@@ -9,6 +9,10 @@ Enhancing Ethereum through cryptographic research and collective experimentation
|
||||
- For adding new features, please open PR and first merge to staging/dev for QA, or open issue for suggestion, bug report.
|
||||
- For any misc. update such as typo, PR to main and two approval is needed.
|
||||
|
||||
### Add/Edit article
|
||||
|
||||
- For updating/adding a new article [you can follow this guide](https://github.com/privacy-scaling-explorations/pse.dev/blob/main/articles/README.md)
|
||||
|
||||
### Add/Edit project list
|
||||
|
||||
- For updating/adding project detail [you can follow this guide](https://github.com/privacy-scaling-explorations/pse.dev/blob/main/data/projects/README.md)
|
||||
|
||||
92
app/[lang]/blog/[slug]/page.tsx
Normal file
@@ -0,0 +1,92 @@
|
||||
import { blogArticleCardTagCardVariants } from "@/components/blog/blog-article-card"
|
||||
import { BlogContent } from "@/components/blog/blog-content"
|
||||
import { AppContent } from "@/components/ui/app-content"
|
||||
import { Label } from "@/components/ui/label"
|
||||
import { Markdown } from "@/components/ui/markdown"
|
||||
import { getArticles, getArticleById } from "@/lib/blog"
|
||||
import { Metadata } from "next"
|
||||
|
||||
export const generateStaticParams = async () => {
|
||||
const articles = await getArticles()
|
||||
return articles.map(({ id }) => ({
|
||||
slug: id,
|
||||
}))
|
||||
}
|
||||
|
||||
export async function generateMetadata({ params }: any): Promise<Metadata> {
|
||||
const post = await getArticleById(params.slug)
|
||||
|
||||
const imageUrl =
|
||||
(post?.image ?? "")?.length > 0
|
||||
? `/articles/${post?.id}/${post?.image}`
|
||||
: "/og-image.png"
|
||||
|
||||
const metadata: Metadata = {
|
||||
title: post?.title,
|
||||
description: post?.tldr,
|
||||
openGraph: {
|
||||
images: [{ url: imageUrl, width: 1200, height: 630 }],
|
||||
},
|
||||
}
|
||||
|
||||
// Add canonical URL if post has canonical property
|
||||
if (post && "canonical" in post) {
|
||||
metadata.alternates = {
|
||||
canonical: post.canonical as string,
|
||||
}
|
||||
}
|
||||
|
||||
return metadata
|
||||
}
|
||||
|
||||
export default function BlogArticle({ params }: any) {
|
||||
const slug = params.slug
|
||||
const post = getArticleById(slug)
|
||||
|
||||
if (!post) return null
|
||||
return (
|
||||
<div className="flex flex-col">
|
||||
<div className="flex items-start justify-center background-gradient z-0">
|
||||
<div className="w-full bg-cover-gradient border-b border-tuatara-300">
|
||||
<AppContent className="flex flex-col gap-8 py-10 max-w-[978px]">
|
||||
<Label.PageTitle label={post?.title} />
|
||||
{post?.date || post?.tldr ? (
|
||||
<div className="flex flex-col gap-2">
|
||||
{post?.date && (
|
||||
<div
|
||||
className={blogArticleCardTagCardVariants({
|
||||
variant: "secondary",
|
||||
})}
|
||||
>
|
||||
{new Date(post?.date).toLocaleDateString("en-US", {
|
||||
month: "long",
|
||||
day: "numeric",
|
||||
year: "numeric",
|
||||
})}
|
||||
</div>
|
||||
)}
|
||||
{post?.canonical && (
|
||||
<div className="text-sm italic text-gray-500 mt-1">
|
||||
This post was originally posted in{" "}
|
||||
<a
|
||||
href={post.canonical}
|
||||
target="_blank"
|
||||
rel="noopener noreferrer canonical"
|
||||
className="text-primary hover:underline"
|
||||
>
|
||||
{new URL(post.canonical).hostname.replace(/^www\./, "")}
|
||||
</a>
|
||||
</div>
|
||||
)}
|
||||
{post?.tldr && <Markdown>{post?.tldr}</Markdown>}
|
||||
</div>
|
||||
) : null}
|
||||
</AppContent>
|
||||
</div>
|
||||
</div>
|
||||
<div className="pt-10 md:pt-16 pb-32">
|
||||
<BlogContent post={post} />
|
||||
</div>
|
||||
</div>
|
||||
)
|
||||
}
|
||||
33
app/[lang]/blog/page.tsx
Normal file
@@ -0,0 +1,33 @@
|
||||
import { useTranslation } from "@/app/i18n"
|
||||
import { BlogArticles } from "@/components/blog/blog-articles"
|
||||
import { AppContent } from "@/components/ui/app-content"
|
||||
import { Label } from "@/components/ui/label"
|
||||
import { Metadata } from "next"
|
||||
|
||||
export const metadata: Metadata = {
|
||||
title: "Blog",
|
||||
description: "",
|
||||
}
|
||||
|
||||
const BlogPage = async ({ params: { lang } }: any) => {
|
||||
const { t } = await useTranslation(lang, "blog-page")
|
||||
|
||||
return (
|
||||
<div className="flex flex-col">
|
||||
<div className="w-full bg-cover-gradient border-b border-tuatara-300">
|
||||
<AppContent className="flex flex-col gap-4 py-10 w-full">
|
||||
<Label.PageTitle label={t("title")} />
|
||||
<h6 className="font-sans text-base font-normal text-tuatara-950 md:text-[18px] md:leading-[27px] md:max-w-[700px]">
|
||||
{t("subtitle")}
|
||||
</h6>
|
||||
</AppContent>
|
||||
</div>
|
||||
|
||||
<AppContent className="flex flex-col gap-10 py-10">
|
||||
<BlogArticles />
|
||||
</AppContent>
|
||||
</div>
|
||||
)
|
||||
}
|
||||
|
||||
export default BlogPage
|
||||
@@ -1,152 +1,36 @@
|
||||
"use client"
|
||||
|
||||
import Image from "next/image"
|
||||
import Link from "next/link"
|
||||
import PSELogo from "@/public/icons/archstar.webp"
|
||||
import { motion } from "framer-motion"
|
||||
|
||||
import { siteConfig } from "@/config/site"
|
||||
import { Button } from "@/components/ui/button"
|
||||
import { Label } from "@/components/ui/label"
|
||||
import { Banner } from "@/components/banner"
|
||||
import { Divider } from "@/components/divider"
|
||||
import { Icons } from "@/components/icons"
|
||||
import { PageHeader } from "@/components/page-header"
|
||||
import { ConnectWithUs } from "@/components/sections/ConnectWithUs"
|
||||
import { NewsSection } from "@/components/sections/NewsSection"
|
||||
import { WhatWeDo } from "@/components/sections/WhatWeDo"
|
||||
|
||||
import { useTranslation } from "../i18n/client"
|
||||
import { BlogRecentArticles } from "@/components/blog/blog-recent-articles"
|
||||
import { HomepageHeader } from "@/components/sections/HomepageHeader"
|
||||
import { HomepageBanner } from "@/components/sections/HomepageBanner"
|
||||
import { Suspense } from "react"
|
||||
|
||||
/*
|
||||
const Devcon7Banner = () => {
|
||||
function BlogSection({ lang }: { lang: string }) {
|
||||
return (
|
||||
<div className="bg-[#FFDE17] relative py-6">
|
||||
<AppContent>
|
||||
<div className="flex flex-col lg:flex-row items-center gap-4 justify-between">
|
||||
<Image
|
||||
src="/images/devcon-7-banner-title-mobile.svg"
|
||||
alt="Devcon 7 Banner"
|
||||
className="block object-cover md:hidden"
|
||||
width={204}
|
||||
height={54}
|
||||
/>
|
||||
|
||||
<Image
|
||||
src="/images/devcon-7-banner-title-desktop.svg"
|
||||
alt="Devcon 7 Banner"
|
||||
width={559}
|
||||
height={38}
|
||||
className="hidden object-cover md:block"
|
||||
priority
|
||||
/>
|
||||
<span className="hidden lg:flex font-sans font-bold text-[#006838] tracking-[2.5px]">
|
||||
BANGKOK, THAILAND // NOVEMBER 2024
|
||||
</span>
|
||||
<Link
|
||||
href="/en/devcon-7"
|
||||
className="bg-[#EC008C] cursor-pointer hover:scale-105 duration-200 flex items-center py-0.5 px-4 min-h-8 gap-2 rounded-[6px] text-[#FFDE17] text-sm font-medium font-sans"
|
||||
>
|
||||
<span>SEE THE SCHEDULE</span>
|
||||
<Icons.arrowRight />
|
||||
</Link>
|
||||
</div>
|
||||
</AppContent>
|
||||
</div>
|
||||
<Suspense
|
||||
fallback={
|
||||
<div className="py-10 lg:py-16">Loading recent articles...</div>
|
||||
}
|
||||
>
|
||||
{/* @ts-expect-error - This is a valid server component pattern */}
|
||||
<BlogRecentArticles lang={lang} />
|
||||
</Suspense>
|
||||
)
|
||||
}
|
||||
*/
|
||||
|
||||
export default function IndexPage({ params: { lang } }: any) {
|
||||
const { t } = useTranslation(lang, "homepage")
|
||||
const { t: common } = useTranslation(lang, "common")
|
||||
|
||||
return (
|
||||
<section className="flex flex-col">
|
||||
<Divider.Section>
|
||||
<PageHeader
|
||||
title={
|
||||
<motion.h1
|
||||
initial={{ y: 16, opacity: 0 }}
|
||||
animate={{ y: 0, opacity: 1 }}
|
||||
transition={{ duration: 0.8, cubicBezier: "easeOut" }}
|
||||
>
|
||||
<Label.PageTitle label={t("headerTitle")} />
|
||||
</motion.h1>
|
||||
}
|
||||
subtitle={t("headerSubtitle")}
|
||||
image={
|
||||
<div className="m-auto flex h-[320px] w-full max-w-[280px] items-center justify-center md:m-0 md:h-full md:w-full lg:max-w-[380px]">
|
||||
<Image
|
||||
src={PSELogo}
|
||||
alt="pselogo"
|
||||
style={{ objectFit: "cover" }}
|
||||
/>
|
||||
</div>
|
||||
}
|
||||
actions={
|
||||
<div className="flex flex-col lg:flex-row gap-10">
|
||||
<Link
|
||||
href={"/research"}
|
||||
className="flex items-center gap-2 group"
|
||||
>
|
||||
<Button className="w-full sm:w-auto">
|
||||
<div className="flex items-center gap-1">
|
||||
<span className="text-base font-medium uppercase">
|
||||
{common("research")}
|
||||
</span>
|
||||
<Icons.arrowRight
|
||||
fill="white"
|
||||
className="h-5 duration-200 ease-in-out group-hover:translate-x-2"
|
||||
/>
|
||||
</div>
|
||||
</Button>
|
||||
</Link>
|
||||
<Link
|
||||
href={"/projects"}
|
||||
className="flex items-center gap-2 group"
|
||||
>
|
||||
<Button className="w-full sm:w-auto">
|
||||
<div className="flex items-center gap-1">
|
||||
<span className="text-base font-medium uppercase">
|
||||
{common("developmentProjects")}
|
||||
</span>
|
||||
<Icons.arrowRight
|
||||
fill="white"
|
||||
className="h-5 duration-200 ease-in-out group-hover:translate-x-2"
|
||||
/>
|
||||
</div>
|
||||
</Button>
|
||||
</Link>
|
||||
</div>
|
||||
}
|
||||
/>
|
||||
<HomepageHeader lang={lang} />
|
||||
|
||||
<NewsSection lang={lang} />
|
||||
<BlogSection lang={lang} />
|
||||
|
||||
<WhatWeDo lang={lang} />
|
||||
|
||||
<Banner
|
||||
title={common("connectWithUs")}
|
||||
subtitle={common("connectWithUsDescription")}
|
||||
>
|
||||
<Link
|
||||
href={siteConfig.links.discord}
|
||||
target="_blank"
|
||||
rel="noreferrer"
|
||||
passHref
|
||||
>
|
||||
<Button>
|
||||
<div className="flex items-center gap-2">
|
||||
<Icons.discord fill="white" className="h-4" />
|
||||
<span className="text-[14px] uppercase">
|
||||
{t("joinOurDiscord")}
|
||||
</span>
|
||||
<Icons.externalUrl fill="white" className="h-5" />
|
||||
</div>
|
||||
</Button>
|
||||
</Link>
|
||||
</Banner>
|
||||
<HomepageBanner lang={lang} />
|
||||
</Divider.Section>
|
||||
</section>
|
||||
)
|
||||
|
||||
6
app/i18n/locales/en/blog-page.json
Normal file
@@ -0,0 +1,6 @@
|
||||
{
|
||||
"title": "Blog",
|
||||
"subtitle": "Read our latest articles and stay updated on the latest news in the world of cryptography.",
|
||||
"recentArticles": "Recent",
|
||||
"seeMore": "See more"
|
||||
}
|
||||
72
articles/README.md
Normal file
@@ -0,0 +1,72 @@
|
||||
# Adding New Articles
|
||||
|
||||
This document explains how to add new articles to into pse.dev blog section.
|
||||
|
||||
## Step 1: Create the Article File
|
||||
|
||||
1. Duplicate the `_article-template.md` file in the `articles` directory
|
||||
2. Rename it to match your article's title using kebab-case (e.g., `my-new-article.md`)
|
||||
|
||||
## Step 2: Fill in the Article Information
|
||||
|
||||
Edit the frontmatter section at the top of the file:
|
||||
|
||||
```
|
||||
---
|
||||
authors: ["Your Name"] # Add your name or multiple authors in an array
|
||||
title: "Your Article Title" # The title of your article
|
||||
image: "/articles/my-new-article/cover.webp" # Image used as cover
|
||||
tldr: "A brief summary of your article" #Short summary
|
||||
date: "YYYY-MM-DD" # Publication date in ISO format
|
||||
canonical: "mirror.xyz/my-new-article" # (Optional) The original source URL, this tells search engines the primary version of the content
|
||||
---
|
||||
```
|
||||
|
||||
Write your article content using Markdown formatting:
|
||||
|
||||
- Use `#` for main headings (H1), `##` for subheadings (H2), etc.
|
||||
- Use `*italic*` for italic text and `**bold**` for bold text
|
||||
- For code blocks, use triple backticks with optional language specification:
|
||||
```javascript
|
||||
// Your code here
|
||||
```
|
||||
- For images, use the Markdown image syntax: ``
|
||||
- For LaTeX math formulas:
|
||||
- Use single dollar signs for inline math: `$E=mc^2$` will render as $E=mc^2$
|
||||
- Use double dollar signs for block math:
|
||||
```
|
||||
$$
|
||||
F(x) = \int_{-\infty}^{x} f(t) dt
|
||||
$$
|
||||
```
|
||||
Will render as a centered math equation block
|
||||
|
||||
## Step 3: Add Images
|
||||
|
||||
1. Create a new folder in the `/public/articles` directory with **exactly the same name** as your markdown file (without the .md extension)
|
||||
|
||||
- Example: If your article is named `my-new-article.md`, create a folder named `my-new-article`
|
||||
|
||||
2. Add your images to this folder:
|
||||
- Any additional images you want to use in your article should be placed in this folder
|
||||
- Reference images in your article using just the file name and the extensions of it
|
||||
|
||||
## Step 4: Preview Your Article
|
||||
|
||||
Before submitting, make sure to:
|
||||
|
||||
1. Check that your markdown formatting is correct
|
||||
2. Verify all images are displaying properly
|
||||
|
||||
## Step 5: PR Review process
|
||||
|
||||
Open Pull request following the previews step and for any help
|
||||
|
||||
- Suggest to tag: @kalidiagne, @b1gk4t, @AtHeartEngineer for PR review.
|
||||
- If question, please reach out in discord channel #website-pse
|
||||
|
||||
## Important Notes
|
||||
|
||||
- The folder name in `/public/articles` must **exactly match** your markdown filename (without the .md extension)
|
||||
- Use descriptive file names for your additional images
|
||||
- Optimize your images for web before adding them to keep page load times fast
|
||||
7
articles/_article-template.md
Normal file
@@ -0,0 +1,7 @@
|
||||
---
|
||||
authors: [""]
|
||||
title: "Examle Title"
|
||||
image: "cover.png"
|
||||
tldr: ""
|
||||
date: "2024-04-07"
|
||||
---
|
||||
@@ -0,0 +1,163 @@
|
||||
---
|
||||
authors: ["PSE Team"]
|
||||
title: "A Technical Introduction to Arbitrum's Optimistic Rollup"
|
||||
image: null
|
||||
tldr: ""
|
||||
date: "2022-08-29"
|
||||
canonical: "https://mirror.xyz/privacy-scaling-explorations.eth/UlHGv9KIk_2MOHr7POfwZAXP01k221hZwQsLCF63cLQ"
|
||||
---
|
||||
|
||||

|
||||
|
||||
Originally published on Sep 30, 2021:
|
||||
|
||||
Arbitrum is Offchain Labs’ optimistic rollup implementation that aims to greatly increase the throughput of the Ethereum network. This guide is an introduction to how the Arbitrum design works and is meant for anyone looking to get a somewhat technical overview on this layer 2 solution. This article assumes that the reader has some knowledge of Ethereum and optimistic rollups. The following links may be helpful to those who would like more info on optimistic rollups:
|
||||
|
||||
1. [Optimistic Rollups](https://docs.ethhub.io/ethereum-roadmap/layer-2-scaling/optimistic_rollups/)
|
||||
2. [An Incomplete Guide to Rollups](https://vitalik.ca/general/2021/01/05/rollup.html)
|
||||
3. [A Rollup-Centric Ethereum Roadmap](https://ethereum-magicians.org/t/a-rollup-centric-ethereum-roadmap/4698)
|
||||
4. [(Almost) Everything you need to know about the Optimistic Rollup](https://research.paradigm.xyz/rollups)
|
||||
|
||||
The Arbitrum network is run by two main types of nodes — batchers and validators. Together these nodes interact with Ethereum mainnet (layer 1, L1) in order to maintain a separate chain with its own state, known as layer 2 (L2). Batchers are responsible for taking user L2 transactions and submitting the transaction data onto L1. Validators on the other hand, are responsible for reading the transaction data on L1, processing the transaction and therefore updating the L2 state. Validators will then post the updated L2 state data to L1 so that anyone can verify the validity of this new state. The transaction and state data that is actually stored on L1 is described in more detail in the ‘Transaction and State Data Storage on L1’ section.
|
||||
|
||||
**Basic Workflow**
|
||||
|
||||
1. The basic workflow begins with users sending L2 transactions to a batcher node, usually the sequencer.
|
||||
2. Once the sequencer receives enough transactions, it will post them into an L1 smart contract as a batch.
|
||||
3. A validator node will read these transactions from the L1 smart contract and process them on their local copy of the L2 state.
|
||||
4. Once processed, a new L2 state is generated locally and the validator will post this new state root into an L1 smart contract.
|
||||
5. Then, all other validators will process the same transactions on their local copies of the L2 state.
|
||||
6. They will compare their resultant L2 state root with the original one posted to the L1 smart contract.
|
||||
7. If one of the validators gets a different state root than the one posted to L1, they will begin a challenge on L1 (explained in more detail in the ‘Challenges’ section).
|
||||
8. The challenge will require the challenger and the validator that posted the original state root to take turns proving what the correct state root should be.
|
||||
9. Whichever user loses the challenge, gets their initial deposit (stake) slashed. If the original L2 state root posted was invalid, it will be destroyed by future validators and will not be included in the L2 chain.
|
||||
|
||||
The following diagram illustrates this basic workflow for steps 1–6.
|
||||
|
||||
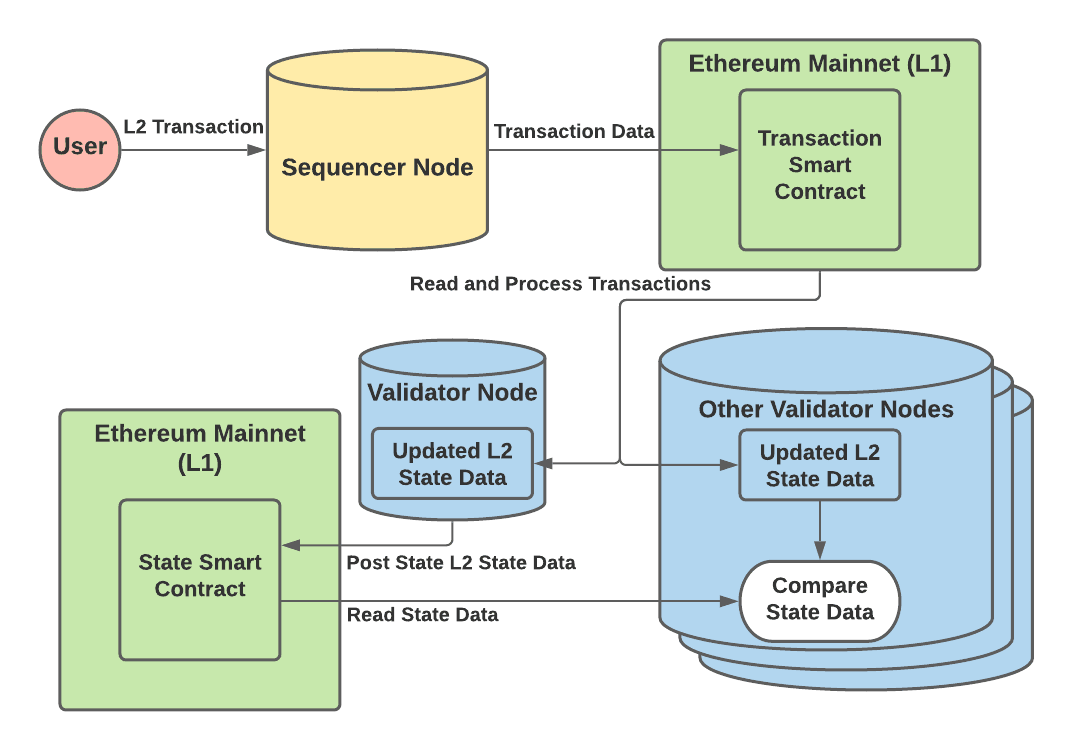
|
||||
|
||||
## Batcher Nodes and Submitting L2 Transaction Data
|
||||
|
||||
There are two different L1 smart contracts that batcher nodes will use to post the transaction data. One is known as the ‘delayed inbox’ while the other is known as the ‘sequencer inbox’. Anyone can send transactions to the delayed inbox, whereas only the sequencer can send transactions to the sequencer inbox. The sequencer inbox pulls in transaction data from the delayed inbox and interweaves it with the other L2 transactions submitted by the sequencer. Therefore, the sequencer inbox is the primary contract where every validator pulls in the latest L2 transaction data.
|
||||
|
||||
There are 3 types of batcher nodes — forwarders, aggregators, and sequencers. Users can send their L2 transactions to any of these 3 nodes. Forwarder nodes forward any L2 transactions to a designated address of another node. The designated node can be either a sequencer or an aggregator and is referred to as the aggregator address.
|
||||
|
||||
Aggregator nodes will take a group of incoming L2 transactions and batch them into a single message to the delayed inbox. The sequencer node will also take a group of incoming L2 transactions and batch them into a single message, but it will send the batch message to the sequencer inbox instead. If the sequencer node stops adding transactions to the sequencer inbox, anyone can force the sequencer inbox to include transactions from the delayed inbox via a smart contract function call. This allows the Arbitrum network to always be available and resistant to a malicious sequencer. Currently Arbitrum is running their own single sequencer for Arbitrum mainnet, but they have plans to decentralize the sequencer role in the future.
|
||||
|
||||
The different L2 transaction paths are shown below.
|
||||
|
||||
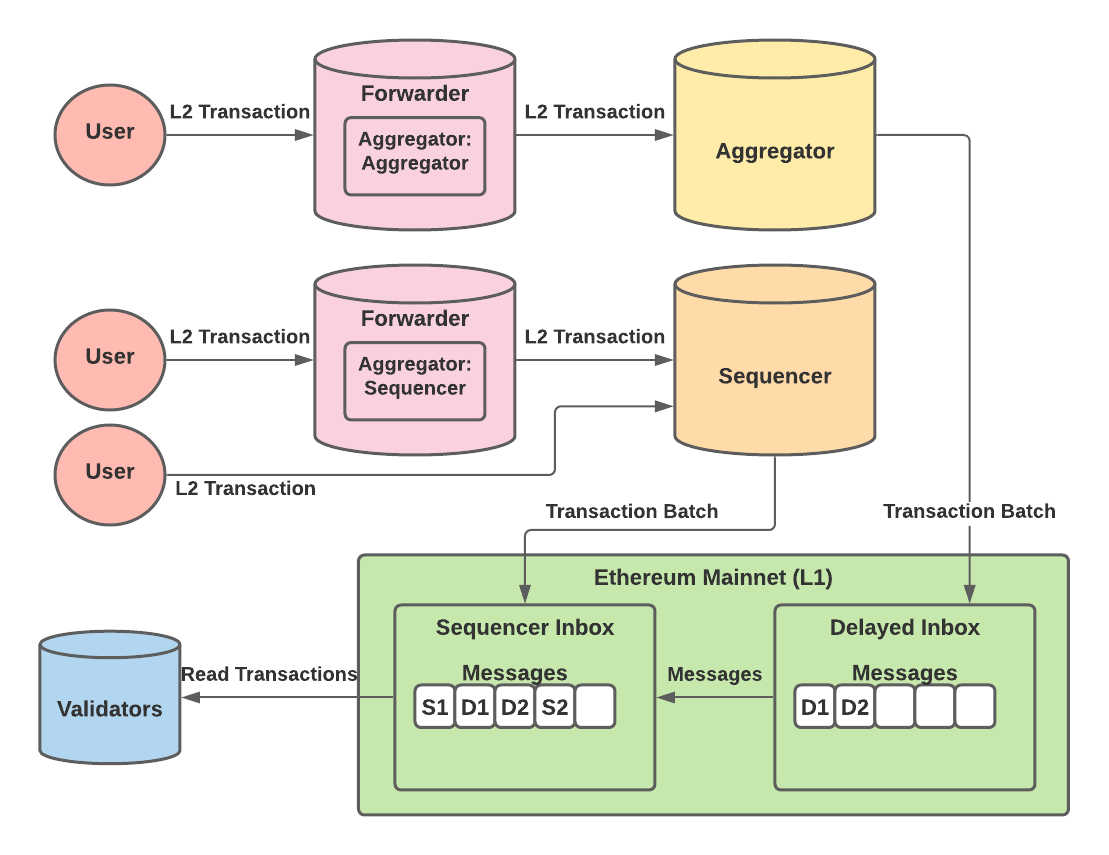
|
||||
|
||||
Essentially, batcher nodes are responsible for submitting any L2 transaction data onto L1. Once these transactions are processed on L2 and a new state is generated, a validator must submit that state data onto L1 as well. That process is covered in the next section.
|
||||
|
||||
## Validator Nodes and Submitting L2 State Data
|
||||
|
||||
The set of smart contracts that enable validators to submit and store L2 state data is known as the rollup. The rollup is essentially a chain of blocks, so in other words, the rollup is the L2 chain. Note that the Arbitrum codebase refers to these blocks as ‘nodes’. However, to prevent confusion with the terms ‘validator nodes’ and ‘batcher nodes’, I will continue to refer to these rollup nodes as blocks throughout the article.
|
||||
|
||||
Each block contains a hash of the L2 state data. So, validators will read and process transactions from the sequencer inbox, and then submit the updated L2 state data hash to the rollup smart contract. The rollup, which stores a chain of blocks, will create a new block with this data and add it as the latest block to the chain. When the validator submits the L2 state data to the rollup smart contract, they also specify which block in the current chain is the parent block to this new block.
|
||||
|
||||
In order to penalize validators that submit invalid state data, a staking system has been implemented. In order to submit new L2 state data to the rollup, a validator must be a staker — they must have deposited a certain amount of Eth (or other tokens depending on the rollup). That way, if a malicious validator submits invalid state data, another validator can challenge that block and the malicious validator will lose their stake.
|
||||
|
||||
Once a validator becomes a staker, they can then stake on different blocks. Here are some of the important rules to staking:
|
||||
|
||||
- Stakers must stake on any block they create.
|
||||
- Multiple stakers can stake on the same block.
|
||||
- Stakers cannot stake on two separate block paths — when a staker stakes on a new block, it must be a descendant of the block they were previously staked on (unless this is the stakers first stake).
|
||||
- Stakers do not have to add an additional deposit anytime they stake on a new block.
|
||||
- If a block loses a challenge, all stakers staked on that block or any descendant of that block will lose their stake.
|
||||
|
||||
A block will be confirmed — permanently accepted in L1 and never reverted — if all of the following are true:
|
||||
|
||||
- The 7 day period has passed since the block’s creation
|
||||
- There are no existing challenging blocks
|
||||
- At least one staker is staked on it
|
||||
|
||||
A block can be rejected (destroyed) if all of the following are true:
|
||||
|
||||
- It’s parent block is older than the latest confirmed block (the latest confirmed block is on another branch)
|
||||
- There is a staker staked on a sibling block
|
||||
- There are no stakers staked on this block
|
||||
- The 7 day period has passed since the block’s creation
|
||||
|
||||
Take the following diagram as an example:
|
||||
|
||||
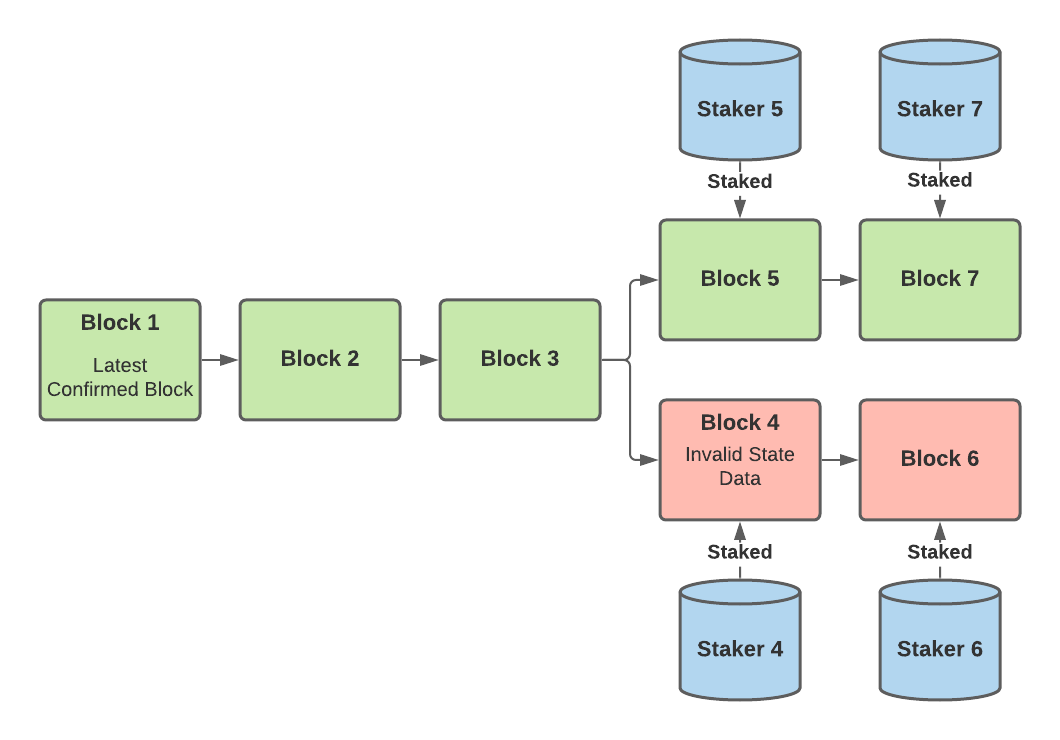
|
||||
|
||||
In this example, since blocks 4 and 5 share the same parent, staker 5 decides to challenge staker 4 and wins since block 4 contains invalid state data. Therefore, both staker 4 and staker 6 will lose their stakes. Stakers will continue adding new blocks to the chain that contains blocks 5 and 7. Blocks 4 and 6 will then be destroyed after the 7 day period has passed. Even though stakers are necessary for the system to work, not all validator nodes are stakers. The different types of validators are explained in the next section.
|
||||
|
||||
**Validator Types**
|
||||
|
||||
Each validator may use a different strategy to keep the network secure. Currently, there are three types of supported validating strategies — Defensive, StakeLatest, and MakeBlocks (known as MakeNodes in the codebase). Defensive validators will monitor the rollup chain of blocks and look out for any forks/conflicting blocks. If a fork is detected, that validator will switch to the StakeLatest strategy. Therefore, if there are no conflicting blocks, defensive validators will not have any stakes.
|
||||
|
||||
StakeLatest validators will stake on the existing blocks in the rollup if the blocks have valid L2 state data. They will advance their stake to the furthest correct block in the chain as possible. StakeLatest validators normally do not create new blocks unless they have identified a block with incorrect state data. In that case, the validators will create a new block with correct data and mandatorily stake on it.
|
||||
|
||||
MakeBlocks validators will stake on the furthest correct block in the rollup chain as well. However, even when there are no invalid blocks, MakeBlocks validators will create new blocks once they have advanced their stake to the end of the chain. These are the primary validators responsible for progressing the chain forward with new state data.
|
||||
|
||||
The following diagram illustrates the actions of the different validator strategies:
|
||||
|
||||
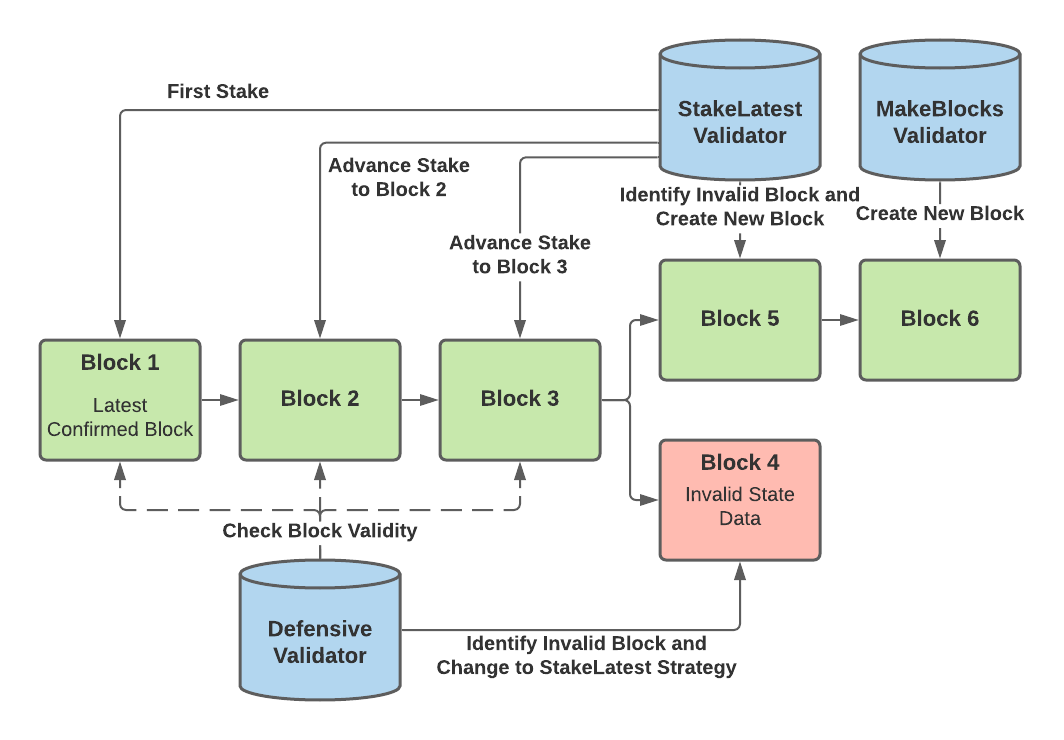
|
||||
|
||||
## Transaction and State Data Storage on L1
|
||||
|
||||
**Transaction Data Storage**
|
||||
|
||||
As explained above, aggregator and sequencer nodes receive L2 transactions and submit them to the L1 delayed and sequencer inboxes. Posting this data to L1 is where most of the expenses of L2 come from. Therefore, it is important to understand how this data is stored on L1 and the methods used to reduce this storage requirement as much as possible.
|
||||
|
||||
Aggregator nodes receive user L2 transactions, compress the calldata into a byte array, and then combine multiple of these compressed transactions into an array of byte arrays known as a transaction batch. Finally, they will submit the transaction batch to the delayed inbox. The inbox will then hash the transaction batch and store the hash in contract storage. Sequencer nodes follow a very similar pattern, but the sequencer inbox must also include data about the number of messages to include from the delayed inbox. This data will be part of the final hash that the sequencer inbox stores in contract storage.
|
||||
|
||||
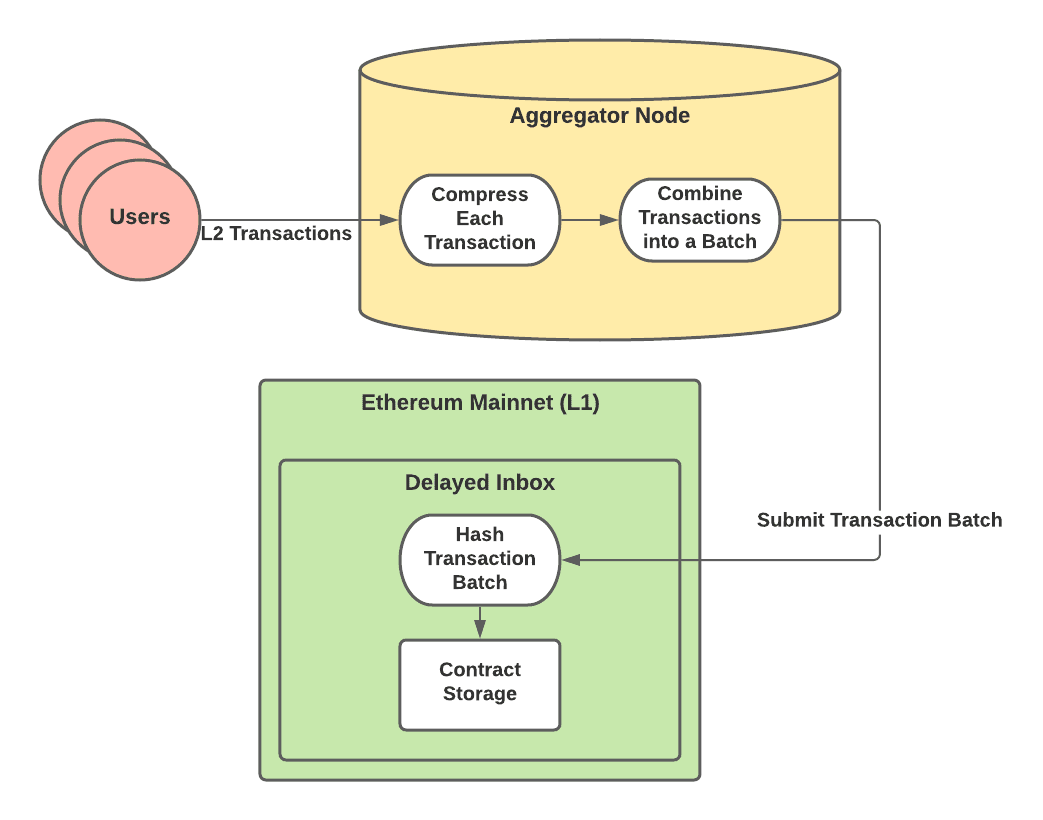
|
||||
|
||||
**State Data Storage**
|
||||
|
||||
After MakeBlocks validators read and process L2 transactions from the sequencer inbox, they will submit their updated L2 state data to the rollup smart contract. The rollup smart contract then hashes the state data and stores the hash in contract storage.
|
||||
|
||||
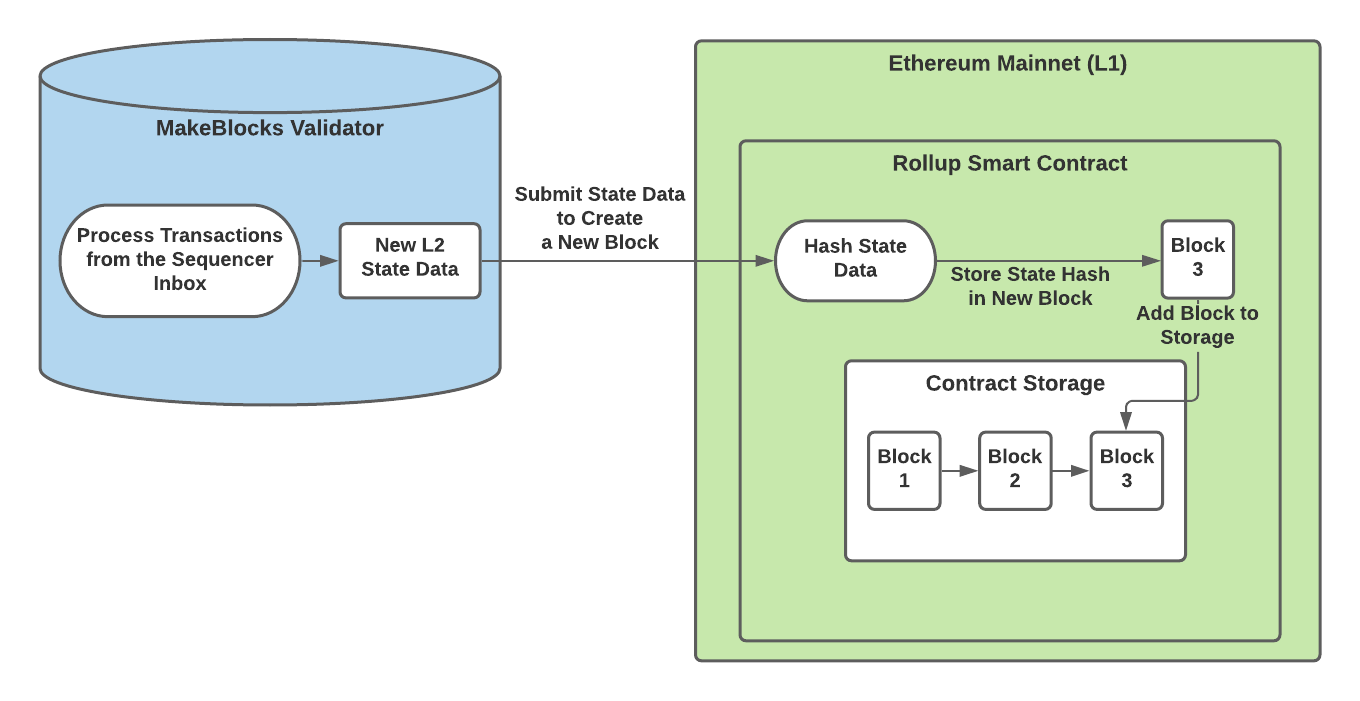
|
||||
|
||||
**Retrieving Transaction and State Data**
|
||||
|
||||
Even though only the hash of the transaction and state data is stored in contract storage, other nodes can see the original data by retrieving the calldata of the transaction that submitted the data to L1 from an Ethereum full node. The calldata of transactions to the delayed or sequencer inboxes contain the data for every L2 transaction that the aggregator or sequencer batched. The calldata of transactions to the rollup contract contain all of the relevant state data — enough for other validators to determine if it is valid or invalid — for L2 at that time. To make looking up the transaction easier, the smart contracts emit an event to the Ethereum logs that allows anyone to easily search for either the L2 transaction data or the L2 state data.
|
||||
|
||||
Since the smart contracts only have to store hashes in their storage rather than the full transaction or state data, a lot of gas is saved. The primary cost of rollups comes from storing this data on L1. Therefore, this storage mechanism is able to reduce gas expenses even further.
|
||||
|
||||
## The AVM and ArbOS
|
||||
|
||||
**The Arbitrum Virtual Machine**
|
||||
|
||||
Since Arbitrum L2 transactions are not executed on L1, they don’t have to follow the same exact rules as the EVM for computation. Therefore, the Arbitrum team built their own virtual machine known as the Arbitrum Virtual Machine (AVM). The AVM is very similar to the EVM because a primary goal was to support compatibility with EVM compiled smart contracts. However, there are a few important differences.
|
||||
|
||||
A major difference between the AVM and EVM is that the AVM must support Arbitrum’s challenges. Challenges, covered in more detail in the next section, require that a step of transaction execution must be provable. Therefore, Arbitrum has introduced the use of CodePoints to their virtual machine. Normally, when code is executed, the instructions are stored in a linear array with a program counter (PC) pointing to the current instruction. Using the program counter to prove which instruction is being executed would take logarithmic time. In order to reduce this time complexity to constant time, the Arbitrum team implemented CodePoints — a pair of the current instruction and the hash of the next codepoint. Every instruction in the array has a codepoint and this allows the AVM to instantly prove which instruction was being executed at that program counter. CodePoints do add some complexity to the AVM, but the Arbitrum system only uses codepoints when it needs to make a proof about transaction execution. Normally, it will use the normal program counter architecture instead.
|
||||
|
||||
There are quite a few other important differences that are well documented on Arbitrum’s site — [Why AVM Differs from EVM](https://developer.offchainlabs.com/docs/inside_arbitrum#why-avm-differs-from-evm)
|
||||
|
||||
**ArbOS**
|
||||
|
||||
ArbOS is Arbitrum’s own operating system. It is responsible for managing and tracking the resources of smart contracts used during execution. So, ArbOS keeps an account table that keeps track of the state for each account. Additionally, it operates the funding model for validators participating in the rollup protocol.
|
||||
|
||||
The AVM has built in instructions to aid the execution of ArbOS and its ability to track resources. This support for ArbOS in the AVM allows ArbOS to implement certain rules of execution at layer 2 instead of in the rollup smart contracts on layer 1. Any computation moved from layer 1 to layer 2 saves gas and lowers expenses.
|
||||
|
||||
## Challenges
|
||||
|
||||
Optimistic rollup designs require there be a way to tell whether the L2 state data submitted to L1 is valid or invalid. Currently, there are two widely known methods — replayability and interactive proving. Arbitrum has implemented interactive proving as their choice for proving an invalid state.
|
||||
|
||||
When a validator submits updated state data to the rollup, any staker can challenge that block and submit the correct version of it. When a challenge begins, the two stakers involved (challenger and challenged staker) must take turns dividing the execution into an equal number of parts and claim which of those parts is invalid. Then they must submit their version of that part. The other staker will then dissect that part into an equal number of parts as well, and select which part they believe is invalid. They will then submit their version of that part.
|
||||
|
||||
This process continues until the contested part of execution is only one instruction long. At this point, the smart contracts on L1 will perform a one step proof. Essentially, the one step proof executes that one instruction and returns an updated state. The block whose state matches that of the one step proof will win the challenge and the other block will lose their stake. The following diagram illustrates an example of a challenge.
|
||||
|
||||
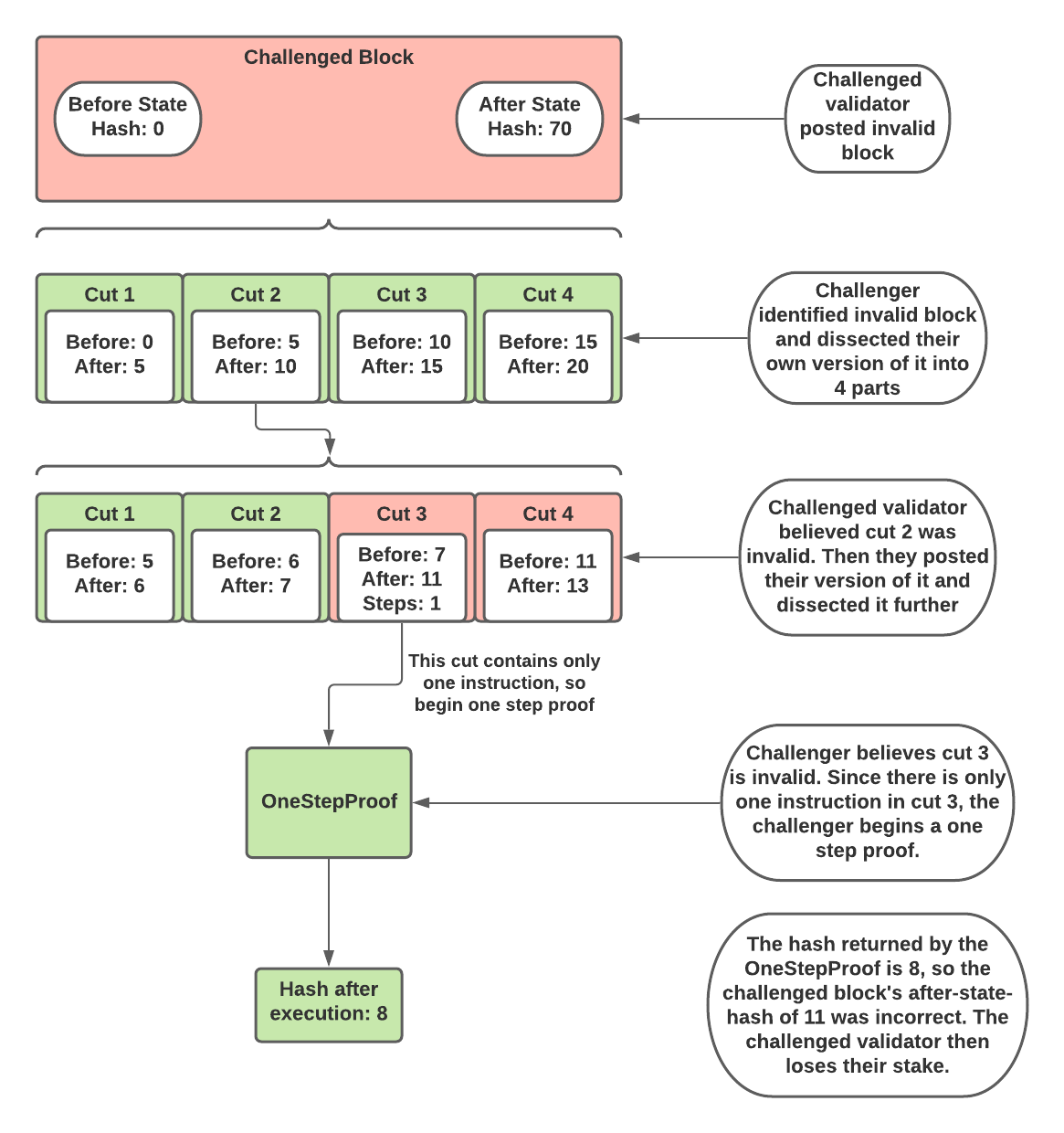
|
||||
|
||||
## Conclusion
|
||||
|
||||
**How does this raise Ethereum’s transaction per second and lower transaction costs?**
|
||||
|
||||
Arbitrum, along with all optimistic rollups, greatly improves the scalability of the Ethereum network and therefore lowers the gas costs (holding throughput constant). In L1 every Ethereum full node in the network will process the transaction, and since the network contains so many nodes, computation becomes very expensive. With Arbitrum, transactions will only be processed by a small set of nodes — the sequencer, aggregators, and validators. So, the computation of each transaction has been moved off of L1 while only the transaction calldata remains on L1. This clears a lot of space on L1 and allows many more transactions to be processed. The greater throughput reduces the gas costs since the competition for getting a transaction added to a block is lower.
|
||||
|
||||
**Anything special about Abritrum’s implementation of optimistic rollups?**
|
||||
|
||||
Arbitrum’s design gives many advantages that other rollup implementations don’t have because of its use of interactive proving. Interactive proving provides a great number of benefits, such as no limits on contract size, that are outlined in good detail on Arbitrum’s site — [Why Interactive Proving is Better](https://developer.offchainlabs.com/docs/inside_arbitrum#why-interactive-proving-is-better). With Arbitrum’s successful mainnet launch (though still early), it’s clear that the project has achieved an incredible feat.
|
||||
|
||||
If you’re interested in reading more on Arbitrum’s optimistic rollup, their documentation covers a lot more ground and is easy to read.
|
||||
|
||||
- [Arbitrum Doc — Inside Arbitrum](https://developer.offchainlabs.com/docs/inside_arbitrum)
|
||||
- [Arbitrum Doc — Rollup Protocol](https://developer.offchainlabs.com/docs/rollup_protocol)
|
||||
- [Arbitrum Doc — AVM Design Rationale](https://developer.offchainlabs.com/docs/avm_design)
|
||||
- [Arbitrum Doc — Overview of Differences with Ethereum](https://developer.offchainlabs.com/docs/differences_overview)
|
||||
@@ -0,0 +1,205 @@
|
||||
---
|
||||
authors: ["PSE Team"]
|
||||
title: "A Technical Introduction to MACI 1.0 - Privacy & Scaling Explorations"
|
||||
image: null
|
||||
tldr: ""
|
||||
date: "2022-08-29"
|
||||
canonical: "https://mirror.xyz/privacy-scaling-explorations.eth/IlWP_ITvmeZ2-elTJl44SCEGlBiemKt3uxXv2A6Dqy4"
|
||||
---
|
||||
|
||||

|
||||
|
||||
Originally published on Jan 18, 2022:
|
||||
|
||||
1. [Introduction](https://mirror.xyz/privacy-scaling-explorations.eth/IlWP_ITvmeZ2-elTJl44SCEGlBiemKt3uxXv2A6Dqy4#5e4c)
|
||||
|
||||
a. [Background](https://mirror.xyz/privacy-scaling-explorations.eth/IlWP_ITvmeZ2-elTJl44SCEGlBiemKt3uxXv2A6Dqy4#2bcd)
|
||||
|
||||
2. [System Overview](https://mirror.xyz/privacy-scaling-explorations.eth/IlWP_ITvmeZ2-elTJl44SCEGlBiemKt3uxXv2A6Dqy4#6ca2)
|
||||
|
||||
a. [Roles](https://mirror.xyz/privacy-scaling-explorations.eth/IlWP_ITvmeZ2-elTJl44SCEGlBiemKt3uxXv2A6Dqy4#f130)
|
||||
|
||||
b. [Vote Overriding and Public Key Switching](https://mirror.xyz/privacy-scaling-explorations.eth/IlWP_ITvmeZ2-elTJl44SCEGlBiemKt3uxXv2A6Dqy4#0b6f)
|
||||
|
||||
c. [zk-SNARKs](https://mirror.xyz/privacy-scaling-explorations.eth/IlWP_ITvmeZ2-elTJl44SCEGlBiemKt3uxXv2A6Dqy4#aa08)
|
||||
|
||||
3. [Workflow](https://mirror.xyz/privacy-scaling-explorations.eth/IlWP_ITvmeZ2-elTJl44SCEGlBiemKt3uxXv2A6Dqy4#357c)
|
||||
|
||||
a. [Sign Up](https://mirror.xyz/privacy-scaling-explorations.eth/IlWP_ITvmeZ2-elTJl44SCEGlBiemKt3uxXv2A6Dqy4#a35f)
|
||||
|
||||
b. [Publish Message](https://mirror.xyz/privacy-scaling-explorations.eth/IlWP_ITvmeZ2-elTJl44SCEGlBiemKt3uxXv2A6Dqy4#37df)
|
||||
|
||||
c. [Process Messages](https://mirror.xyz/privacy-scaling-explorations.eth/IlWP_ITvmeZ2-elTJl44SCEGlBiemKt3uxXv2A6Dqy4#493a)
|
||||
|
||||
d. [Tally Votes](https://mirror.xyz/privacy-scaling-explorations.eth/IlWP_ITvmeZ2-elTJl44SCEGlBiemKt3uxXv2A6Dqy4#56b5)
|
||||
|
||||
4. [Conclusion](https://mirror.xyz/privacy-scaling-explorations.eth/IlWP_ITvmeZ2-elTJl44SCEGlBiemKt3uxXv2A6Dqy4#53c9)
|
||||
|
||||
MACI, which stands for Minimal Anti-Collusion Infrastructure, is an application that allows users to have an on-chain voting process with greatly increased collusion resistance. A common problem among today’s on-chain voting processes is how easy it is to bribe voters into voting for a particular option. Oftentimes this bribery takes the form of “join our pool (vote our way) and we will give you a cut of the rewards (the bribe)”. Since all transactions on the blockchain are public, without MACI, voters can easily prove to the briber which option they voted for and therefore receive the bribe rewards.
|
||||
|
||||
MACI counters this by using zk-SNARKs to essentially hide how each person voted while still revealing the final vote result. User’s cannot prove which option they voted for, and therefore bribers cannot reliably trust that a user voted for their preferred option. For example, a voter can tell a briber that they are voting for option A, but in reality they voted for option B. There is no reliable way to prove which option the voter actually voted for, so the briber does not have the incentive to pay voters to vote their way.
|
||||
|
||||
## a. Background
|
||||
|
||||
For a general overview, the history and the importance of MACI, see [Release Announcement: MACI 1.0](https://medium.com/privacy-scaling-explorations/release-announcement-maci-1-0-c032bddd2157) by Wei Jie, one of the creators. He also created a very helpful [youtube video](https://www.youtube.com/watch?v=sKuNj_IQVYI) on the overview of MACI. To see the origin of the idea of MACI, see Vitalik’s research post on [Minimal Anti-Collusion Infrastructure](https://ethresear.ch/t/minimal-anti-collusion-infrastructure/5413?u=weijiekoh). Lastly, it is recommended to understand the basic idea behind zk-SNARKs, as these are a core component of MACI. The following articles are great resources:
|
||||
|
||||
- [Introduction to zk-SNARKs](https://consensys.net/blog/developers/introduction-to-zk-snarks/) — Consensys
|
||||
- [What are zk-SNARKs](https://z.cash/technology/zksnarks/) — Zcash
|
||||
- [An approximate introduction to how zk-SNARKs are possible](https://vitalik.ca/general/2021/01/26/snarks.html) — Vitalik
|
||||
- [zkSNARKs in a nutshell](https://blog.ethereum.org/2016/12/05/zksnarks-in-a-nutshell/) — Ethereum.org
|
||||
|
||||
This article will go over the general workflow of MACI and how it is capable of providing the following tenets (taken word for word from Wei Jie’s article):
|
||||
|
||||
1. **Collusion Resistance**: No one except a trusted coordinator should be certain of the validity of a vote, reducing the effectiveness of bribery
|
||||
2. **Receipt-freeness**: No voter may prove (besides to the coordinator) which way they voted
|
||||
3. **Privacy**: No one except a trusted coordinator should be able to decrypt a vote
|
||||
4. **Uncensorability**: No one (not even the trusted coordinator) should be able to censor a vote
|
||||
5. **Unforgeability**: Only the owner of a user’s private key may cast a vote tied to its corresponding public key
|
||||
6. **Non-repudiation**: No one may modify or delete a vote after it is cast, although a user may cast another vote to nullify it
|
||||
7. **Correct execution**: No one (not even the trusted coordinator) should be able to produce a false tally of votes
|
||||
|
||||
## 2\. System Overview
|
||||
|
||||
## a. Roles
|
||||
|
||||
In the MACI workflow, there are two different roles: users (voters) and a single trusted coordinator. The users vote on the blockchain via MACI smart contracts, and the coordinator tallies up the votes and releases the final results.
|
||||
|
||||
The coordinators must use zk-SNARKs to prove that their final tally result is valid without releasing the vote of every individual. Therefore, even if a coordinator is corrupt, they are unable to change a user’s vote or add extra votes themselves. A corrupt coordinator can stop a vote by never publishing the results, but they can’t publish false results.
|
||||
|
||||
Before sending their vote on the blockchain, users encrypt their vote using a shared key that only the user and coordinator can know. This key scheme is designed so that every individual user shares a distinct key with the coordinator. This prevents any bribers from simply reading the transaction data to see which option a user voted for. The encrypted vote is now considered a “message” and the user sends this message to a MACI smart contract to be stored on-chain.
|
||||
|
||||
A very simplified illustration of this encryption can be seen below:
|
||||
|
||||
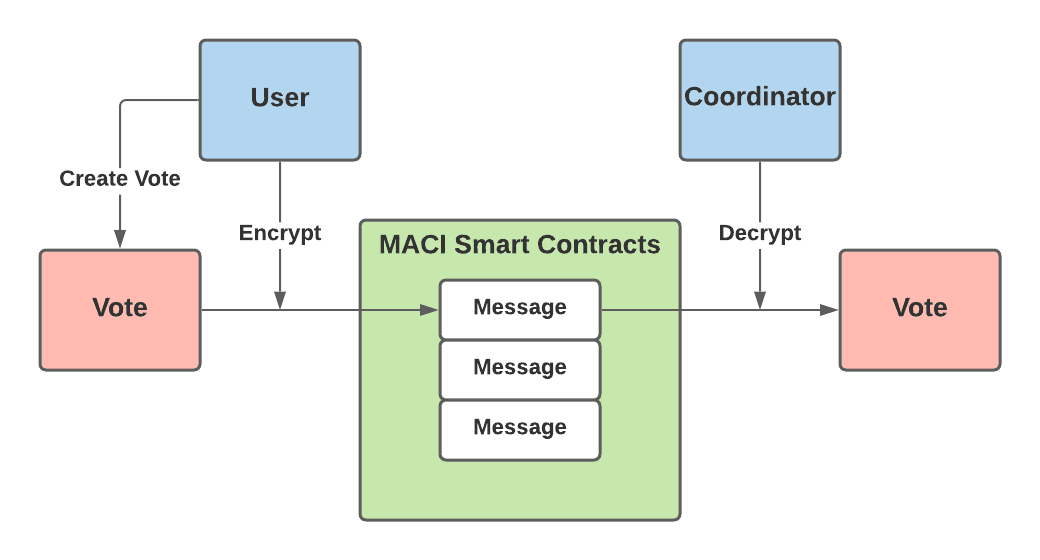
|
||||
|
||||
## b. Vote Overriding and Public Key Switching
|
||||
|
||||
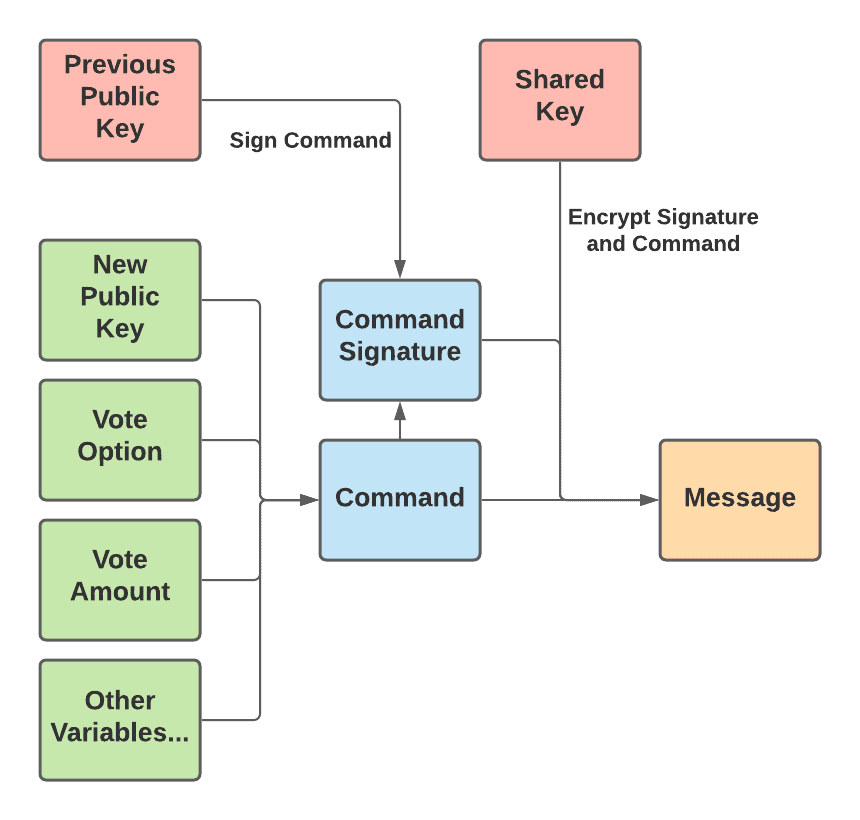
Before a user can cast a vote, they must sign up by sending the public key they wish to use to vote to a MACI smart contract. This public key acts as their identity when voting. They can vote from any address, but their message must contain a signature from that public key. When casting an actual vote after signing up, a user will bundle a few variables — including a public key, their vote option, their vote amount, and a few others — into what is called a “command”. Then, the user signs the command with the public key they originally used to sign up. After that, the user encrypts the signature and command together so that it is now considered a message. This more complex description of how a message is constructed is illustrated below:
|
||||
|
||||
|
||||
|
||||
Users are able to override their previous vote as long as they sign their command with the previous public key. If the command is properly signed by the user’s previous public key, then the message is considered valid and the coordinator will count this as the correct vote. So, when a user provides a public key in their vote that is different than their previous public key, they may now submit a new vote signed by this new public key to override their previous vote. If the signature is not from the previous public key, the message will be marked as invalid and not counted toward the tally. Therefore, the public key can be thought of as the user’s voting username, and the signature is the voting password. If they provide the correct signature, they can submit a vote or change their public key — or both.
|
||||
|
||||
This feature, which I refer to as public key switching, is designed to counter the bribery attack where a user simply shows the briber their message, and then decrypts it for the briber to see which way the user voted. Public key switching allows users to change their public key and create invalid messages in favor of the bribers. The bribers have no way of telling if the user switched their public keys before sending in the vote shown to the bribers.
|
||||
|
||||
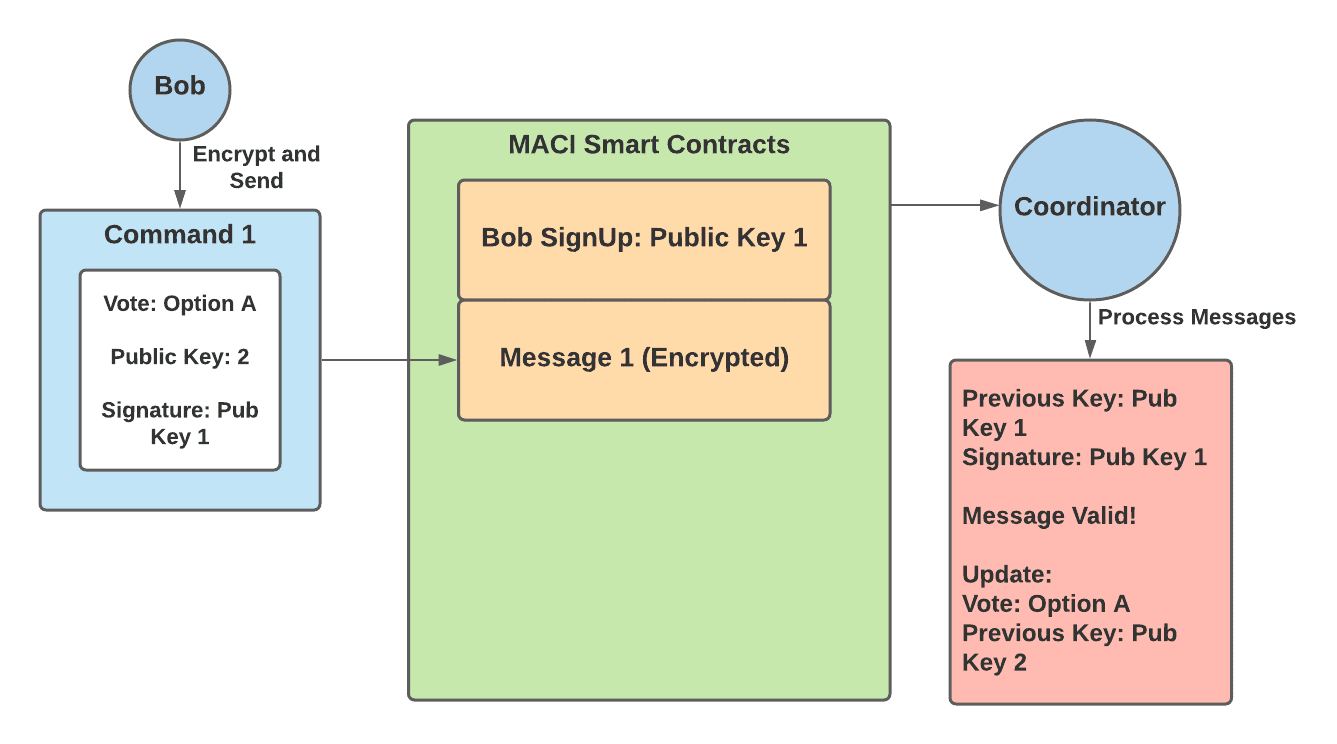
This can be quite confusing so here is an example:
|
||||
|
||||
1. Bob signs up with public key 1
|
||||
2. Bob then creates a command that contains — a vote for option A and public key 2
|
||||
3. Bob signs this command with public key 1, the key he used to sign up
|
||||
4. Bob encrypts this command into a message and submits it to the MACI smart contracts
|
||||
5. The coordinator decrypts this message, and checks to ensure that the command is signed by Bob’s previous key — public key 1. This message is valid.
|
||||
6. The coordinator then records Bob’s vote for option A and updates his public key to public key 2
|
||||
|
||||
|
||||
|
||||
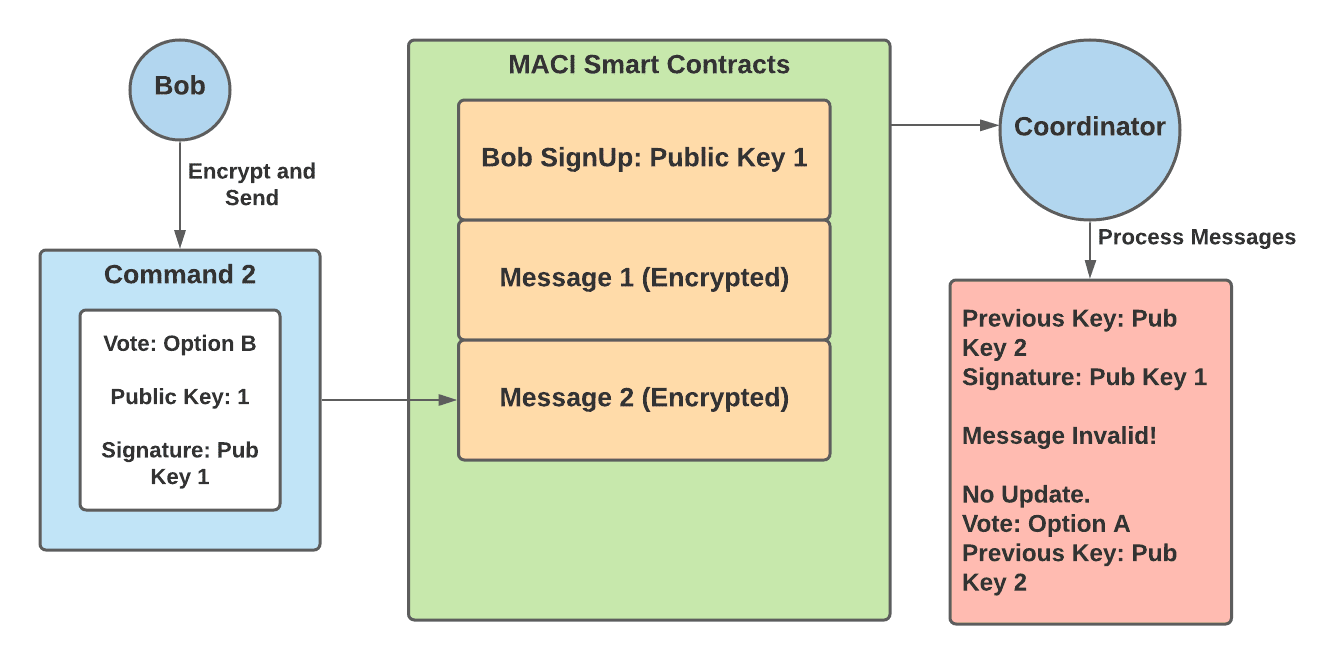
At this point, Bob has successfully voted for option A, and in order to override this vote must send in a new vote with a signature from public key 2. At this point, a briber now tries to get Bob to vote for option B:
|
||||
|
||||
1. Bob creates a command that contains — a vote for option B and public key 1
|
||||
2. Bob signs this command with public key 1, encrypts the message and submits it to the MACI smart contracts
|
||||
3. Bob shows the briber the decrypted message as proof of his vote for option B
|
||||
4. The coordinator decrypts Bob’s message and sees that the signature does not match up with public key 2 — Bob’s previous key added in his previous message. Therefore this message is invalid and this vote is not counted in the final tally.
|
||||
5. The briber has no way of knowing whether the vote was valid or invalid, and so is not incentivized to offer bribes to other users.
|
||||
|
||||
|
||||
|
||||
In order to get a good idea of how MACI works, it’s important to know how the zk-SNARKs are able to prove that the coordinator decrypted each message and tallied the votes properly. The next section gives a quick and much oversimplified overview of zk-SNARKs, although the readings listed in the introduction are much more helpful.
|
||||
|
||||
## c. zk-SNARKs
|
||||
|
||||
Essentially, zk-SNARKs allow users to prove they know an answer to a specific mathematical equation, without revealing what that answer is. Take the following equation for example,
|
||||
|
||||
> X + Y = 15
|
||||
|
||||
I can prove that I know 2 values, X and Y that satisfy the equation without revealing what those two values are. When I create a zk-SNARK for my answer, anyone can use the SNARK (a group of numbers) and validate it against the equation above to prove that I do know a solution to that equation. The user is unable to use the SNARK to find out my answers for X and Y.
|
||||
|
||||
For MACI, the equation is much more complicated but can be summarized as the following equations:
|
||||
|
||||
> encrypt(command1) = message1
|
||||
>
|
||||
> encrypt(command2) = message2
|
||||
>
|
||||
> encrypt(command3) = message3
|
||||
>
|
||||
> …
|
||||
>
|
||||
> Command1 from user1 + command2 from user2 + command3 from user3 + … = total tally result
|
||||
|
||||
Here, everyone is able to see the messages on the blockchain and the total tally result. Only the coordinator knows what the individual commands/votes are by decrypting the messages. So, the coordinator uses a zk-SNARK to prove they know all of the votes that:
|
||||
|
||||
1. Encrypt to the messages present on the blockchain
|
||||
2. Sum to the tally result
|
||||
|
||||
Users can then use the SNARK to prove that the tally result is correct, but cannot use it to prove any individual’s vote choices.
|
||||
|
||||
Now that the core components of MACI have been covered, it is helpful to dive deeper into the MACI workflow and specific smart contracts.
|
||||
|
||||
## 3\. Workflow
|
||||
|
||||
The general workflow process can be broken down into 4 different phases:
|
||||
|
||||
1. Sign Up
|
||||
2. Publish Message
|
||||
3. Process Messages
|
||||
4. Tally Results
|
||||
|
||||
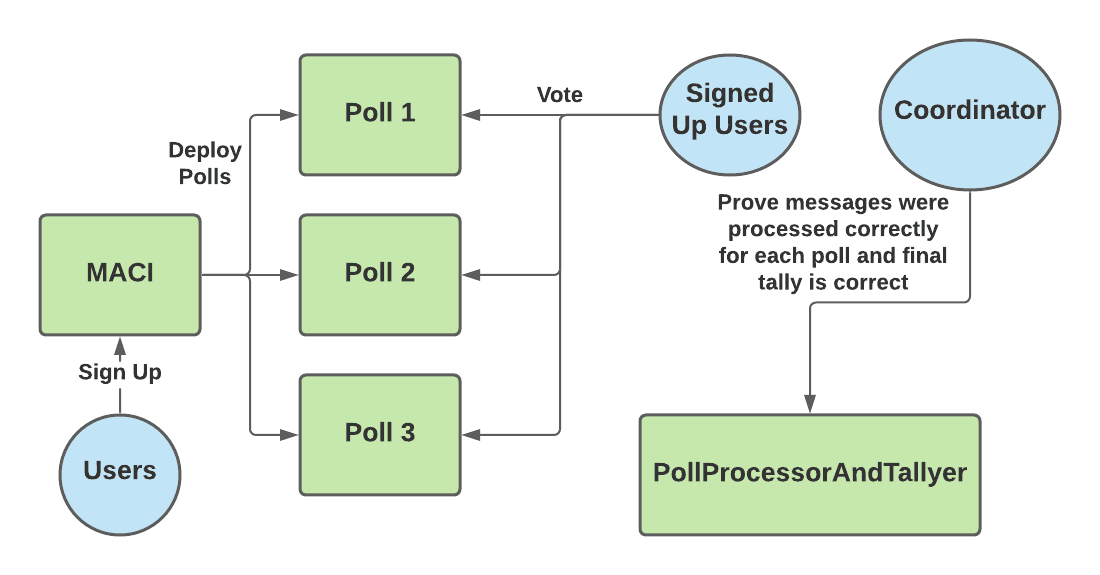
These phases make use of 3 main smart contracts — MACI, Poll and PollProcessorAndTallyer. These contracts can be found on the [MACI github page](https://github.com/appliedzkp/maci/tree/v1/contracts/contracts). The MACI contract is responsible for keeping track of all the user sign ups by recording the initial public key for each user. When a vote is going to take place, users can deploy a Poll smart contract via MACI.deployPoll().
|
||||
|
||||
The Poll smart contract is where users submit their messages. One MACI contract can be used for multiple polls. In other words, the users that signed up to the MACI contract can vote on multiple issues, with each issue represented by a distinct Poll contract.
|
||||
|
||||
Finally, the PollProcessorAndTallyer contract is used by the coordinator to prove on-chain that they are correctly tallying each vote. This process is explained in more detail in the Process Messages and Tally Results sections below.
|
||||
|
||||
|
||||
|
||||
## a. Sign Up
|
||||
|
||||
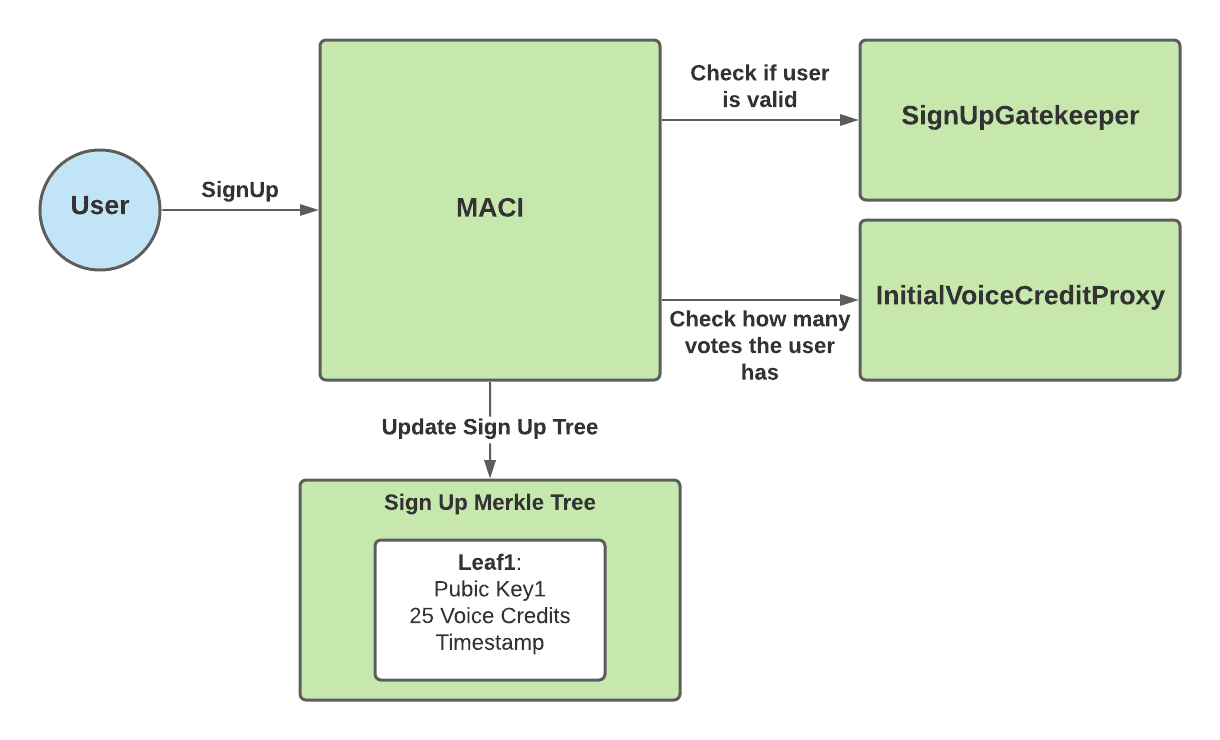
The sign up process for MACI is handled via the MACI.sol smart contract. Users need to send three pieces of information when calling MACI.signUp():
|
||||
|
||||
1. Public Key
|
||||
2. Sign Up Gatekeeper Data
|
||||
3. Initial Voice Credit Proxy Data
|
||||
|
||||
The public key is the original public key mentioned in above sections that the user will need to vote. As explained in earlier sections, they can change this public key later once voting starts. The user’s public key used to sign up is shared amongst every poll.
|
||||
|
||||
MACI allows the contract creator/owner to set a “signUpGateKeeper”. The sign up gatekeeper is meant to be the address of another smart contract that determines the rules to sign up. So, when a user calls MACI.signUp(), the function will call the sign up gatekeeper to check if this user is valid to sign up.
|
||||
|
||||
MACI also allows the contract creator/owner to set an “initialVoiceCreditProxy”. This represents the contract that determines how many votes a given user gets. So, when a user calls MACI.signUp(), the function will call the initial voice credit proxy to check how many votes they can spend. The user’s voice credit balance is reset to this number for every new poll.
|
||||
|
||||
Once MACI has checked that the user is valid and retrieved how many voice credits they have, MACI stores the following user info into the Sign Up Merkle Tree:
|
||||
|
||||
1. Public Key
|
||||
2. Voice Credits
|
||||
3. Timestamp
|
||||
|
||||
|
||||
|
||||
## b. Publish Message
|
||||
|
||||
Once it is time to vote, the MACI creator/owner will deploy a Poll smart contract. Then, users will call Poll.publishMessage() and send the following data:
|
||||
|
||||
1. Message
|
||||
2. Encryption Key
|
||||
|
||||
As explained in sections above, the coordinator will need to use the encryption key in order to derive a shared key. The coordinator can then use the shared key to decrypt the message into a command, which contains the vote.
|
||||
|
||||
Once a user publishes their message, the Poll contract will store the message and encryption key into the Message Merkle Tree.
|
||||
|
||||
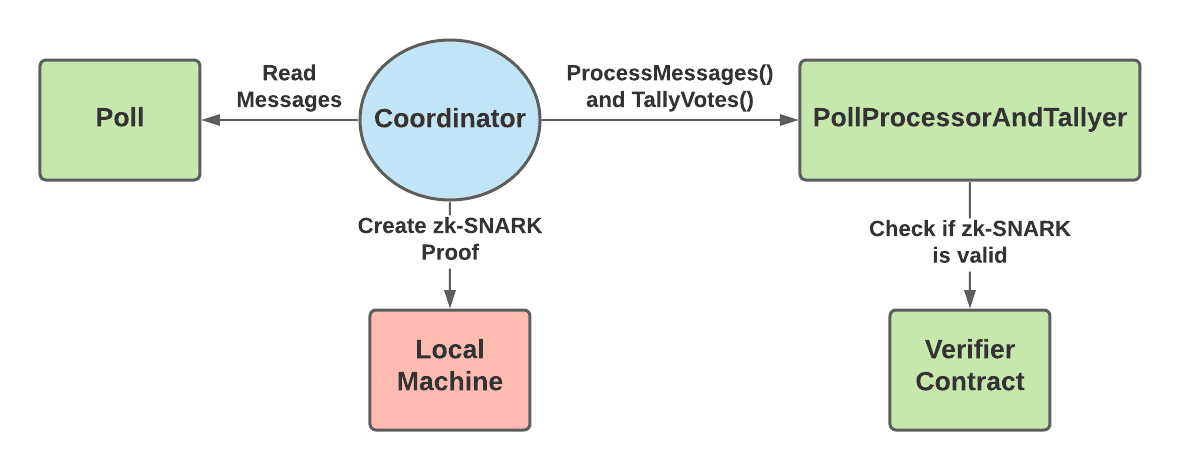
## c. Process Messages
|
||||
|
||||
Once the voting is done for a specific poll, the coordinator will use the PollProcessAndTallyer contract to first prove that they have correctly decrypted each message and applied them to correctly create an updated state tree. This state tree keeps an account of all the valid votes that should be counted. So, when processing the messages, the coordinator will not keep messages that are later overridden by a newer message inside the state tree. For example, if a user votes for option A, but then later sends a new message to vote for option B, the coordinator will only count the vote for option B.
|
||||
|
||||
The coordinator must process messages in groups so that proving on chain does not exceed the data limit. The coordinator then creates a zk-SNARK proving their state tree correctly contains only the valid messages. Once the proof is ready, the coordinator calls PollProcessorAndTallyer.processMessages(), providing a hash of the state tree and the zk-SNARK proof as an input parameters.
|
||||
|
||||
The PollProcessorAndTallyer contract will send the proof to a separate verifier contract. The verifier contract is specifically built to read MACI zk-SNARK proofs and tell if they are valid or not. So, if the verifier contract returns true, then everyone can see on-chain that the coordinator correctly processed that batch of messages. The coordinator repeats this process until all messages have been processed.
|
||||
|
||||
## d. Tally Votes
|
||||
|
||||
Finally, once all messages have been processed, the coordinator tallies the votes of the valid messages. The coordinator creates a zk-SNARK proving that the valid messages in the state tree (proved in Process Messages step) contain votes that sum to the given tally result. Then, they call PollProcessorAndTallyer.tallyVotes() with a hash of the correct tally results and the zk-SNARK proof. Similarly to the processMessages function, the tallyVotes function will send the proof to a verifier contract to ensure that it is valid.
|
||||
|
||||
The tallyVotes function is only successful if the verifier contract returns that the proof is valid. Therefore, once the tallyVotes function succeeds, users can trust that the coordinator has correctly tallied all of the valid votes. After this step, anyone can see the final tally results and the proof that these results are a correct result of the messages sent to the Poll contract. The users won’t be able to see how any individual voted, but will be able to trust that these votes were properly processed and counted.
|
||||
|
||||
|
||||
|
||||
## 4\. Conclusion
|
||||
|
||||
MACI is a huge step forward in preventing collusion for on-chain votes. While it doesn’t prevent all possibilities of collusion, it does make it much harder. MACI can already be [seen](https://twitter.com/vitalikbuterin/status/1329012998585733120) to be in use by the [clr.fund](https://blog.clr.fund/round-4-review/), which has users vote on which projects to receive funding. When the possible funding amount becomes very large, users and organizations have a large incentive to collude to receive parts of these funds. This is where MACI can truly make a difference, to protect the fairness of such important voting processes such as those at clr.fund.
|
||||
64
articles/advancing-anon-aadhaar-whats-new-in-v100.md
Normal file
@@ -0,0 +1,64 @@
|
||||
---
|
||||
authors: ["Anon Aadhaar Team"]
|
||||
title: "Advancing Anon Aadhaar: what's new in v1.0.0"
|
||||
image: "cover.webp"
|
||||
tldr: "This post was written by the Anon Aadhaar team. If you’re new to Anon Aadhaar make sure to read our [initial announcement post](https://mirror.xyz/privacy-scaling-explorations.eth/6R8kACTYp9mF3eIpLZMXs8JAQmTyb6Uy8KnZqzmDFZI)."
|
||||
date: "2024-02-14"
|
||||
canonical: "https://mirror.xyz/privacy-scaling-explorations.eth/YnqHAxpjoWl4e_K2opKPN4OAy5EU4sIJYYYHFCjkNOE"
|
||||
---
|
||||
|
||||
### **Introducing Anon Aadhaar v1.0.0**
|
||||
|
||||
[Anon Aadhaar](https://github.com/anon-aadhaar/anon-aadhaar) is a protocol that enables [Aadhaar](https://en.wikipedia.org/wiki/Aadhaar) holders to prove their identity anonymously. It works by verifying the Aadhaar card's issuer signature, which is issued by the Indian government in formats like *PDF*, _XML_, and _Secure QR_ code. These digital versions are signed using RSA, involving a pair of keys: a private key for signing data and a public key for verification.
|
||||
|
||||
Our protocol leverages the [UIDAI's](https://uidai.gov.in/en/about-uidai.html) (government authority) RSA signature, enabling us to verify the documents as anyone could. The novelty of our approach is the use of a SNARK proof in the verification process, which hides sensitive data from the verifier, maintaining the same level of verification while enhancing privacy.
|
||||
|
||||
**Recap of Previous Version Developments**
|
||||
|
||||
In the previous version, we implemented RSA verification in Circom using Groth16. We used the eAadhaar PDF, which is easily downloadable by Aadhaar residents, for signature verification.
|
||||
|
||||
However, we encountered two major issues:
|
||||
|
||||
1. The PDF's size was too large for circuit input
|
||||
2. A changing timestamp in the document made it impossible to have a consistent identity hash
|
||||
|
||||
To overcome these obstacles, we transitioned to use the [Aadhaar secure QR code](https://uidai.gov.in/en/ecosystem/authentication-devices-documents/qr-code-reader.html) for verification purposes.
|
||||
|
||||
This method is not only broadly adopted but also readily accessible through the [mAadhaar](https://uidai.gov.in/en/contact-support/have-any-question/285-english-uk/faqs/your-aadhaar/maadhaar-faqs.html) mobile application or via the printed version of the e-Aadhaar PDF. This adjustment enhances the efficiency of verifying signed identity data and streamlines the process of document parsing within our system.
|
||||
|
||||
**Key Features in v1.0.0**
|
||||
|
||||
1. **SHA-256 Hash Verification**: leveraging [zk-email](https://github.com/zkemail) implementation, we've integrated SHA-256 hash verification alongside RSA verification, allowing us to work effectively with the signed data.
|
||||
2. **Extractor**: with verified data, our new Circom extractor implementation enables selective extraction of identity fields from the document.
|
||||
3. **Nullifiers**: we're now computing two types of nullifiers:
|
||||
|
||||
- **userNullifier**: this nullifier serves as a high-entropy, unique identifier for each user, virtually eliminating the possibility of collisions between the identifiers of different individuals. It is generated by hashing the combination of the last four digits of a user's Aadhaar number and their identity photo. The unique byte data of the photo enhances the identifier's uniqueness, ensuring distinctness even in the vast pool of users. This approach is particularly useful for app interactions, where collision avoidance is crucial.
|
||||
|
||||
```jsx
|
||||
userNullifier = Hash(last4, photo)
|
||||
```
|
||||
|
||||
- **identityNullifier**: This nullifier is constructed from a hash of various personal identity elements, including the last four digits of the Aadhaar number, date of birth (DOB), name, gender, and PIN code. The design of the identity nullifier allows for its easy recomputation by users, should there be any changes to their identity data. This feature is particularly valuable for maintaining continuity of identity within the system. For instance, if a user updates their photo—thus altering their user nullifier—they can still be linked to their historical interactions by recalculating the identity nullifier using readily available personal information.
|
||||
|
||||
```jsx
|
||||
identityNullifier=Hash(last4,name,DOB,gender,pin code)
|
||||
```
|
||||
|
||||
The dual nullifier system ensures both robust identity verification and the flexibility to accommodate changes in user data, maintaining a seamless user experience while safeguarding against identity collisions and enhancing privacy and security.
|
||||
|
||||
4. **Timestamp Check**: our circuit extracts the IST signature timestamp, captured at the moment the QR code is signed, and convert it to UNIX UTC timestamp. This serves as a real-time indicator of document issuance and user access to their UIDAI portal, functioning akin to a Time-based One-Time Password (TOTP) system. It ensures document freshness and validates recent user interaction, requiring proofs to be signed within a specified timeframe (e.g., less than 1 hour ago) for verification purposes.
|
||||
5. **Signal Signing**: this functionality empowers both applications and users to securely sign any data during the proof generation process, a critical component for implementing ERC-4337 standards. It facilitates the creation of Aadhaar-linked transaction hash signatures, offering a robust mechanism to deter front-running in on-chain transactions by anchoring the _msg.sender_ identity within smart contract interactions. This advancement paves the way for the development of Account Abstraction Wallets, enabling users to authenticate and execute transactions directly with their identity, streamlining the user experience while enhancing security.
|
||||
6. **Improved On-chain Verification Gas Cost**: outputting the issuer's public key hash from the circuit allows us to store this value in the AnonAadhaar smart contract, reducing on-chain verification costs.
|
||||
|
||||
**Looking Forward**
|
||||
|
||||
We are incredibly excited to see what developers will build using Anon Aadhaar v1! And invite you to join the [Anon Aadhaar Community](https://t.me/anon_aadhaar) to continue the conversation. To support and inspire your innovative projects, we prepared a variety of resources for you to try:
|
||||
|
||||
- **[GitHub Repository](https://github.com/anon-aadhaar/anon-aadhaar)**: dive into the codebase and explore the inner workings of our protocol.
|
||||
- **[Project ideas to Build with Anon Aadhaar:](https://github.com/anon-aadhaar/anon-aadhaar/discussions/155)** looking for inspiration? Here are some ideas we’ve compiled.
|
||||
- **[On-chain voting Example App](https://github.com/anon-aadhaar/boilerplate)**: get hands-on with a practical implementation to see how Anon Aadhaar can be integrated into real-world applications.
|
||||
- **[Quick Setup Repository](https://github.com/anon-aadhaar/quick-setup)**: for those eager to get started, this repository provides a streamlined Nextjs setup process.
|
||||
- **[Documentation](https://anon-aadhaar-documentation.vercel.app/)**: comprehensive and detailed, our documentation covers everything from basic setup to advanced features, ensuring you have the information needed at your fingertips.
|
||||
- **[Roadmap](https://github.com/privacy-scaling-explorations/bandada/discussions/350)**: get an idea about how we’re thinking of evolving the protocol.
|
||||
|
||||
We're eager to witness the creative and impactful ways in which the developer community will utilize Anon Aadhaar, pushing the boundaries of privacy and security in digital identity verification. Happy coding!
|
||||
85
articles/announcing-anon-aadhaar.md
Normal file
@@ -0,0 +1,85 @@
|
||||
---
|
||||
authors: ["Anon Aadhaar team"]
|
||||
title: "Announcing Anon Aadhaar"
|
||||
image: "cover.webp"
|
||||
tldr: "_This post was written by the Anon Aadhaar team._ /n/n _We’re excited to announce the public release of Anon Aadhaar!_"
|
||||
date: "2023-09-21"
|
||||
canonical: "https://mirror.xyz/privacy-scaling-explorations.eth/6R8kACTYp9mF3eIpLZMXs8JAQmTyb6Uy8KnZqzmDFZI"
|
||||
---
|
||||
|
||||
### What is Anon Aadhaar?
|
||||
|
||||
Anon Aadhaar is a protocol that lets users anonymously prove their Aadhaar (Indian) identity, in a very fast and simple way. The core of the protocol is the [circuits](https://github.com/privacy-scaling-explorations/anon-aadhaar/tree/main/packages/anon-aadhaar-pcd/circuits), but we also provide a SDK to let any app use the protocol.
|
||||
|
||||
[Try our demo](https://anon-aadhaar-example.vercel.app/) with your Aadhaar card or example files ([signed pdf](https://anon-aadhaar-documentation.vercel.app/assets/files/signed-66a64f9f9b3da47ff19b81f6510e26fe.pdf), [certificate file](https://anon-aadhaar-documentation.vercel.app/assets/files/certificate-8bda87cda7bd74771f70cc0df28fc400.cer)). Follow our tutorial by [building a voting app with Anon Aadhaar](https://anon-aadhaar-documentation.vercel.app/blog), fork our [example app](https://github.com/anon-aadhaar-private/anon-aadhaar-example) and build your own.
|
||||
|
||||
### Why Aadhaar cards?
|
||||
|
||||
The [Aadhaar program](https://en.wikipedia.org/wiki/Aadhaar) is among the largest digital identity schemes in the world. There are 1.2 billion people enrolled, accounting for around 90% of India’s population.
|
||||
|
||||
Aadhaar cards carry both demographic and biometric data, including the holder’s date of birth and its fingerprint. They are used in a variety of contexts such as loan agreements or housing applications. Bring this onchain in a privacy preserving way opens the possibility for many more applications on Ethereum.
|
||||
|
||||
Anon Aadhaar is one instantiation of the broader “Anonymous Credentials" with the goals of “[proof of citizenship](https://discord.com/channels/943612659163602974/1141757600568971304/1141759379578822707)”, “proof of identity”, “proof of passport”, “proof of personhood”, among others. Our approach leverages government identities, in this case Aadhaar Cards, to enhance digital interactions.
|
||||
|
||||
### Importance of Anonymity
|
||||
|
||||
A healthy society enables people to voice their concerns, opinions and ideas without fear or reprimands. Although there are many protocols that provide anonymity, anonymity without context lowers the value of the interactions. How can I be sure the opinions shared are not part of a bot network, campaign, or external influence for my country/DAO/company?
|
||||
|
||||
**Contextual anonymity is key to build trust** and enhance the value of noise to signal.
|
||||
|
||||
In the broader context, Anon Aadhaar supports [proof of personhood](https://vitalik.ca/general/2023/07/24/biometric.html) by adding a convenient privacy layer. We can talk about a “forth column” that leverages existing PKI and public government ID programs to enhance digital interactions.
|
||||
|
||||

