mirror of
https://github.com/privacy-scaling-explorations/pse.dev.git
synced 2026-04-23 03:01:03 -04:00
feat: blog section
This commit is contained in:
@@ -1,5 +1,5 @@
|
||||
{
|
||||
"singleQuote": true,
|
||||
"singleQuote": false,
|
||||
"semi": false,
|
||||
"trailingComma": "es5"
|
||||
}
|
||||
|
||||
48
app/[lang]/blog/[slug]/page.tsx
Normal file
48
app/[lang]/blog/[slug]/page.tsx
Normal file
@@ -0,0 +1,48 @@
|
||||
import { BlogContent } from "@/components/blog/blog-content"
|
||||
import { AppContent } from "@/components/ui/app-content"
|
||||
import { Label } from "@/components/ui/label"
|
||||
import { getArticles, getArticleById } from "@/lib/blog"
|
||||
|
||||
export const generateStaticParams = async () => {
|
||||
const articles = getArticles()
|
||||
return articles.map(({ id }) => ({
|
||||
slug: id,
|
||||
}))
|
||||
}
|
||||
|
||||
export async function generateMetadata({ params }: any) {
|
||||
const post = getArticleById(params.slug)
|
||||
|
||||
return {
|
||||
title: post?.title ? `${post?.title} - Cursive` : "Cursive",
|
||||
description:
|
||||
post?.tldr ??
|
||||
"A cryptography and design lab focused on applications of signed data.",
|
||||
}
|
||||
}
|
||||
|
||||
export default function BlogArticle({ params }: any) {
|
||||
const slug = params.slug
|
||||
const post = getArticleById(slug)
|
||||
|
||||
if (!post) return null
|
||||
return (
|
||||
<div className="flex flex-col">
|
||||
<div className="flex items-start justify-center background-gradient z-0">
|
||||
<div className="w-full bg-cover-gradient border-b border-tuatara-300">
|
||||
<AppContent className="flex flex-col gap-4 py-10 max-w-[978px]">
|
||||
<Label.PageTitle label={post?.title} />
|
||||
{post?.tldr && (
|
||||
<h6 className="font-sans text-base font-normal text-tuatara-950 md:text-[18px] md:leading-[27px] md:max-w-[700px]">
|
||||
{post?.tldr}
|
||||
</h6>
|
||||
)}
|
||||
</AppContent>
|
||||
</div>
|
||||
</div>
|
||||
<div className="pt-10 md:pt-16 pb-32">
|
||||
<BlogContent post={post} />
|
||||
</div>
|
||||
</div>
|
||||
)
|
||||
}
|
||||
33
app/[lang]/blog/page.tsx
Normal file
33
app/[lang]/blog/page.tsx
Normal file
@@ -0,0 +1,33 @@
|
||||
import { useTranslation } from "@/app/i18n"
|
||||
import { BlogArticles } from "@/components/blog/blog-articles"
|
||||
import { AppContent } from "@/components/ui/app-content"
|
||||
import { Label } from "@/components/ui/label"
|
||||
import { Metadata } from "next"
|
||||
|
||||
export const metadata: Metadata = {
|
||||
title: "Blog",
|
||||
description: "Blog",
|
||||
}
|
||||
|
||||
const BlogPage = async ({ params: { lang } }: any) => {
|
||||
const { t } = await useTranslation(lang, "blog-page")
|
||||
|
||||
return (
|
||||
<div className="flex flex-col">
|
||||
<div className="w-full bg-cover-gradient border-b border-tuatara-300">
|
||||
<AppContent className="flex flex-col gap-4 py-10 w-full">
|
||||
<Label.PageTitle label={t("title")} />
|
||||
<h6 className="font-sans text-base font-normal text-tuatara-950 md:text-[18px] md:leading-[27px] md:max-w-[700px]">
|
||||
{t("subtitle")}
|
||||
</h6>
|
||||
</AppContent>
|
||||
</div>
|
||||
|
||||
<AppContent className="flex flex-col gap-10 py-10">
|
||||
<BlogArticles />
|
||||
</AppContent>
|
||||
</div>
|
||||
)
|
||||
}
|
||||
|
||||
export default BlogPage
|
||||
4
app/i18n/locales/en/blog-page.json
Normal file
4
app/i18n/locales/en/blog-page.json
Normal file
@@ -0,0 +1,4 @@
|
||||
{
|
||||
"title": "Blog",
|
||||
"subtitle": "Read our latest articles and stay updated on the latest news in the world of cryptography."
|
||||
}
|
||||
7
articles/article-template.md
Normal file
7
articles/article-template.md
Normal file
@@ -0,0 +1,7 @@
|
||||
---
|
||||
authors: [""]
|
||||
title: "Title"
|
||||
image: "/articles/code-optimizations-in-post-quantum-cryptography/cover.png"
|
||||
tldr: ""
|
||||
date: "2024-04-07"
|
||||
---
|
||||
223
articles/circom-mpc-retrospective.md
Normal file
223
articles/circom-mpc-retrospective.md
Normal file
@@ -0,0 +1,223 @@
|
||||
---
|
||||
authors: ["Circom MPC research team"]
|
||||
title: "Circom MPC: TL;DR and Retrospective"
|
||||
image: "cover.jpeg"
|
||||
tldr: ""
|
||||
date: "2025-03-06"
|
||||
---
|
||||
|
||||
Circom-MPC is a PSE Research project that enables the use of the Circom language to develop MPC applications. In this project, we envisioned MPC as a [broader paradigm](#MPC-as-a-Paradigm), where MPC serves as an umbrella for generic techniques such as Zero-Knowledge Proof, Garbled Circuit, Secret-Sharing, or Fully Homomorphic Encryption.
|
||||
|
||||
Throughout this research the team produced some valuable resources and insights, including:
|
||||
|
||||
- Implementation of [circom-2-arithc](https://github.com/namnc/circom-2-arithc), a fork of the Circom compiler that targets arithmetic circuits, which can be fed into any MPC backend
|
||||
- Example integration of circom-2-arithc with the popular Secret-Sharing based backend MP-SPDZ in [circom-MP-SPDZ](https://github.com/namnc/circom-mp-spdz).
|
||||
- Proof of concept application using [MPC-ML](https://hackmd.io/YsWhryEtQ0WwKyerSL8oCw#Circomlib-ML-Patches-and-Benchmarks) with [keras-2-circom-MP-SPDZ](https://github.com/namnc/circom-mp-spdz/blob/main/ML-TESTS.md) which extends keras-2-circom-ZK to [keras-2-circom-MPC](https://github.com/namnc/keras2circom).
|
||||
- [Modular Layer benchmarks](#Modular-Layer-Benchmark) for the keras model.
|
||||
|
||||
We decided to sunset the project for a few reasons:
|
||||
|
||||
- The overwhelming amount of effort to fully implement it.
|
||||
- The low current traction of users (could be due to Circom). Hence a [Typescript-MPC](https://github.com/voltrevo/mpc-framework) variant may be of more public interest.
|
||||
- The existence of competitors such as [Sharemind MPC into Carbyne Stack](https://cyber.ee/uploads/Sharemind_MPC_CS_integration_a01ca476a7.pdf).
|
||||
|
||||
Therefore, we will leave it as a paradigm, and we hope that any interested party will pick it up and continue its development.
|
||||
|
||||
In what follows we explain:
|
||||
|
||||
- MPC as a Paradigm
|
||||
- Our Circom-MPC framework
|
||||
- Our patched Circomlib-ML and modular benchmark to have a taste of MPC-ML
|
||||
|
||||
## MPC as a Paradigm
|
||||
|
||||
Secure Multiparty Computation (MPC), as it is defined, allows mutually distrustful parties to jointly compute a functionality while keeping the inputs of the participants private.
|
||||
|
||||

|
||||
|
||||
An MPC protocol can be either application-specific or generic:
|
||||
|
||||

