
|
||||
) # the tuple of file types
|
||||
args.ckpt_loc = ""
|
||||
args.hf_model_id = ""
|
||||
if custom_model == "None":
|
||||
if not hf_model_id:
|
||||
return (
|
||||
None,
|
||||
"Please provide either custom model or huggingface model ID, both must not be empty",
|
||||
)
|
||||
args.hf_model_id = hf_model_id
|
||||
elif ".ckpt" in custom_model or ".safetensors" in custom_model:
|
||||
args.ckpt_loc = custom_model
|
||||
else:
|
||||
args.hf_model_id = custom_model
|
||||
|
||||
args.save_metadata_to_json = save_metadata_to_json
|
||||
args.write_metadata_to_png = save_metadata_to_png
|
||||
|
||||
dtype = torch.float32 if precision == "fp32" else torch.half
|
||||
cpu_scheduling = not scheduler.startswith("Shark")
|
||||
new_config_obj = Config(
|
||||
args.hf_model_id,
|
||||
args.ckpt_loc,
|
||||
precision,
|
||||
batch_size,
|
||||
max_length,
|
||||
height,
|
||||
width,
|
||||
device,
|
||||
)
|
||||
if not outpaint_obj or config_obj != new_config_obj:
|
||||
config_obj = new_config_obj
|
||||
args.precision = precision
|
||||
args.batch_size = batch_size
|
||||
args.max_length = max_length
|
||||
args.height = height
|
||||
args.width = width
|
||||
args.device = device.split("=>", 1)[1].strip()
|
||||
args.iree_vulkan_target_triple = init_iree_vulkan_target_triple
|
||||
args.use_tuned = init_use_tuned
|
||||
args.import_mlir = init_import_mlir
|
||||
set_init_device_flags()
|
||||
model_id = (
|
||||
args.hf_model_id
|
||||
if args.hf_model_id
|
||||
else "stabilityai/stable-diffusion-2-inpainting"
|
||||
)
|
||||
schedulers = get_schedulers(model_id)
|
||||
scheduler_obj = schedulers[scheduler]
|
||||
outpaint_obj = OutpaintPipeline.from_pretrained(
|
||||
scheduler_obj,
|
||||
args.import_mlir,
|
||||
args.hf_model_id,
|
||||
args.ckpt_loc,
|
||||
args.custom_vae,
|
||||
args.precision,
|
||||
args.max_length,
|
||||
args.batch_size,
|
||||
args.height,
|
||||
args.width,
|
||||
args.use_base_vae,
|
||||
args.use_tuned,
|
||||
)
|
||||
|
||||
outpaint_obj.scheduler = schedulers[scheduler]
|
||||
|
||||
start_time = time.time()
|
||||
outpaint_obj.log = ""
|
||||
generated_imgs = []
|
||||
seeds = []
|
||||
img_seed = utils.sanitize_seed(seed)
|
||||
|
||||
left = True if "left" in directions else False
|
||||
right = True if "right" in directions else False
|
||||
top = True if "up" in directions else False
|
||||
bottom = True if "down" in directions else False
|
||||
|
||||
for i in range(batch_count):
|
||||
if i > 0:
|
||||
img_seed = utils.sanitize_seed(-1)
|
||||
out_imgs = outpaint_obj.generate_images(
|
||||
prompt,
|
||||
negative_prompt,
|
||||
init_image,
|
||||
pixels,
|
||||
mask_blur,
|
||||
left,
|
||||
right,
|
||||
top,
|
||||
bottom,
|
||||
noise_q,
|
||||
color_variation,
|
||||
batch_size,
|
||||
height,
|
||||
width,
|
||||
steps,
|
||||
guidance_scale,
|
||||
img_seed,
|
||||
args.max_length,
|
||||
dtype,
|
||||
args.use_base_vae,
|
||||
cpu_scheduling,
|
||||
)
|
||||
save_output_img(out_imgs[0], img_seed)
|
||||
generated_imgs.extend(out_imgs)
|
||||
seeds.append(img_seed)
|
||||
outpaint_obj.log += "\n"
|
||||
|
||||
total_time = time.time() - start_time
|
||||
text_output = f"prompt={args.prompts}"
|
||||
text_output += f"\nnegative prompt={args.negative_prompts}"
|
||||
text_output += f"\nmodel_id={args.hf_model_id}, ckpt_loc={args.ckpt_loc}"
|
||||
text_output += f"\nscheduler={args.scheduler}, device={device}"
|
||||
text_output += f"\nsteps={args.steps}, guidance_scale={args.guidance_scale}, seed={seeds}"
|
||||
text_output += f"\nsize={args.height}x{args.width}, batch-count={batch_count}, batch-size={args.batch_size}, max_length={args.max_length}"
|
||||
text_output += outpaint_obj.log
|
||||
text_output += f"\nTotal image generation time: {total_time:.4f}sec"
|
||||
|
||||
return generated_imgs, text_output
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
if args.clear_all:
|
||||
clear_all()
|
||||
|
||||
if args.img_path is None:
|
||||
print("Flag --img_path is required.")
|
||||
exit()
|
||||
|
||||
dtype = torch.float32 if args.precision == "fp32" else torch.half
|
||||
cpu_scheduling = not args.scheduler.startswith("Shark")
|
||||
set_init_device_flags()
|
||||
model_id = (
|
||||
args.hf_model_id
|
||||
if "inpaint" in args.hf_model_id
|
||||
else "stabilityai/stable-diffusion-2-inpainting"
|
||||
)
|
||||
schedulers = get_schedulers(model_id)
|
||||
scheduler_obj = schedulers[args.scheduler]
|
||||
seed = args.seed
|
||||
image = Image.open(args.img_path)
|
||||
|
||||
outpaint_obj = OutpaintPipeline.from_pretrained(
|
||||
scheduler_obj,
|
||||
args.import_mlir,
|
||||
args.hf_model_id,
|
||||
args.ckpt_loc,
|
||||
args.custom_vae,
|
||||
args.precision,
|
||||
args.max_length,
|
||||
args.batch_size,
|
||||
args.height,
|
||||
args.width,
|
||||
args.use_base_vae,
|
||||
args.use_tuned,
|
||||
)
|
||||
|
||||
for current_batch in range(args.batch_count):
|
||||
if current_batch > 0:
|
||||
seed = -1
|
||||
seed = utils.sanitize_seed(seed)
|
||||
|
||||
start_time = time.time()
|
||||
generated_imgs = outpaint_obj.generate_images(
|
||||
args.prompts,
|
||||
args.negative_prompts,
|
||||
image,
|
||||
args.pixels,
|
||||
args.mask_blur,
|
||||
args.left,
|
||||
args.right,
|
||||
args.top,
|
||||
args.bottom,
|
||||
args.noise_q,
|
||||
args.color_variation,
|
||||
args.batch_size,
|
||||
args.height,
|
||||
args.width,
|
||||
args.steps,
|
||||
args.guidance_scale,
|
||||
seed,
|
||||
args.max_length,
|
||||
dtype,
|
||||
args.use_base_vae,
|
||||
cpu_scheduling,
|
||||
)
|
||||
total_time = time.time() - start_time
|
||||
text_output = f"prompt={args.prompts}"
|
||||
text_output += f"\nnegative prompt={args.negative_prompts}"
|
||||
text_output += (
|
||||
f"\nmodel_id={args.hf_model_id}, ckpt_loc={args.ckpt_loc}"
|
||||
)
|
||||
text_output += f"\nscheduler={args.scheduler}, device={args.device}"
|
||||
text_output += f"\nsteps={args.steps}, guidance_scale={args.guidance_scale}, seed={seed}, size={args.height}x{args.width}"
|
||||
text_output += (
|
||||
f", batch size={args.batch_size}, max_length={args.max_length}"
|
||||
)
|
||||
text_output += outpaint_obj.log
|
||||
text_output += f"\nTotal image generation time: {total_time:.4f}sec"
|
||||
|
||||
# save this information as metadata of output generated image.
|
||||
directions = []
|
||||
if args.left:
|
||||
directions.append("left")
|
||||
if args.right:
|
||||
directions.append("right")
|
||||
if args.top:
|
||||
directions.append("up")
|
||||
if args.bottom:
|
||||
directions.append("down")
|
||||
extra_info = {
|
||||
"PIXELS": args.pixels,
|
||||
"MASK_BLUR": args.mask_blur,
|
||||
"DIRECTIONS": directions,
|
||||
"NOISE_Q": args.noise_q,
|
||||
"COLOR_VARIATION": args.color_variation,
|
||||
}
|
||||
save_output_img(generated_imgs[0], seed, extra_info)
|
||||
print(text_output)
|
||||
@@ -29,6 +29,11 @@ txt2img_obj = None
|
||||
config_obj = None
|
||||
schedulers = None
|
||||
|
||||
# set initial values of iree_vulkan_target_triple, use_tuned and import_mlir.
|
||||
init_iree_vulkan_target_triple = args.iree_vulkan_target_triple
|
||||
init_use_tuned = args.use_tuned
|
||||
init_import_mlir = args.import_mlir
|
||||
|
||||
|
||||
# Exposed to UI.
|
||||
def txt2img_inf(
|
||||
@@ -94,7 +99,7 @@ def txt2img_inf(
|
||||
width,
|
||||
device,
|
||||
)
|
||||
if config_obj != new_config_obj:
|
||||
if not txt2img_obj or config_obj != new_config_obj:
|
||||
config_obj = new_config_obj
|
||||
args.precision = precision
|
||||
args.batch_size = batch_size
|
||||
@@ -102,9 +107,10 @@ def txt2img_inf(
|
||||
args.height = height
|
||||
args.width = width
|
||||
args.device = device.split("=>", 1)[1].strip()
|
||||
args.iree_vulkan_target_triple = ""
|
||||
args.use_tuned = True
|
||||
args.import_mlir = False
|
||||
args.iree_vulkan_target_triple = init_iree_vulkan_target_triple
|
||||
args.use_tuned = init_use_tuned
|
||||
args.import_mlir = init_import_mlir
|
||||
args.img_path = None
|
||||
set_init_device_flags()
|
||||
model_id = (
|
||||
args.hf_model_id
|
||||
@@ -126,11 +132,9 @@ def txt2img_inf(
|
||||
args.width,
|
||||
args.use_base_vae,
|
||||
args.use_tuned,
|
||||
low_cpu_mem_usage=args.low_cpu_mem_usage,
|
||||
)
|
||||
|
||||
if not txt2img_obj:
|
||||
sys.exit("text to image pipeline must not return a null value")
|
||||
|
||||
txt2img_obj.scheduler = schedulers[scheduler]
|
||||
|
||||
start_time = time.time()
|
||||
@@ -159,6 +163,7 @@ def txt2img_inf(
|
||||
generated_imgs.extend(out_imgs)
|
||||
seeds.append(img_seed)
|
||||
txt2img_obj.log += "\n"
|
||||
yield generated_imgs, generated_imgs[0], txt2img_obj.log
|
||||
|
||||
total_time = time.time() - start_time
|
||||
text_output = f"prompt={args.prompts}"
|
||||
@@ -169,10 +174,10 @@ def txt2img_inf(
|
||||
f"\nsteps={steps}, guidance_scale={guidance_scale}, seed={seeds}"
|
||||
)
|
||||
text_output += f"\nsize={height}x{width}, batch_count={batch_count}, batch_size={batch_size}, max_length={args.max_length}"
|
||||
text_output += txt2img_obj.log
|
||||
# text_output += txt2img_obj.log
|
||||
text_output += f"\nTotal image generation time: {total_time:.4f}sec"
|
||||
|
||||
return generated_imgs, text_output
|
||||
yield generated_imgs, text_output
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
@@ -199,6 +204,7 @@ if __name__ == "__main__":
|
||||
args.width,
|
||||
args.use_base_vae,
|
||||
args.use_tuned,
|
||||
low_cpu_mem_usage=args.low_cpu_mem_usage,
|
||||
)
|
||||
|
||||
for current_batch in range(args.batch_count):
|
||||
|
||||
@@ -15,12 +15,12 @@ datas += copy_metadata('filelock')
|
||||
datas += copy_metadata('numpy')
|
||||
datas += copy_metadata('tokenizers')
|
||||
datas += copy_metadata('importlib_metadata')
|
||||
datas += copy_metadata('torchvision')
|
||||
datas += copy_metadata('torch-mlir')
|
||||
datas += copy_metadata('diffusers')
|
||||
datas += copy_metadata('transformers')
|
||||
datas += copy_metadata('omegaconf')
|
||||
datas += copy_metadata('safetensors')
|
||||
datas += collect_data_files('diffusers')
|
||||
datas += collect_data_files('transformers')
|
||||
datas += collect_data_files('opencv-python')
|
||||
datas += collect_data_files('gradio')
|
||||
datas += collect_data_files('iree')
|
||||
datas += collect_data_files('google-cloud-storage')
|
||||
@@ -44,7 +44,7 @@ a = Analysis(
|
||||
pathex=['.'],
|
||||
binaries=binaries,
|
||||
datas=datas,
|
||||
hiddenimports=['shark', 'shark.*', 'shark.shark_inference', 'shark_inference', 'iree.tools.core', 'gradio', 'apps'],
|
||||
hiddenimports=['shark', 'shark.shark_inference', 'apps'],
|
||||
hookspath=[],
|
||||
hooksconfig={},
|
||||
runtime_hooks=[],
|
||||
|
||||
@@ -15,12 +15,12 @@ datas += copy_metadata('filelock')
|
||||
datas += copy_metadata('numpy')
|
||||
datas += copy_metadata('tokenizers')
|
||||
datas += copy_metadata('importlib_metadata')
|
||||
datas += copy_metadata('torchvision')
|
||||
datas += copy_metadata('torch-mlir')
|
||||
datas += copy_metadata('diffusers')
|
||||
datas += copy_metadata('transformers')
|
||||
datas += copy_metadata('omegaconf')
|
||||
datas += copy_metadata('safetensors')
|
||||
datas += collect_data_files('diffusers')
|
||||
datas += collect_data_files('transformers')
|
||||
datas += collect_data_files('opencv-python')
|
||||
datas += collect_data_files('gradio')
|
||||
datas += collect_data_files('iree')
|
||||
datas += collect_data_files('google-cloud-storage')
|
||||
@@ -42,7 +42,7 @@ a = Analysis(
|
||||
pathex=['.'],
|
||||
binaries=binaries,
|
||||
datas=datas,
|
||||
hiddenimports=['shark', 'shark.*', 'shark.shark_inference', 'shark_inference', 'iree.tools.core', 'gradio', 'apps'],
|
||||
hiddenimports=['shark', 'shark.shark_inference', 'apps'],
|
||||
hookspath=[],
|
||||
hooksconfig={},
|
||||
runtime_hooks=[],
|
||||
|
||||
@@ -8,7 +8,9 @@ from apps.stable_diffusion.src.utils import (
|
||||
)
|
||||
from apps.stable_diffusion.src.pipelines import (
|
||||
Text2ImagePipeline,
|
||||
InpaintPipeline,
|
||||
Image2ImagePipeline,
|
||||
InpaintPipeline,
|
||||
OutpaintPipeline,
|
||||
StencilPipeline,
|
||||
)
|
||||
from apps.stable_diffusion.src.schedulers import get_schedulers
|
||||
|
||||
@@ -1,4 +1,4 @@
|
||||
from diffusers import AutoencoderKL, UNet2DConditionModel
|
||||
from diffusers import AutoencoderKL, UNet2DConditionModel, ControlNetModel
|
||||
from transformers import CLIPTextModel
|
||||
from collections import defaultdict
|
||||
import torch
|
||||
@@ -16,6 +16,7 @@ from apps.stable_diffusion.src.utils import (
|
||||
fetch_and_update_base_model_id,
|
||||
get_path_stem,
|
||||
get_extended_name,
|
||||
get_stencil_model_id,
|
||||
)
|
||||
|
||||
|
||||
@@ -80,6 +81,9 @@ class SharkifyStableDiffusionModel:
|
||||
batch_size: int = 1,
|
||||
use_base_vae: bool = False,
|
||||
use_tuned: bool = False,
|
||||
low_cpu_mem_usage: bool = False,
|
||||
is_inpaint: bool = False,
|
||||
use_stencil: str = None
|
||||
):
|
||||
self.check_params(max_len, width, height)
|
||||
self.max_len = max_len
|
||||
@@ -114,11 +118,18 @@ class SharkifyStableDiffusionModel:
|
||||
if use_tuned:
|
||||
self.model_name = self.model_name + "_tuned"
|
||||
self.model_name = self.model_name + "_" + get_path_stem(self.model_id)
|
||||
self.low_cpu_mem_usage = low_cpu_mem_usage
|
||||
self.is_inpaint = is_inpaint
|
||||
self.use_stencil = get_stencil_model_id(use_stencil)
|
||||
|
||||
def get_extended_name_for_all_model(self):
|
||||
def get_extended_name_for_all_model(self, mask_to_fetch):
|
||||
model_name = {}
|
||||
sub_model_list = ["clip", "unet", "vae", "vae_encode"]
|
||||
sub_model_list = ["clip", "unet", "stencil_unet", "vae", "vae_encode", "stencil_adaptor"]
|
||||
index = 0
|
||||
for model in sub_model_list:
|
||||
if mask_to_fetch[index] == False:
|
||||
index += 1
|
||||
continue
|
||||
sub_model = model
|
||||
model_config = self.model_name
|
||||
if "vae" == model:
|
||||
@@ -127,6 +138,7 @@ class SharkifyStableDiffusionModel:
|
||||
if self.base_vae:
|
||||
sub_model = "base_vae"
|
||||
model_name[model] = get_extended_name(sub_model + model_config)
|
||||
index += 1
|
||||
return model_name
|
||||
|
||||
def check_params(self, max_len, width, height):
|
||||
@@ -139,11 +151,12 @@ class SharkifyStableDiffusionModel:
|
||||
|
||||
def get_vae_encode(self):
|
||||
class VaeEncodeModel(torch.nn.Module):
|
||||
def __init__(self, model_id=self.model_id):
|
||||
def __init__(self, model_id=self.model_id, low_cpu_mem_usage=False):
|
||||
super().__init__()
|
||||
self.vae = AutoencoderKL.from_pretrained(
|
||||
model_id,
|
||||
subfolder="vae",
|
||||
low_cpu_mem_usage=low_cpu_mem_usage,
|
||||
)
|
||||
|
||||
def forward(self, input):
|
||||
@@ -165,23 +178,26 @@ class SharkifyStableDiffusionModel:
|
||||
|
||||
def get_vae(self):
|
||||
class VaeModel(torch.nn.Module):
|
||||
def __init__(self, model_id=self.model_id, base_vae=self.base_vae, custom_vae=self.custom_vae):
|
||||
def __init__(self, model_id=self.model_id, base_vae=self.base_vae, custom_vae=self.custom_vae, low_cpu_mem_usage=False):
|
||||
super().__init__()
|
||||
self.vae = None
|
||||
if custom_vae == "":
|
||||
self.vae = AutoencoderKL.from_pretrained(
|
||||
model_id,
|
||||
subfolder="vae",
|
||||
low_cpu_mem_usage=low_cpu_mem_usage,
|
||||
)
|
||||
elif not isinstance(custom_vae, dict):
|
||||
self.vae = AutoencoderKL.from_pretrained(
|
||||
custom_vae,
|
||||
subfolder="vae",
|
||||
low_cpu_mem_usage=low_cpu_mem_usage,
|
||||
)
|
||||
else:
|
||||
self.vae = AutoencoderKL.from_pretrained(
|
||||
model_id,
|
||||
subfolder="vae",
|
||||
low_cpu_mem_usage=low_cpu_mem_usage,
|
||||
)
|
||||
self.vae.load_state_dict(custom_vae)
|
||||
self.base_vae = base_vae
|
||||
@@ -196,7 +212,7 @@ class SharkifyStableDiffusionModel:
|
||||
x = x * 255.0
|
||||
return x.round()
|
||||
|
||||
vae = VaeModel()
|
||||
vae = VaeModel(low_cpu_mem_usage=self.low_cpu_mem_usage)
|
||||
inputs = tuple(self.inputs["vae"])
|
||||
is_f16 = True if self.precision == "fp16" else False
|
||||
shark_vae = compile_through_fx(
|
||||
@@ -209,19 +225,131 @@ class SharkifyStableDiffusionModel:
|
||||
)
|
||||
return shark_vae
|
||||
|
||||
def get_unet(self):
|
||||
class UnetModel(torch.nn.Module):
|
||||
def __init__(self, model_id=self.model_id):
|
||||
def get_controlled_unet(self):
|
||||
class ControlledUnetModel(torch.nn.Module):
|
||||
def __init__(
|
||||
self, model_id=self.model_id, low_cpu_mem_usage=False
|
||||
):
|
||||
super().__init__()
|
||||
self.unet = UNet2DConditionModel.from_pretrained(
|
||||
model_id,
|
||||
subfolder="unet",
|
||||
low_cpu_mem_usage=low_cpu_mem_usage,
|
||||
)
|
||||
self.in_channels = self.unet.in_channels
|
||||
self.train(False)
|
||||
|
||||
def forward( self, latent, timestep, text_embedding, guidance_scale, control1,
|
||||
control2, control3, control4, control5, control6, control7,
|
||||
control8, control9, control10, control11, control12, control13,
|
||||
):
|
||||
# expand the latents if we are doing classifier-free guidance to avoid doing two forward passes.
|
||||
db_res_samples = tuple([ control1, control2, control3, control4, control5, control6, control7, control8, control9, control10, control11, control12,])
|
||||
mb_res_samples = control13
|
||||
latents = torch.cat([latent] * 2)
|
||||
unet_out = self.unet.forward(
|
||||
latents,
|
||||
timestep,
|
||||
encoder_hidden_states=text_embedding,
|
||||
down_block_additional_residuals=db_res_samples,
|
||||
mid_block_additional_residual=mb_res_samples,
|
||||
return_dict=False,
|
||||
)[0]
|
||||
noise_pred_uncond, noise_pred_text = unet_out.chunk(2)
|
||||
noise_pred = noise_pred_uncond + guidance_scale * (
|
||||
noise_pred_text - noise_pred_uncond
|
||||
)
|
||||
return noise_pred
|
||||
|
||||
unet = ControlledUnetModel(low_cpu_mem_usage=self.low_cpu_mem_usage)
|
||||
is_f16 = True if self.precision == "fp16" else False
|
||||
|
||||
inputs = tuple(self.inputs["stencil_unet"])
|
||||
input_mask = [True, True, True, False, True, True, True, True, True, True, True, True, True, True, True, True, True,]
|
||||
shark_controlled_unet = compile_through_fx(
|
||||
unet,
|
||||
inputs,
|
||||
model_name=self.model_name["stencil_unet"],
|
||||
is_f16=is_f16,
|
||||
f16_input_mask=input_mask,
|
||||
use_tuned=self.use_tuned,
|
||||
extra_args=get_opt_flags("unet", precision=self.precision),
|
||||
)
|
||||
return shark_controlled_unet
|
||||
|
||||
def get_control_net(self):
|
||||
class StencilControlNetModel(torch.nn.Module):
|
||||
def __init__(
|
||||
self, model_id=self.use_stencil, low_cpu_mem_usage=False
|
||||
):
|
||||
super().__init__()
|
||||
self.cnet = ControlNetModel.from_pretrained(
|
||||
model_id,
|
||||
low_cpu_mem_usage=low_cpu_mem_usage,
|
||||
)
|
||||
self.in_channels = self.cnet.in_channels
|
||||
self.train(False)
|
||||
|
||||
def forward(
|
||||
self, latent, timestep, text_embedding, guidance_scale
|
||||
self,
|
||||
latent,
|
||||
timestep,
|
||||
text_embedding,
|
||||
stencil_image_input,
|
||||
):
|
||||
# expand the latents if we are doing classifier-free guidance to avoid doing two forward passes.
|
||||
# TODO: guidance NOT NEEDED change in `get_input_info` later
|
||||
latents = torch.cat(
|
||||
[latent] * 2
|
||||
) # needs to be same as controlledUNET latents
|
||||
stencil_image = torch.cat(
|
||||
[stencil_image_input] * 2
|
||||
) # needs to be same as controlledUNET latents
|
||||
down_block_res_samples, mid_block_res_sample = self.cnet.forward(
|
||||
latents,
|
||||
timestep,
|
||||
encoder_hidden_states=text_embedding,
|
||||
controlnet_cond=stencil_image,
|
||||
return_dict=False,
|
||||
)
|
||||
return tuple(list(down_block_res_samples) + [mid_block_res_sample])
|
||||
|
||||
scnet = StencilControlNetModel(low_cpu_mem_usage=self.low_cpu_mem_usage)
|
||||
is_f16 = True if self.precision == "fp16" else False
|
||||
|
||||
inputs = tuple(self.inputs["stencil_adaptor"])
|
||||
input_mask = [True, True, True, True]
|
||||
shark_cnet = compile_through_fx(
|
||||
scnet,
|
||||
inputs,
|
||||
model_name=self.model_name["stencil_adaptor"],
|
||||
is_f16=is_f16,
|
||||
f16_input_mask=input_mask,
|
||||
use_tuned=self.use_tuned,
|
||||
extra_args=get_opt_flags("unet", precision=self.precision),
|
||||
)
|
||||
return shark_cnet
|
||||
|
||||
def get_unet(self):
|
||||
class UnetModel(torch.nn.Module):
|
||||
def __init__(self, model_id=self.model_id, low_cpu_mem_usage=False):
|
||||
super().__init__()
|
||||
self.unet = UNet2DConditionModel.from_pretrained(
|
||||
model_id,
|
||||
subfolder="unet",
|
||||
low_cpu_mem_usage=low_cpu_mem_usage,
|
||||
)
|
||||
self.in_channels = self.unet.in_channels
|
||||
self.train(False)
|
||||
if(args.attention_slicing is not None and args.attention_slicing != "none"):
|
||||
if(args.attention_slicing.isdigit()):
|
||||
self.unet.set_attention_slice(int(args.attention_slicing))
|
||||
else:
|
||||
self.unet.set_attention_slice(args.attention_slicing)
|
||||
|
||||
# TODO: Instead of flattening the `control` try to use the list.
|
||||
def forward(
|
||||
self, latent, timestep, text_embedding, guidance_scale,
|
||||
):
|
||||
# expand the latents if we are doing classifier-free guidance to avoid doing two forward passes.
|
||||
latents = torch.cat([latent] * 2)
|
||||
@@ -234,7 +362,7 @@ class SharkifyStableDiffusionModel:
|
||||
)
|
||||
return noise_pred
|
||||
|
||||
unet = UnetModel()
|
||||
unet = UnetModel(low_cpu_mem_usage=self.low_cpu_mem_usage)
|
||||
is_f16 = True if self.precision == "fp16" else False
|
||||
inputs = tuple(self.inputs["unet"])
|
||||
input_mask = [True, True, True, False]
|
||||
@@ -251,17 +379,18 @@ class SharkifyStableDiffusionModel:
|
||||
|
||||
def get_clip(self):
|
||||
class CLIPText(torch.nn.Module):
|
||||
def __init__(self, model_id=self.model_id):
|
||||
def __init__(self, model_id=self.model_id, low_cpu_mem_usage=False):
|
||||
super().__init__()
|
||||
self.text_encoder = CLIPTextModel.from_pretrained(
|
||||
model_id,
|
||||
subfolder="text_encoder",
|
||||
low_cpu_mem_usage=low_cpu_mem_usage,
|
||||
)
|
||||
|
||||
def forward(self, input):
|
||||
return self.text_encoder(input)[0]
|
||||
|
||||
clip_model = CLIPText()
|
||||
clip_model = CLIPText(low_cpu_mem_usage=self.low_cpu_mem_usage)
|
||||
shark_clip = compile_through_fx(
|
||||
clip_model,
|
||||
tuple(self.inputs["clip"]),
|
||||
@@ -293,7 +422,7 @@ class SharkifyStableDiffusionModel:
|
||||
|
||||
# Compiles Clip, Unet and Vae with `base_model_id` as defining their input
|
||||
# configiration.
|
||||
def compile_all(self, base_model_id, need_vae_encode):
|
||||
def compile_all(self, base_model_id, need_vae_encode, need_stencil):
|
||||
self.inputs = get_input_info(
|
||||
base_models[base_model_id],
|
||||
self.max_len,
|
||||
@@ -301,11 +430,21 @@ class SharkifyStableDiffusionModel:
|
||||
self.height,
|
||||
self.batch_size,
|
||||
)
|
||||
compiled_unet = self.get_unet()
|
||||
compiled_controlnet = None
|
||||
compiled_controlled_unet = None
|
||||
compiled_unet = None
|
||||
if need_stencil:
|
||||
compiled_controlnet = self.get_control_net()
|
||||
compiled_controlled_unet = self.get_controlled_unet()
|
||||
else:
|
||||
compiled_unet = self.get_unet()
|
||||
if self.custom_vae != "":
|
||||
print("Plugging in custom Vae")
|
||||
compiled_vae = self.get_vae()
|
||||
compiled_clip = self.get_clip()
|
||||
|
||||
if need_stencil:
|
||||
return compiled_clip, compiled_controlled_unet, compiled_vae, compiled_controlnet
|
||||
if need_vae_encode:
|
||||
compiled_vae_encode = self.get_vae_encode()
|
||||
return compiled_clip, compiled_unet, compiled_vae, compiled_vae_encode
|
||||
@@ -315,9 +454,21 @@ class SharkifyStableDiffusionModel:
|
||||
def __call__(self):
|
||||
# Step 1:
|
||||
# -- Fetch all vmfbs for the model, if present, else delete the lot.
|
||||
need_vae_encode = args.img_path is not None
|
||||
self.model_name = self.get_extended_name_for_all_model()
|
||||
vmfbs = fetch_or_delete_vmfbs(self.model_name, need_vae_encode, self.precision)
|
||||
need_vae_encode, need_stencil = False, False
|
||||
if args.img_path is not None:
|
||||
if self.use_stencil is not None:
|
||||
need_stencil = True
|
||||
else:
|
||||
need_vae_encode = True
|
||||
# `mask_to_fetch` prepares a mask to pick a combination out of :-
|
||||
# ["clip", "unet", "stencil_unet", "vae", "vae_encode", "stencil_adaptor"]
|
||||
mask_to_fetch = [True, True, False, True, False, False]
|
||||
if need_vae_encode:
|
||||
mask_to_fetch = [True, True, False, True, True, False]
|
||||
elif need_stencil:
|
||||
mask_to_fetch = [True, False, True, True, False, True]
|
||||
self.model_name = self.get_extended_name_for_all_model(mask_to_fetch)
|
||||
vmfbs = fetch_or_delete_vmfbs(self.model_name, self.precision)
|
||||
if vmfbs[0]:
|
||||
# -- If all vmfbs are indeed present, we also try and fetch the base
|
||||
# model configuration for running SD with custom checkpoints.
|
||||
@@ -337,7 +488,7 @@ class SharkifyStableDiffusionModel:
|
||||
assert self.custom_weights.lower().endswith(
|
||||
(".ckpt", ".safetensors")
|
||||
), "checkpoint files supported can be any of [.ckpt, .safetensors] type"
|
||||
preprocessCKPT(self.custom_weights)
|
||||
preprocessCKPT(self.custom_weights, self.is_inpaint)
|
||||
else:
|
||||
model_to_run = args.hf_model_id
|
||||
# For custom Vae user can provide either the repo-id or a checkpoint file,
|
||||
@@ -348,7 +499,7 @@ class SharkifyStableDiffusionModel:
|
||||
print("Compiling all the models with the fetched base model configuration.")
