mirror of
https://github.com/nod-ai/SHARK-Studio.git
synced 2026-01-11 14:58:11 -05:00
Compare commits
922 Commits
20221225.4
...
decomp
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
dedb995af3 | ||
|
|
c199ac78eb | ||
|
|
fa95ed30d1 | ||
|
|
788cc9157c | ||
|
|
ebfcfec338 | ||
|
|
f692a012e1 | ||
|
|
3cc643b2de | ||
|
|
bf70e80d20 | ||
|
|
7159698496 | ||
|
|
7e12d1782a | ||
|
|
bb5f133e1c | ||
|
|
3af0c6c658 | ||
|
|
3322b7264f | ||
|
|
eeb7bdd143 | ||
|
|
2d6f48821d | ||
|
|
c74b55f24e | ||
|
|
1a723645fb | ||
|
|
dfdd3b1f78 | ||
|
|
6384780d16 | ||
|
|
db0c53ae59 | ||
|
|
ce9ce3a7c8 | ||
|
|
d72da3801f | ||
|
|
9c50edc664 | ||
|
|
a1b7110550 | ||
|
|
ff15fd74f6 | ||
|
|
552b2c3ee3 | ||
|
|
795fc33001 | ||
|
|
2910841fe6 | ||
|
|
396a054856 | ||
|
|
5c66948d4f | ||
|
|
ed3dda94c0 | ||
|
|
d31d28b082 | ||
|
|
78c607e1d3 | ||
|
|
666e601dd9 | ||
|
|
ca58908e5b | ||
|
|
1f5b39f56e | ||
|
|
2da31c4109 | ||
|
|
da50a16242 | ||
|
|
ce38d49f05 | ||
|
|
2f780f0d38 | ||
|
|
d051c3a4a7 | ||
|
|
1b11c82c9d | ||
|
|
80a33d427f | ||
|
|
4125a26294 | ||
|
|
905d0103ff | ||
|
|
192b3b2c61 | ||
|
|
8f9adc4a2a | ||
|
|
70817bb50a | ||
|
|
dd37c26d36 | ||
|
|
a708879c6c | ||
|
|
bb1b49eb6f | ||
|
|
f6d41affd9 | ||
|
|
c2163488d8 | ||
|
|
54bff4611d | ||
|
|
11510d5111 | ||
|
|
32cab73a29 | ||
|
|
392bade0bf | ||
|
|
91df5f0613 | ||
|
|
df20cf9c8a | ||
|
|
c4a908c3ea | ||
|
|
6285430d8a | ||
|
|
51afe19e20 | ||
|
|
31005bcf73 | ||
|
|
f41ad87ef6 | ||
|
|
d811524a00 | ||
|
|
51e1bd1c5d | ||
|
|
db89b1bdc1 | ||
|
|
2754e2e257 | ||
|
|
ab0e870c43 | ||
|
|
fb30e8c226 | ||
|
|
a07d542400 | ||
|
|
ad55cb696f | ||
|
|
488a172292 | ||
|
|
500c4f2306 | ||
|
|
92b694db4d | ||
|
|
322874f7f9 | ||
|
|
5001db3415 | ||
|
|
71846344a2 | ||
|
|
72e27c96fc | ||
|
|
7963abb8ec | ||
|
|
98244232dd | ||
|
|
679a452139 | ||
|
|
72c0a8abc8 | ||
|
|
ea920f2955 | ||
|
|
486202377a | ||
|
|
0c38c33d0a | ||
|
|
841773fa32 | ||
|
|
0361db46f9 | ||
|
|
a012433ffd | ||
|
|
5061193da3 | ||
|
|
bff48924be | ||
|
|
825b36cbdd | ||
|
|
134441957d | ||
|
|
7cd14fdc47 | ||
|
|
e6cb5cef57 | ||
|
|
66abee8e5b | ||
|
|
4797bb89f5 | ||
|
|
205e57683a | ||
|
|
2866d665ee | ||
|
|
71d25ec5d8 | ||
|
|
202ffff67b | ||
|
|
0b77059628 | ||
|
|
a208302bb9 | ||
|
|
b83d32fafe | ||
|
|
0a618e1863 | ||
|
|
a731eb6ed4 | ||
|
|
2004d16945 | ||
|
|
6e409bfb77 | ||
|
|
77727d149c | ||
|
|
66f6e79d68 | ||
|
|
3b825579a7 | ||
|
|
9f0a421764 | ||
|
|
c28682110c | ||
|
|
caf6cc5d8f | ||
|
|
8614a18474 | ||
|
|
86c1c0c215 | ||
|
|
8bb364bcb8 | ||
|
|
7abddd01ec | ||
|
|
2a451fa0c7 | ||
|
|
9c4610b9da | ||
|
|
a38cc9d216 | ||
|
|
1c382449ec | ||
|
|
7cc9b3f8e8 | ||
|
|
e54517e967 | ||
|
|
326327a799 | ||
|
|
785b65c7b0 | ||
|
|
0d16c81687 | ||
|
|
8dd7850c69 | ||
|
|
e930ba85b4 | ||
|
|
cd732e7a38 | ||
|
|
8e0f8b3227 | ||
|
|
b8210ef796 | ||
|
|
94594542a9 | ||
|
|
82f833e87d | ||
|
|
c9d6870105 | ||
|
|
4fec03a6cc | ||
|
|
9a27f51378 | ||
|
|
ad1a0f35ff | ||
|
|
6773278ec2 | ||
|
|
9a0efffcca | ||
|
|
61c6f153d9 | ||
|
|
effd42e8f5 | ||
|
|
b5fbb1a8a0 | ||
|
|
ded74d09cd | ||
|
|
79267931c1 | ||
|
|
9eceba69b7 | ||
|
|
ca609afb6a | ||
|
|
11bdce9790 | ||
|
|
684943a4a6 | ||
|
|
b817bb8455 | ||
|
|
780f520f02 | ||
|
|
c61b6f8d65 | ||
|
|
c854208d49 | ||
|
|
c5dcfc1f13 | ||
|
|
bde63ee8ae | ||
|
|
9681d494eb | ||
|
|
ede6bf83e2 | ||
|
|
2c2693fb7d | ||
|
|
1d31b2b2c6 | ||
|
|
d2f64eefa3 | ||
|
|
87ae14b6ff | ||
|
|
1ccafa1fc1 | ||
|
|
4c3d8a0a7f | ||
|
|
3601dc7c3b | ||
|
|
671881cf87 | ||
|
|
4e9be6be59 | ||
|
|
9c8cbaf498 | ||
|
|
9e348a114e | ||
|
|
51f90a4d56 | ||
|
|
310d5d0a49 | ||
|
|
9697981004 | ||
|
|
450c231171 | ||
|
|
07f6f4a2f7 | ||
|
|
610813c72f | ||
|
|
8e3860c9e6 | ||
|
|
e37d6720eb | ||
|
|
16160d9a7d | ||
|
|
79075a1a07 | ||
|
|
db990826d3 | ||
|
|
7ee3e4ba5d | ||
|
|
05889a8fe1 | ||
|
|
b87efe7686 | ||
|
|
82b462de3a | ||
|
|
d8f0f7bade | ||
|
|
79bd0b84a1 | ||
|
|
8738571d1e | ||
|
|
a4c354ce54 | ||
|
|
cc53efa89f | ||
|
|
9ae8bc921e | ||
|
|
32eb78f0f9 | ||
|
|
cb509343d9 | ||
|
|
6da391c9b1 | ||
|
|
9dee7ae652 | ||
|
|
343dfd901c | ||
|
|
57260b9c37 | ||
|
|
18e7d2d061 | ||
|
|
51a1009796 | ||
|
|
045c3c3852 | ||
|
|
0139dd58d9 | ||
|
|
c96571855a | ||
|
|
4f61d69d86 | ||
|
|
531d447768 | ||
|
|
16f46f8de9 | ||
|
|
c4723f469f | ||
|
|
d804f45a61 | ||
|
|
d22177f936 | ||
|
|
75e68f02f4 | ||
|
|
4dc9c59611 | ||
|
|
18801dcabc | ||
|
|
3c577f7168 | ||
|
|
f5e4fa6ffe | ||
|
|
48de445325 | ||
|
|
8e90f1b81a | ||
|
|
e8c1203be2 | ||
|
|
e4d7abb519 | ||
|
|
96185c9dc1 | ||
|
|
bc22a81925 | ||
|
|
5203679f1f | ||
|
|
bf073f8f37 | ||
|
|
cec6eda6b4 | ||
|
|
9e37e03741 | ||
|
|
9b8c4401b5 | ||
|
|
a9f95a218b | ||
|
|
872bd72d0b | ||
|
|
fd1c4db5d0 | ||
|
|
759664bb48 | ||
|
|
14fd0cdd87 | ||
|
|
a57eccc997 | ||
|
|
a686d7d89f | ||
|
|
ed484b8253 | ||
|
|
7fe57ebaaf | ||
|
|
c287fd2be8 | ||
|
|
51ec1a1360 | ||
|
|
bd30044c0b | ||
|
|
c9de2729b2 | ||
|
|
a5b13fcc2f | ||
|
|
6bb329c4af | ||
|
|
98fb6c52df | ||
|
|
206c1b70f4 | ||
|
|
cdb037ee54 | ||
|
|
ce2fd84538 | ||
|
|
4684afad34 | ||
|
|
8d65456b7a | ||
|
|
d6759a852b | ||
|
|
ab57af43c1 | ||
|
|
4d5c55dd9f | ||
|
|
07399ad65c | ||
|
|
776a9c2293 | ||
|
|
9d399eb988 | ||
|
|
927b662aa7 | ||
|
|
47f8a79c75 | ||
|
|
289f983f41 | ||
|
|
453e46562f | ||
|
|
5497af1f56 | ||
|
|
f3cb63fc9c | ||
|
|
d7092aafaa | ||
|
|
a415f3f70e | ||
|
|
c292e5c9d7 | ||
|
|
03c4d9e171 | ||
|
|
3662224c04 | ||
|
|
db3f222933 | ||
|
|
68b3021325 | ||
|
|
336469154d | ||
|
|
41e5088908 | ||
|
|
0a8f7673f4 | ||
|
|
c482ab78da | ||
|
|
4be80f7158 | ||
|
|
536aba1424 | ||
|
|
dd738a0e02 | ||
|
|
8927cb0a2c | ||
|
|
8c317e4809 | ||
|
|
b0136593df | ||
|
|
11f62d7fac | ||
|
|
14559dd620 | ||
|
|
e503a3e8d6 | ||
|
|
22a4254adf | ||
|
|
ab01f0f048 | ||
|
|
c471d17cca | ||
|
|
a2a436eb0c | ||
|
|
1adb51b29d | ||
|
|
aab2233e25 | ||
|
|
e20cd71314 | ||
|
|
5ec91143f5 | ||
|
|
7cf19230e2 | ||
|
|
1bcf6b2c5b | ||
|
|
91027f8719 | ||
|
|
a909fc2e78 | ||
|
|
247f69cf9d | ||
|
|
3b8f7cc231 | ||
|
|
6e8dbf72bd | ||
|
|
38e5b62d80 | ||
|
|
1c7eecc981 | ||
|
|
be417f0bf4 | ||
|
|
a517e217b0 | ||
|
|
9fcae4f808 | ||
|
|
788d469c5b | ||
|
|
8a59f7cc27 | ||
|
|
1c2ec3c7a2 | ||
|
|
af0f715e20 | ||
|
|
47ec7275e6 | ||
|
|
3a24cff901 | ||
|
|
1f72907886 | ||
|
|
06c8aabd01 | ||
|
|
55a12cc0c4 | ||
|
|
7dcbbde523 | ||
|
|
1b62dc4529 | ||
|
|
c5a47887f4 | ||
|
|
c72d0eaf87 | ||
|
|
c41f58042a | ||
|
|
043e5a5c7a | ||
|
|
a1b1ce935c | ||
|
|
bc6fee1a0c | ||
|
|
91ab594744 | ||
|
|
4015793f84 | ||
|
|
d63ce76dd8 | ||
|
|
1c32915570 | ||
|
|
6d286c0609 | ||
|
|
7392b22731 | ||
|
|
534de05791 | ||
|
|
5779e8c039 | ||
|
|
d496053590 | ||
|
|
6274a813c9 | ||
|
|
1d6a1f9f8a | ||
|
|
75672c0e28 | ||
|
|
74a7202173 | ||
|
|
27a08735db | ||
|
|
eaa49cce17 | ||
|
|
10657d6fb1 | ||
|
|
e3ab844cd1 | ||
|
|
5ce6001b41 | ||
|
|
501d0ca52e | ||
|
|
b444528715 | ||
|
|
6e6c90f62b | ||
|
|
8cdb38496e | ||
|
|
726d73d6ba | ||
|
|
4d55e51d46 | ||
|
|
6ef78ee7ba | ||
|
|
4002da7161 | ||
|
|
ecb5e8e5d8 | ||
|
|
28e0919321 | ||
|
|
28f4d44a6b | ||
|
|
97f7e79391 | ||
|
|
44a8f2f8db | ||
|
|
8822b9acd7 | ||
|
|
0ca3b9fce3 | ||
|
|
045f2bb147 | ||
|
|
a811b867b9 | ||
|
|
cdd505e2dd | ||
|
|
1b0f39107c | ||
|
|
b9b8955f74 | ||
|
|
6f7a85eee3 | ||
|
|
18c8e9e51e | ||
|
|
a202bb466a | ||
|
|
07c1e1d712 | ||
|
|
18daec78c8 | ||
|
|
1a8e2024d6 | ||
|
|
d61b6641fb | ||
|
|
88cc2423cc | ||
|
|
ccf944c1bd | ||
|
|
0def74f520 | ||
|
|
3fb72e192e | ||
|
|
855435ee24 | ||
|
|
6f9f868fc0 | ||
|
|
fb865f1b99 | ||
|
|
3e5c50f07b | ||
|
|
a544f30a8f | ||
|
|
1fe56d460a | ||
|
|
fafd713141 | ||
|
|
015d0132c3 | ||
|
|
20ddd96ef7 | ||
|
|
ee33cfd2d1 | ||
|
|
a3cba21d5b | ||
|
|
a7b6ec4095 | ||
|
|
d80b087d95 | ||
|
|
297a209608 | ||
|
|
b204113563 | ||
|
|
f60ab1f4fa | ||
|
|
b203779462 | ||
|
|
38570a9bbb | ||
|
|
a5c882f296 | ||
|
|
eb6d11cfed | ||
|
|
46184a81ac | ||
|
|
149165a2f0 | ||
|
|
bec82a665f | ||
|
|
9551490341 | ||
|
|
49b3ecdbca | ||
|
|
f53e3594c3 | ||
|
|
5562d1dfda | ||
|
|
c7b0c2961e | ||
|
|
44273b0791 | ||
|
|
0a4c8fcb3e | ||
|
|
2fec3c8169 | ||
|
|
5e7d5930dd | ||
|
|
b6dbd20250 | ||
|
|
34f1295349 | ||
|
|
1980d7b2c3 | ||
|
|
2cfacc5051 | ||
|
|
436f58ddc4 | ||
|
|
6b29bd17c8 | ||
|
|
2c3485ca3e | ||
|
|
f206ecc635 | ||
|
|
a187e05ae6 | ||
|
|
8c21960486 | ||
|
|
be62fce676 | ||
|
|
f23b778a6c | ||
|
|
436edf900d | ||
|
|
ed58c2553f | ||
|
|
f2ca58e844 | ||
|
|
1dbcc736eb | ||
|
|
a83808ddc5 | ||
|
|
a07fe80530 | ||
|
|
d0ba3ef8fa | ||
|
|
8400529c2c | ||
|
|
7eaee9c242 | ||
|
|
8230eebce5 | ||
|
|
6296ea4be9 | ||
|
|
4151ec3a8f | ||
|
|
a2467e8d43 | ||
|
|
e677178bcc | ||
|
|
7ef1bea953 | ||
|
|
ad89bb1413 | ||
|
|
218ed78c40 | ||
|
|
6046f36ab6 | ||
|
|
5915bf7de3 | ||
|
|
f0a4e59758 | ||
|
|
1ddef26af5 | ||
|
|
ba8eddb12f | ||
|
|
47b346d428 | ||
|
|
1b4f4f5f4d | ||
|
|
73cd7e8320 | ||
|
|
19c0ae3702 | ||
|
|
54e57f7771 | ||
|
|
6d64b8e273 | ||
|
|
a8ea0326f5 | ||
|
|
58e9194553 | ||
|
|
eb360e255d | ||
|
|
a6f88d7f72 | ||
|
|
8e571d165f | ||
|
|
3cddd01b10 | ||
|
|
64c2b2d96b | ||
|
|
f5ce121988 | ||
|
|
991f144598 | ||
|
|
09bea17e59 | ||
|
|
aefcf80b48 | ||
|
|
512235892e | ||
|
|
6602a2f5ba | ||
|
|
20114deea0 | ||
|
|
9acf519078 | ||
|
|
bdf37b5311 | ||
|
|
8ee2ac89f8 | ||
|
|
60cb48be2e | ||
|
|
86a215b063 | ||
|
|
d6e3a9a236 | ||
|
|
a0097a1ead | ||
|
|
a9bae00606 | ||
|
|
4731c1a835 | ||
|
|
4c07e47e8c | ||
|
|
e0cc2871bb | ||
|
|
649f39408b | ||
|
|
c142297d73 | ||
|
|
9e07360b00 | ||
|
|
7b74c86e42 | ||
|
|
fa833f8366 | ||
|
|
fcb059aa38 | ||
|
|
517c670f82 | ||
|
|
59df14f18b | ||
|
|
6c95ac0f37 | ||
|
|
7a4a51ae73 | ||
|
|
d816cc015e | ||
|
|
54ce3d48ca | ||
|
|
0e4a8ca240 | ||
|
|
6ca1298675 | ||
|
|
bbef7a6464 | ||
|
|
cdf2d61d53 | ||
|
|
6c14847d1f | ||
|
|
68ecdd2a73 | ||
|
|
3f4d444d18 | ||
|
|
e473d0375b | ||
|
|
e38d96850f | ||
|
|
fed63dfd4b | ||
|
|
eba4d06405 | ||
|
|
4cfba153d2 | ||
|
|
307c05f38d | ||
|
|
696df349cb | ||
|
|
cb54cb1348 | ||
|
|
9bdb86637d | ||
|
|
fb6f26517f | ||
|
|
aa8ada9da9 | ||
|
|
1db906a373 | ||
|
|
9d1d1617d8 | ||
|
|
7112789cb8 | ||
|
|
d6b8be2849 | ||
|
|
822171277c | ||
|
|
a5ae9d9f02 | ||
|
|
09e3f63d5b | ||
|
|
d60a5a9396 | ||
|
|
90df0ee365 | ||
|
|
133c1bcadd | ||
|
|
caadbe14e9 | ||
|
|
5f5823ccd9 | ||
|
|
d2f7e03b7e | ||
|
|
0b01bbe479 | ||
|
|
25c5fc44ae | ||
|
|
7330729c92 | ||
|
|
ce16cd5431 | ||
|
|
598dc5f79d | ||
|
|
1f8e332cbe | ||
|
|
17b9632659 | ||
|
|
bda92a54ab | ||
|
|
747ed383b1 | ||
|
|
1afe07c296 | ||
|
|
b70919b38d | ||
|
|
4e513d647f | ||
|
|
94cd2a0fed | ||
|
|
606029c01c | ||
|
|
1aa85222e9 | ||
|
|
1b3f468c04 | ||
|
|
35de7e27fa | ||
|
|
467f900759 | ||
|
|
0bd9d582c7 | ||
|
|
428cfe8dae | ||
|
|
f17915bedc | ||
|
|
1b49b5149a | ||
|
|
3002793301 | ||
|
|
d25ef5529f | ||
|
|
308856a947 | ||
|
|
151b4e142f | ||
|
|
e5a69a7c36 | ||
|
|
450b6cafc4 | ||
|
|
237d26baa2 | ||
|
|
67d6ee1104 | ||
|
|
98b069488e | ||
|
|
e0f227643a | ||
|
|
a0af3bb0cb | ||
|
|
2cd61a5b96 | ||
|
|
f49d41a807 | ||
|
|
2191fc8952 | ||
|
|
aea7796e60 | ||
|
|
a376619f1e | ||
|
|
02d52bb626 | ||
|
|
3b63645f79 | ||
|
|
d6f740b998 | ||
|
|
594c6b8ea2 | ||
|
|
96b1560da5 | ||
|
|
0ef6a0e234 | ||
|
|
641d535f44 | ||
|
|
5bb7846227 | ||
|
|
8f84258fb8 | ||
|
|
7619e76bbd | ||
|
|
9267eadbfa | ||
|
|
431132b8ee | ||
|
|
fb35e13e7a | ||
|
|
17a67897d1 | ||
|
|
da449b73aa | ||
|
|
0b0526699a | ||
|
|
4fac46f7bb | ||
|
|
49925950f1 | ||
|
|
807947c0c8 | ||
|
|
593428bda4 | ||
|
|
cede9b4fec | ||
|
|
c2360303f0 | ||
|
|
420366c1b8 | ||
|
|
d31bae488c | ||
|
|
c23fcf3748 | ||
|
|
7dbbb1726a | ||
|
|
8b8cc7fd33 | ||
|
|
e3c96a2b9d | ||
|
|
5e3f50647d | ||
|
|
7899e1803a | ||
|
|
d105246b9c | ||
|
|
90c958bca2 | ||
|
|
f99903e023 | ||
|
|
c6f44ef1b3 | ||
|
|
8dcd4d5aeb | ||
|
|
d319f4684e | ||
|
|
54d7b6d83e | ||
|
|
4a622532e5 | ||
|
|
650b2ada58 | ||
|
|
f87f8949f3 | ||
|
|
7dc9bf8148 | ||
|
|
ba48ff8d25 | ||
|
|
638840925c | ||
|
|
b661656c03 | ||
|
|
0225434389 | ||
|
|
7ffe20b1c2 | ||
|
|
d8f0c4655d | ||
|
|
7e8d3ec0df | ||
|
|
9c08eec565 | ||
|
|
2d2c523ac5 | ||
|
|
f17b3128c0 | ||
|
|
7c7e630099 | ||
|
|
2dd1491ec1 | ||
|
|
236357fb61 | ||
|
|
7bc38719de | ||
|
|
bdbe992769 | ||
|
|
e6b925e012 | ||
|
|
771120b76c | ||
|
|
a8ce7680db | ||
|
|
b6dcf2401b | ||
|
|
62b5a9fd49 | ||
|
|
2f133e9d5c | ||
|
|
f898a1d332 | ||
|
|
b94266d2b9 | ||
|
|
1b08242aaa | ||
|
|
691030fbab | ||
|
|
16ad7d57a3 | ||
|
|
c561ebf43c | ||
|
|
97fdff7f19 | ||
|
|
ce6d82eab2 | ||
|
|
b8f4b18951 | ||
|
|
b23d3aa584 | ||
|
|
495670d9b6 | ||
|
|
815e23a0b8 | ||
|
|
783538fe11 | ||
|
|
996c645f6a | ||
|
|
1f7d249a62 | ||
|
|
7f6c9a2dc2 | ||
|
|
93891984f3 | ||
|
|
cc0ef54e0e | ||
|
|
812152485d | ||
|
|
0816fb403a | ||
|
|
4f171772be | ||
|
|
a52331d4aa | ||
|
|
ad821a1fc8 | ||
|
|
116b128802 | ||
|
|
b118f183d1 | ||
|
|
911dff16f1 | ||
|
|
de59a66ae4 | ||
|
|
23f1468cc6 | ||
|
|
080350d311 | ||
|
|
7f3f92b9d5 | ||
|
|
be3cdec290 | ||
|
|
f09574538c | ||
|
|
b1113ab551 | ||
|
|
ef756389e3 | ||
|
|
cb17d017df | ||
|
|
798f231792 | ||
|
|
7136890da3 | ||
|
|
d567192fd3 | ||
|
|
dcc4025c78 | ||
|
|
c6c8ec36a1 | ||
|
|
1344c0659a | ||
|
|
973f6d20f4 | ||
|
|
8b5c9c51e7 | ||
|
|
bae208bcc4 | ||
|
|
b6c14ad468 | ||
|
|
0064cc2a6e | ||
|
|
0a0567e944 | ||
|
|
694b1d43a8 | ||
|
|
e7eb116bd2 | ||
|
|
596499a08c | ||
|
|
2a2e460df2 | ||
|
|
a9039b35ed | ||
|
|
a01154a507 | ||
|
|
1d9204282d | ||
|
|
5ff40a0d2d | ||
|
|
fab6d2e4e0 | ||
|
|
abab59c25f | ||
|
|
c25840b585 | ||
|
|
1b3f9125bb | ||
|
|
b5d9f5ba49 | ||
|
|
1c22aa9c8f | ||
|
|
e1d7fb879c | ||
|
|
e912c42bf0 | ||
|
|
e6841acf36 | ||
|
|
bc4459b6f4 | ||
|
|
9b544491e0 | ||
|
|
9c5415b598 | ||
|
|
040dbc317f | ||
|
|
65775046d8 | ||
|
|
b18bc36127 | ||
|
|
f01c526efd | ||
|
|
16168ab6b3 | ||
|
|
4233218629 | ||
|
|
b63fb36dc0 | ||
|
|
4e92304b89 | ||
|
|
2ae047f1a8 | ||
|
|
6d2a485264 | ||
|
|
4f045db024 | ||
|
|
5b33597b6d | ||
|
|
962470f610 | ||
|
|
ba8c116380 | ||
|
|
ad7330eae4 | ||
|
|
cf126e4839 | ||
|
|
c96d25c3e2 | ||
|
|
006aa0dae2 | ||
|
|
5b204bee86 | ||
|
|
d98b2afbe9 | ||
|
|
681332ef32 | ||
|
|
c3a4fdcbfc | ||
|
|
aac5de5b02 | ||
|
|
13a255afad | ||
|
|
3bffda52f9 | ||
|
|
d4e62ce557 | ||
|
|
9738483b18 | ||
|
|
143492fe94 | ||
|
|
ecc5c662c4 | ||
|
|
d973ba191d | ||
|
|
0198b183a2 | ||
|
|
0d44a3527b | ||
|
|
2147b6a397 | ||
|
|
6b5b4ba27b | ||
|
|
67005bf57c | ||
|
|
0430c741c6 | ||
|
|
1ce02e365d | ||
|
|
eae862adc2 | ||
|
|
dffa89524a | ||
|
|
2af1102441 | ||
|
|
c4b472842a | ||
|
|
750a7d806f | ||
|
|
bc7333f1e5 | ||
|
|
55ae50f991 | ||
|
|
a590c331ef | ||
|
|
8c241b06cb | ||
|
|
9c072c8068 | ||
|
|
ebd8b5122a | ||
|
|
055e484a40 | ||
|
|
912c4a1d12 | ||
|
|
c203b65bf1 | ||
|
|
307f0334ee | ||
|
|
5167df08b9 | ||
|
|
dd2e482214 | ||
|
|
87fd13d8eb | ||
|
|
dd423bc6de | ||
|
|
899cb9cc1f | ||
|
|
0464c7e558 | ||
|
|
f64e1fb926 | ||
|
|
ef7d31293d | ||
|
|
6d54eb68dc | ||
|
|
30eb10c990 | ||
|
|
591bbcd058 | ||
|
|
99aa77d036 | ||
|
|
9c13f1e635 | ||
|
|
24af983cfb | ||
|
|
67842a7525 | ||
|
|
3159a6f3e1 | ||
|
|
b2f3c96835 | ||
|
|
6582475955 | ||
|
|
41ee65b377 | ||
|
|
83fe477066 | ||
|
|
4ca84ee4ee | ||
|
|
c28cc4c919 | ||
|
|
e9864cb3f7 | ||
|
|
83c69ecd49 | ||
|
|
3595b4aaff | ||
|
|
3a9cfe113a | ||
|
|
c9966127da | ||
|
|
51300d33a7 | ||
|
|
5af124c5a5 | ||
|
|
eeb20b531a | ||
|
|
9dca842c22 | ||
|
|
1eb9436836 | ||
|
|
9604d9ce81 | ||
|
|
481d0553d8 | ||
|
|
60035cd63a | ||
|
|
d35f992ace | ||
|
|
157ae64f9d | ||
|
|
ffa17f6057 | ||
|
|
d695a43e32 | ||
|
|
01f6b4e6f0 | ||
|
|
7cf31a6ae4 | ||
|
|
fbd6224b04 | ||
|
|
8115b26079 | ||
|
|
820586ac68 | ||
|
|
4a7441ed07 | ||
|
|
383741f284 | ||
|
|
2bbc4e0e9f | ||
|
|
a7237244b0 | ||
|
|
1d38d49162 | ||
|
|
a783c089a9 | ||
|
|
e7907dc532 | ||
|
|
394413679d | ||
|
|
37189f14cb | ||
|
|
0b1ee81901 | ||
|
|
00cf73f9b8 | ||
|
|
5a5f285493 | ||
|
|
7f2ea454b6 | ||
|
|
7c14002118 | ||
|
|
3e9554f0a1 | ||
|
|
e11ffec544 | ||
|
|
8a47ddbe99 | ||
|
|
821108c7bd | ||
|
|
339738f8a3 | ||
|
|
9b90672f63 | ||
|
|
ba07e94a5e | ||
|
|
b3fc0f29cc | ||
|
|
5c7deb3611 | ||
|
|
15604e374f | ||
|
|
7cfc0fa55b | ||
|
|
a90812133b | ||
|
|
e26a70aa4f | ||
|
|
6a32a4e26c | ||
|
|
e853abf98b | ||
|
|
51e81e6ef8 | ||
|
|
e355000ceb | ||
|
|
e374074013 | ||
|
|
81e3d1c2c6 | ||
|
|
ab0cbb4475 | ||
|
|
1c64e40722 | ||
|
|
8cafe56eb4 | ||
|
|
3eceeb7b23 | ||
|
|
1a37675435 | ||
|
|
198ebede8d | ||
|
|
a504903dd5 | ||
|
|
842adef29c | ||
|
|
7edcaf5a06 | ||
|
|
c124b76328 | ||
|
|
e9c744ee5d | ||
|
|
83302930d8 | ||
|
|
a4634632ba | ||
|
|
d17e8dc5ad | ||
|
|
9fe63de4d4 | ||
|
|
8111f8bf35 | ||
|
|
fcd62513cf | ||
|
|
c3c701e654 | ||
|
|
6bf991edf6 | ||
|
|
9644e78545 | ||
|
|
c911189ef0 | ||
|
|
1118b4b651 | ||
|
|
4be75d4418 | ||
|
|
fb6beae27c | ||
|
|
fee73b0b63 | ||
|
|
9bbffa519e | ||
|
|
c3a641f0ab | ||
|
|
aafe7c4701 | ||
|
|
9a0b082cf8 | ||
|
|
8265e34a29 | ||
|
|
8ef8ae097f | ||
|
|
c3d14293c0 | ||
|
|
d55d8be504 | ||
|
|
03543030d3 | ||
|
|
fc6b474b92 | ||
|
|
a5db785dd7 | ||
|
|
1c1c5cd611 | ||
|
|
6ed02f70ec | ||
|
|
cb78cd8ac0 | ||
|
|
0c4590b45a | ||
|
|
d2e2ee6efa | ||
|
|
6a380a0b48 | ||
|
|
e5d5acbf1f | ||
|
|
00e38abbf0 | ||
|
|
e3e4ea5443 | ||
|
|
a3e4ea3228 | ||
|
|
56f16d6baf | ||
|
|
7a55ab900e | ||
|
|
137643fe72 | ||
|
|
d6e59c6241 | ||
|
|
458eb5d34c | ||
|
|
8259f08864 | ||
|
|
b3ab0a1843 | ||
|
|
f09f217478 | ||
|
|
e842c8c19b | ||
|
|
f6c3112d44 | ||
|
|
7059610632 | ||
|
|
2d272930d9 | ||
|
|
6c470d8131 | ||
|
|
30b29ce8cd | ||
|
|
1a9933002f | ||
|
|
c4a9365aa1 | ||
|
|
9d3af37104 | ||
|
|
7b3d57cff7 | ||
|
|
a802270da9 | ||
|
|
dd194a8758 | ||
|
|
6de02de221 | ||
|
|
85259750bf | ||
|
|
1249f0007d | ||
|
|
db0514d3fa | ||
|
|
dce42a7fad | ||
|
|
ec0b380194 | ||
|
|
7f27b61c98 | ||
|
|
f0b3557b02 | ||
|
|
2a1d1c1001 | ||
|
|
df7eb80e5b | ||
|
|
b9d947ce6f | ||
|
|
e6589d2454 | ||
|
|
0f5ac6afcf | ||
|
|
bc1bb1d188 | ||
|
|
3af2dd10ce | ||
|
|
dd22c65855 | ||
|
|
48137ced19 | ||
|
|
6eb47c12d1 | ||
|
|
5a1fc6675a | ||
|
|
6f80825814 | ||
|
|
f0dd48ed2a | ||
|
|
15e2df0db0 | ||
|
|
4ad0109769 | ||
|
|
ee0009d4b8 | ||
|
|
9d851c3346 | ||
|
|
5d117af8ae | ||
|
|
bb41c2d15e | ||
|
|
eba138ee4a | ||
|
|
3b2bbb74f8 | ||
|
|
dbc0f81211 | ||
|
|
d0b613d22e | ||
|
|
72f29b67d5 | ||
|
|
9570045cc3 | ||
|
|
e4efdb5cbb | ||
|
|
187f0fa70c | ||
|
|
472185c3e4 | ||
|
|
f94a571773 | ||
|
|
183e447d35 | ||
|
|
12f844d93a | ||
|
|
47a119a37f | ||
|
|
ee56559b9a | ||
|
|
00e594deea | ||
|
|
6ad9b213b9 | ||
|
|
e4375e8195 | ||
|
|
487bf8e29b | ||
|
|
fea1694e74 | ||
|
|
4102c124a9 | ||
|
|
135bad3280 | ||
|
|
b604f36881 | ||
|
|
782b449c71 | ||
|
|
017dcab685 | ||
|
|
e60b4568c6 | ||
|
|
4ee3d95a5a | ||
|
|
f18725bacc | ||
|
|
f6064a2b84 | ||
|
|
2e90cb7b95 | ||
|
|
2c09d63cd9 | ||
|
|
cc6fbdb0c3 | ||
|
|
ecfdec12f3 |
5
.flake8
Normal file
5
.flake8
Normal file
@@ -0,0 +1,5 @@
|
||||
[flake8]
|
||||
count = 1
|
||||
show-source = 1
|
||||
select = E9,F63,F7,F82
|
||||
exclude = lit.cfg.py, apps/language_models/scripts/vicuna.py, apps/language_models/src/pipelines/minigpt4_pipeline.py, apps/language_models/langchain/h2oai_pipeline.py
|
||||
43
.github/workflows/nightly.yml
vendored
43
.github/workflows/nightly.yml
vendored
@@ -10,14 +10,14 @@ on:
|
||||
|
||||
jobs:
|
||||
windows-build:
|
||||
runs-on: windows-latest
|
||||
runs-on: 7950X
|
||||
strategy:
|
||||
fail-fast: false
|
||||
matrix:
|
||||
python-version: ["3.10"]
|
||||
python-version: ["3.11"]
|
||||
|
||||
steps:
|
||||
- uses: actions/checkout@v3
|
||||
- uses: actions/checkout@v2
|
||||
- name: Set up Python ${{ matrix.python-version }}
|
||||
uses: actions/setup-python@v3
|
||||
with:
|
||||
@@ -44,27 +44,19 @@ jobs:
|
||||
body: |
|
||||
Automatic snapshot release of nod.ai SHARK.
|
||||
draft: true
|
||||
prerelease: false
|
||||
prerelease: true
|
||||
|
||||
- name: Build Package
|
||||
shell: powershell
|
||||
run: |
|
||||
./setup_venv.ps1
|
||||
pyinstaller web/shark_sd.spec
|
||||
mv ./dist/shark_sd.exe ./dist/shark_sd_${{ env.package_version_ }}.exe
|
||||
|
||||
|
||||
# GHA windows VM OOMs so disable for now
|
||||
#- name: Build and validate the SHARK Runtime package
|
||||
# shell: powershell
|
||||
# run: |
|
||||
# $env:SHARK_PACKAGE_VERSION=${{ env.package_version }}
|
||||
# pip wheel -v -w dist . --pre -f https://download.pytorch.org/whl/nightly/torch -f https://llvm.github.io/torch-mlir/package-index/ -f https://nod-ai.github.io/SHARK-Runtime/pip-release-links.html
|
||||
|
||||
- uses: actions/upload-artifact@v2
|
||||
with:
|
||||
path: dist/*
|
||||
|
||||
$env:SHARK_PACKAGE_VERSION=${{ env.package_version }}
|
||||
pip wheel -v -w dist . --pre -f https://download.pytorch.org/whl/nightly/cpu -f https://llvm.github.io/torch-mlir/package-index/ -f https://nod-ai.github.io/SRT/pip-release-links.html
|
||||
python process_skipfiles.py
|
||||
pyinstaller .\apps\stable_diffusion\shark_sd.spec
|
||||
mv ./dist/nodai_shark_studio.exe ./dist/nodai_shark_studio_${{ env.package_version_ }}.exe
|
||||
signtool sign /f c:\g\shark_02152023.cer /fd certHash /csp "eToken Base Cryptographic Provider" /k "${{ secrets.CI_CERT }}" ./dist/nodai_shark_studio_${{ env.package_version_ }}.exe
|
||||
|
||||
- name: Upload Release Assets
|
||||
id: upload-release-assets
|
||||
uses: dwenegar/upload-release-assets@v1
|
||||
@@ -72,7 +64,8 @@ jobs:
|
||||
GITHUB_TOKEN: ${{ secrets.NODAI_INVOCATION_TOKEN }}
|
||||
with:
|
||||
release_id: ${{ steps.create_release.outputs.id }}
|
||||
assets_path: ./dist/*
|
||||
assets_path: ./dist/nodai*
|
||||
#asset_content_type: application/vnd.microsoft.portable-executable
|
||||
|
||||
- name: Publish Release
|
||||
id: publish_release
|
||||
@@ -88,7 +81,7 @@ jobs:
|
||||
strategy:
|
||||
fail-fast: false
|
||||
matrix:
|
||||
python-version: ["3.10"]
|
||||
python-version: ["3.11"]
|
||||
backend: [IREE, SHARK]
|
||||
|
||||
steps:
|
||||
@@ -111,7 +104,7 @@ jobs:
|
||||
echo "DATE=$(date +'%Y-%m-%d')" >> $GITHUB_ENV
|
||||
python -m pip install --upgrade pip
|
||||
python -m pip install flake8 pytest toml
|
||||
if [ -f requirements.txt ]; then pip install -r requirements.txt -f https://llvm.github.io/torch-mlir/package-index/ -f https://nod-ai.github.io/SHARK-Runtime/pip-release-links.html; fi
|
||||
if [ -f requirements.txt ]; then pip install -r requirements.txt -f https://llvm.github.io/torch-mlir/package-index/ -f https://nod-ai.github.io/SRT/pip-release-links.html; fi
|
||||
- name: Lint with flake8
|
||||
run: |
|
||||
# stop the build if there are Python syntax errors or undefined names
|
||||
@@ -127,7 +120,7 @@ jobs:
|
||||
source iree.venv/bin/activate
|
||||
package_version="$(printf '%(%Y%m%d)T.${{ github.run_number }}')"
|
||||
SHARK_PACKAGE_VERSION=${package_version} \
|
||||
pip wheel -v -w wheelhouse . --pre -f https://download.pytorch.org/whl/nightly/torch -f https://llvm.github.io/torch-mlir/package-index/ -f https://iree-org.github.io/iree/pip-release-links.html
|
||||
pip wheel -v -w wheelhouse . --pre -f https://download.pytorch.org/whl/nightly/torch -f https://llvm.github.io/torch-mlir/package-index/ -f https://openxla.github.io/iree/pip-release-links.html
|
||||
# Install the built wheel
|
||||
pip install ./wheelhouse/nodai*
|
||||
# Validate the Models
|
||||
@@ -139,7 +132,7 @@ jobs:
|
||||
then
|
||||
export SHA=$(git log -1 --format='%h')
|
||||
gsutil -m cp -r $GITHUB_WORKSPACE/gen_shark_tank/* gs://shark_tank/${DATE}_$SHA
|
||||
gsutil -m cp -r gs://shark_tank/${DATE}_$SHA/* gs://shark_tank/latest/
|
||||
gsutil -m cp -r gs://shark_tank/${DATE}_$SHA/* gs://shark_tank/nightly/
|
||||
fi
|
||||
rm -rf ./wheelhouse/nodai*
|
||||
|
||||
@@ -151,7 +144,7 @@ jobs:
|
||||
source shark.venv/bin/activate
|
||||
package_version="$(printf '%(%Y%m%d)T.${{ github.run_number }}')"
|
||||
SHARK_PACKAGE_VERSION=${package_version} \
|
||||
pip wheel -v -w wheelhouse . --pre -f https://download.pytorch.org/whl/nightly/torch -f https://llvm.github.io/torch-mlir/package-index/ -f https://nod-ai.github.io/SHARK-Runtime/pip-release-links.html
|
||||
pip wheel -v -w wheelhouse . --pre -f https://download.pytorch.org/whl/nightly/torch -f https://llvm.github.io/torch-mlir/package-index/ -f https://nod-ai.github.io/SRT/pip-release-links.html
|
||||
# Install the built wheel
|
||||
pip install ./wheelhouse/nodai*
|
||||
# Validate the Models
|
||||
|
||||
136
.github/workflows/test-models.yml
vendored
136
.github/workflows/test-models.yml
vendored
@@ -1,136 +0,0 @@
|
||||
# This workflow will install Python dependencies, run tests and lint with a variety of Python versions
|
||||
# For more information see: https://help.github.com/actions/language-and-framework-guides/using-python-with-github-actions
|
||||
|
||||
name: Validate Models on Shark Runtime
|
||||
|
||||
on:
|
||||
push:
|
||||
branches: [ main ]
|
||||
paths-ignore:
|
||||
- '**.md'
|
||||
- 'shark/examples/**'
|
||||
pull_request:
|
||||
branches: [ main ]
|
||||
paths-ignore:
|
||||
- '**.md'
|
||||
- 'shark/examples/**'
|
||||
workflow_dispatch:
|
||||
|
||||
# Ensure that only a single job or workflow using the same
|
||||
# concurrency group will run at a time. This would cancel
|
||||
# any in-progress jobs in the same github workflow and github
|
||||
# ref (e.g. refs/heads/main or refs/pull/<pr_number>/merge).
|
||||
concurrency:
|
||||
group: ${{ github.workflow }}-${{ github.ref }}
|
||||
cancel-in-progress: true
|
||||
|
||||
jobs:
|
||||
build-validate:
|
||||
strategy:
|
||||
fail-fast: true
|
||||
matrix:
|
||||
os: [icelake, a100, MacStudio, ubuntu-latest]
|
||||
suite: [cpu,cuda,vulkan]
|
||||
python-version: ["3.10"]
|
||||
include:
|
||||
- os: ubuntu-latest
|
||||
suite: lint
|
||||
exclude:
|
||||
- os: ubuntu-latest
|
||||
suite: vulkan
|
||||
- os: ubuntu-latest
|
||||
suite: cuda
|
||||
- os: ubuntu-latest
|
||||
suite: cpu
|
||||
- os: MacStudio
|
||||
suite: cuda
|
||||
- os: MacStudio
|
||||
suite: cpu
|
||||
- os: icelake
|
||||
suite: vulkan
|
||||
- os: icelake
|
||||
suite: cuda
|
||||
- os: a100
|
||||
suite: cpu
|
||||
|
||||
runs-on: ${{ matrix.os }}
|
||||
|
||||
steps:
|
||||
- uses: actions/checkout@v3
|
||||
|
||||
- name: Set Environment Variables
|
||||
run: |
|
||||
echo "SHORT_SHA=`git rev-parse --short=4 HEAD`" >> $GITHUB_ENV
|
||||
echo "DATE=$(date +'%Y-%m-%d')" >> $GITHUB_ENV
|
||||
|
||||
- name: Set up Python Version File ${{ matrix.python-version }}
|
||||
if: matrix.os == 'a100' || matrix.os == 'ubuntu-latest' || matrix.os == 'icelake'
|
||||
run: |
|
||||
# See https://github.com/actions/setup-python/issues/433
|
||||
echo ${{ matrix.python-version }} >> $GITHUB_WORKSPACE/.python-version
|
||||
|
||||
- name: Set up Python ${{ matrix.python-version }}
|
||||
if: matrix.os == 'a100' || matrix.os == 'ubuntu-latest' || matrix.os == 'icelake'
|
||||
uses: actions/setup-python@v4
|
||||
with:
|
||||
python-version: '${{ matrix.python-version }}'
|
||||
#cache: 'pip'
|
||||
#cache-dependency-path: |
|
||||
# **/requirements-importer.txt
|
||||
# **/requirements.txt
|
||||
|
||||
- name: Install dependencies
|
||||
if: matrix.suite == 'lint'
|
||||
run: |
|
||||
python -m pip install --upgrade pip
|
||||
python -m pip install flake8 pytest toml black
|
||||
|
||||
- name: Lint with flake8
|
||||
if: matrix.suite == 'lint'
|
||||
run: |
|
||||
# black format check
|
||||
black --version
|
||||
black --line-length 79 --check .
|
||||
# stop the build if there are Python syntax errors or undefined names
|
||||
flake8 . --count --select=E9,F63,F7,F82 --show-source --statistics --exclude lit.cfg.py
|
||||
# exit-zero treats all errors as warnings. The GitHub editor is 127 chars wide
|
||||
flake8 . --count --exit-zero --max-complexity=10 --max-line-length=127 --statistics --exclude lit.cfg.py
|
||||
|
||||
- name: Validate Models on CPU
|
||||
if: matrix.suite == 'cpu'
|
||||
run: |
|
||||
cd $GITHUB_WORKSPACE
|
||||
PYTHON=python${{ matrix.python-version }} BENCHMARK=1 IMPORTER=1 ./setup_venv.sh
|
||||
source shark.venv/bin/activate
|
||||
pytest --benchmark --ci --ci_sha=${SHORT_SHA} -s --local_tank_cache="/data/anush/shark_cache" tank/test_models.py -k cpu --update_tank
|
||||
gsutil cp ./bench_results.csv gs://shark-public/builder/bench_results/${DATE}/bench_results_cpu_${SHORT_SHA}.csv
|
||||
gsutil cp gs://shark-public/builder/bench_results/${DATE}/bench_results_cpu_${SHORT_SHA}.csv gs://shark-public/builder/bench_results/latest/bench_results_cpu_latest.csv
|
||||
|
||||
- name: Validate Models on NVIDIA GPU
|
||||
if: matrix.suite == 'cuda'
|
||||
run: |
|
||||
cd $GITHUB_WORKSPACE
|
||||
PYTHON=python${{ matrix.python-version }} BENCHMARK=1 IMPORTER=1 ./setup_venv.sh
|
||||
source shark.venv/bin/activate
|
||||
pytest --benchmark --ci --ci_sha=${SHORT_SHA} -s --local_tank_cache="/data/anush/shark_cache" tank/test_models.py -k cuda --update_tank
|
||||
gsutil cp ./bench_results.csv gs://shark-public/builder/bench_results/${DATE}/bench_results_cuda_${SHORT_SHA}.csv
|
||||
gsutil cp gs://shark-public/builder/bench_results/${DATE}/bench_results_cuda_${SHORT_SHA}.csv gs://shark-public/builder/bench_results/latest/bench_results_cuda_latest.csv
|
||||
|
||||
- name: Validate Vulkan Models (MacOS)
|
||||
if: matrix.suite == 'vulkan' && matrix.os == 'MacStudio'
|
||||
run: |
|
||||
cd $GITHUB_WORKSPACE
|
||||
PYTHON=python${{ matrix.python-version }} IMPORTER=1 ./setup_venv.sh
|
||||
source shark.venv/bin/activate
|
||||
export DYLD_LIBRARY_PATH=/usr/local/lib/
|
||||
echo $PATH
|
||||
pip list | grep -E "torch|iree"
|
||||
pytest -s --ci --ci_sha=${SHORT_SHA} --local_tank_cache="/Volumes/builder/anush/shark_cache" tank/test_models.py -k vulkan --update_tank
|
||||
|
||||
- name: Validate Vulkan Models (a100)
|
||||
if: matrix.suite == 'vulkan' && matrix.os != 'MacStudio'
|
||||
run: |
|
||||
cd $GITHUB_WORKSPACE
|
||||
PYTHON=python${{ matrix.python-version }} ./setup_venv.sh
|
||||
source shark.venv/bin/activate
|
||||
pytest --benchmark --ci --ci_sha=${SHORT_SHA} -s --local_tank_cache="/data/anush/shark_cache" tank/test_models.py -k vulkan --update_tank
|
||||
86
.github/workflows/test-studio.yml
vendored
Normal file
86
.github/workflows/test-studio.yml
vendored
Normal file
@@ -0,0 +1,86 @@
|
||||
# This workflow will install Python dependencies, run tests and lint with a variety of Python versions
|
||||
# For more information see: https://help.github.com/actions/language-and-framework-guides/using-python-with-github-actions
|
||||
|
||||
name: Validate Shark Studio
|
||||
|
||||
on:
|
||||
push:
|
||||
branches: [ main ]
|
||||
paths-ignore:
|
||||
- '**.md'
|
||||
- 'shark/examples/**'
|
||||
pull_request:
|
||||
branches: [ main ]
|
||||
paths-ignore:
|
||||
- '**.md'
|
||||
- 'shark/examples/**'
|
||||
workflow_dispatch:
|
||||
|
||||
# Ensure that only a single job or workflow using the same
|
||||
# concurrency group will run at a time. This would cancel
|
||||
# any in-progress jobs in the same github workflow and github
|
||||
# ref (e.g. refs/heads/main or refs/pull/<pr_number>/merge).
|
||||
concurrency:
|
||||
group: ${{ github.workflow }}-${{ github.ref }}
|
||||
cancel-in-progress: true
|
||||
|
||||
jobs:
|
||||
build-validate:
|
||||
strategy:
|
||||
fail-fast: true
|
||||
matrix:
|
||||
os: [nodai-ubuntu-builder-large]
|
||||
suite: [cpu] #,cuda,vulkan]
|
||||
python-version: ["3.11"]
|
||||
include:
|
||||
- os: nodai-ubuntu-builder-large
|
||||
suite: lint
|
||||
|
||||
runs-on: ${{ matrix.os }}
|
||||
|
||||
steps:
|
||||
- uses: actions/checkout@v3
|
||||
|
||||
- name: Set Environment Variables
|
||||
run: |
|
||||
echo "SHORT_SHA=`git rev-parse --short=4 HEAD`" >> $GITHUB_ENV
|
||||
echo "DATE=$(date +'%Y-%m-%d')" >> $GITHUB_ENV
|
||||
|
||||
- name: Set up Python Version File ${{ matrix.python-version }}
|
||||
run: |
|
||||
echo ${{ matrix.python-version }} >> $GITHUB_WORKSPACE/.python-version
|
||||
|
||||
- name: Set up Python ${{ matrix.python-version }}
|
||||
uses: actions/setup-python@v4
|
||||
with:
|
||||
python-version: '${{ matrix.python-version }}'
|
||||
|
||||
- name: Install dependencies
|
||||
if: matrix.suite == 'lint'
|
||||
run: |
|
||||
python -m pip install --upgrade pip
|
||||
python -m pip install flake8 pytest toml black
|
||||
|
||||
- name: Lint with flake8
|
||||
if: matrix.suite == 'lint'
|
||||
run: |
|
||||
# black format check
|
||||
black --version
|
||||
black --check apps/shark_studio
|
||||
# stop the build if there are Python syntax errors or undefined names
|
||||
flake8 . --statistics
|
||||
# exit-zero treats all errors as warnings. The GitHub editor is 127 chars wide
|
||||
flake8 . --isolated --count --exit-zero --max-complexity=10 --max-line-length=127 \
|
||||
--statistics --exclude lit.cfg.py
|
||||
|
||||
- name: Validate Models on CPU
|
||||
if: matrix.suite == 'cpu'
|
||||
run: |
|
||||
cd $GITHUB_WORKSPACE
|
||||
python${{ matrix.python-version }} -m venv shark.venv
|
||||
source shark.venv/bin/activate
|
||||
pip install -r requirements.txt --no-cache-dir
|
||||
pip install -e .
|
||||
pip uninstall -y torch
|
||||
pip install torch==2.1.0+cpu -f https://download.pytorch.org/whl/torch_stable.html
|
||||
python apps/shark_studio/tests/api_test.py
|
||||
37
.gitignore
vendored
37
.gitignore
vendored
@@ -2,6 +2,8 @@
|
||||
__pycache__/
|
||||
*.py[cod]
|
||||
*$py.class
|
||||
*.mlir
|
||||
*.vmfb
|
||||
|
||||
# C extensions
|
||||
*.so
|
||||
@@ -157,7 +159,10 @@ cython_debug/
|
||||
# be found at https://github.com/github/gitignore/blob/main/Global/JetBrains.gitignore
|
||||
# and can be added to the global gitignore or merged into this file. For a more nuclear
|
||||
# option (not recommended) you can uncomment the following to ignore the entire idea folder.
|
||||
#.idea/
|
||||
.idea/
|
||||
|
||||
# vscode related
|
||||
.vscode
|
||||
|
||||
# Shark related artefacts
|
||||
*venv/
|
||||
@@ -165,11 +170,35 @@ shark_tmp/
|
||||
*.vmfb
|
||||
.use-iree
|
||||
tank/dict_configs.py
|
||||
*.csv
|
||||
reproducers/
|
||||
|
||||
# ORT related artefacts
|
||||
cache_models/
|
||||
onnx_models/
|
||||
|
||||
#web logging
|
||||
web/logs/
|
||||
web/stored_results/stable_diffusion/
|
||||
# Generated images
|
||||
generated_imgs/
|
||||
|
||||
# Custom model related artefacts
|
||||
variants.json
|
||||
/models/
|
||||
|
||||
# models folder
|
||||
apps/stable_diffusion/web/models/
|
||||
|
||||
# Stencil annotators.
|
||||
stencil_annotator/
|
||||
|
||||
# For DocuChat
|
||||
apps/language_models/langchain/user_path/
|
||||
db_dir_UserData
|
||||
|
||||
# Embeded browser cache and other
|
||||
apps/stable_diffusion/web/EBWebView/
|
||||
|
||||
# Llama2 tokenizer configs
|
||||
llama2_tokenizer_configs/
|
||||
|
||||
# Webview2 runtime artefacts
|
||||
EBWebView/
|
||||
|
||||
2
.gitmodules
vendored
2
.gitmodules
vendored
@@ -1,4 +1,4 @@
|
||||
[submodule "inference/thirdparty/shark-runtime"]
|
||||
path = inference/thirdparty/shark-runtime
|
||||
url =https://github.com/nod-ai/SHARK-Runtime.git
|
||||
url =https://github.com/nod-ai/SRT.git
|
||||
branch = shark-06032022
|
||||
|
||||
@@ -1,3 +0,0 @@
|
||||
[style]
|
||||
based_on_style = google
|
||||
column_limit = 80
|
||||
132
README.md
132
README.md
@@ -1,12 +1,61 @@
|
||||
# SHARK
|
||||
|
||||
High Performance Machine Learning and Data Analytics for CPUs, GPUs, Accelerators and Heterogeneous Clusters
|
||||
High Performance Machine Learning Distribution
|
||||
|
||||
[](https://github.com/nod-ai/SHARK/actions/workflows/nightly.yml)
|
||||
[](https://github.com/nod-ai/SHARK/actions/workflows/test-models.yml)
|
||||
|
||||
|
||||
## Installation (Windows, Linux and macOS)
|
||||
<details>
|
||||
<summary>Prerequisites - Drivers </summary>
|
||||
|
||||
#### Install your Windows hardware drivers
|
||||
* [AMD RDNA Users] Download the latest driver (23.2.1 is the oldest supported) [here](https://www.amd.com/en/support).
|
||||
* [macOS Users] Download and install the 1.3.216 Vulkan SDK from [here](https://sdk.lunarg.com/sdk/download/1.3.216.0/mac/vulkansdk-macos-1.3.216.0.dmg). Newer versions of the SDK will not work.
|
||||
* [Nvidia Users] Download and install the latest CUDA / Vulkan drivers from [here](https://developer.nvidia.com/cuda-downloads)
|
||||
|
||||
#### Linux Drivers
|
||||
* MESA / RADV drivers wont work with FP16. Please use the latest AMGPU-PRO drivers (non-pro OSS drivers also wont work) or the latest NVidia Linux Drivers.
|
||||
|
||||
Other users please ensure you have your latest vendor drivers and Vulkan SDK from [here](https://vulkan.lunarg.com/sdk/home) and if you are using vulkan check `vulkaninfo` works in a terminal window
|
||||
|
||||
</details>
|
||||
|
||||
|
||||
|
||||
### Quick Start for SHARK Stable Diffusion for Windows 10/11 Users
|
||||
|
||||
Install the Driver from [Prerequisites](https://github.com/nod-ai/SHARK#install-your-hardware-drivers) above
|
||||
|
||||
Download the [stable release](https://github.com/nod-ai/shark/releases/latest)
|
||||
|
||||
Double click the .exe and you should have the [UI](http://localhost:8080/) in the browser.
|
||||
|
||||
If you have custom models put them in a `models/` directory where the .exe is.
|
||||
|
||||
Enjoy.
|
||||
|
||||
<details>
|
||||
<summary>More installation notes</summary>
|
||||
* We recommend that you download EXE in a new folder, whenever you download a new EXE version. If you download it in the same folder as a previous install, you must delete the old `*.vmfb` files with `rm *.vmfb`. You can also use `--clear_all` flag once to clean all the old files.
|
||||
* If you recently updated the driver or this binary (EXE file), we recommend you clear all the local artifacts with `--clear_all`
|
||||
|
||||
## Running
|
||||
|
||||
* Open a Command Prompt or Powershell terminal, change folder (`cd`) to the .exe folder. Then run the EXE from the command prompt. That way, if an error occurs, you'll be able to cut-and-paste it to ask for help. (if it always works for you without error, you may simply double-click the EXE)
|
||||
* The first run may take few minutes when the models are downloaded and compiled. Your patience is appreciated. The download could be about 5GB.
|
||||
* You will likely see a Windows Defender message asking you to give permission to open a web server port. Accept it.
|
||||
* Open a browser to access the Stable Diffusion web server. By default, the port is 8080, so you can go to http://localhost:8080/.
|
||||
|
||||
## Stopping
|
||||
|
||||
* Select the command prompt that's running the EXE. Press CTRL-C and wait a moment or close the terminal.
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>Advanced Installation (Only for developers)</summary>
|
||||
|
||||
## Advanced Installation (Windows, Linux and macOS) for developers
|
||||
|
||||
## Check out the code
|
||||
|
||||
@@ -19,7 +68,7 @@ cd SHARK
|
||||
|
||||
### Windows 10/11 Users
|
||||
|
||||
* Install the latest Python 3.10.x version from [here](https://www.python.org/downloads/windows/)
|
||||
* Install the latest Python 3.11.x version from [here](https://www.python.org/downloads/windows/)
|
||||
|
||||
* Install Git for Windows from [here](https://git-scm.com/download/win)
|
||||
|
||||
@@ -45,12 +94,12 @@ source shark.venv/bin/activate
|
||||
|
||||
#### Windows 10/11 Users
|
||||
```powershell
|
||||
(shark.venv) PS C:\Users\nod\SHARK> cd web
|
||||
(shark.venv) PS C:\Users\nod\SHARK\web> python index.py
|
||||
(shark.venv) PS C:\g\shark> cd .\apps\stable_diffusion\web\
|
||||
(shark.venv) PS C:\g\shark\apps\stable_diffusion\web> python .\index.py
|
||||
```
|
||||
#### Linux Users
|
||||
#### Linux / macOS Users
|
||||
```shell
|
||||
(shark.venv) > cd web
|
||||
(shark.venv) > cd apps/stable_diffusion/web
|
||||
(shark.venv) > python index.py
|
||||
```
|
||||
|
||||
@@ -63,39 +112,27 @@ source shark.venv/bin/activate
|
||||
|
||||
### Run Stable Diffusion on your device - Commandline
|
||||
|
||||
#### Install your hardware drivers
|
||||
* [AMD RDNA Users] Download the latest driver [here](https://www.amd.com/en/support/kb/release-notes/rn-rad-win-22-11-1-mril-iree)
|
||||
* [macOS Users] Download and install the latest Vulkan SDK from [here](https://vulkan.lunarg.com/sdk/home)
|
||||
* [Nvidia Users] Download and install the latest CUDA / Vulkan drivers from [here](https://developer.nvidia.com/cuda-downloads)
|
||||
|
||||
Other users please ensure you have your latest vendor drivers and Vulkan SDK from [here](https://vulkan.lunarg.com/sdk/home) and if you are using vulkan check `vulkaninfo` works in a terminal window
|
||||
|
||||
|
||||
#### Windows 10/11 Users
|
||||
```powershell
|
||||
(shark.venv) PS C:\g\shark> python .\shark\examples\shark_inference\stable_diffusion\main.py --precision="fp16" --prompt="tajmahal, snow, sunflowers, oil on canvas" --device="vulkan"
|
||||
(shark.venv) PS C:\g\shark> python .\apps\stable_diffusion\scripts\main.py --app="txt2img" --precision="fp16" --prompt="tajmahal, snow, sunflowers, oil on canvas" --device="vulkan"
|
||||
```
|
||||
|
||||
#### Linux / macOS Users
|
||||
```shell
|
||||
python3.10 shark/examples/shark_inference/stable_diffusion/main.py --precision=fp16 --device=vulkan --prompt="tajmahal, oil on canvas, sunflowers, 4k, uhd"
|
||||
python3.11 apps/stable_diffusion/scripts/main.py --app=txt2img --precision=fp16 --device=vulkan --prompt="tajmahal, oil on canvas, sunflowers, 4k, uhd"
|
||||
```
|
||||
|
||||
You can replace `vulkan` with `cpu` to run on your CPU or with `cuda` to run on CUDA devices. If you have multiple vulkan devices you can address them with `--device=vulkan://1` etc
|
||||
</details>
|
||||
|
||||
The output on a 6900XT would like:
|
||||
The output on a AMD 7900XTX would look something like:
|
||||
|
||||
```shell
|
||||
44it [00:08, 5.14it/s]i = 44 t = 120 (191ms)
|
||||
45it [00:08, 5.15it/s]i = 45 t = 100 (191ms)
|
||||
46it [00:08, 5.16it/s]i = 46 t = 80 (191ms)
|
||||
47it [00:09, 5.16it/s]i = 47 t = 60 (193ms)
|
||||
48it [00:09, 5.15it/s]i = 48 t = 40 (195ms)
|
||||
49it [00:09, 5.12it/s]i = 49 t = 20 (196ms)
|
||||
50it [00:09, 5.14it/s]
|
||||
