mirror of
https://github.com/invoke-ai/InvokeAI.git
synced 2026-01-15 16:18:06 -05:00
Compare commits
558 Commits
v5.0.1
...
ebr/pin-py
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
fe6ba3571a | ||
|
|
e6ab6e0293 | ||
|
|
66d9c7c631 | ||
|
|
fec45f3eb6 | ||
|
|
7211d1a6fc | ||
|
|
f3069754a9 | ||
|
|
4f43152aeb | ||
|
|
7125055d02 | ||
|
|
c91a9ce390 | ||
|
|
3e7b73da2c | ||
|
|
61ac50c00d | ||
|
|
c1201f0bce | ||
|
|
acdffac5ad | ||
|
|
e420300fa4 | ||
|
|
260a5a4f9a | ||
|
|
ed0c2006fe | ||
|
|
9ffd888c86 | ||
|
|
175a9dc28d | ||
|
|
5764e4f7f2 | ||
|
|
4275a494b9 | ||
|
|
a3deb8d30d | ||
|
|
aafdb0a37b | ||
|
|
56a815719a | ||
|
|
4db26bfa3a | ||
|
|
8d84ccb12b | ||
|
|
3321d14997 | ||
|
|
43cc4684e1 | ||
|
|
afa5a4b17c | ||
|
|
33c433fe59 | ||
|
|
9cd47fa857 | ||
|
|
32d9abe802 | ||
|
|
3947d4a165 | ||
|
|
3583d03b70 | ||
|
|
bc954b9996 | ||
|
|
c08075946a | ||
|
|
df8df914e8 | ||
|
|
33924e8491 | ||
|
|
7e5ce1d69d | ||
|
|
6a24594140 | ||
|
|
61d26cffe6 | ||
|
|
fdbc244dbe | ||
|
|
0eea84c90d | ||
|
|
e079a91800 | ||
|
|
eb20173487 | ||
|
|
20dd0779b5 | ||
|
|
b384a92f5c | ||
|
|
116d32fbbe | ||
|
|
b044f31a61 | ||
|
|
6c3c24403b | ||
|
|
591f48bb95 | ||
|
|
dc6e45485c | ||
|
|
829820479d | ||
|
|
48a471bfb8 | ||
|
|
ff72315db2 | ||
|
|
790846297a | ||
|
|
230b455a13 | ||
|
|
71f0fff55b | ||
|
|
7f2c83b9e6 | ||
|
|
bc85bd4bd4 | ||
|
|
38b09d73e4 | ||
|
|
606c4ae88c | ||
|
|
f666bac77f | ||
|
|
c9bf7da23a | ||
|
|
dfc65b93e9 | ||
|
|
9ca40b4cf5 | ||
|
|
d571e71d5e | ||
|
|
ad1e6c3fe6 | ||
|
|
21d02911dd | ||
|
|
43afe0bd9a | ||
|
|
e7a68c446d | ||
|
|
b9c68a2e7e | ||
|
|
371a1b1af3 | ||
|
|
dae4591de6 | ||
|
|
8ccb2e30ce | ||
|
|
b8106a4613 | ||
|
|
ce51e9582a | ||
|
|
00848eb631 | ||
|
|
b48430a892 | ||
|
|
f94a218561 | ||
|
|
9b6ed40875 | ||
|
|
26553dbb0e | ||
|
|
9eb695d0b4 | ||
|
|
babab17e1d | ||
|
|
d0a80f3347 | ||
|
|
9b30363177 | ||
|
|
89bde36b0c | ||
|
|
86a8476d97 | ||
|
|
afa0661e55 | ||
|
|
ba09c1277f | ||
|
|
80bf9ddb71 | ||
|
|
1dbc98d747 | ||
|
|
0698188ea2 | ||
|
|
59d0ad4505 | ||
|
|
074a5692dd | ||
|
|
bb0741146a | ||
|
|
1845d9a87a | ||
|
|
748c393e71 | ||
|
|
9bd17ea02f | ||
|
|
24f9b46fbc | ||
|
|
54b3aa1d01 | ||
|
|
d85733f22b | ||
|
|
aff6ad0316 | ||
|
|
61496fdcbc | ||
|
|
ee8975401a | ||
|
|
bf3260446d | ||
|
|
f53823b45e | ||
|
|
5cbe89afdd | ||
|
|
c466d50c3d | ||
|
|
d20b894a61 | ||
|
|
20362448b9 | ||
|
|
5df10cc494 | ||
|
|
da171114ea | ||
|
|
62919a443c | ||
|
|
ffcec91d87 | ||
|
|
0a96466b60 | ||
|
|
e48cab0276 | ||
|
|
740f6eb19f | ||
|
|
d1bb4c2c70 | ||
|
|
e545f18a45 | ||
|
|
e8cd1bb3d8 | ||
|
|
90a906e203 | ||
|
|
5546110127 | ||
|
|
73bbb12f7a | ||
|
|
dde54740c5 | ||
|
|
f70a8e2c1a | ||
|
|
fdccdd52d5 | ||
|
|
31ffd73423 | ||
|
|
3fa1012879 | ||
|
|
c2a8fbd8d6 | ||
|
|
d6643d7263 | ||
|
|
412e79d8e6 | ||
|
|
f939dbdc33 | ||
|
|
24a0ca86f5 | ||
|
|
95c30f6a8b | ||
|
|
ac7441e606 | ||
|
|
9c9af312fe | ||
|
|
7bf5927c43 | ||
|
|
32c7cdd856 | ||
|
|
bbd89d54b4 | ||
|
|
ee61006a49 | ||
|
|
0b43f5fd64 | ||
|
|
6c61266990 | ||
|
|
2d5afe8094 | ||
|
|
2430137d19 | ||
|
|
6df4ee5fc8 | ||
|
|
371742d8f9 | ||
|
|
5440c03767 | ||
|
|
358dbdbf84 | ||
|
|
5ec2d71be0 | ||
|
|
8f28903c81 | ||
|
|
73d4c4d56d | ||
|
|
a071f2788a | ||
|
|
d9a257ef8a | ||
|
|
23fada3eea | ||
|
|
2917e59c38 | ||
|
|
c691855a67 | ||
|
|
a00347379b | ||
|
|
ad1a8fbb8d | ||
|
|
f03b77e882 | ||
|
|
2b000cb006 | ||
|
|
af636f08b8 | ||
|
|
f8150f46a5 | ||
|
|
b613be0f5d | ||
|
|
a833d74913 | ||
|
|
02df055e8a | ||
|
|
add31ce596 | ||
|
|
7d7ad3052e | ||
|
|
3b16dbffb2 | ||
|
|
d8b0648766 | ||
|
|
ae64ee224f | ||
|
|
1251dfd7f6 | ||
|
|
804ee3a7fb | ||
|
|
fc5f9047c2 | ||
|
|
0b208220e5 | ||
|
|
916b9f7741 | ||
|
|
0947a006cc | ||
|
|
2c2df6423e | ||
|
|
c3df9d38c0 | ||
|
|
3790c254f5 | ||
|
|
abf46eaacd | ||
|
|
166548246d | ||
|
|
985dcd9862 | ||
|
|
b1df592506 | ||
|
|
a09a0eff69 | ||
|
|
e73bd09d93 | ||
|
|
6f5477a3f0 | ||
|
|
f78a542401 | ||
|
|
8613efb03a | ||
|
|
d8347d856d | ||
|
|
336e6e0c19 | ||
|
|
5bd87ca89b | ||
|
|
fe87c198eb | ||
|
|
69a4a88925 | ||
|
|
6e7491b086 | ||
|
|
3da8076a2b | ||
|
|
80360a8abb | ||
|
|
acfeb4a276 | ||
|
|
b33dbfc95f | ||
|
|
f9bc29203b | ||
|
|
cbe7717409 | ||
|
|
d6add93901 | ||
|
|
ea45dce9dc | ||
|
|
8d44363d49 | ||
|
|
9933cdb6b7 | ||
|
|
e3e9d1f27c | ||
|
|
bb59ad438a | ||
|
|
e38f5b1576 | ||
|
|
1bb49b698f | ||
|
|
fa1fbd89fe | ||
|
|
190ef6732c | ||
|
|
947cd4694b | ||
|
|
ee32d0666d | ||
|
|
bc8ad9ccbf | ||
|
|
e96b290fa9 | ||
|
|
b9f83eae6a | ||
|
|
9868e23235 | ||
|
|
0060cae17c | ||
|
|
56f0845552 | ||
|
|
da3f85dd8b | ||
|
|
7185363f17 | ||
|
|
ac08c31fbc | ||
|
|
ea54a2655a | ||
|
|
cc83dede9f | ||
|
|
8464fd2ced | ||
|
|
c3316368d9 | ||
|
|
8b2d5ab28a | ||
|
|
3f6acdc2d3 | ||
|
|
4aa20a95b2 | ||
|
|
2d82e69a33 | ||
|
|
683f9a70e7 | ||
|
|
bb6d073828 | ||
|
|
7f7d8e5177 | ||
|
|
f37c5011f4 | ||
|
|
bb947c6162 | ||
|
|
a654dad20f | ||
|
|
2bd44662f3 | ||
|
|
e7f9086006 | ||
|
|
5141be8009 | ||
|
|
eacdfc660b | ||
|
|
5fd3c39431 | ||
|
|
7daf3b7d4a | ||
|
|
908f65698d | ||
|
|
63c4ac58e9 | ||
|
|
8c125681ea | ||
|
|
118f0ba3bf | ||
|
|
b3b7d084d0 | ||
|
|
812940eb95 | ||
|
|
0559480dd6 | ||
|
|
d99e7dd4e4 | ||
|
|
e854181417 | ||
|
|
de414c09fd | ||
|
|
ce4624f72b | ||
|
|
47c7df3476 | ||
|
|
4289b5e6c3 | ||
|
|
c8d1d14662 | ||
|
|
44c588d778 | ||
|
|
d75ac56d00 | ||
|
|
714dd5f0be | ||
|
|
2f4d3cb5e6 | ||
|
|
b76555bda9 | ||
|
|
1cdd501a0a | ||
|
|
1125218bc5 | ||
|
|
683504bfb5 | ||
|
|
03cf953398 | ||
|
|
24c115663d | ||
|
|
a9e7ecad49 | ||
|
|
76f4766324 | ||
|
|
3dfc242f77 | ||
|
|
1e43389cb4 | ||
|
|
cb33de34f7 | ||
|
|
7562ea48dc | ||
|
|
83f4700f5a | ||
|
|
704e7479b2 | ||
|
|
5f44559f30 | ||
|
|
7a22819100 | ||
|
|
70495665c5 | ||
|
|
ca30acc5b4 | ||
|
|
8121843d86 | ||
|
|
bc0ded0a23 | ||
|
|
30f6034f88 | ||
|
|
7d56a8ce54 | ||
|
|
e7dc439006 | ||
|
|
bce5a93eb1 | ||
|
|
93e98a1f63 | ||
|
|
0f93deab3b | ||
|
|
3f3aba8b10 | ||
|
|
0b84f567f1 | ||
|
|
69c0d7dcc9 | ||
|
|
5307248fcf | ||
|
|
2efaea8f79 | ||
|
|
c1dfd9b7d9 | ||
|
|
c594ef89d2 | ||
|
|
563db67b80 | ||
|
|
236c065edd | ||
|
|
1f5d744d01 | ||
|
|
b36c6af0ae | ||
|
|
4e431a9d5f | ||
|
|
48a8232285 | ||
|
|
94007fef5b | ||
|
|
9e6fb3bd3f | ||
|
|
8522129639 | ||
|
|
15033b1a9d | ||
|
|
743d78f82b | ||
|
|
06a434b0a2 | ||
|
|
7f2fdae870 | ||
|
|
00be03b5b9 | ||
|
|
0f98806a25 | ||
|
|
0f1541d091 | ||
|
|
c49bbb22e5 | ||
|
|
7bd4b586a6 | ||
|
|
754f049f54 | ||
|
|
883beb90eb | ||
|
|
ad76399702 | ||
|
|
69773a791d | ||
|
|
99e88e601d | ||
|
|
4050f7deae | ||
|
|
0399b04f29 | ||
|
|
3b349b2686 | ||
|
|
aa34dbe1e1 | ||
|
|
ac2476c63c | ||
|
|
f16489f1ce | ||
|
|
3b38b69192 | ||
|
|
2c601438eb | ||
|
|
5d6a2a3709 | ||
|
|
1d7a264050 | ||
|
|
c494e0642a | ||
|
|
849b9e8d86 | ||
|
|
4a66b7ac83 | ||
|
|
751eb59afa | ||
|
|
f537cf1916 | ||
|
|
0cc6f67bb1 | ||
|
|
b2bf03fd37 | ||
|
|
14bc06ab66 | ||
|
|
9c82cc7fcb | ||
|
|
c60cab97a7 | ||
|
|
eda979341a | ||
|
|
b6c7949bb7 | ||
|
|
d691f672a2 | ||
|
|
8deeac1372 | ||
|
|
4aace24f1f | ||
|
|
b1567fe0e4 | ||
|
|
3953e60a4f | ||
|
|
3c46522595 | ||
|
|
63a2e17f6b | ||
|
|
8b1ef4b902 | ||
|
|
5f2279c984 | ||
|
|
e82d67849c | ||
|
|
3977ffaa3e | ||
|
|
9a8a858fe4 | ||
|
|
859944f848 | ||
|
|
8d1a45863c | ||
|
|
6798bbab26 | ||
|
|
2c92e8a495 | ||
|
|
216b36c75d | ||
|
|
8bf8742984 | ||
|
|
c78eeb1645 | ||
|
|
cd88723a80 | ||
|
|
dea6cbd599 | ||
|
|
0dd9f1f772 | ||
|
|
5d11c30ce6 | ||
|
|
a783539cd2 | ||
|
|
2f8f30b497 | ||
|
|
f878e5e74e | ||
|
|
bfc460a5c6 | ||
|
|
a24581ede2 | ||
|
|
56731766ca | ||
|
|
80bc4ebee3 | ||
|
|
745b6dbd5d | ||
|
|
c7628945c4 | ||
|
|
728927ecff | ||
|
|
1a7eece695 | ||
|
|
2cd14dd066 | ||
|
|
5872f05342 | ||
|
|
4ad135c6ae | ||
|
|
c72c2770fe | ||
|
|
e733a1f30e | ||
|
|
4be3a33744 | ||
|
|
1751c380db | ||
|
|
16cda33025 | ||
|
|
8308e7d186 | ||
|
|
c0aab56d08 | ||
|
|
1795f4f8a2 | ||
|
|
5bfd2ec6b7 | ||
|
|
a35b229a9d | ||
|
|
e93da5d4b2 | ||
|
|
a17ea9bfad | ||
|
|
3578010ba4 | ||
|
|
459cf52043 | ||
|
|
9bcb93f575 | ||
|
|
d1a0e99701 | ||
|
|
92b1515d9d | ||
|
|
36515e1e2a | ||
|
|
c81bb761ed | ||
|
|
1d4a58e52b | ||
|
|
62d12e6468 | ||
|
|
9541156ce5 | ||
|
|
eb5b6625ea | ||
|
|
9758e5a622 | ||
|
|
58eba8bdbd | ||
|
|
2821ba8967 | ||
|
|
2cc72b19bc | ||
|
|
8544ba3798 | ||
|
|
65fe79fa0e | ||
|
|
c99852657e | ||
|
|
ed54b89e9e | ||
|
|
d56c80af8e | ||
|
|
0a65a01db8 | ||
|
|
5f416ee4fa | ||
|
|
115c82231b | ||
|
|
ccc1d4417e | ||
|
|
5806a4bc73 | ||
|
|
734631bfe4 | ||
|
|
8d6996cdf0 | ||
|
|
965d6be1f4 | ||
|
|
e31f253b90 | ||
|
|
5a94575603 | ||
|
|
1c3d06dc83 | ||
|
|
09b19e3640 | ||
|
|
1e0a4dfa3c | ||
|
|
5a1ab4aa9c | ||
|
|
d5c872292f | ||
|
|
0d7edbce25 | ||
|
|
e20d964b59 | ||
|
|
ee95321801 | ||
|
|
179c6d206c | ||
|
|
ffecd83815 | ||
|
|
f1c538fafc | ||
|
|
ed88b096f3 | ||
|
|
a28cabdf97 | ||
|
|
db25be3ba2 | ||
|
|
3b9d1e8218 | ||
|
|
05d9ba8fa0 | ||
|
|
3eee1ba113 | ||
|
|
7882e9beae | ||
|
|
7c9779b496 | ||
|
|
5832228fea | ||
|
|
1d32e70a75 | ||
|
|
9092280583 | ||
|
|
96dd1d5102 | ||
|
|
969f8b8e8d | ||
|
|
ccb5f90556 | ||
|
|
4770d9895d | ||
|
|
aeb2275bd8 | ||
|
|
aff5524457 | ||
|
|
825c564089 | ||
|
|
9b97c57f00 | ||
|
|
4b3a201790 | ||
|
|
7e1b9567c1 | ||
|
|
56ef754292 | ||
|
|
2de99ec32d | ||
|
|
889e63d585 | ||
|
|
56de2b3a51 | ||
|
|
eb40bdb810 | ||
|
|
0840e5fa65 | ||
|
|
b79f2a4e4f | ||
|
|
76a533e67e | ||
|
|
188974988c | ||
|
|
b47aae2165 | ||
|
|
7105a22e0f | ||
|
|
eee4175e4d | ||
|
|
e0b63559d0 | ||
|
|
aa54c1f969 | ||
|
|
87fdea4cc6 | ||
|
|
53443084c5 | ||
|
|
8d2e5bfd77 | ||
|
|
05e285c95a | ||
|
|
25f19a35d7 | ||
|
|
01bbd32598 | ||
|
|
0e2761d5c6 | ||
|
|
d5b51cca56 | ||
|
|
a303777777 | ||
|
|
e90b3de706 | ||
|
|
3ce94e5b84 | ||
|
|
42e5ec3916 | ||
|
|
ffa00d1d9a | ||
|
|
1648a2af6e | ||
|
|
852e9e280a | ||
|
|
af72412d3f | ||
|
|
72f715e688 | ||
|
|
3b567bef3d | ||
|
|
3d867db315 | ||
|
|
a8c7dd74d0 | ||
|
|
2dc069d759 | ||
|
|
2a90f4f59e | ||
|
|
af5f342347 | ||
|
|
6dd53b6a32 | ||
|
|
0ca8351911 | ||
|
|
b14cbfde13 | ||
|
|
46dc633df9 | ||
|
|
d4a981fc1c | ||
|
|
e0474ce822 | ||
|
|
9e5ce6b2d4 | ||
|
|
98fa946f77 | ||
|
|
ef80d40b63 | ||
|
|
7a9f923d35 | ||
|
|
fd982fa7c2 | ||
|
|
df86ed653a | ||
|
|
0be8aacee6 | ||
|
|
4f993a4f32 | ||
|
|
0158320940 | ||
|
|
bb2dc6c78b | ||
|
|
80d7d69c2f | ||
|
|
1010c9877c | ||
|
|
8fd8994ee8 | ||
|
|
262c2f1fc7 | ||
|
|
150d3239e3 | ||
|
|
e49e5e9782 | ||
|
|
2d1e745594 | ||
|
|
b793328edd | ||
|
|
e79b316645 | ||
|
|
8297e7964c | ||
|
|
26832c1a0e | ||
|
|
c29259ccdb | ||
|
|
3d4bd71098 | ||
|
|
814be44cd7 | ||
|
|
d328eaf743 | ||
|
|
b502c05009 | ||
|
|
0f333388bb | ||
|
|
bc63e2acc5 | ||
|
|
ec7e771942 | ||
|
|
fe84013392 | ||
|
|
710f81266b | ||
|
|
446e2884bc | ||
|
|
7d9f125232 | ||
|
|
66bbd62758 | ||
|
|
0875e861f5 | ||
|
|
0267d73dfc | ||
|
|
c9ab7c5233 | ||
|
|
f06765dfba | ||
|
|
f347b26999 | ||
|
|
c665cf3525 | ||
|
|
8cf19c4124 | ||
|
|
f7112ae57b | ||
|
|
2bfb0ddff5 | ||
|
|
950c9f5d0c | ||
|
|
db283d21f9 | ||
|
|
70cca7a431 | ||
|
|
3c3938cfc8 | ||
|
|
4455fc4092 | ||
|
|
4b7e920612 | ||
|
|
433146d08f | ||
|
|
324a46d0c8 | ||
|
|
c4421241f6 | ||
|
|
43b417be6b | ||
|
|
4a135c1017 | ||
|
|
dd591abc2b | ||
|
|
0e65f295ac | ||
|
|
ab7fbb7b30 | ||
|
|
92aed5e4fc | ||
|
|
d9b0697d1f | ||
|
|
34a9409bc1 | ||
|
|
319d82751a | ||
|
|
9b90834248 | ||
|
|
a8957aa50d | ||
|
|
807f458f13 | ||
|
|
68dbe45315 | ||
|
|
bd3d1dcdf9 | ||
|
|
386c01ede1 |
@@ -105,7 +105,7 @@ Invoke features an organized gallery system for easily storing, accessing, and r
|
||||
### Other features
|
||||
|
||||
- Support for both ckpt and diffusers models
|
||||
- SD1.5, SD2.0, and SDXL support
|
||||
- SD1.5, SD2.0, SDXL, and FLUX support
|
||||
- Upscaling Tools
|
||||
- Embedding Manager & Support
|
||||
- Model Manager & Support
|
||||
|
||||
@@ -38,9 +38,9 @@ RUN --mount=type=cache,target=/root/.cache/pip \
|
||||
if [ "$TARGETPLATFORM" = "linux/arm64" ] || [ "$GPU_DRIVER" = "cpu" ]; then \
|
||||
extra_index_url_arg="--extra-index-url https://download.pytorch.org/whl/cpu"; \
|
||||
elif [ "$GPU_DRIVER" = "rocm" ]; then \
|
||||
extra_index_url_arg="--extra-index-url https://download.pytorch.org/whl/rocm5.6"; \
|
||||
extra_index_url_arg="--extra-index-url https://download.pytorch.org/whl/rocm6.1"; \
|
||||
else \
|
||||
extra_index_url_arg="--extra-index-url https://download.pytorch.org/whl/cu121"; \
|
||||
extra_index_url_arg="--extra-index-url https://download.pytorch.org/whl/cu124"; \
|
||||
fi &&\
|
||||
|
||||
# xformers + triton fails to install on arm64
|
||||
|
||||
@@ -1,7 +1,7 @@
|
||||
# Copyright (c) 2023 Eugene Brodsky https://github.com/ebr
|
||||
|
||||
x-invokeai: &invokeai
|
||||
image: "local/invokeai:latest"
|
||||
image: "ghcr.io/invoke-ai/invokeai:latest"
|
||||
build:
|
||||
context: ..
|
||||
dockerfile: docker/Dockerfile
|
||||
|
||||
@@ -144,7 +144,7 @@ As you might have noticed, we added two new arguments to the `InputField`
|
||||
definition for `width` and `height`, called `gt` and `le`. They stand for
|
||||
_greater than or equal to_ and _less than or equal to_.
|
||||
|
||||
These impose contraints on those fields, and will raise an exception if the
|
||||
These impose constraints on those fields, and will raise an exception if the
|
||||
values do not meet the constraints. Field constraints are provided by
|
||||
**pydantic**, so anything you see in the **pydantic docs** will work.
|
||||
|
||||
|
||||
@@ -239,7 +239,7 @@ Consult the
|
||||
get it set up.
|
||||
|
||||
Suggest using VSCode's included settings sync so that your remote dev host has
|
||||
all the same app settings and extensions automagically.
|
||||
all the same app settings and extensions automatically.
|
||||
|
||||
##### One remote dev gotcha
|
||||
|
||||
|
||||
@@ -2,7 +2,7 @@
|
||||
|
||||
## **What do I need to know to help?**
|
||||
|
||||
If you are looking to help to with a code contribution, InvokeAI uses several different technologies under the hood: Python (Pydantic, FastAPI, diffusers) and Typescript (React, Redux Toolkit, ChakraUI, Mantine, Konva). Familiarity with StableDiffusion and image generation concepts is helpful, but not essential.
|
||||
If you are looking to help with a code contribution, InvokeAI uses several different technologies under the hood: Python (Pydantic, FastAPI, diffusers) and Typescript (React, Redux Toolkit, ChakraUI, Mantine, Konva). Familiarity with StableDiffusion and image generation concepts is helpful, but not essential.
|
||||
|
||||
|
||||
## **Get Started**
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
# Tutorials
|
||||
|
||||
Tutorials help new & existing users expand their abilty to use InvokeAI to the full extent of our features and services.
|
||||
Tutorials help new & existing users expand their ability to use InvokeAI to the full extent of our features and services.
|
||||
|
||||
Currently, we have a set of tutorials available on our [YouTube channel](https://www.youtube.com/@invokeai), but as InvokeAI continues to evolve with new updates, we want to ensure that we are giving our users the resources they need to succeed.
|
||||
|
||||
@@ -8,4 +8,4 @@ Tutorials can be in the form of videos or article walkthroughs on a subject of y
|
||||
|
||||
## Contributing
|
||||
|
||||
Please reach out to @imic or @hipsterusername on [Discord](https://discord.gg/ZmtBAhwWhy) to help create tutorials for InvokeAI.
|
||||
Please reach out to @imic or @hipsterusername on [Discord](https://discord.gg/ZmtBAhwWhy) to help create tutorials for InvokeAI.
|
||||
|
||||
@@ -21,6 +21,7 @@ To use a community workflow, download the `.json` node graph file and load it in
|
||||
+ [Clothing Mask](#clothing-mask)
|
||||
+ [Contrast Limited Adaptive Histogram Equalization](#contrast-limited-adaptive-histogram-equalization)
|
||||
+ [Depth Map from Wavefront OBJ](#depth-map-from-wavefront-obj)
|
||||
+ [Enhance Detail](#enhance-detail)
|
||||
+ [Film Grain](#film-grain)
|
||||
+ [Generative Grammar-Based Prompt Nodes](#generative-grammar-based-prompt-nodes)
|
||||
+ [GPT2RandomPromptMaker](#gpt2randompromptmaker)
|
||||
@@ -40,6 +41,7 @@ To use a community workflow, download the `.json` node graph file and load it in
|
||||
+ [Metadata-Linked](#metadata-linked-nodes)
|
||||
+ [Negative Image](#negative-image)
|
||||
+ [Nightmare Promptgen](#nightmare-promptgen)
|
||||
+ [Ollama](#ollama-node)
|
||||
+ [One Button Prompt](#one-button-prompt)
|
||||
+ [Oobabooga](#oobabooga)
|
||||
+ [Prompt Tools](#prompt-tools)
|
||||
@@ -80,7 +82,7 @@ Note: These are inherited from the core nodes so any update to the core nodes sh
|
||||
|
||||
**Example Usage:**
|
||||
</br>
|
||||
<img src="https://github.com/skunkworxdark/autostereogram_nodes/blob/main/images/spider.png" width="200" /> -> <img src="https://github.com/skunkworxdark/autostereogram_nodes/blob/main/images/spider-depth.png" width="200" /> -> <img src="https://github.com/skunkworxdark/autostereogram_nodes/raw/main/images/spider-dots.png" width="200" /> <img src="https://github.com/skunkworxdark/autostereogram_nodes/raw/main/images/spider-pattern.png" width="200" />
|
||||
<img src="https://raw.githubusercontent.com/skunkworxdark/autostereogram_nodes/refs/heads/main/images/spider.png" width="200" /> -> <img src="https://raw.githubusercontent.com/skunkworxdark/autostereogram_nodes/refs/heads/main/images/spider-depth.png" width="200" /> -> <img src="https://raw.githubusercontent.com/skunkworxdark/autostereogram_nodes/refs/heads/main/images/spider-dots.png" width="200" /> <img src="https://raw.githubusercontent.com/skunkworxdark/autostereogram_nodes/refs/heads/main/images/spider-pattern.png" width="200" />
|
||||
|
||||
--------------------------------
|
||||
### Average Images
|
||||
@@ -141,6 +143,17 @@ To be imported, an .obj must use triangulated meshes, so make sure to enable tha
|
||||
**Example Usage:**
|
||||
</br><img src="https://raw.githubusercontent.com/dwringer/depth-from-obj-node/main/depth_from_obj_usage.jpg" width="500" />
|
||||
|
||||
--------------------------------
|
||||
### Enhance Detail
|
||||
|
||||
**Description:** A single node that can enhance the detail in an image. Increase or decrease details in an image using a guided filter (as opposed to the typical Gaussian blur used by most sharpening filters.) Based on the `Enhance Detail` ComfyUI node from https://github.com/spacepxl/ComfyUI-Image-Filters
|
||||
|
||||
**Node Link:** https://github.com/skunkworxdark/enhance-detail-node
|
||||
|
||||
**Example Usage:**
|
||||
</br>
|
||||
<img src="https://raw.githubusercontent.com/skunkworxdark/enhance-detail-node/refs/heads/main/images/Comparison.png" />
|
||||
|
||||
--------------------------------
|
||||
### Film Grain
|
||||
|
||||
@@ -307,7 +320,7 @@ View:
|
||||
**Node Link:** https://github.com/helix4u/load_video_frame
|
||||
|
||||
**Output Example:**
|
||||
<img src="https://raw.githubusercontent.com/helix4u/load_video_frame/main/_git_assets/testmp4_embed_converted.gif" width="500" />
|
||||
<img src="https://raw.githubusercontent.com/helix4u/load_video_frame/refs/heads/main/_git_assets/dance1736978273.gif" width="500" />
|
||||
|
||||
--------------------------------
|
||||
### Make 3D
|
||||
@@ -348,7 +361,7 @@ See full docs here: https://github.com/skunkworxdark/Prompt-tools-nodes/edit/mai
|
||||
|
||||
**Output Examples**
|
||||
|
||||
<img src="https://github.com/skunkworxdark/match_histogram/assets/21961335/ed12f329-a0ef-444a-9bae-129ed60d6097" width="300" />
|
||||
<img src="https://github.com/skunkworxdark/match_histogram/assets/21961335/ed12f329-a0ef-444a-9bae-129ed60d6097" />
|
||||
|
||||
--------------------------------
|
||||
### Metadata Linked Nodes
|
||||
@@ -390,10 +403,23 @@ View:
|
||||
|
||||
**Node Link:** [https://github.com/gogurtenjoyer/nightmare-promptgen](https://github.com/gogurtenjoyer/nightmare-promptgen)
|
||||
|
||||
--------------------------------
|
||||
### Ollama Node
|
||||
|
||||
**Description:** Uses Ollama API to expand text prompts for text-to-image generation using local LLMs. Works great for expanding basic prompts into detailed natural language prompts for Flux. Also provides a toggle to unload the LLM model immediately after expanding, to free up VRAM for Invoke to continue the image generation workflow.
|
||||
|
||||
**Node Link:** https://github.com/Jonseed/Ollama-Node
|
||||
|
||||
**Example Node Graph:** https://github.com/Jonseed/Ollama-Node/blob/main/Ollama-Node-Flux-example.json
|
||||
|
||||
**View:**
|
||||
|
||||
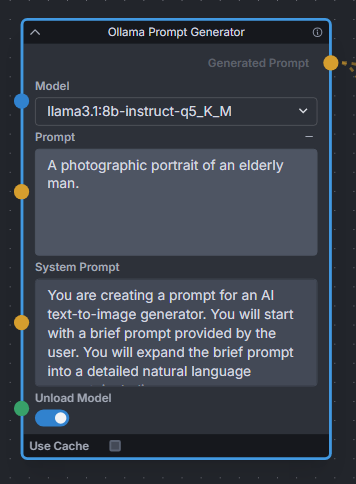
|
||||
|
||||
--------------------------------
|
||||
### One Button Prompt
|
||||
|
||||
<img src="https://github.com/AIrjen/OneButtonPrompt_X_InvokeAI/blob/main/images/background.png" width="800" />
|
||||
<img src="https://raw.githubusercontent.com/AIrjen/OneButtonPrompt_X_InvokeAI/refs/heads/main/images/background.png" width="800" />
|
||||
|
||||
**Description:** an extensive suite of auto prompt generation and prompt helper nodes based on extensive logic. Get creative with the best prompt generator in the world.
|
||||
|
||||
@@ -403,7 +429,7 @@ The main node generates interesting prompts based on a set of parameters. There
|
||||
|
||||
**Nodes:**
|
||||
|
||||
<img src="https://github.com/AIrjen/OneButtonPrompt_X_InvokeAI/blob/main/images/OBP_nodes_invokeai.png" width="800" />
|
||||
<img src="https://raw.githubusercontent.com/AIrjen/OneButtonPrompt_X_InvokeAI/refs/heads/main/images/OBP_nodes_invokeai.png" width="800" />
|
||||
|
||||
--------------------------------
|
||||
### Oobabooga
|
||||
@@ -456,7 +482,7 @@ See full docs here: https://github.com/skunkworxdark/Prompt-tools-nodes/edit/mai
|
||||
|
||||
**Workflow Examples**
|
||||
|
||||
<img src="https://github.com/skunkworxdark/prompt-tools/blob/main/images/CSVToIndexStringNode.png" width="300" />
|
||||
<img src="https://raw.githubusercontent.com/skunkworxdark/prompt-tools/refs/heads/main/images/CSVToIndexStringNode.png"/>
|
||||
|
||||
--------------------------------
|
||||
### Remote Image
|
||||
@@ -594,7 +620,7 @@ See full docs here: https://github.com/skunkworxdark/XYGrid_nodes/edit/main/READ
|
||||
|
||||
**Output Examples**
|
||||
|
||||
<img src="https://github.com/skunkworxdark/XYGrid_nodes/blob/main/images/collage.png" width="300" />
|
||||
<img src="https://raw.githubusercontent.com/skunkworxdark/XYGrid_nodes/refs/heads/main/images/collage.png" />
|
||||
|
||||
|
||||
--------------------------------
|
||||
|
||||
6
flake.lock
generated
6
flake.lock
generated
@@ -2,11 +2,11 @@
|
||||
"nodes": {
|
||||
"nixpkgs": {
|
||||
"locked": {
|
||||
"lastModified": 1690630721,
|
||||
"narHash": "sha256-Y04onHyBQT4Erfr2fc82dbJTfXGYrf4V0ysLUYnPOP8=",
|
||||
"lastModified": 1727955264,
|
||||
"narHash": "sha256-lrd+7mmb5NauRoMa8+J1jFKYVa+rc8aq2qc9+CxPDKc=",
|
||||
"owner": "NixOS",
|
||||
"repo": "nixpkgs",
|
||||
"rev": "d2b52322f35597c62abf56de91b0236746b2a03d",
|
||||
"rev": "71cd616696bd199ef18de62524f3df3ffe8b9333",
|
||||
"type": "github"
|
||||
},
|
||||
"original": {
|
||||
|
||||
@@ -34,7 +34,7 @@
|
||||
cudaPackages.cudnn
|
||||
cudaPackages.cuda_nvrtc
|
||||
cudatoolkit
|
||||
pkgconfig
|
||||
pkg-config
|
||||
libconfig
|
||||
cmake
|
||||
blas
|
||||
@@ -66,7 +66,7 @@
|
||||
black
|
||||
|
||||
# Frontend.
|
||||
yarn
|
||||
pnpm_8
|
||||
nodejs
|
||||
];
|
||||
LD_LIBRARY_PATH = pkgs.lib.makeLibraryPath buildInputs;
|
||||
|
||||
@@ -12,7 +12,7 @@ MINIMUM_PYTHON_VERSION=3.10.0
|
||||
MAXIMUM_PYTHON_VERSION=3.11.100
|
||||
PYTHON=""
|
||||
for candidate in python3.11 python3.10 python3 python ; do
|
||||
if ppath=`which $candidate`; then
|
||||
if ppath=`which $candidate 2>/dev/null`; then
|
||||
# when using `pyenv`, the executable for an inactive Python version will exist but will not be operational
|
||||
# we check that this found executable can actually run
|
||||
if [ $($candidate --version &>/dev/null; echo ${PIPESTATUS}) -gt 0 ]; then continue; fi
|
||||
@@ -30,10 +30,11 @@ done
|
||||
if [ -z "$PYTHON" ]; then
|
||||
echo "A suitable Python interpreter could not be found"
|
||||
echo "Please install Python $MINIMUM_PYTHON_VERSION or higher (maximum $MAXIMUM_PYTHON_VERSION) before running this script. See instructions at $INSTRUCTIONS for help."
