mirror of
https://github.com/nod-ai/SHARK-Studio.git
synced 2026-01-11 23:08:19 -05:00
Compare commits
778 Commits
RefVideo
...
20230410.6
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
3002793301 | ||
|
|
d25ef5529f | ||
|
|
308856a947 | ||
|
|
151b4e142f | ||
|
|
e5a69a7c36 | ||
|
|
450b6cafc4 | ||
|
|
237d26baa2 | ||
|
|
67d6ee1104 | ||
|
|
98b069488e | ||
|
|
e0f227643a | ||
|
|
a0af3bb0cb | ||
|
|
2cd61a5b96 | ||
|
|
f49d41a807 | ||
|
|
2191fc8952 | ||
|
|
aea7796e60 | ||
|
|
a376619f1e | ||
|
|
02d52bb626 | ||
|
|
3b63645f79 | ||
|
|
d6f740b998 | ||
|
|
594c6b8ea2 | ||
|
|
96b1560da5 | ||
|
|
0ef6a0e234 | ||
|
|
641d535f44 | ||
|
|
5bb7846227 | ||
|
|
8f84258fb8 | ||
|
|
7619e76bbd | ||
|
|
9267eadbfa | ||
|
|
431132b8ee | ||
|
|
fb35e13e7a | ||
|
|
17a67897d1 | ||
|
|
da449b73aa | ||
|
|
0b0526699a | ||
|
|
4fac46f7bb | ||
|
|
49925950f1 | ||
|
|
807947c0c8 | ||
|
|
593428bda4 | ||
|
|
cede9b4fec | ||
|
|
c2360303f0 | ||
|
|
420366c1b8 | ||
|
|
d31bae488c | ||
|
|
c23fcf3748 | ||
|
|
7dbbb1726a | ||
|
|
8b8cc7fd33 | ||
|
|
e3c96a2b9d | ||
|
|
5e3f50647d | ||
|
|
7899e1803a | ||
|
|
d105246b9c | ||
|
|
90c958bca2 | ||
|
|
f99903e023 | ||
|
|
c6f44ef1b3 | ||
|
|
8dcd4d5aeb | ||
|
|
d319f4684e | ||
|
|
54d7b6d83e | ||
|
|
4a622532e5 | ||
|
|
650b2ada58 | ||
|
|
f87f8949f3 | ||
|
|
7dc9bf8148 | ||
|
|
ba48ff8d25 | ||
|
|
638840925c | ||
|
|
b661656c03 | ||
|
|
0225434389 | ||
|
|
7ffe20b1c2 | ||
|
|
d8f0c4655d | ||
|
|
7e8d3ec0df | ||
|
|
9c08eec565 | ||
|
|
2d2c523ac5 | ||
|
|
f17b3128c0 | ||
|
|
7c7e630099 | ||
|
|
2dd1491ec1 | ||
|
|
236357fb61 | ||
|
|
7bc38719de | ||
|
|
bdbe992769 | ||
|
|
e6b925e012 | ||
|
|
771120b76c | ||
|
|
a8ce7680db | ||
|
|
b6dcf2401b | ||
|
|
62b5a9fd49 | ||
|
|
2f133e9d5c | ||
|
|
f898a1d332 | ||
|
|
b94266d2b9 | ||
|
|
1b08242aaa | ||
|
|
691030fbab | ||
|
|
16ad7d57a3 | ||
|
|
c561ebf43c | ||
|
|
97fdff7f19 | ||
|
|
ce6d82eab2 | ||
|
|
b8f4b18951 | ||
|
|
b23d3aa584 | ||
|
|
495670d9b6 | ||
|
|
815e23a0b8 | ||
|
|
783538fe11 | ||
|
|
996c645f6a | ||
|
|
1f7d249a62 | ||
|
|
7f6c9a2dc2 | ||
|
|
93891984f3 | ||
|
|
cc0ef54e0e | ||
|
|
812152485d | ||
|
|
0816fb403a | ||
|
|
4f171772be | ||
|
|
a52331d4aa | ||
|
|
ad821a1fc8 | ||
|
|
116b128802 | ||
|
|
b118f183d1 | ||
|
|
911dff16f1 | ||
|
|
de59a66ae4 | ||
|
|
23f1468cc6 | ||
|
|
080350d311 | ||
|
|
7f3f92b9d5 | ||
|
|
be3cdec290 | ||
|
|
f09574538c | ||
|
|
b1113ab551 | ||
|
|
ef756389e3 | ||
|
|
cb17d017df | ||
|
|
798f231792 | ||
|
|
7136890da3 | ||
|
|
d567192fd3 | ||
|
|
dcc4025c78 | ||
|
|
c6c8ec36a1 | ||
|
|
1344c0659a | ||
|
|
973f6d20f4 | ||
|
|
8b5c9c51e7 | ||
|
|
bae208bcc4 | ||
|
|
b6c14ad468 | ||
|
|
0064cc2a6e | ||
|
|
0a0567e944 | ||
|
|
694b1d43a8 | ||
|
|
e7eb116bd2 | ||
|
|
596499a08c | ||
|
|
2a2e460df2 | ||
|
|
a9039b35ed | ||
|
|
a01154a507 | ||
|
|
1d9204282d | ||
|
|
5ff40a0d2d | ||
|
|
fab6d2e4e0 | ||
|
|
abab59c25f | ||
|
|
c25840b585 | ||
|
|
1b3f9125bb | ||
|
|
b5d9f5ba49 | ||
|
|
1c22aa9c8f | ||
|
|
e1d7fb879c | ||
|
|
e912c42bf0 | ||
|
|
e6841acf36 | ||
|
|
bc4459b6f4 | ||
|
|
9b544491e0 | ||
|
|
9c5415b598 | ||
|
|
040dbc317f | ||
|
|
65775046d8 | ||
|
|
b18bc36127 | ||
|
|
f01c526efd | ||
|
|
16168ab6b3 | ||
|
|
4233218629 | ||
|
|
b63fb36dc0 | ||
|
|
4e92304b89 | ||
|
|
2ae047f1a8 | ||
|
|
6d2a485264 | ||
|
|
4f045db024 | ||
|
|
5b33597b6d | ||
|
|
962470f610 | ||
|
|
ba8c116380 | ||
|
|
ad7330eae4 | ||
|
|
cf126e4839 | ||
|
|
c96d25c3e2 | ||
|
|
006aa0dae2 | ||
|
|
5b204bee86 | ||
|
|
d98b2afbe9 | ||
|
|
681332ef32 | ||
|
|
c3a4fdcbfc | ||
|
|
aac5de5b02 | ||
|
|
13a255afad | ||
|
|
3bffda52f9 | ||
|
|
d4e62ce557 | ||
|
|
9738483b18 | ||
|
|
143492fe94 | ||
|
|
ecc5c662c4 | ||
|
|
d973ba191d | ||
|
|
0198b183a2 | ||
|
|
0d44a3527b | ||
|
|
2147b6a397 | ||
|
|
6b5b4ba27b | ||
|
|
67005bf57c | ||
|
|
0430c741c6 | ||
|
|
1ce02e365d | ||
|
|
eae862adc2 | ||
|
|
dffa89524a | ||
|
|
2af1102441 | ||
|
|
c4b472842a | ||
|
|
750a7d806f | ||
|
|
bc7333f1e5 | ||
|
|
55ae50f991 | ||
|
|
a590c331ef | ||
|
|
8c241b06cb | ||
|
|
9c072c8068 | ||
|
|
ebd8b5122a | ||
|
|
055e484a40 | ||
|
|
912c4a1d12 | ||
|
|
c203b65bf1 | ||
|
|
307f0334ee | ||
|
|
5167df08b9 | ||
|
|
dd2e482214 | ||
|
|
87fd13d8eb | ||
|
|
dd423bc6de | ||
|
|
899cb9cc1f | ||
|
|
0464c7e558 | ||
|
|
f64e1fb926 | ||
|
|
ef7d31293d | ||
|
|
6d54eb68dc | ||
|
|
30eb10c990 | ||
|
|
591bbcd058 | ||
|
|
99aa77d036 | ||
|
|
9c13f1e635 | ||
|
|
24af983cfb | ||
|
|
67842a7525 | ||
|
|
3159a6f3e1 | ||
|
|
b2f3c96835 | ||
|
|
6582475955 | ||
|
|
41ee65b377 | ||
|
|
83fe477066 | ||
|
|
4ca84ee4ee | ||
|
|
c28cc4c919 | ||
|
|
e9864cb3f7 | ||
|
|
83c69ecd49 | ||
|
|
3595b4aaff | ||
|
|
3a9cfe113a | ||
|
|
c9966127da | ||
|
|
51300d33a7 | ||
|
|
5af124c5a5 | ||
|
|
eeb20b531a | ||
|
|
9dca842c22 | ||
|
|
1eb9436836 | ||
|
|
9604d9ce81 | ||
|
|
481d0553d8 | ||
|
|
60035cd63a | ||
|
|
d35f992ace | ||
|
|
157ae64f9d | ||
|
|
ffa17f6057 | ||
|
|
d695a43e32 | ||
|
|
01f6b4e6f0 | ||
|
|
7cf31a6ae4 | ||
|
|
fbd6224b04 | ||
|
|
8115b26079 | ||
|
|
820586ac68 | ||
|
|
4a7441ed07 | ||
|
|
383741f284 | ||
|
|
2bbc4e0e9f | ||
|
|
a7237244b0 | ||
|
|
1d38d49162 | ||
|
|
a783c089a9 | ||
|
|
e7907dc532 | ||
|
|
394413679d | ||
|
|
37189f14cb | ||
|
|
0b1ee81901 | ||
|
|
00cf73f9b8 | ||
|
|
5a5f285493 | ||
|
|
7f2ea454b6 | ||
|
|
7c14002118 | ||
|
|
3e9554f0a1 | ||
|
|
e11ffec544 | ||
|
|
8a47ddbe99 | ||
|
|
821108c7bd | ||
|
|
339738f8a3 | ||
|
|
9b90672f63 | ||
|
|
ba07e94a5e | ||
|
|
b3fc0f29cc | ||
|
|
5c7deb3611 | ||
|
|
15604e374f | ||
|
|
7cfc0fa55b | ||
|
|
a90812133b | ||
|
|
e26a70aa4f | ||
|
|
6a32a4e26c | ||
|
|
e853abf98b | ||
|
|
51e81e6ef8 | ||
|
|
e355000ceb | ||
|
|
e374074013 | ||
|
|
81e3d1c2c6 | ||
|
|
ab0cbb4475 | ||
|
|
1c64e40722 | ||
|
|
8cafe56eb4 | ||
|
|
3eceeb7b23 | ||
|
|
1a37675435 | ||
|
|
198ebede8d | ||
|
|
a504903dd5 | ||
|
|
842adef29c | ||
|
|
7edcaf5a06 | ||
|
|
c124b76328 | ||
|
|
e9c744ee5d | ||
|
|
83302930d8 | ||
|
|
a4634632ba | ||
|
|
d17e8dc5ad | ||
|
|
9fe63de4d4 | ||
|
|
8111f8bf35 | ||
|
|
fcd62513cf | ||
|
|
c3c701e654 | ||
|
|
6bf991edf6 | ||
|
|
9644e78545 | ||
|
|
c911189ef0 | ||
|
|
1118b4b651 | ||
|
|
4be75d4418 | ||
|
|
fb6beae27c | ||
|
|
fee73b0b63 | ||
|
|
9bbffa519e | ||
|
|
c3a641f0ab | ||
|
|
aafe7c4701 | ||
|
|
9a0b082cf8 | ||
|
|
8265e34a29 | ||
|
|
8ef8ae097f | ||
|
|
c3d14293c0 | ||
|
|
d55d8be504 | ||
|
|
03543030d3 | ||
|
|
fc6b474b92 | ||
|
|
a5db785dd7 | ||
|
|
1c1c5cd611 | ||
|
|
6ed02f70ec | ||
|
|
cb78cd8ac0 | ||
|
|
0c4590b45a | ||
|
|
d2e2ee6efa | ||
|
|
6a380a0b48 | ||
|
|
e5d5acbf1f | ||
|
|
00e38abbf0 | ||
|
|
e3e4ea5443 | ||
|
|
a3e4ea3228 | ||
|
|
56f16d6baf | ||
|
|
7a55ab900e | ||
|
|
137643fe72 | ||
|
|
d6e59c6241 | ||
|
|
458eb5d34c | ||
|
|
8259f08864 | ||
|
|
b3ab0a1843 | ||
|
|
f09f217478 | ||
|
|
e842c8c19b | ||
|
|
f6c3112d44 | ||
|
|
7059610632 | ||
|
|
2d272930d9 | ||
|
|
6c470d8131 | ||
|
|
30b29ce8cd | ||
|
|
1a9933002f | ||
|
|
c4a9365aa1 | ||
|
|
9d3af37104 | ||
|
|
7b3d57cff7 | ||
|
|
a802270da9 | ||
|
|
dd194a8758 | ||
|
|
6de02de221 | ||
|
|
85259750bf | ||
|
|
1249f0007d | ||
|
|
db0514d3fa | ||
|
|
dce42a7fad | ||
|
|
ec0b380194 | ||
|
|
7f27b61c98 | ||
|
|
f0b3557b02 | ||
|
|
2a1d1c1001 | ||
|
|
df7eb80e5b | ||
|
|
b9d947ce6f | ||
|
|
e6589d2454 | ||
|
|
0f5ac6afcf | ||
|
|
bc1bb1d188 | ||
|
|
3af2dd10ce | ||
|
|
dd22c65855 | ||
|
|
48137ced19 | ||
|
|
6eb47c12d1 | ||
|
|
5a1fc6675a | ||
|
|
6f80825814 | ||
|
|
f0dd48ed2a | ||
|
|
15e2df0db0 | ||
|
|
4ad0109769 | ||
|
|
ee0009d4b8 | ||
|
|
9d851c3346 | ||
|
|
5d117af8ae | ||
|
|
bb41c2d15e | ||
|
|
eba138ee4a | ||
|
|
3b2bbb74f8 | ||
|
|
dbc0f81211 | ||
|
|
d0b613d22e | ||
|
|
72f29b67d5 | ||
|
|
9570045cc3 | ||
|
|
e4efdb5cbb | ||
|
|
187f0fa70c | ||
|
|
472185c3e4 | ||
|
|
f94a571773 | ||
|
|
183e447d35 | ||
|
|
12f844d93a | ||
|
|
47a119a37f | ||
|
|
ee56559b9a | ||
|
|
00e594deea | ||
|
|
6ad9b213b9 | ||
|
|
e4375e8195 | ||
|
|
487bf8e29b | ||
|
|
fea1694e74 | ||
|
|
4102c124a9 | ||
|
|
135bad3280 | ||
|
|
b604f36881 | ||
|
|
782b449c71 | ||
|
|
017dcab685 | ||
|
|
e60b4568c6 | ||
|
|
4ee3d95a5a | ||
|
|
f18725bacc | ||
|
|
f6064a2b84 | ||
|
|
2e90cb7b95 | ||
|
|
2c09d63cd9 | ||
|
|
cc6fbdb0c3 | ||
|
|
ecfdec12f3 | ||
|
|
45af40fd14 | ||
|
|
d11cf42501 | ||
|
|
c3c1e3b055 | ||
|
|
7c5e3b1d99 | ||
|
|
ed6cec71e7 | ||
|
|
d6bcdd069c | ||
|
|
a26347826d | ||
|
|
5d1c099b31 | ||
|
|
220bee1365 | ||
|
|
1261074d95 | ||
|
|
136021424c | ||
|
|
fee4ba3746 | ||
|
|
a5b70335d4 | ||
|
|
5cf4976054 | ||
|
|
1aa3255061 | ||
|
|
b01f29f10d | ||
|
|
2673abca88 | ||
|
|
7eeb7f0715 | ||
|
|
37262a2479 | ||
|
|
de6e304959 | ||
|
|
234475bbc7 | ||
|
|
abbd9f7cfc | ||
|
|
dfd6ba67b3 | ||
|
|
1595254eab | ||
|
|
6964c5eeba | ||
|
|
2befe771b3 | ||
|
|
b133a035a4 | ||
|
|
726c062327 | ||
|
|
9083672de3 | ||
|
|
cdbaf880af | ||
|
|
9434981cdc | ||
|
|
8b3706f557 | ||
|
|
0d5173833d | ||
|
|
bf1178eb79 | ||
|
|
abcd3fa94a | ||
|
|
62aa1614b6 | ||
|
|
7027356126 | ||
|
|
5ebe13a13d | ||
|
|
c3bed9a2b7 | ||
|
|
f865222882 | ||
|
|
e2fe2e4095 | ||
|
|
0532a95f08 | ||
|
|
ff536f6015 | ||
|
|
097d0f27bb | ||
|
|
2257f87edf | ||
|
|
a17800da00 | ||
|
|
059c1b3a19 | ||
|
|
9a36816d27 | ||
|
|
7986b9b20b | ||
|
|
b2b3a0a62b | ||
|
|
3173b7d1d9 | ||
|
|
9d716d70d6 | ||
|
|
e1901a8608 | ||
|
|
7d0cbd8d90 | ||
|
|
59358361f9 | ||
|
|
7fea2d3b68 | ||
|
|
b6d3ff26bd | ||
|
|
523e63f5c1 | ||
|
|
10630ab597 | ||
|
|
2bc6de650d | ||
|
|
ffef1681e3 | ||
|
|
d935006a4a | ||
|
|
660cb5946e | ||
|
|
10160a066a | ||
|
|
72976a2ece | ||
|
|
831f206cd0 | ||
|
|
72648aa9f2 | ||
|
|
35e623deaf | ||
|
|
6263636738 | ||
|
|
535d012ded | ||
|
|
c73eed2e51 | ||
|
|
30fdc99f37 | ||
|
|
acb905f0cc | ||
|
|
bba06d0142 | ||
|
|
a14a47af12 | ||
|
|
73457336bc | ||
|
|
a14c53ad31 | ||
|
|
e7e763551a | ||
|
|
2928179331 | ||
|
|
24a16a4cfe | ||
|
|
6aed4423b2 | ||
|
|
6508e3fcc9 | ||
|
|
a15cb140ae | ||
|
|
898bc9e009 | ||
|
|
e67ea31ee2 | ||
|
|
986c126a5c | ||
|
|
0eee7616b9 | ||
|
|
5ddce749b8 | ||
|
|
d946cffabc | ||
|
|
fe618811ee | ||
|
|
09c45bfb80 | ||
|
|
e9e9ccd379 | ||
|
|
a9b27c78a3 | ||
|
|
bc17c29b2e | ||
|
|
aaf60bdee6 | ||
|
|
d913453e57 | ||
|
|
08e373aef4 | ||
|
|
4cb50a3d06 | ||
|
|
b03038222d | ||
|
|
5f5e0766dd | ||
|
|
48ec11c514 | ||
|
|
8ae76d18b5 | ||
|
|
e5be1790e5 | ||
|
|
e64aa40b17 | ||
|
|
eb8114ece8 | ||
|
|
616ee9b824 | ||
|
|
57c94f8f80 | ||
|
|
2a59c4f670 | ||
|
|
192ff487c4 | ||
|
|
b62ee3fcb9 | ||
|
|
0225292a44 | ||
|
|
589a7ed02f | ||
|
|
b3a42cd0b1 | ||
|
|
e3e1ca7cc6 | ||
|
|
57e417d174 | ||
|
|
1699db79b5 | ||
|
|
dab9403b8f | ||
|
|
9a14298146 | ||
|
|
40eea21863 | ||
|
|
d2475ec169 | ||
|
|
b3bcf4bf44 | ||
|
|
6049f86bc4 | ||
|
|
ff649b52ef | ||
|
|
e9e138c757 | ||
|
|
1096936a15 | ||
|
|
29cc478525 | ||
|
|
05e9eb40b5 | ||
|
|
c4444ff695 | ||
|
|
27b34f3929 | ||
|
|
2b8d784660 | ||
|
|
18f447d8d8 | ||
|
|
d7e1078d68 | ||
|
|
6be592653f | ||
|
|
8859853b41 | ||
|
|
3c46021102 | ||
|
|
bba8646669 | ||
|
|
b0dc19a910 | ||
|
|
df79ebd0f2 | ||
|
|
e19a97f316 | ||
|
|
482ffd6275 | ||
|
|
5117e50602 | ||
|
|
83b138208d | ||
|
|
1870cb4557 | ||
|
|
42ad5b9c5c | ||
|
|
333975eb8f | ||
|
|
aa0195e4ef | ||
|
|
56109fe09b | ||
|
|
e74046478b | ||
|
|
aa5a60812f | ||
|
|
ebb60019aa | ||
|
|
6393dc5d14 | ||
|
|
8c158f2452 | ||
|
|
8c3eabdcee | ||
|
|
8aa0ce6a24 | ||
|
|
a27ee141b3 | ||
|
|
1106456651 | ||
|
|
8856878cbd | ||
|
|
a9bac0287d | ||
|
|
efbd3dc778 | ||
|
|
a0d0eaa408 | ||
|
|
e2bf734b67 | ||
|
|
a333a90441 | ||
|
|
6dc0057d3d | ||
|
|
0f9e69d48c | ||
|
|
e6a7c019ab | ||
|
|
1d32eabd14 | ||
|
|
53d03f06a6 | ||
|
|
a2d8c40455 | ||
|
|
4f7d950c8d | ||
|
|
cac54b8c26 | ||
|
|
cd0e881d7d | ||
|
|
fee406e220 | ||
|
|
128342f47f | ||
|
|
024487c5fe | ||
|
|
879ba27ccb | ||
|
|
6d6d9627e7 | ||
|
|
af4bc82543 | ||
|
|
439a18bcc3 | ||
|
|
e12a1e0444 | ||
|
|
4400b0d3c3 | ||
|
|
5dff28ff99 | ||
|
|
d5ac841a1a | ||
|
|
232ce12e9b | ||
|
|
9a8638a6d0 | ||
|
|
a5445866b8 | ||
|
|
e8ded71a7b | ||
|
|
a14c615def | ||
|
|
3903b6ff0c | ||
|
|
41bf262482 | ||
|
|
645b658da0 | ||
|
|
6ee8f61fbe | ||
|
|
3c4c4231ce | ||
|
|
d0eef19eba | ||
|
|
6ca2eb3ad7 | ||
|
|
74aeb55733 | ||
|
|
3eb7965ca0 | ||
|
|
04f20070d1 | ||
|
|
88937fcb2f | ||
|
|
f80b85f10c | ||
|
|
32a2ec432d | ||
|
|
f4821d0d39 | ||
|
|
fdf2aa54ef | ||
|
|
275c032264 | ||
|
|
d88979fe19 | ||
|
|
e67bcffea7 | ||
|
|
005ded3c6f | ||
|
|
d624940e12 | ||
|
|
7763403b0e | ||
|
|
88c58244b9 | ||
|
|
0754c6ea20 | ||
|
|
7b1f04d121 | ||
|
|
d8a9bee244 | ||
|
|
ac0ea6bd3c | ||
|
|
45677c1e23 | ||
|
|
d9f4a9954a | ||
|
|
ec461a4456 | ||
|
|
559928e93b | ||
|
|
a526f7d5b8 | ||
|
|
749a2c2dec | ||
|
|
29a317dbb6 | ||
|
|
2f36de319a | ||
|
|
2005bce419 | ||
|
|
8a02d7729d | ||
|
|
1cdf301c14 | ||
|
|
9a86e5c476 | ||
|
|
32d3f4bd5f | ||
|
|
18689afc1a | ||
|
|
64d6da75c7 | ||
|
|
1e95e4b502 | ||
|
|
c63009a6db | ||
|
|
88f8718635 | ||
|
|
a081733a42 | ||
|
|
06ccfb0533 | ||
|
|
b18d75e3f7 | ||
|
|
3e7efaa048 | ||
|
|
a3fdfc81db | ||
|
|
f4c91df1df | ||
|
|
32e1ba8c0d | ||
|
|
1939376d72 | ||
|
|
25931d48a3 | ||
|
|
024c5e153a | ||
|
|
83f34b645d | ||
|
|
3f9f450e0d | ||
|
|
fd89b06641 | ||
|
|
f8dc996004 | ||
|
|
e6a964088b | ||
|
|
e3e767c7eb | ||
|
|
239c19eb12 | ||
|
|
7f37599a60 | ||
|
|
77c9a2c5ea | ||
|
|
fd7baae548 | ||
|
|
01fdf5ee16 | ||
|
|
e52f533c16 | ||
|
|
fbd77dc936 | ||
|
|
cdc6dd19e3 | ||
|
|
fd578a48a9 | ||
|
|
9956099516 | ||
|
|
f97b8fffed | ||
|
|
7b9e309724 | ||
|
|
1d33913d48 | ||
|
|
a48eaaed20 | ||
|
|
2741b8be53 | ||
|
|
4f906a265c | ||
|
|
0dff8d7af0 | ||
|
|
4f0d0d8167 | ||
|
|
d513060b21 | ||
|
|
d1a25ce4f3 | ||
|
|
51c98695b2 | ||
|
|
b448770ec2 | ||
|
|
5fe22a7980 | ||
|
|
38ae6b5af4 | ||
|
|
0bfe30d75d | ||
|
|
7be1d7d0be | ||
|
|
0d74c873f0 | ||
|
|
139aff2938 | ||
|
|
a3f733490c | ||
|
|
8a11f138d1 | ||
|
|
3405607917 | ||
|
|
7c99a6bd33 | ||
|
|
3fba8ce0e6 | ||
|
|
f3bde3c7fc | ||
|
|
21fee8ef33 | ||
|
|
0e217d6180 | ||
|
|
00a8ce75d1 | ||
|
|
8f3f00cd99 | ||
|
|
13bae2538a | ||
|
|
f508c80c23 | ||
|
|
53df0620e3 | ||
|
|
a63755bc24 | ||
|
|
d93d0783a8 | ||
|
|
d38e37bd99 | ||
|
|
3618fb3ada | ||
|
|
70a29b03e0 | ||
|
|
006adf8746 | ||
|
|
33b53e7caf | ||
|
|
c54815de17 | ||
|
|
0013fb0753 | ||
|
|
56f8a0d85a | ||
|
|
9035a2eed3 | ||
|
|
28daf410b6 | ||
|
|
cbf3f784aa | ||
|
|
ef4b306c7b | ||
|
|
5316c1e0bf | ||
|
|
0228973eef | ||
|
|
d4eeff0a5d | ||
|
|
c7b2d39ab2 | ||
|
|
21958cc02a | ||
|
|
de23e5d9d7 | ||
|
|
6438bce023 | ||
|
|
587d74b449 | ||
|
|
b9c8985047 | ||
|
|
93ebe07d2b | ||
|
|
d82b305781 | ||
|
|
1df20fac95 | ||
|
|
991e7043d1 | ||
|
|
1c4d6c23fa | ||
|
|
87895446a5 | ||
|
|
c0f3a09a40 | ||
|
|
e9ad4b9fc4 | ||
|
|
c061a8897d | ||
|
|
4253551b67 | ||
|
|
e4991c049e | ||
|
|
5df582e7e8 | ||
|
|
814a6f8295 | ||
|
|
7013c3cd4a | ||
|
|
0ddd65b6f1 | ||
|
|
44d8f08bfc | ||
|
|
fc8aa6ae63 | ||
|
|
9bd951b083 | ||
|
|
c43448a826 | ||
|
|
864723a473 | ||
|
|
3b0ec8ce4e | ||
|
|
174b171913 | ||
|
|
cfd9733c2b | ||
|
|
8d4d543a49 | ||
|
|
1b9c88a052 | ||
|
|
e212ff2071 | ||
|
|
8d21292d34 | ||
|
|
e304041574 | ||
|
|
1776c55e73 | ||
|
|
4e4c34c717 | ||
|
|
23378b6be8 | ||
|
|
6cf5564c84 | ||
|
|
7143902a90 | ||
|
|
15186db73f | ||
|
|
ccd7a01ce2 | ||
|
|
1d7035117d | ||
|
|
1710abd366 | ||
|
|
6aeda3670f | ||
|
|
bb52b224d0 | ||
|
|
95ec3d7216 | ||
|
|
18872222d3 | ||
|
|
d453f2e49d | ||
|
|
3824d37d27 | ||
|
|
d946287723 | ||
|
|
885b0969f5 | ||
|
|
a886cba655 | ||
|
|
4afe2e3adb | ||
|
|
fe080eaee6 | ||
|
|
3703f014d9 | ||
|
|
d45a496030 | ||
|
|
4ee164c66f | ||
|
|
bf84c033bb | ||
|
|
5105f62551 | ||
|
|
99be837d84 | ||
|
|
b7766898ee | ||
|
|
57f73dfbc9 | ||
|
|
50b2b9638d | ||
|
|
1bfd00e2f8 | ||
|
|
64424877ac | ||
|
|
02d857260c | ||
|
|
1322ec5935 | ||
|
|
48e9818f7e | ||
|
|
14857770dc | ||
|
|
f79a6bf5aa | ||
|
|
7dc27a7477 | ||
|
|
17dba601c8 | ||
|
|
064aa3b1f4 | ||
|
|
4960efc686 |
5
.flake8
Normal file
5
.flake8
Normal file
@@ -0,0 +1,5 @@
|
||||
[flake8]
|
||||
count = 1
|
||||
show-source = 1
|
||||
select = E9,F63,F7,F82
|
||||
exclude = lit.cfg.py
|
||||
37
.github/workflows/gh-pages-releases.yml
vendored
Normal file
37
.github/workflows/gh-pages-releases.yml
vendored
Normal file
@@ -0,0 +1,37 @@
|
||||
# See: https://github.com/llvm/torch-mlir/issues/1374
|
||||
name: Publish releases page
|
||||
|
||||
on:
|
||||
workflow_dispatch:
|
||||
|
||||
jobs:
|
||||
scrape_and_publish_releases:
|
||||
name: "Scrape and publish releases"
|
||||
runs-on: ubuntu-latest
|
||||
|
||||
# Don't run this in everyone's forks.
|
||||
if: github.repository == 'nod-ai/SHARK'
|
||||
|
||||
steps:
|
||||
- name: Checking out repository
|
||||
uses: actions/checkout@v2
|
||||
with:
|
||||
token: ${{ secrets.NODAI_INVOCATION_TOKEN }}
|
||||
- name: Run scrape releases script
|
||||
run: python ./build_tools/scrape_releases.py nod-ai SHARK > /tmp/index.html
|
||||
shell: bash
|
||||
- run: git fetch --all
|
||||
- run: git switch github-pages
|
||||
- run: git config --global user.email "none@none.com"
|
||||
- run: git config --global user.name "nod-ai"
|
||||
- run: mv /tmp/index.html package-index/index.html
|
||||
- run: git add package-index/index.html
|
||||
|
||||
# Only try to make a commit if the file has changed.
|
||||
- run: git diff --cached --exit-code || git commit -m "Update releases."
|
||||
|
||||
- name: GitHub Push
|
||||
uses: ad-m/github-push-action@v0.6.0
|
||||
with:
|
||||
github_token: ${{ secrets.NODAI_INVOCATION_TOKEN }}
|
||||
branch: github-pages
|
||||
163
.github/workflows/nightly.yml
vendored
163
.github/workflows/nightly.yml
vendored
@@ -9,13 +9,94 @@ on:
|
||||
workflow_dispatch:
|
||||
|
||||
jobs:
|
||||
build:
|
||||
windows-build:
|
||||
runs-on: 7950X
|
||||
strategy:
|
||||
fail-fast: false
|
||||
matrix:
|
||||
python-version: ["3.11"]
|
||||
|
||||
steps:
|
||||
- uses: actions/checkout@v2
|
||||
- name: Set up Python ${{ matrix.python-version }}
|
||||
uses: actions/setup-python@v3
|
||||
with:
|
||||
python-version: ${{ matrix.python-version }}
|
||||
|
||||
- name: Compute version
|
||||
shell: powershell
|
||||
run: |
|
||||
$package_version = $(Get-Date -UFormat "%Y%m%d")+"."+${{ github.run_number }}
|
||||
$package_version_ = $(Get-Date -UFormat "%Y%m%d")+"_"+${{ github.run_number }}
|
||||
$tag_name=$package_version
|
||||
echo "package_version=$package_version" | Out-File -FilePath $Env:GITHUB_ENV -Encoding utf8 -Append
|
||||
echo "package_version_=$package_version_" | Out-File -FilePath $Env:GITHUB_ENV -Encoding utf8 -Append
|
||||
echo "tag_name=$tag_name" | Out-File -FilePath $Env:GITHUB_ENV -Encoding utf8 -Append
|
||||
|
||||
- name: Create Release
|
||||
id: create_release
|
||||
uses: actions/create-release@v1
|
||||
env:
|
||||
GITHUB_TOKEN: ${{ secrets.NODAI_INVOCATION_TOKEN }}
|
||||
with:
|
||||
tag_name: ${{ env.tag_name }}
|
||||
release_name: nod.ai SHARK ${{ env.tag_name }}
|
||||
body: |
|
||||
Automatic snapshot release of nod.ai SHARK.
|
||||
draft: true
|
||||
prerelease: true
|
||||
|
||||
- name: Build Package
|
||||
shell: powershell
|
||||
run: |
|
||||
./setup_venv.ps1
|
||||
python process_skipfiles.py
|
||||
pyinstaller .\apps\stable_diffusion\shark_sd.spec
|
||||
mv ./dist/shark_sd.exe ./dist/shark_sd_${{ env.package_version_ }}.exe
|
||||
signtool sign /f c:\g\shark_02152023.cer /csp "eToken Base Cryptographic Provider" /k "${{ secrets.CI_CERT }}" ./dist/shark_sd_${{ env.package_version_ }}.exe
|
||||
pyinstaller .\apps\stable_diffusion\shark_sd_cli.spec
|
||||
python process_skipfiles.py
|
||||
mv ./dist/shark_sd_cli.exe ./dist/shark_sd_cli_${{ env.package_version_ }}.exe
|
||||
signtool sign /f c:\g\shark_02152023.cer /csp "eToken Base Cryptographic Provider" /k "${{ secrets.CI_CERT }}" ./dist/shark_sd_cli_${{ env.package_version_ }}.exe
|
||||
|
||||
|
||||
# GHA windows VM OOMs so disable for now
|
||||
#- name: Build and validate the SHARK Runtime package
|
||||
# shell: powershell
|
||||
# run: |
|
||||
# $env:SHARK_PACKAGE_VERSION=${{ env.package_version }}
|
||||
# pip wheel -v -w dist . --pre -f https://download.pytorch.org/whl/nightly/torch -f https://llvm.github.io/torch-mlir/package-index/ -f https://nod-ai.github.io/SHARK-Runtime/pip-release-links.html
|
||||
|
||||
#- uses: actions/upload-artifact@v2
|
||||
# with:
|
||||
# path: dist/*
|
||||
|
||||
- name: Upload Release Assets
|
||||
id: upload-release-assets
|
||||
uses: dwenegar/upload-release-assets@v1
|
||||
env:
|
||||
GITHUB_TOKEN: ${{ secrets.NODAI_INVOCATION_TOKEN }}
|
||||
with:
|
||||
release_id: ${{ steps.create_release.outputs.id }}
|
||||
assets_path: ./dist/*
|
||||
#asset_content_type: application/vnd.microsoft.portable-executable
|
||||
|
||||
- name: Publish Release
|
||||
id: publish_release
|
||||
uses: eregon/publish-release@v1
|
||||
env:
|
||||
GITHUB_TOKEN: ${{ secrets.NODAI_INVOCATION_TOKEN }}
|
||||
with:
|
||||
release_id: ${{ steps.create_release.outputs.id }}
|
||||
|
||||
linux-build:
|
||||
|
||||
runs-on: a100
|
||||
strategy:
|
||||
fail-fast: false
|
||||
matrix:
|
||||
python-version: ["3.10"]
|
||||
python-version: ["3.11"]
|
||||
backend: [IREE, SHARK]
|
||||
|
||||
steps:
|
||||
- uses: actions/checkout@v3
|
||||
@@ -31,30 +112,13 @@ jobs:
|
||||
key: ${{ runner.os }}-pip-${{ hashFiles('**/requirements.txt') }}
|
||||
restore-keys: |
|
||||
${{ runner.os }}-pip-
|
||||
|
||||
- name: Compute version
|
||||
run: |
|
||||
package_version="$(printf '%(%Y%m%d)T.${{ github.run_number }}')"
|
||||
tag_name="${package_version}"
|
||||
echo "package_version=${package_version}" >> $GITHUB_ENV
|
||||
echo "tag_name=${tag_name}" >> $GITHUB_ENV
|
||||
- name: Create Release
|
||||
id: create_release
|
||||
uses: actions/create-release@v1
|
||||
env:
|
||||
GITHUB_TOKEN: ${{ secrets.NODAI_INVOCATION_TOKEN }}
|
||||
with:
|
||||
tag_name: ${{ env.tag_name }}
|
||||
release_name: nod.ai SHARK ${{ env.tag_name }}
|
||||
body: |
|
||||
Automatic snapshot release of nod.ai SHARK.
|
||||
draft: true
|
||||
prerelease: false
|
||||
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
echo "DATE=$(date +'%Y-%m-%d')" >> $GITHUB_ENV
|
||||
python -m pip install --upgrade pip
|
||||
python -m pip install flake8 pytest toml
|
||||
if [ -f requirements.txt ]; then pip install -r requirements.txt --extra-index-url https://download.pytorch.org/whl/nightly/cpu -f https://github.com/llvm/torch-mlir/releases -f https://github.com/nod-ai/SHARK-Runtime/releases; fi
|
||||
if [ -f requirements.txt ]; then pip install -r requirements.txt -f https://llvm.github.io/torch-mlir/package-index/ -f https://nod-ai.github.io/SHARK-Runtime/pip-release-links.html; fi
|
||||
- name: Lint with flake8
|
||||
run: |
|
||||
# stop the build if there are Python syntax errors or undefined names
|
||||
@@ -62,71 +126,42 @@ jobs:
|
||||
# exit-zero treats all errors as warnings. The GitHub editor is 127 chars wide
|
||||
flake8 . --count --exit-zero --max-complexity=10 --max-line-length=127 --statistics --exclude shark.venv,lit.cfg.py
|
||||
- name: Build and validate the IREE package
|
||||
if: ${{ matrix.backend == 'IREE' }}
|
||||
continue-on-error: true
|
||||
run: |
|
||||
cd $GITHUB_WORKSPACE
|
||||
USE_IREE=1 VENV_DIR=iree.venv ./setup_venv.sh
|
||||
source iree.venv/bin/activate
|
||||
package_version="$(printf '%(%Y%m%d)T.${{ github.run_number }}')"
|
||||
SHARK_PACKAGE_VERSION=${package_version} \
|
||||
pip wheel -v -w wheelhouse . --pre -f https://download.pytorch.org/whl/nightly/torch -f https://github.com/llvm/torch-mlir/releases -f https://github.com/iree-org/iree/releases
|
||||
pip wheel -v -w wheelhouse . --pre -f https://download.pytorch.org/whl/nightly/torch -f https://llvm.github.io/torch-mlir/package-index/ -f https://openxla.github.io/iree/pip-release-links.html
|
||||
# Install the built wheel
|
||||
pip install ./wheelhouse/nodai*
|
||||
# Validate the Models
|
||||
/bin/bash "$GITHUB_WORKSPACE/build_tools/populate_sharktank_ci.sh"
|
||||
pytest -k 'cpu' --ignore=benchmarks/tests/test_hf_benchmark.py --ignore=benchmarks/tests/test_benchmark.py --ignore=shark/tests/test_shark_importer.py --ignore=tank/tf/ |
|
||||
tail -n 1 |
|
||||
tee -a pytest_results.txt
|
||||
pytest -k 'gpu' --ignore=benchmarks/tests/test_hf_benchmark.py --ignore=benchmarks/tests/test_benchmark.py --ignore=shark/tests/test_shark_importer.py --ignore=tank/tf/ |
|
||||
tail -n 1 |
|
||||
tee -a pytest_results.txt
|
||||
pytest -k 'vulkan' --ignore=benchmarks/tests/test_hf_benchmark.py --ignore=benchmarks/tests/test_benchmark.py --ignore=shark/tests/test_shark_importer.py --ignore=tank/tf/ |
|
||||
pytest --ci --ci_sha=${SHORT_SHA} --local_tank_cache="./gen_shark_tank/" -k "not metal" |
|
||||
tail -n 1 |
|
||||
tee -a pytest_results.txt
|
||||
if !(grep -Fxq " failed" pytest_results.txt)
|
||||
then
|
||||
export SHA=$(git log -1 --format='%h')
|
||||
gsutil -m cp -r $GITHUB_WORKSPACE/gen_shark_tank/* gs://shark_tank/${DATE}_$SHA
|
||||
gsutil -m cp -r gs://shark_tank/${DATE}_$SHA/* gs://shark_tank/nightly/
|
||||
fi
|
||||
rm -rf ./wheelhouse/nodai*
|
||||
|
||||
- name: Build and validate the SHARK Runtime package
|
||||
if: ${{ matrix.backend == 'SHARK' }}
|
||||
run: |
|
||||
cd $GITHUB_WORKSPACE
|
||||
./setup_venv.sh
|
||||
source shark.venv/bin/activate
|
||||
package_version="$(printf '%(%Y%m%d)T.${{ github.run_number }}')"
|
||||
SHARK_PACKAGE_VERSION=${package_version} \
|
||||
pip wheel -v -w wheelhouse . --pre -f https://download.pytorch.org/whl/nightly/torch -f https://github.com/llvm/torch-mlir/releases -f https://github.com/nod-ai/SHARK-Runtime/releases
|
||||
pip wheel -v -w wheelhouse . --pre -f https://download.pytorch.org/whl/nightly/torch -f https://llvm.github.io/torch-mlir/package-index/ -f https://nod-ai.github.io/SHARK-Runtime/pip-release-links.html
|
||||
# Install the built wheel
|
||||
pip install ./wheelhouse/nodai*
|
||||
# Validate the Models
|
||||
pytest -k 'cpu' --ignore=benchmarks/tests/test_hf_benchmark.py --ignore=benchmarks/tests/test_benchmark.py --ignore=shark/tests/test_shark_importer.py --ignore=tank/tf/ |
|
||||
pytest --ci --ci_sha=${SHORT_SHA} -k "not metal" |
|
||||
tail -n 1 |
|
||||
tee -a pytest_results.txt
|
||||
pytest -k 'gpu' --ignore=benchmarks/tests/test_hf_benchmark.py --ignore=benchmarks/tests/test_benchmark.py --ignore=shark/tests/test_shark_importer.py --ignore=tank/tf/ |
|
||||
tail -n 1 |
|
||||
tee -a pytest_results.txt
|
||||
pytest -k 'vulkan' --ignore=benchmarks/tests/test_hf_benchmark.py --ignore=benchmarks/tests/test_benchmark.py --ignore=shark/tests/test_shark_importer.py --ignore=tank/tf/ |
|
||||
tail -n 1 |
|
||||
tee -a pytest_results.txt
|
||||
if !(grep -Fxq " failed" pytest_results.txt)
|
||||
then
|
||||
export SHA=$(git log -1 --format='%h')
|
||||
gsutil -m cp -r $GITHUB_WORKSPACE/gen_shark_tank/* gs://shark_tank/$SHA
|
||||
gsutil -m cp -r gs://shark_tank/$SHA/* gs://shark_tank/latest/
|
||||
fi
|
||||
rm pytest_results.txt
|
||||
rm -rf ./wheelhouse/nodai*
|
||||
|
||||
|
||||
- name: Upload Release Assets
|
||||
id: upload-release-assets
|
||||
uses: dwenegar/upload-release-assets@v1
|
||||
env:
|
||||
GITHUB_TOKEN: ${{ secrets.NODAI_INVOCATION_TOKEN }}
|
||||
with:
|
||||
release_id: ${{ steps.create_release.outputs.id }}
|
||||
assets_path: ./wheelhouse/nodai_*.whl
|
||||
|
||||
- name: Publish Release
|
||||
id: publish_release
|
||||
uses: eregon/publish-release@v1
|
||||
env:
|
||||
GITHUB_TOKEN: ${{ secrets.NODAI_INVOCATION_TOKEN }}
|
||||
with:
|
||||
release_id: ${{ steps.create_release.outputs.id }}
|
||||
|
||||
109
.github/workflows/test-models.yml
vendored
109
.github/workflows/test-models.yml
vendored
@@ -6,18 +6,32 @@ name: Validate Models on Shark Runtime
|
||||
on:
|
||||
push:
|
||||
branches: [ main ]
|
||||
paths-ignore:
|
||||
- '**.md'
|
||||
- 'shark/examples/**'
|
||||
pull_request:
|
||||
branches: [ main ]
|
||||
paths-ignore:
|
||||
- '**.md'
|
||||
- 'shark/examples/**'
|
||||
workflow_dispatch:
|
||||
|
||||
# Ensure that only a single job or workflow using the same
|
||||
# concurrency group will run at a time. This would cancel
|
||||
# any in-progress jobs in the same github workflow and github
|
||||
# ref (e.g. refs/heads/main or refs/pull/<pr_number>/merge).
|
||||
concurrency:
|
||||
group: ${{ github.workflow }}-${{ github.ref }}
|
||||
cancel-in-progress: true
|
||||
|
||||
jobs:
|
||||
build-validate:
|
||||
strategy:
|
||||
fail-fast: true
|
||||
matrix:
|
||||
os: [a100, MacStudio, ubuntu-latest]
|
||||
suite: [cpu,gpu,vulkan]
|
||||
python-version: ["3.10"]
|
||||
os: [7950x, icelake, a100, MacStudio, ubuntu-latest]
|
||||
suite: [cpu,cuda,vulkan]
|
||||
python-version: ["3.11"]
|
||||
include:
|
||||
- os: ubuntu-latest
|
||||
suite: lint
|
||||
@@ -25,34 +39,44 @@ jobs:
|
||||
- os: ubuntu-latest
|
||||
suite: vulkan
|
||||
- os: ubuntu-latest
|
||||
suite: gpu
|
||||
suite: cuda
|
||||
- os: ubuntu-latest
|
||||
suite: cpu
|
||||
- os: MacStudio
|
||||
suite: gpu
|
||||
suite: cuda
|
||||
- os: MacStudio
|
||||
suite: cpu
|
||||
- os: MacStudio
|
||||
- os: icelake
|
||||
suite: vulkan
|
||||
- os: icelake
|
||||
suite: cuda
|
||||
- os: a100
|
||||
suite: cpu
|
||||
- os: 7950x
|
||||
suite: cpu
|
||||
- os: 7950x
|
||||
suite: cuda
|
||||
|
||||
runs-on: ${{ matrix.os }}
|
||||
|
||||
steps:
|
||||
- uses: actions/checkout@v3
|
||||
if: matrix.os != '7950x'
|
||||
|
||||
- name: Set Environment Variables
|
||||
if: matrix.os != '7950x'
|
||||
run: |
|
||||
echo "SHORT_SHA=`git rev-parse --short=4 HEAD`" >> $GITHUB_ENV
|
||||
echo "DATE=$(date +'%Y-%m-%d')" >> $GITHUB_ENV
|
||||
|
||||
- name: Set up Python Version File ${{ matrix.python-version }}
|
||||
if: matrix.os == 'a100' || matrix.os == 'ubuntu-latest'
|
||||
if: matrix.os == 'a100' || matrix.os == 'ubuntu-latest' || matrix.os == 'icelake'
|
||||
run: |
|
||||
# See https://github.com/actions/setup-python/issues/433
|
||||
echo ${{ matrix.python-version }} >> $GITHUB_WORKSPACE/.python-version
|
||||
|
||||
- name: Set up Python ${{ matrix.python-version }}
|
||||
if: matrix.os == 'a100' || matrix.os == 'ubuntu-latest'
|
||||
if: matrix.os == 'a100' || matrix.os == 'ubuntu-latest' || matrix.os == 'icelake'
|
||||
uses: actions/setup-python@v4
|
||||
with:
|
||||
python-version: '${{ matrix.python-version }}'
|
||||
@@ -60,6 +84,9 @@ jobs:
|
||||
#cache-dependency-path: |
|
||||
# **/requirements-importer.txt
|
||||
# **/requirements.txt
|
||||
|
||||
- uses: actions/checkout@v2
|
||||
if: matrix.os == '7950x'
|
||||
|
||||
- name: Install dependencies
|
||||
if: matrix.suite == 'lint'
|
||||
@@ -72,33 +99,65 @@ jobs:
|
||||
run: |
|
||||
# black format check
|
||||
black --version
|
||||
black --line-length 79 --check .
|
||||
black --check .
|
||||
# stop the build if there are Python syntax errors or undefined names
|
||||
flake8 . --count --select=E9,F63,F7,F82 --show-source --statistics --exclude lit.cfg.py
|
||||
flake8 . --statistics
|
||||
# exit-zero treats all errors as warnings. The GitHub editor is 127 chars wide
|
||||
flake8 . --count --exit-zero --max-complexity=10 --max-line-length=127 --statistics --exclude lit.cfg.py
|
||||
flake8 . --isolated --count --exit-zero --max-complexity=10 --max-line-length=127 \
|
||||
--statistics --exclude lit.cfg.py
|
||||
|
||||
- name: Validate CPU Models
|
||||
- name: Validate Models on CPU
|
||||
if: matrix.suite == 'cpu'
|
||||
run: |
|
||||
cd $GITHUB_WORKSPACE
|
||||
PYTHON=python${{ matrix.python-version }} IMPORTER=1 ./setup_venv.sh
|
||||
source shark.venv/bin/activate
|
||||
pytest -k 'cpu' --ignore=shark/tests/test_shark_importer.py --ignore=benchmarks/tests/test_hf_benchmark.py --ignore=benchmarks/tests/test_benchmark.py
|
||||
pytest --forked --benchmark=native --ci --ci_sha=${SHORT_SHA} --update_tank --tank_url="gs://shark_tank/nightly/" -k cpu
|
||||
gsutil cp ./bench_results.csv gs://shark-public/builder/bench_results/${DATE}/bench_results_cpu_${SHORT_SHA}.csv
|
||||
gsutil cp gs://shark-public/builder/bench_results/${DATE}/bench_results_cpu_${SHORT_SHA}.csv gs://shark-public/builder/bench_results/latest/bench_results_cpu_latest.csv
|
||||
|
||||
- name: Validate GPU Models
|
||||
if: matrix.suite == 'gpu'
|
||||
run: |
|
||||
cd $GITHUB_WORKSPACE
|
||||
PYTHON=python${{ matrix.python-version }} IMPORTER=1 ./setup_venv.sh
|
||||
source shark.venv/bin/activate
|
||||
pytest --benchmark -k "gpu" --ignore=shark/tests/test_shark_importer.py --ignore=benchmarks/tests/test_hf_benchmark.py --ignore=benchmarks/tests/test_benchmark.py
|
||||
gsutil cp ./bench_results.csv gs://shark-public/builder/bench_results/${DATE}/bench_results_gpu_${SHORT_SHA}.csv
|
||||
|
||||
- name: Validate Vulkan Models
|
||||
if: matrix.suite == 'vulkan'
|
||||
- name: Validate Models on NVIDIA GPU
|
||||
if: matrix.suite == 'cuda'
|
||||
run: |
|
||||
cd $GITHUB_WORKSPACE
|
||||
PYTHON=python${{ matrix.python-version }} ./setup_venv.sh
|
||||
source shark.venv/bin/activate
|
||||
pytest -k 'vulkan' --ignore=shark/tests/test_shark_importer.py --ignore=benchmarks/tests/test_hf_benchmark.py --ignore=benchmarks/tests/test_benchmark.py
|
||||
pytest --forked --benchmark=native --ci --ci_sha=${SHORT_SHA} --update_tank --tank_url="gs://shark_tank/nightly/" -k cuda
|
||||
gsutil cp ./bench_results.csv gs://shark-public/builder/bench_results/${DATE}/bench_results_cuda_${SHORT_SHA}.csv
|
||||
gsutil cp gs://shark-public/builder/bench_results/${DATE}/bench_results_cuda_${SHORT_SHA}.csv gs://shark-public/builder/bench_results/latest/bench_results_cuda_latest.csv
|
||||
# Disabled due to black image bug
|
||||
# python build_tools/stable_diffusion_testing.py --device=cuda
|
||||
|
||||
- name: Validate Vulkan Models (MacOS)
|
||||
if: matrix.suite == 'vulkan' && matrix.os == 'MacStudio'
|
||||
run: |
|
||||
cd $GITHUB_WORKSPACE
|
||||
PYTHON=python${{ matrix.python-version }} ./setup_venv.sh
|
||||
source shark.venv/bin/activate
|
||||
export DYLD_LIBRARY_PATH=/usr/local/lib/
|
||||
echo $PATH
|
||||
pip list | grep -E "torch|iree"
|
||||
pytest --ci --ci_sha=${SHORT_SHA} --local_tank_cache="/Volumes/builder/anush/shark_cache" --tank_url="gs://shark_tank/nightly/" -k vulkan --update_tank
|
||||
|
||||
- name: Validate Vulkan Models (a100)
|
||||
if: matrix.suite == 'vulkan' && matrix.os == 'a100'
|
||||
run: |
|
||||
cd $GITHUB_WORKSPACE
|
||||
PYTHON=python${{ matrix.python-version }} ./setup_venv.sh
|
||||
source shark.venv/bin/activate
|
||||
pytest --forked --benchmark="native" --ci --ci_sha=${SHORT_SHA} --update_tank --tank_url="gs://shark_tank/nightly/" -k vulkan
|
||||
python build_tools/stable_diffusion_testing.py --device=vulkan
|
||||
|
||||
- name: Validate Vulkan Models (Windows)
|
||||
if: matrix.suite == 'vulkan' && matrix.os == '7950x'
|
||||
run: |
|
||||
./setup_venv.ps1
|
||||
pytest -k vulkan -s --ci
|
||||
|
||||
- name: Validate Stable Diffusion Models (Windows)
|
||||
if: matrix.suite == 'vulkan' && matrix.os == '7950x'
|
||||
run: |
|
||||
./setup_venv.ps1
|
||||
python process_skipfiles.py
|
||||
pyinstaller .\apps\stable_diffusion\shark_sd.spec
|
||||
python build_tools/stable_diffusion_testing.py --device=vulkan
|
||||
|
||||
22
.gitignore
vendored
22
.gitignore
vendored
@@ -31,7 +31,6 @@ MANIFEST
|
||||
# Usually these files are written by a python script from a template
|
||||
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
||||
*.manifest
|
||||
*.spec
|
||||
|
||||
# Installer logs
|
||||
pip-log.txt
|
||||
@@ -160,10 +159,31 @@ cython_debug/
|
||||
# option (not recommended) you can uncomment the following to ignore the entire idea folder.
|
||||
#.idea/
|
||||
|
||||
# vscode related
|
||||
.vscode
|
||||
|
||||
# Shark related artefacts
|
||||
*venv/
|
||||
shark_tmp/
|
||||
*.vmfb
|
||||
.use-iree
|
||||
tank/dict_configs.py
|
||||
*.csv
|
||||
reproducers/
|
||||
|
||||
# ORT related artefacts
|
||||
cache_models/
|
||||
onnx_models/
|
||||
|
||||
# Generated images
|
||||
generated_imgs/
|
||||
|
||||
# Custom model related artefacts
|
||||
variants.json
|
||||
models/
|
||||
|
||||
# models folder
|
||||
apps/stable_diffusion/web/models/
|
||||
|
||||
# Stencil annotators.
|
||||
stencil_annotator/
|
||||
|
||||
@@ -1,3 +0,0 @@
|
||||
[style]
|
||||
based_on_style = google
|
||||
column_limit = 80
|
||||
218
LICENSE
Normal file
218
LICENSE
Normal file
@@ -0,0 +1,218 @@
|
||||
Apache License
|
||||
Version 2.0, January 2004
|
||||
http://www.apache.org/licenses/
|
||||
|
||||
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
||||
|
||||
1. Definitions.
|
||||
|
||||
"License" shall mean the terms and conditions for use, reproduction,
|
||||
and distribution as defined by Sections 1 through 9 of this document.
|
||||
|
||||
"Licensor" shall mean the copyright owner or entity authorized by
|
||||
the copyright owner that is granting the License.
|
||||
|
||||
"Legal Entity" shall mean the union of the acting entity and all
|
||||
other entities that control, are controlled by, or are under common
|
||||
control with that entity. For the purposes of this definition,
|
||||
"control" means (i) the power, direct or indirect, to cause the
|
||||
direction or management of such entity, whether by contract or
|
||||
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
||||
outstanding shares, or (iii) beneficial ownership of such entity.
|
||||
|
||||
"You" (or "Your") shall mean an individual or Legal Entity
|
||||
exercising permissions granted by this License.
|
||||
|
||||
"Source" form shall mean the preferred form for making modifications,
|
||||
including but not limited to software source code, documentation
|
||||
source, and configuration files.
|
||||
|
||||
"Object" form shall mean any form resulting from mechanical
|
||||
transformation or translation of a Source form, including but
|
||||
not limited to compiled object code, generated documentation,
|
||||
and conversions to other media types.
|
||||
|
||||
"Work" shall mean the work of authorship, whether in Source or
|
||||
Object form, made available under the License, as indicated by a
|
||||
copyright notice that is included in or attached to the work
|
||||
(an example is provided in the Appendix below).
|
||||
|
||||
"Derivative Works" shall mean any work, whether in Source or Object
|
||||
form, that is based on (or derived from) the Work and for which the
|
||||
editorial revisions, annotations, elaborations, or other modifications
|
||||
represent, as a whole, an original work of authorship. For the purposes
|
||||
of this License, Derivative Works shall not include works that remain
|
||||
separable from, or merely link (or bind by name) to the interfaces of,
|
||||
the Work and Derivative Works thereof.
|
||||
|
||||
"Contribution" shall mean any work of authorship, including
|
||||
the original version of the Work and any modifications or additions
|
||||
to that Work or Derivative Works thereof, that is intentionally
|
||||
submitted to Licensor for inclusion in the Work by the copyright owner
|
||||
or by an individual or Legal Entity authorized to submit on behalf of
|
||||
the copyright owner. For the purposes of this definition, "submitted"
|
||||
means any form of electronic, verbal, or written communication sent
|
||||
to the Licensor or its representatives, including but not limited to
|
||||
communication on electronic mailing lists, source code control systems,
|
||||
and issue tracking systems that are managed by, or on behalf of, the
|
||||
Licensor for the purpose of discussing and improving the Work, but
|
||||
excluding communication that is conspicuously marked or otherwise
|
||||
designated in writing by the copyright owner as "Not a Contribution."
|
||||
|
||||
"Contributor" shall mean Licensor and any individual or Legal Entity
|
||||
on behalf of whom a Contribution has been received by Licensor and
|
||||
subsequently incorporated within the Work.
|
||||
|
||||
2. Grant of Copyright License. Subject to the terms and conditions of
|
||||
this License, each Contributor hereby grants to You a perpetual,
|
||||
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
||||
copyright license to reproduce, prepare Derivative Works of,
|
||||
publicly display, publicly perform, sublicense, and distribute the
|
||||
Work and such Derivative Works in Source or Object form.
|
||||
|
||||
3. Grant of Patent License. Subject to the terms and conditions of
|
||||
this License, each Contributor hereby grants to You a perpetual,
|
||||
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
||||
(except as stated in this section) patent license to make, have made,
|
||||
use, offer to sell, sell, import, and otherwise transfer the Work,
|
||||
where such license applies only to those patent claims licensable
|
||||
by such Contributor that are necessarily infringed by their
|
||||
Contribution(s) alone or by combination of their Contribution(s)
|
||||
with the Work to which such Contribution(s) was submitted. If You
|
||||
institute patent litigation against any entity (including a
|
||||
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
||||
or a Contribution incorporated within the Work constitutes direct
|
||||
or contributory patent infringement, then any patent licenses
|
||||
granted to You under this License for that Work shall terminate
|
||||
as of the date such litigation is filed.
|
||||
|
||||
4. Redistribution. You may reproduce and distribute copies of the
|
||||
Work or Derivative Works thereof in any medium, with or without
|
||||
modifications, and in Source or Object form, provided that You
|
||||
meet the following conditions:
|
||||
|
||||
(a) You must give any other recipients of the Work or
|
||||
Derivative Works a copy of this License; and
|
||||
|
||||
(b) You must cause any modified files to carry prominent notices
|
||||
stating that You changed the files; and
|
||||
|
||||
(c) You must retain, in the Source form of any Derivative Works
|
||||
that You distribute, all copyright, patent, trademark, and
|
||||
attribution notices from the Source form of the Work,
|
||||
excluding those notices that do not pertain to any part of
|
||||
the Derivative Works; and
|
||||
|
||||
(d) If the Work includes a "NOTICE" text file as part of its
|
||||
distribution, then any Derivative Works that You distribute must
|
||||
include a readable copy of the attribution notices contained
|
||||
within such NOTICE file, excluding those notices that do not
|
||||
pertain to any part of the Derivative Works, in at least one
|
||||
of the following places: within a NOTICE text file distributed
|
||||
as part of the Derivative Works; within the Source form or
|
||||
documentation, if provided along with the Derivative Works; or,
|
||||
within a display generated by the Derivative Works, if and
|
||||
wherever such third-party notices normally appear. The contents
|
||||
of the NOTICE file are for informational purposes only and
|
||||
do not modify the License. You may add Your own attribution
|
||||
notices within Derivative Works that You distribute, alongside
|
||||
or as an addendum to the NOTICE text from the Work, provided
|
||||
that such additional attribution notices cannot be construed
|
||||
as modifying the License.
|
||||
|
||||
You may add Your own copyright statement to Your modifications and
|
||||
may provide additional or different license terms and conditions
|
||||
for use, reproduction, or distribution of Your modifications, or
|
||||
for any such Derivative Works as a whole, provided Your use,
|
||||
reproduction, and distribution of the Work otherwise complies with
|
||||
the conditions stated in this License.
|
||||
|
||||
5. Submission of Contributions. Unless You explicitly state otherwise,
|
||||
any Contribution intentionally submitted for inclusion in the Work
|
||||
by You to the Licensor shall be under the terms and conditions of
|
||||
this License, without any additional terms or conditions.
|
||||
Notwithstanding the above, nothing herein shall supersede or modify
|
||||
the terms of any separate license agreement you may have executed
|
||||
with Licensor regarding such Contributions.
|
||||
|
||||
6. Trademarks. This License does not grant permission to use the trade
|
||||
names, trademarks, service marks, or product names of the Licensor,
|
||||
except as required for reasonable and customary use in describing the
|
||||
origin of the Work and reproducing the content of the NOTICE file.
|
||||
|
||||
7. Disclaimer of Warranty. Unless required by applicable law or
|
||||
agreed to in writing, Licensor provides the Work (and each
|
||||
Contributor provides its Contributions) on an "AS IS" BASIS,
|
||||
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
||||
implied, including, without limitation, any warranties or conditions
|
||||
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
||||
PARTICULAR PURPOSE. You are solely responsible for determining the
|
||||
appropriateness of using or redistributing the Work and assume any
|
||||
risks associated with Your exercise of permissions under this License.
|
||||
|
||||
8. Limitation of Liability. In no event and under no legal theory,
|
||||
whether in tort (including negligence), contract, or otherwise,
|
||||
unless required by applicable law (such as deliberate and grossly
|
||||
negligent acts) or agreed to in writing, shall any Contributor be
|
||||
liable to You for damages, including any direct, indirect, special,
|
||||
incidental, or consequential damages of any character arising as a
|
||||
result of this License or out of the use or inability to use the
|
||||
Work (including but not limited to damages for loss of goodwill,
|
||||
work stoppage, computer failure or malfunction, or any and all
|
||||
other commercial damages or losses), even if such Contributor
|
||||
has been advised of the possibility of such damages.
|
||||
|
||||
9. Accepting Warranty or Additional Liability. While redistributing
|
||||
the Work or Derivative Works thereof, You may choose to offer,
|
||||
and charge a fee for, acceptance of support, warranty, indemnity,
|
||||
or other liability obligations and/or rights consistent with this
|
||||
License. However, in accepting such obligations, You may act only
|
||||
on Your own behalf and on Your sole responsibility, not on behalf
|
||||
of any other Contributor, and only if You agree to indemnify,
|
||||
defend, and hold each Contributor harmless for any liability
|
||||
incurred by, or claims asserted against, such Contributor by reason
|
||||
of your accepting any such warranty or additional liability.
|
||||
|
||||
END OF TERMS AND CONDITIONS
|
||||
|
||||
APPENDIX: How to apply the Apache License to your work.
|
||||
|
||||
To apply the Apache License to your work, attach the following
|
||||
boilerplate notice, with the fields enclosed by brackets "[]"
|
||||
replaced with your own identifying information. (Don't include
|
||||
the brackets!) The text should be enclosed in the appropriate
|
||||
comment syntax for the file format. We also recommend that a
|
||||
file or class name and description of purpose be included on the
|
||||
same "printed page" as the copyright notice for easier
|
||||
identification within third-party archives.
|
||||
|
||||
Copyright [yyyy] [name of copyright owner]
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software
|
||||
distributed under the License is distributed on an "AS IS" BASIS,
|
||||
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
See the License for the specific language governing permissions and
|
||||
limitations under the License.
|
||||
|
||||
|
||||
---- LLVM Exceptions to the Apache 2.0 License ----
|
||||
|
||||
As an exception, if, as a result of your compiling your source code, portions
|
||||
of this Software are embedded into an Object form of such source code, you
|
||||
may redistribute such embedded portions in such Object form without complying
|
||||
with the conditions of Sections 4(a), 4(b) and 4(d) of the License.
|
||||
|
||||
In addition, if you combine or link compiled forms of this Software with
|
||||
software that is licensed under the GPLv2 ("Combined Software") and if a
|
||||
court of competent jurisdiction determines that the patent provision (Section
|
||||
3), the indemnity provision (Section 9) or other Section of the License
|
||||
conflicts with the conditions of the GPLv2, you may retroactively and
|
||||
prospectively choose to deem waived or otherwise exclude such Section(s) of
|
||||
the License, but only in their entirety and only with respect to the Combined
|
||||
Software.
|
||||
480
README.md
480
README.md
@@ -1,29 +1,161 @@
|
||||
# SHARK
|
||||
|
||||
High Performance Machine Learning and Data Analytics for CPUs, GPUs, Accelerators and Heterogeneous Clusters
|
||||
High Performance Machine Learning Distribution
|
||||
|
||||
[](https://github.com/nod-ai/SHARK/actions/workflows/nightly.yml)
|
||||
[](https://github.com/nod-ai/SHARK/actions/workflows/test-models.yml)
|
||||
|
||||
## Communication Channels
|
||||
|
||||
* [SHARK Discord server](https://discord.gg/RUqY2h2s9u): Real time discussions with the SHARK team and other users
|
||||
* [GitHub issues](https://github.com/nod-ai/SHARK/issues): Feature requests, bugs etc
|
||||
|
||||
|
||||
## Installation
|
||||
|
||||
<details>
|
||||
<summary>Installation (Linux and macOS)</summary>
|
||||
<summary>Prerequisites - Drivers </summary>
|
||||
|
||||
#### Install your Windows hardware drivers
|
||||
* [AMD RDNA Users] Download the latest driver [here](https://www.amd.com/en/support/kb/release-notes/rn-rad-win-23-2-1).
|
||||
* [macOS Users] Download and install the 1.3.216 Vulkan SDK from [here](https://sdk.lunarg.com/sdk/download/1.3.216.0/mac/vulkansdk-macos-1.3.216.0.dmg). Newer versions of the SDK will not work.
|
||||
* [Nvidia Users] Download and install the latest CUDA / Vulkan drivers from [here](https://developer.nvidia.com/cuda-downloads)
|
||||
|
||||
#### Linux Drivers
|
||||
* MESA / RADV drivers wont work with FP16. Please use the latest AMGPU-PRO drivers (non-pro OSS drivers also wont work) or the latest NVidia Linux Drivers.
|
||||
|
||||
Other users please ensure you have your latest vendor drivers and Vulkan SDK from [here](https://vulkan.lunarg.com/sdk/home) and if you are using vulkan check `vulkaninfo` works in a terminal window
|
||||
|
||||
</details>
|
||||
|
||||
|
||||
|
||||
### Quick Start for SHARK Stable Diffusion for Windows 10/11 Users
|
||||
|
||||
Install the Driver from [Prerequisites](https://github.com/nod-ai/SHARK#install-your-hardware-drivers) above
|
||||
|
||||
Download the [stable release](https://github.com/nod-ai/shark/releases/latest)
|
||||
|
||||
Double click the .exe and you should have the [UI](http://localhost:8080/) in the browser.
|
||||
|
||||
If you have custom models put them in a `models/` directory where the .exe is.
|
||||
|
||||
Enjoy.
|
||||
|
||||
<details>
|
||||
<summary>More installation notes</summary>
|
||||
* We recommend that you download EXE in a new folder, whenever you download a new EXE version. If you download it in the same folder as a previous install, you must delete the old `*.vmfb` files with `rm *.vmfb`. You can also use `--clear_all` flag once to clean all the old files.
|
||||
* If you recently updated the driver or this binary (EXE file), we recommend you clear all the local artifacts with `--clear_all`
|
||||
|
||||
## Running
|
||||
|
||||
* Open a Command Prompt or Powershell terminal, change folder (`cd`) to the .exe folder. Then run the EXE from the command prompt. That way, if an error occurs, you'll be able to cut-and-paste it to ask for help. (if it always works for you without error, you may simply double-click the EXE)
|
||||
* The first run may take few minutes when the models are downloaded and compiled. Your patience is appreciated. The download could be about 5GB.
|
||||
* You will likely see a Windows Defender message asking you to give permission to open a web server port. Accept it.
|
||||
* Open a browser to access the Stable Diffusion web server. By default, the port is 8080, so you can go to http://localhost:8080/.
|
||||
|
||||
## Stopping
|
||||
|
||||
* Select the command prompt that's running the EXE. Press CTRL-C and wait a moment or close the terminal.
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>Advanced Installation (Only for developers)</summary>
|
||||
|
||||
## Advanced Installation (Windows, Linux and macOS) for developers
|
||||
|
||||
## Check out the code
|
||||
|
||||
```shell
|
||||
git clone https://github.com/nod-ai/SHARK.git
|
||||
cd SHARK
|
||||
```
|
||||
|
||||
## Setup your Python VirtualEnvironment and Dependencies
|
||||
|
||||
### Windows 10/11 Users
|
||||
|
||||
* Install the latest Python 3.11.x version from [here](https://www.python.org/downloads/windows/)
|
||||
|
||||
* Install Git for Windows from [here](https://git-scm.com/download/win)
|
||||
|
||||
#### Allow the install script to run in Powershell
|
||||
```powershell
|
||||
set-executionpolicy remotesigned
|
||||
```
|
||||
|
||||
#### Setup venv and install necessary packages (torch-mlir, nodLabs/Shark, ...)
|
||||
```powershell
|
||||
./setup_venv.ps1 #You can re-run this script to get the latest version
|
||||
```
|
||||
|
||||
### Linux / macOS Users
|
||||
|
||||
```shell
|
||||
./setup_venv.sh
|
||||
source shark.venv/bin/activate
|
||||
```
|
||||
|
||||
|
||||
### Run Stable Diffusion on your device - WebUI
|
||||
|
||||
#### Windows 10/11 Users
|
||||
```powershell
|
||||
(shark.venv) PS C:\g\shark> cd .\apps\stable_diffusion\web\
|
||||
(shark.venv) PS C:\g\shark\apps\stable_diffusion\web> python .\index.py
|
||||
```
|
||||
#### Linux / macOS Users
|
||||
```shell
|
||||
(shark.venv) > cd apps/stable_diffusion/web
|
||||
(shark.venv) > python index.py
|
||||
```
|
||||
|
||||
#### Access Stable Diffusion on http://localhost:8080/?__theme=dark
|
||||
|
||||
|
||||
<img width="1607" alt="webui" src="https://user-images.githubusercontent.com/74956/204939260-b8308bc2-8dc4-47f6-9ac0-f60b66edab99.png">
|
||||
|
||||
|
||||
|
||||
### Run Stable Diffusion on your device - Commandline
|
||||
|
||||
#### Windows 10/11 Users
|
||||
```powershell
|
||||
(shark.venv) PS C:\g\shark> python .\apps\stable_diffusion\scripts\main.py --app="txt2img" --precision="fp16" --prompt="tajmahal, snow, sunflowers, oil on canvas" --device="vulkan"
|
||||
```
|
||||
|
||||
#### Linux / macOS Users
|
||||
```shell
|
||||
python3.11 apps/stable_diffusion/scripts/main.py --app=txt2img --precision=fp16 --device=vulkan --prompt="tajmahal, oil on canvas, sunflowers, 4k, uhd"
|
||||
```
|
||||
|
||||
You can replace `vulkan` with `cpu` to run on your CPU or with `cuda` to run on CUDA devices. If you have multiple vulkan devices you can address them with `--device=vulkan://1` etc
|
||||
</details>
|
||||
|
||||
The output on a AMD 7900XTX would look something like:
|
||||
|
||||
```shell
|
||||
Average step time: 47.19188690185547ms/it
|
||||
Clip Inference time (ms) = 109.531
|
||||
VAE Inference time (ms): 78.590
|
||||
|
||||
Total image generation time: 2.5788655281066895sec
|
||||
```
|
||||
|
||||
Here are some samples generated:
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
|
||||
Find us on [SHARK Discord server](https://discord.gg/RUqY2h2s9u) if you have any trouble with running it on your hardware.
|
||||
|
||||
|
||||
<details>
|
||||
<summary>Binary Installation</summary>
|
||||
|
||||
### Setup a new pip Virtual Environment
|
||||
|
||||
This step sets up a new VirtualEnv for Python
|
||||
|
||||
```shell
|
||||
python --version #Check you have 3.7->3.10 on Linux or 3.10 on macOS
|
||||
python --version #Check you have 3.11 on Linux, macOS or Windows Powershell
|
||||
python -m venv shark_venv
|
||||
source shark_venv/bin/activate
|
||||
source shark_venv/bin/activate # Use shark_venv/Scripts/activate on Windows
|
||||
|
||||
# If you are using conda create and activate a new conda env
|
||||
|
||||
@@ -35,19 +167,24 @@ python -m pip install --upgrade pip
|
||||
|
||||
### Install SHARK
|
||||
|
||||
This step pip installs SHARK and related packages on Linux Python 3.7, 3.8, 3.9, 3.10 and macOS Python 3.10
|
||||
This step pip installs SHARK and related packages on Linux Python 3.8, 3.10 and 3.11 and macOS / Windows Python 3.11
|
||||
|
||||
```shell
|
||||
pip install nodai-shark -f https://github.com/nod-ai/SHARK/releases -f https://github.com/llvm/torch-mlir/releases -f https://github.com/nod-ai/shark-runtime/releases --extra-index-url https://download.pytorch.org/whl/nightly/cpu
|
||||
pip install nodai-shark -f https://nod-ai.github.io/SHARK/package-index/ -f https://llvm.github.io/torch-mlir/package-index/ -f https://nod-ai.github.io/SHARK-Runtime/pip-release-links.html --extra-index-url https://download.pytorch.org/whl/nightly/cpu
|
||||
```
|
||||
If you are on an Intel macOS machine you need this [workaround](https://github.com/nod-ai/SHARK/issues/102) for an upstream issue.
|
||||
|
||||
### Run shark tank model tests.
|
||||
```shell
|
||||
pytest tank/test_models.py
|
||||
```
|
||||
See tank/README.md for a more detailed walkthrough of our pytest suite and CLI.
|
||||
|
||||
### Download and run Resnet50 sample
|
||||
|
||||
```shell
|
||||
curl -O https://raw.githubusercontent.com/nod-ai/SHARK/main/shark/examples/shark_inference/resnet50_script.py
|
||||
#Install deps for test script
|
||||
pip install --pre torch torchvision torchaudio tqdm pillow --extra-index-url https://download.pytorch.org/whl/nightly/cpu
|
||||
pip install --pre torch torchvision torchaudio tqdm pillow gsutil --extra-index-url https://download.pytorch.org/whl/nightly/cpu
|
||||
python ./resnet50_script.py --device="cpu" #use cuda or vulkan or metal
|
||||
```
|
||||
|
||||
@@ -61,103 +198,84 @@ python ./minilm_jit.py --device="cpu" #use cuda or vulkan or metal
|
||||
</details>
|
||||
|
||||
|
||||
|
||||
<details>
|
||||
<summary>Source Installation</summary>
|
||||
<summary>Development, Testing and Benchmarks</summary>
|
||||
|
||||
## Check out the code
|
||||
|
||||
```shell
|
||||
git clone https://github.com/nod-ai/SHARK.git
|
||||
If you want to use Python3.11 and with TF Import tools you can use the environment variables like:
|
||||
Set `USE_IREE=1` to use upstream IREE
|
||||
```
|
||||
# PYTHON=python3.11 VENV_DIR=0617_venv IMPORTER=1 ./setup_venv.sh
|
||||
```
|
||||
|
||||
## Setup your Python VirtualEnvironment and Dependencies
|
||||
```shell
|
||||
# Setup venv and install necessary packages (torch-mlir, nodLabs/Shark, ...).
|
||||
./setup_venv.sh
|
||||
source shark.venv/bin/activate
|
||||
```
|
||||
For example if you want to use Python3.10 and upstream IREE with TF Import tools you can use the environment variables like:
|
||||
```
|
||||
# PYTHON=python3.10 VENV_DIR=0617_venv IMPORTER=1 USE_IREE=1 ./setup_venv.sh
|
||||
```
|
||||
|
||||
If you are a Torch-mlir developer or an IREE developer and want to test local changes you can uninstall
|
||||
the provided packages with `pip uninstall torch-mlir` and / or `pip uninstall iree-compiler iree-runtime` and build locally
|
||||
with Python bindings and set your PYTHONPATH as mentioned [here](https://google.github.io/iree/bindings/python/)
|
||||
for IREE and [here](https://github.com/llvm/torch-mlir/blob/main/development.md#setup-python-environment-to-export-the-built-python-packages)
|
||||
for Torch-MLIR.
|
||||
|
||||
### Run a demo script
|
||||
### Run any of the hundreds of SHARK tank models via the test framework
|
||||
```shell
|
||||
python -m shark.examples.shark_inference.resnet50_script --device="cpu" # Use gpu | vulkan
|
||||
# Or a pytest
|
||||
pytest tank/tf/hf_masked_lm/albert-base-v2_test.py::AlbertBaseModuleTest::test_module_static_cpu
|
||||
pytest tank/test_models.py -k "MiniLM"
|
||||
```
|
||||
|
||||
### How to use your locally built IREE / Torch-MLIR with SHARK
|
||||
If you are a *Torch-mlir developer or an IREE developer* and want to test local changes you can uninstall
|
||||
the provided packages with `pip uninstall torch-mlir` and / or `pip uninstall iree-compiler iree-runtime` and build locally
|
||||
with Python bindings and set your PYTHONPATH as mentioned [here](https://github.com/iree-org/iree/tree/main/docs/api_docs/python#install-iree-binaries)
|
||||
for IREE and [here](https://github.com/llvm/torch-mlir/blob/main/development.md#setup-python-environment-to-export-the-built-python-packages)
|
||||
for Torch-MLIR.
|
||||
|
||||
How to use your locally built Torch-MLIR with SHARK:
|
||||
```shell
|
||||
1.) Run `./setup_venv.sh in SHARK` and activate `shark.venv` virtual env.
|
||||
2.) Run `pip uninstall torch-mlir`.
|
||||
3.) Go to your local Torch-MLIR directory.
|
||||
4.) Activate mlir_venv virtual envirnoment.
|
||||
5.) Run `pip uninstall -r requirements.txt`.
|
||||
6.) Run `pip install -r requirements.txt`.
|
||||
7.) Build Torch-MLIR.
|
||||
8.) Activate shark.venv virtual environment from the Torch-MLIR directory.
|
||||
8.) Run `export PYTHONPATH=`pwd`/build/tools/torch-mlir/python_packages/torch_mlir:`pwd`/examples` in the Torch-MLIR directory.
|
||||
9.) Go to the SHARK directory.
|
||||
```
|
||||
Now the SHARK will use your locally build Torch-MLIR repo.
|
||||
|
||||
|
||||
## Benchmarking Dispatches
|
||||
|
||||
To produce benchmarks of individual dispatches, you can add `--dispatch_benchmarks=All --dispatch_benchmarks_dir=<output_dir>` to your pytest command line argument.
|
||||
If you only want to compile specific dispatches, you can specify them with a space seperated string instead of `"All"`. E.G. `--dispatch_benchmarks="0 1 2 10"`
|
||||
|
||||
For example, to generate and run dispatch benchmarks for MiniLM on CUDA:
|
||||
```
|
||||
pytest -k "MiniLM and torch and static and cuda" --benchmark_dispatches=All -s --dispatch_benchmarks_dir=./my_dispatch_benchmarks
|
||||
```
|
||||
The given command will populate `<dispatch_benchmarks_dir>/<model_name>/` with an `ordered_dispatches.txt` that lists and orders the dispatches and their latencies, as well as folders for each dispatch that contain .mlir, .vmfb, and results of the benchmark for that dispatch.
|
||||
|
||||
if you want to instead incorporate this into a python script, you can pass the `dispatch_benchmarks` and `dispatch_benchmarks_dir` commands when initializing `SharkInference`, and the benchmarks will be generated when compiled. E.G:
|
||||
|
||||
```
|
||||
shark_module = SharkInference(
|
||||
mlir_model,
|
||||
func_name,
|
||||
device=args.device,
|
||||
mlir_dialect="tm_tensor",
|
||||
dispatch_benchmarks="all",
|
||||
dispatch_benchmarks_dir="results"
|
||||
)
|
||||
```
|
||||
|
||||
Output will include:
|
||||
- An ordered list ordered-dispatches.txt of all the dispatches with their runtime
|
||||
- Inside the specified directory, there will be a directory for each dispatch (there will be mlir files for all dispatches, but only compiled binaries and benchmark data for the specified dispatches)
|
||||
- An .mlir file containing the dispatch benchmark
|
||||
- A compiled .vmfb file containing the dispatch benchmark
|
||||
- An .mlir file containing just the hal executable
|
||||
- A compiled .vmfb file of the hal executable
|
||||
- A .txt file containing benchmark output
|
||||
|
||||
|
||||
See tank/README.md for further instructions on how to run model tests and benchmarks from the SHARK tank.
|
||||
|
||||
</details>
|
||||
|
||||
|
||||
<details>
|
||||
<summary>Testing</summary>
|
||||
|
||||
### Run all model tests on CPU/GPU/VULKAN/Metal
|
||||
```shell
|
||||
pytest tank
|
||||
|
||||
# If on Linux for multithreading on CPU (faster results):
|
||||
pytest tank -n auto
|
||||
```
|
||||
|
||||
### Running specific tests
|
||||
```shell
|
||||
# Run tests for a specific model:
|
||||
pytest tank/<MODEL_NAME> #i.e., pytest tank/bert-base-uncased
|
||||
|
||||
# Run tests for a specific case:
|
||||
pytest tank/<MODEL_NAME> -k "keyword"
|
||||
# i.e., pytest tank/bert-base-uncased/bert-base-uncased_test.py -k "static_gpu"
|
||||
|
||||
```
|
||||
|
||||
### Run benchmarks on SHARK tank pytests and generate bench_results.csv with results.
|
||||
|
||||
(requires source installation with `IMPORTER=1 ./setup_venv.sh`)
|
||||
|
||||
```shell
|
||||
pytest --benchmark tank
|
||||
|
||||
# Just do static GPU benchmarks for PyTorch tests:
|
||||
pytest --benchmark tank --ignore-glob="_tf*" -k "static_gpu"
|
||||
```
|
||||
|
||||
### Benchmark Resnet50, MiniLM on CPU
|
||||
|
||||
(requires source installation with `IMPORTER=1 ./setup_venv.sh`)
|
||||
|
||||
```shell
|
||||
# We suggest running the following commands as root before running benchmarks on CPU:
|
||||
|
||||
cat /sys/devices/system/cpu/cpu*/topology/thread_siblings_list | awk -F, '{print $2}' | sort -n | uniq | ( while read X ; do echo $X ; echo 0 > /sys/devices/system/cpu/cpu$X/online ; done )
|
||||
echo 1 > /sys/devices/system/cpu/intel_pstate/no_turbo
|
||||
|
||||
# Benchmark canonical Resnet50 on CPU via pytest
|
||||
pytest --benchmark tank/resnet50/ -k "cpu"
|
||||
|
||||
# Benchmark canonical MiniLM on CPU via pytest
|
||||
pytest --benchmark tank/MiniLM-L12-H384-uncased/ -k "cpu"
|
||||
|
||||
# Benchmark MiniLM on CPU via transformer-benchmarks:
|
||||
git clone --recursive https://github.com/nod-ai/transformer-benchmarks.git
|
||||
cd transformer-benchmarks
|
||||
./perf-ci.sh -n
|
||||
# Check detail.csv for MLIR/IREE results.
|
||||
|
||||
```
|
||||
|
||||
</details>
|
||||
|
||||
|
||||
<details>
|
||||
<summary>API Reference</summary>
|
||||
|
||||
@@ -208,160 +326,26 @@ result = shark_module.forward((arg0, arg1))
|
||||
```
|
||||
</details>
|
||||
|
||||
|
||||
## Supported and Validated Models
|
||||
|
||||
<details>
|
||||
<summary>PyTorch Models</summary>
|
||||
SHARK is maintained to support the latest innovations in ML Models:
|
||||
|
||||
### Huggingface PyTorch Models
|
||||
| TF HuggingFace Models | SHARK-CPU | SHARK-CUDA | SHARK-METAL |
|
||||
|---------------------|----------|----------|-------------|
|
||||
| BERT | :green_heart: | :green_heart: | :green_heart: |
|
||||
| DistilBERT | :green_heart: | :green_heart: | :green_heart: |
|
||||
| GPT2 | :green_heart: | :green_heart: | :green_heart: |
|
||||
| BLOOM | :green_heart: | :green_heart: | :green_heart: |
|
||||
| Stable Diffusion | :green_heart: | :green_heart: | :green_heart: |
|
||||
| Vision Transformer | :green_heart: | :green_heart: | :green_heart: |
|
||||
| ResNet50 | :green_heart: | :green_heart: | :green_heart: |
|
||||
|
||||
| Hugging Face Models | Torch-MLIR lowerable | SHARK-CPU | SHARK-CUDA | SHARK-METAL |
|
||||
|---------------------|----------------------|----------|----------|-------------|
|
||||
| BERT | :green_heart: (JIT) | :green_heart: | :green_heart: | :green_heart: |
|
||||
| Albert | :green_heart: (JIT) | :green_heart: | :green_heart: | :green_heart: |
|
||||
| BigBird | :green_heart: (AOT) | | | |
|
||||
| DistilBERT | :green_heart: (JIT) | :green_heart: | :green_heart: | :green_heart: |
|
||||
| GPT2 | :broken_heart: (AOT) | | | |
|
||||
| MobileBert | :green_heart: (JIT) | :green_heart: | :green_heart: | :green_heart: |
|
||||
For a complete list of the models supported in SHARK, please refer to [tank/README.md](https://github.com/nod-ai/SHARK/blob/main/tank/README.md).
|
||||
|
||||
### Torchvision Models
|
||||
## Communication Channels
|
||||
|
||||
| TORCHVISION Models | Torch-MLIR lowerable | SHARK-CPU | SHARK-CUDA | SHARK-METAL |
|
||||
|--------------------|----------------------|----------|----------|-------------|
|
||||
| AlexNet | :green_heart: (Script) | :green_heart: | :green_heart: | :green_heart: |
|
||||
| DenseNet121 | :green_heart: (Script) | | | |
|
||||
| MNasNet1_0 | :green_heart: (Script) | :green_heart: | :green_heart: | :green_heart: |
|
||||
| MobileNetV2 | :green_heart: (Script) | :green_heart: | :green_heart: | :green_heart: |
|
||||
| MobileNetV3 | :green_heart: (Script) | :green_heart: | :green_heart: | :green_heart: |
|
||||
| Unet | :broken_heart: (Script) | | | |
|
||||
| Resnet18 | :green_heart: (Script) | :green_heart: | :green_heart: | :green_heart: |
|
||||
| Resnet50 | :green_heart: (Script) | :green_heart: | :green_heart: | :green_heart: |
|
||||
| Resnet101 | :green_heart: (Script) | :green_heart: | :green_heart: | :green_heart: |
|
||||
| Resnext50_32x4d | :green_heart: (Script) | :green_heart: | :green_heart: | :green_heart: |
|
||||
| ShuffleNet_v2 | :broken_heart: (Script) | | | |
|
||||
| SqueezeNet | :green_heart: (Script) | :green_heart: | :green_heart: | :green_heart: |
|
||||
| EfficientNet | :green_heart: (Script) | | | |
|
||||
| Regnet | :green_heart: (Script) | :green_heart: | :green_heart: | :green_heart: |
|
||||
| Resnest | :broken_heart: (Script) | | | |
|
||||
| Vision Transformer | :green_heart: (Script) | | | |
|
||||
| VGG 16 | :green_heart: (Script) | :green_heart: | :green_heart: | |
|
||||
| Wide Resnet | :green_heart: (Script) | :green_heart: | :green_heart: | :green_heart: |
|
||||
| RAFT | :broken_heart: (JIT) | | | |
|
||||
|
||||
For more information refer to [MODEL TRACKING SHEET](https://docs.google.com/spreadsheets/d/15PcjKeHZIrB5LfDyuw7DGEEE8XnQEX2aX8lm8qbxV8A/edit#gid=0)
|
||||
|
||||
### PyTorch Training Models
|
||||
|
||||
| Models | Torch-MLIR lowerable | SHARK-CPU | SHARK-CUDA | SHARK-METAL |
|
||||
|---------------------|----------------------|----------|----------|-------------|
|
||||
| BERT | :broken_heart: | :broken_heart: | | |
|
||||
| FullyConnected | :green_heart: | :green_heart: | | |
|
||||
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>JAX Models</summary>
|
||||
|
||||
|
||||
### JAX Models
|
||||
|
||||
| Models | JAX-MHLO lowerable | SHARK-CPU | SHARK-CUDA | SHARK-METAL |
|
||||
|---------------------|----------------------|----------|----------|-------------|
|
||||
| DALL-E | :broken_heart: | :broken_heart: | | |
|
||||
| FullyConnected | :green_heart: | :green_heart: | | |
|
||||
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>TFLite Models</summary>
|
||||
|
||||
### TFLite Models
|
||||
|
||||
| Models | TOSA/LinAlg | SHARK-CPU | SHARK-CUDA | SHARK-METAL |
|
||||
|---------------------|----------------------|----------|----------|-------------|
|
||||
| BERT | :broken_heart: | :broken_heart: | | |
|
||||
| FullyConnected | :green_heart: | :green_heart: | | |
|
||||
| albert | :green_heart: | :green_heart: | | |
|
||||
| asr_conformer | :green_heart: | :green_heart: | | |
|
||||
| bird_classifier | :green_heart: | :green_heart: | | |
|
||||
| cartoon_gan | :green_heart: | :green_heart: | | |
|
||||
| craft_text | :green_heart: | :green_heart: | | |
|
||||
| deeplab_v3 | :green_heart: | :green_heart: | | |
|
||||
| densenet | :green_heart: | :green_heart: | | |
|
||||
| east_text_detector | :green_heart: | :green_heart: | | |
|
||||
| efficientnet_lite0_int8 | :green_heart: | :green_heart: | | |
|
||||
| efficientnet | :green_heart: | :green_heart: | | |
|
||||
| gpt2 | :green_heart: | :green_heart: | | |
|
||||
| image_stylization | :green_heart: | :green_heart: | | |
|
||||
| inception_v4 | :green_heart: | :green_heart: | | |
|
||||
| inception_v4_uint8 | :green_heart: | :green_heart: | | |
|
||||
| lightning_fp16 | :green_heart: | :green_heart: | | |
|
||||
| lightning_i8 | :green_heart: | :green_heart: | | |
|
||||
| lightning | :green_heart: | :green_heart: | | |
|
||||
| magenta | :green_heart: | :green_heart: | | |
|
||||
| midas | :green_heart: | :green_heart: | | |
|
||||
| mirnet | :green_heart: | :green_heart: | | |
|
||||
| mnasnet | :green_heart: | :green_heart: | | |
|
||||
| mobilebert_edgetpu_s_float | :green_heart: | :green_heart: | | |
|
||||
| mobilebert_edgetpu_s_quant | :green_heart: | :green_heart: | | |
|
||||
| mobilebert | :green_heart: | :green_heart: | | |
|
||||
| mobilebert_tf2_float | :green_heart: | :green_heart: | | |
|
||||
| mobilebert_tf2_quant | :green_heart: | :green_heart: | | |
|
||||
| mobilenet_ssd_quant | :green_heart: | :green_heart: | | |
|
||||
| mobilenet_v1 | :green_heart: | :green_heart: | | |
|
||||
| mobilenet_v1_uint8 | :green_heart: | :green_heart: | | |
|
||||
| mobilenet_v2_int8 | :green_heart: | :green_heart: | | |
|
||||
| mobilenet_v2 | :green_heart: | :green_heart: | | |
|
||||
| mobilenet_v2_uint8 | :green_heart: | :green_heart: | | |
|
||||
| mobilenet_v3-large | :green_heart: | :green_heart: | | |
|
||||
| mobilenet_v3-large_uint8 | :green_heart: | :green_heart: | | |
|
||||
| mobilenet_v35-int8 | :green_heart: | :green_heart: | | |
|
||||
| nasnet | :green_heart: | :green_heart: | | |
|
||||
| person_detect | :green_heart: | :green_heart: | | |
|
||||
| posenet | :green_heart: | :green_heart: | | |
|
||||
| resnet_50_int8 | :green_heart: | :green_heart: | | |
|
||||
| rosetta | :green_heart: | :green_heart: | | |
|
||||
| spice | :green_heart: | :green_heart: | | |
|
||||
| squeezenet | :green_heart: | :green_heart: | | |
|
||||
| ssd_mobilenet_v1 | :green_heart: | :green_heart: | | |
|
||||
| ssd_mobilenet_v1_uint8 | :green_heart: | :green_heart: | | |
|
||||
| ssd_mobilenet_v2_fpnlite | :green_heart: | :green_heart: | | |
|
||||
| ssd_mobilenet_v2_fpnlite_uint8 | :green_heart: | :green_heart: | | |
|
||||
| ssd_mobilenet_v2_int8 | :green_heart: | :green_heart: | | |
|
||||
| ssd_mobilenet_v2 | :green_heart: | :green_heart: | | |
|
||||
| ssd_spaghettinet_large | :green_heart: | :green_heart: | | |
|
||||
| ssd_spaghettinet_large_uint8 | :green_heart: | :green_heart: | | |
|
||||
| visual_wake_words_i8 | :green_heart: | :green_heart: | | |
|
||||
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>TF Models</summary>
|
||||
|
||||
### Tensorflow Models (Inference)
|
||||
|
||||
| Hugging Face Models | tf-mhlo lowerable | SHARK-CPU | SHARK-CUDA | SHARK-METAL |
|
||||
|---------------------|----------------------|----------|----------|-------------|
|
||||
| BERT | :green_heart: | :green_heart: | :green_heart: | :green_heart: |
|
||||
| albert-base-v2 | :green_heart: | :green_heart: | :green_heart: | :green_heart: |
|
||||
| DistilBERT | :green_heart: | :green_heart: | :green_heart: | :green_heart: |
|
||||
| CamemBert | :green_heart: | :green_heart: | :green_heart: | :green_heart: |
|
||||
| ConvBert | :green_heart: | :green_heart: | :green_heart: | :green_heart: |
|
||||
| Deberta | | | | |
|
||||
| electra | :green_heart: | :green_heart: | :green_heart: | :green_heart: |
|
||||
| funnel | | | | |
|
||||
| layoutlm | :green_heart: | :green_heart: | :green_heart: | :green_heart: |
|
||||
| longformer | | | | |
|
||||
| mobile-bert | :green_heart: | :green_heart: | :green_heart: | :green_heart: |
|
||||
| remembert | | | | |
|
||||
| tapas | | | | |
|
||||
| flaubert | :green_heart: | :green_heart: | :green_heart: | :green_heart: |
|
||||
| roberta | :green_heart: | :green_heart: | :green_heart: | :green_heart: |
|
||||
| xlm-roberta | :green_heart: | :green_heart: | :green_heart: | :green_heart: |
|
||||
| mpnet | :green_heart: | :green_heart: | :green_heart: | :green_heart: |
|
||||
|
||||
</details>
|
||||
* [SHARK Discord server](https://discord.gg/RUqY2h2s9u): Real time discussions with the SHARK team and other users
|
||||
* [GitHub issues](https://github.com/nod-ai/SHARK/issues): Feature requests, bugs etc
|
||||
|
||||
## Related Projects
|
||||
|
||||
|
||||
0
apps/__init__.py
Normal file
0
apps/__init__.py
Normal file
0
apps/stable_diffusion/__init__.py
Normal file
0
apps/stable_diffusion/__init__.py
Normal file
87
apps/stable_diffusion/profiling_with_iree.md
Normal file
87
apps/stable_diffusion/profiling_with_iree.md
Normal file
@@ -0,0 +1,87 @@
|
||||
Compile / Run Instructions:
|
||||
|
||||
To compile .vmfb for SD (vae, unet, CLIP), run the following commands with the .mlir in your local shark_tank cache (default location for Linux users is `~/.local/shark_tank`). These will be available once the script from [this README](https://github.com/nod-ai/SHARK/blob/main/shark/examples/shark_inference/stable_diffusion/README.md) is run once.
