mirror of
https://github.com/invoke-ai/InvokeAI.git
synced 2026-01-18 07:27:57 -05:00
Compare commits
33 Commits
feat/blend
...
psychedeli
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
75624e9158 | ||
|
|
a2613948d8 | ||
|
|
f8392b2f78 | ||
|
|
358116bc22 | ||
|
|
1e3590111d | ||
|
|
063b800280 | ||
|
|
3935bf92c8 | ||
|
|
066e09b517 | ||
|
|
869b4a8d49 | ||
|
|
13919ff300 | ||
|
|
634e5652ef | ||
|
|
9bdc718df5 | ||
|
|
73ca8ccdb3 | ||
|
|
f37ffda966 | ||
|
|
5a9777d443 | ||
|
|
8072c05ee0 | ||
|
|
75ff4f4ca3 | ||
|
|
30df123221 | ||
|
|
06193ddbe8 | ||
|
|
ce5122f87c | ||
|
|
43ebd68313 | ||
|
|
ec19fcafb1 | ||
|
|
6fcc7d4c4b | ||
|
|
912087e4dc | ||
|
|
593fb95213 | ||
|
|
6d821b32d3 | ||
|
|
297f96c16b | ||
|
|
0e53b27655 | ||
|
|
35ae9f6e71 | ||
|
|
a1d9e6b871 | ||
|
|
f05379f965 | ||
|
|
e34e6d6e80 | ||
|
|
86cb53342a |
@@ -296,8 +296,18 @@ code for InvokeAI. For this to work, you will need to install the
|
||||
on your system, please see the [Git Installation
|
||||
Guide](https://github.com/git-guides/install-git)
|
||||
|
||||
You will also need to install the [frontend development toolchain](https://github.com/invoke-ai/InvokeAI/blob/main/docs/contributing/contribution_guides/contributingToFrontend.md).
|
||||
|
||||
If you have a "normal" installation, you should create a totally separate virtual environment for the git-based installation, else the two may interfere.
|
||||
|
||||
> **Why do I need the frontend toolchain**?
|
||||
>
|
||||
> The InvokeAI project uses trunk-based development. That means our `main` branch is the development branch, and releases are tags on that branch. Because development is very active, we don't keep an updated build of the UI in `main` - we only build it for production releases.
|
||||
>
|
||||
> That means that between releases, to have a functioning application when running directly from the repo, you will need to run the UI in dev mode or build it regularly (any time the UI code changes).
|
||||
|
||||
1. Create a fork of the InvokeAI repository through the GitHub UI or [this link](https://github.com/invoke-ai/InvokeAI/fork)
|
||||
1. From the command line, run this command:
|
||||
2. From the command line, run this command:
|
||||
```bash
|
||||
git clone https://github.com/<your_github_username>/InvokeAI.git
|
||||
```
|
||||
@@ -305,10 +315,10 @@ Guide](https://github.com/git-guides/install-git)
|
||||
This will create a directory named `InvokeAI` and populate it with the
|
||||
full source code from your fork of the InvokeAI repository.
|
||||
|
||||
2. Activate the InvokeAI virtual environment as per step (4) of the manual
|
||||
3. Activate the InvokeAI virtual environment as per step (4) of the manual
|
||||
installation protocol (important!)
|
||||
|
||||
3. Enter the InvokeAI repository directory and run one of these
|
||||
4. Enter the InvokeAI repository directory and run one of these
|
||||
commands, based on your GPU:
|
||||
|
||||
=== "CUDA (NVidia)"
|
||||
@@ -334,11 +344,15 @@ installation protocol (important!)
|
||||
Be sure to pass `-e` (for an editable install) and don't forget the
|
||||
dot ("."). It is part of the command.
|
||||
|
||||
You can now run `invokeai` and its related commands. The code will be
|
||||
5. Install the [frontend toolchain](https://github.com/invoke-ai/InvokeAI/blob/main/docs/contributing/contribution_guides/contributingToFrontend.md) and do a production build of the UI as described.
|
||||
|
||||
6. You can now run `invokeai` and its related commands. The code will be
|
||||
read from the repository, so that you can edit the .py source files
|
||||
and watch the code's behavior change.
|
||||
|
||||
4. If you wish to contribute to the InvokeAI project, you are
|
||||
When you pull in new changes to the repo, be sure to re-build the UI.
|
||||
|
||||
7. If you wish to contribute to the InvokeAI project, you are
|
||||
encouraged to establish a GitHub account and "fork"
|
||||
https://github.com/invoke-ai/InvokeAI into your own copy of the
|
||||
repository. You can then use GitHub functions to create and submit
|
||||
|
||||
@@ -121,18 +121,6 @@ To be imported, an .obj must use triangulated meshes, so make sure to enable tha
|
||||
**Example Usage:**
|
||||
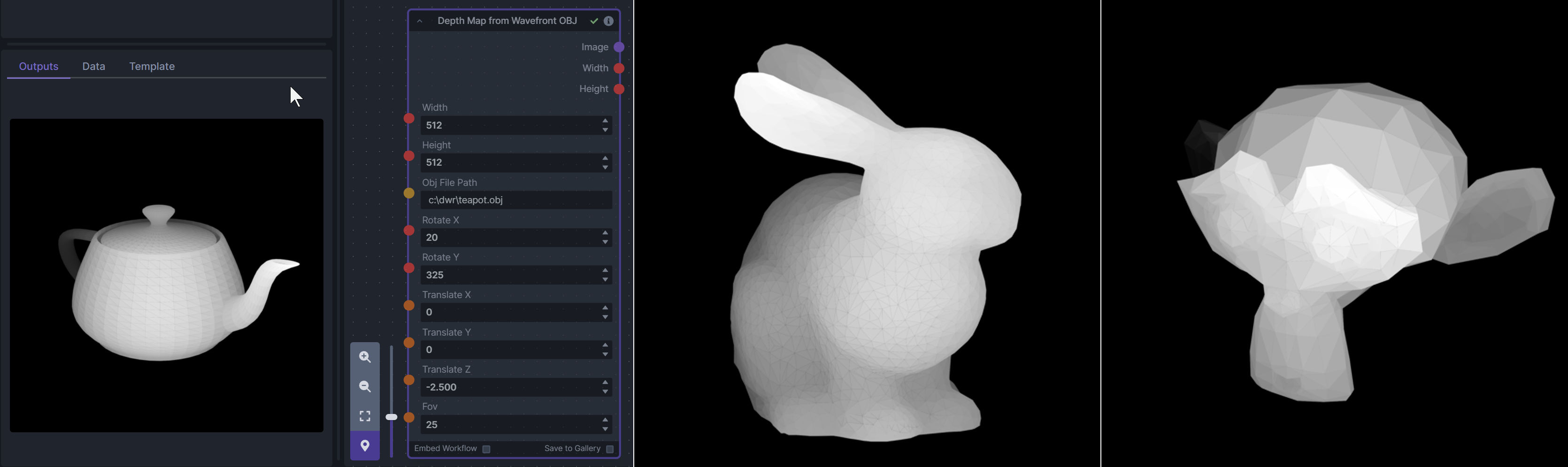
|
||||
|
||||
--------------------------------
|
||||
### Enhance Image (simple adjustments)
|
||||
|
||||
**Description:** Boost or reduce color saturation, contrast, brightness, sharpness, or invert colors of any image at any stage with this simple wrapper for pillow [PIL]'s ImageEnhance module.
|
||||
|
||||
Color inversion is toggled with a simple switch, while each of the four enhancer modes are activated by entering a value other than 1 in each corresponding input field. Values less than 1 will reduce the corresponding property, while values greater than 1 will enhance it.
