mirror of
https://github.com/invoke-ai/InvokeAI.git
synced 2026-01-16 06:38:08 -05:00
Compare commits
126 Commits
feat/blend
...
psychedeli
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
ff68ae7710 | ||
|
|
dedead672f | ||
|
|
67366921c0 | ||
|
|
5a1019d858 | ||
|
|
f4ba7be918 | ||
|
|
069d8b5812 | ||
|
|
24d73d484a | ||
|
|
4bda7d7df5 | ||
|
|
920c5dd686 | ||
|
|
4ce00a32f4 | ||
|
|
dcbb25dfea | ||
|
|
6c8270dae2 | ||
|
|
b19572199f | ||
|
|
a673c0aa14 | ||
|
|
955ef3bc54 | ||
|
|
f002ae8da5 | ||
|
|
208bf68ba2 | ||
|
|
1aba369c83 | ||
|
|
9ac11e793c | ||
|
|
9b39888e2f | ||
|
|
c1715144f0 | ||
|
|
929557bc6f | ||
|
|
811dd93912 | ||
|
|
9a60dbd5cb | ||
|
|
637c5b0747 | ||
|
|
27164de8b8 | ||
|
|
08e40d6d16 | ||
|
|
d905c54795 | ||
|
|
dc1e804887 | ||
|
|
95fd2ee6ff | ||
|
|
5f4eb0c3b3 | ||
|
|
d464ce509b | ||
|
|
3909e68527 | ||
|
|
848e51f72b | ||
|
|
52f8c9e16f | ||
|
|
5174f382b9 | ||
|
|
c7f80cd163 | ||
|
|
309e2414ce | ||
|
|
6704f77d87 | ||
|
|
045d3f6139 | ||
|
|
a0bd8c638e | ||
|
|
de04a5f441 | ||
|
|
40ed218c26 | ||
|
|
807c6b41c5 | ||
|
|
f6bbcd0589 | ||
|
|
ada22a799e | ||
|
|
a42ef9c855 | ||
|
|
034af2d9f8 | ||
|
|
676ccd8ebb | ||
|
|
a263a4f4cc | ||
|
|
ef0754cdec | ||
|
|
8158124679 | ||
|
|
5d31df0cb7 | ||
|
|
bd63454e51 | ||
|
|
062df07de2 | ||
|
|
0fc14afcf0 | ||
|
|
4a0a1c30db | ||
|
|
3432fd72f8 | ||
|
|
05a43c41f9 | ||
|
|
bb48617101 | ||
|
|
aa2f68f608 | ||
|
|
fbccce7573 | ||
|
|
a35087ee6e | ||
|
|
03e463dc89 | ||
|
|
d467e138a4 | ||
|
|
ba4aaea45b | ||
|
|
53eb23b8b6 | ||
|
|
8b969053e7 | ||
|
|
98a076260b | ||
|
|
164877b610 | ||
|
|
b3f4f28d76 | ||
|
|
acee4bd282 | ||
|
|
fc9a7320eb | ||
|
|
7c0a083b13 | ||
|
|
50d254fdb7 | ||
|
|
0cfc1c5f86 | ||
|
|
f35dfa06bb | ||
|
|
407bca5063 | ||
|
|
1419977e89 | ||
|
|
a953944894 | ||
|
|
a4cdaa245e | ||
|
|
105a4234b0 | ||
|
|
34c563060f | ||
|
|
d45c47db81 | ||
|
|
c771a4027f | ||
|
|
3fd27b1aa9 | ||
|
|
d59e534cad | ||
|
|
0c97a1e7e7 | ||
|
|
c8b306d9f8 | ||
|
|
edd2c54b9e | ||
|
|
727cc0dafe | ||
|
|
4530bd46dc | ||
|
|
c8b109f52e | ||
|
|
a2613948d8 | ||
|
|
f8392b2f78 | ||
|
|
358116bc22 | ||
|
|
1e3590111d | ||
|
|
063b800280 | ||
|
|
3935bf92c8 | ||
|
|
066e09b517 | ||
|
|
869b4a8d49 | ||
|
|
399ebe443e | ||
|
|
13919ff300 | ||
|
|
634e5652ef | ||
|
|
9bdc718df5 | ||
|
|
73ca8ccdb3 | ||
|
|
f37ffda966 | ||
|
|
5a9777d443 | ||
|
|
8072c05ee0 | ||
|
|
75ff4f4ca3 | ||
|
|
30df123221 | ||
|
|
06193ddbe8 | ||
|
|
ce5122f87c | ||
|
|
43ebd68313 | ||
|
|
ec19fcafb1 | ||
|
|
6fcc7d4c4b | ||
|
|
912087e4dc | ||
|
|
593fb95213 | ||
|
|
6d821b32d3 | ||
|
|
297f96c16b | ||
|
|
0e53b27655 | ||
|
|
35ae9f6e71 | ||
|
|
a1d9e6b871 | ||
|
|
f05379f965 | ||
|
|
e34e6d6e80 | ||
|
|
86cb53342a |
@@ -167,6 +167,23 @@ and so you'll have access to the same python environment as the InvokeAI app.
|
||||
|
||||
This is _super_ handy.
|
||||
|
||||
#### Enabling Type-Checking with Pylance
|
||||
|
||||
We use python's typing system in InvokeAI. PR reviews will include checking that types are present and correct. We don't enforce types with `mypy` at this time, but that is on the horizon.
|
||||
|
||||
Using a code analysis tool to automatically type check your code (and types) is very important when writing with types. These tools provide immediate feedback in your editor when types are incorrect, and following their suggestions lead to fewer runtime bugs.
|
||||
|
||||
Pylance, installed at the beginning of this guide, is the de-facto python LSP (language server protocol). It provides type checking in the editor (among many other features). Once installed, you do need to enable type checking manually:
|
||||
|
||||
- Open a python file
|
||||
- Look along the status bar in VSCode for `{ } Python`
|
||||
- Click the `{ }`
|
||||
- Turn type checking on - basic is fine
|
||||
|
||||
You'll now see red squiggly lines where type issues are detected. Hover your cursor over the indicated symbols to see what's wrong.
|
||||
|
||||
In 99% of cases when the type checker says there is a problem, there really is a problem, and you should take some time to understand and resolve what it is pointing out.
|
||||
|
||||
#### Debugging configs with `launch.json`
|
||||
|
||||
Debugging configs are managed in a `launch.json` file. Like most VSCode configs,
|
||||
@@ -208,6 +225,14 @@ Now we can create the InvokeAI debugging configs:
|
||||
"program": "scripts/invokeai-cli.py",
|
||||
"justMyCode": true
|
||||
},
|
||||
{
|
||||
"type": "chrome",
|
||||
"request": "launch",
|
||||
"name": "InvokeAI UI",
|
||||
// You have to run the UI with `yarn dev` for this to work
|
||||
"url": "http://localhost:5173",
|
||||
"webRoot": "${workspaceFolder}/invokeai/frontend/web"
|
||||
},
|
||||
{
|
||||
// Run tests
|
||||
"name": "InvokeAI Test",
|
||||
@@ -243,7 +268,8 @@ Now we can create the InvokeAI debugging configs:
|
||||
|
||||
You'll see these configs in the debugging configs drop down. Running them will
|
||||
start InvokeAI with attached debugger, in the correct environment, and work just
|
||||
like the normal app.
|
||||
like the normal app, though the UI debugger requires you to run the UI in dev
|
||||
mode. See the [frontend guide](contribution_guides/contributingToFrontend.md) for setting that up.
|
||||
|
||||
Enjoy debugging InvokeAI with ease (not that we have any bugs of course).
|
||||
|
||||
|
||||
@@ -38,9 +38,9 @@ There are two paths to making a development contribution:
|
||||
|
||||
If you need help, you can ask questions in the [#dev-chat](https://discord.com/channels/1020123559063990373/1049495067846524939) channel of the Discord.
|
||||
|
||||
For frontend related work, **@pyschedelicious** is the best person to reach out to.
|
||||
For frontend related work, **@psychedelicious** is the best person to reach out to.
|
||||
|
||||
For backend related work, please reach out to **@blessedcoolant**, **@lstein**, **@StAlKeR7779** or **@pyschedelicious**.
|
||||
For backend related work, please reach out to **@blessedcoolant**, **@lstein**, **@StAlKeR7779** or **@psychedelicious**.
|
||||
|
||||
|
||||
## **What does the Code of Conduct mean for me?**
|
||||
|
||||
@@ -10,4 +10,4 @@ When updating or creating documentation, please keep in mind InvokeAI is a tool
|
||||
|
||||
## Help & Questions
|
||||
|
||||
Please ping @imic1 or @hipsterusername in the [Discord](https://discord.com/channels/1020123559063990373/1049495067846524939) if you have any questions.
|
||||
Please ping @imic or @hipsterusername in the [Discord](https://discord.com/channels/1020123559063990373/1049495067846524939) if you have any questions.
|
||||
@@ -1,13 +1,11 @@
|
||||
---
|
||||
title: ControlNet
|
||||
title: Control Adapters
|
||||
---
|
||||
|
||||
# :material-loupe: ControlNet
|
||||
# :material-loupe: Control Adapters
|
||||
|
||||
## ControlNet
|
||||
|
||||
ControlNet
|
||||
|
||||
ControlNet is a powerful set of features developed by the open-source
|
||||
community (notably, Stanford researcher
|
||||
[**@ilyasviel**](https://github.com/lllyasviel)) that allows you to
|
||||
@@ -20,7 +18,7 @@ towards generating images that better fit your desired style or
|
||||
outcome.
|
||||
|
||||
|
||||
### How it works
|
||||
#### How it works
|
||||
|
||||
ControlNet works by analyzing an input image, pre-processing that
|
||||
image to identify relevant information that can be interpreted by each
|
||||
@@ -30,7 +28,7 @@ composition, or other aspects of the image to better achieve a
|
||||
specific result.
|
||||
|
||||
|
||||
### Models
|
||||
#### Models
|
||||
|
||||
InvokeAI provides access to a series of ControlNet models that provide
|
||||
different effects or styles in your generated images. Currently
|
||||
@@ -96,6 +94,8 @@ A model that generates normal maps from input images, allowing for more realisti
|
||||
**Image Segmentation**:
|
||||
A model that divides input images into segments or regions, each of which corresponds to a different object or part of the image. (More details coming soon)
|
||||
|
||||
**QR Code Monster**:
|
||||
A model that helps generate creative QR codes that still scan. Can also be used to create images with text, logos or shapes within them.
|
||||
|
||||
**Openpose**:
|
||||
The OpenPose control model allows for the identification of the general pose of a character by pre-processing an existing image with a clear human structure. With advanced options, Openpose can also detect the face or hands in the image.
|
||||
@@ -120,7 +120,7 @@ With Pix2Pix, you can input an image into the controlnet, and then "instruct" th
|
||||
Each of these models can be adjusted and combined with other ControlNet models to achieve different results, giving you even more control over your image generation process.
|
||||
|
||||
|
||||
## Using ControlNet
|
||||
### Using ControlNet
|
||||
|
||||
To use ControlNet, you can simply select the desired model and adjust both the ControlNet and Pre-processor settings to achieve the desired result. You can also use multiple ControlNet models at the same time, allowing you to achieve even more complex effects or styles in your generated images.
|
||||
|
||||
@@ -132,3 +132,31 @@ Weight - Strength of the Controlnet model applied to the generation for the sect
|
||||
Start/End - 0 represents the start of the generation, 1 represents the end. The Start/end setting controls what steps during the generation process have the ControlNet applied.
|
||||
|
||||
Additionally, each ControlNet section can be expanded in order to manipulate settings for the image pre-processor that adjusts your uploaded image before using it in when you Invoke.
|
||||
|
||||
|
||||
## IP-Adapter
|
||||
|
||||
[IP-Adapter](https://ip-adapter.github.io) is a tooling that allows for image prompt capabilities with text-to-image diffusion models. IP-Adapter works by analyzing the given image prompt to extract features, then passing those features to the UNet along with any other conditioning provided.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
#### Installation
|
||||
There are several ways to install IP-Adapter models with an existing InvokeAI installation:
|
||||
|
||||
1. Through the command line interface launched from the invoke.sh / invoke.bat scripts, option [5] to download models.
|
||||
2. Through the Model Manager UI with models from the *Tools* section of [www.models.invoke.ai](www.models.invoke.ai). To do this, copy the repo ID from the desired model page, and paste it in the Add Model field of the model manager. **Note** Both the IP-Adapter and the Image Encoder must be installed for IP-Adapter to work. For example, the [SD 1.5 IP-Adapter](https://models.invoke.ai/InvokeAI/ip_adapter_plus_sd15) and [SD1.5 Image Encoder](https://models.invoke.ai/InvokeAI/ip_adapter_sd_image_encoder) must be installed to use IP-Adapter with SD1.5 based models.
|
||||
3. **Advanced -- Not recommended ** Manually downloading the IP-Adapter and Image Encoder files - Image Encoder folders shouid be placed in the `models\any\clip_vision` folders. IP Adapter Model folders should be placed in the relevant `ip-adapter` folder of relevant base model folder of Invoke root directory. For example, for the SDXL IP-Adapter, files should be added to the `model/sdxl/ip_adapter/` folder.
|
||||
|
||||
#### Using IP-Adapter
|
||||
|
||||
IP-Adapter can be used by navigating to the *Control Adapters* options and enabling IP-Adapter.
|
||||
|
||||
IP-Adapter requires an image to be used as the Image Prompt. It can also be used in conjunction with text prompts, Image-to-Image, Inpainting, Outpainting, ControlNets and LoRAs.
|
||||
|
||||
|
||||
Each IP-Adapter has two settings that are applied to the IP-Adapter:
|
||||
|
||||
* Weight - Strength of the IP-Adapter model applied to the generation for the section, defined by start/end
|
||||
* Start/End - 0 represents the start of the generation, 1 represents the end. The Start/end setting controls what steps during the generation process have the IP-Adapter applied.
|
||||
|
||||
@@ -296,8 +296,18 @@ code for InvokeAI. For this to work, you will need to install the
|
||||
on your system, please see the [Git Installation
|
||||
Guide](https://github.com/git-guides/install-git)
|
||||
|
||||
You will also need to install the [frontend development toolchain](https://github.com/invoke-ai/InvokeAI/blob/main/docs/contributing/contribution_guides/contributingToFrontend.md).
|
||||
|
||||
If you have a "normal" installation, you should create a totally separate virtual environment for the git-based installation, else the two may interfere.
|
||||
|
||||
> **Why do I need the frontend toolchain**?
|
||||
>
|
||||
> The InvokeAI project uses trunk-based development. That means our `main` branch is the development branch, and releases are tags on that branch. Because development is very active, we don't keep an updated build of the UI in `main` - we only build it for production releases.
|
||||
>
|
||||
> That means that between releases, to have a functioning application when running directly from the repo, you will need to run the UI in dev mode or build it regularly (any time the UI code changes).
|
||||
|
||||
1. Create a fork of the InvokeAI repository through the GitHub UI or [this link](https://github.com/invoke-ai/InvokeAI/fork)
|
||||
1. From the command line, run this command:
|
||||
2. From the command line, run this command:
|
||||
```bash
|
||||
git clone https://github.com/<your_github_username>/InvokeAI.git
|
||||
```
|
||||
@@ -305,10 +315,10 @@ Guide](https://github.com/git-guides/install-git)
|
||||
This will create a directory named `InvokeAI` and populate it with the
|
||||
full source code from your fork of the InvokeAI repository.
|
||||
|
||||
2. Activate the InvokeAI virtual environment as per step (4) of the manual
|
||||
3. Activate the InvokeAI virtual environment as per step (4) of the manual
|
||||
installation protocol (important!)
|
||||
|
||||
3. Enter the InvokeAI repository directory and run one of these
|
||||
4. Enter the InvokeAI repository directory and run one of these
|
||||
commands, based on your GPU:
|
||||
|
||||
=== "CUDA (NVidia)"
|
||||
@@ -334,11 +344,15 @@ installation protocol (important!)
|
||||
Be sure to pass `-e` (for an editable install) and don't forget the
|
||||
dot ("."). It is part of the command.
|
||||
|
||||
You can now run `invokeai` and its related commands. The code will be
|
||||
5. Install the [frontend toolchain](https://github.com/invoke-ai/InvokeAI/blob/main/docs/contributing/contribution_guides/contributingToFrontend.md) and do a production build of the UI as described.
|
||||
|
||||
6. You can now run `invokeai` and its related commands. The code will be
|
||||
read from the repository, so that you can edit the .py source files
|
||||
and watch the code's behavior change.
|
||||
|
||||
4. If you wish to contribute to the InvokeAI project, you are
|
||||
When you pull in new changes to the repo, be sure to re-build the UI.
|
||||
|
||||
7. If you wish to contribute to the InvokeAI project, you are
|
||||
encouraged to establish a GitHub account and "fork"
|
||||
https://github.com/invoke-ai/InvokeAI into your own copy of the
|
||||
repository. You can then use GitHub functions to create and submit
|
||||
|
||||
@@ -171,3 +171,16 @@ subfolders and organize them as you wish.
|
||||
|
||||
The location of the autoimport directories are controlled by settings
|
||||
in `invokeai.yaml`. See [Configuration](../features/CONFIGURATION.md).
|
||||
|
||||
### Installing models that live in HuggingFace subfolders
|
||||
|
||||
On rare occasions you may need to install a diffusers-style model that
|
||||
lives in a subfolder of a HuggingFace repo id. In this event, simply
|
||||
add ":_subfolder-name_" to the end of the repo id. For example, if the
|
||||
repo id is "monster-labs/control_v1p_sd15_qrcode_monster" and the model
|
||||
you wish to fetch lives in a subfolder named "v2", then the repo id to
|
||||
pass to the various model installers should be
|
||||
|
||||
```
|
||||
monster-labs/control_v1p_sd15_qrcode_monster:v2
|
||||
```
|
||||
|
||||
@@ -4,12 +4,12 @@ The workflow editor is a blank canvas allowing for the use of individual functio
|
||||
|
||||
If you're not familiar with Diffusion, take a look at our [Diffusion Overview.](../help/diffusion.md) Understanding how diffusion works will enable you to more easily use the Workflow Editor and build workflows to suit your needs.
|
||||
|
||||
## UI Features
|
||||
## Features
|
||||
|
||||
### Linear View
|
||||
The Workflow Editor allows you to create a UI for your workflow, to make it easier to iterate on your generations.
|
||||
|
||||
To add an input to the Linear UI, right click on the input and select "Add to Linear View".
|
||||
To add an input to the Linear UI, right click on the input label and select "Add to Linear View".
|
||||
|
||||
The Linear UI View will also be part of the saved workflow, allowing you share workflows and enable other to use them, regardless of complexity.
|
||||
|
||||
@@ -25,6 +25,10 @@ Any node or input field can be renamed in the workflow editor. If the input fiel
|
||||
* Backspace/Delete to delete a node
|
||||
* Shift+Click to drag and select multiple nodes
|
||||
|
||||
### Node Caching
|
||||
|
||||
Nodes have a "Use Cache" option in their footer. This allows for performance improvements by using the previously cached values during the workflow processing.
|
||||
|
||||
|
||||
## Important Concepts
|
||||
|
||||
|
||||
@@ -8,19 +8,7 @@ To download a node, simply download the `.py` node file from the link and add it
|
||||
|
||||
To use a community workflow, download the the `.json` node graph file and load it into Invoke AI via the **Load Workflow** button in the Workflow Editor.
|
||||
|
||||
## Community Nodes
|
||||
|
||||
### FaceTools
|
||||
|
||||
**Description:** FaceTools is a collection of nodes created to manipulate faces as you would in Unified Canvas. It includes FaceMask, FaceOff, and FacePlace. FaceMask autodetects a face in the image using MediaPipe and creates a mask from it. FaceOff similarly detects a face, then takes the face off of the image by adding a square bounding box around it and cropping/scaling it. FacePlace puts the bounded face image from FaceOff back onto the original image. Using these nodes with other inpainting node(s), you can put new faces on existing things, put new things around existing faces, and work closer with a face as a bounded image. Additionally, you can supply X and Y offset values to scale/change the shape of the mask for finer control on FaceMask and FaceOff. See GitHub repository below for usage examples.
|
||||
|
||||
**Node Link:** https://github.com/ymgenesis/FaceTools/
|
||||
|
||||
**FaceMask Output Examples**
|
||||
|
||||

|
||||

|
||||

|
||||
--------------------------------
|
||||
|
||||
--------------------------------
|
||||
### Ideal Size
|
||||
@@ -43,6 +31,52 @@ To use a community workflow, download the the `.json` node graph file and load i
|
||||
|
||||
**Node Link:** https://github.com/JPPhoto/image-picker-node
|
||||
|
||||
--------------------------------
|
||||
### Thresholding
|
||||
|
||||
**Description:** This node generates masks for highlights, midtones, and shadows given an input image. You can optionally specify a blur for the lookup table used in making those masks from the source image.
|
||||
|
||||
**Node Link:** https://github.com/JPPhoto/thresholding-node
|
||||
|
||||
**Examples**
|
||||
|
||||
Input:
|
||||
|
||||
{: style="height:512px;width:512px"}
|
||||
|
||||
Highlights/Midtones/Shadows:
|
||||
|
||||
<img src="https://github.com/invoke-ai/InvokeAI/assets/34005131/727021c1-36ff-4ec8-90c8-105e00de986d" style="width: 30%" />
|
||||
<img src="https://github.com/invoke-ai/InvokeAI/assets/34005131/0b721bfc-f051-404e-b905-2f16b824ddfe" style="width: 30%" />
|
||||
<img src="https://github.com/invoke-ai/InvokeAI/assets/34005131/04c1297f-1c88-42b6-a7df-dd090b976286" style="width: 30%" />
|
||||
|
||||
Highlights/Midtones/Shadows (with LUT blur enabled):
|
||||
|
||||
<img src="https://github.com/invoke-ai/InvokeAI/assets/34005131/19aa718a-70c1-4668-8169-d68f4bd13771" style="width: 30%" />
|
||||
<img src="https://github.com/invoke-ai/InvokeAI/assets/34005131/0a440e43-697f-4d17-82ee-f287467df0a5" style="width: 30%" />
|
||||
<img src="https://github.com/invoke-ai/InvokeAI/assets/34005131/0701fd0f-2ca7-4fe2-8613-2b52547bafce" style="width: 30%" />
|
||||
|
||||
--------------------------------
|
||||
### Halftone
|
||||
|
||||
**Description**: Halftone converts the source image to grayscale and then performs halftoning. CMYK Halftone converts the image to CMYK and applies a per-channel halftoning to make the source image look like a magazine or newspaper. For both nodes, you can specify angles and halftone dot spacing.
|
||||
|
||||
**Node Link:** https://github.com/JPPhoto/halftone-node
|
||||
|
||||
**Example**
|
||||
|
||||
Input:
|
||||
|
||||
{: style="height:512px;width:512px"}
|
||||
|
||||
Halftone Output:
|
||||
|
||||
{: style="height:512px;width:512px"}
|
||||
|
||||
CMYK Halftone Output:
|
||||
|
||||
{: style="height:512px;width:512px"}
|
||||
|
||||
--------------------------------
|
||||
### Retroize
|
||||
|
||||
@@ -77,7 +111,7 @@ Generated Prompt: An enchanted weapon will be usable by any character regardless
|
||||
**Example Node Graph:** https://github.com/helix4u/load_video_frame/blob/main/Example_Workflow.json
|
||||
|
||||
**Output Example:**
|
||||
=======
|
||||
|
||||

|
||||
[Full mp4 of Example Output test.mp4](https://github.com/helix4u/load_video_frame/blob/main/test.mp4)
|
||||
|
||||
@@ -121,18 +155,6 @@ To be imported, an .obj must use triangulated meshes, so make sure to enable tha
|
||||
**Example Usage:**
|
||||
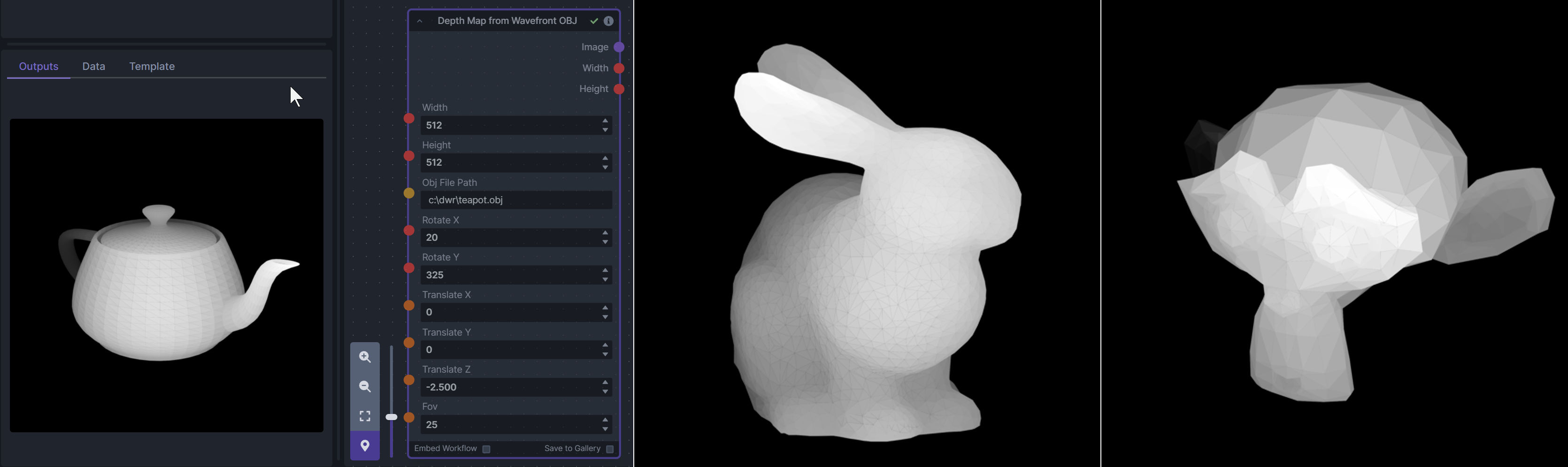
|
||||
|
||||
--------------------------------
|
||||
### Enhance Image (simple adjustments)
|
||||
|
||||
**Description:** Boost or reduce color saturation, contrast, brightness, sharpness, or invert colors of any image at any stage with this simple wrapper for pillow [PIL]'s ImageEnhance module.
|
||||
|
||||
Color inversion is toggled with a simple switch, while each of the four enhancer modes are activated by entering a value other than 1 in each corresponding input field. Values less than 1 will reduce the corresponding property, while values greater than 1 will enhance it.
|
||||
|
||||
**Node Link:** https://github.com/dwringer/image-enhance-node
|
||||
|
||||
**Example Usage:**
|
||||
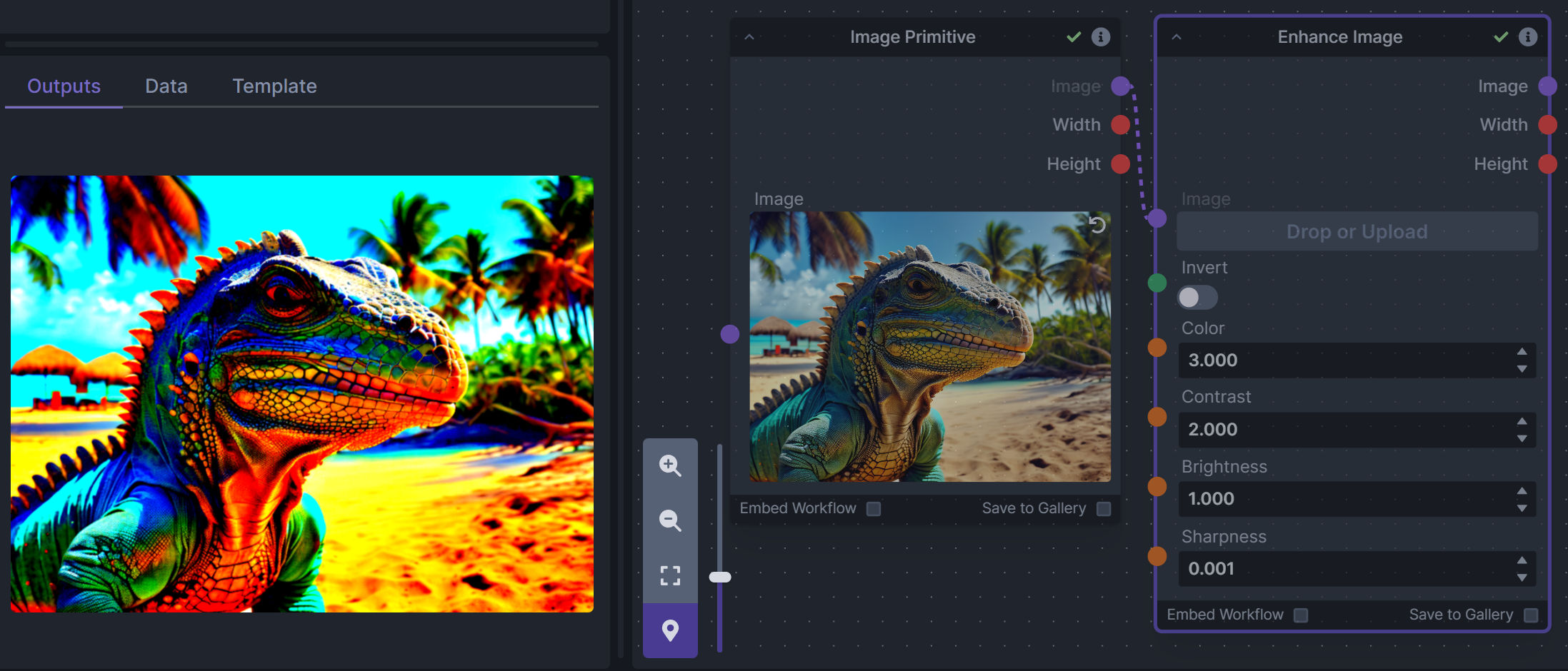
|
||||
|
||||
--------------------------------
|
||||
### Generative Grammar-Based Prompt Nodes
|
||||
|
||||
@@ -153,16 +175,28 @@ This includes 3 Nodes:
|
||||
|
||||
**Description:** This is a pack of nodes for composing masks and images, including a simple text mask creator and both image and latent offset nodes. The offsets wrap around, so these can be used in conjunction with the Seamless node to progressively generate centered on different parts of the seamless tiling.
|
||||
|
||||
This includes 4 Nodes:
|
||||
- *Text Mask (simple 2D)* - create and position a white on black (or black on white) line of text using any font locally available to Invoke.
|
||||
This includes 15 Nodes:
|
||||
|
||||
- *Adjust Image Hue Plus* - Rotate the hue of an image in one of several different color spaces.
|
||||
- *Blend Latents/Noise (Masked)* - Use a mask to blend part of one latents tensor [including Noise outputs] into another. Can be used to "renoise" sections during a multi-stage [masked] denoising process.
|
||||
- *Enhance Image* - Boost or reduce color saturation, contrast, brightness, sharpness, or invert colors of any image at any stage with this simple wrapper for pillow [PIL]'s ImageEnhance module.
|
||||
- *Equivalent Achromatic Lightness* - Calculates image lightness accounting for Helmholtz-Kohlrausch effect based on a method described by High, Green, and Nussbaum (2023).
|
||||
- *Text to Mask (Clipseg)* - Input a prompt and an image to generate a mask representing areas of the image matched by the prompt.
|
||||
- *Text to Mask Advanced (Clipseg)* - Output up to four prompt masks combined with logical "and", logical "or", or as separate channels of an RGBA image.
|
||||
- *Image Layer Blend* - Perform a layered blend of two images using alpha compositing. Opacity of top layer is selectable, with optional mask and several different blend modes/color spaces.
|
||||
- *Image Compositor* - Take a subject from an image with a flat backdrop and layer it on another image using a chroma key or flood select background removal.
|
||||
- *Image Dilate or Erode* - Dilate or expand a mask (or any image!). This is equivalent to an expand/contract operation.
|
||||
- *Image Value Thresholds* - Clip an image to pure black/white beyond specified thresholds.
|
||||
- *Offset Latents* - Offset a latents tensor in the vertical and/or horizontal dimensions, wrapping it around.
|
||||
- *Offset Image* - Offset an image in the vertical and/or horizontal dimensions, wrapping it around.
|
||||
- *Rotate/Flip Image* - Rotate an image in degrees clockwise/counterclockwise about its center, optionally resizing the image boundaries to fit, or flipping it about the vertical and/or horizontal axes.
|
||||
- *Shadows/Highlights/Midtones* - Extract three masks (with adjustable hard or soft thresholds) representing shadows, midtones, and highlights regions of an image.
|
||||
- *Text Mask (simple 2D)* - create and position a white on black (or black on white) line of text using any font locally available to Invoke.