|
||||
Running the script mentioned above with the `--save_vmfb` flag will also save the .vmfb in your SHARK base directory if you want to skip straight to benchmarks.
|
||||
|
||||
Compile Commands FP32/FP16:
|
||||
|
||||
```shell
|
||||
Vulkan AMD:
|
||||
iree-compile --iree-input-type=none --iree-hal-target-backends=vulkan --iree-vulkan-target-triple=rdna2-unknown-linux --iree-stream-resource-index-bits=64 --iree-vm-target-index-bits=64 /path/to/input/mlir -o /path/to/output/vmfb
|
||||
|
||||
# add --mlir-print-debuginfo --mlir-print-op-on-diagnostic=true for debug
|
||||
# use –iree-input-type=mhlo for tf models
|
||||
|
||||
CUDA NVIDIA:
|
||||
iree-compile --iree-input-type=none --iree-hal-target-backends=cuda --iree-stream-resource-index-bits=64 --iree-vm-target-index-bits=64 /path/to/input/mlir -o /path/to/output/vmfb
|
||||
|
||||
CPU:
|
||||
iree-compile --iree-input-type=none --iree-hal-target-backends=llvm-cpu --iree-stream-resource-index-bits=64 --iree-vm-target-index-bits=64 /path/to/input/mlir -o /path/to/output/vmfb
|
||||
```
|
||||
|
||||
|
||||
|
||||
Run / Benchmark Command (FP32 - NCHW):
|
||||
(NEED to use BS=2 since we do two forward passes to unet as a result of classifier free guidance.)
|
||||
|
||||
```shell
|
||||
## Vulkan AMD:
|
||||
iree-benchmark-module --module=/path/to/output/vmfb --function=forward --device=vulkan --input=1x4x64x64xf32 --input=1xf32 --input=2x77x768xf32 --input=f32=1.0 --input=f32=1.0
|
||||
|
||||
## CUDA:
|
||||
iree-benchmark-module --module=/path/to/vmfb --function=forward --device=cuda --input=1x4x64x64xf32 --input=1xf32 --input=2x77x768xf32 --input=f32=1.0 --input=f32=1.0
|
||||
|
||||
## CPU:
|
||||
iree-benchmark-module --module=/path/to/vmfb --function=forward --device=local-task --input=1x4x64x64xf32 --input=1xf32 --input=2x77x768xf32 --input=f32=1.0 --input=f32=1.0
|
||||
|
||||
```
|
||||
|
||||
Run via vulkan_gui for RGP Profiling:
|
||||
|
||||
To build the vulkan app for profiling UNet follow the instructions [here](https://github.com/nod-ai/SHARK/tree/main/cpp) and then run the following command from the cpp directory with your compiled stable_diff.vmfb
|
||||
```shell
|
||||
./build/vulkan_gui/iree-vulkan-gui --module=/path/to/unet.vmfb --input=1x4x64x64xf32 --input=1xf32 --input=2x77x768xf32 --input=f32=1.0 --input=f32=1.0
|
||||
```
|
||||
|
||||
</details>
|
||||
<details>
|
||||
<summary>Debug Commands</summary>
|
||||
|
||||
## Debug commands and other advanced usage follows.
|
||||
|
||||
```shell
|
||||
python txt2img.py --precision="fp32"|"fp16" --device="cpu"|"cuda"|"vulkan" --import_mlir|--no-import_mlir --prompt "enter the text"
|
||||
```
|
||||
|
||||
## dump all dispatch .spv and isa using amdllpc
|
||||
|
||||
```shell
|
||||
python txt2img.py --precision="fp16" --device="vulkan" --iree-vulkan-target-triple=rdna3-unknown-linux --no-load_vmfb --dispatch_benchmarks="all" --dispatch_benchmarks_dir="SD_dispatches" --dump_isa
|
||||
```
|
||||
|
||||
## Compile and save the .vmfb (using vulkan fp16 as an example):
|
||||
|
||||
```shell
|
||||
python txt2img.py --precision=fp16 --device=vulkan --steps=50 --save_vmfb
|
||||
```
|
||||
|
||||
## Capture an RGP trace
|
||||
|
||||
```shell
|
||||
python txt2img.py --precision=fp16 --device=vulkan --steps=50 --save_vmfb --enable_rgp
|
||||
```
|
||||
|
||||
## Run the vae module with iree-benchmark-module (NCHW, fp16, vulkan, for example):
|
||||
|
||||
```shell
|
||||
iree-benchmark-module --module=/path/to/output/vmfb --function=forward --device=vulkan --input=1x4x64x64xf16
|
||||
```
|
||||
|
||||
## Run the unet module with iree-benchmark-module (same config as above):
|
||||
```shell
|
||||
##if you want to use .npz inputs:
|
||||
unzip ~/.local/shark_tank/<your unet>/inputs.npz
|
||||
iree-benchmark-module --module=/path/to/output/vmfb --function=forward --input=@arr_0.npy --input=1xf16 --input=@arr_2.npy --input=@arr_3.npy --input=@arr_4.npy
|
||||
```
|
||||
|
||||
</details>
|
||||
5
apps/stable_diffusion/scripts/__init__.py
Normal file
5
apps/stable_diffusion/scripts/__init__.py
Normal file
@@ -0,0 +1,5 @@
|
||||
from apps.stable_diffusion.scripts.img2img import img2img_inf
|
||||
from apps.stable_diffusion.scripts.inpaint import inpaint_inf
|
||||
from apps.stable_diffusion.scripts.outpaint import outpaint_inf
|
||||
from apps.stable_diffusion.scripts.upscaler import upscaler_inf
|
||||
from apps.stable_diffusion.scripts.train_lora_word import lora_train
|
||||
399
apps/stable_diffusion/scripts/img2img.py
Normal file
399
apps/stable_diffusion/scripts/img2img.py
Normal file
@@ -0,0 +1,399 @@
|
||||
import sys
|
||||
import torch
|
||||
import time
|
||||
from PIL import Image
|
||||
import transformers
|
||||
from apps.stable_diffusion.src import (
|
||||
args,
|
||||
Image2ImagePipeline,
|
||||
StencilPipeline,
|
||||
get_schedulers,
|
||||
set_init_device_flags,
|
||||
utils,
|
||||
clear_all,
|
||||
save_output_img,
|
||||
)
|
||||
from apps.stable_diffusion.src.utils import get_generation_text_info
|
||||
|
||||
|
||||
# set initial values of iree_vulkan_target_triple, use_tuned and import_mlir.
|
||||
init_iree_vulkan_target_triple = args.iree_vulkan_target_triple
|
||||
init_use_tuned = args.use_tuned
|
||||
init_import_mlir = args.import_mlir
|
||||
|
||||
|
||||
# For stencil, the input image can be of any size but we need to ensure that
|
||||
# it conforms with our model contraints :-
|
||||
# Both width and height should be in the range of [128, 768] and multiple of 8.
|
||||
# This utility function performs the transformation on the input image while
|
||||
# also maintaining the aspect ratio before sending it to the stencil pipeline.
|
||||
def resize_stencil(image: Image.Image):
|
||||
width, height = image.size
|
||||
aspect_ratio = width / height
|
||||
min_size = min(width, height)
|
||||
if min_size < 128:
|
||||
n_size = 128
|
||||
if width == min_size:
|
||||
width = n_size
|
||||
height = n_size / aspect_ratio
|
||||
else:
|
||||
height = n_size
|
||||
width = n_size * aspect_ratio
|
||||
width = int(width)
|
||||
height = int(height)
|
||||
n_width = width // 8
|
||||
n_height = height // 8
|
||||
n_width *= 8
|
||||
n_height *= 8
|
||||
|
||||
min_size = min(width, height)
|
||||
if min_size > 768:
|
||||
n_size = 768
|
||||
if width == min_size:
|
||||
height = n_size
|
||||
width = n_size * aspect_ratio
|
||||
else:
|
||||
width = n_size
|
||||
height = n_size / aspect_ratio
|
||||
width = int(width)
|
||||
height = int(height)
|
||||
n_width = width // 8
|
||||
n_height = height // 8
|
||||
n_width *= 8
|
||||
n_height *= 8
|
||||
new_image = image.resize((n_width, n_height))
|
||||
return new_image, n_width, n_height
|
||||
|
||||
|
||||
# Exposed to UI.
|
||||
def img2img_inf(
|
||||
prompt: str,
|
||||
negative_prompt: str,
|
||||
init_image,
|
||||
height: int,
|
||||
width: int,
|
||||
steps: int,
|
||||
strength: float,
|
||||
guidance_scale: float,
|
||||
seed: int,
|
||||
batch_count: int,
|
||||
batch_size: int,
|
||||
scheduler: str,
|
||||
custom_model: str,
|
||||
hf_model_id: str,
|
||||
precision: str,
|
||||
device: str,
|
||||
max_length: int,
|
||||
use_stencil: str,
|
||||
save_metadata_to_json: bool,
|
||||
save_metadata_to_png: bool,
|
||||
lora_weights: str,
|
||||
lora_hf_id: str,
|
||||
ondemand: bool,
|
||||
):
|
||||
from apps.stable_diffusion.web.ui.utils import (
|
||||
get_custom_model_pathfile,
|
||||
get_custom_vae_or_lora_weights,
|
||||
Config,
|
||||
)
|
||||
import apps.stable_diffusion.web.utils.global_obj as global_obj
|
||||
from apps.stable_diffusion.src.pipelines.pipeline_shark_stable_diffusion_utils import (
|
||||
SD_STATE_CANCEL,
|
||||
)
|
||||
|
||||
args.prompts = [prompt]
|
||||
args.negative_prompts = [negative_prompt]
|
||||
args.guidance_scale = guidance_scale
|
||||
args.seed = seed
|
||||
args.steps = steps
|
||||
args.strength = strength
|
||||
args.scheduler = scheduler
|
||||
args.img_path = "not none"
|
||||
args.ondemand = ondemand
|
||||
|
||||
if init_image is None:
|
||||
return None, "An Initial Image is required"
|
||||
image = init_image.convert("RGB")
|
||||
|
||||
# set ckpt_loc and hf_model_id.
|
||||
args.ckpt_loc = ""
|
||||
args.hf_model_id = ""
|
||||
if custom_model == "None":
|
||||
if not hf_model_id:
|
||||
return (
|
||||
None,
|
||||
"Please provide either custom model or huggingface model ID, both must not be empty",
|
||||
)
|
||||
args.hf_model_id = hf_model_id
|
||||
elif ".ckpt" in custom_model or ".safetensors" in custom_model:
|
||||
args.ckpt_loc = get_custom_model_pathfile(custom_model)
|
||||
else:
|
||||
args.hf_model_id = custom_model
|
||||
|
||||
args.use_lora = get_custom_vae_or_lora_weights(
|
||||
lora_weights, lora_hf_id, "lora"
|
||||
)
|
||||
|
||||
args.save_metadata_to_json = save_metadata_to_json
|
||||
args.write_metadata_to_png = save_metadata_to_png
|
||||
|
||||
use_stencil = None if use_stencil == "None" else use_stencil
|
||||
args.use_stencil = use_stencil
|
||||
if use_stencil is not None:
|
||||
args.scheduler = "DDIM"
|
||||
args.hf_model_id = "runwayml/stable-diffusion-v1-5"
|
||||
image, width, height = resize_stencil(image)
|
||||
elif args.scheduler != "PNDM":
|
||||
if "Shark" in args.scheduler:
|
||||
print(
|
||||
f"SharkEulerDiscrete scheduler not supported. Switching to PNDM scheduler"
|
||||
)
|
||||
args.scheduler = "PNDM"
|
||||
else:
|
||||
sys.exit(
|
||||
"Img2Img works best with PNDM scheduler. Other schedulers are not supported yet."
|
||||
)
|
||||
cpu_scheduling = not args.scheduler.startswith("Shark")
|
||||
args.precision = precision
|
||||
dtype = torch.float32 if precision == "fp32" else torch.half
|
||||
new_config_obj = Config(
|
||||
"img2img",
|
||||
args.hf_model_id,
|
||||
args.ckpt_loc,
|
||||
precision,
|
||||
batch_size,
|
||||
max_length,
|
||||
height,
|
||||
width,
|
||||
device,
|
||||
use_lora=args.use_lora,
|
||||
use_stencil=use_stencil,
|
||||
)
|
||||
if (
|
||||
args.ondemand
|
||||
or not global_obj.get_sd_obj()
|
||||
or global_obj.get_cfg_obj() != new_config_obj
|
||||
):
|
||||
global_obj.clear_cache()
|
||||
global_obj.set_cfg_obj(new_config_obj)
|
||||
args.batch_count = batch_count
|
||||
args.batch_size = batch_size
|
||||
args.max_length = max_length
|
||||
args.height = height
|
||||
args.width = width
|
||||
args.device = device.split("=>", 1)[1].strip()
|
||||
args.iree_vulkan_target_triple = init_iree_vulkan_target_triple
|
||||
args.use_tuned = init_use_tuned
|
||||
args.import_mlir = init_import_mlir
|
||||
set_init_device_flags()
|
||||
model_id = (
|
||||
args.hf_model_id
|
||||
if args.hf_model_id
|
||||
else "stabilityai/stable-diffusion-2-1-base"
|
||||
)
|
||||
global_obj.set_schedulers(get_schedulers(model_id))
|
||||
scheduler_obj = global_obj.get_scheduler(args.scheduler)
|
||||
|
||||
if use_stencil is not None:
|
||||
args.use_tuned = False
|
||||
global_obj.set_sd_obj(
|
||||
StencilPipeline.from_pretrained(
|
||||
scheduler_obj,
|
||||
args.import_mlir,
|
||||
args.hf_model_id,
|
||||
args.ckpt_loc,
|
||||
args.custom_vae,
|
||||
args.precision,
|
||||
args.max_length,
|
||||
args.batch_size,
|
||||
args.height,
|
||||
args.width,
|
||||
args.use_base_vae,
|
||||
args.use_tuned,
|
||||
low_cpu_mem_usage=args.low_cpu_mem_usage,
|
||||
use_stencil=use_stencil,
|
||||
debug=args.import_debug if args.import_mlir else False,
|
||||
use_lora=args.use_lora,
|
||||
ondemand=args.ondemand,
|
||||
)
|
||||
)
|
||||
else:
|
||||
global_obj.set_sd_obj(
|
||||
Image2ImagePipeline.from_pretrained(
|
||||
scheduler_obj,
|
||||
args.import_mlir,
|
||||
args.hf_model_id,
|
||||
args.ckpt_loc,
|
||||
args.custom_vae,
|
||||
args.precision,
|
||||
args.max_length,
|
||||
args.batch_size,
|
||||
args.height,
|
||||
args.width,
|
||||
args.use_base_vae,
|
||||
args.use_tuned,
|
||||
low_cpu_mem_usage=args.low_cpu_mem_usage,
|
||||
debug=args.import_debug if args.import_mlir else False,
|
||||
use_lora=args.use_lora,
|
||||
ondemand=args.ondemand,
|
||||
)
|
||||
)
|
||||
|
||||
global_obj.set_sd_scheduler(args.scheduler)
|
||||
global_obj.set_sd_ondemand(args.ondemand)
|
||||
|
||||
start_time = time.time()
|
||||
global_obj.get_sd_obj().log = ""
|
||||
generated_imgs = []
|
||||
seeds = []
|
||||
img_seed = utils.sanitize_seed(seed)
|
||||
extra_info = {"STRENGTH": strength}
|
||||
text_output = ""
|
||||
for current_batch in range(batch_count):
|
||||
if current_batch > 0:
|
||||
img_seed = utils.sanitize_seed(-1)
|
||||
out_imgs = global_obj.get_sd_obj().generate_images(
|
||||
prompt,
|
||||
negative_prompt,
|
||||
image,
|
||||
batch_size,
|
||||
height,
|
||||
width,
|
||||
steps,
|
||||
strength,
|
||||
guidance_scale,
|
||||
img_seed,
|
||||
args.max_length,
|
||||
dtype,
|
||||
args.use_base_vae,
|
||||
cpu_scheduling,
|
||||
use_stencil=use_stencil,
|
||||
)
|
||||
seeds.append(img_seed)
|
||||
total_time = time.time() - start_time
|
||||
text_output = get_generation_text_info(seeds, device)
|
||||
text_output += "\n" + global_obj.get_sd_obj().log
|
||||
text_output += f"\nTotal image(s) generation time: {total_time:.4f}sec"
|
||||
|
||||
if global_obj.get_sd_status() == SD_STATE_CANCEL:
|
||||
break
|
||||
else:
|
||||
save_output_img(out_imgs[0], img_seed, extra_info)
|
||||
generated_imgs.extend(out_imgs)
|
||||
yield generated_imgs, text_output
|
||||
|
||||
return generated_imgs, text_output
|
||||
|
||||
|
||||
def main():
|
||||
if args.clear_all:
|
||||
clear_all()
|
||||
|
||||
if args.img_path is None:
|
||||
print("Flag --img_path is required.")
|
||||
exit()
|
||||
|
||||
image = Image.open(args.img_path).convert("RGB")
|
||||
# When the models get uploaded, it should be default to False.
|
||||
args.import_mlir = True
|
||||
|
||||
use_stencil = args.use_stencil
|
||||
if use_stencil:
|
||||
args.scheduler = "DDIM"
|
||||
args.hf_model_id = "runwayml/stable-diffusion-v1-5"
|
||||
image, args.width, args.height = resize_stencil(image)
|
||||
elif args.scheduler != "PNDM":
|
||||
if "Shark" in args.scheduler:
|
||||
print(
|
||||
f"SharkEulerDiscrete scheduler not supported. Switching to PNDM scheduler"
|
||||
)
|
||||
args.scheduler = "PNDM"
|
||||
else:
|
||||
sys.exit(
|
||||
"Img2Img works best with PNDM scheduler. Other schedulers are not supported yet."
|
||||
)
|
||||
cpu_scheduling = not args.scheduler.startswith("Shark")
|
||||
dtype = torch.float32 if args.precision == "fp32" else torch.half
|
||||
set_init_device_flags()
|
||||
schedulers = get_schedulers(args.hf_model_id)
|
||||
scheduler_obj = schedulers[args.scheduler]
|
||||
seed = utils.sanitize_seed(args.seed)
|
||||
# Adjust for height and width based on model
|
||||
|
||||
if use_stencil:
|
||||
img2img_obj = StencilPipeline.from_pretrained(
|
||||
scheduler_obj,
|
||||
args.import_mlir,
|
||||
args.hf_model_id,
|
||||
args.ckpt_loc,
|
||||
args.custom_vae,
|
||||
args.precision,
|
||||
args.max_length,
|
||||
args.batch_size,
|
||||
args.height,
|
||||
args.width,
|
||||
args.use_base_vae,
|
||||
args.use_tuned,
|
||||
low_cpu_mem_usage=args.low_cpu_mem_usage,
|
||||
use_stencil=use_stencil,
|
||||
debug=args.import_debug if args.import_mlir else False,
|
||||
use_lora=args.use_lora,
|
||||
ondemand=args.ondemand,
|
||||
)
|
||||
else:
|
||||
img2img_obj = Image2ImagePipeline.from_pretrained(
|
||||
scheduler_obj,
|
||||
args.import_mlir,
|
||||
args.hf_model_id,
|
||||
args.ckpt_loc,
|
||||
args.custom_vae,
|
||||
args.precision,
|
||||
args.max_length,
|
||||
args.batch_size,
|
||||
args.height,
|
||||
args.width,
|
||||
args.use_base_vae,
|
||||
args.use_tuned,
|
||||
low_cpu_mem_usage=args.low_cpu_mem_usage,
|
||||
debug=args.import_debug if args.import_mlir else False,
|
||||
use_lora=args.use_lora,
|
||||
ondemand=args.ondemand,
|
||||
)
|
||||
|
||||
start_time = time.time()
|
||||
generated_imgs = img2img_obj.generate_images(
|
||||
args.prompts,
|
||||
args.negative_prompts,
|
||||
image,
|
||||
args.batch_size,
|
||||
args.height,
|
||||
args.width,
|
||||
args.steps,
|
||||
args.strength,
|
||||
args.guidance_scale,
|
||||
seed,
|
||||
args.max_length,
|
||||
dtype,
|
||||
args.use_base_vae,
|
||||
cpu_scheduling,
|
||||
use_stencil=use_stencil,
|
||||
)
|
||||
total_time = time.time() - start_time
|
||||
text_output = f"prompt={args.prompts}"
|
||||
text_output += f"\nnegative prompt={args.negative_prompts}"
|
||||
text_output += f"\nmodel_id={args.hf_model_id}, ckpt_loc={args.ckpt_loc}"
|
||||
text_output += f"\nscheduler={args.scheduler}, device={args.device}"
|
||||
text_output += f"\nsteps={args.steps}, strength={args.strength}, guidance_scale={args.guidance_scale}, seed={seed}, size={args.height}x{args.width}"
|
||||
text_output += (
|
||||
f", batch size={args.batch_size}, max_length={args.max_length}"
|
||||
)
|
||||
text_output += img2img_obj.log
|
||||
text_output += f"\nTotal image generation time: {total_time:.4f}sec"
|
||||
|
||||
extra_info = {"STRENGTH": args.strength}
|
||||
save_output_img(generated_imgs[0], seed, extra_info)
|
||||
print(text_output)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
286
apps/stable_diffusion/scripts/inpaint.py
Normal file
286
apps/stable_diffusion/scripts/inpaint.py
Normal file
@@ -0,0 +1,286 @@
|
||||
import torch
|
||||
import time
|
||||
from PIL import Image
|
||||
import transformers
|
||||
from apps.stable_diffusion.src import (
|
||||
args,
|
||||
InpaintPipeline,
|
||||
get_schedulers,
|
||||
set_init_device_flags,
|
||||
utils,
|
||||
clear_all,
|
||||
save_output_img,
|
||||
)
|
||||
from apps.stable_diffusion.src.utils import get_generation_text_info
|
||||
|
||||
|
||||
# set initial values of iree_vulkan_target_triple, use_tuned and import_mlir.
|
||||
init_iree_vulkan_target_triple = args.iree_vulkan_target_triple
|
||||
init_use_tuned = args.use_tuned
|
||||
init_import_mlir = args.import_mlir
|
||||
|
||||
|
||||
# Exposed to UI.
|
||||
def inpaint_inf(
|
||||
prompt: str,
|
||||
negative_prompt: str,
|
||||
image_dict,
|
||||
height: int,
|
||||
width: int,
|
||||
inpaint_full_res: bool,
|
||||
inpaint_full_res_padding: int,
|
||||
steps: int,
|
||||
guidance_scale: float,
|
||||
seed: int,
|
||||
batch_count: int,
|
||||
batch_size: int,
|
||||
scheduler: str,
|
||||
custom_model: str,
|
||||
hf_model_id: str,
|
||||
precision: str,
|
||||
device: str,
|
||||
max_length: int,
|
||||
save_metadata_to_json: bool,
|
||||
save_metadata_to_png: bool,
|
||||
lora_weights: str,
|
||||
lora_hf_id: str,
|
||||
ondemand: bool,
|
||||
):
|
||||
from apps.stable_diffusion.web.ui.utils import (
|
||||
get_custom_model_pathfile,
|
||||
get_custom_vae_or_lora_weights,
|
||||
Config,
|
||||
)
|
||||
import apps.stable_diffusion.web.utils.global_obj as global_obj
|
||||
from apps.stable_diffusion.src.pipelines.pipeline_shark_stable_diffusion_utils import (
|
||||
SD_STATE_CANCEL,
|
||||
)
|
||||
|
||||
args.prompts = [prompt]
|
||||
args.negative_prompts = [negative_prompt]
|
||||
args.guidance_scale = guidance_scale
|
||||
args.steps = steps
|
||||
args.scheduler = scheduler
|
||||
args.img_path = "not none"
|
||||
args.mask_path = "not none"
|
||||
args.ondemand = ondemand
|
||||
|
||||
# set ckpt_loc and hf_model_id.
|
||||
args.ckpt_loc = ""
|
||||
args.hf_model_id = ""
|
||||
if custom_model == "None":
|
||||
if not hf_model_id:
|
||||
return (
|
||||
None,
|
||||
"Please provide either custom model or huggingface model ID, both must not be empty",
|
||||
)
|
||||
args.hf_model_id = hf_model_id
|
||||
elif ".ckpt" in custom_model or ".safetensors" in custom_model:
|
||||
args.ckpt_loc = get_custom_model_pathfile(custom_model)
|
||||
else:
|
||||
args.hf_model_id = custom_model
|
||||
|
||||
args.use_lora = get_custom_vae_or_lora_weights(
|
||||
lora_weights, lora_hf_id, "lora"
|
||||
)
|
||||
|
||||
args.save_metadata_to_json = save_metadata_to_json
|
||||
args.write_metadata_to_png = save_metadata_to_png
|
||||
|
||||
dtype = torch.float32 if precision == "fp32" else torch.half
|
||||
cpu_scheduling = not scheduler.startswith("Shark")
|
||||
new_config_obj = Config(
|
||||
"inpaint",
|
||||
args.hf_model_id,
|
||||
args.ckpt_loc,
|
||||
precision,
|
||||
batch_size,
|
||||
max_length,
|
||||
height,
|
||||
width,
|
||||
device,
|
||||
use_lora=args.use_lora,
|
||||
use_stencil=None,
|
||||
)
|
||||
if (
|
||||
args.ondemand
|
||||
or not global_obj.get_sd_obj()
|
||||
or global_obj.get_cfg_obj() != new_config_obj
|
||||
):
|
||||
global_obj.clear_cache()
|
||||
global_obj.set_cfg_obj(new_config_obj)
|
||||
args.precision = precision
|
||||
args.batch_count = batch_count
|
||||
args.batch_size = batch_size
|
||||
args.max_length = max_length
|
||||
args.height = height
|
||||
args.width = width
|
||||
args.device = device.split("=>", 1)[1].strip()
|
||||
args.iree_vulkan_target_triple = init_iree_vulkan_target_triple
|
||||
args.use_tuned = init_use_tuned
|
||||
args.import_mlir = init_import_mlir
|
||||
set_init_device_flags()
|
||||
model_id = (
|
||||
args.hf_model_id
|
||||
if args.hf_model_id
|
||||
else "stabilityai/stable-diffusion-2-inpainting"
|
||||
)
|
||||
global_obj.set_schedulers(get_schedulers(model_id))
|
||||
scheduler_obj = global_obj.get_scheduler(scheduler)
|
||||
global_obj.set_sd_obj(
|
||||
InpaintPipeline.from_pretrained(
|
||||
scheduler=scheduler_obj,
|
||||
import_mlir=args.import_mlir,
|
||||
model_id=args.hf_model_id,
|
||||
ckpt_loc=args.ckpt_loc,
|
||||
custom_vae=args.custom_vae,
|
||||
precision=args.precision,
|
||||
max_length=args.max_length,
|
||||
batch_size=args.batch_size,
|
||||
height=args.height,
|
||||
width=args.width,
|
||||
use_base_vae=args.use_base_vae,
|
||||
use_tuned=args.use_tuned,
|
||||
low_cpu_mem_usage=args.low_cpu_mem_usage,
|
||||
debug=args.import_debug if args.import_mlir else False,
|
||||
use_lora=args.use_lora,
|
||||
ondemand=args.ondemand,
|
||||
)
|
||||
)
|
||||
|
||||
global_obj.set_sd_scheduler(scheduler)
|
||||
global_obj.set_sd_ondemand(args.ondemand)
|
||||
|
||||
start_time = time.time()
|
||||
global_obj.get_sd_obj().log = ""
|
||||
generated_imgs = []
|
||||
seeds = []
|
||||
img_seed = utils.sanitize_seed(seed)
|
||||
image = image_dict["image"]
|
||||
mask_image = image_dict["mask"]
|
||||
text_output = ""
|
||||
for i in range(batch_count):
|
||||
if i > 0:
|
||||
img_seed = utils.sanitize_seed(-1)
|
||||
out_imgs = global_obj.get_sd_obj().generate_images(
|
||||
prompt,
|
||||
negative_prompt,
|
||||
image,
|
||||
mask_image,
|
||||
batch_size,
|
||||
height,
|
||||
width,
|
||||
inpaint_full_res,
|
||||
inpaint_full_res_padding,
|
||||
steps,
|
||||
guidance_scale,
|
||||
img_seed,
|
||||
args.max_length,
|
||||
dtype,
|
||||
args.use_base_vae,
|
||||
cpu_scheduling,
|
||||
)
|
||||
seeds.append(img_seed)
|
||||
total_time = time.time() - start_time
|
||||
text_output = get_generation_text_info(seeds, device)
|
||||
text_output += "\n" + global_obj.get_sd_obj().log
|
||||
text_output += f"\nTotal image(s) generation time: {total_time:.4f}sec"
|
||||
|
||||
if global_obj.get_sd_status() == SD_STATE_CANCEL:
|
||||
break
|
||||
else:
|
||||
save_output_img(out_imgs[0], img_seed)
|
||||
generated_imgs.extend(out_imgs)
|
||||
yield generated_imgs, text_output
|
||||
|
||||
return generated_imgs, text_output
|
||||
|
||||
|
||||
def main():
|
||||
if args.clear_all:
|
||||
clear_all()
|
||||
|
||||
if args.img_path is None:
|
||||
print("Flag --img_path is required.")
|
||||
exit()
|
||||
if args.mask_path is None:
|
||||
print("Flag --mask_path is required.")
|
||||
exit()
|
||||
|
||||
dtype = torch.float32 if args.precision == "fp32" else torch.half
|
||||
cpu_scheduling = not args.scheduler.startswith("Shark")
|
||||
set_init_device_flags()
|
||||
model_id = (
|
||||
args.hf_model_id
|
||||
if "inpaint" in args.hf_model_id
|
||||
else "stabilityai/stable-diffusion-2-inpainting"
|
||||
)
|
||||
schedulers = get_schedulers(model_id)
|
||||
scheduler_obj = schedulers[args.scheduler]
|
||||
seed = args.seed
|
||||
image = Image.open(args.img_path)
|
||||
mask_image = Image.open(args.mask_path)
|
||||
|
||||
inpaint_obj = InpaintPipeline.from_pretrained(
|
||||
scheduler=scheduler_obj,
|
||||
import_mlir=args.import_mlir,
|
||||
model_id=args.hf_model_id,
|
||||
ckpt_loc=args.ckpt_loc,
|
||||
custom_vae=args.custom_vae,
|
||||
precision=args.precision,
|
||||
max_length=args.max_length,
|
||||
batch_size=args.batch_size,
|
||||
height=args.height,
|
||||
width=args.width,
|
||||
use_base_vae=args.use_base_vae,
|
||||
use_tuned=args.use_tuned,
|
||||
low_cpu_mem_usage=args.low_cpu_mem_usage,
|
||||
debug=args.import_debug if args.import_mlir else False,
|
||||
use_lora=args.use_lora,
|
||||
ondemand=args.ondemand,
|
||||
)
|
||||
|
||||
for current_batch in range(args.batch_count):
|
||||
if current_batch > 0:
|
||||
seed = -1
|
||||
seed = utils.sanitize_seed(seed)
|
||||
|
||||
start_time = time.time()
|
||||
generated_imgs = inpaint_obj.generate_images(
|
||||
args.prompts,
|
||||
args.negative_prompts,
|
||||
image,
|
||||
mask_image,
|
||||
args.batch_size,
|
||||
args.height,
|
||||
args.width,
|
||||
args.inpaint_full_res,
|
||||
args.inpaint_full_res_padding,
|
||||
args.steps,
|
||||
args.guidance_scale,
|
||||
seed,
|
||||
args.max_length,
|
||||
dtype,
|
||||
args.use_base_vae,
|
||||
cpu_scheduling,
|
||||
)
|
||||
total_time = time.time() - start_time
|
||||
text_output = f"prompt={args.prompts}"
|
||||
text_output += f"\nnegative prompt={args.negative_prompts}"
|
||||
text_output += (
|
||||
f"\nmodel_id={args.hf_model_id}, ckpt_loc={args.ckpt_loc}"
|
||||
)
|
||||
text_output += f"\nscheduler={args.scheduler}, device={args.device}"
|
||||
text_output += f"\nsteps={args.steps}, guidance_scale={args.guidance_scale}, seed={seed}, size={args.height}x{args.width}"
|
||||
text_output += (
|
||||
f", batch size={args.batch_size}, max_length={args.max_length}"
|
||||
)
|
||||
text_output += inpaint_obj.log
|
||||
text_output += f"\nTotal image generation time: {total_time:.4f}sec"
|
||||
|
||||
save_output_img(generated_imgs[0], seed)
|
||||
print(text_output)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
19
apps/stable_diffusion/scripts/main.py
Normal file
19
apps/stable_diffusion/scripts/main.py
Normal file
@@ -0,0 +1,19 @@
|
||||
from apps.stable_diffusion.src import args
|
||||
from apps.stable_diffusion.scripts import (
|
||||
img2img,
|
||||
txt2img,
|
||||
# inpaint,
|
||||
# outpaint,
|
||||
)
|
||||
|
||||
if __name__ == "__main__":
|
||||
if args.app == "txt2img":
|
||||
txt2img.main()
|
||||
elif args.app == "img2img":
|
||||
img2img.main()
|
||||
# elif args.app == "inpaint":
|
||||
# inpaint.main()
|
||||
# elif args.app == "outpaint":
|
||||
# outpaint.main()
|
||||
else:
|
||||
print(f"args.app value is {args.app} but this isn't supported")
|
||||
312
apps/stable_diffusion/scripts/outpaint.py
Normal file
312
apps/stable_diffusion/scripts/outpaint.py
Normal file
@@ -0,0 +1,312 @@
|
||||
import torch
|
||||
import time
|
||||
from PIL import Image
|
||||
import transformers
|
||||
from apps.stable_diffusion.src import (
|
||||
args,
|
||||
OutpaintPipeline,
|
||||
get_schedulers,
|
||||
set_init_device_flags,
|
||||
utils,
|
||||
clear_all,
|
||||
save_output_img,
|
||||
)
|
||||
from apps.stable_diffusion.src.utils import get_generation_text_info
|
||||
|
||||
|
||||
# set initial values of iree_vulkan_target_triple, use_tuned and import_mlir.
|
||||
init_iree_vulkan_target_triple = args.iree_vulkan_target_triple
|
||||
init_use_tuned = args.use_tuned
|
||||
init_import_mlir = args.import_mlir
|
||||
|
||||
|
||||
# Exposed to UI.
|
||||
def outpaint_inf(
|
||||
prompt: str,
|
||||
negative_prompt: str,
|
||||
init_image,
|
||||
pixels: int,
|
||||
mask_blur: int,
|
||||
directions: list,
|
||||
noise_q: float,
|
||||
color_variation: float,
|
||||
height: int,
|
||||
width: int,
|
||||
steps: int,
|
||||
guidance_scale: float,
|
||||
seed: int,
|
||||
batch_count: int,
|
||||
batch_size: int,
|
||||
scheduler: str,
|
||||
custom_model: str,
|
||||
hf_model_id: str,
|
||||
precision: str,
|
||||
device: str,
|
||||
max_length: int,
|
||||
save_metadata_to_json: bool,
|
||||
save_metadata_to_png: bool,
|
||||
lora_weights: str,
|
||||
lora_hf_id: str,
|
||||
ondemand: bool,
|
||||
):
|
||||
from apps.stable_diffusion.web.ui.utils import (
|
||||
get_custom_model_pathfile,
|
||||
get_custom_vae_or_lora_weights,
|
||||
Config,
|
||||
)
|
||||
import apps.stable_diffusion.web.utils.global_obj as global_obj
|
||||
from apps.stable_diffusion.src.pipelines.pipeline_shark_stable_diffusion_utils import (
|
||||
SD_STATE_CANCEL,
|
||||
)
|
||||
|
||||
args.prompts = [prompt]
|
||||
args.negative_prompts = [negative_prompt]
|
||||
args.guidance_scale = guidance_scale
|
||||
args.steps = steps
|
||||
args.scheduler = scheduler
|
||||
args.img_path = "not none"
|
||||
if ondemand:
|
||||
print("Outpainting is not supporting ondemand yet.")
|
||||
ondemand = False
|
||||
args.ondemand = ondemand
|
||||
|
||||
# set ckpt_loc and hf_model_id.
|
||||
args.ckpt_loc = ""
|
||||
args.hf_model_id = ""
|
||||
if custom_model == "None":
|
||||
if not hf_model_id:
|
||||
return (
|
||||
None,
|
||||
"Please provide either custom model or huggingface model ID, both must not be empty",
|
||||
)
|
||||
args.hf_model_id = hf_model_id
|
||||
elif ".ckpt" in custom_model or ".safetensors" in custom_model:
|
||||
args.ckpt_loc = get_custom_model_pathfile(custom_model)
|
||||
else:
|
||||
args.hf_model_id = custom_model
|
||||
|
||||
args.use_lora = get_custom_vae_or_lora_weights(
|
||||
lora_weights, lora_hf_id, "lora"
|
||||
)
|
||||
|
||||
args.save_metadata_to_json = save_metadata_to_json
|
||||
args.write_metadata_to_png = save_metadata_to_png
|
||||
|
||||
dtype = torch.float32 if precision == "fp32" else torch.half
|
||||
cpu_scheduling = not scheduler.startswith("Shark")
|
||||
new_config_obj = Config(
|
||||
"outpaint",
|
||||
args.hf_model_id,
|
||||
args.ckpt_loc,
|
||||
precision,
|
||||
batch_size,
|
||||
max_length,
|
||||
height,
|
||||
width,
|
||||
device,
|
||||
use_lora=args.use_lora,
|
||||
use_stencil=None,
|
||||
)
|
||||
if (
|
||||
not global_obj.get_sd_obj()
|
||||
or global_obj.get_cfg_obj() != new_config_obj
|
||||
):
|
||||
global_obj.clear_cache()
|
||||
global_obj.set_cfg_obj(new_config_obj)
|
||||
args.precision = precision
|
||||
args.batch_count = batch_count
|
||||
args.batch_size = batch_size
|
||||
args.max_length = max_length
|
||||
args.height = height
|
||||
args.width = width
|
||||
args.device = device.split("=>", 1)[1].strip()
|
||||
args.iree_vulkan_target_triple = init_iree_vulkan_target_triple
|
||||
args.use_tuned = init_use_tuned
|
||||
args.import_mlir = init_import_mlir
|
||||
set_init_device_flags()
|
||||
model_id = (
|
||||
args.hf_model_id
|
||||
if args.hf_model_id
|
||||
else "stabilityai/stable-diffusion-2-inpainting"
|
||||
)
|
||||
global_obj.set_schedulers(get_schedulers(model_id))
|
||||
scheduler_obj = global_obj.get_scheduler(scheduler)
|
||||
global_obj.set_sd_obj(
|
||||
OutpaintPipeline.from_pretrained(
|
||||
scheduler_obj,
|
||||
args.import_mlir,
|
||||
args.hf_model_id,
|
||||
args.ckpt_loc,
|
||||
args.custom_vae,
|
||||
args.precision,
|
||||
args.max_length,
|
||||
args.batch_size,
|
||||
args.height,
|
||||
args.width,
|
||||
args.use_base_vae,
|
||||
args.use_tuned,
|
||||
use_lora=args.use_lora,
|
||||
ondemand=args.ondemand,
|
||||
)
|
||||
)
|
||||
|
||||
global_obj.set_sd_scheduler(scheduler)
|
||||
|
||||
start_time = time.time()
|
||||
global_obj.get_sd_obj().log = ""
|
||||
generated_imgs = []
|
||||
seeds = []
|
||||
img_seed = utils.sanitize_seed(seed)
|
||||
|
||||
left = True if "left" in directions else False
|
||||
right = True if "right" in directions else False
|
||||
top = True if "up" in directions else False
|
||||
bottom = True if "down" in directions else False
|
||||
|
||||
text_output = ""
|
||||
for i in range(batch_count):
|
||||
if i > 0:
|
||||
img_seed = utils.sanitize_seed(-1)
|
||||
out_imgs = global_obj.get_sd_obj().generate_images(
|
||||
prompt,
|
||||
negative_prompt,
|
||||
init_image,
|
||||
pixels,
|
||||
mask_blur,
|
||||
left,
|
||||
right,
|
||||
top,
|
||||
bottom,
|
||||
noise_q,
|
||||
color_variation,
|
||||
batch_size,
|
||||
height,
|
||||
width,
|
||||
steps,
|
||||
guidance_scale,
|
||||
img_seed,
|
||||
args.max_length,
|
||||
dtype,
|
||||
args.use_base_vae,
|
||||
cpu_scheduling,
|
||||
)
|
||||
seeds.append(img_seed)
|
||||
total_time = time.time() - start_time
|
||||
text_output = get_generation_text_info(seeds, device)
|
||||
text_output += "\n" + global_obj.get_sd_obj().log
|
||||
text_output += f"\nTotal image(s) generation time: {total_time:.4f}sec"
|
||||
|
||||
if global_obj.get_sd_status() == SD_STATE_CANCEL:
|
||||
break
|
||||
else:
|
||||
save_output_img(out_imgs[0], img_seed)
|
||||
generated_imgs.extend(out_imgs)
|
||||
yield generated_imgs, text_output
|
||||
|
||||
return generated_imgs, text_output
|
||||
|
||||
|
||||
def main():
|
||||
if args.clear_all:
|
||||
clear_all()
|
||||
|
||||
if args.img_path is None:
|
||||
print("Flag --img_path is required.")
|
||||
exit()
|
||||
|
||||
dtype = torch.float32 if args.precision == "fp32" else torch.half
|
||||
cpu_scheduling = not args.scheduler.startswith("Shark")
|
||||
set_init_device_flags()
|
||||
model_id = (
|
||||
args.hf_model_id
|
||||
if "inpaint" in args.hf_model_id
|
||||
else "stabilityai/stable-diffusion-2-inpainting"
|
||||
)
|
||||
schedulers = get_schedulers(model_id)
|
||||
scheduler_obj = schedulers[args.scheduler]
|
||||
seed = args.seed
|
||||
image = Image.open(args.img_path)
|
||||
|
||||
outpaint_obj = OutpaintPipeline.from_pretrained(
|
||||
scheduler_obj,
|
||||
args.import_mlir,
|
||||
args.hf_model_id,
|
||||
args.ckpt_loc,
|
||||
args.custom_vae,
|
||||
args.precision,
|
||||
args.max_length,
|
||||
args.batch_size,
|
||||
args.height,
|
||||
args.width,
|
||||
args.use_base_vae,
|
||||
args.use_tuned,
|
||||
use_lora=args.use_lora,
|
||||
ondemand=args.ondemand,
|
||||
)
|
||||
|
||||
for current_batch in range(args.batch_count):
|
||||
if current_batch > 0:
|
||||
seed = -1
|
||||
seed = utils.sanitize_seed(seed)
|
||||
|
||||
start_time = time.time()
|
||||
generated_imgs = outpaint_obj.generate_images(
|
||||
args.prompts,
|
||||
args.negative_prompts,
|
||||
image,
|
||||
args.pixels,
|
||||
args.mask_blur,
|
||||
args.left,
|
||||
args.right,
|
||||
args.top,
|
||||
args.bottom,
|
||||
args.noise_q,
|
||||
args.color_variation,
|
||||
args.batch_size,
|
||||
args.height,
|
||||
args.width,
|
||||
args.steps,
|
||||
args.guidance_scale,
|
||||
seed,
|
||||
args.max_length,
|
||||
dtype,
|
||||
args.use_base_vae,
|
||||
cpu_scheduling,
|
||||
)
|
||||
total_time = time.time() - start_time
|
||||
text_output = f"prompt={args.prompts}"
|
||||
text_output += f"\nnegative prompt={args.negative_prompts}"
|
||||
text_output += (
|
||||
f"\nmodel_id={args.hf_model_id}, ckpt_loc={args.ckpt_loc}"
|
||||
)
|
||||
text_output += f"\nscheduler={args.scheduler}, device={args.device}"
|
||||
text_output += f"\nsteps={args.steps}, guidance_scale={args.guidance_scale}, seed={seed}, size={args.height}x{args.width}"
|
||||
text_output += (
|
||||
f", batch size={args.batch_size}, max_length={args.max_length}"
|
||||
)
|
||||
text_output += outpaint_obj.log
|
||||
text_output += f"\nTotal image generation time: {total_time:.4f}sec"
|
||||
|
||||
# save this information as metadata of output generated image.
|
||||
directions = []
|
||||
if args.left:
|
||||
directions.append("left")
|
||||
if args.right:
|
||||
directions.append("right")
|
||||
if args.top:
|
||||
directions.append("up")
|
||||
if args.bottom:
|
||||
directions.append("down")
|
||||
extra_info = {
|
||||
"PIXELS": args.pixels,
|
||||
"MASK_BLUR": args.mask_blur,
|
||||
"DIRECTIONS": directions,
|
||||
"NOISE_Q": args.noise_q,
|
||||
"COLOR_VARIATION": args.color_variation,
|
||||
}
|
||||
save_output_img(generated_imgs[0], seed, extra_info)
|
||||
print(text_output)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
240
apps/stable_diffusion/scripts/telegram_bot.py
Normal file
240
apps/stable_diffusion/scripts/telegram_bot.py
Normal file
@@ -0,0 +1,240 @@
|
||||
import logging
|
||||
import os
|
||||
from models.stable_diffusion.main import stable_diff_inf
|
||||
from models.stable_diffusion.utils import get_available_devices
|
||||
from dotenv import load_dotenv
|
||||
from telegram import Update, InlineKeyboardButton, InlineKeyboardMarkup
|
||||
from telegram import BotCommand
|
||||
from telegram.ext import Application, ApplicationBuilder, CallbackQueryHandler
|
||||
from telegram.ext import ContextTypes, MessageHandler, CommandHandler, filters
|
||||
from io import BytesIO
|
||||
import random
|
||||
|
||||
log = logging.getLogger("TG.Bot")
|
||||
logging.basicConfig()
|
||||
log.warning("Start")
|
||||
load_dotenv()
|
||||
os.environ["AMD_ENABLE_LLPC"] = "0"
|
||||
TG_TOKEN = os.getenv("TG_TOKEN")
|
||||
SELECTED_MODEL = "stablediffusion"
|
||||
SELECTED_SCHEDULER = "EulerAncestralDiscrete"
|
||||
STEPS = 30
|
||||
NEGATIVE_PROMPT = (
|
||||
"Ugly,Morbid,Extra fingers,Poorly drawn hands,Mutation,Blurry,Extra"
|
||||
" limbs,Gross proportions,Missing arms,Mutated hands,Long"
|
||||
" neck,Duplicate,Mutilated,Mutilated hands,Poorly drawn face,Deformed,Bad"
|
||||
" anatomy,Cloned face,Malformed limbs,Missing legs,Too many"
|
||||
" fingers,blurry, lowres, text, error, cropped, worst quality, low"
|
||||
" quality, jpeg artifacts, out of frame, extra fingers, mutated hands,"
|
||||
" poorly drawn hands, poorly drawn face, bad anatomy, extra limbs, cloned"
|
||||
" face, malformed limbs, missing arms, missing legs, extra arms, extra"
|
||||
" legs, fused fingers, too many fingers"
|
||||
)
|
||||
GUIDANCE_SCALE = 6
|
||||
available_devices = get_available_devices()
|
||||
models_list = [
|
||||
"stablediffusion",
|
||||
"anythingv3",
|
||||
"analogdiffusion",
|
||||
"openjourney",
|
||||
"dreamlike",
|
||||
]
|
||||
sheds_list = [
|
||||
"DDIM",
|
||||
"PNDM",
|
||||
"LMSDiscrete",
|
||||
"DPMSolverMultistep",
|
||||
"EulerDiscrete",
|
||||
"EulerAncestralDiscrete",
|
||||
"SharkEulerDiscrete",
|
||||
]
|
||||
|
||||
|
||||
def image_to_bytes(image):
|
||||
bio = BytesIO()
|
||||
bio.name = "image.jpeg"
|
||||
image.save(bio, "JPEG")
|
||||
bio.seek(0)
|
||||
return bio
|
||||
|
||||
|
||||
def get_try_again_markup():
|
||||
keyboard = [[InlineKeyboardButton("Try again", callback_data="TRYAGAIN")]]
|
||||
reply_markup = InlineKeyboardMarkup(keyboard)
|
||||
return reply_markup
|
||||
|
||||
|
||||
def generate_image(prompt):
|
||||
seed = random.randint(1, 10000)
|
||||
log.warning(SELECTED_MODEL)
|
||||
log.warning(STEPS)
|
||||
image, text = stable_diff_inf(
|
||||
prompt=prompt,
|
||||
negative_prompt=NEGATIVE_PROMPT,
|
||||
steps=STEPS,
|
||||
guidance_scale=GUIDANCE_SCALE,
|
||||
seed=seed,
|
||||
scheduler_key=SELECTED_SCHEDULER,
|
||||
variant=SELECTED_MODEL,
|
||||
device_key=available_devices[0],
|
||||
)
|
||||
|
||||
return image, seed
|
||||
|
||||
|
||||
async def generate_and_send_photo(
|
||||
update: Update, context: ContextTypes.DEFAULT_TYPE
|
||||
) -> None:
|
||||
progress_msg = await update.message.reply_text(
|
||||
"Generating image...", reply_to_message_id=update.message.message_id
|
||||
)
|
||||
im, seed = generate_image(prompt=update.message.text)
|
||||
await context.bot.delete_message(
|
||||
chat_id=progress_msg.chat_id, message_id=progress_msg.message_id
|
||||
)
|
||||
await context.bot.send_photo(
|
||||
update.effective_user.id,
|
||||
image_to_bytes(im),
|
||||
caption=f'"{update.message.text}" (Seed: {seed})',
|
||||
reply_markup=get_try_again_markup(),
|
||||
reply_to_message_id=update.message.message_id,
|
||||
)
|
||||
|
||||
|
||||
async def button(update: Update, context: ContextTypes.DEFAULT_TYPE) -> None:
|
||||
query = update.callback_query
|
||||
if query.data in models_list:
|
||||
global SELECTED_MODEL
|
||||
SELECTED_MODEL = query.data
|
||||
await query.answer()
|
||||
await query.edit_message_text(text=f"Selected model: {query.data}")
|
||||
return
|
||||
if query.data in sheds_list:
|
||||
global SELECTED_SCHEDULER
|
||||
SELECTED_SCHEDULER = query.data
|
||||
await query.answer()
|
||||
await query.edit_message_text(text=f"Selected scheduler: {query.data}")
|
||||
return
|
||||
replied_message = query.message.reply_to_message
|
||||
await query.answer()
|
||||
progress_msg = await query.message.reply_text(
|
||||
"Generating image...", reply_to_message_id=replied_message.message_id
|
||||
)
|
||||
|
||||
if query.data == "TRYAGAIN":
|
||||
prompt = replied_message.text
|
||||
im, seed = generate_image(prompt)
|
||||
|
||||
await context.bot.delete_message(
|
||||
chat_id=progress_msg.chat_id, message_id=progress_msg.message_id
|
||||
)
|
||||
await context.bot.send_photo(
|
||||
update.effective_user.id,
|
||||
image_to_bytes(im),
|
||||
caption=f'"{prompt}" (Seed: {seed})',
|
||||
reply_markup=get_try_again_markup(),
|
||||
reply_to_message_id=replied_message.message_id,
|
||||
)
|
||||
|
||||
|
||||
async def select_model_handler(update, context):
|
||||
text = "Select model"
|
||||
keyboard = []
|
||||
for model in models_list:
|
||||
keyboard.append(
|
||||
[
|
||||
InlineKeyboardButton(text=model, callback_data=model),
|
||||
]
|
||||
)
|
||||
markup = InlineKeyboardMarkup(keyboard)
|
||||
await update.message.reply_text(text=text, reply_markup=markup)
|
||||
|
||||
|
||||
async def select_scheduler_handler(update, context):
|
||||
text = "Select schedule"
|
||||
keyboard = []
|
||||
for shed in sheds_list:
|
||||
keyboard.append(
|
||||
[
|
||||
InlineKeyboardButton(text=shed, callback_data=shed),
|
||||
]
|
||||
)
|
||||
markup = InlineKeyboardMarkup(keyboard)
|
||||
await update.message.reply_text(text=text, reply_markup=markup)
|
||||
|
||||
|
||||
async def set_steps_handler(update, context):
|
||||
input_mex = update.message.text
|
||||
log.warning(input_mex)
|
||||
try:
|
||||
input_args = input_mex.split("/set_steps ")[1]
|
||||
global STEPS
|
||||
STEPS = int(input_args)
|
||||
except Exception:
|
||||
input_args = (
|
||||
"Invalid parameter for command. Correct command looks like\n"
|
||||
" /set_steps 30"
|
||||
)
|
||||
await update.message.reply_text(input_args)
|
||||
|
||||
|
||||
async def set_negative_prompt_handler(update, context):
|
||||
input_mex = update.message.text
|
||||
log.warning(input_mex)
|
||||
try:
|
||||
input_args = input_mex.split("/set_negative_prompt ")[1]
|
||||
global NEGATIVE_PROMPT
|
||||
NEGATIVE_PROMPT = input_args
|
||||
except Exception:
|
||||
input_args = (
|
||||
"Invalid parameter for command. Correct command looks like\n"
|
||||
" /set_negative_prompt ugly, bad art, mutated"
|
||||
)
|
||||
await update.message.reply_text(input_args)
|
||||
|
||||
|
||||
async def set_guidance_scale_handler(update, context):
|
||||
input_mex = update.message.text
|
||||
log.warning(input_mex)
|
||||
try:
|
||||
input_args = input_mex.split("/set_guidance_scale ")[1]
|
||||
global GUIDANCE_SCALE
|
||||
GUIDANCE_SCALE = int(input_args)
|
||||
except Exception:
|
||||
input_args = (
|
||||
"Invalid parameter for command. Correct command looks like\n"
|
||||
" /set_guidance_scale 7"
|
||||
)
|
||||
await update.message.reply_text(input_args)
|
||||
|
||||
|
||||
async def setup_bot_commands(application: Application) -> None:
|
||||
await application.bot.set_my_commands(
|
||||
[
|
||||
BotCommand("select_model", "to select model"),
|
||||
BotCommand("select_scheduler", "to select scheduler"),
|
||||
BotCommand("set_steps", "to set steps"),
|
||||
BotCommand("set_guidance_scale", "to set guidance scale"),
|
||||
BotCommand("set_negative_prompt", "to set negative prompt"),
|
||||
]
|
||||
)
|
||||
|
||||
|
||||
app = (
|
||||
ApplicationBuilder().token(TG_TOKEN).post_init(setup_bot_commands).build()
|
||||
)
|
||||
app.add_handler(CommandHandler("select_model", select_model_handler))
|
||||
app.add_handler(CommandHandler("select_scheduler", select_scheduler_handler))
|
||||
app.add_handler(CommandHandler("set_steps", set_steps_handler))
|
||||
app.add_handler(
|
||||
CommandHandler("set_guidance_scale", set_guidance_scale_handler)
|
||||
)
|
||||
app.add_handler(
|
||||
CommandHandler("set_negative_prompt", set_negative_prompt_handler)
|
||||
)
|
||||
app.add_handler(
|
||||
MessageHandler(filters.TEXT & ~filters.COMMAND, generate_and_send_photo)
|
||||
)
|
||||
app.add_handler(CallbackQueryHandler(button))
|
||||
log.warning("Start bot")
|
||||
app.run_polling()
|
||||
674
apps/stable_diffusion/scripts/train_lora_word.py
Normal file
674
apps/stable_diffusion/scripts/train_lora_word.py
Normal file
@@ -0,0 +1,674 @@
|
||||
# Install the required libs
|
||||
# pip install -U git+https://github.com/huggingface/diffusers.git
|
||||
# pip install accelerate transformers ftfy
|
||||
|
||||
# HuggingFace Token
|
||||
# YOUR_TOKEN = "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"
|
||||
|
||||
|
||||
# Import required libraries
|
||||
import itertools
|
||||
import math
|
||||
import os
|
||||
from typing import List
|
||||
import random
|
||||
import torch_mlir
|
||||
|
||||
import numpy as np
|
||||
import torch
|
||||
import torch.nn.functional as F
|
||||
import torch.utils.checkpoint
|
||||
from torch.utils.data import Dataset
|
||||
|
||||
import PIL
|
||||
import logging
|
||||
|
||||
from diffusers import (
|
||||
AutoencoderKL,
|
||||
DDPMScheduler,
|
||||
PNDMScheduler,
|
||||
StableDiffusionPipeline,
|
||||
UNet2DConditionModel,
|
||||
)
|
||||
from PIL import Image
|
||||
from tqdm.auto import tqdm
|
||||
from transformers import CLIPFeatureExtractor, CLIPTextModel, CLIPTokenizer
|
||||
from diffusers.loaders import AttnProcsLayers
|
||||
from diffusers.models.cross_attention import LoRACrossAttnProcessor
|
||||
|
||||
import torch_mlir
|
||||
from torch_mlir.dynamo import make_simple_dynamo_backend
|
||||
import torch._dynamo as dynamo
|
||||
from torch.fx.experimental.proxy_tensor import make_fx
|
||||
from torch_mlir_e2e_test.linalg_on_tensors_backends import refbackend
|
||||
from shark.shark_inference import SharkInference
|
||||
|
||||
torch._dynamo.config.verbose = True
|
||||
|
||||
from diffusers import (
|
||||
AutoencoderKL,
|
||||
DDPMScheduler,
|
||||
PNDMScheduler,
|
||||
StableDiffusionPipeline,
|
||||
UNet2DConditionModel,
|
||||
)
|
||||
from diffusers.optimization import get_scheduler
|
||||
from diffusers.pipelines.stable_diffusion import (
|
||||
StableDiffusionSafetyChecker,
|
||||
)
|
||||
from PIL import Image
|
||||
from tqdm.auto import tqdm
|
||||
from transformers import (
|
||||
CLIPFeatureExtractor,
|
||||
CLIPTextModel,
|
||||
CLIPTokenizer,
|
||||
)
|
||||
|
||||
from io import BytesIO
|
||||
|
||||
from dataclasses import dataclass
|
||||
from apps.stable_diffusion.src import (
|
||||
args,
|
||||
get_schedulers,
|
||||
set_init_device_flags,
|
||||
clear_all,
|
||||
)
|
||||
|
||||
|
||||
# Setup the dataset
|
||||
class LoraDataset(Dataset):
|
||||
def __init__(
|
||||
self,
|
||||
data_root,
|
||||
tokenizer,
|
||||
size=512,
|
||||
repeats=100,
|
||||
interpolation="bicubic",
|
||||
set="train",
|
||||
prompt="myloraprompt",
|
||||
center_crop=False,
|
||||
):
|
||||
self.data_root = data_root
|
||||
self.tokenizer = tokenizer
|
||||
self.size = size
|
||||
self.center_crop = center_crop
|
||||
self.prompt = prompt
|
||||
|
||||
self.image_paths = [
|
||||
os.path.join(self.data_root, file_path)
|
||||
for file_path in os.listdir(self.data_root)
|
||||
]
|
||||
|
||||
self.num_images = len(self.image_paths)
|
||||
self._length = self.num_images
|
||||
|
||||
if set == "train":
|
||||
self._length = self.num_images * repeats
|
||||
|
||||
self.interpolation = {
|
||||
"linear": PIL.Image.LINEAR,
|
||||
"bilinear": PIL.Image.BILINEAR,
|
||||
"bicubic": PIL.Image.BICUBIC,
|
||||
"lanczos": PIL.Image.LANCZOS,
|
||||
}[interpolation]
|
||||
|
||||
def __len__(self):
|
||||
return self._length
|
||||
|
||||
def __getitem__(self, i):
|
||||
example = {}
|
||||
image = Image.open(self.image_paths[i % self.num_images])
|
||||
|
||||
if not image.mode == "RGB":
|
||||
image = image.convert("RGB")
|
||||
|
||||
example["input_ids"] = self.tokenizer(
|
||||
self.prompt,
|
||||
padding="max_length",
|
||||
truncation=True,
|
||||
max_length=self.tokenizer.model_max_length,
|
||||
return_tensors="pt",
|
||||
).input_ids[0]
|
||||
|
||||
# default to score-sde preprocessing
|
||||
img = np.array(image).astype(np.uint8)
|
||||
|
||||
if self.center_crop:
|
||||
crop = min(img.shape[0], img.shape[1])
|
||||
(
|
||||
h,
|
||||
w,
|
||||
) = (
|
||||
img.shape[0],
|
||||
img.shape[1],
|
||||
)
|
||||
img = img[
|
||||
(h - crop) // 2 : (h + crop) // 2,
|
||||
(w - crop) // 2 : (w + crop) // 2,
|
||||
]
|
||||
|
||||
image = Image.fromarray(img)
|
||||
image = image.resize(
|
||||
(self.size, self.size), resample=self.interpolation
|
||||
)
|
||||
|
||||
image = np.array(image).astype(np.uint8)
|
||||
image = (image / 127.5 - 1.0).astype(np.float32)
|
||||
|
||||
example["pixel_values"] = torch.from_numpy(image).permute(2, 0, 1)
|
||||
return example
|
||||
|
||||
|
||||
########## Setting up the model ##########
|
||||
def lora_train(
|
||||
prompt: str,
|
||||
height: int,
|
||||
width: int,
|
||||
steps: int,
|
||||
guidance_scale: float,
|
||||
seed: int,
|
||||
batch_count: int,
|
||||
batch_size: int,
|
||||
scheduler: str,
|
||||
custom_model: str,
|
||||
hf_model_id: str,
|
||||
precision: str,
|
||||
device: str,
|
||||
max_length: int,
|
||||
training_images_dir: str,
|
||||
lora_save_dir: str,
|
||||
):
|
||||
from apps.stable_diffusion.web.ui.utils import (
|
||||
get_custom_model_pathfile,
|
||||
Config,
|
||||
)
|
||||
import apps.stable_diffusion.web.utils.global_obj as global_obj
|
||||
|
||||
print(
|
||||
"Note LoRA training is not compatible with the latest torch-mlir branch"
|
||||
)
|
||||
print(
|
||||
"To run LoRA training you'll need this to follow this guide for the torch-mlir branch: https://github.com/nod-ai/SHARK/tree/main/shark/examples/shark_training/stable_diffusion"
|
||||
)
|
||||
torch.manual_seed(seed)
|
||||
|
||||
args.prompts = [prompt]
|
||||
args.steps = steps
|
||||
|
||||
# set ckpt_loc and hf_model_id.
|
||||
types = (
|
||||
".ckpt",
|
||||
".safetensors",
|
||||
) # the tuple of file types
|
||||
args.ckpt_loc = ""
|
||||
args.hf_model_id = ""
|
||||
if custom_model == "None":
|
||||
if not hf_model_id:
|
||||
return (
|
||||
None,
|
||||
"Please provide either custom model or huggingface model ID, both must not be empty",
|
||||
)
|
||||
args.hf_model_id = hf_model_id
|
||||
elif ".ckpt" in custom_model or ".safetensors" in custom_model:
|
||||
args.ckpt_loc = custom_model
|
||||
else:
|
||||
args.hf_model_id = custom_model
|
||||
|
||||
args.training_images_dir = training_images_dir
|
||||
args.lora_save_dir = lora_save_dir
|
||||
|
||||
args.precision = precision
|
||||
args.batch_size = batch_size
|
||||
args.max_length = max_length
|
||||
args.height = height
|
||||
args.width = width
|
||||
device_str = device.split("=>", 1)[1].strip().split("://")
|
||||
if len(device_str) > 1:
|
||||
device_str = device_str[0] + ":" + device_str[1]
|
||||
else:
|
||||
device_str = device_str[0]
|
||||
args.device = device_str
|
||||
|
||||
# Load the Stable Diffusion model
|
||||
text_encoder = CLIPTextModel.from_pretrained(
|
||||
args.hf_model_id, subfolder="text_encoder"
|
||||
)
|
||||
vae = AutoencoderKL.from_pretrained(args.hf_model_id, subfolder="vae")
|
||||
unet = UNet2DConditionModel.from_pretrained(
|
||||
args.hf_model_id, subfolder="unet"
|
||||
)
|
||||
|
||||
def freeze_params(params):
|
||||
for param in params:
|
||||
param.requires_grad = False
|
||||
|
||||
# Freeze everything but LoRA
|
||||
freeze_params(vae.parameters())
|
||||
freeze_params(unet.parameters())
|
||||
freeze_params(text_encoder.parameters())
|
||||
|
||||
# Move vae and unet to device
|
||||
vae.to(args.device)
|
||||
unet.to(args.device)
|
||||
text_encoder.to(args.device)
|
||||
|
||||
lora_attn_procs = {}
|
||||
for name in unet.attn_processors.keys():
|
||||
cross_attention_dim = (
|
||||
None
|
||||
if name.endswith("attn1.processor")
|
||||
else unet.config.cross_attention_dim
|
||||
)
|
||||
if name.startswith("mid_block"):
|
||||
hidden_size = unet.config.block_out_channels[-1]
|
||||
elif name.startswith("up_blocks"):
|
||||
block_id = int(name[len("up_blocks.")])
|
||||
hidden_size = list(reversed(unet.config.block_out_channels))[
|
||||
block_id
|
||||
]
|
||||
elif name.startswith("down_blocks"):
|
||||
block_id = int(name[len("down_blocks.")])
|
||||
hidden_size = unet.config.block_out_channels[block_id]
|
||||
|
||||
lora_attn_procs[name] = LoRACrossAttnProcessor(
|
||||
hidden_size=hidden_size, cross_attention_dim=cross_attention_dim
|
||||
)
|
||||
|
||||
unet.set_attn_processor(lora_attn_procs)
|
||||
lora_layers = AttnProcsLayers(unet.attn_processors)
|
||||
|
||||
class VaeModel(torch.nn.Module):
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
self.vae = vae
|
||||
|
||||
def forward(self, input):
|
||||
x = self.vae.encode(input, return_dict=False)[0]
|
||||
return x
|
||||
|
||||
class UnetModel(torch.nn.Module):
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
self.unet = unet
|
||||
|
||||
def forward(self, x, y, z):
|
||||
return self.unet.forward(x, y, z, return_dict=False)[0]
|
||||
|
||||
shark_vae = VaeModel()
|
||||
shark_unet = UnetModel()
|
||||
|
||||
####### Creating our training data ########
|
||||
|
||||
tokenizer = CLIPTokenizer.from_pretrained(
|
||||
args.hf_model_id,
|
||||
subfolder="tokenizer",
|
||||
)
|
||||
|
||||
# Let's create the Dataset and Dataloader
|
||||
train_dataset = LoraDataset(
|
||||
data_root=args.training_images_dir,
|
||||
tokenizer=tokenizer,
|
||||
size=vae.sample_size,
|
||||
prompt=args.prompts[0],
|
||||
repeats=100,
|
||||
center_crop=False,
|
||||
set="train",
|
||||
)
|
||||
|
||||
def create_dataloader(train_batch_size=1):
|
||||
return torch.utils.data.DataLoader(
|
||||
train_dataset, batch_size=train_batch_size, shuffle=True
|
||||
)
|
||||
|
||||
# Create noise_scheduler for training
|
||||
noise_scheduler = DDPMScheduler.from_config(
|
||||
args.hf_model_id, subfolder="scheduler"
|
||||
)
|
||||
|
||||
######## Training ###########
|
||||
|
||||
# Define hyperparameters for our training. If you are not happy with your results,
|
||||
# you can tune the `learning_rate` and the `max_train_steps`
|
||||
|
||||
# Setting up all training args
|
||||
hyperparameters = {
|
||||
"learning_rate": 5e-04,
|
||||
"scale_lr": True,
|
||||
"max_train_steps": steps,
|
||||
"train_batch_size": batch_size,
|
||||
"gradient_accumulation_steps": 1,
|
||||
"gradient_checkpointing": True,
|
||||
"mixed_precision": "fp16",
|
||||
"seed": 42,
|
||||
"output_dir": "sd-concept-output",
|
||||
}
|
||||
# creating output directory
|
||||
cwd = os.getcwd()
|
||||
out_dir = os.path.join(cwd, hyperparameters["output_dir"])
|
||||
while not os.path.exists(str(out_dir)):
|
||||
try:
|
||||
os.mkdir(out_dir)
|
||||
except OSError as error:
|
||||
print("Output directory not created")
|
||||
|
||||
###### Torch-MLIR Compilation ######
|
||||
|
||||
def _remove_nones(fx_g: torch.fx.GraphModule) -> List[int]:
|
||||
removed_indexes = []
|
||||
for node in fx_g.graph.nodes:
|
||||
if node.op == "output":
|
||||
assert (
|
||||
len(node.args) == 1
|
||||
), "Output node must have a single argument"
|
||||
node_arg = node.args[0]
|
||||
if isinstance(node_arg, (list, tuple)):
|
||||
node_arg = list(node_arg)
|
||||
node_args_len = len(node_arg)
|
||||
for i in range(node_args_len):
|
||||
curr_index = node_args_len - (i + 1)
|
||||
if node_arg[curr_index] is None:
|
||||
removed_indexes.append(curr_index)
|
||||
node_arg.pop(curr_index)
|
||||
node.args = (tuple(node_arg),)
|
||||
break
|
||||
|
||||
if len(removed_indexes) > 0:
|
||||
fx_g.graph.lint()
|
||||
fx_g.graph.eliminate_dead_code()
|
||||
fx_g.recompile()
|
||||
removed_indexes.sort()
|
||||
return removed_indexes
|
||||
|
||||
def _unwrap_single_tuple_return(fx_g: torch.fx.GraphModule) -> bool:
|
||||
"""
|
||||
Replace tuple with tuple element in functions that return one-element tuples.
|
||||
Returns true if an unwrapping took place, and false otherwise.
|
||||
"""
|
||||
unwrapped_tuple = False
|
||||
for node in fx_g.graph.nodes:
|
||||
if node.op == "output":
|
||||
assert (
|
||||
len(node.args) == 1
|
||||
), "Output node must have a single argument"
|
||||
node_arg = node.args[0]
|
||||
if isinstance(node_arg, tuple):
|
||||
if len(node_arg) == 1:
|
||||
node.args = (node_arg[0],)
|
||||
unwrapped_tuple = True
|
||||
break
|
||||
|
||||
if unwrapped_tuple:
|
||||
fx_g.graph.lint()
|
||||
fx_g.recompile()
|
||||
return unwrapped_tuple
|
||||
|
||||
def _returns_nothing(fx_g: torch.fx.GraphModule) -> bool:
|
||||
for node in fx_g.graph.nodes:
|
||||
if node.op == "output":
|
||||
assert (
|
||||
len(node.args) == 1
|
||||
), "Output node must have a single argument"
|
||||
node_arg = node.args[0]
|
||||
if isinstance(node_arg, tuple):
|
||||
return len(node_arg) == 0
|
||||
return False
|
||||
|
||||
def transform_fx(fx_g):
|
||||
for node in fx_g.graph.nodes:
|
||||
if node.op == "call_function":
|
||||
if node.target in [
|
||||
torch.ops.aten.empty,
|
||||
]:
|
||||
# aten.empty should be filled with zeros.
|
||||
if node.target in [torch.ops.aten.empty]:
|
||||
with fx_g.graph.inserting_after(node):
|
||||
new_node = fx_g.graph.call_function(
|
||||
torch.ops.aten.zero_,
|
||||
args=(node,),
|
||||
)
|
||||
node.append(new_node)
|
||||
node.replace_all_uses_with(new_node)
|
||||
new_node.args = (node,)
|
||||
|
||||
fx_g.graph.lint()
|
||||
|
||||
@make_simple_dynamo_backend
|
||||
def refbackend_torchdynamo_backend(
|
||||
fx_graph: torch.fx.GraphModule, example_inputs: List[torch.Tensor]
|
||||
):
|
||||
# handling usage of empty tensor without initializing
|
||||
transform_fx(fx_graph)
|
||||
fx_graph.recompile()
|
||||
if _returns_nothing(fx_graph):
|
||||
return fx_graph
|
||||
removed_none_indexes = _remove_nones(fx_graph)
|
||||
was_unwrapped = _unwrap_single_tuple_return(fx_graph)
|
||||
|
||||
mlir_module = torch_mlir.compile(
|
||||
fx_graph, example_inputs, output_type="linalg-on-tensors"
|
||||
)
|
||||
|
||||
bytecode_stream = BytesIO()
|
||||
mlir_module.operation.write_bytecode(bytecode_stream)
|
||||
bytecode = bytecode_stream.getvalue()
|
||||
|
||||
shark_module = SharkInference(
|
||||
mlir_module=bytecode, device=args.device, mlir_dialect="tm_tensor"
|
||||
)
|
||||
shark_module.compile()
|
||||
|
||||
def compiled_callable(*inputs):
|
||||
inputs = [x.numpy() for x in inputs]
|
||||
result = shark_module("forward", inputs)
|
||||
if was_unwrapped:
|
||||
result = [
|
||||
result,
|
||||
]
|
||||
if not isinstance(result, list):
|
||||
result = torch.from_numpy(result)
|
||||
else:
|
||||
result = tuple(torch.from_numpy(x) for x in result)
|
||||
result = list(result)
|
||||
for removed_index in removed_none_indexes:
|
||||
result.insert(removed_index, None)
|
||||
result = tuple(result)
|
||||
return result
|
||||
|
||||
return compiled_callable
|
||||
|
||||
def predictions(torch_func, jit_func, batchA, batchB):
|
||||
res = jit_func(batchA.numpy(), batchB.numpy())
|
||||
if res is not None:
|
||||
# prediction = torch.from_numpy(res)
|
||||
prediction = res
|
||||
else:
|
||||
prediction = None
|
||||
return prediction
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
train_batch_size = hyperparameters["train_batch_size"]
|
||||
gradient_accumulation_steps = hyperparameters[
|
||||
"gradient_accumulation_steps"
|
||||
]
|
||||
learning_rate = hyperparameters["learning_rate"]
|
||||
if hyperparameters["scale_lr"]:
|
||||
learning_rate = (
|
||||
learning_rate
|
||||
* gradient_accumulation_steps
|
||||
* train_batch_size
|
||||
# * accelerator.num_processes
|
||||
)
|
||||
|
||||
# Initialize the optimizer
|
||||
optimizer = torch.optim.AdamW(
|
||||
lora_layers.parameters(), # only optimize the embeddings
|
||||
lr=learning_rate,
|
||||
)
|
||||
|
||||
# Training function
|
||||
def train_func(batch_pixel_values, batch_input_ids):
|
||||
# Convert images to latent space
|
||||
latents = shark_vae(batch_pixel_values).sample().detach()
|
||||
latents = latents * 0.18215
|
||||
|
||||
# Sample noise that we'll add to the latents
|
||||
noise = torch.randn_like(latents)
|
||||
bsz = latents.shape[0]
|
||||
# Sample a random timestep for each image
|
||||
timesteps = torch.randint(
|
||||
0,
|
||||
noise_scheduler.num_train_timesteps,
|
||||
(bsz,),
|
||||
device=latents.device,
|
||||
).long()
|
||||
|
||||
# Add noise to the latents according to the noise magnitude at each timestep
|
||||
# (this is the forward diffusion process)
|
||||
noisy_latents = noise_scheduler.add_noise(latents, noise, timesteps)
|
||||
|
||||
# Get the text embedding for conditioning
|
||||
encoder_hidden_states = text_encoder(batch_input_ids)[0]
|
||||
|
||||
# Predict the noise residual
|
||||
noise_pred = shark_unet(
|
||||
noisy_latents,
|
||||
timesteps,
|
||||
encoder_hidden_states,
|
||||
)
|
||||
|
||||
# Get the target for loss depending on the prediction type
|
||||
if noise_scheduler.config.prediction_type == "epsilon":
|
||||
target = noise
|
||||
elif noise_scheduler.config.prediction_type == "v_prediction":
|
||||
target = noise_scheduler.get_velocity(latents, noise, timesteps)
|
||||
else:
|
||||
raise ValueError(
|
||||
f"Unknown prediction type {noise_scheduler.config.prediction_type}"
|
||||
)
|
||||
|
||||
loss = (
|
||||
F.mse_loss(noise_pred, target, reduction="none")
|
||||
.mean([1, 2, 3])
|
||||
.mean()
|
||||
)
|
||||
loss.backward()
|
||||
|
||||
optimizer.step()
|
||||
optimizer.zero_grad()
|
||||
|
||||
return loss
|
||||
|
||||
def training_function():
|
||||
max_train_steps = hyperparameters["max_train_steps"]
|
||||
output_dir = hyperparameters["output_dir"]
|
||||
gradient_checkpointing = hyperparameters["gradient_checkpointing"]
|
||||
|
||||
train_dataloader = create_dataloader(train_batch_size)
|
||||
|
||||
# We need to recalculate our total training steps as the size of the training dataloader may have changed.
|
||||
num_update_steps_per_epoch = math.ceil(
|
||||
len(train_dataloader) / gradient_accumulation_steps
|
||||
)
|
||||
num_train_epochs = math.ceil(
|
||||
max_train_steps / num_update_steps_per_epoch
|
||||
)
|
||||
|
||||
# Train!
|
||||
total_batch_size = (
|
||||
train_batch_size
|
||||
* gradient_accumulation_steps
|
||||
# train_batch_size * accelerator.num_processes * gradient_accumulation_steps
|
||||
)
|
||||
|
||||
logger.info("***** Running training *****")
|
||||
logger.info(f" Num examples = {len(train_dataset)}")
|
||||
logger.info(
|
||||
f" Instantaneous batch size per device = {train_batch_size}"
|
||||
)
|
||||
logger.info(
|
||||
f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}"
|
||||
)
|
||||
logger.info(
|
||||
f" Gradient Accumulation steps = {gradient_accumulation_steps}"
|
||||
)
|
||||
logger.info(f" Total optimization steps = {max_train_steps}")
|
||||
# Only show the progress bar once on each machine.
|
||||
progress_bar = tqdm(
|
||||
# range(max_train_steps), disable=not accelerator.is_local_main_process
|
||||
range(max_train_steps)
|
||||
)
|
||||
progress_bar.set_description("Steps")
|
||||
global_step = 0
|
||||
|
||||
params__ = [
|
||||
i for i in text_encoder.get_input_embeddings().parameters()
|
||||
]
|
||||
|
||||
for epoch in range(num_train_epochs):
|
||||
unet.train()
|
||||
for step, batch in enumerate(train_dataloader):
|
||||
dynamo_callable = dynamo.optimize(
|
||||
refbackend_torchdynamo_backend
|
||||
)(train_func)
|
||||
lam_func = lambda x, y: dynamo_callable(
|
||||
torch.from_numpy(x), torch.from_numpy(y)
|
||||
)
|
||||
loss = predictions(
|
||||
train_func,
|
||||
lam_func,
|
||||
batch["pixel_values"],
|
||||
batch["input_ids"],
|
||||
)
|
||||
|
||||
# Checks if the accelerator has performed an optimization step behind the scenes
|
||||
progress_bar.update(1)
|
||||
global_step += 1
|
||||
|
||||
logs = {"loss": loss.detach().item()}
|
||||
progress_bar.set_postfix(**logs)
|
||||
|
||||
if global_step >= max_train_steps:
|
||||
break
|
||||
|
||||
training_function()
|
||||
|
||||
# Save the lora weights
|
||||
unet.save_attn_procs(args.lora_save_dir)
|
||||
|
||||
for param in itertools.chain(unet.parameters(), text_encoder.parameters()):
|
||||
if param.grad is not None:
|
||||
del param.grad # free some memory
|
||||
torch.cuda.empty_cache()
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
if args.clear_all:
|
||||
clear_all()
|
||||
|
||||
dtype = torch.float32 if args.precision == "fp32" else torch.half
|
||||
cpu_scheduling = not args.scheduler.startswith("Shark")
|
||||
set_init_device_flags()
|
||||
schedulers = get_schedulers(args.hf_model_id)
|
||||
scheduler_obj = schedulers[args.scheduler]
|
||||
seed = args.seed
|
||||
if len(args.prompts) != 1:
|
||||
print("Need exactly one prompt for the LoRA word")
|
||||
lora_train(
|
||||
args.prompts[0],
|
||||
args.height,
|
||||
args.width,
|
||||
args.training_steps,
|
||||
args.guidance_scale,
|
||||
args.seed,
|
||||
args.batch_count,
|
||||
args.batch_size,
|
||||
args.scheduler,
|
||||
"None",
|
||||
args.hf_model_id,
|
||||
args.precision,
|
||||
args.device,
|
||||
args.max_length,
|
||||
args.training_images_dir,
|
||||
args.lora_save_dir,
|
||||
)
|
||||
85
apps/stable_diffusion/scripts/txt2img.py
Normal file
85
apps/stable_diffusion/scripts/txt2img.py
Normal file
@@ -0,0 +1,85 @@
|
||||
import torch
|
||||
import transformers
|
||||
import time
|
||||
from apps.stable_diffusion.src import (
|
||||
args,
|
||||
Text2ImagePipeline,
|
||||
get_schedulers,
|
||||
set_init_device_flags,
|
||||
utils,
|
||||
clear_all,
|
||||
save_output_img,
|
||||
)
|
||||
|
||||
|
||||
def main():
|
||||
if args.clear_all:
|
||||
clear_all()
|
||||
|
||||
dtype = torch.float32 if args.precision == "fp32" else torch.half
|
||||
cpu_scheduling = not args.scheduler.startswith("Shark")
|
||||
set_init_device_flags()
|
||||
schedulers = get_schedulers(args.hf_model_id)
|
||||
scheduler_obj = schedulers[args.scheduler]
|
||||
seed = args.seed
|
||||
txt2img_obj = Text2ImagePipeline.from_pretrained(
|
||||
scheduler=scheduler_obj,
|
||||
import_mlir=args.import_mlir,
|
||||
model_id=args.hf_model_id,
|
||||
ckpt_loc=args.ckpt_loc,
|
||||
precision=args.precision,
|
||||
max_length=args.max_length,
|
||||
batch_size=args.batch_size,
|
||||
height=args.height,
|
||||
width=args.width,
|
||||
use_base_vae=args.use_base_vae,
|
||||
use_tuned=args.use_tuned,
|
||||
custom_vae=args.custom_vae,
|
||||
low_cpu_mem_usage=args.low_cpu_mem_usage,
|
||||
debug=args.import_debug if args.import_mlir else False,
|
||||
use_lora=args.use_lora,
|
||||
use_quantize=args.use_quantize,
|
||||
ondemand=args.ondemand,
|
||||
)
|
||||
|
||||
for current_batch in range(args.batch_count):
|
||||
if current_batch > 0:
|
||||
seed = -1
|
||||
seed = utils.sanitize_seed(seed)
|
||||
|
||||
start_time = time.time()
|
||||
generated_imgs = txt2img_obj.generate_images(
|
||||
args.prompts,
|
||||
args.negative_prompts,
|
||||
args.batch_size,
|
||||
args.height,
|
||||
args.width,
|
||||
args.steps,
|
||||
args.guidance_scale,
|
||||
seed,
|
||||
args.max_length,
|
||||
dtype,
|
||||
args.use_base_vae,
|
||||
cpu_scheduling,
|
||||
)
|
||||
total_time = time.time() - start_time
|
||||
text_output = f"prompt={args.prompts}"
|
||||
text_output += f"\nnegative prompt={args.negative_prompts}"
|
||||
text_output += (
|
||||
f"\nmodel_id={args.hf_model_id}, ckpt_loc={args.ckpt_loc}"
|
||||
)
|
||||
text_output += f"\nscheduler={args.scheduler}, device={args.device}"
|
||||
text_output += f"\nsteps={args.steps}, guidance_scale={args.guidance_scale}, seed={seed}, size={args.height}x{args.width}"
|
||||
text_output += (
|
||||
f", batch size={args.batch_size}, max_length={args.max_length}"
|
||||
)
|
||||
# TODO: if using --batch_count=x txt2img_obj.log will output on each display every iteration infos from the start
|
||||
text_output += txt2img_obj.log
|
||||
text_output += f"\nTotal image generation time: {total_time:.4f}sec"
|
||||
|
||||
save_output_img(generated_imgs[0], seed)
|
||||
print(text_output)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
279
apps/stable_diffusion/scripts/upscaler.py
Normal file
279
apps/stable_diffusion/scripts/upscaler.py
Normal file
@@ -0,0 +1,279 @@
|
||||
import torch
|
||||
import time
|
||||
from PIL import Image
|
||||
import transformers
|
||||
from apps.stable_diffusion.src import (
|
||||
args,
|
||||
UpscalerPipeline,
|
||||
get_schedulers,
|
||||
set_init_device_flags,
|
||||
utils,
|
||||
clear_all,
|
||||
save_output_img,
|
||||
)
|
||||
|
||||
|
||||
# set initial values of iree_vulkan_target_triple, use_tuned and import_mlir.
|
||||
init_iree_vulkan_target_triple = args.iree_vulkan_target_triple
|
||||
init_use_tuned = args.use_tuned
|
||||
init_import_mlir = args.import_mlir
|
||||
|
||||
|
||||
# Exposed to UI.
|
||||
def upscaler_inf(
|
||||
prompt: str,
|
||||
negative_prompt: str,
|
||||
init_image,
|
||||
height: int,
|
||||
width: int,
|
||||
steps: int,
|
||||
noise_level: int,
|
||||
guidance_scale: float,
|
||||
seed: int,
|
||||
batch_count: int,
|
||||
batch_size: int,
|
||||
scheduler: str,
|
||||
custom_model: str,
|
||||
hf_model_id: str,
|
||||
precision: str,
|
||||
device: str,
|
||||
max_length: int,
|
||||
save_metadata_to_json: bool,
|
||||
save_metadata_to_png: bool,
|
||||
lora_weights: str,
|
||||
lora_hf_id: str,
|
||||
ondemand: bool,
|
||||
):
|
||||
from apps.stable_diffusion.web.ui.utils import (
|
||||
get_custom_model_pathfile,
|
||||
get_custom_vae_or_lora_weights,
|
||||
Config,
|
||||
)
|
||||
import apps.stable_diffusion.web.utils.global_obj as global_obj
|
||||
|
||||
args.prompts = [prompt]
|
||||
args.negative_prompts = [negative_prompt]
|
||||
args.guidance_scale = guidance_scale
|
||||
args.seed = seed
|
||||
args.steps = steps
|
||||
args.scheduler = scheduler
|
||||
args.ondemand = ondemand
|
||||
|
||||
if init_image is None:
|
||||
return None, "An Initial Image is required"
|
||||
image = init_image.convert("RGB").resize((height, width))
|
||||
|
||||
# set ckpt_loc and hf_model_id.
|
||||
args.ckpt_loc = ""
|
||||
args.hf_model_id = ""
|
||||
if custom_model == "None":
|
||||
if not hf_model_id:
|
||||
return (
|
||||
None,
|
||||
"Please provide either custom model or huggingface model ID, both must not be empty",
|
||||
)
|
||||
args.hf_model_id = hf_model_id
|
||||
elif ".ckpt" in custom_model or ".safetensors" in custom_model:
|
||||
args.ckpt_loc = get_custom_model_pathfile(custom_model)
|
||||
else:
|
||||
args.hf_model_id = custom_model
|
||||
|
||||
args.save_metadata_to_json = save_metadata_to_json
|
||||
args.write_metadata_to_png = save_metadata_to_png
|
||||
|
||||
args.use_lora = get_custom_vae_or_lora_weights(
|
||||
lora_weights, lora_hf_id, "lora"
|
||||
)
|
||||
|
||||
dtype = torch.float32 if precision == "fp32" else torch.half
|
||||
cpu_scheduling = not scheduler.startswith("Shark")
|
||||
args.height = 128
|
||||
args.width = 128
|
||||
new_config_obj = Config(
|
||||
"upscaler",
|
||||
args.hf_model_id,
|
||||
args.ckpt_loc,
|
||||
precision,
|
||||
batch_size,
|
||||
max_length,
|
||||
args.height,
|
||||
args.width,
|
||||
device,
|
||||
use_lora=args.use_lora,
|
||||
use_stencil=None,
|
||||
)
|
||||
if (
|
||||
args.ondemand
|
||||
or not global_obj.get_sd_obj()
|
||||
or global_obj.get_cfg_obj() != new_config_obj
|
||||
):
|
||||
global_obj.clear_cache()
|
||||
global_obj.set_cfg_obj(new_config_obj)
|
||||
args.batch_size = batch_size
|
||||
args.max_length = max_length
|
||||
args.device = device.split("=>", 1)[1].strip()
|
||||
args.iree_vulkan_target_triple = init_iree_vulkan_target_triple
|
||||
args.use_tuned = init_use_tuned
|
||||
args.import_mlir = init_import_mlir
|
||||
set_init_device_flags()
|
||||
model_id = (
|
||||
args.hf_model_id
|
||||
if args.hf_model_id
|
||||
else "stabilityai/stable-diffusion-2-1-base"
|
||||
)
|
||||
global_obj.set_schedulers(get_schedulers(model_id))
|
||||
scheduler_obj = global_obj.get_scheduler(scheduler)
|
||||
global_obj.set_sd_obj(
|
||||
UpscalerPipeline.from_pretrained(
|
||||
scheduler_obj,
|
||||
args.import_mlir,
|
||||
args.hf_model_id,
|
||||
args.ckpt_loc,
|
||||
args.custom_vae,
|
||||
args.precision,
|
||||
args.max_length,
|
||||
args.batch_size,
|
||||
args.height,
|
||||
args.width,
|
||||
args.use_base_vae,
|
||||
args.use_tuned,
|
||||
low_cpu_mem_usage=args.low_cpu_mem_usage,
|
||||
use_lora=args.use_lora,
|
||||
ondemand=args.ondemand,
|
||||
)
|
||||
)
|
||||
|
||||
global_obj.set_sd_scheduler(scheduler)
|
||||
global_obj.get_sd_obj().low_res_scheduler = global_obj.get_scheduler(
|
||||
"DDPM"
|
||||
)
|
||||
global_obj.set_sd_ondemand(args.ondemand)
|
||||
|
||||
start_time = time.time()
|
||||
global_obj.get_sd_obj().log = ""
|
||||
generated_imgs = []
|
||||
seeds = []
|
||||
img_seed = utils.sanitize_seed(seed)
|
||||
extra_info = {"NOISE LEVEL": noise_level}
|
||||
for current_batch in range(batch_count):
|
||||
if current_batch > 0:
|
||||
img_seed = utils.sanitize_seed(-1)
|
||||
low_res_img = image
|
||||
high_res_img = Image.new("RGB", (height * 4, width * 4))
|
||||
|
||||
for i in range(0, width, 128):
|
||||
for j in range(0, height, 128):
|
||||
box = (j, i, j + 128, i + 128)
|
||||
upscaled_image = global_obj.get_sd_obj().generate_images(
|
||||
prompt,
|
||||
negative_prompt,
|
||||
low_res_img.crop(box),
|
||||
batch_size,
|
||||
args.height,
|
||||
args.width,
|
||||
steps,
|
||||
noise_level,
|
||||
guidance_scale,
|
||||
img_seed,
|
||||
args.max_length,
|
||||
dtype,
|
||||
args.use_base_vae,
|
||||
cpu_scheduling,
|
||||
)
|
||||
high_res_img.paste(upscaled_image[0], (j * 4, i * 4))
|
||||
|
||||
save_output_img(high_res_img, img_seed, extra_info)
|
||||
generated_imgs.append(high_res_img)
|
||||
seeds.append(img_seed)
|
||||
global_obj.get_sd_obj().log += "\n"
|
||||
yield generated_imgs, global_obj.get_sd_obj().log
|
||||
|
||||
total_time = time.time() - start_time
|
||||
text_output = f"prompt={args.prompts}"
|
||||
text_output += f"\nnegative prompt={args.negative_prompts}"
|
||||
text_output += f"\nmodel_id={args.hf_model_id}, ckpt_loc={args.ckpt_loc}"
|
||||
text_output += f"\nscheduler={args.scheduler}, device={device}"
|
||||
text_output += f"\nsteps={steps}, noise_level={noise_level}, guidance_scale={guidance_scale}, seed={seeds}"
|
||||
text_output += f"\nsize={height}x{width}, batch_count={batch_count}, batch_size={batch_size}, max_length={args.max_length}"
|
||||
text_output += global_obj.get_sd_obj().log
|
||||
text_output += f"\nTotal image generation time: {total_time:.4f}sec"
|
||||
|
||||
yield generated_imgs, text_output
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
if args.clear_all:
|
||||
clear_all()
|
||||
|
||||
if args.img_path is None:
|
||||
print("Flag --img_path is required.")