|
||||
|
||||
**Node Link:** https://github.com/dwringer/image-enhance-node
|
||||
|
||||
**Example Usage:**
|
||||
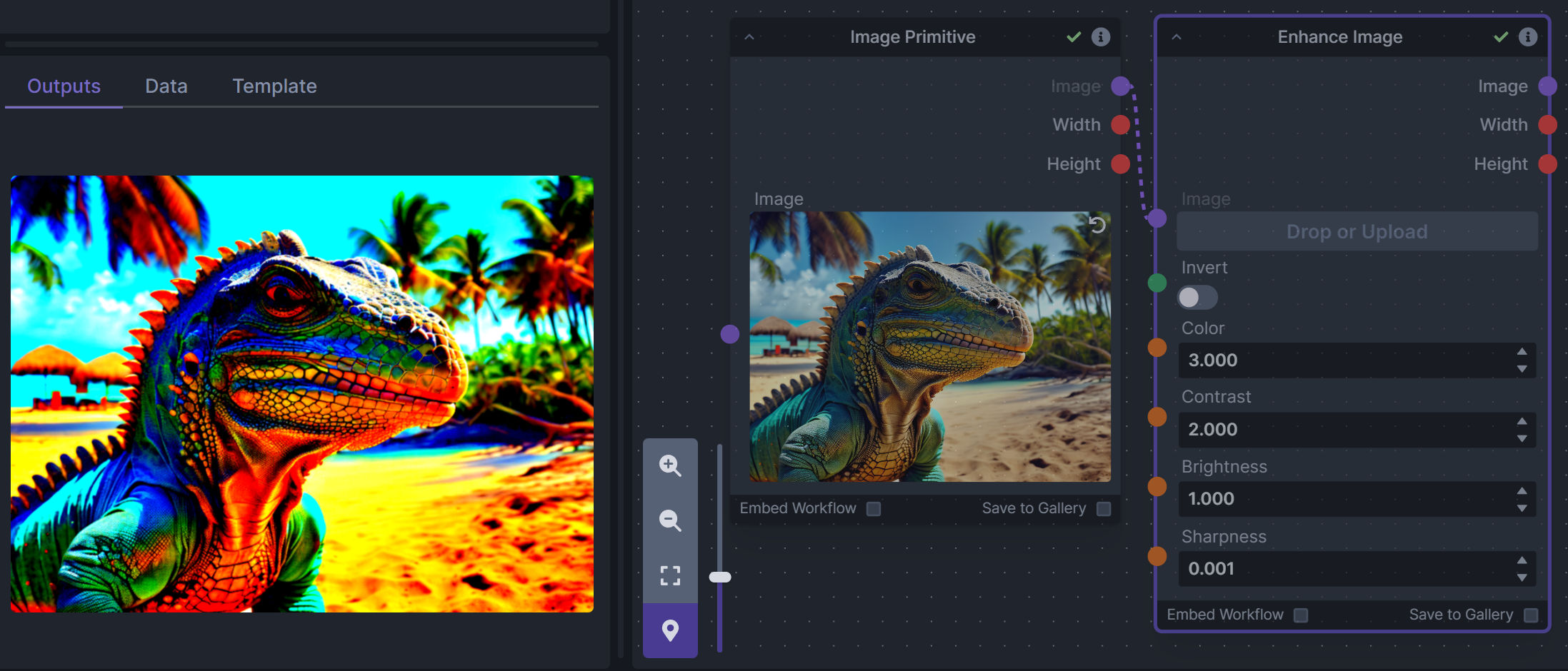
|
||||
|
||||
--------------------------------
|
||||
### Generative Grammar-Based Prompt Nodes
|
||||
|
||||
@@ -153,16 +141,26 @@ This includes 3 Nodes:
|
||||
|
||||
**Description:** This is a pack of nodes for composing masks and images, including a simple text mask creator and both image and latent offset nodes. The offsets wrap around, so these can be used in conjunction with the Seamless node to progressively generate centered on different parts of the seamless tiling.
|
||||
|
||||
This includes 4 Nodes:
|
||||
- *Text Mask (simple 2D)* - create and position a white on black (or black on white) line of text using any font locally available to Invoke.
|
||||
This includes 14 Nodes:
|
||||
- *Adjust Image Hue Plus* - Rotate the hue of an image in one of several different color spaces.
|
||||
- *Blend Latents/Noise (Masked)* - Use a mask to blend part of one latents tensor [including Noise outputs] into another. Can be used to "renoise" sections during a multi-stage [masked] denoising process.
|
||||
- *Enhance Image* - Boost or reduce color saturation, contrast, brightness, sharpness, or invert colors of any image at any stage with this simple wrapper for pillow [PIL]'s ImageEnhance module.
|
||||
- *Equivalent Achromatic Lightness* - Calculates image lightness accounting for Helmholtz-Kohlrausch effect based on a method described by High, Green, and Nussbaum (2023).
|
||||
- *Text to Mask (Clipseg)* - Input a prompt and an image to generate a mask representing areas of the image matched by the prompt.
|
||||
- *Text to Mask Advanced (Clipseg)* - Output up to four prompt masks combined with logical "and", logical "or", or as separate channels of an RGBA image.
|
||||
- *Image Layer Blend* - Perform a layered blend of two images using alpha compositing. Opacity of top layer is selectable, with optional mask and several different blend modes/color spaces.
|
||||
- *Image Compositor* - Take a subject from an image with a flat backdrop and layer it on another image using a chroma key or flood select background removal.
|
||||
- *Image Dilate or Erode* - Dilate or expand a mask (or any image!). This is equivalent to an expand/contract operation.
|
||||
- *Image Value Thresholds* - Clip an image to pure black/white beyond specified thresholds.
|
||||
- *Offset Latents* - Offset a latents tensor in the vertical and/or horizontal dimensions, wrapping it around.
|
||||
- *Offset Image* - Offset an image in the vertical and/or horizontal dimensions, wrapping it around.
|
||||
- *Shadows/Highlights/Midtones* - Extract three masks (with adjustable hard or soft thresholds) representing shadows, midtones, and highlights regions of an image.
|
||||
- *Text Mask (simple 2D)* - create and position a white on black (or black on white) line of text using any font locally available to Invoke.
|
||||
|
||||
**Node Link:** https://github.com/dwringer/composition-nodes
|
||||
|
||||
**Example Usage:**
|
||||
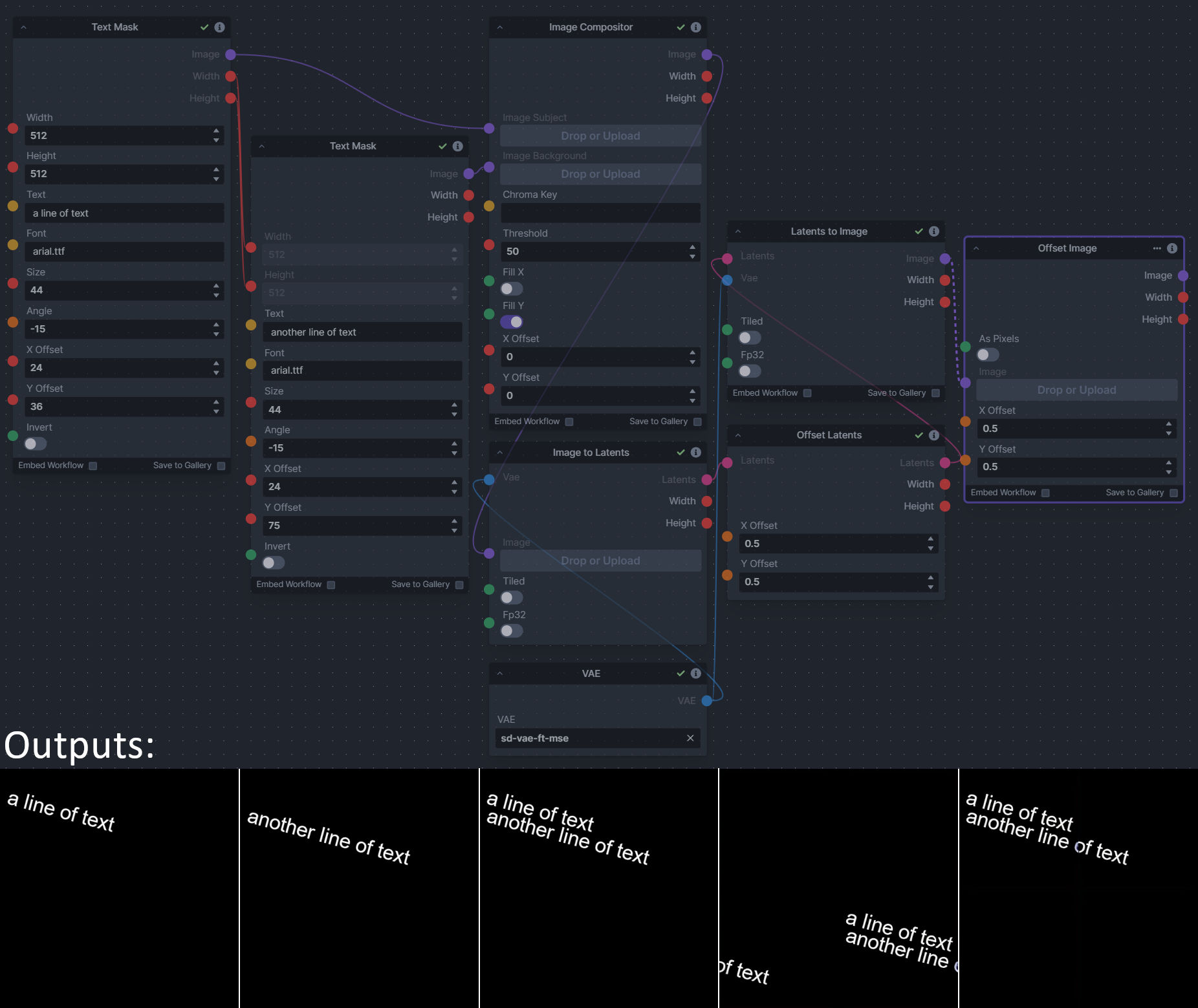
|
||||
**Nodes and Output Examples:**
|
||||
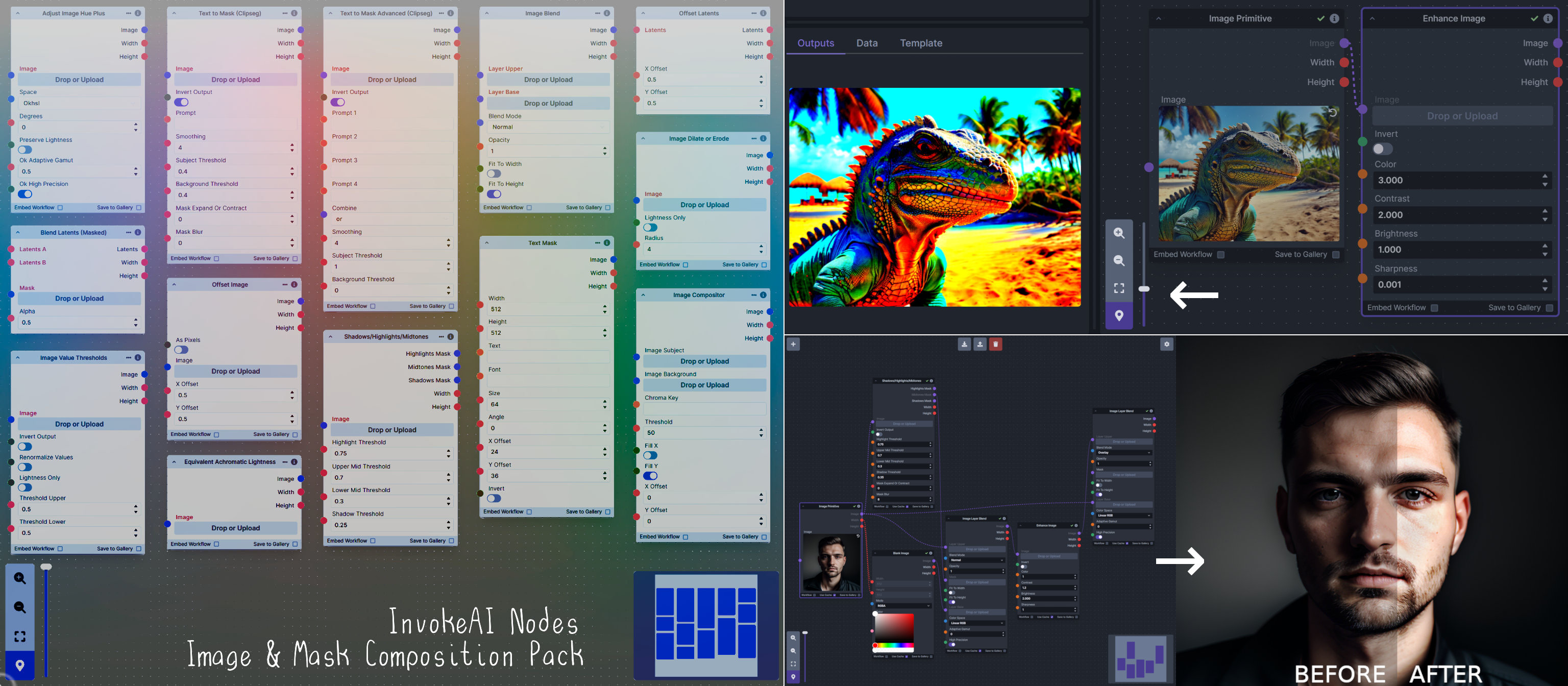
|
||||
|
||||
--------------------------------
|
||||
### Size Stepper Nodes
|
||||
|
||||
@@ -146,7 +146,8 @@ async def update_model(
|
||||
async def import_model(
|
||||
location: str = Body(description="A model path, repo_id or URL to import"),
|
||||
prediction_type: Optional[Literal["v_prediction", "epsilon", "sample"]] = Body(
|
||||
description="Prediction type for SDv2 checkpoint files", default="v_prediction"
|
||||
description="Prediction type for SDv2 checkpoints and rare SDv1 checkpoints",
|
||||
default=None,
|
||||
),
|
||||
) -> ImportModelResponse:
|
||||
"""Add a model using its local path, repo_id, or remote URL. Model characteristics will be probed and configured automatically"""
|
||||
|
||||
@@ -8,7 +8,6 @@ app_config.parse_args()
|
||||
|
||||
if True: # hack to make flake8 happy with imports coming after setting up the config
|
||||
import asyncio
|
||||
import logging
|
||||
import mimetypes
|
||||
import socket
|
||||
from inspect import signature
|
||||
|
||||
@@ -1,4 +1,7 @@
|
||||
from queue import Queue
|
||||
from collections import OrderedDict
|
||||
from dataclasses import dataclass, field
|
||||
from threading import Lock
|
||||
from time import time
|
||||
from typing import Optional, Union
|
||||
|
||||
from invokeai.app.invocations.baseinvocation import BaseInvocation, BaseInvocationOutput
|
||||
@@ -7,22 +10,28 @@ from invokeai.app.services.invocation_cache.invocation_cache_common import Invoc
|
||||
from invokeai.app.services.invoker import Invoker
|
||||
|
||||
|
||||
@dataclass(order=True)
|
||||
class CachedItem:
|
||||
invocation_output: BaseInvocationOutput = field(compare=False)
|
||||
invocation_output_json: str = field(compare=False)
|
||||
|
||||
|
||||
class MemoryInvocationCache(InvocationCacheBase):
|
||||
_cache: dict[Union[int, str], tuple[BaseInvocationOutput, str]]
|
||||
_cache: OrderedDict[Union[int, str], CachedItem]
|
||||
_max_cache_size: int
|
||||
_disabled: bool
|
||||
_hits: int
|
||||
_misses: int
|
||||
_cache_ids: Queue
|
||||
_invoker: Invoker
|
||||
_lock: Lock
|
||||
|
||||
def __init__(self, max_cache_size: int = 0) -> None:
|
||||
self._cache = dict()
|
||||
self._cache = OrderedDict()
|
||||