|
||||
|
||||
**Node Link:** https://github.com/dwringer/composition-nodes
|
||||
|
||||
**Example Usage:**
|
||||
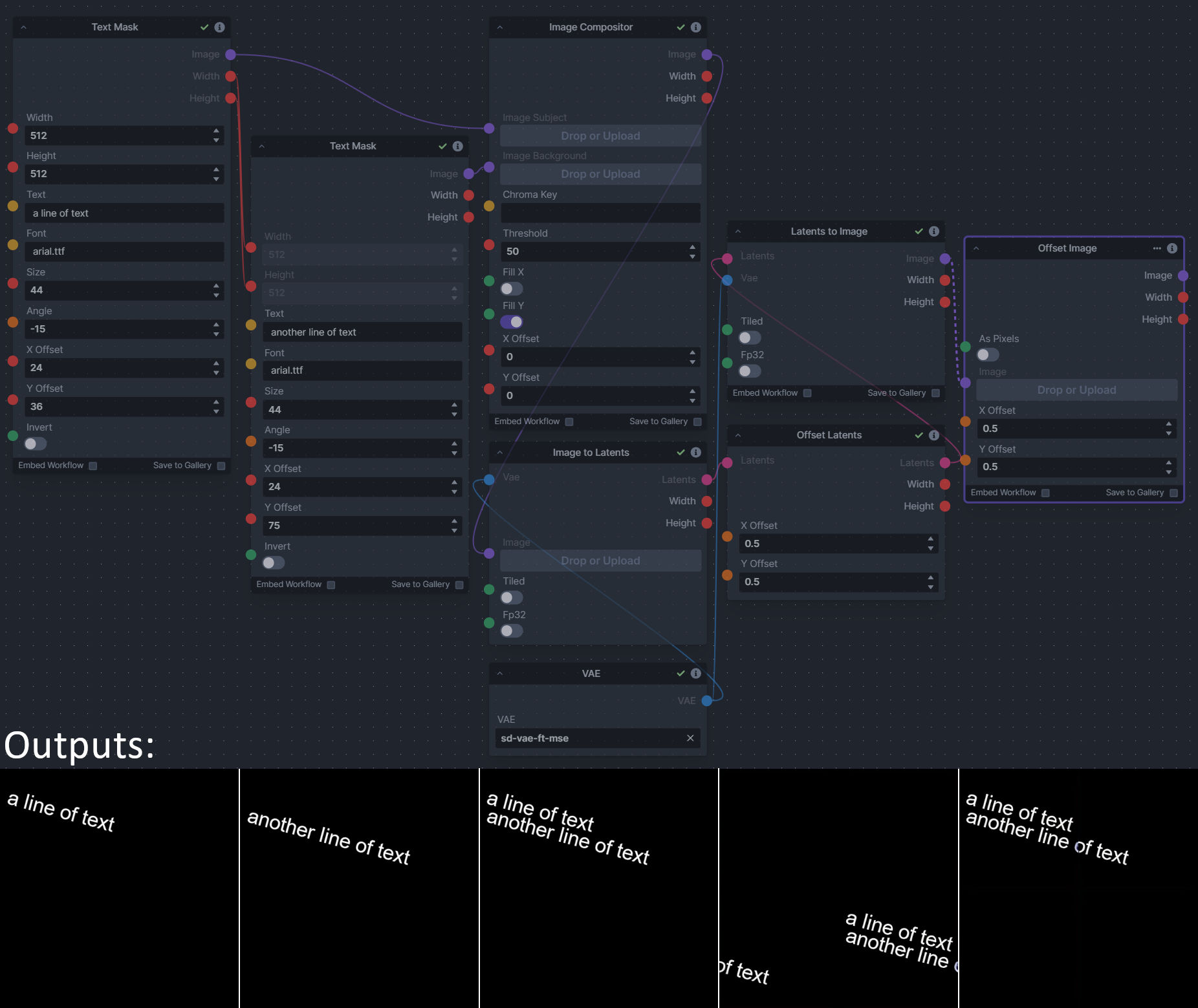
|
||||
**Nodes and Output Examples:**
|
||||
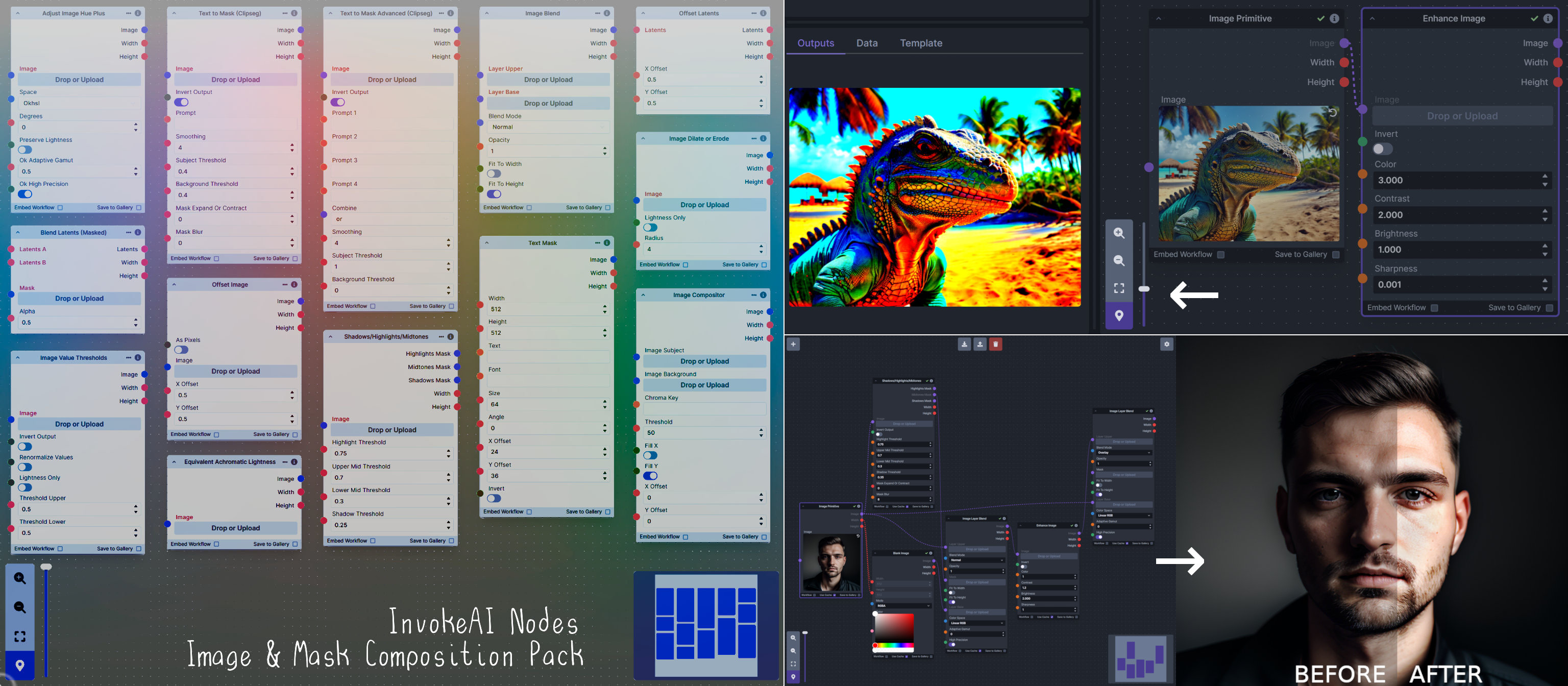
|
||||
|
||||
--------------------------------
|
||||
### Size Stepper Nodes
|
||||
@@ -230,6 +264,36 @@ See full docs here: https://github.com/skunkworxdark/XYGrid_nodes/edit/main/READ
|
||||
|
||||
--------------------------------
|
||||
|
||||
### Image to Character Art Image Node's
|
||||
|
||||
**Description:** Group of nodes to convert an input image into ascii/unicode art Image
|
||||
|
||||
**Node Link:** https://github.com/mickr777/imagetoasciiimage
|
||||
|
||||
**Output Examples**
|
||||
|
||||
<img src="https://github.com/invoke-ai/InvokeAI/assets/115216705/8e061fcc-9a2c-4fa9-bcc7-c0f7b01e9056" width="300" />
|
||||
<img src="https://github.com/mickr777/imagetoasciiimage/assets/115216705/3c4990eb-2f42-46b9-90f9-0088b939dc6a" width="300" /></br>
|
||||
<img src="https://github.com/mickr777/imagetoasciiimage/assets/115216705/fee7f800-a4a8-41e2-a66b-c66e4343307e" width="300" />
|
||||
<img src="https://github.com/mickr777/imagetoasciiimage/assets/115216705/1d9c1003-a45f-45c2-aac7-46470bb89330" width="300" />
|
||||
|
||||
--------------------------------
|
||||
|
||||
### Grid to Gif
|
||||
|
||||
**Description:** One node that turns a grid image into an image colletion, one node that turns an image collection into a gif
|
||||
|
||||
**Node Link:** https://github.com/mildmisery/invokeai-GridToGifNode/blob/main/GridToGif.py
|
||||
|
||||
**Example Node Graph:** https://github.com/mildmisery/invokeai-GridToGifNode/blob/main/Grid%20to%20Gif%20Example%20Workflow.json
|
||||
|
||||
**Output Examples**
|
||||
|
||||
<img src="https://raw.githubusercontent.com/mildmisery/invokeai-GridToGifNode/main/input.png" width="300" />
|
||||
<img src="https://raw.githubusercontent.com/mildmisery/invokeai-GridToGifNode/main/output.gif" width="300" />
|
||||
|
||||
--------------------------------
|
||||
|
||||
### Example Node Template
|
||||
|
||||
**Description:** This node allows you to do super cool things with InvokeAI.
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
# List of Default Nodes
|
||||
|
||||
The table below contains a list of the default nodes shipped with InvokeAI and their descriptions.
|
||||
The table below contains a list of the default nodes shipped with InvokeAI and their descriptions.
|
||||
|
||||
| Node <img width=160 align="right"> | Function |
|
||||
|: ---------------------------------- | :--------------------------------------------------------------------------------------|
|
||||
@@ -17,11 +17,12 @@ The table below contains a list of the default nodes shipped with InvokeAI and t
|
||||
|Conditioning Primitive | A conditioning tensor primitive value|
|
||||
|Content Shuffle Processor | Applies content shuffle processing to image|
|
||||
|ControlNet | Collects ControlNet info to pass to other nodes|
|
||||
|OpenCV Inpaint | Simple inpaint using opencv.|
|
||||
|Denoise Latents | Denoises noisy latents to decodable images|
|
||||
|Divide Integers | Divides two numbers|
|
||||
|Dynamic Prompt | Parses a prompt using adieyal/dynamicprompts' random or combinatorial generator|
|
||||
|Upscale (RealESRGAN) | Upscales an image using RealESRGAN.|
|
||||
|[FaceMask](./detailedNodes/faceTools.md#facemask) | Generates masks for faces in an image to use with Inpainting|
|
||||
|[FaceIdentifier](./detailedNodes/faceTools.md#faceidentifier) | Identifies and labels faces in an image|
|
||||
|[FaceOff](./detailedNodes/faceTools.md#faceoff) | Creates a new image that is a scaled bounding box with a mask on the face for Inpainting|
|
||||
|Float Math | Perform basic math operations on two floats|
|
||||
|Float Primitive Collection | A collection of float primitive values|
|
||||
|Float Primitive | A float primitive value|
|
||||
@@ -76,6 +77,7 @@ The table below contains a list of the default nodes shipped with InvokeAI and t
|
||||
|ONNX Prompt (Raw) | A node to process inputs and produce outputs. May use dependency injection in __init__ to receive providers.|
|
||||
|ONNX Text to Latents | Generates latents from conditionings.|
|
||||
|ONNX Model Loader | Loads a main model, outputting its submodels.|
|
||||
|OpenCV Inpaint | Simple inpaint using opencv.|
|
||||
|Openpose Processor | Applies Openpose processing to image|
|
||||
|PIDI Processor | Applies PIDI processing to image|
|
||||
|Prompts from File | Loads prompts from a text file|
|
||||
@@ -97,5 +99,6 @@ The table below contains a list of the default nodes shipped with InvokeAI and t
|
||||
|String Primitive | A string primitive value|
|
||||
|Subtract Integers | Subtracts two numbers|
|
||||
|Tile Resample Processor | Tile resampler processor|
|
||||
|Upscale (RealESRGAN) | Upscales an image using RealESRGAN.|
|
||||
|VAE Loader | Loads a VAE model, outputting a VaeLoaderOutput|
|
||||
|Zoe (Depth) Processor | Applies Zoe depth processing to image|
|
||||
154
docs/nodes/detailedNodes/faceTools.md
Normal file
154
docs/nodes/detailedNodes/faceTools.md
Normal file
@@ -0,0 +1,154 @@
|
||||
# Face Nodes
|
||||
|
||||
## FaceOff
|
||||
|
||||
FaceOff mimics a user finding a face in an image and resizing the bounding box
|
||||
around the head in Canvas.
|
||||
|
||||
Enter a face ID (found with FaceIdentifier) to choose which face to mask.
|
||||
|
||||
Just as you would add more context inside the bounding box by making it larger
|
||||
in Canvas, the node gives you a padding input (in pixels) which will
|
||||
simultaneously add more context, and increase the resolution of the bounding box
|
||||
so the face remains the same size inside it.
|
||||
|
||||
The "Minimum Confidence" input defaults to 0.5 (50%), and represents a pass/fail
|
||||
threshold a detected face must reach for it to be processed. Lowering this value
|
||||
may help if detection is failing. If the detected masks are imperfect and stray
|
||||
too far outside/inside of faces, the node gives you X & Y offsets to shrink/grow
|
||||
the masks by a multiplier.
|
||||
|
||||
FaceOff will output the face in a bounded image, taking the face off of the
|
||||
original image for input into any node that accepts image inputs. The node also
|
||||
outputs a face mask with the dimensions of the bounded image. The X & Y outputs
|
||||
are for connecting to the X & Y inputs of the Paste Image node, which will place
|
||||
the bounded image back on the original image using these coordinates.
|
||||
|
||||
###### Inputs/Outputs
|
||||
|
||||
| Input | Description |
|
||||
| ------------------ | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| Image | Image for face detection |
|
||||
| Face ID | The face ID to process, numbered from 0. Multiple faces not supported. Find a face's ID with FaceIdentifier node. |
|
||||
| Minimum Confidence | Minimum confidence for face detection (lower if detection is failing) |
|
||||
| X Offset | X-axis offset of the mask |
|
||||
| Y Offset | Y-axis offset of the mask |
|
||||
| Padding | All-axis padding around the mask in pixels |
|
||||
| Chunk | Chunk (or divide) the image into sections to greatly improve face detection success. Defaults to off, but will activate if no faces are detected normally. Activate to chunk by default. |
|
||||
|
||||
| Output | Description |
|
||||
| ------------- | ------------------------------------------------ |
|
||||
| Bounded Image | Original image bound, cropped, and resized |
|
||||
| Width | The width of the bounded image in pixels |
|
||||
| Height | The height of the bounded image in pixels |
|
||||
| Mask | The output mask |
|
||||
| X | The x coordinate of the bounding box's left side |
|
||||
| Y | The y coordinate of the bounding box's top side |
|
||||
|
||||
## FaceMask
|
||||
|
||||
FaceMask mimics a user drawing masks on faces in an image in Canvas.
|
||||
|
||||
The "Face IDs" input allows the user to select specific faces to be masked.
|
||||
Leave empty to detect and mask all faces, or a comma-separated list for a
|
||||
specific combination of faces (ex: `1,2,4`). A single integer will detect and
|
||||
mask that specific face. Find face IDs with the FaceIdentifier node.
|
||||
|
||||
The "Minimum Confidence" input defaults to 0.5 (50%), and represents a pass/fail
|
||||
threshold a detected face must reach for it to be processed. Lowering this value
|
||||
may help if detection is failing.
|
||||
|
||||
If the detected masks are imperfect and stray too far outside/inside of faces,
|
||||
the node gives you X & Y offsets to shrink/grow the masks by a multiplier. All
|
||||
masks shrink/grow together by the X & Y offset values.
|
||||
|
||||
By default, masks are created to change faces. When masks are inverted, they
|
||||
change surrounding areas, protecting faces.
|
||||
|
||||
###### Inputs/Outputs
|
||||
|
||||
| Input | Description |
|
||||
| ------------------ | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| Image | Image for face detection |
|
||||
| Face IDs | Comma-separated list of face ids to mask eg '0,2,7'. Numbered from 0. Leave empty to mask all. Find face IDs with FaceIdentifier node. |
|
||||
| Minimum Confidence | Minimum confidence for face detection (lower if detection is failing) |
|
||||
| X Offset | X-axis offset of the mask |
|
||||
| Y Offset | Y-axis offset of the mask |
|
||||
| Chunk | Chunk (or divide) the image into sections to greatly improve face detection success. Defaults to off, but will activate if no faces are detected normally. Activate to chunk by default. |
|
||||
| Invert Mask | Toggle to invert the face mask |
|
||||
|
||||
| Output | Description |
|
||||
| ------ | --------------------------------- |
|
||||
| Image | The original image |
|
||||
| Width | The width of the image in pixels |
|
||||
| Height | The height of the image in pixels |
|
||||
| Mask | The output face mask |
|
||||
|
||||
## FaceIdentifier
|
||||
|
||||
FaceIdentifier outputs an image with detected face IDs printed in white numbers
|
||||
onto each face.
|
||||
|
||||
Face IDs can then be used in FaceMask and FaceOff to selectively mask all, a
|
||||
specific combination, or single faces.
|
||||
|
||||
The FaceIdentifier output image is generated for user reference, and isn't meant
|
||||
to be passed on to other image-processing nodes.
|
||||
|
||||
The "Minimum Confidence" input defaults to 0.5 (50%), and represents a pass/fail
|
||||
threshold a detected face must reach for it to be processed. Lowering this value
|
||||
may help if detection is failing. If an image is changed in the slightest, run
|
||||
it through FaceIdentifier again to get updated FaceIDs.
|
||||
|
||||
###### Inputs/Outputs
|
||||
|
||||
| Input | Description |
|
||||
| ------------------ | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| Image | Image for face detection |
|
||||
| Minimum Confidence | Minimum confidence for face detection (lower if detection is failing) |
|
||||
| Chunk | Chunk (or divide) the image into sections to greatly improve face detection success. Defaults to off, but will activate if no faces are detected normally. Activate to chunk by default. |
|
||||
|
||||
| Output | Description |
|
||||
| ------ | ------------------------------------------------------------------------------------------------ |
|
||||
| Image | The original image with small face ID numbers printed in white onto each face for user reference |
|
||||
| Width | The width of the original image in pixels |
|
||||
| Height | The height of the original image in pixels |
|
||||
|
||||
## Tips
|
||||
|
||||
- If not all target faces are being detected, activate Chunk to bypass full
|
||||
image face detection and greatly improve detection success.
|
||||
- Final results will vary between full-image detection and chunking for faces
|
||||
that are detectable by both due to the nature of the process. Try either to
|
||||
your taste.
|
||||
- Be sure Minimum Confidence is set the same when using FaceIdentifier with
|
||||
FaceOff/FaceMask.
|
||||
- For FaceOff, use the color correction node before faceplace to correct edges
|
||||
being noticeable in the final image (see example screenshot).
|
||||
- Non-inpainting models may struggle to paint/generate correctly around faces.
|
||||
- If your face won't change the way you want it to no matter what you change,
|
||||
consider that the change you're trying to make is too much at that resolution.
|
||||
For example, if an image is only 512x768 total, the face might only be 128x128
|
||||
or 256x256, much smaller than the 512x512 your SD1.5 model was probably
|
||||
trained on. Try increasing the resolution of the image by upscaling or
|
||||
resizing, add padding to increase the bounding box's resolution, or use an
|
||||
image where the face takes up more pixels.
|
||||
- If the resulting face seems out of place pasted back on the original image
|
||||
(ie. too large, not proportional), add more padding on the FaceOff node to
|
||||
give inpainting more context. Context and good prompting are important to
|
||||
keeping things proportional.
|
||||
- If you find the mask is too big/small and going too far outside/inside the
|
||||
area you want to affect, adjust the x & y offsets to shrink/grow the mask area
|
||||
- Use a higher denoise start value to resemble aspects of the original face or
|
||||
surroundings. Denoise start = 0 & denoise end = 1 will make something new,
|
||||
while denoise start = 0.50 & denoise end = 1 will be 50% old and 50% new.
|
||||
- mediapipe isn't good at detecting faces with lots of face paint, hair covering
|
||||
the face, etc. Anything that obstructs the face will likely result in no faces
|
||||
being detected.
|
||||
- If you find your face isn't being detected, try lowering the minimum
|
||||
confidence value from 0.5. This could result in false positives, however
|
||||
(random areas being detected as faces and masked).
|
||||
- After altering an image and wanting to process a different face in the newly
|
||||
altered image, run the altered image through FaceIdentifier again to see the
|
||||
new Face IDs. MediaPipe will most likely detect faces in a different order
|
||||
after an image has been changed in the slightest.
|
||||
@@ -9,5 +9,6 @@ If you're interested in finding more workflows, checkout the [#share-your-workfl
|
||||
* [SD1.5 / SD2 Text to Image](https://github.com/invoke-ai/InvokeAI/blob/main/docs/workflows/Text_to_Image.json)
|
||||
* [SDXL Text to Image](https://github.com/invoke-ai/InvokeAI/blob/main/docs/workflows/SDXL_Text_to_Image.json)
|
||||
* [SDXL (with Refiner) Text to Image](https://github.com/invoke-ai/InvokeAI/blob/main/docs/workflows/SDXL_Text_to_Image.json)
|
||||
* [Tiled Upscaling with ControlNet](https://github.com/invoke-ai/InvokeAI/blob/main/docs/workflows/ESRGAN_img2img_upscale w_Canny_ControlNet.json)ß
|
||||
|
||||
* [Tiled Upscaling with ControlNet](https://github.com/invoke-ai/InvokeAI/blob/main/docs/workflows/ESRGAN_img2img_upscale w_Canny_ControlNet.json)
|
||||
* [FaceMask](https://github.com/invoke-ai/InvokeAI/blob/main/docs/workflows/FaceMask.json)
|
||||
* [FaceOff with 2x Face Scaling](https://github.com/invoke-ai/InvokeAI/blob/main/docs/workflows/FaceOff_FaceScale2x.json)
|
||||
|
||||
1041
docs/workflows/FaceMask.json
Normal file
1041
docs/workflows/FaceMask.json
Normal file
File diff suppressed because it is too large
Load Diff
1395
docs/workflows/FaceOff_FaceScale2x.json
Normal file
1395
docs/workflows/FaceOff_FaceScale2x.json
Normal file
File diff suppressed because it is too large
Load Diff
@@ -332,6 +332,7 @@ class InvokeAiInstance:
|
||||
Configure the InvokeAI runtime directory
|
||||
"""
|
||||
|
||||
auto_install = False
|
||||
# set sys.argv to a consistent state
|
||||
new_argv = [sys.argv[0]]
|
||||
for i in range(1, len(sys.argv)):
|
||||
@@ -340,13 +341,17 @@ class InvokeAiInstance:
|
||||
new_argv.append(el)
|
||||
new_argv.append(sys.argv[i + 1])
|
||||
elif el in ["-y", "--yes", "--yes-to-all"]:
|
||||
new_argv.append(el)
|
||||
auto_install = True
|
||||
sys.argv = new_argv
|
||||
|
||||
import messages
|
||||
import requests # to catch download exceptions
|
||||
from messages import introduction
|
||||
|
||||
introduction()
|
||||
auto_install = auto_install or messages.user_wants_auto_configuration()
|
||||
if auto_install:
|
||||
sys.argv.append("--yes")
|
||||
else:
|
||||
messages.introduction()
|
||||
|
||||
from invokeai.frontend.install.invokeai_configure import invokeai_configure
|
||||
|
||||
|
||||
@@ -7,7 +7,7 @@ import os
|
||||
import platform
|
||||
from pathlib import Path
|
||||
|
||||
from prompt_toolkit import prompt
|
||||
from prompt_toolkit import HTML, prompt
|
||||
from prompt_toolkit.completion import PathCompleter
|
||||
from prompt_toolkit.validation import Validator
|
||||
from rich import box, print
|
||||
@@ -65,17 +65,50 @@ def confirm_install(dest: Path) -> bool:
|
||||
if dest.exists():
|
||||
print(f":exclamation: Directory {dest} already exists :exclamation:")
|
||||
dest_confirmed = Confirm.ask(
|
||||
":stop_sign: Are you sure you want to (re)install in this location?",
|
||||
":stop_sign: (re)install in this location?",
|
||||
default=False,
|
||||
)
|
||||
else:
|
||||
print(f"InvokeAI will be installed in {dest}")
|
||||
dest_confirmed = not Confirm.ask("Would you like to pick a different location?", default=False)
|
||||
dest_confirmed = Confirm.ask("Use this location?", default=True)
|
||||
console.line()
|
||||
|
||||
return dest_confirmed
|
||||
|
||||
|
||||
def user_wants_auto_configuration() -> bool:
|
||||
"""Prompt the user to choose between manual and auto configuration."""
|
||||
console.rule("InvokeAI Configuration Section")
|
||||
console.print(
|
||||
Panel(
|
||||
Group(
|
||||
"\n".join(
|
||||
[
|
||||
"Libraries are installed and InvokeAI will now set up its root directory and configuration. Choose between:",
|
||||
"",
|
||||
" * AUTOMATIC configuration: install reasonable defaults and a minimal set of starter models.",
|
||||
" * MANUAL configuration: manually inspect and adjust configuration options and pick from a larger set of starter models.",
|
||||
"",
|
||||
"Later you can fine tune your configuration by selecting option [6] 'Change InvokeAI startup options' from the invoke.bat/invoke.sh launcher script.",
|
||||
]
|
||||
),
|
||||
),
|
||||
box=box.MINIMAL,
|
||||
padding=(1, 1),
|
||||
)
|
||||
)
|
||||
choice = (
|
||||
prompt(
|
||||
HTML("Choose <b><a></b>utomatic or <b><m></b>anual configuration [a/m] (a): "),
|
||||
validator=Validator.from_callable(
|
||||
lambda n: n == "" or n.startswith(("a", "A", "m", "M")), error_message="Please select 'a' or 'm'"
|
||||
),
|
||||
)
|
||||
or "a"
|
||||
)
|
||||
return choice.lower().startswith("a")
|
||||
|
||||
|
||||
def dest_path(dest=None) -> Path:
|
||||
"""
|
||||
Prompt the user for the destination path and create the path
|
||||
|
||||
@@ -146,7 +146,8 @@ async def update_model(
|
||||
async def import_model(
|
||||
location: str = Body(description="A model path, repo_id or URL to import"),
|
||||
prediction_type: Optional[Literal["v_prediction", "epsilon", "sample"]] = Body(
|
||||
description="Prediction type for SDv2 checkpoint files", default="v_prediction"
|
||||
description="Prediction type for SDv2 checkpoints and rare SDv1 checkpoints",
|
||||
default=None,
|
||||
),
|
||||
) -> ImportModelResponse:
|
||||
"""Add a model using its local path, repo_id, or remote URL. Model characteristics will be probed and configured automatically"""
|
||||
|
||||
@@ -8,7 +8,6 @@ app_config.parse_args()
|
||||
|
||||
if True: # hack to make flake8 happy with imports coming after setting up the config
|
||||
import asyncio
|
||||
import logging
|
||||
import mimetypes
|
||||
import socket
|
||||
from inspect import signature
|
||||
|
||||
@@ -91,6 +91,9 @@ class FieldDescriptions:
|
||||
board = "The board to save the image to"
|
||||
image = "The image to process"
|
||||
tile_size = "Tile size"
|
||||
inclusive_low = "The inclusive low value"
|
||||
exclusive_high = "The exclusive high value"
|
||||
decimal_places = "The number of decimal places to round to"
|
||||
|
||||
|
||||
class Input(str, Enum):
|
||||
|
||||
692
invokeai/app/invocations/facetools.py
Normal file
692
invokeai/app/invocations/facetools.py
Normal file
@@ -0,0 +1,692 @@
|
||||
import math
|
||||
import re
|
||||
from pathlib import Path
|
||||
from typing import Optional, TypedDict
|
||||
|
||||
import cv2
|
||||
import numpy as np
|
||||
from mediapipe.python.solutions.face_mesh import FaceMesh # type: ignore[import]
|
||||
from PIL import Image, ImageDraw, ImageFilter, ImageFont, ImageOps
|
||||
from PIL.Image import Image as ImageType
|
||||
from pydantic import validator
|
||||
|
||||
import invokeai.assets.fonts as font_assets
|
||||
from invokeai.app.invocations.baseinvocation import (
|
||||
BaseInvocation,
|
||||
InputField,
|
||||
InvocationContext,
|
||||
OutputField,
|
||||
invocation,
|
||||
invocation_output,
|
||||
)
|
||||
from invokeai.app.invocations.primitives import ImageField, ImageOutput
|
||||
from invokeai.app.models.image import ImageCategory, ResourceOrigin
|
||||
|
||||
|
||||
@invocation_output("face_mask_output")
|
||||
class FaceMaskOutput(ImageOutput):
|
||||
"""Base class for FaceMask output"""
|
||||
|
||||
mask: ImageField = OutputField(description="The output mask")
|
||||
|
||||
|
||||
@invocation_output("face_off_output")
|
||||
class FaceOffOutput(ImageOutput):
|
||||
"""Base class for FaceOff Output"""
|
||||
|
||||
mask: ImageField = OutputField(description="The output mask")
|
||||
x: int = OutputField(description="The x coordinate of the bounding box's left side")
|
||||
y: int = OutputField(description="The y coordinate of the bounding box's top side")
|
||||
|
||||
|
||||
class FaceResultData(TypedDict):
|
||||
image: ImageType
|
||||
mask: ImageType
|
||||
x_center: float
|
||||
y_center: float
|
||||
mesh_width: int
|
||||
mesh_height: int
|
||||
|
||||
|
||||
class FaceResultDataWithId(FaceResultData):
|
||||
face_id: int
|
||||
|
||||
|
||||
class ExtractFaceData(TypedDict):
|
||||
bounded_image: ImageType
|
||||
bounded_mask: ImageType
|
||||
x_min: int
|
||||
y_min: int
|
||||
x_max: int
|
||||
y_max: int
|
||||
|
||||
|
||||
class FaceMaskResult(TypedDict):
|
||||
image: ImageType
|
||||
mask: ImageType
|
||||
|
||||
|
||||
def create_white_image(w: int, h: int) -> ImageType:
|
||||
return Image.new("L", (w, h), color=255)
|
||||
|
||||
|
||||
def create_black_image(w: int, h: int) -> ImageType:
|
||||
return Image.new("L", (w, h), color=0)
|
||||
|
||||
|
||||
FONT_SIZE = 32
|
||||
FONT_STROKE_WIDTH = 4
|
||||
|
||||
|
||||
def prepare_faces_list(
|
||||
face_result_list: list[FaceResultData],
|
||||
) -> list[FaceResultDataWithId]:
|
||||
"""Deduplicates a list of faces, adding IDs to them."""
|
||||
deduped_faces: list[FaceResultData] = []
|
||||
|
||||
if len(face_result_list) == 0:
|
||||
return list()
|
||||
|
||||
for candidate in face_result_list:
|
||||
should_add = True
|
||||
candidate_x_center = candidate["x_center"]
|
||||
candidate_y_center = candidate["y_center"]
|
||||
for face in deduped_faces:
|
||||
face_center_x = face["x_center"]
|
||||
face_center_y = face["y_center"]
|
||||
face_radius_w = face["mesh_width"] / 2
|
||||
face_radius_h = face["mesh_height"] / 2
|
||||
# Determine if the center of the candidate_face is inside the ellipse of the added face
|
||||
# p < 1 -> Inside
|
||||
# p = 1 -> Exactly on the ellipse
|
||||
# p > 1 -> Outside
|
||||
p = (math.pow((candidate_x_center - face_center_x), 2) / math.pow(face_radius_w, 2)) + (
|
||||
math.pow((candidate_y_center - face_center_y), 2) / math.pow(face_radius_h, 2)
|
||||
)
|
||||
|
||||
if p < 1: # Inside of the already-added face's radius
|
||||
should_add = False
|
||||
break
|
||||
|
||||
if should_add is True:
|
||||
deduped_faces.append(candidate)
|
||||
|
||||
sorted_faces = sorted(deduped_faces, key=lambda x: x["y_center"])
|
||||
sorted_faces = sorted(sorted_faces, key=lambda x: x["x_center"])
|
||||
|
||||
# add face_id for reference
|
||||
sorted_faces_with_ids: list[FaceResultDataWithId] = []
|
||||
face_id_counter = 0
|
||||
for face in sorted_faces:
|
||||
sorted_faces_with_ids.append(
|
||||
FaceResultDataWithId(
|
||||
**face,
|
||||
face_id=face_id_counter,
|
||||
)
|
||||
)
|
||||
face_id_counter += 1
|
||||
|
||||
return sorted_faces_with_ids
|
||||
|
||||
|
||||
def generate_face_box_mask(
|
||||
context: InvocationContext,
|
||||
minimum_confidence: float,
|
||||
x_offset: float,
|
||||
y_offset: float,
|
||||
pil_image: ImageType,
|
||||
chunk_x_offset: int = 0,
|
||||
chunk_y_offset: int = 0,
|
||||
draw_mesh: bool = True,
|
||||
check_bounds: bool = True,
|
||||
) -> list[FaceResultData]:
|
||||
result = []
|
||||
mask_pil = None
|
||||
|
||||
# Convert the PIL image to a NumPy array.
|
||||
np_image = np.array(pil_image, dtype=np.uint8)
|
||||
|
||||
# Check if the input image has four channels (RGBA).
|
||||
if np_image.shape[2] == 4:
|
||||
# Convert RGBA to RGB by removing the alpha channel.
|
||||
np_image = np_image[:, :, :3]
|
||||
|
||||
# Create a FaceMesh object for face landmark detection and mesh generation.
|
||||
face_mesh = FaceMesh(
|
||||
max_num_faces=999,
|
||||
min_detection_confidence=minimum_confidence,
|
||||
min_tracking_confidence=minimum_confidence,
|
||||
)
|
||||
|
||||
# Detect the face landmarks and mesh in the input image.
|
||||
results = face_mesh.process(np_image)
|
||||
|
||||
# Check if any face is detected.
|
||||
if results.multi_face_landmarks: # type: ignore # this are via protobuf and not typed
|
||||
# Search for the face_id in the detected faces.
|
||||
for face_id, face_landmarks in enumerate(results.multi_face_landmarks): # type: ignore #this are via protobuf and not typed
|
||||
# Get the bounding box of the face mesh.
|
||||
x_coordinates = [landmark.x for landmark in face_landmarks.landmark]
|
||||
y_coordinates = [landmark.y for landmark in face_landmarks.landmark]
|
||||
x_min, x_max = min(x_coordinates), max(x_coordinates)
|
||||
y_min, y_max = min(y_coordinates), max(y_coordinates)
|
||||
|
||||
# Calculate the width and height of the face mesh.
|
||||
mesh_width = int((x_max - x_min) * np_image.shape[1])
|
||||
mesh_height = int((y_max - y_min) * np_image.shape[0])
|
||||
|
||||
# Get the center of the face.
|
||||
x_center = np.mean([landmark.x * np_image.shape[1] for landmark in face_landmarks.landmark])
|
||||
y_center = np.mean([landmark.y * np_image.shape[0] for landmark in face_landmarks.landmark])
|
||||
|
||||
face_landmark_points = np.array(
|
||||
[
|
||||
[landmark.x * np_image.shape[1], landmark.y * np_image.shape[0]]
|
||||
for landmark in face_landmarks.landmark
|
||||
]
|
||||
)
|
||||
|
||||
# Apply the scaling offsets to the face landmark points with a multiplier.
|
||||
scale_multiplier = 0.2
|
||||
x_center = np.mean(face_landmark_points[:, 0])
|
||||
y_center = np.mean(face_landmark_points[:, 1])
|
||||
|
||||
if draw_mesh:
|
||||
x_scaled = face_landmark_points[:, 0] + scale_multiplier * x_offset * (
|
||||
face_landmark_points[:, 0] - x_center
|
||||
)
|
||||
y_scaled = face_landmark_points[:, 1] + scale_multiplier * y_offset * (
|
||||
face_landmark_points[:, 1] - y_center
|
||||
)
|
||||
|
||||
convex_hull = cv2.convexHull(np.column_stack((x_scaled, y_scaled)).astype(np.int32))
|
||||
|
||||
# Generate a binary face mask using the face mesh.
|
||||
mask_image = np.ones(np_image.shape[:2], dtype=np.uint8) * 255
|
||||
cv2.fillConvexPoly(mask_image, convex_hull, 0)
|
||||
|
||||
# Convert the binary mask image to a PIL Image.
|
||||
init_mask_pil = Image.fromarray(mask_image, mode="L")
|
||||
w, h = init_mask_pil.size
|
||||
mask_pil = create_white_image(w + chunk_x_offset, h + chunk_y_offset)
|
||||
mask_pil.paste(init_mask_pil, (chunk_x_offset, chunk_y_offset))
|
||||
|
||||
left_side = x_center - mesh_width
|
||||
right_side = x_center + mesh_width
|
||||
top_side = y_center - mesh_height
|
||||
bottom_side = y_center + mesh_height
|
||||
im_width, im_height = pil_image.size
|
||||
over_w = im_width * 0.1
|
||||
over_h = im_height * 0.1
|
||||
if not check_bounds or (
|
||||
(left_side >= -over_w)
|
||||
and (right_side < im_width + over_w)
|
||||
and (top_side >= -over_h)
|
||||
and (bottom_side < im_height + over_h)
|
||||
):
|
||||
x_center = float(x_center)
|
||||
y_center = float(y_center)
|
||||
face = FaceResultData(
|
||||
image=pil_image,
|
||||
mask=mask_pil or create_white_image(*pil_image.size),
|
||||
x_center=x_center + chunk_x_offset,
|
||||
y_center=y_center + chunk_y_offset,
|
||||
mesh_width=mesh_width,
|
||||
mesh_height=mesh_height,
|
||||
)
|
||||
|
||||
result.append(face)
|
||||
else:
|
||||
context.services.logger.info("FaceTools --> Face out of bounds, ignoring.")