|
||||
echo "For the best user experience we suggest enlarging or maximizing this window now."
|
||||
read -p "Press any key to exit"
|
||||
exit -1
|
||||
fi
|
||||
|
||||
echo "For the best user experience we suggest enlarging or maximizing this window now."
|
||||
|
||||
exec $PYTHON ./lib/main.py ${@}
|
||||
read -p "Press any key to exit"
|
||||
|
||||
@@ -245,6 +245,9 @@ class InvokeAiInstance:
|
||||
|
||||
pip = local[self.pip]
|
||||
|
||||
# Uninstall xformers if it is present; the correct version of it will be reinstalled if needed
|
||||
_ = pip["uninstall", "-yqq", "xformers"] & FG
|
||||
|
||||
pipeline = pip[
|
||||
"install",
|
||||
"--require-virtualenv",
|
||||
@@ -282,12 +285,6 @@ class InvokeAiInstance:
|
||||
shutil.copy(src, dest)
|
||||
os.chmod(dest, 0o0755)
|
||||
|
||||
def update(self):
|
||||
pass
|
||||
|
||||
def remove(self):
|
||||
pass
|
||||
|
||||
|
||||
### Utility functions ###
|
||||
|
||||
@@ -402,7 +399,7 @@ def get_torch_source() -> Tuple[str | None, str | None]:
|
||||
:rtype: list
|
||||
"""
|
||||
|
||||
from messages import select_gpu
|
||||
from messages import GpuType, select_gpu
|
||||
|
||||
# device can be one of: "cuda", "rocm", "cpu", "cuda_and_dml, autodetect"
|
||||
device = select_gpu()
|
||||
@@ -412,16 +409,22 @@ def get_torch_source() -> Tuple[str | None, str | None]:
|
||||
url = None
|
||||
optional_modules: str | None = None
|
||||
if OS == "Linux":
|
||||
if device.value == "rocm":
|
||||
url = "https://download.pytorch.org/whl/rocm5.6"
|
||||
elif device.value == "cpu":
|
||||
if device == GpuType.ROCM:
|
||||
url = "https://download.pytorch.org/whl/rocm6.1"
|
||||
elif device == GpuType.CPU:
|
||||
url = "https://download.pytorch.org/whl/cpu"
|
||||
elif device.value == "cuda":
|
||||
# CUDA uses the default PyPi index
|
||||
elif device == GpuType.CUDA:
|
||||
url = "https://download.pytorch.org/whl/cu124"
|
||||
optional_modules = "[onnx-cuda]"
|
||||
elif device == GpuType.CUDA_WITH_XFORMERS:
|
||||
url = "https://download.pytorch.org/whl/cu124"
|
||||
optional_modules = "[xformers,onnx-cuda]"
|
||||
elif OS == "Windows":
|
||||
if device.value == "cuda":
|
||||
url = "https://download.pytorch.org/whl/cu121"
|
||||
if device == GpuType.CUDA:
|
||||
url = "https://download.pytorch.org/whl/cu124"
|
||||
optional_modules = "[onnx-cuda]"
|
||||
elif device == GpuType.CUDA_WITH_XFORMERS:
|
||||
url = "https://download.pytorch.org/whl/cu124"
|
||||
optional_modules = "[xformers,onnx-cuda]"
|
||||
elif device.value == "cpu":
|
||||
# CPU uses the default PyPi index, no optional modules
|
||||
|
||||
@@ -206,6 +206,7 @@ def dest_path(dest: Optional[str | Path] = None) -> Path | None:
|
||||
|
||||
|
||||
class GpuType(Enum):
|
||||
CUDA_WITH_XFORMERS = "xformers"
|
||||
CUDA = "cuda"
|
||||
ROCM = "rocm"
|
||||
CPU = "cpu"
|
||||
@@ -221,11 +222,15 @@ def select_gpu() -> GpuType:
|
||||
return GpuType.CPU
|
||||
|
||||
nvidia = (
|
||||
"an [gold1 b]NVIDIA[/] GPU (using CUDA™)",
|
||||
"an [gold1 b]NVIDIA[/] RTX 3060 or newer GPU using CUDA",
|
||||
GpuType.CUDA,
|
||||
)
|
||||
vintage_nvidia = (
|
||||
"an [gold1 b]NVIDIA[/] RTX 20xx or older GPU using CUDA+xFormers",
|
||||
GpuType.CUDA_WITH_XFORMERS,
|
||||
)
|
||||
amd = (
|
||||
"an [gold1 b]AMD[/] GPU (using ROCm™)",
|
||||
"an [gold1 b]AMD[/] GPU using ROCm",
|
||||
GpuType.ROCM,
|
||||
)
|
||||
cpu = (
|
||||
@@ -235,14 +240,13 @@ def select_gpu() -> GpuType:
|
||||
|
||||
options = []
|
||||
if OS == "Windows":
|
||||
options = [nvidia, cpu]
|
||||
options = [nvidia, vintage_nvidia, cpu]
|
||||
if OS == "Linux":
|
||||
options = [nvidia, amd, cpu]
|
||||
options = [nvidia, vintage_nvidia, amd, cpu]
|
||||
elif OS == "Darwin":
|
||||
options = [cpu]
|
||||
|
||||
if len(options) == 1:
|
||||
print(f'Your platform [gold1]{OS}-{ARCH}[/] only supports the "{options[0][1]}" driver. Proceeding with that.')
|
||||
return options[0][1]
|
||||
|
||||
options = {str(i): opt for i, opt in enumerate(options, 1)}
|
||||
|
||||
@@ -5,9 +5,10 @@ from fastapi.routing import APIRouter
|
||||
from pydantic import BaseModel, Field
|
||||
|
||||
from invokeai.app.api.dependencies import ApiDependencies
|
||||
from invokeai.app.services.board_records.board_records_common import BoardChanges
|
||||
from invokeai.app.services.board_records.board_records_common import BoardChanges, BoardRecordOrderBy
|
||||
from invokeai.app.services.boards.boards_common import BoardDTO
|
||||
from invokeai.app.services.shared.pagination import OffsetPaginatedResults
|
||||
from invokeai.app.services.shared.sqlite.sqlite_common import SQLiteDirection
|
||||
|
||||
boards_router = APIRouter(prefix="/v1/boards", tags=["boards"])
|
||||
|
||||
@@ -115,6 +116,8 @@ async def delete_board(
|
||||
response_model=Union[OffsetPaginatedResults[BoardDTO], list[BoardDTO]],
|
||||
)
|
||||
async def list_boards(
|
||||
order_by: BoardRecordOrderBy = Query(default=BoardRecordOrderBy.CreatedAt, description="The attribute to order by"),
|
||||
direction: SQLiteDirection = Query(default=SQLiteDirection.Descending, description="The direction to order by"),
|
||||
all: Optional[bool] = Query(default=None, description="Whether to list all boards"),
|
||||
offset: Optional[int] = Query(default=None, description="The page offset"),
|
||||
limit: Optional[int] = Query(default=None, description="The number of boards per page"),
|
||||
@@ -122,9 +125,9 @@ async def list_boards(
|
||||
) -> Union[OffsetPaginatedResults[BoardDTO], list[BoardDTO]]:
|
||||
"""Gets a list of boards"""
|
||||
if all:
|
||||
return ApiDependencies.invoker.services.boards.get_all(include_archived)
|
||||
return ApiDependencies.invoker.services.boards.get_all(order_by, direction, include_archived)
|
||||
elif offset is not None and limit is not None:
|
||||
return ApiDependencies.invoker.services.boards.get_many(offset, limit, include_archived)
|
||||
return ApiDependencies.invoker.services.boards.get_many(order_by, direction, offset, limit, include_archived)
|
||||
else:
|
||||
raise HTTPException(
|
||||
status_code=400,
|
||||
|
||||
@@ -38,7 +38,12 @@ from invokeai.backend.model_manager.load.model_cache.model_cache_base import Cac
|
||||
from invokeai.backend.model_manager.metadata.fetch.huggingface import HuggingFaceMetadataFetch
|
||||
from invokeai.backend.model_manager.metadata.metadata_base import ModelMetadataWithFiles, UnknownMetadataException
|
||||
from invokeai.backend.model_manager.search import ModelSearch
|
||||
from invokeai.backend.model_manager.starter_models import STARTER_MODELS, StarterModel, StarterModelWithoutDependencies
|
||||
from invokeai.backend.model_manager.starter_models import (
|
||||
STARTER_BUNDLES,
|
||||
STARTER_MODELS,
|
||||
StarterModel,
|
||||
StarterModelWithoutDependencies,
|
||||
)
|
||||
|
||||
model_manager_router = APIRouter(prefix="/v2/models", tags=["model_manager"])
|
||||
|
||||
@@ -792,22 +797,52 @@ async def convert_model(
|
||||
return new_config
|
||||
|
||||
|
||||
@model_manager_router.get("/starter_models", operation_id="get_starter_models", response_model=list[StarterModel])
|
||||
async def get_starter_models() -> list[StarterModel]:
|
||||
class StarterModelResponse(BaseModel):
|
||||
starter_models: list[StarterModel]
|
||||
starter_bundles: dict[str, list[StarterModel]]
|
||||
|
||||
|
||||
def get_is_installed(
|
||||
starter_model: StarterModel | StarterModelWithoutDependencies, installed_models: list[AnyModelConfig]
|
||||
) -> bool:
|
||||
for model in installed_models:
|
||||
if model.source == starter_model.source:
|
||||
return True
|
||||
if (
|
||||
(model.name == starter_model.name or model.name in starter_model.previous_names)
|
||||
and model.base == starter_model.base
|
||||
and model.type == starter_model.type
|
||||
):
|
||||
return True
|
||||
return False
|
||||
|
||||
|
||||
@model_manager_router.get("/starter_models", operation_id="get_starter_models", response_model=StarterModelResponse)
|
||||
async def get_starter_models() -> StarterModelResponse:
|
||||
installed_models = ApiDependencies.invoker.services.model_manager.store.search_by_attr()
|
||||
installed_model_sources = {m.source for m in installed_models}
|
||||
starter_models = deepcopy(STARTER_MODELS)
|
||||
starter_bundles = deepcopy(STARTER_BUNDLES)
|
||||
for model in starter_models:
|
||||
if model.source in installed_model_sources:
|
||||
model.is_installed = True
|
||||
model.is_installed = get_is_installed(model, installed_models)
|
||||
# Remove already-installed dependencies
|
||||
missing_deps: list[StarterModelWithoutDependencies] = []
|
||||
|
||||
for dep in model.dependencies or []:
|
||||
if dep.source not in installed_model_sources:
|
||||
if not get_is_installed(dep, installed_models):
|
||||
missing_deps.append(dep)
|
||||
model.dependencies = missing_deps
|
||||
|
||||
return starter_models
|
||||
for bundle in starter_bundles.values():
|
||||
for model in bundle:
|
||||
model.is_installed = get_is_installed(model, installed_models)
|
||||
# Remove already-installed dependencies
|
||||
missing_deps: list[StarterModelWithoutDependencies] = []
|
||||
for dep in model.dependencies or []:
|
||||
if not get_is_installed(dep, installed_models):
|
||||
missing_deps.append(dep)
|
||||
model.dependencies = missing_deps
|
||||
|
||||
return StarterModelResponse(starter_models=starter_models, starter_bundles=starter_bundles)
|
||||
|
||||
|
||||
@model_manager_router.get(
|
||||
|
||||
@@ -83,7 +83,7 @@ async def create_workflow(
|
||||
)
|
||||
async def list_workflows(
|
||||
page: int = Query(default=0, description="The page to get"),
|
||||
per_page: int = Query(default=10, description="The number of workflows per page"),
|
||||
per_page: Optional[int] = Query(default=None, description="The number of workflows per page"),
|
||||
order_by: WorkflowRecordOrderBy = Query(
|
||||
default=WorkflowRecordOrderBy.Name, description="The attribute to order by"
|
||||
),
|
||||
@@ -93,5 +93,5 @@ async def list_workflows(
|
||||
) -> PaginatedResults[WorkflowRecordListItemDTO]:
|
||||
"""Gets a page of workflows"""
|
||||
return ApiDependencies.invoker.services.workflow_records.get_many(
|
||||
page=page, per_page=per_page, order_by=order_by, direction=direction, query=query, category=category
|
||||
order_by=order_by, direction=direction, page=page, per_page=per_page, query=query, category=category
|
||||
)
|
||||
|
||||
@@ -547,7 +547,9 @@ class DenoiseLatentsInvocation(BaseInvocation):
|
||||
if not isinstance(single_ipa_image_fields, list):
|
||||
single_ipa_image_fields = [single_ipa_image_fields]
|
||||
|
||||
single_ipa_images = [context.images.get_pil(image.image_name) for image in single_ipa_image_fields]
|
||||
single_ipa_images = [
|
||||
context.images.get_pil(image.image_name, mode="RGB") for image in single_ipa_image_fields
|
||||
]
|
||||
with image_encoder_model_info as image_encoder_model:
|
||||
assert isinstance(image_encoder_model, CLIPVisionModelWithProjection)
|
||||
# Get image embeddings from CLIP and ImageProjModel.
|
||||
|
||||
@@ -192,6 +192,7 @@ class FieldDescriptions:
|
||||
freeu_s2 = 'Scaling factor for stage 2 to attenuate the contributions of the skip features. This is done to mitigate the "oversmoothing effect" in the enhanced denoising process.'
|
||||
freeu_b1 = "Scaling factor for stage 1 to amplify the contributions of backbone features."
|
||||
freeu_b2 = "Scaling factor for stage 2 to amplify the contributions of backbone features."
|
||||
instantx_control_mode = "The control mode for InstantX ControlNet union models. Ignored for other ControlNet models. The standard mapping is: canny (0), tile (1), depth (2), blur (3), pose (4), gray (5), low quality (6). Negative values will be treated as 'None'."
|
||||
|
||||
|
||||
class ImageField(BaseModel):
|
||||
|
||||
99
invokeai/app/invocations/flux_controlnet.py
Normal file
99
invokeai/app/invocations/flux_controlnet.py
Normal file
@@ -0,0 +1,99 @@
|
||||
from pydantic import BaseModel, Field, field_validator, model_validator
|
||||
|
||||
from invokeai.app.invocations.baseinvocation import (
|
||||
BaseInvocation,
|
||||
BaseInvocationOutput,
|
||||
Classification,
|
||||
invocation,
|
||||
invocation_output,
|
||||
)
|
||||
from invokeai.app.invocations.fields import FieldDescriptions, ImageField, InputField, OutputField, UIType
|
||||
from invokeai.app.invocations.model import ModelIdentifierField
|
||||
from invokeai.app.invocations.util import validate_begin_end_step, validate_weights
|
||||
from invokeai.app.services.shared.invocation_context import InvocationContext
|
||||
from invokeai.app.util.controlnet_utils import CONTROLNET_RESIZE_VALUES
|
||||
|
||||
|
||||
class FluxControlNetField(BaseModel):
|
||||
image: ImageField = Field(description="The control image")
|
||||
control_model: ModelIdentifierField = Field(description="The ControlNet model to use")
|
||||
control_weight: float | list[float] = Field(default=1, description="The weight given to the ControlNet")
|
||||
begin_step_percent: float = Field(
|
||||
default=0, ge=0, le=1, description="When the ControlNet is first applied (% of total steps)"
|
||||
)
|
||||
end_step_percent: float = Field(
|
||||
default=1, ge=0, le=1, description="When the ControlNet is last applied (% of total steps)"
|
||||
)
|
||||
resize_mode: CONTROLNET_RESIZE_VALUES = Field(default="just_resize", description="The resize mode to use")
|
||||
instantx_control_mode: int | None = Field(default=-1, description=FieldDescriptions.instantx_control_mode)
|
||||
|
||||
@field_validator("control_weight")
|
||||
@classmethod
|
||||
def validate_control_weight(cls, v: float | list[float]) -> float | list[float]:
|
||||
validate_weights(v)
|
||||
return v
|
||||
|
||||
@model_validator(mode="after")
|
||||
def validate_begin_end_step_percent(self):
|
||||
validate_begin_end_step(self.begin_step_percent, self.end_step_percent)
|
||||
return self
|
||||
|
||||
|
||||
@invocation_output("flux_controlnet_output")
|
||||
class FluxControlNetOutput(BaseInvocationOutput):
|
||||
"""FLUX ControlNet info"""
|
||||
|
||||
control: FluxControlNetField = OutputField(description=FieldDescriptions.control)
|
||||
|
||||
|
||||
@invocation(
|
||||
"flux_controlnet",
|
||||
title="FLUX ControlNet",
|
||||
tags=["controlnet", "flux"],
|
||||
category="controlnet",
|
||||
version="1.0.0",
|
||||
classification=Classification.Prototype,
|
||||
)
|
||||
class FluxControlNetInvocation(BaseInvocation):
|
||||
"""Collect FLUX ControlNet info to pass to other nodes."""
|
||||
|
||||
image: ImageField = InputField(description="The control image")
|
||||
control_model: ModelIdentifierField = InputField(
|
||||
description=FieldDescriptions.controlnet_model, ui_type=UIType.ControlNetModel
|
||||
)
|
||||
control_weight: float | list[float] = InputField(
|
||||
default=1.0, ge=-1, le=2, description="The weight given to the ControlNet"
|
||||
)
|
||||
begin_step_percent: float = InputField(
|
||||
default=0, ge=0, le=1, description="When the ControlNet is first applied (% of total steps)"
|
||||
)
|
||||
end_step_percent: float = InputField(
|
||||
default=1, ge=0, le=1, description="When the ControlNet is last applied (% of total steps)"
|
||||
)
|
||||
resize_mode: CONTROLNET_RESIZE_VALUES = InputField(default="just_resize", description="The resize mode used")
|
||||
# Note: We default to -1 instead of None, because in the workflow editor UI None is not currently supported.
|
||||
instantx_control_mode: int | None = InputField(default=-1, description=FieldDescriptions.instantx_control_mode)
|
||||
|
||||
@field_validator("control_weight")
|
||||
@classmethod
|
||||
def validate_control_weight(cls, v: float | list[float]) -> float | list[float]:
|
||||
validate_weights(v)
|
||||
return v
|
||||
|
||||
@model_validator(mode="after")
|
||||
def validate_begin_end_step_percent(self):
|
||||
validate_begin_end_step(self.begin_step_percent, self.end_step_percent)
|
||||
return self
|
||||
|
||||
def invoke(self, context: InvocationContext) -> FluxControlNetOutput:
|
||||
return FluxControlNetOutput(
|
||||
control=FluxControlNetField(
|
||||
image=self.image,
|
||||
control_model=self.control_model,
|
||||
control_weight=self.control_weight,
|
||||
begin_step_percent=self.begin_step_percent,
|
||||
end_step_percent=self.end_step_percent,
|
||||
resize_mode=self.resize_mode,
|
||||
instantx_control_mode=self.instantx_control_mode,
|
||||
),
|
||||
)
|
||||
@@ -1,26 +1,38 @@
|
||||
from contextlib import ExitStack
|
||||
from typing import Callable, Iterator, Optional, Tuple
|
||||
|
||||
import numpy as np
|
||||
import numpy.typing as npt
|
||||
import torch
|
||||
import torchvision.transforms as tv_transforms
|
||||
from torchvision.transforms.functional import resize as tv_resize
|
||||
from transformers import CLIPImageProcessor, CLIPVisionModelWithProjection
|
||||
|
||||
from invokeai.app.invocations.baseinvocation import BaseInvocation, Classification, invocation
|
||||
from invokeai.app.invocations.fields import (
|
||||
DenoiseMaskField,
|
||||
FieldDescriptions,
|
||||
FluxConditioningField,
|
||||
ImageField,
|
||||
Input,
|
||||
InputField,
|
||||
LatentsField,
|
||||
WithBoard,
|
||||
WithMetadata,
|
||||
)
|
||||
from invokeai.app.invocations.model import TransformerField
|
||||
from invokeai.app.invocations.flux_controlnet import FluxControlNetField
|
||||
from invokeai.app.invocations.ip_adapter import IPAdapterField
|
||||
from invokeai.app.invocations.model import TransformerField, VAEField
|
||||
from invokeai.app.invocations.primitives import LatentsOutput
|
||||
from invokeai.app.services.shared.invocation_context import InvocationContext
|
||||
from invokeai.backend.flux.controlnet.instantx_controlnet_flux import InstantXControlNetFlux
|
||||
from invokeai.backend.flux.controlnet.xlabs_controlnet_flux import XLabsControlNetFlux
|
||||
from invokeai.backend.flux.denoise import denoise
|
||||
from invokeai.backend.flux.inpaint_extension import InpaintExtension
|
||||
from invokeai.backend.flux.extensions.inpaint_extension import InpaintExtension
|
||||
from invokeai.backend.flux.extensions.instantx_controlnet_extension import InstantXControlNetExtension
|
||||
from invokeai.backend.flux.extensions.xlabs_controlnet_extension import XLabsControlNetExtension
|
||||
from invokeai.backend.flux.extensions.xlabs_ip_adapter_extension import XLabsIPAdapterExtension
|
||||
from invokeai.backend.flux.ip_adapter.xlabs_ip_adapter_flux import XlabsIpAdapterFlux
|
||||
from invokeai.backend.flux.model import Flux
|
||||
from invokeai.backend.flux.sampling_utils import (
|
||||
clip_timestep_schedule_fractional,
|
||||
@@ -30,7 +42,7 @@ from invokeai.backend.flux.sampling_utils import (
|
||||
pack,
|
||||
unpack,
|
||||
)
|
||||
from invokeai.backend.lora.conversions.flux_kohya_lora_conversion_utils import FLUX_KOHYA_TRANFORMER_PREFIX
|
||||
from invokeai.backend.lora.conversions.flux_lora_constants import FLUX_LORA_TRANSFORMER_PREFIX
|
||||
from invokeai.backend.lora.lora_model_raw import LoRAModelRaw
|
||||
from invokeai.backend.lora.lora_patcher import LoRAPatcher
|
||||
from invokeai.backend.model_manager.config import ModelFormat
|
||||
@@ -44,7 +56,7 @@ from invokeai.backend.util.devices import TorchDevice
|
||||
title="FLUX Denoise",
|
||||
tags=["image", "flux"],
|
||||
category="image",
|
||||
version="3.0.0",
|
||||
version="3.2.0",
|
||||
classification=Classification.Prototype,
|
||||
)
|
||||
class FluxDenoiseInvocation(BaseInvocation, WithMetadata, WithBoard):
|
||||
@@ -77,6 +89,24 @@ class FluxDenoiseInvocation(BaseInvocation, WithMetadata, WithBoard):
|
||||
positive_text_conditioning: FluxConditioningField = InputField(
|
||||
description=FieldDescriptions.positive_cond, input=Input.Connection
|
||||
)
|
||||
negative_text_conditioning: FluxConditioningField | None = InputField(
|
||||
default=None,
|
||||
description="Negative conditioning tensor. Can be None if cfg_scale is 1.0.",
|
||||
input=Input.Connection,
|
||||
)
|
||||
cfg_scale: float | list[float] = InputField(default=1.0, description=FieldDescriptions.cfg_scale, title="CFG Scale")
|
||||
cfg_scale_start_step: int = InputField(
|
||||
default=0,
|
||||
title="CFG Scale Start Step",
|
||||
description="Index of the first step to apply cfg_scale. Negative indices count backwards from the "
|
||||
+ "the last step (e.g. a value of -1 refers to the final step).",
|
||||
)
|
||||
cfg_scale_end_step: int = InputField(
|
||||
default=-1,
|
||||
title="CFG Scale End Step",
|
||||
description="Index of the last step to apply cfg_scale. Negative indices count backwards from the "
|
||||
+ "last step (e.g. a value of -1 refers to the final step).",
|
||||
)
|
||||
width: int = InputField(default=1024, multiple_of=16, description="Width of the generated image.")
|
||||
height: int = InputField(default=1024, multiple_of=16, description="Height of the generated image.")
|
||||
num_steps: int = InputField(
|
||||
@@ -87,6 +117,18 @@ class FluxDenoiseInvocation(BaseInvocation, WithMetadata, WithBoard):
|
||||
description="The guidance strength. Higher values adhere more strictly to the prompt, and will produce less diverse images. FLUX dev only, ignored for schnell.",
|
||||
)
|
||||
seed: int = InputField(default=0, description="Randomness seed for reproducibility.")
|
||||
control: FluxControlNetField | list[FluxControlNetField] | None = InputField(
|
||||
default=None, input=Input.Connection, description="ControlNet models."
|
||||
)
|
||||
controlnet_vae: VAEField | None = InputField(
|
||||
default=None,
|
||||
description=FieldDescriptions.vae,
|
||||
input=Input.Connection,
|
||||
)
|
||||
|
||||
ip_adapter: IPAdapterField | list[IPAdapterField] | None = InputField(
|
||||
description=FieldDescriptions.ip_adapter, title="IP-Adapter", default=None, input=Input.Connection
|
||||
)
|
||||
|
||||
@torch.no_grad()
|
||||
def invoke(self, context: InvocationContext) -> LatentsOutput:
|
||||
@@ -96,6 +138,19 @@ class FluxDenoiseInvocation(BaseInvocation, WithMetadata, WithBoard):
|
||||
name = context.tensors.save(tensor=latents)
|
||||
return LatentsOutput.build(latents_name=name, latents=latents, seed=None)
|
||||
|
||||
def _load_text_conditioning(
|
||||
self, context: InvocationContext, conditioning_name: str, dtype: torch.dtype
|
||||
) -> Tuple[torch.Tensor, torch.Tensor]:
|
||||
# Load the conditioning data.
|
||||
cond_data = context.conditioning.load(conditioning_name)
|
||||
assert len(cond_data.conditionings) == 1
|
||||
flux_conditioning = cond_data.conditionings[0]
|
||||
assert isinstance(flux_conditioning, FLUXConditioningInfo)
|
||||
flux_conditioning = flux_conditioning.to(dtype=dtype)
|
||||
t5_embeddings = flux_conditioning.t5_embeds
|
||||
clip_embeddings = flux_conditioning.clip_embeds
|
||||
return t5_embeddings, clip_embeddings
|
||||
|
||||
def _run_diffusion(
|
||||
self,
|
||||
context: InvocationContext,
|
||||
@@ -103,13 +158,15 @@ class FluxDenoiseInvocation(BaseInvocation, WithMetadata, WithBoard):
|
||||
inference_dtype = torch.bfloat16
|
||||
|
||||
# Load the conditioning data.
|
||||
cond_data = context.conditioning.load(self.positive_text_conditioning.conditioning_name)
|
||||
assert len(cond_data.conditionings) == 1
|
||||
flux_conditioning = cond_data.conditionings[0]
|
||||
assert isinstance(flux_conditioning, FLUXConditioningInfo)
|
||||
flux_conditioning = flux_conditioning.to(dtype=inference_dtype)
|
||||
t5_embeddings = flux_conditioning.t5_embeds
|
||||
clip_embeddings = flux_conditioning.clip_embeds
|
||||
pos_t5_embeddings, pos_clip_embeddings = self._load_text_conditioning(
|
||||
context, self.positive_text_conditioning.conditioning_name, inference_dtype
|
||||
)
|
||||
neg_t5_embeddings: torch.Tensor | None = None
|
||||
neg_clip_embeddings: torch.Tensor | None = None
|
||||
if self.negative_text_conditioning is not None:
|
||||
neg_t5_embeddings, neg_clip_embeddings = self._load_text_conditioning(
|
||||
context, self.negative_text_conditioning.conditioning_name, inference_dtype
|
||||
)
|
||||
|
||||
# Load the input latents, if provided.
|
||||
init_latents = context.tensors.load(self.latents.latents_name) if self.latents else None
|
||||
@@ -167,11 +224,19 @@ class FluxDenoiseInvocation(BaseInvocation, WithMetadata, WithBoard):
|
||||
|
||||
inpaint_mask = self._prep_inpaint_mask(context, x)
|
||||
|
||||
b, _c, h, w = x.shape
|
||||
img_ids = generate_img_ids(h=h, w=w, batch_size=b, device=x.device, dtype=x.dtype)
|
||||
b, _c, latent_h, latent_w = x.shape
|
||||
img_ids = generate_img_ids(h=latent_h, w=latent_w, batch_size=b, device=x.device, dtype=x.dtype)
|
||||
|
||||
bs, t5_seq_len, _ = t5_embeddings.shape
|
||||
txt_ids = torch.zeros(bs, t5_seq_len, 3, dtype=inference_dtype, device=TorchDevice.choose_torch_device())
|
||||
pos_bs, pos_t5_seq_len, _ = pos_t5_embeddings.shape
|
||||
pos_txt_ids = torch.zeros(
|
||||
pos_bs, pos_t5_seq_len, 3, dtype=inference_dtype, device=TorchDevice.choose_torch_device()
|
||||
)
|
||||
neg_txt_ids: torch.Tensor | None = None
|
||||
if neg_t5_embeddings is not None:
|
||||
neg_bs, neg_t5_seq_len, _ = neg_t5_embeddings.shape
|
||||
neg_txt_ids = torch.zeros(
|
||||
neg_bs, neg_t5_seq_len, 3, dtype=inference_dtype, device=TorchDevice.choose_torch_device()
|
||||
)
|
||||
|
||||
# Pack all latent tensors.
|
||||
init_latents = pack(init_latents) if init_latents is not None else None
|
||||
@@ -192,12 +257,36 @@ class FluxDenoiseInvocation(BaseInvocation, WithMetadata, WithBoard):
|
||||
noise=noise,
|
||||
)
|
||||
|
||||
with (
|
||||
transformer_info.model_on_device() as (cached_weights, transformer),
|
||||
ExitStack() as exit_stack,
|
||||
):
|
||||
assert isinstance(transformer, Flux)
|
||||
# Compute the IP-Adapter image prompt clip embeddings.
|
||||
# We do this before loading other models to minimize peak memory.
|
||||
# TODO(ryand): We should really do this in a separate invocation to benefit from caching.
|
||||
ip_adapter_fields = self._normalize_ip_adapter_fields()
|
||||
pos_image_prompt_clip_embeds, neg_image_prompt_clip_embeds = self._prep_ip_adapter_image_prompt_clip_embeds(
|
||||
ip_adapter_fields, context
|
||||
)
|
||||
|
||||
cfg_scale = self.prep_cfg_scale(
|
||||
cfg_scale=self.cfg_scale,
|
||||
timesteps=timesteps,
|
||||
cfg_scale_start_step=self.cfg_scale_start_step,
|
||||
cfg_scale_end_step=self.cfg_scale_end_step,
|
||||
)
|
||||
|
||||
with ExitStack() as exit_stack:
|
||||
# Prepare ControlNet extensions.
|
||||
# Note: We do this before loading the transformer model to minimize peak memory (see implementation).
|
||||
controlnet_extensions = self._prep_controlnet_extensions(
|
||||
context=context,
|
||||
exit_stack=exit_stack,
|
||||
latent_height=latent_h,
|
||||
latent_width=latent_w,
|
||||
dtype=inference_dtype,
|
||||
device=x.device,
|
||||
)
|
||||
|
||||
# Load the transformer model.
|
||||
(cached_weights, transformer) = exit_stack.enter_context(transformer_info.model_on_device())
|
||||
assert isinstance(transformer, Flux)
|
||||
config = transformer_info.config
|
||||
assert config is not None
|
||||
|
||||
@@ -209,40 +298,110 @@ class FluxDenoiseInvocation(BaseInvocation, WithMetadata, WithBoard):
|
||||
LoRAPatcher.apply_lora_patches(
|
||||
model=transformer,
|
||||
patches=self._lora_iterator(context),
|
||||
prefix=FLUX_KOHYA_TRANFORMER_PREFIX,
|
||||
prefix=FLUX_LORA_TRANSFORMER_PREFIX,
|
||||
cached_weights=cached_weights,
|
||||
)
|
||||
)
|
||||
elif config.format in [ModelFormat.BnbQuantizedLlmInt8b, ModelFormat.BnbQuantizednf4b]:
|
||||
elif config.format in [
|
||||
ModelFormat.BnbQuantizedLlmInt8b,
|
||||
ModelFormat.BnbQuantizednf4b,
|
||||
ModelFormat.GGUFQuantized,
|
||||
]:
|
||||
# The model is quantized, so apply the LoRA weights as sidecar layers. This results in slower inference,
|
||||
# than directly patching the weights, but is agnostic to the quantization format.
|
||||
exit_stack.enter_context(
|
||||
LoRAPatcher.apply_lora_sidecar_patches(
|
||||
model=transformer,
|
||||
patches=self._lora_iterator(context),
|
||||
prefix=FLUX_KOHYA_TRANFORMER_PREFIX,
|
||||
prefix=FLUX_LORA_TRANSFORMER_PREFIX,
|
||||
dtype=inference_dtype,
|
||||
)
|
||||
)
|
||||
else:
|
||||
raise ValueError(f"Unsupported model format: {config.format}")
|
||||
|
||||
# Prepare IP-Adapter extensions.
|
||||
pos_ip_adapter_extensions, neg_ip_adapter_extensions = self._prep_ip_adapter_extensions(
|
||||
pos_image_prompt_clip_embeds=pos_image_prompt_clip_embeds,
|
||||
neg_image_prompt_clip_embeds=neg_image_prompt_clip_embeds,
|
||||
ip_adapter_fields=ip_adapter_fields,
|
||||
context=context,
|
||||
exit_stack=exit_stack,
|
||||
dtype=inference_dtype,
|
||||
)
|
||||
|
||||
x = denoise(
|
||||
model=transformer,
|
||||
img=x,
|
||||
img_ids=img_ids,
|
||||
txt=t5_embeddings,
|
||||
txt_ids=txt_ids,
|
||||
vec=clip_embeddings,
|
||||
txt=pos_t5_embeddings,
|
||||
txt_ids=pos_txt_ids,
|
||||
vec=pos_clip_embeddings,
|
||||
neg_txt=neg_t5_embeddings,
|
||||
neg_txt_ids=neg_txt_ids,
|
||||
neg_vec=neg_clip_embeddings,
|
||||
timesteps=timesteps,
|
||||
step_callback=self._build_step_callback(context),
|
||||
guidance=self.guidance,
|
||||
cfg_scale=cfg_scale,
|
||||
inpaint_extension=inpaint_extension,
|
||||
controlnet_extensions=controlnet_extensions,
|
||||
pos_ip_adapter_extensions=pos_ip_adapter_extensions,
|
||||
neg_ip_adapter_extensions=neg_ip_adapter_extensions,
|
||||
)
|
||||
|
||||
x = unpack(x.float(), self.height, self.width)
|
||||
return x
|
||||
|
||||
@classmethod
|
||||
def prep_cfg_scale(
|
||||
cls, cfg_scale: float | list[float], timesteps: list[float], cfg_scale_start_step: int, cfg_scale_end_step: int
|
||||
) -> list[float]:
|
||||
"""Prepare the cfg_scale schedule.