|
||||
exit()
|
||||
|
||||
# When the models get uploaded, it should be default to False.
|
||||
args.import_mlir = True
|
||||
|
||||
cpu_scheduling = not args.scheduler.startswith("Shark")
|
||||
dtype = torch.float32 if args.precision == "fp32" else torch.half
|
||||
set_init_device_flags()
|
||||
schedulers = get_schedulers(args.hf_model_id)
|
||||
|
||||
scheduler_obj = schedulers[args.scheduler]
|
||||
image = (
|
||||
Image.open(args.img_path)
|
||||
.convert("RGB")
|
||||
.resize((args.height, args.width))
|
||||
)
|
||||
seed = utils.sanitize_seed(args.seed)
|
||||
# Adjust for height and width based on model
|
||||
|
||||
upscaler_obj = UpscalerPipeline.from_pretrained(
|
||||
scheduler_obj,
|
||||
args.import_mlir,
|
||||
args.hf_model_id,
|
||||
args.ckpt_loc,
|
||||
args.custom_vae,
|
||||
args.precision,
|
||||
args.max_length,
|
||||
args.batch_size,
|
||||
args.height,
|
||||
args.width,
|
||||
args.use_base_vae,
|
||||
args.use_tuned,
|
||||
low_cpu_mem_usage=args.low_cpu_mem_usage,
|
||||
use_lora=args.use_lora,
|
||||
ddpm_scheduler=schedulers["DDPM"],
|
||||
ondemand=args.ondemand,
|
||||
)
|
||||
|
||||
start_time = time.time()
|
||||
generated_imgs = upscaler_obj.generate_images(
|
||||
args.prompts,
|
||||
args.negative_prompts,
|
||||
image,
|
||||
args.batch_size,
|
||||
args.height,
|
||||
args.width,
|
||||
args.steps,
|
||||
args.noise_level,
|
||||
args.guidance_scale,
|
||||
seed,
|
||||
args.max_length,
|
||||
dtype,
|
||||
args.use_base_vae,
|
||||
cpu_scheduling,
|
||||
)
|
||||
total_time = time.time() - start_time
|
||||
text_output = f"prompt={args.prompts}"
|
||||
text_output += f"\nnegative prompt={args.negative_prompts}"
|
||||
text_output += f"\nmodel_id={args.hf_model_id}, ckpt_loc={args.ckpt_loc}"
|
||||
text_output += f"\nscheduler={args.scheduler}, device={args.device}"
|
||||
text_output += f"\nsteps={args.steps}, noise_level={args.noise_level}, guidance_scale={args.guidance_scale}, seed={seed}, size={args.height}x{args.width}"
|
||||
text_output += (
|
||||
f", batch size={args.batch_size}, max_length={args.max_length}"
|
||||
)
|
||||
text_output += upscaler_obj.log
|
||||
text_output += f"\nTotal image generation time: {total_time:.4f}sec"
|
||||
|
||||
extra_info = {"NOISE LEVEL": args.noise_level}
|
||||
save_output_img(generated_imgs[0], seed, extra_info)
|
||||
print(text_output)
|
||||
85
apps/stable_diffusion/shark_sd.spec
Normal file
85
apps/stable_diffusion/shark_sd.spec
Normal file
@@ -0,0 +1,85 @@
|
||||
# -*- mode: python ; coding: utf-8 -*-
|
||||
from PyInstaller.utils.hooks import collect_data_files
|
||||
from PyInstaller.utils.hooks import copy_metadata
|
||||
from PyInstaller.utils.hooks import collect_submodules
|
||||
|
||||
import sys ; sys.setrecursionlimit(sys.getrecursionlimit() * 5)
|
||||
|
||||
datas = []
|
||||
datas += collect_data_files('torch')
|
||||
datas += copy_metadata('torch')
|
||||
datas += copy_metadata('tqdm')
|
||||
datas += copy_metadata('regex')
|
||||
datas += copy_metadata('requests')
|
||||
datas += copy_metadata('packaging')
|
||||
datas += copy_metadata('filelock')
|
||||
datas += copy_metadata('numpy')
|
||||
datas += copy_metadata('tokenizers')
|
||||
datas += copy_metadata('importlib_metadata')
|
||||
datas += copy_metadata('torch-mlir')
|
||||
datas += copy_metadata('omegaconf')
|
||||
datas += copy_metadata('safetensors')
|
||||
datas += collect_data_files('diffusers')
|
||||
datas += collect_data_files('transformers')
|
||||
datas += collect_data_files('pytorch_lightning')
|
||||
datas += collect_data_files('opencv-python')
|
||||
datas += collect_data_files('skimage')
|
||||
datas += collect_data_files('gradio')
|
||||
datas += collect_data_files('gradio_client')
|
||||
datas += collect_data_files('iree')
|
||||
datas += collect_data_files('google-cloud-storage')
|
||||
datas += collect_data_files('shark')
|
||||
datas += [
|
||||
( 'src/utils/resources/prompts.json', 'resources' ),
|
||||
( 'src/utils/resources/model_db.json', 'resources' ),
|
||||
( 'src/utils/resources/opt_flags.json', 'resources' ),
|
||||
( 'src/utils/resources/base_model.json', 'resources' ),
|
||||
( 'web/ui/css/*', 'ui/css' ),
|
||||
( 'web/ui/logos/*', 'logos' )
|
||||
]
|
||||
|
||||
binaries = []
|
||||
|
||||
block_cipher = None
|
||||
|
||||
hiddenimports = ['shark', 'shark.shark_inference', 'apps']
|
||||
hiddenimports += [x for x in collect_submodules("skimage") if "tests" not in x]
|
||||
|
||||
a = Analysis(
|
||||
['web/index.py'],
|
||||
pathex=['.'],
|
||||
binaries=binaries,
|
||||
datas=datas,
|
||||
hiddenimports=hiddenimports,
|
||||
hookspath=[],
|
||||
hooksconfig={},
|
||||
runtime_hooks=[],
|
||||
excludes=[],
|
||||
win_no_prefer_redirects=False,
|
||||
win_private_assemblies=False,
|
||||
cipher=block_cipher,
|
||||
noarchive=False,
|
||||
)
|
||||
pyz = PYZ(a.pure, a.zipped_data, cipher=block_cipher)
|
||||
|
||||
exe = EXE(
|
||||
pyz,
|
||||
a.scripts,
|
||||
a.binaries,
|
||||
a.zipfiles,
|
||||
a.datas,
|
||||
[],
|
||||
name='shark_sd',
|
||||
debug=False,
|
||||
bootloader_ignore_signals=False,
|
||||
strip=False,
|
||||
upx=True,
|
||||
upx_exclude=[],
|
||||
runtime_tmpdir=None,
|
||||
console=True,
|
||||
disable_windowed_traceback=False,
|
||||
argv_emulation=False,
|
||||
target_arch=None,
|
||||
codesign_identity=None,
|
||||
entitlements_file=None,
|
||||
)
|
||||
83
apps/stable_diffusion/shark_sd_cli.spec
Normal file
83
apps/stable_diffusion/shark_sd_cli.spec
Normal file
@@ -0,0 +1,83 @@
|
||||
# -*- mode: python ; coding: utf-8 -*-
|
||||
from PyInstaller.utils.hooks import collect_data_files
|
||||
from PyInstaller.utils.hooks import collect_submodules
|
||||
from PyInstaller.utils.hooks import copy_metadata
|
||||
|
||||
import sys ; sys.setrecursionlimit(sys.getrecursionlimit() * 5)
|
||||
|
||||
datas = []
|
||||
datas += collect_data_files('torch')
|
||||
datas += copy_metadata('torch')
|
||||
datas += copy_metadata('tqdm')
|
||||
datas += copy_metadata('regex')
|
||||
datas += copy_metadata('requests')
|
||||
datas += copy_metadata('packaging')
|
||||
datas += copy_metadata('filelock')
|
||||
datas += copy_metadata('numpy')
|
||||
datas += copy_metadata('tokenizers')
|
||||
datas += copy_metadata('importlib_metadata')
|
||||
datas += copy_metadata('torch-mlir')
|
||||
datas += copy_metadata('omegaconf')
|
||||
datas += copy_metadata('safetensors')
|
||||
datas += collect_data_files('diffusers')
|
||||
datas += collect_data_files('transformers')
|
||||
datas += collect_data_files('opencv-python')
|
||||
datas += collect_data_files('pytorch_lightning')
|
||||
datas += collect_data_files('skimage')
|
||||
datas += collect_data_files('gradio')
|
||||
datas += collect_data_files('gradio_client')
|
||||
datas += collect_data_files('iree')
|
||||
datas += collect_data_files('google-cloud-storage')
|
||||
datas += collect_data_files('shark')
|
||||
datas += [
|
||||
( 'src/utils/resources/prompts.json', 'resources' ),
|
||||
( 'src/utils/resources/model_db.json', 'resources' ),
|
||||
( 'src/utils/resources/opt_flags.json', 'resources' ),
|
||||
( 'src/utils/resources/base_model.json', 'resources' ),
|
||||
]
|
||||
|
||||
binaries = []
|
||||
|
||||
block_cipher = None
|
||||
|
||||
hiddenimports = ['shark', 'shark.shark_inference', 'apps']
|
||||
hiddenimports += [x for x in collect_submodules("skimage") if "tests" not in x]
|
||||
|
||||
a = Analysis(
|
||||
['scripts/main.py'],
|
||||
pathex=['.'],
|
||||
binaries=binaries,
|
||||
datas=datas,
|
||||
hiddenimports=hiddenimports,
|
||||
hookspath=[],
|
||||
hooksconfig={},
|
||||
runtime_hooks=[],
|
||||
excludes=[],
|
||||
win_no_prefer_redirects=False,
|
||||
win_private_assemblies=False,
|
||||
cipher=block_cipher,
|
||||
noarchive=False,
|
||||
)
|
||||
pyz = PYZ(a.pure, a.zipped_data, cipher=block_cipher)
|
||||
|
||||
exe = EXE(
|
||||
pyz,
|
||||
a.scripts,
|
||||
a.binaries,
|
||||
a.zipfiles,
|
||||
a.datas,
|
||||
[],
|
||||
name='shark_sd_cli',
|
||||
debug=False,
|
||||
bootloader_ignore_signals=False,
|
||||
strip=False,
|
||||
upx=True,
|
||||
upx_exclude=[],
|
||||
runtime_tmpdir=None,
|
||||
console=True,
|
||||
disable_windowed_traceback=False,
|
||||
argv_emulation=False,
|
||||
target_arch=None,
|
||||
codesign_identity=None,
|
||||
entitlements_file=None,
|
||||
)
|
||||
17
apps/stable_diffusion/src/__init__.py
Normal file
17
apps/stable_diffusion/src/__init__.py
Normal file
@@ -0,0 +1,17 @@
|
||||
from apps.stable_diffusion.src.utils import (
|
||||
args,
|
||||
set_init_device_flags,
|
||||
prompt_examples,
|
||||
get_available_devices,
|
||||
clear_all,
|
||||
save_output_img,
|
||||
)
|
||||
from apps.stable_diffusion.src.pipelines import (
|
||||
Text2ImagePipeline,
|
||||
Image2ImagePipeline,
|
||||
InpaintPipeline,
|
||||
OutpaintPipeline,
|
||||
StencilPipeline,
|
||||
UpscalerPipeline,
|
||||
)
|
||||
from apps.stable_diffusion.src.schedulers import get_schedulers
|
||||
12
apps/stable_diffusion/src/models/__init__.py
Normal file
12
apps/stable_diffusion/src/models/__init__.py
Normal file
@@ -0,0 +1,12 @@
|
||||
from apps.stable_diffusion.src.models.model_wrappers import (
|
||||
SharkifyStableDiffusionModel,
|
||||
)
|
||||
from apps.stable_diffusion.src.models.opt_params import (
|
||||
get_vae_encode,
|
||||
get_vae,
|
||||
get_unet,
|
||||
get_clip,
|
||||
get_tokenizer,
|
||||
get_params,
|
||||
get_variant_version,
|
||||
)
|
||||
657
apps/stable_diffusion/src/models/model_wrappers.py
Normal file
657
apps/stable_diffusion/src/models/model_wrappers.py
Normal file
@@ -0,0 +1,657 @@
|
||||
from diffusers import AutoencoderKL, UNet2DConditionModel, ControlNetModel
|
||||
from transformers import CLIPTextModel
|
||||
from collections import defaultdict
|
||||
import torch
|
||||
import safetensors.torch
|
||||
import traceback
|
||||
import sys
|
||||
import os
|
||||
from apps.stable_diffusion.src.utils import (
|
||||
compile_through_fx,
|
||||
get_opt_flags,
|
||||
base_models,
|
||||
args,
|
||||
fetch_vmfb,
|
||||
preprocessCKPT,
|
||||
get_path_to_diffusers_checkpoint,
|
||||
fetch_and_update_base_model_id,
|
||||
get_path_stem,
|
||||
get_extended_name,
|
||||
get_stencil_model_id,
|
||||
update_lora_weight,
|
||||
)
|
||||
|
||||
|
||||
# These shapes are parameter dependent.
|
||||
def replace_shape_str(shape, max_len, width, height, batch_size):
|
||||
new_shape = []
|
||||
for i in range(len(shape)):
|
||||
if shape[i] == "max_len":
|
||||
new_shape.append(max_len)
|
||||
elif shape[i] == "height":
|
||||
new_shape.append(height)
|
||||
elif shape[i] == "width":
|
||||
new_shape.append(width)
|
||||
elif isinstance(shape[i], str):
|
||||
if "*" in shape[i]:
|
||||
mul_val = int(shape[i].split("*")[0])
|
||||
if "batch_size" in shape[i]:
|
||||
new_shape.append(batch_size * mul_val)
|
||||
elif "height" in shape[i]:
|
||||
new_shape.append(height * mul_val)
|
||||
elif "width" in shape[i]:
|
||||
new_shape.append(width * mul_val)
|
||||
elif "/" in shape[i]:
|
||||
import math
|
||||
div_val = int(shape[i].split("/")[1])
|
||||
if "batch_size" in shape[i]:
|
||||
new_shape.append(math.ceil(batch_size / div_val))
|
||||
elif "height" in shape[i]:
|
||||
new_shape.append(math.ceil(height / div_val))
|
||||
elif "width" in shape[i]:
|
||||
new_shape.append(math.ceil(width / div_val))
|
||||
else:
|
||||
new_shape.append(shape[i])
|
||||
return new_shape
|
||||
|
||||
|
||||
def check_compilation(model, model_name):
|
||||
if not model:
|
||||
raise Exception(f"Could not compile {model_name}. Please create an issue with the detailed log at https://github.com/nod-ai/SHARK/issues")
|
||||
|
||||
|
||||
class SharkifyStableDiffusionModel:
|
||||
def __init__(
|
||||
self,
|
||||
model_id: str,
|
||||
custom_weights: str,
|
||||
custom_vae: str,
|
||||
precision: str,
|
||||
max_len: int = 64,
|
||||
width: int = 512,
|
||||
height: int = 512,
|
||||
batch_size: int = 1,
|
||||
use_base_vae: bool = False,
|
||||
use_tuned: bool = False,
|
||||
low_cpu_mem_usage: bool = False,
|
||||
debug: bool = False,
|
||||
sharktank_dir: str = "",
|
||||
generate_vmfb: bool = True,
|
||||
is_inpaint: bool = False,
|
||||
is_upscaler: bool = False,
|
||||
use_stencil: str = None,
|
||||
use_lora: str = "",
|
||||
use_quantize: str = None,
|
||||
):
|
||||
self.check_params(max_len, width, height)
|
||||
self.max_len = max_len
|
||||
self.height = height // 8
|
||||
self.width = width // 8
|
||||
self.batch_size = batch_size
|
||||
self.custom_weights = custom_weights
|
||||
self.use_quantize = use_quantize
|
||||
if custom_weights != "":
|
||||
assert custom_weights.lower().endswith(
|
||||
(".ckpt", ".safetensors")
|
||||
), "checkpoint files supported can be any of [.ckpt, .safetensors] type"
|
||||
custom_weights = get_path_to_diffusers_checkpoint(custom_weights)
|
||||
self.model_id = model_id if custom_weights == "" else custom_weights
|
||||
# TODO: remove the following line when stable-diffusion-2-1 works
|
||||
if self.model_id == "stabilityai/stable-diffusion-2-1":
|
||||
self.model_id = "stabilityai/stable-diffusion-2-1-base"
|
||||
self.custom_vae = custom_vae
|
||||
self.precision = precision
|
||||
self.base_vae = use_base_vae
|
||||
self.model_name = (
|
||||
"_"
|
||||
+ str(batch_size)
|
||||
+ "_"
|
||||
+ str(max_len)
|
||||
+ "_"
|
||||
+ str(height)
|
||||
+ "_"
|
||||
+ str(width)
|
||||
+ "_"
|
||||
+ precision
|
||||
)
|
||||
print(f'use_tuned? sharkify: {use_tuned}')
|
||||
self.use_tuned = use_tuned
|
||||
if use_tuned:
|
||||
self.model_name = self.model_name + "_tuned"
|
||||
self.model_name = self.model_name + "_" + get_path_stem(self.model_id)
|
||||
self.low_cpu_mem_usage = low_cpu_mem_usage
|
||||
self.is_inpaint = is_inpaint
|
||||
self.is_upscaler = is_upscaler
|
||||
self.use_stencil = get_stencil_model_id(use_stencil)
|
||||
if use_lora != "":
|
||||
self.model_name = self.model_name + "_" + get_path_stem(use_lora)
|
||||
self.use_lora = use_lora
|
||||
|
||||
print(self.model_name)
|
||||
self.model_name = self.get_extended_name_for_all_model()
|
||||
self.debug = debug
|
||||
self.sharktank_dir = sharktank_dir
|
||||
self.generate_vmfb = generate_vmfb
|
||||
|
||||
self.inputs = dict()
|
||||
self.model_to_run = ""
|
||||
if self.custom_weights != "":
|
||||
self.model_to_run = self.custom_weights
|
||||
assert self.custom_weights.lower().endswith(
|
||||
(".ckpt", ".safetensors")
|
||||
), "checkpoint files supported can be any of [.ckpt, .safetensors] type"
|
||||
preprocessCKPT(self.custom_weights, self.is_inpaint)
|
||||
else:
|
||||
self.model_to_run = args.hf_model_id
|
||||
self.custom_vae = self.process_custom_vae()
|
||||
self.base_model_id = fetch_and_update_base_model_id(self.model_to_run)
|
||||
if self.base_model_id != "" and args.ckpt_loc != "":
|
||||
args.hf_model_id = self.base_model_id
|
||||
|
||||
def get_extended_name_for_all_model(self):
|
||||
model_name = {}
|
||||
sub_model_list = ["clip", "unet", "stencil_unet", "vae", "vae_encode", "stencil_adaptor"]
|
||||
index = 0
|
||||
for model in sub_model_list:
|
||||
sub_model = model
|
||||
model_config = self.model_name
|
||||
if "vae" == model:
|
||||
if self.custom_vae != "":
|
||||
model_config = model_config + get_path_stem(self.custom_vae)
|
||||
if self.base_vae:
|
||||
sub_model = "base_vae"
|
||||
model_name[model] = get_extended_name(sub_model + model_config)
|
||||
index += 1
|
||||
return model_name
|
||||
|
||||
def check_params(self, max_len, width, height):
|
||||
if not (max_len >= 32 and max_len <= 77):
|
||||
sys.exit("please specify max_len in the range [32, 77].")
|
||||
if not (width % 8 == 0 and width >= 128):
|
||||
sys.exit("width should be greater than 128 and multiple of 8")
|
||||
if not (height % 8 == 0 and height >= 128):
|
||||
sys.exit("height should be greater than 128 and multiple of 8")
|
||||
|
||||
# Get the input info for a model i.e. "unet", "clip", "vae", etc.
|
||||
def get_input_info_for(self, model_info):
|
||||
dtype_config = {"f32": torch.float32, "i64": torch.int64}
|
||||
input_map = []
|
||||
for inp in model_info:
|
||||
shape = model_info[inp]["shape"]
|
||||
dtype = dtype_config[model_info[inp]["dtype"]]
|
||||
tensor = None
|
||||
if isinstance(shape, list):
|
||||
clean_shape = replace_shape_str(
|
||||
shape, self.max_len, self.width, self.height, self.batch_size
|
||||
)
|
||||
if dtype == torch.int64:
|
||||
tensor = torch.randint(1, 3, tuple(clean_shape))
|
||||
else:
|
||||
tensor = torch.randn(*clean_shape).to(dtype)
|
||||
elif isinstance(shape, int):
|
||||
tensor = torch.tensor(shape).to(dtype)
|
||||
else:
|
||||
sys.exit("shape isn't specified correctly.")
|
||||
input_map.append(tensor)
|
||||
return input_map
|
||||
|
||||
def get_vae_encode(self):
|
||||
class VaeEncodeModel(torch.nn.Module):
|
||||
def __init__(self, model_id=self.model_id, low_cpu_mem_usage=False):
|
||||
super().__init__()
|
||||
self.vae = AutoencoderKL.from_pretrained(
|
||||
model_id,
|
||||
subfolder="vae",
|
||||
low_cpu_mem_usage=low_cpu_mem_usage,
|
||||
)
|
||||
|
||||
def forward(self, input):
|
||||
latents = self.vae.encode(input).latent_dist.sample()
|
||||
return 0.18215 * latents
|
||||
|
||||
vae_encode = VaeEncodeModel()
|
||||
inputs = tuple(self.inputs["vae_encode"])
|
||||
is_f16 = True if not self.is_upscaler and self.precision == "fp16" else False
|
||||
shark_vae_encode = compile_through_fx(
|
||||
vae_encode,
|
||||
inputs,
|
||||
is_f16=is_f16,
|
||||
use_tuned=self.use_tuned,
|
||||
model_name=self.model_name["vae_encode"],
|
||||
extra_args=get_opt_flags("vae", precision=self.precision),
|
||||
base_model_id=self.base_model_id,
|
||||
)
|
||||
return shark_vae_encode
|
||||
|
||||
def get_vae(self):
|
||||
class VaeModel(torch.nn.Module):
|
||||
def __init__(self, model_id=self.model_id, base_vae=self.base_vae, custom_vae=self.custom_vae, low_cpu_mem_usage=False):
|
||||
super().__init__()
|
||||
self.vae = None
|
||||
if custom_vae == "":
|
||||
self.vae = AutoencoderKL.from_pretrained(
|
||||
model_id,
|
||||
subfolder="vae",
|
||||
low_cpu_mem_usage=low_cpu_mem_usage,
|
||||
)
|
||||
elif not isinstance(custom_vae, dict):
|
||||
self.vae = AutoencoderKL.from_pretrained(
|
||||
custom_vae,
|
||||
subfolder="vae",
|
||||
low_cpu_mem_usage=low_cpu_mem_usage,
|
||||
)
|
||||
else:
|
||||
self.vae = AutoencoderKL.from_pretrained(
|
||||
model_id,
|
||||
subfolder="vae",
|
||||
low_cpu_mem_usage=low_cpu_mem_usage,
|
||||
)
|
||||
self.vae.load_state_dict(custom_vae)
|
||||
self.base_vae = base_vae
|
||||
|
||||
def forward(self, input):
|
||||
if not self.base_vae:
|
||||
input = 1 / 0.18215 * input
|
||||
x = self.vae.decode(input, return_dict=False)[0]
|
||||
x = (x / 2 + 0.5).clamp(0, 1)
|
||||
if self.base_vae:
|
||||
return x
|
||||
x = x * 255.0
|
||||
return x.round()
|
||||
|
||||
vae = VaeModel(low_cpu_mem_usage=self.low_cpu_mem_usage)
|
||||
inputs = tuple(self.inputs["vae"])
|
||||
is_f16 = True if self.precision == "fp16" else False
|
||||
save_dir = os.path.join(self.sharktank_dir, self.model_name["vae"])
|
||||
if self.debug:
|
||||
os.makedirs(save_dir, exist_ok=True)
|
||||
shark_vae = compile_through_fx(
|
||||
vae,
|
||||
inputs,
|
||||
is_f16=is_f16,
|
||||
use_tuned=self.use_tuned,
|
||||
model_name=self.model_name["vae"],
|
||||
debug=self.debug,
|
||||
generate_vmfb=self.generate_vmfb,
|
||||
save_dir=save_dir,
|
||||
extra_args=get_opt_flags("vae", precision=self.precision),
|
||||
base_model_id=self.base_model_id,
|
||||
)
|
||||
return shark_vae
|
||||
|
||||
def get_controlled_unet(self):
|
||||
class ControlledUnetModel(torch.nn.Module):
|
||||
def __init__(
|
||||
self, model_id=self.model_id, low_cpu_mem_usage=False, use_lora=self.use_lora
|
||||
):
|
||||
super().__init__()
|
||||
self.unet = UNet2DConditionModel.from_pretrained(
|
||||
model_id,
|
||||
subfolder="unet",
|
||||
low_cpu_mem_usage=low_cpu_mem_usage,
|
||||
)
|
||||
if use_lora != "":
|
||||
update_lora_weight(self.unet, use_lora, "unet")
|
||||
self.in_channels = self.unet.in_channels
|
||||
self.train(False)
|
||||
|
||||
def forward( self, latent, timestep, text_embedding, guidance_scale, control1,
|
||||
control2, control3, control4, control5, control6, control7,
|
||||
control8, control9, control10, control11, control12, control13,
|
||||
):
|
||||
# expand the latents if we are doing classifier-free guidance to avoid doing two forward passes.
|
||||
db_res_samples = tuple([ control1, control2, control3, control4, control5, control6, control7, control8, control9, control10, control11, control12,])
|
||||
mb_res_samples = control13
|
||||
latents = torch.cat([latent] * 2)
|
||||
unet_out = self.unet.forward(
|
||||
latents,
|
||||
timestep,
|
||||
encoder_hidden_states=text_embedding,
|
||||
down_block_additional_residuals=db_res_samples,
|
||||
mid_block_additional_residual=mb_res_samples,
|
||||
return_dict=False,
|
||||
)[0]
|
||||
noise_pred_uncond, noise_pred_text = unet_out.chunk(2)
|
||||
noise_pred = noise_pred_uncond + guidance_scale * (
|
||||
noise_pred_text - noise_pred_uncond
|
||||
)
|
||||
return noise_pred
|
||||
|
||||
unet = ControlledUnetModel(low_cpu_mem_usage=self.low_cpu_mem_usage)
|
||||
is_f16 = True if self.precision == "fp16" else False
|
||||
|
||||
inputs = tuple(self.inputs["unet"])
|
||||
input_mask = [True, True, True, False, True, True, True, True, True, True, True, True, True, True, True, True, True,]
|
||||
shark_controlled_unet = compile_through_fx(
|
||||
unet,
|
||||
inputs,
|
||||
model_name=self.model_name["stencil_unet"],
|
||||
is_f16=is_f16,
|
||||
f16_input_mask=input_mask,
|
||||
use_tuned=self.use_tuned,
|
||||
extra_args=get_opt_flags("unet", precision=self.precision),
|
||||
base_model_id=self.base_model_id,
|
||||
)
|
||||
return shark_controlled_unet
|
||||
|
||||
def get_control_net(self):
|
||||
class StencilControlNetModel(torch.nn.Module):
|
||||
def __init__(
|
||||
self, model_id=self.use_stencil, low_cpu_mem_usage=False
|
||||
):
|
||||
super().__init__()
|
||||
self.cnet = ControlNetModel.from_pretrained(
|
||||
model_id,
|
||||
low_cpu_mem_usage=low_cpu_mem_usage,
|
||||
)
|
||||
self.in_channels = self.cnet.in_channels
|
||||
self.train(False)
|
||||
|
||||
def forward(
|
||||
self,
|
||||
latent,
|
||||
timestep,
|
||||
text_embedding,
|
||||
stencil_image_input,
|
||||
):
|
||||
# expand the latents if we are doing classifier-free guidance to avoid doing two forward passes.
|
||||
# TODO: guidance NOT NEEDED change in `get_input_info` later
|
||||
latents = torch.cat(
|
||||
[latent] * 2
|
||||
) # needs to be same as controlledUNET latents
|
||||
stencil_image = torch.cat(
|
||||
[stencil_image_input] * 2
|
||||
) # needs to be same as controlledUNET latents
|
||||
down_block_res_samples, mid_block_res_sample = self.cnet.forward(
|
||||
latents,
|
||||
timestep,
|
||||
encoder_hidden_states=text_embedding,
|
||||
controlnet_cond=stencil_image,
|
||||
return_dict=False,
|
||||
)
|
||||
return tuple(list(down_block_res_samples) + [mid_block_res_sample])
|
||||
|
||||
scnet = StencilControlNetModel(low_cpu_mem_usage=self.low_cpu_mem_usage)
|
||||
is_f16 = True if self.precision == "fp16" else False
|
||||
|
||||
inputs = tuple(self.inputs["stencil_adaptor"])
|
||||
input_mask = [True, True, True, True]
|
||||
shark_cnet = compile_through_fx(
|
||||
scnet,
|
||||
inputs,
|
||||
model_name=self.model_name["stencil_adaptor"],
|
||||
is_f16=is_f16,
|
||||
f16_input_mask=input_mask,
|
||||
use_tuned=self.use_tuned,
|
||||
extra_args=get_opt_flags("unet", precision=self.precision),
|
||||
base_model_id=self.base_model_id,
|
||||
)
|
||||
return shark_cnet
|
||||
|
||||
def get_unet(self):
|
||||
class UnetModel(torch.nn.Module):
|
||||
def __init__(self, model_id=self.model_id, low_cpu_mem_usage=False, use_lora=self.use_lora):
|
||||
super().__init__()
|
||||
self.unet = UNet2DConditionModel.from_pretrained(
|
||||
model_id,
|
||||
subfolder="unet",
|
||||
low_cpu_mem_usage=low_cpu_mem_usage,
|
||||
)
|
||||
if use_lora != "":
|
||||
update_lora_weight(self.unet, use_lora, "unet")
|
||||
self.in_channels = self.unet.in_channels
|
||||
self.train(False)
|
||||
if(args.attention_slicing is not None and args.attention_slicing != "none"):
|
||||
if(args.attention_slicing.isdigit()):
|
||||
self.unet.set_attention_slice(int(args.attention_slicing))
|
||||
else:
|
||||
self.unet.set_attention_slice(args.attention_slicing)
|
||||
|
||||
# TODO: Instead of flattening the `control` try to use the list.
|
||||
def forward(
|
||||
self, latent, timestep, text_embedding, guidance_scale,
|
||||
):
|
||||
# expand the latents if we are doing classifier-free guidance to avoid doing two forward passes.
|
||||
latents = torch.cat([latent] * 2)
|
||||
unet_out = self.unet.forward(
|
||||
latents, timestep, text_embedding, return_dict=False
|
||||
)[0]
|
||||
noise_pred_uncond, noise_pred_text = unet_out.chunk(2)
|
||||
noise_pred = noise_pred_uncond + guidance_scale * (
|
||||
noise_pred_text - noise_pred_uncond
|
||||
)
|
||||
return noise_pred
|
||||
|
||||
unet = UnetModel(low_cpu_mem_usage=self.low_cpu_mem_usage)
|
||||
is_f16 = True if self.precision == "fp16" else False
|
||||
inputs = tuple(self.inputs["unet"])
|
||||
input_mask = [True, True, True, False]
|
||||
save_dir = os.path.join(self.sharktank_dir, self.model_name["unet"])
|
||||
if self.debug:
|
||||
os.makedirs(
|
||||
save_dir,
|
||||
exist_ok=True,
|
||||
)
|
||||
shark_unet = compile_through_fx(
|
||||
unet,
|
||||
inputs,
|
||||
model_name=self.model_name["unet"],
|
||||
is_f16=is_f16,
|
||||
f16_input_mask=input_mask,
|
||||
use_tuned=self.use_tuned,
|
||||
debug=self.debug,
|
||||
generate_vmfb=self.generate_vmfb,
|
||||
save_dir=save_dir,
|
||||
extra_args=get_opt_flags("unet", precision=self.precision),
|
||||
base_model_id=self.base_model_id,
|
||||
)
|
||||
return shark_unet
|
||||
|
||||
def get_unet_upscaler(self):
|
||||
class UnetModel(torch.nn.Module):
|
||||
def __init__(self, model_id=self.model_id, low_cpu_mem_usage=False):
|
||||
super().__init__()
|
||||
self.unet = UNet2DConditionModel.from_pretrained(
|
||||
model_id,
|
||||
subfolder="unet",
|
||||
low_cpu_mem_usage=low_cpu_mem_usage,
|
||||
)
|
||||
self.in_channels = self.unet.in_channels
|
||||
self.train(False)
|
||||
|
||||
def forward(self, latent, timestep, text_embedding, noise_level):
|
||||
unet_out = self.unet.forward(
|
||||
latent,
|
||||
timestep,
|
||||
text_embedding,
|
||||
noise_level,
|
||||
return_dict=False,
|
||||
)[0]
|
||||
return unet_out
|
||||
|
||||
unet = UnetModel(low_cpu_mem_usage=self.low_cpu_mem_usage)
|
||||
is_f16 = True if self.precision == "fp16" else False
|
||||
inputs = tuple(self.inputs["unet"])
|
||||
input_mask = [True, True, True, False]
|
||||
shark_unet = compile_through_fx(
|
||||
unet,
|
||||
inputs,
|
||||
model_name=self.model_name["unet"],
|
||||
is_f16=is_f16,
|
||||
f16_input_mask=input_mask,
|
||||
use_tuned=self.use_tuned,
|
||||
extra_args=get_opt_flags("unet", precision=self.precision),
|
||||
base_model_id=self.base_model_id,
|
||||
)
|
||||
return shark_unet
|
||||
|
||||
def get_clip(self):
|
||||
class CLIPText(torch.nn.Module):
|
||||
def __init__(self, model_id=self.model_id, low_cpu_mem_usage=False, use_lora=self.use_lora):
|
||||
super().__init__()
|
||||
self.text_encoder = CLIPTextModel.from_pretrained(
|
||||
model_id,
|
||||
subfolder="text_encoder",
|
||||
low_cpu_mem_usage=low_cpu_mem_usage,
|
||||
)
|
||||
if use_lora != "":
|
||||
update_lora_weight(self.text_encoder, use_lora, "text_encoder")
|
||||
|
||||
def forward(self, input):
|
||||
return self.text_encoder(input)[0]
|
||||
|
||||
clip_model = CLIPText(low_cpu_mem_usage=self.low_cpu_mem_usage)
|
||||
save_dir = os.path.join(self.sharktank_dir, self.model_name["clip"])
|
||||
if self.debug:
|
||||
os.makedirs(
|
||||
save_dir,
|
||||
exist_ok=True,
|
||||
)
|
||||
shark_clip = compile_through_fx(
|
||||
clip_model,
|
||||
tuple(self.inputs["clip"]),
|
||||
model_name=self.model_name["clip"],
|
||||
debug=self.debug,
|
||||
generate_vmfb=self.generate_vmfb,
|
||||
save_dir=save_dir,
|
||||
extra_args=get_opt_flags("clip", precision="fp32"),
|
||||
base_model_id=self.base_model_id,
|
||||
)
|
||||
return shark_clip
|
||||
|
||||
def process_custom_vae(self):
|
||||
custom_vae = self.custom_vae.lower()
|
||||
if not custom_vae.endswith((".ckpt", ".safetensors")):
|
||||
return self.custom_vae
|
||||
try:
|
||||
preprocessCKPT(self.custom_vae)
|
||||
return get_path_to_diffusers_checkpoint(self.custom_vae)
|
||||
except:
|
||||
print("Processing standalone Vae checkpoint")
|
||||
vae_checkpoint = None
|
||||
vae_ignore_keys = {"model_ema.decay", "model_ema.num_updates"}
|
||||
if custom_vae.endswith(".ckpt"):
|
||||
vae_checkpoint = torch.load(self.custom_vae, map_location="cpu")
|
||||
else:
|
||||
vae_checkpoint = safetensors.torch.load_file(self.custom_vae, device="cpu")
|
||||
if "state_dict" in vae_checkpoint:
|
||||
vae_checkpoint = vae_checkpoint["state_dict"]
|
||||
vae_dict = {k: v for k, v in vae_checkpoint.items() if k[0:4] != "loss" and k not in vae_ignore_keys}
|
||||
return vae_dict
|
||||
|
||||
def compile_unet_variants(self, model):
|
||||
if model == "unet":
|
||||
if self.is_upscaler:
|
||||
return self.get_unet_upscaler()
|
||||
# TODO: Plug the experimental "int8" support at right place.
|
||||
elif self.use_quantize == "int8":
|
||||
from apps.stable_diffusion.src.models.opt_params import get_unet
|
||||
return get_unet()
|
||||
else:
|
||||
return self.get_unet()
|
||||
else:
|
||||
return self.get_controlled_unet()
|
||||
|
||||
def vae_encode(self):
|
||||
# Fetch vmfb for the model if present
|
||||
vmfb = fetch_vmfb("vae_encode", self.model_name["vae_encode"], self.precision)
|
||||
if vmfb:
|
||||
return vmfb
|
||||
|
||||
try:
|
||||
self.inputs["vae_encode"] = self.get_input_info_for(base_models["vae_encode"])
|
||||
compiled_vae_encode = self.get_vae_encode()
|
||||
|
||||
check_compilation(compiled_vae_encode, "Vae Encode")
|
||||
return compiled_vae_encode
|
||||
except Exception as e:
|
||||
sys.exit(e)
|
||||
|
||||
def clip(self):
|
||||
vmfb = fetch_vmfb("clip", self.model_name["clip"], self.precision)
|
||||
if vmfb:
|
||||
return vmfb
|
||||
|
||||
try:
|
||||
self.inputs["clip"] = self.get_input_info_for(base_models["clip"])
|
||||
compiled_clip = self.get_clip()
|
||||
|
||||
check_compilation(compiled_clip, "Clip")
|
||||
return compiled_clip
|
||||
except Exception as e:
|
||||
sys.exit(e)
|
||||
|
||||
def unet(self):
|
||||
model = "stencil_unet" if self.use_stencil is not None else "unet"
|
||||
vmfb = fetch_vmfb(model, self.model_name[model], self.precision)
|
||||
if vmfb:
|
||||
return vmfb
|
||||
|
||||
try:
|
||||
compiled_unet = None
|
||||
unet_inputs = base_models[model]
|
||||
|
||||
if self.base_model_id != "":
|
||||
self.inputs["unet"] = self.get_input_info_for(unet_inputs[self.base_model_id])
|
||||
compiled_unet = self.compile_unet_variants(model)
|
||||
else:
|
||||
for model_id in unet_inputs:
|
||||
self.base_model_id = model_id
|
||||
self.inputs["unet"] = self.get_input_info_for(unet_inputs[model_id])
|
||||
|
||||
try:
|
||||
compiled_unet = self.compile_unet_variants(model)
|
||||
except Exception as e:
|
||||
print(e)
|
||||
print("Retrying with a different base model configuration")
|
||||
continue
|
||||
|
||||
# -- Once a successful compilation has taken place we'd want to store
|
||||
# the base model's configuration inferred.
|
||||
fetch_and_update_base_model_id(self.model_to_run, model_id)
|
||||
# This is done just because in main.py we are basing the choice of tokenizer and scheduler
|
||||
# on `args.hf_model_id`. Since now, we don't maintain 1:1 mapping of variants and the base
|
||||
# model and rely on retrying method to find the input configuration, we should also update
|
||||
# the knowledge of base model id accordingly into `args.hf_model_id`.
|
||||
if args.ckpt_loc != "":
|
||||
args.hf_model_id = model_id
|
||||
break
|
||||
|
||||
check_compilation(compiled_unet, "Unet")
|
||||
return compiled_unet
|
||||
except Exception as e:
|
||||
sys.exit(e)
|
||||
|
||||
def vae(self):
|
||||
vmfb = fetch_vmfb("vae", self.model_name["vae"], self.precision)
|
||||
if vmfb:
|
||||
return vmfb
|
||||
|
||||
try:
|
||||
vae_input = base_models["vae"]["vae_upscaler"] if self.is_upscaler else base_models["vae"]["vae"]
|
||||
self.inputs["vae"] = self.get_input_info_for(vae_input)
|
||||
|
||||
is_base_vae = self.base_vae
|
||||
if self.is_upscaler:
|
||||
self.base_vae = True
|
||||
compiled_vae = self.get_vae()
|
||||
self.base_vae = is_base_vae
|
||||
|
||||
check_compilation(compiled_vae, "Vae")
|
||||
return compiled_vae
|
||||
except Exception as e:
|
||||
sys.exit(e)
|
||||
|
||||
def controlnet(self):
|
||||
vmfb = fetch_vmfb("stencil_adaptor", self.model_name["stencil_adaptor"], self.precision)
|
||||
if vmfb:
|
||||
return vmfb
|
||||
|
||||
try:
|
||||
self.inputs["stencil_adaptor"] = self.get_input_info_for(base_models["stencil_adaptor"])
|
||||
compiled_stencil_adaptor = self.get_control_net()
|
||||
|
||||
check_compilation(compiled_stencil_adaptor, "Stencil")
|
||||
return compiled_stencil_adaptor
|
||||
except Exception as e:
|
||||
sys.exit(e)
|
||||
123
apps/stable_diffusion/src/models/opt_params.py
Normal file
123
apps/stable_diffusion/src/models/opt_params.py
Normal file
@@ -0,0 +1,123 @@
|
||||
import sys
|
||||
from transformers import CLIPTokenizer
|
||||
from apps.stable_diffusion.src.utils import (
|
||||
models_db,
|
||||
args,
|
||||
get_shark_model,
|
||||
get_opt_flags,
|
||||
)
|
||||
|
||||
|
||||
hf_model_variant_map = {
|
||||
"Linaqruf/anything-v3.0": ["anythingv3", "v1_4"],
|
||||
"dreamlike-art/dreamlike-diffusion-1.0": ["dreamlike", "v1_4"],
|
||||
"prompthero/openjourney": ["openjourney", "v1_4"],
|
||||
"wavymulder/Analog-Diffusion": ["analogdiffusion", "v1_4"],
|
||||
"stabilityai/stable-diffusion-2-1": ["stablediffusion", "v2_1base"],
|
||||
"stabilityai/stable-diffusion-2-1-base": ["stablediffusion", "v2_1base"],
|
||||
"CompVis/stable-diffusion-v1-4": ["stablediffusion", "v1_4"],
|
||||
"runwayml/stable-diffusion-inpainting": ["stablediffusion", "inpaint_v1"],
|
||||
"stabilityai/stable-diffusion-2-inpainting": ["stablediffusion", "inpaint_v2"],
|
||||
}
|
||||
|
||||
# TODO: Add the quantized model as a part model_db.json.
|
||||
# This is currently in experimental phase.
|
||||
def get_quantize_model():
|
||||
bucket_key = "gs://shark_tank/prashant_nod"
|
||||
model_key = "unet_int8"
|
||||
iree_flags = get_opt_flags("unet", precision="fp16")
|
||||
if args.height != 512 and args.width != 512 and args.max_length != 77:
|
||||
sys.exit("The int8 quantized model currently requires the height and width to be 512, and max_length to be 77")
|
||||
return bucket_key, model_key, iree_flags
|
||||
|
||||
def get_variant_version(hf_model_id):
|
||||
return hf_model_variant_map[hf_model_id]
|
||||
|
||||
|
||||
def get_params(bucket_key, model_key, model, is_tuned, precision):
|
||||
try:
|
||||
bucket = models_db[0][bucket_key]
|
||||
model_name = models_db[1][model_key]
|
||||
except KeyError:
|
||||
raise Exception(
|
||||
f"{bucket_key}/{model_key} is not present in the models database"
|
||||
)
|
||||
iree_flags = get_opt_flags(model, precision="fp16")
|
||||
return bucket, model_name, iree_flags
|
||||
|
||||
|
||||
def get_unet():
|
||||
variant, version = get_variant_version(args.hf_model_id)
|
||||
# Tuned model is present only for `fp16` precision.
|
||||
is_tuned = "tuned" if args.use_tuned else "untuned"
|
||||
|
||||
# TODO: Get the quantize model from model_db.json
|
||||
if args.use_quantize == "int8":
|
||||
bk, mk, flags = get_quantize_model()
|
||||
return get_shark_model(bk, mk, flags)
|
||||
|
||||
if "vulkan" not in args.device and args.use_tuned:
|
||||
bucket_key = f"{variant}/{is_tuned}/{args.device}"
|
||||
model_key = f"{variant}/{version}/unet/{args.precision}/length_{args.max_length}/{is_tuned}/{args.device}"
|
||||
else:
|
||||
bucket_key = f"{variant}/{is_tuned}"
|
||||
model_key = f"{variant}/{version}/unet/{args.precision}/length_{args.max_length}/{is_tuned}"
|
||||
|
||||
bucket, model_name, iree_flags = get_params(
|
||||
bucket_key, model_key, "unet", is_tuned, args.precision
|
||||
)
|
||||
return get_shark_model(bucket, model_name, iree_flags)
|
||||
|
||||
|
||||
def get_vae_encode():
|
||||
variant, version = get_variant_version(args.hf_model_id)
|
||||
# Tuned model is present only for `fp16` precision.
|
||||
is_tuned = "tuned" if args.use_tuned else "untuned"
|
||||
if "vulkan" not in args.device and args.use_tuned:
|
||||
bucket_key = f"{variant}/{is_tuned}/{args.device}"
|
||||
model_key = f"{variant}/{version}/vae_encode/{args.precision}/length_77/{is_tuned}/{args.device}"
|
||||
else:
|
||||
bucket_key = f"{variant}/{is_tuned}"
|
||||
model_key = f"{variant}/{version}/vae_encode/{args.precision}/length_77/{is_tuned}"
|
||||
|
||||
bucket, model_name, iree_flags = get_params(
|
||||
bucket_key, model_key, "vae", is_tuned, args.precision
|
||||
)
|
||||
return get_shark_model(bucket, model_name, iree_flags)
|
||||
|
||||
|
||||
def get_vae():
|
||||
variant, version = get_variant_version(args.hf_model_id)
|
||||
# Tuned model is present only for `fp16` precision.
|
||||
is_tuned = "tuned" if args.use_tuned else "untuned"
|
||||
is_base = "/base" if args.use_base_vae else ""
|
||||
if "vulkan" not in args.device and args.use_tuned:
|
||||
bucket_key = f"{variant}/{is_tuned}/{args.device}"
|
||||
model_key = f"{variant}/{version}/vae/{args.precision}/length_77/{is_tuned}{is_base}/{args.device}"
|
||||
else:
|
||||
bucket_key = f"{variant}/{is_tuned}"
|
||||
model_key = f"{variant}/{version}/vae/{args.precision}/length_77/{is_tuned}{is_base}"
|
||||
|
||||
bucket, model_name, iree_flags = get_params(
|
||||
bucket_key, model_key, "vae", is_tuned, args.precision
|
||||
)
|
||||
return get_shark_model(bucket, model_name, iree_flags)
|
||||
|
||||
|
||||
def get_clip():
|
||||
variant, version = get_variant_version(args.hf_model_id)
|
||||
bucket_key = f"{variant}/untuned"
|
||||
model_key = (
|
||||
f"{variant}/{version}/clip/fp32/length_{args.max_length}/untuned"
|
||||
)
|
||||
bucket, model_name, iree_flags = get_params(
|
||||
bucket_key, model_key, "clip", "untuned", "fp32"
|
||||
)
|
||||
return get_shark_model(bucket, model_name, iree_flags)
|
||||
|
||||
|
||||
def get_tokenizer():
|
||||
tokenizer = CLIPTokenizer.from_pretrained(
|
||||
args.hf_model_id, subfolder="tokenizer"
|
||||
)
|
||||
return tokenizer
|
||||
18
apps/stable_diffusion/src/pipelines/__init__.py
Normal file
18
apps/stable_diffusion/src/pipelines/__init__.py
Normal file
@@ -0,0 +1,18 @@
|
||||
from apps.stable_diffusion.src.pipelines.pipeline_shark_stable_diffusion_txt2img import (
|
||||
Text2ImagePipeline,
|
||||
)
|
||||
from apps.stable_diffusion.src.pipelines.pipeline_shark_stable_diffusion_img2img import (
|
||||
Image2ImagePipeline,
|
||||
)
|
||||
from apps.stable_diffusion.src.pipelines.pipeline_shark_stable_diffusion_inpaint import (
|
||||
InpaintPipeline,
|
||||
)
|
||||
from apps.stable_diffusion.src.pipelines.pipeline_shark_stable_diffusion_outpaint import (
|
||||
OutpaintPipeline,
|
||||
)
|
||||
from apps.stable_diffusion.src.pipelines.pipeline_shark_stable_diffusion_stencil import (
|
||||
StencilPipeline,
|
||||
)
|
||||
from apps.stable_diffusion.src.pipelines.pipeline_shark_stable_diffusion_upscaler import (
|
||||
UpscalerPipeline,
|
||||
)
|
||||
@@ -0,0 +1,200 @@
|
||||
import torch
|
||||
import time
|
||||
import numpy as np
|
||||
from tqdm.auto import tqdm
|
||||
from random import randint
|
||||
from PIL import Image
|
||||
from transformers import CLIPTokenizer
|
||||
from typing import Union
|
||||
from shark.shark_inference import SharkInference
|
||||
from diffusers import (
|
||||
DDIMScheduler,
|
||||
PNDMScheduler,
|
||||
LMSDiscreteScheduler,
|
||||
EulerDiscreteScheduler,
|
||||
EulerAncestralDiscreteScheduler,
|
||||
DPMSolverMultistepScheduler,
|
||||
DEISMultistepScheduler,
|
||||
)
|
||||
from apps.stable_diffusion.src.schedulers import SharkEulerDiscreteScheduler
|
||||
from apps.stable_diffusion.src.pipelines.pipeline_shark_stable_diffusion_utils import (
|
||||
StableDiffusionPipeline,
|
||||
)
|
||||
from apps.stable_diffusion.src.models import (
|
||||
SharkifyStableDiffusionModel,
|
||||
get_vae_encode,
|
||||
)
|
||||
|
||||
|
||||
class Image2ImagePipeline(StableDiffusionPipeline):
|
||||
def __init__(
|
||||
self,
|
||||
scheduler: Union[
|
||||
DDIMScheduler,
|
||||
PNDMScheduler,
|
||||
LMSDiscreteScheduler,
|
||||
EulerDiscreteScheduler,
|
||||
EulerAncestralDiscreteScheduler,
|
||||
DPMSolverMultistepScheduler,
|
||||
SharkEulerDiscreteScheduler,
|
||||
DEISMultistepScheduler,
|
||||
],
|
||||
sd_model: SharkifyStableDiffusionModel,
|
||||
import_mlir: bool,
|
||||
use_lora: str,
|
||||
ondemand: bool,
|
||||
):
|
||||
super().__init__(scheduler, sd_model, import_mlir, use_lora, ondemand)
|
||||
self.vae_encode = None
|
||||
|
||||
def load_vae_encode(self):
|
||||
if self.vae_encode is not None:
|
||||
return
|
||||
|
||||
if self.import_mlir or self.use_lora:
|
||||
self.vae_encode = self.sd_model.vae_encode()
|
||||
else:
|
||||
try:
|
||||
self.vae_encode = get_vae_encode()
|
||||
except:
|
||||
print("download pipeline failed, falling back to import_mlir")
|
||||
self.vae_encode = self.sd_model.vae_encode()
|
||||
|
||||
def unload_vae_encode(self):
|
||||
del self.vae_encode
|
||||
self.vae_encode = None
|
||||
|
||||
def prepare_image_latents(
|
||||
self,
|
||||
image,
|
||||
batch_size,
|
||||
height,
|
||||
width,
|
||||
generator,
|
||||
num_inference_steps,
|
||||
strength,
|
||||
dtype,
|
||||
):
|
||||
# Pre process image -> get image encoded -> process latents
|
||||
|
||||
# TODO: process with variable HxW combos
|
||||
|
||||
# Pre process image
|
||||
image = image.resize((width, height))
|
||||
image_arr = np.stack([np.array(i) for i in (image,)], axis=0)
|
||||
image_arr = image_arr / 255.0
|
||||
image_arr = torch.from_numpy(image_arr).permute(0, 3, 1, 2).to(dtype)
|
||||
image_arr = 2 * (image_arr - 0.5)
|
||||
|
||||
# set scheduler steps
|
||||
self.scheduler.set_timesteps(num_inference_steps)
|
||||
init_timestep = min(
|
||||
int(num_inference_steps * strength), num_inference_steps
|
||||
)
|
||||
t_start = max(num_inference_steps - init_timestep, 0)
|
||||
# timesteps reduced as per strength
|
||||
timesteps = self.scheduler.timesteps[t_start:]
|
||||
# new number of steps to be used as per strength will be
|
||||
# num_inference_steps = num_inference_steps - t_start
|
||||
|
||||
# image encode
|
||||
latents = self.encode_image((image_arr,))
|
||||
latents = torch.from_numpy(latents).to(dtype)
|
||||
# add noise to data
|
||||
noise = torch.randn(latents.shape, generator=generator, dtype=dtype)
|
||||
latents = self.scheduler.add_noise(
|
||||
latents, noise, timesteps[0].repeat(1)
|
||||
)
|
||||
|
||||
return latents, timesteps
|
||||
|
||||
def encode_image(self, input_image):
|
||||
self.load_vae_encode()
|
||||
vae_encode_start = time.time()
|
||||
latents = self.vae_encode("forward", input_image)
|
||||
vae_inf_time = (time.time() - vae_encode_start) * 1000
|
||||
if self.ondemand:
|
||||
self.unload_vae_encode()
|
||||
self.log += f"\nVAE Encode Inference time (ms): {vae_inf_time:.3f}"
|
||||
|
||||
return latents
|
||||
|
||||
def generate_images(
|
||||
self,
|
||||
prompts,
|
||||
neg_prompts,
|
||||
image,
|
||||
batch_size,
|
||||
height,
|
||||
width,
|
||||
num_inference_steps,
|
||||
strength,
|
||||
guidance_scale,
|
||||
seed,
|
||||
max_length,
|
||||
dtype,
|
||||
use_base_vae,
|
||||
cpu_scheduling,
|
||||
use_stencil,
|
||||
):
|
||||
# prompts and negative prompts must be a list.
|
||||
if isinstance(prompts, str):
|
||||
prompts = [prompts]
|
||||
|
||||
if isinstance(neg_prompts, str):
|
||||
neg_prompts = [neg_prompts]
|
||||
|
||||
prompts = prompts * batch_size
|
||||
neg_prompts = neg_prompts * batch_size
|
||||
|
||||
# seed generator to create the inital latent noise. Also handle out of range seeds.
|
||||
uint32_info = np.iinfo(np.uint32)
|
||||
uint32_min, uint32_max = uint32_info.min, uint32_info.max
|
||||
if seed < uint32_min or seed >= uint32_max:
|
||||
seed = randint(uint32_min, uint32_max)
|
||||
generator = torch.manual_seed(seed)
|
||||
|
||||
# Get text embeddings with weight emphasis from prompts
|
||||
text_embeddings = self.encode_prompts_weight(
|
||||
prompts, neg_prompts, max_length
|
||||
)
|
||||
|
||||
# guidance scale as a float32 tensor.
|
||||
guidance_scale = torch.tensor(guidance_scale).to(torch.float32)
|
||||
|
||||
# Prepare input image latent
|
||||
image_latents, final_timesteps = self.prepare_image_latents(
|
||||
image=image,
|
||||
batch_size=batch_size,
|
||||
height=height,
|
||||
width=width,
|
||||
generator=generator,
|
||||
num_inference_steps=num_inference_steps,
|
||||
strength=strength,
|
||||
dtype=dtype,
|
||||
)
|
||||
|
||||
# Get Image latents
|
||||
latents = self.produce_img_latents(
|
||||
latents=image_latents,
|
||||
text_embeddings=text_embeddings,
|
||||
guidance_scale=guidance_scale,
|
||||
total_timesteps=final_timesteps,
|
||||
dtype=dtype,
|
||||
cpu_scheduling=cpu_scheduling,
|
||||
)
|
||||
|
||||
# Img latents -> PIL images
|
||||
all_imgs = []
|
||||
self.load_vae()
|
||||
for i in tqdm(range(0, latents.shape[0], batch_size)):
|
||||
imgs = self.decode_latents(
|
||||
latents=latents[i : i + batch_size],
|
||||
use_base_vae=use_base_vae,
|
||||
cpu_scheduling=cpu_scheduling,
|
||||
)
|
||||
all_imgs.extend(imgs)
|
||||
if self.ondemand:
|
||||
self.unload_vae()
|
||||
|
||||
return all_imgs
|
||||
@@ -0,0 +1,473 @@
|
||||
import torch
|
||||
from tqdm.auto import tqdm
|
||||
import numpy as np
|
||||
from random import randint
|
||||
from PIL import Image, ImageOps
|
||||
from transformers import CLIPTokenizer
|
||||
from typing import Union
|
||||
from shark.shark_inference import SharkInference
|
||||
from diffusers import (
|
||||
DDIMScheduler,
|
||||
PNDMScheduler,
|
||||
LMSDiscreteScheduler,
|
||||
EulerDiscreteScheduler,
|
||||
EulerAncestralDiscreteScheduler,
|
||||
DPMSolverMultistepScheduler,
|
||||
DEISMultistepScheduler,
|
||||
)
|
||||
from apps.stable_diffusion.src.schedulers import SharkEulerDiscreteScheduler
|
||||
from apps.stable_diffusion.src.pipelines.pipeline_shark_stable_diffusion_utils import (
|
||||
StableDiffusionPipeline,
|
||||
)
|
||||
from apps.stable_diffusion.src.models import (
|
||||
SharkifyStableDiffusionModel,
|
||||
get_vae_encode,
|
||||
)
|
||||
|
||||
|
||||
class InpaintPipeline(StableDiffusionPipeline):
|
||||
def __init__(
|
||||
self,
|
||||
scheduler: Union[
|
||||
DDIMScheduler,
|
||||
PNDMScheduler,
|
||||
LMSDiscreteScheduler,
|
||||
EulerDiscreteScheduler,
|
||||
EulerAncestralDiscreteScheduler,
|
||||
DPMSolverMultistepScheduler,
|
||||
SharkEulerDiscreteScheduler,
|
||||
DEISMultistepScheduler,
|
||||
],
|
||||
sd_model: SharkifyStableDiffusionModel,
|
||||
import_mlir: bool,
|
||||
use_lora: str,
|
||||
ondemand: bool,
|
||||
):
|
||||
super().__init__(scheduler, sd_model, import_mlir, use_lora, ondemand)
|
||||
self.vae_encode = None
|
||||
|
||||
def load_vae_encode(self):
|
||||
if self.vae_encode is not None:
|
||||
return
|
||||
|
||||
if self.import_mlir or self.use_lora:
|
||||
self.vae_encode = self.sd_model.vae_encode()
|
||||
else:
|
||||
try:
|
||||
self.vae_encode = get_vae_encode()
|
||||
except:
|
||||
print("download pipeline failed, falling back to import_mlir")
|
||||
self.vae_encode = self.sd_model.vae_encode()
|
||||
|
||||
def unload_vae_encode(self):
|
||||
del self.vae_encode
|
||||
self.vae_encode = None
|
||||
|
||||
def prepare_latents(
|
||||
self,
|
||||
batch_size,
|
||||
height,
|
||||
width,
|
||||
generator,
|
||||
num_inference_steps,
|
||||
dtype,
|
||||
):
|
||||
latents = torch.randn(
|
||||
(
|
||||
batch_size,
|
||||
4,
|
||||
height // 8,
|
||||
width // 8,
|
||||
),
|
||||
generator=generator,
|
||||
dtype=torch.float32,
|
||||
).to(dtype)
|
||||
|
||||
self.scheduler.set_timesteps(num_inference_steps)
|
||||
latents = latents * self.scheduler.init_noise_sigma
|
||||
return latents
|
||||
|
||||
def get_crop_region(self, mask, pad=0):
|
||||
h, w = mask.shape
|
||||
|
||||
crop_left = 0
|
||||
for i in range(w):
|
||||
if not (mask[:, i] == 0).all():
|
||||
break
|
||||
crop_left += 1
|
||||
|
||||
crop_right = 0
|
||||
for i in reversed(range(w)):
|
||||
if not (mask[:, i] == 0).all():
|
||||
break
|
||||
crop_right += 1
|
||||
|
||||
crop_top = 0
|
||||
for i in range(h):
|
||||
if not (mask[i] == 0).all():
|
||||
break
|
||||
crop_top += 1
|
||||
|
||||
crop_bottom = 0
|
||||
for i in reversed(range(h)):
|
||||
if not (mask[i] == 0).all():
|
||||
break
|
||||
crop_bottom += 1
|
||||
|
||||
return (
|
||||
int(max(crop_left - pad, 0)),
|
||||
int(max(crop_top - pad, 0)),
|
||||
int(min(w - crop_right + pad, w)),
|
||||
int(min(h - crop_bottom + pad, h)),
|
||||
)
|
||||
|
||||
def expand_crop_region(
|
||||
self,
|
||||
crop_region,
|
||||
processing_width,
|
||||
processing_height,
|
||||
image_width,
|
||||
image_height,
|
||||
):
|
||||
x1, y1, x2, y2 = crop_region
|
||||
|
||||
ratio_crop_region = (x2 - x1) / (y2 - y1)
|
||||
ratio_processing = processing_width / processing_height
|
||||
|
||||
if ratio_crop_region > ratio_processing:
|
||||
desired_height = (x2 - x1) / ratio_processing
|
||||
desired_height_diff = int(desired_height - (y2 - y1))
|
||||
y1 -= desired_height_diff // 2
|
||||
y2 += desired_height_diff - desired_height_diff // 2
|
||||
if y2 >= image_height:
|
||||
diff = y2 - image_height
|
||||
y2 -= diff
|
||||
y1 -= diff
|
||||
if y1 < 0:
|
||||
y2 -= y1
|
||||
y1 -= y1
|
||||
if y2 >= image_height:
|
||||
y2 = image_height
|
||||
else:
|
||||
desired_width = (y2 - y1) * ratio_processing
|
||||
desired_width_diff = int(desired_width - (x2 - x1))
|
||||
x1 -= desired_width_diff // 2
|
||||
x2 += desired_width_diff - desired_width_diff // 2
|
||||
if x2 >= image_width:
|
||||
diff = x2 - image_width
|
||||
x2 -= diff
|
||||
x1 -= diff
|
||||
if x1 < 0:
|
||||
x2 -= x1
|
||||
x1 -= x1
|
||||
if x2 >= image_width:
|
||||
x2 = image_width
|
||||
|
||||
return x1, y1, x2, y2
|
||||
|
||||
def resize_image(self, resize_mode, im, width, height):
|
||||
"""
|
||||
resize_mode:
|
||||
0: Resize the image to fill the specified width and height, maintaining the aspect ratio, and then center the image within the dimensions, cropping the excess.
|
||||
1: Resize the image to fit within the specified width and height, maintaining the aspect ratio, and then center the image within the dimensions, filling empty with data from image.
|
||||
"""
|
||||
|
||||
if resize_mode == 0:
|
||||
ratio = width / height
|
||||
src_ratio = im.width / im.height
|
||||
|
||||
src_w = (
|
||||
width if ratio > src_ratio else im.width * height // im.height
|
||||
)
|
||||
src_h = (
|
||||
height if ratio <= src_ratio else im.height * width // im.width
|
||||
)
|
||||
|
||||
resized = im.resize((src_w, src_h), resample=Image.LANCZOS)
|
||||
res = Image.new("RGB", (width, height))
|
||||
res.paste(
|
||||
resized,
|
||||
box=(width // 2 - src_w // 2, height // 2 - src_h // 2),
|
||||
)
|
||||
|
||||
else:
|
||||
ratio = width / height
|
||||
src_ratio = im.width / im.height
|
||||
|
||||
src_w = (
|
||||
width if ratio < src_ratio else im.width * height // im.height
|
||||
)
|
||||
src_h = (
|
||||
height if ratio >= src_ratio else im.height * width // im.width
|
||||
)
|
||||
|
||||
resized = im.resize((src_w, src_h), resample=Image.LANCZOS)
|
||||
res = Image.new("RGB", (width, height))
|
||||
res.paste(
|
||||
resized,
|
||||
box=(width // 2 - src_w // 2, height // 2 - src_h // 2),
|
||||
)
|
||||
|
||||
if ratio < src_ratio:
|
||||
fill_height = height // 2 - src_h // 2
|
||||
res.paste(
|
||||
resized.resize((width, fill_height), box=(0, 0, width, 0)),
|
||||
box=(0, 0),
|
||||
)
|
||||
res.paste(
|
||||
resized.resize(
|
||||
(width, fill_height),
|
||||
box=(0, resized.height, width, resized.height),
|
||||
),
|
||||
box=(0, fill_height + src_h),
|
||||
)
|
||||
elif ratio > src_ratio:
|
||||
fill_width = width // 2 - src_w // 2
|
||||
res.paste(
|
||||
resized.resize(
|
||||
(fill_width, height), box=(0, 0, 0, height)
|
||||
),
|
||||
box=(0, 0),
|
||||
)
|
||||
res.paste(
|
||||
resized.resize(
|
||||
(fill_width, height),
|
||||
box=(resized.width, 0, resized.width, height),
|
||||
),
|
||||
box=(fill_width + src_w, 0),
|
||||
)
|
||||
|
||||
return res
|
||||
|
||||
def prepare_mask_and_masked_image(
|
||||
self,
|
||||
image,
|
||||
mask,
|
||||
height,
|
||||
width,
|
||||
inpaint_full_res,
|
||||
inpaint_full_res_padding,
|
||||
):
|
||||
# preprocess image
|
||||
image = image.resize((width, height))
|
||||
mask = mask.resize((width, height))
|
||||
|
||||
paste_to = ()
|
||||
overlay_image = None
|
||||
if inpaint_full_res:
|
||||
# prepare overlay image
|
||||
overlay_image = Image.new("RGB", (image.width, image.height))
|
||||
overlay_image.paste(
|
||||
image.convert("RGB"),
|
||||
mask=ImageOps.invert(mask.convert("L")),
|
||||
)
|
||||
|
||||
# prepare mask
|
||||
mask = mask.convert("L")
|
||||
crop_region = self.get_crop_region(
|
||||
np.array(mask), inpaint_full_res_padding
|
||||
)
|
||||
crop_region = self.expand_crop_region(
|
||||
crop_region, width, height, mask.width, mask.height
|
||||
)
|
||||
x1, y1, x2, y2 = crop_region
|
||||
mask = mask.crop(crop_region)
|
||||
mask = self.resize_image(1, mask, width, height)
|
||||
paste_to = (x1, y1, x2 - x1, y2 - y1)
|
||||
|
||||
# prepare image
|
||||
image = image.crop(crop_region)
|
||||
image = self.resize_image(1, image, width, height)
|
||||
|
||||
if isinstance(image, (Image.Image, np.ndarray)):
|
||||
image = [image]
|
||||
|
||||
if isinstance(image, list) and isinstance(image[0], Image.Image):
|
||||
image = [np.array(i.convert("RGB"))[None, :] for i in image]
|
||||
image = np.concatenate(image, axis=0)
|
||||
elif isinstance(image, list) and isinstance(image[0], np.ndarray):
|
||||
image = np.concatenate([i[None, :] for i in image], axis=0)
|
||||
|
||||
image = image.transpose(0, 3, 1, 2)
|
||||
image = torch.from_numpy(image).to(dtype=torch.float32) / 127.5 - 1.0
|
||||
|
||||
# preprocess mask
|
||||
if isinstance(mask, (Image.Image, np.ndarray)):
|
||||
mask = [mask]
|
||||
|
||||
if isinstance(mask, list) and isinstance(mask[0], Image.Image):
|
||||
mask = np.concatenate(
|
||||
[np.array(m.convert("L"))[None, None, :] for m in mask], axis=0
|
||||
)
|
||||
mask = mask.astype(np.float32) / 255.0
|
||||
elif isinstance(mask, list) and isinstance(mask[0], np.ndarray):
|
||||
mask = np.concatenate([m[None, None, :] for m in mask], axis=0)
|
||||
|
||||
mask[mask < 0.5] = 0
|
||||
mask[mask >= 0.5] = 1
|
||||
mask = torch.from_numpy(mask)
|
||||
|
||||
masked_image = image * (mask < 0.5)
|
||||
|
||||
return mask, masked_image, paste_to, overlay_image
|
||||
|
||||
def prepare_mask_latents(
|
||||
self,
|
||||
mask,
|
||||
masked_image,
|
||||
batch_size,
|
||||
height,
|
||||
width,
|
||||
dtype,
|
||||
):
|
||||
mask = torch.nn.functional.interpolate(
|
||||
mask, size=(height // 8, width // 8)
|
||||
)
|
||||
mask = mask.to(dtype)
|
||||
|
||||
self.load_vae_encode()
|
||||
masked_image = masked_image.to(dtype)
|
||||
masked_image_latents = self.vae_encode("forward", (masked_image,))
|
||||
masked_image_latents = torch.from_numpy(masked_image_latents)
|
||||
if self.ondemand:
|
||||
self.unload_vae_encode()
|
||||
|
||||
# duplicate mask and masked_image_latents for each generation per prompt, using mps friendly method
|
||||
if mask.shape[0] < batch_size:
|
||||
if not batch_size % mask.shape[0] == 0:
|
||||
raise ValueError(
|
||||
"The passed mask and the required batch size don't match. Masks are supposed to be duplicated to"
|
||||
f" a total batch size of {batch_size}, but {mask.shape[0]} masks were passed. Make sure the number"
|
||||
" of masks that you pass is divisible by the total requested batch size."
|
||||
)
|
||||
mask = mask.repeat(batch_size // mask.shape[0], 1, 1, 1)
|
||||
if masked_image_latents.shape[0] < batch_size:
|
||||
if not batch_size % masked_image_latents.shape[0] == 0:
|
||||
raise ValueError(
|
||||
"The passed images and the required batch size don't match. Images are supposed to be duplicated"
|
||||
f" to a total batch size of {batch_size}, but {masked_image_latents.shape[0]} images were passed."
|
||||
" Make sure the number of images that you pass is divisible by the total requested batch size."
|
||||
)
|
||||
masked_image_latents = masked_image_latents.repeat(
|
||||
batch_size // masked_image_latents.shape[0], 1, 1, 1
|
||||
)
|
||||
return mask, masked_image_latents
|
||||
|
||||
def apply_overlay(self, image, paste_loc, overlay):
|
||||
x, y, w, h = paste_loc
|
||||
image = self.resize_image(0, image, w, h)
|
||||
overlay.paste(image, (x, y))
|
||||
|
||||
return overlay
|
||||
|
||||
def generate_images(
|
||||
self,
|
||||
prompts,
|
||||
neg_prompts,
|
||||
image,
|
||||
mask_image,
|
||||
batch_size,
|
||||
height,
|
||||
width,
|
||||
inpaint_full_res,
|
||||
inpaint_full_res_padding,
|
||||
num_inference_steps,
|
||||
guidance_scale,
|
||||
seed,
|
||||
max_length,
|
||||
dtype,
|
||||
use_base_vae,
|
||||
cpu_scheduling,
|
||||
):
|
||||
# prompts and negative prompts must be a list.
|
||||
if isinstance(prompts, str):
|
||||
prompts = [prompts]
|
||||
|
||||
if isinstance(neg_prompts, str):
|
||||
neg_prompts = [neg_prompts]
|
||||
|
||||
prompts = prompts * batch_size
|
||||
neg_prompts = neg_prompts * batch_size
|
||||
|
||||
# seed generator to create the inital latent noise. Also handle out of range seeds.
|
||||
uint32_info = np.iinfo(np.uint32)
|
||||
uint32_min, uint32_max = uint32_info.min, uint32_info.max
|
||||
if seed < uint32_min or seed >= uint32_max:
|
||||
seed = randint(uint32_min, uint32_max)
|
||||
generator = torch.manual_seed(seed)
|
||||
|
||||
# Get initial latents
|
||||
init_latents = self.prepare_latents(
|
||||
batch_size=batch_size,
|
||||
height=height,
|
||||
width=width,
|
||||
generator=generator,
|
||||
num_inference_steps=num_inference_steps,
|
||||
dtype=dtype,
|
||||
)
|
||||
|
||||
# Get text embeddings with weight emphasis from prompts
|
||||
text_embeddings = self.encode_prompts_weight(
|
||||
prompts, neg_prompts, max_length
|
||||
)
|
||||
|
||||
# guidance scale as a float32 tensor.
|
||||
guidance_scale = torch.tensor(guidance_scale).to(torch.float32)
|
||||
|
||||
# Preprocess mask and image
|
||||
(
|
||||
mask,
|
||||
masked_image,
|
||||
paste_to,
|
||||
overlay_image,
|
||||
) = self.prepare_mask_and_masked_image(
|
||||
image,
|
||||
mask_image,
|
||||
height,
|
||||
width,
|
||||
inpaint_full_res,
|
||||
inpaint_full_res_padding,
|
||||
)
|
||||
|
||||
# Prepare mask latent variables
|
||||
mask, masked_image_latents = self.prepare_mask_latents(
|
||||
mask=mask,
|
||||
masked_image=masked_image,
|
||||
batch_size=batch_size,
|
||||
height=height,
|
||||
width=width,
|
||||
dtype=dtype,
|
||||
)
|
||||
|
||||
# Get Image latents
|
||||
latents = self.produce_img_latents(
|
||||
latents=init_latents,
|
||||
text_embeddings=text_embeddings,
|
||||
guidance_scale=guidance_scale,
|
||||
total_timesteps=self.scheduler.timesteps,
|
||||
dtype=dtype,
|
||||
cpu_scheduling=cpu_scheduling,
|
||||
mask=mask,
|
||||
masked_image_latents=masked_image_latents,
|
||||
)
|
||||
|
||||
# Img latents -> PIL images
|
||||
all_imgs = []
|
||||
self.load_vae()
|
||||
for i in tqdm(range(0, latents.shape[0], batch_size)):
|
||||
imgs = self.decode_latents(
|
||||
latents=latents[i : i + batch_size],
|
||||
use_base_vae=use_base_vae,
|
||||
cpu_scheduling=cpu_scheduling,
|
||||
)
|
||||
all_imgs.extend(imgs)
|
||||
if self.ondemand:
|
||||
self.unload_vae()
|
||||
|
||||
if inpaint_full_res:
|
||||
output_image = self.apply_overlay(
|
||||
all_imgs[0], paste_to, overlay_image
|
||||
)
|
||||
return [output_image]
|
||||
|
||||
return all_imgs
|
||||
@@ -0,0 +1,567 @@
|
||||
import torch
|
||||
from tqdm.auto import tqdm
|
||||
import numpy as np
|
||||
from random import randint
|
||||
from PIL import Image, ImageDraw, ImageFilter
|
||||
from transformers import CLIPTokenizer
|
||||
from typing import Union
|
||||
from shark.shark_inference import SharkInference
|
||||
from diffusers import (
|
||||
DDIMScheduler,
|
||||
PNDMScheduler,
|
||||
LMSDiscreteScheduler,
|
||||
EulerDiscreteScheduler,
|
||||
EulerAncestralDiscreteScheduler,
|
||||
DPMSolverMultistepScheduler,
|
||||
DEISMultistepScheduler,
|
||||
)
|
||||
from apps.stable_diffusion.src.schedulers import SharkEulerDiscreteScheduler
|
||||
from apps.stable_diffusion.src.pipelines.pipeline_shark_stable_diffusion_utils import (
|
||||
StableDiffusionPipeline,
|
||||
)
|
||||
import math
|
||||
from apps.stable_diffusion.src.models import (
|
||||
SharkifyStableDiffusionModel,
|
||||
get_vae_encode,
|
||||
)
|
||||
|
||||
|
||||
class OutpaintPipeline(StableDiffusionPipeline):
|
||||
def __init__(
|
||||
self,
|
||||
scheduler: Union[
|
||||
DDIMScheduler,
|
||||
PNDMScheduler,
|
||||
LMSDiscreteScheduler,
|
||||
EulerDiscreteScheduler,
|
||||
EulerAncestralDiscreteScheduler,
|
||||
DPMSolverMultistepScheduler,
|
||||
SharkEulerDiscreteScheduler,
|
||||
DEISMultistepScheduler,
|
||||
],
|
||||
sd_model: SharkifyStableDiffusionModel,
|
||||
import_mlir: bool,
|
||||
use_lora: str,
|
||||
ondemand: bool,
|
||||
):
|
||||
super().__init__(scheduler, sd_model, import_mlir, use_lora, ondemand)
|
||||
self.vae_encode = None
|
||||
|
||||
def load_vae_encode(self):
|
||||
if self.vae_encode is not None:
|
||||
return
|
||||
|
||||
if self.import_mlir or self.use_lora:
|
||||
self.vae_encode = self.sd_model.vae_encode()
|
||||
else:
|
||||
try:
|
||||
self.vae_encode = get_vae_encode()
|
||||
except:
|
||||
print("download pipeline failed, falling back to import_mlir")
|
||||
self.vae_encode = self.sd_model.vae_encode()
|
||||
|
||||
def unload_vae_encode(self):
|
||||
del self.vae_encode
|
||||
self.vae_encode = None
|
||||
|
||||
def prepare_latents(
|
||||
self,
|
||||
batch_size,
|
||||
height,
|
||||
width,
|
||||
generator,
|
||||
num_inference_steps,
|
||||
dtype,
|
||||
):
|
||||
latents = torch.randn(
|
||||
(
|
||||
batch_size,
|
||||
4,
|
||||
height // 8,
|
||||
width // 8,
|
||||
),
|
||||
generator=generator,
|
||||
dtype=torch.float32,
|
||||
).to(dtype)
|
||||
|
||||
self.scheduler.set_timesteps(num_inference_steps)
|
||||
latents = latents * self.scheduler.init_noise_sigma
|
||||
return latents
|
||||
|
||||
def prepare_mask_and_masked_image(
|
||||
self, image, mask, mask_blur, width, height
|
||||
):
|
||||
if mask_blur > 0:
|
||||
mask = mask.filter(ImageFilter.GaussianBlur(mask_blur))
|
||||
image = image.resize((width, height))
|
||||
mask = mask.resize((width, height))
|
||||
|
||||
# preprocess image
|
||||
if isinstance(image, (Image.Image, np.ndarray)):
|
||||
image = [image]
|
||||
|
||||
if isinstance(image, list) and isinstance(image[0], Image.Image):
|
||||
image = [np.array(i.convert("RGB"))[None, :] for i in image]
|
||||
image = np.concatenate(image, axis=0)
|
||||
elif isinstance(image, list) and isinstance(image[0], np.ndarray):
|
||||
image = np.concatenate([i[None, :] for i in image], axis=0)
|
||||
|
||||
image = image.transpose(0, 3, 1, 2)
|
||||
image = torch.from_numpy(image).to(dtype=torch.float32) / 127.5 - 1.0
|
||||
|
||||
# preprocess mask
|
||||
if isinstance(mask, (Image.Image, np.ndarray)):
|
||||
mask = [mask]
|
||||
|
||||
if isinstance(mask, list) and isinstance(mask[0], Image.Image):
|
||||
mask = np.concatenate(
|
||||
[np.array(m.convert("L"))[None, None, :] for m in mask], axis=0
|
||||
)
|
||||
mask = mask.astype(np.float32) / 255.0
|
||||
elif isinstance(mask, list) and isinstance(mask[0], np.ndarray):
|
||||
mask = np.concatenate([m[None, None, :] for m in mask], axis=0)
|
||||
|
||||
mask[mask < 0.5] = 0
|
||||
mask[mask >= 0.5] = 1
|
||||
mask = torch.from_numpy(mask)
|
||||
|
||||
masked_image = image * (mask < 0.5)
|
||||
|
||||
return mask, masked_image
|
||||
|
||||
def prepare_mask_latents(
|
||||
self,
|
||||
mask,
|
||||
masked_image,
|
||||
batch_size,
|
||||
height,
|
||||
width,
|
||||
dtype,
|
||||
):
|
||||
mask = torch.nn.functional.interpolate(
|
||||
mask, size=(height // 8, width // 8)
|
||||
)
|
||||
mask = mask.to(dtype)
|
||||
|
||||
self.load_vae_encode()
|
||||
masked_image = masked_image.to(dtype)
|
||||
masked_image_latents = self.vae_encode("forward", (masked_image,))
|
||||
masked_image_latents = torch.from_numpy(masked_image_latents)
|
||||
if self.ondemand:
|
||||
self.unload_vae_encode()
|
||||
|
||||
# duplicate mask and masked_image_latents for each generation per prompt, using mps friendly method
|
||||
if mask.shape[0] < batch_size:
|
||||
if not batch_size % mask.shape[0] == 0:
|
||||
raise ValueError(
|
||||
"The passed mask and the required batch size don't match. Masks are supposed to be duplicated to"
|
||||
f" a total batch size of {batch_size}, but {mask.shape[0]} masks were passed. Make sure the number"
|
||||
" of masks that you pass is divisible by the total requested batch size."
|
||||
)
|
||||
mask = mask.repeat(batch_size // mask.shape[0], 1, 1, 1)
|
||||
if masked_image_latents.shape[0] < batch_size:
|
||||
if not batch_size % masked_image_latents.shape[0] == 0:
|
||||
raise ValueError(
|
||||
"The passed images and the required batch size don't match. Images are supposed to be duplicated"
|
||||
f" to a total batch size of {batch_size}, but {masked_image_latents.shape[0]} images were passed."
|
||||
" Make sure the number of images that you pass is divisible by the total requested batch size."
|
||||
)
|
||||
masked_image_latents = masked_image_latents.repeat(
|
||||
batch_size // masked_image_latents.shape[0], 1, 1, 1
|
||||
)
|
||||
return mask, masked_image_latents
|
||||
|
||||
def get_matched_noise(
|
||||
self, _np_src_image, np_mask_rgb, noise_q=1, color_variation=0.05
|
||||
):
|
||||
# helper fft routines that keep ortho normalization and auto-shift before and after fft
|
||||
def _fft2(data):
|
||||
if data.ndim > 2: # has channels
|
||||
out_fft = np.zeros(
|
||||
(data.shape[0], data.shape[1], data.shape[2]),
|
||||
dtype=np.complex128,
|
||||
)
|
||||
for c in range(data.shape[2]):
|
||||
c_data = data[:, :, c]
|
||||
out_fft[:, :, c] = np.fft.fft2(
|
||||
np.fft.fftshift(c_data), norm="ortho"
|
||||
)
|
||||
out_fft[:, :, c] = np.fft.ifftshift(out_fft[:, :, c])
|
||||
else: # one channel
|
||||
out_fft = np.zeros(
|
||||
(data.shape[0], data.shape[1]), dtype=np.complex128
|
||||
)
|
||||
out_fft[:, :] = np.fft.fft2(
|
||||
np.fft.fftshift(data), norm="ortho"
|
||||
)
|
||||
out_fft[:, :] = np.fft.ifftshift(out_fft[:, :])
|
||||
|
||||
return out_fft
|
||||
|
||||
def _ifft2(data):
|
||||
if data.ndim > 2: # has channels
|
||||
out_ifft = np.zeros(
|
||||
(data.shape[0], data.shape[1], data.shape[2]),
|
||||
dtype=np.complex128,
|
||||
)
|
||||
for c in range(data.shape[2]):
|
||||
c_data = data[:, :, c]
|
||||
out_ifft[:, :, c] = np.fft.ifft2(
|
||||
np.fft.fftshift(c_data), norm="ortho"
|
||||
)
|
||||
out_ifft[:, :, c] = np.fft.ifftshift(out_ifft[:, :, c])
|
||||
else: # one channel
|
||||
out_ifft = np.zeros(
|
||||
(data.shape[0], data.shape[1]), dtype=np.complex128
|
||||
)
|
||||
out_ifft[:, :] = np.fft.ifft2(
|
||||
np.fft.fftshift(data), norm="ortho"
|
||||
)
|
||||
out_ifft[:, :] = np.fft.ifftshift(out_ifft[:, :])
|
||||
|
||||
return out_ifft
|
||||
|
||||
def _get_gaussian_window(width, height, std=3.14, mode=0):
|
||||
window_scale_x = float(width / min(width, height))
|
||||
window_scale_y = float(height / min(width, height))
|
||||
|
||||
window = np.zeros((width, height))
|
||||
x = (np.arange(width) / width * 2.0 - 1.0) * window_scale_x
|
||||
for y in range(height):
|
||||
fy = (y / height * 2.0 - 1.0) * window_scale_y
|
||||
if mode == 0:
|
||||
window[:, y] = np.exp(-(x**2 + fy**2) * std)
|
||||
else:
|
||||
window[:, y] = (
|
||||
1 / ((x**2 + 1.0) * (fy**2 + 1.0))
|
||||
) ** (std / 3.14)
|
||||
|
||||
return window
|
||||
|
||||
def _get_masked_window_rgb(np_mask_grey, hardness=1.0):
|
||||
np_mask_rgb = np.zeros(
|
||||
(np_mask_grey.shape[0], np_mask_grey.shape[1], 3)
|
||||
)
|
||||
if hardness != 1.0:
|
||||
hardened = np_mask_grey[:] ** hardness
|
||||
else:
|
||||
hardened = np_mask_grey[:]
|
||||
for c in range(3):
|
||||
np_mask_rgb[:, :, c] = hardened[:]
|
||||
return np_mask_rgb
|
||||
|
||||
def _match_cumulative_cdf(source, template):
|
||||
src_values, src_unique_indices, src_counts = np.unique(
|
||||
source.ravel(), return_inverse=True, return_counts=True
|
||||
)
|
||||
tmpl_values, tmpl_counts = np.unique(
|
||||
template.ravel(), return_counts=True
|
||||
)
|
||||
|
||||
# calculate normalized quantiles for each array
|
||||
src_quantiles = np.cumsum(src_counts) / source.size
|
||||
tmpl_quantiles = np.cumsum(tmpl_counts) / template.size
|
||||
|
||||
interp_a_values = np.interp(
|
||||
src_quantiles, tmpl_quantiles, tmpl_values
|
||||
)
|
||||
return interp_a_values[src_unique_indices].reshape(source.shape)
|
||||
|
||||
def _match_histograms(image, reference):
|
||||
if image.ndim != reference.ndim:
|
||||
raise ValueError(
|
||||
"Image and reference must have the same number of channels."
|
||||
)
|
||||
|
||||
if image.shape[-1] != reference.shape[-1]:
|
||||
raise ValueError(
|
||||
"Number of channels in the input image and reference image must match!"