Average step time: 192.8154182434082ms/it
|
||||
Total image generation runtime (s): 10.390909433364868
|
||||
(shark.venv) PS C:\g\shark>
|
||||
```shell
|
||||
Average step time: 47.19188690185547ms/it
|
||||
Clip Inference time (ms) = 109.531
|
||||
VAE Inference time (ms): 78.590
|
||||
|
||||
Total image generation time: 2.5788655281066895sec
|
||||
```
|
||||
|
||||
Here are some samples generated:
|
||||
@@ -105,9 +142,6 @@ Here are some samples generated:
|
||||

|
||||
|
||||
|
||||
|
||||
For more options to the Stable Diffusion model read [this](https://github.com/nod-ai/SHARK/blob/main/shark/examples/shark_inference/stable_diffusion/README.md)
|
||||
|
||||
Find us on [SHARK Discord server](https://discord.gg/RUqY2h2s9u) if you have any trouble with running it on your hardware.
|
||||
|
||||
|
||||
@@ -119,7 +153,7 @@ Find us on [SHARK Discord server](https://discord.gg/RUqY2h2s9u) if you have any
|
||||
This step sets up a new VirtualEnv for Python
|
||||
|
||||
```shell
|
||||
python --version #Check you have 3.10 on Linux, macOS or Windows Powershell
|
||||
python --version #Check you have 3.11 on Linux, macOS or Windows Powershell
|
||||
python -m venv shark_venv
|
||||
source shark_venv/bin/activate # Use shark_venv/Scripts/activate on Windows
|
||||
|
||||
@@ -133,10 +167,10 @@ python -m pip install --upgrade pip
|
||||
|
||||
### Install SHARK
|
||||
|
||||
This step pip installs SHARK and related packages on Linux Python 3.7, 3.8, 3.9, 3.10 and macOS Python 3.10
|
||||
This step pip installs SHARK and related packages on Linux Python 3.8, 3.10 and 3.11 and macOS / Windows Python 3.11
|
||||
|
||||
```shell
|
||||
pip install nodai-shark -f https://nod-ai.github.io/SHARK/package-index/ -f https://llvm.github.io/torch-mlir/package-index/ -f https://nod-ai.github.io/SHARK-Runtime/pip-release-links.html --extra-index-url https://download.pytorch.org/whl/nightly/cpu
|
||||
pip install nodai-shark -f https://nod-ai.github.io/SHARK/package-index/ -f https://llvm.github.io/torch-mlir/package-index/ -f https://nod-ai.github.io/SRT/pip-release-links.html --extra-index-url https://download.pytorch.org/whl/nightly/cpu
|
||||
```
|
||||
|
||||
### Run shark tank model tests.
|
||||
@@ -168,10 +202,10 @@ python ./minilm_jit.py --device="cpu" #use cuda or vulkan or metal
|
||||
<details>
|
||||
<summary>Development, Testing and Benchmarks</summary>
|
||||
|
||||
If you want to use Python3.10 and with TF Import tools you can use the environment variables like:
|
||||
If you want to use Python3.11 and with TF Import tools you can use the environment variables like:
|
||||
Set `USE_IREE=1` to use upstream IREE
|
||||
```
|
||||
# PYTHON=python3.10 VENV_DIR=0617_venv IMPORTER=1 ./setup_venv.sh
|
||||
# PYTHON=python3.11 VENV_DIR=0617_venv IMPORTER=1 ./setup_venv.sh
|
||||
```
|
||||
|
||||
### Run any of the hundreds of SHARK tank models via the test framework
|
||||
@@ -181,14 +215,14 @@ python -m shark.examples.shark_inference.resnet50_script --device="cpu" # Use g
|
||||
pytest tank/test_models.py -k "MiniLM"
|
||||
```
|
||||
|
||||
|
||||
### How to use your locally built IREE / Torch-MLIR with SHARK
|
||||
If you are a *Torch-mlir developer or an IREE developer* and want to test local changes you can uninstall
|
||||
the provided packages with `pip uninstall torch-mlir` and / or `pip uninstall iree-compiler iree-runtime` and build locally
|
||||
with Python bindings and set your PYTHONPATH as mentioned [here](https://github.com/iree-org/iree/tree/main/docs/api_docs/python#install-iree-binaries)
|
||||
for IREE and [here](https://github.com/llvm/torch-mlir/blob/main/development.md#setup-python-environment-to-export-the-built-python-packages)
|
||||
for Torch-MLIR.
|
||||
|
||||
### How to use your locally built Torch-MLIR with SHARK
|
||||
How to use your locally built Torch-MLIR with SHARK:
|
||||
```shell
|
||||
1.) Run `./setup_venv.sh in SHARK` and activate `shark.venv` virtual env.
|
||||
2.) Run `pip uninstall torch-mlir`.
|
||||
@@ -206,15 +240,20 @@ Now the SHARK will use your locally build Torch-MLIR repo.
|
||||
|
||||
## Benchmarking Dispatches
|
||||
|
||||
To produce benchmarks of individual dispatches, you can add `--dispatch_benchmarks=All --dispatch_benchmarks_dir=<output_dir>` to your command line argument.
|
||||
To produce benchmarks of individual dispatches, you can add `--dispatch_benchmarks=All --dispatch_benchmarks_dir=<output_dir>` to your pytest command line argument.
|
||||
If you only want to compile specific dispatches, you can specify them with a space seperated string instead of `"All"`. E.G. `--dispatch_benchmarks="0 1 2 10"`
|
||||
|
||||
For example, to generate and run dispatch benchmarks for MiniLM on CUDA:
|
||||
```
|
||||
pytest -k "MiniLM and torch and static and cuda" --benchmark_dispatches=All -s --dispatch_benchmarks_dir=./my_dispatch_benchmarks
|
||||
```
|
||||
The given command will populate `<dispatch_benchmarks_dir>/<model_name>/` with an `ordered_dispatches.txt` that lists and orders the dispatches and their latencies, as well as folders for each dispatch that contain .mlir, .vmfb, and results of the benchmark for that dispatch.
|
||||
|
||||
if you want to instead incorporate this into a python script, you can pass the `dispatch_benchmarks` and `dispatch_benchmarks_dir` commands when initializing `SharkInference`, and the benchmarks will be generated when compiled. E.G:
|
||||
|
||||
```
|
||||
shark_module = SharkInference(
|
||||
mlir_model,
|
||||
func_name,
|
||||
device=args.device,
|
||||
mlir_dialect="tm_tensor",
|
||||
dispatch_benchmarks="all",
|
||||
@@ -232,7 +271,7 @@ Output will include:
|
||||
- A .txt file containing benchmark output
|
||||
|
||||
|
||||
See tank/README.md for instructions on how to run model tests and benchmarks from the SHARK tank.
|
||||
See tank/README.md for further instructions on how to run model tests and benchmarks from the SHARK tank.
|
||||
|
||||
</details>
|
||||
|
||||
@@ -257,7 +296,7 @@ torch_mlir, func_name = mlir_importer.import_mlir(tracing_required=True)
|
||||
# SharkInference accepts mlir in linalg, mhlo, and tosa dialect.
|
||||
|
||||
from shark.shark_inference import SharkInference
|
||||
shark_module = SharkInference(torch_mlir, func_name, device="cpu", mlir_dialect="linalg")
|
||||
shark_module = SharkInference(torch_mlir, device="cpu", mlir_dialect="linalg")
|
||||
shark_module.compile()
|
||||
result = shark_module.forward((input))
|
||||
|
||||
@@ -280,12 +319,17 @@ mhlo_ir = r"""builtin.module {
|
||||
|
||||
arg0 = np.ones((1, 4)).astype(np.float32)
|
||||
arg1 = np.ones((4, 1)).astype(np.float32)
|
||||
shark_module = SharkInference(mhlo_ir, func_name="forward", device="cpu", mlir_dialect="mhlo")
|
||||
shark_module = SharkInference(mhlo_ir, device="cpu", mlir_dialect="mhlo")
|
||||
shark_module.compile()
|
||||
result = shark_module.forward((arg0, arg1))
|
||||
```
|
||||
</details>
|
||||
|
||||
## Examples Using the REST API
|
||||
|
||||
* [Setting up SHARK for use with Blender](./docs/shark_sd_blender.md)
|
||||
* [Setting up SHARK for use with Koboldcpp](./docs/shark_sd_koboldcpp.md)
|
||||
|
||||
## Supported and Validated Models
|
||||
|
||||
SHARK is maintained to support the latest innovations in ML Models:
|
||||
|
||||
179
apps/shark_studio/api/llm.py
Normal file
179
apps/shark_studio/api/llm.py
Normal file
@@ -0,0 +1,179 @@
|
||||
from turbine_models.custom_models import stateless_llama
|
||||
import time
|
||||
from shark.iree_utils.compile_utils import (
|
||||
get_iree_compiled_module,
|
||||
load_vmfb_using_mmap,
|
||||
)
|
||||
from apps.shark_studio.api.utils import get_resource_path
|
||||
import iree.runtime as ireert
|
||||
from itertools import chain
|
||||
import gc
|
||||
import os
|
||||
import torch
|
||||
from transformers import AutoTokenizer
|
||||
|
||||
llm_model_map = {
|
||||
"llama2_7b": {
|
||||
"initializer": stateless_llama.export_transformer_model,
|
||||
"hf_model_name": "meta-llama/Llama-2-7b-chat-hf",
|
||||
"stop_token": 2,
|
||||
"max_tokens": 4096,
|
||||
"system_prompt": """<s>[INST] <<SYS>>Be concise. You are a helpful, respectful and honest assistant. If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information. <</SYS>>""",
|
||||
},
|
||||
"Trelis/Llama-2-7b-chat-hf-function-calling-v2": {
|
||||
"initializer": stateless_llama.export_transformer_model,
|
||||
"hf_model_name": "Trelis/Llama-2-7b-chat-hf-function-calling-v2",
|
||||
"stop_token": 2,
|
||||
"max_tokens": 4096,
|
||||
"system_prompt": """<s>[INST] <<SYS>>Be concise. You are a helpful, respectful and honest assistant. If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information. <</SYS>>""",
|
||||
},
|
||||
}
|
||||
|
||||
|
||||
class LanguageModel:
|
||||
def __init__(
|
||||
self,
|
||||
model_name,
|
||||
hf_auth_token=None,
|
||||
device=None,
|
||||
precision="fp32",
|
||||
external_weights=None,
|
||||
use_system_prompt=True,
|
||||
):
|
||||
print(llm_model_map[model_name])
|
||||
self.hf_model_name = llm_model_map[model_name]["hf_model_name"]
|
||||
self.tempfile_name = get_resource_path("llm.torch.tempfile")
|
||||
self.vmfb_name = get_resource_path("llm.vmfb.tempfile")
|
||||
self.device = device
|
||||
self.precision = precision
|
||||
self.safe_name = self.hf_model_name.strip("/").replace("/", "_")
|
||||
self.max_tokens = llm_model_map[model_name]["max_tokens"]
|
||||
self.iree_module_dict = None
|
||||
self.external_weight_file = None
|
||||
if external_weights is not None:
|
||||
self.external_weight_file = get_resource_path(
|
||||
self.safe_name + "." + external_weights
|
||||
)
|
||||
self.use_system_prompt = use_system_prompt
|
||||
self.global_iter = 0
|
||||
if os.path.exists(self.vmfb_name) and (
|
||||
external_weights is None or os.path.exists(str(self.external_weight_file))
|
||||
):
|
||||
self.iree_module_dict = dict()
|
||||
(
|
||||
self.iree_module_dict["vmfb"],
|
||||
self.iree_module_dict["config"],
|
||||
self.iree_module_dict["temp_file_to_unlink"],
|
||||
) = load_vmfb_using_mmap(
|
||||
self.vmfb_name,
|
||||
device,
|
||||
device_idx=0,
|
||||
rt_flags=[],
|
||||
external_weight_file=self.external_weight_file,
|
||||
)
|
||||
self.tokenizer = AutoTokenizer.from_pretrained(
|
||||
self.hf_model_name,
|
||||
use_fast=False,
|
||||
use_auth_token=hf_auth_token,
|
||||
)
|
||||
elif not os.path.exists(self.tempfile_name):
|
||||
self.torch_ir, self.tokenizer = llm_model_map[model_name]["initializer"](
|
||||
self.hf_model_name,
|
||||
hf_auth_token,
|
||||
compile_to="torch",
|
||||
external_weights=external_weights,
|
||||
external_weight_file=self.external_weight_file,
|
||||
)
|
||||
with open(self.tempfile_name, "w+") as f:
|
||||
f.write(self.torch_ir)
|
||||
del self.torch_ir
|
||||
gc.collect()
|
||||
self.compile()
|
||||
else:
|
||||
self.tokenizer = AutoTokenizer.from_pretrained(
|
||||
self.hf_model_name,
|
||||
use_fast=False,
|
||||
use_auth_token=hf_auth_token,
|
||||
)
|
||||
self.compile()
|
||||
|
||||
def compile(self) -> None:
|
||||
# this comes with keys: "vmfb", "config", and "temp_file_to_unlink".
|
||||
self.iree_module_dict = get_iree_compiled_module(
|
||||
self.tempfile_name,
|
||||
device=self.device,
|
||||
mmap=True,
|
||||
frontend="torch",
|
||||
external_weight_file=self.external_weight_file,
|
||||
write_to=self.vmfb_name,
|
||||
extra_args=["--iree-global-opt-enable-quantized-matmul-reassociation"],
|
||||
)
|
||||
# TODO: delete the temp file
|
||||
|
||||
def sanitize_prompt(self, prompt):
|
||||
print(prompt)
|
||||
if isinstance(prompt, list):
|
||||
prompt = list(chain.from_iterable(prompt))
|
||||
prompt = " ".join([x for x in prompt if isinstance(x, str)])
|
||||
prompt = prompt.replace("\n", " ")
|
||||
prompt = prompt.replace("\t", " ")
|
||||
prompt = prompt.replace("\r", " ")
|
||||
if self.use_system_prompt and self.global_iter == 0:
|
||||
prompt = llm_model_map["llama2_7b"]["system_prompt"] + prompt
|
||||
prompt += " [/INST]"
|
||||
print(prompt)
|
||||
return prompt
|
||||
|
||||
def chat(self, prompt):
|
||||
prompt = self.sanitize_prompt(prompt)
|
||||
|
||||
input_tensor = self.tokenizer(prompt, return_tensors="pt").input_ids
|
||||
|
||||
def format_out(results):
|
||||
return torch.tensor(results.to_host()[0][0])
|
||||
|
||||
history = []
|
||||
for iter in range(self.max_tokens):
|
||||
st_time = time.time()
|
||||
if iter == 0:
|
||||
device_inputs = [
|
||||
ireert.asdevicearray(
|
||||
self.iree_module_dict["config"].device, input_tensor
|
||||
)
|
||||
]
|
||||
token = self.iree_module_dict["vmfb"]["run_initialize"](*device_inputs)
|
||||
else:
|
||||
device_inputs = [
|
||||
ireert.asdevicearray(
|
||||
self.iree_module_dict["config"].device,
|
||||
token,
|
||||
)
|
||||
]
|
||||
token = self.iree_module_dict["vmfb"]["run_forward"](*device_inputs)
|
||||
|
||||
total_time = time.time() - st_time
|
||||
history.append(format_out(token))
|
||||
yield self.tokenizer.decode(history), total_time
|
||||
|
||||
if format_out(token) == llm_model_map["llama2_7b"]["stop_token"]:
|
||||
break
|
||||
|
||||
for i in range(len(history)):
|
||||
if type(history[i]) != int:
|
||||
history[i] = int(history[i])
|
||||
result_output = self.tokenizer.decode(history)
|
||||
self.global_iter += 1
|
||||
return result_output, total_time
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
lm = LanguageModel(
|
||||
"Trelis/Llama-2-7b-chat-hf-function-calling-v2",
|
||||
hf_auth_token=None,
|
||||
device="cpu-task",
|
||||
external_weights="safetensors",
|
||||
)
|
||||
|
||||
print("model loaded")
|
||||
for i in lm.chat("hi, what are you?"):
|
||||
print(i)
|
||||
12
apps/shark_studio/api/utils.py
Normal file
12
apps/shark_studio/api/utils.py
Normal file
@@ -0,0 +1,12 @@
|
||||
import os
|
||||
import sys
|
||||
|
||||
|
||||
def get_available_devices():
|
||||
return ["cpu-task"]
|
||||
|
||||
|
||||
def get_resource_path(relative_path):
|
||||
"""Get absolute path to resource, works for dev and for PyInstaller"""
|
||||
base_path = getattr(sys, "_MEIPASS", os.path.dirname(os.path.abspath(__file__)))
|
||||
return os.path.join(base_path, relative_path)
|
||||
34
apps/shark_studio/tests/api_test.py
Normal file
34
apps/shark_studio/tests/api_test.py
Normal file
@@ -0,0 +1,34 @@
|
||||
# Copyright 2023 Nod Labs, Inc
|
||||
#
|
||||
# Licensed under the Apache License v2.0 with LLVM Exceptions.
|
||||
# See https://llvm.org/LICENSE.txt for license information.
|
||||
# SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception
|
||||
|
||||
import logging
|
||||
import unittest
|
||||
from apps.shark_studio.api.llm import LanguageModel
|
||||
|
||||
|
||||
class LLMAPITest(unittest.TestCase):
|
||||
def testLLMSimple(self):
|
||||
lm = LanguageModel(
|
||||
"Trelis/Llama-2-7b-chat-hf-function-calling-v2",
|
||||
hf_auth_token=None,
|
||||
device="cpu-task",
|
||||
external_weights="safetensors",
|
||||
)
|
||||
count = 0
|
||||
for msg, _ in lm.chat("hi, what are you?"):
|
||||
# skip first token output
|
||||
if count == 0:
|
||||
count += 1
|
||||
continue
|
||||
assert (
|
||||
msg.strip(" ") == "Hello"
|
||||
), f"LLM API failed to return correct response, expected 'Hello', received {msg}"
|
||||
break
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
logging.basicConfig(level=logging.DEBUG)
|
||||
unittest.main()
|
||||
426
apps/shark_studio/web/index.py
Normal file
426
apps/shark_studio/web/index.py
Normal file
@@ -0,0 +1,426 @@
|
||||
from multiprocessing import Process, freeze_support
|
||||
import os
|
||||
import sys
|
||||
import logging
|
||||
from ui.chat import chat_element
|
||||
|
||||
if sys.platform == "darwin":
|
||||
os.environ["DYLD_LIBRARY_PATH"] = "/usr/local/lib"
|
||||
# import before IREE to avoid MLIR library issues
|
||||
import torch_mlir
|
||||
|
||||
# import PIL, transformers, sentencepiece # ensures inclusion in pysintaller exe generation
|
||||
# from apps.stable_diffusion.src import args, clear_all
|
||||
# import apps.stable_diffusion.web.utils.global_obj as global_obj
|
||||
|
||||
|
||||
def launch_app(address):
|
||||
from tkinter import Tk
|
||||
import webview
|
||||
|
||||
window = Tk()
|
||||
|
||||
# get screen width and height of display and make it more reasonably
|
||||
# sized as we aren't making it full-screen or maximized
|
||||
width = int(window.winfo_screenwidth() * 0.81)
|
||||
height = int(window.winfo_screenheight() * 0.91)
|
||||
webview.create_window(
|
||||
"SHARK AI Studio",
|
||||
url=address,
|
||||
width=width,
|
||||
height=height,
|
||||
text_select=True,
|
||||
)
|
||||
webview.start(private_mode=False, storage_path=os.getcwd())
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
# if args.debug:
|
||||
logging.basicConfig(level=logging.DEBUG)
|
||||
# required to do multiprocessing in a pyinstaller freeze
|
||||
freeze_support()
|
||||
# if args.api or "api" in args.ui.split(","):
|
||||
# from apps.stable_diffusion.web.ui import (
|
||||
# txt2img_api,
|
||||
# img2img_api,
|
||||
# upscaler_api,
|
||||
# inpaint_api,
|
||||
# outpaint_api,
|
||||
# llm_chat_api,
|
||||
# )
|
||||
#
|
||||
# from fastapi import FastAPI, APIRouter
|
||||
# import uvicorn
|
||||
#
|
||||
# # init global sd pipeline and config
|
||||
# global_obj._init()
|
||||
#
|
||||
# app = FastAPI()
|
||||
# app.add_api_route("/sdapi/v1/txt2img", txt2img_api, methods=["post"])
|
||||
# app.add_api_route("/sdapi/v1/img2img", img2img_api, methods=["post"])
|
||||
# app.add_api_route("/sdapi/v1/inpaint", inpaint_api, methods=["post"])
|
||||
# app.add_api_route("/sdapi/v1/outpaint", outpaint_api, methods=["post"])
|
||||
# app.add_api_route("/sdapi/v1/upscaler", upscaler_api, methods=["post"])
|
||||
#
|
||||
# # chat APIs needed for compatibility with multiple extensions using OpenAI API
|
||||
# app.add_api_route(
|
||||
# "/v1/chat/completions", llm_chat_api, methods=["post"]
|
||||
# )
|
||||
# app.add_api_route("/v1/completions", llm_chat_api, methods=["post"])
|
||||
# app.add_api_route("/chat/completions", llm_chat_api, methods=["post"])
|
||||
# app.add_api_route("/completions", llm_chat_api, methods=["post"])
|
||||
# app.add_api_route(
|
||||
# "/v1/engines/codegen/completions", llm_chat_api, methods=["post"]
|
||||
# )
|
||||
# app.include_router(APIRouter())
|
||||
# uvicorn.run(app, host="0.0.0.0", port=args.server_port)
|
||||
# sys.exit(0)
|
||||
#
|
||||
# Setup to use shark_tmp for gradio's temporary image files and clear any
|
||||
# existing temporary images there if they exist. Then we can import gradio.
|
||||
# It has to be in this order or gradio ignores what we've set up.
|
||||
# from apps.stable_diffusion.web.utils.gradio_configs import (
|
||||
# config_gradio_tmp_imgs_folder,
|
||||
# )
|
||||
|
||||
# config_gradio_tmp_imgs_folder()
|
||||
import gradio as gr
|
||||
|
||||
# Create custom models folders if they don't exist
|
||||
# from apps.stable_diffusion.web.ui.utils import create_custom_models_folders
|
||||
|
||||
# create_custom_models_folders()
|
||||
|
||||
def resource_path(relative_path):
|
||||
"""Get absolute path to resource, works for dev and for PyInstaller"""
|
||||
base_path = getattr(sys, "_MEIPASS", os.path.dirname(os.path.abspath(__file__)))
|
||||
return os.path.join(base_path, relative_path)
|
||||
|
||||
dark_theme = resource_path("ui/css/sd_dark_theme.css")
|
||||
|
||||
# from apps.stable_diffusion.web.ui import (
|
||||
# txt2img_web,
|
||||
# txt2img_custom_model,
|
||||
# txt2img_gallery,
|
||||
# txt2img_png_info_img,
|
||||
# txt2img_status,
|
||||
# txt2img_sendto_img2img,
|
||||
# txt2img_sendto_inpaint,
|
||||
# txt2img_sendto_outpaint,
|
||||
# txt2img_sendto_upscaler,
|
||||
## h2ogpt_upload,
|
||||
## h2ogpt_web,
|
||||
# img2img_web,
|
||||
# img2img_custom_model,
|
||||
# img2img_gallery,
|
||||
# img2img_init_image,
|
||||
# img2img_status,
|
||||
# img2img_sendto_inpaint,
|
||||
# img2img_sendto_outpaint,
|
||||
# img2img_sendto_upscaler,
|
||||
# inpaint_web,
|
||||
# inpaint_custom_model,
|
||||
# inpaint_gallery,
|
||||
# inpaint_init_image,
|
||||
# inpaint_status,
|
||||
# inpaint_sendto_img2img,
|
||||
# inpaint_sendto_outpaint,
|
||||
# inpaint_sendto_upscaler,
|
||||
# outpaint_web,
|
||||
# outpaint_custom_model,
|
||||
# outpaint_gallery,
|
||||
# outpaint_init_image,
|
||||
# outpaint_status,
|
||||
# outpaint_sendto_img2img,
|
||||
# outpaint_sendto_inpaint,
|
||||
# outpaint_sendto_upscaler,
|
||||
# upscaler_web,
|
||||
# upscaler_custom_model,
|
||||
# upscaler_gallery,
|
||||
# upscaler_init_image,
|
||||
# upscaler_status,
|
||||
# upscaler_sendto_img2img,
|
||||
# upscaler_sendto_inpaint,
|
||||
# upscaler_sendto_outpaint,
|
||||
## lora_train_web,
|
||||
## model_web,
|
||||
## model_config_web,
|
||||
# hf_models,
|
||||
# modelmanager_sendto_txt2img,
|
||||
# modelmanager_sendto_img2img,
|
||||
# modelmanager_sendto_inpaint,
|
||||
# modelmanager_sendto_outpaint,
|
||||
# modelmanager_sendto_upscaler,
|
||||
# stablelm_chat,
|
||||
# minigpt4_web,
|
||||
# outputgallery_web,
|
||||
# outputgallery_tab_select,
|
||||
# outputgallery_watch,
|
||||
# outputgallery_filename,
|
||||
# outputgallery_sendto_txt2img,
|
||||
# outputgallery_sendto_img2img,
|
||||
# outputgallery_sendto_inpaint,
|
||||
# outputgallery_sendto_outpaint,
|
||||
# outputgallery_sendto_upscaler,
|
||||
# )
|
||||
|
||||
# init global sd pipeline and config
|
||||
# global_obj._init()
|
||||
|
||||
def register_button_click(button, selectedid, inputs, outputs):
|
||||
button.click(
|
||||
lambda x: (
|
||||
x[0]["name"] if len(x) != 0 else None,
|
||||
gr.Tabs.update(selected=selectedid),
|
||||
),
|
||||
inputs,
|
||||
outputs,
|
||||
)
|
||||
|
||||
def register_modelmanager_button(button, selectedid, inputs, outputs):
|
||||
button.click(
|
||||
lambda x: (
|
||||
"None",
|
||||
x,
|
||||
gr.Tabs.update(selected=selectedid),
|
||||
),
|
||||
inputs,
|
||||
outputs,
|
||||
)
|
||||
|
||||
def register_outputgallery_button(button, selectedid, inputs, outputs):
|
||||
button.click(
|
||||
lambda x: (
|
||||
x,
|
||||
gr.Tabs.update(selected=selectedid),
|
||||
),
|
||||
inputs,
|
||||
outputs,
|
||||
)
|
||||
|
||||
with gr.Blocks(
|
||||
css=dark_theme, analytics_enabled=False, title="Shark Studio 2.0 Beta"
|
||||
) as sd_web:
|
||||
with gr.Tabs() as tabs:
|
||||
# NOTE: If adding, removing, or re-ordering tabs, make sure that they
|
||||
# have a unique id that doesn't clash with any of the other tabs,
|
||||
# and that the order in the code here is the order they should
|
||||
# appear in the ui, as the id value doesn't determine the order.
|
||||
|
||||
# Where possible, avoid changing the id of any tab that is the
|
||||
# destination of one of the 'send to' buttons. If you do have to change
|
||||
# that id, make sure you update the relevant register_button_click calls
|
||||
# further down with the new id.
|
||||
# with gr.TabItem(label="Text-to-Image", id=0):
|
||||
# txt2img_web.render()
|
||||
# with gr.TabItem(label="Image-to-Image", id=1):
|
||||
# img2img_web.render()
|
||||
# with gr.TabItem(label="Inpainting", id=2):
|
||||
# inpaint_web.render()
|
||||
# with gr.TabItem(label="Outpainting", id=3):
|
||||
# outpaint_web.render()
|
||||
# with gr.TabItem(label="Upscaler", id=4):
|
||||
# upscaler_web.render()
|
||||
# if args.output_gallery:
|
||||
# with gr.TabItem(label="Output Gallery", id=5) as og_tab:
|
||||
# outputgallery_web.render()
|
||||
|
||||
# # extra output gallery configuration
|
||||
# outputgallery_tab_select(og_tab.select)
|
||||
# outputgallery_watch(
|
||||
# [
|
||||
# txt2img_status,
|
||||
# img2img_status,
|
||||
# inpaint_status,
|
||||
# outpaint_status,
|
||||
# upscaler_status,
|
||||
# ]
|
||||
# )
|
||||
## with gr.TabItem(label="Model Manager", id=6):
|
||||
## model_web.render()
|
||||
## with gr.TabItem(label="LoRA Training (Experimental)", id=7):
|
||||
## lora_train_web.render()
|
||||
with gr.TabItem(label="Chat Bot", id=0):
|
||||
chat_element.render()
|
||||
## with gr.TabItem(
|
||||
## label="Generate Sharding Config (Experimental)", id=9
|
||||
## ):
|
||||
## model_config_web.render()
|
||||
# with gr.TabItem(label="MultiModal (Experimental)", id=10):
|
||||
# minigpt4_web.render()
|
||||
# with gr.TabItem(label="DocuChat Upload", id=11):
|
||||
# h2ogpt_upload.render()
|
||||
# with gr.TabItem(label="DocuChat(Experimental)", id=12):
|
||||
# h2ogpt_web.render()
|
||||
|
||||
# send to buttons
|
||||
# register_button_click(
|
||||
# txt2img_sendto_img2img,
|
||||
# 1,
|
||||
# [txt2img_gallery],
|
||||
# [img2img_init_image, tabs],
|
||||
# )
|
||||
# register_button_click(
|
||||
# txt2img_sendto_inpaint,
|
||||
# 2,
|
||||
# [txt2img_gallery],
|
||||
# [inpaint_init_image, tabs],
|
||||
# )
|
||||
# register_button_click(
|
||||
# txt2img_sendto_outpaint,
|
||||
# 3,
|
||||
# [txt2img_gallery],
|
||||
# [outpaint_init_image, tabs],
|
||||
# )
|
||||
# register_button_click(
|
||||
# txt2img_sendto_upscaler,
|
||||
# 4,
|
||||
# [txt2img_gallery],
|
||||
# [upscaler_init_image, tabs],
|
||||
# )
|
||||
# register_button_click(
|
||||
# img2img_sendto_inpaint,
|
||||
# 2,
|
||||
# [img2img_gallery],
|
||||
# [inpaint_init_image, tabs],
|
||||
# )
|
||||
# register_button_click(
|
||||
# img2img_sendto_outpaint,
|
||||
# 3,
|
||||
# [img2img_gallery],
|
||||
# [outpaint_init_image, tabs],
|
||||
# )
|
||||
# register_button_click(
|
||||
# img2img_sendto_upscaler,
|
||||
# 4,
|
||||
# [img2img_gallery],
|
||||
# [upscaler_init_image, tabs],
|
||||
# )
|
||||
# register_button_click(
|
||||
# inpaint_sendto_img2img,
|
||||
# 1,
|
||||
# [inpaint_gallery],
|
||||
# [img2img_init_image, tabs],
|
||||
# )
|
||||
# register_button_click(
|
||||
# inpaint_sendto_outpaint,
|
||||
# 3,
|
||||
# [inpaint_gallery],
|
||||
# [outpaint_init_image, tabs],
|
||||
# )
|
||||
# register_button_click(
|
||||
# inpaint_sendto_upscaler,
|
||||
# 4,
|
||||
# [inpaint_gallery],
|
||||
# [upscaler_init_image, tabs],
|
||||
# )
|
||||
# register_button_click(
|
||||
# outpaint_sendto_img2img,
|
||||
# 1,
|
||||
# [outpaint_gallery],
|
||||
# [img2img_init_image, tabs],
|
||||
# )
|
||||
# register_button_click(
|
||||
# outpaint_sendto_inpaint,
|
||||
# 2,
|
||||
# [outpaint_gallery],
|
||||
# [inpaint_init_image, tabs],
|
||||
# )
|
||||
# register_button_click(
|
||||
# outpaint_sendto_upscaler,
|
||||
# 4,
|
||||
# [outpaint_gallery],
|
||||
# [upscaler_init_image, tabs],
|
||||
# )
|
||||
# register_button_click(
|
||||
# upscaler_sendto_img2img,
|
||||
# 1,
|
||||
# [upscaler_gallery],
|
||||
# [img2img_init_image, tabs],
|
||||
# )
|
||||
# register_button_click(
|
||||
# upscaler_sendto_inpaint,
|
||||
# 2,
|
||||
# [upscaler_gallery],
|
||||
# [inpaint_init_image, tabs],
|
||||
# )
|
||||
# register_button_click(
|
||||
# upscaler_sendto_outpaint,
|
||||
# 3,
|
||||
# [upscaler_gallery],
|
||||
# [outpaint_init_image, tabs],
|
||||
# )
|
||||
# if args.output_gallery:
|
||||
# register_outputgallery_button(
|
||||
# outputgallery_sendto_txt2img,
|
||||
# 0,
|
||||
# [outputgallery_filename],
|
||||
# [txt2img_png_info_img, tabs],
|
||||
# )
|
||||
# register_outputgallery_button(
|
||||
# outputgallery_sendto_img2img,
|
||||
# 1,
|
||||
# [outputgallery_filename],
|
||||
# [img2img_init_image, tabs],
|
||||
# )
|
||||
# register_outputgallery_button(
|
||||
# outputgallery_sendto_inpaint,
|
||||
# 2,
|
||||
# [outputgallery_filename],
|
||||
# [inpaint_init_image, tabs],
|
||||
# )
|
||||
# register_outputgallery_button(
|
||||
# outputgallery_sendto_outpaint,
|
||||
# 3,
|
||||
# [outputgallery_filename],
|
||||
# [outpaint_init_image, tabs],
|
||||
# )
|
||||
# register_outputgallery_button(
|
||||
# outputgallery_sendto_upscaler,
|
||||
# 4,
|
||||
# [outputgallery_filename],
|
||||
# [upscaler_init_image, tabs],
|
||||
# )
|
||||
# register_modelmanager_button(
|
||||
# modelmanager_sendto_txt2img,
|
||||
# 0,
|
||||
# [hf_models],
|
||||
# [txt2img_custom_model, tabs],
|
||||
# )
|
||||
# register_modelmanager_button(
|
||||
# modelmanager_sendto_img2img,
|
||||
# 1,
|
||||
# [hf_models],
|
||||
# [img2img_custom_model, tabs],
|
||||
# )
|
||||
# register_modelmanager_button(
|
||||
# modelmanager_sendto_inpaint,
|
||||
# 2,
|
||||
# [hf_models],
|
||||
# [inpaint_custom_model, tabs],
|
||||
# )
|
||||
# register_modelmanager_button(
|
||||
# modelmanager_sendto_outpaint,
|
||||
# 3,
|
||||
# [hf_models],
|
||||
# [outpaint_custom_model, tabs],
|
||||
# )
|
||||
# register_modelmanager_button(
|
||||
# modelmanager_sendto_upscaler,
|
||||
# 4,
|
||||
# [hf_models],
|
||||
# [upscaler_custom_model, tabs],
|
||||
# )
|
||||
|
||||
sd_web.queue()
|
||||
# if args.ui == "app":
|
||||
# t = Process(
|
||||
# target=launch_app, args=[f"http://localhost:{args.server_port}"]
|
||||
# )
|
||||
# t.start()
|
||||
sd_web.launch(
|
||||
share=True,
|
||||
inbrowser=True,
|
||||
server_name="0.0.0.0",
|
||||
server_port=11911, # args.server_port,
|
||||
)
|
||||
298
apps/shark_studio/web/ui/chat.py
Normal file
298
apps/shark_studio/web/ui/chat.py
Normal file
@@ -0,0 +1,298 @@
|
||||
import gradio as gr
|
||||
import time
|
||||
import os
|
||||
from pathlib import Path
|
||||
from datetime import datetime as dt
|
||||
import json
|
||||
import sys
|
||||
from apps.shark_studio.api.utils import (
|
||||
get_available_devices,
|
||||
)
|
||||
from apps.shark_studio.api.llm import (
|
||||
llm_model_map,
|
||||
LanguageModel,
|
||||
)
|
||||
|
||||
|
||||
def user(message, history):
|
||||
# Append the user's message to the conversation history
|
||||
return "", history + [[message, ""]]
|
||||
|
||||
|
||||
language_model = None
|
||||
|
||||
|
||||
def create_prompt(model_name, history, prompt_prefix):
|
||||
return ""
|
||||
|
||||
|
||||
def get_default_config():
|
||||
return False
|
||||
|
||||
|
||||
# model_vmfb_key = ""
|
||||
|
||||
|
||||
def chat_fn(
|
||||
prompt_prefix,
|
||||
history,
|
||||
model,
|
||||
device,
|
||||
precision,
|
||||
download_vmfb,
|
||||
config_file,
|
||||
cli=False,
|
||||
):
|
||||
global language_model
|
||||
if language_model is None:
|
||||
history[-1][-1] = "Getting the model ready..."
|
||||
yield history, ""
|
||||
language_model = LanguageModel(
|
||||
model,
|
||||
device=device,
|
||||
precision=precision,
|
||||
external_weights="safetensors",
|
||||
external_weight_file="llama2_7b.safetensors",
|
||||
use_system_prompt=prompt_prefix,
|
||||
)
|
||||
history[-1][-1] = "Getting the model ready... Done"
|
||||
yield history, ""
|
||||
history[-1][-1] = ""
|
||||
token_count = 0
|
||||
total_time = 0.001 # In order to avoid divide by zero error
|
||||
prefill_time = 0
|
||||
is_first = True
|
||||
for text, exec_time in language_model.chat(history):
|
||||
history[-1][-1] = text
|
||||
if is_first:
|
||||
prefill_time = exec_time
|
||||
is_first = False
|
||||
yield history, f"Prefill: {prefill_time:.2f}"
|
||||
else:
|
||||
total_time += exec_time
|
||||
token_count += 1
|
||||
tokens_per_sec = token_count / total_time
|
||||
yield history, f"Prefill: {prefill_time:.2f} seconds\n Decode: {tokens_per_sec:.2f} tokens/sec"
|
||||
|
||||
|
||||
def llm_chat_api(InputData: dict):
|
||||
return None
|
||||
print(f"Input keys : {InputData.keys()}")
|
||||
# print(f"model : {InputData['model']}")
|
||||
is_chat_completion_api = (
|
||||
"messages" in InputData.keys()
|
||||
) # else it is the legacy `completion` api
|
||||
# For Debugging input data from API
|
||||
# if is_chat_completion_api:
|
||||
# print(f"message -> role : {InputData['messages'][0]['role']}")
|
||||
# print(f"message -> content : {InputData['messages'][0]['content']}")
|
||||
# else:
|
||||
# print(f"prompt : {InputData['prompt']}")
|
||||
# print(f"max_tokens : {InputData['max_tokens']}") # Default to 128 for now
|
||||
global vicuna_model
|
||||
model_name = InputData["model"] if "model" in InputData.keys() else "codegen"
|
||||
model_path = llm_model_map[model_name]
|
||||
device = "cpu-task"
|
||||
precision = "fp16"
|
||||
max_toks = None if "max_tokens" not in InputData.keys() else InputData["max_tokens"]
|
||||
if max_toks is None:
|
||||
max_toks = 128 if model_name == "codegen" else 512
|
||||
|
||||
# make it working for codegen first
|
||||
from apps.language_models.scripts.vicuna import (
|
||||
UnshardedVicuna,
|
||||
)
|
||||
|
||||
device_id = None
|
||||
if vicuna_model == 0:
|
||||
if "cuda" in device:
|
||||
device = "cuda"
|
||||
elif "sync" in device:
|
||||
device = "cpu-sync"
|
||||
elif "task" in device:
|
||||
device = "cpu-task"
|
||||
elif "vulkan" in device:
|
||||
device_id = int(device.split("://")[1])
|
||||
device = "vulkan"
|
||||
else:
|
||||
print("unrecognized device")
|
||||
|
||||
vicuna_model = UnshardedVicuna(
|
||||
model_name,
|
||||
hf_model_path=model_path,
|
||||
device=device,
|
||||
precision=precision,
|
||||
max_num_tokens=max_toks,
|
||||
download_vmfb=True,
|
||||
load_mlir_from_shark_tank=True,
|
||||
device_id=device_id,
|
||||
)
|
||||
|
||||
# TODO: add role dict for different models
|
||||
if is_chat_completion_api:
|
||||
# TODO: add funtionality for multiple messages
|
||||
prompt = create_prompt(model_name, [(InputData["messages"][0]["content"], "")])
|
||||
else:
|
||||
prompt = InputData["prompt"]
|
||||
print("prompt = ", prompt)
|
||||
|
||||
res = vicuna_model.generate(prompt)
|
||||
res_op = None
|
||||
for op in res:
|
||||
res_op = op
|
||||
|
||||
if is_chat_completion_api:
|
||||
choices = [
|
||||
{
|
||||
"index": 0,
|
||||
"message": {
|
||||
"role": "assistant",
|
||||
"content": res_op, # since we are yeilding the result
|
||||
},
|
||||
"finish_reason": "stop", # or length
|
||||
}
|
||||
]
|
||||
else:
|
||||
choices = [
|
||||
{
|
||||
"text": res_op,
|
||||
"index": 0,
|
||||
"logprobs": None,
|
||||
"finish_reason": "stop", # or length
|
||||
}
|
||||
]
|
||||
end_time = dt.now().strftime("%Y%m%d%H%M%S%f")
|
||||
return {
|
||||
"id": end_time,
|
||||
"object": "chat.completion" if is_chat_completion_api else "text_completion",
|
||||
"created": int(end_time),
|
||||
"choices": choices,
|
||||
}
|
||||
|
||||
|
||||
def view_json_file(file_obj):
|
||||
content = ""
|
||||
with open(file_obj.name, "r") as fopen:
|
||||
content = fopen.read()
|
||||
return content
|
||||
|
||||
|
||||
with gr.Blocks(title="Chat") as chat_element:
|
||||
with gr.Row():
|
||||
model_choices = list(llm_model_map.keys())
|
||||
model = gr.Dropdown(
|
||||
label="Select Model",
|
||||
value=model_choices[0],
|
||||
choices=model_choices,
|
||||
allow_custom_value=True,
|
||||
)
|
||||
supported_devices = get_available_devices()
|
||||
enabled = True
|
||||
if len(supported_devices) == 0:
|
||||
supported_devices = ["cpu-task"]
|
||||
supported_devices = [x for x in supported_devices if "sync" not in x]
|
||||
device = gr.Dropdown(
|
||||
label="Device",
|
||||
value=supported_devices[0],
|
||||
choices=supported_devices,
|
||||
interactive=enabled,
|
||||
allow_custom_value=True,
|
||||
)
|
||||
precision = gr.Radio(
|
||||
label="Precision",
|
||||
value="int4",
|
||||
choices=[
|
||||
# "int4",
|
||||
# "int8",
|
||||
# "fp16",
|
||||
"fp32",
|
||||
],
|
||||
visible=False,
|
||||
)
|
||||
tokens_time = gr.Textbox(label="Tokens generated per second")
|
||||
with gr.Column():
|
||||
download_vmfb = gr.Checkbox(
|
||||
label="Download vmfb from Shark tank if available",
|
||||
value=True,
|
||||
interactive=True,
|
||||
)
|
||||
prompt_prefix = gr.Checkbox(
|
||||
label="Add System Prompt",
|
||||
value=False,
|
||||
interactive=True,
|
||||
)
|
||||
|
||||
chatbot = gr.Chatbot(height=500)
|
||||
with gr.Row():
|
||||
with gr.Column():
|
||||
msg = gr.Textbox(
|
||||
label="Chat Message Box",
|
||||
placeholder="Chat Message Box",
|
||||
show_label=False,
|
||||
interactive=enabled,
|
||||
container=False,
|
||||
)
|
||||
with gr.Column():
|
||||
with gr.Row():
|
||||
submit = gr.Button("Submit", interactive=enabled)
|
||||
stop = gr.Button("Stop", interactive=enabled)
|
||||
clear = gr.Button("Clear", interactive=enabled)
|
||||
|
||||
with gr.Row(visible=False):
|
||||
with gr.Group():
|
||||
config_file = gr.File(label="Upload sharding configuration", visible=False)
|
||||
json_view_button = gr.Button(label="View as JSON", visible=False)
|
||||
json_view = gr.JSON(interactive=True, visible=False)
|
||||
json_view_button.click(
|
||||
fn=view_json_file, inputs=[config_file], outputs=[json_view]
|
||||
)
|
||||
submit_event = msg.submit(
|
||||
fn=user,
|
||||
inputs=[msg, chatbot],
|
||||
outputs=[msg, chatbot],
|
||||
show_progress=False,
|
||||
queue=False,
|
||||
).then(
|
||||
fn=chat_fn,
|
||||
inputs=[
|
||||
prompt_prefix,
|
||||
chatbot,
|
||||
model,
|
||||
device,
|
||||
precision,
|
||||
download_vmfb,
|
||||
config_file,
|
||||
],
|
||||
outputs=[chatbot, tokens_time],
|
||||
show_progress=False,
|
||||
queue=True,
|
||||
)
|
||||
submit_click_event = submit.click(
|
||||
fn=user,
|
||||
inputs=[msg, chatbot],
|
||||
outputs=[msg, chatbot],
|
||||
show_progress=False,
|
||||
queue=False,
|
||||
).then(
|
||||
fn=chat_fn,
|
||||
inputs=[
|
||||
prompt_prefix,
|
||||
chatbot,
|
||||
model,
|
||||
device,
|
||||
precision,
|
||||
download_vmfb,
|
||||
config_file,
|
||||
],
|
||||
outputs=[chatbot, tokens_time],
|
||||
show_progress=False,
|
||||
queue=True,
|
||||
)
|
||||
stop.click(
|
||||
fn=None,
|
||||
inputs=None,
|
||||
outputs=None,
|
||||
cancels=[submit_event, submit_click_event],
|
||||
queue=False,
|
||||
)
|
||||
clear.click(lambda: None, None, [chatbot], queue=False)
|
||||
@@ -129,12 +129,12 @@ pytest_benchmark_param = pytest.mark.parametrize(
|
||||
pytest.param(True, "cpu", marks=pytest.mark.skip),
|
||||
pytest.param(
|
||||
False,
|
||||
"gpu",
|
||||
"cuda",
|
||||
marks=pytest.mark.skipif(
|
||||
check_device_drivers("gpu"), reason="nvidia-smi not found"
|
||||
check_device_drivers("cuda"), reason="nvidia-smi not found"
|
||||
),
|
||||
),
|
||||
pytest.param(True, "gpu", marks=pytest.mark.skip),
|
||||
pytest.param(True, "cuda", marks=pytest.mark.skip),
|
||||
pytest.param(
|
||||
False,
|
||||
"vulkan",
|
||||
|
||||
88
build_tools/docker/Dockerfile-ubuntu-22.04
Normal file
88
build_tools/docker/Dockerfile-ubuntu-22.04
Normal file
@@ -0,0 +1,88 @@
|
||||
ARG IMAGE_NAME
|
||||
FROM ${IMAGE_NAME}:12.2.0-runtime-ubuntu22.04 as base
|
||||
|
||||
ENV NV_CUDA_LIB_VERSION "12.2.0-1"
|
||||
|
||||
FROM base as base-amd64
|
||||
|
||||
ENV NV_CUDA_CUDART_DEV_VERSION 12.2.53-1
|
||||
ENV NV_NVML_DEV_VERSION 12.2.81-1
|
||||
ENV NV_LIBCUSPARSE_DEV_VERSION 12.1.1.53-1
|
||||
ENV NV_LIBNPP_DEV_VERSION 12.1.1.14-1
|
||||
ENV NV_LIBNPP_DEV_PACKAGE libnpp-dev-12-2=${NV_LIBNPP_DEV_VERSION}
|
||||
|
||||
ENV NV_LIBCUBLAS_DEV_VERSION 12.2.1.16-1
|
||||
ENV NV_LIBCUBLAS_DEV_PACKAGE_NAME libcublas-dev-12-2
|
||||
ENV NV_LIBCUBLAS_DEV_PACKAGE ${NV_LIBCUBLAS_DEV_PACKAGE_NAME}=${NV_LIBCUBLAS_DEV_VERSION}
|
||||
|
||||
ENV NV_CUDA_NSIGHT_COMPUTE_VERSION 12.2.0-1
|
||||
ENV NV_CUDA_NSIGHT_COMPUTE_DEV_PACKAGE cuda-nsight-compute-12-2=${NV_CUDA_NSIGHT_COMPUTE_VERSION}
|
||||
|
||||
ENV NV_NVPROF_VERSION 12.2.60-1
|
||||
ENV NV_NVPROF_DEV_PACKAGE cuda-nvprof-12-2=${NV_NVPROF_VERSION}
|
||||
FROM base as base-arm64
|
||||
|
||||
ENV NV_CUDA_CUDART_DEV_VERSION 12.2.53-1
|
||||
ENV NV_NVML_DEV_VERSION 12.2.81-1
|
||||
ENV NV_LIBCUSPARSE_DEV_VERSION 12.1.1.53-1
|
||||
ENV NV_LIBNPP_DEV_VERSION 12.1.1.14-1
|
||||
ENV NV_LIBNPP_DEV_PACKAGE libnpp-dev-12-2=${NV_LIBNPP_DEV_VERSION}
|
||||
|
||||
ENV NV_LIBCUBLAS_DEV_PACKAGE_NAME libcublas-dev-12-2
|
||||
ENV NV_LIBCUBLAS_DEV_VERSION 12.2.1.16-1
|
||||
ENV NV_LIBCUBLAS_DEV_PACKAGE ${NV_LIBCUBLAS_DEV_PACKAGE_NAME}=${NV_LIBCUBLAS_DEV_VERSION}
|
||||
|
||||
ENV NV_CUDA_NSIGHT_COMPUTE_VERSION 12.2.0-1
|
||||
ENV NV_CUDA_NSIGHT_COMPUTE_DEV_PACKAGE cuda-nsight-compute-12-2=${NV_CUDA_NSIGHT_COMPUTE_VERSION}
|
||||
|
||||
FROM base-${TARGETARCH}
|
||||
|
||||
ARG TARGETARCH
|
||||
|
||||
LABEL maintainer "SHARK<stdin@nod.com>"
|
||||
|
||||
# Register the ROCM package repository, and install rocm-dev package
|
||||
ARG ROCM_VERSION=5.6
|
||||
ARG AMDGPU_VERSION=5.6
|
||||
|
||||
ARG APT_PREF
|
||||
RUN echo "$APT_PREF" > /etc/apt/preferences.d/rocm-pin-600
|
||||
RUN apt-get update && DEBIAN_FRONTEND=noninteractive apt-get install -y --no-install-recommends ca-certificates curl libnuma-dev gnupg \
|
||||
&& curl -sL https://repo.radeon.com/rocm/rocm.gpg.key | apt-key add - \
|
||||
&& printf "deb [arch=amd64] https://repo.radeon.com/rocm/apt/$ROCM_VERSION/ jammy main" | tee /etc/apt/sources.list.d/rocm.list \
|
||||
&& printf "deb [arch=amd64] https://repo.radeon.com/amdgpu/$AMDGPU_VERSION/ubuntu jammy main" | tee /etc/apt/sources.list.d/amdgpu.list \
|
||||
&& apt-get update && DEBIAN_FRONTEND=noninteractive apt-get install -y --no-install-recommends \
|
||||
sudo \
|
||||
libelf1 \
|
||||
kmod \
|
||||
file \
|
||||
python3 \
|
||||
python3-pip \
|
||||
rocm-dev \
|
||||
rocm-libs \
|
||||
rocm-hip-libraries \
|
||||
build-essential && \
|
||||
apt-get clean && \
|
||||
rm -rf /var/lib/apt/lists/*
|
||||
|
||||
RUN groupadd -g 109 render
|
||||
|
||||
RUN apt-get update && apt-get install -y --no-install-recommends \
|
||||
cuda-cudart-dev-12-2=${NV_CUDA_CUDART_DEV_VERSION} \
|
||||
cuda-command-line-tools-12-2=${NV_CUDA_LIB_VERSION} \
|
||||
cuda-minimal-build-12-2=${NV_CUDA_LIB_VERSION} \
|
||||
cuda-libraries-dev-12-2=${NV_CUDA_LIB_VERSION} \
|
||||
cuda-nvml-dev-12-2=${NV_NVML_DEV_VERSION} \
|
||||
${NV_NVPROF_DEV_PACKAGE} \
|
||||
${NV_LIBNPP_DEV_PACKAGE} \
|
||||
libcusparse-dev-12-2=${NV_LIBCUSPARSE_DEV_VERSION} \
|
||||
${NV_LIBCUBLAS_DEV_PACKAGE} \
|
||||
${NV_CUDA_NSIGHT_COMPUTE_DEV_PACKAGE} \
|
||||
&& rm -rf /var/lib/apt/lists/*
|
||||
|
||||
RUN apt install rocm-hip-libraries
|
||||
|
||||
# Keep apt from auto upgrading the cublas and nccl packages. See https://gitlab.com/nvidia/container-images/cuda/-/issues/88
|
||||