|
||||
|
||||
- Clips the cfg_scale schedule based on cfg_scale_start_step and cfg_scale_end_step.
|
||||
- If cfg_scale is a list, then it is assumed to be a schedule and is returned as-is.
|
||||
- If cfg_scale is a scalar, then a linear schedule is created from cfg_scale_start_step to cfg_scale_end_step.
|
||||
"""
|
||||
# num_steps is the number of denoising steps, which is one less than the number of timesteps.
|
||||
num_steps = len(timesteps) - 1
|
||||
|
||||
# Normalize cfg_scale to a list if it is a scalar.
|
||||
cfg_scale_list: list[float]
|
||||
if isinstance(cfg_scale, float):
|
||||
cfg_scale_list = [cfg_scale] * num_steps
|
||||
elif isinstance(cfg_scale, list):
|
||||
cfg_scale_list = cfg_scale
|
||||
else:
|
||||
raise ValueError(f"Unsupported cfg_scale type: {type(cfg_scale)}")
|
||||
assert len(cfg_scale_list) == num_steps
|
||||
|
||||
# Handle negative indices for cfg_scale_start_step and cfg_scale_end_step.
|
||||
start_step_index = cfg_scale_start_step
|
||||
if start_step_index < 0:
|
||||
start_step_index = num_steps + start_step_index
|
||||
end_step_index = cfg_scale_end_step
|
||||
if end_step_index < 0:
|
||||
end_step_index = num_steps + end_step_index
|
||||
|
||||
# Validate the start and end step indices.
|
||||
if not (0 <= start_step_index < num_steps):
|
||||
raise ValueError(f"Invalid cfg_scale_start_step. Out of range: {cfg_scale_start_step}.")
|
||||
if not (0 <= end_step_index < num_steps):
|
||||
raise ValueError(f"Invalid cfg_scale_end_step. Out of range: {cfg_scale_end_step}.")
|
||||
if start_step_index > end_step_index:
|
||||
raise ValueError(
|
||||
f"cfg_scale_start_step ({cfg_scale_start_step}) must be before cfg_scale_end_step "
|
||||
+ f"({cfg_scale_end_step})."
|
||||
)
|
||||
|
||||
# Set values outside the start and end step indices to 1.0. This is equivalent to disabling cfg_scale for those
|
||||
# steps.
|
||||
clipped_cfg_scale = [1.0] * num_steps
|
||||
clipped_cfg_scale[start_step_index : end_step_index + 1] = cfg_scale_list[start_step_index : end_step_index + 1]
|
||||
|
||||
return clipped_cfg_scale
|
||||
|
||||
def _prep_inpaint_mask(self, context: InvocationContext, latents: torch.Tensor) -> torch.Tensor | None:
|
||||
"""Prepare the inpaint mask.
|
||||
|
||||
@@ -284,6 +443,210 @@ class FluxDenoiseInvocation(BaseInvocation, WithMetadata, WithBoard):
|
||||
# `latents`.
|
||||
return mask.expand_as(latents)
|
||||
|
||||
def _prep_controlnet_extensions(
|
||||
self,
|
||||
context: InvocationContext,
|
||||
exit_stack: ExitStack,
|
||||
latent_height: int,
|
||||
latent_width: int,
|
||||
dtype: torch.dtype,
|
||||
device: torch.device,
|
||||
) -> list[XLabsControlNetExtension | InstantXControlNetExtension]:
|
||||
# Normalize the controlnet input to list[ControlField].
|
||||
controlnets: list[FluxControlNetField]
|
||||
if self.control is None:
|
||||
controlnets = []
|
||||
elif isinstance(self.control, FluxControlNetField):
|
||||
controlnets = [self.control]
|
||||
elif isinstance(self.control, list):
|
||||
controlnets = self.control
|
||||
else:
|
||||
raise ValueError(f"Unsupported controlnet type: {type(self.control)}")
|
||||
|
||||
# TODO(ryand): Add a field to the model config so that we can distinguish between XLabs and InstantX ControlNets
|
||||
# before loading the models. Then make sure that all VAE encoding is done before loading the ControlNets to
|
||||
# minimize peak memory.
|
||||
|
||||
# First, load the ControlNet models so that we can determine the ControlNet types.
|
||||
controlnet_models = [context.models.load(controlnet.control_model) for controlnet in controlnets]
|
||||
|
||||
# Calculate the controlnet conditioning tensors.
|
||||
# We do this before loading the ControlNet models because it may require running the VAE, and we are trying to
|
||||
# keep peak memory down.
|
||||
controlnet_conds: list[torch.Tensor] = []
|
||||
for controlnet, controlnet_model in zip(controlnets, controlnet_models, strict=True):
|
||||
image = context.images.get_pil(controlnet.image.image_name)
|
||||
if isinstance(controlnet_model.model, InstantXControlNetFlux):
|
||||
if self.controlnet_vae is None:
|
||||
raise ValueError("A ControlNet VAE is required when using an InstantX FLUX ControlNet.")
|
||||
vae_info = context.models.load(self.controlnet_vae.vae)
|
||||
controlnet_conds.append(
|
||||
InstantXControlNetExtension.prepare_controlnet_cond(
|
||||
controlnet_image=image,
|
||||
vae_info=vae_info,
|
||||
latent_height=latent_height,
|
||||
latent_width=latent_width,
|
||||
dtype=dtype,
|
||||
device=device,
|
||||
resize_mode=controlnet.resize_mode,
|
||||
)
|
||||
)
|
||||
elif isinstance(controlnet_model.model, XLabsControlNetFlux):
|
||||
controlnet_conds.append(
|
||||
XLabsControlNetExtension.prepare_controlnet_cond(
|
||||
controlnet_image=image,
|
||||
latent_height=latent_height,
|
||||
latent_width=latent_width,
|
||||
dtype=dtype,
|
||||
device=device,
|
||||
resize_mode=controlnet.resize_mode,
|
||||
)
|
||||
)
|
||||
|
||||
# Finally, load the ControlNet models and initialize the ControlNet extensions.
|
||||
controlnet_extensions: list[XLabsControlNetExtension | InstantXControlNetExtension] = []
|
||||
for controlnet, controlnet_cond, controlnet_model in zip(
|
||||
controlnets, controlnet_conds, controlnet_models, strict=True
|
||||
):
|
||||
model = exit_stack.enter_context(controlnet_model)
|
||||
|
||||
if isinstance(model, XLabsControlNetFlux):
|
||||
controlnet_extensions.append(
|
||||
XLabsControlNetExtension(
|
||||
model=model,
|
||||
controlnet_cond=controlnet_cond,
|
||||
weight=controlnet.control_weight,
|
||||
begin_step_percent=controlnet.begin_step_percent,
|
||||
end_step_percent=controlnet.end_step_percent,
|
||||
)
|
||||
)
|
||||
elif isinstance(model, InstantXControlNetFlux):
|
||||
instantx_control_mode: torch.Tensor | None = None
|
||||
if controlnet.instantx_control_mode is not None and controlnet.instantx_control_mode >= 0:
|
||||
instantx_control_mode = torch.tensor(controlnet.instantx_control_mode, dtype=torch.long)
|
||||
instantx_control_mode = instantx_control_mode.reshape([-1, 1])
|
||||
|
||||
controlnet_extensions.append(
|
||||
InstantXControlNetExtension(
|
||||
model=model,
|
||||
controlnet_cond=controlnet_cond,
|
||||
instantx_control_mode=instantx_control_mode,
|
||||
weight=controlnet.control_weight,
|
||||
begin_step_percent=controlnet.begin_step_percent,
|
||||
end_step_percent=controlnet.end_step_percent,
|
||||
)
|
||||
)
|
||||
else:
|
||||
raise ValueError(f"Unsupported ControlNet model type: {type(model)}")
|
||||
|
||||
return controlnet_extensions
|
||||
|
||||
def _normalize_ip_adapter_fields(self) -> list[IPAdapterField]:
|
||||
if self.ip_adapter is None:
|
||||
return []
|
||||
elif isinstance(self.ip_adapter, IPAdapterField):
|
||||
return [self.ip_adapter]
|
||||
elif isinstance(self.ip_adapter, list):
|
||||
return self.ip_adapter
|
||||
else:
|
||||
raise ValueError(f"Unsupported IP-Adapter type: {type(self.ip_adapter)}")
|
||||
|
||||
def _prep_ip_adapter_image_prompt_clip_embeds(
|
||||
self,
|
||||
ip_adapter_fields: list[IPAdapterField],
|
||||
context: InvocationContext,
|
||||
) -> tuple[list[torch.Tensor], list[torch.Tensor]]:
|
||||
"""Run the IPAdapter CLIPVisionModel, returning image prompt embeddings."""
|
||||
clip_image_processor = CLIPImageProcessor()
|
||||
|
||||
pos_image_prompt_clip_embeds: list[torch.Tensor] = []
|
||||
neg_image_prompt_clip_embeds: list[torch.Tensor] = []
|
||||
for ip_adapter_field in ip_adapter_fields:
|
||||
# `ip_adapter_field.image` could be a list or a single ImageField. Normalize to a list here.
|
||||
ipa_image_fields: list[ImageField]
|
||||
if isinstance(ip_adapter_field.image, ImageField):
|
||||
ipa_image_fields = [ip_adapter_field.image]
|
||||
elif isinstance(ip_adapter_field.image, list):
|
||||
ipa_image_fields = ip_adapter_field.image
|
||||
else:
|
||||
raise ValueError(f"Unsupported IP-Adapter image type: {type(ip_adapter_field.image)}")
|
||||
|
||||
if len(ipa_image_fields) != 1:
|
||||
raise ValueError(
|
||||
f"FLUX IP-Adapter only supports a single image prompt (received {len(ipa_image_fields)})."
|
||||
)
|
||||
|
||||
ipa_images = [context.images.get_pil(image.image_name, mode="RGB") for image in ipa_image_fields]
|
||||
|
||||
pos_images: list[npt.NDArray[np.uint8]] = []
|
||||
neg_images: list[npt.NDArray[np.uint8]] = []
|
||||
for ipa_image in ipa_images:
|
||||
assert ipa_image.mode == "RGB"
|
||||
pos_image = np.array(ipa_image)
|
||||
# We use a black image as the negative image prompt for parity with
|
||||
# https://github.com/XLabs-AI/x-flux-comfyui/blob/45c834727dd2141aebc505ae4b01f193a8414e38/nodes.py#L592-L593
|
||||
# An alternative scheme would be to apply zeros_like() after calling the clip_image_processor.
|
||||
neg_image = np.zeros_like(pos_image)
|
||||
pos_images.append(pos_image)
|
||||
neg_images.append(neg_image)
|
||||
|
||||
with context.models.load(ip_adapter_field.image_encoder_model) as image_encoder_model:
|
||||
assert isinstance(image_encoder_model, CLIPVisionModelWithProjection)
|
||||
|
||||
clip_image: torch.Tensor = clip_image_processor(images=pos_images, return_tensors="pt").pixel_values
|
||||
clip_image = clip_image.to(device=image_encoder_model.device, dtype=image_encoder_model.dtype)
|
||||
pos_clip_image_embeds = image_encoder_model(clip_image).image_embeds
|
||||
|
||||
clip_image = clip_image_processor(images=neg_images, return_tensors="pt").pixel_values
|
||||
clip_image = clip_image.to(device=image_encoder_model.device, dtype=image_encoder_model.dtype)
|
||||
neg_clip_image_embeds = image_encoder_model(clip_image).image_embeds
|
||||
|
||||
pos_image_prompt_clip_embeds.append(pos_clip_image_embeds)
|
||||
neg_image_prompt_clip_embeds.append(neg_clip_image_embeds)
|
||||
|
||||
return pos_image_prompt_clip_embeds, neg_image_prompt_clip_embeds
|
||||
|
||||
def _prep_ip_adapter_extensions(
|
||||
self,
|
||||
ip_adapter_fields: list[IPAdapterField],
|
||||
pos_image_prompt_clip_embeds: list[torch.Tensor],
|
||||
neg_image_prompt_clip_embeds: list[torch.Tensor],
|
||||
context: InvocationContext,
|
||||
exit_stack: ExitStack,
|
||||
dtype: torch.dtype,
|
||||
) -> tuple[list[XLabsIPAdapterExtension], list[XLabsIPAdapterExtension]]:
|
||||
pos_ip_adapter_extensions: list[XLabsIPAdapterExtension] = []
|
||||
neg_ip_adapter_extensions: list[XLabsIPAdapterExtension] = []
|
||||
for ip_adapter_field, pos_image_prompt_clip_embed, neg_image_prompt_clip_embed in zip(
|
||||
ip_adapter_fields, pos_image_prompt_clip_embeds, neg_image_prompt_clip_embeds, strict=True
|
||||
):
|
||||
ip_adapter_model = exit_stack.enter_context(context.models.load(ip_adapter_field.ip_adapter_model))
|
||||
assert isinstance(ip_adapter_model, XlabsIpAdapterFlux)
|
||||
ip_adapter_model = ip_adapter_model.to(dtype=dtype)
|
||||
if ip_adapter_field.mask is not None:
|
||||
raise ValueError("IP-Adapter masks are not yet supported in Flux.")
|
||||
ip_adapter_extension = XLabsIPAdapterExtension(
|
||||
model=ip_adapter_model,
|
||||
image_prompt_clip_embed=pos_image_prompt_clip_embed,
|
||||
weight=ip_adapter_field.weight,
|
||||
begin_step_percent=ip_adapter_field.begin_step_percent,
|
||||
end_step_percent=ip_adapter_field.end_step_percent,
|
||||
)
|
||||
ip_adapter_extension.run_image_proj(dtype=dtype)
|
||||
pos_ip_adapter_extensions.append(ip_adapter_extension)
|
||||
|
||||
ip_adapter_extension = XLabsIPAdapterExtension(
|
||||
model=ip_adapter_model,
|
||||
image_prompt_clip_embed=neg_image_prompt_clip_embed,
|
||||
weight=ip_adapter_field.weight,
|
||||
begin_step_percent=ip_adapter_field.begin_step_percent,
|
||||
end_step_percent=ip_adapter_field.end_step_percent,
|
||||
)
|
||||
ip_adapter_extension.run_image_proj(dtype=dtype)
|
||||
neg_ip_adapter_extensions.append(ip_adapter_extension)
|
||||
|
||||
return pos_ip_adapter_extensions, neg_ip_adapter_extensions
|
||||
|
||||
def _lora_iterator(self, context: InvocationContext) -> Iterator[Tuple[LoRAModelRaw, float]]:
|
||||
for lora in self.transformer.loras:
|
||||
lora_info = context.models.load(lora.lora)
|
||||
|
||||
89
invokeai/app/invocations/flux_ip_adapter.py
Normal file
89
invokeai/app/invocations/flux_ip_adapter.py
Normal file
@@ -0,0 +1,89 @@
|
||||
from builtins import float
|
||||
from typing import List, Literal, Union
|
||||
|
||||
from pydantic import field_validator, model_validator
|
||||
from typing_extensions import Self
|
||||
|
||||
from invokeai.app.invocations.baseinvocation import BaseInvocation, Classification, invocation
|
||||
from invokeai.app.invocations.fields import InputField, UIType
|
||||
from invokeai.app.invocations.ip_adapter import (
|
||||
CLIP_VISION_MODEL_MAP,
|
||||
IPAdapterField,
|
||||
IPAdapterInvocation,
|
||||
IPAdapterOutput,
|
||||
)
|
||||
from invokeai.app.invocations.model import ModelIdentifierField
|
||||
from invokeai.app.invocations.primitives import ImageField
|
||||
from invokeai.app.invocations.util import validate_begin_end_step, validate_weights
|
||||
from invokeai.app.services.shared.invocation_context import InvocationContext
|
||||
from invokeai.backend.model_manager.config import (
|
||||
IPAdapterCheckpointConfig,
|
||||
IPAdapterInvokeAIConfig,
|
||||
)
|
||||
|
||||
|
||||
@invocation(
|
||||
"flux_ip_adapter",
|
||||
title="FLUX IP-Adapter",
|
||||
tags=["ip_adapter", "control"],
|
||||
category="ip_adapter",
|
||||
version="1.0.0",
|
||||
classification=Classification.Prototype,
|
||||
)
|
||||
class FluxIPAdapterInvocation(BaseInvocation):
|
||||
"""Collects FLUX IP-Adapter info to pass to other nodes."""
|
||||
|
||||
# FLUXIPAdapterInvocation is based closely on IPAdapterInvocation, but with some unsupported features removed.
|
||||
|
||||
image: ImageField = InputField(description="The IP-Adapter image prompt(s).")
|
||||
ip_adapter_model: ModelIdentifierField = InputField(
|
||||
description="The IP-Adapter model.", title="IP-Adapter Model", ui_type=UIType.IPAdapterModel
|
||||
)
|
||||
# Currently, the only known ViT model used by FLUX IP-Adapters is ViT-L.
|
||||
clip_vision_model: Literal["ViT-L"] = InputField(description="CLIP Vision model to use.", default="ViT-L")
|
||||
weight: Union[float, List[float]] = InputField(
|
||||
default=1, description="The weight given to the IP-Adapter", title="Weight"
|
||||
)
|
||||
begin_step_percent: float = InputField(
|
||||
default=0, ge=0, le=1, description="When the IP-Adapter is first applied (% of total steps)"
|
||||
)
|
||||
end_step_percent: float = InputField(
|
||||
default=1, ge=0, le=1, description="When the IP-Adapter is last applied (% of total steps)"
|
||||
)
|
||||
|
||||
@field_validator("weight")
|
||||
@classmethod
|
||||
def validate_ip_adapter_weight(cls, v: float) -> float:
|
||||
validate_weights(v)
|
||||
return v
|
||||
|
||||
@model_validator(mode="after")
|
||||
def validate_begin_end_step_percent(self) -> Self:
|
||||
validate_begin_end_step(self.begin_step_percent, self.end_step_percent)
|
||||
return self
|
||||
|
||||
def invoke(self, context: InvocationContext) -> IPAdapterOutput:
|
||||
# Lookup the CLIP Vision encoder that is intended to be used with the IP-Adapter model.
|
||||
ip_adapter_info = context.models.get_config(self.ip_adapter_model.key)
|
||||
assert isinstance(ip_adapter_info, (IPAdapterInvokeAIConfig, IPAdapterCheckpointConfig))
|
||||
|
||||
# Note: There is a IPAdapterInvokeAIConfig.image_encoder_model_id field, but it isn't trustworthy.
|
||||
image_encoder_starter_model = CLIP_VISION_MODEL_MAP[self.clip_vision_model]
|
||||
image_encoder_model_id = image_encoder_starter_model.source
|
||||
image_encoder_model_name = image_encoder_starter_model.name
|
||||
image_encoder_model = IPAdapterInvocation.get_clip_image_encoder(
|
||||
context, image_encoder_model_id, image_encoder_model_name
|
||||
)
|
||||
|
||||
return IPAdapterOutput(
|
||||
ip_adapter=IPAdapterField(
|
||||
image=self.image,
|
||||
ip_adapter_model=self.ip_adapter_model,
|
||||
image_encoder_model=ModelIdentifierField.from_config(image_encoder_model),
|
||||
weight=self.weight,
|
||||
target_blocks=[], # target_blocks is currently unused for FLUX IP-Adapters.
|
||||
begin_step_percent=self.begin_step_percent,
|
||||
end_step_percent=self.end_step_percent,
|
||||
mask=None, # mask is currently unused for FLUX IP-Adapters.
|
||||
),
|
||||
)
|
||||
@@ -10,7 +10,7 @@ from invokeai.app.invocations.model import CLIPField, T5EncoderField
|
||||
from invokeai.app.invocations.primitives import FluxConditioningOutput
|
||||
from invokeai.app.services.shared.invocation_context import InvocationContext
|
||||
from invokeai.backend.flux.modules.conditioner import HFEncoder
|
||||
from invokeai.backend.lora.conversions.flux_kohya_lora_conversion_utils import FLUX_KOHYA_CLIP_PREFIX
|
||||
from invokeai.backend.lora.conversions.flux_lora_constants import FLUX_LORA_CLIP_PREFIX
|
||||
from invokeai.backend.lora.lora_model_raw import LoRAModelRaw
|
||||
from invokeai.backend.lora.lora_patcher import LoRAPatcher
|
||||
from invokeai.backend.model_manager.config import ModelFormat
|
||||
@@ -101,7 +101,7 @@ class FluxTextEncoderInvocation(BaseInvocation):
|
||||
LoRAPatcher.apply_lora_patches(
|
||||
model=clip_text_encoder,
|
||||
patches=self._clip_lora_iterator(context),
|
||||
prefix=FLUX_KOHYA_CLIP_PREFIX,
|
||||
prefix=FLUX_LORA_CLIP_PREFIX,
|
||||
cached_weights=cached_weights,
|
||||
)
|
||||
)
|
||||
|
||||
@@ -9,6 +9,7 @@ from invokeai.app.invocations.fields import FieldDescriptions, InputField, Outpu
|
||||
from invokeai.app.invocations.model import ModelIdentifierField
|
||||
from invokeai.app.invocations.primitives import ImageField
|
||||
from invokeai.app.invocations.util import validate_begin_end_step, validate_weights
|
||||
from invokeai.app.services.model_records.model_records_base import ModelRecordChanges
|
||||
from invokeai.app.services.shared.invocation_context import InvocationContext
|
||||
from invokeai.backend.model_manager.config import (
|
||||
AnyModelConfig,
|
||||
@@ -17,6 +18,12 @@ from invokeai.backend.model_manager.config import (
|
||||
IPAdapterInvokeAIConfig,
|
||||
ModelType,
|
||||
)
|
||||
from invokeai.backend.model_manager.starter_models import (
|
||||
StarterModel,
|
||||
clip_vit_l_image_encoder,
|
||||
ip_adapter_sd_image_encoder,
|
||||
ip_adapter_sdxl_image_encoder,
|
||||
)
|
||||
|
||||
|
||||
class IPAdapterField(BaseModel):
|
||||
@@ -55,10 +62,14 @@ class IPAdapterOutput(BaseInvocationOutput):
|
||||
ip_adapter: IPAdapterField = OutputField(description=FieldDescriptions.ip_adapter, title="IP-Adapter")
|
||||
|
||||
|
||||
CLIP_VISION_MODEL_MAP = {"ViT-H": "ip_adapter_sd_image_encoder", "ViT-G": "ip_adapter_sdxl_image_encoder"}
|
||||
CLIP_VISION_MODEL_MAP: dict[Literal["ViT-L", "ViT-H", "ViT-G"], StarterModel] = {
|
||||
"ViT-L": clip_vit_l_image_encoder,
|
||||
"ViT-H": ip_adapter_sd_image_encoder,
|
||||
"ViT-G": ip_adapter_sdxl_image_encoder,
|
||||
}
|
||||
|
||||
|
||||
@invocation("ip_adapter", title="IP-Adapter", tags=["ip_adapter", "control"], category="ip_adapter", version="1.4.1")
|
||||
@invocation("ip_adapter", title="IP-Adapter", tags=["ip_adapter", "control"], category="ip_adapter", version="1.5.0")
|
||||
class IPAdapterInvocation(BaseInvocation):
|
||||
"""Collects IP-Adapter info to pass to other nodes."""
|
||||
|
||||
@@ -70,7 +81,7 @@ class IPAdapterInvocation(BaseInvocation):
|
||||
ui_order=-1,
|
||||
ui_type=UIType.IPAdapterModel,
|
||||
)
|
||||
clip_vision_model: Literal["ViT-H", "ViT-G"] = InputField(
|
||||
clip_vision_model: Literal["ViT-H", "ViT-G", "ViT-L"] = InputField(
|
||||
description="CLIP Vision model to use. Overrides model settings. Mandatory for checkpoint models.",
|
||||
default="ViT-H",
|
||||
ui_order=2,
|
||||
@@ -111,9 +122,11 @@ class IPAdapterInvocation(BaseInvocation):
|
||||
image_encoder_model_id = ip_adapter_info.image_encoder_model_id
|
||||
image_encoder_model_name = image_encoder_model_id.split("/")[-1].strip()
|
||||
else:
|
||||
image_encoder_model_name = CLIP_VISION_MODEL_MAP[self.clip_vision_model]
|
||||
image_encoder_starter_model = CLIP_VISION_MODEL_MAP[self.clip_vision_model]
|
||||
image_encoder_model_id = image_encoder_starter_model.source
|
||||
image_encoder_model_name = image_encoder_starter_model.name
|
||||
|
||||
image_encoder_model = self._get_image_encoder(context, image_encoder_model_name)
|
||||
image_encoder_model = self.get_clip_image_encoder(context, image_encoder_model_id, image_encoder_model_name)
|
||||
|
||||
if self.method == "style":
|
||||
if ip_adapter_info.base == "sd-1":
|
||||
@@ -147,7 +160,10 @@ class IPAdapterInvocation(BaseInvocation):
|
||||
),
|
||||
)
|
||||
|
||||
def _get_image_encoder(self, context: InvocationContext, image_encoder_model_name: str) -> AnyModelConfig:
|
||||
@classmethod
|
||||
def get_clip_image_encoder(
|
||||
cls, context: InvocationContext, image_encoder_model_id: str, image_encoder_model_name: str
|
||||
) -> AnyModelConfig:
|
||||
image_encoder_models = context.models.search_by_attrs(
|
||||
name=image_encoder_model_name, base=BaseModelType.Any, type=ModelType.CLIPVision
|
||||
)
|
||||
@@ -159,7 +175,11 @@ class IPAdapterInvocation(BaseInvocation):
|
||||
)
|
||||
|
||||
installer = context._services.model_manager.install
|
||||
job = installer.heuristic_import(f"InvokeAI/{image_encoder_model_name}")
|
||||
# Note: We hard-code the type to CLIPVision here because if the model contains both a CLIPVision and a
|
||||
# CLIPText model, the probe may treat it as a CLIPText model.
|
||||
job = installer.heuristic_import(
|
||||
image_encoder_model_id, ModelRecordChanges(name=image_encoder_model_name, type=ModelType.CLIPVision)
|
||||
)
|
||||
installer.wait_for_job(job, timeout=600) # Wait for up to 10 minutes
|
||||
image_encoder_models = context.models.search_by_attrs(
|
||||
name=image_encoder_model_name, base=BaseModelType.Any, type=ModelType.CLIPVision
|
||||
|
||||
@@ -5,6 +5,7 @@ from PIL import Image
|
||||
from invokeai.app.invocations.baseinvocation import BaseInvocation, Classification, InvocationContext, invocation
|
||||
from invokeai.app.invocations.fields import ImageField, InputField, TensorField, WithBoard, WithMetadata
|
||||
from invokeai.app.invocations.primitives import ImageOutput, MaskOutput
|
||||
from invokeai.backend.image_util.util import pil_to_np
|
||||
|
||||
|
||||
@invocation(
|
||||
@@ -148,3 +149,51 @@ class MaskTensorToImageInvocation(BaseInvocation, WithMetadata, WithBoard):
|
||||
mask_pil = Image.fromarray(mask_np, mode="L")
|
||||
image_dto = context.images.save(image=mask_pil)
|
||||
return ImageOutput.build(image_dto)
|
||||
|
||||
|
||||
@invocation(
|
||||
"apply_tensor_mask_to_image",
|
||||
title="Apply Tensor Mask to Image",
|
||||
tags=["mask"],
|
||||
category="mask",
|
||||
version="1.0.0",
|
||||
)
|
||||
class ApplyMaskTensorToImageInvocation(BaseInvocation, WithMetadata, WithBoard):
|
||||
"""Applies a tensor mask to an image.
|
||||
|
||||
The image is converted to RGBA and the mask is applied to the alpha channel."""
|
||||
|
||||
mask: TensorField = InputField(description="The mask tensor to apply.")
|
||||
image: ImageField = InputField(description="The image to apply the mask to.")
|
||||
|
||||
def invoke(self, context: InvocationContext) -> ImageOutput:
|
||||
image = context.images.get_pil(self.image.image_name, mode="RGBA")
|
||||
mask = context.tensors.load(self.mask.tensor_name)
|
||||
|
||||
# Squeeze the channel dimension if it exists.
|
||||
if mask.dim() == 3:
|
||||
mask = mask.squeeze(0)
|
||||
|
||||
# Ensure that the mask is binary.
|
||||
if mask.dtype != torch.bool:
|
||||
mask = mask > 0.5
|
||||
mask_np = (mask.float() * 255).byte().cpu().numpy().astype(np.uint8)
|
||||
|
||||
# Apply the mask only to the alpha channel where the original alpha is non-zero. This preserves the original
|
||||
# image's transparency - else the transparent regions would end up as opaque black.
|
||||
|
||||
# Separate the image into R, G, B, and A channels
|
||||
image_np = pil_to_np(image)
|
||||
r, g, b, a = np.split(image_np, 4, axis=-1)
|
||||
|
||||
# Apply the mask to the alpha channel
|
||||
new_alpha = np.where(a.squeeze() > 0, mask_np, a.squeeze())
|
||||
|
||||
# Stack the RGB channels with the modified alpha
|
||||
masked_image_np = np.dstack([r.squeeze(), g.squeeze(), b.squeeze(), new_alpha])
|
||||
|
||||
# Convert back to an image (RGBA)
|
||||
masked_image = Image.fromarray(masked_image_np.astype(np.uint8), "RGBA")
|
||||
image_dto = context.images.save(image=masked_image)
|
||||
|
||||
return ImageOutput.build(image_dto)
|
||||
|
||||
@@ -40,7 +40,7 @@ class IPAdapterMetadataField(BaseModel):
|
||||
|
||||
image: ImageField = Field(description="The IP-Adapter image prompt.")
|
||||
ip_adapter_model: ModelIdentifierField = Field(description="The IP-Adapter model.")
|
||||
clip_vision_model: Literal["ViT-H", "ViT-G"] = Field(description="The CLIP Vision model")
|
||||
clip_vision_model: Literal["ViT-L", "ViT-H", "ViT-G"] = Field(description="The CLIP Vision model")
|
||||
method: Literal["full", "style", "composition"] = Field(description="Method to apply IP Weights with")
|
||||
weight: Union[float, list[float]] = Field(description="The weight given to the IP-Adapter")
|
||||
begin_step_percent: float = Field(description="When the IP-Adapter is first applied (% of total steps)")
|
||||
|
||||
@@ -1,9 +1,11 @@
|
||||
from enum import Enum
|
||||
from pathlib import Path
|
||||
from typing import Literal
|
||||
|
||||
import numpy as np
|
||||
import torch
|
||||
from PIL import Image
|
||||
from pydantic import BaseModel, Field, model_validator
|
||||
from transformers import AutoModelForMaskGeneration, AutoProcessor
|
||||
from transformers.models.sam import SamModel
|
||||
from transformers.models.sam.processing_sam import SamProcessor
|
||||
@@ -23,12 +25,31 @@ SEGMENT_ANYTHING_MODEL_IDS: dict[SegmentAnythingModelKey, str] = {
|
||||
}
|
||||
|
||||
|
||||
class SAMPointLabel(Enum):
|
||||
negative = -1
|
||||
neutral = 0
|
||||
positive = 1
|
||||
|
||||
|
||||
class SAMPoint(BaseModel):
|
||||
x: int = Field(..., description="The x-coordinate of the point")
|
||||
y: int = Field(..., description="The y-coordinate of the point")
|
||||
label: SAMPointLabel = Field(..., description="The label of the point")
|
||||
|
||||
|
||||
class SAMPointsField(BaseModel):
|
||||
points: list[SAMPoint] = Field(..., description="The points of the object")
|
||||
|
||||
def to_list(self) -> list[list[int]]:
|
||||
return [[point.x, point.y, point.label.value] for point in self.points]
|
||||
|
||||
|
||||
@invocation(
|
||||
"segment_anything",
|
||||
title="Segment Anything",
|
||||
tags=["prompt", "segmentation"],
|
||||
category="segmentation",
|
||||
version="1.0.0",
|
||||
version="1.1.0",
|
||||
)
|
||||
class SegmentAnythingInvocation(BaseInvocation):
|
||||
"""Runs a Segment Anything Model."""
|
||||
@@ -40,7 +61,13 @@ class SegmentAnythingInvocation(BaseInvocation):
|
||||
|
||||
model: SegmentAnythingModelKey = InputField(description="The Segment Anything model to use.")
|
||||
image: ImageField = InputField(description="The image to segment.")
|
||||
bounding_boxes: list[BoundingBoxField] = InputField(description="The bounding boxes to prompt the SAM model with.")
|
||||
bounding_boxes: list[BoundingBoxField] | None = InputField(
|
||||
default=None, description="The bounding boxes to prompt the SAM model with."
|
||||
)
|
||||
point_lists: list[SAMPointsField] | None = InputField(
|
||||
default=None,
|
||||
description="The list of point lists to prompt the SAM model with. Each list of points represents a single object.",
|
||||
)
|
||||
apply_polygon_refinement: bool = InputField(
|
||||
description="Whether to apply polygon refinement to the masks. This will smooth the edges of the masks slightly and ensure that each mask consists of a single closed polygon (before merging).",
|
||||
default=True,
|
||||
@@ -50,12 +77,22 @@ class SegmentAnythingInvocation(BaseInvocation):
|
||||
default="all",
|
||||
)
|
||||
|
||||
@model_validator(mode="after")
|
||||
def check_point_lists_or_bounding_box(self):
|
||||
if self.point_lists is None and self.bounding_boxes is None:
|
||||
raise ValueError("Either point_lists or bounding_box must be provided.")
|
||||
elif self.point_lists is not None and self.bounding_boxes is not None:
|
||||
raise ValueError("Only one of point_lists or bounding_box can be provided.")
|
||||
return self
|
||||
|
||||
@torch.no_grad()
|
||||
def invoke(self, context: InvocationContext) -> MaskOutput:
|
||||
# The models expect a 3-channel RGB image.
|
||||
image_pil = context.images.get_pil(self.image.image_name, mode="RGB")
|
||||
|
||||
if len(self.bounding_boxes) == 0:
|
||||
if (not self.bounding_boxes or len(self.bounding_boxes) == 0) and (
|
||||
not self.point_lists or len(self.point_lists) == 0
|
||||
):
|
||||
combined_mask = torch.zeros(image_pil.size[::-1], dtype=torch.bool)
|
||||
else:
|
||||
masks = self._segment(context=context, image=image_pil)
|
||||
@@ -83,14 +120,13 @@ class SegmentAnythingInvocation(BaseInvocation):
|
||||
assert isinstance(sam_processor, SamProcessor)
|
||||
return SegmentAnythingPipeline(sam_model=sam_model, sam_processor=sam_processor)
|
||||
|
||||
def _segment(
|
||||
self,
|
||||
context: InvocationContext,
|
||||
image: Image.Image,
|
||||
) -> list[torch.Tensor]:
|
||||
def _segment(self, context: InvocationContext, image: Image.Image) -> list[torch.Tensor]:
|
||||
"""Use Segment Anything (SAM) to generate masks given an image + a set of bounding boxes."""