self._max_cache_size = max_cache_size
|
||||
self._disabled = False
|
||||
self._hits = 0
|
||||
self._misses = 0
|
||||
self._cache_ids = Queue()
|
||||
self._lock = Lock()
|
||||
|
||||
def start(self, invoker: Invoker) -> None:
|
||||
self._invoker = invoker
|
||||
@@ -32,80 +41,87 @@ class MemoryInvocationCache(InvocationCacheBase):
|
||||
self._invoker.services.latents.on_deleted(self._delete_by_match)
|
||||
|
||||
def get(self, key: Union[int, str]) -> Optional[BaseInvocationOutput]:
|
||||
if self._max_cache_size == 0 or self._disabled:
|
||||
return
|
||||
|
||||
item = self._cache.get(key, None)
|
||||
if item is not None:
|
||||
self._hits += 1
|
||||
return item[0]
|
||||
self._misses += 1
|
||||
with self._lock:
|
||||
if self._max_cache_size == 0 or self._disabled:
|
||||
return None
|
||||
item = self._cache.get(key, None)
|
||||
if item is not None:
|
||||
self._hits += 1
|
||||
self._cache.move_to_end(key)
|
||||
return item.invocation_output
|
||||
self._misses += 1
|
||||
return None
|
||||
|
||||
def save(self, key: Union[int, str], invocation_output: BaseInvocationOutput) -> None:
|
||||
if self._max_cache_size == 0 or self._disabled:
|
||||
return
|
||||
with self._lock:
|
||||
if self._max_cache_size == 0 or self._disabled or key in self._cache:
|
||||
return
|
||||
# If the cache is full, we need to remove the least used
|
||||
number_to_delete = len(self._cache) + 1 - self._max_cache_size
|
||||
self._delete_oldest_access(number_to_delete)
|
||||
self._cache[key] = CachedItem(invocation_output, invocation_output.json())
|
||||
|
||||
if key not in self._cache:
|
||||
self._cache[key] = (invocation_output, invocation_output.json())
|
||||
self._cache_ids.put(key)
|
||||
if self._cache_ids.qsize() > self._max_cache_size:
|
||||
try:
|
||||
self._cache.pop(self._cache_ids.get())
|
||||
except KeyError:
|
||||
# this means the cache_ids are somehow out of sync w/ the cache
|
||||
pass
|
||||
def _delete_oldest_access(self, number_to_delete: int) -> None:
|
||||
number_to_delete = min(number_to_delete, len(self._cache))
|
||||
for _ in range(number_to_delete):
|
||||
self._cache.popitem(last=False)
|
||||
|
||||
def delete(self, key: Union[int, str]) -> None:
|
||||
def _delete(self, key: Union[int, str]) -> None:
|
||||
if self._max_cache_size == 0:
|
||||
return
|
||||
|
||||
if key in self._cache:
|
||||
del self._cache[key]
|
||||
|
||||
def delete(self, key: Union[int, str]) -> None:
|
||||
with self._lock:
|
||||
return self._delete(key)
|
||||
|
||||
def clear(self, *args, **kwargs) -> None:
|
||||
if self._max_cache_size == 0:
|
||||
return
|
||||
with self._lock:
|
||||
if self._max_cache_size == 0:
|
||||
return
|
||||
self._cache.clear()
|
||||
self._misses = 0
|
||||
self._hits = 0
|
||||
|
||||
self._cache.clear()
|
||||
self._cache_ids = Queue()
|
||||
self._misses = 0
|
||||
self._hits = 0
|
||||
|
||||
def create_key(self, invocation: BaseInvocation) -> int:
|
||||
@staticmethod
|
||||
def create_key(invocation: BaseInvocation) -> int:
|
||||
return hash(invocation.json(exclude={"id"}))
|
||||
|
||||
def disable(self) -> None:
|
||||
if self._max_cache_size == 0:
|
||||
return
|
||||
self._disabled = True
|
||||
with self._lock:
|
||||
if self._max_cache_size == 0:
|
||||
return
|
||||
self._disabled = True
|
||||
|
||||
def enable(self) -> None:
|
||||
if self._max_cache_size == 0:
|
||||
return
|
||||
self._disabled = False
|
||||
with self._lock:
|
||||
if self._max_cache_size == 0:
|
||||
return
|
||||
self._disabled = False
|
||||
|
||||
def get_status(self) -> InvocationCacheStatus:
|
||||
return InvocationCacheStatus(
|
||||
hits=self._hits,
|
||||
misses=self._misses,
|
||||
enabled=not self._disabled and self._max_cache_size > 0,
|
||||
size=len(self._cache),
|
||||
max_size=self._max_cache_size,
|
||||
)
|
||||
with self._lock:
|
||||
return InvocationCacheStatus(
|
||||
hits=self._hits,
|
||||
misses=self._misses,
|
||||
enabled=not self._disabled and self._max_cache_size > 0,
|
||||
size=len(self._cache),
|
||||
max_size=self._max_cache_size,
|
||||
)
|
||||
|
||||
def _delete_by_match(self, to_match: str) -> None:
|
||||
if self._max_cache_size == 0:
|
||||
return
|
||||
|
||||
keys_to_delete = set()
|
||||
for key, value_tuple in self._cache.items():
|
||||
if to_match in value_tuple[1]:
|
||||
keys_to_delete.add(key)
|
||||
|
||||
if not keys_to_delete:
|
||||
return
|
||||
|
||||
for key in keys_to_delete:
|
||||
self.delete(key)
|
||||
|
||||
self._invoker.services.logger.debug(f"Deleted {len(keys_to_delete)} cached invocation outputs for {to_match}")
|
||||
with self._lock:
|
||||
if self._max_cache_size == 0:
|
||||
return
|
||||
keys_to_delete = set()
|
||||
for key, cached_item in self._cache.items():
|
||||
if to_match in cached_item.invocation_output_json:
|
||||
keys_to_delete.add(key)
|
||||
if not keys_to_delete:
|
||||
return
|
||||
for key in keys_to_delete:
|
||||
self._delete(key)
|
||||
self._invoker.services.logger.debug(
|
||||
f"Deleted {len(keys_to_delete)} cached invocation outputs for {to_match}"
|
||||
)
|
||||
|
||||
@@ -47,20 +47,27 @@ class DefaultSessionProcessor(SessionProcessorBase):
|
||||
async def _on_queue_event(self, event: FastAPIEvent) -> None:
|
||||
event_name = event[1]["event"]
|
||||
|
||||
match event_name:
|
||||
case "graph_execution_state_complete" | "invocation_error" | "session_retrieval_error" | "invocation_retrieval_error":
|
||||