|
||||
|
||||
_Table modified from [https://vitalik.ca/general/2023/07/24/biometric.html](https://vitalik.ca/general/2023/07/24/biometric.html)_
|
||||
|
||||
\*Low decentralization in regard to the Government being the single issuer of the IDs. But high decentralization in the verification and permissionless applications that can be built on top of them.
|
||||
|
||||
## Highlight Features
|
||||
|
||||
- SDK to directly integrate with your dapp
|
||||
- PCD package to leverage this framework
|
||||
- React package to quickly integrate your front-end
|
||||
- Example app to try it and and fork
|
||||
- Proving time ~30s (avg on browser)
|
||||
|
||||
### What it contains
|
||||
|
||||
- **[anon-aadhaar-contracts:](https://github.com/privacy-scaling-explorations/anon-aadhaar/tree/main/packages/anon-aadhaar-contracts)** import it directly in your smart contract to check on-chain that a user has a valid anon Aadhaar identity proof.
|
||||
- **[anon-aadhaar-pcd:](https://github.com/privacy-scaling-explorations/anon-aadhaar/tree/main/packages/anon-aadhaar-pcd)** [PCD](https://pcd.team/) is a clever framework for programmable cryptography to facilitate composability and interoperability. This package facilitates building dapps using PCDs.
|
||||
- **[anon-aadhaar-react](https://github.com/privacy-scaling-explorations/anon-aadhaar/tree/main/packages/anon-aadhaar-react)** React component library to embed the [anon-aadhaar](https://github.com/privacy-scaling-explorations/anon-aadhaar) circuit in your project, and let you verify that a user has a regular Aadhaar ID, by generating ZKProofs, and authenticating them.
|
||||
|
||||
Check our [documentation](https://anon-aadhaar-documentation.vercel.app/docs/intro) and feel free to try our [Integration Tutorial](https://anon-aadhaar-documentation.vercel.app/docs/integration-tuto).
|
||||
|
||||
### Building with Anon Aadhaar
|
||||
|
||||
Anonymous protocols are very versatile, so get creating! If you want inspiration here are some ideas:
|
||||
|
||||
- **HeyIndia:** a copy of [HeyAnon](https://heyanon.xyz/) app, but need to prove you’re from India in order to post.
|
||||
- **Aadhaar Wallet:** similar to [Myna](https://ethglobal.com/showcase/myna-uxzdd), create an ERC-4337 compatible wallet that uses your Aadhaar card to approve transactions or social recover with other users.
|
||||
- **Voting App for Quadratic Voting:** vote if you can prove your citizenship.
|
||||
- **Telegram private groups:** where you need to prove you’re an Indian citizen in order to join
|
||||
- **[Bandada](https://pse.dev/projects/bandada) credential groups**: gatekept by Anon Aadhaar proofs and then integrated to anonymous chats using [Discreetly](https://pse.dev/projects/discreetly).
|
||||
- **SSO Server:** anonymously login with your “proof of citizenship” in any website. Explore integrations with Sign in with Ethereum
|
||||
- **Payment Channel:** use Anon Aadhaar SDK to create payment channel. Help people can verify another party with zkp. This is only for demo how people can use our SDK.
|
||||
- **Loan Approval Platform:** create a platform for secure and anonymous loan approvals based on Aadhaar information.
|
||||
- **Ethereum Wallet Recovery:** design a dApp that helps users recover their Ethereum wallets using their Aadhaar credentials.
|
||||
- **Web3 API Access Control:** develop a dApp that enables developers to control access to their web3 APIs based on verified Aadhaar identities.
|
||||
- **Privacy-Preserving Developer Communities:** decentralized developer communities where members can engage in discussions and collaborations while maintaining their anonymity.
|
||||
|
||||
### Additional Links
|
||||
|
||||
- [Anon Aadhaar - Install Solidity Verifier](https://anon-aadhaar-documentation.vercel.app/docs/install-solidity-verifier)
|
||||
- [Ethresear.ch](http://ethresear.ch/) - [Leveraging an existing PKI for a trustless and privacy preserving identity verification scheme](https://ethresear.ch/t/leveraging-an-existing-pki-for-a-trustless-and-privacy-preserving-identity-verification-scheme/15154)
|
||||
- [https://polygon.technology/blog/polygon-id-is-more-than-biometric-proof-of-personhood](https://polygon.technology/blog/polygon-id-is-more-than-biometric-proof-of-personhood?utm_source=twitter&utm_medium=social&utm_content=polygon-id-more-than-biometric)
|
||||
- [https://whitepaper.worldcoin.org/proof-of-personhood](https://whitepaper.worldcoin.org/proof-of-personhood)
|
||||
- [https://ethglobal.com/showcase/proof-of-baguette-ing99](https://ethglobal.com/showcase/proof-of-baguette-ing99)
|
||||
- [https://ethglobal.com/showcase/myna-uxzdd](https://ethglobal.com/showcase/myna-uxzdd)
|
||||
|
||||
### Looking ahead
|
||||
|
||||
Our two key next features are 🏍️ **Supporting Nullifiers** & 🏍️ **iOS Support**. Future ideas include: faster proving times, supporting more countries, etc.
|
||||
|
||||
Check our [roadmap](https://www.notion.so/Anon-Aadhaar-H2-2023-Roadmap-30206f5cb8654fdd959f4aa1470ad2f0?pvs=21) and feel free to give feedback at [#proof-of-citizenship](https://discord.com/channels/943612659163602974/1141757600568971304)
|
||||
|
||||
Thanks to [@vuvoth](https://github.com/vuvoth), [@Meyanis95](https://github.com/Meyanis95) , [@andy](https://twitter.com/AndyGuzmanEth), [@jmall](https://twitter.com/Janmajaya_mall), [@xyz_pierre](https://twitter.com/xyz_pierre)**, @PSE design team**
|
||||
105
articles/announcing-maci-v111.md
Normal file
@@ -0,0 +1,105 @@
|
||||
---
|
||||
authors: ["Alessandro", "Chao"]
|
||||
title: "Announcing MACI v1.1.1"
|
||||
image: "cover.webp"
|
||||
tldr: "This post was authored by [Alessandro](https://github.com/ctrlc03) and [Chao](https://github.com/chaosma)"
|
||||
date: "2023-01-18"
|
||||
canonical: "https://mirror.xyz/privacy-scaling-explorations.eth/ltCt68hslI5jmMf1AnfkrP2eUwkeZ8_fgkHc_WyD9Nc"
|
||||
---
|
||||
|
||||
We are pleased to announce the release of an updated version of MACI - Minimal Anti-Collusion Infrastructure v1.1.1.
|
||||
|
||||
This new release brings a more secure product, new features, and a much needed documentation refresh. Before we dive into the updates, let’s refresh your memory on what MACI is and what it was created to achieve.
|
||||
|
||||
## Background
|
||||
|
||||
MACI is an application that provides collusion resistance for on-chain voting processes. It was originally created after Vitalik’s [post](https://ethresear.ch/t/minimal-anti-collusion-infrastructure/5413), and has since been revisited and improved.
|
||||
|
||||
MACI revolves around the need for a trusted coordinator. The coordinator is in charge of setting up the system, publishing its public key, and computing the tally of the votes. Below are the main properties of MACI:
|
||||
|
||||

|
||||
|
||||
Since its inception, MACI has been adopted by different projects, most notably [clr.fund](https://github.com/clrfund) and [QFI](https://github.com/quadratic-funding/qfi/tree/feat/code-freeze). These projects prove how effective MACI can be, especially when integrated with applications that are otherwise prone to collusion, such as funding Public Goods.
|
||||
|
||||
For a more detailed description of MACI, please refer to the [v1 technical introduction article](https://medium.com/privacy-scaling-explorations/a-technical-introduction-to-maci-1-0-db95c3a9439a).
|
||||
|
||||
## Security Audit
|
||||
|
||||
MACI was [audited](https://github.com/privacy-scaling-explorations/maci/blob/v1/audit/202220930_Hashcloak_audit_report.pdf) by HashCloack in the summer of 2022. The audit team discovered certain high risk vulnerabilities, whose fixes were the focus of the MACI team in the past months.
|
||||
|
||||
In more details, the audit revealed two high risk issues within the zk-SNARK circuits:
|
||||
|
||||
- Incomplete validation when processing messages
|
||||
- Integer overflow which could have allowed users to affect a coordinator’s effort of calculating the subsidy by either making it incorrect or by intercepting the calculation
|
||||
|
||||
Another notable security issue was the lack of initialization of the `AccQueue` contract. This contract is used to store messages (votes or topups) for the different polls. Without inserting a zero value hash into the merkle tree contract as the first message during initialization, a malicious user could have performed a denial of service attack on a poll. This could have resulted in the poll results taking a very long time before being tallied by the coordinator.
|
||||
|
||||
All of these issues have been successfully resolved, on top of fixing minor issues and general code optimizations. The updated product uses a more up to date and secure version of Solidity, and more thorough test cases to verify the correctness of the solution.
|
||||
|
||||
## New Features
|
||||
|
||||
The following sections provide a quick introduction to the newest features introduced in MACI’s codebase.
|
||||
|
||||

|
||||
|
||||
### Top Up Credit
|
||||
|
||||
Rather than requiring a user to sign up multiple times, it is now possible to top up voice credits by sending a top up message on the Poll contract. Withdrawals are not enabled as this would allow a malicious user to bribe others offline to transfer their keys.
|
||||
|
||||
Now, the Poll contract will hold all the funds deposited from users for the current poll. At the end of a poll, the coordinator can transfer the funds to a hardcoded address which can be used to fund public goods.
|
||||
|
||||
When a user deposits tokens by calling topup, they will also need to specify the stateTree index. The topup function will insert a topup message into the message queue for them. When the voting period ends, any call of topup function will be rejected. Both voting and topup messages have the same ending time, which ensures there is a well-defined ending state for each poll.
|
||||
|
||||
Please note that in this approach, the initial credit is still shared across multiple polls, and the actual credit an user can spend in a given poll is the following: `totalCredit=initialCredit+topupCredit` where the `topupCredit` is the voice credit amount deposited by the user during the voting period of the given pollID.
|
||||
|
||||
For a detailed description, please refer to this [document.](https://hackmd.io/@chaosma/rkyPfI7Iq)
|
||||
|
||||
### Pairwise Subsidy
|
||||
|
||||
Pairwise subsidy is a new way to reduce collusion in quadratic funding applications. If two contributors with access to enough collude with each other, they can extract most of the public funding pool if they have enough funds.
|
||||
|
||||
In this [post](https://ethresear.ch/t/pairwise-coordination-subsidies-a-new-quadratic-funding-design/5553), Vitalik introduced this kind of collusion and also proposed a protocol to penalize this behavior. As a generalized solution, the more correlation between contributions, the smaller subsidy should be allocated to this project, as this reduces the risk of collusion between contributors. It should be noted that this solution assumes that an identity system is in place to prevent the same entity from registering with two different identities.
|
||||
|
||||
Please refer to this [post](https://hackmd.io/@chaosma/H1_9xmT2K) for a more detailed explanation of the implementation.
|
||||
|
||||
Finally, please note that currently it is not possible to generate the `zkeys` for the subsidy circuit with with the `vote options` parameter larger than 5252. This issue is documented [here](https://github.com/privacy-scaling-explorations/maci/issues/584) and the team will focus on finding a solution to be able to support larger vote options.
|
||||
|
||||
### Coordinator Service
|
||||
|
||||
MACI now includes a sample [coordinator service](https://github.com/privacy-scaling-explorations/maci/tree/v1/server).
|
||||
|
||||
There are two roles in the coordinator service: admin (i.e. MACI coordinator) and user (i.e. a voter). The admin’s responsibility is to ensure that the code remains updated and that the backend services are live. The user can then simply send HTTP requests to the backend server to interact with MACI, for instance, by signing up and publishing a message on chain.
|
||||
|
||||
The coordinator service has been wrapped into two docker instances: one for the backend server to accept user requests; one for the Mongodb service to store all necessary information on the current state such as smart contract addresses, zero knowledge proof keys and so on.
|
||||
|
||||
For further reading on coordinator services, please refer to this [doc](https://hackmd.io/@chaosma/SJtsfzKnF).
|
||||
|
||||
## How to use MACI
|
||||
|
||||
MACI can be used as a standalone application to carry out on-chain polls, or be implemented into new projects that can then benefit from its properties.
|
||||
|
||||
For use as a standalone application, a `cli` package is provided which allows coordinators and voters to use MACI. Please refer to this [doc](https://privacy-scaling-explorations.github.io/maci/cli.html) for details on how to use it.
|
||||
|
||||
To implement MACI into a project, the [documentation](https://privacy-scaling-explorations.github.io/maci/) can be used a reference, as well as reviewing how [clr.fund](https://github.com/clrfund) and [qfi](https://github.com/quadratic-funding/qfi/tree/feat/code-freeze) use MACI in their code.
|
||||
|
||||
## MACI 0.x
|
||||
|
||||
MACI version 0.x will be discontinued. MACI 1.x has feature parity, more robust code and newest features. Users are encouraged to use the latest version. Starting February 7th 2023, the team will focus solely on resolving issues for MACI 1.x, and will cease to provide support for version 0.x.
|
||||
|
||||
## How to get involved
|
||||
|
||||
Should you wish to get involved with MACI or simply report a bug, feel free to visit the [repository](https://github.com/privacy-scaling-explorations/maci/tree/v1) and open an issue, or comment under an open issue to notify the team of your intention to work on it.
|
||||
|
||||
For any other enquiry, please reach out to us via the Privacy and Scaling Explorations (PSE) [Discord](https://discord.gg/bTdZfpc69U).
|
||||
|
||||
## References
|
||||
|
||||
- [MACI GitHub repository](https://github.com/privacy-scaling-explorations/maci/tree/v1)
|
||||
- [A technical introduction to MACI 1.0 - Kyle Charbonnet](https://medium.com/privacy-scaling-explorations/a-technical-introduction-to-maci-1-0-db95c3a9439a)
|
||||
- [Minimal anti-collusion infrastructure - Vitalik](https://ethresear.ch/t/minimal-anti-collusion-infrastructure/5413)
|
||||
- [Pairwise Subsidy](https://ethresear.ch/t/pairwise-coordination-subsidies-a-new-quadratic-funding-design/5553)
|
||||
- [Security Audit](https://github.com/privacy-scaling-explorations/maci/blob/v1/audit/202220930_Hashcloak_audit_report.pdf)
|
||||
|
||||
## Release
|
||||
|
||||
Here is a link to the new release code in GitHub - [v1.1.1 Release](https://github.com/privacy-scaling-explorations/maci/releases/tag/v1.1.1).
|
||||
@@ -0,0 +1,87 @@
|
||||
---
|
||||
authors: ["AnonKlub Team"]
|
||||
title: "AnonKlub: Reflections on Our Journey in Privacy-Preserving Solutions"
|
||||
image: "cover.webp"
|
||||
tldr: "This post was written by the AnonKlub team."
|
||||
date: "2024-10-01"
|
||||
canonical: "https://mirror.xyz/privacy-scaling-explorations.eth/7VTKFVR4PM75WtNnBzuQSBZW-UYoJOsnzBBQmB9MWbY"
|
||||
---
|
||||
|
||||
One year and half ago, we embarked on an ambitious journey to explore the potential of zk-ECDSA in bringing enhanced privacy to the Ethereum ecosystem. This research initiative was introduced to the community through a **[blog post detailing the state of zk-ECDSA and its promising applications](https://mirror.xyz/privacy-scaling-explorations.eth/djxf2g9VzUcss1e-gWIL2DSRD4stWggtTOcgsv1RlxY)**.
|
||||
|
||||
As our research progressed and we began to develop practical implementations, our project evolved and was eventually rebranded as AnonKlub. This name change reflected our shift from pure research to a more application-focused approach, aiming to bring privacy-preserving solutions directly to Ethereum users.
|
||||
|
||||
Today, as we announce the sunsetting of AnonKlub, we'd like to reflect on our journey from those early days of zk-ECDSA exploration to our efforts in building real-world privacy tools. We'll share our achievements, the challenges we faced, and the valuable lessons we've learned along the way.
|
||||
|
||||
## Our Vision and What We Built
|
||||
|
||||
AnonKlub began with the ambitious goal of leveraging zk-ECDSA to create privacy-preserving solutions for Ethereum users by allowing anonymously proving ownership of an ethereum address. We envisioned an ecosystem where users could interact with dApps, participate in DAOs, and manage their digital assets without compromising their privacy, that is without doxxing their address(es).
|
||||
|
||||
Over the course of the project, we managed to generate anonymous Ethereum address ownership proofs using three distinct proving frameworks: Circom, Spartan/Sapir, and Halo2.
|
||||
|
||||

|
||||
|
||||
The AnonKlub architecture (https://anonklub.github.io/#/architecture)
|
||||
|
||||
## Challenges We Faced
|
||||
|
||||
Despite our achievements, we encountered several significant challenges:
|
||||
|
||||
### Framework selection
|
||||
|
||||
One of the most valuable lessons from our AnonKlub journey came from our framework selection process. Three requirements were paramount, yet impossible to fulfill simultaneously given the current maturity of zero-knowledge technology:
|
||||
|
||||
1. **Privacy**: Client-side proving is crucial to prevent leaking any link between proof inputs and proof results to a proving server. Users should not have to let their private data leave their device.
|
||||
2. **Trustlessness**: On-chain verification via smart contracts ensures a trustless system, whereas relying on off-chain servers (the server that hosts a web client that does the verification in the browser) introduces trust assumptions.
|
||||
3. **Performance**: In today's fast-paced digital world, users expect quick interactions. Any proving process taking longer than 30 seconds significantly degrades user experience. Considering the approximate proving time of 1 minute, this falls short when compared to typical Web2 experiences, where users are accustomed to near-instantaneous responses. This presents a challenge for building more impactful products that attract a wider user base. While a 1-minute proving time may not be fast enough for many applications, it's important to consider:
|
||||
|
||||
- The type of applications using these proofs: For instance, generating an anonklub proof is likely an occasional or rare event, rather than a frequent action. In such cases, users might be more tolerant of longer processing times.
|
||||
- The use of web workers: By triggering the proof generation in the background, users can continue interacting with the application without a frozen UI. They can perform other tasks and receive a notification when the proof is complete.
|
||||
|
||||
These factors can help mitigate the impact of longer proving times. However, continued efforts to optimize and reduce proving time will be crucial for broader adoption and improved user experience in the long run.
|
||||
|
||||
Our journey through three different frameworks highlighted the challenges in balancing these requirements.
|
||||
|
||||

|
||||
|
||||
Benchmarking Results of ZK Frameworks Used
|
||||
|
||||

|
||||
|
||||
Halo2 Proving Time Breakdown (no GPU)
|
||||
|
||||

|
||||
|
||||
Privacy vs Performance Trade-Offs Of Different ZK Frameworks Used
|
||||
|
||||
### **PLUME signature/nullifier scheme adoption hurdles**
|
||||
|
||||
Nullifying zk ECDSA proofs is hard. The best candidate for robust and secure nullifier for zk proofs of ecdsa signature is [PLUME](https://blog.aayushg.com/nullifier/). PLUME signatures aren’t standard signatures that mainstream wallets can build out of the box: the PLUME signature scheme is a new feature that needs to be implemented into mainstream wallets. As long as mainstream wallets don’t adopt PLUME, users can’t easily generate “deterministic and verifiable nullifiers on ECDSA”. Meaning they can’t use any applications that would make use of ECDSA zk proofs, such as AnonKlub.
|
||||
|
||||
## Why We're Stopping
|
||||
|
||||
The decision to sunset AnonKlub was not taken lightly, but was ultimately driven by a combination of challenges such as the ones mentioned above and strategic considerations:
|
||||
|
||||
1. **Technological Limitations**: As outlined above, we found ourselves at an impasse. The current state of zero-knowledge technology made it impossible to simultaneously achieve the level of privacy, trustlessness, and performance we deemed necessary for a truly user-friendly and secure solution. This fundamental challenge proved more persistent and resource-intensive to overcome than we initially anticipated.
|
||||
2. **Ecosystem Readiness**: The slow adoption of critical components like PLUME in mainstream wallets has created a significant bottleneck for the practical application of our work. Without widespread integration of these foundational elements, the real-world impact of our solutions remains limited.
|
||||
3. **Evolving Privacy Landscape**: As with any ambitious project in the cutting-edge tech space, we've had to continually evaluate the balance between our goals, available resources, and potential impact. The rapid evolution of privacy solutions in the Ethereum ecosystem has opened up new, promising avenues for research and development. Given the challenges we've faced and this changing landscape, we've concluded that our resources could potentially drive greater innovation and progress if redirected to other pressing challenges.
|
||||
|
||||
## Future Hopes
|
||||
|
||||
Looking to the future, we hope that our work with AnonKlub will serve as a stepping stone for others in the privacy-preserving space. We believe that the challenges we faced and the solutions we explored will provide valuable insights for future projects.
|
||||
|
||||
We remain optimistic about the future of privacy in the Ethereum ecosystem. We hope to see continued development in areas such as:
|
||||
|
||||
1. Improved performance in zk-ECDSA implementations, possibly through GPU acceleration or innovative uses of folding schemes.
|
||||
2. Wider adoption of privacy-preserving technologies like PLUME in mainstream wallets.
|
||||
3. New approaches to balancing privacy, usability, and decentralization in blockchain applications.
|
||||
|
||||
## Conclusion
|
||||
|
||||
While AnonKlub is ending, our commitment to advancing privacy solutions in the blockchain space remains strong. We're grateful for the support and interest from the community throughout this journey. We encourage others to build upon our work, learn from our experiences, and continue pushing the boundaries of what's possible in blockchain privacy.
|
||||
|
||||
The [code](https://github.com/anonklub/anonklub) and [documentation](https://anonklub.github.io/) from AnonKlub will remain available as a resource for the community. We look forward to seeing how future projects will take these ideas further and bring robust, user-friendly privacy solutions to the Ethereum ecosystem.
|
||||
|
||||
For more about PSE, visit our [website](https://pse.dev/),
|
||||
|
||||
_Header image credit © [Jonathan Kington](https://www.geograph.org.uk/profile/31463) ([cc-by-sa/2.0](http://creativecommons.org/licenses/by-sa/2.0/))_
|
||||
107
articles/bandada-is-live.md
Normal file
@@ -0,0 +1,107 @@
|
||||
---
|
||||
authors: ["Bandada Team"]
|
||||
title: "Bandada is live!"
|
||||
image: "cover.webp"
|
||||
tldr: "This post was written by the Bandada team. /n/n We are happy to announce the public release of Bandada V1! Try our [app](https://bandada.pse.dev/) out or run it yourself locally [v1.0.0-alpha](https://github.com/privacy-scaling-explorations/bandada/releases/tag/v1.0.0-alpha)"
|
||||
date: "2023-08-23"
|
||||
canonical: "https://mirror.xyz/privacy-scaling-explorations.eth/p3Mtft28FG1ctgeUARVEKLTK_KexnWC6T4CUHaQark4"
|
||||
---
|
||||
|
||||
## **Background**
|
||||
|
||||
Bandada is a public infrastructure project that allows you to easily create and manage privacy-preserving groups of anonymous individuals. It is a plug-and-play, free [SaaS](https://en.wikipedia.org/wiki/Software_as_a_service) or self-hosted solution, for developers, DAOs, governments, and individuals that care about privacy.
|
||||
|
||||
## Anonymous Groups and Credentials
|
||||
|
||||
Groups are an important concept when we speak about privacy and zero knowledge technologies, they can be thought of as anonymity sets. Credentials are a way to establish necessary trust between a set of participants while letting users keep control over how their identities are stored and used.
|
||||
|
||||
Bandada allows you to create groups and establish trust within the participants by ensuring that everyone who joined the group needed to meet the credential requirements.
|
||||
|
||||
## Why _Bandada_?
|
||||
|
||||
In Spanish, "Bandada" means "flock" or "group” of birds or animals moving together in a coordinated manner.
|
||||
|
||||
1. **Representation of Anonymous Groups:** Just like a flock of birds or animals moving together, Bandada aims to create privacy-preserving groups where individuals can act collectively without revealing their identities.
|
||||
2. **Coordinated and Secure Interaction:** Birds in a flock exhibit coordinated movements for navigation, safety, or foraging. Similarly, Bandada enables coordinated and secure interactions among the members of anonymous groups. The infrastructure provided allows for seamless communication and collaboration within these groups without compromising individual identities.
|
||||
|
||||
## **Highlights**
|
||||
|
||||
### F**eatures**
|
||||
|
||||
- Easily create onchain or offchain anonymous groups with a few clicks using our **Bandada Admin Dashboard**
|
||||
- Decide **how members will join,** with a unique invitation URL or by proving credentials
|
||||
- Select **which credentials** they will need to prove to join the group (GitHub, Twitter, etc.)
|
||||
- **Build your application** on top of Bandada, leveraging completely anonymous signals (like votes, endorsements, claims, messages, etc.)
|
||||
|
||||
### Use Cases
|
||||
|
||||
- Group with members who have contributed to a specific GitHub repository
|
||||
|
||||
- “Whitelist” a group of GitHub devs who have contributed to top DAOs repositories.
|
||||
|
||||
- Group of people with more than X followers on Twitter
|
||||
|
||||
- Custom anti-sybil mechanism
|
||||
|
||||
- Group of people in an organization like DAO, company, etc.
|
||||
|
||||
- Unlocking private interactions like anonymous feedback, whistleblowing, chat, and voting.
|
||||
|
||||
- (future) Groups of wallets holding a specific NFT
|
||||
|
||||
- Token-gated access to content
|
||||
|
||||
### Documentation:
|
||||
|
||||
- **Bandada API Docs** [https://api.bandada.pse.dev](https://api.bandada.appliedzkp.org/)
|
||||
- **Bandada API SDK** [https://github.com/privacy-scaling-explorations/bandada/tree/main/libs/api-sdk#readme](https://github.com/privacy-scaling-explorations/bandada/tree/main/libs/api-sdk#readme)
|
||||
- **Bandada credentials library** [https://github.com/privacy-scaling-explorations/bandada/tree/main/libs/credentials](https://github.com/privacy-scaling-explorations/bandada/tree/main/libs/credentials)
|
||||
- **Install it locally** [https://github.com/privacy-scaling-explorations/bandada#-install](https://github.com/privacy-scaling-explorations/bandada#-install)
|
||||
- **Run it with Docke**r [https://github.com/privacy-scaling-explorations/bandada#running-in-docker](https://github.com/privacy-scaling-explorations/bandada#running-in-docker)
|
||||
|
||||
## How does it work?
|
||||
|
||||
Bandada consists of a back-end to store the groups and provide the **[API](https://github.com/privacy-scaling-explorations/bandada/blob/docs/readme-files/apps/api)**, two front-ends: the **[dashboard](https://github.com/privacy-scaling-explorations/bandada/blob/docs/readme-files/apps/dashboard)** to manage groups and members and a **[demo](https://github.com/privacy-scaling-explorations/bandada/blob/docs/readme-files/apps/client)** application to allow end-users to join the groups, and the **[contracts](https://github.com/privacy-scaling-explorations/bandada/blob/docs/readme-files/apps/contracts).** Additionally, it also provides a set of JavaScript libraries to support developers.
|
||||
|
||||

|
||||
|
||||
The groups are currently binary Merkle trees compatible with the [Semaphore protocol,](https://semaphore.appliedzkp.org/) but additional data structures will be integrated in the future.
|
||||
|
||||
Two types of groups can be created from the dashboard: manual or credential groups. In the former, you can add members by entering IDs directly or by creating invite links, while in the latter you can define credentials that members must prove they have in order to access the group.
|
||||
|
||||
Once you create your manual group in the dashboard you can either create an API key to add or remove members or use the invite codes to add members with the `@bandada/api-sdk` library.
|
||||
|
||||
Credential groups can instead be accessed by redirecting users to an appropriate page in the dashboard. Bandada will ask users permissions to fetch their credentials and check if they are eligible.
|
||||
|
||||
Bandada also provides a preset of credential validators that can be extended with the `@bandada/credentials` library.
|
||||
|
||||
## Learning Resources & Project Ideas
|
||||
|
||||
Check [here](https://www.notion.so/Bandada-Learning-Resources-Project-Ideas-68803d6da8374a4399824e9a93995ff3?pvs=21) for new and upcoming learning resources like tutorials, videos, and additional documentation and growing project ideas to do with Bandada.
|
||||
|
||||
Lastly, keep exploring our [Bandada Notion](https://www.notion.so/Bandada-82d0d9d3c6b64b7bb2a09d4c7647c083?pvs=21) where we’ll keep it updated with the latest news.
|
||||
|
||||
## Bandada Moonrise
|
||||
|
||||
Shortly after this announcement, we´re starting Bandada Moonrise, a focused effort, and campaign to showcase Bandada and gather as much feedback as possible from the community to tailor the future roadmap.
|
||||
|
||||
If you’re part of a DAO, Web3, or ZK Dev community and want us to give a presentation, please reach us out!
|
||||
|
||||
## **What's coming in the future?**
|
||||
|
||||
- Onchain invitation groups
|
||||
- Onchain credential groups (like POAPs, NFTs, and tokens balance)
|
||||
- Easier deployments using Docker containers
|
||||
- Combining credential providers
|
||||
- Supporting different identity protocols
|
||||
- And much more!
|
||||
|
||||
Check our [Bandada - **Features** Roadmap](https://www.notion.so/Bandada-Features-Roadmap-8f9b1cf68e2b4a48a03ce898521370c5?pvs=21) to explore more
|
||||
|
||||
Want to share ideas? Want to help us build Bandada? Reach us by tagging us with @Bandada in [PSE Discord](https://discord.com/invite/sF5CT5rzrR) or by discussing issues in our [GitHub project board](https://github.com/orgs/privacy-scaling-explorations/projects/18/views/1).
|
||||
|
||||
Also if you contribute to Bandada´s codebase, then you´re eligible to claim a special POAP!
|
||||
|
||||
🥳 Check if you´re eligible and get yours here: [https://www.gitpoap.io/eligibility](https://www.gitpoap.io/eligibility)
|
||||
|
||||
Thanks to all contributors and Bandada supporters! In particular @cedoor, @vplasencia, @saleel, @aguzmant103, @rachelaux, @beyondr, @wanseob, @mari, @kat
|
||||
@@ -0,0 +1,134 @@
|
||||
---
|
||||
authors: ["kichong"]
|
||||
title: "Beyond Zero-Knowledge: What's Next in Programmable Cryptography?"
|
||||
image: "cover.webp"
|
||||
tldr: "_This post was written by [kichong](https://twitter.com/kichongtran) with helpful feedback and comments from [sinu](https://twitter.com/sinu_eth) and [jmall](https://twitter.com/Janmajaya_mall)._"
|
||||
date: "2023-11-09"
|
||||
canonical: "https://mirror.xyz/privacy-scaling-explorations.eth/xXcRj5QfvA_qhkiZCVg46Gn9uX8P_Ld-DXlqY51roPY"
|
||||
---
|
||||
|
||||
MPC, FHE, iO. If these combinations of letters make little sense to you, then you’re in the right place. This post attempts to review, at a high level, the world of programmable cryptography beyond the borders of zero-knowledge (ZK).
|
||||
|
||||
The intent is to expose people to the idea that ZK is only one part of a constantly shifting landscape of cryptographic primitives, techniques, and protocols. And what remains is more powerful, more private, and more confusing than the average cryptography-curious person is aware of.
|
||||
|
||||
This post makes no claims, conclusions, or predictions. This is no deep dive. At best, it’s an informal skimming of the surface in the quest for the holy grail of cryptography.
|
||||
|
||||
While encryption has been around for thousands of years, programmable cryptography is a modern technology. Described as “[general-purpose cryptography … \[or\] an expressive language for claims”](https://archive.devcon.org/archive/watch/6/zkps-and-programmable-cryptography/?tab=YouTube), it’s the idea that a cryptographic primitive like a ZK proof could be made flexible and adaptive enough that a developer could program nearly any function on top of it. That there can exist an unbroken chain of logic from someone clicking a button on a website to the mathematical proof that guarantees the security of a cryptographic operation.
|
||||
|
||||

|
||||
|
||||
https://youtu.be/qAfprVCBhdQ?t=1024
|
||||
|
||||
While traditional cryptography relied on fixed sets of functionalities, which required a skilled cryptographer to build a specialized system for every new mechanism, programmable cryptography lets developers deploy cryptographic properties and functionality in a language closer to what they already understand. It gives developers who are not cryptography experts a more familiar interface.
|
||||
|
||||
ZK proofs were first [conceived of in 1985](https://people.csail.mit.edu/silvio/Selected%20Scientific%20Papers/Proof%20Systems/The_Knowledge_Complexity_Of_Interactive_Proof_Systems.pdf). The concept was officially published in 1989, but remained mostly theoretical until 2012 when a type of ZK proof called a [zk-SNARK](https://eprint.iacr.org/2011/443.pdf) was discovered. This new primitive allowed ZK proofs to prove or authenticate nearly any function or arbitrary computation.
|
||||
|
||||
Since zkSNARKS became possible, resources and talent have poured into building zCash, zkRollups, zkEVMs, and a host of other applications beginning with the letter z. It turned out, decentralized systems like Ethereum, and blockchains in general, were the perfect motivation to get people interested in cryptography, turning a once-impractical research field into an active ecosystem with actual end-user applications.
|
||||
|
||||
There are no guarantees that [Multi-Party Computation (MPC)](https://en.wikipedia.org/wiki/Secure_multi-party_computation), [Fully Homomorphic Encryption (FHE)](https://en.wikipedia.org/wiki/Homomorphic_encryption), and [Indistinguishable Obfuscation (iO)](https://en.wikipedia.org/wiki/Indistinguishability_obfuscation) will follow the same path as ZK, becoming more practical, optimized, and general-purpose as time goes on. But at this early stage, it is certainly possible.
|
||||
|
||||
If you think of programmable cryptography as a type of digital computer, built on certain assumptions that allow for certain properties and guarantees, then we are still at the hardware stage. We are still actively figuring out the best way to construct the logical gates or circuits for this new computer.
|
||||
|
||||
## **Relatively intuitive comparisons**
|
||||
|
||||
To better understand the general landscape of programmable cryptography, let’s start by very roughly approximating where MPC, FHE, and IO stand in relation to ZK, and each other. In this section, and really all the sections that come after, we will trade-off nuance, precision, and formality in favor of simplicity and accessibility.
|
||||
|
||||
The simplest way to reason about cryptography is what information is kept hidden or secret. And what the system proves or reveals.
|
||||
|
||||

|
||||
|
||||
You can also think of each of these systems as standing in for an imaginary mutual friend. [Wikipedia calls this friend “Tony”.](https://en.wikipedia.org/wiki/Secure_multi-party_computation#Definition_and_overview) Tony is infallible, incorruptible, and totally trustworthy. Tony’s job is to keep secrets. In the table below, think of the “Private Elements” as what secrets Tony can be trusted to keep, the “Use Cases” as tasks Tony could perform reasonably well, and the “Practicality” as how skillfully Tony could perform these tasks today.
|
||||
|
||||

|
||||
|
||||
The tables above are intended to give a rough idea for different areas of programmable cryptography. Now, let’s go a bit deeper and review what MPC, FHE, and iO do along with some interesting tidbits about each field.
|
||||
|
||||
## **Multi-Party Computation (MPC)**
|
||||
|
||||
Multi-Party Computation (MPC) allows many parties to jointly compute some agreed upon function without revealing any data to the other participants. With MPC, the same computation is applied to everyone's data, but each party’s input is kept secret. Intermediate values would also stay secret. Only the output is revealed at the end.
|
||||
|
||||
As opposed to ZK, MPC is collaborative. It allows different parties to collaborate on the same computation, each contributing their own data, to get some mutual result everyone wants.
|
||||
|
||||
We can compare ZK and MPC in the context of an AI system to get more context. ZK would be good at authenticating or verifying a piece of data came from a real person or from a person’s phone. MPC is better for training an AI system because different individuals, groups, or organizations could share sensitive data with the AI system but trust that the data won’t be revealed to anyone else.
|
||||
|
||||
## **Millionaire problems**
|
||||
|
||||
MPC was thought of in [1982 by Andrew Yao](https://research.cs.wisc.edu/areas/sec/yao1982-ocr.pdf) to solve a thought experiment called the “Millionaire’s Problem” where two millionaire’s want to know who is richer without telling each other how much money they have. The solution was to use [garbled circuits, which according to Vitalik Buterin,](https://vitalik.ca/general/2020/03/21/garbled.html) frequent explainer of cryptographic concepts, is also one of the most basic ways to wrap your head around MPC.
|
||||
|
||||
\[Before learning about a garbled circuit, you need to know what a arithmetic circuit is in general. If you’re new to the idea of circuits, there’s a [simple explanation here.](https://mirror.xyz/privacy-scaling-explorations.eth/AW854RXMqS3SU8WCA7Yz-LVnTXCOjpwhmwUq30UNi1Q)\]
|
||||
|
||||
MPC is a multi-step, interactive process where millionaire #1 (Alice the Garbler) must first create the circuit, enter her net worth, then transform it into a garbled or encrypted form before passing it along to millionaire #2 (Bob the Evaluator). When Bob gets his hands on the circuit, his job is to add his own net worth, then evaluate or run the circuit to make sure it’s correct. Finally, Bob decrypts the final output and, for example, learns Alice is richer, but never learns that Alice is, in fact, way richer, and he shouldn’t have made assumptions.
|
||||
|
||||
The Millionaire’s Problem and garbled circuits as a solution were crucial to the early development of MPC. But its application was limited. A more complex and nuanced version of the problem, called the [Socialist Millionaire’s Problem](https://en.wikipedia.org/wiki/Socialist_millionaire_problem), checked if the two millionaires were equally rich, instead of revealing which one had more money. This subtle difference significantly extended MPC functionality but required more complex cryptographic solutions and techniques beyond the scope of this article.
|
||||
|
||||
## **Fully Homomorphic Encryption (FHE)**
|
||||
|
||||
Fully Homomorphic Encryption (FHE) allows computations on encrypted data. It can perform a function on encrypted data just as if it had remained unencrypted. The output of the function is only decrypted by the party with the secret key. If we think of encryption as a black box that hides secrets, then FHE ensures that the data and the computations on that data remain within that black box.
|
||||
|
||||
Though there are no famous thought experiments like the Millionaire’s Problem for MPC, FHE does solve a fundamental security weakness: [“the need to decrypt before processing data.”](https://blog.cryptographyengineering.com/2012/01/02/very-casual-introduction-to-fully/)
|
||||
|
||||

|
||||
|
||||
https://www.zama.ai/post/the-revolution-of-fhe
|
||||
|
||||
In an AI context, FHE would keep all the data between the user (secret key holder) and the AI system encrypted. The user interacts with the system as normal, but the user could be confident that the AI never “learned” anything about the data being given. The entire interaction would be encrypted. The AI never learns what you typed or asked, what pictures you sent, or who sent it, but can still respond as if it did know the information.
|
||||
|
||||
If it works, FHE will be one of the most powerful privacy-preserving technologies available. And who knows? [In 10 years, we may even have FHE-EVMs](https://youtu.be/ptoKckmRLBw?si=WQDbSStGkqWCx5JM&t=1734).
|
||||
|
||||
## **Noise management**
|
||||
|
||||
Compared to MPC and ZK, FHE is – at the moment – on the more theoretical or less practical end of the spectrum. The technology was only considered to be feasible in [2009 when Craig Gentry](https://www.cs.cmu.edu/~odonnell/hits09/gentry-homomorphic-encryption.pdf) figured out how to deal with noise.
|
||||
|
||||
FHE operations are computationally very intensive because “noise” is added during the encryption process to enhance security. Noise in FHE is a small random value added to the plaintext (unencrypted data) before it is turned into ciphertext (encrypted data). Each operation increases noise. While addition and subtraction operations cause negligible noise growth, multiplication is more computationally expensive, which results in significant noise growth. So as the complexity of a program increases, noise – the space required to accommodate noise and the computational resources needed to process noise – accumulates.
|
||||
|
||||
Gentry’s breakthrough was a technique called bootstrapping, which could reduce noise and allow for more computation on encrypted data in FHE systems. Bootstrapping takes the ciphertext and decrypts it homomorphically, which means reducing the noise level on an encrypted piece of data without actually revealing what it is. The result is a ciphertext with much lower pre-defined noise, thus allowing us to compute on the ciphertext further. Bootstrapping, in general, allows us to circumvent the need of having higher space for noise growth as complexity of computation increases. We can limit the space to a few operations and repeatedly bootstrap to compute arbitrarily large computations without compromising the original data.
|
||||
|
||||
Depending on the FHE scheme, bootstrapping can either take several minutes or milliseconds. If bootstrapping is slower, the computational cost can be spread out by applying it to several ciphertexts at once. If bootstrapping is faster, it usually comes with the trade-off of only working with small pieces of plaintext (usually 8 bits) at a time to stay efficient.
|
||||
|
||||
## **Indistinguishability Obfuscation (iO)**
|
||||
|
||||
If FHE turns all the elements of the computation into a black box, then iO turns the computation itself into a black box.
|
||||
|
||||
Indistinguishability Obfuscation (iO) is considered the most powerful cryptographic system within the realm of theoretic possibility. In [one article](https://www.quantamagazine.org/computer-scientists-achieve-crown-jewel-of-cryptography-20201110/), iO is described as a “master tool from which nearly every other cryptographic protocol could be built” and referred to by cryptography experts as a “crown jewel” and “one cryptographic primitive to rule them all.”
|
||||
|
||||
According to Amit Sahai, the professor known for [explaining ZK proofs to kids](https://www.youtube.com/watch?v=fOGdb1CTu5c), and one of the researchers who devised a way [build iO on well-founded assumptions](https://eprint.iacr.org/2020/1003), iO works on a fundamentally different paradigm than previous cryptographic systems. IO assumes the adversary can already read your mind (a metaphor for your computer). Your secrets are already known so can’t be hidden. The only thing you can do is obfuscate what the adversary can already see.
|
||||
|
||||

|
||||
|
||||
https://youtu.be/v2RR\_c5hn1E
|
||||
|
||||
The point of iO is to make two functions or computations equally obscure. If you turn two computations into a form that is indistinguishable from each other, then you can hide how the program works. If you can’t tell the difference between two programs, you don’t know which of the two programs is being executed, and no information can be deduced from either one, other than that they both perform the same function. Both programs take the same inputs and produce the same outputs, but iO makes it so no one can figure out how.
|
||||
|
||||
With iO, you can conceal the structure of every type of function including nearly all the functions that make up cryptography. In other words, by obscuring nearly anything, you reach the most general-purpose programmable cryptography on which other primitives can be programmed on top of.
|
||||
|
||||
Technically, there is a black box bigger than iO. It’s literally called [black box obfuscation](https://en.wikipedia.org/wiki/Black-box_obfuscation). But that one is still impossible.
|
||||
|
||||
## **Well-founded assumptions**
|
||||
|
||||
No one knew how to build iO [until 2013, when multilinear maps were proposed by Garg, Gentry, Halevi, Raykova, Sahai, Waters.](https://eprint.iacr.org/2013/451.pdf) A computer program could be broken up like puzzle pieces then obscured using multilinear maps. The obscured pieces could be reassembled to achieve the same functionality as the original program without revealing its inner workings.
|
||||
|
||||
Multilinear maps are a generalization of the bilinear maps or pairings used in [Elliptic Curves Cryptography (ECC](https://blog.cloudflare.com/a-relatively-easy-to-understand-primer-on-elliptic-curve-cryptography/)). While bilinear maps are foundational to existing cryptographic schemes like [BLS signatures](https://en.wikipedia.org/wiki/BLS_digital_signature), they are not complex or expressive enough for iO. And while multilinear maps could handle iO, this newly developed algebraic structure was easily attackable and wasn’t secure so relying on multilinear maps was generally unsatisfying for cryptographers. The field was stuck again.
|
||||
|
||||
Then, in 2020, [Jain, Lin, and Sahai proposed](https://eprint.iacr.org/2020/1003) a solution that while unusual and new, was simple enough for cryptographers to reason about, and instead of relying on newly developed assumptions like multilinear maps, this version of iO could be built on more standard and well-founded assumptions that have been studied for decades such as [Learning with Errors (LWE).](https://en.wikipedia.org/wiki/Learning_with_errors) With this latest breakthrough, iO became feasible again. The holy grail was still in reach.
|
||||
|
||||
## **Untamed wilderness**
|
||||
|
||||
Each cryptographic system is made of different mathematical assumptions and cryptographic techniques. No single breakthrough solves all the problems in a system. Instead, discoveries follow an unpredictable series of small steps and big leaps that alter existing assumptions and techniques, which in turn lead to more breakthroughs and discoveries. And for every discovery that worked, many more did not.
|
||||
|
||||

|
||||
|
||||
In a presentation on iO, Sahai described the field as being in the “[untamed wilderness](https://youtu.be/v2RR_c5hn1E?t=1317),” where it wasn’t even clear what was not understood and what the right problems to solve were.
|
||||
|
||||
Teams like [PSE](https://www.appliedzkp.org/) primarily work on the practical or applied side of programmable cryptography, focusing on primitives like ZK and MPC with well-founded assumptions that have been battle-tested, relatively optimized, and thought to be secure and effective. Though there are plenty of optimizations left, ZK is now firmly within the realm of practicality. But there was also a time when ZK was confined to the untamed wilderness.
|
||||
|
||||
To maximize the number of privacy-preserving, security-guaranteeing, claim-verifying, cryptography-enabled tools the world has access to, we should keep, at least, one eye squinted toward the horizon of what’s to come because no one can predict what will be practical in 10 years.
|
||||
|
||||
Sahai’s presentation includes a quote from a [2003 Nature article by Steven Weinberg called Four Golden Lessons](https://www.nature.com/articles/426389a), which highlights another reason to work on the currently impractical.
|
||||
|
||||
“When I was teaching at the Massachusetts Institute of Technology in the late 1960s, a student told me that he wanted to go into general relativity rather than the area I was working on, elementary particle physics, because the principles of the former were well known, while the latter seemed like a mess to him. It struck me that he had just given a perfectly good reason for doing the opposite… My advice is to go for the messes — that's where the action is.”
|
||||
|
||||
---
|
||||
|
||||
Programmable Cryptography is being explored by a variety of teams including [PSE](https://pse.dev/) and [0xPARC](https://0xparc.org/), co-organizers of a 2-day event called the [Programmable Cryptography Conference](https://progcrypto.org/) happening in Istanbul, Turkey on November 16 & 17, 2023.
|
||||
|
||||
Come say hello! Or find [PSE online on Discord](https://discord.com/invite/sF5CT5rzrR).
|
||||
@@ -0,0 +1,128 @@
|
||||
---
|
||||
authors: ["PSE Team"]
|
||||
title: "BLS Wallet: Bundling up data - Privacy & Scaling Explorations"
|
||||
image: null
|
||||
tldr: ""
|
||||
date: "2022-08-26"
|
||||
canonical: "https://mirror.xyz/privacy-scaling-explorations.eth/e8Xy1X1phqdqGwkzaLMlyT9BY-8MpLoelYTsJc_DzfU"
|
||||
---
|
||||
|
||||

|
||||
|
||||
Originally published on Aug 5, 2022:
|
||||
|
||||
[Rollups](https://ethereum.org/en/developers/docs/scaling/#rollups) are providing faster and cheaper ways to use Ethereum, but they still face a key constraint: the need to store and pay for data on layer 1. BLS Wallet uses [BLS signatures](https://en.wikipedia.org/wiki/BLS_digital_signature) for transactions, so multiple signatures can be combined into one while still being able to verify all signed transactions. By requiring one signature where many were needed before, less data needs to be stored on-chain and layer 2 (L2) solutions become even cheaper.
|
||||
|
||||
[BLS Wallet](https://blswallet.org/) is an end-to-end system allowing wallets, dapps, and L2 nodes to easily plug the moon math magic of BLS signatures directly into their code.
|
||||
|
||||
## BLS Signatures: Just addition
|
||||
|
||||
BLS signatures are a cryptographic primitive most notably used [in the Beacon Chain](https://eth2book.info/altair/part2/building_blocks/signatures) to verify large numbers of signatures. According to Vitalik Buterin, BLS signatures are actually “very simple (aside from the extreme complexity in elliptic curve pairings themselves).” Luckily, the inventors of this signature scheme (Dan Boneh, Ben Lynn and Hovav Shacham) have done that extremely complex math for us.
|
||||
|
||||
|
||||
|
||||
Elliptic curve, from Vitalik Buterin and Justin Drake’s [presentation on BLS aggregation](https://www.youtube.com/watch?v=DpV0Hh9YajU)
|
||||
|
||||
In optimistic rollups such as [Arbitrum](https://bridge.arbitrum.io/) and [Optimism](https://www.optimism.io/), each transaction must be accompanied by its own signature. These signatures end up being stored on layer 1 (L1) as calldata, a read-only format that’s committed as part of a transaction rather than to (much more expensive) contract storage. Storing transactions and signatures as [calldata](https://ethereum.org/en/developers/tutorials/short-abi/#main-content) is the cheapest method available for rollups to keep data on L1, but calldata costs still add up.
|
||||
|
||||
The key property of BLS signatures is that multiple signatures can be combined into one; so instead of needing to verify each individual signature, only one aggregate signature needs to be verified and stored on-chain.
|
||||
|
||||
For the Ethereum developer and user, less on-chain data means less gas fees.
|
||||
|
||||
|
||||
|
||||
Ethereum’s scalability and usability problems are being chipped away from all angles. Protocol-level changes such as [sharding](https://ethereum.org/en/upgrades/sharding/#main-content) and [EIP-4488](https://eips.ethereum.org/EIPS/eip-4488) are intended to increase data availability and reduce the cost of storing data on Ethereum. Layer 2 solutions like optimistic and zk rollups are already here, with more on the way. BLS aggregation is a powerful technique that can be used right now in combination with other efforts.
|
||||
|
||||
By improving costs using readily available and proven cryptographic primitives, more adoption and more use cases become possible sooner rather than later.
|
||||
|
||||
## Storage is expensive
|
||||
|
||||
L1 data storage is expensive and remains the main bottleneck for rollups. For the rollup to have L1 security guarantees, the rollup’s compressed state must be stored on L1, and L1 storage is the most significant cost factor.
|
||||
|
||||
All rollups bundle multiple transactions on L2 and write the results of the transactions to L1. BLS Wallet is a means to further reduce rollup costs by enabling on-chain verification of multiple transactions via a single aggregated signature. Data and transaction signatures are aggregated from a variety of different users, wallets, and dapps that have integrated BLS Wallet, resulting in a cascade of bundled transactions.
|
||||
|
||||
The bundling of transactions using a system like BLS Wallet has a compounding effect on reducing gas costs. The more transactions get included in a bundle, the cheaper each transaction is. In other words, more people using BLS Wallet at the same time means greater savings for each user or application. This allows [optimistic rollups](https://ethereum.org/en/developers/docs/scaling/optimistic-rollups/) to remain competitive in cost with [ZK rollups](https://ethereum.org/en/developers/docs/scaling/zk-rollups/) while still enjoying the EVM-equivalency we’ve all come to know and love.
|
||||
|
||||
**What’s in a bundle?**
|
||||
|
||||
BLS Wallet bundles can contain both simple transactions (“send money from account A to account B”) and more complex interactions. A single, basic L2 transaction is called an _action_. An _operation_ is an array of actions to be performed atomically, which means all actions in an operation are successfully executed or none are. Operations guarantee complex, multi-step actions can be executed without unwanted interference. Using a single operation instead of multiple separate actions means users and dapps never have to worry about partial completion of an intended function or lingering token approvals.
|
||||
|
||||
An operation must contain the nonce of the smart contract wallet, a BLS signature, and the action(s) to be executed including the address of the smart contract to be called and the function to call.
|
||||
|
||||
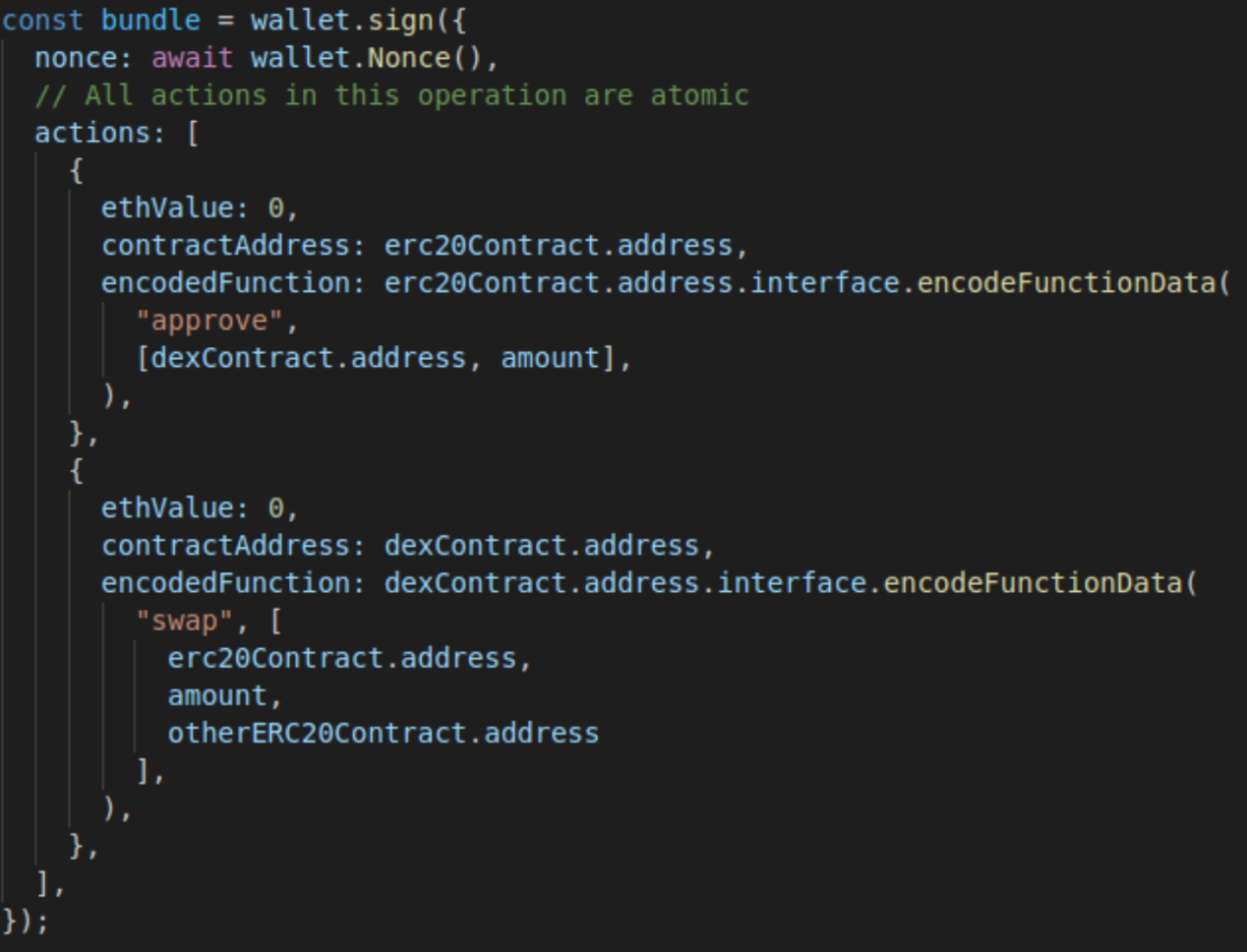
|
||||
|
||||
Example of a single operation bundle
|
||||
|
||||
## A better wallet
|
||||
|
||||
Today, nearly all transactions on Ethereum begin with an [Externally Owned Account (EOA)](https://ethereum.org/en/developers/docs/accounts/), otherwise known as a standard Ethereum address, which has limited functionality. Smart contract wallets allow more flexibility for a better user experience.
|
||||
|
||||
The main barrier to widespread smart contract wallet usage has been, to the surprise of probably no one reading this, high gas fees! Smart contract wallets are expensive to deploy and use on L1 Ethereum. However, they become practical on L2 where gas fees are lower and it is much cheaper to execute complex transactions.
|
||||
|
||||
BLS Wallet provides the infrastructure for a smart contract wallet for EVM-compatible L2s. Besides the cheaper fees from compressed data and BLS signature aggregation, you also get other features enabled by smart contract wallets:
|
||||
|
||||
- \*\*Gasless transactions: \*\*Developers can choose to cover the fees for users and abstract away gas costs in the process.
|
||||
- \*\*Account abstraction: \*\*Authorization logic of an account is decoupled from that of the protocol.
|
||||
- \*\*Account recovery: \*\*Recovery is implemented by nominating an address to recover from lost or compromised BLS keys.
|
||||
- \*\*Upgradeability: \*\*At the user’s discretion, wallets can be upgraded, ensuring they are futureproof.
|
||||
- \*\*Multi-action: \*\*Transactions can be grouped together, allowing dapp developers to think in terms of multi-step operations instead of single transactions.
|
||||
|
||||
With a smart contract wallet, the user experience can be designed to feel more familiar to a non-crypto user. Instead of needing to know about contract interactions and gas fees as a prerequisite to using a dapp, users can learn about Ethereum at their own pace.
|
||||
|
||||
## BLS Wallet in action
|
||||
|
||||
BLS Wallet can be thought of as a 3-part system consisting of the:
|
||||
|
||||
1. Client Module
|
||||
2. Aggregator
|
||||
3. Verification Gateway
|
||||
|
||||
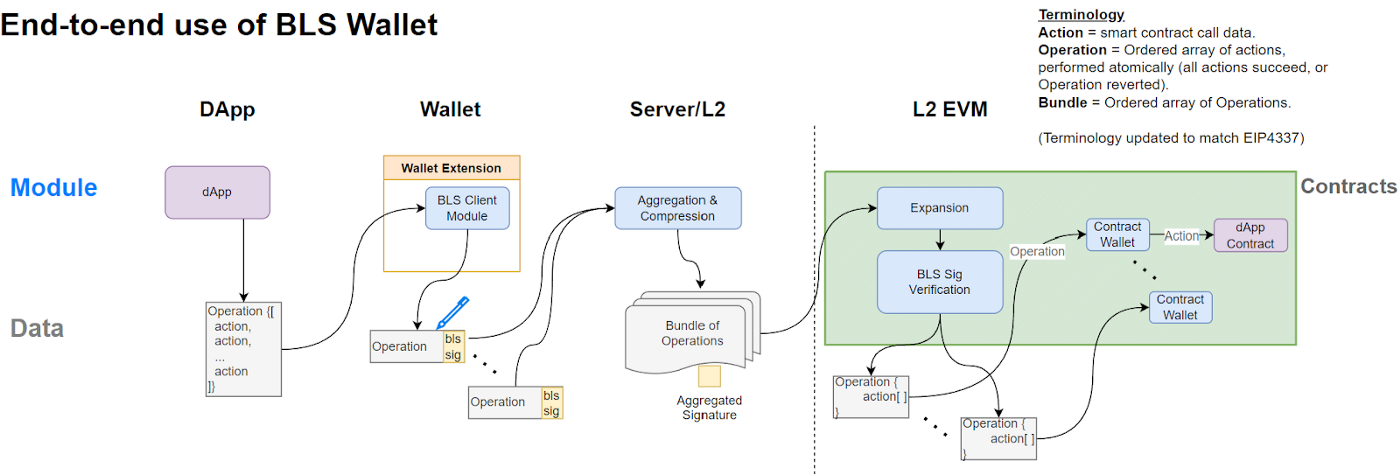
|
||||
|
||||
**Client Module**
|
||||
|
||||
The Client Module, where the first bundling of actions occurs, acts as the gateway for most users or dapps to interact with the BLS Wallet system. The Client Module provides the interface for users to generate BLS keypairs and create new smart contract wallets as well as sign transactions and operations.
|
||||
|
||||
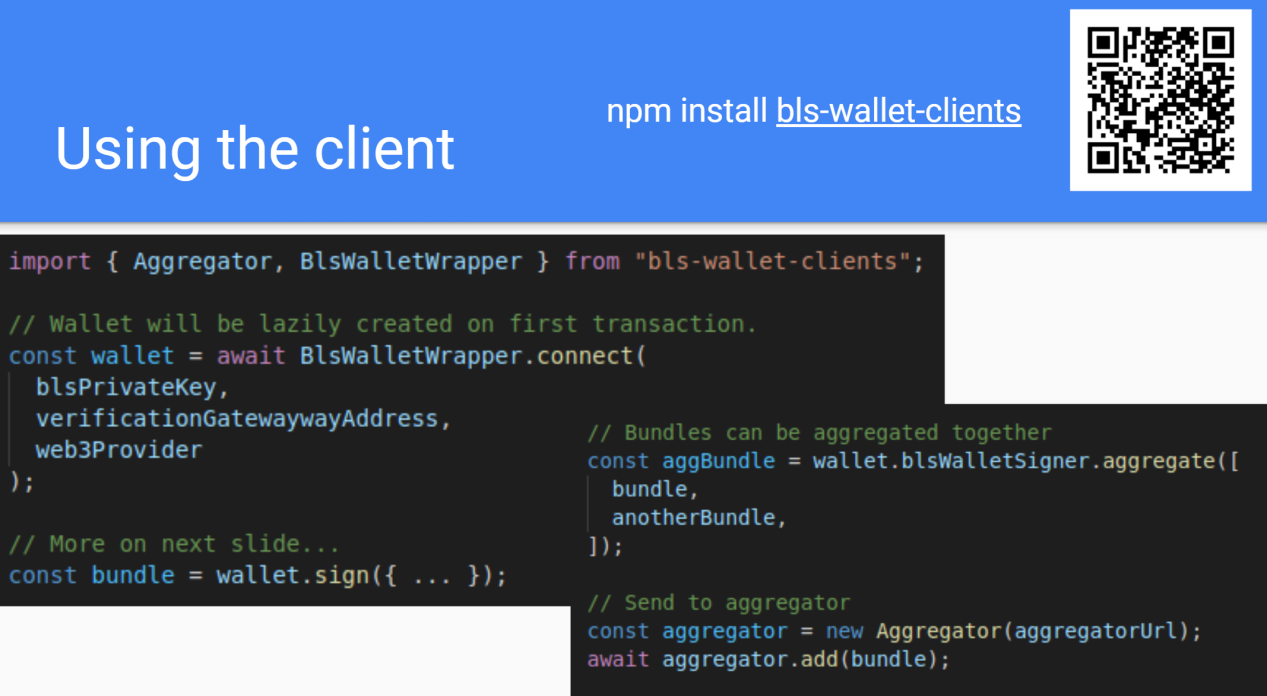
|
||||
|
||||
The BLS Client Module can be integrated into an existing wallet.
|
||||
|
||||
With the Client Module, users and dapps can:
|
||||
|
||||
1. Create single or multiple actions
|
||||
2. Sign action bundles with BLS signatures
|
||||
3. Send signed actions to the Aggregator
|
||||
|
||||
**Aggregator**
|
||||
|
||||
[The Aggregator](https://github.com/web3well/bls-wallet/tree/main/aggregator) is currently a hosted off-chain server for EVM-compatible L2s. The Aggregator receives actions and operations from the Client Module and further bundles them with other actions received from other Client Modules. One bundle can contain actions and operations from a variety of Client Modules operating on behalf of multiple wallets or dapps.
|
||||
|
||||
The Aggregator creates a single bundle, aggregates all the signatures, and further compresses the data where possible. The new aggregated and signed bundle is sent to the Verification Gateway on the L2 node.
|
||||
|
||||
In production, the Aggregator will most likely need to be paid a fee to perform its services so each bundle will need to include a reward or incentive for the Aggregator.
|
||||
|
||||
**Verification Gateway**
|
||||
|
||||
The [Verification Gateway](https://github.com/web3well/bls-wallet/tree/main/contracts) is the on-chain EVM smart contract on L2. It verifies that the signatures match the correct public keys before sending the actions to the corresponding smart contract wallets for processing. Though the Verification Gateway submits one transaction on-chain, multiple contract calls can occur within that single transaction.
|
||||
|
||||
The Verification Gateway processes transactions by:
|
||||
|
||||
1\. Expanding the compressed data and aggregated signatures
|
||||
|
||||
2\. Checking all operations and public keys against the aggregated signature to verify they are correct and matching
|
||||
|
||||
3\. Sending validly signed actions to the corresponding smart contract wallets to be executed one at a time on behalf of the user and dapps
|
||||
|
||||
## Building with BLS Wallet
|
||||
|
||||
All of the BLS Wallet components are open source and available in the [BLS Wallet Repo](https://github.com/web3well/bls-wallet). If you’re interested in integrating BLS Wallet into a wallet or L2 project, [here](https://github.com/web3well/bls-wallet/blob/main/docs/use_bls_wallet_clients.md) is a good place to start.
|
||||
|
||||
You can also try out Quill, a prototype BLS Wallet browser plugin. Quill generates new BLS keypairs and smart contract wallets capable of bundling multiple transactions and sending them to the Aggregator. Watch the [Quill demo](https://www.youtube.com/watch?v=MOQ3sCLP56g) presented by Kautuk at L2 Amsterdam, or [try installing it yourself](https://github.com/web3well/bls-wallet/tree/main/extension).
|
||||
|
||||
Let us know it goes! We welcome contributions, comments and questions on [Github](https://github.com/web3well/bls-wallet/blob/main/CONTRIBUTING.md) or [Discord](https://discord.gg/Wz3NvbB8Br).
|
||||
|
||||
## Web3well
|
||||
|
||||
[Web3well](https://github.com/web3well/) aims to be a neutral place for competing ecosystem teams to gather and explore how advanced features like BLS signatures can be used to achieve faster adoption and new use cases through improved usability. BLS Wallet is the primer for what we hope will be more collaborative conversations around wallets, designs and ideas.
|
||||
|
||||
Web3well and BLS Wallet are possible thanks to the work of contributors including [James Zaki](https://github.com/jzaki) (project lead), [Jake Caban-Tomski](https://github.com/jacque006), [Kautuk Kundan](https://github.com/kautukkundan) and [Andrew Morris](https://github.com/voltrevo).
|
||||
232
articles/certificate-transparency-using-newtonpir.md
Normal file
@@ -0,0 +1,232 @@
|
||||
---
|
||||
authors: ["PSE Team"]
|
||||
title: "Certificate Transparency Using NewtonPIR"
|
||||
image: "cover.webp"
|
||||
tldr: "This post was written by PSE grantee Vishal Kulkarni."
|
||||
date: "2025-01-28"
|
||||
canonical: "https://mirror.xyz/privacy-scaling-explorations.eth/V0PIyv1d_e_WPsAVhBP7zkDvn0XACY63uSvFFxBvjrk"
|
||||
---
|
||||
|
||||
## Introduction
|
||||
|
||||
### Key concepts
|
||||
|
||||
**Certificate Transparency**
|
||||
|
||||
[Certificate Transparency (CT)](https://certificate.transparency.dev/howctworks/) is a standard for verifying digital certificates such as those used by websites secured by HTTPS. CT employs a transparent log of certificates issued by a trusted Certificate authority (CA), which anyone can check to verify that a certificate is valid (for most people surfing the web, this is done automatically by the browser).
|
||||
|
||||

|
||||
|
||||
If you've ever seen this screen, you've witnessed Certificate Transparency in action!
|
||||
|
||||
Certificate transparency is an important tool for protecting users from security risks like website spoofing or malicious interference in web traffic, but it also raises some privacy concerns: parties that keep CT logs can potentially gain information about users based on their queries.
|
||||
|
||||
**NewtonPIR**
|
||||
|
||||
[Private Information Retrieval (PIR)](https://arxiv.org/abs/2304.14397) is a protocol that lets a user get information from a database without revealing to the owner what data they retrieved. PIR has many potential uses in privacy-preserving applications, but it requires complex communication and computation which can be prohibitively expensive with large databases. There are many PIR implementations taking different approaches cryptographic techniques. [NewtonPIR](https://eprint.iacr.org/2024/1909.pdf) is a proposed scheme for highly efficient PIR using [Fully Homomorphic Encryption (FHE)](https://mirror.xyz/privacy-scaling-explorations.eth/D8UHFW1t48x2liWb5wuP6LDdCRbgUH_8vOFvA0tNDJA).
|
||||
|
||||
### Private CT queries with NewtonPIR
|
||||
|
||||
NewtonPIR enhances privacy in CT by enabling users to query public logs for SSL/TLS certificates without revealing which domains they are checking. This application helps domain owners and auditors ensure no unauthorized certificates have been issued for their domains while maintaining privacy. It prevents CT log operators or third parties from inferring sensitive information about user interests or monitoring activities.
|
||||
|
||||
By integrating privacy-preserving queries, this approach supports the core goals of CT ensuring transparency and accountability in certificate issuance without compromising the privacy of the querying parties. It is particularly valuable for large-scale monitoring of CT logs, protecting user confidentiality while upholding security and trust in SSL/TLS ecosystems.
|
||||
|
||||
This application would allow users (domain owners, auditors) to query public CT logs for SSL/TLS certificates without revealing the domain names they are checking.This application was initially discussed in this [paper](https://eprint.iacr.org/2022/949.pdf). For further details and insights into their proposed solutions, please refer to the paper.
|
||||
|
||||

|
||||
|
||||
CT Workflow
|
||||
|
||||
The figure above illustrates the overall workflow of Certificate Transparency, showing how the domain owner requests certificates from the CA, how the CA responds with the SCT, and how logs are monitored.
|
||||
|
||||
## Existing SCT Auditing Approaches
|
||||
|
||||
Signed Certificate Timestamp (SCT) is a cryptographic proof that a digital certificate has been submitted to a Certificate Transparency (CT) log. It ensures that the certificate is publicly logged and visible. The client uses the SCT received from the server during the TLS handshake to verify if it has been publicly logged.
|
||||
|
||||
### 1\. Opt-Out Auditing (Current Chrome Approach)
|
||||
|
||||
Rather than client directly interacting with the CT log server Google’s solution involves an SCT auditor which maintains a global set of all valid SCTs for active certificates. Allows clients to check if an SCT is valid without directly revealing which SCT they are verifying.
|
||||
|
||||
#### How it Works
|
||||
|
||||
- Client calculates the hash of the SCT
|
||||
- Clients reveal the first 20 bits of an SCT’s hash to the auditor.
|
||||
- The auditor provides all matching SCTs (around 1000), achieving k-anonymity (with k=1000).
|
||||
- Drawback: Partial SCT hash leakage can still compromise privacy.
|
||||
|
||||
#### Efficiency
|
||||
|
||||
- Google Chrome's model randomly samples 0.01% of SCTs for auditing, drastically reducing costs but also decreasing the chance of catching invalid SCTs.
|
||||
- Despite this low per-client detection rate, the distributed nature of auditing across many clients ensures high detection probabilities for invalid SCTs.
|
||||
|
||||
### 2\. Anonymizing Proxies
|
||||
|
||||
- Clients use anonymity-preserving networks like Tor to query the auditor which are intermediaries that hide a user's identity and online activity.
|
||||
- While anonymity is preserved, the entire distribution of SCTs can still be observed by the auditor.
|
||||
- When using anonymizing proxies, bugs like [timing attacks](https://medium.com/spidernitt/introduction-to-timing-attacks-4e1e8c84b32b) can exploit variations in response times to infer sensitive information about user activities, such as the websites they visit or the content they access. This is done by correlating the time it takes for requests to pass through the proxy with specific patterns. Similarly, [deanonymization](https://www.techtarget.com/whatis/definition/de-anonymization-deanonymization) can occur through traffic analysis, where the size, frequency, or timing of requests is matched to a user's behavior, or through leaks of metadata or unique identifiers, which expose the user's identity despite the use of the proxy.
|
||||
|
||||
## Overview of PIR-CT
|
||||
|
||||
**Goal**
|
||||
|
||||
- Enable private queries to Certificate Transparency logs using NewtonPIR.
|
||||
- Prevent CT log operators from learning which certificate (or domain name) a user is querying.
|
||||
|
||||
**Core Components**
|
||||
|
||||
- NewtonPIR: Efficient single-server PIR to retrieve entries privately from large CT logs.
|
||||
- Certificate Transparency Logs: Public, append-only logs that store SSL/TLS certificates.
|
||||
- Client Application: Queries the CT logs using PIR while hiding its query intent.
|
||||
- Server (CT Log Operator): Hosts the CT logs and responds to PIR-based queries.
|
||||
|
||||
## System Design
|
||||
|
||||
### Certificate Transparency Logs
|
||||
|
||||
- CT logs are stored as a database of certificates where each entry includes: Domain name (e.g., [example.com](http://example.com/)) Certificate details (e.g., public key, issuer, serial number, validity)
|
||||
- Timestamp: When the certificate was issued.
|
||||
- SCT (Signed Certificate Timestamp): Proof of inclusion in the log.
|
||||
|
||||
Each certificate is uniquely identified by an index in the database.
|
||||
|
||||
### Database Setup for NewtonPIR
|
||||
|
||||
NewtonPIR operates on a single-server model, where the server stores the CT log database.
|
||||
|
||||
Database Format: The CT log is represented as an array:
|
||||
|
||||
- D=\[d1,d2,d3,...dn\] where di is the i-th certificate.N is the total number of certificates in the CT log.
|
||||
- Storage: The CT log operator (server) stores the entire log database in a form accessible for PIR queries. Certificates are indexed sequentially.
|
||||
- Index Mapping:A mapping is maintained to relate domain names to their corresponding indices.Example: [example.com](http://example.com/) → index 524.
|
||||
|
||||
### NewtonPIR Overview
|
||||
|
||||
NewtonPIR introduces an efficient single-server PIR scheme that:
|
||||
|
||||
- Reduces communication overhead independent of the database size N. Utilizes single-ciphertext Fully Homomorphic Encryption (FHE).
|
||||
- Leverages Newton interpolation polynomials to optimize query computation.
|
||||
|
||||
### Querying Process
|
||||
|
||||
The querying process includes the following steps:
|
||||
|
||||
- Step 1: Preprocessing (Client Setup)
|
||||
|
||||
- The client initializes the NewtonPIR protocol and generates a query for a specific index i.
|
||||
- The query is homomorphically encrypted (FHE-based) so that the server cannot determine which index the client is requesting.
|
||||
|
||||
- Step 2: Server Response:-
|
||||
|
||||
- The server processes the PIR query using the NewtonPIR protocol:
|
||||
- The query is evaluated over the CT log database. The server computes a response using Newton interpolation polynomials, which reduces computation complexity.
|
||||
- The server sends back the encrypted response to the client.
|
||||
|
||||
- Step 3: Client Decryption
|
||||
|
||||
- The client decrypts the server’s response using their secret key to retrieve the certificate at the requested index.
|
||||
|
||||
### Steps for Integrating NewtonPIR into CT
|
||||
|
||||
- Log Database Setup:
|
||||
|
||||
- Store the CT logs in an indexed array format on the server.
|
||||
- Use NewtonPIR to enable private access to the log entries.
|
||||
|
||||
- Query Interface:
|
||||
|
||||
- Build a client-side application where users input a domain name.
|
||||
- Convert the domain name into a queryable index (e.g., using a hash or pre-built mapping).
|
||||
|
||||
- Private Query:
|
||||
|
||||
- The client formulates a NewtonPIR query for the corresponding index.
|
||||
- The query is encrypted and sent to the server.
|
||||
|
||||
- Server Computation:
|
||||
|
||||
- The server applies NewtonPIR to process the encrypted query and sends the result back.
|
||||
|
||||
- Client Validation:
|
||||
|
||||
- The client decrypts the response to retrieve the certificate.
|
||||
- Optionally, verify the certificate’s SCT and ensure its correctness.
|
||||
|
||||
## Technical Architecture of PIR-CT
|
||||
|
||||
- Client-Side Components:
|
||||
|
||||
- Query Generator: Generates homomorphic PIR queries using NewtonPIR.
|
||||
- Domain-to-Index Mapping: Resolves domain names to indices in the CT log database.
|
||||
- Decryption Module: Decrypts responses from the server.
|
||||
- Validation Module: Verifies certificates and SCTs.
|
||||
|
||||
- Server-Side Components:
|
||||
|
||||
- NewtonPIR Engine: Processes PIR queries using Newton interpolation and FHE.
|
||||
- CT Log Database: Hosts the CT logs in a structured array format.
|
||||
- Query Processor: Responds to encrypted client queries.
|
||||
|
||||
### Advantages of NewtonPIR for CT
|
||||
|
||||
- Efficient Communication:
|
||||
|
||||
- NewtonPIR's communication cost does not depend on the database size N, making it ideal for large CT logs. Privacy-Preserving:
|
||||
- The server learns nothing about the client's query (index or domain name).
|
||||
|
||||
- Scalability:
|
||||
|
||||
- CT logs can grow to millions of entries without increasing communication overhead.
|
||||
|
||||
- Fast Computation:
|
||||
|
||||
- NewtonPIR reduces computational overhead using Newton interpolation polynomials, making it practical for real-world use.
|
||||
- Since the logs operate as append-only databases, computing the polynomial using Newton interpolation becomes highly efficient.
|
||||
|
||||
- Single-Server Deployment:
|
||||
|
||||
- NewtonPIR works with a single server, simplifying infrastructure requirements.
|
||||
|
||||
- Benchmark compared to other PIR Scheme
|
||||
|
||||

|
||||
|
||||
### Challenges and Solutions
|
||||
|
||||
- Domain-to-Index Mapping:
|
||||
|
||||
- Challenge: Efficiently map domain names to database indices.
|
||||
- Solution: Use a hash table or a precomputed index mapping. Log Updates:
|
||||
- Challenge: CT logs are constantly updated with new certificates.
|
||||
- Solution: Periodically re-index the database to reflect new entries
|
||||
|
||||
In this example, I used a simple method with a hashmap, but checking the SCT of every visited site is inefficient. Maybe we should use a data structure like Bloom Filters, which allows for occasional false positives.
|
||||
|
||||
- Initial Setup:
|
||||
|
||||
- NewtonPIR requires a preprocessing step to set up the FHE keys and mappings.
|
||||
|
||||
### Use Case Workflow
|
||||
|
||||
- Client Request:
|
||||
|
||||
- Input: Domain name (e.g., [example.com](http://example.com/)). Convert domain to an index i.
|
||||
|
||||
- NewtonPIR Query:
|
||||
|
||||
- Generate an encrypted query for i.
|
||||
- Send the query to the CT log server.
|
||||
|
||||
- Server Response:
|
||||
|
||||
- The server evaluates the query using NewtonPIR and sends back the encrypted result.
|
||||
|
||||
- Client Validation:
|
||||
|
||||
- Decrypt the response to retrieve the certificate.
|
||||
- Validate the certificate and its SCT.
|
||||
|
||||
## Conclusion
|
||||
|
||||
So, does this enable fully private web search? Not entirely. While it prevents the client’s browser history from being visible to the CT server, the source server can still identify who is accessing the page, and attackers can use metadata or [fingerprinting](https://www.recordedfuture.com/threat-intelligence-101/vulnerability-management-threat-hunting/fingerprinting-in-cybersecurity) to determine the user’s identity.
|
||||
|
||||
This blog provides only a basic overview of how PIR can be applied to CT to address a privacy concern. There may be other PIR schemes that could perform better in this context. I’d love to hear your feedback and suggestions for improvement! Join the conversation [here](https://forum.pse.dev/post/1/21).
|
||||
213
articles/circom-mpc-tldr-and-retrospective.md
Normal file
@@ -0,0 +1,213 @@
|
||||
---
|
||||
authors: ["Circom MPC research team"]
|
||||
title: "Circom MPC: TL;DR and Retrospective"
|
||||
image: "cover.webp"
|
||||
tldr: "This post was authored by the Circom MPC research team."
|
||||
date: "2025-03-06"
|
||||
canonical: "https://mirror.xyz/privacy-scaling-explorations.eth/qelA6kAr-CMq-dgmvFUKMMqxf6GoDaP8Cs-5sRWYfO4"
|
||||
---
|
||||
|
||||
Circom-MPC is a PSE Research project that enables the use of the Circom language to develop MPC applications. In this project, we envisioned MPC as a [broader paradigm](https://mirror.xyz/privacy-scaling-explorations.eth/qelA6kAr-CMq-dgmvFUKMMqxf6GoDaP8Cs-5sRWYfO4#MPC-as-a-Paradigm), where MPC serves as an umbrella for generic techniques such as Zero-Knowledge Proof, Garbled Circuit, Secret-Sharing, or Fully Homomorphic Encryption.
|
||||
|
||||
Throughout this research the team produced some valuable resources and insights, including:
|
||||
|
||||
- Implementation of [circom-2-arithc](https://github.com/namnc/circom-2-arithc), a fork of the Circom compiler that targets arithmetic circuits, which can be fed into any MPC backend
|
||||
- Example integration of circom-2-arithc with the popular Secret-Sharing based backend MP-SPDZ in [circom-MP-SPDZ](https://github.com/namnc/circom-mp-spdz).
|
||||
- Proof of concept application using [MPC-ML](https://hackmd.io/YsWhryEtQ0WwKyerSL8oCw#Circomlib-ML-Patches-and-Benchmarks) with [keras-2-circom-MP-SPDZ](https://github.com/namnc/circom-mp-spdz/blob/main/ML-TESTS.md) which extends keras-2-circom-ZK to [keras-2-circom-MPC](https://github.com/namnc/keras2circom).
|
||||
- [Modular Layer benchmarks](https://mirror.xyz/privacy-scaling-explorations.eth/qelA6kAr-CMq-dgmvFUKMMqxf6GoDaP8Cs-5sRWYfO4#Modular-Layer-Benchmark) for the keras model.
|
||||
|
||||
We decided to sunset the project for a few reasons:
|
||||
|
||||
- The overwhelming amount of effort to fully implement it.
|
||||
- The low current traction of users (could be due to Circom). Hence a [Typescript-MPC](https://github.com/voltrevo/mpc-framework) variant may be of more public interest.
|
||||
- The existence of competitors such as [Sharemind MPC into Carbyne Stack](https://cyber.ee/uploads/Sharemind_MPC_CS_integration_a01ca476a7.pdf).
|
||||
|
||||
Therefore, we will leave it as a paradigm, and we hope that any interested party will pick it up and continue its development.
|
||||
|
||||
In what follows we explain:
|
||||
|
||||
- MPC as a Paradigm
|
||||
- Our Circom-MPC framework
|
||||
- Our patched Circomlib-ML and modular benchmark to have a taste of MPC-ML
|
||||
|
||||
## MPC as a Paradigm
|
||||
|
||||
Secure Multiparty Computation (MPC), as it is defined, allows mutually distrustful parties to jointly compute a functionality while keeping the inputs of the participants private.
|
||||
|
||||

|
||||
|
||||
An MPC protocol can be either application-specific or generic:
|
||||
|
||||

|
||||
|
||||
While it is clear that Threshold Signature exemplifies application-specific MPC, one can think of generic MPC as an efficient MPC protocol for a Virtual Machine (VM) functionality that takes the joint function as a common program and the private inputs as parameters to the program and the secure execution of the program is within the said VM.
|
||||
|
||||
_For readers who are familiar with Zero-Knowledge Proof (ZKP), MPC is a generalization of ZKP in which the MPC consists of two parties namely the Prover and the Verifier, where only the Prover has a secret input which is the witness._
|
||||
|
||||

|
||||
|
||||
And yes, Fully Homomorphic Encryption (FHE) is among techniques (along side Garbled-Circuit and Secret-Sharing) that can be used for MPC construction in the most straightforward mental model:
|
||||
|
||||

|
||||
|
||||
## Programmable MPC
|
||||
|
||||
That said, MPC is not a primitive but a [collection of techniques](https://mpc.cs.berkeley.edu/) aimed to achieve the above purpose. Efficient MPC protocols exist for specific functionalities from simple statistical aggregation such as mean aggregation (for ads), Private Set Intersection (PSI) to complex ones such as RAM (called [Oblivious-RAM](https://en.wikipedia.org/wiki/Oblivious_RAM)) and even Machine Learning (ML).
|
||||
|
||||

|
||||
|
||||
As each technique GC/SS/FHE and specialized MPC has its own advantage, it is typical to combine them into one's privacy preserving protocol for efficiency:
|
||||
|
||||

|
||||
|
||||
In what follows, we present work that enables the use of Circom as a front-end language for developing privacy-preserving systems, starting with the MP-SPDZ backend.
|
||||
|
||||

|
||||
|
||||
_[Detailed explanation of Progammable-MPC with Circom-MPC.](https://docs.google.com/presentation/d/1dPvNyrBWyqyX2oTGcnM52ldpISGrhwEhIZXJPwYWE6I/edit#slide=id.g2818c557dad_0_261)_
|
||||
|
||||
The Circom-MPC project aims to allow a developer to write a Circom program (a Circom circuit) and run it using an MPC backend.
|
||||
|
||||
### The workflow
|
||||
|
||||
- A circom program (prog.circom and the included libraries such as circomlib or circomlib-ml) will be interpreted as an arithmetic circuit (a [DAG](https://en.wikipedia.org/wiki/Directed_acyclic_graph) of wires connected with nodes with an input layer and an output layer) using [circom-2-arithc](https://github.com/namnc/circom-2-arithc).
|
||||
- A transpiler/builder, given the arithmetic circuit and the native capabilities of the MPC backend, translates a gate to a set of native gates so we can run the arithmetic circuit with the MPC backend.
|
||||
|
||||
### Circom-MP-SPDZ
|
||||
|
||||
[Circom-MP-SDPZ](https://github.com/namnc/circom-mp-spdz/) allows parties to perform Multi-Party Computation (MPC) by writing Circom code using the MP-SPDZ framework. Circom code is compiled into an arithmetic circuit and then translated gate by gate to the corresponding MP-SPDZ operators.
|
||||
|
||||
The Circom-MP-SDPZ workflow is described [here](https://hackmd.io/@mhchia/r17ibd1X0).
|
||||
|
||||
## Circomlib-ML Patches and Benchmarks
|
||||
|
||||
With MPC we can achieve privacy-preserving machine learning (PPML). This can be done easily by reusing [circomlib-ml](https://github.com/socathie/circomlib-ml) stack with Circom-MPC. We demonstrated PoC with [ml_tests](https://github.com/namnc/circom-mp-spdz/tree/main/ml_tests) - a set of ML circuits (fork of [circomlib-ml](https://github.com/socathie/circomlib-ml)).
|
||||
|
||||
More info on ML Tests [here](https://github.com/namnc/circom-mp-spdz/blob/main/ML-TESTS.md).
|
||||
|
||||
### Patches
|
||||
|
||||
**Basic Circom ops on circuit signals**
|
||||
|
||||
Circom-2-arithc enables direct usage of comparisons and division on signals. Hence the original Circom templates for comparisons or the division-to-multiplication trick are no longer needed, e.g.
|
||||
|
||||
- GreaterThan can be replaced with ">"
|
||||
- IsPositive can be replaced with "> 0"
|
||||
- x = d \* q + r can be written as "q = x / d"
|
||||
|
||||
**Scaling, Descaling and Quantized Aware Computation**
|
||||
|
||||
Circomlib-ML "scaled" a float to int to maintain precision using $10^{18}$:
|
||||
|
||||
- for input $a$, weight $w$, and bias $b$ that are floats
|
||||
- $a$, $w$ are scaled to $a' = a10^{18}$ _and_ $w' = w10^{18}$
|
||||
- $b$ is scaled to $b' = b10^{36}$_,_ due to in a layer we have computation in the form of $aw + b \longrightarrow$ the outputs of this layer is scaled with $10^{36}$
|
||||
- To proceed to the next layer, we have to "descale" the outputs of the current layer by (int) dividing the outputs with $10^{18}$
|
||||
|
||||
- say, with an output $x$, we want to obtain $x'$ s.t.
|
||||
- $x = x'*10^{18} + r$
|
||||
- so effectively in this case $x'$ is our actual output
|
||||
- in ZK $x'$ and $r$ are provided as witness
|
||||
- in MPC $x'$ and $r$ have to be computed using division (expensive)
|
||||
|
||||
For efficiency we replace this type of scaling with bit shifting, i.e.
|
||||
|
||||
- instead of $*10^{18}$ ($*10^{36}$) we do $*2^s$ ($*2^{2s}$)where $s$ is called the scaling factor
|
||||
|
||||
- The scaling is done prior to the MPC
|
||||
- $s$ can be set accordingly to the bitwidth of the MPC protocol
|
||||
|
||||
- now, descaling is simply truncation or right-shifting, which is a commonly supported and relatively cheap operation in MPC.
|
||||
|
||||
- $x' = x >> s$
|
||||
|
||||
**The "all inputs" Circom template**
|
||||
|
||||
Some of the Circomlib-ML circuits have no "output" signals; we patched them to treat the outputs as 'output' signals.
|
||||
|
||||
The following circuits were changed:
|
||||
|
||||
- ArgMax, AveragePooling2D, BatchNormalization2D, Conv1D, Conv2D, Dense, DepthwiseConv2D, Flatten2D, GlobalAveragePooling2D, GlobalMaxPooling2D, LeakyReLU, MaxPooling2D, PointwiseConv2D, ReLU, Reshape2D, SeparableConv2D, UpSampling2D
|
||||
|
||||
_**Some templates (Zanh, ZeLU and Zigmoid) are "unpatchable" due to their complexity for MPC computation.**_
|
||||
|
||||
### Keras2Circom Patches
|
||||
|
||||
> keras2circom expects a convolutional NN;
|
||||
|
||||
We forked keras2circom and create a [compatible version](https://github.com/namnc/keras2circom).
|
||||
|
||||
### Benchmarks
|
||||
|
||||
After patching Circomlib-ML we can run the benchmark separately for each patched layer above.
|
||||
|
||||
**Docker Settings and running MP-SPDZ on multiple machines**
|
||||
|
||||
For all benchmarks we inject synthetic network latency inside a Docker container.
|
||||
|
||||
We have two settings with set latency & bandwidth:
|
||||
|
||||
1. One region - Europe & Europe
|
||||
2. Different regions - Europe & US
|
||||
|
||||
We used `tc` to limit latency and set a bandwidth:
|
||||
|
||||
```bash
|
||||
tc qdisc add dev eth0 root handle 1:0 netem delay 2ms tc qdisc add dev eth0 parent 1:1 handle 10:0 tbf rate 5gbit burst 200kb limit 20000kb
|
||||
```
|
||||
|
||||
Here we set delay to 2ms & rate to 5gb to imitate a running within the same region (the commands will be applied automatically when you run the script).
|
||||
|
||||
There's a [Dockerfile](https://github.com/namnc/circom-mp-spdz/blob/main/Dockerfile), as well as different benchmark scripts in the repo, so that it's easier to test & benchmark.
|
||||
|
||||
If you want to run these tests yourself:
|
||||
|
||||
1\. Set up the python environment:
|
||||
|
||||
```bash
|
||||
python3 -m venv .venv source .venv/bin/activate
|
||||
```
|
||||
|
||||
2\. Run a local benchmarking script:
|
||||
|
||||
```bash
|
||||
python3 benchmark_script.py --tests-run=true
|
||||
```
|
||||
|
||||
3\. Build & Organize & Run Docker container:
|
||||
|
||||
```bash
|
||||
docker build -t circom-mp-spdz . docker network create test-network docker run -it --rm --cap-add=NET_ADMIN --name=party1 --network test-network -p 3000:3000 -p 22:22 circom-mp-spdz
|
||||
```
|
||||
|
||||
4\. In the Docker container:
|
||||
|
||||
```bash
|
||||
service ssh start
|
||||
```
|
||||
|
||||
5\. Run benchmarking script that imitates few machines:
|
||||
|
||||
```bash
|
||||
python3 remote_benchmark.py --party1 127.0.0.1:3000
|
||||
```
|
||||
|
||||
6\. Deactivate venv
|
||||
|
||||
```bash
|
||||
deactivate
|
||||
```
|
||||
|
||||
**Benchmarks**
|
||||
|
||||
Below we provide benchmark for each different layer separately, a model that combines different layers will yield corresponding combined performance.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
Accuracy of the circuits compared to Keras reference implementation:
|
||||
|
||||

|
||||
|
||||
Our above benchmark only gives a taste of how performance looks for MPC-ML; any interested party can understand approximate performance of a model that combines different layers.
|
||||
@@ -0,0 +1,153 @@
|
||||
---
|
||||
authors: ["Miha Stopar"]
|
||||
title: "Code Optimizations in the Landscape of Post-Quantum Cryptography"
|
||||
image: "cover.webp"
|
||||
tldr: "This post was written by PSE researcher Miha Stopar."
|
||||
date: "2025-04-07"
|
||||
canonical: "https://mirror.xyz/privacy-scaling-explorations.eth/BKI3tyauHIiUCYHgma-EHeSRXNTNDtLUQV9VNGQWLUg"
|
||||
---
|
||||
|
||||
There's no doubt that lattice-based cryptography is currently the most promising branch of post-quantum cryptography. Not only is it highly performant and versatile, it also provides the only known technique to achieve fully homomorphic encryption.
|
||||
|
||||
One reason lattice-based cryptography is so fast is that it can be heavily vectorized. This contrasts noticeably with isogeny-based cryptography, which offers far fewer opportunities for parallelism. In this post, I will briefly compare the potential for vectorization in both cryptographic paradigms. Of course, these two branches represent only a subset of the broader landscape of post-quantum cryptography.
|
||||
|
||||
Let's first take a look at what vectorization is.
|
||||
|
||||
## Vectorization
|
||||
|
||||
Vectorization refers to the process of performing multiple operations simultaneously using Single Instruction, Multiple Data (SIMD) techniques. This is a powerful way to speed up computations by leveraging modern CPU instructions like SSE (Streaming SIMD Extensions), AVX (Advanced Vector Extensions), and their newer versions like AVX-512.
|
||||
|
||||
But what does that mean, really?
|
||||
|
||||
Let's say we would like to XOR 32 bytes as given below:
|
||||
|
||||
```
|
||||
Input: 11001010 10101100 00011011 ...
|
||||
Key : 10110110 01100100 11100011 ...
|
||||
---------------------------------
|
||||
Output: 01111100 11001000 11111000 ...
|
||||
```
|
||||
|
||||
Instead of doing 32 operations one byte at a time, AVX can XOR 32 bytes at once:
|
||||
|
||||
```
|
||||
__m256i data = _mm256_loadu_si256(input)
|
||||
__m256i key = _mm256_loadu_si256(key)
|
||||
__m256i hash = _mm256_xor_si256(data, key)
|
||||
```
|
||||
|
||||
First, the AVX2 register uses `input` to load 32 bytes (256 bits) into one 256-bit register. Then, it loads 32 bytes of `key` into another register. Finally, it performs bitwise XOR between `data` and `key`, element by element. But here, 32 bytes are processed in one instruction!
|
||||
|
||||
## Lattice-based cryptography
|
||||
|
||||
At the core of lattice-based cryptography lies matrix-vector multiplication. For example, let's consider a two-dimensional lattice $L$ with a basis $\{v_1, v_2\}$. Lattice elements are vectors of the form $a_1 v_1 + a_2 v_2$, where $a_1, a_2 \in \mathbb{Z}$. If we construct a matrix $M$ such that $v_1$ and $v_2$ are the two columns of this matrix, then multiplying $M$ by the vector $(a_1, a_2)^T$ gives a lattice element.
|
||||
|
||||

|
||||
|
||||
Matrix multiplication illustration
|
||||
|
||||
For performance reasons, lattice-based cryptography relies on polynomial rings rather than ordinary vectors. I won’t go into the details, but let’s consider the following example.
|
||||
|
||||

|
||||
|
||||
The matrix-vector multiplication above is actually the multiplication of two polynomials
|
||||
|
||||

|
||||
|
||||
in the ring $\mathbb{Z}[x]/(x^3 + 1)$. Note that in this ring, it holds $x^3 = -1$. In practice, $n$ is typically a power of $2$, for example $n = 64$.
|
||||
|
||||
So, multiplying $a(x)$ and $b(x)$ and considering $x^3 = -1$, we obtain the same result as with the matrix-vector multiplication above:
|
||||
|
||||

|
||||
|
||||
Having matrices of this form is beneficial for two reasons: less space is required to store the matrix (only $3$ elements for a $3 \times 3$ matrix), and we can apply the [Number Theoretic Transform](https://en.wikipedia.org/wiki/Discrete_Fourier_transform_over_a_ring) (NTT) algorithm for polynomial multiplication instead of performing matrix-vector multiplication. When using the NTT, we multiply polynomial evaluations rather than working with polynomial coefficients, which reduces the complexity from $O(n^2)$ to $O(n \log n)$ operations.
|
||||
|
||||
That means that instead of directly multiplying the polynomials
|
||||
|
||||

|
||||
|
||||
as
|
||||
|
||||

|
||||
|
||||
we apply the NTT to compute the evaluations $a(\omega_1), …, a(\omega_n)$ and $b(\omega_1), …, b(\omega_n)$. This allows us to perform only $n$ pointwise multiplications, significantly improving efficiency:
|
||||
|
||||

|
||||
|
||||
This way we obtain the evaluations of $a(x)b(x)$ at $\omega_1, ..., \omega_n$. To recover the coefficients of $a(x)b(x)$, we apply the inverse NTT. In the next section, we will see how vectorization can further accelerate such pointwise operations.
|
||||
|
||||
### Lattices and vectorization
|
||||
|
||||
So, why is lattice-based cryptography particularly well-suited for vectorization?
|
||||
|
||||
Remember, typically lattice-based cryptography deals with polynomials in $\mathbb{Z}[x]/(x^{64}+1)$ or $\mathbb{Z}[x]/(x^{128}+1)$. For $n = 64$, each polynomial has $64$ coefficients, for example:
|
||||
|
||||

|
||||
|
||||
Now, if you want, for example, to compute $a(x) + b(x)$, you need to compute
|
||||
|
||||

|
||||
|
||||
This is simple to vectorize: we need to load $a_i$ and $b_i$ into an AVX register. Suppose the register has $32$ slots, each of length 16 bits. If the coefficients are smaller than 16 bits, we can use two registers for a single polynomial. With a single instruction, we compute the sum of the first $32$ coefficients:
|
||||
|
||||
```
|
||||
a_1 | a_2 | ... | a_31 |
|
||||
b_1 | b_2 | ... | b_31 |
|
||||
->
|
||||
a_1 + b_1 | a_2 + b_2 | ... | a_31 + b_31 |
|
||||
```
|
||||
|
||||
In the second instruction, we compute the sum of the next $32$ coefficients:
|
||||
|
||||
```
|
||||
a_32 | a_33 | ... | a_63 |
|
||||
b_32 | b_33 | ... | b_63 |
|
||||
->
|
||||
a_32 + b_32 | a_33 + b_33 | ... | a_63 + b_63 |
|
||||
```
|
||||
|
||||
Many lattice-based schemes heavily rely on matrix-vector multiplications, and similar to the approach above, these operations can be naturally expressed using vectorized instructions. Returning to the NTT, we see that these two polynomials can be multiplied efficiently using vectorization in just two instructions (performing 32 pointwise multiplications in a single instruction), along with the NTT and its inverse.
|
||||
|
||||
## Isogenies and vectorization
|
||||
|
||||
On the contrary, vectorizing isogeny-based schemes appears to be challenging. An isogeny is a homomorphism between two elliptic curves, and isogeny-based cryptography relies on the assumption that finding an isogeny between two given curves is difficult.
|
||||
|
||||

|
||||
|
||||
In isogeny-based cryptography, there are no structures with $64$ or $128$ elements that would allow straightforward vectorization. The optimizations used in isogeny-based cryptography are similar to those in traditional elliptic curve cryptography. Note, however, that traditional elliptic curve cryptography based on the discrete logarithm problem is not quantum-safe, while isogeny-based cryptography is believed to be quantum-safe: there is no known quantum algorithm that can efficiently find an isogeny between two elliptic curves.
|
||||
|
||||
Let's have a look at some optimizations used in elliptic curve cryptography:
|
||||
|
||||
- Choosing the prime $p$ such that the arithmetic in $\mathbb{F}_p$ is efficient,
|
||||
- Montgomery Reduction: efficiently computes modular reductions without expensive division operations,
|
||||
- Montgomery Inversion: avoids divisions entirely when used with Montgomery multiplication,
|
||||
- Using Montgomery or Edwards curves: enables efficient arithmetic,
|
||||
- Shamir’s Trick: computes $kP+mQ$ simultaneously, reducing the number of operations.
|
||||
|
||||
It is worth noting that some of these optimizations—such as Montgomery reduction and Montgomery multiplication—also apply to lattice-based cryptography.
|
||||
|
||||
Let's observe a simple example that illustrates the importance of choosing a suitable prime $p$ for efficient finite field arithmetic. If we choose $p \equiv 3\pmod{4}$ (that means $p+1$ is divisible by $4$), then computing square roots becomes straightforward: to find the square root of $x$, one simply computes:
|
||||
|
||||