|
||||
|
||||
return result
|
||||
|
||||
|
||||
def extract_face(
|
||||
context: InvocationContext,
|
||||
image: ImageType,
|
||||
face: FaceResultData,
|
||||
padding: int,
|
||||
) -> ExtractFaceData:
|
||||
mask = face["mask"]
|
||||
center_x = face["x_center"]
|
||||
center_y = face["y_center"]
|
||||
mesh_width = face["mesh_width"]
|
||||
mesh_height = face["mesh_height"]
|
||||
|
||||
# Determine the minimum size of the square crop
|
||||
min_size = min(mask.width, mask.height)
|
||||
|
||||
# Calculate the crop boundaries for the output image and mask.
|
||||
mesh_width += 128 + padding # add pixels to account for mask variance
|
||||
mesh_height += 128 + padding # add pixels to account for mask variance
|
||||
crop_size = min(
|
||||
max(mesh_width, mesh_height, 128), min_size
|
||||
) # Choose the smaller of the two (given value or face mask size)
|
||||
if crop_size > 128:
|
||||
crop_size = (crop_size + 7) // 8 * 8 # Ensure crop side is multiple of 8
|
||||
|
||||
# Calculate the actual crop boundaries within the bounds of the original image.
|
||||
x_min = int(center_x - crop_size / 2)
|
||||
y_min = int(center_y - crop_size / 2)
|
||||
x_max = int(center_x + crop_size / 2)
|
||||
y_max = int(center_y + crop_size / 2)
|
||||
|
||||
# Adjust the crop boundaries to stay within the original image's dimensions
|
||||
if x_min < 0:
|
||||
context.services.logger.warning("FaceTools --> -X-axis padding reached image edge.")
|
||||
x_max -= x_min
|
||||
x_min = 0
|
||||
elif x_max > mask.width:
|
||||
context.services.logger.warning("FaceTools --> +X-axis padding reached image edge.")
|
||||
x_min -= x_max - mask.width
|
||||
x_max = mask.width
|
||||
|
||||
if y_min < 0:
|
||||
context.services.logger.warning("FaceTools --> +Y-axis padding reached image edge.")
|
||||
y_max -= y_min
|
||||
y_min = 0
|
||||
elif y_max > mask.height:
|
||||
context.services.logger.warning("FaceTools --> -Y-axis padding reached image edge.")
|
||||
y_min -= y_max - mask.height
|
||||
y_max = mask.height
|
||||
|
||||
# Ensure the crop is square and adjust the boundaries if needed
|
||||
if x_max - x_min != crop_size:
|
||||
context.services.logger.warning("FaceTools --> Limiting x-axis padding to constrain bounding box to a square.")
|
||||
diff = crop_size - (x_max - x_min)
|
||||
x_min -= diff // 2
|
||||
x_max += diff - diff // 2
|
||||
|
||||
if y_max - y_min != crop_size:
|
||||
context.services.logger.warning("FaceTools --> Limiting y-axis padding to constrain bounding box to a square.")
|
||||
diff = crop_size - (y_max - y_min)
|
||||
y_min -= diff // 2
|
||||
y_max += diff - diff // 2
|
||||
|
||||
context.services.logger.info(f"FaceTools --> Calculated bounding box (8 multiple): {crop_size}")
|
||||
|
||||
# Crop the output image to the specified size with the center of the face mesh as the center.
|
||||
mask = mask.crop((x_min, y_min, x_max, y_max))
|
||||
bounded_image = image.crop((x_min, y_min, x_max, y_max))
|
||||
|
||||
# blur mask edge by small radius
|
||||
mask = mask.filter(ImageFilter.GaussianBlur(radius=2))
|
||||
|
||||
return ExtractFaceData(
|
||||
bounded_image=bounded_image,
|
||||
bounded_mask=mask,
|
||||
x_min=x_min,
|
||||
y_min=y_min,
|
||||
x_max=x_max,
|
||||
y_max=y_max,
|
||||
)
|
||||
|
||||
|
||||
def get_faces_list(
|
||||
context: InvocationContext,
|
||||
image: ImageType,
|
||||
should_chunk: bool,
|
||||
minimum_confidence: float,
|
||||
x_offset: float,
|
||||
y_offset: float,
|
||||
draw_mesh: bool = True,
|
||||
) -> list[FaceResultDataWithId]:
|
||||
result = []
|
||||
|
||||
# Generate the face box mask and get the center of the face.
|
||||
if not should_chunk:
|
||||
context.services.logger.info("FaceTools --> Attempting full image face detection.")
|
||||
result = generate_face_box_mask(
|
||||
context=context,
|
||||
minimum_confidence=minimum_confidence,
|
||||
x_offset=x_offset,
|
||||
y_offset=y_offset,
|
||||
pil_image=image,
|
||||
chunk_x_offset=0,
|
||||
chunk_y_offset=0,
|
||||
draw_mesh=draw_mesh,
|
||||
check_bounds=False,
|
||||
)
|
||||
if should_chunk or len(result) == 0:
|
||||
context.services.logger.info("FaceTools --> Chunking image (chunk toggled on, or no face found in full image).")
|
||||
width, height = image.size
|
||||
image_chunks = []
|
||||
x_offsets = []
|
||||
y_offsets = []
|
||||
result = []
|
||||
|
||||
# If width == height, there's nothing more we can do... otherwise...
|
||||
if width > height:
|
||||
# Landscape - slice the image horizontally
|
||||
fx = 0.0
|
||||
steps = int(width * 2 / height)
|
||||
while fx <= (width - height):
|
||||
x = int(fx)
|
||||
image_chunks.append(image.crop((x, 0, x + height - 1, height - 1)))
|
||||
x_offsets.append(x)
|
||||
y_offsets.append(0)
|
||||
fx += (width - height) / steps
|
||||
context.services.logger.info(f"FaceTools --> Chunk starting at x = {x}")
|
||||
elif height > width:
|
||||
# Portrait - slice the image vertically
|
||||
fy = 0.0
|
||||
steps = int(height * 2 / width)
|
||||
while fy <= (height - width):
|
||||
y = int(fy)
|
||||
image_chunks.append(image.crop((0, y, width - 1, y + width - 1)))
|
||||
x_offsets.append(0)
|
||||
y_offsets.append(y)
|
||||
fy += (height - width) / steps
|
||||
context.services.logger.info(f"FaceTools --> Chunk starting at y = {y}")
|
||||
|
||||
for idx in range(len(image_chunks)):
|
||||
context.services.logger.info(f"FaceTools --> Evaluating faces in chunk {idx}")
|
||||
result = result + generate_face_box_mask(
|
||||
context=context,
|
||||
minimum_confidence=minimum_confidence,
|
||||
x_offset=x_offset,
|
||||
y_offset=y_offset,
|
||||
pil_image=image_chunks[idx],
|
||||
chunk_x_offset=x_offsets[idx],
|
||||
chunk_y_offset=y_offsets[idx],
|
||||
draw_mesh=draw_mesh,
|
||||
)
|
||||
|
||||
if len(result) == 0:
|
||||
# Give up
|
||||
context.services.logger.warning(
|
||||
"FaceTools --> No face detected in chunked input image. Passing through original image."
|
||||
)
|
||||
|
||||
all_faces = prepare_faces_list(result)
|
||||
|
||||
return all_faces
|
||||
|
||||
|
||||
@invocation("face_off", title="FaceOff", tags=["image", "faceoff", "face", "mask"], category="image", version="1.0.1")
|
||||
class FaceOffInvocation(BaseInvocation):
|
||||
"""Bound, extract, and mask a face from an image using MediaPipe detection"""
|
||||
|
||||
image: ImageField = InputField(description="Image for face detection")
|
||||
face_id: int = InputField(
|
||||
default=0,
|
||||
ge=0,
|
||||
description="The face ID to process, numbered from 0. Multiple faces not supported. Find a face's ID with FaceIdentifier node.",
|
||||
)
|
||||
minimum_confidence: float = InputField(
|
||||
default=0.5, description="Minimum confidence for face detection (lower if detection is failing)"
|
||||
)
|
||||
x_offset: float = InputField(default=0.0, description="X-axis offset of the mask")
|
||||
y_offset: float = InputField(default=0.0, description="Y-axis offset of the mask")
|
||||
padding: int = InputField(default=0, description="All-axis padding around the mask in pixels")
|
||||
chunk: bool = InputField(
|
||||
default=False,
|
||||
description="Whether to bypass full image face detection and default to image chunking. Chunking will occur if no faces are found in the full image.",
|
||||
)
|
||||
|
||||
def faceoff(self, context: InvocationContext, image: ImageType) -> Optional[ExtractFaceData]:
|
||||
all_faces = get_faces_list(
|
||||
context=context,
|
||||
image=image,
|
||||
should_chunk=self.chunk,
|
||||
minimum_confidence=self.minimum_confidence,
|
||||
x_offset=self.x_offset,
|
||||
y_offset=self.y_offset,
|
||||
draw_mesh=True,
|
||||
)
|
||||
|
||||
if len(all_faces) == 0:
|
||||
context.services.logger.warning("FaceOff --> No faces detected. Passing through original image.")
|
||||
return None
|
||||
|
||||
if self.face_id > len(all_faces) - 1:
|
||||
context.services.logger.warning(
|
||||
f"FaceOff --> Face ID {self.face_id} is outside of the number of faces detected ({len(all_faces)}). Passing through original image."
|
||||
)
|
||||
return None
|
||||
|
||||
face_data = extract_face(context=context, image=image, face=all_faces[self.face_id], padding=self.padding)
|
||||
# Convert the input image to RGBA mode to ensure it has an alpha channel.
|
||||
face_data["bounded_image"] = face_data["bounded_image"].convert("RGBA")
|
||||
|
||||
return face_data
|
||||
|
||||
def invoke(self, context: InvocationContext) -> FaceOffOutput:
|
||||
image = context.services.images.get_pil_image(self.image.image_name)
|
||||
result = self.faceoff(context=context, image=image)
|
||||
|
||||
if result is None:
|
||||
result_image = image
|
||||
result_mask = create_white_image(*image.size)
|
||||
x = 0
|
||||
y = 0
|
||||
else:
|
||||
result_image = result["bounded_image"]
|
||||
result_mask = result["bounded_mask"]
|
||||
x = result["x_min"]
|
||||
y = result["y_min"]
|
||||
|
||||
image_dto = context.services.images.create(
|
||||
image=result_image,
|
||||
image_origin=ResourceOrigin.INTERNAL,
|
||||
image_category=ImageCategory.GENERAL,
|
||||
node_id=self.id,
|
||||
session_id=context.graph_execution_state_id,
|
||||
is_intermediate=self.is_intermediate,
|
||||
workflow=self.workflow,
|
||||
)
|
||||
|
||||
mask_dto = context.services.images.create(
|
||||
image=result_mask,
|
||||
image_origin=ResourceOrigin.INTERNAL,
|
||||
image_category=ImageCategory.MASK,
|
||||
node_id=self.id,
|
||||
session_id=context.graph_execution_state_id,
|
||||
is_intermediate=self.is_intermediate,
|
||||
)
|
||||
|
||||
output = FaceOffOutput(
|
||||
image=ImageField(image_name=image_dto.image_name),
|
||||
width=image_dto.width,
|
||||
height=image_dto.height,
|
||||
mask=ImageField(image_name=mask_dto.image_name),
|
||||
x=x,
|
||||
y=y,
|
||||
)
|
||||
|
||||
return output
|
||||
|
||||
|
||||
@invocation("face_mask_detection", title="FaceMask", tags=["image", "face", "mask"], category="image", version="1.0.1")
|
||||
class FaceMaskInvocation(BaseInvocation):
|
||||
"""Face mask creation using mediapipe face detection"""
|
||||
|
||||
image: ImageField = InputField(description="Image to face detect")
|
||||
face_ids: str = InputField(
|
||||
default="",
|
||||
description="Comma-separated list of face ids to mask eg '0,2,7'. Numbered from 0. Leave empty to mask all. Find face IDs with FaceIdentifier node.",
|
||||
)
|
||||
minimum_confidence: float = InputField(
|
||||
default=0.5, description="Minimum confidence for face detection (lower if detection is failing)"
|
||||
)
|
||||
x_offset: float = InputField(default=0.0, description="Offset for the X-axis of the face mask")
|
||||
y_offset: float = InputField(default=0.0, description="Offset for the Y-axis of the face mask")
|
||||
chunk: bool = InputField(
|
||||
default=False,
|
||||
description="Whether to bypass full image face detection and default to image chunking. Chunking will occur if no faces are found in the full image.",
|
||||
)
|
||||
invert_mask: bool = InputField(default=False, description="Toggle to invert the mask")
|
||||
|
||||
@validator("face_ids")
|
||||
def validate_comma_separated_ints(cls, v) -> str:
|
||||
comma_separated_ints_regex = re.compile(r"^\d*(,\d+)*$")
|
||||
if comma_separated_ints_regex.match(v) is None:
|
||||
raise ValueError('Face IDs must be a comma-separated list of integers (e.g. "1,2,3")')
|
||||
return v
|
||||
|
||||
def facemask(self, context: InvocationContext, image: ImageType) -> FaceMaskResult:
|
||||
all_faces = get_faces_list(
|
||||
context=context,
|
||||
image=image,
|
||||
should_chunk=self.chunk,
|
||||
minimum_confidence=self.minimum_confidence,
|
||||
x_offset=self.x_offset,
|
||||
y_offset=self.y_offset,
|
||||
draw_mesh=True,
|
||||
)
|
||||
|
||||
mask_pil = create_white_image(*image.size)
|
||||
|
||||
id_range = list(range(0, len(all_faces)))
|
||||
ids_to_extract = id_range
|
||||
if self.face_ids != "":
|
||||
parsed_face_ids = [int(id) for id in self.face_ids.split(",")]
|
||||
# get requested face_ids that are in range
|
||||
intersected_face_ids = set(parsed_face_ids) & set(id_range)
|
||||
|
||||
if len(intersected_face_ids) == 0:
|
||||
id_range_str = ",".join([str(id) for id in id_range])
|
||||
context.services.logger.warning(
|
||||
f"Face IDs must be in range of detected faces - requested {self.face_ids}, detected {id_range_str}. Passing through original image."
|
||||
)
|
||||
return FaceMaskResult(
|
||||
image=image, # original image
|
||||
mask=mask_pil, # white mask
|
||||
)
|
||||
|
||||
ids_to_extract = list(intersected_face_ids)
|
||||
|
||||
for face_id in ids_to_extract:
|
||||
face_data = extract_face(context=context, image=image, face=all_faces[face_id], padding=0)
|
||||
face_mask_pil = face_data["bounded_mask"]
|
||||
x_min = face_data["x_min"]
|
||||
y_min = face_data["y_min"]
|
||||
x_max = face_data["x_max"]
|
||||
y_max = face_data["y_max"]
|
||||
|
||||
mask_pil.paste(
|
||||
create_black_image(x_max - x_min, y_max - y_min),
|
||||
box=(x_min, y_min),
|
||||
mask=ImageOps.invert(face_mask_pil),
|
||||
)
|
||||
|
||||
if self.invert_mask:
|
||||
mask_pil = ImageOps.invert(mask_pil)
|
||||
|
||||
# Create an RGBA image with transparency
|
||||
image = image.convert("RGBA")
|
||||
|
||||
return FaceMaskResult(
|
||||
image=image,
|
||||
mask=mask_pil,
|
||||
)
|
||||
|
||||
def invoke(self, context: InvocationContext) -> FaceMaskOutput:
|
||||
image = context.services.images.get_pil_image(self.image.image_name)
|
||||
result = self.facemask(context=context, image=image)
|
||||
|
||||
image_dto = context.services.images.create(
|
||||
image=result["image"],
|
||||
image_origin=ResourceOrigin.INTERNAL,
|
||||
image_category=ImageCategory.GENERAL,
|
||||
node_id=self.id,
|
||||
session_id=context.graph_execution_state_id,
|
||||
is_intermediate=self.is_intermediate,
|
||||
workflow=self.workflow,
|
||||
)
|
||||
|
||||
mask_dto = context.services.images.create(
|
||||
image=result["mask"],
|
||||
image_origin=ResourceOrigin.INTERNAL,
|
||||
image_category=ImageCategory.MASK,
|
||||
node_id=self.id,
|
||||
session_id=context.graph_execution_state_id,
|
||||
is_intermediate=self.is_intermediate,
|
||||
)
|
||||
|
||||
output = FaceMaskOutput(
|
||||
image=ImageField(image_name=image_dto.image_name),
|
||||
width=image_dto.width,
|
||||
height=image_dto.height,
|
||||
mask=ImageField(image_name=mask_dto.image_name),
|
||||
)
|
||||
|
||||
return output
|
||||
|
||||
|
||||
@invocation(
|
||||
"face_identifier", title="FaceIdentifier", tags=["image", "face", "identifier"], category="image", version="1.0.1"
|
||||
)
|
||||
class FaceIdentifierInvocation(BaseInvocation):
|
||||
"""Outputs an image with detected face IDs printed on each face. For use with other FaceTools."""
|
||||
|
||||
image: ImageField = InputField(description="Image to face detect")
|
||||
minimum_confidence: float = InputField(
|
||||
default=0.5, description="Minimum confidence for face detection (lower if detection is failing)"
|
||||
)
|
||||
chunk: bool = InputField(
|
||||
default=False,
|
||||
description="Whether to bypass full image face detection and default to image chunking. Chunking will occur if no faces are found in the full image.",
|
||||
)
|
||||
|
||||
def faceidentifier(self, context: InvocationContext, image: ImageType) -> ImageType:
|
||||
image = image.copy()
|
||||
|
||||
all_faces = get_faces_list(
|
||||
context=context,
|
||||
image=image,
|
||||
should_chunk=self.chunk,
|
||||
minimum_confidence=self.minimum_confidence,
|
||||
x_offset=0,
|
||||
y_offset=0,
|
||||
draw_mesh=False,
|
||||
)
|
||||
|
||||
# Note - font may be found either in the repo if running an editable install, or in the venv if running a package install
|
||||
font_path = [x for x in [Path(y, "inter/Inter-Regular.ttf") for y in font_assets.__path__] if x.exists()]
|
||||
font = ImageFont.truetype(font_path[0].as_posix(), FONT_SIZE)
|
||||
|
||||
# Paste face IDs on the output image
|
||||
draw = ImageDraw.Draw(image)
|
||||
for face in all_faces:
|
||||
x_coord = face["x_center"]
|
||||
y_coord = face["y_center"]
|
||||
text = str(face["face_id"])
|
||||
# get bbox of the text so we can center the id on the face
|
||||
_, _, bbox_w, bbox_h = draw.textbbox(xy=(0, 0), text=text, font=font, stroke_width=FONT_STROKE_WIDTH)
|
||||
x = x_coord - bbox_w / 2
|
||||
y = y_coord - bbox_h / 2
|
||||
draw.text(
|
||||
xy=(x, y),
|
||||
text=str(text),
|
||||
fill=(255, 255, 255, 255),
|
||||
font=font,
|
||||
stroke_width=FONT_STROKE_WIDTH,
|
||||
stroke_fill=(0, 0, 0, 255),
|
||||
)
|
||||
|
||||
# Create an RGBA image with transparency
|
||||
image = image.convert("RGBA")
|
||||
|
||||
return image
|
||||
|
||||
def invoke(self, context: InvocationContext) -> ImageOutput:
|
||||
image = context.services.images.get_pil_image(self.image.image_name)
|
||||
result_image = self.faceidentifier(context=context, image=image)
|
||||
|
||||
image_dto = context.services.images.create(
|
||||
image=result_image,
|
||||
image_origin=ResourceOrigin.INTERNAL,
|
||||
image_category=ImageCategory.GENERAL,
|
||||
node_id=self.id,
|
||||
session_id=context.graph_execution_state_id,
|
||||
is_intermediate=self.is_intermediate,
|
||||
workflow=self.workflow,
|
||||
)
|
||||
|
||||
return ImageOutput(
|
||||
image=ImageField(image_name=image_dto.image_name),
|
||||
width=image_dto.width,
|
||||
height=image_dto.height,
|
||||
)
|
||||
@@ -269,7 +269,7 @@ class LaMaInfillInvocation(BaseInvocation):
|
||||
)
|
||||
|
||||
|
||||
@invocation("infill_cv2", title="CV2 Infill", tags=["image", "inpaint"], category="inpaint")
|
||||
@invocation("infill_cv2", title="CV2 Infill", tags=["image", "inpaint"], category="inpaint", version="1.0.0")
|
||||
class CV2InfillInvocation(BaseInvocation):
|
||||
"""Infills transparent areas of an image using OpenCV Inpainting"""
|
||||
|
||||
|
||||
@@ -65,13 +65,27 @@ class DivideInvocation(BaseInvocation):
|
||||
class RandomIntInvocation(BaseInvocation):
|
||||
"""Outputs a single random integer."""
|
||||
|
||||
low: int = InputField(default=0, description="The inclusive low value")
|
||||
high: int = InputField(default=np.iinfo(np.int32).max, description="The exclusive high value")
|
||||
low: int = InputField(default=0, description=FieldDescriptions.inclusive_low)
|
||||
high: int = InputField(default=np.iinfo(np.int32).max, description=FieldDescriptions.exclusive_high)
|
||||
|
||||
def invoke(self, context: InvocationContext) -> IntegerOutput:
|
||||
return IntegerOutput(value=np.random.randint(self.low, self.high))
|
||||
|
||||
|
||||
@invocation("rand_float", title="Random Float", tags=["math", "float", "random"], category="math", version="1.0.0")
|
||||
class RandomFloatInvocation(BaseInvocation):
|
||||
"""Outputs a single random float"""
|
||||
|
||||
low: float = InputField(default=0.0, description=FieldDescriptions.inclusive_low)
|
||||
high: float = InputField(default=1.0, description=FieldDescriptions.exclusive_high)
|
||||
decimals: int = InputField(default=2, description=FieldDescriptions.decimal_places)
|
||||
|
||||
def invoke(self, context: InvocationContext) -> FloatOutput:
|
||||
random_float = np.random.uniform(self.low, self.high)
|
||||
rounded_float = round(random_float, self.decimals)
|
||||
return FloatOutput(value=rounded_float)
|
||||
|
||||
|
||||
@invocation(
|
||||
"float_to_int",
|
||||
title="Float To Integer",
|
||||
|
||||
@@ -12,7 +12,9 @@ from invokeai.app.invocations.baseinvocation import (
|
||||
invocation_output,
|
||||
)
|
||||
from invokeai.app.invocations.controlnet_image_processors import ControlField
|
||||
from invokeai.app.invocations.ip_adapter import IPAdapterModelField
|
||||
from invokeai.app.invocations.model import LoRAModelField, MainModelField, VAEModelField
|
||||
from invokeai.app.invocations.primitives import ImageField
|
||||
from invokeai.app.util.model_exclude_null import BaseModelExcludeNull
|
||||
|
||||
from ...version import __version__
|
||||
@@ -25,6 +27,18 @@ class LoRAMetadataField(BaseModelExcludeNull):
|
||||
weight: float = Field(description="The weight of the LoRA model")
|
||||
|
||||
|
||||
class IPAdapterMetadataField(BaseModelExcludeNull):
|
||||
image: ImageField = Field(description="The IP-Adapter image prompt.")
|
||||
ip_adapter_model: IPAdapterModelField = Field(description="The IP-Adapter model to use.")
|
||||
weight: float = Field(description="The weight of the IP-Adapter model")
|
||||
begin_step_percent: float = Field(
|
||||
default=0, ge=0, le=1, description="When the IP-Adapter is first applied (% of total steps)"
|
||||
)
|
||||
end_step_percent: float = Field(
|
||||
default=1, ge=0, le=1, description="When the IP-Adapter is last applied (% of total steps)"
|
||||
)
|
||||
|
||||
|
||||
class CoreMetadata(BaseModelExcludeNull):
|
||||
"""Core generation metadata for an image generated in InvokeAI."""
|
||||
|
||||
@@ -48,6 +62,7 @@ class CoreMetadata(BaseModelExcludeNull):
|
||||
)
|
||||
model: MainModelField = Field(description="The main model used for inference")
|
||||
controlnets: list[ControlField] = Field(description="The ControlNets used for inference")
|
||||
ipAdapters: list[IPAdapterMetadataField] = Field(description="The IP Adapters used for inference")
|
||||
loras: list[LoRAMetadataField] = Field(description="The LoRAs used for inference")
|
||||
vae: Optional[VAEModelField] = Field(
|
||||
default=None,
|
||||
@@ -123,6 +138,7 @@ class MetadataAccumulatorInvocation(BaseInvocation):
|
||||
)
|
||||
model: MainModelField = InputField(description="The main model used for inference")
|
||||
controlnets: list[ControlField] = InputField(description="The ControlNets used for inference")
|
||||
ipAdapters: list[IPAdapterMetadataField] = InputField(description="The IP Adapters used for inference")
|
||||
loras: list[LoRAMetadataField] = InputField(description="The LoRAs used for inference")
|
||||
strength: Optional[float] = InputField(
|
||||
default=None,
|
||||
|
||||
@@ -241,7 +241,7 @@ class InvokeAIAppConfig(InvokeAISettings):
|
||||
version : bool = Field(default=False, description="Show InvokeAI version and exit", category="Other")
|
||||
|
||||
# CACHE
|
||||
ram : Union[float, Literal["auto"]] = Field(default=6.0, gt=0, description="Maximum memory amount used by model cache for rapid switching (floating point number or 'auto')", category="Model Cache", )
|
||||
ram : Union[float, Literal["auto"]] = Field(default=7.5, gt=0, description="Maximum memory amount used by model cache for rapid switching (floating point number or 'auto')", category="Model Cache", )
|
||||
vram : Union[float, Literal["auto"]] = Field(default=0.25, ge=0, description="Amount of VRAM reserved for model storage (floating point number or 'auto')", category="Model Cache", )
|
||||
lazy_offload : bool = Field(default=True, description="Keep models in VRAM until their space is needed", category="Model Cache", )
|
||||
|
||||
|
||||
@@ -584,7 +584,7 @@ class SqliteImageRecordStorage(ImageRecordStorageBase):
|
||||
FROM images
|
||||
JOIN board_images ON images.image_name = board_images.image_name
|
||||
WHERE board_images.board_id = ?
|
||||
ORDER BY images.created_at DESC
|
||||
ORDER BY images.starred DESC, images.created_at DESC
|
||||
LIMIT 1;
|
||||
""",
|
||||
(board_id,),
|
||||
|
||||
@@ -1,4 +1,6 @@
|
||||
from queue import Queue
|
||||
from collections import OrderedDict
|
||||
from dataclasses import dataclass, field
|
||||
from threading import Lock
|
||||
from typing import Optional, Union
|
||||
|
||||
from invokeai.app.invocations.baseinvocation import BaseInvocation, BaseInvocationOutput
|
||||
@@ -7,22 +9,28 @@ from invokeai.app.services.invocation_cache.invocation_cache_common import Invoc
|
||||
from invokeai.app.services.invoker import Invoker
|
||||
|
||||
|
||||
@dataclass(order=True)
|
||||
class CachedItem:
|
||||
invocation_output: BaseInvocationOutput = field(compare=False)
|
||||
invocation_output_json: str = field(compare=False)
|
||||
|
||||
|
||||
class MemoryInvocationCache(InvocationCacheBase):
|
||||
_cache: dict[Union[int, str], tuple[BaseInvocationOutput, str]]
|
||||
_cache: OrderedDict[Union[int, str], CachedItem]
|
||||
_max_cache_size: int
|
||||
_disabled: bool
|
||||
_hits: int
|
||||
_misses: int
|
||||
_cache_ids: Queue
|
||||
_invoker: Invoker
|
||||
_lock: Lock
|
||||
|
||||
def __init__(self, max_cache_size: int = 0) -> None:
|
||||
self._cache = dict()
|
||||
self._cache = OrderedDict()
|
||||
self._max_cache_size = max_cache_size
|
||||
self._disabled = False
|
||||
self._hits = 0
|
||||
self._misses = 0
|
||||
self._cache_ids = Queue()
|
||||
self._lock = Lock()
|
||||
|
||||
def start(self, invoker: Invoker) -> None:
|
||||
self._invoker = invoker
|
||||
@@ -32,80 +40,87 @@ class MemoryInvocationCache(InvocationCacheBase):
|
||||
self._invoker.services.latents.on_deleted(self._delete_by_match)
|
||||
|
||||
def get(self, key: Union[int, str]) -> Optional[BaseInvocationOutput]:
|
||||
if self._max_cache_size == 0 or self._disabled:
|
||||
return
|
||||
|
||||
item = self._cache.get(key, None)
|
||||
if item is not None:
|
||||
self._hits += 1
|
||||
return item[0]
|
||||
self._misses += 1
|
||||
with self._lock:
|
||||
if self._max_cache_size == 0 or self._disabled:
|
||||
return None
|
||||
item = self._cache.get(key, None)
|
||||
if item is not None:
|
||||
self._hits += 1
|
||||
self._cache.move_to_end(key)
|
||||
return item.invocation_output
|
||||
self._misses += 1
|
||||
return None
|
||||
|
||||
def save(self, key: Union[int, str], invocation_output: BaseInvocationOutput) -> None:
|
||||
if self._max_cache_size == 0 or self._disabled:
|
||||
return
|
||||
with self._lock:
|
||||
if self._max_cache_size == 0 or self._disabled or key in self._cache:
|
||||
return
|
||||
# If the cache is full, we need to remove the least used
|
||||
number_to_delete = len(self._cache) + 1 - self._max_cache_size
|
||||
self._delete_oldest_access(number_to_delete)
|
||||
self._cache[key] = CachedItem(invocation_output, invocation_output.json())
|
||||
|
||||
if key not in self._cache:
|
||||
self._cache[key] = (invocation_output, invocation_output.json())
|
||||
self._cache_ids.put(key)
|
||||
if self._cache_ids.qsize() > self._max_cache_size:
|
||||
try:
|
||||
self._cache.pop(self._cache_ids.get())
|
||||
except KeyError:
|
||||
# this means the cache_ids are somehow out of sync w/ the cache
|
||||
pass
|
||||
def _delete_oldest_access(self, number_to_delete: int) -> None:
|
||||
number_to_delete = min(number_to_delete, len(self._cache))
|
||||
for _ in range(number_to_delete):
|
||||
self._cache.popitem(last=False)
|
||||
|
||||
def delete(self, key: Union[int, str]) -> None:
|
||||
def _delete(self, key: Union[int, str]) -> None:
|
||||
if self._max_cache_size == 0:
|
||||
return
|
||||
|
||||
if key in self._cache:
|
||||
del self._cache[key]
|
||||
|
||||
def delete(self, key: Union[int, str]) -> None:
|
||||
with self._lock:
|
||||
return self._delete(key)
|
||||
|
||||
def clear(self, *args, **kwargs) -> None:
|
||||
if self._max_cache_size == 0:
|
||||
return
|
||||
with self._lock:
|
||||
if self._max_cache_size == 0:
|
||||
return
|
||||
self._cache.clear()
|
||||
self._misses = 0
|
||||
self._hits = 0
|
||||
|
||||
self._cache.clear()
|
||||
self._cache_ids = Queue()
|
||||
self._misses = 0
|
||||
self._hits = 0
|
||||
|
||||
def create_key(self, invocation: BaseInvocation) -> int:
|
||||
@staticmethod
|
||||
def create_key(invocation: BaseInvocation) -> int:
|
||||
return hash(invocation.json(exclude={"id"}))
|
||||
|
||||
def disable(self) -> None:
|
||||
if self._max_cache_size == 0:
|
||||
return
|
||||
self._disabled = True
|
||||
with self._lock:
|
||||
if self._max_cache_size == 0:
|
||||
return
|
||||
self._disabled = True
|
||||
|
||||
def enable(self) -> None:
|
||||
if self._max_cache_size == 0:
|
||||
return
|
||||
self._disabled = False
|
||||
with self._lock:
|
||||
if self._max_cache_size == 0:
|
||||
return
|
||||
self._disabled = False
|
||||
|
||||
def get_status(self) -> InvocationCacheStatus:
|
||||
return InvocationCacheStatus(
|
||||
hits=self._hits,
|
||||
misses=self._misses,
|
||||
enabled=not self._disabled and self._max_cache_size > 0,
|
||||
size=len(self._cache),
|
||||
max_size=self._max_cache_size,
|
||||
)
|
||||
with self._lock:
|
||||
return InvocationCacheStatus(
|
||||
hits=self._hits,
|
||||
misses=self._misses,
|
||||
enabled=not self._disabled and self._max_cache_size > 0,
|
||||
size=len(self._cache),
|
||||
max_size=self._max_cache_size,
|
||||
)
|
||||
|
||||
def _delete_by_match(self, to_match: str) -> None:
|
||||
if self._max_cache_size == 0:
|
||||
return
|
||||
|
||||
keys_to_delete = set()
|
||||
for key, value_tuple in self._cache.items():
|
||||
if to_match in value_tuple[1]:
|
||||
keys_to_delete.add(key)
|
||||
|
||||
if not keys_to_delete:
|
||||
return
|
||||
|
||||
for key in keys_to_delete:
|
||||
self.delete(key)
|
||||
|
||||
self._invoker.services.logger.debug(f"Deleted {len(keys_to_delete)} cached invocation outputs for {to_match}")
|
||||
with self._lock:
|
||||
if self._max_cache_size == 0:
|
||||
return
|
||||
keys_to_delete = set()
|
||||
for key, cached_item in self._cache.items():
|
||||
if to_match in cached_item.invocation_output_json:
|
||||
keys_to_delete.add(key)
|
||||
if not keys_to_delete:
|
||||
return
|
||||
for key in keys_to_delete:
|
||||
self._delete(key)
|
||||
self._invoker.services.logger.debug(
|
||||
f"Deleted {len(keys_to_delete)} cached invocation outputs for {to_match}"
|
||||
)
|
||||
|
||||
@@ -47,20 +47,27 @@ class DefaultSessionProcessor(SessionProcessorBase):
|
||||
async def _on_queue_event(self, event: FastAPIEvent) -> None:
|
||||
event_name = event[1]["event"]
|
||||
|
||||
match event_name:
|
||||
case "graph_execution_state_complete" | "invocation_error" | "session_retrieval_error" | "invocation_retrieval_error":
|
||||
self.__queue_item = None
|
||||
self._poll_now()
|
||||
case "session_canceled" if self.__queue_item is not None and self.__queue_item.session_id == event[1][
|
||||
"data"
|
||||
]["graph_execution_state_id"]:
|
||||
self.__queue_item = None
|
||||
self._poll_now()
|
||||
case "batch_enqueued":
|
||||
self._poll_now()
|
||||
case "queue_cleared":
|
||||
self.__queue_item = None
|
||||
self._poll_now()
|
||||
# This was a match statement, but match is not supported on python 3.9
|
||||
if event_name in [
|
||||
"graph_execution_state_complete",
|
||||
"invocation_error",
|
||||
"session_retrieval_error",
|
||||
"invocation_retrieval_error",
|
||||
]:
|
||||
self.__queue_item = None
|
||||
self._poll_now()
|
||||
elif (
|
||||
event_name == "session_canceled"
|
||||
and self.__queue_item is not None
|
||||
and self.__queue_item.session_id == event[1]["data"]["graph_execution_state_id"]
|
||||
):
|
||||
self.__queue_item = None
|
||||
self._poll_now()
|
||||
elif event_name == "batch_enqueued":
|
||||
self._poll_now()
|
||||
elif event_name == "queue_cleared":
|
||||
self.__queue_item = None
|
||||
self._poll_now()
|
||||
|
||||
def resume(self) -> SessionProcessorStatus:
|
||||
if not self.__resume_event.is_set():
|
||||
|
||||
@@ -59,13 +59,14 @@ class SqliteSessionQueue(SessionQueueBase):
|
||||
|
||||
async def _on_session_event(self, event: FastAPIEvent) -> FastAPIEvent:
|
||||
event_name = event[1]["event"]
|
||||
match event_name:
|
||||
case "graph_execution_state_complete":
|
||||
await self._handle_complete_event(event)
|
||||
case "invocation_error" | "session_retrieval_error" | "invocation_retrieval_error":
|
||||
await self._handle_error_event(event)
|
||||
case "session_canceled":
|
||||
await self._handle_cancel_event(event)
|
||||
|
||||
# This was a match statement, but match is not supported on python 3.9
|
||||
if event_name == "graph_execution_state_complete":
|
||||
await self._handle_complete_event(event)
|
||||
elif event_name in ["invocation_error", "session_retrieval_error", "invocation_retrieval_error"]:
|
||||
await self._handle_error_event(event)
|
||||
elif event_name == "session_canceled":
|
||||
await self._handle_cancel_event(event)
|
||||
return event
|
||||
|
||||
async def _handle_complete_event(self, event: FastAPIEvent) -> None:
|
||||
|
||||
BIN
invokeai/assets/fonts/inter/Inter-Regular.ttf
Executable file
BIN
invokeai/assets/fonts/inter/Inter-Regular.ttf
Executable file
Binary file not shown.