self.__queue_item = None
|
||||
self._poll_now()
|
||||
case "session_canceled" if self.__queue_item is not None and self.__queue_item.session_id == event[1][
|
||||
"data"
|
||||
]["graph_execution_state_id"]:
|
||||
self.__queue_item = None
|
||||
self._poll_now()
|
||||
case "batch_enqueued":
|
||||
self._poll_now()
|
||||
case "queue_cleared":
|
||||
self.__queue_item = None
|
||||
self._poll_now()
|
||||
# This was a match statement, but match is not supported on python 3.9
|
||||
if event_name in [
|
||||
"graph_execution_state_complete",
|
||||
"invocation_error",
|
||||
"session_retrieval_error",
|
||||
"invocation_retrieval_error",
|
||||
]:
|
||||
self.__queue_item = None
|
||||
self._poll_now()
|
||||
elif (
|
||||
event_name == "session_canceled"
|
||||
and self.__queue_item is not None
|
||||
and self.__queue_item.session_id == event[1]["data"]["graph_execution_state_id"]
|
||||
):
|
||||
self.__queue_item = None
|
||||
self._poll_now()
|
||||
elif event_name == "batch_enqueued":
|
||||
self._poll_now()
|
||||
elif event_name == "queue_cleared":
|
||||
self.__queue_item = None
|
||||
self._poll_now()
|
||||
|
||||
def resume(self) -> SessionProcessorStatus:
|
||||
if not self.__resume_event.is_set():
|
||||
|
||||
@@ -59,13 +59,14 @@ class SqliteSessionQueue(SessionQueueBase):
|
||||
|
||||
async def _on_session_event(self, event: FastAPIEvent) -> FastAPIEvent:
|
||||
event_name = event[1]["event"]
|
||||
match event_name:
|
||||
case "graph_execution_state_complete":
|
||||
await self._handle_complete_event(event)
|
||||
case "invocation_error" | "session_retrieval_error" | "invocation_retrieval_error":
|
||||
await self._handle_error_event(event)
|
||||
case "session_canceled":
|
||||
await self._handle_cancel_event(event)
|
||||
|
||||
# This was a match statement, but match is not supported on python 3.9
|
||||
if event_name == "graph_execution_state_complete":
|
||||
await self._handle_complete_event(event)
|
||||
elif event_name in ["invocation_error", "session_retrieval_error", "invocation_retrieval_error"]:
|
||||
await self._handle_error_event(event)
|
||||
elif event_name == "session_canceled":
|
||||
await self._handle_cancel_event(event)
|
||||
return event
|
||||
|
||||
async def _handle_complete_event(self, event: FastAPIEvent) -> None:
|
||||
|
||||
@@ -47,8 +47,14 @@ Config_preamble = """
|
||||
|
||||
LEGACY_CONFIGS = {
|
||||
BaseModelType.StableDiffusion1: {
|
||||
ModelVariantType.Normal: "v1-inference.yaml",
|
||||
ModelVariantType.Inpaint: "v1-inpainting-inference.yaml",
|
||||
ModelVariantType.Normal: {
|
||||
SchedulerPredictionType.Epsilon: "v1-inference.yaml",
|
||||
SchedulerPredictionType.VPrediction: "v1-inference-v.yaml",
|
||||
},
|
||||
ModelVariantType.Inpaint: {
|
||||
SchedulerPredictionType.Epsilon: "v1-inpainting-inference.yaml",
|
||||
SchedulerPredictionType.VPrediction: "v1-inpainting-inference-v.yaml",
|
||||
},
|
||||
},
|
||||
BaseModelType.StableDiffusion2: {
|
||||
ModelVariantType.Normal: {
|
||||
@@ -69,14 +75,6 @@ LEGACY_CONFIGS = {
|
||||
}
|
||||
|
||||
|
||||
@dataclass
|
||||
class ModelInstallList:
|
||||
"""Class for listing models to be installed/removed"""
|
||||
|
||||
install_models: List[str] = field(default_factory=list)
|
||||
remove_models: List[str] = field(default_factory=list)
|
||||
|
||||
|
||||
@dataclass
|
||||
class InstallSelections:
|
||||
install_models: List[str] = field(default_factory=list)
|
||||
@@ -94,6 +92,7 @@ class ModelLoadInfo:
|
||||
installed: bool = False
|
||||
recommended: bool = False
|
||||
default: bool = False
|
||||
requires: Optional[List[str]] = field(default_factory=list)
|
||||
|
||||
|
||||
class ModelInstall(object):
|
||||
@@ -131,8 +130,6 @@ class ModelInstall(object):
|
||||
|
||||
# supplement with entries in models.yaml
|
||||
installed_models = [x for x in self.mgr.list_models()]
|
||||
# suppresses autoloaded models
|
||||
# installed_models = [x for x in self.mgr.list_models() if not self._is_autoloaded(x)]
|
||||
|
||||
for md in installed_models:
|
||||
base = md["base_model"]
|
||||
@@ -164,9 +161,12 @@ class ModelInstall(object):
|
||||
|
||||
def list_models(self, model_type):
|
||||
installed = self.mgr.list_models(model_type=model_type)
|
||||
print()
|
||||
print(f"Installed models of type `{model_type}`:")
|
||||
print(f"{'Model Key':50} Model Path")
|
||||
for i in installed:
|
||||
print(f"{i['model_name']}\t{i['base_model']}\t{i['path']}")
|
||||
print(f"{'/'.join([i['base_model'],i['model_type'],i['model_name']]):50} {i['path']}")
|
||||
print()
|
||||
|
||||
# logic here a little reversed to maintain backward compatibility
|
||||
def starter_models(self, all_models: bool = False) -> Set[str]:
|
||||
@@ -204,6 +204,8 @@ class ModelInstall(object):
|
||||
job += 1
|
||||
|
||||
# add requested models
|
||||
self._remove_installed(selections.install_models)
|
||||
self._add_required_models(selections.install_models)
|
||||
for path in selections.install_models:
|
||||
logger.info(f"Installing {path} [{job}/{jobs}]")
|
||||
try:
|
||||
@@ -263,6 +265,26 @@ class ModelInstall(object):
|
||||
|
||||
return models_installed
|
||||
|
||||
def _remove_installed(self, model_list: List[str]):
|
||||
all_models = self.all_models()
|
||||
for path in model_list:
|
||||
key = self.reverse_paths.get(path)
|
||||
if key and all_models[key].installed:
|
||||
logger.warning(f"{path} already installed. Skipping.")