|
||||
# Convert the bounding boxes to the SAM input format.
|
||||
sam_bounding_boxes = [[bb.x_min, bb.y_min, bb.x_max, bb.y_max] for bb in self.bounding_boxes]
|
||||
sam_bounding_boxes = (
|
||||
[[bb.x_min, bb.y_min, bb.x_max, bb.y_max] for bb in self.bounding_boxes] if self.bounding_boxes else None
|
||||
)
|
||||
sam_points = [p.to_list() for p in self.point_lists] if self.point_lists else None
|
||||
|
||||
with (
|
||||
context.models.load_remote_model(
|
||||
@@ -98,7 +134,7 @@ class SegmentAnythingInvocation(BaseInvocation):
|
||||
) as sam_pipeline,
|
||||
):
|
||||
assert isinstance(sam_pipeline, SegmentAnythingPipeline)
|
||||
masks = sam_pipeline.segment(image=image, bounding_boxes=sam_bounding_boxes)
|
||||
masks = sam_pipeline.segment(image=image, bounding_boxes=sam_bounding_boxes, point_lists=sam_points)
|
||||
|
||||
masks = self._process_masks(masks)
|
||||
if self.apply_polygon_refinement:
|
||||
@@ -141,9 +177,10 @@ class SegmentAnythingInvocation(BaseInvocation):
|
||||
|
||||
return masks
|
||||
|
||||
def _filter_masks(self, masks: list[torch.Tensor], bounding_boxes: list[BoundingBoxField]) -> list[torch.Tensor]:
|
||||
def _filter_masks(
|
||||
self, masks: list[torch.Tensor], bounding_boxes: list[BoundingBoxField] | None
|
||||
) -> list[torch.Tensor]:
|
||||
"""Filter the detected masks based on the specified mask filter."""
|
||||
assert len(masks) == len(bounding_boxes)
|
||||
|
||||
if self.mask_filter == "all":
|
||||
return masks
|
||||
@@ -151,6 +188,10 @@ class SegmentAnythingInvocation(BaseInvocation):
|
||||
# Find the largest mask.
|
||||
return [max(masks, key=lambda x: float(x.sum()))]
|
||||
elif self.mask_filter == "highest_box_score":
|
||||
assert (
|
||||
bounding_boxes is not None
|
||||
), "Bounding boxes must be provided to use the 'highest_box_score' mask filter."
|
||||
assert len(masks) == len(bounding_boxes)
|
||||
# Find the index of the bounding box with the highest score.
|
||||
# Note that we fallback to -1.0 if the score is None. This is mainly to satisfy the type checker. In most
|
||||
# cases the scores should all be non-None when using this filtering mode. That being said, -1.0 is a
|
||||
|
||||
@@ -1,7 +1,8 @@
|
||||
from abc import ABC, abstractmethod
|
||||
|
||||
from invokeai.app.services.board_records.board_records_common import BoardChanges, BoardRecord
|
||||
from invokeai.app.services.board_records.board_records_common import BoardChanges, BoardRecord, BoardRecordOrderBy
|
||||
from invokeai.app.services.shared.pagination import OffsetPaginatedResults
|
||||
from invokeai.app.services.shared.sqlite.sqlite_common import SQLiteDirection
|
||||
|
||||
|
||||
class BoardRecordStorageBase(ABC):
|
||||
@@ -39,12 +40,19 @@ class BoardRecordStorageBase(ABC):
|
||||
|
||||
@abstractmethod
|
||||
def get_many(
|
||||
self, offset: int = 0, limit: int = 10, include_archived: bool = False
|
||||
self,
|
||||
order_by: BoardRecordOrderBy,
|
||||
direction: SQLiteDirection,
|
||||
offset: int = 0,
|
||||
limit: int = 10,
|
||||
include_archived: bool = False,
|
||||
) -> OffsetPaginatedResults[BoardRecord]:
|
||||
"""Gets many board records."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def get_all(self, include_archived: bool = False) -> list[BoardRecord]:
|
||||
def get_all(
|
||||
self, order_by: BoardRecordOrderBy, direction: SQLiteDirection, include_archived: bool = False
|
||||
) -> list[BoardRecord]:
|
||||
"""Gets all board records."""
|
||||
pass
|
||||
|
||||
@@ -1,8 +1,10 @@
|
||||
from datetime import datetime
|
||||
from enum import Enum
|
||||
from typing import Optional, Union
|
||||
|
||||
from pydantic import BaseModel, Field
|
||||
|
||||
from invokeai.app.util.metaenum import MetaEnum
|
||||
from invokeai.app.util.misc import get_iso_timestamp
|
||||
from invokeai.app.util.model_exclude_null import BaseModelExcludeNull
|
||||
|
||||
@@ -60,6 +62,13 @@ class BoardChanges(BaseModel, extra="forbid"):
|
||||
archived: Optional[bool] = Field(default=None, description="Whether or not the board is archived")
|
||||
|
||||
|
||||
class BoardRecordOrderBy(str, Enum, metaclass=MetaEnum):
|
||||
"""The order by options for board records"""
|
||||
|
||||
CreatedAt = "created_at"
|
||||
Name = "board_name"
|
||||
|
||||
|
||||
class BoardRecordNotFoundException(Exception):
|
||||
"""Raised when an board record is not found."""
|
||||
|
||||
|
||||
@@ -8,10 +8,12 @@ from invokeai.app.services.board_records.board_records_common import (
|
||||
BoardRecord,
|
||||
BoardRecordDeleteException,
|
||||
BoardRecordNotFoundException,
|
||||
BoardRecordOrderBy,
|
||||
BoardRecordSaveException,
|
||||
deserialize_board_record,
|
||||
)
|
||||
from invokeai.app.services.shared.pagination import OffsetPaginatedResults
|
||||
from invokeai.app.services.shared.sqlite.sqlite_common import SQLiteDirection
|
||||
from invokeai.app.services.shared.sqlite.sqlite_database import SqliteDatabase
|
||||
from invokeai.app.util.misc import uuid_string
|
||||
|
||||
@@ -144,7 +146,12 @@ class SqliteBoardRecordStorage(BoardRecordStorageBase):
|
||||
return self.get(board_id)
|
||||
|
||||
def get_many(
|
||||
self, offset: int = 0, limit: int = 10, include_archived: bool = False
|
||||
self,
|
||||
order_by: BoardRecordOrderBy,
|
||||
direction: SQLiteDirection,
|
||||
offset: int = 0,
|
||||
limit: int = 10,
|
||||
include_archived: bool = False,
|
||||
) -> OffsetPaginatedResults[BoardRecord]:
|
||||
try:
|
||||
self._lock.acquire()
|
||||
@@ -154,17 +161,16 @@ class SqliteBoardRecordStorage(BoardRecordStorageBase):
|
||||
SELECT *
|
||||
FROM boards
|
||||
{archived_filter}
|
||||
ORDER BY created_at DESC
|
||||
ORDER BY {order_by} {direction}
|
||||
LIMIT ? OFFSET ?;
|
||||
"""
|
||||
|
||||
# Determine archived filter condition
|
||||
if include_archived:
|
||||
archived_filter = ""
|
||||
else:
|
||||
archived_filter = "WHERE archived = 0"
|
||||
archived_filter = "" if include_archived else "WHERE archived = 0"
|
||||
|
||||
final_query = base_query.format(archived_filter=archived_filter)
|
||||
final_query = base_query.format(
|
||||
archived_filter=archived_filter, order_by=order_by.value, direction=direction.value
|
||||
)
|
||||
|
||||
# Execute query to fetch boards
|
||||
self._cursor.execute(final_query, (limit, offset))
|
||||
@@ -198,23 +204,32 @@ class SqliteBoardRecordStorage(BoardRecordStorageBase):
|
||||
finally:
|
||||
self._lock.release()
|
||||
|
||||
def get_all(self, include_archived: bool = False) -> list[BoardRecord]:
|
||||
def get_all(
|
||||
self, order_by: BoardRecordOrderBy, direction: SQLiteDirection, include_archived: bool = False
|
||||
) -> list[BoardRecord]:
|
||||
try:
|
||||
self._lock.acquire()
|
||||
|
||||
base_query = """
|
||||
SELECT *
|
||||
FROM boards
|
||||
{archived_filter}
|
||||
ORDER BY created_at DESC
|
||||
"""
|
||||
|
||||
if include_archived:
|
||||
archived_filter = ""
|
||||
if order_by == BoardRecordOrderBy.Name:
|
||||
base_query = """
|
||||
SELECT *
|
||||
FROM boards
|
||||
{archived_filter}
|
||||
ORDER BY LOWER(board_name) {direction}
|
||||
"""
|
||||
else:
|
||||
archived_filter = "WHERE archived = 0"
|
||||
base_query = """
|
||||
SELECT *
|
||||
FROM boards
|
||||
{archived_filter}
|
||||
ORDER BY {order_by} {direction}
|
||||
"""
|
||||
|
||||
final_query = base_query.format(archived_filter=archived_filter)
|
||||
archived_filter = "" if include_archived else "WHERE archived = 0"
|
||||
|
||||
final_query = base_query.format(
|
||||
archived_filter=archived_filter, order_by=order_by.value, direction=direction.value
|
||||
)
|
||||
|
||||
self._cursor.execute(final_query)
|
||||
|
||||
|
||||
@@ -1,8 +1,9 @@
|
||||
from abc import ABC, abstractmethod
|
||||
|
||||
from invokeai.app.services.board_records.board_records_common import BoardChanges
|
||||
from invokeai.app.services.board_records.board_records_common import BoardChanges, BoardRecordOrderBy
|
||||
from invokeai.app.services.boards.boards_common import BoardDTO
|
||||
from invokeai.app.services.shared.pagination import OffsetPaginatedResults
|
||||
from invokeai.app.services.shared.sqlite.sqlite_common import SQLiteDirection
|
||||
|
||||
|
||||
class BoardServiceABC(ABC):
|
||||
@@ -43,12 +44,19 @@ class BoardServiceABC(ABC):
|
||||
|
||||
@abstractmethod
|
||||
def get_many(
|
||||
self, offset: int = 0, limit: int = 10, include_archived: bool = False
|
||||
self,
|
||||
order_by: BoardRecordOrderBy,
|
||||
direction: SQLiteDirection,
|
||||
offset: int = 0,
|
||||
limit: int = 10,
|
||||
include_archived: bool = False,
|
||||
) -> OffsetPaginatedResults[BoardDTO]:
|
||||
"""Gets many boards."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def get_all(self, include_archived: bool = False) -> list[BoardDTO]:
|
||||
def get_all(
|
||||
self, order_by: BoardRecordOrderBy, direction: SQLiteDirection, include_archived: bool = False
|
||||
) -> list[BoardDTO]:
|
||||
"""Gets all boards."""
|
||||
pass
|
||||
|
||||
@@ -1,8 +1,9 @@
|
||||
from invokeai.app.services.board_records.board_records_common import BoardChanges
|
||||
from invokeai.app.services.board_records.board_records_common import BoardChanges, BoardRecordOrderBy
|
||||
from invokeai.app.services.boards.boards_base import BoardServiceABC
|
||||
from invokeai.app.services.boards.boards_common import BoardDTO, board_record_to_dto
|
||||
from invokeai.app.services.invoker import Invoker
|
||||
from invokeai.app.services.shared.pagination import OffsetPaginatedResults
|
||||
from invokeai.app.services.shared.sqlite.sqlite_common import SQLiteDirection
|
||||
|
||||
|
||||
class BoardService(BoardServiceABC):
|
||||
@@ -47,9 +48,16 @@ class BoardService(BoardServiceABC):
|
||||
self.__invoker.services.board_records.delete(board_id)
|
||||
|
||||
def get_many(
|
||||
self, offset: int = 0, limit: int = 10, include_archived: bool = False
|
||||
self,
|
||||
order_by: BoardRecordOrderBy,
|
||||
direction: SQLiteDirection,
|
||||
offset: int = 0,
|
||||
limit: int = 10,
|
||||
include_archived: bool = False,
|
||||
) -> OffsetPaginatedResults[BoardDTO]:
|
||||
board_records = self.__invoker.services.board_records.get_many(offset, limit, include_archived)
|
||||
board_records = self.__invoker.services.board_records.get_many(
|
||||
order_by, direction, offset, limit, include_archived
|
||||
)
|
||||
board_dtos = []
|
||||
for r in board_records.items:
|
||||
cover_image = self.__invoker.services.image_records.get_most_recent_image_for_board(r.board_id)
|
||||
@@ -63,8 +71,10 @@ class BoardService(BoardServiceABC):
|
||||
|
||||
return OffsetPaginatedResults[BoardDTO](items=board_dtos, offset=offset, limit=limit, total=len(board_dtos))
|
||||
|
||||
def get_all(self, include_archived: bool = False) -> list[BoardDTO]:
|
||||
board_records = self.__invoker.services.board_records.get_all(include_archived)
|
||||
def get_all(
|
||||
self, order_by: BoardRecordOrderBy, direction: SQLiteDirection, include_archived: bool = False
|
||||
) -> list[BoardDTO]:
|
||||
board_records = self.__invoker.services.board_records.get_all(order_by, direction, include_archived)
|
||||
board_dtos = []
|
||||
for r in board_records:
|
||||
cover_image = self.__invoker.services.image_records.get_most_recent_image_for_board(r.board_id)
|
||||
|
||||
@@ -250,9 +250,9 @@ class InvokeAIAppConfig(BaseSettings):
|
||||
)
|
||||
|
||||
if as_example:
|
||||
file.write(
|
||||
"# This is an example file with default and example settings. Use the values here as a baseline.\n\n"
|
||||
)
|
||||
file.write("# This is an example file with default and example settings.\n")
|
||||
file.write("# You should not copy this whole file into your config.\n")
|
||||
file.write("# Only add the settings you need to change to your config file.\n\n")
|
||||
file.write("# Internal metadata - do not edit:\n")
|
||||
file.write(yaml.dump(meta_dict, sort_keys=False))
|
||||
file.write("\n")
|
||||
|
||||
@@ -110,15 +110,26 @@ class DiskImageFileStorage(ImageFileStorageBase):
|
||||
except Exception as e:
|
||||
raise ImageFileDeleteException from e
|
||||
|
||||
# TODO: make this a bit more flexible for e.g. cloud storage
|
||||
def get_path(self, image_name: str, thumbnail: bool = False) -> Path:
|
||||
path = self.__output_folder / image_name
|
||||
base_folder = self.__thumbnails_folder if thumbnail else self.__output_folder
|
||||
filename = get_thumbnail_name(image_name) if thumbnail else image_name
|
||||
|
||||
if thumbnail:
|
||||
thumbnail_name = get_thumbnail_name(image_name)
|
||||
path = self.__thumbnails_folder / thumbnail_name
|
||||
# Strip any path information from the filename
|
||||
basename = Path(filename).name
|
||||
|
||||
return path
|
||||
if basename != filename:
|
||||
raise ValueError("Invalid image name, potential directory traversal detected")
|
||||
|
||||
image_path = base_folder / basename
|
||||
|
||||
# Ensure the image path is within the base folder to prevent directory traversal
|
||||
resolved_base = base_folder.resolve()
|
||||
resolved_image_path = image_path.resolve()
|
||||
|
||||
if not resolved_image_path.is_relative_to(resolved_base):
|
||||
raise ValueError("Image path outside outputs folder, potential directory traversal detected")
|
||||
|
||||
return resolved_image_path
|
||||
|
||||
def validate_path(self, path: Union[str, Path]) -> bool:
|
||||
"""Validates the path given for an image or thumbnail."""
|
||||
|
||||
@@ -39,11 +39,11 @@ class WorkflowRecordsStorageBase(ABC):
|
||||
@abstractmethod
|
||||
def get_many(
|
||||
self,
|
||||
page: int,
|
||||
per_page: int,
|
||||
order_by: WorkflowRecordOrderBy,
|
||||
direction: SQLiteDirection,
|
||||
category: WorkflowCategory,
|
||||
page: int,
|
||||
per_page: Optional[int],
|
||||
query: Optional[str],
|
||||
) -> PaginatedResults[WorkflowRecordListItemDTO]:
|
||||
"""Gets many workflows."""
|
||||
|
||||
@@ -125,11 +125,11 @@ class SqliteWorkflowRecordsStorage(WorkflowRecordsStorageBase):
|
||||
|
||||
def get_many(
|
||||
self,
|
||||
page: int,
|
||||
per_page: int,
|
||||
order_by: WorkflowRecordOrderBy,
|
||||
direction: SQLiteDirection,
|
||||
category: WorkflowCategory,
|
||||
page: int = 0,
|
||||
per_page: Optional[int] = None,
|
||||
query: Optional[str] = None,
|
||||
) -> PaginatedResults[WorkflowRecordListItemDTO]:
|
||||
try:
|
||||
@@ -153,6 +153,7 @@ class SqliteWorkflowRecordsStorage(WorkflowRecordsStorageBase):
|
||||
"""
|
||||
main_params: list[int | str] = [category.value]
|
||||
count_params: list[int | str] = [category.value]
|
||||
|
||||
stripped_query = query.strip() if query else None
|
||||
if stripped_query:
|
||||
wildcard_query = "%" + stripped_query + "%"
|
||||
@@ -161,20 +162,28 @@ class SqliteWorkflowRecordsStorage(WorkflowRecordsStorageBase):
|
||||
main_params.extend([wildcard_query, wildcard_query])
|
||||
count_params.extend([wildcard_query, wildcard_query])
|
||||
|
||||
main_query += f" ORDER BY {order_by.value} {direction.value} LIMIT ? OFFSET ?;"
|
||||
main_params.extend([per_page, page * per_page])
|
||||
main_query += f" ORDER BY {order_by.value} {direction.value}"
|
||||
|
||||
if per_page:
|
||||
main_query += " LIMIT ? OFFSET ?"
|
||||
main_params.extend([per_page, page * per_page])
|
||||
|
||||
self._cursor.execute(main_query, main_params)
|
||||
rows = self._cursor.fetchall()
|
||||
workflows = [WorkflowRecordListItemDTOValidator.validate_python(dict(row)) for row in rows]
|
||||
|
||||
self._cursor.execute(count_query, count_params)
|
||||
total = self._cursor.fetchone()[0]
|
||||
pages = total // per_page + (total % per_page > 0)
|
||||
|
||||
if per_page:
|
||||
pages = total // per_page + (total % per_page > 0)
|
||||
else:
|
||||
pages = 1 # If no pagination, there is only one page
|
||||
|
||||
return PaginatedResults(
|
||||
items=workflows,
|
||||
page=page,
|
||||
per_page=per_page,
|
||||
per_page=per_page if per_page else total,
|
||||
pages=pages,
|
||||
total=total,
|
||||
)
|
||||
|
||||
0
invokeai/backend/flux/controlnet/__init__.py
Normal file
0
invokeai/backend/flux/controlnet/__init__.py
Normal file
58
invokeai/backend/flux/controlnet/controlnet_flux_output.py
Normal file
58
invokeai/backend/flux/controlnet/controlnet_flux_output.py
Normal file
@@ -0,0 +1,58 @@
|
||||
from dataclasses import dataclass
|
||||
|
||||
import torch
|
||||
|
||||
|
||||
@dataclass
|
||||
class ControlNetFluxOutput:
|
||||
single_block_residuals: list[torch.Tensor] | None
|
||||
double_block_residuals: list[torch.Tensor] | None
|
||||
|
||||
def apply_weight(self, weight: float):
|
||||
if self.single_block_residuals is not None:
|
||||
for i in range(len(self.single_block_residuals)):
|
||||
self.single_block_residuals[i] = self.single_block_residuals[i] * weight
|
||||
if self.double_block_residuals is not None:
|
||||
for i in range(len(self.double_block_residuals)):
|
||||
self.double_block_residuals[i] = self.double_block_residuals[i] * weight
|
||||
|
||||
|
||||
def add_tensor_lists_elementwise(
|
||||
list1: list[torch.Tensor] | None, list2: list[torch.Tensor] | None
|
||||
) -> list[torch.Tensor] | None:
|
||||
"""Add two tensor lists elementwise that could be None."""
|
||||
if list1 is None and list2 is None:
|
||||
return None
|
||||
if list1 is None:
|
||||
return list2
|
||||
if list2 is None:
|
||||
return list1
|
||||
|
||||
new_list: list[torch.Tensor] = []
|
||||
for list1_tensor, list2_tensor in zip(list1, list2, strict=True):
|
||||
new_list.append(list1_tensor + list2_tensor)
|
||||
return new_list
|
||||
|
||||
|
||||
def add_controlnet_flux_outputs(
|
||||
controlnet_output_1: ControlNetFluxOutput, controlnet_output_2: ControlNetFluxOutput
|
||||
) -> ControlNetFluxOutput:
|
||||
return ControlNetFluxOutput(
|
||||
single_block_residuals=add_tensor_lists_elementwise(
|
||||
controlnet_output_1.single_block_residuals, controlnet_output_2.single_block_residuals
|
||||
),
|
||||
double_block_residuals=add_tensor_lists_elementwise(
|
||||
controlnet_output_1.double_block_residuals, controlnet_output_2.double_block_residuals
|
||||
),
|
||||
)
|
||||
|
||||
|
||||
def sum_controlnet_flux_outputs(
|
||||
controlnet_outputs: list[ControlNetFluxOutput],
|
||||
) -> ControlNetFluxOutput:
|
||||
controlnet_output_sum = ControlNetFluxOutput(single_block_residuals=None, double_block_residuals=None)
|
||||
|
||||
for controlnet_output in controlnet_outputs:
|
||||
controlnet_output_sum = add_controlnet_flux_outputs(controlnet_output_sum, controlnet_output)
|
||||
|
||||
return controlnet_output_sum
|
||||
180
invokeai/backend/flux/controlnet/instantx_controlnet_flux.py
Normal file
180
invokeai/backend/flux/controlnet/instantx_controlnet_flux.py
Normal file
@@ -0,0 +1,180 @@
|
||||
# This file was initially copied from:
|
||||
# https://github.com/huggingface/diffusers/blob/99f608218caa069a2f16dcf9efab46959b15aec0/src/diffusers/models/controlnet_flux.py
|
||||
|
||||
|
||||
from dataclasses import dataclass
|
||||
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
|
||||
from invokeai.backend.flux.controlnet.zero_module import zero_module
|
||||
from invokeai.backend.flux.model import FluxParams
|
||||
from invokeai.backend.flux.modules.layers import (
|
||||
DoubleStreamBlock,
|
||||
EmbedND,
|
||||
MLPEmbedder,
|
||||
SingleStreamBlock,
|
||||
timestep_embedding,
|
||||
)
|
||||
|
||||
|
||||
@dataclass
|
||||
class InstantXControlNetFluxOutput:
|
||||
controlnet_block_samples: list[torch.Tensor] | None
|
||||
controlnet_single_block_samples: list[torch.Tensor] | None
|
||||
|
||||
|
||||
# NOTE(ryand): Mapping between diffusers FLUX transformer params and BFL FLUX transformer params:
|
||||
# - Diffusers: BFL
|
||||
# - in_channels: in_channels
|
||||
# - num_layers: depth
|
||||
# - num_single_layers: depth_single_blocks
|
||||
# - attention_head_dim: hidden_size // num_heads
|
||||
# - num_attention_heads: num_heads
|
||||
# - joint_attention_dim: context_in_dim
|
||||
# - pooled_projection_dim: vec_in_dim
|
||||
# - guidance_embeds: guidance_embed
|
||||
# - axes_dims_rope: axes_dim
|
||||
|
||||
|
||||
class InstantXControlNetFlux(torch.nn.Module):
|
||||
def __init__(self, params: FluxParams, num_control_modes: int | None = None):
|
||||
"""
|
||||
Args:
|
||||
params (FluxParams): The parameters for the FLUX model.
|
||||
num_control_modes (int | None, optional): The number of controlnet modes. If non-None, then the model is a
|
||||
'union controlnet' model and expects a mode conditioning input at runtime.
|
||||
"""
|
||||
super().__init__()
|
||||
|
||||
# The following modules mirror the base FLUX transformer model.
|
||||
# -------------------------------------------------------------
|
||||
self.params = params
|
||||
self.in_channels = params.in_channels
|
||||
self.out_channels = self.in_channels
|
||||
if params.hidden_size % params.num_heads != 0:
|
||||
raise ValueError(f"Hidden size {params.hidden_size} must be divisible by num_heads {params.num_heads}")
|
||||
pe_dim = params.hidden_size // params.num_heads
|
||||
if sum(params.axes_dim) != pe_dim:
|
||||
raise ValueError(f"Got {params.axes_dim} but expected positional dim {pe_dim}")
|
||||
self.hidden_size = params.hidden_size
|
||||
self.num_heads = params.num_heads
|
||||
self.pe_embedder = EmbedND(dim=pe_dim, theta=params.theta, axes_dim=params.axes_dim)
|
||||
self.img_in = nn.Linear(self.in_channels, self.hidden_size, bias=True)
|
||||
self.time_in = MLPEmbedder(in_dim=256, hidden_dim=self.hidden_size)
|
||||
self.vector_in = MLPEmbedder(params.vec_in_dim, self.hidden_size)
|
||||
self.guidance_in = (
|
||||
MLPEmbedder(in_dim=256, hidden_dim=self.hidden_size) if params.guidance_embed else nn.Identity()
|
||||
)
|
||||
self.txt_in = nn.Linear(params.context_in_dim, self.hidden_size)
|
||||
|
||||
self.double_blocks = nn.ModuleList(
|
||||
[
|
||||
DoubleStreamBlock(
|
||||
self.hidden_size,
|
||||
self.num_heads,
|
||||
mlp_ratio=params.mlp_ratio,
|
||||
qkv_bias=params.qkv_bias,
|
||||
)
|
||||
for _ in range(params.depth)
|
||||
]
|
||||
)
|
||||
|
||||
self.single_blocks = nn.ModuleList(
|
||||
[
|
||||
SingleStreamBlock(self.hidden_size, self.num_heads, mlp_ratio=params.mlp_ratio)
|
||||
for _ in range(params.depth_single_blocks)
|
||||
]
|
||||
)
|
||||
|
||||
# The following modules are specific to the ControlNet model.
|
||||
# -----------------------------------------------------------
|
||||
self.controlnet_blocks = nn.ModuleList([])
|
||||
for _ in range(len(self.double_blocks)):
|
||||
self.controlnet_blocks.append(zero_module(nn.Linear(self.hidden_size, self.hidden_size)))
|
||||
|
||||
self.controlnet_single_blocks = nn.ModuleList([])
|
||||
for _ in range(len(self.single_blocks)):
|
||||
self.controlnet_single_blocks.append(zero_module(nn.Linear(self.hidden_size, self.hidden_size)))
|
||||
|
||||
self.is_union = False
|
||||
if num_control_modes is not None:
|
||||
self.is_union = True
|
||||
self.controlnet_mode_embedder = nn.Embedding(num_control_modes, self.hidden_size)
|
||||
|
||||
self.controlnet_x_embedder = zero_module(torch.nn.Linear(self.in_channels, self.hidden_size))
|
||||
|
||||
def forward(
|
||||
self,
|
||||
controlnet_cond: torch.Tensor,
|
||||
controlnet_mode: torch.Tensor | None,
|
||||
img: torch.Tensor,
|
||||
img_ids: torch.Tensor,
|
||||
txt: torch.Tensor,
|
||||
txt_ids: torch.Tensor,
|
||||
timesteps: torch.Tensor,
|
||||
y: torch.Tensor,
|
||||
guidance: torch.Tensor | None = None,
|
||||
) -> InstantXControlNetFluxOutput:
|
||||
if img.ndim != 3 or txt.ndim != 3:
|
||||
raise ValueError("Input img and txt tensors must have 3 dimensions.")
|
||||
|
||||
img = self.img_in(img)
|
||||
|
||||
# Add controlnet_cond embedding.
|
||||
img = img + self.controlnet_x_embedder(controlnet_cond)
|
||||
|
||||
vec = self.time_in(timestep_embedding(timesteps, 256))
|
||||
if self.params.guidance_embed:
|
||||
if guidance is None:
|
||||
raise ValueError("Didn't get guidance strength for guidance distilled model.")
|
||||
vec = vec + self.guidance_in(timestep_embedding(guidance, 256))
|
||||
vec = vec + self.vector_in(y)
|
||||
txt = self.txt_in(txt)
|
||||
|
||||
# If this is a union ControlNet, then concat the control mode embedding to the T5 text embedding.
|
||||
if self.is_union:
|
||||
if controlnet_mode is None:
|
||||
# We allow users to enter 'None' as the controlnet_mode if they don't want to worry about this input.
|
||||
# We've chosen to use a zero-embedding in this case.
|
||||
zero_index = torch.zeros([1, 1], dtype=torch.long, device=txt.device)
|
||||
controlnet_mode_emb = torch.zeros_like(self.controlnet_mode_embedder(zero_index))
|
||||
else:
|
||||
controlnet_mode_emb = self.controlnet_mode_embedder(controlnet_mode)
|
||||
txt = torch.cat([controlnet_mode_emb, txt], dim=1)
|
||||
txt_ids = torch.cat([txt_ids[:, :1, :], txt_ids], dim=1)
|
||||
else:
|
||||
assert controlnet_mode is None
|
||||
|
||||
ids = torch.cat((txt_ids, img_ids), dim=1)
|
||||
pe = self.pe_embedder(ids)
|
||||
|
||||
double_block_samples: list[torch.Tensor] = []
|
||||
for block in self.double_blocks:
|
||||
img, txt = block(img=img, txt=txt, vec=vec, pe=pe)
|
||||
double_block_samples.append(img)
|
||||
|
||||
img = torch.cat((txt, img), 1)
|
||||
|
||||
single_block_samples: list[torch.Tensor] = []
|
||||
for block in self.single_blocks:
|
||||
img = block(img, vec=vec, pe=pe)
|
||||
single_block_samples.append(img[:, txt.shape[1] :])
|
||||
|
||||
# ControlNet Block
|
||||
controlnet_double_block_samples: list[torch.Tensor] = []
|
||||
for double_block_sample, controlnet_block in zip(double_block_samples, self.controlnet_blocks, strict=True):
|
||||
double_block_sample = controlnet_block(double_block_sample)
|
||||
controlnet_double_block_samples.append(double_block_sample)
|
||||
|
||||
controlnet_single_block_samples: list[torch.Tensor] = []
|
||||
for single_block_sample, controlnet_block in zip(
|
||||
single_block_samples, self.controlnet_single_blocks, strict=True
|
||||
):
|
||||
single_block_sample = controlnet_block(single_block_sample)
|
||||
controlnet_single_block_samples.append(single_block_sample)
|
||||
|
||||
return InstantXControlNetFluxOutput(
|
||||
controlnet_block_samples=controlnet_double_block_samples or None,
|
||||
controlnet_single_block_samples=controlnet_single_block_samples or None,
|
||||
)
|
||||
295
invokeai/backend/flux/controlnet/state_dict_utils.py
Normal file
295
invokeai/backend/flux/controlnet/state_dict_utils.py
Normal file
@@ -0,0 +1,295 @@
|
||||
from typing import Any, Dict
|
||||
|
||||
import torch
|
||||
|
||||
from invokeai.backend.flux.model import FluxParams
|
||||
|
||||
|
||||
def is_state_dict_xlabs_controlnet(sd: Dict[str, Any]) -> bool:
|
||||
"""Is the state dict for an XLabs ControlNet model?
|
||||
|
||||
This is intended to be a reasonably high-precision detector, but it is not guaranteed to have perfect precision.
|
||||
"""
|
||||
# If all of the expected keys are present, then this is very likely an XLabs ControlNet model.
|
||||
expected_keys = {
|
||||
"controlnet_blocks.0.bias",
|
||||
"controlnet_blocks.0.weight",
|
||||
"input_hint_block.0.bias",
|
||||
"input_hint_block.0.weight",
|
||||
"pos_embed_input.bias",
|
||||
"pos_embed_input.weight",
|
||||
}
|
||||
|
||||
if expected_keys.issubset(sd.keys()):
|
||||
return True
|
||||
return False
|
||||
|
||||
|
||||
def is_state_dict_instantx_controlnet(sd: Dict[str, Any]) -> bool:
|
||||
"""Is the state dict for an InstantX ControlNet model?
|
||||
|
||||
This is intended to be a reasonably high-precision detector, but it is not guaranteed to have perfect precision.
|
||||
"""
|
||||
# If all of the expected keys are present, then this is very likely an InstantX ControlNet model.
|
||||
expected_keys = {
|
||||
"controlnet_blocks.0.bias",
|
||||
"controlnet_blocks.0.weight",
|
||||
"controlnet_x_embedder.bias",
|
||||
"controlnet_x_embedder.weight",
|
||||
}
|
||||
|
||||
if expected_keys.issubset(sd.keys()):
|
||||
return True
|
||||
return False
|
||||
|
||||
|
||||
def _fuse_weights(*t: torch.Tensor) -> torch.Tensor:
|
||||
"""Fuse weights along dimension 0.
|
||||
|
||||
Used to fuse q, k, v attention weights into a single qkv tensor when converting from diffusers to BFL format.
|
||||
"""
|
||||
# TODO(ryand): Double check dim=0 is correct.
|
||||
return torch.cat(t, dim=0)
|
||||
|
||||
|
||||
def _convert_flux_double_block_sd_from_diffusers_to_bfl_format(
|
||||
sd: Dict[str, torch.Tensor], double_block_index: int
|
||||
) -> Dict[str, torch.Tensor]:
|
||||
"""Convert the state dict for a double block from diffusers format to BFL format."""
|
||||
to_prefix = f"double_blocks.{double_block_index}"
|
||||
from_prefix = f"transformer_blocks.{double_block_index}"
|
||||
|
||||
new_sd: dict[str, torch.Tensor] = {}
|
||||
|
||||
# Check one key to determine if this block exists.
|
||||
if f"{from_prefix}.attn.add_q_proj.bias" not in sd:
|
||||
return new_sd
|
||||
|
||||
# txt_attn.qkv
|
||||
new_sd[f"{to_prefix}.txt_attn.qkv.bias"] = _fuse_weights(
|
||||
sd.pop(f"{from_prefix}.attn.add_q_proj.bias"),
|
||||
sd.pop(f"{from_prefix}.attn.add_k_proj.bias"),
|
||||
sd.pop(f"{from_prefix}.attn.add_v_proj.bias"),
|
||||
)
|
||||
new_sd[f"{to_prefix}.txt_attn.qkv.weight"] = _fuse_weights(
|
||||
sd.pop(f"{from_prefix}.attn.add_q_proj.weight"),
|
||||
sd.pop(f"{from_prefix}.attn.add_k_proj.weight"),
|
||||
sd.pop(f"{from_prefix}.attn.add_v_proj.weight"),
|
||||
)
|
||||
|
||||
# img_attn.qkv
|
||||
new_sd[f"{to_prefix}.img_attn.qkv.bias"] = _fuse_weights(
|
||||
sd.pop(f"{from_prefix}.attn.to_q.bias"),
|
||||
sd.pop(f"{from_prefix}.attn.to_k.bias"),
|
||||
sd.pop(f"{from_prefix}.attn.to_v.bias"),
|
||||
)
|
||||
new_sd[f"{to_prefix}.img_attn.qkv.weight"] = _fuse_weights(
|
||||
sd.pop(f"{from_prefix}.attn.to_q.weight"),
|
||||
sd.pop(f"{from_prefix}.attn.to_k.weight"),
|
||||
sd.pop(f"{from_prefix}.attn.to_v.weight"),
|
||||
)
|
||||
|
||||
# Handle basic 1-to-1 key conversions.
|
||||
key_map = {
|
||||
# img_attn
|
||||
"attn.norm_k.weight": "img_attn.norm.key_norm.scale",
|
||||
"attn.norm_q.weight": "img_attn.norm.query_norm.scale",
|
||||
"attn.to_out.0.weight": "img_attn.proj.weight",
|
||||
"attn.to_out.0.bias": "img_attn.proj.bias",
|
||||
# img_mlp
|
||||
"ff.net.0.proj.weight": "img_mlp.0.weight",
|
||||
"ff.net.0.proj.bias": "img_mlp.0.bias",
|
||||
"ff.net.2.weight": "img_mlp.2.weight",
|
||||
"ff.net.2.bias": "img_mlp.2.bias",
|
||||
# img_mod
|
||||
"norm1.linear.weight": "img_mod.lin.weight",
|
||||
"norm1.linear.bias": "img_mod.lin.bias",
|
||||
# txt_attn
|
||||
"attn.norm_added_q.weight": "txt_attn.norm.query_norm.scale",
|
||||
"attn.norm_added_k.weight": "txt_attn.norm.key_norm.scale",
|
||||
"attn.to_add_out.weight": "txt_attn.proj.weight",
|
||||
"attn.to_add_out.bias": "txt_attn.proj.bias",
|
||||
# txt_mlp
|
||||
"ff_context.net.0.proj.weight": "txt_mlp.0.weight",
|
||||
"ff_context.net.0.proj.bias": "txt_mlp.0.bias",
|
||||
"ff_context.net.2.weight": "txt_mlp.2.weight",
|
||||
"ff_context.net.2.bias": "txt_mlp.2.bias",
|
||||
# txt_mod
|
||||
"norm1_context.linear.weight": "txt_mod.lin.weight",
|
||||
"norm1_context.linear.bias": "txt_mod.lin.bias",
|
||||
}
|
||||
for from_key, to_key in key_map.items():
|
||||
new_sd[f"{to_prefix}.{to_key}"] = sd.pop(f"{from_prefix}.{from_key}")
|
||||
|
||||
return new_sd
|
||||
|
||||
|
||||
def _convert_flux_single_block_sd_from_diffusers_to_bfl_format(
|
||||
sd: Dict[str, torch.Tensor], single_block_index: int
|
||||
) -> Dict[str, torch.Tensor]:
|
||||
"""Convert the state dict for a single block from diffusers format to BFL format."""