RUN apt-mark hold ${NV_LIBCUBLAS_DEV_PACKAGE_NAME}
|
||||
ENV LIBRARY_PATH /usr/local/cuda/lib64/stubs
|
||||
|
||||
41
build_tools/docker/README.md
Normal file
41
build_tools/docker/README.md
Normal file
@@ -0,0 +1,41 @@
|
||||
On your host install your Nvidia or AMD gpu drivers.
|
||||
|
||||
**HOST Setup**
|
||||
|
||||
*Ubuntu 23.04 Nvidia*
|
||||
```
|
||||
sudo ubuntu-drivers install
|
||||
```
|
||||
|
||||
Install [docker](https://docs.docker.com/engine/install/ubuntu/) and the post-install to run as a [user](https://docs.docker.com/engine/install/linux-postinstall/)
|
||||
|
||||
Install Nvidia [Container and register it](https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.html). In Ubuntu 23.04 systems follow [this](https://github.com/NVIDIA/nvidia-container-toolkit/issues/72#issuecomment-1584574298)
|
||||
|
||||
|
||||
Build docker with :
|
||||
|
||||
```
|
||||
docker build . -f Dockerfile-ubuntu-22.04 -t shark/dev-22.04:5.6 --build-arg=ROCM_VERSION=5.6 --build-arg=AMDGPU_VERSION=5.6 --build-arg=APT_PREF="Package: *\nPin: release o=repo.radeon.com\nPin-Priority: 600" --build-arg=IMAGE_NAME=nvidia/cuda --build-arg=TARGETARCH=amd64
|
||||
```
|
||||
|
||||
Run with:
|
||||
|
||||
*CPU*
|
||||
|
||||
```
|
||||
docker run -it docker.io/shark/dev-22.04:5.6
|
||||
```
|
||||
|
||||
*Nvidia GPU*
|
||||
|
||||
```
|
||||
docker run --rm -it --gpus all docker.io/shark/dev-22.04:5.6
|
||||
```
|
||||
|
||||
*AMD GPUs*
|
||||
|
||||
```
|
||||
docker run --device /dev/kfd --device /dev/dri docker.io/shark/dev-22.04:5.6
|
||||
```
|
||||
|
||||
More AMD instructions are [here](https://docs.amd.com/en/latest/deploy/docker.html)
|
||||
51
build_tools/image_comparison.py
Normal file
51
build_tools/image_comparison.py
Normal file
@@ -0,0 +1,51 @@
|
||||
import argparse
|
||||
from PIL import Image
|
||||
import numpy as np
|
||||
|
||||
import requests
|
||||
import shutil
|
||||
import os
|
||||
import subprocess
|
||||
|
||||
parser = argparse.ArgumentParser()
|
||||
|
||||
parser.add_argument("-n", "--newfile")
|
||||
parser.add_argument(
|
||||
"-g",
|
||||
"--golden_url",
|
||||
default="https://storage.googleapis.com/shark_tank/testdata/cyberpunk_fores_42_0_230119_021148.png",
|
||||
)
|
||||
|
||||
|
||||
def get_image(url, local_filename):
|
||||
res = requests.get(url, stream=True)
|
||||
if res.status_code == 200:
|
||||
with open(local_filename, "wb") as f:
|
||||
shutil.copyfileobj(res.raw, f)
|
||||
|
||||
|
||||
def compare_images(new_filename, golden_filename, upload=False):
|
||||
new = np.array(Image.open(new_filename)) / 255.0
|
||||
golden = np.array(Image.open(golden_filename)) / 255.0
|
||||
diff = np.abs(new - golden)
|
||||
mean = np.mean(diff)
|
||||
if mean > 0.1:
|
||||
if os.name != "nt" and upload == True:
|
||||
subprocess.run(
|
||||
[
|
||||
"gsutil",
|
||||
"cp",
|
||||
new_filename,
|
||||
"gs://shark_tank/testdata/builder/",
|
||||
]
|
||||
)
|
||||
raise AssertionError("new and golden not close")
|
||||
else:
|
||||
print("SUCCESS")
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
args = parser.parse_args()
|
||||
tempfile_name = os.path.join(os.getcwd(), "golden.png")
|
||||
get_image(args.golden_url, tempfile_name)
|
||||
compare_images(args.newfile, tempfile_name)
|
||||
@@ -1,5 +1,6 @@
|
||||
#!/bin/bash
|
||||
|
||||
IMPORTER=1 ./setup_venv.sh
|
||||
IMPORTER=1 BENCHMARK=1 NO_BREVITAS=1 ./setup_venv.sh
|
||||
source $GITHUB_WORKSPACE/shark.venv/bin/activate
|
||||
python generate_sharktank.py --upload=False --ci_tank_dir=True
|
||||
python build_tools/stable_diffusion_testing.py --gen
|
||||
python tank/generate_sharktank.py
|
||||
|
||||
284
build_tools/stable_diffusion_testing.py
Normal file
284
build_tools/stable_diffusion_testing.py
Normal file
@@ -0,0 +1,284 @@
|
||||
import os
|
||||
from sys import executable
|
||||
import subprocess
|
||||
from apps.stable_diffusion.src.utils.resources import (
|
||||
get_json_file,
|
||||
)
|
||||
from datetime import datetime as dt
|
||||
from shark.shark_downloader import download_public_file
|
||||
from image_comparison import compare_images
|
||||
import argparse
|
||||
from glob import glob
|
||||
import shutil
|
||||
import requests
|
||||
|
||||
model_config_dicts = get_json_file(
|
||||
os.path.join(
|
||||
os.getcwd(),
|
||||
"apps/stable_diffusion/src/utils/resources/model_config.json",
|
||||
)
|
||||
)
|
||||
|
||||
|
||||
def parse_sd_out(filename, command, device, use_tune, model_name, import_mlir):
|
||||
with open(filename, "r+") as f:
|
||||
lines = f.readlines()
|
||||
metrics = {}
|
||||
vals_to_read = [
|
||||
"Clip Inference time",
|
||||
"Average step",
|
||||
"VAE Inference time",
|
||||
"Total image generation",
|
||||
]
|
||||
for line in lines:
|
||||
for val in vals_to_read:
|
||||
if val in line:
|
||||
metrics[val] = line.split(" ")[-1].strip("\n")
|
||||
|
||||
metrics["Average step"] = metrics["Average step"].strip("ms/it")
|
||||
metrics["Total image generation"] = metrics["Total image generation"].strip("sec")
|
||||
metrics["device"] = device
|
||||
metrics["use_tune"] = use_tune
|
||||
metrics["model_name"] = model_name
|
||||
metrics["import_mlir"] = import_mlir
|
||||
metrics["command"] = command
|
||||
return metrics
|
||||
|
||||
|
||||
def get_inpaint_inputs():
|
||||
os.mkdir("./test_images/inputs")
|
||||
img_url = (
|
||||
"https://huggingface.co/datasets/diffusers/test-arrays/resolve"
|
||||
"/main/stable_diffusion_inpaint/input_bench_image.png"
|
||||
)
|
||||
mask_url = (
|
||||
"https://huggingface.co/datasets/diffusers/test-arrays/resolve"
|
||||
"/main/stable_diffusion_inpaint/input_bench_mask.png"
|
||||
)
|
||||
img = requests.get(img_url)
|
||||
mask = requests.get(mask_url)
|
||||
open("./test_images/inputs/image.png", "wb").write(img.content)
|
||||
open("./test_images/inputs/mask.png", "wb").write(mask.content)
|
||||
|
||||
|
||||
def test_loop(
|
||||
device="vulkan",
|
||||
beta=False,
|
||||
extra_flags=[],
|
||||
upload_bool=True,
|
||||
exit_on_fail=True,
|
||||
do_gen=False,
|
||||
):
|
||||
# Get golden values from tank
|
||||
shutil.rmtree("./test_images", ignore_errors=True)
|
||||
model_metrics = []
|
||||
os.mkdir("./test_images")
|
||||
os.mkdir("./test_images/golden")
|
||||
get_inpaint_inputs()
|
||||
hf_model_names = model_config_dicts[0].values()
|
||||
tuned_options = [
|
||||
"--no-use_tuned",
|
||||
"--use_tuned",
|
||||
]
|
||||
import_options = ["--import_mlir", "--no-import_mlir"]
|
||||
prompt_text = "--prompt=cyberpunk forest by Salvador Dali"
|
||||
inpaint_prompt_text = (
|
||||
"--prompt=Face of a yellow cat, high resolution, sitting on a park bench"
|
||||
)
|
||||
if os.name == "nt":
|
||||
prompt_text = '--prompt="cyberpunk forest by Salvador Dali"'
|
||||
inpaint_prompt_text = (
|
||||
'--prompt="Face of a yellow cat, high resolution, sitting on a park bench"'
|
||||
)
|
||||
if beta:
|
||||
extra_flags.append("--beta_models=True")
|
||||
extra_flags.append("--no-progress_bar")
|
||||
if do_gen:
|
||||
extra_flags.append("--import_debug")
|
||||
to_skip = [
|
||||
"Linaqruf/anything-v3.0",
|
||||
"prompthero/openjourney",
|
||||
"wavymulder/Analog-Diffusion",
|
||||
"dreamlike-art/dreamlike-diffusion-1.0",
|
||||
]
|
||||
counter = 0
|
||||
for import_opt in import_options:
|
||||
for model_name in hf_model_names:
|
||||
if model_name in to_skip:
|
||||
continue
|
||||
for use_tune in tuned_options:
|
||||
if (
|
||||
model_name == "stabilityai/stable-diffusion-2-1"
|
||||
and use_tune == tuned_options[0]
|
||||
):
|
||||
continue
|
||||
elif (
|
||||
model_name == "stabilityai/stable-diffusion-2-1-base"
|
||||
and use_tune == tuned_options[1]
|
||||
):
|
||||
continue
|
||||
elif use_tune == tuned_options[1]:
|
||||
continue
|
||||
command = (
|
||||
[
|
||||
executable, # executable is the python from the venv used to run this
|
||||
"apps/stable_diffusion/scripts/txt2img.py",
|
||||
"--device=" + device,
|
||||
prompt_text,
|
||||
"--negative_prompts=" + '""',
|
||||
"--seed=42",
|
||||
import_opt,
|
||||
"--output_dir="
|
||||
+ os.path.join(os.getcwd(), "test_images", model_name),
|
||||
"--hf_model_id=" + model_name,
|
||||
use_tune,
|
||||
]
|
||||
if "inpainting" not in model_name
|
||||
else [
|
||||
executable,
|
||||
"apps/stable_diffusion/scripts/inpaint.py",
|
||||
"--device=" + device,
|
||||
inpaint_prompt_text,
|
||||
"--negative_prompts=" + '""',
|
||||
"--img_path=./test_images/inputs/image.png",
|
||||
"--mask_path=./test_images/inputs/mask.png",
|
||||
"--seed=42",
|
||||
"--import_mlir",
|
||||
"--output_dir="
|
||||
+ os.path.join(os.getcwd(), "test_images", model_name),
|
||||
"--hf_model_id=" + model_name,
|
||||
use_tune,
|
||||
]
|
||||
)
|
||||
command += extra_flags
|
||||
if os.name == "nt":
|
||||
command = " ".join(command)
|
||||
dumpfile_name = "_".join(model_name.split("/")) + ".txt"
|
||||
dumpfile_name = os.path.join(os.getcwd(), dumpfile_name)
|
||||
with open(dumpfile_name, "w+") as f:
|
||||
generated_image = not subprocess.call(
|
||||
command,
|
||||
stdout=f,
|
||||
stderr=f,
|
||||
)
|
||||
if os.name != "nt":
|
||||
command = " ".join(command)
|
||||
if generated_image:
|
||||
model_metrics.append(
|
||||
parse_sd_out(
|
||||
dumpfile_name,
|
||||
command,
|
||||
device,
|
||||
use_tune,
|
||||
model_name,
|
||||
import_opt,
|
||||
)
|
||||
)
|
||||
print(command)
|
||||
print("Successfully generated image")
|
||||
os.makedirs("./test_images/golden/" + model_name, exist_ok=True)
|
||||
download_public_file(
|
||||
"gs://shark_tank/testdata/golden/" + model_name,
|
||||
"./test_images/golden/" + model_name,
|
||||
)
|
||||
test_file_path = os.path.join(
|
||||
os.getcwd(),
|
||||
"test_images",
|
||||
model_name,
|
||||
"generated_imgs",
|
||||
dt.now().strftime("%Y%m%d"),
|
||||
"*.png",
|
||||
)
|
||||
test_file = glob(test_file_path)[0]
|
||||
|
||||
golden_path = "./test_images/golden/" + model_name + "/*.png"
|
||||
golden_file = glob(golden_path)[0]
|
||||
try:
|
||||
compare_images(test_file, golden_file, upload=upload_bool)
|
||||
except AssertionError as e:
|
||||
print(e)
|
||||
if exit_on_fail == True:
|
||||
raise
|
||||
else:
|
||||
print(command)
|
||||
print("failed to generate image for this configuration")
|
||||
with open(dumpfile_name, "r+") as f:
|
||||
output = f.readlines()
|
||||
print("\n".join(output))
|
||||
exit(1)
|
||||
if os.name == "nt":
|
||||
counter += 1
|
||||
if counter % 2 == 0:
|
||||
extra_flags.append(
|
||||
"--iree_vulkan_target_triple=rdna2-unknown-windows"
|
||||
)
|
||||
else:
|
||||
if counter != 1:
|
||||
extra_flags.remove(
|
||||
"--iree_vulkan_target_triple=rdna2-unknown-windows"
|
||||
)
|
||||
if do_gen:
|
||||
prepare_artifacts()
|
||||
|
||||
with open(os.path.join(os.getcwd(), "sd_testing_metrics.csv"), "w+") as f:
|
||||
header = "model_name;device;use_tune;import_opt;Clip Inference time(ms);Average Step (ms/it);VAE Inference time(ms);total image generation(s);command\n"
|
||||
f.write(header)
|
||||
for metric in model_metrics:
|
||||
output = [
|
||||
metric["model_name"],
|
||||
metric["device"],
|
||||
metric["use_tune"],
|
||||
metric["import_mlir"],
|
||||
metric["Clip Inference time"],
|
||||
metric["Average step"],
|
||||
metric["VAE Inference time"],
|
||||
metric["Total image generation"],
|
||||
metric["command"],
|
||||
]
|
||||
f.write(";".join(output) + "\n")
|
||||
|
||||
|
||||
def prepare_artifacts():
|
||||
gen_path = os.path.join(os.getcwd(), "gen_shark_tank")
|
||||
if not os.path.isdir(gen_path):
|
||||
os.mkdir(gen_path)
|
||||
for dirname in os.listdir(os.getcwd()):
|
||||
for modelname in ["clip", "unet", "vae"]:
|
||||
if modelname in dirname and "vmfb" not in dirname:
|
||||
if not os.path.isdir(os.path.join(gen_path, dirname)):
|
||||
shutil.move(os.path.join(os.getcwd(), dirname), gen_path)
|
||||
print(f"Moved dir: {dirname} to {gen_path}.")
|
||||
|
||||
|
||||
parser = argparse.ArgumentParser()
|
||||
|
||||
parser.add_argument("-d", "--device", default="vulkan")
|
||||
parser.add_argument(
|
||||
"-b", "--beta", action=argparse.BooleanOptionalAction, default=False
|
||||
)
|
||||
parser.add_argument("-e", "--extra_args", type=str, default=None)
|
||||
parser.add_argument(
|
||||
"-u", "--upload", action=argparse.BooleanOptionalAction, default=True
|
||||
)
|
||||
parser.add_argument(
|
||||
"-x", "--exit_on_fail", action=argparse.BooleanOptionalAction, default=True
|
||||
)
|
||||
parser.add_argument("-g", "--gen", action=argparse.BooleanOptionalAction, default=False)
|
||||
|
||||
if __name__ == "__main__":
|
||||
args = parser.parse_args()
|
||||
print(args)
|
||||
extra_args = []
|
||||
if args.extra_args:
|
||||
for arg in args.extra_args.split(","):
|
||||
extra_args.append(arg)
|
||||
test_loop(
|
||||
args.device,
|
||||
args.beta,
|
||||
extra_args,
|
||||
args.upload,
|
||||
args.exit_on_fail,
|
||||
args.gen,
|
||||
)
|
||||
if args.gen:
|
||||
prepare_artifacts()
|
||||
14
build_tools/vicuna_testing.py
Normal file
14
build_tools/vicuna_testing.py
Normal file
@@ -0,0 +1,14 @@
|
||||
import os
|
||||
from sys import executable
|
||||
import subprocess
|
||||
from apps.language_models.scripts import vicuna
|
||||
|
||||
|
||||
def test_loop():
|
||||
precisions = ["fp16", "int8", "int4"]
|
||||
devices = ["cpu"]
|
||||
for precision in precisions:
|
||||
for device in devices:
|
||||
model = vicuna.UnshardedVicuna(device=device, precision=precision)
|
||||
model.compile()
|
||||
del model
|
||||
42
conftest.py
42
conftest.py
@@ -2,9 +2,11 @@ def pytest_addoption(parser):
|
||||
# Attaches SHARK command-line arguments to the pytest machinery.
|
||||
parser.addoption(
|
||||
"--benchmark",
|
||||
action="store_true",
|
||||
default="False",
|
||||
help="Pass option to benchmark and write results.csv",
|
||||
action="store",
|
||||
type=str,
|
||||
default=None,
|
||||
choices=("baseline", "native", "all"),
|
||||
help="Benchmarks specified engine(s) and writes bench_results.csv.",
|
||||
)
|
||||
parser.addoption(
|
||||
"--onnx_bench",
|
||||
@@ -40,7 +42,13 @@ def pytest_addoption(parser):
|
||||
"--update_tank",
|
||||
action="store_true",
|
||||
default="False",
|
||||
help="Update local shark tank with latest artifacts.",
|
||||
help="Update local shark tank with latest artifacts if model artifact hash mismatched.",
|
||||
)
|
||||
parser.addoption(
|
||||
"--force_update_tank",
|
||||
action="store_true",
|
||||
default="False",
|
||||
help="Force-update local shark tank with artifacts from specified shark_tank URL (defaults to nightly).",
|
||||
)
|
||||
parser.addoption(
|
||||
"--ci_sha",
|
||||
@@ -51,12 +59,34 @@ def pytest_addoption(parser):
|
||||
parser.addoption(
|
||||
"--local_tank_cache",
|
||||
action="store",
|
||||
default="",
|
||||
default=None,
|
||||
help="Specify the directory in which all downloaded shark_tank artifacts will be cached.",
|
||||
)
|
||||
parser.addoption(
|
||||
"--tank_url",
|
||||
type=str,
|
||||
default="gs://shark_tank/latest",
|
||||
default="gs://shark_tank/nightly",
|
||||
help="URL to bucket from which to download SHARK tank artifacts. Default is gs://shark_tank/latest",
|
||||
)
|
||||
parser.addoption(
|
||||
"--tank_prefix",
|
||||
type=str,
|
||||
default=None,
|
||||
help="Prefix to gs://shark_tank/ model directories from which to download SHARK tank artifacts. Default is nightly.",
|
||||
)
|
||||
parser.addoption(
|
||||
"--benchmark_dispatches",
|
||||
default=None,
|
||||
help="Benchmark individual dispatch kernels produced by IREE compiler. Use 'All' for all, or specific dispatches e.g. '0 1 2 10'",
|
||||
)
|
||||
parser.addoption(
|
||||
"--dispatch_benchmarks_dir",
|
||||
default="./temp_dispatch_benchmarks",
|
||||
help="Directory in which dispatch benchmarks are saved.",
|
||||
)
|
||||
parser.addoption(
|
||||
"--batchsize",
|
||||
default=1,
|
||||
type=int,
|
||||
help="Batch size for the tested model.",
|
||||
)
|
||||
|
||||
@@ -27,7 +27,7 @@ include(FetchContent)
|
||||
|
||||
FetchContent_Declare(
|
||||
iree
|
||||
GIT_REPOSITORY https://github.com/nod-ai/shark-runtime.git
|
||||
GIT_REPOSITORY https://github.com/nod-ai/srt.git
|
||||
GIT_TAG shark
|
||||
GIT_SUBMODULES_RECURSE OFF
|
||||
GIT_SHALLOW OFF
|
||||
|
||||
@@ -40,7 +40,7 @@ cmake --build build/
|
||||
*Prepare the model*
|
||||
```bash
|
||||
wget https://storage.googleapis.com/shark_tank/latest/resnet50_tf/resnet50_tf.mlir
|
||||
iree-compile --iree-input-type=mhlo --iree-vm-bytecode-module-output-format=flatbuffer-binary --iree-hal-target-backends=vulkan --iree-llvm-embedded-linker-path=`python3 -c 'import sysconfig; print(sysconfig.get_paths()["purelib"])'`/iree/compiler/tools/../_mlir_libs/iree-lld --mlir-print-debuginfo --mlir-print-op-on-diagnostic=false --mlir-pass-pipeline-crash-reproducer=ist/core-reproducer.mlir --iree-llvm-target-cpu-features=host -iree-vulkan-target-triple=rdna2-unknown-linux --iree-stream-resource-index-bits=64 --iree-vm-target-index-bits=64 resnet50_tf.mlir -o resnet50_tf.vmfb
|
||||
iree-compile --iree-input-type=auto --iree-vm-bytecode-module-output-format=flatbuffer-binary --iree-hal-target-backends=vulkan --iree-llvmcpu-embedded-linker-path=`python3 -c 'import sysconfig; print(sysconfig.get_paths()["purelib"])'`/iree/compiler/tools/../_mlir_libs/iree-lld --mlir-print-debuginfo --mlir-print-op-on-diagnostic=false --mlir-pass-pipeline-crash-reproducer=ist/core-reproducer.mlir --iree-llvmcpu-target-cpu-features=host -iree-vulkan-target-triple=rdna2-unknown-linux resnet50_tf.mlir -o resnet50_tf.vmfb
|
||||
```
|
||||
*Prepare the input*
|
||||
|
||||
@@ -65,18 +65,18 @@ A tool for benchmarking other models is built and can be invoked with a command
|
||||
see `./build/vulkan_gui/iree-vulkan-gui --help` for an explanation on the function input. For example, stable diffusion unet can be tested with the following commands:
|
||||
```bash
|
||||
wget https://storage.googleapis.com/shark_tank/quinn/stable_diff_tf/stable_diff_tf.mlir
|
||||
iree-compile --iree-input-type=mhlo --iree-vm-bytecode-module-output-format=flatbuffer-binary --iree-hal-target-backends=vulkan --mlir-print-debuginfo --mlir-print-op-on-diagnostic=false --iree-llvm-target-cpu-features=host -iree-vulkan-target-triple=rdna2-unknown-linux --iree-stream-resource-index-bits=64 --iree-vm-target-index-bits=64 stable_diff_tf.mlir -o stable_diff_tf.vmfb
|
||||
iree-compile --iree-input-type=auto --iree-vm-bytecode-module-output-format=flatbuffer-binary --iree-hal-target-backends=vulkan --mlir-print-debuginfo --mlir-print-op-on-diagnostic=false --iree-llvmcpu-target-cpu-features=host -iree-vulkan-target-triple=rdna2-unknown-linux stable_diff_tf.mlir -o stable_diff_tf.vmfb
|
||||
./build/vulkan_gui/iree-vulkan-gui --module-file=stable_diff_tf.vmfb --function_input=2x4x64x64xf32 --function_input=1xf32 --function_input=2x77x768xf32
|
||||
```
|
||||
VAE and Autoencoder are also available
|
||||
```bash
|
||||
# VAE
|
||||
wget https://storage.googleapis.com/shark_tank/quinn/stable_diff_tf/vae_tf/vae.mlir
|
||||
iree-compile --iree-input-type=mhlo --iree-vm-bytecode-module-output-format=flatbuffer-binary --iree-hal-target-backends=vulkan --mlir-print-debuginfo --mlir-print-op-on-diagnostic=false --iree-llvm-target-cpu-features=host -iree-vulkan-target-triple=rdna2-unknown-linux --iree-stream-resource-index-bits=64 --iree-vm-target-index-bits=64 vae.mlir -o vae.vmfb
|
||||
iree-compile --iree-input-type=auto --iree-vm-bytecode-module-output-format=flatbuffer-binary --iree-hal-target-backends=vulkan --mlir-print-debuginfo --mlir-print-op-on-diagnostic=false --iree-llvmcpu-target-cpu-features=host -iree-vulkan-target-triple=rdna2-unknown-linux vae.mlir -o vae.vmfb
|
||||
./build/vulkan_gui/iree-vulkan-gui --module-file=stable_diff_tf.vmfb --function_input=1x4x64x64xf32
|
||||
|
||||
# CLIP Autoencoder
|
||||
wget https://storage.googleapis.com/shark_tank/quinn/stable_diff_tf/clip_tf/clip_autoencoder.mlir
|
||||
iree-compile --iree-input-type=mhlo --iree-vm-bytecode-module-output-format=flatbuffer-binary --iree-hal-target-backends=vulkan --mlir-print-debuginfo --mlir-print-op-on-diagnostic=false --iree-llvm-target-cpu-features=host -iree-vulkan-target-triple=rdna2-unknown-linux --iree-stream-resource-index-bits=64 --iree-vm-target-index-bits=64 clip_autoencoder.mlir -o clip_autoencoder.vmfb
|
||||
iree-compile --iree-input-type=auto --iree-vm-bytecode-module-output-format=flatbuffer-binary --iree-hal-target-backends=vulkan --mlir-print-debuginfo --mlir-print-op-on-diagnostic=false --iree-llvmcpu-target-cpu-features=host -iree-vulkan-target-triple=rdna2-unknown-linux clip_autoencoder.mlir -o clip_autoencoder.vmfb
|
||||
./build/vulkan_gui/iree-vulkan-gui --module-file=stable_diff_tf.vmfb --function_input=1x77xi32 --function_input=1x77xi32
|
||||
```
|
||||
|
||||
@@ -21,7 +21,7 @@ endif()
|
||||
# Compile mnist.mlir to mnist.vmfb.
|
||||
set(_COMPILE_TOOL_EXECUTABLE $<TARGET_FILE:iree-compile>)
|
||||
set(_COMPILE_ARGS)
|
||||
list(APPEND _COMPILE_ARGS "--iree-input-type=mhlo")
|
||||
list(APPEND _COMPILE_ARGS "--iree-input-type=auto")
|
||||
list(APPEND _COMPILE_ARGS "--iree-hal-target-backends=llvm-cpu")
|
||||
list(APPEND _COMPILE_ARGS "${IREE_SOURCE_DIR}/samples/models/mnist.mlir")
|
||||
list(APPEND _COMPILE_ARGS "-o")
|
||||
|
||||
27
dataset/README.md
Normal file
27
dataset/README.md
Normal file
@@ -0,0 +1,27 @@
|
||||
# Dataset annotation tool
|
||||
|
||||
SHARK annotator for adding or modifying prompts of dataset images
|
||||
|
||||
## Set up
|
||||
|
||||
Activate SHARK Python virtual environment and install additional packages
|
||||
```shell
|
||||
source ../shark.venv/bin/activate
|
||||
pip install -r requirements.txt
|
||||
```
|
||||
|
||||
## Run annotator
|
||||
|
||||
```shell
|
||||
python annotation_tool.py
|
||||
```
|
||||
|
||||
<img width="1280" alt="annotator" src="https://user-images.githubusercontent.com/49575973/214521137-7ef6ae10-7cd8-46e6-b270-b6c0445157f1.png">
|
||||
|
||||
* Select a dataset from `Dataset` dropdown list
|
||||
* Select an image from `Image` dropdown list
|
||||
* Image and the existing prompt will be loaded
|
||||
* Select a prompt from `Prompt` dropdown list to modify or "Add new" to add a prompt
|
||||
* Click `Save` to save changes, click `Delete` to delete prompt
|
||||
* Click `Back` or `Next` to switch image, you could also select other images from `Image`
|
||||
* Click `Finish` when finishing annotation or before switching dataset
|
||||
233
dataset/annotation_tool.py
Normal file
233
dataset/annotation_tool.py
Normal file
@@ -0,0 +1,233 @@
|
||||
import gradio as gr
|
||||
import json
|
||||
import jsonlines
|
||||
import os
|
||||
from args import args
|
||||
from pathlib import Path
|
||||
from PIL import Image
|
||||
from utils import get_datasets
|
||||
|
||||
|
||||
shark_root = Path(__file__).parent.parent
|
||||
demo_css = shark_root.joinpath("web/demo.css").resolve()
|
||||
nodlogo_loc = shark_root.joinpath("web/models/stable_diffusion/logos/nod-logo.png")
|
||||
|
||||
|
||||
with gr.Blocks(title="Dataset Annotation Tool", css=demo_css) as shark_web:
|
||||
with gr.Row(elem_id="ui_title"):
|
||||
nod_logo = Image.open(nodlogo_loc)
|
||||
with gr.Column(scale=1, elem_id="demo_title_outer"):
|
||||
gr.Image(
|
||||
value=nod_logo,
|
||||
show_label=False,
|
||||
interactive=False,
|
||||
show_download_button=False,
|
||||
elem_id="top_logo",
|
||||
width=150,
|
||||
height=100,
|
||||
)
|
||||
|
||||
datasets, images, ds_w_prompts = get_datasets(args.gs_url)
|
||||
prompt_data = dict()
|
||||
|
||||
with gr.Row(elem_id="ui_body"):
|
||||
# TODO: add multiselect dataset, there is a gradio version conflict
|
||||
dataset = gr.Dropdown(label="Dataset", choices=datasets)
|
||||
image_name = gr.Dropdown(label="Image", choices=[])
|
||||
|
||||
with gr.Row(elem_id="ui_body"):
|
||||
# TODO: add ability to search image by typing
|
||||
with gr.Column(scale=1, min_width=600):
|
||||
image = gr.Image(type="filepath", height=512)
|
||||
|
||||
with gr.Column(scale=1, min_width=600):
|
||||
prompts = gr.Dropdown(
|
||||
label="Prompts",
|
||||
choices=[],
|
||||
)
|
||||
prompt = gr.Textbox(
|
||||
label="Editor",
|
||||
lines=3,
|
||||
)
|
||||
with gr.Row():
|
||||
save = gr.Button("Save")
|
||||
delete = gr.Button("Delete")
|
||||
with gr.Row():
|
||||
back_image = gr.Button("Back")
|
||||
next_image = gr.Button("Next")
|
||||
finish = gr.Button("Finish")
|
||||
|
||||
def filter_datasets(dataset):
|
||||
if dataset is None:
|
||||
return gr.Dropdown.update(value=None, choices=[])
|
||||
|
||||
# create the dataset dir if doesn't exist and download prompt file
|
||||
dataset_path = str(shark_root) + "/dataset/" + dataset
|
||||
if not os.path.exists(dataset_path):
|
||||
os.mkdir(dataset_path)
|
||||
|
||||
# read prompt jsonlines file
|
||||
prompt_data.clear()
|
||||
if dataset in ds_w_prompts:
|
||||
prompt_gs_path = args.gs_url + "/" + dataset + "/metadata.jsonl"
|
||||
os.system(f'gsutil cp "{prompt_gs_path}" "{dataset_path}"/')
|
||||
with jsonlines.open(dataset_path + "/metadata.jsonl") as reader:
|
||||
for line in reader.iter(type=dict, skip_invalid=True):
|
||||
prompt_data[line["file_name"]] = (
|
||||
[line["text"]] if type(line["text"]) is str else line["text"]
|
||||
)
|
||||
|
||||
return gr.Dropdown.update(choices=images[dataset])
|
||||
|
||||
dataset.change(fn=filter_datasets, inputs=dataset, outputs=image_name)
|
||||
|
||||
def display_image(dataset, image_name):
|
||||
if dataset is None or image_name is None:
|
||||
return gr.Image.update(value=None), gr.Dropdown.update(value=None)
|
||||
|
||||
# download and load the image
|
||||
img_gs_path = args.gs_url + "/" + dataset + "/" + image_name
|
||||
img_sub_path = "/".join(image_name.split("/")[:-1])
|
||||
img_dst_path = (
|
||||
str(shark_root) + "/dataset/" + dataset + "/" + img_sub_path + "/"
|
||||
)
|
||||
if not os.path.exists(img_dst_path):
|
||||
os.mkdir(img_dst_path)
|
||||
os.system(f'gsutil cp "{img_gs_path}" "{img_dst_path}"')
|
||||
img = Image.open(img_dst_path + image_name.split("/")[-1])
|
||||
|
||||
if image_name not in prompt_data.keys():
|
||||
prompt_data[image_name] = []
|
||||
prompt_choices = ["Add new"]
|
||||
prompt_choices += prompt_data[image_name]
|
||||
return gr.Image.update(value=img), gr.Dropdown.update(choices=prompt_choices)
|
||||
|
||||
image_name.change(
|
||||
fn=display_image,
|
||||
inputs=[dataset, image_name],
|
||||
outputs=[image, prompts],
|
||||
)
|
||||
|
||||
def edit_prompt(prompts):
|
||||
if prompts == "Add new":
|
||||
return gr.Textbox.update(value=None)
|
||||
|
||||
return gr.Textbox.update(value=prompts)
|
||||
|
||||
prompts.change(fn=edit_prompt, inputs=prompts, outputs=prompt)
|
||||
|
||||
def save_prompt(dataset, image_name, prompts, prompt):
|
||||
if dataset is None or image_name is None or prompts is None or prompt is None:
|
||||
return
|
||||
|
||||
if prompts == "Add new":
|
||||
prompt_data[image_name].append(prompt)
|
||||
else:
|
||||
idx = prompt_data[image_name].index(prompts)
|
||||
prompt_data[image_name][idx] = prompt
|
||||
|
||||
prompt_path = str(shark_root) + "/dataset/" + dataset + "/metadata.jsonl"
|
||||
# write prompt jsonlines file
|
||||
with open(prompt_path, "w") as f:
|
||||
for key, value in prompt_data.items():
|
||||
if not value:
|
||||
continue
|
||||
v = value if len(value) > 1 else value[0]
|
||||
f.write(json.dumps({"file_name": key, "text": v}))
|
||||
f.write("\n")
|
||||
|
||||
prompt_choices = ["Add new"]
|
||||
prompt_choices += prompt_data[image_name]
|
||||
return gr.Dropdown.update(choices=prompt_choices, value=None)
|
||||
|
||||
save.click(
|
||||
fn=save_prompt,
|
||||
inputs=[dataset, image_name, prompts, prompt],
|
||||
outputs=prompts,
|
||||
)
|
||||
|
||||
def delete_prompt(dataset, image_name, prompts):
|
||||
if dataset is None or image_name is None or prompts is None:
|
||||
return
|
||||
if prompts == "Add new":
|
||||
return
|
||||
|
||||
prompt_data[image_name].remove(prompts)
|
||||
prompt_path = str(shark_root) + "/dataset/" + dataset + "/metadata.jsonl"
|
||||
# write prompt jsonlines file
|
||||
with open(prompt_path, "w") as f:
|
||||
for key, value in prompt_data.items():
|
||||
if not value:
|
||||
continue
|
||||
v = value if len(value) > 1 else value[0]
|
||||
f.write(json.dumps({"file_name": key, "text": v}))
|
||||
f.write("\n")
|
||||
|
||||
prompt_choices = ["Add new"]
|
||||
prompt_choices += prompt_data[image_name]
|
||||
return gr.Dropdown.update(choices=prompt_choices, value=None)
|
||||
|
||||
delete.click(
|
||||
fn=delete_prompt,
|
||||
inputs=[dataset, image_name, prompts],
|
||||
outputs=prompts,
|
||||
)
|
||||
|
||||
def get_back_image(dataset, image_name):
|
||||
if dataset is None or image_name is None:
|
||||
return
|
||||
|
||||
# remove local image
|
||||
img_path = str(shark_root) + "/dataset/" + dataset + "/" + image_name
|
||||
os.system(f'rm "{img_path}"')
|
||||
# get the index for the back image
|
||||
idx = images[dataset].index(image_name)
|
||||
if idx == 0:
|
||||
return gr.Dropdown.update(value=None)
|
||||
|
||||
return gr.Dropdown.update(value=images[dataset][idx - 1])
|
||||
|
||||
back_image.click(
|
||||
fn=get_back_image, inputs=[dataset, image_name], outputs=image_name
|
||||
)
|
||||
|
||||
def get_next_image(dataset, image_name):
|
||||
if dataset is None or image_name is None:
|
||||
return
|
||||
|
||||
# remove local image
|
||||
img_path = str(shark_root) + "/dataset/" + dataset + "/" + image_name
|
||||
os.system(f'rm "{img_path}"')
|
||||
# get the index for the next image
|
||||
idx = images[dataset].index(image_name)
|
||||
if idx == len(images[dataset]) - 1:
|
||||
return gr.Dropdown.update(value=None)
|
||||
|
||||
return gr.Dropdown.update(value=images[dataset][idx + 1])
|
||||
|
||||
next_image.click(
|
||||
fn=get_next_image, inputs=[dataset, image_name], outputs=image_name
|
||||
)
|
||||
|
||||
def finish_annotation(dataset):
|
||||
if dataset is None:
|
||||
return
|
||||
|
||||
# upload prompt and remove local data
|
||||
dataset_path = str(shark_root) + "/dataset/" + dataset
|
||||
dataset_gs_path = args.gs_url + "/" + dataset + "/"
|
||||
os.system(f'gsutil cp "{dataset_path}/metadata.jsonl" "{dataset_gs_path}"')
|
||||
os.system(f'rm -rf "{dataset_path}"')
|
||||
|
||||
return gr.Dropdown.update(value=None)
|
||||
|
||||
finish.click(fn=finish_annotation, inputs=dataset, outputs=dataset)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
shark_web.launch(
|
||||
share=args.share,
|
||||
inbrowser=True,
|
||||
server_name="0.0.0.0",
|
||||
server_port=args.server_port,
|
||||
)
|
||||
34
dataset/args.py
Normal file
34
dataset/args.py
Normal file
@@ -0,0 +1,34 @@
|
||||
import argparse
|
||||
|
||||
p = argparse.ArgumentParser(
|
||||
description=__doc__, formatter_class=argparse.ArgumentDefaultsHelpFormatter
|
||||
)
|
||||
|
||||
##############################################################################
|
||||
### Dataset Annotator flags
|
||||
##############################################################################
|
||||
|
||||
p.add_argument(
|
||||
"--gs_url",
|
||||
type=str,
|
||||
required=True,
|
||||
help="URL to datasets in GS bucket",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--share",
|
||||
default=False,
|
||||
action=argparse.BooleanOptionalAction,
|
||||
help="flag for generating a public URL",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--server_port",
|
||||
type=int,
|
||||
default=8080,
|
||||
help="flag for setting server port",
|
||||
)
|
||||
|
||||
##############################################################################
|
||||
|
||||
args = p.parse_args()
|
||||
3
dataset/requirements.txt
Normal file
3
dataset/requirements.txt
Normal file
@@ -0,0 +1,3 @@
|
||||
# SHARK Annotator
|
||||
gradio==3.34.0
|
||||
jsonlines
|
||||
29
dataset/utils.py
Normal file
29
dataset/utils.py
Normal file
@@ -0,0 +1,29 @@
|
||||
from google.cloud import storage
|
||||
|
||||
|
||||
def get_datasets(gs_url):
|
||||
datasets = set()
|
||||
images = dict()
|
||||
ds_w_prompts = []
|
||||
|
||||
storage_client = storage.Client()
|
||||
bucket_name = gs_url.split("/")[2]
|
||||
source_blob_name = "/".join(gs_url.split("/")[3:])
|
||||
blobs = storage_client.list_blobs(bucket_name, prefix=source_blob_name)
|
||||
|
||||
for blob in blobs:
|
||||
dataset_name = blob.name.split("/")[1]
|
||||
if dataset_name == "":
|
||||
continue
|
||||
datasets.add(dataset_name)
|
||||
if dataset_name not in images.keys():
|
||||
images[dataset_name] = []
|
||||
|
||||
# check if image or jsonl
|
||||
file_sub_path = "/".join(blob.name.split("/")[2:])
|
||||
if "/" in file_sub_path:
|
||||
images[dataset_name] += [file_sub_path]
|
||||
elif "metadata.jsonl" in file_sub_path:
|
||||
ds_w_prompts.append(dataset_name)
|
||||
|
||||
return list(datasets), images, ds_w_prompts
|
||||
118
docs/shark_iree_profiling.md
Normal file
118
docs/shark_iree_profiling.md
Normal file
@@ -0,0 +1,118 @@
|
||||
# Overview
|
||||
|
||||
This document is intended to provide a starting point for profiling with SHARK/IREE. At it's core
|
||||
[SHARK](https://github.com/nod-ai/SHARK/tree/main/tank) is a python API that links the MLIR lowerings from various
|
||||
frameworks + frontends (e.g. PyTorch -> Torch-MLIR) with the compiler + runtime offered by IREE. More information
|
||||
on model coverage and framework support can be found [here](https://github.com/nod-ai/SHARK/tree/main/tank). The intended
|
||||
use case for SHARK is for compilation and deployment of performant state of the art AI models.
|
||||
|
||||
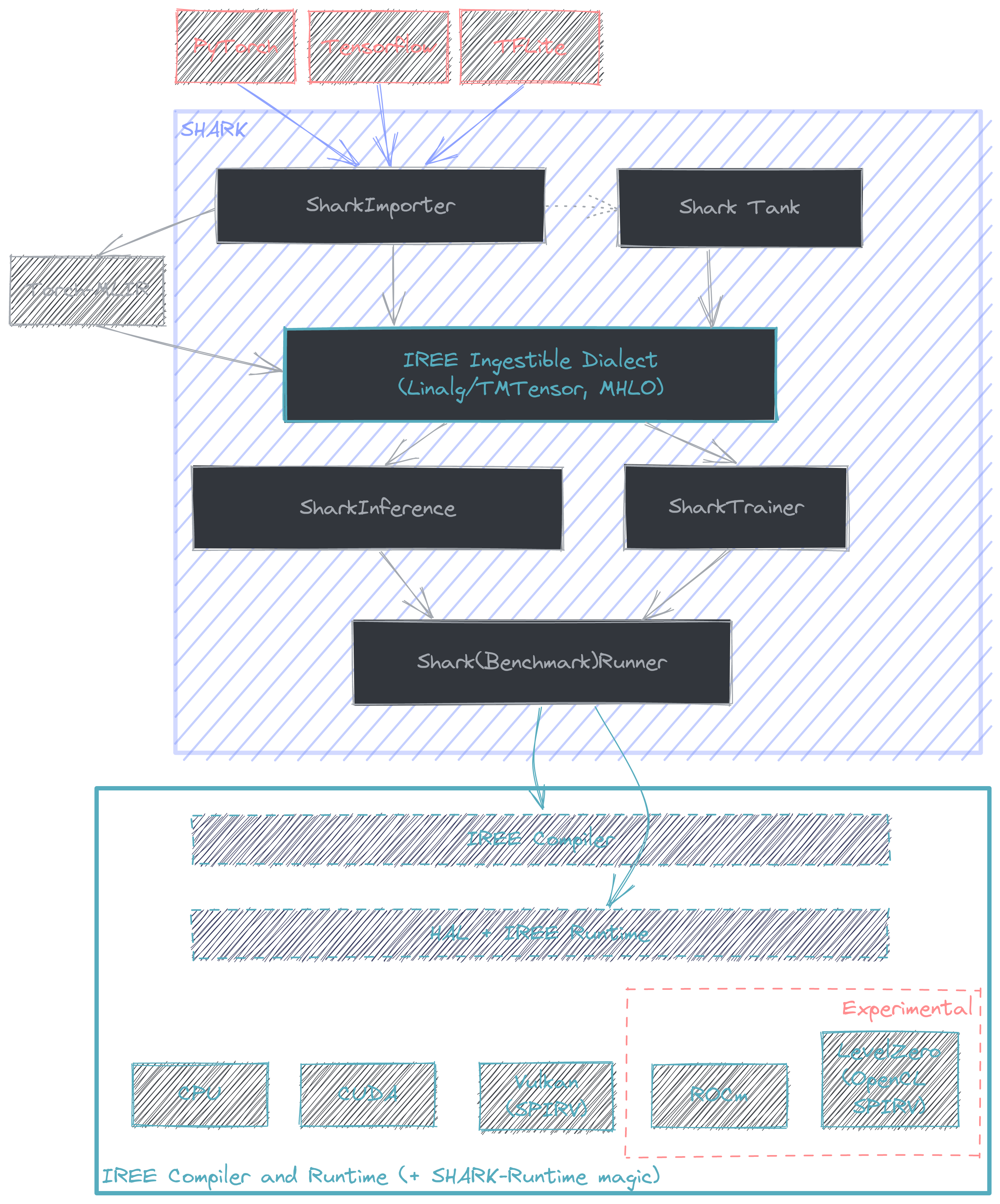
|
||||
|
||||
## Benchmarking with SHARK
|
||||
|
||||
TODO: Expand this section.
|
||||
|
||||
SHARK offers native benchmarking support, although because it is model focused, fine grain profiling is
|
||||
hidden when compared against the common "model benchmarking suite" use case SHARK is good at.
|
||||
|
||||
### SharkBenchmarkRunner
|
||||
|
||||
SharkBenchmarkRunner is a class designed for benchmarking models against other runtimes.
|
||||
TODO: List supported runtimes for comparison + example on how to benchmark with it.
|
||||
|
||||
## Directly profiling IREE
|
||||
|
||||
A number of excellent developer resources on profiling with IREE can be
|
||||
found [here](https://github.com/iree-org/iree/tree/main/docs/developers/developing_iree). As a result this section will
|
||||
focus on the bridging the gap between the two.
|
||||
- https://github.com/iree-org/iree/blob/main/docs/developers/developing_iree/profiling.md
|
||||
- https://github.com/iree-org/iree/blob/main/docs/developers/developing_iree/profiling_with_tracy.md
|
||||
- https://github.com/iree-org/iree/blob/main/docs/developers/developing_iree/profiling_vulkan_gpu.md
|
||||
- https://github.com/iree-org/iree/blob/main/docs/developers/developing_iree/profiling_cpu_events.md
|
||||
|
||||
Internally, SHARK builds a pair of IREE commands to compile + run a model. At a high level the flow starts with the
|
||||
model represented with a high level dialect (commonly Linalg) and is compiled to a flatbuffer (.vmfb) that
|
||||
the runtime is capable of ingesting. At this point (with potentially a few runtime flags) the compiled model is then run
|
||||
through the IREE runtime. This is all facilitated with the IREE python bindings, which offers a convenient method
|
||||
to capture the compile command SHARK comes up with. This is done by setting the environment variable
|
||||
`IREE_SAVE_TEMPS` to point to a directory of choice, e.g. for stable diffusion
|
||||
```
|
||||
# Linux
|
||||
$ export IREE_SAVE_TEMPS=/path/to/some/directory
|
||||
# Windows
|
||||
$ $env:IREE_SAVE_TEMPS="C:\path\to\some\directory"
|
||||
$ python apps/stable_diffusion/scripts/txt2img.py -p "a photograph of an astronaut riding a horse" --save_vmfb
|
||||
```
|
||||
NOTE: Currently this will only save the compile command + input MLIR for a single model if run in a pipeline.
|
||||
In the case of stable diffusion this (should) be UNet so to get examples for other models in the pipeline they
|
||||
need to be extracted and tested individually.
|
||||
|
||||
The save temps directory should contain three files: `core-command-line.txt`, `core-input.mlir`, and `core-output.bin`.
|
||||
The command line for compilation will start something like this, where the `-` needs to be replaced with the path to `core-input.mlir`.
|
||||
```
|
||||
/home/quinn/nod/iree-build/compiler/bindings/python/iree/compiler/tools/../_mlir_libs/iree-compile - --iree-input-type=none ...
|
||||
```
|
||||
The `-o output_filename.vmfb` flag can be used to specify the location to save the compiled vmfb. Note that a dump of the
|
||||
dispatches that can be compiled + run in isolation can be generated by adding `--iree-hal-dump-executable-benchmarks-to=/some/directory`. Say, if they are in the `benchmarks` directory, the following compile/run commands would work for Vulkan on RDNA3.
|
||||
```
|
||||
iree-compile --iree-input-type=none --iree-hal-target-backends=vulkan --iree-vulkan-target-triple=rdna3-unknown-linux benchmarks/module_forward_dispatch_${NUM}_vulkan_spirv_fb.mlir -o benchmarks/module_forward_dispatch_${NUM}_vulkan_spirv_fb.vmfb
|
||||
|
||||
iree-benchmark-module --module=benchmarks/module_forward_dispatch_${NUM}_vulkan_spirv_fb.vmfb --function=forward --device=vulkan
|
||||
```
|
||||
Where `${NUM}` is the dispatch number that you want to benchmark/profile in isolation.
|
||||
|
||||
### Enabling Tracy for Vulkan profiling
|
||||
|
||||
To begin profiling with Tracy, a build of IREE runtime with tracing enabled is needed. SHARK-Runtime (SRT) builds an
|
||||
instrumented version alongside the normal version nightly (.whls typically found [here](https://github.com/nod-ai/SRT/releases)), however this is only available for Linux. For Windows, tracing can be enabled by enabling a CMake flag.
|
||||
```
|
||||
$env:IREE_ENABLE_RUNTIME_TRACING="ON"
|
||||
```
|
||||
Getting a trace can then be done by setting environment variable `TRACY_NO_EXIT=1` and running the program that is to be
|
||||
traced. Then, to actually capture the trace, use the `iree-tracy-capture` tool in a different terminal. Note that to get
|
||||
the capture and profiler tools the `IREE_BUILD_TRACY=ON` CMake flag needs to be set.
|
||||
```
|
||||
TRACY_NO_EXIT=1 python apps/stable_diffusion/scripts/txt2img.py -p "a photograph of an astronaut riding a horse"
|
||||
|
||||
# (in another terminal, either on the same machine or through ssh with a tunnel through port 8086)
|
||||
iree-tracy-capture -o trace_filename.tracy
|
||||
```
|
||||
To do it over ssh, the flow looks like this
|
||||
```
|
||||
# From terminal 1 on local machine
|
||||
ssh -L 8086:localhost:8086 <remote_server_name>
|
||||
TRACY_NO_EXIT=1 python apps/stable_diffusion/scripts/txt2img.py -p "a photograph of an astronaut riding a horse"
|
||||
|
||||
# From terminal 2 on local machine. Requires having built IREE with the CMake flag `IREE_BUILD_TRACY=ON` to build the required tooling.
|
||||
iree-tracy-capture -o /path/to/trace.tracy
|
||||
```
|
||||
|
||||
The trace can then be viewed with
|
||||
```
|
||||
iree-tracy-profiler /path/to/trace.tracy
|
||||
```
|
||||
Capturing a runtime trace will work with any IREE tooling that uses the runtime. For example, `iree-benchmark-module`
|
||||
can be used for benchmarking an individual module. Importantly this means that any SHARK script can be profiled with tracy.
|
||||
|
||||
NOTE: Not all backends have the same tracy support. This writeup is focused on CPU/Vulkan backends but there is recently added support for tracing on CUDA (requires the `--cuda_tracing` flag).
|
||||
|
||||
## Experimental RGP support
|
||||
|
||||
TODO: This section is temporary until proper RGP support is added.
|
||||
|
||||
Currently, for stable diffusion there is a flag for enabling UNet to be visible to RGP with `--enable_rgp`. To get a proper capture though, the `DevModeSqttPrepareFrameCount=1` flag needs to be set for the driver (done with `VkPanel` on Windows).
|
||||
With these two settings, a single iteration of UNet can be captured.
|
||||
|
||||
(AMD only) To get a dump of the pipelines (result of compiled SPIR-V) the `EnablePipelineDump=1` driver flag can be set. The
|
||||
files will typically be dumped to a directory called `spvPipeline` (on Linux `/var/tmp/spvPipeline`. The dumped files will
|
||||
include header information that can be used to map back to the source dispatch/SPIR-V, e.g.
|
||||
```
|
||||
[Version]
|
||||
version = 57
|
||||
|
||||
[CsSpvFile]
|
||||
fileName = Shader_0x946C08DFD0C10D9A.spv
|
||||
|
||||
[CsInfo]
|
||||
entryPoint = forward_dispatch_193_matmul_256x65536x2304
|
||||
```
|
||||
75
docs/shark_sd_blender.md
Normal file
75
docs/shark_sd_blender.md
Normal file
@@ -0,0 +1,75 @@
|
||||
# Overview
|
||||
|
||||
This document is intended to provide a starting point for using SHARK stable diffusion with Blender.
|
||||
|
||||
We currently make use of the [AI-Render Plugin](https://github.com/benrugg/AI-Render) to integrate with Blender.
|
||||
|
||||
## Setup SHARK and prerequisites:
|
||||
|
||||
* Download the latest SHARK SD webui .exe from [here](https://github.com/nod-ai/SHARK/releases) or follow instructions on the [README](https://github.com/nod-ai/SHARK#readme)
|
||||
* Once you have the .exe where you would like SHARK to install, run the .exe from terminal/PowerShell with the `--api` flag:
|
||||
```
|
||||
## Run the .exe in API mode:
|
||||
.\shark_sd_<date>_<ver>.exe --api
|
||||
|
||||
## For example:
|
||||
.\shark_sd_20230411_671.exe --api --server_port=8082
|
||||
|
||||
## From a the base directory of a source clone of SHARK:
|
||||
./setup_venv.ps1
|
||||
python apps\stable_diffusion\web\index.py --api
|
||||
|
||||
```
|
||||
|
||||
Your local SD server should start and look something like this:
|
||||