|
||||
if args.ckpt_loc != "":
|
||||
args.hf_model_id = base_model_fetched
|
||||
return self.compile_all(base_model_fetched, need_vae_encode)
|
||||
return self.compile_all(base_model_fetched, need_vae_encode, need_stencil)
|
||||
|
||||
# Step 3:
|
||||
# -- This is the retry mechanism where the base model's configuration is not
|
||||
@@ -357,9 +508,11 @@ class SharkifyStableDiffusionModel:
|
||||
for model_id in base_models:
|
||||
try:
|
||||
if need_vae_encode:
|
||||
compiled_clip, compiled_unet, compiled_vae, compiled_vae_encode = self.compile_all(model_id, need_vae_encode)
|
||||
compiled_clip, compiled_unet, compiled_vae, compiled_vae_encode = self.compile_all(model_id, need_vae_encode, need_stencil)
|
||||
elif need_stencil:
|
||||
compiled_clip, compiled_unet, compiled_vae, compiled_controlnet = self.compile_all(model_id, need_vae_encode, need_stencil)
|
||||
else:
|
||||
compiled_clip, compiled_unet, compiled_vae = self.compile_all(model_id, need_vae_encode)
|
||||
compiled_clip, compiled_unet, compiled_vae = self.compile_all(model_id, need_vae_encode, need_stencil)
|
||||
except Exception as e:
|
||||
print("Retrying with a different base model configuration")
|
||||
continue
|
||||
@@ -379,6 +532,13 @@ class SharkifyStableDiffusionModel:
|
||||
compiled_vae,
|
||||
compiled_vae_encode,
|
||||
)
|
||||
if need_stencil:
|
||||
return (
|
||||
compiled_clip,
|
||||
compiled_unet,
|
||||
compiled_vae,
|
||||
compiled_controlnet,
|
||||
)
|
||||
return compiled_clip, compiled_unet, compiled_vae
|
||||
sys.exit(
|
||||
"Cannot compile the model. Please create an issue with the detailed log at https://github.com/nod-ai/SHARK/issues"
|
||||
|
||||
@@ -1,9 +1,15 @@
|
||||
from apps.stable_diffusion.src.pipelines.pipeline_shark_stable_diffusion_txt2img import (
|
||||
Text2ImagePipeline,
|
||||
)
|
||||
from apps.stable_diffusion.src.pipelines.pipeline_shark_stable_diffusion_inpaint import (
|
||||
InpaintPipeline,
|
||||
)
|
||||
from apps.stable_diffusion.src.pipelines.pipeline_shark_stable_diffusion_img2img import (
|
||||
Image2ImagePipeline,
|
||||
)
|
||||
from apps.stable_diffusion.src.pipelines.pipeline_shark_stable_diffusion_inpaint import (
|
||||
InpaintPipeline,
|
||||
)
|
||||
from apps.stable_diffusion.src.pipelines.pipeline_shark_stable_diffusion_outpaint import (
|
||||
OutpaintPipeline,
|
||||
)
|
||||
from apps.stable_diffusion.src.pipelines.pipeline_shark_stable_diffusion_stencil import (
|
||||
StencilPipeline,
|
||||
)
|
||||
|
||||
@@ -14,6 +14,7 @@ from diffusers import (
|
||||
EulerDiscreteScheduler,
|
||||
EulerAncestralDiscreteScheduler,
|
||||
DPMSolverMultistepScheduler,
|
||||
DEISMultistepScheduler,
|
||||
)
|
||||
from apps.stable_diffusion.src.schedulers import SharkEulerDiscreteScheduler
|
||||
from apps.stable_diffusion.src.pipelines.pipeline_shark_stable_diffusion_utils import (
|
||||
@@ -37,6 +38,7 @@ class Image2ImagePipeline(StableDiffusionPipeline):
|
||||
EulerAncestralDiscreteScheduler,
|
||||
DPMSolverMultistepScheduler,
|
||||
SharkEulerDiscreteScheduler,
|
||||
DEISMultistepScheduler,
|
||||
],
|
||||
):
|
||||
super().__init__(vae, text_encoder, tokenizer, unet, scheduler)
|
||||
@@ -110,6 +112,7 @@ class Image2ImagePipeline(StableDiffusionPipeline):
|
||||
dtype,
|
||||
use_base_vae,
|
||||
cpu_scheduling,
|
||||
use_stencil,
|
||||
):
|
||||
# prompts and negative prompts must be a list.
|
||||
if isinstance(prompts, str):
|
||||
|
||||
@@ -2,7 +2,7 @@ import torch
|
||||
from tqdm.auto import tqdm
|
||||
import numpy as np
|
||||
from random import randint
|
||||
from PIL import Image
|
||||
from PIL import Image, ImageOps
|
||||
from transformers import CLIPTokenizer
|
||||
from typing import Union
|
||||
from shark.shark_inference import SharkInference
|
||||
@@ -13,6 +13,7 @@ from diffusers import (
|
||||
EulerDiscreteScheduler,
|
||||
EulerAncestralDiscreteScheduler,
|
||||
DPMSolverMultistepScheduler,
|
||||
DEISMultistepScheduler,
|
||||
)
|
||||
from apps.stable_diffusion.src.schedulers import SharkEulerDiscreteScheduler
|
||||
from apps.stable_diffusion.src.pipelines.pipeline_shark_stable_diffusion_utils import (
|
||||
@@ -36,13 +37,228 @@ class InpaintPipeline(StableDiffusionPipeline):
|
||||
EulerAncestralDiscreteScheduler,
|
||||
DPMSolverMultistepScheduler,
|
||||
SharkEulerDiscreteScheduler,
|
||||
DEISMultistepScheduler,
|
||||
],
|
||||
):
|
||||
super().__init__(vae, text_encoder, tokenizer, unet, scheduler)
|
||||
self.vae_encode = vae_encode
|
||||
|
||||
def prepare_mask_and_masked_image(self, image, mask):
|
||||
def prepare_latents(
|
||||
self,
|
||||
batch_size,
|
||||
height,
|
||||
width,
|
||||
generator,
|
||||
num_inference_steps,
|
||||
dtype,
|
||||
):
|
||||
latents = torch.randn(
|
||||
(
|
||||
batch_size,
|
||||
4,
|
||||
height // 8,
|
||||
width // 8,
|
||||
),
|
||||
generator=generator,
|
||||
dtype=torch.float32,
|
||||
).to(dtype)
|
||||
|
||||
self.scheduler.set_timesteps(num_inference_steps)
|
||||
latents = latents * self.scheduler.init_noise_sigma
|
||||
return latents
|
||||
|
||||
def get_crop_region(self, mask, pad=0):
|
||||
h, w = mask.shape
|
||||
|
||||
crop_left = 0
|
||||
for i in range(w):
|
||||
if not (mask[:, i] == 0).all():
|
||||
break
|
||||
crop_left += 1
|
||||
|
||||
crop_right = 0
|
||||
for i in reversed(range(w)):
|
||||
if not (mask[:, i] == 0).all():
|
||||
break
|
||||
crop_right += 1
|
||||
|
||||
crop_top = 0
|
||||
for i in range(h):
|
||||
if not (mask[i] == 0).all():
|
||||
break
|
||||
crop_top += 1
|
||||
|
||||
crop_bottom = 0
|
||||
for i in reversed(range(h)):
|
||||
if not (mask[i] == 0).all():
|
||||
break
|
||||
crop_bottom += 1
|
||||
|
||||
return (
|
||||
int(max(crop_left - pad, 0)),
|
||||
int(max(crop_top - pad, 0)),
|
||||
int(min(w - crop_right + pad, w)),
|
||||
int(min(h - crop_bottom + pad, h)),
|
||||
)
|
||||
|
||||
def expand_crop_region(
|
||||
self,
|
||||
crop_region,
|
||||
processing_width,
|
||||
processing_height,
|
||||
image_width,
|
||||
image_height,
|
||||
):
|
||||
x1, y1, x2, y2 = crop_region
|
||||
|
||||
ratio_crop_region = (x2 - x1) / (y2 - y1)
|
||||
ratio_processing = processing_width / processing_height
|
||||
|
||||
if ratio_crop_region > ratio_processing:
|
||||
desired_height = (x2 - x1) / ratio_processing
|
||||
desired_height_diff = int(desired_height - (y2 - y1))
|
||||
y1 -= desired_height_diff // 2
|
||||
y2 += desired_height_diff - desired_height_diff // 2
|
||||
if y2 >= image_height:
|
||||
diff = y2 - image_height
|
||||
y2 -= diff
|
||||
y1 -= diff
|
||||
if y1 < 0:
|
||||
y2 -= y1
|
||||
y1 -= y1
|
||||
if y2 >= image_height:
|
||||
y2 = image_height
|
||||
else:
|
||||
desired_width = (y2 - y1) * ratio_processing
|
||||
desired_width_diff = int(desired_width - (x2 - x1))
|
||||
x1 -= desired_width_diff // 2
|
||||
x2 += desired_width_diff - desired_width_diff // 2
|
||||
if x2 >= image_width:
|
||||
diff = x2 - image_width
|
||||
x2 -= diff
|
||||
x1 -= diff
|
||||
if x1 < 0:
|
||||
x2 -= x1
|
||||
x1 -= x1
|
||||
if x2 >= image_width:
|
||||
x2 = image_width
|
||||
|
||||
return x1, y1, x2, y2
|
||||
|
||||
def resize_image(self, resize_mode, im, width, height):
|
||||
"""
|
||||
resize_mode:
|
||||
0: Resize the image to fill the specified width and height, maintaining the aspect ratio, and then center the image within the dimensions, cropping the excess.
|
||||
1: Resize the image to fit within the specified width and height, maintaining the aspect ratio, and then center the image within the dimensions, filling empty with data from image.
|
||||
"""
|
||||
|
||||
if resize_mode == 0:
|
||||
ratio = width / height
|
||||
src_ratio = im.width / im.height
|
||||
|
||||
src_w = (
|
||||
width if ratio > src_ratio else im.width * height // im.height
|
||||
)
|
||||
src_h = (
|
||||
height if ratio <= src_ratio else im.height * width // im.width
|
||||
)
|
||||
|
||||
resized = im.resize((src_w, src_h), resample=Image.LANCZOS)
|
||||
res = Image.new("RGB", (width, height))
|
||||
res.paste(
|
||||
resized,
|
||||
box=(width // 2 - src_w // 2, height // 2 - src_h // 2),
|
||||
)
|
||||
|
||||
else:
|
||||
ratio = width / height
|
||||
src_ratio = im.width / im.height
|
||||
|
||||
src_w = (
|
||||
width if ratio < src_ratio else im.width * height // im.height
|
||||
)
|
||||
src_h = (
|
||||
height if ratio >= src_ratio else im.height * width // im.width
|
||||
)
|
||||
|
||||
resized = im.resize((src_w, src_h), resample=Image.LANCZOS)
|
||||
res = Image.new("RGB", (width, height))
|
||||
res.paste(
|
||||
resized,
|
||||
box=(width // 2 - src_w // 2, height // 2 - src_h // 2),
|
||||
)
|
||||
|
||||
if ratio < src_ratio:
|
||||
fill_height = height // 2 - src_h // 2
|
||||
res.paste(
|
||||
resized.resize((width, fill_height), box=(0, 0, width, 0)),
|
||||
box=(0, 0),
|
||||
)
|
||||
res.paste(
|
||||
resized.resize(
|
||||
(width, fill_height),
|
||||
box=(0, resized.height, width, resized.height),
|
||||
),
|
||||
box=(0, fill_height + src_h),
|
||||
)
|
||||
elif ratio > src_ratio:
|
||||
fill_width = width // 2 - src_w // 2
|
||||
res.paste(
|
||||
resized.resize(
|
||||
(fill_width, height), box=(0, 0, 0, height)
|
||||
),
|
||||
box=(0, 0),
|
||||
)
|
||||
res.paste(
|
||||
resized.resize(
|
||||
(fill_width, height),
|
||||
box=(resized.width, 0, resized.width, height),
|
||||
),
|
||||
box=(fill_width + src_w, 0),
|
||||
)
|
||||
|
||||
return res
|
||||
|
||||
def prepare_mask_and_masked_image(
|
||||
self,
|
||||
image,
|
||||
mask,
|
||||
height,
|
||||
width,
|
||||
inpaint_full_res,
|
||||
inpaint_full_res_padding,
|
||||
):
|
||||
# preprocess image
|
||||
image = image.resize((width, height))
|
||||
mask = mask.resize((width, height))
|
||||
|
||||
paste_to = ()
|
||||
overlay_image = None
|
||||
if inpaint_full_res:
|
||||
# prepare overlay image
|
||||
overlay_image = Image.new("RGB", (image.width, image.height))
|
||||
overlay_image.paste(
|
||||
image.convert("RGB"),
|
||||
mask=ImageOps.invert(mask.convert("L")),
|
||||
)
|
||||
|
||||
# prepare mask
|
||||
mask = mask.convert("L")
|
||||
crop_region = self.get_crop_region(
|
||||
np.array(mask), inpaint_full_res_padding
|
||||
)
|
||||
crop_region = self.expand_crop_region(
|
||||
crop_region, width, height, mask.width, mask.height
|
||||
)
|
||||
x1, y1, x2, y2 = crop_region
|
||||
mask = mask.crop(crop_region)
|
||||
mask = self.resize_image(1, mask, width, height)
|
||||
paste_to = (x1, y1, x2 - x1, y2 - y1)
|
||||
|
||||
# prepare image
|
||||
image = image.crop(crop_region)
|
||||
image = self.resize_image(1, image, width, height)
|
||||
|
||||
if isinstance(image, (Image.Image, np.ndarray)):
|
||||
image = [image]
|
||||
|
||||
@@ -73,32 +289,7 @@ class InpaintPipeline(StableDiffusionPipeline):
|
||||
|
||||
masked_image = image * (mask < 0.5)
|
||||
|
||||
return mask, masked_image
|
||||
|
||||
def prepare_latents(
|
||||
self,
|
||||
batch_size,
|
||||
height,
|
||||
width,
|
||||
generator,
|
||||
num_inference_steps,
|
||||
dtype,
|
||||
):
|
||||
latents = torch.randn(
|
||||
(
|
||||
batch_size,
|
||||
4,
|
||||
height // 8,
|
||||
width // 8,
|
||||
),
|
||||
generator=generator,
|
||||
dtype=torch.float32,
|
||||
).to(dtype)
|
||||
|
||||
self.scheduler.set_timesteps(num_inference_steps)
|
||||
self.scheduler.is_scale_input_called = True
|
||||
latents = latents * self.scheduler.init_noise_sigma
|
||||
return latents
|
||||
return mask, masked_image, paste_to, overlay_image
|
||||
|
||||
def prepare_mask_latents(
|
||||
self,
|
||||
@@ -139,6 +330,13 @@ class InpaintPipeline(StableDiffusionPipeline):
|
||||
)
|
||||
return mask, masked_image_latents
|
||||
|
||||
def apply_overlay(self, image, paste_loc, overlay):
|
||||
x, y, w, h = paste_loc
|
||||
image = self.resize_image(0, image, w, h)
|
||||
overlay.paste(image, (x, y))
|
||||
|
||||
return overlay
|
||||
|
||||
def generate_images(
|
||||
self,
|
||||
prompts,
|
||||
@@ -148,6 +346,8 @@ class InpaintPipeline(StableDiffusionPipeline):
|
||||
batch_size,
|
||||
height,
|
||||
width,
|
||||
inpaint_full_res,
|
||||
inpaint_full_res_padding,
|
||||
num_inference_steps,
|
||||
guidance_scale,
|
||||
seed,
|
||||
@@ -190,8 +390,18 @@ class InpaintPipeline(StableDiffusionPipeline):
|
||||
guidance_scale = torch.tensor(guidance_scale).to(torch.float32)
|
||||
|
||||
# Preprocess mask and image
|
||||
mask, masked_image = self.prepare_mask_and_masked_image(
|
||||
image, mask_image
|
||||
(
|
||||
mask,
|
||||
masked_image,
|
||||
paste_to,
|
||||
overlay_image,
|
||||
) = self.prepare_mask_and_masked_image(
|
||||
image,
|
||||
mask_image,
|
||||
height,
|
||||
width,
|
||||
inpaint_full_res,
|
||||
inpaint_full_res_padding,
|
||||
)
|
||||
|
||||
# Prepare mask latent variables
|
||||
@@ -226,4 +436,10 @@ class InpaintPipeline(StableDiffusionPipeline):
|
||||
)
|
||||
all_imgs.extend(imgs)
|
||||
|
||||
if inpaint_full_res:
|
||||
output_image = self.apply_overlay(
|
||||
all_imgs[0], paste_to, overlay_image
|
||||
)
|
||||
return [output_image]
|
||||
|
||||
return all_imgs
|
||||
|
||||
@@ -0,0 +1,541 @@
|
||||
import torch
|
||||
from tqdm.auto import tqdm
|
||||
import numpy as np
|
||||
from random import randint
|
||||
from PIL import Image, ImageDraw, ImageFilter
|
||||
from transformers import CLIPTokenizer
|
||||
from typing import Union
|
||||
from shark.shark_inference import SharkInference
|
||||
from diffusers import (
|
||||
DDIMScheduler,
|
||||
PNDMScheduler,
|
||||
LMSDiscreteScheduler,
|
||||
EulerDiscreteScheduler,
|
||||
EulerAncestralDiscreteScheduler,
|
||||
DPMSolverMultistepScheduler,
|
||||
DEISMultistepScheduler,
|
||||
)
|
||||
from apps.stable_diffusion.src.schedulers import SharkEulerDiscreteScheduler
|
||||
from apps.stable_diffusion.src.pipelines.pipeline_shark_stable_diffusion_utils import (
|
||||
StableDiffusionPipeline,
|
||||
)
|
||||
import math
|
||||
|
||||
|
||||
class OutpaintPipeline(StableDiffusionPipeline):
|
||||
def __init__(
|
||||
self,
|
||||
vae_encode: SharkInference,
|
||||
vae: SharkInference,
|
||||
text_encoder: SharkInference,
|
||||
tokenizer: CLIPTokenizer,
|
||||
unet: SharkInference,
|
||||
scheduler: Union[
|
||||
DDIMScheduler,
|
||||
PNDMScheduler,
|
||||
LMSDiscreteScheduler,
|
||||
EulerDiscreteScheduler,
|
||||
EulerAncestralDiscreteScheduler,
|
||||
DPMSolverMultistepScheduler,
|
||||
SharkEulerDiscreteScheduler,
|
||||
DEISMultistepScheduler,
|
||||
],
|
||||
):
|
||||
super().__init__(vae, text_encoder, tokenizer, unet, scheduler)
|
||||
self.vae_encode = vae_encode
|
||||
|
||||
def prepare_latents(
|
||||
self,
|
||||
batch_size,
|
||||
height,
|
||||
width,
|
||||
generator,
|
||||
num_inference_steps,
|
||||
dtype,
|
||||
):
|
||||
latents = torch.randn(
|
||||
(
|
||||
batch_size,
|
||||
4,
|
||||
height // 8,
|
||||
width // 8,
|
||||
),
|
||||
generator=generator,
|
||||
dtype=torch.float32,
|
||||
).to(dtype)
|
||||
|
||||
self.scheduler.set_timesteps(num_inference_steps)
|
||||
latents = latents * self.scheduler.init_noise_sigma
|
||||
return latents
|
||||
|
||||
def prepare_mask_and_masked_image(
|
||||
self, image, mask, mask_blur, width, height
|
||||
):
|
||||
if mask_blur > 0:
|
||||
mask = mask.filter(ImageFilter.GaussianBlur(mask_blur))
|
||||
image = image.resize((width, height))
|
||||
mask = mask.resize((width, height))
|
||||
|
||||
# preprocess image
|
||||
if isinstance(image, (Image.Image, np.ndarray)):
|
||||
image = [image]
|
||||
|
||||
if isinstance(image, list) and isinstance(image[0], Image.Image):
|
||||
image = [np.array(i.convert("RGB"))[None, :] for i in image]
|
||||
image = np.concatenate(image, axis=0)
|
||||
elif isinstance(image, list) and isinstance(image[0], np.ndarray):
|
||||
image = np.concatenate([i[None, :] for i in image], axis=0)
|
||||
|
||||
image = image.transpose(0, 3, 1, 2)
|
||||
image = torch.from_numpy(image).to(dtype=torch.float32) / 127.5 - 1.0
|
||||
|
||||
# preprocess mask
|
||||
if isinstance(mask, (Image.Image, np.ndarray)):
|
||||
mask = [mask]
|
||||
|
||||
if isinstance(mask, list) and isinstance(mask[0], Image.Image):
|
||||
mask = np.concatenate(
|
||||
[np.array(m.convert("L"))[None, None, :] for m in mask], axis=0
|
||||
)
|
||||
mask = mask.astype(np.float32) / 255.0
|
||||
elif isinstance(mask, list) and isinstance(mask[0], np.ndarray):
|
||||
mask = np.concatenate([m[None, None, :] for m in mask], axis=0)
|
||||
|
||||
mask[mask < 0.5] = 0
|
||||
mask[mask >= 0.5] = 1
|
||||
mask = torch.from_numpy(mask)
|
||||
|
||||
masked_image = image * (mask < 0.5)
|
||||
|
||||
return mask, masked_image
|
||||
|
||||
def prepare_mask_latents(
|
||||
self,
|
||||
mask,
|
||||
masked_image,
|
||||
batch_size,
|
||||
height,
|
||||
width,
|
||||
dtype,
|
||||
):
|
||||
mask = torch.nn.functional.interpolate(
|
||||
mask, size=(height // 8, width // 8)
|
||||
)
|
||||
mask = mask.to(dtype)
|
||||
|
||||
masked_image = masked_image.to(dtype)
|
||||
masked_image_latents = self.vae_encode("forward", (masked_image,))
|
||||
masked_image_latents = torch.from_numpy(masked_image_latents)
|
||||
|
||||
# duplicate mask and masked_image_latents for each generation per prompt, using mps friendly method
|
||||
if mask.shape[0] < batch_size:
|
||||
if not batch_size % mask.shape[0] == 0:
|
||||
raise ValueError(
|
||||
"The passed mask and the required batch size don't match. Masks are supposed to be duplicated to"
|
||||
f" a total batch size of {batch_size}, but {mask.shape[0]} masks were passed. Make sure the number"
|
||||
" of masks that you pass is divisible by the total requested batch size."
|
||||
)
|
||||
mask = mask.repeat(batch_size // mask.shape[0], 1, 1, 1)
|
||||
if masked_image_latents.shape[0] < batch_size:
|
||||
if not batch_size % masked_image_latents.shape[0] == 0:
|
||||
raise ValueError(
|
||||
"The passed images and the required batch size don't match. Images are supposed to be duplicated"
|
||||
f" to a total batch size of {batch_size}, but {masked_image_latents.shape[0]} images were passed."
|
||||
" Make sure the number of images that you pass is divisible by the total requested batch size."
|
||||
)
|
||||
masked_image_latents = masked_image_latents.repeat(
|
||||
batch_size // masked_image_latents.shape[0], 1, 1, 1
|
||||
)
|
||||
return mask, masked_image_latents
|
||||
|
||||
def get_matched_noise(
|
||||
self, _np_src_image, np_mask_rgb, noise_q=1, color_variation=0.05
|
||||
):
|
||||
# helper fft routines that keep ortho normalization and auto-shift before and after fft
|
||||
def _fft2(data):
|
||||
if data.ndim > 2: # has channels
|
||||
out_fft = np.zeros(
|
||||
(data.shape[0], data.shape[1], data.shape[2]),
|
||||
dtype=np.complex128,
|
||||
)
|
||||
for c in range(data.shape[2]):
|
||||
c_data = data[:, :, c]
|
||||
out_fft[:, :, c] = np.fft.fft2(
|
||||
np.fft.fftshift(c_data), norm="ortho"
|
||||
)
|
||||
out_fft[:, :, c] = np.fft.ifftshift(out_fft[:, :, c])
|
||||
else: # one channel
|
||||
out_fft = np.zeros(
|
||||
(data.shape[0], data.shape[1]), dtype=np.complex128
|
||||
)
|
||||
out_fft[:, :] = np.fft.fft2(
|
||||
np.fft.fftshift(data), norm="ortho"
|
||||
)
|
||||
out_fft[:, :] = np.fft.ifftshift(out_fft[:, :])
|
||||
|
||||
return out_fft
|
||||
|
||||
def _ifft2(data):
|
||||
if data.ndim > 2: # has channels
|
||||
out_ifft = np.zeros(
|
||||
(data.shape[0], data.shape[1], data.shape[2]),
|
||||
dtype=np.complex128,
|
||||
)
|
||||
for c in range(data.shape[2]):
|
||||
c_data = data[:, :, c]
|
||||
out_ifft[:, :, c] = np.fft.ifft2(
|
||||
np.fft.fftshift(c_data), norm="ortho"
|
||||
)
|
||||
out_ifft[:, :, c] = np.fft.ifftshift(out_ifft[:, :, c])
|
||||
else: # one channel
|
||||
out_ifft = np.zeros(
|
||||
(data.shape[0], data.shape[1]), dtype=np.complex128
|
||||
)
|
||||
out_ifft[:, :] = np.fft.ifft2(
|
||||
np.fft.fftshift(data), norm="ortho"
|
||||
)
|
||||
out_ifft[:, :] = np.fft.ifftshift(out_ifft[:, :])
|
||||
|
||||
return out_ifft
|
||||
|
||||
def _get_gaussian_window(width, height, std=3.14, mode=0):
|
||||
window_scale_x = float(width / min(width, height))
|
||||
window_scale_y = float(height / min(width, height))
|
||||
|
||||
window = np.zeros((width, height))
|
||||
x = (np.arange(width) / width * 2.0 - 1.0) * window_scale_x
|
||||
for y in range(height):
|
||||
fy = (y / height * 2.0 - 1.0) * window_scale_y
|
||||
if mode == 0:
|
||||
window[:, y] = np.exp(-(x**2 + fy**2) * std)
|
||||
else:
|
||||
window[:, y] = (
|
||||
1 / ((x**2 + 1.0) * (fy**2 + 1.0))
|
||||
) ** (std / 3.14)
|
||||
|
||||
return window
|
||||
|
||||
def _get_masked_window_rgb(np_mask_grey, hardness=1.0):
|
||||
np_mask_rgb = np.zeros(
|
||||
(np_mask_grey.shape[0], np_mask_grey.shape[1], 3)
|
||||
)
|
||||
if hardness != 1.0:
|
||||
hardened = np_mask_grey[:] ** hardness
|
||||
else:
|
||||
hardened = np_mask_grey[:]
|
||||
for c in range(3):
|
||||
np_mask_rgb[:, :, c] = hardened[:]
|
||||
return np_mask_rgb
|
||||
|
||||
def _match_cumulative_cdf(source, template):
|
||||
src_values, src_unique_indices, src_counts = np.unique(
|
||||
source.ravel(), return_inverse=True, return_counts=True
|
||||
)
|
||||
tmpl_values, tmpl_counts = np.unique(
|
||||
template.ravel(), return_counts=True
|
||||
)
|
||||
|
||||
# calculate normalized quantiles for each array
|
||||
src_quantiles = np.cumsum(src_counts) / source.size
|
||||
tmpl_quantiles = np.cumsum(tmpl_counts) / template.size
|
||||
|
||||
interp_a_values = np.interp(
|
||||
src_quantiles, tmpl_quantiles, tmpl_values
|
||||
)
|
||||
return interp_a_values[src_unique_indices].reshape(source.shape)
|
||||
|
||||
def _match_histograms(image, reference):
|
||||
if image.ndim != reference.ndim:
|
||||
raise ValueError(
|
||||
"Image and reference must have the same number of channels."
|
||||
)
|
||||
|
||||
if image.shape[-1] != reference.shape[-1]:
|
||||
raise ValueError(
|
||||
"Number of channels in the input image and reference image must match!"
|
||||
)
|
||||
|
||||
matched = np.empty(image.shape, dtype=image.dtype)
|
||||
for channel in range(image.shape[-1]):
|
||||
matched_channel = _match_cumulative_cdf(
|
||||
image[..., channel], reference[..., channel]
|
||||
)
|
||||
matched[..., channel] = matched_channel
|
||||
|
||||
matched = matched.astype(np.float64, copy=False)
|
||||
return matched
|
||||
|
||||
width = _np_src_image.shape[0]
|
||||
height = _np_src_image.shape[1]
|
||||
num_channels = _np_src_image.shape[2]
|
||||
|
||||
np_src_image = _np_src_image[:] * (1.0 - np_mask_rgb)
|
||||
np_mask_grey = np.sum(np_mask_rgb, axis=2) / 3.0
|
||||
img_mask = np_mask_grey > 1e-6
|
||||
ref_mask = np_mask_grey < 1e-3
|
||||
|
||||
# rather than leave the masked area black, we get better results from fft by filling the average unmasked color
|
||||
windowed_image = _np_src_image * (
|
||||
1.0 - _get_masked_window_rgb(np_mask_grey)
|
||||
)
|
||||
windowed_image /= np.max(windowed_image)
|
||||
windowed_image += np.average(_np_src_image) * np_mask_rgb
|
||||
|
||||
src_fft = _fft2(
|
||||
windowed_image
|
||||
) # get feature statistics from masked src img
|
||||
src_dist = np.absolute(src_fft)
|
||||
src_phase = src_fft / src_dist
|
||||
|
||||
# create a generator with a static seed to make outpainting deterministic / only follow global seed
|
||||
rng = np.random.default_rng(0)
|
||||
|
||||
noise_window = _get_gaussian_window(
|
||||
width, height, mode=1
|
||||
) # start with simple gaussian noise
|
||||
noise_rgb = rng.random((width, height, num_channels))
|
||||
noise_grey = np.sum(noise_rgb, axis=2) / 3.0
|
||||
# the colorfulness of the starting noise is blended to greyscale with a parameter
|
||||
noise_rgb *= color_variation
|
||||
for c in range(num_channels):
|
||||
noise_rgb[:, :, c] += (1.0 - color_variation) * noise_grey
|
||||
|
||||
noise_fft = _fft2(noise_rgb)
|
||||
for c in range(num_channels):
|
||||
noise_fft[:, :, c] *= noise_window
|
||||
noise_rgb = np.real(_ifft2(noise_fft))
|
||||
shaped_noise_fft = _fft2(noise_rgb)
|
||||
shaped_noise_fft[:, :, :] = (
|
||||
np.absolute(shaped_noise_fft[:, :, :]) ** 2
|
||||
* (src_dist**noise_q)
|
||||
* src_phase
|
||||
) # perform the actual shaping
|
||||
|
||||
# color_variation
|
||||
brightness_variation = 0.0
|
||||
contrast_adjusted_np_src = (
|
||||
_np_src_image[:] * (brightness_variation + 1.0)
|
||||
- brightness_variation * 2.0
|
||||
)
|
||||
|
||||
shaped_noise = np.real(_ifft2(shaped_noise_fft))
|
||||
shaped_noise -= np.min(shaped_noise)
|
||||
shaped_noise /= np.max(shaped_noise)
|
||||
shaped_noise[img_mask, :] = _match_histograms(
|
||||
shaped_noise[img_mask, :] ** 1.0,
|
||||
contrast_adjusted_np_src[ref_mask, :],
|
||||
)
|
||||
shaped_noise = (
|
||||
_np_src_image[:] * (1.0 - np_mask_rgb) + shaped_noise * np_mask_rgb
|
||||
)
|
||||
|
||||
matched_noise = shaped_noise[:]
|
||||
|
||||
return np.clip(matched_noise, 0.0, 1.0)
|
||||
|
||||
def generate_images(
|
||||
self,
|
||||
prompts,
|
||||
neg_prompts,
|
||||
image,
|
||||
pixels,
|
||||
mask_blur,
|
||||
is_left,
|
||||
is_right,
|
||||
is_top,
|
||||
is_bottom,
|
||||
noise_q,
|
||||
color_variation,
|
||||
batch_size,
|
||||
height,
|
||||
width,
|
||||
num_inference_steps,
|
||||
guidance_scale,
|
||||
seed,
|
||||
max_length,
|
||||
dtype,
|
||||
use_base_vae,
|
||||
cpu_scheduling,
|
||||
):
|
||||
# prompts and negative prompts must be a list.
|
||||
if isinstance(prompts, str):
|
||||
prompts = [prompts]
|
||||
|
||||
if isinstance(neg_prompts, str):
|
||||
neg_prompts = [neg_prompts]
|
||||
|
||||
prompts = prompts * batch_size
|
||||
neg_prompts = neg_prompts * batch_size
|
||||
|
||||
# seed generator to create the inital latent noise. Also handle out of range seeds.
|
||||
uint32_info = np.iinfo(np.uint32)
|
||||
uint32_min, uint32_max = uint32_info.min, uint32_info.max
|
||||
if seed < uint32_min or seed >= uint32_max:
|
||||
seed = randint(uint32_min, uint32_max)
|
||||
generator = torch.manual_seed(seed)
|
||||
|
||||
# Get initial latents
|
||||
init_latents = self.prepare_latents(
|
||||
batch_size=batch_size,
|
||||
height=height,
|
||||
width=width,
|
||||
generator=generator,
|
||||
num_inference_steps=num_inference_steps,
|
||||
dtype=dtype,
|
||||
)
|
||||
|
||||
# Get text embeddings from prompts
|
||||
text_embeddings = self.encode_prompts(prompts, neg_prompts, max_length)
|
||||
|
||||
# guidance scale as a float32 tensor.
|
||||
guidance_scale = torch.tensor(guidance_scale).to(torch.float32)
|
||||
|
||||
process_width = width
|
||||
process_height = height
|
||||
left = pixels if is_left else 0
|
||||
right = pixels if is_right else 0
|
||||
up = pixels if is_top else 0
|
||||
down = pixels if is_bottom else 0
|
||||
target_w = math.ceil((image.width + left + right) / 64) * 64
|
||||
target_h = math.ceil((image.height + up + down) / 64) * 64
|
||||
|
||||
if left > 0:
|
||||
left = left * (target_w - image.width) // (left + right)
|
||||
if right > 0:
|
||||
right = target_w - image.width - left
|
||||
if up > 0:
|
||||
up = up * (target_h - image.height) // (up + down)
|
||||
if down > 0:
|
||||
down = target_h - image.height - up
|
||||
|
||||
def expand(
|
||||
init_img,
|
||||
expand_pixels,
|
||||
is_left=False,
|
||||
is_right=False,
|
||||
is_top=False,
|
||||
is_bottom=False,
|
||||
):
|
||||
is_horiz = is_left or is_right
|
||||
is_vert = is_top or is_bottom
|
||||
pixels_horiz = expand_pixels if is_horiz else 0
|
||||
pixels_vert = expand_pixels if is_vert else 0
|
||||
|
||||
res_w = init_img.width + pixels_horiz
|
||||
res_h = init_img.height + pixels_vert
|
||||
process_res_w = math.ceil(res_w / 64) * 64
|
||||
process_res_h = math.ceil(res_h / 64) * 64
|
||||
|
||||
img = Image.new("RGB", (process_res_w, process_res_h))
|
||||
img.paste(
|
||||
init_img,
|
||||
(pixels_horiz if is_left else 0, pixels_vert if is_top else 0),
|
||||
)
|
||||
|
||||
msk = Image.new("RGB", (process_res_w, process_res_h), "white")
|
||||
draw = ImageDraw.Draw(msk)
|
||||
draw.rectangle(
|
||||
(
|
||||
expand_pixels + mask_blur if is_left else 0,
|
||||
expand_pixels + mask_blur if is_top else 0,
|
||||
msk.width - expand_pixels - mask_blur
|
||||
if is_right
|
||||
else res_w,
|
||||
msk.height - expand_pixels - mask_blur
|
||||
if is_bottom
|
||||
else res_h,
|
||||
),
|
||||
fill="black",
|
||||
)
|
||||
|
||||
np_image = (np.asarray(img) / 255.0).astype(np.float64)
|
||||
np_mask = (np.asarray(msk) / 255.0).astype(np.float64)
|
||||
noised = self.get_matched_noise(
|
||||
np_image, np_mask, noise_q, color_variation
|
||||
)
|
||||
output_image = Image.fromarray(
|
||||
np.clip(noised * 255.0, 0.0, 255.0).astype(np.uint8),
|
||||
mode="RGB",
|
||||
)
|
||||
|
||||
target_width = (
|
||||
min(width, init_img.width + pixels_horiz)
|
||||
if is_horiz
|
||||
else img.width
|
||||
)
|
||||
target_height = (
|
||||
min(height, init_img.height + pixels_vert)
|
||||
if is_vert
|
||||
else img.height
|
||||
)
|
||||
crop_region = (
|
||||
0 if is_left else output_image.width - target_width,
|
||||
0 if is_top else output_image.height - target_height,
|
||||
target_width if is_left else output_image.width,
|
||||
target_height if is_top else output_image.height,
|
||||
)
|
||||
mask_to_process = msk.crop(crop_region)
|
||||
image_to_process = output_image.crop(crop_region)
|
||||
|
||||
# Preprocess mask and image
|
||||
mask, masked_image = self.prepare_mask_and_masked_image(
|
||||
image_to_process, mask_to_process, mask_blur, width, height
|
||||
)
|
||||
|
||||
# Prepare mask latent variables
|
||||
mask, masked_image_latents = self.prepare_mask_latents(
|
||||
mask=mask,
|
||||
masked_image=masked_image,
|
||||
batch_size=batch_size,
|
||||
height=height,
|
||||
width=width,
|
||||
dtype=dtype,
|
||||
)
|
||||
|
||||
# Get Image latents
|
||||
latents = self.produce_img_latents(
|
||||
latents=init_latents,
|
||||
text_embeddings=text_embeddings,
|
||||
guidance_scale=guidance_scale,
|
||||
total_timesteps=self.scheduler.timesteps,
|
||||
dtype=dtype,
|
||||
cpu_scheduling=cpu_scheduling,
|
||||
mask=mask,
|
||||
masked_image_latents=masked_image_latents,
|
||||
)
|
||||
|
||||
# Img latents -> PIL images
|
||||
all_imgs = []
|
||||
for i in tqdm(range(0, latents.shape[0], batch_size)):
|
||||
imgs = self.decode_latents(
|
||||
latents=latents[i : i + batch_size],
|
||||
use_base_vae=use_base_vae,
|
||||
cpu_scheduling=cpu_scheduling,
|
||||
)
|
||||
all_imgs.extend(imgs)
|
||||
|
||||
res_img = all_imgs[0].resize(
|
||||
(image_to_process.width, image_to_process.height)
|
||||
)
|
||||
output_image.paste(
|
||||
res_img,
|
||||
(
|
||||
0 if is_left else output_image.width - res_img.width,
|
||||
0 if is_top else output_image.height - res_img.height,
|
||||
),
|
||||
)
|
||||
output_image = output_image.crop((0, 0, res_w, res_h))
|
||||
|
||||
return output_image
|
||||
|
||||
img = image.resize((width, height))
|
||||
if left > 0:
|
||||
img = expand(img, left, is_left=True)
|
||||
if right > 0:
|
||||
img = expand(img, right, is_right=True)
|
||||
if up > 0:
|
||||
img = expand(img, up, is_top=True)
|
||||
if down > 0:
|
||||
img = expand(img, down, is_bottom=True)
|
||||
|
||||
return [img]
|
||||
@@ -0,0 +1,150 @@
|
||||
import torch
|
||||
import time
|
||||
import numpy as np
|
||||
from tqdm.auto import tqdm
|
||||
from random import randint
|
||||
from PIL import Image
|
||||
from transformers import CLIPTokenizer
|
||||
from typing import Union
|
||||
from shark.shark_inference import SharkInference
|
||||
from diffusers import (
|
||||
DDIMScheduler,
|
||||
PNDMScheduler,
|
||||
LMSDiscreteScheduler,
|
||||
EulerDiscreteScheduler,
|
||||
EulerAncestralDiscreteScheduler,
|
||||
DPMSolverMultistepScheduler,
|
||||
)
|
||||
from apps.stable_diffusion.src.schedulers import SharkEulerDiscreteScheduler
|
||||
from apps.stable_diffusion.src.pipelines.pipeline_shark_stable_diffusion_utils import (
|
||||
StableDiffusionPipeline,
|
||||
)
|
||||
from apps.stable_diffusion.src.utils import controlnet_hint_conversion
|
||||
|
||||
|
||||
class StencilPipeline(StableDiffusionPipeline):
|
||||
def __init__(
|
||||
self,
|
||||
controlnet: SharkInference,
|
||||
vae: SharkInference,
|
||||
text_encoder: SharkInference,
|
||||
tokenizer: CLIPTokenizer,
|
||||
unet: SharkInference,
|
||||
scheduler: Union[
|
||||
DDIMScheduler,
|
||||
PNDMScheduler,
|
||||
LMSDiscreteScheduler,
|
||||
EulerDiscreteScheduler,
|
||||
EulerAncestralDiscreteScheduler,
|
||||
DPMSolverMultistepScheduler,
|
||||
SharkEulerDiscreteScheduler,
|
||||
],
|
||||
):
|
||||
super().__init__(vae, text_encoder, tokenizer, unet, scheduler)
|
||||
self.controlnet = controlnet
|
||||
|
||||
def prepare_latents(
|
||||
self,
|
||||
batch_size,
|
||||
height,
|
||||
width,
|
||||
generator,
|
||||
num_inference_steps,
|
||||
dtype,
|
||||
):
|
||||
latents = torch.randn(
|
||||
(
|
||||
batch_size,
|
||||
4,
|
||||
height // 8,
|
||||
width // 8,
|
||||
),
|
||||
generator=generator,
|
||||
dtype=torch.float32,
|
||||
).to(dtype)
|
||||
|
||||
self.scheduler.set_timesteps(num_inference_steps)
|
||||
self.scheduler.is_scale_input_called = True
|
||||
latents = latents * self.scheduler.init_noise_sigma
|
||||
return latents
|
||||
|
||||
def generate_images(
|
||||
self,
|
||||
prompts,
|
||||
neg_prompts,
|
||||
image,
|
||||
batch_size,
|
||||
height,
|
||||
width,
|
||||
num_inference_steps,
|
||||
strength,
|
||||
guidance_scale,
|
||||
seed,
|
||||
max_length,
|
||||
dtype,
|
||||
use_base_vae,
|
||||
cpu_scheduling,
|
||||
use_stencil,
|
||||
):