|
||||
)
|
||||
|
||||
matched = np.empty(image.shape, dtype=image.dtype)
|
||||
for channel in range(image.shape[-1]):
|
||||
matched_channel = _match_cumulative_cdf(
|
||||
image[..., channel], reference[..., channel]
|
||||
)
|
||||
matched[..., channel] = matched_channel
|
||||
|
||||
matched = matched.astype(np.float64, copy=False)
|
||||
return matched
|
||||
|
||||
width = _np_src_image.shape[0]
|
||||
height = _np_src_image.shape[1]
|
||||
num_channels = _np_src_image.shape[2]
|
||||
|
||||
np_src_image = _np_src_image[:] * (1.0 - np_mask_rgb)
|
||||
np_mask_grey = np.sum(np_mask_rgb, axis=2) / 3.0
|
||||
img_mask = np_mask_grey > 1e-6
|
||||
ref_mask = np_mask_grey < 1e-3
|
||||
|
||||
# rather than leave the masked area black, we get better results from fft by filling the average unmasked color
|
||||
windowed_image = _np_src_image * (
|
||||
1.0 - _get_masked_window_rgb(np_mask_grey)
|
||||
)
|
||||
windowed_image /= np.max(windowed_image)
|
||||
windowed_image += np.average(_np_src_image) * np_mask_rgb
|
||||
|
||||
src_fft = _fft2(
|
||||
windowed_image
|
||||
) # get feature statistics from masked src img
|
||||
src_dist = np.absolute(src_fft)
|
||||
src_phase = src_fft / src_dist
|
||||
|
||||
# create a generator with a static seed to make outpainting deterministic / only follow global seed
|
||||
rng = np.random.default_rng(0)
|
||||
|
||||
noise_window = _get_gaussian_window(
|
||||
width, height, mode=1
|
||||
) # start with simple gaussian noise
|
||||
noise_rgb = rng.random((width, height, num_channels))
|
||||
noise_grey = np.sum(noise_rgb, axis=2) / 3.0
|
||||
# the colorfulness of the starting noise is blended to greyscale with a parameter
|
||||
noise_rgb *= color_variation
|
||||
for c in range(num_channels):
|
||||
noise_rgb[:, :, c] += (1.0 - color_variation) * noise_grey
|
||||
|
||||
noise_fft = _fft2(noise_rgb)
|
||||
for c in range(num_channels):
|
||||
noise_fft[:, :, c] *= noise_window
|
||||
noise_rgb = np.real(_ifft2(noise_fft))
|
||||
shaped_noise_fft = _fft2(noise_rgb)
|
||||
shaped_noise_fft[:, :, :] = (
|
||||
np.absolute(shaped_noise_fft[:, :, :]) ** 2
|
||||
* (src_dist**noise_q)
|
||||
* src_phase
|
||||
) # perform the actual shaping
|
||||
|
||||
# color_variation
|
||||
brightness_variation = 0.0
|
||||
contrast_adjusted_np_src = (
|
||||
_np_src_image[:] * (brightness_variation + 1.0)
|
||||
- brightness_variation * 2.0
|
||||
)
|
||||
|
||||
shaped_noise = np.real(_ifft2(shaped_noise_fft))
|
||||
shaped_noise -= np.min(shaped_noise)
|
||||
shaped_noise /= np.max(shaped_noise)
|
||||
shaped_noise[img_mask, :] = _match_histograms(
|
||||
shaped_noise[img_mask, :] ** 1.0,
|
||||
contrast_adjusted_np_src[ref_mask, :],
|
||||
)
|
||||
shaped_noise = (
|
||||
_np_src_image[:] * (1.0 - np_mask_rgb) + shaped_noise * np_mask_rgb
|
||||
)
|
||||
|
||||
matched_noise = shaped_noise[:]
|
||||
|
||||
return np.clip(matched_noise, 0.0, 1.0)
|
||||
|
||||
def generate_images(
|
||||
self,
|
||||
prompts,
|
||||
neg_prompts,
|
||||
image,
|
||||
pixels,
|
||||
mask_blur,
|
||||
is_left,
|
||||
is_right,
|
||||
is_top,
|
||||
is_bottom,
|
||||
noise_q,
|
||||
color_variation,
|
||||
batch_size,
|
||||
height,
|
||||
width,
|
||||
num_inference_steps,
|
||||
guidance_scale,
|
||||
seed,
|
||||
max_length,
|
||||
dtype,
|
||||
use_base_vae,
|
||||
cpu_scheduling,
|
||||
):
|
||||
# prompts and negative prompts must be a list.
|
||||
if isinstance(prompts, str):
|
||||
prompts = [prompts]
|
||||
|
||||
if isinstance(neg_prompts, str):
|
||||
neg_prompts = [neg_prompts]
|
||||
|
||||
prompts = prompts * batch_size
|
||||
neg_prompts = neg_prompts * batch_size
|
||||
|
||||
# seed generator to create the inital latent noise. Also handle out of range seeds.
|
||||
uint32_info = np.iinfo(np.uint32)
|
||||
uint32_min, uint32_max = uint32_info.min, uint32_info.max
|
||||
if seed < uint32_min or seed >= uint32_max:
|
||||
seed = randint(uint32_min, uint32_max)
|
||||
generator = torch.manual_seed(seed)
|
||||
|
||||
# Get initial latents
|
||||
init_latents = self.prepare_latents(
|
||||
batch_size=batch_size,
|
||||
height=height,
|
||||
width=width,
|
||||
generator=generator,
|
||||
num_inference_steps=num_inference_steps,
|
||||
dtype=dtype,
|
||||
)
|
||||
|
||||
# Get text embeddings with weight emphasis from prompts
|
||||
text_embeddings = self.encode_prompts_weight(
|
||||
prompts, neg_prompts, max_length
|
||||
)
|
||||
|
||||
# guidance scale as a float32 tensor.
|
||||
guidance_scale = torch.tensor(guidance_scale).to(torch.float32)
|
||||
|
||||
process_width = width
|
||||
process_height = height
|
||||
left = pixels if is_left else 0
|
||||
right = pixels if is_right else 0
|
||||
up = pixels if is_top else 0
|
||||
down = pixels if is_bottom else 0
|
||||
target_w = math.ceil((image.width + left + right) / 64) * 64
|
||||
target_h = math.ceil((image.height + up + down) / 64) * 64
|
||||
|
||||
if left > 0:
|
||||
left = left * (target_w - image.width) // (left + right)
|
||||
if right > 0:
|
||||
right = target_w - image.width - left
|
||||
if up > 0:
|
||||
up = up * (target_h - image.height) // (up + down)
|
||||
if down > 0:
|
||||
down = target_h - image.height - up
|
||||
|
||||
def expand(
|
||||
init_img,
|
||||
expand_pixels,
|
||||
is_left=False,
|
||||
is_right=False,
|
||||
is_top=False,
|
||||
is_bottom=False,
|
||||
):
|
||||
is_horiz = is_left or is_right
|
||||
is_vert = is_top or is_bottom
|
||||
pixels_horiz = expand_pixels if is_horiz else 0
|
||||
pixels_vert = expand_pixels if is_vert else 0
|
||||
|
||||
res_w = init_img.width + pixels_horiz
|
||||
res_h = init_img.height + pixels_vert
|
||||
process_res_w = math.ceil(res_w / 64) * 64
|
||||
process_res_h = math.ceil(res_h / 64) * 64
|
||||
|
||||
img = Image.new("RGB", (process_res_w, process_res_h))
|
||||
img.paste(
|
||||
init_img,
|
||||
(pixels_horiz if is_left else 0, pixels_vert if is_top else 0),
|
||||
)
|
||||
|
||||
msk = Image.new("RGB", (process_res_w, process_res_h), "white")
|
||||
draw = ImageDraw.Draw(msk)
|
||||
draw.rectangle(
|
||||
(
|
||||
expand_pixels + mask_blur if is_left else 0,
|
||||
expand_pixels + mask_blur if is_top else 0,
|
||||
msk.width - expand_pixels - mask_blur
|
||||
if is_right
|
||||
else res_w,
|
||||
msk.height - expand_pixels - mask_blur
|
||||
if is_bottom
|
||||
else res_h,
|
||||
),
|
||||
fill="black",
|
||||
)
|
||||
|
||||
np_image = (np.asarray(img) / 255.0).astype(np.float64)
|
||||
np_mask = (np.asarray(msk) / 255.0).astype(np.float64)
|
||||
noised = self.get_matched_noise(
|
||||
np_image, np_mask, noise_q, color_variation
|
||||
)
|
||||
output_image = Image.fromarray(
|
||||
np.clip(noised * 255.0, 0.0, 255.0).astype(np.uint8),
|
||||
mode="RGB",
|
||||
)
|
||||
|
||||
target_width = (
|
||||
min(width, init_img.width + pixels_horiz)
|
||||
if is_horiz
|
||||
else img.width
|
||||
)
|
||||
target_height = (
|
||||
min(height, init_img.height + pixels_vert)
|
||||
if is_vert
|
||||
else img.height
|
||||
)
|
||||
crop_region = (
|
||||
0 if is_left else output_image.width - target_width,
|
||||
0 if is_top else output_image.height - target_height,
|
||||
target_width if is_left else output_image.width,
|
||||
target_height if is_top else output_image.height,
|
||||
)
|
||||
mask_to_process = msk.crop(crop_region)
|
||||
image_to_process = output_image.crop(crop_region)
|
||||
|
||||
# Preprocess mask and image
|
||||
mask, masked_image = self.prepare_mask_and_masked_image(
|
||||
image_to_process, mask_to_process, mask_blur, width, height
|
||||
)
|
||||
|
||||
# Prepare mask latent variables
|
||||
mask, masked_image_latents = self.prepare_mask_latents(
|
||||
mask=mask,
|
||||
masked_image=masked_image,
|
||||
batch_size=batch_size,
|
||||
height=height,
|
||||
width=width,
|
||||
dtype=dtype,
|
||||
)
|
||||
|
||||
# Get Image latents
|
||||
latents = self.produce_img_latents(
|
||||
latents=init_latents,
|
||||
text_embeddings=text_embeddings,
|
||||
guidance_scale=guidance_scale,
|
||||
total_timesteps=self.scheduler.timesteps,
|
||||
dtype=dtype,
|
||||
cpu_scheduling=cpu_scheduling,
|
||||
mask=mask,
|
||||
masked_image_latents=masked_image_latents,
|
||||
)
|
||||
|
||||
# Img latents -> PIL images
|
||||
all_imgs = []
|
||||
self.load_vae()
|
||||
for i in tqdm(range(0, latents.shape[0], batch_size)):
|
||||
imgs = self.decode_latents(
|
||||
latents=latents[i : i + batch_size],
|
||||
use_base_vae=use_base_vae,
|
||||
cpu_scheduling=cpu_scheduling,
|
||||
)
|
||||
all_imgs.extend(imgs)
|
||||
|
||||
res_img = all_imgs[0].resize(
|
||||
(image_to_process.width, image_to_process.height)
|
||||
)
|
||||
output_image.paste(
|
||||
res_img,
|
||||
(
|
||||
0 if is_left else output_image.width - res_img.width,
|
||||
0 if is_top else output_image.height - res_img.height,
|
||||
),
|
||||
)
|
||||
output_image = output_image.crop((0, 0, res_w, res_h))
|
||||
|
||||
return output_image
|
||||
|
||||
img = image.resize((width, height))
|
||||
if left > 0:
|
||||
img = expand(img, left, is_left=True)
|
||||
if right > 0:
|
||||
img = expand(img, right, is_right=True)
|
||||
if up > 0:
|
||||
img = expand(img, up, is_top=True)
|
||||
if down > 0:
|
||||
img = expand(img, down, is_bottom=True)
|
||||
|
||||
return [img]
|
||||
@@ -0,0 +1,274 @@
|
||||
import torch
|
||||
import time
|
||||
import numpy as np
|
||||
from tqdm.auto import tqdm
|
||||
from random import randint
|
||||
from PIL import Image
|
||||
from transformers import CLIPTokenizer
|
||||
from typing import Union
|
||||
from shark.shark_inference import SharkInference
|
||||
from diffusers import (
|
||||
DDIMScheduler,
|
||||
PNDMScheduler,
|
||||
LMSDiscreteScheduler,
|
||||
EulerDiscreteScheduler,
|
||||
EulerAncestralDiscreteScheduler,
|
||||
DPMSolverMultistepScheduler,
|
||||
)
|
||||
from apps.stable_diffusion.src.schedulers import SharkEulerDiscreteScheduler
|
||||
from apps.stable_diffusion.src.pipelines.pipeline_shark_stable_diffusion_utils import (
|
||||
StableDiffusionPipeline,
|
||||
)
|
||||
from apps.stable_diffusion.src.utils import controlnet_hint_conversion
|
||||
from apps.stable_diffusion.src.utils import (
|
||||
start_profiling,
|
||||
end_profiling,
|
||||
)
|
||||
from apps.stable_diffusion.src.models import SharkifyStableDiffusionModel
|
||||
|
||||
|
||||
class StencilPipeline(StableDiffusionPipeline):
|
||||
def __init__(
|
||||
self,
|
||||
scheduler: Union[
|
||||
DDIMScheduler,
|
||||
PNDMScheduler,
|
||||
LMSDiscreteScheduler,
|
||||
EulerDiscreteScheduler,
|
||||
EulerAncestralDiscreteScheduler,
|
||||
DPMSolverMultistepScheduler,
|
||||
SharkEulerDiscreteScheduler,
|
||||
],
|
||||
sd_model: SharkifyStableDiffusionModel,
|
||||
import_mlir: bool,
|
||||
use_lora: str,
|
||||
ondemand: bool,
|
||||
):
|
||||
super().__init__(scheduler, sd_model, import_mlir, use_lora, ondemand)
|
||||
self.controlnet = None
|
||||
|
||||
def load_controlnet(self):
|
||||
if self.controlnet is not None:
|
||||
return
|
||||
self.controlnet = self.sd_model.controlnet()
|
||||
|
||||
def unload_controlnet(self):
|
||||
del self.controlnet
|
||||
self.controlnet = None
|
||||
|
||||
def prepare_latents(
|
||||
self,
|
||||
batch_size,
|
||||
height,
|
||||
width,
|
||||
generator,
|
||||
num_inference_steps,
|
||||
dtype,
|
||||
):
|
||||
latents = torch.randn(
|
||||
(
|
||||
batch_size,
|
||||
4,
|
||||
height // 8,
|
||||
width // 8,
|
||||
),
|
||||
generator=generator,
|
||||
dtype=torch.float32,
|
||||
).to(dtype)
|
||||
|
||||
self.scheduler.set_timesteps(num_inference_steps)
|
||||
self.scheduler.is_scale_input_called = True
|
||||
latents = latents * self.scheduler.init_noise_sigma
|
||||
return latents
|
||||
|
||||
def produce_stencil_latents(
|
||||
self,
|
||||
latents,
|
||||
text_embeddings,
|
||||
guidance_scale,
|
||||
total_timesteps,
|
||||
dtype,
|
||||
cpu_scheduling,
|
||||
controlnet_hint=None,
|
||||
controlnet_conditioning_scale: float = 1.0,
|
||||
mask=None,
|
||||
masked_image_latents=None,
|
||||
return_all_latents=False,
|
||||
):
|
||||
step_time_sum = 0
|
||||
latent_history = [latents]
|
||||
text_embeddings = torch.from_numpy(text_embeddings).to(dtype)
|
||||
text_embeddings_numpy = text_embeddings.detach().numpy()
|
||||
self.load_unet()
|
||||
self.load_controlnet()
|
||||
for i, t in tqdm(enumerate(total_timesteps)):
|
||||
step_start_time = time.time()
|
||||
timestep = torch.tensor([t]).to(dtype)
|
||||
latent_model_input = self.scheduler.scale_model_input(latents, t)
|
||||
if mask is not None and masked_image_latents is not None:
|
||||
latent_model_input = torch.cat(
|
||||
[
|
||||
torch.from_numpy(np.asarray(latent_model_input)),
|
||||
mask,
|
||||
masked_image_latents,
|
||||
],
|
||||
dim=1,
|
||||
).to(dtype)
|
||||
if cpu_scheduling:
|
||||
latent_model_input = latent_model_input.detach().numpy()
|
||||
|
||||
if not torch.is_tensor(latent_model_input):
|
||||
latent_model_input_1 = torch.from_numpy(
|
||||
np.asarray(latent_model_input)
|
||||
).to(dtype)
|
||||
else:
|
||||
latent_model_input_1 = latent_model_input
|
||||
control = self.controlnet(
|
||||
"forward",
|
||||
(
|
||||
latent_model_input_1,
|
||||
timestep,
|
||||
text_embeddings,
|
||||
controlnet_hint,
|
||||
),
|
||||
send_to_host=False,
|
||||
)
|
||||
timestep = timestep.detach().numpy()
|
||||
# Profiling Unet.
|
||||
profile_device = start_profiling(file_path="unet.rdc")
|
||||
# TODO: Pass `control` as it is to Unet. Same as TODO mentioned in model_wrappers.py.
|
||||
noise_pred = self.unet(
|
||||
"forward",
|
||||
(
|
||||
latent_model_input,
|
||||
timestep,
|
||||
text_embeddings_numpy,
|
||||
guidance_scale,
|
||||
control[0],
|
||||
control[1],
|
||||
control[2],
|
||||
control[3],
|
||||
control[4],
|
||||
control[5],
|
||||
control[6],
|
||||
control[7],
|
||||
control[8],
|
||||
control[9],
|
||||
control[10],
|
||||
control[11],
|
||||
control[12],
|
||||
),
|
||||
send_to_host=False,
|
||||
)
|
||||
end_profiling(profile_device)
|
||||
|
||||
if cpu_scheduling:
|
||||
noise_pred = torch.from_numpy(noise_pred.to_host())
|
||||
latents = self.scheduler.step(
|
||||
noise_pred, t, latents
|
||||
).prev_sample
|
||||
else:
|
||||
latents = self.scheduler.step(noise_pred, t, latents)
|
||||
|
||||
latent_history.append(latents)
|
||||
step_time = (time.time() - step_start_time) * 1000
|
||||
# self.log += (
|
||||
# f"\nstep = {i} | timestep = {t} | time = {step_time:.2f}ms"
|
||||
# )
|
||||
step_time_sum += step_time
|
||||
|
||||
if self.ondemand:
|
||||
self.unload_unet()
|
||||
self.unload_controlnet()
|
||||
avg_step_time = step_time_sum / len(total_timesteps)
|
||||
self.log += f"\nAverage step time: {avg_step_time}ms/it"
|
||||
|
||||
if not return_all_latents:
|
||||
return latents
|
||||
all_latents = torch.cat(latent_history, dim=0)
|
||||
return all_latents
|
||||
|
||||
def generate_images(
|
||||
self,
|
||||
prompts,
|
||||
neg_prompts,
|
||||
image,
|
||||
batch_size,
|
||||
height,
|
||||
width,
|
||||
num_inference_steps,
|
||||
strength,
|
||||
guidance_scale,
|
||||
seed,
|
||||
max_length,
|
||||
dtype,
|
||||
use_base_vae,
|
||||
cpu_scheduling,
|
||||
use_stencil,
|
||||
):
|
||||
# Control Embedding check & conversion
|
||||
# TODO: 1. Change `num_images_per_prompt`.
|
||||
controlnet_hint = controlnet_hint_conversion(
|
||||
image, use_stencil, height, width, dtype, num_images_per_prompt=1
|
||||
)
|
||||
# prompts and negative prompts must be a list.
|
||||
if isinstance(prompts, str):
|
||||
prompts = [prompts]
|
||||
|
||||
if isinstance(neg_prompts, str):
|
||||
neg_prompts = [neg_prompts]
|
||||
|
||||
prompts = prompts * batch_size
|
||||
neg_prompts = neg_prompts * batch_size
|
||||
|
||||
# seed generator to create the inital latent noise. Also handle out of range seeds.
|
||||
uint32_info = np.iinfo(np.uint32)
|
||||
uint32_min, uint32_max = uint32_info.min, uint32_info.max
|
||||
if seed < uint32_min or seed >= uint32_max:
|
||||
seed = randint(uint32_min, uint32_max)
|
||||
generator = torch.manual_seed(seed)
|
||||
|
||||
# Get text embeddings with weight emphasis from prompts
|
||||
text_embeddings = self.encode_prompts_weight(
|
||||
prompts, neg_prompts, max_length
|
||||
)
|
||||
|
||||
# guidance scale as a float32 tensor.
|
||||
guidance_scale = torch.tensor(guidance_scale).to(torch.float32)
|
||||
|
||||
# Prepare initial latent.
|
||||
init_latents = self.prepare_latents(
|
||||
batch_size=batch_size,
|
||||
height=height,
|
||||
width=width,
|
||||
generator=generator,
|
||||
num_inference_steps=num_inference_steps,
|
||||
dtype=dtype,
|
||||
)
|
||||
final_timesteps = self.scheduler.timesteps
|
||||
|
||||
# Get Image latents
|
||||
latents = self.produce_stencil_latents(
|
||||
latents=init_latents,
|
||||
text_embeddings=text_embeddings,
|
||||
guidance_scale=guidance_scale,
|
||||
total_timesteps=final_timesteps,
|
||||
dtype=dtype,
|
||||
cpu_scheduling=cpu_scheduling,
|
||||
controlnet_hint=controlnet_hint,
|
||||
)
|
||||
|
||||
# Img latents -> PIL images
|
||||
all_imgs = []
|
||||
self.load_vae()
|
||||
for i in tqdm(range(0, latents.shape[0], batch_size)):
|
||||
imgs = self.decode_latents(
|
||||
latents=latents[i : i + batch_size],
|
||||
use_base_vae=use_base_vae,
|
||||
cpu_scheduling=cpu_scheduling,
|
||||
)
|
||||
all_imgs.extend(imgs)
|
||||
if self.ondemand:
|
||||
self.unload_vae()
|
||||
|
||||
return all_imgs
|
||||
@@ -0,0 +1,144 @@
|
||||
import torch
|
||||
import numpy as np
|
||||
from random import randint
|
||||
from transformers import CLIPTokenizer
|
||||
from typing import Union
|
||||
from shark.shark_inference import SharkInference
|
||||
from diffusers import (
|
||||
DDIMScheduler,
|
||||
PNDMScheduler,
|
||||
LMSDiscreteScheduler,
|
||||
KDPM2DiscreteScheduler,
|
||||
EulerDiscreteScheduler,
|
||||
EulerAncestralDiscreteScheduler,
|
||||
DPMSolverMultistepScheduler,
|
||||
DEISMultistepScheduler,
|
||||
)
|
||||
from apps.stable_diffusion.src.schedulers import SharkEulerDiscreteScheduler
|
||||
from apps.stable_diffusion.src.pipelines.pipeline_shark_stable_diffusion_utils import (
|
||||
StableDiffusionPipeline,
|
||||
)
|
||||
from apps.stable_diffusion.src.models import SharkifyStableDiffusionModel
|
||||
|
||||
|
||||
class Text2ImagePipeline(StableDiffusionPipeline):
|
||||
def __init__(
|
||||
self,
|
||||
scheduler: Union[
|
||||
DDIMScheduler,
|
||||
PNDMScheduler,
|
||||
LMSDiscreteScheduler,
|
||||
KDPM2DiscreteScheduler,
|
||||
EulerDiscreteScheduler,
|
||||
EulerAncestralDiscreteScheduler,
|
||||
DPMSolverMultistepScheduler,
|
||||
SharkEulerDiscreteScheduler,
|
||||
DEISMultistepScheduler,
|
||||
],
|
||||
sd_model: SharkifyStableDiffusionModel,
|
||||
import_mlir: bool,
|
||||
use_lora: str,
|
||||
ondemand: bool,
|
||||
):
|
||||
super().__init__(scheduler, sd_model, import_mlir, use_lora, ondemand)
|
||||
|
||||
def prepare_latents(
|
||||
self,
|
||||
batch_size,
|
||||
height,
|
||||
width,
|
||||
generator,
|
||||
num_inference_steps,
|
||||
dtype,
|
||||
):
|
||||
latents = torch.randn(
|
||||
(
|
||||
batch_size,
|
||||
4,
|
||||
height // 8,
|
||||
width // 8,
|
||||
),
|
||||
generator=generator,
|
||||
dtype=torch.float32,
|
||||
).to(dtype)
|
||||
|
||||
self.scheduler.set_timesteps(num_inference_steps)
|
||||
self.scheduler.is_scale_input_called = True
|
||||
latents = latents * self.scheduler.init_noise_sigma
|
||||
return latents
|
||||
|
||||
def generate_images(
|
||||
self,
|
||||
prompts,
|
||||
neg_prompts,
|
||||
batch_size,
|
||||
height,
|
||||
width,
|
||||
num_inference_steps,
|
||||
guidance_scale,
|
||||
seed,
|
||||
max_length,
|
||||
dtype,
|
||||
use_base_vae,
|
||||
cpu_scheduling,
|
||||
):
|
||||
# prompts and negative prompts must be a list.
|
||||
if isinstance(prompts, str):
|
||||
prompts = [prompts]
|
||||
|
||||
if isinstance(neg_prompts, str):
|
||||
neg_prompts = [neg_prompts]
|
||||
|
||||
prompts = prompts * batch_size
|
||||
neg_prompts = neg_prompts * batch_size
|
||||
|
||||
# seed generator to create the inital latent noise. Also handle out of range seeds.
|
||||
# TODO: Wouldn't it be preferable to just report an error instead of modifying the seed on the fly?
|
||||
uint32_info = np.iinfo(np.uint32)
|
||||
uint32_min, uint32_max = uint32_info.min, uint32_info.max
|
||||
if seed < uint32_min or seed >= uint32_max:
|
||||
seed = randint(uint32_min, uint32_max)
|
||||
generator = torch.manual_seed(seed)
|
||||
|
||||
# Get initial latents
|
||||
init_latents = self.prepare_latents(
|
||||
batch_size=batch_size,
|
||||
height=height,
|
||||
width=width,
|
||||
generator=generator,
|
||||
num_inference_steps=num_inference_steps,
|
||||
dtype=dtype,
|
||||
)
|
||||
|
||||
# Get text embeddings with weight emphasis from prompts
|
||||
text_embeddings = self.encode_prompts_weight(
|
||||
prompts, neg_prompts, max_length
|
||||
)
|
||||
|
||||
# guidance scale as a float32 tensor.
|
||||
guidance_scale = torch.tensor(guidance_scale).to(torch.float32)
|
||||
|
||||
# Get Image latents
|
||||
latents = self.produce_img_latents(
|
||||
latents=init_latents,
|
||||
text_embeddings=text_embeddings,
|
||||
guidance_scale=guidance_scale,
|
||||
total_timesteps=self.scheduler.timesteps,
|
||||
dtype=dtype,
|
||||
cpu_scheduling=cpu_scheduling,
|
||||
)
|
||||
|
||||
# Img latents -> PIL images
|
||||
all_imgs = []
|
||||
self.load_vae()
|
||||
for i in range(0, latents.shape[0], batch_size):
|
||||
imgs = self.decode_latents(
|
||||
latents=latents[i : i + batch_size],
|
||||
use_base_vae=use_base_vae,
|
||||
cpu_scheduling=cpu_scheduling,
|
||||
)
|
||||
all_imgs.extend(imgs)
|
||||
if self.ondemand:
|
||||
self.unload_vae()
|
||||
|
||||
return all_imgs
|
||||
@@ -0,0 +1,319 @@
|
||||
import inspect
|
||||
import torch
|
||||
import time
|
||||
from tqdm.auto import tqdm
|
||||
import numpy as np
|
||||
from random import randint
|
||||
from transformers import CLIPTokenizer
|
||||
from typing import Union
|
||||
from shark.shark_inference import SharkInference
|
||||
from diffusers import (
|
||||
DDIMScheduler,
|
||||
DDPMScheduler,
|
||||
PNDMScheduler,
|
||||
LMSDiscreteScheduler,
|
||||
KDPM2DiscreteScheduler,
|
||||
EulerDiscreteScheduler,
|
||||
EulerAncestralDiscreteScheduler,
|
||||
DPMSolverMultistepScheduler,
|
||||
DEISMultistepScheduler,
|
||||
)
|
||||
from apps.stable_diffusion.src.schedulers import SharkEulerDiscreteScheduler
|
||||
from apps.stable_diffusion.src.pipelines.pipeline_shark_stable_diffusion_utils import (
|
||||
StableDiffusionPipeline,
|
||||
)
|
||||
from apps.stable_diffusion.src.utils import (
|
||||
start_profiling,
|
||||
end_profiling,
|
||||
)
|
||||
from PIL import Image
|
||||
from apps.stable_diffusion.src.models import SharkifyStableDiffusionModel
|
||||
|
||||
|
||||
def preprocess(image):
|
||||
if isinstance(image, torch.Tensor):
|
||||
return image
|
||||
elif isinstance(image, Image.Image):
|
||||
image = [image]
|
||||
|
||||
if isinstance(image[0], Image.Image):
|
||||
w, h = image[0].size
|
||||
w, h = map(
|
||||
lambda x: x - x % 64, (w, h)
|
||||
) # resize to integer multiple of 64
|
||||
|
||||
image = [np.array(i.resize((w, h)))[None, :] for i in image]
|
||||
image = np.concatenate(image, axis=0)
|
||||
image = np.array(image).astype(np.float32) / 255.0
|
||||
image = image.transpose(0, 3, 1, 2)
|
||||
image = 2.0 * image - 1.0
|
||||
image = torch.from_numpy(image)
|
||||
elif isinstance(image[0], torch.Tensor):
|
||||
image = torch.cat(image, dim=0)
|
||||
return image
|
||||
|
||||
|
||||
class UpscalerPipeline(StableDiffusionPipeline):
|
||||
def __init__(
|
||||
self,
|
||||
scheduler: Union[
|
||||
DDIMScheduler,
|
||||
PNDMScheduler,
|
||||
LMSDiscreteScheduler,
|
||||
EulerDiscreteScheduler,
|
||||
EulerAncestralDiscreteScheduler,
|
||||
DPMSolverMultistepScheduler,
|
||||
SharkEulerDiscreteScheduler,
|
||||
DEISMultistepScheduler,
|
||||
],
|
||||
low_res_scheduler: Union[
|
||||
DDIMScheduler,
|
||||
DDPMScheduler,
|
||||
PNDMScheduler,
|
||||
LMSDiscreteScheduler,
|
||||
EulerDiscreteScheduler,
|
||||
EulerAncestralDiscreteScheduler,
|
||||
DPMSolverMultistepScheduler,
|
||||
SharkEulerDiscreteScheduler,
|
||||
DEISMultistepScheduler,
|
||||
],
|
||||
sd_model: SharkifyStableDiffusionModel,
|
||||
import_mlir: bool,
|
||||
use_lora: str,
|
||||
ondemand: bool,
|
||||
):
|
||||
super().__init__(scheduler, sd_model, import_mlir, use_lora, ondemand)
|
||||
self.low_res_scheduler = low_res_scheduler
|
||||
|
||||
def prepare_extra_step_kwargs(self, generator, eta):
|
||||
accepts_eta = "eta" in set(
|
||||
inspect.signature(self.scheduler.step).parameters.keys()
|
||||
)
|
||||
extra_step_kwargs = {}
|
||||
if accepts_eta:
|
||||
extra_step_kwargs["eta"] = eta
|
||||
|
||||
# check if the scheduler accepts generator
|
||||
accepts_generator = "generator" in set(
|
||||
inspect.signature(self.scheduler.step).parameters.keys()
|
||||
)
|
||||
if accepts_generator:
|
||||
extra_step_kwargs["generator"] = generator
|
||||
return extra_step_kwargs
|
||||
|
||||
def decode_latents(self, latents, use_base_vae, cpu_scheduling):
|
||||
latents = 1 / 0.08333 * (latents.float())
|
||||
latents_numpy = latents
|
||||
if cpu_scheduling:
|
||||
latents_numpy = latents.detach().numpy()
|
||||
|
||||
profile_device = start_profiling(file_path="vae.rdc")
|
||||
vae_start = time.time()
|
||||
images = self.vae("forward", (latents_numpy,))
|
||||
vae_inf_time = (time.time() - vae_start) * 1000
|
||||
end_profiling(profile_device)
|
||||
self.log += f"\nVAE Inference time (ms): {vae_inf_time:.3f}"
|
||||
|
||||
images = torch.from_numpy(images)
|
||||
images = (images.detach().cpu() * 255.0).numpy()
|
||||
images = images.round()
|
||||
|
||||
images = torch.from_numpy(images).to(torch.uint8).permute(0, 2, 3, 1)
|
||||
pil_images = [Image.fromarray(image) for image in images.numpy()]
|
||||
return pil_images
|
||||
|
||||
def prepare_latents(
|
||||
self,
|
||||
batch_size,
|
||||
height,
|
||||
width,
|
||||
generator,
|
||||
num_inference_steps,
|
||||
dtype,
|
||||
):
|
||||
latents = torch.randn(
|
||||
(
|
||||
batch_size,
|
||||
4,
|
||||
height,
|
||||
width,
|
||||
),
|
||||
generator=generator,
|
||||
dtype=torch.float32,
|
||||
).to(dtype)
|
||||
|
||||
self.scheduler.set_timesteps(num_inference_steps)
|
||||
self.scheduler.is_scale_input_called = True
|
||||
latents = latents * self.scheduler.init_noise_sigma
|
||||
return latents
|
||||
|
||||
def produce_img_latents(
|
||||
self,
|
||||
latents,
|
||||
image,
|
||||
text_embeddings,
|
||||
guidance_scale,
|
||||
noise_level,
|
||||
total_timesteps,
|
||||
dtype,
|
||||
cpu_scheduling,
|
||||
extra_step_kwargs,
|
||||
return_all_latents=False,
|
||||
):
|
||||
step_time_sum = 0
|
||||
latent_history = [latents]
|
||||
text_embeddings = torch.from_numpy(text_embeddings).to(dtype)
|
||||
text_embeddings_numpy = text_embeddings.detach().numpy()
|
||||
self.load_unet()
|
||||
for i, t in tqdm(enumerate(total_timesteps)):
|
||||
step_start_time = time.time()
|
||||
latent_model_input = torch.cat([latents] * 2)
|
||||
latent_model_input = self.scheduler.scale_model_input(
|
||||
latent_model_input, t
|
||||
)
|
||||
latent_model_input = torch.cat([latent_model_input, image], dim=1)
|
||||
timestep = torch.tensor([t]).to(dtype).detach().numpy()
|
||||
if cpu_scheduling:
|
||||
latent_model_input = latent_model_input.detach().numpy()
|
||||
|
||||
# Profiling Unet.
|
||||
profile_device = start_profiling(file_path="unet.rdc")
|
||||
noise_pred = self.unet(
|
||||
"forward",
|
||||
(
|
||||
latent_model_input,
|
||||
timestep,
|
||||
text_embeddings_numpy,
|
||||
noise_level,
|
||||
),
|
||||
)
|
||||
end_profiling(profile_device)
|
||||
noise_pred = torch.from_numpy(noise_pred)
|
||||
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
|
||||
noise_pred = noise_pred_uncond + guidance_scale * (
|
||||
noise_pred_text - noise_pred_uncond
|
||||
)
|
||||
|
||||
if cpu_scheduling:
|
||||
latents = self.scheduler.step(
|
||||
noise_pred, t, latents, **extra_step_kwargs
|
||||
).prev_sample
|
||||
else:
|
||||
latents = self.scheduler.step(
|
||||
noise_pred, t, latents, **extra_step_kwargs
|
||||
)
|
||||
|
||||
latent_history.append(latents)
|
||||
step_time = (time.time() - step_start_time) * 1000
|
||||
# self.log += (
|
||||
# f"\nstep = {i} | timestep = {t} | time = {step_time:.2f}ms"
|
||||
# )
|
||||
step_time_sum += step_time
|
||||
|
||||
if self.ondemand:
|
||||
self.unload_unet()
|
||||
avg_step_time = step_time_sum / len(total_timesteps)
|
||||
self.log += f"\nAverage step time: {avg_step_time}ms/it"
|
||||
|
||||
if not return_all_latents:
|
||||
return latents
|
||||
all_latents = torch.cat(latent_history, dim=0)
|
||||
return all_latents
|
||||
|
||||
def generate_images(
|
||||
self,
|
||||
prompts,
|
||||
neg_prompts,
|
||||
image,
|
||||
batch_size,
|
||||
height,
|
||||
width,
|
||||
num_inference_steps,
|
||||
noise_level,
|
||||
guidance_scale,
|
||||
seed,
|
||||
max_length,
|
||||
dtype,
|
||||
use_base_vae,
|
||||
cpu_scheduling,
|
||||
):
|
||||
# prompts and negative prompts must be a list.
|
||||
if isinstance(prompts, str):
|
||||
prompts = [prompts]
|
||||
|
||||
if isinstance(neg_prompts, str):
|
||||
neg_prompts = [neg_prompts]
|
||||
|
||||
prompts = prompts * batch_size
|
||||
neg_prompts = neg_prompts * batch_size
|
||||
|
||||
# seed generator to create the inital latent noise. Also handle out of range seeds.
|
||||
# TODO: Wouldn't it be preferable to just report an error instead of modifying the seed on the fly?
|
||||
uint32_info = np.iinfo(np.uint32)
|
||||
uint32_min, uint32_max = uint32_info.min, uint32_info.max
|
||||
if seed < uint32_min or seed >= uint32_max:
|
||||
seed = randint(uint32_min, uint32_max)
|
||||
generator = torch.manual_seed(seed)
|
||||
|
||||
# Get text embeddings with weight emphasis from prompts
|
||||
text_embeddings = self.encode_prompts_weight(
|
||||
prompts, neg_prompts, max_length
|
||||
)
|
||||
|
||||
# 4. Preprocess image
|
||||
image = preprocess(image).to(dtype)
|
||||
|
||||
# 5. Add noise to image
|
||||
noise_level = torch.tensor([noise_level], dtype=torch.long)
|
||||
noise = torch.randn(
|
||||
image.shape,
|
||||
generator=generator,
|
||||
).to(dtype)
|
||||
image = self.low_res_scheduler.add_noise(image, noise, noise_level)
|
||||
image = torch.cat([image] * 2)
|
||||
noise_level = torch.cat([noise_level] * image.shape[0])
|
||||
|
||||
height, width = image.shape[2:]
|
||||
# Get initial latents
|
||||
init_latents = self.prepare_latents(
|
||||
batch_size=batch_size,
|
||||
height=height,
|
||||
width=width,
|
||||
generator=generator,
|
||||
num_inference_steps=num_inference_steps,
|
||||
dtype=dtype,
|
||||
)
|
||||
|
||||
eta = 0.0
|
||||
extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
|
||||
|
||||
# guidance scale as a float32 tensor.
|
||||
# guidance_scale = torch.tensor(guidance_scale).to(torch.float32)
|
||||
|
||||
# Get Image latents
|
||||
latents = self.produce_img_latents(
|
||||
latents=init_latents,
|
||||
image=image,
|
||||
text_embeddings=text_embeddings,
|
||||
guidance_scale=guidance_scale,
|
||||
noise_level=noise_level,
|
||||
total_timesteps=self.scheduler.timesteps,
|
||||
dtype=dtype,
|
||||
cpu_scheduling=cpu_scheduling,
|
||||
extra_step_kwargs=extra_step_kwargs,
|
||||
)
|
||||
|
||||
# Img latents -> PIL images
|
||||
all_imgs = []
|
||||
self.load_vae()
|
||||
for i in tqdm(range(0, latents.shape[0], batch_size)):
|
||||
imgs = self.decode_latents(
|
||||
latents=latents[i : i + batch_size],
|
||||
use_base_vae=use_base_vae,
|
||||
cpu_scheduling=cpu_scheduling,
|
||||
)
|
||||
all_imgs.extend(imgs)
|
||||
if self.ondemand:
|
||||
self.unload_vae()
|
||||
|
||||
return all_imgs
|
||||
@@ -0,0 +1,839 @@
|
||||
import torch
|
||||
import numpy as np
|
||||
from transformers import CLIPTokenizer
|
||||
from PIL import Image
|
||||
from tqdm.auto import tqdm
|
||||
import time
|
||||
from typing import Union
|
||||
from diffusers import (
|
||||
DDIMScheduler,
|
||||
DDPMScheduler,
|
||||
PNDMScheduler,
|
||||
LMSDiscreteScheduler,
|
||||
KDPM2DiscreteScheduler,
|
||||
EulerDiscreteScheduler,
|
||||
EulerAncestralDiscreteScheduler,
|
||||
DPMSolverMultistepScheduler,
|
||||
DEISMultistepScheduler,
|
||||
)
|
||||
from shark.shark_inference import SharkInference
|
||||
from apps.stable_diffusion.src.schedulers import SharkEulerDiscreteScheduler
|
||||
from apps.stable_diffusion.src.models import (
|
||||
SharkifyStableDiffusionModel,
|
||||
get_vae,
|
||||
get_clip,
|
||||
get_unet,
|
||||
get_tokenizer,
|
||||
)
|
||||
from apps.stable_diffusion.src.utils import (
|
||||
start_profiling,
|
||||
end_profiling,
|
||||
)
|
||||
import sys
|
||||
|
||||
SD_STATE_IDLE = "idle"
|
||||
SD_STATE_CANCEL = "cancel"
|
||||
|
||||
|
||||
class StableDiffusionPipeline:
|
||||
def __init__(
|
||||
self,
|
||||
scheduler: Union[
|
||||
DDIMScheduler,
|
||||
PNDMScheduler,
|
||||
LMSDiscreteScheduler,
|
||||
KDPM2DiscreteScheduler,
|
||||
EulerDiscreteScheduler,
|
||||
EulerAncestralDiscreteScheduler,
|
||||
DPMSolverMultistepScheduler,
|
||||
SharkEulerDiscreteScheduler,
|
||||
DEISMultistepScheduler,
|
||||
],
|
||||
sd_model: SharkifyStableDiffusionModel,
|
||||
import_mlir: bool,
|
||||
use_lora: str,
|
||||
ondemand: bool,
|
||||
):
|
||||
self.vae = None
|
||||
self.text_encoder = None
|
||||
self.unet = None
|
||||
self.model_max_length = 77
|
||||
self.scheduler = scheduler
|
||||
# TODO: Implement using logging python utility.
|
||||
self.log = ""
|
||||
self.status = SD_STATE_IDLE
|
||||
self.sd_model = sd_model
|
||||
self.import_mlir = import_mlir
|
||||
self.use_lora = use_lora
|
||||
self.ondemand = ondemand
|
||||
# TODO: Find a better workaround for fetching base_model_id early enough for CLIPTokenizer.
|
||||
try:
|
||||
self.tokenizer = get_tokenizer()
|
||||
except:
|
||||
self.load_unet()
|
||||
self.unload_unet()
|
||||
self.tokenizer = get_tokenizer()
|
||||
|
||||
def load_clip(self):
|
||||
if self.text_encoder is not None:
|
||||
return
|
||||
|
||||
if self.import_mlir or self.use_lora:
|
||||
if not self.import_mlir:
|
||||
print(
|
||||
"Warning: LoRA provided but import_mlir not specified. Importing MLIR anyways."
|
||||
)
|
||||
self.text_encoder = self.sd_model.clip()
|
||||
else:
|
||||
try:
|
||||
self.text_encoder = get_clip()
|
||||
except:
|
||||
print("download pipeline failed, falling back to import_mlir")
|
||||
self.text_encoder = self.sd_model.clip()
|
||||
|
||||
def unload_clip(self):
|
||||
del self.text_encoder
|
||||
self.text_encoder = None
|
||||
|
||||
def load_unet(self):
|
||||
if self.unet is not None:
|
||||
return
|
||||
|
||||
if self.import_mlir or self.use_lora:
|
||||
self.unet = self.sd_model.unet()
|
||||
else:
|
||||
try:
|
||||
self.unet = get_unet()
|
||||
except:
|
||||
print("download pipeline failed, falling back to import_mlir")
|
||||
self.unet = self.sd_model.unet()
|
||||
|
||||
def unload_unet(self):
|
||||
del self.unet
|
||||
self.unet = None
|
||||
|
||||
def load_vae(self):
|
||||
if self.vae is not None:
|
||||
return
|
||||
|
||||
if self.import_mlir or self.use_lora:
|
||||
self.vae = self.sd_model.vae()
|
||||
else:
|
||||
try:
|
||||
self.vae = get_vae()
|
||||
except:
|
||||
print("download pipeline failed, falling back to import_mlir")
|
||||
self.vae = self.sd_model.vae()
|
||||
|
||||
def unload_vae(self):
|
||||
del self.vae
|
||||
self.vae = None
|
||||
|
||||
def encode_prompts(self, prompts, neg_prompts, max_length):
|
||||
# Tokenize text and get embeddings
|
||||
text_input = self.tokenizer(
|
||||
prompts,
|
||||
padding="max_length",
|
||||
max_length=max_length,
|
||||
truncation=True,
|
||||
return_tensors="pt",
|
||||
)
|
||||
|
||||
# Get unconditional embeddings as well
|
||||
uncond_input = self.tokenizer(
|
||||
neg_prompts,
|
||||
padding="max_length",
|
||||
max_length=max_length,
|
||||
truncation=True,
|
||||
return_tensors="pt",
|
||||
)
|
||||
text_input = torch.cat([uncond_input.input_ids, text_input.input_ids])
|
||||
|
||||
self.load_clip()
|
||||
clip_inf_start = time.time()
|
||||
text_embeddings = self.text_encoder("forward", (text_input,))
|
||||
clip_inf_time = (time.time() - clip_inf_start) * 1000
|
||||
if self.ondemand:
|
||||
self.unload_clip()
|
||||
self.log += f"\nClip Inference time (ms) = {clip_inf_time:.3f}"
|
||||
|
||||
return text_embeddings
|
||||
|
||||
def decode_latents(self, latents, use_base_vae, cpu_scheduling):
|
||||
if use_base_vae:
|
||||
latents = 1 / 0.18215 * latents
|
||||
|
||||
latents_numpy = latents
|
||||
if cpu_scheduling:
|
||||
latents_numpy = latents.detach().numpy()
|
||||
|
||||
profile_device = start_profiling(file_path="vae.rdc")
|
||||
vae_start = time.time()
|
||||
images = self.vae("forward", (latents_numpy,))
|
||||
vae_inf_time = (time.time() - vae_start) * 1000
|
||||
end_profiling(profile_device)
|
||||
self.log += f"\nVAE Inference time (ms): {vae_inf_time:.3f}"
|
||||
|
||||
if use_base_vae:
|
||||
images = torch.from_numpy(images)
|
||||
images = (images.detach().cpu() * 255.0).numpy()
|
||||
images = images.round()
|
||||
|
||||
images = torch.from_numpy(images).to(torch.uint8).permute(0, 2, 3, 1)
|
||||
pil_images = [Image.fromarray(image) for image in images.numpy()]
|
||||
return pil_images
|
||||
|
||||
def produce_img_latents(
|
||||
self,
|
||||
latents,
|
||||
text_embeddings,
|
||||
guidance_scale,
|
||||
total_timesteps,
|
||||
dtype,
|
||||
cpu_scheduling,
|
||||
mask=None,
|
||||
masked_image_latents=None,
|
||||
return_all_latents=False,
|
||||
):
|
||||
self.status = SD_STATE_IDLE
|
||||
step_time_sum = 0
|
||||
latent_history = [latents]
|
||||
text_embeddings = torch.from_numpy(text_embeddings).to(dtype)
|
||||
text_embeddings_numpy = text_embeddings.detach().numpy()
|
||||
self.load_unet()
|
||||
for i, t in tqdm(enumerate(total_timesteps)):
|
||||
step_start_time = time.time()
|
||||
timestep = torch.tensor([t]).to(dtype).detach().numpy()
|
||||
latent_model_input = self.scheduler.scale_model_input(latents, t)
|
||||
if mask is not None and masked_image_latents is not None:
|
||||
latent_model_input = torch.cat(
|
||||
[
|
||||
torch.from_numpy(np.asarray(latent_model_input)),
|
||||
mask,
|
||||
masked_image_latents,
|
||||
],
|
||||
dim=1,
|
||||
).to(dtype)
|
||||
if cpu_scheduling:
|
||||
latent_model_input = latent_model_input.detach().numpy()
|
||||
|
||||
# Profiling Unet.
|
||||
profile_device = start_profiling(file_path="unet.rdc")
|
||||
noise_pred = self.unet(
|
||||
"forward",
|
||||
(
|
||||
latent_model_input,
|
||||
timestep,
|
||||
text_embeddings_numpy,
|
||||
guidance_scale,
|
||||
),
|
||||
send_to_host=False,
|
||||
)
|
||||
end_profiling(profile_device)
|
||||
|
||||
if cpu_scheduling:
|
||||
noise_pred = torch.from_numpy(noise_pred.to_host())
|
||||
latents = self.scheduler.step(
|
||||
noise_pred, t, latents
|
||||
).prev_sample
|
||||
else:
|
||||
latents = self.scheduler.step(noise_pred, t, latents)
|
||||
|
||||
latent_history.append(latents)
|
||||
step_time = (time.time() - step_start_time) * 1000
|
||||
# self.log += (
|
||||
# f"\nstep = {i} | timestep = {t} | time = {step_time:.2f}ms"
|
||||
# )
|
||||
step_time_sum += step_time
|
||||
|
||||
if self.status == SD_STATE_CANCEL:
|
||||
break
|
||||
|
||||
if self.ondemand:
|
||||
self.unload_unet()
|
||||
avg_step_time = step_time_sum / len(total_timesteps)
|
||||
self.log += f"\nAverage step time: {avg_step_time}ms/it"
|
||||
|
||||
if not return_all_latents:
|
||||
return latents
|
||||
all_latents = torch.cat(latent_history, dim=0)
|
||||
return all_latents
|
||||
|
||||
@classmethod
|
||||
def from_pretrained(
|
||||
cls,
|
||||
scheduler: Union[
|
||||
DDIMScheduler,
|
||||
PNDMScheduler,
|
||||
LMSDiscreteScheduler,
|
||||
KDPM2DiscreteScheduler,
|
||||
EulerDiscreteScheduler,
|
||||
EulerAncestralDiscreteScheduler,
|
||||
DPMSolverMultistepScheduler,
|
||||
SharkEulerDiscreteScheduler,
|
||||
DEISMultistepScheduler,
|
||||
],
|
||||
import_mlir: bool,
|
||||
model_id: str,
|
||||
ckpt_loc: str,
|
||||
custom_vae: str,
|
||||
precision: str,
|
||||
max_length: int,
|
||||
batch_size: int,
|
||||
height: int,
|
||||
width: int,
|
||||
use_base_vae: bool,
|
||||
use_tuned: bool,
|
||||
ondemand: bool,
|
||||
low_cpu_mem_usage: bool = False,
|
||||
debug: bool = False,
|
||||
use_stencil: str = None,
|
||||
use_lora: str = "",
|
||||
ddpm_scheduler: DDPMScheduler = None,
|
||||
use_quantize=None,
|
||||
):
|
||||
if (
|
||||
not import_mlir
|
||||
and not use_lora
|
||||
and cls.__name__ == "StencilPipeline"
|
||||
):
|
||||
sys.exit("StencilPipeline not supported with SharkTank currently.")
|
||||
|
||||
is_inpaint = cls.__name__ in [
|
||||
"InpaintPipeline",
|
||||
"OutpaintPipeline",
|
||||
]
|
||||
is_upscaler = cls.__name__ in ["UpscalerPipeline"]
|
||||
|
||||
sd_model = SharkifyStableDiffusionModel(
|
||||
model_id,
|
||||
ckpt_loc,
|
||||
custom_vae,
|
||||
precision,
|
||||
max_len=max_length,
|
||||
batch_size=batch_size,
|
||||
height=height,
|
||||
width=width,
|
||||
use_base_vae=use_base_vae,
|
||||
use_tuned=use_tuned,
|
||||
low_cpu_mem_usage=low_cpu_mem_usage,
|
||||
debug=debug,
|
||||
is_inpaint=is_inpaint,
|
||||
is_upscaler=is_upscaler,
|
||||
use_stencil=use_stencil,
|
||||
use_lora=use_lora,
|
||||
use_quantize=use_quantize,
|
||||
)
|
||||
|
||||
if cls.__name__ in ["UpscalerPipeline"]:
|
||||
return cls(
|
||||
scheduler,
|
||||
ddpm_scheduler,
|
||||
sd_model,
|
||||
import_mlir,
|
||||
use_lora,
|
||||
ondemand,
|
||||
)
|
||||
|
||||
return cls(scheduler, sd_model, import_mlir, use_lora, ondemand)
|
||||
|
||||
# #####################################################
|
||||
# Implements text embeddings with weights from prompts
|
||||
# https://huggingface.co/AlanB/lpw_stable_diffusion_mod
|
||||
# #####################################################
|
||||
def encode_prompts_weight(
|
||||
self,
|
||||
prompt,
|
||||
negative_prompt,
|
||||
model_max_length,
|
||||
do_classifier_free_guidance=True,
|
||||
max_embeddings_multiples=1,
|
||||
num_images_per_prompt=1,
|
||||
):
|
||||
r"""
|
||||
Encodes the prompt into text encoder hidden states.
|
||||
Args:
|
||||
prompt (`str` or `list(int)`):
|
||||
prompt to be encoded
|
||||
negative_prompt (`str` or `List[str]`):
|
||||
The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
|
||||
if `guidance_scale` is less than `1`).
|
||||
model_max_length (int):
|
||||
SHARK: pass the max length instead of relying on pipe.tokenizer.model_max_length
|
||||
do_classifier_free_guidance (`bool`):
|
||||
whether to use classifier free guidance or not,
|
||||
SHARK: must be set to True as we always expect neg embeddings (defaulted to True)
|
||||
max_embeddings_multiples (`int`, *optional*, defaults to `3`):
|
||||
The max multiple length of prompt embeddings compared to the max output length of text encoder.
|
||||
SHARK: max_embeddings_multiples>1 produce a tensor shape error (defaulted to 1)
|
||||
num_images_per_prompt (`int`):
|
||||
number of images that should be generated per prompt
|
||||
SHARK: num_images_per_prompt is not used (defaulted to 1)
|
||||
"""
|
||||
|
||||
# SHARK: Save model_max_length, load the clip and init inference time
|
||||
self.model_max_length = model_max_length
|
||||
self.load_clip()
|
||||
clip_inf_start = time.time()
|
||||
|
||||
batch_size = len(prompt) if isinstance(prompt, list) else 1
|
||||
|
||||
if negative_prompt is None:
|
||||
negative_prompt = [""] * batch_size
|
||||
elif isinstance(negative_prompt, str):
|
||||
negative_prompt = [negative_prompt] * batch_size
|
||||
if batch_size != len(negative_prompt):
|
||||
raise ValueError(
|
||||
f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
|
||||
f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
|
||||
" the batch size of `prompt`."
|
||||
)
|
||||
|
||||
text_embeddings, uncond_embeddings = get_weighted_text_embeddings(
|
||||
pipe=self,
|
||||
prompt=prompt,
|
||||
uncond_prompt=negative_prompt
|
||||
if do_classifier_free_guidance
|
||||
else None,
|
||||
max_embeddings_multiples=max_embeddings_multiples,
|
||||
)
|
||||
# SHARK: we are not using num_images_per_prompt
|
||||
# bs_embed, seq_len, _ = text_embeddings.shape
|
||||
# text_embeddings = text_embeddings.repeat(1, num_images_per_prompt, 1)
|
||||
# text_embeddings = text_embeddings.view(bs_embed * num_images_per_prompt, seq_len, -1)
|
||||
|
||||
if do_classifier_free_guidance:
|
||||
# SHARK: we are not using num_images_per_prompt
|
||||
# bs_embed, seq_len, _ = uncond_embeddings.shape
|
||||
# uncond_embeddings = uncond_embeddings.repeat(1, num_images_per_prompt, 1)
|
||||
# uncond_embeddings = uncond_embeddings.view(bs_embed * num_images_per_prompt, seq_len, -1)
|
||||
text_embeddings = torch.cat([uncond_embeddings, text_embeddings])
|
||||
|
||||
# SHARK: Report clip inference time
|
||||
clip_inf_time = (time.time() - clip_inf_start) * 1000
|
||||
if self.ondemand:
|
||||
self.unload_clip()
|
||||
self.log += f"\nClip Inference time (ms) = {clip_inf_time:.3f}"
|
||||
|
||||
return text_embeddings.numpy()
|
||||
|
||||
|
||||
from typing import List, Optional, Union
|
||||
import re
|
||||
|
||||
re_attention = re.compile(
|
||||
r"""
|
||||
\\\(|
|
||||
\\\)|
|
||||
\\\[|
|
||||
\\]|
|
||||
\\\\|
|
||||
\\|
|
||||
\(|
|
||||
\[|
|
||||
:([+-]?[.\d]+)\)|
|
||||
\)|
|
||||
]|
|
||||
[^\\()\[\]:]+|
|
||||
:
|
||||
""",
|
||||
re.X,
|
||||
)
|
||||
|
||||
|
||||
def parse_prompt_attention(text):
|
||||
"""
|
||||
Parses a string with attention tokens and returns a list of pairs: text and its associated weight.
|
||||
Accepted tokens are:
|
||||
(abc) - increases attention to abc by a multiplier of 1.1
|
||||
(abc:3.12) - increases attention to abc by a multiplier of 3.12
|
||||
[abc] - decreases attention to abc by a multiplier of 1.1
|
||||
\( - literal character '('
|
||||
\[ - literal character '['
|
||||
\) - literal character ')'
|
||||
\] - literal character ']'
|
||||
\\ - literal character '\'
|
||||
anything else - just text
|
||||
>>> parse_prompt_attention('normal text')
|
||||
[['normal text', 1.0]]
|
||||
>>> parse_prompt_attention('an (important) word')
|
||||
[['an ', 1.0], ['important', 1.1], [' word', 1.0]]
|
||||
>>> parse_prompt_attention('(unbalanced')
|
||||
[['unbalanced', 1.1]]
|
||||
>>> parse_prompt_attention('\(literal\]')
|
||||
[['(literal]', 1.0]]
|
||||
>>> parse_prompt_attention('(unnecessary)(parens)')
|
||||
[['unnecessaryparens', 1.1]]
|
||||
>>> parse_prompt_attention('a (((house:1.3)) [on] a (hill:0.5), sun, (((sky))).')
|
||||
[['a ', 1.0],
|
||||
['house', 1.5730000000000004],
|
||||
[' ', 1.1],
|
||||
['on', 1.0],
|
||||
[' a ', 1.1],
|
||||
['hill', 0.55],
|
||||
[', sun, ', 1.1],
|
||||
['sky', 1.4641000000000006],
|
||||
['.', 1.1]]
|
||||
"""
|
||||
|
||||
res = []
|
||||
round_brackets = []
|
||||
square_brackets = []
|
||||
|
||||
round_bracket_multiplier = 1.1
|
||||
square_bracket_multiplier = 1 / 1.1
|
||||
|
||||
def multiply_range(start_position, multiplier):
|
||||
for p in range(start_position, len(res)):
|
||||
res[p][1] *= multiplier
|
||||
|
||||
for m in re_attention.finditer(text):
|
||||
text = m.group(0)
|
||||
weight = m.group(1)
|
||||
|
||||
if text.startswith("\\"):
|
||||
res.append([text[1:], 1.0])
|
||||
elif text == "(":
|
||||
round_brackets.append(len(res))
|
||||
elif text == "[":
|
||||
square_brackets.append(len(res))
|
||||
elif weight is not None and len(round_brackets) > 0:
|
||||
multiply_range(round_brackets.pop(), float(weight))
|
||||
elif text == ")" and len(round_brackets) > 0:
|
||||
multiply_range(round_brackets.pop(), round_bracket_multiplier)
|
||||
elif text == "]" and len(square_brackets) > 0:
|
||||
multiply_range(square_brackets.pop(), square_bracket_multiplier)
|
||||
else:
|
||||
res.append([text, 1.0])
|
||||
|
||||
for pos in round_brackets:
|
||||
multiply_range(pos, round_bracket_multiplier)
|
||||
|
||||
for pos in square_brackets:
|
||||
multiply_range(pos, square_bracket_multiplier)
|
||||
|
||||
if len(res) == 0:
|
||||
res = [["", 1.0]]
|
||||
|
||||
# merge runs of identical weights
|
||||
i = 0
|
||||
while i + 1 < len(res):
|
||||
if res[i][1] == res[i + 1][1]:
|
||||
res[i][0] += res[i + 1][0]
|
||||
res.pop(i + 1)
|
||||
else:
|
||||
i += 1
|
||||
|
||||
return res
|
||||
|
||||
|
||||
def get_prompts_with_weights(
|
||||
pipe: StableDiffusionPipeline, prompt: List[str], max_length: int
|
||||
):
|
||||
r"""
|
||||
Tokenize a list of prompts and return its tokens with weights of each token.
|
||||
No padding, starting or ending token is included.
|
||||
"""
|
||||
tokens = []
|
||||
weights = []
|
||||
truncated = False
|
||||
for text in prompt:
|
||||
texts_and_weights = parse_prompt_attention(text)
|
||||
text_token = []
|
||||
text_weight = []
|
||||
for word, weight in texts_and_weights:
|
||||
# tokenize and discard the starting and the ending token
|
||||
token = pipe.tokenizer(word).input_ids[1:-1]
|
||||
text_token += token
|
||||
# copy the weight by length of token
|
||||
text_weight += [weight] * len(token)
|
||||
# stop if the text is too long (longer than truncation limit)
|
||||
if len(text_token) > max_length:
|
||||
truncated = True
|
||||
break
|
||||
# truncate
|
||||
if len(text_token) > max_length:
|
||||
truncated = True
|
||||
text_token = text_token[:max_length]
|
||||
text_weight = text_weight[:max_length]
|
||||
tokens.append(text_token)
|
||||
weights.append(text_weight)
|
||||
if truncated:
|
||||
print(
|
||||
"Prompt was truncated. Try to shorten the prompt or increase max_embeddings_multiples"
|
||||
)
|
||||
return tokens, weights
|
||||
|
||||
|
||||
def pad_tokens_and_weights(
|
||||
tokens,
|
||||
weights,
|
||||
max_length,
|
||||
bos,
|
||||
eos,
|
||||
no_boseos_middle=True,
|
||||
chunk_length=77,
|
||||
):
|
||||
r"""
|
||||
Pad the tokens (with starting and ending tokens) and weights (with 1.0) to max_length.
|
||||
"""
|
||||
max_embeddings_multiples = (max_length - 2) // (chunk_length - 2)
|
||||
weights_length = (
|
||||
max_length
|
||||
if no_boseos_middle
|
||||
else max_embeddings_multiples * chunk_length
|
||||
)
|
||||
for i in range(len(tokens)):
|
||||
tokens[i] = (
|
||||
[bos] + tokens[i] + [eos] * (max_length - 1 - len(tokens[i]))
|
||||
)
|
||||
if no_boseos_middle:
|
||||
weights[i] = (
|
||||
[1.0] + weights[i] + [1.0] * (max_length - 1 - len(weights[i]))
|
||||
)
|
||||
else:
|
||||
w = []
|
||||
if len(weights[i]) == 0:
|
||||
w = [1.0] * weights_length
|
||||
else:
|
||||
for j in range(max_embeddings_multiples):
|
||||
w.append(1.0) # weight for starting token in this chunk
|
||||
w += weights[i][
|
||||
j
|
||||
* (chunk_length - 2) : min(
|
||||
len(weights[i]), (j + 1) * (chunk_length - 2)
|
||||
)
|
||||
]
|
||||
w.append(1.0) # weight for ending token in this chunk
|
||||
w += [1.0] * (weights_length - len(w))
|
||||
weights[i] = w[:]
|
||||
|
||||
return tokens, weights
|
||||
|
||||
|
||||
def get_unweighted_text_embeddings(
|
||||
pipe: StableDiffusionPipeline,
|
||||
text_input: torch.Tensor,
|
||||
chunk_length: int,
|
||||
no_boseos_middle: Optional[bool] = True,
|
||||
):
|
||||
"""
|
||||
When the length of tokens is a multiple of the capacity of the text encoder,
|
||||
it should be split into chunks and sent to the text encoder individually.
|
||||
"""
|
||||
max_embeddings_multiples = (text_input.shape[1] - 2) // (chunk_length - 2)
|
||||
if max_embeddings_multiples > 1:
|
||||
text_embeddings = []
|
||||
for i in range(max_embeddings_multiples):
|
||||
# extract the i-th chunk
|
||||
text_input_chunk = text_input[
|
||||
:, i * (chunk_length - 2) : (i + 1) * (chunk_length - 2) + 2
|
||||
].clone()
|
||||
|
||||
# cover the head and the tail by the starting and the ending tokens
|
||||
text_input_chunk[:, 0] = text_input[0, 0]
|
||||
text_input_chunk[:, -1] = text_input[0, -1]
|
||||
# text_embedding = pipe.text_encoder(text_input_chunk)[0]
|
||||
# SHARK: deplicate the text_input as Shark runner expects tokens and neg tokens
|
||||
formatted_text_input_chunk = torch.cat(
|
||||
[text_input_chunk, text_input_chunk]
|
||||
)
|
||||
text_embedding = pipe.text_encoder(
|
||||
"forward", (formatted_text_input_chunk,)
|
||||
)[0]
|
||||
|
||||
if no_boseos_middle:
|
||||
if i == 0:
|
||||
# discard the ending token
|
||||
text_embedding = text_embedding[:, :-1]
|
||||
elif i == max_embeddings_multiples - 1:
|
||||
# discard the starting token
|
||||
text_embedding = text_embedding[:, 1:]
|
||||
else:
|
||||
# discard both starting and ending tokens
|
||||
text_embedding = text_embedding[:, 1:-1]
|
||||
|
||||
text_embeddings.append(text_embedding)
|
||||
# SHARK: Convert the result to tensor
|
||||
# text_embeddings = torch.concat(text_embeddings, axis=1)
|
||||
text_embeddings_np = np.concatenate(np.array(text_embeddings))
|
||||
text_embeddings = torch.from_numpy(text_embeddings_np)[None, :]
|
||||
else:
|
||||
# SHARK: deplicate the text_input as Shark runner expects tokens and neg tokens
|
||||
# Convert the result to tensor
|
||||
# text_embeddings = pipe.text_encoder(text_input)[0]
|
||||
formatted_text_input = torch.cat([text_input, text_input])
|
||||
text_embeddings = pipe.text_encoder(
|
||||
"forward", (formatted_text_input,)
|
||||
)[0]
|
||||
text_embeddings = torch.from_numpy(text_embeddings)[None, :]
|
||||
return text_embeddings
|
||||
|
||||
|
||||
def get_weighted_text_embeddings(
|
||||
pipe: StableDiffusionPipeline,
|
||||
prompt: Union[str, List[str]],
|
||||
uncond_prompt: Optional[Union[str, List[str]]] = None,
|
||||
max_embeddings_multiples: Optional[int] = 3,
|
||||
no_boseos_middle: Optional[bool] = False,
|
||||
skip_parsing: Optional[bool] = False,
|
||||
skip_weighting: Optional[bool] = False,
|
||||
):
|
||||
r"""
|
||||
Prompts can be assigned with local weights using brackets. For example,
|
||||
prompt 'A (very beautiful) masterpiece' highlights the words 'very beautiful',
|
||||
and the embedding tokens corresponding to the words get multiplied by a constant, 1.1.
|
||||
Also, to regularize of the embedding, the weighted embedding would be scaled to preserve the original mean.
|
||||
Args:
|
||||
pipe (`StableDiffusionPipeline`):
|
||||
Pipe to provide access to the tokenizer and the text encoder.
|
||||
prompt (`str` or `List[str]`):
|
||||
The prompt or prompts to guide the image generation.
|
||||
uncond_prompt (`str` or `List[str]`):
|
||||
The unconditional prompt or prompts for guide the image generation. If unconditional prompt
|
||||
is provided, the embeddings of prompt and uncond_prompt are concatenated.
|
||||
max_embeddings_multiples (`int`, *optional*, defaults to `3`):
|
||||
The max multiple length of prompt embeddings compared to the max output length of text encoder.
|
||||
no_boseos_middle (`bool`, *optional*, defaults to `False`):
|
||||
If the length of text token is multiples of the capacity of text encoder, whether reserve the starting and
|
||||
ending token in each of the chunk in the middle.
|
||||
skip_parsing (`bool`, *optional*, defaults to `False`):
|
||||
Skip the parsing of brackets.
|
||||
skip_weighting (`bool`, *optional*, defaults to `False`):
|
||||
Skip the weighting. When the parsing is skipped, it is forced True.
|
||||
"""
|
||||
max_length = (pipe.model_max_length - 2) * max_embeddings_multiples + 2
|
||||
if isinstance(prompt, str):
|
||||
prompt = [prompt]
|
||||
|
||||
if not skip_parsing:
|
||||
prompt_tokens, prompt_weights = get_prompts_with_weights(
|
||||
pipe, prompt, max_length - 2
|
||||
)
|
||||
if uncond_prompt is not None:
|
||||
if isinstance(uncond_prompt, str):
|
||||
uncond_prompt = [uncond_prompt]
|
||||
uncond_tokens, uncond_weights = get_prompts_with_weights(
|
||||
pipe, uncond_prompt, max_length - 2
|
||||
)
|
||||
else:
|
||||
prompt_tokens = [
|
||||
token[1:-1]
|
||||
for token in pipe.tokenizer(
|
||||
prompt, max_length=max_length, truncation=True
|
||||
).input_ids
|
||||
]
|
||||
prompt_weights = [[1.0] * len(token) for token in prompt_tokens]
|
||||
if uncond_prompt is not None:
|
||||
if isinstance(uncond_prompt, str):
|
||||
uncond_prompt = [uncond_prompt]
|
||||
uncond_tokens = [
|
||||
token[1:-1]
|
||||
for token in pipe.tokenizer(
|
||||
uncond_prompt, max_length=max_length, truncation=True
|
||||
).input_ids
|
||||
]
|
||||
uncond_weights = [[1.0] * len(token) for token in uncond_tokens]
|
||||
|
||||
# round up the longest length of tokens to a multiple of (model_max_length - 2)
|
||||
max_length = max([len(token) for token in prompt_tokens])
|
||||
if uncond_prompt is not None:
|
||||
max_length = max(
|
||||
max_length, max([len(token) for token in uncond_tokens])
|
||||
)
|
||||
|
||||
max_embeddings_multiples = min(
|
||||
max_embeddings_multiples,
|
||||
(max_length - 1) // (pipe.model_max_length - 2) + 1,
|
||||
)
|
||||
max_embeddings_multiples = max(1, max_embeddings_multiples)
|
||||
max_length = (pipe.model_max_length - 2) * max_embeddings_multiples + 2
|
||||
|
||||
# pad the length of tokens and weights
|
||||
bos = pipe.tokenizer.bos_token_id
|
||||
eos = pipe.tokenizer.eos_token_id
|
||||
prompt_tokens, prompt_weights = pad_tokens_and_weights(
|
||||
prompt_tokens,
|
||||
prompt_weights,
|
||||
max_length,
|
||||
bos,
|
||||
eos,
|
||||
no_boseos_middle=no_boseos_middle,
|
||||
chunk_length=pipe.model_max_length,
|
||||
)
|
||||
# prompt_tokens = torch.tensor(prompt_tokens, dtype=torch.long, device=pipe.device)
|
||||
prompt_tokens = torch.tensor(prompt_tokens, dtype=torch.long, device="cpu")
|
||||
if uncond_prompt is not None:
|
||||
uncond_tokens, uncond_weights = pad_tokens_and_weights(
|
||||
uncond_tokens,
|
||||
uncond_weights,
|
||||
max_length,
|
||||
bos,
|
||||
eos,
|
||||
no_boseos_middle=no_boseos_middle,
|
||||
chunk_length=pipe.model_max_length,
|
||||
)
|
||||
# uncond_tokens = torch.tensor(uncond_tokens, dtype=torch.long, device=pipe.device)
|
||||
uncond_tokens = torch.tensor(
|
||||
uncond_tokens, dtype=torch.long, device="cpu"
|
||||
)
|
||||
|
||||
# get the embeddings
|
||||
text_embeddings = get_unweighted_text_embeddings(
|
||||
pipe,
|
||||
prompt_tokens,
|
||||
pipe.model_max_length,
|
||||
no_boseos_middle=no_boseos_middle,
|
||||
)
|
||||
# prompt_weights = torch.tensor(prompt_weights, dtype=text_embeddings.dtype, device=pipe.device)
|
||||
prompt_weights = torch.tensor(
|
||||
prompt_weights, dtype=torch.float, device="cpu"
|
||||
)
|
||||
if uncond_prompt is not None:
|
||||
uncond_embeddings = get_unweighted_text_embeddings(
|
||||
pipe,
|
||||
uncond_tokens,
|
||||
pipe.model_max_length,
|
||||
no_boseos_middle=no_boseos_middle,
|
||||
)
|
||||
# uncond_weights = torch.tensor(uncond_weights, dtype=uncond_embeddings.dtype, device=pipe.device)
|
||||
uncond_weights = torch.tensor(
|
||||
uncond_weights, dtype=torch.float, device="cpu"
|
||||
)
|
||||
|
||||
# assign weights to the prompts and normalize in the sense of mean
|
||||
# TODO: should we normalize by chunk or in a whole (current implementation)?
|
||||
if (not skip_parsing) and (not skip_weighting):
|
||||
previous_mean = (
|
||||
text_embeddings.float()
|
||||
.mean(axis=[-2, -1])
|
||||
.to(text_embeddings.dtype)
|
||||
)
|
||||
text_embeddings *= prompt_weights.unsqueeze(-1)
|
||||
current_mean = (
|
||||
text_embeddings.float()
|
||||
.mean(axis=[-2, -1])
|
||||
.to(text_embeddings.dtype)
|
||||
)
|
||||
text_embeddings *= (
|
||||
(previous_mean / current_mean).unsqueeze(-1).unsqueeze(-1)
|
||||
)
|
||||
if uncond_prompt is not None:
|
||||
previous_mean = (
|
||||
uncond_embeddings.float()
|
||||
.mean(axis=[-2, -1])
|
||||
.to(uncond_embeddings.dtype)
|
||||
)
|
||||
uncond_embeddings *= uncond_weights.unsqueeze(-1)
|
||||
current_mean = (
|
||||
uncond_embeddings.float()
|
||||
.mean(axis=[-2, -1])
|
||||
.to(uncond_embeddings.dtype)
|
||||
)
|
||||
uncond_embeddings *= (
|
||||
(previous_mean / current_mean).unsqueeze(-1).unsqueeze(-1)
|
||||
)
|
||||
|
||||
if uncond_prompt is not None:
|
||||
return text_embeddings, uncond_embeddings
|
||||
return text_embeddings, None
|
||||
4
apps/stable_diffusion/src/schedulers/__init__.py
Normal file
4
apps/stable_diffusion/src/schedulers/__init__.py
Normal file
@@ -0,0 +1,4 @@
|
||||
from apps.stable_diffusion.src.schedulers.sd_schedulers import get_schedulers
|
||||
from apps.stable_diffusion.src.schedulers.shark_eulerdiscrete import (
|
||||
SharkEulerDiscreteScheduler,
|
||||
)
|
||||
66
apps/stable_diffusion/src/schedulers/sd_schedulers.py
Normal file
66
apps/stable_diffusion/src/schedulers/sd_schedulers.py
Normal file
@@ -0,0 +1,66 @@
|
||||
from diffusers import (
|
||||
LMSDiscreteScheduler,
|
||||
PNDMScheduler,
|
||||
DDPMScheduler,
|
||||
DDIMScheduler,
|
||||
DPMSolverMultistepScheduler,
|
||||
KDPM2DiscreteScheduler,
|
||||
EulerDiscreteScheduler,
|
||||
EulerAncestralDiscreteScheduler,
|
||||
DEISMultistepScheduler,
|
||||
)
|
||||
from apps.stable_diffusion.src.schedulers.shark_eulerdiscrete import (
|
||||
SharkEulerDiscreteScheduler,
|
||||
)
|
||||
|
||||
|
||||
def get_schedulers(model_id):
|
||||
schedulers = dict()
|
||||
schedulers["PNDM"] = PNDMScheduler.from_pretrained(
|
||||
model_id,
|
||||
subfolder="scheduler",
|
||||
)
|
||||
schedulers["DDPM"] = DDPMScheduler.from_pretrained(
|
||||
model_id,
|
||||
subfolder="scheduler",
|
||||
)
|
||||
schedulers["KDPM2Discrete"] = KDPM2DiscreteScheduler.from_pretrained(
|
||||
model_id,
|
||||
subfolder="scheduler",
|
||||
)
|
||||
schedulers["LMSDiscrete"] = LMSDiscreteScheduler.from_pretrained(
|
||||
model_id,
|
||||
subfolder="scheduler",
|
||||
)
|
||||
schedulers["DDIM"] = DDIMScheduler.from_pretrained(
|
||||
model_id,
|
||||
subfolder="scheduler",
|
||||
)
|
||||
schedulers[
|
||||
"DPMSolverMultistep"
|
||||
] = DPMSolverMultistepScheduler.from_pretrained(
|
||||
model_id,
|
||||
subfolder="scheduler",
|
||||
)
|
||||
schedulers["EulerDiscrete"] = EulerDiscreteScheduler.from_pretrained(
|
||||
model_id,
|
||||
subfolder="scheduler",
|
||||
)
|
||||
schedulers[
|
||||
"EulerAncestralDiscrete"
|
||||
] = EulerAncestralDiscreteScheduler.from_pretrained(
|
||||
model_id,
|
||||
subfolder="scheduler",
|
||||
)
|
||||
schedulers["DEISMultistep"] = DEISMultistepScheduler.from_pretrained(
|
||||
model_id,
|
||||
subfolder="scheduler",
|
||||
)
|
||||
schedulers[
|
||||
"SharkEulerDiscrete"
|
||||
] = SharkEulerDiscreteScheduler.from_pretrained(
|
||||
model_id,
|
||||
subfolder="scheduler",
|
||||
)
|
||||
schedulers["SharkEulerDiscrete"].compile()
|
||||
return schedulers
|
||||
156
apps/stable_diffusion/src/schedulers/shark_eulerdiscrete.py
Normal file
156
apps/stable_diffusion/src/schedulers/shark_eulerdiscrete.py
Normal file
@@ -0,0 +1,156 @@
|
||||
import sys
|
||||
import numpy as np
|
||||
from typing import List, Optional, Tuple, Union
|
||||
from diffusers import (
|
||||
LMSDiscreteScheduler,
|
||||
PNDMScheduler,
|
||||
DDIMScheduler,
|
||||
DPMSolverMultistepScheduler,
|
||||
EulerDiscreteScheduler,
|
||||
)
|
||||
from diffusers.configuration_utils import register_to_config
|
||||
from apps.stable_diffusion.src.utils import (
|
||||
compile_through_fx,
|
||||
get_shark_model,
|
||||
args,
|
||||
)
|
||||
import torch
|
||||
|
||||
|
||||
class SharkEulerDiscreteScheduler(EulerDiscreteScheduler):
|
||||
@register_to_config
|
||||
def __init__(
|
||||
self,
|
||||
num_train_timesteps: int = 1000,
|
||||
beta_start: float = 0.0001,
|
||||
beta_end: float = 0.02,
|
||||
beta_schedule: str = "linear",
|
||||
trained_betas: Optional[Union[np.ndarray, List[float]]] = None,
|
||||
prediction_type: str = "epsilon",
|
||||
):
|
||||
super().__init__(
|
||||
num_train_timesteps,
|
||||
beta_start,
|
||||
beta_end,
|
||||
beta_schedule,
|
||||
trained_betas,
|
||||
prediction_type,
|
||||
)
|
||||
|
||||
def compile(self):
|
||||
SCHEDULER_BUCKET = "gs://shark_tank/stable_diffusion/schedulers"
|
||||
BATCH_SIZE = args.batch_size
|
||||
|
||||
model_input = {
|
||||
"euler": {
|
||||
"latent": torch.randn(
|
||||
BATCH_SIZE, 4, args.height // 8, args.width // 8
|
||||
),
|
||||
"output": torch.randn(
|
||||
BATCH_SIZE, 4, args.height // 8, args.width // 8
|
||||
),
|
||||
"sigma": torch.tensor(1).to(torch.float32),
|
||||
"dt": torch.tensor(1).to(torch.float32),
|
||||
},
|
||||
}
|
||||
|
||||
example_latent = model_input["euler"]["latent"]
|
||||
example_output = model_input["euler"]["output"]
|
||||
if args.precision == "fp16":
|
||||
example_latent = example_latent.half()
|
||||
example_output = example_output.half()
|
||||
example_sigma = model_input["euler"]["sigma"]
|
||||
example_dt = model_input["euler"]["dt"]
|
||||
|
||||
class ScalingModel(torch.nn.Module):
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
|
||||
def forward(self, latent, sigma):
|
||||
return latent / ((sigma**2 + 1) ** 0.5)
|
||||
|
||||
class SchedulerStepModel(torch.nn.Module):
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
|
||||
def forward(self, noise_pred, sigma, latent, dt):
|
||||
pred_original_sample = latent - sigma * noise_pred
|
||||
derivative = (latent - pred_original_sample) / sigma
|
||||
return latent + derivative * dt
|
||||
|
||||
iree_flags = []
|
||||
if len(args.iree_vulkan_target_triple) > 0:
|
||||
iree_flags.append(
|
||||
f"-iree-vulkan-target-triple={args.iree_vulkan_target_triple}"
|
||||
)
|
||||
# Disable bindings fusion to work with moltenVK.
|
||||
if sys.platform == "darwin":
|
||||
iree_flags.append("-iree-stream-fuse-binding=false")
|
||||
|
||||
def _import(self):
|
||||
scaling_model = ScalingModel()
|
||||
self.scaling_model = compile_through_fx(
|
||||
model=scaling_model,
|
||||
inputs=(example_latent, example_sigma),
|
||||
model_name=f"euler_scale_model_input_{BATCH_SIZE}_{args.height}_{args.width}"
|
||||
+ args.precision,
|
||||
extra_args=iree_flags,
|
||||
)
|
||||
|
||||
step_model = SchedulerStepModel()
|
||||
self.step_model = compile_through_fx(
|
||||
step_model,
|
||||
(example_output, example_sigma, example_latent, example_dt),
|
||||
model_name=f"euler_step_{BATCH_SIZE}_{args.height}_{args.width}"
|
||||
+ args.precision,
|
||||
extra_args=iree_flags,
|
||||
)
|
||||
|
||||
if args.import_mlir:
|
||||
_import(self)
|
||||
|
||||
else:
|
||||
try:
|
||||
self.scaling_model = get_shark_model(
|
||||
SCHEDULER_BUCKET,
|
||||
"euler_scale_model_input_" + args.precision,
|
||||
iree_flags,
|
||||
)
|
||||
self.step_model = get_shark_model(
|
||||
SCHEDULER_BUCKET,
|
||||
"euler_step_" + args.precision,
|
||||
iree_flags,
|
||||
)
|
||||
except:
|
||||
print(
|
||||
"failed to download model, falling back and using import_mlir"
|
||||
)
|
||||
args.import_mlir = True
|
||||
_import(self)
|
||||
|
||||
def scale_model_input(self, sample, timestep):
|
||||
step_index = (self.timesteps == timestep).nonzero().item()
|
||||
sigma = self.sigmas[step_index]
|
||||
return self.scaling_model(
|
||||
"forward",
|
||||
(
|
||||
sample,
|
||||
sigma,
|
||||
),
|
||||
send_to_host=False,
|
||||
)
|
||||
|
||||
def step(self, noise_pred, timestep, latent):
|
||||
step_index = (self.timesteps == timestep).nonzero().item()
|
||||
sigma = self.sigmas[step_index]
|
||||
dt = self.sigmas[step_index + 1] - sigma
|
||||
return self.step_model(
|
||||
"forward",
|
||||
(
|
||||
noise_pred,
|
||||
sigma,
|
||||
latent,
|
||||
dt,
|
||||
),
|
||||
send_to_host=False,
|
||||
)
|
||||
37
apps/stable_diffusion/src/utils/__init__.py
Normal file
37
apps/stable_diffusion/src/utils/__init__.py
Normal file
@@ -0,0 +1,37 @@
|
||||
from apps.stable_diffusion.src.utils.profiler import (
|
||||
start_profiling,
|
||||
end_profiling,
|
||||
)
|
||||
from apps.stable_diffusion.src.utils.resources import (
|
||||
prompt_examples,
|
||||
models_db,
|
||||
base_models,
|
||||
opt_flags,
|
||||
resource_path,
|
||||
)
|
||||
from apps.stable_diffusion.src.utils.sd_annotation import sd_model_annotation
|
||||
from apps.stable_diffusion.src.utils.stable_args import args
|
||||
from apps.stable_diffusion.src.utils.stencils.stencil_utils import (
|
||||
controlnet_hint_conversion,
|
||||
get_stencil_model_id,
|
||||
)
|
||||
from apps.stable_diffusion.src.utils.utils import (
|
||||
get_shark_model,
|
||||
compile_through_fx,
|
||||
set_iree_runtime_flags,
|
||||
map_device_to_name_path,
|
||||
set_init_device_flags,
|
||||
get_available_devices,
|
||||
get_opt_flags,
|
||||
preprocessCKPT,
|
||||
fetch_vmfb,
|
||||
fetch_and_update_base_model_id,
|
||||
get_path_to_diffusers_checkpoint,
|
||||
sanitize_seed,
|
||||
get_path_stem,
|
||||
get_extended_name,
|
||||
clear_all,
|
||||
save_output_img,
|
||||
get_generation_text_info,
|
||||
update_lora_weight,
|
||||
)
|
||||
18
apps/stable_diffusion/src/utils/profiler.py
Normal file
18
apps/stable_diffusion/src/utils/profiler.py
Normal file
@@ -0,0 +1,18 @@
|
||||
from apps.stable_diffusion.src.utils.stable_args import args
|
||||
|
||||
|
||||
# Helper function to profile the vulkan device.
|
||||
def start_profiling(file_path="foo.rdc", profiling_mode="queue"):
|
||||
if args.vulkan_debug_utils and "vulkan" in args.device:
|
||||
import iree
|
||||
|
||||
print(f"Profiling and saving to {file_path}.")