|
||||
|
||||
Note that by Fermat's Little Theorem, it holds that $x^p = x \pmod{p}$, which means:
|
||||
|
||||

|
||||
|
||||
Elliptic curve operations can be vectorized but to a lesser extent as lattice-based operations. One [example](https://orbilu.uni.lu/bitstream/10993/48810/1/SAC2020.pdf) is handling field elements in radix-$2^{29}$ representation:
|
||||
|
||||

|
||||
|
||||
where $0 \leq f_i < 2^{29}$ for $0 \leq i \leq 8.$
|
||||
|
||||
However, the number of lanes plays a crucial role in SIMD optimizations. In lattice-based cryptography, it is straightforward to have $64$ or $128$ lanes, which can significantly enhance parallel processing capabilities. In contrast, the example above only utilizes $9$ lanes, which limits the potential for SIMD optimization.
|
||||
|
||||
## Conclusion
|
||||
|
||||
Lattice-based cryptography is currently at the forefront of post-quantum cryptographic advancements, with performance being one of the key reasons for its prominence. Somewhat unjustly, isogeny-based cryptography has gained a reputation for being broken in recent years. This is due to the [Castryck-Decru attack](https://eprint.iacr.org/2022/975), which, however, applies only to schemes that expose additional information about the isogeny, namely the image of two points:
|
||||
|
||||

|
||||
|
||||
Given the images of two points under an isogeny $\psi$, one can compute the images of other points as well. For this, [Kani's lemma](https://mast.queensu.ca/~kani/papers/numgenl.pdf), a remarkable result from 1997, is used. Thankfully, many isogeny-based schemes do not expose the images of points. One such example is [SQIsign](https://sqisign.org/), which features super-compact keys and signatures, making them comparable in size to those used in elliptic-curve-based signature schemes. In summary, isogeny-based cryptography is less performant and less versatile than lattice-based cryptography; however, it offers advantages such as significantly smaller keys and signatures.
|
||||
|
||||
It will be interesting to see which area of post-quantum cryptography emerges as the dominant choice in the coming years. I haven't explored code-based, multivariate, or hash-based cryptography in depth yet, and each of these approaches comes with its own strengths and challenges.
|
||||
74
articles/continuing-the-zero-gravity-journey.md
Normal file
@@ -0,0 +1,74 @@
|
||||
---
|
||||
authors: ["George Wiese"]
|
||||
title: "Continuing the Zero Gravity Journey"
|
||||
image: "cover.webp"
|
||||
tldr: "_This post was written by [George Wiese](https://github.com/georgwiese) and [Artem Grigor](https://github.com/ElusAegis). After Zero Gravity's 1st place finish at [ZK Hack Lisbon in April](https://zkhack.dev/2023/07/11/zk-hack-lisbon/), PSE recognized the potential of the Zero Gravity project and provided a grant for further research in the ZKML area._"
|
||||
date: "2023-10-19"
|
||||
canonical: "https://mirror.xyz/privacy-scaling-explorations.eth/Jpy-PUcH1tpOWrqSdGS4gCxa72F-aZCssACJnFDD1U0"
|
||||
---
|
||||
|
||||
It's been an incredible journey since our team first ventured into the world of zero-knowledge proofs for Weightless Neural Networks (WNNs) at the ZK Hack Lisbon event. For an in-depth look at where we started, we recommend checking out [Ben's insightful post](https://hackmd.io/@benjaminwilson/zero-gravity).
|
||||
|
||||
Since then, we have improved the implementation from a python script that generates Aleo code to a Halo2 CLI that anyone can use. Check out our [previous blogpost](https://hackmd.io/FJIP2lSjRlesSHeG04LQ9Q?both=) to understand how you can prove and verify WNN evaluation on Ethereum.
|
||||
|
||||
## Pushing Boundaries
|
||||
|
||||
Fast-forward to today, and we're excited to share our latest research findings, revealing the progress we've made in the fields of cryptography and weightless neural network. We believe that the best way to describe our work is through the exciting discoveries we've uncovered.
|
||||
|
||||
## Rust Prover: Enhancing Efficiency
|
||||
|
||||
Our journey started with a deep dive into optimizing the Rust Prover, a crucial component in cryptographic protocols. Our goal was clear: find ways to significantly enhance the efficiency of lookups, a task that consumes a substantial portion of constraints in these protocols.
|
||||
|
||||
### Exploring Folding Schemes
|
||||
|
||||
One of our paths of exploration led us to investigate folding schemes like [Sangria](https://geometry.xyz/notebook/sangria-a-folding-scheme-for-plonk) and [Origami](https://hackmd.io/@aardvark/rkHqa3NZ2). These schemes showed promise in reducing constraints associated with lookups in cryptographic proofs. However, to fully leverage their potential, they require further development and integration into the Halo2 library.
|
||||
|
||||
### Innovative Lookup Compression Techniques
|
||||
|
||||
As we were determined to improve the performance despite all the wonderful technology like [Sangria](https://geometry.xyz/notebook/sangria-a-folding-scheme-for-plonk) and [Lasso](https://eprint.iacr.org/2023/1216) still being unavailable, we introduced [our own compression scheme](https://github.com/zkp-gravity/optimisation-research/tree/main/lookup_compression) for optimizing lookups. It compresses several binary lookup rows into a single field lookup, which significantly raises the performance for sparse lookup tables, such as ones we have in WNN Bloom Filter.
|
||||
|
||||
The result has been 14 fold theoretical lookup table compression, though we are sure we could get it to **30 fold**, making it twice as efficient as our current optimised version.
|
||||
|
||||
## WNN: Elevating Performance
|
||||
|
||||
Our research extended to improving data preprocessing and feature selection for Weightless Neural Networks (WNNs), with the aim of taking their performance to new heights.
|
||||
|
||||
### Unleashing the Power of Data Augmentation
|
||||
|
||||
Our exploration uncovered the value of data augmentation as a powerful tool to combat overfitting and enhance the generalization of WNNs. However, we learned that caution must be exercised when applying data augmentation to smaller models, as it may lead to performance degradation. Larger models, on the other hand, excel at handling the increased variety of patterns introduced by data augmentation.
|
||||
|
||||
### The Art of Model Reduction through Feature Selection
|
||||
|
||||
One of our standout achievements was the development of a feature selection algorithm that proved highly effective in reducing model size while maintaining commendable accuracy. Even for smaller models, we achieved remarkable reductions in size, sometimes up to 50%, with only a modest drop in accuracy.
|
||||
|
||||
### Feature Selection: Constructing Models with Precision
|
||||
|
||||
We delved into the world of feature selection algorithms and introduced the greedy algorithm. Though computationally demanding, it offers a means to construct models with precisely selected features. The impact of this approach varies depending on the dataset's complexity, making it a valuable tool for larger and more intricate datasets.
|
||||
|
||||
## Charting the Future
|
||||
|
||||
As we conclude this phase of our journey, we look ahead with eagerness to what lies beyond. We have identified crucial areas for further exploration and development that will shape the future of zero-knowledge proofs for Weightless Neural Networks.
|
||||
|
||||
### Improved Lookup Compression
|
||||
|
||||
Our efforts will continue to focus on enhancing lookup compression algorithms, such as Lasso, and ensuring their seamless integration with existing cryptographic libraries like Halo2. The quest for novel compression techniques that reduce constraints in lookup operations remains a central research area.
|
||||
|
||||
### Scaling Feature Selection to Larger Datasets
|
||||
|
||||
The application of feature selection algorithms to larger and more complex datasets is on our horizon. Evaluating their performance and scalability on datasets beyond MNIST will provide valuable insights into their practical utility.
|
||||
|
||||
## In Conclusion
|
||||
|
||||
Our journey has been filled with challenges, breakthroughs, and innovative solutions. We've taken steps forward, fueled by the belief that our work contributes to a collective understanding of these complex fields.
|
||||
|
||||
---
|
||||
|
||||
## Explore Our Research
|
||||
|
||||
- [Research Repository](https://github.com/zkp-gravity/optimisation-research/tree/main)
|
||||
- [Detailed Research Writeup](https://github.com/zkp-gravity/optimisation-research/blob/main/writeup.pdf)
|
||||
- [Implementation of Lookup Compression](https://github.com/zkp-gravity/optimisation-research/tree/main/lookup_compression)
|
||||
|
||||
For a deeper dive into our research findings, we invite you to explore our research repository, read our detailed research writeup, and examine the implementation of lookup compression. Join us on this exciting journey of exploration, where innovation and privacy-preserving technologies intersect.
|
||||
|
||||
To revisit where our journey began, take a look at our [Initial Blog Post from the Hackathon](https://hackmd.io/@benjaminwilson/zero-gravity).
|
||||
145
articles/devcon-vi-recap.md
Normal file
@@ -0,0 +1,145 @@
|
||||
---
|
||||
authors: ["PSE Team"]
|
||||
title: "Devcon VI Recap"
|
||||
image: null
|
||||
tldr: ""
|
||||
date: "2022-11-16"
|
||||
canonical: "https://mirror.xyz/privacy-scaling-explorations.eth/plfDBIpiKZVyNSJWhE9vix76JaJoJ1seDfRAddV7HEc"
|
||||
---
|
||||
|
||||
The potential of [zero-knowledge](https://ethereum.org/en/zero-knowledge-proofs/#what-are-zk-proofs) cryptography was on full display at Devcon VI in Bogota, which featured a [dedicated ZK track](https://archive.devcon.org/archive/playlists/devcon-6-zkps-privacy-identity-infrastructure-and-more/) for the first time ever. Since most of [PSE’s work](https://appliedzkp.org/) has happened in the 3 years since [Devcon V in Osaka](https://archive.devcon.org/archive/watch?edition=5&order=desc&sort=edition), it was also a debut for many of our projects – and many of our team members met for the first time! There was a lot we were excited to share with the community. In this post, we’ll revisit some highlights of our time in Bogota, including talks by PSE team members and the Devcon VI Temporary Anonymous Zone.
|
||||
|
||||
## Temporary Anonymous Zone (TAZ)
|
||||
|
||||
Devcon VI [Community Hubs](https://forum.devcon.org/t/rfp-5-community-hubs-closed/454) were dedicated community spaces to gather around topics or initiatives, each hosted by a different group or organization. The PSE team had the opportunity to design one of these hubs, which we called the Temporary Anonymous Zone (TAZ).
|
||||
|
||||

|
||||
|
||||
ZKPs may have earned a track on the Devcon schedule, but the technology we work on can still sometimes feel mysterious – even scary – so we hoped to create a friendly and welcoming place for experts and beginners alike.
|
||||
|
||||

|
||||
|
||||
The TAZ allowed us to show the human side of our work and create a space for open questions and conversations about ZK. There were plenty of “aha” moments and realizations for both the people we talked to and the PSE team itself.
|
||||
|
||||
The PSE team’s work revolves around exploration and community support. Conversations at the TAZ helped us understand more about our place within the Ethereum community and how we might decide which directions to explore next.
|
||||
|
||||

|
||||
|
||||
We also heard from more than one totally unpaid person that we had the “best swag”…
|
||||
|
||||

|
||||
|
||||
https://twitter.com/shumochu/status/1580258439829168128
|
||||
|
||||
### TAZ App
|
||||
|
||||
When the WiFi permitted it, the [TAZ app](https://taz.appliedzkp.org/) allowed many visitors to use ZKPs for the first time in a low-stakes and accessible way. With just a QR code and their phone, people could easily generate a Semaphore ID and interact anonymously with other Devcon attendees by drawing or asking and answering questions. Live applications like [heyanon](https://twitter.com/DevconAnon) and [zkitter](https://www.zkitter.com/explore/) let users get a sense for how anonymity could change the way they expressed themselves.
|
||||
|
||||

|
||||
|
||||
https://taz.appliedzkp.org/
|
||||
|
||||
The TAZ app was a practical showcase for how Semaphore could be integrated into different applications and let people try using ZK proofs for anonymous social interaction. We hope to continue building and improving on this idea in the future. One thing we wish we did with the app was get feedback!
|
||||
|
||||
If you were with us at Devcon and still have your Semaphore ID QR code, you can log back into the app and [share your feedback](https://taz.appliedzkp.org/feedback) anonymously. We’re already making plans for future TAZ experiments, and your feedback on the first version will help us make the next one even better.
|
||||
|
||||
You can also let us know how we did on the [PSE Discord.](https://discord.gg/jCpW67a6CG) Or just come say hi!
|
||||
|
||||
## PSE Talks Roundup
|
||||
|
||||
### PSE: What We Do and How to Get Involved
|
||||
|
||||
If this is your first time hearing of the PSE team, this talk is a good place to start. It gives an overview of the primitives, infrastructure, tools the PSE team has been building and how we support contributors.
|
||||
|
||||

|
||||
|
||||
Watch [PSE: What We Do and How to Get Involved](https://www.youtube.com/watch?v=HnGmgVo3nWw)
|
||||
|
||||
### Semaphore: Anonymous Signaling on Ethereum
|
||||
|
||||
[Semaphore](https://semaphore.appliedzkp.org/), the protocol used in the TAZ to allow users to interact anonymously with the Devcon group, is one of PSE’s most used privacy primitives.
|
||||
|
||||

|
||||
|
||||
Watch [Semaphore: Anonymous Signaling on Ethereum](https://archive.devcon.org/archive/watch/6/anonymous-signalling-on-ethereum/?tab=YouTube)
|
||||
|
||||
### Interep: An Identity Bridge from Web2 to Web3
|
||||
|
||||
[Interep](https://interep.link/), built using Semaphore, is a practical solution for preventing sybil attacks on Ethereum. Geoff explained how the protocol uses ZK proofs to anonymously import reputation from Web2 networks such as Github, Reddit, and Twitter.
|
||||
|
||||

|
||||
|
||||
Watch [Interep: An Identity Bridge from Web2 to Web3](https://archive.devcon.org/archive/watch/6/interep-an-identity-bridge-from-web2-to-web3/?tab=YouTube)
|
||||
|
||||
### Private Exchange on Zkopru
|
||||
|
||||
[Zkopru](https://zkopru.network/), an optimistic rollup that uses ZK proofs to protect the privacy of its users and one of PSE’s longest-running projects, was featured in two presentations:
|
||||
|
||||

|
||||
|
||||
- [Private Exchange on Zkopru](https://archive.devcon.org/archive/watch/6/private-exchange-on-zkopru/?tab=Swarm) focused on the implementation of Zkopru with other zero knowledge protocols in a private exchange application.
|
||||
- [Public Goods, Experiments and the Journey of Zkopru](https://archive.devcon.org/archive/watch/6/public-goods-and-experiments-the-journey-of-zkopru/?tab=Swarm) traced the development of Zkopru and how it fits into the PSE ethos of experimentation and building public goods.
|
||||
|
||||
### Onboard The World Into Your Rollup dApp with BLS Wallet
|
||||
|
||||
[Account abstraction](https://archive.devcon.org/archive/watch/6/account-abstraction-panel/?tab=YouTube) continued to gain steam in Bogota, with some great hackathon projects at ETHBogota and [talks at Devcon](https://archive.devcon.org/archive/watch/?order=desc&q=account%20abstraction&sort=edition). Adoption challenges still remain, but a friendlier and faster user experience is gaining adoption via innovations like BLS signatures and account abstraction.
|
||||
|
||||

|
||||
|
||||
Watch [Onboard The World Into Your Rollup dApp with BLS Wallet](https://archive.devcon.org/archive/watch/6/onboard-the-world-into-your-rollup-dapp-with-bls-wallet/?tab=YouTube)
|
||||
|
||||
### Designing Public Goods Using ZKPs
|
||||
|
||||
At the PSE, we take design seriously. Thinking deeply about the best ways to help people understand and use tools enabled by ZK proofs (ZKPs) is a huge part of the team’s work. Rachel shared some of the processes and philosophies PSE’s design team uses to translate complex concepts into recognizable mental models.
|
||||
|
||||

|
||||
|
||||
Watch [Designing Public Goods Using ZKPs](https://archive.devcon.org/archive/watch/6/designing-public-goods-using-zkps/?tab=YouTube)
|
||||
|
||||
### ELI5: Zero Knowledge
|
||||
|
||||
If all this ZK stuff is sorcery to you, you’re not alone. This field is complex, confusing, and intimidating – especially for beginners – so sometimes learning like a 5-year-old is the best way to get started. Check out this introductory talk to increase your knowledge from zero to slightly more than zero.
|
||||
|
||||

|
||||
|
||||
And if you don’t know, now you know.
|
||||
|
||||
Watch [ELI5: Zero Knowledge](https://archive.devcon.org/archive/watch/6/eli5-zero-knowledge/?tab=YouTube)
|
||||
|
||||
### What to know about Zero Knowledge
|
||||
|
||||
One of our favorite panels was a conversation moderated by Albert Ni between Barry Whitehat, Vitalik Buterin, and Gubsheep. If you’re interested in high-level ideas surrounding ZK and why so many in the community are excited about this area of research, this is one to watch (or rewatch)!
|
||||
|
||||

|
||||
|
||||
Watch [What to know about Zero Knowledge](https://archive.devcon.org/archive/watch/6/what-to-know-about-zero-knowledge/?tab=YouTube)
|
||||
|
||||
BONUS: For another high-level perspective about the potential of zero-knowledge cryptography, check out gubsheep’s talk: [ZKPs and "Programmable Cryptography"](https://archive.devcon.org/archive/watch/6/zkps-and-programmable-cryptography/?tab=YouTube).
|
||||
|
||||
### Sessions with 0xPARC
|
||||
|
||||
PSE is just one of many teams and organizations in the broader ZK community. We’re all trying to push the boundaries of ZK research and figure out what’s possible through exploration and experimentation. At Devcon, we were fortunate enough to organize a full day of programming with our friends and frequent collaborators at [0xPARC](https://0xparc.org/), with presenters from all over the ecosystem covering a range of topics in the applied ZK field.
|
||||
|
||||
Unfortunately there were some recording issues during these sessions so some presentations were missing sections of video or audio 🙁. We’ve collected the recordings we do have into playlists below, and we’ll work with presenters to re-record and upload talks that were affected by the technical difficulties.
|
||||
|
||||
The **Future of ZK Proving Systems** session explored techniques, tools, and applications enabling the interoperable and efficient proof systems of the future. \[[https://www.youtube.com/playlist?list=PLV91V4b0yVqSyooZlCxKhYn3my9Mh6Tgn](https://www.youtube.com/playlist?list=PLV91V4b0yVqSyooZlCxKhYn3my9Mh6Tgn)\]
|
||||
|
||||
The **ZK Security workshop** brought together experts in ZK, formal verification and assurance to discuss approaches to securing ZK apps. \[Videos coming soon at: [https://www.youtube.com/playlist?list=PLV91V4b0yVqQBwxoUGqoHHuif1GRfg2Ih](https://www.youtube.com/playlist?list=PLV91V4b0yVqQBwxoUGqoHHuif1GRfg2Ih)\]
|
||||
|
||||
The **ZK Application Showcase** was a rapid-fire series of presentations and demos to get up to speed on some of the newest projects from across the ZK community.
|
||||
|
||||

|
||||
|
||||
Watch [ZK Application Showcase](https://www.youtube.com/playlist?list=PLV91V4b0yVqSR2OJhFv-0ZxEvTWnm7bDR)
|
||||
|
||||
### PSE Playlist
|
||||
|
||||
This is just a sampling of presentations by the PSE team, but there are many other projects at varying levels of maturity. If you want to get up to speed on all things PSE at Devcon, we’ve curated a playlist to get you started.
|
||||
|
||||

|
||||
|
||||
Watch [PSE Playlist](https://www.youtube.com/playlist?list=PLV91V4b0yVqRQ62Mv0nUgWxJhi4E67XSY)
|
||||
|
||||
## ¡Muchas Gracias, Bogotá!
|
||||
|
||||
For the PSE team, Devcon was a time to finally put a face to the voice or avatar on Discord. We had an amazing time meeting and getting to know each other and the Ethereum community. Hope to see you next time!
|
||||
191
articles/from-cex-to-ccex-with-summa-part-1.md
Normal file
@@ -0,0 +1,191 @@
|
||||
---
|
||||
authors: ["Enrico Bottazzi"]
|
||||
title: "From CEX to CCEX with Summa Part 1"
|
||||
image: "cover.webp"
|
||||
tldr: "This post was written by [Enrico Bottazzi](https://github.com/enricobottazzi) /n/n Special thanks to Yi-Hsiu Chen (Coinbase), Shashank Agrawal (Coinbase), Stenton Mayne (kn0x1y), Michelle Lai and Kostas Chalkias (Mysten Labs) for review and discussion. /n/n Part 1 introduces the main concepts behind the Summa protocol and can be skipped if already familiar to the reader. /n/n [Part 2](https://mirror.xyz/privacy-scaling-explorations.eth/f2ZfkPXZpvc6DUmG5-SyLjjYf78bcOcFeiJX2tb2hS0) dives into a full Proof of Solvency flow."
|
||||
date: "2023-09-14"
|
||||
canonical: "https://mirror.xyz/privacy-scaling-explorations.eth/_1Y6ExFD_Rs3oDxwx5_kWAj_Tl_L9c0Hm7E6SVJei0A"
|
||||
---
|
||||
|
||||
## Part 1 - Introduction
|
||||
|
||||
In 1494 [Luca Pacioli](https://en.wikipedia.org/wiki/Luca_Pacioli), a Franciscan Friar, published _Summa de arithmetica, geometria, Proportioni et proportionalita_. The book laid out for the first time in history the principles of double-entry bookkeeping and paved the way for the creation of the study field known as accounting.
|
||||
|
||||

|
||||
|
||||
More than 5 centuries later, book authentication still relies on the same principles. The financial integrity of the businesses is guaranteed by government licenses or manual background checks performed by some authorities or auditors.
|
||||
|
||||
In the context of cryptocurrencies, the fragility of such a financial paradigm becomes evident every time a major centralized exchange (CEX) blows up.
|
||||
|
||||

|
||||
|
||||
In November 2022, Vitalik shared a [blog post](https://vitalik.ca/general/2022/11/19/proof_of_solvency.html) where he envisioned a transition from the "don't be evil" aspiring-good-guy CEX to a more secure cryptographically constrained exchange (CCEX).
|
||||
|
||||
[Summa](https://github.com/summa-dev) was created in March 2023 within the [PSE Team](https://pse.dev/projects/summa) to build the tooling to power such a transition: **[summa-solvency](https://github.com/summa-dev/summa-solvency)** is a zero-knowledge proof of solvency solution.
|
||||
|
||||
This blog post provides a technical overview of such a solution.
|
||||
|
||||
The goal is to gather feedback from the community to establish an industry-wide standard for Proof of Solvency (also known as [Proof of Reserves](https://niccarter.info/proof-of-reserves/)). Exchanges and any custodial wallet solution should freely fork and adapt the repository to their needs, moving away from self-established practices. In the short term, the goal is to [collaborate with exchanges during a Beta program](https://docs.google.com/forms/d/e/1FAIpQLSctGXMIUSdUahQr5DvTuc2cpOj9XVYQGo8_A3WhPleCXEcdIw/viewform) to help them bring Summa to production, gain insight into their operations and requirements, and foster mutual learning.
|
||||
|
||||
Before diving into the specification of Summa, Part 1 of the blog post introduces the three main ideas underlying Summa, namely:
|
||||
|
||||
1. Proof of Solvency
|
||||
2. Cryptographic Commitments
|
||||
3. Zero Knowledge Proof
|
||||
|
||||
Readers familiar with these concepts can skip them and jump to [Part 2: Summa Protocol.](https://mirror.xyz/privacy-scaling-explorations.eth/f2ZfkPXZpvc6DUmG5-SyLjjYf78bcOcFeiJX2tb2hS0)
|
||||
|
||||
## Part 1 - Introduction
|
||||
|
||||
### Proof of Solvency
|
||||
|
||||
The role of a Centralized Exchange (Exchange) is to collect deposits from users and custody cryptocurrencies on their behalf. Those **assets** are managed by the Exchange's private keys and live on the blockchain.
|
||||
|
||||
The deposit of a user into an Exchange is not necessarily recorded on the blockchain, usually only being recorded on the Exchange’s servers. While this allows saving blockchain transaction fees for the users, a malicious Exchange could unilaterally modify the record of a user balance without the user’s consent and without leaving any cryptographic trace of the manipulation. These deposits are defined as **liabilities** of the Exchange because they are owed by the Exchange to its customers.
|
||||
|
||||

|
||||
|
||||
The relation between a user and an Exchange is based on a trust agreement that for every deposit, the Exchange will hold a corresponding amount of (the same!) cryptocurrency within their wallet. As long as the Exchange abides by this trust-based agreement, the Exchange is **solvent** and users are confident that they can safely withdraw at any time.
|
||||
|
||||
Whenever trust is involved, there are many ways it could go wrong. Two relevant examples are:
|
||||
|
||||
- The liabilities denominated in a cryptocurrency are backed by a different one (FTX, I’m looking at you!). Given the volatility of the relative value of these two currencies and the lack of liquidity in the market, the Exchange can not guarantee a safe withdrawal of ETH to all its users at any time.
|
||||
- The liabilities denominated in a cryptocurrency (i.e. ETH) are not backed at all (or just a fraction of) and the Exchange is YOLO investing the deposits of the users. Again, the Exchange cannot guarantee a safe withdrawal to its users.
|
||||
|
||||
A Proof of Solvency protocol provides a solution for that. The cryptographic constraint that must be met by the Exchange is
|
||||
|
||||

|
||||
|
||||
in which _n_ are all the addresses controlled by the Exchange holding a specific asset, and _m_ are all the users of the Exchange that have invested in that asset. Note that:
|
||||
|
||||
- This constraint should be satisfied **separately** for **every** asset supported by the Exchange.
|
||||
- In the formula, _asset,_ and _liability_ refer to their state at a time _t_. Performing Proof of Solvency is not a one-time operation but should be performed many times (rounds). The more frequent these rounds are, the more reliable the Exchange is.
|
||||
|
||||
### Cryptographic Commitments
|
||||
|
||||
[Cryptographic Commitment Schemes](https://en.wikipedia.org/wiki/Commitment_scheme) are a fundamental component in cryptography, particularly in protocols that require a party to commit to a value without revealing it initially and then reveal the value (or just some property of the value) later.
|
||||
|
||||
The simplest and most popular cryptographic commitment scheme is hashing.
|
||||
|
||||
Let us consider a scenario in which Alice wants to publicly commit to a prediction about an upcoming event, say the first scorer in a football match, without revealing her prediction until the match has ended.
|
||||
|
||||
Alice can take her winner prediction "BenjaminPavard", run a hash function on top of this, and publish the resulting output (hash digest) on her Twitter profile. At this point, no one can learn Alice's prediction just from the hash digest.
|
||||
|
||||

|
||||
|
||||
In fact, to decrease the likelihood that someone unmasks Alice's hash and discovers her prediction, it would be safer to add some random large number (technically known as _salt_) together with the prediction as hash input, in order to avoid brute-force and [Rainbow Table attacks](https://en.wikipedia.org/wiki/Rainbow_table).
|
||||
|
||||
After the end of the event, she can reveal her prediction _"BenjaminPavard"_. Anyone can re-run the hash function on the prediction to check whether it matches the _hashDigest_ previously published on Twitter. If Alice reveals a different prediction, such as _"TheoHernandez"_, the result of hashing such a prediction will result in something different from the previously published _hashDigest_.
|
||||
|
||||
Cryptographic commitment schemes guarantee two very cool properties:
|
||||
|
||||
1. **Hiding**: The commitment hides the value, and everyone who sees the commitment cannot determine the actual value until Alice decides to reveal it.
|
||||
2. **Binding**: Once Alice has made the commitment, she cannot change the value she committed to. In other words, when revealing, the committer cannot reveal different values as these wouldn’t match the original commitment. That’s because modern hash functions are computationally collision-free and we cannot find two inputs that result in the same hash digest
|
||||
|
||||
Another popular commitment scheme, useful when dealing with larger data structures, is a [Merkle Tree](https://en.wikipedia.org/wiki/Merkle_tree). In a Merkle Tree, each data entry is hashed and inserted as a _leaf_ of the tree. Each leaf is hashed with the sibling one to produce a middle node. This process is repeated for each level of the tree until it gets to a single node at the top, called the _Merkle Root_, which acts as a commitment to the entire set of data.
|
||||
|
||||
Merkle Trees are especially useful when you want to prove the existence (typically known as "inclusion proofs") of a specific piece of entry data within a large set without revealing the entire set in a time-efficient manner.
|
||||
|
||||
Summa makes use of a modified version of a Merkle Tree as a cryptographic commitment scheme which is a **[Merkle Sum Tree](https://github.com/summa-dev/summa-solvency/blob/master/zk_prover/src/merkle_sum_tree/mst.rs)**. In the context of Summa, the data entries to the Merkle Sum Tree are the liabilities of the Exchange, while the _Merkle Root_ contains a commitment to the state of the Exchange's liabilities.
|
||||
|
||||

|
||||
|
||||
The core properties of a Merkle Sum Tree are:
|
||||
|
||||
- Each entry of a Merkle Sum Tree is a pair of a username and the associated balance.
|
||||
- Each Leaf Node contains a hash and a balance. The hash is equal to `H(username, balance)`. There is a 1-1 relationship between entries and leaf nodes. The balance of a leaf node is equal to the balance of the associated entry, and ditto for the username.
|
||||
- Each Middle Node contains a hash and a balance. The hash is equal to `H(LeftChild.hash, LeftChild.balance, RightChild.hash, RightChild.balance).` The balance is equal to the sum of the balances of the two child nodes.
|
||||
|
||||
- The Root Node contains a hash and a balance
|
||||
|
||||
- Analogous to a traditional Merkle Tree, the Merkle Root contains a commitment to the state of the entries
|
||||
- In addition to a traditional Merkle Tree the Merkle Root makes it possible to easily fetch the sum of balances of entries of the tree.
|
||||
|
||||
While the example uses a balance in only a single cryptocurrency (ETH), in Summa balances in multiple currencies are supported in the same Merkle Sum Tree
|
||||
|
||||
Let's consider the case in which an Exchange wants to prove to user Carl that he has been accounted for correctly in their database at time _t_. Here are the steps:
|
||||
|
||||
1. The Exchange locally builds a Merkle Sum Tree out of its database state at time _t_
|
||||
2. The Exchange publishes the Merkle Root of the tree, which represents a commitment to the state of the entire tree
|
||||
3. The Exchange generates a Merkle Proof of Inclusion for Carl. That is, all the nodes (in blue) that Carl needs to verify his inclusion in the tree
|
||||
4. Carl computes his corresponding leaf node starting from his data (username and ETH balance) at time _t_ and performs the subsequent hashing with the nodes provided in the Merkle Proof until he gets to the Merkle Root. If the resulting Merkle Root matches the one committed by the Exchange at step 2, Carl can be confident that his account has been accounted for correctly in the database at time _t_. The operation of verifying the correct inclusion in the tree is described in the following pseudo-algorithm.
|
||||
|
||||

|
||||
|
||||
```python
|
||||
def verify_merkle_proof(leaf_data, merkle_proof, committed_root): current_node = compute_leaf_node(leaf_data) for proof_node in merkle_proof: # Decide which child (left or right) the current node is # This information can be part of the merkle_proof or determined otherwise if is_left_child(current_node, proof_node): current_node = compute_internal_node(current_node, proof_node) else: current_node = compute_internal_node(proof_node, current_node) return current_node == committed_root leaf_data_for_carl = ("Carl", 10) # This would be Carl's username and ETH balance at time t assert verify_merkle_proof(leaf_data_for_carl, merkle_proof, committed_root)
|
||||
```
|
||||
|
||||
Let's take a step back and analyze what has been achieved in the protocol. The Exchange has proven the correct inclusion of some users' data within their database without having to reveal the whole database to the public (since Carl only needed the blue nodes). Furthermore, Carl only needed to perform 3 hashing operations to verify his correct inclusion. This number is always equal to _log₂n_ where _n_ in the number of entries in the tree. The verification of a correct inclusion in a Merkle Sum Tree with over 130M entries only requires 27 hashing operations!
|
||||
|
||||
While this is already a big achievement both in terms of efficiency and data protection, precious information is leaked in the process. The Merkle Proof reveals to Carl that an unknown user has a balance of 15 ETH. Furthermore, it also reveals the partial sums of the balances of _some_ users and the aggregated liabilities of the Exchange.
|
||||
|
||||
By tracking the progression of these data across time Carl gets to know the trades of its sibling leaf Daisy, and, more importantly, how the aggregated liabilities change through time, which represents the main insight into the performance of the Exchange as a business.
|
||||
|
||||
Furthermore, the users of the Exchange could come together and reconstruct the whole database of the Exchange by pooling together each of their individual Merkle Proofs.
|
||||
|
||||
The next section introduces the concept of Zero Knowledge Proof. Its properties combined with the Merkle Sum Tree commitment scheme would allow an Exchange to perform a fully cryptographically auditable Proof of Solvency while keeping all sensitive information private.
|
||||
|
||||
The reader may have noticed that this cryptographic commitment scheme only covers the liabilities while the assets have not been mentioned yet. The concept is introduced in a later section.
|
||||
|
||||
### Zero Knowledge Proof
|
||||
|
||||
A core concept that I often use to explain zero-knowledge proof, or, more specifically, [zkSNARKs](https://vitalik.ca/general/2021/01/26/snarks.html) is **Computational Integrity Guarantee**.
|
||||
|
||||
A computation is defined as any set of rules (or **constraints**) that can be encoded into a computer program.
|
||||
|
||||
A computation can be as simple as performing the sum of 2 numbers.
|
||||
|
||||

|
||||
|
||||
A more complex computation is validating blockchain transactions and bundling them into a block.
|
||||
|
||||

|
||||
|
||||
You can see that a computation is made of a list of inputs, a program that sets the constraints of the computation, and a list of outputs (it can be more than one).
|
||||
|
||||
Most of the time, after an actor performs the computation, there are other people who need to verify that the computation was done correctly. This is especially relevant in the context of zero-trust such as block building (or mining).
|
||||
|
||||
More formally, given a computation with constraints known by everyone, a Prover wants to prove to a Verifier that the output is the result of running a computation on certain inputs.
|
||||
|
||||
The naive way to achieve such **Computational Integrity Guarantee** is for the Verifier to rerun the same computation with the same inputs and check that the output matches.
|
||||
|
||||

|
||||
|
||||
Such an approach has two main issues:
|
||||
|
||||
- The verification time is exactly the same as the time it takes to perform the computation. In order to achieve consensus to a new block header, every node has to perform this computationally intensive operation, which is the main bottleneck to Blockchain scalability.
|
||||
- To achieve computational integrity guarantee the list of inputs and outputs has to be public.
|
||||
|
||||
zkSNARKs elegantly solve these 2 issues by providing a new protocol to run any arbitrary computation that, together with the output, also returns a proof π. Such proof, despite being very tiny and faster to verify than running the original computation, carries enough information to provide the **Computational Integrity Guarantee**.
|
||||
|
||||

|
||||
|
||||
The Verifier doesn't need to re-run the whole algorithm again but only needs to run a lightweight program using π as input. While the time required by the original computation grows proportionally to its complexity or the size of the inputs, the time to verify a zkSNARK proof grows logarithmically with the complexity/input size, or is even constant.
|
||||
|
||||
A further characteristic of such protocols is that the prover can selectively decide whether to keep an input of the computation private or public. The proof provides the verifier with **zero knowledge** of potentially any of the inputs of the computation.
|
||||
|
||||
Summa leverages the properties of zkSNARKs to allow an Exchange to generate a Proof of Solvency that:
|
||||
|
||||
- Provides a cryptographic-based guarantee that the statement is satisfied.
|
||||
- Can be verified quickly on any consumer device
|
||||
- Keeps the sensitive data of the Exchange (and its users) private
|
||||
|
||||
As anything in engineering, switching to a zkSNARK Protocol comes with trade-offs:
|
||||
|
||||
- **Trusted Setup**: each zkSNARK protocol relies on a [trusted setup](https://vitalik.ca/general/2022/03/14/trustedsetup.html). You can think of the setup as the parameters that guarantee the integrity of a protocol. These parameters are the result of a ceremony in which many parties contribute some random inputs. If these parties get together and recompose the whole input used to create the parameters, they can potentially attack a ZK protocol and generate valid proofs even without performing the computation that follows the pre-defined rules.
|
||||
- **Prover Overhead**: the reduction of the verification time comes at the cost of proving time. In fact, running the same computation inside a ZK circuit takes, on average, > 100x times more than performing it without having to generate a ZK proof.
|
||||
|
||||
Summa uses [Halo2](https://github.com/privacy-scaling-explorations/halo2), a proving system that was originally built by [ZCash](https://github.com/zcash/halo2). Beyond high proving speed, Halo2 allows the reuse of existing and reputable trusted setups such as the [Hermez 1.0 Trusted Setup](https://docs.hermez.io/Hermez_1.0/about/security/#multi-party-computation-for-the-trusted-setup) for any application-specific circuit.
|
||||
|
||||
The reader is now fully equipped with the background to understand the functioning of any part of the Summa ZK Proof of Solvency Protocol.
|
||||
|
||||
## End Part 1
|
||||
|
||||
[Part 2](https://mirror.xyz/privacy-scaling-explorations.eth/f2ZfkPXZpvc6DUmG5-SyLjjYf78bcOcFeiJX2tb2hS0) dives into a full Proof of Solvency flow. At each step, a detailed explanation of the cryptographic tooling being used is provided.
|
||||
|
||||
The path toward establishing an industry-wide standard for proof of solvency requires the definition of a protocol that is agreed upon by Exchanges, Cryptographers, and Application Developers. The goal is to collaborate with Exchanges during a Beta program to bring Summa to production and, eventually, come up with a [EIP](https://github.com/summa-dev/eip-draft) to define a standard.
|
||||
|
||||
Complete this [Google Form](https://forms.gle/uYNnHq3vjNHi5iRh9) if your Exchange (or Custodial Wallet) is interested in joining the program.
|
||||
|
||||
Furthermore, if you are interested in sharing feedback or simply entering the community discussion, join the [Summa Solvency Telegram Chat](https://t.me/summazk).Summa is made possible because of contributions from [JinHwan](https://github.com/sifnoc), [Alex Kuzmin](https://github.com/alxkzmn), [Enrico Bottazzi](https://github.com/enricobottazzi).
|
||||
254
articles/from-cex-to-ccex-with-summa-part-2.md
Normal file
@@ -0,0 +1,254 @@
|
||||
---
|
||||
authors: ["Enrico Bottazzi"]
|
||||
title: "From CEX to CCEX with Summa Part 2"
|
||||
image: "cover.webp"
|
||||
tldr: "This post was written by [Enrico Bottazzi](https://github.com/enricobottazzi) /n/n Special thanks to Yi-Hsiu Chen (Coinbase), Shashank Agrawal (Coinbase), Stenton Mayne (kn0x1y), Michelle Lai and Kostas Chalkias (Mysten Labs) for review and discussion. /n/n [Part 1](https://mirror.xyz/privacy-scaling-explorations.eth/_1Y6ExFD_Rs3oDxwx5_kWAj_Tl_L9c0Hm7E6SVJei0A) introduces the main concepts behind the Summa protocol. /n/n Part 2 dives into a full Proof of Solvency flow."
|
||||
date: "2023-09-14"
|
||||
canonical: "https://mirror.xyz/privacy-scaling-explorations.eth/f2ZfkPXZpvc6DUmG5-SyLjjYf78bcOcFeiJX2tb2hS0"
|
||||
---
|
||||
|
||||
## Part 2 - Summa Protocol
|
||||
|
||||
This section analyzes the flow of an Exchange performing Proof of Solvency using Summa.
|
||||
|
||||
The core idea to enable the transition from CEX to CCEX is to build _ZK programs_ that enforce the constraints that define the Solvency of an Exchange. The proof generated by the Exchange running these programs is then verified either automatically by a smart contract or by a user.
|
||||
|
||||
Each step describes in detail the core cryptographic components of the protocol imposing these cryptographic constraints. When possible, benchmarks related to the performance of such components are also provided.
|
||||
|
||||
The actors involved in the Protocol are the Exchange, the users of the Exchange, and the [Summa Smart Contract](https://github.com/summa-dev/summa-solvency/blob/master/contracts/src/Summa.sol) (SSC) (to be deployed on a EVM-compatible blockchain).
|
||||
|
||||
The Smart Contract, and therefore the protocol, supports any cryptocurrency beyond ETH or ERC20.
|
||||
|
||||
The protocol is made of 2 macro-phases:
|
||||
|
||||
- `AddressOwnership:` In this phase, the Exchange is required to provide a signature proof that they control a specific set of addresses and submit it to the SSC. This phase happens asynchronously to a Proof of Solvency Round.
|
||||
- `Proof of Solvency Round:` In this phase, the Exchange needs to prove its solvency at a specific timestamp _t_
|
||||
|
||||
Leveraging zkSNARKs enforces computational integrity guarantee **while** protecting sensitive data of the Exchange which is used as input to the proofs. Summa is designed to protect Exchanges’ business intelligence data such as:
|
||||
|
||||
- The number of its users
|
||||
- The individual balances of these users
|
||||
- The aggregated balances of any group of users
|
||||
- The aggregated balances of the whole user base, namely the total amount deposited on the Exchange
|
||||
- The pattern of changes of these data across time
|
||||
|
||||
In the following example, we’ll describe an Exchange performing¹ a full Proof of Solvency flow involving multiple currencies at once.
|
||||
|
||||
### AddressOwnership
|
||||
|
||||
In this phase, the Exchange has to prove ownership of a certain set of addresses. This information is later used in the Proof of Solvency round run at _t_ to infer `Exchange owns 0x123 -> 0x123 owns 20 ETH at t -> Exchange owns 20 ETH at t`
|
||||
|
||||
The Exchange needs to sign an off-chain arbitrary message like _"these funds belong to XYZExchange"_ for each of these addresses, and then submit these signatures, together with the addresses and the message, to the SSC.
|
||||
|
||||

|
||||
|
||||
The SSC operates optimistically by storing the triples `{signature, address, message}` within its state **without** performing any verification of their correctness. Any external actor can verify the correctness of those signatures and, if anything wrong is spotted, kick off a dispute.
|
||||
|
||||
The ownership of an address can be proven only once and "reused" across any number of Proof of Solvency rounds (although providing it at each round would decrease the likelihood of a [friend attack](https://hackmd.io/j85xBCYZRjWVI0eeXWudwA#Proof-of-Assets-PoA---attacks-by-the-exchange)). If the Exchange moves the funds to a new address for any reason, this procedure has to be run again only for this new address.
|
||||
|
||||
This phase happens asynchronously to a Proof of Solvency round.
|
||||
|
||||
Up to now, only crypto addresses have been taken into account. But what if the Exchange is holding reserves in fiat currencies? In that case, the Proof of Ownership of these assets can still be carried out by, inevitably, having to trust the bank. In such a scenario, the bank would need to sign a certificate that attests that _XYZExchange holds x$ in their bank_. This certificate can be used during a Proof of Solvency Round (next section).
|
||||
|
||||
## Proof of Solvency Round
|
||||
|
||||
In this phase, both the assets and the liabilities are snapshotted at a specific timestamp `t` to kick off a Proof of Solvency Round. Within a round, the Exchange needs to provide a ZK `ProofOfSolvency` that constrains their assets to be greater than their liabilities at `t`. Furthermore, the Exchange is required to generate a `ProofOfInclusion` for each user, which proves that the user has been accounted for correctly within the liabilities tree.
|
||||
|
||||

|
||||
|
||||
### 1\. Snapshot
|
||||
|
||||
In order for a Proof of Solvency round to start, the Exchange has to snapshot the state of its _liabilities_ and its _assets_ at a specific _timestamp t_.
|
||||
|
||||
For the liabilities, it means building a Merkle Sum Tree² out of the database containing the users' entries at _t_ . The logic of building the Merkle Sum Tree is the one [previously described](https://mirror.xyz/privacy-scaling-explorations.eth/_1Y6ExFD_Rs3oDxwx5_kWAj_Tl_L9c0Hm7E6SVJei0A).
|
||||
|
||||
For the assets, it means fetching, from an archive node, the balances of the addresses controlled by the Exchange, as proven in **AddressOwnership**, at the next available block at _t_ for each asset involved in the Proof of Solvency.
|
||||
|
||||
This operation happens entirely locally on the Exchange premises. No ZK program is involved at this step. No data is shared with the public.
|
||||
|
||||
Building the Merkle Sum Tree doesn’t require auditing or oversight. Any malicious operation that the Exchange can perform here, such as:
|
||||
|
||||
- Adding users with negative balances
|
||||
- Excluding users
|
||||
- Understating users’ balances
|
||||
|
||||
will be detected when the Proof of Inclusion (step 3) is handed over to individual users for verification.
|
||||
|
||||
Note that the protocol doesn’t have to worry if the Exchange is adding fake users to the Merkle Sum Tree. Each user added to the tree would increase the liabilities of the Exchange which is against their interest. This is true as long as 1) the user balance is not negative and 2) the accumulated sum of the balances doesn’t overflow the prime field. These constraints are enforced at step 3.
|
||||
|
||||
### 2\. Proof of Solvency
|
||||
|
||||
In order to prove³ their Solvency at time _t_, the Exchange needs to provide cryptographic proof that constraints the assets controlled by the Exchange at _t_ to be greater than the liabilities at _t_.
|
||||
|
||||
It is necessary to avoid the liabilities denominated in a cryptocurrency being backed by assets denominated in a different currency. This may result in a solvency “only on paper”, that may crash due to a lack of liquidity or rate volatility. Because of this, each asset is compared against the total liabilities denominated in the same cryptocurrency.
|
||||
|
||||
The Proof of Solvency is generated leveraging the following ZK [Circuit](https://github.com/summa-dev/summa-solvency/blob/master/zk_prover/src/circuits/solvency.rs).
|
||||
|
||||

|
||||
|
||||
**inputs**
|
||||
|
||||
- The private inputs `penultimate_level_left_hash, penultimate_level_left_balances[], penultimate_level_right_hash and penultimate_level_right_balances[]` represent the two nodes in the penultimate level of the Merkle sum tree and can be extracted from the Merkle Sum Tree data structure build in the previous step.
|
||||
- The public input `ccex_asset_sums[]` represents the amount of assets owned by the Exchange for each cryptocurrency that is part of the Round as per the assets Snapshot performed in the previous step.
|
||||
|
||||
**constraints**
|
||||
|
||||
- Perform a hashing of the penultimate nodes of the tree to get the Root Node (`root_hash` and `root_balances[]`). `root_balances[]` is an intermediary value that represents an array of the balances stored in the Root Node. In particular, Summa uses Poseidon hashing, which is a very efficient hashing algorithm when used inside zkSNARKs.
|
||||
- Checks that the liability sums for each cryptocurrency in the `root_balances[]` are less than the respective `ccex_asset_sums[]` passed as input
|
||||
|
||||
In the example, the Exchange is generating a Proof of Solvency for multiple assets `N_ASSETS`, therefore the length of the arrays `penultimate_level_left_balances[]`, `penultimate_level_right_balances[]`, `ccex_asset_sums[]` , and `root_balances[]` is equal to `N_ASSETS.`
|
||||
|
||||
**(public) output**
|
||||
|
||||
- `root_hash` of the Merkle Sum Tree
|
||||
|
||||
After the proof is being generated locally by the Exchange, it is sent for verification to the SSC along with its public inputs `ccex_asset_sums[]`, `root_hash` and the timestamp.
|
||||
|
||||
SSC verifies the validity of the proof. On successful verification, the Contract stores the public inputs.
|
||||
|
||||
The immutability of a Smart Contract guarantees that people have consistent views of such information. If the same data were published on a centralized server, these would be subject to modifications from a malicious exchange. This attack is described in [Broken Proofs of Solvency in Blockchain Custodial Wallets and Exchanges, Chalkias, Chatzigiannis, Ji - 2022 - Paragraph 4.4](https://eprint.iacr.org/2022/043.pdf).
|
||||
|
||||
At this point, it's worth noting that no constraints on `ccex_asset_sums[]` are performed within the Circuit nor within the Smart Contract. Instead, Summa adopts an optimistic approach in which these data are accepted as they are. As in the case of `AddressOwnership`, external actors can kick off a dispute if the Exchange is trying to claim ownership of assets in excess of what they actually own.
|
||||
|
||||
Spotting a malicious exchange is very straightforward: it only requires checking whether the assets controlled by the Exchange Addresses at the next available block at timestamp `t` match `ccex_asset_sums[].`
|
||||
|
||||
### 3\. Proof of Inclusion
|
||||
|
||||
Up to this point the Exchange has proven its solvency, but the liabilities could have been calculated maliciously. For example, an Exchange might have arbitrarily excluded "whales" from the liabilities tree to achieve dishonest proof of solvency.
|
||||
|
||||
Proof of Inclusion means proving that a user, identified by their username and balances denominated in different currencies, has been accounted for correctly in the liabilities. In practice, it means generating a ZK proof that an entry `username -> balanceEth`, `balanceBTC`, ... is included in a Merkle sum tree with a root equal to the one published onc-hain in the previous step.
|
||||
|
||||
The Proof of Inclusion is generated⁴ leveraging the following zk [Circuit](https://github.com/summa-dev/summa-solvency/blob/master/zk_prover/src/circuits/merkle_sum_tree.rs).
|
||||
|
||||

|
||||
|
||||
**inputs**
|
||||
|
||||
- The private inputs `username` and `balances[]` represent the data related to the user whose proof of inclusion is being generated.
|
||||
- The private inputs `path_indices[]`, `path_element_hashes[]` and `path_element_balances[][]` represent the Merkle Proof for the user leaf node.
|
||||
- The public input `leaf_hash` is generated by hashing the concatenation of `username` and `balances[]`.
|
||||
|
||||
Note that it would have been functionally the same to expose `username` and `balances[]` as public inputs of the circuit instead of `leaf_hash` but that would have made the proof subject to private data leaks if accessed by an adversarial actor. Instead, by only exposing `leaf_hash`, a malicious actor that comes across the proof cannot access any user-related data.
|
||||
|
||||
**constraints**
|
||||
|
||||
- For the first level of the Merkle Tree, `leaf_hash` and `balances` represent the current Node while p`ath_element_hashes[0]` and `path_element_balances[0][]` represents the sibling Node.
|
||||
|
||||
- Performs the hashing between the current Node and the sibling Node `H(leaf_hash, balances[0], ..., balances[n], path_element_hashes[0], path_element_balances[0][0], path_element_balances[0][n])` to get the hash of the next Node. In particular, `path_indices[0]` is a binary value that indicates the relative position between the current Node and the sibling Node.
|
||||
- Constrains each value in `balances[]` and `path_element_balances[0][]` to be within the range of 14 bytes to avoid overflow and negative values being added to the tree.
|
||||
- For each currency `i` performs the sum between `balances[i]` of the current Node and the `path_element_balances[0][i]` of the sibling Node to get the balances of the next Node.
|
||||
|
||||
- For any remaining level `j` of the Merkle Tree, the next Node from level `j-1` represents the current node, while `path_element_hashes[j]` and `path_element_balances[j][]` represents the sibling Node
|
||||
|
||||
- Performs the hashing between the current Node and the corresponding sibling Node to get the hash of the next Node
|
||||
- Constrains each balance of current Node and each balance of the corresponding sibling Node to be within the range of 14 bytes to avoid overflow and negative values being added to the tree.
|
||||
- For each currency `i` perform the sum between the balances of the current Node and the balances of the sibling Node to get the balances of the next Node.
|
||||
|
||||
In the example, the Exchange is generating a Proof of Solvency for multiple assets `(N_ASSETS)`. All the users' information is stored in a Merkle Sum Tree with height `LEVELS`. `path_indices` and `path_element_hashes` are arrays of length `LEVELS`. `path_element_balances` is a bidimensional array in which the first dimension is the `LEVELS` and the second is `N_ASSETS` .
|
||||
|
||||
**(public) output**
|
||||
|
||||
- `root_hash` of the Merkle Sum Tree result of the last level of hashing.
|
||||
|
||||
The proof is generated by the Exchange and shared with each individual user. Nothing is recorded on a blockchain in this process. The proof doesn't reveal to the receiving user any information about the balances of any other users, the number of the users of the Exchange or even the aggregated liabilities of the Exchange.
|
||||
|
||||
The verification of the π of Inclusion happens locally on the user device. It involves verifying that:
|
||||
|
||||
- The cryptographic proof is valid
|
||||
- The `leaf_hash`, public input of the circuit, matches the combination `H(username, balance[0], ..., balance[n])` of the user with balances as snapshotted at _t_
|
||||
- The `root_hash`, public output of the circuit, matches the one published on-chain in step 3.
|
||||
|
||||
If any user finds out that they haven't been included in the Merkle Sum Tree, or have been included with an understated balance, a warning related to the potential non-solvency of the Exchange has to be raised, and a dispute should open.
|
||||
|
||||
The rule is simple: if enough users request a Proof of Inclusion and they can all verify it, it becomes evident that the Exchange is not lying or understating its liabilities. If just one user cannot verify their π of Inclusion, it means that the Exchange is lying about its liabilities (and, therefore, its solvency).
|
||||
|
||||
At the current state of ZK research, the user has to verify the correct inclusion inside the Merkle Sum Tree **in each** Proof of Solvency Round. An [experimental feature](https://github.com/summa-dev/summa-solvency/pull/153) using more advanced Folding Schemes, such as [Nova](https://www.youtube.com/watch?v=SwonTtOQzAk), would allow users to verify their correct inclusion in any round **up to the current round** with a single tiny proof.
|
||||
|
||||
## What makes for a good Proof of Solvency
|
||||
|
||||
Summa provides the cryptography layer required for an Exchange to run a Proof of Solvency. But that's not all; there are further procedures outside of the Summa protocol that determine the legitimacy of a Proof of Solvency process.
|
||||
|
||||
### Incentive Mechanism
|
||||
|
||||
As explained in the **Proof of Inclusion** section, the more users verify their correct inclusion in the Liability Tree, the more sound this proof is.
|
||||
|
||||
If not enough users verify their Proof of Inclusions, a malicious Exchange can manipulate or discard the liabilities of users and still be able to submit a valid Proof of Solvency without being detected. The probability of this to happen is denoted as the **failure probability**.
|
||||
|
||||
The Failure Probability is common to any Proof of Solvency scheme as described by [Generalized Proof of Liabilities, Chalkias and Ji - section 5](https://eprint.iacr.org/2021/1350.pdf). A finding of the paper is that within an Exchange of 150𝑀 users, only 0.05% of users verifying inclusion proofs can guarantee an overwhelming chance of detecting an adversarial Exchange manipulating 0.01% of the entries in the Liabilities Tree.
|
||||
|
||||
To reduce the Failure Probability, the Exchange is invited to run programs to incentivize users to perform the Proof of Inclusion Verification.
|
||||
|
||||
For example, the Exchange can provide a discount trading fee for a limited period of time for each user that successfully performs the Proof Verification. On top of that, the percentage of users that performed such verification can be shared with the public as a metric of the soundness of such a Proof of Solvency process.
|
||||
|
||||
### Proof of Inclusion Retrieval
|
||||
|
||||
The finding related to Failure Probability described in the previous paragraph relies on the hypothesis that the Exchange doesn’t know which users will verify their inclusion proof in advance. Instead, if the Exchange knows this information, they could exclude from the Liabilities Tree those users who won’t verify their correct inclusion. This would lead to a higher failure probability. But how would the Exchange know?
|
||||
|
||||
If the process of retrieving the Proof of Inclusion is performed on demand by the user, for example, passing through the Exchange UI, the Exchange gets to know which users are actually performing the verification. If this process is repeated across many rounds, the Exchange can forecast with high probability the users who are not likely to perform verification.
|
||||
|
||||
A solution to this issue is to store the proofs on a distributed file system such as IPFS (remember that the proof doesn’t reveal any sensitive data about the Exchange’s user)
|
||||
|
||||
Users would fetch the data from a network of nodes. As long as these nodes don’t collude with the Exchange, the Exchange won’t know which proof has been fetched and which has not. An even more exotic solution is to rely on [Private Information Retrieval](https://en.wikipedia.org/wiki/Private_information_retrieval) techniques.
|
||||
|
||||
This solution necessitates that the Exchange generates all Proofs of Inclusion simultaneously. Even though this operation is infinitely parallelizable, it introduces an overhead for the Exchange when compared to the on-demand proof generation solution. A further cost for Exchange involves the storage of such proofs.
|
||||
|
||||
### Frequency
|
||||
|
||||
Proof of Solvency refers to a specific snapshot in time. Even though the Exchange might result in solvent at _t_ nothing stops them from going insolvent at _t+1s_. The Exchange can potentially borrow money just to perform the Proof of Solvency and then return it as soon as it is completed.
|
||||
|
||||
Increasing the frequency of Proof of Solvency rounds makes such [attacks](https://hackmd.io/@summa/SJYZUtpA2) impractical. [BitMEX](https://blog.bitmex.com/bitmex-provides-snapshot-update-to-proof-of-reserves-proof-of-liabilities/) performs it on a bi-weekly basis. While this is already a remarkable achievement, given the technology provided by Summa, this can be performed on a per-minute basis.
|
||||
|
||||
From a performance point of view, the main bottleneck is the creation and update of the Merkle Sum Tree. This process can be sped up by parallelization being performed on machines with many cores. Surprisingly, Prover time is not a bottleneck, given that proof can be generated in the orders of seconds (or milliseconds) on any consumer device.
|
||||
|
||||
Another solution to avoid such attacks is to enforce proof of solvency in the past. Practically, it means that the Exchange is asked to perform a proof of solvency round related to a randomly sampled past timestamp.
|
||||
|
||||
### Independent Dispute Resolution Committee
|
||||
|
||||
The whole Proof of Solvency flow requires oversight on the actions performed by the Exchange at three steps:
|
||||
|
||||
- When the Exchange is submitting the `AddressOwnership` proof, the validity of the signatures must be checked
|
||||
- When the Exchange is submitting the `ProofOfSolvency`, the validity of the `asset_sums` used as input must be checked
|
||||
- When the users verifies their `ProofOfInclusion`, the validity of the user data used as input must be verified.
|
||||
|
||||
The action of performing the first two verification might be overwhelming for many users. Instead, a set of committees (independent of Summa and any of the Exchange) might be assigned to perform such verification and raise a flag whenever malicious proof is submitted.
|
||||
|
||||
While the first two verifications can be performed by anyone, the last one can only be validated by the user that is receiving the proof itself, since he/she is the only one (beyond the Exchange) that has access to their user data. Note that the Exchange can unilaterally modify the users' data in their database (and even in the interface that the users interact with). Because of that, the resolution of a dispute regarding the correct accounting of a user within the liabilities tree is not a trivial task as described by [Generalized Proof of Liabilities, Chalkias and Ji - section 4.2](https://eprint.iacr.org/2021/1350.pdf)
|
||||
|
||||
A solution to this is to bind these data to a timestamped commitment signed by both the User and the Exchange. By signing such data, the user would approve its status. Therefore any non-signed data added to the liabilities tree can be unanimously identified as malicious.
|
||||
|
||||
### UX
|
||||
|
||||
Once a user receives a Proof of Inclusion, there are many ways in which the verification process can be performed. For example, the whole verification can be performed by clicking a magic _verify_ button. Given that the premise of a Proof of Solvency protocol is to not trust the Exchange, it is likely that a user won't trust the black-boxed API that the Exchange provides to verify the proof.
|
||||
|
||||
A more transparent way to design the verification flow is to allow the users to fork a repo and run the verification code locally. A similar approach is adopted by both [BitMEX](https://blog.bitmex.com/bitmex-provides-snapshot-update-to-proof-of-reserves-proof-of-liabilities/) and [Binance](https://www.binance.com/en/proof-of-reserves).
|
||||
|
||||
While this latter approach is preferred, it also may seem intimidating and time-consuming for many users.
|
||||
|
||||
A third way would be to have a user-friendly open-source interface (or, even better, many interfaces) run by independent actors that allow the verification of such proofs. In such a scenario, the soundness of the verification process is guaranteed by the auditability of the code and by the independent nature of the operator, without sacrificing the UX.
|
||||
|
||||
Alternatively, the verification function can be exposed as a _view function_ in the Summa Smart Contract. In such case, the benefit would be twofold:
|
||||
|
||||
- The code running the verification is public so everyone can audit it
|
||||
- There are many existing interfaces, such as Etherscan, that allow users to interact with the Smart Contract and call the function.
|
||||
|
||||
## Conclusion
|
||||
|
||||
This blog post presented the detailed implementation of how an Exchange can start providing Proof of Solvency to their users as a first step towards a fully Cryptographically Constrained Exchange (CCEX). By doing so, the users of the Exchange can benefit from the privacy and performance of a Centralized Exchange (in terms of transaction settlement speed and close to zero fee), while still having cryptographic-based proof that their deposits are covered.
|
||||
|
||||
A follow-up blog post will provide a more practical tutorial on how to leverage Summa Backend to perform the operations described before.
|
||||
|
||||
The path toward establishing an industry-wide standard for proof of solvency requires the definition of a protocol that is agreed upon by Exchanges, Cryptographers, and Application Developers. The goal is to collaborate with Exchanges during a Beta program to bring Summa to production and, eventually, come up with a [EIP](https://github.com/summa-dev/eip-draft) to define a standard.
|
||||
|
||||
Complete this [Google Form](https://forms.gle/uYNnHq3vjNHi5iRh9) if your Exchange (or Custodial Wallet) is interested in joining the program.
|
||||
|
||||
### Benchmark Notes:
|
||||
|
||||
1. All the benchmarks related to the round are provided considering an Exchange with 500k users performing a Proof of Solvency for 20 different cryptocurrencies. The benches are run on a MacBook Pro 2023, M2 Pro, 32GB RAM, 12 cores. All the benchmarks can be reproduced [here](https://github.com/summa-dev/summa-solvency/tree/benches-blogpost/zk_prover) running:
|
||||
|
||||
`cd zk_prover`
|
||||
|
||||
`cargo bench`
|
||||
|
||||
2. `461.08s` to build a Merkle Sum Tree from scratch. At any subsequent round, the process only requires leaf updates therefore the required time is significantly reduced.
|
||||
3. `460.20s` to generate the proof of `1568` bytes. The proof costs `395579` gas units for onchain verification.
|
||||
4. `3.61s` to generate the proof of `1632` bytes. The verification of the proof takes `6.36ms`.
|
||||
148
articles/interep-on-ramp-for-reputaion.md
Normal file
@@ -0,0 +1,148 @@
|
||||
---
|
||||
authors: []
|
||||
title: "Interep: An on-ramp for reputation"
|
||||
image: null
|
||||
tldr: ""
|
||||
date: "2022-09-13"
|
||||
canonical: "https://mirror.xyz/privacy-scaling-explorations.eth/w7zCHj0xoxIfhoJIxI-ZeYIXwvNatP1t4w0TsqSIBe4"
|
||||
---
|
||||
|
||||
Reputation is built one block at a time, on and off-chain.
|
||||
|
||||
[Interep](https://interep.link/) is a bridge for moving reputation from centralized into decentralized systems. Centralized social media and other web2 platforms have captured decades’ worth of social history, so that even people who would prefer to exit these systems are dependent on them as a source of reputation. Interep gives developers a headstart for building sybil-resistant decentralized identity on web3 by leveraging social history built on web2.
|
||||
|
||||
With Interep, users don’t need to build their on-chain identities from scratch. Reputation can be imported from existing platforms like Github, Reddit, and Twitter, then anonymized for use on decentralized platforms. Using [zero-knowledge proofs](https://ethereum.org/en/zero-knowledge-proofs/), only the minimum necessary information is revealed. The result is a modular system of provable, private, and portable reputation.
|
||||
|
||||
Interep is built on [Semaphore](https://semaphore.appliedzkp.org/), a zero knowledge protocol which allows Ethereum users to prove their membership of a group and send signals anonymously. Interep is currently on testnet. You can [join a group](https://kovan.interep.link/) using your Github, Reddit or Twitter account, or with a POAP held in a connected wallet. Developers can integrate Interep into their dapps using the Interep [APIs](https://docs.interep.link/api/) and [libraries](https://github.com/interep-project/interep.js).
|
||||
|
||||
## Anonymity and trust
|
||||
|
||||
Anonymity is important for both free expression and safety online – but trust is important too. In an online community, you want to know that the people you interact with are really people; you may also want to know whether they are members of a certain group or have some level of credibility.
|
||||
|
||||
Offline, it’s easy to tell whether someone is a real person: they’re standing in front of you. Online, it’s often much harder to know. Bots, spammers and [sybil attacks](https://en.wikipedia.org/wiki/Sybil_attack) (creating large numbers of anonymous or pseudonymous accounts) are rampant in anonymous environments where it’s trivial to create new accounts and difficult or impossible to distinguish legitimate accounts from fake or duplicate ones.
|
||||
|
||||
## Identity and reputation
|
||||
|
||||
Identity is multifaceted, and reputation is just one important aspect. Reputation is dynamic, spread across a complex web of relationships and past actions. Each person in your orbit holds a partial map of your character: personality traits like reliability, honesty or generosity, your skills, your work history, your associations with other people and organizations. Context is important, too – if you’re notoriously dishonest but very good at your job, you might be in high demand professionally but unwelcome at a poker night.
|
||||
|
||||
Similarly online, there is a wide range of contexts where varying levels of reputation and trust are needed. Online social, community and professional networks provide a relatively reliable source of reputation, but often at the cost of giving up control over how other aspects of identity are shared.
|
||||
|
||||
In any interaction, on or offline, some aspects of your identity are relevant and others are not. Sometimes, the fact that you are a person is the only relevant detail. In online settings where anonymity is desirable but some level of trust is required, we need a way of sharing what’s relevant and keeping the rest private.
|
||||
|
||||
## Reputation Legos
|
||||
|
||||
Determining whether someone on the internet is a “real” human, let alone a trustworthy one, is an ongoing challenge, but only minimal information is needed to make significant progress in preventing spam bots and [Sybil attacks](https://en.wikipedia.org/wiki/Sybil_attack). Having >10,000 karma and >5000 coins on Reddit is enough “proof of humanity” for most applications. Everything else on your Reddit profile is irrelevant to the question of whether you’re a real person.
|
||||
|
||||
Interep is designed to be a modular piece of a larger reputation system that developers can plug into their stack. Like the building blocks that make up [decentralized finance (DeFi](https://ethereum.org/en/defi/)), these pieces can be permissionless, composable, and interoperable – and may one day form a rich and complex system of identity on Ethereum.
|
||||
|
||||
It may not be possible to completely eliminate Sybil attackers and spam bots, but Interep is providing a powerful building block to bring pieces of reputation on to Ethereum. Over time, these reputational building blocks can construct more provably human identities.
|
||||
|
||||
## Interep in action
|
||||
|
||||
Reputation can be simply defined as recognition by other people of some characteristic or ability. In the Interep system, _providers_ act as the other people, _parameters_ represent characteristics or abilities, and _signals_ are proof of recognition.
|
||||
|
||||
Interep begins by defining a source of reputation, then calculating the parameters of reputation, before allowing users to privately signal that they meet a pre-defined reputation criteria.
|
||||
|
||||
### Providers
|
||||
|
||||
Reputation is only as good as its source. Interep itself does not provide a source of reputation but rather acts as a bridge to make reputation portable from different sources. The current Interep system includes Reddit, Twitter, Github, and [POAP NFTs](https://poap.xyz/) as sources of reputation, referred to as providers.
|
||||
|
||||
The Interep process of exporting reputation begins when users select a provider. A provider such as Reddit (via [OAuth](https://docs.interep.link/technical-reference/groups/oauth)) shares information about a user’s profile with Interep. Interep takes the authenticated information and calculates a reputation score. The type of provider is used to generate a new identity and the reputation score determines which group the user can join.
|
||||
|
||||
### Parameters
|
||||
|
||||
Reputational parameters determine a user’s reputation level as either gold, silver, or bronze. The more difficult-to-fake parameters a user has, the higher their reputation level, and the higher probability of them being an authentic or non-malicious user.
|
||||
|
||||
Reddit parameters are defined as the following:
|
||||
|
||||
- Premium subscription: true if the user has subscribed to a premium plan, false otherwise;
|
||||
- Karma: amount of user's karma;
|
||||
- Coins: amount of user's coins;
|
||||
- Linked identities: number of identities linked to the account (Twitter, Google).
|
||||
|
||||
To be included in the Reddit gold reputation level, a user would need to have a premium subscription and a minimum of 10000 karma, 5000 coins, and 3 linked identities.
|
||||
|
||||

|
||||
|
||||
https://docs.interep.link/technical-reference/reputation/reddit
|
||||
|
||||
Defining parameters and reputation levels is an ongoing and collaborative process – one that you can help with by [contributing your knowledge and opinions to the Interep survey.](https://docs.google.com/forms/d/e/1FAIpQLSdMKSIL-3RBriGqA_v-tJhNJOCciQEX7bwFvOW7ptWeDDhjpQ/viewform)
|
||||
|
||||
### Signals
|
||||
|
||||
If a user meets the criteria for the Reddit gold reputation level, they can now join the group with other users who have met the same criteria. Once you are a member of an Interep group, you can generate zero-knowledge proofs and signal to the world in a private, publicly verifiable way that you are very likely human.
|
||||
|
||||
If you’re interested in seeing Interep in action, the smart contracts have been [deployed to Goerli](https://goerli.etherscan.io/address/0x9f44be9F69aF1e049dCeCDb2d9296f36C49Ceafb) along with a [staging app for end users.](https://goerli.interep.link/)
|
||||
|
||||
## Preserving privacy with Semaphore
|
||||
|
||||
Interep integrates zero-knowledge proofs through [Semaphore](https://semaphore.appliedzkp.org/) so users only reveal the minimum amount of information necessary to join a group. Using Interep, Reddit users can keep everything about their profiles private including the exact number of karma or coins they possess. The only information revealed is that they meet the group’s requirements.
|
||||
|
||||
Semaphore is a privacy protocol with a few simple, but powerful, functions:
|
||||
|
||||
1. Create a private identity
|
||||
2. Use private identities to join a group
|
||||
3. Send signals and prove you are a member of a group anonymously
|
||||
|
||||
A Semaphore group is simply a Merkle tree, with each leaf corresponding to a unique identity. Interep checks a user’s reputation and adds them to a group based on their reputation level. After joining a group, users can generate valid zero knowledge proofs that act as an anonymous proof-of-membership in a group and prove they meet a certain reputation criteria.
|
||||
|
||||
Platforms and dapps can verify if a user belongs to a group by verifying the users' zk-proofs and be confident that anyone in an Interep group has met the reputation requirements without having to identify individual users.
|
||||
|
||||

|
||||
|
||||
https://github.com/interep-project/presentations/blob/main/DevConnect%20Amsterdam%20April%202022.pdf
|
||||
|
||||
To join an Interep group, you must first generate a Semaphore ID. Semaphore IDs are always created in the same way: they are derived from a message signed with an Ethereum account. On Interep, the Semaphore ID is generated using information from a provider such as Reddit, Github, Twitter, or POAP NFTs. These are called “deterministic identities” because the identity is generated using a specific message. A Reddit Semaphore ID and a Github Semaphore ID would be two different identities because they were generated using two different messages or inputs.
|
||||
|
||||

|
||||
|
||||
https://semaphore.appliedzkp.org/docs/guides/identities#create-deterministic-identities
|
||||
|
||||
Interep and Semaphore are interrelated. Semaphore acts as a privacy layer capable of generating and verifying zero-knowledge proofs. Interep bridges reputation from a variety of external sources while also managing user groups. Together, they create a system where off-chain reputation can be privately proven and verified on the blockchain.
|
||||
|
||||
You can generate a Semaphore identity using the [@interep/identity](https://github.com/interep-project/interep.js/tree/main/packages/identity) package.
|
||||
|
||||
Learn more about how Semaphore works in [this post](https://mirror.xyz/privacy-scaling-explorations.eth/ImQNsJsJuDf_VFDm9EUr4njAuf3unhAGiPu5MzpDIjI).
|
||||
|
||||
## Using reputation on-chain
|
||||
|
||||
Establishing reputation on-chain is an important step to unlocking new use cases or improving existing use cases, many of which have been difficult to develop due to concerns about sybil attacks, a desire to curate the user base, or resistance to rebuilding existing reputation in a new environment. Some possibilities include:
|
||||
|
||||
**Social Networks**
|
||||
|
||||
Social networks (even decentralized ones) are generally meant for humans. Requiring users to have multiple sources of reputation to engage on a platform provides a practical anti-Sybil solution for a social network, while reputation tiers give users who have worked to establish a reputation elsewhere a head start on credibility.
|
||||
|
||||
**Specialized DAOs**
|
||||
|
||||
DAOs or any digital organization can filter out or select for specific reputation parameters. For example, a protocol needing experienced developers would prize a higher Github reputation. A DAO focused on marketing may only accept members with a certain Twitter follower account. Organizations especially focused on community building may only want members who have proven reputations on Reddit.
|
||||
|
||||
**Voting**
|
||||
|
||||
Online voting has long been a promise of blockchain technology, but strong privacy and identity guarantees have been missing. Anonymous on-chain reputation helps us get closer to a world where eligible humans can privately vote using the blockchain. Voting goes beyond traditional elections and can be used for [on-chain governance](https://vitalik.ca/general/2021/08/16/voting3.html) and [quadratic funding](https://ethereum.org/en/defi/#quadratic-funding) where unique humanity is more important than holding the most tokens.
|
||||
|
||||
**Airdrops**
|
||||
|
||||
Everyone likes an airdrop, but no one likes a Sybil attack. Reputation as “proof of individual” could help weed out users who try to game airdrops with multiple accounts while preserving more of the token allocation for authentic community members.
|
||||
|
||||
## Limitations
|
||||
|
||||
Interep can do a lot of things, but it can’t do everything. Some current limitations include:
|
||||
|
||||
- Centralization of reputation service: only Interep can calculate reputation.
|
||||
- Data availability: groups are currently saved in mongodb instance, which presents a single point of failure. This could be mitigated in the long term by moving to distributed storage.
|
||||
- Members cannot be removed.
|
||||
- The Interep server is a point of centralization. If a malicious actor gained access, they could censor new group additions or try to analyze stored data to reveal links between IDs.
|
||||
- It is possible for someone with access to the Interep database to determine which provider accounts have been used to create Interep identities
|
||||
- The way reputation is calculated is still very basic. We’d love your [feedback](https://docs.google.com/forms/d/e/1FAIpQLSdMKSIL-3RBriGqA_v-tJhNJOCciQEX7bwFvOW7ptWeDDhjpQ/viewform) on how to make it more robust!
|
||||
|
||||
## Credible humanity
|
||||
|
||||
Existing web2 platforms can be centralized, opaque, and reckless with their user’s private information – all problems the Ethereum community is actively building solutions and alternatives for. However, these platforms also have well-developed user bases with strong reputational networks and social ties.
|
||||
|
||||
All the digital reputation amassed over the years need not be thrown away in order to build a new decentralized version of the internet. With a pragmatic reputational on-ramp our Ethereum identities can become much more than a history of our financial transactions. They can become more contextual, more relational, more social, and more credibly human.
|
||||
|
||||
## Build with Interep
|
||||
|
||||
If you’d like to learn more or build with Interep, check out our [documentation](https://docs.interep.link/), [presentation](https://www.youtube.com/watch?v=CoRV0V_9qMs), and Github [repo](https://github.com/interep-project). To get involved, join the conversation on [Discord](https://discord.gg/Tp9He7qws4) or help [contribute](https://docs.interep.link/contributing).
|
||||
|
||||
Interep is possible thanks to the work of contributors including [Geoff Lamperd](https://github.com/glamperd) (project lead) and [Cedoor](https://github.com/cedoor).
|
||||
@@ -0,0 +1,124 @@
|
||||
---
|
||||
authors: ["PSE researcher Pierre"]
|
||||
title: "Intmax: a scalable payment L2 from plasma and validity proofs"
|
||||
image: "cover.webp"
|
||||
tldr: "This post was written by PSE researcher Pierre and originally posted on his [personal blog](https://www.pierredm.xyz/posts/intmax). Thanks to the Intmax team for their helpful review on this post!"
|
||||
date: "2025-03-04"
|
||||
canonical: "https://mirror.xyz/privacy-scaling-explorations.eth/__VLZrfjSScx42E786k-Ba4YptQfv8ujCWY_DuN1k4o"
|
||||
---
|
||||
|
||||
[Intmax](https://www.intmax.io/) has been pioneering L2 transaction-only constructions based on [client-side validation](https://eprint.iacr.org/2025/068.pdf) (CSV), where transaction validation relies on cryptographic proofs rather than blockchain consensus rules. Data is intermittently posted on a dedicated blockchain, primarily for deposits, withdrawals, and account checkpoints.
|
||||
|
||||
The Intmax2 [paper](https://eprint.iacr.org/2023/1082) is an instantiation of CSV. It consists of two core primitives: a Plasma-like data availability (DA) mechanism and validity proofs. It demonstrated that such a combination can help L2s achieve quite high TPS numbers. In this piece, we will explore why that is the case and how Intmax operates under the hood.
|
||||
|
||||
## Plasma
|
||||
|
||||
Originally, plasma was considered a strong L2 architecture candidate, distinct from both optimistic and zk-rollups. Its two key differences lay in the role assigned to the block builder (or "aggregator") and the amount of data posted on-chain. Until recently, this data primarily consisted of block hashes produced by plasma aggregators, resulting in a minimal on-chain data footprint for plasma rollups.
|
||||
|
||||
To enable that DA model, plasma designers assumed that (1) users would stay online and participate in non-trivial challenge games when aggregators misbehave (e.g., using fraud proofs) and (2) mechanisms would be in place to prevent the aggregator from withholding block data (e.g., requiring signatures on blocks submitted by the aggregator).
|
||||
|
||||
Many plasma designs have been proposed in the past ([original plasma](https://www.plasma.io/plasma.pdf), [plasma cash](https://arxiv.org/abs/1911.12095), and various [ethresearch posts](https://ethresear.ch/tags/plasma), among others1^11). However, a key difference today is the cambrian explosion in sn(t)ark development—both in new constructions and improved frameworks—that has taken place in the meantime.
|
||||
|
||||
Given today's DA scarcity and relatively [low TPS numbers](https://l2beat.com/scaling/activity), there are strong incentives to revisit these designs while leveraging the best of both validity proofs and plasma DA. This research is particularly relevant for ecosystems with expensive blockspace and emerging L2s, such as Bitcoin.
|
||||
|
||||

|
||||
|
||||
## Preventing data withholding with BLS Signatures
|
||||
|
||||
The first attack plasma chains aim to address is data withholding by the aggregator. Since (roughly) only block roots are posted on-chain, plasma users must ensure that block data (i.e., transaction inclusion proofs) is properly delivered to the transaction senders included in the posted block.
|
||||
|
||||
To address this, Intmax aggregators send [block proposals](https://github.com/InternetMaximalism/intmax2-zkp/blob/8f511d8ee5f2f3286ecb1d6854f31b056872a57a/src/mock/block_builder.rs#L135) to users, who then [BLS-sign](https://github.com/InternetMaximalism/intmax2-zkp/blob/8f511d8ee5f2f3286ecb1d6854f31b056872a57a/src/mock/client.rs#L285) them—attesting to data availability—and send them back to the aggregator. When the block is posted on-chain, the block proposer submits an [aggregated BLS signature](https://github.com/InternetMaximalism/intmax2-zkp/blob/4f43690a9cd005686f1283746204845f13dcea8b/src/mock/block_builder.rs#L345), composed of all the signatures received from senders. This aggregated signature, along with all sender addresses, is then [verified](https://github.com/InternetMaximalism/intmax2-contract/blob/2e77bbbe77a5b86449b588691183b05d9887603b/contracts/rollup/Rollup.sol#L184) within the plasma rollup contract.
|
||||
|
||||
You could still observe that the data withholding problem could be flipped on its head: can't users delay block production by retaining their signatures when asked by the aggregator? To avoid this, if the aggregator does not receive the signature in some specified timeframe, the transaction will still be included in the block but the aggregator will [include a boolean flag](https://github.com/InternetMaximalism/intmax2-zkp/blob/4f43690a9cd005686f1283746204845f13dcea8b/src/mock/block_builder.rs#L327) indicating that the signature was not sent back.
|
||||
|
||||
## Preventing malicious aggregators with validity proofs
|
||||
|
||||
The second attack plasma chains want to solve is the aggregator including malicious transactions - i.e. spending coins which do not exist. To prevent this, Intmax leverages [proof-carrying data](https://dspace.mit.edu/bitstream/handle/1721.1/61151/698133641-MIT.pdf) (PCD) to compose together proofs which end up attesting to the validity of coins being spent. In Intmax, users prove their balance by aggregating proofs, each attesting to the validity of either its own balance (such as in the case of deposits, withdrawals or coin sends) or of others (such as in the case of coin receipts). The aggregated proof is called the "balance proof": πbalance. It attests to the user's balance on the plasma chain and results from composing proofs originating from various sources.
|
||||
|
||||
There are 4 important different action types which will contribute to changing the user's balance proof. Each action type update the user's πbalance balance proof:
|
||||
|
||||
1. send: updates the balance if the user knows a valid witness attesting to a send operation.
|
||||
2. receive: updates the balance if the user knows a valid witness attesting to the user receiving a coin transfer.
|
||||
3. deposit: updates the balance if the user knows a valid witness attesting to the user performing a deposit.
|
||||
4. update: a "utility" which updates the balance from one block Bt−i to another Bt−j if the user knows a valid witness attesting to the correctness of the balance at block Bt−j.
|
||||
|
||||
An instantiation of this logic is Intmax's `BalanceProcessor` struct, implementing four methods, all corresponding to each of the different types described above: `prove_send`, `prove_update`, `prove_receive_transfer` and `prove_receive_deposit`. This struct's method will be invoked each time an intmax user will perform the corresponding state changing actions on the plasma chain.
|
||||
|
||||
## How scalable is this design?
|
||||
|
||||
Intmax's has one of the lowest onchain data footprint among all L2s. This directly stems from its plasma design and the clever trick they found for identifying plasma users on the L1. Briefly, senders ids are stored with approx. 4.15 bytes of data on the L1: this means that with 12s block time and 0.375mb of da, Intmax has some of the highest _theoretical_ TPS, hovering around 7k transactions/second - and _doable today_!
|
||||
|
||||
## Main algorithms
|
||||
|
||||
Intmax uses [plonky2](https://github.com/0xPolygonZero/plonky2) to entangle proofs together to yield one single balance proof. This means that Intmax's code is a bit involved. We lay out here in a somewhat detailed, yet informal fashion the main algorithms used by intmax's plasma according to the [code](https://github.com/InternetMaximalism/intmax2-zkp/tree/cli)2^22, instead of the paper. The implementation contains interesting details, which probably in the name of succintness, were not included in the paper.
|
||||
|
||||
One pattern of Intmax's PCD flow is for users to (1) update their balance proof to show the state of the account right before a plasma action happened, (2) generate a transition proof attesting to the validity of the transition of the account private state when the plasma action is applied and (3) generate a new public balance proof attesting to the balance of the user once the action has been processed. We now review how the balance proof is updated according to each action triggered by an Intmax plasma user.
|
||||
|
||||
### Deposit
|
||||
|
||||
A deposit consists in a user sending funds to the Intmax rollup contract, an aggregator building a block acknowledging the deposit and the depositor updating his balance proof using deposit witness data.
|
||||
|
||||
1. User deposits [onchain](https://github.com/InternetMaximalism/intmax2-zkp/blob/8f511d8ee5f2f3286ecb1d6854f31b056872a57a/src/mock/client.rs#L119) (a mocked contract here), updating the onchain [deposit tree](https://github.com/InternetMaximalism/intmax2-zkp/blob/233a26eb1d8b2580f66136a95319ad99eb1f62f2/src/mock/contract.rs#L88) and [generates a proof](https://github.com/InternetMaximalism/intmax2-zkp/blob/233a26eb1d8b2580f66136a95319ad99eb1f62f2/src/mock/balance_logic.rs#L34) attesting to the existence of the block BtB_tBt where the deposit occurred onchain and of his account inclusion within the account tree.
|
||||
2. User [updates his balance proof](https://github.com/InternetMaximalism/intmax2-zkp/blob/233a26eb1d8b2580f66136a95319ad99eb1f62f2/src/mock/balance_logic.rs#L50) πt−ibalance→πt−1balance, right before the deposit block BtB\_{t}Bt. To this end, he uses an update witness wt−1update _attesting to block_ Bt−1B\_{t-1}Bt−1 correctness and to the existence of the user's account at that block.
|
||||
3. User retrieves a deposit witness wtdeposit _attesting to the onchain deposit validity - i.e. the deposit is present at block_ BtB{t}Bt, which has been built correctly.
|
||||
4. User generates a balance transition proof πt−1,ttransition _using the deposit witness_ wtdeposit attesting to the validity of the account's state transition.
|
||||
5. Uses the πt−1,ttransition* proof to generate the [final, public, balance proof](https://github.com/InternetMaximalism/intmax2-zkp/blob/233a26eb1d8b2580f66136a95319ad99eb1f62f2/src/mock/balance_logic.rs#L91) *πtbalance
|
||||
|
||||
### Transfer
|
||||
|
||||
A transfer involves a sender and an aggregator communicating over a block proposal. Once the block proposal has been signed by the sender and posted onchain by the aggregator, the sender is able to update his balance proof and convince the receiver of the transaction's validity.
|
||||
|
||||
1. Sender makes a transaction request to the aggregator. a. Generates a [transfer tree](https://github.com/InternetMaximalism/intmax2-zkp/blob/233a26eb1d8b2580f66136a95319ad99eb1f62f2/src/mock/client.rs#L183) TttransferT^{transfer}\_{t}Tttransfer*b. Generates a [spent witness](https://github.com/InternetMaximalism/intmax2-zkp/blob/233a26eb1d8b2580f66136a95319ad99eb1f62f2/src/mock/client.rs#L189) *wtspentw^{spent}\_{t}wtspent, used later on to prove a valid send operation. c. Generates a [spent proof](https://github.com/InternetMaximalism/intmax2-zkp/blob/233a26eb1d8b2580f66136a95319ad99eb1f62f2/src/mock/client.rs#L197) πtspent attestingstesting to the user's transaction validity. d. [Sends a transaction request](https://github.com/InternetMaximalism/intmax2-zkp/blob/233a26eb1d8b2580f66136a95319ad99eb1f62f2/src/mock/client.rs#L203) (containing the nonce and the transfer tree root) to the aggregator.
|
||||
2. Aggregator builds block and sends transaction inclusion merkle proof πtinclusion to senders.
|
||||
3. Sender finalizes the transaction: a. Checks the transaction merkle inclusion proof πtinclusion* b. [BLS signs](https://github.com/InternetMaximalism/intmax2-zkp/blob/233a26eb1d8b2580f66136a95319ad99eb1f62f2/src/mock/client.rs#L285) the transaction merkle inclusion proof *πtinclusion c. Sends transaction data (πtspent,πtinclusion) to the transaction receiver
|
||||
4. Builder posts BproposalB^{proposal}Bproposal onchain along with [aggregated signatures](https://github.com/InternetMaximalism/intmax2-zkp/blob/233a26eb1d8b2580f66136a95319ad99eb1f62f2/src/mock/client.rs#L286) from senders
|
||||
|
||||
### Receive
|
||||
|
||||
Receiving a transfer means both receiver and sender update their balance proofs. On the sender side:
|
||||
|
||||
1. Updates his balance proof πt−ibalance→πt−1balance, up to right before the transfer block BtB_tBt.
|
||||
2. Using the transaction TxtTx\_{t}Txt and the spent proof πtspent*, [generates a transition proof](https://github.com/InternetMaximalism/intmax2-zkp/blob/233a26eb1d8b2580f66136a95319ad99eb1f62f2/src/circuits/balance/transition/transition_processor.rs#L87) *πt−1,ttransition attesting to a valid send operation and uses it to update his balance proof πt−ibalance→πtbalance
|
||||
3. Updates his private state accordingly: updates his asset tree (removing the corresponding sent transfer amounts), increments his nonce.
|
||||
|
||||
On the receiver side:
|
||||
|
||||
1. [Updates his balance proof](https://github.com/InternetMaximalism/intmax2-zkp/blob/233a26eb1d8b2580f66136a95319ad99eb1f62f2/src/mock/balance_logic.rs#L127) πt−ibalance→πt−1balance, up to right before the transfer block BtB_tBt.
|
||||
2. Generates a balance transition proof πt−1,ttransition*, which [attests to the receipt of a valid transfer](https://github.com/InternetMaximalism/intmax2-zkp/blob/233a26eb1d8b2580f66136a95319ad99eb1f62f2/src/circuits/balance/transition/transition_processor.rs#L215) πt−1,ttransferπt−1,ttransfer. It uses the transfer witness wttransfer*, which contains transaction data (πtspent,πtinclusion*) and the sender's balance proof* πbalancet.
|
||||
3. Generates the [new balance proof](https://github.com/InternetMaximalism/intmax2-zkp/blob/233a26eb1d8b2580f66136a95319ad99eb1f62f2/src/circuits/balance/transition/transition_processor.rs#L235) πtbalance _using the balance transition proof_ πt−1,ttransition.
|
||||
|
||||
### Withdraw
|
||||
|
||||
Withdraws are akin to regular transfers, but occur between an Intmax account and an L1 address. This means that users initiate a transfer by simply sending their funds to the L1 address that they would like to withdraw to. Since it is easy [to detect an L1 pubkey](https://github.com/InternetMaximalism/intmax2-zkp/blob/8f511d8ee5f2f3286ecb1d6854f31b056872a57a/src/common/generic_address.rs#L58), intmax clients can easily [detect and sync](https://github.com/InternetMaximalism/intmax2-zkp/blob/8f511d8ee5f2f3286ecb1d6854f31b056872a57a/src/mock/client.rs#L278) to new withdrawal requests. This also means that all the steps used in the transfer process are effectively the same in the case of a withdraw. The major difference is when retrieving funds from the L1 contract:
|
||||
|
||||
1. The client syncs with withdrawals requests that have been done so far and picks the one relevant to the user from an [encrypted vault](https://github.com/InternetMaximalism/intmax2-zkp/blob/233a26eb1d8b2580f66136a95319ad99eb1f62f2/src/mock/client.rs#L401) storing withdrawals proofs.
|
||||
2. If needed, the user updates his balance proof πtbalance _by applying the withdrawal transfer_ TtwithdrawT^{withdraw}\_{t}Ttwithdraw which occurred at block BtB_tBt.
|
||||
3. The user generates a [withdrawal proof](https://github.com/InternetMaximalism/intmax2-zkp/blob/233a26eb1d8b2580f66136a95319ad99eb1f62f2/src/mock/client.rs#L630) πtwithdraw using a withdrawal witness wtwithdraw*t \_attesting to a transfer occuring from an intmax to an L1 address and included within block* BtB_tBt*. The withdrawal proof* πtwithdraw is sent to a withdrawal aggregator.
|
||||
4. A withdrawal aggregator chains together withdrawal proofs πtwithdraw,0,...,πtwithdraw,k and verifies them on the L1, triggering effective funds withdrawals on the rollup contract.
|
||||
|
||||
## Common questions
|
||||
|
||||
1. Can't the transaction sender retain data from the recipient?
|
||||
|
||||
There is no sender data withholding problem: the sender of a coin wants the receiver to acknowledge he received and validated the spent - think in terms of buying a coffee, how would he be able to buy it otherwise? So this isn't a problem in our case, the sender of a coin hasn't really any incentive to retain his spent proof from the recipient.
|
||||
|
||||
1. Can't I just double spend my coins to two people at the same time?
|
||||
|
||||
No. Validity proofs prevent a sender from doing so since he will need to provide a balance proof to each of the recipients, thereby attesting to the fact that their transaction has been processed correctly and with a sufficient balance.
|
||||
|
||||
1. Does it mean users have to keep their data on their device?
|
||||
|
||||
Yes, one drawback of such designs is to assume users will safegard their data on their local devices. To alleviate some of the risks attached to this (keys aren't the only thing you should keep safely in this model), the initial intmax implementation features a server vault in charge of storing (not yet) encrypted users data.
|
||||
|
||||
## Footnotes
|
||||
|
||||
1. [Plasma World Map](https://ethresear.ch/t/plasma-world-map-the-hitchhiker-s-guide-to-the-plasma/4333), [Minimal Viable Plasma](https://ethresear.ch/t/minimal-viable-plasma/426), [Roll_up](https://ethresear.ch/t/roll-up-roll-back-snark-side-chain-17000-tps/3675), [Plasma Cash with much less per user data checking](https://ethresear.ch/t/plasma-cash-plasma-with-much-less-per-user-data-checking/1298/116?u=pierre)
|
||||
2. We will be working on the `cli` branch
|
||||
|
||||
## Verification
|
||||
|
||||
| | |
|
||||
| ----------------------- | -------------------------------------------------------------------------------------------------------------- |
|
||||
| **ARWEAVE TRANSACTION** | [dg39kqSRB8RgH9H…h3vmfJBRpMpleUo](https://viewblock.io/arweave/tx/dg39kqSRB8RgH9HqJ4enlzm9WsXUh3vmfJBRpMpleUo) |
|
||||
| **AUTHOR ADDRESS** | [0xe8D02b67Bd04A49…67a2c8f3fb02e9c](https://etherscan.io/address/0xe8D02b67Bd04A490ef4f1126b67a2c8f3fb02e9c) |
|
||||
| **CONTENT DIGEST** | \_\_VLZrfjSScx42E…v8ujCWY_DuN1k4o |
|
||||
200
articles/lattice-based-proof-systems.md
Normal file
@@ -0,0 +1,200 @@
|
||||
---
|
||||
authors: ["Miha Stopar"]
|
||||
title: "Lattice-Based Proof Systems"
|
||||
image: "cover.webp"
|
||||
tldr: "This post was written by PSE researcher Miha Stopar."
|
||||
date: "2025-02-18"
|
||||
canonical: "https://mirror.xyz/privacy-scaling-explorations.eth/4OyAht_dHsVT1MgcZTwrK2qJ-bwxpINcpBmLNfF4I2E"
|
||||
---
|
||||
|
||||
Post-quantum cryptography (PQC) is important because it addresses the potential threat posed by quantum computers to classical cryptographic systems.
|
||||
|
||||
Quantum computers leverage the principles of quantum mechanics to perform calculations exponentially faster than classical computers in certain cases. Two algorithms, in particular, pose significant threats:
|
||||
|
||||
- [Shor’s Algorithm](https://en.wikipedia.org/wiki/Shor%27s_algorithm): Efficiently solves integer factorization and discrete logarithm problems, which are the basis of widely used cryptographic protocols like RSA, DSA, and Diffie-Hellman.
|
||||
- [Grover’s Algorithm](https://en.wikipedia.org/wiki/Grover%27s_algorithm): Reduces the security of symmetric-key algorithms by effectively halving the key length (e.g., a 128-bit AES key would offer only 64 bits of security against Grover’s algorithm).
|
||||
|
||||
If large-scale, fault-tolerant quantum computers become practical, many of today’s encryption, digital signature, and key exchange protocols would be rendered insecure.
|
||||
|
||||
Lattice-based cryptography is a promising area within modern cryptography. It is likely the most versatile and performant subfield of PQC. For example, the folding scheme [LatticeFold](https://eprint.iacr.org/2024/257.pdf) is believed to be as efficient as the fastest traditional elliptic curve-based folding schemes.
|
||||
|
||||
The competing non-lattice PQC zero-knowledge proof systems ([Ligero](https://eprint.iacr.org/2022/1608.pdf), [Aurora](https://eprint.iacr.org/2018/828.pdf)) base their security only on the security of unstructured hash functions, but they suffer from extremely high demands for computational resources.
|
||||
|
||||
In this post, we will discuss some of the challenges involved in constructing zero-knowledge proof systems based on lattices. For a more in-depth explanation, please refer to the video by [Vadim Lyubashevsky](https://www.youtube.com/watch?v=xEDZ4tyesMY&t=148s).
|
||||
|
||||
## Zero-knowledge proofs based on discrete logarithm
|
||||
|
||||
A zero-knowledge proof (ZKP) is a cryptographic protocol that allows one party (the prover) to convince another party (the verifier) that a specific statement is true without revealing any additional information beyond the fact that the statement is true.
|
||||
|
||||
Typically, the prover may also wish to demonstrate additional properties of these statements. For instance, suppose the prover wants to prove the knowledge of $x_1$ such that:
|
||||
|
||||
$g^{x_1} = h_1$
|
||||
|
||||
and the knowledge of $x_2$ such that
|
||||
|
||||
$g^{x_2} = h_2$
|
||||
|
||||
for some public values $g, h_1, h_2$. Furthermore, the prover would like to prove
|
||||
|
||||
$x_1 = u \cdot x_2$
|
||||
|
||||
for some $u$.
|
||||
|
||||
For the zero-knowledge proof of $x_1$ such that $g^{x_1} = h_1$, the [Schnorr protocol](https://en.wikipedia.org/wiki/Proof_of_knowledge) can be employed (technically, it is an honest-verifier zero-knowledge proof, but we will set this detail aside):
|
||||
|
||||
- The prover chooses $y_1$ and sends $t_1 = g^{y_1}$ to the verifier.
|
||||
- The verifier chooses a challenge $d$ and sends it to the prover.
|
||||
- The prover sends $z_1 = y_1 + x_1 d$ to the verifier.
|
||||
- The verifier checks whether $g^{z_1} = t_1 h_1^d$.
|
||||
|
||||

|
||||
|
||||
Now, the protocol can be easily extended to prove the knowledge of $x_2$ such that $g^{x_2} = h_2$. In this case, the prover would also send $t_2 = g^{y_2}$ in the first step and $z_2 = y_2 + x_1 d$ in the third one. The verifier would then check whether $g^{z_2} = t_2 h_2^d$.
|
||||
|
||||