|
||||
|
||||
* Note: When running in api mode with `--api`, the .exe will not function as a webUI. Thus, the address in the terminal output will only be useful for API requests.
|
||||
|
||||
### Install AI Render
|
||||
|
||||
- Get AI Render on [Blender Market](https://blendermarket.com/products/ai-render) or [Gumroad](https://airender.gumroad.com/l/ai-render)
|
||||
- Open Blender, then go to Edit > Preferences > Add-ons > Install and then find the zip file
|
||||
- We will be using the Automatic1111 SD backend for the AI-Render plugin. Follow instructions [here](https://github.com/benrugg/AI-Render/wiki/Local-Installation) to setup local SD backend.
|
||||
|
||||
Your AI-Render preferences should be configured as shown; the highlighted part should match your terminal output:
|
||||

|
||||
|
||||
|
||||
The [AI-Render README](https://github.com/benrugg/AI-Render/blob/main/README.md) has more details on installation and usage, as well as video tutorials.
|
||||
|
||||
## Using AI-Render + SHARK in your Blender project
|
||||
|
||||
- In the Render Properties tab, in the AI-Render dropdown, enable AI-Render.
|
||||
|
||||

|
||||
|
||||
- Select an image size (it's usually better to upscale later than go high on the img2img resolution here.)
|
||||
|
||||

|
||||
|
||||
- From here, you can enter a prompt and configure img2img Stable Diffusion parameters, and AI-Render will run SHARK SD img2img on the rendered scene.
|
||||
- AI-Render has useful presets for aesthetic styles, so you should be able to keep your subject prompt simple and focus on creating a decent Blender scene to start from.
|
||||
|
||||

|
||||
|
||||
## Examples:
|
||||
Scene (Input image):
|
||||
|
||||

|
||||
|
||||
Prompt:
|
||||
"A bowl of tangerines in front of rocks, masterpiece, oil on canvas, by Georgia O'Keefe, trending on artstation, landscape painting by Caspar David Friedrich"
|
||||
|
||||
Negative Prompt (default):
|
||||
"ugly, bad art, poorly drawn hands, poorly drawn feet, poorly drawn face, out of frame, extra limbs, disfigured, deformed, body out of frame, blurry, bad anatomy, blurred, watermark, grainy, tiling, signature, cut off, draft"
|
||||
|
||||
Example output:
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
140
docs/shark_sd_koboldcpp.md
Normal file
140
docs/shark_sd_koboldcpp.md
Normal file
@@ -0,0 +1,140 @@
|
||||
# Overview
|
||||
|
||||
In [1.47.2](https://github.com/LostRuins/koboldcpp/releases/tag/v1.47.2) [Koboldcpp](https://github.com/LostRuins/koboldcpp) added AUTOMATIC1111 integration for image generation. Since SHARK implements a small subset of the A1111 REST api, you can also use SHARK for this. This document gives a starting point for how to get this working.
|
||||
|
||||
## In Action
|
||||
|
||||

|
||||
|
||||
## Memory considerations
|
||||
|
||||
Since both Koboldcpp and SHARK will use VRAM on your graphic card(s) running both at the same time using the same card will impose extra limitations on the model size you can fully offload to the video card in Koboldcpp. For me, on a RX 7900 XTX on Windows with 24 GiB of VRAM, the limit was about a 13 Billion parameter model with Q5_K_M quantisation.
|
||||
|
||||
## Performance Considerations
|
||||
|
||||
When using SHARK for image generation, especially with Koboldcpp, you need to be aware that it is currently designed to pay a large upfront cost in time compiling and tuning the model you select, to get an optimal individual image generation time. You need to be the judge as to whether this trade-off is going to be worth it for your OS and hardware combination.
|
||||
|
||||
It means that the first time you run a particular Stable Diffusion model for a particular combination of image size, LoRA, and VAE, SHARK will spend *many minutes* - even on a beefy machaine with very fast graphics card with lots of memory - building that model combination just so it can save it to disk. It may even have to go away and download the model if it doesn't already have it locally. Once it has done its build of a model combination for your hardware once, it shouldn't need to do it again until you upgrade to a newer SHARK version, install different drivers or change your graphics hardware. It will just upload the files it generated the first time to your graphics card and proceed from there.
|
||||
|
||||
This does mean however, that on a brand new fresh install of SHARK that has not generated any images on a model you haven't selected before, the first image Koboldcpp requests may look like it is *never* going finish and that the whole process has broken. Be forewarned, make yourself a cup of coffee, and expect a lot of messages about compilation and tuning from SHARK in the terminal you ran it from.
|
||||
|
||||
## Setup SHARK and prerequisites:
|
||||
|
||||
* Make sure you have suitable drivers for your graphics card installed. See the prerequisties section of the [README](https://github.com/nod-ai/SHARK#readme).
|
||||
* Download the latest SHARK studio .exe from [here](https://github.com/nod-ai/SHARK/releases) or follow the instructions in the [README](https://github.com/nod-ai/SHARK#readme) for an advanced, Linux or Mac install.
|
||||
* Run SHARK from terminal/PowerShell with the `--api` flag. Since koboldcpp also expects both CORS support and the image generator to be running on port `7860` rather than SHARK default of `8080`, also include both the `--api_accept_origin` flag with a suitable origin (use `="*"` to enable all origins) and `--server_port=7860` on the command line. (See the if you want to run SHARK on a different port)
|
||||
|
||||
```powershell
|
||||
## Run the .exe in API mode, with CORS support, on the A1111 endpoint port:
|
||||
.\node_ai_shark_studio_<date>_<ver>.exe --api --api_accept_origin="*" --server_port=7860
|
||||
|
||||
## Run trom the base directory of a source clone of SHARK on Windows:
|
||||
.\setup_venv.ps1
|
||||
python .\apps\stable_diffusion\web\index.py --api --api_accept_origin="*" --server_port=7860
|
||||
|
||||
## Run a the base directory of a source clone of SHARK on Linux:
|
||||
./setup_venv.sh
|
||||
source shark.venv/bin/activate
|
||||
python ./apps/stable_diffusion/web/index.py --api --api_accept_origin="*" --server_port=7860
|
||||
|
||||
## An example giving improved performance on AMD cards using vulkan, that runs on the same port as A1111
|
||||
.\node_ai_shark_studio_20320901_2525.exe --api --api_accept_origin="*" --device_allocator="caching" --server_port=7860
|
||||
|
||||
## Since the api respects most applicable SHARK command line arguments for options not specified,
|
||||
## or currently unimplemented by API, there might be some you want to set, as listed in `--help`
|
||||
.\node_ai_shark_studio_20320901_2525.exe --help
|
||||
|
||||
## For instance, the example above, but with a a custom VAE specified
|
||||
.\node_ai_shark_studio_20320901_2525.exe --api --api_accept_origin="*" --device_allocator="caching" --server_port=7860 --custom_vae="clearvae_v23.safetensors"
|
||||
|
||||
## An example with multiple specific CORS origins
|
||||
python apps/stable_diffusion/web/index.py --api --api_accept_origin="koboldcpp.example.com:7001" --api_accept_origin="koboldcpp.example.com:7002" --server_port=7860
|
||||
```
|
||||
|
||||
SHARK should start in server mode, and you should see something like this:
|
||||
|
||||

|
||||
|
||||
* Note: When running in api mode with `--api`, the .exe will not function as a webUI. Thus, the address or port shown in the terminal output will only be useful for API requests.
|
||||
|
||||
|
||||
## Configure Koboldcpp for local image generation:
|
||||
|
||||
* Get the latest [Koboldcpp](https://github.com/LostRuins/koboldcpp/releases) if you don't already have it. If you have a recent AMD card that has ROCm HIP [support for Windows](https://rocmdocs.amd.com/en/latest/release/windows_support.html#windows-supported-gpus) or [support for Linux](https://rocmdocs.amd.com/en/latest/release/gpu_os_support.html#linux-supported-gpus), you'll likely prefer [YellowRosecx's ROCm fork](https://github.com/YellowRoseCx/koboldcpp-rocm).
|
||||
* Start Koboldcpp in another terminal/Powershell and setup your model configuration. Refer to the [Koboldcpp README](https://github.com/YellowRoseCx/koboldcpp-rocm) for more details on how to do this if this is your first time using Koboldcpp.
|
||||
* Once the main UI has loaded into your browser click the settings button, go to the advanced tab, and then choose *Local A1111* from the generate images dropdown:
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
*if you get an error here, see the next section [below](#connecting-to-shark-on-a-different-address-or-port)*
|
||||
|
||||
* A list of Stable Diffusion models available to your SHARK instance should now be listed in the box below *generate images*. The default value will usually be set to `stabilityai/stable-diffusion-2-1-base`. Choose the model you want to use for image generation from the list (but see [performance considerations](#performance-considerations)).
|
||||
* You should now be ready to generate images, either by clicking the 'Add Img' button above the text entry box:
|
||||
|
||||

|
||||
|
||||
...or by selecting the 'Autogenerate' option in the settings:
|
||||
|
||||

|
||||
|
||||
*I often find that even if I have selected autogenerate I have to do an 'add img' to get things started off*
|
||||
|
||||
* There is one final piece of image generation configuration within Koboldcpp you might want to do. This is also in the generate images section of advanced settings. Here there is, not very obviously, a 'style' button:
|
||||
|
||||

|
||||
|
||||
This will bring up a dialog box where you can enter a short text that will sent as a prefix to the Prompt sent to SHARK:
|
||||
|
||||

|
||||
|
||||
|
||||
## Connecting to SHARK on a different address or port
|
||||
|
||||
If you didn't set the port to `--server_port=7860` when starting SHARK, or you are running it on different machine on your network than you are running Koboldcpp, or to where you are running the koboldcpp's kdlite client frontend, then you very likely got the following error:
|
||||
|
||||

|
||||
|
||||
As long as SHARK is running correctly, this means you need to set the url and port to the correct values in Koboldcpp. For instance. to set the port that Koboldcpp looks for an image generator to SHARK's default port of 8080:
|
||||
|
||||
* Select the cog icon the Generate Images section of Advanced settings:
|
||||
|
||||

|
||||
|
||||
* Then edit the port number at the end of the url in the 'A1111 Endpoint Selection' dialog box to read 8080:
|
||||
|
||||

|
||||
|
||||
* Similarly, when running SHARK on a different machine you will need to change host part of the endpoint url to the hostname or ip address where SHARK is running, similarly:
|
||||
|
||||

|
||||
|
||||
## Examples
|
||||
|
||||
Here's how Koboldcpp shows an image being requested:
|
||||
|
||||

|
||||
|
||||
The generated image in context in story mode:
|
||||
|
||||

|
||||
|
||||
And the same image when clicked on:
|
||||
|
||||

|
||||
|
||||
|
||||
## Where to find the images in SHARK
|
||||
|
||||
Even though Koboldcpp requests images at a size of 512x512, it resizes then to 256x256, converts them to `.jpeg`, and only shows them at 200x200 in the main text window. It does this so it can save them compactly embedded in your story as a `data://` uri.
|
||||
|
||||
However the images at the original size are saved by SHARK in its `output_dir` which is usually a folder named for the current date. inside `generated_imgs` folder in the SHARK installation directory.
|
||||
|
||||
You can browse these, either using the Output Gallery tab from within the SHARK web ui:
|
||||
|
||||

|
||||
|
||||
...or by browsing to the `output_dir` in your operating system's file manager:
|
||||
|
||||