|
||||
|
||||
While it is clear that Threshold Signature exemplifies application-specific MPC, one can think of generic MPC as an efficient MPC protocol for a Virtual Machine (VM) functionality that takes the joint function as a common program and the private inputs as parameters to the program and the secure execution of the program is within the said VM.
|
||||
|
||||
_For readers who are familiar with Zero-Knowledge Proof (ZKP), MPC is a generalization of ZKP in which the MPC consists of two parties namely the Prover and the Verifier, where only the Prover has a secret input which is the witness._
|
||||
|
||||

|
||||
|
||||
And yes, Fully Homomorphic Encryption (FHE) is among techniques (along side Garbled-Circuit and Secret-Sharing) that can be used for MPC construction in the most straightforward mental model:
|
||||
|
||||

|
||||
|
||||
## Programmable MPC
|
||||
|
||||
That said, MPC is not a primitive but a [collection of techniques](https://mpc.cs.berkeley.edu/) aimed to achieve the above purpose. Efficient MPC protocols exist for specific functionalities from simple statistical aggregation such as mean aggregation (for ads), Private Set Intersection (PSI) to complex ones such as RAM (called [Oblivious-RAM](https://en.wikipedia.org/wiki/Oblivious_RAM)) and even Machine Learning (ML).
|
||||
|
||||

|
||||
|
||||
As each technique GC/SS/FHE and specialized MPC has its own advantage, it is typical to combine them into one's privacy preserving protocol for efficiency:
|
||||
|
||||

|
||||
|
||||
In what follows, we present work that enables the use of Circom as a front-end language for developing privacy-preserving systems, starting with the MP-SPDZ backend.
|
||||
|
||||

|
||||
|
||||
_[Detailed explanation of Progammable-MPC with Circom-MPC.](https://docs.google.com/presentation/d/1dPvNyrBWyqyX2oTGcnM52ldpISGrhwEhIZXJPwYWE6I/edit#slide=id.g2818c557dad_0_261)_
|
||||
|
||||
The Circom-MPC project aims to allow a developer to write a Circom program (a Circom circuit) and run it using an MPC backend.
|
||||
|
||||
### The workflow
|
||||
|
||||
- A circom program (prog.circom and the included libraries such as circomlib or circomlib-ml) will be interpreted as an arithmetic circuit (a [DAG](https://en.wikipedia.org/wiki/Directed_acyclic_graph) of wires connected with nodes with an input layer and an output layer) using [circom-2-arithc](https://github.com/namnc/circom-2-arithc).
|
||||
- A transpiler/builder, given the arithmetic circuit and the native capabilities of the MPC backend, translates a gate to a set of native gates so we can run the arithmetic circuit with the MPC backend.
|
||||
|
||||
### Circom-MP-SPDZ
|
||||
|
||||
[Circom-MP-SDPZ](https://github.com/namnc/circom-mp-spdz/) allows parties to perform Multi-Party Computation (MPC) by writing Circom code using the MP-SPDZ framework. Circom code is compiled into an arithmetic circuit and then translated gate by gate to the corresponding MP-SPDZ operators.
|
||||
|
||||
The Circom-MP-SDPZ workflow is described [here](https://hackmd.io/@mhchia/r17ibd1X0).
|
||||
|
||||
## Circomlib-ML Patches and Benchmarks
|
||||
|
||||
With MPC we can achieve privacy-preserving machine learning (PPML). This can be done easily by reusing [circomlib-ml](https://github.com/socathie/circomlib-ml) stack with Circom-MPC. We demonstrated PoC with [ml_tests](https://github.com/namnc/circom-mp-spdz/tree/main/ml_tests) - a set of ML circuits (fork of [circomlib-ml](https://github.com/socathie/circomlib-ml)).
|
||||
|
||||
More info on ML Tests [here](https://github.com/namnc/circom-mp-spdz/blob/main/ML-TESTS.md).
|
||||
|
||||
### Patches
|
||||
|
||||
**Basic Circom ops on circuit signals**
|
||||
|
||||
Circom-2-arithc enables direct usage of comparisons and division on signals. Hence the original Circom templates for comparisons or the division-to-multiplication trick are no longer needed, e.g.
|
||||
|
||||
- GreaterThan can be replaced with ">"
|
||||
- IsPositive can be replaced with "> 0"
|
||||
- x = d \* q + r can be written as "q = x / d"
|
||||
|
||||
**Scaling, Descaling and Quantized Aware Computation**
|
||||
|
||||
Circomlib-ML "scaled" a float to int to maintain precision using 101810^{18}:
|
||||
|
||||
- for input aa, weight ww, and bias bb that are floats
|
||||
- aa, ww are scaled to a′\=a1018a' = a10^{18} _and_ w′\=w1018w' = w10^{18}
|
||||
- bb is scaled to b′\=b1036b' = b10^{36}_,_ due to in a layer we have computation in the form of aw+b⟶aw + b \\longrightarrow the outputs of this layer is scaled with 103610^{36}
|
||||
- To proceed to the next layer, we have to "descale" the outputs of the current layer by (int) dividing the outputs with 101810^{18}
|
||||
|
||||
- say, with an output xx, we want to obtain x′x' s.t.
|
||||
- x\=x′∗1018+rx = x'\*10^{18} + r
|
||||
- so effectively in this case x′x' is our actual output
|
||||
- in ZK x′x' and rr are provided as witness
|
||||
- in MPC x′x' and rr have to be computed using division (expensive)
|
||||
|
||||
For efficiency we replace this type of scaling with bit shifting, i.e.
|
||||
|
||||
- instead of ∗1018\*10^{18} (∗1036\*10^{36}) we do ∗2s\*2^s (∗22s\*2^{2s})where ss is called the scaling factor
|
||||
|
||||
- The scaling is done prior to the MPC
|
||||
- ss can be set accordingly to the bitwidth of the MPC protocol
|
||||
|
||||
- now, descaling is simply truncation or right-shifting, which is a commonly supported and relatively cheap operation in MPC.
|
||||
|
||||
- x′\=x\>\>sx' = x >> s
|
||||
|
||||
**The "all inputs" Circom template**
|
||||
|
||||
Some of the Circomlib-ML circuits have no "output" signals; we patched them to treat the outputs as 'output' signals.
|
||||
|
||||
The following circuits were changed:
|
||||
|
||||
- ArgMax, AveragePooling2D, BatchNormalization2D, Conv1D, Conv2D, Dense, DepthwiseConv2D, Flatten2D, GlobalAveragePooling2D, GlobalMaxPooling2D, LeakyReLU, MaxPooling2D, PointwiseConv2D, ReLU, Reshape2D, SeparableConv2D, UpSampling2D
|
||||
|
||||
_**Some templates (Zanh, ZeLU and Zigmoid) are "unpatchable" due to their complexity for MPC computation.**_
|
||||
|
||||
### Keras2Circom Patches
|
||||
|
||||
> keras2circom expects a convolutional NN;
|
||||
|
||||
We forked keras2circom and create a [compatible version](https://github.com/namnc/keras2circom).
|
||||
|
||||
### Benchmarks
|
||||
|
||||
After patching Circomlib-ML we can run the benchmark separately for each patched layer above.
|
||||
|
||||
**Docker Settings and running MP-SPDZ on multiple machines**
|
||||
|
||||
For all benchmarks we inject synthetic network latency inside a Docker container.
|
||||
|
||||
We have two settings with set latency & bandwidth:
|
||||
|
||||
1. One region - Europe & Europe
|
||||
2. Different regions - Europe & US
|
||||
|
||||
We used `tc` to limit latency and set a bandwidth:
|
||||
|
||||
```
|
||||
tc qdisc add dev eth0 root handle 1:0 netem delay 2ms
|
||||
tc qdisc add dev eth0 parent 1:1 handle 10:0 tbf rate 5gbit burst 200kb limit 20000kb
|
||||
|
||||
```
|
||||
|
||||
Here we set delay to 2ms & rate to 5gb to imitate a running within the same region (the commands will be applied automatically when you run the script).
|
||||
|
||||
There's a [Dockerfile](https://github.com/namnc/circom-mp-spdz/blob/main/Dockerfile), as well as different benchmark scripts in the repo, so that it's easier to test & benchmark.
|
||||
|
||||
If you want to run these tests yourself:
|
||||
|
||||
1\. Set up the python environment:
|
||||
|
||||
```
|
||||
python3 -m venv .venv
|
||||
source .venv/bin/activate
|
||||
|
||||
```
|
||||
|
||||
2\. Run a local benchmarking script:
|
||||
|
||||
```
|
||||
python3 benchmark_script.py --tests-run=true
|
||||
|
||||
```
|
||||
|
||||
3\. Build & Organize & Run Docker container:
|
||||
|
||||
```
|
||||
docker build -t circom-mp-spdz .
|
||||
docker network create test-network
|
||||
docker run -it --rm --cap-add=NET_ADMIN --name=party1 --network test-network -p 3000:3000 -p 22:22 circom-mp-spdz
|
||||
|
||||
```
|
||||
|
||||
4\. In the Docker container:
|
||||
|
||||
```
|
||||
service ssh start
|
||||
|
||||
```
|
||||
|
||||
5\. Run benchmarking script that imitates few machines:
|
||||
|
||||
```
|
||||
python3 remote_benchmark.py --party1 127.0.0.1:3000
|
||||
|
||||
```
|
||||
|
||||
6\. Deactivate venv
|
||||
|
||||
```
|
||||
deactivate
|
||||
|
||||
```
|
||||
|
||||
**Benchmarks**
|
||||
|
||||
Below we provide benchmark for each different layer separately, a model that combines different layers will yield corresponding combined performance.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
Accuracy of the circuits compared to Keras reference implementation:
|
||||
|
||||