|
||||
model_list.remove(path)
|
||||
|
||||
def _add_required_models(self, model_list: List[str]):
|
||||
additional_models = []
|
||||
all_models = self.all_models()
|
||||
for path in model_list:
|
||||
if not (key := self.reverse_paths.get(path)):
|
||||
continue
|
||||
for requirement in all_models[key].requires:
|
||||
requirement_key = self.reverse_paths.get(requirement)
|
||||
if not all_models[requirement_key].installed:
|
||||
additional_models.append(requirement)
|
||||
model_list.extend(additional_models)
|
||||
|
||||
# install a model from a local path. The optional info parameter is there to prevent
|
||||
# the model from being probed twice in the event that it has already been probed.
|
||||
def _install_path(self, path: Path, info: ModelProbeInfo = None) -> AddModelResult:
|
||||
@@ -286,7 +308,7 @@ class ModelInstall(object):
|
||||
location = download_with_resume(url, Path(staging))
|
||||
if not location:
|
||||
logger.error(f"Unable to download {url}. Skipping.")
|
||||
info = ModelProbe().heuristic_probe(location)
|
||||
info = ModelProbe().heuristic_probe(location, self.prediction_helper)
|
||||
dest = self.config.models_path / info.base_type.value / info.model_type.value / location.name
|
||||
dest.parent.mkdir(parents=True, exist_ok=True)
|
||||
models_path = shutil.move(location, dest)
|
||||
@@ -393,7 +415,7 @@ class ModelInstall(object):
|
||||
possible_conf = path.with_suffix(".yaml")
|
||||
if possible_conf.exists():
|
||||
legacy_conf = str(self.relative_to_root(possible_conf))
|
||||
elif info.base_type == BaseModelType.StableDiffusion2:
|
||||
elif info.base_type in [BaseModelType.StableDiffusion1, BaseModelType.StableDiffusion2]:
|
||||
legacy_conf = Path(
|
||||
self.config.legacy_conf_dir,
|
||||
LEGACY_CONFIGS[info.base_type][info.variant_type][info.prediction_type],
|
||||
|
||||
@@ -1279,12 +1279,12 @@ def download_from_original_stable_diffusion_ckpt(
|
||||
extract_ema = original_config["model"]["params"]["use_ema"]
|
||||
|
||||
if (
|
||||
model_version == BaseModelType.StableDiffusion2
|
||||
model_version in [BaseModelType.StableDiffusion2, BaseModelType.StableDiffusion1]
|
||||
and original_config["model"]["params"].get("parameterization") == "v"
|
||||
):
|
||||
prediction_type = "v_prediction"
|
||||
upcast_attention = True
|
||||
image_size = 768
|
||||
image_size = 768 if model_version == BaseModelType.StableDiffusion2 else 512
|
||||
else:
|
||||
prediction_type = "epsilon"
|
||||
upcast_attention = False
|
||||
|
||||
@@ -90,8 +90,7 @@ class ModelProbe(object):
|
||||
to place it somewhere in the models directory hierarchy. If the model is
|
||||
already loaded into memory, you may provide it as model in order to avoid
|
||||
opening it a second time. The prediction_type_helper callable is a function that receives
|
||||
the path to the model and returns the BaseModelType. It is called to distinguish
|
||||
between V2-Base and V2-768 SD models.
|
||||
the path to the model and returns the SchedulerPredictionType.
|
||||
"""
|
||||
if model_path:
|
||||
format_type = "diffusers" if model_path.is_dir() else "checkpoint"
|
||||
@@ -305,25 +304,36 @@ class PipelineCheckpointProbe(CheckpointProbeBase):
|
||||
else:
|
||||
raise InvalidModelException("Cannot determine base type")
|
||||
|
||||
def get_scheduler_prediction_type(self) -> SchedulerPredictionType:
|
||||
def get_scheduler_prediction_type(self) -> Optional[SchedulerPredictionType]:
|
||||
"""Return model prediction type."""
|
||||
# if there is a .yaml associated with this checkpoint, then we do not need
|
||||
# to probe for the prediction type as it will be ignored.
|
||||
if self.checkpoint_path and self.checkpoint_path.with_suffix(".yaml").exists():
|
||||
return None
|
||||
|
||||
type = self.get_base_type()
|
||||
if type == BaseModelType.StableDiffusion1:
|
||||
return SchedulerPredictionType.Epsilon
|
||||
checkpoint = self.checkpoint
|
||||
state_dict = self.checkpoint.get("state_dict") or checkpoint
|
||||
key_name = "model.diffusion_model.input_blocks.2.1.transformer_blocks.0.attn2.to_k.weight"
|
||||
if key_name in state_dict and state_dict[key_name].shape[-1] == 1024:
|
||||
if "global_step" in checkpoint:
|
||||
if checkpoint["global_step"] == 220000:
|
||||
return SchedulerPredictionType.Epsilon
|
||||
elif checkpoint["global_step"] == 110000:
|
||||
return SchedulerPredictionType.VPrediction
|
||||
if (
|
||||
self.checkpoint_path and self.helper and not self.checkpoint_path.with_suffix(".yaml").exists()
|
||||
): # if a .yaml config file exists, then this step not needed
|
||||
return self.helper(self.checkpoint_path)
|
||||
else:
|
||||
return None
|
||||
if type == BaseModelType.StableDiffusion2:
|
||||
checkpoint = self.checkpoint
|
||||
state_dict = self.checkpoint.get("state_dict") or checkpoint
|
||||
key_name = "model.diffusion_model.input_blocks.2.1.transformer_blocks.0.attn2.to_k.weight"
|
||||
if key_name in state_dict and state_dict[key_name].shape[-1] == 1024:
|
||||
if "global_step" in checkpoint:
|
||||
if checkpoint["global_step"] == 220000:
|
||||
return SchedulerPredictionType.Epsilon
|
||||
elif checkpoint["global_step"] == 110000:
|
||||
return SchedulerPredictionType.VPrediction
|
||||
if self.helper and self.checkpoint_path:
|
||||
if helper_guess := self.helper(self.checkpoint_path):
|
||||
return helper_guess
|
||||
return SchedulerPredictionType.VPrediction # a guess for sd2 ckpts
|
||||
|
||||
elif type == BaseModelType.StableDiffusion1:
|
||||
if self.helper and self.checkpoint_path:
|
||||
if helper_guess := self.helper(self.checkpoint_path):
|
||||
return helper_guess
|
||||
return SchedulerPredictionType.Epsilon # a reasonable guess for sd1 ckpts
|
||||
else:
|
||||
return None
|
||||
|
||||
|
||||
class VaeCheckpointProbe(CheckpointProbeBase):
|
||||
|
||||
@@ -71,7 +71,13 @@ class ModelSearch(ABC):
|
||||
if any(
|
||||
[
|
||||
(path / x).exists()
|
||||