|
||||
|
||||
Note that checking the additional property $x_1 = u \cdot x_2$ is straightforward:
|
||||
|
||||
$h_1 = h_2^u$
|
||||
|
||||
Also, for instance, if we had $g^{x_3} = h_3$, the linear relation $x_3 = a \cdot x_1 + b \cdot x_2$ is easy to check:
|
||||
|
||||
$g^{z_3} = t_3 \cdot (h_1^a h_2^b)^d$
|
||||
|
||||
However, the Schnorr protocol is not quantum-safe, as it relies on the discrete logarithm problem, which can be broken by Shor's algorithm. Can we construct similar zero-knowledge proofs using lattices instead?
|
||||
|
||||
## Zero-knowledge proofs based on lattices
|
||||
|
||||
The discrete logarithm problem is to find $x$ given $g^x$. There is a somewhat analogous problem in the lattice-based cryptography world: the Shortest Integer Solution (SIS) problem.
|
||||
|
||||
The system of linear equations
|
||||
|
||||
$Ax = h \; mod \; q$
|
||||
|
||||
where $A \in \mathbb{Z}^{m \times n}_q$ and $h \in \mathbb{Z}^n_q$ can be solved in polynomial time with [Gaussian elimination](https://en.wikipedia.org/wiki/Gaussian_elimination).
|
||||
|
||||
But variations of this problem can be hard. For example, when we require that the norm of$x$ is smaller than some bound $B$. Note that the bound needs to be smaller than $q$; otherwise, $(q, 0, ..., 0)$ is a trivial solution.
|
||||
|
||||
The SIS problem $SIS(m, n, q, B)$ is the problem of finding $x = (x_1, ..., x_n)$ such that
|
||||
|
||||
$Ax = 0 \; mod \; q$
|
||||
|
||||
and
|
||||
|
||||
$||x|| \leq B$
|
||||
|
||||
Can we do Schnorr-like ZKP for such $x$?
|
||||
|
||||
### Schnorr for lattices
|
||||
|
||||
Let's have $x_1$ such that
|
||||
|
||||
$Ax_1 = h_1 \; mod \; q$
|
||||
|
||||
and
|
||||
|
||||
$||x_1|| \leq B$
|
||||
|
||||
Would the following protocol work?
|
||||
|
||||

|
||||
|
||||
The last step of the protocol would be verifier checking whether $A z_1 = A y_1 + d A x_1 = t_1 + d h_1$.
|
||||
|
||||
However, this would not work. The problem is that $z_1$ might not be short, and if we don't require $z_1$ to be short, the prover could provide $z_1$ such that $A z_1 = t_1 + dh_1$ by using Gauss elimination!
|
||||
|
||||
So, $z_1$ needs to be small. To achieve this, $d$ needs to be small as well (note that $z_1 = y_1 + x_1 d$), but on the other hand, we want the challenge space to be large—the larger it is, the better the soundness property. Note that if the prover can guess the challenge $d$, the prover sets the first message to $g^y (g^s)^{-d} $ and the last one to $z_1 = y - s d + s d = y$.
|
||||
|
||||
This is one of the reasons why the ring $\mathbb{Z}_q[x]/(x^n + 1)$ is used—it provides a larger set of elements with small norm this way (polynomials with small coefficients, as opposed to small integers).
|
||||
|
||||
In the last step, the verifier must verify whether $z_1$ is small as well.
|
||||
|
||||
However, that’s not the end of the problems with the lattice-based version of Schnorr.
|
||||
|
||||
Now, if this is a proof of knowledge of $x$, we can extract the value $x$ from the prover. This is typically done by rewinding: we run the prover as a black box twice and obtain two transcripts: $y$, $d_1$, $z_1 = y + x d_1$ and $y$, $d_2$, $z_2 = y + x d_2$. We get:
|
||||
|
||||
$z_2 - z_1 = x(d_2 - d_1)$
|
||||
|
||||
In the Schnorr algorithm, one can simply compute
|
||||
|
||||
$x = \frac{z_2 - z_1}{d_2 - d_1}$
|
||||
|
||||
to obtain the secret $x$ such that $g^x = h$. Using lattices, we obtain $x$ (we can assume $d_2 - d_1$ is invertible) such that $Ax = h$. However, again, $x$ might not be small!
|
||||
|
||||
Thus, using lattices, one can only extract $\bar{z}$ such that
|
||||
|
||||
$A \bar{z} = \bar{d} h$
|
||||
|
||||
where $\\bar{z} = z\_2 - z\_1 $ and $\bar{d} = d_2 - d_1$.
|
||||
|
||||
Note that the value $\bar{z}$ is still small (though not as small as $x$), and given $A$ and $h$, it is still hard to get such $\bar{z}$ and $\bar{d}$.
|
||||
|
||||
In what follows, you will see how the extractor, which returns "only" $\bar{z}$, can still be utilized to construct lattice-based proof systems.
|
||||
|
||||
### Lattice-based commitment scheme
|
||||
|
||||
One of the key steps in the development of lattice-based proof systems was the publication of the paper [More Efficient Commitments from Structured Lattice Assumptions](https://eprint.iacr.org/2016/997.pdf). The commitment scheme described in the paper proceeds as follows.
|
||||
|
||||
#### Key generation
|
||||
|
||||
The key generation returns $\bf{A}_1 \in R_q^{n \times k}$ and $\bf{A}_2 \in R_q^{l \times k}$ as
|
||||
|
||||
$\mathbf{A}_1 = [\mathbf{I}_n | \mathbf{A}_1']$
|
||||
|
||||
$\mathbf{A}_2 = [\mathbf{0}^{l \times n} | \mathbf{I}_l | \mathbf{A}_2']$
|
||||
|
||||
where $\mathbf{A}_1'$ is random from $R_q^{n \times (k-n)}$ and $\mathbf{A}_2'$ is random from $R_q^{n \times (k-n-l)}$.
|
||||
|
||||
#### Commitment
|
||||
|
||||
To commit to $\mathbf{x} \in R_q^l$, we choose a random polynomial vector $\mathbf{r}$ with a small norm and output the commitment
|
||||
|
||||
$Com(\mathbf{x}, \mathbf{r}) := \begin{pmatrix} \mathbf{c}_1 \\ \mathbf{c}_2 \end{pmatrix} = \begin{pmatrix} \mathbf{A}_1 \\ \mathbf{A}_2 \end{pmatrix} \cdot \mathbf{r} + \begin{pmatrix} \mathbf{0}^n \\ \mathbf{x} \end{pmatrix}$
|
||||
|
||||
#### Opening
|
||||
|
||||
A valid opening of a commitment
|
||||
|
||||
$\begin{pmatrix} \mathbf{c}_1 \\ \mathbf{c}_2 \end{pmatrix}$
|
||||
|
||||
is a 3-tuple consisting of $\mathbf{x} \in R_q^l$, $r = \begin{pmatrix} \mathbf{r}_1 \ ... \ \mathbf{r}_k \end{pmatrix} \in R_q^k$, and $f \in \bar{C}.$
|
||||
|
||||
The verifier checks that:
|
||||
|
||||
$f \cdot \begin{pmatrix} \mathbf{c}_1 \\ \mathbf{c}_2 \end{pmatrix} = \begin{pmatrix} \mathbf{A}_1 \\ \mathbf{A}_2 \end{pmatrix} \cdot \mathbf{r} + f \cdot \begin{pmatrix} \mathbf{0}^n \\ \mathbf{x} \end{pmatrix}$
|
||||
|
||||
#### Proof of opening
|
||||
|
||||

|
||||
|
||||
Note that the opening for this commitment schemes is not simply $\mathbf{r}$ and $\mathbf{x}$; it also includes a polynomial $f \in \bar{C}.$ This is due to the issue with the extractor described above.
|
||||
|
||||
The extractor needs to return the triple $\mathbf{x}, \mathbf{r}, f$ such that:
|
||||
|
||||
$f \cdot \begin{pmatrix} \mathbf{c}_1 \\ \mathbf{c}_2 \end{pmatrix} = \begin{pmatrix} \mathbf{A}_1 \\ \mathbf{A}_2 \end{pmatrix} \cdot \mathbf{r} + f \cdot \begin{pmatrix} \mathbf{0}^n \\ \mathbf{x} \end{pmatrix}$
|
||||
|
||||
Such a triple can be obtained through rewinding:
|
||||
|
||||
$\mathbf{z}_2 - \mathbf{z}_1 = (d_2 - d_1) \mathbf{r}$
|
||||
|
||||
Then we have:
|
||||
|
||||
$\mathbf{A}_1 (\mathbf{z}_2 - \mathbf{z}_1) = (d_2 - d_1) \mathbf{A}_1 \mathbf{r} = (d_2 - d_1) \mathbf{c}_1$
|
||||
|
||||
$\mathbf{A}_1 \bar{\mathbf{z}} = f \mathbf{c}_1$
|
||||
|
||||
where $\bar{\mathbf{z}} = \mathbf{z}_2 - \mathbf{z}_1$ and $f = d_2 - d_1$.
|
||||
|
||||
Thus, instead of having $\mathbf{A}_1 \mathbf{r} = \mathbf{c}_1$, we have $\mathbf{A}_1 \bar{\mathbf{z}} = f \mathbf{c}_1$.
|
||||
|
||||
We extract the message $\mathbf{x}_f$ as:
|
||||
|
||||
$\mathbf{x}_f = \mathbf{c}_2 −f^{-1} ·\mathbf{A}_2 ·r$
|
||||
|
||||
The extracted triple is $\mathbf{x}_f, \mathbf{\bar{z}}, f$. It can be easily seen ($\mathbf{\bar{z}} = f \mathbf{r}$):
|
||||
|
||||
$f \cdot \begin{pmatrix} \mathbf{c}_1 \\ \mathbf{c}_2 \end{pmatrix} = \begin{pmatrix} \mathbf{A}_1 \\ \mathbf{A}_2 \end{pmatrix} \cdot \mathbf{\bar{z}} + f \cdot \begin{pmatrix} \mathbf{0}^n \\ \mathbf{x}_f \end{pmatrix}$
|
||||
|
||||
## Conclusion
|
||||
|
||||
Since the commitment scheme described above, there have been many new improvements in the field of lattice-based zero-knowledge proofs. So expect some new material describing lattice-based and other post-quantum cryptographic schemes soon :). At PSE, we are committed to staying at the forefront of this rapidly evolving field by continuously following and testing the latest advancements in post-quantum cryptography. Our goal is to ensure that we are well-prepared for the challenges and opportunities that come with the transition to quantum-safe systems.
|
||||
86
articles/learnings-from-the-kzg-ceremony.md
Normal file
@@ -0,0 +1,86 @@
|
||||
---
|
||||
authors: ["Nico"]
|
||||
title: "Learnings from the KZG Ceremony"
|
||||
image: "cover.webp"
|
||||
tldr: "This post was authored by [Nico](https://github.com/NicoSerranoP/), a frontend developer working in the [Privacy & Scaling Explorations Team (PSE)](https://appliedzkp.org/). Nico summarizes the learnings and challenges he faced during the development and deployment of the [KZG Ceremony](https://ceremony.ethereum.org/)."
|
||||
date: "2023-07-11"
|
||||
canonical: "https://mirror.xyz/privacy-scaling-explorations.eth/naTdx-u7kyirczTLSAnWwH6ZdedfTQu1yCWQj1m_n-E"
|
||||
---
|
||||
|
||||
## What is the KZG Ceremony?
|
||||
|
||||
Rollups and L2s are a way to scale Ethereum without sacrificing security and decentralization. They abstract execution to layer 2 and post resulting data to layer 1. By reducing L1 data storage costs, rollups can reduce their transaction fees considerably.
|
||||
|
||||
Most blockchains (Ethereum included) use hashes to link transactions, blocks, and subsequent transactions. For example, to get a block hash you need to hash all its transaction information plus the previous block hash. This means that the nodes need to store the whole blockchain history in order to synchronize a valid state. If we use polynomial commitments (a nice explanation can be found [here](https://arxiv.org/abs/1906.07221)) instead of hash commitments, we could reduce the need to store data on L1. Only specific information would be stored by specific network L2 nodes.
|
||||
|
||||
Polynomial commitments need an encrypted secret to work. If one person generates a secret and encrypts it, then that person could form invalid proofs that would satisfy the polynomial commitment (aka: create fraudulent proofs of the data posted in L1). To prevent this, we could make N participants generate their own secret and add it to the main one in a sequential order. If only one participant forgets his secret then the main secret would be secure. This process is called a ceremony and because we are going to use the KZG scheme we call it the "KZG Ceremony".
|
||||
|
||||
## Architecture overview
|
||||
|
||||
We need each participant to generate a secret on their side (client side). The contribution computation has to be sequential so we need a central sequencer that would control the participants’ queue (who has the current turn, who is next, check the contribution was performed correctly, etc). Even though the sequencer is a centralized web server, the only malicious attack it could perform would be to censor you from participating. All the secret generation and the contribution computation is done on the client side. To summarize:
|
||||
|
||||
1. Multiple client-side programs would generate a secret and add it to the main secret on their turn.
|
||||
2. A centralized sequencer that would coordinate the participants’ queue and check each contribution’s validity.
|
||||
3. Client and server communication would be done through an API. The main secret file (called Structured Reference String: SRS) is a JSON with very large number values.
|
||||
|
||||
## Crypto-library implementation
|
||||
|
||||
The core part of this process lays on the cryptographic functions to compute contributions and verify their validity. These functions were written in Rust by the Ethereum core devs team because of Rust’s default security properties and its portability to web browsers using WASM. This code is used in the sequencer and in some of the client implementations.
|
||||
|
||||
We needed 3 functions:
|
||||
|
||||
1. `contribute(previous_SRS, secret)` returns `new_SRS`: add a randomly generated secret into the SRS (a bunch of [group multiplications](https://arxiv.org/abs/1906.07221)).
|
||||
2. `contribute(previous_SRS, secret, identity)` returns `new_SRS`: performs the previous function and also signs your input identity using the secret as the secret key. This way you have linked your identity to your contribution for future recognition of your participation in this ceremony. It also helps the sequencer know who has already contributed and who hasn't. The SRS contributions have an attribute dedicated to this signature.
|
||||
3. `check(previous_SRS, post_SRS)` returns `true/false`: checks that the contribution operation was performed correctly. It does not reveal the secret, but it can tell that the participant used the previous SRS as a base and did not send some random value.
|
||||
|
||||
To improve portability, we created a wrapper repository written in Rust that uses the crypto library as a package. That way the crypto code is abstracted from the wrapper/API code being used on the client-side. It also helped us to configure the required tools to run WASM efficiently in a browser (e.g. wasm-pack, rayon, etc).
|
||||
|
||||
- Crypto-library repository: [https://github.com/ethereum/kzg-ceremony-sequencer/tree/master/crypto](https://github.com/ethereum/kzg-ceremony-sequencer/tree/master/crypto)
|
||||
- Wrapper repository: [https://github.com/zkparty/wrapper-small-pot](https://github.com/zkparty/wrapper-small-pot)
|
||||
|
||||
## Sequencer implementation
|
||||
|
||||
The sequencer is a web server application that uses the crypto library as a package to check participants' contributions. To prevent a spam/bot attack, a sign-in feature was implemented. It allowed participants to [sign in with their Ethereum wallet](https://github.com/spruceid/siwe/tree/main) (SIWE modal that allowed multiple wallet-connect compatible wallets) or with their GitHub account. At the development phase we thought that a requirement of 3 or more transactions before a specific snapshot would be enough but we were wrong. In production, a lot of spam bots tried to contribute and therefore the waiting time increased exponentially. We believe these bots were trying to farm tokens or airdrops (which we didn't have and we will not have in the future).
|
||||
|
||||
In terms of the participants' coordination process, we decided to use a lobby strategy rather than a queue strategy. A lobby means that participants have to sign-in and keep pinging the sequencer in a specific time frame until they get randomly selected to participate in the next slot. This way we ensure that participants (clients programs) are active. The ceremony had over 110,000 contributions so if a couple of thousand participants took more time than the expected (around 90 seconds), the waiting time could have increased exponentially. At the same time, a lobby gives everyone the same chances of being selected for the next slot. So if a participant client had suddenly stopped pinging the sequencer, they could rejoin the lobby and still have the same chances as before (contrary to a first-in-first-out queue mechanism that would have sent the unlucky participant to the end of the line). We expected most participants would be using the browsers on their everyday computers and most would not have had a good internet connection.
|
||||
|
||||
We defined "malicious" users as client programs who would send a corrupt SRS (or not send a SRS at all) after being given a slot to participate. This wastes time and delays other participants from contributing. The sequencer would be able to detect corrupt SRS, blacklist them and would not let them participate afterwards unless they explicitly asked through an official channel (Telegram, Discord, Twitter and even GitHub issues).
|
||||
|
||||
The sequencer implemented different API routes to accomplish its tasks:
|
||||
|
||||
1. `/info/current_state`: Serve the initial and the subsequent SRS to the participants and anybody who wanted to check the ceremony state at a specific time.
|
||||
2. `/lobby/try_contribute`: participants would regularly ping into this route to report liveness and if selected, the sequencer would send the participant the current SRS for them to compute their contribution.
|
||||
3. `/contribute`: it would receive the SRS before a specific time frame (to avoid participants taking too much time and making others wait) and check its validity. If true, it would save it and pass it to the next participant. If false, it would just ignore that new SRS, blacklist the participant, and send the previous SRS to the next participant to compute
|
||||
4. `/info/status`: it would serve information about the ceremony such as the number of contributions, lobby size and the sequencer public address used to sign the receipts sent after each participant contribution.
|
||||
|
||||
The sequencer was deployed in a beefy machine that could handle the amount of requests and the bandwidth to send the SRS over and over. A caching of 5 seconds was added for the /current_state route so browsers showcasing the ceremony status and its record wouldn't collapse the bandwidth. There were some changes done to the proxy to avoid a huge spam/bots attack.
|
||||
|
||||
- Sequencer repository: [https://github.com/ethereum/kzg-ceremony-sequencer](https://github.com/ethereum/kzg-ceremony-sequencer)
|
||||
|
||||
## Client implementation
|
||||
|
||||
Ethereum is built by and for its community and it was extremely important for us to create mechanisms so non-experts could participate in the ceremony. That is why the official client implementation is browser-based.
|
||||
|
||||
We used React as our frontend framework and wasm-pack to port the crypto library Rust code as WASM to be run on the browser. The first thing the web application would ask participants is to generate entropy by moving their mouses around the screen and writing some "secret" into an input element. Behind the scenes, we would take the mouse x,y position and the instance timestamp plus the text secret and input it as the seed generation for the random secret that would go into the contribute function in WASM.
|
||||
|
||||
After that, the website would ask the participants to sign-in and depending on the method, an extra BLS signature step would be added (only for SIWE). This method would sign the participant's secret with his wallet to let them prove their participation authenticity later in the future.
|
||||
|
||||
Then the participant would enter into the lobby page which would show how many participants are in the lobby at that moment and the chances of being accepted (there was a time when these chances were less than 0.5%). The browser would keep pinging the sequencer every now and then. The participants could move to another tab to keep working and the pinging would continue but if they run out of battery, close their laptop, close the browser or log out from their session then the pinging would stop and they would need to re-do the process again (including a new entropy generation).
|
||||
|
||||
If a slot were assigned, the client would have around 90 seconds to download the file, perform the computation and upload the new file. The browser will load the generated entropy into the WASM code through the wrapper functions and get the new SRS ready to be sent to the sequencer. A verification check would be performed in the client just in case any function became corrupted. If a false value were returned, we would notify the participant to post a GitHub issue asap (this particular case never happened).
|
||||
|
||||
The biggest challenge we faced was on the deployment part. We didn't want anyone to trust us with the client implementation so we decided to build it and upload it to IPFS which returned a hash of the frontend content that can be used to access the web application itself (the frontend was also audited by an [external company](https://github.com/ethereum/kzg-ceremony#audits)).
|
||||
|
||||
Inside our code we had two opposite components: third party popups related to custom wallets in the SIWE modals and compiled WASM code. The browser would not let you run both at the same time because it presented a vulnerability risk: the third party code (that you don't control) could run compiled WASM (that you cannot read) and execute a malicious script. To solve it we needed to set up different HTTP headers in the sign-in page and in the contributing page.
|
||||
|
||||
The problem with this was that IPFS does not allow you to easily configure HTTP headers (you would need to configure them on the IPFS node settings and not in the application). [Geoff](https://github.com/glamperd) came up with this interesting trick involving service workers:
|
||||
|
||||
Service workers work as a middleware between the client and the server, they were specifically designed to run offline Progressive Web Applications and device-cache strategies. We would use them to set up different HTTP headers and then the browser would recognize them and proceed normally. But because we were using a Single Page Application, we would need to refresh the page every time the participant entered the sign-in or the contributing page. So putting together service workers and a refreshing function, we were able to upload the frontend to IPFS that would allow users to login using all SIWE modal wallets and would allow WASM code computation.
|
||||
|
||||
- Official client repository: [https://github.com/zkparty/trusted-setup-frontend](https://github.com/zkparty/trusted-setup-frontend)
|
||||
- DogeKZG repository: [https://github.com/Savid/dogekzg](https://github.com/Savid/dogekzg)
|
||||
- Other client CLI implementations: [https://github.com/ethereum/kzg-ceremony#client-implementations](https://github.com/ethereum/kzg-ceremony#client-implementations)
|
||||
|
||||
## Conclusion
|
||||
|
||||
We have a team dedicated to trusted setups in the [PSE discord](https://discord.com/invite/sF5CT5rzrR) that helps developers build and deploy their own ceremonies for zero-knowledge circuits. If you need help or want to contribute to our work, feel free to ping us about questions and issues.
|
||||
72
articles/meet-coco-privacy-scaling-explorations.md
Normal file
@@ -0,0 +1,72 @@
|
||||
---
|
||||
authors: ["PSE Team"]
|
||||
title: "Meet COCO! - Privacy & Scaling Explorations"
|
||||
image: null
|
||||
tldr: "Originally published on Jan 27, 2022"
|
||||
date: "2022-08-29"
|
||||
canonical: "https://mirror.xyz/privacy-scaling-explorations.eth/tEf7iYa8l7ECZwN2T57yyiws7h9Uchip30CQvx-JBBQ"
|
||||
---
|
||||
|
||||

|
||||
|
||||
Originally published on Jan 27, 2022:
|
||||
|
||||
COCO is live on testnet! Try it now: [https://www.cocoverse.club](https://www.cocoverse.club/)
|
||||
|
||||
Below, we introduce COCO and give short explanation on how it works. For a deeper understanding of COCO visit the [docs](http://docs.cocoverse.club/).
|
||||
|
||||
## COCO tl;dr
|
||||
|
||||
With Coco, groups can collaborate to curate feeds of any topic they’re interested in. As you scroll through your Coco feed, rather than upvoting or downvoting posts, you’ll spend WETH to predict what other group members and the group’s moderators will want to see. When you’re right, you’ll get back your original WETH and more — but if you’re wrong, you’ll lose what you put in. Through this process, you help Coco filter value from noise to make sure group feeds only consist of posts that the group cares about.
|
||||
|
||||
## **How does prediction = curation?**
|
||||
|
||||
Predictions are made by buying shares in the outcome you think is correct. If you think others and moderators will like the post, you buy YES shares, otherwise you buy NO shares. The price of a share during prediction period depends on the proportion of YES/NO shares bought before you. When a final outcome is set (whether as the favored one, or through challenges, or by group moderators) one share of final outcome will be worth 1 WETH and a share of the losing outcome will be worth 0.
|
||||
|
||||
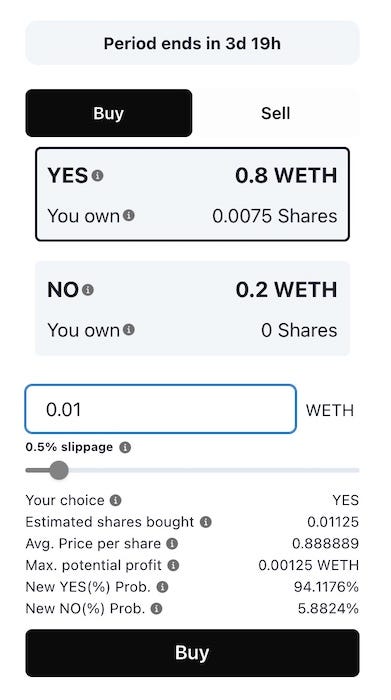
|
||||
|
||||
**Buying YES outcome shares for 0.01 WETH**
|
||||
|
||||
In other words, every post is a [prediction market](https://www.cultivatelabs.com/posts/prediction-markets-beginner-to-intermediate), and the proportion of YES vs NO predictions determine the likelihood of group members and moderators appreciating the post. That’s the essence of curation in Coco: a group’s feed consists of posts that have high probability of being enjoyed by group members and moderators.
|
||||
|
||||
## **Life cycle of a post**
|
||||
|
||||
**Creation**
|
||||
|
||||
You need to spend WETH in order to post content in a group. This “creation value” is used both to make a YES prediction for your own post, and to create a pool of YES and NO outcome shares to facilitate predictions by other users.
|
||||
|
||||
**Prediction**
|
||||
|
||||
Once a post is created, anyone can make predictions on whether the post will stay on the feed or be buried. At the end of the prediction period, the most favored outcome is set as the “temporary outcome”, and will become the final outcome if not challenged.
|
||||
|
||||
**Challenge and Resolution**
|
||||
|
||||
During the Challenge Period, users can stake WETH to challenge the temporary outcome. The temporary outcome is then switched to the outcome favored by the challenger, and the time restarts. If another challenge isn’t submitted before the time limit, then it is set as the final outcome and the post enters the “Final” state. If an outcome is challenged repeatedly, group moderators step in to set the final outcome.
|
||||
|
||||
**Final State**
|
||||
|
||||
Once a final outcome is set, the post is in “Final” state. It is either considered suitable for the group’s feed, if final outcome is YES, or not suitable, if the outcome is NO. Now is the time you can redeem your rewards if your prediction was right, and get your stake (+ some reward) back if you staked for the right outcome during challenge period.
|
||||
|
||||
## Role of moderators
|
||||
|
||||
For the most part, group moderators won’t have to get involved in deciding which posts stay in the feed, as long as users agree upon what the moderators _would_ decide. You can think of predictions behaving like a vote, with WETH at stake representing one’s confidence on the post, to encourage voting in the best interest of the group.
|
||||
|
||||
Moderators don’t control who can join, post, or make predictions on posts in the group. Instead, the key roles of the moderators are to set expectations for what belongs in the feed, decide parameters like the length of the prediction and challenge periods, and declare outcomes when the prediction mechanism doesn’t do its job.
|
||||
|
||||
As of now, only the user that creates a group is able to act as a moderator of that group. We have plans to enable multiple moderators to coordinate within the app in future releases.
|
||||
|
||||
## What’s COCO capable of?
|
||||
|
||||
The scope of topics for groups is unlimited. You can have groups on Funniest crypto memes of week, Trending NFTs of the month, Top articles of the week in crypto, Most insightful research papers in ML, Most secure contracts, or even Top bars in Switzerland. Whatever the topic, Coco’s curation mechanism will ensure that only the best posts stay on the group’s feed.
|
||||
|
||||
Right now, it’s only possible to post images. More content types are coming, along with comments and other features.
|
||||
|
||||
## Learn more
|
||||
|
||||
Everything above is good to get you started with Coco, but if you are looking for more guidance around how to use the app or want to understand Coco better, check out our [docs](https://docs.cocoverse.club/).
|
||||
|
||||
## Tell us what you think!
|
||||
|
||||
COCO is still being developed, and we’d love to hear your feedback and ideas. Fill out [this form](https://airtable.com/shrsVVVLBuawaCDvE) to share your thoughts! Also join our [telegram group](https://t.me/+A47HJeqh0-tlODI1) for any questions and further discussions.
|
||||
|
||||
_Thanks to Althea, Barry, Rachel, and Thore for discussions and ideas around Coco, which truly helped shaping Coco._
|
||||
111
articles/mopro-comparison-of-circom-provers.md
Normal file
@@ -0,0 +1,111 @@
|
||||
---
|
||||
authors: ["Vivian Jeng"]
|
||||
title: "Mopro: Comparison of Circom Provers"
|
||||
image: "cover.webp"
|
||||
tldr: "This post was written by [Vivian Jeng](https://mirror.xyz/privacy-scaling-explorations.eth/GLbuCflH0hu_DncKxiC2No5w3LZJAGw4QaCB-HYD5e0), a developer on the Mopro team."
|
||||
date: "2025-01-21"
|
||||
canonical: "https://mirror.xyz/privacy-scaling-explorations.eth/GLbuCflH0hu_DncKxiC2No5w3LZJAGw4QaCB-HYD5e0"
|
||||
---
|
||||
|
||||
[Mopro](https://github.com/zkmopro/mopro) is a toolkit designed to make mobile proving simple and efficient. With the growing dominance of mobile app users over web app users, and the observation that `snarkjs` is less performant compared to native provers like `rapidsnark`, we recognized the need to optimize proving speed for mobile devices. To address this, one of Mopro's primary goals is to evaluate various provers across different platforms to identify the most effective solution, ensuring we focus on the best-performing prover for mobile environments.
|
||||
|
||||
## Introduction
|
||||
|
||||
Throughout 2024, we compared various Groth16 provers for Circom. Our goal was to demonstrate that native provers (written in C++ or Rust) outperform `snarkjs` in terms of speed. Along the way, we uncovered some fascinating insights, which we’re excited to share with you in this post.
|
||||
|
||||
To understand a Groth16 prover, let’s break it down into two main components: **witness generation** and **proof generation**.
|
||||
|
||||
**Witness Generation:** This step involves processing inputs along with witness calculation functions to produce the necessary witness values for a circuit. It's a purely computational step and does not involve any zero-knowledge properties.
|
||||
|
||||
**Proof Generation:** Once the witness is generated, this step takes the witness and the zkey (generated by `snarkjs`) to compute the polynomial commitments and produce a succinct zero-knowledge proof.
|
||||
|
||||
Ideally, developers should have the flexibility to switch between different witness generation and proof generation implementations. This would allow them to leverage the fastest options available, optimizing performance and enhancing their development experience.
|
||||
|
||||
However, each of these tools presents unique challenges. In the following sections, we will delve into these challenges in detail and provide a comparison table for clarity.
|
||||
|
||||
## Witness Generation
|
||||
|
||||
### `snarkjs`
|
||||
|
||||
- [https://github.com/iden3/snarkjs](https://github.com/iden3/snarkjs)
|
||||
|
||||
`snarkjs` is one of the most widely used tools for generating Groth16 proofs and witnesses. Written in JavaScript, it runs seamlessly across various environments, including browsers on both desktops and mobile devices. However, it faces performance challenges with large circuits. For instance, an RSA circuit can take around 15 seconds to process, while a more complex circuit like zk-email may require up to a minute to generate a proof. This highlights the need for optimized solutions, such as leveraging mobile-native capabilities and even mobile GPUs, to significantly enhance performance.
|
||||
|
||||
### `witnesscalc`
|
||||
|
||||
- [https://github.com/0xPolygonID/witnesscalc](https://github.com/0xPolygonID/witnesscalc)
|
||||
|
||||
`witnesscalc` is a lightweight, C++-based tool designed for efficient witness generation for circuits compiled with Circom. It offers a faster alternative to JavaScript-based tools like `snarkjs`. With cross-platform support and compatibility with other ZKP tools, Witnesscalc is ideal for handling performance-sensitive applications and large circuits.
|
||||
|
||||
While Witnesscalc performs exceptionally well with circuits such as RSA, Anon Aadhaar, Open Passport, and zkEmail, integrating it into Mopro presents challenges due to its C++ implementation, whereas Mopro is built on Rust. We are actively working to bridge this gap to leverage its performance benefits within the mobile proving ecosystem.
|
||||
|
||||
### `wasmer`
|
||||
|
||||
- [https://github.com/arkworks-rs/circom-compat](https://github.com/arkworks-rs/circom-compat)
|
||||
|
||||
One option available in Rust is `circom-compat`, maintained by the Arkworks team. This library uses the `.wasm` file generated by Circom and relies on the Rust crate `wasmer` to execute the witness generation. However, wasmer doesn’t run natively on devices—it creates a WebAssembly execution environment for the `.wasm` file. As a result, the performance of wasmer is comparable to the WebAssembly performance of `snarkjs` running in a browser.
|
||||
|
||||
Initially, we encountered memory issues with wasmer during implementation ([issue #1](https://github.com/zkmopro/mopro/issues/1)). Later, we discovered that the Apple App Store does not support any wasmer functions or frameworks, making it impossible to publish apps using this solution on the App Store or TestFlight ([issue #107](https://github.com/zkmopro/mopro/issues/107)). As a result, we decided to abandon this approach for Mopro.
|
||||
|
||||
### `circom-witness-rs`
|
||||
|
||||
- [https://github.com/philsippl/circom-witness-rs](https://github.com/philsippl/circom-witness-rs)
|
||||
|
||||
Another Rust-based option is `circom-witness-rs`, developed by the Worldcoin team. Unlike solutions that rely on WebAssembly (wasm) output from the Circom compiler, this tool directly utilizes `.cpp` and `.dat` files generated by Circom. It employs the `cxx` crate to execute functions within the `.cpp` files, enhanced with optimizations such as dead code elimination. This approach has demonstrated excellent performance, particularly with Semaphore circuits. However, we discovered that it encounters compatibility issues with certain circuits, such as RSA, limiting its applicability for broader use cases.
|
||||
|
||||
### `circom-witnesscalc`
|
||||
|
||||
- [https://github.com/iden3/circom-witnesscalc](https://github.com/iden3/circom-witnesscalc)
|
||||
|
||||
The team at iden3 took over this project and began maintaining it under the name `circom-witnesscalc`. While it heavily draws inspiration from `circom-witness-rs`, it inherits the same limitation—it does not support RSA circuits. For more details, refer to the "Unimplemented Features" section in the [README](https://github.com/iden3/circom-witnesscalc?tab=readme-ov-file#unimplemented-features).
|
||||
|
||||
### `rust-witness`
|
||||
|
||||
- [https://github.com/chancehudson/rust-witness](https://github.com/chancehudson/rust-witness)
|
||||
|
||||
Currently, Mopro utilizes a tool called `rust-witness`, developed by a member of the Mopro team. This tool leverages `w2c2` to translate WebAssembly (`.wasm`) files into portable C code. By transpiling `.wasm` files from Circom into C binaries, rust-witness has demonstrated compatibility across all circuits and platforms tested so far, including desktop, iOS, and Android. Additionally, its performance has shown to be slightly better than that of wasmer.
|
||||
|
||||
## Proof Generation
|
||||
|
||||
### `snarkjs`
|
||||
|
||||
- [https://github.com/iden3/snarkjs](https://github.com/iden3/snarkjs)
|
||||
|
||||
As mentioned earlier, `snarkjs` is the most commonly used tool for generating Groth16 proofs. However, its performance still has room for improvement.
|
||||
|
||||
### `rapidsnark`
|
||||
|
||||
- [https://github.com/iden3/rapidsnark](https://github.com/iden3/rapidsnark)
|
||||
|
||||
Rapidsnark, developed by the iden3 team, is an alternative to `snarkjs` designed to deliver faster Groth16 proof generation. Similar to `witnesscalc`, it is written in C++. While it shows promising performance, we are still working on integrating it into Mopro.
|
||||
|
||||
### `ark-works`
|
||||
|
||||
- [https://github.com/arkworks-rs/circom-compat](https://github.com/arkworks-rs/circom-compat)
|
||||
|
||||
The primary Rust-based option is `circom-compat`, maintained by the Arkworks team. Arkworks is a Rust ecosystem designed for programmable cryptography, deliberately avoiding dependencies on native libraries like `gmp`. In our experiments, Arkworks has proven to work seamlessly with all circuits and platforms. If you have Rust installed, you can easily execute Groth16 proving using Arkworks without any issues. As a result, Mopro has adopted this approach to generate proofs for cross-platform applications.
|
||||
|
||||
## Comparison Table
|
||||
|
||||
Here, we present a table comparing different witness generators and proof generators to provide a clearer understanding of their features and performance.
|
||||
|
||||
In this comparison, we use `circom-witnesscalc` as a representative for both `circom-witness-rs` and `circom-witnesscalc`, as they share fundamentally similar implementations and characteristics.
|
||||
|
||||

|
||||
|
||||
Comparison of witness generators
|
||||
|
||||

|
||||
|
||||
Comparison of proof generators
|
||||
|
||||
## Conclusion
|
||||
|
||||
In conclusion, we found that the `witnesscalc` and `rapidsnark` stack offers the best performance, but integrating it into Rust presents significant challenges. These tools rely heavily on C++ and native dependencies like `gmp`, `cmake`, and `nasm`. Our goal is to integrate these tools into Rust to make them more accessible for application development. Similar to how `snarkjs` seamlessly integrates into JavaScript projects like Semaphore and ZuPass, having a Rust-compatible stack would simplify building cross-platform applications. Providing only an executable limits flexibility and usability for developers. In 2025, we are prioritizing efforts to enable seamless integration of these tools into Rust or to provide templates for customized circuits.
|
||||
|
||||
We recognize the difficulty in choosing the right tools and are committed to supporting developers in this journey. If you need assistance, feel free to reach out to the Mopro team on Telegram: [@zkmopro](https://t.me/zkmopro).
|
||||
|
||||
1. We are actively working on integrating `witnesscalc` into Mopro. Please refer to [issue #284](https://github.com/zkmopro/mopro/issues/284) [↩](https://doc-compare-circom.mopro.pages.dev/blog/circom-comparison/#user-content-fnref-1-ca0b0e)
|
||||
2. Please refer to [PR #255](https://github.com/zkmopro/mopro/pull/255) to see how to use `circom-witnesscalc` with Mopro. [↩](https://doc-compare-circom.mopro.pages.dev/blog/circom-comparison/#user-content-fnref-2-ca0b0e)
|
||||
3. [waku-org](https://github.com/waku-org) has investigated this approach; however, it does not outperform snarkjs in terms of performance. Please refer to [this comment](https://github.com/zkmopro/mopro/issues/202#issuecomment-2236923108) for more details. [↩](https://doc-compare-circom.mopro.pages.dev/blog/circom-comparison/#user-content-fnref-3-ca0b0e)
|
||||
4. We are actively working on integrating `rapidsnark` into Mopro. Please refer to [issue #285](https://github.com/zkmopro/mopro/issues/285) [↩](https://doc-compare-circom.mopro.pages.dev/blog/circom-comparison/#user-content-fnref-4-ca0b0e)
|
||||
43
articles/p0tion-v10-release.md
Normal file
@@ -0,0 +1,43 @@
|
||||
---
|
||||
authors: ["MACI Team", "Trusted Setup Team", "RLN Team", "Design Team"]
|
||||
title: "p0tion V1.0 Release"
|
||||
image: "cover.webp"
|
||||
tldr: "P0tion was built with love by: MACI, Trusted Setup, RLN, and Design Teams at PSE."
|
||||
date: "2023-08-08"
|
||||
canonical: "https://mirror.xyz/privacy-scaling-explorations.eth/TuLZRdgCQsydC8JJgCNH4F7GzifRBQ6fr31DHGLFVWM"
|
||||
---
|
||||
|
||||
We are excited to unveil p0tion V1, a versatile and comprehensive toolkit designed to streamline Groth16 zk-application development and enable them to become production-ready. The goal is to facilitate Phase 2 Trusted Setup ceremonies for multiple circuits simultaneously, making the entire process more efficient and scalable.
|
||||
|
||||
## **Motivation**
|
||||
|
||||
The Groth16 proving system has gained popularity for its ability to produce small, fast, and cost-effective proofs. However, its lack of universality poses a challenge for production use. Each modification to a circuit necessitates a new Phase 2 Trusted Setup ceremony, adding complexity and time to the process. To address this, Groth16 zk-SNARK circuits require an MPC Trusted Setup ceremony to generate the parameters needed for zkSNARKs-based systems. Creating a protocol for these ceremonies involves considerable time and development resources, including design, auditing, testing, security measures, operational planning, guides, and more. To simplify this process and eliminate the burdens associated with MPC ceremonies, we are proud to introduce p0tion – an all-in-one toolkit that automates the setup, execution, coordination, and finalization of Phase 2 Trusted Setup ceremonies for one or more zkSNARKs circuits.
|
||||
|
||||
[p0tion](https://github.com/privacy-scaling-explorations/p0tion), was originally built by the MACI team to conduct trusted setup ceremonies for large circuits (aka number of constraints), as in [MACI](https://github.com/privacy-scaling-explorations/maci) V1. You may think of p0tion as a toolkit to manage Trusted Setup Phase 2 ceremonies for multiple circuits simultaneously. Its aim is to democratize the process, allowing individuals and teams to easily deploy the infrastructure required to run their ceremonies. Our vision is based on four core values:
|
||||
|
||||
- **Secure Groth16 Circuits in Production**: With p0tion, Circom developers, including the MACI team, can implement continuous delivery of secure Groth16 zkApps within an agile setting. By automating Phase 2 ceremonies, they can ensure the security and efficiency of their applications.
|
||||
- **Easy to Read and Use**: The documentation and code of p0tion are clear, concise, and articulate. Even newcomers to the tool can quickly grasp its functionalities and deploy a ceremony in less than one hour.
|
||||
- **Ready for Change**: Developers can have full confidence in the security of the ceremony tool. Moreover, they can easily fork and adapt the code to suit their own ceremony requirements, fostering flexibility and customization.
|
||||
- **Infrastructure as Code**: p0tion streamlines the entire process for infrastructure setup, coordination, scaling, and ceremony conduction. It provides a black-box approach to simplify the complexity of the underlying operations.
|
||||
|
||||
## **RLN Trusted Setup Ceremony**
|
||||
|
||||
We are happy to announce that p0tion is being used for the RLN (Rate-Limiting Nullifier) zero-knowledge gadget that enables spam prevention. You can find more information on how to help make the protocol more secure at the end of this [blog post](https://mirror.xyz/privacy-scaling-explorations.eth/iCLmH1JVb7fDqp6Mms2NR001m2_n5OOSHsLF2QrxDnQ).
|
||||
|
||||
## **How it works**
|
||||
|
||||
Running a Trusted Setup ceremony with [p0tion](https://github.com/privacy-scaling-explorations/p0tion) is a straightforward process, consisting of three main steps. To access these steps, both coordinators and participants need to authenticate with the CLI using OAuth2.0, with the current version supporting the Github Device Flow authentication mechanism, by simply running the auth command.
|
||||
|
||||
1. **Setup**: The coordinator initiates the ceremony by preparing it interactively or non-interactively using the setup command. This involves providing the output of the circuit compilation as input to the setup command. This command enables coordinators to configure the ceremony based on their needs by providing the data of one or more circuits, selecting timeout mechanisms (fixed/dynamic), whether to use custom ad-hoc EC2 instances for contribution verification or Cloud Functions and so on.
|
||||
2. **Contribution**: During the contribution period, participants authenticate themselves and contribute to the ceremony by providing entropy (referred to as toxic waste) using the CLI via the contribute command. Participants can provide their own entropy or generate it for them.
|
||||
3. **Finalization**: Once the contribution period ends, the coordinator finalizes the ceremony to extract the keys required for proof generation and verification and the Verifier (smart contract), by running the finalize command.
|
||||
|
||||
To guarantee the flexibility and satisfaction of this workflow, the p0tion codebase (v1.x) is designed with modularity in mind, split into three distinct packages: actions, contains key features, types, and helpers forming an agnostic set of ready-to-use functions (SDK), backend for configuration and deployment of the infrastructure, utilizing Firebase Authentication and Cloud Functions, AWS S3 and EC2 instances and, phase2cli a command-line interface which serves coordinators and contributors in Trusted Setup Phase 2 ceremonies, operating with multiple commands on top of the p0tion infrastructure. Additionally, the CLI enables contributors to fully use their machine computing power, allowing contributions on a larger scale compared to ordinary web-browser clients.
|
||||
|
||||
## **How to get involved?**
|
||||
|
||||
We built p0tion as zk-developers, for zk-developers. We’d like to onboard as many zk-SNARK developers as possible to run ceremonies for their circuits, but at the same time, we would love to see the community helping to make this framework even better.
|
||||
|
||||
You could learn more about Trusted Setups ceremonies, coordinating and contributing using p0tion by visiting the [documentation and guidelines](https://p0tion.super.site/) and the [Github Repository](https://github.com/privacy-scaling-explorations/p0tion). Any feedback can be submitted to the [PSE Discord](https://discord.gg/jy3eax25) or opening a [Github Issues](https://github.com/privacy-scaling-explorations/p0tion/issues). Contributors are always welcome! If you are a zk-SNARK developer, either working as an individual or as a team, feel free to reach out to one of our team members. We will be happy to show you how to use p0tion, or potentially setup and host a trusted setup ceremony for your project.
|
||||
|
||||
_This post was written by the MACI team._
|
||||
@@ -0,0 +1,130 @@
|
||||
---
|
||||
authors: ["PSE Team"]
|
||||
title: "Rate Limiting Nullifier: A spam-protection mechanism for anonymous environments"
|
||||
image: null
|
||||
tldr: "In this post we describe a mechanism that can be used to prevent spam in anonymous environments. We provide a technical overview, some examples and use cases. The goal is to get more people excited about the idea and hopefully implement it in practice."
|
||||
date: "2022-08-29"
|
||||
canonical: "https://mirror.xyz/privacy-scaling-explorations.eth/aKjLmLVyunELnGObrzPlbhXWu5lZI9QU-P3OuBK8mOY"
|
||||
---
|
||||
|
||||
Originally published on Aug 30, 2021:
|
||||
|
||||
RLN (Rate limiting nullfier) is a construct based on [zero-knowledge proofs](https://en.wikipedia.org/wiki/Zero-knowledge_proof) that enables spam prevention mechanism for decentralized, anonymous environments. In anonymous environments, the identity of the entities is unknown.
|
||||
|
||||
The anonymity property opens up the possibility for spam attack and sybil attack vectors for certain applications, which could seriously degrade the user experience and the overall functioning of the application. For example, imagine a decentralised voting application where the user identities are anonymous. Without any spam protection mechanism the voting outcomes can be easily manipulated, thus making the application unusable.
|
||||
|
||||
Let’s take a fully anonymous group chat application as another example. Not having a proper spam prevention mechanism enables anyone to pollute the group chats easily. The application would not be able to recognise the spammer and remove them, because the origin of the messages is unknown. For a pseudo-anonymous group chat application, sybil attacks represent a bigger treat. Even if the application can properly remove the spammers, new pseudo-anonymous identities can be spawned easily and pollute the application.
|
||||
|
||||
Thus having a reliable spam detection and prevention mechanism, which enables anonymity is very important.
|
||||
|
||||
The RLN construct prevents sybil attacks by increasing the cost of identity replication. To be able to use an application that leverages the RLN construct and be an active participant, the users must provide a stake first. The stake can be of economic or social form, and it should represent something of high value for the user. The user identity replication will be very costly or impossible in some cases (again depending on the application). Providing a stake does not reveal the user’s identity, it is just a membership permit for application usage, a requirement for the user to participate in the app’s specific activities.
|
||||
|
||||
An example for an economic stake is cryptocurrency such as Ether, and example for social stake is a reputable social media profile.
|
||||
|
||||
Staking also disincentivizes the users to spam, as spamming is contrary to their interest.
|
||||
|
||||
The proof system of the RLN contract enforces revealing the user credentials upon breaking the anti-spam rules. By having the user’s credentials, anyone can remove the user from the application and withdraw their stake. The user credentials are associated with the user’s stake.
|
||||
|
||||
## Technical overview
|
||||
|
||||
The RLN construct’s functionality consists of three parts, which when integrated together provide spam and sybil attack protection. These parts should be integrated by the upstream applications which require anonymity and spam protection. The applications can be centralized or decentralized. For decentralized applications, each user maintains a separate storage and compute resources for the application. The three parts are:
|
||||
|
||||
- user registration
|
||||
- user interactions
|
||||
- user removal
|
||||
|
||||
## User registrations
|
||||
|
||||
Before registering to the application the user needs to generate a secret key and derive an identity commitment from the secret key using the [Poseidon hash function](https://eprint.iacr.org/2019/458.pdf) (_identityCommitment = posseidonHash(secretKey))._
|
||||
|
||||
The user registers to the application by providing a form of stake and their identity commitment, which is derived from the secret key. The application maintains a [Merkle tree](https://en.wikipedia.org/wiki/Merkle_tree) data structure (in the latest iteration of the RLN construct we use the [Incremental Merkle Tree](https://arxiv.org/pdf/2105.06009v1.pdf) algorithm), which stores the identity commitments of the registered users. Upon successful registration the user’s identity commitment is stored in a leaf of the Merkle tree and an index is given to them, representing their position in the tree.
|
||||
|
||||
## User interactions
|
||||
|
||||
For each interaction that the user wants to make with the application, the user must generate a zero-knowledge proof which ensures the other participants (the verifiers) that they are a valid member of the application and their identity commitment is part of the membership Merkle tree.
|
||||
|
||||
The interactions are app specific, such as voting for voting application and message sending for chat applications. The verifier is usually a server for centralized applications, or the other users for decentralized applications.
|
||||
|
||||
Anti-spam rule is also introduced for the protocol. The rule is usually in the form of:
|
||||
|
||||
`Users must not make more than X interactions per epoch`.
|
||||
|
||||
The epoch can be translated as time interval of `Y` units of time unit `Z`. For simplicity sake, let’s transform the rule into:
|
||||
|
||||
`Users must not send more than 1 message per second.`
|
||||
|
||||
The anti-spam rule is implemented using the [Shamir’s Secret Sharing scheme](https://en.wikipedia.org/wiki/Shamir%27s_Secret_Sharing), which enables secret sharing by using polynomials. SSS allows for a secret to be split into multiple shares, from which a minimum number is needed to reconstruct the original secret. This can be also written as: any M of N shares are needed to reliably reconstruct the secret (M, N).
|
||||
|
||||
The minimum number is determined by the polynomial used for the scheme. If the minimum number of shares needed to recover the secret is set to `X` then `X-1` degree polynomial needs to be used.
|
||||
|
||||
In our case the secret is the user’s secret key, and the shares are parts of the secret key.
|
||||
|
||||
To implement the simplified anti-spam rule we can implement a (2,3) SSS scheme using a linear polynomial. This means that the user’s secret key can be reconstructed if they send two messages per epoch.
|
||||
|
||||
For these claims to hold true, the user’s ZK proof must also include shares of their secret key (the X and Y shares) and the epoch. By not having any of these fields included the ZK proof will be treated as invalid.
|
||||
|
||||
For each interaction they make, the users are leaking a portion of their secret key. Thus if they make more interactions than allowed per epoch their secret key can be fully reconstructed by the verifiers.
|
||||
|
||||
## User removal
|
||||
|
||||
The final property of the RLN mechanism is that it allows for the users to be removed from the membership tree by anyone that knows their secret key. The membership tree contains the identity commitments of all registered users. User’s identity commitment is derived from their secret key, and the secret key of the user is only revealed in a spam event (except for the scenarios where the original users wants to remove themselves, which they can always do because they know their secret key). When an economic stake is present, the RLN mechanism can be implemented in a way that the spammer’s stake is sent to the first user that correctly reports the spammer by providing the reconstructed secret key of the spammer as a proof.
|
||||
|
||||
## RLN example
|
||||
|
||||
The following is an example scenario for a decentralised anonymous chat application. The chat application uses a smart contract as a registry which holds the registered users stake and stores a list of registered users. The registry smart contract has only two functions, register and withdrawal, and it also emits events when a new member registers and when a member is slashed. The users maintain RLN membership trees locally, which represent the state of registered users for the application. By “pubKey”, we refer to the user’s identity commitment, and by “privKey” to their secret key.
|
||||
|
||||
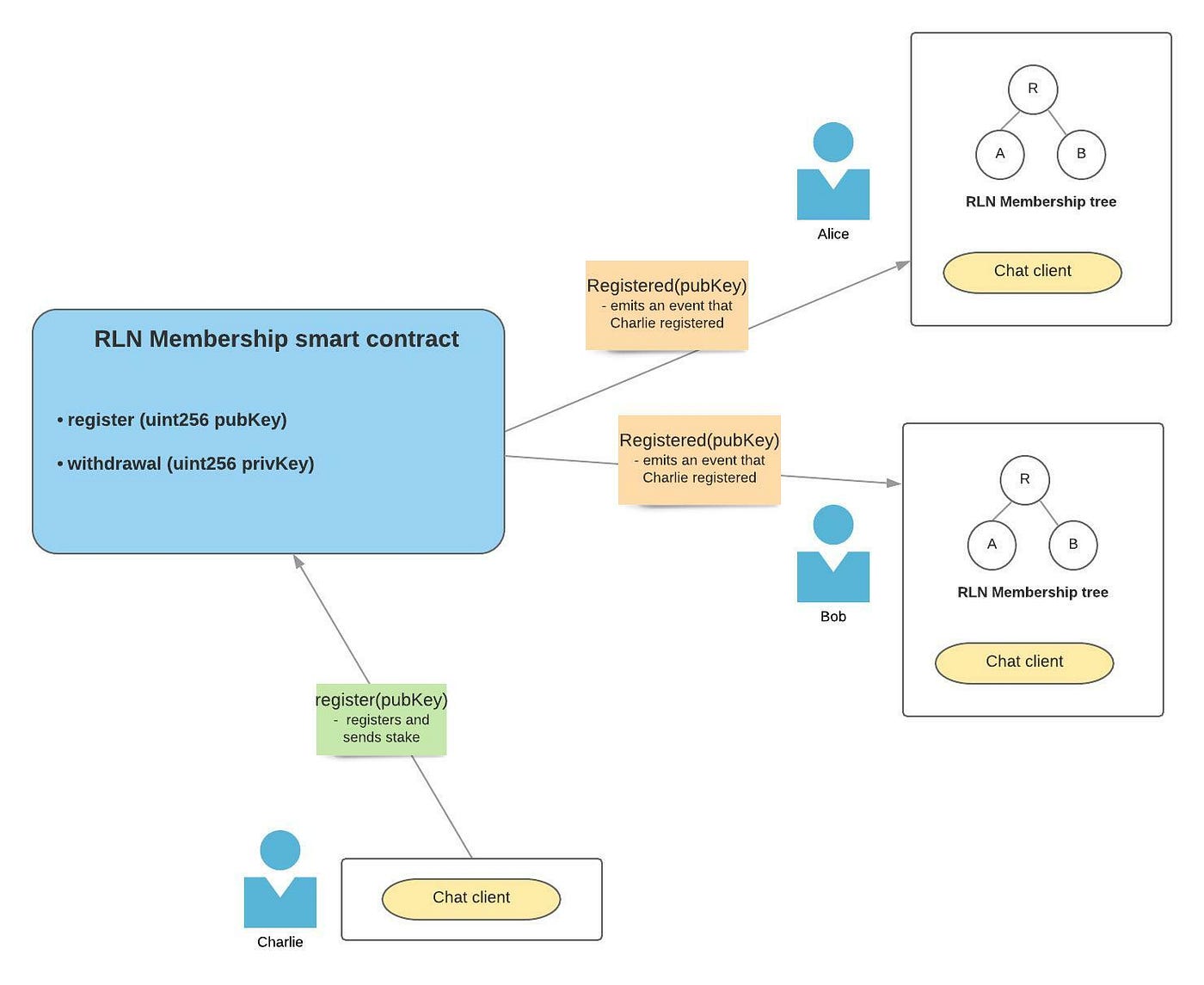
|
||||
|
||||
Step 1: Charlie wants to be an active participants and sends a registration transaction to the smart contract, providing his stake. The smart contract emits event that a new identity commitment was registered and each user should update their RLN membership tree with the newly registered identity commitment.
|
||||
|
||||
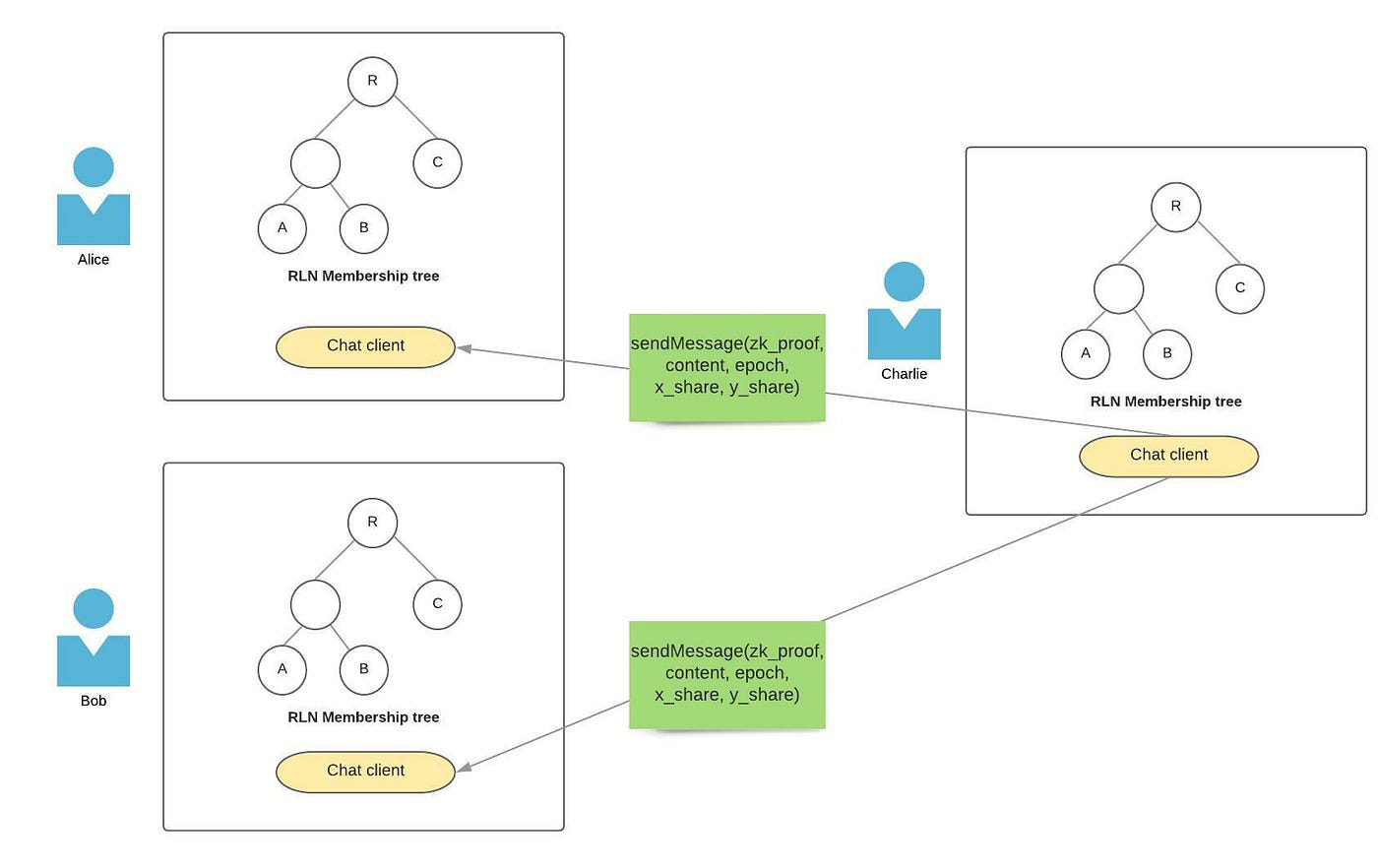
|
||||
|
||||
Step 2: Charlie sends a message in epoch 1 to Alice and Bob, with all of the required parameters and valid ZK proof.
|
||||
|
||||
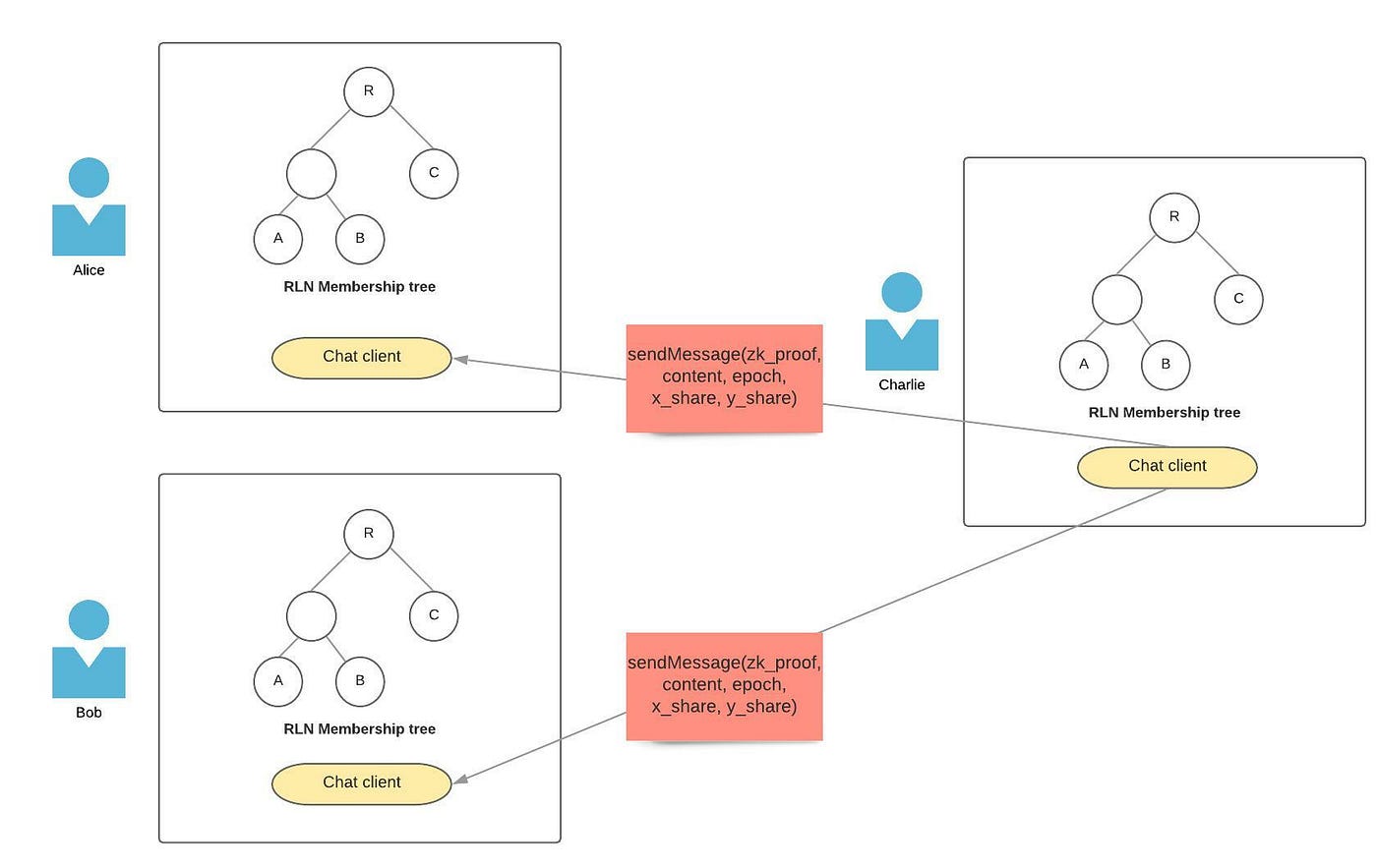
|
||||
|
||||
Step 3: Charlie sends second message in epoch 1 to Alice and Bob. All the message parameters are valid as well as the ZK proof. Charlie violated the anti-spam rules and Alice and Bob can reconstruct Charlie’s secret key and remove him from their RLN membership tree.
|
||||
|
||||
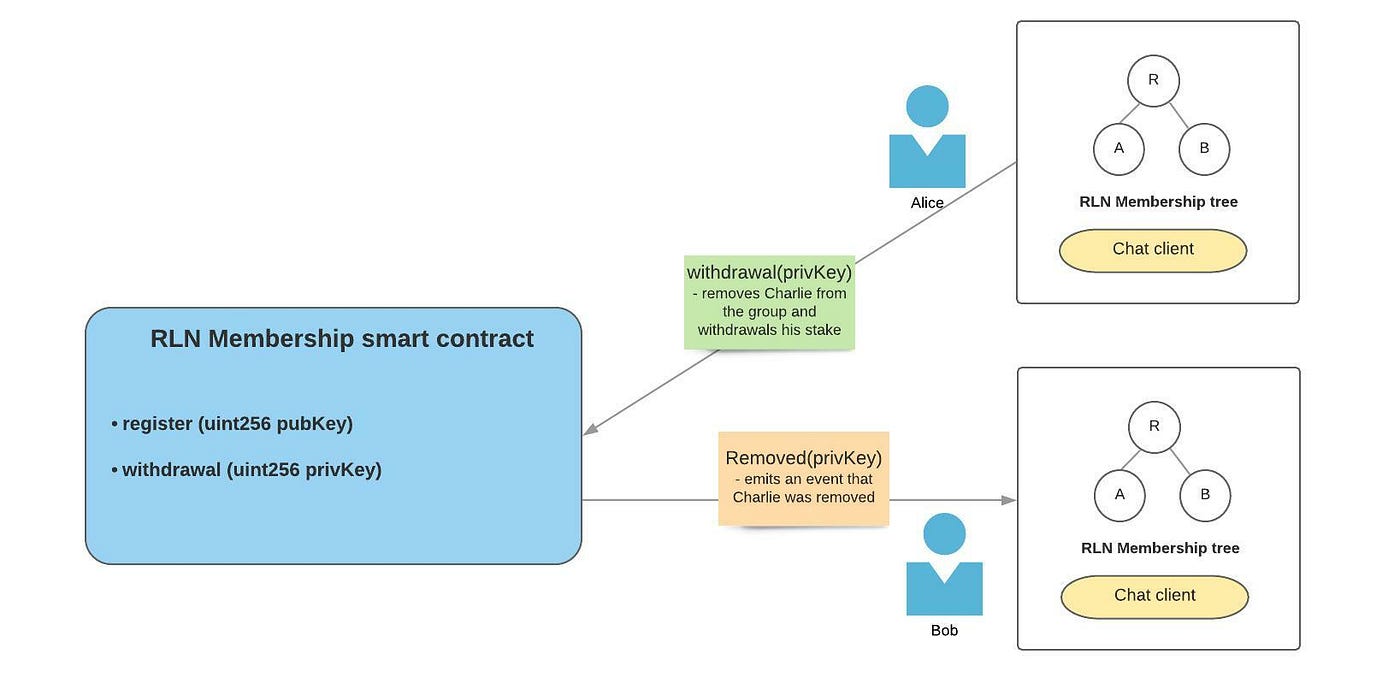
|
||||
|
||||
Step 4: Alice sends withdrawal transaction to the RLN Membership smart contract to withdraw Charlie’s stake. The smart contract emits an event which signals that Charlie is banned from the application and should be flagged as such by all of the users.
|
||||
|
||||
## Use cases
|
||||
|
||||
The RLN construct can be used by broad range of applications which operate in anonymous environments. Essentially every application that enables interactions for users with anonymous identities needs a spam protection by some degree.
|
||||
|
||||
There are many use cases, but we’ve identified few which we think are very interesting for applying the RLN construct and experimenting with it:
|
||||
|
||||
- [Private communication channel for ETH2 validators](https://ethresear.ch/t/private-message-sharing-for-eth2-validators/10664)
|
||||
- Instant messaging applications for private and anonymous communications
|
||||
- [Cloudflare-like service which uses RLN for spam protection (instead of captcha)](https://ethresear.ch/t/decentralised-cloudflare-using-rln-and-rich-user-identities/10774)
|
||||
- Decentralised, anonymous voting applications
|
||||
- Privacy preserving peer to peer networks
|
||||
|
||||
In the upcoming posts that we will publish on [ethresear.ch](https://ethresear.ch/), we will provide detailed overview as well as technical specifications for these ideas.
|
||||
|
||||
## History
|
||||
|
||||
The initial idea and the needs for RLN are described by Barry WhiteHat in [this post.](https://ethresear.ch/t/semaphore-rln-rate-limiting-nullifier-for-spam-prevention-in-anonymous-p2p-setting/5009) The RLN construct was implemented by [Onur Kilic](https://github.com/kilic) which can be found [here](https://github.com/kilic/rln). He also created a [demo application](https://github.com/kilic/rlnapp) using the RLN construct.
|
||||
|
||||
[The Vac research team](https://vac.dev/) has been heavily experimenting with the RLN construct. Their plan is to use it in production for [Waku v2](https://vac.dev/waku-v2-plan) which is a privacy-preserving peer-to-peer messaging protocol for resource restricted devices.
|
||||
|
||||
## Additional resources
|
||||
|
||||
The RLN construct specification — [https://hackmd.io/@aeAuSD7mSCKofwwx445eAQ/BJcfDByNF](https://hackmd.io/@aeAuSD7mSCKofwwx445eAQ/BJcfDByNF)
|
||||
|
||||
The updated RLN circuits — [https://github.com/appliedzkp/rln](https://github.com/appliedzkp/rln)
|
||||
|
||||
A great post about why RLN is important and how it can solve the spam attack problems for Waku v2 — [https://vac.dev/rln-relay](https://vac.dev/rln-relay).
|
||||
|
||||
Video by Barry Whitehat explaining the needs for spam protection and also the RLN construct and some potential application — [https://www.youtube.com/watch?v=cfx1udF7IJI](https://www.youtube.com/watch?v=cfx1udF7IJI).
|
||||
|
||||
Thoughts on DoS protection and spam related problems for the Status chat application — [https://discuss.status.im/t/longer-form-thoughts-on-dos-spam-prevention/1973](https://discuss.status.im/t/longer-form-thoughts-on-dos-spam-prevention/1973)
|
||||
|
||||
RLN incentives for p2p networks — [https://ethresear.ch/t/rln-incentives-for-p2p-networks/8085](https://ethresear.ch/t/rln-incentives-for-p2p-networks/8085)
|
||||
|
||||
Tutorial and PoC application on how to use RLN in practice — [https://github.com/bdim1/rln-anonymous-chat-app](https://github.com/bdim1/rln-anonymous-chat-app)
|
||||
|
||||
## Call to action
|
||||
|
||||
We are actively searching for developers to implement RLN. If you are interested reach out in our [Telegram channel](https://t.me/joinchat/Le3cTB0izAjf1jzHyJfeOg).
|
||||
199
articles/rate-limiting-nullifier-rln.md
Normal file
@@ -0,0 +1,199 @@
|
||||
---
|
||||
authors: ["curryrasul"]
|
||||
title: "Rate-Limiting Nullifier (RLN)"
|
||||
image: "cover.webp"
|
||||
tldr: "This post was authored by [@curryrasul](https://twitter.com/curryrasul)."
|
||||
date: "2023-08-01"
|
||||
canonical: "https://mirror.xyz/privacy-scaling-explorations.eth/iCLmH1JVb7fDqp6Mms2NR001m2_n5OOSHsLF2QrxDnQ"
|
||||
---
|
||||
|
||||
We’re pleased to announce the “production-ready” release of **[Rate-Limiting Nullifier](https://github.com/Rate-Limiting-Nullifier)** (RLN) protocol.
|
||||
|
||||
## **What’s RLN?**
|
||||
|
||||
Developing zero-knowledge protocols (such as [Semaphore](https://semaphore.appliedzkp.org/)) allows us to create truly anonymous apps. But anonymous environments allow spammers to act with impunity because they are impossible to find.
|
||||
|
||||
RLN is a zero-knowledge gadget that enables spam prevention. It is a solution to this problem.
|
||||
|
||||
Even though spam prevention is the primary use case for RLN, it can also be used for any rate-limiting in anonymous systems (for example, limit-bid anonymous auctions, voting, etc.).
|
||||
|
||||
## **How does it work?**
|
||||
|
||||
Let’s start by diving a bit into the [Semaphore](https://semaphore.appliedzkp.org/) protocol. Semaphore allows users to prove membership in a group without revealing their individual identities. The system uses zk-proofs of inclusion or “membership” in a [Merkle tree](https://en.wikipedia.org/wiki/Merkle_tree): users have to generate zk-proofs that they know some secret value that’s in the Merkle tree.
|
||||
|
||||
If users decide to spam, we cannot just ban them by their IP or blockchain address, because they still will be able to generate proofs of inclusion, and therefore use the system.
|
||||
|
||||
The only thing we can do is remove spammers from the “membership” Merkle tree. We need _a mechanism_ that will reveal the user’s identity if they spam, so we can remove them.
|
||||
|
||||
But since spammers can just re-register and spam again, we also need an economic mechanism to deter them from spamming again. For that, we require users to stake some amount of money (RLN contract receives ERC-20 tokens) to register in the RLN system.
|
||||
|
||||
It’s possible to remove yourself from the app and get back your stake by making a zk-proof of the secret, **but** if you spam, someone else will be able to withdraw your stake before you.
|
||||
|
||||
The mechanism we need is **Shamir’s Secret Sharing (SSS)**.
|
||||
|
||||
What’s the SSS scheme? It’s a scheme that can split a value into `N` parts and recover it using `K` parts where `K <= N`. You can learn more by reading [our explanation here](https://rate-limiting-nullifier.github.io/rln-docs/sss.html).
|
||||
|
||||
That mechanism allows us to construct the rule: if users overuse the system and exceed the limit, their secret key can be immediately recovered by anyone and therefore they’ll lose the stake (this process is also called “slashing”).
|
||||
|
||||
---
|
||||
|
||||
Now, knowing how RLN works on a high level, we can dive a bit deeper.
|
||||
|
||||
The **RLN** protocol consists of three parts:
|
||||
|
||||
- registration;
|
||||
- interaction (signaling);
|
||||
- removal/withdrawal (or slashing).
|
||||
|
||||
Let’s discuss these parts in detail.
|
||||
|
||||
### **Registration**
|
||||
|
||||
The first part of **RLN** is registration. To register in the system users must submit an `identityCommitment` and place it in the Merkle Tree.
|
||||
|
||||
Users generate random secret key value _\-_ `a₀`. Identity commitment is the Poseidon hash of the secret key:
|
||||
|
||||
`identityCommitment = Poseidon(a₀)`
|
||||
|
||||
### **Signaling**
|
||||
|
||||
Now that users are registered, they can interact with the system. Imagine that the system is an _anonymous chat_ and the interaction is a sending of messages.
|
||||
|
||||
The SSS scheme used in the RLN protocol means users implicitly “own” their polynomial, that contains their secret key in it. We use linear polynomial
|
||||
`f(x) = kx + b`
|
||||
|
||||
To send a message, users need to generate a zk-proof of membership in the Merkle tree and that a _share_ = `(x,y)` from their polynomial is valid.
|
||||
|
||||
We denote:
|
||||
|
||||
`x = Poseidon(message)`
|
||||
|
||||
`y = A(x)`
|
||||
|
||||
As the first-degree polynomial is used, having two shares is enough to recover it and a secret key. It’s important to remember that anyone who has user’s secret key, can remove them from the system and take their stake.
|
||||
|
||||
#### **Range check trick and resulting polynomial**
|
||||
|
||||
We use first-degree polynomial for simplicity of the protocol and circuits. But limiting the system to only one message is really undesirable, because we want to have higher rate-limits. What we can do is use polynomial of higher degree, but this makes the protocol more complex. Instead, we can do a clever trick: introduce an additional circuit input: `messageId`, that will serve as a counter.
|
||||
|
||||
Let’s say we make `messageLimit = n`. Then for each message we send, we also need an additional input `messageId`. This value will be range checked to show it is less than `messageLimit` (to be more precise: `0 ≤ messageId < messageLimit`.
|
||||
|
||||
And our polynomial will depend on this input as well, so that for each message - different `messageId` will be used, therefore the resulting polynomials will be different.
|
||||
|
||||
Our polynomial will be:
|
||||
|
||||
`A(x) = a₁ ∗ x + a₀`
|
||||
|
||||
`a₁ = Poseidon(a₀, externalNullifier, messageId)`
|
||||
|
||||
The general anti-spam rule is in the form of: users must not make more than X interactions per epoch. The epoch can be translated as just a time interval.
|
||||
|
||||
`externalNullifier` value is a public parameter that denotes the epoch. More formally:
|
||||
|
||||
`externalNullifier = Poseidon(epoch, rlnIidentifier)`
|
||||
|
||||
where `rlnIdentifier` is a random finite field value, unique per RLN app.
|
||||
|
||||
`rlnIdentifier` value is used as a “salt” parameter. Without that salt, using the same secret key in different RLN apps with the same epoch value will lead to unintentional sharing of different points from their polynomial, which means it will be possible to recover a user’s secret key even if they did not spam.
|
||||
|
||||
#### **Different rate-limits for different users**
|
||||
|
||||
It also may be desired to have different rate-limits for different users, for example based on their stake amount. We can achieve that by calculating `userMessageLimit` value and then deriving `rateCommitment:`
|
||||
|
||||
`rateCommitment = Poseidon(identityCommitment, userMessageLimit)` during the registration phase.
|
||||
|
||||
And it’s the `rateCommitment` values that are stored in the membership Merkle tree.
|
||||
|
||||
Therefore, in the circuit users will have to prove that the:
|
||||
`identityCommitment = Poseidon(identitySecret)`
|
||||
|
||||
`rateCommitment = Poseidon(identityCommitment,userMessageLimit)`
|
||||
|
||||
`0 ≤ messageId < userMessageLimit`
|
||||
|
||||
We use the scheme with `userMessageLimit` as it’s more general, though it is not necessary to have different rate-limits for different users. We can enforce users to have the same rate-limit during the registration.
|
||||
|
||||
### **Slashing**
|
||||
|
||||
Recall how RLN works: if a user sends more than one message, everyone else will be able to recover their secret, slash them and take their stake.
|
||||
|
||||
Now, imagine there are a lot of users sending messages, and after each received message, we need to check if any member should be slashed. To do this, we can use all combinations of received shares and try to recover the polynomial, but this is a naive and non-optimal approach. Suppose we have a mechanism that will tell us about the connection between a person and their messages while not revealing their identity. In that case, we can solve this without brute-forcing all possibilities by making users also send the `nullifier = Poseidon(a₁)`\- so if a user sends more than one message, it will be immediately visible to everyone. Validity of `nullifier` value is also checked with zkp.
|
||||
|
||||
Based on `nullifier` we can find the spammer and use SSS recovery, using their shares.
|
||||
|
||||
---
|
||||
|
||||
The current version of RLN consists of:
|
||||
|
||||
- [RLN circuits in circom](https://github.com/Rate-Limiting-Nullifier/circom-rln);
|
||||
- [registry smart-contract](https://github.com/Rate-Limiting-Nullifier/rln-contract);
|
||||
- dev libraries ([rlnjs](https://github.com/Rate-Limiting-Nullifier/rlnjs), [zerokit](https://github.com/vacp2p/zerokit)).
|
||||
|
||||
The Vac team also works on RLN (especially Waku) and collaborates with us on the [CLI app](https://github.com/vacp2p/zerokit/tree/master/rln-cli) that can be used to easily work with Zerokit library and use the RLN API.
|
||||
|
||||
Circuits were audited by **Veridise**. Their audit also included formal verification of the protocol. In addition, they were also audited during the **yAcademy fellowhship**. In general, there were no critical bugs found in the circuits. All other findings of the auditors were taken into account and fixed.
|
||||
|
||||
---
|
||||
|
||||
Even though the circuits are simple and zk-proofs for RLN can be generated fast (~1s using snarkjs), in some use cases, such as validator privacy, Tor anti-spam it’s still considered slow. That’s why our team is working on newer RLN versions, such as [KZG-RLN](https://zkresear.ch/t/rln-on-kzg-polynomial-commitment-scheme-cross-posted/114), that will allow us to generate RLN proofs faster.
|
||||
|
||||
## **RLN trusted setup ceremony**
|
||||
|
||||
RLN is powered by the Groth16 proof system, which requires trusted setup.
|
||||
|
||||
We are pleased to invite you to join our **RLN trusted setup ceremony**. The ceremony includes trusted setup for the RLN circuits with different parameters (such as the depth of membership Merkle tree). The [p0tion](https://p0tion.super.site/) tool is used for the trusted setup ceremony coordination.
|
||||
|
||||
**Instruction**:
|
||||
|
||||
1\. To install p0tion trusted setup tool:
|
||||
|
||||
```
|
||||
npm install -g @p0tion/phase2cli -f
|
||||
```
|
||||
|
||||
2\. If you used p0tion before, then you need to logout first:
|
||||
|
||||
```
|
||||
phase2cli logout
|
||||
```
|
||||
|
||||
3\. After that you need to auth with GitHub:
|
||||
|
||||
```
|
||||
phase2cli auth
|
||||
```
|
||||
|
||||
4\. Finally, to join the ceremony:
|
||||
|
||||
```
|
||||
phase2cli contribute --ceremony rln-trusted-setup-ceremony
|
||||
```
|
||||
|
||||
or if you want to enter your entropy manually:
|
||||
|
||||
```
|
||||
phase2cli contribute --ceremony rln-trusted-setup-ceremony --entropy <YOUR_ENTROPY>
|
||||
```
|
||||
|
||||
To participate, you need to have at least 5 following, 1 follower and 1 public repo on GitHub.
|
||||
|
||||
If you want to learn more on trusted setups, you may be interested in these posts:
|
||||
|
||||
- [How do trusted setups work?](https://vitalik.ca/general/2022/03/14/trustedsetup.html)
|
||||
- [Learnings from the KZG Ceremony](https://mirror.xyz/privacy-scaling-explorations.eth/naTdx-u7kyirczTLSAnWwH6ZdedfTQu1yCWQj1m_n-E)
|
||||
|
||||
## **How to get involved?**
|
||||
|
||||
Should you wish to get involved with RLN or report a bug, feel free to visit repositories in our [GitHub organization](https://github.com/Rate-Limiting-Nullifier) and open an issue or comment under an open issue to notify the team!
|
||||
|
||||
You can also help us with [KZG-RLN](https://github.com/Rate-Limiting-Nullifier/kzg-rln) development.
|
||||
|
||||
## **Useful references**
|
||||
|
||||
- [Documentation](https://rate-limiting-nullifier.github.io/rln-docs/);
|
||||
- [circom-rln](https://github.com/Rate-Limiting-Nullifier/circom-rln);
|
||||
- [smart-contract](https://github.com/Rate-Limiting-Nullifier/rln-contract);
|
||||
- [rlnjs](https://github.com/Rate-Limiting-Nullifier/rlnjs);
|
||||
- [GitHub organization](https://github.com/Rate-Limiting-Nullifier);
|
||||
- [kzg-rln](https://github.com/Rate-Limiting-Nullifier/kzg-rln);
|
||||
- [first proposal/idea of RLN by Barry WhiteHat](https://ethresear.ch/t/semaphore-rln-rate-limiting-nullifier-for-spam-prevention-in-anonymous-p2p-setting/5009).
|
||||
@@ -0,0 +1,104 @@
|
||||
---
|
||||
authors: ["PSE Team"]
|
||||
title: "Release Announcement: MACI 1.0 - Privacy & Scaling Explorations"
|
||||
image: null
|
||||
tldr: ""
|
||||
date: "2022-08-29"
|
||||
canonical: "https://mirror.xyz/privacy-scaling-explorations.eth/V0QkCAtsYUd5y7RO7L5OAwmawhY9LTJ7jlOZ4KW1J7M"
|
||||
---
|
||||
|
||||

|
||||
|
||||
Originally published on Oct 12, 2021:
|
||||
|
||||
The Privacy & Scaling Explorations team is proud to release version 1.0 of Minimal Anti-Collusion Infrastructure (MACI). MACI enables collusion resistance for decentralised applications, particularly voting and quadratic funding systems. This release is a major upgrade to the project and provides better developer experience and gas savings for users.
|
||||
|
||||
The code is in the `v1` branch of the `appliedzkp/maci`repository and will be merged soon.
|
||||
|
||||
MACI 1.0 was audited by [Hashcloak](https://hashcloak.com/). All vulnerabilities found have been fixed. The audit report can be found [here](https://github.com/appliedzkp/maci/blob/v1/audit/20210922%20Hashcloak%20audit%20report.pdf). We would like to thank our highly professional and responsive auditors for surfacing these issues and providing clear feedback for addressing them.
|
||||
|
||||
## About MACI
|
||||
|
||||
MACI is a set of smart contracts and zero-knowledge circuits upon which which developers can build collusion-resistant applications, such as voting systems or quadratic funding platforms. MACI per se is not a user-facing application. Rather, developers may build applications on top of it. In turn, such applications can benefit from the following properties:
|
||||
|
||||
Comment
|
||||
|
||||
- **Collusion resistance**: no-one, except a trusted coordinator, can be convinced of the validity of a vote, reducing the effectiveness of bribery.
|
||||
- **Receipt-freeness**: a voter cannot prove, besides to the coordinator, which way they voted.
|
||||
- **Privacy**: no-one, except a trusted coordinator, should be able to decrypt a vote.
|
||||
- **Uncensorability**: no-one, not even the trusted coordinator, should be able to censor a vote.
|
||||
- **Unforgeability**: only the owner of a user’s private key may cast a vote tied to its corresponding public key.
|
||||
- **Non-repudiation**: no-one may modify or delete a vote after it is cast, although a user may cast another vote to nullify it.
|
||||
- **Correct execution**: no-one, not even the trusted coordinator, should be able to produce a false tally of votes.
|
||||
|
||||
Practically speaking, MACI provides a set of Typescript packages, Ethereum smart contracts and zero-knowledge circuits. It inherits security and uncensorability from the underlying Ethereum blockchain, ensures unforgeability via asymmetric encryption, and achieves collusion resistance, privacy, and correct execution via [zk-SNARKs](https://docs.ethhub.io/ethereum-roadmap/privacy/).
|
||||
|
||||
**Please note that MACI does not and will not have a token. In other words, it does not represent an investment opportunity.**
|
||||
|
||||
## MACI’s history
|
||||
|
||||
MACI stems from an [ethresear.ch post by Vitalik Buterin](https://ethresear.ch/t/minimal-anti-collusion-infrastructure/5413?u=weijiekoh). Subsequently, the initial codebase was written in late 2019 and early 2020 by grantees with the Ethereum Foundation, namely [Kendrick Tan](https://twitter.com/kendrick_tn), [Koh Wei Jie](https://kohweijie.com/), and [Chih-Cheng Liang](https://twitter.com/chihchengliang). MACI then saw developer adoption at ETHDenver in February 2020, where [Auryn Macmillan](https://twitter.com/auryn_macmillan) and others started work on [clr.fund](https://clr.fund/), a protocol for the Ethereum community to allocate funds for Ethereum-based public goods.
|
||||
|
||||
After the event, we continued to work with clr.fund to improve MACI and integrate it with their application. clr.fund has completed seven rounds of public goods funding, the last of which saw more than US$6000 worth of contributions. At the time of writing, it is currently running an [eighth round](https://clr.fund/#/round/0xd07AA7FAeBA14EFde87f2538699C0D6C9a566C20) with more than US$20k in contributions.
|
||||
|
||||
Work on version 1.0 started in late 2020 with the goal of reducing the gas and computational requirements, as well as to improve its flexibility and usability, without compromising any of its anti-collusion, security, and trust guarantees. We also took this opportunity to keep up with new techniques, ideas, and tooling from the rapidly advancing Ethereum and zero-knowledge ecosystem.
|
||||
|
||||
Finally, in early 2021 we were very fortunate to bring on [Cory Dickson](http://corydickson.com/) to the team. His work on writing documentation, revamping MACI’s integration test suites, working with our auditors to fix bugs, and collaborating with external teams has been invaluable to the project.
|
||||
|
||||
## Why is MACI important?
|
||||
|
||||
It is very difficult for naive voting systems, particularly those which are integrated into smart contract platforms, to prevent collusion. For instance, if a simple Ethereum transaction represents a vote, a briber can easily examine its calldata, tell how its sender voted, and reward or punish them accordingly.
|
||||
|
||||
More broadly, collusion resistance is particulary important for cryptoeconomic systems. Vitalik Buterin describes the motivations behind MACI in _[On Collusion](https://vitalik.ca/general/2019/04/03/collusion.html)_. He argues that systems that use cryptoeconomic incentive mechanisms to align participants’ behaviour can be vulnerable to collusion attacks, such as bribery. In [another post](https://vitalik.ca/general/2021/05/25/voting2.html), he elaborates:
|
||||
|
||||
> _if you can prove how you voted, selling your vote becomes very easy. Provability of votes would also enable forms of coercion where the coercer demands to see some kind of proof of voting for their preferred candidate._
|
||||
|
||||
To illustrate this point, consider an alleged example of collusion that [occurred in round 6 of Gitcoin grants](https://gitcoin.co/blog/how-to-attack-and-defend-quadratic-funding/) (a platform for quadratic funding software projects which contribute to public goods). In _[How to Attack and Defend Quadratic Funding](https://gitcoin.co/blog/how-to-attack-and-defend-quadratic-funding/)_, an author from Gitcoin highlights a tweet by a potential grant beneficiary appeared to offer 0.01 ETH in exchange for matching funds:
|
||||
|
||||
|
||||
|
||||
They explain the nature of this scheme:
|
||||
|
||||
> _While creating fake accounts to attract matching funds can be prevented by sybil resistant design, **colluders can easily up their game by coordinating a group of real accounts to “mine Gitcoin matching funds” and split the “interest” among the group**._
|
||||
|
||||
Finally, MACI is important because as crypto communities are increasingly adopting Decentralised Autonomous Organisations (DAOs) which [govern through token voting](https://vitalik.ca/general/2021/08/16/voting3.html). The threat of bribery attacks and other forms of collusion will only increase if left unchecked, since such attacks target a fundamental vulnerability of such systems.
|
||||
|
||||
## What’s new?
|
||||
|
||||
In this release, we rearchitected MACI’s smart contracts to allow for greater flexiblity and separation of concerns. In particular, we support multiple polls within a single instance of MACI. This allows the coordinator to run and tally many elections either subsequently or concurrently.
|
||||
|
||||
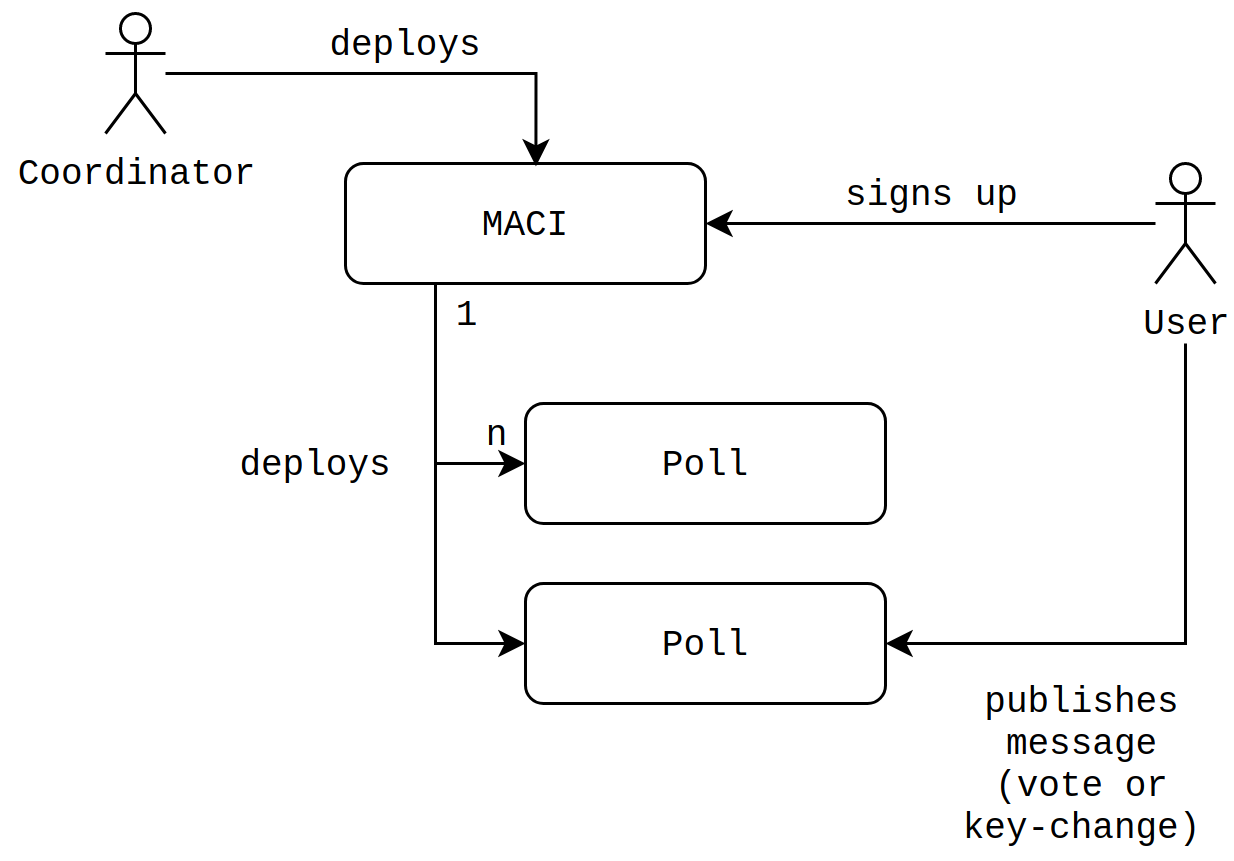
|
||||
|
||||
We’ve kept the ability for developers to provide their own set of logic to gate-keep signups. For instance, application developers can write custom logic that only allows addresses which own a certain token to sign up once to MACI in order to participate in polls.
|
||||
|
||||
An additional upgrade we have implemented is greater capacity for signups, votes, and vote options. With MACI 1.0, a coordinator can run a round that supports more users, votes, and choices than before, even with the same hardware.
|
||||
|
||||
We adopted iden3’s tools for [faster proof generation](https://github.com/iden3/rapidsnark). Furthermore, we rewrote our zk-SNARK circuits using the latest versions of [snarkjs](https://github.com/iden3/snarkjs), [circom](https://github.com/iden3/circom), and [circomlib](https://github.com/iden3/circomlib). We also developed additional developer tooling such as [circom-helper](https://github.com/weijiekoh/circom-helper) and [zkey-manager](https://github.com/appliedzkp/zkey-manager).
|
||||
|
||||
Finally, we significantly reduced gas costs borne by users by replacing our incremental Merkle tree contracts with a modified [deposit queue mechanism](https://ethresear.ch/t/batch-deposits-for-op-zk-rollup-mixers-maci/6883). While this new mechanism achieves the same outcome, it shifts some gas costs from users to the coordinator. A comparison of approximate gas costs for user-executed operations is as follows:
|
||||
|
||||
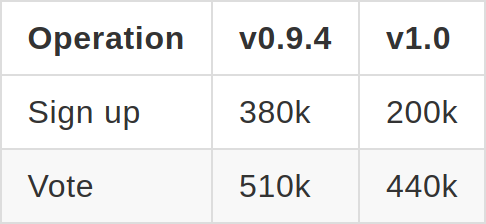
|
||||
|
||||
Finally, we are looking forward to collaborating with other projects and supporting their development of client applications and new use cases. For instance, clr.fund team has indicated that they would like to upgrade their stack to MACI v1.0, and other projects have expressed interest in adopting MACI. We hope that through collaboration, the Ethereum community can benefit from our work, and vice versa.
|
||||
|
||||
## Further work
|
||||
|
||||
There is plenty of space for MACI to grow and we welcome new ideas. We are keen to work with developers who wish to do interesting and impactful work, especially folks who would like to learn how to build applications with zk-SNARKs and Ethereum.
|
||||
|
||||
## Negative voting
|
||||
|
||||
We thank [Samuel Gosling](https://twitter.com/xGozzy) for completing a grant for work on [negative voting](https://github.com/appliedzkp/maci/pull/283). This allows voters to use their voice credits to not only signal approval of a vote option, but also disapproval. Please note that the negative voting branch, while complete, is currently unaudited and therefore not yet merged into the main MACI codebase.
|
||||
|
||||
## Anonymisation
|
||||
|
||||
A [suggested upgrade to MACI is to use ElGamal re-randomisation for anonymity of voters](https://ethresear.ch/t/maci-anonymization-using-rerandomizable-encryption/7054). While all votes are encrypted, currently the coordinator is able to decrypt and read them. With re-randomisation, the coordinator would not be able to tell which user took which action.
|
||||
|
||||
We are working on tooling that makes it easier for coordinators to interface with deployed contracts and manage tallies for multiple polls. This will allow users to generate proofs and query inputs and outputs from existing circuits through an easy-to-use API. We hope that this will drive more adoption of MACI and offload the need for bespoke infrastructure.
|
||||
|
||||
## Trusted setup
|
||||
|
||||
Unlike other ZKP projects, MACI does not have an official [trusted setup](https://zeroknowledge.fm/133-2/). Instead, we hope to assist teams implementing MACI in their applications to run their own trusted setup. For instance, [clr.fund recently completed a trusted setup](https://blog.clr.fund/trusted-setup-completed/) (on a previous version of MACI) for a specific set of circuit parameters. Other teams may wish to use a different set of parameters on MACI 1.0, which calls for a different trusted setup.
|
||||
|
||||
## Conclusion
|
||||
|
||||
This release marks a step towards the hard problem of preventing collusion in decentralised voting and quadratic funding systems. We are excited to share our work and please get in touch if you are a developer and are interested in getting involved in any way.
|
||||
104
articles/retrospective-summa.md
Normal file
@@ -0,0 +1,104 @@
|
||||
---
|
||||
authors: ["Summa Team"]
|
||||
title: "Retrospective: Summa"
|
||||
image: "cover.webp"
|
||||
tldr: "This post was authored by the Summa team."
|
||||
date: "2025-02-10"
|
||||
canonical: "https://mirror.xyz/privacy-scaling-explorations.eth/HRlshQwWxo66EMt3lwk6PSuDkitJCr_-ltCETZHNeu0"
|
||||
---
|
||||
|
||||
### History and Goals of the project
|
||||
|
||||
The Summa project began in March of 2023 in response to the collapse of FTX months prior. It aimed to solve an issue that has plagued centralized exchanges since the Mt Gox collapse in 2013; how can users be assured that the funds they entrust to the exchange are going to be available when they choose to withdrawal them?
|
||||
|
||||
The goal was to create software that helps centralized exchanges (CEX’s) provide _auditor-less_ and _private_ Proof of Reserves\* with instant finality to their users. The project aimed to provide custodial services with tools that allowed more accountable to their users, with minimal additional overhead, while at the same time protecting user privacy. The vision was for frequent audits of a custodian’s reserves possible on the scale of millions of users.
|
||||
|
||||
\*_Note that in general, while the terms “Proof of Reserves” and “Proof of Solvency” are used interchangeably throughout documentation and references, we use the term “Proof of Reserves” in this post exclusively._
|
||||
|
||||
### Notable contributors
|
||||
|
||||
- Enrico, Jin, Alex
|
||||
- Nam as consultant
|
||||
|
||||
### Technical Approach
|
||||
|
||||
While the overall technical goal was to optimise both the _time_ and _cost_ for generating a liabilities commitment, each version of Summa had a slightly different approach:
|
||||
|
||||
- In Summa **Version 1**, Halo2 circuits were used for the proving system, with the verifier and prover written to an onchain smart contract on the Ethereum network. The proofs were then managed via a merkle tree. You can read more about Summa Version 1 in the documentation [here](https://summa.gitbook.io/summa/1).
|
||||
- Summa **Version 2** used the same basic tech stack as version 1, but replaced the merkle tree with the use of univariate sumcheck protocol. This version also made some custom modifications to the Halo2 zero knowledge prover. You can read more about Summa Version 2 in the [official documentation](https://summa.gitbook.io/summa) and technical reports: [Summa V2: Polynomial Interpolation Approach](https://hackmd.io/Rh8_F4blTTGmuJSmmUIB3g) and [Summa 2.0 aka SNARKless Proof Of Solvency for CEX](https://hackmd.io/@summa/r18MaCK7p)
|
||||
- Summa **Version 3** is made up of three different iterations using HyperPlonk, each with distinct tradeoffs. You can learn more about each iteration in [this report](https://hackmd.io/khqyQzoiQ32UjkJd7fegnw).
|
||||
|
||||
You can learn more about the differences between the three versions, including benchmarking, [here.](https://hackmd.io/wt4NkeUWSWi2ym6DNcsT-Q)
|
||||
|
||||
### Achievements
|
||||
|
||||
Ultimately what the team successfully built was the core infrastructure of a cryptographically provable Proof of Reserves (PoR) system that addresses scalability where many other PoR systems fall short. While many additional components of a comprehensive PoR system aren’t addressed by this work (addressed further down), there is a significant foundation to build on from here.
|
||||
|
||||
In short, this system operates as follows:
|
||||
|
||||
- The Custodian verifies their onchain liabilities (customer deposits) by committing a batch of signatures from their addresses to a smart contract.
|
||||
- The Custodian then generates a liabilities commitment, which represents the sum of all user account balances on their platform.
|
||||
- To ensure all account balances were accounted for in the liabilities commitment, the custodian generates and supplies zero knowledge inclusion proofs to each of its customers, who can then independently verify that their individual balance was included.
|
||||
|
||||
The following are some of the breakthroughs the team made throughout the life of the project:
|
||||
|
||||
- **Summa Version 1** made improvements over previous PoR systems by including the verifier directly in the contract. This increased the transparency of the verifying contract, ensuring that users were using one standard verifier when verifying their inclusion proofs, and also improved UX and security by reducing the need to run additional local software.
|
||||
- **Summa Version 2**
|
||||
|
||||
- Offered a novel alternative to merkle trees via the use of the univariate sumcheck protocol, which provided a significant improvement of commitment performance. This was achieved through the development of a more optimised and readable solidity KZG verifier to handle using using univariate polynomials in a smart contract.
|
||||
- Used a technique called [Amortized KZG](https://hackmd.io/@summa/HJ-dtmNdT), developed by another team within PSE, to enable batch proofing. This allowed for the verification of customer groups numbering fewer than approximately 10 million, effectively thwarting a profiling attack for groups of this size.
|
||||
|
||||
- **Summa Version 3** showed a significant improvement over v1 and v2 when it came to generating inclusion proof performance. A benchmark comparison can be seen [here](https://hackmd.io/wt4NkeUWSWi2ym6DNcsT-Q#Performance-Comparison-by-Summa-versions).
|
||||
- Additionally, the team published this [vulnerability report on Binance’s Proof of Reserves system](https://hackmd.io/@summa/HygFa2eek0).
|
||||
|
||||
## Challenges and Learnings
|
||||
|
||||
### Technical Challenges
|
||||
|
||||
Implementing robust Proof of Reserve systems presents significant technical challenges that extend far beyond simple data verification. It’s imperative to consider things such as performance tradeoffs, security vulnerabilities, attack vectors and scalability limitations. Intention must be given to carefully balance commitment times, proof generation efficiency, and protection against potential profiling attacks; all while maintaining the core goal of creating a transparent, verifiable system that can demonstrate cryptocurrency custodial holdings without compromising user privacy or introducing systemic risks.
|
||||
|
||||
The following are technical challenges the team faced throughout the development process:
|
||||
|
||||
- The team was not able to create a system that is cryptographically provable from beginning to end. The address ownership proof is optimistically verifiable, and there is no recourse for customers if their proof does end up being invalid.
|
||||
- In general, any improvement of the commitment time introduced performance tradeoffs by increasing the inclusion proof time, and vice versa.
|
||||
- Discrete Fourier transform (DFT) presented a scalability bottleneck in v2 when using univariate sumcheck protocol. This inspired the exploration of hyperplonk in v3 to try to mitigate that bottleneck, which ultimately led to a regression.
|
||||
- In v3 it was no longer possible to use the KZG verifier in the smart contract due to the lack of a hyperplonk verifier written in solidity, and we reverted to the use of additional software for verification. This unfortunately negated the improvements introduced in Version 1 and 2 of having the verifier placed in the contract.
|
||||
- V3 also introduced a balancing attack due to the non-zero constraint feature introduced to remove the running sum. Due to this, two alternative iterations of v3 were briefly explored, each offering their own tradeoffs; you can find a detailed comparison of the different iterations [here](https://hackmd.io/khqyQzoiQ32UjkJd7fegnw).
|
||||
- Due to the lack of structured reference strings (SRS) in hyperplonk Summa, Version 3 requires its own trusted setup. Switching to plonkish backend could potentially solve the trusted setup issue, but more research would be needed to confirm this.
|
||||
- Big datasets using the same proof were limited to generating proofs for only 9-10 currencies without the need for more commitment proofs to be generated. This isn’t an insurmountable issue, but the team chose not to pursue it toward the end of the project’s life.
|
||||
- There are general limitations associated with generating all inclusion proofs at once, especially for large batches. By generating proofs on demand instead of all at once, the custodian can easily see which customers are actively verifying proofs or not. This opens up a profiling attack, explained in more detail [here](https://www.notion.so/Challenges-8c0e4718b93f4a1ca3537c348e8a621d?pvs=21).
|
||||
- Additional Summa attack vectors are documented [here](https://hackmd.io/@summa/SJYZUtpA2).
|
||||
|
||||
### Organizational Challenges
|
||||
|
||||
The development also faced significant organizational challenges, primarily due to a lack of clear goals and a structured roadmap with defined milestones. The team reflected that approaching the initiative as a research project rather than a product would have allowed for deeper exploration of concepts instead of prioritizing user experience optimizations prematurely. Additionally, the assumption that adoption would naturally follow development (“build it and they will come”) proved false, further emphasizing the need for clearer objectives and strategic planning from the outset to measure success effectively.
|
||||
|
||||
### Adoption
|
||||
|
||||
Adoption of the software faced significant hurdles due to a lack of thorough research into the problem space and unclear project goals, which hindered the team’s ability to engage effectively with CEXs and gather meaningful feedback. Additionally, it became evident that custodians had little incentive to implement robust Proof of Reserves systems, as there was limited demand or pressure from their customers to prioritize transparency and accountability, despite a vocal call to do so in the wake of the FTX collapse. The team found that even in cases where CEXs had implemented some form of PoR, it often fell short of a true Proof of Reserves system, insufficient for ensuring transparency, privacy and recourse for exchange users.
|
||||
|
||||
### Discontinuing the project
|
||||
|
||||
Following an [analysis](https://pse-team.notion.site/summa-analysis?pvs=74) of the status and impact of Summa, the team decided to halt development. The decision to discontinue the project stemmed from a growing understanding that the issues it aimed to address — such as reducing the cost of generating liability commitments for large customer sets — were only one small part of a much larger problem space in the Proof of Reserves landscape. Key components necessary for a truly robust PoR system, such as offchain asset verification, dispute resolution mechanisms, and zero-knowledge address ownership verification, were identified as critical but clearly fell outside the project’s scope.
|
||||
|
||||
Additionally, the assumption that improving the speed and cost-efficiency of commitments and proofs would drive industry-wide adoption proved overly simplistic. The team also recognized that other, more impactful PoR challenges existed but were beyond their capacity to address, making it clear that solving these broader issues alongside the specific ones the team addressed would be essential for scalable adoption.
|
||||
|
||||
### The Future
|
||||
|
||||
The Summa project, born in response to the FTX collapse, made significant strides in developing a scalable and cryptographically robust Proof of Reserves system for centralized cryptocurrency exchanges. Despite facing various challenges, the team achieved several notable outcomes:
|
||||
|
||||
- Creating three versions of the Summa system, each [iterating on performance](https://hackmd.io/wt4NkeUWSWi2ym6DNcsT-Q?view=#Performance-Comparison-by-Summa-versions) and [security aspects.](https://hackmd.io/wt4NkeUWSWi2ym6DNcsT-Q?stext=11843%3A1719%3A0%3A1738307701%3A1ckFiy&view=)
|
||||
- [Implementing an innovative alternative to Merkle trees using the sumcheck protocol.](https://hackmd.io/wt4NkeUWSWi2ym6DNcsT-Q#Summa-V2)
|
||||
- Developing a Solidity KZG verifier for improved smart contract integration.
|
||||
- [Significantly improving inclusion proof generation performance in the final version.](https://hackmd.io/wt4NkeUWSWi2ym6DNcsT-Q#Performance-Comparison-by-Summa-versions)
|
||||
|
||||
These tools and resources provide a solid foundation for future PoR system development. While the project is no longer under active development, its findings and technical achievements remain valuable. Future researchers and developers can build upon this work by addressing identified gaps, such as off-chain asset verification and dispute resolution mechanisms, to create more comprehensive PoR solutions.
|
||||
|
||||
For those interested in continuing this work:
|
||||
|
||||
- A comprehensive project analysis is available [here](https://pse-team.notion.site/summa-analysis?pvs=74).
|
||||
- A list of potential improvement components can be found [here](https://www.notion.so/Improvement-Components-390eb0fd89944631a162c3223de02a68?pvs=21)
|
||||
- An audit by yAcademy has been [completed](https://github.com/electisec/summa-audit-report/blob/main/README.md) and the issues raised in the audit have been addressed [here](https://github.com/summa-dev/summa-solvency/pull/300).
|
||||
- The project’s [GitHub repository](https://github.com/summa-dev) will remain open source.
|
||||
|
||||
While no further development is currently planned, the Summa project’s contributions to the field of Proof of Reserves systems provide a valuable starting point for future innovations in cryptocurrency exchange transparency and security.
|
||||
135
articles/retrospective-trusted-setups-and-p0tion-project.md
Normal file
@@ -0,0 +1,135 @@
|
||||
---
|
||||
authors: ["PSE Trusted Setup Team"]
|
||||
title: "Retrospective: Trusted Setups and P0tion Project"
|
||||
image: "cover.webp"
|
||||
tldr: "This post was written by the PSE Trusted Setup Team."
|
||||
date: "2025-01-15"
|
||||
canonical: "https://mirror.xyz/privacy-scaling-explorations.eth/Cf9nYvSlATGks8IcFaHQe3H5mgZ_Va767Zk5I8jPYXk"
|
||||
---
|
||||
|
||||
## Chronological look back
|
||||
|
||||
### **Early Stages and Foundation**
|
||||
|
||||
PSE’s Trusted Setups team began two years ago with a focus on understanding and implementing trusted setup ceremonies, which are crucial in generating secure cryptographic keys for production-ready zkSNARKs circuits. The team was formed to continue work on ongoing projects as well as starting to work on new initiatives.
|
||||
|
||||
In a trusted setup ceremony, multiple participants collaborate to compute the cryptographic parameters for the circuit, each contributing their own entropy - some [secret](https://www.youtube.com/watch?v=I4cDAqeEmpU), [randomly](https://web.archive.org/web/20230501054531/https:/proofof.cat/) [generated](https://web.archive.org/web/20230504180930/https:/hackmd.io/axUX8pFUQD-yCiBzQEDrYQ?view) [value](https://www.vice.com/en/article/power-tau-zcash-radioactive-toxic-waste/) - that is [destroyed](https://x.com/saint_rat/status/1647601259724275713) after the computation is complete. As long as at least one participant runs the computation securely and properly disposes of their “toxic waste”, the setup is secure.
|
||||
|
||||
Historically, trusted setups have been difficult and time-consuming, requiring teams to implement infrastructure and coordinate participation for each new zkSNARK, often across two separate phases. The time, resources and technical expertise required to run a trusted setup ceremony placed a big burden on teams working on zero knowledge protocols - [this podcast](https://radiolab.org/podcast/ceremony) famously documents the elaborate precautions taken to secure Zcash’s 2016 trusted setup ceremony.
|
||||
|
||||
Our team identified a need for accessible and replicable tools that would help teams run trusted setups with less overhead. We quickly developed expertise in this niche but critical area, laying the groundwork for innovative tools to make trusted setups easier and more efficient.
|
||||
|
||||
### **Perpetual Powers of Tau**
|
||||
|
||||
In a two-phase trusted setup, the second phase is circuit-specific; but the first phase can be used by any number of projects as long as they trust that it’s secure. Our team took on the challenge of implementing a Phase 1 ceremony that could be trusted by anyone who might want to build on it. Since a setup is secure as long as any one participant has behaved honestly, that meant creating a ceremony that could stay open indefinitely and accept any number of contributions. This way, anyone who wanted to build on the setup but wasn’t confident in its integrity could ensure it was secure for their project by simply making their own contribution.
|
||||
|
||||
The result was the [Perpetual Powers of Tau ceremony](https://github.com/privacy-scaling-explorations/perpetualpowersoftau), focusing on producing phase-1 files crucial for all zkSNARKs. This ongoing ceremony has been running since 2019, with 85 contributors to date. Contributing to PPoT involves managing complex 100GB files, which requires contributors to have enough technical knowledge to spin up a server large enough to compute the contribution. It also requires the contributor to know how to install the right tools, download the files and upload the files after they finished their contribution.
|
||||
|
||||