|
||||
vulkan_device = iree.runtime.get_device(args.device)
|
||||
vulkan_device.begin_profiling(mode=profiling_mode, file_path=file_path)
|
||||
return vulkan_device
|
||||
return None
|
||||
|
||||
|
||||
def end_profiling(device):
|
||||
if device:
|
||||
return device.end_profiling()
|
||||
37
apps/stable_diffusion/src/utils/resources.py
Normal file
37
apps/stable_diffusion/src/utils/resources.py
Normal file
@@ -0,0 +1,37 @@
|
||||
import os
|
||||
import json
|
||||
import sys
|
||||
|
||||
|
||||
def resource_path(relative_path):
|
||||
"""Get absolute path to resource, works for dev and for PyInstaller"""
|
||||
base_path = getattr(
|
||||
sys, "_MEIPASS", os.path.dirname(os.path.abspath(__file__))
|
||||
)
|
||||
return os.path.join(base_path, relative_path)
|
||||
|
||||
|
||||
def get_json_file(path):
|
||||
json_var = []
|
||||
loc_json = resource_path(path)
|
||||
if os.path.exists(loc_json):
|
||||
with open(loc_json, encoding="utf-8") as fopen:
|
||||
json_var = json.load(fopen)
|
||||
|
||||
if not json_var:
|
||||
print(f"Unable to fetch {path}")
|
||||
|
||||
return json_var
|
||||
|
||||
|
||||
# TODO: This shouldn't be called from here, every time the file imports
|
||||
# it will run all the global vars.
|
||||
prompt_examples = get_json_file("resources/prompts.json")
|
||||
models_db = get_json_file("resources/model_db.json")
|
||||
|
||||
# The base_model contains the input configuration for the different
|
||||
# models and also helps in providing information for the variants.
|
||||
base_models = get_json_file("resources/base_model.json")
|
||||
|
||||
# Contains optimization flags for different models.
|
||||
opt_flags = get_json_file("resources/opt_flags.json")
|
||||
296
apps/stable_diffusion/src/utils/resources/base_model.json
Normal file
296
apps/stable_diffusion/src/utils/resources/base_model.json
Normal file
@@ -0,0 +1,296 @@
|
||||
{
|
||||
"clip": {
|
||||
"token" : {
|
||||
"shape" : [
|
||||
"2*batch_size",
|
||||
"max_len"
|
||||
],
|
||||
"dtype":"i64"
|
||||
}
|
||||
},
|
||||
"vae_encode": {
|
||||
"image" : {
|
||||
"shape" : [
|
||||
"1*batch_size",3,"8*height","8*width"
|
||||
],
|
||||
"dtype":"f32"
|
||||
}
|
||||
},
|
||||
"vae": {
|
||||
"vae": {
|
||||
"latents" : {
|
||||
"shape" : [
|
||||
"1*batch_size",4,"height","width"
|
||||
],
|
||||
"dtype":"f32"
|
||||
}
|
||||
},
|
||||
"vae_upscaler": {
|
||||
"latents" : {
|
||||
"shape" : [
|
||||
"1*batch_size",4,"8*height","8*width"
|
||||
],
|
||||
"dtype":"f32"
|
||||
}
|
||||
}
|
||||
},
|
||||
"unet": {
|
||||
"stabilityai/stable-diffusion-2-1": {
|
||||
"latents": {
|
||||
"shape": [
|
||||
"1*batch_size",
|
||||
4,
|
||||
"height",
|
||||
"width"
|
||||
],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"timesteps": {
|
||||
"shape": [
|
||||
1
|
||||
],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"embedding": {
|
||||
"shape": [
|
||||
"2*batch_size",
|
||||
"max_len",
|
||||
1024
|
||||
],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"guidance_scale": {
|
||||
"shape": 2,
|
||||
"dtype": "f32"
|
||||
}
|
||||
},
|
||||
"CompVis/stable-diffusion-v1-4": {
|
||||
"latents": {
|
||||
"shape": [
|
||||
"1*batch_size",
|
||||
4,
|
||||
"height",
|
||||
"width"
|
||||
],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"timesteps": {
|
||||
"shape": [
|
||||
1
|
||||
],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"embedding": {
|
||||
"shape": [
|
||||
"2*batch_size",
|
||||
"max_len",
|
||||
768
|
||||
],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"guidance_scale": {
|
||||
"shape": 2,
|
||||
"dtype": "f32"
|
||||
}
|
||||
},
|
||||
"stabilityai/stable-diffusion-2-inpainting": {
|
||||
"latents": {
|
||||
"shape": [
|
||||
"1*batch_size",
|
||||
9,
|
||||
"height",
|
||||
"width"
|
||||
],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"timesteps": {
|
||||
"shape": [
|
||||
1
|
||||
],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"embedding": {
|
||||
"shape": [
|
||||
"2*batch_size",
|
||||
"max_len",
|
||||
1024
|
||||
],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"guidance_scale": {
|
||||
"shape": 2,
|
||||
"dtype": "f32"
|
||||
}
|
||||
},
|
||||
"runwayml/stable-diffusion-inpainting": {
|
||||
"latents": {
|
||||
"shape": [
|
||||
"1*batch_size",
|
||||
9,
|
||||
"height",
|
||||
"width"
|
||||
],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"timesteps": {
|
||||
"shape": [
|
||||
1
|
||||
],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"embedding": {
|
||||
"shape": [
|
||||
"2*batch_size",
|
||||
"max_len",
|
||||
768
|
||||
],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"guidance_scale": {
|
||||
"shape": 2,
|
||||
"dtype": "f32"
|
||||
}
|
||||
},
|
||||
"stabilityai/stable-diffusion-x4-upscaler": {
|
||||
"latents": {
|
||||
"shape": [
|
||||
"2*batch_size",
|
||||
7,
|
||||
"8*height",
|
||||
"8*width"
|
||||
],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"timesteps": {
|
||||
"shape": [
|
||||
1
|
||||
],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"embedding": {
|
||||
"shape": [
|
||||
"2*batch_size",
|
||||
"max_len",
|
||||
1024
|
||||
],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"noise_level": {
|
||||
"shape": [2],
|
||||
"dtype": "i64"
|
||||
}
|
||||
}
|
||||
},
|
||||
"stencil_adaptor": {
|
||||
"latents": {
|
||||
"shape": [
|
||||
"1*batch_size",
|
||||
4,
|
||||
"height",
|
||||
"width"
|
||||
],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"timesteps": {
|
||||
"shape": [
|
||||
1
|
||||
],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"embedding": {
|
||||
"shape": [
|
||||
"2*batch_size",
|
||||
"max_len",
|
||||
768
|
||||
],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"controlnet_hint": {
|
||||
"shape": [1, 3, "8*height", "8*width"],
|
||||
"dtype": "f32"
|
||||
}
|
||||
},
|
||||
"stencil_unet": {
|
||||
"CompVis/stable-diffusion-v1-4": {
|
||||
"latents": {
|
||||
"shape": [
|
||||
"1*batch_size",
|
||||
4,
|
||||
"height",
|
||||
"width"
|
||||
],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"timesteps": {
|
||||
"shape": [
|
||||
1
|
||||
],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"embedding": {
|
||||
"shape": [
|
||||
"2*batch_size",
|
||||
"max_len",
|
||||
768
|
||||
],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"guidance_scale": {
|
||||
"shape": 2,
|
||||
"dtype": "f32"
|
||||
},
|
||||
"control1": {
|
||||
"shape": [2, 320, "height", "width"],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"control2": {
|
||||
"shape": [2, 320, "height", "width"],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"control3": {
|
||||
"shape": [2, 320, "height", "width"],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"control4": {
|
||||
"shape": [2, 320, "height/2", "width/2"],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"control5": {
|
||||
"shape": [2, 640, "height/2", "width/2"],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"control6": {
|
||||
"shape": [2, 640, "height/2", "width/2"],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"control7": {
|
||||
"shape": [2, 640, "height/4", "width/4"],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"control8": {
|
||||
"shape": [2, 1280, "height/4", "width/4"],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"control9": {
|
||||
"shape": [2, 1280, "height/4", "width/4"],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"control10": {
|
||||
"shape": [2, 1280, "height/8", "width/8"],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"control11": {
|
||||
"shape": [2, 1280, "height/8", "width/8"],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"control12": {
|
||||
"shape": [2, 1280, "height/8", "width/8"],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"control13": {
|
||||
"shape": [2, 1280, "height/8", "width/8"],
|
||||
"dtype": "f32"
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
23
apps/stable_diffusion/src/utils/resources/model_config.json
Normal file
23
apps/stable_diffusion/src/utils/resources/model_config.json
Normal file
@@ -0,0 +1,23 @@
|
||||
[
|
||||
{
|
||||
"stablediffusion/v1_4":"CompVis/stable-diffusion-v1-4",
|
||||
"stablediffusion/v2_1base":"stabilityai/stable-diffusion-2-1-base",
|
||||
"stablediffusion/v2_1":"stabilityai/stable-diffusion-2-1",
|
||||
"stablediffusion/inpaint_v1":"runwayml/stable-diffusion-inpainting",
|
||||
"stablediffusion/inpaint_v2":"stabilityai/stable-diffusion-2-inpainting",
|
||||
"anythingv3/v1_4":"Linaqruf/anything-v3.0",
|
||||
"analogdiffusion/v1_4":"wavymulder/Analog-Diffusion",
|
||||
"openjourney/v1_4":"prompthero/openjourney",
|
||||
"dreamlike/v1_4":"dreamlike-art/dreamlike-diffusion-1.0"
|
||||
},
|
||||
{
|
||||
"stablediffusion/fp16":"fp16",
|
||||
"stablediffusion/fp32":"main",
|
||||
"anythingv3/fp16":"diffusers",
|
||||
"anythingv3/fp32":"diffusers",
|
||||
"analogdiffusion/fp16":"main",
|
||||
"analogdiffusion/fp32":"main",
|
||||
"openjourney/fp16":"main",
|
||||
"openjourney/fp32":"main"
|
||||
}
|
||||
]
|
||||
19
apps/stable_diffusion/src/utils/resources/model_db.json
Normal file
19
apps/stable_diffusion/src/utils/resources/model_db.json
Normal file
@@ -0,0 +1,19 @@
|
||||
[
|
||||
{
|
||||
"stablediffusion/untuned":"gs://shark_tank/nightly"
|
||||
},
|
||||
{
|
||||
"stablediffusion/v1_4/unet/fp16/length_64/untuned":"unet_1_64_512_512_fp16_stable-diffusion-2-1-base_vulkan",
|
||||
"stablediffusion/v1_4/vae/fp16/length_77/untuned":"vae_1_64_512_512_fp16_stable-diffusion-v1-4_vulkan",
|
||||
"stablediffusion/v1_4/vae/fp16/length_64/untuned":"vae_1_64_512_512_fp16_stable-diffusion-v1-4_vulkan",
|
||||
"stablediffusion/v1_4/clip/fp32/length_64/untuned":"clip_1_64_512_512_fp16_stable-diffusion-v1-4_vulkan",
|
||||
"stablediffusion/v2_1base/unet/fp16/length_77/untuned":"unet_1_77_512_512_fp16_stable-diffusion-2-1-base_vulkan",
|
||||
"stablediffusion/v2_1base/unet/fp16/length_64/untuned":"unet_1_64_512_512_fp16_stable-diffusion-2-1-base_vulkan",
|
||||
"stablediffusion/v2_1base/vae/fp16/length_77/untuned":"vae_1_64_512_512_fp16_stable-diffusion-2-1-base_vulkan",
|
||||
"stablediffusion/v2_1base/clip/fp32/length_77/untuned":"clip_1_77_512_512_fp16_stable-diffusion-2-1-base_vulkan",
|
||||
"stablediffusion/v2_1base/clip/fp32/length_64/untuned":"clip_1_64_512_512_fp16_stable-diffusion-2-1-base_vulkan",
|
||||
"stablediffusion/v2_1/unet/fp16/length_77/untuned":"unet_1_77_512_512_fp16_stable-diffusion-2-1-base_vulkan",
|
||||
"stablediffusion/v2_1/vae/fp16/length_77/untuned":"vae_1_64_512_512_fp16_stable-diffusion-2-1-base_vulkan",
|
||||
"stablediffusion/v2_1/clip/fp32/length_77/untuned":"clip_1_64_512_512_fp16_stable-diffusion-2-1-base_vulkan"
|
||||
}
|
||||
]
|
||||
84
apps/stable_diffusion/src/utils/resources/opt_flags.json
Normal file
84
apps/stable_diffusion/src/utils/resources/opt_flags.json
Normal file
@@ -0,0 +1,84 @@
|
||||
{
|
||||
"unet": {
|
||||
"tuned": {
|
||||
"fp16": {
|
||||
"default_compilation_flags": []
|
||||
},
|
||||
"fp32": {
|
||||
"default_compilation_flags": []
|
||||
}
|
||||
},
|
||||
"untuned": {
|
||||
"fp16": {
|
||||
"default_compilation_flags": [
|
||||
"--iree-preprocessing-pass-pipeline=builtin.module(func.func(iree-flow-detach-elementwise-from-named-ops,iree-flow-convert-1x1-filter-conv2d-to-matmul,iree-preprocessing-convert-conv2d-to-img2col,iree-preprocessing-pad-linalg-ops{pad-size=32}))"
|
||||
]
|
||||
},
|
||||
"fp32": {
|
||||
"default_compilation_flags": [
|
||||
"--iree-preprocessing-pass-pipeline=builtin.module(func.func(iree-flow-detach-elementwise-from-named-ops,iree-flow-convert-1x1-filter-conv2d-to-matmul,iree-preprocessing-convert-conv2d-to-img2col,iree-preprocessing-pad-linalg-ops{pad-size=16}))"
|
||||
]
|
||||
}
|
||||
}
|
||||
},
|
||||
"vae": {
|
||||
"tuned": {
|
||||
"fp16": {
|
||||
"default_compilation_flags": [],
|
||||
"specified_compilation_flags": {
|
||||
"cuda": [],
|
||||
"default_device": [
|
||||
"--iree-preprocessing-pass-pipeline=builtin.module(func.func(iree-flow-detach-elementwise-from-named-ops,iree-flow-convert-1x1-filter-conv2d-to-matmul,iree-preprocessing-convert-conv2d-to-img2col,iree-preprocessing-pad-linalg-ops{pad-size=32},iree-linalg-ext-convert-conv2d-to-winograd))"
|
||||
]
|
||||
}
|
||||
},
|
||||
"fp32": {
|
||||
"default_compilation_flags": [],
|
||||
"specified_compilation_flags": {
|
||||
"cuda": [],
|
||||
"default_device": [
|
||||
"--iree-preprocessing-pass-pipeline=builtin.module(func.func(iree-flow-detach-elementwise-from-named-ops,iree-flow-convert-1x1-filter-conv2d-to-matmul,iree-preprocessing-convert-conv2d-to-img2col,iree-preprocessing-pad-linalg-ops{pad-size=16},iree-linalg-ext-convert-conv2d-to-winograd))"
|
||||
]
|
||||
}
|
||||
}
|
||||
},
|
||||
"untuned": {
|
||||
"fp16": {
|
||||
"default_compilation_flags": [
|
||||
"--iree-preprocessing-pass-pipeline=builtin.module(func.func(iree-flow-detach-elementwise-from-named-ops,iree-preprocessing-pad-linalg-ops{pad-size=32}))"
|
||||
]
|
||||
},
|
||||
"fp32": {
|
||||
"default_compilation_flags": [
|
||||
"--iree-preprocessing-pass-pipeline=builtin.module(func.func(iree-flow-detach-elementwise-from-named-ops,iree-preprocessing-pad-linalg-ops{pad-size=16}))"
|
||||
]
|
||||
}
|
||||
}
|
||||
},
|
||||
"clip": {
|
||||
"tuned": {
|
||||
"fp16": {
|
||||
"default_compilation_flags": [
|
||||
"--iree-preprocessing-pass-pipeline=builtin.module(func.func(iree-preprocessing-pad-linalg-ops{pad-size=16}))"
|
||||
]
|
||||
},
|
||||
"fp32": {
|
||||
"default_compilation_flags": [
|
||||
"--iree-preprocessing-pass-pipeline=builtin.module(func.func(iree-preprocessing-pad-linalg-ops{pad-size=16}))"
|
||||
]
|
||||
}
|
||||
},
|
||||
"untuned": {
|
||||
"fp16": {
|
||||
"default_compilation_flags": [
|
||||
"--iree-preprocessing-pass-pipeline=builtin.module(func.func(iree-preprocessing-pad-linalg-ops{pad-size=16}))"
|
||||
]
|
||||
},
|
||||
"fp32": {
|
||||
"default_compilation_flags": [
|
||||
"--iree-preprocessing-pass-pipeline=builtin.module(func.func(iree-preprocessing-pad-linalg-ops{pad-size=16}))"
|
||||
]
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
8
apps/stable_diffusion/src/utils/resources/prompts.json
Normal file
8
apps/stable_diffusion/src/utils/resources/prompts.json
Normal file
@@ -0,0 +1,8 @@
|
||||
[["A high tech solarpunk utopia in the Amazon rainforest"],
|
||||
["A pikachu fine dining with a view to the Eiffel Tower"],
|
||||
["A mecha robot in a favela in expressionist style"],
|
||||
["an insect robot preparing a delicious meal"],
|
||||
["A digital Illustration of the Babel tower, 4k, detailed, trending in artstation, fantasy vivid colors"],
|
||||
["Cluttered house in the woods, anime, oil painting, high resolution, cottagecore, ghibli inspired, 4k"],
|
||||
["A beautiful mansion beside a waterfall in the woods, by josef thoma, matte painting, trending on artstation HQ"],
|
||||
["portrait photo of a asia old warrior chief, tribal panther make up, blue on red, side profile, looking away, serious eyes"]]
|
||||
252
apps/stable_diffusion/src/utils/sd_annotation.py
Normal file
252
apps/stable_diffusion/src/utils/sd_annotation.py
Normal file
@@ -0,0 +1,252 @@
|
||||
import os
|
||||
import io
|
||||
from shark.model_annotation import model_annotation, create_context
|
||||
from shark.iree_utils._common import iree_target_map, run_cmd
|
||||
from shark.shark_downloader import (
|
||||
download_model,
|
||||
download_public_file,
|
||||
WORKDIR,
|
||||
)
|
||||
from shark.parser import shark_args
|
||||
from apps.stable_diffusion.src.utils.stable_args import args
|
||||
|
||||
|
||||
def get_device():
|
||||
device = (
|
||||
args.device
|
||||
if "://" not in args.device
|
||||
else args.device.split("://")[0]
|
||||
)
|
||||
return device
|
||||
|
||||
|
||||
def get_device_args():
|
||||
device = get_device()
|
||||
device_spec_args = []
|
||||
if device == "cuda":
|
||||
from shark.iree_utils.gpu_utils import get_iree_gpu_args
|
||||
|
||||
gpu_flags = get_iree_gpu_args()
|
||||
for flag in gpu_flags:
|
||||
device_spec_args.append(flag)
|
||||
elif device == "vulkan":
|
||||
device_spec_args.append(
|
||||
f"--iree-vulkan-target-triple={args.iree_vulkan_target_triple} "
|
||||
)
|
||||
return device, device_spec_args
|
||||
|
||||
|
||||
# Download the model (Unet or VAE fp16) from shark_tank
|
||||
def load_model_from_tank():
|
||||
from apps.stable_diffusion.src.models import (
|
||||
get_params,
|
||||
get_variant_version,
|
||||
)
|
||||
|
||||
variant, version = get_variant_version(args.hf_model_id)
|
||||
|
||||
shark_args.local_tank_cache = args.local_tank_cache
|
||||
bucket_key = f"{variant}/untuned"
|
||||
if args.annotation_model == "unet":
|
||||
model_key = f"{variant}/{version}/unet/{args.precision}/length_{args.max_length}/untuned"
|
||||
elif args.annotation_model == "vae":
|
||||
is_base = "/base" if args.use_base_vae else ""
|
||||
model_key = f"{variant}/{version}/vae/{args.precision}/length_77/untuned{is_base}"
|
||||
|
||||
bucket, model_name, iree_flags = get_params(
|
||||
bucket_key, model_key, args.annotation_model, "untuned", args.precision
|
||||
)
|
||||
mlir_model, func_name, inputs, golden_out = download_model(
|
||||
model_name,
|
||||
tank_url=bucket,
|
||||
frontend="torch",
|
||||
)
|
||||
return mlir_model, model_name
|
||||
|
||||
|
||||
# Download the tuned config files from shark_tank
|
||||
def load_winograd_configs():
|
||||
device = get_device()
|
||||
config_bucket = "gs://shark_tank/sd_tuned/configs/"
|
||||
config_name = f"{args.annotation_model}_winograd_{device}.json"
|
||||
full_gs_url = config_bucket + config_name
|
||||
winograd_config_dir = os.path.join(WORKDIR, "configs", config_name)
|
||||
print("Loading Winograd config file from ", winograd_config_dir)
|
||||
download_public_file(full_gs_url, winograd_config_dir, True)
|
||||
return winograd_config_dir
|
||||
|
||||
|
||||
def load_lower_configs(base_model_id=None):
|
||||
from apps.stable_diffusion.src.models import get_variant_version
|
||||
from apps.stable_diffusion.src.utils.utils import (
|
||||
fetch_and_update_base_model_id,
|
||||
)
|
||||
|
||||
if not base_model_id:
|
||||
if args.ckpt_loc != "":
|
||||
base_model_id = fetch_and_update_base_model_id(args.ckpt_loc)
|
||||
else:
|
||||
base_model_id = fetch_and_update_base_model_id(args.hf_model_id)
|
||||
if base_model_id == "":
|
||||
base_model_id = args.hf_model_id
|
||||
|
||||
variant, version = get_variant_version(base_model_id)
|
||||
|
||||
if version == "inpaint_v1":
|
||||
version = "v1_4"
|
||||
elif version == "inpaint_v2":
|
||||
version = "v2_1base"
|
||||
|
||||
config_bucket = "gs://shark_tank/sd_tuned_configs/"
|
||||
|
||||
device, device_spec_args = get_device_args()
|
||||
spec = ""
|
||||
if device_spec_args:
|
||||
spec = device_spec_args[-1].split("=")[-1].strip()
|
||||
if device == "vulkan":
|
||||
spec = spec.split("-")[0]
|
||||
|
||||
if args.annotation_model == "vae":
|
||||
if not spec or spec in ["rdna3", "sm_80"]:
|
||||
config_name = (
|
||||
f"{args.annotation_model}_{args.precision}_{device}.json"
|
||||
)
|
||||
else:
|
||||
config_name = f"{args.annotation_model}_{args.precision}_{device}_{spec}.json"
|
||||
else:
|
||||
if not spec or spec in ["rdna3", "sm_80"]:
|
||||
if (
|
||||
version in ["v2_1", "v2_1base"]
|
||||
and args.height == 768
|
||||
and args.width == 768
|
||||
):
|
||||
config_name = f"{args.annotation_model}_v2_1_768_{args.precision}_{device}.json"
|
||||
else:
|
||||
config_name = f"{args.annotation_model}_{version}_{args.precision}_{device}.json"
|
||||
else:
|
||||
config_name = f"{args.annotation_model}_{version}_{args.precision}_{device}_{spec}.json"
|
||||
|
||||
full_gs_url = config_bucket + config_name
|
||||
lowering_config_dir = os.path.join(WORKDIR, "configs", config_name)
|
||||
print("Loading lowering config file from ", lowering_config_dir)
|
||||
download_public_file(full_gs_url, lowering_config_dir, True)
|
||||
return lowering_config_dir
|
||||
|
||||
|
||||
# Annotate the model with Winograd attribute on selected conv ops
|
||||
def annotate_with_winograd(input_mlir, winograd_config_dir, model_name):
|
||||
with create_context() as ctx:
|
||||
winograd_model = model_annotation(
|
||||
ctx,
|
||||
input_contents=input_mlir,
|
||||
config_path=winograd_config_dir,
|
||||
search_op="conv",
|
||||
winograd=True,
|
||||
)
|
||||
|
||||
bytecode_stream = io.BytesIO()
|
||||
winograd_model.operation.write_bytecode(bytecode_stream)
|
||||
bytecode = bytecode_stream.getvalue()
|
||||
|
||||
if args.save_annotation:
|
||||
if model_name.split("_")[-1] != "tuned":
|
||||
out_file_path = os.path.join(
|
||||
args.annotation_output, model_name + "_tuned_torch.mlir"
|
||||
)
|
||||
else:
|
||||
out_file_path = os.path.join(
|
||||
args.annotation_output, model_name + "_torch.mlir"
|
||||
)
|
||||
with open(out_file_path, "w") as f:
|
||||
f.write(str(winograd_model))
|
||||
f.close()
|
||||
|
||||
return bytecode
|
||||
|
||||
|
||||
def dump_after_mlir(input_mlir, use_winograd):
|
||||
import iree.compiler as ireec
|
||||
|
||||
device, device_spec_args = get_device_args()
|
||||
if use_winograd:
|
||||
preprocess_flag = "--iree-preprocessing-pass-pipeline=builtin.module(func.func(iree-flow-detach-elementwise-from-named-ops,iree-flow-convert-1x1-filter-conv2d-to-matmul,iree-preprocessing-convert-conv2d-to-img2col,iree-preprocessing-pad-linalg-ops{pad-size=32},iree-linalg-ext-convert-conv2d-to-winograd))"
|
||||
else:
|
||||
preprocess_flag = "--iree-preprocessing-pass-pipeline=builtin.module(func.func(iree-flow-detach-elementwise-from-named-ops,iree-flow-convert-1x1-filter-conv2d-to-matmul,iree-preprocessing-convert-conv2d-to-img2col,iree-preprocessing-pad-linalg-ops{pad-size=32}))"
|
||||
|
||||
dump_module = ireec.compile_str(
|
||||
input_mlir,
|
||||
target_backends=[iree_target_map(device)],
|
||||
extra_args=device_spec_args
|
||||
+ [
|
||||
preprocess_flag,
|
||||
"--compile-to=preprocessing",
|
||||
],
|
||||
)
|
||||
return dump_module
|
||||
|
||||
|
||||
# For Unet annotate the model with tuned lowering configs
|
||||
def annotate_with_lower_configs(
|
||||
input_mlir, lowering_config_dir, model_name, use_winograd
|
||||
):
|
||||
# Dump IR after padding/img2col/winograd passes
|
||||
dump_module = dump_after_mlir(input_mlir, use_winograd)
|
||||
print("Applying tuned configs on", model_name)
|
||||
|
||||
# Annotate the model with lowering configs in the config file
|
||||
with create_context() as ctx:
|
||||
tuned_model = model_annotation(
|
||||
ctx,
|
||||
input_contents=dump_module,
|
||||
config_path=lowering_config_dir,
|
||||
search_op="all",
|
||||
)
|
||||
|
||||
bytecode_stream = io.BytesIO()
|
||||
tuned_model.operation.write_bytecode(bytecode_stream)
|
||||
bytecode = bytecode_stream.getvalue()
|
||||
|
||||
if args.save_annotation:
|
||||
if model_name.split("_")[-1] != "tuned":
|
||||
out_file_path = (
|
||||
f"{args.annotation_output}/{model_name}_tuned_torch.mlir"
|
||||
)
|
||||
else:
|
||||
out_file_path = f"{args.annotation_output}/{model_name}_torch.mlir"
|
||||
with open(out_file_path, "w") as f:
|
||||
f.write(str(tuned_model))
|
||||
f.close()
|
||||
|
||||
return bytecode
|
||||
|
||||
|
||||
def sd_model_annotation(mlir_model, model_name, base_model_id=None):
|
||||
device = get_device()
|
||||
if args.annotation_model == "unet" and device == "vulkan":
|
||||
use_winograd = True
|
||||
winograd_config_dir = load_winograd_configs()
|
||||
winograd_model = annotate_with_winograd(
|
||||
mlir_model, winograd_config_dir, model_name
|
||||
)
|
||||
lowering_config_dir = load_lower_configs(base_model_id)
|
||||
tuned_model = annotate_with_lower_configs(
|
||||
winograd_model, lowering_config_dir, model_name, use_winograd
|
||||
)
|
||||
elif args.annotation_model == "vae" and device == "vulkan":
|
||||
use_winograd = True
|
||||
winograd_config_dir = load_winograd_configs()
|
||||
tuned_model = annotate_with_winograd(
|
||||
mlir_model, winograd_config_dir, model_name
|
||||
)
|
||||
else:
|
||||
use_winograd = False
|
||||
lowering_config_dir = load_lower_configs(base_model_id)
|
||||
tuned_model = annotate_with_lower_configs(
|
||||
mlir_model, lowering_config_dir, model_name, use_winograd
|
||||
)
|
||||
return tuned_model
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
mlir_model, model_name = load_model_from_tank()
|
||||
sd_model_annotation(mlir_model, model_name)
|
||||
547
apps/stable_diffusion/src/utils/stable_args.py
Normal file
547
apps/stable_diffusion/src/utils/stable_args.py
Normal file
@@ -0,0 +1,547 @@
|
||||
import argparse
|
||||
import os
|
||||
from pathlib import Path
|
||||
|
||||
|
||||
def path_expand(s):
|
||||
return Path(s).expanduser().resolve()
|
||||
|
||||
|
||||
def is_valid_file(arg):
|
||||
if not os.path.exists(arg):
|
||||
return None
|
||||
else:
|
||||
return arg
|
||||
|
||||
|
||||
p = argparse.ArgumentParser(
|
||||
description=__doc__, formatter_class=argparse.ArgumentDefaultsHelpFormatter
|
||||
)
|
||||
|
||||
##############################################################################
|
||||
### Stable Diffusion Params
|
||||
##############################################################################
|
||||
|
||||
p.add_argument(
|
||||
"-a",
|
||||
"--app",
|
||||
default="txt2img",
|
||||
help="which app to use, one of: txt2img, img2img, outpaint, inpaint",
|
||||
)
|
||||
p.add_argument(
|
||||
"-p",
|
||||
"--prompts",
|
||||
nargs="+",
|
||||
default=["cyberpunk forest by Salvador Dali"],
|
||||
help="text of which images to be generated.",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--negative_prompts",
|
||||
nargs="+",
|
||||
default=["trees, green"],
|
||||
help="text you don't want to see in the generated image.",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--img_path",
|
||||
type=str,
|
||||
help="Path to the image input for img2img/inpainting",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--steps",
|
||||
type=int,
|
||||
default=50,
|
||||
help="the no. of steps to do the sampling.",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--seed",
|
||||
type=int,
|
||||
default=-1,
|
||||
help="the seed to use. -1 for a random one.",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--batch_size",
|
||||
type=int,
|
||||
default=1,
|
||||
choices=range(1, 4),
|
||||
help="the number of inferences to be made in a single `batch_count`.",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--height",
|
||||
type=int,
|
||||
default=512,
|
||||
choices=range(128, 769, 8),
|
||||
help="the height of the output image.",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--width",
|
||||
type=int,
|
||||
default=512,
|
||||
choices=range(128, 769, 8),
|
||||
help="the width of the output image.",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--guidance_scale",
|
||||
type=float,
|
||||
default=7.5,
|
||||
help="the value to be used for guidance scaling.",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--noise_level",
|
||||
type=int,
|
||||
default=20,
|
||||
help="the value to be used for noise level of upscaler.",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--max_length",
|
||||
type=int,
|
||||
default=64,
|
||||
help="max length of the tokenizer output, options are 64 and 77.",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--strength",
|
||||
type=float,
|
||||
default=0.8,
|
||||
help="the strength of change applied on the given input image for img2img",
|
||||
)
|
||||
|
||||
##############################################################################
|
||||
### Stable Diffusion Training Params
|
||||
##############################################################################
|
||||
|
||||
p.add_argument(
|
||||
"--lora_save_dir",
|
||||
type=str,
|
||||
default="models/lora/",
|
||||
help="Directory to save the lora fine tuned model",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--training_images_dir",
|
||||
type=str,
|
||||
default="models/lora/training_images/",
|
||||
help="Directory containing images that are an example of the prompt",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--training_steps",
|
||||
type=int,
|
||||
default=2000,
|
||||
help="The no. of steps to train",
|
||||
)
|
||||
|
||||
##############################################################################
|
||||
### Inpainting and Outpainting Params
|
||||
##############################################################################
|
||||
|
||||
p.add_argument(
|
||||
"--mask_path",
|
||||
type=str,
|
||||
help="Path to the mask image input for inpainting",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--inpaint_full_res",
|
||||
default=False,
|
||||
action=argparse.BooleanOptionalAction,
|
||||
help="If inpaint only masked area or whole picture",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--inpaint_full_res_padding",
|
||||
type=int,
|
||||
default=32,
|
||||
choices=range(0, 257, 4),
|
||||
help="Number of pixels for only masked padding",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--pixels",
|
||||
type=int,
|
||||
default=128,
|
||||
choices=range(8, 257, 8),
|
||||
help="Number of expended pixels for one direction for outpainting",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--mask_blur",
|
||||
type=int,
|
||||
default=8,
|
||||
choices=range(0, 65),
|
||||
help="Number of blur pixels for outpainting",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--left",
|
||||
default=False,
|
||||
action=argparse.BooleanOptionalAction,
|
||||
help="If expend left for outpainting",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--right",
|
||||
default=False,
|
||||
action=argparse.BooleanOptionalAction,
|
||||
help="If expend right for outpainting",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--top",
|
||||
default=False,
|
||||
action=argparse.BooleanOptionalAction,
|
||||
help="If expend top for outpainting",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--bottom",
|
||||
default=False,
|
||||
action=argparse.BooleanOptionalAction,
|
||||
help="If expend bottom for outpainting",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--noise_q",
|
||||
type=float,
|
||||
default=1.0,
|
||||
help="Fall-off exponent for outpainting (lower=higher detail) (min=0.0, max=4.0)",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--color_variation",
|
||||
type=float,
|
||||
default=0.05,
|
||||
help="Color variation for outpainting (min=0.0, max=1.0)",
|
||||
)
|
||||
|
||||
##############################################################################
|
||||
### Model Config and Usage Params
|
||||
##############################################################################
|
||||
|
||||
p.add_argument(
|
||||
"--device", type=str, default="vulkan", help="device to run the model."
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--precision", type=str, default="fp16", help="precision to run the model."
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--import_mlir",
|
||||
default=False,
|
||||
action=argparse.BooleanOptionalAction,
|
||||
help="imports the model from torch module to shark_module otherwise downloads the model from shark_tank.",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--load_vmfb",
|
||||
default=True,
|
||||
action=argparse.BooleanOptionalAction,
|
||||
help="attempts to load the model from a precompiled flatbuffer and compiles + saves it if not found.",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--save_vmfb",
|
||||
default=False,
|
||||
action=argparse.BooleanOptionalAction,
|
||||
help="saves the compiled flatbuffer to the local directory",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--use_tuned",
|
||||
default=True,
|
||||
action=argparse.BooleanOptionalAction,
|
||||
help="Download and use the tuned version of the model if available",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--use_base_vae",
|
||||
default=False,
|
||||
action=argparse.BooleanOptionalAction,
|
||||
help="Do conversion from the VAE output to pixel space on cpu.",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--scheduler",
|
||||
type=str,
|
||||
default="SharkEulerDiscrete",
|
||||
help="other supported schedulers are [PNDM, DDIM, LMSDiscrete, EulerDiscrete, DPMSolverMultistep]",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--output_img_format",
|
||||
type=str,
|
||||
default="png",
|
||||
help="specify the format in which output image is save. Supported options: jpg / png",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--output_dir",
|
||||
type=str,
|
||||
default=None,
|
||||
help="Directory path to save the output images and json",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--batch_count",
|
||||
type=int,
|
||||
default=1,
|
||||
help="number of batch to be generated with random seeds in single execution",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--ckpt_loc",
|
||||
type=str,
|
||||
default="",
|
||||
help="Path to SD's .ckpt file.",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--custom_vae",
|
||||
type=str,
|
||||
default="",
|
||||
help="HuggingFace repo-id or path to SD model's checkpoint whose Vae needs to be plugged in.",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--hf_model_id",
|
||||
type=str,
|
||||
default="stabilityai/stable-diffusion-2-1-base",
|
||||
help="The repo-id of hugging face.",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--low_cpu_mem_usage",
|
||||
default=False,
|
||||
action=argparse.BooleanOptionalAction,
|
||||
help="Use the accelerate package to reduce cpu memory consumption",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--attention_slicing",
|
||||
type=str,
|
||||
default="none",
|
||||
help="Amount of attention slicing to use (one of 'max', 'auto', 'none', or an integer)",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--use_stencil",
|
||||
choices=["canny", "openpose", "scribble"],
|
||||
help="Enable the stencil feature.",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--use_lora",
|
||||
type=str,
|
||||
default="",
|
||||
help="Use standalone LoRA weight using a HF ID or a checkpoint file (~3 MB)",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--use_quantize",
|
||||
type=str,
|
||||
default="none",
|
||||
help="""Runs the quantized version of stable diffusion model. This is currently in experimental phase.
|
||||
Currently, only runs the stable-diffusion-2-1-base model in int8 quantization.""",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--ondemand",
|
||||
default=False,
|
||||
action=argparse.BooleanOptionalAction,
|
||||
help="Load and unload models for low VRAM",
|
||||
)
|
||||
|
||||
##############################################################################
|
||||
### IREE - Vulkan supported flags
|
||||
##############################################################################
|
||||
|
||||
p.add_argument(
|
||||
"--iree_vulkan_target_triple",
|
||||
type=str,
|
||||
default="",
|
||||
help="Specify target triple for vulkan",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--vulkan_debug_utils",
|
||||
default=False,
|
||||
action=argparse.BooleanOptionalAction,
|
||||
help="Profiles vulkan device and collects the .rdc info",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--vulkan_large_heap_block_size",
|
||||
default="2073741824",
|
||||
help="flag for setting VMA preferredLargeHeapBlockSize for vulkan device, default is 4G",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--vulkan_validation_layers",
|
||||
default=False,
|
||||
action=argparse.BooleanOptionalAction,
|
||||
help="flag for disabling vulkan validation layers when benchmarking",
|
||||
)
|
||||
|
||||
##############################################################################
|
||||
### Misc. Debug and Optimization flags
|
||||
##############################################################################
|
||||
|
||||
p.add_argument(
|
||||
"--use_compiled_scheduler",
|
||||
default=True,
|
||||
action=argparse.BooleanOptionalAction,
|
||||
help="use the default scheduler precompiled into the model if available",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--local_tank_cache",
|
||||
default="",
|
||||
help="Specify where to save downloaded shark_tank artifacts. If this is not set, the default is ~/.local/shark_tank/.",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--dump_isa",
|
||||
default=False,
|
||||
action="store_true",
|
||||
help="When enabled call amdllpc to get ISA dumps. use with dispatch benchmarks.",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--dispatch_benchmarks",
|
||||
default=None,
|
||||
help='dispatches to return benchamrk data on. use "All" for all, and None for none.',
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--dispatch_benchmarks_dir",
|
||||
default="temp_dispatch_benchmarks",
|
||||
help='directory where you want to store dispatch data generated with "--dispatch_benchmarks"',
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--enable_rgp",
|
||||
default=False,
|
||||
action=argparse.BooleanOptionalAction,
|
||||
help="flag for inserting debug frames between iterations for use with rgp.",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--hide_steps",
|
||||
default=True,
|
||||
action=argparse.BooleanOptionalAction,
|
||||
help="flag for hiding the details of iteration/sec for each step.",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--warmup_count",
|
||||
type=int,
|
||||
default=0,
|
||||
help="flag setting warmup count for clip and vae [>= 0].",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--clear_all",
|
||||
default=False,
|
||||
action=argparse.BooleanOptionalAction,
|
||||
help="flag to clear all mlir and vmfb from common locations. Recompiling will take several minutes",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--save_metadata_to_json",
|
||||
default=False,
|
||||
action=argparse.BooleanOptionalAction,
|
||||
help="flag for whether or not to save a generation information json file with the image.",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--write_metadata_to_png",
|
||||
default=True,
|
||||
action=argparse.BooleanOptionalAction,
|
||||
help="flag for whether or not to save generation information in PNG chunk text to generated images.",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--import_debug",
|
||||
default=False,
|
||||
action=argparse.BooleanOptionalAction,
|
||||
help="if import_mlir is True, saves mlir via the debug option in shark importer. Does nothing if import_mlir is false (the default)",
|
||||
)
|
||||
##############################################################################
|
||||
### Web UI flags
|
||||
##############################################################################
|
||||
|
||||
p.add_argument(
|
||||
"--progress_bar",
|
||||
default=True,
|
||||
action=argparse.BooleanOptionalAction,
|
||||
help="flag for removing the progress bar animation during image generation",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--ckpt_dir",
|
||||
type=str,
|
||||
default="",
|
||||
help="Path to directory where all .ckpts are stored in order to populate them in the web UI",
|
||||
)
|
||||
|
||||
|
||||
p.add_argument(
|
||||
"--share",
|
||||
default=False,
|
||||
action=argparse.BooleanOptionalAction,
|
||||
help="flag for generating a public URL",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--server_port",
|
||||
type=int,
|
||||
default=8080,
|
||||
help="flag for setting server port",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--api",
|
||||
default=False,
|
||||
action=argparse.BooleanOptionalAction,
|
||||
help="flag for enabling rest API",
|
||||
)
|
||||
##############################################################################
|
||||
### SD model auto-annotation flags
|
||||
##############################################################################
|
||||
|
||||
p.add_argument(
|
||||
"--annotation_output",
|
||||
type=path_expand,
|
||||
default="./",
|
||||
help="Directory to save the annotated mlir file",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--annotation_model",
|
||||
type=str,
|
||||
default="unet",
|
||||
help="Options are unet and vae.",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--save_annotation",
|
||||
default=False,
|
||||
action=argparse.BooleanOptionalAction,
|
||||
help="Save annotated mlir file",
|
||||
)
|
||||
|
||||
args, unknown = p.parse_known_args()
|
||||
if args.import_debug:
|
||||
os.environ["IREE_SAVE_TEMPS"] = os.path.join(
|
||||
os.getcwd(), args.hf_model_id.replace("/", "_")
|
||||
)
|
||||
2
apps/stable_diffusion/src/utils/stencils/__init__.py
Normal file
2
apps/stable_diffusion/src/utils/stencils/__init__.py
Normal file
@@ -0,0 +1,2 @@
|
||||
from apps.stable_diffusion.src.utils.stencils.canny import CannyDetector
|
||||
from apps.stable_diffusion.src.utils.stencils.openpose import OpenposeDetector
|
||||
@@ -0,0 +1,6 @@
|
||||
import cv2
|
||||
|
||||
|
||||
class CannyDetector:
|
||||
def __call__(self, img, low_threshold, high_threshold):
|
||||
return cv2.Canny(img, low_threshold, high_threshold)
|
||||
@@ -0,0 +1,62 @@
|
||||
import requests
|
||||
from pathlib import Path
|
||||
|
||||
import torch
|
||||
import numpy as np
|
||||
|
||||
# from annotator.util import annotator_ckpts_path
|
||||
from apps.stable_diffusion.src.utils.stencils.openpose.body import Body
|
||||
from apps.stable_diffusion.src.utils.stencils.openpose.hand import Hand
|
||||
from apps.stable_diffusion.src.utils.stencils.openpose.openpose_util import (
|
||||
draw_bodypose,
|
||||
draw_handpose,
|
||||
handDetect,
|
||||
)
|
||||
|
||||
|
||||
body_model_path = "https://huggingface.co/lllyasviel/ControlNet/resolve/main/annotator/ckpts/body_pose_model.pth"
|
||||
hand_model_path = "https://huggingface.co/lllyasviel/ControlNet/resolve/main/annotator/ckpts/hand_pose_model.pth"
|
||||
|
||||
|
||||
class OpenposeDetector:
|
||||
def __init__(self):
|
||||
cwd = Path.cwd()
|
||||
ckpt_path = Path(cwd, "stencil_annotator")
|
||||
ckpt_path.mkdir(parents=True, exist_ok=True)
|
||||
body_modelpath = ckpt_path / "body_pose_model.pth"
|
||||
hand_modelpath = ckpt_path / "hand_pose_model.pth"
|
||||
|
||||
if not body_modelpath.is_file():
|
||||
r = requests.get(body_model_path, allow_redirects=True)
|
||||
open(body_modelpath, "wb").write(r.content)
|
||||
if not hand_modelpath.is_file():
|
||||
r = requests.get(hand_model_path, allow_redirects=True)
|
||||
open(hand_modelpath, "wb").write(r.content)
|
||||
|
||||
self.body_estimation = Body(body_modelpath)
|
||||
self.hand_estimation = Hand(hand_modelpath)
|
||||
|
||||
def __call__(self, oriImg, hand=False):
|
||||
oriImg = oriImg[:, :, ::-1].copy()
|
||||
with torch.no_grad():
|
||||
candidate, subset = self.body_estimation(oriImg)
|
||||
canvas = np.zeros_like(oriImg)
|
||||
canvas = draw_bodypose(canvas, candidate, subset)
|
||||
if hand:
|
||||
hands_list = handDetect(candidate, subset, oriImg)
|
||||
all_hand_peaks = []
|
||||
for x, y, w, is_left in hands_list:
|
||||
peaks = self.hand_estimation(
|
||||
oriImg[y : y + w, x : x + w, :]
|
||||
)
|
||||
peaks[:, 0] = np.where(
|
||||
peaks[:, 0] == 0, peaks[:, 0], peaks[:, 0] + x
|
||||
)
|
||||
peaks[:, 1] = np.where(
|
||||
peaks[:, 1] == 0, peaks[:, 1], peaks[:, 1] + y
|
||||
)
|
||||
all_hand_peaks.append(peaks)
|
||||
canvas = draw_handpose(canvas, all_hand_peaks)
|
||||
return canvas, dict(
|
||||
candidate=candidate.tolist(), subset=subset.tolist()
|
||||
)
|
||||
499
apps/stable_diffusion/src/utils/stencils/openpose/body.py
Normal file
499
apps/stable_diffusion/src/utils/stencils/openpose/body.py
Normal file
@@ -0,0 +1,499 @@
|
||||
import cv2
|
||||
import numpy as np
|
||||
import math
|
||||
from scipy.ndimage.filters import gaussian_filter
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
from collections import OrderedDict
|
||||
from apps.stable_diffusion.src.utils.stencils.openpose.openpose_util import (
|
||||
make_layers,
|
||||
transfer,
|
||||
padRightDownCorner,
|
||||
)
|
||||
|
||||
|
||||
class BodyPoseModel(nn.Module):
|
||||
def __init__(self):
|
||||
super(BodyPoseModel, self).__init__()
|
||||
|
||||
# these layers have no relu layer
|
||||
no_relu_layers = [
|
||||
"conv5_5_CPM_L1",
|
||||
"conv5_5_CPM_L2",
|
||||
"Mconv7_stage2_L1",
|
||||
"Mconv7_stage2_L2",
|
||||
"Mconv7_stage3_L1",
|
||||
"Mconv7_stage3_L2",
|
||||
"Mconv7_stage4_L1",
|
||||
"Mconv7_stage4_L2",
|
||||
"Mconv7_stage5_L1",
|
||||
"Mconv7_stage5_L2",
|
||||
"Mconv7_stage6_L1",
|
||||
"Mconv7_stage6_L1",
|
||||
]
|
||||
blocks = {}
|
||||
block0 = OrderedDict(
|
||||
[
|
||||
("conv1_1", [3, 64, 3, 1, 1]),
|
||||
("conv1_2", [64, 64, 3, 1, 1]),
|
||||
("pool1_stage1", [2, 2, 0]),
|
||||
("conv2_1", [64, 128, 3, 1, 1]),
|
||||
("conv2_2", [128, 128, 3, 1, 1]),
|
||||
("pool2_stage1", [2, 2, 0]),
|
||||
("conv3_1", [128, 256, 3, 1, 1]),
|
||||
("conv3_2", [256, 256, 3, 1, 1]),
|
||||
("conv3_3", [256, 256, 3, 1, 1]),
|
||||
("conv3_4", [256, 256, 3, 1, 1]),
|
||||
("pool3_stage1", [2, 2, 0]),
|
||||
("conv4_1", [256, 512, 3, 1, 1]),
|
||||
("conv4_2", [512, 512, 3, 1, 1]),
|
||||
("conv4_3_CPM", [512, 256, 3, 1, 1]),
|
||||
("conv4_4_CPM", [256, 128, 3, 1, 1]),
|
||||
]
|
||||
)
|
||||
|
||||
# Stage 1
|
||||
block1_1 = OrderedDict(
|
||||
[
|
||||
("conv5_1_CPM_L1", [128, 128, 3, 1, 1]),
|
||||
("conv5_2_CPM_L1", [128, 128, 3, 1, 1]),
|
||||
("conv5_3_CPM_L1", [128, 128, 3, 1, 1]),
|
||||
("conv5_4_CPM_L1", [128, 512, 1, 1, 0]),
|
||||
("conv5_5_CPM_L1", [512, 38, 1, 1, 0]),
|
||||
]
|
||||
)
|
||||
|
||||
block1_2 = OrderedDict(
|
||||
[
|
||||
("conv5_1_CPM_L2", [128, 128, 3, 1, 1]),
|
||||
("conv5_2_CPM_L2", [128, 128, 3, 1, 1]),
|
||||
("conv5_3_CPM_L2", [128, 128, 3, 1, 1]),
|
||||
("conv5_4_CPM_L2", [128, 512, 1, 1, 0]),
|
||||
("conv5_5_CPM_L2", [512, 19, 1, 1, 0]),
|
||||
]
|
||||
)
|
||||
blocks["block1_1"] = block1_1
|
||||
blocks["block1_2"] = block1_2
|
||||
|
||||
self.model0 = make_layers(block0, no_relu_layers)
|
||||
|
||||
# Stages 2 - 6
|
||||
for i in range(2, 7):
|
||||
blocks["block%d_1" % i] = OrderedDict(
|
||||
[
|
||||
("Mconv1_stage%d_L1" % i, [185, 128, 7, 1, 3]),
|
||||
("Mconv2_stage%d_L1" % i, [128, 128, 7, 1, 3]),
|
||||
("Mconv3_stage%d_L1" % i, [128, 128, 7, 1, 3]),
|
||||
("Mconv4_stage%d_L1" % i, [128, 128, 7, 1, 3]),
|
||||
("Mconv5_stage%d_L1" % i, [128, 128, 7, 1, 3]),
|
||||
("Mconv6_stage%d_L1" % i, [128, 128, 1, 1, 0]),
|
||||
("Mconv7_stage%d_L1" % i, [128, 38, 1, 1, 0]),
|
||||
]
|
||||
)
|
||||
|
||||
blocks["block%d_2" % i] = OrderedDict(
|
||||
[
|
||||
("Mconv1_stage%d_L2" % i, [185, 128, 7, 1, 3]),
|
||||
("Mconv2_stage%d_L2" % i, [128, 128, 7, 1, 3]),
|
||||
("Mconv3_stage%d_L2" % i, [128, 128, 7, 1, 3]),
|
||||
("Mconv4_stage%d_L2" % i, [128, 128, 7, 1, 3]),
|
||||
("Mconv5_stage%d_L2" % i, [128, 128, 7, 1, 3]),
|
||||
("Mconv6_stage%d_L2" % i, [128, 128, 1, 1, 0]),
|
||||
("Mconv7_stage%d_L2" % i, [128, 19, 1, 1, 0]),
|
||||
]
|
||||
)
|
||||
|
||||
for k in blocks.keys():
|
||||
blocks[k] = make_layers(blocks[k], no_relu_layers)
|
||||
|
||||
self.model1_1 = blocks["block1_1"]
|
||||
self.model2_1 = blocks["block2_1"]
|
||||
self.model3_1 = blocks["block3_1"]
|
||||
self.model4_1 = blocks["block4_1"]
|
||||
self.model5_1 = blocks["block5_1"]
|
||||
self.model6_1 = blocks["block6_1"]
|
||||
|
||||
self.model1_2 = blocks["block1_2"]
|
||||
self.model2_2 = blocks["block2_2"]
|
||||
self.model3_2 = blocks["block3_2"]
|
||||
self.model4_2 = blocks["block4_2"]
|
||||
self.model5_2 = blocks["block5_2"]
|
||||
self.model6_2 = blocks["block6_2"]
|
||||
|
||||
def forward(self, x):
|
||||
out1 = self.model0(x)
|
||||
|
||||
out1_1 = self.model1_1(out1)
|
||||
out1_2 = self.model1_2(out1)
|
||||
out2 = torch.cat([out1_1, out1_2, out1], 1)
|
||||
|
||||
out2_1 = self.model2_1(out2)
|
||||
out2_2 = self.model2_2(out2)
|
||||
out3 = torch.cat([out2_1, out2_2, out1], 1)
|
||||
|
||||
out3_1 = self.model3_1(out3)
|
||||
out3_2 = self.model3_2(out3)
|
||||
out4 = torch.cat([out3_1, out3_2, out1], 1)
|
||||
|
||||
out4_1 = self.model4_1(out4)
|
||||
out4_2 = self.model4_2(out4)
|
||||
out5 = torch.cat([out4_1, out4_2, out1], 1)
|
||||
|
||||
out5_1 = self.model5_1(out5)
|
||||
out5_2 = self.model5_2(out5)
|
||||
out6 = torch.cat([out5_1, out5_2, out1], 1)
|
||||
|
||||
out6_1 = self.model6_1(out6)
|
||||
out6_2 = self.model6_2(out6)
|
||||
|
||||
return out6_1, out6_2
|
||||
|
||||
|
||||
class Body(object):
|
||||
def __init__(self, model_path):
|
||||
self.model = BodyPoseModel()
|
||||
if torch.cuda.is_available():
|
||||
self.model = self.model.cuda()
|
||||
model_dict = transfer(self.model, torch.load(model_path))
|
||||
self.model.load_state_dict(model_dict)
|
||||
self.model.eval()
|
||||
|
||||
def __call__(self, oriImg):
|
||||
scale_search = [0.5]
|
||||
boxsize = 368
|
||||
stride = 8
|
||||
padValue = 128
|
||||
thre1 = 0.1
|
||||
thre2 = 0.05
|
||||
multiplier = [x * boxsize / oriImg.shape[0] for x in scale_search]
|
||||
heatmap_avg = np.zeros((oriImg.shape[0], oriImg.shape[1], 19))
|
||||
paf_avg = np.zeros((oriImg.shape[0], oriImg.shape[1], 38))
|
||||
|
||||
for m in range(len(multiplier)):
|
||||
scale = multiplier[m]
|
||||
imageToTest = cv2.resize(
|
||||
oriImg,
|
||||
(0, 0),
|
||||
fx=scale,
|
||||
fy=scale,
|
||||
interpolation=cv2.INTER_CUBIC,
|
||||
)
|
||||
imageToTest_padded, pad = padRightDownCorner(
|
||||
imageToTest, stride, padValue
|
||||
)
|
||||
im = (
|
||||
np.transpose(
|
||||
np.float32(imageToTest_padded[:, :, :, np.newaxis]),
|
||||
(3, 2, 0, 1),
|
||||
)
|
||||
/ 256
|
||||
- 0.5
|
||||
)
|
||||
im = np.ascontiguousarray(im)
|
||||
|
||||
data = torch.from_numpy(im).float()
|
||||
if torch.cuda.is_available():
|
||||
data = data.cuda()
|
||||
with torch.no_grad():
|
||||
Mconv7_stage6_L1, Mconv7_stage6_L2 = self.model(data)
|
||||
Mconv7_stage6_L1 = Mconv7_stage6_L1.cpu().numpy()
|
||||
Mconv7_stage6_L2 = Mconv7_stage6_L2.cpu().numpy()
|
||||
|
||||
# extract outputs, resize, and remove padding
|
||||
heatmap = np.transpose(
|
||||
np.squeeze(Mconv7_stage6_L2), (1, 2, 0)
|
||||
) # output 1 is heatmaps
|
||||
heatmap = cv2.resize(
|
||||
heatmap,
|
||||
(0, 0),
|
||||
fx=stride,
|
||||
fy=stride,
|
||||
interpolation=cv2.INTER_CUBIC,
|
||||
)
|
||||
heatmap = heatmap[
|
||||
: imageToTest_padded.shape[0] - pad[2],
|
||||
: imageToTest_padded.shape[1] - pad[3],
|
||||
:,
|
||||
]
|
||||
heatmap = cv2.resize(
|
||||
heatmap,
|
||||
(oriImg.shape[1], oriImg.shape[0]),
|
||||
interpolation=cv2.INTER_CUBIC,
|
||||
)
|
||||
|
||||
# paf = np.transpose(np.squeeze(net.blobs[output_blobs.keys()[0]].data), (1, 2, 0)) # output 0 is PAFs
|
||||
paf = np.transpose(
|
||||
np.squeeze(Mconv7_stage6_L1), (1, 2, 0)
|
||||
) # output 0 is PAFs
|
||||
paf = cv2.resize(
|
||||
paf,
|
||||
(0, 0),
|
||||
fx=stride,
|
||||
fy=stride,
|
||||
interpolation=cv2.INTER_CUBIC,
|
||||
)
|
||||
paf = paf[
|
||||
: imageToTest_padded.shape[0] - pad[2],
|
||||
: imageToTest_padded.shape[1] - pad[3],
|
||||
:,
|
||||
]
|
||||
paf = cv2.resize(
|
||||
paf,
|
||||
(oriImg.shape[1], oriImg.shape[0]),
|
||||
interpolation=cv2.INTER_CUBIC,
|
||||
)
|
||||
|
||||
heatmap_avg += heatmap_avg + heatmap / len(multiplier)
|
||||
paf_avg += +paf / len(multiplier)
|
||||
|
||||
all_peaks = []
|
||||
peak_counter = 0
|
||||
|
||||
for part in range(18):
|
||||
map_ori = heatmap_avg[:, :, part]
|
||||
one_heatmap = gaussian_filter(map_ori, sigma=3)
|
||||
|
||||
map_left = np.zeros(one_heatmap.shape)
|
||||
map_left[1:, :] = one_heatmap[:-1, :]
|
||||
map_right = np.zeros(one_heatmap.shape)
|
||||
map_right[:-1, :] = one_heatmap[1:, :]
|
||||
map_up = np.zeros(one_heatmap.shape)
|
||||
map_up[:, 1:] = one_heatmap[:, :-1]
|
||||
map_down = np.zeros(one_heatmap.shape)
|
||||
map_down[:, :-1] = one_heatmap[:, 1:]
|
||||
|
||||
peaks_binary = np.logical_and.reduce(
|
||||
(
|
||||
one_heatmap >= map_left,
|
||||
one_heatmap >= map_right,
|
||||
one_heatmap >= map_up,
|
||||
one_heatmap >= map_down,
|
||||
one_heatmap > thre1,
|
||||
)
|
||||
)
|
||||
peaks = list(
|
||||
zip(np.nonzero(peaks_binary)[1], np.nonzero(peaks_binary)[0])
|
||||
) # note reverse
|
||||
peaks_with_score = [x + (map_ori[x[1], x[0]],) for x in peaks]
|
||||
peak_id = range(peak_counter, peak_counter + len(peaks))
|
||||
peaks_with_score_and_id = [
|
||||
peaks_with_score[i] + (peak_id[i],)
|
||||
for i in range(len(peak_id))
|
||||
]
|
||||
|
||||
all_peaks.append(peaks_with_score_and_id)
|
||||
peak_counter += len(peaks)
|
||||
|
||||
# find connection in the specified sequence, center 29 is in the position 15
|
||||
limbSeq = [
|
||||
[2, 3],
|
||||
[2, 6],
|
||||
[3, 4],
|
||||
[4, 5],
|
||||
[6, 7],
|
||||
[7, 8],
|
||||
[2, 9],
|
||||
[9, 10],
|
||||
[10, 11],
|
||||
[2, 12],
|
||||
[12, 13],
|
||||
[13, 14],
|
||||
[2, 1],
|
||||
[1, 15],
|
||||
[15, 17],
|
||||
[1, 16],
|
||||
[16, 18],
|
||||
[3, 17],
|
||||
[6, 18],
|
||||
]
|
||||
# the middle joints heatmap correpondence
|
||||
mapIdx = [
|
||||
[31, 32],
|
||||
[39, 40],
|
||||
[33, 34],
|
||||
[35, 36],
|
||||
[41, 42],
|
||||
[43, 44],
|
||||
[19, 20],
|
||||
[21, 22],
|
||||
[23, 24],
|
||||
[25, 26],
|
||||
[27, 28],
|
||||
[29, 30],
|
||||
[47, 48],
|
||||
[49, 50],
|
||||
[53, 54],
|
||||
[51, 52],
|
||||
[55, 56],
|
||||
[37, 38],
|
||||
[45, 46],
|
||||
]
|
||||
|
||||
connection_all = []
|
||||
special_k = []
|
||||
mid_num = 10
|
||||
|
||||
for k in range(len(mapIdx)):
|
||||
score_mid = paf_avg[:, :, [x - 19 for x in mapIdx[k]]]
|
||||
candA = all_peaks[limbSeq[k][0] - 1]
|
||||
candB = all_peaks[limbSeq[k][1] - 1]
|
||||
nA = len(candA)
|
||||
nB = len(candB)
|
||||
indexA, indexB = limbSeq[k]
|
||||
if nA != 0 and nB != 0:
|
||||
connection_candidate = []
|
||||
for i in range(nA):
|
||||
for j in range(nB):
|
||||
vec = np.subtract(candB[j][:2], candA[i][:2])
|
||||
norm = math.sqrt(vec[0] * vec[0] + vec[1] * vec[1])
|
||||
norm = max(0.001, norm)
|
||||
vec = np.divide(vec, norm)
|
||||
|
||||
startend = list(
|
||||
zip(
|
||||
np.linspace(
|
||||
candA[i][0], candB[j][0], num=mid_num
|
||||
),
|
||||
np.linspace(
|
||||
candA[i][1], candB[j][1], num=mid_num
|
||||
),
|
||||
)
|
||||
)
|
||||
|
||||
vec_x = np.array(
|
||||
[
|
||||
score_mid[
|
||||
int(round(startend[I][1])),
|
||||
int(round(startend[I][0])),
|
||||
0,
|
||||
]
|
||||
for I in range(len(startend))
|
||||
]
|
||||
)
|
||||
vec_y = np.array(
|
||||
[
|
||||
score_mid[
|
||||
int(round(startend[I][1])),
|
||||
int(round(startend[I][0])),
|
||||
1,
|
||||
]
|
||||
for I in range(len(startend))
|
||||
]
|
||||
)
|
||||
|
||||
score_midpts = np.multiply(
|
||||
vec_x, vec[0]
|
||||
) + np.multiply(vec_y, vec[1])
|
||||
score_with_dist_prior = sum(score_midpts) / len(
|
||||
score_midpts
|
||||
) + min(0.5 * oriImg.shape[0] / norm - 1, 0)
|
||||
criterion1 = len(
|
||||
np.nonzero(score_midpts > thre2)[0]
|
||||
) > 0.8 * len(score_midpts)
|
||||
criterion2 = score_with_dist_prior > 0
|
||||
if criterion1 and criterion2:
|
||||
connection_candidate.append(
|
||||
[
|
||||
i,
|
||||
j,
|
||||
score_with_dist_prior,
|
||||
score_with_dist_prior
|
||||
+ candA[i][2]
|
||||
+ candB[j][2],
|
||||
]
|
||||
)
|
||||
|
||||
connection_candidate = sorted(
|
||||
connection_candidate, key=lambda x: x[2], reverse=True
|
||||
)
|
||||
connection = np.zeros((0, 5))
|
||||
for c in range(len(connection_candidate)):
|
||||
i, j, s = connection_candidate[c][0:3]
|
||||
if i not in connection[:, 3] and j not in connection[:, 4]:
|
||||
connection = np.vstack(
|
||||
[connection, [candA[i][3], candB[j][3], s, i, j]]
|
||||
)
|
||||
if len(connection) >= min(nA, nB):
|
||||
break
|
||||
|
||||
connection_all.append(connection)
|
||||
else:
|
||||
special_k.append(k)
|
||||
connection_all.append([])
|
||||
|
||||
# last number in each row is the total parts number of that person
|
||||
# the second last number in each row is the score of the overall configuration
|
||||
subset = -1 * np.ones((0, 20))
|
||||
candidate = np.array(
|
||||
[item for sublist in all_peaks for item in sublist]
|
||||
)
|
||||
|
||||
for k in range(len(mapIdx)):
|
||||
if k not in special_k:
|
||||
partAs = connection_all[k][:, 0]
|
||||
partBs = connection_all[k][:, 1]
|
||||
indexA, indexB = np.array(limbSeq[k]) - 1
|
||||
|
||||
for i in range(len(connection_all[k])): # = 1:size(temp,1)
|
||||
found = 0
|
||||
subset_idx = [-1, -1]
|
||||
for j in range(len(subset)): # 1:size(subset,1):
|
||||
if (
|
||||
subset[j][indexA] == partAs[i]
|
||||
or subset[j][indexB] == partBs[i]
|
||||
):
|
||||
subset_idx[found] = j
|
||||
found += 1
|
||||
|
||||
if found == 1:
|
||||
j = subset_idx[0]
|
||||
if subset[j][indexB] != partBs[i]:
|
||||
subset[j][indexB] = partBs[i]
|
||||
subset[j][-1] += 1
|
||||
subset[j][-2] += (
|
||||
candidate[partBs[i].astype(int), 2]
|
||||
+ connection_all[k][i][2]
|
||||
)
|
||||
elif found == 2: # if found 2 and disjoint, merge them
|
||||
j1, j2 = subset_idx
|
||||
membership = (
|
||||
(subset[j1] >= 0).astype(int)
|
||||
+ (subset[j2] >= 0).astype(int)
|
||||
)[:-2]
|
||||
if len(np.nonzero(membership == 2)[0]) == 0: # merge
|
||||
subset[j1][:-2] += subset[j2][:-2] + 1
|
||||
subset[j1][-2:] += subset[j2][-2:]
|
||||
subset[j1][-2] += connection_all[k][i][2]
|
||||
subset = np.delete(subset, j2, 0)
|
||||
else: # as like found == 1
|
||||
subset[j1][indexB] = partBs[i]
|
||||
subset[j1][-1] += 1
|
||||
subset[j1][-2] += (
|
||||
candidate[partBs[i].astype(int), 2]
|
||||
+ connection_all[k][i][2]
|
||||
)
|
||||
|
||||
# if find no partA in the subset, create a new subset
|
||||
elif not found and k < 17:
|
||||
row = -1 * np.ones(20)
|
||||
row[indexA] = partAs[i]
|
||||
row[indexB] = partBs[i]
|
||||
row[-1] = 2
|
||||
row[-2] = (
|
||||
sum(
|
||||
candidate[
|
||||
connection_all[k][i, :2].astype(int), 2
|
||||
]
|
||||
)
|
||||
+ connection_all[k][i][2]
|
||||
)
|
||||
subset = np.vstack([subset, row])
|
||||
# delete some rows of subset which has few parts occur
|
||||
deleteIdx = []
|
||||
for i in range(len(subset)):
|
||||
if subset[i][-1] < 4 or subset[i][-2] / subset[i][-1] < 0.4:
|
||||
deleteIdx.append(i)
|
||||
subset = np.delete(subset, deleteIdx, axis=0)
|
||||
|
||||
# candidate: x, y, score, id
|
||||
return candidate, subset
|
||||
205
apps/stable_diffusion/src/utils/stencils/openpose/hand.py
Normal file
205
apps/stable_diffusion/src/utils/stencils/openpose/hand.py
Normal file
@@ -0,0 +1,205 @@
|
||||
import cv2
|
||||
import numpy as np
|
||||
from scipy.ndimage.filters import gaussian_filter
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
from skimage.measure import label
|
||||
from collections import OrderedDict
|
||||
from apps.stable_diffusion.src.utils.stencils.openpose.openpose_util import (
|
||||
make_layers,
|
||||
transfer,
|
||||
padRightDownCorner,
|
||||
npmax,
|
||||
)
|
||||
|
||||
|
||||
class HandPoseModel(nn.Module):
|
||||
def __init__(self):
|
||||
super(HandPoseModel, self).__init__()
|
||||
|
||||
# these layers have no relu layer
|
||||
no_relu_layers = [
|
||||
"conv6_2_CPM",
|
||||
"Mconv7_stage2",
|
||||
"Mconv7_stage3",
|
||||
"Mconv7_stage4",
|
||||
"Mconv7_stage5",
|
||||
"Mconv7_stage6",
|
||||
]
|
||||
# stage 1
|
||||
block1_0 = OrderedDict(
|
||||
[
|
||||
("conv1_1", [3, 64, 3, 1, 1]),
|
||||
("conv1_2", [64, 64, 3, 1, 1]),
|
||||
("pool1_stage1", [2, 2, 0]),
|
||||
("conv2_1", [64, 128, 3, 1, 1]),
|
||||
("conv2_2", [128, 128, 3, 1, 1]),
|
||||
("pool2_stage1", [2, 2, 0]),
|
||||
("conv3_1", [128, 256, 3, 1, 1]),
|
||||
("conv3_2", [256, 256, 3, 1, 1]),
|
||||
("conv3_3", [256, 256, 3, 1, 1]),
|
||||
("conv3_4", [256, 256, 3, 1, 1]),
|
||||
("pool3_stage1", [2, 2, 0]),
|
||||
("conv4_1", [256, 512, 3, 1, 1]),
|
||||
("conv4_2", [512, 512, 3, 1, 1]),
|
||||
("conv4_3", [512, 512, 3, 1, 1]),
|
||||
("conv4_4", [512, 512, 3, 1, 1]),
|
||||
("conv5_1", [512, 512, 3, 1, 1]),
|
||||
("conv5_2", [512, 512, 3, 1, 1]),
|
||||
("conv5_3_CPM", [512, 128, 3, 1, 1]),
|
||||
]
|
||||
)
|
||||
|
||||
block1_1 = OrderedDict(
|
||||
[
|
||||
("conv6_1_CPM", [128, 512, 1, 1, 0]),
|
||||
("conv6_2_CPM", [512, 22, 1, 1, 0]),
|
||||
]
|
||||
)
|
||||
|
||||
blocks = {}
|
||||
blocks["block1_0"] = block1_0
|
||||
blocks["block1_1"] = block1_1
|
||||
|
||||
# stage 2-6
|
||||
for i in range(2, 7):
|
||||
blocks["block%d" % i] = OrderedDict(
|
||||
[
|
||||
("Mconv1_stage%d" % i, [150, 128, 7, 1, 3]),
|
||||
("Mconv2_stage%d" % i, [128, 128, 7, 1, 3]),
|
||||
("Mconv3_stage%d" % i, [128, 128, 7, 1, 3]),
|
||||
("Mconv4_stage%d" % i, [128, 128, 7, 1, 3]),
|
||||
("Mconv5_stage%d" % i, [128, 128, 7, 1, 3]),
|
||||
("Mconv6_stage%d" % i, [128, 128, 1, 1, 0]),
|
||||
("Mconv7_stage%d" % i, [128, 22, 1, 1, 0]),
|
||||
]
|
||||
)
|
||||
|
||||
for k in blocks.keys():
|
||||
blocks[k] = make_layers(blocks[k], no_relu_layers)
|
||||
|
||||
self.model1_0 = blocks["block1_0"]
|
||||
self.model1_1 = blocks["block1_1"]
|
||||
self.model2 = blocks["block2"]
|
||||
self.model3 = blocks["block3"]
|
||||
self.model4 = blocks["block4"]
|
||||
self.model5 = blocks["block5"]
|
||||
self.model6 = blocks["block6"]
|
||||
|
||||
def forward(self, x):
|
||||
out1_0 = self.model1_0(x)
|
||||
out1_1 = self.model1_1(out1_0)
|
||||
concat_stage2 = torch.cat([out1_1, out1_0], 1)
|
||||
out_stage2 = self.model2(concat_stage2)
|
||||
concat_stage3 = torch.cat([out_stage2, out1_0], 1)
|
||||
out_stage3 = self.model3(concat_stage3)
|
||||
concat_stage4 = torch.cat([out_stage3, out1_0], 1)
|
||||
out_stage4 = self.model4(concat_stage4)
|
||||
concat_stage5 = torch.cat([out_stage4, out1_0], 1)
|
||||
out_stage5 = self.model5(concat_stage5)
|
||||
concat_stage6 = torch.cat([out_stage5, out1_0], 1)
|
||||
out_stage6 = self.model6(concat_stage6)
|
||||
return out_stage6
|
||||
|
||||
|
||||
class Hand(object):
|
||||
def __init__(self, model_path):
|
||||
self.model = HandPoseModel()
|
||||
if torch.cuda.is_available():
|
||||
self.model = self.model.cuda()
|
||||
model_dict = transfer(self.model, torch.load(model_path))
|
||||
self.model.load_state_dict(model_dict)
|
||||
self.model.eval()
|
||||
|
||||
def __call__(self, oriImg):
|
||||
scale_search = [0.5, 1.0, 1.5, 2.0]
|
||||
# scale_search = [0.5]
|
||||
boxsize = 368
|
||||
stride = 8
|
||||
padValue = 128
|
||||
thre = 0.05
|
||||
multiplier = [x * boxsize / oriImg.shape[0] for x in scale_search]
|
||||
heatmap_avg = np.zeros((oriImg.shape[0], oriImg.shape[1], 22))
|
||||
# paf_avg = np.zeros((oriImg.shape[0], oriImg.shape[1], 38))
|
||||
|
||||
for m in range(len(multiplier)):
|
||||
scale = multiplier[m]
|
||||
imageToTest = cv2.resize(
|
||||
oriImg,
|
||||
(0, 0),
|
||||
fx=scale,
|
||||
fy=scale,
|
||||
interpolation=cv2.INTER_CUBIC,
|
||||
)
|
||||
imageToTest_padded, pad = padRightDownCorner(
|
||||
imageToTest, stride, padValue
|
||||
)
|
||||
im = (
|
||||
np.transpose(
|
||||
np.float32(imageToTest_padded[:, :, :, np.newaxis]),
|
||||
(3, 2, 0, 1),
|
||||
)
|
||||
/ 256
|
||||
- 0.5
|
||||
)
|
||||
im = np.ascontiguousarray(im)
|
||||
|
||||
data = torch.from_numpy(im).float()
|
||||
if torch.cuda.is_available():
|
||||
data = data.cuda()
|
||||
# data = data.permute([2, 0, 1]).unsqueeze(0).float()
|
||||
with torch.no_grad():
|
||||
output = self.model(data).cpu().numpy()
|
||||
# output = self.model(data).numpy()q
|
||||
|
||||
# extract outputs, resize, and remove padding
|
||||
heatmap = np.transpose(
|
||||
np.squeeze(output), (1, 2, 0)
|
||||
) # output 1 is heatmaps
|
||||
heatmap = cv2.resize(
|
||||
heatmap,
|
||||
(0, 0),
|
||||
fx=stride,
|
||||
fy=stride,
|
||||
interpolation=cv2.INTER_CUBIC,
|
||||
)
|
||||
heatmap = heatmap[
|
||||
: imageToTest_padded.shape[0] - pad[2],
|
||||
: imageToTest_padded.shape[1] - pad[3],
|
||||
:,
|
||||
]
|
||||
heatmap = cv2.resize(
|
||||
heatmap,
|
||||
(oriImg.shape[1], oriImg.shape[0]),
|
||||
interpolation=cv2.INTER_CUBIC,
|
||||
)
|
||||
|
||||
heatmap_avg += heatmap / len(multiplier)
|
||||
|
||||
all_peaks = []
|
||||
for part in range(21):
|
||||
map_ori = heatmap_avg[:, :, part]
|
||||
one_heatmap = gaussian_filter(map_ori, sigma=3)
|
||||
binary = np.ascontiguousarray(one_heatmap > thre, dtype=np.uint8)
|
||||
# 全部小于阈值
|
||||
if np.sum(binary) == 0:
|
||||
all_peaks.append([0, 0])
|
||||
continue
|
||||
label_img, label_numbers = label(
|
||||
binary, return_num=True, connectivity=binary.ndim
|
||||
)
|
||||
max_index = (
|
||||
np.argmax(
|
||||
[
|
||||
np.sum(map_ori[label_img == i])
|
||||
for i in range(1, label_numbers + 1)
|
||||
]
|
||||
)
|
||||
+ 1
|
||||
)
|
||||
label_img[label_img != max_index] = 0
|
||||
map_ori[label_img == 0] = 0
|
||||
|
||||
y, x = npmax(map_ori)
|
||||
all_peaks.append([x, y])
|
||||
return np.array(all_peaks)
|
||||
@@ -0,0 +1,272 @@
|
||||
import math
|
||||
import numpy as np
|
||||
import matplotlib
|
||||
import cv2
|
||||
from collections import OrderedDict
|
||||
import torch.nn as nn
|
||||
|
||||
|
||||
def make_layers(block, no_relu_layers):
|
||||
layers = []
|
||||
for layer_name, v in block.items():
|
||||
if "pool" in layer_name:
|
||||
layer = nn.MaxPool2d(kernel_size=v[0], stride=v[1], padding=v[2])
|
||||
layers.append((layer_name, layer))
|
||||
else:
|
||||
conv2d = nn.Conv2d(
|
||||
in_channels=v[0],
|
||||
out_channels=v[1],
|
||||
kernel_size=v[2],
|
||||
stride=v[3],
|
||||
padding=v[4],
|
||||
)
|
||||
layers.append((layer_name, conv2d))
|
||||
if layer_name not in no_relu_layers:
|
||||
layers.append(("relu_" + layer_name, nn.ReLU(inplace=True)))
|
||||
|
||||
return nn.Sequential(OrderedDict(layers))
|
||||
|
||||
|
||||
def padRightDownCorner(img, stride, padValue):
|
||||
h = img.shape[0]
|
||||
w = img.shape[1]
|
||||
|
||||
pad = 4 * [None]
|
||||
pad[0] = 0 # up
|
||||
pad[1] = 0 # left
|
||||
pad[2] = 0 if (h % stride == 0) else stride - (h % stride) # down
|
||||
pad[3] = 0 if (w % stride == 0) else stride - (w % stride) # right
|
||||
|
||||
img_padded = img
|
||||
pad_up = np.tile(img_padded[0:1, :, :] * 0 + padValue, (pad[0], 1, 1))
|
||||
img_padded = np.concatenate((pad_up, img_padded), axis=0)
|
||||
pad_left = np.tile(img_padded[:, 0:1, :] * 0 + padValue, (1, pad[1], 1))
|
||||
img_padded = np.concatenate((pad_left, img_padded), axis=1)
|
||||
pad_down = np.tile(img_padded[-2:-1, :, :] * 0 + padValue, (pad[2], 1, 1))
|
||||
img_padded = np.concatenate((img_padded, pad_down), axis=0)
|
||||
pad_right = np.tile(img_padded[:, -2:-1, :] * 0 + padValue, (1, pad[3], 1))
|
||||
img_padded = np.concatenate((img_padded, pad_right), axis=1)
|
||||
|
||||
return img_padded, pad
|
||||
|
||||
|
||||
# transfer caffe model to pytorch which will match the layer name
|
||||
def transfer(model, model_weights):
|
||||
transfered_model_weights = {}
|
||||
for weights_name in model.state_dict().keys():
|
||||
transfered_model_weights[weights_name] = model_weights[
|
||||
".".join(weights_name.split(".")[1:])
|
||||
]
|
||||
return transfered_model_weights
|
||||
|
||||
|
||||
# draw the body keypoint and lims
|
||||
def draw_bodypose(canvas, candidate, subset):
|
||||
stickwidth = 4
|
||||
limbSeq = [
|
||||
[2, 3],
|
||||
[2, 6],
|
||||
[3, 4],
|
||||
[4, 5],
|
||||
[6, 7],
|
||||
[7, 8],
|
||||
[2, 9],
|
||||
[9, 10],
|
||||
[10, 11],
|
||||
[2, 12],
|
||||
[12, 13],
|
||||
[13, 14],
|
||||
[2, 1],
|
||||
[1, 15],
|
||||
[15, 17],
|
||||
[1, 16],
|
||||
[16, 18],
|
||||
[3, 17],
|
||||
[6, 18],
|
||||
]
|
||||
|
||||
colors = [
|
||||
[255, 0, 0],
|
||||
[255, 85, 0],
|
||||
[255, 170, 0],
|
||||
[255, 255, 0],
|
||||
[170, 255, 0],
|
||||
[85, 255, 0],
|
||||
[0, 255, 0],
|
||||
[0, 255, 85],
|
||||
[0, 255, 170],
|
||||
[0, 255, 255],
|
||||
[0, 170, 255],
|
||||
[0, 85, 255],
|
||||
[0, 0, 255],
|
||||
[85, 0, 255],
|
||||
[170, 0, 255],
|
||||
[255, 0, 255],
|
||||
[255, 0, 170],
|
||||
[255, 0, 85],
|
||||
]
|
||||
for i in range(18):
|
||||
for n in range(len(subset)):
|
||||
index = int(subset[n][i])
|
||||
if index == -1:
|
||||
continue
|
||||
x, y = candidate[index][0:2]
|
||||
cv2.circle(canvas, (int(x), int(y)), 4, colors[i], thickness=-1)
|
||||
for i in range(17):
|
||||
for n in range(len(subset)):
|
||||
index = subset[n][np.array(limbSeq[i]) - 1]
|
||||
if -1 in index:
|
||||
continue
|
||||
cur_canvas = canvas.copy()
|
||||
Y = candidate[index.astype(int), 0]
|
||||
X = candidate[index.astype(int), 1]
|
||||
mX = np.mean(X)
|
||||
mY = np.mean(Y)
|
||||
length = ((X[0] - X[1]) ** 2 + (Y[0] - Y[1]) ** 2) ** 0.5
|
||||
angle = math.degrees(math.atan2(X[0] - X[1], Y[0] - Y[1]))
|
||||
polygon = cv2.ellipse2Poly(
|
||||
(int(mY), int(mX)),
|
||||
(int(length / 2), stickwidth),
|
||||
int(angle),
|
||||
0,
|
||||
360,
|
||||
1,
|
||||
)
|
||||
cv2.fillConvexPoly(cur_canvas, polygon, colors[i])
|
||||
canvas = cv2.addWeighted(canvas, 0.4, cur_canvas, 0.6, 0)
|
||||
return canvas
|
||||
|
||||
|
||||
# image drawed by opencv is not good.
|
||||
def draw_handpose(canvas, all_hand_peaks, show_number=False):
|
||||
edges = [
|
||||
[0, 1],
|
||||
[1, 2],
|
||||
[2, 3],
|
||||
[3, 4],
|
||||
[0, 5],
|
||||
[5, 6],
|
||||
[6, 7],
|
||||
[7, 8],
|
||||
[0, 9],
|
||||
[9, 10],
|
||||
[10, 11],
|
||||
[11, 12],
|
||||
[0, 13],
|
||||
[13, 14],
|
||||
[14, 15],
|
||||
[15, 16],
|
||||
[0, 17],
|
||||
[17, 18],
|
||||
[18, 19],
|
||||
[19, 20],
|
||||
]
|
||||
|
||||
for peaks in all_hand_peaks:
|
||||
for ie, e in enumerate(edges):
|
||||
if np.sum(np.all(peaks[e], axis=1) == 0) == 0:
|
||||
x1, y1 = peaks[e[0]]
|
||||
x2, y2 = peaks[e[1]]
|
||||
cv2.line(
|
||||
canvas,
|
||||
(x1, y1),
|
||||
(x2, y2),
|
||||
matplotlib.colors.hsv_to_rgb(
|
||||
[ie / float(len(edges)), 1.0, 1.0]
|
||||
)
|
||||
* 255,
|
||||
thickness=2,
|
||||
)
|
||||
|
||||
for i, keyponit in enumerate(peaks):
|
||||
x, y = keyponit
|
||||
cv2.circle(canvas, (x, y), 4, (0, 0, 255), thickness=-1)
|
||||
if show_number:
|
||||
cv2.putText(
|
||||
canvas,
|
||||
str(i),
|
||||
(x, y),
|
||||
cv2.FONT_HERSHEY_SIMPLEX,
|
||||
0.3,
|
||||
(0, 0, 0),
|
||||
lineType=cv2.LINE_AA,
|
||||
)
|
||||
return canvas
|
||||
|
||||
|
||||
# detect hand according to body pose keypoints
|
||||
# please refer to https://github.com/CMU-Perceptual-Computing-Lab/openpose/blob/master/src/openpose/hand/handDetector.cpp
|
||||
def handDetect(candidate, subset, oriImg):
|
||||
# right hand: wrist 4, elbow 3, shoulder 2
|
||||
# left hand: wrist 7, elbow 6, shoulder 5
|
||||
ratioWristElbow = 0.33
|
||||
detect_result = []
|
||||
image_height, image_width = oriImg.shape[0:2]
|
||||
for person in subset.astype(int):
|
||||
# if any of three not detected
|
||||
has_left = np.sum(person[[5, 6, 7]] == -1) == 0
|
||||
has_right = np.sum(person[[2, 3, 4]] == -1) == 0
|
||||
if not (has_left or has_right):
|
||||
continue
|
||||
hands = []
|
||||
# left hand
|
||||
if has_left:
|
||||
left_shoulder_index, left_elbow_index, left_wrist_index = person[
|
||||
[5, 6, 7]
|
||||
]
|
||||
x1, y1 = candidate[left_shoulder_index][:2]
|
||||
x2, y2 = candidate[left_elbow_index][:2]
|
||||
x3, y3 = candidate[left_wrist_index][:2]
|
||||
hands.append([x1, y1, x2, y2, x3, y3, True])
|
||||
# right hand
|
||||
if has_right:
|
||||
(
|
||||
right_shoulder_index,
|
||||
right_elbow_index,
|
||||
right_wrist_index,
|
||||
) = person[[2, 3, 4]]
|
||||
x1, y1 = candidate[right_shoulder_index][:2]
|
||||
x2, y2 = candidate[right_elbow_index][:2]
|
||||
x3, y3 = candidate[right_wrist_index][:2]
|
||||
hands.append([x1, y1, x2, y2, x3, y3, False])
|
||||
|
||||
for x1, y1, x2, y2, x3, y3, is_left in hands:
|
||||
x = x3 + ratioWristElbow * (x3 - x2)
|
||||
y = y3 + ratioWristElbow * (y3 - y2)
|
||||
distanceWristElbow = math.sqrt((x3 - x2) ** 2 + (y3 - y2) ** 2)
|
||||
distanceElbowShoulder = math.sqrt((x2 - x1) ** 2 + (y2 - y1) ** 2)
|
||||
width = 1.5 * max(distanceWristElbow, 0.9 * distanceElbowShoulder)
|
||||
# x-y refers to the center --> offset to topLeft point
|
||||
x -= width / 2
|
||||
y -= width / 2 # width = height
|
||||
# overflow the image
|
||||
if x < 0:
|
||||
x = 0
|
||||
if y < 0:
|
||||
y = 0
|
||||
width1 = width
|
||||
width2 = width
|
||||
if x + width > image_width:
|
||||
width1 = image_width - x
|
||||
if y + width > image_height:
|
||||
width2 = image_height - y
|
||||
width = min(width1, width2)
|
||||
# the max hand box value is 20 pixels
|
||||
if width >= 20:
|
||||
detect_result.append([int(x), int(y), int(width), is_left])
|
||||
|
||||
"""
|
||||
return value: [[x, y, w, True if left hand else False]].
|
||||
width=height since the network require squared input.
|
||||
x, y is the coordinate of top left
|
||||
"""
|
||||
return detect_result
|
||||
|
||||
|
||||
# get max index of 2d array
|
||||
def npmax(array):
|
||||
arrayindex = array.argmax(1)
|
||||
arrayvalue = array.max(1)
|
||||
i = arrayvalue.argmax()
|
||||
j = arrayindex[i]
|
||||
return (i,)
|
||||
186
apps/stable_diffusion/src/utils/stencils/stencil_utils.py
Normal file
186
apps/stable_diffusion/src/utils/stencils/stencil_utils.py
Normal file
@@ -0,0 +1,186 @@
|
||||
import numpy as np
|
||||
from PIL import Image
|
||||
import torch
|
||||
from apps.stable_diffusion.src.utils.stencils import (
|
||||
CannyDetector,
|
||||
OpenposeDetector,
|
||||
)
|
||||
|
||||
stencil = {}
|
||||
|
||||
|
||||
def HWC3(x):
|
||||
assert x.dtype == np.uint8
|
||||
if x.ndim == 2:
|
||||
x = x[:, :, None]
|
||||
assert x.ndim == 3
|
||||
H, W, C = x.shape
|
||||
assert C == 1 or C == 3 or C == 4
|
||||
if C == 3:
|
||||
return x
|
||||
if C == 1:
|
||||
return np.concatenate([x, x, x], axis=2)
|
||||
if C == 4:
|
||||
color = x[:, :, 0:3].astype(np.float32)
|
||||
alpha = x[:, :, 3:4].astype(np.float32) / 255.0
|
||||
y = color * alpha + 255.0 * (1.0 - alpha)
|
||||
y = y.clip(0, 255).astype(np.uint8)
|
||||
return y
|
||||
|
||||
|
||||
def controlnet_hint_shaping(
|
||||
controlnet_hint, height, width, dtype, num_images_per_prompt=1
|
||||
):
|
||||
channels = 3
|
||||
if isinstance(controlnet_hint, torch.Tensor):
|
||||
# torch.Tensor: acceptble shape are any of chw, bchw(b==1) or bchw(b==num_images_per_prompt)
|
||||
shape_chw = (channels, height, width)
|
||||
shape_bchw = (1, channels, height, width)
|
||||
shape_nchw = (num_images_per_prompt, channels, height, width)
|
||||
if controlnet_hint.shape in [shape_chw, shape_bchw, shape_nchw]:
|
||||
controlnet_hint = controlnet_hint.to(
|
||||
dtype=dtype, device=torch.device("cpu")
|
||||
)
|
||||
if controlnet_hint.shape != shape_nchw:
|
||||
controlnet_hint = controlnet_hint.repeat(
|
||||
num_images_per_prompt, 1, 1, 1
|
||||
)
|
||||
return controlnet_hint
|
||||
else:
|
||||
raise ValueError(
|
||||
f"Acceptble shape of `stencil` are any of ({channels}, {height}, {width}),"
|
||||
+ f" (1, {channels}, {height}, {width}) or ({num_images_per_prompt}, "
|
||||
+ f"{channels}, {height}, {width}) but is {controlnet_hint.shape}"
|
||||
)
|
||||
elif isinstance(controlnet_hint, np.ndarray):
|
||||
# np.ndarray: acceptable shape is any of hw, hwc, bhwc(b==1) or bhwc(b==num_images_per_promot)
|
||||
# hwc is opencv compatible image format. Color channel must be BGR Format.
|
||||
if controlnet_hint.shape == (height, width):
|
||||
controlnet_hint = np.repeat(
|
||||
controlnet_hint[:, :, np.newaxis], channels, axis=2
|
||||
) # hw -> hwc(c==3)
|
||||
shape_hwc = (height, width, channels)
|
||||
shape_bhwc = (1, height, width, channels)
|
||||
shape_nhwc = (num_images_per_prompt, height, width, channels)
|
||||
if controlnet_hint.shape in [shape_hwc, shape_bhwc, shape_nhwc]:
|
||||
controlnet_hint = torch.from_numpy(controlnet_hint.copy())
|
||||
controlnet_hint = controlnet_hint.to(
|
||||
dtype=dtype, device=torch.device("cpu")
|
||||
)
|
||||
controlnet_hint /= 255.0
|
||||
if controlnet_hint.shape != shape_nhwc:
|
||||
controlnet_hint = controlnet_hint.repeat(
|
||||
num_images_per_prompt, 1, 1, 1
|
||||
)
|
||||
controlnet_hint = controlnet_hint.permute(
|
||||
0, 3, 1, 2
|
||||
) # b h w c -> b c h w
|
||||
return controlnet_hint
|
||||
else:
|
||||
raise ValueError(
|
||||
f"Acceptble shape of `stencil` are any of ({width}, {channels}), "
|
||||
+ f"({height}, {width}, {channels}), "
|
||||
+ f"(1, {height}, {width}, {channels}) or "
|
||||
+ f"({num_images_per_prompt}, {channels}, {height}, {width}) but is {controlnet_hint.shape}"
|
||||
)
|
||||
elif isinstance(controlnet_hint, Image.Image):
|
||||
if controlnet_hint.size == (width, height):
|
||||
controlnet_hint = controlnet_hint.convert(
|
||||
"RGB"
|
||||
) # make sure 3 channel RGB format
|
||||
controlnet_hint = np.array(controlnet_hint) # to numpy
|
||||
controlnet_hint = controlnet_hint[:, :, ::-1] # RGB -> BGR
|
||||
return controlnet_hint_shaping(
|
||||
controlnet_hint, height, width, num_images_per_prompt
|
||||
)
|
||||
else:
|
||||
raise ValueError(
|
||||
f"Acceptable image size of `stencil` is ({width}, {height}) but is {controlnet_hint.size}"
|
||||
)
|
||||
else:
|
||||
raise ValueError(
|
||||
f"Acceptable type of `stencil` are any of torch.Tensor, np.ndarray, PIL.Image.Image but is {type(controlnet_hint)}"
|
||||
)
|
||||
|
||||
|
||||
def controlnet_hint_conversion(
|
||||
image, use_stencil, height, width, dtype, num_images_per_prompt=1
|
||||
):
|
||||
controlnet_hint = None
|
||||
match use_stencil:
|
||||
case "canny":
|
||||
print("Detecting edge with canny")
|
||||
controlnet_hint = hint_canny(image)
|
||||
case "openpose":
|
||||
print("Detecting human pose")
|
||||
controlnet_hint = hint_openpose(image)
|
||||
case "scribble":
|
||||
print("Working with scribble")
|
||||
controlnet_hint = hint_scribble(image)
|
||||
case _:
|
||||
return None
|
||||
controlnet_hint = controlnet_hint_shaping(
|
||||
controlnet_hint, height, width, dtype, num_images_per_prompt
|
||||
)
|
||||
return controlnet_hint
|
||||
|
||||
|
||||
stencil_to_model_id_map = {
|
||||
"canny": "lllyasviel/sd-controlnet-canny",
|
||||
"depth": "lllyasviel/sd-controlnet-depth",
|
||||
"hed": "lllyasviel/sd-controlnet-hed",
|
||||
"mlsd": "lllyasviel/sd-controlnet-mlsd",
|
||||
"normal": "lllyasviel/sd-controlnet-normal",
|
||||
"openpose": "lllyasviel/sd-controlnet-openpose",
|
||||
"scribble": "lllyasviel/sd-controlnet-scribble",
|
||||
"seg": "lllyasviel/sd-controlnet-seg",
|
||||
}
|
||||
|
||||
|
||||
def get_stencil_model_id(use_stencil):
|
||||
if use_stencil in stencil_to_model_id_map:
|
||||
return stencil_to_model_id_map[use_stencil]
|
||||
return None
|
||||
|
||||
|
||||
# Stencil 1. Canny
|
||||
def hint_canny(
|
||||
image: Image.Image,
|
||||
low_threshold=100,
|
||||
high_threshold=200,
|
||||
):
|
||||
with torch.no_grad():
|
||||
input_image = np.array(image)
|
||||
|
||||
if not "canny" in stencil:
|
||||
stencil["canny"] = CannyDetector()
|
||||
detected_map = stencil["canny"](
|
||||
input_image, low_threshold, high_threshold
|
||||
)
|
||||
detected_map = HWC3(detected_map)
|
||||
return detected_map
|
||||
|
||||
|
||||
# Stencil 2. OpenPose.
|
||||
def hint_openpose(
|
||||
image: Image.Image,
|
||||
):
|
||||
with torch.no_grad():
|
||||
input_image = np.array(image)
|
||||
|
||||
if not "openpose" in stencil:
|
||||
stencil["openpose"] = OpenposeDetector()
|
||||
|
||||
detected_map, _ = stencil["openpose"](input_image)
|
||||
detected_map = HWC3(detected_map)
|
||||
return detected_map
|
||||
|
||||
|
||||
# Stencil 3. Scribble.
|
||||
def hint_scribble(image: Image.Image):
|
||||
with torch.no_grad():
|
||||
input_image = np.array(image)
|
||||
|
||||
detected_map = np.zeros_like(input_image, dtype=np.uint8)
|
||||
detected_map[np.min(input_image, axis=2) < 127] = 255
|
||||
return detected_map
|
||||
751
apps/stable_diffusion/src/utils/utils.py
Normal file
751
apps/stable_diffusion/src/utils/utils.py
Normal file
@@ -0,0 +1,751 @@
|
||||
import os
|
||||
import gc
|
||||
import json
|
||||
import re
|
||||
from PIL import PngImagePlugin
|
||||
from datetime import datetime as dt
|
||||
from csv import DictWriter
|
||||
from pathlib import Path
|
||||
import numpy as np
|
||||
from random import randint
|
||||
import tempfile
|
||||
import torch
|
||||
from safetensors.torch import load_file
|
||||
from shark.shark_inference import SharkInference
|
||||
from shark.shark_importer import import_with_fx
|
||||
from shark.iree_utils.vulkan_utils import (
|
||||
set_iree_vulkan_runtime_flags,
|
||||
get_vulkan_target_triple,
|
||||
)
|
||||
from shark.iree_utils.gpu_utils import get_cuda_sm_cc
|
||||
from apps.stable_diffusion.src.utils.stable_args import args
|
||||
from apps.stable_diffusion.src.utils.resources import opt_flags
|
||||
from apps.stable_diffusion.src.utils.sd_annotation import sd_model_annotation
|
||||
import sys
|
||||
from diffusers.pipelines.stable_diffusion.convert_from_ckpt import (
|
||||
download_from_original_stable_diffusion_ckpt,
|
||||
)
|
||||
|
||||
|
||||
def get_extended_name(model_name):
|
||||
device = args.device.split("://", 1)[0]
|
||||
extended_name = "{}_{}".format(model_name, device)
|
||||
return extended_name
|
||||
|
||||
|
||||
def get_vmfb_path_name(model_name):
|
||||
vmfb_path = os.path.join(os.getcwd(), model_name + ".vmfb")
|
||||
return vmfb_path
|
||||
|
||||
|
||||
def _compile_module(shark_module, model_name, extra_args=[]):
|
||||
if args.load_vmfb or args.save_vmfb:
|
||||
vmfb_path = get_vmfb_path_name(model_name)
|
||||
if args.load_vmfb and os.path.isfile(vmfb_path) and not args.save_vmfb:
|
||||
print(f"loading existing vmfb from: {vmfb_path}")
|
||||
shark_module.load_module(vmfb_path, extra_args=extra_args)
|
||||
else:
|
||||
if args.save_vmfb:
|
||||
print("Saving to {}".format(vmfb_path))
|
||||
else:
|
||||
print(
|
||||
"No vmfb found. Compiling and saving to {}".format(
|
||||
vmfb_path
|
||||
)
|
||||
)
|
||||
path = shark_module.save_module(
|
||||
os.getcwd(), model_name, extra_args
|
||||
)
|
||||
shark_module.load_module(path, extra_args=extra_args)
|
||||
else:
|
||||
shark_module.compile(extra_args)
|
||||
return shark_module
|
||||
|
||||
|
||||
# Downloads the model from shark_tank and returns the shark_module.
|
||||
def get_shark_model(tank_url, model_name, extra_args=[]):
|
||||
from shark.parser import shark_args
|
||||
|
||||
# Set local shark_tank cache directory.
|
||||
shark_args.local_tank_cache = args.local_tank_cache
|
||||
|
||||
from shark.shark_downloader import download_model
|
||||
|
||||
if "cuda" in args.device:
|
||||
shark_args.enable_tf32 = True
|
||||
|
||||
mlir_model, func_name, inputs, golden_out = download_model(
|
||||
model_name,
|
||||
tank_url=tank_url,
|
||||
frontend="torch",
|
||||
)
|
||||
shark_module = SharkInference(
|
||||
mlir_model, device=args.device, mlir_dialect="tm_tensor"
|
||||
)
|
||||
return _compile_module(shark_module, model_name, extra_args)
|
||||
|
||||
|
||||
# Converts the torch-module into a shark_module.
|
||||
def compile_through_fx(
|
||||
model,
|
||||
inputs,
|
||||
model_name,
|
||||
is_f16=False,
|
||||
f16_input_mask=None,
|
||||
use_tuned=False,
|
||||
save_dir=tempfile.gettempdir(),
|
||||
debug=False,
|
||||
generate_vmfb=True,
|
||||
extra_args=[],
|
||||
base_model_id=None,
|
||||
):
|
||||
from shark.parser import shark_args
|
||||
|
||||
if "cuda" in args.device:
|
||||
shark_args.enable_tf32 = True
|
||||
|
||||
(
|
||||
mlir_module,
|
||||
func_name,
|
||||
) = import_with_fx(
|
||||
model=model,
|
||||
inputs=inputs,
|
||||
is_f16=is_f16,
|
||||
f16_input_mask=f16_input_mask,
|
||||
debug=debug,
|
||||
model_name=model_name,
|
||||
save_dir=save_dir,
|
||||
)
|
||||
if use_tuned:
|
||||
if "vae" in model_name.split("_")[0]:
|
||||
args.annotation_model = "vae"
|
||||
mlir_module = sd_model_annotation(
|
||||
mlir_module, model_name, base_model_id
|
||||
)
|
||||
|
||||
shark_module = SharkInference(
|
||||
mlir_module,
|
||||
device=args.device,
|
||||
mlir_dialect="tm_tensor",
|
||||
)
|
||||
|
||||
if generate_vmfb:
|
||||
shark_module = SharkInference(
|
||||
mlir_module,
|
||||
device=args.device,
|
||||
mlir_dialect="tm_tensor",
|
||||
)
|
||||
del mlir_module
|
||||
gc.collect()
|
||||
return _compile_module(shark_module, model_name, extra_args)
|
||||
|
||||
del mlir_module
|
||||
gc.collect()
|
||||
|
||||
|
||||
def set_iree_runtime_flags():
|
||||
vulkan_runtime_flags = [
|
||||
f"--vulkan_large_heap_block_size={args.vulkan_large_heap_block_size}",
|
||||
f"--vulkan_validation_layers={'true' if args.vulkan_validation_layers else 'false'}",
|
||||
]
|
||||
if args.enable_rgp:
|
||||
vulkan_runtime_flags += [
|
||||
f"--enable_rgp=true",
|
||||
f"--vulkan_debug_utils=true",
|
||||
]
|
||||
set_iree_vulkan_runtime_flags(flags=vulkan_runtime_flags)
|
||||
|
||||
|
||||
def get_all_devices(driver_name):
|
||||
"""
|
||||
Inputs: driver_name
|
||||
Returns a list of all the available devices for a given driver sorted by
|
||||
the iree path names of the device as in --list_devices option in iree.