|
||||
# Control Embedding check & conversion
|
||||
# TODO: 1. Change `num_images_per_prompt`.
|
||||
controlnet_hint = controlnet_hint_conversion(
|
||||
image, use_stencil, height, width, dtype, num_images_per_prompt=1
|
||||
)
|
||||
# prompts and negative prompts must be a list.
|
||||
if isinstance(prompts, str):
|
||||
prompts = [prompts]
|
||||
|
||||
if isinstance(neg_prompts, str):
|
||||
neg_prompts = [neg_prompts]
|
||||
|
||||
prompts = prompts * batch_size
|
||||
neg_prompts = neg_prompts * batch_size
|
||||
|
||||
# seed generator to create the inital latent noise. Also handle out of range seeds.
|
||||
uint32_info = np.iinfo(np.uint32)
|
||||
uint32_min, uint32_max = uint32_info.min, uint32_info.max
|
||||
if seed < uint32_min or seed >= uint32_max:
|
||||
seed = randint(uint32_min, uint32_max)
|
||||
generator = torch.manual_seed(seed)
|
||||
|
||||
# Get text embeddings from prompts
|
||||
text_embeddings = self.encode_prompts(prompts, neg_prompts, max_length)
|
||||
|
||||
# guidance scale as a float32 tensor.
|
||||
guidance_scale = torch.tensor(guidance_scale).to(torch.float32)
|
||||
|
||||
# Prepare initial latent.
|
||||
init_latents = self.prepare_latents(
|
||||
batch_size=batch_size,
|
||||
height=height,
|
||||
width=width,
|
||||
generator=generator,
|
||||
num_inference_steps=num_inference_steps,
|
||||
dtype=dtype,
|
||||
)
|
||||
final_timesteps = self.scheduler.timesteps
|
||||
|
||||
# Get Image latents
|
||||
latents = self.produce_stencil_latents(
|
||||
latents=init_latents,
|
||||
text_embeddings=text_embeddings,
|
||||
guidance_scale=guidance_scale,
|
||||
total_timesteps=final_timesteps,
|
||||
dtype=dtype,
|
||||
cpu_scheduling=cpu_scheduling,
|
||||
controlnet_hint=controlnet_hint,
|
||||
controlnet=self.controlnet,
|
||||
)
|
||||
|
||||
# Img latents -> PIL images
|
||||
all_imgs = []
|
||||
for i in tqdm(range(0, latents.shape[0], batch_size)):
|
||||
imgs = self.decode_latents(
|
||||
latents=latents[i : i + batch_size],
|
||||
use_base_vae=use_base_vae,
|
||||
cpu_scheduling=cpu_scheduling,
|
||||
)
|
||||
all_imgs.extend(imgs)
|
||||
|
||||
return all_imgs
|
||||
@@ -13,12 +13,16 @@ from diffusers import (
|
||||
EulerDiscreteScheduler,
|
||||
EulerAncestralDiscreteScheduler,
|
||||
DPMSolverMultistepScheduler,
|
||||
DEISMultistepScheduler,
|
||||
)
|
||||
from apps.stable_diffusion.src.schedulers import SharkEulerDiscreteScheduler
|
||||
from apps.stable_diffusion.src.pipelines.pipeline_shark_stable_diffusion_utils import (
|
||||
StableDiffusionPipeline,
|
||||
)
|
||||
|
||||
import cv2
|
||||
from PIL import Image
|
||||
|
||||
|
||||
class Text2ImagePipeline(StableDiffusionPipeline):
|
||||
def __init__(
|
||||
@@ -36,6 +40,7 @@ class Text2ImagePipeline(StableDiffusionPipeline):
|
||||
EulerAncestralDiscreteScheduler,
|
||||
DPMSolverMultistepScheduler,
|
||||
SharkEulerDiscreteScheduler,
|
||||
DEISMultistepScheduler,
|
||||
],
|
||||
):
|
||||
super().__init__(vae, text_encoder, tokenizer, unet, scheduler)
|
||||
|
||||
@@ -13,6 +13,7 @@ from diffusers import (
|
||||
EulerDiscreteScheduler,
|
||||
EulerAncestralDiscreteScheduler,
|
||||
DPMSolverMultistepScheduler,
|
||||
DEISMultistepScheduler,
|
||||
)
|
||||
from shark.shark_inference import SharkInference
|
||||
from apps.stable_diffusion.src.schedulers import SharkEulerDiscreteScheduler
|
||||
@@ -46,6 +47,7 @@ class StableDiffusionPipeline:
|
||||
EulerAncestralDiscreteScheduler,
|
||||
DPMSolverMultistepScheduler,
|
||||
SharkEulerDiscreteScheduler,
|
||||
DEISMultistepScheduler,
|
||||
],
|
||||
):
|
||||
self.vae = vae
|
||||
@@ -108,6 +110,118 @@ class StableDiffusionPipeline:
|
||||
pil_images = [Image.fromarray(image) for image in images.numpy()]
|
||||
return pil_images
|
||||
|
||||
def produce_stencil_latents(
|
||||
self,
|
||||
latents,
|
||||
text_embeddings,
|
||||
guidance_scale,
|
||||
total_timesteps,
|
||||
dtype,
|
||||
cpu_scheduling,
|
||||
controlnet_hint=None,
|
||||
controlnet=None,
|
||||
controlnet_conditioning_scale: float = 1.0,
|
||||
mask=None,
|
||||
masked_image_latents=None,
|
||||
return_all_latents=False,
|
||||
):
|
||||
step_time_sum = 0
|
||||
latent_history = [latents]
|
||||
text_embeddings = torch.from_numpy(text_embeddings).to(dtype)
|
||||
text_embeddings_numpy = text_embeddings.detach().numpy()
|
||||
for i, t in tqdm(enumerate(total_timesteps)):
|
||||
step_start_time = time.time()
|
||||
timestep = torch.tensor([t]).to(dtype)
|
||||
latent_model_input = self.scheduler.scale_model_input(latents, t)
|
||||
if mask is not None and masked_image_latents is not None:
|
||||
latent_model_input = torch.cat(
|
||||
[
|
||||
torch.from_numpy(np.asarray(latent_model_input)),
|
||||
mask,
|
||||
masked_image_latents,
|
||||
],
|
||||
dim=1,
|
||||
).to(dtype)
|
||||
if cpu_scheduling:
|
||||
latent_model_input = latent_model_input.detach().numpy()
|
||||
|
||||
if not torch.is_tensor(latent_model_input):
|
||||
latent_model_input_1 = torch.from_numpy(
|
||||
np.asarray(latent_model_input)
|
||||
).to(dtype)
|
||||
else:
|
||||
latent_model_input_1 = latent_model_input
|
||||
control = controlnet(
|
||||
"forward",
|
||||
(
|
||||
latent_model_input_1,
|
||||
timestep,
|
||||
text_embeddings,
|
||||
controlnet_hint,
|
||||
),
|
||||
send_to_host=False,
|
||||
)
|
||||
down_block_res_samples = control[0:12]
|
||||
mid_block_res_sample = control[12:]
|
||||
down_block_res_samples = [
|
||||
down_block_res_sample * controlnet_conditioning_scale
|
||||
for down_block_res_sample in down_block_res_samples
|
||||
]
|
||||
mid_block_res_sample = (
|
||||
mid_block_res_sample[0] * controlnet_conditioning_scale
|
||||
)
|
||||
timestep = timestep.detach().numpy()
|
||||
# Profiling Unet.
|
||||
profile_device = start_profiling(file_path="unet.rdc")
|
||||
# TODO: Pass `control` as it is to Unet. Same as TODO mentioned in model_wrappers.py.
|
||||
noise_pred = self.unet(
|
||||
"forward",
|
||||
(
|
||||
latent_model_input,
|
||||
timestep,
|
||||
text_embeddings_numpy,
|
||||
guidance_scale,
|
||||
down_block_res_samples[0],
|
||||
down_block_res_samples[1],
|
||||
down_block_res_samples[2],
|
||||
down_block_res_samples[3],
|
||||
down_block_res_samples[4],
|
||||
down_block_res_samples[5],
|
||||
down_block_res_samples[6],
|
||||
down_block_res_samples[7],
|
||||
down_block_res_samples[8],
|
||||
down_block_res_samples[9],
|
||||
down_block_res_samples[10],
|
||||
down_block_res_samples[11],
|
||||
mid_block_res_sample,
|
||||
),
|
||||
send_to_host=False,
|
||||
)
|
||||
end_profiling(profile_device)
|
||||
|
||||
if cpu_scheduling:
|
||||
noise_pred = torch.from_numpy(noise_pred.to_host())
|
||||
latents = self.scheduler.step(
|
||||
noise_pred, t, latents
|
||||
).prev_sample
|
||||
else:
|
||||
latents = self.scheduler.step(noise_pred, t, latents)
|
||||
|
||||
latent_history.append(latents)
|
||||
step_time = (time.time() - step_start_time) * 1000
|
||||
# self.log += (
|
||||
# f"\nstep = {i} | timestep = {t} | time = {step_time:.2f}ms"
|
||||
# )
|
||||
step_time_sum += step_time
|
||||
|
||||
avg_step_time = step_time_sum / len(total_timesteps)
|
||||
self.log += f"\nAverage step time: {avg_step_time}ms/it"
|
||||
|
||||
if not return_all_latents:
|
||||
return latents
|
||||
all_latents = torch.cat(latent_history, dim=0)
|
||||
return all_latents
|
||||
|
||||
def produce_img_latents(
|
||||
self,
|
||||
latents,
|
||||
@@ -189,6 +303,7 @@ class StableDiffusionPipeline:
|
||||
EulerAncestralDiscreteScheduler,
|
||||
DPMSolverMultistepScheduler,
|
||||
SharkEulerDiscreteScheduler,
|
||||
DEISMultistepScheduler,
|
||||
],
|
||||
import_mlir: bool,
|
||||
model_id: str,
|
||||
@@ -201,7 +316,13 @@ class StableDiffusionPipeline:
|
||||
width: int,
|
||||
use_base_vae: bool,
|
||||
use_tuned: bool,
|
||||
low_cpu_mem_usage: bool = False,
|
||||
use_stencil: str = None,
|
||||
):
|
||||
is_inpaint = cls.__name__ in [
|
||||
"InpaintPipeline",
|
||||
"OutpaintPipeline",
|
||||
]
|
||||
if import_mlir:
|
||||
mlir_import = SharkifyStableDiffusionModel(
|
||||
model_id,
|
||||
@@ -214,16 +335,32 @@ class StableDiffusionPipeline:
|
||||
width=width,
|
||||
use_base_vae=use_base_vae,
|
||||
use_tuned=use_tuned,
|
||||
low_cpu_mem_usage=low_cpu_mem_usage,
|
||||
is_inpaint=is_inpaint,
|
||||
use_stencil=use_stencil,
|
||||
)
|
||||
if cls.__name__ in ["Image2ImagePipeline", "InpaintPipeline"]:
|
||||
if cls.__name__ in [
|
||||
"Image2ImagePipeline",
|
||||
"InpaintPipeline",
|
||||
"OutpaintPipeline",
|
||||
]:
|
||||
clip, unet, vae, vae_encode = mlir_import()
|
||||
return cls(
|
||||
vae_encode, vae, clip, get_tokenizer(), unet, scheduler
|
||||
)
|
||||
if cls.__name__ in ["StencilPipeline"]:
|
||||
clip, unet, vae, controlnet = mlir_import()
|
||||
return cls(
|
||||
controlnet, vae, clip, get_tokenizer(), unet, scheduler
|
||||
)
|
||||
clip, unet, vae = mlir_import()
|
||||
return cls(vae, clip, get_tokenizer(), unet, scheduler)
|
||||
try:
|
||||
if cls.__name__ in ["Image2ImagePipeline", "InpaintPipeline"]:
|
||||
if cls.__name__ in [
|
||||
"Image2ImagePipeline",
|
||||
"InpaintPipeline",
|
||||
"OutpaintPipeline",
|
||||
]:
|
||||
return cls(
|
||||
get_vae_encode(),
|
||||
get_vae(),
|
||||
@@ -232,6 +369,12 @@ class StableDiffusionPipeline:
|
||||
get_unet(),
|
||||
scheduler,
|
||||
)
|
||||
if cls.__name__ == "StencilPipeline":
|
||||
import sys
|
||||
|
||||
sys.exit(
|
||||
"StencilPipeline not supported with SharkTank currently."
|
||||
)
|
||||
return cls(
|
||||
get_vae(), get_clip(), get_tokenizer(), get_unet(), scheduler
|
||||
)
|
||||
@@ -248,11 +391,22 @@ class StableDiffusionPipeline:
|
||||
width=width,
|
||||
use_base_vae=use_base_vae,
|
||||
use_tuned=use_tuned,
|
||||
low_cpu_mem_usage=low_cpu_mem_usage,
|
||||
is_inpaint=is_inpaint,
|
||||
)
|
||||
if cls.__name__ in ["Image2ImagePipeline", "InpaintPipeline"]:
|
||||
if cls.__name__ in [
|
||||
"Image2ImagePipeline",
|
||||
"InpaintPipeline",
|
||||
"OutpaintPipeline",
|
||||
]:
|
||||
clip, unet, vae, vae_encode = mlir_import()
|
||||
return cls(
|
||||
vae_encode, vae, clip, get_tokenizer(), unet, scheduler
|
||||
)
|
||||
if cls.__name__ == "StencilPipeline":
|
||||
clip, unet, vae, controlnet = mlir_import()
|
||||
return cls(
|
||||
controlnet, vae, clip, get_tokenizer(), unet, scheduler
|
||||
)
|
||||
clip, unet, vae = mlir_import()
|
||||
return cls(vae, clip, get_tokenizer(), unet, scheduler)
|
||||
|
||||
@@ -6,6 +6,7 @@ from diffusers import (
|
||||
KDPM2DiscreteScheduler,
|
||||
EulerDiscreteScheduler,
|
||||
EulerAncestralDiscreteScheduler,
|
||||
DEISMultistepScheduler,
|
||||
)
|
||||
from apps.stable_diffusion.src.schedulers.shark_eulerdiscrete import (
|
||||
SharkEulerDiscreteScheduler,
|
||||
@@ -46,6 +47,10 @@ def get_schedulers(model_id):
|
||||
model_id,
|
||||
subfolder="scheduler",
|
||||
)
|
||||
schedulers["DEISMultistep"] = DEISMultistepScheduler.from_pretrained(
|
||||
model_id,
|
||||
subfolder="scheduler",
|
||||
)
|
||||
schedulers[
|
||||
"SharkEulerDiscrete"
|
||||
] = SharkEulerDiscreteScheduler.from_pretrained(
|
||||
|
||||
@@ -11,6 +11,10 @@ from apps.stable_diffusion.src.utils.resources import (
|
||||
)
|
||||
from apps.stable_diffusion.src.utils.sd_annotation import sd_model_annotation
|
||||
from apps.stable_diffusion.src.utils.stable_args import args
|
||||
from apps.stable_diffusion.src.utils.stencils.stencil_utils import (
|
||||
controlnet_hint_conversion,
|
||||
get_stencil_model_id,
|
||||
)
|
||||
from apps.stable_diffusion.src.utils.utils import (
|
||||
get_shark_model,
|
||||
compile_through_fx,
|
||||
|
||||
@@ -85,6 +85,172 @@
|
||||
"dtype": "f32"
|
||||
}
|
||||
},
|
||||
"stencil_adaptor": {
|
||||
"latents": {
|
||||
"shape": [
|
||||
"1*batch_size",
|
||||
4,
|
||||
"height",
|
||||
"width"
|
||||
],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"timesteps": {
|
||||
"shape": [
|
||||
1
|
||||
],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"embedding": {
|
||||
"shape": [
|
||||
"2*batch_size",
|
||||
"max_len",
|
||||
768
|
||||
],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"controlnet_hint": {
|
||||
"shape": [1, 3, 512, 512],
|
||||
"dtype": "f32"
|
||||
}
|
||||
},
|
||||
"stencil_unet": {
|
||||
"latents": {
|
||||
"shape": [
|
||||
"1*batch_size",
|
||||
4,
|
||||
"height",
|
||||
"width"
|
||||
],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"timesteps": {
|
||||
"shape": [
|
||||
1
|
||||
],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"embedding": {
|
||||
"shape": [
|
||||
"2*batch_size",
|
||||
"max_len",
|
||||
768
|
||||
],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"guidance_scale": {
|
||||
"shape": 2,
|
||||
"dtype": "f32"
|
||||
},
|
||||
"control1": {
|
||||
"shape": [2, 320, 64, 64],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"control2": {
|
||||
"shape": [2, 320, 64, 64],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"control3": {
|
||||
"shape": [2, 320, 64, 64],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"control4": {
|
||||
"shape": [2, 320, 32, 32],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"control5": {
|
||||
"shape": [2, 640, 32, 32],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"control6": {
|
||||
"shape": [2, 640, 32, 32],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"control7": {
|
||||
"shape": [2, 640, 16, 16],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"control8": {
|
||||
"shape": [2, 1280, 16, 16],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"control9": {
|
||||
"shape": [2, 1280, 16, 16],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"control10": {
|
||||
"shape": [2, 1280, 8, 8],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"control11": {
|
||||
"shape": [2, 1280, 8, 8],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"control12": {
|
||||
"shape": [2, 1280, 8, 8],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"control13": {
|
||||
"shape": [2, 1280, 8, 8],
|
||||
"dtype": "f32"
|
||||
}
|
||||
},
|
||||
"vae_encode": {
|
||||
"image" : {
|
||||
"shape" : [
|
||||
"1*batch_size",3,"8*height","8*width"
|
||||
],
|
||||
"dtype":"f32"
|
||||
}
|
||||
},
|
||||
"vae": {
|
||||
"latents" : {
|
||||
"shape" : [
|
||||
"1*batch_size",4,"height","width"
|
||||
],
|
||||
"dtype":"f32"
|
||||
}
|
||||
},
|
||||
"clip": {
|
||||
"token" : {
|
||||
"shape" : [
|
||||
"2*batch_size",
|
||||
"max_len"
|
||||
],
|
||||
"dtype":"i64"
|
||||
}
|
||||
}
|
||||
},
|
||||
"stabilityai/stable-diffusion-2-inpainting": {
|
||||
"unet": {
|
||||
"latents": {
|
||||
"shape": [
|
||||
"1*batch_size",
|
||||
9,
|
||||
"height",
|
||||
"width"
|
||||
],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"timesteps": {
|
||||
"shape": [
|
||||
1
|
||||
],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"embedding": {
|
||||
"shape": [
|
||||
"2*batch_size",
|
||||
"max_len",
|
||||
1024
|
||||
],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"guidance_scale": {
|
||||
"shape": 2,
|
||||
"dtype": "f32"
|
||||
}
|
||||
},
|
||||
"vae_encode": {
|
||||
"image" : {
|
||||
"shape" : [
|
||||
@@ -166,61 +332,5 @@
|
||||
"dtype":"i64"
|
||||
}
|
||||
}
|
||||
},
|
||||
"stabilityai/stable-diffusion-2-inpainting": {
|
||||
"unet": {
|
||||
"latents": {
|
||||
"shape": [
|
||||
"1*batch_size",
|
||||
9,
|
||||
"height",
|
||||
"width"
|
||||
],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"timesteps": {
|
||||
"shape": [
|
||||
1
|
||||
],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"embedding": {
|
||||
"shape": [
|
||||
"2*batch_size",
|
||||
"max_len",
|
||||
1024
|
||||
],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"guidance_scale": {
|
||||
"shape": 2,
|
||||
"dtype": "f32"
|
||||
}
|
||||
},
|
||||
"vae_encode": {
|
||||
"image" : {
|
||||
"shape" : [
|
||||
"1*batch_size",3,"8*height","8*width"
|
||||
],
|
||||
"dtype":"f32"
|
||||
}
|
||||
},
|
||||
"vae": {
|
||||
"latents" : {
|
||||
"shape" : [
|
||||
"1*batch_size",4,"height","width"
|
||||
],
|
||||
"dtype":"f32"
|
||||
}
|
||||
},
|
||||
"clip": {
|
||||
"token" : {
|
||||
"shape" : [
|
||||
"2*batch_size",
|
||||
"max_len"
|
||||
],
|
||||
"dtype":"i64"
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
@@ -40,17 +40,6 @@
|
||||
"stablediffusion/v2_1/vae/fp16/length_77/untuned":"vae77_512_512_fp16_stabilityai_stable_diffusion_2_1_base",
|
||||
"stablediffusion/v2_1/vae/fp16/length_77/untuned/base":"vae2_8dec_fp16",
|
||||
"stablediffusion/v2_1/clip/fp32/length_77/untuned":"clip77_512_512_fp16_stabilityai_stable_diffusion_2_1_base",
|
||||
"stablediffusion/inpaint_v1/unet/fp16/length_77/untuned":"unet_inpaint_fp16",
|
||||
"stablediffusion/inpaint_v1/unet/fp32/length_77/untuned":"unet_inpaint_fp32",
|
||||
"stablediffusion/inpaint_v1/vae_encode/fp16/length_77/untuned":"vae_encode_inpaint_fp16",
|
||||
"stablediffusion/inpaint_v1/vae_encode/fp32/length_77/untuned":"vae_encode_inpaint_fp32",
|
||||
"stablediffusion/inpaint_v1/vae/fp16/length_77/untuned":"vae_inpaint_fp16",
|
||||
"stablediffusion/inpaint_v1/vae/fp32/length_77/untuned":"vae_inpaint_fp32",
|
||||
"stablediffusion/inpaint_v1/clip/fp32/length_77/untuned":"clip_inpaint_fp32",
|
||||
"stablediffusion/inpaint_v2/unet/fp16/length_77/untuned":"unet_inpaint_fp16",
|
||||
"stablediffusion/inpaint_v2/vae_encode/fp16/length_77/untuned":"vae_encode_inpaint_fp16",
|
||||
"stablediffusion/inpaint_v2/vae/fp16/length_77/untuned":"vae_inpaint_fp16",
|
||||
"stablediffusion/inpaint_v2/clip/fp32/length_77/untuned":"clip_inpaint_fp32",
|
||||
"anythingv3/v1_4/unet/fp16/length_77/untuned":"av3_unet_19dec_fp16",
|
||||
"anythingv3/v1_4/unet/fp16/length_77/tuned":"av3_unet_19dec_fp16_tuned",
|
||||
"anythingv3/v1_4/unet/fp16/length_77/tuned/cuda":"av3_unet_19dec_fp16_cuda_tuned",
|
||||
|
||||
@@ -70,7 +70,7 @@ def load_winograd_configs():
|
||||
config_bucket = "gs://shark_tank/sd_tuned/configs/"
|
||||
config_name = f"{args.annotation_model}_winograd_{device}.json"
|
||||
full_gs_url = config_bucket + config_name
|
||||
winograd_config_dir = f"{WORKDIR}configs/" + config_name
|
||||
winograd_config_dir = os.path.join(WORKDIR, "configs", config_name)
|
||||
print("Loading Winograd config file from ", winograd_config_dir)
|
||||
download_public_file(full_gs_url, winograd_config_dir, True)
|
||||
return winograd_config_dir
|
||||
@@ -82,14 +82,20 @@ def load_lower_configs():
|
||||
fetch_and_update_base_model_id,
|
||||
)
|
||||
|
||||
base_model_id = args.hf_model_id
|
||||
if args.ckpt_loc != "":
|
||||
base_model_id = fetch_and_update_base_model_id(args.ckpt_loc)
|
||||
if base_model_id == "runwayml/stable-diffusion-v1-5":
|
||||
base_model_id = "CompVis/stable-diffusion-v1-4"
|
||||
else:
|
||||
base_model_id = fetch_and_update_base_model_id(args.hf_model_id)
|
||||
if base_model_id == "":
|
||||
base_model_id = args.hf_model_id
|
||||
|
||||
variant, version = get_variant_version(base_model_id)
|
||||
|
||||
if version == "inpaint_v1":
|
||||
version = "v1_4"
|
||||
elif version == "inpaint_v2":
|
||||
version = "v2_1base"
|
||||
|
||||
config_bucket = "gs://shark_tank/sd_tuned_configs/"
|
||||
|
||||
device, device_spec_args = get_device_args()
|
||||
@@ -113,7 +119,7 @@ def load_lower_configs():
|
||||
config_name = f"{args.annotation_model}_{version}_{args.precision}_{device}_{spec}.json"
|
||||
|
||||
full_gs_url = config_bucket + config_name
|
||||
lowering_config_dir = f"{WORKDIR}configs/" + config_name
|
||||
lowering_config_dir = os.path.join(WORKDIR, "configs", config_name)
|
||||
print("Loading lowering config file from ", lowering_config_dir)
|
||||
download_public_file(full_gs_url, lowering_config_dir, True)
|
||||
return lowering_config_dir
|
||||
@@ -136,11 +142,13 @@ def annotate_with_winograd(input_mlir, winograd_config_dir, model_name):
|
||||
|
||||
if args.save_annotation:
|
||||
if model_name.split("_")[-1] != "tuned":
|
||||
out_file_path = (
|
||||
f"{args.annotation_output}/{model_name}_tuned_torch.mlir"
|
||||
out_file_path = os.path.join(
|
||||
args.annotation_output, model_name + "_tuned_torch.mlir"
|
||||
)
|
||||
else:
|
||||
out_file_path = f"{args.annotation_output}/{model_name}_torch.mlir"
|
||||
out_file_path = os.path.join(
|
||||
args.annotation_output, model_name + "_torch.mlir"
|
||||
)
|
||||
with open(out_file_path, "w") as f:
|
||||
f.write(str(winograd_model))
|
||||
f.close()
|
||||
|
||||
@@ -35,12 +35,6 @@ p.add_argument(
|
||||
help="Path to the image input for img2img/inpainting",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--mask_path",
|
||||
type=str,
|
||||
help="Path to the mask image input for inpainting",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--steps",
|
||||
type=int,
|
||||
@@ -67,6 +61,7 @@ p.add_argument(
|
||||
"--height",
|
||||
type=int,
|
||||
default=512,
|
||||
choices=range(384, 769, 8),
|
||||
help="the height of the output image.",
|
||||
)
|
||||
|
||||
@@ -74,6 +69,7 @@ p.add_argument(
|
||||
"--width",
|
||||
type=int,
|
||||
default=512,
|
||||
choices=range(384, 769, 8),
|
||||
help="the width of the output image.",
|
||||
)
|
||||
|
||||
@@ -97,6 +93,90 @@ p.add_argument(
|
||||
default=0.8,
|
||||
help="the strength of change applied on the given input image for img2img",
|
||||
)
|
||||
|
||||
##############################################################################
|
||||
### Inpainting and Outpainting Params
|
||||
##############################################################################
|
||||
|
||||
p.add_argument(
|
||||
"--mask_path",
|
||||
type=str,
|
||||
help="Path to the mask image input for inpainting",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--inpaint_full_res",
|
||||
default=False,
|
||||
action=argparse.BooleanOptionalAction,
|
||||
help="If inpaint only masked area or whole picture",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--inpaint_full_res_padding",
|
||||
type=int,
|
||||
default=32,
|
||||
choices=range(0, 257, 4),
|
||||
help="Number of pixels for only masked padding",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--pixels",
|
||||
type=int,
|
||||
default=128,
|
||||
choices=range(8, 257, 8),
|
||||
help="Number of expended pixels for one direction for outpainting",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--mask_blur",
|
||||
type=int,
|
||||
default=8,
|
||||
choices=range(0, 65),
|
||||
help="Number of blur pixels for outpainting",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--left",
|
||||
default=False,
|
||||
action=argparse.BooleanOptionalAction,
|
||||
help="If expend left for outpainting",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--right",
|
||||
default=False,
|
||||
action=argparse.BooleanOptionalAction,
|
||||
help="If expend right for outpainting",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--top",
|
||||
default=False,
|
||||
action=argparse.BooleanOptionalAction,
|
||||
help="If expend top for outpainting",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--bottom",
|
||||
default=False,
|
||||
action=argparse.BooleanOptionalAction,
|
||||
help="If expend bottom for outpainting",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--noise_q",
|
||||
type=float,
|
||||
default=1.0,
|
||||
help="Fall-off exponent for outpainting (lower=higher detail) (min=0.0, max=4.0)",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--color_variation",
|
||||
type=float,
|
||||
default=0.05,
|
||||
help="Color variation for outpainting (min=0.0, max=1.0)",
|
||||
)
|
||||
|
||||
##############################################################################
|
||||
### Model Config and Usage Params
|
||||
##############################################################################
|
||||
@@ -193,6 +273,26 @@ p.add_argument(
|
||||
help="The repo-id of hugging face.",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--low_cpu_mem_usage",
|
||||
default=False,
|
||||
action=argparse.BooleanOptionalAction,
|
||||
help="Use the accelerate package to reduce cpu memory consumption",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--attention_slicing",
|
||||
type=str,
|
||||
default="none",
|
||||
help="Amount of attention slicing to use (one of 'max', 'auto', 'none', or an integer)",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--use_stencil",
|
||||
choices=["canny"],
|
||||
help="Enable the stencil feature.",
|
||||
)
|
||||
|
||||
##############################################################################
|
||||
### IREE - Vulkan supported flags
|
||||
##############################################################################
|
||||
|
||||
@@ -0,0 +1,6 @@
|
||||
import cv2
|
||||
|
||||
|
||||
class CannyDetector:
|
||||
def __call__(self, img, low_threshold, high_threshold):
|
||||
return cv2.Canny(img, low_threshold, high_threshold)
|
||||
173
apps/stable_diffusion/src/utils/stencils/stencil_utils.py
Normal file
173
apps/stable_diffusion/src/utils/stencils/stencil_utils.py
Normal file
@@ -0,0 +1,173 @@
|
||||
import cv2
|
||||
import numpy as np
|
||||
from PIL import Image
|
||||
import torch
|
||||
from apps.stable_diffusion.src.utils.stencils.canny import CannyDetector
|
||||
|
||||
stencil = {}
|
||||
|
||||
|
||||
def HWC3(x):
|
||||
assert x.dtype == np.uint8
|
||||
if x.ndim == 2:
|
||||
x = x[:, :, None]
|
||||
assert x.ndim == 3
|
||||
H, W, C = x.shape
|
||||
assert C == 1 or C == 3 or C == 4
|
||||
if C == 3:
|
||||
return x
|
||||
if C == 1:
|
||||
return np.concatenate([x, x, x], axis=2)
|
||||
if C == 4:
|
||||
color = x[:, :, 0:3].astype(np.float32)
|
||||
alpha = x[:, :, 3:4].astype(np.float32) / 255.0
|
||||
y = color * alpha + 255.0 * (1.0 - alpha)
|
||||
y = y.clip(0, 255).astype(np.uint8)
|
||||
return y
|
||||
|
||||
|
||||
def resize_image(input_image, resolution):
|
||||
H, W, C = input_image.shape
|
||||
H = float(H)
|
||||
W = float(W)
|
||||
k = float(resolution) / min(H, W)
|
||||
H *= k
|
||||
W *= k
|
||||
H = int(np.round(H / 64.0)) * 64
|
||||
W = int(np.round(W / 64.0)) * 64
|
||||
img = cv2.resize(
|
||||
input_image,
|
||||
(W, H),
|
||||
interpolation=cv2.INTER_LANCZOS4 if k > 1 else cv2.INTER_AREA,
|
||||
)
|
||||
return img
|
||||
|
||||
|
||||
def controlnet_hint_shaping(
|
||||
controlnet_hint, height, width, dtype, num_images_per_prompt=1
|
||||
):
|
||||
channels = 3
|
||||
if isinstance(controlnet_hint, torch.Tensor):
|
||||
# torch.Tensor: acceptble shape are any of chw, bchw(b==1) or bchw(b==num_images_per_prompt)
|
||||
shape_chw = (channels, height, width)
|
||||
shape_bchw = (1, channels, height, width)
|
||||
shape_nchw = (num_images_per_prompt, channels, height, width)
|
||||
if controlnet_hint.shape in [shape_chw, shape_bchw, shape_nchw]:
|
||||
controlnet_hint = controlnet_hint.to(
|
||||
dtype=dtype, device=torch.device("cpu")
|
||||
)
|
||||
if controlnet_hint.shape != shape_nchw:
|
||||
controlnet_hint = controlnet_hint.repeat(
|
||||
num_images_per_prompt, 1, 1, 1
|
||||
)
|
||||
return controlnet_hint
|
||||
else:
|
||||
raise ValueError(
|
||||
f"Acceptble shape of `stencil` are any of ({channels}, {height}, {width}),"
|
||||
+ f" (1, {channels}, {height}, {width}) or ({num_images_per_prompt}, "
|
||||
+ f"{channels}, {height}, {width}) but is {controlnet_hint.shape}"
|
||||
)
|
||||
elif isinstance(controlnet_hint, np.ndarray):