|
||||
@@ -1,251 +0,0 @@
|
||||
# Lint as: python3
|
||||
"""SHARK Tank"""
|
||||
# python generate_sharktank.py, you have to give a csv tile with [model_name, model_download_url]
|
||||
# will generate local shark tank folder like this:
|
||||
# HOME
|
||||
# /.local
|
||||
# /shark_tank
|
||||
# /albert_lite_base
|
||||
# /...model_name...
|
||||
#
|
||||
|
||||
import os
|
||||
import csv
|
||||
import argparse
|
||||
from shark.shark_importer import SharkImporter
|
||||
from shark.parser import shark_args
|
||||
import tensorflow as tf
|
||||
import subprocess as sp
|
||||
import hashlib
|
||||
import numpy as np
|
||||
from pathlib import Path
|
||||
|
||||
visible_default = tf.config.list_physical_devices("GPU")
|
||||
try:
|
||||
tf.config.set_visible_devices([], "GPU")
|
||||
visible_devices = tf.config.get_visible_devices()
|
||||
for device in visible_devices:
|
||||
assert device.device_type != "GPU"
|
||||
except:
|
||||
# Invalid device or cannot modify virtual devices once initialized.
|
||||
pass
|
||||
|
||||
|
||||
def create_hash(file_name):
|
||||
with open(file_name, "rb") as f:
|
||||
file_hash = hashlib.blake2b()
|
||||
while chunk := f.read(2**20):
|
||||
file_hash.update(chunk)
|
||||
|
||||
return file_hash.hexdigest()
|
||||
|
||||
|
||||
def save_torch_model(torch_model_list):
|
||||
from tank.model_utils import get_hf_model
|
||||
from tank.model_utils import get_vision_model
|
||||
from tank.model_utils import get_hf_img_cls_model
|
||||
|
||||
with open(torch_model_list) as csvfile:
|
||||
torch_reader = csv.reader(csvfile, delimiter=",")
|
||||
fields = next(torch_reader)
|
||||
for row in torch_reader:
|
||||
torch_model_name = row[0]
|
||||
tracing_required = row[1]
|
||||
model_type = row[2]
|
||||
is_dynamic = row[3]
|
||||
|
||||
tracing_required = False if tracing_required == "False" else True
|
||||
is_dynamic = False if is_dynamic == "False" else True
|
||||
|
||||
model = None
|
||||
input = None
|
||||
if model_type == "vision":
|
||||
model, input, _ = get_vision_model(torch_model_name)
|
||||
elif model_type == "hf":
|
||||
model, input, _ = get_hf_model(torch_model_name)
|
||||
elif model_type == "hf_img_cls":
|
||||
model, input, _ = get_hf_img_cls_model(torch_model_name)
|
||||
|
||||
torch_model_name = torch_model_name.replace("/", "_")
|
||||
torch_model_dir = os.path.join(
|
||||
WORKDIR, str(torch_model_name) + "_torch"
|
||||
)
|
||||
os.makedirs(torch_model_dir, exist_ok=True)
|
||||
|
||||
mlir_importer = SharkImporter(
|
||||
model,
|
||||
(input,),
|
||||
frontend="torch",
|
||||
)
|
||||
mlir_importer.import_debug(
|
||||
is_dynamic=False,
|
||||
tracing_required=tracing_required,
|
||||
dir=torch_model_dir,
|
||||
model_name=torch_model_name,
|
||||
)
|
||||
mlir_hash = create_hash(
|
||||
os.path.join(
|
||||
torch_model_dir, torch_model_name + "_torch" + ".mlir"
|
||||
)
|
||||
)
|
||||
np.save(os.path.join(torch_model_dir, "hash"), np.array(mlir_hash))
|
||||
# Generate torch dynamic models.
|
||||
if is_dynamic:
|
||||
mlir_importer.import_debug(
|
||||
is_dynamic=True,
|
||||
tracing_required=tracing_required,
|
||||
dir=torch_model_dir,
|
||||
model_name=torch_model_name + "_dynamic",
|
||||
)
|
||||
|
||||
|
||||
def save_tf_model(tf_model_list):
|
||||
from tank.model_utils_tf import (
|
||||
get_causal_image_model,
|
||||
get_causal_lm_model,
|
||||
get_keras_model,
|
||||
get_TFhf_model,
|
||||
)
|
||||
|
||||
with open(tf_model_list) as csvfile:
|
||||
tf_reader = csv.reader(csvfile, delimiter=",")
|
||||
fields = next(tf_reader)
|
||||
for row in tf_reader:
|
||||
tf_model_name = row[0]
|
||||
model_type = row[1]
|
||||
|
||||
model = None
|
||||
input = None
|
||||
print(f"Generating artifacts for model {tf_model_name}")
|
||||
if model_type == "hf":
|
||||
model, input, _ = get_causal_lm_model(tf_model_name)
|
||||
if model_type == "img":
|
||||
model, input, _ = get_causal_image_model(tf_model_name)
|
||||
if model_type == "keras":
|
||||
model, input, _ = get_keras_model(tf_model_name)
|
||||
if model_type == "TFhf":
|
||||
model, input, _ = get_TFhf_model(tf_model_name)
|
||||
|
||||
tf_model_name = tf_model_name.replace("/", "_")
|
||||
tf_model_dir = os.path.join(WORKDIR, str(tf_model_name) + "_tf")
|
||||
os.makedirs(tf_model_dir, exist_ok=True)
|
||||
|
||||
mlir_importer = SharkImporter(
|
||||
model,
|
||||
input,
|
||||
frontend="tf",
|
||||
)
|
||||
mlir_importer.import_debug(
|
||||
dir=tf_model_dir,
|
||||
model_name=tf_model_name,
|
||||
)
|
||||
mlir_hash = create_hash(
|
||||
os.path.join(tf_model_dir, tf_model_name + "_tf" + ".mlir")
|
||||
)
|
||||
np.save(os.path.join(tf_model_dir, "hash"), np.array(mlir_hash))
|
||||
|
||||
|
||||
def save_tflite_model(tflite_model_list):
|
||||
from shark.tflite_utils import TFLitePreprocessor
|
||||
|
||||
with open(tflite_model_list) as csvfile:
|
||||
tflite_reader = csv.reader(csvfile, delimiter=",")
|
||||
for row in tflite_reader:
|
||||
print("\n")
|
||||
tflite_model_name = row[0]
|
||||
tflite_model_link = row[1]
|
||||
print("tflite_model_name", tflite_model_name)
|
||||
print("tflite_model_link", tflite_model_link)
|
||||
tflite_model_name_dir = os.path.join(
|
||||
WORKDIR, str(tflite_model_name) + "_tflite"
|
||||
)
|
||||
os.makedirs(tflite_model_name_dir, exist_ok=True)
|
||||
print(f"TMP_TFLITE_MODELNAME_DIR = {tflite_model_name_dir}")
|
||||
|
||||
# Preprocess to get SharkImporter input args
|
||||
tflite_preprocessor = TFLitePreprocessor(str(tflite_model_name))
|
||||
raw_model_file_path = tflite_preprocessor.get_raw_model_file()
|
||||
inputs = tflite_preprocessor.get_inputs()
|
||||
tflite_interpreter = tflite_preprocessor.get_interpreter()
|
||||
|
||||
# Use SharkImporter to get SharkInference input args
|
||||
my_shark_importer = SharkImporter(
|
||||
module=tflite_interpreter,
|
||||
inputs=inputs,
|
||||
frontend="tflite",
|
||||
raw_model_file=raw_model_file_path,
|
||||
)
|
||||
my_shark_importer.import_debug(
|
||||
dir=tflite_model_name_dir,
|
||||
model_name=tflite_model_name,
|
||||
func_name="main",
|
||||
)
|
||||
mlir_hash = create_hash(
|
||||
os.path.join(
|
||||
tflite_model_name_dir,
|
||||
tflite_model_name + "_tflite" + ".mlir",
|
||||
)
|
||||
)
|
||||
np.save(
|
||||
os.path.join(tflite_model_name_dir, "hash"),
|
||||
np.array(mlir_hash),
|
||||
)
|
||||
|
||||
|
||||
# Validates whether the file is present or not.
|
||||
def is_valid_file(arg):
|
||||
if not os.path.exists(arg):
|
||||
return None
|
||||
else:
|
||||
return arg
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument(
|
||||
"--torch_model_csv",
|
||||
type=lambda x: is_valid_file(x),
|
||||
default="./tank/torch_model_list.csv",
|
||||
help="""Contains the file with torch_model name and args.
|
||||
Please see: https://github.com/nod-ai/SHARK/blob/main/tank/torch_model_list.csv""",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--tf_model_csv",
|
||||
type=lambda x: is_valid_file(x),
|
||||
default="./tank/tf_model_list.csv",
|
||||
help="Contains the file with tf model name and args.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--tflite_model_csv",
|
||||
type=lambda x: is_valid_file(x),
|
||||
default="./tank/tflite/tflite_model_list.csv",
|
||||
help="Contains the file with tf model name and args.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--ci_tank_dir",
|
||||
type=bool,
|
||||
default=False,
|
||||
)
|
||||
parser.add_argument("--upload", type=bool, default=False)
|
||||
|
||||
args = parser.parse_args()
|
||||
|
||||
home = str(Path.home())
|
||||
if args.ci_tank_dir == True:
|
||||
WORKDIR = os.path.join(os.path.dirname(__file__), "gen_shark_tank")
|
||||
else:
|
||||
WORKDIR = os.path.join(home, ".local/shark_tank/")
|
||||
|
||||
if args.torch_model_csv:
|
||||
save_torch_model(args.torch_model_csv)
|
||||
|
||||
if args.tf_model_csv:
|
||||
save_tf_model(args.tf_model_csv)
|
||||
|
||||
if args.tflite_model_csv:
|
||||
save_tflite_model(args.tflite_model_csv)
|
||||
|
||||
if args.upload:
|
||||
git_hash = sp.getoutput("git log -1 --format='%h'") + "/"
|
||||
print("uploading files to gs://shark_tank/" + git_hash)
|
||||
os.system(f"gsutil cp -r {WORKDIR}* gs://shark_tank/" + git_hash)
|
||||
@@ -1,192 +0,0 @@
|
||||
# Copyright 2021, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
#
|
||||
# Redistribution and use in source and binary forms, with or without
|
||||
# modification, are permitted provided that the following conditions
|
||||
# are met:
|
||||
# * Redistributions of source code must retain the above copyright
|
||||
# notice, this list of conditions and the following disclaimer.
|
||||
# * Redistributions in binary form must reproduce the above copyright
|
||||
# notice, this list of conditions and the following disclaimer in the
|
||||
# documentation and/or other materials provided with the distribution.
|
||||
# * Neither the name of NVIDIA CORPORATION nor the names of its
|
||||
# contributors may be used to endorse or promote products derived
|
||||
# from this software without specific prior written permission.
|
||||
#
|
||||
# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS ``AS IS'' AND ANY
|
||||
# EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
|
||||
# IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR
|
||||
# PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR
|
||||
# CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL,
|
||||
# EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO,
|
||||
# PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR
|
||||
# PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY
|
||||
# OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
|
||||
# (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
|
||||
# OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
|
||||
|
||||
cmake_minimum_required(VERSION 3.17)
|
||||
|
||||
project(sharkbackend LANGUAGES C CXX)
|
||||
|
||||
#
|
||||
# Options
|
||||
#
|
||||
|
||||
option(TRITON_ENABLE_GPU "Enable GPU support in backend" ON)
|
||||
option(TRITON_ENABLE_STATS "Include statistics collections in backend" ON)
|
||||
|
||||
set(TRITON_COMMON_REPO_TAG "main" CACHE STRING "Tag for triton-inference-server/common repo")
|
||||
set(TRITON_CORE_REPO_TAG "main" CACHE STRING "Tag for triton-inference-server/core repo")
|
||||
set(TRITON_BACKEND_REPO_TAG "main" CACHE STRING "Tag for triton-inference-server/backend repo")
|
||||
|
||||
if(NOT CMAKE_BUILD_TYPE)
|
||||
set(CMAKE_BUILD_TYPE Release)
|
||||
endif()
|
||||
|
||||
#
|
||||
# Dependencies
|
||||
#
|
||||
# FetchContent requires us to include the transitive closure of all
|
||||
# repos that we depend on so that we can override the tags.
|
||||
#
|
||||
include(FetchContent)
|
||||
|
||||
FetchContent_Declare(
|
||||
repo-common
|
||||
GIT_REPOSITORY https://github.com/triton-inference-server/common.git
|
||||
GIT_TAG ${TRITON_COMMON_REPO_TAG}
|
||||
GIT_SHALLOW ON
|
||||
)
|
||||
FetchContent_Declare(
|
||||
repo-core
|
||||
GIT_REPOSITORY https://github.com/triton-inference-server/core.git
|
||||
GIT_TAG ${TRITON_CORE_REPO_TAG}
|
||||
GIT_SHALLOW ON
|
||||
)
|
||||
FetchContent_Declare(
|
||||
repo-backend
|
||||
GIT_REPOSITORY https://github.com/triton-inference-server/backend.git
|
||||
GIT_TAG ${TRITON_BACKEND_REPO_TAG}
|
||||
GIT_SHALLOW ON
|
||||
)
|
||||
FetchContent_MakeAvailable(repo-common repo-core repo-backend)
|
||||
|
||||
#
|
||||
# The backend must be built into a shared library. Use an ldscript to
|
||||
# hide all symbols except for the TRITONBACKEND API.
|
||||
#
|
||||
configure_file(src/libtriton_dshark.ldscript libtriton_dshark.ldscript COPYONLY)
|
||||
|
||||
add_library(
|
||||
triton-dshark-backend SHARED
|
||||
src/dshark.cc
|
||||
#src/dshark_driver_module.c
|
||||
)
|
||||
|
||||
add_library(
|
||||
SharkBackend::triton-dshark-backend ALIAS triton-dshark-backend
|
||||
)
|
||||
|
||||
target_include_directories(
|
||||
triton-dshark-backend
|
||||
PRIVATE
|
||||
${CMAKE_CURRENT_SOURCE_DIR}/src
|
||||
)
|
||||
|
||||
list(APPEND CMAKE_MODULE_PATH "${PROJECT_BINARY_DIR}/lib/cmake/mlir")
|
||||
|
||||
add_subdirectory(thirdparty/shark-runtime EXCLUDE_FROM_ALL)
|
||||
|
||||
target_link_libraries(triton-dshark-backend PRIVATE iree_base_base
|
||||
iree_hal_hal
|
||||
iree_hal_cuda_cuda
|
||||
iree_hal_cuda_registration_registration
|
||||
iree_hal_vmvx_registration_registration
|
||||
iree_hal_dylib_registration_registration
|
||||
iree_modules_hal_hal
|
||||
iree_vm_vm
|
||||
iree_vm_bytecode_module
|
||||
iree_hal_local_loaders_system_library_loader
|
||||
iree_hal_local_loaders_vmvx_module_loader
|
||||
)
|
||||
|
||||
target_compile_features(triton-dshark-backend PRIVATE cxx_std_11)
|
||||
|
||||
|
||||
target_link_libraries(
|
||||
triton-dshark-backend
|
||||
PRIVATE
|
||||
triton-core-serverapi # from repo-core
|
||||
triton-core-backendapi # from repo-core
|
||||
triton-core-serverstub # from repo-core
|
||||
triton-backend-utils # from repo-backend
|
||||
)
|
||||
|
||||
if(WIN32)
|
||||
set_target_properties(
|
||||
triton-dshark-backend PROPERTIES
|
||||
POSITION_INDEPENDENT_CODE ON
|
||||
OUTPUT_NAME triton_dshark
|
||||
)
|
||||
else()
|
||||
set_target_properties(
|
||||
triton-dshark-backend PROPERTIES
|
||||
POSITION_INDEPENDENT_CODE ON
|
||||
OUTPUT_NAME triton_dshark
|
||||
LINK_DEPENDS ${CMAKE_CURRENT_BINARY_DIR}/libtriton_dshark.ldscript
|
||||
LINK_FLAGS "-Wl,--version-script libtriton_dshark.ldscript"
|
||||
)
|
||||
endif()
|
||||
|
||||
|
||||
|
||||
#
|
||||
# Install
|
||||
#
|
||||
include(GNUInstallDirs)
|
||||
set(INSTALL_CONFIGDIR ${CMAKE_INSTALL_LIBDIR}/cmake/SharkBackend)
|
||||
|
||||
install(
|
||||
TARGETS
|
||||
triton-dshark-backend
|
||||
EXPORT
|
||||
triton-dshark-backend-targets
|
||||
LIBRARY DESTINATION ${CMAKE_INSTALL_PREFIX}/backends/dshark
|
||||
RUNTIME DESTINATION ${CMAKE_INSTALL_PREFIX}/backends/dshark
|
||||
)
|
||||
|
||||
install(
|
||||
EXPORT
|
||||
triton-dshark-backend-targets
|
||||
FILE
|
||||
SharkBackendTargets.cmake
|
||||
NAMESPACE
|
||||
SharkBackend::
|
||||
DESTINATION
|
||||
${INSTALL_CONFIGDIR}
|
||||
)
|
||||
|
||||
include(CMakePackageConfigHelpers)
|
||||
configure_package_config_file(
|
||||
${CMAKE_CURRENT_LIST_DIR}/cmake/SharkBackendConfig.cmake.in
|
||||
${CMAKE_CURRENT_BINARY_DIR}/SharkBackendConfig.cmake
|
||||
INSTALL_DESTINATION ${INSTALL_CONFIGDIR}
|
||||
)
|
||||
|
||||
install(
|
||||
FILES
|
||||
${CMAKE_CURRENT_BINARY_DIR}/SharkBackendConfig.cmake
|
||||
DESTINATION ${INSTALL_CONFIGDIR}
|
||||
)
|
||||
|
||||
#
|
||||
# Export from build tree
|
||||
#
|
||||
export(
|
||||
EXPORT triton-dshark-backend-targets
|
||||
FILE ${CMAKE_CURRENT_BINARY_DIR}/SharkBackendTargets.cmake
|
||||
NAMESPACE SharkBackend::
|
||||
)
|
||||
|
||||
export(PACKAGE SharkBackend)
|
||||
|
||||
@@ -1,100 +0,0 @@
|
||||
# SHARK Triton Backend
|
||||
|
||||
The triton backend for shark.
|
||||
|
||||
# Build
|
||||
|
||||
Install SHARK
|
||||
|
||||
```
|
||||
git clone https://github.com/nod-ai/SHARK.git
|
||||
# skip above step if dshark is already installed
|
||||
cd SHARK/inference
|
||||
```
|
||||
|
||||
install dependancies
|
||||
|
||||
```
|
||||
apt-get install patchelf rapidjson-dev python3-dev
|
||||
git submodule update --init
|
||||
```
|
||||
|
||||
update the submodules of iree
|
||||
|
||||
```
|
||||
cd thirdparty/shark-runtime
|
||||
git submodule update --init
|
||||
```
|
||||
|
||||
Next, make the backend and install it
|
||||
|
||||
```
|
||||
cd ../..
|
||||
mkdir build && cd build
|
||||
cmake -DTRITON_ENABLE_GPU=ON \
|
||||
-DIREE_HAL_DRIVER_CUDA=ON \
|
||||
-DIREE_TARGET_BACKEND_CUDA=ON \
|
||||
-DMLIR_ENABLE_CUDA_RUNNER=ON \
|
||||
-DCMAKE_INSTALL_PREFIX:PATH=`pwd`/install \
|
||||
-DTRITON_BACKEND_REPO_TAG=r22.02 \
|
||||
-DTRITON_CORE_REPO_TAG=r22.02 \
|
||||
-DTRITON_COMMON_REPO_TAG=r22.02 ..
|
||||
make install
|
||||
```
|
||||
|
||||
# Incorporating into Triton
|
||||
|
||||
There are much more in depth explenations for the following steps in triton's documentation:
|
||||
https://github.com/triton-inference-server/server/blob/main/docs/compose.md#triton-with-unsupported-and-custom-backends
|
||||
|
||||
There should be a file at /build/install/backends/dshark/libtriton_dshark.so. You will need to copy it into your triton server image.
|
||||
More documentation is in the link above, but to create the docker image, you need to run the compose.py command in the triton-backend server repo
|
||||
|
||||
|
||||
To first build your image, clone the tritonserver repo.
|
||||
|
||||
```
|
||||
git clone https://github.com/triton-inference-server/server.git
|
||||
```
|
||||
|
||||
then run `compose.py` to build a docker compose file
|
||||
```
|
||||
cd server
|
||||
python3 compose.py --repoagent checksum --dry-run
|
||||
```
|
||||
|
||||
Because dshark is a third party backend, you will need to manually modify the `Dockerfile.compose` to include the dshark backend. To do this, in the Dockerfile.compose file produced, copy this line.
|
||||
the dshark backend will be located in the build folder from earlier under `/build/install/backends`
|
||||
|
||||
```
|
||||
COPY /path/to/build/install/backends/dshark /opt/tritonserver/backends/dshark
|
||||
```
|
||||
|
||||
Next run
|
||||
```
|
||||
docker build -t tritonserver_custom -f Dockerfile.compose .
|
||||
docker run -it --gpus=1 --net=host -v/path/to/model_repos:/models tritonserver_custom:latest tritonserver --model-repository=/models
|
||||
```
|
||||
|
||||
where `path/to/model_repos` is where you are storing the models you want to run
|
||||
|
||||
if your not using gpus, omit `--gpus=1`
|
||||
|
||||
```
|
||||
docker run -it --net=host -v/path/to/model_repos:/models tritonserver_custom:latest tritonserver --model-repository=/models
|
||||
```
|
||||
|
||||
# Setting up a model
|
||||
|
||||
to include a model in your backend, add a directory with your model name to your model repository directory. examples of models can be seen here: https://github.com/triton-inference-server/backend/tree/main/examples/model_repos/minimal_models
|
||||
|
||||
make sure to adjust the input correctly in the config.pbtxt file, and save a vmfb file under 1/model.vmfb
|
||||
|
||||
# CUDA
|
||||
|
||||
if you're having issues with cuda, make sure your correct drivers are installed, and that `nvidia-smi` works, and also make sure that the nvcc compiler is on the path.
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@@ -1,39 +0,0 @@
|
||||
# Copyright 2021, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
#
|
||||
# Redistribution and use in source and binary forms, with or without
|
||||
# modification, are permitted provided that the following conditions
|
||||
# are met:
|
||||
# * Redistributions of source code must retain the above copyright
|
||||
# notice, this list of conditions and the following disclaimer.
|
||||
# * Redistributions in binary form must reproduce the above copyright
|
||||
# notice, this list of conditions and the following disclaimer in the
|
||||
# documentation and/or other materials provided with the distribution.
|
||||
# * Neither the name of NVIDIA CORPORATION nor the names of its
|
||||
# contributors may be used to endorse or promote products derived
|
||||
# from this software without specific prior written permission.
|
||||
#
|
||||
# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS ``AS IS'' AND ANY
|
||||
# EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
|
||||
# IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR
|
||||
# PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR
|
||||
# CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL,
|
||||
# EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO,
|
||||
# PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR
|
||||
# PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY
|
||||
# OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
|
||||
# (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
|
||||
# OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
|
||||
|
||||
include(CMakeFindDependencyMacro)
|
||||
|
||||
get_filename_component(
|
||||
SHARKBACKEND_CMAKE_DIR "${CMAKE_CURRENT_LIST_FILE}" PATH
|
||||
)
|
||||
|
||||
list(APPEND CMAKE_MODULE_PATH ${SHARKBACKEND_CMAKE_DIR})
|
||||
|
||||
if(NOT TARGET SharkBackend::triton-dshark-backend)
|
||||
include("${SHARKBACKEND_CMAKE_DIR}/SharkBackendTargets.cmake")
|
||||
endif()
|
||||
|
||||
set(SHARKBACKEND_LIBRARIES SharkBackend::triton-dshark-backend)
|
||||
File diff suppressed because it is too large
Load Diff
@@ -1,30 +0,0 @@
|
||||
# Copyright 2021, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
#
|
||||
# Redistribution and use in source and binary forms, with or without
|
||||
# modification, are permitted provided that the following conditions
|
||||
# are met:
|
||||
# * Redistributions of source code must retain the above copyright
|
||||
# notice, this list of conditions and the following disclaimer.
|
||||
# * Redistributions in binary form must reproduce the above copyright
|
||||
# notice, this list of conditions and the following disclaimer in the
|
||||
# documentation and/or other materials provided with the distribution.
|
||||
# * Neither the name of NVIDIA CORPORATION nor the names of its
|
||||
# contributors may be used to endorse or promote products derived
|
||||
# from this software without specific prior written permission.
|
||||
#
|
||||
# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS ``AS IS'' AND ANY
|
||||
# EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
|
||||
# IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR
|
||||
# PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR
|
||||
# CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL,
|
||||
# EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO,
|
||||
# PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR
|
||||
# PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY
|
||||
# OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
|
||||
# (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
|
||||
# OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
|
||||
{
|
||||
global:
|
||||
TRITONBACKEND_*;
|
||||
local: *;
|
||||
};
|
||||
1
inference/thirdparty/shark-runtime
vendored
1
inference/thirdparty/shark-runtime
vendored
Submodule inference/thirdparty/shark-runtime deleted from 7b82d90c72
66
process_skipfiles.py
Normal file
66
process_skipfiles.py
Normal file
@@ -0,0 +1,66 @@
|
||||
# This script will toggle the comment/uncommenting aspect for dealing
|
||||
# with __file__ AttributeError arising in case of a few modules in
|
||||
# `torch/_dynamo/skipfiles.py` (within shark.venv)
|
||||
|
||||
from distutils.sysconfig import get_python_lib
|
||||
import fileinput
|
||||
from pathlib import Path
|
||||
|
||||
# Temporary workaround for transformers/__init__.py.
|
||||
path_to_transformers_hook = Path(
|
||||
get_python_lib() + "/_pyinstaller_hooks_contrib/hooks/stdhooks/hook-transformers.py"
|
||||
)
|
||||
if path_to_transformers_hook.is_file():
|
||||
pass
|
||||
else:
|
||||
with open(path_to_transformers_hook, "w") as f:
|
||||
f.write("module_collection_mode = 'pyz+py'")
|
||||
|
||||
path_to_skipfiles = Path(get_python_lib() + "/torch/_dynamo/skipfiles.py")
|
||||
|
||||
modules_to_comment = ["abc,", "os,", "posixpath,", "_collections_abc,"]
|
||||
startMonitoring = 0
|
||||
for line in fileinput.input(path_to_skipfiles, inplace=True):
|
||||
if "SKIP_DIRS = " in line:
|
||||
startMonitoring = 1
|
||||
print(line, end="")
|
||||
elif startMonitoring in [1, 2]:
|
||||
if "]" in line:
|
||||
startMonitoring += 1
|
||||
print(line, end="")
|
||||
else:
|
||||
flag = True
|
||||
for module in modules_to_comment:
|
||||
if module in line:
|
||||
if not line.startswith("#"):
|
||||
print(f"#{line}", end="")
|
||||
else:
|
||||
print(f"{line[1:]}", end="")
|
||||
flag = False
|
||||
break
|
||||
if flag:
|
||||
print(line, end="")
|
||||
else:
|
||||
print(line, end="")
|
||||
|
||||
# For getting around scikit-image's packaging, laze_loader has had a patch merged but yet to be released.
|
||||
# Refer: https://github.com/scientific-python/lazy_loader
|
||||
path_to_lazy_loader = Path(get_python_lib() + "/lazy_loader/__init__.py")
|
||||
|
||||
for line in fileinput.input(path_to_lazy_loader, inplace=True):
|
||||
if 'stubfile = filename if filename.endswith("i")' in line:
|
||||
print(
|
||||
' stubfile = (filename if filename.endswith("i") else f"{os.path.splitext(filename)[0]}.pyi")',
|
||||
end="",
|
||||
)
|
||||
else:
|
||||
print(line, end="")
|
||||
|
||||
# For getting around timm's packaging.
|
||||
# Refer: https://github.com/pyinstaller/pyinstaller/issues/5673#issuecomment-808731505
|
||||
path_to_timm_activations = Path(get_python_lib() + "/timm/layers/activations_jit.py")
|
||||
for line in fileinput.input(path_to_timm_activations, inplace=True):
|
||||
if "@torch.jit.script" in line:
|
||||
print("@torch.jit._script_if_tracing", end="\n")
|
||||
else:
|
||||
print(line, end="")
|
||||
@@ -5,8 +5,25 @@ requires = [
|
||||
"packaging",
|
||||
|
||||
"numpy>=1.22.4",
|
||||
"torch-mlir>=20221021.633",
|
||||
"iree-compiler>=20221022.190",
|
||||
"iree-runtime>=20221022.190",
|
||||
]
|
||||
build-backend = "setuptools.build_meta"
|
||||
|
||||
[tool.black]
|
||||
include = '\.pyi?$'
|
||||
exclude = '''
|
||||
(
|
||||
/(
|
||||
| apps/stable_diffusion
|
||||
| apps/language_models
|
||||
| shark
|
||||
| benchmarks
|
||||
| tank
|
||||
| build
|
||||
| generated_imgs
|
||||
| shark.venv
|
||||
)/
|
||||
| setup.py
|
||||
)
|
||||
'''
|
||||
|
||||
@@ -1,3 +1,3 @@
|
||||
[pytest]
|
||||
addopts = --verbose -p no:warnings
|
||||
norecursedirs = inference tank/tflite examples benchmarks shark
|
||||
addopts = --verbose -s -p no:warnings
|
||||
norecursedirs = inference tank/tflite examples benchmarks shark apps/shark_studio
|
||||
|
||||
@@ -8,19 +8,8 @@ torchvision
|
||||
tqdm
|
||||
|
||||
#iree-compiler | iree-runtime should already be installed
|
||||
#these dont work ok osx
|
||||
#iree-tools-tflite
|
||||
#iree-tools-xla
|
||||
#iree-tools-tf
|
||||
|
||||
# TensorFlow and JAX.
|
||||
gin-config
|
||||
tensorflow-macos
|
||||
tensorflow-metal
|
||||
#tf-models-nightly
|
||||
#tensorflow-text-nightly
|
||||
transformers
|
||||
tensorflow-probability
|
||||
#jax[cpu]
|
||||
|
||||
# tflitehub dependencies.
|
||||
|
||||
@@ -1,29 +1,21 @@
|
||||
-f https://download.pytorch.org/whl/nightly/cpu/torch_nightly.html
|
||||
--pre
|
||||
|
||||
numpy==1.22.4
|
||||
torchvision
|
||||
numpy>1.22.4
|
||||
pytorch-triton
|
||||
torchvision
|
||||
tabulate
|
||||
|
||||
tqdm
|
||||
|
||||
#iree-compiler | iree-runtime should already be installed
|
||||
iree-tools-tflite
|
||||
iree-tools-xla
|
||||
iree-tools-tf
|
||||
|
||||
# TensorFlow and JAX.
|
||||
# Modelling and JAX.
|
||||
gin-config
|
||||
tensorflow==2.10
|
||||
keras==2.10
|
||||
#tf-models-nightly
|
||||
#tensorflow-text-nightly
|
||||
transformers
|
||||
diffusers
|
||||
#tensorflow-probability
|
||||
#jax[cpu]
|
||||
|
||||
|
||||
# tflitehub dependencies.
|
||||
Pillow
|
||||
|
||||
# Testing and support.
|
||||
@@ -31,9 +23,10 @@ lit
|
||||
pyyaml
|
||||
python-dateutil
|
||||
sacremoses
|
||||
sentencepiece
|
||||
|
||||
# web dependecies.
|
||||
gradio
|
||||
gradio==3.44.3
|
||||
altair
|
||||
scipy
|
||||
|
||||
|
||||
@@ -1,6 +1,12 @@
|
||||
-f https://download.pytorch.org/whl/nightly/cpu/torch_nightly.html
|
||||
-f https://openxla.github.io/iree/pip-release-links.html
|
||||
--pre
|
||||
|
||||
setuptools
|
||||
wheel
|
||||
pyinstaller
|
||||
|
||||
shark-turbine @ git+https://github.com/nod-ai/SHARK-Turbine.git@main
|
||||
turbine-models @ git+https://github.com/nod-ai/SHARK-Turbine#egg=turbine-models&subdirectory=python/turbine_models
|
||||
|
||||
# SHARK Runner
|
||||
tqdm
|
||||
@@ -11,13 +17,38 @@ google-cloud-storage
|
||||
# Testing
|
||||
pytest
|
||||
pytest-xdist
|
||||
pytest-forked
|
||||
Pillow
|
||||
parameterized
|
||||
|
||||
# Add transformers, diffusers and scipy since it most commonly used
|
||||
transformers
|
||||
diffusers
|
||||
#accelerate is now required for diffusers import from ckpt.
|
||||
accelerate
|
||||
scipy
|
||||
ftfy
|
||||
gradio
|
||||
gradio==4.8.0
|
||||
altair
|
||||
omegaconf
|
||||
# 0.3.2 doesn't have binaries for arm64
|
||||
safetensors==0.3.1
|
||||
opencv-python
|
||||
scikit-image
|
||||
pytorch_lightning # for runwayml models
|
||||
tk
|
||||
pywebview
|
||||
sentencepiece
|
||||
py-cpuinfo
|
||||
tiktoken # for codegen
|
||||
joblib # for langchain
|
||||
timm # for MiniGPT4
|
||||
langchain
|
||||
einops # for zoedepth
|
||||
pydantic==2.4.1 # pin until pyinstaller-hooks-contrib works with beta versions
|
||||
|
||||
# Keep PyInstaller at the end. Sometimes Windows Defender flags it but most folks can continue even if it errors
|
||||
pefile
|
||||
pyinstaller
|
||||
|
||||
# For quantized GPTQ models
|
||||
optimum
|
||||
auto_gptq
|
||||
|
||||
348
rest_api_tests/api_test.py
Normal file
348
rest_api_tests/api_test.py
Normal file
@@ -0,0 +1,348 @@
|
||||
import requests
|
||||
from PIL import Image
|
||||
import base64
|
||||
from io import BytesIO
|
||||
|
||||
|
||||
def upscaler_test(verbose=False):
|
||||
# Define values here
|
||||
prompt = ""
|
||||
negative_prompt = ""
|
||||
seed = 2121991605
|
||||
height = 512
|
||||
width = 512
|
||||
steps = 50
|
||||
noise_level = 10
|
||||
cfg_scale = 7
|
||||
image_path = r"./rest_api_tests/dog.png"
|
||||
|
||||
# Converting Image to base64
|
||||
img_file = open(image_path, "rb")
|
||||
init_images = [
|
||||
"data:image/png;base64," + base64.b64encode(img_file.read()).decode()
|
||||
]
|
||||
|
||||
url = "http://127.0.0.1:8080/sdapi/v1/upscaler"
|
||||
|
||||
headers = {
|
||||
"User-Agent": "PythonTest",
|
||||
"Accept": "*/*",
|
||||
"Accept-Encoding": "gzip, deflate, br",
|
||||
}
|
||||
|
||||
data = {
|
||||
"prompt": prompt,
|
||||
"negative_prompt": negative_prompt,
|
||||
"seed": seed,
|
||||
"height": height,
|
||||
"width": width,
|
||||
"steps": steps,
|
||||
"noise_level": noise_level,
|
||||
"cfg_scale": cfg_scale,
|
||||
"init_images": init_images,
|
||||
}
|
||||
|
||||
res = requests.post(url=url, json=data, headers=headers, timeout=1000)
|
||||
|
||||
print(f"[upscaler] response from server was : {res.status_code} {res.reason}")
|
||||
|
||||
if verbose or res.status_code != 200:
|
||||
print(f"\n{res.json()['info'] if res.status_code == 200 else res.content}\n")
|
||||
|
||||
|
||||
def img2img_test(verbose=False):
|
||||
# Define values here
|
||||
prompt = "Paint a rabbit riding on the dog"
|
||||
negative_prompt = "ugly, bad art, poorly drawn hands, poorly drawn feet, poorly drawn face, out of frame, extra limbs, disfigured, deformed, body out of frame, blurry, bad anatomy, blurred, watermark, grainy, tiling, signature, cut off, draft"
|
||||
seed = 2121991605
|
||||
height = 512
|
||||
width = 512
|
||||
steps = 50
|
||||
denoising_strength = 0.75
|
||||
cfg_scale = 7
|
||||
image_path = r"./rest_api_tests/dog.png"
|
||||
|
||||
# Converting Image to Base64
|
||||
img_file = open(image_path, "rb")
|
||||
init_images = [
|
||||
"data:image/png;base64," + base64.b64encode(img_file.read()).decode()
|
||||
]
|
||||
|
||||
url = "http://127.0.0.1:8080/sdapi/v1/img2img"
|
||||
|
||||
headers = {
|
||||
"User-Agent": "PythonTest",
|
||||
"Accept": "*/*",
|
||||
"Accept-Encoding": "gzip, deflate, br",
|
||||
}
|
||||
|
||||
data = {
|
||||
"prompt": prompt,
|
||||
"negative_prompt": negative_prompt,
|
||||
"init_images": init_images,
|
||||
"height": height,
|
||||
"width": width,
|
||||
"steps": steps,
|
||||
"denoising_strength": denoising_strength,
|
||||
"cfg_scale": cfg_scale,
|
||||
"seed": seed,
|
||||
}
|
||||
|
||||
res = requests.post(url=url, json=data, headers=headers, timeout=1000)
|
||||
|
||||
res = requests.post(url=url, json=data, headers=headers, timeout=1000)
|
||||
|
||||
print(f"[img2img] response from server was : {res.status_code} {res.reason}")
|
||||
|
||||
if verbose or res.status_code != 200:
|
||||
print(f"\n{res.json()['info'] if res.status_code == 200 else res.content}\n")
|
||||
|
||||
# NOTE Uncomment below to save the picture
|
||||
|
||||
# print("Extracting response object")
|
||||
# response_obj = res.json()
|
||||
# img_b64 = response_obj.get("images", [False])[0] or response_obj.get(
|
||||
# "image"
|
||||
# )
|
||||
# img_b2 = base64.b64decode(img_b64.replace("data:image/png;base64,", ""))
|
||||
# im_file = BytesIO(img_b2)
|
||||
# response_img = Image.open(im_file)
|
||||
# print("Saving Response Image to: response_img")
|
||||
# response_img.save(r"rest_api_tests/response_img.png")
|
||||
|
||||
|
||||
def inpainting_test(verbose=False):
|
||||
prompt = "Paint a rabbit riding on the dog"
|
||||
negative_prompt = "ugly, bad art, poorly drawn hands, poorly drawn feet, poorly drawn face, out of frame, extra limbs, disfigured, deformed, body out of frame, blurry, bad anatomy, blurred, watermark, grainy, tiling, signature, cut off, draft"
|
||||
seed = 2121991605
|
||||
height = 512
|
||||
width = 512
|
||||
steps = 50
|
||||
noise_level = 10
|
||||
cfg_scale = 7
|
||||
is_full_res = False
|
||||
full_res_padding = 32
|
||||
image_path = r"./rest_api_tests/dog.png"
|
||||
|
||||
img_file = open(image_path, "rb")
|
||||
image = "data:image/png;base64," + base64.b64encode(img_file.read()).decode()
|
||||
img_file = open(image_path, "rb")
|
||||
mask = "data:image/png;base64," + base64.b64encode(img_file.read()).decode()
|
||||
|
||||
url = "http://127.0.0.1:8080/sdapi/v1/inpaint"
|
||||
|
||||
headers = {
|
||||
"User-Agent": "PythonTest",
|
||||
"Accept": "*/*",
|
||||
"Accept-Encoding": "gzip, deflate, br",
|
||||
}
|
||||
|
||||
data = {
|
||||
"prompt": prompt,
|
||||
"negative_prompt": negative_prompt,
|
||||
"image": image,
|
||||
"mask": mask,
|
||||
"height": height,
|
||||
"width": width,
|
||||
"steps": steps,
|
||||
"noise_level": noise_level,
|
||||
"cfg_scale": cfg_scale,
|
||||
"seed": seed,
|
||||
"is_full_res": is_full_res,
|
||||
"full_res_padding": full_res_padding,
|
||||
}
|
||||
|
||||
res = requests.post(url=url, json=data, headers=headers, timeout=1000)
|
||||
|
||||
print(f"[inpaint] response from server was : {res.status_code} {res.reason}")
|
||||
|
||||
if verbose or res.status_code != 200:
|
||||
print(f"\n{res.json()['info'] if res.status_code == 200 else res.content}\n")
|
||||
|
||||
|
||||
def outpainting_test(verbose=False):
|
||||
prompt = "Paint a rabbit riding on the dog"
|
||||
negative_prompt = "ugly, bad art, poorly drawn hands, poorly drawn feet, poorly drawn face, out of frame, extra limbs, disfigured, deformed, body out of frame, blurry, bad anatomy, blurred, watermark, grainy, tiling, signature, cut off, draft"
|
||||
seed = 2121991605
|
||||
height = 512
|
||||
width = 512
|
||||
steps = 50
|
||||
cfg_scale = 7
|
||||
color_variation = 0.2
|
||||
noise_q = 0.2
|
||||
directions = ["up", "down", "right", "left"]
|
||||
pixels = 32
|
||||
mask_blur = 64
|
||||
image_path = r"./rest_api_tests/dog.png"
|
||||
|
||||
# Converting Image to Base64
|
||||
img_file = open(image_path, "rb")
|
||||
init_images = [
|
||||
"data:image/png;base64," + base64.b64encode(img_file.read()).decode()
|
||||
]
|
||||
|
||||
url = "http://127.0.0.1:8080/sdapi/v1/outpaint"
|
||||
|
||||
headers = {
|
||||
"User-Agent": "PythonTest",
|
||||
"Accept": "*/*",
|
||||
"Accept-Encoding": "gzip, deflate, br",
|
||||
}
|
||||
|
||||
data = {
|
||||
"prompt": prompt,
|
||||
"negative_prompt": negative_prompt,
|
||||
"seed": seed,
|
||||
"height": height,
|
||||
"width": width,
|
||||
"steps": steps,
|
||||
"cfg_scale": cfg_scale,
|
||||
"color_variation": color_variation,
|
||||
"noise_q": noise_q,
|
||||
"directions": directions,
|
||||
"pixels": pixels,
|
||||
"mask_blur": mask_blur,
|
||||
"init_images": init_images,
|
||||
}
|
||||
|
||||
res = requests.post(url=url, json=data, headers=headers, timeout=1000)
|
||||
|
||||
print(f"[outpaint] response from server was : {res.status_code} {res.reason}")
|
||||
|
||||
if verbose or res.status_code != 200:
|
||||
print(f"\n{res.json()['info'] if res.status_code == 200 else res.content}\n")
|
||||
|
||||
|
||||
def txt2img_test(verbose=False):
|
||||
prompt = "Paint a rabbit in a top hate"
|
||||
negative_prompt = "ugly, bad art, poorly drawn hands, poorly drawn feet, poorly drawn face, out of frame, extra limbs, disfigured, deformed, body out of frame, blurry, bad anatomy, blurred, watermark, grainy, tiling, signature, cut off, draft"
|
||||
seed = 2121991605
|
||||
height = 512
|
||||
width = 512
|
||||
steps = 50
|
||||
cfg_scale = 7
|
||||
|
||||
url = "http://127.0.0.1:8080/sdapi/v1/txt2img"
|
||||
|
||||
headers = {
|
||||
"User-Agent": "PythonTest",
|
||||
"Accept": "*/*",
|
||||
"Accept-Encoding": "gzip, deflate, br",
|
||||
}
|
||||
|
||||
data = {
|
||||
"prompt": prompt,
|
||||
"negative_prompt": negative_prompt,
|
||||
"seed": seed,
|
||||
"height": height,
|
||||
"width": width,
|
||||
"steps": steps,
|
||||
"cfg_scale": cfg_scale,
|
||||
}
|
||||
|
||||
res = requests.post(url=url, json=data, headers=headers, timeout=1000)
|
||||
|
||||
print(f"[txt2img] response from server was : {res.status_code} {res.reason}")
|
||||
|
||||
if verbose or res.status_code != 200:
|
||||
print(f"\n{res.json()['info'] if res.status_code == 200 else res.content}\n")
|
||||
|
||||
|
||||
def sd_models_test(verbose=False):
|
||||
url = "http://127.0.0.1:8080/sdapi/v1/sd-models"
|
||||
|
||||
headers = {
|
||||
"User-Agent": "PythonTest",
|
||||
"Accept": "*/*",
|
||||
"Accept-Encoding": "gzip, deflate, br",
|
||||
}
|
||||
|
||||
res = requests.get(url=url, headers=headers, timeout=1000)
|
||||
|
||||
print(f"[sd_models] response from server was : {res.status_code} {res.reason}")
|
||||
|
||||
if verbose or res.status_code != 200:
|
||||
print(f"\n{res.json() if res.status_code == 200 else res.content}\n")
|
||||
|
||||
|
||||
def sd_samplers_test(verbose=False):
|
||||
url = "http://127.0.0.1:8080/sdapi/v1/samplers"
|
||||
|
||||
headers = {
|
||||
"User-Agent": "PythonTest",
|
||||
"Accept": "*/*",
|
||||
"Accept-Encoding": "gzip, deflate, br",
|
||||
}
|
||||
|
||||
res = requests.get(url=url, headers=headers, timeout=1000)
|
||||
|
||||
print(f"[sd_samplers] response from server was : {res.status_code} {res.reason}")
|
||||
|
||||
if verbose or res.status_code != 200:
|
||||
print(f"\n{res.json() if res.status_code == 200 else res.content}\n")
|
||||
|
||||
|
||||
def options_test(verbose=False):
|
||||
url = "http://127.0.0.1:8080/sdapi/v1/options"
|
||||
|
||||
headers = {
|
||||
"User-Agent": "PythonTest",
|
||||
"Accept": "*/*",
|
||||
"Accept-Encoding": "gzip, deflate, br",
|
||||
}
|
||||
|
||||
res = requests.get(url=url, headers=headers, timeout=1000)
|
||||
|
||||
print(f"[options] response from server was : {res.status_code} {res.reason}")
|
||||
|
||||
if verbose or res.status_code != 200:
|
||||
print(f"\n{res.json() if res.status_code == 200 else res.content}\n")
|
||||
|
||||
|
||||
def cmd_flags_test(verbose=False):
|
||||
url = "http://127.0.0.1:8080/sdapi/v1/cmd-flags"
|
||||
|
||||
headers = {
|
||||
"User-Agent": "PythonTest",
|
||||
"Accept": "*/*",
|
||||
"Accept-Encoding": "gzip, deflate, br",
|
||||
}
|
||||
|
||||
res = requests.get(url=url, headers=headers, timeout=1000)
|
||||
|
||||
print(f"[cmd-flags] response from server was : {res.status_code} {res.reason}")
|
||||
|
||||
if verbose or res.status_code != 200:
|
||||
print(f"\n{res.json() if res.status_code == 200 else res.content}\n")
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
import argparse
|
||||
|
||||
parser = argparse.ArgumentParser(
|
||||
description=(
|
||||
"Exercises the Stable Diffusion REST API of Shark. Make sure "
|
||||
"Shark is running in API mode on 127.0.0.1:8080 before running"
|
||||
"this script."
|
||||
),
|
||||
)
|
||||
parser.add_argument(
|
||||
"-v",
|
||||
"--verbose",
|
||||
action="store_true",
|
||||
help=(
|
||||
"also display selected info from the JSON response for "
|
||||
"successful requests"
|
||||
),
|
||||
)
|
||||
args = parser.parse_args()
|
||||
|
||||
sd_models_test(args.verbose)
|
||||
sd_samplers_test(args.verbose)
|
||||
options_test(args.verbose)
|
||||
cmd_flags_test(args.verbose)
|
||||
txt2img_test(args.verbose)
|
||||
img2img_test(args.verbose)
|
||||
upscaler_test(args.verbose)
|
||||
inpainting_test(args.verbose)
|
||||
outpainting_test(args.verbose)
|
||||
BIN
rest_api_tests/dog.png
Normal file
BIN
rest_api_tests/dog.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 4.5 KiB |
11
setup.py
11
setup.py
@@ -2,17 +2,13 @@ from setuptools import find_packages
|
||||
from setuptools import setup
|
||||
|
||||
import os
|
||||
import glob
|
||||
|
||||
with open("README.md", "r", encoding="utf-8") as fh:
|
||||
long_description = fh.read()
|
||||
|
||||
PACKAGE_VERSION = os.environ.get("SHARK_PACKAGE_VERSION") or "0.0.4"
|
||||
PACKAGE_VERSION = os.environ.get("SHARK_PACKAGE_VERSION") or "0.0.5"
|
||||
backend_deps = []
|
||||
if "NO_BACKEND" in os.environ.keys():
|
||||
backend_deps = [
|
||||
"iree-compiler>=20221022.190",
|
||||
"iree-runtime>=20221022.190",
|
||||
]
|
||||
|
||||
setup(
|
||||
name="nodai-SHARK",
|
||||
@@ -34,10 +30,9 @@ setup(
|
||||
],
|
||||
packages=find_packages(exclude=("examples")),
|
||||
python_requires=">=3.9",
|
||||
data_files=glob.glob("apps/stable_diffusion/resources/**"),
|
||||
install_requires=[
|
||||
"numpy",
|
||||
"PyYAML",
|
||||
"torch-mlir>=20221021.633",
|
||||
]
|
||||
+ backend_deps,
|
||||
)
|
||||
|
||||
@@ -1,13 +1,54 @@
|
||||
#Write-Host "Installing python"
|
||||
<#
|
||||
.SYNOPSIS
|
||||
A script to update and install the SHARK runtime and its dependencies.
|
||||
|
||||
#Start-Process winget install Python.Python.3.10 '/quiet InstallAllUsers=1 PrependPath=1' -wait -NoNewWindow
|
||||
.DESCRIPTION
|
||||
This script updates and installs the SHARK runtime and its dependencies.
|
||||
It checks the Python version installed and installs any required build
|
||||
dependencies into a Python virtual environment.
|
||||
If that environment does not exist, it creates it.
|
||||
|
||||
.PARAMETER update-src
|
||||
git pulls latest version
|
||||
|
||||
#Write-Host "python installation completed successfully"
|
||||
.PARAMETER force
|
||||
removes and recreates venv to force update of all dependencies
|
||||
|
||||
.EXAMPLE
|
||||
.\setup_venv.ps1 --force
|
||||
|
||||
#Write-Host "Reload environment variables"
|
||||
#$env:Path = [System.Environment]::GetEnvironmentVariable("Path","Machine") + ";" + [System.Environment]::GetEnvironmentVariable("Path","User")
|
||||
#Write-Host "Reloaded environment variables"
|
||||
.EXAMPLE
|
||||
.\setup_venv.ps1 --update-src
|
||||
|
||||
.INPUTS
|
||||
None
|
||||
|
||||
.OUTPUTS
|
||||
None
|
||||
|
||||
#>
|
||||
|
||||
param([string]$arguments)
|
||||
|
||||
if ($arguments -eq "--update-src"){
|
||||
git pull
|
||||
}
|
||||
|
||||
if ($arguments -eq "--force"){
|
||||
if (Test-Path env:VIRTUAL_ENV) {
|
||||
Write-Host "deactivating..."
|
||||
Deactivate
|
||||
}
|
||||
|
||||
if (Test-Path .\shark.venv\) {
|
||||
Write-Host "removing and recreating venv..."
|
||||
Remove-Item .\shark.venv -Force -Recurse
|
||||
if (Test-Path .\shark.venv\) {
|
||||
Write-Host 'could not remove .\shark-venv - please try running ".\setup_venv.ps1 --force" again!'
|
||||
exit 1
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
# redirect stderr into stdout
|
||||
$p = &{python -V} 2>&1
|
||||
@@ -19,21 +60,38 @@ $version = if($p -is [System.Management.Automation.ErrorRecord])
|
||||
}
|
||||
else
|
||||
{
|
||||
# otherwise return as is
|
||||
$p
|
||||
# otherwise return complete Python list
|
||||
$ErrorActionPreference = 'SilentlyContinue'
|
||||
$PyVer = py --list
|
||||
}
|
||||
|
||||
Write-Host "Python version found is"
|
||||
Write-Host $p
|
||||
# deactivate any activated venvs
|
||||
if ($PyVer -like "*venv*")
|
||||
{
|
||||
deactivate # make sure we don't update the wrong venv
|
||||
$PyVer = py --list # update list
|
||||
}
|
||||
|
||||
Write-Host "Python versions found are"
|
||||
Write-Host ($PyVer | Out-String) # formatted output with line breaks
|
||||
if (!($PyVer.length -ne 0)) {$p} # return Python --version String if py.exe is unavailable
|
||||
if (!($PyVer -like "*3.11*") -and !($p -like "*3.11*")) # if 3.11 is not in any list
|
||||
{
|
||||
Write-Host "Please install Python 3.11 and try again"
|
||||
exit 34
|
||||
}
|
||||
|
||||
Write-Host "Installing Build Dependencies"
|
||||
python -m venv .\shark.venv\
|
||||
# make sure we really use 3.11 from list, even if it's not the default.
|
||||
if ($NULL -ne $PyVer) {py -3.11 -m venv .\shark.venv\}
|
||||
else {python -m venv .\shark.venv\}
|
||||
.\shark.venv\Scripts\activate
|
||||
python -m pip install --upgrade pip
|
||||
pip install wheel
|
||||
pip install -r requirements.txt
|
||||
pip install --pre torch-mlir torch torchvision --extra-index-url https://download.pytorch.org/whl/nightly/cpu -f https://llvm.github.io/torch-mlir/package-index/
|
||||
pip install --upgrade -f https://nod-ai.github.io/SHARK-Runtime/pip-release-links.html iree-compiler iree-runtime
|
||||
pip install --pre torch-mlir torchvision torch --extra-index-url https://download.pytorch.org/whl/nightly/cpu -f https://llvm.github.io/torch-mlir/package-index/
|
||||
pip install --upgrade -f https://nod-ai.github.io/SRT/pip-release-links.html iree-compiler iree-runtime
|
||||
Write-Host "Building SHARK..."
|
||||
pip install -e . -f https://llvm.github.io/torch-mlir/package-index/ -f https://nod-ai.github.io/SHARK-Runtime/pip-release-links.html
|
||||
pip install -e . -f https://llvm.github.io/torch-mlir/package-index/ -f https://nod-ai.github.io/SRT/pip-release-links.html
|
||||
Write-Host "Build and installation completed successfully"
|
||||
Write-Host "Source your venv with ./shark.venv/Scripts/activate"
|
||||
|
||||
@@ -2,9 +2,10 @@
|
||||
# Sets up a venv suitable for running samples.
|
||||
# e.g:
|
||||
# ./setup_venv.sh #setup a default $PYTHON3 shark.venv
|
||||
# Environment Variables by the script.
|
||||
# Environment variables used by the script.
|
||||
# PYTHON=$PYTHON3.10 ./setup_venv.sh #pass a version of $PYTHON to use
|
||||
# VENV_DIR=myshark.venv #create a venv called myshark.venv
|
||||
# SKIP_VENV=1 #Don't create and activate a Python venv. Use the current environment.
|
||||
# USE_IREE=1 #use stock IREE instead of Nod.ai's SHARK build
|
||||
# IMPORTER=1 #Install importer deps
|
||||
# BENCHMARK=1 #Install benchmark deps
|
||||
@@ -26,15 +27,22 @@ PYTHON_VERSION_X_Y=`${PYTHON} -c 'import sys; version=sys.version_info[:2]; prin
|
||||
echo "Python: $PYTHON"
|
||||
echo "Python version: $PYTHON_VERSION_X_Y"
|
||||
|
||||
if [[ -z "${CONDA_PREFIX}" ]]; then
|
||||
# Not a conda env. So create a new VENV dir
|
||||
VENV_DIR=${VENV_DIR:-shark.venv}
|
||||
echo "Using pip venv.. Setting up venv dir: $VENV_DIR"
|
||||
$PYTHON -m venv "$VENV_DIR" || die "Could not create venv."
|
||||
source "$VENV_DIR/bin/activate" || die "Could not activate venv"
|
||||
PYTHON="$(which python3)"
|
||||
else
|
||||
echo "Found conda env $CONDA_DEFAULT_ENV. Running pip install inside the conda env"
|
||||
if [ "$PYTHON_VERSION_X_Y" != "3.11" ]; then
|
||||
echo "Error: Python version 3.11 is required."
|
||||
exit 1
|
||||
fi
|
||||
|
||||
if [[ "$SKIP_VENV" != "1" ]]; then
|
||||
if [[ -z "${CONDA_PREFIX}" ]]; then
|
||||
# Not a conda env. So create a new VENV dir
|
||||
VENV_DIR=${VENV_DIR:-shark.venv}
|
||||
echo "Using pip venv.. Setting up venv dir: $VENV_DIR"
|
||||
$PYTHON -m venv "$VENV_DIR" || die "Could not create venv."
|
||||
source "$VENV_DIR/bin/activate" || die "Could not activate venv"
|
||||
PYTHON="$(which python3)"
|
||||
else
|
||||
echo "Found conda env $CONDA_DEFAULT_ENV. Running pip install inside the conda env"
|
||||
fi
|
||||
fi
|
||||
|
||||
Red=`tput setaf 1`
|
||||
@@ -42,7 +50,7 @@ Green=`tput setaf 2`
|
||||
Yellow=`tput setaf 3`
|
||||
|
||||
# Assume no binary torch-mlir.
|
||||
# Currently available for macOS m1&intel (3.10) and Linux(3.7,3.8,3.9,3.10)
|
||||
# Currently available for macOS m1&intel (3.11) and Linux(3.8,3.10,3.11)
|
||||
torch_mlir_bin=false
|
||||
if [[ $(uname -s) = 'Darwin' ]]; then
|
||||
echo "${Yellow}Apple macOS detected"
|
||||
@@ -60,12 +68,12 @@ if [[ $(uname -s) = 'Darwin' ]]; then
|
||||
fi
|
||||
echo "${Yellow}Run the following commands to setup your SSL certs for your Python version if you see SSL errors with tests"
|
||||
echo "${Yellow}/Applications/Python\ 3.XX/Install\ Certificates.command"
|
||||
if [ "$PYTHON_VERSION_X_Y" == "3.10" ]; then
|
||||
if [ "$PYTHON_VERSION_X_Y" == "3.11" ]; then
|
||||
torch_mlir_bin=true
|
||||
fi
|
||||
elif [[ $(uname -s) = 'Linux' ]]; then
|
||||
echo "${Yellow}Linux detected"
|
||||
if [ "$PYTHON_VERSION_X_Y" == "3.7" ] || [ "$PYTHON_VERSION_X_Y" == "3.8" ] || [ "$PYTHON_VERSION_X_Y" == "3.9" ] || [ "$PYTHON_VERSION_X_Y" == "3.10" ] ; then
|
||||
if [ "$PYTHON_VERSION_X_Y" == "3.8" ] || [ "$PYTHON_VERSION_X_Y" == "3.10" ] || [ "$PYTHON_VERSION_X_Y" == "3.11" ] ; then
|
||||
torch_mlir_bin=true
|
||||
fi
|
||||
else
|
||||
@@ -78,7 +86,8 @@ $PYTHON -m pip install --upgrade -r "$TD/requirements.txt"
|
||||
if [ "$torch_mlir_bin" = true ]; then
|
||||
if [[ $(uname -s) = 'Darwin' ]]; then
|
||||
echo "MacOS detected. Installing torch-mlir from .whl, to avoid dependency problems with torch."
|
||||
$PYTHON -m pip install --pre --no-cache-dir torch-mlir -f https://llvm.github.io/torch-mlir/package-index/ -f https://download.pytorch.org/whl/nightly/torch/
|
||||
$PYTHON -m pip uninstall -y timm #TEMP FIX FOR MAC
|
||||
$PYTHON -m pip install --pre --no-cache-dir torch-mlir -f https://llvm.github.io/torch-mlir/package-index/ -f https://download.pytorch.org/whl/nightly/torch/
|
||||
else
|
||||
$PYTHON -m pip install --pre torch-mlir -f https://llvm.github.io/torch-mlir/package-index/
|
||||
if [ $? -eq 0 ];then
|
||||
@@ -89,20 +98,20 @@ if [ "$torch_mlir_bin" = true ]; then
|
||||
fi
|
||||
else
|
||||
echo "${Red}No binaries found for Python $PYTHON_VERSION_X_Y on $(uname -s)"
|
||||
echo "${Yello}Python 3.10 supported on macOS and 3.7,3.8,3.9 and 3.10 on Linux"
|
||||
echo "${Yello}Python 3.11 supported on macOS and 3.8,3.10 and 3.11 on Linux"
|
||||
echo "${Red}Please build torch-mlir from source in your environment"
|
||||
exit 1
|
||||
fi
|
||||
if [[ -z "${USE_IREE}" ]]; then
|
||||
rm .use-iree
|
||||
RUNTIME="https://nod-ai.github.io/SHARK-Runtime/pip-release-links.html"
|
||||
RUNTIME="https://nod-ai.github.io/SRT/pip-release-links.html"
|
||||
else
|
||||
touch ./.use-iree
|
||||
RUNTIME="https://iree-org.github.io/iree/pip-release-links.html"
|
||||
RUNTIME="https://openxla.github.io/iree/pip-release-links.html"
|
||||
fi
|
||||
if [[ -z "${NO_BACKEND}" ]]; then
|
||||
echo "Installing ${RUNTIME}..."
|
||||
$PYTHON -m pip install --upgrade --find-links ${RUNTIME} iree-compiler iree-runtime
|
||||
$PYTHON -m pip install --pre --upgrade --no-index --find-links ${RUNTIME} iree-compiler iree-runtime
|
||||
else
|
||||
echo "Not installing a backend, please make sure to add your backend to PYTHONPATH"
|
||||
fi
|
||||
@@ -112,7 +121,7 @@ if [[ ! -z "${IMPORTER}" ]]; then
|
||||
if [[ $(uname -s) = 'Linux' ]]; then
|
||||
echo "${Yellow}Linux detected.. installing Linux importer tools"
|
||||
#Always get the importer tools from upstream IREE
|
||||
$PYTHON -m pip install --no-warn-conflicts --upgrade -r "$TD/requirements-importer.txt" -f https://iree-org.github.io/iree/pip-release-links.html --extra-index-url https://download.pytorch.org/whl/nightly/cpu
|
||||
$PYTHON -m pip install --no-warn-conflicts --upgrade -r "$TD/requirements-importer.txt" -f https://openxla.github.io/iree/pip-release-links.html --extra-index-url https://download.pytorch.org/whl/nightly/cpu
|
||||
elif [[ $(uname -s) = 'Darwin' ]]; then
|
||||
echo "${Yellow}macOS detected.. installing macOS importer tools"
|
||||
#Conda seems to have some problems installing these packages and hope they get resolved upstream.
|
||||
@@ -120,30 +129,33 @@ if [[ ! -z "${IMPORTER}" ]]; then
|
||||
fi
|
||||
fi
|
||||
|
||||
$PYTHON -m pip install --no-warn-conflicts -e . -f https://llvm.github.io/torch-mlir/package-index/ -f ${RUNTIME} -f https://download.pytorch.org/whl/nightly/torch/
|
||||
if [[ $(uname -s) = 'Darwin' ]]; then
|
||||
PYTORCH_URL=https://download.pytorch.org/whl/nightly/torch/
|
||||
else
|
||||
PYTORCH_URL=https://download.pytorch.org/whl/nightly/cpu/
|
||||
fi
|
||||
|
||||
if [[ $(uname -s) = 'Linux' && ! -z "${BENCHMARK}" ]]; then
|
||||
$PYTHON -m pip uninstall -y torch torchvision
|
||||
$PYTHON -m pip install --pre torch torchvision --extra-index-url https://download.pytorch.org/whl/nightly/cu117
|
||||
$PYTHON -m pip install --no-warn-conflicts -e . -f https://llvm.github.io/torch-mlir/package-index/ -f ${RUNTIME} -f ${PYTORCH_URL}
|
||||
|
||||
if [[ $(uname -s) = 'Linux' && ! -z "${IMPORTER}" ]]; then
|
||||
T_VER=$($PYTHON -m pip show torch | grep Version)
|
||||
T_VER_MIN=${T_VER:14:12}
|
||||
TV_VER=$($PYTHON -m pip show torchvision | grep Version)
|
||||
TV_VER_MAJ=${TV_VER:9:6}
|
||||
$PYTHON -m pip uninstall -y torchvision
|
||||
$PYTHON -m pip install torchvision==${TV_VER_MAJ}${T_VER_MIN} --no-deps -f https://download.pytorch.org/whl/nightly/cpu/torchvision/
|
||||
if [ $? -eq 0 ];then
|
||||
echo "Successfully Installed torch + cu117."
|
||||
echo "Successfully Installed torch + cu118."
|
||||
else
|
||||
echo "Could not install torch + cu117." >&2
|
||||
echo "Could not install torch + cu118." >&2
|
||||
fi
|
||||
fi
|
||||
|
||||
if [[ ! -z "${ONNX}" ]]; then
|
||||
echo "${Yellow}Installing ONNX and onnxruntime for benchmarks..."
|
||||
$PYTHON -m pip install onnx onnxruntime psutil
|
||||
if [ $? -eq 0 ];then
|
||||
echo "Successfully installed ONNX and ONNX runtime."
|
||||
else
|
||||
echo "Could not install ONNX." >&2
|
||||
fi
|
||||
if [[ -z "${NO_BREVITAS}" ]]; then
|
||||
$PYTHON -m pip install git+https://github.com/Xilinx/brevitas.git@dev
|
||||
fi
|
||||
|
||||
if [[ -z "${CONDA_PREFIX}" ]]; then
|
||||
if [[ -z "${CONDA_PREFIX}" && "$SKIP_VENV" != "1" ]]; then
|
||||
echo "${Green}Before running examples activate venv with:"
|
||||
echo " ${Green}source $VENV_DIR/bin/activate"
|
||||
fi
|
||||
|
||||
|
||||
@@ -0,0 +1,28 @@
|
||||
import importlib
|
||||
import logging
|
||||
|
||||
from torch._dynamo import register_backend
|
||||
|
||||
log = logging.getLogger(__name__)
|
||||
|
||||
|
||||
@register_backend
|
||||
def shark(model, inputs, *, options):
|
||||
try:
|
||||
from shark.dynamo_backend.utils import SharkBackend
|
||||
except ImportError:
|
||||
log.exception(
|
||||
"Unable to import SHARK - High Performance Machine Learning Distribution"
|
||||
"Please install the right version of SHARK that matches the PyTorch version being used. "
|
||||
"Refer to https://github.com/nod-ai/SHARK/ for details."
|
||||
)
|
||||
raise
|
||||
return SharkBackend(model, inputs, options)
|
||||
|
||||
|
||||
def has_shark():
|
||||
try:
|
||||
importlib.import_module("shark")
|
||||
return True
|
||||
except ImportError:
|
||||
return False
|
||||
|
||||
@@ -15,7 +15,7 @@
|
||||
import torch
|
||||
from torch._decomp import get_decompositions
|
||||
from torch.fx.experimental.proxy_tensor import make_fx
|
||||
from torch.nn.utils import _stateless
|
||||
from torch.nn.utils import stateless
|
||||
|
||||
from torch import fx
|
||||
import tempfile
|
||||
|
||||
154
shark/dynamo_backend/utils.py
Normal file
154
shark/dynamo_backend/utils.py
Normal file
@@ -0,0 +1,154 @@
|
||||
import functools
|
||||
from typing import List, Optional
|
||||
import torch
|
||||
from torch.fx.experimental.proxy_tensor import make_fx
|
||||
from torch._functorch.compile_utils import strip_overloads
|
||||
from shark.shark_inference import SharkInference
|
||||
from torch._decomp import get_decompositions
|
||||
from torch.func import functionalize
|
||||
import io
|
||||
import torch_mlir
|
||||
|
||||
|
||||
# TODO: Control decompositions.
|
||||
def default_decompositions():
|
||||
return get_decompositions(
|
||||
[
|
||||
torch.ops.aten.embedding_dense_backward,
|
||||
torch.ops.aten.native_layer_norm_backward,
|
||||
torch.ops.aten.slice_backward,
|
||||
torch.ops.aten.select_backward,
|
||||
torch.ops.aten.norm.ScalarOpt_dim,
|
||||
torch.ops.aten.native_group_norm,
|
||||
torch.ops.aten.upsample_bilinear2d.vec,
|
||||
torch.ops.aten.split.Tensor,
|
||||
torch.ops.aten.split_with_sizes,
|
||||
torch.ops.aten.native_layer_norm,
|
||||