for x in {"config.json", "model_index.json", "learned_embeds.bin", "pytorch_lora_weights.bin"}
|
||||
for x in {
|
||||
"config.json",
|
||||
"model_index.json",
|
||||
"learned_embeds.bin",
|
||||
"pytorch_lora_weights.bin",
|
||||
"image_encoder.txt",
|
||||
}
|
||||
]
|
||||
):
|
||||
try:
|
||||
|
||||
@@ -103,3 +103,35 @@ sd-1/lora/LowRA:
|
||||
recommended: True
|
||||
sd-1/lora/Ink scenery:
|
||||
path: https://civitai.com/api/download/models/83390
|
||||
sd-1/ip_adapter/ip_adapter_sd15:
|
||||
repo_id: InvokeAI/ip_adapter_sd15
|
||||
recommended: True
|
||||
requires:
|
||||
- InvokeAI/ip_adapter_sd_image_encoder
|
||||
description: IP-Adapter for SD 1.5 models
|
||||
sd-1/ip_adapter/ip_adapter_plus_sd15:
|
||||
repo_id: InvokeAI/ip_adapter_plus_sd15
|
||||
recommended: False
|
||||
requires:
|
||||
- InvokeAI/ip_adapter_sd_image_encoder
|
||||
description: Refined IP-Adapter for SD 1.5 models
|
||||
sd-1/ip_adapter/ip_adapter_plus_face_sd15:
|
||||
repo_id: InvokeAI/ip_adapter_plus_face_sd15
|
||||
recommended: False
|
||||
requires:
|
||||
- InvokeAI/ip_adapter_sd_image_encoder
|
||||
description: Refined IP-Adapter for SD 1.5 models, adapted for faces
|
||||
sdxl/ip_adapter/ip_adapter_sdxl:
|
||||
repo_id: InvokeAI/ip_adapter_sdxl
|
||||
recommended: False
|
||||
requires:
|
||||
- InvokeAI/ip_adapter_sdxl_image_encoder
|
||||
description: IP-Adapter for SDXL models
|
||||
any/clip_vision/ip_adapter_sd_image_encoder:
|
||||
repo_id: InvokeAI/ip_adapter_sd_image_encoder
|
||||
recommended: False
|
||||
description: Required model for using IP-Adapters with SD-1/2 models
|
||||
any/clip_vision/ip_adapter_sdxl_image_encoder:
|
||||
repo_id: InvokeAI/ip_adapter_sdxl_image_encoder
|
||||
recommended: False
|
||||
description: Required model for using IP-Adapters with SDXL models
|
||||
|
||||
80
invokeai/configs/stable-diffusion/v1-inference-v.yaml
Normal file
80
invokeai/configs/stable-diffusion/v1-inference-v.yaml
Normal file
@@ -0,0 +1,80 @@
|
||||
model:
|
||||
base_learning_rate: 1.0e-04
|
||||
target: invokeai.backend.models.diffusion.ddpm.LatentDiffusion
|
||||
params:
|
||||
parameterization: "v"
|
||||
linear_start: 0.00085
|
||||
linear_end: 0.0120
|
||||
num_timesteps_cond: 1
|
||||
log_every_t: 200
|
||||
timesteps: 1000
|
||||
first_stage_key: "jpg"
|
||||
cond_stage_key: "txt"
|
||||
image_size: 64
|
||||
channels: 4
|
||||
cond_stage_trainable: false # Note: different from the one we trained before
|
||||
conditioning_key: crossattn
|
||||
monitor: val/loss_simple_ema
|
||||
scale_factor: 0.18215
|
||||
use_ema: False
|
||||
|
||||
scheduler_config: # 10000 warmup steps
|
||||
target: invokeai.backend.stable_diffusion.lr_scheduler.LambdaLinearScheduler
|
||||
params:
|
||||
warm_up_steps: [ 10000 ]
|
||||
cycle_lengths: [ 10000000000000 ] # incredibly large number to prevent corner cases
|
||||
f_start: [ 1.e-6 ]
|
||||
f_max: [ 1. ]
|
||||
f_min: [ 1. ]
|
||||
|
||||
personalization_config:
|
||||
target: invokeai.backend.stable_diffusion.embedding_manager.EmbeddingManager
|
||||
params:
|
||||
placeholder_strings: ["*"]
|
||||
initializer_words: ['sculpture']
|
||||
per_image_tokens: false
|
||||
num_vectors_per_token: 1
|
||||
progressive_words: False
|
||||
|
||||
unet_config:
|
||||
target: invokeai.backend.stable_diffusion.diffusionmodules.openaimodel.UNetModel
|
||||
params:
|
||||
image_size: 32 # unused
|
||||
in_channels: 4
|
||||
out_channels: 4
|
||||
model_channels: 320
|
||||
attention_resolutions: [ 4, 2, 1 ]
|
||||
num_res_blocks: 2
|
||||
channel_mult: [ 1, 2, 4, 4 ]
|
||||
num_heads: 8
|
||||
use_spatial_transformer: True
|
||||
transformer_depth: 1
|
||||
context_dim: 768
|
||||
use_checkpoint: True
|
||||
legacy: False
|
||||
|
||||
first_stage_config:
|
||||
target: invokeai.backend.stable_diffusion.autoencoder.AutoencoderKL
|
||||
params:
|
||||
embed_dim: 4
|
||||
monitor: val/rec_loss
|
||||
ddconfig:
|
||||
double_z: true
|
||||
z_channels: 4
|
||||
resolution: 256
|
||||
in_channels: 3
|
||||
out_ch: 3
|
||||
ch: 128
|
||||
ch_mult:
|
||||
- 1
|
||||
- 2
|
||||
- 4
|
||||
- 4
|
||||
num_res_blocks: 2
|
||||
attn_resolutions: []
|
||||
dropout: 0.0
|
||||
lossconfig:
|
||||
target: torch.nn.Identity
|
||||
|
||||
cond_stage_config:
|
||||
target: invokeai.backend.stable_diffusion.encoders.modules.WeightedFrozenCLIPEmbedder
|
||||
@@ -101,11 +101,12 @@ class addModelsForm(CyclingForm, npyscreen.FormMultiPage):
|
||||
"STARTER MODELS",
|
||||
"MAIN MODELS",
|
||||
"CONTROLNETS",
|
||||
"IP-ADAPTERS",
|
||||
"LORA/LYCORIS",
|
||||
"TEXTUAL INVERSION",
|
||||
],
|
||||
value=[self.current_tab],
|
||||
columns=5,
|
||||
columns=6,
|
||||
max_height=2,
|
||||
relx=8,
|
||||
scroll_exit=True,
|
||||
@@ -130,6 +131,13 @@ class addModelsForm(CyclingForm, npyscreen.FormMultiPage):
|
||||
)
|
||||
bottom_of_table = max(bottom_of_table, self.nextrely)
|
||||
|
||||
self.nextrely = top_of_table
|
||||
self.ipadapter_models = self.add_model_widgets(
|
||||
model_type=ModelType.IPAdapter,
|
||||
window_width=window_width,
|
||||
)
|
||||
bottom_of_table = max(bottom_of_table, self.nextrely)
|
||||
|
||||
self.nextrely = top_of_table
|
||||
self.lora_models = self.add_model_widgets(
|
||||
model_type=ModelType.Lora,
|
||||
@@ -343,6 +351,7 @@ class addModelsForm(CyclingForm, npyscreen.FormMultiPage):
|
||||
self.starter_pipelines,
|
||||
self.pipeline_models,
|
||||
self.controlnet_models,
|
||||
self.ipadapter_models,
|
||||
self.lora_models,
|
||||
self.ti_models,
|
||||
]
|
||||
@@ -532,6 +541,7 @@ class addModelsForm(CyclingForm, npyscreen.FormMultiPage):
|
||||
self.starter_pipelines,
|
||||
self.pipeline_models,
|
||||
self.controlnet_models,
|
||||
self.ipadapter_models,
|
||||
self.lora_models,
|
||||
self.ti_models,
|
||||
]
|
||||
@@ -553,6 +563,25 @@ class addModelsForm(CyclingForm, npyscreen.FormMultiPage):
|
||||
if downloads := section.get("download_ids"):
|
||||
selections.install_models.extend(downloads.value.split())