|
||||
# np.ndarray: acceptable shape is any of hw, hwc, bhwc(b==1) or bhwc(b==num_images_per_promot)
|
||||
# hwc is opencv compatible image format. Color channel must be BGR Format.
|
||||
if controlnet_hint.shape == (height, width):
|
||||
controlnet_hint = np.repeat(
|
||||
controlnet_hint[:, :, np.newaxis], channels, axis=2
|
||||
) # hw -> hwc(c==3)
|
||||
shape_hwc = (height, width, channels)
|
||||
shape_bhwc = (1, height, width, channels)
|
||||
shape_nhwc = (num_images_per_prompt, height, width, channels)
|
||||
if controlnet_hint.shape in [shape_hwc, shape_bhwc, shape_nhwc]:
|
||||
controlnet_hint = torch.from_numpy(controlnet_hint.copy())
|
||||
controlnet_hint = controlnet_hint.to(
|
||||
dtype=dtype, device=torch.device("cpu")
|
||||
)
|
||||
controlnet_hint /= 255.0
|
||||
if controlnet_hint.shape != shape_nhwc:
|
||||
controlnet_hint = controlnet_hint.repeat(
|
||||
num_images_per_prompt, 1, 1, 1
|
||||
)
|
||||
controlnet_hint = controlnet_hint.permute(
|
||||
0, 3, 1, 2
|
||||
) # b h w c -> b c h w
|
||||
return controlnet_hint
|
||||
else:
|
||||
raise ValueError(
|
||||
f"Acceptble shape of `stencil` are any of ({width}, {channels}), "
|
||||
+ f"({height}, {width}, {channels}), "
|
||||
+ f"(1, {height}, {width}, {channels}) or "
|
||||
+ f"({num_images_per_prompt}, {channels}, {height}, {width}) but is {controlnet_hint.shape}"
|
||||
)
|
||||
elif isinstance(controlnet_hint, Image.Image):
|
||||
if controlnet_hint.size == (width, height):
|
||||
controlnet_hint = controlnet_hint.convert(
|
||||
"RGB"
|
||||
) # make sure 3 channel RGB format
|
||||
controlnet_hint = np.array(controlnet_hint) # to numpy
|
||||
controlnet_hint = controlnet_hint[:, :, ::-1] # RGB -> BGR
|
||||
return controlnet_hint_shaping(
|
||||
controlnet_hint, height, width, num_images_per_prompt
|
||||
)
|
||||
else:
|
||||
raise ValueError(
|
||||
f"Acceptable image size of `stencil` is ({width}, {height}) but is {controlnet_hint.size}"
|
||||
)
|
||||
else:
|
||||
raise ValueError(
|
||||
f"Acceptable type of `stencil` are any of torch.Tensor, np.ndarray, PIL.Image.Image but is {type(controlnet_hint)}"
|
||||
)
|
||||
|
||||
|
||||
def controlnet_hint_conversion(
|
||||
image, use_stencil, height, width, dtype, num_images_per_prompt=1
|
||||
):
|
||||
controlnet_hint = None
|
||||
match use_stencil:
|
||||
case "canny":
|
||||
print("Detecting edge with canny")
|
||||
controlnet_hint = hint_canny(image, width)
|
||||
case _:
|
||||
return None
|
||||
controlnet_hint = controlnet_hint_shaping(
|
||||
controlnet_hint, height, width, dtype, num_images_per_prompt
|
||||
)
|
||||
return controlnet_hint
|
||||
|
||||
|
||||
stencil_to_model_id_map = {
|
||||
"canny": "lllyasviel/sd-controlnet-canny",
|
||||
"depth": "lllyasviel/sd-controlnet-depth",
|
||||
"hed": "lllyasviel/sd-controlnet-hed",
|
||||
"mlsd": "lllyasviel/sd-controlnet-mlsd",
|
||||
"normal": "lllyasviel/sd-controlnet-normal",
|
||||
"openpose": "lllyasviel/sd-controlnet-openpose",
|
||||
"scribble": "lllyasviel/sd-controlnet-scribble",
|
||||
"seg": "lllyasviel/sd-controlnet-seg",
|
||||
}
|
||||
|
||||
|
||||
def get_stencil_model_id(use_stencil):
|
||||
if use_stencil in stencil_to_model_id_map:
|
||||
return stencil_to_model_id_map[use_stencil]
|
||||
return None
|
||||
|
||||
|
||||
# Stencil 1. Canny
|
||||
def hint_canny(
|
||||
image: Image.Image,
|
||||
width=512,
|
||||
height=512,
|
||||
low_threshold=100,
|
||||
high_threshold=200,
|
||||
):
|
||||
with torch.no_grad():
|
||||
input_image = np.array(image)
|
||||
image_resolution = width
|
||||
|
||||
img = resize_image(HWC3(input_image), image_resolution)
|
||||
|
||||
if not "canny" in stencil:
|
||||
stencil["canny"] = CannyDetector()
|
||||
detected_map = stencil["canny"](img, low_threshold, high_threshold)
|
||||
detected_map = HWC3(detected_map)
|
||||
return detected_map
|
||||
@@ -25,11 +25,7 @@ from diffusers.pipelines.stable_diffusion.convert_from_ckpt import (
|
||||
|
||||
|
||||
def get_extended_name(model_name):
|
||||
device = (
|
||||
args.device
|
||||
if "://" not in args.device
|
||||
else "-".join(args.device.split("://"))
|
||||
)
|
||||
device = args.device.split("://", 1)[0]
|
||||
extended_name = "{}_{}".format(model_name, device)
|
||||
return extended_name
|
||||
|
||||
@@ -239,17 +235,15 @@ def set_init_device_flags():
|
||||
args.max_length = 64
|
||||
|
||||
# Use tuned models in the case of fp16, vulkan rdna3 or cuda sm devices.
|
||||
base_model_id = args.hf_model_id
|
||||
if args.ckpt_loc != "":
|
||||
base_model_id = fetch_and_update_base_model_id(args.ckpt_loc)
|
||||
else:
|
||||
base_model_id = fetch_and_update_base_model_id(args.hf_model_id)
|
||||
if base_model_id == "":
|
||||
base_model_id = args.hf_model_id
|
||||
|
||||
if (
|
||||
args.hf_model_id
|
||||
in [
|
||||
"runwayml/stable-diffusion-inpainting",
|
||||
"stabilityai/stable-diffusion-2-inpainting",
|
||||
]
|
||||
or args.precision != "fp16"
|
||||
args.precision != "fp16"
|
||||
or args.height != 512
|
||||
or args.width != 512
|
||||
or args.batch_size != 1
|
||||
@@ -257,7 +251,7 @@ def set_init_device_flags():
|
||||
):
|
||||
args.use_tuned = False
|
||||
|
||||
elif args.ckpt_loc != "" and base_model_id not in [
|
||||
elif base_model_id not in [
|
||||
"Linaqruf/anything-v3.0",
|
||||
"dreamlike-art/dreamlike-diffusion-1.0",
|
||||
"prompthero/openjourney",
|
||||
@@ -266,6 +260,8 @@ def set_init_device_flags():
|
||||
"stabilityai/stable-diffusion-2-1-base",
|
||||
"CompVis/stable-diffusion-v1-4",
|
||||
"runwayml/stable-diffusion-v1-5",
|
||||
"runwayml/stable-diffusion-inpainting",
|
||||
"stabilityai/stable-diffusion-2-inpainting",
|
||||
]:
|
||||
args.use_tuned = False
|
||||
|
||||
@@ -300,8 +296,6 @@ def set_init_device_flags():
|
||||
"stabilityai/stable-diffusion-2-1",
|
||||
"stabilityai/stable-diffusion-2-1-base",
|
||||
"CompVis/stable-diffusion-v1-4",
|
||||
"runwayml/stable-diffusion-inpainting",
|
||||
"stabilityai/stable-diffusion-2-inpainting",
|
||||
]:
|
||||
args.import_mlir = True
|
||||
|
||||
@@ -418,7 +412,7 @@ def get_path_to_diffusers_checkpoint(custom_weights):
|
||||
return path_to_diffusers
|
||||
|
||||
|
||||
def preprocessCKPT(custom_weights):
|
||||
def preprocessCKPT(custom_weights, is_inpaint=False):
|
||||
path_to_diffusers = get_path_to_diffusers_checkpoint(custom_weights)
|
||||
if next(Path(path_to_diffusers).iterdir(), None):
|
||||
print("Checkpoint already loaded at : ", path_to_diffusers)
|
||||
@@ -439,10 +433,12 @@ def preprocessCKPT(custom_weights):
|
||||
print(
|
||||
"Loading diffusers' pipeline from original stable diffusion checkpoint"
|
||||
)
|
||||
num_in_channels = 9 if is_inpaint else 4
|
||||
pipe = load_pipeline_from_original_stable_diffusion_ckpt(
|
||||
checkpoint_path=custom_weights,
|
||||
extract_ema=extract_ema,
|
||||
from_safetensors=from_safetensors,
|
||||
num_in_channels=num_in_channels,
|
||||
)
|
||||
pipe.save_pretrained(path_to_diffusers)
|
||||
print("Loading complete")
|
||||
@@ -450,6 +446,7 @@ def preprocessCKPT(custom_weights):
|
||||
|
||||
def load_vmfb(vmfb_path, model, precision):
|
||||
model = "vae" if "base_vae" in model or "vae_encode" in model else model
|
||||
model = "unet" if "stencil" in model else model
|
||||
precision = "fp32" if "clip" in model else precision
|
||||
extra_args = get_opt_flags(model, precision)
|
||||
shark_module = SharkInference(mlir_module=None, device=args.device)
|
||||
@@ -459,32 +456,28 @@ def load_vmfb(vmfb_path, model, precision):
|
||||
|
||||
# This utility returns vmfbs of Clip, Unet, Vae and Vae_encode, in case all of them
|
||||
# are present; deletes them otherwise.
|
||||
def fetch_or_delete_vmfbs(
|
||||
extended_model_name, need_vae_encode, precision="fp32"
|
||||
):
|
||||
def fetch_or_delete_vmfbs(extended_model_name, precision="fp32"):
|
||||
vmfb_path = [
|
||||
get_vmfb_path_name(extended_model_name[model])
|
||||
for model in extended_model_name
|
||||
]
|
||||
number_of_vmfbs = len(vmfb_path)
|
||||
vmfb_present = [os.path.isfile(vmfb) for vmfb in vmfb_path]
|
||||
all_vmfb_present = True
|
||||
compiled_models = []
|
||||
for i in range(3):
|
||||
compiled_models = [None] * number_of_vmfbs
|
||||
|
||||
for i in range(number_of_vmfbs):
|
||||
all_vmfb_present = all_vmfb_present and vmfb_present[i]
|
||||
compiled_models.append(None)
|
||||
if need_vae_encode:
|
||||
all_vmfb_present = all_vmfb_present and vmfb_present[3]
|
||||
compiled_models.append(None)
|
||||
|
||||
# We need to delete vmfbs only if some of the models were compiled.
|
||||
if not all_vmfb_present:
|
||||
for i in range(len(compiled_models)):
|
||||
for i in range(number_of_vmfbs):
|
||||
if vmfb_present[i]:
|
||||
os.remove(vmfb_path[i])
|
||||
print("Deleted: ", vmfb_path[i])
|
||||
else:
|
||||
model_name = [model for model in extended_model_name.keys()]
|
||||
for i in range(len(compiled_models)):
|
||||
for i in range(number_of_vmfbs):
|
||||
compiled_models[i] = load_vmfb(
|
||||
vmfb_path[i], model_name[i], precision
|
||||
)
|
||||
@@ -551,7 +544,7 @@ def clear_all():
|
||||
|
||||
|
||||
# save output images and the inputs corresponding to it.
|
||||
def save_output_img(output_img, img_seed):
|
||||
def save_output_img(output_img, img_seed, extra_info={}):
|
||||
output_path = args.output_dir if args.output_dir else Path.cwd()
|
||||
generated_imgs_path = Path(
|
||||
output_path, "generated_imgs", dt.now().strftime("%Y%m%d")
|
||||
@@ -604,7 +597,9 @@ def save_output_img(output_img, img_seed):
|
||||
"OUTPUT": out_img_path,
|
||||
}
|
||||
|
||||
with open(csv_path, "a") as csv_obj:
|
||||
new_entry.update(extra_info)
|
||||
|
||||
with open(csv_path, "a", encoding="utf-8") as csv_obj:
|
||||
dictwriter_obj = DictWriter(csv_obj, fieldnames=list(new_entry.keys()))
|
||||
dictwriter_obj.writerow(new_entry)
|
||||
csv_obj.close()
|
||||
|
||||
@@ -9,9 +9,12 @@ from apps.stable_diffusion.src import args, clear_all
|
||||
from apps.stable_diffusion.web.utils.gradio_configs import (
|
||||
clear_gradio_tmp_imgs_folder,
|
||||
)
|
||||
from apps.stable_diffusion.web.ui.utils import get_custom_model_path
|
||||
|
||||
# clear all gradio tmp images from the last session
|
||||
# Clear all gradio tmp images from the last session
|
||||
clear_gradio_tmp_imgs_folder()
|
||||
# Create the custom model folder if it doesn't already exist
|
||||
get_custom_model_path().mkdir(parents=True, exist_ok=True)
|
||||
|
||||
if args.clear_all:
|
||||
clear_all()
|
||||
@@ -27,14 +30,110 @@ def resource_path(relative_path):
|
||||
|
||||
dark_theme = resource_path("ui/css/sd_dark_theme.css")
|
||||
|
||||
from apps.stable_diffusion.web.ui import txt2img_web, img2img_web
|
||||
|
||||
sd_web = gr.TabbedInterface(
|
||||
[txt2img_web, img2img_web],
|
||||
["Text-to-Image", "Image-to-Image"],
|
||||
css=dark_theme,
|
||||
from apps.stable_diffusion.web.ui import (
|
||||
txt2img_web,
|
||||
txt2img_gallery,
|
||||
txt2img_sendto_img2img,
|
||||
txt2img_sendto_inpaint,
|
||||
txt2img_sendto_outpaint,
|
||||
img2img_web,
|
||||
img2img_gallery,
|
||||
img2img_init_image,
|
||||
img2img_sendto_inpaint,
|
||||
img2img_sendto_outpaint,
|
||||
inpaint_web,
|
||||
inpaint_gallery,
|
||||
inpaint_init_image,
|
||||
inpaint_sendto_img2img,
|
||||
inpaint_sendto_outpaint,
|
||||
outpaint_web,
|
||||
outpaint_gallery,
|
||||
outpaint_init_image,
|
||||
outpaint_sendto_img2img,
|
||||
outpaint_sendto_inpaint,
|
||||
)
|
||||
|
||||
|
||||
def register_button_click(button, selectedid, inputs, outputs):
|
||||
button.click(
|
||||
lambda x: (
|
||||
x[0]["name"] if len(x) != 0 else None,
|
||||
gr.Tabs.update(selected=selectedid),
|
||||
),
|
||||
inputs,
|
||||
outputs,
|
||||
)
|
||||
|
||||
|
||||
with gr.Blocks(
|
||||
css=dark_theme, analytics_enabled=False, title="Stable Diffusion"
|
||||
) as sd_web:
|
||||
with gr.Tabs() as tabs:
|
||||
with gr.TabItem(label="Text-to-Image", id=0):
|
||||
txt2img_web.render()
|
||||
with gr.TabItem(label="Image-to-Image", id=1):
|
||||
img2img_web.render()
|
||||
with gr.TabItem(label="Inpainting", id=2):
|
||||
inpaint_web.render()
|
||||
with gr.TabItem(label="Outpainting", id=3):
|
||||
outpaint_web.render()
|
||||
|
||||
register_button_click(
|
||||
txt2img_sendto_img2img,
|
||||
1,
|
||||
[txt2img_gallery],
|
||||
[img2img_init_image, tabs],
|
||||
)
|
||||
register_button_click(
|
||||
txt2img_sendto_inpaint,
|
||||
2,
|
||||
[txt2img_gallery],
|
||||
[inpaint_init_image, tabs],
|
||||
)
|
||||
register_button_click(
|
||||
txt2img_sendto_outpaint,
|
||||
3,
|
||||
[txt2img_gallery],
|
||||
[outpaint_init_image, tabs],
|
||||
)
|
||||
register_button_click(
|
||||
img2img_sendto_inpaint,
|
||||
2,
|
||||
[img2img_gallery],
|
||||
[inpaint_init_image, tabs],
|
||||
)
|
||||
register_button_click(
|
||||
img2img_sendto_outpaint,
|
||||
3,
|
||||
[img2img_gallery],
|
||||
[outpaint_init_image, tabs],
|
||||
)
|
||||
register_button_click(
|
||||
inpaint_sendto_img2img,
|
||||
1,
|
||||
[inpaint_gallery],
|
||||
[img2img_init_image, tabs],
|
||||
)
|
||||
register_button_click(
|
||||
inpaint_sendto_outpaint,
|
||||
3,
|
||||
[inpaint_gallery],
|
||||
[outpaint_init_image, tabs],
|
||||
)
|
||||
register_button_click(
|
||||
outpaint_sendto_img2img,
|
||||
1,
|
||||
[outpaint_gallery],
|
||||
[img2img_init_image, tabs],
|
||||
)
|
||||
register_button_click(
|
||||
outpaint_sendto_inpaint,
|
||||
2,
|
||||
[outpaint_gallery],
|
||||
[inpaint_init_image, tabs],
|
||||
)
|
||||
|
||||
|
||||
sd_web.queue()
|
||||
sd_web.launch(
|
||||
share=args.share,
|
||||
|
||||
@@ -1,2 +1,28 @@
|
||||
from apps.stable_diffusion.web.ui.txt2img_ui import txt2img_web
|
||||
from apps.stable_diffusion.web.ui.img2img_ui import img2img_web
|
||||
from apps.stable_diffusion.web.ui.txt2img_ui import (
|
||||
txt2img_web,
|
||||
txt2img_gallery,
|
||||
txt2img_sendto_img2img,
|
||||
txt2img_sendto_inpaint,
|
||||
txt2img_sendto_outpaint,
|
||||
)
|
||||
from apps.stable_diffusion.web.ui.img2img_ui import (
|
||||
img2img_web,
|
||||
img2img_gallery,
|
||||
img2img_init_image,
|
||||
img2img_sendto_inpaint,
|
||||
img2img_sendto_outpaint,
|
||||
)
|
||||
from apps.stable_diffusion.web.ui.inpaint_ui import (
|
||||
inpaint_web,
|
||||
inpaint_gallery,
|
||||
inpaint_init_image,
|
||||
inpaint_sendto_img2img,
|
||||
inpaint_sendto_outpaint,
|
||||
)
|
||||
from apps.stable_diffusion.web.ui.outpaint_ui import (
|
||||
outpaint_web,
|
||||
outpaint_gallery,
|
||||
outpaint_init_image,
|
||||
outpaint_sendto_img2img,
|
||||
outpaint_sendto_inpaint,
|
||||
)
|
||||
|
||||
@@ -145,11 +145,14 @@
|
||||
}
|
||||
|
||||
/* SHARK theme */
|
||||
body {
|
||||
background-color: var(--color-background-primary);
|
||||
}
|
||||
|
||||
/* display in full width for desktop devices */
|
||||
@media (min-width: 1536px)
|
||||
{
|
||||
.gradio-container .contain {
|
||||
.gradio-container {
|
||||
max-width: var(--size-full) !important;
|
||||
}
|
||||
}
|
||||
@@ -158,10 +161,6 @@
|
||||
padding: 0 var(--size-4) !important;
|
||||
}
|
||||
|
||||
.gradio-container {
|
||||
background-color: var(--color-background-primary);
|
||||
}
|
||||
|
||||
.container {
|
||||
background-color: black !important;
|
||||
padding-top: var(--size-5) !important;
|
||||
@@ -214,3 +213,13 @@ footer {
|
||||
#gallery + div {
|
||||
border-radius: 0 !important;
|
||||
}
|
||||
|
||||
/* Prevent progress bar to block gallery navigation while building images (Gradio V3.19.0) */
|
||||
#gallery .wrap.default {
|
||||
pointer-events: none;
|
||||
}
|
||||
|
||||
/* Import Png info box */
|
||||
#txt2img_prompt_image .fixed-height {
|
||||
height: var(--size-32);
|
||||
}
|
||||
|
||||
@@ -1,6 +1,3 @@
|
||||
import os
|
||||
import sys
|
||||
import glob
|
||||
from pathlib import Path
|
||||
import gradio as gr
|
||||
from PIL import Image
|
||||
@@ -9,6 +6,10 @@ from apps.stable_diffusion.src import args
|
||||
from apps.stable_diffusion.web.ui.utils import (
|
||||
available_devices,
|
||||
nodlogo_loc,
|
||||
get_custom_model_path,
|
||||
get_custom_model_files,
|
||||
scheduler_list,
|
||||
predefined_models,
|
||||
)
|
||||
|
||||
|
||||
@@ -27,32 +28,10 @@ with gr.Blocks(title="Image-to-Image") as img2img_web:
|
||||
with gr.Row():
|
||||
with gr.Column(scale=1, min_width=600):
|
||||
with gr.Row():
|
||||
ckpt_path = (
|
||||
Path(args.ckpt_dir)
|
||||
if args.ckpt_dir
|
||||
else Path(Path.cwd(), "models")
|
||||
)
|
||||
ckpt_path.mkdir(parents=True, exist_ok=True)
|
||||
types = (
|
||||
"*.ckpt",
|
||||
"*.safetensors",
|
||||
) # the tuple of file types
|
||||
ckpt_files = ["None"]
|
||||
for extn in types:
|
||||
files = glob.glob(os.path.join(ckpt_path, extn))
|
||||
ckpt_files.extend(files)
|
||||
custom_model = gr.Dropdown(
|
||||
label=f"Models (Custom Model path: {ckpt_path})",
|
||||
label=f"Models (Custom Model path: {get_custom_model_path()})",
|
||||
value=args.ckpt_loc if args.ckpt_loc else "None",
|
||||
choices=ckpt_files
|
||||
+ [
|
||||
"Linaqruf/anything-v3.0",
|
||||
"prompthero/openjourney",
|
||||
"wavymulder/Analog-Diffusion",
|
||||
"stabilityai/stable-diffusion-2-1",
|
||||
"stabilityai/stable-diffusion-2-1-base",
|
||||
"CompVis/stable-diffusion-v1-4",
|
||||
],
|
||||
choices=get_custom_model_files() + predefined_models,
|
||||
)
|
||||
hf_model_id = gr.Textbox(
|
||||
placeholder="Select 'None' in the Models dropdown on the left and enter model ID here e.g: SG161222/Realistic_Vision_V1.3",
|
||||
@@ -75,19 +54,23 @@ with gr.Blocks(title="Image-to-Image") as img2img_web:
|
||||
elem_id="negative_prompt_box",
|
||||
)
|
||||
|
||||
init_image = gr.Image(label="Input Image", type="filepath")
|
||||
img2img_init_image = gr.Image(
|
||||
label="Input Image", type="pil"
|
||||
).style(height=300)
|
||||
|
||||
with gr.Accordion(label="Stencil Options", open=False):
|
||||
with gr.Row():
|
||||
use_stencil = gr.Dropdown(
|
||||
label="Stencil model",
|
||||
value="None",
|
||||
choices=["None", "canny"],
|
||||
)
|
||||
with gr.Accordion(label="Advanced Options", open=False):
|
||||
with gr.Row():
|
||||
scheduler = gr.Dropdown(
|
||||
label="Scheduler",
|
||||
value="PNDM",
|
||||
choices=[
|
||||
"DDIM",
|
||||
"PNDM",
|
||||
"DPMSolverMultistep",
|
||||
"EulerAncestralDiscrete",
|
||||
],
|
||||
choices=scheduler_list,
|
||||
)
|
||||
with gr.Group():
|
||||
save_metadata_to_png = gr.Checkbox(
|
||||
@@ -102,10 +85,10 @@ with gr.Blocks(title="Image-to-Image") as img2img_web:
|
||||
)
|
||||
with gr.Row():
|
||||
height = gr.Slider(
|
||||
384, 786, value=args.height, step=8, label="Height"
|
||||
384, 768, value=args.height, step=8, label="Height"
|
||||
)
|
||||
width = gr.Slider(
|
||||
384, 786, value=args.width, step=8, label="Width"
|
||||
384, 768, value=args.width, step=8, label="Width"
|
||||
)
|
||||
precision = gr.Radio(
|
||||
label="Precision",
|
||||
@@ -114,7 +97,7 @@ with gr.Blocks(title="Image-to-Image") as img2img_web:
|
||||
"fp16",
|
||||
"fp32",
|
||||
],
|
||||
visible=False,
|
||||
visible=True,
|
||||
)
|
||||
max_length = gr.Radio(
|
||||
label="Max Length",
|
||||
@@ -133,7 +116,7 @@ with gr.Blocks(title="Image-to-Image") as img2img_web:
|
||||
0,
|
||||
1,
|
||||
value=args.strength,
|
||||
step=0.1,
|
||||
step=0.01,
|
||||
label="Strength",
|
||||
)
|
||||
with gr.Row():
|
||||
@@ -182,7 +165,7 @@ with gr.Blocks(title="Image-to-Image") as img2img_web:
|
||||
|
||||
with gr.Column(scale=1, min_width=600):
|
||||
with gr.Group():
|
||||
gallery = gr.Gallery(
|
||||
img2img_gallery = gr.Gallery(
|
||||
label="Generated images",
|
||||
show_label=False,
|
||||
elem_id="gallery",
|
||||
@@ -199,12 +182,18 @@ with gr.Blocks(title="Image-to-Image") as img2img_web:
|
||||
value=output_dir,
|
||||
interactive=False,
|
||||
)
|
||||
with gr.Row():
|
||||
img2img_sendto_inpaint = gr.Button(value="SendTo Inpaint")
|
||||
img2img_sendto_outpaint = gr.Button(
|
||||
value="SendTo Outpaint"
|
||||
)
|
||||
|
||||
kwargs = dict(
|
||||
fn=img2img_inf,
|
||||
inputs=[
|
||||
prompt,
|
||||
negative_prompt,
|
||||
init_image,
|
||||
img2img_init_image,
|
||||
height,
|
||||
width,
|
||||
steps,
|
||||
@@ -219,10 +208,11 @@ with gr.Blocks(title="Image-to-Image") as img2img_web:
|
||||
precision,
|
||||
device,
|
||||
max_length,
|
||||
use_stencil,
|
||||
save_metadata_to_json,
|
||||
save_metadata_to_png,
|
||||
],
|
||||
outputs=[gallery, std_output],
|
||||
outputs=[img2img_gallery, std_output],
|
||||
show_progress=args.progress_bar,
|
||||
)
|
||||
|
||||
|
||||
225
apps/stable_diffusion/web/ui/inpaint_ui.py
Normal file
225
apps/stable_diffusion/web/ui/inpaint_ui.py
Normal file
@@ -0,0 +1,225 @@
|
||||
from pathlib import Path
|
||||
import gradio as gr
|
||||
from PIL import Image
|
||||
from apps.stable_diffusion.scripts import inpaint_inf
|
||||
from apps.stable_diffusion.src import args
|
||||
from apps.stable_diffusion.web.ui.utils import (
|
||||
available_devices,
|
||||
nodlogo_loc,
|
||||
get_custom_model_path,
|
||||
get_custom_model_files,
|
||||
scheduler_list,
|
||||
predefined_paint_models,
|
||||
)
|
||||
|
||||
|
||||
with gr.Blocks(title="Inpainting") as inpaint_web:
|
||||
with gr.Row(elem_id="ui_title"):
|
||||
nod_logo = Image.open(nodlogo_loc)
|
||||
with gr.Row():
|
||||
with gr.Column(scale=1, elem_id="demo_title_outer"):
|
||||
gr.Image(
|
||||
value=nod_logo,
|
||||
show_label=False,
|
||||
interactive=False,
|
||||
elem_id="top_logo",
|
||||
).style(width=150, height=50)
|
||||
with gr.Row(elem_id="ui_body"):
|
||||
with gr.Row():
|
||||
with gr.Column(scale=1, min_width=600):
|
||||
with gr.Row():
|
||||
custom_model = gr.Dropdown(
|
||||
label=f"Models (Custom Model path: {get_custom_model_path()})",
|
||||
value=args.ckpt_loc if args.ckpt_loc else "None",
|
||||
choices=get_custom_model_files()
|
||||
+ predefined_paint_models,
|
||||
)
|
||||
hf_model_id = gr.Textbox(
|
||||
placeholder="Select 'None' in the Models dropdown on the left and enter model ID here e.g: ghunkins/stable-diffusion-liberty-inpainting",
|
||||
value="",
|
||||
label="HuggingFace Model ID",
|
||||
lines=3,
|
||||
)
|
||||
|
||||
with gr.Group(elem_id="prompt_box_outer"):
|
||||
prompt = gr.Textbox(
|
||||
label="Prompt",
|
||||
value=args.prompts[0],
|
||||
lines=1,
|
||||
elem_id="prompt_box",
|
||||
)
|
||||
negative_prompt = gr.Textbox(
|
||||
label="Negative Prompt",
|
||||
value=args.negative_prompts[0],
|
||||
lines=1,
|
||||
elem_id="negative_prompt_box",
|
||||
)
|
||||
|
||||
inpaint_init_image = gr.Image(
|
||||
label="Masked Image",
|
||||
source="upload",
|
||||
tool="sketch",
|
||||
type="pil",
|
||||
).style(height=350)
|
||||
|
||||
with gr.Accordion(label="Advanced Options", open=False):
|
||||
with gr.Row():
|
||||
scheduler = gr.Dropdown(
|
||||
label="Scheduler",
|
||||
value="PNDM",
|
||||
choices=scheduler_list,
|
||||
)
|
||||
with gr.Group():
|
||||
save_metadata_to_png = gr.Checkbox(
|
||||
label="Save prompt information to PNG",
|
||||
value=args.write_metadata_to_png,
|
||||
interactive=True,
|
||||
)
|
||||
save_metadata_to_json = gr.Checkbox(
|
||||
label="Save prompt information to JSON file",
|
||||
value=args.save_metadata_to_json,
|
||||
interactive=True,
|
||||
)
|
||||
with gr.Row():
|
||||
height = gr.Slider(
|
||||
384, 768, value=args.height, step=8, label="Height"
|
||||
)
|
||||
width = gr.Slider(
|
||||
384, 768, value=args.width, step=8, label="Width"
|
||||
)
|
||||
precision = gr.Radio(
|
||||
label="Precision",
|
||||
value=args.precision,
|
||||
choices=[
|
||||
"fp16",
|
||||
"fp32",
|
||||
],
|
||||
visible=False,
|
||||
)
|
||||
max_length = gr.Radio(
|
||||
label="Max Length",
|
||||
value=args.max_length,
|
||||
choices=[
|
||||
64,
|
||||
77,
|
||||
],
|
||||
visible=False,
|
||||
)
|
||||
with gr.Row():
|
||||
inpaint_full_res = gr.Radio(
|
||||
choices=["Whole picture", "Only masked"],
|
||||
type="index",
|
||||
value="Whole picture",
|
||||
label="Inpaint area",
|
||||
)
|
||||
inpaint_full_res_padding = gr.Slider(
|
||||
minimum=0,
|
||||
maximum=256,
|
||||
step=4,
|
||||
value=32,
|
||||
label="Only masked padding, pixels",
|
||||
)
|
||||
with gr.Row():
|
||||
steps = gr.Slider(
|
||||
1, 100, value=args.steps, step=1, label="Steps"
|
||||
)
|
||||
with gr.Row():
|
||||
guidance_scale = gr.Slider(
|
||||
0,
|
||||
50,
|
||||
value=args.guidance_scale,
|
||||
step=0.1,
|
||||
label="CFG Scale",
|
||||
)
|
||||
batch_count = gr.Slider(
|
||||
1,
|
||||
100,
|
||||
value=args.batch_count,
|
||||
step=1,
|
||||
label="Batch Count",
|
||||
interactive=True,
|
||||
)
|
||||
batch_size = gr.Slider(
|
||||
1,
|
||||
4,
|
||||
value=args.batch_size,
|
||||
step=1,
|
||||
label="Batch Size",
|
||||
interactive=False,
|
||||
visible=False,
|
||||
)
|
||||
with gr.Row():
|
||||
seed = gr.Number(
|
||||
value=args.seed, precision=0, label="Seed"
|
||||
)
|
||||
device = gr.Dropdown(
|
||||
label="Device",
|
||||
value=available_devices[0],
|
||||
choices=available_devices,
|
||||
)
|
||||
with gr.Row():
|
||||
random_seed = gr.Button("Randomize Seed")
|
||||
random_seed.click(
|
||||
None,
|
||||
inputs=[],
|
||||
outputs=[seed],
|
||||
_js="() => Math.floor(Math.random() * 4294967295)",
|
||||
)
|
||||
stable_diffusion = gr.Button("Generate Image(s)")
|
||||
|
||||
with gr.Column(scale=1, min_width=600):
|
||||
with gr.Group():
|
||||
inpaint_gallery = gr.Gallery(
|
||||
label="Generated images",
|
||||
show_label=False,
|
||||
elem_id="gallery",
|
||||
).style(grid=[2])
|
||||
std_output = gr.Textbox(
|
||||
value="Nothing to show.",
|
||||
lines=1,
|
||||
show_label=False,
|
||||
)
|
||||
output_dir = args.output_dir if args.output_dir else Path.cwd()
|
||||
output_dir = Path(output_dir, "generated_imgs")
|
||||
output_loc = gr.Textbox(
|
||||
label="Saving Images at",
|
||||
value=output_dir,
|
||||
interactive=False,
|
||||
)
|
||||
with gr.Row():
|
||||
inpaint_sendto_img2img = gr.Button(value="SendTo Img2Img")
|
||||
inpaint_sendto_outpaint = gr.Button(
|
||||
value="SendTo Outpaint"
|
||||
)
|
||||
|
||||
kwargs = dict(
|
||||
fn=inpaint_inf,
|
||||
inputs=[
|
||||
prompt,
|
||||
negative_prompt,
|
||||
inpaint_init_image,
|
||||
height,
|
||||
width,
|
||||
inpaint_full_res,
|
||||
inpaint_full_res_padding,
|
||||
steps,
|
||||
guidance_scale,
|
||||
seed,
|
||||
batch_count,
|
||||
batch_size,
|
||||
scheduler,
|
||||
custom_model,
|
||||
hf_model_id,
|
||||
precision,
|
||||
device,
|
||||
max_length,
|
||||
save_metadata_to_json,
|
||||
save_metadata_to_png,
|
||||
],
|
||||
outputs=[inpaint_gallery, std_output],
|
||||
show_progress=args.progress_bar,
|
||||
)
|
||||
|
||||
prompt.submit(**kwargs)
|
||||
negative_prompt.submit(**kwargs)
|
||||
stable_diffusion.click(**kwargs)
|
||||
245
apps/stable_diffusion/web/ui/outpaint_ui.py
Normal file
245
apps/stable_diffusion/web/ui/outpaint_ui.py
Normal file
@@ -0,0 +1,245 @@
|
||||
from pathlib import Path
|
||||
import gradio as gr
|
||||
from PIL import Image
|
||||
from apps.stable_diffusion.scripts import outpaint_inf
|
||||
from apps.stable_diffusion.src import args
|
||||
from apps.stable_diffusion.web.ui.utils import (
|
||||
available_devices,
|
||||
nodlogo_loc,
|
||||
get_custom_model_path,
|
||||
get_custom_model_files,
|
||||
scheduler_list,
|
||||
predefined_paint_models,
|
||||
)
|
||||
|