|
||||
|
||||
Our above benchmark only gives a taste of how performance looks for MPC-ML; any interested party can understand approximate performance of a model that combines different layers.
|
||||
156
articles/code-optimizations-in-post-quantum-cryptography.md
Normal file
156
articles/code-optimizations-in-post-quantum-cryptography.md
Normal file
@@ -0,0 +1,156 @@
|
||||
---
|
||||
authors: ["PSE researcher Miha Stopar"]
|
||||
title: "Code Optimizations in the Landscape of Post-Quantum Cryptography"
|
||||
image: "cover.png"
|
||||
tldr: ""
|
||||
date: "2024-04-07"
|
||||
---
|
||||
|
||||
There's no doubt that lattice-based cryptography is currently the most promising branch of post-quantum cryptography. Not only is it highly performant and versatile, it also provides the only known technique to achieve fully homomorphic encryption.
|
||||
|
||||
One reason lattice-based cryptography is so fast is that it can be heavily vectorized. This contrasts noticeably with isogeny-based cryptography, which offers far fewer opportunities for parallelism. In this post, I will briefly compare the potential for vectorization in both cryptographic paradigms. Of course, these two branches represent only a subset of the broader landscape of post-quantum cryptography.
|
||||
|
||||
Let's first take a look at what vectorization is.
|
||||
|
||||
## Vectorization
|
||||
|
||||
Vectorization refers to the process of performing multiple operations simultaneously using Single Instruction, Multiple Data (SIMD) techniques. This is a powerful way to speed up computations by leveraging modern CPU instructions like SSE (Streaming SIMD Extensions), AVX (Advanced Vector Extensions), and their newer versions like AVX-512.
|
||||
|
||||
But what does that mean, really?
|
||||
|
||||
Let's say we would like to XOR 32 bytes as given below:
|
||||
|
||||
```
|
||||
Input: 11001010 10101100 00011011 ...
|
||||
Key : 10110110 01100100 11100011 ...
|
||||
---------------------------------
|
||||
Output: 01111100 11001000 11111000 ...
|
||||
|
||||
```
|
||||
|
||||
Instead of doing 32 operations one byte at a time, AVX can XOR 32 bytes at once:
|
||||
|
||||
```
|
||||
__m256i data = _mm256_loadu_si256(input)
|
||||
__m256i key = _mm256_loadu_si256(key)
|
||||
__m256i hash = _mm256_xor_si256(data, key)
|
||||
|
||||
```
|
||||
|
||||
First, the AVX2 register uses `input` to load 32 bytes (256 bits) into one 256-bit register. Then, it loads 32 bytes of `key` into another register. Finally, it performs bitwise XOR between `data` and `key`, element by element. But here, 32 bytes are processed in one instruction!
|
||||
|
||||
## Lattice-based cryptography
|
||||
|
||||
At the core of lattice-based cryptography lies matrix-vector multiplication. For example, let's consider a two-dimensional lattice LL with a basis {v1,v2}\\{v_1, v_2\\}. Lattice elements are vectors of the form a1v1+a2v2a_1 v_1 + a_2 v_2, where a1,a2∈Za_1, a_2 \\in \\mathbb{Z}. If we construct a matrix MM such that v1v_1 and v2v_2 are the two columns of this matrix, then multiplying MM by the vector (a1,a2)T(a_1, a_2)^T gives a lattice element.
|
||||
|
||||

|
||||
|
||||
Matrix multiplication illustration
|
||||
|
||||
For performance reasons, lattice-based cryptography relies on polynomial rings rather than ordinary vectors. I won’t go into the details, but let’s consider the following example.
|
||||
|
||||

|
||||
|
||||
The matrix-vector multiplication above is actually the multiplication of two polynomials
|
||||
|
||||

|
||||
|
||||
in the ring Z\[x\]/(x3+1)\\mathbb{Z}\[x\]/(x^3 + 1). Note that in this ring, it holds x3\=−1x^3 = -1. In practice, nn is typically a power of 22, for example n\=64n = 64.
|
||||
|
||||
So, multiplying a(x)a(x) and b(x)b(x) and considering x3\=−1x^3 = -1, we obtain the same result as with the matrix-vector multiplication above:
|
||||
|
||||

|
||||
|
||||
Having matrices of this form is beneficial for two reasons: less space is required to store the matrix (only 33 elements for a 3×33 \\times 3 matrix), and we can apply the [Number Theoretic Transform](https://en.wikipedia.org/wiki/Discrete_Fourier_transform_over_a_ring) (NTT) algorithm for polynomial multiplication instead of performing matrix-vector multiplication. When using the NTT, we multiply polynomial evaluations rather than working with polynomial coefficients, which reduces the complexity from O(n2)O(n^2) to O(nlogn)O(n \\log n) operations.
|
||||
|
||||
That means that instead of directly multiplying the polynomials
|
||||
|
||||

|
||||
|
||||
as
|
||||
|
||||

|
||||
|
||||
we apply the NTT to compute the evaluations a(ω1),…,a(ωn)a(\\omega_1), …, a(\\omega_n) and b(ω1),…,b(ωn)b(\\omega_1), …, b(\\omega_n). This allows us to perform only nn pointwise multiplications, significantly improving efficiency:
|
||||
|
||||

|
||||
|
||||
This way we obtain the evaluations of a(x)b(x)a(x)b(x) at ω1,...,ωn\\omega_1, ..., \\omega_n. To recover the coefficients of a(x)b(x)a(x)b(x), we apply the inverse NTT. In the next section, we will see how vectorization can further accelerate such pointwise operations.
|
||||
|
||||
### Lattices and vectorization
|
||||
|
||||
So, why is lattice-based cryptography particularly well-suited for vectorization?
|
||||
|
||||
Remember, typically lattice-based cryptography deals with polynomials in Z\[x\]/(x64+1)\\mathbb{Z}\[x\]/(x^{64}+1) or Z\[x\]/(x128+1)\\mathbb{Z}\[x\]/(x^{128}+1). For n\=64n = 64, each polynomial has 6464 coefficients, for example:
|
||||
|
||||