|
||||
to_prefix = f"single_blocks.{single_block_index}"
|
||||
from_prefix = f"single_transformer_blocks.{single_block_index}"
|
||||
|
||||
new_sd: dict[str, torch.Tensor] = {}
|
||||
|
||||
# Check one key to determine if this block exists.
|
||||
if f"{from_prefix}.attn.to_q.bias" not in sd:
|
||||
return new_sd
|
||||
|
||||
# linear1 (qkv)
|
||||
new_sd[f"{to_prefix}.linear1.bias"] = _fuse_weights(
|
||||
sd.pop(f"{from_prefix}.attn.to_q.bias"),
|
||||
sd.pop(f"{from_prefix}.attn.to_k.bias"),
|
||||
sd.pop(f"{from_prefix}.attn.to_v.bias"),
|
||||
sd.pop(f"{from_prefix}.proj_mlp.bias"),
|
||||
)
|
||||
new_sd[f"{to_prefix}.linear1.weight"] = _fuse_weights(
|
||||
sd.pop(f"{from_prefix}.attn.to_q.weight"),
|
||||
sd.pop(f"{from_prefix}.attn.to_k.weight"),
|
||||
sd.pop(f"{from_prefix}.attn.to_v.weight"),
|
||||
sd.pop(f"{from_prefix}.proj_mlp.weight"),
|
||||
)
|
||||
|
||||
# Handle basic 1-to-1 key conversions.
|
||||
key_map = {
|
||||
# linear2
|
||||
"proj_out.weight": "linear2.weight",
|
||||
"proj_out.bias": "linear2.bias",
|
||||
# modulation
|
||||
"norm.linear.weight": "modulation.lin.weight",
|
||||
"norm.linear.bias": "modulation.lin.bias",
|
||||
# norm
|
||||
"attn.norm_k.weight": "norm.key_norm.scale",
|
||||
"attn.norm_q.weight": "norm.query_norm.scale",
|
||||
}
|
||||
for from_key, to_key in key_map.items():
|
||||
new_sd[f"{to_prefix}.{to_key}"] = sd.pop(f"{from_prefix}.{from_key}")
|
||||
|
||||
return new_sd
|
||||
|
||||
|
||||
def convert_diffusers_instantx_state_dict_to_bfl_format(sd: Dict[str, torch.Tensor]) -> Dict[str, torch.Tensor]:
|
||||
"""Convert an InstantX ControlNet state dict to the format that can be loaded by our internal
|
||||
InstantXControlNetFlux model.
|
||||
|
||||
The original InstantX ControlNet model was developed to be used in diffusers. We have ported the original
|
||||
implementation to InstantXControlNetFlux to make it compatible with BFL-style models. This function converts the
|
||||
original state dict to the format expected by InstantXControlNetFlux.
|
||||
"""
|
||||
# Shallow copy sd so that we can pop keys from it without modifying the original.
|
||||
sd = sd.copy()
|
||||
|
||||
new_sd: dict[str, torch.Tensor] = {}
|
||||
|
||||
# Handle basic 1-to-1 key conversions.
|
||||
basic_key_map = {
|
||||
# Base model keys.
|
||||
# ----------------
|
||||
# txt_in keys.
|
||||
"context_embedder.bias": "txt_in.bias",
|
||||
"context_embedder.weight": "txt_in.weight",
|
||||
# guidance_in MLPEmbedder keys.
|
||||
"time_text_embed.guidance_embedder.linear_1.bias": "guidance_in.in_layer.bias",
|
||||
"time_text_embed.guidance_embedder.linear_1.weight": "guidance_in.in_layer.weight",
|
||||
"time_text_embed.guidance_embedder.linear_2.bias": "guidance_in.out_layer.bias",
|
||||
"time_text_embed.guidance_embedder.linear_2.weight": "guidance_in.out_layer.weight",
|
||||
# vector_in MLPEmbedder keys.
|
||||
"time_text_embed.text_embedder.linear_1.bias": "vector_in.in_layer.bias",
|
||||
"time_text_embed.text_embedder.linear_1.weight": "vector_in.in_layer.weight",
|
||||
"time_text_embed.text_embedder.linear_2.bias": "vector_in.out_layer.bias",
|
||||
"time_text_embed.text_embedder.linear_2.weight": "vector_in.out_layer.weight",
|
||||
# time_in MLPEmbedder keys.
|
||||
"time_text_embed.timestep_embedder.linear_1.bias": "time_in.in_layer.bias",
|
||||
"time_text_embed.timestep_embedder.linear_1.weight": "time_in.in_layer.weight",
|
||||
"time_text_embed.timestep_embedder.linear_2.bias": "time_in.out_layer.bias",
|
||||
"time_text_embed.timestep_embedder.linear_2.weight": "time_in.out_layer.weight",
|
||||
# img_in keys.
|
||||
"x_embedder.bias": "img_in.bias",
|
||||
"x_embedder.weight": "img_in.weight",
|
||||
}
|
||||
for old_key, new_key in basic_key_map.items():
|
||||
v = sd.pop(old_key, None)
|
||||
if v is not None:
|
||||
new_sd[new_key] = v
|
||||
|
||||
# Handle the double_blocks.
|
||||
block_index = 0
|
||||
while True:
|
||||
converted_double_block_sd = _convert_flux_double_block_sd_from_diffusers_to_bfl_format(sd, block_index)
|
||||
if len(converted_double_block_sd) == 0:
|
||||
break
|
||||
new_sd.update(converted_double_block_sd)
|
||||
block_index += 1
|
||||
|
||||
# Handle the single_blocks.
|
||||
block_index = 0
|
||||
while True:
|
||||
converted_singe_block_sd = _convert_flux_single_block_sd_from_diffusers_to_bfl_format(sd, block_index)
|
||||
if len(converted_singe_block_sd) == 0:
|
||||
break
|
||||
new_sd.update(converted_singe_block_sd)
|
||||
block_index += 1
|
||||
|
||||
# Transfer controlnet keys as-is.
|
||||
for k in list(sd.keys()):
|
||||
if k.startswith("controlnet_"):
|
||||
new_sd[k] = sd.pop(k)
|
||||
|
||||
# Assert that all keys have been handled.
|
||||
assert len(sd) == 0
|
||||
return new_sd
|
||||
|
||||
|
||||
def infer_flux_params_from_state_dict(sd: Dict[str, torch.Tensor]) -> FluxParams:
|
||||
"""Infer the FluxParams from the shape of a FLUX state dict. When a model is distributed in diffusers format, this
|
||||
information is all contained in the config.json file that accompanies the model. However, being apple to infer the
|
||||
params from the state dict enables us to load models (e.g. an InstantX ControlNet) from a single weight file.
|
||||
"""
|
||||
hidden_size = sd["img_in.weight"].shape[0]
|
||||
mlp_hidden_dim = sd["double_blocks.0.img_mlp.0.weight"].shape[0]
|
||||
# mlp_ratio is a float, but we treat it as an int here to avoid having to think about possible float precision
|
||||
# issues. In practice, mlp_ratio is usually 4.
|
||||
mlp_ratio = mlp_hidden_dim // hidden_size
|
||||
|
||||
head_dim = sd["double_blocks.0.img_attn.norm.query_norm.scale"].shape[0]
|
||||
num_heads = hidden_size // head_dim
|
||||
|
||||
# Count the number of double blocks.
|
||||
double_block_index = 0
|
||||
while f"double_blocks.{double_block_index}.img_attn.qkv.weight" in sd:
|
||||
double_block_index += 1
|
||||
|
||||
# Count the number of single blocks.
|
||||
single_block_index = 0
|
||||
while f"single_blocks.{single_block_index}.linear1.weight" in sd:
|
||||
single_block_index += 1
|
||||
|
||||
return FluxParams(
|
||||
in_channels=sd["img_in.weight"].shape[1],
|
||||
vec_in_dim=sd["vector_in.in_layer.weight"].shape[1],
|
||||
context_in_dim=sd["txt_in.weight"].shape[1],
|
||||
hidden_size=hidden_size,
|
||||
mlp_ratio=mlp_ratio,
|
||||
num_heads=num_heads,
|
||||
depth=double_block_index,
|
||||
depth_single_blocks=single_block_index,
|
||||
# axes_dim cannot be inferred from the state dict. The hard-coded value is correct for dev/schnell models.
|
||||
axes_dim=[16, 56, 56],
|
||||
# theta cannot be inferred from the state dict. The hard-coded value is correct for dev/schnell models.
|
||||
theta=10_000,
|
||||
qkv_bias="double_blocks.0.img_attn.qkv.bias" in sd,
|
||||
guidance_embed="guidance_in.in_layer.weight" in sd,
|
||||
)
|
||||
|
||||
|
||||
def infer_instantx_num_control_modes_from_state_dict(sd: Dict[str, torch.Tensor]) -> int | None:
|
||||
"""Infer the number of ControlNet Union modes from the shape of a InstantX ControlNet state dict.
|
||||
|
||||
Returns None if the model is not a ControlNet Union model. Otherwise returns the number of modes.
|
||||
"""
|
||||
mode_embedder_key = "controlnet_mode_embedder.weight"
|
||||
if mode_embedder_key not in sd:
|
||||
return None
|
||||
|
||||
return sd[mode_embedder_key].shape[0]
|
||||
130
invokeai/backend/flux/controlnet/xlabs_controlnet_flux.py
Normal file
130
invokeai/backend/flux/controlnet/xlabs_controlnet_flux.py
Normal file
@@ -0,0 +1,130 @@
|
||||
# This file was initially based on:
|
||||
# https://github.com/XLabs-AI/x-flux/blob/47495425dbed499be1e8e5a6e52628b07349cba2/src/flux/controlnet.py
|
||||
|
||||
|
||||
from dataclasses import dataclass
|
||||
|
||||
import torch
|
||||
from einops import rearrange
|
||||
|
||||
from invokeai.backend.flux.controlnet.zero_module import zero_module
|
||||
from invokeai.backend.flux.model import FluxParams
|
||||
from invokeai.backend.flux.modules.layers import DoubleStreamBlock, EmbedND, MLPEmbedder, timestep_embedding
|
||||
|
||||
|
||||
@dataclass
|
||||
class XLabsControlNetFluxOutput:
|
||||
controlnet_double_block_residuals: list[torch.Tensor] | None
|
||||
|
||||
|
||||
class XLabsControlNetFlux(torch.nn.Module):
|
||||
"""A ControlNet model for FLUX.
|
||||
|
||||
The architecture is very similar to the base FLUX model, with the following differences:
|
||||
- A `controlnet_depth` parameter is passed to control the number of double_blocks that the ControlNet is applied to.
|
||||
In order to keep the ControlNet small, this is typically much less than the depth of the base FLUX model.
|
||||
- There is a set of `controlnet_blocks` that are applied to the output of each double_block.
|
||||
"""
|
||||
|
||||
def __init__(self, params: FluxParams, controlnet_depth: int = 2):
|
||||
super().__init__()
|
||||
|
||||
self.params = params
|
||||
self.in_channels = params.in_channels
|
||||
self.out_channels = self.in_channels
|
||||
if params.hidden_size % params.num_heads != 0:
|
||||
raise ValueError(f"Hidden size {params.hidden_size} must be divisible by num_heads {params.num_heads}")
|
||||
pe_dim = params.hidden_size // params.num_heads
|
||||
if sum(params.axes_dim) != pe_dim:
|
||||
raise ValueError(f"Got {params.axes_dim} but expected positional dim {pe_dim}")
|
||||
self.hidden_size = params.hidden_size
|
||||
self.num_heads = params.num_heads
|
||||
self.pe_embedder = EmbedND(dim=pe_dim, theta=params.theta, axes_dim=params.axes_dim)
|
||||
self.img_in = torch.nn.Linear(self.in_channels, self.hidden_size, bias=True)
|
||||
self.time_in = MLPEmbedder(in_dim=256, hidden_dim=self.hidden_size)
|
||||
self.vector_in = MLPEmbedder(params.vec_in_dim, self.hidden_size)
|
||||
self.guidance_in = (
|
||||
MLPEmbedder(in_dim=256, hidden_dim=self.hidden_size) if params.guidance_embed else torch.nn.Identity()
|
||||
)
|
||||
self.txt_in = torch.nn.Linear(params.context_in_dim, self.hidden_size)
|
||||
|
||||
self.double_blocks = torch.nn.ModuleList(
|
||||
[
|
||||
DoubleStreamBlock(
|
||||
self.hidden_size,
|
||||
self.num_heads,
|
||||
mlp_ratio=params.mlp_ratio,
|
||||
qkv_bias=params.qkv_bias,
|
||||
)
|
||||
for _ in range(controlnet_depth)
|
||||
]
|
||||
)
|
||||
|
||||
# Add ControlNet blocks.
|
||||
self.controlnet_blocks = torch.nn.ModuleList([])
|
||||
for _ in range(controlnet_depth):
|
||||
controlnet_block = torch.nn.Linear(self.hidden_size, self.hidden_size)
|
||||
controlnet_block = zero_module(controlnet_block)
|
||||
self.controlnet_blocks.append(controlnet_block)
|
||||
self.pos_embed_input = torch.nn.Linear(self.in_channels, self.hidden_size, bias=True)
|
||||
self.input_hint_block = torch.nn.Sequential(
|
||||
torch.nn.Conv2d(3, 16, 3, padding=1),
|
||||
torch.nn.SiLU(),
|
||||
torch.nn.Conv2d(16, 16, 3, padding=1),
|
||||
torch.nn.SiLU(),
|
||||
torch.nn.Conv2d(16, 16, 3, padding=1, stride=2),
|
||||
torch.nn.SiLU(),
|
||||
torch.nn.Conv2d(16, 16, 3, padding=1),
|
||||
torch.nn.SiLU(),
|
||||
torch.nn.Conv2d(16, 16, 3, padding=1, stride=2),
|
||||
torch.nn.SiLU(),
|
||||
torch.nn.Conv2d(16, 16, 3, padding=1),
|
||||
torch.nn.SiLU(),
|
||||
torch.nn.Conv2d(16, 16, 3, padding=1, stride=2),
|
||||
torch.nn.SiLU(),
|
||||
zero_module(torch.nn.Conv2d(16, 16, 3, padding=1)),
|
||||
)
|
||||
|
||||
def forward(
|
||||
self,
|
||||
img: torch.Tensor,
|
||||
img_ids: torch.Tensor,
|
||||
controlnet_cond: torch.Tensor,
|
||||
txt: torch.Tensor,
|
||||
txt_ids: torch.Tensor,
|
||||
timesteps: torch.Tensor,
|
||||
y: torch.Tensor,
|
||||
guidance: torch.Tensor | None = None,
|
||||
) -> XLabsControlNetFluxOutput:
|
||||
if img.ndim != 3 or txt.ndim != 3:
|
||||
raise ValueError("Input img and txt tensors must have 3 dimensions.")
|
||||
|
||||
# running on sequences img
|
||||
img = self.img_in(img)
|
||||
controlnet_cond = self.input_hint_block(controlnet_cond)
|
||||
controlnet_cond = rearrange(controlnet_cond, "b c (h ph) (w pw) -> b (h w) (c ph pw)", ph=2, pw=2)
|
||||
controlnet_cond = self.pos_embed_input(controlnet_cond)
|
||||
img = img + controlnet_cond
|
||||
vec = self.time_in(timestep_embedding(timesteps, 256))
|
||||
if self.params.guidance_embed:
|
||||
if guidance is None:
|
||||
raise ValueError("Didn't get guidance strength for guidance distilled model.")
|
||||
vec = vec + self.guidance_in(timestep_embedding(guidance, 256))
|
||||
vec = vec + self.vector_in(y)
|
||||
txt = self.txt_in(txt)
|
||||
|
||||
ids = torch.cat((txt_ids, img_ids), dim=1)
|
||||
pe = self.pe_embedder(ids)
|
||||
|
||||
block_res_samples: list[torch.Tensor] = []
|
||||
|
||||
for block in self.double_blocks:
|
||||
img, txt = block(img=img, txt=txt, vec=vec, pe=pe)
|
||||
block_res_samples.append(img)
|
||||
|
||||
controlnet_block_res_samples: list[torch.Tensor] = []
|
||||
for block_res_sample, controlnet_block in zip(block_res_samples, self.controlnet_blocks, strict=True):
|
||||
block_res_sample = controlnet_block(block_res_sample)
|
||||
controlnet_block_res_samples.append(block_res_sample)
|
||||
|
||||
return XLabsControlNetFluxOutput(controlnet_double_block_residuals=controlnet_block_res_samples)
|
||||
12
invokeai/backend/flux/controlnet/zero_module.py
Normal file
12
invokeai/backend/flux/controlnet/zero_module.py
Normal file
@@ -0,0 +1,12 @@
|
||||
from typing import TypeVar
|
||||
|
||||
import torch
|
||||
|
||||
T = TypeVar("T", bound=torch.nn.Module)
|
||||
|
||||
|
||||
def zero_module(module: T) -> T:
|
||||
"""Initialize the parameters of a module to zero."""
|
||||
for p in module.parameters():
|
||||
torch.nn.init.zeros_(p)
|
||||
return module
|
||||
83
invokeai/backend/flux/custom_block_processor.py
Normal file
83
invokeai/backend/flux/custom_block_processor.py
Normal file
@@ -0,0 +1,83 @@
|
||||
import einops
|
||||
import torch
|
||||
|
||||
from invokeai.backend.flux.extensions.xlabs_ip_adapter_extension import XLabsIPAdapterExtension
|
||||
from invokeai.backend.flux.math import attention
|
||||
from invokeai.backend.flux.modules.layers import DoubleStreamBlock
|
||||
|
||||
|
||||
class CustomDoubleStreamBlockProcessor:
|
||||
"""A class containing a custom implementation of DoubleStreamBlock.forward() with additional features
|
||||
(IP-Adapter, etc.).
|
||||
"""
|
||||
|
||||
@staticmethod
|
||||
def _double_stream_block_forward(
|
||||
block: DoubleStreamBlock, img: torch.Tensor, txt: torch.Tensor, vec: torch.Tensor, pe: torch.Tensor
|
||||
) -> tuple[torch.Tensor, torch.Tensor, torch.Tensor]:
|
||||
"""This function is a direct copy of DoubleStreamBlock.forward(), but it returns some of the intermediate
|
||||
values.
|
||||
"""
|
||||
img_mod1, img_mod2 = block.img_mod(vec)
|
||||
txt_mod1, txt_mod2 = block.txt_mod(vec)
|
||||
|
||||
# prepare image for attention
|
||||
img_modulated = block.img_norm1(img)
|
||||
img_modulated = (1 + img_mod1.scale) * img_modulated + img_mod1.shift
|
||||
img_qkv = block.img_attn.qkv(img_modulated)
|
||||
img_q, img_k, img_v = einops.rearrange(img_qkv, "B L (K H D) -> K B H L D", K=3, H=block.num_heads)
|
||||
img_q, img_k = block.img_attn.norm(img_q, img_k, img_v)
|
||||
|
||||
# prepare txt for attention
|
||||
txt_modulated = block.txt_norm1(txt)
|
||||
txt_modulated = (1 + txt_mod1.scale) * txt_modulated + txt_mod1.shift
|
||||
txt_qkv = block.txt_attn.qkv(txt_modulated)
|
||||
txt_q, txt_k, txt_v = einops.rearrange(txt_qkv, "B L (K H D) -> K B H L D", K=3, H=block.num_heads)
|
||||
txt_q, txt_k = block.txt_attn.norm(txt_q, txt_k, txt_v)
|
||||
|
||||
# run actual attention
|
||||
q = torch.cat((txt_q, img_q), dim=2)
|
||||
k = torch.cat((txt_k, img_k), dim=2)
|
||||
v = torch.cat((txt_v, img_v), dim=2)
|
||||
|
||||
attn = attention(q, k, v, pe=pe)
|
||||
txt_attn, img_attn = attn[:, : txt.shape[1]], attn[:, txt.shape[1] :]
|
||||
|
||||
# calculate the img bloks
|
||||
img = img + img_mod1.gate * block.img_attn.proj(img_attn)
|
||||
img = img + img_mod2.gate * block.img_mlp((1 + img_mod2.scale) * block.img_norm2(img) + img_mod2.shift)
|
||||
|
||||
# calculate the txt bloks
|
||||
txt = txt + txt_mod1.gate * block.txt_attn.proj(txt_attn)
|
||||
txt = txt + txt_mod2.gate * block.txt_mlp((1 + txt_mod2.scale) * block.txt_norm2(txt) + txt_mod2.shift)
|
||||
return img, txt, img_q
|
||||
|
||||
@staticmethod
|
||||
def custom_double_block_forward(
|
||||
timestep_index: int,
|
||||
total_num_timesteps: int,
|
||||
block_index: int,
|
||||
block: DoubleStreamBlock,
|
||||
img: torch.Tensor,
|
||||
txt: torch.Tensor,
|
||||
vec: torch.Tensor,
|
||||
pe: torch.Tensor,
|
||||
ip_adapter_extensions: list[XLabsIPAdapterExtension],
|
||||
) -> tuple[torch.Tensor, torch.Tensor]:
|
||||
"""A custom implementation of DoubleStreamBlock.forward() with additional features:
|
||||
- IP-Adapter support
|
||||
"""
|
||||
img, txt, img_q = CustomDoubleStreamBlockProcessor._double_stream_block_forward(block, img, txt, vec, pe)
|
||||
|
||||
# Apply IP-Adapter conditioning.
|
||||
for ip_adapter_extension in ip_adapter_extensions:
|
||||
img = ip_adapter_extension.run_ip_adapter(
|
||||
timestep_index=timestep_index,
|
||||
total_num_timesteps=total_num_timesteps,
|
||||
block_index=block_index,
|
||||
block=block,
|
||||
img_q=img_q,
|
||||
img=img,
|
||||
)
|
||||
|
||||
return img, txt
|
||||
@@ -1,9 +1,14 @@
|
||||
import math
|
||||
from typing import Callable
|
||||
|
||||
import torch
|
||||
from tqdm import tqdm
|
||||
|
||||
from invokeai.backend.flux.inpaint_extension import InpaintExtension
|
||||
from invokeai.backend.flux.controlnet.controlnet_flux_output import ControlNetFluxOutput, sum_controlnet_flux_outputs
|
||||
from invokeai.backend.flux.extensions.inpaint_extension import InpaintExtension
|
||||
from invokeai.backend.flux.extensions.instantx_controlnet_extension import InstantXControlNetExtension
|
||||
from invokeai.backend.flux.extensions.xlabs_controlnet_extension import XLabsControlNetExtension
|
||||
from invokeai.backend.flux.extensions.xlabs_ip_adapter_extension import XLabsIPAdapterExtension
|
||||
from invokeai.backend.flux.model import Flux
|
||||
from invokeai.backend.stable_diffusion.diffusers_pipeline import PipelineIntermediateState
|
||||
|
||||
@@ -13,14 +18,23 @@ def denoise(
|
||||
# model input
|
||||
img: torch.Tensor,
|
||||
img_ids: torch.Tensor,
|
||||
# positive text conditioning
|
||||
txt: torch.Tensor,
|
||||
txt_ids: torch.Tensor,
|
||||
vec: torch.Tensor,
|
||||
# negative text conditioning
|
||||
neg_txt: torch.Tensor | None,
|
||||
neg_txt_ids: torch.Tensor | None,
|
||||
neg_vec: torch.Tensor | None,
|
||||
# sampling parameters
|
||||
timesteps: list[float],
|
||||
step_callback: Callable[[PipelineIntermediateState], None],
|
||||
guidance: float,
|
||||
cfg_scale: list[float],
|
||||
inpaint_extension: InpaintExtension | None,
|
||||
controlnet_extensions: list[XLabsControlNetExtension | InstantXControlNetExtension],
|
||||
pos_ip_adapter_extensions: list[XLabsIPAdapterExtension],
|
||||
neg_ip_adapter_extensions: list[XLabsIPAdapterExtension],
|
||||
):
|
||||
# step 0 is the initial state
|
||||
total_steps = len(timesteps) - 1
|
||||
@@ -33,11 +47,34 @@ def denoise(
|
||||
latents=img,
|
||||
),
|
||||
)
|
||||
step = 1
|
||||
# guidance_vec is ignored for schnell.
|
||||
guidance_vec = torch.full((img.shape[0],), guidance, device=img.device, dtype=img.dtype)
|
||||
for t_curr, t_prev in tqdm(list(zip(timesteps[:-1], timesteps[1:], strict=True))):
|
||||
for step_index, (t_curr, t_prev) in tqdm(list(enumerate(zip(timesteps[:-1], timesteps[1:], strict=True)))):
|
||||
t_vec = torch.full((img.shape[0],), t_curr, dtype=img.dtype, device=img.device)
|
||||
|
||||
# Run ControlNet models.
|
||||
controlnet_residuals: list[ControlNetFluxOutput] = []
|
||||
for controlnet_extension in controlnet_extensions:
|
||||
controlnet_residuals.append(
|
||||
controlnet_extension.run_controlnet(
|
||||
timestep_index=step_index,
|
||||
total_num_timesteps=total_steps,
|
||||
img=img,
|
||||
img_ids=img_ids,
|
||||
txt=txt,
|
||||
txt_ids=txt_ids,
|
||||
y=vec,
|
||||
timesteps=t_vec,
|
||||
guidance=guidance_vec,
|
||||
)
|
||||
)
|
||||
|
||||
# Merge the ControlNet residuals from multiple ControlNets.
|
||||
# TODO(ryand): We may want to calculate the sum just-in-time to keep peak memory low. Keep in mind, that the
|
||||
# controlnet_residuals datastructure is efficient in that it likely contains multiple references to the same
|
||||
# tensors. Calculating the sum materializes each tensor into its own instance.
|
||||
merged_controlnet_residuals = sum_controlnet_flux_outputs(controlnet_residuals)
|
||||
|
||||
pred = model(
|
||||
img=img,
|
||||
img_ids=img_ids,
|
||||
@@ -46,8 +83,39 @@ def denoise(
|
||||
y=vec,
|
||||
timesteps=t_vec,
|
||||
guidance=guidance_vec,
|
||||
timestep_index=step_index,
|
||||
total_num_timesteps=total_steps,
|
||||
controlnet_double_block_residuals=merged_controlnet_residuals.double_block_residuals,
|
||||
controlnet_single_block_residuals=merged_controlnet_residuals.single_block_residuals,
|
||||
ip_adapter_extensions=pos_ip_adapter_extensions,
|
||||
)
|
||||
|
||||
step_cfg_scale = cfg_scale[step_index]
|
||||
|
||||
# If step_cfg_scale, is 1.0, then we don't need to run the negative prediction.
|
||||
if not math.isclose(step_cfg_scale, 1.0):
|
||||
# TODO(ryand): Add option to run positive and negative predictions in a single batch for better performance
|
||||
# on systems with sufficient VRAM.
|
||||
|
||||
if neg_txt is None or neg_txt_ids is None or neg_vec is None:
|
||||
raise ValueError("Negative text conditioning is required when cfg_scale is not 1.0.")
|
||||
|
||||
neg_pred = model(
|
||||
img=img,
|
||||
img_ids=img_ids,
|
||||
txt=neg_txt,
|
||||
txt_ids=neg_txt_ids,
|
||||
y=neg_vec,
|
||||
timesteps=t_vec,
|
||||
guidance=guidance_vec,
|
||||
timestep_index=step_index,
|
||||
total_num_timesteps=total_steps,
|
||||
controlnet_double_block_residuals=None,
|
||||
controlnet_single_block_residuals=None,
|
||||
ip_adapter_extensions=neg_ip_adapter_extensions,
|
||||
)
|
||||
pred = neg_pred + step_cfg_scale * (pred - neg_pred)
|
||||
|
||||
preview_img = img - t_curr * pred
|
||||
img = img + (t_prev - t_curr) * pred
|
||||
|
||||
@@ -57,13 +125,12 @@ def denoise(
|
||||
|
||||
step_callback(
|
||||
PipelineIntermediateState(
|
||||
step=step,
|
||||
step=step_index + 1,
|
||||
order=1,
|
||||
total_steps=total_steps,
|
||||
timestep=int(t_curr),
|
||||
latents=preview_img,
|
||||
),
|
||||
)
|
||||
step += 1
|
||||
|
||||
return img
|
||||
|
||||
0
invokeai/backend/flux/extensions/__init__.py
Normal file
0
invokeai/backend/flux/extensions/__init__.py
Normal file
@@ -0,0 +1,45 @@
|
||||
import math
|
||||
from abc import ABC, abstractmethod
|
||||
from typing import List, Union
|
||||
|
||||
import torch
|
||||
|
||||
from invokeai.backend.flux.controlnet.controlnet_flux_output import ControlNetFluxOutput
|
||||
|
||||
|
||||
class BaseControlNetExtension(ABC):
|
||||
def __init__(
|
||||
self,
|
||||
weight: Union[float, List[float]],
|
||||
begin_step_percent: float,
|
||||
end_step_percent: float,
|
||||
):
|
||||
self._weight = weight
|
||||
self._begin_step_percent = begin_step_percent
|
||||
self._end_step_percent = end_step_percent
|
||||
|
||||
def _get_weight(self, timestep_index: int, total_num_timesteps: int) -> float:
|
||||
first_step = math.floor(self._begin_step_percent * total_num_timesteps)
|
||||
last_step = math.ceil(self._end_step_percent * total_num_timesteps)
|
||||
|
||||
if timestep_index < first_step or timestep_index > last_step:
|
||||
return 0.0
|
||||
|
||||
if isinstance(self._weight, list):
|
||||
return self._weight[timestep_index]
|
||||
|
||||
return self._weight
|
||||
|
||||
@abstractmethod
|
||||
def run_controlnet(
|
||||
self,
|
||||
timestep_index: int,
|
||||
total_num_timesteps: int,
|
||||
img: torch.Tensor,
|
||||
img_ids: torch.Tensor,
|
||||
txt: torch.Tensor,
|
||||
txt_ids: torch.Tensor,
|
||||
y: torch.Tensor,
|
||||
timesteps: torch.Tensor,
|
||||
guidance: torch.Tensor | None,
|
||||
) -> ControlNetFluxOutput: ...