||||
|
||||
with gr.Blocks(title="Outpainting") as outpaint_web:
|
||||
with gr.Row(elem_id="ui_title"):
|
||||
nod_logo = Image.open(nodlogo_loc)
|
||||
with gr.Row():
|
||||
with gr.Column(scale=1, elem_id="demo_title_outer"):
|
||||
gr.Image(
|
||||
value=nod_logo,
|
||||
show_label=False,
|
||||
interactive=False,
|
||||
elem_id="top_logo",
|
||||
).style(width=150, height=50)
|
||||
with gr.Row(elem_id="ui_body"):
|
||||
with gr.Row():
|
||||
with gr.Column(scale=1, min_width=600):
|
||||
with gr.Row():
|
||||
custom_model = gr.Dropdown(
|
||||
label=f"Models (Custom Model path: {get_custom_model_path()})",
|
||||
value=args.ckpt_loc if args.ckpt_loc else "None",
|
||||
choices=get_custom_model_files()
|
||||
+ predefined_paint_models,
|
||||
)
|
||||
hf_model_id = gr.Textbox(
|
||||
placeholder="Select 'None' in the Models dropdown on the left and enter model ID here e.g: ghunkins/stable-diffusion-liberty-inpainting",
|
||||
value="",
|
||||
label="HuggingFace Model ID",
|
||||
lines=3,
|
||||
)
|
||||
|
||||
with gr.Group(elem_id="prompt_box_outer"):
|
||||
prompt = gr.Textbox(
|
||||
label="Prompt",
|
||||
value=args.prompts[0],
|
||||
lines=1,
|
||||
elem_id="prompt_box",
|
||||
)
|
||||
negative_prompt = gr.Textbox(
|
||||
label="Negative Prompt",
|
||||
value=args.negative_prompts[0],
|
||||
lines=1,
|
||||
elem_id="negative_prompt_box",
|
||||
)
|
||||
|
||||
outpaint_init_image = gr.Image(
|
||||
label="Input Image", type="pil"
|
||||
).style(height=300)
|
||||
|
||||
with gr.Accordion(label="Advanced Options", open=False):
|
||||
with gr.Row():
|
||||
scheduler = gr.Dropdown(
|
||||
label="Scheduler",
|
||||
value="PNDM",
|
||||
choices=scheduler_list,
|
||||
)
|
||||
with gr.Group():
|
||||
save_metadata_to_png = gr.Checkbox(
|
||||
label="Save prompt information to PNG",
|
||||
value=args.write_metadata_to_png,
|
||||
interactive=True,
|
||||
)
|
||||
save_metadata_to_json = gr.Checkbox(
|
||||
label="Save prompt information to JSON file",
|
||||
value=args.save_metadata_to_json,
|
||||
interactive=True,
|
||||
)
|
||||
with gr.Row():
|
||||
pixels = gr.Slider(
|
||||
8,
|
||||
256,
|
||||
value=args.pixels,
|
||||
step=8,
|
||||
label="Pixels to expand",
|
||||
)
|
||||
mask_blur = gr.Slider(
|
||||
0,
|
||||
64,
|
||||
value=args.mask_blur,
|
||||
step=1,
|
||||
label="Mask blur",
|
||||
)
|
||||
with gr.Row():
|
||||
directions = gr.CheckboxGroup(
|
||||
label="Outpainting direction",
|
||||
choices=["left", "right", "up", "down"],
|
||||
value=["left", "right", "up", "down"],
|
||||
)
|
||||
with gr.Row():
|
||||
noise_q = gr.Slider(
|
||||
0.0,
|
||||
4.0,
|
||||
value=1.0,
|
||||
step=0.01,
|
||||
label="Fall-off exponent (lower=higher detail)",
|
||||
)
|
||||
color_variation = gr.Slider(
|
||||
0.0,
|
||||
1.0,
|
||||
value=0.05,
|
||||
step=0.01,
|
||||
label="Color variation",
|
||||
)
|
||||
with gr.Row():
|
||||
height = gr.Slider(
|
||||
384, 768, value=args.height, step=8, label="Height"
|
||||
)
|
||||
width = gr.Slider(
|
||||
384, 768, value=args.width, step=8, label="Width"
|
||||
)
|
||||
precision = gr.Radio(
|
||||
label="Precision",
|
||||
value=args.precision,
|
||||
choices=[
|
||||
"fp16",
|
||||
"fp32",
|
||||
],
|
||||
visible=False,
|
||||
)
|
||||
max_length = gr.Radio(
|
||||
label="Max Length",
|
||||
value=args.max_length,
|
||||
choices=[
|
||||
64,
|
||||
77,
|
||||
],
|
||||
visible=False,
|
||||
)
|
||||
with gr.Row():
|
||||
steps = gr.Slider(
|
||||
1, 100, value=20, step=1, label="Steps"
|
||||
)
|
||||
with gr.Row():
|
||||
guidance_scale = gr.Slider(
|
||||
0,
|
||||
50,
|
||||
value=args.guidance_scale,
|
||||
step=0.1,
|
||||
label="CFG Scale",
|
||||
)
|
||||
batch_count = gr.Slider(
|
||||
1,
|
||||
100,
|
||||
value=args.batch_count,
|
||||
step=1,
|
||||
label="Batch Count",
|
||||
interactive=True,
|
||||
)
|
||||
batch_size = gr.Slider(
|
||||
1,
|
||||
4,
|
||||
value=args.batch_size,
|
||||
step=1,
|
||||
label="Batch Size",
|
||||
interactive=False,
|
||||
visible=False,
|
||||
)
|
||||
with gr.Row():
|
||||
seed = gr.Number(
|
||||
value=args.seed, precision=0, label="Seed"
|
||||
)
|
||||
device = gr.Dropdown(
|
||||
label="Device",
|
||||
value=available_devices[0],
|
||||
choices=available_devices,
|
||||
)
|
||||
with gr.Row():
|
||||
random_seed = gr.Button("Randomize Seed")
|
||||
random_seed.click(
|
||||
None,
|
||||
inputs=[],
|
||||
outputs=[seed],
|
||||
_js="() => Math.floor(Math.random() * 4294967295)",
|
||||
)
|
||||
stable_diffusion = gr.Button("Generate Image(s)")
|
||||
|
||||
with gr.Column(scale=1, min_width=600):
|
||||
with gr.Group():
|
||||
outpaint_gallery = gr.Gallery(
|
||||
label="Generated images",
|
||||
show_label=False,
|
||||
elem_id="gallery",
|
||||
).style(grid=[2])
|
||||
std_output = gr.Textbox(
|
||||
value="Nothing to show.",
|
||||
lines=1,
|
||||
show_label=False,
|
||||
)
|
||||
output_dir = args.output_dir if args.output_dir else Path.cwd()
|
||||
output_dir = Path(output_dir, "generated_imgs")
|
||||
output_loc = gr.Textbox(
|
||||
label="Saving Images at",
|
||||
value=output_dir,
|
||||
interactive=False,
|
||||
)
|
||||
with gr.Row():
|
||||
outpaint_sendto_img2img = gr.Button(value="SendTo Img2Img")
|
||||
outpaint_sendto_inpaint = gr.Button(value="SendTo Inpaint")
|
||||
|
||||
kwargs = dict(
|
||||
fn=outpaint_inf,
|
||||
inputs=[
|
||||
prompt,
|
||||
negative_prompt,
|
||||
outpaint_init_image,
|
||||
pixels,
|
||||
mask_blur,
|
||||
directions,
|
||||
noise_q,
|
||||
color_variation,
|
||||
height,
|
||||
width,
|
||||
steps,
|
||||
guidance_scale,
|
||||
seed,
|
||||
batch_count,
|
||||
batch_size,
|
||||
scheduler,
|
||||
custom_model,
|
||||
hf_model_id,
|
||||
precision,
|
||||
device,
|
||||
max_length,
|
||||
save_metadata_to_json,
|
||||
save_metadata_to_png,
|
||||
],
|
||||
outputs=[outpaint_gallery, std_output],
|
||||
show_progress=args.progress_bar,
|
||||
)
|
||||
|
||||
prompt.submit(**kwargs)
|
||||
negative_prompt.submit(**kwargs)
|
||||
stable_diffusion.click(**kwargs)
|
||||
@@ -1,6 +1,3 @@
|
||||
import os
|
||||
import sys
|
||||
import glob
|
||||
from pathlib import Path
|
||||
import gradio as gr
|
||||
from PIL import Image
|
||||
@@ -9,9 +6,12 @@ from apps.stable_diffusion.src import prompt_examples, args
|
||||
from apps.stable_diffusion.web.ui.utils import (
|
||||
available_devices,
|
||||
nodlogo_loc,
|
||||
get_custom_model_path,
|
||||
get_custom_model_files,
|
||||
scheduler_list_txt2img,
|
||||
predefined_models,
|
||||
)
|
||||
|
||||
|
||||
with gr.Blocks(title="Text-to-Image") as txt2img_web:
|
||||
with gr.Row(elem_id="ui_title"):
|
||||
nod_logo = Image.open(nodlogo_loc)
|
||||
@@ -27,39 +27,30 @@ with gr.Blocks(title="Text-to-Image") as txt2img_web:
|
||||
with gr.Row():
|
||||
with gr.Column(scale=1, min_width=600):
|
||||
with gr.Row():
|
||||
ckpt_path = (
|
||||
Path(args.ckpt_dir)
|
||||
if args.ckpt_dir
|
||||
else Path(Path.cwd(), "models")
|
||||
)
|
||||
ckpt_path.mkdir(parents=True, exist_ok=True)
|
||||
types = (
|
||||
"*.ckpt",
|
||||
"*.safetensors",
|
||||
) # the tuple of file types
|
||||
ckpt_files = ["None"]
|
||||
for extn in types:
|
||||
files = glob.glob(os.path.join(ckpt_path, extn))
|
||||
ckpt_files.extend(files)
|
||||
custom_model = gr.Dropdown(
|
||||
label=f"Models (Custom Model path: {ckpt_path})",
|
||||
value=args.ckpt_loc if args.ckpt_loc else "None",
|
||||
choices=ckpt_files
|
||||
+ [
|
||||
"Linaqruf/anything-v3.0",
|
||||
"prompthero/openjourney",
|
||||
"wavymulder/Analog-Diffusion",
|
||||
"stabilityai/stable-diffusion-2-1",
|
||||
"stabilityai/stable-diffusion-2-1-base",
|
||||
"CompVis/stable-diffusion-v1-4",
|
||||
],
|
||||
)
|
||||
hf_model_id = gr.Textbox(
|
||||
placeholder="Select 'None' in the Models dropdown on the left and enter model ID here e.g: SG161222/Realistic_Vision_V1.3",
|
||||
value="",
|
||||
label="HuggingFace Model ID",
|
||||
lines=3,
|
||||
)
|
||||
with gr.Column(scale=10):
|
||||
with gr.Row():
|
||||
custom_model = gr.Dropdown(
|
||||
label=f"Models (Custom Model path: {get_custom_model_path()})",
|
||||
value=args.ckpt_loc
|
||||
if args.ckpt_loc
|
||||
else "None",
|
||||
choices=get_custom_model_files()
|
||||
+ predefined_models,
|
||||
)
|
||||
hf_model_id = gr.Textbox(
|
||||
placeholder="Select 'None' in the Models dropdown on the left and enter model ID here e.g: SG161222/Realistic_Vision_V1.3",
|
||||
value="",
|
||||
label="HuggingFace Model ID",
|
||||
lines=3,
|
||||
)
|
||||
with gr.Column(scale=1, min_width=170):
|
||||
png_info_img = gr.Image(
|
||||
label="Import PNG info",
|
||||
elem_id="txt2img_prompt_image",
|
||||
type="pil",
|
||||
tool="None",
|
||||
visible=True,
|
||||
)
|
||||
|
||||
with gr.Group(elem_id="prompt_box_outer"):
|
||||
prompt = gr.Textbox(
|
||||
@@ -79,16 +70,7 @@ with gr.Blocks(title="Text-to-Image") as txt2img_web:
|
||||
scheduler = gr.Dropdown(
|
||||
label="Scheduler",
|
||||
value=args.scheduler,
|
||||
choices=[
|
||||
"DDIM",
|
||||
"PNDM",
|
||||
"LMSDiscrete",
|
||||
"KDPM2Discrete",
|
||||
"DPMSolverMultistep",
|
||||
"EulerDiscrete",
|
||||
"EulerAncestralDiscrete",
|
||||
"SharkEulerDiscrete",
|
||||
],
|
||||
choices=scheduler_list_txt2img,
|
||||
)
|
||||
with gr.Group():
|
||||
save_metadata_to_png = gr.Checkbox(
|
||||
@@ -103,10 +85,10 @@ with gr.Blocks(title="Text-to-Image") as txt2img_web:
|
||||
)
|
||||
with gr.Row():
|
||||
height = gr.Slider(
|
||||
384, 786, value=args.height, step=8, label="Height"
|
||||
384, 768, value=args.height, step=8, label="Height"
|
||||
)
|
||||
width = gr.Slider(
|
||||
384, 786, value=args.width, step=8, label="Width"
|
||||
384, 768, value=args.width, step=8, label="Width"
|
||||
)
|
||||
precision = gr.Radio(
|
||||
label="Precision",
|
||||
@@ -182,7 +164,7 @@ with gr.Blocks(title="Text-to-Image") as txt2img_web:
|
||||
|
||||
with gr.Column(scale=1, min_width=600):
|
||||
with gr.Group():
|
||||
gallery = gr.Gallery(
|
||||
txt2img_gallery = gr.Gallery(
|
||||
label="Generated images",
|
||||
show_label=False,
|
||||
elem_id="gallery",
|
||||
@@ -199,6 +181,13 @@ with gr.Blocks(title="Text-to-Image") as txt2img_web:
|
||||
value=output_dir,
|
||||
interactive=False,
|
||||
)
|
||||
with gr.Row():
|
||||
txt2img_sendto_img2img = gr.Button(value="SendTo Img2Img")
|
||||
txt2img_sendto_inpaint = gr.Button(value="SendTo Inpaint")
|
||||
txt2img_sendto_outpaint = gr.Button(
|
||||
value="SendTo Outpaint"
|
||||
)
|
||||
|
||||
kwargs = dict(
|
||||
fn=txt2img_inf,
|
||||
inputs=[
|
||||
@@ -220,10 +209,34 @@ with gr.Blocks(title="Text-to-Image") as txt2img_web:
|
||||
save_metadata_to_json,
|
||||
save_metadata_to_png,
|
||||
],
|
||||
outputs=[gallery, std_output],
|
||||
outputs=[txt2img_gallery, std_output],
|
||||
show_progress=args.progress_bar,
|
||||
)
|
||||
|
||||
prompt.submit(**kwargs)
|
||||
negative_prompt.submit(**kwargs)
|
||||
stable_diffusion.click(**kwargs)
|
||||
|
||||
from apps.stable_diffusion.web.utils.png_metadata import (
|
||||
import_png_metadata,
|
||||
)
|
||||
|
||||
png_info_img.change(
|
||||
fn=import_png_metadata,
|
||||
inputs=[
|
||||
png_info_img,
|
||||
],
|
||||
outputs=[
|
||||
png_info_img,
|
||||
prompt,
|
||||
negative_prompt,
|
||||
steps,
|
||||
scheduler,
|
||||
guidance_scale,
|
||||
seed,
|
||||
width,
|
||||
height,
|
||||
custom_model,
|
||||
hf_model_id,
|
||||
],
|
||||
)
|
||||
|
||||
@@ -1,6 +1,44 @@
|
||||
import os
|
||||
import sys
|
||||
from apps.stable_diffusion.src import get_available_devices
|
||||
import glob
|
||||
from pathlib import Path
|
||||
from apps.stable_diffusion.src import args
|
||||
|
||||
custom_model_filetypes = (
|
||||
"*.ckpt",
|
||||
"*.safetensors",
|
||||
) # the tuple of file types
|
||||
|
||||
scheduler_list = [
|
||||
"DDIM",
|
||||
"PNDM",
|
||||
"DPMSolverMultistep",
|
||||
"EulerAncestralDiscrete",
|
||||
]
|
||||
scheduler_list_txt2img = [
|
||||
"DDIM",
|
||||
"PNDM",
|
||||
"LMSDiscrete",
|
||||
"KDPM2Discrete",
|
||||
"DPMSolverMultistep",
|
||||
"EulerDiscrete",
|
||||
"EulerAncestralDiscrete",
|
||||
"SharkEulerDiscrete",
|
||||
]
|
||||
|
||||
predefined_models = [
|
||||
"Linaqruf/anything-v3.0",
|
||||
"prompthero/openjourney",
|
||||
"wavymulder/Analog-Diffusion",
|
||||
"stabilityai/stable-diffusion-2-1",
|
||||
"stabilityai/stable-diffusion-2-1-base",
|
||||
"CompVis/stable-diffusion-v1-4",
|
||||
]
|
||||
predefined_paint_models = [
|
||||
"runwayml/stable-diffusion-inpainting",
|
||||
"stabilityai/stable-diffusion-2-inpainting",
|
||||
]
|
||||
|
||||
|
||||
def resource_path(relative_path):
|
||||
@@ -11,5 +49,17 @@ def resource_path(relative_path):
|
||||
return os.path.join(base_path, relative_path)
|
||||
|
||||
|
||||
def get_custom_model_path():
|
||||
return Path(args.ckpt_dir) if args.ckpt_dir else Path(Path.cwd(), "models")
|
||||
|
||||
|
||||
def get_custom_model_files():
|
||||
ckpt_files = ["None"]
|
||||
for extn in custom_model_filetypes:
|
||||
files = glob.glob(os.path.join(get_custom_model_path(), extn))
|
||||
ckpt_files.extend(files)
|
||||
return ckpt_files
|
||||
|
||||
|
||||
nodlogo_loc = resource_path("logos/nod-logo.png")
|
||||
available_devices = get_available_devices()
|
||||
|
||||
121
apps/stable_diffusion/web/utils/png_metadata.py
Normal file
121
apps/stable_diffusion/web/utils/png_metadata.py
Normal file
@@ -0,0 +1,121 @@
|
||||
import re
|
||||
import os
|
||||
from pathlib import Path
|
||||
from apps.stable_diffusion.web.ui.txt2img_ui import (
|
||||
png_info_img,
|
||||
prompt,
|
||||
negative_prompt,
|
||||
steps,
|
||||
scheduler,
|
||||
guidance_scale,
|
||||
seed,
|
||||
width,
|
||||
height,
|
||||
custom_model,
|
||||
hf_model_id,
|
||||
)
|
||||
from apps.stable_diffusion.web.ui.utils import (
|
||||
get_custom_model_path,
|
||||
scheduler_list_txt2img,
|
||||
predefined_models,
|
||||
)
|
||||
|
||||
re_param_code = r'\s*([\w ]+):\s*("(?:\\"[^,]|\\"|\\|[^\"])+"|[^,]*)(?:,|$)'
|
||||
re_param = re.compile(re_param_code)
|
||||
re_imagesize = re.compile(r"^(\d+)x(\d+)$")
|
||||
|
||||
|
||||
def parse_generation_parameters(x: str):
|
||||
res = {}
|
||||
prompt = ""
|
||||
negative_prompt = ""
|
||||
done_with_prompt = False
|
||||
|
||||
*lines, lastline = x.strip().split("\n")
|
||||
if len(re_param.findall(lastline)) < 3:
|
||||
lines.append(lastline)
|
||||
lastline = ""
|
||||
|
||||
for i, line in enumerate(lines):
|
||||
line = line.strip()
|
||||
if line.startswith("Negative prompt:"):
|
||||
done_with_prompt = True
|
||||
line = line[16:].strip()
|
||||
|
||||
if done_with_prompt:
|
||||
negative_prompt += ("" if negative_prompt == "" else "\n") + line
|
||||
else:
|
||||
prompt += ("" if prompt == "" else "\n") + line
|
||||
|
||||
res["Prompt"] = prompt
|
||||
res["Negative prompt"] = negative_prompt
|
||||
|
||||
for k, v in re_param.findall(lastline):
|
||||
v = v[1:-1] if v[0] == '"' and v[-1] == '"' else v
|
||||
m = re_imagesize.match(v)
|
||||
if m is not None:
|
||||
res[k + "-1"] = m.group(1)
|
||||
res[k + "-2"] = m.group(2)
|
||||
else:
|
||||
res[k] = v
|
||||
|
||||
# Missing CLIP skip means it was set to 1 (the default)
|
||||
if "Clip skip" not in res:
|
||||
res["Clip skip"] = "1"
|
||||
|
||||
hypernet = res.get("Hypernet", None)
|
||||
if hypernet is not None:
|
||||
res[
|
||||
"Prompt"
|
||||
] += f"""<hypernet:{hypernet}:{res.get("Hypernet strength", "1.0")}>"""
|
||||
|
||||
if "Hires resize-1" not in res:
|
||||
res["Hires resize-1"] = 0
|
||||
res["Hires resize-2"] = 0
|
||||
|
||||
return res
|
||||
|
||||
|
||||
def import_png_metadata(pil_data):
|
||||
try:
|
||||
png_info = pil_data.info["parameters"]
|
||||
metadata = parse_generation_parameters(png_info)
|
||||
png_hf_model_id = ""
|
||||
|
||||
# Check for a model match with one of the local ckpt or safetensors files
|
||||
ckpt_path = get_custom_model_path()
|
||||
png_custom_model = os.path.join(ckpt_path, metadata["Model"])
|
||||
if not Path(png_custom_model).is_file():
|
||||
png_custom_model = "None"
|
||||
# Check for a model match with one of the default model list (ex: "Linaqruf/anything-v3.0")
|
||||
if metadata["Model"] in predefined_models:
|
||||
png_custom_model = metadata["Model"]
|
||||
# If nothing was found, fallback to hf model id
|
||||
if png_custom_model == "None":
|
||||
png_hf_model_id = metadata["Model"]
|
||||
|
||||
outputs = {
|
||||
png_info_img: None,
|
||||
negative_prompt: metadata["Negative prompt"],
|
||||
steps: int(metadata["Steps"]),
|
||||
guidance_scale: float(metadata["CFG scale"]),
|
||||
seed: int(metadata["Seed"]),
|
||||
width: float(metadata["Size-1"]),
|
||||
height: float(metadata["Size-2"]),
|
||||
custom_model: png_custom_model,
|
||||
hf_model_id: png_hf_model_id,
|
||||
}
|
||||
if metadata["Prompt"]:
|
||||
outputs[prompt] = metadata["Prompt"]
|
||||
if metadata["Sampler"] in scheduler_list_txt2img:
|
||||
outputs[scheduler] = metadata["Sampler"]
|
||||
return outputs
|
||||
|
||||
except Exception as ex:
|
||||
if pil_data and pil_data.info.get("parameters"):
|
||||
print("import_png_metadata failed with %s" % ex)
|
||||
pass
|
||||
|
||||
return {
|
||||
png_info_img: None,
|
||||
}
|
||||
@@ -20,6 +20,33 @@ model_config_dicts = get_json_file(
|
||||
)
|
||||
|
||||
|
||||
def parse_sd_out(filename, command, device, use_tune, model_name, import_mlir):
|
||||
with open(filename, "r+") as f:
|
||||
lines = f.readlines()
|
||||
metrics = {}
|
||||
vals_to_read = [
|
||||
"Clip Inference time",
|
||||
"Average step",
|
||||
"VAE Inference time",
|
||||
"Total image generation",
|
||||
]
|
||||
for line in lines:
|
||||
for val in vals_to_read:
|
||||
if val in line:
|
||||
metrics[val] = line.split(" ")[-1].strip("\n")
|
||||
|
||||
metrics["Average step"] = metrics["Average step"].strip("ms/it")
|
||||
metrics["Total image generation"] = metrics[
|
||||
"Total image generation"
|
||||
].strip("sec")
|
||||
metrics["device"] = device
|
||||
metrics["use_tune"] = use_tune
|
||||
metrics["model_name"] = model_name
|
||||
metrics["import_mlir"] = import_mlir
|
||||
metrics["command"] = command
|
||||
return metrics
|
||||
|
||||
|
||||
def get_inpaint_inputs():
|
||||
os.mkdir("./test_images/inputs")
|
||||
img_url = (
|
||||
@@ -39,6 +66,7 @@ def get_inpaint_inputs():
|
||||
def test_loop(device="vulkan", beta=False, extra_flags=[]):
|
||||
# Get golden values from tank
|
||||
shutil.rmtree("./test_images", ignore_errors=True)
|
||||
model_metrics = []
|
||||
os.mkdir("./test_images")
|
||||
os.mkdir("./test_images/golden")
|
||||
get_inpaint_inputs()
|
||||
@@ -52,9 +80,16 @@ def test_loop(device="vulkan", beta=False, extra_flags=[]):
|
||||
inpaint_prompt_text = '--prompt="Face of a yellow cat, high resolution, sitting on a park bench"'
|
||||
if beta:
|
||||
extra_flags.append("--beta_models=True")
|
||||
extra_flags.append("--no-progress_bar")
|
||||
to_skip = [
|
||||
"Linaqruf/anything-v3.0",
|
||||
"prompthero/openjourney",
|
||||
"wavymulder/Analog-Diffusion",
|
||||
"dreamlike-art/dreamlike-diffusion-1.0",
|
||||
]
|
||||
for import_opt in import_options:
|
||||
for model_name in hf_model_names:
|
||||
if model_name == "Linaqruf/anything-v3.0":
|
||||
if model_name in to_skip:
|
||||
continue
|
||||
for use_tune in tuned_options:
|
||||
command = (
|
||||
@@ -73,7 +108,7 @@ def test_loop(device="vulkan", beta=False, extra_flags=[]):
|
||||
]
|
||||
if "inpainting" not in model_name
|
||||
else [
|
||||
"python",
|
||||
executable,
|
||||
"apps/stable_diffusion/scripts/inpaint.py",
|
||||
"--device=" + device,
|
||||
inpaint_prompt_text,
|
||||
@@ -91,12 +126,27 @@ def test_loop(device="vulkan", beta=False, extra_flags=[]):
|
||||
command += extra_flags
|
||||
if os.name == "nt":
|
||||
command = " ".join(command)
|
||||
generated_image = not subprocess.call(
|
||||
command, stdout=subprocess.DEVNULL
|
||||
)
|
||||
dumpfile_name = "_".join(model_name.split("/")) + ".txt"
|
||||
dumpfile_name = os.path.join(os.getcwd(), dumpfile_name)
|
||||
with open(dumpfile_name, "w+") as f:
|
||||
generated_image = not subprocess.call(
|
||||
command,
|
||||
stdout=f,
|
||||
stderr=f,
|
||||
)
|
||||
if os.name != "nt":
|
||||
command = " ".join(command)
|
||||
if generated_image:
|
||||
model_metrics.append(
|
||||
parse_sd_out(
|
||||
dumpfile_name,
|
||||
command,
|
||||
device,
|
||||
use_tune,
|
||||
model_name,
|
||||
import_opt,
|
||||
)
|
||||
)
|
||||
print(command)
|
||||
print("Successfully generated image")
|
||||
os.makedirs(
|
||||
@@ -127,6 +177,22 @@ def test_loop(device="vulkan", beta=False, extra_flags=[]):
|
||||
if "2_1_base" in model_name:
|
||||
print("failed a known successful model.")
|
||||
exit(1)
|
||||
with open(os.path.join(os.getcwd(), "sd_testing_metrics.csv"), "w+") as f:
|
||||
header = "model_name;device;use_tune;import_opt;Clip Inference time(ms);Average Step (ms/it);VAE Inference time(ms);total image generation(s);command\n"
|
||||
f.write(header)
|
||||
for metric in model_metrics:
|
||||
output = [
|
||||
metric["model_name"],
|
||||
metric["device"],
|
||||
metric["use_tune"],
|
||||
metric["import_mlir"],
|
||||
metric["Clip Inference time"],
|
||||
metric["Average step"],
|
||||
metric["VAE Inference time"],
|
||||
metric["Total image generation"],
|
||||
metric["command"],
|
||||
]
|
||||
f.write(";".join(output) + "\n")
|
||||
|
||||
|
||||
parser = argparse.ArgumentParser()
|
||||
|
||||
@@ -40,7 +40,7 @@ cmake --build build/
|
||||
*Prepare the model*
|
||||
```bash
|
||||
wget https://storage.googleapis.com/shark_tank/latest/resnet50_tf/resnet50_tf.mlir
|
||||
iree-compile --iree-input-type=mhlo --iree-vm-bytecode-module-output-format=flatbuffer-binary --iree-hal-target-backends=vulkan --iree-llvm-embedded-linker-path=`python3 -c 'import sysconfig; print(sysconfig.get_paths()["purelib"])'`/iree/compiler/tools/../_mlir_libs/iree-lld --mlir-print-debuginfo --mlir-print-op-on-diagnostic=false --mlir-pass-pipeline-crash-reproducer=ist/core-reproducer.mlir --iree-llvm-target-cpu-features=host -iree-vulkan-target-triple=rdna2-unknown-linux --iree-stream-resource-index-bits=64 --iree-vm-target-index-bits=64 resnet50_tf.mlir -o resnet50_tf.vmfb
|
||||
iree-compile --iree-input-type=mhlo --iree-vm-bytecode-module-output-format=flatbuffer-binary --iree-hal-target-backends=vulkan --iree-llvmcpu-embedded-linker-path=`python3 -c 'import sysconfig; print(sysconfig.get_paths()["purelib"])'`/iree/compiler/tools/../_mlir_libs/iree-lld --mlir-print-debuginfo --mlir-print-op-on-diagnostic=false --mlir-pass-pipeline-crash-reproducer=ist/core-reproducer.mlir --iree-llvmcpu-target-cpu-features=host -iree-vulkan-target-triple=rdna2-unknown-linux --iree-stream-resource-index-bits=64 --iree-vm-target-index-bits=64 resnet50_tf.mlir -o resnet50_tf.vmfb
|
||||
```
|
||||
*Prepare the input*
|
||||
|
||||
@@ -65,18 +65,18 @@ A tool for benchmarking other models is built and can be invoked with a command
|
||||
see `./build/vulkan_gui/iree-vulkan-gui --help` for an explanation on the function input. For example, stable diffusion unet can be tested with the following commands:
|
||||
```bash
|
||||
wget https://storage.googleapis.com/shark_tank/quinn/stable_diff_tf/stable_diff_tf.mlir
|
||||
iree-compile --iree-input-type=mhlo --iree-vm-bytecode-module-output-format=flatbuffer-binary --iree-hal-target-backends=vulkan --mlir-print-debuginfo --mlir-print-op-on-diagnostic=false --iree-llvm-target-cpu-features=host -iree-vulkan-target-triple=rdna2-unknown-linux --iree-stream-resource-index-bits=64 --iree-vm-target-index-bits=64 stable_diff_tf.mlir -o stable_diff_tf.vmfb
|
||||
iree-compile --iree-input-type=mhlo --iree-vm-bytecode-module-output-format=flatbuffer-binary --iree-hal-target-backends=vulkan --mlir-print-debuginfo --mlir-print-op-on-diagnostic=false --iree-llvmcpu-target-cpu-features=host -iree-vulkan-target-triple=rdna2-unknown-linux --iree-stream-resource-index-bits=64 --iree-vm-target-index-bits=64 stable_diff_tf.mlir -o stable_diff_tf.vmfb
|
||||
./build/vulkan_gui/iree-vulkan-gui --module-file=stable_diff_tf.vmfb --function_input=2x4x64x64xf32 --function_input=1xf32 --function_input=2x77x768xf32
|
||||
```
|
||||
VAE and Autoencoder are also available
|
||||
```bash
|
||||
# VAE
|
||||
wget https://storage.googleapis.com/shark_tank/quinn/stable_diff_tf/vae_tf/vae.mlir
|
||||
iree-compile --iree-input-type=mhlo --iree-vm-bytecode-module-output-format=flatbuffer-binary --iree-hal-target-backends=vulkan --mlir-print-debuginfo --mlir-print-op-on-diagnostic=false --iree-llvm-target-cpu-features=host -iree-vulkan-target-triple=rdna2-unknown-linux --iree-stream-resource-index-bits=64 --iree-vm-target-index-bits=64 vae.mlir -o vae.vmfb
|
||||
iree-compile --iree-input-type=mhlo --iree-vm-bytecode-module-output-format=flatbuffer-binary --iree-hal-target-backends=vulkan --mlir-print-debuginfo --mlir-print-op-on-diagnostic=false --iree-llvmcpu-target-cpu-features=host -iree-vulkan-target-triple=rdna2-unknown-linux --iree-stream-resource-index-bits=64 --iree-vm-target-index-bits=64 vae.mlir -o vae.vmfb
|
||||
./build/vulkan_gui/iree-vulkan-gui --module-file=stable_diff_tf.vmfb --function_input=1x4x64x64xf32
|
||||
|
||||
# CLIP Autoencoder
|
||||
wget https://storage.googleapis.com/shark_tank/quinn/stable_diff_tf/clip_tf/clip_autoencoder.mlir
|
||||
iree-compile --iree-input-type=mhlo --iree-vm-bytecode-module-output-format=flatbuffer-binary --iree-hal-target-backends=vulkan --mlir-print-debuginfo --mlir-print-op-on-diagnostic=false --iree-llvm-target-cpu-features=host -iree-vulkan-target-triple=rdna2-unknown-linux --iree-stream-resource-index-bits=64 --iree-vm-target-index-bits=64 clip_autoencoder.mlir -o clip_autoencoder.vmfb
|
||||
iree-compile --iree-input-type=mhlo --iree-vm-bytecode-module-output-format=flatbuffer-binary --iree-hal-target-backends=vulkan --mlir-print-debuginfo --mlir-print-op-on-diagnostic=false --iree-llvmcpu-target-cpu-features=host -iree-vulkan-target-triple=rdna2-unknown-linux --iree-stream-resource-index-bits=64 --iree-vm-target-index-bits=64 clip_autoencoder.mlir -o clip_autoencoder.vmfb
|
||||
./build/vulkan_gui/iree-vulkan-gui --module-file=stable_diff_tf.vmfb --function_input=1x77xi32 --function_input=1x77xi32
|
||||
```
|
||||
|
||||
118
docs/shark_iree_profiling.md
Normal file
118
docs/shark_iree_profiling.md
Normal file
@@ -0,0 +1,118 @@
|
||||
# Overview
|
||||
|
||||
This document is intended to provide a starting point for profiling with SHARK/IREE. At it's core
|
||||
[SHARK](https://github.com/nod-ai/SHARK/tree/main/tank) is a python API that links the MLIR lowerings from various
|
||||
frameworks + frontends (e.g. PyTorch -> Torch-MLIR) with the compiler + runtime offered by IREE. More information
|
||||
on model coverage and framework support can be found [here](https://github.com/nod-ai/SHARK/tree/main/tank). The intended
|
||||
use case for SHARK is for compilation and deployment of performant state of the art AI models.
|
||||
|
||||
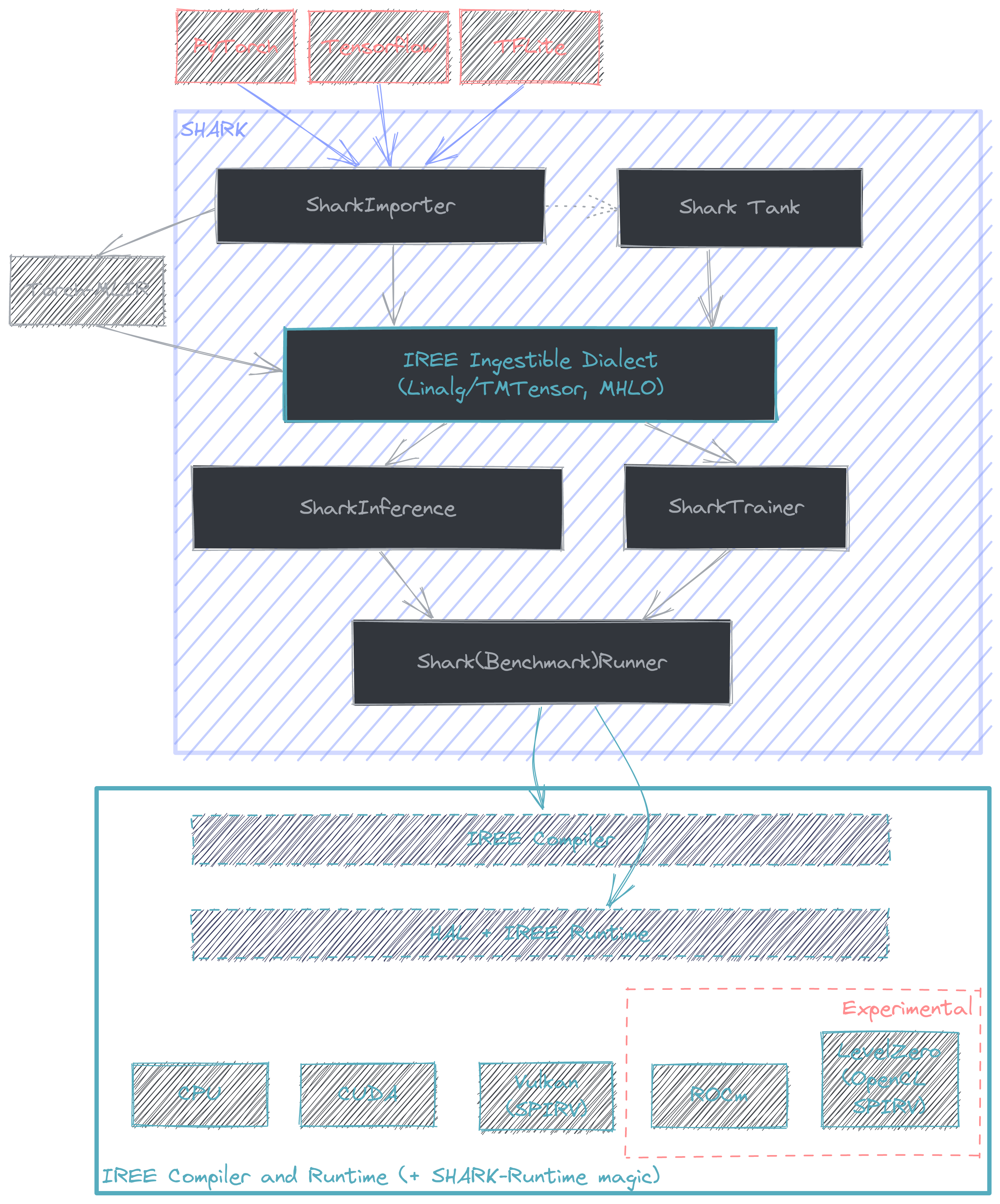
|
||||
|
||||
## Benchmarking with SHARK
|
||||
|
||||
TODO: Expand this section.
|
||||
|
||||
SHARK offers native benchmarking support, although because it is model focused, fine grain profiling is
|
||||
hidden when compared against the common "model benchmarking suite" use case SHARK is good at.