|
||||
|
||||
Now, if you want, for example, to compute a(x)+b(x)a(x) + b(x), you need to compute
|
||||
|
||||

|
||||
|
||||
This is simple to vectorize: we need to load aia_i and bib_i into an AVX register. Suppose the register has 3232 slots, each of length 16 bits. If the coefficients are smaller than 16 bits, we can use two registers for a single polynomial. With a single instruction, we compute the sum of the first 3232 coefficients:
|
||||
|
||||
```
|
||||
a_1 | a_2 | ... | a_31 |
|
||||
b_1 | b_2 | ... | b_31 |
|
||||
->
|
||||
a_1 + b_1 | a_2 + b_2 | ... | a_31 + b_31 |
|
||||
|
||||
```
|
||||
|
||||
In the second instruction, we compute the sum of the next 3232 coefficients:
|
||||
|
||||
```
|
||||
a_32 | a_33 | ... | a_63 |
|
||||
b_32 | b_33 | ... | b_63 |
|
||||
->
|
||||
a_32 + b_32 | a_33 + b_33 | ... | a_63 + b_63 |
|
||||
|
||||
```
|
||||
|
||||
Many lattice-based schemes heavily rely on matrix-vector multiplications, and similar to the approach above, these operations can be naturally expressed using vectorized instructions. Returning to the NTT, we see that these two polynomials can be multiplied efficiently using vectorization in just two instructions (performing 32 pointwise multiplications in a single instruction), along with the NTT and its inverse.
|
||||
|
||||
## Isogenies and vectorization
|
||||
|
||||
On the contrary, vectorizing isogeny-based schemes appears to be challenging. An isogeny is a homomorphism between two elliptic curves, and isogeny-based cryptography relies on the assumption that finding an isogeny between two given curves is difficult.
|
||||
|
||||

|
||||
|
||||
In isogeny-based cryptography, there are no structures with 6464 or 128128 elements that would allow straightforward vectorization. The optimizations used in isogeny-based cryptography are similar to those in traditional elliptic curve cryptography. Note, however, that traditional elliptic curve cryptography based on the discrete logarithm problem is not quantum-safe, while isogeny-based cryptography is believed to be quantum-safe: there is no known quantum algorithm that can efficiently find an isogeny between two elliptic curves.
|
||||
|
||||
Let's have a look at some optimizations used in elliptic curve cryptography:
|
||||
|
||||
- Choosing the prime pp such that the arithmetic in Fp\\mathbb{F}\_p is efficient,
|
||||
- Montgomery Reduction: efficiently computes modular reductions without expensive division operations,
|
||||
- Montgomery Inversion: avoids divisions entirely when used with Montgomery multiplication,
|
||||
- Using Montgomery or Edwards curves: enables efficient arithmetic,
|
||||
- Shamir’s Trick: computes kP+mQkP+mQ simultaneously, reducing the number of operations.
|
||||
|
||||
It is worth noting that some of these optimizations—such as Montgomery reduction and Montgomery multiplication—also apply to lattice-based cryptography.
|
||||
|
||||
Let's observe a simple example that illustrates the importance of choosing a suitable prime pp for efficient finite field arithmetic. If we choose p≡3(mod4)p \\equiv 3\\pmod{4} (that means p+1p+1 is divisible by 44), then computing square roots becomes straightforward: to find the square root of xx, one simply computes:
|
||||
|
||||
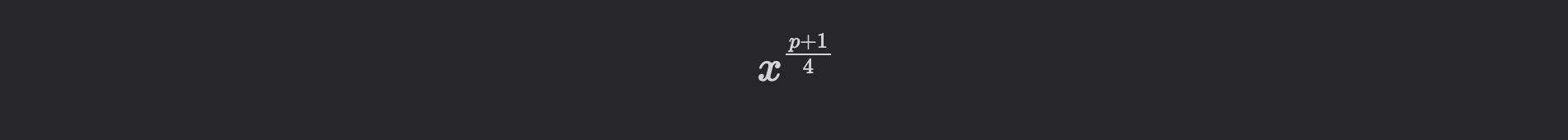
|
||||
|
||||
Note that by Fermat's Little Theorem, it holds that xp\=x(modp)x^p = x \\pmod{p}, which means:
|
||||
|
||||

|
||||
|
||||
Elliptic curve operations can be vectorized but to a lesser extent as lattice-based operations. One [example](https://orbilu.uni.lu/bitstream/10993/48810/1/SAC2020.pdf) is handling field elements in radix-2292^{29} representation:
|
||||
|
||||

|
||||
|
||||
where 0≤fi<2290 \\leq f_i < 2^{29} for 0≤i≤8.0 \\leq i \\leq 8.
|
||||
|
||||
However, the number of lanes plays a crucial role in SIMD optimizations. In lattice-based cryptography, it is straightforward to have 6464 or 128128 lanes, which can significantly enhance parallel processing capabilities. In contrast, the example above only utilizes 99 lanes, which limits the potential for SIMD optimization.
|
||||
|
||||
## Conclusion
|
||||
|
||||
Lattice-based cryptography is currently at the forefront of post-quantum cryptographic advancements, with performance being one of the key reasons for its prominence. Somewhat unjustly, isogeny-based cryptography has gained a reputation for being broken in recent years. This is due to the [Castryck-Decru attack](https://eprint.iacr.org/2022/975), which, however, applies only to schemes that expose additional information about the isogeny, namely the image of two points:
|
||||
|
||||