torch.ops.aten.masked_fill.Tensor,
|
||||
torch.ops.aten.masked_fill.Scalar,
|
||||
]
|
||||
)
|
||||
|
||||
|
||||
def _remove_nones(fx_g: torch.fx.GraphModule) -> List[int]:
|
||||
removed_indexes = []
|
||||
for node in fx_g.graph.nodes:
|
||||
if node.op == "output":
|
||||
assert (
|
||||
len(node.args) == 1
|
||||
), "Output node must have a single argument"
|
||||
node_arg = node.args[0]
|
||||
if isinstance(node_arg, (list, tuple)):
|
||||
node_arg = list(node_arg)
|
||||
node_args_len = len(node_arg)
|
||||
for i in range(node_args_len):
|
||||
curr_index = node_args_len - (i + 1)
|
||||
if node_arg[curr_index] is None:
|
||||
removed_indexes.append(curr_index)
|
||||
node_arg.pop(curr_index)
|
||||
node.args = (tuple(node_arg),)
|
||||
break
|
||||
|
||||
if len(removed_indexes) > 0:
|
||||
fx_g.graph.lint()
|
||||
fx_g.graph.eliminate_dead_code()
|
||||
fx_g.recompile()
|
||||
removed_indexes.sort()
|
||||
return removed_indexes
|
||||
|
||||
|
||||
def _returns_nothing(fx_g: torch.fx.GraphModule) -> bool:
|
||||
for node in fx_g.graph.nodes:
|
||||
if node.op == "output":
|
||||
assert (
|
||||
len(node.args) == 1
|
||||
), "Output node must have a single argument"
|
||||
node_arg = node.args[0]
|
||||
if isinstance(node_arg, tuple):
|
||||
return len(node_arg) == 0
|
||||
return False
|
||||
|
||||
|
||||
def _unwrap_single_tuple_return(fx_g: torch.fx.GraphModule) -> bool:
|
||||
"""
|
||||
Replace tuple with tuple element in functions that return one-element tuples.
|
||||
Returns true if an unwrapping took place, and false otherwise.
|
||||
"""
|
||||
unwrapped_tuple = False
|
||||
for node in fx_g.graph.nodes:
|
||||
if node.op == "output":
|
||||
assert (
|
||||
len(node.args) == 1
|
||||
), "Output node must have a single argument"
|
||||
node_arg = node.args[0]
|
||||
if isinstance(node_arg, tuple):
|
||||
if len(node_arg) == 1:
|
||||
node.args = (node_arg[0],)
|
||||
unwrapped_tuple = True
|
||||
break
|
||||
|
||||
if unwrapped_tuple:
|
||||
fx_g.graph.lint()
|
||||
fx_g.recompile()
|
||||
return unwrapped_tuple
|
||||
|
||||
|
||||
class SharkBackend:
|
||||
def __init__(
|
||||
self, fx_g: torch.fx.GraphModule, inputs: tuple, options: dict
|
||||
):
|
||||
self.fx_g = fx_g
|
||||
self.inputs = inputs
|
||||
self.shark_module = None
|
||||
self.device: str = options.get("device", "cpu")
|
||||
self.was_unwrapped: bool = False
|
||||
self.none_indices: list = []
|
||||
self._modify_fx_g()
|
||||
self.compile()
|
||||
|
||||
def _modify_fx_g(self):
|
||||
self.none_indices = _remove_nones(self.fx_g)
|
||||
self.was_unwrapped = _unwrap_single_tuple_return(self.fx_g)
|
||||
|
||||
def compile(self):
|
||||
gm = make_fx(
|
||||
functionalize(self.fx_g),
|
||||
decomposition_table=default_decompositions(),
|
||||
)(*self.inputs)
|
||||
gm.graph.set_codegen(torch.fx.graph.CodeGen())
|
||||
gm.recompile()
|
||||
strip_overloads(gm)
|
||||
ts_g = torch.jit.script(gm)
|
||||
mlir_module = torch_mlir.compile(
|
||||
ts_g, self.inputs, output_type="linalg-on-tensors"
|
||||
)
|
||||
bytecode_stream = io.BytesIO()
|
||||
mlir_module.operation.write_bytecode(bytecode_stream)
|
||||
bytecode = bytecode_stream.getvalue()
|
||||
from shark.shark_inference import SharkInference
|
||||
|
||||
shark_module = SharkInference(
|
||||
mlir_module=bytecode,
|
||||
device=self.device,
|
||||
mlir_dialect="tm_tensor",
|
||||
)
|
||||
shark_module.compile(extra_args=[])
|
||||
self.shark_module = shark_module
|
||||
|
||||
def __call__(self, *inputs):
|
||||
np_inputs = [x.contiguous().detach().cpu().numpy() for x in inputs]
|
||||
np_outs = self.shark_module("forward", np_inputs)
|
||||
if self.was_unwrapped:
|
||||
np_outs = [
|
||||
np_outs,
|
||||
]
|
||||
|
||||
if not isinstance(np_outs, list):
|
||||
res = torch.from_numpy(np_outs)
|
||||
return res
|
||||
|
||||
result = [torch.from_numpy(x) for x in np_outs]
|
||||
for r_in in self.none_indices:
|
||||
result.insert(r_in, None)
|
||||
result = tuple(result)
|
||||
return result
|
||||
@@ -1,70 +1,25 @@
|
||||
import torchdynamo
|
||||
import torch
|
||||
import torch_mlir
|
||||
from shark.sharkdynamo.utils import make_shark_compiler
|
||||
import shark
|
||||
|
||||
|
||||
import warnings, logging
|
||||
|
||||
warnings.simplefilter("ignore")
|
||||
torchdynamo.config.log_level = logging.ERROR
|
||||
def foo(x, a):
|
||||
if x.shape[0] > 3:
|
||||
return x + a
|
||||
else:
|
||||
return x + 3
|
||||
|
||||
|
||||
torchdynamo.reset()
|
||||
shark_options = {"device": "cpu"}
|
||||
compiled = torch.compile(foo, backend="shark", options=shark_options)
|
||||
|
||||
input = torch.ones(4)
|
||||
|
||||
@torchdynamo.optimize(
|
||||
make_shark_compiler(use_tracing=False, device="cuda", verbose=False)
|
||||
)
|
||||
def foo(t):
|
||||
return 2 * t
|
||||
x = compiled(input, input)
|
||||
|
||||
|
||||
example_input = torch.rand((2, 3))
|
||||
x = foo(example_input)
|
||||
print(x)
|
||||
|
||||
input = torch.ones(3)
|
||||
|
||||
torchdynamo.reset()
|
||||
x = compiled(input, input)
|
||||
|
||||
|
||||
@torchdynamo.optimize(
|
||||
make_shark_compiler(use_tracing=False, device="cuda", verbose=False)
|
||||
)
|
||||
def foo(a, b):
|
||||
x = a / (a + 1)
|
||||
if b.sum() < 0:
|
||||
b = b * -1
|
||||
return x * b
|
||||
|
||||
|
||||
print(foo(torch.rand((2, 3)), -torch.rand((2, 3))))
|
||||
|
||||
|
||||
torchdynamo.reset()
|
||||
|
||||
|
||||
@torchdynamo.optimize(
|
||||
make_shark_compiler(use_tracing=False, device="cuda", verbose=True)
|
||||
)
|
||||
def foo(a):
|
||||
for i in range(10):
|
||||
a += 1.0
|
||||
return a
|
||||
|
||||
|
||||
print(foo(torch.rand((1, 2))))
|
||||
|
||||
torchdynamo.reset()
|
||||
|
||||
|
||||
@torchdynamo.optimize(
|
||||
make_shark_compiler(use_tracing=False, device="cuda", verbose=True)
|
||||
)
|
||||
def test_unsupported_types(t, y):
|
||||
return t, 2 * y
|
||||
|
||||
|
||||
str_input = "hello"
|
||||
tensor_input = torch.randn(2)
|
||||
print(test_unsupported_types(str_input, tensor_input))
|
||||
print(x)
|
||||
|
||||
@@ -128,7 +128,6 @@ def load_mlir(mlir_loc):
|
||||
|
||||
|
||||
def compile_through_fx(model, inputs, mlir_loc=None):
|
||||
|
||||
module = load_mlir(mlir_loc)
|
||||
if module == None:
|
||||
fx_g = make_fx(
|
||||
@@ -178,7 +177,7 @@ def compile_through_fx(model, inputs, mlir_loc=None):
|
||||
mlir_model = str(module)
|
||||
func_name = "forward"
|
||||
shark_module = SharkInference(
|
||||
mlir_model, func_name, device=args.device, mlir_dialect="linalg"
|
||||
mlir_model, device=args.device, mlir_dialect="linalg"
|
||||
)
|
||||
shark_module.compile()
|
||||
|
||||
|
||||
@@ -43,9 +43,7 @@ if __name__ == "__main__":
|
||||
minilm_mlir, func_name = mlir_importer.import_mlir(
|
||||
is_dynamic=False, tracing_required=True
|
||||
)
|
||||
shark_module = SharkInference(
|
||||
minilm_mlir, func_name, mlir_dialect="linalg"
|
||||
)
|
||||
shark_module = SharkInference(minilm_mlir)
|
||||
shark_module.compile()
|
||||
token_logits = torch.tensor(shark_module.forward(inputs))
|
||||
mask_id = torch.where(
|
||||
|
||||
@@ -54,7 +54,7 @@ if __name__ == "__main__":
|
||||
minilm_mlir, func_name = mlir_importer.import_mlir(
|
||||
is_dynamic=False, tracing_required=False
|
||||
)
|
||||
shark_module = SharkInference(minilm_mlir, func_name, mlir_dialect="mhlo")
|
||||
shark_module = SharkInference(minilm_mlir, mlir_dialect="mhlo")
|
||||
shark_module.compile()
|
||||
output_idx = 0
|
||||
data_idx = 1
|
||||
|
||||
@@ -6,7 +6,7 @@ mlir_model, func_name, inputs, golden_out = download_model(
|
||||
)
|
||||
|
||||
shark_module = SharkInference(
|
||||
mlir_model, func_name, device="cpu", mlir_dialect="tm_tensor"
|
||||
mlir_model, device="cpu", mlir_dialect="tm_tensor"
|
||||
)
|
||||
shark_module.compile()
|
||||
result = shark_module.forward(inputs)
|
||||
|
||||
18
shark/examples/shark_inference/llama/README.md
Normal file
18
shark/examples/shark_inference/llama/README.md
Normal file
@@ -0,0 +1,18 @@
|
||||
# SHARK LLaMA
|
||||
|
||||
## TORCH-MLIR Version
|
||||
|
||||
```
|
||||
https://github.com/nod-ai/torch-mlir.git
|
||||
```
|
||||
Then check out the `complex` branch and `git submodule update --init` and then build with `.\build_tools\python_deploy\build_windows.ps1`
|
||||
|
||||
### Setup & Run
|
||||
```
|
||||
git clone https://github.com/nod-ai/llama.git
|
||||
```
|
||||
Then in this repository
|
||||
```
|
||||
pip install -e .
|
||||
python llama/shark_model.py
|
||||
```
|
||||
72
shark/examples/shark_inference/mega_test.py
Normal file
72
shark/examples/shark_inference/mega_test.py
Normal file
@@ -0,0 +1,72 @@
|
||||
import torch
|
||||
import torch_mlir
|
||||
from shark.shark_inference import SharkInference
|
||||
from shark.shark_compile import shark_compile_through_fx
|
||||
from MEGABYTE_pytorch import MEGABYTE
|
||||
|
||||
import os
|
||||
|
||||
|
||||
class MegaModel(torch.nn.Module):
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
self.model = MEGABYTE(
|
||||
num_tokens=16000, # number of tokens
|
||||
dim=(
|
||||
512,
|
||||
256,
|
||||
), # transformer model dimension (512 for coarsest, 256 for fine in this example)
|
||||
max_seq_len=(
|
||||
1024,
|
||||
4,
|
||||
), # sequence length for global and then local. this can be more than 2
|
||||
depth=(
|
||||
6,
|
||||
4,
|
||||
), # number of layers for global and then local. this can be more than 2, but length must match the max_seq_len's
|
||||
dim_head=64, # dimension per head
|
||||
heads=8, # number of attention heads
|
||||
flash_attn=True, # use flash attention
|
||||
)
|
||||
|
||||
def forward(self, input):
|
||||
return self.model(input)
|
||||
|
||||
|
||||
megaModel = MegaModel()
|
||||
inputs = [torch.randint(0, 16000, (1, 1024, 4))]
|
||||
|
||||
# CURRENTLY IT BAILS OUT HERE BECAUSE OF MISSING OP LOWERINGS :-
|
||||
# 1. aten.alias
|
||||
shark_module, _ = shark_compile_through_fx(
|
||||
model=megaModel,
|
||||
inputs=inputs,
|
||||
extended_model_name="mega_shark",
|
||||
is_f16=False,
|
||||
f16_input_mask=None,
|
||||
save_dir=os.getcwd(),
|
||||
debug=False,
|
||||
generate_or_load_vmfb=True,
|
||||
extra_args=[],
|
||||
device="cuda",
|
||||
mlir_dialect="tm_tensor",
|
||||
)
|
||||
# logits = model(x)
|
||||
|
||||
|
||||
def print_output_info(output, msg):
|
||||
print("\n", msg)
|
||||
print("\n\t", output.shape)
|
||||
|
||||
|
||||
ans = shark_module("forward", inputs)
|
||||
print_output_info(torch.from_numpy(ans), "SHARK's output")
|
||||
|
||||
ans = megaModel.forward(*inputs)
|
||||
print_output_info(ans, "ORIGINAL Model's output")
|
||||
|
||||
# and sample from the logits accordingly
|
||||
# or you can use the generate function
|
||||
|
||||
# NEED TO LOOK AT THIS LATER IF REQUIRED IN SHARK.
|
||||
# sampled = model.generate(temperature = 0.9, filter_thres = 0.9) # (1, 1024, 4)
|
||||
@@ -13,9 +13,7 @@ arg0 = np.ones((1, 4)).astype(np.float32)
|
||||
arg1 = np.ones((4, 1)).astype(np.float32)
|
||||
|
||||
print("Running shark on cpu backend")
|
||||
shark_module = SharkInference(
|
||||
mhlo_ir, function_name="forward", device="cpu", mlir_dialect="mhlo"
|
||||
)
|
||||
shark_module = SharkInference(mhlo_ir, device="cpu", mlir_dialect="mhlo")
|
||||
|
||||
# Generate the random inputs and feed into the graph.
|
||||
x = shark_module.generate_random_inputs()
|
||||
@@ -23,15 +21,11 @@ shark_module.compile()
|
||||
print(shark_module.forward(x))
|
||||
|
||||
print("Running shark on cuda backend")
|
||||
shark_module = SharkInference(
|
||||
mhlo_ir, function_name="forward", device="cuda", mlir_dialect="mhlo"
|
||||
)
|
||||
shark_module = SharkInference(mhlo_ir, device="cuda", mlir_dialect="mhlo")
|
||||
shark_module.compile()
|
||||
print(shark_module.forward(x))
|
||||
|
||||
print("Running shark on vulkan backend")
|
||||
shark_module = SharkInference(
|
||||
mhlo_ir, function_name="forward", device="vulkan", mlir_dialect="mhlo"
|
||||
)
|
||||
shark_module = SharkInference(mhlo_ir, device="vulkan", mlir_dialect="mhlo")
|
||||
shark_module.compile()
|
||||
print(shark_module.forward(x))
|
||||
|
||||
73
shark/examples/shark_inference/minilm_jax.py
Normal file
73
shark/examples/shark_inference/minilm_jax.py
Normal file
@@ -0,0 +1,73 @@
|
||||
from transformers import AutoTokenizer, FlaxAutoModel
|
||||
import torch
|
||||
import jax
|
||||
from typing import Union, Dict, List, Any
|
||||
import numpy as np
|
||||
from shark.shark_inference import SharkInference
|
||||
import io
|
||||
|
||||
NumpyTree = Union[np.ndarray, Dict[str, np.ndarray], List[np.ndarray]]
|
||||
|
||||
|
||||
def convert_torch_tensor_tree_to_numpy(
|
||||
tree: Union[torch.tensor, Dict[str, torch.tensor], List[torch.tensor]]
|
||||
) -> NumpyTree:
|
||||
return jax.tree_util.tree_map(
|
||||
lambda torch_tensor: torch_tensor.cpu().detach().numpy(), tree
|
||||
)
|
||||
|
||||
|
||||
def convert_int64_to_int32(tree: NumpyTree) -> NumpyTree:
|
||||
return jax.tree_util.tree_map(
|
||||
lambda tensor: np.array(tensor, dtype=np.int32)
|
||||
if tensor.dtype == np.int64
|
||||
else tensor,
|
||||
tree,
|
||||
)
|
||||
|
||||
|
||||
def get_sample_input():
|
||||
tokenizer = AutoTokenizer.from_pretrained(
|
||||
"microsoft/MiniLM-L12-H384-uncased"
|
||||
)
|
||||
inputs_torch = tokenizer("Hello, World!", return_tensors="pt")
|
||||
return convert_int64_to_int32(
|
||||
convert_torch_tensor_tree_to_numpy(inputs_torch.data)
|
||||
)
|
||||
|
||||
|
||||
def get_jax_model():
|
||||
return FlaxAutoModel.from_pretrained("microsoft/MiniLM-L12-H384-uncased")
|
||||
|
||||
|
||||
def export_jax_to_mlir(jax_model: Any, sample_input: NumpyTree):
|
||||
model_mlir = jax.jit(jax_model).lower(**sample_input).compiler_ir()
|
||||
byte_stream = io.BytesIO()
|
||||
model_mlir.operation.write_bytecode(file=byte_stream)
|
||||
return byte_stream.getvalue()
|
||||
|
||||
|
||||
def assert_array_list_allclose(x, y, *args, **kwargs):
|
||||
assert len(x) == len(y)
|
||||
for a, b in zip(x, y):
|
||||
np.testing.assert_allclose(
|
||||
np.asarray(a), np.asarray(b), *args, **kwargs
|
||||
)
|
||||
|
||||
|
||||
sample_input = get_sample_input()
|
||||
jax_model = get_jax_model()
|
||||
mlir = export_jax_to_mlir(jax_model, sample_input)
|
||||
|
||||
# Compile and load module.
|
||||
shark_inference = SharkInference(mlir_module=mlir, mlir_dialect="mhlo")
|
||||
shark_inference.compile()
|
||||
|
||||
# Run main function.
|
||||
result = shark_inference("main", jax.tree_util.tree_flatten(sample_input)[0])
|
||||
|
||||
# Run JAX model.
|
||||
reference_result = jax.tree_util.tree_flatten(jax_model(**sample_input))[0]
|
||||
|
||||
# Verify result.
|
||||
assert_array_list_allclose(result, reference_result, atol=1e-5)
|
||||
@@ -0,0 +1,6 @@
|
||||
flax
|
||||
jax[cpu]
|
||||
nodai-SHARK
|
||||
orbax
|
||||
transformers
|
||||
torch
|
||||
@@ -8,9 +8,7 @@ mlir_model, func_name, inputs, golden_out = download_model(
|
||||
)
|
||||
|
||||
|
||||
shark_module = SharkInference(
|
||||
mlir_model, func_name, device="cpu", mlir_dialect="linalg"
|
||||
)
|
||||
shark_module = SharkInference(mlir_model, device="cpu", mlir_dialect="linalg")
|
||||
shark_module.compile()
|
||||
result = shark_module.forward(inputs)
|
||||
print("The obtained result via shark is: ", result)
|
||||
|
||||
@@ -33,7 +33,7 @@ mlir_importer = SharkImporter(
|
||||
|
||||
print(golden_out)
|
||||
|
||||
shark_module = SharkInference(vision_mlir, func_name, mlir_dialect="linalg")
|
||||
shark_module = SharkInference(vision_mlir, mlir_dialect="linalg")
|
||||
shark_module.compile()
|
||||
result = shark_module.forward((input,))
|
||||
print("Obtained result", result)
|
||||
|
||||
@@ -49,9 +49,7 @@ module = torch_mlir.compile(
|
||||
mlir_model = module
|
||||
func_name = "forward"
|
||||
|
||||
shark_module = SharkInference(
|
||||
mlir_model, func_name, device="cuda", mlir_dialect="linalg"
|
||||
)
|
||||
shark_module = SharkInference(mlir_model, device="cuda", mlir_dialect="linalg")
|
||||
shark_module.compile()
|
||||
|
||||
|
||||
|
||||
@@ -70,11 +70,11 @@ mlir_model, func_name, inputs, golden_out = download_model(
|
||||
"resnet50", frontend="torch"
|
||||
)
|
||||
|
||||
shark_module = SharkInference(mlir_model, func_name, mlir_dialect="linalg")
|
||||
shark_module = SharkInference(mlir_model, mlir_dialect="linalg")
|
||||
shark_module.compile()
|
||||
path = shark_module.save_module()
|
||||
shark_module.load_module(path)
|
||||
result = shark_module.forward((img.detach().numpy(),))
|
||||
result = shark_module("forward", (img.detach().numpy(),))
|
||||
|
||||
print("The top 3 results obtained via shark_runner is:")
|
||||
print(top3_possibilities(torch.from_numpy(result)))
|
||||
|
||||
842
shark/examples/shark_inference/sharded_bloom.py
Normal file
842
shark/examples/shark_inference/sharded_bloom.py
Normal file
@@ -0,0 +1,842 @@
|
||||
####################################################################################
|
||||
# Please make sure you have transformers 4.21.2 installed before running this demo
|
||||
#
|
||||
# -p --model_path: the directory in which you want to store the bloom files.
|
||||
# -dl --device_list: the list of device indices you want to use. if you want to only use the first device, or you are running on cpu leave this blank.
|
||||
# Otherwise, please give this argument in this format: "[0, 1, 2]"
|
||||
# -de --device: the device you want to run bloom on. E.G. cpu, cuda
|
||||
# -c, --recompile: set to true if you want to recompile to vmfb.
|
||||
# -d, --download: set to true if you want to redownload the mlir files
|
||||
# -cm, --create_mlirs: set to true if you want to create the mlir files from scratch. please make sure you have transformers 4.21.2 before using this option
|
||||
# -t --token_count: the number of tokens you want to generate
|
||||
# -pr --prompt: the prompt you want to feed to the model
|
||||
# -m --model_name: the name of the model, e.g. bloom-560m
|
||||
#
|
||||
# If you don't specify a prompt when you run this example, you will be able to give prompts through the terminal. Run the
|
||||
# example in this way if you want to run multiple examples without reinitializing the model
|
||||
#####################################################################################
|
||||
|
||||
import os
|
||||
import io
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
from collections import OrderedDict
|
||||
import torch_mlir
|
||||
from torch_mlir import TensorPlaceholder
|
||||
import re
|
||||
from transformers.models.bloom.configuration_bloom import BloomConfig
|
||||
import json
|
||||
import sys
|
||||
import argparse
|
||||
import json
|
||||
import urllib.request
|
||||
import subprocess
|
||||
|
||||
from torch.fx.experimental.proxy_tensor import make_fx
|
||||
from torch._decomp import get_decompositions
|
||||
from shark.shark_inference import SharkInference
|
||||
from shark.shark_downloader import download_public_file
|
||||
from transformers import (
|
||||
BloomTokenizerFast,
|
||||
BloomForSequenceClassification,
|
||||
BloomForCausalLM,
|
||||
)
|
||||
from transformers.models.bloom.modeling_bloom import (
|
||||
BloomBlock,
|
||||
build_alibi_tensor,
|
||||
)
|
||||
|
||||
IS_CUDA = False
|
||||
|
||||
|
||||
class ShardedBloom:
|
||||
def __init__(self, src_folder):
|
||||
f = open(f"{src_folder}/config.json")
|
||||
config = json.load(f)
|
||||
f.close()
|
||||
|
||||
self.layers_initialized = False
|
||||
|
||||
self.src_folder = src_folder
|
||||
try:
|
||||
self.n_embed = config["n_embed"]
|
||||
except KeyError:
|
||||
self.n_embed = config["hidden_size"]
|
||||
self.vocab_size = config["vocab_size"]
|
||||
self.n_layer = config["n_layer"]
|
||||
try:
|
||||
self.n_head = config["num_attention_heads"]
|
||||
except KeyError:
|
||||
self.n_head = config["n_head"]
|
||||
|
||||
def _init_layer(self, layer_name, device, replace, device_idx):
|
||||
if replace or not os.path.exists(
|
||||
f"{self.src_folder}/{layer_name}.vmfb"
|
||||
):
|
||||
f_ = open(f"{self.src_folder}/{layer_name}.mlir", encoding="utf-8")
|
||||
module = f_.read()
|
||||
f_.close()
|
||||
module = bytes(module, "utf-8")
|
||||
shark_module = SharkInference(
|
||||
module,
|
||||
device=device,
|
||||
mlir_dialect="tm_tensor",
|
||||
device_idx=device_idx,
|
||||
)
|
||||
shark_module.save_module(
|
||||
module_name=f"{self.src_folder}/{layer_name}",
|
||||
extra_args=[
|
||||
"--iree-vm-bytecode-module-output-format=flatbuffer-binary",
|
||||
"--iree-stream-resource-max-allocation-size=1000000000",
|
||||
"--iree-codegen-check-ir-before-llvm-conversion=false",
|
||||
],
|
||||
)
|
||||
else:
|
||||
shark_module = SharkInference(
|
||||
"",
|
||||
device=device,
|
||||
mlir_dialect="tm_tensor",
|
||||
device_idx=device_idx,
|
||||
)
|
||||
|
||||
return shark_module
|
||||
|
||||
def init_layers(self, device, replace=False, device_idx=[0]):
|
||||
if device_idx is not None:
|
||||
n_devices = len(device_idx)
|
||||
|
||||
self.word_embeddings_module = self._init_layer(
|
||||
"word_embeddings",
|
||||
device,
|
||||
replace,
|
||||
device_idx if device_idx is None else device_idx[0 % n_devices],
|
||||
)
|
||||
self.word_embeddings_layernorm_module = self._init_layer(
|
||||
"word_embeddings_layernorm",
|
||||
device,
|
||||
replace,
|
||||
device_idx if device_idx is None else device_idx[1 % n_devices],
|
||||
)
|
||||
self.ln_f_module = self._init_layer(
|
||||
"ln_f",
|
||||
device,
|
||||
replace,
|
||||
device_idx if device_idx is None else device_idx[2 % n_devices],
|
||||
)
|
||||
self.lm_head_module = self._init_layer(
|
||||
"lm_head",
|
||||
device,
|
||||
replace,
|
||||
device_idx if device_idx is None else device_idx[3 % n_devices],
|
||||
)
|
||||
self.block_modules = [
|
||||
self._init_layer(
|
||||
f"bloom_block_{i}",
|
||||
device,
|
||||
replace,
|
||||
device_idx
|
||||
if device_idx is None
|
||||
else device_idx[(i + 4) % n_devices],
|
||||
)
|
||||
for i in range(self.n_layer)
|
||||
]
|
||||
|
||||
self.layers_initialized = True
|
||||
|
||||
def load_layers(self):
|
||||
assert self.layers_initialized
|
||||
|
||||
self.word_embeddings_module.load_module(
|
||||
f"{self.src_folder}/word_embeddings.vmfb"
|
||||
)
|
||||
self.word_embeddings_layernorm_module.load_module(
|
||||
f"{self.src_folder}/word_embeddings_layernorm.vmfb"
|
||||
)
|
||||
for block_module, i in zip(self.block_modules, range(self.n_layer)):
|
||||
block_module.load_module(f"{self.src_folder}/bloom_block_{i}.vmfb")
|
||||
self.ln_f_module.load_module(f"{self.src_folder}/ln_f.vmfb")
|
||||
self.lm_head_module.load_module(f"{self.src_folder}/lm_head.vmfb")
|
||||
|
||||
def forward_pass(self, input_ids, device):
|
||||
if IS_CUDA:
|
||||
cudaSetDevice(self.word_embeddings_module.device_idx)
|
||||
|
||||
input_embeds = self.word_embeddings_module(
|
||||
inputs=(input_ids,), function_name="forward"
|
||||
)
|
||||
|
||||
input_embeds = torch.tensor(input_embeds).float()
|
||||
if IS_CUDA:
|
||||
cudaSetDevice(self.word_embeddings_layernorm_module.device_idx)
|
||||
hidden_states = self.word_embeddings_layernorm_module(
|
||||
inputs=(input_embeds,), function_name="forward"
|
||||
)
|
||||
|
||||
hidden_states = torch.tensor(hidden_states).float()
|
||||
|
||||
attention_mask = torch.ones(
|
||||
[hidden_states.shape[0], len(input_ids[0])]
|
||||
)
|
||||
alibi = build_alibi_tensor(
|
||||
attention_mask,
|
||||
self.n_head,
|
||||
hidden_states.dtype,
|
||||
hidden_states.device,
|
||||
)
|
||||
|
||||
causal_mask = _prepare_attn_mask(
|
||||
attention_mask, input_ids.size(), input_embeds, 0
|
||||
)
|
||||
causal_mask = torch.tensor(causal_mask).float()
|
||||
|
||||
presents = ()
|
||||
all_hidden_states = tuple(hidden_states)
|
||||
|
||||
for block_module, i in zip(self.block_modules, range(self.n_layer)):
|
||||
if IS_CUDA:
|
||||
cudaSetDevice(block_module.device_idx)
|
||||
|
||||
output = block_module(
|
||||
inputs=(
|
||||
hidden_states.detach().numpy(),
|
||||
alibi.detach().numpy(),
|
||||
causal_mask.detach().numpy(),
|
||||
),
|
||||
function_name="forward",
|
||||
)
|
||||
hidden_states = torch.tensor(output[0]).float()
|
||||
all_hidden_states = all_hidden_states + (hidden_states,)
|
||||
presents = presents + (
|
||||
tuple(
|
||||
(
|
||||
output[1],
|
||||
output[2],
|
||||
)
|
||||
),
|
||||
)
|
||||
if IS_CUDA:
|
||||
cudaSetDevice(self.ln_f_module.device_idx)
|
||||
|
||||
hidden_states = self.ln_f_module(
|
||||
inputs=(hidden_states,), function_name="forward"
|
||||
)
|
||||
if IS_CUDA:
|
||||
cudaSetDevice(self.lm_head_module.device_idx)
|
||||
|
||||
logits = self.lm_head_module(
|
||||
inputs=(hidden_states,), function_name="forward"
|
||||
)
|
||||
logits = torch.tensor(logits).float()
|
||||
|
||||
return torch.argmax(logits[:, -1, :], dim=-1)
|
||||
|
||||
|
||||
def _make_causal_mask(
|
||||
input_ids_shape: torch.Size,
|
||||
dtype: torch.dtype,
|
||||
past_key_values_length: int = 0,
|
||||
):
|
||||
"""
|
||||
Make causal mask used for bi-directional self-attention.
|
||||
"""
|
||||
batch_size, target_length = input_ids_shape
|
||||
mask = torch.full((target_length, target_length), torch.finfo(dtype).min)
|
||||
mask_cond = torch.arange(mask.size(-1))
|
||||
intermediate_mask = mask_cond < (mask_cond + 1).view(mask.size(-1), 1)
|
||||
mask.masked_fill_(intermediate_mask, 0)
|
||||
mask = mask.to(dtype)
|
||||
|
||||
if past_key_values_length > 0:
|
||||
mask = torch.cat(
|
||||
[
|
||||
torch.zeros(
|
||||
target_length, past_key_values_length, dtype=dtype
|
||||
),
|
||||
mask,
|
||||
],
|
||||
dim=-1,
|
||||
)
|
||||
expanded_mask = mask[None, None, :, :].expand(
|
||||
batch_size, 1, target_length, target_length + past_key_values_length
|
||||
)
|
||||
return expanded_mask
|
||||
|
||||
|
||||
def _expand_mask(mask: torch.Tensor, dtype: torch.dtype, tgt_len: int = None):
|
||||
"""
|
||||
Expands attention_mask from `[bsz, seq_len]` to `[bsz, 1, tgt_seq_len, src_seq_len]`.
|
||||
"""
|
||||
batch_size, source_length = mask.size()
|
||||
tgt_len = tgt_len if tgt_len is not None else source_length
|
||||
|
||||
expanded_mask = (
|
||||
mask[:, None, None, :]
|
||||
.expand(batch_size, 1, tgt_len, source_length)
|
||||
.to(dtype)
|
||||
)
|
||||
|
||||
inverted_mask = 1.0 - expanded_mask
|
||||
|
||||
return inverted_mask.masked_fill(
|
||||
inverted_mask.to(torch.bool), torch.finfo(dtype).min
|
||||
)
|
||||
|
||||
|
||||
def _prepare_attn_mask(
|
||||
attention_mask, input_shape, inputs_embeds, past_key_values_length
|
||||
):
|
||||
# create causal mask
|
||||
# [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
|
||||
combined_attention_mask = None
|
||||
if input_shape[-1] > 1:
|
||||
combined_attention_mask = _make_causal_mask(
|
||||
input_shape,
|
||||
inputs_embeds.dtype,
|
||||
past_key_values_length=past_key_values_length,
|
||||
).to(attention_mask.device)
|
||||
|
||||
if attention_mask is not None:
|
||||
# [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
|
||||
expanded_attn_mask = _expand_mask(
|
||||
attention_mask, inputs_embeds.dtype, tgt_len=input_shape[-1]
|
||||
)
|
||||
combined_attention_mask = (
|
||||
expanded_attn_mask
|
||||
if combined_attention_mask is None
|
||||
else expanded_attn_mask + combined_attention_mask
|
||||
)
|
||||
|
||||
return combined_attention_mask
|
||||
|
||||
|
||||
def download_model(destination_folder, model_name):
|
||||
download_public_file(
|
||||
f"gs://shark_tank/sharded_bloom/{model_name}/", destination_folder
|
||||
)
|
||||
|
||||
|
||||
def compile_embeddings(embeddings_layer, input_ids, path):
|
||||
input_ids_placeholder = torch_mlir.TensorPlaceholder.like(
|
||||
input_ids, dynamic_axes=[1]
|
||||
)
|
||||
module = torch_mlir.compile(
|
||||
embeddings_layer,
|
||||
(input_ids_placeholder),
|
||||
torch_mlir.OutputType.LINALG_ON_TENSORS,
|
||||
use_tracing=False,
|
||||
verbose=False,
|
||||
)
|
||||
|
||||
bytecode_stream = io.BytesIO()
|
||||
module.operation.write_bytecode(bytecode_stream)
|
||||
bytecode = bytecode_stream.getvalue()
|
||||
|
||||
f_ = open(path, "w+")
|
||||
f_.write(str(module))
|
||||
f_.close()
|
||||
return
|
||||
|
||||
|
||||
def compile_word_embeddings_layernorm(
|
||||
embeddings_layer_layernorm, embeds, path
|
||||
):
|
||||
embeds_placeholder = torch_mlir.TensorPlaceholder.like(
|
||||
embeds, dynamic_axes=[1]
|
||||
)
|
||||
module = torch_mlir.compile(
|
||||
embeddings_layer_layernorm,
|
||||
(embeds_placeholder),
|
||||
torch_mlir.OutputType.LINALG_ON_TENSORS,
|
||||
use_tracing=False,
|
||||
verbose=False,
|
||||
)
|
||||
|
||||
bytecode_stream = io.BytesIO()
|
||||
module.operation.write_bytecode(bytecode_stream)
|
||||
bytecode = bytecode_stream.getvalue()
|
||||
|
||||
f_ = open(path, "w+")
|
||||
f_.write(str(module))
|
||||
f_.close()
|
||||
return
|
||||
|
||||
|
||||
def strip_overloads(gm):
|
||||
"""
|
||||
Modifies the target of graph nodes in :attr:`gm` to strip overloads.
|
||||
Args:
|
||||
gm(fx.GraphModule): The input Fx graph module to be modified
|
||||
"""
|
||||
for node in gm.graph.nodes:
|
||||
if isinstance(node.target, torch._ops.OpOverload):
|
||||
node.target = node.target.overloadpacket
|
||||
gm.recompile()
|
||||
|
||||
|
||||
def compile_to_mlir(
|
||||
bblock,
|
||||
hidden_states,
|
||||
layer_past=None,
|
||||
attention_mask=None,
|
||||
head_mask=None,
|
||||
use_cache=None,
|
||||
output_attentions=False,
|
||||
alibi=None,
|
||||
block_index=0,
|
||||
path=".",
|
||||
):
|
||||
fx_g = make_fx(
|
||||
bblock,
|
||||
decomposition_table=get_decompositions(
|
||||
[
|
||||
torch.ops.aten.split.Tensor,
|
||||
torch.ops.aten.split_with_sizes,
|
||||
]
|
||||
),
|
||||
tracing_mode="real",
|
||||
_allow_non_fake_inputs=False,
|
||||
)(hidden_states, alibi, attention_mask)
|
||||
|
||||
fx_g.graph.set_codegen(torch.fx.graph.CodeGen())
|
||||
fx_g.recompile()
|
||||
|
||||
strip_overloads(fx_g)
|
||||
|
||||
hidden_states_placeholder = TensorPlaceholder.like(
|
||||
hidden_states, dynamic_axes=[1]
|
||||
)
|
||||
attention_mask_placeholder = TensorPlaceholder.like(
|
||||
attention_mask, dynamic_axes=[2, 3]
|
||||
)
|
||||
alibi_placeholder = TensorPlaceholder.like(alibi, dynamic_axes=[2])
|
||||
|
||||
ts_g = torch.jit.script(fx_g)
|
||||
|
||||
module = torch_mlir.compile(
|
||||
ts_g,
|
||||
(
|
||||
hidden_states_placeholder,
|
||||
alibi_placeholder,
|
||||
attention_mask_placeholder,
|
||||
),
|
||||
torch_mlir.OutputType.LINALG_ON_TENSORS,
|
||||
use_tracing=False,
|
||||
verbose=False,
|
||||
)
|
||||
|
||||
module_placeholder = module
|
||||
module_context = module_placeholder.context
|
||||
|
||||
def check_valid_line(line, line_n, mlir_file_len):
|
||||
if "private" in line:
|
||||
return False
|
||||
if "attributes" in line:
|
||||
return False
|
||||
if mlir_file_len - line_n == 2:
|
||||
return False
|
||||
|
||||
return True
|
||||
|
||||
mlir_file_len = len(str(module).split("\n"))
|
||||
|
||||
def remove_constant_dim(line):
|
||||
if "17x" in line:
|
||||
line = re.sub("17x", "?x", line)
|
||||
line = re.sub("tensor.empty\(\)", "tensor.empty(%dim)", line)
|
||||
if "tensor.empty" in line and "?x?" in line:
|
||||
line = re.sub(
|
||||
"tensor.empty\(%dim\)", "tensor.empty(%dim, %dim)", line
|
||||
)
|
||||
if "arith.cmpi eq" in line:
|
||||
line = re.sub("c17", "dim", line)
|
||||
if " 17," in line:
|
||||
line = re.sub(" 17,", " %dim,", line)
|
||||
return line
|
||||
|
||||
module = "\n".join(
|
||||
[
|
||||
remove_constant_dim(line)
|
||||
for line, line_n in zip(
|
||||
str(module).split("\n"), range(mlir_file_len)
|
||||
)
|
||||
if check_valid_line(line, line_n, mlir_file_len)
|
||||
]
|
||||
)
|
||||
|
||||
module = module_placeholder.parse(module, context=module_context)
|
||||
bytecode_stream = io.BytesIO()
|
||||
module.operation.write_bytecode(bytecode_stream)
|
||||
bytecode = bytecode_stream.getvalue()
|
||||
|
||||
f_ = open(path, "w+")
|
||||
f_.write(str(module))
|
||||
f_.close()
|
||||
return
|
||||
|
||||
|
||||
def compile_ln_f(ln_f, hidden_layers, path):
|
||||
hidden_layers_placeholder = torch_mlir.TensorPlaceholder.like(
|
||||
hidden_layers, dynamic_axes=[1]
|
||||
)
|
||||
module = torch_mlir.compile(
|
||||
ln_f,
|
||||
(hidden_layers_placeholder),
|
||||
torch_mlir.OutputType.LINALG_ON_TENSORS,
|
||||
use_tracing=False,
|
||||
verbose=False,
|
||||
)
|
||||
|
||||
bytecode_stream = io.BytesIO()
|
||||
module.operation.write_bytecode(bytecode_stream)
|
||||
bytecode = bytecode_stream.getvalue()
|
||||
|
||||
f_ = open(path, "w+")
|
||||
f_.write(str(module))
|
||||
f_.close()
|
||||
return
|
||||
|
||||
|
||||
def compile_lm_head(lm_head, hidden_layers, path):
|
||||
hidden_layers_placeholder = torch_mlir.TensorPlaceholder.like(
|
||||
hidden_layers, dynamic_axes=[1]
|
||||
)
|
||||
module = torch_mlir.compile(
|
||||
lm_head,
|
||||
(hidden_layers_placeholder),
|
||||
torch_mlir.OutputType.LINALG_ON_TENSORS,
|
||||
use_tracing=False,
|
||||
verbose=False,
|
||||
)
|
||||
|
||||
bytecode_stream = io.BytesIO()
|
||||
module.operation.write_bytecode(bytecode_stream)
|
||||
bytecode = bytecode_stream.getvalue()
|
||||
|
||||
f_ = open(path, "w+")
|
||||
f_.write(str(module))
|
||||
f_.close()
|
||||
return
|
||||
|
||||
|
||||
def create_mlirs(destination_folder, model_name):
|
||||
model_config = "bigscience/" + model_name
|
||||
sample_input_ids = torch.ones([1, 17], dtype=torch.int64)
|
||||
|
||||
urllib.request.urlretrieve(
|
||||
f"https://huggingface.co/bigscience/{model_name}/resolve/main/config.json",
|
||||
filename=f"{destination_folder}/config.json",
|
||||
)
|
||||
urllib.request.urlretrieve(
|
||||
f"https://huggingface.co/bigscience/bloom/resolve/main/tokenizer.json",
|
||||
filename=f"{destination_folder}/tokenizer.json",
|
||||
)
|
||||
|
||||
class HuggingFaceLanguage(torch.nn.Module):
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
self.model = BloomForCausalLM.from_pretrained(model_config)
|
||||
|
||||
def forward(self, tokens):
|
||||
return self.model.forward(tokens)[0]
|
||||
|
||||
class HuggingFaceBlock(torch.nn.Module):
|
||||
def __init__(self, block):
|
||||
super().__init__()
|
||||
self.model = block
|
||||
|
||||
def forward(self, tokens, alibi, attention_mask):
|
||||
output = self.model(
|
||||
hidden_states=tokens,
|
||||
alibi=alibi,
|
||||
attention_mask=attention_mask,
|
||||
use_cache=True,
|
||||
output_attentions=False,
|
||||
)
|
||||
return (output[0], output[1][0], output[1][1])
|
||||
|
||||
model = HuggingFaceLanguage()
|
||||
|
||||
compile_embeddings(
|
||||
model.model.transformer.word_embeddings,
|
||||
sample_input_ids,
|
||||
f"{destination_folder}/word_embeddings.mlir",
|
||||
)
|
||||
|
||||
inputs_embeds = model.model.transformer.word_embeddings(sample_input_ids)
|
||||
|
||||
compile_word_embeddings_layernorm(
|
||||
model.model.transformer.word_embeddings_layernorm,
|
||||
inputs_embeds,
|
||||
f"{destination_folder}/word_embeddings_layernorm.mlir",
|
||||
)
|
||||
|
||||
hidden_states = model.model.transformer.word_embeddings_layernorm(
|
||||
inputs_embeds
|
||||
)
|
||||
|
||||
input_shape = sample_input_ids.size()
|
||||
|
||||
current_sequence_length = hidden_states.shape[1]
|
||||
past_key_values_length = 0
|
||||
past_key_values = tuple([None] * len(model.model.transformer.h))
|
||||
|
||||
attention_mask = torch.ones(
|
||||
(hidden_states.shape[0], current_sequence_length), device="cpu"
|
||||
)
|
||||
|
||||
alibi = build_alibi_tensor(
|
||||
attention_mask,
|
||||
model.model.transformer.n_head,
|
||||
hidden_states.dtype,
|
||||
"cpu",
|
||||
)
|
||||
|
||||
causal_mask = _prepare_attn_mask(
|
||||
attention_mask, input_shape, inputs_embeds, past_key_values_length
|
||||
)
|
||||
|
||||
head_mask = model.model.transformer.get_head_mask(
|
||||
None, model.model.transformer.config.n_layer
|
||||
)
|
||||
output_attentions = model.model.transformer.config.output_attentions
|
||||
|
||||
all_hidden_states = ()
|
||||
|
||||
for i, (block, layer_past) in enumerate(
|
||||
zip(model.model.transformer.h, past_key_values)
|
||||
):
|
||||
all_hidden_states = all_hidden_states + (hidden_states,)
|
||||
|
||||
proxy_model = HuggingFaceBlock(block)
|
||||
|
||||
compile_to_mlir(
|
||||
proxy_model,
|
||||
hidden_states,
|
||||
layer_past=layer_past,
|
||||
attention_mask=causal_mask,
|
||||
head_mask=head_mask[i],
|
||||
use_cache=True,
|
||||
output_attentions=output_attentions,
|
||||
alibi=alibi,
|
||||
block_index=i,
|
||||
path=f"{destination_folder}/bloom_block_{i}.mlir",
|
||||
)
|
||||
|
||||
compile_ln_f(
|
||||
model.model.transformer.ln_f,
|
||||
hidden_states,
|
||||
f"{destination_folder}/ln_f.mlir",
|
||||
)
|
||||
hidden_states = model.model.transformer.ln_f(hidden_states)
|
||||
compile_lm_head(
|
||||
model.model.lm_head,
|
||||
hidden_states,
|
||||
f"{destination_folder}/lm_head.mlir",
|
||||
)
|
||||
|
||||
|
||||
def run_large_model(
|
||||
token_count,
|
||||
recompile,
|
||||
model_path,
|
||||
prompt,
|
||||
device_list,
|
||||
script_path,
|
||||
device,
|
||||
):
|
||||
f = open(f"{model_path}/prompt.txt", "w+")
|
||||
f.write(prompt)
|
||||
f.close()
|
||||
for i in range(token_count):
|
||||
if i == 0:
|
||||
will_compile = recompile
|
||||
else:
|
||||
will_compile = False
|
||||
f = open(f"{model_path}/prompt.txt", "r")
|
||||
prompt = f.read()
|
||||
f.close()
|
||||
|
||||
subprocess.run(
|
||||
[
|
||||
"python",
|
||||
script_path,
|
||||
model_path,
|
||||
"start",
|
||||
str(will_compile),
|
||||
"cpu",
|
||||
"None",
|
||||
prompt,
|
||||
]
|
||||
)
|
||||
for i in range(config["n_layer"]):
|
||||
if device_list is not None:
|
||||
device_idx = str(device_list[i % len(device_list)])
|
||||
else:
|
||||
device_idx = "None"
|
||||
subprocess.run(
|
||||
[
|
||||
"python",
|
||||
script_path,
|
||||
model_path,
|
||||
str(i),
|
||||
str(will_compile),
|
||||
device,
|
||||
device_idx,
|
||||
prompt,
|
||||
]
|
||||
)
|
||||
subprocess.run(
|
||||
[
|
||||
"python",
|
||||
script_path,
|
||||
model_path,
|
||||
"end",
|
||||
str(will_compile),
|
||||
"cpu",
|
||||
"None",
|
||||
prompt,
|
||||
]
|
||||
)
|
||||
|
||||
f = open(f"{model_path}/prompt.txt", "r")
|
||||
output = f.read()
|
||||
f.close()
|
||||
print(output)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = argparse.ArgumentParser(prog="Bloom-560m")
|
||||
parser.add_argument("-p", "--model_path")
|
||||
parser.add_argument("-dl", "--device_list", default=None)
|
||||
parser.add_argument("-de", "--device", default="cpu")
|
||||
parser.add_argument("-c", "--recompile", default=False, type=bool)
|
||||
parser.add_argument("-d", "--download", default=False, type=bool)
|
||||
parser.add_argument("-t", "--token_count", default=10, type=int)
|
||||
parser.add_argument("-m", "--model_name", default="bloom-560m")
|
||||
parser.add_argument("-cm", "--create_mlirs", default=False, type=bool)
|
||||
|
||||
parser.add_argument(
|
||||
"-lm", "--large_model_memory_efficient", default=False, type=bool
|
||||
)
|
||||
|
||||
parser.add_argument(
|
||||
"-pr",
|
||||
"--prompt",
|
||||
default=None,
|
||||
)
|
||||
args = parser.parse_args()
|
||||
|
||||
if args.create_mlirs and args.large_model_memory_efficient:
|
||||
print(
|
||||
"Warning: If you need to use memory efficient mode, you probably want to use 'download' instead"
|
||||
)
|
||||
|
||||
if not os.path.isdir(args.model_path):
|
||||
os.mkdir(args.model_path)
|
||||
|
||||
if args.device_list is not None:
|
||||
args.device_list = json.loads(args.device_list)
|
||||
|
||||
if args.device == "cuda" and args.device_list is not None:
|
||||
IS_CUDA = True
|
||||
from cuda.cudart import cudaSetDevice
|
||||
if args.download and args.create_mlirs:
|
||||
print(
|
||||
"WARNING: It is not advised to turn on both download and create_mlirs"
|
||||
)
|
||||
if args.download:
|
||||
download_model(args.model_path, args.model_name)
|
||||
if args.create_mlirs:
|
||||
create_mlirs(args.model_path, args.model_name)
|
||||
from transformers import AutoTokenizer, AutoModelForCausalLM, BloomConfig
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained(args.model_path)
|
||||
if args.prompt is not None:
|
||||
input_ids = tokenizer.encode(args.prompt, return_tensors="pt")
|
||||
|
||||
if args.large_model_memory_efficient:
|
||||
f = open(f"{args.model_path}/config.json")
|
||||
config = json.load(f)
|
||||
f.close()
|
||||
|
||||
self_path = os.path.dirname(os.path.abspath(__file__))
|
||||
script_path = os.path.join(self_path, "sharded_bloom_large_models.py")
|
||||
|
||||
if args.prompt is not None:
|
||||
run_large_model(
|
||||
args.token_count,
|
||||
args.recompile,
|
||||
args.model_path,
|
||||
args.prompt,
|
||||
args.device_list,
|
||||
script_path,
|
||||
args.device,
|
||||
)
|
||||
|
||||
else:
|
||||
while True:
|
||||
prompt = input("Enter Prompt: ")
|
||||
try:
|
||||
token_count = int(
|
||||
input("Enter number of tokens you want to generate: ")
|
||||
)
|
||||
except:
|
||||
print(
|
||||
"Invalid integer entered. Using default value of 10"
|
||||
)
|
||||
token_count = 10
|
||||
|
||||
run_large_model(
|
||||
token_count,
|
||||
args.recompile,
|
||||
args.model_path,
|
||||
prompt,
|
||||
args.device_list,
|
||||
script_path,
|
||||
args.device,
|
||||
)
|
||||
|
||||
else:
|
||||
shardedbloom = ShardedBloom(args.model_path)
|
||||
shardedbloom.init_layers(
|
||||
device=args.device,
|
||||
replace=args.recompile,
|
||||
device_idx=args.device_list,
|
||||
)
|
||||
shardedbloom.load_layers()
|
||||
|
||||
if args.prompt is not None:
|
||||
for _ in range(args.token_count):
|
||||
next_token = shardedbloom.forward_pass(
|
||||
torch.tensor(input_ids), device=args.device
|
||||
)
|
||||
input_ids = torch.cat(
|
||||
[input_ids, next_token.unsqueeze(-1)], dim=-1
|
||||
)
|
||||
|
||||
print(tokenizer.decode(input_ids.squeeze()))
|
||||
|
||||
else:
|
||||
while True:
|
||||
prompt = input("Enter Prompt: ")
|
||||
try:
|
||||
token_count = int(
|
||||
input("Enter number of tokens you want to generate: ")
|
||||
)
|
||||
except:
|
||||
print(
|
||||
"Invalid integer entered. Using default value of 10"
|
||||
)
|
||||
token_count = 10
|
||||
|
||||
input_ids = tokenizer.encode(prompt, return_tensors="pt")
|
||||
|
||||
for _ in range(token_count):
|
||||
next_token = shardedbloom.forward_pass(
|
||||
torch.tensor(input_ids), device=args.device
|
||||
)
|
||||
input_ids = torch.cat(
|
||||
[input_ids, next_token.unsqueeze(-1)], dim=-1
|
||||
)
|
||||
|
||||
print(tokenizer.decode(input_ids.squeeze()))
|
||||
381
shark/examples/shark_inference/sharded_bloom_large_models.py
Normal file
381
shark/examples/shark_inference/sharded_bloom_large_models.py
Normal file
@@ -0,0 +1,381 @@
|
||||
import sys
|
||||
import os
|
||||
from transformers import AutoTokenizer, AutoModelForCausalLM, BloomConfig
|
||||
import re
|
||||
from shark.shark_inference import SharkInference
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
from collections import OrderedDict
|
||||
from transformers.models.bloom.modeling_bloom import (
|
||||
BloomBlock,
|
||||
build_alibi_tensor,
|
||||
)
|
||||
import time
|
||||
import json
|
||||
|
||||
|
||||
def _expand_mask(mask: torch.Tensor, dtype: torch.dtype, tgt_len: int = None):
|
||||
"""
|
||||
Expands attention_mask from `[bsz, seq_len]` to `[bsz, 1, tgt_seq_len, src_seq_len]`.
|
||||
"""
|
||||
batch_size, source_length = mask.size()
|
||||
tgt_len = tgt_len if tgt_len is not None else source_length
|
||||
|
||||
expanded_mask = (
|
||||
mask[:, None, None, :]
|
||||
.expand(batch_size, 1, tgt_len, source_length)
|
||||
.to(dtype)
|
||||
)
|
||||
|
||||
inverted_mask = 1.0 - expanded_mask
|
||||
|
||||
return inverted_mask.masked_fill(
|
||||
inverted_mask.to(torch.bool), torch.finfo(dtype).min
|
||||
)
|
||||
|
||||
|
||||
def _prepare_attn_mask(
|
||||
attention_mask, input_shape, inputs_embeds, past_key_values_length
|
||||
):
|
||||
# create causal mask
|
||||
# [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
|
||||
combined_attention_mask = None
|
||||
if input_shape[-1] > 1:
|
||||
combined_attention_mask = _make_causal_mask(
|
||||
input_shape,
|
||||
inputs_embeds.dtype,
|
||||
past_key_values_length=past_key_values_length,
|
||||
).to(attention_mask.device)
|
||||
|
||||
if attention_mask is not None:
|
||||
# [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
|
||||
expanded_attn_mask = _expand_mask(
|
||||
attention_mask, inputs_embeds.dtype, tgt_len=input_shape[-1]
|
||||
)
|
||||
combined_attention_mask = (
|
||||
expanded_attn_mask
|
||||
if combined_attention_mask is None
|
||||
else expanded_attn_mask + combined_attention_mask
|
||||
)
|
||||
|
||||
return combined_attention_mask
|
||||
|
||||
|
||||
def _make_causal_mask(
|
||||
input_ids_shape: torch.Size,
|
||||
dtype: torch.dtype,
|
||||
past_key_values_length: int = 0,
|
||||
):
|
||||
"""
|
||||
Make causal mask used for bi-directional self-attention.
|
||||
"""
|
||||
batch_size, target_length = input_ids_shape
|
||||
mask = torch.full((target_length, target_length), torch.finfo(dtype).min)
|
||||
mask_cond = torch.arange(mask.size(-1))
|
||||
intermediate_mask = mask_cond < (mask_cond + 1).view(mask.size(-1), 1)
|
||||
mask.masked_fill_(intermediate_mask, 0)
|
||||
mask = mask.to(dtype)
|
||||
|
||||
if past_key_values_length > 0:
|
||||
mask = torch.cat(
|
||||
[
|
||||
torch.zeros(
|
||||
target_length, past_key_values_length, dtype=dtype
|
||||
),
|
||||
mask,
|
||||
],
|
||||
dim=-1,
|
||||
)
|
||||
expanded_mask = mask[None, None, :, :].expand(
|
||||
batch_size, 1, target_length, target_length + past_key_values_length
|
||||
)
|
||||
return expanded_mask
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
working_dir = sys.argv[1]
|
||||
layer_name = sys.argv[2]
|
||||
will_compile = sys.argv[3]
|
||||
device = sys.argv[4]
|
||||
device_idx = sys.argv[5]
|
||||
prompt = sys.argv[6]
|
||||
|
||||
if device_idx.lower().strip() == "none":
|
||||
device_idx = None
|
||||
else:
|
||||
device_idx = int(device_idx)
|
||||
|
||||
if will_compile.lower().strip() == "true":
|
||||
will_compile = True
|
||||
else:
|
||||
will_compile = False
|
||||
|
||||
f = open(f"{working_dir}/config.json")
|
||||
config = json.load(f)
|
||||
f.close()
|
||||
|
||||
layers_initialized = False
|
||||
try:
|
||||
n_embed = config["n_embed"]
|
||||
except KeyError:
|
||||
n_embed = config["hidden_size"]
|
||||
vocab_size = config["vocab_size"]
|
||||
n_layer = config["n_layer"]
|
||||
try:
|
||||
n_head = config["num_attention_heads"]
|
||||
except KeyError:
|
||||
n_head = config["n_head"]
|
||||
|
||||
if not os.path.isdir(working_dir):
|
||||
os.mkdir(working_dir)
|
||||
|
||||
if layer_name == "start":
|
||||
tokenizer = AutoTokenizer.from_pretrained(working_dir)
|
||||
input_ids = tokenizer.encode(prompt, return_tensors="pt")
|
||||
|
||||
mlir_str = ""
|
||||
|
||||
if will_compile:
|
||||
f = open(f"{working_dir}/word_embeddings.mlir", encoding="utf-8")
|
||||
mlir_str = f.read()
|
||||
f.close()
|
||||
|
||||
mlir_str = bytes(mlir_str, "utf-8")
|
||||
|
||||
shark_module = SharkInference(
|
||||
mlir_str,
|
||||
device="cpu",
|
||||
mlir_dialect="tm_tensor",
|
||||
device_idx=None,
|
||||
)
|
||||
|
||||
if will_compile:
|
||||
shark_module.save_module(
|
||||
module_name=f"{working_dir}/word_embeddings",
|
||||
extra_args=[
|
||||
"--iree-vm-bytecode-module-output-format=flatbuffer-binary",
|
||||
"--iree-stream-resource-max-allocation-size=1000000000",
|
||||
"--iree-codegen-check-ir-before-llvm-conversion=false",
|
||||
],
|
||||
)
|
||||
|
||||
shark_module.load_module(f"{working_dir}/word_embeddings.vmfb")
|
||||
input_embeds = shark_module(
|
||||
inputs=(input_ids,), function_name="forward"
|
||||
)
|
||||
input_embeds = torch.tensor(input_embeds).float()
|
||||
|
||||
mlir_str = ""
|
||||
|
||||
if will_compile:
|
||||
f = open(
|
||||
f"{working_dir}/word_embeddings_layernorm.mlir",
|
||||
encoding="utf-8",
|
||||
)
|
||||
mlir_str = f.read()
|
||||
f.close()
|
||||
|
||||
shark_module = SharkInference(
|
||||
mlir_str,
|
||||
device="cpu",
|
||||
mlir_dialect="tm_tensor",
|
||||
device_idx=None,
|
||||
)
|
||||
|
||||
if will_compile:
|
||||
shark_module.save_module(
|
||||
module_name=f"{working_dir}/word_embeddings_layernorm",
|
||||
extra_args=[
|
||||
"--iree-vm-bytecode-module-output-format=flatbuffer-binary",
|
||||
"--iree-stream-resource-max-allocation-size=1000000000",
|
||||
"--iree-codegen-check-ir-before-llvm-conversion=false",
|
||||
],
|
||||
)
|
||||
|
||||
shark_module.load_module(
|
||||
f"{working_dir}/word_embeddings_layernorm.vmfb"
|
||||
)
|
||||
hidden_states = shark_module(
|
||||
inputs=(input_embeds,), function_name="forward"
|
||||
)
|
||||
hidden_states = torch.tensor(hidden_states).float()
|
||||
|
||||
torch.save(hidden_states, f"{working_dir}/hidden_states_0.pt")
|
||||
|
||||
attention_mask = torch.ones(
|
||||
[hidden_states.shape[0], len(input_ids[0])]
|
||||
)
|
||||
|
||||
attention_mask = torch.tensor(attention_mask).float()
|
||||
|
||||
alibi = build_alibi_tensor(
|
||||
attention_mask,
|
||||
n_head,
|
||||
hidden_states.dtype,
|
||||
device="cpu",
|
||||
)
|
||||
|
||||
torch.save(alibi, f"{working_dir}/alibi.pt")
|
||||
|
||||
causal_mask = _prepare_attn_mask(
|
||||
attention_mask, input_ids.size(), input_embeds, 0
|
||||
)
|
||||
causal_mask = torch.tensor(causal_mask).float()
|
||||
|
||||
torch.save(causal_mask, f"{working_dir}/causal_mask.pt")
|
||||
|
||||
elif layer_name in [str(x) for x in range(n_layer)]:
|
||||
hidden_states = torch.load(
|
||||
f"{working_dir}/hidden_states_{layer_name}.pt"
|
||||
)
|
||||
alibi = torch.load(f"{working_dir}/alibi.pt")
|
||||
causal_mask = torch.load(f"{working_dir}/causal_mask.pt")
|
||||
|
||||
mlir_str = ""
|
||||
|
||||
if will_compile:
|
||||
f = open(
|
||||
f"{working_dir}/bloom_block_{layer_name}.mlir",
|
||||
encoding="utf-8",
|
||||
)
|
||||
mlir_str = f.read()
|
||||
f.close()
|
||||
|
||||
mlir_str = bytes(mlir_str, "utf-8")
|
||||
|
||||
shark_module = SharkInference(
|
||||
mlir_str,
|
||||
device=device,
|
||||
mlir_dialect="tm_tensor",
|
||||
device_idx=device_idx,
|
||||
)
|
||||
|
||||
if will_compile:
|
||||
shark_module.save_module(
|
||||
module_name=f"{working_dir}/bloom_block_{layer_name}",
|
||||
extra_args=[
|
||||
"--iree-vm-bytecode-module-output-format=flatbuffer-binary",
|
||||
"--iree-stream-resource-max-allocation-size=1000000000",
|
||||
"--iree-codegen-check-ir-before-llvm-conversion=false",
|
||||
],
|
||||
)
|
||||
|
||||
shark_module.load_module(
|
||||
f"{working_dir}/bloom_block_{layer_name}.vmfb"
|
||||
)
|
||||
|
||||
output = shark_module(
|
||||
inputs=(
|
||||
hidden_states.detach().numpy(),
|
||||
alibi.detach().numpy(),
|
||||
causal_mask.detach().numpy(),
|
||||
),
|
||||
function_name="forward",
|
||||
)
|
||||
|
||||
hidden_states = torch.tensor(output[0]).float()
|
||||
|
||||
torch.save(
|
||||
hidden_states,
|
||||
f"{working_dir}/hidden_states_{int(layer_name) + 1}.pt",
|
||||
)
|
||||
|
||||
elif layer_name == "end":
|
||||
mlir_str = ""
|
||||
|
||||
if will_compile:
|
||||
f = open(f"{working_dir}/ln_f.mlir", encoding="utf-8")
|
||||
mlir_str = f.read()
|
||||
f.close()
|
||||
|
||||
mlir_str = bytes(mlir_str, "utf-8")
|
||||
|
||||
shark_module = SharkInference(
|
||||
mlir_str,
|
||||
device="cpu",
|
||||
mlir_dialect="tm_tensor",
|
||||
device_idx=None,
|
||||
)
|
||||
|
||||
if will_compile:
|
||||
shark_module.save_module(
|
||||
module_name=f"{working_dir}/ln_f",
|
||||
extra_args=[
|
||||
"--iree-vm-bytecode-module-output-format=flatbuffer-binary",
|
||||
"--iree-stream-resource-max-allocation-size=1000000000",
|
||||
"--iree-codegen-check-ir-before-llvm-conversion=false",
|
||||
],
|
||||
)
|
||||
|
||||
shark_module.load_module(f"{working_dir}/ln_f.vmfb")
|
||||
|
||||
hidden_states = torch.load(f"{working_dir}/hidden_states_{n_layer}.pt")
|
||||
|
||||
hidden_states = shark_module(
|
||||
inputs=(hidden_states,), function_name="forward"
|
||||
)
|
||||
|
||||
mlir_str = ""
|
||||
|
||||
if will_compile:
|
||||
f = open(f"{working_dir}/lm_head.mlir", encoding="utf-8")
|
||||
mlir_str = f.read()
|
||||
f.close()
|
||||
|
||||
mlir_str = bytes(mlir_str, "utf-8")
|
||||
|
||||
if config["n_embed"] == 14336:
|
||||
|
||||
def get_state_dict():
|
||||
d = torch.load(
|
||||
f"{working_dir}/pytorch_model_00001-of-00072.bin"
|
||||
)
|
||||
return OrderedDict(
|
||||
(k.replace("word_embeddings.", ""), v)
|
||||
for k, v in d.items()
|
||||
)
|
||||
|
||||
def load_causal_lm_head():
|
||||
linear = nn.utils.skip_init(
|
||||
nn.Linear, 14336, 250880, bias=False, dtype=torch.float
|
||||
)
|
||||
linear.load_state_dict(get_state_dict(), strict=False)
|
||||
return linear.float()
|
||||
|
||||
lm_head = load_causal_lm_head()
|
||||
|
||||
logits = lm_head(torch.tensor(hidden_states).float())
|
||||
|
||||
else:
|
||||
shark_module = SharkInference(
|
||||
mlir_str,
|
||||
device="cpu",
|
||||
mlir_dialect="tm_tensor",
|
||||
device_idx=None,
|
||||
)
|
||||
|
||||
if will_compile:
|
||||
shark_module.save_module(
|
||||
module_name=f"{working_dir}/lm_head",
|
||||
extra_args=[
|
||||
"--iree-vm-bytecode-module-output-format=flatbuffer-binary",
|
||||
"--iree-stream-resource-max-allocation-size=1000000000",
|
||||
"--iree-codegen-check-ir-before-llvm-conversion=false",
|
||||
],
|
||||
)
|
||||
|
||||
shark_module.load_module(f"{working_dir}/lm_head.vmfb")
|
||||
|
||||
logits = shark_module(
|
||||
inputs=(hidden_states,), function_name="forward"
|
||||
)
|
||||
|
||||
logits = torch.tensor(logits).float()
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained(working_dir)
|
||||
|
||||
next_token = tokenizer.decode(torch.argmax(logits[:, -1, :], dim=-1))
|
||||
|
||||
f = open(f"{working_dir}/prompt.txt", "w+")
|
||||
f.write(prompt + next_token)
|
||||
f.close()
|
||||
@@ -151,7 +151,6 @@ class DLRM_Net(nn.Module):
|
||||
and (ln_top is not None)
|
||||
and (arch_interaction_op is not None)
|
||||
):
|
||||
|
||||
# save arguments
|
||||
self.output_d = 0
|
||||
self.arch_interaction_op = arch_interaction_op
|
||||
@@ -216,7 +215,6 @@ class DLRM_Net(nn.Module):
|
||||
return ly
|
||||
|
||||
def interact_features(self, x, ly):
|
||||
|
||||
if self.arch_interaction_op == "dot":
|
||||
# concatenate dense and sparse features
|
||||
(batch_size, d) = x.shape
|
||||
@@ -362,7 +360,7 @@ mlir_importer = SharkImporter(
|
||||
)
|
||||
|
||||
shark_module = SharkInference(
|
||||
dlrm_mlir, func_name, device="vulkan", mlir_dialect="linalg"
|
||||
dlrm_mlir, device="vulkan", mlir_dialect="linalg"
|
||||
)
|
||||
shark_module.compile()
|
||||
result = shark_module.forward(input_dlrm)
|
||||
|
||||
@@ -99,7 +99,6 @@ class SparseArchShark(nn.Module):
|
||||
)
|
||||
|
||||
def forward(self, *batched_inputs):
|
||||
|
||||
concatenated_list = []
|
||||
input_enum, embedding_enum = 0, 0
|
||||
|
||||
@@ -121,7 +120,6 @@ class SparseArchShark(nn.Module):
|
||||
|
||||
|
||||
def test_sparse_arch() -> None:
|
||||
|
||||
D = 3
|
||||
eb1_config = EmbeddingBagConfig(
|
||||
name="t1",
|
||||
@@ -211,7 +209,6 @@ class DLRMShark(nn.Module):
|
||||
def forward(
|
||||
self, dense_features: torch.Tensor, *sparse_features
|
||||
) -> torch.Tensor:
|
||||
|
||||
embedded_dense = self.dense_arch(dense_features)
|
||||
embedded_sparse = self.sparse_arch(*sparse_features)
|
||||
concatenated_dense = self.inter_arch(
|
||||
@@ -297,7 +294,7 @@ def test_dlrm() -> None:
|
||||
)
|
||||
|
||||
shark_module = SharkInference(
|
||||
dlrm_mlir, func_name, device="cpu", mlir_dialect="linalg"
|
||||
dlrm_mlir, device="cpu", mlir_dialect="linalg"
|
||||
)
|
||||
shark_module.compile()
|
||||
result = shark_module.forward(inputs)
|
||||
|
||||
@@ -1,272 +0,0 @@
|
||||
from transformers import CLIPTextModel, CLIPTokenizer
|
||||
from diffusers import AutoencoderKL, UNet2DConditionModel, PNDMScheduler
|
||||
import torch
|
||||
from PIL import Image
|
||||
from diffusers import LMSDiscreteScheduler
|
||||
from tqdm.auto import tqdm
|
||||
from shark.shark_inference import SharkInference
|
||||
from torch.fx.experimental.proxy_tensor import make_fx
|
||||
from torch._decomp import get_decompositions
|
||||
import torch_mlir
|
||||
import tempfile
|
||||
import numpy as np
|
||||
|
||||
# pip install diffusers
|
||||
# pip install scipy
|
||||
|
||||
############### Parsing args #####################
|
||||
import argparse
|
||||
|
||||
p = argparse.ArgumentParser(
|
||||
description=__doc__, formatter_class=argparse.ArgumentDefaultsHelpFormatter
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--prompt",
|
||||
type=str,
|
||||
default="a photograph of an astronaut riding a horse",
|
||||
help="the text prompt to use",
|
||||
)
|
||||
p.add_argument("--device", type=str, default="cpu", help="the device to use")
|
||||
p.add_argument("--steps", type=int, default=10, help="the device to use")
|
||||