|
||||
|
||||
### SharkBenchmarkRunner
|
||||
|
||||
SharkBenchmarkRunner is a class designed for benchmarking models against other runtimes.
|
||||
TODO: List supported runtimes for comparison + example on how to benchmark with it.
|
||||
|
||||
## Directly profiling IREE
|
||||
|
||||
A number of excellent developer resources on profiling with IREE can be
|
||||
found [here](https://github.com/iree-org/iree/tree/main/docs/developers/developing_iree). As a result this section will
|
||||
focus on the bridging the gap between the two.
|
||||
- https://github.com/iree-org/iree/blob/main/docs/developers/developing_iree/profiling.md
|
||||
- https://github.com/iree-org/iree/blob/main/docs/developers/developing_iree/profiling_with_tracy.md
|
||||
- https://github.com/iree-org/iree/blob/main/docs/developers/developing_iree/profiling_vulkan_gpu.md
|
||||
- https://github.com/iree-org/iree/blob/main/docs/developers/developing_iree/profiling_cpu_events.md
|
||||
|
||||
Internally, SHARK builds a pair of IREE commands to compile + run a model. At a high level the flow starts with the
|
||||
model represented with a high level dialect (commonly Linalg) and is compiled to a flatbuffer (.vmfb) that
|
||||
the runtime is capable of ingesting. At this point (with potentially a few runtime flags) the compiled model is then run
|
||||
through the IREE runtime. This is all facilitated with the IREE python bindings, which offers a convenient method
|
||||
to capture the compile command SHARK comes up with. This is done by setting the environment variable
|
||||
`IREE_SAVE_TEMPS` to point to a directory of choice, e.g. for stable diffusion
|
||||
```
|
||||
# Linux
|
||||
$ export IREE_SAVE_TEMPS=/path/to/some/directory
|
||||
# Windows
|
||||
$ $env:IREE_SAVE_TEMPS="C:\path\to\some\directory"
|
||||
$ python apps/stable_diffusion/scripts/txt2img.py -p "a photograph of an astronaut riding a horse" --save_vmfb
|
||||
```
|
||||
NOTE: Currently this will only save the compile command + input MLIR for a single model if run in a pipeline.
|
||||
In the case of stable diffusion this (should) be UNet so to get examples for other models in the pipeline they
|
||||
need to be extracted and tested individually.
|
||||
|
||||
The save temps directory should contain three files: `core-command-line.txt`, `core-input.mlir`, and `core-output.bin`.
|
||||
The command line for compilation will start something like this, where the `-` needs to be replaced with the path to `core-input.mlir`.
|
||||
```
|
||||
/home/quinn/nod/iree-build/compiler/bindings/python/iree/compiler/tools/../_mlir_libs/iree-compile - --iree-input-type=none ...
|
||||
```
|
||||
The `-o output_filename.vmfb` flag can be used to specify the location to save the compiled vmfb. Note that a dump of the
|
||||
dispatches that can be compiled + run in isolation can be generated by adding `--iree-hal-dump-executable-benchmarks-to=/some/directory`. Say, if they are in the `benchmarks` directory, the following compile/run commands would work for Vulkan on RDNA3.
|
||||
```
|
||||
iree-compile --iree-input-type=none --iree-hal-target-backends=vulkan --iree-vulkan-target-triple=rdna3-unknown-linux --iree-stream-resource-index-bits=64 --iree-vm-target-index-bits=64 benchmarks/module_forward_dispatch_${NUM}_vulkan_spirv_fb.mlir -o benchmarks/module_forward_dispatch_${NUM}_vulkan_spirv_fb.vmfb
|
||||
|
||||
iree-benchmark-module --module=benchmarks/module_forward_dispatch_${NUM}_vulkan_spirv_fb.vmfb --function=forward --device=vulkan
|
||||
```
|
||||
Where `${NUM}` is the dispatch number that you want to benchmark/profile in isolation.
|
||||
|
||||
### Enabling Tracy for Vulkan profiling
|
||||
|
||||
To begin profiling with Tracy, a build of IREE runtime with tracing enabled is needed. SHARK-Runtime builds an
|
||||
instrumented version alongside the normal version nightly (.whls typically found [here](https://github.com/nod-ai/SHARK-Runtime/releases)), however this is only available for Linux. For Windows, tracing can be enabled by enabling a CMake flag.
|
||||
```
|
||||
$env:IREE_ENABLE_RUNTIME_TRACING="ON"
|
||||
```
|
||||
Getting a trace can then be done by setting environment variable `TRACY_NO_EXIT=1` and running the program that is to be
|
||||
traced. Then, to actually capture the trace, use the `iree-tracy-capture` tool in a different terminal. Note that to get
|
||||
the capture and profiler tools the `IREE_BUILD_TRACY=ON` CMake flag needs to be set.
|
||||
```
|
||||
TRACY_NO_EXIT=1 python apps/stable_diffusion/scripts/txt2img.py -p "a photograph of an astronaut riding a horse"
|
||||
|
||||
# (in another terminal, either on the same machine or through ssh with a tunnel through port 8086)
|
||||
iree-tracy-capture -o trace_filename.tracy
|
||||
```
|
||||
To do it over ssh, the flow looks like this
|
||||
```
|
||||
# From terminal 1 on local machine
|
||||
ssh -L 8086:localhost:8086 <remote_server_name>
|
||||
TRACY_NO_EXIT=1 python apps/stable_diffusion/scripts/txt2img.py -p "a photograph of an astronaut riding a horse"
|
||||
|
||||
# From terminal 2 on local machine. Requires having built IREE with the CMake flag `IREE_BUILD_TRACY=ON` to build the required tooling.
|
||||
iree-tracy-capture -o /path/to/trace.tracy
|
||||
```
|
||||
|
||||
The trace can then be viewed with
|
||||
```
|
||||
iree-tracy-profiler /path/to/trace.tracy
|
||||
```
|
||||
Capturing a runtime trace will work with any IREE tooling that uses the runtime. For example, `iree-benchmark-module`
|
||||
can be used for benchmarking an individual module. Importantly this means that any SHARK script can be profiled with tracy.
|
||||
|
||||
NOTE: Not all backends have the same tracy support. This writeup is focused on CPU/Vulkan backends but there is recently added support for tracing on CUDA (requires the `--cuda_tracing` flag).
|
||||
|
||||
## Experimental RGP support
|
||||
|
||||
TODO: This section is temporary until proper RGP support is added.
|
||||
|
||||
Currently, for stable diffusion there is a flag for enabling UNet to be visible to RGP with `--enable_rgp`. To get a proper capture though, the `DevModeSqttPrepareFrameCount=1` flag needs to be set for the driver (done with `VkPanel` on Windows).
|
||||
With these two settings, a single iteration of UNet can be captured.
|
||||
|
||||
(AMD only) To get a dump of the pipelines (result of compiled SPIR-V) the `EnablePipelineDump=1` driver flag can be set. The
|
||||
files will typically be dumped to a directory called `spvPipeline` (on Linux `/var/tmp/spvPipeline`. The dumped files will
|
||||
include header information that can be used to map back to the source dispatch/SPIR-V, e.g.
|
||||
```
|
||||
[Version]
|
||||
version = 57
|
||||
|
||||
[CsSpvFile]
|
||||
fileName = Shader_0x946C08DFD0C10D9A.spv
|
||||
|
||||
[CsInfo]
|
||||
entryPoint = forward_dispatch_193_matmul_256x65536x2304
|
||||
```
|
||||
@@ -162,13 +162,13 @@ def save_tf_model(tf_model_list):
|
||||
tf_model_name = tf_model_name.replace("/", "_")
|
||||
tf_model_dir = os.path.join(WORKDIR, str(tf_model_name) + "_tf")
|
||||
os.makedirs(tf_model_dir, exist_ok=True)
|
||||
|
||||
mlir_importer = SharkImporter(
|
||||
model,
|
||||
input,
|
||||
inputs=input,
|
||||
frontend="tf",
|
||||
)
|
||||
mlir_importer.import_debug(
|
||||
is_dynamic=False,
|
||||
dir=tf_model_dir,
|
||||
model_name=tf_model_name,
|
||||
)
|
||||
|
||||
@@ -6,6 +6,16 @@ from distutils.sysconfig import get_python_lib
|
||||
import fileinput
|
||||
from pathlib import Path
|
||||
|
||||
# Diffusers 0.13.1 fails with transformers __init.py errros in BLIP. So remove it for now until we fork it
|
||||
pix2pix_file = Path(
|
||||
get_python_lib()
|
||||
+ "/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_pix2pix_zero.py"
|
||||
)
|
||||
if pix2pix_file.exists():
|
||||
print("Removing..%s", pix2pix_file)
|
||||
pix2pix_file.unlink()
|
||||
|
||||
|
||||
path_to_skipfiles = Path(get_python_lib() + "/torch/_dynamo/skipfiles.py")
|
||||
|
||||
modules_to_comment = ["abc,", "os,", "posixpath,", "_collections_abc,"]
|
||||
|
||||
@@ -10,3 +10,6 @@ requires = [
|
||||
"iree-runtime>=20221022.190",
|
||||
]
|
||||
build-backend = "setuptools.build_meta"
|
||||
|
||||
[tool.black]
|
||||
line-length = 79
|
||||
|
||||
@@ -1,7 +1,7 @@
|
||||
-f https://download.pytorch.org/whl/nightly/cpu/torch_nightly.html
|
||||
--pre
|
||||
|
||||
numpy==1.22.4
|
||||
numpy>1.22.4
|
||||
torchvision
|
||||
pytorch-triton
|
||||
tabulate
|
||||
@@ -15,8 +15,8 @@ iree-tools-tf
|
||||
|
||||
# TensorFlow and JAX.
|
||||
gin-config
|
||||
tensorflow==2.10.1
|
||||
keras==2.10
|
||||
tf-nightly
|
||||
keras>=2.10
|
||||
#tf-models-nightly
|
||||
#tensorflow-text-nightly
|
||||
transformers
|
||||
|
||||
@@ -16,13 +16,14 @@ parameterized
|
||||
|
||||
# Add transformers, diffusers and scipy since it most commonly used
|
||||
transformers
|
||||
diffusers @ git+https://github.com/huggingface/diffusers@4c52982a0be7dd850fb9eac55b11509846e4bbe6
|
||||
diffusers @ git+https://github.com/nod-ai/diffusers@stable_stencil
|
||||
scipy
|
||||
ftfy
|
||||
gradio
|
||||
altair
|
||||
omegaconf
|
||||
safetensors
|
||||
opencv-python
|
||||
|
||||
# Keep PyInstaller at the end. Sometimes Windows Defender flags it but most folks can continue even if it errors
|
||||
pefile
|
||||
|
||||
@@ -9,10 +9,10 @@
|
||||
If that environment does not exist, it creates it.
|
||||
|
||||
.PARAMETER update-src
|
||||
updates to latest version from git .\source
|
||||
git pulls latest version
|
||||
|
||||
.PARAMETER force
|
||||
removes and recreates venv to force update all dependencies
|
||||
removes and recreates venv to force update of all dependencies
|
||||
|
||||
.EXAMPLE
|
||||
.\setup_venv.ps1 --force
|
||||
@@ -26,12 +26,6 @@
|
||||
.OUTPUTS
|
||||
None
|
||||
|
||||
.NOTES
|
||||
Version 1.0
|
||||
Author powderluv, xzuyn
|
||||
Creation Date 2023-02-17
|
||||
PurposeChange Initial script development
|
||||
|
||||
#>
|
||||
|
||||
param([string]$arguments)
|
||||
@@ -56,18 +50,6 @@ if ($arguments -eq "--force"){
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
#Write-Host "Installing python"
|
||||
|
||||
#Start-Process winget install Python.Python.3.10 '/quiet InstallAllUsers=1 PrependPath=1' -wait -NoNewWindow
|
||||
|
||||
#Write-Host "python installation completed successfully"
|
||||
|
||||
#Write-Host "Reload environment variables"
|
||||
#$env:Path = [System.Environment]::GetEnvironmentVariable("Path","Machine") + ";" + [System.Environment]::GetEnvironmentVariable("Path","User")
|
||||
#Write-Host "Reloaded environment variables"
|
||||
|
||||
|
||||
# redirect stderr into stdout
|
||||
$p = &{python -V} 2>&1
|
||||
# check if an ErrorRecord was returned
|
||||
@@ -78,25 +60,36 @@ $version = if($p -is [System.Management.Automation.ErrorRecord])
|
||||
}
|
||||
else
|
||||
{
|
||||
# otherwise return as is
|
||||
$p
|
||||
# otherwise return complete Python list
|
||||
$ErrorActionPreference = 'SilentlyContinue'
|
||||
$PyVer = py --list
|
||||
}
|
||||
|
||||
Write-Host "Python version found is"
|
||||
Write-Host $p
|
||||
if ($p -notlike "*3.11*")
|
||||
# deactivate any activated venvs
|
||||
if ($PyVer -like "*venv*")
|
||||
{
|
||||
deactivate # make sure we don't update the wrong venv
|
||||
$PyVer = py --list # update list
|
||||
}
|
||||
|
||||
Write-Host "Python versions found are"
|
||||
Write-Host ($PyVer | Out-String) # formatted output with line breaks
|
||||
if (!($PyVer.length -ne 0)) {$p} # return Python --version String if py.exe is unavailable
|
||||
if (!($PyVer -like "*3.11*") -and !($p -like "*3.11*")) # if 3.11 is not in any list
|
||||
{
|
||||
Write-Host "Please install Python 3.11 and try again"
|
||||
break
|
||||
}
|
||||
|
||||
Write-Host "Installing Build Dependencies"
|
||||
py -3.11 -m venv .\shark.venv\
|
||||
# make sure we really use 3.11 from list, even if it's not the default.
|
||||
if (!($PyVer.length -ne 0)) {py -3.11 -m venv .\shark.venv\}
|
||||
else {python -m venv .\shark.venv\}
|
||||
.\shark.venv\Scripts\activate
|
||||
python -m pip install --upgrade pip
|
||||
pip install wheel
|
||||
pip install -r requirements.txt
|
||||
pip install --pre torch-mlir torch torchvision --extra-index-url https://download.pytorch.org/whl/nightly/cpu -f https://llvm.github.io/torch-mlir/package-index/
|
||||
pip install --pre torch-mlir torch --extra-index-url https://download.pytorch.org/whl/nightly/cpu -f https://llvm.github.io/torch-mlir/package-index/
|
||||
pip install --upgrade -f https://nod-ai.github.io/SHARK-Runtime/pip-release-links.html iree-compiler iree-runtime
|
||||
Write-Host "Building SHARK..."
|
||||
pip install -e . -f https://llvm.github.io/torch-mlir/package-index/ -f https://nod-ai.github.io/SHARK-Runtime/pip-release-links.html
|
||||
|
||||
@@ -78,7 +78,7 @@ $PYTHON -m pip install --upgrade -r "$TD/requirements.txt"
|
||||
if [ "$torch_mlir_bin" = true ]; then
|
||||
if [[ $(uname -s) = 'Darwin' ]]; then
|
||||
echo "MacOS detected. Installing torch-mlir from .whl, to avoid dependency problems with torch."
|
||||
$PYTHON -m pip install --pre --no-cache-dir torch-mlir -f https://llvm.github.io/torch-mlir/package-index/ -f https://download.pytorch.org/whl/nightly/torch/
|
||||
$PYTHON -m pip install --pre --no-cache-dir torch-mlir -f https://llvm.github.io/torch-mlir/package-index/ -f https://download.pytorch.org/whl/nightly/torch/
|
||||
else
|
||||
$PYTHON -m pip install --pre torch-mlir -f https://llvm.github.io/torch-mlir/package-index/
|
||||
if [ $? -eq 0 ];then
|
||||
@@ -98,11 +98,11 @@ if [[ -z "${USE_IREE}" ]]; then
|
||||
RUNTIME="https://nod-ai.github.io/SHARK-Runtime/pip-release-links.html"
|
||||
else
|
||||
touch ./.use-iree
|
||||
RUNTIME="https://iree-org.github.io/iree/pip-release-links.html"
|
||||
RUNTIME="https://openxla.github.io/iree/pip-release-links.html"
|
||||
fi
|
||||
if [[ -z "${NO_BACKEND}" ]]; then
|
||||
echo "Installing ${RUNTIME}..."
|
||||
$PYTHON -m pip install --upgrade --find-links ${RUNTIME} iree-compiler iree-runtime
|
||||
$PYTHON -m pip install --pre --upgrade --find-links ${RUNTIME} iree-compiler iree-runtime
|
||||
else
|
||||
echo "Not installing a backend, please make sure to add your backend to PYTHONPATH"
|
||||
fi
|
||||
@@ -112,7 +112,7 @@ if [[ ! -z "${IMPORTER}" ]]; then
|
||||
if [[ $(uname -s) = 'Linux' ]]; then
|
||||
echo "${Yellow}Linux detected.. installing Linux importer tools"
|
||||
#Always get the importer tools from upstream IREE
|
||||
$PYTHON -m pip install --no-warn-conflicts --upgrade -r "$TD/requirements-importer.txt" -f https://iree-org.github.io/iree/pip-release-links.html --extra-index-url https://download.pytorch.org/whl/nightly/cpu
|
||||
$PYTHON -m pip install --no-warn-conflicts --upgrade -r "$TD/requirements-importer.txt" -f https://openxla.github.io/iree/pip-release-links.html --extra-index-url https://download.pytorch.org/whl/nightly/cpu
|
||||
elif [[ $(uname -s) = 'Darwin' ]]; then
|
||||
echo "${Yellow}macOS detected.. installing macOS importer tools"
|
||||
#Conda seems to have some problems installing these packages and hope they get resolved upstream.
|
||||
@@ -129,7 +129,7 @@ if [[ $(uname -s) = 'Linux' && ! -z "${BENCHMARK}" ]]; then
|
||||
TV_VERSION=${TV_VER:9:18}
|
||||
$PYTHON -m pip uninstall -y torch torchvision
|
||||
$PYTHON -m pip install -U --pre --no-warn-conflicts triton
|
||||
$PYTHON -m pip install --no-deps https://download.pytorch.org/whl/nightly/cu117/torch-${TORCH_VERSION}%2Bcu117-cp310-cp310-linux_x86_64.whl https://download.pytorch.org/whl/nightly/cu117/torchvision-${TV_VERSION}%2Bcu117-cp310-cp310-linux_x86_64.whl
|
||||
$PYTHON -m pip install --no-deps https://download.pytorch.org/whl/nightly/cu117/torch-${TORCH_VERSION}%2Bcu117-cp311-cp311-linux_x86_64.whl https://download.pytorch.org/whl/nightly/cu117/torchvision-${TV_VERSION}%2Bcu117-cp311-cp311-linux_x86_64.whl
|
||||
if [ $? -eq 0 ];then
|
||||
echo "Successfully Installed torch + cu117."
|
||||
else
|
||||
|
||||
18
shark/examples/shark_inference/llama/README.md
Normal file
18
shark/examples/shark_inference/llama/README.md
Normal file
@@ -0,0 +1,18 @@
|
||||
# SHARK LLaMA
|
||||
|
||||
## TORCH-MLIR Version
|
||||
|
||||
```
|
||||
https://github.com/nod-ai/torch-mlir.git
|
||||
```
|
||||
Then check out the `complex` branch and build.
|
||||
|
||||
### Setup & Run
|
||||
```
|
||||
git clone https://github.com/nod-ai/llama.git
|
||||
```
|
||||
Then in this repository
|
||||
```
|
||||
pip install -e .
|
||||
python llama/shark_model.py
|
||||
```
|
||||
@@ -7,11 +7,17 @@
|
||||
# -de --device: the device you want to run bloom on. E.G. cpu, cuda
|
||||
# -c, --recompile: set to true if you want to recompile to vmfb.
|
||||
# -d, --download: set to true if you want to redownload the mlir files
|
||||
# -cm, --create_mlirs: set to true if you want to create the mlir files from scratch. please make sure you have transformers 4.21.2 before using this option
|
||||
# -t --token_count: the number of tokens you want to generate
|
||||
# -pr --prompt: the prompt you want to feed to the model
|
||||
# -m --model_name: the name of the model, e.g. bloom-560m
|
||||
#
|
||||
# If you don't specify a prompt when you run this example, you will be able to give prompts through the terminal. Run the
|
||||
# example in this way if you want to run multiple examples without reinitializing the model
|
||||
#####################################################################################
|
||||
|
||||
import os
|
||||
import io
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
from collections import OrderedDict
|
||||
@@ -22,14 +28,19 @@ from transformers.models.bloom.configuration_bloom import BloomConfig
|
||||
import json
|
||||
import sys
|
||||
import argparse
|
||||
from cuda.cudart import cudaSetDevice
|
||||
import json
|
||||
import urllib.request
|
||||
import subprocess
|
||||
|
||||
from torch.fx.experimental.proxy_tensor import make_fx
|
||||
from torch._decomp import get_decompositions
|
||||
from shark.shark_inference import SharkInference
|
||||
from shark.shark_downloader import download_public_file
|
||||
|
||||
from transformers import (
|
||||
BloomTokenizerFast,
|
||||
BloomForSequenceClassification,
|
||||
BloomForCausalLM,
|
||||
)
|
||||
from transformers.models.bloom.modeling_bloom import (
|
||||
BloomBlock,
|
||||
build_alibi_tensor,
|
||||
@@ -47,16 +58,22 @@ class ShardedBloom:
|
||||
self.layers_initialized = False
|
||||
|
||||
self.src_folder = src_folder
|
||||
self.n_embed = config["n_embed"]
|
||||
try:
|
||||
self.n_embed = config["n_embed"]
|
||||
except KeyError:
|
||||
self.n_embed = config["hidden_size"]
|
||||
self.vocab_size = config["vocab_size"]
|
||||
self.n_layer = config["n_layer"]
|
||||
self.n_head = config["num_attention_heads"]
|
||||
try:
|
||||
self.n_head = config["num_attention_heads"]
|
||||
except KeyError:
|
||||
self.n_head = config["n_head"]
|
||||
|
||||
def _init_layer(self, layer_name, device, replace, device_idx):
|
||||
if replace or not os.path.exists(
|
||||
f"{self.src_folder}/{layer_name}.vmfb"
|
||||
):
|
||||
f_ = open(f"{self.src_folder}/{layer_name}.mlir")
|
||||
f_ = open(f"{self.src_folder}/{layer_name}.mlir", encoding="utf-8")
|
||||
module = f_.read()
|
||||
f_.close()
|
||||
module = bytes(module, "utf-8")
|
||||
@@ -292,93 +309,401 @@ def _prepare_attn_mask(
|
||||
return combined_attention_mask
|
||||
|
||||
|
||||
def download_560m(destination_folder):
|
||||
def download_model(destination_folder, model_name):
|
||||
download_public_file(
|
||||
"https://bloom-560m/bloom_block_0.mlir", destination_folder
|
||||
f"gs://shark_tank/sharded_bloom/{model_name}/", destination_folder
|
||||
)
|
||||
download_public_file(
|
||||
"https://bloom-560m/bloom_block_1.mlir", destination_folder
|
||||
|
||||
|
||||
def compile_embeddings(embeddings_layer, input_ids, path):
|
||||
input_ids_placeholder = torch_mlir.TensorPlaceholder.like(
|
||||
input_ids, dynamic_axes=[1]
|
||||
)
|
||||
download_public_file(
|
||||
"https://bloom-560m/bloom_block_2.mlir", destination_folder
|
||||
module = torch_mlir.compile(
|
||||
embeddings_layer,
|
||||
(input_ids_placeholder),
|
||||
torch_mlir.OutputType.LINALG_ON_TENSORS,
|
||||
use_tracing=False,
|
||||
verbose=False,
|
||||
)
|
||||
download_public_file(
|
||||
"https://bloom-560m/bloom_block_3.mlir", destination_folder
|
||||
|
||||
bytecode_stream = io.BytesIO()
|
||||
module.operation.write_bytecode(bytecode_stream)
|
||||
bytecode = bytecode_stream.getvalue()
|
||||
|
||||
f_ = open(path, "w+")
|
||||
f_.write(str(module))
|
||||
f_.close()
|
||||
return
|
||||
|
||||
|
||||
def compile_word_embeddings_layernorm(
|
||||
embeddings_layer_layernorm, embeds, path
|
||||
):
|
||||
embeds_placeholder = torch_mlir.TensorPlaceholder.like(
|
||||
embeds, dynamic_axes=[1]
|
||||
)
|
||||
download_public_file(
|
||||
"https://bloom-560m/bloom_block_4.mlir", destination_folder
|
||||
module = torch_mlir.compile(
|
||||
embeddings_layer_layernorm,
|
||||
(embeds_placeholder),
|
||||
torch_mlir.OutputType.LINALG_ON_TENSORS,
|
||||
use_tracing=False,
|
||||
verbose=False,
|
||||
)
|
||||
download_public_file(
|
||||
"https://bloom-560m/bloom_block_5.mlir", destination_folder
|
||||
|
||||
bytecode_stream = io.BytesIO()
|
||||
module.operation.write_bytecode(bytecode_stream)
|
||||
bytecode = bytecode_stream.getvalue()
|
||||
|
||||
f_ = open(path, "w+")
|
||||
f_.write(str(module))
|
||||
f_.close()
|
||||
return
|
||||
|
||||
|
||||
def strip_overloads(gm):
|
||||
"""
|
||||
Modifies the target of graph nodes in :attr:`gm` to strip overloads.
|
||||
Args:
|
||||
gm(fx.GraphModule): The input Fx graph module to be modified
|
||||
"""
|
||||
for node in gm.graph.nodes:
|
||||
if isinstance(node.target, torch._ops.OpOverload):
|
||||
node.target = node.target.overloadpacket
|
||||
gm.recompile()
|
||||
|
||||
|
||||
def compile_to_mlir(
|
||||
bblock,
|
||||
hidden_states,
|
||||
layer_past=None,
|
||||
attention_mask=None,
|
||||
head_mask=None,
|
||||
use_cache=None,
|
||||
output_attentions=False,
|
||||
alibi=None,
|
||||
block_index=0,
|
||||
path=".",
|
||||
):
|
||||
fx_g = make_fx(
|
||||
bblock,
|
||||
decomposition_table=get_decompositions(
|
||||
[
|
||||
torch.ops.aten.split.Tensor,
|
||||
torch.ops.aten.split_with_sizes,
|
||||
]
|
||||
),
|
||||
tracing_mode="real",
|
||||
_allow_non_fake_inputs=False,
|
||||
)(hidden_states, alibi, attention_mask)
|
||||
|
||||
fx_g.graph.set_codegen(torch.fx.graph.CodeGen())
|
||||
fx_g.recompile()
|
||||
|
||||
strip_overloads(fx_g)
|
||||
|
||||
hidden_states_placeholder = TensorPlaceholder.like(
|
||||
hidden_states, dynamic_axes=[1]
|
||||
)
|
||||
download_public_file(
|
||||
"https://bloom-560m/bloom_block_6.mlir", destination_folder
|
||||
attention_mask_placeholder = TensorPlaceholder.like(
|
||||
attention_mask, dynamic_axes=[2, 3]
|
||||
)
|
||||
download_public_file(
|
||||
"https://bloom-560m/bloom_block_7.mlir", destination_folder
|
||||
alibi_placeholder = TensorPlaceholder.like(alibi, dynamic_axes=[2])
|
||||
|
||||
ts_g = torch.jit.script(fx_g)
|
||||
|
||||
module = torch_mlir.compile(
|
||||
ts_g,
|
||||
(
|
||||
hidden_states_placeholder,
|
||||
alibi_placeholder,
|
||||
attention_mask_placeholder,
|
||||
),
|
||||
torch_mlir.OutputType.LINALG_ON_TENSORS,
|
||||
use_tracing=False,
|
||||
verbose=False,
|
||||
)
|
||||
download_public_file(
|
||||
"https://bloom-560m/bloom_block_8.mlir", destination_folder
|
||||
|
||||
module_placeholder = module
|
||||
module_context = module_placeholder.context
|
||||
|
||||
def check_valid_line(line, line_n, mlir_file_len):
|
||||
if "private" in line:
|
||||
return False
|
||||
if "attributes" in line:
|
||||
return False
|
||||
if mlir_file_len - line_n == 2:
|
||||
return False
|
||||
|
||||
return True
|
||||
|
||||
mlir_file_len = len(str(module).split("\n"))
|
||||
|
||||
def remove_constant_dim(line):
|
||||
if "17x" in line:
|
||||
line = re.sub("17x", "?x", line)
|
||||
line = re.sub("tensor.empty\(\)", "tensor.empty(%dim)", line)
|
||||
if "tensor.empty" in line and "?x?" in line:
|
||||
line = re.sub(
|
||||
"tensor.empty\(%dim\)", "tensor.empty(%dim, %dim)", line
|
||||
)
|
||||
if "arith.cmpi eq" in line:
|
||||
line = re.sub("c17", "dim", line)
|
||||
if " 17," in line:
|
||||
line = re.sub(" 17,", " %dim,", line)
|
||||
return line
|
||||
|
||||
module = "\n".join(
|
||||
[
|
||||
remove_constant_dim(line)
|
||||
for line, line_n in zip(
|
||||
str(module).split("\n"), range(mlir_file_len)
|
||||
)
|
||||
if check_valid_line(line, line_n, mlir_file_len)
|
||||
]
|
||||
)
|
||||
download_public_file(
|
||||
"https://bloom-560m/bloom_block_9.mlir", destination_folder
|
||||
|
||||
module = module_placeholder.parse(module, context=module_context)
|
||||
bytecode_stream = io.BytesIO()
|
||||
module.operation.write_bytecode(bytecode_stream)
|
||||
bytecode = bytecode_stream.getvalue()
|
||||
|
||||
f_ = open(path, "w+")
|
||||
f_.write(str(module))
|
||||
f_.close()
|
||||
return
|
||||
|
||||
|
||||
def compile_ln_f(ln_f, hidden_layers, path):
|
||||
hidden_layers_placeholder = torch_mlir.TensorPlaceholder.like(
|
||||
hidden_layers, dynamic_axes=[1]
|
||||
)
|
||||
download_public_file(
|
||||
"https://bloom-560m/bloom_block_10.mlir", destination_folder
|
||||
module = torch_mlir.compile(
|
||||
ln_f,
|
||||
(hidden_layers_placeholder),
|
||||
torch_mlir.OutputType.LINALG_ON_TENSORS,
|
||||
use_tracing=False,
|
||||
verbose=False,
|
||||
)
|
||||
download_public_file(
|
||||
"https://bloom-560m/bloom_block_11.mlir", destination_folder
|
||||
|
||||
bytecode_stream = io.BytesIO()
|
||||
module.operation.write_bytecode(bytecode_stream)
|
||||
bytecode = bytecode_stream.getvalue()
|
||||
|
||||
f_ = open(path, "w+")
|
||||
f_.write(str(module))
|
||||
f_.close()
|
||||
return
|
||||
|
||||
|
||||
def compile_lm_head(lm_head, hidden_layers, path):
|
||||
hidden_layers_placeholder = torch_mlir.TensorPlaceholder.like(
|
||||
hidden_layers, dynamic_axes=[1]
|
||||
)
|
||||
download_public_file(
|
||||
"https://bloom-560m/bloom_block_12.mlir", destination_folder
|
||||
module = torch_mlir.compile(
|
||||
lm_head,
|
||||
(hidden_layers_placeholder),
|
||||
torch_mlir.OutputType.LINALG_ON_TENSORS,
|
||||
use_tracing=False,
|
||||
verbose=False,
|
||||
)
|
||||
download_public_file(
|
||||
"https://bloom-560m/bloom_block_13.mlir", destination_folder
|
||||
|
||||
bytecode_stream = io.BytesIO()
|
||||
module.operation.write_bytecode(bytecode_stream)
|
||||
bytecode = bytecode_stream.getvalue()
|
||||
|
||||
f_ = open(path, "w+")
|
||||
f_.write(str(module))
|
||||
f_.close()
|
||||
return
|
||||
|
||||
|
||||
def create_mlirs(destination_folder, model_name):
|
||||
model_config = "bigscience/" + model_name
|
||||
sample_input_ids = torch.ones([1, 17], dtype=torch.int64)
|
||||
|
||||
urllib.request.urlretrieve(
|
||||
f"https://huggingface.co/bigscience/{model_name}/resolve/main/config.json",
|
||||
filename=f"{destination_folder}/config.json",
|
||||
)
|
||||
download_public_file(
|
||||
"https://bloom-560m/bloom_block_14.mlir", destination_folder
|
||||
urllib.request.urlretrieve(
|
||||
f"https://huggingface.co/bigscience/bloom/resolve/main/tokenizer.json",
|
||||
filename=f"{destination_folder}/tokenizer.json",
|
||||
)
|
||||
download_public_file(
|
||||
"https://bloom-560m/bloom_block_15.mlir", destination_folder
|
||||
|
||||
class HuggingFaceLanguage(torch.nn.Module):
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
self.model = BloomForCausalLM.from_pretrained(model_config)
|
||||
|
||||
def forward(self, tokens):
|
||||
return self.model.forward(tokens)[0]
|
||||
|
||||
class HuggingFaceBlock(torch.nn.Module):
|
||||
def __init__(self, block):
|
||||
super().__init__()
|
||||
self.model = block
|
||||
|
||||
def forward(self, tokens, alibi, attention_mask):
|
||||
output = self.model(
|
||||
hidden_states=tokens,
|
||||
alibi=alibi,
|
||||
attention_mask=attention_mask,
|
||||
use_cache=True,
|
||||
output_attentions=False,
|
||||
)
|
||||
return (output[0], output[1][0], output[1][1])
|
||||
|
||||
model = HuggingFaceLanguage()
|
||||
|
||||
compile_embeddings(
|
||||
model.model.transformer.word_embeddings,
|
||||
sample_input_ids,
|
||||
f"{destination_folder}/word_embeddings.mlir",
|
||||
)
|
||||
download_public_file(
|
||||
"https://bloom-560m/bloom_block_16.mlir", destination_folder
|
||||
|
||||
inputs_embeds = model.model.transformer.word_embeddings(sample_input_ids)
|
||||
|
||||
compile_word_embeddings_layernorm(
|
||||
model.model.transformer.word_embeddings_layernorm,
|
||||
inputs_embeds,
|
||||
f"{destination_folder}/word_embeddings_layernorm.mlir",
|
||||
)
|
||||
download_public_file(
|
||||
"https://bloom-560m/bloom_block_17.mlir", destination_folder
|
||||
|
||||
hidden_states = model.model.transformer.word_embeddings_layernorm(
|
||||
inputs_embeds
|
||||
)
|
||||
download_public_file(
|
||||
"https://bloom-560m/bloom_block_18.mlir", destination_folder
|
||||
|
||||
input_shape = sample_input_ids.size()
|
||||
|
||||
current_sequence_length = hidden_states.shape[1]
|
||||
past_key_values_length = 0
|
||||
past_key_values = tuple([None] * len(model.model.transformer.h))
|
||||
|
||||
attention_mask = torch.ones(
|
||||
(hidden_states.shape[0], current_sequence_length), device="cpu"
|
||||
)
|
||||
download_public_file(
|
||||
"https://bloom-560m/bloom_block_19.mlir", destination_folder
|
||||
|
||||
alibi = build_alibi_tensor(
|
||||
attention_mask,
|
||||
model.model.transformer.n_head,
|
||||
hidden_states.dtype,
|
||||
"cpu",
|
||||
)
|
||||
download_public_file(
|
||||
"https://bloom-560m/bloom_block_20.mlir", destination_folder
|
||||
|
||||
causal_mask = _prepare_attn_mask(
|
||||
attention_mask, input_shape, inputs_embeds, past_key_values_length
|
||||
)
|
||||
download_public_file(
|
||||
"https://bloom-560m/bloom_block_21.mlir", destination_folder
|
||||
|
||||
head_mask = model.model.transformer.get_head_mask(
|
||||
None, model.model.transformer.config.n_layer
|
||||
)
|
||||
download_public_file(
|
||||
"https://bloom-560m/bloom_block_22.mlir", destination_folder
|
||||
output_attentions = model.model.transformer.config.output_attentions
|
||||
|
||||
all_hidden_states = ()
|
||||
|
||||
for i, (block, layer_past) in enumerate(
|
||||
zip(model.model.transformer.h, past_key_values)
|
||||
):
|
||||
all_hidden_states = all_hidden_states + (hidden_states,)
|
||||
|
||||
proxy_model = HuggingFaceBlock(block)
|
||||
|
||||
compile_to_mlir(
|
||||
proxy_model,
|
||||
hidden_states,
|
||||
layer_past=layer_past,
|
||||
attention_mask=causal_mask,
|
||||
head_mask=head_mask[i],
|
||||
use_cache=True,
|
||||
output_attentions=output_attentions,
|
||||
alibi=alibi,
|
||||
block_index=i,
|
||||
path=f"{destination_folder}/bloom_block_{i}.mlir",
|
||||
)
|
||||
|
||||
compile_ln_f(
|
||||
model.model.transformer.ln_f,
|
||||
hidden_states,
|
||||
f"{destination_folder}/ln_f.mlir",
|
||||
)
|
||||
download_public_file(
|
||||
"https://bloom-560m/bloom_block_23.mlir", destination_folder
|
||||
)
|
||||
download_public_file("https://bloom-560m/config.json", destination_folder)
|
||||
download_public_file("https://bloom-560m/lm_head.mlir", destination_folder)
|
||||
download_public_file("https://bloom-560m/ln_f.mlir", destination_folder)
|
||||
download_public_file(
|
||||
"https://bloom-560m/word_embeddings.mlir", destination_folder
|
||||
)
|
||||
download_public_file(
|
||||
"https://bloom-560m/word_embeddings_layernorm.mlir", destination_folder
|
||||
)
|
||||
download_public_file(
|
||||
"https://bloom-560m/tokenizer.json", destination_folder
|
||||
hidden_states = model.model.transformer.ln_f(hidden_states)
|
||||
compile_lm_head(
|
||||
model.model.lm_head,
|
||||
hidden_states,
|
||||
f"{destination_folder}/lm_head.mlir",
|
||||
)
|
||||
|
||||
|
||||
def run_large_model(
|
||||
token_count,
|
||||
recompile,
|
||||
model_path,
|
||||
prompt,
|
||||
device_list,
|
||||
script_path,
|
||||
device,
|
||||
):
|
||||
f = open(f"{model_path}/prompt.txt", "w+")
|
||||
f.write(prompt)
|
||||
f.close()
|
||||
for i in range(token_count):
|
||||
if i == 0:
|
||||
will_compile = recompile
|
||||
else:
|
||||
will_compile = False
|
||||
f = open(f"{model_path}/prompt.txt", "r")
|
||||
prompt = f.read()
|
||||
f.close()
|
||||
|
||||
subprocess.run(
|
||||
[
|
||||
"python",
|
||||
script_path,
|
||||
model_path,
|
||||
"start",
|
||||
str(will_compile),
|
||||
"cpu",
|
||||
"None",
|
||||
prompt,
|
||||
]
|
||||
)
|
||||
for i in range(config["n_layer"]):
|
||||
if device_list is not None:
|
||||
device_idx = str(device_list[i % len(device_list)])
|
||||
else:
|
||||
device_idx = "None"
|
||||
subprocess.run(
|
||||
[
|
||||
"python",
|
||||
script_path,
|
||||
model_path,
|
||||
str(i),
|
||||
str(will_compile),
|
||||
device,
|
||||
device_idx,
|
||||
prompt,
|
||||
]
|
||||
)
|
||||
subprocess.run(
|
||||
[
|
||||
"python",
|
||||
script_path,
|
||||
model_path,
|
||||
"end",
|
||||
str(will_compile),
|
||||
"cpu",
|
||||
"None",
|
||||
prompt,
|
||||
]
|
||||
)
|
||||
|
||||
f = open(f"{model_path}/prompt.txt", "r")
|
||||
output = f.read()
|
||||
f.close()
|
||||
print(output)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = argparse.ArgumentParser(prog="Bloom-560m")
|
||||
parser.add_argument("-p", "--model_path")
|
||||
@@ -387,35 +712,131 @@ if __name__ == "__main__":
|
||||
parser.add_argument("-c", "--recompile", default=False, type=bool)
|
||||
parser.add_argument("-d", "--download", default=False, type=bool)
|
||||
parser.add_argument("-t", "--token_count", default=10, type=int)
|
||||
parser.add_argument("-m", "--model_name", default="bloom-560m")
|
||||
parser.add_argument("-cm", "--create_mlirs", default=False, type=bool)
|
||||
|
||||
parser.add_argument(
|
||||
"-lm", "--large_model_memory_efficient", default=False, type=bool
|
||||
)
|
||||
|
||||
parser.add_argument(
|
||||
"-pr",
|
||||
"--prompt",
|
||||
default="The SQL command to extract all the users whose name starts with A is: ",
|
||||
default=None,
|
||||
)
|
||||
args = parser.parse_args()
|
||||
|
||||
if args.create_mlirs and args.large_model_memory_efficient:
|
||||
print(
|
||||
"Warning: If you need to use memory efficient mode, you probably want to use 'download' instead"
|
||||
)
|
||||
|
||||
if not os.path.isdir(args.model_path):
|
||||
os.mkdir(args.model_path)
|
||||
|
||||
if args.device_list is not None:
|
||||
args.device_list = json.loads(args.device_list)
|
||||
|
||||
if args.device == "cuda" and args.device_list is not None:
|
||||
IS_CUDA = True
|
||||
from cuda.cudart import cudaSetDevice
|
||||
if args.download and args.create_mlirs:
|
||||
print(
|
||||
"WARNING: It is not advised to turn on both download and create_mlirs"
|
||||
)
|
||||
if args.download:
|
||||
download_560m(args.model_path)
|
||||
download_model(args.model_path, args.model_name)
|
||||
if args.create_mlirs:
|
||||
create_mlirs(args.model_path, args.model_name)
|
||||
from transformers import AutoTokenizer, AutoModelForCausalLM, BloomConfig
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained(args.model_path)
|
||||
input_ids = tokenizer.encode(args.prompt, return_tensors="pt")
|
||||
if args.prompt is not None:
|
||||
input_ids = tokenizer.encode(args.prompt, return_tensors="pt")
|
||||
|
||||
shardedbloom = ShardedBloom(args.model_path)
|
||||
shardedbloom.init_layers(
|
||||
device=args.device, replace=args.recompile, device_idx=args.device_list
|
||||
)
|
||||
shardedbloom.load_layers()
|
||||
if args.large_model_memory_efficient:
|
||||
f = open(f"{args.model_path}/config.json")
|
||||
config = json.load(f)
|
||||
f.close()
|
||||
|
||||
for _ in range(args.token_count):
|
||||
next_token = shardedbloom.forward_pass(
|
||||
torch.tensor(input_ids), device=args.device
|
||||
self_path = os.path.dirname(os.path.abspath(__file__))
|
||||
script_path = os.path.join(self_path, "sharded_bloom_large_models.py")
|
||||
|
||||
if args.prompt is not None:
|
||||
run_large_model(
|
||||
args.token_count,
|
||||
args.recompile,
|
||||
args.model_path,
|
||||
args.prompt,
|
||||
args.device_list,
|
||||
script_path,
|
||||
args.device,
|
||||
)
|
||||
|
||||
else:
|
||||
while True:
|
||||
prompt = input("Enter Prompt: ")
|
||||
try:
|
||||
token_count = int(
|
||||
input("Enter number of tokens you want to generate: ")
|
||||
)
|
||||
except:
|
||||
print(
|
||||
"Invalid integer entered. Using default value of 10"
|
||||
)
|
||||
token_count = 10
|
||||
|
||||
run_large_model(
|
||||
token_count,
|
||||
args.recompile,
|
||||
args.model_path,
|
||||
prompt,
|
||||
args.device_list,
|
||||
script_path,
|
||||
args.device,
|
||||
)
|
||||
|
||||
else:
|
||||
shardedbloom = ShardedBloom(args.model_path)
|
||||
shardedbloom.init_layers(
|
||||
device=args.device,
|
||||
replace=args.recompile,
|
||||
device_idx=args.device_list,
|
||||
)
|
||||
input_ids = torch.cat([input_ids, next_token.unsqueeze(-1)], dim=-1)
|
||||
shardedbloom.load_layers()
|
||||
|
||||
print(tokenizer.decode(input_ids.squeeze()))
|
||||
if args.prompt is not None:
|
||||
for _ in range(args.token_count):
|
||||
next_token = shardedbloom.forward_pass(
|
||||
torch.tensor(input_ids), device=args.device
|
||||
)
|
||||
input_ids = torch.cat(
|
||||
[input_ids, next_token.unsqueeze(-1)], dim=-1
|
||||
)
|
||||
|
||||
print(tokenizer.decode(input_ids.squeeze()))
|
||||
|
||||
else:
|
||||
while True:
|
||||
prompt = input("Enter Prompt: ")
|
||||
try:
|
||||
token_count = int(
|
||||
input("Enter number of tokens you want to generate: ")
|
||||
)
|
||||
except:
|
||||
print(
|
||||
"Invalid integer entered. Using default value of 10"
|
||||
)
|
||||
token_count = 10
|
||||
|
||||
input_ids = tokenizer.encode(prompt, return_tensors="pt")
|
||||
|
||||
for _ in range(token_count):
|
||||
next_token = shardedbloom.forward_pass(
|
||||
torch.tensor(input_ids), device=args.device
|
||||
)
|
||||
input_ids = torch.cat(
|
||||
[input_ids, next_token.unsqueeze(-1)], dim=-1
|
||||
)
|
||||
|
||||
print(tokenizer.decode(input_ids.squeeze()))
|
||||
|
||||
381
shark/examples/shark_inference/sharded_bloom_large_models.py
Normal file
381
shark/examples/shark_inference/sharded_bloom_large_models.py
Normal file
@@ -0,0 +1,381 @@
|
||||
import sys
|
||||
import os
|
||||
from transformers import AutoTokenizer, AutoModelForCausalLM, BloomConfig
|
||||
import re
|
||||
from shark.shark_inference import SharkInference
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
from collections import OrderedDict
|
||||
from transformers.models.bloom.modeling_bloom import (
|
||||
BloomBlock,
|
||||
build_alibi_tensor,
|
||||
)
|
||||
import time
|
||||
import json
|
||||
|
||||
|
||||
def _expand_mask(mask: torch.Tensor, dtype: torch.dtype, tgt_len: int = None):
|
||||
"""
|
||||
Expands attention_mask from `[bsz, seq_len]` to `[bsz, 1, tgt_seq_len, src_seq_len]`.