|
||||
|
||||
Given the images of two points under an isogeny ψ\\psi, one can compute the images of other points as well. For this, [Kani's lemma](https://mast.queensu.ca/~kani/papers/numgenl.pdf), a remarkable result from 1997, is used. Thankfully, many isogeny-based schemes do not expose the images of points. One such example is [SQIsign](https://sqisign.org/), which features super-compact keys and signatures, making them comparable in size to those used in elliptic-curve-based signature schemes. In summary, isogeny-based cryptography is less performant and less versatile than lattice-based cryptography; however, it offers advantages such as significantly smaller keys and signatures.
|
||||
|
||||
It will be interesting to see which area of post-quantum cryptography emerges as the dominant choice in the coming years. I haven't explored code-based, multivariate, or hash-based cryptography in depth yet, and each of these approaches comes with its own strengths and challenges.
|
||||
77
components/blog/blog-article-card.tsx
Normal file
77
components/blog/blog-article-card.tsx
Normal file
@@ -0,0 +1,77 @@
|
||||
import { Article } from "@/lib/blog"
|
||||
import { cva } from "class-variance-authority"
|
||||
import Image from "next/image"
|
||||
|
||||
const tagCardVariants = cva(
|
||||
"text-xs font-sans text-tuatara-950 rounded-[3px] py-[2px] px-[6px] w-fit",
|
||||
{
|
||||
variants: {
|
||||
variant: {
|
||||
primary: "bg-[#D8FEA8]",
|
||||
secondary: "bg-[#C2E8F5]",
|
||||
},
|
||||
},
|
||||
}
|
||||
)
|
||||
|
||||
export const BlogArticleCard = ({
|
||||
id,
|
||||
image,
|
||||
title,
|
||||
date,
|
||||
authors,
|
||||
}: Article) => {
|
||||
const imageUrl = `/articles/${id}/${image}`
|
||||
return (
|
||||
<div className="flex flex-col h-full">
|
||||
<div className="relative h-48 w-full overflow-hidden">
|
||||
{image && (
|
||||
<Image
|
||||
src={imageUrl}
|
||||
alt={title}
|
||||
fill
|
||||
className="object-cover"
|
||||
quality={90}
|
||||
/>
|
||||
)}
|
||||
</div>
|
||||
|
||||
<div className="p-5 flex flex-col gap-5 lg:gap-8 min-h-[180px]">
|
||||
<div className="flex flex-col gap-2">
|
||||
<div className="flex items-center gap-1">
|
||||
<Image
|
||||
src="/logos/pse-logo-bg.svg"
|
||||
alt="Privacy and Scaling Explorations"
|
||||
width={24}
|
||||
height={24}
|
||||
/>
|
||||
<span className="text-black/50 font-medium text-sm">
|
||||
Privacy and Scaling Explorations
|
||||
</span>
|
||||
</div>
|
||||
<h2 className="text-2xl font-bold leading-7 text-black duration-200 cursor-pointer hover:text-anakiwa-500">
|
||||
{title}
|
||||
</h2>
|
||||
</div>
|
||||
|
||||
<div className="flex justify-between mt-auto">
|
||||
{date && (
|
||||
<div className={tagCardVariants({ variant: "secondary" })}>
|
||||
{new Date(date).toLocaleDateString("en-US", {
|
||||
month: "long",
|
||||
day: "numeric",
|
||||
year: "numeric",
|
||||
})}
|
||||
</div>
|
||||
)}
|
||||
|
||||
{authors && authors.length > 0 && (
|
||||
<p className="text-gray-500 text-sm mt-auto">
|
||||
By {authors.join(", ")}
|
||||
</p>
|
||||
)}
|
||||
</div>
|
||||
</div>
|
||||
</div>
|
||||
)
|
||||
}
|
||||
36
components/blog/blog-articles.tsx
Normal file
36
components/blog/blog-articles.tsx
Normal file
@@ -0,0 +1,36 @@
|
||||
import { Article, getArticles } from "@/lib/blog"
|
||||
import Link from "next/link"
|
||||
import Image from "next/image"
|
||||
import { cva } from "class-variance-authority"
|
||||
import { BlogArticleCard } from "./blog-article-card"
|
||||
|
||||
export const BlogArticles = () => {
|
||||
const articles = getArticles()
|
||||
|
||||
return (
|
||||
<div className="grid grid-cols-1 md:grid-cols-3 gap-8">
|
||||
{articles.map(
|
||||
({ id, title, image, tldr = "", date, authors, content }: Article) => {
|
||||
const url = `/blog/${id}`
|
||||
return (
|
||||
<Link
|
||||
className="flex-1 w-full h-full group hover:opacity-90 transition-opacity duration-300 rounded-xl overflow-hidden bg-white shadow-sm border border-slate-900/10"
|
||||
key={id}
|
||||
href={url}
|
||||
rel="noreferrer"
|
||||
>
|
||||
<BlogArticleCard
|
||||
id={id}
|
||||
image={image}
|
||||
title={title}
|
||||
date={date}
|
||||
authors={authors}
|
||||
content={content}
|
||||
/>
|
||||
</Link>
|
||||
)
|
||||
}
|
||||
)}
|
||||
</div>
|
||||
)
|
||||
}
|
||||
105
components/blog/blog-content.tsx
Normal file
105
components/blog/blog-content.tsx
Normal file
@@ -0,0 +1,105 @@
|
||||
import Blog, { Article, getArticles } from "@/lib/blog"
|
||||
import Link from "next/link"
|
||||
import { AppContent } from "../ui/app-content"
|
||||
import { Markdown } from "../ui/markdown"
|
||||
import { BlogArticleCard } from "./blog-article-card"
|
||||
interface BlogContentProps {
|
||||
post: Article
|
||||
}
|
||||
|
||||
interface BlogImageProps {
|
||||
image: string
|
||||
alt?: string
|
||||
description?: string
|
||||
}
|
||||
|
||||
export function BlogImage({ image, alt, description }: BlogImageProps) {
|
||||
return (
|
||||
<div className="flex flex-col">
|
||||
<img src={image} alt={alt} className="mb-1" />
|
||||
{alt && (
|
||||
<span className="font-semibold text-black text-center capitalize text-sm">
|
||||
{alt}
|
||||
</span>
|
||||
)}
|
||||
{description && (
|
||||
<span className="font-normal text-gray-600 dark:text-gray-200 text-center text-sm mt-2">
|
||||
{description}
|
||||
</span>
|
||||
)}
|
||||
</div>
|
||||
)
|
||||
}
|
||||
|
||||
export function BlogContent({ post }: BlogContentProps) {
|
||||
const articleIndex = getArticles().findIndex(
|
||||
(article) => article.id === post.id
|
||||
)
|
||||
|
||||
const prevArticle = articleIndex > 0 ? getArticles()[articleIndex - 1] : null
|
||||
|
||||
const nextArticle =
|
||||
articleIndex < getArticles().length - 1
|
||||
? getArticles()[articleIndex + 1]
|
||||
: null
|
||||
|
||||
const moreArticles = [prevArticle, nextArticle].filter(Boolean) as Article[]
|
||||
|
||||
return (
|
||||
<AppContent className="max-w-[978px]">
|
||||
<div className="flex flex-col gap-10">
|
||||
<div className="flex flex-col gap-5">
|
||||
<Markdown>{post?.content ?? ""}</Markdown>
|
||||
</div>
|
||||
|
||||
{moreArticles?.length > 0 && (
|
||||
<div className="flex flex-col gap-8">
|
||||
<div className="flex items-center justify-between">
|
||||