|
||||
|
||||
From PPoT announcement post by Wei Jie Koh https://medium.com/coinmonks/announcing-the-perpetual-powers-of-tau-ceremony-to-benefit-all-zk-snark-projects-c3da86af8377
|
||||
|
||||
Since Perpetual Powers of Tau began, the team has successfully coordinated, prepared and published a range of Phase 1 output files for use in Phase 2 ceremonies depending on their number of constraints, demonstrating long-term commitment to this critical infrastructure.
|
||||
|
||||
### **KZG Ceremony**
|
||||
|
||||
A pivotal moment for the project was the implementation of the [KZG Ceremony](https://blog.ethereum.org/2024/01/23/kzg-wrap), essential for [EIP 4844](https://eips.ethereum.org/EIPS/eip-4844) (Proto-Danksharding). This Ethereum core upgrade aimed to reduce gas prices by creating a separate market for data storage, benefiting layer 2 protocols.
|
||||
|
||||
We developed a [user-friendly web application](https://ceremony.ethereum.org/) to invite broad community participation, with a user-friendly process that guided contributors through the ceremony step by step, automating and abstracting away the complex operations of computation and toxic waste disposal. PSE’s design team created a beautiful user interface that made participating in the ceremony feel more like a sacred ritual than collective math.
|
||||
|
||||

|
||||
|
||||
ceremony.ethereum.org landing page at the time the ceremony was active
|
||||
|
||||
The ceremony was a resounding success, achieving an impressive 141,416 contributors worldwide. The [codebase](https://github.com/zkparty/trusted-setup-frontend) has been forked 66 times and garnered 229 stars on Github, indicating strong community interest and potential for reuse.
|
||||
|
||||
### **p0tion**
|
||||
|
||||
In response to internal needs, the team took on the development of [p0tion](https://github.com/privacy-scaling-explorations/p0tion), a toolkit for deploying and running trusted setup ceremonies. Whereas the KZG implementation was designed for a very specific use, p0tion is intended to be more generalized and adaptable to the needs of many different projects.
|
||||
|
||||
The p0tion toolkit utilizes a mix of cloud functions and virtual machines for efficiency in running secure Groth16 zk-applications via automated Phase 2 ceremonies. We focused on streamlining the process of executing a trusted setup, as well as creating a [unified interface](https://ceremony.pse.dev/) for ceremonies implemented with p0tion.
|
||||
|
||||

|
||||
|
||||
Trusted setup for ZKEmail circuits on ceremony.pse.dev
|
||||
|
||||
The team later adapted the toolkit into a stand-alone tool with minimal infrastructure requirements, making it more accessible and easier to deploy on external servers.
|
||||
|
||||
## Successes
|
||||
|
||||
### Technical Achievements
|
||||
|
||||
The team developed some of PSE's most utilized public good tools, including p0tion for trusted setup ceremonies. They created a user-friendly KZG Ceremony interface attracting 140,000 participants and successfully conducted ceremonies for Groth16 PSE projects and external initiatives. The manual execution of Perpetual Powers of Tau demonstrated their capability in coordinating, verifying and backing up large files.
|
||||
|
||||
### Community Engagement and Impact
|
||||
|
||||
Widespread participation in the KZG Ceremony enhanced Ethereum's security and fostered community involvement. The project contributed significantly to the growth and security of the Ethereum ecosystem, benefiting deployed dapps and zkApps.
|
||||
|
||||
Providing valuable generalized tools as public goods extended the project's influence across the crypto community. To date, p0tion has been used in [over 15 internal and external ceremonies](https://ceremony.pse.dev/). The #🧪-p0tion channel in the [PSE public Discord](https://discord.com/invite/yujxyBdCfM) has been a great tool for the community to participate in the ceremonies and help us debug code issues.
|
||||
|
||||
### Knowledge Sharing and Collaboration
|
||||
|
||||
The team collaborated effectively with Ethereum core developers and external team members from various projects. They shared experiences through talks and workshops at events like Devconnect, positioning themselves as a valuable resource in the crypto community. Some of the talks are:
|
||||
|
||||
- [https://www.youtube.com/watch?v=Z2jR75njZKc](https://www.youtube.com/watch?v=Z2jR75njZKc)
|
||||
- [https://www.youtube.com/watch?v=SnLDI8PLyDc](https://www.youtube.com/watch?v=SnLDI8PLyDc)
|
||||
- [https://www.youtube.com/watch?v=ZIfNk7DIQy4](https://www.youtube.com/watch?v=ZIfNk7DIQy4)
|
||||
- [https://www.youtube.com/watch?v=U1Lh2fMcto8](https://www.youtube.com/watch?v=U1Lh2fMcto8)
|
||||
|
||||
## Challenges & Lessons Learned
|
||||
|
||||
### Project Management
|
||||
|
||||
A critical insight from this project was recognizing the pitfall of assuming that a small team (in our case, just two people) doesn't require formal project management methodologies or structured communication processes. We fell into the trap of believing that with such a small team, informal, ad-hoc discussions would suffice for planning, coordination, and staying aligned. This led to loose processes, inadequate planning, unclear task ownership, sometimes duplicate work and ultimately, poor organization. **For future projects, regardless of team size, we recommend implementing structured project management and communication approaches. Even for small teams, (light) sprint planning, regular stand-ups, and clearly defined goals and milestones are crucial.**
|
||||
|
||||
### Development Process
|
||||
|
||||
The team worked on different projects and solutions. Each one of them presented a different set of challenges and opportunities to learn:
|
||||
|
||||
1. **Perpetual Powers of Tau**: The project was manually maintained and run by a single team member. This approach allowed to move fast and provide great user support but it also created barriers when the team member left PSE. The solution for this was to document all the process and procedures.
|
||||
2. **KZG ceremony**: The project was developed by multiple external teams that needed coordination and a strict project management workflow. Even though we were able to successfully finish the project without major issues, a key lesson learned was to plan and prioritize the roadmap with all parties involved before starting work on the project.
|
||||
3. **p0tion:** The project was inherited from another team. The initial project was built prioritizing infrastructure prices rather than flexibility to use on any infrastructure platform. This approach helped to save costs and easily manage the tool, but external parties would have to invest time and knowledge to set up all the required infrastructure for their specific needs.
|
||||
|
||||
Overall we learned the importance of a clear and structured roadmap and project management process. We also learned that it's far more efficient and beneficial to get early feedback on a work-in-progress rather than waiting to present a finished but potentially misguided solution.
|
||||
|
||||
**Besides the previous recommendation of implementing a structured project management approach, we recommend encouraging a culture of early code review, even on incomplete work: a discussion on a “half-baked” code is better than no discussion that leads to the development of an off-target solution.**
|
||||
|
||||
### Technical Considerations
|
||||
|
||||
The team encountered different technical challenges in each project that were addressed through team collaboration and external advisory:
|
||||
|
||||
1. **Perpetual Powers of Tau:** Large files and long computations require knowledge on devops: instances spin-up and file backups. There are different procedures and nomenclatures depending on the infrastructure provider that the team members and maintainers have to consider when running a large ceremony like Perpetual Powers of Tau
|
||||
2. **KZG ceremony:** It is important that team members have flexibility to learn about different programming languages fast in order to collaborate with external teams. The main KZG ceremony server and crypto library was built using Rust and the team needed to understand the code in order to integrate it into a frontend (Typescript + React)
|
||||
3. **p0tion**: The mix between different infrastructure providers can help reduce costs, but it would increase complexity when deploying the tool. In our opinion, when building open-source tools, developers should aim for easy-to-deploy strategies.
|
||||
|
||||
In general the project highlighted the potential benefits of diversifying the technology stack and carefully weighing the convenience of third-party packages against the benefits of custom solutions, such as reduced prices, computation time and greater backup flexibility.
|
||||
|
||||
## Conclusion and Future Outlook
|
||||
|
||||
### Long Term Support (LTS)
|
||||
|
||||
As we conclude active development, these trusted setup projects are entering a Long-Term Support phase. Specifically:
|
||||
|
||||
- [Perpetual Powers of Tau](https://github.com/privacy-scaling-explorations/perpetualpowersoftau)
|
||||
|
||||
- Maintain the archive of past contribution files
|
||||
- Coordinate future contributions manually through the #⛩-ppot channel on the PSE Discord
|
||||
|
||||
- [KZG ceremony](https://github.com/zkparty/trusted-setup-frontend)
|
||||
|
||||
- No further development planned
|
||||
- Website [www.ceremony.ethereum.org](http://www.ceremony.ethereum.org/) will stay up and running for users to check the contributors’ list and the final transcript
|
||||
- Codebase will remain public, but developers are generally recommended to use p0tion as a more general tool for all ceremonies
|
||||
|
||||
- [p0tion](https://github.com/privacy-scaling-explorations/p0tion)
|
||||
|
||||
- Cease development of new features
|
||||
- Address critical bugs if and when discovered
|
||||
- Maintain the Discord channel open for community questions and issues
|
||||
- The project is available for community development of new features (faster computations, better UI dashboards, etc).
|
||||
|
||||
The Trusted Setups project has made significant contributions to the Ethereum ecosystem and the field of zero-knowledge proofs. As it transitions into a new phase, its legacy continues through shared tools and knowledge. The experiences and lessons learned will inform future initiatives in cryptography and blockchain.
|
||||
|
||||
\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_
|
||||
|
||||
_PSE is an Ethereum Foundation team building free resources_ for people expanding the world of programmable cryptography. _Learn more at [pse.dev](https://pse.dev/), join our [Discord](https://discord.gg/yujxyBdCfM), or [follow us on X](https://x.com/PrivacyScaling)._
|
||||
@@ -0,0 +1,128 @@
|
||||
---
|
||||
authors: ["Sora Suegami"]
|
||||
title: "RSA Verification Circuit in Halo2 and its Applications"
|
||||
image: null
|
||||
tldr: "This post was authored by grantee **Sora Suegami** ([Twitter](https://twitter.com/SoraSue77), [Github](https://github.com/SoraSuegami))"
|
||||
date: "2022-11-14"
|
||||
canonical: "https://mirror.xyz/privacy-scaling-explorations.eth/mmkG4uB2PR_peGucULAa7zHag-jz1Y5biZH8W6K2LYM"
|
||||
---
|
||||
|
||||
## Introduction
|
||||
|
||||
We released an RSA verification circuit compatible with the [halo2 library developed by the privacy-scaling-explorations team](https://github.com/privacy-scaling-explorations/halo2). It allows halo2 developers to write circuits to verify RSA-based cryptographic schemes such as RSA signature, RSA accumulator, and [verifiable delay function based on groups of unknown order](https://eprint.iacr.org/2018/623.pdf). This post describes the background design and its applications.
|
||||
|
||||
Github repo: [halo2-rsa](https://github.com/SoraSuegami/halo2_rsa)
|
||||
|
||||
## Circuit Specification
|
||||
|
||||
Our circuit supports verification of the RSA relationship, i.e., ***x*ᵉ mod _n_** for the integer _**x**_ and RSA public key (_**n,e**_). At a high level, it provides the following three functions.
|
||||
|
||||
1. Modular exponentiation It takes as inputs the integer _**x**_ and the RSA public key (_**n,e**_), outputs an integer ***x*ᵉ mod _n_**
|
||||
2. Modular exponentiation with fixed _**e**_
|
||||
|
||||
Its functionality is equivalent to that of the first one, except that the exponent integer _**e**_ is fixed in advance.
|
||||
|
||||
3. Pkcs1v15 signature verification.
|
||||
It takes as inputs the pkcs1v15 signature _**c**_, the RSA public key (_**n,e**_), and the signed message _**m**_, makes constraints to verify that _**c**_ is a valid signature for (_**n,e**_) and _**m**_. Note that pkcs1v15 is a specification of the RSA signature defined in [RFC3447](https://www.rfc-editor.org/rfc/rfc3447).
|
||||
|
||||
The above functions were developed with reference to the [circom-rsa-verify repository](https://github.com/zkp-application/circom-rsa-verify), which contains a circuit for pkcs1v15 signature verification in the [circom language](https://docs.circom.io/). It first defines a circuit for modular multiplication of big integers, that is to say, integers whose size is larger than that of the native field of the arithmetic circuit, and then verifies the signature by computing modular exponentiation with that circuit. We took a similar approach for our circuits. In addition, the range check, the verification of whether a given integer is within a certain range, was optimized with a lookup table.
|
||||
|
||||
Specifically, the constraints for the big integer computation is defined as follows.
|
||||
|
||||
## Big Integer Computations on the Circuit
|
||||
|
||||
A big integer is represented by multiple values in the native field of the arithmetic circuit, each value being called a limb. It is classified into two types: **Fresh type** and **Muled type**. The former type is assigned to the big integers that have not yet been multiplied, while the latter type is assigned after multiplication. We distinguish them to manage the maximum value of the limbs; the limbs of the Fresh type big integer must fit into _**w**_\-bit, and those of the Muled type may overflow it.
|
||||
|
||||
For example, we consider a 2048-bit big integer that consists of 32 64-bit limbs. The big integer has the Fresh type when newly allocated on the circuit, and its limb value is less than _**2⁶⁴**_. When two big integers are added or subtracted, the resulting big integer has the Fresh type, and only the number of limbs is modified. However, in multiplication, the output big integer has Muled type, whose limb can be larger than _**2⁶⁴-1**_.
|
||||
|
||||
This is because the big integer multiplication is computed in the same way as polynomial multiplication. Formally, for two big integers _**a = a₀x⁰ +**_ _**a₁x¹ + ⋯ + a₃₁x³¹**_ and _**b₀x⁰ +**_ _**b₁x¹ + ⋯ +b₃₁x³¹**_, where _**x=2⁶⁴**_, their multiplication is defined as follows.
|
||||
|
||||

|
||||
|
||||
To convert the Muled type big integer back into the Fresh type one, our circuit provides a refresh function that creates a big integer equal to the given big integer where each limb value is 64-bit with increasing the number of limbs. By refreshing the product with that function, multiplication can be performed multiple times.
|
||||
|
||||
Our circuit also supports modular multiplication, i.e., **_a ∗ b_ mod _n_** for big integers _**a**_,_**b**_ and a modulus _**n**_. It first calculates the quotient _**q = ab/n**_ and the remainder _**r =**_ **_ab_ mod** _**n**_ without making constraints. It then constrains _**q**_ and _**r**_ to satisfy the following conditions.
|
||||
|
||||
1. The product _**ab**_ is equal to _**qn + r**_.
|
||||
2. Each limb of _**q**_ and _**r**_ is in the range of \[_**0, 2⁶⁴**_).
|
||||
|
||||
To verify the first condition, the (not modular) multiplication function is used. For the second condition, existing circuits such as [circom-bigint](https://github.com/alex-ozdemir/circom-bigint) assign a new value to each bit and verify that the composed value is equal to the original value; however, our circuit uses a lookup table. This optimization allows the prover to prove that multiple values are in the specified range in batch as described in [Plookup protocol](https://eprint.iacr.org/2020/315.pdf).
|
||||
|
||||
By repeating the modular multiplication described above, the modular power _**aᵉ**_ **mod _n_** for an exponent big integer _**e**_ is computed. Formally, it is implemented as follows.
|
||||
|
||||
1. Decompose _**e**_ into _**n**_ bits (_**e₀**_,**_a₁,…,eₙ_**₋**_₁_**).
|
||||
2. Let _**y = 1**_ be a modular power result.
|
||||
3. For ***i*∈** _**{0,…,n−1}**_, update _**y**_ to _**eᵢya²^ⁱ + (1−e₁)y**_.
|
||||
|
||||
Notably, if _**e**_ is fixed in the circuit, we can reduce the number of the modular multiplication because _**ya²^ⁱ**_ does not need to be computed for _**i**_ where _**eᵢ = 0**_ holds. Our circuit switches the definition of the constraints depending on whether _**e**_ is variable or fixed. Therefore, when _**e**_ of the RSA public key is fixed, e.g., pkcs1v15 signature verification, the number of constraints for modular multiplication is minimum.
|
||||
|
||||
## Application: ZK-Mail
|
||||
|
||||
As an application of the RSA verification circuit, we are considering ZK-Mail, a smart contract that performs email verification using ZKP. Today, digital signatures, especially RSA signatures, are widely used in email protocols such as S/MIME and DKIM to authenticate email senders. Our main idea is that a smart contract can authenticate those emails by verifying the RSA signatures with ZKP. If they pass the authentication, the smart contract can interpret their contents as oracle data provided by the email senders.
|
||||
|
||||
The smart contract described above is also useful as a contract wallet. Instead of using the wallet application to make a transaction, the user sends an email to the operator of the contract wallet specifying the transfer amount and the destination in its email message. The operator generates a ZK proof indicating that the received email has been authorized, submitting it to the smart contract. The smart contract verifies the proof and transfers the user’s assets according to the contents of the email. It allows users to manage their assets on Ethereum without modifying current email systems or installing new tools.
|
||||
|
||||
If the user is different from the administrator of the sending email server, the security of the user’s assets depends on trust in the administrator because the administrator can steal them by forging the user’s emails. However, trust in the operator is not necessary. This is because even if the operator modifies the contents of the received emails, the operator cannot forge the signature corresponding to the email sender. In summary, this is a custodial wallet whose security is guaranteed under trust in the email server administrator, allowing users to manage their assets by simply sending emails using their existing email services.
|
||||
|
||||
In the following, we present two situations where the ZK-Mail can be used.
|
||||
|
||||
### Scenario 1: Email as oracle data
|
||||
|
||||
#### Players and situations
|
||||
|
||||
- Alice delivers the latest cryptocurrency prices via email. She attaches her RSA signature to the email following the DKIM protocol.
|
||||
- Bob subscribes to Alice’s emails and provides them for some DeFi contracts as price oracle data.
|
||||
|
||||
#### Assumptions
|
||||
|
||||
- A public key corresponding to Alice’s domain name (e.g. [alice.com](http://alice.com/)) is published in DNS and not changed.
|
||||
- Alice’s public key and email address are registered in the ZK-Mail contract in advance.
|
||||
|
||||
#### Procedures
|
||||
|
||||
1. Bob receives Alice’s latest email.
|
||||
2. Bob extracts the cryptocurrency name and price data from the contents of the email.
|
||||
3. Taking Alice’s RSA signature and the header/contents of the email as private inputs (witnesses), and her public key, her email address, and the cryptocurrency name and price data as public inputs (statements), Bob generates a ZKP proof confirming the following conditions.
|
||||
|
||||
- The RSA signature is valid for the header/contents and the public key.
|
||||
- The From field in the header is equivalent to the provided email address, i.e., Alice’s email address.
|
||||
- The contents include the cryptocurrency name and price data.
|
||||
|
||||
4. Bob provides the price oracle contract with the cryptocurrency name and price data and the ZKP proof.
|
||||
5. The contract calls the ZK-Mail contract with the provided data. It verifies the ZKP proof using Alice’s public key and email address registered in advance.
|
||||
6. If the proof passes the verification, the price oracle contract accepts the provided name and price data.
|
||||
|
||||

|
||||
|
||||
### Scenario 2: Email as transaction data for the contract wallet
|
||||
|
||||
#### Players and situations
|
||||
|
||||
- Alice operates an email service. She attaches her RSA signature to her users’ emails following the DKIM protocol. Her domain name is [alice.com](http://alice.com/).
|
||||
- Bob is a user of Alice’s email service. His email address is [bob@alice.com](http://mailto:bob@alice.com/).
|
||||
- Carol operates a contract wallet service. Her email address is [carol@wallet.com](http://mailto:carol@wallet.com/).
|
||||
|
||||
#### Assumptions
|
||||
|
||||
- A public key corresponding to Alice’s domain name (e.g. [alice.com](http://alice.com/)) is published in DNS and does not change.
|
||||
- Alice’s public key is registered in the ZK-Mail contract in advance.
|
||||
- Bob already registered Carol’s wallet service. His email address is registered in the ZK-Mail contract, and he has 2 ETH in his wallet.
|
||||
- **Alice never attaches her RSA signature to forged emails.**
|
||||
|
||||
#### Procedures
|
||||
|
||||
1. Bob wants to transfer 1 ETH to his friend whose email address is [friend@alice.com](http://mailto:friend@alice.com/).
|
||||
2. Bob sends an email to [carol@wallet.com](http://mailto:carol@wallet.com/). Its message is “Transfer 1 ETH to [friend@alice.com](http://mailto:friend@alice.com/)”.
|
||||
3. Alice attaches her RSA signature to the Bob’s email.
|
||||
4. Carol receives the email from Bob. She extracts the transfer amount and the destination (1 ETH and [friend@alice.com](http://mailto:friend@alice.com/) in this case) from the contents of the email.
|
||||
5. Taking Alice’s RSA signature and the header/contents of the email as private inputs (witnesses), and her public key, sender’s email address, and the transfer amount and the destination as public inputs (statements), Carol generates a ZKP proof confirming the following conditions.
|
||||
|
||||
- The RSA signature is valid for the header/contents and the public key.
|
||||
- The From field in the header is equivalent to the provided email address, i.e., [bob@alice.com](http://mailto:bob@alice.com/).
|
||||
- The message in the contents is in the form of “Transfer (transfer amount) to (destination)”.
|
||||
|
||||
6. Carol provides her service’s contract with transaction data including the transfer amount and the destination and the ZKP proof.
|
||||
7. The contract calls the ZK-Mail contract with the provided data. It verifies the ZKP proof using Alice’s public key and Bob’s email address registered in advance.
|
||||
8. If the proof passes the verification, the contract wallet transfers Bob’s 1 ETH to the wallet corresponding to the email address of [friend@alice.com](http://mailto:friend@alice.com/). (In detail, the contract wallet has storage where the hash of the email address is mapped to the ETH balance. It decreases 1 from the balance of Hash([bob@alice.com](http://mailto:bob@alice.com/)) and increases that of Hash([friend@alice.com](http://mailto:friend@alice.com/)) by the same amount.)
|
||||
|
||||

|
||||
367
articles/secure-multi-party-computation.md
Normal file
@@ -0,0 +1,367 @@
|
||||
---
|
||||
authors: ["Brechy"]
|
||||
title: "Secure Multi-Party Computation"
|
||||
image: "cover.webp"
|
||||
tldr: "This post was written by [Brechy](https://github.com/brech1). Thanks [Nam Ngo](https://github.com/namnc) for the feedback and review!"
|
||||
date: "2024-08-06"
|
||||
canonical: "https://mirror.xyz/privacy-scaling-explorations.eth/v_KNOV_NwQwKV0tb81uBS4m-rbs-qJGvCx7WvwP4sDg"
|
||||
---
|
||||
|
||||
Secure multi-party computation (MPC) enables a group of participants to collaborate on a specific task that requires their data as input, ensuring the privacy of their inputs and the correctness of the output.
|
||||
|
||||

|
||||
|
||||
This allows performing operations on private information without disclosing it or involving a trusted third party. The only data each party receives is the function's result.
|
||||
|
||||
There are several MPC protocols. This post provides an overview of the most general concepts and tools shared by many of them.
|
||||
|
||||
## Introduction
|
||||
|
||||
MPC enables multiple parties to collaborate on a specific function without revealing their private data to one another. This ensures that no single party can access the data of others. The participants agree on a particular task or function to perform, and then use an MPC protocol to collectively determine the result.
|
||||
|
||||
We can think of a sample use case of managing the private keys of an Ethereum account:
|
||||
|
||||
- A set of participants is each given a segment of the secret key.
|
||||
- Using an MPC protocol, they can input their segments and run the protocol to execute the signature function.
|
||||
|
||||
No single participant can sign a transaction unless **all or a sufficient number** of participants input their secret key segments, and no participant has enough information to reconstruct the secret key.
|
||||
|
||||
## Protocol Scope
|
||||
|
||||
MPC protocols can be categorized based on the functions they are designed to run, falling into two main categories: generic and specialized.
|
||||
|
||||
### Specialized Protocols
|
||||
|
||||
Specialized protocols are designed and optimized for a specific functionality. These protocols are built around a specific task, like Private Set Intersection (PSI) or voting. Specialized protocols leveraging the specific structure of a function can offer significant performance improvements.
|
||||
|
||||
### Generic Protocols
|
||||
|
||||
Generic protocols can compute any function that can be represented as a fixed-size circuit. Yao’s Garbled Circuits protocol is an example of a generic protocol. They can be applied to a wide range of problems.
|
||||
|
||||
## Secure Protocol Requirements
|
||||
|
||||
We can use the following properties to help us define an **ideal** secure protocol:
|
||||
|
||||
- **Privacy:** No party should learn anything more than the function output.
|
||||
- **Correctness:** Each party is guaranteed to receive the correct output.
|
||||
- **Independence of Inputs:** Every party can decide its input independently of other parties.
|
||||
- **Guaranteed Output Delivery:** No party can prevent other parties from receiving the function output.
|
||||
- **Fairness:** If one party receives the function output, every party will receive the output.
|
||||
|
||||
These guarantee the correctness of the output and ensure that no party can disrupt the process or gain an unfair advantage. However, additional measures are needed to ensure input integrity and protect the output from giving away information.
|
||||
|
||||
### Input Integrity
|
||||
|
||||
Participants can input any value, potentially manipulating the process. For instance, in an auction, a participant could falsely input an extremely high bid to ensure they win, even though their actual bid is much lower. To mitigate this, mechanisms like requiring signed inputs verified can be used, though this can increase computational costs.
|
||||
|
||||
### Result Information
|
||||
|
||||
The process result could reveal information about the inputs or the participants. Using the auction example, if the final highest bid is revealed, other participants can infer details about the highest bidder's strategy or budget.
|
||||
|
||||
## Use Cases
|
||||
|
||||
Let's explore some real world use cases.
|
||||
|
||||
### Privacy Preserving Machine Learning
|
||||
|
||||
It's possible to enhance privacy during the machine learning training and inference phases. During training, multiple parties can collaboratively train a model without disclosing their individual datasets. For inference, it can ensure that both the client's input data and the server's model remain confidential. This allows clients to receive model outputs without exposing their data and ensures that the provider’s model remains private.
|
||||
|
||||
### Threshold Cryptography
|
||||
|
||||
Companies can enhance key protection by distributing key shares across multiple secure environments. This ensures that no single location holds the entire private key, reducing the risk of key compromise. An adversary would need to breach all environments to access the complete key. This protects cryptographic keys, secures authentication processes and enforces signature approval policies.
|
||||
|
||||
### Collaborative Data Analysis
|
||||
|
||||
Multiple parties can combine and analyze datasets without disclosing private information. Organizations can securely integrate various records to study trends while adhering to privacy regulations. This application enables data analysis without compromising confidentiality.
|
||||
|
||||
## Circuits
|
||||
|
||||
Many protocols use a circuit to represent the function being computed. The circuit's structure and operations remain constant and are not influenced by user inputs. As a result, the runtime of the protocol does not disclose any information about the inputs.
|
||||
|
||||

|
||||
|
||||
A simple circuit:
|
||||
|
||||
$Output = ((A + B) * (C + D)) + E$
|
||||
|
||||
These circuits can be either **boolean** circuits that process binary variables using logic gates, or **arithmetic** circuits that perform operations on numerical values.
|
||||
|
||||
Boolean circuits need to redefine basic operations for **every bit width**: supporting arithmetic on n-bit integers in such a protocol requires implementing n-bit addition and multiplication circuits.
|
||||
|
||||
Arithmetic circuits typically operate over a finite field, where the size of the field is set in advance. Although arithmetic circuits are primarily designed for arithmetic operations, non-arithmetic operations such as comparisons and equality checks can also be implemented.
|
||||
|
||||
Expressing the target computation as a circuit can be challenging since not every function can be easily converted into a circuit format, but compilers can be used for this. However, every function must be deterministic and free of indefinite loops.
|
||||
|
||||
A compiler converts a program written in a specialized, high-level language to an intermediate representation (often a circuit). The circuit is then passed as input to a runtime, which executes an MPC protocol and produces an output.
|
||||
|
||||
Let's consider an example where our function performs matrix element-wise multiplication, and our input and output are 2x2 matrices. We can use Circom and the [circom-2-arithc](https://github.com/namnc/circom-2-arithc/) compiler to create our circuit.
|
||||
|
||||
```
|
||||
template matrixElementMul (m,n) {
|
||||
signal input a[m][n];
|
||||
signal input b[m][n];
|
||||
signal output out[m][n];
|
||||
|
||||
for (var i=0; i < m; i++) {
|
||||
for (var j=0; j < n; j++) {
|
||||
out[i][j] <== a[i][j] * b[i][j];
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
component main = matrixElementMul(2,2);
|
||||
```
|
||||
|
||||
The compiled circuit will consist of four arithmetic multiplication gates:
|
||||
|
||||
```json
|
||||
[
|
||||
{ "op": "AMul", "lh_in": 0, "rh_in": 4, "out": 8 },
|
||||
{ "op": "AMul", "lh_in": 1, "rh_in": 5, "out": 9 },
|
||||
{ "op": "AMul", "lh_in": 2, "rh_in": 6, "out": 11 },
|
||||
{ "op": "AMul", "lh_in": 3, "rh_in": 7, "out": 10 }
|
||||
]
|
||||
```
|
||||
|
||||
### Circuit Diagram
|
||||
|
||||

|
||||
|
||||
For this example, it might have been quicker to manually construct the gates. However, we now have a function that can serve as a building block for actual matrix multiplication or more complex operations.
|
||||
|
||||
## Oblivious Transfer
|
||||
|
||||
Oblivious transfer (OT) is a cryptographic two-party protocol. It allows the receiving party to [obliviously](https://www.oxfordlearnersdictionaries.com/definition/english/obliviously) select one of the sending party’s inputs . The protocol’s privacy guarantees ensure that the sender does not learn the choice of the receiver and the receiver does not learn the non selected inputs.
|
||||
|
||||
Let's review a basic example, the **1-out-of-2 oblivious transfer**. In this protocol, the sender has two messages, 𝑚 0 and 𝑚 1 . The receiver wants to learn one of these messages, 𝑚 𝑏 , without the sender knowing which message was chosen.
|
||||
|
||||

|
||||
|
||||
1-out-of-2 Oblivious Transfer protocol
|
||||
|
||||
- Initialization:
|
||||
|
||||
- The sender has two messages: 𝑚 0 and 𝑚 1 .
|
||||
- The receiver wants to choose one of these messages, indexed by 𝑏 , where 𝑏 ∈ { 0 , 1 } .
|
||||
|
||||
- Communication Phase:
|
||||
|
||||
- The receiver generates a pair of public and secret keys ( 𝑝 𝑘 , 𝑠 𝑘 ) .
|
||||
- The receiver sends 𝑝 𝑘 to the sender.
|
||||
- The sender encrypts 𝑚 0 and 𝑚 1 using 𝑝 𝑘 in such a way that only the selected message 𝑚 𝑏 can be decrypted by the receiver using the secret key 𝑠 𝑘 .
|
||||
|
||||
- Transfer Phase:
|
||||
|
||||
- The sender sends the encrypted messages to the receiver. The receiver uses 𝑠 𝑘 to decrypt the chosen message 𝑚 𝑏 .
|
||||
|
||||
- This way we ensure that data privacy is maintained:
|
||||
|
||||
- The receiver learns only the chosen message 𝑚 𝑏 and nothing about the other message 𝑚 1 − 𝑏
|
||||
- The sender does not learn which message the receiver chose.
|
||||
|
||||
## Garbled Circuits
|
||||
|
||||
Garbled circuits (GCs) were introduced by Andrew Yao in the 1980s as a technique for secure **two-party computation (2PC)**. The GC protocol involves two parties, the garbler and the evaluator, who work together to securely evaluate a function represented as a Boolean circuit. The function consists of AND and XOR gates, and each party contributes part of the input.
|
||||
|
||||

|
||||
|
||||
_Garbled Circuit protocol_
|
||||
|
||||
Here's a step-by-step overview of how the GC protocol works for a simple circuit.
|
||||
|
||||
### Circuit
|
||||
|
||||
Our circuit will be constructed with only one AND gate. The truth table shows the output for all possible input combinations:
|
||||
|
||||

|
||||
|
||||
### Garbling
|
||||
|
||||
Garbling is a process by which the truth table is obfuscated. The garbler picks four random strings, or **labels:**
|
||||
|
||||

|
||||
|
||||
The garbler then uses every pair of labels corresponding to a possible scenario to encrypt the output corresponding to that scenario.
|
||||
|
||||

|
||||
|
||||
The two relevant labels are put through a key derivation function 𝐻 to derive a symmetric encryption key, and that key is used to encrypt 𝑎 ∧ 𝑏 . Then the garbled gate consists of the four resulting ciphertexts, in a random order.
|
||||
|
||||

|
||||
|
||||
### Evaluation
|
||||
|
||||
Once the evaluator receives the garbled gate, it needs to decrypt exactly one ciphertext: the one corresponding to the real values 𝑎 and 𝑏 , encrypted with $H(W_{a}^A, W_{b}^B)$.
|
||||
|
||||
In order to do this, it needs to receive from the garbler $W_{a}^A$ and $W_{b}^B$.
|
||||
|
||||
Since the garbler knows 𝑎 , he can send the evaluator $W_{a}^A$. The labels are all random, independent, and identically distributed, so the evaluator won’t learn anything about 𝑎 from $W_{a}^A$
|
||||
|
||||
However, getting $W_{b}^B$ to the evaluator is harder. The garbler can’t send both $W_{0}^B$ and $W_{1}^B$ to the evaluator because that will allow them to decrypt two ciphertexts in the garbled gate. Similarly, the evaluator can’t simply ask for the one they want because they don’t want the garbler to learn 𝑏 .
|
||||
|
||||
So, the garbler and the evaluator use Oblivious Transfer, which allows the evaluator to learn only $W_{b}^B$ without revealing 𝑏 to the garbler.
|
||||
|
||||
Note that in order for this to work, the evaluator needs to know when decryption succeeds and when it doesn’t. Otherwise, there’s no way for them to know which ciphertext yields the correct answer.
|
||||
|
||||
### Example Walkthrough
|
||||
|
||||
Let's create an example walkthrough for the case where the garbler's input is $a = 0$ and the evaluator's input is $b = 1$.
|
||||
|
||||
1. **Initialization**:
|
||||
|
||||
- Garbler generates labels for inputs $a$ and $b$.
|
||||
- Garbler creates and transfer the garbled circuit.
|
||||
|
||||
2. **Input Label Distribution**:
|
||||
|
||||
- Garbler sends $W_{0}^A$ to evaluator (since $a = 0$).
|
||||
|
||||
3. **Oblivious Transfer**:
|
||||
|
||||
- Evaluator uses Oblivious Transfer to receive $W_{1}^B$ (since $b = 1$).
|
||||
|
||||
4. **Evaluation**:
|
||||
|
||||
- Evaluator uses the keys $W_{0}^A$ and $W_{1}^B$ to decrypt the corresponding entry in the garbled table:
|
||||
- $Enc(H(W_{0}^A, W_{1}^B), W_{0}^{out}) \rightarrow W_{0}^{out}$
|
||||
|
||||
5. **Output Reconstruction**:
|
||||
|
||||
- Evaluator maps the decrypted key $W_{0}^{out}$ to the output value 0.
|
||||
|
||||
## Secret Sharing
|
||||
|
||||
Secret sharing is an approach for distributing a secret value using **shares** that separately do not reveal any information about the secret. The secret value can only be reconstructed if all or a sufficient number of shares are combined.
|
||||
|
||||
Let's review how **Additive Secret Sharing** works, in an example involving 3 participants and an addition operation. In this scheme, the secret is divided into $m$ parts, and the secret can only be reconstructed when all parts are combined.
|
||||
|
||||
### Secret Splitting
|
||||
|
||||
- Choose a secret value.
|
||||
|
||||
- $S = 1337$
|
||||
|
||||
- Choose $m-1$ random numbers as shares.
|
||||
|
||||
- $m = 3$
|
||||
- $S_1 = 220$
|
||||
- $S_2 = 540$
|
||||
|
||||
- Calculate the final share $S_3$.
|
||||
|
||||
- $S = S_1 + S_2 + S_3$
|
||||
- $S_3 = S - (S_1 + S_2) = 1337 - (220 + 540) = 577$
|
||||
|
||||
Let's split another secret to perform an addition:
|
||||
|
||||
- $T = 1440$
|
||||
|
||||
- $T_1 = 118$
|
||||
- $T_2 = 330$
|
||||
- $T_3 = 992$
|
||||
|
||||
Distribute the shares to the participants.
|
||||
|
||||
- Participant 1: $S_1$ and $T_1$
|
||||
- Participant 2: $S_2$ and $T_2$
|
||||
- Participant 3: $S_3$ and $T_3$
|
||||
|
||||
### Perform Operation
|
||||
|
||||
Each participant can perform the addition locally.
|
||||
|
||||
- $R_1 = S_1 + T_1 = 220 + 118 = 338$
|
||||
- $R_2 = S_2 + T_2 = 540 + 330 = 870$
|
||||
- $R_3 = S_3 + T_3 = 577 + 992 = 1569$
|
||||
|
||||
### Secret Reconstruction
|
||||
|
||||
Reconstruct the result from the shares:
|
||||
|
||||
- $R = S + T$
|
||||
- $R = (S_1 + S_2 + S_3) + (T_1 + T_2 + T_3) = (S_1 + T_1) + (S_2 + T_2) + (S_3 + T_3)$
|
||||
- $R = 338 + 870 + 1569 = 2777$
|
||||
|
||||
Since operations on secret-shared numbers produce secret-shared numbers, they can be executed one after the other and create more complex functions. This way, any function given as a circuit can be evaluated on secret-shared numbers:
|
||||
|
||||
- The secret inputs of the parties are secret-shared between them.
|
||||
- The circuit is evaluated, gate by gate, using secret-shared numbers.
|
||||
- The output is reconstructed from the final shares.
|
||||
|
||||
**Reconstruction only happens at the end.** In all previous steps, parties work with their own shares, so as not to reveal anything about the secret inputs.
|
||||
|
||||
## Security Implications
|
||||
|
||||
**No single party can be inherently trusted.** Parties interact with each other through the protocol and this outlines the expected behaviors and communications for each participant. The protocol specifies the actions to take at each step, including what messages to send, to whom, and when to stop.
|
||||
|
||||
Adversaries can **corrupt** parties at any stage of the process. Depending on the threat model, corrupted parties might either follow the protocol or deviate from it:
|
||||
|
||||
- **Semi-honest (Honest-but-curious)**: These adversaries corrupt parties but follow the protocol as specified. While they execute the protocol honestly, they try to learn as much as possible from the messages they receive from other parties.
|
||||
- **Malicious (Active)**: These adversaries may cause corrupted parties to deviate from the protocol.
|
||||
|
||||
In terms of security guarantees, we can classify protocols in:
|
||||
|
||||
- Protocols guaranteeing security in the presence of an **honest majority**
|
||||
- Protocols guaranteeing security against an **arbitrary number of corrupted parties**
|
||||
|
||||
Protocols of the first type are generally more **efficient** than those of the second type, even in hybrid models that implement ideal cryptographic primitives such as oblivious transfer. However, the second type of protocols offers a significant qualitative advantage, as they provide security without requiring any trust among parties. This is especially important in secure **two-party computation**.
|
||||
|
||||
## Performance
|
||||
|
||||
Despite the demand for this technology, its practical adoption remains limited. This limitation is mainly due to the efficiency challenges associated with the underlying protocols. Although generic protocols have been known for over 30 years, they were largely theoretical and too inefficient for practical use.
|
||||
|
||||
Two key factors impact performance: **communication** and **computation**.
|
||||
|
||||
### Communication
|
||||
|
||||
This includes the volume of data exchanged and the number of communication rounds required.
|
||||
|
||||
- **Data Volume**: Total size of messages exchanged between parties during the protocol execution.
|
||||
- **Communication Rounds**: Number of back-and-forth message exchanges required to complete the protocol.
|
||||
|
||||
### Computation
|
||||
|
||||
Refers to the amount of processing power required. The key factors here are the **complexity** and the **number** of cryptographic operations.
|
||||
|
||||
As evidenced by the results in \[[1](https://www.net.in.tum.de/fileadmin/TUM/NET/NET-2019-06-1/NET-2019-06-1_02.pdf)\], MPC is feasible for intranet applications with **limited peers, low latency, and high transmission rates**. However, it faces significant execution time increases under less optimal conditions. Specifically:
|
||||
|
||||
- **Transmission Rate**: Lower transmission rates lead to notable execution time delays.
|
||||
- **Number of Peers**: An increase in the number of peers results in longer execution times.
|
||||
- **Network Latency**: Even small delays in network latency can cause **substantial** increases in execution time.
|
||||
|
||||
Therefore, while real-time applications of MPC currently seem unfeasible, use cases with softer time constraints or faster infrastructure remain viable.
|
||||
|
||||
## Programmable Cryptography
|
||||
|
||||
MPC can be integrated with zero-knowledge proofs and fully homomorphic encryption to enhance security and functionality. Consider exploring the following resources on the [PSE Blog](https://mirror.xyz/privacy-scaling-explorations.eth/):
|
||||
|
||||
- [Zero to Start: Applied Fully Homomorphic Encryption](https://mirror.xyz/privacy-scaling-explorations.eth/D8UHFW1t48x2liWb5wuP6LDdCRbgUH_8vOFvA0tNDJA)
|
||||
- [Beyond Zero-Knowledge: What’s Next in Programmable Cryptography?](https://mirror.xyz/privacy-scaling-explorations.eth/xXcRj5QfvA_qhkiZCVg46Gn9uX8P_Ld-DXlqY51roPY)
|
||||
|
||||
## Conclusion
|
||||
|
||||
Secure multi-party computation is a powerful cryptographic tool that allows multiple parties to work together on a function without revealing their private data. Despite its potential, practical use has been slow due to issues like high communication costs and intense computational needs. However, as technology improves and protocols are refined, MPC applications are growing. This technology is key for enabling secure, distributed computation and data analysis in our increasingly connected digital world.
|
||||
|
||||
## Resources
|
||||
|
||||
These are some MPC projects we're building at [PSE](https://pse.dev/):
|
||||
|
||||
- [mpz](https://github.com/privacy-scaling-explorations/mpz): Collection of multi-party computation libraries written in Rust :crab:.
|
||||
- [tls-notary](https://github.com/tlsnotary/tlsn): Data provenance and privacy with secure multi-party computation.
|
||||
- [circom-2-arithc](https://github.com/namnc/circom-2-arithc): Circom to Arithmetic Circuit compiler.
|
||||
- [circom-2-arithc-ts](https://github.com/voltrevo/circom-2-arithc-ts): Circom to Arithmetic Circuit compiler TypeScript library.
|
||||
|
||||
And this is a great list of software libraries and frameworks to start building:
|
||||
|
||||
- [awesome-mpc](https://github.com/rdragos/awesome-mpc?tab=readme-ov-file#software)
|
||||
|
||||
## References
|
||||
|
||||
1. Dickmanns Ludwig and von Maltitz Marcel. "Performance of Secure Multiparty Computation." [PDF](https://www.net.in.tum.de/fileadmin/TUM/NET/NET-2019-06-1/NET-2019-06-1_02.pdf), 2019.
|
||||
2. Escudero Daniel. "An Introduction to Secret-Sharing-Based Secure Multiparty Computation." [PDF](https://eprint.iacr.org/2022/062.pdf), 2022.
|
||||
3. Evans David, Kolesnikov Vladimir, and Rosulek Mike. "A Pragmatic Introduction to Secure Multi-Party Computation." [PDF](https://securecomputation.org/docs/pragmaticmpc.pdf), 2018.
|
||||
4. Hastings Marcella, Hemenway Brett, Noble Daniel, and Zdancewic Steve. "SoK: General Purpose Compilers for Secure Multi-Party Computation." [PDF](https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=8835312), 2019.
|
||||
5. Ishai Yuval, Prabhakaran Manoj, and Sahai Amit. "Founding Cryptography on Oblivious Transfer – Efficiently." [PDF](https://iacr.org/archive/crypto2008/51570574/51570574.pdf), 2008.
|
||||
6. Lindell Yehuda. "Secure Multiparty Computation (MPC)." [PDF](https://eprint.iacr.org/2020/300.pdf), 2020.
|
||||
7. Mann Zoltán Ádám, Weinert Christian, Chabal Daphnee, and Bos Joppe W. "Towards Practical Secure Neural Network Inference: The Journey So Far and the Road Ahead." [PDF](https://eprint.iacr.org/2022/1483.pdf), 2022.
|
||||
8. Yakoubov Sophia. "A Gentle Introduction to Yao’s Garbled Circuits." [PDF](https://web.mit.edu/sonka89/www/papers/2017ygc.pdf), 2017.
|
||||
@@ -0,0 +1,245 @@
|
||||
---
|
||||
authors: ["0xZoey"]
|
||||
title: "Self-Sovereign Identity & Programmable Cryptography: Challenges Ahead"
|
||||
image: "cover.webp"
|
||||
tldr: "This post was written by [0xZoey](https://twitter.com/0xZoey), with contributions from Chance."
|
||||
date: "2025-01-23"
|
||||
canonical: "https://mirror.xyz/privacy-scaling-explorations.eth/zRM7qQSt_igfoSxdSa0Pts9MFdAoD96DD3m43bPQJT8"
|
||||
---
|
||||
|
||||
## Introduction
|
||||
|
||||
Self-Sovereign Identity (SSI) and its implementation through decentralized ledgers represents one of blockchain technology's most promising applications, particularly within the Ethereum ecosystem. While SSI adoption faces both technical and social challenges, this article focuses specifically on the advancement of privacy-preserving cryptographic primitives essential to its implementation.
|
||||
|
||||
Similar to decentralization, the fulfillment of fundamental “SSI” properties by current stacks currently exists on a wide spectrum. It is not uncommon for identity stacks to be agnostic to the choice of a digital wallet or verifiable data registry (distributed ledger), however, the interactions between information query, storage, and retrieval are often opaque. The flexibility and lack of oversight on how each stack is used in production and real-world applications means that some of these properties are lost in implementation, making understanding the technical nuance of SSI all the more critical.
|
||||
|
||||

|
||||
|
||||
Through extensive ecosystem consultation and research conducted by the zkID team at PSE over the past year, this article aims to contribute to the broader dialogue on SSI development. Enhanced industry collaboration can accelerate progress toward a unified vision of decentralized digital identity.
|
||||
|
||||
## What is Self-Sovereign Identity (SSI)?
|
||||
|
||||
Self-sovereign Identity is more than a technological concept - it's a philosophical reimagining of personal digital autonomy. Unlike traditional identity systems where third parties control and validate your personal information, the idea empowers individuals through:
|
||||
|
||||
- **Protection**: Utilizing advanced cryptographic techniques to protect personal information from unauthorized access or manipulation
|
||||
- **Selective Disclosure**: The ability to selectively disclose or choose exactly what data to share in any given interaction
|
||||
- **Portability**: The ability to move identity credentials across different platforms without losing reputation or data, avoiding vendor lock-in
|
||||
- **Interoperability**: Create and adhere to a unified identity standard that works seamlessly across various systems and jurisdictions
|
||||
|
||||
We highlight only a few [fundamental properties of SSI](https://ieeexplore.ieee.org/document/8776589) here most relevant to cryptography, but there are many more, each falling into foundational, security, controllability, flexibility, and sustainability categories and further subdivided into defined criteria. In our initial research, we attempted to evaluate stacks based on a standard [framework](https://www.notion.so/Evaluation-Framework-for-SSI-Solutions-8eceb793a5b442cb8da65acc3c337d5c?pvs=21), using these fundamental properties, in addition to [Digital Public Good Alliance’s Criteria](https://www.digitalpublicgoods.net/submission-guide), [Decentralized Identity Foundation’s](https://identity.foundation/) standards, [OpenSource Observer](https://www.opensource.observer/) Github Metrics, and an internal assessment of the cryptographic primitives used. The framework and the result of our research can be found [here](https://www.notion.so/pse-team/2e1e89e5192e409cacbfe3ea115baff4?v=92680356554a42cb981f41edd4a71820).
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
The use of digital signatures is prevalent across digital identities, but the use of [programmable cryptography](https://0xparc.org/blog/programmable-cryptography-1) is severely underutilized. Several standard bodies are exploring Zero-Knowledge Proofs (ZKPs) through various working groups including:
|
||||
|
||||
- [NIST](https://csrc.nist.gov/projects/pec/zkproof)
|
||||
- [W3C](https://www.w3.org/TR/vc-imp-guide/#zero-knowledge-proofs)
|
||||
- [Decentralized Identity Foundation (DIF)](https://identity.foundation/)
|
||||
- [Crypto Forum Research Group (CFRG) of the IETF](https://datatracker.ietf.org/rg/cfrg/documents/)
|
||||
- [zkProof.org](http://zkproof.org/)
|
||||
|
||||
It is worth mentioning that Verfiable Credential and Verfiable Presentation are [agnostic to proof types](https://www.w3.org/TR/vc-data-model-2.0/#proofs-signatures) and can be secured using both digital signatures and zero-knowledge proofs
|
||||
|
||||

|
||||
|
||||
Verifiable Credential Proof Example
|
||||
|
||||
Most of the work around ZKPs by standard groups is largely academic, but there are several cryptographic mechanisms [currently used](https://arxiv.org/pdf/2401.08196) for selective disclosure of verifiable credentials. We mention the three main ones here. They fall into two general categories, hashed values or selective disclosure signatures.
|
||||
|
||||
- [BBS+ Signature Scheme](https://identity.foundation/bbs-signature/draft-irtf-cfrg-bbs-signatures.html) (Used by MATTR)
|
||||
|
||||
- Enables selective disclosure of subsets of signed messages
|
||||
- Not currently compatible with mobile
|
||||
- Does not provide onchain verifiability
|
||||
- [Diffie-Hellman assumption](https://www.youtube.com/watch?v=QISNNmS8tMU)
|
||||
|
||||
- [CL signatures](https://github.com/hyperledger/anoncreds-clsignatures-rs) (Used by AnonCreds/Hyperledger)
|
||||
|
||||
- Predates-circom and the use of circuits
|
||||
- Only allows predicated proofs i.e. Proof you are above 18, AND have a driver's license.
|
||||
- Restricted by custom proofs
|
||||
- Requires interaction with identity holder
|
||||
- Computationally intensive
|
||||
- Does not provide onchain verifiability
|
||||
- Relies on RSA
|
||||
|
||||
- [Merkle Trees](https://docs.iden3.io/) (Used by PrivadoID/Iden3)
|
||||
|
||||
- Allows onchain verifiability
|
||||
- Capable of client-side proofs
|
||||
- Supports ZK Circuits
|
||||
- SNARK-based -currently not post-quantum
|
||||
|
||||
The availability of these schemes allows selective disclosure of data within verifiable credentials but as demonstrated, each comes with [unique drawbacks, and attributes](https://arxiv.org/pdf/2401.08196). In addition to the traditional “web2” identity there are also multiple projects working on onchain ZKP-enabled attestations, which can potentially provide unlinkable data structures onchain. The recent advancements in programmable cryptography particularly with ZKPs and MPC, provide potential alternative solutions for more robust SSI infrastructure throughout the entire stack from identifiers, secure communication, credentials, and frameworks. We discuss some of the key challenges to overcome for these technologies to be fully utilized.
|
||||
|
||||
## Overview: Key Challenges
|
||||
|
||||
At Devcon, PSE members convened with identity project leaders and standards organizations to identify critical barriers to SSI adoption. The following section examines each major challenge category, exploring its significance and proposed solutions. We analyze each challenge's fundamental nature, importance to the ecosystem, and the specific technical developments required to address it.
|
||||
|
||||
1. Client-side proving & Performance.
|
||||
2. Recursion and composability
|
||||
3. Proof of Personhood
|
||||
4. Post Quantum
|
||||
5. Unlinkability
|
||||
6. Usability & UX
|
||||
7. Governments and Regulation
|
||||
8. Standards and Interoperability
|
||||
|
||||
## Client Side Proving & Performance
|
||||
|
||||
Client-side proving enables users to generate cryptographic proofs directly on their devices, such as smartphones. It is crucial for digital identity systems because it ensures that sensitive personal information remains completely local, never leaving the device or being exposed to external servers or third-party provers.
|
||||
|
||||
The table below demonstrates the state of client-side proving with benchmarks provided by [mopro](https://github.com/zkmopro/mopro/blob/main/README.md#performance).
|
||||
|
||||

|
||||
|
||||
For widespread adoption, the performance of client-side proof generation must become efficient enough to run smoothly on the most common mobile hardware used by the target population, for practicality and accessibility. The development of client-side proving technologies faces these current bottlenecks:
|
||||
|
||||
- Performance on low-end mobile devices
|
||||
- Reducing computational complexity
|
||||
- Minimizing memory consumption
|
||||
- Lack of published benchmarks and comparisons of proving schemes
|
||||
|
||||
Offline, client-side verification will be equally important. The ability for mobile device verification in remote areas with a lack of connectivity is a minimum requirement for state or national-level implementation.
|
||||
|
||||
## Post Quantum
|
||||
|
||||
Current identity systems are vulnerable to a Post Quantum (PQ) future for several reasons. Many elliptical curve-based digital signature schemes currently in use, like ECDSA, are not PQ proof. With NIST moving the PQ timeline up to 2030, there is an urgent need to develop quantum-resistant cryptographic primitives. It is widely speculated that entities and organizations are already collecting encrypted data for PQ decryption in the future. With that in mind identity data onchain is not practical until we solve [PQ Ethereum](https://ethresear.ch/t/so-you-wanna-post-quantum-ethereum-transaction-signature/21291). With quantum computing on the horizon, more research must be done on PQ primitives, signature aggregation techniques, and benchmarking.
|
||||
|
||||
## Unlinkability
|
||||
|
||||
The potential for privacy leaks exist during information query, and retrieval, and by observing public data structures (i.e. DIDs or schemas) on verifiable data registries. Unless all information is stored locally, during an information query you reveal to the server what information was fetched. Malicious parties can also analyze data access patterns to derive information about a user and their data.
|
||||
|
||||
To fully represent human identity in all its dimensions, there is a fundamental need for the ability to aggregate identity data across different platforms and accumulate it into a body of reputation. Data provenance must be maintained through aggregation and transfer between accounts, whilst preserving unlinkability properties to protect privacy. An example of this is porting all your data between Twitter to Farcaster without losing social reputation.
|
||||
|
||||
Solutions for data provenance of web data with protocols such as [TLSNotary](https://tlsnotary.org/) are close to production, the next steps are to make these protocols compatible with Verifiable Credentials and [integrated with web browsers](https://brave.com/blog/distefano/).
|
||||
|
||||
Some other possible explorations include:
|
||||
|
||||
- [Oblivious RAM](https://www.youtube.com/watch?v=iGfgngtVLr4) (ORAM)
|
||||
- [Private Information Retrieval](https://blintzbase.com/posts/pir-and-fhe-from-scratch/) (PIR)
|
||||
- [Web2 Nullifiers using Verifiable Oblivious Pseudorandom Functions](https://curryrasul.com/blog/web2-nullifiers/) (vOPRF)
|
||||
- Private onchain [trust registries](http://drive.google.com/drive/home)
|
||||
- Research on different types of data structures
|
||||
- Atomic checks of DID-linked resources
|
||||
|
||||
## Liveness and Proof of Personhood
|
||||
|
||||
In an era of increasing digital impersonation, deepfakes, and sophisticated bot networks, proving that an online identity represents a real, unique human becomes critical. Proof of Personhood (PoP) tackles the challenge of gatekeeping anonymous actions such as voting via [MACI.](https://maci.pse.dev/) Biometric authentication whether it be facial recognition, fingerprints, or iris scanning is increasingly becoming more popular. The shift in trust assumptions to hardware components poses a centralization risk.
|
||||
|
||||
A [study](https://ia601600.us.archive.org/35/items/elopio-papers/2024-compressed_to_0-annotated.pdf) between 2019-2022 showed current methods are susceptible to programmatic gaming. It was found that “bots” can be substituted with human puppeteers. [The](https://ia601600.us.archive.org/35/items/elopio-papers/2024-compressed_to_0-annotated.pdf) research [has shown that individuals can be incentivized to surrender their identity for as little as two dollars, highlighting the urgent need for more robust incentive mechanis](https://ia601600.us.archive.org/35/items/elopio-papers/2024-compressed_to_0-annotated.pdf)ms on a social level. The prevention of manipulation of web of trust systems is required not just for Sybil resistance but also for collusion resistance, particularly when it exists off-chain. Some projects have adopted a tiered approach where points are assigned to different levels of authentication.
|
||||
|
||||
The use of state-issued RFID-equipped documentation as Proof of Personhood by teams like [Anon Aadhaar](https://github.com/anon-aadhaar/anon-aadhaar), [Openpassport](https://www.openpassport.app/), and [zkPassport](https://zkpassport.id/) are working on client-side verification and supporting signature algorithms used by different states. Although this is one viable method for PoP, it fails to serve individuals not recognized by any government or state. Another downside of web-of-trust systems is reliance on unique identifiers (nullifiers) to prevent double-spending, there is a non-zero chance that this can be [gamed or manipulated](https://www.youtube.com/watch?v=-mwUQp2qwjk).
|
||||
|
||||
## Recursion and Composability
|
||||
|
||||
[Recursion](https://www.youtube.com/watch?v=VmYpbFxBdtM) is the ability to prove a proof inside a proof. For example: If Bob can prove he knows Vitalik, Alice can prove she knows Bob, and if Joe knows Alice, Joe can prove he is 2 degrees of separation from Vitalik without revealing the intermediary, Bob. Existing frameworks like Circom and Groth16 currently suffer from recursion challenges.
|
||||
|
||||
Efficient recursion will unlock the ability to not only derive data from proofs but the ability to perform computation over the derived knowledge without exposing it to the proof-generating party. Creating a composable system that is capable of ingesting different data formats whilst allowing recursion will be a massive unlock for how verifiers and holders interact with credentials.
|
||||
|
||||
General purpose circuits that can be re-used to prove different types of data means that developers will not have to write custom circuits for each specific piece of identity data.
|
||||
|
||||
### **Progcrypto DX**
|
||||
|
||||
Developer experience is at the intersection of many key challenges. There are two groups of people, researchers writing proving systems, and engineers building with proving systems.
|
||||
|
||||
Researchers tend to implement program constraints directly in Rust. This allows them to write highly optimized code close to their prover implementations. Examples of this include Halo2 and Stwo. Unfortunately such systems are inaccessible to people unfamiliar with the codebase, and encourage poor design principles.
|
||||
|
||||
Engineers tend to use abstractions in the form of domain specific languages. By far the most popular language is circom: a 5 year old language with a limited standard library. Other attempts have been made to design languages, but they optimize toward features/abstraction and away from simplicity/runtime agnosticism. This makes them harder to reason about in the context of proofs, harder to adapt to new proving systems, and harder to write alternative compiler implementations.
|
||||
|
||||
There is significant room for innovation in the expression of cryptographic programs.
|
||||
|
||||
## Standards and Interoperability
|
||||
|
||||

|
||||
|
||||
https://xkcd.com/927/
|
||||
|
||||
The current digital identity landscape is largely fragmented: there are over 100 DID methods. Interoperability is not just a technical challenge but a fundamental requirement for creating a truly global, inclusive digital identity ecosystem. Some of these issues include:
|
||||
|
||||
- **Standardization Gaps**
|
||||
|
||||
- Lack of technical specifications particularly for ZKP-related schemes
|
||||
- Inconsistent standards between W3C and OpenID
|
||||
- Fragmented Decentralized Identifier (DID) approaches
|
||||
- Lack of Cross-Platform Verification solutions
|
||||
|
||||
- **Credential Formats**
|
||||
|
||||
- Existence of many incompatible data formats
|
||||
- Absence of a universal trust registry
|
||||
- Lack of a “unified” identity layer capable of ingesting credential formats for proof generation
|
||||
|
||||
Although it may be too early to define standards around programmable cryptography, writing initial technical specifications describing protocols, security assumptions, requirements, and verification procedures can serve as a reference and communication tool for all stakeholders. For those interested in contributing, specifications can be added in [this repo](https://github.com/zkspecs/zkspecs?tab=readme-ov-file); see an example specification [here](https://github.com/zkspecs/zkspecs/blob/specs/anon-aadhaar/specs/anon-aadhaar/specs.md).
|
||||
|
||||
## Usability and UX
|
||||
|
||||
User experience in SSI is about more than smooth interfaces – it's about creating systems that feel intuitive and respectful of individual agency by effectively managing consent. Vitalik elaborates on desired wallet functions such as Private Key Management for revocation, recovery and guardianship in this [post.](https://vitalik.eth.limo/general/2024/12/03/wallets.html) The issues of recovery and guardianship are non-trivial when it comes to key rotation. There are solutions currently in development with the use of account abstraction and protocols such as [ZK Email](https://prove.email/) are promising.
|
||||
|
||||
## Governments and Regulation
|
||||
|
||||
Traditional trust systems often rely on centralized government issuers and institutions. The challenge is creating identity systems that are not just technologically robust, but also legally compliant. In complying with [GPDR policies](https://gdpr-info.eu/art-17-gdpr/), in particular the [right to erasure](https://gdpr-info.eu/art-17-gdpr/) we are seeing projects tackle this through less secure, more centralized methods like the use of [validiums](https://ethereum.org/en/developers/docs/scaling/validium/) over other cryptographic primitives available. In particular with the EUID ARF framework, the ambiguity left in the choice of wallet and [Verifiable Data Registry](https://identity.foundation/faq/#what-is-a-verifiable-data-registry) means individual states are at risk of selecting less decentralized options.
|
||||
|
||||
When it comes to state-wide adoption, the ease of integration with government services and third-party vendors like banks and healthcare providers becomes an important consideration. Recent [studies](https://www.biometricupdate.com/202402/digital-id-can-boost-gdp-of-implementing-countries-up-to-13-uneca#:~:text=%E2%80%9CAnalysis%20of%20digital%20ID%20Systems,under%20the%20theme%20%E2%80%9CBuilding%20Inclusive) indicated that _“individual countries could unlock economic value equivalent to between 3 and 13 percent of GDP in 2030 from implementing digital ID programs”._ Aligning economic incentives and establishing appropriate legal frameworks to enable regulated entities will accelerate adoption.
|
||||
|
||||
The top-down approach of state-driven SSI adoption may seem like a quick path to adoption, but does pose a centralization risk with credential issuance. Some possible paths of exploration include the use of [MPC](https://mirror.xyz/privacy-scaling-explorations.eth/v_KNOV_NwQwKV0tb81uBS4m-rbs-qJGvCx7WvwP4sDg) for decentralized DID controllers and decentralized issuers.
|
||||
|
||||
## Possible Futures
|
||||
|
||||
The evolution of self-sovereign identity (SSI) could follow several distinct paths, each shaped by different technological and social forces.
|
||||
|
||||
### Government-Led SSI
|
||||
|
||||
Governments, particularly smaller nations, become primary advocates for SSI systems in this scenario. This shift would be driven by:
|
||||
|
||||
- Recognition of digital identity as critical national infrastructure
|
||||
- A desire to protect citizens from external existential threats
|
||||
- A willingness for sovereign control over identity systems driven by democratic or civic movements
|
||||
- Cross-border identity verification requirements set by international standard bodies like ICAO or EU leading member states change.
|
||||
|
||||
On a smaller scale, using SSI for micro-economies can serve as a good testing ground for this potential future, like a university campus or local community.
|
||||
|
||||
### Absence of Government-Led SSI
|
||||
|
||||
Governments and established issuers have little incentive to push for SSI infrastructure because they are already the source of trusted issuance. In this scenario, a path towards [self-attestation](https://hackmd.io/@wFJY6cGcRfmvPHiQ5VYP6w/BJjh3X2JJl) seems most probable, where users create their own proofs and self-issue credentials before presenting them to the verifier. The assumption here is that these self-attestations become an acceptable format for verification by third parties without communication with issuers.
|
||||
|
||||
### Technology Monopolies Dominate
|
||||
|
||||
Without proper technological safeguards, major technology companies could consolidate their control over digital identity through:
|
||||
|
||||
- Extensive data collection and correlation
|
||||
- Widespread third-party integration networks
|
||||
- Single sign-on authentication mechanisms.
|
||||
|
||||
This is a very present future as it is already evident that technology companies are creating inescapable dependencies.
|
||||
|
||||
A more distributed approach could emerge through social graph-based identity systems, characterized by:
|
||||
|
||||
- Localized trust networks
|
||||
- Reputation scoring
|
||||
- Community-based attestation mechanisms
|
||||
|
||||
While this approach offers enhanced privacy, its effectiveness may be limited to smaller communities, and corrupt actors could compromise trust networks. This is one less probable future as social graphs are localized and fragmented. Protocols like [Openrank](https://docs.openrank.com/) could serve as a peer-to-peer reputation system using [EigenTrust](https://nlp.stanford.edu/pubs/eigentrust.pdf) if capable of being private; the difficulty in implementation will then lie with the nuance in the context of trust between parties. One high potential use case for social graphs is bootstrapping decentralized issuance, where credentials are issued based on verified reputation using MPC.
|
||||
|
||||
### Global Registry
|
||||
|
||||
There is a need for a global identity registry to provide the largest anonymity set possible. Currently, there is a lack of a credibly neutral onchain registry capable of ensuring authentication across multiple chains. ENS’s future Namechain is a possible solution for a public version of this, with blockspace reserved for identity-specific use cases, and the ability to attach and detach from parent domains and subdomains. This loosely replicates the revocation and persistence characteristics needed for onchain identity attestation. PSE is currently [exploring](https://curryrasul.com/blog/web2-nullifiers/) possible solutions using vORPF to generate nullifiers for Web2 identities to serve as a global registry. Rarimo is also currently working on a [zk registry.](https://docs.rarimo.com/zk-registry/)
|
||||
|
||||
As of now, only DID and schemas are posted onchain. Identity data onchain is not a practical path forward until we shift to the use of post-quantum primitives. Identity data is not currently safe onchain as entities may already collect encrypted data for decryption in a PQ future. Supposing we solve PQ and unlinkable data structures, there lies a possible future for identity data to exist on a data availability layer, enabling the properties of persistence and access.
|
||||
|
||||
## Conclusion
|
||||
|
||||
Human identity is multifaceted and composed of many dimensions in real life. Replicating similar data structures in digital form is equally, if not more complex. The way we preserve privacy for human identity can essentially be deconstructed to how we interact with data itself, a matter prevalent beyond digital identity.
|
||||
|
||||
Some tangible actions the applied cryptography community can do are:
|
||||
|
||||
1. Write technical specifications
|
||||
2. Publish Performance benchmarks
|
||||
3. Research private data structures for trust registries
|
||||
4. Optimize existing tools for client-side proving and improve performance and memory usage
|
||||
5. Educate Governments and institutions on the availability of cryptography primitives to support their goals
|
||||
6. Establish cross-industry working groups for standardization and greater collaboration
|
||||
|
||||
We hope participants found the workshop and roundtable as insightful and engaging as we did! If you’re interested in joining future events or exploring opportunities to collaborate, we’d love to hear from you—feel free to [reach out!](https://discord.com/channels/943612659163602974/955585525081837628)
|
||||
51
articles/semaphore-community-grants-awarded-projects.md
Normal file
@@ -0,0 +1,51 @@
|
||||
---
|
||||
authors: ["PSE Team"]
|
||||
title: "Semaphore Community Grants: Awarded Projects"
|
||||
image: "cover.webp"
|
||||
tldr: ""
|
||||
date: "2023-01-24"
|
||||
canonical: "https://mirror.xyz/privacy-scaling-explorations.eth/5w1v6rxpP-E03rWDr3RliPyFJkptQwIPzet3Vb5jdcI"
|
||||
---
|
||||
|
||||
We are thrilled to announce the awarded projects from the recent [Semaphore Community Grants](https://esp.ethereum.foundation/semaphore-grants) round. This grants round invited builders, researchers, developers and privacy advocates to build privacy preserving applications integrating [Semaphore](http://semaphore.appliedzkp.org/), an anonymous signaling protocol.
|
||||
|
||||
The project proposals vary broadly in scope and geographic representation with teams from Afghanistan, Argentina, Canada, Côte d'Ivoire, China, Costa Rica, France, Germany, Hungary, Japan, Kenya, Slovenia, Turkey, United Kingdom, United States.
|
||||
|
||||
Through a thorough selection process, the four selected projects are:
|
||||
|
||||
## Block Qualified
|
||||
|
||||
Block Qualified aims to become an open education platform where anyone can create their own learning experience, gain credentials that attest to their knowledge, or verify the qualifications of others. All of this will be done directly on-chain, with verifiable data, and preserving the privacy of users via [ZK proofs](https://ethereum.org/en/zero-knowledge-proofs/).
|
||||
|
||||
- Semaphore will enable:
|
||||
|
||||
- Having a private reputation system for credential issuers, similar in scope to [Unirep](https://github.com/unirep).
|
||||
- Proving ownership of a given credential without revealing ownership of any other credential.
|
||||
- Proving credential prerequisites without revealing their identity.
|
||||
- Creating groups for users holding certain credentials.
|
||||
|
||||
Lens Protocol is a composable and decentralized social graph, ready for you to build on so you can focus on creating a great experience, not scaling your users.
|
||||
|
||||
[Lens Protocol](https://www.lens.xyz/) + Semaphore integration will allow users of the Lens protocol to create ZK Proofs using Semaphore that are verified and enforced by Lens to govern post interactions. This will allow users to regulate who can interact with their content (comment, mirror, etc).
|
||||
|
||||
## zkPoH - ZK Proof of Humanity
|
||||
|
||||
The main idea of this project is to prevent doxing in [Proof of Humanity (PoH)](https://proofofhumanity.id/) through ZK proofs.
|
||||
|
||||
Using Semaphore, a registered PoH user can anonymously prove their humanity and uniqueness. This provides a private sibyl resistance mechanism and prevents double-signaling.
|
||||
|
||||
## TAZ - Temporary Anonymous Zone
|
||||
|
||||
TAZ allowed [Devcon VI](https://mirror.xyz/privacy-scaling-explorations.eth/plfDBIpiKZVyNSJWhE9vix76JaJoJ1seDfRAddV7HEc) attendees to experience privacy and anonymity and explore the possibilities that can be built with Semaphore protocol.
|
||||
|
||||
Visitors were offered different paths to explore: anonymously ask and answer questions, give feedback, or co-create generative art. TAZ also included identity integrations with [heyAnon](https://www.heyanon.xyz/) (post anonymously on Twitter) and [Zkitter](https://www.zkitter.com/explore) (anonymous Twitter)
|
||||
|
||||
Semaphore identities were the centerpiece of TAZ identity management. Users generated a new Semaphore identity each time a physical QR code from Devcon VI was scanned. Users sent signals like feedback, art submission and posts. Each signal included a proof that the signal was sent from a member of the Devcon VI group.
|
||||
|
||||
## Get involved
|
||||
|
||||
We are thankful for [Semaphore community](https://discord.gg/6mSdGHnstH) and we´re looking forward to hearing from more cool projects building on top of Semaphore!
|
||||
|
||||
If you missed this round and are researching something in this space, consider submitting a project inquiry to the [Ecosystem Support Program.](https://esp.ethereum.foundation/)
|
||||
|
||||
Keep up with these and other awesome projects built on top of Semaphore in our [Discord](https://discord.com/invite/6mSdGHnstH).
|
||||
115
articles/semaphore-community-grants.md
Normal file
@@ -0,0 +1,115 @@
|
||||
---
|
||||
authors: ["PSE Team"]
|
||||
title: "Semaphore Community Grants"
|
||||
image: "cover.webp"
|
||||
tldr: ""
|
||||
date: "2022-09-21"
|
||||
canonical: "https://mirror.xyz/privacy-scaling-explorations.eth/g5WjOtK4R3rYfLKyqpSXsbNBcj36jzsjgnV2KT2rthM"
|
||||
---
|
||||
|
||||
**The [Privacy and Scaling Explorations Team](https://appliedzkp.org/) is sponsoring a dedicated round of grants for applications that integrate the [Semaphore](https://semaphore.appliedzkp.org/) anonymous signaling protocol. Semaphore provides zero-knowledge primitives that enable developers to build powerful privacy preserving applications. With this grant round, we’re encouraging builders to try out these tools in real-world applications that matter to your communities.**
|
||||
|
||||
## Privacy matters
|
||||
|
||||
Whether it’s talking confidentially with friends, anonymously broadcasting messages, or simply wanting to choose which aspects of our identity we reveal in which contexts, privacy allows us to express ourselves freely and without fear. Privacy is a tool that should be accessible to as many people as possible, and PSE’s goal is to foster a collaborative community to make access to privacy a reality in everyday life.
|
||||
|
||||
\*\*
|
||||
\*\*If you’re a developer with an idea to use Semaphore for good, we want to hear from you!
|
||||
|
||||
## Semaphore as a privacy layer
|
||||
|
||||
Semaphore is designed to be a simple and generic *privacy layer* for decentralized applications (dApps) on Ethereum.
|
||||
|
||||
Semaphore is a [zero-knowledge](https://z.cash/technology/zksnarks) protocol that allows Ethereum users to prove their membership of a group and send signals such as votes or endorsements without revealing their original identity.
|
||||
|
||||
With Semaphore, you can allow your users to do the following:
|
||||
|
||||
1. [Create a private identity and receive a provable anonymous public identity](https://semaphore.appliedzkp.org/docs/guides/identities).
|
||||
2. [Add an anonymous public identity to a group (a *Merkle tree*)](https://semaphore.appliedzkp.org/docs/guides/groups).
|
||||
3. [Send a verifiable, anonymous vote or endorsement (a *signal*)](https://semaphore.appliedzkp.org/docs/guides/proofs).
|
||||
|
||||
## Semaphore in action
|
||||
|
||||
You can integrate Semaphore into other primitives, POCs, or end-user applications. Below is a list of several apps already using Semaphore. They may give you an idea of what to build.
|
||||
|
||||
- [Unirep](https://github.com/Unirep/Unirep) is a social media platform that uses anonymous reputation. Semaphore identities allow users to join with a unique identity, prove they’re eligible to post or give feedback, and choose how much of their stable identity they reveal in any given interaction.
|
||||
- [Interep](https://interep.link/) uses zero knowledge proofs to verify reputation from an existing account such as Github or Twitter without retaining any identifying information.
|
||||
- [Zkitter](https://www.zkitter.com/explore/) is a decentralized social network based on Ethereum and ENS. It uses Semaphore for anonymous user identities.
|
||||
- [Emergence](https://ethglobal.com/showcase/emergence-o3tns) incentivizes communities to participate or contribute to online meetings. The project uses Semaphore to preserve the anonymity of group members and was a finalist at the ETHMexico hackathon.
|
||||
|
||||
## Wishlist
|
||||
|
||||
Surprise us with your creativity! But here are a few ideas for privacy-preserving applications we would love to see built out:
|
||||
|
||||
- General
|
||||
|
||||
- Anonymous feedback
|
||||
- Anonymous voting
|
||||
- Whistleblower protection
|
||||
- Anonymous chat for members of an organization or school
|
||||
|
||||
- Professional
|
||||
|
||||
- Prove professional skills, credentials, or certificates without revealing identity
|
||||
- Prove one does not have a criminal record without revealing identifying information
|
||||
|
||||
- Medical
|
||||
|
||||
- Privately share vaccination status
|
||||
- Privately share medical history
|
||||
|
||||
- Government
|
||||
|
||||
- Privately prove income or residence to access government benefits and services
|
||||
- Privately prove the number of countries one can visit with a certain passport
|
||||
- Privately share one’s age
|
||||
|
||||
- Cybersecurity
|
||||
|
||||
- Prove a device has the latest security patches and versions without disclosing any personal identifying information
|
||||
|
||||
## How to apply
|
||||
|
||||
Grants are decided on a case-by-case basis. You can apply with more than one proposal so long as each proposal is unique and meets the requirements.
|
||||
|
||||
- Ideas and projects at any stage are welcome:
|
||||
|
||||
- Idea phase
|
||||
- Proof-of-concept
|
||||
- Work in progress
|
||||
- Fully fleshed-out project
|
||||
|
||||
- Requirements:
|
||||
|
||||
- Proposals must be in English
|
||||
- Work must be open source with a free and permissive license
|
||||
- Published work must be accessible by a URL
|
||||
|
||||
- What we look for:
|
||||
|
||||
- Potential impact on broadening the Semaphore community
|
||||
- Quality of contribution to the Semaphore ecosystem
|
||||
- Clarity, conciseness, and organization of documentation
|
||||
- Novelty in reducing the barrier of entry to zero knowledge and privacy applications
|
||||
- Overall quality and clarity of data analysis or data visualization.
|
||||
|
||||
- Application details
|
||||
|
||||
- Application dates: September 16th to October 28th, 2022
|
||||
- Apple here: [https://esp.ethereum.foundation/semaphore-grants](https://esp.ethereum.foundation/semaphore-grants)
|
||||
|
||||
## FAQ
|
||||
|
||||
- How can I learn more about Semaphore?
|
||||
|
||||
- Check out the [Semaphore Github](https://github.com/semaphore-protocol) repo or go to the [Semaphore website](http://semaphore.appliedzkp.org/).
|
||||
|
||||
- I have more questions, where do I go?
|
||||
|
||||
- The best place to ask technical questions about the Semaphore protocol or questions about this grant round is in our [Discord server](https://discord.gg/6mSdGHnstH).
|
||||
- We will also be at Devcon VI in Bogota. Come say hello if you’re in town! We will be located at the Temporary Anonymous Zone (TAZ) in the Community Hub.
|
||||
- You can also email questions to: [semaphore-grants@ethereum.org](http://mailto:semaphore-grants@ethereum.org/)
|
||||
|
||||
- What if I miss the deadline?
|
||||
|
||||
- The Ethereum Foundation has a general grants initiative called the [Ecosystem Support Program (ESP)](https://esp.ethereum.foundation/). If you miss the deadline for this dedicated round of grants, but have a proposal, head on over to ESP for a rolling grants process.
|
||||
137
articles/semaphore-v2-is-live-privacy-scaling-explorations.md
Normal file
@@ -0,0 +1,137 @@
|
||||
---
|
||||
authors: ["PSE Team"]
|
||||
title: "Semaphore V2 is Live! - Privacy & Scaling Explorations"
|
||||
image: null
|
||||
tldr: ""
|
||||
date: "2022-08-26"
|
||||
canonical: "https://mirror.xyz/privacy-scaling-explorations.eth/ImQNsJsJuDf_VFDm9EUr4njAuf3unhAGiPu5MzpDIjI"
|
||||
---
|
||||
|
||||
|
||||
|
||||
Originally published on Jul 6, 2022:
|
||||
|
||||
Semaphore is a zero-knowledge protocol that lets Ethereum users prove their membership of a group and send signals such as votes or endorsements without revealing their original identity. The ability to do these two simple things anonymously opens up a world of possibilities — some of which are already being worked on, some we can’t wait to see explored and hopefully some we haven’t even thought of yet :D.
|
||||
|
||||
Semaphore is not a user-facing application, but is designed to provide powerful and simple tools for Ethereum devs to build dapps with private credentials. It was first [proposed](https://semaphore.appliedzkp.org/whitepaper-v1.pdf) by [Kobi Gurkan](https://github.com/kobigurk), [Koh Wei Jie](https://github.com/weijiekoh) and [Barry Whitehat](https://github.com/barryWhiteHat), and [V1](https://github.com/semaphore-protocol/semaphore/tree/version/1.0.0) was released in 2019.
|
||||
|
||||
We’re excited to share that [Semaphore V2](https://github.com/semaphore-protocol/semaphore/releases/tag/v2.0.0) has just been released with lots of improvements to the protocol and developer tooling, thanks to extensive contributions by [Cedoor](https://github.com/cedoor) and [Andrija Novakovic](https://github.com/akinovak). Contracts have been [deployed](https://semaphore.appliedzkp.org/docs/deployed-contracts) to Kovan, Goerli and Arbitrum.
|
||||
|
||||
## How does Semaphore work?
|
||||
|
||||
Semaphore provides three main functions — creating private identities, adding identities to groups and sending anonymous signals.
|
||||
|
||||
## Identities
|
||||
|
||||
There are several public and private values associated with a user’s identity:
|
||||
|
||||
- **Identity trapdoor:** a secret value that can be used to derive a public value, but not vice versa — similar to how you can derive an Ethereum address from a private key, but you can’t determine the private key from the public address.
|
||||
- \*\*Identity nullifier: \*\*a secret value which is hashed with a public value to detect double signaling while preserving anonymity.
|
||||
- \*\*Identity secret: \*\*a secret value representing the user’s identity, derived by hashing together the identity trapdoor and identity nullifier.
|
||||
- **Identity commitment:** a public value which is a hash of the identity secret.
|
||||
|
||||

|
||||
|
||||
Generating a Semaphore identity
|
||||
|
||||
The identity trapdoor, identity nullifier and identity secret are generated by the user when they create their Semaphore identity. These values are never revealed on-chain; instead, they are used to create zero knowledge proofs so the user can prove things about themselves publicly without revealing their identity.
|
||||
|
||||
## Groups
|
||||
|
||||
Groups are an important concept when we speak about privacy and zero knowledge technologies. They can be thought of as anonymity sets, and are a way to establish necessary trust between a set of participants while letting users keep control over how their identities are stored and used.
|
||||
|
||||
In Semaphore, a “group” can mean many things. It might be people who have an account on some platform, employees of a specific company, voters in an election — essentially, any set of individuals who are eligible to participate in something.
|
||||
|
||||
For example, you might require an email address from a particular university in order to join a group. Rather than storing that email in a database and using it to log in, tying all of their activity to their identity, a user proves only that they have the credential. There is no stored record of which email address was used. Members of the group can be confident that they are interacting with fellow students or colleagues, even though individual identities are unknown.
|
||||
|
||||