|
||||
"""
|
||||
batch_size, source_length = mask.size()
|
||||
tgt_len = tgt_len if tgt_len is not None else source_length
|
||||
|
||||
expanded_mask = (
|
||||
mask[:, None, None, :]
|
||||
.expand(batch_size, 1, tgt_len, source_length)
|
||||
.to(dtype)
|
||||
)
|
||||
|
||||
inverted_mask = 1.0 - expanded_mask
|
||||
|
||||
return inverted_mask.masked_fill(
|
||||
inverted_mask.to(torch.bool), torch.finfo(dtype).min
|
||||
)
|
||||
|
||||
|
||||
def _prepare_attn_mask(
|
||||
attention_mask, input_shape, inputs_embeds, past_key_values_length
|
||||
):
|
||||
# create causal mask
|
||||
# [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
|
||||
combined_attention_mask = None
|
||||
if input_shape[-1] > 1:
|
||||
combined_attention_mask = _make_causal_mask(
|
||||
input_shape,
|
||||
inputs_embeds.dtype,
|
||||
past_key_values_length=past_key_values_length,
|
||||
).to(attention_mask.device)
|
||||
|
||||
if attention_mask is not None:
|
||||
# [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
|
||||
expanded_attn_mask = _expand_mask(
|
||||
attention_mask, inputs_embeds.dtype, tgt_len=input_shape[-1]
|
||||
)
|
||||
combined_attention_mask = (
|
||||
expanded_attn_mask
|
||||
if combined_attention_mask is None
|
||||
else expanded_attn_mask + combined_attention_mask
|
||||
)
|
||||
|
||||
return combined_attention_mask
|
||||
|
||||
|
||||
def _make_causal_mask(
|
||||
input_ids_shape: torch.Size,
|
||||
dtype: torch.dtype,
|
||||
past_key_values_length: int = 0,
|
||||
):
|
||||
"""
|
||||
Make causal mask used for bi-directional self-attention.
|
||||
"""
|
||||
batch_size, target_length = input_ids_shape
|
||||
mask = torch.full((target_length, target_length), torch.finfo(dtype).min)
|
||||
mask_cond = torch.arange(mask.size(-1))
|
||||
intermediate_mask = mask_cond < (mask_cond + 1).view(mask.size(-1), 1)
|
||||
mask.masked_fill_(intermediate_mask, 0)
|
||||
mask = mask.to(dtype)
|
||||
|
||||
if past_key_values_length > 0:
|
||||
mask = torch.cat(
|
||||
[
|
||||
torch.zeros(
|
||||
target_length, past_key_values_length, dtype=dtype
|
||||
),
|
||||
mask,
|
||||
],
|
||||
dim=-1,
|
||||
)
|
||||
expanded_mask = mask[None, None, :, :].expand(
|
||||
batch_size, 1, target_length, target_length + past_key_values_length
|
||||
)
|
||||
return expanded_mask
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
working_dir = sys.argv[1]
|
||||
layer_name = sys.argv[2]
|
||||
will_compile = sys.argv[3]
|
||||
device = sys.argv[4]
|
||||
device_idx = sys.argv[5]
|
||||
prompt = sys.argv[6]
|
||||
|
||||
if device_idx.lower().strip() == "none":
|
||||
device_idx = None
|
||||
else:
|
||||
device_idx = int(device_idx)
|
||||
|
||||
if will_compile.lower().strip() == "true":
|
||||
will_compile = True
|
||||
else:
|
||||
will_compile = False
|
||||
|
||||
f = open(f"{working_dir}/config.json")
|
||||
config = json.load(f)
|
||||
f.close()
|
||||
|
||||
layers_initialized = False
|
||||
try:
|
||||
n_embed = config["n_embed"]
|
||||
except KeyError:
|
||||
n_embed = config["hidden_size"]
|
||||
vocab_size = config["vocab_size"]
|
||||
n_layer = config["n_layer"]
|
||||
try:
|
||||
n_head = config["num_attention_heads"]
|
||||
except KeyError:
|
||||
n_head = config["n_head"]
|
||||
|
||||
if not os.path.isdir(working_dir):
|
||||
os.mkdir(working_dir)
|
||||
|
||||
if layer_name == "start":
|
||||
tokenizer = AutoTokenizer.from_pretrained(working_dir)
|
||||
input_ids = tokenizer.encode(prompt, return_tensors="pt")
|
||||
|
||||
mlir_str = ""
|
||||
|
||||
if will_compile:
|
||||
f = open(f"{working_dir}/word_embeddings.mlir", encoding="utf-8")
|
||||
mlir_str = f.read()
|
||||
f.close()
|
||||
|
||||
mlir_str = bytes(mlir_str, "utf-8")
|
||||
|
||||
shark_module = SharkInference(
|
||||
mlir_str,
|
||||
device="cpu",
|
||||
mlir_dialect="tm_tensor",
|
||||
device_idx=None,
|
||||
)
|
||||
|
||||
if will_compile:
|
||||
shark_module.save_module(
|
||||
module_name=f"{working_dir}/word_embeddings",
|
||||
extra_args=[
|
||||
"--iree-vm-bytecode-module-output-format=flatbuffer-binary",
|
||||
"--iree-stream-resource-max-allocation-size=1000000000",
|
||||
"--iree-codegen-check-ir-before-llvm-conversion=false",
|
||||
],
|
||||
)
|
||||
|
||||
shark_module.load_module(f"{working_dir}/word_embeddings.vmfb")
|
||||
input_embeds = shark_module(
|
||||
inputs=(input_ids,), function_name="forward"
|
||||
)
|
||||
input_embeds = torch.tensor(input_embeds).float()
|
||||
|
||||
mlir_str = ""
|
||||
|
||||
if will_compile:
|
||||
f = open(
|
||||
f"{working_dir}/word_embeddings_layernorm.mlir",
|
||||
encoding="utf-8",
|
||||
)
|
||||
mlir_str = f.read()
|
||||
f.close()
|
||||
|
||||
shark_module = SharkInference(
|
||||
mlir_str,
|
||||
device="cpu",
|
||||
mlir_dialect="tm_tensor",
|
||||
device_idx=None,
|
||||
)
|
||||
|
||||
if will_compile:
|
||||
shark_module.save_module(
|
||||
module_name=f"{working_dir}/word_embeddings_layernorm",
|
||||
extra_args=[
|
||||
"--iree-vm-bytecode-module-output-format=flatbuffer-binary",
|
||||
"--iree-stream-resource-max-allocation-size=1000000000",
|
||||
"--iree-codegen-check-ir-before-llvm-conversion=false",
|
||||
],
|
||||
)
|
||||
|
||||
shark_module.load_module(
|
||||
f"{working_dir}/word_embeddings_layernorm.vmfb"
|
||||
)
|
||||
hidden_states = shark_module(
|
||||
inputs=(input_embeds,), function_name="forward"
|
||||
)
|
||||
hidden_states = torch.tensor(hidden_states).float()
|
||||
|
||||
torch.save(hidden_states, f"{working_dir}/hidden_states_0.pt")
|
||||
|
||||
attention_mask = torch.ones(
|
||||
[hidden_states.shape[0], len(input_ids[0])]
|
||||
)
|
||||
|
||||
attention_mask = torch.tensor(attention_mask).float()
|
||||
|
||||
alibi = build_alibi_tensor(
|
||||
attention_mask,
|
||||
n_head,
|
||||
hidden_states.dtype,
|
||||
device="cpu",
|
||||
)
|
||||
|
||||
torch.save(alibi, f"{working_dir}/alibi.pt")
|
||||
|
||||
causal_mask = _prepare_attn_mask(
|
||||
attention_mask, input_ids.size(), input_embeds, 0
|
||||
)
|
||||
causal_mask = torch.tensor(causal_mask).float()
|
||||
|
||||
torch.save(causal_mask, f"{working_dir}/causal_mask.pt")
|
||||
|
||||
elif layer_name in [str(x) for x in range(n_layer)]:
|
||||
hidden_states = torch.load(
|
||||
f"{working_dir}/hidden_states_{layer_name}.pt"
|
||||
)
|
||||
alibi = torch.load(f"{working_dir}/alibi.pt")
|
||||
causal_mask = torch.load(f"{working_dir}/causal_mask.pt")
|
||||
|
||||
mlir_str = ""
|
||||
|
||||
if will_compile:
|
||||
f = open(
|
||||
f"{working_dir}/bloom_block_{layer_name}.mlir",
|
||||
encoding="utf-8",
|
||||
)
|
||||
mlir_str = f.read()
|
||||
f.close()
|
||||
|
||||
mlir_str = bytes(mlir_str, "utf-8")
|
||||
|
||||
shark_module = SharkInference(
|
||||
mlir_str,
|
||||
device=device,
|
||||
mlir_dialect="tm_tensor",
|
||||
device_idx=device_idx,
|
||||
)
|
||||
|
||||
if will_compile:
|
||||
shark_module.save_module(
|
||||
module_name=f"{working_dir}/bloom_block_{layer_name}",
|
||||
extra_args=[
|
||||
"--iree-vm-bytecode-module-output-format=flatbuffer-binary",
|
||||
"--iree-stream-resource-max-allocation-size=1000000000",
|
||||
"--iree-codegen-check-ir-before-llvm-conversion=false",
|
||||
],
|
||||
)
|
||||
|
||||
shark_module.load_module(
|
||||
f"{working_dir}/bloom_block_{layer_name}.vmfb"
|
||||
)
|
||||
|
||||
output = shark_module(
|
||||
inputs=(
|
||||
hidden_states.detach().numpy(),
|
||||
alibi.detach().numpy(),
|
||||
causal_mask.detach().numpy(),
|
||||
),
|
||||
function_name="forward",
|
||||
)
|
||||
|
||||
hidden_states = torch.tensor(output[0]).float()
|
||||
|
||||
torch.save(
|
||||
hidden_states,
|
||||
f"{working_dir}/hidden_states_{int(layer_name) + 1}.pt",
|
||||
)
|
||||
|
||||
elif layer_name == "end":
|
||||
mlir_str = ""
|
||||
|
||||
if will_compile:
|
||||
f = open(f"{working_dir}/ln_f.mlir", encoding="utf-8")
|
||||
mlir_str = f.read()
|
||||
f.close()
|
||||
|
||||
mlir_str = bytes(mlir_str, "utf-8")
|
||||
|
||||
shark_module = SharkInference(
|
||||
mlir_str,
|
||||
device="cpu",
|
||||
mlir_dialect="tm_tensor",
|
||||
device_idx=None,
|
||||
)
|
||||
|
||||
if will_compile:
|
||||
shark_module.save_module(
|
||||
module_name=f"{working_dir}/ln_f",
|
||||
extra_args=[
|
||||
"--iree-vm-bytecode-module-output-format=flatbuffer-binary",
|
||||
"--iree-stream-resource-max-allocation-size=1000000000",
|
||||
"--iree-codegen-check-ir-before-llvm-conversion=false",
|
||||
],
|
||||
)
|
||||
|
||||
shark_module.load_module(f"{working_dir}/ln_f.vmfb")
|
||||
|
||||
hidden_states = torch.load(f"{working_dir}/hidden_states_{n_layer}.pt")
|
||||
|
||||
hidden_states = shark_module(
|
||||
inputs=(hidden_states,), function_name="forward"
|
||||
)
|
||||
|
||||
mlir_str = ""
|
||||
|
||||
if will_compile:
|
||||
f = open(f"{working_dir}/lm_head.mlir", encoding="utf-8")
|
||||
mlir_str = f.read()
|
||||
f.close()
|
||||
|
||||
mlir_str = bytes(mlir_str, "utf-8")
|
||||
|
||||
if config["n_embed"] == 14336:
|
||||
|
||||
def get_state_dict():
|
||||
d = torch.load(
|
||||
f"{working_dir}/pytorch_model_00001-of-00072.bin"
|
||||
)
|
||||
return OrderedDict(
|
||||
(k.replace("word_embeddings.", ""), v)
|
||||
for k, v in d.items()
|
||||
)
|
||||
|
||||
def load_causal_lm_head():
|
||||
linear = nn.utils.skip_init(
|
||||
nn.Linear, 14336, 250880, bias=False, dtype=torch.float
|
||||
)
|
||||
linear.load_state_dict(get_state_dict(), strict=False)
|
||||
return linear.float()
|
||||
|
||||
lm_head = load_causal_lm_head()
|
||||
|
||||
logits = lm_head(torch.tensor(hidden_states).float())
|
||||
|
||||
else:
|
||||
shark_module = SharkInference(
|
||||
mlir_str,
|
||||
device="cpu",
|
||||
mlir_dialect="tm_tensor",
|
||||
device_idx=None,
|
||||
)
|
||||
|
||||
if will_compile:
|
||||
shark_module.save_module(
|
||||
module_name=f"{working_dir}/lm_head",
|
||||
extra_args=[
|
||||
"--iree-vm-bytecode-module-output-format=flatbuffer-binary",
|
||||
"--iree-stream-resource-max-allocation-size=1000000000",
|
||||
"--iree-codegen-check-ir-before-llvm-conversion=false",
|
||||
],
|
||||
)
|
||||
|
||||
shark_module.load_module(f"{working_dir}/lm_head.vmfb")
|
||||
|
||||
logits = shark_module(
|
||||
inputs=(hidden_states,), function_name="forward"
|
||||
)
|
||||
|
||||
logits = torch.tensor(logits).float()
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained(working_dir)
|
||||
|
||||
next_token = tokenizer.decode(torch.argmax(logits[:, -1, :], dim=-1))
|
||||
|
||||
f = open(f"{working_dir}/prompt.txt", "w+")
|
||||
f.write(prompt + next_token)
|
||||
f.close()
|
||||
43
shark/examples/shark_training/stable_diffusion/README.md
Normal file
43
shark/examples/shark_training/stable_diffusion/README.md
Normal file
@@ -0,0 +1,43 @@
|
||||
# Stable Diffusion Fine Tuning
|
||||
|
||||
## Installation (Linux)
|
||||
|
||||
### Activate shark.venv Virtual Environment
|
||||
|
||||
```shell
|
||||
source shark.venv/bin/activate
|
||||
|
||||
# Some older pip installs may not be able to handle the recent PyTorch deps
|
||||
python -m pip install --upgrade pip
|
||||
```
|
||||
|
||||
## Install dependencies
|
||||
|
||||
### Run the following installation commands:
|
||||
```
|
||||
pip install -U git+https://github.com/huggingface/diffusers.git
|
||||
pip install accelerate transformers ftfy
|
||||
```
|
||||
|
||||
### Build torch-mlir with the following branch:
|
||||
|
||||
Please cherry-pick this branch of torch-mlir: https://github.com/vivekkhandelwal1/torch-mlir/tree/sd-ops
|
||||
and build it locally. You can find the instructions for using locally build Torch-MLIR,
|
||||
here: https://github.com/nod-ai/SHARK#how-to-use-your-locally-built-iree--torch-mlir-with-shark
|
||||
|
||||
## Run the Stable diffusion fine tuning
|
||||
|
||||
To run the model with the default set of images and params, run:
|
||||
```shell
|
||||
python stable_diffusion_fine_tuning.py
|
||||
```
|
||||
By default the training is run through the PyTorch path. If you want to train the model using the Torchdynamo path of Torch-MLIR, you need to specify `--use_torchdynamo=True`.
|
||||
|
||||
The default number of training steps are `2000`, which would take many hours to complete based on your system config. You can pass the smaller value with the arg `--training_steps`. You can specify the number of images to be sampled for the result with the `--num_inference_samples` arg. For the number of inference steps you can use `--inference_steps` flag.
|
||||
|
||||
For example, you can run the training for a limited set of steps via the dynamo path by using the following command:
|
||||
```
|
||||
python stable_diffusion_fine_tuning.py --training_steps=1 --inference_steps=1 --num_inference_samples=1 --train_batch_size=1 --use_torchdynamo=True
|
||||
```
|
||||
|
||||
You can also specify the device to be used via the flag `--device`. The default value is `cpu`, for GPU execution you can specify `--device="cuda"`.
|
||||
@@ -0,0 +1,914 @@
|
||||
# Install the required libs
|
||||
# pip install -U git+https://github.com/huggingface/diffusers.git
|
||||
# pip install accelerate transformers ftfy
|
||||
|
||||
# Import required libraries
|
||||
import argparse
|
||||
import itertools
|
||||
import math
|
||||
import os
|
||||
from typing import List
|
||||
import random
|
||||
|
||||
import numpy as np
|
||||
import torch
|
||||
import torch.nn.functional as F
|
||||
import torch.utils.checkpoint
|
||||
from torch.utils.data import Dataset
|
||||
|
||||
import PIL
|
||||
import logging
|
||||
|
||||
import torch_mlir
|
||||
from torch_mlir.dynamo import make_simple_dynamo_backend
|
||||
import torch._dynamo as dynamo
|
||||
from torch.fx.experimental.proxy_tensor import make_fx
|
||||
from torch_mlir_e2e_test.linalg_on_tensors_backends import refbackend
|
||||
from shark.shark_inference import SharkInference
|
||||
|
||||
torch._dynamo.config.verbose = True
|
||||
|
||||
from diffusers import (
|
||||
AutoencoderKL,
|
||||
DDPMScheduler,
|
||||
PNDMScheduler,
|
||||
StableDiffusionPipeline,
|
||||
UNet2DConditionModel,
|
||||
)
|
||||
from diffusers.optimization import get_scheduler
|
||||
from diffusers.pipelines.stable_diffusion import (
|
||||
StableDiffusionSafetyChecker,
|
||||
)
|
||||
from PIL import Image
|
||||
from torchvision import transforms
|
||||
from tqdm.auto import tqdm
|
||||
from transformers import (
|
||||
CLIPFeatureExtractor,
|
||||
CLIPTextModel,
|
||||
CLIPTokenizer,
|
||||
)
|
||||
|
||||
|
||||
# Enter your HuggingFace Token
|
||||
# Note: You can comment this prompt and just set your token instead of passing it through cli for every execution.
|
||||
hf_token = input("Please enter your huggingface token here: ")
|
||||
YOUR_TOKEN = hf_token
|
||||
|
||||
|
||||
def image_grid(imgs, rows, cols):
|
||||
assert len(imgs) == rows * cols
|
||||
|
||||
w, h = imgs[0].size
|
||||
grid = Image.new("RGB", size=(cols * w, rows * h))
|
||||
grid_w, grid_h = grid.size
|
||||
|
||||
for i, img in enumerate(imgs):
|
||||
grid.paste(img, box=(i % cols * w, i // cols * h))
|
||||
return grid
|
||||
|
||||
|
||||
# `pretrained_model_name_or_path` which Stable Diffusion checkpoint you want to use
|
||||
# Options: 1.) "stabilityai/stable-diffusion-2"
|
||||
# 2.) "stabilityai/stable-diffusion-2-base"
|
||||
# 3.) "CompVis/stable-diffusion-v1-4"
|
||||
# 4.) "runwayml/stable-diffusion-v1-5"
|
||||
pretrained_model_name_or_path = "stabilityai/stable-diffusion-2"
|
||||
|
||||
# Add here the URLs to the images of the concept you are adding. 3-5 should be fine
|
||||
urls = [
|
||||
"https://huggingface.co/datasets/valhalla/images/resolve/main/2.jpeg",
|
||||
"https://huggingface.co/datasets/valhalla/images/resolve/main/3.jpeg",
|
||||
"https://huggingface.co/datasets/valhalla/images/resolve/main/5.jpeg",
|
||||
"https://huggingface.co/datasets/valhalla/images/resolve/main/6.jpeg",
|
||||
## You can add additional images here
|
||||
]
|
||||
|
||||
# Downloading Images
|
||||
import requests
|
||||
import glob
|
||||
from io import BytesIO
|
||||
|
||||
|
||||
def download_image(url):
|
||||
try:
|
||||
response = requests.get(url)
|
||||
except:
|
||||
return None
|
||||
return Image.open(BytesIO(response.content)).convert("RGB")
|
||||
|
||||
|
||||
images = list(filter(None, [download_image(url) for url in urls]))
|
||||
save_path = "./my_concept"
|
||||
if not os.path.exists(save_path):
|
||||
os.mkdir(save_path)
|
||||
[image.save(f"{save_path}/{i}.jpeg") for i, image in enumerate(images)]
|
||||
|
||||
p = argparse.ArgumentParser(
|
||||
description=__doc__,
|
||||
formatter_class=argparse.ArgumentDefaultsHelpFormatter,
|
||||
)
|
||||
p.add_argument(
|
||||
"--input_dir",
|
||||
type=str,
|
||||
default="my_concept/",
|
||||
help="the directory contains the images used for fine tuning",
|
||||
)
|
||||
p.add_argument(
|
||||
"--output_dir",
|
||||
type=str,
|
||||
default="sd_result",
|
||||
help="the directory contains the images used for fine tuning",
|
||||
)
|
||||
p.add_argument(
|
||||
"--training_steps",
|
||||
type=int,
|
||||
default=2000,
|
||||
help="the maximum number of training steps",
|
||||
)
|
||||
p.add_argument(
|
||||
"--train_batch_size",
|
||||
type=int,
|
||||
default=4,
|
||||
help="The batch size for training",
|
||||
)
|
||||
p.add_argument(
|
||||
"--save_steps",
|
||||
type=int,
|
||||
default=250,
|
||||
help="the number of steps after which to save the learned concept",
|
||||
)
|
||||
p.add_argument("--seed", type=int, default=42, help="the random seed")
|
||||
p.add_argument(
|
||||
"--what_to_teach",
|
||||
type=str,
|
||||
choices=["object", "style"],
|
||||
default="object",
|
||||
help="what is it that you are teaching?",
|
||||
)
|
||||
p.add_argument(
|
||||
"--placeholder_token",
|
||||
type=str,
|
||||
default="<cat-toy>",
|
||||
help="It is the token you are going to use to represent your new concept",
|
||||
)
|
||||
p.add_argument(
|
||||
"--initializer_token",
|
||||
type=str,
|
||||
default="toy",
|
||||
help="It is a word that can summarise what is your new concept",
|
||||
)
|
||||
p.add_argument(
|
||||
"--inference_steps",
|
||||
type=int,
|
||||
default=50,
|
||||
help="the number of steps for inference",
|
||||
)
|
||||
p.add_argument(
|
||||
"--num_inference_samples",
|
||||
type=int,
|
||||
default=4,
|
||||
help="the number of samples for inference",
|
||||
)
|
||||
p.add_argument(
|
||||
"--prompt",
|
||||
type=str,
|
||||
default="a grafitti in a wall with a *s on it",
|
||||
help="the text prompt to use",
|
||||
)
|
||||
p.add_argument(
|
||||
"--device",
|
||||
type=str,
|
||||
default="cpu",
|
||||
help="The device to use",
|
||||
)
|
||||
p.add_argument(
|
||||
"--use_torchdynamo",
|
||||
type=bool,
|
||||
default=False,
|
||||
help="This flag is used to determine whether the training has to be done through the torchdynamo path or not.",
|
||||
)
|
||||
args = p.parse_args()
|
||||
torch.manual_seed(args.seed)
|
||||
|
||||
if "*s" not in args.prompt:
|
||||
raise ValueError(
|
||||
f'The prompt should have a "*s" which will be replaced by a placeholder token.'
|
||||
)
|
||||
|
||||
prompt1, prompt2 = args.prompt.split("*s")
|
||||
args.prompt = prompt1 + args.placeholder_token + prompt2
|
||||
|
||||
# `images_path` is a path to directory containing the training images.
|
||||
images_path = args.input_dir
|
||||
while not os.path.exists(str(images_path)):
|
||||
print(
|
||||
"The images_path specified does not exist, use the colab file explorer to copy the path :"
|
||||
)
|
||||
images_path = input("")
|
||||
save_path = images_path
|
||||
|
||||
# Setup and check the images you have just added
|
||||
images = []
|
||||
for file_path in os.listdir(save_path):
|
||||
try:
|
||||
image_path = os.path.join(save_path, file_path)
|
||||
images.append(Image.open(image_path).resize((512, 512)))
|
||||
except:
|
||||
print(
|
||||
f"{image_path} is not a valid image, please make sure to remove this file from the directory otherwise the training could fail."