<span className="text-tuatara-950 text-lg font-semibold leading-6">
|
||||
More articles
|
||||
</span>
|
||||
<Link
|
||||
href="/blog"
|
||||
className="text-black font-bold text-base leading-6 hover:underline hover:text-anakiwa-500"
|
||||
>
|
||||
View all
|
||||
</Link>
|
||||
</div>
|
||||
<div className="grid grid-cols-1 gap-8 md:grid-cols-2">
|
||||
{moreArticles.map(
|
||||
({
|
||||
id,
|
||||
title,
|
||||
image,
|
||||
tldr = "",
|
||||
date,
|
||||
content,
|
||||
authors,
|
||||
}: Article) => {
|
||||
const url = `/blog/${id}`
|
||||
return (
|
||||
<Link
|
||||
href={url}
|
||||
key={id}
|
||||
className="flex-1 w-full h-full group hover:opacity-90 transition-opacity duration-300 rounded-xl overflow-hidden bg-white shadow-sm border border-slate-900/10"
|
||||
>
|
||||
<BlogArticleCard
|
||||
id={id}
|
||||
image={image}
|
||||
title={title}
|
||||
date={date}
|
||||
content={content}
|
||||
authors={authors}
|
||||
tldr={tldr}
|
||||
/>
|
||||
</Link>
|
||||
)
|
||||
}
|
||||
)}
|
||||
</div>
|
||||
</div>
|
||||
)}
|
||||
</div>
|
||||
</AppContent>
|
||||
)
|
||||
}
|
||||
@@ -1,19 +1,19 @@
|
||||
import React from 'react'
|
||||
import Image from 'next/image'
|
||||
import { useRouter } from 'next/navigation'
|
||||
import { VariantProps, cva } from 'class-variance-authority'
|
||||
import React from "react"
|
||||
import Image from "next/image"
|
||||
import { useRouter } from "next/navigation"
|
||||
import { VariantProps, cva } from "class-variance-authority"
|
||||
|
||||
import { getProjectById } from '@/lib/projectsUtils'
|
||||
import { getProjectById } from "@/lib/projectsUtils"
|
||||
import {
|
||||
ProjectInterface,
|
||||
ProjectLinkWebsite,
|
||||
ProjectStatus,
|
||||
ProjectStatusLabelMapping,
|
||||
} from '@/lib/types'
|
||||
import { cn } from '@/lib/utils'
|
||||
import { LocaleTypes } from '@/app/i18n/settings'
|
||||
} from "@/lib/types"
|
||||
import { cn } from "@/lib/utils"
|
||||
import { LocaleTypes } from "@/app/i18n/settings"
|
||||
|
||||
import { ProjectLink } from './project-link'
|
||||
import { ProjectLink } from "./project-link"
|
||||
|
||||
interface ProjectCardProps
|
||||
extends React.HTMLAttributes<HTMLDivElement>,
|
||||
@@ -24,35 +24,35 @@ interface ProjectCardProps
|
||||
}
|
||||
|
||||
const tagCardVariants = cva(
|
||||
'text-xs font-sans text-tuatara-950 rounded-[3px] py-[2px] px-[6px]',
|
||||
"text-xs font-sans text-tuatara-950 rounded-[3px] py-[2px] px-[6px]",
|
||||
{
|
||||
variants: {
|
||||
variant: {
|
||||
primary: 'bg-[#D8FEA8]',
|
||||
secondary: 'bg-[#C2E8F5]',
|
||||
primary: "bg-[#D8FEA8]",
|
||||
secondary: "bg-[#C2E8F5]",
|
||||
},
|
||||
},
|
||||
}
|
||||
)
|
||||
const projectCardVariants = cva(
|
||||
'flex flex-col overflow-hidden rounded-lg transition duration-200 ease-in border border-transparent',
|
||||
"flex flex-col overflow-hidden rounded-lg transition duration-200 ease-in border border-transparent",
|
||||
{
|
||||
variants: {
|
||||
showLinks: {
|
||||
true: 'min-h-[280px]',
|
||||
false: 'min-h-[200px]',
|
||||
true: "min-h-[280px]",
|
||||
false: "min-h-[200px]",
|
||||
},
|
||||
border: {
|
||||
true: 'border border-slate-900/20',
|
||||
true: "border border-slate-900/20",
|
||||
},
|
||||
},
|
||||
}
|
||||
)
|
||||
|
||||
export const ProjectStatusColorMapping: Record<ProjectStatus, string> = {
|
||||
active: '#D8FEA8',
|
||||
inactive: '#FFB7AA',
|
||||
maintained: '#FFEC9E',
|
||||
active: "#D8FEA8",
|
||||
inactive: "#FFB7AA",
|
||||
maintained: "#FFEC9E",
|
||||
}
|
||||
|
||||
export default function ProjectCard({
|
||||
@@ -73,7 +73,7 @@ export default function ProjectCard({
|
||||
return (
|
||||
<div
|
||||
className={cn(
|
||||
'group',
|
||||
"group",
|
||||
projectCardVariants({ showLinks, border, className })
|
||||
)}
|
||||
>
|
||||
@@ -85,7 +85,7 @@ export default function ProjectCard({
|
||||
}}
|
||||
>
|
||||
<Image
|
||||
src={`/project-banners/${image ? image : 'fallback.webp'}`}
|
||||
src={`/project-banners/${image ? image : "fallback.webp"}`}
|
||||
alt={`${name} banner`}
|
||||
width={1200}
|
||||
height={630}
|
||||
@@ -143,12 +143,12 @@ export default function ProjectCard({
|
||||
{cardTags && (
|
||||
<div className="flex items-center gap-1">
|
||||
{cardTags?.primary && (
|
||||
<div className={tagCardVariants({ variant: 'primary' })}>
|
||||
<div className={tagCardVariants({ variant: "primary" })}>
|
||||
{cardTags?.primary}
|
||||
</div>
|
||||
)}
|
||||
{cardTags?.secondary && (
|
||||
<div className={tagCardVariants({ variant: 'secondary' })}>
|
||||
<div className={tagCardVariants({ variant: "secondary" })}>
|
||||
{cardTags?.secondary}
|
||||
</div>
|
||||
)}
|
||||
|
||||
@@ -1,9 +1,11 @@
|
||||
import React from 'react'
|
||||
import ReactMarkdown, { Components } from 'react-markdown'
|
||||
import remarkGfm from 'remark-gfm'
|
||||
"use client"
|
||||
|
||||
import React from "react"
|
||||
import ReactMarkdown, { Components } from "react-markdown"
|
||||
import remarkGfm from "remark-gfm"
|
||||
|
||||
const generateSectionId = (text: string) => {
|
||||
return text.toLowerCase().replace(/[^a-z0-9]+/g, '-')
|
||||
return text.toLowerCase().replace(/[^a-z0-9]+/g, "-")
|
||||
}
|
||||
|
||||
export const createMarkdownElement = (
|
||||
@@ -15,7 +17,7 @@ export const createMarkdownElement = (
|
||||
ref: (node: HTMLElement | null) => {
|
||||
if (node && node.textContent) {
|
||||
node.setAttribute(
|
||||
'data-section-id',
|
||||
"data-section-id",
|
||||
generateSectionId(node.textContent)
|
||||
)
|
||||
}
|
||||
@@ -33,59 +35,69 @@ const Table = (props: any) => {
|
||||
// Styling for HTML attributes for markdown component
|
||||
const REACT_MARKDOWN_CONFIG: Components = {
|
||||
a: ({ ...props }) =>
|
||||
createMarkdownElement('a', {
|
||||
className: 'text-anakiwa-500 hover:text-orange duration-200',
|
||||
target: '_blank',
|
||||
createMarkdownElement("a", {
|
||||
className: "text-anakiwa-500 hover:text-orange duration-200",
|
||||
target: "_blank",
|
||||
...props,
|
||||
}),
|
||||
h1: ({ ...props }) =>
|
||||
createMarkdownElement('h1', {
|
||||
className: 'text-neutral-800 text-4xl md:text-5xl font-bold',
|
||||
createMarkdownElement("h1", {
|
||||
className: "text-neutral-800 text-4xl md:text-5xl font-bold",
|
||||
...props,
|
||||
}),
|
||||
h2: ({ ...props }) =>
|
||||