|
||||
|
||||
Adding members to a Semaphore group
|
||||
|
||||
When a user joins a group, their public identity commitment is added to that group’s [Merkle tree](https://en.wikipedia.org/wiki/Merkle_tree). This lets the protocol check that the user is in the group and is therefore eligible to send signals, without seeing their identity.
|
||||
|
||||
There’s no single approach to groups. Semaphore uses incremental binary Merkle trees, Poseidon hashes and Semaphore identity commitments as tree leaves (more on that later), but different types of Merkle trees, hash functions, or leaf values could theoretically be used. The goal is that Semaphore groups can act as a standard to improve composability and interoperability between protocols and applications in the Ethereum ecosystem.
|
||||
|
||||
## Signals
|
||||
|
||||
Signals are signed messages which are broadcast on-chain. They contain an endorsement of some data, such as a vote, along with proofs that:
|
||||
|
||||
- The user is a member of the group, i.e. the sender belongs to a valid Merkle tree
|
||||
- The same user created the signal and the proof.
|
||||
|
||||
Each signal also contains a nullifier, which is a hash of the identity nullifier and a public **external nullifier**. If the nullifier has been used before, the protocol knows that the user has signaled more than once.
|
||||
|
||||
## New in V2
|
||||
|
||||
The recently-released V2 introduced a number of changes and improvements, including:
|
||||
|
||||
- Circuits have been simplified: it is no longer necessary to have an EdDSA private key, enabling a simpler circuit and more efficient zero-knowledge proof generation.
|
||||
- The hash function used for identity commitments and Merkle trees moved from MiMC to Poseidon, which has some security advantages, roughly halves the proving time and improves gas efficiency.
|
||||
- Contracts have been modularized, giving developers more freedom to use what they need and choose between different implementation levels.
|
||||
- Three new JavaScript libraries were created: [Semaphore identities](https://github.com/semaphore-protocol/semaphore.js/tree/main/packages/identity), [Semaphore groups](https://github.com/semaphore-protocol/semaphore.js/tree/main/packages/group), [Zero-knowledge proofs](https://github.com/semaphore-protocol/semaphore.js/tree/main/packages/proof)
|
||||
- An [audit](https://semaphore.appliedzkp.org/audit-v2.pdf) of Semaphore v2 was completed in May.
|
||||
|
||||
## Semaphore in Action
|
||||
|
||||
There are several apps already using Semaphore.
|
||||
|
||||
- [Unirep](https://github.com/Unirep/Unirep) is a social media platform that uses anonymous reputation. Semaphore identities allow users to join with a unique identity, prove they’re eligible to post or give feedback, and use pseudonymous “personas” while choosing how much of their stable identity they reveal in any given interaction.
|
||||
- [Interep](https://interep.link/) uses zero knowledge proofs to verify reputation from an existing account such as Github or Twitter without retaining any identifying information. Users’ Semaphore identities are added to a “group” according to the strength of their imported reputation. Interep group membership can then be used as an access point for apps and services that need proof of humanity for sybil protection.
|
||||
- [Auti.sm](https://docs.auti.sm/) is a decentralized social network based on Ethereum and ENS. It uses Semaphore for anonymous user identities.
|
||||
|
||||
## What’s inside?
|
||||
|
||||
On a more technical level, Semaphore combines **zero knowledge proofs** and **Ethereum smart contracts**.
|
||||
|
||||
## Proofs
|
||||
|
||||
[Zero knowledge proofs](https://semaphore.appliedzkp.org/docs/guides/proofs) are the key to Semaphore’s ability to provide sybil- and spam-resistant private credentials. Every signal sent by a user contains proofs of the user’s group membership and the validity of the signal. Proofs are generated off-chain, and can be verified either on-chain or off-chain.
|
||||
|
||||
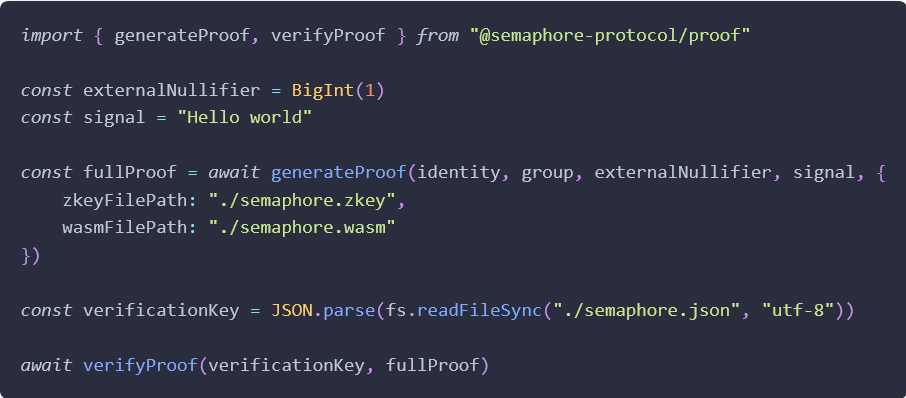
|
||||
|
||||
Semaphore proof
|
||||
|
||||
The secure parameters for these proofs were generated in a t[rusted setup ceremony](https://storage.googleapis.com/trustedsetup-a86f4.appspot.com/semaphore/semaphore_top_index.html) which was recently completed with over 300 participants.
|
||||
|
||||
## Circuit
|
||||
|
||||
The [circuit](https://semaphore.appliedzkp.org/docs/technical-reference/circuits) structures how the ZKP inputs and outputs are generated, hashed and verified. It has three main components:
|
||||
|
||||
- \*\*Proof of membership: \*\*An identity commitment is generated from the hash of the identity trapdoor and identity nullifier, then verifies the membership proof against the Merkle root and identity commitment.
|
||||
- \*\*Nullifier hash: \*\*nullifier hashes are saved in a Semaphore smart contract, so that the smart contract itself can reject a proof with an already used nullifier hash. The circuit hashes the identity nullifier and the external nullifier, then checks that it matches the given nullifier hash.
|
||||
- \*\*Signal: \*\*The circuit calculates a dummy square of the signal hash to prevent any tampering with the proof; if the public input changes then verification will fail.
|
||||
|
||||
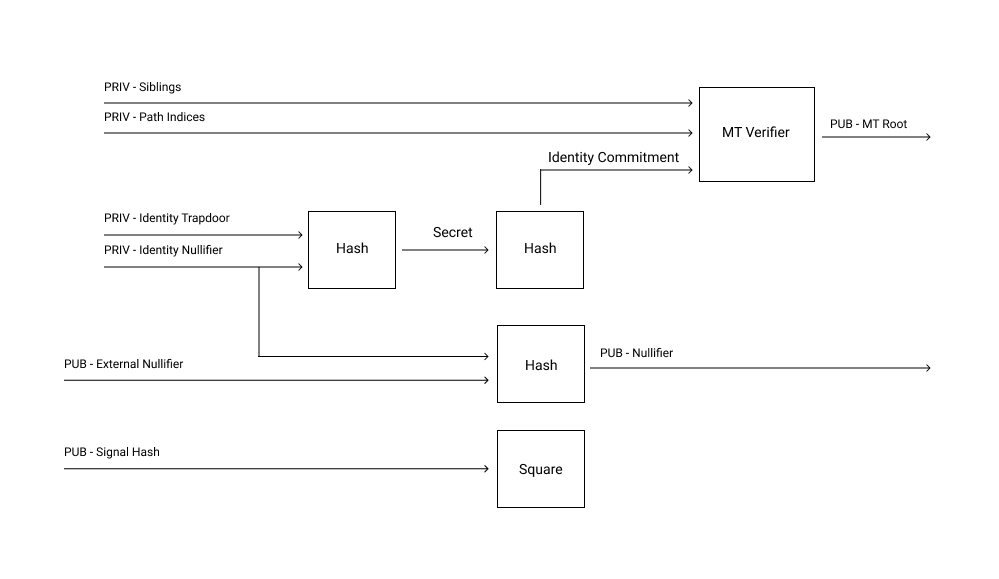
|
||||
|
||||
Semaphore circuit
|
||||
|
||||
## Smart Contracts
|
||||
|
||||
Semaphore includes three types of [contracts](https://semaphore.appliedzkp.org/docs/technical-reference/contracts):
|
||||
|
||||
- \*\*Base contracts **provide the core functions.** \*\*\`SemaphoreCore.sol\` contains the functions to verify Semaphore proofs and to save the nullifier hash in order to avoid double signaling; \`SemaphoreGroups.sol\` contains the functions to create groups and add or remove members.
|
||||
- \*\*Extension contracts \*\*contain application logic for specific use-cases. \`SemaphoreVoting.sol\` contains essential functions to create polls, add voters and cast votes anonymously; \`SemaphoreWhistleblowing.sol\` contains essential functions to create entities, add whistleblowers and publish leaks anonymously. More extensions will be added in the future.
|
||||
- \*\*Verifier contracts \*\*verify Semaphore proofs generated with a specific tree depth. For example \`Verifier20.sol\` can verify proofs where the depth of the tree is 20, which means that the group used for those proofs can have a maximum of 2 ^20=1048576 members. A developer can choose to use a [pre-deployed verifier](https://semaphore.appliedzkp.org/docs/deployed-contracts#verifiers) or [deploy their own](https://github.com/semaphore-protocol/semaphore/tree/main/contracts/verifiers), with depth ranging from 16–32.
|
||||
|
||||
## What’s next?
|
||||
|
||||
Semaphore will continue to be developed and improved over time. Some potential future directions include:
|
||||
|
||||
Improving the developer experience:
|
||||
|
||||
- Admin dashboard and APIs to manage zero-knowledge groups with a cloud or self-hosted infrastructure
|
||||
- Special contracts to allow only qualified users to join specific Semaphore groups (e.g. contract to allow only eth users with POAP to join the ‘poap’ group).
|
||||
- Improve current extension contracts and add new use cases.
|
||||
|
||||
Maturing the protocol:
|
||||
|
||||
- Investigate plonkish circuits and other proving systems
|
||||
- Support proof aggregation
|
||||
|
||||
**How to get involved**
|
||||
|
||||
Semaphore is a project by and for the Ethereum community, and we welcome all kinds of [contributions](https://github.com/semaphore-protocol#ways-to-contribute). You can find guidelines for contributing code on [this page](https://github.com/semaphore-protocol/semaphore/blob/main/CONTRIBUTING.md).
|
||||
|
||||
If you want to experiment with Semaphore, the [Quick Setup guide](https://semaphore.appliedzkp.org/docs/quick-setup) and [Semaphore Boilerplate](https://github.com/semaphore-protocol/boilerplate) are great places to start. Feel free to [get in touch](https://t.me/joinchat/B-PQx1U3GtAh--Z4Fwo56A) with any questions or suggestions, or just to tell us about your experience!
|
||||
|
||||
We would also love to hear from developers who are interested in integrating Semaphore into new or existing dapps. Let us know what you’re working on by [opening an issue](https://github.com/semaphore-protocol/semaphore/issues/new?assignees=&labels=documentation++%F0%9F%93%96&template=----project.md&title=), or get in touch through the Semaphore [Telegram group](https://t.me/joinchat/B-PQx1U3GtAh--Z4Fwo56A) or the [PSE Discord](https://discord.com/invite/g5YTV7HHbh).
|
||||
148
articles/semaphore-v3-announcement.md
Normal file
@@ -0,0 +1,148 @@
|
||||
---
|
||||
authors: ["PSE Team"]
|
||||
title: "Semaphore v3 Announcement"
|
||||
image: "cover.webp"
|
||||
tldr: ""
|
||||
date: "2023-02-09"
|
||||
canonical: "https://mirror.xyz/privacy-scaling-explorations.eth/Yi4muh-vzDZmIqJIcM9Mawu2e7jw8MRnwxvhFcyfns8"
|
||||
---
|
||||
|
||||
Semaphore V3 is live!
|
||||
|
||||
We are happy to announce the release of Semaphore [v3.0.0](https://github.com/semaphore-protocol/semaphore/releases) with lots of improvements to the protocol and developer tooling.
|
||||
|
||||
## Background
|
||||
|
||||
Semaphore is a zero-knowledge protocol that lets Ethereum users prove their membership of a group and send signals such as votes or endorsements without revealing their original identity. The ability to do these two simple things anonymously opens up a world of possibilities — some of which are already being worked on, some we can’t wait to see explored and hopefully some we haven’t even thought of yet :D.
|
||||
|
||||
Semaphore is not a user-facing application. The protocol is designed to allow Ethereum developers to build dapps with privacy as a foundation.
|
||||
|
||||
## Highlights
|
||||
|
||||
### New features
|
||||
|
||||
- **[Semaphore CLI](https://github.com/semaphore-protocol/semaphore/tree/main/packages/cli):** Your Semaphore project can now be created with a simple command-line tool.
|
||||
- **[Semaphore Hardhat plugin](https://github.com/semaphore-protocol/semaphore/tree/main/packages/hardhat):** The Hardhat plugin for Semaphore can be used to deploy the `Semaphore.sol` contract with a Hardhat task.
|
||||
- **[Boilerplate](https://github.com/semaphore-protocol/boilerplate):** Try Semaphore with our new boilerplate demo and learn more about how it works by exploring the code. The boilerplate is also a GitHub template you can use for your project.
|
||||
|
||||
Read the whole list of features in the [ChangeLog](https://github.com/semaphore-protocol/semaphore/releases) and learn how to upgrade in the Migration section.
|
||||
|
||||
### Refactoring
|
||||
|
||||
- One Verifier to rule them all: 17 verifier contracts were consolidated to a single one, keeping the same capabilities but reducing 3800 lines of code - thus making Semaphore deployments much cheaper.
|
||||
- New Poseidon library: @semaphore-protocol/identity now uses poseidon-lite, a stripped down Poseidon implementation pulled from circomlibjs v0.0.8. This made it possible to drastically reduce previously unused code imported from the circomlibjs library.
|
||||
|
||||
### Bug fixes
|
||||
|
||||
- Editor’s entity may be overwritten (V-SEM-VUL-003)
|
||||
- merkleRootDuration cannot be changed (V-SEM-VUL-007)
|
||||
- Infinite loop if input array is too large (V-SEM-VUL-006)
|
||||
- Different checks used to determine if group exists (V-SEM-VUL-010)
|
||||
- No zero value validation (V-SEM-VUL-001)
|
||||
|
||||
See the audit report for some of the major bugs we addressed.
|
||||
|
||||
### Audit
|
||||
|
||||
Semaphore v3 was formally audited and verified by our friends at [Veridise](https://twitter.com/VeridiseInc). You can read the full report here: [Veridise Auditing Report - Semaphore version 3.0](https://github.com/semaphore-protocol/semaphore/files/10492413/VAR_Semaphore.pdf) and their blogpost [Breaking the Tree: Violating Invariants in Semaphore](https://medium.com/veridise/breaking-the-tree-violating-invariants-in-semaphore-4be73be3858d)
|
||||
|
||||
We believe that building on secure foundations increases trust for all layers, a trust that is essential to propelling our industry forward. We´re very happy to have worked with Veridise and look forward to continuing our collaboration in the future.
|
||||
|
||||
### Documentation
|
||||
|
||||
- [Documentation V3](https://semaphore.appliedzkp.org/docs/introduction) is released
|
||||
- [i18n Support](https://lingoport.com/what-is-i18n/): our website now supports local languages and cultural settings. We are [happy to welcome](https://github.com/semaphore-protocol#ways-to-contribute) anyone who would like to help us translate the Semaphore website and documentation into other languages.
|
||||
- Search bar: we’re incorporating a search bar to our documentation.
|
||||
|
||||
### Translations
|
||||
|
||||
We completed our first efforts for the website documentation translation:
|
||||
|
||||
🇪🇸 [#67](https://github.com/semaphore-protocol/website/pull/67): completes Spanish translations
|
||||
|
||||
A blogpost sharing the translation decisions and rationale will be shared soon, as well as future approaches to make the translation process scalable to other languages.
|
||||
|
||||
## Semaphore in Action
|
||||
|
||||
There are many dapps already using Semaphore in categories spanning voting, social media, gaming, IoT and education. These dapps are in different stages of maturity, from POC and demos to live products. Below is a subset that shows a range of what’s possible, which we hope will inspire future projects:
|
||||
|
||||
**Governance**
|
||||
|
||||
- [Coeo](https://showcase.ethglobal.com/hackfs/coeo) is a decentralized collaboration platform that prioritizes privacy and enables organizations to collaborate through a network-wide discussion forum and social network.
|
||||
- [Ethereum Social Contract](https://ethglobal.com/showcase/ethereum-social-contract-gwt57) proposes a decentralized and compliant justice system for web3. Semaphore provides the zkSNARK underpinning for our private transaction dApp.
|
||||
- [Emergence](https://ethglobal.com/showcase/emergence-o3tns) is an on-chain video platform that distribute tokens during calls, generates a script for DAO documentation and increases DAO health and onboarding quality.
|
||||
- [heyanon](https://www.heyanon.xyz/) is a way for people who are in cool groups or did cool stuff on Ethereum to broadcast messages anonymously on Twitter.
|
||||
- [Heyanoun](https://www.heyanoun.xyz/) allow Nouners to express what they believe while maintaining anonymity. Nouners can post credible pseudonymous messages at heyanoun.xyz.
|
||||
- [Om](https://om-rose.vercel.app/) is a DAO platform that has a decentralized and private data storage layer. In this type of access, specific users will have access to properties of the data and not the full data.
|
||||
- [Sacred](https://www.thatsacred.place/) is an anonymous forum to foster horizontal, inclusive and effective communities.
|
||||
- [Zero Voting](https://zkvote.vercel.app/) allows you to vote quadratically among the choices you get without revealing your address.
|
||||
- [zkPoH](https://github.com/elmol/zk-proof-of-humanity) brings privacy to Proof of Humanity (PoH). By using Semaphore, a registered PoH user can prove their humanity without doxing themselves.
|
||||
- [zkVoice](https://ethglobal.com/showcase/zkvoice-fighting-plutocrat-dao-communities-ptrzp) is a coordination tool that allows community members with less voting power to secretly signal their disapproval and come together to beat the Plutocrat Moloch.
|
||||
|
||||
**IoT Gating**
|
||||
|
||||
- [zMorpheus](https://github.com/a42io/ETHBogota) delivers a pseudonymous, seamless zk-based token-gating solution for real-world use cases of proving ownership of NFTs with privacy on IoT Devices.
|
||||
|
||||
**Education / Professional**
|
||||
|
||||
- [Block Qualified](https://github.com/0xdeenz/bq-core) aims to become an open education platform where anyone can create their own learning experience, gain credentials and attest qualifications while preserving their privacy.
|
||||
- [Continuum](https://continuum.tomoima525.com/home) proves your web2 work experience on-chain without revealing your identity.
|
||||
|
||||
**Proof of Personhood / Anti Sybil**
|
||||
|
||||
- [Interep](https://interep.link/) uses zero knowledge proofs to verify reputation from an existing account such as Github or Twitter without retaining any identifying information.
|
||||
- [Menshen](https://ethglobal.com/showcase/menshen-i2kq1) provides sybil resistant proof-of-personhood NFTs, and is built for everyone. It does this by allowing anyone with a smartphone camera or webcam to mint a Menshen ID.
|
||||
- [Worldcoin](https://worldcoin.org/blog/developer/the-worldcoin-protocol) is a Privacy-Preserving Proof-of-Personhood Protocol (PPPoPP). Biometric data is hashed to create a Semaphore identity which is added to a group for future UBI.
|
||||
|
||||
**NFT Identity**
|
||||
|
||||
- [Arbor](https://arbor.audio/) is a Schelling game where the objective is to publicly co-create songs worthy of purchase by NFT collectors using Semaphore as anonymous voting on stems.
|
||||
- [ClubSpace](https://www.joinclubspace.xyz/) is a virtual party platform that enables creators to import music playlists, promote NFTs, and provide free NFTs to attendees who can prove their attendance via ZKPs.
|
||||
- [ZKTokenProof](https://polygon.zktokenproof.xyz/) token-gating solution for ticketing features with privacy. Anyone can manage events with NFT gating where participants don’t need to reveal their wallet addresses.
|
||||
|
||||
**Social Media**
|
||||
|
||||
- [Unirep](https://github.com/Unirep/Unirep) is a social media platform that uses anonymous reputation, allowing people to provide relational context without revealing specifics of their history.
|
||||
- [Truth](https://ethglobal.com/showcase/truth-2wbd7) is a photo based social media network where pictures need to be taken in real-time inside the app.
|
||||
- [Zkitter](https://mirror.xyz/privacy-scaling-explorations.eth/P4jDH1gLrVQ-DP5VyIKQrlPAJUTDhtXZkFl2vp8ewSg) is an anon-friendly social network that provides familiar social media functions such as posting, chatting, following, and liking, but with a private identity layer under the hood.
|
||||
- [ZK3](https://github.com/monemetrics/lensbot-docs/blob/master/docs/zk3.md) is a Lens Protocol + Semaphore Integration that allows users of the Lens protocol to govern post interactions (who can comment, mirror, etc) through ZKPs and group membership.
|
||||
|
||||
**Gaming / DeFi**
|
||||
|
||||
- [Chain Statements](https://ethglobal.com/showcase/chain-statements-kdurw) is a way to generate statements for your crypto funds using ZKPs privately and permissionlessly.
|
||||
- [zkIdentity](https://github.com/sigridjineth/zkIdentity) is a private identity claim system with zero-knowledge for DarkForest.eth. It allows a a previous winner claim prizes without revealing the recipient's Ethereum address.
|
||||
|
||||
**Interoperability**
|
||||
|
||||
- [Anchor](https://github.com/webb-tools/semaphore-anchor) is an interoperable privacy gadget for creating anonymous proof of membership on blockchains. In other words, modifying Semaphore to be used multichain.
|
||||
- [World ID @ Mina](https://ethglobal.com/showcase/world-id-mina-embt9) aims to integrate the World ID proof of personhood (PoP) system into snarkyjs, to make PoP available on Mina smart contracts and other applications.
|
||||
- [zkVote](https://github.com/KimiWu123/zkvote) is a method for an approved user to broadcast an arbitrary string without exposing their identity. It uses Semaphore as a base to achieve private voting.
|
||||
- [Zerokit](https://github.com/vacp2p/zerokit) Rust support library for using Semaphore. Rust rewrite of zk-kit, but just focuses on Semaphore (for now).
|
||||
|
||||
**Ecosystem & Environment**
|
||||
|
||||
- [PreciDatos](https://github.com/datadrivenenvirolab/PreciDatos) is a blockchain-based system for incentivizing actors to disclose accurate climate data.
|
||||
- [Terrarium](https://ethglobal.com/showcase/terrarium-ztoes) enables proving membership of Terrarium Conservation Group, sending signals (votes, endorsements) on species protection using ZK and enabling secured conversations.
|
||||
|
||||
**Experience**
|
||||
|
||||
- [TAZ](https://taz.appliedzkp.org/) was a Devcon 6 experience that allowed participants to experience anonymous protocols. Participants joined with a QR code and could anonymously co-create art, engage in Q&A and use heyAnon and Zkitter.
|
||||
|
||||
_Disclaimer: the Semaphore/ PSE team has not verified the security or reliability of these projects. Do your own research before using or integrating with a live product._
|
||||
|
||||
## GitPOAPs
|
||||
|
||||
If you contributed to Semaphore´s codebase, then you´re eligible to claim a special POAP!
|
||||
|
||||
🥳 Check if you´re eligible and get yours here: [https://www.gitpoap.io/eligibility](https://www.gitpoap.io/eligibility)
|
||||
|
||||
🏗 Nothing to claim yet? Well no worries! There are many issues in the codebase that you can help us with. You can contribute to Semaphore today to get the 2023 POAP. [https://github.com/semaphore-protocol/#ways-to-contribute](https://github.com/semaphore-protocol/#ways-to-contribute)
|
||||
|
||||
## What's coming in the future?
|
||||
|
||||
- [Semaphore v4](https://github.com/orgs/semaphore-protocol/projects/10/views/3) [research](https://github.com/privacy-scaling-explorations/researches/issues/2) is underway. We're researching new ways to generate memberships proof and anonymous signaling, adding composability and recursiveness.
|
||||
- We'll continue to explore new approaches for translations and bring Semaphore to more communities.
|
||||
- Semaphore website v3 will come later this year after usability and user research.
|
||||
- Lastly, we will continue to explore ways to improve the DevEx (Developer Experience) whenever possible in the 3.X.X versions of Semaphore.
|
||||
|
||||
Thanks to all contributors and Semaphore supporters! In particular @cedoor, @vplasencia, @rachelaux, @aguzmant103, @0xyNaMu, @recmo , @0xorbus, @uniyj, @vojtechsimetka, @marciob, @omahs, @namrapatel
|
||||
24
articles/the-next-chapter-for-zkevm-community-edition.md
Normal file
@@ -0,0 +1,24 @@
|
||||
---
|
||||
authors: ["PSE Team"]
|
||||
title: "The next chapter for zkEVM Community Edition"
|
||||
image: "cover.webp"
|
||||
tldr: ""
|
||||
date: "2024-06-05"
|
||||
canonical: "https://mirror.xyz/privacy-scaling-explorations.eth/hqLMwLfKmQLj773QCRLTOT-Z8sSUaTEfQpBSdTbitbs"
|
||||
---
|
||||
|
||||
We are excited to share some updates on our road to building a zkEVM, as we generalize our exploration towards the design and implementation of a general-purpose zkVM.
|
||||
|
||||
Zero-knowledge research and development in the broader Ethereum ecosystem has been bearing wholesome fruits over the past three years. That came after years of vibrant ideation with an uncompromising approach to security, building on the shoulders of giants of the prover-verifier computational model in computer science and cryptography.
|
||||
|
||||
Progress has been accelerating in the theory, design, and engineering of general-compute ZK systems since 2021, when we started working on a zkEVM implementation alongside our collaborators. We replaced the backend of the Halo2 instantiation of PLONK with the KZG commitment scheme in order to facilitate verification on Ethereum, and with it we collectively built highly-optimized circuits of self-contained components of the Ethereum protocol. We extend our thanks and appreciation to the Scroll and Taiko teams, who developed the project with us from the early days, as well as the many amazing community contributors, for their great contributions to this effort.
|
||||
|
||||
We are lifting circuits of some [primitives](https://github.com/privacy-scaling-explorations/zkevm-circuits/blob/main/zkevm-circuits/src/keccak_circuit.rs) into their own libraries for the community to take advantage of, especially in the emerging paradigm of zkVMs with hand-optimized precompiles. Today, our fork of Halo2 has a [distinct architecture](https://github.com/privacy-scaling-explorations/halo2/pull/254), [expanded features](https://github.com/privacy-scaling-explorations/halo2curves), and an active community of contributors [pushing it forward](https://github.com/privacy-scaling-explorations/halo2/pull/277). We congratulate Scroll for bringing the fruits of our collaboration to a [successful zkRollup deployment](https://scroll.io/blog/founder-letter).
|
||||
|
||||
With our experience building a zkEVM, and with libraries, [designs](https://github.com/privacy-scaling-explorations/zkevm-circuits/pull/1785), and a state-of-the-art proof development kit under our belt, we now shift our focus to a new zkVM design that explores different ideas — [old](https://dl.acm.org/doi/abs/10.1145/2699436) and [new](https://eprint.iacr.org/2024/325) — and researches and fine-tunes new ones, particularly given the improvements in prover efficiency that weren't available 2 years ago. There is a lot that goes into proving the validity of an Ethereum block, and targeting a lower-level VM for arithmetization simplifies proving the parts for light clients, and reduces the complexity of proving the whole of Ethereum blocks.
|
||||
|
||||
The generality of zkVMs incurs overhead, but that is outweighed by gains in lower complexity, better auditability, and easier maintenance as the proof system of the execution environment gets abstracted away from changes to the base Ethereum protocol.
|
||||
|
||||
We remain focused on our long-term goal: accessible proving and verification of Ethereum blocks — and without additional trust assumptions on light clients. Combined with upcoming upgrades such as danksharding, the end-game of maximally decentralized, scalable, and secure Ethereum is firmly in-sight, and we are thrilled to continue playing a major role towards that wonderful destination.
|
||||
|
||||
We build in the open, and welcome collaboration with and contributions from builders in our ecosystem who share our values and commitment to advancing free, open, secure, and privacy-preserving software for our societies.
|
||||
@@ -0,0 +1,93 @@
|
||||
---
|
||||
authors: ["@0xDatapunk"]
|
||||
title: "The Power of Crowdsourcing Smart Contract Security for L2 Scaling Solutions"
|
||||
image: "cover.webp"
|
||||
tldr: "This post was authored by [@0xDatapunk](https://github.com/0xDatapunk) at [PSE Security](https://github.com/privacy-scaling-explorations/security)."
|
||||
date: "2023-07-18"
|
||||
canonical: "https://mirror.xyz/privacy-scaling-explorations.eth/Zjgt8YUAeW8XX5-wc1f6uNI8vx-5q_qBTYR4KFRGpTE"
|
||||
---
|
||||
|
||||
### Introduction
|
||||
|
||||
Smart contract security is of paramount importance in the blockchain ecosystem. As the adoption of Layer 2 (L2) solutions increases, ensuring the security of these contracts becomes even more critical. Due to their complexity and the potential for significant value stored in L2 contracts, they become attractive targets for malicious actors. In this article, we will explore the power of crowdsourcing smart contract security and how it compares to traditional audit firms for two leading L2 scaling solutions (Optimism and zkSync). We will delve into their engagement with auditing firms and the surprising findings from crowdsourced security competitions.
|
||||
|
||||
### **Traditional audit firms vs crowdsourcing security**
|
||||
|
||||
Traditional audit firms and crowdsourcing security offer different approaches to enhancing smart contract security.
|
||||
|
||||
Traditional audit firms typically involve a select group of experts who conduct a comprehensive review of the smart contracts. They bring deep expertise and experience in identifying vulnerabilities and providing recommendations. These firms follow established methodologies and provide a sense of assurance due to their reputation and track record.
|
||||
|
||||
On the other hand, crowdsourcing security lives by Linus’s law that “given enough eyeballs, all bugs are shallow”. By leveraging the collective intelligence of a diverse group of participants, crowdsourcing platforms, like [Sherlock](https://www.sherlock.xyz/) and [Code4rena](https://code4rena.com/), tap into a wide range of expertise and perspectives, potentially identifying vulnerabilities that may have been overlooked by traditional audits. Here are a few benefits yielded by such platforms:
|
||||
|
||||
- Scalability. Crowdsourcing allows for a large number of people to review and test the contract simultaneously. This can make the security review process more scalable, particularly for projects that have a large number of smart contracts. In Code4rena competitions, for example, it is not uncommon to see more than 500 submits per codebase.
|
||||
- Efficiency and Speed. While auditing firms are often booked months into the future, crowdsourcing platforms can start a competition fairly quickly.
|
||||
- Cost-effectiveness. In some cases, crowdsourcing can be more cost-effective than hiring a dedicated team of security experts. This can be particularly beneficial for smaller projects or startups.
|
||||
- Community Engagement. Crowdsourcing the security auditing can engage the community around a project. This can lead to increased trust and participation from users and stakeholders.
|
||||
|
||||
Both approaches have their strengths and limitations. Traditional audits provide a structured and controlled environment, while crowdsourcing offers broader insights and the ability to detect complex or novel vulnerabilities. A combination of both can provide a comprehensive and robust security assessment for smart contracts.
|
||||
|
||||
### **L2 Smart Contract Security**
|
||||
|
||||
Layer 2 solutions aim to alleviate scalability issues in blockchain networks by moving a significant portion of transactions off-chain while leveraging the underlying security of the base layer. However, the complexity introduced by L2 and the potential value stored in L2 contracts make them attractive targets for hackers. [Several notable hacks involving L2 and bridges have occurred](https://github.com/0xDatapunk/Bridge-Bug-Tracker), underscoring the need for stringent security practices.
|
||||
|
||||
Recognizing the importance of smart contract security, L2 teams conduct multiple rounds of audits before deployment. Here, we highlight the efforts put forth by Optimism and zkSync teams.
|
||||
|
||||
### **Optimism**
|
||||
|
||||
#### **Engagement with Auditing Firms**
|
||||
|
||||
To validate the security of their smart contracts, Optimism engaged in multiple rounds of auditing with renowned auditing firms specializing in blockchain security. The table below summarizes the audit results, highlighting the identification and severity of vulnerabilities discovered for Optimism’s bedrock.
|
||||
|
||||

|
||||
|
||||
#### **Sherlock competition**
|
||||
|
||||
##### **Unique Payout Structure Reflecting Confidence**
|
||||
|
||||
Prior to launching the Sherlock competition, Optimism’s confidence in their security measures led them to structure the payout in a unique way. They believed that no high or medium severity bugs could be found, and thus capped the reward pool if only low-severity bugs are found. The reward structure was designed to reflect their confidence in their security measures.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
##### **Surprising Findings**
|
||||
|
||||
Contrary to their initial expectations, the Sherlock competition yielded multiple high and medium severity bug findings. Optimism promptly addressed these vulnerabilities, showcasing their commitment to continuous improvement and security. They followed up with additional competitions to further review and enhance the security of their smart contracts.
|
||||
|
||||
The summaries of the competition results are as follows:
|
||||
|
||||

|
||||
|
||||
#### **The Power of Crowdsourcing Security**
|
||||
|
||||
The results of the Sherlock competitions demonstrate the power of crowdsourcing security. By opening the process to a diverse group of participants, Optimism was able to tap into a wide range of expertise and uncover vulnerabilities that may have otherwise gone unnoticed and been catastrophic for the Bedrock upgrade. Crowdsourcing provides a valuable mechanism for enhancing the security of smart contracts by leveraging the collective intelligence of the community.
|
||||
|
||||
#### **Findings from Sherlock Competitions**
|
||||
|
||||
The following links provide detailed findings from the Sherlock competitions conducted for Optimism:
|
||||
|
||||
[January 2023 Optimism Sherlock Competition](https://github.com/sherlock-audit/2023-01-optimism-judging/issues)[March 2023 Optimism Sherlock Competition](https://github.com/sherlock-audit/2023-03-optimism-judging/issues)
|
||||
|
||||
### **zkSync**
|
||||
|
||||
Similarly, zkSync engaged multiple rounds of audits with well known auditing firms:
|
||||
|
||||

|
||||
|
||||
However, their engagement with crowdsourcing platforms also revealed and fixed further vulnerabilities.
|
||||
|
||||

|
||||
|
||||
[zkSync Era System Contracts code4rena contest](https://code4rena.com/reports/2023-03-zksync)[zkSync Secure3 competitive security assessment](https://github.com/Secure3Audit/Secure3Academy/tree/main/audit_reports/zkSync)[zkSync v2 code4rena contest](https://code4rena.com/reports/2022-10-zksync)**Beyond Audits**
|
||||
|
||||
While traditional audits and crowdsourcing security through competitions can significantly enhance smart contract security, it is not a panacea. The crowdsourced findings serve as valuable inputs, but they do not guarantee that all vulnerabilities have been identified. To align the interests of various stakeholders, including the project owners and security researchers, Sherlock provides different levels of coverage to its customers for potential exploits, while promising high APRs for its stakers ([more details here](https://docs.sherlock.xyz/coverage/staking-apy/overview)). So far, Sherlock has had two claims against its audited contracts.
|
||||
|
||||

|
||||
|
||||
The true security of L2 contracts, like any other complex system, remains an ongoing effort and requires a combination of rigorous audits, [proactive bug bounty programs](https://immunefi.com/bounty/optimism/), and continuous vigilance.
|
||||
|
||||
### **Conclusion**
|
||||
|
||||
Smart contract security is a critical aspect of blockchain technology, especially in the context of Layer 2 solutions. L2 teams’ commitment to ensuring the security of their smart contracts is evident through their engagement with auditing firms and their participation in crowdsourced security competitions. The surprising findings from the Sherlock competitions highlight the value of crowdsourcing security, enabling the identification and remediation of vulnerabilities that contribute to a safer and more secure ecosystem. As blockchain technology continues to evolve, crowdsourcing security will remain a powerful tool in mitigating risks and building robust smart contract systems.
|
||||
|
||||
_**The [PSE security team](https://github.com/privacy-scaling-explorations/security) works on improving the security of many different projects - both internal and external to PSE. So based on these results, the PSE security team advises projects to heavily consider both traditional audits and crowdsourced audits if possible.**_
|
||||
144
articles/the-zk-ecdsa-landscape.md
Normal file
@@ -0,0 +1,144 @@
|
||||
---
|
||||
authors: ["Blake M Scurr"]
|
||||
title: "The zk-ECDSA Landscape"
|
||||
image: "cover.webp"
|
||||
tldr: "This post was authored by grantee [Blake M Scurr](https://github.com/BlakeMScurr). His mandate was to explore zk-ECDSA, build applications with zk-ECDSA, and contribute to ZKPs to make this vision come true."
|
||||
date: "2023-04-18"
|
||||
canonical: "https://mirror.xyz/privacy-scaling-explorations.eth/djxf2g9VzUcss1e-gWIL2DSRD4stWggtTOcgsv1RlxY"
|
||||
---
|
||||
|
||||
## Introduction
|
||||
|
||||
Ethereum is a principled project, popular for being a credibly neutral payment, financial, and computing system.
|
||||
|
||||
Unfortunately, to achieve neutrality, it has sacrificed privacy because every transaction must be public to be verified. Recent advances in [ZKP (Zero-Knowledge Proof)](https://ethereum.org/en/zero-knowledge-proofs/) systems have made it practical to achieve privacy while maintaining verifiability. There are new privacy focused ZK blockchains such as [Mina](https://minaprotocol.com/), [Aleo](https://www.aleo.org/) and [Zcash](https://z.cash/), but L1 development is hard and slow, especially on a large, established protocol like Ethereum. Instead of adding privacy to the underlying system, we as smart contract developers can rewrite the ecosystem to respect privacy, while keeping the L1 simple and transparent. This is the promise of zk-ECDSA.
|
||||
|
||||
Normally, dApps work by verifying signatures on transactions then executing smart contract logic. Ethereum uses a particular signature scheme called [ECDSA](https://en.wikipedia.org/wiki/Elliptic_Curve_Digital_Signature_Algorithm) because the signatures are very short and efficient for any given security level as opposed to, say, [RSA signatures](<https://en.wikipedia.org/wiki/RSA_(cryptosystem)>). This means there are millions of ECDSA keys for Ethereum addresses ready to be utilised.
|
||||
|
||||
To support privacy on-chain with these existing keys, we need to add some extra logic to our smart contracts. Instead of directly verifying signatures, we can verify ECDSA signatures and execute arbitrary logic inside ZKPs, then verify those proofs on-chain, then execute our smart contract logic. Thus, without any change to Ethereum itself, we can support privacy where users want it.
|
||||
|
||||
## Use Cases
|
||||
|
||||
### Mixers
|
||||
|
||||
Mixers were one of the first widespread use cases for ZKPs on Ethereum, with Tornado Cash handling [over $7B](https://home.treasury.gov/news/press-releases/jy0916). Tornado Cash prevents double spending by using an interactive nullifier, which is a special piece of data the user must hold onto to access their funds. Keeping this nullifier secure can be just as important as keeping a private key secure, but in practice it needs to, at some point, be in plaintext outside the wallet or secure enclave in order to generate the ZKP. This is a significant UX problem, especially for a security conscious user who has already gone to great lengths to protect their private key.
|
||||
|
||||
zk-ECDSA can solve this by generating a nullifier deterministically from the private key, while keeping the user private. This is a subtle problem, and existing ECDSA signatures aren't quite suitable. We explain the PLUME nullifier, the top contender to solve this problem below.
|
||||
|
||||
#### Blacklists
|
||||
|
||||
Financial privacy is good, but it can have downsides. The US Treasury [accused Tornado Cash](https://home.treasury.gov/news/press-releases/jy0916) of laundering over $455M of funds stolen by a US sanctioned North Korean hacker group. Tornado Cash itself was subsequently sanctioned.
|
||||
|
||||
There may be a middle ground, where privacy is preserved for normal users, but authorities can prevent hackers receiving their funds. The following is not an ideal scheme, as it gives authorities power to freeze funds of law-abiding citizens, but it is a start.
|
||||
|
||||
In order to get your funds out of a compliant mixer, you must prove in a ZKP that you own an address that deposited funds, has not already retrieved their funds, and _does not belong to a blacklist_. This means having to do a proof of non-membership inside the ZKP.
|
||||
|
||||
### Private Safes
|
||||
|
||||
Many projects use safes like [Safe](https://safe.global/) (formerly Gnosis Safe) to control funds split between multiple parties. Generally this means using your personal key to sign votes for how the money is spent, those votes are then sent to the chain and executed when enough parties agree. However, this means publicly linking your personal finances to some project, which is generally not desirable. Instead of sending a publicly readable signature, the user can send a ZKP proving their vote without revealing their identity on-chain. [zkShield](https://github.com/bankisan/zkShield) is an example of a private safe in development.
|
||||
|
||||
It may be surprising that we don't need nullifiers for safes, since they are usually required for private financial applications. If you wanted to keep your votes private from other owners of the same safe you would need nullifiers. However, people sharing a safe are generally cooperative, so the sensible approach by zkShield is to create non-private signatures off-chain with efficient-ecdsa, and verify them in a ZKP. Nullifiers are also often used in financial applications to prevent double-spending, but that is irrelevant here because safes don't have an inbuilt payment system.
|
||||
|
||||
### Private Voting
|
||||
|
||||
Voting on, for example, a DAO proposal (or on political candidates or legislation!) should generally be done privately to prevent retribution, bribery, and collusion. Instead of collating signatures, we can collate ZKPs, provided they output a deterministic nullifier to prevent double votes.
|
||||
|
||||
### Airdrops
|
||||
|
||||
Many projects such as [Arbitrum](https://arbitrum.io/) and [ENS](https://ens.domains/) have introduced a governance token as they mature. This is generally done to reward early users, and give the community power over the protocol. However, if a token holder wants to vote on a proposal anonymously, they will have to sell their token, use a mixer, buy the token back at another address, and then vote with that unlinked address. Instead, we could offer airdrops anonymously by default. To do this, you simply make a list of all the addresses eligible for the drop, hash them into a Merkle tree, and allow people to claim their tokens by proving membership in that list.
|
||||
|
||||
Airdrops usually offer granular rewards, giving more tokens to earlier users, etc. Unfortunately, high granularity would reduce the anonymity set. The easiest implementation would be if every address received the same amount. You could also mitigate the loss of privacy while allowing different rewards by letting people claim the airdrop for multiple addresses at a time, and offering multiple rewards per address, though this would introduce additional complexity in the circuit.
|
||||
|
||||
### Private NFTs
|
||||
|
||||
Privacy can be used in creative ways in NFTs too. For example, you could allow any CryptoPunk holder to mint a "DarkPunk," where their original address is not linked to their original CryptoPunk. This would be done by taking a snapshot of addresses holding CryptoPunks, and gateminting by requiring a ZKP that shows you own some address in that list. Note, any set of addresses could be used for gating - i.e., people who lost money in The DAO hack, or people who have burned 100+ ETH.
|
||||
|
||||
Similarly, a new NFT project could allow private minting. First you'd buy a ticket publicly on-chain, then privately prove you are a ticket holder to mint the NFT. This could be implemented with an interactive nullifier, but zk-ECDSA could be used to save on-chain costs at the expense of prover time.
|
||||
|
||||
### Message Boards
|
||||
|
||||
zk-ECDSA will also enable off-chain use cases.
|
||||
|
||||
Anonymity can be a useful tool for voicing controversial ideas, or givng a voice to less powerful people. Suppose a DAO is trying to coordinate on how to spend its treasury, political factions inevitably form and it can be hard to oppose consensus, or it might be hard to get your voice heard. Instead of relying on a traditional message board where every message is tied to a username, you can conduct discussions anonymously, or pseudonymously using ZKPs rather than signatures directly. Traditional anonymous boards are subject to sybil attacks, but in zk message boards you have to prove membership in a group and/or prove you are using a unique deterministic pseudonym derived from your public key.
|
||||
|
||||
[heyanoun.xyz](https://www.heyanoun.xyz/) from PersonaeLabs is a project exploring this area.
|
||||
|
||||
### Gated Content
|
||||
|
||||
zk-ECDSA can be used as an authentication for access to web content.
|
||||
|
||||
For example, suppose you want to create some private content for [Nouns NFT](https://nouns.wtf/) holders. The standard solution would be "Sign in with Ethereum", where you would verify your address, and the server could verify that you own a Noun on-chain. However, this gives the website your personal financial details for that address, which may be enough to track and target you. This is dangerous, especially since you are known to hold a valuable NFT. Instead we can create "Sign in as Noun" functionality by simply proving you own an address in the set of Nouns holders.
|
||||
|
||||
Using zk-ECDSA is still not easy. You have to carefully choose the right library and proof system for your use case. There are two critical questions: do you need nullifiers, and do you need on-chain verification? It's important to choose the right tool for your use case, because prover time can be radically improved if you don't need nullifiers or on-chain verification.
|
||||
|
||||
Most of the work below was done at [PersonaeLabs](http://personaelabs.org/) and [0xparc](https://0xparc.org/). As part of this grant, I wrote the initial verifier circuit for the nullifier library.
|
||||
|
||||
### Merkle Tree Basics
|
||||
|
||||
The circuits for most applications require some kind of signature/nullifier verification, and set membership. [Merkle trees](https://en.wikipedia.org/wiki/Merkle_tree) are a simple, efficient method of set membership, where security relies on a hash function. A circom implementation of Merkle trees originating from Tornado Cash has been well battle tested. During my grant I used a Merkle tree with the Poseidon hash, which is a hash function that's efficient in ZK circuits. [This implementation](https://github.com/privacy-scaling-explorations/e2e-zk-ecdsa/blob/a5f7d6908faac1aab47e0c705bc91d4bccea1a73/circuits/circom/membership.circom#L13), which verifies a public key, signature, and Merkle proof may be a useful starting point for your application. Note, that you should remove the public key check if unnecessary, and swap the signature verification out for the most efficient version possible for your constraints.
|
||||
|
||||
### Non-Membership
|
||||
|
||||
Merkle trees don't naturally enable us to prove that an address is _not_ in a given list. There are two possible modifications we can make to make this possible, and the first is [probably the best option](https://alinush.github.io/2023/02/05/Why-you-should-probably-never-sort-your-Merkle-trees-leaves.html).
|
||||
|
||||
The recommended approach is using a sparse Merkle tree. A sparse Merkle tree of addresses contains every possible address arranged in order. Since Ethereum addresses are 160 bits, the Merkle tree will be of depth 160 (note the amazing power of logarithmic complexity!), meaning Merkle proofs can still be efficiently verified in a ZKP circuit. The leaves of the tree will be 1 if the address is included in the set, and 0 if it is not. So by providing a normal Merkle proof that the leaf corresponding to an address is 0, we prove that the address is not in the list.
|
||||
|
||||
The alternative is sorting a list of addresses, and using 2 adjacent Merkle proofs to show that the address's point in the list is unoccupied. This is the approach [I used](https://github.com/privacy-scaling-explorations/e2e-zk-ecdsa/pull/76) in this grant, but I wouldn't recommend it due to the complexity of the circuit, and additional proof required to show that the list is sorted, which introduces [systemic complexity](https://vitalik.ca/general/2022/02/28/complexity.html).
|
||||
|
||||
### Off-chain, no nullifiers
|
||||
|
||||
The fastest way to privately verify a signature is [spartan-ecdsa](https://personaelabs.org/posts/spartan-ecdsa/), with a 4 second proving time in a browser. ECDSA uses elliptic curves, and the specific curve used for Ethereum signatures is called secp256k1. Spartan-ecdsa is primarily fast because it uses right-field arithmetic by using a related elliptic curve called secq256k1. This secp256k1's base field is the same as secq256k1's scalar field, the arithmetic is simple, but this means we have to use a proof system defined for secq256k1 such as [Spartan](https://github.com/microsoft/Spartan) (note, Groth16, PlonK etc aren't available as they rely on [pairings](https://medium.com/@VitalikButerin/exploring-elliptic-curve-pairings-c73c1864e627), which aren't available in secq256k1). Unfortunately, Spartan does not yet have an efficient verifier that runs on-chain (though [this is being worked on](https://github.com/personaelabs/spartan-ecdsa/tree/hoplite)). Ultimately, this is just an way to verify ECDSA schemes in ZKPs, so, like all plain ECDSA schemes, it can't be used as a nullifier.
|
||||
|
||||
### On-chain, no nullifiers
|
||||
|
||||
A predecessor to spartan-ecdsa is [efficient-ecdsa](https://personaelabs.org/posts/efficient-ecdsa-1/). The difference is it uses expensive wrong-field arithmetic implemented with multi-register big-integers. The current implementation is circom, which is a natural frontend to any R1CS proof system such as Groth16, as well as having built in support for PlonK and fflonk. This means it can be verified on-chain at minimal cost. However, the prover is significantly slower than for spartan-ecdsa since the circuit requires 163,239 constraints compared to spartan-ecdsa's astonishing 8,076. Efficient-ecdsa is a major ~9x improvement over 0xparc's initial [circom-ecdsa](https://github.com/0xPARC/circom-ecdsa) implementation, which is achieved by computing several values outside the circuit.
|
||||
|
||||
### Nullifiers
|
||||
|
||||
Nullifiers are deterministic values that don't reveal one's private identity, but do prove set membership. These are necessary for financial applications to prevent double spending, in addition to private voting and pseudonymous messaging. Intuitively, an ECDSA signature should work as a nullifier, but it is not, in fact, deterministic on the message/private key. ECDSA signatures include a random scalar (known [in the wikipedia article](https://en.wikipedia.org/wiki/Elliptic_Curve_Digital_Signature_Algorithm#Signature_generation_algorithm) as _k_) which is used to hide the private key. Even if this scalar is [generated pseudorandomly](https://www.rfc-editor.org/rfc/rfc6979), there is no way for the verifier to distinguish between a deterministic and random version of the same signature. Therefore, new schemes are required. [This blog](https://blog.aayushg.com/posts/nullifier) contains a more detailed exploration of the problem, including a solution called PLUME.
|
||||
|
||||
The [PLUME nullifier](https://github.com/zk-nullifier-sig/zk-nullifier-sig) is the only existing candidate solution for this problem. There is some work required to get these into wallets, and the circuits (for which [I wrote](https://github.com/zk-nullifier-sig/zk-nullifier-sig/pull/7) the initial implementation as part of this grant) are not yet audited or production ready. PLUME's circom implementation currently has ~6.5 million constraints, and even with optimisation, I suspect it will always be more expensive than efficient-ecdsa or spartan-ecdsa, as the verification equations are inherently longer.
|
||||
|
||||
## My Work
|
||||
|
||||
My grant ended up being a fairly meandering path toward the state of the art in zk-ECDSA. My main contribution, as I see it, is the [circuit for the PLUME nullifier](https://github.com/zk-nullifier-sig/zk-nullifier-sig/pull/7), as well as transmitting understanding zk-ECDSA in house, and now hopefully to the outside world.
|
||||
|
||||
The initial exploratory work included a Merkle tree based membership and non-membership proofs, and public key validation in circom using [circom-ecdsa](https://github.com/0xPARC/circom-ecdsa) (which is the founding project in this space). About halfway through the grant I realised how critical nullifiers are for most applications, and pivoted to working on the PLUME nullifiers.
|
||||
|
||||
### Membership/Non-membership proofs
|
||||
|
||||
The first task was to make a basic circuit that proves membership in an address set. I used a [modified version](https://github.com/ChihChengLiang/poseidon-tornado) of tornado cash for the Merkle proof, and circom-ecdsa for the signature verification (because I wasn't yet aware of efficient-ecdsa or spartan-ecdsa).
|
||||
|
||||
We were also interested in non-membership proofs for use cases like the [gated mixer](https://mirror.xyz/privacy-scaling-explorations.eth/djxf2g9VzUcss1e-gWIL2DSRD4stWggtTOcgsv1RlxY#blacklists) above. [I did this](https://github.com/privacy-scaling-explorations/e2e-zk-ecdsa/pull/76) with a simple sorted Merkle tree, and two adjacent Merkle proofs showing that the proof is not between them. I have since been [convinced](https://alinush.github.io/2023/02/05/Why-you-should-probably-never-sort-your-Merkle-trees-leaves.html) that sparse Merkle trees are a more robust solution, and we intend to implement this.
|
||||
|
||||
### Public Key Validation
|
||||
|
||||
Part of the signature verification algorithm involves validating that the public key is in fact a valid point on an elliptic curve ([Johnson et al 2001](https://www.cs.miami.edu/home/burt/learning/Csc609.142/ecdsa-cert.pdf) section 6.2). In previous applications this was done outside the circuit, which was possible because the full public key set was known ahead of time.
|
||||
|
||||
However, we were interested in use cases where developers would be able to generate arbitrary address lists, such as [gated web content](https://mirror.xyz/privacy-scaling-explorations.eth/djxf2g9VzUcss1e-gWIL2DSRD4stWggtTOcgsv1RlxY#gated-content). The problem is, it's non-trivial to go from an address list to a public key list, as not all addresses have some associated signature from which we can deduce the public key. This means that the developers would not necessarily be able to validate the public keys for every address in the list.
|
||||
|
||||
The solution was to [implement public key verification inside the circuit](https://github.com/privacy-scaling-explorations/e2e-zk-ecdsa/blob/a5f7d6908faac1aab47e0c705bc91d4bccea1a73/circuits/circom/membership.circom#L138-L177) using primitives from circom-ecdsa. This means that any ZKP purporting to prove membership also must be done with a valid public key.
|
||||
|
||||
It is not exactly clear how important this check is, and you should think about it on a case-by-case basis for your use case. It is probably not necessary for an anonymous message board, for example, since the worst attack one could possibly achieve with an invalid public key is falsifying an anonymous signature. However, in order to do that, one has to know the SHA256 preimage of some address, in which case they, in practice, hold secret information (the public key) which is somewhat equivalent to a private key.
|
||||
|
||||
More work needs to be done to characterise the cases where we need to verify the public key.
|
||||
|
||||
### Plume Nullifiers
|
||||
|
||||
Having improved our understanding, we brainstormed use cases, and found (as can be seen [above](https://mirror.xyz/privacy-scaling-explorations.eth/djxf2g9VzUcss1e-gWIL2DSRD4stWggtTOcgsv1RlxY#use-cases)) that the lack of nullifiers was blocking many interesting applications.
|
||||
|
||||
The PLUME nullifier scheme had not been implemented yet in a zero-knowledge circuit, and since I now had some experience with circom-ecdsa, I was well situated for the job. I wrote it in circom, with circom-ecdsa, ultimately ending up with 6.5 million constraints (about 2M in hashing, and 4.5M in elliptic curve operations).
|
||||
|
||||
This was by far the most challenging part of the grant (future grantees be warned - don't be too optimistic about what you can fit in one milestone).
|
||||
|
||||
One interesting bug demonstrates that difficulties of a low level language like circom, was when I simply wasn't getting the right final hash result out. It turned out (after many log statements) that part of the algorithm implicitly compresses a particular elliptic curve point before hashing it. This compression is so trivial in JS you barely notice it, but I ended up having to write it from scratch in [these two rather nice subcircuits](https://github.com/zk-nullifier-sig/zk-nullifier-sig/pull/7/files#diff-f59503380952aa2926ad22e3f7fcfb442043dd90242d81f70ffff91094f46d8fR243-R294).
|
||||
|
||||
Another subtlety was that an elliptic curve equation calculating _a/b^c_ inexplicably started giving the wrong result on ~50% of inputs for _c_. It turned out that my circom code was right, but the JS that I was comparing against took a wrong modulus, using `CURVE.p` rather than `CURVE.n`, which essentially confuses the base and scalar fields of the elliptic curve. And, since `CURVE.p` is still rather large, and the value whose modulus was being taken was quite small, the result was usually the same, which accounts for the confusing irregularity of the bug!
|
||||
|
||||
### Proving Server
|
||||
|
||||
For on-chain nullifiers especially, the proving time is very high, so we wanted to create a trusted server which would generate the proof for you. However, this server must be trusted with your privacy, so it will be deprecated as proving times improve.
|
||||
|
||||
## Conclusion
|
||||
|
||||
The frontier for private applications on Ethereum is about to burst wide open. The cryptography and optimisations are almost solved. Now we need a new wave of projects with sleek UX focused on solving real problems for Ethereum’s users. If you want to make any of the use cases above a reality, check out [our repo](https://github.com/privacy-scaling-explorations/e2e-zk-ecdsa) to get started.
|
||||
202
articles/tlsnotary-updates.md
Normal file
@@ -0,0 +1,202 @@
|
||||
---
|
||||
authors: ["sinu"]
|
||||
title: "TLSNotary Updates"
|
||||
image: "cover.webp"
|
||||
tldr: "This post was written by [sinu](https://github.com/sinui0)."
|
||||
date: "2023-09-19"
|
||||
canonical: "https://mirror.xyz/privacy-scaling-explorations.eth/T4MR2PgBzBmN2I3dhDJpILXkQsqZp1Bp8GSm_Oo3Vnw"
|
||||
---
|
||||
|
||||
## Introduction
|
||||
|
||||
TLSNotary is a protocol which allows people to export data from any web application and prove facts about it to a third-party in a privacy preserving way.
|
||||
|
||||
It enables privacy-preserving **data provenance and data portability**, empowering users to share their data with others as they see fit.
|
||||
|
||||
To do this, TLSNotary leverages secure multi-party computation (MPC) to authenticate data communicated between a Prover and a TLS-enabled web server, as depicted in Figure 1.
|
||||
|
||||

|
||||
|
||||
Figure 1: Simple Overview
|
||||
|
||||
Importantly, the protocol supports _selective disclosure_ of data to a Verifier. This way the Prover can keep secrets hidden, such as passwords or any other information not necessary to prove some specific statement.
|
||||
|
||||
Selective disclosure may involve simple redactions, or more advanced techniques such as a zero-knowledge proof that a number in the data is within a specific range, without disclosing its exact value.
|
||||
|
||||

|
||||
|
||||
Figure 2: Selective Disclosure
|
||||
|
||||
The TLSNotary protocol presents a compelling alternative to other solutions for sharing data for the following reasons:
|
||||
|
||||
- It does not require the Server to integrate data sharing into its application, such as OAuth.
|
||||
- The act of disclosing data to a third-party is not known to the Server, nor can it be practically censored.
|
||||
- The Prover has very fine-grained control over _exactly_ what data is disclosed to the Verifier.
|
||||
- The Verifier does not need to trust that the Prover is honest, the authenticity of the data comes with cryptographic assurances.
|
||||
|
||||
For more introductory information, see our [website](https://tlsnotary.org/) which also includes some example use-cases and a link to our (work-in-progress) documentation.
|
||||
|
||||
TLSNotary is a project under the [Privacy & Scaling Explorations (PSE)](https://pse.dev/) team at the Ethereum Foundation. PSE is a multi-disciplinary team exploring how programmable cryptography can be applied to enhance privacy and scale trust-minimized systems.
|
||||
|
||||
### General-purpose Verifier: Notary
|
||||
|
||||
We envision an ecosystem of general-purpose verifiers, called Notaries, which help users take back control of their data in a privacy preserving way.
|
||||
|
||||
We find it important that our protocol supports hiding the identity of the Server, as well as hiding virtually _all information_ about the application the Prover is interacting with.
|
||||
|
||||
A Notary is a special kind of verifier which allows the Prover to do just that. It decouples the process of proving the authenticity of data from the process of selective disclosure. Notaries being completely blind of context preserves neutrality, and helps mitigate bad incentives or censorship which could arise in circumstances with an application-specific Verifier.
|
||||
|
||||
Of course, we still need to support selective disclosure of the data to _someone_. How do we do that if a Notary is to know nothing? Fortunately this is still possible to do in a relatively simple way.
|
||||
|
||||

|
||||
|
||||
Figure 3: Notaries
|
||||
|
||||
During the MPC, efficient commitments to the data are generated and we can reuse them for selective disclosure. The Notary simply signs an attestation which includes these commitments, as well as a commitment to the Server identity, which the Prover can store and carry around (in a data backpack? 🎒). Later the Prover can use this attestation to selectively disclose data to someone else.
|
||||
|
||||
This enables users to privately export data with the help of a neutral third-party, receiving an attestation to its authenticity. Using these attestations, other verifiers can accept proofs if they consider the attesting Notary trustworthy. Of course, a verifier can require attestations from multiple Notaries, which reduces to a 1-of-N trust assumption!
|
||||
|
||||
## How It Works
|
||||
|
||||
As mentioned in the introduction, TLSNotary leverages MPC to provide cryptographic assurances that the Prover can not cheat or lie about the communications with the Server. Additionally, the Verifier can not tamper with the connection as to leak secrets or cause malicious state updates within the application. In other words, the protocol is designed to be [malicious secure](https://en.wikipedia.org/wiki/Secure_multi-party_computation#Security_definitions) for both parties.
|
||||
|
||||
The Prover and Verifier securely secret-share the TLS session keys such that neither party is able to unilaterally send or receive messages from the Server. This ensures the authenticity of data, while hiding the plaintext from the Verifier.
|
||||
|
||||
Under the hood we employ primitives such as [Garbled Circuits](https://en.wikipedia.org/wiki/Garbled_circuit), [Oblivious Transfer](https://en.wikipedia.org/wiki/Oblivious_transfer#1%E2%80%932_oblivious_transfer) and Oblivious Linear Evaluation (OLE) to do this. These primitives have historically suffered from high resource costs in terms of both compute and bandwidth requirements, particularly in adversarial settings which require malicious security. Fortunately, over the past decade or so, there have been many breakthroughs in concrete efficiency which have brought MPC closer to a practical reality for many applications.
|
||||
|
||||
Even so, implementing a protocol like TLSNotary pushes up against the bounds of practical feasability in the malicious setting.
|
||||
|
||||
For example, the dominant cost of our protocol comes from performing binary computation using Garbled Circuits. Modern techniques such as free-XOR\[1\] and half-gates\[2\] still comes with a cost of ~200kB of communication to evaluate a single AES block (the most widely used cipher in TLS) in the semi-honest setting. Extrapolating, it costs ~50MB to encrypt only 4kB of data! Doing so with malicious security can easily add an order of magnitude to this cost figure, rendering such pursuits practically infeasible.
|
||||
|
||||

|
||||
|
||||
Figure 4: 2PC AES with Garbled Circuits
|
||||
|
||||
Naturally, we require the TLSNotary protocol to be secure against malicious adversaries. We must find a way to make it malicious secure, but malicious security is expensive. Wat do?
|
||||
|
||||
Before we get into how we solved this problem for our protocol, we wanted to highlight a viable alternative approach which we decided not to take.
|
||||
|
||||
### Alternative: Proxy Mode
|
||||
|
||||
An alternative approach to this problem is to side-step the need to use expensive MPC techniques and stick to cheaper approaches which operate in the zero-knowledge setting. Or more specifically, the setting where only 1 party has private inputs (the Prover).
|
||||
|
||||
Rather than having the Prover connect directly to the Server and operating the connection cooperatively with the Verifier, instead, the Verifier is situated in-between the Prover and Server, as shown in Figure 5.
|
||||
|
||||

|
||||
|
||||
Figure 5: Proxy Mode
|
||||
|
||||
In this configuration, the Verifier acts as a proxy and simply records the encrypted data being communicated between the Prover and Server. Afterwards, the Prover can selectively disclose parts of the data with a zero-knowledge proof using their TLS keys as private inputs.
|
||||
|
||||
This approach is quite viable and is one which other teams are pursuing. However, it comes with a different set of security assumptions. Rather than relying just on cryptographic assumptions, the proxy approach also makes _network topology_ assumptions. It assumes that the Verifier has a direct connection to the Server, and that a malicious Prover can not bypass or otherwise insert themselves in-between the Verifier and Server. As the Prover holds the full TLS session keys, if they are able to invalidate this assumption it completely breaks the integrity of the protocol.
|
||||
|
||||
As explained in the above section on Notaries, we find the ability to hide the identity of the Server from the Verifier important. This is clearly not possible with this model.
|
||||
|
||||
To be fair, there are viable mitigations to network attacks and in many scenarios these assumptions are acceptable. We look forward to seeing what is unlocked with the application of this model, as the simplicity and efficiency of this approach is enticing.
|
||||
|
||||
However, we decided to pursue the MPC approach and found a way to practically achieve malicious security without making such network assumptions.
|
||||
|
||||
### Achieving Practicality with MPC
|
||||
|
||||
A key observation enabling our approach is that all private inputs from the Verifier in the MPC are ephemeral. That is, after the TLS connection has been terminated the Verifier can reveal their share of the TLS session keys to the Prover without consequence. Moreover, multiple bits of the Verifier's inputs can be leaked prematurely without compromising security of the overall protocol.
|
||||
|
||||
Malicious secure protocols typically aim to prevent _any_ leakage of any parties inputs, employing techniques such as authenticated garbling or variants of cut-and-choose, which add significant compute and/or communication overhead.
|
||||
|
||||
For our needs, we implemented a novel\* variant of so-called Dual Execution, which we dubbed Dual Execution with Asymmetric Privacy (DEAP). Is there a better name for it? Probably. Nonetheless, you can read our informal [explanation of it here](https://docs.tlsnotary.org/mpc/deap.html).
|
||||
|
||||
The jist of it is this: During the TLS session one party, the Prover, acts as the Garbler while also committing to their inputs prior to learning the output of the circuit. Later, these commitments are used to prove the Prover acted honestly (or at least leakage was statistically bounded), and aborting otherwise.
|
||||
|
||||
Some key take aways of this approach:
|
||||
|
||||
- Garbled circuits on their own are secure against a malicious evaluator. The Verifier, acting as the evaluator, can not cheat or otherwise corrupt the output without detection. This ensures the privacy and integrity of the data to the Prover during the TLS session.
|
||||
- In the final phase of DEAP the Verifier opens all their inputs to the Prover. This allows the Prover to check the Verifier has behaved honestly and ensures _no leakage_ of the private data, contrary to the leakage inherent in the equality check of standard Dual Execution.
|
||||
|
||||
Exploiting the rather niche privacy requirements of our protocol allows us to achieve malicious security without the typical overhead that comes with it.
|
||||
|
||||
In fact, the final phase of DEAP reduces to the much cheaper zero-knowledge scenario. While we currently use garbled circuits for this ZK phase, as pioneered in JKO13\[4\], we can take advantage of even more efficient ZK proof systems. We're planning on switching to new methods known as VOLE-based IZK\[5\], which boast over 100x reduction in communication cost compared to garbled circuits. Doing so will make our protocol marginally more expensive than the semi-honest security setting.
|
||||
|
||||
Using the efficient VOLE-based IZK in combination with the simple trick of deferring decryption until after the TLS connection is closed, **TLSNotary will achieve efficiency similar to that of the proxy mode configuration**. Specifically, we do not need to utilize expensive Garbled Circuits for proving Server response data, which is typically the dominant cost.
|
||||
|
||||
\* This approach has recently also been articulated by XYWY23\[3\]
|
||||
|
||||
### A note on Oracles
|
||||
|
||||
While the TLSNotary protocol can be used to construct a [blockchain oracle protocol](https://ethereum.org/en/developers/docs/oracles/), that is not its primary purpose, especially in regards to _public_ data feeds. TLSNotary is best suited for contexts which require proving of _private_ data which is typically only accessible to an authenticated user. Moreover, because it is an _interactive_ protocol, it must be run by an off-chain Verifier. Bringing data on-chain still requires a trust assumption, ie an attestation from a trusted party(s).
|
||||
|
||||
## Where We Are
|
||||
|
||||
An alpha version of the TLSNotary protocol is [available for testing](https://github.com/tlsnotary/tlsn). We welcome folks to start playing around with it, including trying to break it! We have some examples available and a quick start to get you running.
|
||||
|
||||
The underlying MPC primitives are contained in a separate project named `mpz` which is intended to evolve into a general-purpose MPC stack.
|
||||
|
||||
Both codebases are 100% Rust 🦀 and compile to WASM targets with an eye on deployment into browser environments.
|
||||
|
||||
All our code is and always will be open source! Dual-licensed under Apache 2 and MIT, at your choice.
|
||||
|
||||
We've invested effort into making sure our code is modular and capable of evolving. We hope that others may find some of the components independently interesting and useful. Contributions are welcome!
|
||||
|
||||
### Current Limitations
|
||||
|
||||
While we're excited to start experimenting with TLSNotary, we acknowledge the work we have ahead of us.
|
||||
|
||||
Below are some important points to consider:
|
||||
|
||||
- Our protocol currently lacks security proofs and has not been audited.
|
||||
- It is functional but under active development.
|
||||
- Until we integrate VOLE-based IZK, it is only practical to prove data volumes in the **low kB** range (largely dependent on network bandwidth between the Prover and Verifier). This works for many use-cases involving API queries for succinct representations of data, eg. identity information.
|
||||
- Selective disclosure _tooling_ is currently limited to simple redactions.
|
||||
|
||||
## Roadmap
|
||||
|
||||
We have a number of items on our roadmap that we are tackling across a few different areas.
|
||||
|
||||
### Core Protocol (MPC TLS)
|
||||
|
||||
In addition to standard things like better tests, audits and documentation, we have a number of improvements in mind for our core protocol:
|
||||
|
||||
- The security proofs for the protocol we use for OT extension, KOS15\[6\], was called into question around the time we adopted and implemented it. We're due to replace it with the more recent SoftSpokenOT protocol, Roy22\[7\]
|
||||
- Implement and integrate VOLE-based IZK. As mentioned earlier, this is a critical piece which will significantly boost efficiency and make proving larger data volumes (MBs) practical.
|
||||
- Improve the P256 point-addition protocol used in the ECDHE key exchange, as well as the protocol for GHASH used in AES-GCM. We implement both using Gilboa-style (Gil99\[8\]) OLE with additional consistency checks, but a more efficient approach was recently demonstrated by XYWY23\[3\].
|
||||
- Add support for the ChaCha20-Poly1305 ciphersuite. ChaCha20 has ~50% lower communication cost compared to AES when executed in MPC.
|
||||
- TLS 1.3 support.
|
||||
|
||||
### Selective Disclosure
|
||||
|
||||
Being able to prove the authenticity of data is one thing, but it's important that selective disclosure tooling is available for developers to easily build privacy preserving applications.
|
||||
|
||||
Below are some items we will be prioritizing:
|
||||
|
||||
- Gadgets and examples for using the commitments with SNARKs. We intend to make it easy to integrate SNARKs using tooling such as Circom.
|
||||
- Support proving arbitrary statements to the Verifier with IZK. Presently, we only provide tools for simple redactions out of the box.
|
||||
- Tooling for common application contexts, eg. HTTP, and JSON. Web applications do not represent data in formats friendly to ZK proofs, so it can be quite burdensome to work with. Developers need good abstractions at their disposal for working with these formats.
|
||||
|
||||
## Infrastructure
|
||||
|
||||
### Reference Notary Server
|
||||
|
||||
We're building a reference [Notary server implementation](https://github.com/tlsnotary/notary-server) which enables anyone to spin up a Notary and start attesting!
|
||||
|
||||
This implementation will also serve as a reference for building application-specific verifiers.
|
||||
|
||||
### Browser extension
|
||||
|
||||
Desktop applications have mostly fallen out of style, which is a shame because building cryptography applications in the browser is _difficult_! But we work with what we've got. So we're building a [web extension](https://github.com/tlsnotary/tlsn-extension) to let people run the TLSNotary protocol in their browser using WASM.
|
||||
|
||||
It is still in very early stages, but the plan is to provide some UI conveniences for users, and a plugin system for developers to build proving flows in a sandboxed environment. We envision an open ecosystem of these plugins which users can select depending on their needs. This no doubt will come with some security challenges!
|
||||
|
||||
## Join Us!
|
||||
|
||||
Come find us in our [public Discord server](https://discord.gg/9XwESXtcN7), and tune in for further updates on [Twitter](https://twitter.com/tlsnotary).
|
||||
|
||||
We're looking forward to seeing all the great privacy-centric applications folks can come up with!TLSNotary is made possible because of contributions from [dan](https://github.com/themighty1), [th4s](https://github.com/th4s), [Hendrik Eeckhaut](https://github.com/heeckhau), [Christopher Chong](https://github.com/yuroitaki), [tsukino](https://github.com/0xtsukino), [Kevin Mai-Husan Chia](https://github.com/mhchia), [sinu](https://github.com/sinui0).
|
||||
|
||||
## References
|
||||
|
||||
- \[1\] Kolesnikov, V., Schneider, T.: Improved garbled circuit: Free XOR gates and applications. In: ICALP 2008, Part II (2008)
|
||||
- \[2\] Zahur, S., Rosulek, M., and Evans, D.: Two Halves Make a Whole Reducing Data Transfer in Garbled Circuits using Half Gates. In: 34th Eurocrypt, Sofia, Bulgaria, April 2015
|
||||
- \[3\] Xie, X., Yang, K., Wang, X., Yu, Y.: Lightweight Authentication of Web Data via Garble-Then-Prove
|
||||
- \[4\] Jawurek, M., Kerschbaum, F., Orlandi, C.: Zero-Knowledge Using Garbled Circuits or How To Prove Non-Algebraic Statements Efficiently.
|
||||
- \[5\] Baum, C., Dittmer, S., Scholl, P., Wang, X.: SoK: Vector OLE-Based Zero-Knowledge Protocols
|
||||
- \[6\] Keller, M., Orsini, E., Scholl, P.: Actively Secure OT Extension with Optimal Overhead
|
||||
- \[7\] Roy, L.: SoftSpokenOT: Communication–Computation Tradeoffs in OT Extension
|
||||
- \[8\] Gilboa, N.: Two Party RSA Key Generation. In: Advances in Cryptology - Crypto '99
|
||||
@@ -0,0 +1,112 @@
|
||||
---
|
||||
authors: ["PSE Team"]
|
||||
title: "Unirep: A private and non-repudiable reputation system"
|
||||
image: null
|
||||
tldr: ""
|
||||
date: "2022-08-29"
|
||||
canonical: "https://mirror.xyz/privacy-scaling-explorations.eth/S04tvQuLbRjf_9ZrzDTE0T2aho9_GoSuok5NEFyHNO4"
|
||||
---
|
||||
|
||||
Originally published on Aug 26, 2021:
|
||||
|
||||
\*tl;dr: \*Unirep is a protocol that allows users to receive and give reputation anonymously and prove their own reputation on other platforms that support the protocol.
|
||||
|
||||

|
||||
|
||||
## What is the Unirep protocol?
|
||||
|
||||
[Unirep](https://github.com/Unirep/Unirep) is a private and non-repudiable reputation protocol built on Ethereum using zero knowledge proof technology. The protocol offers a system where users can:
|
||||
|
||||
- Anonymously give positive and negative reputation to others
|
||||
- Receive positive and negative reputation from other anonymous users while not being able to refuse to accept the reputation (non-repudiable).
|
||||
- Voluntarily prove that they have at least a certain amount of reputation without revealing the exact amount.
|
||||
|
||||
Using Unirep, we can build applications that provide people with new types of experiences where they can build private reputation. Named after **Uni**versal\*\* Rep\*\*utation, \*\*UniRep \*\*technology allows people to easily apply their reputation across multiple communities using interoperable smart contracts all while preserving user privacy using zero knowledge proofs.
|
||||
|
||||
This allows us to reimagine how existing web applications work. Many services from online shopping, social media to the sharing-economy, not to mention blockchain applications leverage reputation systems and could benefit from this approach.
|
||||
|
||||
One use case, which we are working on, is a social media application on top of Unirep, let’s call it Unirep Social for this post. The motivation is to foster open dialogue among anonymous users who are all participating with only the reputation they’ve built up within platforms using the Unirep Protocol.
|
||||
|
||||
Imagine Alice has an account on a reddit-like platform and has received a lot of karma from other users. A minimum amount of karma is required to make posts in some subreddits and other users will take posts of accounts with high Karma scores more seriously. One day Alice wants to make a post about something that she doesn’t want to be associated with for the rest of her internet life. She could create a new account on the platform but this would mean she needs to start accumulating karma from scratch. Using Unirep we can allow Alice to stay completely private but still accumulate karma and allow her to prove her karma score to others.
|
||||
|
||||
## Why does this matter?
|
||||
|
||||
Traditional social media apps have built entire economies around public reputation. The more content (regardless of quality) and engagement with that content (positive or negative) the greater the reputation can be. It costs nothing to post, comment or like/dislike cultivating a reactive communication environment. Following are some of the issues caused by public, reputable protocols:
|
||||
|
||||
- Public figures often receive [irrelevant responses](https://youtu.be/oLsb7clrXMQ?t=1000) to their posts regardless of their posts intellectual merit (or lack thereof).
|
||||
- People with few followers can go unheard regardless of the quality of what they have shared.
|
||||
- Anyone can receive a response skewed by the threat of social repercussions if the opinion they post differs from their followers expectations.
|
||||
|
||||
Public prominence (or lack thereof) need not influence the collective attention paid to any post or comment. The community anonymously chooses which anonymous content creators it empowers and disempowers. Furthermore, if a person chooses to share their reputation score, it can be proven that they meet a selected threshold without revealing their exact reputation.
|
||||
|
||||
## The Unirep Protocol Explained
|
||||
|
||||
The following is a high level overview of the Unirep protocol. We use the social media application Unirep Social as an illustrative example. If you are interested to learn more stay tuned for a more detailed post or dive right in on [Github](https://github.com/Unirep/Unirep). To begin, let us define the two different actors who interact with the Unirep protocol: users and attesters.
|
||||
|
||||
**Users** can receive and spend reputation, prove their reputation, and use temporary identities called **epoch keys** to interact with other people. Users can generate five new epoch keys every epoch (in this case, 7 days). In a way, the user gets a completely new identity every epoch which preserves their privacy.
|
||||
|
||||
**Attesters** represent users to give reputation to an epoch key. Attester IDs are public and unchangeable so users can always prove that the reputation is from the attester.
|
||||
|
||||
In the Unirep Social example an attester would be the Unirep Social application and Users are users of the application who vote on each other’s comments.
|
||||
|
||||
## **1\. Registration**
|
||||
|
||||
Users and attesters use different ways to sign up in Unirep.
|
||||
|
||||
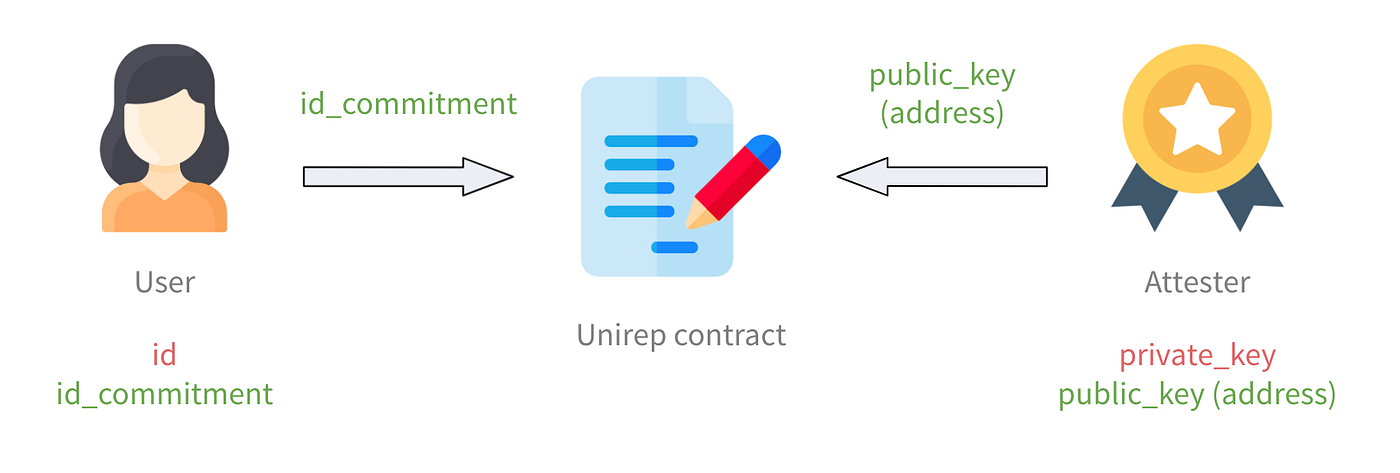
|
||||
|
||||
_User signup and attester signup in Unirep_
|
||||
|
||||
## User
|
||||
|
||||
A user generates identity and identity commitment through [Semaphore](https://github.com/appliedzkp/semaphore).\*\* \*\*Semaphore is a zero-knowledge gadget which allows Ethereum users to prove their membership of a set which they had previously joined without revealing their original identity.
|
||||
|
||||
The user hoIds the identity like a private key, and the identity commitment is like a public key that is submitted to the Unirep contract.
|
||||
|
||||
## Attester
|
||||
|
||||
The attester uses his own wallet or the address of a smart contract to register. After calling the attester sign up function, the Unirep contract will assign an attester ID to this address.
|
||||
|
||||
Whenever the attester gives an attestation, the Unirep contract will check whether the address is registered. If it is registered, the attester is allowed to give reputation to an epoch key.
|
||||
|
||||
**Note:** Everyone can sign up as an attester with their wallet address and will receive a new attester ID
|
||||
|
||||
## 2\. Give Reputation
|
||||
|
||||
Only epoch keys can receive attestations. The next graphic shows how attesters and users interact in the Unirep Protocol.
|
||||
|
||||
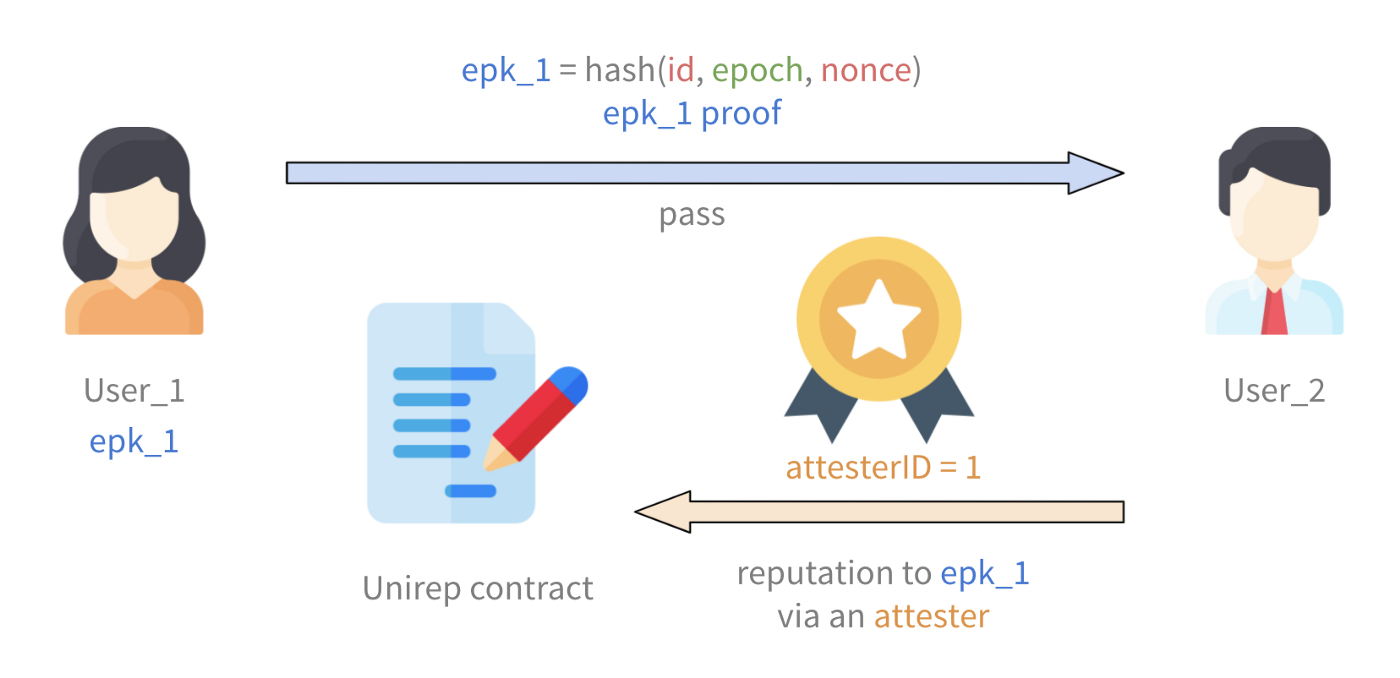
|
||||
|
||||
_How an attester attests to an epoch key_
|
||||
|
||||
After Alice signs up to Unirep, she can generate epoch keys to receive reputation. These epoch keys change every epoch, are unique to every user and look completely random. In the Unirep Social example users can make posts with their epoch keys. Now, when a user sees a post made by an epoch key, how can others know that it is indeed from a registered user? And how can they be sure that the epoch key is computed correctly with the current epoch and a valid nonce? Alice can not simply provide this information since this would enable everyone to calculate what reputation Alice has received, removing the desired privacy.
|
||||
|
||||
This is where zero-knowledge proofs (ZKP) come into play. A ZKP is used to prove that the epoch key is valid without revealing additional information. For details, please refer to the [epoch key proof](https://github.com/Unirep/Unirep/blob/f69b39c6011ae80cd2cb868f8da0eea594ab8cff/packages/circuits/circuits/verifyEpochKey.circom), which proves that the user is indeed registered, and the epoch and nonce are valid numbers.
|
||||
|
||||
The user can see the `epoch_key` in the post and the `epoch_key_proof` provided by Alice, and verifies them through the Unirep contract, and then can give an attestation through the attester (in our example Unirep Social) to the epoch key.
|
||||
|
||||
Users can also _spend_ reputation if it makes sense for the application. They would generate a reputation proof about their current amount of reputation and the attester will send a negative reputation to decrease the balance. Spending reputation is a way for users to give reputation to other users through an attester without having to register as an attester themselves.
|
||||
|
||||
## 3\. Receive Reputation
|
||||
|
||||
A user can prove which epoch key she owns and everyone can easily query how much reputation the epoch key has from the contract. A user that has received some bad reputation during a certain epoch could decide not to show those epoch keys to other users. Therefore, after an epoch ends and all epoch keys are sealed, Unirep restricts users to generate a User State Transition proof that is used to update their reputation status.
|
||||
|
||||
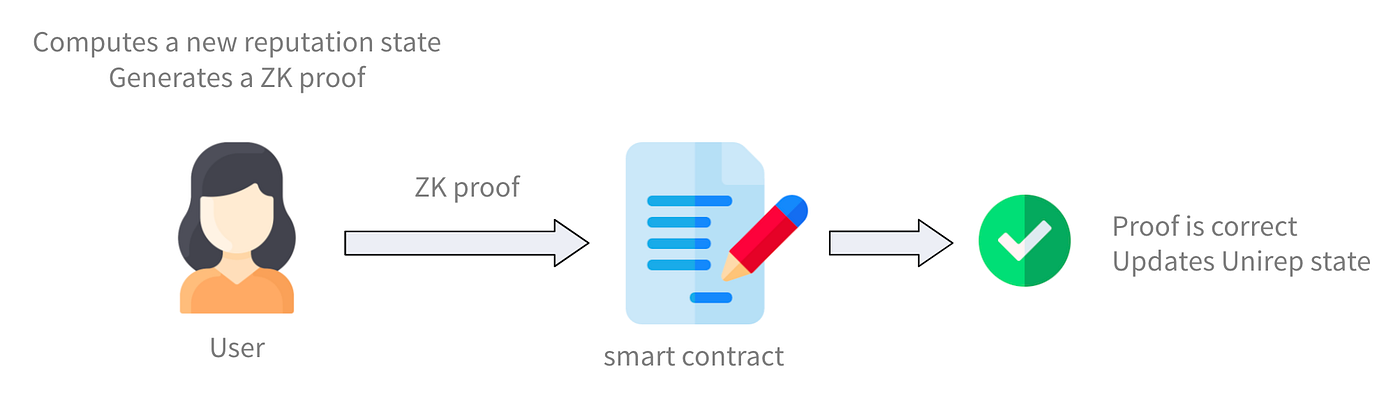
|
||||
|
||||
_User State Transition in Unirep_
|
||||
|
||||
The [User State Transition Proof](https://github.com/Unirep/Unirep/blob/f69b39c6011ae80cd2cb868f8da0eea594ab8cff/packages/circuits/circuits/userStateTransition.circom) is used to ensure that the user calculates the latest user state in the correct way, and the user does not miss any attestation.
|
||||
|
||||
In other words, after an epoch is over, Alice can collect reputation from other users (via Unirep Social) through User State Transition and update her reputation status.
|
||||
|
||||
## 4\. Prove Reputation
|
||||
|
||||
After Alice performs a User State Transition, she will have the latest user state. At this time, Alice can prove to everyone on the platform how many reputation points she has in Unirep Social through a [reputation proof](https://github.com/Unirep/Unirep/blob/f69b39c6011ae80cd2cb868f8da0eea594ab8cff/packages/circuits/circuits/proveReputation.circom). The reputation proof checks whether the user exists, has the claimed reputation (for example it sums up positive and negative reputation from specified attester IDs), and performs User State Transition.
|
||||
|
||||
For privacy reasons it could be disadvantageous to reveal the exact amount of reputation one has received. If Alice has 100 karma in total, Unirep allows Alice to prove that she has \*“at least 10 karma” \*instead of revealing that the total is 100.
|
||||
|
||||
## Conclusion
|
||||
|
||||
Unirep s a reputation system with privacy protection. Thanks to ZKP magic, users can receive reputation, give reputation, and prove reputation to others **anonymously**. Unirep can be used for cross-application reputation certification. One can obtain reputation in application A, and prove in application B how much reputation is obtained. If you want to learn more about Unirep, you can refer to [Github](https://github.com/Unirep/Unirep), [documents](https://unirep.gitbook.io/unirep/) or join the [Discord channel](https://discord.gg/VzMMDJmYc5) to discuss.
|
||||
|
||||
_Special thanks to Thore and Rachel for feedback and review._
|
||||
@@ -0,0 +1,68 @@
|
||||
---
|
||||
authors: ["Chance"]
|
||||
title: "UniRep Ceremony: An Invitation to the Celestial Call and UniRep v2"
|
||||
image: "cover.webp"
|
||||
tldr: "The initial ideas for this blog post originated from UniRep core contributor [Chance](https://github.com/vimwitch). Additional write up and review by [CJ](https://github.com/CJ-Rose), [Chiali](https://github.com/ChialiT), [Vivian](https://github.com/vivianjeng), [Doris](https://github.com/kittybest), and [Anthony](https://github.com/AnthonyMadia)."
|
||||
date: "2023-10-24"
|
||||
canonical: "https://mirror.xyz/privacy-scaling-explorations.eth/z-gW2RtgFTV18ZkRGED2XKLn_wDd-SwMSs17vWQwfLs"
|
||||
---
|
||||
|
||||
## **Introduction**
|
||||
|
||||
[“The Celestial Call”](https://ceremony.unirep.io/) is UniRep protocol’s trusted setup ceremony, aiming to gather a collective input to secure the foundation of the protocol. The keys generated from your input will solidify the next frontier of digital reputation, anonymity, and data sovereignty! The ceremony opened for contributions on October 10, 2023 and will remain open for 64 days. But first let’s expand our concept of what can be accomplished when building with UniRep, by moving beyond simplistic notions of reputation.
|
||||
|
||||
## **Rethinking reputation**
|
||||
|
||||
[Historically](https://mirror.xyz/privacy-scaling-explorations.eth/FCVVfy-TQ6R7_wavKj1lCr5dd1zqRvwjnDOYRM5NtsE), we’ve used the term “reputation” in Universal Reputation (UniRep) to mean positive or negative reputation. This definition is very limiting in application and does not express what UniRep is capable of storing. Instead, reputation should be thought of as **user data**, including things like historical actions, preferences, associations, balances, ownership, friends, etc.
|
||||
|
||||
UniRep allows applications to associate user data with anonymous users. Applications attest to changes to user data using anonymous identifiers ([epoch keys](https://developer.unirep.io/docs/2.0.0-beta-4/protocol/epoch-key)). A user’s data is the combination of all changes to all identifiers controlled by the user. The application cannot determine what changes belong to what user.
|
||||
|
||||
Thus we can build non-custodial applications: applications that never have custody of user data. Users can interact with UniRep based applications trustlessly. Applications negate the risk of user data being hacked or stolen by never *knowing* user data.
|
||||
|
||||
## **Privacy-preserving personalization**
|
||||
|
||||
Many of the platforms and services we rely on for our everyday needs — for communication, entertainment, shopping, banking, transportation, travel, etc .— give us no control over the security or privacy of our personal data. UniRep offers an opportunity for building privacy-first applications that invert the prevailing model and place control of information in the hands of its users.
|
||||
|
||||
Imagine a consumer product platform where users’ viewing history, preferences, and transactions aren’t stored as user profiles on the platform’s servers, but as disassociated data points on a public blockchain. Because this data is attributed to ephemeral anonymous identifiers, and not names or accounts, the platform can’t associate any data to any individual user. Instead, the user will submit a ZK proof to verify their ownership of data relevant to a specific interaction or request.
|
||||
|
||||
For example:
|
||||
|
||||
- **anonymously request updates** (e.g. processing/delivery) by proving ownership of a purchase
|
||||
- **anonymously leave a rating** for a product by proving ownership of a purchase and generating a nullifier.
|
||||
- **anonymously request a refund** by proving ownership of a purchase, generating a nullifier, and providing information about the refund request.
|
||||
|
||||
With this new model, applications can use information about user interactions to offer services like recommendations and reviews, without connecting that information to any individual’s persistent identity.
|
||||
|
||||
## **Identity trapdoor**
|
||||
|
||||
For this post, let’s define three levels of identity.
|
||||
|
||||
1. Fully identified. e.g. That’s John, he lives on Fig Street and works at the bank
|
||||
2. Pseudonymous. e.g. That’s trundleop, they write posts about bridges and trolls.
|
||||
3. Anonymous. e.g. Identifier _0x219fa91a9b9299bf_ wrote a post about bees. This identifier will never be seen again.
|
||||
|
||||
It’s very hard to go from lower levels of identity to higher levels of identity. If I see John spraypaint graffiti on the back of the bank he works at in real life, he’s going to have a hard time convincing me it was someone else.
|
||||
|
||||
Conversely, it’s very easy to go from fully anonymous to less anonymity – or less identifiable to more identifiable. If I control identifier _0x219fa91a9b9299bf_, I can always make a ZK proof showing control or linking it to a pseudonym, identity, or another anonymous identifier.
|
||||
|
||||
Identification is basically a trapdoor. It makes sense to build primitives that are *anonymous by default*. Users, or even applications, can choose to operate at lower levels of identity, depending on their priorities. To support anonymity for everyone, UniRep is designed to be fully anonymous by default.
|
||||
|
||||
As we eagerly anticipate the unveiling of UniRep V2, we’re highlighting a foundational cryptographic layer: the trusted setup. This ceremony is more than just a formality; it's a multiparty computation designed to establish the secure parameters vital for common UniRep proofs. Within the UniRep framework, there are pivotal tasks — like user sign-ups and state transitions — that rely on these parameters.
|
||||
|
||||
The trusted setup ceremony has two phases. For phase 1, we’ve used [Perpetual Powers of Tau](https://github.com/privacy-scaling-explorations/perpetualpowersoftau), a universal ceremony first launched in 2019. Phase 2, which we’ve named “The Celestial Call”, is specific to UniRep’s circuits. This setup ensures these circuits are distributed safely alongside our package code, fortifying every interaction within the system, and [you’re invited to participate](https://ceremony.unirep.io/).
|
||||
|
||||
By joining “The Celestial Call”, you're not just contributing—you're helping to anchor a decentralized, anonymous, and deeply personal multiverse. The next chapter in anonymous, secure, and personalized interactions awaits your contribution.
|
||||
|
||||
## **Join the Celestial Call**
|
||||
|
||||
The ceremony is planned to run for 64 days, beginning on October 10th, 2023 and concluding on December 12th, 2023. After this period, we'll compile all contributions, finalize the transcripts, and unveil the collaborative multiverse. You are welcome to revisit and verify your individual contribution and the final result.
|
||||
|
||||
## **Learn more about UniRep**
|
||||
|
||||
Check out the website: [https://developer.unirep.io/](https://developer.unirep.io/)
|
||||
|
||||
Build an application: [https://developer.unirep.io/docs/next/getting-started/create-unirep-app](https://developer.unirep.io/docs/next/getting-started/create-unirep-app)
|
||||
|
||||
Try the attester demo app: [https://demo.unirep.io](https://demo.unirep.io/)
|
||||
|
||||
Join our discord! [https://discord.gg/umW6qATuUP](https://discord.gg/umW6qATuUP)
|
||||
74
articles/unirep-protocol.md
Normal file
@@ -0,0 +1,74 @@
|
||||
---
|
||||
authors: ["PSE Team"]
|
||||
title: "UniRep Protocol"
|
||||
image: "cover.webp"
|
||||
tldr: ""
|
||||
date: "2023-01-04"
|
||||
canonical: "https://mirror.xyz/privacy-scaling-explorations.eth/FCVVfy-TQ6R7_wavKj1lCr5dd1zqRvwjnDOYRM5NtsE"
|
||||
---
|
||||
|
||||
Anonymity gives people a clean slate to express themselves, unconnected to an existing identity. Reputation provides context: it reveals an aspect about a person’s history in relation to others. [UniRep protocol](https://github.com/unirep) adds reputation to anonymity, allowing people to provide relational context without revealing specifics of their history.
|
||||
|
||||
UniRep stands for [Universal Reputation](https://mirror.xyz/privacy-scaling-explorations.eth/S04tvQuLbRjf_9ZrzDTE0T2aho9_GoSuok5NEFyHNO4) and serves as a base layer for applying reputation across multiple communities using interoperable smart contracts while preserving user privacy through [zero-knowledge proofs](https://ethereum.org/en/zero-knowledge-proofs/).
|
||||
|
||||
## Universal reputation
|
||||
|
||||
Reputation is relational: it is built on claims about a person’s behavior or character. It’s also subjective and context-dependent. It can take a qualitative form such as a reference letter from an acquaintance or an Airbnb review, or it can be an upvote or downvote on Reddit, or a positive or negative integer in a database. Many of the apps and services we depend on wouldn’t work without reputation acting as a reference for deciding whether and how to interact with strangers on the internet.
|
||||
|
||||
UniRep protocol is a standard on which different reputational rules can interoperate. It doesn’t dictate how reputation is used in a given application, but instead functions as a generic and [extensible](https://www.youtube.com/watch?v=jd2Dg9czJzI&list=PLV91V4b0yVqRQ62Mv0nUgWxJhi4E67XSY&index=5) system where platforms such as AirBNB, Uber, Reddit, Medium, Trip Advisor, or Trust Pilot would be [attesters](https://developer.unirep.io/docs/protocol/users-and-attesters): providers of negative or positive reputation.
|
||||
|
||||
Attesters are at the application layer. They are the platforms, businesses, and communities in the ZK social ecosystem. They act as world builders and community managers. Attesters have great flexibility in what to build. They decide how many user identities are used, how users are onboarded, and how users interact with each other. Most importantly, attesters decide why someone receives a positive reputation and why someone receives a negative reputation. In other words, attesters provide accountability.
|
||||
|
||||
Attesters use publicly known Ethereum addresses while user identities are always kept private. Users receive reputation from attesters and can create a zero-knowledge proof verifying they have a certain level of reputation from a certain attester.
|
||||
|
||||
UniRep users are always in control of how their reputation is used: only they can see how much they’ve accrued and only they have the power to reveal their reputation – and only to who they want.
|
||||
|
||||
## How UniRep works: adding accountability to anonymity
|
||||
|
||||
The UniRep protocol evolved from an [ethresearch proposal by Barry WhiteHat](https://ethresear.ch/t/anonymous-reputation-risking-and-burning/3926) for a system where users could be banned or have their reputation destroyed even if they are anonymous. The proposal outlined a mechanism for giving positive and negative reputation in a way that the user must accept while maintaining privacy. To guarantee reputation is non-repudiable (cannot be refused) UniRep employs a system of epochs, temporary identities, and the migration of reputation and user information from one state to the next via ZK proofs.
|
||||
|
||||

|
||||
|
||||
## Temporary identities
|
||||
|
||||
Reputation is accumulated to users via rotating identities called [epoch keys](https://developer.unirep.io/docs/protocol/epoch-key). Epoch keys can be thought of as temporary Ethereum addresses that change regularly but are tied to a persistent user, which preserves anonymity for users while maintaining the history needed for a meaningful reputation.
|
||||
|
||||
[Epochs](https://developer.unirep.io/docs/protocol/epoch) represent the ticking of time. Similar to blocks in a blockchain, they can be thought of as cycles in the UniRep system: with each transition, the reputation balances of all users are finalized and carried over into the new epoch. Each attester sets their own epoch length.
|
||||
|
||||
Epoch keys are created from an [identity commitment](https://semaphore.appliedzkp.org/docs/guides/identities) generated via [Semaphore](https://semaphore.appliedzkp.org/), a generic privacy layer where users can anonymously send signals from within a group. Inside of a Semaphore group, users’ actions are unconnected to their “outside” identities. Instead of interacting with people as a uniquely identifiable individual, Semaphore identities are expressed simply as a member of the group.
|
||||
|
||||
Epoch keys change every epoch, are unique to every user, and look completely random. Only the user knows if they are receiving an attestation or reputation; others would see only an attestation to a random value. Epochs and changing epoch keys help preserve privacy by mixing up where reputation accrues and what identities people use to interact.
|
||||
|
||||
## All about the trees
|
||||
|
||||
UniRep uses a system of migrating [Merkle tees](https://www.youtube.com/watch?v=YIc6MNfv5iQ) to maintain reputation and privacy at the same time. Merkle trees are data structures capable of efficiently storing and verifying information; reputation and user data are stored as leaves in UniRep’s Merkle trees. Proving a UniRep reputation means generating a proof that a user’s claim (their reputation level) exists in a valid Merkle tree.
|
||||
|
||||
When users first sign up, their data is entered into a [State Tree](https://developer.unirep.io/docs/protocol/trees#state-tree). Each attester has their own separate version of a State Tree, which changes every epoch. State Trees can be thought of as the meta reputation tracker for a specific attester: containing relevant UniRep users and their starting reputations at the beginning of an epoch.
|
||||
|
||||
Since epoch keys are temporary, the reputations they accumulate must be migrated to a new Merkle tree. When users transition into the new epoch, they receive new epoch keys and the old epoch keys become invalid. In the background, their reputation follows them to the next iteration of an attester’s State Tree via ZK proofs. Moving to the new State Tree means creating a [User State Transition Proof](https://developer.unirep.io/docs/circuits-api/circuits#user-state-transition-proof) verifying the user followed all the rules of the protocol. The proofs show there was no cheating: no omitting negative attestations or adding fraudulent positive attestations.
|
||||
|
||||