|
||||
@@ -0,0 +1,194 @@
|
||||
import math
|
||||
from typing import List, Union
|
||||
|
||||
import torch
|
||||
from PIL.Image import Image
|
||||
|
||||
from invokeai.app.invocations.constants import LATENT_SCALE_FACTOR
|
||||
from invokeai.app.invocations.flux_vae_encode import FluxVaeEncodeInvocation
|
||||
from invokeai.app.util.controlnet_utils import CONTROLNET_RESIZE_VALUES, prepare_control_image
|
||||
from invokeai.backend.flux.controlnet.controlnet_flux_output import ControlNetFluxOutput
|
||||
from invokeai.backend.flux.controlnet.instantx_controlnet_flux import (
|
||||
InstantXControlNetFlux,
|
||||
InstantXControlNetFluxOutput,
|
||||
)
|
||||
from invokeai.backend.flux.extensions.base_controlnet_extension import BaseControlNetExtension
|
||||
from invokeai.backend.flux.sampling_utils import pack
|
||||
from invokeai.backend.model_manager.load.load_base import LoadedModel
|
||||
|
||||
|
||||
class InstantXControlNetExtension(BaseControlNetExtension):
|
||||
def __init__(
|
||||
self,
|
||||
model: InstantXControlNetFlux,
|
||||
controlnet_cond: torch.Tensor,
|
||||
instantx_control_mode: torch.Tensor | None,
|
||||
weight: Union[float, List[float]],
|
||||
begin_step_percent: float,
|
||||
end_step_percent: float,
|
||||
):
|
||||
super().__init__(
|
||||
weight=weight,
|
||||
begin_step_percent=begin_step_percent,
|
||||
end_step_percent=end_step_percent,
|
||||
)
|
||||
self._model = model
|
||||
# The VAE-encoded and 'packed' control image to pass to the ControlNet model.
|
||||
self._controlnet_cond = controlnet_cond
|
||||
# TODO(ryand): Should we define an enum for the instantx_control_mode? Is it likely to change for future models?
|
||||
# The control mode for InstantX ControlNet union models.
|
||||
# See the values defined here: https://huggingface.co/InstantX/FLUX.1-dev-Controlnet-Union#control-mode
|
||||
# Expected shape: (batch_size, 1), Expected dtype: torch.long
|
||||
# If None, a zero-embedding will be used.
|
||||
self._instantx_control_mode = instantx_control_mode
|
||||
|
||||
# TODO(ryand): Pass in these params if a new base transformer / InstantX ControlNet pair get released.
|
||||
self._flux_transformer_num_double_blocks = 19
|
||||
self._flux_transformer_num_single_blocks = 38
|
||||
|
||||
@classmethod
|
||||
def prepare_controlnet_cond(
|
||||
cls,
|
||||
controlnet_image: Image,
|
||||
vae_info: LoadedModel,
|
||||
latent_height: int,
|
||||
latent_width: int,
|
||||
dtype: torch.dtype,
|
||||
device: torch.device,
|
||||
resize_mode: CONTROLNET_RESIZE_VALUES,
|
||||
):
|
||||
image_height = latent_height * LATENT_SCALE_FACTOR
|
||||
image_width = latent_width * LATENT_SCALE_FACTOR
|
||||
|
||||
resized_controlnet_image = prepare_control_image(
|
||||
image=controlnet_image,
|
||||
do_classifier_free_guidance=False,
|
||||
width=image_width,
|
||||
height=image_height,
|
||||
device=device,
|
||||
dtype=dtype,
|
||||
control_mode="balanced",
|
||||
resize_mode=resize_mode,
|
||||
)
|
||||
|
||||
# Shift the image from [0, 1] to [-1, 1].
|
||||
resized_controlnet_image = resized_controlnet_image * 2 - 1
|
||||
|
||||
# Run VAE encoder.
|
||||
controlnet_cond = FluxVaeEncodeInvocation.vae_encode(vae_info=vae_info, image_tensor=resized_controlnet_image)
|
||||
controlnet_cond = pack(controlnet_cond)
|
||||
|
||||
return controlnet_cond
|
||||
|
||||
@classmethod
|
||||
def from_controlnet_image(
|
||||
cls,
|
||||
model: InstantXControlNetFlux,
|
||||
controlnet_image: Image,
|
||||
instantx_control_mode: torch.Tensor | None,
|
||||
vae_info: LoadedModel,
|
||||
latent_height: int,
|
||||
latent_width: int,
|
||||
dtype: torch.dtype,
|
||||
device: torch.device,
|
||||
resize_mode: CONTROLNET_RESIZE_VALUES,
|
||||
weight: Union[float, List[float]],
|
||||
begin_step_percent: float,
|
||||
end_step_percent: float,
|
||||
):
|
||||
image_height = latent_height * LATENT_SCALE_FACTOR
|
||||
image_width = latent_width * LATENT_SCALE_FACTOR
|
||||
|
||||
resized_controlnet_image = prepare_control_image(
|
||||
image=controlnet_image,
|
||||
do_classifier_free_guidance=False,
|
||||
width=image_width,
|
||||
height=image_height,
|
||||
device=device,
|
||||
dtype=dtype,
|
||||
control_mode="balanced",
|
||||
resize_mode=resize_mode,
|
||||
)
|
||||
|
||||
# Shift the image from [0, 1] to [-1, 1].
|
||||
resized_controlnet_image = resized_controlnet_image * 2 - 1
|
||||
|
||||
# Run VAE encoder.
|
||||
controlnet_cond = FluxVaeEncodeInvocation.vae_encode(vae_info=vae_info, image_tensor=resized_controlnet_image)
|
||||
controlnet_cond = pack(controlnet_cond)
|
||||
|
||||
return cls(
|
||||
model=model,
|
||||
controlnet_cond=controlnet_cond,
|
||||
instantx_control_mode=instantx_control_mode,
|
||||
weight=weight,
|
||||
begin_step_percent=begin_step_percent,
|
||||
end_step_percent=end_step_percent,
|
||||
)
|
||||
|
||||
def _instantx_output_to_controlnet_output(
|
||||
self, instantx_output: InstantXControlNetFluxOutput
|
||||
) -> ControlNetFluxOutput:
|
||||
# The `interval_control` logic here is based on
|
||||
# https://github.com/huggingface/diffusers/blob/31058cdaef63ca660a1a045281d156239fba8192/src/diffusers/models/transformers/transformer_flux.py#L507-L511
|
||||
|
||||
# Handle double block residuals.
|
||||
double_block_residuals: list[torch.Tensor] = []
|
||||
double_block_samples = instantx_output.controlnet_block_samples
|
||||
if double_block_samples:
|
||||
interval_control = self._flux_transformer_num_double_blocks / len(double_block_samples)
|
||||
interval_control = int(math.ceil(interval_control))
|
||||
for i in range(self._flux_transformer_num_double_blocks):
|
||||
double_block_residuals.append(double_block_samples[i // interval_control])
|
||||
|
||||
# Handle single block residuals.
|
||||
single_block_residuals: list[torch.Tensor] = []
|
||||
single_block_samples = instantx_output.controlnet_single_block_samples
|
||||
if single_block_samples:
|
||||
interval_control = self._flux_transformer_num_single_blocks / len(single_block_samples)
|
||||
interval_control = int(math.ceil(interval_control))
|
||||
for i in range(self._flux_transformer_num_single_blocks):
|
||||
single_block_residuals.append(single_block_samples[i // interval_control])
|
||||
|
||||
return ControlNetFluxOutput(
|
||||
double_block_residuals=double_block_residuals or None,
|
||||
single_block_residuals=single_block_residuals or None,
|
||||
)
|
||||
|
||||
def run_controlnet(
|
||||
self,
|
||||
timestep_index: int,
|
||||
total_num_timesteps: int,
|
||||
img: torch.Tensor,
|
||||
img_ids: torch.Tensor,
|
||||
txt: torch.Tensor,
|
||||
txt_ids: torch.Tensor,
|
||||
y: torch.Tensor,
|
||||
timesteps: torch.Tensor,
|
||||
guidance: torch.Tensor | None,
|
||||
) -> ControlNetFluxOutput:
|
||||
weight = self._get_weight(timestep_index=timestep_index, total_num_timesteps=total_num_timesteps)
|
||||
if weight < 1e-6:
|
||||
return ControlNetFluxOutput(single_block_residuals=None, double_block_residuals=None)
|
||||
|
||||
# Make sure inputs have correct device and dtype.
|
||||
self._controlnet_cond = self._controlnet_cond.to(device=img.device, dtype=img.dtype)
|
||||
self._instantx_control_mode = (
|
||||
self._instantx_control_mode.to(device=img.device) if self._instantx_control_mode is not None else None
|
||||
)
|
||||
|
||||
instantx_output: InstantXControlNetFluxOutput = self._model(
|
||||
controlnet_cond=self._controlnet_cond,
|
||||
controlnet_mode=self._instantx_control_mode,
|
||||
img=img,
|
||||
img_ids=img_ids,
|
||||
txt=txt,
|
||||
txt_ids=txt_ids,
|
||||
timesteps=timesteps,
|
||||
y=y,
|
||||
guidance=guidance,
|
||||
)
|
||||
|
||||
controlnet_output = self._instantx_output_to_controlnet_output(instantx_output)
|
||||
controlnet_output.apply_weight(weight)
|
||||
return controlnet_output
|
||||
150
invokeai/backend/flux/extensions/xlabs_controlnet_extension.py
Normal file
150
invokeai/backend/flux/extensions/xlabs_controlnet_extension.py
Normal file
@@ -0,0 +1,150 @@
|
||||
from typing import List, Union
|
||||
|
||||
import torch
|
||||
from PIL.Image import Image
|
||||
|
||||
from invokeai.app.invocations.constants import LATENT_SCALE_FACTOR
|
||||
from invokeai.app.util.controlnet_utils import CONTROLNET_RESIZE_VALUES, prepare_control_image
|
||||
from invokeai.backend.flux.controlnet.controlnet_flux_output import ControlNetFluxOutput
|
||||
from invokeai.backend.flux.controlnet.xlabs_controlnet_flux import XLabsControlNetFlux, XLabsControlNetFluxOutput
|
||||
from invokeai.backend.flux.extensions.base_controlnet_extension import BaseControlNetExtension
|
||||
|
||||
|
||||
class XLabsControlNetExtension(BaseControlNetExtension):
|
||||
def __init__(
|
||||
self,
|
||||
model: XLabsControlNetFlux,
|
||||
controlnet_cond: torch.Tensor,
|
||||
weight: Union[float, List[float]],
|
||||
begin_step_percent: float,
|
||||
end_step_percent: float,
|
||||
):
|
||||
super().__init__(
|
||||
weight=weight,
|
||||
begin_step_percent=begin_step_percent,
|
||||
end_step_percent=end_step_percent,
|
||||
)
|
||||
|
||||
self._model = model
|
||||
# _controlnet_cond is the control image passed to the ControlNet model.
|
||||
# Pixel values are in the range [-1, 1]. Shape: (batch_size, 3, height, width).
|
||||
self._controlnet_cond = controlnet_cond
|
||||
|
||||
# TODO(ryand): Pass in these params if a new base transformer / XLabs ControlNet pair get released.
|
||||
self._flux_transformer_num_double_blocks = 19
|
||||
self._flux_transformer_num_single_blocks = 38
|
||||
|
||||
@classmethod
|
||||
def prepare_controlnet_cond(
|
||||
cls,
|
||||
controlnet_image: Image,
|
||||
latent_height: int,
|
||||
latent_width: int,
|
||||
dtype: torch.dtype,
|
||||
device: torch.device,
|
||||
resize_mode: CONTROLNET_RESIZE_VALUES,
|
||||
):
|
||||
image_height = latent_height * LATENT_SCALE_FACTOR
|
||||
image_width = latent_width * LATENT_SCALE_FACTOR
|
||||
|
||||
controlnet_cond = prepare_control_image(
|
||||
image=controlnet_image,
|
||||
do_classifier_free_guidance=False,
|
||||
width=image_width,
|
||||
height=image_height,
|
||||
device=device,
|
||||
dtype=dtype,
|
||||
control_mode="balanced",
|
||||
resize_mode=resize_mode,
|
||||
)
|
||||
|
||||
# Map pixel values from [0, 1] to [-1, 1].
|
||||
controlnet_cond = controlnet_cond * 2 - 1
|
||||
|
||||
return controlnet_cond
|
||||
|
||||
@classmethod
|
||||
def from_controlnet_image(
|
||||
cls,
|
||||
model: XLabsControlNetFlux,
|
||||
controlnet_image: Image,
|
||||
latent_height: int,
|
||||
latent_width: int,
|
||||
dtype: torch.dtype,
|
||||
device: torch.device,
|
||||
resize_mode: CONTROLNET_RESIZE_VALUES,
|
||||
weight: Union[float, List[float]],
|
||||
begin_step_percent: float,
|
||||
end_step_percent: float,
|
||||
):
|
||||
image_height = latent_height * LATENT_SCALE_FACTOR
|
||||
image_width = latent_width * LATENT_SCALE_FACTOR
|
||||
|
||||
controlnet_cond = prepare_control_image(
|
||||
image=controlnet_image,
|
||||
do_classifier_free_guidance=False,
|
||||
width=image_width,
|
||||
height=image_height,
|
||||
device=device,
|
||||
dtype=dtype,
|
||||
control_mode="balanced",
|
||||
resize_mode=resize_mode,
|
||||
)
|
||||
|
||||
# Map pixel values from [0, 1] to [-1, 1].
|
||||
controlnet_cond = controlnet_cond * 2 - 1
|
||||
|
||||
return cls(
|
||||
model=model,
|
||||
controlnet_cond=controlnet_cond,
|
||||
weight=weight,
|
||||
begin_step_percent=begin_step_percent,
|
||||
end_step_percent=end_step_percent,
|
||||
)
|
||||
|
||||
def _xlabs_output_to_controlnet_output(self, xlabs_output: XLabsControlNetFluxOutput) -> ControlNetFluxOutput:
|
||||
# The modulo index logic used here is based on:
|
||||
# https://github.com/XLabs-AI/x-flux/blob/47495425dbed499be1e8e5a6e52628b07349cba2/src/flux/model.py#L198-L200
|
||||
|
||||
# Handle double block residuals.
|
||||
double_block_residuals: list[torch.Tensor] = []
|
||||
xlabs_double_block_residuals = xlabs_output.controlnet_double_block_residuals
|
||||
if xlabs_double_block_residuals is not None:
|
||||
for i in range(self._flux_transformer_num_double_blocks):
|
||||
double_block_residuals.append(xlabs_double_block_residuals[i % len(xlabs_double_block_residuals)])
|
||||
|
||||
return ControlNetFluxOutput(
|
||||
double_block_residuals=double_block_residuals,
|
||||
single_block_residuals=None,
|
||||
)
|
||||
|
||||
def run_controlnet(
|
||||
self,
|
||||
timestep_index: int,
|
||||
total_num_timesteps: int,
|
||||
img: torch.Tensor,
|
||||
img_ids: torch.Tensor,
|
||||
txt: torch.Tensor,
|
||||
txt_ids: torch.Tensor,
|
||||
y: torch.Tensor,
|
||||
timesteps: torch.Tensor,
|
||||
guidance: torch.Tensor | None,
|
||||
) -> ControlNetFluxOutput:
|
||||
weight = self._get_weight(timestep_index=timestep_index, total_num_timesteps=total_num_timesteps)
|
||||
if weight < 1e-6:
|
||||
return ControlNetFluxOutput(single_block_residuals=None, double_block_residuals=None)
|
||||
|
||||
xlabs_output: XLabsControlNetFluxOutput = self._model(
|
||||
img=img,
|
||||
img_ids=img_ids,
|
||||
controlnet_cond=self._controlnet_cond,
|
||||
txt=txt,
|
||||
txt_ids=txt_ids,
|
||||
timesteps=timesteps,
|
||||
y=y,
|
||||
guidance=guidance,
|
||||
)
|
||||
|
||||
controlnet_output = self._xlabs_output_to_controlnet_output(xlabs_output)
|
||||
controlnet_output.apply_weight(weight)
|
||||
return controlnet_output
|
||||
@@ -0,0 +1,89 @@
|
||||
import math
|
||||
from typing import List, Union
|
||||
|
||||
import einops
|
||||
import torch
|
||||
from PIL import Image
|
||||
from transformers import CLIPImageProcessor, CLIPVisionModelWithProjection
|
||||
|
||||
from invokeai.backend.flux.ip_adapter.xlabs_ip_adapter_flux import XlabsIpAdapterFlux
|
||||
from invokeai.backend.flux.modules.layers import DoubleStreamBlock
|
||||
|
||||
|
||||
class XLabsIPAdapterExtension:
|
||||
def __init__(
|
||||
self,
|
||||
model: XlabsIpAdapterFlux,
|
||||
image_prompt_clip_embed: torch.Tensor,
|
||||
weight: Union[float, List[float]],
|
||||
begin_step_percent: float,
|
||||
end_step_percent: float,
|
||||
):
|
||||
self._model = model
|
||||
self._image_prompt_clip_embed = image_prompt_clip_embed
|
||||
self._weight = weight
|
||||
self._begin_step_percent = begin_step_percent
|
||||
self._end_step_percent = end_step_percent
|
||||
|
||||
self._image_proj: torch.Tensor | None = None
|
||||
|
||||
def _get_weight(self, timestep_index: int, total_num_timesteps: int) -> float:
|
||||
first_step = math.floor(self._begin_step_percent * total_num_timesteps)
|
||||
last_step = math.ceil(self._end_step_percent * total_num_timesteps)
|
||||
|
||||
if timestep_index < first_step or timestep_index > last_step:
|
||||
return 0.0
|
||||
|
||||
if isinstance(self._weight, list):
|
||||
return self._weight[timestep_index]
|
||||
|
||||
return self._weight
|
||||
|
||||
@staticmethod
|
||||
def run_clip_image_encoder(
|
||||
pil_image: List[Image.Image], image_encoder: CLIPVisionModelWithProjection
|
||||
) -> torch.Tensor:
|
||||
clip_image_processor = CLIPImageProcessor()
|
||||
clip_image: torch.Tensor = clip_image_processor(images=pil_image, return_tensors="pt").pixel_values
|
||||
clip_image = clip_image.to(device=image_encoder.device, dtype=image_encoder.dtype)
|
||||
clip_image_embeds = image_encoder(clip_image).image_embeds
|
||||
return clip_image_embeds
|
||||
|
||||
def run_image_proj(self, dtype: torch.dtype):
|
||||
image_prompt_clip_embed = self._image_prompt_clip_embed.to(dtype=dtype)
|
||||
self._image_proj = self._model.image_proj(image_prompt_clip_embed)
|
||||
|
||||
def run_ip_adapter(
|
||||
self,
|
||||
timestep_index: int,
|
||||
total_num_timesteps: int,
|
||||
block_index: int,
|
||||
block: DoubleStreamBlock,
|
||||
img_q: torch.Tensor,
|
||||
img: torch.Tensor,
|
||||
) -> torch.Tensor:
|
||||
"""The logic in this function is based on:
|
||||
https://github.com/XLabs-AI/x-flux/blob/47495425dbed499be1e8e5a6e52628b07349cba2/src/flux/modules/layers.py#L245-L301
|
||||
"""
|
||||
weight = self._get_weight(timestep_index=timestep_index, total_num_timesteps=total_num_timesteps)
|
||||
if weight < 1e-6:
|
||||
return img
|
||||
|
||||
ip_adapter_block = self._model.ip_adapter_double_blocks.double_blocks[block_index]
|
||||
|
||||
ip_key = ip_adapter_block.ip_adapter_double_stream_k_proj(self._image_proj)
|
||||
ip_value = ip_adapter_block.ip_adapter_double_stream_v_proj(self._image_proj)
|
||||
|
||||
# Reshape projections for multi-head attention.
|
||||
ip_key = einops.rearrange(ip_key, "B L (H D) -> B H L D", H=block.num_heads)
|
||||
ip_value = einops.rearrange(ip_value, "B L (H D) -> B H L D", H=block.num_heads)
|
||||
|
||||
# Compute attention between IP projections and the latent query.
|
||||
ip_attn = torch.nn.functional.scaled_dot_product_attention(
|
||||
img_q, ip_key, ip_value, dropout_p=0.0, is_causal=False
|
||||
)
|
||||
ip_attn = einops.rearrange(ip_attn, "B H L D -> B L (H D)", H=block.num_heads)
|
||||
|
||||
img = img + weight * ip_attn
|
||||
|
||||
return img
|
||||
0
invokeai/backend/flux/ip_adapter/__init__.py
Normal file
0
invokeai/backend/flux/ip_adapter/__init__.py
Normal file
@@ -0,0 +1,93 @@
|
||||
# This file is based on:
|
||||
# https://github.com/XLabs-AI/x-flux/blob/47495425dbed499be1e8e5a6e52628b07349cba2/src/flux/modules/layers.py#L221
|
||||
import einops
|
||||
import torch
|
||||
|
||||
from invokeai.backend.flux.math import attention
|
||||
from invokeai.backend.flux.modules.layers import DoubleStreamBlock
|
||||
|
||||
|
||||
class IPDoubleStreamBlockProcessor(torch.nn.Module):
|
||||
"""Attention processor for handling IP-adapter with double stream block."""
|
||||
|
||||
def __init__(self, context_dim: int, hidden_dim: int):
|
||||
super().__init__()
|
||||
|
||||
# Ensure context_dim matches the dimension of image_proj
|
||||
self.context_dim = context_dim
|
||||
self.hidden_dim = hidden_dim
|
||||
|
||||
# Initialize projections for IP-adapter
|
||||
self.ip_adapter_double_stream_k_proj = torch.nn.Linear(context_dim, hidden_dim, bias=True)
|
||||
self.ip_adapter_double_stream_v_proj = torch.nn.Linear(context_dim, hidden_dim, bias=True)
|
||||
|
||||
torch.nn.init.zeros_(self.ip_adapter_double_stream_k_proj.weight)
|
||||
torch.nn.init.zeros_(self.ip_adapter_double_stream_k_proj.bias)
|
||||
|
||||
torch.nn.init.zeros_(self.ip_adapter_double_stream_v_proj.weight)
|
||||
torch.nn.init.zeros_(self.ip_adapter_double_stream_v_proj.bias)
|
||||
|
||||
def __call__(
|
||||
self,
|
||||
attn: DoubleStreamBlock,
|
||||
img: torch.Tensor,
|
||||
txt: torch.Tensor,
|
||||
vec: torch.Tensor,
|
||||
pe: torch.Tensor,
|
||||
image_proj: torch.Tensor,
|
||||
ip_scale: float = 1.0,
|
||||
):
|
||||
# Prepare image for attention
|
||||
img_mod1, img_mod2 = attn.img_mod(vec)
|
||||
txt_mod1, txt_mod2 = attn.txt_mod(vec)
|
||||
|
||||
img_modulated = attn.img_norm1(img)
|
||||
img_modulated = (1 + img_mod1.scale) * img_modulated + img_mod1.shift
|
||||
img_qkv = attn.img_attn.qkv(img_modulated)
|
||||
img_q, img_k, img_v = einops.rearrange(
|
||||
img_qkv, "B L (K H D) -> K B H L D", K=3, H=attn.num_heads, D=attn.head_dim
|
||||
)
|
||||
img_q, img_k = attn.img_attn.norm(img_q, img_k, img_v)
|
||||
|
||||
txt_modulated = attn.txt_norm1(txt)
|
||||
txt_modulated = (1 + txt_mod1.scale) * txt_modulated + txt_mod1.shift
|
||||
txt_qkv = attn.txt_attn.qkv(txt_modulated)
|
||||
txt_q, txt_k, txt_v = einops.rearrange(
|
||||
txt_qkv, "B L (K H D) -> K B H L D", K=3, H=attn.num_heads, D=attn.head_dim
|
||||
)
|
||||
txt_q, txt_k = attn.txt_attn.norm(txt_q, txt_k, txt_v)
|
||||
|
||||
q = torch.cat((txt_q, img_q), dim=2)
|
||||
k = torch.cat((txt_k, img_k), dim=2)
|
||||
v = torch.cat((txt_v, img_v), dim=2)
|
||||
|
||||
attn1 = attention(q, k, v, pe=pe)
|
||||
txt_attn, img_attn = attn1[:, : txt.shape[1]], attn1[:, txt.shape[1] :]
|
||||
|
||||
# print(f"txt_attn shape: {txt_attn.size()}")
|
||||
# print(f"img_attn shape: {img_attn.size()}")
|
||||
|
||||
img = img + img_mod1.gate * attn.img_attn.proj(img_attn)
|
||||
img = img + img_mod2.gate * attn.img_mlp((1 + img_mod2.scale) * attn.img_norm2(img) + img_mod2.shift)
|
||||
|
||||
txt = txt + txt_mod1.gate * attn.txt_attn.proj(txt_attn)
|
||||
txt = txt + txt_mod2.gate * attn.txt_mlp((1 + txt_mod2.scale) * attn.txt_norm2(txt) + txt_mod2.shift)
|
||||
|
||||
# IP-adapter processing
|
||||
ip_query = img_q # latent sample query
|
||||
ip_key = self.ip_adapter_double_stream_k_proj(image_proj)
|
||||
ip_value = self.ip_adapter_double_stream_v_proj(image_proj)
|
||||
|
||||
# Reshape projections for multi-head attention
|
||||
ip_key = einops.rearrange(ip_key, "B L (H D) -> B H L D", H=attn.num_heads, D=attn.head_dim)
|
||||
ip_value = einops.rearrange(ip_value, "B L (H D) -> B H L D", H=attn.num_heads, D=attn.head_dim)
|
||||
|
||||
# Compute attention between IP projections and the latent query
|
||||
ip_attention = torch.nn.functional.scaled_dot_product_attention(
|
||||
ip_query, ip_key, ip_value, dropout_p=0.0, is_causal=False
|
||||
)
|
||||
ip_attention = einops.rearrange(ip_attention, "B H L D -> B L (H D)", H=attn.num_heads, D=attn.head_dim)
|
||||
|
||||
img = img + ip_scale * ip_attention
|
||||
|
||||
return img, txt
|
||||
50
invokeai/backend/flux/ip_adapter/state_dict_utils.py
Normal file
50
invokeai/backend/flux/ip_adapter/state_dict_utils.py
Normal file
@@ -0,0 +1,50 @@
|
||||
from typing import Any, Dict
|
||||
|
||||
import torch
|
||||
|
||||
from invokeai.backend.flux.ip_adapter.xlabs_ip_adapter_flux import XlabsIpAdapterParams
|
||||
|
||||
|
||||
def is_state_dict_xlabs_ip_adapter(sd: Dict[str, Any]) -> bool:
|
||||
"""Is the state dict for an XLabs FLUX IP-Adapter model?
|
||||
|
||||
This is intended to be a reasonably high-precision detector, but it is not guaranteed to have perfect precision.
|
||||
"""
|
||||
# If all of the expected keys are present, then this is very likely an XLabs IP-Adapter model.
|
||||
expected_keys = {
|
||||
"double_blocks.0.processor.ip_adapter_double_stream_k_proj.bias",
|
||||
"double_blocks.0.processor.ip_adapter_double_stream_k_proj.weight",
|
||||
"double_blocks.0.processor.ip_adapter_double_stream_v_proj.bias",
|
||||
"double_blocks.0.processor.ip_adapter_double_stream_v_proj.weight",
|
||||
"ip_adapter_proj_model.norm.bias",
|
||||
"ip_adapter_proj_model.norm.weight",
|
||||
"ip_adapter_proj_model.proj.bias",
|
||||
"ip_adapter_proj_model.proj.weight",
|
||||
}
|
||||
|
||||
if expected_keys.issubset(sd.keys()):
|
||||
return True
|
||||
return False
|
||||
|
||||
|
||||
def infer_xlabs_ip_adapter_params_from_state_dict(state_dict: dict[str, torch.Tensor]) -> XlabsIpAdapterParams:
|
||||
num_double_blocks = 0
|
||||
context_dim = 0
|
||||
hidden_dim = 0
|
||||
|
||||
# Count the number of double blocks.
|
||||
double_block_index = 0
|
||||
while f"double_blocks.{double_block_index}.processor.ip_adapter_double_stream_k_proj.weight" in state_dict:
|
||||
double_block_index += 1
|
||||
num_double_blocks = double_block_index
|
||||
|
||||
hidden_dim = state_dict["double_blocks.0.processor.ip_adapter_double_stream_k_proj.weight"].shape[0]
|
||||
context_dim = state_dict["double_blocks.0.processor.ip_adapter_double_stream_k_proj.weight"].shape[1]
|
||||
clip_embeddings_dim = state_dict["ip_adapter_proj_model.proj.weight"].shape[1]
|
||||
|
||||
return XlabsIpAdapterParams(
|
||||
num_double_blocks=num_double_blocks,
|
||||
context_dim=context_dim,
|
||||
hidden_dim=hidden_dim,
|
||||
clip_embeddings_dim=clip_embeddings_dim,
|
||||
)
|
||||
67
invokeai/backend/flux/ip_adapter/xlabs_ip_adapter_flux.py
Normal file
67
invokeai/backend/flux/ip_adapter/xlabs_ip_adapter_flux.py
Normal file
@@ -0,0 +1,67 @@
|
||||
from dataclasses import dataclass
|
||||
|
||||
import torch
|
||||
|
||||
from invokeai.backend.ip_adapter.ip_adapter import ImageProjModel
|
||||
|
||||
|
||||
class IPDoubleStreamBlock(torch.nn.Module):
|
||||
def __init__(self, context_dim: int, hidden_dim: int):
|
||||
super().__init__()
|
||||
|
||||
self.context_dim = context_dim
|
||||
self.hidden_dim = hidden_dim
|
||||
|
||||
self.ip_adapter_double_stream_k_proj = torch.nn.Linear(context_dim, hidden_dim, bias=True)
|
||||
self.ip_adapter_double_stream_v_proj = torch.nn.Linear(context_dim, hidden_dim, bias=True)
|
||||
|
||||
|
||||
class IPAdapterDoubleBlocks(torch.nn.Module):
|
||||
def __init__(self, num_double_blocks: int, context_dim: int, hidden_dim: int):
|
||||
super().__init__()
|
||||
self.double_blocks = torch.nn.ModuleList(
|
||||
[IPDoubleStreamBlock(context_dim, hidden_dim) for _ in range(num_double_blocks)]
|
||||
)
|
||||
|
||||
|
||||
@dataclass
|
||||
class XlabsIpAdapterParams:
|
||||
num_double_blocks: int
|
||||
context_dim: int
|
||||
hidden_dim: int
|
||||
|
||||
clip_embeddings_dim: int
|
||||
|
||||
|
||||
class XlabsIpAdapterFlux(torch.nn.Module):
|
||||
def __init__(self, params: XlabsIpAdapterParams):
|
||||
super().__init__()
|
||||
self.image_proj = ImageProjModel(
|
||||
cross_attention_dim=params.context_dim, clip_embeddings_dim=params.clip_embeddings_dim
|
||||
)
|
||||
self.ip_adapter_double_blocks = IPAdapterDoubleBlocks(
|
||||
num_double_blocks=params.num_double_blocks, context_dim=params.context_dim, hidden_dim=params.hidden_dim
|
||||
)
|
||||
|
||||
def load_xlabs_state_dict(self, state_dict: dict[str, torch.Tensor], assign: bool = False):
|
||||
"""We need this custom function to load state dicts rather than using .load_state_dict(...) because the model
|
||||
structure does not match the state_dict structure.
|
||||
"""
|
||||
# Split the state_dict into the image projection model and the double blocks.
|
||||
image_proj_sd: dict[str, torch.Tensor] = {}
|
||||
double_blocks_sd: dict[str, torch.Tensor] = {}
|
||||
for k, v in state_dict.items():
|
||||
if k.startswith("ip_adapter_proj_model."):
|
||||
image_proj_sd[k] = v
|
||||
elif k.startswith("double_blocks."):
|
||||
double_blocks_sd[k] = v
|
||||
else:
|
||||
raise ValueError(f"Unexpected key: {k}")
|
||||
|
||||
# Initialize the image projection model.
|
||||
image_proj_sd = {k.replace("ip_adapter_proj_model.", ""): v for k, v in image_proj_sd.items()}
|
||||
self.image_proj.load_state_dict(image_proj_sd, assign=assign)
|
||||
|
||||
# Initialize the double blocks.
|
||||
double_blocks_sd = {k.replace("processor.", ""): v for k, v in double_blocks_sd.items()}
|
||||
self.ip_adapter_double_blocks.load_state_dict(double_blocks_sd, assign=assign)
|
||||
@@ -16,7 +16,10 @@ def attention(q: Tensor, k: Tensor, v: Tensor, pe: Tensor) -> Tensor:
|
||||
|
||||
def rope(pos: Tensor, dim: int, theta: int) -> Tensor:
|
||||
assert dim % 2 == 0
|
||||
scale = torch.arange(0, dim, 2, dtype=torch.float64, device=pos.device) / dim
|
||||
scale = (
|
||||
torch.arange(0, dim, 2, dtype=torch.float32 if pos.device.type == "mps" else torch.float64, device=pos.device)
|
||||
/ dim
|
||||
)
|
||||
omega = 1.0 / (theta**scale)
|
||||
out = torch.einsum("...n,d->...nd", pos, omega)
|
||||
out = torch.stack([torch.cos(out), -torch.sin(out), torch.sin(out), torch.cos(out)], dim=-1)
|
||||
|
||||
@@ -5,6 +5,8 @@ from dataclasses import dataclass
|
||||
import torch
|
||||
from torch import Tensor, nn
|
||||
|
||||
from invokeai.backend.flux.custom_block_processor import CustomDoubleStreamBlockProcessor
|
||||
from invokeai.backend.flux.extensions.xlabs_ip_adapter_extension import XLabsIPAdapterExtension
|
||||
from invokeai.backend.flux.modules.layers import (
|
||||
DoubleStreamBlock,
|
||||
EmbedND,
|
||||
@@ -87,7 +89,12 @@ class Flux(nn.Module):
|
||||
txt_ids: Tensor,
|
||||
timesteps: Tensor,
|
||||
y: Tensor,
|
||||
guidance: Tensor | None = None,
|
||||
guidance: Tensor | None,
|
||||
timestep_index: int,
|
||||
total_num_timesteps: int,
|
||||
controlnet_double_block_residuals: list[Tensor] | None,
|
||||
controlnet_single_block_residuals: list[Tensor] | None,
|
||||
ip_adapter_extensions: list[XLabsIPAdapterExtension],
|
||||
) -> Tensor:
|
||||
if img.ndim != 3 or txt.ndim != 3:
|
||||
raise ValueError("Input img and txt tensors must have 3 dimensions.")
|
||||
@@ -105,12 +112,39 @@ class Flux(nn.Module):
|
||||
ids = torch.cat((txt_ids, img_ids), dim=1)
|
||||
pe = self.pe_embedder(ids)
|
||||
|
||||
for block in self.double_blocks:
|
||||
img, txt = block(img=img, txt=txt, vec=vec, pe=pe)
|
||||
# Validate double_block_residuals shape.
|
||||
if controlnet_double_block_residuals is not None:
|
||||
assert len(controlnet_double_block_residuals) == len(self.double_blocks)
|
||||
for block_index, block in enumerate(self.double_blocks):
|
||||
assert isinstance(block, DoubleStreamBlock)
|
||||
|
||||
img, txt = CustomDoubleStreamBlockProcessor.custom_double_block_forward(
|
||||
timestep_index=timestep_index,
|
||||
total_num_timesteps=total_num_timesteps,
|
||||
block_index=block_index,
|
||||
block=block,
|
||||
img=img,
|
||||
txt=txt,
|
||||
vec=vec,
|
||||
pe=pe,
|
||||
ip_adapter_extensions=ip_adapter_extensions,
|
||||
)
|
||||
|
||||
if controlnet_double_block_residuals is not None:
|
||||
img += controlnet_double_block_residuals[block_index]
|
||||
|
||||
img = torch.cat((txt, img), 1)
|
||||
for block in self.single_blocks:
|
||||
|
||||
# Validate single_block_residuals shape.
|
||||
if controlnet_single_block_residuals is not None:
|
||||
assert len(controlnet_single_block_residuals) == len(self.single_blocks)
|
||||
|
||||
for block_index, block in enumerate(self.single_blocks):
|
||||
img = block(img, vec=vec, pe=pe)
|
||||
|
||||
if controlnet_single_block_residuals is not None:
|
||||
img[:, txt.shape[1] :, ...] += controlnet_single_block_residuals[block_index]
|
||||
|
||||
img = img[:, txt.shape[1] :, ...]
|
||||
|
||||
img = self.final_layer(img, vec) # (N, T, patch_size ** 2 * out_channels)
|
||||
|
||||
@@ -168,8 +168,17 @@ def generate_img_ids(h: int, w: int, batch_size: int, device: torch.device, dtyp
|
||||
Returns:
|
||||
torch.Tensor: Image position ids.
|
||||
"""
|
||||
|
||||
if device.type == "mps":
|
||||
orig_dtype = dtype
|
||||
dtype = torch.float16
|
||||
|
||||
img_ids = torch.zeros(h // 2, w // 2, 3, device=device, dtype=dtype)
|
||||
img_ids[..., 1] = img_ids[..., 1] + torch.arange(h // 2, device=device, dtype=dtype)[:, None]
|
||||
img_ids[..., 2] = img_ids[..., 2] + torch.arange(w // 2, device=device, dtype=dtype)[None, :]
|
||||
img_ids = repeat(img_ids, "h w c -> b (h w) c", b=batch_size)
|
||||
|
||||
if device.type == "mps":
|
||||
img_ids.to(orig_dtype)
|
||||
|
||||
return img_ids
|
||||
|
||||
@@ -1,4 +1,4 @@
|
||||
from typing import Optional
|
||||
from typing import Optional, TypeAlias
|
||||
|
||||
import torch
|
||||
from PIL import Image
|
||||
@@ -7,6 +7,14 @@ from transformers.models.sam.processing_sam import SamProcessor
|
||||
|
||||
from invokeai.backend.raw_model import RawModel
|
||||
|
||||
# Type aliases for the inputs to the SAM model.
|
||||
ListOfBoundingBoxes: TypeAlias = list[list[int]]
|
||||
"""A list of bounding boxes. Each bounding box is in the format [xmin, ymin, xmax, ymax]."""
|
||||
ListOfPoints: TypeAlias = list[list[int]]
|
||||
"""A list of points. Each point is in the format [x, y]."""
|
||||
ListOfPointLabels: TypeAlias = list[int]
|
||||
"""A list of SAM point labels. Each label is an integer where -1 is background, 0 is neutral, and 1 is foreground."""
|
||||
|
||||
|
||||
class SegmentAnythingPipeline(RawModel):
|
||||
"""A wrapper class for the transformers SAM model and processor that makes it compatible with the model manager."""
|
||||
@@ -27,20 +35,53 @@ class SegmentAnythingPipeline(RawModel):
|
||||
|
||||
return calc_module_size(self._sam_model)
|
||||
|
||||
def segment(self, image: Image.Image, bounding_boxes: list[list[int]]) -> torch.Tensor:
|
||||
def segment(
|
||||
self,
|
||||
image: Image.Image,
|
||||
bounding_boxes: list[list[int]] | None = None,
|
||||
point_lists: list[list[list[int]]] | None = None,
|
||||
) -> torch.Tensor:
|
||||
"""Run the SAM model.
|
||||
|
||||
Either bounding_boxes or point_lists must be provided. If both are provided, bounding_boxes will be used and
|
||||
point_lists will be ignored.
|
||||
|
||||
Args:
|
||||
image (Image.Image): The image to segment.
|
||||
bounding_boxes (list[list[int]]): The bounding box prompts. Each bounding box is in the format
|
||||
[xmin, ymin, xmax, ymax].
|
||||
point_lists (list[list[list[int]]]): The points prompts. Each point is in the format [x, y, label].