|
||||
)
|
||||
image_grid(images, 1, len(images))
|
||||
|
||||
########### Create Dataset ##########
|
||||
|
||||
# Setup the prompt templates for training
|
||||
imagenet_templates_small = [
|
||||
"a photo of a {}",
|
||||
"a rendering of a {}",
|
||||
"a cropped photo of the {}",
|
||||
"the photo of a {}",
|
||||
"a photo of a clean {}",
|
||||
"a photo of a dirty {}",
|
||||
"a dark photo of the {}",
|
||||
"a photo of my {}",
|
||||
"a photo of the cool {}",
|
||||
"a close-up photo of a {}",
|
||||
"a bright photo of the {}",
|
||||
"a cropped photo of a {}",
|
||||
"a photo of the {}",
|
||||
"a good photo of the {}",
|
||||
"a photo of one {}",
|
||||
"a close-up photo of the {}",
|
||||
"a rendition of the {}",
|
||||
"a photo of the clean {}",
|
||||
"a rendition of a {}",
|
||||
"a photo of a nice {}",
|
||||
"a good photo of a {}",
|
||||
"a photo of the nice {}",
|
||||
"a photo of the small {}",
|
||||
"a photo of the weird {}",
|
||||
"a photo of the large {}",
|
||||
"a photo of a cool {}",
|
||||
"a photo of a small {}",
|
||||
]
|
||||
|
||||
imagenet_style_templates_small = [
|
||||
"a painting in the style of {}",
|
||||
"a rendering in the style of {}",
|
||||
"a cropped painting in the style of {}",
|
||||
"the painting in the style of {}",
|
||||
"a clean painting in the style of {}",
|
||||
"a dirty painting in the style of {}",
|
||||
"a dark painting in the style of {}",
|
||||
"a picture in the style of {}",
|
||||
"a cool painting in the style of {}",
|
||||
"a close-up painting in the style of {}",
|
||||
"a bright painting in the style of {}",
|
||||
"a cropped painting in the style of {}",
|
||||
"a good painting in the style of {}",
|
||||
"a close-up painting in the style of {}",
|
||||
"a rendition in the style of {}",
|
||||
"a nice painting in the style of {}",
|
||||
"a small painting in the style of {}",
|
||||
"a weird painting in the style of {}",
|
||||
"a large painting in the style of {}",
|
||||
]
|
||||
|
||||
|
||||
# Setup the dataset
|
||||
class TextualInversionDataset(Dataset):
|
||||
def __init__(
|
||||
self,
|
||||
data_root,
|
||||
tokenizer,
|
||||
learnable_property="object", # [object, style]
|
||||
size=512,
|
||||
repeats=100,
|
||||
interpolation="bicubic",
|
||||
flip_p=0.5,
|
||||
set="train",
|
||||
placeholder_token="*",
|
||||
center_crop=False,
|
||||
):
|
||||
self.data_root = data_root
|
||||
self.tokenizer = tokenizer
|
||||
self.learnable_property = learnable_property
|
||||
self.size = size
|
||||
self.placeholder_token = placeholder_token
|
||||
self.center_crop = center_crop
|
||||
self.flip_p = flip_p
|
||||
|
||||
self.image_paths = [
|
||||
os.path.join(self.data_root, file_path)
|
||||
for file_path in os.listdir(self.data_root)
|
||||
]
|
||||
|
||||
self.num_images = len(self.image_paths)
|
||||
self._length = self.num_images
|
||||
|
||||
if set == "train":
|
||||
self._length = self.num_images * repeats
|
||||
|
||||
self.interpolation = {
|
||||
"linear": PIL.Image.LINEAR,
|
||||
"bilinear": PIL.Image.BILINEAR,
|
||||
"bicubic": PIL.Image.BICUBIC,
|
||||
"lanczos": PIL.Image.LANCZOS,
|
||||
}[interpolation]
|
||||
|
||||
self.templates = (
|
||||
imagenet_style_templates_small
|
||||
if learnable_property == "style"
|
||||
else imagenet_templates_small
|
||||
)
|
||||
self.flip_transform = transforms.RandomHorizontalFlip(p=self.flip_p)
|
||||
|
||||
def __len__(self):
|
||||
return self._length
|
||||
|
||||
def __getitem__(self, i):
|
||||
example = {}
|
||||
image = Image.open(self.image_paths[i % self.num_images])
|
||||
|
||||
if not image.mode == "RGB":
|
||||
image = image.convert("RGB")
|
||||
|
||||
placeholder_string = self.placeholder_token
|
||||
text = random.choice(self.templates).format(placeholder_string)
|
||||
|
||||
example["input_ids"] = self.tokenizer(
|
||||
text,
|
||||
padding="max_length",
|
||||
truncation=True,
|
||||
max_length=self.tokenizer.model_max_length,
|
||||
return_tensors="pt",
|
||||
).input_ids[0]
|
||||
|
||||
# default to score-sde preprocessing
|
||||
img = np.array(image).astype(np.uint8)
|
||||
|
||||
if self.center_crop:
|
||||
crop = min(img.shape[0], img.shape[1])
|
||||
(
|
||||
h,
|
||||
w,
|
||||
) = (
|
||||
img.shape[0],
|
||||
img.shape[1],
|
||||
)
|
||||
img = img[
|
||||
(h - crop) // 2 : (h + crop) // 2,
|
||||
(w - crop) // 2 : (w + crop) // 2,
|
||||
]
|
||||
|
||||
image = Image.fromarray(img)
|
||||
image = image.resize(
|
||||
(self.size, self.size), resample=self.interpolation
|
||||
)
|
||||
|
||||
image = self.flip_transform(image)
|
||||
image = np.array(image).astype(np.uint8)
|
||||
image = (image / 127.5 - 1.0).astype(np.float32)
|
||||
|
||||
example["pixel_values"] = torch.from_numpy(image).permute(2, 0, 1)
|
||||
return example
|
||||
|
||||
|
||||
########## Setting up the model ##########
|
||||
|
||||
# Load the tokenizer and add the placeholder token as a additional special token.
|
||||
tokenizer = CLIPTokenizer.from_pretrained(
|
||||
pretrained_model_name_or_path,
|
||||
subfolder="tokenizer",
|
||||
)
|
||||
|
||||
# Add the placeholder token in tokenizer
|
||||
num_added_tokens = tokenizer.add_tokens(args.placeholder_token)
|
||||
if num_added_tokens == 0:
|
||||
raise ValueError(
|
||||
f"The tokenizer already contains the token {args.placeholder_token}. Please pass a different"
|
||||
" `placeholder_token` that is not already in the tokenizer."
|
||||
)
|
||||
|
||||
# Get token ids for our placeholder and initializer token.
|
||||
# This code block will complain if initializer string is not a single token
|
||||
# Convert the initializer_token, placeholder_token to ids
|
||||
token_ids = tokenizer.encode(args.initializer_token, add_special_tokens=False)
|
||||
# Check if initializer_token is a single token or a sequence of tokens
|
||||
if len(token_ids) > 1:
|
||||
raise ValueError("The initializer token must be a single token.")
|
||||
|
||||
initializer_token_id = token_ids[0]
|
||||
placeholder_token_id = tokenizer.convert_tokens_to_ids(args.placeholder_token)
|
||||
|
||||
# Load the Stable Diffusion model
|
||||
# Load models and create wrapper for stable diffusion
|
||||
# pipeline = StableDiffusionPipeline.from_pretrained(pretrained_model_name_or_path)
|
||||
# del pipeline
|
||||
text_encoder = CLIPTextModel.from_pretrained(
|
||||
pretrained_model_name_or_path, subfolder="text_encoder"
|
||||
)
|
||||
vae = AutoencoderKL.from_pretrained(
|
||||
pretrained_model_name_or_path, subfolder="vae"
|
||||
)
|
||||
unet = UNet2DConditionModel.from_pretrained(
|
||||
pretrained_model_name_or_path, subfolder="unet"
|
||||
)
|
||||
|
||||
# We have added the placeholder_token in the tokenizer so we resize the token embeddings here
|
||||
# this will a new embedding vector in the token embeddings for our placeholder_token
|
||||
text_encoder.resize_token_embeddings(len(tokenizer))
|
||||
|
||||
# Initialise the newly added placeholder token with the embeddings of the initializer token
|
||||
token_embeds = text_encoder.get_input_embeddings().weight.data
|
||||
token_embeds[placeholder_token_id] = token_embeds[initializer_token_id]
|
||||
|
||||
# In Textual-Inversion we only train the newly added embedding vector
|
||||
# so lets freeze rest of the model parameters here
|
||||
|
||||
|
||||
def freeze_params(params):
|
||||
for param in params:
|
||||
param.requires_grad = False
|
||||
|
||||
|
||||
# Freeze vae and unet
|
||||
freeze_params(vae.parameters())
|
||||
freeze_params(unet.parameters())
|
||||
# Freeze all parameters except for the token embeddings in text encoder
|
||||
params_to_freeze = itertools.chain(
|
||||
text_encoder.text_model.encoder.parameters(),
|
||||
text_encoder.text_model.final_layer_norm.parameters(),
|
||||
text_encoder.text_model.embeddings.position_embedding.parameters(),
|
||||
)
|
||||
freeze_params(params_to_freeze)
|
||||
|
||||
|
||||
# Move vae and unet to device
|
||||
# For the dynamo path default compilation device is `cpu`, since torch-mlir
|
||||
# supports only that. Therefore, convert to device only for PyTorch path.
|
||||
if not args.use_torchdynamo:
|
||||
vae.to(args.device)
|
||||
unet.to(args.device)
|
||||
|
||||
# Keep vae in eval mode as we don't train it
|
||||
vae.eval()
|
||||
# Keep unet in train mode to enable gradient checkpointing
|
||||
unet.train()
|
||||
|
||||
|
||||
class VaeModel(torch.nn.Module):
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
self.vae = vae
|
||||
|
||||
def forward(self, input):
|
||||
x = self.vae.encode(input, return_dict=False)[0]
|
||||
return x
|
||||
|
||||
|
||||
class UnetModel(torch.nn.Module):
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
self.unet = unet
|
||||
|
||||
def forward(self, x, y, z):
|
||||
return self.unet.forward(x, y, z, return_dict=False)[0]
|
||||
|
||||
|
||||
shark_vae = VaeModel()
|
||||
shark_unet = UnetModel()
|
||||
|
||||
####### Creating our training data ########
|
||||
|
||||
# Let's create the Dataset and Dataloader
|
||||
train_dataset = TextualInversionDataset(
|
||||
data_root=save_path,
|
||||
tokenizer=tokenizer,
|
||||
size=vae.sample_size,
|
||||
placeholder_token=args.placeholder_token,
|
||||
repeats=100,
|
||||
learnable_property=args.what_to_teach, # Option selected above between object and style
|
||||
center_crop=False,
|
||||
set="train",
|
||||
)
|
||||
|
||||
|
||||
def create_dataloader(train_batch_size=1):
|
||||
return torch.utils.data.DataLoader(
|
||||
train_dataset, batch_size=train_batch_size, shuffle=True
|
||||
)
|
||||
|
||||
|
||||
# Create noise_scheduler for training
|
||||
noise_scheduler = DDPMScheduler.from_config(
|
||||
pretrained_model_name_or_path, subfolder="scheduler"
|
||||
)
|
||||
|
||||
######## Training ###########
|
||||
|
||||
# Define hyperparameters for our training. If you are not happy with your results,
|
||||
# you can tune the `learning_rate` and the `max_train_steps`
|
||||
|
||||
# Setting up all training args
|
||||
hyperparameters = {
|
||||
"learning_rate": 5e-04,
|
||||
"scale_lr": True,
|
||||
"max_train_steps": args.training_steps,
|
||||
"save_steps": args.save_steps,
|
||||
"train_batch_size": args.train_batch_size,
|
||||
"gradient_accumulation_steps": 1,
|
||||
"gradient_checkpointing": True,
|
||||
"mixed_precision": "fp16",
|
||||
"seed": 42,
|
||||
"output_dir": "sd-concept-output",
|
||||
}
|
||||
# creating output directory
|
||||
cwd = os.getcwd()
|
||||
out_dir = os.path.join(cwd, hyperparameters["output_dir"])
|
||||
while not os.path.exists(str(out_dir)):
|
||||
try:
|
||||
os.mkdir(out_dir)
|
||||
except OSError as error:
|
||||
print("Output directory not created")
|
||||
|
||||
###### Torch-MLIR Compilation ######
|
||||
|
||||
|
||||
def _remove_nones(fx_g: torch.fx.GraphModule) -> List[int]:
|
||||
removed_indexes = []
|
||||
for node in fx_g.graph.nodes:
|
||||
if node.op == "output":
|
||||
assert (
|
||||
len(node.args) == 1
|
||||
), "Output node must have a single argument"
|
||||
node_arg = node.args[0]
|
||||
if isinstance(node_arg, (list, tuple)):
|
||||
node_arg = list(node_arg)
|
||||
node_args_len = len(node_arg)
|
||||
for i in range(node_args_len):
|
||||
curr_index = node_args_len - (i + 1)
|
||||
if node_arg[curr_index] is None:
|
||||
removed_indexes.append(curr_index)
|
||||
node_arg.pop(curr_index)
|
||||
node.args = (tuple(node_arg),)
|
||||
break
|
||||
|
||||
if len(removed_indexes) > 0:
|
||||
fx_g.graph.lint()
|
||||
fx_g.graph.eliminate_dead_code()
|
||||
fx_g.recompile()
|
||||
removed_indexes.sort()
|
||||
return removed_indexes
|
||||
|
||||
|
||||
def _unwrap_single_tuple_return(fx_g: torch.fx.GraphModule) -> bool:
|
||||
"""
|
||||
Replace tuple with tuple element in functions that return one-element tuples.
|
||||
Returns true if an unwrapping took place, and false otherwise.
|
||||
"""
|
||||
unwrapped_tuple = False
|
||||
for node in fx_g.graph.nodes:
|
||||
if node.op == "output":
|
||||
assert (
|
||||
len(node.args) == 1
|
||||
), "Output node must have a single argument"
|
||||
node_arg = node.args[0]
|
||||
if isinstance(node_arg, tuple):
|
||||
if len(node_arg) == 1:
|
||||
node.args = (node_arg[0],)
|
||||
unwrapped_tuple = True
|
||||
break
|
||||
|
||||
if unwrapped_tuple:
|
||||
fx_g.graph.lint()
|
||||
fx_g.recompile()
|
||||
return unwrapped_tuple
|
||||
|
||||
|
||||
def _returns_nothing(fx_g: torch.fx.GraphModule) -> bool:
|
||||
for node in fx_g.graph.nodes:
|
||||
if node.op == "output":
|
||||
assert (
|
||||
len(node.args) == 1
|
||||
), "Output node must have a single argument"
|
||||
node_arg = node.args[0]
|
||||
if isinstance(node_arg, tuple):
|
||||
return len(node_arg) == 0
|
||||
return False
|
||||
|
||||
|
||||
def transform_fx(fx_g):
|
||||
for node in fx_g.graph.nodes:
|
||||
if node.op == "call_function":
|
||||
if node.target in [
|
||||
torch.ops.aten.empty,
|
||||
]:
|
||||
# aten.empty should be filled with zeros.
|
||||
if node.target in [torch.ops.aten.empty]:
|
||||
with fx_g.graph.inserting_after(node):
|
||||
new_node = fx_g.graph.call_function(
|
||||
torch.ops.aten.zero_,
|
||||
args=(node,),
|
||||
)
|
||||
node.append(new_node)
|
||||
node.replace_all_uses_with(new_node)
|
||||
new_node.args = (node,)
|
||||
|
||||
fx_g.graph.lint()
|
||||
|
||||
|
||||
@make_simple_dynamo_backend
|
||||
def refbackend_torchdynamo_backend(
|
||||
fx_graph: torch.fx.GraphModule, example_inputs: List[torch.Tensor]
|
||||
):
|
||||
# handling usage of empty tensor without initializing
|
||||
transform_fx(fx_graph)
|
||||
fx_graph.recompile()
|
||||
if _returns_nothing(fx_graph):
|
||||
return fx_graph
|
||||
removed_none_indexes = _remove_nones(fx_graph)
|
||||
was_unwrapped = _unwrap_single_tuple_return(fx_graph)
|
||||
|
||||
mlir_module = torch_mlir.compile(
|
||||
fx_graph, example_inputs, output_type="linalg-on-tensors"
|
||||
)
|
||||
|
||||
bytecode_stream = BytesIO()
|
||||
mlir_module.operation.write_bytecode(bytecode_stream)
|
||||
bytecode = bytecode_stream.getvalue()
|
||||
|
||||
shark_module = SharkInference(
|
||||
mlir_module=bytecode, device=args.device, mlir_dialect="tm_tensor"
|
||||
)
|
||||
shark_module.compile()
|
||||
|
||||
def compiled_callable(*inputs):
|
||||
inputs = [x.numpy() for x in inputs]
|
||||
result = shark_module("forward", inputs)
|
||||
if was_unwrapped:
|
||||
result = [
|
||||
result,
|
||||
]
|
||||
if not isinstance(result, list):
|
||||
result = torch.from_numpy(result)
|
||||
else:
|
||||
result = tuple(torch.from_numpy(x) for x in result)
|
||||
result = list(result)
|
||||
for removed_index in removed_none_indexes:
|
||||
result.insert(removed_index, None)
|
||||
result = tuple(result)
|
||||
return result
|
||||
|
||||
return compiled_callable
|
||||
|
||||
|
||||
def predictions(torch_func, jit_func, batchA, batchB):
|
||||
res = jit_func(batchA.numpy(), batchB.numpy())
|
||||
if res is not None:
|
||||
prediction = res
|
||||
else:
|
||||
prediction = None
|
||||
return prediction
|
||||
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
|
||||
# def save_progress(text_encoder, placeholder_token_id, accelerator, save_path):
|
||||
def save_progress(text_encoder, placeholder_token_id, save_path):
|
||||
logger.info("Saving embeddings")
|
||||
learned_embeds = (
|
||||
# accelerator.unwrap_model(text_encoder)
|
||||
text_encoder.get_input_embeddings().weight[placeholder_token_id]
|
||||
)
|
||||
learned_embeds_dict = {
|
||||
args.placeholder_token: learned_embeds.detach().cpu()
|
||||
}
|
||||
torch.save(learned_embeds_dict, save_path)
|
||||
|
||||
|
||||
train_batch_size = hyperparameters["train_batch_size"]
|
||||
gradient_accumulation_steps = hyperparameters["gradient_accumulation_steps"]
|
||||
learning_rate = hyperparameters["learning_rate"]
|
||||
if hyperparameters["scale_lr"]:
|
||||
learning_rate = (
|
||||
learning_rate
|
||||
* gradient_accumulation_steps
|
||||
* train_batch_size
|
||||
# * accelerator.num_processes
|
||||
)
|
||||
|
||||
# Initialize the optimizer
|
||||
optimizer = torch.optim.AdamW(
|
||||
text_encoder.get_input_embeddings().parameters(), # only optimize the embeddings
|
||||
lr=learning_rate,
|
||||
)
|
||||
|
||||
|
||||
# Training function
|
||||
def train_func(batch_pixel_values, batch_input_ids):
|
||||
# Convert images to latent space
|
||||
latents = shark_vae(batch_pixel_values).sample().detach()
|
||||
latents = latents * 0.18215
|
||||
|
||||
# Sample noise that we'll add to the latents
|
||||
noise = torch.randn_like(latents)
|
||||
bsz = latents.shape[0]
|
||||
# Sample a random timestep for each image
|
||||
timesteps = torch.randint(
|
||||
0,
|
||||
noise_scheduler.num_train_timesteps,
|
||||
(bsz,),
|
||||
device=latents.device,
|
||||
).long()
|
||||
|
||||
# Add noise to the latents according to the noise magnitude at each timestep
|
||||
# (this is the forward diffusion process)
|
||||
noisy_latents = noise_scheduler.add_noise(latents, noise, timesteps)
|
||||
|
||||
# Get the text embedding for conditioning
|
||||
encoder_hidden_states = text_encoder(batch_input_ids)[0]
|
||||
|
||||
# Predict the noise residual
|
||||
noise_pred = shark_unet(
|
||||
noisy_latents,
|
||||
timesteps,
|
||||
encoder_hidden_states,
|
||||
)
|
||||
|
||||
# Get the target for loss depending on the prediction type
|
||||
if noise_scheduler.config.prediction_type == "epsilon":
|
||||
target = noise
|
||||
elif noise_scheduler.config.prediction_type == "v_prediction":
|
||||
target = noise_scheduler.get_velocity(latents, noise, timesteps)
|
||||
else:
|
||||
raise ValueError(
|
||||
f"Unknown prediction type {noise_scheduler.config.prediction_type}"
|
||||
)
|
||||
|
||||
loss = (
|
||||
F.mse_loss(noise_pred, target, reduction="none").mean([1, 2, 3]).mean()
|
||||
)
|
||||
loss.backward()
|
||||
|
||||
# Zero out the gradients for all token embeddings except the newly added
|
||||
# embeddings for the concept, as we only want to optimize the concept embeddings
|
||||
grads = text_encoder.get_input_embeddings().weight.grad
|
||||
# Get the index for tokens that we want to zero the grads for
|
||||
index_grads_to_zero = torch.arange(len(tokenizer)) != placeholder_token_id
|
||||
grads.data[index_grads_to_zero, :] = grads.data[
|
||||
index_grads_to_zero, :
|
||||
].fill_(0)
|
||||
|
||||
optimizer.step()
|
||||
optimizer.zero_grad()
|
||||
|
||||
return loss
|
||||
|
||||
|
||||
def training_function():
|
||||
max_train_steps = hyperparameters["max_train_steps"]
|
||||
output_dir = hyperparameters["output_dir"]
|
||||
gradient_checkpointing = hyperparameters["gradient_checkpointing"]
|
||||
|
||||
train_dataloader = create_dataloader(train_batch_size)
|
||||
|
||||
# We need to recalculate our total training steps as the size of the training dataloader may have changed.
|
||||
num_update_steps_per_epoch = math.ceil(
|
||||
len(train_dataloader) / gradient_accumulation_steps
|
||||
)
|
||||
num_train_epochs = math.ceil(max_train_steps / num_update_steps_per_epoch)
|
||||
|
||||
# Train!
|
||||
total_batch_size = (
|
||||
train_batch_size
|
||||
* gradient_accumulation_steps
|
||||
# train_batch_size * accelerator.num_processes * gradient_accumulation_steps
|
||||
)
|
||||
|
||||
logger.info("***** Running training *****")
|
||||
logger.info(f" Num examples = {len(train_dataset)}")
|
||||
logger.info(f" Instantaneous batch size per device = {train_batch_size}")
|
||||
logger.info(
|
||||
f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}"
|
||||
)
|
||||
logger.info(
|
||||
f" Gradient Accumulation steps = {gradient_accumulation_steps}"
|
||||
)
|
||||
logger.info(f" Total optimization steps = {max_train_steps}")
|
||||
# Only show the progress bar once on each machine.
|
||||
progress_bar = tqdm(
|
||||
# range(max_train_steps), disable=not accelerator.is_local_main_process
|
||||
range(max_train_steps)
|
||||
)
|
||||
progress_bar.set_description("Steps")
|
||||
global_step = 0
|
||||
|
||||
params_ = [i for i in text_encoder.get_input_embeddings().parameters()]
|
||||
if args.use_torchdynamo:
|
||||
print("******** TRAINING STARTED - TORCHYDNAMO PATH ********")
|
||||
else:
|
||||
print("******** TRAINING STARTED - PYTORCH PATH ********")
|
||||
print("Initial weights:")
|
||||
print(params_, params_[0].shape)
|
||||
|
||||
for epoch in range(num_train_epochs):
|
||||
text_encoder.train()
|
||||
for step, batch in enumerate(train_dataloader):
|
||||
if args.use_torchdynamo:
|
||||
dynamo_callable = dynamo.optimize(
|
||||
refbackend_torchdynamo_backend
|
||||
)(train_func)
|
||||
lam_func = lambda x, y: dynamo_callable(
|
||||
torch.from_numpy(x), torch.from_numpy(y)
|
||||
)
|
||||
loss = predictions(
|
||||
train_func,
|
||||
lam_func,
|
||||
batch["pixel_values"],
|
||||
batch["input_ids"],
|
||||
# params[0].detach(),
|
||||
)
|
||||
else:
|
||||
loss = train_func(batch["pixel_values"], batch["input_ids"])
|
||||
print(loss)
|
||||
|
||||
# Checks if the accelerator has performed an optimization step behind the scenes
|
||||
progress_bar.update(1)
|
||||
global_step += 1
|
||||
if global_step % hyperparameters["save_steps"] == 0:
|
||||
save_path = os.path.join(
|
||||
output_dir,
|
||||
f"learned_embeds-step-{global_step}.bin",
|
||||
)
|
||||
save_progress(
|
||||
text_encoder,
|
||||
placeholder_token_id,
|
||||
save_path,
|
||||
)
|
||||
|
||||
logs = {"loss": loss.detach().item()}
|
||||
progress_bar.set_postfix(**logs)
|
||||
|
||||
if global_step >= max_train_steps:
|
||||
break
|
||||
|
||||
# Create the pipeline using using the trained modules and save it.
|
||||
params__ = [i for i in text_encoder.get_input_embeddings().parameters()]
|
||||
print("******** TRAINING PROCESS FINISHED ********")
|
||||
print("Updated weights:")
|
||||
print(params__, params__[0].shape)
|
||||
pipeline = StableDiffusionPipeline.from_pretrained(
|
||||
pretrained_model_name_or_path,
|
||||
# text_encoder=accelerator.unwrap_model(text_encoder),
|
||||
text_encoder=text_encoder,
|
||||
tokenizer=tokenizer,
|
||||
vae=vae,
|
||||
unet=unet,
|
||||
)
|
||||
pipeline.save_pretrained(output_dir)
|
||||
# Also save the newly trained embeddings
|
||||
save_path = os.path.join(output_dir, f"learned_embeds.bin")
|
||||
save_progress(text_encoder, placeholder_token_id, save_path)
|
||||
|
||||
|
||||
training_function()
|
||||
|
||||
for param in itertools.chain(unet.parameters(), text_encoder.parameters()):
|
||||
if param.grad is not None:
|
||||
del param.grad # free some memory
|
||||
torch.cuda.empty_cache()
|
||||
|
||||
# Set up the pipeline
|
||||
from diffusers import DPMSolverMultistepScheduler
|
||||
|
||||
pipe = StableDiffusionPipeline.from_pretrained(
|
||||
hyperparameters["output_dir"],
|
||||
scheduler=DPMSolverMultistepScheduler.from_pretrained(
|
||||
hyperparameters["output_dir"], subfolder="scheduler"
|
||||
),
|
||||
)
|
||||
if not args.use_torchdynamo:
|
||||
pipe.to(args.device)
|
||||
|
||||
# Run the Stable Diffusion pipeline
|
||||
# Don't forget to use the placeholder token in your prompt
|
||||
|
||||
all_images = []
|
||||
for _ in range(args.num_inference_samples):
|
||||
images = pipe(
|
||||
[args.prompt],
|
||||
num_inference_steps=args.inference_steps,
|
||||
guidance_scale=7.5,
|
||||
).images
|
||||
all_images.extend(images)
|
||||
|
||||
output_path = os.path.abspath(os.path.join(os.getcwd(), args.output_dir))
|
||||
if not os.path.isdir(args.output_dir):
|
||||
os.mkdir(args.output_dir)
|
||||
|
||||
[
|
||||
image.save(f"{args.output_dir}/{i}.jpeg")
|
||||
for i, image in enumerate(all_images)
|
||||
]
|
||||
@@ -53,10 +53,10 @@ def get_iree_device_args(device, extra_args=[]):
|
||||
# Get the iree-compiler arguments given frontend.
|
||||
def get_iree_frontend_args(frontend):
|
||||
if frontend in ["torch", "pytorch", "linalg"]:
|
||||
return ["--iree-llvm-target-cpu-features=host"]
|
||||
return ["--iree-llvmcpu-target-cpu-features=host"]
|
||||
elif frontend in ["tensorflow", "tf", "mhlo"]:
|
||||
return [
|
||||
"--iree-llvm-target-cpu-features=host",
|
||||
"--iree-llvmcpu-target-cpu-features=host",
|
||||
"--iree-mhlo-demote-i64-to-i32=false",
|
||||
"--iree-flow-demote-i64-to-i32",
|
||||
]
|
||||
|
||||
@@ -44,4 +44,4 @@ def get_iree_cpu_args():
|
||||
error_message = f"OS Type f{os_name} not supported and triple can't be determined, open issue to dSHARK team please :)"
|
||||
raise Exception(error_message)
|
||||
print(f"Target triple found:{target_triple}")
|
||||
return [f"-iree-llvm-target-triple={target_triple}"]
|
||||
return [f"--iree-llvmcpu-target-triple={target_triple}"]
|
||||
|
||||
@@ -118,10 +118,11 @@ class SharkBenchmarkRunner(SharkRunner):
|
||||
)
|
||||
HFmodel, input = get_torch_model(modelname)[:2]
|
||||
frontend_model = HFmodel.model
|
||||
# frontend_model = dynamo.optimize("inductor")(frontend_model)
|
||||
frontend_model.to(torch_device)
|
||||
input.to(torch_device)
|
||||
|
||||
# frontend_model = torch.compile(frontend_model, mode="max-autotune", backend="inductor")
|
||||
|
||||
for i in range(shark_args.num_warmup_iterations):
|
||||
frontend_model.forward(input)
|
||||
|
||||
|
||||
@@ -99,6 +99,7 @@ else:
|
||||
print(
|
||||
f"shark_tank local cache is located at {WORKDIR} . You may change this by setting the --local_tank_cache= flag"
|
||||
)
|
||||
os.makedirs(WORKDIR, exist_ok=True)
|
||||
|
||||
|
||||
# Checks whether the directory and files exists.
|
||||
|
||||
@@ -1,25 +1,25 @@
|
||||
resnet50,mhlo,tf,1e-2,1e-3,default,nhcw-nhwc,False,False,False,"","macos"
|
||||
albert-base-v2,mhlo,tf,1e-2,1e-2,default,None,False,False,False,"",""
|
||||
roberta-base,mhlo,tf,1e-02,1e-3,default,nhcw-nhwc,False,False,False,"","macos"
|
||||
bert-base-uncased,mhlo,tf,1e-2,1e-3,default,None,False,False,False,"",""
|
||||
camembert-base,mhlo,tf,1e-2,1e-3,default,None,False,False,False,"",""
|
||||
roberta-base,mhlo,tf,1e-02,1e-3,default,nhcw-nhwc,True,True,True,"","macos"
|
||||
bert-base-uncased,mhlo,tf,1e-2,1e-3,default,None,False,False,False,"","enabled_windows"
|
||||
camembert-base,mhlo,tf,1e-2,1e-3,default,None,True,True,True,"",""
|
||||
dbmdz/convbert-base-turkish-cased,mhlo,tf,1e-2,1e-3,default,nhcw-nhwc,True,True,False,"https://github.com/iree-org/iree/issues/9971",""
|
||||
distilbert-base-uncased,mhlo,tf,1e-2,1e-3,default,None,False,False,False,"",""
|
||||
facebook/convnext-tiny-224,mhlo,tf,1e-2,1e-3,tf_vit,nhcw-nhwc,True,True,False,"https://github.com/nod-ai/SHARK/issues/311 & https://github.com/nod-ai/SHARK/issues/342",""
|
||||
facebook/convnext-tiny-224,mhlo,tf,1e-2,1e-3,tf_vit,nhcw-nhwc,True,True,False,"https://github.com/nod-ai/SHARK/issues/311 & https://github.com/nod-ai/SHARK/issues/342","macos"
|
||||
funnel-transformer/small,mhlo,tf,1e-2,1e-3,default,None,True,True,False,"https://github.com/nod-ai/SHARK/issues/201",""
|
||||
google/electra-small-discriminator,mhlo,tf,1e-2,1e-3,default,None,False,False,False,"",""
|
||||
google/mobilebert-uncased,mhlo,tf,1e-2,1e-3,default,None,True,False,False,"Fails during iree-compile",""
|
||||
google/vit-base-patch16-224,mhlo,tf,1e-2,1e-3,tf_vit,nhcw-nhwc,False,False,False,"",""
|
||||
microsoft/MiniLM-L12-H384-uncased,mhlo,tf,1e-2,1e-3,tf_hf,None,True,False,False,"Fails during iree-compile.",""
|
||||
microsoft/layoutlm-base-uncased,mhlo,tf,1e-2,1e-3,default,None,False,False,False,"",""
|
||||
microsoft/mpnet-base,mhlo,tf,1e-2,1e-2,default,None,False,False,False,"",""
|
||||
microsoft/mpnet-base,mhlo,tf,1e-2,1e-2,default,None,True,True,True,"",""
|
||||
albert-base-v2,linalg,torch,1e-2,1e-3,default,None,True,True,True,"issue with aten.tanh in torch-mlir",""
|
||||
alexnet,linalg,torch,1e-2,1e-3,default,None,True,True,False,"https://github.com/nod-ai/SHARK/issues/879",""
|
||||
bert-base-cased,linalg,torch,1e-2,1e-3,default,None,False,False,False,"",""
|
||||
bert-base-uncased,linalg,torch,1e-2,1e-3,default,None,False,False,False,"",""
|
||||
bert-base-uncased_fp16,linalg,torch,1e-1,1e-1,default,None,True,False,True,"",""
|
||||
bert-large-uncased,linalg,torch,1e-2,1e-3,default,None,True,True,True,"disabled until generateable",""
|
||||
bert-large-uncased,mhlo,tf,1e-2,1e-3,default,None,True,True,True,"disabled until generatedable",""
|
||||
bert-large-uncased,linalg,torch,1e-2,1e-3,default,None,False,False,False,"",""
|
||||
bert-large-uncased,mhlo,tf,1e-2,1e-3,default,None,False,False,False,"",""
|
||||
facebook/deit-small-distilled-patch16-224,linalg,torch,1e-2,1e-3,default,nhcw-nhwc,False,True,False,"Fails during iree-compile.",""
|
||||
google/vit-base-patch16-224,linalg,torch,1e-2,1e-3,default,nhcw-nhwc,False,True,False,"https://github.com/nod-ai/SHARK/issues/311",""
|
||||
microsoft/beit-base-patch16-224-pt22k-ft22k,linalg,torch,1e-2,1e-3,default,nhcw-nhwc,False,True,False,"https://github.com/nod-ai/SHARK/issues/390",""
|
||||
@@ -34,4 +34,4 @@ resnet50_fp16,linalg,torch,1e-2,1e-2,default,nhcw-nhwc/img2col,True,False,True,"
|
||||
squeezenet1_0,linalg,torch,1e-2,1e-3,default,nhcw-nhwc,False,False,False,"","macos"
|
||||
wide_resnet50_2,linalg,torch,1e-2,1e-3,default,nhcw-nhwc/img2col,False,False,False,"","macos"
|
||||
efficientnet-v2-s,mhlo,tf,1e-02,1e-3,default,nhcw-nhwc,False,False,False,"","macos"
|
||||
mnasnet1_0,linalg,torch,1e-2,1e-3,default,nhcw-nhwc,False,False,False,"","macos"
|
||||
mnasnet1_0,linalg,torch,1e-2,1e-3,default,nhcw-nhwc,True,True,True,"","macos"
|
||||
|
||||
|
@@ -63,7 +63,7 @@ if __name__ == "__main__":
|
||||
# Compile the model using IREE
|
||||
backend = "dylib-llvm-aot"
|
||||
args = [
|
||||
"--iree-llvm-target-cpu-features=host",
|
||||
"--iree-llvmcpu-target-cpu-features=host",
|
||||
"--iree-mhlo-demote-i64-to-i32=false",
|
||||
"--iree-flow-demote-i64-to-i32",
|
||||
]
|
||||
|
||||
@@ -136,7 +136,7 @@ if __name__ == "__main__":
|
||||
backend = "dylib-llvm-aot"
|
||||
if backend == "dylib-llvm-aot":
|
||||
args = [
|
||||
"--iree-llvm-target-cpu-features=host",
|
||||
"--iree-llvmcpu-target-cpu-features=host",
|
||||
"--iree-mhlo-demote-i64-to-i32=false",
|
||||
"--iree-flow-demote-i64-to-i32",
|
||||
]
|
||||
|
||||
@@ -83,7 +83,7 @@ if __name__ == "__main__":
|
||||
# Compile the model using IREE
|
||||
backend = "dylib-llvm-aot"
|
||||
args = [
|
||||
"--iree-llvm-target-cpu-features=host",
|
||||
"--iree-llvmcpu-target-cpu-features=host",
|
||||
"--iree-mhlo-demote-i64-to-i32=false",
|
||||
"--iree-stream-resource-index-bits=64",
|
||||
"--iree-vm-target-index-bits=64",
|
||||
|
||||
@@ -79,7 +79,7 @@ if __name__ == "__main__":
|
||||
# Compile the model using IREE
|
||||
backend = "dylib-llvm-aot"
|
||||
args = [
|
||||
"--iree-llvm-target-cpu-features=host",
|
||||
"--iree-llvmcpu-target-cpu-features=host",
|
||||
"--iree-mhlo-demote-i64-to-i32=false",
|
||||
"--iree-flow-demote-i64-to-i32",
|
||||
]
|
||||
|
||||
@@ -307,6 +307,9 @@ class SharkModuleTest(unittest.TestCase):
|
||||
if config["xfail_vkm"] == "True" and device in ["metal", "vulkan"]:
|
||||
pytest.xfail(reason=config["xfail_reason"])
|
||||
|
||||
if os.name == "nt" and "enabled_windows" not in config["xfail_other"]:
|
||||
pytest.xfail(reason="this model skipped on windows")
|
||||
|
||||
# Special cases that need to be marked.
|
||||
if "macos" in config["xfail_other"] and device in [
|
||||
"metal",
|
||||
|
||||
Reference in New Issue
Block a user