|
||||
|
||||
# NOT NEEDED - DONE IN BACKEND NOW
|
||||
# # special case for the ipadapter_models. If any of the adapters are
|
||||
# # chosen, then we add the corresponding encoder(s) to the install list.
|
||||
# section = self.ipadapter_models
|
||||
# if section.get("models_selected"):
|
||||
# selected_adapters = [
|
||||
# self.all_models[section["models"][x]].name for x in section.get("models_selected").value
|
||||
# ]
|
||||
# encoders = []
|
||||
# if any(["sdxl" in x for x in selected_adapters]):
|
||||
# encoders.append("ip_adapter_sdxl_image_encoder")
|
||||
# if any(["sd15" in x for x in selected_adapters]):
|
||||
# encoders.append("ip_adapter_sd_image_encoder")
|
||||
# for encoder in encoders:
|
||||
# key = f"any/clip_vision/{encoder}"
|
||||
# repo_id = f"InvokeAI/{encoder}"
|
||||
# if key not in self.all_models:
|
||||
# selections.install_models.append(repo_id)
|
||||
|
||||
|
||||
class AddModelApplication(npyscreen.NPSAppManaged):
|
||||
def __init__(self, opt):
|
||||
|
||||
2
invokeai/frontend/web/dist/locales/en.json
vendored
2
invokeai/frontend/web/dist/locales/en.json
vendored
@@ -574,7 +574,7 @@
|
||||
"onnxModels": "Onnx",
|
||||
"pathToCustomConfig": "Path To Custom Config",
|
||||
"pickModelType": "Pick Model Type",
|
||||
"predictionType": "Prediction Type (for Stable Diffusion 2.x Models only)",
|
||||
"predictionType": "Prediction Type (for Stable Diffusion 2.x Models and occasional Stable Diffusion 1.x Models)",
|
||||
"quickAdd": "Quick Add",
|
||||
"repo_id": "Repo ID",
|
||||
"repoIDValidationMsg": "Online repository of your model",
|
||||
|
||||
@@ -79,7 +79,7 @@
|
||||
"lightMode": "Light Mode",
|
||||
"linear": "Linear",
|
||||
"load": "Load",
|
||||
"loading": "Loading",
|
||||
"loading": "Loading $t({{noun}})...",
|
||||
"loadingInvokeAI": "Loading Invoke AI",
|
||||
"learnMore": "Learn More",
|
||||
"modelManager": "Model Manager",
|
||||
@@ -655,7 +655,7 @@
|
||||
"onnxModels": "Onnx",
|
||||
"pathToCustomConfig": "Path To Custom Config",
|
||||
"pickModelType": "Pick Model Type",
|
||||
"predictionType": "Prediction Type (for Stable Diffusion 2.x Models only)",
|
||||
"predictionType": "Prediction Type (for Stable Diffusion 2.x Models and occasional Stable Diffusion 1.x Models)",
|
||||
"quickAdd": "Quick Add",
|
||||
"repo_id": "Repo ID",
|
||||
"repoIDValidationMsg": "Online repository of your model",
|
||||
|
||||
@@ -17,7 +17,10 @@ import '../../i18n';
|
||||
import AppDndContext from '../../features/dnd/components/AppDndContext';
|
||||
import { $customStarUI, CustomStarUi } from 'app/store/nanostores/customStarUI';
|
||||
import { $headerComponent } from 'app/store/nanostores/headerComponent';
|
||||
import { $queueId, DEFAULT_QUEUE_ID } from 'features/queue/store/nanoStores';
|
||||
import {
|
||||
$queueId,
|
||||
DEFAULT_QUEUE_ID,
|
||||
} from 'features/queue/store/queueNanoStore';
|
||||
|
||||
const App = lazy(() => import('./App'));
|
||||
const ThemeLocaleProvider = lazy(() => import('./ThemeLocaleProvider'));
|
||||
|
||||
@@ -81,3 +81,38 @@ export const IAINoContentFallback = (props: IAINoImageFallbackProps) => {
|
||||
</Flex>
|
||||
);
|
||||
};
|
||||
|
||||
type IAINoImageFallbackWithSpinnerProps = FlexProps & {
|
||||
label?: string;
|
||||
};
|
||||
|
||||
export const IAINoContentFallbackWithSpinner = (
|
||||
props: IAINoImageFallbackWithSpinnerProps
|
||||
) => {
|
||||
const { sx, ...rest } = props;
|
||||
|
||||
return (
|
||||
<Flex
|
||||
sx={{
|
||||
w: 'full',
|
||||
h: 'full',
|
||||
alignItems: 'center',
|
||||
justifyContent: 'center',
|
||||
borderRadius: 'base',
|
||||
flexDir: 'column',
|
||||
gap: 2,
|
||||
userSelect: 'none',
|
||||
opacity: 0.7,
|
||||
color: 'base.700',
|
||||
_dark: {
|
||||
color: 'base.500',
|
||||
},
|
||||
...sx,
|
||||
}}
|
||||
{...rest}
|
||||
>
|
||||
<Spinner size="xl" />
|
||||
{props.label && <Text textAlign="center">{props.label}</Text>}
|
||||
</Flex>
|
||||
);
|
||||
};
|
||||
|
||||
@@ -44,7 +44,7 @@ const IAIMantineMultiSelect = forwardRef((props: IAIMultiSelectProps, ref) => {
|
||||
|
||||
return (
|
||||
<Tooltip label={tooltip} placement="top" hasArrow isOpen={true}>
|
||||
<FormControl ref={ref} isDisabled={disabled}>
|
||||
<FormControl ref={ref} isDisabled={disabled} position="static">
|
||||
{label && <FormLabel>{label}</FormLabel>}
|
||||
<MultiSelect
|
||||
ref={inputRef}
|
||||
|
||||
@@ -70,11 +70,10 @@ const IAIMantineSearchableSelect = forwardRef((props: IAISelectProps, ref) => {
|
||||
|
||||
return (
|
||||
<Tooltip label={tooltip} placement="top" hasArrow>
|
||||
<FormControl ref={ref} isDisabled={disabled}>
|
||||
<FormControl ref={ref} isDisabled={disabled} position="static">
|
||||
{label && <FormLabel>{label}</FormLabel>}
|
||||
<Select
|
||||
ref={inputRef}
|
||||
withinPortal
|
||||
disabled={disabled}
|
||||
searchValue={searchValue}
|
||||
onSearchChange={setSearchValue}
|
||||
|
||||
@@ -22,7 +22,12 @@ const IAIMantineSelect = forwardRef((props: IAISelectProps, ref) => {
|
||||
|
||||
return (
|
||||
<Tooltip label={tooltip} placement="top" hasArrow>
|
||||
<FormControl ref={ref} isRequired={required} isDisabled={disabled}>
|
||||
<FormControl
|
||||
ref={ref}
|
||||
isRequired={required}
|
||||
isDisabled={disabled}
|
||||
position="static"
|
||||
>
|
||||
<FormLabel>{label}</FormLabel>
|
||||
<Select disabled={disabled} ref={inputRef} styles={styles} {...rest} />
|
||||
</FormControl>
|
||||
|
||||
@@ -254,4 +254,5 @@ export const CONTROLNET_MODEL_DEFAULT_PROCESSORS: {
|
||||
mediapipe: 'mediapipe_face_processor',
|
||||
pidi: 'pidi_image_processor',
|
||||
zoe: 'zoe_depth_image_processor',
|
||||
color: 'color_map_image_processor',
|
||||
};
|
||||
|
||||
@@ -287,7 +287,7 @@ const CurrentImageButtons = (props: CurrentImageButtonsProps) => {
|
||||
icon={<FaSeedling />}
|
||||
tooltip={`${t('parameters.useSeed')} (S)`}
|
||||
aria-label={`${t('parameters.useSeed')} (S)`}
|
||||
isDisabled={!metadata?.seed}
|
||||
isDisabled={metadata?.seed === null || metadata?.seed === undefined}
|
||||
onClick={handleUseSeed}
|
||||
/>
|
||||
<IAIIconButton
|
||||
|
||||
@@ -8,6 +8,7 @@ import InvocationNodeFooter from './InvocationNodeFooter';
|
||||
import InvocationNodeHeader from './InvocationNodeHeader';
|
||||
import InputField from './fields/InputField';
|
||||
import OutputField from './fields/OutputField';
|
||||
import { useWithFooter } from 'features/nodes/hooks/useWithFooter';
|
||||
|
||||
type Props = {
|
||||
nodeId: string;
|
||||
@@ -20,6 +21,7 @@ type Props = {
|
||||
const InvocationNode = ({ nodeId, isOpen, label, type, selected }: Props) => {
|
||||
const inputConnectionFieldNames = useConnectionInputFieldNames(nodeId);
|
||||
const inputAnyOrDirectFieldNames = useAnyOrDirectInputFieldNames(nodeId);
|
||||
const withFooter = useWithFooter(nodeId);
|
||||
const outputFieldNames = useOutputFieldNames(nodeId);
|
||||
|
||||
return (
|
||||
@@ -41,7 +43,7 @@ const InvocationNode = ({ nodeId, isOpen, label, type, selected }: Props) => {
|
||||
h: 'full',
|
||||
py: 2,
|
||||
gap: 1,
|
||||
borderBottomRadius: 0,
|
||||
borderBottomRadius: withFooter ? 0 : 'base',
|
||||
}}
|
||||
>
|
||||
<Flex sx={{ flexDir: 'column', px: 2, w: 'full', h: 'full' }}>
|
||||
@@ -74,7 +76,7 @@ const InvocationNode = ({ nodeId, isOpen, label, type, selected }: Props) => {
|
||||
))}
|
||||
</Flex>
|
||||
</Flex>
|
||||
<InvocationNodeFooter nodeId={nodeId} />
|
||||
{withFooter && <InvocationNodeFooter nodeId={nodeId} />}
|
||||
</>
|
||||
)}
|
||||
</NodeWrapper>
|
||||
|
||||
@@ -5,6 +5,7 @@ import EmbedWorkflowCheckbox from './EmbedWorkflowCheckbox';
|
||||
import SaveToGalleryCheckbox from './SaveToGalleryCheckbox';
|
||||
import UseCacheCheckbox from './UseCacheCheckbox';