94
invokeai/assets/fonts/inter/LICENSE.txt
Executable file
94
invokeai/assets/fonts/inter/LICENSE.txt
Executable file
@@ -0,0 +1,94 @@
|
||||
Copyright (c) 2016-2020 The Inter Project Authors.
|
||||
"Inter" is trademark of Rasmus Andersson.
|
||||
https://github.com/rsms/inter
|
||||
|
||||
This Font Software is licensed under the SIL Open Font License, Version 1.1.
|
||||
This license is copied below, and is also available with a FAQ at:
|
||||
http://scripts.sil.org/OFL
|
||||
|
||||
-----------------------------------------------------------
|
||||
SIL OPEN FONT LICENSE Version 1.1 - 26 February 2007
|
||||
-----------------------------------------------------------
|
||||
|
||||
PREAMBLE
|
||||
The goals of the Open Font License (OFL) are to stimulate worldwide
|
||||
development of collaborative font projects, to support the font creation
|
||||
efforts of academic and linguistic communities, and to provide a free and
|
||||
open framework in which fonts may be shared and improved in partnership
|
||||
with others.
|
||||
|
||||
The OFL allows the licensed fonts to be used, studied, modified and
|
||||
redistributed freely as long as they are not sold by themselves. The
|
||||
fonts, including any derivative works, can be bundled, embedded,
|
||||
redistributed and/or sold with any software provided that any reserved
|
||||
names are not used by derivative works. The fonts and derivatives,
|
||||
however, cannot be released under any other type of license. The
|
||||
requirement for fonts to remain under this license does not apply
|
||||
to any document created using the fonts or their derivatives.
|
||||
|
||||
DEFINITIONS
|
||||
"Font Software" refers to the set of files released by the Copyright
|
||||
Holder(s) under this license and clearly marked as such. This may
|
||||
include source files, build scripts and documentation.
|
||||
|
||||
"Reserved Font Name" refers to any names specified as such after the
|
||||
copyright statement(s).
|
||||
|
||||
"Original Version" refers to the collection of Font Software components as
|
||||
distributed by the Copyright Holder(s).
|
||||
|
||||
"Modified Version" refers to any derivative made by adding to, deleting,
|
||||
or substituting -- in part or in whole -- any of the components of the
|
||||
Original Version, by changing formats or by porting the Font Software to a
|
||||
new environment.
|
||||
|
||||
"Author" refers to any designer, engineer, programmer, technical
|
||||
writer or other person who contributed to the Font Software.
|
||||
|
||||
PERMISSION AND CONDITIONS
|
||||
Permission is hereby granted, free of charge, to any person obtaining
|
||||
a copy of the Font Software, to use, study, copy, merge, embed, modify,
|
||||
redistribute, and sell modified and unmodified copies of the Font
|
||||
Software, subject to the following conditions:
|
||||
|
||||
1) Neither the Font Software nor any of its individual components,
|
||||
in Original or Modified Versions, may be sold by itself.
|
||||
|
||||
2) Original or Modified Versions of the Font Software may be bundled,
|
||||
redistributed and/or sold with any software, provided that each copy
|
||||
contains the above copyright notice and this license. These can be
|
||||
included either as stand-alone text files, human-readable headers or
|
||||
in the appropriate machine-readable metadata fields within text or
|
||||
binary files as long as those fields can be easily viewed by the user.
|
||||
|
||||
3) No Modified Version of the Font Software may use the Reserved Font
|
||||
Name(s) unless explicit written permission is granted by the corresponding
|
||||
Copyright Holder. This restriction only applies to the primary font name as
|
||||
presented to the users.
|
||||
|
||||
4) The name(s) of the Copyright Holder(s) or the Author(s) of the Font
|
||||
Software shall not be used to promote, endorse or advertise any
|
||||
Modified Version, except to acknowledge the contribution(s) of the
|
||||
Copyright Holder(s) and the Author(s) or with their explicit written
|
||||
permission.
|
||||
|
||||
5) The Font Software, modified or unmodified, in part or in whole,
|
||||
must be distributed entirely under this license, and must not be
|
||||
distributed under any other license. The requirement for fonts to
|
||||
remain under this license does not apply to any document created
|
||||
using the Font Software.
|
||||
|
||||
TERMINATION
|
||||
This license becomes null and void if any of the above conditions are
|
||||
not met.
|
||||
|
||||
DISCLAIMER
|
||||
THE FONT SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND,
|
||||
EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO ANY WARRANTIES OF
|
||||
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT
|
||||
OF COPYRIGHT, PATENT, TRADEMARK, OR OTHER RIGHT. IN NO EVENT SHALL THE
|
||||
COPYRIGHT HOLDER BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY,
|
||||
INCLUDING ANY GENERAL, SPECIAL, INDIRECT, INCIDENTAL, OR CONSEQUENTIAL
|
||||
DAMAGES, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
|
||||
FROM, OUT OF THE USE OR INABILITY TO USE THE FONT SOFTWARE OR FROM
|
||||
OTHER DEALINGS IN THE FONT SOFTWARE.
|
||||
@@ -70,7 +70,6 @@ def get_literal_fields(field) -> list[Any]:
|
||||
config = InvokeAIAppConfig.get_config()
|
||||
|
||||
Model_dir = "models"
|
||||
|
||||
Default_config_file = config.model_conf_path
|
||||
SD_Configs = config.legacy_conf_path
|
||||
|
||||
@@ -458,7 +457,7 @@ Use cursor arrows to make a checkbox selection, and space to toggle.
|
||||
)
|
||||
self.add_widget_intelligent(
|
||||
npyscreen.TitleFixedText,
|
||||
name="Model RAM cache size (GB). Make this at least large enough to hold a single full model.",
|
||||
name="Model RAM cache size (GB). Make this at least large enough to hold a single full model (2GB for SD-1, 6GB for SDXL).",
|
||||
begin_entry_at=0,
|
||||
editable=False,
|
||||
color="CONTROL",
|
||||
@@ -651,8 +650,19 @@ def edit_opts(program_opts: Namespace, invokeai_opts: Namespace) -> argparse.Nam
|
||||
return editApp.new_opts()
|
||||
|
||||
|
||||
def default_ramcache() -> float:
|
||||
"""Run a heuristic for the default RAM cache based on installed RAM."""
|
||||
|
||||
# Note that on my 64 GB machine, psutil.virtual_memory().total gives 62 GB,
|
||||
# So we adjust everthing down a bit.
|
||||
return (
|
||||
15.0 if MAX_RAM >= 60 else 7.5 if MAX_RAM >= 30 else 4 if MAX_RAM >= 14 else 2.1
|
||||
) # 2.1 is just large enough for sd 1.5 ;-)
|
||||
|
||||
|
||||
def default_startup_options(init_file: Path) -> Namespace:
|
||||
opts = InvokeAIAppConfig.get_config()
|
||||
opts.ram = default_ramcache()
|
||||
return opts
|
||||
|
||||
|
||||
|
||||
@@ -2,6 +2,7 @@
|
||||
Utility (backend) functions used by model_install.py
|
||||
"""
|
||||
import os
|
||||
import re
|
||||
import shutil
|
||||
import warnings
|
||||
from dataclasses import dataclass, field
|
||||
@@ -47,8 +48,14 @@ Config_preamble = """
|
||||
|
||||
LEGACY_CONFIGS = {
|
||||
BaseModelType.StableDiffusion1: {
|
||||
ModelVariantType.Normal: "v1-inference.yaml",
|
||||
ModelVariantType.Inpaint: "v1-inpainting-inference.yaml",
|
||||
ModelVariantType.Normal: {
|
||||
SchedulerPredictionType.Epsilon: "v1-inference.yaml",
|
||||
SchedulerPredictionType.VPrediction: "v1-inference-v.yaml",
|
||||
},
|
||||
ModelVariantType.Inpaint: {
|
||||
SchedulerPredictionType.Epsilon: "v1-inpainting-inference.yaml",
|
||||
SchedulerPredictionType.VPrediction: "v1-inpainting-inference-v.yaml",
|
||||
},
|
||||
},
|
||||
BaseModelType.StableDiffusion2: {
|
||||
ModelVariantType.Normal: {
|
||||
@@ -69,14 +76,6 @@ LEGACY_CONFIGS = {
|
||||
}
|
||||
|
||||
|
||||
@dataclass
|
||||
class ModelInstallList:
|
||||
"""Class for listing models to be installed/removed"""
|
||||
|
||||
install_models: List[str] = field(default_factory=list)
|
||||
remove_models: List[str] = field(default_factory=list)
|
||||
|
||||
|
||||
@dataclass
|
||||
class InstallSelections:
|
||||
install_models: List[str] = field(default_factory=list)
|
||||
@@ -90,10 +89,12 @@ class ModelLoadInfo:
|
||||
base_type: BaseModelType
|
||||
path: Optional[Path] = None
|
||||
repo_id: Optional[str] = None
|
||||
subfolder: Optional[str] = None
|
||||
description: str = ""
|
||||
installed: bool = False
|
||||
recommended: bool = False
|
||||
default: bool = False
|
||||
requires: Optional[List[str]] = field(default_factory=list)
|
||||
|
||||
|
||||
class ModelInstall(object):
|
||||
@@ -127,12 +128,13 @@ class ModelInstall(object):
|
||||
value["name"] = name
|
||||
value["base_type"] = base
|
||||
value["model_type"] = model_type
|
||||
model_dict[key] = ModelLoadInfo(**value)
|
||||
model_info = ModelLoadInfo(**value)
|
||||
if model_info.subfolder and model_info.repo_id:
|
||||
model_info.repo_id += f":{model_info.subfolder}"
|
||||
model_dict[key] = model_info
|
||||
|
||||
# supplement with entries in models.yaml
|
||||
installed_models = [x for x in self.mgr.list_models()]
|
||||
# suppresses autoloaded models
|
||||
# installed_models = [x for x in self.mgr.list_models() if not self._is_autoloaded(x)]
|
||||
|
||||
for md in installed_models:
|
||||
base = md["base_model"]
|
||||
@@ -164,9 +166,12 @@ class ModelInstall(object):
|
||||
|
||||
def list_models(self, model_type):
|
||||
installed = self.mgr.list_models(model_type=model_type)
|
||||
print()
|
||||
print(f"Installed models of type `{model_type}`:")
|
||||
print(f"{'Model Key':50} Model Path")
|
||||
for i in installed:
|
||||
print(f"{i['model_name']}\t{i['base_model']}\t{i['path']}")
|
||||
print(f"{'/'.join([i['base_model'],i['model_type'],i['model_name']]):50} {i['path']}")
|
||||
print()
|
||||
|
||||
# logic here a little reversed to maintain backward compatibility
|
||||
def starter_models(self, all_models: bool = False) -> Set[str]:
|
||||
@@ -204,6 +209,8 @@ class ModelInstall(object):
|
||||
job += 1
|
||||
|
||||
# add requested models
|
||||
self._remove_installed(selections.install_models)
|
||||
self._add_required_models(selections.install_models)
|
||||
for path in selections.install_models:
|
||||
logger.info(f"Installing {path} [{job}/{jobs}]")
|
||||
try:
|
||||
@@ -263,6 +270,26 @@ class ModelInstall(object):
|
||||
|
||||
return models_installed
|
||||
|
||||
def _remove_installed(self, model_list: List[str]):
|
||||
all_models = self.all_models()
|
||||
for path in model_list:
|
||||
key = self.reverse_paths.get(path)
|
||||
if key and all_models[key].installed:
|
||||
logger.warning(f"{path} already installed. Skipping.")
|
||||
model_list.remove(path)
|
||||
|
||||
def _add_required_models(self, model_list: List[str]):
|
||||
additional_models = []
|
||||
all_models = self.all_models()
|
||||
for path in model_list:
|
||||
if not (key := self.reverse_paths.get(path)):
|
||||
continue
|
||||
for requirement in all_models[key].requires:
|
||||
requirement_key = self.reverse_paths.get(requirement)
|
||||
if not all_models[requirement_key].installed:
|
||||
additional_models.append(requirement)
|
||||
model_list.extend(additional_models)
|
||||
|
||||
# install a model from a local path. The optional info parameter is there to prevent
|
||||
# the model from being probed twice in the event that it has already been probed.
|
||||
def _install_path(self, path: Path, info: ModelProbeInfo = None) -> AddModelResult:
|
||||
@@ -286,7 +313,7 @@ class ModelInstall(object):
|
||||
location = download_with_resume(url, Path(staging))
|
||||
if not location:
|
||||
logger.error(f"Unable to download {url}. Skipping.")
|
||||
info = ModelProbe().heuristic_probe(location)
|
||||
info = ModelProbe().heuristic_probe(location, self.prediction_helper)
|
||||
dest = self.config.models_path / info.base_type.value / info.model_type.value / location.name
|
||||
dest.parent.mkdir(parents=True, exist_ok=True)
|
||||
models_path = shutil.move(location, dest)
|
||||
@@ -295,46 +322,63 @@ class ModelInstall(object):
|
||||
return self._install_path(Path(models_path), info)
|
||||
|
||||
def _install_repo(self, repo_id: str) -> AddModelResult:
|
||||
# hack to recover models stored in subfolders --
|
||||
# Required to get the "v2" model of monster-labs/control_v1p_sd15_qrcode_monster
|
||||
subfolder = None
|
||||
if match := re.match(r"^([^/]+/[^/]+):(\w+)$", repo_id):
|
||||
repo_id = match.group(1)
|
||||
subfolder = match.group(2)
|
||||
|
||||
hinfo = HfApi().model_info(repo_id)
|
||||
|
||||
# we try to figure out how to download this most economically
|
||||
# list all the files in the repo
|
||||
files = [x.rfilename for x in hinfo.siblings]
|
||||
if subfolder:
|
||||
files = [x for x in files if x.startswith("v2/")]
|
||||
prefix = f"{subfolder}/" if subfolder else ""
|
||||
|
||||
location = None
|
||||
|
||||
with TemporaryDirectory(dir=self.config.models_path) as staging:
|
||||
staging = Path(staging)
|
||||
if "model_index.json" in files:
|
||||
location = self._download_hf_pipeline(repo_id, staging) # pipeline
|
||||
elif "unet/model.onnx" in files:
|
||||
if f"{prefix}model_index.json" in files:
|
||||
location = self._download_hf_pipeline(repo_id, staging, subfolder=subfolder) # pipeline
|
||||
elif f"{prefix}unet/model.onnx" in files:
|
||||
location = self._download_hf_model(repo_id, files, staging)
|
||||
else:
|
||||
for suffix in ["safetensors", "bin"]:
|
||||
if f"pytorch_lora_weights.{suffix}" in files:
|
||||
location = self._download_hf_model(repo_id, ["pytorch_lora_weights.bin"], staging) # LoRA
|
||||
if f"{prefix}pytorch_lora_weights.{suffix}" in files:
|
||||
location = self._download_hf_model(
|
||||
repo_id, ["pytorch_lora_weights.bin"], staging, subfolder=subfolder
|
||||
) # LoRA
|
||||
break
|
||||
elif (
|
||||
self.config.precision == "float16" and f"diffusion_pytorch_model.fp16.{suffix}" in files
|
||||
self.config.precision == "float16" and f"{prefix}diffusion_pytorch_model.fp16.{suffix}" in files
|
||||
): # vae, controlnet or some other standalone
|
||||
files = ["config.json", f"diffusion_pytorch_model.fp16.{suffix}"]
|
||||
location = self._download_hf_model(repo_id, files, staging)
|
||||
location = self._download_hf_model(repo_id, files, staging, subfolder=subfolder)
|
||||
break
|
||||
elif f"diffusion_pytorch_model.{suffix}" in files:
|
||||
elif f"{prefix}diffusion_pytorch_model.{suffix}" in files:
|
||||
files = ["config.json", f"diffusion_pytorch_model.{suffix}"]
|
||||
location = self._download_hf_model(repo_id, files, staging)
|
||||
location = self._download_hf_model(repo_id, files, staging, subfolder=subfolder)
|
||||
break
|
||||
elif f"learned_embeds.{suffix}" in files:
|
||||
location = self._download_hf_model(repo_id, [f"learned_embeds.{suffix}"], staging)
|
||||
elif f"{prefix}learned_embeds.{suffix}" in files:
|
||||
location = self._download_hf_model(
|
||||
repo_id, [f"learned_embeds.{suffix}"], staging, subfolder=subfolder
|
||||
)
|
||||
break
|
||||
elif "image_encoder.txt" in files and f"ip_adapter.{suffix}" in files: # IP-Adapter
|
||||
elif (
|
||||
f"{prefix}image_encoder.txt" in files and f"{prefix}ip_adapter.{suffix}" in files
|
||||
): # IP-Adapter
|
||||
files = ["image_encoder.txt", f"ip_adapter.{suffix}"]
|
||||
location = self._download_hf_model(repo_id, files, staging)
|
||||
location = self._download_hf_model(repo_id, files, staging, subfolder=subfolder)
|
||||
break
|
||||
elif f"model.{suffix}" in files and "config.json" in files:
|
||||
elif f"{prefix}model.{suffix}" in files and f"{prefix}config.json" in files:
|
||||
# This elif-condition is pretty fragile, but it is intended to handle CLIP Vision models hosted
|
||||
# by InvokeAI for use with IP-Adapters.
|
||||
files = ["config.json", f"model.{suffix}"]
|
||||
location = self._download_hf_model(repo_id, files, staging)
|
||||
location = self._download_hf_model(repo_id, files, staging, subfolder=subfolder)
|
||||
break
|
||||
if not location:
|
||||
logger.warning(f"Could not determine type of repo {repo_id}. Skipping install.")
|
||||
@@ -393,7 +437,7 @@ class ModelInstall(object):
|
||||
possible_conf = path.with_suffix(".yaml")
|
||||
if possible_conf.exists():
|
||||
legacy_conf = str(self.relative_to_root(possible_conf))
|
||||
elif info.base_type == BaseModelType.StableDiffusion2:
|
||||
elif info.base_type in [BaseModelType.StableDiffusion1, BaseModelType.StableDiffusion2]:
|
||||
legacy_conf = Path(
|
||||
self.config.legacy_conf_dir,
|
||||
LEGACY_CONFIGS[info.base_type][info.variant_type][info.prediction_type],
|
||||
@@ -421,9 +465,9 @@ class ModelInstall(object):
|
||||
else:
|
||||
return path
|
||||
|
||||
def _download_hf_pipeline(self, repo_id: str, staging: Path) -> Path:
|
||||
def _download_hf_pipeline(self, repo_id: str, staging: Path, subfolder: str = None) -> Path:
|
||||
"""
|
||||
This retrieves a StableDiffusion model from cache or remote and then
|
||||
Retrieve a StableDiffusion model from cache or remote and then
|
||||
does a save_pretrained() to the indicated staging area.
|
||||
"""
|
||||
_, name = repo_id.split("/")
|
||||
@@ -438,6 +482,7 @@ class ModelInstall(object):
|
||||
variant=variant,
|
||||
torch_dtype=precision,
|
||||
safety_checker=None,
|
||||
subfolder=subfolder,
|
||||
)
|
||||
except Exception as e: # most errors are due to fp16 not being present. Fix this to catch other errors
|
||||
if "fp16" not in str(e):
|
||||
@@ -452,7 +497,7 @@ class ModelInstall(object):
|
||||
model.save_pretrained(staging / name, safe_serialization=True)
|
||||
return staging / name
|
||||
|
||||
def _download_hf_model(self, repo_id: str, files: List[str], staging: Path) -> Path:
|
||||
def _download_hf_model(self, repo_id: str, files: List[str], staging: Path, subfolder: None) -> Path:
|
||||
_, name = repo_id.split("/")
|
||||
location = staging / name
|
||||
paths = list()
|
||||
@@ -463,7 +508,7 @@ class ModelInstall(object):
|
||||
model_dir=location / filePath.parent,
|
||||
model_name=filePath.name,
|
||||
access_token=self.access_token,
|
||||
subfolder=filePath.parent,
|
||||
subfolder=filePath.parent / subfolder if subfolder else filePath.parent,
|
||||
)
|
||||
if p:
|
||||
paths.append(p)
|
||||
|
||||
@@ -9,6 +9,8 @@ from diffusers.models import UNet2DConditionModel
|
||||
from PIL import Image
|
||||
from transformers import CLIPImageProcessor, CLIPVisionModelWithProjection
|
||||
|
||||
from invokeai.backend.model_management.models.base import calc_model_size_by_data
|
||||
|
||||
from .attention_processor import AttnProcessor2_0, IPAttnProcessor2_0
|
||||
from .resampler import Resampler
|
||||
|
||||
@@ -87,6 +89,20 @@ class IPAdapter:
|
||||
if self._attn_processors is not None:
|
||||
torch.nn.ModuleList(self._attn_processors.values()).to(device=self.device, dtype=self.dtype)
|
||||
|
||||
def calc_size(self):
|
||||
if self._state_dict is not None:
|
||||
image_proj_size = sum(
|
||||
[tensor.nelement() * tensor.element_size() for tensor in self._state_dict["image_proj"].values()]
|
||||
)
|
||||
ip_adapter_size = sum(
|
||||
[tensor.nelement() * tensor.element_size() for tensor in self._state_dict["ip_adapter"].values()]
|
||||
)
|
||||
return image_proj_size + ip_adapter_size
|
||||
else:
|
||||
return calc_model_size_by_data(self._image_proj_model) + calc_model_size_by_data(
|
||||
torch.nn.ModuleList(self._attn_processors.values())
|
||||
)
|
||||
|
||||
def _init_image_proj_model(self, state_dict):
|
||||
return ImageProjModel.from_state_dict(state_dict, self._num_tokens).to(self.device, dtype=self.dtype)
|
||||
|
||||
|
||||
@@ -1279,12 +1279,12 @@ def download_from_original_stable_diffusion_ckpt(
|
||||
extract_ema = original_config["model"]["params"]["use_ema"]
|
||||
|
||||
if (
|
||||
model_version == BaseModelType.StableDiffusion2
|
||||
model_version in [BaseModelType.StableDiffusion2, BaseModelType.StableDiffusion1]
|
||||
and original_config["model"]["params"].get("parameterization") == "v"
|
||||
):
|
||||
prediction_type = "v_prediction"
|
||||
upcast_attention = True
|
||||
image_size = 768
|
||||
image_size = 768 if model_version == BaseModelType.StableDiffusion2 else 512
|
||||
else:
|
||||
prediction_type = "epsilon"
|
||||
upcast_attention = False
|
||||
|
||||
@@ -90,8 +90,7 @@ class ModelProbe(object):
|
||||
to place it somewhere in the models directory hierarchy. If the model is
|
||||
already loaded into memory, you may provide it as model in order to avoid
|
||||
opening it a second time. The prediction_type_helper callable is a function that receives
|
||||
the path to the model and returns the BaseModelType. It is called to distinguish
|
||||
between V2-Base and V2-768 SD models.
|
||||
the path to the model and returns the SchedulerPredictionType.
|
||||
"""
|
||||
if model_path:
|
||||
format_type = "diffusers" if model_path.is_dir() else "checkpoint"
|
||||
@@ -305,25 +304,36 @@ class PipelineCheckpointProbe(CheckpointProbeBase):
|
||||
else:
|
||||
raise InvalidModelException("Cannot determine base type")
|
||||
|
||||
def get_scheduler_prediction_type(self) -> SchedulerPredictionType:
|
||||
def get_scheduler_prediction_type(self) -> Optional[SchedulerPredictionType]:
|
||||
"""Return model prediction type."""
|
||||
# if there is a .yaml associated with this checkpoint, then we do not need
|
||||
# to probe for the prediction type as it will be ignored.
|
||||
if self.checkpoint_path and self.checkpoint_path.with_suffix(".yaml").exists():
|
||||
return None
|
||||
|
||||
type = self.get_base_type()
|
||||
if type == BaseModelType.StableDiffusion1:
|
||||
return SchedulerPredictionType.Epsilon
|
||||
checkpoint = self.checkpoint
|
||||
state_dict = self.checkpoint.get("state_dict") or checkpoint
|
||||
key_name = "model.diffusion_model.input_blocks.2.1.transformer_blocks.0.attn2.to_k.weight"
|
||||
if key_name in state_dict and state_dict[key_name].shape[-1] == 1024:
|
||||
if "global_step" in checkpoint:
|
||||
if checkpoint["global_step"] == 220000:
|
||||
return SchedulerPredictionType.Epsilon
|
||||
elif checkpoint["global_step"] == 110000:
|
||||
return SchedulerPredictionType.VPrediction
|
||||
if (
|
||||
self.checkpoint_path and self.helper and not self.checkpoint_path.with_suffix(".yaml").exists()
|
||||
): # if a .yaml config file exists, then this step not needed
|
||||
return self.helper(self.checkpoint_path)
|
||||
else:
|
||||
return None
|
||||
if type == BaseModelType.StableDiffusion2:
|
||||
checkpoint = self.checkpoint
|
||||
state_dict = self.checkpoint.get("state_dict") or checkpoint
|
||||
key_name = "model.diffusion_model.input_blocks.2.1.transformer_blocks.0.attn2.to_k.weight"
|
||||
if key_name in state_dict and state_dict[key_name].shape[-1] == 1024:
|
||||
if "global_step" in checkpoint:
|
||||
if checkpoint["global_step"] == 220000:
|
||||
return SchedulerPredictionType.Epsilon
|
||||
elif checkpoint["global_step"] == 110000:
|
||||
return SchedulerPredictionType.VPrediction
|
||||
if self.helper and self.checkpoint_path:
|
||||
if helper_guess := self.helper(self.checkpoint_path):
|
||||
return helper_guess
|
||||
return SchedulerPredictionType.VPrediction # a guess for sd2 ckpts
|
||||
|
||||
elif type == BaseModelType.StableDiffusion1:
|
||||
if self.helper and self.checkpoint_path:
|
||||
if helper_guess := self.helper(self.checkpoint_path):
|
||||
return helper_guess
|
||||
return SchedulerPredictionType.Epsilon # a reasonable guess for sd1 ckpts
|
||||
else:
|
||||
return None
|
||||
|
||||
|
||||
class VaeCheckpointProbe(CheckpointProbeBase):
|
||||
|
||||
@@ -71,7 +71,13 @@ class ModelSearch(ABC):
|
||||
if any(
|
||||
[
|
||||
(path / x).exists()
|
||||
for x in {"config.json", "model_index.json", "learned_embeds.bin", "pytorch_lora_weights.bin"}
|
||||
for x in {
|
||||
"config.json",
|
||||
"model_index.json",
|
||||
"learned_embeds.bin",
|
||||
"pytorch_lora_weights.bin",
|
||||
"image_encoder.txt",
|
||||
}
|
||||
]
|
||||
):
|
||||
try:
|
||||
|
||||
@@ -13,6 +13,7 @@ from invokeai.backend.model_management.models.base import (
|
||||
ModelConfigBase,
|
||||
ModelType,
|
||||
SubModelType,
|
||||
calc_model_size_by_fs,
|
||||
classproperty,
|
||||
)
|
||||
|
||||
@@ -30,7 +31,7 @@ class IPAdapterModel(ModelBase):
|
||||
assert model_type == ModelType.IPAdapter
|
||||
super().__init__(model_path, base_model, model_type)
|
||||
|
||||
self.model_size = os.path.getsize(self.model_path)
|
||||
self.model_size = calc_model_size_by_fs(self.model_path)
|
||||
|
||||
@classmethod
|
||||
def detect_format(cls, path: str) -> str:
|
||||
@@ -63,10 +64,13 @@ class IPAdapterModel(ModelBase):
|
||||
if child_type is not None:
|
||||
raise ValueError("There are no child models in an IP-Adapter model.")
|
||||
|
||||
return build_ip_adapter(
|
||||
model = build_ip_adapter(
|
||||
ip_adapter_ckpt_path=os.path.join(self.model_path, "ip_adapter.bin"), device="cpu", dtype=torch_dtype
|
||||
)
|
||||
|
||||
self.model_size = model.calc_size()
|
||||
return model
|
||||
|
||||
@classmethod
|
||||
def convert_if_required(
|
||||
cls,
|
||||
|
||||
@@ -60,6 +60,9 @@ sd-1/main/trinart_stable_diffusion_v2:
|
||||
description: An SD-1.5 model finetuned with ~40K assorted high resolution manga/anime-style images (2.13 GB)
|
||||
repo_id: naclbit/trinart_stable_diffusion_v2
|
||||
recommended: False
|
||||
sd-1/controlnet/qrcode_monster:
|
||||
repo_id: monster-labs/control_v1p_sd15_qrcode_monster
|
||||
subfolder: v2
|
||||
sd-1/controlnet/canny:
|
||||
repo_id: lllyasviel/control_v11p_sd15_canny
|
||||
recommended: True
|
||||
@@ -103,3 +106,35 @@ sd-1/lora/LowRA:
|
||||
recommended: True
|
||||
sd-1/lora/Ink scenery:
|
||||
path: https://civitai.com/api/download/models/83390
|
||||
sd-1/ip_adapter/ip_adapter_sd15:
|
||||
repo_id: InvokeAI/ip_adapter_sd15
|
||||
recommended: True
|
||||
requires:
|
||||
- InvokeAI/ip_adapter_sd_image_encoder
|
||||
description: IP-Adapter for SD 1.5 models
|
||||
sd-1/ip_adapter/ip_adapter_plus_sd15:
|
||||
repo_id: InvokeAI/ip_adapter_plus_sd15
|
||||
recommended: False
|
||||
requires:
|
||||
- InvokeAI/ip_adapter_sd_image_encoder
|
||||
description: Refined IP-Adapter for SD 1.5 models
|
||||
sd-1/ip_adapter/ip_adapter_plus_face_sd15:
|
||||
repo_id: InvokeAI/ip_adapter_plus_face_sd15
|
||||
recommended: False
|
||||
requires:
|
||||
- InvokeAI/ip_adapter_sd_image_encoder
|
||||
description: Refined IP-Adapter for SD 1.5 models, adapted for faces
|
||||
sdxl/ip_adapter/ip_adapter_sdxl:
|
||||
repo_id: InvokeAI/ip_adapter_sdxl
|
||||
recommended: False
|
||||
requires:
|
||||
- InvokeAI/ip_adapter_sdxl_image_encoder
|
||||
description: IP-Adapter for SDXL models
|
||||
any/clip_vision/ip_adapter_sd_image_encoder:
|
||||
repo_id: InvokeAI/ip_adapter_sd_image_encoder
|
||||
recommended: False
|
||||
description: Required model for using IP-Adapters with SD-1/2 models
|
||||
any/clip_vision/ip_adapter_sdxl_image_encoder:
|
||||
repo_id: InvokeAI/ip_adapter_sdxl_image_encoder
|
||||
recommended: False
|
||||
description: Required model for using IP-Adapters with SDXL models
|
||||
|
||||
80
invokeai/configs/stable-diffusion/v1-inference-v.yaml
Normal file
80
invokeai/configs/stable-diffusion/v1-inference-v.yaml
Normal file
@@ -0,0 +1,80 @@
|
||||
model:
|
||||
base_learning_rate: 1.0e-04
|
||||
target: invokeai.backend.models.diffusion.ddpm.LatentDiffusion
|
||||
params:
|
||||
parameterization: "v"
|
||||
linear_start: 0.00085
|
||||
linear_end: 0.0120
|
||||
num_timesteps_cond: 1
|
||||
log_every_t: 200
|
||||
timesteps: 1000
|
||||
first_stage_key: "jpg"
|
||||
cond_stage_key: "txt"
|
||||
image_size: 64
|
||||
channels: 4
|
||||
cond_stage_trainable: false # Note: different from the one we trained before
|
||||
conditioning_key: crossattn
|
||||
monitor: val/loss_simple_ema
|
||||
scale_factor: 0.18215
|
||||
use_ema: False
|
||||
|
||||
scheduler_config: # 10000 warmup steps
|
||||
target: invokeai.backend.stable_diffusion.lr_scheduler.LambdaLinearScheduler
|
||||
params:
|
||||
warm_up_steps: [ 10000 ]
|
||||
cycle_lengths: [ 10000000000000 ] # incredibly large number to prevent corner cases
|
||||
f_start: [ 1.e-6 ]
|
||||
f_max: [ 1. ]
|
||||
f_min: [ 1. ]
|
||||
|
||||
personalization_config:
|
||||
target: invokeai.backend.stable_diffusion.embedding_manager.EmbeddingManager
|
||||
params:
|
||||
placeholder_strings: ["*"]
|
||||
initializer_words: ['sculpture']
|
||||
per_image_tokens: false
|
||||
num_vectors_per_token: 1
|
||||
progressive_words: False
|
||||
|
||||
unet_config:
|
||||
target: invokeai.backend.stable_diffusion.diffusionmodules.openaimodel.UNetModel
|
||||
params:
|
||||
image_size: 32 # unused
|
||||
in_channels: 4
|
||||
out_channels: 4
|
||||
model_channels: 320
|
||||
attention_resolutions: [ 4, 2, 1 ]
|
||||
num_res_blocks: 2
|
||||
channel_mult: [ 1, 2, 4, 4 ]
|
||||
num_heads: 8
|
||||
use_spatial_transformer: True
|
||||
transformer_depth: 1
|
||||
context_dim: 768
|
||||
use_checkpoint: True
|
||||
legacy: False
|
||||
|
||||
first_stage_config:
|
||||
target: invokeai.backend.stable_diffusion.autoencoder.AutoencoderKL
|
||||
params:
|
||||
embed_dim: 4
|
||||
monitor: val/rec_loss
|
||||
ddconfig:
|
||||
double_z: true
|
||||
z_channels: 4
|
||||
resolution: 256
|
||||
in_channels: 3
|
||||
out_ch: 3
|
||||
ch: 128
|
||||
ch_mult:
|
||||
- 1
|
||||
- 2
|
||||
- 4
|
||||
- 4
|
||||
num_res_blocks: 2
|
||||
attn_resolutions: []
|
||||
dropout: 0.0
|
||||
lossconfig:
|
||||
target: torch.nn.Identity
|
||||
|
||||
cond_stage_config:
|
||||
target: invokeai.backend.stable_diffusion.encoders.modules.WeightedFrozenCLIPEmbedder
|
||||
@@ -101,11 +101,12 @@ class addModelsForm(CyclingForm, npyscreen.FormMultiPage):
|
||||
"STARTER MODELS",
|
||||
"MAIN MODELS",
|
||||
"CONTROLNETS",
|
||||
"IP-ADAPTERS",
|
||||
"LORA/LYCORIS",
|
||||
"TEXTUAL INVERSION",
|
||||
],
|
||||
value=[self.current_tab],
|
||||
columns=5,
|
||||
columns=6,
|
||||
max_height=2,
|
||||
relx=8,
|
||||
scroll_exit=True,
|
||||
@@ -130,6 +131,13 @@ class addModelsForm(CyclingForm, npyscreen.FormMultiPage):
|
||||
)
|
||||
bottom_of_table = max(bottom_of_table, self.nextrely)
|
||||
|
||||
self.nextrely = top_of_table
|
||||
self.ipadapter_models = self.add_model_widgets(
|
||||
model_type=ModelType.IPAdapter,
|
||||
window_width=window_width,
|
||||
)
|
||||
bottom_of_table = max(bottom_of_table, self.nextrely)
|
||||
|
||||
self.nextrely = top_of_table
|
||||
self.lora_models = self.add_model_widgets(
|
||||
model_type=ModelType.Lora,
|
||||
@@ -343,6 +351,7 @@ class addModelsForm(CyclingForm, npyscreen.FormMultiPage):
|
||||
self.starter_pipelines,
|
||||
self.pipeline_models,
|
||||
self.controlnet_models,
|
||||
self.ipadapter_models,
|
||||
self.lora_models,
|
||||
self.ti_models,
|
||||
]
|
||||
@@ -532,6 +541,7 @@ class addModelsForm(CyclingForm, npyscreen.FormMultiPage):
|
||||
self.starter_pipelines,
|
||||
self.pipeline_models,
|
||||
self.controlnet_models,
|
||||
self.ipadapter_models,
|
||||
self.lora_models,
|
||||
self.ti_models,
|
||||
]
|
||||
@@ -553,6 +563,25 @@ class addModelsForm(CyclingForm, npyscreen.FormMultiPage):
|
||||
if downloads := section.get("download_ids"):
|
||||
selections.install_models.extend(downloads.value.split())