|
||||
"""
|
||||
from iree.runtime import get_driver
|
||||
|
||||
driver = get_driver(driver_name)
|
||||
device_list_src = driver.query_available_devices()
|
||||
device_list_src.sort(key=lambda d: d["path"])
|
||||
return device_list_src
|
||||
|
||||
|
||||
def get_device_mapping(driver, key_combination=3):
|
||||
"""This method ensures consistent device ordering when choosing
|
||||
specific devices for execution
|
||||
Args:
|
||||
driver (str): execution driver (vulkan, cuda, rocm, etc)
|
||||
key_combination (int, optional): choice for mapping value for device name.
|
||||
1 : path
|
||||
2 : name
|
||||
3 : (name, path)
|
||||
Defaults to 3.
|
||||
Returns:
|
||||
dict: map to possible device names user can input mapped to desired combination of name/path.
|
||||
"""
|
||||
from shark.iree_utils._common import iree_device_map
|
||||
|
||||
driver = iree_device_map(driver)
|
||||
device_list = get_all_devices(driver)
|
||||
device_map = dict()
|
||||
|
||||
def get_output_value(dev_dict):
|
||||
if key_combination == 1:
|
||||
return f"{driver}://{dev_dict['path']}"
|
||||
if key_combination == 2:
|
||||
return dev_dict["name"]
|
||||
if key_combination == 3:
|
||||
return (dev_dict["name"], f"{driver}://{dev_dict['path']}")
|
||||
|
||||
# mapping driver name to default device (driver://0)
|
||||
device_map[f"{driver}"] = get_output_value(device_list[0])
|
||||
for i, device in enumerate(device_list):
|
||||
# mapping with index
|
||||
device_map[f"{driver}://{i}"] = get_output_value(device)
|
||||
# mapping with full path
|
||||
device_map[f"{driver}://{device['path']}"] = get_output_value(device)
|
||||
return device_map
|
||||
|
||||
|
||||
def map_device_to_name_path(device, key_combination=3):
|
||||
"""Gives the appropriate device data (supported name/path) for user selected execution device
|
||||
Args:
|
||||
device (str): user
|
||||
key_combination (int, optional): choice for mapping value for device name.
|
||||
1 : path
|
||||
2 : name
|
||||
3 : (name, path)
|
||||
Defaults to 3.
|
||||
Raises:
|
||||
ValueError:
|
||||
Returns:
|
||||
str / tuple: returns the mapping str or tuple of mapping str for the device depending on key_combination value
|
||||
"""
|
||||
driver = device.split("://")[0]
|
||||
device_map = get_device_mapping(driver, key_combination)
|
||||
try:
|
||||
device_mapping = device_map[device]
|
||||
except KeyError:
|
||||
raise ValueError(f"Device '{device}' is not a valid device.")
|
||||
return device_mapping
|
||||
|
||||
|
||||
def set_init_device_flags():
|
||||
if "vulkan" in args.device:
|
||||
# set runtime flags for vulkan.
|
||||
set_iree_runtime_flags()
|
||||
|
||||
# set triple flag to avoid multiple calls to get_vulkan_triple_flag
|
||||
device_name, args.device = map_device_to_name_path(args.device)
|
||||
if not args.iree_vulkan_target_triple:
|
||||
triple = get_vulkan_target_triple(device_name)
|
||||
if triple is not None:
|
||||
args.iree_vulkan_target_triple = triple
|
||||
print(
|
||||
f"Found device {device_name}. Using target triple {args.iree_vulkan_target_triple}."
|
||||
)
|
||||
elif "cuda" in args.device:
|
||||
args.device = "cuda"
|
||||
elif "cpu" in args.device:
|
||||
args.device = "cpu"
|
||||
|
||||
# set max_length based on availability.
|
||||
if args.hf_model_id in [
|
||||
"Linaqruf/anything-v3.0",
|
||||
"wavymulder/Analog-Diffusion",
|
||||
"dreamlike-art/dreamlike-diffusion-1.0",
|
||||
]:
|
||||
args.max_length = 77
|
||||
elif args.hf_model_id == "prompthero/openjourney":
|
||||
args.max_length = 64
|
||||
|
||||
# Use tuned models in the case of fp16, vulkan rdna3 or cuda sm devices.
|
||||
if args.ckpt_loc != "":
|
||||
base_model_id = fetch_and_update_base_model_id(args.ckpt_loc)
|
||||
else:
|
||||
base_model_id = fetch_and_update_base_model_id(args.hf_model_id)
|
||||
if base_model_id == "":
|
||||
base_model_id = args.hf_model_id
|
||||
|
||||
if (
|
||||
args.precision != "fp16"
|
||||
or args.height not in [512, 768]
|
||||
or (args.height == 512 and args.width != 512)
|
||||
or (args.height == 768 and args.width != 768)
|
||||
or args.batch_size != 1
|
||||
or ("vulkan" not in args.device and "cuda" not in args.device)
|
||||
):
|
||||
args.use_tuned = False
|
||||
|
||||
elif base_model_id not in [
|
||||
"Linaqruf/anything-v3.0",
|
||||
"dreamlike-art/dreamlike-diffusion-1.0",
|
||||
"prompthero/openjourney",
|
||||
"wavymulder/Analog-Diffusion",
|
||||
"stabilityai/stable-diffusion-2-1",
|
||||
"stabilityai/stable-diffusion-2-1-base",
|
||||
"CompVis/stable-diffusion-v1-4",
|
||||
"runwayml/stable-diffusion-v1-5",
|
||||
"runwayml/stable-diffusion-inpainting",
|
||||
"stabilityai/stable-diffusion-2-inpainting",
|
||||
]:
|
||||
args.use_tuned = False
|
||||
|
||||
elif "vulkan" in args.device and not any(
|
||||
x in args.iree_vulkan_target_triple for x in ["rdna2", "rdna3"]
|
||||
):
|
||||
args.use_tuned = False
|
||||
|
||||
elif "cuda" in args.device and get_cuda_sm_cc() not in ["sm_80", "sm_89"]:
|
||||
args.use_tuned = False
|
||||
|
||||
elif args.use_base_vae and args.hf_model_id not in [
|
||||
"stabilityai/stable-diffusion-2-1-base",
|
||||
"CompVis/stable-diffusion-v1-4",
|
||||
]:
|
||||
args.use_tuned = False
|
||||
|
||||
elif (
|
||||
args.height == 768
|
||||
and args.width == 768
|
||||
and (
|
||||
base_model_id
|
||||
not in [
|
||||
"stabilityai/stable-diffusion-2-1",
|
||||
"stabilityai/stable-diffusion-2-1-base",
|
||||
]
|
||||
or "rdna3" not in args.iree_vulkan_target_triple
|
||||
)
|
||||
):
|
||||
args.use_tuned = False
|
||||
|
||||
if args.use_tuned:
|
||||
print(f"Using tuned models for {base_model_id}/fp16/{args.device}.")
|
||||
else:
|
||||
print("Tuned models are currently not supported for this setting.")
|
||||
|
||||
# set import_mlir to True for unuploaded models.
|
||||
if args.ckpt_loc != "":
|
||||
args.import_mlir = True
|
||||
|
||||
elif args.hf_model_id not in [
|
||||
"Linaqruf/anything-v3.0",
|
||||
"dreamlike-art/dreamlike-diffusion-1.0",
|
||||
"prompthero/openjourney",
|
||||
"wavymulder/Analog-Diffusion",
|
||||
"stabilityai/stable-diffusion-2-1",
|
||||
"stabilityai/stable-diffusion-2-1-base",
|
||||
"CompVis/stable-diffusion-v1-4",
|
||||
]:
|
||||
args.import_mlir = True
|
||||
|
||||
elif args.height != 512 or args.width != 512 or args.batch_size != 1:
|
||||
args.import_mlir = True
|
||||
|
||||
elif args.use_tuned and args.hf_model_id in [
|
||||
"dreamlike-art/dreamlike-diffusion-1.0",
|
||||
"prompthero/openjourney",
|
||||
"stabilityai/stable-diffusion-2-1",
|
||||
]:
|
||||
args.import_mlir = True
|
||||
|
||||
elif (
|
||||
args.use_tuned
|
||||
and "vulkan" in args.device
|
||||
and "rdna2" in args.iree_vulkan_target_triple
|
||||
):
|
||||
args.import_mlir = True
|
||||
|
||||
elif (
|
||||
args.use_tuned
|
||||
and "cuda" in args.device
|
||||
and get_cuda_sm_cc() == "sm_89"
|
||||
):
|
||||
args.import_mlir = True
|
||||
|
||||
|
||||
# Utility to get list of devices available.
|
||||
def get_available_devices():
|
||||
def get_devices_by_name(driver_name):
|
||||
from shark.iree_utils._common import iree_device_map
|
||||
|
||||
device_list = []
|
||||
try:
|
||||
driver_name = iree_device_map(driver_name)
|
||||
device_list_dict = get_all_devices(driver_name)
|
||||
print(f"{driver_name} devices are available.")
|
||||
except:
|
||||
print(f"{driver_name} devices are not available.")
|
||||
else:
|
||||
for i, device in enumerate(device_list_dict):
|
||||
device_list.append(f"{device['name']} => {driver_name}://{i}")
|
||||
return device_list
|
||||
|
||||
set_iree_runtime_flags()
|
||||
|
||||
available_devices = []
|
||||
vulkan_devices = get_devices_by_name("vulkan")
|
||||
available_devices.extend(vulkan_devices)
|
||||
cuda_devices = get_devices_by_name("cuda")
|
||||
available_devices.extend(cuda_devices)
|
||||
available_devices.append("device => cpu")
|
||||
return available_devices
|
||||
|
||||
|
||||
def disk_space_check(path, lim=20):
|
||||
from shutil import disk_usage
|
||||
|
||||
du = disk_usage(path)
|
||||
free = du.free / (1024 * 1024 * 1024)
|
||||
if free <= lim:
|
||||
print(f"[WARNING] Only {free:.2f}GB space available in {path}.")
|
||||
|
||||
|
||||
def get_opt_flags(model, precision="fp16"):
|
||||
iree_flags = []
|
||||
is_tuned = "tuned" if args.use_tuned else "untuned"
|
||||
if len(args.iree_vulkan_target_triple) > 0:
|
||||
iree_flags.append(
|
||||
f"-iree-vulkan-target-triple={args.iree_vulkan_target_triple}"
|
||||
)
|
||||
|
||||
# Disable bindings fusion to work with moltenVK.
|
||||
if sys.platform == "darwin":
|
||||
iree_flags.append("-iree-stream-fuse-binding=false")
|
||||
|
||||
if "default_compilation_flags" in opt_flags[model][is_tuned][precision]:
|
||||
iree_flags += opt_flags[model][is_tuned][precision][
|
||||
"default_compilation_flags"
|
||||
]
|
||||
|
||||
if "specified_compilation_flags" in opt_flags[model][is_tuned][precision]:
|
||||
device = (
|
||||
args.device
|
||||
if "://" not in args.device
|
||||
else args.device.split("://")[0]
|
||||
)
|
||||
if (
|
||||
device
|
||||
not in opt_flags[model][is_tuned][precision][
|
||||
"specified_compilation_flags"
|
||||
]
|
||||
):
|
||||
device = "default_device"
|
||||
iree_flags += opt_flags[model][is_tuned][precision][
|
||||
"specified_compilation_flags"
|
||||
][device]
|
||||
return iree_flags
|
||||
|
||||
|
||||
def get_path_stem(path):
|
||||
path = Path(path)
|
||||
return path.stem
|
||||
|
||||
|
||||
def get_path_to_diffusers_checkpoint(custom_weights):
|
||||
path = Path(custom_weights)
|
||||
diffusers_path = path.parent.absolute()
|
||||
diffusers_directory_name = path.stem
|
||||
complete_path_to_diffusers = diffusers_path / diffusers_directory_name
|
||||
complete_path_to_diffusers.mkdir(parents=True, exist_ok=True)
|
||||
path_to_diffusers = complete_path_to_diffusers.as_posix()
|
||||
return path_to_diffusers
|
||||
|
||||
|
||||
def preprocessCKPT(custom_weights, is_inpaint=False):
|
||||
path_to_diffusers = get_path_to_diffusers_checkpoint(custom_weights)
|
||||
if next(Path(path_to_diffusers).iterdir(), None):
|
||||
print("Checkpoint already loaded at : ", path_to_diffusers)
|
||||
return
|
||||
else:
|
||||
print(
|
||||
"Diffusers' checkpoint will be identified here : ",
|
||||
path_to_diffusers,
|
||||
)
|
||||
from_safetensors = (
|
||||
True if custom_weights.lower().endswith(".safetensors") else False
|
||||
)
|
||||
# EMA weights usually yield higher quality images for inference but non-EMA weights have
|
||||
# been yielding better results in our case.
|
||||
# TODO: Add an option `--ema` (`--no-ema`) for users to specify if they want to go for EMA
|
||||
# weight extraction or not.
|
||||
extract_ema = False
|
||||
print(
|
||||
"Loading diffusers' pipeline from original stable diffusion checkpoint"
|
||||
)
|
||||
num_in_channels = 9 if is_inpaint else 4
|
||||
pipe = download_from_original_stable_diffusion_ckpt(
|
||||
checkpoint_path=custom_weights,
|
||||
extract_ema=extract_ema,
|
||||
from_safetensors=from_safetensors,
|
||||
num_in_channels=num_in_channels,
|
||||
)
|
||||
pipe.save_pretrained(path_to_diffusers)
|
||||
print("Loading complete")
|
||||
|
||||
|
||||
def processLoRA(model, use_lora, splitting_prefix):
|
||||
state_dict = ""
|
||||
if ".safetensors" in use_lora:
|
||||
state_dict = load_file(use_lora)
|
||||
else:
|
||||
state_dict = torch.load(use_lora)
|
||||
alpha = 0.75
|
||||
visited = []
|
||||
|
||||
# directly update weight in model
|
||||
process_unet = "te" not in splitting_prefix
|
||||
for key in state_dict:
|
||||
if ".alpha" in key or key in visited:
|
||||
continue
|
||||
|
||||
curr_layer = model
|
||||
if ("text" not in key and process_unet) or (
|
||||
"text" in key and not process_unet
|
||||
):
|
||||
layer_infos = (
|
||||
key.split(".")[0].split(splitting_prefix)[-1].split("_")
|
||||
)
|
||||
else:
|
||||
continue
|
||||
|
||||
# find the target layer
|
||||
temp_name = layer_infos.pop(0)
|
||||
while len(layer_infos) > -1:
|
||||
try:
|
||||
curr_layer = curr_layer.__getattr__(temp_name)
|
||||
if len(layer_infos) > 0:
|
||||
temp_name = layer_infos.pop(0)
|
||||
elif len(layer_infos) == 0:
|
||||
break
|
||||
except Exception:
|
||||
if len(temp_name) > 0:
|
||||
temp_name += "_" + layer_infos.pop(0)
|
||||
else:
|
||||
temp_name = layer_infos.pop(0)
|
||||
|
||||
pair_keys = []
|
||||
if "lora_down" in key:
|
||||
pair_keys.append(key.replace("lora_down", "lora_up"))
|
||||
pair_keys.append(key)
|
||||
else:
|
||||
pair_keys.append(key)
|
||||
pair_keys.append(key.replace("lora_up", "lora_down"))
|
||||
|
||||
# update weight
|
||||
if len(state_dict[pair_keys[0]].shape) == 4:
|
||||
weight_up = (
|
||||
state_dict[pair_keys[0]]
|
||||
.squeeze(3)
|
||||
.squeeze(2)
|
||||
.to(torch.float32)
|
||||
)
|
||||
weight_down = (
|
||||
state_dict[pair_keys[1]]
|
||||
.squeeze(3)
|
||||
.squeeze(2)
|
||||
.to(torch.float32)
|
||||
)
|
||||
curr_layer.weight.data += alpha * torch.mm(
|
||||
weight_up, weight_down
|
||||
).unsqueeze(2).unsqueeze(3)
|
||||
else:
|
||||
weight_up = state_dict[pair_keys[0]].to(torch.float32)
|
||||
weight_down = state_dict[pair_keys[1]].to(torch.float32)
|
||||
curr_layer.weight.data += alpha * torch.mm(weight_up, weight_down)
|
||||
# update visited list
|
||||
for item in pair_keys:
|
||||
visited.append(item)
|
||||
return model
|
||||
|
||||
|
||||
def update_lora_weight_for_unet(unet, use_lora):
|
||||
extensions = [".bin", ".safetensors", ".pt"]
|
||||
if not any([extension in use_lora for extension in extensions]):
|
||||
# We assume if it is a HF ID with standalone LoRA weights.
|
||||
unet.load_attn_procs(use_lora)
|
||||
return unet
|
||||
|
||||
main_file_name = get_path_stem(use_lora)
|
||||
if ".bin" in use_lora:
|
||||
main_file_name += ".bin"
|
||||
elif ".safetensors" in use_lora:
|
||||
main_file_name += ".safetensors"
|
||||
elif ".pt" in use_lora:
|
||||
main_file_name += ".pt"
|
||||
else:
|
||||
sys.exit("Only .bin and .safetensors format for LoRA is supported")
|
||||
|
||||
try:
|
||||
dir_name = os.path.dirname(use_lora)
|
||||
unet.load_attn_procs(dir_name, weight_name=main_file_name)
|
||||
return unet
|
||||
except:
|
||||
return processLoRA(unet, use_lora, "lora_unet_")
|
||||
|
||||
|
||||
def update_lora_weight(model, use_lora, model_name):
|
||||
if "unet" in model_name:
|
||||
return update_lora_weight_for_unet(model, use_lora)
|
||||
try:
|
||||
return processLoRA(model, use_lora, "lora_te_")
|
||||
except:
|
||||
return None
|
||||
|
||||
|
||||
def load_vmfb(vmfb_path, model, precision):
|
||||
model = "vae" if "base_vae" in model or "vae_encode" in model else model
|
||||
model = "unet" if "stencil" in model else model
|
||||
precision = "fp32" if "clip" in model else precision
|
||||
extra_args = get_opt_flags(model, precision)
|
||||
shark_module = SharkInference(mlir_module=None, device=args.device)
|
||||
shark_module.load_module(vmfb_path, extra_args=extra_args)
|
||||
return shark_module
|
||||
|
||||
|
||||
# This utility returns vmfb of sub-model of the SD pipeline, if present.
|
||||
def fetch_vmfb(model, extended_model_name, precision="fp32"):
|
||||
vmfb_path = get_vmfb_path_name(extended_model_name)
|
||||
vmfb_present = os.path.isfile(vmfb_path)
|
||||
compiled_model = (
|
||||
load_vmfb(vmfb_path, model, precision) if vmfb_present else None
|
||||
)
|
||||
return compiled_model
|
||||
|
||||
|
||||
# `fetch_and_update_base_model_id` is a resource utility function which
|
||||
# helps maintaining mapping of the model to run with its base model.
|
||||
# If `base_model` is "", then this function tries to fetch the base model
|
||||
# info for the `model_to_run`.
|
||||
def fetch_and_update_base_model_id(model_to_run, base_model=""):
|
||||
variants_path = os.path.join(os.getcwd(), "variants.json")
|
||||
data = {model_to_run: base_model}
|
||||
json_data = {}
|
||||
if os.path.exists(variants_path):
|
||||
with open(variants_path, "r", encoding="utf-8") as jsonFile:
|
||||
json_data = json.load(jsonFile)
|
||||
# Return with base_model's info if base_model is "".
|
||||
if base_model == "":
|
||||
if model_to_run in json_data:
|
||||
base_model = json_data[model_to_run]
|
||||
return base_model
|
||||
elif base_model == "":
|
||||
return base_model
|
||||
# Update JSON data to contain an entry mapping model_to_run with base_model.
|
||||
json_data.update(data)
|
||||
with open(variants_path, "w", encoding="utf-8") as jsonFile:
|
||||
json.dump(json_data, jsonFile)
|
||||
|
||||
|
||||
# Generate and return a new seed if the provided one is not in the supported range (including -1)
|
||||
def sanitize_seed(seed):
|
||||
uint32_info = np.iinfo(np.uint32)
|
||||
uint32_min, uint32_max = uint32_info.min, uint32_info.max
|
||||
if seed < uint32_min or seed >= uint32_max:
|
||||
seed = randint(uint32_min, uint32_max)
|
||||
return seed
|
||||
|
||||
|
||||
# clear all the cached objects to recompile cleanly.
|
||||
def clear_all():
|
||||
print("CLEARING ALL, EXPECT SEVERAL MINUTES TO RECOMPILE")
|
||||
from glob import glob
|
||||
import shutil
|
||||
|
||||
vmfbs = glob(os.path.join(os.getcwd(), "*.vmfb"))
|
||||
for vmfb in vmfbs:
|
||||
if os.path.exists(vmfb):
|
||||
os.remove(vmfb)
|
||||
# Temporary workaround of deleting yaml files to incorporate diffusers' pipeline.
|
||||
# TODO: Remove this once we have better weight updation logic.
|
||||
inference_yaml = ["v2-inference-v.yaml", "v1-inference.yaml"]
|
||||
for yaml in inference_yaml:
|
||||
if os.path.exists(yaml):
|
||||
os.remove(yaml)
|
||||
home = os.path.expanduser("~")
|
||||
if os.name == "nt": # Windows
|
||||
appdata = os.getenv("LOCALAPPDATA")
|
||||
shutil.rmtree(os.path.join(appdata, "AMD/VkCache"), ignore_errors=True)
|
||||
shutil.rmtree(os.path.join(home, "shark_tank"), ignore_errors=True)
|
||||
elif os.name == "unix":
|
||||
shutil.rmtree(os.path.join(home, ".cache/AMD/VkCache"))
|
||||
shutil.rmtree(os.path.join(home, ".local/shark_tank"))
|
||||
|
||||
|
||||
# save output images and the inputs corresponding to it.
|
||||
def save_output_img(output_img, img_seed, extra_info={}):
|
||||
output_path = args.output_dir if args.output_dir else Path.cwd()
|
||||
generated_imgs_path = Path(
|
||||
output_path, "generated_imgs", dt.now().strftime("%Y%m%d")
|
||||
)
|
||||
generated_imgs_path.mkdir(parents=True, exist_ok=True)
|
||||
csv_path = Path(generated_imgs_path, "imgs_details.csv")
|
||||
|
||||
prompt_slice = re.sub("[^a-zA-Z0-9]", "_", args.prompts[0][:15])
|
||||
out_img_name = (
|
||||
f"{prompt_slice}_{img_seed}_{dt.now().strftime('%y%m%d_%H%M%S')}"
|
||||
)
|
||||
|
||||
img_model = args.hf_model_id
|
||||
if args.ckpt_loc:
|
||||
img_model = Path(os.path.basename(args.ckpt_loc)).stem
|
||||
|
||||
if args.output_img_format == "jpg":
|
||||
out_img_path = Path(generated_imgs_path, f"{out_img_name}.jpg")
|
||||
output_img.save(out_img_path, quality=95, subsampling=0)
|
||||
else:
|
||||
out_img_path = Path(generated_imgs_path, f"{out_img_name}.png")
|
||||
pngInfo = PngImagePlugin.PngInfo()
|
||||
|
||||
if args.write_metadata_to_png:
|
||||
pngInfo.add_text(
|
||||
"parameters",
|
||||
f"{args.prompts[0]}\nNegative prompt: {args.negative_prompts[0]}\nSteps:{args.steps}, Sampler: {args.scheduler}, CFG scale: {args.guidance_scale}, Seed: {img_seed}, Size: {args.width}x{args.height}, Model: {img_model}",
|
||||
)
|
||||
|
||||
output_img.save(out_img_path, "PNG", pnginfo=pngInfo)
|
||||
|
||||
if args.output_img_format not in ["png", "jpg"]:
|
||||
print(
|
||||
f"[ERROR] Format {args.output_img_format} is not supported yet."
|
||||
"Image saved as png instead. Supported formats: png / jpg"
|
||||
)
|
||||
|
||||
new_entry = {
|
||||
"VARIANT": img_model,
|
||||
"SCHEDULER": args.scheduler,
|
||||
"PROMPT": args.prompts[0],
|
||||
"NEG_PROMPT": args.negative_prompts[0],
|
||||
"SEED": img_seed,
|
||||
"CFG_SCALE": args.guidance_scale,
|
||||
"PRECISION": args.precision,
|
||||
"STEPS": args.steps,
|
||||
"HEIGHT": args.height,
|
||||
"WIDTH": args.width,
|
||||
"MAX_LENGTH": args.max_length,
|
||||
"OUTPUT": out_img_path,
|
||||
}
|
||||
|
||||
new_entry.update(extra_info)
|
||||
|
||||
with open(csv_path, "a", encoding="utf-8") as csv_obj:
|
||||
dictwriter_obj = DictWriter(csv_obj, fieldnames=list(new_entry.keys()))
|
||||
dictwriter_obj.writerow(new_entry)
|
||||
csv_obj.close()
|
||||
|
||||
if args.save_metadata_to_json:
|
||||
del new_entry["OUTPUT"]
|
||||
json_path = Path(generated_imgs_path, f"{out_img_name}.json")
|
||||
with open(json_path, "w") as f:
|
||||
json.dump(new_entry, f, indent=4)
|
||||
|
||||
|
||||
def get_generation_text_info(seeds, device):
|
||||
text_output = f"prompt={args.prompts}"
|
||||
text_output += f"\nnegative prompt={args.negative_prompts}"
|
||||
text_output += f"\nmodel_id={args.hf_model_id}, ckpt_loc={args.ckpt_loc}"
|
||||
text_output += f"\nscheduler={args.scheduler}, device={device}"
|
||||
text_output += f"\nsteps={args.steps}, guidance_scale={args.guidance_scale}, seed={seeds}"
|
||||
text_output += f"\nsize={args.height}x{args.width}, batch_count={args.batch_count}, batch_size={args.batch_size}, max_length={args.max_length}"
|
||||
|
||||
return text_output
|
||||
15
apps/stable_diffusion/stable_diffusion_telegram_bot.md
Normal file
15
apps/stable_diffusion/stable_diffusion_telegram_bot.md
Normal file
@@ -0,0 +1,15 @@
|
||||
You need to pre-create your bot (https://core.telegram.org/bots#how-do-i-create-a-bot)
|
||||
Then create in the directory web file .env
|
||||
In it the record:
|
||||
TG_TOKEN="your_token"
|
||||
specifying your bot's token from previous step.
|
||||
Then run telegram_bot.py with the same parameters that you use when running index.py, for example:
|
||||
python telegram_bot.py --max_length=77 --vulkan_large_heap_block_size=0 --use_base_vae --local_tank_cache h:\shark\TEMP
|
||||
|
||||
Bot commands:
|
||||
/select_model
|
||||
/select_scheduler
|
||||
/set_steps "integer number of steps"
|
||||
/set_guidance_scale "integer number"
|
||||
/set_negative_prompt "negative text"
|
||||
Any other text triggers the creation of an image based on it.
|
||||
215
apps/stable_diffusion/web/index.py
Normal file
215
apps/stable_diffusion/web/index.py
Normal file
@@ -0,0 +1,215 @@
|
||||
import os
|
||||
import sys
|
||||
import transformers
|
||||
from apps.stable_diffusion.src import args, clear_all
|
||||
|
||||
if sys.platform == "darwin":
|
||||
os.environ["DYLD_LIBRARY_PATH"] = "/usr/local/lib"
|
||||
|
||||
if args.clear_all:
|
||||
clear_all()
|
||||
|
||||
if __name__ == "__main__":
|
||||
if args.api:
|
||||
from apps.stable_diffusion.web.ui import txt2img_inf
|
||||
from fastapi import FastAPI, APIRouter
|
||||
import uvicorn
|
||||
|
||||
app = FastAPI()
|
||||
app.add_api_route("/sdapi/txt2img", txt2img_inf, methods=["post"])
|
||||
app.include_router(APIRouter())
|
||||
uvicorn.run(app, host="0.0.0.0", port=args.server_port)
|
||||
sys.exit(0)
|
||||
|
||||
import gradio as gr
|
||||
import apps.stable_diffusion.web.utils.global_obj as global_obj
|
||||
from apps.stable_diffusion.web.utils.gradio_configs import (
|
||||
clear_gradio_tmp_imgs_folder,
|
||||
)
|
||||
from apps.stable_diffusion.web.ui.utils import get_custom_model_path
|
||||
|
||||
# Clear all gradio tmp images from the last session
|
||||
clear_gradio_tmp_imgs_folder()
|
||||
# Create the custom model folder if it doesn't already exist
|
||||
dir = ["models", "vae", "lora"]
|
||||
for root in dir:
|
||||
get_custom_model_path(root).mkdir(parents=True, exist_ok=True)
|
||||
|
||||
def resource_path(relative_path):
|
||||
"""Get absolute path to resource, works for dev and for PyInstaller"""
|
||||
base_path = getattr(
|
||||
sys, "_MEIPASS", os.path.dirname(os.path.abspath(__file__))
|
||||
)
|
||||
return os.path.join(base_path, relative_path)
|
||||
|
||||
dark_theme = resource_path("ui/css/sd_dark_theme.css")
|
||||
|
||||
from apps.stable_diffusion.web.ui import (
|
||||
txt2img_web,
|
||||
txt2img_gallery,
|
||||
txt2img_sendto_img2img,
|
||||
txt2img_sendto_inpaint,
|
||||
txt2img_sendto_outpaint,
|
||||
txt2img_sendto_upscaler,
|
||||
img2img_web,
|
||||
img2img_gallery,
|
||||
img2img_init_image,
|
||||
img2img_sendto_inpaint,
|
||||
img2img_sendto_outpaint,
|
||||
img2img_sendto_upscaler,
|
||||
inpaint_web,
|
||||
inpaint_gallery,
|
||||
inpaint_init_image,
|
||||
inpaint_sendto_img2img,
|
||||
inpaint_sendto_outpaint,
|
||||
inpaint_sendto_upscaler,
|
||||
outpaint_web,
|
||||
outpaint_gallery,
|
||||
outpaint_init_image,
|
||||
outpaint_sendto_img2img,
|
||||
outpaint_sendto_inpaint,
|
||||
outpaint_sendto_upscaler,
|
||||
upscaler_web,
|
||||
upscaler_gallery,
|
||||
upscaler_init_image,
|
||||
upscaler_sendto_img2img,
|
||||
upscaler_sendto_inpaint,
|
||||
upscaler_sendto_outpaint,
|
||||
lora_train_web,
|
||||
)
|
||||
|
||||
# init global sd pipeline and config
|
||||
global_obj._init()
|
||||
|
||||
def register_button_click(button, selectedid, inputs, outputs):
|
||||
button.click(
|
||||
lambda x: (
|
||||
x[0]["name"] if len(x) != 0 else None,
|
||||
gr.Tabs.update(selected=selectedid),
|
||||
),
|
||||
inputs,
|
||||
outputs,
|
||||
)
|
||||
|
||||
with gr.Blocks(
|
||||
css=dark_theme, analytics_enabled=False, title="Stable Diffusion"
|
||||
) as sd_web:
|
||||
with gr.Tabs() as tabs:
|
||||
with gr.TabItem(label="Text-to-Image", id=0):
|
||||
txt2img_web.render()
|
||||
with gr.TabItem(label="Image-to-Image", id=1):
|
||||
img2img_web.render()
|
||||
with gr.TabItem(label="Inpainting", id=2):
|
||||
inpaint_web.render()
|
||||
with gr.TabItem(label="Outpainting", id=3):
|
||||
outpaint_web.render()
|
||||
with gr.TabItem(label="Upscaler", id=4):
|
||||
upscaler_web.render()
|
||||
|
||||
with gr.Tabs(visible=False) as experimental_tabs:
|
||||
with gr.TabItem(label="LoRA Training", id=5):
|
||||
lora_train_web.render()
|
||||
|
||||
register_button_click(
|
||||
txt2img_sendto_img2img,
|
||||
1,
|
||||
[txt2img_gallery],
|
||||
[img2img_init_image, tabs],
|
||||
)
|
||||
register_button_click(
|
||||
txt2img_sendto_inpaint,
|
||||
2,
|
||||
[txt2img_gallery],
|
||||
[inpaint_init_image, tabs],
|
||||
)
|
||||
register_button_click(
|
||||
txt2img_sendto_outpaint,
|
||||
3,
|
||||
[txt2img_gallery],
|
||||
[outpaint_init_image, tabs],
|
||||
)
|
||||
register_button_click(
|
||||
txt2img_sendto_upscaler,
|
||||
4,
|
||||
[txt2img_gallery],
|
||||
[upscaler_init_image, tabs],
|
||||
)
|
||||
register_button_click(
|
||||
img2img_sendto_inpaint,
|
||||
2,
|
||||
[img2img_gallery],
|
||||
[inpaint_init_image, tabs],
|
||||
)
|
||||
register_button_click(
|
||||
img2img_sendto_outpaint,
|
||||
3,
|
||||
[img2img_gallery],
|
||||
[outpaint_init_image, tabs],
|
||||
)
|
||||
register_button_click(
|
||||
img2img_sendto_upscaler,
|
||||
4,
|
||||
[img2img_gallery],
|
||||
[upscaler_init_image, tabs],
|
||||
)
|
||||
register_button_click(
|
||||
inpaint_sendto_img2img,
|
||||
1,
|
||||
[inpaint_gallery],
|
||||
[img2img_init_image, tabs],
|
||||
)
|
||||
register_button_click(
|
||||
inpaint_sendto_outpaint,
|
||||
3,
|
||||
[inpaint_gallery],
|
||||
[outpaint_init_image, tabs],
|
||||
)
|
||||
register_button_click(
|
||||
inpaint_sendto_upscaler,
|
||||
4,
|
||||
[inpaint_gallery],
|
||||
[upscaler_init_image, tabs],
|
||||
)
|
||||
register_button_click(
|
||||
outpaint_sendto_img2img,
|
||||
1,
|
||||
[outpaint_gallery],
|
||||
[img2img_init_image, tabs],
|
||||
)
|
||||
register_button_click(
|
||||
outpaint_sendto_inpaint,
|
||||
2,
|
||||
[outpaint_gallery],
|
||||
[inpaint_init_image, tabs],
|
||||
)
|
||||
register_button_click(
|
||||
outpaint_sendto_upscaler,
|
||||
4,
|
||||
[outpaint_gallery],
|
||||
[upscaler_init_image, tabs],
|
||||
)
|
||||
register_button_click(
|
||||
upscaler_sendto_img2img,
|
||||
1,
|
||||
[upscaler_gallery],
|
||||
[img2img_init_image, tabs],
|
||||
)
|
||||
register_button_click(
|
||||
upscaler_sendto_inpaint,
|
||||
2,
|
||||
[upscaler_gallery],
|
||||
[inpaint_init_image, tabs],
|
||||
)
|
||||
register_button_click(
|
||||
upscaler_sendto_outpaint,
|
||||
3,
|
||||
[upscaler_gallery],
|
||||
[outpaint_init_image, tabs],
|
||||
)
|
||||
sd_web.queue()
|
||||
sd_web.launch(
|
||||
share=args.share,
|
||||
inbrowser=True,
|
||||
server_name="0.0.0.0",
|
||||
server_port=args.server_port,
|
||||
)
|
||||
42
apps/stable_diffusion/web/ui/__init__.py
Normal file
42
apps/stable_diffusion/web/ui/__init__.py
Normal file
@@ -0,0 +1,42 @@
|
||||
from apps.stable_diffusion.web.ui.txt2img_ui import (
|
||||
txt2img_inf,
|
||||
txt2img_web,
|
||||
txt2img_gallery,
|
||||
txt2img_sendto_img2img,
|
||||
txt2img_sendto_inpaint,
|
||||
txt2img_sendto_outpaint,
|
||||
txt2img_sendto_upscaler,
|
||||
)
|
||||
from apps.stable_diffusion.web.ui.img2img_ui import (
|
||||
img2img_web,
|
||||
img2img_gallery,
|
||||
img2img_init_image,
|
||||
img2img_sendto_inpaint,
|
||||
img2img_sendto_outpaint,
|
||||
img2img_sendto_upscaler,
|
||||
)
|
||||
from apps.stable_diffusion.web.ui.inpaint_ui import (
|
||||
inpaint_web,
|
||||
inpaint_gallery,
|
||||
inpaint_init_image,
|
||||
inpaint_sendto_img2img,
|
||||
inpaint_sendto_outpaint,
|
||||
inpaint_sendto_upscaler,
|
||||
)
|
||||
from apps.stable_diffusion.web.ui.outpaint_ui import (
|
||||
outpaint_web,
|
||||
outpaint_gallery,
|
||||
outpaint_init_image,
|
||||
outpaint_sendto_img2img,
|
||||
outpaint_sendto_inpaint,
|
||||
outpaint_sendto_upscaler,
|
||||
)
|
||||
from apps.stable_diffusion.web.ui.upscaler_ui import (
|
||||
upscaler_web,
|
||||
upscaler_gallery,
|
||||
upscaler_init_image,
|
||||
upscaler_sendto_img2img,
|
||||
upscaler_sendto_inpaint,
|
||||
upscaler_sendto_outpaint,
|
||||
)
|
||||
from apps.stable_diffusion.web.ui.lora_train_ui import lora_train_web
|
||||
199
apps/stable_diffusion/web/ui/css/sd_dark_theme.css
Normal file
199
apps/stable_diffusion/web/ui/css/sd_dark_theme.css
Normal file
@@ -0,0 +1,199 @@
|
||||
/*
|
||||
Apply Gradio dark theme to the default Gradio theme.
|
||||
Procedure to upgrade the dark theme:
|
||||
- Using your browser, visit http://localhost:8080/?__theme=dark
|
||||
- Open your browser inspector, search for the .dark css class
|
||||
- Copy .dark class declarations, apply them here into :root
|
||||
*/
|
||||
|
||||
:root {
|
||||
--body-background-fill: var(--background-fill-primary);
|
||||
--body-text-color: var(--neutral-100);
|
||||
--color-accent-soft: var(--neutral-700);
|
||||
--background-fill-primary: var(--neutral-950);
|
||||
--background-fill-secondary: var(--neutral-900);
|
||||
--border-color-accent: var(--neutral-600);
|
||||
--border-color-primary: var(--neutral-700);
|
||||
--link-text-color-active: var(--secondary-500);
|
||||
--link-text-color: var(--secondary-500);
|
||||
--link-text-color-hover: var(--secondary-400);
|
||||
--link-text-color-visited: var(--secondary-600);
|
||||
--body-text-color-subdued: var(--neutral-400);
|
||||
--shadow-spread: 1px;
|
||||
--block-background-fill: var(--neutral-800);
|
||||
--block-border-color: var(--border-color-primary);
|
||||
--block_border_width: None;
|
||||
--block-info-text-color: var(--body-text-color-subdued);
|
||||
--block-label-background-fill: var(--background-fill-secondary);
|
||||
--block-label-border-color: var(--border-color-primary);
|
||||
--block_label_border_width: None;
|
||||
--block-label-text-color: var(--neutral-200);
|
||||
--block_shadow: None;
|
||||
--block_title_background_fill: None;
|
||||
--block_title_border_color: None;
|
||||
--block_title_border_width: None;
|
||||
--block-title-text-color: var(--neutral-200);
|
||||
--panel-background-fill: var(--background-fill-secondary);
|
||||
--panel-border-color: var(--border-color-primary);
|
||||
--panel_border_width: None;
|
||||
--checkbox-background-color: var(--neutral-800);
|
||||
--checkbox-background-color-focus: var(--checkbox-background-color);
|
||||
--checkbox-background-color-hover: var(--checkbox-background-color);
|
||||
--checkbox-background-color-selected: var(--secondary-600);
|
||||
--checkbox-border-color: var(--neutral-700);
|
||||
--checkbox-border-color-focus: var(--secondary-500);
|
||||
--checkbox-border-color-hover: var(--neutral-600);
|
||||
--checkbox-border-color-selected: var(--secondary-600);
|
||||
--checkbox-border-width: var(--input-border-width);
|
||||
--checkbox-label-background-fill: linear-gradient(to top, var(--neutral-900), var(--neutral-800));
|
||||
--checkbox-label-background-fill-hover: linear-gradient(to top, var(--neutral-900), var(--neutral-800));
|
||||
--checkbox-label-background-fill-selected: var(--checkbox-label-background-fill);
|
||||
--checkbox-label-border-color: var(--border-color-primary);
|
||||
--checkbox-label-border-color-hover: var(--checkbox-label-border-color);
|
||||
--checkbox-label-border-width: var(--input-border-width);
|
||||
--checkbox-label-text-color: var(--body-text-color);
|
||||
--checkbox-label-text-color-selected: var(--checkbox-label-text-color);
|
||||
--error-background-fill: var(--background-fill-primary);
|
||||
--error-border-color: var(--border-color-primary);
|
||||
--error_border_width: None;
|
||||
--error-text-color: #ef4444;
|
||||
--input-background-fill: var(--neutral-800);
|
||||
--input-background-fill-focus: var(--secondary-600);
|
||||
--input-background-fill-hover: var(--input-background-fill);
|
||||
--input-border-color: var(--border-color-primary);
|
||||
--input-border-color-focus: var(--neutral-700);
|
||||
--input-border-color-hover: var(--input-border-color);
|
||||
--input_border_width: None;
|
||||
--input-placeholder-color: var(--neutral-500);
|
||||
--input_shadow: None;
|
||||
--input-shadow-focus: 0 0 0 var(--shadow-spread) var(--neutral-700), var(--shadow-inset);
|
||||
--loader_color: None;
|
||||
--slider_color: None;
|
||||
--stat-background-fill: linear-gradient(to right, var(--primary-400), var(--primary-600));
|
||||
--table-border-color: var(--neutral-700);
|
||||
--table-even-background-fill: var(--neutral-950);
|
||||
--table-odd-background-fill: var(--neutral-900);
|
||||
--table-row-focus: var(--color-accent-soft);
|
||||
--button-border-width: var(--input-border-width);
|
||||
--button-cancel-background-fill: linear-gradient(to bottom right, #dc2626, #b91c1c);
|
||||
--button-cancel-background-fill-hover: linear-gradient(to bottom right, #dc2626, #dc2626);
|
||||
--button-cancel-border-color: #dc2626;
|
||||
--button-cancel-border-color-hover: var(--button-cancel-border-color);
|
||||
--button-cancel-text-color: white;
|
||||
--button-cancel-text-color-hover: var(--button-cancel-text-color);
|
||||
--button-primary-background-fill: linear-gradient(to bottom right, var(--primary-500), var(--primary-600));
|
||||
--button-primary-background-fill-hover: linear-gradient(to bottom right, var(--primary-500), var(--primary-500));
|
||||
--button-primary-border-color: var(--primary-500);
|
||||
--button-primary-border-color-hover: var(--button-primary-border-color);
|
||||
--button-primary-text-color: white;
|
||||
--button-primary-text-color-hover: var(--button-primary-text-color);
|
||||
--button-secondary-background-fill: linear-gradient(to bottom right, var(--neutral-600), var(--neutral-700));
|
||||
--button-secondary-background-fill-hover: linear-gradient(to bottom right, var(--neutral-600), var(--neutral-600));
|
||||
--button-secondary-border-color: var(--neutral-600);
|
||||
--button-secondary-border-color-hover: var(--button-secondary-border-color);
|
||||
--button-secondary-text-color: white;
|
||||
--button-secondary-text-color-hover: var(--button-secondary-text-color);
|
||||
--block-border-width: 1px;
|
||||
--block-label-border-width: 1px;
|
||||
--form-gap-width: 1px;
|
||||
--error-border-width: 1px;
|
||||
--input-border-width: 1px;
|
||||
}
|
||||
|
||||
/* SHARK theme */
|
||||
|
||||
/* display in full width for desktop devices */
|
||||
@media (min-width: 1536px)
|
||||
{
|
||||
.gradio-container {
|
||||
max-width: var(--size-full) !important;
|
||||
}
|
||||
}
|
||||
|
||||
.gradio-container .contain {
|
||||
padding: 0 var(--size-4) !important;
|
||||
}
|
||||
|
||||
.container {
|
||||
background-color: black !important;
|
||||
padding-top: var(--size-5) !important;
|
||||
}
|
||||
|
||||
#ui_title {
|
||||
padding: var(--size-2) 0 0 var(--size-1);
|
||||
}
|
||||
|
||||
#top_logo {
|
||||
background-color: transparent;
|
||||
border-radius: 0 !important;
|
||||
border: 0;
|
||||
}
|
||||
|
||||
#demo_title_outer {
|
||||
border-radius: 0;
|
||||
}
|
||||
|
||||
#prompt_box_outer div:first-child {
|
||||
border-radius: 0 !important
|
||||
}
|
||||
|
||||
#prompt_box textarea, #negative_prompt_box textarea {
|
||||
background-color: var(--background-fill-primary) !important;
|
||||
}
|
||||
|
||||
#prompt_examples {
|
||||
margin: 0 !important;
|
||||
}
|
||||
|
||||
#prompt_examples svg {
|
||||
display: none !important;
|
||||
}
|
||||
|
||||
#ui_body {
|
||||
padding: var(--size-2) !important;
|
||||
border-radius: 0.5em !important;
|
||||
}
|
||||
|
||||
#img_result+div {
|
||||
display: none !important;
|
||||
}
|
||||
|
||||
footer {
|
||||
display: none !important;
|
||||
}
|
||||
|
||||
#gallery + div {
|
||||
border-radius: 0 !important;
|
||||
}
|
||||
|
||||
/* Prevent progress bar to block gallery navigation while building images (Gradio V3.19.0) */
|
||||
#gallery .wrap.default {
|
||||
pointer-events: none;
|
||||
}
|
||||
|
||||
/* Import Png info box */
|
||||
#txt2img_prompt_image .fixed-height {
|
||||
height: var(--size-32);
|
||||
}
|
||||
|
||||
/* Hide "remove buttons" from ui dropdowns */
|
||||
#custom_model .token-remove.remove-all,
|
||||
#lora_weights .token-remove.remove-all,
|
||||
#scheduler .token-remove.remove-all,
|
||||
#device .token-remove.remove-all,
|
||||
#stencil_model .token-remove.remove-all {
|
||||
display: none;
|
||||
}
|
||||
|
||||
/* Hide selected items from ui dropdowns */
|
||||
#custom_model .options .item .inner-item,
|
||||
#scheduler .options .item .inner-item,
|
||||
#device .options .item .inner-item,
|
||||
#stencil_model .options .item .inner-item {
|
||||
display:none;
|
||||
}
|
||||
|
||||
/* Hide the download icon from the nod logo */
|
||||
#top_logo .download {
|
||||
display: none;
|
||||
}
|
||||
267
apps/stable_diffusion/web/ui/img2img_ui.py
Normal file
267
apps/stable_diffusion/web/ui/img2img_ui.py
Normal file
@@ -0,0 +1,267 @@
|
||||
from pathlib import Path
|
||||
import os
|
||||
import gradio as gr
|
||||
from PIL import Image
|
||||
from apps.stable_diffusion.scripts import img2img_inf
|
||||
from apps.stable_diffusion.src import args
|
||||
from apps.stable_diffusion.web.ui.utils import (
|
||||
available_devices,
|
||||
nodlogo_loc,
|
||||
get_custom_model_path,
|
||||
get_custom_model_files,
|
||||
scheduler_list,
|
||||
predefined_models,
|
||||
cancel_sd,
|
||||
)
|
||||
|
||||
|
||||
with gr.Blocks(title="Image-to-Image") as img2img_web:
|
||||
with gr.Row(elem_id="ui_title"):
|
||||
nod_logo = Image.open(nodlogo_loc)
|
||||
with gr.Row():
|
||||
with gr.Column(scale=1, elem_id="demo_title_outer"):
|
||||
gr.Image(
|
||||
value=nod_logo,
|
||||
show_label=False,
|
||||
interactive=False,
|
||||
elem_id="top_logo",
|
||||
).style(width=150, height=50)
|
||||
with gr.Row(elem_id="ui_body"):
|
||||
with gr.Row():
|
||||
with gr.Column(scale=1, min_width=600):
|
||||
with gr.Row():
|
||||
custom_model = gr.Dropdown(
|
||||
label=f"Models (Custom Model path: {get_custom_model_path()})",
|
||||
elem_id="custom_model",
|
||||
value=os.path.basename(args.ckpt_loc)
|
||||
if args.ckpt_loc
|
||||
else "None",
|
||||
choices=["None"]
|
||||
+ get_custom_model_files()
|
||||
+ predefined_models,
|
||||
)
|
||||
hf_model_id = gr.Textbox(
|
||||
elem_id="hf_model_id",
|
||||
placeholder="Select 'None' in the Models dropdown on the left and enter model ID here e.g: SG161222/Realistic_Vision_V1.3",
|
||||
value="",
|
||||
label="HuggingFace Model ID",
|
||||
lines=3,
|
||||
)
|
||||
|
||||
with gr.Group(elem_id="prompt_box_outer"):
|
||||
prompt = gr.Textbox(
|
||||
label="Prompt",
|
||||
value=args.prompts[0],
|
||||
lines=1,
|
||||
elem_id="prompt_box",
|
||||
)
|
||||
negative_prompt = gr.Textbox(
|
||||
label="Negative Prompt",
|
||||
value=args.negative_prompts[0],
|
||||
lines=1,
|
||||
elem_id="negative_prompt_box",
|
||||
)
|
||||
|
||||
img2img_init_image = gr.Image(
|
||||
label="Input Image", type="pil"
|
||||
).style(height=300)
|
||||
|
||||
with gr.Accordion(label="Stencil Options", open=False):
|
||||
with gr.Row():
|
||||
use_stencil = gr.Dropdown(
|
||||
elem_id="stencil_model",
|
||||
label="Stencil model",
|
||||
value="None",
|
||||
choices=["None", "canny", "openpose", "scribble"],
|
||||
)
|
||||
with gr.Accordion(label="LoRA Options", open=False):
|
||||
with gr.Row():
|
||||
lora_weights = gr.Dropdown(
|
||||
label=f"Standlone LoRA weights (Path: {get_custom_model_path('lora')})",
|
||||
elem_id="lora_weights",
|
||||
value="None",
|
||||
choices=["None"] + get_custom_model_files("lora"),
|
||||
)
|
||||
lora_hf_id = gr.Textbox(
|
||||
elem_id="lora_hf_id",
|
||||
placeholder="Select 'None' in the Standlone LoRA weights dropdown on the left if you want to use a standalone HuggingFace model ID for LoRA here e.g: sayakpaul/sd-model-finetuned-lora-t4",
|
||||
value="",
|
||||
label="HuggingFace Model ID",
|
||||
lines=3,
|
||||
)
|
||||
with gr.Accordion(label="Advanced Options", open=False):
|
||||
with gr.Row():
|
||||
scheduler = gr.Dropdown(
|
||||
elem_id="scheduler",
|
||||
label="Scheduler",
|
||||
value="PNDM",
|
||||
choices=scheduler_list,
|
||||
)
|
||||
with gr.Group():
|
||||
save_metadata_to_png = gr.Checkbox(
|
||||
label="Save prompt information to PNG",
|
||||
value=args.write_metadata_to_png,
|
||||
interactive=True,
|
||||
)
|
||||
save_metadata_to_json = gr.Checkbox(
|
||||
label="Save prompt information to JSON file",
|
||||
value=args.save_metadata_to_json,
|
||||
interactive=True,
|
||||
)
|
||||
with gr.Row():
|
||||
height = gr.Slider(
|
||||
384, 768, value=args.height, step=8, label="Height"
|
||||
)
|
||||
width = gr.Slider(
|
||||
384, 768, value=args.width, step=8, label="Width"
|
||||
)
|
||||
precision = gr.Radio(
|
||||
label="Precision",
|
||||
value=args.precision,
|
||||
choices=[
|
||||
"fp16",
|
||||
"fp32",
|
||||
],
|
||||
visible=True,
|
||||
)
|
||||
max_length = gr.Radio(
|
||||
label="Max Length",
|
||||
value=args.max_length,
|
||||
choices=[
|
||||
64,
|
||||
77,
|
||||
],
|
||||
visible=False,
|
||||
)
|
||||
with gr.Row():
|
||||
steps = gr.Slider(
|
||||
1, 100, value=args.steps, step=1, label="Steps"
|
||||
)
|
||||
strength = gr.Slider(
|
||||
0,
|
||||
1,
|
||||
value=args.strength,
|
||||
step=0.01,
|
||||
label="Denoising Strength",
|
||||
)
|
||||
ondemand = gr.Checkbox(
|
||||
value=args.ondemand,
|
||||
label="Low VRAM",
|
||||
interactive=True,
|
||||
)
|
||||
with gr.Row():
|
||||
with gr.Column(scale=3):
|
||||
guidance_scale = gr.Slider(
|
||||
0,
|
||||
50,
|
||||
value=args.guidance_scale,
|
||||
step=0.1,
|
||||
label="CFG Scale",
|
||||
)
|
||||
with gr.Column(scale=3):
|
||||
batch_count = gr.Slider(
|
||||
1,
|
||||
100,
|
||||
value=args.batch_count,
|
||||
step=1,
|
||||
label="Batch Count",
|
||||
interactive=True,
|
||||
)
|
||||
batch_size = gr.Slider(
|
||||
1,
|
||||
4,
|
||||
value=args.batch_size,
|
||||
step=1,
|
||||
label="Batch Size",
|
||||
interactive=False,
|
||||
visible=False,
|
||||
)
|
||||
stop_batch = gr.Button("Stop Batch")
|
||||
with gr.Row():
|
||||
seed = gr.Number(
|
||||
value=args.seed, precision=0, label="Seed"
|
||||
)
|
||||
device = gr.Dropdown(
|
||||
elem_id="device",
|
||||
label="Device",
|
||||
value=available_devices[0],
|
||||
choices=available_devices,
|
||||
)
|
||||
with gr.Row():
|
||||
with gr.Column(scale=2):
|
||||
random_seed = gr.Button("Randomize Seed")
|
||||
random_seed.click(
|
||||
None,
|
||||
inputs=[],
|
||||
outputs=[seed],
|
||||
_js="() => -1",
|
||||
)
|
||||
with gr.Column(scale=6):
|
||||
stable_diffusion = gr.Button("Generate Image(s)")
|
||||
|
||||
with gr.Column(scale=1, min_width=600):
|
||||
with gr.Group():
|
||||
img2img_gallery = gr.Gallery(
|
||||
label="Generated images",
|
||||
show_label=False,
|
||||
elem_id="gallery",
|
||||
).style(grid=[2])
|
||||
std_output = gr.Textbox(
|
||||
value="Nothing to show.",
|
||||
lines=1,
|
||||
show_label=False,
|
||||
)
|
||||
output_dir = args.output_dir if args.output_dir else Path.cwd()
|
||||
output_dir = Path(output_dir, "generated_imgs")
|
||||
output_loc = gr.Textbox(
|
||||
label="Saving Images at",
|
||||
value=output_dir,
|
||||
interactive=False,
|
||||
)
|
||||
with gr.Row():
|
||||
img2img_sendto_inpaint = gr.Button(value="SendTo Inpaint")
|
||||
img2img_sendto_outpaint = gr.Button(
|
||||
value="SendTo Outpaint"
|
||||
)
|
||||
img2img_sendto_upscaler = gr.Button(
|
||||
value="SendTo Upscaler"
|
||||
)
|
||||
|
||||
kwargs = dict(
|
||||
fn=img2img_inf,
|
||||
inputs=[
|
||||
prompt,
|
||||
negative_prompt,
|
||||
img2img_init_image,
|
||||
height,
|
||||
width,
|
||||
steps,
|
||||
strength,
|
||||
guidance_scale,
|
||||
seed,
|
||||
batch_count,
|
||||
batch_size,
|
||||
scheduler,
|
||||
custom_model,
|
||||
hf_model_id,
|
||||
precision,
|
||||
device,
|
||||
max_length,
|
||||
use_stencil,
|
||||
save_metadata_to_json,
|
||||
save_metadata_to_png,
|
||||
lora_weights,
|
||||
lora_hf_id,
|
||||
ondemand,
|
||||
],
|
||||
outputs=[img2img_gallery, std_output],
|
||||
show_progress=args.progress_bar,
|
||||
)
|
||||
|
||||
prompt_submit = prompt.submit(**kwargs)
|
||||
neg_prompt_submit = negative_prompt.submit(**kwargs)
|
||||
generate_click = stable_diffusion.click(**kwargs)
|
||||
stop_batch.click(
|
||||
fn=cancel_sd,
|
||||
cancels=[prompt_submit, neg_prompt_submit, generate_click],
|
||||
)
|
||||
269
apps/stable_diffusion/web/ui/inpaint_ui.py
Normal file
269
apps/stable_diffusion/web/ui/inpaint_ui.py
Normal file
@@ -0,0 +1,269 @@
|
||||
from pathlib import Path
|
||||
import os
|
||||
import gradio as gr
|
||||
from PIL import Image
|
||||
from apps.stable_diffusion.scripts import inpaint_inf
|
||||
from apps.stable_diffusion.src import args
|
||||
from apps.stable_diffusion.web.ui.utils import (
|
||||
available_devices,
|
||||
nodlogo_loc,
|
||||
get_custom_model_path,
|
||||
get_custom_model_files,
|
||||
scheduler_list,
|
||||
predefined_paint_models,
|
||||
cancel_sd,
|
||||
)
|
||||
|
||||
|
||||
with gr.Blocks(title="Inpainting") as inpaint_web:
|
||||
with gr.Row(elem_id="ui_title"):
|
||||
nod_logo = Image.open(nodlogo_loc)
|
||||
with gr.Row():
|
||||
with gr.Column(scale=1, elem_id="demo_title_outer"):
|
||||
gr.Image(
|
||||
value=nod_logo,
|
||||
show_label=False,
|
||||
interactive=False,
|
||||
elem_id="top_logo",
|
||||
).style(width=150, height=50)
|
||||
with gr.Row(elem_id="ui_body"):
|
||||
with gr.Row():
|
||||
with gr.Column(scale=1, min_width=600):
|
||||
with gr.Row():
|
||||
custom_model = gr.Dropdown(
|
||||
label=f"Models (Custom Model path: {get_custom_model_path()})",
|
||||
elem_id="custom_model",
|
||||
value=os.path.basename(args.ckpt_loc)
|
||||
if args.ckpt_loc
|
||||
else "None",
|
||||
choices=["None"]
|
||||
+ get_custom_model_files()
|
||||
+ predefined_paint_models,
|
||||
)
|
||||
hf_model_id = gr.Textbox(
|
||||
elem_id="hf_model_id",
|
||||
placeholder="Select 'None' in the Models dropdown on the left and enter model ID here e.g: ghunkins/stable-diffusion-liberty-inpainting",
|
||||
value="",
|
||||
label="HuggingFace Model ID",
|
||||
lines=3,
|
||||
)
|
||||
|
||||
with gr.Group(elem_id="prompt_box_outer"):
|
||||
prompt = gr.Textbox(
|
||||
label="Prompt",
|
||||
value=args.prompts[0],
|
||||
lines=1,
|
||||
elem_id="prompt_box",
|
||||
)
|
||||
negative_prompt = gr.Textbox(
|
||||
label="Negative Prompt",
|
||||
value=args.negative_prompts[0],
|
||||
lines=1,
|
||||
elem_id="negative_prompt_box",
|
||||
)
|
||||
|
||||
inpaint_init_image = gr.Image(
|
||||
label="Masked Image",
|
||||
source="upload",
|
||||
tool="sketch",
|
||||
type="pil",
|
||||
).style(height=350)
|
||||
|
||||
with gr.Accordion(label="LoRA Options", open=False):
|
||||
with gr.Row():
|
||||
lora_weights = gr.Dropdown(
|
||||
label=f"Standlone LoRA weights (Path: {get_custom_model_path('lora')})",
|
||||
elem_id="lora_weights",
|
||||
value="None",
|
||||
choices=["None"] + get_custom_model_files("lora"),
|
||||
)
|
||||
lora_hf_id = gr.Textbox(
|
||||
elem_id="lora_hf_id",
|
||||
placeholder="Select 'None' in the Standlone LoRA weights dropdown on the left if you want to use a standalone HuggingFace model ID for LoRA here e.g: sayakpaul/sd-model-finetuned-lora-t4",
|
||||
value="",
|
||||
label="HuggingFace Model ID",
|
||||
lines=3,
|
||||
)
|
||||
with gr.Accordion(label="Advanced Options", open=False):
|
||||
with gr.Row():
|
||||
scheduler = gr.Dropdown(
|
||||
elem_id="scheduler",
|
||||
label="Scheduler",
|
||||
value="PNDM",
|
||||
choices=scheduler_list,
|
||||
)
|
||||
with gr.Group():
|
||||
save_metadata_to_png = gr.Checkbox(
|
||||
label="Save prompt information to PNG",
|
||||
value=args.write_metadata_to_png,
|
||||
interactive=True,
|
||||
)
|
||||
save_metadata_to_json = gr.Checkbox(
|
||||
label="Save prompt information to JSON file",
|
||||
value=args.save_metadata_to_json,
|
||||
interactive=True,
|
||||
)
|
||||
with gr.Row():
|
||||
height = gr.Slider(
|
||||
384, 768, value=args.height, step=8, label="Height"
|
||||
)
|
||||
width = gr.Slider(
|
||||
384, 768, value=args.width, step=8, label="Width"
|
||||
)
|
||||
precision = gr.Radio(
|
||||
label="Precision",
|
||||
value=args.precision,
|
||||
choices=[
|
||||
"fp16",
|
||||
"fp32",
|
||||
],
|
||||
visible=False,
|
||||
)
|
||||
max_length = gr.Radio(
|
||||
label="Max Length",
|
||||
value=args.max_length,
|
||||
choices=[
|
||||
64,
|
||||
77,
|
||||
],
|
||||
visible=False,
|
||||
)
|
||||
with gr.Row():
|
||||
inpaint_full_res = gr.Radio(
|
||||
choices=["Whole picture", "Only masked"],
|
||||
type="index",
|
||||
value="Whole picture",
|
||||
label="Inpaint area",
|
||||
)
|
||||
inpaint_full_res_padding = gr.Slider(
|
||||
minimum=0,
|
||||
maximum=256,
|
||||
step=4,
|
||||
value=32,
|
||||
label="Only masked padding, pixels",
|
||||
)
|
||||
with gr.Row():
|
||||
steps = gr.Slider(
|
||||
1, 100, value=args.steps, step=1, label="Steps"
|
||||
)
|
||||
ondemand = gr.Checkbox(
|
||||
value=args.ondemand,
|
||||
label="Low VRAM",
|
||||
interactive=True,
|
||||
)
|
||||
with gr.Row():
|
||||
with gr.Column(scale=3):
|
||||
guidance_scale = gr.Slider(
|
||||
0,
|
||||
50,
|
||||
value=args.guidance_scale,
|
||||
step=0.1,
|
||||
label="CFG Scale",
|
||||
)
|
||||
with gr.Column(scale=3):
|
||||
batch_count = gr.Slider(
|
||||
1,
|
||||
100,
|
||||
value=args.batch_count,
|
||||
step=1,
|
||||
label="Batch Count",
|
||||
interactive=True,
|
||||
)
|
||||
batch_size = gr.Slider(
|
||||
1,
|
||||
4,
|
||||
value=args.batch_size,
|
||||
step=1,
|
||||
label="Batch Size",
|
||||
interactive=False,
|
||||
visible=False,
|
||||
)
|
||||
stop_batch = gr.Button("Stop Batch")
|
||||
with gr.Row():
|
||||
seed = gr.Number(
|
||||
value=args.seed, precision=0, label="Seed"
|
||||
)
|
||||
device = gr.Dropdown(
|
||||
elem_id="device",
|
||||
label="Device",
|
||||
value=available_devices[0],
|
||||
choices=available_devices,
|
||||
)
|
||||
with gr.Row():
|
||||
with gr.Column(scale=2):
|
||||
random_seed = gr.Button("Randomize Seed")
|
||||
random_seed.click(
|
||||
None,
|
||||
inputs=[],
|
||||
outputs=[seed],
|
||||
_js="() => -1",
|
||||
)
|
||||
with gr.Column(scale=6):
|
||||
stable_diffusion = gr.Button("Generate Image(s)")
|
||||
|
||||
with gr.Column(scale=1, min_width=600):
|
||||
with gr.Group():
|
||||
inpaint_gallery = gr.Gallery(
|
||||
label="Generated images",
|
||||
show_label=False,
|
||||
elem_id="gallery",
|
||||
).style(grid=[2])
|
||||
std_output = gr.Textbox(
|
||||
value="Nothing to show.",
|
||||
lines=1,
|
||||
show_label=False,
|
||||
)
|
||||
output_dir = args.output_dir if args.output_dir else Path.cwd()
|
||||
output_dir = Path(output_dir, "generated_imgs")
|
||||
output_loc = gr.Textbox(
|
||||
label="Saving Images at",
|
||||
value=output_dir,
|
||||
interactive=False,
|
||||
)
|
||||
with gr.Row():
|
||||
inpaint_sendto_img2img = gr.Button(value="SendTo Img2Img")
|
||||
inpaint_sendto_outpaint = gr.Button(
|
||||
value="SendTo Outpaint"
|
||||
)
|
||||
inpaint_sendto_upscaler = gr.Button(
|
||||
value="SendTo Upscaler"
|
||||
)
|
||||
|
||||
kwargs = dict(
|
||||
fn=inpaint_inf,
|
||||
inputs=[
|
||||
prompt,
|
||||
negative_prompt,
|
||||
inpaint_init_image,
|
||||
height,
|
||||
width,
|
||||
inpaint_full_res,
|
||||
inpaint_full_res_padding,
|
||||
steps,
|
||||
guidance_scale,
|
||||
seed,
|
||||
batch_count,
|
||||
batch_size,
|
||||
scheduler,
|
||||
custom_model,
|
||||
hf_model_id,
|
||||
precision,
|
||||
device,
|
||||
max_length,
|
||||
save_metadata_to_json,
|
||||
save_metadata_to_png,
|
||||
lora_weights,
|
||||
lora_hf_id,
|
||||
ondemand,
|
||||
],
|
||||
outputs=[inpaint_gallery, std_output],
|
||||
show_progress=args.progress_bar,
|
||||
)
|
||||
|
||||
prompt_submit = prompt.submit(**kwargs)
|
||||
neg_prompt_submit = negative_prompt.submit(**kwargs)
|
||||
generate_click = stable_diffusion.click(**kwargs)
|
||||
stop_batch.click(
|
||||
fn=cancel_sd,
|
||||
cancels=[prompt_submit, neg_prompt_submit, generate_click],
|
||||
)
|
||||
BIN
apps/stable_diffusion/web/ui/logos/nod-logo.png
Normal file
BIN
apps/stable_diffusion/web/ui/logos/nod-logo.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 10 KiB |
205
apps/stable_diffusion/web/ui/lora_train_ui.py
Normal file
205
apps/stable_diffusion/web/ui/lora_train_ui.py
Normal file
@@ -0,0 +1,205 @@
|
||||
from pathlib import Path
|
||||
import os
|
||||
import gradio as gr
|
||||
from PIL import Image
|
||||
from apps.stable_diffusion.scripts import lora_train
|
||||
from apps.stable_diffusion.src import prompt_examples, args
|
||||
from apps.stable_diffusion.web.ui.utils import (
|
||||
available_devices,
|
||||
nodlogo_loc,
|
||||
get_custom_model_path,
|
||||
get_custom_model_files,
|
||||
scheduler_list_txt2img,
|
||||
predefined_models,
|
||||
)
|
||||
|
||||
with gr.Blocks(title="Lora Training") as lora_train_web:
|
||||
with gr.Row(elem_id="ui_title"):
|
||||
nod_logo = Image.open(nodlogo_loc)
|
||||
with gr.Row():
|
||||
with gr.Column(scale=1, elem_id="demo_title_outer"):
|
||||
gr.Image(
|
||||
value=nod_logo,
|
||||
show_label=False,
|
||||
interactive=False,
|
||||
elem_id="top_logo",
|
||||
).style(width=150, height=50)
|
||||
with gr.Row(elem_id="ui_body"):
|
||||
with gr.Row():
|
||||
with gr.Column(scale=1, min_width=600):
|
||||
with gr.Row():
|
||||
with gr.Column(scale=10):
|
||||
with gr.Row():
|
||||
custom_model = gr.Dropdown(
|
||||
label=f"Models (Custom Model path: {get_custom_model_path()})",
|
||||
elem_id="custom_model",
|
||||
value=os.path.basename(args.ckpt_loc)
|
||||
if args.ckpt_loc
|
||||
else "None",
|
||||
choices=["None"]
|
||||
+ get_custom_model_files()
|
||||
+ predefined_models,
|
||||
)
|
||||
hf_model_id = gr.Textbox(
|
||||
elem_id="hf_model_id",
|
||||
placeholder="Select 'None' in the Models dropdown on the left and enter model ID here e.g: SG161222/Realistic_Vision_V1.3",
|
||||
value="",
|
||||
label="HuggingFace Model ID",
|
||||
lines=3,
|
||||
)
|
||||
|
||||
with gr.Group(elem_id="image_dir_box_outer"):
|
||||
training_images_dir = gr.Textbox(
|
||||
label="ImageDirectory",
|
||||
value=args.training_images_dir,
|
||||
lines=1,
|
||||
elem_id="prompt_box",
|
||||
)
|
||||
with gr.Group(elem_id="prompt_box_outer"):
|
||||
prompt = gr.Textbox(
|
||||
label="Prompt",
|
||||
value=args.prompts[0],
|
||||
lines=1,
|
||||
elem_id="prompt_box",
|
||||
)
|
||||
with gr.Accordion(label="Advanced Options", open=False):
|
||||
with gr.Row():
|
||||
scheduler = gr.Dropdown(
|
||||
elem_id="scheduler",
|
||||
label="Scheduler",
|
||||
value=args.scheduler,
|
||||
choices=scheduler_list_txt2img,
|
||||
)
|
||||
with gr.Row():
|
||||
height = gr.Slider(
|
||||
384, 768, value=args.height, step=8, label="Height"
|
||||
)
|
||||
width = gr.Slider(
|
||||
384, 768, value=args.width, step=8, label="Width"
|
||||
)
|
||||
precision = gr.Radio(
|
||||
label="Precision",
|
||||
value=args.precision,
|
||||
choices=[
|
||||
"fp16",
|
||||
"fp32",
|
||||
],
|
||||
visible=False,
|
||||
)
|
||||
max_length = gr.Radio(
|
||||
label="Max Length",
|
||||
value=args.max_length,
|
||||
choices=[
|
||||
64,
|
||||
77,
|
||||
],
|
||||
visible=False,
|
||||
)
|
||||
with gr.Row():
|
||||
steps = gr.Slider(
|
||||
1,
|
||||
2000,
|
||||
value=args.training_steps,
|
||||
step=1,
|
||||
label="Training Steps",
|
||||
)
|
||||
guidance_scale = gr.Slider(
|
||||
0,
|
||||
50,
|
||||
value=args.guidance_scale,
|
||||
step=0.1,
|
||||
label="CFG Scale",
|
||||
)
|
||||
with gr.Row():
|
||||
with gr.Column(scale=3):
|
||||
batch_count = gr.Slider(
|
||||
1,
|
||||
100,
|
||||
value=args.batch_count,
|
||||
step=1,
|
||||
label="Batch Count",
|
||||
interactive=True,
|
||||
)
|
||||
with gr.Column(scale=3):
|
||||
batch_size = gr.Slider(
|
||||
1,
|
||||
4,
|
||||
value=args.batch_size,
|
||||
step=1,
|
||||
label="Batch Size",
|
||||
interactive=True,
|
||||
)
|
||||
stop_batch = gr.Button("Stop Batch")
|
||||
with gr.Row():
|
||||
seed = gr.Number(
|
||||
value=args.seed, precision=0, label="Seed"
|
||||
)
|
||||
device = gr.Dropdown(
|
||||
elem_id="device",
|
||||
label="Device",
|
||||
value=available_devices[0],
|
||||
choices=available_devices,
|
||||
)
|
||||
with gr.Row():
|
||||
with gr.Column(scale=2):
|
||||
random_seed = gr.Button("Randomize Seed")
|
||||
random_seed.click(
|
||||
None,
|
||||
inputs=[],
|
||||
outputs=[seed],
|
||||
_js="() => -1",
|
||||
)
|
||||
with gr.Column(scale=6):
|
||||
train_lora = gr.Button("Train LoRA")
|
||||
|
||||
with gr.Accordion(label="Prompt Examples!", open=False):
|
||||
ex = gr.Examples(
|
||||
examples=prompt_examples,
|
||||
inputs=prompt,
|
||||
cache_examples=False,
|
||||
elem_id="prompt_examples",
|
||||
)
|
||||
|
||||
with gr.Column(scale=1, min_width=600):
|
||||
with gr.Group():
|
||||
std_output = gr.Textbox(
|
||||
value="Nothing to show.",
|
||||
lines=1,
|
||||
show_label=False,
|
||||
)
|
||||
lora_save_dir = (
|
||||
args.lora_save_dir if args.lora_save_dir else Path.cwd()
|
||||
)
|
||||
lora_save_dir = Path(lora_save_dir, "lora")
|
||||
output_loc = gr.Textbox(
|
||||
label="Saving Lora at",
|
||||
value=lora_save_dir,
|
||||
)
|
||||
|
||||
kwargs = dict(
|
||||
fn=lora_train,
|
||||
inputs=[
|
||||
prompt,
|
||||
height,
|
||||
width,
|
||||
steps,
|
||||
guidance_scale,
|
||||
seed,
|
||||
batch_count,
|
||||
batch_size,
|
||||
scheduler,
|
||||
custom_model,
|
||||
hf_model_id,
|
||||
precision,
|
||||
device,
|
||||
max_length,
|
||||
training_images_dir,
|
||||
output_loc,
|
||||
],
|
||||
outputs=[std_output],
|
||||
show_progress=args.progress_bar,
|
||||
)
|
||||
|
||||
prompt_submit = prompt.submit(**kwargs)
|
||||
train_click = train_lora.click(**kwargs)
|
||||
stop_batch.click(fn=None, cancels=[prompt_submit, train_click])
|
||||
289
apps/stable_diffusion/web/ui/outpaint_ui.py
Normal file
289
apps/stable_diffusion/web/ui/outpaint_ui.py
Normal file
@@ -0,0 +1,289 @@
|
||||
from pathlib import Path
|
||||
import os
|
||||
import gradio as gr
|
||||
from PIL import Image
|
||||
from apps.stable_diffusion.scripts import outpaint_inf
|
||||
from apps.stable_diffusion.src import args
|
||||
from apps.stable_diffusion.web.ui.utils import (
|
||||
available_devices,
|
||||
nodlogo_loc,
|
||||
get_custom_model_path,
|
||||
get_custom_model_files,
|
||||
scheduler_list,
|
||||
predefined_paint_models,
|
||||
cancel_sd,
|
||||
)
|
||||
|
||||
|
||||
with gr.Blocks(title="Outpainting") as outpaint_web:
|
||||
with gr.Row(elem_id="ui_title"):
|
||||
nod_logo = Image.open(nodlogo_loc)
|
||||
with gr.Row():
|
||||
with gr.Column(scale=1, elem_id="demo_title_outer"):
|
||||
gr.Image(
|
||||
value=nod_logo,
|
||||
show_label=False,
|
||||
interactive=False,
|
||||
elem_id="top_logo",
|
||||
).style(width=150, height=50)
|
||||
with gr.Row(elem_id="ui_body"):
|
||||
with gr.Row():
|
||||
with gr.Column(scale=1, min_width=600):
|
||||
with gr.Row():
|
||||
custom_model = gr.Dropdown(
|
||||
label=f"Models (Custom Model path: {get_custom_model_path()})",
|
||||
elem_id="custom_model",
|
||||
value=os.path.basename(args.ckpt_loc)
|
||||
if args.ckpt_loc
|
||||
else "None",
|
||||
choices=["None"]
|
||||
+ get_custom_model_files()
|
||||
+ predefined_paint_models,
|
||||
)
|
||||
hf_model_id = gr.Textbox(
|
||||
elem_id="hf_model_id",
|
||||
placeholder="Select 'None' in the Models dropdown on the left and enter model ID here e.g: ghunkins/stable-diffusion-liberty-inpainting",
|
||||
value="",
|
||||
label="HuggingFace Model ID",
|
||||
lines=3,
|
||||
)
|
||||
|
||||
with gr.Group(elem_id="prompt_box_outer"):
|
||||
prompt = gr.Textbox(
|
||||
label="Prompt",
|
||||
value=args.prompts[0],
|
||||
lines=1,
|
||||
elem_id="prompt_box",
|
||||
)
|
||||
negative_prompt = gr.Textbox(
|
||||
label="Negative Prompt",
|
||||
value=args.negative_prompts[0],
|
||||
lines=1,
|
||||
elem_id="negative_prompt_box",
|
||||
)
|
||||
|
||||
outpaint_init_image = gr.Image(
|
||||
label="Input Image", type="pil"
|
||||
).style(height=300)
|
||||
|
||||
with gr.Accordion(label="LoRA Options", open=False):
|
||||
with gr.Row():
|
||||
lora_weights = gr.Dropdown(
|
||||
label=f"Standlone LoRA weights (Path: {get_custom_model_path('lora')})",
|
||||
elem_id="lora_weights",
|
||||
value="None",
|
||||
choices=["None"] + get_custom_model_files("lora"),
|
||||
)
|
||||
lora_hf_id = gr.Textbox(
|
||||
elem_id="lora_hf_id",
|
||||
placeholder="Select 'None' in the Standlone LoRA weights dropdown on the left if you want to use a standalone HuggingFace model ID for LoRA here e.g: sayakpaul/sd-model-finetuned-lora-t4",
|
||||
value="",
|
||||
label="HuggingFace Model ID",
|
||||
lines=3,
|
||||
)
|
||||
with gr.Accordion(label="Advanced Options", open=False):
|
||||
with gr.Row():
|
||||
scheduler = gr.Dropdown(
|
||||
elem_id="scheduler",
|
||||
label="Scheduler",
|
||||
value="PNDM",
|
||||
choices=scheduler_list,
|
||||
)
|
||||
with gr.Group():
|
||||
save_metadata_to_png = gr.Checkbox(
|
||||
label="Save prompt information to PNG",
|
||||
value=args.write_metadata_to_png,
|
||||
interactive=True,
|
||||
)
|
||||
save_metadata_to_json = gr.Checkbox(
|
||||
label="Save prompt information to JSON file",
|
||||
value=args.save_metadata_to_json,
|
||||
interactive=True,
|
||||
)
|
||||
with gr.Row():
|
||||
pixels = gr.Slider(
|
||||
8,
|
||||
256,
|
||||
value=args.pixels,
|
||||
step=8,
|
||||
label="Pixels to expand",
|
||||
)
|
||||
mask_blur = gr.Slider(
|
||||
0,
|
||||
64,
|
||||
value=args.mask_blur,
|
||||
step=1,
|
||||
label="Mask blur",
|
||||
)
|
||||
with gr.Row():
|
||||
directions = gr.CheckboxGroup(
|
||||
label="Outpainting direction",
|
||||
choices=["left", "right", "up", "down"],
|
||||
value=["left", "right", "up", "down"],
|
||||
)
|
||||
with gr.Row():
|
||||
noise_q = gr.Slider(
|
||||
0.0,
|
||||
4.0,
|
||||
value=1.0,
|
||||
step=0.01,
|
||||
label="Fall-off exponent (lower=higher detail)",
|
||||
)
|
||||
color_variation = gr.Slider(
|
||||
0.0,
|
||||
1.0,
|
||||
value=0.05,
|
||||
step=0.01,
|
||||
label="Color variation",
|
||||
)
|
||||
with gr.Row():
|
||||
height = gr.Slider(
|
||||
384, 768, value=args.height, step=8, label="Height"
|
||||
)
|
||||
width = gr.Slider(
|
||||
384, 768, value=args.width, step=8, label="Width"
|
||||
)
|
||||
precision = gr.Radio(
|
||||
label="Precision",
|
||||
value=args.precision,
|
||||
choices=[
|
||||
"fp16",
|
||||
"fp32",
|
||||
],
|
||||
visible=False,
|
||||
)
|
||||
max_length = gr.Radio(
|
||||
label="Max Length",
|
||||
value=args.max_length,
|
||||
choices=[
|
||||
64,
|
||||
77,
|
||||
],
|
||||
visible=False,
|
||||
)
|
||||
with gr.Row():
|
||||
steps = gr.Slider(
|
||||
1, 100, value=20, step=1, label="Steps"
|
||||
)
|
||||
ondemand = gr.Checkbox(
|
||||
value=args.ondemand,
|
||||
label="Low VRAM",
|
||||
interactive=True,
|
||||
)
|
||||
with gr.Row():
|
||||
with gr.Column(scale=3):
|
||||
guidance_scale = gr.Slider(
|
||||
0,
|
||||
50,
|
||||
value=args.guidance_scale,
|
||||
step=0.1,
|
||||
label="CFG Scale",
|
||||
)
|
||||
with gr.Column(scale=3):
|
||||
batch_count = gr.Slider(
|
||||
1,
|
||||
100,
|
||||
value=args.batch_count,
|
||||
step=1,
|
||||
label="Batch Count",
|
||||
interactive=True,
|
||||
)
|
||||
batch_size = gr.Slider(
|
||||
1,
|
||||
4,
|
||||
value=args.batch_size,
|
||||
step=1,
|
||||
label="Batch Size",
|
||||
interactive=False,
|
||||
visible=False,
|
||||
)
|
||||
stop_batch = gr.Button("Stop Batch")
|
||||
with gr.Row():
|
||||
seed = gr.Number(
|
||||
value=args.seed, precision=0, label="Seed"
|
||||
)
|
||||
device = gr.Dropdown(
|
||||
elem_id="device",
|
||||
label="Device",
|
||||
value=available_devices[0],
|
||||
choices=available_devices,
|
||||
)
|
||||
with gr.Row():
|
||||
with gr.Column(scale=2):
|
||||
random_seed = gr.Button("Randomize Seed")
|
||||
random_seed.click(
|
||||
None,
|
||||
inputs=[],
|
||||
outputs=[seed],
|
||||
_js="() => -1",
|
||||
)
|
||||
with gr.Column(scale=6):
|
||||
stable_diffusion = gr.Button("Generate Image(s)")
|
||||
|
||||
with gr.Column(scale=1, min_width=600):
|
||||
with gr.Group():
|
||||
outpaint_gallery = gr.Gallery(
|
||||
label="Generated images",
|
||||
show_label=False,
|
||||
elem_id="gallery",
|
||||
).style(grid=[2])
|
||||
std_output = gr.Textbox(
|
||||
value="Nothing to show.",
|
||||
lines=1,
|
||||
show_label=False,
|
||||
)
|
||||
output_dir = args.output_dir if args.output_dir else Path.cwd()
|
||||
output_dir = Path(output_dir, "generated_imgs")
|
||||
output_loc = gr.Textbox(
|
||||
label="Saving Images at",
|
||||
value=output_dir,
|
||||
interactive=False,
|
||||
)
|
||||
with gr.Row():
|
||||
outpaint_sendto_img2img = gr.Button(value="SendTo Img2Img")
|
||||
outpaint_sendto_inpaint = gr.Button(value="SendTo Inpaint")
|
||||
outpaint_sendto_upscaler = gr.Button(
|
||||
value="SendTo Upscaler"
|
||||
)
|
||||
|
||||
kwargs = dict(
|
||||
fn=outpaint_inf,
|
||||
inputs=[
|
||||
prompt,
|
||||
negative_prompt,
|
||||
outpaint_init_image,
|
||||
pixels,
|
||||
mask_blur,
|
||||
directions,
|
||||
noise_q,
|
||||
color_variation,
|
||||
height,
|
||||
width,
|
||||
steps,
|
||||
guidance_scale,
|
||||
seed,
|
||||
batch_count,
|
||||
batch_size,
|
||||
scheduler,
|
||||
custom_model,
|
||||
hf_model_id,
|
||||
precision,
|
||||
device,
|
||||
max_length,
|
||||
save_metadata_to_json,
|
||||
save_metadata_to_png,
|
||||
lora_weights,
|
||||
lora_hf_id,
|
||||
ondemand,
|
||||
],
|
||||
outputs=[outpaint_gallery, std_output],
|
||||
show_progress=args.progress_bar,
|
||||
)
|
||||
|
||||
prompt_submit = prompt.submit(**kwargs)
|
||||
neg_prompt_submit = negative_prompt.submit(**kwargs)
|
||||
generate_click = stable_diffusion.click(**kwargs)
|
||||
stop_batch.click(
|
||||
fn=cancel_sd,
|
||||
cancels=[prompt_submit, neg_prompt_submit, generate_click],
|
||||
)
|
||||
474
apps/stable_diffusion/web/ui/txt2img_ui.py
Normal file
474
apps/stable_diffusion/web/ui/txt2img_ui.py
Normal file
@@ -0,0 +1,474 @@
|
||||
from pathlib import Path
|
||||
import os
|
||||
import torch
|
||||
import time
|
||||
import gradio as gr
|
||||
from PIL import Image
|
||||
from apps.stable_diffusion.web.ui.utils import (
|
||||
available_devices,
|
||||
nodlogo_loc,
|
||||
get_custom_model_path,
|
||||
get_custom_model_files,
|
||||
scheduler_list_txt2img,
|
||||
predefined_models,
|
||||
cancel_sd,
|
||||
)
|
||||
from apps.stable_diffusion.src import (
|
||||
args,
|
||||
Text2ImagePipeline,
|
||||
get_schedulers,
|
||||
set_init_device_flags,
|
||||
utils,
|
||||
save_output_img,
|
||||
prompt_examples,
|
||||
)
|
||||
from apps.stable_diffusion.src.utils import get_generation_text_info
|
||||
|
||||
# set initial values of iree_vulkan_target_triple, use_tuned and import_mlir.
|
||||
init_iree_vulkan_target_triple = args.iree_vulkan_target_triple
|
||||
init_use_tuned = args.use_tuned
|
||||
init_import_mlir = args.import_mlir
|
||||
|
||||
|
||||
def txt2img_inf(
|
||||
prompt: str,
|
||||
negative_prompt: str,
|
||||
height: int,
|
||||
width: int,
|
||||
steps: int,
|
||||
guidance_scale: float,
|
||||
seed: int,
|
||||
batch_count: int,
|
||||
batch_size: int,
|
||||
scheduler: str,
|
||||
custom_model: str,
|
||||
hf_model_id: str,
|
||||
precision: str,
|
||||
device: str,
|
||||
max_length: int,
|
||||
save_metadata_to_json: bool,
|
||||
save_metadata_to_png: bool,
|
||||
lora_weights: str,
|
||||
lora_hf_id: str,
|
||||
ondemand: bool,
|
||||
):
|
||||
from apps.stable_diffusion.web.ui.utils import (
|
||||
get_custom_model_pathfile,
|
||||
get_custom_vae_or_lora_weights,
|
||||
Config,
|
||||
)
|
||||
import apps.stable_diffusion.web.utils.global_obj as global_obj
|
||||
from apps.stable_diffusion.src.pipelines.pipeline_shark_stable_diffusion_utils import (
|
||||
SD_STATE_CANCEL,
|
||||
)
|
||||
|
||||
args.prompts = [prompt]
|
||||
args.negative_prompts = [negative_prompt]