createMarkdownElement('h2', {
|
||||
className: 'text-neutral-800 text-4xl',
|
||||
createMarkdownElement("h2", {
|
||||
className: "text-neutral-800 text-4xl",
|
||||
...props,
|
||||
}),
|
||||
h3: ({ ...props }) =>
|
||||
createMarkdownElement('h3', {
|
||||
className: 'text-neutral-800 text-3xl',
|
||||
createMarkdownElement("h3", {
|
||||
className: "text-neutral-800 text-3xl",
|
||||
...props,
|
||||
}),
|
||||
h4: ({ ...props }) =>
|
||||
createMarkdownElement('h4', {
|
||||
className: 'text-neutral-800 text-xl',
|
||||
createMarkdownElement("h4", {
|
||||
className: "text-neutral-800 text-xl",
|
||||
...props,
|
||||
}),
|
||||
h5: ({ ...props }) =>
|
||||
createMarkdownElement('h5', {
|
||||
className: 'text-neutral-800 text-lg font-bold',
|
||||
createMarkdownElement("h5", {
|
||||
className: "text-neutral-800 text-lg font-bold",
|
||||
...props,
|
||||
}),
|
||||
h6: ({ ...props }) =>
|
||||
createMarkdownElement('h6', {
|
||||
className: 'text-neutral-800 text-md font-bold',
|
||||
createMarkdownElement("h6", {
|
||||
className: "text-neutral-800 text-md font-bold",
|
||||
...props,
|
||||
}),
|
||||
p: ({ ...props }) =>
|
||||
createMarkdownElement('p', {
|
||||
className: 'text-tuatara-700 font-sans text-base font-normal',
|
||||
createMarkdownElement("p", {
|
||||
className: "text-tuatara-700 font-sans text-base font-normal",
|
||||
...props,
|
||||
}),
|
||||
ul: ({ ordered, ...props }) =>
|
||||
createMarkdownElement(ordered ? 'ol' : 'ul', {
|
||||
createMarkdownElement(ordered ? "ol" : "ul", {
|
||||
className:
|
||||
'ml-6 list-disc text-tuatara-700 font-sans text-base font-normal',
|
||||
"ml-6 list-disc text-tuatara-700 font-sans text-base font-normal",
|
||||
...props,
|
||||
}),
|
||||
ol: ({ ordered, ...props }) =>
|
||||
createMarkdownElement(ordered ? 'ol' : 'ul', {
|
||||
createMarkdownElement(ordered ? "ol" : "ul", {
|
||||
className:
|
||||
'ml-6 list-disc text-tuatara-700 font-sans text-base font-normal',
|
||||
"ml-6 list-disc text-tuatara-700 font-sans text-base font-normal",
|
||||
...props,
|
||||
}),
|
||||
table: Table,
|
||||
pre: ({ ...props }) =>
|
||||
createMarkdownElement("pre", {
|
||||
className: "bg-tuatara-950 p-4 rounded-lg text-white",
|
||||
...props,
|
||||
}),
|
||||
img: ({ ...props }) =>
|
||||
createMarkdownElement("img", {
|
||||
className: "w-full rounded-lg object-cover",
|
||||
...props,
|
||||
}),
|
||||
}
|
||||
|
||||
interface MarkdownProps {
|
||||
|
||||
@@ -1,47 +1,46 @@
|
||||
import { MainNavProps } from '@/components/main-nav'
|
||||
import { useTranslation } from '@/app/i18n/client'
|
||||
import { LocaleTypes, fallbackLng, languageList } from '@/app/i18n/settings'
|
||||
import { MainNavProps } from "@/components/main-nav"
|
||||
import { useTranslation } from "@/app/i18n/client"
|
||||
import { LocaleTypes, fallbackLng, languageList } from "@/app/i18n/settings"
|
||||
|
||||
export function useAppSettings(lang: LocaleTypes) {
|
||||
const { t } = useTranslation(lang, 'common')
|
||||
const { t } = useTranslation(lang, "common")
|
||||
|
||||
// get the active language label
|
||||
const activeLanguage =
|
||||
languageList.find((language) => language.key === lang)?.label ??
|
||||
languageList.find((language) => language.key === fallbackLng)?.label
|
||||
|
||||
const MAIN_NAV: MainNavProps['items'] = [
|
||||
const MAIN_NAV: MainNavProps["items"] = [
|
||||
{
|
||||
title: t('menu.home'),
|
||||
href: '/',
|
||||
title: t("menu.home"),
|
||||
href: "/",
|
||||
onlyMobile: true,
|
||||
},
|
||||
{
|
||||
title: 'Devcon 7',
|
||||
href: '/devcon-7',
|
||||
title: "Devcon 7",
|
||||
href: "/devcon-7",
|
||||
onlyFooter: true,
|
||||
},
|
||||
{
|
||||
title: t('menu.projectLibrary'),
|
||||
href: '/projects',
|
||||
title: t("menu.projectLibrary"),
|
||||
href: "/projects",
|
||||
},
|
||||
{
|
||||
title: t('menu.programs'),
|
||||
href: '/programs',
|
||||
title: t("menu.programs"),
|
||||
href: "/programs",
|
||||
onlyFooter: true,
|
||||
},
|
||||
{
|
||||
title: t('menu.about'),
|
||||
href: '/about',
|
||||
title: t("menu.about"),
|
||||
href: "/about",
|
||||
},
|
||||
{
|
||||
title: t('menu.resources'),
|
||||
href: '/resources',
|
||||
title: t("menu.resources"),
|
||||
href: "/resources",
|
||||
},
|
||||
{
|
||||
title: t('menu.blog'),
|
||||
href: 'https://mirror.xyz/privacy-scaling-explorations.eth',
|
||||
external: true,
|
||||
title: t("menu.blog"),
|
||||
href: "/blog",
|
||||
onlyHeader: true,
|
||||
},
|
||||
]
|
||||
|
||||
64
lib/blog.ts
Normal file
64
lib/blog.ts
Normal file
@@ -0,0 +1,64 @@
|
||||
import fs from "fs"
|
||||
import path from "path"
|
||||
import matter from "gray-matter"
|
||||
|
||||
export interface Article {
|
||||
id: string
|
||||
title: string
|
||||
image?: string
|
||||
tldr?: string
|
||||
content: string
|
||||
date: string
|
||||
authors?: string[]
|
||||
signature?: string
|
||||
publicKey?: string
|
||||
hash?: string
|
||||
}
|
||||
|
||||
const articlesDirectory = path.join(process.cwd(), "articles")
|
||||
|
||||
// Get all articles from /articles
|
||||
export function getArticles() {
|
||||
// Get file names under /articles
|
||||
const fileNames = fs.readdirSync(articlesDirectory)
|
||||
const allArticlesData = fileNames.map((fileName) => {
|
||||
// Remove ".md" from file name to get id
|
||||
const id = fileName.replace(/\.md$/, "")
|
||||
if (id.toLowerCase() === "readme") {
|
||||
return null
|
||||
}
|
||||
|
||||
// Read markdown file as string
|
||||
const fullPath = path.join(articlesDirectory, fileName)
|
||||
const fileContents = fs.readFileSync(fullPath, "utf8")
|
||||
|
||||
const matterResult = matter(fileContents)
|
||||
|
||||
return {
|
||||
id,
|
||||
...matterResult.data,
|
||||
content: matterResult.content,
|
||||
}
|
||||
})
|
||||
// Sort posts by date
|
||||
return allArticlesData
|
||||
.filter(Boolean)
|
||||
.sort((a: any, b: any) => {
|
||||
if (a.date > b.date) {
|
||||
return 1
|
||||
} else {
|
||||
return -1
|
||||
}
|
||||
})
|
||||
.filter((article: any) => article.id !== "article-template") as Article[]
|
||||
}
|
||||
|
||||
export function getArticleById(slug?: string) {
|
||||
const articles = getArticles()
|
||||
|
||||
return articles.find((article) => article.id === slug)
|
||||
}
|
||||
|
||||
const lib = { getArticles, getArticleById }
|
||||
|