|
||||
|
||||
# NOT NEEDED - DONE IN BACKEND NOW
|
||||
# # special case for the ipadapter_models. If any of the adapters are
|
||||
# # chosen, then we add the corresponding encoder(s) to the install list.
|
||||
# section = self.ipadapter_models
|
||||
# if section.get("models_selected"):
|
||||
# selected_adapters = [
|
||||
# self.all_models[section["models"][x]].name for x in section.get("models_selected").value
|
||||
# ]
|
||||
# encoders = []
|
||||
# if any(["sdxl" in x for x in selected_adapters]):
|
||||
# encoders.append("ip_adapter_sdxl_image_encoder")
|
||||
# if any(["sd15" in x for x in selected_adapters]):
|
||||
# encoders.append("ip_adapter_sd_image_encoder")
|
||||
# for encoder in encoders:
|
||||
# key = f"any/clip_vision/{encoder}"
|
||||
# repo_id = f"InvokeAI/{encoder}"
|
||||
# if key not in self.all_models:
|
||||
# selections.install_models.append(repo_id)
|
||||
|
||||
|
||||
class AddModelApplication(npyscreen.NPSAppManaged):
|
||||
def __init__(self, opt):
|
||||
|
||||
169
invokeai/frontend/web/dist/assets/App-ba2d118a.js
vendored
Normal file
169
invokeai/frontend/web/dist/assets/App-ba2d118a.js
vendored
Normal file
File diff suppressed because one or more lines are too long
169
invokeai/frontend/web/dist/assets/App-dbf8f111.js
vendored
169
invokeai/frontend/web/dist/assets/App-dbf8f111.js
vendored
File diff suppressed because one or more lines are too long
1
invokeai/frontend/web/dist/assets/MantineProvider-a057bfc9.js
vendored
Normal file
1
invokeai/frontend/web/dist/assets/MantineProvider-a057bfc9.js
vendored
Normal file
File diff suppressed because one or more lines are too long
280
invokeai/frontend/web/dist/assets/ThemeLocaleProvider-632b3401.js
vendored
Normal file
280
invokeai/frontend/web/dist/assets/ThemeLocaleProvider-632b3401.js
vendored
Normal file
@@ -0,0 +1,280 @@
|
||||
import{w as s,hY as T,v as l,a2 as I,hZ as R,ae as V,h_ as z,h$ as j,i0 as D,i1 as F,i2 as G,i3 as W,i4 as K,aG as Y,i5 as Z,i6 as H}from"./index-94062f76.js";import{M as U}from"./MantineProvider-a057bfc9.js";var P=String.raw,E=P`
|
||||
:root,
|
||||
:host {
|
||||
--chakra-vh: 100vh;
|
||||
}
|
||||
|
||||
@supports (height: -webkit-fill-available) {
|
||||
:root,
|
||||
:host {
|
||||
--chakra-vh: -webkit-fill-available;
|
||||
}
|
||||
}
|
||||
|
||||
@supports (height: -moz-fill-available) {
|
||||
:root,
|
||||
:host {
|
||||
--chakra-vh: -moz-fill-available;
|
||||
}
|
||||
}
|
||||
|
||||
@supports (height: 100dvh) {
|
||||
:root,
|
||||
:host {
|
||||
--chakra-vh: 100dvh;
|
||||
}
|
||||
}
|
||||
`,B=()=>s.jsx(T,{styles:E}),J=({scope:e=""})=>s.jsx(T,{styles:P`
|
||||
html {
|
||||
line-height: 1.5;
|
||||
-webkit-text-size-adjust: 100%;
|
||||
font-family: system-ui, sans-serif;
|
||||
-webkit-font-smoothing: antialiased;
|
||||
text-rendering: optimizeLegibility;
|
||||
-moz-osx-font-smoothing: grayscale;
|
||||
touch-action: manipulation;
|
||||
}
|
||||
|
||||
body {
|
||||
position: relative;
|
||||
min-height: 100%;
|
||||
margin: 0;
|
||||
font-feature-settings: "kern";
|
||||
}
|
||||
|
||||
${e} :where(*, *::before, *::after) {
|
||||
border-width: 0;
|
||||
border-style: solid;
|
||||
box-sizing: border-box;
|
||||
word-wrap: break-word;
|
||||
}
|
||||
|
||||
main {
|
||||
display: block;
|
||||
}
|
||||
|
||||
${e} hr {
|
||||
border-top-width: 1px;
|
||||
box-sizing: content-box;
|
||||
height: 0;
|
||||
overflow: visible;
|
||||
}
|
||||
|
||||
${e} :where(pre, code, kbd,samp) {
|
||||
font-family: SFMono-Regular, Menlo, Monaco, Consolas, monospace;
|
||||
font-size: 1em;
|
||||
}
|
||||
|
||||
${e} a {
|
||||
background-color: transparent;
|
||||
color: inherit;
|
||||
text-decoration: inherit;
|
||||
}
|
||||
|
||||
${e} abbr[title] {
|
||||
border-bottom: none;
|
||||
text-decoration: underline;
|
||||
-webkit-text-decoration: underline dotted;
|
||||
text-decoration: underline dotted;
|
||||
}
|
||||
|
||||
${e} :where(b, strong) {
|
||||
font-weight: bold;
|
||||
}
|
||||
|
||||
${e} small {
|
||||
font-size: 80%;
|
||||
}
|
||||
|
||||
${e} :where(sub,sup) {
|
||||
font-size: 75%;
|
||||
line-height: 0;
|
||||
position: relative;
|
||||
vertical-align: baseline;
|
||||
}
|
||||
|
||||
${e} sub {
|
||||
bottom: -0.25em;
|
||||
}
|
||||
|
||||
${e} sup {
|
||||
top: -0.5em;
|
||||
}
|
||||
|
||||
${e} img {
|
||||
border-style: none;
|
||||
}
|
||||
|
||||
${e} :where(button, input, optgroup, select, textarea) {
|
||||
font-family: inherit;
|
||||
font-size: 100%;
|
||||
line-height: 1.15;
|
||||
margin: 0;
|
||||
}
|
||||
|
||||
${e} :where(button, input) {
|
||||
overflow: visible;
|
||||
}
|
||||
|
||||
${e} :where(button, select) {
|
||||
text-transform: none;
|
||||
}
|
||||
|
||||
${e} :where(
|
||||
button::-moz-focus-inner,
|
||||
[type="button"]::-moz-focus-inner,
|
||||
[type="reset"]::-moz-focus-inner,
|
||||
[type="submit"]::-moz-focus-inner
|
||||
) {
|
||||
border-style: none;
|
||||
padding: 0;
|
||||
}
|
||||
|
||||
${e} fieldset {
|
||||
padding: 0.35em 0.75em 0.625em;
|
||||
}
|
||||
|
||||
${e} legend {
|
||||
box-sizing: border-box;
|
||||
color: inherit;
|
||||
display: table;
|
||||
max-width: 100%;
|
||||
padding: 0;
|
||||
white-space: normal;
|
||||
}
|
||||
|
||||
${e} progress {
|
||||
vertical-align: baseline;
|
||||
}
|
||||
|
||||
${e} textarea {
|
||||
overflow: auto;
|
||||
}
|
||||
|
||||
${e} :where([type="checkbox"], [type="radio"]) {
|
||||
box-sizing: border-box;
|
||||
padding: 0;
|
||||
}
|
||||
|
||||
${e} input[type="number"]::-webkit-inner-spin-button,
|
||||
${e} input[type="number"]::-webkit-outer-spin-button {
|
||||
-webkit-appearance: none !important;
|
||||
}
|
||||
|
||||
${e} input[type="number"] {
|
||||
-moz-appearance: textfield;
|
||||
}
|
||||
|
||||
${e} input[type="search"] {
|
||||
-webkit-appearance: textfield;
|
||||
outline-offset: -2px;
|
||||
}
|
||||
|
||||
${e} input[type="search"]::-webkit-search-decoration {
|
||||
-webkit-appearance: none !important;
|
||||
}
|
||||
|
||||
${e} ::-webkit-file-upload-button {
|
||||
-webkit-appearance: button;
|
||||
font: inherit;
|
||||
}
|
||||
|
||||
${e} details {
|
||||
display: block;
|
||||
}
|
||||
|
||||
${e} summary {
|
||||
display: list-item;
|
||||
}
|
||||
|
||||
template {
|
||||
display: none;
|
||||
}
|
||||
|
||||
[hidden] {
|
||||
display: none !important;
|
||||
}
|
||||
|
||||
${e} :where(
|
||||
blockquote,
|
||||
dl,
|
||||
dd,
|
||||
h1,
|
||||
h2,
|
||||
h3,
|
||||
h4,
|
||||
h5,
|
||||
h6,
|
||||
hr,
|
||||
figure,
|
||||
p,
|
||||
pre
|
||||
) {
|
||||
margin: 0;
|
||||
}
|
||||
|
||||
${e} button {
|
||||
background: transparent;
|
||||
padding: 0;
|
||||
}
|
||||
|
||||
${e} fieldset {
|
||||
margin: 0;
|
||||
padding: 0;
|
||||
}
|
||||
|
||||
${e} :where(ol, ul) {
|
||||
margin: 0;
|
||||
padding: 0;
|
||||
}
|
||||
|
||||
${e} textarea {
|
||||
resize: vertical;
|
||||
}
|
||||
|
||||
${e} :where(button, [role="button"]) {
|
||||
cursor: pointer;
|
||||
}
|
||||
|
||||
${e} button::-moz-focus-inner {
|
||||
border: 0 !important;
|
||||
}
|
||||
|
||||
${e} table {
|
||||
border-collapse: collapse;
|
||||
}
|
||||
|
||||
${e} :where(h1, h2, h3, h4, h5, h6) {
|
||||
font-size: inherit;
|
||||
font-weight: inherit;
|
||||
}
|
||||
|
||||
${e} :where(button, input, optgroup, select, textarea) {
|
||||
padding: 0;
|
||||
line-height: inherit;
|
||||
color: inherit;
|
||||
}
|
||||
|
||||
${e} :where(img, svg, video, canvas, audio, iframe, embed, object) {
|
||||
display: block;
|
||||
}
|
||||
|
||||
${e} :where(img, video) {
|
||||
max-width: 100%;
|
||||
height: auto;
|
||||
}
|
||||
|
||||
[data-js-focus-visible]
|
||||
:focus:not([data-focus-visible-added]):not(
|
||||
[data-focus-visible-disabled]
|
||||
) {
|
||||
outline: none;
|
||||
box-shadow: none;
|
||||
}
|
||||
|
||||
${e} select::-ms-expand {
|
||||
display: none;
|
||||
}
|
||||
|
||||
${E}
|
||||
`}),g={light:"chakra-ui-light",dark:"chakra-ui-dark"};function Q(e={}){const{preventTransition:o=!0}=e,n={setDataset:r=>{const t=o?n.preventTransition():void 0;document.documentElement.dataset.theme=r,document.documentElement.style.colorScheme=r,t==null||t()},setClassName(r){document.body.classList.add(r?g.dark:g.light),document.body.classList.remove(r?g.light:g.dark)},query(){return window.matchMedia("(prefers-color-scheme: dark)")},getSystemTheme(r){var t;return((t=n.query().matches)!=null?t:r==="dark")?"dark":"light"},addListener(r){const t=n.query(),i=a=>{r(a.matches?"dark":"light")};return typeof t.addListener=="function"?t.addListener(i):t.addEventListener("change",i),()=>{typeof t.removeListener=="function"?t.removeListener(i):t.removeEventListener("change",i)}},preventTransition(){const r=document.createElement("style");return r.appendChild(document.createTextNode("*{-webkit-transition:none!important;-moz-transition:none!important;-o-transition:none!important;-ms-transition:none!important;transition:none!important}")),document.head.appendChild(r),()=>{window.getComputedStyle(document.body),requestAnimationFrame(()=>{requestAnimationFrame(()=>{document.head.removeChild(r)})})}}};return n}var X="chakra-ui-color-mode";function L(e){return{ssr:!1,type:"localStorage",get(o){if(!(globalThis!=null&&globalThis.document))return o;let n;try{n=localStorage.getItem(e)||o}catch{}return n||o},set(o){try{localStorage.setItem(e,o)}catch{}}}}var ee=L(X),M=()=>{};function S(e,o){return e.type==="cookie"&&e.ssr?e.get(o):o}function O(e){const{value:o,children:n,options:{useSystemColorMode:r,initialColorMode:t,disableTransitionOnChange:i}={},colorModeManager:a=ee}=e,d=t==="dark"?"dark":"light",[u,p]=l.useState(()=>S(a,d)),[y,b]=l.useState(()=>S(a)),{getSystemTheme:w,setClassName:k,setDataset:x,addListener:$}=l.useMemo(()=>Q({preventTransition:i}),[i]),v=t==="system"&&!u?y:u,c=l.useCallback(h=>{const f=h==="system"?w():h;p(f),k(f==="dark"),x(f),a.set(f)},[a,w,k,x]);I(()=>{t==="system"&&b(w())},[]),l.useEffect(()=>{const h=a.get();if(h){c(h);return}if(t==="system"){c("system");return}c(d)},[a,d,t,c]);const C=l.useCallback(()=>{c(v==="dark"?"light":"dark")},[v,c]);l.useEffect(()=>{if(r)return $(c)},[r,$,c]);const A=l.useMemo(()=>({colorMode:o??v,toggleColorMode:o?M:C,setColorMode:o?M:c,forced:o!==void 0}),[v,C,c,o]);return s.jsx(R.Provider,{value:A,children:n})}O.displayName="ColorModeProvider";var te=["borders","breakpoints","colors","components","config","direction","fonts","fontSizes","fontWeights","letterSpacings","lineHeights","radii","shadows","sizes","space","styles","transition","zIndices"];function re(e){return V(e)?te.every(o=>Object.prototype.hasOwnProperty.call(e,o)):!1}function m(e){return typeof e=="function"}function oe(...e){return o=>e.reduce((n,r)=>r(n),o)}var ne=e=>function(...n){let r=[...n],t=n[n.length-1];return re(t)&&r.length>1?r=r.slice(0,r.length-1):t=e,oe(...r.map(i=>a=>m(i)?i(a):ae(a,i)))(t)},ie=ne(j);function ae(...e){return z({},...e,_)}function _(e,o,n,r){if((m(e)||m(o))&&Object.prototype.hasOwnProperty.call(r,n))return(...t)=>{const i=m(e)?e(...t):e,a=m(o)?o(...t):o;return z({},i,a,_)}}var q=l.createContext({getDocument(){return document},getWindow(){return window}});q.displayName="EnvironmentContext";function N(e){const{children:o,environment:n,disabled:r}=e,t=l.useRef(null),i=l.useMemo(()=>n||{getDocument:()=>{var d,u;return(u=(d=t.current)==null?void 0:d.ownerDocument)!=null?u:document},getWindow:()=>{var d,u;return(u=(d=t.current)==null?void 0:d.ownerDocument.defaultView)!=null?u:window}},[n]),a=!r||!n;return s.jsxs(q.Provider,{value:i,children:[o,a&&s.jsx("span",{id:"__chakra_env",hidden:!0,ref:t})]})}N.displayName="EnvironmentProvider";var se=e=>{const{children:o,colorModeManager:n,portalZIndex:r,resetScope:t,resetCSS:i=!0,theme:a={},environment:d,cssVarsRoot:u,disableEnvironment:p,disableGlobalStyle:y}=e,b=s.jsx(N,{environment:d,disabled:p,children:o});return s.jsx(D,{theme:a,cssVarsRoot:u,children:s.jsxs(O,{colorModeManager:n,options:a.config,children:[i?s.jsx(J,{scope:t}):s.jsx(B,{}),!y&&s.jsx(F,{}),r?s.jsx(G,{zIndex:r,children:b}):b]})})},le=e=>function({children:n,theme:r=e,toastOptions:t,...i}){return s.jsxs(se,{theme:r,...i,children:[s.jsx(W,{value:t==null?void 0:t.defaultOptions,children:n}),s.jsx(K,{...t})]})},de=le(j);const ue=()=>l.useMemo(()=>({colorScheme:"dark",fontFamily:"'Inter Variable', sans-serif",components:{ScrollArea:{defaultProps:{scrollbarSize:10},styles:{scrollbar:{"&:hover":{backgroundColor:"var(--invokeai-colors-baseAlpha-300)"}},thumb:{backgroundColor:"var(--invokeai-colors-baseAlpha-300)"}}}}}),[]),ce=L("@@invokeai-color-mode");function he({children:e}){const{i18n:o}=Y(),n=o.dir(),r=l.useMemo(()=>ie({...Z,direction:n}),[n]);l.useEffect(()=>{document.body.dir=n},[n]);const t=ue();return s.jsx(U,{theme:t,children:s.jsx(de,{theme:r,colorModeManager:ce,toastOptions:H,children:e})})}const ve=l.memo(he);export{ve as default};
|
||||
File diff suppressed because one or more lines are too long
158
invokeai/frontend/web/dist/assets/index-94062f76.js
vendored
Normal file
158
invokeai/frontend/web/dist/assets/index-94062f76.js
vendored
Normal file
File diff suppressed because one or more lines are too long
128
invokeai/frontend/web/dist/assets/index-f6c3f475.js
vendored
128
invokeai/frontend/web/dist/assets/index-f6c3f475.js
vendored
File diff suppressed because one or more lines are too long
File diff suppressed because one or more lines are too long
2
invokeai/frontend/web/dist/index.html
vendored
2
invokeai/frontend/web/dist/index.html
vendored
@@ -12,7 +12,7 @@
|
||||
margin: 0;
|
||||
}
|
||||
</style>
|
||||
<script type="module" crossorigin src="./assets/index-f6c3f475.js"></script>
|
||||
<script type="module" crossorigin src="./assets/index-94062f76.js"></script>
|
||||
</head>
|
||||
|
||||
<body dir="ltr">
|
||||
|
||||
348
invokeai/frontend/web/dist/locales/en.json
vendored
348
invokeai/frontend/web/dist/locales/en.json
vendored
@@ -13,14 +13,15 @@
|
||||
"reset": "Reset",
|
||||
"rotateClockwise": "Rotate Clockwise",
|
||||
"rotateCounterClockwise": "Rotate Counter-Clockwise",
|
||||
"showGallery": "Show Gallery",
|
||||
"showGalleryPanel": "Show Gallery Panel",
|
||||
"showOptionsPanel": "Show Side Panel",
|
||||
"toggleAutoscroll": "Toggle autoscroll",
|
||||
"toggleLogViewer": "Toggle Log Viewer",
|
||||
"uploadImage": "Upload Image",
|
||||
"useThisParameter": "Use this parameter",
|
||||
"zoomIn": "Zoom In",
|
||||
"zoomOut": "Zoom Out"
|
||||
"zoomOut": "Zoom Out",
|
||||
"loadMore": "Load More"
|
||||
},
|
||||
"boards": {
|
||||
"addBoard": "Add Board",
|
||||
@@ -57,6 +58,7 @@
|
||||
"githubLabel": "Github",
|
||||
"hotkeysLabel": "Hotkeys",
|
||||
"imagePrompt": "Image Prompt",
|
||||
"imageFailedToLoad": "Unable to Load Image",
|
||||
"img2img": "Image To Image",
|
||||
"langArabic": "العربية",
|
||||
"langBrPortuguese": "Português do Brasil",
|
||||
@@ -80,6 +82,7 @@
|
||||
"load": "Load",
|
||||
"loading": "Loading",
|
||||
"loadingInvokeAI": "Loading Invoke AI",
|
||||
"learnMore": "Learn More",
|
||||
"modelManager": "Model Manager",
|
||||
"nodeEditor": "Node Editor",
|
||||
"nodes": "Workflow Editor",
|
||||
@@ -110,6 +113,7 @@
|
||||
"statusModelChanged": "Model Changed",
|
||||
"statusModelConverted": "Model Converted",
|
||||
"statusPreparing": "Preparing",
|
||||
"statusProcessing": "Processing",
|
||||
"statusProcessingCanceled": "Processing Canceled",
|
||||
"statusProcessingComplete": "Processing Complete",
|
||||
"statusRestoringFaces": "Restoring Faces",
|
||||
@@ -133,6 +137,8 @@
|
||||
"bgth": "bg_th",
|
||||
"canny": "Canny",
|
||||
"cannyDescription": "Canny edge detection",
|
||||
"colorMap": "Color",
|
||||
"colorMapDescription": "Generates a color map from the image",
|
||||
"coarse": "Coarse",
|
||||
"contentShuffle": "Content Shuffle",
|
||||
"contentShuffleDescription": "Shuffles the content in an image",
|
||||
@@ -156,6 +162,7 @@
|
||||
"hideAdvanced": "Hide Advanced",
|
||||
"highThreshold": "High Threshold",
|
||||
"imageResolution": "Image Resolution",
|
||||
"colorMapTileSize": "Tile Size",
|
||||
"importImageFromCanvas": "Import Image From Canvas",
|
||||
"importMaskFromCanvas": "Import Mask From Canvas",
|
||||
"incompatibleBaseModel": "Incompatible base model:",
|
||||
@@ -203,6 +210,81 @@
|
||||
"incompatibleModel": "Incompatible base model:",
|
||||
"noMatchingEmbedding": "No matching Embeddings"
|
||||
},
|
||||
"queue": {
|
||||
"queue": "Queue",
|
||||
"queueFront": "Add to Front of Queue",
|
||||
"queueBack": "Add to Queue",
|
||||
"queueCountPrediction": "Add {{predicted}} to Queue",
|
||||
"queueMaxExceeded": "Max of {{max_queue_size}} exceeded, would skip {{skip}}",
|
||||
"queuedCount": "{{pending}} Pending",
|
||||
"queueTotal": "{{total}} Total",
|
||||
"queueEmpty": "Queue Empty",
|
||||
"enqueueing": "Queueing Batch",
|
||||
"resume": "Resume",
|
||||
"resumeTooltip": "Resume Processor",
|
||||
"resumeSucceeded": "Processor Resumed",
|
||||
"resumeFailed": "Problem Resuming Processor",
|
||||
"pause": "Pause",
|
||||
"pauseTooltip": "Pause Processor",
|
||||
"pauseSucceeded": "Processor Paused",
|
||||
"pauseFailed": "Problem Pausing Processor",
|
||||
"cancel": "Cancel",
|
||||
"cancelTooltip": "Cancel Current Item",
|
||||
"cancelSucceeded": "Item Canceled",
|
||||
"cancelFailed": "Problem Canceling Item",
|
||||
"prune": "Prune",
|
||||
"pruneTooltip": "Prune {{item_count}} Completed Items",
|
||||
"pruneSucceeded": "Pruned {{item_count}} Completed Items from Queue",
|
||||
"pruneFailed": "Problem Pruning Queue",
|
||||
"clear": "Clear",
|
||||
"clearTooltip": "Cancel and Clear All Items",
|
||||
"clearSucceeded": "Queue Cleared",
|
||||
"clearFailed": "Problem Clearing Queue",
|
||||
"cancelBatch": "Cancel Batch",
|
||||
"cancelItem": "Cancel Item",
|
||||
"cancelBatchSucceeded": "Batch Canceled",
|
||||
"cancelBatchFailed": "Problem Canceling Batch",
|
||||
"clearQueueAlertDialog": "Clearing the queue immediately cancels any processing items and clears the queue entirely.",
|
||||
"clearQueueAlertDialog2": "Are you sure you want to clear the queue?",
|
||||
"current": "Current",
|
||||
"next": "Next",
|
||||
"status": "Status",
|
||||
"total": "Total",
|
||||
"pending": "Pending",
|
||||
"in_progress": "In Progress",
|
||||
"completed": "Completed",
|
||||
"failed": "Failed",
|
||||
"canceled": "Canceled",
|
||||
"completedIn": "Completed in",
|
||||
"batch": "Batch",
|
||||
"item": "Item",
|
||||
"session": "Session",
|
||||
"batchValues": "Batch Values",
|
||||
"notReady": "Unable to Queue",
|
||||
"batchQueued": "Batch Queued",
|
||||
"batchQueuedDesc": "Added {{item_count}} sessions to {{direction}} of queue",
|
||||
"front": "front",
|
||||
"back": "back",
|
||||
"batchFailedToQueue": "Failed to Queue Batch",
|
||||
"graphQueued": "Graph queued",
|
||||
"graphFailedToQueue": "Failed to queue graph"
|
||||
},
|
||||
"invocationCache": {
|
||||
"invocationCache": "Invocation Cache",
|
||||
"cacheSize": "Cache Size",
|
||||
"maxCacheSize": "Max Cache Size",
|
||||
"hits": "Cache Hits",
|
||||
"misses": "Cache Misses",
|
||||
"clear": "Clear",
|
||||
"clearSucceeded": "Invocation Cache Cleared",
|
||||
"clearFailed": "Problem Clearing Invocation Cache",
|
||||
"enable": "Enable",
|
||||
"enableSucceeded": "Invocation Cache Enabled",
|
||||
"enableFailed": "Problem Enabling Invocation Cache",
|
||||
"disable": "Disable",
|
||||
"disableSucceeded": "Invocation Cache Disabled",
|
||||
"disableFailed": "Problem Disabling Invocation Cache"
|
||||
},
|
||||
"gallery": {
|
||||
"allImagesLoaded": "All Images Loaded",
|
||||
"assets": "Assets",
|
||||
@@ -574,7 +656,7 @@
|
||||
"onnxModels": "Onnx",
|
||||
"pathToCustomConfig": "Path To Custom Config",
|
||||
"pickModelType": "Pick Model Type",
|
||||
"predictionType": "Prediction Type (for Stable Diffusion 2.x Models only)",
|
||||
"predictionType": "Prediction Type (for Stable Diffusion 2.x Models and occasional Stable Diffusion 1.x Models)",
|
||||
"quickAdd": "Quick Add",
|
||||
"repo_id": "Repo ID",
|
||||
"repoIDValidationMsg": "Online repository of your model",
|
||||
@@ -624,6 +706,8 @@
|
||||
"addNodeToolTip": "Add Node (Shift+A, Space)",
|
||||
"animatedEdges": "Animated Edges",
|
||||
"animatedEdgesHelp": "Animate selected edges and edges connected to selected nodes",
|
||||
"boardField": "Board",
|
||||
"boardFieldDescription": "A gallery board",
|
||||
"boolean": "Booleans",
|
||||
"booleanCollection": "Boolean Collection",
|
||||
"booleanCollectionDescription": "A collection of booleans.",
|
||||
@@ -633,6 +717,7 @@
|
||||
"cannotConnectInputToInput": "Cannot connect input to input",
|
||||
"cannotConnectOutputToOutput": "Cannot connect output to output",
|
||||
"cannotConnectToSelf": "Cannot connect to self",
|
||||
"cannotDuplicateConnection": "Cannot create duplicate connections",
|
||||
"clipField": "Clip",
|
||||
"clipFieldDescription": "Tokenizer and text_encoder submodels.",
|
||||
"collection": "Collection",
|
||||
@@ -641,7 +726,8 @@
|
||||
"collectionItemDescription": "TODO",
|
||||
"colorCodeEdges": "Color-Code Edges",
|
||||
"colorCodeEdgesHelp": "Color-code edges according to their connected fields",
|
||||
"colorCollectionDescription": "A collection of colors.",
|
||||
"colorCollection": "A collection of colors.",
|
||||
"colorCollectionDescription": "TODO",
|
||||
"colorField": "Color",
|
||||
"colorFieldDescription": "A RGBA color.",
|
||||
"colorPolymorphic": "Color Polymorphic",
|
||||
@@ -688,7 +774,8 @@
|
||||
"imageFieldDescription": "Images may be passed between nodes.",
|
||||
"imagePolymorphic": "Image Polymorphic",
|
||||
"imagePolymorphicDescription": "A collection of images.",
|
||||
"inputFields": "Input Feilds",
|
||||
"inputField": "Input Field",
|
||||
"inputFields": "Input Fields",
|
||||
"inputMayOnlyHaveOneConnection": "Input may only have one connection",
|
||||
"inputNode": "Input Node",
|
||||
"integer": "Integer",
|
||||
@@ -706,6 +793,7 @@
|
||||
"latentsPolymorphicDescription": "Latents may be passed between nodes.",
|
||||
"loadingNodes": "Loading Nodes...",
|
||||
"loadWorkflow": "Load Workflow",
|
||||
"noWorkflow": "No Workflow",
|
||||
"loRAModelField": "LoRA",
|
||||
"loRAModelFieldDescription": "TODO",
|
||||
"mainModelField": "Model",
|
||||
@@ -727,14 +815,15 @@
|
||||
"noImageFoundState": "No initial image found in state",
|
||||
"noMatchingNodes": "No matching nodes",
|
||||
"noNodeSelected": "No node selected",
|
||||
"noOpacity": "Node Opacity",
|
||||
"nodeOpacity": "Node Opacity",
|
||||
"noOutputRecorded": "No outputs recorded",
|
||||
"noOutputSchemaName": "No output schema name found in ref object",
|
||||
"notes": "Notes",
|
||||
"notesDescription": "Add notes about your workflow",
|
||||
"oNNXModelField": "ONNX Model",
|
||||
"oNNXModelFieldDescription": "ONNX model field.",
|
||||
"outputFields": "Output Feilds",
|
||||
"outputField": "Output Field",
|
||||
"outputFields": "Output Fields",
|
||||
"outputNode": "Output node",
|
||||
"outputSchemaNotFound": "Output schema not found",
|
||||
"pickOne": "Pick One",
|
||||
@@ -783,6 +872,7 @@
|
||||
"unknownNode": "Unknown Node",
|
||||
"unknownTemplate": "Unknown Template",
|
||||
"unkownInvocation": "Unknown Invocation type",
|
||||
"updateNode": "Update Node",
|
||||
"updateApp": "Update App",
|
||||
"vaeField": "Vae",
|
||||
"vaeFieldDescription": "Vae submodel.",
|
||||
@@ -806,7 +896,7 @@
|
||||
"zoomOutNodes": "Zoom Out"
|
||||
},
|
||||
"parameters": {
|
||||
"aspectRatio": "Ratio",
|
||||
"aspectRatio": "Aspect Ratio",
|
||||
"boundingBoxHeader": "Bounding Box",
|
||||
"boundingBoxHeight": "Bounding Box Height",
|
||||
"boundingBoxWidth": "Bounding Box Width",
|
||||
@@ -819,6 +909,7 @@
|
||||
},
|
||||
"cfgScale": "CFG Scale",
|
||||
"clipSkip": "CLIP Skip",
|
||||
"clipSkipWithLayerCount": "CLIP Skip {{layerCount}}",
|
||||
"closeViewer": "Close Viewer",
|
||||
"codeformerFidelity": "Fidelity",
|
||||
"coherenceMode": "Mode",
|
||||
@@ -857,6 +948,7 @@
|
||||
"noInitialImageSelected": "No initial image selected",
|
||||
"noModelForControlNet": "ControlNet {{index}} has no model selected.",
|
||||
"noModelSelected": "No model selected",
|
||||
"noPrompts": "No prompts generated",
|
||||
"noNodesInGraph": "No nodes in graph",
|
||||
"readyToInvoke": "Ready to Invoke",
|
||||
"systemBusy": "System busy",
|
||||
@@ -875,7 +967,12 @@
|
||||
"perlinNoise": "Perlin Noise",
|
||||
"positivePromptPlaceholder": "Positive Prompt",
|
||||
"randomizeSeed": "Randomize Seed",
|
||||
"manualSeed": "Manual Seed",
|
||||
"randomSeed": "Random Seed",
|
||||
"restoreFaces": "Restore Faces",
|
||||
"iterations": "Iterations",
|
||||
"iterationsWithCount_one": "{{count}} Iteration",
|
||||
"iterationsWithCount_other": "{{count}} Iterations",
|
||||
"scale": "Scale",
|
||||
"scaleBeforeProcessing": "Scale Before Processing",
|
||||
"scaledHeight": "Scaled H",
|
||||
@@ -886,13 +983,17 @@
|
||||
"seamlessTiling": "Seamless Tiling",
|
||||
"seamlessXAxis": "X Axis",
|
||||
"seamlessYAxis": "Y Axis",
|
||||
"seamlessX": "Seamless X",
|
||||
"seamlessY": "Seamless Y",
|
||||
"seamlessX&Y": "Seamless X & Y",
|
||||
"seamLowThreshold": "Low",
|
||||
"seed": "Seed",
|
||||
"seedWeights": "Seed Weights",
|
||||
"imageActions": "Image Actions",
|
||||
"sendTo": "Send to",
|
||||
"sendToImg2Img": "Send to Image to Image",
|
||||
"sendToUnifiedCanvas": "Send To Unified Canvas",
|
||||
"showOptionsPanel": "Show Options Panel",
|
||||
"showOptionsPanel": "Show Side Panel (O or T)",
|
||||
"showPreview": "Show Preview",
|
||||
"shuffle": "Shuffle Seed",
|
||||
"steps": "Steps",
|
||||
@@ -901,24 +1002,39 @@
|
||||
"tileSize": "Tile Size",
|
||||
"toggleLoopback": "Toggle Loopback",
|
||||
"type": "Type",
|
||||
"upscale": "Upscale",
|
||||
"upscale": "Upscale (Shift + U)",
|
||||
"upscaleImage": "Upscale Image",
|
||||
"upscaling": "Upscaling",
|
||||
"useAll": "Use All",
|
||||
"useCpuNoise": "Use CPU Noise",
|
||||
"cpuNoise": "CPU Noise",
|
||||
"gpuNoise": "GPU Noise",
|
||||
"useInitImg": "Use Initial Image",
|
||||
"usePrompt": "Use Prompt",
|
||||
"useSeed": "Use Seed",
|
||||
"variationAmount": "Variation Amount",
|
||||
"variations": "Variations",
|
||||
"vSymmetryStep": "V Symmetry Step",
|
||||
"width": "Width"
|
||||
"width": "Width",
|
||||
"isAllowedToUpscale": {
|
||||
"useX2Model": "Image is too large to upscale with x4 model, use x2 model",
|
||||
"tooLarge": "Image is too large to upscale, select smaller image"
|
||||
}
|
||||
},
|
||||
"prompt": {
|
||||
"dynamicPrompts": {
|
||||
"combinatorial": "Combinatorial Generation",
|
||||
"dynamicPrompts": "Dynamic Prompts",
|
||||
"enableDynamicPrompts": "Enable Dynamic Prompts",
|
||||
"maxPrompts": "Max Prompts"
|
||||
"maxPrompts": "Max Prompts",
|
||||
"promptsWithCount_one": "{{count}} Prompt",
|
||||
"promptsWithCount_other": "{{count}} Prompts",
|
||||
"seedBehaviour": {
|
||||
"label": "Seed Behaviour",
|
||||
"perIterationLabel": "Seed per Iteration",
|
||||
"perIterationDesc": "Use a different seed for each iteration",
|
||||
"perPromptLabel": "Seed per Image",
|
||||
"perPromptDesc": "Use a different seed for each image"
|
||||
}
|
||||
},
|
||||
"sdxl": {
|
||||
"cfgScale": "CFG Scale",
|
||||
@@ -1066,6 +1182,210 @@
|
||||
"variations": "Try a variation with a value between 0.1 and 1.0 to change the result for a given seed. Interesting variations of the seed are between 0.1 and 0.3."