|
||||
|
||||
The user generates a User State Transition proof containing a new state tree leaf containing the attester ID, the user’s [Semaphore identity nullifier](https://semaphore.appliedzkp.org/docs/guides/identities), sum of the user’s positive and negative reputation from the previous epoch, timestamp and “graffiti” - a value given to the user by the attester. This new leaf is provided to the smart contract, which verifies the proof and inserts it into the new State Tree.
|
||||
|
||||
Once a user accrues reputation, they can prove how many reputation points they’ve accumulated through a [reputation proof](https://developer.unirep.io/docs/circuits-api/reputation-proof). The reputation proof is a ZK proof that verifies the user exists, has the claimed reputation, and has performed all the necessary transitions or migrations. The reputation proof makes sure the user’s claims are consistent with the data in the State Tree.
|
||||
|
||||
There are many parallel efforts to reimagine and rearchitect online social systems to be more decentralized, permissionless, and censorship-resistant. Though different in their approaches, all these initiatives are creating basic building blocks for identity and reputation, then playing with different ways to stack the structure.
|
||||
|
||||
Efforts such as [Decentralized Identifiers (DIDs)](https://www.w3.org/TR/2022/REC-did-core-20220719/#abstract), [Decentralized Society (DeSoc)](https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4105763), [peer-to-peer networks](https://scuttlebutt.nz/about/) and [Federated universes](https://eric442.substack.com/p/what-is-the-fediverse-0d6) or [networks](https://blueskyweb.xyz/blog/10-18-2022-the-at-protocol) allow anyone to join in, express themselves, and have the freedom to choose how they connect and participate with others. In these systems, users own their accounts, their data and their social graphs; users can choose how they interface with the network; and independent servers or systems are able to talk to each other by default.
|
||||
|
||||
When we hear "social applications" we tend to think of social media platforms like Twitter or Reddit – but restaurant reviews, marketplaces, rideshares and homestays are all highly social and highly dependent on reliable reputation systems. ZK social or [ZK identity](https://0xparc.org/blog/zk-id-2) share many of the principles of the decentralized social efforts mentioned previously, but ZK social starts with privacy as the foundational layer to build upon – which is especially important in use cases like homestays that cross into “real life” – and uses zero-knowledge proofs as the primary mechanism to make claims about identities or reputations. UniRep protocol is one building block in the ZK social stack.
|
||||
|
||||
Adding on complexity and data to an anonymous system allows people to regain the color that is lost when users can’t be individually identified. Building social primitives from scratch means having to consider and experiment with new ways to layer in constraints, rules, and feedback mechanisms.
|
||||
|
||||
Eventually, interesting, multi-dimensional, user-owned, privacy-preserving, digital identity and reputation systems – all interoperating – are expected to emerge. But it’s still early days. Protocols such as Semaphore and UniRep are meant to serve as foundational building blocks near the base of the ZK social stack. These primitives can’t decide how this ZK-enabled social future will look or feel; that can only be decided by users, attesters, and builders.
|
||||
|
||||
## Next steps
|
||||
|
||||
UniRep is still in the early stages of development, but the team is already working on the [next version](https://github.com/Unirep/Unirep/issues/134) of the protocol, which aims to make the system more customizable and easy for attesters as well as more scalable by reducing the complexity of creating ZK proofs.
|
||||
|
||||
You can try a [demo app](https://unirep.social/) built with UniRep Protocol, which resembles Reddit but with anonymity and privacy by default.
|
||||
|
||||
If you’d like to contribute to helping build the next version of [UniRep Protocol](https://github.com/unirep) or integrating this anonymous reputation layer to your project, check out the [docs](https://developer.unirep.io/docs/welcome) and join the [UniRep Discord here](https://discord.gg/VzMMDJmYc5).
|
||||
|
||||
UniRep Protocol is possible thanks to the contributions of [Vivian](https://github.com/vivianjeng), [Chance](https://github.com/vimwitch), [Doris](https://github.com/kittybest), [Anthony](https://github.com/AnthonyMadia), [Yuriko](https://github.com/yuriko627), [CJ](https://github.com/CJ-Rose), and [Chiali](https://github.com/ChialiTsai).
|
||||
@@ -0,0 +1,47 @@
|
||||
---
|
||||
authors: ["PSE EcoDev Team"]
|
||||
title: "Unleashing Potential: Introducing the PSE Core Program"
|
||||
image: "cover.webp"
|
||||
tldr: "This post was written by the PSE EcoDev Team."
|
||||
date: "2024-04-24"
|
||||
canonical: "https://mirror.xyz/privacy-scaling-explorations.eth/PvNKlzp8Xlaic_DeIFEW20-ai4eN1AqJO26d4YRqWwM"
|
||||
---
|
||||
|
||||
Hey there, curious minds! Are you ready to dive into the world of practical skills and open-source project contributions? Well, buckle up because we're about to embark on an exciting journey through the **PSE Core Program**!
|
||||
|
||||
In today’s digital landscape, privacy and security are paramount. That’s where Zero Knowledge (ZK) technologies come into play. By allowing parties to verify information without revealing any underlying data, ZK protocols offer a revolutionary solution to protect sensitive information in a world where data breaches and privacy violations are all too common.
|
||||
|
||||
With ZK protocols, individuals can engage in transactions, authenticate identities, and share information without compromising their privacy. It's a game-changer for industries ranging from finance and healthcare to communications and beyond.
|
||||
|
||||
So, what exactly is this program all about? Picture this: you're a student in Latin America or Asia, eager to enhance your skills and make a meaningful impact in the tech world. That's where the PSE Core Program swoops in to save the day. It's like a beacon of opportunity, shining a light on the path towards knowledge and growth.
|
||||
|
||||
Let's delve into the workings:
|
||||
|
||||
The program works in a **Hybrid Learning Model.** We blend the flexibility of self-learning with weekly in-person meetups. These sessions are all about sparking discussions, networking, and solving challenges together.
|
||||
|
||||
1. **Stage 0 (Preparation):** Before we kick off, we've got some prep work for you. Dive into modules that cover program logistics, open-source culture, and essential background knowledge for zero-knowledge technology.
|
||||
2. **Stage 1 (Weeks 1-5):** It's time to roll up your sleeves and dive into zero-knowledge tech. Guided by seasoned mentors, you'll tackle complex topics with hands-on coding and curated study materials. Plus, Week 3 brings a thrilling hackathon for a break from studying.
|
||||
3. **Stage 2 (Weeks 6-8):** Here's where the magic happens. Armed with newfound knowledge and experience, you'll contribute to real-world open-source projects. It's your chance to shine as an open-source developer.
|
||||
|
||||
Throughout the program, you'll dive into exciting topics such as:
|
||||
|
||||
- Cryptography basics: getting started with Circom, hash functions and more
|
||||
- KZG commitments and zkSNARKs
|
||||
- Overview of trusted setups and Groth16
|
||||
- Deep Dive into PLONK
|
||||
- Halo2, FHE, MPC
|
||||
- Explore projects like Sempahore, Bandada, TLSNotary, ZKEmail
|
||||
|
||||
But here's the best part: you won't be navigating this journey alone. You'll have mentors, community managers, and more people from the PSE team by your side; plus, weekly in-person meetings where you can network with fellow enthusiasts.
|
||||
|
||||
Who knows? You might even meet your future co-founder in one of these sessions.
|
||||
|
||||
Throughout the PSE Core Program, participants will dive deep into ZK fundamentals, gain hands-on experience with cutting-edge technologies, and contribute to real-world projects. As the demand for ZK expertise continues to grow, this program presents a unique opportunity for participants to carve out a successful career path in a field with a brilliant future ahead.
|
||||
|
||||
Join us in our Telegram group to connect with fellow enthusiasts, ask questions, and stay updated on program news and events. You can also explore our program website for more details and to apply today!
|
||||
|
||||
Telegram group: [https://t.me/+ebGauHbpDE0yZGIx](https://t.me/+ebGauHbpDE0yZGIx)
|
||||
|
||||
Core Program Website: [https://www.notion.so/pse-team/PSE-Core-Program-2024-64ae61c3d7e74bf4bf9c15914ef22460](https://www.notion.so/PSE-Core-Program-2024-64ae61c3d7e74bf4bf9c15914ef22460?pvs=21)
|
||||
|
||||
So, what are you waiting for? Get ready to unleash your full potential. The world of ZK awaits, and we're here to help you conquer it. Let's do this!
|
||||
120
articles/web2-nullifiers-using-voprf.md
Normal file
@@ -0,0 +1,120 @@
|
||||
---
|
||||
authors: ["Rasul Ibragimov"]
|
||||
title: "Web2 Nullifiers using vOPRF"
|
||||
image: "cover.webp"
|
||||
tldr: "This post was written by PSE researcher Rasul Ibragimov. Big thanks to Lev Soukhanov for explaining the majority of this to me - without him, this blog post wouldn't exist."
|
||||
date: "2025-01-30"
|
||||
canonical: "https://mirror.xyz/privacy-scaling-explorations.eth/L4LSAWflNocKolhV6ZVaqt3KDxdSjFPNSv0U5SCc__0"
|
||||
---
|
||||
|
||||
## Abstract
|
||||
|
||||
Recent development of protocols, that allow us to make Web2 data portable & verifiable such as [ZK Email](https://prove.email/) or [TLSNotary](https://tlsnotary.org/) opens new use-cases and opportunities for us. For example, we can make proof of ownership of some x.com username or email address and verify it on-chain with ZK Email. Projects like [OpenPassport](https://www.openpassport.app/), [Anon Aadhaar](https://github.com/anon-aadhaar/anon-aadhaar) (and others) are also the case.
|
||||
|
||||
We can also do more complex things, e.g. forum where holders of @ethereum.org email addresses will be able to post anonymously, using zk proofs of membership.
|
||||
|
||||
Projects like [Semaphore](https://semaphore.pse.dev/) helps us to build pseudonymous systems¹ with membership proofs for "Web3 identities".
|
||||
|
||||
In Semaphore users have their $\text{public\_id} = \text{hash(secret, nullifier)}$, and $\text{nullifier}$ actually serves as an id of user - we still don't know who exactly used the system, but we'll be able to find out if they used it more than once. But the thing is **we don't have any nullifiers** in ZK Email/TLS, etc. - that's why it's not possible to create such systems for Web2 identities out of the box. The solution for that is vOPRF.
|
||||
|
||||
vOPRFs (verifiable Oblivious PseudoRandom Functions) - are protocols that allow a client to generate deterministic random based on their input, while keeping it private. So, there're two parties in the protocol - first one as I said is a client, and second one is a OPRF network (usually [MPC](https://en.wikipedia.org/wiki/Secure_multi-party_computation) is used for that).
|
||||
|
||||
With OPRF we'll be able to generate nullifiers for Web2 ID's': users will just need to ask the MPC to generate it, e.g., based on their email address (without revealing plain text of course).
|
||||
|
||||
We can do many things based on that:
|
||||
|
||||
- Anonymous voting with ported Web2 identities;
|
||||
- Anonymous airdrops - projects can just list Github accounts, that are eligible for airdrop, and users will be able to claim (only once) with proof of Github using ZK Email;
|
||||
- Pseudonymous forums - I mentioned it before, but with OPRF we can have pseudonyms and limit user to only one account + it might be easier to track & ban spammers
|
||||
- ... many more.
|
||||
|
||||
Read the next section for more details.
|
||||
|
||||
## Detailed explanation
|
||||
|
||||
### Main protocol
|
||||
|
||||
There are three parties involved in protocol:
|
||||
|
||||
- **User**, that is trying to do some action with their Web2 identity (e.g. google account) pseudonymously (e.g. anonymously participate in voting).
|
||||
- **OPRF** Server/Network (will just call OPRF).
|
||||
|
||||
- We use MPC, because in the case of having only one node generating nullifiers for users - it'll be able to bruteforce and find out which Web2 identity corresponds to a given nullifier. Every node has to commit to their identity somehow - e.g., by storing their EC public key on a blockchain. For simplicity I'll explain the case with one node OPRF first, and in the OPRF-MPC section I'll explain how we can extend it to multiple nodes.
|
||||
|
||||
- **Ethereum** (or any other smart-contract platform)
|
||||
|
||||
**1)** User makes ZK Email/TLS auth proof with salted commitment to UserID (or email, name, etc.) as a public output:
|
||||
|
||||
$\text{commitment₁} = \text{hash} \text{(UserID,salt)}$
|
||||
|
||||
I'll call it just **Auth proof.**
|
||||
|
||||
**2)** User sends new commitment to their UserID to OPRF:
|
||||
|
||||
$\text{commitment₂} = r * G$
|
||||
|
||||
where $G = \text{hashToCurve}(\text{UserID})$, and $\\r$ is random scalar. We want to prevent users from sending arbitrary requests (because they would be able to attack the system by sending commitments to different user's identities), so user must additionally provide a small zk proof, that checks the relation between the commitments, where:
|
||||
|
||||
Public inputs: $\text{commitment₁}$, $\text{commitment₂}$
|
||||
|
||||
- Private inputs: $\text{UserID}, \text{salt}, r$
|
||||
|
||||
and constraints:
|
||||
|
||||
$\text{commitment₁} = \text{hash}(\text{UserID},\text{salt})$
|
||||
|
||||
$\text{G} = \text{hashToCurve}(\text{UserID})$
|
||||
|
||||
$\text{commitment₂} = r * G$
|
||||
|
||||
**3)** OPRF replies with:
|
||||
|
||||
$\text{oprf \textunderscore response} = s * \text{commitment₂}$
|
||||
|
||||
where $s$ is a private key of OPRF node; and also replies with proof of correctness of such multiplication, which is in this case might be a Chaum-Pedersen proof of discrete log equality (check [this blog post](https://muens.io/chaum-pedersen-protocol) on that).
|
||||
|
||||
**4)** User creates zk proof with the following parameters:
|
||||
|
||||
- Public outputs: $\text{commitment₁}, \text{nullifier}$
|
||||
- Private inputs: $r, \text{UserID}, \text{salt}, \text{chaum \textunderscore pedersen \textunderscore proof}, \text{oprf \textunderscore response}$
|
||||
|
||||
and validates that:
|
||||
|
||||
$\text{commitment₁} = \text{hash}(\text{UserID},\text{salt})$
|
||||
|
||||
$G \longleftarrow \text{hashToCurve}(\text{UserID})$
|
||||
|
||||
$\text{chaumPedersenVerify} (\text{oprf \textunderscore response})$
|
||||
|
||||
$\text{nullifier} \longleftarrow r^{-1} * \text{oprf \textunderscore response}$
|
||||
|
||||
### On nullifiers
|
||||
|
||||
That's it, we have a nullifier - and now users can use the system as in Semaphore. If we go a bit further, it's worth to mention that users shouldn't reveal nullifier, because it's linked with their $\text{UserID}$; and if they use the same $\text{UserID}$ in different apps - it'll be possible to track them. We can do it a bit differently - instead of revealing nullifier we can reveal $hash(\text{nullifier}, \text{AppID})$ - where $\text{AppID}$ is a unique identifier of the app, and that's gonna be our real nullifier.
|
||||
|
||||
## OPRF MPC
|
||||
|
||||
In the example above we used only one node OPRF, but we can easily extend it to multiple nodes. There're many ways to do that, I'll explain few:
|
||||
|
||||
**1)** N of N MPC:
|
||||
|
||||
- 1.1. All nodes have their own pair of keys.
|
||||
- 1.2. Every node does step 3 individually: we get $\text{oprf \textunderscore response}_i = s_i * r * G$
|
||||
- 1.3. On step 4 we verify $\text{chaum \textunderscore pedersen \textunderscore proof}$ for every node
|
||||
- 1.4 We calculate $\text{nullifier}_i = \text{oprf \textunderscore response}_i * r^{-1}$
|
||||
- 1.5 We calculate $\sum_{i=1}^N\text{nullifier}_i = s * G$
|
||||
|
||||
_Important to mention that we have to verify/calculate everything in the circuit._
|
||||
|
||||
**2)** M of N MPC using linear combination for Shamir Secret Sharing:
|
||||
|
||||
- Similar to N of N MPC, but we need only M shares
|
||||
|
||||
**3)** Using BLS:
|
||||
|
||||
- 3.1. Calculate common public key of all OPRF nodes by summing individual public keys
|
||||
- 3.2. The same as in N of N MPC case
|
||||
- 3.3., 3.4, 3.5. - The same as in N of N MPC case, **BUT** we can do it outside the circuit
|
||||
- 3.6. Verify BLS pairing in the circuit
|
||||
|
||||
1. Pseudonymous system - a privacy-preserving system, where users' transactions are linked to unique identifiers (pseudonyms), but not their actual identities.
|
||||
@@ -0,0 +1,74 @@
|
||||
---
|
||||
authors: ["Enrico Bottazzi"]
|
||||
title: "Why We Can't Build Perfectly Secure Multi-Party Applications (yet)"
|
||||
image: "cover.webp"
|
||||
tldr: "This post was written by PSE researcher Enrico Bottazzi. Thanks to Pia Park for discussions and reviews."
|
||||
date: "2025-01-14"
|
||||
canonical: "https://mirror.xyz/privacy-scaling-explorations.eth/nXUhkZ84ckZi_5mYRFCCKgkLVFAmM2ECdEFCQul2jPs"
|
||||
---
|
||||
|
||||
In this post, we’ll explore why building secure multi-party applications, which aim to compute a function over inputs from different parties while keeping those inputs private, is impossible today. We use Multi-party Trade Credit Set-off (MTCS) as an example, showing how technologies like multi-party computation and fully homomorphic encryption fall short of perfect security due to a fundamental tradeoff between security and liveness. The current solution involves a delegated security model, but it’s not ideal. Are there any robust patches to this problem, or will we have to wait for indistinguishability obfuscation?
|
||||
|
||||
### Multilateral Trade Credit Set-off
|
||||
|
||||
Multilateral Trade Credit Set-off (MTCS) is a process run by a service provider that collects trade credit data (i.e. obligations from a firm to pay another firm) from a network of firms and detects cycles of debts that can be removed from the system. The process yields liquidity savings for the participants, who can discharge their debts without relying on expensive loans.
|
||||
|
||||

|
||||
|
||||
Trade credit network before and after MTCS
|
||||
|
||||
We propose an MTCS protocol that protects firms' sensitive data, such as the obligation amount or the identity of the firms they trade with. The results are presented in the paper _[Multilateral Trade Credit Set-off in MPC via Graph Anonymization and Network Simplex](https://eprint.iacr.org/2024/2037),_ authored by Enrico Bottazzi, Chan Nam Ngo, and Masato Tsutsumi.
|
||||
|
||||
Despite what you might think, I am not here to celebrate our results. The curious reader who is interested in how we _reduced the asymptotic round complexity of the secure minimum cost flow algorithm_ is warmly invited to check out the paper. Instead, I want to abstract the characteristics of this specific application to **any** secure multi-party application and analyze how technologies such as fully homomorphic encryption (FHE) or secure multi-party computation (MPC) yield an **imperfect security model** given an inherent tradeoff between security and liveness.
|
||||
|
||||
However, not all hope is lost: we present some temporary patches until we reach [indistinguishability obfuscation](https://www.leku.blog/io/), which will break this tradeoff once and for all and allow us to build fully secure multi-party applications.
|
||||
|
||||
### Secure multi-party applications
|
||||
|
||||
A secure multi-party application is an application in which a function has to be computed over inputs coming from different parties, and this input should remain private: each party should not learn anything beyond what can be inferred from their input and the output of the function. Note that this definition is independent from the technology used to build such application.
|
||||
|
||||
In the real world, these applications are usually built leveraging a third party that performs the function and is **trusted** to keep the data for themselves and not do anything malicious with it. This is also the case for MTCS: Slovenia has been running it country-wide since 1991. The process is run every month by having the national firms submit their invoice to a government agency, which performs the clearing by having access to the entire trade credit graph. The low [participation rate](https://www.ajpes.si/Bonitetne_storitve/Vecstranski_pobot/Porocila#b671) (1500 firms, 0.2% of the total, in 2022) suggests that Slovenian firms might feel more comfortable in keeping their sensitive trade credit data for themselves and not join the process, despite the benefits that it yields. In the following sections, we'll iteratively try to build such a secure multi-party app, that does not depend on a single trusted third party.
|
||||
|
||||

|
||||
|
||||
MTCS via a trusted third party
|
||||
|
||||
### Building secure multi-party applications with MPC
|
||||
|
||||
MPC allows $n$ parties to compute a function on their combined private input without disclosing it to each other. In its most secure form, each input is split within $n$ shares such that any combination of $n-1$ shares reveals absolutely nothing about the underlying information. Functions can be performed "obliviously" by having the parties exchange information every time a multiplication is performed. With the strongest security assumptions, privacy and correctness of the executed function are guaranteed as long as one participant is honest. From the point of view of a firm, this is ideal: as long as I keep my shares protected, no one can learn any information.
|
||||
|
||||
But the devil lies in the details! In a protocol with $n$ participants, $n \* (n-1) / 2$, communication channels need to exist to carry out the computation correctly, making the system highly inefficient (and therefore impractical) for networks of tens of thousands of firms. More importantly, those channels need to remain active during the whole protocol to guarantee its finality. Any malicious actor can decide to drop off in the middle of the algorithm execution, making it impossible for the others to recover their output.
|
||||
|
||||
### Building secure multi-party applications with FHE
|
||||
|
||||
When it comes to performing computation over encrypted data, fully homomorphic encryption (FHE) is another possible solution. The mental model for FHE is straightforward: any untrusted server can perform $f$ on encrypted data without learning any information about the underlying data. While MPC is information-theoretic secure, in FHE the privacy of the data is guaranteed by the hardness of solving a specific mathematical problem. A further guarantee of correct computation can be achieved, with an additional cost, by slapping a zkSNARK on top of the server's operation.
|
||||
|
||||
But there's a caveat: FHE still requires someone to hold the decryption key. Outsourcing the ownership of the decryption key to a single party is not a good idea since this party would have god-mode read access to every encrypted data. A more secure approach is to run a [distributed key generation](https://en.wikipedia.org/wiki/Distributed_key_generation) (DKG) ceremony between the $n$ firms, encrypt all the data under the generated encryption key, outsource the computation of $f$ to a server and require the firms to come together again to decrypt each output and deliver it to the designated receiver firm. The decryption part must be done via MPC.
|
||||
|
||||
This brings us to the same problem we encountered before: one negligent (or malicious) firm that loses its decryption key share is sufficient to bring the whole protocol to a halt.
|
||||
|
||||
### The delegated security model
|
||||
|
||||
A perfect security model, "trust no one but yourself," presents limitations given the interaction needed between the $n$ protocol participants. Given that a secure MTCS protocol should support tens of thousands of firms, the price of this security level is too high for a practical instantiation. Sora describes this as a tradeoff between safety and liveness.
|
||||
|
||||

|
||||
|
||||
Where x-axis represents the probability of success based on liveness assumptions. Source: https://speakerdeck.com/sorasuegami/ideal-obfuscation-io
|
||||
|
||||
And indeed, the solution we proposed in the paper does not achieve a perfect security model. Instead, we rely on a client-to-server MPC protocol in which the computation (and the security) of the security is delegated to three servers. The strongest security assumption can guarantee that the privacy of the firm's data is safe as long as at least one of the servers is honest. However, the firms cannot do much to prevent the server managers from secretly meeting and gathering their shares to reconstruct any data involved. To make things even worse, there is no immediate way to detect this malicious action and keep the servers accountable for any misbehaviour.
|
||||
|
||||

|
||||
|
||||
MTCS via MPC
|
||||
|
||||
### Temporary patches and endgame
|
||||
|
||||
There is a set of patches that aim to partially increase the security of such "imperfect" secure multi-party applications. The easiest to implement relies on social dynamics and involves choosing delegates that have conflicting interests with each other, such that a collusion between them is unlikely. For example, in the paper, we propose a delegated security model in which the three server managers are the National Chamber of Commerce, the tax authority, and a payment processor.
|
||||
|
||||
A more advanced implementation requires the servers to wrap their computation inside a TEE to add an additional layer of security: to assemble their shares, the servers must first break the TEE security. A more theoretical approach involves [traitor tracing](https://eprint.iacr.org/2023/1724) systems to add accountability for misbehaving servers.
|
||||
|
||||
The endgame for secure multi-party applications is [indistiguishability obfuscation](https://www.leku.blog/io/) (iO), which promises to be able to break the tradeoff between safety and liveness by removing any need for interaction during the decryption/output reconstruction phase. In particular, the decryption key of a FHE scheme can be embedded inside an obfuscated program as a result of a trusted set-up ceremony: as long as one participant is honest, no human can recover the key. The obfuscated program is designed to take a FHE ciphertext as input together with a proof that such ciphertext is allowed to be decrypted according to the predefined application logic. The program will verify the proof, and, on successful verification, output the decryption of the ciphertext. Since the obfuscated program is public, the decryption can be performed by anyone without requiring any interaction between parties holding the key.
|
||||
|
||||
While there are no practical iO implementations yet, the potential impact on secure multi-party applications is profound. At PSE, we're starting a new team to explore novel approaches based on recent publications to build practical iO.
|
||||
|
||||
If you're a researcher interested in contributing, reach out to [me](https://t.me/demivoleegaston)! You can also join the discussion on our brand new [PSE forum](https://forum.pse.dev/post/1/7) 🙌
|
||||
@@ -0,0 +1,155 @@
|
||||
---
|
||||
authors: ["0xZoey"]
|
||||
title: "Zero to Start: Applied Fully Homomorphic Encryption (FHE) Part 1"
|
||||
image: "cover.webp"
|
||||
tldr: "This post was written by [0xZoey](https://twitter.com/0xZoey). Special thanks to [Janmajaya](https://twitter.com/Janmajaya_mall), [Enrico](https://twitter.com/backaes?lang=en), and [Owen](https://twitter.com/omurovec) who generously gave their time and expertise to review this piece. Your valuable contributions and feedback have greatly enhanced the quality and depth of this work. /n/n Find [Part 2: Fundamental Concepts, FHE Development, Applied FHE, Challenges and Open Problems](https://mirror.xyz/privacy-scaling-explorations.eth/wQZqa9acMdGS7LTXmKX-fR05VHfkgFf9Wrjso7XxDzs) here…"
|
||||
date: "2023-12-21"
|
||||
canonical: "https://mirror.xyz/privacy-scaling-explorations.eth/D8UHFW1t48x2liWb5wuP6LDdCRbgUH_8vOFvA0tNDJA"
|
||||
---
|
||||
|
||||
## **What is FHE?**
|
||||
|
||||
Present privacy technology ensures secure communication and storage, encrypting our emails during transit and safeguarding databases in storage. However, accessing data for **processing** requires the data to be first decrypted. What if secure processing could occur without compromising data privacy?
|
||||
|
||||

|
||||
|
||||
FHE allows computation over encrypted data
|
||||
|
||||
**Fully Homomorphic Encryption (FHE) is a technology that allows computation over encrypted data, where only the owner of the key can decrypt the result of the computation.**
|
||||
|
||||
This article focuses on the current state of FHE, fundamental concepts, applied FHE, and design challenges ahead. It is meant to help users understand the thought framework around applied FHE without requiring the reader to understand complex math or cryptography.
|
||||
|
||||
The idea for FHE was initially proposed in 1978 by Rivest, Adleman, and Dertouzous (the "R" and "A" of [RSA](<https://en.wikipedia.org/wiki/RSA_(cryptosystem)>)). FHE is an extension of public key cryptography; the encryption is "homomorphic" because it works on the principle that for every function performed on unencrypted text (Plaintext), there is an equivalent function for encrypted text (Ciphertext).
|
||||
|
||||

|
||||
|
||||
Homomorphic Encryption
|
||||
|
||||
FHE shares fundamental components with traditional cryptography like encryption, decryption, and key generation. In addition to this, it uniquely enables arithmetic operations such as addition and multiplication on ciphertexts.
|
||||
|
||||
There are generally four categories of homomorphic encryption:
|
||||
|
||||
1. **Partially homomorphic**: enables only one type of operation (addition or multiplication). RSA is an example of partially homomorphic encryption only using multiplication and not addition.
|
||||
2. **Somewhat homomorphic**: limited for one operation but unlimited for the other. For example, limited multiplications but unlimited additions.
|
||||
3. **Leveled homomorphic**: limited operations for both addition and multiplication
|
||||
4. **Fully homomorphic**: unlimited operations for both addition and multiplication (and others).
|
||||
|
||||

|
||||
|
||||
In the past, the difficulty in achieving FHE was due to the "noise" that accumulated with every subsequent operation. The excess overflow in noise eventually makes decryption impossible. Craig Gentry proposed the first FHE scheme in 2009, where he solved this problem with a method called bootstrapping. Bootstrapping is used to recursively evaluate the decryption circuit to reduce and manage noise accumulation.
|
||||
|
||||
## **Why is FHE important?**
|
||||
|
||||
Fully Homomorphic Encryption (FHE) signifies a groundbreaking shift in privacy, enabling data-centric systems to preserve privacy with minimal data exposure inherently. FHE, built using lattice-based cryptography, also offers the notable advantage of being post-quantum resistant, ensuring robust security against future potential threats from quantum computing.
|
||||
|
||||
Some [general](https://homomorphicencryption.org/wp-content/uploads/2018/10/CCS-HE-Tutorial-Slides.pdf?ref=blog.sunscreen.tech) FHE use cases include:
|
||||
|
||||
- Private inference & training: FHE could be used to protect the privacy of both the model and data (likely 3-5 years away).
|
||||
- Encrypted searches: query an encrypted file and only see the result of your specific query without the entire contents of the database revealed, also known as Private Information Retrieval (PIR).
|
||||
- Policy Compliance & Identity Management: Secure identity management by enabling the processing of identity-related data without exposure, allowing organizations to comply with regulators' KYC policies.
|
||||
|
||||

|
||||
|
||||
General FHE Use Cases
|
||||
|
||||
Fully Homomorphic Encryption (FHE) holds immense significance in blockchain technology because it can perform encrypted data computations within a trustless environment. We won't dive into the importance of privacy on the blockchain and how off-chain ZKPs are not the complete solution, but Wei Dai's article [Navigating Privacy on Public Blockchains](https://wdai.us/posts/navigating-privacy/) is a great primer.
|
||||
|
||||
Here are some theoretical blockchain use cases that FHE could facilitate:
|
||||
|
||||
- [Private Transactions](https://eprint.iacr.org/2022/1119.pdf): the processing of confidential transactions by smart contracts, allowing private transactions in dark pools, AMMs, blind auctions, and voting.
|
||||
- [MEV](https://collective.flashbots.net/t/frp-10-distributed-blockbuilding-networks-via-secure-knapsack-auctions/1955) (Maximal Extractable Value) Mitigation: FHE could potentially allow proposing blocks and ordering transactions while ensuring Pre-execution, failed execution, and post-execution privacy, offering a potential solution to prevent front-running.
|
||||
- Scaling: [Leveraging](https://www.fhenix.io/fhe-rollups-scaling-confidential-smart-contracts-on-ethereum-and-beyond-whitepaper/) [FHE Rollups](https://www.fhenix.io/wp-content/uploads/2023/11/FHE_Rollups_Whitepaper.pdf) presents a scalable approach to execute private smart contracts utilizing the security derived from Ethereum for state transitions
|
||||
- [Private Blockchains](https://eprint.iacr.org/2022/1119.pdf): encrypted chain states that are programmatically decrypted via consensus using Threshold FHE.
|
||||
|
||||

|
||||
|
||||
FHE: Blockchain Use Cases
|
||||
|
||||
The applied use cases for FHE are far-reaching, there are non-trivial technical challenges to overcome, and many are still being explored today. At its core, FHE ensures secure **data processing**, which, combined with other cryptographic primitives, can be incredibly powerful. In our exploration of Applied FHE, we dive deeper into real-world applications and use cases.
|
||||
|
||||
## **ZKP, MPC, & FHE**
|
||||
|
||||
The terms ZKPs, MPC, and FHE have often been misused and interchanged and have been the source of much confusion. The post, [Beyond Zero-Knowledge: What's Next in Programmable Cryptography?](https://mirror.xyz/privacy-scaling-explorations.eth/xXcRj5QfvA_qhkiZCVg46Gn9uX8P_Ld-DXlqY51roPY) provides a succinct overview and comparisons of Zero-Knowledge Proofs (ZKPs), Multi-Party Computation (MPC), Fully Homomorphic Encryption (FHE) and Indistinguishability Obfuscation (iO). All fall under the broader umbrella of programmable cryptography.
|
||||
|
||||
To briefly summarize how the three concepts are connected:
|
||||
|
||||
**[Multi-Party Computation (MPC)](https://www.youtube.com/watch?v=aDL_KScy6hA&t=571s)**: MPC, when described as a **_general function_**, is any setup where mutually distrustful parties can individually provide inputs (private to others) to collaboratively compute a public outcome. MPC can be used as the term used to describe the **_technology_** itself, where randomized data shares from each individual are delegated for compute across servers.
|
||||
|
||||

|
||||
|
||||
MPC
|
||||
|
||||
To add to the confusion, it is also often used to describe MPC **_use cases_**, most notably in the context of [Distributed Key Generation](https://en.wikipedia.org/wiki/Distributed_key_generation) (DKG) and [Threshold Signature Schemes](https://link.springer.com/referenceworkentry/10.1007/0-387-23483-7_429#:~:text=Threshold%20signatures%20are%20digital%20signatures,structure%20of%20a%20threshold%20scheme.) (TSS).
|
||||
|
||||
Three leading technologies form the [building blocks](https://open.spotify.com/episode/4zfrPFbPWZvn6fXwrrEa5f?si=9ab56d47510f4da0) of MPC **_applications_**: [Garbled Circuits (GC)](https://www.youtube.com/watch?v=La6LkUZ4P_s), Linear Secret Sharing Schemes (LSSS), and Fully Homomorphic Encryption (FHE). These can be used both conjunctively or exclusively.
|
||||
|
||||

|
||||
|
||||
MPC & ZKPs
|
||||
|
||||
**Zero-Knowledge Proofs (ZKPs):** A method that allows a single party (prover) to prove to another party (verifier) knowledge about a piece of data without revealing the data itself. Using both public and private inputs, ZKPs enable the prover to present a true or false output to the verifier.
|
||||
|
||||

|
||||
|
||||
ZKPs
|
||||
|
||||
In Web 3 applications, the integration of ZKPs alongside FHE becomes crucial for constructing private and secure systems. ZKPs are vital because they can be used to generate proofs of correctly constructed FHE ciphertexts. Otherwise, users can encrypt any unverified gibberish. Hence corrupting the entire FHE circuit evaluation.
|
||||
|
||||
Note the difference in ZKPs, FHE, and MPCs, where the input element of each primitive is distinct when evaluating the exposure of private data.
|
||||
|
||||
- In ZKPs, private data contained in the input is only *visible to the prover*
|
||||
- In MPC, private data contained in each input is only *visible to the owner*
|
||||
- In FHE, private data contained in the input is encrypted and is **_never revealed_**
|
||||
|
||||
While MPC is network bound, FHE and ZKPs are compute bound. The three primitives also differ regarding relative computation costs and interactiveness required between parties.
|
||||
|
||||

|
||||
|
||||
ZKPs, MPC, FHE, computation costs and interactiveness
|
||||
|
||||
In summary,
|
||||
|
||||
- ZKPs focus on proving the truth of a statement without revealing the underlying data; it is useful for preserving private states for the prover.
|
||||
- MPC enables joint computation; it is useful when users want to keep their state private from others.
|
||||
- FHE allows computations on encrypted data without decryption; it is non-interactive and useful for preserving privacy throughout the entire computation process.
|
||||
|
||||
FHE is an extension of public key cryptography, not a replacement for ZKPs or MPC. Each can act as an individual building block and serve a distinct cryptographic purpose. An assessment needs to be made on where and which primitive should be applied within different applications.
|
||||
|
||||
## **The State of FHE Today**
|
||||
|
||||
Early concepts of FHE developed in the 1970s-90s laid the theoretical groundwork for homomorphic encryption. However, the real breakthrough came with Gentry's solution for FHE in 2009. The initial construction needed to be faster to be practically applied. Performance at the time was close to 30mins per bit operation and only applicable in a single key setting. Much of the research published following Gentry's paper has been focused on performance improvements that address these issues through:
|
||||
|
||||
- [refining schemes](https://eprint.iacr.org/2021/315.pdf)
|
||||
- [reducing computation complexity](https://eprint.iacr.org/2023/1788)
|
||||
- [faster bootstrapping](https://eprint.iacr.org/2023/759), and
|
||||
- [hardware acceleration](https://eprint.iacr.org/2023/618)
|
||||
|
||||
FHE is not possible with Ethereum today due to the size of ciphertexts and the cost of computation on-chain. It is estimated with the current rate of hardware acceleration, we may see applications in production by 2025.
|
||||
|
||||
Zama’s implementation of [fhEVM](https://docs.zama.ai/fhevm/) is a fork of Ethereum; they have several [tools](https://docs.zama.ai/homepage/) available:
|
||||
|
||||
- **[TFHE-rs](https://docs.zama.ai/tfhe-rs)**: Pure Rust implementation of TFHE for boolean and small integer arithmetics over encrypted data
|
||||
- **[fhEVM](https://docs.zama.ai/fhevm)**: Private smart contracts on the EVM using homomorphic encryption
|
||||
|
||||
There are some challenges with ZAMA's fhEVM approach that are yet to be improved. Networks using ZAMA's fhEVM are limited to about 2 FHE transactions per second (tps). Compared to Ethereum's ~15 tps this is not far off; however, it will need to be greatly improved for many time-sensitive applications.
|
||||
|
||||
Additionally, operations on encrypted integers are much more difficult to perform than on plaintext integers. For example, on an Amazon m6i.metal machine (one of Amazon's top machines costing $2-4k per month to operate):
|
||||
|
||||
- adding or subtracting two **encrypted** uint8 values takes around 70ms
|
||||
- adding **plaintext** uint8 values is essentially free and instant on any modern device
|
||||
|
||||
There are also limitations to the size of unsigned integers available in the fhEVM context. Encrypted uint32 values are the largest possible in the fhEVM, while uint256 are the largest in the standard EVM and are used frequently by many protocols on Ethereum. Due to the challenge of operating on encrypted values in the fhEVM it is currently unreasonable to run validators at home, which makes this more suitable for networks with a smaller, more trusted validator set.
|
||||
|
||||
[Sunscreen](https://docs.sunscreen.tech/) is another project actively working on FHE; they have a Rust-based FHE compiler using the BFV scheme with a [playground](https://playground.sunscreen.tech/). They’ve deployed a [blind auction](https://demo.sunscreen.tech/auctionwithweb3) proof of concept on SepoliaETH.
|
||||
|
||||
[Fhenix](https://docs.fhenix.io/), a team working on a modular “FHE blockchain extension”, plans on launching their testnet in January 2024. They also recently released their [whitepaper on FHE-Rollups](https://www.fhenix.io/fhe-rollups-scaling-confidential-smart-contracts-on-ethereum-and-beyond-whitepaper/).
|
||||
|
||||
In the last five years, significant advancements have been made to make FHE more usable. Shruthi Gorantala's [framework](https://youtu.be/Q3glyMsaWIE?si=TbhlNxGsozbalIHU&t=1278) for thinking about FHE development as a hierarchy of needs is particularly helpful. The performance improvements listed above address deficiency needs and are contained in Layers 1-3 within the FHE tech stack. For FHE to realize its full potential, we also need to address the growth needs listed in Layers 4-5.
|
||||
|
||||

|
||||
|
||||
FHE Hierarchy of Needs
|
||||
|
||||
A critical aspect of systems integration is figuring out how to combine FHE technology with other privacy-enhancing primitives like ZKPs and MPC in a way that suits each unique trust model and protocol.
|
||||
|
||||
Continue to [Part 2: Fundamental Concepts, FHE Development, Applied FHE, Challenges and Open Problems](https://mirror.xyz/privacy-scaling-explorations.eth/wQZqa9acMdGS7LTXmKX-fR05VHfkgFf9Wrjso7XxDzs).
|
||||
@@ -0,0 +1,330 @@
|
||||
---
|
||||
authors: ["0xZoey"]
|
||||
title: "Zero to Start: Applied Fully Homomorphic Encryption (FHE) Part 2"
|
||||
image: "cover.webp"
|
||||
tldr: "This post was written by [0xZoey](https://twitter.com/0xZoey), with contributions from Chance. /n This is an extension of [Part 1: An Introduction to FHE, ZKPs & MPC, and The State of FHE Development](https://mirror.xyz/privacy-scaling-explorations.eth/D8UHFW1t48x2liWb5wuP6LDdCRbgUH_8vOFvA0tNDJA)."
|
||||
date: "2023-12-21"
|
||||
canonical: "https://mirror.xyz/privacy-scaling-explorations.eth/wQZqa9acMdGS7LTXmKX-fR05VHfkgFf9Wrjso7XxDzs"
|
||||
---
|
||||
|
||||
## **Fundamental Concepts**
|
||||
|
||||
### **Threshold FHE**
|
||||
|
||||
Threshold cryptography involves splitting a single cryptographic key into “shares” across multiple parties. You may already be familiar with Threshold Signatures Schemes (TSS), which are most commonly used in MPC wallets. The required threshold of parties to collaborate to gain access to the private key is usually predefined. This is different from a multi-sig scenario where multiple “whole” keys are used.
|
||||
|
||||

|
||||
|
||||
Threshold Cryptography vs Multi-Sig
|
||||
|
||||
In [Threshold FHE](https://eprint.iacr.org/2017/257), the concept acts similarly to TSS, but key shares are extended to the decryption process, requiring multiple entities to cooperate to decrypt data. This reinforces security by distributing decryption authority.
|
||||
|
||||
In the [PESCA](https://eprint.iacr.org/2022/1119.pdf) blueprint and [Zama](https://github.com/zama-ai/fhevm/blob/main/fhevm-whitepaper.pdf)’s implementation, an example of threshold FHE is used to compute over encrypted blockchain states. The transparent and public nature of blockchain data means that to maintain privacy, we need to be able to decrypt states and allow smart contracts to be composable selectively. The private key shares are distributed to validators, and a certain threshold of private keys is required for decryption. No single validator or group smaller than the threshold is able to decrypt the blockchain state. [Note](https://discord.com/channels/901152454077452399/1126507772524113930/1156317837850329098) that the threshold only applies to privacy and the risk is on confidentiality, not on actual assets.
|
||||
|
||||
Dynamic Proactive Secret Sharing could theoretically be used to support a consensus set where validator nodes are joining and leaving. There are some caveats to a Threshold FHE setup that requires an honest majority, which we discuss further in the challenges section.
|
||||
|
||||
### **FHE & MPC**
|
||||
|
||||
With Threshold-FHE, trust is placed with a group of private key holders; in [FHE-MPC,](https://link.springer.com/article/10.1007/s10623-022-01160-x) trust assumptions are minimized to each individual party. A simple example between 2 parties:
|
||||
|
||||
- The first party encrypts their input to create a ciphertext
|
||||
- The ciphertext is passed to the second party
|
||||
- The second party performs a function using FHE on the ciphertext and their own input, producing a second ciphertext.
|
||||
- The second ciphertext is returned to the first person who performs the decryption.
|
||||
|
||||

|
||||
|
||||
FHE-MPC
|
||||
|
||||
MPC and FHE can be combined in several ways:
|
||||
|
||||
- Multi-Key FHE-based MPC: Multiple FHE key pairs are combined to perform MPC
|
||||
- Multi-Party FHE-based MPC: Key generation is distributed, and Decryption is also distributed.
|
||||
|
||||
The [takeaway](https://eprint.iacr.org/2023/981.pdf) here is the combination of the two technologies allow the key properties of MPC to be combined with FHE. However, managing FHE ciphertext size with the communication complexity between parties in MPC is an important consideration.
|
||||
|
||||
### **Lattice-based cryptography**
|
||||
|
||||
Lattice-based cryptography provides the mathematical framework that underpins every FHE scheme. It is also used in the three post-quantum computing (PQC) standardization digital signature schemes [selected by NIST](https://csrc.nist.gov/news/2023/additional-pqc-digital-signature-candidates), CRYSTALS-Dilithium, FALCON, and SPHINCS+. The security of lattice-based cryptography comes from the inherent difficulty of solving lattice problems.
|
||||
|
||||
Think of [lattice-based cryptography](https://www.youtube.com/watch?v=K026C5YaB3A) as two vectors forming a pattern over a grid. As we add more vectors across multiple dimensions, this pattern becomes increasingly complex.
|
||||
|
||||

|
||||
|
||||
Lattice-Based Cryptography
|
||||
|
||||
Finding the shortest vector to the point of origin of the very first vector becomes extremely difficult, almost impossible. This is known as the Shortest Vector Problem (SVP).
|
||||
|
||||
### **Learning With Errors (LWE) & Ring-LWE**
|
||||
|
||||
[Learning With Errors](https://www.youtube.com/watch?v=K026C5YaB3A) (LWE) is a hard math problem based on the approximate Shortest Vector Problem (SVP). Similar to lattice problems, its hardness makes it a good candidate for use in PQC cryptography. Ring-LWE is a progression of LWE based on the SVP over ideal lattices. It is significant for FHE because the second generation of FHE schemes utilise LWE and RLWE to reduce ciphertext size and reduce noise, thus increasing performance.
|
||||
|
||||
### **Managing Noise**
|
||||
|
||||
In FHE, noise refers to the distortion or error accumulating during homomorphic operations on encrypted data. Noise arises due to the mathematical properties of the homomorphic encryption and scale with the operations performed on encrypted values.
|
||||
|
||||
The [diagram](https://homomorphicencryption.org/wp-content/uploads/2018/10/CCS-HE-Tutorial-Slides.pdf?ref=blog.sunscreen.tech) below represents fresh encryption, where each component can be expressed as a coefficient in a polynomial or a vector. The height of the element represents the size of the coefficients. Note that in the first step, the initial noise is small.
|
||||
|
||||

|
||||
|
||||
As the number of computations (operations) increases, we see a corresponding growth in noise. The growth in noise can be described as exponential, polynomial, linear, constant, or logarithmic.
|
||||
|
||||

|
||||
|
||||
When working with FHE, the primary goal is to manage the noise reservoir. When there is an excessive number of operations, we experience noise overflow, at which point decryption becomes impossible.
|
||||
|
||||

|
||||
|
||||
Noise management techniques in FHE aim to control or reduce the noise level to maintain the correctness of computations. The main types of noise management include
|
||||
|
||||
- **Bootstrapping**: this maintains the correctness of computations on encrypted data by reducing the impact of accumulated noise.
|
||||
- **Modulous Switching**: lightweight noise management without secret-key use, rescaling ciphertexts. It is most effective when applied after each homomorphic multiplication.
|
||||
- **Batching:** increasing efficiency by packing multiple plaintexts into the same ciphertext so FHE can be conducted on multiple inputs
|
||||
|
||||
### **Bootstrapping**
|
||||
|
||||
Bootstrapping is the key technique used to manage noise overflow. When bootstrapping, the initial private key is encrypted as the bootstrapping key, allowing you to use it in a decryption circuit. This is secure as long as one assumes circular security.
|
||||
|
||||

|
||||
|
||||
Bootstrapping
|
||||
|
||||
The ciphertext is re-encrypted recursively, and the noise level is reset to the same level created by the bootstrapping operation itself. Think of each recursive encryption as layers of wrapping over the original ciphertext, giving you a ciphertext of a ciphertext.
|
||||
|
||||
Using our layers example, each "inner layer" is homomorphically decrypted. As long as your noise reservoir allows room to do one more homomorphic operation (addition or multiplication), you can achieve FHE by running bootstrapping.
|
||||
|
||||
### **Relinerization**
|
||||
|
||||
Relinerization is a technique to transform quadratic equations into linear ones, effectively shortening ciphertext size. It is the key to fine-tuning FHE performance independent of bootstrapping and is particularly useful for homomorphic multiplication, where the cost of computation linearly increases with input size. Despite being computationally heavy, it can reduce computation costs and storage burdens.
|
||||
|
||||
## **FHE Schemes**
|
||||
|
||||
The development of FHE [schemes](https://queue.acm.org/detail.cfm?id=3561800) in the last decade has been rapid, with TFHE and BGV being the most popular blockchain applications. We focus on three main schemes in this article, but [many](https://github.com/jonaschn/awesome-he) others exist. Like any programming language, each comes with its unique properties suited for various use cases.
|
||||
|
||||

|
||||
|
||||
Generations of FHE Schemes
|
||||
|
||||
### **BGV & BFV**
|
||||
|
||||
[Second-generation](https://queue.acm.org/detail.cfm?id=3561800) FHE schemes [BGV](https://eprint.iacr.org/2011/277.pdf) (2011) drastically improved performance and allowed for weaker security assumptions. With BGV, the concept of [Learning With Errors](https://www.youtube.com/watch?v=K026C5YaB3A&t=28s) (LWE) was introduced, reducing the 30 minutes per bit operation performance time down to seconds. [BFV](https://eprint.iacr.org/2012/144.pdf) (2012) was published very shortly after BGV, where instead of using linear equations with LWE, polynomial rings over finite fields, Ring-LWE, is used.
|
||||
|
||||
BGV and BFV's computations use modular arithmetic circuits and work well with applications that require large vectors of small integers. These schemes are particularly useful for private information retrieval and database query applications.
|
||||
|
||||
### **TFHE**
|
||||
|
||||
Fully Homomorphic Encryption over the Torus (TFHE)(2016) is an improved version of [FHEW](https://link.springer.com/chapter/10.1007/978-3-662-46800-5_24) (2014). It was the first scheme to [realize programable bootstrapping](https://www.tfhe.com/evolution-of-homomorphic-encryption-schemes) using a lookup table over a ciphertext with a managed level of noise. It drastically [improved](https://link.springer.com/epdf/10.1007/978-3-662-53887-6_1?sharing_token=YsC3Hu6iPFp104kZQ6tZgPe4RwlQNchNByi7wbcMAY5bBAyAdgprN5xaaLEWgAqi3OyJt9tYY67Qr-JCwidvui2AFZZY23Iilns5cEmIIZMMdU8UUbfVmV_DCtPpkTVuaYBGgF2rZ79A9GuOu_QQi5L1eWufxVcTMf8_0-DEecE%3D) comparison and bootstrapping speeds, reducing times from seconds to milliseconds. TFHE's original implementation only allowed for Boolean circuits, but newer implementations like TFHErs are capable of bootstrapping over integers. It is most suitable for general-purpose computation.
|
||||
|
||||
### **CKKS**
|
||||
|
||||
CKKS (2016) is most appropriate for applications working with real numbers, such as practical machine learning problems, regression training, neural network inference, and statistical computations. CKKS [deals with](https://dualitytech.com/blog/bootstrapping-in-fully-homomorphic-encryption-fhe/) approximate arithmetic and so is not compatible with web3 applications where precise financial data is required. However, we list it here as a particularly efficient scheme and has proven to be a significant advancement in the last few years.
|
||||
|
||||
## **Scheme Comparisons**
|
||||
|
||||
Here is a high-level [comparison](https://www.youtube.com/watch?v=VJZSGM4DdZ0) of the three most relevant FHE schemes:
|
||||
|
||||

|
||||
|
||||
FHE Scheme Comparisons
|
||||
|
||||
## **Step-by-Step Development**
|
||||
|
||||
Now that we have foundational concepts down, we dive into some practical considerations for building with FHE. Development can be broken down into the following [steps](https://homomorphicencryption.org/wp-content/uploads/2018/10/CCS-HE-Tutorial-Slides.pdf?ref=blog.sunscreen.tech):
|
||||
|
||||
- Pick a FHE scheme appropriate for your use case
|
||||
|
||||
- BFV or TFHE most appropriate for web3 development at the moment
|
||||
|
||||
- Determine how data should be encoded
|
||||
|
||||
- Will batching be used?
|
||||
- Will you use one ciphertext per integer, vector, or matrix?
|
||||
- Aim to reduce ciphertext/plaintext size ratio
|
||||
|
||||
- Pick scheme parameters
|
||||
|
||||
- Some compilers do this automatically
|
||||
- [Considerations:](https://www.youtube.com/watch?v=VJZSGM4DdZ0)
|
||||
|
||||
- What kinds of computation are you looking to do?
|
||||
- What, if any, limitations do you have on ciphertext and key sizes?
|
||||
- What level of performance are you looking to attain?
|
||||
- Is relinerization required?
|
||||
|
||||
- Prove information about your encrypted data (may include ZKP element)
|
||||
|
||||
- Prove that the inputs are valid ie. the transaction amount
|
||||
- Prove that the data satisfies the condition i.e. check that the transacted amount is smaller than the balance in the account
|
||||
|
||||
So far, we have discussed FHE theoretically as a general concept in cryptography. Applied implementations of FHE can be categorized as relevant to the web3 stack as follows:
|
||||
|
||||
- FHE Applications: Implementations of FHE that are compatible with existing blockchains and smart contracts
|
||||
- FHE Infrastructure: Implementations of FHE that relate to data availability, scaling, block building, or consensus mechanisms
|
||||
|
||||
We outline a few examples of FHE Applications here; despite their diversity, they share common elements. In each scenario, we:
|
||||
|
||||
1. **Encrypt data**: presented as an encrypted integer (i.e., euint8), which serves as a wrapper over FHE ciphertext.
|
||||
2. **Perform an Operation**: computation is run on the encrypted data using FHE (i.e, add, sum, diff)
|
||||
3. **Apply the Condition**: the result of the operation is used to take some action. This is achieved by using an “If…else…” multiplexer operator (i.e., [cmux](https://docs.zama.ai/fhevm/writing-contracts/functions#multiplexer-operator-cmux), where three inputs return one output). Think of this like a railroad switch where two tracks converge to a single destination.
|
||||
|
||||
### **Confidential ERC20 Tokens**
|
||||
|
||||
In this implementation of a [confidential ERC20](https://www.zama.ai/post/confidential-erc-20-tokens-using-homomorphic-encryption) token contract by Zama, FHE is used to check that the wallet viewing the balance also owns the balance, effectively keeping the balance hidden from everyone else.
|
||||
|
||||
1. During a token transfer, the amount sent is encrypted.
|
||||
2. The sender user balance is checked to make sure that it is greater than the transfer amount to prevent overspending using FHE.
|
||||
3. The transfer is then executed on-chain, deducting the sender's balance and adding it to the recipient's balance.
|
||||
|
||||
Additional measures are also taken with token minting to prevent information about balances from leaking. In a [different implementation](https://docs.fhenix.io/examples/reference-dapps/wrapped-erc20) by Fhenix, a wrapped ERC20 keeps balances and amounts confidential, but the sender and receiver remain public. Note that these implementations are used as an extension of the existing ERC20 standard and not a replacement.
|
||||
|
||||
### **Order matching**
|
||||
|
||||
In a privacy-preserving [dark pool](https://www.ifaamas.org/Proceedings/aamas2020/pdfs/p1747.pdf):
|
||||
|
||||
1. Traders can send their buy and sell orders encrypted to an exchange.
|
||||
2. The exchange uses FHE to find a match in the order book without knowing the order type, amount, or price.
|
||||
3. Once a match is found, the order is executed on the public market.
|
||||
|
||||

|
||||
|
||||
Dark Pools: Order Matching using FHE
|
||||
|
||||
In this use case, traders can place orders without "alerting" the open market of their intentions, potentially giving away high-value alpha. Exchange operators remain neutral and establish trust, as their role here is purely used in order matching and execution. Regulatory authorities can ensure compliance with an additional layer, mitigating conflicts of interest between traders and operators. For an [on-chain darkpool](https://github.com/omurovec/fhe-darkpools/blob/master/src/DarkPool.sol), trades can be encrypted to prevent MEV. Zama has an FHE implementation of a [dark market](https://www.zama.ai/post/dark-market-tfhe-rs), and Sunscreen provides an AMM example [here](https://docs.sunscreen.tech/fhe/fhe_programs/example.html). Note that most of these are partial implementations, and privacy leaks exist.
|
||||
|
||||
### **Private Voting**
|
||||
|
||||
Tokens or NFT owners can anonymously vote on proposals for DAO governance. Details such as token circulation amount, voting decisions, and delegation selection can be kept confidential with FHE.
|
||||
|
||||
In this specific delegation [example](https://www.zama.ai/post/confidential-dao-voting-using-homomorphic-encryption), an existing Compound contract is used:
|
||||
|
||||
1. The COMP token contract, including token balances, is first encrypted.
|
||||
2. Any changes in vote delegation are subsequently run over the encrypted token contract using FHE.
|
||||
3. The number of votes per delegate is then stored for each specific block.
|
||||
|
||||
The Governor contract subsequently manages proposals and votes:
|
||||
|
||||
1. Each delegate's "for" or "against" vote is encrypted.
|
||||
2. The vote tally is made over encrypted votes with FHE.
|
||||
3. The vote is cast for the respective proposal.
|
||||
|
||||
### **Blind Auctions**
|
||||
|
||||
In previous blind auctions with ZKP implementations, bid data and compute is off-chain, requiring the trust of a third-party entity for proof creation. FHE allows [blind auctions](https://www.zama.ai/post/on-chain-blind-auctions-using-homomorphic-encryption) to run entirely on-chain, allowing parties to submit an encrypted private bid. In the bidding process:
|
||||
|
||||
1. The bid amount by each user is kept encrypted.
|
||||
2. FHE is used to check if a previous bid has been made and determines the highest bid from all bidders.
|
||||
3. The contract returns the auction object to the winner and returns losing bids back to other auction participants.
|
||||
|
||||
### **Other Novel Applications**
|
||||
|
||||
Some other fhEVM novel use cases are being explored by the community [here](https://fhevm-explorers.notion.site/fhevm-explorers/fhEVM-Novel-Use-Cases-c1e637b0ca5740afa7fe598407b7266f); they include:
|
||||
|
||||
- Private Surveys: Survey answers are encrypted, and FHE is used to run analytics on the results whilst keeping participants and their answers anonymized
|
||||
- DIDs: NFTs could contain encrypted metadata; FHE is run on the private metadata to enable entry into gated communities or authentication for access
|
||||
- Gaming: Poker, battleship, rock paper scissors - game results are calculated with FHE from encrypted play submissions.
|
||||
|
||||
## **Challenges and Open Problems**
|
||||
|
||||
The open problems for FHE fall into three categories: usability, composability, and performance. Expanding the scope of feasible computations remains a challenge, and different schemes excel in different areas, but generally, there needs to be more standardization between schemes. Performance issues predominantly revolve around data efficiency due to large ciphertext and bootstrapping key sizes. Note that most challenges are often scheme-specific; we only discuss them at a high level for simplicity.
|
||||
|
||||

|
||||
|
||||
Applied FHE Challenges
|
||||
|
||||
## **Transciphering/ Hybrid Homomorphic Encryption**
|
||||
|
||||
The large size of ciphertexts is one of the greatest barriers to practical implementation due to its associated computation time and bandwidth usage. [Transciphering](https://eprint.iacr.org/2023/1531.pdf), or Hybrid Homomorphic Encryption, is a method of carrying out compression encryption within the FHE setup. Data is first compacted with a scheme like [AES](https://en.wikipedia.org/wiki/Advanced_Encryption_Standard) before creating a ciphertext, which FHE is then run on. There are several [methods of transciphering](https://eprint.iacr.org/2023/980.pdf) being explored at the moment that are compatible with TFHE schemes.
|
||||
|
||||
## **Hardware Acceleration**
|
||||
|
||||
Whilst bootstrapping reduces ciphertext noise to make FHE practically possible, it still requires a large amount of computation and time. [Hardware acceleration](https://dualitytech.com/blog/hardware-acceleration-of-fully-homomorphic-encryption-making-privacy-preserving-machine-learning-practical/) allows for computing tasks to be offloaded to specialized hardware components. At the moment, there are several teams working on ASICs for TFHE; the speedup with the use of more efficient hardware is likely to hit 1000x by 2025.
|
||||
|
||||
Reducing the complexity of FHE for developers is crucial. Creating user-friendly libraries, tools, and APIs that abstract the cryptography-heavy aspects of FHE while offering easy integration into existing development frameworks can encourage wider adoption. At the moment, there is a lack of standardization when it comes to APIs, schemes, and compilers. Improving [library interoperability](https://homomorphicencryption.org/wp-content/uploads/2018/10/CCS-HE-Tutorial-Slides.pdf?ref=blog.sunscreen.tech) and higher-level automation for developers will make FHE more usable.
|
||||
|
||||
## **FHE Compilers**
|
||||
|
||||
A compiler is a piece of software that converts source code to binary code in one go. Think of it as a translator for human readable languages (programming languages) to machine-readable languages (binary code). The majority of FHE compilers that exist at the moment add a significant amount of time to computation. The most efficient compiler at the time of writing (Sunscreen) has 1.3x overhead when compared to a low-level FHE library.
|
||||
|
||||
One of the barriers to wider FHE adoption is the need for developer-friendly compilers. [Sunscreen](https://blog.sunscreen.tech/from-toy-programs-to-real-life-building-an-fhe-compiler/) and [Zama](https://docs.zama.ai/concrete/) are actively building compilers that increase the usability of FHE by automating parameters and key selection. At the moment, both compilers currently only support single-key FHE schemes and are standalone. The compatibility of the two is being worked on so that ZKPs can be used to prove information with FHE ciphertexts.
|
||||
|
||||
## **FHE for Blockchain**
|
||||
|
||||
### Performance
|
||||
|
||||
Improving the performance of FHE schemes is essential for responsive Web3 applications. As blockchains are limited by block size, we need to find a way to maximize throughput without sacrificing block space. When it comes to user experience, both cost and latency need to be managed to usable levels. Reducing ciphertext size will be key here.
|
||||
|
||||
### **Gas Cost**
|
||||
|
||||
Gas cost estimations are possible on the blockchain because transaction data is public. In the case of FHE, smart contract execution flow logic will differ depending on the outcome of computation (which may be hidden), making it difficult to accurately estimate gas costs. However, there are currently some [proposed ways](https://github.com/zama-ai/fhevm/blob/main/fhevm-whitepaper.pdf) to navigate this, and more accurate techniques will need to be developed to create a desirable user experience.
|
||||
|
||||
### **Trust assumptions**
|
||||
|
||||
The implementation of Threshold FHE for encrypted states on a private blockchain utilizes the security assumptions of a network of decentralized validators. In order to perform the decryption, only 2/3rds of the validators or the number predetermined in the Threshold-FHE setup is required. Unlike a public blockchain, any form of collusion would be [undetectable](https://hackmd.io/cd7YCyEqQh-n_LJ0kArtQw); malicious activity would, therefore, leave no verifiable trace. Some would argue that a setup requiring stronger trust assumptions, like FHE-MPC, is more prudent. Decryption nodes and validator notes could also be potentially [separate entities](https://discord.com/channels/901152454077452399/1126507772524113930/1153599900244791397), varying the trust assumptions and threshold of the two operations.
|
||||
|
||||
### **Privacy Leaks**
|
||||
|
||||
The simple act of the client sending a command to the server running the fhEVM may already disclose more information than the user is willing to. Similarly, any wallet that interacts with a smart contract to run the FHE application like voting will disclose, at a minimum they have voted. On the transaction level, we may be able to hide specific balances or amounts, but external parties may be able to deduce details from the macro state. Creating a cohesive system that prevents critical data leakage is a challenge, one which the composability of FHE, ZKPs and MPC might help to solve.
|
||||
|
||||
## **Conclusion**
|
||||
|
||||
FHE opens up new frontiers in secure computation, realizing its full potential demands overcoming challenges such as usability, performance, and integration with other cryptographic primitives. While practical applications of FHE across domains are just emerging, its integration into decentralized systems remains an ongoing narrative. The technology's potential to reshape data privacy is vast, promising a future where we default to privacy-centric systems.
|
||||
|
||||
The road ahead involves deeper dives into advanced concepts and integration strategies like [Ring-LWE](https://www.mdpi.com/2227-7390/10/5/728), [ZK](https://github.com/emilianobonassi/zkFHE)\-[FHE](https://github.com/enricobottazzi/zk-fhe), [FHE Rollups](https://www.fhenix.io/wp-content/uploads/2023/11/FHE_Rollups_Whitepaper.pdf), [FHE-MPC](https://eprint.iacr.org/2023/981.pdf), and Latticed-based [ZKP](https://eprint.iacr.org/2022/284)s.
|
||||
|
||||
## **FHE Resources**
|
||||
|
||||
Craig Gentry: A Fully Homomorphic Encryption Scheme [https://cdn.sanity.io/files/r000fwn3/production/5496636b7474ef68f79248de4a63dd879db55334.pdf](https://cdn.sanity.io/files/r000fwn3/production/5496636b7474ef68f79248de4a63dd879db55334.pdf)
|
||||
|
||||
Slides: CSS_HE tutorial slides [https://homomorphicencryption.org/wp-content/uploads/2018/10/CCS-HE-Tutorial-Slides.pdf?ref=blog.sunscreen.tech](https://homomorphicencryption.org/wp-content/uploads/2018/10/CCS-HE-Tutorial-Slides.pdf?ref=blog.sunscreen.tech)
|
||||
|
||||
Slides: Computing Arbitrary Functions of Encrypted Data [https://crypto.stanford.edu/craig/easy-fhe.pdf](https://crypto.stanford.edu/craig/easy-fhe.pdf)
|
||||
|
||||
Fhenix: FHE Rollups
|
||||
|
||||
**[FHE-Rollups: Scaling Confidential Smart Contracts on Ethereum and Beyond – whitepaper](https://www.fhenix.io/fhe-rollups-scaling-confidential-smart-contracts-on-ethereum-and-beyond-whitepaper/)**
|
||||
|
||||
fhEVM Whitepaper:
|
||||
|
||||
**[fhevm/fhevm-whitepaper.pdf at main · zama-ai/fhevm](https://github.com/zama-ai/fhevm/blob/main/fhevm-whitepaper.pdf)**
|
||||
|
||||
fhEVM Novel Use cases: [https://fhevm-explorers.notion.site/fhevm-explorers/fhEVM-Novel-Use-Cases-c1e637b0ca5740afa7fe598407b7266f](https://fhevm-explorers.notion.site/fhevm-explorers/fhEVM-Novel-Use-Cases-c1e637b0ca5740afa7fe598407b7266f)
|
||||
|
||||
FHE-MPC Advanced Grad Course
|
||||
|
||||
**[homes.esat.kuleuven.be](https://homes.esat.kuleuven.be/~nsmart/FHE-MPC/)**
|
||||
|
||||
Fully Composable Homomorphic Encryption
|
||||
|
||||
**[cseweb.ucsd.edu](https://cseweb.ucsd.edu/classes/fa23/cse208-a/cfhe-draft.pdf)**
|
||||
|
||||
Video: FHE and MPC by Shruthi Gorantala [https://www.youtube.com/watch?v=Q3glyMsaWIE](https://www.youtube.com/watch?v=Q3glyMsaWIE)
|
||||
|
||||
Github: FHE awesome list
|
||||
|
||||
**[GitHub - jonaschn/awesome-he: ✨ Awesome - A curated list of amazing Homomorphic Encryption libraries, software and resources](https://github.com/jonaschn/awesome-he)**
|
||||
|
||||
Pesca: A Privacy Enhancing Smart Contract Architecture
|
||||
|
||||
**[eprint.iacr.org](https://eprint.iacr.org/2022/1119.pdf)**
|
||||
|
||||
Slides: MPC from Theory to Practice, Nigel Smart
|
||||
|
||||
**[crypto.stanford.edu](https://crypto.stanford.edu/RealWorldCrypto/slides/smart.pdf)**
|
||||
|
||||
Video: Prog Crypto
|
||||
|
||||
**[PROGCRYPTO - Archive](https://app.streameth.org/devconnect/progcrypto/archive)**
|
||||
|
||||
Sunscreen:
|
||||
|
||||
An Intro to FHE: [https://blog.sunscreen.tech/an-intro-to-fully-homomorphic-encryption-for-engineers/](https://blog.sunscreen.tech/an-intro-to-fully-homomorphic-encryption-for-engineers/)
|
||||
|
||||
Building Private Dapps:[https://www.youtube.com/watch?v=\_AiEmS8ojvU](https://www.youtube.com/watch?v=_AiEmS8ojvU)
|
||||
|
||||
Documentation: [https://docs.sunscreen.tech/](https://docs.sunscreen.tech/)
|
||||
|
||||
ZK9 Building an FHE Compiler: [https://www.youtube.com/watch?v=VJZSGM4DdZ0](https://www.youtube.com/watch?v=VJZSGM4DdZ0)
|
||||
|
||||
ZK Podcast: Episode 295 The Return to MPC with Nigel Smart
|
||||
|
||||
**[Episode 295: Return to MPC with Nigel Smart](https://open.spotify.com/episode/4zfrPFbPWZvn6fXwrrEa5f?si=9ab56d47510f4da0)**
|
||||
77
articles/zkevm-community-edition-part-1-introduction.md
Normal file
@@ -0,0 +1,77 @@
|
||||
---
|
||||
authors: ["PSE Team"]
|
||||
title: "zkEVM Community Edition Part 1: Introduction"
|
||||
image: "cover.webp"
|
||||
tldr: ""
|
||||
date: "2023-05-23"
|
||||
canonical: "https://mirror.xyz/privacy-scaling-explorations.eth/I5BzurX-T6slFaPbA4i3hVrO7U2VkBR45eO-N3CSnSg"
|
||||
---
|
||||
|
||||
The task of making Ethereum faster, cheaper, and easier to verify is a globally distributed effort with many moving parts. Developing zkEVMs is one piece of the effort with the majority of zkEVM projects being built as Layer 2 scaling solutions. A zkEVM capable of validating L1 blocks is on a long – and often changing – roadmap for scaling Ethereum that has been referenced as part of [“The Splurge”](https://twitter.com/VitalikButerin/status/1466411377107558402), [“ZK-SNARKing everything” on the rollup centric roadmap,](https://www.reddit.com/r/ethereum/comments/j3px5s/a_rollupcentric_ethereum_roadmap_vitalik/) [“enshrined rollups”](https://www.reddit.com/r/ethereum/comments/vrx9xe/comment/if7auu7/), and most recently [“The Verge”](https://twitter.com/VitalikButerin/status/1588669782471368704).
|
||||
|
||||
The [zkEVM Community Edition](https://github.com/privacy-scaling-explorations/zkevm-specs) is working toward the end goal of leveraging zero-knowledge proofs to verify every L1 block: a concept known as proof of validity.
|
||||
|
||||
There are many ways to design and build a zkEVM. The Community Edition is a collective exploration into one possible set of solutions, but [many other solutions](https://vitalik.ca/general/2022/08/04/zkevm.html) are being worked on.
|
||||
|
||||
_This series intends to provide an overview of the zkEVM Community Edition in a way that is broadly accessible. Part 1 is an introduction to zkEVMs._
|
||||
|
||||
_[Part 2: Components](https://mirror.xyz/privacy-scaling-explorations.eth/AW854RXMqS3SU8WCA7Yz-LVnTXCOjpwhmwUq30UNi1Q)_
|
||||
|
||||
_[Part 3: Logic and Structure](https://mirror.xyz/privacy-scaling-explorations.eth/shl8eMBiObd6_AUBikXZrjKD4fibI6xUZd7d9Yv5ezE)_
|
||||
|
||||
## World computer
|
||||
|
||||
A virtual machine is a simulated computer running as software on a physical computer. In the early days, Ethereum was described as a “[world computer](https://www.youtube.com/watch?v=j23HnORQXvs)” to convey the concept of a shared virtual machine run on a distributed network. Ethereum’s innovation was a virtual machine on top of a blockchain. The virtual machine created an environment for software execution, storage, and state. The blockchain allowed each node or physical computer to reach consensus or agreement on the state of the “world computer.” The result was a common, persistent software environment across a distributed network called the [Ethereum Virtual Machine (EVM)](https://ethereum.org/en/developers/docs/evm/).
|
||||
|
||||
To guarantee the same results are achieved across the network, full nodes must receive and re-execute every transaction since the first Ethereum block, which requires substantial computing resources.
|
||||
|
||||
The zkEVM takes the EVM and adds [zero-knowledge (ZK) proofs](https://ethereum.org/en/zero-knowledge-proofs/#zk-snarks). ZK proofs can mathematically guarantee [Layer 1 (L1)](https://ethereum.org/en/layer-2/#what-is-layer-1) Ethereum transactions were run correctly. On the standard EVM, nodes run on general-purpose computers, which makes running a node accessible to everyone and allowing the network to have hundreds of thousands of participants. However, proof generation is expensive and resource-intensive. Instead of running this process on all nodes, it must be outsourced to a single specialized node: a powerful computer with specific features that make it suitable for proof generation, such as GPU acceleration or FPGA acceleration. The rest of the nodes – using general purpose computers – need only verify one proof per block.
|
||||
|
||||
## Levels of zkEVMs
|
||||
|
||||
The EVM has been described as a [“beast of complexity”](https://youtu.be/W2f_GLEtobo?t=448). Many approaches exist for applying ZK proofs to the EVM – all with their own tradeoffs. As a result, building zkEVMs is an ecosystem-wide, multi-polar research and engineering effort with a variety of teams collaborating and competing to scale Ethereum at different levels.
|
||||
|
||||
A key difference between these approaches is the level of compatibility with the EVM. Different levels of compatibility come with different tradeoffs, from complexity, decentralization and speed of implementation to the familiarity of the user experience and how much of the existing code, infrastructure and tooling can be retained. The range of zkEVMs can be separated into language-level, bytecode level, and consensus-level compatibility.
|
||||
|
||||
- Language-level compatibility will require developers to use new code and infrastructure, but is also the fastest zkEVM to become production ready.
|
||||
- Bytecode compatibility requires minimal code and tooling modifications from developers.
|
||||
- Consensus-level compatibility happens on L1 and is the hardest to achieve, but has the benefit of scaling everything built on Ethereum by default.
|
||||
|
||||
So far, the majority of zkEVM projects have focused on building bytecode and language compatible ZK rollups on L2.
|
||||
|
||||
Vitalik Buterin categorized zkEVMs into different “types”, each with different pros and cons. “Type 1” zkEVMs aim to deliver an experience closest to Ethereum as it is today but face challenges regarding proving time and centralization risk, while “Type 4” have the lowest cost and centralization risks but are less compatible with existing infrastructure.
|
||||
|
||||

|
||||
|
||||
https://vitalik.ca/general/2022/08/04/zkevm.html
|
||||
|
||||
## Consensus-level compatibility
|
||||
|
||||
The [zkEVM Community Edition](https://github.com/privacy-scaling-explorations/zkevm-circuits) is a collaborative effort focused on creating a zkEVM capable of verifying Ethereum’s current execution layer. The goal is to be [“fully and uncompromisingly Ethereum-equivalent.”](https://vitalik.ca/general/2022/08/04/zkevm.html) The project is being stewarded by [Privacy & Scaling Explorations (PSE)](https://appliedzkp.org/), a team within the [Ethereum Foundation](https://ethereum.foundation/) specializing in applied zero-knowledge cryptography.
|
||||
|
||||
The work toward completing the zkEVM Community Edition will result in two scalability solutions:
|
||||
|
||||
1. A 100% EVM-compatible zero-knowledge rollup on L2
|
||||
2. A proof of validity for every L1 block
|
||||
|
||||
An EVM-compatible ZK rollup will be achieved first as a byproduct of the more difficult and long-term challenge of creating a proof of validity for every L1 block. If a proof of validity is achieved, it would be possible to embed the solution inside of an L1 smart contract and use the smart contract to validate the L1 itself.
|
||||
|
||||
The PSE team does not exist in a vacuum and welcomes contributions from anyone working towards Ethereum scalability and ZK research. Some zkEVM projects and individuals have already made valuable research and development contributions as well as incorporated Community Edition code into their own ZK rollup solutions.
|
||||
|
||||
The more collaboration and communication there is between different zkEVM projects with their own long-term and short-term objectives and strategies, the more the Ethereum community will benefit.
|
||||
|
||||
---
|
||||
|
||||
The zkEVM Community Edition is possible thanks to the contribution of many teams including the [PSE](https://appliedzkp.org/), [Scroll Tech](https://scroll.io/), and [Taiko](https://taiko.xyz/) along with many individual contributors. Teams such as [Zcash](https://electriccoin.co/) have also researched and developed proving systems and libraries that have greatly benefited zkEVM efforts.
|
||||
|
||||
The zkEVM Community Edition is an open-source project and can be accessed in the [main repo](https://github.com/privacy-scaling-explorations/zkevm-specs). If you’re interested in helping, you can learn more by visiting the [contribution guidelines](https://github.com/privacy-scaling-explorations/zkevm-circuits/blob/main/CONTRIBUTING.md). The Community Edition is being built in public and its current status can be viewed on the [project board](https://github.com/orgs/privacy-scaling-explorations/projects/3/views/1).
|
||||
|
||||
For any general questions, feel free to ask in the [PSE Discord](https://discord.com/invite/sF5CT5rzrR).
|
||||
|
||||
---
|
||||
|
||||
_This series intends to provide an overview of the zkEVM Community Edition in a way that is broadly accessible. Part 1 is an introduction to zkEVMs._
|
||||
|
||||
_[Part 2: Components](https://mirror.xyz/privacy-scaling-explorations.eth/AW854RXMqS3SU8WCA7Yz-LVnTXCOjpwhmwUq30UNi1Q)_
|
||||
|
||||
_[Part 3: Logic and Structure](https://mirror.xyz/privacy-scaling-explorations.eth/shl8eMBiObd6_AUBikXZrjKD4fibI6xUZd7d9Yv5ezE)_
|
||||
114
articles/zkevm-community-edition-part-2-components.md
Normal file
@@ -0,0 +1,114 @@
|
||||
---
|
||||
authors: ["PSE Team"]
|
||||
title: "zkEVM Community Edition Part 2: Components"
|
||||
image: "cover.webp"
|
||||
tldr: "This series of articles intends to provide an overview of the zkEVM Community Edition in a way that is broadly accessible. Part 2 is a summary of the common components used in most zkEVMs."
|
||||
date: "2023-05-23"
|
||||
canonical: "https://mirror.xyz/privacy-scaling-explorations.eth/AW854RXMqS3SU8WCA7Yz-LVnTXCOjpwhmwUq30UNi1Q"
|
||||
---
|
||||
|
||||
_[Part 1: Introduction](https://mirror.xyz/privacy-scaling-explorations.eth/I5BzurX-T6slFaPbA4i3hVrO7U2VkBR45eO-N3CSnSg)_
|
||||
|
||||
_[Part 3: Logic and Structure](https://mirror.xyz/privacy-scaling-explorations.eth/shl8eMBiObd6_AUBikXZrjKD4fibI6xUZd7d9Yv5ezE)_
|
||||
|
||||
Before diving deeper into how the zkEVM Community Edition works, it is necessary to understand some basic concepts that are common among zkEVM projects. The following section is not technically complete and is written as a simplified introduction to zkSNARKs, opcodes, and arithmetic circuits.
|
||||
|
||||
At a high level, the EVM state transitions from one block to the next via instructions called opcodes. To prove the EVM transitioned correctly, a ZK proof must be generated for each block and constructing this ZK proof means representing each opcode or change in the EVM as a circuit. Building a zkEVM requires finding optimal ways to efficiently translate opcodes into circuit form. Let’s break down what this all means.
|
||||
|
||||
## Zero-knowledge proofs
|
||||
|
||||
> “\[Zero knowledge proofs\] deliver *scalability* by exponentially compressing the amount of computation needed to verify the integrity of a large batch of transactions.” [\- Eli Ben-Sasson](https://nakamoto.com/cambrian-explosion-of-crypto-proofs/)
|
||||
|
||||
A ZK proof involves two parties: the prover and the verifier. In a zkEVM, the prover generates the proof of validity. The verifier checks if the proof was done correctly.
|
||||
|
||||
An L1 proof of validity confirms every transaction on Mainnet Ethereum. For a [ZK-rollup](https://ethereum.org/en/developers/docs/scaling/zk-rollups/), the proof of validity confirms every L2 transaction on the rollup and is verified as a single L1 transaction.
|
||||
|
||||
Zero-knowledge proofs offer the same level of security as re-executing transactions to verify their correctness. However, they require less computation and resources during the verification process. This means that more people can participate in maintaining the network by running nodes and contributing to consensus.
|
||||
|
||||
Nodes using specialized hardware will be required to generate proofs of validity, but once the proof is posted on-chain, nearly any node will be able to verify the proof with a low-resource cryptographic operation.
|
||||
|
||||
A zkEVM makes it theoretically possible to run an Ethereum [node on your phone](https://youtu.be/hBupNf1igbY?t=590).
|
||||
|
||||
## SNARKs
|
||||
|
||||
The zkEVM uses [zkSNARKs](https://blog.ethereum.org/2016/12/05/zksnarks-in-a-nutshell): a type of ZK protocol that is general purpose and capable of turning nearly any computation into a ZK proof. Before zkSNARKs, building ZK proofs was a highly specialized math problem that required a skilled cryptographer to create a unique ZK protocol for every new function. The discovery of zkSNARKs turned the creation of ZK protocols from a specialized math problem to a [generalized programming task](https://archive.devcon.org/archive/watch/6/zkps-and-programmable-cryptography/?tab=YouTube).
|
||||
|
||||
[zkSNARKs stand for Zero-Knowledge Succinct Non-interactive ARguments of Knowledge](https://z.cash/technology/zksnarks/). Zero-knowledge refers to the protocol’s capacity to prove a statement is true “without revealing any information beyond the validity of the statement itself.” Though the ZK part tends to get the most attention, it is in fact optional and unnecessary for zkEVMs. The most relevant property is succinctness.
|
||||
|
||||

|
||||
|
||||
https://www.youtube.com/watch?v=h-94UhJLeck
|
||||
|
||||
Succinct proofs are short and fast to verify. It must take less time to verify a SNARK than to recompute the statements the SNARK is proving. Quickly verifying transactions via short proofs is how zkEVMs achieve scalability.
|
||||
|
||||
In a non-interactive proof, a single proof is submitted, and the verifier can either reject or accept the proof as valid. There is no need to go back and forth between the prover and verifier. The proof of validity is created once and stored on-chain where it can be verified by anyone at any time.
|
||||
|
||||
## Opcodes
|
||||
|
||||
Every time a user makes a transaction on Ethereum, they set off a chain of instructions to change the state of the [Ethereum Virtual Machine (EVM).](https://ethereum.org/en/developers/docs/evm/) These instructions are [opcodes](https://ethereum.org/en/developers/docs/evm/opcodes/). Opcodes are the language of the EVM and each opcode has a distinct function specified in the Ethereum [yellow paper](https://ethereum.org/en/developers/tutorials/yellow-paper-evm/). Opcodes can read values from the EVM, write values to the EVM, and compute values in the EVM. Popular programming languages such as [Solidity](https://soliditylang.org/) must be translated or compiled to opcodes that the EVM can understand and run.
|
||||
|
||||
Opcodes change the state of the EVM, whether that is the balance of ETH in an address or data stored in a smart contract. All the changes are distributed or updated to every node in the network. Each node takes the same inputs or transactions and should arrive at the same outputs or state transition as every other node in the network – a secure and decentralized, but slow and expensive way to reach consensus.
|
||||
|
||||
The zkEVM is attempting to prove the EVM transitioned from its current state to its new state correctly. To prove the entire state transitioned correctly, the zkEVM must prove each opcode was executed correctly. To create a proof, circuits must be built.
|
||||
|
||||
## Circuits
|
||||
|
||||
SNARKs are created using [arithmetic circuits](https://en.wikipedia.org/wiki/Arithmetic_circuit_complexity), a process also known as [arithmetization](https://medium.com/starkware/arithmetization-i-15c046390862). Circuits are a necessary intermediate step between EVM opcodes and the ZK proofs that validate them.
|
||||
|
||||
A circuit defines the relation between public (revealed) and private (hidden) inputs. A circuit is designed so that only a specific set of inputs can satisfy it. If a prover can satisfy the circuit, then it is enough to convince the verifier that they know the private inputs without having to reveal them. This is the zero-knowledge part of zkSNARKs. The inputs do not need to be made public to prove they are known.
|
||||
|
||||

|
||||
|
||||
https://archive.devcon.org/archive/watch/6/eli5-zero-knowledge/?tab=YouTube
|
||||
|
||||
To create a SNARK, you must first convert a function to circuit form. Writing a circuit breaks down the function into its simplest arithmetic logic of addition and multiplication. Because addition can express linear computations and multiplication can express exponential computations, these two simple operations become highly expressive when stacked together and applied to polynomials.
|
||||
|
||||

|
||||
|
||||
Polynomials are math expressions with “many terms.”
|
||||
|
||||
In the context of this article, it is only necessary to know that polynomials have two useful properties: they are easy to work with and can efficiently encode a lot of information without needing to reveal all the information it represents. In other words, polynomials can be succinct: they can represent a complex computation yet remain short and fast to verify. For a complete explanation of how zkSNARKs work and why polynomials are used, [this paper](https://arxiv.org/pdf/1906.07221.pdf) is a good resource. For a practical explanation of how polynomial commitments schemes are applied in Ethereum scaling solutions, check out [this blog post](https://scroll.io/blog/kzg).
|
||||
|
||||
With the basic mathematical building blocks of polynomials, addition, and multiplication, circuits can turn nearly any statement into a ZK proof. In circuit form, statements become testable: verifiable and provable.
|
||||
|
||||

|
||||
|
||||
Visualization of a simple arithmetic circuit https://node101.io/blog/a\_non\_mathematical\_introduction\_to\_zero\_knowledge\_proofs
|
||||
|
||||
In a circuit, gates represent arithmetic operations (addition or multiplication). Gates are connected by wires and every wire has a value. In the image above:
|
||||
|
||||
- Left hand circuit represents the equation: _a + b = c_
|
||||
- Right hand circuit represents the equation: _a x b = c_
|
||||
|
||||
The input wires are _a_ and _b_; and can be made public or kept private. The output wire is _c_. The circuit itself and output _c_ is public and known to both the prover and verifier.
|
||||
|
||||

|
||||
|
||||
Example of a slightly more complex circuit https://nmohnblatt.github.io/zk-jargon-decoder/definitions/circuit.html
|
||||
|
||||
In the image above, the circuit expects:
|
||||
|
||||
- Inputs are *x*₀, *x*₁, and *x*₂
|
||||
- Output is *y = 5x*₀ *\+ 3(x*₁ *\+ x*₂)
|
||||
|
||||
For a prover to demonstrate they know the private inputs without revealing them to the verifier, they must be able to complete the circuit and reach the same output known to both parties. Circuits are designed so that only the correct inputs can go through all the gates and arrive at the same publicly known output. Each step is iterative and must be done in a predetermined order to satisfy the circuit logic. In a sufficiently designed circuit, there should be no feasible way a prover can make it through the circuit without knowing the correct inputs.
|
||||
|
||||
In the zkEVM Community Edition, circuits must prove that each transaction, all the opcodes used in the transaction, and the sequence of the operations are correct. As building circuits is a new and rapidly evolving field, there is still no “right way” to define the computation the circuit is trying to verify. To be practical, circuits must also be written efficiently in a way that minimizes the number of steps required while still being capable of satisfying the verifier. The difficulty of building a zkEVM is compounded by the fact that the skills required to build the necessary components are rare.
|
||||
|
||||
The Community Edition is an attempt to overcome both the technical and organizational challenges of building a consensus-level compatible zkEVM. The goal is to create a public good that serves as a common point of collaboration for the zkEVM community.
|
||||
|
||||
---
|
||||
|
||||
The zkEVM Community Edition is possible thanks to the contribution of many teams including the [PSE](https://appliedzkp.org/), [Scroll Tech](https://scroll.io/), and [Taiko](https://taiko.xyz/) along with many individual contributors. Teams such as [Zcash](https://electriccoin.co/) have also researched and developed proving systems and libraries that have greatly benefited zkEVM efforts.
|
||||
|
||||
The zkEVM Community Edition is an open-source project and can be accessed in the [main repo](https://github.com/privacy-scaling-explorations/zkevm-specs). If you’re interested in helping, you can learn more by visiting the [contribution guidelines](https://github.com/privacy-scaling-explorations/zkevm-circuits/blob/main/CONTRIBUTING.md). The Community Edition is being built in public and its current status can be viewed on the [project board](https://github.com/orgs/privacy-scaling-explorations/projects/3/views/1).
|
||||
|
||||
For any general questions, feel free to ask in the [PSE Discord.](https://discord.com/invite/sF5CT5rzrR)
|
||||
|
||||
---
|
||||
|
||||
_This series of articles intends to provide an overview of the zkEVM Community Edition in a way that is broadly accessible. Part 2 is a summary of the common components used in most zkEVMs._
|
||||
|
||||
_[Part 1: Introduction](https://mirror.xyz/privacy-scaling-explorations.eth/I5BzurX-T6slFaPbA4i3hVrO7U2VkBR45eO-N3CSnSg)_
|
||||
|
||||
_[Part 3: Logic and Structure](https://mirror.xyz/privacy-scaling-explorations.eth/shl8eMBiObd6_AUBikXZrjKD4fibI6xUZd7d9Yv5ezE)_
|
||||
146
articles/zkevm-community-edition-part-3-logic-and-structure.md
Normal file
@@ -0,0 +1,146 @@
|
||||
---
|
||||
authors: ["PSE Team"]
|
||||
title: "zkEVM Community Edition Part 3: Logic and Structure"
|
||||
image: "cover.webp"
|
||||
tldr: "This series intends to provide an overview of the zkEVM Community Edition in a way that is broadly accessible. Part 3 reviews the general logic and structure of the zkEVM Community Edition."
|
||||
date: "2023-05-23"
|
||||
canonical: "https://mirror.xyz/privacy-scaling-explorations.eth/shl8eMBiObd6_AUBikXZrjKD4fibI6xUZd7d9Yv5ezE"
|
||||
---
|
||||
|
||||
_[Part 1: Introduction](https://mirror.xyz/privacy-scaling-explorations.eth/I5BzurX-T6slFaPbA4i3hVrO7U2VkBR45eO-N3CSnSg)_
|
||||
|
||||
_[Part 2: Components](https://mirror.xyz/privacy-scaling-explorations.eth/AW854RXMqS3SU8WCA7Yz-LVnTXCOjpwhmwUq30UNi1Q)_
|
||||
|
||||
The zkEVM Community Edition has the challenge of creating proofs to validate EVM execution as it is today. To make this feasible, a system of interconnected circuits has been designed to prove the correctness of EVM opcodes while dealing with the inefficiencies of converting EVM opcodes to ZK proofs.
|
||||
|
||||
There are many ways to design and build a zkEVM. This post explains one possible architecture. Other valid solutions exist and are being worked on throughout the ecosystem.
|
||||
|
||||
## An unfriendly virtual machine
|
||||
|
||||
Creating a 100% EVM compatible zkEVM means not having the luxury of changing anything about the current EVM. No modifications. No shortcuts. Unfortunately for zkEVM developers, many EVM operations such as random read-write data access and traditional hash functions like Keccak256 are not friendly to SNARKs. To make things even more difficult, building efficient circuits is still a highly manual process requiring a high level of both mathematical ability and programming skills.
|
||||
|
||||
A good proof of validity should minimize proving time (how long it takes to generate a ZK proof) and proof size (how much data the proof takes up) while still being able to satisfy the verifier and be secure. If both are too high, the zkEVM becomes too costly to be practical. Generating and storing proofs of validity would be prohibitively expensive and only those with powerful computers could participate.
|
||||
|
||||
EVM opcodes are unfriendly to SNARKs for two main reasons:
|
||||
|
||||
1. 256-bit operations vs prime field operations
|
||||
|
||||
The EVM uses different sets of numbers and mathematical operations compared to SNARKs. SNARKs are cheap because they use addition and multiplication over a finite set of numbers called a prime field. In contrast, the EVM uses many arithmetic operations in 256-bit words. Emulating the EVM’s 256-bit operations with the prime field operations used by SNARKs is expensive and requires clever circuit design to be practical.
|
||||
|
||||
2. Variable paths vs fixed paths
|
||||
|
||||
The other unfriendly aspect of the EVM is it uses a common CPU architecture where execution can take conditional or variable paths. The state of the EVM changes frequently within a single block, but in SNARKs, conditional execution is expensive. In general, the cost adds up with every variable path. If there are 100 paths that could be taken, all of them must be paid for even if only one is taken.
|
||||
|
||||
To deal with variable paths, the zkEVM dynamically transfers data between circuits using [lookup tables](https://eprint.iacr.org/2020/315): arrays of data that match inputs to outputs. With lookup tables, an expensive (and recurrent) variable path can be outsourced to another circuit that has a repeating pattern. For example, if an operation has 100 steps that may take the expensive variable path, the circuit can limit the number of times the variable path is taken. Instead of paying the cost of the path 100 times, the cost is limited to a smaller number of times in the outsourcing circuit. The cost is still more than simply paying for the minimum necessary steps required, but it is less than the cost if lookup tables were not used at all. Variable paths are a big challenge in regards to programming circuits and lookup tables are a practical (but not completely efficient) solution.
|
||||
|
||||
Though creating an efficient system of circuits is a substantial technical challenge, overcoming this challenge will result in scalability benefits shared by the entire Ethereum ecosystem. Developers automatically get SNARK-enabled scalability without needing to write their own circuits.
|
||||
|
||||
## Aggregated proofs
|
||||
|
||||
The zkEVM is designed to create a proof of validity for each L1 block. Under the hood, a proof of validity is an aggregate proof made of smaller, interdependent proofs and circuits. The proof of validity is a proof of other proofs.
|
||||
|
||||
To create an aggregate proof system, the zkEVM uses a custom [fork of HALO2](https://github.com/privacy-scaling-explorations/halo2/), which is a zkSNARK system allowing for [recursive proof composition](https://www.michaelstraka.com/posts/recursivesnarks/), in which a single aggregate proof can be used to verify a practically unlimited number of other proofs.
|
||||
|
||||
In the current implementation, the system generates two proofs. The first proof is created from a comprehensive circuit that encompasses all subcomponents necessary to verify an Ethereum block. The second proof verifies the first proof and produces a smaller, more manageable proof that is suitable for on-chain storage and verification.
|
||||
|
||||

|
||||
|
||||
https://privacy-scaling-explorations.github.io/zkevm-docs/design/recursion.html
|
||||
|
||||
All the operations in a transaction are validated by circuits. Proofs are derived from circuits. An aggregation circuit could take the EVM and State proofs as inputs, then the aggregation proof – derived from the aggregation circuit – becomes our proof of validity: the single ZK proof that verifies all the transactions in a block.
|
||||
|
||||
The zkEVM Community Edition is rapidly evolving and designs may change, but the general logic of the system is to split the EVM into modular pieces with different circuits representing various sets of similar opcodes. Breakthroughs in cryptography may also change how the zkEVM is designed. For example, the recursive proof composition technique used in [HALO2](https://electriccoin.co/blog/explaining-halo-2/) was only [discovered in 2019](https://eprint.iacr.org/2019/1021.pdf).
|
||||
|
||||
## Modular circuits
|
||||
|
||||
The zkEVM architecture is designed so each circuit validates a set of operations and different circuits talk to each other. Each circuit has their own custom constraints and no one circuit does all the work. The architecture is modular. Different circuits have different roles, and some circuits can absorb the workload from other circuits through the use of [lookup tables](https://privacy-scaling-explorations.github.io/zkevm-docs/architecture.html#circuit-as-a-lookup-table).
|
||||
|
||||
Lookup tables allow specialized circuits to communicate with each other. For example, in the EVM Circuit, the SHA3 opcode requires computation of the Keccak hash function, but computing Keccak is a complicated circuit to implement. Instead of implementing the Keccak circuit inside the EVM circuit, we create a lookup table of Keccak inputs to outputs. A specialized Keccak circuit was built to ensure the input-to-output values in the lookup table are correctly computed. The EVM circuit can then safely consume the values in the lookup table because the values were validated by the Keccak circuit.
|
||||
|
||||
A circuit does two things, verify the operation or computation it was designed to verify and generate lookup tables that can be used by other circuits. The data generated by the lookup table is also verified by the circuit. For example, once the State Circuit is verified to satisfy its own relation, its columns are synthesized to be a lookup table for the EVM Circuit to do random access.
|
||||
|
||||
The EVM relies on random access memory to store and retrieve data during execution. Each step in the execution verifies an opcode, and these opcodes often involve reading or writing memory at arbitrary locations. To ensure correctness, it is crucial to prove that each step accesses the correct memory value.
|
||||
|
||||
The Community Edition adopts a dual table approach – an idea invented by the broader zkVM community – in order to handle random access memory.
|
||||
|
||||
1. The Execution Trace contains all the instruction steps of a trace with their associated memory accesses, which can be reads or writes. These steps are sorted chronologically, the same way they happened originally in the execution of the program. Here we associate a timestamp on each memory access, which is proved to increase sequentially.
|
||||
2. Read/Write Trace keeps track of all the memory accesses (the same ones that appear in the execution trace), but they are sorted by memory location first, and timestamp second. This spatial sorting verifies that each successive memory access at the same location contains the correct value.
|
||||
3. Finally a permutation check is performed on the memory accesses from both sides to guarantee that the same entries appear on both sides. All this guarantees that every time a memory location is read in the execution trace, it will contain the same value that was previously written at that location, no matter how many steps ago that happened.
|
||||
|
||||

|
||||
|
||||
The zkEVM Community Edition is a rapidly evolving design. Each circuit iterates over and validates different parts of the computation required to process an Ethereum block, and they are all coordinated from the EVM Circuit which processes the steps (opcodes) of each transaction.
|
||||
|
||||