p.add_argument("--mlir_loc", type=str, default=None, help="the device to use")
|
||||
p.add_argument("--vae_loc", type=str, default=None, help="the device to use")
|
||||
args = p.parse_args()
|
||||
|
||||
#####################################################
|
||||
|
||||
|
||||
def load_mlir(mlir_loc):
|
||||
import os
|
||||
|
||||
if mlir_loc == None:
|
||||
return None
|
||||
print(f"Trying to load the model from {mlir_loc}.")
|
||||
with open(os.path.join(mlir_loc)) as f:
|
||||
mlir_module = f.read()
|
||||
return mlir_module
|
||||
|
||||
|
||||
def compile_through_fx(model, inputs, mlir_loc=None, extra_args=[]):
|
||||
|
||||
module = load_mlir(mlir_loc)
|
||||
if mlir_loc == None:
|
||||
fx_g = make_fx(
|
||||
model,
|
||||
decomposition_table=get_decompositions(
|
||||
[
|
||||
torch.ops.aten.embedding_dense_backward,
|
||||
torch.ops.aten.native_layer_norm_backward,
|
||||
torch.ops.aten.slice_backward,
|
||||
torch.ops.aten.select_backward,
|
||||
torch.ops.aten.norm.ScalarOpt_dim,
|
||||
torch.ops.aten.native_group_norm,
|
||||
torch.ops.aten.upsample_bilinear2d.vec,
|
||||
torch.ops.aten.split.Tensor,
|
||||
torch.ops.aten.split_with_sizes,
|
||||
]
|
||||
),
|
||||
)(*inputs)
|
||||
|
||||
fx_g.graph.set_codegen(torch.fx.graph.CodeGen())
|
||||
fx_g.recompile()
|
||||
|
||||
def strip_overloads(gm):
|
||||
"""
|
||||
Modifies the target of graph nodes in :attr:`gm` to strip overloads.
|
||||
Args:
|
||||
gm(fx.GraphModule): The input Fx graph module to be modified
|
||||
"""
|
||||
for node in gm.graph.nodes:
|
||||
if isinstance(node.target, torch._ops.OpOverload):
|
||||
node.target = node.target.overloadpacket
|
||||
gm.recompile()
|
||||
|
||||
strip_overloads(fx_g)
|
||||
|
||||
ts_g = torch.jit.script(fx_g)
|
||||
|
||||
module = torch_mlir.compile(
|
||||
ts_g,
|
||||
inputs,
|
||||
torch_mlir.OutputType.LINALG_ON_TENSORS,
|
||||
use_tracing=False,
|
||||
verbose=False,
|
||||
)
|
||||
|
||||
mlir_model = module
|
||||
func_name = "forward"
|
||||
|
||||
shark_module = SharkInference(
|
||||
mlir_model,
|
||||
func_name,
|
||||
device=args.device,
|
||||
mlir_dialect="tm_tensor",
|
||||
)
|
||||
shark_module.compile(extra_args)
|
||||
|
||||
return shark_module
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
|
||||
YOUR_TOKEN = "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"
|
||||
|
||||
# 1. Load the autoencoder model which will be used to decode the latents into image space.
|
||||
vae = AutoencoderKL.from_pretrained(
|
||||
"CompVis/stable-diffusion-v1-4",
|
||||
subfolder="vae",
|
||||
use_auth_token=YOUR_TOKEN,
|
||||
)
|
||||
|
||||
# 2. Load the tokenizer and text encoder to tokenize and encode the text.
|
||||
tokenizer = CLIPTokenizer.from_pretrained("openai/clip-vit-large-patch14")
|
||||
text_encoder = CLIPTextModel.from_pretrained(
|
||||
"openai/clip-vit-large-patch14"
|
||||
)
|
||||
|
||||
class VaeModel(torch.nn.Module):
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
self.vae = AutoencoderKL.from_pretrained(
|
||||
"CompVis/stable-diffusion-v1-4",
|
||||
subfolder="vae",
|
||||
use_auth_token=YOUR_TOKEN,
|
||||
)
|
||||
|
||||
def forward(self, input):
|
||||
return self.vae.decode(input, return_dict=False)[0]
|
||||
|
||||
vae = VaeModel()
|
||||
vae_input = torch.rand(1, 4, 64, 64)
|
||||
shark_vae = compile_through_fx(vae, (vae_input,), args.vae_loc)
|
||||
|
||||
# Wrap the unet model to return tuples.
|
||||
class UnetModel(torch.nn.Module):
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
self.unet = UNet2DConditionModel.from_pretrained(
|
||||
"CompVis/stable-diffusion-v1-4",
|
||||
subfolder="unet",
|
||||
use_auth_token=YOUR_TOKEN,
|
||||
)
|
||||
self.in_channels = self.unet.in_channels
|
||||
self.train(False)
|
||||
|
||||
def forward(self, x, y, z):
|
||||
return self.unet.forward(x, y, z, return_dict=False)[0]
|
||||
|
||||
# 3. The UNet model for generating the latents.
|
||||
unet = UnetModel()
|
||||
latent_model_input = torch.rand([2, 4, 64, 64])
|
||||
text_embeddings = torch.rand([2, 77, 768])
|
||||
shark_unet = compile_through_fx(
|
||||
unet,
|
||||
(latent_model_input, torch.tensor([1.0]), text_embeddings),
|
||||
args.mlir_loc,
|
||||
["--iree-flow-enable-conv-nchw-to-nhwc-transform"],
|
||||
)
|
||||
|
||||
# torch.jit.script(unet)
|
||||
|
||||
scheduler = LMSDiscreteScheduler(
|
||||
beta_start=0.00085,
|
||||
beta_end=0.012,
|
||||
beta_schedule="scaled_linear",
|
||||
num_train_timesteps=1000,
|
||||
)
|
||||
|
||||
prompt = [args.prompt]
|
||||
|
||||
height = 512 # default height of Stable Diffusion
|
||||
width = 512 # default width of Stable Diffusion
|
||||
|
||||
num_inference_steps = args.steps # Number of denoising steps
|
||||
|
||||
guidance_scale = 7.5 # Scale for classifier-free guidance
|
||||
|
||||
generator = torch.manual_seed(
|
||||
42
|
||||
) # Seed generator to create the inital latent noise
|
||||
|
||||
batch_size = len(prompt)
|
||||
|
||||
text_input = tokenizer(
|
||||
prompt,
|
||||
padding="max_length",
|
||||
max_length=tokenizer.model_max_length,
|
||||
truncation=True,
|
||||
return_tensors="pt",
|
||||
)
|
||||
|
||||
text_embeddings = text_encoder(text_input.input_ids)[0]
|
||||
|
||||
max_length = text_input.input_ids.shape[-1]
|
||||
uncond_input = tokenizer(
|
||||
[""] * batch_size,
|
||||
padding="max_length",
|
||||
max_length=max_length,
|
||||
return_tensors="pt",
|
||||
)
|
||||
uncond_embeddings = text_encoder(uncond_input.input_ids)[0]
|
||||
|
||||
text_embeddings = torch.cat([uncond_embeddings, text_embeddings])
|
||||
|
||||
latents = torch.randn(
|
||||
(batch_size, unet.in_channels, height // 8, width // 8),
|
||||
generator=generator,
|
||||
)
|
||||
# latents = latents.to(torch_device)
|
||||
|
||||
scheduler.set_timesteps(num_inference_steps)
|
||||
|
||||
latents = latents * scheduler.sigmas[0]
|
||||
# print(latents, latents.shape)
|
||||
|
||||
for i, t in tqdm(enumerate(scheduler.timesteps)):
|
||||
|
||||
print(f"i = {i} t = {t}")
|
||||
# expand the latents if we are doing classifier-free guidance to avoid doing two forward passes.
|
||||
latent_model_input = torch.cat([latents] * 2)
|
||||
sigma = scheduler.sigmas[i]
|
||||
latent_model_input = latent_model_input / ((sigma**2 + 1) ** 0.5)
|
||||
|
||||
# predict the noise residual
|
||||
|
||||
# with torch.no_grad():
|
||||
# noise_pred = unet(latent_model_input, t, encoder_hidden_states=text_embeddings)
|
||||
|
||||
latent_model_input_numpy = latent_model_input.detach().numpy()
|
||||
text_embeddings_numpy = text_embeddings.detach().numpy()
|
||||
|
||||
noise_pred = shark_unet.forward(
|
||||
(
|
||||
latent_model_input_numpy,
|
||||
np.array([t]).astype(np.float32),
|
||||
text_embeddings_numpy,
|
||||
)
|
||||
)
|
||||
noise_pred = torch.from_numpy(noise_pred)
|
||||
|
||||
# perform guidance
|
||||
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
|
||||
noise_pred = noise_pred_uncond + guidance_scale * (
|
||||
noise_pred_text - noise_pred_uncond
|
||||
)
|
||||
|
||||
# compute the previous noisy sample x_t -> x_t-1
|
||||
latents = scheduler.step(noise_pred, i, latents)["prev_sample"]
|
||||
|
||||
# print("Latents shape : ", latents.shape)
|
||||
|
||||
# scale and decode the image latents with vae
|
||||
latents = 1 / 0.18215 * latents
|
||||
latents_numpy = latents.detach().numpy()
|
||||
image = shark_vae.forward((latents_numpy,))
|
||||
image = torch.from_numpy(image)
|
||||
|
||||
image = (image / 2 + 0.5).clamp(0, 1)
|
||||
image = image.detach().cpu().permute(0, 2, 3, 1).numpy()
|
||||
images = (image * 255).round().astype("uint8")
|
||||
pil_images = [Image.fromarray(image) for image in images]
|
||||
pil_images[0].save("astro.jpg")
|
||||
@@ -1,280 +0,0 @@
|
||||
from transformers import CLIPTextModel, CLIPTokenizer
|
||||
from diffusers import AutoencoderKL, UNet2DConditionModel, PNDMScheduler
|
||||
import torch
|
||||
from PIL import Image
|
||||
from diffusers import LMSDiscreteScheduler
|
||||
from tqdm.auto import tqdm
|
||||
from shark.shark_inference import SharkInference
|
||||
from torch.fx.experimental.proxy_tensor import make_fx
|
||||
from torch._decomp import get_decompositions
|
||||
import torch_mlir
|
||||
import tempfile
|
||||
import numpy as np
|
||||
|
||||
# pip install diffusers
|
||||
# pip install scipy
|
||||
|
||||
############### Parsing args #####################
|
||||
import argparse
|
||||
|
||||
p = argparse.ArgumentParser(
|
||||
description=__doc__, formatter_class=argparse.ArgumentDefaultsHelpFormatter
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--prompt",
|
||||
type=str,
|
||||
default="a photograph of an astronaut riding a horse",
|
||||
help="the text prompt to use",
|
||||
)
|
||||
p.add_argument("--device", type=str, default="cpu", help="the device to use")
|
||||
p.add_argument("--steps", type=int, default=50, help="the device to use")
|
||||
p.add_argument("--mlir_loc", type=str, default=None, help="the device to use")
|
||||
p.add_argument("--vae_loc", type=str, default=None, help="the device to use")
|
||||
args = p.parse_args()
|
||||
|
||||
#####################################################
|
||||
|
||||
|
||||
def fp16_unet():
|
||||
from shark.shark_downloader import download_model
|
||||
|
||||
mlir_model, func_name, inputs, golden_out = download_model(
|
||||
"stable_diff_f16_18_OCT",
|
||||
tank_url="gs://shark_tank/prashant_nod",
|
||||
frontend="torch",
|
||||
)
|
||||
shark_module = SharkInference(
|
||||
mlir_model, func_name, device=args.device, mlir_dialect="linalg"
|
||||
)
|
||||
shark_module.compile()
|
||||
return shark_module
|
||||
|
||||
|
||||
def load_mlir(mlir_loc):
|
||||
import os
|
||||
|
||||
if mlir_loc == None:
|
||||
return None
|
||||
print(f"Trying to load the model from {mlir_loc}.")
|
||||
with open(os.path.join(mlir_loc)) as f:
|
||||
mlir_module = f.read()
|
||||
return mlir_module
|
||||
|
||||
|
||||
def compile_through_fx(model, inputs, mlir_loc=None):
|
||||
|
||||
module = load_mlir(mlir_loc)
|
||||
if mlir_loc == None:
|
||||
fx_g = make_fx(
|
||||
model,
|
||||
decomposition_table=get_decompositions(
|
||||
[
|
||||
torch.ops.aten.embedding_dense_backward,
|
||||
torch.ops.aten.native_layer_norm_backward,
|
||||
torch.ops.aten.slice_backward,
|
||||
torch.ops.aten.select_backward,
|
||||
torch.ops.aten.norm.ScalarOpt_dim,
|
||||
torch.ops.aten.native_group_norm,
|
||||
torch.ops.aten.upsample_bilinear2d.vec,
|
||||
torch.ops.aten.split.Tensor,
|
||||
torch.ops.aten.split_with_sizes,
|
||||
]
|
||||
),
|
||||
)(*inputs)
|
||||
|
||||
fx_g.graph.set_codegen(torch.fx.graph.CodeGen())
|
||||
fx_g.recompile()
|
||||
|
||||
def strip_overloads(gm):
|
||||
"""
|
||||
Modifies the target of graph nodes in :attr:`gm` to strip overloads.
|
||||
Args:
|
||||
gm(fx.GraphModule): The input Fx graph module to be modified
|
||||
"""
|
||||
for node in gm.graph.nodes:
|
||||
if isinstance(node.target, torch._ops.OpOverload):
|
||||
node.target = node.target.overloadpacket
|
||||
gm.recompile()
|
||||
|
||||
strip_overloads(fx_g)
|
||||
|
||||
ts_g = torch.jit.script(fx_g)
|
||||
|
||||
module = torch_mlir.compile(
|
||||
ts_g,
|
||||
inputs,
|
||||
torch_mlir.OutputType.LINALG_ON_TENSORS,
|
||||
use_tracing=False,
|
||||
verbose=False,
|
||||
)
|
||||
|
||||
mlir_model = module
|
||||
func_name = "forward"
|
||||
|
||||
shark_module = SharkInference(
|
||||
mlir_model, func_name, device=args.device, mlir_dialect="linalg"
|
||||
)
|
||||
shark_module.compile()
|
||||
|
||||
return shark_module
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
|
||||
YOUR_TOKEN = "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"
|
||||
|
||||
# 1. Load the autoencoder model which will be used to decode the latents into image space.
|
||||
vae = AutoencoderKL.from_pretrained(
|
||||
"CompVis/stable-diffusion-v1-4",
|
||||
subfolder="vae",
|
||||
use_auth_token=YOUR_TOKEN,
|
||||
)
|
||||
|
||||
# 2. Load the tokenizer and text encoder to tokenize and encode the text.
|
||||
tokenizer = CLIPTokenizer.from_pretrained("openai/clip-vit-large-patch14")
|
||||
text_encoder = CLIPTextModel.from_pretrained(
|
||||
"openai/clip-vit-large-patch14"
|
||||
)
|
||||
|
||||
class VaeModel(torch.nn.Module):
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
self.vae = AutoencoderKL.from_pretrained(
|
||||
"CompVis/stable-diffusion-v1-4",
|
||||
subfolder="vae",
|
||||
use_auth_token=YOUR_TOKEN,
|
||||
)
|
||||
|
||||
def forward(self, input):
|
||||
return self.vae.decode(input, return_dict=False)[0]
|
||||
|
||||
vae = VaeModel()
|
||||
vae_input = torch.rand(1, 4, 64, 64)
|
||||
shark_vae = compile_through_fx(vae, (vae_input,), args.vae_loc)
|
||||
|
||||
# Wrap the unet model to return tuples.
|
||||
class UnetModel(torch.nn.Module):
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
self.unet = UNet2DConditionModel.from_pretrained(
|
||||
"CompVis/stable-diffusion-v1-4",
|
||||
subfolder="unet",
|
||||
use_auth_token=YOUR_TOKEN,
|
||||
)
|
||||
self.in_channels = self.unet.in_channels
|
||||
self.train(False)
|
||||
|
||||
def forward(self, x, y, z):
|
||||
return self.unet.forward(x, y, z, return_dict=False)[0]
|
||||
|
||||
# # 3. The UNet model for generating the latents.
|
||||
unet = UnetModel()
|
||||
|
||||
shark_unet = fp16_unet()
|
||||
|
||||
scheduler = LMSDiscreteScheduler(
|
||||
beta_start=0.00085,
|
||||
beta_end=0.012,
|
||||
beta_schedule="scaled_linear",
|
||||
num_train_timesteps=1000,
|
||||
)
|
||||
|
||||
prompt = [args.prompt]
|
||||
|
||||
height = 512 # default height of Stable Diffusion
|
||||
width = 512 # default width of Stable Diffusion
|
||||
|
||||
num_inference_steps = args.steps # Number of denoising steps
|
||||
|
||||
guidance_scale = 7.5 # Scale for classifier-free guidance
|
||||
|
||||
generator = torch.manual_seed(
|
||||
42
|
||||
) # Seed generator to create the inital latent noise
|
||||
|
||||
batch_size = len(prompt)
|
||||
|
||||
text_input = tokenizer(
|
||||
prompt,
|
||||
padding="max_length",
|
||||
max_length=tokenizer.model_max_length,
|
||||
truncation=True,
|
||||
return_tensors="pt",
|
||||
)
|
||||
|
||||
text_embeddings = text_encoder(text_input.input_ids)[0]
|
||||
|
||||
max_length = text_input.input_ids.shape[-1]
|
||||
uncond_input = tokenizer(
|
||||
[""] * batch_size,
|
||||
padding="max_length",
|
||||
max_length=max_length,
|
||||
return_tensors="pt",
|
||||
)
|
||||
uncond_embeddings = text_encoder(uncond_input.input_ids)[0]
|
||||
|
||||
text_embeddings = torch.cat([uncond_embeddings, text_embeddings])
|
||||
|
||||
latents = torch.randn(
|
||||
(batch_size, unet.in_channels, height // 8, width // 8),
|
||||
generator=generator,
|
||||
)
|
||||
# latents = latents.to(torch_device)
|
||||
|
||||
scheduler.set_timesteps(num_inference_steps)
|
||||
|
||||
latents = latents * scheduler.sigmas[0]
|
||||
# print(latents, latents.shape)
|
||||
|
||||
for i, t in tqdm(enumerate(scheduler.timesteps)):
|
||||
|
||||
print(f"i = {i} t = {t}")
|
||||
# expand the latents if we are doing classifier-free guidance to avoid doing two forward passes.
|
||||
latent_model_input = torch.cat([latents] * 2)
|
||||
sigma = scheduler.sigmas[i]
|
||||
latent_model_input = latent_model_input / ((sigma**2 + 1) ** 0.5)
|
||||
|
||||
# predict the noise residual
|
||||
|
||||
# with torch.no_grad():
|
||||
# noise_pred = unet(latent_model_input, t, encoder_hidden_states=text_embeddings)
|
||||
|
||||
latent_model_input_numpy = (
|
||||
latent_model_input.detach().numpy().astype(np.half)
|
||||
)
|
||||
text_embeddings_numpy = (
|
||||
text_embeddings.detach().numpy().astype(np.half)
|
||||
)
|
||||
|
||||
noise_pred = shark_unet.forward(
|
||||
(
|
||||
latent_model_input_numpy,
|
||||
np.array([t]).astype(np.half),
|
||||
text_embeddings_numpy,
|
||||
)
|
||||
)
|
||||
noise_pred = torch.from_numpy(noise_pred).to(torch.float32)
|
||||
|
||||
# perform guidance
|
||||
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
|
||||
noise_pred = noise_pred_uncond + guidance_scale * (
|
||||
noise_pred_text - noise_pred_uncond
|
||||
)
|
||||
|
||||
# compute the previous noisy sample x_t -> x_t-1
|
||||
latents = scheduler.step(noise_pred, i, latents)["prev_sample"]
|
||||
|
||||
# print("Latents shape : ", latents.shape)
|
||||
|
||||
# scale and decode the image latents with vae
|
||||
latents = 1 / 0.18215 * latents
|
||||
latents_numpy = latents.detach().numpy()
|
||||
image = shark_vae.forward((latents_numpy,))
|
||||
image = torch.from_numpy(image)
|
||||
|
||||
image = (image / 2 + 0.5).clamp(0, 1)
|
||||
image = image.detach().cpu().permute(0, 2, 3, 1).numpy()
|
||||
images = (image * 255).round().astype("uint8")
|
||||
pil_images = [Image.fromarray(image) for image in images]
|
||||
pil_images[0].save("astro.jpg")
|
||||
@@ -1,313 +0,0 @@
|
||||
import math
|
||||
import numpy as np
|
||||
import tensorflow as tf
|
||||
from tensorflow import keras
|
||||
from keras_cv.models.generative.stable_diffusion.clip_tokenizer import (
|
||||
SimpleTokenizer,
|
||||
)
|
||||
from keras_cv.models.generative.stable_diffusion.constants import (
|
||||
_ALPHAS_CUMPROD,
|
||||
)
|
||||
from keras_cv.models.generative.stable_diffusion.constants import (
|
||||
_UNCONDITIONAL_TOKENS,
|
||||
)
|
||||
from keras_cv.models.generative.stable_diffusion.decoder import Decoder
|
||||
from keras_cv.models.generative.stable_diffusion.text_encoder import (
|
||||
TextEncoder,
|
||||
)
|
||||
|
||||
from shark.shark_inference import SharkInference
|
||||
from shark.shark_downloader import download_model
|
||||
from PIL import Image
|
||||
|
||||
# pip install "git+https://github.com/keras-team/keras-cv.git"
|
||||
# pip install tensorflow_dataset
|
||||
|
||||
############### Parsing args #####################
|
||||
import argparse
|
||||
|
||||
p = argparse.ArgumentParser(
|
||||
description=__doc__, formatter_class=argparse.ArgumentDefaultsHelpFormatter
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--prompt",
|
||||
type=str,
|
||||
default="a photograph of an astronaut riding a horse",
|
||||
help="the text prompt to use",
|
||||
)
|
||||
p.add_argument("--device", type=str, default="cpu", help="the device to use")
|
||||
p.add_argument(
|
||||
"--steps", type=int, default=10, help="the number of steps to use"
|
||||
)
|
||||
p.add_argument(
|
||||
"--save_path",
|
||||
type=str,
|
||||
default=None,
|
||||
help="the file to save the resulting image to. (default to <input prompt>.jpg)",
|
||||
)
|
||||
args = p.parse_args()
|
||||
|
||||
#####################################################
|
||||
|
||||
MAX_PROMPT_LENGTH = 77
|
||||
|
||||
|
||||
class SharkStableDiffusion:
|
||||
"""Shark implementation of Stable Diffusion based on model from keras_cv.
|
||||
Stable Diffusion is a powerful image generation model that can be used,
|
||||
among other things, to generate pictures according to a short text description
|
||||
(called a "prompt").
|
||||
Arguments:
|
||||
device: Device to use with SHARK. Default: cpu
|
||||
jit_compile: Whether to compile the underlying models to XLA.
|
||||
This can lead to a significant speedup on some systems. Default: False.
|
||||
References:
|
||||
- [About Stable Diffusion](https://stability.ai/blog/stable-diffusion-announcement)
|
||||
- [Original implementation](https://github.com/CompVis/stable-diffusion)
|
||||
"""
|
||||
|
||||
def __init__(self, device="cpu", jit_compile=True):
|
||||
self.img_height = 512
|
||||
self.img_width = 512
|
||||
self.tokenizer = SimpleTokenizer()
|
||||
|
||||
# Create models
|
||||
self.text_encoder = TextEncoder(MAX_PROMPT_LENGTH)
|
||||
|
||||
mlir_model, func_name, inputs, golden_out = download_model(
|
||||
"stable_diff", tank_url="gs://shark_tank/quinn", frontend="tf"
|
||||
)
|
||||
shark_module = SharkInference(
|
||||
mlir_model, func_name, device=device, mlir_dialect="mhlo"
|
||||
)
|
||||
shark_module.compile()
|
||||
self.diffusion_model = shark_module
|
||||
self.decoder = Decoder(self.img_height, self.img_width)
|
||||
if jit_compile:
|
||||
self.text_encoder.compile(jit_compile=True)
|
||||
self.decoder.compile(jit_compile=True)
|
||||
|
||||
print(
|
||||
"By using this model checkpoint, you acknowledge that its usage is "
|
||||
"subject to the terms of the CreativeML Open RAIL-M license at "
|
||||
"https://raw.githubusercontent.com/CompVis/stable-diffusion/main/LICENSE"
|
||||
)
|
||||
# Load weights
|
||||
text_encoder_weights_fpath = keras.utils.get_file(
|
||||
origin="https://huggingface.co/fchollet/stable-diffusion/resolve/main/kcv_encoder.h5",
|
||||
file_hash="4789e63e07c0e54d6a34a29b45ce81ece27060c499a709d556c7755b42bb0dc4",
|
||||
)
|
||||
decoder_weights_fpath = keras.utils.get_file(
|
||||
origin="https://huggingface.co/fchollet/stable-diffusion/resolve/main/kcv_decoder.h5",
|
||||
file_hash="ad350a65cc8bc4a80c8103367e039a3329b4231c2469a1093869a345f55b1962",
|
||||
)
|
||||
self.text_encoder.load_weights(text_encoder_weights_fpath)
|
||||
self.decoder.load_weights(decoder_weights_fpath)
|
||||
|
||||
def text_to_image(
|
||||
self,
|
||||
prompt,
|
||||
batch_size=1,
|
||||
num_steps=25,
|
||||
unconditional_guidance_scale=7.5,
|
||||
seed=None,
|
||||
):
|
||||
encoded_text = self.encode_text(prompt)
|
||||
|
||||
return self.generate_image(
|
||||
encoded_text,
|
||||
batch_size=batch_size,
|
||||
num_steps=num_steps,
|
||||
unconditional_guidance_scale=unconditional_guidance_scale,
|
||||
seed=seed,
|
||||
)
|
||||
|
||||
def encode_text(self, prompt):
|
||||
"""Encodes a prompt into a latent text encoding.
|
||||
The encoding produced by this method should be used as the
|
||||
`encoded_text` parameter of `StableDiffusion.generate_image`. Encoding
|
||||
text separately from generating an image can be used to arbitrarily
|
||||
modify the text encoding priot to image generation, e.g. for walking
|
||||
between two prompts.
|
||||
Args:
|
||||
prompt: a string to encode, must be 77 tokens or shorter.
|
||||
Example:
|
||||
```python
|
||||
from keras_cv.models import StableDiffusion
|
||||
model = StableDiffusion(img_height=512, img_width=512, jit_compile=True)
|
||||
encoded_text = model.encode_text("Tacos at dawn")
|
||||
img = model.generate_image(encoded_text)
|
||||
```
|
||||
"""
|
||||
# Tokenize prompt (i.e. starting context)
|
||||
inputs = self.tokenizer.encode(prompt)
|
||||
if len(inputs) > MAX_PROMPT_LENGTH:
|
||||
raise ValueError(
|
||||
f"Prompt is too long (should be <= {MAX_PROMPT_LENGTH} tokens)"
|
||||
)
|
||||
phrase = inputs + [49407] * (MAX_PROMPT_LENGTH - len(inputs))
|
||||
phrase = tf.convert_to_tensor([phrase], dtype=tf.int32)
|
||||
|
||||
context = self.text_encoder.predict_on_batch(
|
||||
[phrase, self._get_pos_ids()]
|
||||
)
|
||||
|
||||
return context
|
||||
|
||||
def generate_image(
|
||||
self,
|
||||
encoded_text,
|
||||
batch_size=1,
|
||||
num_steps=25,
|
||||
unconditional_guidance_scale=7.5,
|
||||
diffusion_noise=None,
|
||||
seed=None,
|
||||
):
|
||||
"""Generates an image based on encoded text.
|
||||
The encoding passed to this method should be derived from
|
||||
`StableDiffusion.encode_text`.
|
||||
Args:
|
||||
encoded_text: Tensor of shape (`batch_size`, 77, 768), or a Tensor
|
||||
of shape (77, 768). When the batch axis is omitted, the same encoded
|
||||
text will be used to produce every generated image.
|
||||
batch_size: number of images to generate. Default: 1.
|
||||
num_steps: number of diffusion steps (controls image quality).
|
||||
Default: 25.
|
||||
unconditional_guidance_scale: float controling how closely the image
|
||||
should adhere to the prompt. Larger values result in more
|
||||
closely adhering to the prompt, but will make the image noisier.
|
||||
Default: 7.5.
|
||||
diffusion_noise: Tensor of shape (`batch_size`, img_height // 8,
|
||||
img_width // 8, 4), or a Tensor of shape (img_height // 8,
|
||||
img_width // 8, 4). Optional custom noise to seed the diffusion
|
||||
process. When the batch axis is omitted, the same noise will be
|
||||
used to seed diffusion for every generated image.
|
||||
seed: integer which is used to seed the random generation of
|
||||
diffusion noise, only to be specified if `diffusion_noise` is
|
||||
None.
|
||||
Example:
|
||||
```python
|
||||
from keras_cv.models import StableDiffusion
|
||||
batch_size = 8
|
||||
model = StableDiffusion(img_height=512, img_width=512, jit_compile=True)
|
||||
e_tacos = model.encode_text("Tacos at dawn")
|
||||
e_watermelons = model.encode_text("Watermelons at dusk")
|
||||
e_interpolated = tf.linspace(e_tacos, e_watermelons, batch_size)
|
||||
images = model.generate_image(e_interpolated, batch_size=batch_size)
|
||||
```
|
||||
"""
|
||||
if diffusion_noise is not None and seed is not None:
|
||||
raise ValueError(
|
||||
"`diffusion_noise` and `seed` should not both be passed to "
|
||||
"`generate_image`. `seed` is only used to generate diffusion "
|
||||
"noise when it's not already user-specified."
|
||||
)
|
||||
|
||||
encoded_text = tf.squeeze(encoded_text)
|
||||
if encoded_text.shape.rank == 2:
|
||||
encoded_text = tf.repeat(
|
||||
tf.expand_dims(encoded_text, axis=0), batch_size, axis=0
|
||||
)
|
||||
|
||||
context = encoded_text
|
||||
unconditional_context = tf.repeat(
|
||||
self._get_unconditional_context(), batch_size, axis=0
|
||||
)
|
||||
context = tf.concat([context, unconditional_context], 0)
|
||||
|
||||
if diffusion_noise is not None:
|
||||
diffusion_noise = tf.squeeze(diffusion_noise)
|
||||
if diffusion_noise.shape.rank == 3:
|
||||
diffusion_noise = tf.repeat(
|
||||
tf.expand_dims(diffusion_noise, axis=0), batch_size, axis=0
|
||||
)
|
||||
latent = diffusion_noise
|
||||
else:
|
||||
latent = self._get_initial_diffusion_noise(batch_size, seed)
|
||||
|
||||
# Iterative reverse diffusion stage
|
||||
timesteps = tf.range(1, 1000, 1000 // num_steps)
|
||||
alphas, alphas_prev = self._get_initial_alphas(timesteps)
|
||||
progbar = keras.utils.Progbar(len(timesteps))
|
||||
iteration = 0
|
||||
for index, timestep in list(enumerate(timesteps))[::-1]:
|
||||
latent_prev = latent # Set aside the previous latent vector
|
||||
t_emb = self._get_timestep_embedding(timestep, batch_size)
|
||||
|
||||
# Prepare the latent and unconditional latent to be run with a single forward call
|
||||
latent = tf.concat([latent, latent], 0)
|
||||
t_emb = tf.concat([t_emb, t_emb], 0)
|
||||
latent_numpy = self.diffusion_model.forward(
|
||||
[latent.numpy(), t_emb.numpy(), context.numpy()]
|
||||
)
|
||||
latent = tf.convert_to_tensor(latent_numpy, dtype=tf.float32)
|
||||
latent, unconditional_latent = tf.split(latent, 2)
|
||||
|
||||
latent = unconditional_latent + unconditional_guidance_scale * (
|
||||
latent - unconditional_latent
|
||||
)
|
||||
a_t, a_prev = alphas[index], alphas_prev[index]
|
||||
pred_x0 = (latent_prev - math.sqrt(1 - a_t) * latent) / math.sqrt(
|
||||
a_t
|
||||
)
|
||||
latent = (
|
||||
latent * math.sqrt(1.0 - a_prev) + math.sqrt(a_prev) * pred_x0
|
||||
)
|
||||
iteration += 1
|
||||
progbar.update(iteration)
|
||||
|
||||
# Decoding stage
|
||||
decoded = self.decoder.predict_on_batch(latent)
|
||||
decoded = ((decoded + 1) / 2) * 255
|
||||
return np.clip(decoded, 0, 255).astype("uint8")
|
||||
|
||||
def _get_unconditional_context(self):
|
||||
unconditional_tokens = tf.convert_to_tensor(
|
||||
[_UNCONDITIONAL_TOKENS], dtype=tf.int32
|
||||
)
|
||||
unconditional_context = self.text_encoder.predict_on_batch(
|
||||
[unconditional_tokens, self._get_pos_ids()]
|
||||
)
|
||||
|
||||
return unconditional_context
|
||||
|
||||
def _get_timestep_embedding(
|
||||
self, timestep, batch_size, dim=320, max_period=10000
|
||||
):
|
||||
half = dim // 2
|
||||
freqs = tf.math.exp(
|
||||
-math.log(max_period) * tf.range(0, half, dtype=tf.float32) / half
|
||||
)
|
||||
args = tf.convert_to_tensor([timestep], dtype=tf.float32) * freqs
|
||||
embedding = tf.concat([tf.math.cos(args), tf.math.sin(args)], 0)
|
||||
embedding = tf.reshape(embedding, [1, -1])
|
||||
return tf.repeat(embedding, batch_size, axis=0)
|
||||
|
||||
def _get_initial_alphas(self, timesteps):
|
||||
alphas = [_ALPHAS_CUMPROD[t] for t in timesteps]
|
||||
alphas_prev = [1.0] + alphas[:-1]
|
||||
|
||||
return alphas, alphas_prev
|
||||
|
||||
def _get_initial_diffusion_noise(self, batch_size, seed):
|
||||
return tf.random.normal(
|
||||
(batch_size, self.img_height // 8, self.img_width // 8, 4),
|
||||
seed=seed,
|
||||
)
|
||||
|
||||
@staticmethod
|
||||
def _get_pos_ids():
|
||||
return tf.convert_to_tensor(
|
||||
[list(range(MAX_PROMPT_LENGTH))], dtype=tf.int32
|
||||
)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
SD = SharkStableDiffusion(device=args.device)
|
||||
images = SD.text_to_image(args.prompt, num_steps=args.steps)
|
||||
pil_images = [Image.fromarray(image) for image in images]
|
||||
save_fname = args.prompt + ".jpg"
|
||||
if args.save_path is not None:
|
||||
save_fname = args.save_path
|
||||
pil_images[0].save(save_fname)
|
||||
@@ -1,2 +0,0 @@
|
||||
*.vmfb
|
||||
*.jpg
|
||||
@@ -1,56 +0,0 @@
|
||||
# STABLE DIFFUSION
|
||||
|
||||
## Installation
|
||||
|
||||
Follow setup instructions in the main [README.md](https://github.com/nod-ai/SHARK#readme) for regular usage.
|
||||
|
||||
## Debug commands and other advanced usage follows.
|
||||
|
||||
```shell
|
||||
python main.py --precision="fp32"|"fp16" --device="cpu"|"cuda"|"vulkan" --import_mlir|--no-import_mlir --prompt "enter the text"
|
||||
|
||||
```
|
||||
|
||||
## dump all dispatch .spv and isa using amdllpc
|
||||
|
||||
```shell
|
||||
python main.py --precision="fp16" --device="vulkan" --iree-vulkan-target-triple=rdna3-unknown-linux --no-load_vmfb --dispatch_benchmarks="all" --dispatch_benchmarks_dir="SD_dispatches" --dump_isa
|
||||
```
|
||||
|
||||
## Compile and save the .vmfb (using vulkan fp16 as an example):
|
||||
|
||||
```shell
|
||||
python shark/examples/shark_inference/stable_diffusion/main.py --precision=fp16 --device=vulkan --steps=50 --save_vmfb
|
||||
```
|
||||
|
||||
## Capture an RGP trace
|
||||
|
||||
```shell
|
||||
python shark/examples/shark_inference/stable_diffusion/main.py --precision=fp16 --device=vulkan --steps=50 --save_vmfb --enable_rgp
|
||||
```
|
||||
|
||||
## Run the vae module with iree-benchmark-module (NCHW, fp16, vulkan, for example):
|
||||
|
||||
```shell
|
||||
iree-benchmark-module --module_file=/path/to/output/vmfb --entry_function=forward --device=vulkan --function_input=1x4x64x64xf16
|
||||
```
|
||||
|
||||
## Run the unet module with iree-benchmark-module (same config as above):
|
||||
```shell
|
||||
##if you want to use .npz inputs:
|
||||
unzip ~/.local/shark_tank/<your unet>/inputs.npz
|
||||
|
||||
iree-benchmark-module --module_file=/path/to/output/vmfb --entry_function=forward --function_input=@arr_0.npy --function_input=1xf16 --function_input=@arr_2.npy --function_input=@arr_3.npy --function_input=@arr_4.npy
|
||||
```
|
||||
|
||||
## Using other supported Stable Diffusion variants with SHARK:
|
||||
|
||||
Currently we support the following fine-tuned versions of Stable Diffusion:
|
||||
- [AnythingV3](https://huggingface.co/Linaqruf/anything-v3.0)
|
||||
- [Analog Diffusion](https://huggingface.co/wavymulder/Analog-Diffusion)
|
||||
|
||||
use the flag `--variant=` to specify the model to be used.
|
||||
|
||||
```shell
|
||||
python .\shark\examples\shark_inference\stable_diffusion\main.py --variant=anythingv3 --max_length=77 --prompt="1girl, brown hair, green eyes, colorful, autumn, cumulonimbus clouds, lighting, blue sky, falling leaves, garden"
|
||||
```
|
||||
@@ -1,25 +0,0 @@
|
||||
from PIL import Image
|
||||
import requests
|
||||
|
||||
from transformers import CLIPProcessor, CLIPModel
|
||||
|
||||
model = CLIPModel.from_pretrained("openai/clip-vit-large-patch14")
|
||||
processor = CLIPProcessor.from_pretrained("openai/clip-vit-large-patch14")
|
||||
|
||||
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
|
||||
image = Image.open(requests.get(url, stream=True).raw)
|
||||
|
||||
inputs = processor(
|
||||
text=["a photo of a cat", "a photo of a dog"],
|
||||
images=image,
|
||||
return_tensors="pt",
|
||||
padding=True,
|
||||
)
|
||||
|
||||
outputs = model(**inputs)
|
||||
logits_per_image = (
|
||||
outputs.logits_per_image
|
||||
) # this is the image-text similarity score
|
||||
probs = logits_per_image.softmax(
|
||||
dim=1
|
||||
) # we can take the softmax to get the label probabilities
|
||||
@@ -1,253 +0,0 @@
|
||||
import os
|
||||
|
||||
os.environ["AMD_ENABLE_LLPC"] = "1"
|
||||
|
||||
from transformers import CLIPTextModel, CLIPTokenizer
|
||||
import torch
|
||||
from PIL import Image
|
||||
import torchvision.transforms as T
|
||||
from diffusers import (
|
||||
LMSDiscreteScheduler,
|
||||
PNDMScheduler,
|
||||
DDIMScheduler,
|
||||
DPMSolverMultistepScheduler,
|
||||
EulerDiscreteScheduler,
|
||||
)
|
||||
from tqdm.auto import tqdm
|
||||
import numpy as np
|
||||
from random import randint
|
||||
from stable_args import args
|
||||
|
||||
# This has to come before importing cache objects
|
||||
if args.clear_all:
|
||||
print("CLEARING ALL, EXPECT SEVERAL MINUTES TO RECOMPILE")
|
||||
from glob import glob
|
||||
import shutil
|
||||
|
||||
vmfbs = glob(os.path.join(os.getcwd(), "*.vmfb"))
|
||||
for vmfb in vmfbs:
|
||||
if os.path.exists(vmfb):
|
||||
os.remove(vmfb)
|
||||
home = os.path.expanduser("~")
|
||||
if os.name == "nt": # Windows
|
||||
appdata = os.getenv("LOCALAPPDATA")
|
||||
shutil.rmtree(os.path.join(appdata, "AMD/VkCache"), ignore_errors=True)
|
||||
shutil.rmtree(os.path.join(home, "shark_tank"), ignore_errors=True)
|
||||
elif os.name == "unix":
|
||||
shutil.rmtree(os.path.join(home, ".cache/AMD/VkCache"))
|
||||
shutil.rmtree(os.path.join(home, ".local/shark_tank"))
|
||||
|
||||
|
||||
from utils import set_init_device_flags
|
||||
|
||||
from opt_params import get_unet, get_vae, get_clip
|
||||
from schedulers import (
|
||||
SharkEulerDiscreteScheduler,
|
||||
)
|
||||
import time
|
||||
import sys
|
||||
from shark.iree_utils.compile_utils import dump_isas
|
||||
|
||||
# Helper function to profile the vulkan device.
|
||||
def start_profiling(file_path="foo.rdc", profiling_mode="queue"):
|
||||
if args.vulkan_debug_utils and "vulkan" in args.device:
|
||||
import iree
|
||||
|
||||
print(f"Profiling and saving to {file_path}.")
|
||||
vulkan_device = iree.runtime.get_device(args.device)
|
||||
vulkan_device.begin_profiling(mode=profiling_mode, file_path=file_path)
|
||||
return vulkan_device
|
||||
return None
|
||||
|
||||
|
||||
def end_profiling(device):
|
||||
if device:
|
||||
return device.end_profiling()
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
|
||||
dtype = torch.float32 if args.precision == "fp32" else torch.half
|
||||
|
||||
prompt = args.prompts
|
||||
neg_prompt = args.negative_prompts
|
||||
height = 512 # default height of Stable Diffusion
|
||||
width = 512 # default width of Stable Diffusion
|
||||
if args.version == "v2_1":
|
||||
height = 768
|
||||
width = 768
|
||||
|
||||
num_inference_steps = args.steps # Number of denoising steps
|
||||
|
||||
# Scale for classifier-free guidance
|
||||
guidance_scale = torch.tensor(args.guidance_scale).to(torch.float32)
|
||||
|
||||
# Handle out of range seeds.
|
||||
uint32_info = np.iinfo(np.uint32)
|
||||
uint32_min, uint32_max = uint32_info.min, uint32_info.max
|
||||
seed = args.seed
|
||||
if seed < uint32_min or seed >= uint32_max:
|
||||
seed = randint(uint32_min, uint32_max)
|
||||
generator = torch.manual_seed(
|
||||
seed
|
||||
) # Seed generator to create the inital latent noise
|
||||
|
||||
# TODO: Add support for batch_size > 1.
|
||||
batch_size = len(prompt)
|
||||
if batch_size != 1:
|
||||
sys.exit("More than one prompt is not supported yet.")
|
||||
if batch_size != len(neg_prompt):
|
||||
sys.exit("prompts and negative prompts must be of same length")
|
||||
|
||||
set_init_device_flags()
|
||||
clip = get_clip()
|
||||
unet = get_unet()
|
||||
vae = get_vae()
|
||||
if args.dump_isa:
|
||||
dump_isas(args.dispatch_benchmarks_dir)
|
||||
|
||||
tokenizer = CLIPTokenizer.from_pretrained("openai/clip-vit-large-patch14")
|
||||
scheduler = DPMSolverMultistepScheduler.from_pretrained(
|
||||
"CompVis/stable-diffusion-v1-4",
|
||||
subfolder="scheduler",
|
||||
)
|
||||
cpu_scheduling = True
|
||||
if args.version == "v2_1":
|
||||
tokenizer = CLIPTokenizer.from_pretrained(
|
||||
"stabilityai/stable-diffusion-2-1", subfolder="tokenizer"
|
||||
)
|
||||
|
||||
scheduler = DPMSolverMultistepScheduler.from_pretrained(
|
||||
"stabilityai/stable-diffusion-2-1",
|
||||
subfolder="scheduler",
|
||||
)
|
||||
|
||||
if args.version == "v2_1base" and args.variant == "stablediffusion":
|
||||
tokenizer = CLIPTokenizer.from_pretrained(
|
||||
"stabilityai/stable-diffusion-2-1-base", subfolder="tokenizer"
|
||||
)
|
||||
|
||||
if args.use_compiled_scheduler:
|
||||
scheduler = SharkEulerDiscreteScheduler.from_pretrained(
|
||||
"stabilityai/stable-diffusion-2-1-base",
|
||||
subfolder="scheduler",
|
||||
)
|
||||
scheduler.compile()
|
||||
cpu_scheduling = False
|
||||
else:
|
||||
scheduler = EulerDiscreteScheduler.from_pretrained(
|
||||
"stabilityai/stable-diffusion-2-1-base",
|
||||
subfolder="scheduler",
|
||||
)
|
||||
|
||||
# create a random initial latent.
|
||||
latents = torch.randn(
|
||||
(batch_size, 4, height // 8, width // 8),
|
||||
generator=generator,
|
||||
dtype=torch.float32,
|
||||
).to(dtype)
|
||||
# Warmup phase to improve performance.
|
||||
if args.warmup_count >= 1:
|
||||
vae_warmup_input = torch.clone(latents).detach().numpy()
|
||||
clip_warmup_input = torch.randint(1, 2, (2, args.max_length))
|
||||
for i in range(args.warmup_count):
|
||||
vae.forward((vae_warmup_input,))
|
||||
clip.forward((clip_warmup_input,))
|
||||
|
||||
start = time.time()
|
||||
|
||||
text_input = tokenizer(
|
||||
prompt,
|
||||
padding="max_length",
|
||||
max_length=args.max_length,
|
||||
truncation=True,
|
||||
return_tensors="pt",
|
||||
)
|
||||
max_length = text_input.input_ids.shape[-1]
|
||||
uncond_input = tokenizer(
|
||||
neg_prompt,
|
||||
padding="max_length",
|
||||
max_length=max_length,
|
||||
truncation=True,
|
||||
return_tensors="pt",
|
||||
)
|
||||
text_input = torch.cat([uncond_input.input_ids, text_input.input_ids])
|
||||
|
||||
clip_inf_start = time.time()
|
||||
text_embeddings = clip.forward((text_input,))
|
||||
clip_inf_end = time.time()
|
||||
text_embeddings = torch.from_numpy(text_embeddings).to(dtype)
|
||||
text_embeddings_numpy = text_embeddings.detach().numpy()
|
||||
|
||||
scheduler.set_timesteps(num_inference_steps)
|
||||
scheduler.is_scale_input_called = True
|
||||
|
||||
latents = latents * scheduler.init_noise_sigma
|
||||
|
||||
avg_ms = 0
|
||||
for i, t in tqdm(enumerate(scheduler.timesteps), disable=args.hide_steps):
|
||||
step_start = time.time()
|
||||
if not args.hide_steps:
|
||||
print(f"i = {i} t = {t}", end="")
|
||||
timestep = torch.tensor([t]).to(dtype).detach().numpy()
|
||||
latent_model_input = scheduler.scale_model_input(latents, t)
|
||||
if cpu_scheduling:
|
||||
latent_model_input = latent_model_input.detach().numpy()
|
||||
|
||||
profile_device = start_profiling(file_path="unet.rdc")
|
||||
|
||||
noise_pred = unet.forward(
|
||||
(
|
||||
latent_model_input,
|
||||
timestep,
|
||||
text_embeddings_numpy,
|
||||
guidance_scale,
|
||||
),
|
||||
send_to_host=False,
|
||||
)
|
||||
|
||||
end_profiling(profile_device)
|
||||
|
||||
if cpu_scheduling:
|
||||
noise_pred = torch.from_numpy(noise_pred.to_host())
|
||||
latents = scheduler.step(noise_pred, t, latents).prev_sample
|
||||
else:
|
||||
latents = scheduler.step(noise_pred, t, latents)
|
||||
step_time = time.time() - step_start
|
||||
avg_ms += step_time
|
||||
step_ms = int((step_time) * 1000)
|
||||
if not args.hide_steps:
|
||||
print(f" ({step_ms}ms)")
|
||||
|
||||
# scale and decode the image latents with vae
|
||||
if args.use_base_vae:
|
||||
latents = 1 / 0.18215 * latents
|
||||
latents_numpy = latents
|
||||
if cpu_scheduling:
|
||||
latents_numpy = latents.detach().numpy()
|
||||
profile_device = start_profiling(file_path="vae.rdc")
|
||||
vae_start = time.time()
|
||||
images = vae.forward((latents_numpy,))
|
||||
vae_end = time.time()
|
||||
end_profiling(profile_device)
|
||||
if args.use_base_vae:
|
||||
image = torch.from_numpy(images)
|
||||
image = (image.detach().cpu() * 255.0).numpy()
|
||||
images = image.round()
|
||||
end_time = time.time()
|
||||
|
||||
avg_ms = 1000 * avg_ms / args.steps
|
||||
clip_inf_time = (clip_inf_end - clip_inf_start) * 1000
|
||||
vae_inf_time = (vae_end - vae_start) * 1000
|
||||
total_time = end_time - start
|
||||
print(f"\nAverage step time: {avg_ms}ms/it")
|
||||
print(f"Clip Inference time (ms) = {clip_inf_time:.3f}")
|
||||
print(f"VAE Inference time (ms): {vae_inf_time:.3f}")
|
||||
print(f"\nTotal image generation time: {total_time}sec")
|
||||
|
||||
transform = T.ToPILImage()
|
||||
pil_images = [
|
||||
transform(image) for image in torch.from_numpy(images).to(torch.uint8)
|
||||
]
|
||||
for i in range(batch_size):
|
||||
pil_images[i].save(f"{args.prompts[i]}_{i}.jpg")
|
||||
@@ -1,285 +0,0 @@
|
||||
from diffusers import AutoencoderKL, UNet2DConditionModel
|
||||
from transformers import CLIPTextModel
|
||||
from utils import compile_through_fx
|
||||
from stable_args import args
|
||||
import torch
|
||||
|
||||
model_config = {
|
||||
"v2_1": "stabilityai/stable-diffusion-2-1",
|
||||
"v2_1base": "stabilityai/stable-diffusion-2-1-base",
|
||||
"v1_4": "CompVis/stable-diffusion-v1-4",
|
||||
}
|
||||
|
||||
# clip has 2 variants of max length 77 or 64.
|
||||
model_clip_max_length = 64 if args.max_length == 64 else 77
|
||||
if args.variant in ["anythingv3", "analogdiffusion", "dreamlike"]:
|
||||
model_clip_max_length = 77
|
||||
elif args.variant == "openjourney":
|
||||
model_clip_max_length = 64
|
||||
|
||||
model_variant = {
|
||||
"stablediffusion": "SD",
|
||||
"anythingv3": "Linaqruf/anything-v3.0",
|
||||
"dreamlike": "dreamlike-art/dreamlike-diffusion-1.0",
|
||||
"openjourney": "prompthero/openjourney",
|
||||
"analogdiffusion": "wavymulder/Analog-Diffusion",
|
||||
}
|
||||
|
||||
model_input = {
|
||||
"v2_1": {
|
||||
"clip": (torch.randint(1, 2, (2, model_clip_max_length)),),
|
||||
"vae": (torch.randn(1, 4, 96, 96),),
|
||||
"unet": (
|
||||
torch.randn(1, 4, 96, 96), # latents
|
||||
torch.tensor([1]).to(torch.float32), # timestep
|
||||
torch.randn(2, model_clip_max_length, 1024), # embedding
|
||||
torch.tensor(1).to(torch.float32), # guidance_scale
|
||||
),
|
||||
},
|
||||
"v2_1base": {
|
||||
"clip": (torch.randint(1, 2, (2, model_clip_max_length)),),
|
||||
"vae": (torch.randn(1, 4, 64, 64),),
|
||||
"unet": (
|
||||
torch.randn(1, 4, 64, 64), # latents
|
||||
torch.tensor([1]).to(torch.float32), # timestep
|
||||
torch.randn(2, model_clip_max_length, 1024), # embedding
|
||||
torch.tensor(1).to(torch.float32), # guidance_scale
|
||||
),
|
||||
},
|
||||
"v1_4": {
|
||||
"clip": (torch.randint(1, 2, (2, model_clip_max_length)),),
|
||||
"vae": (torch.randn(1, 4, 64, 64),),
|
||||
"unet": (
|
||||
torch.randn(1, 4, 64, 64),
|
||||
torch.tensor([1]).to(torch.float32), # timestep
|
||||
torch.randn(2, model_clip_max_length, 768),
|
||||
torch.tensor(1).to(torch.float32),
|
||||
),
|
||||
},
|
||||
}
|
||||
|
||||
# revision param for from_pretrained defaults to "main" => fp32
|
||||
model_revision = {
|
||||
"stablediffusion": "fp16" if args.precision == "fp16" else "main",
|
||||
"anythingv3": "diffusers",
|
||||
"analogdiffusion": "main",
|
||||
"openjourney": "main",
|
||||
"dreamlike": "main",
|
||||
}
|
||||
|
||||
|
||||
def get_clip_mlir(model_name="clip_text", extra_args=[]):
|
||||
|
||||
text_encoder = CLIPTextModel.from_pretrained(
|
||||
"openai/clip-vit-large-patch14"
|
||||
)
|
||||
if args.variant == "stablediffusion":
|
||||
if args.version != "v1_4":
|
||||
text_encoder = CLIPTextModel.from_pretrained(
|
||||
model_config[args.version], subfolder="text_encoder"
|
||||
)
|
||||
|
||||
elif args.variant in [
|
||||
"anythingv3",
|
||||
"analogdiffusion",
|
||||
"openjourney",
|
||||
"dreamlike",
|
||||
]:
|
||||
text_encoder = CLIPTextModel.from_pretrained(
|
||||
model_variant[args.variant],
|
||||
subfolder="text_encoder",
|
||||
revision=model_revision[args.variant],
|
||||
)
|
||||
else:
|
||||
raise ValueError(f"{args.variant} not yet added")
|
||||
|
||||
class CLIPText(torch.nn.Module):
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
self.text_encoder = text_encoder
|
||||
|
||||
def forward(self, input):
|
||||
return self.text_encoder(input)[0]
|
||||
|
||||
clip_model = CLIPText()
|
||||
shark_clip = compile_through_fx(
|
||||
clip_model,
|
||||
model_input[args.version]["clip"],
|
||||
model_name=model_name,
|
||||
extra_args=extra_args,
|
||||
)
|
||||
return shark_clip
|
||||
|
||||
|
||||
def get_base_vae_mlir(model_name="vae", extra_args=[]):
|
||||
class BaseVaeModel(torch.nn.Module):
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
self.vae = AutoencoderKL.from_pretrained(
|
||||
model_config[args.version]
|
||||
if args.variant == "stablediffusion"
|
||||
else model_variant[args.variant],
|
||||
subfolder="vae",
|
||||
revision=model_revision[args.variant],
|
||||
)
|
||||
|
||||
def forward(self, input):
|
||||
x = self.vae.decode(input, return_dict=False)[0]
|
||||
return (x / 2 + 0.5).clamp(0, 1)
|
||||
|
||||
vae = BaseVaeModel()
|
||||
if args.variant == "stablediffusion":
|
||||
if args.precision == "fp16":
|
||||
vae = vae.half().cuda()
|
||||
inputs = tuple(
|
||||
[
|
||||
inputs.half().cuda()
|
||||
for inputs in model_input[args.version]["vae"]
|
||||
]
|
||||
)
|
||||
else:
|
||||
inputs = model_input[args.version]["vae"]
|
||||
elif args.variant in [
|
||||
"anythingv3",
|
||||
"analogdiffusion",
|
||||
"openjourney",
|
||||
"dreamlike",
|
||||
]:
|
||||
if args.precision == "fp16":
|
||||
vae = vae.half().cuda()
|
||||
inputs = tuple(
|
||||
[inputs.half().cuda() for inputs in model_input["v1_4"]["vae"]]
|
||||
)
|
||||
else:
|
||||
inputs = model_input["v1_4"]["vae"]
|
||||
else:
|
||||
raise ValueError(f"{args.variant} not yet added")
|
||||
|
||||
shark_vae = compile_through_fx(
|
||||
vae,
|
||||
inputs,
|
||||
model_name=model_name,
|
||||
extra_args=extra_args,
|
||||
)
|
||||
return shark_vae
|
||||
|
||||
|
||||
def get_vae_mlir(model_name="vae", extra_args=[]):
|
||||
class VaeModel(torch.nn.Module):
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
self.vae = AutoencoderKL.from_pretrained(
|
||||
model_config[args.version]
|
||||
if args.variant == "stablediffusion"
|
||||
else model_variant[args.variant],
|
||||
subfolder="vae",
|
||||
revision=model_revision[args.variant],
|
||||
)
|
||||
|
||||
def forward(self, input):
|
||||
input = 1 / 0.18215 * input
|
||||
x = self.vae.decode(input, return_dict=False)[0]
|
||||
x = (x / 2 + 0.5).clamp(0, 1)
|
||||
x = x * 255.0
|
||||
return x.round()
|
||||
|
||||
vae = VaeModel()
|
||||
if args.variant == "stablediffusion":
|
||||
if args.precision == "fp16":
|
||||
vae = vae.half().cuda()
|
||||
inputs = tuple(
|
||||
[
|
||||
inputs.half().cuda()
|
||||
for inputs in model_input[args.version]["vae"]
|
||||
]
|
||||
)
|
||||
else:
|
||||
inputs = model_input[args.version]["vae"]
|
||||
elif args.variant in [
|
||||
"anythingv3",
|
||||
"analogdiffusion",
|
||||
"openjourney",
|
||||
"dreamlike",
|
||||
]:
|
||||
if args.precision == "fp16":
|
||||
vae = vae.half().cuda()
|
||||
inputs = tuple(
|
||||
[inputs.half().cuda() for inputs in model_input["v1_4"]["vae"]]
|
||||
)
|
||||
else:
|
||||
inputs = model_input["v1_4"]["vae"]
|
||||
else:
|
||||
raise ValueError(f"{args.variant} not yet added")
|
||||
|
||||
shark_vae = compile_through_fx(
|
||||
vae,
|
||||
inputs,
|
||||
model_name=model_name,
|
||||
extra_args=extra_args,
|
||||
)
|
||||
return shark_vae
|
||||
|
||||
|
||||
def get_unet_mlir(model_name="unet", extra_args=[]):
|
||||
class UnetModel(torch.nn.Module):
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
self.unet = UNet2DConditionModel.from_pretrained(
|
||||
model_config[args.version]
|
||||
if args.variant == "stablediffusion"
|
||||
else model_variant[args.variant],
|
||||
subfolder="unet",
|
||||
revision=model_revision[args.variant],
|
||||
)
|
||||
self.in_channels = self.unet.in_channels
|
||||
self.train(False)
|
||||
|
||||
def forward(self, latent, timestep, text_embedding, guidance_scale):
|
||||
# expand the latents if we are doing classifier-free guidance to avoid doing two forward passes.
|
||||
latents = torch.cat([latent] * 2)
|
||||
unet_out = self.unet.forward(
|
||||
latents, timestep, text_embedding, return_dict=False
|
||||
)[0]
|
||||
noise_pred_uncond, noise_pred_text = unet_out.chunk(2)
|
||||
noise_pred = noise_pred_uncond + guidance_scale * (
|
||||
noise_pred_text - noise_pred_uncond
|
||||
)
|
||||
return noise_pred
|
||||
|
||||
unet = UnetModel()
|
||||
if args.variant == "stablediffusion":
|
||||
if args.precision == "fp16":
|
||||
unet = unet.half().cuda()
|
||||
inputs = tuple(
|
||||
[
|
||||
inputs.half().cuda() if len(inputs.shape) != 0 else inputs
|
||||
for inputs in model_input[args.version]["unet"]
|
||||
]
|
||||
)
|
||||
else:
|
||||
inputs = model_input[args.version]["unet"]
|
||||
elif args.variant in [
|
||||
"anythingv3",
|
||||
"analogdiffusion",
|
||||
"openjourney",
|
||||
"dreamlike",
|
||||
]:
|
||||
if args.precision == "fp16":
|
||||
unet = unet.half().cuda()
|
||||
inputs = tuple(
|
||||
[
|
||||
inputs.half().cuda() if len(inputs.shape) != 0 else inputs
|
||||
for inputs in model_input["v1_4"]["unet"]
|
||||
]
|
||||
)
|
||||
else:
|
||||
inputs = model_input["v1_4"]["unet"]
|
||||
else:
|
||||
raise ValueError(f"{args.variant} is not yet added")
|
||||
shark_unet = compile_through_fx(
|
||||
unet,
|
||||
inputs,
|
||||
model_name=model_name,
|
||||
extra_args=extra_args,
|
||||
)
|
||||
return shark_unet
|
||||
@@ -1,115 +0,0 @@
|
||||
import sys
|
||||
from model_wrappers import (
|
||||
get_base_vae_mlir,
|
||||
get_vae_mlir,
|
||||
get_unet_mlir,
|
||||
get_clip_mlir,
|
||||
)
|
||||
from resources import models_db
|
||||
from stable_args import args
|
||||
from utils import get_shark_model
|
||||
|
||||
BATCH_SIZE = len(args.prompts)
|
||||
if BATCH_SIZE != 1:
|
||||
sys.exit("Only batch size 1 is supported.")
|
||||
|
||||
|
||||
def get_params(bucket_key, model_key):
|
||||
iree_flags = []
|
||||
if len(args.iree_vulkan_target_triple) > 0:
|
||||
iree_flags.append(
|
||||
f"-iree-vulkan-target-triple={args.iree_vulkan_target_triple}"
|
||||
)
|
||||
|
||||
# Disable bindings fusion to work with moltenVK.
|
||||
if sys.platform == "darwin":
|
||||
iree_flags.append("-iree-stream-fuse-binding=false")
|
||||
|
||||
try:
|
||||
bucket = models_db[0][bucket_key]
|
||||
model_name = models_db[1][model_key]
|
||||
except KeyError:
|
||||
raise Exception(
|
||||
f"{bucket}/{model_key} is not present in the models database"
|
||||
)
|
||||
|
||||
return bucket, model_name, iree_flags
|
||||
|
||||
|
||||
def get_unet():
|
||||
# Tuned model is present only for `fp16` precision.
|
||||
is_tuned = "/tuned" if args.use_tuned else "/untuned"
|
||||
bucket_key = f"{args.variant}{is_tuned}"
|
||||
model_key = f"{args.variant}/{args.version}/unet/{args.precision}/length_{args.max_length}{is_tuned}"
|
||||
bucket, model_name, iree_flags = get_params(bucket_key, model_key)
|
||||
if args.use_tuned:
|
||||
return get_shark_model(bucket, model_name, iree_flags)
|
||||
else:
|
||||
if args.precision == "fp16":
|
||||
iree_flags += [
|
||||
"--iree-flow-enable-padding-linalg-ops",
|
||||
"--iree-flow-linalg-ops-padding-size=32",
|
||||
]
|
||||
if args.device == "cuda":
|
||||
iree_flags += [
|
||||
"--iree-flow-enable-conv-nchw-to-nhwc-transform"
|
||||
]
|
||||
else:
|
||||
iree_flags += ["--iree-flow-enable-conv-img2col-transform"]
|
||||
elif args.precision == "fp32":
|
||||
iree_flags += [
|
||||
"--iree-flow-enable-conv-nchw-to-nhwc-transform",
|
||||
"--iree-flow-enable-padding-linalg-ops",
|
||||
"--iree-flow-linalg-ops-padding-size=16",
|
||||
]
|
||||
if args.import_mlir:
|
||||
return get_unet_mlir(model_name, iree_flags)
|
||||
return get_shark_model(bucket, model_name, iree_flags)
|
||||
|
||||
|
||||
def get_vae():
|
||||
# Tuned model is present only for `fp16` precision.
|
||||
is_tuned = "/tuned" if args.use_tuned else "/untuned"
|
||||
is_base = "/base" if args.use_base_vae else ""
|
||||
bucket_key = f"{args.variant}{is_tuned}"
|
||||
model_key = f"{args.variant}/{args.version}/vae/{args.precision}/length_77{is_tuned}{is_base}"
|
||||
bucket, model_name, iree_flags = get_params(bucket_key, model_key)
|
||||
if args.use_tuned:
|
||||
iree_flags += [
|
||||
"--iree-flow-enable-padding-linalg-ops",
|
||||
"--iree-flow-linalg-ops-padding-size=32",
|
||||
"--iree-flow-enable-conv-img2col-transform",
|
||||
"--iree-flow-enable-conv-winograd-transform",
|
||||
]
|
||||
return get_shark_model(bucket, model_name, iree_flags)
|
||||
else:
|
||||
if args.precision == "fp16":
|
||||
iree_flags += [
|
||||
"--iree-flow-enable-padding-linalg-ops",
|
||||
"--iree-flow-linalg-ops-padding-size=32",
|
||||
"--iree-flow-enable-conv-img2col-transform",
|
||||
]
|
||||
elif args.precision == "fp32":
|
||||
iree_flags += [
|
||||
"--iree-flow-enable-conv-nchw-to-nhwc-transform",
|
||||
"--iree-flow-enable-padding-linalg-ops",
|
||||
"--iree-flow-linalg-ops-padding-size=16",
|
||||
]
|
||||
if args.import_mlir:
|
||||
if args.use_base_vae:
|
||||
return get_base_vae_mlir(model_name, iree_flags)
|
||||
return get_vae_mlir(model_name, iree_flags)
|
||||
return get_shark_model(bucket, model_name, iree_flags)
|
||||
|
||||
|
||||
def get_clip():
|
||||
bucket_key = f"{args.variant}/untuned"
|
||||
model_key = f"{args.variant}/{args.version}/clip/fp32/length_{args.max_length}/untuned"
|
||||
bucket, model_name, iree_flags = get_params(bucket_key, model_key)
|
||||
iree_flags += [
|
||||
"--iree-flow-linalg-ops-padding-size=16",
|
||||
"--iree-flow-enable-padding-linalg-ops",
|
||||
]
|
||||
if args.import_mlir:
|
||||
return get_clip_mlir(model_name, iree_flags)
|
||||
return get_shark_model(bucket, model_name, iree_flags)
|
||||
@@ -1,44 +0,0 @@
|
||||
Compile / Run Instructions:
|
||||
|
||||
To compile .vmfb for SD (vae, unet, CLIP), run the following commands with the .mlir in your local shark_tank cache (default location for Linux users is `~/.local/shark_tank`). These will be available once the script from [this README](https://github.com/nod-ai/SHARK/blob/main/shark/examples/shark_inference/stable_diffusion/README.md) is run once.
|
||||
Running the script mentioned above with the `--save_vmfb` flag will also save the .vmfb in your SHARK base directory if you want to skip straight to benchmarks.
|
||||
|
||||
Compile Commands FP32/FP16:
|
||||
|
||||
```shell
|
||||
Vulkan AMD:
|
||||
iree-compile --iree-input-type=none --iree-hal-target-backends=vulkan --iree-vulkan-target-triple=rdna2-unknown-linux --iree-stream-resource-index-bits=64 --iree-vm-target-index-bits=64 /path/to/input/mlir -o /path/to/output/vmfb
|
||||
|
||||
# add --mlir-print-debuginfo --mlir-print-op-on-diagnostic=true for debug
|
||||
# use –iree-input-type=mhlo for tf models
|
||||
|
||||
CUDA NVIDIA:
|
||||
iree-compile --iree-input-type=none --iree-hal-target-backends=cuda --iree-stream-resource-index-bits=64 --iree-vm-target-index-bits=64 /path/to/input/mlir -o /path/to/output/vmfb
|
||||
|
||||
CPU:
|
||||
iree-compile --iree-input-type=none --iree-hal-target-backends=llvm-cpu --iree-stream-resource-index-bits=64 --iree-vm-target-index-bits=64 /path/to/input/mlir -o /path/to/output/vmfb
|
||||
```
|
||||
|
||||
|
||||
|
||||
Run / Benchmark Command (FP32 - NCHW):
|
||||
(NEED to use BS=2 since we do two forward passes to unet as a result of classifier free guidance.)
|
||||
|
||||
```shell
|
||||
## Vulkan AMD:
|
||||
iree-benchmark-module --module_file=/path/to/output/vmfb --entry_function=forward --device=vulkan --function_input=1x4x64x64xf32 --function_input=1xf32 --function_input=2x77x768xf32 --function_input=f32=1.0 --function_input=f32=1.0
|
||||
|
||||
## CUDA:
|
||||
iree-benchmark-module --module_file=/path/to/vmfb --entry_function=forward --device=cuda --function_input=1x4x64x64xf32 --function_input=1xf32 --function_input=2x77x768xf32 --function_input=f32=1.0 --function_input=f32=1.0
|
||||
|
||||
## CPU:
|
||||
iree-benchmark-module --module_file=/path/to/vmfb --entry_function=forward --device=local-task --function_input=1x4x64x64xf32 --function_input=1xf32 --function_input=2x77x768xf32 --function_input=f32=1.0 --function_input=f32=1.0
|
||||
|