|
||||
}
|
||||
},
|
||||
"popovers": {
|
||||
"clipSkip": {
|
||||
"heading": "CLIP Skip",
|
||||
"paragraphs": [
|
||||
"Choose how many layers of the CLIP model to skip.",
|
||||
"Some models work better with certain CLIP Skip settings.",
|
||||
"A higher value typically results in a less detailed image."
|
||||
]
|
||||
},
|
||||
"paramNegativeConditioning": {
|
||||
"heading": "Negative Prompt",
|
||||
"paragraphs": [
|
||||
"The generation process avoids the concepts in the negative prompt. Use this to exclude qualities or objects from the output.",
|
||||
"Supports Compel syntax and embeddings."
|
||||
]
|
||||
},
|
||||
"paramPositiveConditioning": {
|
||||
"heading": "Positive Prompt",
|
||||
"paragraphs": [
|
||||
"Guides the generation process. You may use any words or phrases.",
|
||||
"Compel and Dynamic Prompts syntaxes and embeddings."
|
||||
]
|
||||
},
|
||||
"paramScheduler": {
|
||||
"heading": "Scheduler",
|
||||
"paragraphs": [
|
||||
"Scheduler defines how to iteratively add noise to an image or how to update a sample based on a model's output."
|
||||
]
|
||||
},
|
||||
"compositingBlur": {
|
||||
"heading": "Blur",
|
||||
"paragraphs": ["The blur radius of the mask."]
|
||||
},
|
||||
"compositingBlurMethod": {
|
||||
"heading": "Blur Method",
|
||||
"paragraphs": ["The method of blur applied to the masked area."]
|
||||
},
|
||||
"compositingCoherencePass": {
|
||||
"heading": "Coherence Pass",
|
||||
"paragraphs": [
|
||||
"A second round of denoising helps to composite the Inpainted/Outpainted image."
|
||||
]
|
||||
},
|
||||
"compositingCoherenceMode": {
|
||||
"heading": "Mode",
|
||||
"paragraphs": ["The mode of the Coherence Pass."]
|
||||
},
|
||||
"compositingCoherenceSteps": {
|
||||
"heading": "Steps",
|
||||
"paragraphs": [
|
||||
"Number of denoising steps used in the Coherence Pass.",
|
||||
"Same as the main Steps parameter."
|
||||
]
|
||||
},
|
||||
"compositingStrength": {
|
||||
"heading": "Strength",
|
||||
"paragraphs": [
|
||||
"Denoising strength for the Coherence Pass.",
|
||||
"Same as the Image to Image Denoising Strength parameter."
|
||||
]
|
||||
},
|
||||
"compositingMaskAdjustments": {
|
||||
"heading": "Mask Adjustments",
|
||||
"paragraphs": ["Adjust the mask."]
|
||||
},
|
||||
"controlNetBeginEnd": {
|
||||
"heading": "Begin / End Step Percentage",
|
||||
"paragraphs": [
|
||||
"Which steps of the denoising process will have the ControlNet applied.",
|
||||
"ControlNets applied at the beginning of the process guide composition, and ControlNets applied at the end guide details."
|
||||
]
|
||||
},
|
||||
"controlNetControlMode": {
|
||||
"heading": "Control Mode",
|
||||
"paragraphs": [
|
||||
"Lends more weight to either the prompt or ControlNet."
|
||||
]
|
||||
},
|
||||
"controlNetResizeMode": {
|
||||
"heading": "Resize Mode",
|
||||
"paragraphs": [
|
||||
"How the ControlNet image will be fit to the image output size."
|
||||
]
|
||||
},
|
||||
"controlNet": {
|
||||
"heading": "ControlNet",
|
||||
"paragraphs": [
|
||||
"ControlNets provide guidance to the generation process, helping create images with controlled composition, structure, or style, depending on the model selected."
|
||||
]
|
||||
},
|
||||
"controlNetWeight": {
|
||||
"heading": "Weight",
|
||||
"paragraphs": [
|
||||
"How strongly the ControlNet will impact the generated image."
|
||||
]
|
||||
},
|
||||
"dynamicPrompts": {
|
||||
"heading": "Dynamic Prompts",
|
||||
"paragraphs": [
|
||||
"Dynamic Prompts parses a single prompt into many.",
|
||||
"The basic syntax is \"a {red|green|blue} ball\". This will produce three prompts: \"a red ball\", \"a green ball\" and \"a blue ball\".",
|
||||
"You can use the syntax as many times as you like in a single prompt, but be sure to keep the number of prompts generated in check with the Max Prompts setting."
|
||||
]
|
||||
},
|
||||
"dynamicPromptsMaxPrompts": {
|
||||
"heading": "Max Prompts",
|
||||
"paragraphs": [
|
||||
"Limits the number of prompts that can be generated by Dynamic Prompts."
|
||||
]
|
||||
},
|
||||
"dynamicPromptsSeedBehaviour": {
|
||||
"heading": "Seed Behaviour",
|
||||
"paragraphs": [
|
||||
"Controls how the seed is used when generating prompts.",
|
||||
"Per Iteration will use a unique seed for each iteration. Use this to explore prompt variations on a single seed.",
|
||||
"For example, if you have 5 prompts, each image will use the same seed.",
|
||||
"Per Image will use a unique seed for each image. This provides more variation."
|
||||
]
|
||||
},
|
||||
"infillMethod": {
|
||||
"heading": "Infill Method",
|
||||
"paragraphs": ["Method to infill the selected area."]
|
||||
},
|
||||
"lora": {
|
||||
"heading": "LoRA Weight",
|
||||
"paragraphs": [
|
||||
"Higher LoRA weight will lead to larger impacts on the final image."
|
||||
]
|
||||
},
|
||||
"noiseUseCPU": {
|
||||
"heading": "Use CPU Noise",
|
||||
"paragraphs": [
|
||||
"Controls whether noise is generated on the CPU or GPU.",
|
||||
"With CPU Noise enabled, a particular seed will produce the same image on any machine.",
|
||||
"There is no performance impact to enabling CPU Noise."
|
||||
]
|
||||
},
|
||||
"paramCFGScale": {
|
||||
"heading": "CFG Scale",
|
||||
"paragraphs": [
|
||||
"Controls how much your prompt influences the generation process."
|
||||
]
|
||||
},
|
||||
"paramDenoisingStrength": {
|
||||
"heading": "Denoising Strength",
|
||||
"paragraphs": [
|
||||
"How much noise is added to the input image.",
|
||||
"0 will result in an identical image, while 1 will result in a completely new image."
|
||||
]
|
||||
},
|
||||
"paramIterations": {
|
||||
"heading": "Iterations",
|
||||
"paragraphs": [
|
||||
"The number of images to generate.",
|
||||
"If Dynamic Prompts is enabled, each of the prompts will be generated this many times."
|
||||
]
|
||||
},
|
||||
"paramModel": {
|
||||
"heading": "Model",
|
||||
"paragraphs": [
|
||||
"Model used for the denoising steps.",
|
||||
"Different models are typically trained to specialize in producing particular aesthetic results and content."
|
||||
]
|
||||
},
|
||||
"paramRatio": {
|
||||
"heading": "Aspect Ratio",
|
||||
"paragraphs": [
|
||||
"The aspect ratio of the dimensions of the image generated.",
|
||||
"An image size (in number of pixels) equivalent to 512x512 is recommended for SD1.5 models and a size equivalent to 1024x1024 is recommended for SDXL models."
|
||||
]
|
||||
},
|
||||
"paramSeed": {
|
||||
"heading": "Seed",
|
||||
"paragraphs": [
|
||||
"Controls the starting noise used for generation.",
|
||||
"Disable “Random Seed” to produce identical results with the same generation settings."
|
||||
]
|
||||
},
|
||||
"paramSteps": {
|
||||
"heading": "Steps",
|
||||
"paragraphs": [
|
||||
"Number of steps that will be performed in each generation.",
|
||||
"Higher step counts will typically create better images but will require more generation time."
|
||||
]
|
||||
},
|
||||
"paramVAE": {
|
||||
"heading": "VAE",
|
||||
"paragraphs": [
|
||||
"Model used for translating AI output into the final image."
|
||||
]
|
||||
},
|
||||
"paramVAEPrecision": {
|
||||
"heading": "VAE Precision",
|
||||
"paragraphs": [
|
||||
"The precision used during VAE encoding and decoding. FP16/half precision is more efficient, at the expense of minor image variations."
|
||||
]
|
||||
},
|
||||
"scaleBeforeProcessing": {
|
||||
"heading": "Scale Before Processing",
|
||||
"paragraphs": [
|
||||
"Scales the selected area to the size best suited for the model before the image generation process."
|
||||
]
|
||||
}
|
||||
},
|
||||
"ui": {
|
||||
"hideProgressImages": "Hide Progress Images",
|
||||
"lockRatio": "Lock Ratio",
|
||||
@@ -1128,6 +1448,8 @@
|
||||
"showCanvasDebugInfo": "Show Additional Canvas Info",
|
||||
"showGrid": "Show Grid",
|
||||
"showHide": "Show/Hide",
|
||||
"showResultsOn": "Show Results (On)",
|
||||
"showResultsOff": "Show Results (Off)",
|
||||
"showIntermediates": "Show Intermediates",
|
||||
"snapToGrid": "Snap to Grid",
|
||||
"undo": "Undo"
|
||||
|
||||
@@ -58,6 +58,7 @@
|
||||
"githubLabel": "Github",
|
||||
"hotkeysLabel": "Hotkeys",
|
||||
"imagePrompt": "Image Prompt",
|
||||
"imageFailedToLoad": "Unable to Load Image",
|
||||
"img2img": "Image To Image",
|
||||
"langArabic": "العربية",
|
||||
"langBrPortuguese": "Português do Brasil",
|
||||
@@ -655,7 +656,7 @@
|
||||
"onnxModels": "Onnx",
|
||||
"pathToCustomConfig": "Path To Custom Config",
|
||||
"pickModelType": "Pick Model Type",
|
||||
"predictionType": "Prediction Type (for Stable Diffusion 2.x Models only)",
|
||||
"predictionType": "Prediction Type (for Stable Diffusion 2.x Models and occasional Stable Diffusion 1.x Models)",
|
||||
"quickAdd": "Quick Add",
|
||||
"repo_id": "Repo ID",
|
||||
"repoIDValidationMsg": "Online repository of your model",
|
||||
@@ -696,7 +697,7 @@
|
||||
"noLoRAsAvailable": "No LoRAs available",
|
||||
"noMatchingLoRAs": "No matching LoRAs",
|
||||
"noMatchingModels": "No matching Models",
|
||||
"noModelsAvailable": "No Modelss available",
|
||||
"noModelsAvailable": "No models available",
|
||||
"selectLoRA": "Select a LoRA",
|
||||
"selectModel": "Select a Model"
|
||||
},
|
||||
@@ -716,6 +717,7 @@
|
||||
"cannotConnectInputToInput": "Cannot connect input to input",
|
||||
"cannotConnectOutputToOutput": "Cannot connect output to output",
|
||||
"cannotConnectToSelf": "Cannot connect to self",
|
||||
"cannotDuplicateConnection": "Cannot create duplicate connections",
|
||||
"clipField": "Clip",
|
||||
"clipFieldDescription": "Tokenizer and text_encoder submodels.",
|
||||
"collection": "Collection",
|
||||
@@ -1013,7 +1015,11 @@
|
||||
"variationAmount": "Variation Amount",
|
||||
"variations": "Variations",
|
||||
"vSymmetryStep": "V Symmetry Step",
|
||||
"width": "Width"
|
||||
"width": "Width",
|
||||
"isAllowedToUpscale": {
|
||||
"useX2Model": "Image is too large to upscale with x4 model, use x2 model",
|
||||
"tooLarge": "Image is too large to upscale, select smaller image"
|
||||
}
|
||||
},
|
||||
"dynamicPrompts": {
|
||||
"combinatorial": "Combinatorial Generation",
|
||||
@@ -1442,6 +1448,8 @@
|
||||
"showCanvasDebugInfo": "Show Additional Canvas Info",
|
||||
"showGrid": "Show Grid",
|
||||
"showHide": "Show/Hide",
|
||||
"showResultsOn": "Show Results (On)",
|
||||
"showResultsOff": "Show Results (Off)",
|
||||
"showIntermediates": "Show Intermediates",
|
||||
"snapToGrid": "Snap to Grid",
|
||||
"undo": "Undo"
|
||||
|
||||
@@ -1,6 +1,8 @@
|
||||
import { Flex, Grid } from '@chakra-ui/react';
|
||||
import { useStore } from '@nanostores/react';
|
||||
import { useLogger } from 'app/logging/useLogger';
|
||||
import { appStarted } from 'app/store/middleware/listenerMiddleware/listeners/appStarted';
|
||||
import { $headerComponent } from 'app/store/nanostores/headerComponent';
|
||||
import { useAppDispatch, useAppSelector } from 'app/store/storeHooks';
|
||||
import { PartialAppConfig } from 'app/types/invokeai';
|
||||
import ImageUploader from 'common/components/ImageUploader';
|
||||
@@ -14,12 +16,10 @@ import i18n from 'i18n';
|
||||
import { size } from 'lodash-es';
|
||||
import { memo, useCallback, useEffect } from 'react';
|
||||
import { ErrorBoundary } from 'react-error-boundary';
|
||||
import { usePreselectedImage } from '../../features/parameters/hooks/usePreselectedImage';
|
||||
import AppErrorBoundaryFallback from './AppErrorBoundaryFallback';
|
||||
import GlobalHotkeys from './GlobalHotkeys';
|
||||
import PreselectedImage from './PreselectedImage';
|
||||
import Toaster from './Toaster';
|
||||
import { useStore } from '@nanostores/react';
|
||||
import { $headerComponent } from 'app/store/nanostores/headerComponent';
|
||||
|
||||
const DEFAULT_CONFIG = {};
|
||||
|
||||
@@ -36,8 +36,7 @@ const App = ({ config = DEFAULT_CONFIG, selectedImage }: Props) => {
|
||||
|
||||
const logger = useLogger('system');
|
||||
const dispatch = useAppDispatch();
|
||||
const { handleSendToCanvas, handleSendToImg2Img, handleUseAllMetadata } =
|
||||
usePreselectedImage(selectedImage?.imageName);
|
||||
|
||||
const handleReset = useCallback(() => {
|
||||
localStorage.clear();
|
||||
location.reload();
|
||||
@@ -59,24 +58,6 @@ const App = ({ config = DEFAULT_CONFIG, selectedImage }: Props) => {
|
||||
dispatch(appStarted());
|
||||
}, [dispatch]);
|
||||
|
||||
useEffect(() => {
|
||||
if (selectedImage && selectedImage.action === 'sendToCanvas') {
|
||||
handleSendToCanvas();
|
||||
}
|
||||
}, [selectedImage, handleSendToCanvas]);
|
||||
|
||||
useEffect(() => {
|
||||
if (selectedImage && selectedImage.action === 'sendToImg2Img') {
|
||||
handleSendToImg2Img();
|
||||
}
|
||||
}, [selectedImage, handleSendToImg2Img]);
|
||||
|
||||
useEffect(() => {
|
||||
if (selectedImage && selectedImage.action === 'useAllParameters') {
|
||||
handleUseAllMetadata();
|
||||
}
|
||||
}, [selectedImage, handleUseAllMetadata]);
|
||||
|
||||
const headerComponent = useStore($headerComponent);
|
||||
|
||||
return (
|
||||
@@ -112,6 +93,7 @@ const App = ({ config = DEFAULT_CONFIG, selectedImage }: Props) => {
|
||||
<ChangeBoardModal />
|
||||
<Toaster />
|
||||
<GlobalHotkeys />
|
||||
<PreselectedImage selectedImage={selectedImage} />
|
||||
</ErrorBoundary>
|
||||
);
|
||||
};
|
||||
|
||||
@@ -17,7 +17,10 @@ import '../../i18n';
|
||||
import AppDndContext from '../../features/dnd/components/AppDndContext';
|
||||
import { $customStarUI, CustomStarUi } from 'app/store/nanostores/customStarUI';
|
||||
import { $headerComponent } from 'app/store/nanostores/headerComponent';
|
||||
import { $queueId, DEFAULT_QUEUE_ID } from 'features/queue/store/nanoStores';
|
||||
import {
|
||||
$queueId,
|
||||
DEFAULT_QUEUE_ID,
|
||||
} from 'features/queue/store/queueNanoStore';
|
||||
|
||||
const App = lazy(() => import('./App'));
|
||||
const ThemeLocaleProvider = lazy(() => import('./ThemeLocaleProvider'));
|
||||
|
||||
@@ -0,0 +1,16 @@
|
||||
import { usePreselectedImage } from 'features/parameters/hooks/usePreselectedImage';
|
||||
import { memo } from 'react';
|
||||
|
||||
type Props = {
|
||||
selectedImage?: {
|
||||
imageName: string;
|
||||
action: 'sendToImg2Img' | 'sendToCanvas' | 'useAllParameters';
|
||||
};
|
||||
};
|
||||
|
||||
const PreselectedImage = (props: Props) => {
|
||||
usePreselectedImage(props.selectedImage);
|
||||
return null;
|
||||
};
|
||||
|
||||
export default memo(PreselectedImage);
|
||||
@@ -5,7 +5,7 @@ import {
|
||||
} from '@chakra-ui/react';
|
||||
import { ReactNode, memo, useEffect, useMemo } from 'react';
|
||||
import { useTranslation } from 'react-i18next';
|
||||
import { theme as invokeAITheme } from 'theme/theme';
|
||||
import { TOAST_OPTIONS, theme as invokeAITheme } from 'theme/theme';
|
||||
|
||||
import '@fontsource-variable/inter';
|
||||
import { MantineProvider } from '@mantine/core';
|
||||
@@ -39,7 +39,11 @@ function ThemeLocaleProvider({ children }: ThemeLocaleProviderProps) {
|
||||
|
||||
return (
|
||||
<MantineProvider theme={mantineTheme}>
|
||||
<ChakraProvider theme={theme} colorModeManager={manager}>
|
||||
<ChakraProvider
|
||||
theme={theme}
|
||||
colorModeManager={manager}
|
||||
toastOptions={TOAST_OPTIONS}
|
||||
>
|
||||
{children}
|
||||
</ChakraProvider>
|
||||
</MantineProvider>
|
||||
|
||||
@@ -54,21 +54,6 @@ import { addModelSelectedListener } from './listeners/modelSelected';
|
||||
import { addModelsLoadedListener } from './listeners/modelsLoaded';
|
||||
import { addDynamicPromptsListener } from './listeners/promptChanged';
|
||||
import { addReceivedOpenAPISchemaListener } from './listeners/receivedOpenAPISchema';
|
||||
import {
|
||||
addSessionCanceledFulfilledListener,
|
||||
addSessionCanceledPendingListener,
|
||||
addSessionCanceledRejectedListener,
|
||||
} from './listeners/sessionCanceled';
|
||||
import {
|
||||
addSessionCreatedFulfilledListener,
|
||||
addSessionCreatedPendingListener,
|
||||
addSessionCreatedRejectedListener,
|
||||
} from './listeners/sessionCreated';
|
||||
import {
|
||||
addSessionInvokedFulfilledListener,
|
||||
addSessionInvokedPendingListener,
|
||||
addSessionInvokedRejectedListener,
|
||||
} from './listeners/sessionInvoked';
|
||||
import { addSocketConnectedEventListener as addSocketConnectedListener } from './listeners/socketio/socketConnected';
|
||||
import { addSocketDisconnectedEventListener as addSocketDisconnectedListener } from './listeners/socketio/socketDisconnected';
|
||||
import { addGeneratorProgressEventListener as addGeneratorProgressListener } from './listeners/socketio/socketGeneratorProgress';
|
||||
@@ -86,6 +71,7 @@ import { addStagingAreaImageSavedListener } from './listeners/stagingAreaImageSa
|
||||
import { addTabChangedListener } from './listeners/tabChanged';
|
||||
import { addUpscaleRequestedListener } from './listeners/upscaleRequested';
|
||||
import { addWorkflowLoadedListener } from './listeners/workflowLoaded';
|
||||
import { addBatchEnqueuedListener } from './listeners/batchEnqueued';
|
||||
|
||||
export const listenerMiddleware = createListenerMiddleware();
|
||||
|
||||
@@ -136,6 +122,7 @@ addEnqueueRequestedCanvasListener();
|
||||
addEnqueueRequestedNodes();
|
||||
addEnqueueRequestedLinear();
|
||||
addAnyEnqueuedListener();
|
||||
addBatchEnqueuedListener();
|
||||
|
||||
// Canvas actions
|
||||
addCanvasSavedToGalleryListener();
|
||||
@@ -175,21 +162,6 @@ addSessionRetrievalErrorEventListener();
|
||||
addInvocationRetrievalErrorEventListener();
|
||||
addSocketQueueItemStatusChangedEventListener();
|
||||
|
||||
// Session Created
|
||||
addSessionCreatedPendingListener();
|
||||
addSessionCreatedFulfilledListener();
|
||||
addSessionCreatedRejectedListener();
|
||||
|
||||
// Session Invoked
|
||||
addSessionInvokedPendingListener();
|
||||
addSessionInvokedFulfilledListener();
|
||||
addSessionInvokedRejectedListener();
|
||||
|
||||
// Session Canceled
|
||||
addSessionCanceledPendingListener();
|
||||
addSessionCanceledFulfilledListener();
|
||||
addSessionCanceledRejectedListener();
|
||||
|
||||
// ControlNet
|
||||
addControlNetImageProcessedListener();
|
||||
addControlNetAutoProcessListener();
|
||||
|
||||
@@ -0,0 +1,101 @@
|
||||
import { createStandaloneToast } from '@chakra-ui/react';
|
||||
import { logger } from 'app/logging/logger';
|
||||
import { parseify } from 'common/util/serialize';
|
||||
import { zPydanticValidationError } from 'features/system/store/zodSchemas';
|
||||
import { t } from 'i18next';
|
||||
import { get, truncate, upperFirst } from 'lodash-es';
|
||||
import { queueApi } from 'services/api/endpoints/queue';
|
||||
import { TOAST_OPTIONS, theme } from 'theme/theme';
|
||||
import { startAppListening } from '..';
|
||||
|
||||
const { toast } = createStandaloneToast({
|
||||
theme: theme,
|
||||
defaultOptions: TOAST_OPTIONS.defaultOptions,
|
||||
});
|
||||
|
||||
export const addBatchEnqueuedListener = () => {
|
||||
// success
|
||||
startAppListening({
|
||||
matcher: queueApi.endpoints.enqueueBatch.matchFulfilled,
|
||||
effect: async (action) => {
|
||||
const response = action.payload;
|
||||
const arg = action.meta.arg.originalArgs;
|
||||
logger('queue').debug(
|
||||
{ enqueueResult: parseify(response) },
|
||||
'Batch enqueued'
|
||||
);
|
||||
|
||||
if (!toast.isActive('batch-queued')) {
|
||||
toast({
|
||||
id: 'batch-queued',
|
||||
title: t('queue.batchQueued'),
|
||||
description: t('queue.batchQueuedDesc', {
|
||||
item_count: response.enqueued,
|
||||
direction: arg.prepend ? t('queue.front') : t('queue.back'),
|
||||
}),
|
||||
duration: 1000,
|
||||
status: 'success',
|
||||
});
|
||||
}
|
||||
},
|
||||
});
|
||||
|
||||
// error
|
||||
startAppListening({
|
||||
matcher: queueApi.endpoints.enqueueBatch.matchRejected,
|
||||
effect: async (action) => {
|
||||
const response = action.payload;
|
||||
const arg = action.meta.arg.originalArgs;
|
||||
|
||||
if (!response) {
|
||||
toast({
|
||||
title: t('queue.batchFailedToQueue'),
|
||||
status: 'error',
|
||||
description: 'Unknown Error',
|
||||
});
|
||||
logger('queue').error(
|
||||
{ batchConfig: parseify(arg), error: parseify(response) },
|
||||
t('queue.batchFailedToQueue')
|
||||
);
|
||||
return;
|
||||
}
|
||||
|
||||
const result = zPydanticValidationError.safeParse(response);
|
||||
if (result.success) {
|
||||
result.data.data.detail.map((e) => {
|
||||
toast({
|
||||
id: 'batch-failed-to-queue',
|
||||
title: truncate(upperFirst(e.msg), { length: 128 }),
|
||||
status: 'error',
|
||||
description: truncate(
|
||||
`Path:
|
||||
${e.loc.join('.')}`,
|
||||
{ length: 128 }
|
||||
),
|
||||
});
|
||||
});
|
||||
} else {
|
||||
let detail = 'Unknown Error';
|
||||
let duration = undefined;
|
||||
if (response.status === 403 && 'body' in response) {
|
||||
detail = get(response, 'body.detail', 'Unknown Error');
|
||||
} else if (response.status === 403 && 'error' in response) {
|
||||
detail = get(response, 'error.detail', 'Unknown Error');
|
||||
} else if (response.status === 403 && 'data' in response) {
|
||||
detail = get(response, 'data.detail', 'Unknown Error');
|
||||
duration = 15000;
|
||||
}
|
||||
toast({
|
||||
title: t('queue.batchFailedToQueue'),
|
||||
status: 'error',
|
||||
description: detail,
|
||||
...(duration ? { duration } : {}),
|
||||
});
|
||||
}
|
||||
logger('queue').error(
|
||||
{ batchConfig: parseify(arg), error: parseify(response) },
|
||||
t('queue.batchFailedToQueue')
|
||||
);
|
||||
},
|
||||
});
|
||||
};
|
||||
@@ -25,7 +25,7 @@ export const addBoardIdSelectedListener = () => {
|
||||
const state = getState();
|
||||
|
||||
const board_id = boardIdSelected.match(action)
|
||||
? action.payload
|
||||
? action.payload.boardId
|
||||
: state.gallery.selectedBoardId;
|
||||
|
||||
const galleryView = galleryViewChanged.match(action)
|
||||
@@ -55,7 +55,12 @@ export const addBoardIdSelectedListener = () => {
|
||||
|
||||
if (boardImagesData) {
|
||||
const firstImage = imagesSelectors.selectAll(boardImagesData)[0];
|
||||
dispatch(imageSelected(firstImage ?? null));
|
||||
const selectedImage = imagesSelectors.selectById(
|
||||
boardImagesData,
|
||||
action.payload.selectedImageName
|
||||
);
|
||||
|
||||
dispatch(imageSelected(selectedImage || firstImage || null));
|
||||
} else {
|
||||
// board has no images - deselect
|
||||
dispatch(imageSelected(null));
|
||||
|
||||
@@ -3,9 +3,9 @@ import { canvasImageToControlNet } from 'features/canvas/store/actions';
|
||||
import { getBaseLayerBlob } from 'features/canvas/util/getBaseLayerBlob';
|
||||
import { controlNetImageChanged } from 'features/controlNet/store/controlNetSlice';
|
||||
import { addToast } from 'features/system/store/systemSlice';
|
||||
import { t } from 'i18next';
|
||||
import { imagesApi } from 'services/api/endpoints/images';
|
||||
import { startAppListening } from '..';
|
||||
import { t } from 'i18next';
|
||||
|
||||
export const addCanvasImageToControlNetListener = () => {
|
||||
startAppListening({
|
||||
@@ -16,7 +16,7 @@ export const addCanvasImageToControlNetListener = () => {
|
||||
|
||||
let blob;
|
||||
try {
|
||||
blob = await getBaseLayerBlob(state);
|
||||
blob = await getBaseLayerBlob(state, true);
|
||||
} catch (err) {
|
||||
log.error(String(err));
|
||||
dispatch(
|
||||
@@ -36,10 +36,10 @@ export const addCanvasImageToControlNetListener = () => {
|
||||
file: new File([blob], 'savedCanvas.png', {
|
||||
type: 'image/png',
|
||||
}),
|
||||
image_category: 'mask',
|
||||
image_category: 'control',
|
||||
is_intermediate: false,
|
||||
board_id: autoAddBoardId === 'none' ? undefined : autoAddBoardId,
|
||||
crop_visible: true,
|
||||
crop_visible: false,
|
||||
postUploadAction: {
|
||||
type: 'TOAST',
|
||||
toastOptions: { title: t('toast.canvasSentControlnetAssets') },
|
||||
|
||||
@@ -3,9 +3,9 @@ import { canvasMaskToControlNet } from 'features/canvas/store/actions';
|
||||
import { getCanvasData } from 'features/canvas/util/getCanvasData';
|
||||
import { controlNetImageChanged } from 'features/controlNet/store/controlNetSlice';
|
||||
import { addToast } from 'features/system/store/systemSlice';
|
||||
import { t } from 'i18next';
|
||||
import { imagesApi } from 'services/api/endpoints/images';
|
||||
import { startAppListening } from '..';
|
||||
import { t } from 'i18next';
|
||||
|
||||
export const addCanvasMaskToControlNetListener = () => {
|
||||
startAppListening({
|
||||
@@ -50,7 +50,7 @@ export const addCanvasMaskToControlNetListener = () => {
|
||||
image_category: 'mask',
|
||||
is_intermediate: false,
|
||||
board_id: autoAddBoardId === 'none' ? undefined : autoAddBoardId,
|
||||
crop_visible: true,
|
||||
crop_visible: false,
|
||||
postUploadAction: {
|
||||
type: 'TOAST',
|
||||
toastOptions: { title: t('toast.maskSentControlnetAssets') },
|
||||
|
||||
@@ -1,7 +1,11 @@
|
||||
import { logger } from 'app/logging/logger';
|
||||
import { parseify } from 'common/util/serialize';
|
||||
import { controlNetImageProcessed } from 'features/controlNet/store/actions';
|
||||
import { controlNetProcessedImageChanged } from 'features/controlNet/store/controlNetSlice';
|
||||
import {
|
||||
clearPendingControlImages,
|
||||
controlNetImageChanged,
|
||||
controlNetProcessedImageChanged,
|
||||
} from 'features/controlNet/store/controlNetSlice';
|
||||
import { SAVE_IMAGE } from 'features/nodes/util/graphBuilders/constants';
|
||||
import { addToast } from 'features/system/store/systemSlice';
|
||||
import { t } from 'i18next';
|
||||
@@ -105,8 +109,32 @@ export const addControlNetImageProcessedListener = () => {
|
||||
})
|
||||
);
|
||||
}
|
||||
} catch {
|
||||
} catch (error) {
|
||||
log.error({ graph: parseify(graph) }, t('queue.graphFailedToQueue'));
|
||||
|
||||
// handle usage-related errors
|
||||
if (error instanceof Object) {
|
||||
if ('data' in error && 'status' in error) {
|
||||
if (error.status === 403) {
|
||||
// eslint-disable-next-line @typescript-eslint/no-explicit-any
|
||||
const detail = (error.data as any)?.detail || 'Unknown Error';
|
||||
dispatch(
|
||||
addToast({
|
||||
title: t('queue.graphFailedToQueue'),
|
||||
status: 'error',
|
||||
description: detail,
|
||||
duration: 15000,
|
||||
})
|
||||
);
|
||||
dispatch(clearPendingControlImages());
|
||||
dispatch(
|
||||
controlNetImageChanged({ controlNetId, controlImage: null })
|
||||
);
|
||||
return;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
dispatch(
|
||||
addToast({
|
||||
title: t('queue.graphFailedToQueue'),
|
||||
|
||||
@@ -12,8 +12,6 @@ import { getCanvasGenerationMode } from 'features/canvas/util/getCanvasGeneratio
|
||||
import { canvasGraphBuilt } from 'features/nodes/store/actions';
|
||||
import { buildCanvasGraph } from 'features/nodes/util/graphBuilders/buildCanvasGraph';
|
||||
import { prepareLinearUIBatch } from 'features/nodes/util/graphBuilders/buildLinearBatchConfig';
|
||||
import { addToast } from 'features/system/store/systemSlice';
|
||||
import { t } from 'i18next';
|
||||
import { imagesApi } from 'services/api/endpoints/images';
|
||||
import { queueApi } from 'services/api/endpoints/queue';
|
||||
import { ImageDTO } from 'services/api/types';
|
||||
@@ -140,8 +138,6 @@ export const addEnqueueRequestedCanvasListener = () => {
|
||||
const enqueueResult = await req.unwrap();
|
||||
req.reset();
|
||||
|
||||
log.debug({ enqueueResult: parseify(enqueueResult) }, 'Batch enqueued');
|
||||
|
||||
const batchId = enqueueResult.batch.batch_id as string; // we know the is a string, backend provides it
|
||||
|
||||
// Prep the canvas staging area if it is not yet initialized
|
||||
@@ -158,28 +154,8 @@ export const addEnqueueRequestedCanvasListener = () => {
|
||||
|
||||
// Associate the session with the canvas session ID
|
||||
dispatch(canvasBatchIdAdded(batchId));
|
||||
|
||||
dispatch(
|
||||
addToast({
|
||||
title: t('queue.batchQueued'),
|
||||
description: t('queue.batchQueuedDesc', {
|
||||
item_count: enqueueResult.enqueued,
|
||||
direction: prepend ? t('queue.front') : t('queue.back'),
|
||||
}),
|
||||
status: 'success',
|
||||
})
|
||||
);
|
||||
} catch {
|
||||
log.error(
|
||||
{ batchConfig: parseify(batchConfig) },
|
||||
t('queue.batchFailedToQueue')
|
||||
);
|
||||
dispatch(
|
||||
addToast({
|
||||
title: t('queue.batchFailedToQueue'),
|
||||
status: 'error',
|
||||
})
|
||||
);
|
||||
// no-op
|
||||
}
|
||||
},
|
||||
});
|
||||
|
||||
@@ -1,13 +1,9 @@
|
||||
import { logger } from 'app/logging/logger';
|
||||
import { enqueueRequested } from 'app/store/actions';
|
||||
import { parseify } from 'common/util/serialize';
|
||||
import { prepareLinearUIBatch } from 'features/nodes/util/graphBuilders/buildLinearBatchConfig';
|
||||
import { buildLinearImageToImageGraph } from 'features/nodes/util/graphBuilders/buildLinearImageToImageGraph';
|
||||
import { buildLinearSDXLImageToImageGraph } from 'features/nodes/util/graphBuilders/buildLinearSDXLImageToImageGraph';
|
||||
import { buildLinearSDXLTextToImageGraph } from 'features/nodes/util/graphBuilders/buildLinearSDXLTextToImageGraph';
|
||||
import { buildLinearTextToImageGraph } from 'features/nodes/util/graphBuilders/buildLinearTextToImageGraph';
|
||||
import { addToast } from 'features/system/store/systemSlice';
|
||||
import { t } from 'i18next';
|
||||
import { queueApi } from 'services/api/endpoints/queue';
|
||||
import { startAppListening } from '..';
|
||||
|
||||
@@ -18,7 +14,6 @@ export const addEnqueueRequestedLinear = () => {
|
||||
(action.payload.tabName === 'txt2img' ||
|
||||
action.payload.tabName === 'img2img'),
|
||||
effect: async (action, { getState, dispatch }) => {
|
||||
const log = logger('queue');
|
||||
const state = getState();
|
||||
const model = state.generation.model;
|
||||
const { prepend } = action.payload;
|
||||
@@ -41,38 +36,12 @@ export const addEnqueueRequestedLinear = () => {
|
||||
|
||||
const batchConfig = prepareLinearUIBatch(state, graph, prepend);
|
||||
|
||||
try {
|
||||
const req = dispatch(
|
||||
queueApi.endpoints.enqueueBatch.initiate(batchConfig, {
|
||||
fixedCacheKey: 'enqueueBatch',
|
||||
})
|
||||
);
|
||||
const enqueueResult = await req.unwrap();
|
||||
req.reset();
|
||||
|
||||
log.debug({ enqueueResult: parseify(enqueueResult) }, 'Batch enqueued');
|
||||
dispatch(
|
||||
addToast({
|
||||
title: t('queue.batchQueued'),
|
||||
description: t('queue.batchQueuedDesc', {
|
||||
item_count: enqueueResult.enqueued,
|
||||
direction: prepend ? t('queue.front') : t('queue.back'),
|
||||
}),
|
||||
status: 'success',
|
||||
})
|
||||
);
|
||||
} catch {
|
||||
log.error(
|
||||
{ batchConfig: parseify(batchConfig) },
|
||||
t('queue.batchFailedToQueue')
|
||||
);
|
||||
dispatch(
|
||||
addToast({
|
||||
title: t('queue.batchFailedToQueue'),
|
||||
status: 'error',
|
||||
})
|
||||
);
|
||||
}
|
||||
const req = dispatch(
|
||||
queueApi.endpoints.enqueueBatch.initiate(batchConfig, {
|
||||
fixedCacheKey: 'enqueueBatch',
|
||||
})
|
||||
);
|
||||
req.reset();
|
||||
},
|
||||
});
|
||||
};
|
||||
|
||||
@@ -1,9 +1,5 @@
|
||||
import { logger } from 'app/logging/logger';
|
||||
import { enqueueRequested } from 'app/store/actions';
|
||||
import { parseify } from 'common/util/serialize';
|
||||
import { buildNodesGraph } from 'features/nodes/util/graphBuilders/buildNodesGraph';
|
||||
import { addToast } from 'features/system/store/systemSlice';
|
||||
import { t } from 'i18next';
|
||||
import { queueApi } from 'services/api/endpoints/queue';
|
||||
import { BatchConfig } from 'services/api/types';
|
||||
import { startAppListening } from '..';
|
||||
@@ -13,9 +9,7 @@ export const addEnqueueRequestedNodes = () => {
|
||||
predicate: (action): action is ReturnType<typeof enqueueRequested> =>
|
||||
enqueueRequested.match(action) && action.payload.tabName === 'nodes',
|
||||
effect: async (action, { getState, dispatch }) => {
|
||||
const log = logger('queue');
|
||||
const state = getState();
|
||||
const { prepend } = action.payload;
|
||||
const graph = buildNodesGraph(state.nodes);
|
||||
const batchConfig: BatchConfig = {
|
||||
batch: {
|
||||
@@ -25,38 +19,12 @@ export const addEnqueueRequestedNodes = () => {
|
||||
prepend: action.payload.prepend,
|
||||
};
|
||||
|
||||
try {
|
||||
const req = dispatch(
|
||||
queueApi.endpoints.enqueueBatch.initiate(batchConfig, {
|
||||
fixedCacheKey: 'enqueueBatch',
|
||||
})
|
||||
);
|
||||
const enqueueResult = await req.unwrap();
|
||||
req.reset();
|
||||
|
||||
log.debug({ enqueueResult: parseify(enqueueResult) }, 'Batch enqueued');
|
||||
dispatch(
|
||||
addToast({
|
||||
title: t('queue.batchQueued'),
|
||||
description: t('queue.batchQueuedDesc', {
|
||||
item_count: enqueueResult.enqueued,
|
||||
direction: prepend ? t('queue.front') : t('queue.back'),
|
||||
}),
|
||||
status: 'success',
|
||||
})
|
||||
);
|
||||
} catch {
|
||||
log.error(
|
||||
{ batchConfig: parseify(batchConfig) },
|
||||
'Failed to enqueue batch'
|
||||
);
|
||||
dispatch(
|
||||
addToast({
|
||||
title: t('queue.batchFailedToQueue'),
|
||||
status: 'error',
|
||||
})
|
||||
);
|
||||
}
|
||||
const req = dispatch(
|
||||
queueApi.endpoints.enqueueBatch.initiate(batchConfig, {
|
||||
fixedCacheKey: 'enqueueBatch',
|
||||
})
|
||||
);
|
||||
req.reset();
|
||||
},
|
||||
});
|
||||
};
|
||||
|
||||
@@ -113,7 +113,7 @@ export const addRequestedSingleImageDeletionListener = () => {
|
||||
|
||||
// Remove IP Adapter Set Image if image is deleted.