|
||||
`label` is an integer where -1 is background, 0 is neutral, and 1 is foreground.
|
||||
|
||||
Returns:
|
||||
torch.Tensor: The segmentation masks. dtype: torch.bool. shape: [num_masks, channels, height, width].
|
||||
"""
|
||||
# Add batch dimension of 1 to the bounding boxes.
|
||||
boxes = [bounding_boxes]
|
||||
inputs = self._sam_processor(images=image, input_boxes=boxes, return_tensors="pt").to(self._sam_model.device)
|
||||
|
||||
# Prep the inputs:
|
||||
# - Create a list of bounding boxes or points and labels.
|
||||
# - Add a batch dimension of 1 to the inputs.
|
||||
if bounding_boxes:
|
||||
input_boxes: list[ListOfBoundingBoxes] | None = [bounding_boxes]
|
||||
input_points: list[ListOfPoints] | None = None
|
||||
input_labels: list[ListOfPointLabels] | None = None
|
||||
elif point_lists:
|
||||
input_boxes: list[ListOfBoundingBoxes] | None = None
|
||||
input_points: list[ListOfPoints] | None = []
|
||||
input_labels: list[ListOfPointLabels] | None = []
|
||||
for point_list in point_lists:
|
||||
input_points.append([[p[0], p[1]] for p in point_list])
|
||||
input_labels.append([p[2] for p in point_list])
|
||||
|
||||
else:
|
||||
raise ValueError("Either bounding_boxes or points and labels must be provided.")
|
||||
|
||||
inputs = self._sam_processor(
|
||||
images=image,
|
||||
input_boxes=input_boxes,
|
||||
input_points=input_points,
|
||||
input_labels=input_labels,
|
||||
return_tensors="pt",
|
||||
).to(self._sam_model.device)
|
||||
outputs = self._sam_model(**inputs)
|
||||
masks = self._sam_processor.post_process_masks(
|
||||
masks=outputs.pred_masks,
|
||||
|
||||
@@ -2,6 +2,7 @@ from typing import Dict
|
||||
|
||||
import torch
|
||||
|
||||
from invokeai.backend.lora.conversions.flux_lora_constants import FLUX_LORA_TRANSFORMER_PREFIX
|
||||
from invokeai.backend.lora.layers.any_lora_layer import AnyLoRALayer
|
||||
from invokeai.backend.lora.layers.concatenated_lora_layer import ConcatenatedLoRALayer
|
||||
from invokeai.backend.lora.layers.lora_layer import LoRALayer
|
||||
@@ -189,7 +190,9 @@ def lora_model_from_flux_diffusers_state_dict(state_dict: Dict[str, torch.Tensor
|
||||
# Assert that all keys were processed.
|
||||
assert len(grouped_state_dict) == 0
|
||||
|
||||
return LoRAModelRaw(layers=layers)
|
||||
layers_with_prefix = {f"{FLUX_LORA_TRANSFORMER_PREFIX}{k}": v for k, v in layers.items()}
|
||||
|
||||
return LoRAModelRaw(layers=layers_with_prefix)
|
||||
|
||||
|
||||
def _group_by_layer(state_dict: Dict[str, torch.Tensor]) -> dict[str, dict[str, torch.Tensor]]:
|
||||
|
||||
@@ -3,6 +3,7 @@ from typing import Any, Dict, TypeVar
|
||||
|
||||
import torch
|
||||
|
||||
from invokeai.backend.lora.conversions.flux_lora_constants import FLUX_LORA_CLIP_PREFIX, FLUX_LORA_TRANSFORMER_PREFIX
|
||||
from invokeai.backend.lora.layers.any_lora_layer import AnyLoRALayer
|
||||
from invokeai.backend.lora.layers.utils import any_lora_layer_from_state_dict
|
||||
from invokeai.backend.lora.lora_model_raw import LoRAModelRaw
|
||||
@@ -23,11 +24,6 @@ FLUX_KOHYA_TRANSFORMER_KEY_REGEX = (
|
||||
FLUX_KOHYA_CLIP_KEY_REGEX = r"lora_te1_text_model_encoder_layers_(\d+)_(mlp|self_attn)_(\w+)\.?.*"
|
||||
|
||||
|
||||
# Prefixes used to distinguish between transformer and CLIP text encoder keys in the InvokeAI LoRA format.
|
||||
FLUX_KOHYA_TRANFORMER_PREFIX = "lora_transformer-"
|
||||
FLUX_KOHYA_CLIP_PREFIX = "lora_clip-"
|
||||
|
||||
|
||||
def is_state_dict_likely_in_flux_kohya_format(state_dict: Dict[str, Any]) -> bool:
|
||||
"""Checks if the provided state dict is likely in the Kohya FLUX LoRA format.
|
||||
|
||||
@@ -67,9 +63,9 @@ def lora_model_from_flux_kohya_state_dict(state_dict: Dict[str, torch.Tensor]) -
|
||||
# Create LoRA layers.
|
||||
layers: dict[str, AnyLoRALayer] = {}
|
||||
for layer_key, layer_state_dict in transformer_grouped_sd.items():
|
||||
layers[FLUX_KOHYA_TRANFORMER_PREFIX + layer_key] = any_lora_layer_from_state_dict(layer_state_dict)
|
||||
layers[FLUX_LORA_TRANSFORMER_PREFIX + layer_key] = any_lora_layer_from_state_dict(layer_state_dict)
|
||||
for layer_key, layer_state_dict in clip_grouped_sd.items():
|
||||
layers[FLUX_KOHYA_CLIP_PREFIX + layer_key] = any_lora_layer_from_state_dict(layer_state_dict)
|
||||
layers[FLUX_LORA_CLIP_PREFIX + layer_key] = any_lora_layer_from_state_dict(layer_state_dict)
|
||||
|
||||
# Create and return the LoRAModelRaw.
|
||||
return LoRAModelRaw(layers=layers)
|
||||
|
||||
3
invokeai/backend/lora/conversions/flux_lora_constants.py
Normal file
3
invokeai/backend/lora/conversions/flux_lora_constants.py
Normal file
@@ -0,0 +1,3 @@
|
||||
# Prefixes used to distinguish between transformer and CLIP text encoder keys in the FLUX InvokeAI LoRA format.
|
||||
FLUX_LORA_TRANSFORMER_PREFIX = "lora_transformer-"
|
||||
FLUX_LORA_CLIP_PREFIX = "lora_clip-"
|
||||
@@ -114,6 +114,7 @@ class ModelFormat(str, Enum):
|
||||
T5Encoder = "t5_encoder"
|
||||
BnbQuantizedLlmInt8b = "bnb_quantized_int8b"
|
||||
BnbQuantizednf4b = "bnb_quantized_nf4b"
|
||||
GGUFQuantized = "gguf_quantized"
|
||||
|
||||
|
||||
class SchedulerPredictionType(str, Enum):
|
||||
@@ -197,7 +198,7 @@ class ModelConfigBase(BaseModel):
|
||||
class CheckpointConfigBase(ModelConfigBase):
|
||||
"""Model config for checkpoint-style models."""
|
||||
|
||||
format: Literal[ModelFormat.Checkpoint, ModelFormat.BnbQuantizednf4b] = Field(
|
||||
format: Literal[ModelFormat.Checkpoint, ModelFormat.BnbQuantizednf4b, ModelFormat.GGUFQuantized] = Field(
|
||||
description="Format of the provided checkpoint model", default=ModelFormat.Checkpoint
|
||||
)
|
||||
config_path: str = Field(description="path to the checkpoint model config file")
|
||||
@@ -363,6 +364,21 @@ class MainBnbQuantized4bCheckpointConfig(CheckpointConfigBase, MainConfigBase):
|
||||
return Tag(f"{ModelType.Main.value}.{ModelFormat.BnbQuantizednf4b.value}")
|
||||
|
||||
|
||||
class MainGGUFCheckpointConfig(CheckpointConfigBase, MainConfigBase):
|
||||
"""Model config for main checkpoint models."""
|
||||
|
||||
prediction_type: SchedulerPredictionType = SchedulerPredictionType.Epsilon
|
||||
upcast_attention: bool = False
|
||||
|
||||
def __init__(self, *args, **kwargs):
|
||||
super().__init__(*args, **kwargs)
|
||||
self.format = ModelFormat.GGUFQuantized
|
||||
|
||||
@staticmethod
|
||||
def get_tag() -> Tag:
|
||||
return Tag(f"{ModelType.Main.value}.{ModelFormat.GGUFQuantized.value}")
|
||||
|
||||
|
||||
class MainDiffusersConfig(DiffusersConfigBase, MainConfigBase):
|
||||
"""Model config for main diffusers models."""
|
||||
|
||||
@@ -378,6 +394,8 @@ class IPAdapterBaseConfig(ModelConfigBase):
|
||||
class IPAdapterInvokeAIConfig(IPAdapterBaseConfig):
|
||||
"""Model config for IP Adapter diffusers format models."""
|
||||
|
||||
# TODO(ryand): Should we deprecate this field? From what I can tell, it hasn't been probed correctly for a long
|
||||
# time. Need to go through the history to make sure I'm understanding this fully.
|
||||
image_encoder_model_id: str
|
||||
format: Literal[ModelFormat.InvokeAI]
|
||||
|
||||
@@ -466,6 +484,7 @@ AnyModelConfig = Annotated[
|
||||
Annotated[MainDiffusersConfig, MainDiffusersConfig.get_tag()],
|
||||
Annotated[MainCheckpointConfig, MainCheckpointConfig.get_tag()],
|
||||
Annotated[MainBnbQuantized4bCheckpointConfig, MainBnbQuantized4bCheckpointConfig.get_tag()],
|
||||
Annotated[MainGGUFCheckpointConfig, MainGGUFCheckpointConfig.get_tag()],
|
||||
Annotated[VAEDiffusersConfig, VAEDiffusersConfig.get_tag()],
|
||||
Annotated[VAECheckpointConfig, VAECheckpointConfig.get_tag()],
|
||||
Annotated[ControlNetDiffusersConfig, ControlNetDiffusersConfig.get_tag()],
|
||||
|
||||
@@ -0,0 +1,41 @@
|
||||
from pathlib import Path
|
||||
from typing import Optional
|
||||
|
||||
from transformers import CLIPVisionModelWithProjection
|
||||
|
||||
from invokeai.backend.model_manager.config import (
|
||||
AnyModel,
|
||||
AnyModelConfig,
|
||||
BaseModelType,
|
||||
DiffusersConfigBase,
|
||||
ModelFormat,
|
||||
ModelType,
|
||||
SubModelType,
|
||||
)
|
||||
from invokeai.backend.model_manager.load.load_default import ModelLoader
|
||||
from invokeai.backend.model_manager.load.model_loader_registry import ModelLoaderRegistry
|
||||
|
||||
|
||||
@ModelLoaderRegistry.register(base=BaseModelType.Any, type=ModelType.CLIPVision, format=ModelFormat.Diffusers)
|
||||
class ClipVisionLoader(ModelLoader):
|
||||
"""Class to load CLIPVision models."""
|
||||
|
||||
def _load_model(
|
||||
self,
|
||||
config: AnyModelConfig,
|
||||
submodel_type: Optional[SubModelType] = None,
|
||||
) -> AnyModel:
|
||||
if not isinstance(config, DiffusersConfigBase):
|
||||
raise ValueError("Only DiffusersConfigBase models are currently supported here.")
|
||||
|
||||
if submodel_type is not None:
|
||||
raise Exception("There are no submodels in CLIP Vision models.")
|
||||
|
||||
model_path = Path(config.path)
|
||||
|
||||
model = CLIPVisionModelWithProjection.from_pretrained(
|
||||
model_path, torch_dtype=self._torch_dtype, local_files_only=True
|
||||
)
|
||||
assert isinstance(model, CLIPVisionModelWithProjection)
|
||||
|
||||
return model
|
||||
@@ -8,17 +8,36 @@ from diffusers import ControlNetModel
|
||||
from invokeai.backend.model_manager import (
|
||||
AnyModel,
|
||||
AnyModelConfig,
|
||||
)
|
||||
from invokeai.backend.model_manager.config import (
|
||||
BaseModelType,
|
||||
ControlNetCheckpointConfig,
|
||||
ModelFormat,
|
||||
ModelType,
|
||||
SubModelType,
|
||||
)
|
||||
from invokeai.backend.model_manager.config import ControlNetCheckpointConfig, SubModelType
|
||||
from invokeai.backend.model_manager.load.model_loader_registry import ModelLoaderRegistry
|
||||
from invokeai.backend.model_manager.load.model_loaders.generic_diffusers import GenericDiffusersLoader
|
||||
|
||||
|
||||
@ModelLoaderRegistry.register(base=BaseModelType.Any, type=ModelType.ControlNet, format=ModelFormat.Diffusers)
|
||||
@ModelLoaderRegistry.register(base=BaseModelType.Any, type=ModelType.ControlNet, format=ModelFormat.Checkpoint)
|
||||
@ModelLoaderRegistry.register(
|
||||
base=BaseModelType.StableDiffusion1, type=ModelType.ControlNet, format=ModelFormat.Diffusers
|
||||
)
|
||||
@ModelLoaderRegistry.register(
|
||||
base=BaseModelType.StableDiffusion1, type=ModelType.ControlNet, format=ModelFormat.Checkpoint
|
||||
)
|
||||
@ModelLoaderRegistry.register(
|
||||
base=BaseModelType.StableDiffusion2, type=ModelType.ControlNet, format=ModelFormat.Diffusers
|
||||
)
|
||||
@ModelLoaderRegistry.register(
|
||||
base=BaseModelType.StableDiffusion2, type=ModelType.ControlNet, format=ModelFormat.Checkpoint
|
||||
)
|
||||
@ModelLoaderRegistry.register(
|
||||
base=BaseModelType.StableDiffusionXL, type=ModelType.ControlNet, format=ModelFormat.Diffusers
|
||||
)
|
||||
@ModelLoaderRegistry.register(
|
||||
base=BaseModelType.StableDiffusionXL, type=ModelType.ControlNet, format=ModelFormat.Checkpoint
|
||||
)
|
||||
class ControlNetLoader(GenericDiffusersLoader):
|
||||
"""Class to load ControlNet models."""
|
||||
|
||||
|
||||
@@ -10,6 +10,19 @@ from safetensors.torch import load_file
|
||||
from transformers import AutoConfig, AutoModelForTextEncoding, CLIPTextModel, CLIPTokenizer, T5EncoderModel, T5Tokenizer
|
||||
|
||||
from invokeai.app.services.config.config_default import get_config
|
||||
from invokeai.backend.flux.controlnet.instantx_controlnet_flux import InstantXControlNetFlux
|
||||
from invokeai.backend.flux.controlnet.state_dict_utils import (
|
||||
convert_diffusers_instantx_state_dict_to_bfl_format,
|
||||
infer_flux_params_from_state_dict,
|
||||
infer_instantx_num_control_modes_from_state_dict,
|
||||
is_state_dict_instantx_controlnet,
|
||||
is_state_dict_xlabs_controlnet,
|
||||
)
|
||||
from invokeai.backend.flux.controlnet.xlabs_controlnet_flux import XLabsControlNetFlux
|
||||
from invokeai.backend.flux.ip_adapter.state_dict_utils import infer_xlabs_ip_adapter_params_from_state_dict
|
||||
from invokeai.backend.flux.ip_adapter.xlabs_ip_adapter_flux import (
|
||||
XlabsIpAdapterFlux,
|
||||
)
|
||||
from invokeai.backend.flux.model import Flux
|
||||
from invokeai.backend.flux.modules.autoencoder import AutoEncoder
|
||||
from invokeai.backend.flux.util import ae_params, params
|
||||
@@ -24,8 +37,12 @@ from invokeai.backend.model_manager import (
|
||||
from invokeai.backend.model_manager.config import (
|
||||
CheckpointConfigBase,
|
||||
CLIPEmbedDiffusersConfig,
|
||||
ControlNetCheckpointConfig,
|
||||
ControlNetDiffusersConfig,
|
||||
IPAdapterCheckpointConfig,
|
||||
MainBnbQuantized4bCheckpointConfig,
|
||||
MainCheckpointConfig,
|
||||
MainGGUFCheckpointConfig,
|
||||
T5EncoderBnbQuantizedLlmInt8bConfig,
|
||||
T5EncoderConfig,
|
||||
VAECheckpointConfig,
|
||||
@@ -35,6 +52,8 @@ from invokeai.backend.model_manager.load.model_loader_registry import ModelLoade
|
||||
from invokeai.backend.model_manager.util.model_util import (
|
||||
convert_bundle_to_flux_transformer_checkpoint,
|
||||
)
|
||||
from invokeai.backend.quantization.gguf.loaders import gguf_sd_loader
|
||||
from invokeai.backend.quantization.gguf.utils import TORCH_COMPATIBLE_QTYPES
|
||||
from invokeai.backend.util.silence_warnings import SilenceWarnings
|
||||
|
||||
try:
|
||||
@@ -156,7 +175,7 @@ class T5EncoderCheckpointModel(ModelLoader):
|
||||
case SubModelType.Tokenizer2:
|
||||
return T5Tokenizer.from_pretrained(Path(config.path) / "tokenizer_2", max_length=512)
|
||||
case SubModelType.TextEncoder2:
|
||||
return T5EncoderModel.from_pretrained(Path(config.path) / "text_encoder_2")
|
||||
return T5EncoderModel.from_pretrained(Path(config.path) / "text_encoder_2", torch_dtype="auto")
|
||||
|
||||
raise ValueError(
|
||||
f"Only Tokenizer and TextEncoder submodels are currently supported. Received: {submodel_type.value if submodel_type else 'None'}"
|
||||
@@ -204,6 +223,52 @@ class FluxCheckpointModel(ModelLoader):
|
||||
return model
|
||||
|
||||
|
||||
@ModelLoaderRegistry.register(base=BaseModelType.Flux, type=ModelType.Main, format=ModelFormat.GGUFQuantized)
|
||||
class FluxGGUFCheckpointModel(ModelLoader):
|
||||
"""Class to load GGUF main models."""
|
||||
|
||||
def _load_model(
|
||||
self,
|
||||
config: AnyModelConfig,
|
||||
submodel_type: Optional[SubModelType] = None,
|
||||
) -> AnyModel:
|
||||
if not isinstance(config, CheckpointConfigBase):
|
||||
raise ValueError("Only CheckpointConfigBase models are currently supported here.")
|
||||
|
||||
match submodel_type:
|
||||
case SubModelType.Transformer:
|
||||
return self._load_from_singlefile(config)
|
||||
|
||||
raise ValueError(
|
||||
f"Only Transformer submodels are currently supported. Received: {submodel_type.value if submodel_type else 'None'}"
|
||||
)
|
||||
|
||||
def _load_from_singlefile(
|
||||
self,
|
||||
config: AnyModelConfig,
|
||||
) -> AnyModel:
|
||||
assert isinstance(config, MainGGUFCheckpointConfig)
|
||||
model_path = Path(config.path)
|
||||
|
||||
with SilenceWarnings():
|
||||
model = Flux(params[config.config_path])
|
||||
|
||||
# HACK(ryand): We shouldn't be hard-coding the compute_dtype here.
|
||||
sd = gguf_sd_loader(model_path, compute_dtype=torch.bfloat16)
|
||||
|
||||
# HACK(ryand): There are some broken GGUF models in circulation that have the wrong shape for img_in.weight.
|
||||
# We override the shape here to fix the issue.
|
||||
# Example model with this issue (Q4_K_M): https://civitai.com/models/705823/ggufk-flux-unchained-km-quants
|
||||
img_in_weight = sd.get("img_in.weight", None)
|
||||
if img_in_weight is not None and img_in_weight._ggml_quantization_type in TORCH_COMPATIBLE_QTYPES:
|
||||
expected_img_in_weight_shape = model.img_in.weight.shape
|
||||
img_in_weight.quantized_data = img_in_weight.quantized_data.view(expected_img_in_weight_shape)
|
||||
img_in_weight.tensor_shape = expected_img_in_weight_shape
|
||||
|
||||
model.load_state_dict(sd, assign=True)
|
||||
return model
|
||||
|
||||
|
||||
@ModelLoaderRegistry.register(base=BaseModelType.Flux, type=ModelType.Main, format=ModelFormat.BnbQuantizednf4b)
|
||||
class FluxBnbQuantizednf4bCheckpointModel(ModelLoader):
|
||||
"""Class to load main models."""
|
||||
@@ -244,3 +309,74 @@ class FluxBnbQuantizednf4bCheckpointModel(ModelLoader):
|
||||
sd = convert_bundle_to_flux_transformer_checkpoint(sd)
|
||||
model.load_state_dict(sd, assign=True)
|
||||
return model
|
||||
|
||||
|
||||
@ModelLoaderRegistry.register(base=BaseModelType.Flux, type=ModelType.ControlNet, format=ModelFormat.Checkpoint)
|
||||
@ModelLoaderRegistry.register(base=BaseModelType.Flux, type=ModelType.ControlNet, format=ModelFormat.Diffusers)
|
||||
class FluxControlnetModel(ModelLoader):
|
||||
"""Class to load FLUX ControlNet models."""
|
||||
|
||||
def _load_model(
|
||||
self,
|
||||
config: AnyModelConfig,
|
||||
submodel_type: Optional[SubModelType] = None,
|
||||
) -> AnyModel:
|
||||
if isinstance(config, ControlNetCheckpointConfig):
|
||||
model_path = Path(config.path)
|
||||
elif isinstance(config, ControlNetDiffusersConfig):
|
||||
# If this is a diffusers directory, we simply ignore the config file and load from the weight file.
|
||||
model_path = Path(config.path) / "diffusion_pytorch_model.safetensors"
|
||||
else:
|
||||
raise ValueError(f"Unexpected ControlNet model config type: {type(config)}")
|
||||
|
||||
sd = load_file(model_path)
|
||||
|
||||
# Detect the FLUX ControlNet model type from the state dict.
|
||||
if is_state_dict_xlabs_controlnet(sd):
|
||||
return self._load_xlabs_controlnet(sd)
|
||||
elif is_state_dict_instantx_controlnet(sd):
|
||||
return self._load_instantx_controlnet(sd)
|
||||
else:
|
||||
raise ValueError("Do not recognize the state dict as an XLabs or InstantX ControlNet model.")
|
||||
|
||||
def _load_xlabs_controlnet(self, sd: dict[str, torch.Tensor]) -> AnyModel:
|
||||
with accelerate.init_empty_weights():
|
||||
# HACK(ryand): Is it safe to assume dev here?
|
||||
model = XLabsControlNetFlux(params["flux-dev"])
|
||||
|
||||
model.load_state_dict(sd, assign=True)
|
||||
return model
|
||||
|
||||
def _load_instantx_controlnet(self, sd: dict[str, torch.Tensor]) -> AnyModel:
|
||||
sd = convert_diffusers_instantx_state_dict_to_bfl_format(sd)
|
||||
flux_params = infer_flux_params_from_state_dict(sd)
|
||||
num_control_modes = infer_instantx_num_control_modes_from_state_dict(sd)
|
||||
|
||||
with accelerate.init_empty_weights():
|
||||
model = InstantXControlNetFlux(flux_params, num_control_modes)
|
||||
|
||||
model.load_state_dict(sd, assign=True)
|
||||
return model
|
||||
|
||||
|
||||
@ModelLoaderRegistry.register(base=BaseModelType.Flux, type=ModelType.IPAdapter, format=ModelFormat.Checkpoint)
|
||||
class FluxIpAdapterModel(ModelLoader):
|
||||
"""Class to load FLUX IP-Adapter models."""
|
||||
|
||||
def _load_model(
|
||||
self,
|
||||
config: AnyModelConfig,
|
||||
submodel_type: Optional[SubModelType] = None,
|
||||
) -> AnyModel:
|
||||
if not isinstance(config, IPAdapterCheckpointConfig):
|
||||
raise ValueError(f"Unexpected model config type: {type(config)}.")
|
||||
|
||||
sd = load_file(Path(config.path))
|
||||
|
||||
params = infer_xlabs_ip_adapter_params_from_state_dict(sd)
|
||||
|
||||
with accelerate.init_empty_weights():
|
||||
model = XlabsIpAdapterFlux(params=params)
|
||||
|
||||
model.load_xlabs_state_dict(sd, assign=True)
|
||||
return model
|
||||
|
||||
@@ -22,7 +22,6 @@ from invokeai.backend.model_manager.load.load_default import ModelLoader
|
||||
from invokeai.backend.model_manager.load.model_loader_registry import ModelLoaderRegistry
|
||||
|
||||
|
||||
@ModelLoaderRegistry.register(base=BaseModelType.Any, type=ModelType.CLIPVision, format=ModelFormat.Diffusers)
|
||||
@ModelLoaderRegistry.register(base=BaseModelType.Any, type=ModelType.T2IAdapter, format=ModelFormat.Diffusers)
|
||||
class GenericDiffusersLoader(ModelLoader):
|
||||
"""Class to load simple diffusers models."""
|
||||
|
||||
@@ -10,6 +10,11 @@ from picklescan.scanner import scan_file_path
|
||||
|
||||
import invokeai.backend.util.logging as logger
|
||||
from invokeai.app.util.misc import uuid_string
|
||||
from invokeai.backend.flux.controlnet.state_dict_utils import (
|
||||
is_state_dict_instantx_controlnet,
|
||||
is_state_dict_xlabs_controlnet,
|
||||
)
|
||||
from invokeai.backend.flux.ip_adapter.state_dict_utils import is_state_dict_xlabs_ip_adapter
|
||||
from invokeai.backend.lora.conversions.flux_diffusers_lora_conversion_utils import (
|
||||
is_state_dict_likely_in_flux_diffusers_format,
|
||||
)
|
||||
@@ -30,6 +35,8 @@ from invokeai.backend.model_manager.config import (
|
||||
SchedulerPredictionType,
|
||||
)
|
||||
from invokeai.backend.model_manager.util.model_util import lora_token_vector_length, read_checkpoint_meta
|
||||
from invokeai.backend.quantization.gguf.ggml_tensor import GGMLTensor
|
||||
from invokeai.backend.quantization.gguf.loaders import gguf_sd_loader
|
||||
from invokeai.backend.spandrel_image_to_image_model import SpandrelImageToImageModel
|
||||
from invokeai.backend.util.silence_warnings import SilenceWarnings
|
||||
|
||||
@@ -114,6 +121,7 @@ class ModelProbe(object):
|
||||
"CLIPModel": ModelType.CLIPEmbed,
|
||||
"CLIPTextModel": ModelType.CLIPEmbed,
|
||||
"T5EncoderModel": ModelType.T5Encoder,
|
||||
"FluxControlNetModel": ModelType.ControlNet,
|
||||
}
|
||||
|
||||
@classmethod
|
||||
@@ -187,6 +195,7 @@ class ModelProbe(object):
|
||||
if fields["type"] in [ModelType.Main, ModelType.ControlNet, ModelType.VAE] and fields["format"] in [
|
||||
ModelFormat.Checkpoint,
|
||||
ModelFormat.BnbQuantizednf4b,
|
||||
ModelFormat.GGUFQuantized,
|
||||
]:
|
||||
ckpt_config_path = cls._get_checkpoint_config_path(
|
||||
model_path,
|
||||
@@ -220,7 +229,7 @@ class ModelProbe(object):
|
||||
|
||||
@classmethod
|
||||
def get_model_type_from_checkpoint(cls, model_path: Path, checkpoint: Optional[CkptType] = None) -> ModelType:
|
||||
if model_path.suffix not in (".bin", ".pt", ".ckpt", ".safetensors", ".pth"):
|
||||
if model_path.suffix not in (".bin", ".pt", ".ckpt", ".safetensors", ".pth", ".gguf"):
|
||||
raise InvalidModelConfigException(f"{model_path}: unrecognized suffix")
|
||||
|
||||
if model_path.name == "learned_embeds.bin":
|
||||
@@ -235,8 +244,6 @@ class ModelProbe(object):
|
||||
"cond_stage_model.",
|
||||
"first_stage_model.",
|
||||
"model.diffusion_model.",
|
||||
# FLUX models in the official BFL format contain keys with the "double_blocks." prefix.
|
||||
"double_blocks.",
|
||||
# Some FLUX checkpoint files contain transformer keys prefixed with "model.diffusion_model".
|
||||
# This prefix is typically used to distinguish between multiple models bundled in a single file.
|
||||
"model.diffusion_model.double_blocks.",
|
||||
@@ -244,6 +251,10 @@ class ModelProbe(object):
|
||||
):
|
||||
# Keys starting with double_blocks are associated with Flux models
|
||||
return ModelType.Main
|
||||
# FLUX models in the official BFL format contain keys with the "double_blocks." prefix, but we must be
|
||||
# careful to avoid false positives on XLabs FLUX IP-Adapter models.
|
||||
elif key.startswith("double_blocks.") and "ip_adapter" not in key:
|
||||
return ModelType.Main
|
||||
elif key.startswith(("encoder.conv_in", "decoder.conv_in")):
|
||||
return ModelType.VAE
|
||||
elif key.startswith(("lora_te_", "lora_unet_")):
|
||||
@@ -252,9 +263,28 @@ class ModelProbe(object):
|
||||
# LoRA models, but as of the time of writing, we support Diffusers FLUX PEFT LoRA models.
|
||||
elif key.endswith(("to_k_lora.up.weight", "to_q_lora.down.weight", "lora_A.weight", "lora_B.weight")):
|
||||
return ModelType.LoRA
|
||||
elif key.startswith(("controlnet", "control_model", "input_blocks")):
|
||||
elif key.startswith(
|
||||
(
|
||||
"controlnet",
|
||||
"control_model",
|
||||
"input_blocks",
|
||||
# XLabs FLUX ControlNet models have keys starting with "controlnet_blocks."
|
||||
# For example: https://huggingface.co/XLabs-AI/flux-controlnet-collections/blob/86ab1e915a389d5857135c00e0d350e9e38a9048/flux-canny-controlnet_v2.safetensors
|
||||
# TODO(ryand): This is very fragile. XLabs FLUX ControlNet models also contain keys starting with
|
||||
# "double_blocks.", which we check for above. But, I'm afraid to modify this logic because it is so
|
||||
# delicate.
|
||||
"controlnet_blocks",
|
||||
)
|
||||
):
|
||||
return ModelType.ControlNet
|
||||
elif key.startswith(("image_proj.", "ip_adapter.")):
|
||||
elif key.startswith(
|
||||
(
|
||||
"image_proj.",
|
||||
"ip_adapter.",
|
||||
# XLabs FLUX IP-Adapter models have keys startinh with "ip_adapter_proj_model.".
|
||||
"ip_adapter_proj_model.",
|
||||
)
|
||||
):
|
||||
return ModelType.IPAdapter
|
||||
elif key in {"emb_params", "string_to_param"}:
|
||||
return ModelType.TextualInversion
|
||||
@@ -278,12 +308,10 @@ class ModelProbe(object):
|
||||
return ModelType.SpandrelImageToImage
|
||||
except spandrel.UnsupportedModelError:
|
||||
pass
|
||||
except RuntimeError as e:
|
||||
if "No such file or directory" in str(e):
|
||||
# This error is expected if the model_path does not exist (which is the case in some unit tests).
|
||||
pass
|
||||
else:
|
||||
raise e
|
||||
except Exception as e:
|
||||
logger.warning(
|
||||
f"Encountered error while probing to determine if {model_path} is a Spandrel model. Ignoring. Error: {e}"
|
||||
)
|
||||
|
||||
raise InvalidModelConfigException(f"Unable to determine model type for {model_path}")
|
||||
|
||||
@@ -408,6 +436,8 @@ class ModelProbe(object):
|
||||
model = torch.load(model_path, map_location="cpu")
|
||||
assert isinstance(model, dict)
|
||||
return model
|
||||
elif model_path.suffix.endswith(".gguf"):
|
||||
return gguf_sd_loader(model_path, compute_dtype=torch.float32)
|
||||
else:
|
||||
return safetensors.torch.load_file(model_path)
|
||||
|
||||
@@ -432,9 +462,11 @@ MODEL_NAME_TO_PREPROCESSOR = {
|
||||
"normal": "normalbae_image_processor",
|
||||
"sketch": "pidi_image_processor",
|
||||
"scribble": "lineart_image_processor",
|
||||
"lineart": "lineart_image_processor",
|
||||
"lineart anime": "lineart_anime_image_processor",
|
||||
"lineart_anime": "lineart_anime_image_processor",
|
||||
"lineart": "lineart_image_processor",
|
||||
"softedge": "hed_image_processor",
|
||||
"hed": "hed_image_processor",
|
||||
"shuffle": "content_shuffle_image_processor",
|
||||
"pose": "dw_openpose_image_processor",
|
||||
"mediapipe": "mediapipe_face_processor",
|
||||
@@ -446,7 +478,8 @@ MODEL_NAME_TO_PREPROCESSOR = {
|
||||
|
||||
def get_default_settings_controlnet_t2i_adapter(model_name: str) -> Optional[ControlAdapterDefaultSettings]:
|
||||
for k, v in MODEL_NAME_TO_PREPROCESSOR.items():
|
||||
if k in model_name:
|
||||
model_name_lower = model_name.lower()
|
||||
if k in model_name_lower:
|
||||
return ControlAdapterDefaultSettings(preprocessor=v)
|
||||
return None
|
||||
|
||||
@@ -477,6 +510,8 @@ class CheckpointProbeBase(ProbeBase):
|
||||
or "model.diffusion_model.double_blocks.0.img_attn.proj.weight.quant_state.bitsandbytes__nf4" in state_dict
|
||||
):
|
||||
return ModelFormat.BnbQuantizednf4b
|
||||
elif any(isinstance(v, GGMLTensor) for v in state_dict.values()):
|
||||
return ModelFormat.GGUFQuantized
|
||||
return ModelFormat("checkpoint")
|
||||
|
||||
def get_variant_type(self) -> ModelVariantType:
|
||||
@@ -618,6 +653,11 @@ class ControlNetCheckpointProbe(CheckpointProbeBase):
|
||||
|
||||
def get_base_type(self) -> BaseModelType:
|
||||
checkpoint = self.checkpoint
|
||||
if is_state_dict_xlabs_controlnet(checkpoint) or is_state_dict_instantx_controlnet(checkpoint):
|
||||
# TODO(ryand): Should I distinguish between XLabs, InstantX and other ControlNet models by implementing
|
||||
# get_format()?
|
||||
return BaseModelType.Flux
|
||||
|
||||
for key_name in (
|
||||
"control_model.input_blocks.2.1.transformer_blocks.0.attn2.to_k.weight",
|
||||
"controlnet_mid_block.bias",
|
||||
@@ -643,6 +683,10 @@ class IPAdapterCheckpointProbe(CheckpointProbeBase):
|
||||
|
||||
def get_base_type(self) -> BaseModelType:
|
||||
checkpoint = self.checkpoint
|
||||
|
||||
if is_state_dict_xlabs_ip_adapter(checkpoint):
|
||||
return BaseModelType.Flux
|
||||
|
||||
for key in checkpoint.keys():
|
||||
if not key.startswith(("image_proj.", "ip_adapter.")):
|
||||
continue
|
||||
@@ -839,22 +883,19 @@ class ControlNetFolderProbe(FolderProbeBase):
|
||||
raise InvalidModelConfigException(f"Cannot determine base type for {self.model_path}")
|
||||
with open(config_file, "r") as file:
|
||||
config = json.load(file)
|
||||
|
||||
if config.get("_class_name", None) == "FluxControlNetModel":
|
||||
return BaseModelType.Flux
|
||||
|
||||
# no obvious way to distinguish between sd2-base and sd2-768
|
||||
dimension = config["cross_attention_dim"]
|
||||
base_model = (
|
||||
BaseModelType.StableDiffusion1
|
||||
if dimension == 768
|
||||
else (
|
||||
BaseModelType.StableDiffusion2
|
||||
if dimension == 1024
|
||||
else BaseModelType.StableDiffusionXL
|
||||
if dimension == 2048
|
||||
else None
|
||||
)
|
||||
)
|
||||
if not base_model:
|
||||
raise InvalidModelConfigException(f"Unable to determine model base for {self.model_path}")
|
||||
return base_model
|
||||
if dimension == 768:
|
||||
return BaseModelType.StableDiffusion1
|
||||
if dimension == 1024:
|
||||
return BaseModelType.StableDiffusion2
|
||||
if dimension == 2048:
|
||||
return BaseModelType.StableDiffusionXL
|
||||
raise InvalidModelConfigException(f"Unable to determine model base for {self.model_path}")
|
||||
|
||||
|
||||
class LoRAFolderProbe(FolderProbeBase):
|
||||
|
||||
@@ -130,7 +130,7 @@ class ModelSearch:
|
||||
return
|
||||
|
||||
for n in file_names:
|
||||
if n.endswith((".ckpt", ".bin", ".pth", ".safetensors", ".pt")):
|
||||
if n.endswith((".ckpt", ".bin", ".pth", ".safetensors", ".pt", ".gguf")):
|
||||
try:
|
||||
self.model_found(absolute_path / n)
|
||||
except KeyboardInterrupt:
|
||||
|
||||
File diff suppressed because it is too large
Load Diff
@@ -8,6 +8,8 @@ import safetensors
|
||||
import torch
|
||||
from picklescan.scanner import scan_file_path
|
||||
|
||||
from invokeai.backend.quantization.gguf.loaders import gguf_sd_loader
|
||||
|
||||
|
||||
def _fast_safetensors_reader(path: str) -> Dict[str, torch.Tensor]:
|
||||
checkpoint = {}
|
||||
@@ -54,7 +56,11 @@ def read_checkpoint_meta(path: Union[str, Path], scan: bool = False) -> Dict[str
|
||||
scan_result = scan_file_path(path)
|
||||
if scan_result.infected_files != 0:
|
||||
raise Exception(f'The model file "{path}" is potentially infected by malware. Aborting import.')