||||
```
|
||||
|
||||
Run via vulkan_gui for RGP Profiling:
|
||||
|
||||
To build the vulkan app for profiling UNet follow the instructions [here](https://github.com/nod-ai/SHARK/tree/main/cpp) and then run the following command from the cpp directory with your compiled stable_diff.vmfb
|
||||
```shell
|
||||
./build/vulkan_gui/iree-vulkan-gui --module_file=/path/to/unet.vmfb --function_input=1x4x64x64xf32 --function_input=1xf32 --function_input=2x77x768xf32 --function_input=f32=1.0 --function_input=f32=1.0
|
||||
```
|
||||
@@ -1,31 +0,0 @@
|
||||
import os
|
||||
import json
|
||||
import sys
|
||||
|
||||
|
||||
def resource_path(relative_path):
|
||||
"""Get absolute path to resource, works for dev and for PyInstaller"""
|
||||
base_path = getattr(
|
||||
sys, "_MEIPASS", os.path.dirname(os.path.abspath(__file__))
|
||||
)
|
||||
return os.path.join(base_path, relative_path)
|
||||
|
||||
|
||||
prompt_examples = []
|
||||
prompts_loc = resource_path("resources/prompts.json")
|
||||
if os.path.exists(prompts_loc):
|
||||
with open(prompts_loc, encoding="utf-8") as fopen:
|
||||
prompt_examples = json.load(fopen)
|
||||
|
||||
if not prompt_examples:
|
||||
print("Unable to fetch prompt examples.")
|
||||
|
||||
|
||||
models_db = []
|
||||
models_loc = resource_path("resources/model_db.json")
|
||||
if os.path.exists(models_loc):
|
||||
with open(models_loc, encoding="utf-8") as fopen:
|
||||
models_db = json.load(fopen)
|
||||
|
||||
if len(models_db) != 2:
|
||||
sys.exit("Error: Unable to load models database.")
|
||||
@@ -1,68 +0,0 @@
|
||||
[
|
||||
{
|
||||
"stablediffusion/untuned":"gs://shark_tank/stable_diffusion",
|
||||
"stablediffusion/tuned":"gs://shark_tank/sd_tuned",
|
||||
"anythingv3/untuned":"gs://shark_tank/sd_anythingv3",
|
||||
"anythingv3/tuned":"gs://shark_tank/sd_tuned",
|
||||
"analogdiffusion/untuned":"gs://shark_tank/sd_analog_diffusion",
|
||||
"analogdiffusion/tuned":"gs://shark_tank/sd_tuned",
|
||||
"openjourney/untuned":"gs://shark_tank/sd_openjourney",
|
||||
"openjourney/tuned":"gs://shark_tank/sd_tuned",
|
||||
"dreamlike/untuned":"gs://shark_tank/sd_dreamlike_diffusion"
|
||||
},
|
||||
{
|
||||
"stablediffusion/v1_4/unet/fp16/length_77/untuned":"unet_8dec_fp16",
|
||||
"stablediffusion/v1_4/unet/fp16/length_77/tuned":"unet_1dec_fp16_tuned",
|
||||
"stablediffusion/v1_4/unet/fp32/length_77/untuned":"unet_1dec_fp32",
|
||||
"stablediffusion/v1_4/vae/fp16/length_77/untuned":"vae_19dec_fp16",
|
||||
"stablediffusion/v1_4/vae/fp16/length_77/untuned/base":"vae_8dec_fp16",
|
||||
"stablediffusion/v1_4/vae/fp32/length_77/untuned":"vae_1dec_fp32",
|
||||
"stablediffusion/v1_4/clip/fp32/length_77/untuned":"clip_18dec_fp32",
|
||||
"stablediffusion/v2_1base/unet/fp16/length_77/untuned":"unet2base_8dec_fp16",
|
||||
"stablediffusion/v2_1base/unet/fp16/length_77/tuned":"unet2base_8dec_fp16_tuned_v2",
|
||||
"stablediffusion/v2_1base/unet/fp16/length_64/untuned":"unet_19dec_v2p1base_fp16_64",
|
||||
"stablediffusion/v2_1base/unet/fp16/length_64/tuned":"unet_19dec_v2p1base_fp16_64_tuned",
|
||||
"stablediffusion/v2_1base/vae/fp16/length_77/untuned":"vae2base_19dec_fp16",
|
||||
"stablediffusion/v2_1base/vae/fp16/length_77/tuned":"vae2base_19dec_fp16_tuned",
|
||||
"stablediffusion/v2_1base/vae/fp16/length_77/untuned/base":"vae2base_8dec_fp16",
|
||||
"stablediffusion/v2_1base/vae/fp16/length_77/tuned/base":"vae2base_8dec_fp16_tuned",
|
||||
"stablediffusion/v2_1base/clip/fp32/length_77/untuned":"clip2base_18dec_fp32",
|
||||
"stablediffusion/v2_1base/clip/fp32/length_64/untuned":"clip_19dec_v2p1base_fp32_64",
|
||||
"stablediffusion/v2_1/unet/fp16/length_77/untuned":"unet2_14dec_fp16",
|
||||
"stablediffusion/v2_1/vae/fp16/length_77/untuned":"vae2_19dec_fp16",
|
||||
"stablediffusion/v2_1/vae/fp16/length_77/untuned/base":"vae2_8dec_fp16",
|
||||
"stablediffusion/v2_1/clip/fp32/length_77/untuned":"clip2_18dec_fp32",
|
||||
"anythingv3/v2_1base/unet/fp16/length_77/untuned":"av3_unet_19dec_fp16",
|
||||
"anythingv3/v2_1base/unet/fp16/length_77/tuned":"av3_unet_19dec_fp16_tuned",
|
||||
"anythingv3/v2_1base/unet/fp32/length_77/untuned":"av3_unet_19dec_fp32",
|
||||
"anythingv3/v2_1base/vae/fp16/length_77/untuned":"av3_vae_19dec_fp16",
|
||||
"anythingv3/v2_1base/vae/fp16/length_77/tuned":"av3_vae_19dec_fp16_tuned",
|
||||
"anythingv3/v2_1base/vae/fp16/length_77/untuned/base":"av3_vaebase_22dec_fp16",
|
||||
"anythingv3/v2_1base/vae/fp32/length_77/untuned":"av3_vae_19dec_fp32",
|
||||
"anythingv3/v2_1base/vae/fp32/length_77/untuned/base":"av3_vaebase_22dec_fp32",
|
||||
"anythingv3/v2_1base/clip/fp32/length_77/untuned":"av3_clip_19dec_fp32",
|
||||
"analogdiffusion/v2_1base/unet/fp16/length_77/untuned":"ad_unet_19dec_fp16",
|
||||
"analogdiffusion/v2_1base/unet/fp16/length_77/tuned":"ad_unet_19dec_fp16_tuned",
|
||||
"analogdiffusion/v2_1base/unet/fp32/length_77/untuned":"ad_unet_19dec_fp32",
|
||||
"analogdiffusion/v2_1base/vae/fp16/length_77/untuned":"ad_vae_19dec_fp16",
|
||||
"analogdiffusion/v2_1base/vae/fp16/length_77/tuned":"ad_vae_19dec_fp16_tuned",
|
||||
"analogdiffusion/v2_1base/vae/fp16/length_77/untuned/base":"ad_vaebase_22dec_fp16",
|
||||
"analogdiffusion/v2_1base/vae/fp32/length_77/untuned":"ad_vae_19dec_fp32",
|
||||
"analogdiffusion/v2_1base/vae/fp32/length_77/untuned/base":"ad_vaebase_22dec_fp32",
|
||||
"analogdiffusion/v2_1base/clip/fp32/length_77/untuned":"ad_clip_19dec_fp32",
|
||||
"openjourney/v2_1base/unet/fp16/length_64/untuned":"oj_unet_22dec_fp16_64",
|
||||
"openjourney/v2_1base/unet/fp32/length_64/untuned":"oj_unet_22dec_fp32_64",
|
||||
"openjourney/v2_1base/vae/fp16/length_77/untuned":"oj_vae_22dec_fp16",
|
||||
"openjourney/v2_1base/vae/fp16/length_77/untuned/base":"oj_vaebase_22dec_fp16",
|
||||
"openjourney/v2_1base/vae/fp32/length_77/untuned":"oj_vae_22dec_fp32",
|
||||
"openjourney/v2_1base/vae/fp32/length_77/untuned/base":"oj_vaebase_22dec_fp32",
|
||||
"openjourney/v2_1base/clip/fp32/length_64/untuned":"oj_clip_22dec_fp32_64",
|
||||
"dreamlike/v2_1base/unet/fp16/length_77/untuned":"dl_unet_23dec_fp16_77",
|
||||
"dreamlike/v2_1base/unet/fp32/length_77/untuned":"dl_unet_23dec_fp32_77",
|
||||
"dreamlike/v2_1base/vae/fp16/length_77/untuned":"dl_vae_23dec_fp16",
|
||||
"dreamlike/v2_1base/vae/fp16/length_77/untuned/base":"dl_vaebase_23dec_fp16",
|
||||
"dreamlike/v2_1base/vae/fp32/length_77/untuned":"dl_vae_23dec_fp32",
|
||||
"dreamlike/v2_1base/vae/fp32/length_77/untuned/base":"dl_vaebase_23dec_fp32",
|
||||
"dreamlike/v2_1base/clip/fp32/length_77/untuned":"dl_clip_23dec_fp32_77"
|
||||
}
|
||||
]
|
||||
@@ -1,8 +0,0 @@
|
||||
[["A high tech solarpunk utopia in the Amazon rainforest"],
|
||||
["A pikachu fine dining with a view to the Eiffel Tower"],
|
||||
["A mecha robot in a favela in expressionist style"],
|
||||
["an insect robot preparing a delicious meal"],
|
||||
["A digital Illustration of the Babel tower, 4k, detailed, trending in artstation, fantasy vivid colors"],
|
||||
["Cluttered house in the woods, anime, oil painting, high resolution, cottagecore, ghibli inspired, 4k"],
|
||||
["A beautiful mansion beside a waterfall in the woods, by josef thoma, matte painting, trending on artstation HQ"],
|
||||
["portrait photo of a asia old warrior chief, tribal panther make up, blue on red, side profile, looking away, serious eyes"]]
|
||||
@@ -1,131 +0,0 @@
|
||||
import sys
|
||||
import numpy as np
|
||||
from typing import List, Optional, Tuple, Union
|
||||
from diffusers import (
|
||||
LMSDiscreteScheduler,
|
||||
PNDMScheduler,
|
||||
DDIMScheduler,
|
||||
DPMSolverMultistepScheduler,
|
||||
EulerDiscreteScheduler,
|
||||
)
|
||||
from diffusers.configuration_utils import register_to_config
|
||||
from utils import compile_through_fx, get_shark_model
|
||||
from stable_args import args
|
||||
import torch
|
||||
|
||||
SCHEDULER_BUCKET = "gs://shark_tank/stable_diffusion/schedulers"
|
||||
|
||||
model_input = {
|
||||
"euler": {
|
||||
"latent": torch.randn(1, 4, 64, 64),
|
||||
"output": torch.randn(1, 4, 64, 64),
|
||||
"sigma": torch.tensor(1).to(torch.float32),
|
||||
"dt": torch.tensor(1).to(torch.float32),
|
||||
},
|
||||
}
|
||||
|
||||
|
||||
class SharkEulerDiscreteScheduler(EulerDiscreteScheduler):
|
||||
@register_to_config
|
||||
def __init__(
|
||||
self,
|
||||
num_train_timesteps: int = 1000,
|
||||
beta_start: float = 0.0001,
|
||||
beta_end: float = 0.02,
|
||||
beta_schedule: str = "linear",
|
||||
trained_betas: Optional[Union[np.ndarray, List[float]]] = None,
|
||||
prediction_type: str = "epsilon",
|
||||
):
|
||||
super().__init__(
|
||||
num_train_timesteps,
|
||||
beta_start,
|
||||
beta_end,
|
||||
beta_schedule,
|
||||
trained_betas,
|
||||
prediction_type,
|
||||
)
|
||||
|
||||
def compile(self):
|
||||
example_latent = model_input["euler"]["latent"]
|
||||
example_output = model_input["euler"]["output"]
|
||||
if args.precision == "fp16":
|
||||
example_latent = example_latent.half()
|
||||
example_output = example_output.half()
|
||||
example_sigma = model_input["euler"]["sigma"]
|
||||
example_dt = model_input["euler"]["dt"]
|
||||
|
||||
class ScalingModel(torch.nn.Module):
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
|
||||
def forward(self, latent, sigma):
|
||||
return latent / ((sigma**2 + 1) ** 0.5)
|
||||
|
||||
class SchedulerStepModel(torch.nn.Module):
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
|
||||
def forward(self, noise_pred, sigma, latent, dt):
|
||||
pred_original_sample = latent - sigma * noise_pred
|
||||
derivative = (latent - pred_original_sample) / sigma
|
||||
return latent + derivative * dt
|
||||
|
||||
iree_flags = []
|
||||
if len(args.iree_vulkan_target_triple) > 0:
|
||||
iree_flags.append(
|
||||
f"-iree-vulkan-target-triple={args.iree_vulkan_target_triple}"
|
||||
)
|
||||
# Disable bindings fusion to work with moltenVK.
|
||||
if sys.platform == "darwin":
|
||||
iree_flags.append("-iree-stream-fuse-binding=false")
|
||||
|
||||
if args.import_mlir:
|
||||
scaling_model = ScalingModel()
|
||||
self.scaling_model = compile_through_fx(
|
||||
scaling_model,
|
||||
(example_latent, example_sigma),
|
||||
model_name="euler_scale_model_input_" + args.precision,
|
||||
extra_args=iree_flags,
|
||||
)
|
||||
|
||||
step_model = SchedulerStepModel()
|
||||
self.step_model = compile_through_fx(
|
||||
step_model,
|
||||
(example_output, example_sigma, example_latent, example_dt),
|
||||
model_name="euler_step_" + args.precision,
|
||||
extra_args=iree_flags,
|
||||
)
|
||||
else:
|
||||
self.scaling_model = get_shark_model(
|
||||
SCHEDULER_BUCKET,
|
||||
"euler_scale_model_input_" + args.precision,
|
||||
iree_flags,
|
||||
)
|
||||
self.step_model = get_shark_model(
|
||||
SCHEDULER_BUCKET, "euler_step_" + args.precision, iree_flags
|
||||
)
|
||||
|
||||
def scale_model_input(self, sample, timestep):
|
||||
step_index = (self.timesteps == timestep).nonzero().item()
|
||||
sigma = self.sigmas[step_index]
|
||||
return self.scaling_model.forward(
|
||||
(
|
||||
sample,
|
||||
sigma,
|
||||
),
|
||||
send_to_host=False,
|
||||
)
|
||||
|
||||
def step(self, noise_pred, timestep, latent):
|
||||
step_index = (self.timesteps == timestep).nonzero().item()
|
||||
sigma = self.sigmas[step_index]
|
||||
dt = self.sigmas[step_index + 1] - sigma
|
||||
return self.step_model.forward(
|
||||
(
|
||||
noise_pred,
|
||||
sigma,
|
||||
latent,
|
||||
dt,
|
||||
),
|
||||
send_to_host=False,
|
||||
)
|
||||
@@ -1,226 +0,0 @@
|
||||
import argparse
|
||||
|
||||
p = argparse.ArgumentParser(
|
||||
description=__doc__, formatter_class=argparse.ArgumentDefaultsHelpFormatter
|
||||
)
|
||||
|
||||
##############################################################################
|
||||
### Stable Diffusion Params
|
||||
##############################################################################
|
||||
|
||||
p.add_argument(
|
||||
"--prompts",
|
||||
nargs="+",
|
||||
default=["cyberpunk forest by Salvador Dali"],
|
||||
help="text of which images to be generated.",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--negative-prompts",
|
||||
nargs="+",
|
||||
default=[""],
|
||||
help="text you don't want to see in the generated image.",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--steps",
|
||||
type=int,
|
||||
default=50,
|
||||
help="the no. of steps to do the sampling.",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--seed",
|
||||
type=int,
|
||||
default=42,
|
||||
help="the seed to use.",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--guidance_scale",
|
||||
type=float,
|
||||
default=7.5,
|
||||
help="the value to be used for guidance scaling.",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--max_length",
|
||||
type=int,
|
||||
default=64,
|
||||
help="max length of the tokenizer output, options are 64 and 77.",
|
||||
)
|
||||
|
||||
##############################################################################
|
||||
### Model Config and Usage Params
|
||||
##############################################################################
|
||||
|
||||
p.add_argument(
|
||||
"--device", type=str, default="vulkan", help="device to run the model."
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--version",
|
||||
type=str,
|
||||
default="v2_1base",
|
||||
help="Specify version of stable diffusion model",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--precision", type=str, default="fp16", help="precision to run the model."
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--import_mlir",
|
||||
default=False,
|
||||
action=argparse.BooleanOptionalAction,
|
||||
help="imports the model from torch module to shark_module otherwise downloads the model from shark_tank.",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--load_vmfb",
|
||||
default=True,
|
||||
action=argparse.BooleanOptionalAction,
|
||||
help="attempts to load the model from a precompiled flatbuffer and compiles + saves it if not found.",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--save_vmfb",
|
||||
default=False,
|
||||
action=argparse.BooleanOptionalAction,
|
||||
help="saves the compiled flatbuffer to the local directory",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--use_tuned",
|
||||
default=True,
|
||||
action=argparse.BooleanOptionalAction,
|
||||
help="Download and use the tuned version of the model if available",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--use_base_vae",
|
||||
default=False,
|
||||
action=argparse.BooleanOptionalAction,
|
||||
help="Do conversion from the VAE output to pixel space on cpu.",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--variant",
|
||||
default="stablediffusion",
|
||||
help="We now support multiple vairants of SD finetuned for different dataset. you can use the following anythingv3, ...", # TODO add more once supported
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--scheduler",
|
||||
type=str,
|
||||
default="SharkEulerDiscrete",
|
||||
help="other supported schedulers are [PNDM, DDIM, LMSDiscrete, EulerDiscrete, DPMSolverMultistep]",
|
||||
)
|
||||
|
||||
##############################################################################
|
||||
### IREE - Vulkan supported flags
|
||||
##############################################################################
|
||||
|
||||
p.add_argument(
|
||||
"--iree-vulkan-target-triple",
|
||||
type=str,
|
||||
default="",
|
||||
help="Specify target triple for vulkan",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--vulkan_debug_utils",
|
||||
default=False,
|
||||
action=argparse.BooleanOptionalAction,
|
||||
help="Profiles vulkan device and collects the .rdc info",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--vulkan_large_heap_block_size",
|
||||
default="4147483648",
|
||||
help="flag for setting VMA preferredLargeHeapBlockSize for vulkan device, default is 4G",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--vulkan_validation_layers",
|
||||
default=False,
|
||||
action=argparse.BooleanOptionalAction,
|
||||
help="flag for disabling vulkan validation layers when benchmarking",
|
||||
)
|
||||
|
||||
##############################################################################
|
||||
### Misc. Debug and Optimization flags
|
||||
##############################################################################
|
||||
|
||||
p.add_argument(
|
||||
"--use_compiled_scheduler",
|
||||
default=True,
|
||||
action=argparse.BooleanOptionalAction,
|
||||
help="use the default scheduler precompiled into the model if available",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--local_tank_cache",
|
||||
default="",
|
||||
help="Specify where to save downloaded shark_tank artifacts. If this is not set, the default is ~/.local/shark_tank/.",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--dump_isa",
|
||||
default=False,
|
||||
action="store_true",
|
||||
help="When enabled call amdllpc to get ISA dumps. use with dispatch benchmarks.",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--dispatch_benchmarks",
|
||||
default=None,
|
||||
help='dispatches to return benchamrk data on. use "All" for all, and None for none.',
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--dispatch_benchmarks_dir",
|
||||
default="temp_dispatch_benchmarks",
|
||||
help='directory where you want to store dispatch data generated with "--dispatch_benchmarks"',
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--enable_rgp",
|
||||
default=False,
|
||||
action=argparse.BooleanOptionalAction,
|
||||
help="flag for inserting debug frames between iterations for use with rgp.",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--hide_steps",
|
||||
default=True,
|
||||
action=argparse.BooleanOptionalAction,
|
||||
help="flag for hiding the details of iteration/sec for each step.",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--warmup_count",
|
||||
type=int,
|
||||
default=0,
|
||||
help="flag setting warmup count for clip and vae [>= 0].",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--clear_all",
|
||||
default=False,
|
||||
action=argparse.BooleanOptionalAction,
|
||||
help="flag to clear all mlir and vmfb from common locations. Recompiling will take several minutes",
|
||||
)
|
||||
|
||||
##############################################################################
|
||||
### Web UI flags
|
||||
##############################################################################
|
||||
|
||||
p.add_argument(
|
||||
"--progress_bar",
|
||||
default=True,
|
||||
action=argparse.BooleanOptionalAction,
|
||||
help="flag for removing the pregress bar animation during image generation",
|
||||
)
|
||||
|
||||
args = p.parse_args()
|
||||
@@ -1,138 +0,0 @@
|
||||
# Stable Diffusion optimized for AMD RDNA2/RDNA3 GPUs
|
||||
|
||||
Before you start, please be aware that this is beta software that relies on a special AMD driver. Like all StableDiffusion GUIs published so far, you need some technical expertise to set it up. We apologize in advance if you bump into issues. If that happens, please don't hesitate to ask our Discord community for help! If you still can't get it to work, we're sorry, and please be assured that we (Nod and AMD) are working hard to improve the user experience in coming months.
|
||||
If it works well for you, please "star" the following GitHub projects... this is one of the best ways to help and spread the word!
|
||||
|
||||
* https://github.com/nod-ai/SHARK
|
||||
* https://github.com/iree-org/iree
|
||||
|
||||
## Install the latest AMD Drivers
|
||||
|
||||
### AMD KB Drivers for RDNA2 and RDNA3:
|
||||
|
||||
*AMD Software: Adrenalin Edition 22.11.1 for MLIR/IREE Driver Version 22.20.29.09 for Windows® 10 and Windows® 11 (Windows Driver Store Version 31.0.12029.9003)*
|
||||
|
||||
First, download this special driver in a folder of your choice. We recommend you keep that driver around since you may need to re-install it later, if Windows Update decides to overwrite it:
|
||||
https://www.amd.com/en/support/kb/release-notes/rn-rad-win-22-11-1-mlir-iree
|
||||
|
||||
KNOWN ISSUES with this special AMD driver:
|
||||
* `Windows Update` may (depending how it's configured) automatically install a new official AMD driver that overwrites this IREE-specific driver. If Stable Diffusion used to work, then a few days later, it slows down a lot or produces incorrect results (e.g. black images), this may be the cause. To fix this problem, please check the installed driver's version, and re-install the special driver if needed. (TODO: document how to prevent this `Windows Update` behavior!)
|
||||
* Some people using this special driver experience mouse pointer accuracy issues, if you use a larger-than-default mouse pointer. The clicked point isn't centered properly. One possible work-around is to reset the pointer size to "1" in "Change pointer size and color".
|
||||
|
||||
## Installation
|
||||
|
||||
Download the latest Windows SHARK SD binary [here](https://github.com/nod-ai/SHARK/releases/download/20221220.400/shark_sd_20221220_400.exe) in a folder of your choice. Please read carefully the following notes:
|
||||
|
||||
Notes:
|
||||
* We recommend that you download this EXE in a new folder, whenever you download a new EXE version. If you download it in the same folder as a previous install, you must delete the old `*.vmfb` files. Those contain Vulkan dispatches compiled from MLIR, that can get outdated if you run multiple EXE from the same folder.
|
||||
* Your browser may warn you about downloading an .exe file
|
||||
* If you recently updated the driver or this binary (EXE file), we recommend you:
|
||||
* clear the Vulkan shader cache: For Windows users this can be done by clearing the contents of `C:\Users\<username>\AppData\Local\AMD\VkCache\`. On Linux the same cache is typically located at `~/.cache/AMD/VkCache/`.
|
||||
* clear the `huggingface` cache. In Windows, this is `C:\Users\<username>\.cache\huggingface`.
|
||||
|
||||
## Running
|
||||
|
||||
* Open a Command Prompt or Powershell terminal, change folder (`cd`) to the .exe folder. Then run the EXE from the command prompt. That way, if an error occurs, you'll be able to cut-and-paste it to ask for help. (if it always works for you without error, you may simply double-click the EXE to start the web browser)
|
||||
* The first run may take about 10-15 minutes when the models are downloaded and compiled. Your patience is appreciated. The download could be about 5GB.
|
||||
* If successful, you will likely see a Windows Defender message asking you to give permission to open a web server port. Accept it.
|
||||
* Open a browser to access the Stable Diffusion web server. By default, the port is 8080, so you can go to http://localhost:8080/?__theme=dark.
|
||||
|
||||
## Stopping
|
||||
|
||||
* Select the command prompt that's running the EXE. Press CTRL-C and wait a moment. The application should stop.
|
||||
* Please make sure to do the above step before you attempt to update the EXE to a new version.
|
||||
|
||||
# Results
|
||||
|
||||
<img width="1607" alt="webui" src="https://user-images.githubusercontent.com/74956/204939260-b8308bc2-8dc4-47f6-9ac0-f60b66edab99.png">
|
||||
|
||||
|
||||
Here are some samples generated:
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
|
||||
<details>
|
||||
<summary>Advanced Installation </summary>
|
||||
|
||||
|
||||
## Setup your Python VirtualEnvironment and Dependencies
|
||||
|
||||
### Windows 10/11 Users
|
||||
|
||||
* Install the latest Python 3.10.x version from [here](https://www.python.org/downloads/windows/)
|
||||
|
||||
* Install Git for Windows from [here](https://git-scm.com/download/win)
|
||||
|
||||
#### Allow the install script to run in Powershell
|
||||
```powershell
|
||||
set-executionpolicy remotesigned
|
||||
```
|
||||
|
||||
#### Setup venv and install necessary packages (torch-mlir, nodLabs/Shark, ...)
|
||||
```powershell
|
||||
git clone https://github.com/nod-ai/SHARK.git
|
||||
cd SHARK
|
||||
./setup_venv.ps1 #You can re-run this script to get the latest version
|
||||
```
|
||||
|
||||
### Linux
|
||||
|
||||
```shell
|
||||
git clone https://github.com/nod-ai/SHARK.git
|
||||
cd SHARK
|
||||
./setup_venv.sh
|
||||
source shark.venv/bin/activate
|
||||
```
|
||||
|
||||
### Run Stable Diffusion on your device - WebUI
|
||||
|
||||
#### Windows 10/11 Users
|
||||
```powershell
|
||||
(shark.venv) PS C:\Users\nod\SHARK> cd web
|
||||
(shark.venv) PS C:\Users\nod\SHARK\web> python index.py
|
||||
```
|
||||
#### Linux Users
|
||||
```shell
|
||||
(shark.venv) > cd web
|
||||
(shark.venv) > python index.py
|
||||
```
|
||||
|
||||
|
||||
|
||||
### Run Stable Diffusion on your device - Commandline
|
||||
|
||||
#### Windows 10/11 Users
|
||||
```powershell
|
||||
(shark.venv) PS C:\g\shark> python .\shark\examples\shark_inference\stable_diffusion\main.py --precision="fp16" --prompt="tajmahal, snow, sunflowers, oil on canvas" --device="vulkan"
|
||||
```
|
||||
|
||||
#### Linux
|
||||
```shell
|
||||
python3.10 shark/examples/shark_inference/stable_diffusion/main.py --precision=fp16 --device=vulkan --prompt="tajmahal, oil on canvas, sunflowers, 4k, uhd"
|
||||
```
|
||||
|
||||
The output on a 6900XT would like:
|
||||
|
||||
```shell
|
||||
44it [00:08, 5.14it/s]i = 44 t = 120 (191ms)
|
||||
45it [00:08, 5.15it/s]i = 45 t = 100 (191ms)
|
||||
46it [00:08, 5.16it/s]i = 46 t = 80 (191ms)
|
||||
47it [00:09, 5.16it/s]i = 47 t = 60 (193ms)
|
||||
48it [00:09, 5.15it/s]i = 48 t = 40 (195ms)
|
||||
49it [00:09, 5.12it/s]i = 49 t = 20 (196ms)
|
||||
50it [00:09, 5.14it/s]
|
||||
Average step time: 192.8154182434082ms/it
|
||||
Total image generation runtime (s): 10.390909433364868
|
||||
(shark.venv) PS C:\g\shark>
|
||||
```
|
||||
|
||||
|
||||
For more options to the Stable Diffusion model read [this](https://github.com/nod-ai/SHARK/blob/main/shark/examples/shark_inference/stable_diffusion/README.md)
|
||||
</details>
|
||||
<details>
|
||||
<summary>Discord link</summary>
|
||||
Find us on [SHARK Discord server](https://discord.gg/RUqY2h2s9u) if you have any trouble with running it on your hardware.
|
||||
</details>
|
||||
@@ -33,7 +33,7 @@ mlir_importer = SharkImporter(
|
||||
tracing_required=False
|
||||
)
|
||||
|
||||
shark_module = SharkInference(vision_mlir, func_name, mlir_dialect="linalg")
|
||||
shark_module = SharkInference(vision_mlir, mlir_dialect="linalg")
|
||||
shark_module.compile()
|
||||
result = shark_module.forward((input,))
|
||||
np.testing.assert_allclose(golden_out, result, rtol=1e-02, atol=1e-03)
|
||||
|
||||
21
shark/examples/shark_inference/upscaler/main.py
Normal file
21
shark/examples/shark_inference/upscaler/main.py
Normal file
@@ -0,0 +1,21 @@
|
||||
import requests
|
||||
from PIL import Image
|
||||
from io import BytesIO
|
||||
from pipeline_shark_stable_diffusion_upscale import (
|
||||
SharkStableDiffusionUpscalePipeline,
|
||||
)
|
||||
import torch
|
||||
|
||||
model_id = "stabilityai/stable-diffusion-x4-upscaler"
|
||||
pipeline = SharkStableDiffusionUpscalePipeline(model_id)
|
||||
|
||||
# let's download an image
|
||||
url = "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd2-upscale/low_res_cat.png"
|
||||
response = requests.get(url)
|
||||
low_res_img = Image.open(BytesIO(response.content)).convert("RGB")
|
||||
low_res_img = low_res_img.resize((128, 128))
|
||||
|
||||
prompt = "a white cat"
|
||||
|
||||
upscaled_image = pipeline(prompt=prompt, image=low_res_img).images[0]
|
||||
upscaled_image.save("upsampled_cat.png")
|
||||
98
shark/examples/shark_inference/upscaler/model_wrappers.py
Normal file
98
shark/examples/shark_inference/upscaler/model_wrappers.py
Normal file
@@ -0,0 +1,98 @@
|
||||
from diffusers import AutoencoderKL, UNet2DConditionModel
|
||||
from transformers import CLIPTextModel
|
||||
from utils import compile_through_fx
|
||||
import torch
|
||||
|
||||
model_id = "stabilityai/stable-diffusion-x4-upscaler"
|
||||
|
||||
model_input = {
|
||||
"clip": (torch.randint(1, 2, (1, 77)),),
|
||||
"vae": (torch.randn(1, 4, 128, 128),),
|
||||
"unet": (
|
||||
torch.randn(2, 7, 128, 128), # latents
|
||||
torch.tensor([1]).to(torch.float32), # timestep
|
||||
torch.randn(2, 77, 1024), # embedding
|
||||
torch.randn(2).to(torch.int64), # noise_level
|
||||
),
|
||||
}
|
||||
|
||||
|
||||
def get_clip_mlir(model_name="clip_text", extra_args=[]):
|
||||
text_encoder = CLIPTextModel.from_pretrained(
|
||||
model_id,
|
||||
subfolder="text_encoder",
|
||||
)
|
||||
|
||||
class CLIPText(torch.nn.Module):
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
self.text_encoder = text_encoder
|
||||
|
||||
def forward(self, input):
|
||||
return self.text_encoder(input)[0]
|
||||
|
||||
clip_model = CLIPText()
|
||||
shark_clip = compile_through_fx(
|
||||
clip_model,
|
||||
model_input["clip"],
|
||||
model_name=model_name,
|
||||
extra_args=extra_args,
|
||||
)
|
||||
return shark_clip
|
||||
|
||||
|
||||
def get_vae_mlir(model_name="vae", extra_args=[]):
|
||||
class VaeModel(torch.nn.Module):
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
self.vae = AutoencoderKL.from_pretrained(
|
||||
model_id,
|
||||
subfolder="vae",
|
||||
)
|
||||
|
||||
def forward(self, input):
|
||||
x = self.vae.decode(input, return_dict=False)[0]
|
||||
return x
|
||||
|
||||
vae = VaeModel()
|
||||
shark_vae = compile_through_fx(
|
||||
vae,
|
||||
model_input["vae"],
|
||||
model_name=model_name,
|
||||
extra_args=extra_args,
|
||||
)
|
||||
return shark_vae
|
||||
|
||||
|
||||
def get_unet_mlir(model_name="unet", extra_args=[]):
|
||||
class UnetModel(torch.nn.Module):
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
self.unet = UNet2DConditionModel.from_pretrained(
|
||||
model_id,
|
||||
subfolder="unet",
|
||||
)
|
||||
self.in_channels = self.unet.in_channels
|
||||
self.train(False)
|
||||
|
||||
def forward(self, latent, timestep, text_embedding, noise_level):
|
||||
unet_out = self.unet.forward(
|
||||
latent,
|
||||
timestep,
|
||||
text_embedding,
|
||||
noise_level,
|
||||
return_dict=False,
|
||||
)[0]
|
||||
return unet_out
|
||||
|
||||
unet = UnetModel()
|
||||
f16_input_mask = (True, True, True, False)
|
||||
shark_unet = compile_through_fx(
|
||||
unet,
|
||||
model_input["unet"],
|
||||
model_name=model_name,
|
||||
is_f16=True,
|
||||
f16_input_mask=f16_input_mask,
|
||||
extra_args=extra_args,
|
||||
)
|
||||
return shark_unet
|
||||
48
shark/examples/shark_inference/upscaler/opt_params.py
Normal file
48
shark/examples/shark_inference/upscaler/opt_params.py
Normal file
@@ -0,0 +1,48 @@
|
||||
import sys
|
||||
from model_wrappers import (
|
||||
get_vae_mlir,
|
||||
get_unet_mlir,
|
||||
get_clip_mlir,
|
||||
)
|
||||
from upscaler_args import args
|
||||
from utils import get_shark_model
|
||||
|
||||
BATCH_SIZE = len(args.prompts)
|
||||
if BATCH_SIZE != 1:
|
||||
sys.exit("Only batch size 1 is supported.")
|
||||
|
||||
|
||||
unet_flag = [
|
||||
"--iree-preprocessing-pass-pipeline=builtin.module(func.func(iree-preprocessing-convert-conv2d-to-img2col,iree-preprocessing-pad-linalg-ops{pad-size=32}))"
|
||||
]
|
||||
|
||||
vae_flag = [
|
||||
"--iree-preprocessing-pass-pipeline=builtin.module(func.func(iree-flow-convert-conv-nchw-to-nhwc,iree-preprocessing-pad-linalg-ops{pad-size=16}))"
|
||||
]
|
||||
|
||||
clip_flag = [
|
||||
"--iree-preprocessing-pass-pipeline=builtin.module(func.func(iree-preprocessing-pad-linalg-ops{pad-size=16}))"
|
||||
]
|
||||
|
||||
bucket = "gs://shark_tank/stable_diffusion/"
|
||||
|
||||
|
||||
def get_unet():
|
||||
model_name = "upscaler_unet"
|
||||
if args.import_mlir:
|
||||
return get_unet_mlir(model_name, unet_flag)
|
||||
return get_shark_model(bucket, model_name, unet_flag)
|
||||
|
||||
|
||||
def get_vae():
|
||||
model_name = "upscaler_vae"
|
||||
if args.import_mlir:
|
||||
return get_vae_mlir(model_name, vae_flag)
|
||||
return get_shark_model(bucket, model_name, vae_flag)
|
||||
|
||||
|
||||
def get_clip():
|
||||
model_name = "upscaler_clip"
|
||||
if args.import_mlir:
|
||||
return get_clip_mlir(model_name, clip_flag)
|
||||
return get_shark_model(bucket, model_name, clip_flag)
|
||||
@@ -0,0 +1,489 @@
|
||||
import inspect
|
||||
from typing import Callable, List, Optional, Union
|
||||
|
||||
import numpy as np
|
||||
import torch
|
||||
|
||||
import PIL
|
||||
from PIL import Image
|
||||
from diffusers.utils import is_accelerate_available
|
||||
from transformers import CLIPTextModel, CLIPTokenizer
|
||||
from diffusers import AutoencoderKL, UNet2DConditionModel
|
||||
from diffusers import (
|
||||
DDIMScheduler,
|
||||
DDPMScheduler,
|
||||
LMSDiscreteScheduler,
|
||||
PNDMScheduler,
|
||||
)
|
||||
from diffusers import logging
|
||||
from diffusers.pipeline_utils import ImagePipelineOutput
|
||||
from opt_params import get_unet, get_vae, get_clip
|
||||
from tqdm.auto import tqdm
|
||||
|
||||
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
|
||||
|
||||
|
||||
def preprocess(image):
|
||||
if isinstance(image, torch.Tensor):
|
||||
return image
|
||||
elif isinstance(image, PIL.Image.Image):
|
||||
image = [image]
|
||||
|
||||
if isinstance(image[0], PIL.Image.Image):
|
||||
w, h = image[0].size
|
||||
w, h = map(
|
||||
lambda x: x - x % 64, (w, h)
|
||||
) # resize to integer multiple of 64
|
||||
|
||||
image = [np.array(i.resize((w, h)))[None, :] for i in image]
|
||||
image = np.concatenate(image, axis=0)
|
||||
image = np.array(image).astype(np.float32) / 255.0
|
||||
image = image.transpose(0, 3, 1, 2)
|
||||
image = 2.0 * image - 1.0
|
||||
image = torch.from_numpy(image)
|
||||
elif isinstance(image[0], torch.Tensor):
|
||||
image = torch.cat(image, dim=0)
|
||||
return image
|
||||
|
||||
|
||||
def shark_run_wrapper(model, *args):
|
||||
np_inputs = tuple([x.detach().numpy() for x in args])
|
||||
outputs = model("forward", np_inputs)
|
||||
return torch.from_numpy(outputs)
|
||||
|
||||
|
||||
class SharkStableDiffusionUpscalePipeline:
|
||||
def __init__(
|
||||
self,
|
||||
model_id,
|
||||
):
|
||||
self.tokenizer = CLIPTokenizer.from_pretrained(
|
||||
model_id, subfolder="tokenizer"
|
||||
)
|
||||
self.low_res_scheduler = DDPMScheduler.from_pretrained(
|
||||
model_id,
|
||||
subfolder="scheduler",
|
||||
)
|
||||
self.scheduler = DDIMScheduler.from_pretrained(
|
||||
model_id,
|
||||
subfolder="scheduler",
|
||||
)
|
||||
self.vae = get_vae()
|
||||
self.unet = get_unet()
|
||||
self.text_encoder = get_clip()
|
||||
self.max_noise_level = (350,)
|
||||
self._execution_device = "cpu"
|
||||
|
||||
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._encode_prompt
|
||||
def _encode_prompt(
|
||||
self,
|
||||
prompt,
|
||||
device,
|
||||
num_images_per_prompt,
|
||||
do_classifier_free_guidance,
|
||||
negative_prompt,
|
||||
):
|
||||
r"""
|
||||
Encodes the prompt into text encoder hidden states.
|
||||
Args:
|
||||
prompt (`str` or `list(int)`):
|
||||
prompt to be encoded
|
||||
device: (`torch.device`):
|
||||
torch device
|
||||
num_images_per_prompt (`int`):
|
||||
number of images that should be generated per prompt
|
||||
do_classifier_free_guidance (`bool`):
|
||||
whether to use classifier free guidance or not
|
||||
negative_prompt (`str` or `List[str]`):
|
||||
The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
|
||||
if `guidance_scale` is less than `1`).
|
||||
"""
|
||||
batch_size = len(prompt) if isinstance(prompt, list) else 1
|
||||
|
||||
text_inputs = self.tokenizer(
|
||||
prompt,
|
||||
padding="max_length",
|
||||
max_length=self.tokenizer.model_max_length,
|
||||
truncation=True,
|
||||
return_tensors="pt",
|
||||
)
|
||||
text_input_ids = text_inputs.input_ids
|
||||
untruncated_ids = self.tokenizer(
|
||||
prompt, padding="longest", return_tensors="pt"
|
||||
).input_ids
|
||||
|
||||
if untruncated_ids.shape[-1] >= text_input_ids.shape[
|
||||
-1
|
||||
] and not torch.equal(text_input_ids, untruncated_ids):
|
||||
removed_text = self.tokenizer.batch_decode(
|
||||
untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1]
|
||||
)
|
||||
logger.warning(
|
||||
"The following part of your input was truncated because CLIP can only handle sequences up to"
|
||||
f" {self.tokenizer.model_max_length} tokens: {removed_text}"
|
||||
)
|
||||
|
||||
# if (
|
||||
# hasattr(self.text_encoder.config, "use_attention_mask")
|
||||
# and self.text_encoder.config.use_attention_mask
|
||||
# ):
|
||||
# attention_mask = text_inputs.attention_mask.to(device)
|
||||
# else:
|
||||
# attention_mask = None
|
||||
|
||||
text_embeddings = shark_run_wrapper(
|
||||
self.text_encoder, text_input_ids.to(device)
|
||||
)
|
||||
|
||||
# duplicate text embeddings for each generation per prompt, using mps friendly method
|
||||
bs_embed, seq_len, _ = text_embeddings.shape
|
||||
text_embeddings = text_embeddings.repeat(1, num_images_per_prompt, 1)
|
||||
text_embeddings = text_embeddings.view(
|
||||
bs_embed * num_images_per_prompt, seq_len, -1
|
||||
)
|
||||
|
||||
# get unconditional embeddings for classifier free guidance
|
||||
if do_classifier_free_guidance:
|
||||
uncond_tokens: List[str]
|
||||
if negative_prompt is None:
|
||||
uncond_tokens = [""] * batch_size
|
||||
elif type(prompt) is not type(negative_prompt):
|
||||
raise TypeError(
|
||||
f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
|
||||
f" {type(prompt)}."
|
||||
)
|
||||
elif isinstance(negative_prompt, str):
|
||||
uncond_tokens = [negative_prompt]
|
||||
elif batch_size != len(negative_prompt):
|
||||
raise ValueError(
|
||||
f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
|
||||
f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
|
||||
" the batch size of `prompt`."
|
||||
)
|
||||
else:
|
||||
uncond_tokens = negative_prompt
|
||||
|
||||
max_length = text_input_ids.shape[-1]
|
||||
uncond_input = self.tokenizer(
|
||||
uncond_tokens,
|
||||
padding="max_length",
|
||||
max_length=max_length,
|
||||
truncation=True,
|
||||
return_tensors="pt",
|
||||
)
|
||||
|
||||
# if (
|
||||
# hasattr(self.text_encoder.config, "use_attention_mask")
|
||||
# and self.text_encoder.config.use_attention_mask
|
||||
# ):
|
||||
# attention_mask = uncond_input.attention_mask.to(device)
|
||||
# else:
|
||||
# attention_mask = None
|
||||
|
||||
uncond_embeddings = shark_run_wrapper(
|
||||
self.text_encoder,
|
||||
uncond_input.input_ids.to(device),
|
||||
)
|
||||
uncond_embeddings = uncond_embeddings
|
||||
|
||||
# duplicate unconditional embeddings for each generation per prompt, using mps friendly method
|
||||
seq_len = uncond_embeddings.shape[1]
|
||||
uncond_embeddings = uncond_embeddings.repeat(
|
||||
1, num_images_per_prompt, 1
|
||||
)
|
||||
uncond_embeddings = uncond_embeddings.view(
|
||||
batch_size * num_images_per_prompt, seq_len, -1
|
||||
)
|
||||
|
||||
# For classifier free guidance, we need to do two forward passes.
|
||||
# Here we concatenate the unconditional and text embeddings into a single batch
|
||||
# to avoid doing two forward passes
|
||||
text_embeddings = torch.cat([uncond_embeddings, text_embeddings])
|
||||
|
||||
return text_embeddings
|
||||
|
||||
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_extra_step_kwargs
|
||||
def prepare_extra_step_kwargs(self, generator, eta):
|
||||
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
|
||||
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
|
||||
# eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
|
||||
# and should be between [0, 1]
|
||||
|
||||
accepts_eta = "eta" in set(
|
||||
inspect.signature(self.scheduler.step).parameters.keys()
|
||||
)
|
||||
extra_step_kwargs = {}
|
||||
if accepts_eta:
|
||||
extra_step_kwargs["eta"] = eta
|
||||
|
||||
# check if the scheduler accepts generator
|
||||
accepts_generator = "generator" in set(
|
||||
inspect.signature(self.scheduler.step).parameters.keys()
|
||||
)
|
||||
if accepts_generator:
|
||||
extra_step_kwargs["generator"] = generator
|
||||
return extra_step_kwargs
|
||||
|
||||
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.decode_latents with 0.18215->0.08333
|
||||
def decode_latents(self, latents):
|
||||
latents = 1 / 0.08333 * latents
|
||||
image = shark_run_wrapper(self.vae, latents)
|
||||
image = (image / 2 + 0.5).clamp(0, 1)
|
||||
# we always cast to float32 as this does not cause significant overhead and is compatible with bfloa16
|
||||
image = image.cpu().permute(0, 2, 3, 1).float().numpy()
|
||||
return image
|
||||
|
||||
def check_inputs(self, prompt, image, noise_level, callback_steps):
|
||||
if not isinstance(prompt, str) and not isinstance(prompt, list):
|
||||
raise ValueError(
|
||||
f"`prompt` has to be of type `str` or `list` but is {type(prompt)}"
|
||||
)
|
||||
|
||||
if (
|
||||
not isinstance(image, torch.Tensor)
|
||||
and not isinstance(image, PIL.Image.Image)
|
||||
and not isinstance(image, list)
|
||||
):
|
||||
raise ValueError(
|
||||
f"`image` has to be of type `torch.Tensor`, `PIL.Image.Image` or `list` but is {type(image)}"
|
||||
)
|
||||
|
||||
# verify batch size of prompt and image are same if image is a list or tensor
|
||||
if isinstance(image, list) or isinstance(image, torch.Tensor):
|
||||
if isinstance(prompt, str):
|
||||
batch_size = 1
|
||||
else:
|
||||
batch_size = len(prompt)
|
||||
if isinstance(image, list):
|
||||
image_batch_size = len(image)
|
||||
else:
|
||||
image_batch_size = image.shape[0]
|
||||
if batch_size != image_batch_size:
|
||||
raise ValueError(
|
||||
f"`prompt` has batch size {batch_size} and `image` has batch size {image_batch_size}."
|
||||
" Please make sure that passed `prompt` matches the batch size of `image`."
|
||||
)
|
||||
|
||||
@staticmethod
|
||||
def numpy_to_pil(images):
|
||||
"""
|
||||
Convert a numpy image or a batch of images to a PIL image.
|
||||
"""
|
||||
if images.ndim == 3:
|
||||
images = images[None, ...]
|
||||
images = (images * 255).round().astype("uint8")
|
||||
if images.shape[-1] == 1:
|
||||
# special case for grayscale (single channel) images
|
||||
pil_images = [
|
||||
Image.fromarray(image.squeeze(), mode="L") for image in images
|
||||
]
|
||||
else:
|
||||
pil_images = [Image.fromarray(image) for image in images]
|
||||
|
||||
return pil_images
|
||||
|
||||
def prepare_latents(
|
||||
self,
|
||||
batch_size,
|
||||
num_channels_latents,
|
||||
height,
|
||||
width,
|
||||
dtype,
|
||||
device,
|
||||
generator,
|
||||
latents=None,
|
||||
):
|
||||
shape = (batch_size, num_channels_latents, height, width)
|
||||
if latents is None:
|
||||
if device == "mps":
|
||||
# randn does not work reproducibly on mps
|
||||
latents = torch.randn(
|
||||
shape, generator=generator, device="cpu", dtype=dtype
|
||||
).to(device)
|
||||
else:
|
||||
latents = torch.randn(
|
||||
shape, generator=generator, device=device, dtype=dtype
|
||||
)
|
||||
else:
|
||||
if latents.shape != shape:
|
||||
raise ValueError(
|
||||
f"Unexpected latents shape, got {latents.shape}, expected {shape}"
|
||||
)
|
||||
latents = latents.to(device)
|
||||
|
||||
# scale the initial noise by the standard deviation required by the scheduler
|
||||
latents = latents * self.scheduler.init_noise_sigma
|
||||
return latents
|
||||
|
||||
@torch.no_grad()
|
||||
def __call__(
|
||||
self,
|
||||
prompt: Union[str, List[str]],
|
||||
image: Union[
|
||||
torch.FloatTensor, PIL.Image.Image, List[PIL.Image.Image]
|
||||
],
|
||||
num_inference_steps: int = 75,
|
||||
guidance_scale: float = 9.0,
|
||||
noise_level: int = 20,
|
||||
negative_prompt: Optional[Union[str, List[str]]] = None,
|
||||
num_images_per_prompt: Optional[int] = 1,
|
||||
eta: float = 0.0,
|
||||
generator: Optional[
|
||||
Union[torch.Generator, List[torch.Generator]]
|
||||
] = None,
|
||||
latents: Optional[torch.FloatTensor] = None,
|
||||
output_type: Optional[str] = "pil",
|
||||
return_dict: bool = True,
|
||||
callback: Optional[
|
||||
Callable[[int, int, torch.FloatTensor], None]
|
||||
] = None,
|
||||
callback_steps: Optional[int] = 1,
|
||||
):
|
||||
# 1. Check inputs
|
||||
self.check_inputs(prompt, image, noise_level, callback_steps)
|
||||
|
||||
# 2. Define call parameters
|
||||
batch_size = 1 if isinstance(prompt, str) else len(prompt)
|
||||
device = self._execution_device
|
||||
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
|
||||
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
|
||||
# corresponds to doing no classifier free guidance.
|
||||
do_classifier_free_guidance = guidance_scale > 1.0
|
||||
|
||||
# 3. Encode input prompt
|
||||
text_embeddings = self._encode_prompt(
|
||||
prompt,
|
||||
device,
|
||||
num_images_per_prompt,
|
||||
do_classifier_free_guidance,
|
||||
negative_prompt,
|
||||
)
|
||||
|
||||
# 4. Preprocess image
|
||||
image = preprocess(image)
|
||||
image = image.to(dtype=text_embeddings.dtype, device=device)
|
||||
|
||||
# 5. set timesteps
|
||||
self.scheduler.set_timesteps(num_inference_steps, device=device)
|
||||
timesteps = self.scheduler.timesteps
|
||||
|
||||
# 5. Add noise to image
|
||||
noise_level = torch.tensor(
|
||||
[noise_level], dtype=torch.long, device=device
|
||||
)
|
||||
if device == "mps":
|
||||
# randn does not work reproducibly on mps
|
||||
noise = torch.randn(
|
||||
image.shape,
|
||||
generator=generator,
|
||||
device="cpu",
|
||||
dtype=text_embeddings.dtype,
|
||||
).to(device)
|
||||
else:
|
||||
noise = torch.randn(
|
||||
image.shape,
|
||||
generator=generator,
|
||||
device=device,
|
||||
dtype=text_embeddings.dtype,
|
||||
)
|
||||
image = self.low_res_scheduler.add_noise(image, noise, noise_level)
|
||||
|
||||
batch_multiplier = 2 if do_classifier_free_guidance else 1
|
||||
image = torch.cat([image] * batch_multiplier * num_images_per_prompt)
|
||||
noise_level = torch.cat([noise_level] * image.shape[0])
|
||||
|
||||
# 6. Prepare latent variables
|
||||
height, width = image.shape[2:]
|
||||
# num_channels_latents = self.vae.config.latent_channels
|
||||
num_channels_latents = 4
|
||||
latents = self.prepare_latents(
|
||||
batch_size * num_images_per_prompt,
|
||||
num_channels_latents,
|
||||
height,
|
||||
width,
|
||||
text_embeddings.dtype,
|
||||
device,
|
||||
generator,
|
||||
latents,
|
||||
)
|
||||
|
||||
# 7. Check that sizes of image and latents match
|
||||
num_channels_image = image.shape[1]
|
||||
# if (
|
||||
# num_channels_latents + num_channels_image
|
||||
# != self.unet.config.in_channels
|
||||
# ):
|
||||
# raise ValueError(
|
||||
# f"Incorrect configuration settings! The config of `pipeline.unet`: {self.unet.config} expects"
|
||||
# f" {self.unet.config.in_channels} but received `num_channels_latents`: {num_channels_latents} +"
|
||||
# f" `num_channels_image`: {num_channels_image} "
|
||||
# f" = {num_channels_latents+num_channels_image}. Please verify the config of"
|
||||
# " `pipeline.unet` or your `image` input."
|
||||
# )
|
||||
|
||||
# 8. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
|
||||
extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
|
||||
|
||||
# 9. Denoising loop
|
||||
num_warmup_steps = (
|
||||
len(timesteps) - num_inference_steps * self.scheduler.order
|
||||
)
|
||||
for i, t in tqdm(enumerate(timesteps)):
|
||||
# expand the latents if we are doing classifier free guidance
|
||||
latent_model_input = (
|
||||
torch.cat([latents] * 2)
|
||||
if do_classifier_free_guidance
|
||||
else latents
|
||||
)
|
||||
|
||||
# concat latents, mask, masked_image_latents in the channel dimension
|
||||
latent_model_input = self.scheduler.scale_model_input(
|
||||
latent_model_input, t
|
||||
)
|
||||
latent_model_input = torch.cat([latent_model_input, image], dim=1)
|
||||
|
||||
timestep = torch.tensor([t]).to(torch.float32)
|
||||
|
||||
# predict the noise residual
|
||||
noise_pred = shark_run_wrapper(
|
||||
self.unet,
|
||||
latent_model_input.half(),
|
||||
timestep,
|
||||
text_embeddings.half(),
|
||||
noise_level,
|
||||
)
|
||||
|
||||
# perform guidance
|
||||
if do_classifier_free_guidance:
|
||||
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
|
||||
noise_pred = noise_pred_uncond + guidance_scale * (
|
||||
noise_pred_text - noise_pred_uncond
|
||||
)
|
||||
|
||||
# compute the previous noisy sample x_t -> x_t-1
|
||||
latents = self.scheduler.step(
|
||||
noise_pred, t, latents, **extra_step_kwargs
|
||||
).prev_sample
|
||||
|
||||
# # call the callback, if provided
|
||||
# if i == len(timesteps) - 1 or (
|
||||
# (i + 1) > num_warmup_steps
|
||||
# and (i + 1) % self.scheduler.order == 0
|
||||
# ):
|
||||
# progress_bar.update()
|
||||
# if callback is not None and i % callback_steps == 0:
|
||||
# callback(i, t, latents)
|
||||
|
||||
# 10. Post-processing
|
||||
# make sure the VAE is in float32 mode, as it overflows in float16
|
||||
# self.vae.to(dtype=torch.float32)
|
||||
image = self.decode_latents(latents.float())
|
||||
|
||||
# 11. Convert to PIL
|
||||
if output_type == "pil":
|
||||
image = self.numpy_to_pil(image)
|
||||
|
||||
if not return_dict:
|
||||
return (image,)
|
||||
|
||||
return ImagePipelineOutput(images=image)
|
||||
98
shark/examples/shark_inference/upscaler/upscaler_args.py
Normal file
98
shark/examples/shark_inference/upscaler/upscaler_args.py
Normal file
@@ -0,0 +1,98 @@
|
||||
import argparse
|
||||
|
||||
p = argparse.ArgumentParser(
|
||||
description=__doc__, formatter_class=argparse.ArgumentDefaultsHelpFormatter
|
||||
)
|
||||
|
||||
##############################################################################
|
||||
### Stable Diffusion Params
|
||||
##############################################################################
|
||||
|
||||
p.add_argument(
|
||||
"--prompts",
|
||||
nargs="+",
|
||||
default=["cyberpunk forest by Salvador Dali"],
|
||||
help="text of which images to be generated.",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--negative-prompts",
|
||||
nargs="+",
|
||||
default=[""],
|
||||
help="text you don't want to see in the generated image.",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--steps",
|
||||
type=int,
|
||||
default=50,
|
||||
help="the no. of steps to do the sampling.",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--seed",
|
||||
type=int,
|
||||
default=42,
|
||||
help="the seed to use.",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--guidance_scale",
|
||||
type=float,
|
||||
default=7.5,
|
||||
help="the value to be used for guidance scaling.",
|
||||
)
|
||||
|
||||
##############################################################################
|
||||
### Model Config and Usage Params
|
||||
##############################################################################
|
||||
|
||||
p.add_argument(
|
||||
"--device", type=str, default="vulkan", help="device to run the model."
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--precision", type=str, default="fp16", help="precision to run the model."
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--import_mlir",
|
||||
default=False,
|
||||
action=argparse.BooleanOptionalAction,
|
||||
help="imports the model from torch module to shark_module otherwise downloads the model from shark_tank.",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--load_vmfb",
|
||||
default=True,
|
||||
action=argparse.BooleanOptionalAction,
|
||||
help="attempts to load the model from a precompiled flatbuffer and compiles + saves it if not found.",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--save_vmfb",
|
||||
default=False,
|
||||
action=argparse.BooleanOptionalAction,
|
||||
help="saves the compiled flatbuffer to the local directory",
|
||||
)
|
||||
|
||||
##############################################################################
|
||||
### IREE - Vulkan supported flags
|
||||
##############################################################################
|
||||
|
||||
p.add_argument(
|
||||
"--iree-vulkan-target-triple",
|
||||
type=str,
|
||||
default="",
|
||||
help="Specify target triple for vulkan",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--vulkan_debug_utils",
|
||||
default=False,
|
||||
action=argparse.BooleanOptionalAction,
|
||||
help="Profiles vulkan device and collects the .rdc info",
|
||||
)
|
||||
|
||||
|
||||
args = p.parse_args()
|
||||
@@ -1,11 +1,12 @@
|
||||
import os
|
||||
import torch
|
||||
from shark.shark_inference import SharkInference
|
||||
from stable_args import args
|
||||
from upscaler_args import args
|
||||
from shark.shark_importer import import_with_fx
|
||||
from shark.iree_utils.vulkan_utils import (
|
||||
set_iree_vulkan_runtime_flags,
|
||||
get_vulkan_target_triple,
|
||||
get_iree_vulkan_runtime_flags,
|
||||
)
|
||||
|
||||
|
||||
@@ -45,7 +46,7 @@ def get_shark_model(tank_url, model_name, extra_args=[]):
|
||||
from shark.parser import shark_args
|
||||
|
||||
# Set local shark_tank cache directory.
|
||||
shark_args.local_tank_cache = args.local_tank_cache
|
||||
# shark_args.local_tank_cache = args.local_tank_cache
|
||||
|
||||
mlir_model, func_name, inputs, golden_out = download_model(
|
||||
model_name,
|
||||
@@ -53,19 +54,20 @@ def get_shark_model(tank_url, model_name, extra_args=[]):
|
||||
frontend="torch",
|
||||
)
|
||||
shark_module = SharkInference(
|
||||
mlir_model, func_name, device=args.device, mlir_dialect="linalg"
|
||||
mlir_model, device=args.device, mlir_dialect="linalg"
|
||||
)
|
||||
return _compile_module(shark_module, model_name, extra_args)
|
||||
|
||||
|
||||
# Converts the torch-module into a shark_module.
|
||||
def compile_through_fx(model, inputs, model_name, extra_args=[]):
|
||||
|
||||
mlir_module, func_name = import_with_fx(model, inputs)
|
||||
|
||||
def compile_through_fx(
|
||||
model, inputs, model_name, is_f16=False, f16_input_mask=None, extra_args=[]
|
||||
):
|
||||
mlir_module, func_name = import_with_fx(
|
||||
model, inputs, is_f16, f16_input_mask
|
||||
)
|
||||
shark_module = SharkInference(
|
||||
mlir_module,
|
||||
func_name,
|
||||
device=args.device,
|
||||
mlir_dialect="linalg",
|
||||
)
|
||||
@@ -74,11 +76,7 @@ def compile_through_fx(model, inputs, model_name, extra_args=[]):
|
||||
|
||||
|
||||
def set_iree_runtime_flags():
|
||||
|
||||
vulkan_runtime_flags = [
|
||||
f"--vulkan_large_heap_block_size={args.vulkan_large_heap_block_size}",
|
||||
f"--vulkan_validation_layers={'true' if args.vulkan_validation_layers else 'false'}",
|
||||
]
|
||||
vulkan_runtime_flags = get_iree_vulkan_runtime_flags()
|
||||
if args.enable_rgp:
|
||||
vulkan_runtime_flags += [
|
||||
f"--enable_rgp=true",
|
||||
@@ -7,7 +7,7 @@ mlir_model, func_name, inputs, golden_out = download_model(
|
||||
)
|
||||
|
||||
shark_module = SharkInference(
|
||||
mlir_model, func_name, device="vulkan", mlir_dialect="linalg"
|
||||
mlir_model, device="vulkan", mlir_dialect="linalg"
|
||||
)
|
||||
shark_module.compile()
|
||||
result = shark_module.forward(inputs)
|
||||
|
||||
@@ -1,7 +1,7 @@
|
||||
import torch
|
||||
from torch.nn.utils import _stateless
|
||||
from torch.nn.utils import stateless
|
||||
from transformers import AutoTokenizer, AutoModelForSequenceClassification
|
||||
from shark.shark_runner import SharkTrainer
|
||||
from shark.shark_trainer import SharkTrainer
|
||||
|
||||
|
||||
class MiniLMSequenceClassification(torch.nn.Module):
|
||||
@@ -33,7 +33,7 @@ inp = (torch.randint(2, (1, 128)),)
|
||||
|
||||
def forward(params, buffers, args):
|
||||
params_and_buffers = {**params, **buffers}
|
||||
_stateless.functional_call(
|
||||
stateless.functional_call(
|
||||
mod, params_and_buffers, args, {}
|
||||
).sum().backward()
|
||||
optim = torch.optim.SGD(get_sorted_params(params), lr=0.01)
|
||||
@@ -42,6 +42,7 @@ def forward(params, buffers, args):
|
||||
return params, buffers
|
||||
|
||||
|
||||
shark_module = SharkTrainer(mod, inp, custom_inference_fn=forward)
|
||||
|
||||
print(shark_module.forward())
|
||||
shark_module = SharkTrainer(mod, inp)
|
||||
shark_module.compile(forward)
|
||||
shark_module.train(num_iters=2)
|
||||
print("training done")
|
||||
|
||||
@@ -169,6 +169,7 @@ imagenet_style_templates_small = [
|
||||
"a large painting in the style of {}",
|
||||
]
|
||||
|
||||
|
||||
# Setup the dataset
|
||||
class TextualInversionDataset(Dataset):
|
||||
def __init__(
|
||||
@@ -184,7 +185,6 @@ class TextualInversionDataset(Dataset):
|
||||
placeholder_token="*",
|
||||
center_crop=False,
|
||||
):
|
||||
|
||||
self.data_root = data_root
|
||||
self.tokenizer = tokenizer
|
||||
self.learnable_property = learnable_property
|
||||
@@ -244,7 +244,10 @@ class TextualInversionDataset(Dataset):
|
||||
|
||||
if self.center_crop:
|
||||
crop = min(img.shape[0], img.shape[1])
|
||||
h, w, = (
|
||||
(
|
||||
h,
|
||||
w,
|
||||
) = (
|
||||
img.shape[0],
|
||||
img.shape[1],
|
||||
)
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user