|
||||
if (
|
||||
getState().controlNet.ipAdapterInfo.adapterImage?.image_name ===
|
||||
getState().controlNet.ipAdapterInfo.adapterImage ===
|
||||
imageDTO.image_name
|
||||
) {
|
||||
dispatch(ipAdapterImageChanged(null));
|
||||
@@ -238,7 +238,7 @@ export const addRequestedMultipleImageDeletionListener = () => {
|
||||
|
||||
// Remove IP Adapter Set Image if image is deleted.
|
||||
if (
|
||||
getState().controlNet.ipAdapterInfo.adapterImage?.image_name ===
|
||||
getState().controlNet.ipAdapterInfo.adapterImage ===
|
||||
imageDTO.image_name
|
||||
) {
|
||||
dispatch(ipAdapterImageChanged(null));
|
||||
|
||||
@@ -118,7 +118,7 @@ export const addImageDroppedListener = () => {
|
||||
activeData.payloadType === 'IMAGE_DTO' &&
|
||||
activeData.payload.imageDTO
|
||||
) {
|
||||
dispatch(ipAdapterImageChanged(activeData.payload.imageDTO));
|
||||
dispatch(ipAdapterImageChanged(activeData.payload.imageDTO.image_name));
|
||||
dispatch(isIPAdapterEnabledChanged(true));
|
||||
return;
|
||||
}
|
||||
|
||||
@@ -16,11 +16,6 @@ import { boardsApi } from 'services/api/endpoints/boards';
|
||||
import { startAppListening } from '..';
|
||||
import { imagesApi } from '../../../../../services/api/endpoints/images';
|
||||
|
||||
const DEFAULT_UPLOADED_TOAST: UseToastOptions = {
|
||||
title: t('toast.imageUploaded'),
|
||||
status: 'success',
|
||||
};
|
||||
|
||||
export const addImageUploadedFulfilledListener = () => {
|
||||
startAppListening({
|
||||
matcher: imagesApi.endpoints.uploadImage.matchFulfilled,
|
||||
@@ -43,6 +38,11 @@ export const addImageUploadedFulfilledListener = () => {
|
||||
return;
|
||||
}
|
||||
|
||||
const DEFAULT_UPLOADED_TOAST: UseToastOptions = {
|
||||
title: t('toast.imageUploaded'),
|
||||
status: 'success',
|
||||
};
|
||||
|
||||
// default action - just upload and alert user
|
||||
if (postUploadAction?.type === 'TOAST') {
|
||||
const { toastOptions } = postUploadAction;
|
||||
@@ -111,7 +111,7 @@ export const addImageUploadedFulfilledListener = () => {
|
||||
}
|
||||
|
||||
if (postUploadAction?.type === 'SET_IP_ADAPTER_IMAGE') {
|
||||
dispatch(ipAdapterImageChanged(imageDTO));
|
||||
dispatch(ipAdapterImageChanged(imageDTO.image_name));
|
||||
dispatch(isIPAdapterEnabledChanged(true));
|
||||
dispatch(
|
||||
addToast({
|
||||
|
||||
@@ -1,5 +1,8 @@
|
||||
import { logger } from 'app/logging/logger';
|
||||
import { controlNetRemoved } from 'features/controlNet/store/controlNetSlice';
|
||||
import {
|
||||
controlNetRemoved,
|
||||
ipAdapterModelChanged,
|
||||
} from 'features/controlNet/store/controlNetSlice';
|
||||
import { loraRemoved } from 'features/lora/store/loraSlice';
|
||||
import {
|
||||
modelChanged,
|
||||
@@ -16,12 +19,14 @@ import {
|
||||
} from 'features/sdxl/store/sdxlSlice';
|
||||
import { forEach, some } from 'lodash-es';
|
||||
import {
|
||||
ipAdapterModelsAdapter,
|
||||
mainModelsAdapter,
|
||||
modelsApi,
|
||||
vaeModelsAdapter,
|
||||
} from 'services/api/endpoints/models';
|
||||
import { TypeGuardFor } from 'services/api/types';
|
||||
import { startAppListening } from '..';
|
||||
import { zIPAdapterModel } from 'features/nodes/types/types';
|
||||
|
||||
export const addModelsLoadedListener = () => {
|
||||
startAppListening({
|
||||
@@ -234,6 +239,50 @@ export const addModelsLoadedListener = () => {
|
||||
});
|
||||
},
|
||||
});
|
||||
startAppListening({
|
||||
matcher: modelsApi.endpoints.getIPAdapterModels.matchFulfilled,
|
||||
effect: async (action, { getState, dispatch }) => {
|
||||
// ControlNet models loaded - need to remove missing ControlNets from state
|
||||
const log = logger('models');
|
||||
log.info(
|
||||
{ models: action.payload.entities },
|
||||
`IP Adapter models loaded (${action.payload.ids.length})`
|
||||
);
|
||||
|
||||
const { model } = getState().controlNet.ipAdapterInfo;
|
||||
|
||||
const isModelAvailable = some(
|
||||
action.payload.entities,
|
||||
(m) =>
|
||||
m?.model_name === model?.model_name &&
|
||||
m?.base_model === model?.base_model
|
||||
);
|
||||
|
||||
if (isModelAvailable) {
|
||||
return;
|
||||
}
|
||||
|
||||
const firstModel = ipAdapterModelsAdapter
|
||||
.getSelectors()
|
||||
.selectAll(action.payload)[0];
|
||||
|
||||
if (!firstModel) {
|
||||
dispatch(ipAdapterModelChanged(null));
|
||||
}
|
||||
|
||||
const result = zIPAdapterModel.safeParse(firstModel);
|
||||
|
||||
if (!result.success) {
|
||||
log.error(
|
||||
{ error: result.error.format() },
|
||||
'Failed to parse IP Adapter model'
|
||||
);
|
||||
return;
|
||||
}
|
||||
|
||||
dispatch(ipAdapterModelChanged(result.data));
|
||||
},
|
||||
});
|
||||
startAppListening({
|
||||
matcher: modelsApi.endpoints.getTextualInversionModels.matchFulfilled,
|
||||
effect: async (action) => {
|
||||
|
||||
@@ -1,44 +0,0 @@
|
||||
import { logger } from 'app/logging/logger';
|
||||
import { serializeError } from 'serialize-error';
|
||||
import { sessionCanceled } from 'services/api/thunks/session';
|
||||
import { startAppListening } from '..';
|
||||
|
||||
export const addSessionCanceledPendingListener = () => {
|
||||
startAppListening({
|
||||
actionCreator: sessionCanceled.pending,
|
||||
effect: () => {
|
||||
//
|
||||
},
|
||||
});
|
||||
};
|
||||
|
||||
export const addSessionCanceledFulfilledListener = () => {
|
||||
startAppListening({
|
||||
actionCreator: sessionCanceled.fulfilled,
|
||||
effect: (action) => {
|
||||
const log = logger('session');
|
||||
const { session_id } = action.meta.arg;
|
||||
log.debug({ session_id }, `Session canceled (${session_id})`);
|
||||
},
|
||||
});
|
||||
};
|
||||
|
||||
export const addSessionCanceledRejectedListener = () => {
|
||||
startAppListening({
|
||||
actionCreator: sessionCanceled.rejected,
|
||||
effect: (action) => {
|
||||
const log = logger('session');
|
||||
const { session_id } = action.meta.arg;
|
||||
if (action.payload) {
|
||||
const { error } = action.payload;
|
||||
log.error(
|
||||
{
|
||||
session_id,
|
||||
error: serializeError(error),
|
||||
},
|
||||
`Problem canceling session`
|
||||
);
|
||||
}
|
||||
},
|
||||
});
|
||||
};
|
||||
@@ -1,45 +0,0 @@
|
||||
import { logger } from 'app/logging/logger';
|
||||
import { parseify } from 'common/util/serialize';
|
||||
import { serializeError } from 'serialize-error';
|
||||
import { sessionCreated } from 'services/api/thunks/session';
|
||||
import { startAppListening } from '..';
|
||||
|
||||
export const addSessionCreatedPendingListener = () => {
|
||||
startAppListening({
|
||||
actionCreator: sessionCreated.pending,
|
||||
effect: () => {
|
||||
//
|
||||
},
|
||||
});
|
||||
};
|
||||
|
||||
export const addSessionCreatedFulfilledListener = () => {
|
||||
startAppListening({
|
||||
actionCreator: sessionCreated.fulfilled,
|
||||
effect: (action) => {
|
||||
const log = logger('session');
|
||||
const session = action.payload;
|
||||
log.debug(
|
||||
{ session: parseify(session) },
|
||||
`Session created (${session.id})`
|
||||
);
|
||||
},
|
||||
});
|
||||
};
|
||||
|
||||
export const addSessionCreatedRejectedListener = () => {
|
||||
startAppListening({
|
||||
actionCreator: sessionCreated.rejected,
|
||||
effect: (action) => {
|
||||
const log = logger('session');
|
||||
if (action.payload) {
|
||||
const { error, status } = action.payload;
|
||||
const graph = parseify(action.meta.arg);
|
||||
log.error(
|
||||
{ graph, status, error: serializeError(error) },
|
||||
`Problem creating session`
|
||||
);
|
||||
}
|
||||
},
|
||||
});
|
||||
};
|
||||
@@ -1,44 +0,0 @@
|
||||
import { logger } from 'app/logging/logger';
|
||||
import { serializeError } from 'serialize-error';
|
||||
import { sessionInvoked } from 'services/api/thunks/session';
|
||||
import { startAppListening } from '..';
|
||||
|
||||
export const addSessionInvokedPendingListener = () => {
|
||||
startAppListening({
|
||||
actionCreator: sessionInvoked.pending,
|
||||
effect: () => {
|
||||
//
|
||||
},
|
||||
});
|
||||
};
|
||||
|
||||
export const addSessionInvokedFulfilledListener = () => {
|
||||
startAppListening({
|
||||
actionCreator: sessionInvoked.fulfilled,
|
||||
effect: (action) => {
|
||||
const log = logger('session');
|
||||
const { session_id } = action.meta.arg;
|
||||
log.debug({ session_id }, `Session invoked (${session_id})`);
|
||||
},
|
||||
});
|
||||
};
|
||||
|
||||
export const addSessionInvokedRejectedListener = () => {
|
||||
startAppListening({
|
||||
actionCreator: sessionInvoked.rejected,
|
||||
effect: (action) => {
|
||||
const log = logger('session');
|
||||
const { session_id } = action.meta.arg;
|
||||
if (action.payload) {
|
||||
const { error } = action.payload;
|
||||
log.error(
|
||||
{
|
||||
session_id,
|
||||
error: serializeError(error),
|
||||
},
|
||||
`Problem invoking session`
|
||||
);
|
||||
}
|
||||
},
|
||||
});
|
||||
};
|
||||
@@ -74,6 +74,7 @@ export const addInvocationCompleteEventListener = () => {
|
||||
imagesApi.util.invalidateTags([
|
||||
{ type: 'BoardImagesTotal', id: imageDTO.board_id },
|
||||
{ type: 'BoardAssetsTotal', id: imageDTO.board_id },
|
||||
{ type: 'Board', id: imageDTO.board_id },
|
||||
])
|
||||
);
|
||||
|
||||
@@ -81,9 +82,32 @@ export const addInvocationCompleteEventListener = () => {
|
||||
|
||||
// If auto-switch is enabled, select the new image
|
||||
if (shouldAutoSwitch) {
|
||||
// if auto-add is enabled, switch the board as the image comes in
|
||||
dispatch(galleryViewChanged('images'));
|
||||
dispatch(boardIdSelected(imageDTO.board_id ?? 'none'));
|
||||
// if auto-add is enabled, switch the gallery view and board if needed as the image comes in
|
||||
if (gallery.galleryView !== 'images') {
|
||||
dispatch(galleryViewChanged('images'));
|
||||
}
|
||||
|
||||
if (
|
||||
imageDTO.board_id &&
|
||||
imageDTO.board_id !== gallery.selectedBoardId
|
||||
) {
|
||||
dispatch(
|
||||
boardIdSelected({
|
||||
boardId: imageDTO.board_id,
|
||||
selectedImageName: imageDTO.image_name,
|
||||
})
|
||||
);
|
||||
}
|
||||
|
||||
if (!imageDTO.board_id && gallery.selectedBoardId !== 'none') {
|
||||
dispatch(
|
||||
boardIdSelected({
|
||||
boardId: 'none',
|
||||
selectedImageName: imageDTO.image_name,
|
||||
})
|
||||
);
|
||||
}
|
||||
|
||||
dispatch(imageSelected(imageDTO));
|
||||
}
|
||||
}
|
||||
|
||||
@@ -35,6 +35,7 @@ export const addSocketQueueItemStatusChangedEventListener = () => {
|
||||
queueApi.util.invalidateTags([
|
||||
'CurrentSessionQueueItem',
|
||||
'NextSessionQueueItem',
|
||||
'InvocationCacheStatus',
|
||||
{ type: 'SessionQueueItem', id: item_id },
|
||||
{ type: 'SessionQueueItemDTO', id: item_id },
|
||||
{ type: 'BatchStatus', id: queue_batch_id },
|
||||
|
||||
@@ -6,8 +6,10 @@ import { addToast } from 'features/system/store/systemSlice';
|
||||
import { t } from 'i18next';
|
||||
import { queueApi } from 'services/api/endpoints/queue';
|
||||
import { startAppListening } from '..';
|
||||
import { ImageDTO } from 'services/api/types';
|
||||
import { createIsAllowedToUpscaleSelector } from 'features/parameters/hooks/useIsAllowedToUpscale';
|
||||
|
||||
export const upscaleRequested = createAction<{ image_name: string }>(
|
||||
export const upscaleRequested = createAction<{ imageDTO: ImageDTO }>(
|
||||
`upscale/upscaleRequested`
|
||||
);
|
||||
|
||||
@@ -17,8 +19,28 @@ export const addUpscaleRequestedListener = () => {
|
||||
effect: async (action, { dispatch, getState }) => {
|
||||
const log = logger('session');
|
||||
|
||||
const { image_name } = action.payload;
|
||||
const { imageDTO } = action.payload;
|
||||
const { image_name } = imageDTO;
|
||||
const state = getState();
|
||||
|
||||
const { isAllowedToUpscale, detailTKey } =
|
||||
createIsAllowedToUpscaleSelector(imageDTO)(state);
|
||||
|
||||
// if we can't upscale, show a toast and return
|
||||
if (!isAllowedToUpscale) {
|
||||
log.error(
|
||||
{ imageDTO },
|
||||
t(detailTKey ?? 'parameters.isAllowedToUpscale.tooLarge') // should never coalesce
|
||||
);
|
||||
dispatch(
|
||||
addToast({
|
||||
title: t(detailTKey ?? 'parameters.isAllowedToUpscale.tooLarge'), // should never coalesce
|
||||
status: 'error',
|
||||
})
|
||||
);
|
||||
return;
|
||||
}
|
||||
|
||||
const { esrganModelName } = state.postprocessing;
|
||||
const { autoAddBoardId } = state.gallery;
|
||||
|
||||
@@ -44,8 +66,28 @@ export const addUpscaleRequestedListener = () => {
|
||||
{ enqueueResult: parseify(enqueueResult) },
|
||||
t('queue.graphQueued')
|
||||
);
|
||||
} catch {
|
||||
} catch (error) {
|
||||
log.error({ graph: parseify(graph) }, t('queue.graphFailedToQueue'));
|
||||
|
||||
// handle usage-related errors
|
||||
if (error instanceof Object) {
|
||||
if ('data' in error && 'status' in error) {
|
||||
if (error.status === 403) {
|
||||
// eslint-disable-next-line @typescript-eslint/no-explicit-any
|
||||
const detail = (error.data as any)?.detail || 'Unknown Error';
|
||||
dispatch(
|
||||
addToast({
|
||||
title: t('queue.graphFailedToQueue'),
|
||||
status: 'error',
|
||||
description: detail,
|
||||
duration: 15000,
|
||||
})
|
||||
);
|
||||
return;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
dispatch(
|
||||
addToast({
|
||||
title: t('queue.graphFailedToQueue'),
|
||||
|
||||
@@ -1,54 +0,0 @@
|
||||
import { logger } from 'app/logging/logger';
|
||||
import { AppThunkDispatch } from 'app/store/store';
|
||||
import { parseify } from 'common/util/serialize';
|
||||
import { addToast } from 'features/system/store/systemSlice';
|
||||
import { t } from 'i18next';
|
||||
import { queueApi } from 'services/api/endpoints/queue';
|
||||
import { BatchConfig } from 'services/api/types';
|
||||
|
||||
export const enqueueBatch = async (
|
||||
batchConfig: BatchConfig,
|
||||
dispatch: AppThunkDispatch
|
||||
) => {
|
||||
const log = logger('session');
|
||||
const { prepend } = batchConfig;
|
||||
|
||||
try {
|
||||
const req = dispatch(
|
||||
queueApi.endpoints.enqueueBatch.initiate(batchConfig, {
|
||||
fixedCacheKey: 'enqueueBatch',
|
||||
})
|
||||
);
|
||||
const enqueueResult = await req.unwrap();
|
||||
req.reset();
|
||||
|
||||
dispatch(
|
||||
queueApi.endpoints.resumeProcessor.initiate(undefined, {
|
||||
fixedCacheKey: 'resumeProcessor',
|
||||
})
|
||||
);
|
||||
|
||||
log.debug({ enqueueResult: parseify(enqueueResult) }, 'Batch enqueued');
|
||||
dispatch(
|
||||
addToast({
|
||||
title: t('queue.batchQueued'),
|
||||
description: t('queue.batchQueuedDesc', {
|
||||
item_count: enqueueResult.enqueued,
|
||||
direction: prepend ? t('queue.front') : t('queue.back'),
|
||||
}),
|
||||
status: 'success',
|
||||
})
|
||||
);
|
||||
} catch {
|
||||
log.error(
|
||||
{ batchConfig: parseify(batchConfig) },
|
||||
t('queue.batchFailedToQueue')
|
||||
);
|
||||
dispatch(
|
||||
addToast({
|
||||
title: t('queue.batchFailedToQueue'),
|
||||
status: 'error',
|
||||
})
|
||||
);
|
||||
}
|
||||
};
|
||||
@@ -56,6 +56,7 @@ export type AppConfig = {
|
||||
canRestoreDeletedImagesFromBin: boolean;
|
||||
nodesAllowlist: string[] | undefined;
|
||||
nodesDenylist: string[] | undefined;
|
||||
maxUpscalePixels?: number;
|
||||
sd: {
|
||||
defaultModel?: string;
|
||||
disabledControlNetModels: string[];
|
||||
|
||||
@@ -46,6 +46,7 @@ const IAICollapse = (props: IAIToggleCollapseProps) => {
|
||||
transitionDuration: 'normal',
|
||||
userSelect: 'none',
|
||||
}}
|
||||
data-testid={`${label} collapsible`}
|
||||
>
|
||||
{label}
|
||||
<AnimatePresence>
|
||||
|
||||
@@ -1,18 +1,9 @@
|
||||
import { chakra, ChakraProps } from '@chakra-ui/react';
|
||||
import { Box, ChakraProps } from '@chakra-ui/react';
|
||||
import { memo } from 'react';
|
||||
import { RgbaColorPicker } from 'react-colorful';
|
||||
import { ColorPickerBaseProps, RgbaColor } from 'react-colorful/dist/types';
|
||||
|
||||
type IAIColorPickerProps = Omit<ColorPickerBaseProps<RgbaColor>, 'color'> &
|
||||
ChakraProps & {
|
||||
pickerColor: RgbaColor;
|
||||
styleClass?: string;
|
||||
};
|
||||
|
||||
const ChakraRgbaColorPicker = chakra(RgbaColorPicker, {
|
||||
baseStyle: { paddingInline: 4 },
|
||||
shouldForwardProp: (prop) => !['pickerColor'].includes(prop),
|
||||
});
|
||||
type IAIColorPickerProps = ColorPickerBaseProps<RgbaColor>;
|
||||
|
||||
const colorPickerStyles: NonNullable<ChakraProps['sx']> = {
|
||||
width: 6,
|
||||
@@ -20,19 +11,17 @@ const colorPickerStyles: NonNullable<ChakraProps['sx']> = {
|
||||
borderColor: 'base.100',
|
||||
};
|
||||
|
||||
const IAIColorPicker = (props: IAIColorPickerProps) => {
|
||||
const { styleClass = '', ...rest } = props;
|
||||
const sx = {
|
||||
'.react-colorful__hue-pointer': colorPickerStyles,
|
||||
'.react-colorful__saturation-pointer': colorPickerStyles,
|
||||
'.react-colorful__alpha-pointer': colorPickerStyles,
|
||||
};
|
||||
|
||||
const IAIColorPicker = (props: IAIColorPickerProps) => {
|
||||
return (
|
||||
<ChakraRgbaColorPicker
|
||||
sx={{
|
||||
'.react-colorful__hue-pointer': colorPickerStyles,
|
||||
'.react-colorful__saturation-pointer': colorPickerStyles,
|
||||
'.react-colorful__alpha-pointer': colorPickerStyles,
|
||||
}}
|
||||
className={styleClass}
|
||||
{...rest}
|
||||
/>
|
||||
<Box sx={sx}>
|
||||
<RgbaColorPicker {...props} />
|
||||
</Box>
|
||||
);
|
||||
};
|
||||
|
||||
|
||||
@@ -67,6 +67,7 @@ type IAIDndImageProps = FlexProps & {
|
||||
withHoverOverlay?: boolean;
|
||||
children?: JSX.Element;
|
||||
uploadElement?: ReactNode;
|
||||
dataTestId?: string;
|
||||
};
|
||||
|
||||
const IAIDndImage = (props: IAIDndImageProps) => {
|
||||
@@ -94,6 +95,7 @@ const IAIDndImage = (props: IAIDndImageProps) => {
|
||||
children,
|
||||
onMouseOver,
|
||||
onMouseOut,
|
||||
dataTestId,
|
||||
} = props;
|
||||
|
||||
const { colorMode } = useColorMode();
|
||||
@@ -183,6 +185,7 @@ const IAIDndImage = (props: IAIDndImageProps) => {
|
||||
borderRadius: 'base',
|
||||
...imageSx,
|
||||
}}
|
||||
data-testid={dataTestId}
|
||||
/>
|
||||
{withMetadataOverlay && (
|
||||
<ImageMetadataOverlay imageDTO={imageDTO} />
|
||||
|
||||
@@ -39,6 +39,7 @@ const IAIDndImageIcon = (props: Props) => {
|
||||
},
|
||||
...styleOverrides,
|
||||
}}
|
||||
data-testid={tooltip}
|
||||
/>
|
||||
);
|
||||
};
|
||||
|
||||
@@ -30,6 +30,7 @@ const IAIIconButton = forwardRef((props: IAIIconButtonProps, forwardedRef) => {
|
||||
ref={forwardedRef}
|
||||
role={role}
|
||||
colorScheme={isChecked ? 'accent' : 'base'}
|
||||
data-testid={tooltip}
|
||||
{...rest}
|
||||
/>
|
||||
</Tooltip>
|
||||
|
||||
@@ -81,3 +81,38 @@ export const IAINoContentFallback = (props: IAINoImageFallbackProps) => {
|
||||
</Flex>
|
||||
);
|
||||
};
|
||||
|
||||
type IAINoImageFallbackWithSpinnerProps = FlexProps & {
|
||||
label?: string;
|
||||
};
|
||||
|
||||
export const IAINoContentFallbackWithSpinner = (
|
||||
props: IAINoImageFallbackWithSpinnerProps
|
||||
) => {
|
||||
const { sx, ...rest } = props;
|
||||
|
||||
return (
|
||||
<Flex
|
||||
sx={{
|
||||
w: 'full',
|
||||
h: 'full',
|
||||
alignItems: 'center',
|
||||
justifyContent: 'center',
|
||||
borderRadius: 'base',
|
||||
flexDir: 'column',
|
||||
gap: 2,
|
||||
userSelect: 'none',
|
||||
opacity: 0.7,
|
||||
color: 'base.700',
|
||||
_dark: {
|
||||
color: 'base.500',
|
||||
},
|
||||
...sx,
|
||||
}}
|
||||
{...rest}
|
||||
>
|
||||
<Spinner size="xl" />
|
||||
{props.label && <Text textAlign="center">{props.label}</Text>}
|
||||
</Flex>
|
||||
);
|
||||
};
|
||||
|
||||
@@ -44,7 +44,7 @@ const IAIMantineMultiSelect = forwardRef((props: IAIMultiSelectProps, ref) => {
|
||||
|
||||
return (
|
||||
<Tooltip label={tooltip} placement="top" hasArrow isOpen={true}>
|
||||
<FormControl ref={ref} isDisabled={disabled}>
|
||||
<FormControl ref={ref} isDisabled={disabled} position="static">
|
||||
{label && <FormLabel>{label}</FormLabel>}
|
||||
<MultiSelect
|
||||
ref={inputRef}
|
||||
|
||||
@@ -70,11 +70,15 @@ const IAIMantineSearchableSelect = forwardRef((props: IAISelectProps, ref) => {
|
||||
|
||||
return (
|
||||
<Tooltip label={tooltip} placement="top" hasArrow>
|
||||
<FormControl ref={ref} isDisabled={disabled}>
|
||||
<FormControl
|
||||
ref={ref}
|
||||
isDisabled={disabled}
|
||||
position="static"
|
||||
data-testid={`select-${label || props.placeholder}`}
|
||||
>
|
||||
{label && <FormLabel>{label}</FormLabel>}
|
||||
<Select
|
||||
ref={inputRef}
|
||||
withinPortal
|
||||
disabled={disabled}
|
||||
searchValue={searchValue}
|
||||
onSearchChange={setSearchValue}
|
||||
|
||||
@@ -22,7 +22,13 @@ const IAIMantineSelect = forwardRef((props: IAISelectProps, ref) => {
|
||||
|
||||
return (
|
||||
<Tooltip label={tooltip} placement="top" hasArrow>
|
||||
<FormControl ref={ref} isRequired={required} isDisabled={disabled}>
|
||||
<FormControl
|
||||
ref={ref}
|
||||
isRequired={required}
|
||||
isDisabled={disabled}
|
||||
position="static"
|
||||
data-testid={`select-${label || props.placeholder}`}
|
||||
>
|
||||
<FormLabel>{label}</FormLabel>
|
||||
<Select disabled={disabled} ref={inputRef} styles={styles} {...rest} />
|
||||
</FormControl>
|
||||
|
||||
@@ -139,6 +139,11 @@ const IAICanvas = () => {
|
||||
const { handleDragStart, handleDragMove, handleDragEnd } =
|
||||
useCanvasDragMove();
|
||||
|
||||
const handleContextMenu = useCallback(
|
||||
(e: KonvaEventObject<MouseEvent>) => e.evt.preventDefault(),
|
||||
[]
|
||||
);
|
||||
|
||||
useEffect(() => {
|
||||
if (!containerRef.current) {
|
||||
return;
|
||||
@@ -205,9 +210,7 @@ const IAICanvas = () => {
|
||||
onDragStart={handleDragStart}
|
||||
onDragMove={handleDragMove}
|
||||
onDragEnd={handleDragEnd}
|
||||
onContextMenu={(e: KonvaEventObject<MouseEvent>) =>
|
||||
e.evt.preventDefault()
|
||||
}
|
||||
onContextMenu={handleContextMenu}
|
||||
onWheel={handleWheel}
|
||||
draggable={(tool === 'move' || isStaging) && !isModifyingBoundingBox}
|
||||
>
|
||||
@@ -223,7 +226,11 @@ const IAICanvas = () => {
|
||||
>
|
||||
<IAICanvasObjectRenderer />
|
||||
</Layer>
|
||||
<Layer id="mask" visible={isMaskEnabled} listening={false}>
|
||||
<Layer
|
||||
id="mask"
|
||||
visible={isMaskEnabled && !isStaging}
|
||||
listening={false}
|
||||
>
|
||||
<IAICanvasMaskLines visible={true} listening={false} />
|
||||
<IAICanvasMaskCompositer listening={false} />
|
||||
</Layer>
|
||||
|
||||
@@ -1,26 +1,27 @@
|
||||
import { skipToken } from '@reduxjs/toolkit/dist/query';
|
||||
import { Image, Rect } from 'react-konva';
|
||||
import { memo } from 'react';
|
||||
import { Image } from 'react-konva';
|
||||
import { $authToken } from 'services/api/client';
|
||||
import { useGetImageDTOQuery } from 'services/api/endpoints/images';
|
||||
import useImage from 'use-image';
|
||||
import { CanvasImage } from '../store/canvasTypes';
|
||||
import { $authToken } from 'services/api/client';
|
||||
import { memo } from 'react';
|
||||
import IAICanvasImageErrorFallback from './IAICanvasImageErrorFallback';
|
||||
|
||||
type IAICanvasImageProps = {
|
||||
canvasImage: CanvasImage;
|
||||
};
|
||||
const IAICanvasImage = (props: IAICanvasImageProps) => {
|
||||
const { width, height, x, y, imageName } = props.canvasImage;
|
||||
const { x, y, imageName } = props.canvasImage;
|
||||
const { currentData: imageDTO, isError } = useGetImageDTOQuery(
|
||||
imageName ?? skipToken
|
||||
);
|
||||
const [image] = useImage(
|
||||
const [image, status] = useImage(
|
||||
imageDTO?.image_url ?? '',
|
||||
$authToken.get() ? 'use-credentials' : 'anonymous'
|
||||
);
|
||||
|
||||
if (isError) {
|
||||
return <Rect x={x} y={y} width={width} height={height} fill="red" />;
|
||||
if (isError || status === 'failed') {
|
||||
return <IAICanvasImageErrorFallback canvasImage={props.canvasImage} />;
|
||||
}
|
||||
|
||||
return <Image x={x} y={y} image={image} listening={false} />;
|
||||
|
||||
@@ -0,0 +1,44 @@
|
||||
import { useColorModeValue, useToken } from '@chakra-ui/react';
|
||||
import { memo } from 'react';
|
||||
import { useTranslation } from 'react-i18next';
|
||||
import { Group, Rect, Text } from 'react-konva';
|
||||
import { CanvasImage } from '../store/canvasTypes';
|
||||
|
||||
type IAICanvasImageErrorFallbackProps = {
|
||||
canvasImage: CanvasImage;
|
||||
};
|
||||
const IAICanvasImageErrorFallback = ({
|
||||
canvasImage,
|
||||
}: IAICanvasImageErrorFallbackProps) => {
|
||||
const [errorColorLight, errorColorDark, fontColorLight, fontColorDark] =
|
||||
useToken('colors', ['base.400', 'base.500', 'base.700', 'base.900']);
|
||||
const errorColor = useColorModeValue(errorColorLight, errorColorDark);
|
||||
const fontColor = useColorModeValue(fontColorLight, fontColorDark);
|
||||
const { t } = useTranslation();
|
||||
return (
|
||||
<Group>
|
||||
<Rect
|
||||
x={canvasImage.x}
|
||||
y={canvasImage.y}
|
||||
width={canvasImage.width}
|
||||
height={canvasImage.height}
|
||||
fill={errorColor}
|
||||
/>
|
||||
<Text
|
||||
x={canvasImage.x}
|
||||
y={canvasImage.y}
|
||||
width={canvasImage.width}
|
||||
height={canvasImage.height}
|
||||
align="center"
|
||||
verticalAlign="middle"
|
||||
fontFamily='"Inter Variable", sans-serif'
|
||||
fontSize={canvasImage.width / 16}
|
||||
fontStyle="600"
|
||||
text={t('common.imageFailedToLoad')}
|
||||
fill={fontColor}
|
||||
/>
|
||||
</Group>
|
||||
);
|
||||
};
|
||||
|
||||
export default memo(IAICanvasImageErrorFallback);
|
||||
@@ -3,10 +3,9 @@ import { useAppSelector } from 'app/store/storeHooks';
|
||||
import { canvasSelector } from 'features/canvas/store/canvasSelectors';
|
||||
import { GroupConfig } from 'konva/lib/Group';
|
||||
import { isEqual } from 'lodash-es';
|
||||
|
||||
import { memo } from 'react';
|
||||
import { Group, Rect } from 'react-konva';
|
||||