|
||||
args.guidance_scale = guidance_scale
|
||||
args.steps = steps
|
||||
args.scheduler = scheduler
|
||||
args.ondemand = ondemand
|
||||
|
||||
# set ckpt_loc and hf_model_id.
|
||||
args.ckpt_loc = ""
|
||||
args.hf_model_id = ""
|
||||
if custom_model == "None":
|
||||
if not hf_model_id:
|
||||
return (
|
||||
None,
|
||||
"Please provide either custom model or huggingface model ID, both must not be empty",
|
||||
)
|
||||
args.hf_model_id = hf_model_id
|
||||
elif ".ckpt" in custom_model or ".safetensors" in custom_model:
|
||||
args.ckpt_loc = get_custom_model_pathfile(custom_model)
|
||||
else:
|
||||
args.hf_model_id = custom_model
|
||||
|
||||
args.save_metadata_to_json = save_metadata_to_json
|
||||
args.write_metadata_to_png = save_metadata_to_png
|
||||
|
||||
args.use_lora = get_custom_vae_or_lora_weights(
|
||||
lora_weights, lora_hf_id, "lora"
|
||||
)
|
||||
|
||||
dtype = torch.float32 if precision == "fp32" else torch.half
|
||||
cpu_scheduling = not scheduler.startswith("Shark")
|
||||
new_config_obj = Config(
|
||||
"txt2img",
|
||||
args.hf_model_id,
|
||||
args.ckpt_loc,
|
||||
precision,
|
||||
batch_size,
|
||||
max_length,
|
||||
height,
|
||||
width,
|
||||
device,
|
||||
use_lora=args.use_lora,
|
||||
use_stencil=None,
|
||||
)
|
||||
if (
|
||||
args.ondemand
|
||||
or not global_obj.get_sd_obj()
|
||||
or global_obj.get_cfg_obj() != new_config_obj
|
||||
):
|
||||
global_obj.clear_cache()
|
||||
global_obj.set_cfg_obj(new_config_obj)
|
||||
args.precision = precision
|
||||
args.batch_count = batch_count
|
||||
args.batch_size = batch_size
|
||||
args.max_length = max_length
|
||||
args.height = height
|
||||
args.width = width
|
||||
args.device = device.split("=>", 1)[1].strip()
|
||||
args.iree_vulkan_target_triple = init_iree_vulkan_target_triple
|
||||
args.use_tuned = init_use_tuned
|
||||
args.import_mlir = init_import_mlir
|
||||
args.img_path = None
|
||||
set_init_device_flags()
|
||||
model_id = (
|
||||
args.hf_model_id
|
||||
if args.hf_model_id
|
||||
else "stabilityai/stable-diffusion-2-1-base"
|
||||
)
|
||||
global_obj.set_schedulers(get_schedulers(model_id))
|
||||
scheduler_obj = global_obj.get_scheduler(scheduler)
|
||||
global_obj.set_sd_obj(
|
||||
Text2ImagePipeline.from_pretrained(
|
||||
scheduler=scheduler_obj,
|
||||
import_mlir=args.import_mlir,
|
||||
model_id=args.hf_model_id,
|
||||
ckpt_loc=args.ckpt_loc,
|
||||
precision=args.precision,
|
||||
max_length=args.max_length,
|
||||
batch_size=args.batch_size,
|
||||
height=args.height,
|
||||
width=args.width,
|
||||
use_base_vae=args.use_base_vae,
|
||||
use_tuned=args.use_tuned,
|
||||
custom_vae=args.custom_vae,
|
||||
low_cpu_mem_usage=args.low_cpu_mem_usage,
|
||||
debug=args.import_debug if args.import_mlir else False,
|
||||
use_lora=args.use_lora,
|
||||
ondemand=args.ondemand,
|
||||
)
|
||||
)
|
||||
|
||||
global_obj.set_sd_scheduler(scheduler)
|
||||
global_obj.set_sd_ondemand(args.ondemand)
|
||||
|
||||
start_time = time.time()
|
||||
global_obj.get_sd_obj().log = ""
|
||||
generated_imgs = []
|
||||
seeds = []
|
||||
img_seed = utils.sanitize_seed(seed)
|
||||
text_output = ""
|
||||
for i in range(batch_count):
|
||||
if i > 0:
|
||||
img_seed = utils.sanitize_seed(-1)
|
||||
out_imgs = global_obj.get_sd_obj().generate_images(
|
||||
prompt,
|
||||
negative_prompt,
|
||||
batch_size,
|
||||
height,
|
||||
width,
|
||||
steps,
|
||||
guidance_scale,
|
||||
img_seed,
|
||||
args.max_length,
|
||||
dtype,
|
||||
args.use_base_vae,
|
||||
cpu_scheduling,
|
||||
)
|
||||
seeds.append(img_seed)
|
||||
total_time = time.time() - start_time
|
||||
text_output = get_generation_text_info(seeds, device)
|
||||
text_output += "\n" + global_obj.get_sd_obj().log
|
||||
text_output += f"\nTotal image(s) generation time: {total_time:.4f}sec"
|
||||
|
||||
if global_obj.get_sd_status() == SD_STATE_CANCEL:
|
||||
break
|
||||
else:
|
||||
save_output_img(out_imgs[0], img_seed)
|
||||
generated_imgs.extend(out_imgs)
|
||||
yield generated_imgs, text_output
|
||||
|
||||
return generated_imgs, text_output
|
||||
|
||||
|
||||
with gr.Blocks(title="Text-to-Image") as txt2img_web:
|
||||
with gr.Row(elem_id="ui_title"):
|
||||
nod_logo = Image.open(nodlogo_loc)
|
||||
with gr.Row():
|
||||
with gr.Column(scale=1, elem_id="demo_title_outer"):
|
||||
gr.Image(
|
||||
value=nod_logo,
|
||||
show_label=False,
|
||||
interactive=False,
|
||||
elem_id="top_logo",
|
||||
).style(width=150, height=50)
|
||||
with gr.Row(elem_id="ui_body"):
|
||||
with gr.Row():
|
||||
with gr.Column(scale=1, min_width=600):
|
||||
with gr.Row():
|
||||
with gr.Column(scale=10):
|
||||
with gr.Row():
|
||||
custom_model = gr.Dropdown(
|
||||
label=f"Models (Custom Model path: {get_custom_model_path()})",
|
||||
elem_id="custom_model",
|
||||
value=os.path.basename(args.ckpt_loc)
|
||||
if args.ckpt_loc
|
||||
else "None",
|
||||
choices=["None"]
|
||||
+ get_custom_model_files()
|
||||
+ predefined_models,
|
||||
)
|
||||
hf_model_id = gr.Textbox(
|
||||
elem_id="hf_model_id",
|
||||
placeholder="Select 'None' in the Models dropdown on the left and enter model ID here e.g: SG161222/Realistic_Vision_V1.3",
|
||||
value="",
|
||||
label="HuggingFace Model ID",
|
||||
lines=3,
|
||||
)
|
||||
with gr.Column(scale=1, min_width=170):
|
||||
png_info_img = gr.Image(
|
||||
label="Import PNG info",
|
||||
elem_id="txt2img_prompt_image",
|
||||
type="pil",
|
||||
tool="None",
|
||||
visible=True,
|
||||
)
|
||||
|
||||
with gr.Group(elem_id="prompt_box_outer"):
|
||||
prompt = gr.Textbox(
|
||||
label="Prompt",
|
||||
value=args.prompts[0],
|
||||
lines=1,
|
||||
elem_id="prompt_box",
|
||||
)
|
||||
negative_prompt = gr.Textbox(
|
||||
label="Negative Prompt",
|
||||
value=args.negative_prompts[0],
|
||||
lines=1,
|
||||
elem_id="negative_prompt_box",
|
||||
)
|
||||
with gr.Accordion(label="LoRA Options", open=False):
|
||||
with gr.Row():
|
||||
lora_weights = gr.Dropdown(
|
||||
label=f"Standlone LoRA weights (Path: {get_custom_model_path('lora')})",
|
||||
elem_id="lora_weights",
|
||||
value="None",
|
||||
choices=["None"] + get_custom_model_files("lora"),
|
||||
)
|
||||
lora_hf_id = gr.Textbox(
|
||||
elem_id="lora_hf_id",
|
||||
placeholder="Select 'None' in the Standlone LoRA weights dropdown on the left if you want to use a standalone HuggingFace model ID for LoRA here e.g: sayakpaul/sd-model-finetuned-lora-t4",
|
||||
value="",
|
||||
label="HuggingFace Model ID",
|
||||
lines=3,
|
||||
)
|
||||
with gr.Accordion(label="Advanced Options", open=False):
|
||||
with gr.Row():
|
||||
scheduler = gr.Dropdown(
|
||||
elem_id="scheduler",
|
||||
label="Scheduler",
|
||||
value=args.scheduler,
|
||||
choices=scheduler_list_txt2img,
|
||||
)
|
||||
with gr.Group():
|
||||
save_metadata_to_png = gr.Checkbox(
|
||||
label="Save prompt information to PNG",
|
||||
value=args.write_metadata_to_png,
|
||||
interactive=True,
|
||||
)
|
||||
save_metadata_to_json = gr.Checkbox(
|
||||
label="Save prompt information to JSON file",
|
||||
value=args.save_metadata_to_json,
|
||||
interactive=True,
|
||||
)
|
||||
with gr.Row():
|
||||
height = gr.Slider(
|
||||
384,
|
||||
768,
|
||||
value=args.height,
|
||||
step=8,
|
||||
label="Height",
|
||||
)
|
||||
width = gr.Slider(
|
||||
384,
|
||||
768,
|
||||
value=args.width,
|
||||
step=8,
|
||||
label="Width",
|
||||
)
|
||||
precision = gr.Radio(
|
||||
label="Precision",
|
||||
value=args.precision,
|
||||
choices=[
|
||||
"fp16",
|
||||
"fp32",
|
||||
],
|
||||
visible=False,
|
||||
)
|
||||
max_length = gr.Radio(
|
||||
label="Max Length",
|
||||
value=args.max_length,
|
||||
choices=[
|
||||
64,
|
||||
77,
|
||||
],
|
||||
visible=False,
|
||||
)
|
||||
with gr.Row():
|
||||
steps = gr.Slider(
|
||||
1, 100, value=args.steps, step=1, label="Steps"
|
||||
)
|
||||
guidance_scale = gr.Slider(
|
||||
0,
|
||||
50,
|
||||
value=args.guidance_scale,
|
||||
step=0.1,
|
||||
label="CFG Scale",
|
||||
)
|
||||
ondemand = gr.Checkbox(
|
||||
value=args.ondemand,
|
||||
label="Low VRAM",
|
||||
interactive=True,
|
||||
)
|
||||
with gr.Row():
|
||||
with gr.Column(scale=3):
|
||||
batch_count = gr.Slider(
|
||||
1,
|
||||
100,
|
||||
value=args.batch_count,
|
||||
step=1,
|
||||
label="Batch Count",
|
||||
interactive=True,
|
||||
)
|
||||
with gr.Column(scale=3):
|
||||
batch_size = gr.Slider(
|
||||
1,
|
||||
4,
|
||||
value=args.batch_size,
|
||||
step=1,
|
||||
label="Batch Size",
|
||||
interactive=True,
|
||||
)
|
||||
stop_batch = gr.Button("Stop Batch")
|
||||
with gr.Row():
|
||||
seed = gr.Number(
|
||||
value=args.seed, precision=0, label="Seed"
|
||||
)
|
||||
device = gr.Dropdown(
|
||||
elem_id="device",
|
||||
label="Device",
|
||||
value=available_devices[0],
|
||||
choices=available_devices,
|
||||
)
|
||||
with gr.Row():
|
||||
with gr.Column(scale=2):
|
||||
random_seed = gr.Button("Randomize Seed")
|
||||
random_seed.click(
|
||||
None,
|
||||
inputs=[],
|
||||
outputs=[seed],
|
||||
_js="() => -1",
|
||||
)
|
||||
with gr.Column(scale=6):
|
||||
stable_diffusion = gr.Button("Generate Image(s)")
|
||||
|
||||
with gr.Accordion(label="Prompt Examples!", open=False):
|
||||
ex = gr.Examples(
|
||||
examples=prompt_examples,
|
||||
inputs=prompt,
|
||||
cache_examples=False,
|
||||
elem_id="prompt_examples",
|
||||
)
|
||||
|
||||
with gr.Column(scale=1, min_width=600):
|
||||
with gr.Group():
|
||||
txt2img_gallery = gr.Gallery(
|
||||
label="Generated images",
|
||||
show_label=False,
|
||||
elem_id="gallery",
|
||||
).style(grid=[2])
|
||||
std_output = gr.Textbox(
|
||||
value="Nothing to show.",
|
||||
lines=1,
|
||||
show_label=False,
|
||||
)
|
||||
output_dir = args.output_dir if args.output_dir else Path.cwd()
|
||||
output_dir = Path(output_dir, "generated_imgs")
|
||||
output_loc = gr.Textbox(
|
||||
label="Saving Images at",
|
||||
value=output_dir,
|
||||
interactive=False,
|
||||
)
|
||||
with gr.Row():
|
||||
txt2img_sendto_img2img = gr.Button(value="SendTo Img2Img")
|
||||
txt2img_sendto_inpaint = gr.Button(value="SendTo Inpaint")
|
||||
txt2img_sendto_outpaint = gr.Button(
|
||||
value="SendTo Outpaint"
|
||||
)
|
||||
txt2img_sendto_upscaler = gr.Button(
|
||||
value="SendTo Upscaler"
|
||||
)
|
||||
|
||||
kwargs = dict(
|
||||
fn=txt2img_inf,
|
||||
inputs=[
|
||||
prompt,
|
||||
negative_prompt,
|
||||
height,
|
||||
width,
|
||||
steps,
|
||||
guidance_scale,
|
||||
seed,
|
||||
batch_count,
|
||||
batch_size,
|
||||
scheduler,
|
||||
custom_model,
|
||||
hf_model_id,
|
||||
precision,
|
||||
device,
|
||||
max_length,
|
||||
save_metadata_to_json,
|
||||
save_metadata_to_png,
|
||||
lora_weights,
|
||||
lora_hf_id,
|
||||
ondemand,
|
||||
],
|
||||
outputs=[txt2img_gallery, std_output],
|
||||
show_progress=args.progress_bar,
|
||||
)
|
||||
|
||||
prompt_submit = prompt.submit(**kwargs)
|
||||
neg_prompt_submit = negative_prompt.submit(**kwargs)
|
||||
generate_click = stable_diffusion.click(**kwargs)
|
||||
stop_batch.click(
|
||||
fn=cancel_sd,
|
||||
cancels=[prompt_submit, neg_prompt_submit, generate_click],
|
||||
)
|
||||
|
||||
from apps.stable_diffusion.web.utils.png_metadata import (
|
||||
import_png_metadata,
|
||||
)
|
||||
|
||||
png_info_img.change(
|
||||
fn=import_png_metadata,
|
||||
inputs=[
|
||||
png_info_img,
|
||||
],
|
||||
outputs=[
|
||||
png_info_img,
|
||||
prompt,
|
||||
negative_prompt,
|
||||
steps,
|
||||
scheduler,
|
||||
guidance_scale,
|
||||
seed,
|
||||
width,
|
||||
height,
|
||||
custom_model,
|
||||
hf_model_id,
|
||||
],
|
||||
)
|
||||
262
apps/stable_diffusion/web/ui/upscaler_ui.py
Normal file
262
apps/stable_diffusion/web/ui/upscaler_ui.py
Normal file
@@ -0,0 +1,262 @@
|
||||
from pathlib import Path
|
||||
import os
|
||||
import gradio as gr
|
||||
from PIL import Image
|
||||
from apps.stable_diffusion.scripts import upscaler_inf
|
||||
from apps.stable_diffusion.src import args
|
||||
from apps.stable_diffusion.web.ui.utils import (
|
||||
available_devices,
|
||||
nodlogo_loc,
|
||||
get_custom_model_path,
|
||||
get_custom_model_files,
|
||||
scheduler_list,
|
||||
predefined_upscaler_models,
|
||||
)
|
||||
|
||||
|
||||
with gr.Blocks(title="Upscaler") as upscaler_web:
|
||||
with gr.Row(elem_id="ui_title"):
|
||||
nod_logo = Image.open(nodlogo_loc)
|
||||
with gr.Row():
|
||||
with gr.Column(scale=1, elem_id="demo_title_outer"):
|
||||
gr.Image(
|
||||
value=nod_logo,
|
||||
show_label=False,
|
||||
interactive=False,
|
||||
elem_id="top_logo",
|
||||
).style(width=150, height=50)
|
||||
with gr.Row(elem_id="ui_body"):
|
||||
with gr.Row():
|
||||
with gr.Column(scale=1, min_width=600):
|
||||
with gr.Row():
|
||||
custom_model = gr.Dropdown(
|
||||
label=f"Models (Custom Model path: {get_custom_model_path()})",
|
||||
elem_id="custom_model",
|
||||
value=os.path.basename(args.ckpt_loc)
|
||||
if args.ckpt_loc
|
||||
else "None",
|
||||
choices=["None"]
|
||||
+ get_custom_model_files()
|
||||
+ predefined_upscaler_models,
|
||||
)
|
||||
hf_model_id = gr.Textbox(
|
||||
elem_id="hf_model_id",
|
||||
placeholder="Select 'None' in the Models dropdown on the left and enter model ID here e.g: SG161222/Realistic_Vision_V1.3",
|
||||
value="",
|
||||
label="HuggingFace Model ID",
|
||||
lines=3,
|
||||
)
|
||||
|
||||
with gr.Group(elem_id="prompt_box_outer"):
|
||||
prompt = gr.Textbox(
|
||||
label="Prompt",
|
||||
value=args.prompts[0],
|
||||
lines=1,
|
||||
elem_id="prompt_box",
|
||||
)
|
||||
negative_prompt = gr.Textbox(
|
||||
label="Negative Prompt",
|
||||
value=args.negative_prompts[0],
|
||||
lines=1,
|
||||
elem_id="negative_prompt_box",
|
||||
)
|
||||
|
||||
upscaler_init_image = gr.Image(
|
||||
label="Input Image", type="pil"
|
||||
).style(height=300)
|
||||
|
||||
with gr.Accordion(label="LoRA Options", open=False):
|
||||
with gr.Row():
|
||||
lora_weights = gr.Dropdown(
|
||||
label=f"Standlone LoRA weights (Path: {get_custom_model_path('lora')})",
|
||||
elem_id="lora_weights",
|
||||
value="None",
|
||||
choices=["None"] + get_custom_model_files("lora"),
|
||||
)
|
||||
lora_hf_id = gr.Textbox(
|
||||
elem_id="lora_hf_id",
|
||||
placeholder="Select 'None' in the Standlone LoRA weights dropdown on the left if you want to use a standalone HuggingFace model ID for LoRA here e.g: sayakpaul/sd-model-finetuned-lora-t4",
|
||||
value="",
|
||||
label="HuggingFace Model ID",
|
||||
lines=3,
|
||||
)
|
||||
with gr.Accordion(label="Advanced Options", open=False):
|
||||
with gr.Row():
|
||||
scheduler = gr.Dropdown(
|
||||
elem_id="scheduler",
|
||||
label="Scheduler",
|
||||
value="DDIM",
|
||||
choices=scheduler_list,
|
||||
)
|
||||
with gr.Group():
|
||||
save_metadata_to_png = gr.Checkbox(
|
||||
label="Save prompt information to PNG",
|
||||
value=args.write_metadata_to_png,
|
||||
interactive=True,
|
||||
)
|
||||
save_metadata_to_json = gr.Checkbox(
|
||||
label="Save prompt information to JSON file",
|
||||
value=args.save_metadata_to_json,
|
||||
interactive=True,
|
||||
)
|
||||
with gr.Row():
|
||||
height = gr.Slider(
|
||||
128,
|
||||
512,
|
||||
value=args.height,
|
||||
step=128,
|
||||
label="Height",
|
||||
)
|
||||
width = gr.Slider(
|
||||
128,
|
||||
512,
|
||||
value=args.width,
|
||||
step=128,
|
||||
label="Width",
|
||||
)
|
||||
precision = gr.Radio(
|
||||
label="Precision",
|
||||
value=args.precision,
|
||||
choices=[
|
||||
"fp16",
|
||||
"fp32",
|
||||
],
|
||||
visible=True,
|
||||
)
|
||||
max_length = gr.Radio(
|
||||
label="Max Length",
|
||||
value=args.max_length,
|
||||
choices=[
|
||||
64,
|
||||
77,
|
||||
],
|
||||
visible=False,
|
||||
)
|
||||
with gr.Row():
|
||||
steps = gr.Slider(
|
||||
1, 100, value=args.steps, step=1, label="Steps"
|
||||
)
|
||||
noise_level = gr.Slider(
|
||||
0,
|
||||
100,
|
||||
value=args.noise_level,
|
||||
step=1,
|
||||
label="Noise Level",
|
||||
)
|
||||
ondemand = gr.Checkbox(
|
||||
value=args.ondemand,
|
||||
label="Low VRAM",
|
||||
interactive=True,
|
||||
)
|
||||
with gr.Row():
|
||||
with gr.Column(scale=3):
|
||||
guidance_scale = gr.Slider(
|
||||
0,
|
||||
50,
|
||||
value=args.guidance_scale,
|
||||
step=0.1,
|
||||
label="CFG Scale",
|
||||
)
|
||||
with gr.Column(scale=3):
|
||||
batch_count = gr.Slider(
|
||||
1,
|
||||
100,
|
||||
value=args.batch_count,
|
||||
step=1,
|
||||
label="Batch Count",
|
||||
interactive=True,
|
||||
)
|
||||
batch_size = gr.Slider(
|
||||
1,
|
||||
4,
|
||||
value=args.batch_size,
|
||||
step=1,
|
||||
label="Batch Size",
|
||||
interactive=False,
|
||||
visible=False,
|
||||
)
|
||||
stop_batch = gr.Button("Stop Batch")
|
||||
with gr.Row():
|
||||
seed = gr.Number(
|
||||
value=args.seed, precision=0, label="Seed"
|
||||
)
|
||||
device = gr.Dropdown(
|
||||
elem_id="device",
|
||||
label="Device",
|
||||
value=available_devices[0],
|
||||
choices=available_devices,
|
||||
)
|
||||
with gr.Row():
|
||||
with gr.Column(scale=2):
|
||||
random_seed = gr.Button("Randomize Seed")
|
||||
random_seed.click(
|
||||
None,
|
||||
inputs=[],
|
||||
outputs=[seed],
|
||||
_js="() => -1",
|
||||
)
|
||||
with gr.Column(scale=6):
|
||||
stable_diffusion = gr.Button("Generate Image(s)")
|
||||
|
||||
with gr.Column(scale=1, min_width=600):
|
||||
with gr.Group():
|
||||
upscaler_gallery = gr.Gallery(
|
||||
label="Generated images",
|
||||
show_label=False,
|
||||
elem_id="gallery",
|
||||
).style(grid=[2])
|
||||
std_output = gr.Textbox(
|
||||
value="Nothing to show.",
|
||||
lines=1,
|
||||
show_label=False,
|
||||
)
|
||||
output_dir = args.output_dir if args.output_dir else Path.cwd()
|
||||
output_dir = Path(output_dir, "generated_imgs")
|
||||
output_loc = gr.Textbox(
|
||||
label="Saving Images at",
|
||||
value=output_dir,
|
||||
interactive=False,
|
||||
)
|
||||
with gr.Row():
|
||||
upscaler_sendto_img2img = gr.Button(value="SendTo Img2Img")
|
||||
upscaler_sendto_inpaint = gr.Button(value="SendTo Inpaint")
|
||||
upscaler_sendto_outpaint = gr.Button(
|
||||
value="SendTo Outpaint"
|
||||
)
|
||||
|
||||
kwargs = dict(
|
||||
fn=upscaler_inf,
|
||||
inputs=[
|
||||
prompt,
|
||||
negative_prompt,
|
||||
upscaler_init_image,
|
||||
height,
|
||||
width,
|
||||
steps,
|
||||
noise_level,
|
||||
guidance_scale,
|
||||
seed,
|
||||
batch_count,
|
||||
batch_size,
|
||||
scheduler,
|
||||
custom_model,
|
||||
hf_model_id,
|
||||
precision,
|
||||
device,
|
||||
max_length,
|
||||
save_metadata_to_json,
|
||||
save_metadata_to_png,
|
||||
lora_weights,
|
||||
lora_hf_id,
|
||||
ondemand,
|
||||
],
|
||||
outputs=[upscaler_gallery, std_output],
|
||||
show_progress=args.progress_bar,
|
||||
)
|
||||
|
||||
prompt_submit = prompt.submit(**kwargs)
|
||||
neg_prompt_submit = negative_prompt.submit(**kwargs)
|
||||
generate_click = stable_diffusion.click(**kwargs)
|
||||
stop_batch.click(
|
||||
fn=None, cancels=[prompt_submit, neg_prompt_submit, generate_click]
|
||||
)
|
||||
136
apps/stable_diffusion/web/ui/utils.py
Normal file
136
apps/stable_diffusion/web/ui/utils.py
Normal file
@@ -0,0 +1,136 @@
|
||||
import os
|
||||
import sys
|
||||
from apps.stable_diffusion.src import get_available_devices
|
||||
import glob
|
||||
from pathlib import Path
|
||||
from apps.stable_diffusion.src import args
|
||||
from dataclasses import dataclass
|
||||
import apps.stable_diffusion.web.utils.global_obj as global_obj
|
||||
from apps.stable_diffusion.src.pipelines.pipeline_shark_stable_diffusion_utils import (
|
||||
SD_STATE_CANCEL,
|
||||
)
|
||||
|
||||
|
||||
@dataclass
|
||||
class Config:
|
||||
mode: str
|
||||
model_id: str
|
||||
ckpt_loc: str
|
||||
precision: str
|
||||
batch_size: int
|
||||
max_length: int
|
||||
height: int
|
||||
width: int
|
||||
device: str
|
||||
use_lora: str
|
||||
use_stencil: str
|
||||
|
||||
|
||||
custom_model_filetypes = (
|
||||
"*.ckpt",
|
||||
"*.safetensors",
|
||||
) # the tuple of file types
|
||||
|
||||
scheduler_list = [
|
||||
"DDIM",
|
||||
"PNDM",
|
||||
"DPMSolverMultistep",
|
||||
"EulerAncestralDiscrete",
|
||||
]
|
||||
scheduler_list_txt2img = [
|
||||
"DDIM",
|
||||
"PNDM",
|
||||
"LMSDiscrete",
|
||||
"KDPM2Discrete",
|
||||
"DPMSolverMultistep",
|
||||
"EulerDiscrete",
|
||||
"EulerAncestralDiscrete",
|
||||
"SharkEulerDiscrete",
|
||||
]
|
||||
|
||||
predefined_models = [
|
||||
"Linaqruf/anything-v3.0",
|
||||
"prompthero/openjourney",
|
||||
"wavymulder/Analog-Diffusion",
|
||||
"stabilityai/stable-diffusion-2-1",
|
||||
"stabilityai/stable-diffusion-2-1-base",
|
||||
"CompVis/stable-diffusion-v1-4",
|
||||
]
|
||||
|
||||
predefined_paint_models = [
|
||||
"runwayml/stable-diffusion-inpainting",
|
||||
"stabilityai/stable-diffusion-2-inpainting",
|
||||
]
|
||||
predefined_upscaler_models = [
|
||||
"stabilityai/stable-diffusion-x4-upscaler",
|
||||
]
|
||||
|
||||
|
||||
def resource_path(relative_path):
|
||||
"""Get absolute path to resource, works for dev and for PyInstaller"""
|
||||
base_path = getattr(
|
||||
sys, "_MEIPASS", os.path.dirname(os.path.abspath(__file__))
|
||||
)
|
||||
return os.path.join(base_path, relative_path)
|
||||
|
||||
|
||||
def get_custom_model_path(model="models"):
|
||||
# If `--ckpt_dir` is provided it'd override the heirarchical folder
|
||||
# structure in WebUI :-
|
||||
# model
|
||||
# |___lora
|
||||
# |___vae
|
||||
if args.ckpt_dir:
|
||||
return Path(args.ckpt_dir)
|
||||
match model:
|
||||
case "models":
|
||||
return Path(Path.cwd(), "models")
|
||||
case "vae":
|
||||
return Path(Path.cwd(), "models/vae")
|
||||
case "lora":
|
||||
return Path(Path.cwd(), "models/lora")
|
||||
case _:
|
||||
return ""
|
||||
|
||||
|
||||
def get_custom_model_pathfile(custom_model_name, model="models"):
|
||||
return os.path.join(get_custom_model_path(model), custom_model_name)
|
||||
|
||||
|
||||
def get_custom_model_files(model="models"):
|
||||
ckpt_files = []
|
||||
file_types = custom_model_filetypes
|
||||
if model == "lora":
|
||||
file_types = custom_model_filetypes + ("*.pt", "*.bin")
|
||||
for extn in file_types:
|
||||
files = [
|
||||
os.path.basename(x)
|
||||
for x in glob.glob(
|
||||
os.path.join(get_custom_model_path(model), extn)
|
||||
)
|
||||
]
|
||||
ckpt_files.extend(files)
|
||||
return sorted(ckpt_files, key=str.casefold)
|
||||
|
||||
|
||||
def get_custom_vae_or_lora_weights(weights, hf_id, model):
|
||||
use_weight = ""
|
||||
if weights == "None" and not hf_id:
|
||||
use_weight = ""
|
||||
elif not hf_id:
|
||||
use_weight = get_custom_model_pathfile(weights, model)
|
||||
else:
|
||||
use_weight = hf_id
|
||||
return use_weight
|
||||
|
||||
|
||||
def cancel_sd():
|
||||
# Try catch it, as gc can delete global_obj.sd_obj while switching model
|
||||
try:
|
||||
global_obj.set_sd_status(SD_STATE_CANCEL)
|
||||
except Exception:
|
||||
pass
|
||||
|
||||
|
||||
nodlogo_loc = resource_path("logos/nod-logo.png")
|
||||
available_devices = get_available_devices()
|
||||
76
apps/stable_diffusion/web/utils/global_obj.py
Normal file
76
apps/stable_diffusion/web/utils/global_obj.py
Normal file
@@ -0,0 +1,76 @@
|
||||
import gc
|
||||
|
||||
|
||||
"""
|
||||
The global objects include SD pipeline and config.
|
||||
Maintaining the global objects would avoid creating extra pipeline objects when switching modes.
|
||||
Also we could avoid memory leak when switching models by clearing the cache.
|
||||
"""
|
||||
|
||||
|
||||
def _init():
|
||||
global _sd_obj
|
||||
global _config_obj
|
||||
global _schedulers
|
||||
_sd_obj = None
|
||||
_config_obj = None
|
||||
_schedulers = None
|
||||
|
||||
|
||||
def set_sd_obj(value):
|
||||
global _sd_obj
|
||||
_sd_obj = value
|
||||
|
||||
|
||||
def set_sd_scheduler(key):
|
||||
global _sd_obj
|
||||
_sd_obj.scheduler = _schedulers[key]
|
||||
|
||||
|
||||
def set_sd_status(value):
|
||||
global _sd_obj
|
||||
_sd_obj.status = value
|
||||
|
||||
|
||||
def set_sd_ondemand(value):
|
||||
global _sd_obj
|
||||
_sd_obj.ondemand = value
|
||||
|
||||
|
||||
def set_cfg_obj(value):
|
||||
global _config_obj
|
||||
_config_obj = value
|
||||
|
||||
|
||||
def set_schedulers(value):
|
||||
global _schedulers
|
||||
_schedulers = value
|
||||
|
||||
|
||||
def get_sd_obj():
|
||||
return _sd_obj
|
||||
|
||||
|
||||
def get_sd_status():
|
||||
return _sd_obj.status
|
||||
|
||||
|
||||
def get_cfg_obj():
|
||||
return _config_obj
|
||||
|
||||
|
||||
def get_scheduler(key):
|
||||
return _schedulers[key]
|
||||
|
||||
|
||||
def clear_cache():
|
||||
global _sd_obj
|
||||
global _config_obj
|
||||
global _schedulers
|
||||
del _sd_obj
|
||||
del _config_obj
|
||||
del _schedulers
|
||||
gc.collect()
|
||||
_sd_obj = None
|
||||
_config_obj = None
|
||||
_schedulers = None
|
||||
31
apps/stable_diffusion/web/utils/gradio_configs.py
Normal file
31
apps/stable_diffusion/web/utils/gradio_configs.py
Normal file
@@ -0,0 +1,31 @@
|
||||
import os
|
||||
import tempfile
|
||||
import gradio
|
||||
from os import listdir
|
||||
|
||||
gradio_tmp_imgs_folder = os.path.join(os.getcwd(), "shark_tmp/")
|
||||
|
||||
|
||||
# Clear all gradio tmp images
|
||||
def clear_gradio_tmp_imgs_folder():
|
||||
if not os.path.exists(gradio_tmp_imgs_folder):
|
||||
return
|
||||
for fileName in listdir(gradio_tmp_imgs_folder):
|
||||
# Delete tmp png files
|
||||
if fileName.startswith("tmp") and fileName.endswith(".png"):
|
||||
os.remove(gradio_tmp_imgs_folder + fileName)
|
||||
|
||||
|
||||
# Overwrite save_pil_to_file from gradio to save tmp images generated by gradio into our own tmp folder
|
||||
def save_pil_to_file(pil_image, dir=None):
|
||||
if not os.path.exists(gradio_tmp_imgs_folder):
|
||||
os.mkdir(gradio_tmp_imgs_folder)
|
||||
file_obj = tempfile.NamedTemporaryFile(
|
||||
delete=False, suffix=".png", dir=gradio_tmp_imgs_folder
|
||||
)
|
||||
pil_image.save(file_obj)
|
||||
return file_obj
|
||||
|
||||
|
||||
# Register save_pil_to_file override
|
||||
gradio.processing_utils.save_pil_to_file = save_pil_to_file
|
||||
148
apps/stable_diffusion/web/utils/png_metadata.py
Normal file
148
apps/stable_diffusion/web/utils/png_metadata.py
Normal file
@@ -0,0 +1,148 @@
|
||||
import re
|
||||
from pathlib import Path
|
||||
from apps.stable_diffusion.web.ui.txt2img_ui import (
|
||||
png_info_img,
|
||||
prompt,
|
||||
negative_prompt,
|
||||
steps,
|
||||
scheduler,
|
||||
guidance_scale,
|
||||
seed,
|
||||
width,
|
||||
height,
|
||||
custom_model,
|
||||
hf_model_id,
|
||||
)
|
||||
from apps.stable_diffusion.web.ui.utils import (
|
||||
get_custom_model_pathfile,
|
||||
scheduler_list_txt2img,
|
||||
predefined_models,
|
||||
)
|
||||
|
||||
re_param_code = r'\s*([\w ]+):\s*("(?:\\"[^,]|\\"|\\|[^\"])+"|[^,]*)(?:,|$)'
|
||||
re_param = re.compile(re_param_code)
|
||||
re_imagesize = re.compile(r"^(\d+)x(\d+)$")
|
||||
|
||||
|
||||
def parse_generation_parameters(x: str):
|
||||
res = {}
|
||||
prompt = ""
|
||||
negative_prompt = ""
|
||||
done_with_prompt = False
|
||||
|
||||
*lines, lastline = x.strip().split("\n")
|
||||
if len(re_param.findall(lastline)) < 3:
|
||||
lines.append(lastline)
|
||||
lastline = ""
|
||||
|
||||
for i, line in enumerate(lines):
|
||||
line = line.strip()
|
||||
if line.startswith("Negative prompt:"):
|
||||
done_with_prompt = True
|
||||
line = line[16:].strip()
|
||||
|
||||
if done_with_prompt:
|
||||
negative_prompt += ("" if negative_prompt == "" else "\n") + line
|
||||
else:
|
||||
prompt += ("" if prompt == "" else "\n") + line
|
||||
|
||||
res["Prompt"] = prompt
|
||||
res["Negative prompt"] = negative_prompt
|
||||
|
||||
for k, v in re_param.findall(lastline):
|
||||
v = v[1:-1] if v[0] == '"' and v[-1] == '"' else v
|
||||
m = re_imagesize.match(v)
|
||||
if m is not None:
|
||||
res[k + "-1"] = m.group(1)
|
||||
res[k + "-2"] = m.group(2)
|
||||
else:
|
||||
res[k] = v
|
||||
|
||||
# Missing CLIP skip means it was set to 1 (the default)
|
||||
if "Clip skip" not in res:
|
||||
res["Clip skip"] = "1"
|
||||
|
||||
hypernet = res.get("Hypernet", None)
|
||||
if hypernet is not None:
|
||||
res[
|
||||
"Prompt"
|
||||
] += f"""<hypernet:{hypernet}:{res.get("Hypernet strength", "1.0")}>"""
|
||||
|
||||
if "Hires resize-1" not in res:
|
||||
res["Hires resize-1"] = 0
|
||||
res["Hires resize-2"] = 0
|
||||
|
||||
return res
|
||||
|
||||
|
||||
def import_png_metadata(pil_data):
|
||||
try:
|
||||
png_info = pil_data.info["parameters"]
|
||||
metadata = parse_generation_parameters(png_info)
|
||||
png_hf_model_id = ""
|
||||
png_custom_model = ""
|
||||
|
||||
if "Model" in metadata:
|
||||
# Remove extension from model info
|
||||
if metadata["Model"].endswith(".safetensors") or metadata[
|
||||
"Model"
|
||||
].endswith(".ckpt"):
|
||||
metadata["Model"] = Path(metadata["Model"]).stem
|
||||
# Check for the model name match with one of the local ckpt or safetensors files
|
||||
if Path(
|
||||
get_custom_model_pathfile(metadata["Model"] + ".ckpt")
|
||||
).is_file():
|
||||
png_custom_model = metadata["Model"] + ".ckpt"
|
||||
if Path(
|
||||
get_custom_model_pathfile(metadata["Model"] + ".safetensors")
|
||||
).is_file():
|
||||
png_custom_model = metadata["Model"] + ".safetensors"
|
||||
# Check for a model match with one of the default model list (ex: "Linaqruf/anything-v3.0")
|
||||
if metadata["Model"] in predefined_models:
|
||||
png_custom_model = metadata["Model"]
|
||||
# If nothing had matched, check vendor/hf_model_id
|
||||
if not png_custom_model and metadata["Model"].count("/"):
|
||||
png_hf_model_id = metadata["Model"]
|
||||
# No matching model was found
|
||||
if not png_custom_model and not png_hf_model_id:
|
||||
print(
|
||||
"Import PNG info: Unable to find a matching model for %s"
|
||||
% metadata["Model"]
|
||||
)
|
||||
|
||||
outputs = {
|
||||
png_info_img: None,
|
||||
negative_prompt: metadata["Negative prompt"],
|
||||
steps: int(metadata["Steps"]),
|
||||
guidance_scale: float(metadata["CFG scale"]),
|
||||
seed: int(metadata["Seed"]),
|
||||
width: float(metadata["Size-1"]),
|
||||
height: float(metadata["Size-2"]),
|
||||
}
|
||||
if "Model" in metadata and png_custom_model:
|
||||
outputs[custom_model] = png_custom_model
|
||||
outputs[hf_model_id] = ""
|
||||
if "Model" in metadata and png_hf_model_id:
|
||||
outputs[custom_model] = "None"
|
||||
outputs[hf_model_id] = png_hf_model_id
|
||||
if "Prompt" in metadata:
|
||||
outputs[prompt] = metadata["Prompt"]
|
||||
if "Sampler" in metadata:
|
||||
if metadata["Sampler"] in scheduler_list_txt2img:
|
||||
outputs[scheduler] = metadata["Sampler"]
|
||||
else:
|
||||
print(
|
||||
"Import PNG info: Unable to find a scheduler for %s"
|
||||
% metadata["Sampler"]
|
||||
)
|
||||
|
||||
return outputs
|
||||
|
||||
except Exception as ex:
|
||||
if pil_data and pil_data.info.get("parameters"):
|
||||
print("import_png_metadata failed with %s" % ex)
|
||||
pass
|
||||
|
||||
return {
|
||||
png_info_img: None,
|
||||
}
|
||||
@@ -42,7 +42,7 @@ class TFHuggingFaceLanguage(tf.Module):
|
||||
input_ids=x, attention_mask=y, token_type_ids=z, training=False
|
||||
)
|
||||
|
||||
@tf.function(input_signature=tf_bert_input)
|
||||
@tf.function(input_signature=tf_bert_input, jit_compile=True)
|
||||
def forward(self, input_ids, attention_mask, token_type_ids):
|
||||
return self.m.predict(input_ids, attention_mask, token_type_ids)
|
||||
|
||||
|
||||
51
build_tools/image_comparison.py
Normal file
51
build_tools/image_comparison.py
Normal file
@@ -0,0 +1,51 @@
|
||||
import argparse
|
||||
from PIL import Image
|
||||
import numpy as np
|
||||
|
||||
import requests
|
||||
import shutil
|
||||
import os
|
||||
import subprocess
|
||||
|
||||
parser = argparse.ArgumentParser()
|
||||
|
||||
parser.add_argument("-n", "--newfile")
|
||||
parser.add_argument(
|
||||
"-g",
|
||||
"--golden_url",
|
||||
default="https://storage.googleapis.com/shark_tank/testdata/cyberpunk_fores_42_0_230119_021148.png",
|
||||
)
|
||||
|
||||
|
||||
def get_image(url, local_filename):
|
||||
res = requests.get(url, stream=True)
|
||||
if res.status_code == 200:
|
||||
with open(local_filename, "wb") as f:
|
||||
shutil.copyfileobj(res.raw, f)
|
||||
|
||||
|
||||
def compare_images(new_filename, golden_filename):
|
||||
new = np.array(Image.open(new_filename)) / 255.0
|
||||
golden = np.array(Image.open(golden_filename)) / 255.0
|
||||
diff = np.abs(new - golden)
|
||||
mean = np.mean(diff)
|
||||
if mean > 0.1:
|
||||
if os.name != "nt":
|
||||
subprocess.run(
|
||||
[
|
||||
"gsutil",
|
||||
"cp",
|
||||
new_filename,
|
||||
"gs://shark_tank/testdata/builder/",
|
||||
]
|
||||
)
|
||||
raise SystemExit("new and golden not close")
|
||||
else:
|
||||
print("SUCCESS")
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
args = parser.parse_args()
|
||||
tempfile_name = os.path.join(os.getcwd(), "golden.png")
|
||||
get_image(args.golden_url, tempfile_name)
|
||||
compare_images(args.newfile, tempfile_name)
|
||||
@@ -1,5 +1,5 @@
|
||||
#!/bin/bash
|
||||
|
||||
IMPORTER=1 ./setup_venv.sh
|
||||
IMPORTER=1 BENCHMARK=1 ./setup_venv.sh
|
||||
source $GITHUB_WORKSPACE/shark.venv/bin/activate
|
||||
python generate_sharktank.py --upload=False
|
||||
python tank/generate_sharktank.py
|
||||
|
||||
37
build_tools/scrape_releases.py
Normal file
37
build_tools/scrape_releases.py
Normal file
@@ -0,0 +1,37 @@
|
||||
"""Scrapes the github releases API to generate a static pip-install-able releases page.
|
||||
|
||||
See https://github.com/llvm/torch-mlir/issues/1374
|
||||
"""
|
||||
import argparse
|
||||
import json
|
||||
|
||||
import requests
|
||||
|
||||
# Parse arguments
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument("owner", type=str)
|
||||
parser.add_argument("repo", type=str)
|
||||
args = parser.parse_args()
|
||||
|
||||
# Get releases
|
||||
response = requests.get(
|
||||
f"https://api.github.com/repos/{args.owner}/{args.repo}/releases"
|
||||
)
|
||||
body = json.loads(response.content)
|
||||
|
||||
# Parse releases
|
||||
releases = []
|
||||
for row in body:
|
||||
for asset in row["assets"]:
|
||||
releases.append((asset["name"], asset["browser_download_url"]))
|
||||
|
||||
# Output HTML
|
||||
html = """<!DOCTYPE html>
|
||||
<html>
|
||||
<body>
|
||||
"""
|
||||
for name, url in releases:
|
||||
html += f" <a href='{url}'>{name}</a><br />\n"
|
||||
html += """ </body>
|
||||
</html>"""
|
||||
print(html)
|
||||
232
build_tools/stable_diffusion_testing.py
Normal file
232
build_tools/stable_diffusion_testing.py
Normal file
@@ -0,0 +1,232 @@
|
||||
import os
|
||||
from sys import executable
|
||||
import subprocess
|
||||
from apps.stable_diffusion.src.utils.resources import (
|
||||
get_json_file,
|
||||
)
|
||||
from datetime import datetime as dt
|
||||
from shark.shark_downloader import download_public_file
|
||||
from image_comparison import compare_images
|
||||
import argparse
|
||||
from glob import glob
|
||||
import shutil
|
||||
import requests
|
||||
|
||||
model_config_dicts = get_json_file(
|
||||
os.path.join(
|
||||
os.getcwd(),
|
||||
"apps/stable_diffusion/src/utils/resources/model_config.json",
|
||||
)
|
||||
)
|
||||
|
||||
|
||||
def parse_sd_out(filename, command, device, use_tune, model_name, import_mlir):
|
||||
with open(filename, "r+") as f:
|
||||
lines = f.readlines()
|
||||
metrics = {}
|
||||
vals_to_read = [
|
||||
"Clip Inference time",
|
||||
"Average step",
|
||||
"VAE Inference time",
|
||||
"Total image generation",
|
||||
]
|
||||
for line in lines:
|
||||
for val in vals_to_read:
|
||||
if val in line:
|
||||
metrics[val] = line.split(" ")[-1].strip("\n")
|
||||
|
||||
metrics["Average step"] = metrics["Average step"].strip("ms/it")
|
||||
metrics["Total image generation"] = metrics[
|
||||
"Total image generation"
|
||||
].strip("sec")
|
||||
metrics["device"] = device
|
||||
metrics["use_tune"] = use_tune
|
||||
metrics["model_name"] = model_name
|
||||
metrics["import_mlir"] = import_mlir
|
||||
metrics["command"] = command
|
||||
return metrics
|
||||
|
||||
|
||||
def get_inpaint_inputs():
|
||||
os.mkdir("./test_images/inputs")
|
||||
img_url = (
|
||||
"https://huggingface.co/datasets/diffusers/test-arrays/resolve"
|
||||
"/main/stable_diffusion_inpaint/input_bench_image.png"
|
||||
)
|
||||
mask_url = (
|
||||
"https://huggingface.co/datasets/diffusers/test-arrays/resolve"
|
||||
"/main/stable_diffusion_inpaint/input_bench_mask.png"
|
||||
)
|
||||
img = requests.get(img_url)
|
||||
mask = requests.get(mask_url)
|
||||
open("./test_images/inputs/image.png", "wb").write(img.content)
|
||||
open("./test_images/inputs/mask.png", "wb").write(mask.content)
|
||||
|
||||
|
||||
def test_loop(device="vulkan", beta=False, extra_flags=[]):
|
||||
# Get golden values from tank
|
||||
shutil.rmtree("./test_images", ignore_errors=True)
|
||||
model_metrics = []
|
||||
os.mkdir("./test_images")
|
||||
os.mkdir("./test_images/golden")
|
||||
get_inpaint_inputs()
|
||||
hf_model_names = model_config_dicts[0].values()
|
||||
tuned_options = ["--no-use_tuned", "--use_tuned"]
|
||||
import_options = ["--import_mlir", "--no-import_mlir"]
|
||||
prompt_text = "--prompt=cyberpunk forest by Salvador Dali"
|
||||
inpaint_prompt_text = "--prompt=Face of a yellow cat, high resolution, sitting on a park bench"
|
||||
if os.name == "nt":
|
||||
prompt_text = '--prompt="cyberpunk forest by Salvador Dali"'
|
||||
inpaint_prompt_text = '--prompt="Face of a yellow cat, high resolution, sitting on a park bench"'
|
||||
if beta:
|
||||
extra_flags.append("--beta_models=True")
|
||||
extra_flags.append("--no-progress_bar")
|
||||
to_skip = [
|
||||
"Linaqruf/anything-v3.0",
|
||||
"prompthero/openjourney",
|
||||
"wavymulder/Analog-Diffusion",
|
||||
"dreamlike-art/dreamlike-diffusion-1.0",
|
||||
]
|
||||
counter = 0
|
||||
for import_opt in import_options:
|
||||
for model_name in hf_model_names:
|
||||
if model_name in to_skip:
|
||||
continue
|
||||
for use_tune in tuned_options:
|
||||
if (
|
||||
model_name == "stabilityai/stable-diffusion-2-1"
|
||||
and use_tune == tuned_options[0]
|
||||
):
|
||||
continue
|
||||
elif (
|
||||
model_name == "stabilityai/stable-diffusion-2-1-base"
|
||||
and use_tune == tuned_options[1]
|
||||
):
|
||||
continue
|
||||
command = (
|
||||
[
|
||||
executable, # executable is the python from the venv used to run this
|
||||
"apps/stable_diffusion/scripts/txt2img.py",
|
||||
"--device=" + device,
|
||||
prompt_text,
|
||||
"--negative_prompts=" + '""',
|
||||
"--seed=42",
|
||||
import_opt,
|
||||
"--output_dir="
|
||||
+ os.path.join(os.getcwd(), "test_images", model_name),
|
||||
"--hf_model_id=" + model_name,
|
||||
use_tune,
|
||||
]
|
||||
if "inpainting" not in model_name
|
||||
else [
|
||||
executable,
|
||||
"apps/stable_diffusion/scripts/inpaint.py",
|
||||
"--device=" + device,
|
||||
inpaint_prompt_text,
|
||||
"--negative_prompts=" + '""',
|
||||
"--img_path=./test_images/inputs/image.png",
|
||||
"--mask_path=./test_images/inputs/mask.png",
|
||||
"--seed=42",
|
||||
"--import_mlir",
|
||||
"--output_dir="
|
||||
+ os.path.join(os.getcwd(), "test_images", model_name),
|
||||
"--hf_model_id=" + model_name,
|
||||
use_tune,
|
||||
]
|
||||
)
|
||||
command += extra_flags
|
||||
if os.name == "nt":
|
||||
command = " ".join(command)
|
||||
dumpfile_name = "_".join(model_name.split("/")) + ".txt"
|
||||
dumpfile_name = os.path.join(os.getcwd(), dumpfile_name)
|
||||
with open(dumpfile_name, "w+") as f:
|
||||
generated_image = not subprocess.call(
|
||||
command,
|
||||
stdout=f,
|
||||
stderr=f,
|
||||
)
|
||||
if os.name != "nt":
|
||||
command = " ".join(command)
|
||||
if generated_image:
|
||||
model_metrics.append(
|
||||
parse_sd_out(
|
||||
dumpfile_name,
|
||||
command,
|
||||
device,
|
||||
use_tune,
|
||||
model_name,
|
||||
import_opt,
|
||||
)
|
||||
)
|
||||
print(command)
|
||||
print("Successfully generated image")
|
||||
os.makedirs(
|
||||
"./test_images/golden/" + model_name, exist_ok=True
|
||||
)
|
||||
download_public_file(
|
||||
"gs://shark_tank/testdata/golden/" + model_name,
|
||||
"./test_images/golden/" + model_name,
|
||||
)
|
||||
test_file_path = os.path.join(
|
||||
os.getcwd(),
|
||||
"test_images",
|
||||
model_name,
|
||||
"generated_imgs",
|
||||
dt.now().strftime("%Y%m%d"),
|
||||
"*.png",
|
||||
)
|
||||
test_file = glob(test_file_path)[0]
|
||||
|
||||
golden_path = (
|
||||
"./test_images/golden/" + model_name + "/*.png"
|
||||
)
|
||||
golden_file = glob(golden_path)[0]
|
||||
compare_images(test_file, golden_file)
|
||||
else:
|
||||
print(command)
|
||||
print("failed to generate image for this configuration")
|
||||
with open(dumpfile_name, "r+") as f:
|
||||
output = f.readlines()
|
||||
print("\n".join(output))
|
||||
exit(1)
|
||||
if os.name == "nt":
|
||||
counter += 1
|
||||
if counter % 2 == 0:
|
||||
extra_flags.append(
|
||||
"--iree_vulkan_target_triple=rdna2-unknown-windows"
|
||||
)
|
||||
else:
|
||||
if counter != 1:
|
||||
extra_flags.remove(
|
||||
"--iree_vulkan_target_triple=rdna2-unknown-windows"
|
||||
)
|
||||
with open(os.path.join(os.getcwd(), "sd_testing_metrics.csv"), "w+") as f:
|
||||
header = "model_name;device;use_tune;import_opt;Clip Inference time(ms);Average Step (ms/it);VAE Inference time(ms);total image generation(s);command\n"
|
||||
f.write(header)
|
||||
for metric in model_metrics:
|
||||
output = [
|
||||
metric["model_name"],
|
||||
metric["device"],
|
||||
metric["use_tune"],
|
||||
metric["import_mlir"],
|
||||
metric["Clip Inference time"],
|
||||
metric["Average step"],
|
||||
metric["VAE Inference time"],
|
||||
metric["Total image generation"],
|
||||
metric["command"],
|
||||
]
|
||||
f.write(";".join(output) + "\n")
|
||||
|
||||
|
||||
parser = argparse.ArgumentParser()
|
||||
|
||||
parser.add_argument("-d", "--device", default="vulkan")
|
||||
parser.add_argument(
|
||||
"-b", "--beta", action=argparse.BooleanOptionalAction, default=False
|
||||
)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
args = parser.parse_args()
|
||||
print(args)
|
||||
test_loop(args.device, args.beta, [])
|
||||
79
conftest.py
79
conftest.py
@@ -2,9 +2,11 @@ def pytest_addoption(parser):
|
||||
# Attaches SHARK command-line arguments to the pytest machinery.
|
||||
parser.addoption(
|
||||
"--benchmark",
|
||||
action="store_true",
|
||||
default="False",
|
||||
help="Pass option to benchmark and write results.csv",
|
||||
action="store",
|
||||
type=str,
|
||||
default=None,
|
||||
choices=("baseline", "native", "all"),
|
||||
help="Benchmarks specified engine(s) and writes bench_results.csv.",
|
||||
)
|
||||
parser.addoption(
|
||||
"--onnx_bench",
|
||||
@@ -12,22 +14,79 @@ def pytest_addoption(parser):
|
||||
default="False",
|
||||
help="Add ONNX benchmark results to pytest benchmarks.",
|
||||
)
|
||||
# The following options are deprecated and pending removal.
|
||||
parser.addoption(
|
||||
"--save_mlir",
|
||||
"--tf32",
|
||||
action="store_true",
|
||||
default="False",
|
||||
help="Pass option to save input MLIR",
|
||||
help="Use TensorFloat-32 calculations.",
|
||||
)
|
||||
parser.addoption(
|
||||
"--save_vmfb",
|
||||
"--save_repro",
|
||||
action="store_true",
|
||||
default="False",
|
||||
help="Pass option to save IREE output .vmfb",
|
||||
help="Pass option to save reproduction artifacts to SHARK/shark_tmp/test_case/",
|
||||
)
|
||||
parser.addoption(
|
||||
"--save_temps",
|
||||
"--save_fails",
|
||||
action="store_true",
|
||||
default="False",
|
||||
help="Saves IREE reproduction artifacts for filing upstream issues.",
|
||||
help="Save reproduction artifacts for a test case only if it fails. Default is False.",
|
||||
)
|
||||
parser.addoption(
|
||||
"--ci",
|
||||
action="store_true",
|
||||
default="False",
|
||||
help="Enables uploading of reproduction artifacts upon test case failure during iree-compile or validation. Must be passed with --ci_sha option ",
|
||||
)
|
||||
parser.addoption(
|
||||
"--update_tank",
|
||||
action="store_true",
|
||||
default="False",
|
||||
help="Update local shark tank with latest artifacts if model artifact hash mismatched.",
|
||||
)
|
||||
parser.addoption(
|
||||
"--force_update_tank",
|
||||
action="store_true",
|
||||
default="False",
|
||||
help="Force-update local shark tank with artifacts from specified shark_tank URL (defaults to nightly).",
|
||||
)
|
||||
parser.addoption(
|
||||
"--ci_sha",
|
||||
action="store",
|
||||
default="None",
|
||||
help="Passes the github SHA of the CI workflow to include in google storage directory for reproduction artifacts.",
|
||||
)
|
||||
parser.addoption(
|
||||
"--local_tank_cache",
|
||||
action="store",
|
||||
default=None,
|
||||
help="Specify the directory in which all downloaded shark_tank artifacts will be cached.",
|
||||
)
|
||||
parser.addoption(
|
||||
"--tank_url",
|
||||
type=str,
|
||||
default="gs://shark_tank/nightly",
|
||||
help="URL to bucket from which to download SHARK tank artifacts. Default is gs://shark_tank/latest",
|
||||
)
|
||||
parser.addoption(
|
||||
"--tank_prefix",
|
||||
type=str,
|
||||
default=None,
|
||||
help="Prefix to gs://shark_tank/ model directories from which to download SHARK tank artifacts. Default is nightly.",
|
||||
)
|
||||
parser.addoption(
|
||||
"--benchmark_dispatches",
|
||||
default=None,
|
||||
help="Benchmark individual dispatch kernels produced by IREE compiler. Use 'All' for all, or specific dispatches e.g. '0 1 2 10'",
|
||||
)
|
||||
parser.addoption(
|
||||
"--dispatch_benchmarks_dir",
|
||||
default="./temp_dispatch_benchmarks",
|
||||
help="Directory in which dispatch benchmarks are saved.",
|
||||
)
|
||||
parser.addoption(
|
||||
"--batchsize",
|
||||
default=1,
|
||||
type=int,
|
||||
help="Batch size for the tested model.",
|
||||
)
|
||||
|
||||
3
cpp/.gitignore
vendored
Normal file
3
cpp/.gitignore
vendored
Normal file
@@ -0,0 +1,3 @@
|
||||
*.mlir
|
||||
*.vmfb
|
||||
*.ini
|
||||
52
cpp/CMakeLists.txt
Normal file
52
cpp/CMakeLists.txt
Normal file
@@ -0,0 +1,52 @@
|
||||
# Copyright 2022 The IREE Authors
|
||||
#
|
||||
# Licensed under the Apache License v2.0 with LLVM Exceptions.
|
||||
# See https://llvm.org/LICENSE.txt for license information.
|
||||
# SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception
|
||||
|
||||
cmake_minimum_required(VERSION 3.21...3.23)
|
||||
|
||||
#-------------------------------------------------------------------------------
|
||||
# Project configuration
|
||||
#-------------------------------------------------------------------------------
|
||||
|
||||
project(iree-samples C CXX)
|
||||
set(CMAKE_C_STANDARD 11)
|
||||
set(CMAKE_CXX_STANDARD 17)
|
||||
set_property(GLOBAL PROPERTY USE_FOLDERS ON)
|
||||
|
||||
#-------------------------------------------------------------------------------
|
||||
# Core project dependency
|
||||
#-------------------------------------------------------------------------------
|
||||
|
||||
message(STATUS "Fetching core IREE repo (this may take a few minutes)...")
|
||||
# Note: for log output, set -DFETCHCONTENT_QUIET=OFF,
|
||||
# see https://gitlab.kitware.com/cmake/cmake/-/issues/18238#note_440475
|
||||
|
||||
include(FetchContent)
|
||||
|
||||
FetchContent_Declare(
|
||||
iree
|
||||
GIT_REPOSITORY https://github.com/nod-ai/shark-runtime.git
|
||||
GIT_TAG shark
|
||||
GIT_SUBMODULES_RECURSE OFF
|
||||
GIT_SHALLOW OFF
|
||||
GIT_PROGRESS ON
|
||||
USES_TERMINAL_DOWNLOAD ON
|
||||
)
|
||||
|
||||
# Extend module path to find MLIR CMake modules.
|
||||
list(APPEND CMAKE_MODULE_PATH "${CMAKE_CURRENT_BINARY_DIR}/lib/cmake/mlir")
|
||||
|
||||
# Disable core project features not needed for these out of tree samples.
|
||||
set(IREE_BUILD_TESTS OFF CACHE BOOL "" FORCE)
|
||||
set(IREE_BUILD_SAMPLES OFF CACHE BOOL "" FORCE)
|
||||
|
||||
FetchContent_MakeAvailable(iree)
|
||||
FetchContent_GetProperties(iree SOURCE_DIR IREE_SOURCE_DIR)
|
||||
|
||||
#-------------------------------------------------------------------------------
|
||||
# Individual samples
|
||||
#-------------------------------------------------------------------------------
|
||||
|
||||
add_subdirectory(vulkan_gui)
|
||||
82
cpp/README.md
Normal file
82
cpp/README.md
Normal file
@@ -0,0 +1,82 @@
|
||||
# SHARK C/C++ Samples
|
||||
|
||||
These C/C++ samples can be built using CMake. The samples depend on the main
|
||||
SHARK-Runtime project's C/C++ sources, including both the runtime and the compiler.
|
||||
|
||||
Individual samples may require additional dependencies. Watch CMake's output
|
||||
for information about which you are missing for individual samples.
|
||||
|
||||
On Windows we recommend using https://github.com/microsoft/vcpkg to download packages for
|
||||
your system. The general setup flow looks like
|
||||
|
||||
*Install and activate SHARK*
|
||||
|
||||
```bash
|
||||
source shark.venv/bin/activate #follow main repo instructions to setup your venv
|
||||
```
|
||||
|
||||
*Install Dependencies*
|
||||
|
||||
```bash
|
||||
vcpkg install [library] --triplet [your platform]
|
||||
vcpkg integrate install
|
||||
|
||||
# Then pass `-DCMAKE_TOOLCHAIN_FILE=[check logs for path]` when configuring CMake
|
||||
```
|
||||
|
||||
In Ubuntu Linux you can install
|
||||
|
||||
```bash
|
||||
sudo apt install libsdl2-dev
|
||||
```
|
||||
|
||||
*Build*
|
||||
```bash
|
||||
cd cpp
|
||||
cmake -GNinja -B build/
|
||||
cmake --build build/
|
||||
```
|
||||
|
||||
*Prepare the model*
|
||||
```bash
|
||||
wget https://storage.googleapis.com/shark_tank/latest/resnet50_tf/resnet50_tf.mlir
|
||||
iree-compile --iree-input-type=mhlo --iree-vm-bytecode-module-output-format=flatbuffer-binary --iree-hal-target-backends=vulkan --iree-llvmcpu-embedded-linker-path=`python3 -c 'import sysconfig; print(sysconfig.get_paths()["purelib"])'`/iree/compiler/tools/../_mlir_libs/iree-lld --mlir-print-debuginfo --mlir-print-op-on-diagnostic=false --mlir-pass-pipeline-crash-reproducer=ist/core-reproducer.mlir --iree-llvmcpu-target-cpu-features=host -iree-vulkan-target-triple=rdna2-unknown-linux --iree-stream-resource-index-bits=64 --iree-vm-target-index-bits=64 resnet50_tf.mlir -o resnet50_tf.vmfb
|
||||
```
|
||||
*Prepare the input*
|
||||
|
||||
```bash
|
||||
python save_img.py
|
||||
```
|
||||
Note that this requires tensorflow, e.g.
|
||||
```bash
|
||||
python -m pip install tensorflow
|
||||
```
|
||||
|
||||
*Run the vulkan_gui*
|
||||
```bash
|
||||
./build/vulkan_gui/iree-samples-resnet-vulkan-gui
|
||||
```
|
||||
|
||||
## Other models
|
||||
A tool for benchmarking other models is built and can be invoked with a command like the following
|
||||
```bash
|
||||
./build/vulkan_gui/iree-vulkan-gui --module-file=path/to/.vmfb --function_input=...
|
||||
```
|
||||
see `./build/vulkan_gui/iree-vulkan-gui --help` for an explanation on the function input. For example, stable diffusion unet can be tested with the following commands:
|
||||
```bash
|
||||
wget https://storage.googleapis.com/shark_tank/quinn/stable_diff_tf/stable_diff_tf.mlir
|
||||
iree-compile --iree-input-type=mhlo --iree-vm-bytecode-module-output-format=flatbuffer-binary --iree-hal-target-backends=vulkan --mlir-print-debuginfo --mlir-print-op-on-diagnostic=false --iree-llvmcpu-target-cpu-features=host -iree-vulkan-target-triple=rdna2-unknown-linux --iree-stream-resource-index-bits=64 --iree-vm-target-index-bits=64 stable_diff_tf.mlir -o stable_diff_tf.vmfb
|
||||
./build/vulkan_gui/iree-vulkan-gui --module-file=stable_diff_tf.vmfb --function_input=2x4x64x64xf32 --function_input=1xf32 --function_input=2x77x768xf32
|
||||
```
|
||||
VAE and Autoencoder are also available
|
||||
```bash
|
||||
# VAE
|
||||
wget https://storage.googleapis.com/shark_tank/quinn/stable_diff_tf/vae_tf/vae.mlir
|
||||
iree-compile --iree-input-type=mhlo --iree-vm-bytecode-module-output-format=flatbuffer-binary --iree-hal-target-backends=vulkan --mlir-print-debuginfo --mlir-print-op-on-diagnostic=false --iree-llvmcpu-target-cpu-features=host -iree-vulkan-target-triple=rdna2-unknown-linux --iree-stream-resource-index-bits=64 --iree-vm-target-index-bits=64 vae.mlir -o vae.vmfb
|
||||
./build/vulkan_gui/iree-vulkan-gui --module-file=stable_diff_tf.vmfb --function_input=1x4x64x64xf32
|
||||
|
||||
# CLIP Autoencoder
|
||||
wget https://storage.googleapis.com/shark_tank/quinn/stable_diff_tf/clip_tf/clip_autoencoder.mlir
|
||||
iree-compile --iree-input-type=mhlo --iree-vm-bytecode-module-output-format=flatbuffer-binary --iree-hal-target-backends=vulkan --mlir-print-debuginfo --mlir-print-op-on-diagnostic=false --iree-llvmcpu-target-cpu-features=host -iree-vulkan-target-triple=rdna2-unknown-linux --iree-stream-resource-index-bits=64 --iree-vm-target-index-bits=64 clip_autoencoder.mlir -o clip_autoencoder.vmfb
|
||||
./build/vulkan_gui/iree-vulkan-gui --module-file=stable_diff_tf.vmfb --function_input=1x77xi32 --function_input=1x77xi32
|
||||
```
|
||||
BIN
cpp/dog_imagenet.jpg
Normal file
BIN
cpp/dog_imagenet.jpg
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 26 KiB |
18
cpp/save_img.py
Normal file
18
cpp/save_img.py
Normal file
@@ -0,0 +1,18 @@
|
||||
import numpy as np
|
||||
import tensorflow as tf
|
||||
from shark.shark_inference import SharkInference
|
||||
|
||||
|
||||
def load_and_preprocess_image(fname: str):
|
||||
image = tf.io.read_file(fname)
|
||||
image = tf.image.decode_image(image, channels=3)
|
||||
image = tf.image.resize(image, (224, 224))
|
||||
image = image[tf.newaxis, :]
|
||||
# preprocessing pipeline
|
||||
input_tensor = tf.keras.applications.resnet50.preprocess_input(image)
|
||||
return input_tensor
|
||||
|
||||
|
||||
data = load_and_preprocess_image("dog_imagenet.jpg").numpy()
|
||||
|
||||
data.tofile("dog.bin")
|
||||
84
cpp/vision_inference/CMakeLists.txt
Normal file
84
cpp/vision_inference/CMakeLists.txt
Normal file
@@ -0,0 +1,84 @@
|
||||
# Copyright 2022 The IREE Authors
|
||||
#
|
||||
# Licensed under the Apache License v2.0 with LLVM Exceptions.
|
||||
# See https://llvm.org/LICENSE.txt for license information.
|
||||
# SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception
|
||||
|
||||
if(NOT IREE_TARGET_BACKEND_LLVM_CPU OR
|
||||
NOT IREE_HAL_EXECUTABLE_LOADER_EMBEDDED_ELF)
|
||||
message(STATUS "Missing LLVM backend and/or embeddded elf loader, skipping vision_inference sample")
|
||||
return()
|
||||
endif()
|
||||
|
||||
# vcpkg install stb
|
||||
# tested with version 2021-09-10
|
||||
find_package(Stb)
|
||||
if(NOT Stb_FOUND)
|
||||
message(STATUS "Could not find Stb, skipping vision inference sample")
|
||||
return()
|
||||
endif()
|
||||
|
||||
# Compile mnist.mlir to mnist.vmfb.
|
||||
set(_COMPILE_TOOL_EXECUTABLE $<TARGET_FILE:iree-compile>)
|
||||
set(_COMPILE_ARGS)
|
||||
list(APPEND _COMPILE_ARGS "--iree-input-type=mhlo")
|
||||
list(APPEND _COMPILE_ARGS "--iree-hal-target-backends=llvm-cpu")
|
||||
list(APPEND _COMPILE_ARGS "${IREE_SOURCE_DIR}/samples/models/mnist.mlir")
|
||||
list(APPEND _COMPILE_ARGS "-o")
|
||||
list(APPEND _COMPILE_ARGS "mnist.vmfb")
|
||||
add_custom_command(
|
||||
OUTPUT ${CMAKE_CURRENT_BINARY_DIR}/mnist.vmfb
|
||||
COMMAND ${_COMPILE_TOOL_EXECUTABLE} ${_COMPILE_ARGS}
|
||||
DEPENDS ${_COMPILE_TOOL_EXECUTABLE} "${IREE_SOURCE_DIR}/samples/models/mnist.mlir"
|
||||
)
|
||||
# Embed mnist.vmfb into a C file as mnist_bytecode_module_c.[h/c]
|
||||
set(_EMBED_DATA_EXECUTABLE $<TARGET_FILE:generate_embed_data>)
|
||||
set(_EMBED_ARGS)
|
||||
list(APPEND _EMBED_ARGS "--output_header=mnist_bytecode_module_c.h")
|
||||
list(APPEND _EMBED_ARGS "--output_impl=mnist_bytecode_module_c.c")
|
||||
list(APPEND _EMBED_ARGS "--identifier=iree_samples_vision_inference_mnist_bytecode_module")
|
||||
list(APPEND _EMBED_ARGS "--flatten")
|
||||
list(APPEND _EMBED_ARGS "${CMAKE_CURRENT_BINARY_DIR}/mnist.vmfb")
|
||||
add_custom_command(
|
||||
OUTPUT "mnist_bytecode_module_c.h" "mnist_bytecode_module_c.c"
|
||||
COMMAND ${_EMBED_DATA_EXECUTABLE} ${_EMBED_ARGS}
|
||||
DEPENDS ${_EMBED_DATA_EXECUTABLE} ${CMAKE_CURRENT_BINARY_DIR}/mnist.vmfb
|
||||
)
|
||||
# Define a library target for mnist_bytecode_module_c.
|
||||
add_library(iree_samples_vision_inference_mnist_bytecode_module_c OBJECT)
|
||||
target_sources(iree_samples_vision_inference_mnist_bytecode_module_c
|
||||
PRIVATE
|
||||
mnist_bytecode_module_c.h
|
||||
mnist_bytecode_module_c.c
|
||||
)
|
||||
|
||||
# Define the sample executable.
|
||||
set(_NAME "iree-run-mnist-module")
|
||||
add_executable(${_NAME} "")
|
||||
target_sources(${_NAME}
|
||||
PRIVATE
|
||||
"image_util.h"
|
||||
"image_util.c"
|
||||
"iree-run-mnist-module.c"
|
||||
)
|
||||
set_target_properties(${_NAME} PROPERTIES OUTPUT_NAME "iree-run-mnist-module")
|
||||
target_include_directories(${_NAME} PUBLIC
|
||||
$<BUILD_INTERFACE:${CMAKE_CURRENT_BINARY_DIR}>
|
||||
)
|
||||
target_include_directories(${_NAME} PRIVATE
|
||||
${Stb_INCLUDE_DIR}
|
||||
)
|
||||
target_link_libraries(${_NAME}
|
||||
iree_base_base
|
||||
iree_base_tracing
|
||||
iree_hal_hal
|
||||
iree_runtime_runtime
|
||||
iree_samples_vision_inference_mnist_bytecode_module_c
|
||||
)
|
||||
|
||||
# Define a target that copies the test image into the build directory.
|
||||
add_custom_target(iree_samples_vision_inference_test_image
|
||||
COMMAND ${CMAKE_COMMAND} -E copy "${CMAKE_CURRENT_SOURCE_DIR}/mnist_test.png" "${CMAKE_CURRENT_BINARY_DIR}/mnist_test.png")
|
||||
add_dependencies(${_NAME} iree_samples_vision_inference_test_image)
|
||||
|
||||
message(STATUS "Configured vision_inference sample successfully")
|
||||
8
cpp/vision_inference/README.md
Normal file
8
cpp/vision_inference/README.md
Normal file
@@ -0,0 +1,8 @@
|
||||
# Vision Inference Sample (C code)
|
||||
|
||||
This sample demonstrates how to run a MNIST handwritten digit detection vision
|
||||
model on an image using IREE's C API.
|
||||
|
||||
A similar sample is implemented using a Python script and IREE's command line
|
||||
tools over in the primary iree repository at
|
||||
https://github.com/iree-org/iree/tree/main/samples/vision_inference
|
||||
224
cpp/vision_inference/image_util.c
Normal file
224
cpp/vision_inference/image_util.c
Normal file
@@ -0,0 +1,224 @@
|
||||
// Copyright 2021 The IREE Authors
|
||||
//
|
||||
// Licensed under the Apache License v2.0 with LLVM Exceptions.
|
||||
// See https://llvm.org/LICENSE.txt for license information.
|
||||
// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception
|
||||
|
||||
#include "image_util.h"
|
||||
|
||||
#include <math.h>
|
||||
|
||||
#include "iree/base/internal/flags.h"
|
||||
#include "iree/base/tracing.h"
|
||||
|
||||
#define STB_IMAGE_IMPLEMENTATION
|
||||
#include "stb_image.h"
|
||||
|
||||
iree_status_t iree_tools_utils_pixel_rescaled_to_buffer(
|
||||
const uint8_t* pixel_data, iree_host_size_t buffer_length,
|
||||
const float* input_range, iree_host_size_t range_length,
|
||||
float* out_buffer) {
|
||||
IREE_TRACE_ZONE_BEGIN(z0);
|
||||
if (range_length != 2) {
|
||||
IREE_TRACE_ZONE_END(z0);
|
||||
return iree_make_status(IREE_STATUS_INVALID_ARGUMENT,
|
||||
"range defined as 2-element [min, max] array.");
|
||||
}
|
||||
float input_scale = fabsf(input_range[1] - input_range[0]) / 2.0f;
|
||||
float input_offset = (input_range[0] + input_range[1]) / 2.0f;
|
||||
const float kUint8Mean = 127.5f;
|
||||
for (int i = 0; i < buffer_length; ++i) {
|
||||
out_buffer[i] =
|
||||
(((float)(pixel_data[i])) - kUint8Mean) / kUint8Mean * input_scale +
|
||||
input_offset;
|
||||
}
|
||||
IREE_TRACE_ZONE_END(z0);
|
||||
return iree_ok_status();
|
||||
}
|
||||
|
||||
iree_status_t iree_tools_utils_load_pixel_data_impl(
|
||||
const iree_string_view_t filename, const iree_hal_dim_t* shape,
|
||||
iree_host_size_t shape_rank, iree_hal_element_type_t element_type,
|
||||
uint8_t** out_pixel_data, iree_host_size_t* out_buffer_length) {
|
||||
int img_dims[3];
|
||||
if (stbi_info(filename.data, img_dims, &(img_dims[1]), &(img_dims[2])) == 0) {
|
||||
return iree_make_status(IREE_STATUS_NOT_FOUND, "can't load image %.*s",
|
||||
(int)filename.size, filename.data);
|
||||
}
|
||||
if (!(element_type == IREE_HAL_ELEMENT_TYPE_FLOAT_32 ||
|
||||
element_type == IREE_HAL_ELEMENT_TYPE_SINT_8 ||
|
||||
element_type == IREE_HAL_ELEMENT_TYPE_UINT_8)) {
|
||||
char element_type_str[16];
|
||||
IREE_RETURN_IF_ERROR(iree_hal_format_element_type(
|
||||
element_type, sizeof(element_type_str), element_type_str, NULL));
|
||||
return iree_make_status(IREE_STATUS_UNIMPLEMENTED,
|
||||
"element type %s not supported", element_type_str);
|
||||
}
|
||||
switch (shape_rank) {
|
||||
case 2: { // Assume tensor <height x width>
|
||||
if (img_dims[2] != 1 || (shape[0] != img_dims[1]) ||
|
||||
(shape[1] != img_dims[0])) {
|
||||
return iree_make_status(
|
||||
IREE_STATUS_INVALID_ARGUMENT,
|
||||
"image size: %dx%dx%d, expected: %" PRIdim "x%" PRIdim, img_dims[0],
|
||||
img_dims[1], img_dims[2], shape[1], shape[0]);
|
||||
}
|
||||
break;
|
||||
}
|
||||
case 3: { // Assume tensor <height x width x channel>
|
||||
if (shape[0] != img_dims[1] || shape[1] != img_dims[0] ||
|
||||
shape[2] != img_dims[2]) {
|
||||
return iree_make_status(IREE_STATUS_INVALID_ARGUMENT,
|
||||
"image size: %dx%dx%d, expected: %" PRIdim
|
||||
"x%" PRIdim "x%" PRIdim,
|
||||
img_dims[0], img_dims[1], img_dims[2], shape[1],
|
||||
shape[0], shape[2]);
|
||||
}
|
||||
break;
|
||||
}
|
||||
case 4: { // Assume tensor <batch x height x width x channel>
|
||||
if (shape[1] != img_dims[1] || shape[2] != img_dims[0] ||
|
||||
shape[3] != img_dims[2]) {
|
||||
return iree_make_status(IREE_STATUS_INVALID_ARGUMENT,
|
||||
"image size: %dx%dx%d, expected: %" PRIdim
|
||||
"x%" PRIdim "x%" PRIdim,
|
||||
img_dims[0], img_dims[1], img_dims[2], shape[2],
|
||||
shape[1], shape[3]);
|
||||
}
|
||||
break;
|
||||
}
|
||||
default:
|
||||
return iree_make_status(
|
||||
IREE_STATUS_INVALID_ARGUMENT,
|
||||
"Input buffer shape rank %" PRIhsz " not supported", shape_rank);
|
||||
}
|
||||
// Drop the alpha channel if present.
|
||||
int req_ch = (img_dims[2] >= 3) ? 3 : 0;
|
||||
*out_pixel_data = stbi_load(filename.data, img_dims, &(img_dims[1]),
|
||||
&(img_dims[2]), req_ch);
|
||||
if (*out_pixel_data == NULL) {
|
||||
return iree_make_status(IREE_STATUS_NOT_FOUND, "can't load image %.*s",
|
||||
(int)filename.size, filename.data);
|
||||
}
|
||||
*out_buffer_length =
|
||||
img_dims[0] * img_dims[1] * (img_dims[2] > 3 ? 3 : img_dims[2]);
|
||||
return iree_ok_status();
|
||||
}
|
||||
|
||||
iree_status_t iree_tools_utils_load_pixel_data(
|
||||
const iree_string_view_t filename, const iree_hal_dim_t* shape,
|
||||
iree_host_size_t shape_rank, iree_hal_element_type_t element_type,
|
||||
uint8_t** out_pixel_data, iree_host_size_t* out_buffer_length) {
|
||||
IREE_TRACE_ZONE_BEGIN(z0);
|
||||
iree_status_t result = iree_tools_utils_load_pixel_data_impl(
|
||||
filename, shape, shape_rank, element_type, out_pixel_data,
|
||||
out_buffer_length);
|
||||
IREE_TRACE_ZONE_END(z0);
|
||||
return result;
|
||||
}
|
||||
|
||||
iree_status_t iree_tools_utils_buffer_view_from_image(
|
||||
const iree_string_view_t filename, const iree_hal_dim_t* shape,
|
||||
iree_host_size_t shape_rank, iree_hal_element_type_t element_type,
|
||||
iree_hal_allocator_t* allocator, iree_hal_buffer_view_t** out_buffer_view) {
|
||||
IREE_TRACE_ZONE_BEGIN(z0);
|
||||
*out_buffer_view = NULL;
|
||||
if (element_type != IREE_HAL_ELEMENT_TYPE_SINT_8 &&
|
||||
element_type != IREE_HAL_ELEMENT_TYPE_UINT_8) {
|
||||
IREE_TRACE_ZONE_END(z0);
|
||||
return iree_make_status(IREE_STATUS_INVALID_ARGUMENT,
|
||||
"element type should be i8 or u8");
|
||||
}
|
||||
|
||||
iree_status_t result;
|
||||
uint8_t* pixel_data = NULL;
|
||||
iree_host_size_t buffer_length;
|
||||
result = iree_tools_utils_load_pixel_data(
|
||||
filename, shape, shape_rank, element_type, &pixel_data, &buffer_length);
|
||||
if (iree_status_is_ok(result)) {
|
||||
iree_host_size_t element_byte =
|
||||
iree_hal_element_dense_byte_count(element_type);
|
||||
// SINT_8 and UINT_8 perform direct buffer wrap.
|
||||
result = iree_hal_buffer_view_allocate_buffer(
|
||||
allocator, shape_rank, shape, element_type,
|
||||
IREE_HAL_ENCODING_TYPE_DENSE_ROW_MAJOR,
|
||||
(iree_hal_buffer_params_t){
|
||||
.type = IREE_HAL_MEMORY_TYPE_DEVICE_LOCAL,
|
||||
.access = IREE_HAL_MEMORY_ACCESS_READ,
|
||||
.usage = IREE_HAL_BUFFER_USAGE_DISPATCH_STORAGE |
|
||||
IREE_HAL_BUFFER_USAGE_TRANSFER,
|
||||
},
|
||||
iree_make_const_byte_span(pixel_data, element_byte * buffer_length),
|
||||
out_buffer_view);
|
||||
}
|
||||
stbi_image_free(pixel_data);
|
||||
IREE_TRACE_ZONE_END(z0);
|
||||
return result;
|
||||
}
|
||||
|
||||
typedef struct iree_tools_utils_buffer_view_load_params_t {
|
||||
const uint8_t* pixel_data;
|
||||
iree_host_size_t pixel_data_length;
|
||||
const float* input_range;
|
||||
iree_host_size_t input_range_length;
|
||||
} iree_tools_utils_buffer_view_load_params_t;
|
||||
static iree_status_t iree_tools_utils_buffer_view_load_image_rescaled(
|
||||
iree_hal_buffer_mapping_t* mapping, void* user_data) {
|
||||
iree_tools_utils_buffer_view_load_params_t* params =
|
||||
(iree_tools_utils_buffer_view_load_params_t*)user_data;
|
||||
return iree_tools_utils_pixel_rescaled_to_buffer(
|
||||
params->pixel_data, params->pixel_data_length, params->input_range,
|
||||
params->input_range_length, (float*)mapping->contents.data);
|
||||
}
|
||||
|
||||
iree_status_t iree_tools_utils_buffer_view_from_image_rescaled(
|
||||
const iree_string_view_t filename, const iree_hal_dim_t* shape,
|
||||
iree_host_size_t shape_rank, iree_hal_element_type_t element_type,
|
||||
iree_hal_allocator_t* allocator, const float* input_range,
|
||||
iree_host_size_t input_range_length,
|
||||
iree_hal_buffer_view_t** out_buffer_view) {
|
||||
IREE_TRACE_ZONE_BEGIN(z0);
|
||||
*out_buffer_view = NULL;
|
||||
if (element_type != IREE_HAL_ELEMENT_TYPE_FLOAT_32) {
|
||||
IREE_TRACE_ZONE_END(z0);
|
||||
return iree_make_status(IREE_STATUS_INVALID_ARGUMENT,
|
||||
"element type should be f32");
|
||||
}
|
||||
|
||||
// Classic row-major image layout.
|
||||
iree_hal_encoding_type_t encoding_type =
|
||||
IREE_HAL_ENCODING_TYPE_DENSE_ROW_MAJOR;
|
||||
|
||||
// Load pixel data from the file into a new host memory allocation (the only
|
||||
// interface stb_image provides). A real application would want to use the
|
||||
// generation callback to directly decode the image into the target mapped
|
||||
// device buffer.
|
||||
uint8_t* pixel_data = NULL;
|
||||
iree_host_size_t buffer_length = 0;
|
||||
IREE_RETURN_AND_END_ZONE_IF_ERROR(
|
||||
z0, iree_tools_utils_load_pixel_data(filename, shape, shape_rank,
|
||||
element_type, &pixel_data,
|
||||
&buffer_length));
|
||||
|
||||
iree_tools_utils_buffer_view_load_params_t params = {
|
||||
.pixel_data = pixel_data,
|
||||
.pixel_data_length = buffer_length,
|
||||
.input_range = input_range,
|
||||
.input_range_length = input_range_length,
|
||||
};
|
||||
iree_status_t status = iree_hal_buffer_view_generate_buffer(
|
||||
allocator, shape_rank, shape, element_type, encoding_type,
|
||||
(iree_hal_buffer_params_t){
|
||||
.type = IREE_HAL_MEMORY_TYPE_DEVICE_LOCAL |
|
||||
IREE_HAL_MEMORY_TYPE_HOST_VISIBLE,
|
||||
.usage = IREE_HAL_BUFFER_USAGE_DISPATCH_STORAGE |
|
||||
IREE_HAL_BUFFER_USAGE_TRANSFER |
|
||||
IREE_HAL_BUFFER_USAGE_MAPPING,
|
||||
},
|
||||
iree_tools_utils_buffer_view_load_image_rescaled, ¶ms,
|
||||
out_buffer_view);
|
||||
|
||||
stbi_image_free(pixel_data);
|
||||
IREE_TRACE_ZONE_END(z0);
|
||||
return status;
|
||||
}
|
||||
77
cpp/vision_inference/image_util.h
Normal file
77
cpp/vision_inference/image_util.h
Normal file
@@ -0,0 +1,77 @@
|
||||
// Copyright 2021 The IREE Authors
|
||||
//
|
||||
// Licensed under the Apache License v2.0 with LLVM Exceptions.
|
||||
// See https://llvm.org/LICENSE.txt for license information.
|
||||
// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception
|
||||
|
||||
#ifndef IREE_SAMPLES_VISION_INFERENCE_IMAGE_UTIL_H_
|
||||
#define IREE_SAMPLES_VISION_INFERENCE_IMAGE_UTIL_H_
|
||||
|
||||
#include "iree/base/api.h"
|
||||
#include "iree/hal/api.h"
|
||||
#include "iree/hal/buffer_view.h"
|
||||
|
||||
#if __cplusplus
|
||||
extern "C" {
|
||||
#endif // __cplusplus
|
||||
|
||||
// Loads the image at |filename| into |out_pixel_data| and sets
|
||||
// |out_buffer_length| to its length.
|
||||
//
|
||||
// The image dimension must match the width, height, and channel in|shape|,
|
||||
// while 2 <= |shape_rank| <= 4 to match the image tensor format.
|
||||
//
|
||||
// The file must be in a format supported by stb_image.h.
|
||||
// The returned |out_pixel_data| buffer must be released by the caller.
|
||||
iree_status_t iree_tools_utils_load_pixel_data(
|
||||
const iree_string_view_t filename, const iree_hal_dim_t* shape,
|
||||
iree_host_size_t shape_rank, iree_hal_element_type_t element_type,
|
||||
uint8_t** out_pixel_data, iree_host_size_t* out_buffer_length);
|
||||
|
||||
// Parse the content in an image file in |filename| into a HAL buffer view
|
||||
// |out_buffer_view|. |out_buffer_view| properties are defined by |shape|,
|
||||
// |shape_rank|, and |element_type|, while being allocated by |allocator|.
|
||||
//
|
||||
// The |element_type| has to be SINT_8 or UINT_8. For FLOAT_32, use
|
||||
// |iree_tools_utils_buffer_view_from_image_rescaled| instead.
|
||||
//
|
||||
// The returned |out_buffer_view| must be released by the caller.
|
||||
iree_status_t iree_tools_utils_buffer_view_from_image(
|
||||
const iree_string_view_t filename, const iree_hal_dim_t* shape,
|
||||
iree_host_size_t shape_rank, iree_hal_element_type_t element_type,
|
||||
iree_hal_allocator_t* allocator, iree_hal_buffer_view_t** out_buffer_view);
|
||||
|
||||
// Parse the content in an image file in |filename| into a HAL buffer view
|
||||
// |out_buffer_view|. |out_buffer_view| properties are defined by |shape|,
|
||||
// |shape_rank|, and |element_type|, while being allocated by |allocator|.
|
||||
// The value in |out_buffer_view| is rescaled with |input_range|.
|
||||
//
|
||||
// The |element_type| has to be FLOAT_32, For SINT_8 or UINT_8, use
|
||||
// |iree_tools_utils_buffer_view_from_image| instead.
|
||||
//
|
||||
// The returned |out_buffer_view| must be released by the caller.
|
||||
iree_status_t iree_tools_utils_buffer_view_from_image_rescaled(
|
||||
const iree_string_view_t filename, const iree_hal_dim_t* shape,
|
||||
iree_host_size_t shape_rank, iree_hal_element_type_t element_type,
|
||||
iree_hal_allocator_t* allocator, const float* input_range,
|
||||
iree_host_size_t input_range_length,
|
||||
iree_hal_buffer_view_t** out_buffer_view);
|
||||
|
||||
// Normalize uint8_t |pixel_data| of the size |buffer_length| to float buffer
|
||||
// |out_buffer| with the range |input_range|.
|
||||
//
|
||||
// float32_x = (uint8_x - 127.5) / 127.5 * input_scale + input_offset, where
|
||||
// input_scale = abs(|input_range[0]| - |input_range[1]| / 2
|
||||
// input_offset = |input_range[0]| + |input_range[1]| / 2
|
||||
//
|
||||
// |out_buffer| needs to be allocated before the call.
|
||||
iree_status_t iree_tools_utils_pixel_rescaled_to_buffer(
|
||||
const uint8_t* pixel_data, iree_host_size_t pixel_count,
|
||||
const float* input_range, iree_host_size_t input_range_length,
|
||||
float* out_buffer);
|
||||
|
||||
#if __cplusplus
|
||||
}
|
||||
#endif // __cplusplus
|
||||
|
||||
#endif // IREE_SAMPLES_VISION_INFERENCE_IMAGE_UTIL_H_
|
||||
121
cpp/vision_inference/iree-run-mnist-module.c
Normal file
121
cpp/vision_inference/iree-run-mnist-module.c
Normal file
@@ -0,0 +1,121 @@
|
||||
// Copyright 2021 The IREE Authors
|
||||
//
|
||||
// Licensed under the Apache License v2.0 with LLVM Exceptions.
|
||||
// See https://llvm.org/LICENSE.txt for license information.
|
||||
// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception
|
||||
|
||||
// This sample uses image_util to load a hand-written image as an
|
||||
// iree_hal_buffer_view_t then passes it to the bytecode module built from
|
||||
// mnist.mlir on the CPU backend with the local-task driver.
|
||||
|
||||
#include <float.h>
|
||||
|
||||
#include "image_util.h"
|
||||
#include "iree/runtime/api.h"
|
||||
#include "mnist_bytecode_module_c.h"
|
||||
|
||||
iree_status_t Run(const iree_string_view_t image_path) {
|
||||
iree_runtime_instance_options_t instance_options;
|
||||
iree_runtime_instance_options_initialize(IREE_API_VERSION_LATEST,
|
||||
&instance_options);
|
||||
iree_runtime_instance_options_use_all_available_drivers(&instance_options);
|
||||
iree_runtime_instance_t* instance = NULL;
|
||||
IREE_RETURN_IF_ERROR(iree_runtime_instance_create(
|
||||
&instance_options, iree_allocator_system(), &instance));
|
||||
|
||||
// TODO(#5724): move device selection into the compiled modules.
|
||||
iree_hal_device_t* device = NULL;
|
||||
IREE_RETURN_IF_ERROR(iree_runtime_instance_try_create_default_device(
|
||||
instance, iree_make_cstring_view("local-task"), &device));
|
||||
|
||||
// Create one session per loaded module to hold the module state.
|
||||
iree_runtime_session_options_t session_options;
|
||||
iree_runtime_session_options_initialize(&session_options);
|
||||
iree_runtime_session_t* session = NULL;
|
||||
IREE_RETURN_IF_ERROR(iree_runtime_session_create_with_device(
|
||||
instance, &session_options, device,
|
||||
iree_runtime_instance_host_allocator(instance), &session));
|
||||
iree_hal_device_release(device);
|
||||
|
||||
const struct iree_file_toc_t* module_file =
|
||||
iree_samples_vision_inference_mnist_bytecode_module_create();
|
||||
|
||||
IREE_RETURN_IF_ERROR(iree_runtime_session_append_bytecode_module_from_memory(
|
||||
session, iree_make_const_byte_span(module_file->data, module_file->size),
|
||||
iree_allocator_null()));
|
||||
|
||||
iree_runtime_call_t call;
|
||||
IREE_RETURN_IF_ERROR(iree_runtime_call_initialize_by_name(
|
||||
session, iree_make_cstring_view("module.predict"), &call));
|
||||
|
||||
// Prepare the input hal buffer view with image_util library.
|
||||
// The input of the mmist model is single 28x28 pixel image as a
|
||||
// tensor<1x28x28x1xf32>, with pixels in [0.0, 1.0].
|
||||
iree_hal_buffer_view_t* buffer_view = NULL;
|
||||
iree_hal_dim_t buffer_shape[] = {1, 28, 28, 1};
|
||||
iree_hal_element_type_t hal_element_type = IREE_HAL_ELEMENT_TYPE_FLOAT_32;
|
||||
float input_range[2] = {0.0f, 1.0f};
|
||||
IREE_RETURN_IF_ERROR(
|
||||
iree_tools_utils_buffer_view_from_image_rescaled(
|
||||
image_path, buffer_shape, IREE_ARRAYSIZE(buffer_shape),
|
||||
hal_element_type, iree_hal_device_allocator(device), input_range,
|
||||
IREE_ARRAYSIZE(input_range), &buffer_view),
|
||||
"load image");
|
||||
IREE_RETURN_IF_ERROR(
|
||||
iree_runtime_call_inputs_push_back_buffer_view(&call, buffer_view));
|
||||
iree_hal_buffer_view_release(buffer_view);
|
||||
|
||||
IREE_RETURN_IF_ERROR(iree_runtime_call_invoke(&call, /*flags=*/0));
|
||||
|
||||
// Get the result buffers from the invocation.
|
||||
iree_hal_buffer_view_t* ret_buffer_view = NULL;
|
||||
IREE_RETURN_IF_ERROR(
|
||||
iree_runtime_call_outputs_pop_front_buffer_view(&call, &ret_buffer_view));
|
||||
|
||||
// Read back the results. The output of the mnist model is a 1x10 prediction
|
||||
// confidence values for each digit in [0, 9].
|
||||
float predictions[1 * 10] = {0.0f};
|
||||
IREE_RETURN_IF_ERROR(iree_hal_device_transfer_d2h(
|
||||
iree_runtime_session_device(session),
|
||||
iree_hal_buffer_view_buffer(ret_buffer_view), 0, predictions,
|
||||
sizeof(predictions), IREE_HAL_TRANSFER_BUFFER_FLAG_DEFAULT,
|
||||
iree_infinite_timeout()));
|
||||
iree_hal_buffer_view_release(ret_buffer_view);
|
||||
|
||||
// Get the highest index from the output.