||||
export default lib
|
||||
@@ -33,6 +33,7 @@
|
||||
"dotenv": "^16.4.4",
|
||||
"framer-motion": "^10.12.17",
|
||||
"fuse.js": "^6.6.2",
|
||||
"gray-matter": "^4.0.3",
|
||||
"gsap": "^3.12.1",
|
||||
"html-to-react": "^1.7.0",
|
||||
"i18next": "^23.7.16",
|
||||
|
||||
BIN
public/articles/circom-mpc-retrospective/cover.jpeg
Normal file
BIN
public/articles/circom-mpc-retrospective/cover.jpeg
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 2.4 MiB |
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 3.8 MiB |
91
yarn.lock
91
yarn.lock
@@ -1988,6 +1988,15 @@ __metadata:
|
||||
languageName: node
|
||||
linkType: hard
|
||||
|
||||
"argparse@npm:^1.0.7":
|
||||
version: 1.0.10
|
||||
resolution: "argparse@npm:1.0.10"
|
||||
dependencies:
|
||||
sprintf-js: "npm:~1.0.2"
|
||||
checksum: 10/c6a621343a553ff3779390bb5ee9c2263d6643ebcd7843227bdde6cc7adbed796eb5540ca98db19e3fd7b4714e1faa51551f8849b268bb62df27ddb15cbcd91e
|
||||
languageName: node
|
||||
linkType: hard
|
||||
|
||||
"argparse@npm:^2.0.1":
|
||||
version: 2.0.1
|
||||
resolution: "argparse@npm:2.0.1"
|
||||
@@ -3363,6 +3372,16 @@ __metadata:
|
||||
languageName: node
|
||||
linkType: hard
|
||||
|
||||
"esprima@npm:^4.0.0":
|
||||
version: 4.0.1
|
||||
resolution: "esprima@npm:4.0.1"
|
||||
bin:
|
||||
esparse: ./bin/esparse.js
|
||||
esvalidate: ./bin/esvalidate.js
|
||||
checksum: 10/f1d3c622ad992421362294f7acf866aa9409fbad4eb2e8fa230bd33944ce371d32279667b242d8b8907ec2b6ad7353a717f3c0e60e748873a34a7905174bc0eb
|
||||
languageName: node
|
||||
linkType: hard
|
||||
|
||||
"esquery@npm:^1.5.0":
|
||||
version: 1.6.0
|
||||
resolution: "esquery@npm:1.6.0"
|
||||
@@ -3440,6 +3459,15 @@ __metadata:
|
||||
languageName: node
|
||||
linkType: hard
|
||||
|
||||
"extend-shallow@npm:^2.0.1":
|
||||
version: 2.0.1
|
||||
resolution: "extend-shallow@npm:2.0.1"
|
||||
dependencies:
|
||||
is-extendable: "npm:^0.1.0"
|
||||
checksum: 10/8fb58d9d7a511f4baf78d383e637bd7d2e80843bd9cd0853649108ea835208fb614da502a553acc30208e1325240bb7cc4a68473021612496bb89725483656d8
|
||||
languageName: node
|
||||
linkType: hard
|
||||
|
||||
"extend@npm:^3.0.0":
|
||||
version: 3.0.2
|
||||
resolution: "extend@npm:3.0.2"
|
||||
@@ -3871,6 +3899,18 @@ __metadata:
|
||||
languageName: node
|
||||
linkType: hard
|
||||
|
||||
"gray-matter@npm:^4.0.3":
|
||||
version: 4.0.3
|
||||
resolution: "gray-matter@npm:4.0.3"
|
||||
dependencies:
|
||||
js-yaml: "npm:^3.13.1"
|
||||
kind-of: "npm:^6.0.2"
|
||||
section-matter: "npm:^1.0.0"
|
||||
strip-bom-string: "npm:^1.0.0"
|
||||
checksum: 10/9a8f146a7a918d2524d5d60e0b4d45729f5bca54aa41247f971d9e4bc984943fda58159435763d463ec2abc8a0e238e807bd9b05e3a48f4a613a325c9dd5ad0c
|
||||
languageName: node
|
||||
linkType: hard
|
||||
|
||||
"gsap@npm:^3.12.1":
|
||||
version: 3.12.7
|
||||
resolution: "gsap@npm:3.12.7"
|
||||
@@ -4265,6 +4305,13 @@ __metadata:
|
||||
languageName: node
|
||||
linkType: hard
|
||||
|
||||
"is-extendable@npm:^0.1.0":
|
||||
version: 0.1.1
|
||||
resolution: "is-extendable@npm:0.1.1"
|
||||
checksum: 10/3875571d20a7563772ecc7a5f36cb03167e9be31ad259041b4a8f73f33f885441f778cee1f1fe0085eb4bc71679b9d8c923690003a36a6a5fdf8023e6e3f0672
|
||||
languageName: node
|
||||
linkType: hard
|
||||
|
||||
"is-extglob@npm:^2.1.1":
|
||||
version: 2.1.1
|
||||
resolution: "is-extglob@npm:2.1.1"
|
||||
@@ -4525,6 +4572,18 @@ __metadata:
|
||||
languageName: node
|
||||
linkType: hard
|
||||
|
||||
"js-yaml@npm:^3.13.1":
|
||||
version: 3.14.1
|
||||
resolution: "js-yaml@npm:3.14.1"
|
||||
dependencies:
|
||||
argparse: "npm:^1.0.7"
|
||||
esprima: "npm:^4.0.0"
|
||||
bin:
|
||||
js-yaml: bin/js-yaml.js
|
||||
checksum: 10/9e22d80b4d0105b9899135365f746d47466ed53ef4223c529b3c0f7a39907743fdbd3c4379f94f1106f02755b5e90b2faaf84801a891135544e1ea475d1a1379
|
||||
languageName: node
|
||||
linkType: hard
|
||||
|
||||
"js-yaml@npm:^4.1.0":
|
||||
version: 4.1.0
|
||||
resolution: "js-yaml@npm:4.1.0"
|
||||
@@ -4623,6 +4682,13 @@ __metadata:
|
||||
languageName: node
|
||||
linkType: hard
|
||||
|
||||
"kind-of@npm:^6.0.0, kind-of@npm:^6.0.2":
|
||||
version: 6.0.3
|
||||
resolution: "kind-of@npm:6.0.3"
|
||||
checksum: 10/5873d303fb36aad875b7538798867da2ae5c9e328d67194b0162a3659a627d22f742fc9c4ae95cd1704132a24b00cae5041fc00c0f6ef937dc17080dc4dbb962
|
||||
languageName: node
|
||||
linkType: hard
|
||||
|
||||
"kleur@npm:^4.0.3":
|
||||
version: 4.1.5
|
||||
resolution: "kleur@npm:4.1.5"
|
||||
@@ -5607,6 +5673,7 @@ __metadata:
|
||||
framer-motion: "npm:^10.12.17"
|
||||
fuse.js: "npm:^6.6.2"
|
||||
globals: "npm:^15.14.0"
|
||||
gray-matter: "npm:^4.0.3"
|
||||
gsap: "npm:^3.12.1"
|
||||
html-to-react: "npm:^1.7.0"
|
||||
husky: "npm:^9.1.7"
|
||||
@@ -6735,6 +6802,16 @@ __metadata:
|
||||
languageName: node
|
||||
linkType: hard
|
||||
|
||||
"section-matter@npm:^1.0.0":
|
||||
version: 1.0.0
|
||||
resolution: "section-matter@npm:1.0.0"
|
||||
dependencies:
|
||||
extend-shallow: "npm:^2.0.1"
|
||||
kind-of: "npm:^6.0.0"
|
||||
checksum: 10/cedfda3a9238f66942d92531fe043dd134702a462cdc9e254cd6aa418c66ca0d229900e4da78ffd1a07051e7b239251c4dc4748e9d1c76bf41a37bff7a478556
|
||||
languageName: node
|
||||
linkType: hard
|
||||
|
||||
"semver@npm:^6.3.1":
|
||||
version: 6.3.1
|
||||
resolution: "semver@npm:6.3.1"
|
||||
@@ -7061,6 +7138,13 @@ __metadata:
|
||||
languageName: node
|
||||
linkType: hard
|
||||
|
||||
"sprintf-js@npm:~1.0.2":
|
||||
version: 1.0.3
|
||||
resolution: "sprintf-js@npm:1.0.3"
|
||||
checksum: 10/c34828732ab8509c2741e5fd1af6b767c3daf2c642f267788f933a65b1614943c282e74c4284f4fa749c264b18ee016a0d37a3e5b73aee446da46277d3a85daa
|
||||
languageName: node
|
||||
linkType: hard
|
||||
|
||||
"ssri@npm:^12.0.0":
|
||||
version: 12.0.0
|
||||
resolution: "ssri@npm:12.0.0"
|
||||
@@ -7275,6 +7359,13 @@ __metadata:
|
||||
languageName: node
|
||||
linkType: hard
|
||||
|
||||
"strip-bom-string@npm:^1.0.0":
|
||||
version: 1.0.0
|
||||
resolution: "strip-bom-string@npm:1.0.0"
|
||||
checksum: 10/5635a3656d8512a2c194d6c8d5dee7ef0dde6802f7be9413b91e201981ad4132506656d9cf14137f019fd50f0269390d91c7f6a2601b1bee039a4859cfce4934
|
||||
languageName: node
|
||||
linkType: hard
|
||||
|
||||
"strip-bom@npm:^3.0.0":
|
||||
version: 3.0.0
|
||||
resolution: "strip-bom@npm:3.0.0"
|
||||
|
||||
Reference in New Issue
Block a user