|
||||
import { useHasImageOutput } from 'features/nodes/hooks/useHasImageOutput';
|
||||
import { useFeatureStatus } from '../../../../../system/hooks/useFeatureStatus';
|
||||
|
||||
type Props = {
|
||||
nodeId: string;
|
||||
@@ -12,6 +13,7 @@ type Props = {
|
||||
|
||||
const InvocationNodeFooter = ({ nodeId }: Props) => {
|
||||
const hasImageOutput = useHasImageOutput(nodeId);
|
||||
const isCacheEnabled = useFeatureStatus('invocationCache').isFeatureEnabled;
|
||||
return (
|
||||
<Flex
|
||||
className={DRAG_HANDLE_CLASSNAME}
|
||||
@@ -25,7 +27,7 @@ const InvocationNodeFooter = ({ nodeId }: Props) => {
|
||||
justifyContent: 'space-between',
|
||||
}}
|
||||
>
|
||||
<UseCacheCheckbox nodeId={nodeId} />
|
||||
{isCacheEnabled && <UseCacheCheckbox nodeId={nodeId} />}
|
||||
{hasImageOutput && <EmbedWorkflowCheckbox nodeId={nodeId} />}
|
||||
{hasImageOutput && <SaveToGalleryCheckbox nodeId={nodeId} />}
|
||||
</Flex>
|
||||
|
||||
@@ -1,31 +1,14 @@
|
||||
import { createSelector } from '@reduxjs/toolkit';
|
||||
import { stateSelector } from 'app/store/store';
|
||||
import { useAppSelector } from 'app/store/storeHooks';
|
||||
import { defaultSelectorOptions } from 'app/store/util/defaultMemoizeOptions';
|
||||
import { some } from 'lodash-es';
|
||||
import { useFeatureStatus } from 'features/system/hooks/useFeatureStatus';
|
||||
import { useMemo } from 'react';
|
||||
import { FOOTER_FIELDS } from '../types/constants';
|
||||
import { isInvocationNode } from '../types/types';
|
||||
import { useHasImageOutput } from './useHasImageOutput';
|
||||
|
||||
export const useHasImageOutputs = (nodeId: string) => {
|
||||
const selector = useMemo(
|
||||
() =>
|
||||
createSelector(
|
||||
stateSelector,
|
||||
({ nodes }) => {
|
||||
const node = nodes.nodes.find((node) => node.id === nodeId);
|
||||
if (!isInvocationNode(node)) {
|
||||
return false;
|
||||
}
|
||||
return some(node.data.outputs, (output) =>
|
||||
FOOTER_FIELDS.includes(output.type)
|
||||
);
|
||||
},
|
||||
defaultSelectorOptions
|
||||
),
|
||||
[nodeId]
|
||||
export const useWithFooter = (nodeId: string) => {
|
||||
const hasImageOutput = useHasImageOutput(nodeId);
|
||||
const isCacheEnabled = useFeatureStatus('invocationCache').isFeatureEnabled;
|
||||
|
||||
const withFooter = useMemo(
|
||||
() => hasImageOutput || isCacheEnabled,
|
||||
[hasImageOutput, isCacheEnabled]
|
||||
);
|
||||
|
||||
const withFooter = useAppSelector(selector);
|
||||
return withFooter;
|
||||
};
|
||||
|
||||
@@ -0,0 +1,41 @@
|
||||
import { Flex, Skeleton } from '@chakra-ui/react';
|
||||
import { memo } from 'react';
|
||||
import { COLUMN_WIDTHS } from './constants';
|
||||
|
||||
const QueueItemSkeleton = () => {
|
||||
return (
|
||||
<Flex alignItems="center" p={1.5} gap={4} minH={9} h="full" w="full">
|
||||
<Flex
|
||||
w={COLUMN_WIDTHS.number}
|
||||
justifyContent="flex-end"
|
||||
alignItems="center"
|
||||
>
|
||||
<Skeleton w="full" h="full">
|
||||
|
||||
</Skeleton>
|
||||
</Flex>
|
||||
<Flex w={COLUMN_WIDTHS.statusBadge} alignItems="center">
|
||||
<Skeleton w="full" h="full">
|
||||
|
||||
</Skeleton>
|
||||
</Flex>
|
||||
<Flex w={COLUMN_WIDTHS.time} alignItems="center">
|
||||
<Skeleton w="full" h="full">
|
||||
|
||||
</Skeleton>
|
||||
</Flex>
|
||||
<Flex w={COLUMN_WIDTHS.batchId} alignItems="center">
|
||||
<Skeleton w="full" h="full">
|
||||
|
||||
</Skeleton>
|
||||
</Flex>
|
||||
<Flex w={COLUMN_WIDTHS.fieldValues} alignItems="center" flexGrow={1}>
|
||||
<Skeleton w="full" h="full">
|
||||
|
||||
</Skeleton>
|
||||
</Flex>
|
||||
</Flex>
|
||||
);
|
||||
};
|
||||
|
||||
export default memo(QueueItemSkeleton);
|
||||
@@ -3,6 +3,7 @@ import { createSelector } from '@reduxjs/toolkit';
|
||||
import { stateSelector } from 'app/store/store';
|
||||
import { useAppDispatch, useAppSelector } from 'app/store/storeHooks';
|
||||
import { defaultSelectorOptions } from 'app/store/util/defaultMemoizeOptions';
|
||||
import { IAINoContentFallbackWithSpinner } from 'common/components/IAIImageFallback';
|
||||
import {
|
||||
listCursorChanged,
|
||||
listPriorityChanged,
|
||||
@@ -85,7 +86,7 @@ const QueueList = () => {
|
||||
return () => osInstance()?.destroy();
|
||||
}, [scroller, initialize, osInstance]);
|
||||
|
||||
const { data: listQueueItemsData } = useListQueueItemsQuery({
|
||||
const { data: listQueueItemsData, isLoading } = useListQueueItemsQuery({
|
||||
cursor: listCursor,
|
||||
priority: listPriority,
|
||||
});
|
||||
@@ -125,36 +126,40 @@ const QueueList = () => {
|
||||
[openQueueItems, toggleQueueItem]
|
||||
);
|
||||
|
||||
if (isLoading) {
|
||||
return <IAINoContentFallbackWithSpinner />;
|
||||
}
|
||||
|
||||
if (!queueItems.length) {
|
||||
return (
|
||||
<Flex w="full" h="full" alignItems="center" justifyContent="center">
|
||||
<Heading color="base.400" _dark={{ color: 'base.500' }}>
|
||||
{t('queue.queueEmpty')}
|
||||
</Heading>
|
||||
</Flex>
|
||||
);
|
||||
}
|
||||
|
||||
return (
|
||||
<Flex w="full" h="full" flexDir="column">
|
||||
{queueItems.length ? (
|
||||
<>
|
||||
<QueueListHeader />
|
||||
<Flex
|
||||
ref={rootRef}
|
||||
w="full"
|
||||
h="full"
|
||||
alignItems="center"
|
||||
justifyContent="center"
|
||||
>
|
||||
<Virtuoso<SessionQueueItemDTO, ListContext>
|
||||
data={queueItems}
|
||||
endReached={handleLoadMore}
|
||||
scrollerRef={setScroller as TableVirtuosoScrollerRef}
|
||||
itemContent={itemContent}
|
||||
computeItemKey={computeItemKey}
|
||||
components={components}
|
||||
context={context}
|
||||
/>
|
||||
</Flex>
|
||||
</>
|
||||
) : (
|
||||
<Flex w="full" h="full" alignItems="center" justifyContent="center">
|
||||
<Heading color="base.400" _dark={{ color: 'base.500' }}>
|
||||
{t('queue.queueEmpty')}
|
||||
</Heading>
|
||||
</Flex>
|
||||
)}
|
||||
<QueueListHeader />
|
||||
<Flex
|
||||
ref={rootRef}
|
||||
w="full"
|
||||
h="full"
|
||||
alignItems="center"
|
||||
justifyContent="center"
|
||||
>
|
||||
<Virtuoso<SessionQueueItemDTO, ListContext>
|
||||
data={queueItems}
|
||||
endReached={handleLoadMore}
|
||||
scrollerRef={setScroller as TableVirtuosoScrollerRef}
|
||||
itemContent={itemContent}
|
||||
computeItemKey={computeItemKey}
|
||||
components={components}
|
||||
context={context}
|
||||
/>
|
||||
</Flex>
|
||||
</Flex>
|
||||
);
|
||||
};
|
||||
|
||||
@@ -4,7 +4,7 @@ import {
|
||||
ThunkDispatch,
|
||||
createEntityAdapter,
|
||||
} from '@reduxjs/toolkit';
|
||||
import { $queueId } from 'features/queue/store/nanoStores';
|
||||
import { $queueId } from 'features/queue/store/queueNanoStore';
|
||||
import { listParamsReset } from 'features/queue/store/queueSlice';
|
||||
import queryString from 'query-string';
|
||||
import { ApiTagDescription, api } from '..';
|
||||
|
||||
@@ -1,5 +1,5 @@
|
||||
import { createAsyncThunk, isAnyOf } from '@reduxjs/toolkit';
|
||||
import { $queueId } from 'features/queue/store/nanoStores';
|
||||
import { $queueId } from 'features/queue/store/queueNanoStore';
|
||||
import { isObject } from 'lodash-es';
|
||||
import { $client } from 'services/api/client';
|
||||
import { paths } from 'services/api/schema';
|
||||
|
||||
@@ -1,7 +1,7 @@
|
||||
import { MiddlewareAPI } from '@reduxjs/toolkit';
|
||||
import { logger } from 'app/logging/logger';
|
||||
import { AppDispatch, RootState } from 'app/store/store';
|
||||
import { $queueId } from 'features/queue/store/nanoStores';
|
||||
import { $queueId } from 'features/queue/store/queueNanoStore';
|
||||
import { addToast } from 'features/system/store/systemSlice';
|
||||
import { makeToast } from 'features/system/util/makeToast';
|
||||
import { Socket } from 'socket.io-client';
|
||||
|
||||
Reference in New Issue
Block a user