import IAICanvasImage from './IAICanvasImage';
|
||||
import { memo } from 'react';
|
||||
|
||||
const selector = createSelector(
|
||||
[canvasSelector],
|
||||
@@ -15,11 +14,11 @@ const selector = createSelector(
|
||||
layerState,
|
||||
shouldShowStagingImage,
|
||||
shouldShowStagingOutline,
|
||||
boundingBoxCoordinates: { x, y },
|
||||
boundingBoxDimensions: { width, height },
|
||||
boundingBoxCoordinates: stageBoundingBoxCoordinates,
|
||||
boundingBoxDimensions: stageBoundingBoxDimensions,
|
||||
} = canvas;
|
||||
|
||||
const { selectedImageIndex, images } = layerState.stagingArea;
|
||||
const { selectedImageIndex, images, boundingBox } = layerState.stagingArea;
|
||||
|
||||
return {
|
||||
currentStagingAreaImage:
|
||||
@@ -30,10 +29,10 @@ const selector = createSelector(
|
||||
isOnLastImage: selectedImageIndex === images.length - 1,
|
||||
shouldShowStagingImage,
|
||||
shouldShowStagingOutline,
|
||||
x,
|
||||
y,
|
||||
width,
|
||||
height,
|
||||
x: boundingBox?.x ?? stageBoundingBoxCoordinates.x,
|
||||
y: boundingBox?.y ?? stageBoundingBoxCoordinates.y,
|
||||
width: boundingBox?.width ?? stageBoundingBoxDimensions.width,
|
||||
height: boundingBox?.height ?? stageBoundingBoxDimensions.height,
|
||||
};
|
||||
},
|
||||
{
|
||||
|
||||
@@ -14,6 +14,7 @@ import {
|
||||
|
||||
import { skipToken } from '@reduxjs/toolkit/dist/query';
|
||||
import { defaultSelectorOptions } from 'app/store/util/defaultMemoizeOptions';
|
||||
import IAIButton from 'common/components/IAIButton';
|
||||
import { memo, useCallback } from 'react';
|
||||
import { useHotkeys } from 'react-hotkeys-hook';
|
||||
import { useTranslation } from 'react-i18next';
|
||||
@@ -23,8 +24,8 @@ import {
|
||||
FaCheck,
|
||||
FaEye,
|
||||
FaEyeSlash,
|
||||
FaPlus,
|
||||
FaSave,
|
||||
FaTimes,
|
||||
} from 'react-icons/fa';
|
||||
import { useGetImageDTOQuery } from 'services/api/endpoints/images';
|
||||
import { stagingAreaImageSaved } from '../store/actions';
|
||||
@@ -41,10 +42,10 @@ const selector = createSelector(
|
||||
} = canvas;
|
||||
|
||||
return {
|
||||
currentIndex: selectedImageIndex,
|
||||
total: images.length,
|
||||
currentStagingAreaImage:
|
||||
images.length > 0 ? images[selectedImageIndex] : undefined,
|
||||
isOnFirstImage: selectedImageIndex === 0,
|
||||
isOnLastImage: selectedImageIndex === images.length - 1,
|
||||
shouldShowStagingImage,
|
||||
shouldShowStagingOutline,
|
||||
};
|
||||
@@ -55,10 +56,10 @@ const selector = createSelector(
|
||||
const IAICanvasStagingAreaToolbar = () => {
|
||||
const dispatch = useAppDispatch();
|
||||
const {
|
||||
isOnFirstImage,
|
||||
isOnLastImage,
|
||||
currentStagingAreaImage,
|
||||
shouldShowStagingImage,
|
||||
currentIndex,
|
||||
total,
|
||||
} = useAppSelector(selector);
|
||||
|
||||
const { t } = useTranslation();
|
||||
@@ -71,39 +72,6 @@ const IAICanvasStagingAreaToolbar = () => {
|
||||
dispatch(setShouldShowStagingOutline(false));
|
||||
}, [dispatch]);
|
||||
|
||||
useHotkeys(
|
||||
['left'],
|
||||
() => {
|
||||
handlePrevImage();
|
||||
},
|
||||
{
|
||||
enabled: () => true,
|
||||
preventDefault: true,
|
||||
}
|
||||
);
|
||||
|
||||
useHotkeys(
|
||||
['right'],
|
||||
() => {
|
||||
handleNextImage();
|
||||
},
|
||||
{
|
||||
enabled: () => true,
|
||||
preventDefault: true,
|
||||
}
|
||||
);
|
||||
|
||||
useHotkeys(
|
||||
['enter'],
|
||||
() => {
|
||||
handleAccept();
|
||||
},
|
||||
{
|
||||
enabled: () => true,
|
||||
preventDefault: true,
|
||||
}
|
||||
);
|
||||
|
||||
const handlePrevImage = useCallback(
|
||||
() => dispatch(prevStagingAreaImage()),
|
||||
[dispatch]
|
||||
@@ -119,10 +87,45 @@ const IAICanvasStagingAreaToolbar = () => {
|
||||
[dispatch]
|
||||
);
|
||||
|
||||
useHotkeys(['left'], handlePrevImage, {
|
||||
enabled: () => true,
|
||||
preventDefault: true,
|
||||
});
|
||||
|
||||
useHotkeys(['right'], handleNextImage, {
|
||||
enabled: () => true,
|
||||
preventDefault: true,
|
||||
});
|
||||
|
||||
useHotkeys(['enter'], () => handleAccept, {
|
||||
enabled: () => true,
|
||||
preventDefault: true,
|
||||
});
|
||||
|
||||
const { data: imageDTO } = useGetImageDTOQuery(
|
||||
currentStagingAreaImage?.imageName ?? skipToken
|
||||
);
|
||||
|
||||
const handleToggleShouldShowStagingImage = useCallback(() => {
|
||||
dispatch(setShouldShowStagingImage(!shouldShowStagingImage));
|
||||
}, [dispatch, shouldShowStagingImage]);
|
||||
|
||||
const handleSaveToGallery = useCallback(() => {
|
||||
if (!imageDTO) {
|
||||
return;
|
||||
}
|
||||
|
||||
dispatch(
|
||||
stagingAreaImageSaved({
|
||||
imageDTO,
|
||||
})
|
||||
);
|
||||
}, [dispatch, imageDTO]);
|
||||
|
||||
const handleDiscardStagingArea = useCallback(() => {
|
||||
dispatch(discardStagedImages());
|
||||
}, [dispatch]);
|
||||
|
||||
if (!currentStagingAreaImage) {
|
||||
return null;
|
||||
}
|
||||
@@ -131,11 +134,12 @@ const IAICanvasStagingAreaToolbar = () => {
|
||||
<Flex
|
||||
pos="absolute"
|
||||
bottom={4}
|
||||
gap={2}
|
||||
w="100%"
|
||||
align="center"
|
||||
justify="center"
|
||||
onMouseOver={handleMouseOver}
|
||||
onMouseOut={handleMouseOut}
|
||||
onMouseEnter={handleMouseOver}
|
||||
onMouseLeave={handleMouseOut}
|
||||
>
|
||||
<ButtonGroup isAttached borderRadius="base" shadow="dark-lg">
|
||||
<IAIIconButton
|
||||
@@ -144,16 +148,24 @@ const IAICanvasStagingAreaToolbar = () => {
|
||||
icon={<FaArrowLeft />}
|
||||
onClick={handlePrevImage}
|
||||
colorScheme="accent"
|
||||
isDisabled={isOnFirstImage}
|
||||
isDisabled={!shouldShowStagingImage}
|
||||
/>
|
||||
<IAIButton
|
||||
colorScheme="base"
|
||||
pointerEvents="none"
|
||||
isDisabled={!shouldShowStagingImage}
|
||||
minW={20}
|
||||
>{`${currentIndex + 1}/${total}`}</IAIButton>
|
||||
<IAIIconButton
|
||||
tooltip={`${t('unifiedCanvas.next')} (Right)`}
|
||||
aria-label={`${t('unifiedCanvas.next')} (Right)`}
|
||||
icon={<FaArrowRight />}
|
||||
onClick={handleNextImage}
|
||||
colorScheme="accent"
|
||||
isDisabled={isOnLastImage}
|
||||
isDisabled={!shouldShowStagingImage}
|
||||
/>
|
||||
</ButtonGroup>
|
||||
<ButtonGroup isAttached borderRadius="base" shadow="dark-lg">
|
||||
<IAIIconButton
|
||||
tooltip={`${t('unifiedCanvas.accept')} (Enter)`}
|
||||
aria-label={`${t('unifiedCanvas.accept')} (Enter)`}
|
||||
@@ -162,13 +174,19 @@ const IAICanvasStagingAreaToolbar = () => {
|
||||
colorScheme="accent"
|
||||
/>
|
||||
<IAIIconButton
|
||||
tooltip={t('unifiedCanvas.showHide')}
|
||||
aria-label={t('unifiedCanvas.showHide')}
|
||||
tooltip={
|
||||
shouldShowStagingImage
|
||||
? t('unifiedCanvas.showResultsOn')
|
||||
: t('unifiedCanvas.showResultsOff')
|
||||
}
|
||||
aria-label={
|
||||
shouldShowStagingImage
|
||||
? t('unifiedCanvas.showResultsOn')
|
||||
: t('unifiedCanvas.showResultsOff')
|
||||
}
|
||||
data-alert={!shouldShowStagingImage}
|
||||
icon={shouldShowStagingImage ? <FaEye /> : <FaEyeSlash />}
|
||||
onClick={() =>
|
||||
dispatch(setShouldShowStagingImage(!shouldShowStagingImage))
|
||||
}
|
||||
onClick={handleToggleShouldShowStagingImage}
|
||||
colorScheme="accent"
|
||||
/>
|
||||
<IAIIconButton
|
||||
@@ -176,24 +194,14 @@ const IAICanvasStagingAreaToolbar = () => {
|
||||
aria-label={t('unifiedCanvas.saveToGallery')}
|
||||
isDisabled={!imageDTO || !imageDTO.is_intermediate}
|
||||
icon={<FaSave />}
|
||||
onClick={() => {
|
||||
if (!imageDTO) {
|
||||
return;
|
||||
}
|
||||
|
||||
dispatch(
|
||||
stagingAreaImageSaved({
|
||||
imageDTO,
|
||||
})
|
||||
);
|
||||
}}
|
||||
onClick={handleSaveToGallery}
|
||||
colorScheme="accent"
|
||||
/>
|
||||
<IAIIconButton
|
||||
tooltip={t('unifiedCanvas.discardAll')}
|
||||
aria-label={t('unifiedCanvas.discardAll')}
|
||||
icon={<FaPlus style={{ transform: 'rotate(45deg)' }} />}
|
||||
onClick={() => dispatch(discardStagedImages())}
|
||||
icon={<FaTimes />}
|
||||
onClick={handleDiscardStagingArea}
|
||||
colorScheme="error"
|
||||
fontSize={20}
|
||||
/>
|
||||
|
||||
@@ -213,45 +213,45 @@ const IAICanvasBoundingBox = (props: IAICanvasBoundingBoxPreviewProps) => {
|
||||
[scaledStep]
|
||||
);
|
||||
|
||||
const handleStartedTransforming = () => {
|
||||
const handleStartedTransforming = useCallback(() => {
|
||||
dispatch(setIsTransformingBoundingBox(true));
|
||||
};
|
||||
}, [dispatch]);
|
||||
|
||||
const handleEndedTransforming = () => {
|
||||
const handleEndedTransforming = useCallback(() => {
|
||||
dispatch(setIsTransformingBoundingBox(false));
|
||||
dispatch(setIsMovingBoundingBox(false));
|
||||
dispatch(setIsMouseOverBoundingBox(false));
|
||||
setIsMouseOverBoundingBoxOutline(false);
|
||||
};
|
||||
}, [dispatch]);
|
||||
|
||||
const handleStartedMoving = () => {
|
||||
const handleStartedMoving = useCallback(() => {
|
||||
dispatch(setIsMovingBoundingBox(true));
|
||||
};
|
||||
}, [dispatch]);
|
||||
|
||||
const handleEndedModifying = () => {
|
||||
const handleEndedModifying = useCallback(() => {
|
||||
dispatch(setIsTransformingBoundingBox(false));
|
||||
dispatch(setIsMovingBoundingBox(false));
|
||||
dispatch(setIsMouseOverBoundingBox(false));
|
||||
setIsMouseOverBoundingBoxOutline(false);
|
||||
};
|
||||
}, [dispatch]);
|
||||
|
||||
const handleMouseOver = () => {
|
||||
const handleMouseOver = useCallback(() => {
|
||||
setIsMouseOverBoundingBoxOutline(true);
|
||||
};
|
||||
}, []);
|
||||
|
||||
const handleMouseOut = () => {
|
||||
const handleMouseOut = useCallback(() => {
|
||||
!isTransformingBoundingBox &&
|
||||
!isMovingBoundingBox &&
|
||||
setIsMouseOverBoundingBoxOutline(false);
|
||||
};
|
||||
}, [isMovingBoundingBox, isTransformingBoundingBox]);
|
||||
|
||||
const handleMouseEnterBoundingBox = () => {
|
||||
const handleMouseEnterBoundingBox = useCallback(() => {
|
||||
dispatch(setIsMouseOverBoundingBox(true));
|
||||
};
|
||||
}, [dispatch]);
|
||||
|
||||
const handleMouseLeaveBoundingBox = () => {
|
||||
const handleMouseLeaveBoundingBox = useCallback(() => {
|
||||
dispatch(setIsMouseOverBoundingBox(false));
|
||||
};
|
||||
}, [dispatch]);
|
||||
|
||||
return (
|
||||
<Group {...rest}>
|
||||
|
||||
@@ -1,4 +1,4 @@
|
||||
import { ButtonGroup, Flex } from '@chakra-ui/react';
|
||||
import { Box, ButtonGroup, Flex } from '@chakra-ui/react';
|
||||
import { createSelector } from '@reduxjs/toolkit';
|
||||
import { useAppDispatch, useAppSelector } from 'app/store/storeHooks';
|
||||
import IAIButton from 'common/components/IAIButton';
|
||||
@@ -135,11 +135,12 @@ const IAICanvasMaskOptions = () => {
|
||||
dispatch(setShouldPreserveMaskedArea(e.target.checked))
|
||||
}
|
||||
/>
|
||||
<IAIColorPicker
|
||||
sx={{ paddingTop: 2, paddingBottom: 2 }}
|
||||
pickerColor={maskColor}
|
||||
onChange={(newColor) => dispatch(setMaskColor(newColor))}
|
||||
/>
|
||||
<Box sx={{ paddingTop: 2, paddingBottom: 2 }}>
|
||||
<IAIColorPicker
|
||||
color={maskColor}
|
||||
onChange={(newColor) => dispatch(setMaskColor(newColor))}
|
||||
/>
|
||||
</Box>
|
||||
<IAIButton size="sm" leftIcon={<FaSave />} onClick={handleSaveMask}>
|
||||
Save Mask
|
||||
</IAIButton>
|
||||
|
||||
@@ -1,4 +1,4 @@
|
||||
import { ButtonGroup, Flex } from '@chakra-ui/react';
|
||||
import { ButtonGroup, Flex, Box } from '@chakra-ui/react';
|
||||
import { createSelector } from '@reduxjs/toolkit';
|
||||
import { stateSelector } from 'app/store/store';
|
||||
import { useAppDispatch, useAppSelector } from 'app/store/storeHooks';
|
||||
@@ -237,15 +237,18 @@ const IAICanvasToolChooserOptions = () => {
|
||||
sliderNumberInputProps={{ max: 500 }}
|
||||
/>
|
||||
</Flex>
|
||||
<IAIColorPicker
|
||||
<Box
|
||||
sx={{
|
||||
width: '100%',
|
||||
paddingTop: 2,
|
||||
paddingBottom: 2,
|
||||
}}
|
||||
pickerColor={brushColor}
|
||||
onChange={(newColor) => dispatch(setBrushColor(newColor))}
|
||||
/>
|
||||
>
|
||||
<IAIColorPicker
|
||||
color={brushColor}
|
||||
onChange={(newColor) => dispatch(setBrushColor(newColor))}
|
||||
/>
|
||||
</Box>
|
||||
</Flex>
|
||||
</IAIPopover>
|
||||
</ButtonGroup>
|
||||
|
||||
@@ -6,7 +6,9 @@ export const canvasSelector = (state: RootState): CanvasState => state.canvas;
|
||||
|
||||
export const isStagingSelector = createSelector(
|
||||
[stateSelector],
|
||||
({ canvas }) => canvas.layerState.stagingArea.images.length > 0
|
||||
({ canvas }) =>
|
||||
canvas.batchIds.length > 0 ||
|
||||
canvas.layerState.stagingArea.images.length > 0
|
||||
);
|
||||
|
||||
export const initialCanvasImageSelector = (
|
||||
|
||||
@@ -8,7 +8,6 @@ import { setAspectRatio } from 'features/parameters/store/generationSlice';
|
||||
import { IRect, Vector2d } from 'konva/lib/types';
|
||||
import { clamp, cloneDeep } from 'lodash-es';
|
||||
import { RgbaColor } from 'react-colorful';
|
||||
import { sessionCanceled } from 'services/api/thunks/session';
|
||||
import { ImageDTO } from 'services/api/types';
|
||||
import calculateCoordinates from '../util/calculateCoordinates';
|
||||
import calculateScale from '../util/calculateScale';
|
||||
@@ -187,7 +186,7 @@ export const canvasSlice = createSlice({
|
||||
state.pastLayerStates.push(cloneDeep(state.layerState));
|
||||
|
||||
state.layerState = {
|
||||
...initialLayerState,
|
||||
...cloneDeep(initialLayerState),
|
||||
objects: [
|
||||
{
|
||||
kind: 'image',
|
||||
@@ -201,6 +200,7 @@ export const canvasSlice = createSlice({
|
||||
],
|
||||
};
|
||||
state.futureLayerStates = [];
|
||||
state.batchIds = [];
|
||||
|
||||
const newScale = calculateScale(
|
||||
stageDimensions.width,
|
||||
@@ -350,11 +350,14 @@ export const canvasSlice = createSlice({
|
||||
state.pastLayerStates.shift();
|
||||
}
|
||||
|
||||
state.layerState.stagingArea = { ...initialLayerState.stagingArea };
|
||||
state.layerState.stagingArea = cloneDeep(
|
||||
cloneDeep(initialLayerState)
|
||||
).stagingArea;
|
||||
|
||||
state.futureLayerStates = [];
|
||||
state.shouldShowStagingOutline = true;
|
||||
state.shouldShowStagingOutline = true;
|
||||
state.shouldShowStagingImage = true;
|
||||
state.batchIds = [];
|
||||
},
|
||||
addFillRect: (state) => {
|
||||
const { boundingBoxCoordinates, boundingBoxDimensions, brushColor } =
|
||||
@@ -491,8 +494,9 @@ export const canvasSlice = createSlice({
|
||||
resetCanvas: (state) => {
|
||||
state.pastLayerStates.push(cloneDeep(state.layerState));
|
||||
|
||||
state.layerState = initialLayerState;
|
||||
state.layerState = cloneDeep(initialLayerState);
|
||||
state.futureLayerStates = [];
|
||||
state.batchIds = [];
|
||||
},
|
||||
canvasResized: (
|
||||
state,
|
||||
@@ -617,25 +621,22 @@ export const canvasSlice = createSlice({
|
||||
return;
|
||||
}
|
||||
|
||||
const currentIndex = state.layerState.stagingArea.selectedImageIndex;
|
||||
const length = state.layerState.stagingArea.images.length;
|
||||
const nextIndex = state.layerState.stagingArea.selectedImageIndex + 1;
|
||||
const lastIndex = state.layerState.stagingArea.images.length - 1;
|
||||
|
||||
state.layerState.stagingArea.selectedImageIndex = Math.min(
|
||||
currentIndex + 1,
|
||||
length - 1
|
||||
);
|
||||
state.layerState.stagingArea.selectedImageIndex =
|
||||
nextIndex > lastIndex ? 0 : nextIndex;
|
||||
},
|
||||
prevStagingAreaImage: (state) => {
|
||||
if (!state.layerState.stagingArea.images.length) {
|
||||
return;
|
||||
}
|
||||
|
||||
const currentIndex = state.layerState.stagingArea.selectedImageIndex;
|
||||
const prevIndex = state.layerState.stagingArea.selectedImageIndex - 1;
|
||||
const lastIndex = state.layerState.stagingArea.images.length - 1;
|
||||
|
||||
state.layerState.stagingArea.selectedImageIndex = Math.max(
|
||||
currentIndex - 1,
|
||||
0
|
||||
);
|
||||
state.layerState.stagingArea.selectedImageIndex =
|
||||
prevIndex < 0 ? lastIndex : prevIndex;
|
||||
},
|
||||
commitStagingAreaImage: (state) => {
|
||||
if (!state.layerState.stagingArea.images.length) {
|
||||
@@ -657,13 +658,12 @@ export const canvasSlice = createSlice({
|
||||
...imageToCommit,
|
||||
});
|
||||
}
|
||||
state.layerState.stagingArea = {
|
||||
...initialLayerState.stagingArea,
|
||||
};
|
||||
state.layerState.stagingArea = cloneDeep(initialLayerState).stagingArea;
|
||||
|
||||
state.futureLayerStates = [];
|
||||
state.shouldShowStagingOutline = true;
|
||||
state.shouldShowStagingImage = true;
|
||||
state.batchIds = [];
|
||||
},
|
||||
fitBoundingBoxToStage: (state) => {
|
||||
const {
|
||||
@@ -786,11 +786,6 @@ export const canvasSlice = createSlice({
|
||||
},
|
||||
},
|
||||
extraReducers: (builder) => {
|
||||
builder.addCase(sessionCanceled.pending, (state) => {
|
||||
if (!state.layerState.stagingArea.images.length) {
|
||||
state.layerState.stagingArea = initialLayerState.stagingArea;
|
||||
}
|
||||
});
|
||||
builder.addCase(setAspectRatio, (state, action) => {
|
||||
const ratio = action.payload;
|
||||
if (ratio) {
|
||||
|
||||
@@ -1,11 +1,14 @@
|
||||
import { getCanvasBaseLayer } from './konvaInstanceProvider';
|
||||
import { RootState } from 'app/store/store';
|
||||
import { getCanvasBaseLayer } from './konvaInstanceProvider';
|
||||
import { konvaNodeToBlob } from './konvaNodeToBlob';
|
||||
|
||||
/**
|
||||
* Get the canvas base layer blob, with or without bounding box according to `shouldCropToBoundingBoxOnSave`
|
||||
*/
|
||||
export const getBaseLayerBlob = async (state: RootState) => {
|
||||
export const getBaseLayerBlob = async (
|
||||
state: RootState,
|
||||
alwaysUseBoundingBox: boolean = false
|
||||
) => {
|
||||
const canvasBaseLayer = getCanvasBaseLayer();
|
||||
|
||||
if (!canvasBaseLayer) {
|
||||
@@ -24,14 +27,15 @@ export const getBaseLayerBlob = async (state: RootState) => {
|
||||
|
||||
const absPos = clonedBaseLayer.getAbsolutePosition();
|
||||
|
||||
const boundingBox = shouldCropToBoundingBoxOnSave
|
||||
? {
|
||||
x: boundingBoxCoordinates.x + absPos.x,
|
||||
y: boundingBoxCoordinates.y + absPos.y,
|
||||
width: boundingBoxDimensions.width,
|
||||
height: boundingBoxDimensions.height,
|
||||
}
|
||||
: clonedBaseLayer.getClientRect();
|
||||
const boundingBox =
|
||||
shouldCropToBoundingBoxOnSave || alwaysUseBoundingBox
|
||||
? {
|
||||
x: boundingBoxCoordinates.x + absPos.x,
|
||||
y: boundingBoxCoordinates.y + absPos.y,
|
||||
width: boundingBoxDimensions.width,
|
||||
height: boundingBoxDimensions.height,
|
||||
}
|
||||
: clonedBaseLayer.getClientRect();
|
||||
|
||||
return konvaNodeToBlob(clonedBaseLayer, boundingBox);
|
||||
};
|
||||
|
||||
@@ -5,8 +5,23 @@ import ParamIPAdapterFeatureToggle from './ParamIPAdapterFeatureToggle';
|
||||
import ParamIPAdapterImage from './ParamIPAdapterImage';
|
||||
import ParamIPAdapterModelSelect from './ParamIPAdapterModelSelect';
|
||||
import ParamIPAdapterWeight from './ParamIPAdapterWeight';
|
||||
import { createSelector } from '@reduxjs/toolkit';
|
||||
import { stateSelector } from '../../../../app/store/store';
|
||||
import { defaultSelectorOptions } from '../../../../app/store/util/defaultMemoizeOptions';
|
||||
import { useAppSelector } from '../../../../app/store/storeHooks';
|
||||
|
||||
const selector = createSelector(
|
||||
stateSelector,
|
||||
(state) => {
|
||||
const { isIPAdapterEnabled } = state.controlNet;
|
||||
|
||||
return { isIPAdapterEnabled };
|
||||
},
|
||||
defaultSelectorOptions
|
||||
);
|
||||
|
||||
const IPAdapterPanel = () => {
|
||||
const { isIPAdapterEnabled } = useAppSelector(selector);
|
||||
return (
|
||||
<Flex
|
||||
sx={{
|
||||
@@ -14,7 +29,6 @@ const IPAdapterPanel = () => {
|
||||
gap: 3,
|
||||
paddingInline: 3,
|
||||
paddingBlock: 2,
|
||||
paddingBottom: 5,
|
||||
borderRadius: 'base',
|
||||
position: 'relative',
|
||||
bg: 'base.250',
|
||||
@@ -24,10 +38,26 @@ const IPAdapterPanel = () => {
|
||||
}}
|
||||
>
|
||||
<ParamIPAdapterFeatureToggle />
|
||||
<ParamIPAdapterImage />
|
||||
<ParamIPAdapterModelSelect />
|
||||
<ParamIPAdapterWeight />
|
||||
<ParamIPAdapterBeginEnd />
|
||||
{isIPAdapterEnabled && (
|
||||
<>
|
||||
<ParamIPAdapterModelSelect />
|
||||
<Flex gap="3">
|
||||
<Flex
|
||||
flexDirection="column"
|
||||
sx={{
|
||||
h: 28,
|
||||
w: 'full',
|
||||
gap: 4,
|
||||
mb: 4,
|
||||
}}
|
||||
>
|
||||
<ParamIPAdapterWeight />
|
||||
<ParamIPAdapterBeginEnd />
|
||||
</Flex>
|
||||
<ParamIPAdapterImage />
|
||||
</Flex>
|
||||
</>
|
||||
)}
|
||||
</Flex>
|
||||
);
|
||||
};
|
||||
|
||||
@@ -33,7 +33,7 @@ const ParamIPAdapterImage = () => {
|
||||
const { t } = useTranslation();
|
||||
|
||||
const { currentData: imageDTO } = useGetImageDTOQuery(
|
||||
ipAdapterInfo.adapterImage?.image_name ?? skipToken
|
||||
ipAdapterInfo.adapterImage ?? skipToken
|
||||
);
|
||||
|
||||
const draggableData = useMemo<TypesafeDraggableData | undefined>(() => {
|
||||
@@ -63,11 +63,15 @@ const ParamIPAdapterImage = () => {
|
||||
|
||||
return (
|
||||
<Flex
|
||||
layerStyle="second"
|
||||
sx={{
|
||||
position: 'relative',
|
||||
w: 'full',
|
||||
h: 28,
|
||||
w: 28,
|
||||
alignItems: 'center',
|
||||
justifyContent: 'center',
|
||||
aspectRatio: '1/1',
|
||||
borderRadius: 'base',
|
||||
}}
|
||||
>
|
||||
<IAIDndImage
|
||||
|
||||
@@ -88,12 +88,16 @@ const ParamIPAdapterModelSelect = () => {
|
||||
className="nowheel nodrag"
|
||||
tooltip={selectedModel?.description}
|
||||
value={selectedModel?.id ?? null}
|
||||
placeholder="Pick one"
|
||||
error={!selectedModel}
|
||||
placeholder={
|
||||
data.length > 0
|
||||
? t('models.selectModel')
|
||||
: t('models.noModelsAvailable')
|
||||
}
|
||||
error={!selectedModel && data.length > 0}
|
||||
data={data}
|
||||
onChange={handleValueChanged}
|
||||
sx={{ width: '100%' }}
|
||||
disabled={!isEnabled}
|
||||
disabled={!isEnabled || data.length === 0}
|
||||
/>
|
||||
);
|
||||
};
|
||||
|
||||
@@ -254,4 +254,5 @@ export const CONTROLNET_MODEL_DEFAULT_PROCESSORS: {
|
||||
mediapipe: 'mediapipe_face_processor',
|
||||
pidi: 'pidi_image_processor',
|
||||
zoe: 'zoe_depth_image_processor',
|
||||
color: 'color_map_image_processor',
|
||||
};
|
||||
|
||||
@@ -6,8 +6,6 @@ import {
|
||||
import { cloneDeep, forEach } from 'lodash-es';
|
||||
import { imagesApi } from 'services/api/endpoints/images';
|
||||
import { components } from 'services/api/schema';
|
||||
import { isAnySessionRejected } from 'services/api/thunks/session';
|
||||
import { ImageDTO } from 'services/api/types';
|
||||
import { appSocketInvocationError } from 'services/events/actions';
|
||||
import { controlNetImageProcessed } from './actions';
|
||||
import {
|
||||
@@ -61,7 +59,7 @@ export type ControlNetConfig = {
|
||||
};
|
||||
|
||||
export type IPAdapterConfig = {
|
||||
adapterImage: ImageDTO | null;
|
||||
adapterImage: string | null;
|
||||
model: IPAdapterModelParam | null;
|
||||
weight: number;
|
||||
beginStepPct: number;
|
||||
@@ -99,6 +97,9 @@ export const controlNetSlice = createSlice({
|
||||
isControlNetEnabledToggled: (state) => {
|
||||
state.isEnabled = !state.isEnabled;
|
||||
},
|
||||
controlNetEnabled: (state) => {
|
||||
state.isEnabled = true;
|
||||
},
|
||||
controlNetAdded: (
|
||||
state,
|
||||
action: PayloadAction<{
|
||||
@@ -112,6 +113,12 @@ export const controlNetSlice = createSlice({
|
||||
controlNetId,
|
||||
};
|
||||
},
|
||||
controlNetRecalled: (state, action: PayloadAction<ControlNetConfig>) => {
|
||||
const controlNet = action.payload;
|
||||
state.controlNets[controlNet.controlNetId] = {
|
||||
...controlNet,
|
||||
};
|
||||
},
|
||||
controlNetDuplicated: (
|
||||
state,
|
||||
action: PayloadAction<{
|
||||
@@ -380,7 +387,10 @@ export const controlNetSlice = createSlice({
|
||||
isIPAdapterEnabledChanged: (state, action: PayloadAction<boolean>) => {
|
||||
state.isIPAdapterEnabled = action.payload;
|
||||
},
|
||||
ipAdapterImageChanged: (state, action: PayloadAction<ImageDTO | null>) => {
|
||||
ipAdapterRecalled: (state, action: PayloadAction<IPAdapterConfig>) => {
|
||||
state.ipAdapterInfo = action.payload;
|
||||
},
|
||||
ipAdapterImageChanged: (state, action: PayloadAction<string | null>) => {
|
||||
state.ipAdapterInfo.adapterImage = action.payload;
|
||||
},
|
||||
ipAdapterWeightChanged: (state, action: PayloadAction<number>) => {
|
||||
@@ -402,6 +412,9 @@ export const controlNetSlice = createSlice({
|
||||
state.isIPAdapterEnabled = false;
|
||||
state.ipAdapterInfo = { ...initialIPAdapterState };
|
||||
},
|
||||
clearPendingControlImages: (state) => {
|
||||
state.pendingControlImages = [];
|
||||
},
|
||||
},
|
||||
extraReducers: (builder) => {
|
||||
builder.addCase(controlNetImageProcessed, (state, action) => {
|
||||
@@ -418,10 +431,6 @@ export const controlNetSlice = createSlice({
|
||||
state.pendingControlImages = [];
|
||||
});
|
||||
|
||||
builder.addMatcher(isAnySessionRejected, (state) => {
|
||||
state.pendingControlImages = [];
|
||||
});
|
||||
|
||||
builder.addMatcher(
|
||||
imagesApi.endpoints.deleteImage.matchFulfilled,
|
||||
(state, action) => {
|
||||
@@ -444,7 +453,9 @@ export const controlNetSlice = createSlice({
|
||||
|
||||
export const {
|
||||
isControlNetEnabledToggled,
|
||||
controlNetEnabled,
|
||||
controlNetAdded,
|
||||
controlNetRecalled,
|
||||
controlNetDuplicated,
|
||||
controlNetAddedFromImage,
|
||||
controlNetRemoved,
|
||||
@@ -462,12 +473,14 @@ export const {
|
||||
controlNetReset,
|
||||
controlNetAutoConfigToggled,
|
||||
isIPAdapterEnabledChanged,
|
||||
ipAdapterRecalled,
|
||||
ipAdapterImageChanged,
|
||||
ipAdapterWeightChanged,
|
||||
ipAdapterModelChanged,
|
||||
ipAdapterBeginStepPctChanged,
|
||||
ipAdapterEndStepPctChanged,
|
||||
ipAdapterStateReset,
|
||||
clearPendingControlImages,
|
||||
} = controlNetSlice.actions;
|
||||
|
||||
export default controlNetSlice.reducer;
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user