|
||||
float result_val = FLT_MIN;
|
||||
int result_idx = 0;
|
||||
for (iree_host_size_t i = 0; i < IREE_ARRAYSIZE(predictions); ++i) {
|
||||
if (predictions[i] > result_val) {
|
||||
result_val = predictions[i];
|
||||
result_idx = i;
|
||||
}
|
||||
}
|
||||
fprintf(stdout, "Detected number: %d\n", result_idx);
|
||||
|
||||
iree_runtime_call_deinitialize(&call);
|
||||
iree_runtime_session_release(session);
|
||||
iree_runtime_instance_release(instance);
|
||||
return iree_ok_status();
|
||||
}
|
||||
|
||||
int main(int argc, char** argv) {
|
||||
if (argc > 2) {
|
||||
fprintf(stderr, "Usage: iree-run-mnist-module <image file>\n");
|
||||
return -1;
|
||||
}
|
||||
iree_string_view_t image_path;
|
||||
if (argc == 1) {
|
||||
image_path = iree_make_cstring_view("mnist_test.png");
|
||||
} else {
|
||||
image_path = iree_make_cstring_view(argv[1]);
|
||||
}
|
||||
iree_status_t result = Run(image_path);
|
||||
if (!iree_status_is_ok(result)) {
|
||||
iree_status_fprint(stderr, result);
|
||||
iree_status_ignore(result);
|
||||
return -1;
|
||||
}
|
||||
iree_status_ignore(result);
|
||||
return 0;
|
||||
}
|
||||
BIN
cpp/vision_inference/mnist_test.png
Normal file
BIN
cpp/vision_inference/mnist_test.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 261 B |
116
cpp/vulkan_gui/CMakeLists.txt
Normal file
116
cpp/vulkan_gui/CMakeLists.txt
Normal file
@@ -0,0 +1,116 @@
|
||||
# Copyright 2022 The IREE Authors
|
||||
#
|
||||
# Licensed under the Apache License v2.0 with LLVM Exceptions.
|
||||
# See https://llvm.org/LICENSE.txt for license information.
|
||||
# SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception
|
||||
|
||||
if(NOT IREE_TARGET_BACKEND_VULKAN_SPIRV OR
|
||||
NOT IREE_HAL_DRIVER_VULKAN)
|
||||
message(STATUS "Missing Vulkan backend and/or driver, skipping vulkan_gui sample")
|
||||
return()
|
||||
endif()
|
||||
|
||||
# This target statically links against Vulkan.
|
||||
# One way to achieve this is by installing the Vulkan SDK from
|
||||
# https://vulkan.lunarg.com/.
|
||||
include(FindVulkan)
|
||||
if(NOT Vulkan_FOUND)
|
||||
message(STATUS "Could not find Vulkan, skipping vulkan_gui sample")
|
||||
return()
|
||||
endif()
|
||||
|
||||
# vcpkg install sdl2[vulkan]
|
||||
# tested with versions 2.0.14#4 - 2.0.22#1
|
||||
find_package(SDL2)
|
||||
if(NOT SDL2_FOUND)
|
||||
message(STATUS "Could not find SDL2, skipping vulkan_gui sample")
|
||||
return()
|
||||
endif()
|
||||
|
||||
FetchContent_Declare(
|
||||
imgui
|
||||
GIT_REPOSITORY https://github.com/ocornut/imgui
|
||||
GIT_TAG master
|
||||
)
|
||||
|
||||
FetchContent_MakeAvailable(imgui)
|
||||
|
||||
# Dear ImGui
|
||||
set(IMGUI_DIR ${CMAKE_BINARY_DIR}/_deps/imgui-src)
|
||||
message("Looking for Imgui in ${IMGUI_DIR}")
|
||||
include_directories(${IMGUI_DIR} ${IMGUI_DIR}/backends ..)
|
||||
|
||||
|
||||
function(iree_vulkan_sample)
|
||||
|
||||
cmake_parse_arguments(
|
||||
_RULE
|
||||
""
|
||||
"NAME"
|
||||
"SRCS"
|
||||
${ARGN}
|
||||
)
|
||||
|
||||
|
||||
# Define the sample executable.
|
||||
set(_NAME "${_RULE_NAME}")
|
||||
set(SRCS "${_RULE_SRCS}")
|
||||
add_executable(${_NAME} "")
|
||||
target_sources(${_NAME}
|
||||
PRIVATE
|
||||
${SRCS}
|
||||
"${IMGUI_DIR}/backends/imgui_impl_sdl.cpp"
|
||||
"${IMGUI_DIR}/backends/imgui_impl_vulkan.cpp"
|
||||
"${IMGUI_DIR}/imgui.cpp"
|
||||
"${IMGUI_DIR}/imgui_draw.cpp"
|
||||
"${IMGUI_DIR}/imgui_demo.cpp"
|
||||
"${IMGUI_DIR}/imgui_tables.cpp"
|
||||
"${IMGUI_DIR}/imgui_widgets.cpp"
|
||||
)
|
||||
set_target_properties(${_NAME} PROPERTIES OUTPUT_NAME "${_NAME}")
|
||||
target_include_directories(${_NAME} PUBLIC
|
||||
$<BUILD_INTERFACE:${CMAKE_CURRENT_BINARY_DIR}>
|
||||
)
|
||||
target_link_libraries(${_NAME}
|
||||
SDL2::SDL2
|
||||
Vulkan::Vulkan
|
||||
iree_runtime_runtime
|
||||
iree_base_internal_main
|
||||
iree_hal_drivers_vulkan_registration_registration
|
||||
iree_modules_hal_hal
|
||||
iree_vm_vm
|
||||
iree_vm_bytecode_module
|
||||
iree_vm_cc
|
||||
iree_tooling_vm_util_cc
|
||||
iree_tooling_context_util
|
||||
)
|
||||
|
||||
if(${CMAKE_SYSTEM_NAME} STREQUAL "Windows")
|
||||
set(_GUI_LINKOPTS "-SUBSYSTEM:CONSOLE")
|
||||
else()
|
||||
set(_GUI_LINKOPTS "")
|
||||
endif()
|
||||
|
||||
target_link_options(${_NAME}
|
||||
PRIVATE
|
||||
${_GUI_LINKOPTS}
|
||||
)
|
||||
endfunction()
|
||||
|
||||
iree_vulkan_sample(
|
||||
NAME
|
||||
iree-samples-resnet-vulkan-gui
|
||||
|
||||
SRCS
|
||||
vulkan_resnet_inference_gui.cc
|
||||
)
|
||||
|
||||
iree_vulkan_sample(
|
||||
NAME
|
||||
iree-vulkan-gui
|
||||
|
||||
SRCS
|
||||
vulkan_inference_gui.cc
|
||||
)
|
||||
|
||||
message(STATUS "Configured vulkan_gui sample successfully")
|
||||
4
cpp/vulkan_gui/simple_mul.mlir
Normal file
4
cpp/vulkan_gui/simple_mul.mlir
Normal file
@@ -0,0 +1,4 @@
|
||||
func.func @simple_mul(%arg0: tensor<4xf32>, %arg1: tensor<4xf32>) -> tensor<4xf32> {
|
||||
%0 = "arith.mulf"(%arg0, %arg1) : (tensor<4xf32>, tensor<4xf32>) -> tensor<4xf32>
|
||||
return %0 : tensor<4xf32>
|
||||
}
|
||||
BIN
cpp/vulkan_gui/snail_imagenet.jpg
Normal file
BIN
cpp/vulkan_gui/snail_imagenet.jpg
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 14 KiB |
7897
cpp/vulkan_gui/stb_image.h
Normal file
7897
cpp/vulkan_gui/stb_image.h
Normal file
File diff suppressed because it is too large
Load Diff
957
cpp/vulkan_gui/vulkan_inference_gui.cc
Normal file
957
cpp/vulkan_gui/vulkan_inference_gui.cc
Normal file
@@ -0,0 +1,957 @@
|
||||
// Copyright 2019 The IREE Authors
|
||||
//
|
||||
// Licensed under the Apache License v2.0 with LLVM Exceptions.
|
||||
// See https://llvm.org/LICENSE.txt for license information.
|
||||
// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception
|
||||
|
||||
// Vulkan Graphics + IREE API Integration Sample.
|
||||
|
||||
#include <SDL.h>
|
||||
#include <SDL_vulkan.h>
|
||||
#include <imgui.h>
|
||||
#include <imgui_impl_sdl.h>
|
||||
#include <imgui_impl_vulkan.h>
|
||||
#include <vulkan/vulkan.h>
|
||||
|
||||
|
||||
#include <cstring>
|
||||
#include <set>
|
||||
#include <vector>
|
||||
#include <fstream>
|
||||
#include <array>
|
||||
#include <cstdio>
|
||||
#include <cstdlib>
|
||||
#include <iterator>
|
||||
#include <string>
|
||||
#include <utility>
|
||||
|
||||
#include "iree/hal/drivers/vulkan/api.h"
|
||||
|
||||
// IREE's C API:
|
||||
#include "iree/base/api.h"
|
||||
#include "iree/hal/api.h"
|
||||
#include "iree/hal/drivers/vulkan/registration/driver_module.h"
|
||||
#include "iree/modules/hal/module.h"
|
||||
#include "iree/vm/api.h"
|
||||
#include "iree/vm/bytecode_module.h"
|
||||
#include "iree/vm/ref_cc.h"
|
||||
|
||||
// iree-run-module
|
||||
#include "iree/base/internal/flags.h"
|
||||
#include "iree/base/status_cc.h"
|
||||
#include "iree/base/tracing.h"
|
||||
#include "iree/modules/hal/types.h"
|
||||
#include "iree/tooling/comparison.h"
|
||||
#include "iree/tooling/context_util.h"
|
||||
#include "iree/tooling/vm_util_cc.h"
|
||||
|
||||
// Other dependencies (helpers, etc.)
|
||||
#include "iree/base/internal/main.h"
|
||||
|
||||
#define IMGUI_UNLIMITED_FRAME_RATE
|
||||
|
||||
#define STB_IMAGE_IMPLEMENTATION
|
||||
#include "stb_image.h"
|
||||
|
||||
IREE_FLAG(string, entry_function, "",
|
||||
"Name of a function contained in the module specified by module_file "
|
||||
"to run.");
|
||||
|
||||
// TODO(benvanik): move --function_input= flag into a util.
|
||||
static iree_status_t parse_function_io(iree_string_view_t flag_name,
|
||||
void* storage,
|
||||
iree_string_view_t value) {
|
||||
auto* list = (std::vector<std::string>*)storage;
|
||||
list->push_back(std::string(value.data, value.size));
|
||||
return iree_ok_status();
|
||||
}
|
||||
static void print_function_io(iree_string_view_t flag_name, void* storage,
|
||||
FILE* file) {
|
||||
auto* list = (std::vector<std::string>*)storage;
|
||||
if (list->empty()) {
|
||||
fprintf(file, "# --%.*s=\n", (int)flag_name.size, flag_name.data);
|
||||
} else {
|
||||
for (size_t i = 0; i < list->size(); ++i) {
|
||||
fprintf(file, "--%.*s=\"%s\"\n", (int)flag_name.size, flag_name.data,
|
||||
list->at(i).c_str());
|
||||
}
|
||||
}
|
||||
}
|
||||
static std::vector<std::string> FLAG_function_inputs;
|
||||
IREE_FLAG_CALLBACK(
|
||||
parse_function_io, print_function_io, &FLAG_function_inputs, function_input,
|
||||
"An input (a) value or (b) buffer of the format:\n"
|
||||
" (a) scalar value\n"
|
||||
" value\n"
|
||||
" e.g.: --function_input=\"3.14\"\n"
|
||||
" (b) buffer:\n"
|
||||
" [shape]xtype=[value]\n"
|
||||
" e.g.: --function_input=\"2x2xi32=1 2 3 4\"\n"
|
||||
"Optionally, brackets may be used to separate the element values:\n"
|
||||
" 2x2xi32=[[1 2][3 4]]\n"
|
||||
"Raw binary files can be read to provide buffer contents:\n"
|
||||
" 2x2xi32=@some/file.bin\n"
|
||||
"numpy npy files (from numpy.save) can be read to provide 1+ values:\n"
|
||||
" @some.npy\n"
|
||||
"Each occurrence of the flag indicates an input in the order they were\n"
|
||||
"specified on the command line.");
|
||||
|
||||
typedef struct iree_file_toc_t {
|
||||
const char* name; // the file's original name
|
||||
char* data; // beginning of the file
|
||||
size_t size; // length of the file
|
||||
} iree_file_toc_t;
|
||||
|
||||
bool load_file(const char* filename, char** pOut, size_t* pSize)
|
||||
{
|
||||
FILE* f = fopen(filename, "rb");
|
||||
if (f == NULL)
|
||||
{
|
||||
fprintf(stderr, "Can't open %s\n", filename);
|
||||
return false;
|
||||
}
|
||||
|
||||
fseek(f, 0L, SEEK_END);
|
||||
*pSize = ftell(f);
|
||||
fseek(f, 0L, SEEK_SET);
|
||||
|
||||
*pOut = (char*)malloc(*pSize);
|
||||
|
||||
size_t size = fread(*pOut, *pSize, 1, f);
|
||||
|
||||
fclose(f);
|
||||
|
||||
return size != 0;
|
||||
}
|
||||
|
||||
static VkAllocationCallbacks* g_Allocator = NULL;
|
||||
static VkInstance g_Instance = VK_NULL_HANDLE;
|
||||
static VkPhysicalDevice g_PhysicalDevice = VK_NULL_HANDLE;
|
||||
static VkDevice g_Device = VK_NULL_HANDLE;
|
||||
static uint32_t g_QueueFamily = (uint32_t)-1;
|
||||
static VkQueue g_Queue = VK_NULL_HANDLE;
|
||||
static VkPipelineCache g_PipelineCache = VK_NULL_HANDLE;
|
||||
static VkDescriptorPool g_DescriptorPool = VK_NULL_HANDLE;
|
||||
|
||||
static ImGui_ImplVulkanH_Window g_MainWindowData;
|
||||
static uint32_t g_MinImageCount = 2;
|
||||
static bool g_SwapChainRebuild = false;
|
||||
static int g_SwapChainResizeWidth = 0;
|
||||
static int g_SwapChainResizeHeight = 0;
|
||||
|
||||
static void check_vk_result(VkResult err) {
|
||||
if (err == 0) return;
|
||||
fprintf(stderr, "VkResult: %d\n", err);
|
||||
abort();
|
||||
}
|
||||
|
||||
// Returns the names of the Vulkan layers used for the given IREE
|
||||
// |extensibility_set| and |features|.
|
||||
std::vector<const char*> GetIreeLayers(
|
||||
iree_hal_vulkan_extensibility_set_t extensibility_set,
|
||||
iree_hal_vulkan_features_t features) {
|
||||
iree_host_size_t required_count;
|
||||
iree_hal_vulkan_query_extensibility_set(
|
||||
features, extensibility_set, /*string_capacity=*/0, &required_count,
|
||||
/*out_string_values=*/NULL);
|
||||
std::vector<const char*> layers(required_count);
|
||||
iree_hal_vulkan_query_extensibility_set(features, extensibility_set,
|
||||
layers.size(), &required_count,
|
||||
layers.data());
|
||||
return layers;
|
||||
}
|
||||
|
||||
// Returns the names of the Vulkan extensions used for the given IREE
|
||||
// |extensibility_set| and |features|.
|
||||
std::vector<const char*> GetIreeExtensions(
|
||||
iree_hal_vulkan_extensibility_set_t extensibility_set,
|
||||
iree_hal_vulkan_features_t features) {
|
||||
iree_host_size_t required_count;
|
||||
iree_hal_vulkan_query_extensibility_set(
|
||||
features, extensibility_set, /*string_capacity=*/0, &required_count,
|
||||
/*out_string_values=*/NULL);
|
||||
std::vector<const char*> extensions(required_count);
|
||||
iree_hal_vulkan_query_extensibility_set(features, extensibility_set,
|
||||
extensions.size(), &required_count,
|
||||
extensions.data());
|
||||
return extensions;
|
||||
}
|
||||
|
||||
// Returns the names of the Vulkan extensions used for the given IREE
|
||||
// |vulkan_features|.
|
||||
std::vector<const char*> GetDeviceExtensions(
|
||||
VkPhysicalDevice physical_device,
|
||||
iree_hal_vulkan_features_t vulkan_features) {
|
||||
std::vector<const char*> iree_required_extensions = GetIreeExtensions(
|
||||
IREE_HAL_VULKAN_EXTENSIBILITY_DEVICE_EXTENSIONS_REQUIRED,
|
||||
vulkan_features);
|
||||
std::vector<const char*> iree_optional_extensions = GetIreeExtensions(
|
||||
IREE_HAL_VULKAN_EXTENSIBILITY_DEVICE_EXTENSIONS_OPTIONAL,
|
||||
vulkan_features);
|
||||
|
||||
uint32_t extension_count = 0;
|
||||
check_vk_result(vkEnumerateDeviceExtensionProperties(
|
||||
physical_device, nullptr, &extension_count, nullptr));
|
||||
std::vector<VkExtensionProperties> extension_properties(extension_count);
|
||||
check_vk_result(vkEnumerateDeviceExtensionProperties(
|
||||
physical_device, nullptr, &extension_count, extension_properties.data()));
|
||||
|
||||
// Merge extensions lists, including optional and required for simplicity.
|
||||
std::set<const char*> ext_set;
|
||||
ext_set.insert("VK_KHR_swapchain");
|
||||
ext_set.insert(iree_required_extensions.begin(),
|
||||
iree_required_extensions.end());
|
||||
for (int i = 0; i < iree_optional_extensions.size(); ++i) {
|
||||
const char* optional_extension = iree_optional_extensions[i];
|
||||
for (int j = 0; j < extension_count; ++j) {
|
||||
if (strcmp(optional_extension, extension_properties[j].extensionName) ==
|
||||
0) {
|
||||
ext_set.insert(optional_extension);
|
||||
break;
|
||||
}
|
||||
}
|
||||
}
|
||||
std::vector<const char*> extensions(ext_set.begin(), ext_set.end());
|
||||
return extensions;
|
||||
}
|
||||
|
||||
std::vector<const char*> GetInstanceLayers(
|
||||
iree_hal_vulkan_features_t vulkan_features) {
|
||||
// Query the layers that IREE wants / needs.
|
||||
std::vector<const char*> required_layers = GetIreeLayers(
|
||||
IREE_HAL_VULKAN_EXTENSIBILITY_INSTANCE_LAYERS_REQUIRED, vulkan_features);
|
||||
std::vector<const char*> optional_layers = GetIreeLayers(
|
||||
IREE_HAL_VULKAN_EXTENSIBILITY_INSTANCE_LAYERS_OPTIONAL, vulkan_features);
|
||||
|
||||
// Query the layers that are available on the Vulkan ICD.
|
||||
uint32_t layer_property_count = 0;
|
||||
check_vk_result(
|
||||
vkEnumerateInstanceLayerProperties(&layer_property_count, NULL));
|
||||
std::vector<VkLayerProperties> layer_properties(layer_property_count);
|
||||
check_vk_result(vkEnumerateInstanceLayerProperties(&layer_property_count,
|
||||
layer_properties.data()));
|
||||
|
||||
// Match between optional/required and available layers.
|
||||
std::vector<const char*> layers;
|
||||
for (const char* layer_name : required_layers) {
|
||||
bool found = false;
|
||||
for (const auto& layer_property : layer_properties) {
|
||||
if (std::strcmp(layer_name, layer_property.layerName) == 0) {
|
||||
found = true;
|
||||
layers.push_back(layer_name);
|
||||
break;
|
||||
}
|
||||
}
|
||||
if (!found) {
|
||||
fprintf(stderr, "Required layer %s not available\n", layer_name);
|
||||
abort();
|
||||
}
|
||||
}
|
||||
for (const char* layer_name : optional_layers) {
|
||||
for (const auto& layer_property : layer_properties) {
|
||||
if (std::strcmp(layer_name, layer_property.layerName) == 0) {
|
||||
layers.push_back(layer_name);
|
||||
break;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
return layers;
|
||||
}
|
||||
|
||||
std::vector<const char*> GetInstanceExtensions(
|
||||
SDL_Window* window, iree_hal_vulkan_features_t vulkan_features) {
|
||||
// Ask SDL for its list of required instance extensions.
|
||||
uint32_t sdl_extensions_count = 0;
|
||||
SDL_Vulkan_GetInstanceExtensions(window, &sdl_extensions_count, NULL);
|
||||
std::vector<const char*> sdl_extensions(sdl_extensions_count);
|
||||
SDL_Vulkan_GetInstanceExtensions(window, &sdl_extensions_count,
|
||||
sdl_extensions.data());
|
||||
|
||||
std::vector<const char*> iree_required_extensions = GetIreeExtensions(
|
||||
IREE_HAL_VULKAN_EXTENSIBILITY_INSTANCE_EXTENSIONS_REQUIRED,
|
||||
vulkan_features);
|
||||
std::vector<const char*> iree_optional_extensions = GetIreeExtensions(
|
||||
IREE_HAL_VULKAN_EXTENSIBILITY_INSTANCE_EXTENSIONS_OPTIONAL,
|
||||
vulkan_features);
|
||||
|
||||
// Merge extensions lists, including optional and required for simplicity.
|
||||
std::set<const char*> ext_set;
|
||||
ext_set.insert(sdl_extensions.begin(), sdl_extensions.end());
|
||||
ext_set.insert(iree_required_extensions.begin(),
|
||||
iree_required_extensions.end());
|
||||
ext_set.insert(iree_optional_extensions.begin(),
|
||||
iree_optional_extensions.end());
|
||||
std::vector<const char*> extensions(ext_set.begin(), ext_set.end());
|
||||
return extensions;
|
||||
}
|
||||
|
||||
void SetupVulkan(iree_hal_vulkan_features_t vulkan_features,
|
||||
const char** instance_layers, uint32_t instance_layers_count,
|
||||
const char** instance_extensions,
|
||||
uint32_t instance_extensions_count,
|
||||
const VkAllocationCallbacks* allocator, VkInstance* instance,
|
||||
uint32_t* queue_family_index,
|
||||
VkPhysicalDevice* physical_device, VkQueue* queue,
|
||||
VkDevice* device, VkDescriptorPool* descriptor_pool) {
|
||||
VkResult err;
|
||||
|
||||
// Create Vulkan Instance
|
||||
{
|
||||
VkInstanceCreateInfo create_info = {};
|
||||
create_info.sType = VK_STRUCTURE_TYPE_INSTANCE_CREATE_INFO;
|
||||
create_info.enabledLayerCount = instance_layers_count;
|
||||
create_info.ppEnabledLayerNames = instance_layers;
|
||||
create_info.enabledExtensionCount = instance_extensions_count;
|
||||
create_info.ppEnabledExtensionNames = instance_extensions;
|
||||
err = vkCreateInstance(&create_info, allocator, instance);
|
||||
check_vk_result(err);
|
||||
}
|
||||
|
||||
// Select GPU
|
||||
{
|
||||
uint32_t gpu_count;
|
||||
err = vkEnumeratePhysicalDevices(*instance, &gpu_count, NULL);
|
||||
check_vk_result(err);
|
||||
IM_ASSERT(gpu_count > 0);
|
||||
|
||||
VkPhysicalDevice* gpus =
|
||||
(VkPhysicalDevice*)malloc(sizeof(VkPhysicalDevice) * gpu_count);
|
||||
err = vkEnumeratePhysicalDevices(*instance, &gpu_count, gpus);
|
||||
check_vk_result(err);
|
||||
|
||||
// Use the first reported GPU for simplicity.
|
||||
*physical_device = gpus[0];
|
||||
|
||||
VkPhysicalDeviceProperties properties;
|
||||
vkGetPhysicalDeviceProperties(*physical_device, &properties);
|
||||
fprintf(stdout, "Selected Vulkan device: '%s'\n", properties.deviceName);
|
||||
free(gpus);
|
||||
}
|
||||
|
||||
// Select queue family. We want a single queue with graphics and compute for
|
||||
// simplicity, but we could also discover and use separate queues for each.
|
||||
{
|
||||
uint32_t count;
|
||||
vkGetPhysicalDeviceQueueFamilyProperties(*physical_device, &count, NULL);
|
||||
VkQueueFamilyProperties* queues = (VkQueueFamilyProperties*)malloc(
|
||||
sizeof(VkQueueFamilyProperties) * count);
|
||||
vkGetPhysicalDeviceQueueFamilyProperties(*physical_device, &count, queues);
|
||||
for (uint32_t i = 0; i < count; i++) {
|
||||
if (queues[i].queueFlags &
|
||||
(VK_QUEUE_GRAPHICS_BIT | VK_QUEUE_COMPUTE_BIT)) {
|
||||
*queue_family_index = i;
|
||||
break;
|
||||
}
|
||||
}
|
||||
free(queues);
|
||||
IM_ASSERT(*queue_family_index != (uint32_t)-1);
|
||||
}
|
||||
|
||||
// Create Logical Device (with 1 queue)
|
||||
{
|
||||
std::vector<const char*> device_extensions =
|
||||
GetDeviceExtensions(*physical_device, vulkan_features);
|
||||
const float queue_priority[] = {1.0f};
|
||||
VkDeviceQueueCreateInfo queue_info = {};
|
||||
queue_info.sType = VK_STRUCTURE_TYPE_DEVICE_QUEUE_CREATE_INFO;
|
||||
queue_info.queueFamilyIndex = *queue_family_index;
|
||||
queue_info.queueCount = 1;
|
||||
queue_info.pQueuePriorities = queue_priority;
|
||||
VkDeviceCreateInfo create_info = {};
|
||||
create_info.sType = VK_STRUCTURE_TYPE_DEVICE_CREATE_INFO;
|
||||
create_info.queueCreateInfoCount = 1;
|
||||
create_info.pQueueCreateInfos = &queue_info;
|
||||
create_info.enabledExtensionCount =
|
||||
static_cast<uint32_t>(device_extensions.size());
|
||||
create_info.ppEnabledExtensionNames = device_extensions.data();
|
||||
|
||||
// Enable timeline semaphores.
|
||||
VkPhysicalDeviceFeatures2 features2;
|
||||
memset(&features2, 0, sizeof(features2));
|
||||
features2.sType = VK_STRUCTURE_TYPE_PHYSICAL_DEVICE_FEATURES_2;
|
||||
create_info.pNext = &features2;
|
||||
VkPhysicalDeviceTimelineSemaphoreFeatures semaphore_features;
|
||||
memset(&semaphore_features, 0, sizeof(semaphore_features));
|
||||
semaphore_features.sType =
|
||||
VK_STRUCTURE_TYPE_PHYSICAL_DEVICE_TIMELINE_SEMAPHORE_FEATURES;
|
||||
semaphore_features.pNext = features2.pNext;
|
||||
features2.pNext = &semaphore_features;
|
||||
semaphore_features.timelineSemaphore = VK_TRUE;
|
||||
|
||||
err = vkCreateDevice(*physical_device, &create_info, allocator, device);
|
||||
check_vk_result(err);
|
||||
vkGetDeviceQueue(*device, *queue_family_index, 0, queue);
|
||||
}
|
||||
|
||||
// Create Descriptor Pool
|
||||
{
|
||||
VkDescriptorPoolSize pool_sizes[] = {
|
||||
{VK_DESCRIPTOR_TYPE_SAMPLER, 1000},
|
||||
{VK_DESCRIPTOR_TYPE_COMBINED_IMAGE_SAMPLER, 1000},
|
||||
{VK_DESCRIPTOR_TYPE_SAMPLED_IMAGE, 1000},
|
||||
{VK_DESCRIPTOR_TYPE_STORAGE_IMAGE, 1000},
|
||||
{VK_DESCRIPTOR_TYPE_UNIFORM_TEXEL_BUFFER, 1000},
|
||||
{VK_DESCRIPTOR_TYPE_STORAGE_TEXEL_BUFFER, 1000},
|
||||
{VK_DESCRIPTOR_TYPE_UNIFORM_BUFFER, 1000},
|
||||
{VK_DESCRIPTOR_TYPE_STORAGE_BUFFER, 1000},
|
||||
{VK_DESCRIPTOR_TYPE_UNIFORM_BUFFER_DYNAMIC, 1000},
|
||||
{VK_DESCRIPTOR_TYPE_STORAGE_BUFFER_DYNAMIC, 1000},
|
||||
{VK_DESCRIPTOR_TYPE_INPUT_ATTACHMENT, 1000}};
|
||||
VkDescriptorPoolCreateInfo pool_info = {};
|
||||
pool_info.sType = VK_STRUCTURE_TYPE_DESCRIPTOR_POOL_CREATE_INFO;
|
||||
pool_info.flags = VK_DESCRIPTOR_POOL_CREATE_FREE_DESCRIPTOR_SET_BIT;
|
||||
pool_info.maxSets = 1000 * IREE_ARRAYSIZE(pool_sizes);
|
||||
pool_info.poolSizeCount = (uint32_t)IREE_ARRAYSIZE(pool_sizes);
|
||||
pool_info.pPoolSizes = pool_sizes;
|
||||
err =
|
||||
vkCreateDescriptorPool(*device, &pool_info, allocator, descriptor_pool);
|
||||
check_vk_result(err);
|
||||
}
|
||||
}
|
||||
|
||||
void SetupVulkanWindow(ImGui_ImplVulkanH_Window* wd,
|
||||
const VkAllocationCallbacks* allocator,
|
||||
VkInstance instance, uint32_t queue_family_index,
|
||||
VkPhysicalDevice physical_device, VkDevice device,
|
||||
VkSurfaceKHR surface, int width, int height,
|
||||
uint32_t min_image_count) {
|
||||
wd->Surface = surface;
|
||||
|
||||
// Check for WSI support
|
||||
VkBool32 res;
|
||||
vkGetPhysicalDeviceSurfaceSupportKHR(physical_device, queue_family_index,
|
||||
wd->Surface, &res);
|
||||
if (res != VK_TRUE) {
|
||||
fprintf(stderr, "Error no WSI support on physical device 0\n");
|
||||
exit(-1);
|
||||
}
|
||||
|
||||
// Select Surface Format
|
||||
const VkFormat requestSurfaceImageFormat[] = {
|
||||
VK_FORMAT_B8G8R8A8_UNORM, VK_FORMAT_R8G8B8A8_UNORM,
|
||||
VK_FORMAT_B8G8R8_UNORM, VK_FORMAT_R8G8B8_UNORM};
|
||||
const VkColorSpaceKHR requestSurfaceColorSpace =
|
||||
VK_COLORSPACE_SRGB_NONLINEAR_KHR;
|
||||
wd->SurfaceFormat = ImGui_ImplVulkanH_SelectSurfaceFormat(
|
||||
physical_device, wd->Surface, requestSurfaceImageFormat,
|
||||
(size_t)IREE_ARRAYSIZE(requestSurfaceImageFormat),
|
||||
requestSurfaceColorSpace);
|
||||
|
||||
// Select Present Mode
|
||||
#ifdef IMGUI_UNLIMITED_FRAME_RATE
|
||||
VkPresentModeKHR present_modes[] = {VK_PRESENT_MODE_MAILBOX_KHR,
|
||||
VK_PRESENT_MODE_IMMEDIATE_KHR,
|
||||
VK_PRESENT_MODE_FIFO_KHR};
|
||||
#else
|
||||
VkPresentModeKHR present_modes[] = {VK_PRESENT_MODE_FIFO_KHR};
|
||||
#endif
|
||||
wd->PresentMode = ImGui_ImplVulkanH_SelectPresentMode(
|
||||
physical_device, wd->Surface, &present_modes[0],
|
||||
IREE_ARRAYSIZE(present_modes));
|
||||
|
||||
// Create SwapChain, RenderPass, Framebuffer, etc.
|
||||
IM_ASSERT(min_image_count >= 2);
|
||||
ImGui_ImplVulkanH_CreateOrResizeWindow(instance, physical_device, device, wd,
|
||||
queue_family_index, allocator, width,
|
||||
height, min_image_count);
|
||||
|
||||
// Set clear color.
|
||||
ImVec4 clear_color = ImVec4(0.45f, 0.55f, 0.60f, 1.00f);
|
||||
memcpy(&wd->ClearValue.color.float32[0], &clear_color, 4 * sizeof(float));
|
||||
}
|
||||
|
||||
void RenderFrame(ImGui_ImplVulkanH_Window* wd, VkDevice device, VkQueue queue) {
|
||||
VkResult err;
|
||||
|
||||
VkSemaphore image_acquired_semaphore =
|
||||
wd->FrameSemaphores[wd->SemaphoreIndex].ImageAcquiredSemaphore;
|
||||
VkSemaphore render_complete_semaphore =
|
||||
wd->FrameSemaphores[wd->SemaphoreIndex].RenderCompleteSemaphore;
|
||||
err = vkAcquireNextImageKHR(device, wd->Swapchain, UINT64_MAX,
|
||||
image_acquired_semaphore, VK_NULL_HANDLE,
|
||||
&wd->FrameIndex);
|
||||
check_vk_result(err);
|
||||
|
||||
ImGui_ImplVulkanH_Frame* fd = &wd->Frames[wd->FrameIndex];
|
||||
{
|
||||
err = vkWaitForFences(
|
||||
device, 1, &fd->Fence, VK_TRUE,
|
||||
UINT64_MAX); // wait indefinitely instead of periodically checking
|
||||
check_vk_result(err);
|
||||
|
||||
err = vkResetFences(device, 1, &fd->Fence);
|
||||
check_vk_result(err);
|
||||
}
|
||||
{
|
||||
err = vkResetCommandPool(device, fd->CommandPool, 0);
|
||||
check_vk_result(err);
|
||||
VkCommandBufferBeginInfo info = {};
|
||||
info.sType = VK_STRUCTURE_TYPE_COMMAND_BUFFER_BEGIN_INFO;
|
||||
info.flags |= VK_COMMAND_BUFFER_USAGE_ONE_TIME_SUBMIT_BIT;
|
||||
err = vkBeginCommandBuffer(fd->CommandBuffer, &info);
|
||||
check_vk_result(err);
|
||||
}
|
||||
{
|
||||
VkRenderPassBeginInfo info = {};
|
||||
info.sType = VK_STRUCTURE_TYPE_RENDER_PASS_BEGIN_INFO;
|
||||
info.renderPass = wd->RenderPass;
|
||||
info.framebuffer = fd->Framebuffer;
|
||||
info.renderArea.extent.width = wd->Width;
|
||||
info.renderArea.extent.height = wd->Height;
|
||||
info.clearValueCount = 1;
|
||||
info.pClearValues = &wd->ClearValue;
|
||||
vkCmdBeginRenderPass(fd->CommandBuffer, &info, VK_SUBPASS_CONTENTS_INLINE);
|
||||
}
|
||||
|
||||
// Record Imgui Draw Data and draw funcs into command buffer
|
||||
ImGui_ImplVulkan_RenderDrawData(ImGui::GetDrawData(), fd->CommandBuffer);
|
||||
|
||||
// Submit command buffer
|
||||
vkCmdEndRenderPass(fd->CommandBuffer);
|
||||
{
|
||||
VkPipelineStageFlags wait_stage =
|
||||
VK_PIPELINE_STAGE_COLOR_ATTACHMENT_OUTPUT_BIT;
|
||||
VkSubmitInfo info = {};
|
||||
info.sType = VK_STRUCTURE_TYPE_SUBMIT_INFO;
|
||||
info.waitSemaphoreCount = 1;
|
||||
info.pWaitSemaphores = &image_acquired_semaphore;
|
||||
info.pWaitDstStageMask = &wait_stage;
|
||||
info.commandBufferCount = 1;
|
||||
info.pCommandBuffers = &fd->CommandBuffer;
|
||||
info.signalSemaphoreCount = 1;
|
||||
info.pSignalSemaphores = &render_complete_semaphore;
|
||||
|
||||
err = vkEndCommandBuffer(fd->CommandBuffer);
|
||||
check_vk_result(err);
|
||||
err = vkQueueSubmit(queue, 1, &info, fd->Fence);
|
||||
check_vk_result(err);
|
||||
}
|
||||
}
|
||||
|
||||
void PresentFrame(ImGui_ImplVulkanH_Window* wd, VkQueue queue) {
|
||||
VkSemaphore render_complete_semaphore =
|
||||
wd->FrameSemaphores[wd->SemaphoreIndex].RenderCompleteSemaphore;
|
||||
VkPresentInfoKHR info = {};
|
||||
info.sType = VK_STRUCTURE_TYPE_PRESENT_INFO_KHR;
|
||||
info.waitSemaphoreCount = 1;
|
||||
info.pWaitSemaphores = &render_complete_semaphore;
|
||||
info.swapchainCount = 1;
|
||||
info.pSwapchains = &wd->Swapchain;
|
||||
info.pImageIndices = &wd->FrameIndex;
|
||||
VkResult err = vkQueuePresentKHR(queue, &info);
|
||||
check_vk_result(err);
|
||||
wd->SemaphoreIndex =
|
||||
(wd->SemaphoreIndex + 1) %
|
||||
wd->ImageCount; // Now we can use the next set of semaphores
|
||||
}
|
||||
|
||||
static void CleanupVulkan() {
|
||||
vkDestroyDescriptorPool(g_Device, g_DescriptorPool, g_Allocator);
|
||||
|
||||
vkDestroyDevice(g_Device, g_Allocator);
|
||||
vkDestroyInstance(g_Instance, g_Allocator);
|
||||
}
|
||||
|
||||
static void CleanupVulkanWindow() {
|
||||
ImGui_ImplVulkanH_DestroyWindow(g_Instance, g_Device, &g_MainWindowData,
|
||||
g_Allocator);
|
||||
}
|
||||
|
||||
namespace iree {
|
||||
|
||||
extern "C" int iree_main(int argc, char** argv) {
|
||||
|
||||
iree_flags_parse_checked(IREE_FLAGS_PARSE_MODE_DEFAULT, &argc, &argv);
|
||||
if (argc > 1) {
|
||||
// Avoid iree-run-module spinning endlessly on stdin if the user uses single
|
||||
// dashes for flags.
|
||||
printf(
|
||||
"[ERROR] unexpected positional argument (expected none)."
|
||||
" Did you use pass a flag with a single dash ('-')?"
|
||||
" Use '--' instead.\n");
|
||||
return 1;
|
||||
}
|
||||
|
||||
// --------------------------------------------------------------------------
|
||||
// Create a window.
|
||||
if (SDL_Init(SDL_INIT_VIDEO | SDL_INIT_TIMER) != 0) {
|
||||
fprintf(stderr, "Failed to initialize SDL\n");
|
||||
abort();
|
||||
return 1;
|
||||
}
|
||||
|
||||
// Setup window
|
||||
// clang-format off
|
||||
SDL_WindowFlags window_flags = (SDL_WindowFlags)(
|
||||
SDL_WINDOW_VULKAN | SDL_WINDOW_RESIZABLE | SDL_WINDOW_ALLOW_HIGHDPI);
|
||||
// clang-format on
|
||||
SDL_Window* window = SDL_CreateWindow(
|
||||
"IREE Samples - Vulkan Inference GUI", SDL_WINDOWPOS_CENTERED,
|
||||
SDL_WINDOWPOS_CENTERED, 1280, 720, window_flags);
|
||||
if (window == nullptr)
|
||||
{
|
||||
const char* sdl_err = SDL_GetError();
|
||||
fprintf(stderr, "Error, SDL_CreateWindow returned: %s\n", sdl_err);
|
||||
abort();
|
||||
return 1;
|
||||
}
|
||||
|
||||
// Setup Vulkan
|
||||
iree_hal_vulkan_features_t iree_vulkan_features =
|
||||
static_cast<iree_hal_vulkan_features_t>(
|
||||
IREE_HAL_VULKAN_FEATURE_ENABLE_VALIDATION_LAYERS |
|
||||
IREE_HAL_VULKAN_FEATURE_ENABLE_DEBUG_UTILS);
|
||||
std::vector<const char*> layers = GetInstanceLayers(iree_vulkan_features);
|
||||
std::vector<const char*> extensions =
|
||||
GetInstanceExtensions(window, iree_vulkan_features);
|
||||
SetupVulkan(iree_vulkan_features, layers.data(),
|
||||
static_cast<uint32_t>(layers.size()), extensions.data(),
|
||||
static_cast<uint32_t>(extensions.size()), g_Allocator,
|
||||
&g_Instance, &g_QueueFamily, &g_PhysicalDevice, &g_Queue,
|
||||
&g_Device, &g_DescriptorPool);
|
||||
|
||||
// Create Window Surface
|
||||
VkSurfaceKHR surface;
|
||||
VkResult err;
|
||||
if (SDL_Vulkan_CreateSurface(window, g_Instance, &surface) == 0) {
|
||||
fprintf(stderr, "Failed to create Vulkan surface.\n");
|
||||
abort();
|
||||
return 1;
|
||||
}
|
||||
|
||||
// Create Framebuffers
|
||||
int w, h;
|
||||
SDL_GetWindowSize(window, &w, &h);
|
||||
ImGui_ImplVulkanH_Window* wd = &g_MainWindowData;
|
||||
SetupVulkanWindow(wd, g_Allocator, g_Instance, g_QueueFamily,
|
||||
g_PhysicalDevice, g_Device, surface, w, h, g_MinImageCount);
|
||||
|
||||
// Setup Dear ImGui context
|
||||
IMGUI_CHECKVERSION();
|
||||
ImGui::CreateContext();
|
||||
ImGuiIO& io = ImGui::GetIO();
|
||||
(void)io;
|
||||
|
||||
ImGui::StyleColorsDark();
|
||||
|
||||
// Setup Platform/Renderer bindings
|
||||
ImGui_ImplSDL2_InitForVulkan(window);
|
||||
ImGui_ImplVulkan_InitInfo init_info = {};
|
||||
init_info.Instance = g_Instance;
|
||||
init_info.PhysicalDevice = g_PhysicalDevice;
|
||||
init_info.Device = g_Device;
|
||||
init_info.QueueFamily = g_QueueFamily;
|
||||
init_info.Queue = g_Queue;
|
||||
init_info.PipelineCache = g_PipelineCache;
|
||||
init_info.DescriptorPool = g_DescriptorPool;
|
||||
init_info.Allocator = g_Allocator;
|
||||
init_info.MinImageCount = g_MinImageCount;
|
||||
init_info.ImageCount = wd->ImageCount;
|
||||
init_info.CheckVkResultFn = check_vk_result;
|
||||
ImGui_ImplVulkan_Init(&init_info, wd->RenderPass);
|
||||
|
||||
// Upload Fonts
|
||||
{
|
||||
// Use any command queue
|
||||
VkCommandPool command_pool = wd->Frames[wd->FrameIndex].CommandPool;
|
||||
VkCommandBuffer command_buffer = wd->Frames[wd->FrameIndex].CommandBuffer;
|
||||
|
||||
err = vkResetCommandPool(g_Device, command_pool, 0);
|
||||
check_vk_result(err);
|
||||
VkCommandBufferBeginInfo begin_info = {};
|
||||
begin_info.sType = VK_STRUCTURE_TYPE_COMMAND_BUFFER_BEGIN_INFO;
|
||||
begin_info.flags |= VK_COMMAND_BUFFER_USAGE_ONE_TIME_SUBMIT_BIT;
|
||||
err = vkBeginCommandBuffer(command_buffer, &begin_info);
|
||||
check_vk_result(err);
|
||||
|
||||
ImGui_ImplVulkan_CreateFontsTexture(command_buffer);
|
||||
|
||||
VkSubmitInfo end_info = {};
|
||||
end_info.sType = VK_STRUCTURE_TYPE_SUBMIT_INFO;
|
||||
end_info.commandBufferCount = 1;
|
||||
end_info.pCommandBuffers = &command_buffer;
|
||||
err = vkEndCommandBuffer(command_buffer);
|
||||
check_vk_result(err);
|
||||
err = vkQueueSubmit(g_Queue, 1, &end_info, VK_NULL_HANDLE);
|
||||
check_vk_result(err);
|
||||
|
||||
err = vkDeviceWaitIdle(g_Device);
|
||||
check_vk_result(err);
|
||||
ImGui_ImplVulkan_DestroyFontUploadObjects();
|
||||
}
|
||||
|
||||
// Demo state.
|
||||
bool show_iree_window = true;
|
||||
// --------------------------------------------------------------------------
|
||||
// Setup IREE.
|
||||
|
||||
// Check API version.
|
||||
iree_api_version_t actual_version;
|
||||
iree_status_t status =
|
||||
iree_api_version_check(IREE_API_VERSION_LATEST, &actual_version);
|
||||
if (iree_status_is_ok(status)) {
|
||||
fprintf(stdout, "IREE runtime API version: %d\n", actual_version);
|
||||
} else {
|
||||
fprintf(stderr, "Unsupported runtime API version: %d\n", actual_version);
|
||||
abort();
|
||||
}
|
||||
|
||||
// Create a runtime Instance.
|
||||
iree_vm_instance_t* iree_instance = nullptr;
|
||||
IREE_CHECK_OK(
|
||||
iree_vm_instance_create(iree_allocator_system(), &iree_instance));
|
||||
|
||||
// Register HAL drivers and VM module types.
|
||||
IREE_CHECK_OK(iree_hal_vulkan_driver_module_register(
|
||||
iree_hal_driver_registry_default()));
|
||||
IREE_CHECK_OK(iree_hal_module_register_all_types(iree_instance));
|
||||
|
||||
// Create IREE Vulkan Driver and Device, sharing our VkInstance/VkDevice.
|
||||
fprintf(stdout, "Creating Vulkan driver/device\n");
|
||||
// Load symbols from our static `vkGetInstanceProcAddr` for IREE to use.
|
||||
iree_hal_vulkan_syms_t* iree_vk_syms = nullptr;
|
||||
IREE_CHECK_OK(iree_hal_vulkan_syms_create(
|
||||
reinterpret_cast<void*>(&vkGetInstanceProcAddr), iree_allocator_system(),
|
||||
&iree_vk_syms));
|
||||
// Create the driver sharing our VkInstance.
|
||||
iree_hal_driver_t* iree_vk_driver = nullptr;
|
||||
iree_string_view_t driver_identifier = iree_make_cstring_view("vulkan");
|
||||
iree_hal_vulkan_driver_options_t driver_options;
|
||||
driver_options.api_version = VK_API_VERSION_1_0;
|
||||
driver_options.requested_features = static_cast<iree_hal_vulkan_features_t>(
|
||||
IREE_HAL_VULKAN_FEATURE_ENABLE_DEBUG_UTILS);
|
||||
IREE_CHECK_OK(iree_hal_vulkan_driver_create_using_instance(
|
||||
driver_identifier, &driver_options, iree_vk_syms, g_Instance,
|
||||
iree_allocator_system(), &iree_vk_driver));
|
||||
// Create a device sharing our VkDevice and queue.
|
||||
// We could also create a separate (possibly low priority) compute queue for
|
||||
// IREE, and/or provide a dedicated transfer queue.
|
||||
iree_string_view_t device_identifier = iree_make_cstring_view("vulkan");
|
||||
iree_hal_vulkan_queue_set_t compute_queue_set;
|
||||
compute_queue_set.queue_family_index = g_QueueFamily;
|
||||
compute_queue_set.queue_indices = 1 << 0;
|
||||
iree_hal_vulkan_queue_set_t transfer_queue_set;
|
||||
transfer_queue_set.queue_indices = 0;
|
||||
iree_hal_device_t* iree_vk_device = nullptr;
|
||||
IREE_CHECK_OK(iree_hal_vulkan_wrap_device(
|
||||
device_identifier, &driver_options.device_options, iree_vk_syms,
|
||||
g_Instance, g_PhysicalDevice, g_Device, &compute_queue_set,
|
||||
&transfer_queue_set, iree_allocator_system(), &iree_vk_device));
|
||||
// Create a HAL module using the HAL device.
|
||||
iree_vm_module_t* hal_module = nullptr;
|
||||
IREE_CHECK_OK(iree_hal_module_create(iree_instance, iree_vk_device,
|
||||
IREE_HAL_MODULE_FLAG_NONE,
|
||||
iree_allocator_system(), &hal_module));
|
||||
|
||||
|
||||
// Load bytecode module
|
||||
//iree_file_toc_t module_file_toc;
|
||||
//const char network_model[] = "resnet50_tf.vmfb";
|
||||
//fprintf(stdout, "Loading: %s\n", network_model);
|
||||
//if (load_file(network_model, &module_file_toc.data, &module_file_toc.size) == false)
|
||||
//{
|
||||
// abort();
|
||||
// return 1;
|
||||
//}
|
||||
//fprintf(stdout, "module size: %zu\n", module_file_toc.size);
|
||||
|
||||
iree_vm_module_t* bytecode_module = nullptr;
|
||||
iree_status_t module_status = iree_tooling_load_module_from_flags(
|
||||
iree_instance, iree_allocator_system(), &bytecode_module);
|
||||
if (!iree_status_is_ok(module_status))
|
||||
return -1;
|
||||
//IREE_CHECK_OK(iree_vm_bytecode_module_create(
|
||||
// iree_instance,
|
||||
// iree_const_byte_span_t{
|
||||
// reinterpret_cast<const uint8_t*>(module_file_toc.data),
|
||||
// module_file_toc.size},
|
||||
// iree_allocator_null(), iree_allocator_system(), &bytecode_module));
|
||||
//// Query for details about what is in the loaded module.
|
||||
//iree_vm_module_signature_t bytecode_module_signature =
|
||||
// iree_vm_module_signature(bytecode_module);
|
||||
//fprintf(stdout, "Module loaded, have <%" PRIhsz "> exported functions:\n",
|
||||
// bytecode_module_signature.export_function_count);
|
||||
//for (int i = 0; i < bytecode_module_signature.export_function_count; ++i) {
|
||||
// iree_vm_function_t function;
|
||||
// IREE_CHECK_OK(iree_vm_module_lookup_function_by_ordinal(
|
||||
// bytecode_module, IREE_VM_FUNCTION_LINKAGE_EXPORT, i, &function));
|
||||
// auto function_name = iree_vm_function_name(&function);
|
||||
// auto function_signature = iree_vm_function_signature(&function);
|
||||
|
||||
// fprintf(stdout, " %d: '%.*s' with calling convention '%.*s'\n", i,
|
||||
// (int)function_name.size, function_name.data,
|
||||
// (int)function_signature.calling_convention.size,
|
||||
// function_signature.calling_convention.data);
|
||||
//}
|
||||
|
||||
// Allocate a context that will hold the module state across invocations.
|
||||
iree_vm_context_t* iree_context = nullptr;
|
||||
std::vector<iree_vm_module_t*> modules = {hal_module, bytecode_module};
|
||||
IREE_CHECK_OK(iree_vm_context_create_with_modules(
|
||||
iree_instance, IREE_VM_CONTEXT_FLAG_NONE, modules.size(), modules.data(),
|
||||
iree_allocator_system(), &iree_context));
|
||||
fprintf(stdout, "Context with modules is ready for use\n");
|
||||
|
||||
// Lookup the entry point function.
|
||||
iree_vm_function_t main_function;
|
||||
const char kMainFunctionName[] = "module.forward";
|
||||
IREE_CHECK_OK(iree_vm_context_resolve_function(
|
||||
iree_context,
|
||||
iree_string_view_t{kMainFunctionName, sizeof(kMainFunctionName) - 1},
|
||||
&main_function));
|
||||
iree_string_view_t main_function_name = iree_vm_function_name(&main_function);
|
||||
fprintf(stdout, "Resolved main function named '%.*s'\n",
|
||||
(int)main_function_name.size, main_function_name.data);
|
||||
|
||||
// --------------------------------------------------------------------------
|
||||
|
||||
// Write inputs into mappable buffers.
|
||||
iree_hal_allocator_t* allocator =
|
||||
iree_hal_device_allocator(iree_vk_device);
|
||||
//iree_hal_memory_type_t input_memory_type =
|
||||
// static_cast<iree_hal_memory_type_t>(
|
||||
// IREE_HAL_MEMORY_TYPE_HOST_LOCAL |
|
||||
// IREE_HAL_MEMORY_TYPE_DEVICE_VISIBLE);
|
||||
//iree_hal_buffer_usage_t input_buffer_usage =
|
||||
// static_cast<iree_hal_buffer_usage_t>(IREE_HAL_BUFFER_USAGE_DEFAULT);
|
||||
//iree_hal_buffer_params_t buffer_params;
|
||||
//buffer_params.type = input_memory_type;
|
||||
//buffer_params.usage = input_buffer_usage;
|
||||
//buffer_params.access = IREE_HAL_MEMORY_ACCESS_READ | IREE_HAL_MEMORY_ACCESS_WRITE;
|
||||
|
||||
// Wrap input buffers in buffer views.
|
||||
|
||||
vm::ref<iree_vm_list_t> inputs;
|
||||
iree_status_t input_status = ParseToVariantList(
|
||||
allocator,
|
||||
iree::span<const std::string>{FLAG_function_inputs.data(),
|
||||
FLAG_function_inputs.size()},
|
||||
iree_allocator_system(), &inputs);
|
||||
if (!iree_status_is_ok(input_status))
|
||||
return -1;
|
||||
//vm::ref<iree_vm_list_t> inputs;
|
||||
//IREE_CHECK_OK(iree_vm_list_create(/*element_type=*/nullptr, 6, iree_allocator_system(), &inputs));
|
||||
|
||||
//iree_hal_buffer_view_t* input0_buffer_view = nullptr;
|
||||
//constexpr iree_hal_dim_t input_buffer_shape[] = {1, 224, 224, 3};
|
||||
//IREE_CHECK_OK(iree_hal_buffer_view_allocate_buffer(
|
||||
// allocator,
|
||||
// /*shape_rank=*/4, /*shape=*/input_buffer_shape,
|
||||
// IREE_HAL_ELEMENT_TYPE_FLOAT_32,
|
||||
// IREE_HAL_ENCODING_TYPE_DENSE_ROW_MAJOR, buffer_params,
|
||||
// iree_make_const_byte_span(&input_res50, sizeof(input_res50)),
|
||||
// &input0_buffer_view));
|
||||
|
||||
//auto input0_buffer_view_ref = iree_hal_buffer_view_move_ref(input0_buffer_view);
|
||||
//IREE_CHECK_OK(iree_vm_list_push_ref_move(inputs.get(), &input0_buffer_view_ref));
|
||||
|
||||
// Prepare outputs list to accept results from the invocation.
|
||||
|
||||
vm::ref<iree_vm_list_t> outputs;
|
||||
constexpr iree_hal_dim_t kOutputCount = 1000;
|
||||
IREE_CHECK_OK(iree_vm_list_create(/*element_type=*/nullptr, kOutputCount * sizeof(float), iree_allocator_system(), &outputs));
|
||||
|
||||
// --------------------------------------------------------------------------
|
||||
|
||||
// Main loop.
|
||||
bool done = false;
|
||||
while (!done) {
|
||||
SDL_Event event;
|
||||
|
||||
while (SDL_PollEvent(&event)) {
|
||||
if (event.type == SDL_QUIT) {
|
||||
done = true;
|
||||
}
|
||||
|
||||
ImGui_ImplSDL2_ProcessEvent(&event);
|
||||
if (event.type == SDL_QUIT) done = true;
|
||||
if (event.type == SDL_WINDOWEVENT &&
|
||||
event.window.event == SDL_WINDOWEVENT_RESIZED &&
|
||||
event.window.windowID == SDL_GetWindowID(window)) {
|
||||
g_SwapChainResizeWidth = (int)event.window.data1;
|
||||
g_SwapChainResizeHeight = (int)event.window.data2;
|
||||
g_SwapChainRebuild = true;
|
||||
}
|
||||
}
|
||||
|
||||
if (g_SwapChainRebuild) {
|
||||
g_SwapChainRebuild = false;
|
||||
ImGui_ImplVulkan_SetMinImageCount(g_MinImageCount);
|
||||
ImGui_ImplVulkanH_CreateOrResizeWindow(
|
||||
g_Instance, g_PhysicalDevice, g_Device, &g_MainWindowData,
|
||||
g_QueueFamily, g_Allocator, g_SwapChainResizeWidth,
|
||||
g_SwapChainResizeHeight, g_MinImageCount);
|
||||
g_MainWindowData.FrameIndex = 0;
|
||||
}
|
||||
|
||||
// Start the Dear ImGui frame
|
||||
ImGui_ImplVulkan_NewFrame();
|
||||
ImGui_ImplSDL2_NewFrame(window);
|
||||
ImGui::NewFrame();
|
||||
|
||||
// Custom window.
|
||||
{
|
||||
ImGui::Begin("IREE Vulkan Integration Demo", &show_iree_window);
|
||||
|
||||
ImGui::Separator();
|
||||
|
||||
// ImGui Inputs for two input tensors.
|
||||
// Run computation whenever any of the values changes.
|
||||
static bool dirty = true;
|
||||
if (dirty) {
|
||||
|
||||
// Synchronously invoke the function.
|
||||
IREE_CHECK_OK(iree_vm_invoke(iree_context, main_function,
|
||||
IREE_VM_INVOCATION_FLAG_NONE,
|
||||
/*policy=*/nullptr, inputs.get(),
|
||||
outputs.get(), iree_allocator_system()));
|
||||
|
||||
|
||||
// we want to run continuously so we can use tools like RenderDoc, RGP, etc...
|
||||
dirty = true;
|
||||
}
|
||||
|
||||
// Framerate counter.
|
||||
ImGui::Text("Application average %.3f ms/frame (%.1f FPS)",
|
||||
1000.0f / ImGui::GetIO().Framerate, ImGui::GetIO().Framerate);
|
||||
|
||||
ImGui::End();
|
||||
}
|
||||
|
||||
// Rendering
|
||||
ImGui::Render();
|
||||
RenderFrame(wd, g_Device, g_Queue);
|
||||
|
||||
PresentFrame(wd, g_Queue);
|
||||
}
|
||||
// --------------------------------------------------------------------------
|
||||
|
||||
// --------------------------------------------------------------------------
|
||||
// Cleanup
|
||||
iree_vm_module_release(hal_module);
|
||||
iree_vm_module_release(bytecode_module);
|
||||
iree_vm_context_release(iree_context);
|
||||
iree_hal_device_release(iree_vk_device);
|
||||
iree_hal_allocator_release(allocator);
|
||||
iree_hal_driver_release(iree_vk_driver);
|
||||
iree_hal_vulkan_syms_release(iree_vk_syms);
|
||||
iree_vm_instance_release(iree_instance);
|
||||
|
||||
err = vkDeviceWaitIdle(g_Device);
|
||||
check_vk_result(err);
|
||||
ImGui_ImplVulkan_Shutdown();
|
||||
ImGui_ImplSDL2_Shutdown();
|
||||
ImGui::DestroyContext();
|
||||
|
||||
CleanupVulkanWindow();
|
||||
CleanupVulkan();
|
||||
|
||||
SDL_DestroyWindow(window);
|
||||
SDL_Quit();
|
||||
// --------------------------------------------------------------------------
|
||||
|
||||
return 0;
|
||||
}
|
||||
|
||||
} // namespace iree
|
||||
1160
cpp/vulkan_gui/vulkan_resnet_inference_gui.cc
Normal file
1160
cpp/vulkan_gui/vulkan_resnet_inference_gui.cc
Normal file
File diff suppressed because it is too large
Load Diff
27
dataset/README.md
Normal file
27
dataset/README.md
Normal file
@@ -0,0 +1,27 @@
|
||||
# Dataset annotation tool
|
||||
|
||||
SHARK annotator for adding or modifying prompts of dataset images
|
||||
|
||||
## Set up
|
||||
|
||||
Activate SHARK Python virtual environment and install additional packages
|
||||
```shell
|
||||
source ../shark.venv/bin/activate
|
||||
pip install -r requirements.txt
|
||||
```
|
||||
|
||||
## Run annotator
|
||||
|
||||
```shell
|
||||
python annotation_tool.py
|
||||
```
|
||||
|
||||
<img width="1280" alt="annotator" src="https://user-images.githubusercontent.com/49575973/214521137-7ef6ae10-7cd8-46e6-b270-b6c0445157f1.png">
|
||||
|
||||
* Select a dataset from `Dataset` dropdown list
|
||||
* Select an image from `Image` dropdown list
|
||||
* Image and the existing prompt will be loaded
|
||||
* Select a prompt from `Prompt` dropdown list to modify or "Add new" to add a prompt
|
||||
* Click `Save` to save changes, click `Delete` to delete prompt
|
||||
* Click `Back` or `Next` to switch image, you could also select other images from `Image`
|
||||
* Click `Finish` when finishing annotation or before switching dataset
|
||||
247
dataset/annotation_tool.py
Normal file
247
dataset/annotation_tool.py
Normal file
@@ -0,0 +1,247 @@
|
||||
import gradio as gr
|
||||
import json
|
||||
import jsonlines
|
||||
import os
|
||||
from args import args
|
||||
from pathlib import Path
|
||||
from PIL import Image
|
||||
from utils import get_datasets
|
||||
|
||||
|
||||
shark_root = Path(__file__).parent.parent
|
||||
demo_css = shark_root.joinpath("web/demo.css").resolve()
|
||||
nodlogo_loc = shark_root.joinpath(
|
||||
"web/models/stable_diffusion/logos/nod-logo.png"
|
||||
)
|
||||
|
||||
|
||||
with gr.Blocks(title="Dataset Annotation Tool", css=demo_css) as shark_web:
|
||||
with gr.Row(elem_id="ui_title"):
|
||||
nod_logo = Image.open(nodlogo_loc)
|
||||
with gr.Column(scale=1, elem_id="demo_title_outer"):
|
||||
gr.Image(
|
||||
value=nod_logo,
|
||||
show_label=False,
|
||||
interactive=False,
|
||||
elem_id="top_logo",
|
||||
).style(width=150, height=100)
|
||||
|
||||
datasets, images, ds_w_prompts = get_datasets(args.gs_url)
|
||||
prompt_data = dict()
|
||||
|
||||
with gr.Row(elem_id="ui_body"):
|
||||
# TODO: add multiselect dataset, there is a gradio version conflict
|
||||
dataset = gr.Dropdown(label="Dataset", choices=datasets)
|
||||
image_name = gr.Dropdown(label="Image", choices=[])
|
||||
|
||||
with gr.Row(elem_id="ui_body"):
|
||||
# TODO: add ability to search image by typing
|
||||
with gr.Column(scale=1, min_width=600):
|
||||
image = gr.Image(type="filepath").style(height=512)
|
||||
|
||||
with gr.Column(scale=1, min_width=600):
|
||||
prompts = gr.Dropdown(
|
||||
label="Prompts",
|
||||
choices=[],
|
||||
)
|
||||
prompt = gr.Textbox(
|
||||
label="Editor",
|
||||
lines=3,
|
||||
)
|
||||
with gr.Row():
|
||||
save = gr.Button("Save")
|
||||
delete = gr.Button("Delete")
|
||||
with gr.Row():
|
||||
back_image = gr.Button("Back")
|
||||
next_image = gr.Button("Next")
|
||||
finish = gr.Button("Finish")
|
||||
|
||||
def filter_datasets(dataset):
|
||||
if dataset is None:
|
||||
return gr.Dropdown.update(value=None, choices=[])
|
||||
|
||||
# create the dataset dir if doesn't exist and download prompt file
|
||||
dataset_path = str(shark_root) + "/dataset/" + dataset
|
||||
if not os.path.exists(dataset_path):
|
||||
os.mkdir(dataset_path)
|
||||
|
||||
# read prompt jsonlines file
|
||||
prompt_data.clear()
|
||||
if dataset in ds_w_prompts:
|
||||
prompt_gs_path = args.gs_url + "/" + dataset + "/metadata.jsonl"
|
||||
os.system(f'gsutil cp "{prompt_gs_path}" "{dataset_path}"/')
|
||||
with jsonlines.open(dataset_path + "/metadata.jsonl") as reader:
|
||||
for line in reader.iter(type=dict, skip_invalid=True):
|
||||
prompt_data[line["file_name"]] = (
|
||||
[line["text"]]
|
||||
if type(line["text"]) is str
|
||||
else line["text"]
|
||||
)
|
||||
|
||||
return gr.Dropdown.update(choices=images[dataset])
|
||||
|
||||
dataset.change(fn=filter_datasets, inputs=dataset, outputs=image_name)
|
||||
|
||||
def display_image(dataset, image_name):
|
||||
if dataset is None or image_name is None:
|
||||
return gr.Image.update(value=None), gr.Dropdown.update(value=None)
|
||||
|
||||
# download and load the image
|
||||
img_gs_path = args.gs_url + "/" + dataset + "/" + image_name
|
||||
img_sub_path = "/".join(image_name.split("/")[:-1])
|
||||
img_dst_path = (
|
||||
str(shark_root) + "/dataset/" + dataset + "/" + img_sub_path + "/"
|
||||
)
|
||||
if not os.path.exists(img_dst_path):
|
||||
os.mkdir(img_dst_path)
|
||||
os.system(f'gsutil cp "{img_gs_path}" "{img_dst_path}"')
|
||||
img = Image.open(img_dst_path + image_name.split("/")[-1])
|
||||
|
||||
if image_name not in prompt_data.keys():
|
||||
prompt_data[image_name] = []
|
||||
prompt_choices = ["Add new"]
|
||||
prompt_choices += prompt_data[image_name]
|
||||
return gr.Image.update(value=img), gr.Dropdown.update(
|
||||
choices=prompt_choices
|
||||
)
|
||||
|
||||
image_name.change(
|
||||
fn=display_image,
|
||||
inputs=[dataset, image_name],
|
||||
outputs=[image, prompts],
|
||||
)
|
||||
|
||||
def edit_prompt(prompts):
|
||||
if prompts == "Add new":
|
||||
return gr.Textbox.update(value=None)
|
||||
|
||||
return gr.Textbox.update(value=prompts)
|
||||
|
||||
prompts.change(fn=edit_prompt, inputs=prompts, outputs=prompt)
|
||||
|
||||
def save_prompt(dataset, image_name, prompts, prompt):
|
||||
if (
|
||||
dataset is None
|
||||
or image_name is None
|
||||
or prompts is None
|
||||
or prompt is None
|
||||
):
|
||||
return
|
||||
|
||||
if prompts == "Add new":
|
||||
prompt_data[image_name].append(prompt)
|
||||
else:
|
||||
idx = prompt_data[image_name].index(prompts)
|
||||
prompt_data[image_name][idx] = prompt
|
||||
|
||||
prompt_path = (
|
||||
str(shark_root) + "/dataset/" + dataset + "/metadata.jsonl"
|
||||
)
|
||||
# write prompt jsonlines file
|
||||
with open(prompt_path, "w") as f:
|
||||
for key, value in prompt_data.items():
|
||||
if not value:
|
||||
continue
|
||||
v = value if len(value) > 1 else value[0]
|
||||
f.write(json.dumps({"file_name": key, "text": v}))
|
||||
f.write("\n")
|
||||
|
||||
prompt_choices = ["Add new"]
|
||||
prompt_choices += prompt_data[image_name]
|
||||
return gr.Dropdown.update(choices=prompt_choices, value=None)
|
||||
|
||||
save.click(
|
||||
fn=save_prompt,
|
||||
inputs=[dataset, image_name, prompts, prompt],
|
||||
outputs=prompts,
|
||||
)
|
||||
|
||||
def delete_prompt(dataset, image_name, prompts):
|
||||
if dataset is None or image_name is None or prompts is None:
|
||||
return
|
||||
if prompts == "Add new":
|
||||
return
|
||||
|
||||
prompt_data[image_name].remove(prompts)
|
||||
prompt_path = (
|
||||
str(shark_root) + "/dataset/" + dataset + "/metadata.jsonl"
|
||||
)
|
||||
# write prompt jsonlines file
|
||||
with open(prompt_path, "w") as f:
|
||||
for key, value in prompt_data.items():
|
||||
if not value:
|
||||
continue
|
||||
v = value if len(value) > 1 else value[0]
|
||||
f.write(json.dumps({"file_name": key, "text": v}))
|
||||
f.write("\n")
|
||||
|
||||
prompt_choices = ["Add new"]
|
||||
prompt_choices += prompt_data[image_name]
|
||||
return gr.Dropdown.update(choices=prompt_choices, value=None)
|
||||
|
||||
delete.click(
|
||||
fn=delete_prompt,
|
||||
inputs=[dataset, image_name, prompts],
|
||||
outputs=prompts,
|
||||
)
|
||||
|
||||
def get_back_image(dataset, image_name):
|
||||
if dataset is None or image_name is None:
|
||||
return
|
||||
|
||||
# remove local image
|
||||
img_path = str(shark_root) + "/dataset/" + dataset + "/" + image_name
|
||||
os.system(f'rm "{img_path}"')
|
||||
# get the index for the back image
|
||||
idx = images[dataset].index(image_name)
|
||||
if idx == 0:
|
||||
return gr.Dropdown.update(value=None)
|
||||
|
||||
return gr.Dropdown.update(value=images[dataset][idx - 1])
|
||||
|
||||
back_image.click(
|
||||
fn=get_back_image, inputs=[dataset, image_name], outputs=image_name
|
||||
)
|
||||
|
||||
def get_next_image(dataset, image_name):
|
||||
if dataset is None or image_name is None:
|
||||
return
|
||||
|
||||
# remove local image
|
||||
img_path = str(shark_root) + "/dataset/" + dataset + "/" + image_name
|
||||
os.system(f'rm "{img_path}"')
|
||||
# get the index for the next image
|
||||
idx = images[dataset].index(image_name)
|
||||
if idx == len(images[dataset]) - 1:
|
||||
return gr.Dropdown.update(value=None)
|
||||
|
||||
return gr.Dropdown.update(value=images[dataset][idx + 1])
|
||||
|
||||
next_image.click(
|
||||
fn=get_next_image, inputs=[dataset, image_name], outputs=image_name
|
||||
)
|
||||
|
||||
def finish_annotation(dataset):
|
||||
if dataset is None:
|
||||
return
|
||||
|
||||
# upload prompt and remove local data
|
||||
dataset_path = str(shark_root) + "/dataset/" + dataset
|
||||
dataset_gs_path = args.gs_url + "/" + dataset + "/"
|
||||
os.system(
|
||||
f'gsutil cp "{dataset_path}/metadata.jsonl" "{dataset_gs_path}"'
|
||||
)
|
||||
os.system(f'rm -rf "{dataset_path}"')
|
||||
|
||||
return gr.Dropdown.update(value=None)
|
||||
|
||||
finish.click(fn=finish_annotation, inputs=dataset, outputs=dataset)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
shark_web.launch(
|
||||
share=args.share,
|
||||
inbrowser=True,
|
||||
server_name="0.0.0.0",
|
||||
server_port=args.server_port,
|
||||
)
|
||||
34
dataset/args.py
Normal file
34
dataset/args.py
Normal file
@@ -0,0 +1,34 @@
|
||||
import argparse
|
||||
|
||||
p = argparse.ArgumentParser(
|
||||
description=__doc__, formatter_class=argparse.ArgumentDefaultsHelpFormatter
|
||||
)
|
||||
|
||||
##############################################################################
|
||||
### Dataset Annotator flags
|
||||
##############################################################################
|
||||
|
||||
p.add_argument(
|
||||
"--gs_url",
|
||||
type=str,
|
||||
required=True,
|
||||
help="URL to datasets in GS bucket",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--share",
|
||||
default=False,
|
||||
action=argparse.BooleanOptionalAction,
|
||||
help="flag for generating a public URL",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--server_port",
|
||||
type=int,
|
||||
default=8080,
|
||||
help="flag for setting server port",
|
||||
)
|
||||
|
||||
##############################################################################
|
||||
|
||||
args = p.parse_args()
|
||||
3
dataset/requirements.txt
Normal file
3
dataset/requirements.txt
Normal file
@@ -0,0 +1,3 @@
|
||||
# SHARK Annotator
|
||||
gradio==3.15.0
|
||||
jsonlines
|
||||
29
dataset/utils.py
Normal file
29
dataset/utils.py
Normal file
@@ -0,0 +1,29 @@
|
||||
from google.cloud import storage
|
||||
|
||||
|
||||
def get_datasets(gs_url):
|
||||
datasets = set()
|
||||
images = dict()
|
||||
ds_w_prompts = []
|
||||
|
||||
storage_client = storage.Client()
|
||||
bucket_name = gs_url.split("/")[2]
|
||||
source_blob_name = "/".join(gs_url.split("/")[3:])
|
||||
blobs = storage_client.list_blobs(bucket_name, prefix=source_blob_name)
|
||||
|
||||
for blob in blobs:
|
||||
dataset_name = blob.name.split("/")[1]
|
||||
if dataset_name == "":
|
||||
continue
|
||||
datasets.add(dataset_name)
|
||||
if dataset_name not in images.keys():
|
||||
images[dataset_name] = []
|
||||
|
||||
# check if image or jsonl
|
||||
file_sub_path = "/".join(blob.name.split("/")[2:])
|
||||
if "/" in file_sub_path:
|
||||
images[dataset_name] += [file_sub_path]
|
||||
elif "metadata.jsonl" in file_sub_path:
|
||||
ds_w_prompts.append(dataset_name)
|
||||
|
||||
return list(datasets), images, ds_w_prompts
|
||||
118
docs/shark_iree_profiling.md
Normal file
118
docs/shark_iree_profiling.md
Normal file
@@ -0,0 +1,118 @@
|
||||
# Overview
|
||||
|
||||
This document is intended to provide a starting point for profiling with SHARK/IREE. At it's core
|
||||
[SHARK](https://github.com/nod-ai/SHARK/tree/main/tank) is a python API that links the MLIR lowerings from various
|
||||
frameworks + frontends (e.g. PyTorch -> Torch-MLIR) with the compiler + runtime offered by IREE. More information
|
||||
on model coverage and framework support can be found [here](https://github.com/nod-ai/SHARK/tree/main/tank). The intended
|
||||
use case for SHARK is for compilation and deployment of performant state of the art AI models.
|
||||
|
||||
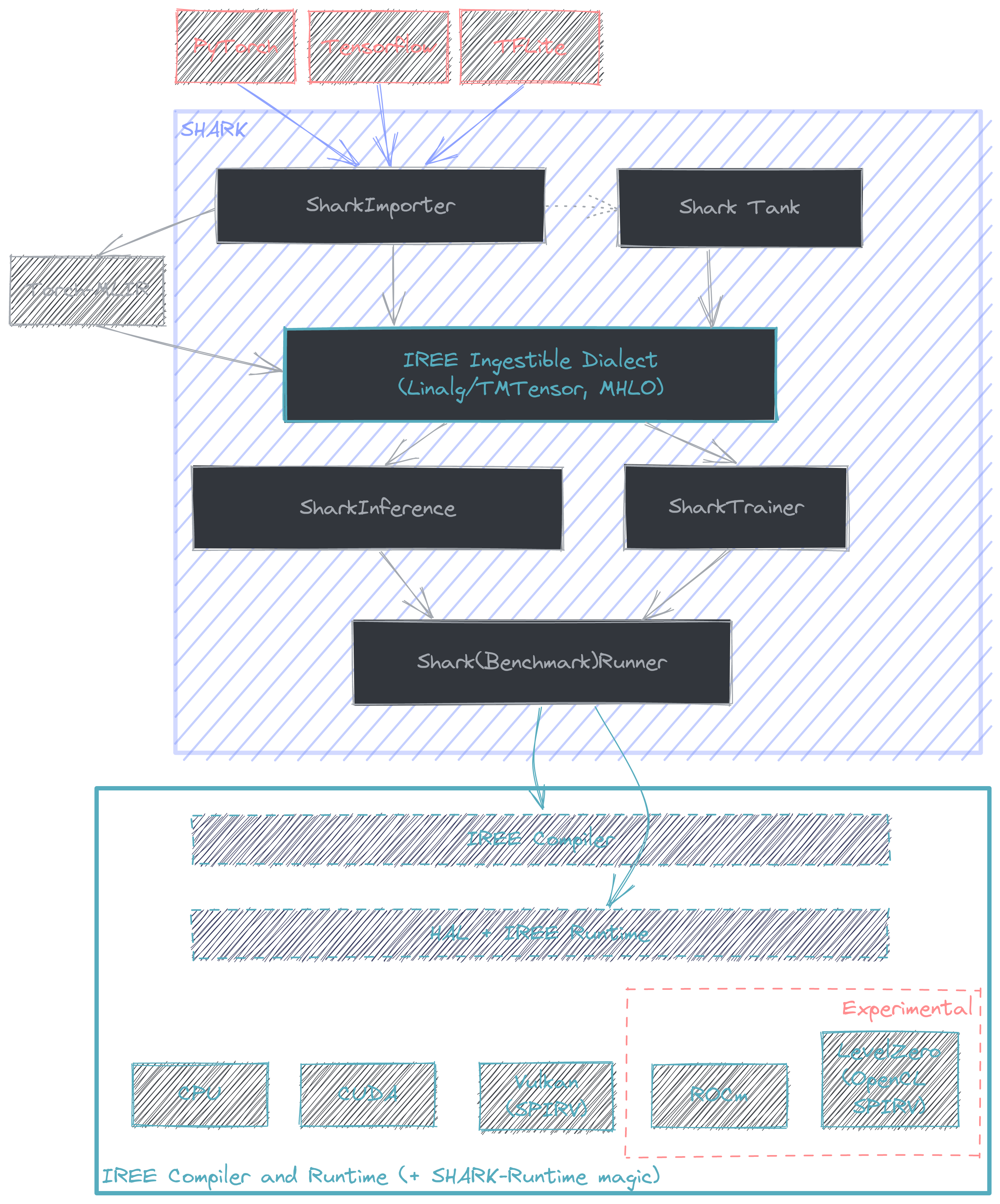
|
||||
|
||||
## Benchmarking with SHARK
|
||||
|
||||
TODO: Expand this section.
|
||||
|
||||
SHARK offers native benchmarking support, although because it is model focused, fine grain profiling is
|
||||
hidden when compared against the common "model benchmarking suite" use case SHARK is good at.
|
||||
|
||||
### SharkBenchmarkRunner
|
||||
|
||||
SharkBenchmarkRunner is a class designed for benchmarking models against other runtimes.
|
||||
TODO: List supported runtimes for comparison + example on how to benchmark with it.
|
||||
|
||||
## Directly profiling IREE
|
||||
|
||||
A number of excellent developer resources on profiling with IREE can be
|
||||
found [here](https://github.com/iree-org/iree/tree/main/docs/developers/developing_iree). As a result this section will
|
||||
focus on the bridging the gap between the two.
|
||||
- https://github.com/iree-org/iree/blob/main/docs/developers/developing_iree/profiling.md
|
||||
- https://github.com/iree-org/iree/blob/main/docs/developers/developing_iree/profiling_with_tracy.md
|
||||
- https://github.com/iree-org/iree/blob/main/docs/developers/developing_iree/profiling_vulkan_gpu.md
|
||||
- https://github.com/iree-org/iree/blob/main/docs/developers/developing_iree/profiling_cpu_events.md
|
||||
|
||||
Internally, SHARK builds a pair of IREE commands to compile + run a model. At a high level the flow starts with the
|
||||
model represented with a high level dialect (commonly Linalg) and is compiled to a flatbuffer (.vmfb) that
|
||||
the runtime is capable of ingesting. At this point (with potentially a few runtime flags) the compiled model is then run
|
||||
through the IREE runtime. This is all facilitated with the IREE python bindings, which offers a convenient method
|
||||
to capture the compile command SHARK comes up with. This is done by setting the environment variable
|
||||
`IREE_SAVE_TEMPS` to point to a directory of choice, e.g. for stable diffusion
|
||||
```
|
||||
# Linux
|
||||
$ export IREE_SAVE_TEMPS=/path/to/some/directory
|
||||
# Windows
|
||||
$ $env:IREE_SAVE_TEMPS="C:\path\to\some\directory"
|
||||
$ python apps/stable_diffusion/scripts/txt2img.py -p "a photograph of an astronaut riding a horse" --save_vmfb
|
||||
```
|
||||
NOTE: Currently this will only save the compile command + input MLIR for a single model if run in a pipeline.
|
||||
In the case of stable diffusion this (should) be UNet so to get examples for other models in the pipeline they
|
||||
need to be extracted and tested individually.
|
||||
|
||||
The save temps directory should contain three files: `core-command-line.txt`, `core-input.mlir`, and `core-output.bin`.
|
||||
The command line for compilation will start something like this, where the `-` needs to be replaced with the path to `core-input.mlir`.
|
||||
```
|
||||
/home/quinn/nod/iree-build/compiler/bindings/python/iree/compiler/tools/../_mlir_libs/iree-compile - --iree-input-type=none ...
|
||||
```
|
||||
The `-o output_filename.vmfb` flag can be used to specify the location to save the compiled vmfb. Note that a dump of the
|
||||
dispatches that can be compiled + run in isolation can be generated by adding `--iree-hal-dump-executable-benchmarks-to=/some/directory`. Say, if they are in the `benchmarks` directory, the following compile/run commands would work for Vulkan on RDNA3.
|
||||
```
|
||||
iree-compile --iree-input-type=none --iree-hal-target-backends=vulkan --iree-vulkan-target-triple=rdna3-unknown-linux --iree-stream-resource-index-bits=64 --iree-vm-target-index-bits=64 benchmarks/module_forward_dispatch_${NUM}_vulkan_spirv_fb.mlir -o benchmarks/module_forward_dispatch_${NUM}_vulkan_spirv_fb.vmfb
|
||||
|
||||
iree-benchmark-module --module=benchmarks/module_forward_dispatch_${NUM}_vulkan_spirv_fb.vmfb --function=forward --device=vulkan
|
||||
```
|
||||
Where `${NUM}` is the dispatch number that you want to benchmark/profile in isolation.
|
||||
|
||||
### Enabling Tracy for Vulkan profiling
|
||||
|
||||
To begin profiling with Tracy, a build of IREE runtime with tracing enabled is needed. SHARK-Runtime builds an
|
||||
instrumented version alongside the normal version nightly (.whls typically found [here](https://github.com/nod-ai/SHARK-Runtime/releases)), however this is only available for Linux. For Windows, tracing can be enabled by enabling a CMake flag.
|
||||
```
|
||||
$env:IREE_ENABLE_RUNTIME_TRACING="ON"
|
||||
```
|
||||
Getting a trace can then be done by setting environment variable `TRACY_NO_EXIT=1` and running the program that is to be
|
||||
traced. Then, to actually capture the trace, use the `iree-tracy-capture` tool in a different terminal. Note that to get
|
||||
the capture and profiler tools the `IREE_BUILD_TRACY=ON` CMake flag needs to be set.
|
||||
```
|
||||
TRACY_NO_EXIT=1 python apps/stable_diffusion/scripts/txt2img.py -p "a photograph of an astronaut riding a horse"
|
||||
|
||||
# (in another terminal, either on the same machine or through ssh with a tunnel through port 8086)
|
||||
iree-tracy-capture -o trace_filename.tracy
|
||||
```
|
||||
To do it over ssh, the flow looks like this
|
||||
```
|
||||
# From terminal 1 on local machine
|
||||
ssh -L 8086:localhost:8086 <remote_server_name>
|
||||
TRACY_NO_EXIT=1 python apps/stable_diffusion/scripts/txt2img.py -p "a photograph of an astronaut riding a horse"
|
||||
|
||||
# From terminal 2 on local machine. Requires having built IREE with the CMake flag `IREE_BUILD_TRACY=ON` to build the required tooling.
|
||||
iree-tracy-capture -o /path/to/trace.tracy
|
||||
```
|
||||
|
||||
The trace can then be viewed with
|
||||
```
|
||||
iree-tracy-profiler /path/to/trace.tracy
|
||||
```
|
||||
Capturing a runtime trace will work with any IREE tooling that uses the runtime. For example, `iree-benchmark-module`
|
||||
can be used for benchmarking an individual module. Importantly this means that any SHARK script can be profiled with tracy.
|
||||
|
||||
NOTE: Not all backends have the same tracy support. This writeup is focused on CPU/Vulkan backends but there is recently added support for tracing on CUDA (requires the `--cuda_tracing` flag).
|
||||
|
||||
## Experimental RGP support
|
||||
|
||||
TODO: This section is temporary until proper RGP support is added.
|
||||
|
||||
Currently, for stable diffusion there is a flag for enabling UNet to be visible to RGP with `--enable_rgp`. To get a proper capture though, the `DevModeSqttPrepareFrameCount=1` flag needs to be set for the driver (done with `VkPanel` on Windows).
|
||||
With these two settings, a single iteration of UNet can be captured.
|
||||
|
||||
(AMD only) To get a dump of the pipelines (result of compiled SPIR-V) the `EnablePipelineDump=1` driver flag can be set. The
|
||||
files will typically be dumped to a directory called `spvPipeline` (on Linux `/var/tmp/spvPipeline`. The dumped files will
|
||||
include header information that can be used to map back to the source dispatch/SPIR-V, e.g.
|
||||
```
|
||||
[Version]
|
||||
version = 57
|
||||
|
||||
[CsSpvFile]
|
||||
fileName = Shader_0x946C08DFD0C10D9A.spv
|
||||
|
||||
[CsInfo]
|
||||
entryPoint = forward_dispatch_193_matmul_256x65536x2304
|
||||
```
|
||||
@@ -1,235 +0,0 @@
|
||||
# Lint as: python3
|
||||
"""SHARK Tank"""
|
||||
# python generate_sharktank.py, you have to give a csv tile with [model_name, model_download_url]
|
||||
# will generate local shark tank folder like this:
|
||||
# /SHARK
|
||||
# /gen_shark_tank
|
||||
# /albert_lite_base
|
||||
# /...model_name...
|
||||
#
|
||||
|
||||
import os
|
||||
import csv
|
||||
import argparse
|
||||
from shark.shark_importer import SharkImporter
|
||||
import tensorflow as tf
|
||||
import subprocess as sp
|
||||
import hashlib
|
||||
import numpy as np
|
||||
|
||||
visible_default = tf.config.list_physical_devices("GPU")
|
||||
try:
|
||||
tf.config.set_visible_devices([], "GPU")
|
||||
visible_devices = tf.config.get_visible_devices()
|
||||
for device in visible_devices:
|
||||
assert device.device_type != "GPU"
|
||||
except:
|
||||
# Invalid device or cannot modify virtual devices once initialized.
|
||||
pass
|
||||
|
||||
# All generated models and metadata will be saved under this directory.
|
||||
WORKDIR = os.path.join(os.path.dirname(__file__), "gen_shark_tank")
|
||||
|
||||
|
||||
def create_hash(file_name):
|
||||
with open(file_name, "rb") as f:
|
||||
file_hash = hashlib.blake2b()
|
||||
while chunk := f.read(2**20):
|
||||
file_hash.update(chunk)
|
||||
|
||||
return file_hash.hexdigest()
|
||||
|
||||
|
||||
def save_torch_model(torch_model_list):
|
||||
from tank.model_utils import get_hf_model
|
||||
from tank.model_utils import get_vision_model
|
||||
|
||||
with open(torch_model_list) as csvfile:
|
||||
torch_reader = csv.reader(csvfile, delimiter=",")
|
||||
fields = next(torch_reader)
|
||||
for row in torch_reader:
|
||||
torch_model_name = row[0]
|
||||
tracing_required = row[1]
|
||||
model_type = row[2]
|
||||
|
||||
tracing_required = False if tracing_required == "False" else True
|
||||
|
||||
model = None
|
||||
input = None
|
||||
if model_type == "vision":
|
||||
model, input, _ = get_vision_model(torch_model_name)
|
||||
elif model_type == "hf":
|
||||
model, input, _ = get_hf_model(torch_model_name)
|
||||
|
||||
torch_model_name = torch_model_name.replace("/", "_")
|
||||
torch_model_dir = os.path.join(
|
||||
WORKDIR, str(torch_model_name) + "_torch"
|
||||
)
|
||||
os.makedirs(torch_model_dir, exist_ok=True)
|
||||
|
||||
mlir_importer = SharkImporter(
|
||||
model,
|
||||
(input,),
|
||||
frontend="torch",
|
||||
)
|
||||
mlir_importer.import_debug(
|
||||
is_dynamic=False,
|
||||
tracing_required=tracing_required,
|
||||
dir=torch_model_dir,
|
||||
model_name=torch_model_name,
|
||||
)
|
||||
mlir_hash = create_hash(
|
||||
os.path.join(
|
||||
torch_model_dir, torch_model_name + "_torch" + ".mlir"
|
||||
)
|
||||
)
|
||||
np.save(os.path.join(torch_model_dir, "hash"), np.array(mlir_hash))
|
||||
# Generate torch dynamic models.
|
||||
mlir_importer.import_debug(
|
||||
is_dynamic=True,
|
||||
tracing_required=tracing_required,
|
||||
dir=torch_model_dir,
|
||||
model_name=torch_model_name + "_dynamic",
|
||||
)
|
||||
|
||||
|
||||
def save_tf_model(tf_model_list):
|
||||
from tank.model_utils_tf import (
|
||||
get_causal_image_model,
|
||||
get_causal_lm_model,
|
||||
get_keras_model,
|
||||
get_TFhf_model,
|
||||
)
|
||||
|
||||
with open(tf_model_list) as csvfile:
|
||||
tf_reader = csv.reader(csvfile, delimiter=",")
|
||||
fields = next(tf_reader)
|
||||
for row in tf_reader:
|
||||
tf_model_name = row[0]
|
||||
model_type = row[1]
|
||||
|
||||
model = None
|
||||
input = None
|
||||
print(f"Generating artifacts for model {tf_model_name}")
|
||||
if model_type == "hf":
|
||||
model, input, _ = get_causal_lm_model(tf_model_name)
|
||||
if model_type == "img":
|
||||
model, input, _ = get_causal_image_model(tf_model_name)
|
||||
if model_type == "keras":
|
||||
model, input, _ = get_keras_model(tf_model_name)
|
||||
if model_type == "TFhf":
|
||||
model, input, _ = get_TFhf_model(tf_model_name)
|
||||
|
||||
tf_model_name = tf_model_name.replace("/", "_")
|
||||
tf_model_dir = os.path.join(WORKDIR, str(tf_model_name) + "_tf")
|
||||
os.makedirs(tf_model_dir, exist_ok=True)
|
||||
|
||||
mlir_importer = SharkImporter(
|
||||
model,
|
||||
input,
|
||||
frontend="tf",
|
||||
)
|
||||
mlir_importer.import_debug(
|
||||
dir=tf_model_dir,
|
||||
model_name=tf_model_name,
|
||||
)
|
||||
mlir_hash = create_hash(
|
||||
os.path.join(tf_model_dir, tf_model_name + "_tf" + ".mlir")
|
||||
)
|
||||
np.save(os.path.join(tf_model_dir, "hash"), np.array(mlir_hash))
|
||||
|
||||
|
||||
def save_tflite_model(tflite_model_list):
|
||||
from shark.tflite_utils import TFLitePreprocessor
|
||||
|
||||
with open(tflite_model_list) as csvfile:
|
||||
tflite_reader = csv.reader(csvfile, delimiter=",")
|
||||
for row in tflite_reader:
|
||||
print("\n")
|
||||
tflite_model_name = row[0]
|
||||
tflite_model_link = row[1]
|
||||
print("tflite_model_name", tflite_model_name)
|
||||
print("tflite_model_link", tflite_model_link)
|
||||
tflite_model_name_dir = os.path.join(
|
||||
WORKDIR, str(tflite_model_name) + "_tflite"
|
||||
)
|
||||
os.makedirs(tflite_model_name_dir, exist_ok=True)
|
||||
print(f"TMP_TFLITE_MODELNAME_DIR = {tflite_model_name_dir}")
|
||||
|
||||
# Preprocess to get SharkImporter input args
|
||||
tflite_preprocessor = TFLitePreprocessor(str(tflite_model_name))
|
||||
raw_model_file_path = tflite_preprocessor.get_raw_model_file()
|
||||
inputs = tflite_preprocessor.get_inputs()
|
||||
tflite_interpreter = tflite_preprocessor.get_interpreter()
|
||||
|
||||
# Use SharkImporter to get SharkInference input args
|
||||
my_shark_importer = SharkImporter(
|
||||
module=tflite_interpreter,
|
||||
inputs=inputs,
|
||||
frontend="tflite",
|
||||
raw_model_file=raw_model_file_path,
|
||||
)
|
||||
my_shark_importer.import_debug(
|
||||
dir=tflite_model_name_dir,
|
||||
model_name=tflite_model_name,
|
||||
func_name="main",
|
||||
)
|
||||
mlir_hash = create_hash(
|
||||
os.path.join(
|
||||
tflite_model_name_dir,
|
||||
tflite_model_name + "_tflite" + ".mlir",
|
||||
)
|
||||
)
|
||||
np.save(
|
||||
os.path.join(tflite_model_name_dir, "hash"),
|
||||
np.array(mlir_hash),
|
||||
)
|
||||
|
||||
|
||||
# Validates whether the file is present or not.
|
||||
def is_valid_file(arg):
|
||||
if not os.path.exists(arg):
|
||||
return None
|
||||
else:
|
||||
return arg
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument(
|
||||
"--torch_model_csv",
|
||||
type=lambda x: is_valid_file(x),
|
||||
default="./tank/pytorch/torch_model_list.csv",
|
||||
help="""Contains the file with torch_model name and args.
|
||||
Please see: https://github.com/nod-ai/SHARK/blob/main/tank/pytorch/torch_model_list.csv""",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--tf_model_csv",
|
||||
type=lambda x: is_valid_file(x),
|
||||
default="./tank/tf/tf_model_list.csv",
|
||||
help="Contains the file with tf model name and args.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--tflite_model_csv",
|
||||
type=lambda x: is_valid_file(x),
|
||||
default="./tank/tflite/tflite_model_list.csv",
|
||||
help="Contains the file with tf model name and args.",
|
||||
)
|
||||
parser.add_argument("--upload", type=bool, default=False)
|
||||
|
||||
args = parser.parse_args()
|
||||
if args.torch_model_csv:
|
||||
save_torch_model(args.torch_model_csv)
|
||||
|
||||
if args.tf_model_csv:
|
||||
save_tf_model(args.tf_model_csv)
|
||||
|
||||
if args.tflite_model_csv:
|
||||
save_tflite_model(args.tflite_model_csv)
|
||||
|
||||
if args.upload:
|
||||
git_hash = sp.getoutput("git log -1 --format='%h'") + "/"
|
||||
print("uploading files to gs://shark_tank/" + git_hash)
|
||||
os.system(
|
||||
"gsutil cp -r ./gen_shark_tank/* gs://shark_tank/" + git_hash
|
||||
)
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user