|
||||
|
||||
The [EVM Circuit](https://github.com/privacy-scaling-explorations/zkevm-specs/blob/83ad4ed571e3ada7c18a411075574110dfc5ae5a/specs/evm-proof.md) is only concerned with execution. Specifically, the EVM Circuit validates [geth execution traces](https://geth.ethereum.org/docs/dapp/tracing) and verifies the transactions in the block have the correct execution results. This is usually done one opcode at a time to check each individual step in the transaction and to confirm the correct opcode was called at the correct time. The EVM Circuit is the final check to confirm the transaction and the State Circuit are valid.
|
||||
|
||||
[State Circuit](https://privacy-scaling-explorations.github.io/zkevm-docs/architecture/state-circuit.html):
|
||||
|
||||
- Verifies that each piece of data is consistent between different reads and writes (i.e. the data was changed correctly). It also serves as the lookup table for the EVM circuit to do random read-write access (i.e. access EVM data).
|
||||
|
||||
[Tx Circuit](https://privacy-scaling-explorations.github.io/zkevm-docs/architecture/tx-circuit.html#tx-circuit):
|
||||
|
||||
- Verifies each transaction has a valid signature. It also serves as a lookup table for the EVM circuit to access data in the transaction.
|
||||
|
||||
[Bytecode Circuit](https://privacy-scaling-explorations.github.io/zkevm-docs/architecture/bytecode-circuit.html#bytecode-circuit):
|
||||
|
||||
- Verifies each bytecode has a valid hash. It also serves as a lookup table for the EVM circuit to access data of any “index of bytecode.”
|
||||
|
||||
[ECDSA Cicruit](https://privacy-scaling-explorations.github.io/zkevm-docs/architecture/ecdsa-circuit.html#ecdsa-cicruit):
|
||||
|
||||
- Verifies the public key from the signature is valid. It also serves as a lookup table for EVM and Tx circuit to do public key recovery.
|
||||
|
||||
[Keccak Circuit](https://privacy-scaling-explorations.github.io/zkevm-docs/architecture/keccak-circuit.html#keccak-circuit):
|
||||
|
||||
- Verifies each hash is valid. It also serves as a lookup table for the EVM, Bytecode, Tx, and MPT circuit to calculate hash functions.
|
||||
|
||||
[Merkle Patricia Trie (MPT) Circuit](https://privacy-scaling-explorations.github.io/zkevm-docs/architecture/mpt-circuit.html#merkle-patricia-trie-circuit):
|
||||
|
||||
- Verifies each update is valid. It also serves as a lookup table for the State and Tx circuit to update the Merkle Patricia Trie.
|
||||
|
||||
**Copy Circuit:**
|
||||
|
||||
- Verifies copies of chunks of bytes. For example, from Memory to Bytecode when deploying a contract, or from Tx to Memory when reading a tx calldata. Used by the EVM Circuit as a lookup table to verify byte array copies
|
||||
|
||||
**Block Circuit:**
|
||||
|
||||
- Verifies the block Hash. Used by the EVM Circuit to lookup block fields.
|
||||
|
||||
**Public Input Circuit:**
|
||||
|
||||
- Serves as the interface between the public information that the verifier sees and the circuits.
|
||||
|
||||
**RLP Circuit**
|
||||
|
||||
- Verifies the RLP serialization into bytes of Ethereum objects like transactions and blocks.
|
||||
|
||||
Writing optimal circuits means creating a system of polynomial equations with the minimum number of sufficient constraints. Though crucial infrastructure and tooling for writing circuits have been developed in recent years, circuit programming languages are still relatively unknown and low-level. Until [simpler languages](https://zkresear.ch/t/lookup-singularity/65) or more automated systems are developed, writing circuits optimally will remain a challenging problem to solve, even for experienced developers. The ability to audit circuits is also a valuable skill in this field.
|
||||
|
||||

|
||||
|
||||
However, the zkEVM community aims to be inclusive and supportive of individuals who are interested in learning and contributing. If you have a background in Rust or experience with other zkSNARK tooling like circom, you already have a good foundation for understanding the concepts behind the zkEVM. With a dedicated learning phase of 1-2 months, you should be well-equipped to make valuable contributions.
|
||||
|
||||
A consensus level zkEVM that proves the validity of Layer 1 must be a community effort. Not enough skills or resources currently exist for one team to do it alone – and reasonably well. There are many approaches to explore and many gaps in a single team’s capabilities.
|
||||
|
||||
Contributing to zkEVMs means entering a world where the tools are limited, the language is nascent, and the skills required are rare, but overcoming the challenge may create the widest practical application of zero-knowledge cryptography to date. If proofs of validity are used to verify every Ethereum block, then every Ethereum user will benefit from zero-knowledge proofs – a benefit that seems worth the effort.
|
||||
|
||||
---
|
||||
|
||||
For those who have found the design of the zkEVM Community Edition interesting or want to contribute to this project and would like to dive deeper, the following video provides a detailed explanation for how the code is structured:
|
||||
|
||||
<iframe allow="accelerometer; autoplay; encrypted-media; gyroscope; picture-in-picture" allowfullscreen="" frameborder="0" loading="lazy" src="https://www.youtube-nocookie.com/embed/01U8O2I3quI"></iframe>
|
||||
|
||||
The zkEVM Community Edition is possible thanks to the contribution of many teams including the [PSE](https://appliedzkp.org/), [Scroll Tech](https://scroll.io/), and [Taiko](https://taiko.xyz/) along with many individual contributors. Teams such as [Zcash](https://electriccoin.co/) have also researched and developed proving systems and libraries that have greatly benefited zkEVM efforts.
|
||||
|
||||
The zkEVM Community Edition is an open-source project and can be accessed in the [main repo](https://github.com/privacy-scaling-explorations/zkevm-specs). If you’re interested in helping, you can learn more by visiting the [contribution guidelines](https://github.com/privacy-scaling-explorations/zkevm-circuits/blob/main/CONTRIBUTING.md). The Community Edition is being built in public and its current status can be viewed on the [project board](https://github.com/orgs/privacy-scaling-explorations/projects/3/views/1).
|
||||
|
||||
For any general questions, feel free to ask in the [PSE Discord.](https://discord.com/invite/sF5CT5rzrR)
|
||||
|
||||
---
|
||||
|
||||
_This series intends to provide an overview of the zkEVM Community Edition in a way that is broadly accessible. Part 3 reviews the general logic and structure of the zkEVM Community Edition._
|
||||
|
||||
_[Part 1: Introduction](https://mirror.xyz/privacy-scaling-explorations.eth/I5BzurX-T6slFaPbA4i3hVrO7U2VkBR45eO-N3CSnSg)_
|
||||
|
||||
_[Part 2: Components](https://mirror.xyz/privacy-scaling-explorations.eth/AW854RXMqS3SU8WCA7Yz-LVnTXCOjpwhmwUq30UNi1Q)_
|
||||
112
articles/zkitter-an-anon-friendly-social-network.md
Normal file
@@ -0,0 +1,112 @@
|
||||
---
|
||||
authors: ["PSE Team"]
|
||||
title: "Zkitter: An Anon-friendly Social Network"
|
||||
image: "cover.webp"
|
||||
tldr: ""
|
||||
date: "2023-01-11"
|
||||
canonical: "https://mirror.xyz/privacy-scaling-explorations.eth/P4jDH1gLrVQ-DP5VyIKQrlPAJUTDhtXZkFl2vp8ewSg"
|
||||
---
|
||||
|
||||
Zkitter is a decentralized social network where users have the option to interact anonymously. The platform provides familiar social media functions such as posting, chatting, following, and liking, but with a private identity layer under the hood.
|
||||
|
||||
Zkitter was created as a public good for more open and honest conversation. With privacy and anonymity enabled by default – and without the fear of damaging or risking one’s personal reputation – the theory is that users will be able to express themselves more freely on Zkitter compared to mainstream platforms.
|
||||
|
||||
Zkitter is a social experiment made possible by decentralized blockchains and privacy-preserving [zero-knowledge proofs](https://ethereum.org/en/zero-knowledge-proofs/), and is currently in [alpha testing.](https://www.zkitter.com/explore/)
|
||||
|
||||
## What is Zkitter?
|
||||
|
||||
Zkitter is a private and decentralized social protocol meant to be an alternative means of communication for the crypto community and an experiment in anonymity and free speech. Data is decentralized and runs on a [peer-to-peer network](https://docs.zkitter.com/developers/overview) of nodes. Private identity functions are enabled by a stack of zero knowledge protocols: [Semaphore](https://semaphore.appliedzkp.org/), [Interep](https://interep.link/), [RLN](https://mirror.xyz/privacy-scaling-explorations.eth/aKjLmLVyunELnGObrzPlbhXWu5lZI9QU-P3OuBK8mOY), and [zkchat](https://github.com/zkitter/zkitterd/tree/main/lib/zk-chat-server).
|
||||
|
||||
**Semaphore**
|
||||
|
||||
Semaphore allows Ethereum users to prove their membership of a group and send signals without revealing their original identity. Zkitter users create a [Semaphore identity](https://semaphore.appliedzkp.org/docs/guides/identities) to join, post, reply, upvote, and chat publicly, either anonymously, or using an Ethereum address or ENS as their username. By using a Semaphore identity, Zkitter users reveal only the content of their messages or posts – and nothing else.
|
||||
|
||||
**Interep**
|
||||
|
||||
Another challenge with anonymity is [Sybil attacks](https://en.wikipedia.org/wiki/Sybil_attack), where a user creates multiple accounts to spam or gain influence. Zkitter uses Interep to increase Sybil resistance by leveraging existing reputations. Before creating an anonymous account on Zkitter, anonymous users need to prove they also own a reputation on an existing web2 social network such as Twitter or Reddit.
|
||||
|
||||
**RLN**
|
||||
|
||||
Spam can be a serious problem in anonymous environments. In “real life”, or on social networks where users have persistent identities, the threat of reputational damage or banning prevents most people from openly spamming. On anonymous networks, where a user’s actions can’t be traced to their identity, we can’t know who’s spamming – so we can’t punish or ban them. [RLN](https://mirror.xyz/privacy-scaling-explorations.eth/aKjLmLVyunELnGObrzPlbhXWu5lZI9QU-P3OuBK8mOY) (Rate Limit Nullifier) requires users to put something at stake, either financial or social, and punishes users who violate the spam rules by either slashing or banning them.
|
||||
|
||||
**Zkchat**
|
||||
|
||||
One of the first use cases for RLN was [“RLN Anonymous Chat”](https://github.com/zkitter/zkitterd/tree/main/lib/zk-chat-server), which later became known as zkchat, a spam resistant instant messaging application for private and anonymous communication. Zkchat powers Zkitter’s chat functionality and the zkchat project is now maintained by Zkitter.
|
||||
|
||||
## Experimenting with anonymity
|
||||
|
||||
> “Man is least himself when he talks in his own person.
|
||||
>
|
||||
> Give him a mask, and he will tell you the truth.”
|
||||
>
|
||||
> \- Oscar Wilde
|
||||
|
||||
Zkitter is a social experiment. Philosophically, it is an experiment in whether the Oscar Wilde quote above is true. Does the option of anonymity, by separating reputation from speech, create a space for more open and honest self-expression? What would happen if the option to be anonymous was available as a default and widely considered to be a “normal” thing to do? How might the conversation change when the content of what’s being said is detached from the reputation of the person saying it?
|
||||
|
||||
As an anon or using a pseudonym, people can say what they really believe, and honest conversation is ultimately the most valuable thing for important topics like governance decisions. Because the stakes are so high, and decisions may potentially last decades or even centuries, debate must be as authentic as possible. Though [DAO](https://ethereum.org/en/dao/) governance may come to mind for most people reading this article; using anonymity, pseudonyms, or aliases to debate controversial topics is not new.
|
||||
|
||||
In the late 1700s, when the newly formed United States of America was deciding between a weak or strong constitution (governance protocol in crypto-speak), the bulk of the conversation took place between anons. Writers of [the Federalist Papers](https://en.wikipedia.org/wiki/The_Federalist_Papers) argued for a strong constitution while the authors of the [Anti-Federalist Papers](https://en.wikipedia.org/wiki/Anti-Federalist_Papers) took the opposite side. Both sides used pseudonyms or aliases such as Publius, Cato, and Brutus to express their arguments as a collective and as individuals. To this day, historians are not completely certain who wrote which paper.
|
||||
|
||||
Modern crypto and its various sub-cultures are built on the work of the anon [Satoshi Nakamoto](https://nakamoto.com/satoshi-nakamoto/) (along with many other anonymous and pseudonymous contributors) so it should be no surprise that anonymity is a regular feature of crypto-related discussions on platforms like Twitter. The idea for Zkitter is to go a step further and create a space where anons are not outliers but first-class citizens – where privacy is the default, going anonymous is as trivial as toggling between dark mode and light mode, and decentralization and censorship resistance are part of the architecture of the system. In other words, align the values of the platform with the values of the community.
|
||||
|
||||
## Using Zkitter
|
||||
|
||||
Zkitter offers many of the basic functions people have come to expect from a social network. Where things get interesting are the anonymity options.
|
||||
|
||||
**Signup**
|
||||
|
||||
When signing up you can decide whether to create an account using an Ethereum address or [ENS name](https://ens.domains/), which will be displayed as your username, or to create an anonymous account.
|
||||
|
||||

|
||||
|
||||
https://www.zkitter.com/signup
|
||||
|
||||
To join Zkitter anonymously, you need to verify your reputation on an existing social network. [Interep](https://mirror.xyz/privacy-scaling-explorations.eth/w7zCHj0xoxIfhoJIxI-ZeYIXwvNatP1t4w0TsqSIBe4) imports a reputation from an existing platform to help prevent spammers or bots from creating many anonymous accounts. You can currently import your Twitter, Reddit, or Github reputation to Zkitter. Thanks to the magic of ZK proofs, the information from your Twitter account is not linked to your anon identity on Zkitter – Interep only verifies that you meet the reputation criteria and does not collect or store any details about either account.
|
||||
|
||||

|
||||
|
||||
https://docs.zkitter.com/faqs/how-to-create-an-anonymous-user
|
||||
|
||||
Once your reputation is verified, instead of a username, your Zkitter posts will simply show your reputation tier.
|
||||
|
||||
When you join Zkitter, you will sign a message to generate a [new ECDSA key pair](https://docs.zkitter.com/developers/identity) and write the public key to a [smart contract](https://arbiscan.io/address/0x6b0a11f9aa5aa275f16e44e1d479a59dd00abe58) on Arbitrum. The ECDSA key pair is used to authenticate messages and recover your Zkitter identity – so you aren’t using your Ethereum account private key to sign for actions on Zkitter.
|
||||
|
||||
**Posting**
|
||||
|
||||
Posting to Zkitter will feel pretty familiar, but with some extra options. You can choose whether to post as yourself, or anonymously – even if you don’t have an anonymous account. You can decide who you want to allow replies from, as well as whether the post will appear on the global feed or only on your own. If you’ve connected your Twitter account, you can also mirror your post to Twitter.
|
||||
|
||||
**Chat**
|
||||
|
||||
Any Zkitter user – anon or publicly known – has the option to chat anonymously.
|
||||
|
||||

|
||||
|
||||
https://docs.zkitter.com/faqs/how-to-chat-anonymously
|
||||
|
||||
Known identities and anonymous identities can interact with each other in private chats or on public threads.
|
||||
|
||||
## Private, on-chain identity
|
||||
|
||||
Zkitter is possible because of composability. The platform combines a variety of zero knowledge primitives and puts them all into one user-friendly package.
|
||||
|
||||
The base primitive of Zkitter is [Semaphore](https://mirror.xyz/privacy-scaling-explorations.eth/ImQNsJsJuDf_VFDm9EUr4njAuf3unhAGiPu5MzpDIjI), a private identity layer that lets users interact and post content anonymously. Semaphore IDs allow users to prove they are in a group and send signals as part of a group without revealing any other information.
|
||||
|
||||
Interep is the anti-Sybil mechanism of Zkitter. Because users are anonymous and anyone can join the network permissionlessly, Zkitter is susceptible to Sybil attacks. Interep allows new users to prove they possess a certain level of reputation from existing social networks.
|
||||
|
||||

|
||||
|
||||
https://www.zkitter.com/explore
|
||||
|
||||
[RLN](https://mirror.xyz/privacy-scaling-explorations.eth/aKjLmLVyunELnGObrzPlbhXWu5lZI9QU-P3OuBK8mOY) provides spam protection for Zkitter and is also integrated with the [zkchat](https://github.com/njofce/zk-chat) encrypted chat function. RLN allows the protocol to set a limit on how many messages a user can send in a certain amount of time, and a user who breaks the spam rules can be [identified and removed](https://rate-limiting-nullifier.github.io/rln-docs/what_is_rln.html#user-removal-slashing).
|
||||
|
||||
A social platform with basic privacy guarantees and protections from spam and Sybil attacks allows users to explore how anonymity affects speech. Whether the option to interact anonymously is useful, or even interesting, will depend on what happens on social experiments like Zkitter. With no name, phone number, or email address to tie your digital identity to the one you use in the physical world, what would you say?
|
||||
|
||||
How would you be different?
|
||||
|
||||
## Join the experiment
|
||||
|
||||
If you are interested in experimenting with anonymous thread posting or chatting, you can [try Zkitter now](https://www.zkitter.com/home). If you have any comments or feedback, please let us know by using [#feedback](https://www.zkitter.com/tag/%23feedback/) directly on [Zkitter](http://zkitter/) or by joining the [PSE Discord channel](https://discord.gg/jCpW67a6CG).
|
||||
|
||||
To help build Zkitter, check out the [Github repo here](https://github.com/zkitter) or learn more by reading the [docs.](https://docs.zkitter.com/developers/identity)
|
||||
|
||||
Zkitter is being built anonymously by [0xtsukino](https://www.zkitter.com/0xtsukino.eth/) with contributions from [AtHeartEngineer](https://github.com/AtHeartEngineer), [r1oga](https://github.com/r1oga), and others.
|
||||
@@ -0,0 +1,207 @@
|
||||
---
|
||||
authors: ["drCathieSo.eth"]
|
||||
title: "ZKML: Bridging AI/ML and Web3 with Zero-Knowledge Proofs"
|
||||
image: "cover.webp"
|
||||
tldr: "This post was authored by [drCathieSo.eth](https://twitter.com/drCathieSo_eth) and was originally published [here](https://hackmd.io/@cathie/zkml)."
|
||||
date: "2023-05-02"
|
||||
canonical: "https://mirror.xyz/privacy-scaling-explorations.eth/K88lOS4XegJGzMoav9K5bLuT9Zhn3Hz2KkhB3ITq-m8"
|
||||
---
|
||||
|
||||
## Introduction
|
||||
|
||||
I am thrilled to share that my project on ZKML has successfully been completed with the invaluable support from the Ecosystem Support Program of [Privacy & Scaling Explorations](https://appliedzkp.org/) (Ethereum Foundation). This platform bridges the AI/ML and Web3 worlds, providing a privacy-preserving solution with immense potential to revolutionize both industries.
|
||||
|
||||
This is a POC of an end-to-end platform for machine learning developers to seamlessly convert their TensorFlow Keras models into ZK-compatible versions. This all-in-one solution consists of three core components:
|
||||
|
||||
1. [circomlib-ml](https://github.com/socathie/circomlib-ml): A comprehensive Circom library containing circuits that compute common layers in TensorFlow Keras.
|
||||
2. [keras2circom](https://github.com/socathie/keras2circom): A user-friendly translator that converts ML models in Python into Circom circuits.
|
||||
3. [ZKaggle](https://github.com/socathie/ZKaggleV2): A decentralized bounty platform for hosting, verifying, and paying out bounties, similar to Kaggle, but with the added benefit of privacy preservation.
|
||||
|
||||
ZKML addresses the limitations of traditional machine learning bounty platforms, which often require full model disclosure for performance verification. The solution leverages ZKPs to enable developers to verify private models with public data, ensuring privacy and security. This is a powerful POC that can attract experienced Web2 developers to the Web3 ecosystem.
|
||||
|
||||
## Background and Rationale
|
||||
|
||||
### The challenges of traditional ML bounties
|
||||
|
||||
Traditional machine learning bounty platforms, such as Kaggle, often require developers to submit their full model to the host for performance verification. This can lead to several issues:
|
||||
|
||||
1. **Loss of intellectual property**: Disclosing the complete model architecture and weights may expose valuable trade secrets or innovative techniques that developers would prefer to keep private.
|
||||
2. **Lack of transparency**: The evaluation process can be opaque, and participants may not be able to verify the rankings of their models against others.
|
||||
3. **Data privacy concerns**: Sharing models that have been trained on sensitive data may inadvertently reveal information about the underlying data, violating privacy norms and regulations.
|
||||
|
||||
These challenges have created a demand for solutions that can protect the privacy of machine learning models and the data they are trained on.
|
||||
|
||||
### The potential of ZKPs in machine learning
|
||||
|
||||
ZKPs present a promising approach to address the challenges faced by traditional ML bounties. By leveraging the power of ZKPs, ZKML offers a privacy-preserving solution with the following benefits:
|
||||
|
||||
1. **Model privacy**: Developers can participate in bounties without disclosing their entire model architecture and weights, protecting their intellectual property.
|
||||
2. **Transparent verification**: ZKPs enable the verification of model performance without revealing the model’s internals, fostering a transparent and trustless evaluation process.
|
||||
3. **Data privacy**: ZKPs can be used to verify private data with public models or private models with public data, ensuring that sensitive information remains undisclosed.
|
||||
|
||||
Integrating ZKPs into the machine learning process provides a secure and privacy-preserving platform that addresses the limitations of traditional ML bounties. This not only promotes the adoption of machine learning in privacy-sensitive industries but also attracts experienced Web2 developers to explore the possibilities within the Web3 ecosystem.
|
||||
|
||||
## Current Scope: A Comprehensive POC
|
||||
|
||||
**[circomlib-ml](https://github.com/socathie/circomlib-ml): A Circom Library for Machine Learning**
|
||||
|
||||
circomlib-ml is a library of circuit templates for machine learning tasks using the circom language. It contains various templates for neural network layers, such as convolutional layers, dense layers, and activation functions. This library enables the creation of custom circuits for machine learning tasks.
|
||||
|
||||
**[keras2circom](https://github.com/socathie/keras2circom): Seamless Model Conversion**
|
||||
|
||||
keras2circom is a Python tool that transpiles TensorFlow Keras models into circom circuits. This enables seamless conversion of machine learning models from the popular deep learning framework into privacy-preserving ZKP circuits.
|
||||
|
||||
### ZKaggle: A Decentralized Bounty Platform for Machine Learning
|
||||
|
||||
ZKaggle’s first version emerged as [a hackathon submission at ETHGlobal FVM Space Warp Hack](https://ethglobal.com/showcase/zkaggle-70g3b). The platform enabled decentralized computing by allowing users to share their processing power and monetize their proprietary machine learning models. With a browser-based frontend, bounty providers could upload their data to Filecoin and create computing tasks with associated rewards. Bounty hunters could browse available bounties, download data, and perform computations locally. Upon completion, they would submit a proof with hashed results on-chain for the bounty provider to review. Once approved, bounty hunters could claim their rewards by providing the pre-image of the hashed results. ZKPs were used to maintain a succinct proof of computation and enable bounty hunters to monetize private models with credibility.
|
||||
|
||||
[ZKaggleV2](https://github.com/socathie/ZKaggleV2) presents an improved version with enhanced features and functionality. In this version, multiple files are aggregated into a single circuit, allowing for more efficient processing. The platform also verifies the accuracy of the computations and incorporates a secure method for transferring model weights from the bounty hunter to the bounty provider using elliptic curve Diffie-Hellman (ECDH) encryption. This added layer of security ensures that only authorized parties can access and utilize the model weights, further solidifying the platform’s commitment to privacy and data protection.
|
||||
|
||||
## Code Highlights
|
||||
|
||||
**[circomlib-ml](https://github.com/socathie/circomlib-ml): ZK-friendly Polynomial Activation**
|
||||
|
||||
**[circomlib-ml/circuits/Poly.circom](https://github.com/socathie/circomlib-ml/blob/master/circuits/Poly.circom)**
|
||||
|
||||
```
|
||||
pragma circom 2.0.0;
|
||||
|
||||
// Poly activation layer: https://arxiv.org/abs/2011.05530
|
||||
template Poly (n) {
|
||||
signal input in;
|
||||
signal output out;
|
||||
|
||||
out <== in * in + n*in;
|
||||
}
|
||||
```
|
||||
|
||||
**[keras2circom](https://github.com/socathie/keras2circom): Model Weights “Quantization”**
|
||||
|
||||
**[keras2circom/keras2circom/circom.py](https://github.com/socathie/keras2circom/blob/main/keras2circom/circom.py)**
|
||||
|
||||
```
|
||||
...
|
||||
def to_json(self, weight_scale: float, current_scale: float) -> typing.Dict[str, typing.Any]:
|
||||
'''convert the component params to json format'''
|
||||
self.weight_scale = weight_scale
|
||||
self.bias_scale = self.calc_bias_scale(weight_scale, current_scale)
|
||||
# print(self.name, current_scale, self.weight_scale, self.bias_scale)
|
||||
|
||||
json_dict = {}
|
||||
for signal in self.inputs:
|
||||
if signal.value is not None:
|
||||
if signal.name == 'bias' or signal.name == 'b':
|
||||
# print(signal.value)
|
||||
json_dict.update({f'{self.name}_{signal.name}': list(map('{:.0f}'.format, (signal.value*self.bias_scale).round().flatten().tolist()))})
|
||||
else:
|
||||
json_dict.update({f'{self.name}_{signal.name}': list(map('{:.0f}'.format, (signal.value*self.weight_scale).round().flatten().tolist()))})
|
||||
return json_dict
|
||||
|
||||
def calc_bias_scale(self, weight_scale: float, current_scale: float) -> float:
|
||||
'''calculate the scale factor of the bias of the component'''
|
||||
if self.template.op_name in ['ReLU', 'Flatten2D', 'ArgMax', 'MaxPooling2D', 'GlobalMaxPooling2D']:
|
||||
return current_scale
|
||||
if self.template.op_name == 'Poly':
|
||||
return current_scale * current_scale
|
||||
return weight_scale * current_scale
|
||||
...
|
||||
```
|
||||
|
||||
Circom only accepts integers as signals, but Tensorflow weights and biases are floating-point numbers. Instead of quantizing the model, weights are scaled up by `10**m` times. The larger `m` is, the higher the precision. Subsequently, biases (if any) must be scaled up by `10**2m` times or even more to maintain the correct output of the network. **keras2circom** automates this process by calculating the maximum `m` possible and scaling each layer accordingly.
|
||||
|
||||
**[ZKaggle](https://github.com/socathie/ZKaggleV2): IPFS CID Matching and Universal Encryption Circuits**
|
||||
|
||||
**[ZKaggleV2/hardhat/circuits/utils/cid.circom](https://github.com/socathie/ZKaggleV2/blob/main/hardhat/circuits/utils/cid.circom)**
|
||||
|
||||
```
|
||||
pragma circom 2.0.0;
|
||||
|
||||
include "../sha256/sha256.circom";
|
||||
include "../../node_modules/circomlib-ml/circuits/circomlib/bitify.circom";
|
||||
|
||||
// convert a 797x8 bit array (pgm) to the corresponding CID (in two parts)
|
||||
template getCid() {
|
||||
signal input in[797*8];
|
||||
signal output out[2];
|
||||
|
||||
component sha = Sha256(797*8);
|
||||
for (var i=0; i<797*8; i++) {
|
||||
sha.in[i] <== in[i];
|
||||
}
|
||||
|
||||
component b2n[2];
|
||||
|
||||
for (var i=1; i>=0; i--) {
|
||||
b2n[i] = Bits2Num(128);
|
||||
for (var j=127; j>=0; j--) {
|
||||
b2n[i].in[127-j] <== sha.out[i*128+j];
|
||||
}
|
||||
out[i] <== b2n[i].out;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Machine learning datasets are frequently too large to be uploaded directly onto the blockchain, so they are instead uploaded to IPFS. To ensure data integrity throughout the model computation process, a proof-of-concept circuit has been designed to demonstrate the capability of computing an IPFS Content Identifier (CID) that is uploaded as a raw buffer in a circom circuit. This approach verifies that the computation is performed on the designated file, thereby maintaining the integrity of the process.
|
||||
|
||||
**[ZKaggleV2/hardhat/circuits/utils/encrypt.circom](https://github.com/socathie/ZKaggleV2/blob/main/hardhat/circuits/utils/encrypt.circom)**
|
||||
|
||||
```
|
||||
pragma circom 2.0.0;
|
||||
|
||||
include "../../node_modules/circomlib-ml/circuits/crypto/encrypt.circom";
|
||||
include "../../node_modules/circomlib-ml/circuits/crypto/ecdh.circom";
|
||||
|
||||
// encrypt 1000 inputs
|
||||
template encrypt1000() {
|
||||
// public inputs
|
||||
signal input public_key[2];
|
||||
|
||||
// private inputs
|
||||
signal input in[1000];
|
||||
signal input private_key;
|
||||
|
||||
// outputs
|
||||
signal output shared_key;
|
||||
signal output out[1001];
|
||||
|
||||
component ecdh = Ecdh();
|
||||
|
||||
ecdh.private_key <== private_key;
|
||||
ecdh.public_key[0] <== public_key[0];
|
||||
ecdh.public_key[1] <== public_key[1];
|
||||
|
||||
component enc = EncryptBits(1000);
|
||||
enc.shared_key <== ecdh.shared_key;
|
||||
|
||||
for (var i = 0; i < 1000; i++) {
|
||||
enc.plaintext[i] <== in[i];
|
||||
}
|
||||
|
||||
for (var i = 0; i < 1001; i++) {
|
||||
out[i] <== enc.out[i];
|
||||
}
|
||||
|
||||
shared_key <== ecdh.shared_key;
|
||||
}
|
||||
...
|
||||
```
|
||||
|
||||
To maintain the integrity of the proof during the bounty claim process, **ZKaggleV2** incorporates a universal model weight encryption circuit. This circuit is precompiled and deployed for use across all bounties and models. The existing implementation supports models with up to 1000 weights, and any model with fewer weights can be zero-padded at the end to conform to the required size. This approach ensures a consistent and secure method of handling model weights
|
||||
|
||||
Please visit the respective repositories linked above for full implementation and usage details.
|
||||
|
||||
## Limitations and Potential Improvements
|
||||
|
||||
**Proving Scheme: Groth16**
|
||||
|
||||
The project currently employs Groth16 as the proving scheme to minimize proof size. However, the platform could be extended to support other proving schemes supported by snarkjs that do not require a circuit-specific trusted setup, such as PLONK or FFLONK.
|
||||
|
||||
**Contract Size and Local Testing**
|
||||
|
||||
At present, the contracts and frontend can only be tested locally due to the contract size exceeding EIP-170 limit. This constraint poses a challenge for deploying the platform on the Ethereum mainnet (or its testnets) and restricts its usability for wider audiences. To address this limitation, developers could investigate alternative L2 solutions or EVM-compatible chains that offer higher capacity for contract size, enabling this POC to be deployed and used more extensively.
|
||||
|
||||
## TLDR and Call to Action
|
||||
|
||||
In summary, this project is an innovative proof-of-concept platform trying to bridge the AI/ML and Web3 worlds using ZKPs, by offering a comprehensive suite of tools, including circomlib-ml, keras2circom, and ZKaggleV2.
|
||||
|
||||
The open-source community is invited to contribute to the ongoing development of ZKML. In particular, contributions in the form of additional templates for circomlib-ml, extending support for more layers in keras2circom, and reporting any bugs or issues encountered are highly encouraged. Through collaboration and contributions to this exciting project, the boundaries of secure and privacy-preserving machine learning in the Web3 ecosystem can be pushed even further.
|
||||
@@ -0,0 +1,30 @@
|
||||
---
|
||||
authors: ["PSE Team"]
|
||||
title: "Zkopru Ceremony: Final Call and Failed Contributions"
|
||||
image: null
|
||||
tldr: "We will end the ceremony on Friday. It was largely a success but we had a few cases of failed contributions. If your first run didn’t succeed you can now head back to our [website](https://zkopru.network/)_ to fix it"
|
||||
date: "2022-08-26"
|
||||
canonical: "https://mirror.xyz/privacy-scaling-explorations.eth/X7O6_Y33NY-nNfzpV5HZRvups2qimQnQ9ef0OD1U8RY"
|
||||
---
|
||||
|
||||

|
||||
|
||||
Our trusted ceremony for Zkopru has attracted a large number of contributors, second only to tornado.cash with their sub-minute contribution time. If you have not yet participated you can do so [here](https://zkopru.network/).
|
||||
|
||||
As mentioned in our [previous post](https://thore-hildebrandt.medium.com/zkopru-trusted-setup-ceremony-f2824bfebb0f), we will wrap up the ceremony and announce a random beacon to seal the ceremony. But before we do that we want to make sure that everybody has a chance to add a valid contribution. We will close the ceremony for contributions on Friday April 16th 2021.
|
||||
|
||||
## Reasons for Failed Contributions
|
||||
|
||||
We found three causes for failures and enabled affected accounts to do a second run on these circuits. Participants may not be aware that something went wrong in scenario 1&2 so it’s worth heading to our [website](https://zkopru.network/) to see if it allows you a second run.
|
||||
|
||||
Note that the ceremony is secure as long as at least one participant was not malicious. We provide the option for a second run to make sure no one feels censored.
|
||||
|
||||
**1\. Conflicting Contributions**We found that most cases occurred during initial periods of high traffic when two or more contributors joined at around the same time. The rate of contribution slowed after that, and we deployed a fix. A contributor may have failures in one or more circuits, but have successful contributions in others. Only the failed contributions have been reset to allow re-run. Each contribution builds on the latest verified contribution, but in this case, both contributors built on the same one. So the contribution looks valid but doesn’t appear in the verification transcript. Similar to an uncle block in Ethereum.
|
||||
|
||||
**2\. Chaining from 0**In a small number of cases a contributor chained from contribution 0, effectively restarting the chain. These cases have also been identified and reset. The code now has a sanity check to prevent this from occurring.
|
||||
|
||||
**3\. Timeouts**Contributions have in some cases also been excluded because of timeouts. This isby design, and happens when a contribution is taking too long and others are waiting in the queue. These cases have not been reset, unless they happen to also have been in the above set.
|
||||
|
||||
## Questions?
|
||||
|
||||
Please join our [telegram channel](https://t.me/zkopru) to ask any questions and follow us on twitter [@ZkopruNetwork](http://twitter.com/ZkopruNetwork).
|
||||
100
articles/zkopru-on-testnet-privacy-scaling-explorations.md
Normal file
@@ -0,0 +1,100 @@
|
||||
---
|
||||
authors: ["PSE Team"]
|
||||
title: "ZKOPRU on Testnet - Privacy & Scaling Explorations"
|
||||
image: null
|
||||
tldr: "Exciting news! ZKOPRU is now live on the Görli testnet. We show you how to use it."
|
||||
date: "2022-08-26"
|
||||
canonical: "https://mirror.xyz/privacy-scaling-explorations.eth/EB0KcMY0k9ucN8iQSBeOYksoupDYRBQ4ZffhRt477FE"
|
||||
---
|
||||
|
||||
Originally published on Nov 30, 2021:
|
||||
|
||||

|
||||
|
||||
## Intro
|
||||
|
||||
After many months of hard work we are excited to announce ZKOPRU is live on the Görli testnet 🎊. You can find the ZKOPRU contracts deployed on Görli [here](https://goerli.etherscan.io/address/0x48458c823df628f0c053b0786d4111529b9fb7b0) and the wallet UI [here](https://wallet.zkopru.network/). We will walk you through the process of depositing assets from Görli to ZKOPRU, making a private transfer on ZKOPRU and withdrawing assets from ZKOPRU to Görli. If you are building a wallet or rollup, check out the UI Research section below to find the user acceptance testing results and analysis.
|
||||
|
||||
## ZKOPRU tl;dr
|
||||
|
||||
We’ll give a very quick overview here, but if you don’t know what ZKOPRU is or need a reminder, we highly recommend reading our previous post [ZKOPRU Wat Y & Wen](https://medium.com/privacy-scaling-explorations/ZKOPRU-wat-y-wen-f5026903cf39) before trying out the wallet.
|
||||
|
||||
ZKOPRU is an [optimistic rollup](https://ethereum.org/en/developers/docs/scaling/layer-2-rollups/#optimistic-rollups) that uses zero knowledge proofs to make individual transfers private. Similar to Ethereum’s miners or validators, rollups have coordinators that receive transactions, calculate the new state and submit data to Ethereum.
|
||||
|
||||
ZKOPRU currently supports deposit, transfer and withdrawal of ETH and ERC-20 tokens (NFTs coming soon™). For the most part these functions work similarly to their layer 1 counterparts, but there are a few key differences from what you might be used to:
|
||||
|
||||
- Although the initial deposit to your ZKOPRU wallet will be visible as a transaction on Ethereum, any subsequent transactions will only be visible to you and the recipient.
|
||||
- Rollups commit only small amounts of data to the main chain, and coordinators can submit transactions in batches, so the price per transaction is drastically lower.
|
||||
- ZKOPRU allows you to deposit multiple assets (ETH and another token) at the same time.
|
||||
- ZKOPRU addresses are \*not\* the same as Ethereum addresses. When you need to receive assets to your ZKOPRU account, you’ll use a ZKOPRU address generated from your connected Ethereum address.
|
||||
- Rollups have a 7 day delay for withdrawals back to the main chain (we’re working on an instant withdrawal mechanism so users can get around this delay).
|
||||
|
||||
## How to use ZKOPRU
|
||||
|
||||
## Setup
|
||||
|
||||
To get started with ZKOPRU, you’ll need the Metamask plugin. Since it’s still on testnet you’ll also need some GörliETH, which you can get from the [Görli Faucet](https://faucet.goerli.mudit.blog/) or the [Paradigm MultiFaucet](https://faucet.paradigm.xyz/).
|
||||
|
||||
> Please note that from here on, when we say ETH we are referring to GörliETH. Don’t send mainnet ETH to your ZKOPRU wallet yet!
|
||||
|
||||
Once you’ve got your ETH, make sure MetaMask is connected to the Görli testnet and head to the ZKOPRU [wallet](https://zkopru.network/).
|
||||
|
||||
You’ll need to connect an Ethereum account using MetaMask. Select the account you want to use and click _Next_, then _Connect_. You’ll see a popup asking your permission to sync — the ZKOPRU wallet runs a client in the browser which needs to sync with the ZKOPRU network. MetaMask will prompt you to sign to unlock your ZKOPRU account and start the sync.
|
||||
|
||||
|
||||
|
||||
Syncing Zkopru
|
||||
|
||||
The sync process could take a few minutes. Wait until the bottom left shows \*Fully synced 100%. \*If the site is blurred, double check if Metamask is connected to Görli. If you weren’t connected to Görli you may need to refresh the page in order to start the sync.
|
||||
|
||||
|
||||
|
||||
ZKOPRU main page
|
||||
|
||||
## Deposit
|
||||
|
||||
In order to start transacting on ZKOPRU, you’ll need to deposit your ETH from Görli into ZKOPRU On the left side of the main page, click _Deposit_. You’ll see options to deposit ETH, ERC20s or both at the same time. The deposit transaction will require some ETH for the L1 transfer and an additional fee for the coordinator. We recommend you deposit at least 0.01ETH — you’ll also need it to pay coordinator fees for any ZKOPRU transactions. After confirming your transaction in MetaMask, head to the _History_ tab to check the deposit status.
|
||||
|
||||
|
||||
|
||||
Depositing
|
||||
|
||||
## Transfer (Send & Receive)
|
||||
|
||||
In order to make a private transfer on ZKOPRU, go to _Send,_ on the main page, enter the recipient address, select the asset and amount you want to send and enter the fee for the coordinator. Remember that the recipient’s ZKOPRU address is different from the Ethereum address — the recipient can generate it by clicking _Receive_ on the ZKOPRU main page, then copy it to send to you.
|
||||
|
||||
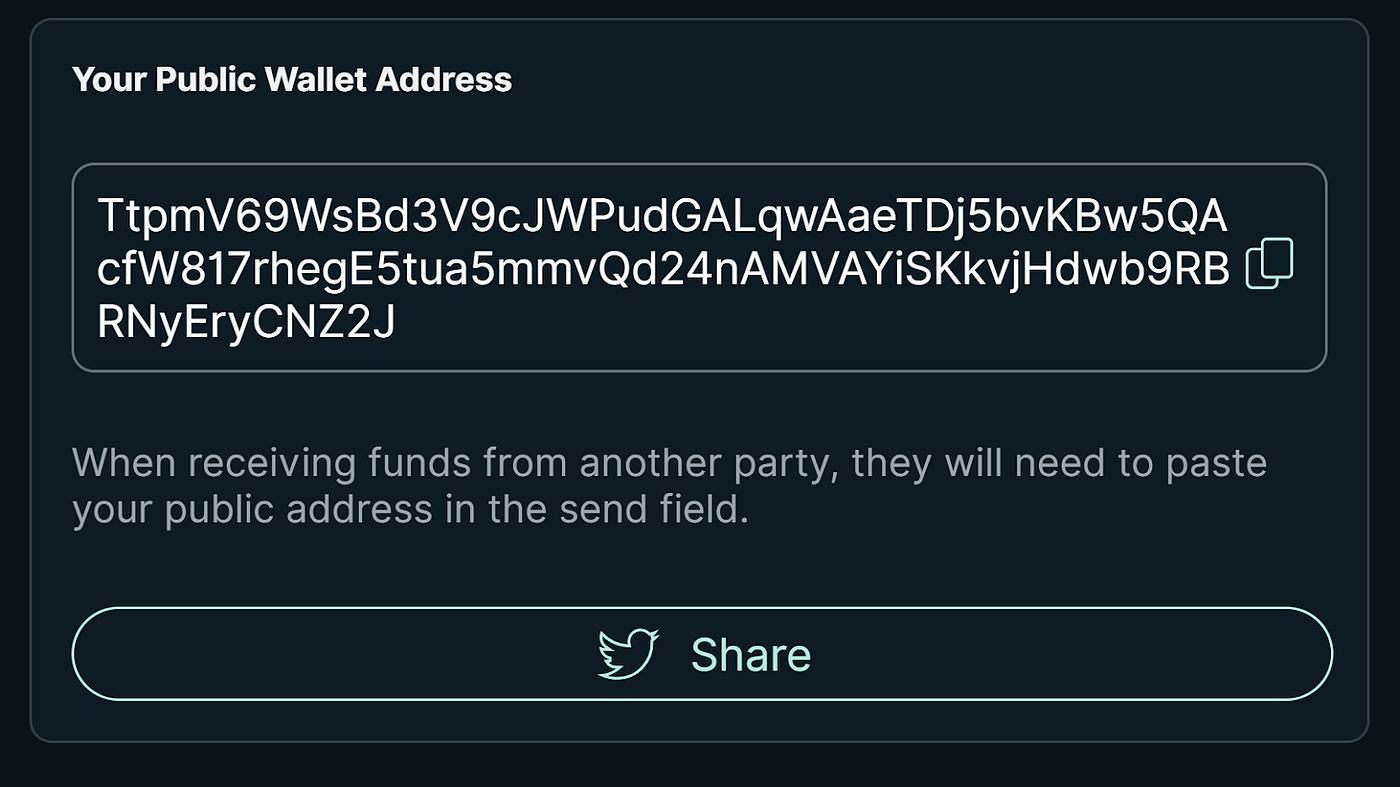
|
||||
|
||||
ZKOPRU Address
|
||||
|
||||
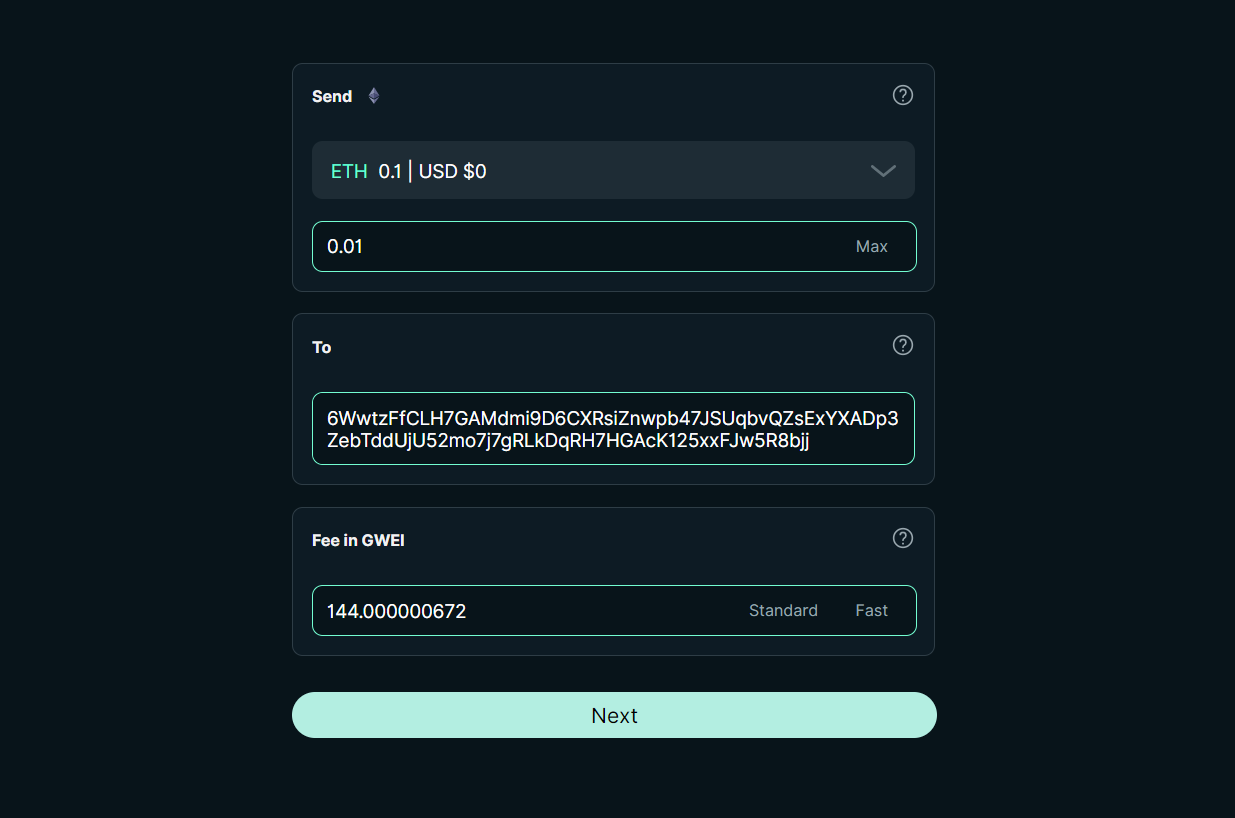
|
||||
|
||||
Transfer
|
||||
|
||||
After hitting S*end*, your transaction is relayed to the coordinator. The actual transfer can take a while if there is not a lot of activity on the network, because the coordinator has to accumulate enough transactions that the combined fees will cover the cost of submitting a batch. Since GörliETH is free you can splash it a bit and use a 2500Gwei transaction fee to help the poor coordinator submit the batch right away. We are building an instant finality mechanism to make that faster in the future :).
|
||||
|
||||
After the transfer you will see something like this in the _My Wallet_ section:
|
||||
|
||||
|
||||
|
||||
This means that your available balance is currently locked until the transfer succeeds. ZKOPRU, like Bitcoin, uses the UTXO model and you can see your notes’ info by hovering over the “\*i” \*next to your balance.
|
||||
|
||||
## Withdraw
|
||||
|
||||
If you want your assets back on Görli, you’ll need to withdraw them from ZKOPRU. Head to _Withdraw_ on the main page, select the asset you want to withdraw and enter the amount as well as the fee for the coordinator. The withdrawal will be initiated once the coordinator has enough transactions lined up to make submission of the batch economical (this can be a few hours).
|
||||
|
||||
Unlike a transfer, you won’t be able to meaningfully speed up the withdrawal via a higher transaction fee. ZKOPRU, like other optimistic rollups, requires a 7 day delay period for withdrawals. So even if you pay enough to incentivize the coordinator to submit the batch a few minutes sooner, you’ll still have to wait 7 days for your assets to be available. This delay serves an important security function, but it’s a UX annoyance — we’re also working on an instant withdrawal mechanism so you’ll have options to get around the withdrawal delay in the future.
|
||||
|
||||
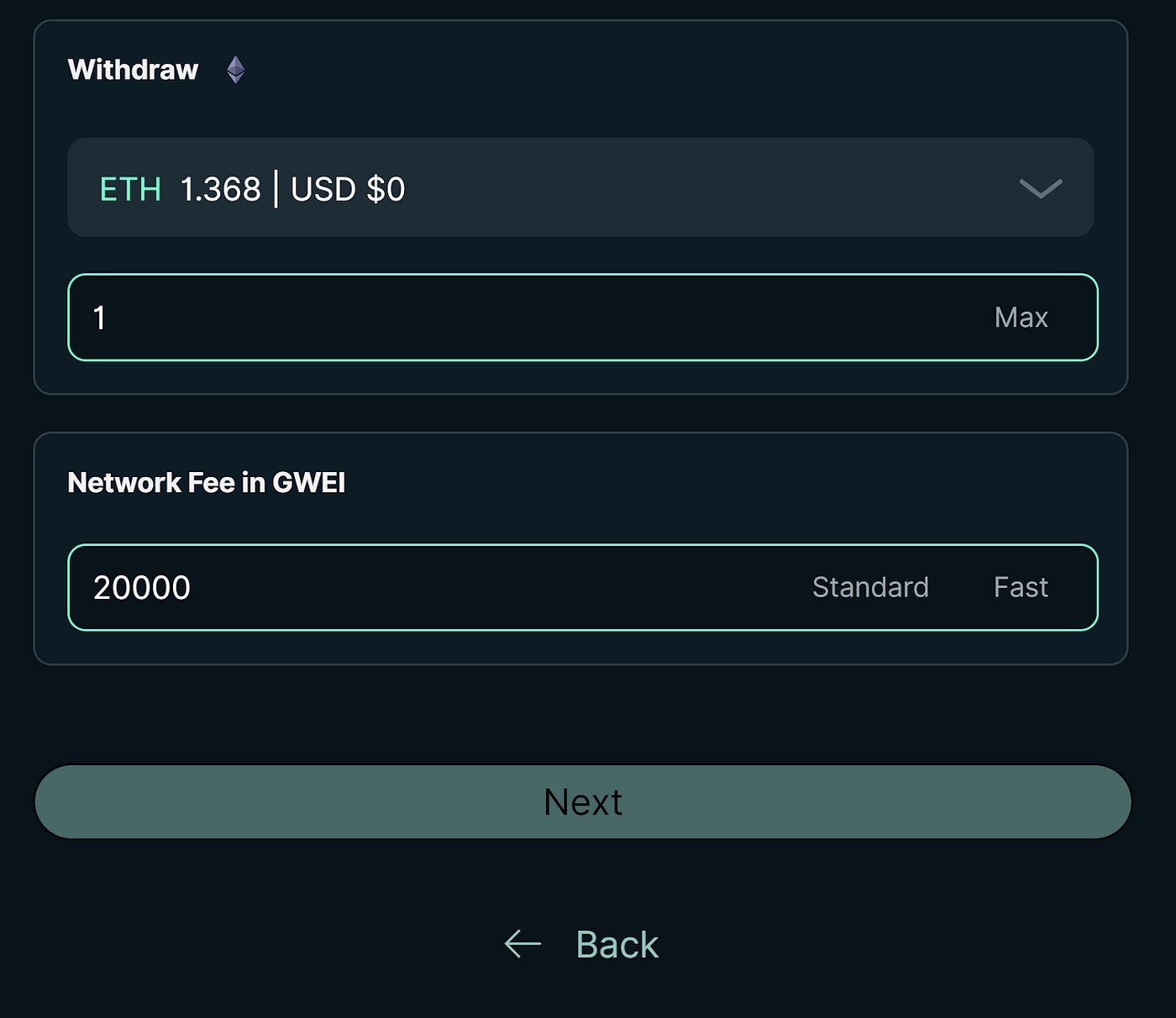
|
||||
|
||||
## UI Research
|
||||
|
||||
Rachel, our awesome designer, has conducted user acceptance testing with users who don’t work in crypto. Users with varying levels of crypto knowledge were asked to complete tasks like adding and withdrawing assets, and describe their experience and impressions. It was especially interesting to hear our users’ first reactions to features we’re excited about, like multi-asset deposits — a good reminder that a new feature is also a new experience for a user, and it’s our job to get them oriented so they can be as excited about it as we are.
|
||||
|
||||
You can find the report [here](https://github.com/zkopru-network/resources/tree/main/ui-ux/wallet). We hope it will be useful for others working on similar design challenges!
|
||||
|
||||
## Conclusion
|
||||
|
||||
ZKOPRU is on testnet! Now [go ahead and make some GörliETH private](https://zkopru.network/wallet). If everything goes smoothly for a few weeks on testnet, we will cut an official release. Stay tuned for the next post, where we will explain more details on how to run a coordinator and how ZKOPRU can be deployed to mainnet. If you are interested in learning more about ZKOPRU check out our [Twitter](https://twitter.com/zkoprunetwork), [Medium](https://medium.com/privacy-scaling-explorations) and [documentation](https://docs.zkopru.network/). Join our brand new [Discord](http://discord.gg/vchXmtWK5Z) and please report any bugs and issues there.
|
||||
|
||||
Contributors are welcome — see our [good first issues](https://github.com/zkopru-network/zkopru/labels/good%20first%20issue) on Github.
|
||||
85
articles/zkopru-trusted-setup-ceremony.md
Normal file
@@ -0,0 +1,85 @@
|
||||
---
|
||||
authors: ["PSE Team"]
|
||||
title: "Zkopru Trusted Setup Ceremony"
|
||||
image: null
|
||||
tldr: "Use this link to participate in the trusted setup (on a desktop, mobile isn’t recommended): [https://mpc.zkopru.network/](https://mpc.zkopru.network/)"
|
||||
date: "2022-08-26"
|
||||
canonical: "https://mirror.xyz/privacy-scaling-explorations.eth/a2Ut19fwRGNJoCd-IoQadyn3sUMRgGNSfRgHEc4iGhw"
|
||||
---
|
||||
|
||||
_Originally posted on Mar 26, 2021:_
|
||||
|
||||
We are excited to announce that the trusted setup ceremony for Zkopru has been launched.
|
||||
|
||||
## What is Zkopru?
|
||||
|
||||

|
||||
|
||||
Zkopru, pronounced \[zikopru\], is short for zk-optimistic-rollup. It’s a novel layer-2 scaling solution that allows for cheap private transactions. It uses optimistic rollup to scale and zk-SNARKs for privacy. Zkopru supports private transfers and private atomic swaps between ETH, ERC20, ERC721 at low cost. It also provides instant withdrawals via the pay-in-advance feature and compliance compatibility using spending key and viewing keys. See Wanseob [presenting](https://www.youtube.com/watch?v=443EZ0ndaio) the project on zkSummit and check out the Zkopru [website](https://zkopru.network/). You can also dive deeper in the original [ethresear.ch](https://ethresear.ch/t/zkopru-zk-optimistic-rollup-for-private-transactions/7717) post.
|
||||
|
||||
We have just completed an audit with Least Authority and the next step is to conduct a trusted setup.
|
||||
|
||||
## Why a trusted setup?
|
||||
|
||||
Zkopru relies on a number of different SNARKs and each requires a trusted setup which ensures that no one is able to fake proofs and steal user funds or compromise privacy. The setup is performed in such a way that, to fake a proof, an attacker must compromise every single participant of the ceremony. Therefore, the security goes up with the number of participants.
|
||||
|
||||
## How exactly does the setup work?
|
||||
|
||||
Our trusted setup is done in 2 steps. The first step is already completed and is called Perpetual Powers of Tau. It’s an ongoing effort led by Wei Jie of the Ethereum Foundation. We are using the output of Iden3’s [selection process](https://blog.hermez.io/hermez-zero-knowledge-proofs/) based on the [54th](https://github.com/weijiekoh/perpetualpowersoftau) Perpetual Powers of Tau contribution.
|
||||
|
||||
The second step is called Phase 2 and is circuit-specific, so it should be done separately for each different SNARK. This is what you participate in here.
|
||||
|
||||
## How to participate?
|
||||
|
||||
It is very simple!
|
||||
|
||||
1. Open the link to our ceremony website: [https://mpc.zkopru.network/](https://mpc.zkopru.network/).
|
||||
2. Log in with your Github account. You can only participate once with your Github account.
|
||||
|
||||
|
||||
|
||||
Click Login
|
||||
|
||||
3\. Click on “Launch Ceremony”.
|
||||
|
||||
|
||||
|
||||
Click Launch Ceremony
|
||||
|
||||
4\. You will contribute to 16 circuits some of them take (much) longer than others. Particiants are queued and if someone is in front of you, you will be put in a line, just wait.
|
||||
|
||||
|
||||
|
||||
5\. While the ceremony is running please don’t close or refresh the site (you can switch browser tabs) otherwise your contribution will be aborted. The process should take 30–50 mins. Once the ceremony is completed you can tweet about your participation to spread the word and make Zkopru more secure.
|
||||
|
||||
|
||||
|
||||
Wait until you see this
|
||||
|
||||
## Troubeshooting
|
||||
|
||||
If the twitter button doesnt show up in your browser you can try this: Refresh > Menu >Logout, then Login, and launch again. It won’t run any circuits, but it might pick up your hashes and allow you to tweet.
|
||||
|
||||
Your browser might go blank, you can just refresh and restart, it will pick up where you left.
|
||||
|
||||
You dont see your contribution hash for any or all circuits? In that case something went wrong and your contribution was discarded. We will give any participant with failed contributions a second chance.
|
||||
|
||||
Encountering any issues? Let us know in the Zkopru telegram group.
|
||||
|
||||
## How to verify?
|
||||
|
||||
After your participation you will be presented with a contribution hash. We will make the files available to download and you will be able to verify your contribution (see more info [here](https://github.com/glamperd/setup-mpc-ui#verifying-the-ceremony-files)). You can also contribute via CLI if you want more control, ask about it in our [telegram](https://t.me/zkopru) group.
|
||||
|
||||
## Whats the time line?
|
||||
|
||||
The ceremony will run for at least 2 weeks from now on. Once we have enough contributions we will announce a public random beacon for the last contribution.
|
||||
|
||||
## Want to learn more?
|
||||
|
||||
Source code for the ceremony is available [here](https://github.com/glamperd/setup-mpc-ui#verifying-the-ceremony-files). Contribution computation is performed in the browser. The computation code is compiled to WASM, based on the repo above, a fork of Kobi Gurkan’s phase 2 computation module which has been [audited](https://research.nccgroup.com/2020/06/24/security-considerations-of-zk-snark-parameter-multi-party-computation/).We made these unaudited changes:
|
||||
|
||||
\- For the WASM build, return the result hash to the caller.- Also for the WASM build: Progress is reported by invoking a callback.- Corrected errors in progress report count totals.
|
||||
|
||||
## More Questions?
|
||||
|
||||
[Join](https://t.me/zkopru) our telegram group.
|
||||
@@ -0,0 +1,44 @@
|
||||
---
|
||||
authors: ["PSE Team"]
|
||||
title: "Zkopru Trusted Setup Completed - Privacy & Scaling Explorations"
|
||||
image: null
|
||||
tldr: "The public participation part of our ceremony has finished, we provide verification details, stats and announce a random beacon"
|
||||
date: "2022-08-26"
|
||||
canonical: "https://mirror.xyz/privacy-scaling-explorations.eth/dQec_qe4VOcKoVH9OH42Ef9WuSqyAJ6S40jRrZ_Mw7g"
|
||||
---
|
||||
|
||||
Originally published on Apr 21, 2021:
|
||||
|
||||

|
||||
|
||||
## **Overview**
|
||||
|
||||
The public participation part of our ceremony is now complete! It ran for 22 days in total and had 5146 successful contributions to all circuits combined. We encourage you to head to [this](https://storage.googleapis.com/zkopru-mpc-files/index.html) website to find your contribution files and instructions on how to verify them.
|
||||
|
||||
## **Statistics**
|
||||
|
||||
By some metrics our trusted setup was the largest ever conducted, we had 5147 contributions across the 16 circuits albeit “only” by 369 individuals. A total computation time of 190,5h (7days) went into the ceremony and the average participant spent 36 minutes. We also had quite number of failed contributions and therefore [gave affected participants an additional week](https://thore-hildebrandt.medium.com/zkopru-ceremony-final-call-and-failed-contributions-5a787cb4885e) to do a second run.
|
||||
|
||||
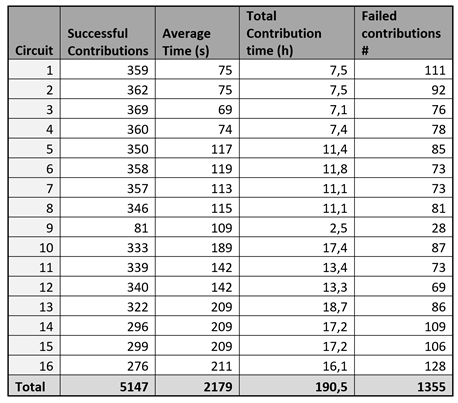
|
||||
|
||||
The largest number of contributions came surprisingly before April 2nd where we posted it on twitter. Before that date we shared it in various Ethereum and ZKP telegram channels.
|
||||
|
||||
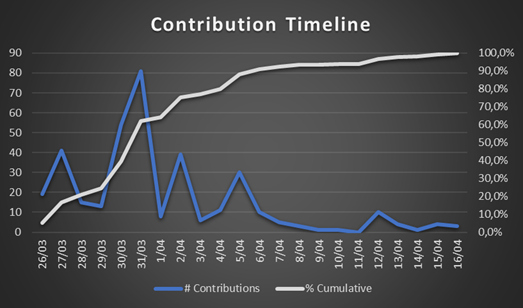
|
||||
|
||||
## **Random beacon**
|
||||
|
||||
As a final step we are sealing the ceremony with a last contribution using a random number generated by [Drand](https://drand.love/) round 805765. This number will be generated close to Wed Apr 28 2021 10:00:00 GMT. After that time, you can find the number [here](https://drand.cloudflare.com/public/805765).
|
||||
|
||||
See [here](https://gateway.pinata.cloud/ipfs/QmYeACjxL4woX9a1SvN6msg1BuKP69oJ5t4KFq5BMDK5NJ) the selection details uploaded to ipfs and [here](https://etherscan.io/tx/0xbe0a7768542e35f44fb1d8658209c94ebdf3604c141429943e9e5ebedf366cc0) an Ethereum transaction that proves that we decided on the procedure before the random number is generated.
|
||||
|
||||
Note that according to [this](https://electriccoin.co/blog/reinforcing-the-security-of-the-sapling-mpc/), a random beacon might not be strictly necessary. Nevertheless, we consider it best practice to do so.
|
||||
|
||||
## **Thanks and next steps**
|
||||
|
||||
We are in the process of stress-testing Zkopru, building a wallet and explorer and hope to launch on Ethereum very soon.
|
||||
|
||||
Thanks to everonye who made this ceremony possible:Barry, Chance, Geoff, Kobi, Rachel, the Iden3 team, Thore, Wanseob, Wei Jie and the Ethereum community ❤
|
||||
|
||||
## Questions?
|
||||
|
||||
Find us on [telegram](https://t.me/zkopru) and on twitter: @ZkopruNetwork.
|
||||
66
articles/zkopru-wat-y-wen-privacy-scaling-explorations.md
Normal file
@@ -0,0 +1,66 @@
|
||||
---
|
||||
authors: ["PSE Team"]
|
||||
title: "Zkopru: Wat, Y & Wen - Privacy & Scaling Explorations"
|
||||
image: null
|
||||
tldr: "Zkopru is almost ready, we explain what it is and why it’s awesome. We also announce a date for the testnet."
|
||||
date: "2022-08-26"
|
||||
canonical: "https://mirror.xyz/privacy-scaling-explorations.eth/kfuuBPtGtDjl_J2wBq-jrtyURGLmQpUhZfDTuZChEy8"
|
||||
---
|
||||
|
||||
Originally published on Aug 10, 2021:
|
||||
|
||||
## Intro
|
||||
|
||||
The Privacy and Scaling Explorations Team works to bridge the gap between cutting-edge research in Zero-Knowledge Proofs (ZKP), and application development on Ethereum.
|
||||
|
||||
One of our recent focus areas has been [zkopru](https://zkopru.network/) (zero knowledge optimistic rollup), a new protocol for gas-efficient private transactions. We completed a [trusted setup](https://medium.com/privacy-scaling-explorations/zkopru-trusted-setup-completed-92e614ba44ef) in April and since then have been heads down working on bringing it to completion. We are in the final stages of completing the web wallet and stress testing the system. A second audit is also on its way. With this post we want to give a high level overview of Zkopru’s features and what will be happening in the upcoming weeks as Zkopru moves to public testnet and mainnet.
|
||||
|
||||
This post assumes that you are generally familiar with Ethereum, layer 2, and the basics of zero knowledge proofs.
|
||||
|
||||

|
||||
|
||||
Zkopru stands for zk (zero knowledge) opru (optimistic rollup). You might have heard about zero knowledge proofs, zk rollups and optimistic rollups, so what is a zk-optimistic rollup? Let’s start with the basics.
|
||||
|
||||
\*\*What is a Zero Knowledge Proof (zkp)?\*\*Zero knowledge proofs such as zkSNARK allow verifying the correctness of computations without having to execute them and without revealing their inputs. Zkps can therefore be used for scaling and privacy. Zkopru uses zkps to make transactions private. [Zcash](https://z.cash/), [AZTEK network](https://aztec.network/) and [tornado.cash](https://tornado.cash/) are other examples where zkps are used for privacy on blockchains.
|
||||
|
||||
\*\*What’s an optimistic rollup?\*\*Optimistic rollups sit in parallel to the main Ethereum chain on layer 2. They can offer improvements in scalability because they don’t do any computation on-chain by default. Instead, after a transaction, they propose only a stateroot to mainnet and transaction data is stored as calldata, which doesn’t grow the state and therefore has reduced gas cost. As modifying the state is the slow, expensive part of using Ethereum, optimistic rollups can offer up to 10–100x improvements in scalability depending on the transaction. See [here](https://ethereum.org/en/developers/docs/scaling/layer-2-rollups/) for more information on optimistic rollups. Instead of miners, rollups have coordinators that receive transactions, calculate the new state and submit data to Ethereum.
|
||||
|
||||
\*\*What is Zk + opru\*\*Zkopru is an optimistic UTXO based rollup. There is also another type of rollup called zk-rollup, which uses zero-knowledge proofs to verify the correct computation of the next state when new transactions are applied — but Zkopru is _not_ a zk-rollup. Whereas zk-rollups use the “zk” part to create a validity proof for the rollup state transition, Zkopru uses it to make individual transfers private.
|
||||
|
||||
This concept has significant advantages in terms of gas consumption. For zk-transactions directly on the main Ethereum chain, it would be necessary to use a SNARK-friendly hash function to construct a Merkle tree, which is very expensive. Using an optimistic rollup, we can update the SNARK friendly Merkle tree at a low cost off chain. As a result, this protocol consumes about 8,800 gas per private transfer (a normal ETH transfer on Ethereum costs 21,000 Gas) 🎊.
|
||||
|
||||
## Y? Features of Zkopru
|
||||
|
||||

|
||||
|
||||
Next, let’s look at the most important user facing functionalities of Zkopru. Users will interact with the system via a web wallet to carry out deposits, withdrawals, transfers and swaps on L2. We’ll give an overview of the UX for each of these functions below; for more detailed technical information check out our [documentation](https://docs.zkopru.network/) and [github](https://github.com/wanseob/zkopru) .
|
||||
|
||||
**Deposit:** The user is able to deposit Ether, ERC-20 or NFTs to the Zkopru contracts on L1 (Ethereum) through the Zkopru user interface. After depositing the user will be able to view and transfer their assets on L2, represented behind the scenes as UTXOs. .
|
||||
|
||||
**Transfer:** After deposit the assets are still linked to the user’s account but the private transfer feature can be used to break the link. For a transfer, the sender needs the Zkopru address of the recipient. This is not an Ethereum address, but a user can use their Ethereum private key to generate a corresponding address in the Zkopru wallet. The wallet generates a zkp that proves the integrity of the system after the transfer without revealing any details and sends the transaction to the Zkopru coordinator. After the coordinator has included the transaction (for a fee) the funds are considered private.
|
||||
|
||||
**Withdraw:** A user that wants to move their assets back from L2 (Zkopru) to L1 (Ethereum) can use the withdraw function of the wallet. Transaction details will need to be revealed for this action, so the address and amount withdrawn are not private anymore. Like other optimistic rollups, Zkopru requires the user to wait for 7 days for withdrawals to be finalized. Anyone who doesn’t want to wait that long can use the instant withdrawal mechanism.
|
||||
|
||||
\*\*Instant withdraw:\*\*If a user wants to make an instant withdrawal, they can make a request to another user to advance the funds in exchange for a fee. The user who advances the funds keeps the fee but takes on any risk of the transaction being invalidated by a fraud proof.
|
||||
|
||||
\*\*Atomic Swap:\*\*Zkopru supports atomic swaps. Two users can ask the coordinator to facilitate the exchange of their two assets, and if the coordinator doesn’t do so they will be slashed. This service will have its own site. At the moment it is difficult to find matching orders efficiently and privately. We’re working on a solution that allows for private order matching.
|
||||
|
||||
\*\*Cost:\*\*Users can deposit and withdraw ETH, ERC20 and NFTs. It’s also possible to combine deposits of NFTs and ERC20s with ETH in the same transaction. The USD values below are the costs incurred on Ethereum assuming a gas price of 25 gwei and an ETH price of USD $2,500.
|
||||
|
||||
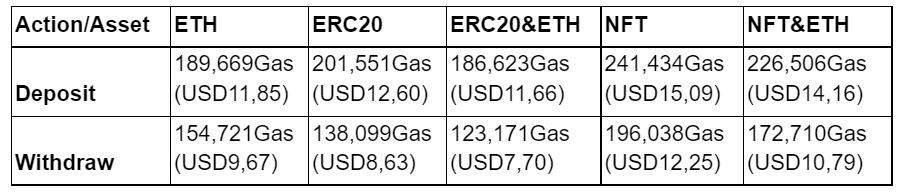
|
||||
|
||||
For private transfers within the rollup, the coordinator will charge fees according to their cost incurred on L1 (Ethereum). Transactions become cheaper in bulk and depend on the number of UTXOs used:
|
||||
|
||||
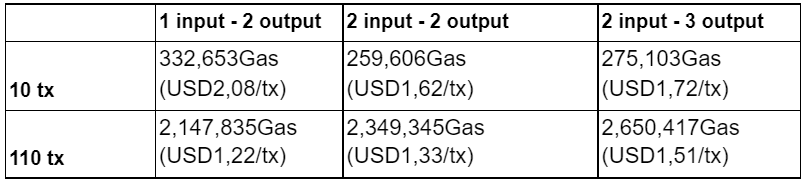
|
||||
|
||||
On top of the costs listed in the table above, the coordinator has to pay a finalization cost of 171,954 Gas, (currently around USD10,75) per batch.
|
||||
|
||||
## Wen can we use Zkopru?
|
||||
|
||||

|
||||
|
||||
In about 2 weeks the Zkopru contracts will be deployed on testnet, the wallet UI will be released and we’ll publish more documentation explaining how to interact with the system. If there are no major issues on testnet for another ~2 weeks we will announce the release of the mainnet contracts. A second audit is also expected to be concluded by that time.
|
||||
|
||||
## Conclusion
|
||||
|
||||
After years of hard work we are stoked that Zkopru will soon be in production providing cheap, private transactions on Ethereum. If you want to use Zkopru on testnet, stay tuned for our next blog post. You can learn more about Zkopru on [github](https://github.com/wanseob/zkopru), our [website](https://zkopru.network/) and [blog](https://medium.com/privacy-scaling-explorations).
|
||||
82
components/blog/blog-article-card.tsx
Normal file
@@ -0,0 +1,82 @@
|
||||
import { Article } from "@/lib/blog"
|
||||
import { cn } from "@/lib/utils"
|
||||
import { cva } from "class-variance-authority"
|
||||
import Image from "next/image"
|
||||
|
||||
export const blogArticleCardTagCardVariants = cva(
|
||||
"text-xs font-sans text-tuatara-950 rounded-[3px] py-[2px] px-[6px] w-fit shrink-[0]",
|
||||
{
|
||||
variants: {
|
||||
variant: {
|
||||
primary: "bg-[#D8FEA8]",
|
||||
secondary: "bg-[#C2E8F5]",
|
||||
},
|
||||
},
|
||||
}
|
||||
)
|
||||
|
||||
export const BlogArticleCard = ({
|
||||
id,
|
||||
image,
|
||||
title,
|
||||
date,
|
||||
authors,
|
||||
}: Article) => {
|
||||
const imageUrl = `/articles/${id}/${image}`
|
||||
return (
|
||||
<div className="flex flex-col h-full">
|
||||
<div className="relative h-48 w-full overflow-hidden bg-gray-100">
|
||||
{!!image && (
|
||||
<Image
|
||||
src={imageUrl}
|
||||
alt={title}
|
||||
fill
|
||||
className="object-cover"
|
||||
quality={90}
|
||||
/>
|
||||
)}
|
||||
</div>
|
||||
|
||||
<div className="p-5 flex flex-col gap-5 lg:gap-8 min-h-[180px]">
|
||||
<div className="flex flex-col gap-2">
|
||||
<div className="flex items-center gap-1">
|
||||
<Image
|
||||
src="/logos/pse-logo-bg.svg"
|
||||
alt="Privacy and Scaling Explorations"
|
||||
width={24}
|
||||
height={24}
|
||||
/>
|
||||
<span className="text-black/50 font-medium text-sm">
|
||||
Privacy and Scaling Explorations
|
||||
</span>
|
||||
</div>
|
||||
<h2 className="text-2xl font-bold leading-7 text-black duration-200 cursor-pointer hover:text-anakiwa-500">
|
||||
{title}
|
||||
</h2>
|
||||
</div>
|
||||
|
||||
<div className="flex justify-between mt-auto gap-4 items-center">
|
||||
{authors && authors.length > 0 && (
|
||||
<p className="text-gray-500 text-sm mt-auto">
|
||||
By {authors.join(", ")}
|
||||
</p>
|
||||
)}
|
||||
{date && (
|
||||
<div
|
||||
className={cn(
|
||||
"ml-auto",
|
||||
blogArticleCardTagCardVariants({ variant: "secondary" })
|
||||
)}
|
||||
>
|
||||
{new Date(date).toLocaleDateString("en-US", {
|
||||
month: "long",
|
||||
day: "numeric",
|
||||
year: "numeric",
|
||||
})}
|
||||
</div>
|
||||
)}
|
||||
</div>
|
||||
</div>
|
||||
</div>
|
||||
)
|
||||
}
|
||||
34
components/blog/blog-articles.tsx
Normal file
@@ -0,0 +1,34 @@
|
||||
import { Article, getArticles } from "@/lib/blog"
|
||||
import Link from "next/link"
|
||||
import { BlogArticleCard } from "./blog-article-card"
|
||||
|
||||
export const BlogArticles = () => {
|
||||
const articles = getArticles()
|
||||
|
||||
return (
|
||||
<div className="grid grid-cols-1 lg:grid-cols-3 gap-8">
|
||||
{articles.map(
|
||||
({ id, title, image, tldr = "", date, authors, content }: Article) => {
|
||||
const url = `/blog/${id}`
|
||||
return (
|
||||
<Link
|
||||
className="flex-1 w-full h-full group hover:opacity-90 transition-opacity duration-300 rounded-xl overflow-hidden bg-white shadow-sm border border-slate-900/10"
|
||||
key={id}
|
||||
href={url}
|
||||
rel="noreferrer"
|
||||
>
|
||||
<BlogArticleCard
|
||||
id={id}
|
||||
image={image}
|
||||
title={title}
|
||||
date={date}
|
||||
authors={authors}
|
||||
content={content}
|
||||
/>
|
||||
</Link>
|
||||
)
|
||||
}
|
||||
)}
|
||||
</div>
|
||||
)
|
||||
}
|
||||
102
components/blog/blog-content.tsx
Normal file
@@ -0,0 +1,102 @@
|
||||
import Blog, { Article, getArticles } from "@/lib/blog"
|
||||
import Link from "next/link"
|
||||
import { AppContent } from "../ui/app-content"
|
||||
import { Markdown } from "../ui/markdown"
|
||||
import { BlogArticleCard } from "./blog-article-card"
|
||||
interface BlogContentProps {
|
||||
post: Article
|
||||
}
|
||||
|
||||
interface BlogImageProps {
|
||||
image: string
|
||||
alt?: string
|
||||
description?: string
|
||||
}
|
||||
|
||||
export function BlogImage({ image, alt, description }: BlogImageProps) {
|
||||
return (
|
||||
<div className="flex flex-col">
|
||||
<img src={image} alt={alt} className="mb-1" />
|
||||
{alt && (
|
||||
<span className="font-semibold text-black text-center capitalize text-sm">
|
||||
{alt}
|
||||
</span>
|
||||
)}
|
||||
{description && (
|
||||
<span className="font-normal text-gray-600 dark:text-gray-200 text-center text-sm mt-2">
|
||||
{description}
|
||||
</span>
|
||||
)}
|
||||
</div>
|
||||
)
|
||||
}
|
||||
|
||||
export function BlogContent({ post }: BlogContentProps) {
|
||||
const articles = getArticles() ?? []
|
||||
const articleIndex = articles.findIndex((article) => article.id === post.id)
|
||||
|
||||
const prevArticle = articleIndex > 0 ? articles[articleIndex - 1] : null
|
||||
|
||||
const nextArticle =
|
||||
articleIndex < articles.length - 1 ? articles[articleIndex + 1] : null
|
||||
|
||||
const moreArticles = [prevArticle, nextArticle].filter(Boolean) as Article[]
|
||||
|
||||
return (
|
||||
<AppContent className="max-w-[978px]">
|
||||
<div className="flex flex-col gap-10">
|
||||
<div className="flex flex-col gap-6">
|
||||
<Markdown>{post?.content ?? ""}</Markdown>
|
||||
</div>
|
||||
|
||||
{moreArticles?.length > 0 && (
|
||||
<div className="flex flex-col gap-8">
|
||||
<div className="flex items-center justify-between">
|
||||
<span className="text-tuatara-950 text-lg font-semibold leading-6">
|
||||
More articles
|
||||
</span>
|
||||
<Link
|
||||
href="/blog"
|
||||
className="text-black font-bold text-base leading-6 hover:underline hover:text-anakiwa-500"
|
||||
>
|
||||
View all
|
||||
</Link>
|
||||
</div>
|
||||
<div className="grid grid-cols-1 gap-8 md:grid-cols-2">
|
||||
{moreArticles.map(
|
||||
({
|
||||
id,
|
||||
title,
|
||||
image,
|
||||
tldr = "",
|
||||
date,
|
||||
content,
|
||||
authors,
|
||||
}: Article) => {
|
||||
const url = `/blog/${id}`
|
||||
return (
|
||||
<Link
|
||||
href={url}
|
||||
key={id}
|
||||
className="flex-1 w-full h-full group hover:opacity-90 transition-opacity duration-300 rounded-xl overflow-hidden bg-white shadow-sm border border-slate-900/10"
|
||||
>
|
||||
<BlogArticleCard
|
||||
id={id}
|
||||
image={image}
|
||||
title={title}
|
||||
date={date}
|
||||
content={content}
|
||||
authors={authors}
|
||||
tldr={tldr}
|
||||
/>
|
||||
</Link>
|
||||
)
|
||||
}
|
||||
)}
|
||||
</div>
|
||||
</div>
|
||||
)}
|
||||
</div>
|
||||
</AppContent>
|
||||
)
|
||||
}
|
||||
84
components/blog/blog-recent-articles.tsx
Normal file
@@ -0,0 +1,84 @@
|
||||
import { useTranslation } from "@/app/i18n"
|
||||
import { AppContent } from "../ui/app-content"
|
||||
import { getArticles } from "@/lib/blog"
|
||||
import Image from "next/image"
|
||||
import Link from "next/link"
|
||||
import { cn } from "@/lib/utils"
|
||||
import { Button } from "../ui/button"
|
||||
import { Icons } from "../icons"
|
||||
|
||||
export async function BlogRecentArticles({ lang }: { lang: any }) {
|
||||
const articles = getArticles(5)
|
||||
const { t } = await useTranslation(lang, "blog-page")
|
||||
|
||||
const lastArticle = articles[0]
|
||||
const otherArticles = articles.slice(1)
|
||||
|
||||
const imageUrl = `/articles/${lastArticle.id}/${lastArticle.image}`
|
||||
|
||||
return (
|
||||
<div className="py-10 lg:py-16">
|
||||
<AppContent>
|
||||
<div className="flex flex-col gap-10">
|
||||
<h3 className="text-base font-bold font-sans text-center uppercase tracking-[3.36px]">
|
||||
{t("recentArticles")}
|
||||
</h3>
|
||||
|
||||
<div className="grid grid-cols-1 lg:grid-cols-3 gap-10">
|
||||
<div className="flex flex-col gap-5 lg:col-span-2">
|
||||
<Image
|
||||
src={imageUrl}
|
||||
alt={lastArticle.title}
|
||||
width={1000}
|
||||
height={1000}
|
||||
className="w-full"
|
||||
/>
|
||||
<Link
|
||||
href={`/blog/${lastArticle.id}`}
|
||||
className="group duration-200 flex flex-col gap-[10px] text-left"
|
||||
>
|
||||
<h4 className="text-3xl font-bold font-display group-hover:text-anakiwa-500 transition-colors">
|
||||
{lastArticle.title}
|
||||
</h4>
|
||||
<span className="text-sm font-sans text-tuatara-400 uppercase">
|
||||
{lastArticle.authors?.join(", ")}
|
||||
</span>
|
||||
{lastArticle.tldr && (
|
||||
<span className="text-base font-sans text-tuatara-950 font-normal">
|
||||
{lastArticle.tldr}
|
||||
</span>
|
||||
)}
|
||||
</Link>
|
||||
</div>
|
||||
<div className="flex flex-col gap-6 lg:col-span-1">
|
||||
{otherArticles.map((article, index) => (
|
||||
<Link
|
||||
key={article.id}
|
||||
href={`/blog/${article.id}`}
|
||||
className={cn("group border-b pb-4")}
|
||||
>
|
||||
<h4 className="text-xl font-medium text-tuatara-950 duration-200 group-hover:text-anakiwa-500 transition-colors">
|
||||
{article.title}
|
||||
</h4>
|
||||
{article.authors && (
|
||||
<span className="text-sm font-sans text-tuatara-400 uppercase">
|
||||
{article.authors?.join(", ")}
|
||||
</span>
|
||||
)}
|
||||
</Link>
|
||||
))}
|
||||
<Link href="/blog">
|
||||
<Button className="uppercase">
|
||||
<div className="flex items-center gap-2">
|
||||
<span>{t("seeMore")}</span>
|
||||
<Icons.arrowRight className="w-4 h-4" />
|
||||
</div>
|
||||
</Button>
|
||||
</Link>
|
||||
</div>
|
||||
</div>
|
||||
</div>
|
||||
</AppContent>
|
||||
</div>
|
||||
)
|
||||
}
|
||||
35
components/sections/HomepageBanner.tsx
Normal file
@@ -0,0 +1,35 @@
|
||||
"use client"
|
||||
|
||||
import { Banner } from "../banner"
|
||||
import { useTranslation } from "@/app/i18n/client"
|
||||
import { Icons } from "../icons"
|
||||
import { siteConfig } from "@/config/site"
|
||||
import Link from "next/link"
|
||||
import { Button } from "../ui/button"
|
||||
|
||||
export const HomepageBanner = ({ lang }: { lang: any }) => {
|
||||
const { t } = useTranslation(lang, "homepage")
|
||||
const { t: common } = useTranslation(lang, "common")
|
||||
|
||||
return (
|
||||
<Banner
|
||||
title={common("connectWithUs")}
|
||||
subtitle={common("connectWithUsDescription")}
|
||||
>
|
||||
<Link
|
||||
href={siteConfig.links.discord}
|
||||
target="_blank"
|
||||
rel="noreferrer"
|
||||
passHref
|
||||
>
|
||||
<Button>
|
||||
<div className="flex items-center gap-2">
|
||||
<Icons.discord fill="white" className="h-4" />
|
||||
<span className="text-[14px] uppercase">{t("joinOurDiscord")}</span>
|
||||
<Icons.externalUrl fill="white" className="h-5" />
|
||||
</div>
|
||||
</Button>
|
||||
</Link>
|
||||
</Banner>
|
||||
)
|
||||
}
|
||||
66
components/sections/HomepageHeader.tsx
Normal file
@@ -0,0 +1,66 @@
|
||||
"use client"
|
||||
|
||||
import { useTranslation } from "@/app/i18n/client"
|
||||
import { Icons } from "../icons"
|
||||
import { PageHeader } from "../page-header"
|
||||
import { Button } from "../ui/button"
|
||||
import { Label } from "../ui/label"
|
||||
import Image from "next/image"
|
||||
import PSELogo from "@/public/icons/archstar.webp"
|
||||
import { motion } from "framer-motion"
|
||||
import Link from "next/link"
|
||||
|
||||
export const HomepageHeader = ({ lang }: { lang: any }) => {
|
||||
const { t } = useTranslation(lang, "homepage")
|
||||
const { t: common } = useTranslation(lang, "common")
|
||||
|
||||
return (
|
||||
<PageHeader
|
||||
title={
|
||||
<motion.h1
|
||||
initial={{ y: 16, opacity: 0 }}
|
||||
animate={{ y: 0, opacity: 1 }}
|
||||
transition={{ duration: 0.8, cubicBezier: "easeOut" }}
|
||||
>
|
||||
<Label.PageTitle label={t("headerTitle")} />
|
||||
</motion.h1>
|
||||
}
|
||||
subtitle={t("headerSubtitle")}
|
||||
image={
|
||||
<div className="m-auto flex h-[320px] w-full max-w-[280px] items-center justify-center md:m-0 md:h-full md:w-full lg:max-w-[380px]">
|
||||
<Image src={PSELogo} alt="pselogo" style={{ objectFit: "cover" }} />
|
||||
</div>
|
||||
}
|
||||
actions={
|
||||
<div className="flex flex-col lg:flex-row gap-10">
|
||||
<Link href={"/research"} className="flex items-center gap-2 group">
|
||||
<Button className="w-full sm:w-auto">
|
||||
<div className="flex items-center gap-1">
|
||||
<span className="text-base font-medium uppercase">
|
||||
{common("research")}
|
||||
</span>
|
||||
<Icons.arrowRight
|
||||
fill="white"
|
||||
className="h-5 duration-200 ease-in-out group-hover:translate-x-2"
|
||||
/>
|
||||
</div>
|
||||
</Button>
|
||||
</Link>
|
||||
<Link href={"/projects"} className="flex items-center gap-2 group">
|
||||
<Button className="w-full sm:w-auto">
|
||||
<div className="flex items-center gap-1">
|
||||
<span className="text-base font-medium uppercase">
|
||||
{common("developmentProjects")}
|
||||
</span>
|
||||
<Icons.arrowRight
|
||||
fill="white"
|
||||
className="h-5 duration-200 ease-in-out group-hover:translate-x-2"
|
||||
/>
|
||||
</div>
|
||||
</Button>
|
||||
</Link>
|
||||
</div>
|
||||
}
|
||||
/>
|
||||
)
|
||||
}
|
||||
@@ -1,4 +1,5 @@
|
||||
import React from "react"
|
||||
"use client"
|
||||
|
||||
import { useEffect, useState } from "react"
|
||||
import Link from "next/link"
|
||||
|
||||
|
||||
@@ -1,6 +1,11 @@
|
||||
"use client"
|
||||
|
||||
import React from "react"
|
||||
import ReactMarkdown, { Components } from "react-markdown"
|
||||
import remarkGfm from "remark-gfm"
|
||||
import remarkMath from "remark-math"
|
||||
import rehypeKatex from "rehype-katex"
|
||||
import "katex/dist/katex.min.css"
|
||||
|
||||
const generateSectionId = (text: string) => {
|
||||
return text.toLowerCase().replace(/[^a-z0-9]+/g, "-")
|
||||
@@ -24,12 +29,84 @@ export const createMarkdownElement = (
|
||||
|
||||
const Table = (props: any) => {
|
||||
return (
|
||||
<div className="border rounded-lg border-tuatara-300">
|
||||
<table data-component="table">{props.children}</table>
|
||||
<div className="w-full overflow-x-auto border rounded-lg border-tuatara-300">
|
||||
<table className="min-w-full" data-component="table">
|
||||
{props.children}
|
||||
</table>
|
||||
</div>
|
||||
)
|
||||
}
|
||||
|
||||
const TableRow = (props: any) => {
|
||||
return <tr data-component="table-row">{props.children}</tr>
|
||||
}
|
||||
|
||||
const TableHead = (props: any) => {
|
||||
const isEmpty = React.Children.toArray(props.children).every((child: any) => {
|
||||
if (!child.props || !child.props.children) return true
|
||||
|
||||
if (child.props.children) {
|
||||
const thChildren = React.Children.toArray(child.props.children)
|
||||
return thChildren.every(
|
||||
(thChild: any) =>
|
||||
!thChild.props ||
|
||||
!thChild.props.children ||
|
||||
thChild.props.children.length === 0
|
||||
)
|
||||
}
|
||||
return true
|
||||
})
|
||||
|
||||
if (isEmpty) {
|
||||
return null
|
||||
}
|
||||
|
||||
return <thead>{props.children}</thead>
|
||||
}
|
||||
|
||||
// Custom plugin to handle /n as newline
|
||||
const remarkCustomNewlines = () => {
|
||||
return (tree: any) => {
|
||||
const visit = (node: any) => {
|
||||
if (node.type === "text" && typeof node.value === "string") {
|
||||
if (node.value.includes("/n")) {
|
||||
const parts = node.value.split("/n")
|
||||
const newChildren: any[] = []
|
||||
|
||||
parts.forEach((part: string, index: number) => {
|
||||
newChildren.push({ type: "text", value: part })
|
||||
|
||||
if (index < parts.length - 1) {
|
||||
newChildren.push({ type: "break" })
|
||||
}
|
||||
})
|
||||
|
||||
return newChildren
|
||||
}
|
||||
}
|
||||
|
||||
if (node.children) {
|
||||
const newChildren: any[] = []
|
||||
for (const child of node.children) {
|
||||
const result = visit(child)
|
||||
if (Array.isArray(result)) {
|
||||
newChildren.push(...result)
|
||||
} else if (result) {
|
||||
newChildren.push(result)
|
||||
} else {
|
||||
newChildren.push(child)
|
||||
}
|
||||
}
|
||||
node.children = newChildren
|
||||
}
|
||||
|
||||
return node
|
||||
}
|
||||
|
||||
return visit(tree)
|
||||
}
|
||||
}
|
||||
|
||||
// Styling for HTML attributes for markdown component
|
||||
const REACT_MARKDOWN_CONFIG: Components = {
|
||||
a: ({ ...props }) =>
|
||||
@@ -86,6 +163,32 @@ const REACT_MARKDOWN_CONFIG: Components = {
|
||||
...props,
|
||||
}),
|
||||
table: Table,
|
||||
tr: TableRow,
|
||||
thead: TableHead,
|
||||
td: (props) => {
|
||||
const { node, ...rest } = props
|
||||
return <td className="p-4 text-left" {...rest} />
|
||||
},
|
||||
th: (props) => {
|
||||
const { node, ...rest } = props
|
||||
if (
|
||||
!props.children ||
|
||||
(Array.isArray(props.children) && props.children.length === 0)
|
||||
) {
|
||||
return null
|
||||
}
|
||||
return <th className="p-4 text-left font-medium" {...rest} />
|
||||
},
|
||||
pre: ({ ...props }) =>
|
||||
createMarkdownElement("pre", {
|
||||
className: "bg-tuatara-950 p-4 rounded-lg text-white",
|
||||
...props,
|
||||
}),
|
||||
img: ({ ...props }) =>
|
||||
createMarkdownElement("img", {
|
||||
className: "w-auto w-auto mx-auto rounded-lg object-cover",
|
||||
...props,
|
||||
}),
|
||||
}
|
||||
|
||||
interface MarkdownProps {
|
||||
@@ -101,7 +204,8 @@ export const Markdown = ({ children, components }: MarkdownProps) => {
|
||||
...REACT_MARKDOWN_CONFIG,
|
||||
...components,
|
||||
}}
|
||||
remarkPlugins={[remarkGfm]}
|
||||
remarkPlugins={[remarkGfm, remarkMath, remarkCustomNewlines]}
|
||||
rehypePlugins={[rehypeKatex as any]}
|
||||
>
|
||||
{children}
|
||||
</ReactMarkdown>
|
||||
|
||||
@@ -44,8 +44,7 @@ export function useAppSettings(lang: LocaleTypes) {
|
||||
},
|
||||
{
|
||||
title: t("menu.blog"),
|
||||
href: "https://mirror.xyz/privacy-scaling-explorations.eth",
|
||||
external: true,
|
||||
href: "/blog",
|
||||
onlyHeader: true,
|
||||
},
|
||||
]
|
||||
|
||||
95
lib/blog.ts
Normal file
@@ -0,0 +1,95 @@
|
||||
import fs from "fs"
|
||||
import path from "path"
|
||||
import matter from "gray-matter"
|
||||
import jsYaml from "js-yaml"
|
||||
|
||||
export interface Article {
|
||||
id: string
|
||||
title: string
|
||||
image?: string
|
||||
tldr?: string
|
||||
content: string
|
||||
date: string
|
||||
authors?: string[]
|
||||
signature?: string
|
||||
publicKey?: string
|
||||
hash?: string
|
||||
canonical?: string
|
||||
}
|
||||
|
||||
const articlesDirectory = path.join(process.cwd(), "articles")
|
||||
|
||||
// Get all articles from /articles
|
||||
export function getArticles(limit: number = 1000) {
|
||||
// Get file names under /articles
|
||||
const fileNames = fs.readdirSync(articlesDirectory)
|
||||
const allArticlesData = fileNames.map((fileName: string) => {
|
||||
const id = fileName.replace(/\.md$/, "")
|
||||
if (id.toLowerCase() === "readme") {
|
||||
return null
|
||||
}
|
||||
|
||||
// Read markdown file as string
|
||||
const fullPath = path.join(articlesDirectory, fileName)
|
||||
const fileContents = fs.readFileSync(fullPath, "utf8")
|
||||
|
||||
try {
|
||||
// Use matter with options to handle multiline strings
|
||||
const matterResult = matter(fileContents, {
|
||||
engines: {
|
||||
yaml: {
|
||||
// Ensure multiline strings are parsed correctly
|
||||
parse: (str: string) => {
|
||||
try {
|
||||
// Use js-yaml's safe load to parse the YAML with type assertion
|
||||
return jsYaml.load(str) as object
|
||||
} catch (e) {
|
||||
console.error(`Error parsing frontmatter in ${fileName}:`, e)
|
||||
// Fallback to empty object if parsing fails
|
||||
return {}
|
||||
}
|
||||
},
|
||||
},
|
||||
},
|
||||
})
|
||||
|
||||
return {
|
||||
id,
|
||||
...matterResult.data,
|
||||
content: matterResult.content,
|
||||
}
|
||||
} catch (error) {
|
||||
console.error(`Error processing ${fileName}:`, error)
|
||||
// Return minimal article data if there's an error
|
||||
return {
|
||||
id,
|
||||
title: `Error processing ${id}`,
|
||||
content: "This article could not be processed due to an error.",
|
||||
date: new Date().toISOString().split("T")[0],
|
||||
}
|
||||
}
|
||||
})
|
||||
|
||||
// Sort posts by date
|
||||
return allArticlesData
|
||||
.filter(Boolean)
|
||||
.sort((a: any, b: any) => {
|
||||
const dateA = new Date(a.date)
|
||||
const dateB = new Date(b.date)
|
||||
|
||||
// Sort in descending order (newest first)
|
||||
return dateB.getTime() - dateA.getTime()
|
||||
})
|
||||
.slice(0, limit)
|
||||
.filter((article: any) => article.id !== "_article-template") as Article[]
|
||||
}
|
||||
|
||||
export function getArticleById(slug?: string) {
|
||||
const articles = getArticles()
|
||||
|
||||
return articles.find((article) => article.id === slug)
|
||||
}
|
||||
|
||||
const lib = { getArticles, getArticleById }
|
||||
|
||||
export default lib
|
||||
@@ -25,7 +25,7 @@ const nextConfig = {
|
||||
pageExtensions: ["js", "jsx", "mdx", "ts", "tsx", "md"],
|
||||
reactStrictMode: true,
|
||||
experimental: {
|
||||
appDir: true,
|
||||
|
||||
mdxRs: true,
|
||||
},
|
||||
}
|
||||
|
||||
9177
package-lock.json
generated
Normal file
@@ -33,6 +33,7 @@
|
||||
"dotenv": "^16.4.4",
|
||||
"framer-motion": "^10.12.17",
|
||||
"fuse.js": "^6.6.2",
|
||||
"gray-matter": "^4.0.3",
|
||||
"gsap": "^3.12.1",
|
||||
"html-to-react": "^1.7.0",
|
||||
"i18next": "^23.7.16",
|
||||
@@ -48,7 +49,9 @@
|
||||
"react-markdown": "^8.0.7",
|
||||
"react-slick": "^0.30.3",
|
||||
"react-use": "^17.4.0",
|
||||
"rehype-katex": "^7.0.1",
|
||||
"remark-gfm": "^3.0.1",
|
||||
"remark-math": "^6.0.0",
|
||||
"sharp": "^0.33.2",
|
||||
"slick-carousel": "^1.8.1",
|
||||
"tailwind-merge": "^1.12.0",
|
||||
@@ -59,6 +62,7 @@
|
||||
"@eslint/js": "^9.19.0",
|
||||
"@ianvs/prettier-plugin-sort-imports": "^3.7.2",
|
||||
"@next/eslint-plugin-next": "^15.2.2",
|
||||
"@types/js-yaml": "^4.0.9",
|
||||
"@types/node": "^17.0.45",
|
||||
"@types/react": "^18.2.7",
|
||||
"@types/react-dom": "^18.2.4",
|
||||
|
||||
{kind=link}
|
After Width: | Height: | Size: 53 KiB |
{kind=link}
|
After Width: | Height: | Size: 66 KiB |
{kind=link}
|
After Width: | Height: | Size: 62 KiB |
{kind=link}
|
After Width: | Height: | Size: 27 KiB |
BIN
public/articles/announcing-anon-aadhaar/cover.webp
Normal file
{kind=link}
|
After Width: | Height: | Size: 26 KiB |
BIN
public/articles/announcing-maci-v111/9GxuqUkAqCpsIiIRaFe7x.webp
Normal file
{kind=link}
|
After Width: | Height: | Size: 121 KiB |
BIN
public/articles/announcing-maci-v111/Gfn-Vu6lKKsJ750LQIXxA.webp
Normal file
{kind=link}
|
After Width: | Height: | Size: 44 KiB |
{kind=link}
|
After Width: | Height: | Size: 10 KiB |
{kind=link}
|
After Width: | Height: | Size: 13 KiB |
{kind=link}
|
After Width: | Height: | Size: 16 KiB |
{kind=link}
|
After Width: | Height: | Size: 472 KiB |
{kind=link}
|
After Width: | Height: | Size: 22 KiB |
BIN
public/articles/bandada-is-live/YLKtfrsyR1gTNXMjHh8ec.webp
Normal file
{kind=link}
|
After Width: | Height: | Size: 17 KiB |
BIN
public/articles/bandada-is-live/cover.webp
Normal file
{kind=link}
|
After Width: | Height: | Size: 43 KiB |
{kind=link}
|
After Width: | Height: | Size: 61 KiB |
{kind=link}
|
After Width: | Height: | Size: 43 KiB |
{kind=link}
|
After Width: | Height: | Size: 45 KiB |
{kind=link}
|
After Width: | Height: | Size: 395 KiB |
{kind=link}
|
After Width: | Height: | Size: 56 KiB |
{kind=link}
|
After Width: | Height: | Size: 80 KiB |
{kind=link}
|
After Width: | Height: | Size: 49 KiB |
{kind=link}
|
After Width: | Height: | Size: 375 KiB |
{kind=link}
|
After Width: | Height: | Size: 38 KiB |