|
||||
checkpoint = torch.load(path, map_location=torch.device("meta"))
|
||||
if str(path).endswith(".gguf"):
|
||||
# The GGUF reader used here uses numpy memmap, so these tensors are not loaded into memory during this function
|
||||
checkpoint = gguf_sd_loader(Path(path), compute_dtype=torch.float32)
|
||||
else:
|
||||
checkpoint = torch.load(path, map_location=torch.device("meta"))
|
||||
return checkpoint
|
||||
|
||||
|
||||
|
||||
157
invokeai/backend/quantization/gguf/ggml_tensor.py
Normal file
157
invokeai/backend/quantization/gguf/ggml_tensor.py
Normal file
@@ -0,0 +1,157 @@
|
||||
from typing import overload
|
||||
|
||||
import gguf
|
||||
import torch
|
||||
|
||||
from invokeai.backend.quantization.gguf.utils import (
|
||||
DEQUANTIZE_FUNCTIONS,
|
||||
TORCH_COMPATIBLE_QTYPES,
|
||||
dequantize,
|
||||
)
|
||||
|
||||
|
||||
def dequantize_and_run(func, args, kwargs):
|
||||
"""A helper function for running math ops on GGMLTensor inputs.
|
||||
|
||||
Dequantizes the inputs, and runs the function.
|
||||
"""
|
||||
dequantized_args = [a.get_dequantized_tensor() if hasattr(a, "get_dequantized_tensor") else a for a in args]
|
||||
dequantized_kwargs = {
|
||||
k: v.get_dequantized_tensor() if hasattr(v, "get_dequantized_tensor") else v for k, v in kwargs.items()
|
||||
}
|
||||
return func(*dequantized_args, **dequantized_kwargs)
|
||||
|
||||
|
||||
def apply_to_quantized_tensor(func, args, kwargs):
|
||||
"""A helper function to apply a function to a quantized GGML tensor, and re-wrap the result in a GGMLTensor.
|
||||
|
||||
Assumes that the first argument is a GGMLTensor.
|
||||
"""
|
||||
# We expect the first argument to be a GGMLTensor, and all other arguments to be non-GGMLTensors.
|
||||
ggml_tensor = args[0]
|
||||
assert isinstance(ggml_tensor, GGMLTensor)
|
||||
assert all(not isinstance(a, GGMLTensor) for a in args[1:])
|
||||
assert all(not isinstance(v, GGMLTensor) for v in kwargs.values())
|
||||
|
||||
new_data = func(ggml_tensor.quantized_data, *args[1:], **kwargs)
|
||||
|
||||
if new_data.dtype != ggml_tensor.quantized_data.dtype:
|
||||
# This is intended to catch calls such as `.to(dtype-torch.float32)`, which are not supported on GGMLTensors.
|
||||
raise ValueError("Operation changed the dtype of GGMLTensor unexpectedly.")
|
||||
|
||||
return GGMLTensor(
|
||||
new_data, ggml_tensor._ggml_quantization_type, ggml_tensor.tensor_shape, ggml_tensor.compute_dtype
|
||||
)
|
||||
|
||||
|
||||
GGML_TENSOR_OP_TABLE = {
|
||||
# Ops to run on the quantized tensor.
|
||||
torch.ops.aten.detach.default: apply_to_quantized_tensor, # pyright: ignore
|
||||
torch.ops.aten._to_copy.default: apply_to_quantized_tensor, # pyright: ignore
|
||||
# Ops to run on dequantized tensors.
|
||||
torch.ops.aten.t.default: dequantize_and_run, # pyright: ignore
|
||||
torch.ops.aten.addmm.default: dequantize_and_run, # pyright: ignore
|
||||
torch.ops.aten.mul.Tensor: dequantize_and_run, # pyright: ignore
|
||||
}
|
||||
|
||||
if torch.backends.mps.is_available():
|
||||
GGML_TENSOR_OP_TABLE.update(
|
||||
{torch.ops.aten.linear.default: dequantize_and_run} # pyright: ignore
|
||||
)
|
||||
|
||||
|
||||
class GGMLTensor(torch.Tensor):
|
||||
"""A torch.Tensor sub-class holding a quantized GGML tensor.
|
||||
|
||||
The underlying tensor is quantized, but the GGMLTensor class provides a dequantized view of the tensor on-the-fly
|
||||
when it is used in operations.
|
||||
"""
|
||||
|
||||
@staticmethod
|
||||
def __new__(
|
||||
cls,
|
||||
data: torch.Tensor,
|
||||
ggml_quantization_type: gguf.GGMLQuantizationType,
|
||||
tensor_shape: torch.Size,
|
||||
compute_dtype: torch.dtype,
|
||||
):
|
||||
# Type hinting is not supported for torch.Tensor._make_wrapper_subclass, so we ignore the errors.
|
||||
return torch.Tensor._make_wrapper_subclass( # pyright: ignore
|
||||
cls,
|
||||
data.shape,
|
||||
dtype=data.dtype,
|
||||
layout=data.layout,
|
||||
device=data.device,
|
||||
strides=data.stride(),
|
||||
storage_offset=data.storage_offset(),
|
||||
)
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
data: torch.Tensor,
|
||||
ggml_quantization_type: gguf.GGMLQuantizationType,
|
||||
tensor_shape: torch.Size,
|
||||
compute_dtype: torch.dtype,
|
||||
):
|
||||
self.quantized_data = data
|
||||
self._ggml_quantization_type = ggml_quantization_type
|
||||
# The dequantized shape of the tensor.
|
||||
self.tensor_shape = tensor_shape
|
||||
self.compute_dtype = compute_dtype
|
||||
|
||||
def __repr__(self, *, tensor_contents=None):
|
||||
return f"GGMLTensor(type={self._ggml_quantization_type.name}, dequantized_shape=({self.tensor_shape})"
|
||||
|
||||
@overload
|
||||
def size(self, dim: None = None) -> torch.Size: ...
|
||||
|
||||
@overload
|
||||
def size(self, dim: int) -> int: ...
|
||||
|
||||
def size(self, dim: int | None = None):
|
||||
"""Return the size of the tensor after dequantization. I.e. the shape that will be used in any math ops."""
|
||||
if dim is not None:
|
||||
return self.tensor_shape[dim]
|
||||
return self.tensor_shape
|
||||
|
||||
@property
|
||||
def shape(self) -> torch.Size: # pyright: ignore[reportIncompatibleVariableOverride] pyright doesn't understand this for some reason.
|
||||
"""The shape of the tensor after dequantization. I.e. the shape that will be used in any math ops."""
|
||||
return self.size()
|
||||
|
||||
@property
|
||||
def quantized_shape(self) -> torch.Size:
|
||||
"""The shape of the quantized tensor."""
|
||||
return self.quantized_data.shape
|
||||
|
||||
def requires_grad_(self, mode: bool = True) -> torch.Tensor:
|
||||
"""The GGMLTensor class is currently only designed for inference (not training). Setting requires_grad to True
|
||||
is not supported. This method is a no-op.
|
||||
"""
|
||||
return self
|
||||
|
||||
def get_dequantized_tensor(self):
|
||||
"""Return the dequantized tensor.
|
||||
|
||||
Args:
|
||||
dtype: The dtype of the dequantized tensor.
|
||||
"""
|
||||
if self._ggml_quantization_type in TORCH_COMPATIBLE_QTYPES:
|
||||
return self.quantized_data.to(self.compute_dtype)
|
||||
elif self._ggml_quantization_type in DEQUANTIZE_FUNCTIONS:
|
||||
# TODO(ryand): Look into how the dtype param is intended to be used.
|
||||
return dequantize(
|
||||
data=self.quantized_data, qtype=self._ggml_quantization_type, oshape=self.tensor_shape, dtype=None
|
||||
).to(self.compute_dtype)
|
||||
else:
|
||||
# There is no GPU implementation for this quantization type, so fallback to the numpy implementation.
|
||||
new = gguf.quants.dequantize(self.quantized_data.cpu().numpy(), self._ggml_quantization_type)
|
||||
return torch.from_numpy(new).to(self.quantized_data.device, dtype=self.compute_dtype)
|
||||
|
||||
@classmethod
|
||||
def __torch_dispatch__(cls, func, types, args, kwargs):
|
||||
# We will likely hit cases here in the future where a new op is encountered that is not yet supported.
|
||||
# The new op simply needs to be added to the GGML_TENSOR_OP_TABLE.
|
||||
if func in GGML_TENSOR_OP_TABLE:
|
||||
return GGML_TENSOR_OP_TABLE[func](func, args, kwargs)
|
||||
return NotImplemented
|
||||
22
invokeai/backend/quantization/gguf/loaders.py
Normal file
22
invokeai/backend/quantization/gguf/loaders.py
Normal file
@@ -0,0 +1,22 @@
|
||||
from pathlib import Path
|
||||
|
||||
import gguf
|
||||
import torch
|
||||
|
||||
from invokeai.backend.quantization.gguf.ggml_tensor import GGMLTensor
|
||||
from invokeai.backend.quantization.gguf.utils import TORCH_COMPATIBLE_QTYPES
|
||||
|
||||
|
||||
def gguf_sd_loader(path: Path, compute_dtype: torch.dtype) -> dict[str, GGMLTensor]:
|
||||
reader = gguf.GGUFReader(path)
|
||||
|
||||
sd: dict[str, GGMLTensor] = {}
|
||||
for tensor in reader.tensors:
|
||||
torch_tensor = torch.from_numpy(tensor.data)
|
||||
shape = torch.Size(tuple(int(v) for v in reversed(tensor.shape)))
|
||||
if tensor.tensor_type in TORCH_COMPATIBLE_QTYPES:
|
||||
torch_tensor = torch_tensor.view(*shape)
|
||||
sd[tensor.name] = GGMLTensor(
|
||||
torch_tensor, ggml_quantization_type=tensor.tensor_type, tensor_shape=shape, compute_dtype=compute_dtype
|
||||
)
|
||||
return sd
|
||||
308
invokeai/backend/quantization/gguf/utils.py
Normal file
308
invokeai/backend/quantization/gguf/utils.py
Normal file
@@ -0,0 +1,308 @@
|
||||
# Largely based on https://github.com/city96/ComfyUI-GGUF
|
||||
|
||||
from typing import Callable, Optional, Union
|
||||
|
||||
import gguf
|
||||
import torch
|
||||
|
||||
TORCH_COMPATIBLE_QTYPES = {None, gguf.GGMLQuantizationType.F32, gguf.GGMLQuantizationType.F16}
|
||||
|
||||
# K Quants #
|
||||
QK_K = 256
|
||||
K_SCALE_SIZE = 12
|
||||
|
||||
|
||||
def get_scale_min(scales: torch.Tensor):
|
||||
n_blocks = scales.shape[0]
|
||||
scales = scales.view(torch.uint8)
|
||||
scales = scales.reshape((n_blocks, 3, 4))
|
||||
|
||||
d, m, m_d = torch.split(scales, scales.shape[-2] // 3, dim=-2)
|
||||
|
||||
sc = torch.cat([d & 0x3F, (m_d & 0x0F) | ((d >> 2) & 0x30)], dim=-1)
|
||||
min = torch.cat([m & 0x3F, (m_d >> 4) | ((m >> 2) & 0x30)], dim=-1)
|
||||
|
||||
return (sc.reshape((n_blocks, 8)), min.reshape((n_blocks, 8)))
|
||||
|
||||
|
||||
# Legacy Quants #
|
||||
def dequantize_blocks_Q8_0(
|
||||
blocks: torch.Tensor, block_size: int, type_size: int, dtype: Optional[torch.dtype] = None
|
||||
) -> torch.Tensor:
|
||||
d, x = split_block_dims(blocks, 2)
|
||||
d = d.view(torch.float16).to(dtype)
|
||||
x = x.view(torch.int8)
|
||||
return d * x
|
||||
|
||||
|
||||
def dequantize_blocks_Q5_1(
|
||||
blocks: torch.Tensor, block_size: int, type_size: int, dtype: Optional[torch.dtype] = None
|
||||
) -> torch.Tensor:
|
||||
n_blocks = blocks.shape[0]
|
||||
|
||||
d, m, qh, qs = split_block_dims(blocks, 2, 2, 4)
|
||||
d = d.view(torch.float16).to(dtype)
|
||||
m = m.view(torch.float16).to(dtype)
|
||||
qh = to_uint32(qh)
|
||||
|
||||
qh = qh.reshape((n_blocks, 1)) >> torch.arange(32, device=d.device, dtype=torch.int32).reshape(1, 32)
|
||||
ql = qs.reshape((n_blocks, -1, 1, block_size // 2)) >> torch.tensor(
|
||||
[0, 4], device=d.device, dtype=torch.uint8
|
||||
).reshape(1, 1, 2, 1)
|
||||
qh = (qh & 1).to(torch.uint8)
|
||||
ql = (ql & 0x0F).reshape((n_blocks, -1))
|
||||
|
||||
qs = ql | (qh << 4)
|
||||
return (d * qs) + m
|
||||
|
||||
|
||||
def dequantize_blocks_Q5_0(
|
||||
blocks: torch.Tensor, block_size: int, type_size: int, dtype: Optional[torch.dtype] = None
|
||||
) -> torch.Tensor:
|
||||
n_blocks = blocks.shape[0]
|
||||
|
||||
d, qh, qs = split_block_dims(blocks, 2, 4)
|
||||
d = d.view(torch.float16).to(dtype)
|
||||
qh = to_uint32(qh)
|
||||
|
||||
qh = qh.reshape(n_blocks, 1) >> torch.arange(32, device=d.device, dtype=torch.int32).reshape(1, 32)
|
||||
ql = qs.reshape(n_blocks, -1, 1, block_size // 2) >> torch.tensor(
|
||||
[0, 4], device=d.device, dtype=torch.uint8
|
||||
).reshape(1, 1, 2, 1)
|
||||
|
||||
qh = (qh & 1).to(torch.uint8)
|
||||
ql = (ql & 0x0F).reshape(n_blocks, -1)
|
||||
|
||||
qs = (ql | (qh << 4)).to(torch.int8) - 16
|
||||
return d * qs
|
||||
|
||||
|
||||
def dequantize_blocks_Q4_1(
|
||||
blocks: torch.Tensor, block_size: int, type_size: int, dtype: Optional[torch.dtype] = None
|
||||
) -> torch.Tensor:
|
||||
n_blocks = blocks.shape[0]
|
||||
|
||||
d, m, qs = split_block_dims(blocks, 2, 2)
|
||||
d = d.view(torch.float16).to(dtype)
|
||||
m = m.view(torch.float16).to(dtype)
|
||||
|
||||
qs = qs.reshape((n_blocks, -1, 1, block_size // 2)) >> torch.tensor(
|
||||
[0, 4], device=d.device, dtype=torch.uint8
|
||||
).reshape(1, 1, 2, 1)
|
||||
qs = (qs & 0x0F).reshape(n_blocks, -1)
|
||||
|
||||
return (d * qs) + m
|
||||
|
||||
|
||||
def dequantize_blocks_Q4_0(
|
||||
blocks: torch.Tensor, block_size: int, type_size: int, dtype: Optional[torch.dtype] = None
|
||||
) -> torch.Tensor:
|
||||
n_blocks = blocks.shape[0]
|
||||
|
||||
d, qs = split_block_dims(blocks, 2)
|
||||
d = d.view(torch.float16).to(dtype)
|
||||
|
||||
qs = qs.reshape((n_blocks, -1, 1, block_size // 2)) >> torch.tensor(
|
||||
[0, 4], device=d.device, dtype=torch.uint8
|
||||
).reshape((1, 1, 2, 1))
|
||||
qs = (qs & 0x0F).reshape((n_blocks, -1)).to(torch.int8) - 8
|
||||
return d * qs
|
||||
|
||||
|
||||
def dequantize_blocks_BF16(
|
||||
blocks: torch.Tensor, block_size: int, type_size: int, dtype: Optional[torch.dtype] = None
|
||||
) -> torch.Tensor:
|
||||
return (blocks.view(torch.int16).to(torch.int32) << 16).view(torch.float32)
|
||||
|
||||
|
||||
def dequantize_blocks_Q6_K(
|
||||
blocks: torch.Tensor, block_size: int, type_size: int, dtype: Optional[torch.dtype] = None
|
||||
) -> torch.Tensor:
|
||||
n_blocks = blocks.shape[0]
|
||||
|
||||
(
|
||||
ql,
|
||||
qh,
|
||||
scales,
|
||||
d,
|
||||
) = split_block_dims(blocks, QK_K // 2, QK_K // 4, QK_K // 16)
|
||||
|
||||
scales = scales.view(torch.int8).to(dtype)
|
||||
d = d.view(torch.float16).to(dtype)
|
||||
d = (d * scales).reshape((n_blocks, QK_K // 16, 1))
|
||||
|
||||
ql = ql.reshape((n_blocks, -1, 1, 64)) >> torch.tensor([0, 4], device=d.device, dtype=torch.uint8).reshape(
|
||||
(1, 1, 2, 1)
|
||||
)
|
||||
ql = (ql & 0x0F).reshape((n_blocks, -1, 32))
|
||||
qh = qh.reshape((n_blocks, -1, 1, 32)) >> torch.tensor([0, 2, 4, 6], device=d.device, dtype=torch.uint8).reshape(
|
||||
(1, 1, 4, 1)
|
||||
)
|
||||
qh = (qh & 0x03).reshape((n_blocks, -1, 32))
|
||||
q = (ql | (qh << 4)).to(torch.int8) - 32
|
||||
q = q.reshape((n_blocks, QK_K // 16, -1))
|
||||
|
||||
return (d * q).reshape((n_blocks, QK_K))
|
||||
|
||||
|
||||
def dequantize_blocks_Q5_K(
|
||||
blocks: torch.Tensor, block_size: int, type_size: int, dtype: Optional[torch.dtype] = None
|
||||
) -> torch.Tensor:
|
||||
n_blocks = blocks.shape[0]
|
||||
|
||||
d, dmin, scales, qh, qs = split_block_dims(blocks, 2, 2, K_SCALE_SIZE, QK_K // 8)
|
||||
|
||||
d = d.view(torch.float16).to(dtype)
|
||||
dmin = dmin.view(torch.float16).to(dtype)
|
||||
|
||||
sc, m = get_scale_min(scales)
|
||||
|
||||
d = (d * sc).reshape((n_blocks, -1, 1))
|
||||
dm = (dmin * m).reshape((n_blocks, -1, 1))
|
||||
|
||||
ql = qs.reshape((n_blocks, -1, 1, 32)) >> torch.tensor([0, 4], device=d.device, dtype=torch.uint8).reshape(
|
||||
(1, 1, 2, 1)
|
||||
)
|
||||
qh = qh.reshape((n_blocks, -1, 1, 32)) >> torch.tensor(list(range(8)), device=d.device, dtype=torch.uint8).reshape(
|
||||
(1, 1, 8, 1)
|
||||
)
|
||||
ql = (ql & 0x0F).reshape((n_blocks, -1, 32))
|
||||
qh = (qh & 0x01).reshape((n_blocks, -1, 32))
|
||||
q = ql | (qh << 4)
|
||||
|
||||
return (d * q - dm).reshape((n_blocks, QK_K))
|
||||
|
||||
|
||||
def dequantize_blocks_Q4_K(
|
||||
blocks: torch.Tensor, block_size: int, type_size: int, dtype: Optional[torch.dtype] = None
|
||||
) -> torch.Tensor:
|
||||
n_blocks = blocks.shape[0]
|
||||
|
||||
d, dmin, scales, qs = split_block_dims(blocks, 2, 2, K_SCALE_SIZE)
|
||||
d = d.view(torch.float16).to(dtype)
|
||||
dmin = dmin.view(torch.float16).to(dtype)
|
||||
|
||||
sc, m = get_scale_min(scales)
|
||||
|
||||
d = (d * sc).reshape((n_blocks, -1, 1))
|
||||
dm = (dmin * m).reshape((n_blocks, -1, 1))
|
||||
|
||||
qs = qs.reshape((n_blocks, -1, 1, 32)) >> torch.tensor([0, 4], device=d.device, dtype=torch.uint8).reshape(
|
||||
(1, 1, 2, 1)
|
||||
)
|
||||
qs = (qs & 0x0F).reshape((n_blocks, -1, 32))
|
||||
|
||||
return (d * qs - dm).reshape((n_blocks, QK_K))
|
||||
|
||||
|
||||
def dequantize_blocks_Q3_K(
|
||||
blocks: torch.Tensor, block_size: int, type_size: int, dtype: Optional[torch.dtype] = None
|
||||
) -> torch.Tensor:
|
||||
n_blocks = blocks.shape[0]
|
||||
|
||||
hmask, qs, scales, d = split_block_dims(blocks, QK_K // 8, QK_K // 4, 12)
|
||||
d = d.view(torch.float16).to(dtype)
|
||||
|
||||
lscales, hscales = scales[:, :8], scales[:, 8:]
|
||||
lscales = lscales.reshape((n_blocks, 1, 8)) >> torch.tensor([0, 4], device=d.device, dtype=torch.uint8).reshape(
|
||||
(1, 2, 1)
|
||||
)
|
||||
lscales = lscales.reshape((n_blocks, 16))
|
||||
hscales = hscales.reshape((n_blocks, 1, 4)) >> torch.tensor(
|
||||
[0, 2, 4, 6], device=d.device, dtype=torch.uint8
|
||||
).reshape((1, 4, 1))
|
||||
hscales = hscales.reshape((n_blocks, 16))
|
||||
scales = (lscales & 0x0F) | ((hscales & 0x03) << 4)
|
||||
scales = scales.to(torch.int8) - 32
|
||||
|
||||
dl = (d * scales).reshape((n_blocks, 16, 1))
|
||||
|
||||
ql = qs.reshape((n_blocks, -1, 1, 32)) >> torch.tensor([0, 2, 4, 6], device=d.device, dtype=torch.uint8).reshape(
|
||||
(1, 1, 4, 1)
|
||||
)
|
||||
qh = hmask.reshape(n_blocks, -1, 1, 32) >> torch.tensor(list(range(8)), device=d.device, dtype=torch.uint8).reshape(
|
||||
(1, 1, 8, 1)
|
||||
)
|
||||
ql = ql.reshape((n_blocks, 16, QK_K // 16)) & 3
|
||||
qh = (qh.reshape((n_blocks, 16, QK_K // 16)) & 1) ^ 1
|
||||
q = ql.to(torch.int8) - (qh << 2).to(torch.int8)
|
||||
|
||||
return (dl * q).reshape((n_blocks, QK_K))
|
||||
|
||||
|
||||
def dequantize_blocks_Q2_K(
|
||||
blocks: torch.Tensor, block_size: int, type_size: int, dtype: Optional[torch.dtype] = None
|
||||
) -> torch.Tensor:
|
||||
n_blocks = blocks.shape[0]
|
||||
|
||||
scales, qs, d, dmin = split_block_dims(blocks, QK_K // 16, QK_K // 4, 2)
|
||||
d = d.view(torch.float16).to(dtype)
|
||||
dmin = dmin.view(torch.float16).to(dtype)
|
||||
|
||||
# (n_blocks, 16, 1)
|
||||
dl = (d * (scales & 0xF)).reshape((n_blocks, QK_K // 16, 1))
|
||||
ml = (dmin * (scales >> 4)).reshape((n_blocks, QK_K // 16, 1))
|
||||
|
||||
shift = torch.tensor([0, 2, 4, 6], device=d.device, dtype=torch.uint8).reshape((1, 1, 4, 1))
|
||||
|
||||
qs = (qs.reshape((n_blocks, -1, 1, 32)) >> shift) & 3
|
||||
qs = qs.reshape((n_blocks, QK_K // 16, 16))
|
||||
qs = dl * qs - ml
|
||||
|
||||
return qs.reshape((n_blocks, -1))
|
||||
|
||||
|
||||
DEQUANTIZE_FUNCTIONS: dict[
|
||||
gguf.GGMLQuantizationType, Callable[[torch.Tensor, int, int, Optional[torch.dtype]], torch.Tensor]
|
||||
] = {
|
||||
gguf.GGMLQuantizationType.BF16: dequantize_blocks_BF16,
|
||||
gguf.GGMLQuantizationType.Q8_0: dequantize_blocks_Q8_0,
|
||||
gguf.GGMLQuantizationType.Q5_1: dequantize_blocks_Q5_1,
|
||||
gguf.GGMLQuantizationType.Q5_0: dequantize_blocks_Q5_0,
|
||||
gguf.GGMLQuantizationType.Q4_1: dequantize_blocks_Q4_1,
|
||||
gguf.GGMLQuantizationType.Q4_0: dequantize_blocks_Q4_0,
|
||||
gguf.GGMLQuantizationType.Q6_K: dequantize_blocks_Q6_K,
|
||||
gguf.GGMLQuantizationType.Q5_K: dequantize_blocks_Q5_K,
|
||||
gguf.GGMLQuantizationType.Q4_K: dequantize_blocks_Q4_K,
|
||||
gguf.GGMLQuantizationType.Q3_K: dequantize_blocks_Q3_K,
|
||||
gguf.GGMLQuantizationType.Q2_K: dequantize_blocks_Q2_K,
|
||||
}
|
||||
|
||||
|
||||
def is_torch_compatible(tensor: Optional[torch.Tensor]):
|
||||
return getattr(tensor, "tensor_type", None) in TORCH_COMPATIBLE_QTYPES
|
||||
|
||||
|
||||
def is_quantized(tensor: torch.Tensor):
|
||||
return not is_torch_compatible(tensor)
|
||||
|
||||
|
||||
def dequantize(
|
||||
data: torch.Tensor, qtype: gguf.GGMLQuantizationType, oshape: torch.Size, dtype: Optional[torch.dtype] = None
|
||||
):
|
||||
"""
|
||||
Dequantize tensor back to usable shape/dtype
|
||||
"""
|
||||
block_size, type_size = gguf.GGML_QUANT_SIZES[qtype]
|
||||
dequantize_blocks = DEQUANTIZE_FUNCTIONS[qtype]
|
||||
|
||||
rows = data.reshape((-1, data.shape[-1])).view(torch.uint8)
|
||||
|
||||
n_blocks = rows.numel() // type_size
|
||||
blocks = rows.reshape((n_blocks, type_size))
|
||||
blocks = dequantize_blocks(blocks, block_size, type_size, dtype)
|
||||
return blocks.reshape(oshape)
|
||||
|
||||
|
||||
def to_uint32(x: torch.Tensor) -> torch.Tensor:
|
||||
x = x.view(torch.uint8).to(torch.int32)
|
||||
return (x[:, 0] | x[:, 1] << 8 | x[:, 2] << 16 | x[:, 3] << 24).unsqueeze(1)
|
||||
|
||||
|
||||
def split_block_dims(blocks: torch.Tensor, *args):
|
||||
n_max = blocks.shape[1]
|
||||
dims = list(args) + [n_max - sum(args)]
|
||||
return torch.split(blocks, dims, dim=1)
|
||||
|
||||
|
||||
PATCH_TYPES = Union[torch.Tensor, list[torch.Tensor], tuple[torch.Tensor]]
|
||||
@@ -171,8 +171,19 @@ class StableDiffusionGeneratorPipeline(StableDiffusionPipeline):
|
||||
"""
|
||||
if xformers is available, use it, otherwise use sliced attention.
|
||||
"""
|
||||
|
||||
# On 30xx and 40xx series GPUs, `torch-sdp` is faster than `xformers`. This corresponds to a CUDA major
|
||||
# version of 8 or higher. So, for major version 7 or below, we prefer `xformers`.
|
||||
# See:
|
||||
# - https://developer.nvidia.com/cuda-gpus
|
||||
# - https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#compute-capabilities
|
||||
try:
|
||||
prefer_xformers = torch.cuda.is_available() and torch.cuda.get_device_properties("cuda").major <= 7 # type: ignore # Type of "get_device_properties" is partially unknown
|
||||
except Exception:
|
||||
prefer_xformers = False
|
||||
|
||||
config = get_config()
|
||||
if config.attention_type == "xformers":
|
||||
if config.attention_type == "xformers" and is_xformers_available() and prefer_xformers:
|
||||
self.enable_xformers_memory_efficient_attention()
|
||||
return
|
||||
elif config.attention_type == "sliced":
|
||||
@@ -187,20 +198,24 @@ class StableDiffusionGeneratorPipeline(StableDiffusionPipeline):
|
||||
self.disable_attention_slicing()
|
||||
return
|
||||
elif config.attention_type == "torch-sdp":
|
||||
if hasattr(torch.nn.functional, "scaled_dot_product_attention"):
|
||||
# diffusers enables sdp automatically
|
||||
return
|
||||
else:
|
||||
raise Exception("torch-sdp attention slicing not available")
|
||||
# torch-sdp is the default in diffusers.
|
||||
return
|
||||
|
||||
# the remainder if this code is called when attention_type=='auto'
|
||||
# See https://github.com/invoke-ai/InvokeAI/issues/7049 for context.
|
||||
# Bumping torch from 2.2.2 to 2.4.1 caused the sliced attention implementation to produce incorrect results.
|
||||
# For now, if a user is on an MPS device and has not explicitly set the attention_type, then we select the
|
||||
# non-sliced torch-sdp implementation. This keeps things working on MPS at the cost of increased peak memory
|
||||
# utilization.
|
||||
if torch.backends.mps.is_available():
|
||||
return
|
||||
|
||||
# The remainder if this code is called when attention_type=='auto'.
|
||||
if self.unet.device.type == "cuda":
|
||||
if is_xformers_available():
|
||||
if is_xformers_available() and prefer_xformers:
|
||||
self.enable_xformers_memory_efficient_attention()
|
||||
return
|
||||
elif hasattr(torch.nn.functional, "scaled_dot_product_attention"):
|
||||
# diffusers enables sdp automatically
|
||||
return
|
||||
# torch-sdp is the default in diffusers.
|
||||
return
|
||||
|
||||
if self.unet.device.type == "cpu" or self.unet.device.type == "mps":
|
||||
mem_free = psutil.virtual_memory().free
|
||||
|
||||
@@ -52,49 +52,51 @@
|
||||
}
|
||||
},
|
||||
"dependencies": {
|
||||
"@dagrejs/dagre": "^1.1.3",
|
||||
"@dagrejs/graphlib": "^2.2.3",
|
||||
"@dagrejs/dagre": "^1.1.4",
|
||||
"@dagrejs/graphlib": "^2.2.4",
|
||||
"@dnd-kit/core": "^6.1.0",
|
||||
"@dnd-kit/sortable": "^8.0.0",
|
||||
"@dnd-kit/utilities": "^3.2.2",
|
||||
"@fontsource-variable/inter": "^5.0.20",
|
||||
"@invoke-ai/ui-library": "^0.0.37",
|
||||
"@fontsource-variable/inter": "^5.1.0",
|
||||
"@invoke-ai/ui-library": "^0.0.43",
|
||||
"@nanostores/react": "^0.7.3",
|
||||
"@reduxjs/toolkit": "2.2.3",
|
||||
"@roarr/browser-log-writer": "^1.3.0",
|
||||
"async-mutex": "^0.5.0",
|
||||
"chakra-react-select": "^4.9.1",
|
||||
"chakra-react-select": "^4.9.2",
|
||||
"cmdk": "^1.0.0",
|
||||
"compare-versions": "^6.1.1",
|
||||
"dateformat": "^5.0.3",
|
||||
"fracturedjsonjs": "^4.0.2",
|
||||
"framer-motion": "^11.3.24",
|
||||
"i18next": "^23.12.2",
|
||||
"i18next-http-backend": "^2.5.2",
|
||||
"framer-motion": "^11.10.0",
|
||||
"i18next": "^23.15.1",
|
||||
"i18next-http-backend": "^2.6.1",
|
||||
"idb-keyval": "^6.2.1",
|
||||
"jsondiffpatch": "^0.6.0",
|
||||
"konva": "^9.3.14",
|
||||
"konva": "^9.3.15",
|
||||
"lodash-es": "^4.17.21",
|
||||
"lru-cache": "^11.0.0",
|
||||
"lru-cache": "^11.0.1",
|
||||
"nanoid": "^5.0.7",
|
||||
"nanostores": "^0.11.2",
|
||||
"nanostores": "^0.11.3",
|
||||
"new-github-issue-url": "^1.0.0",
|
||||
"overlayscrollbars": "^2.10.0",
|
||||
"overlayscrollbars-react": "^0.5.6",
|
||||
"perfect-freehand": "^1.2.2",
|
||||
"query-string": "^9.1.0",
|
||||
"raf-throttle": "^2.0.6",
|
||||
"react": "^18.3.1",
|
||||
"react-colorful": "^5.6.1",
|
||||
"react-dom": "^18.3.1",
|
||||
"react-dropzone": "^14.2.3",
|
||||
"react-dropzone": "^14.2.9",
|
||||
"react-error-boundary": "^4.0.13",
|
||||
"react-hook-form": "^7.52.2",
|
||||
"react-hook-form": "^7.53.0",
|
||||
"react-hotkeys-hook": "4.5.0",
|
||||
"react-i18next": "^14.1.3",
|
||||
"react-icons": "^5.2.1",
|
||||
"react-i18next": "^15.0.2",
|
||||
"react-icons": "^5.3.0",
|
||||
"react-redux": "9.1.2",
|
||||
"react-resizable-panels": "^2.1.2",
|
||||
"react-resizable-panels": "^2.1.4",
|
||||
"react-use": "^17.5.1",
|
||||
"react-virtuoso": "^4.9.0",
|
||||
"react-virtuoso": "^4.10.4",
|
||||
"reactflow": "^11.11.4",
|
||||
"redux-dynamic-middlewares": "^2.2.0",
|
||||
"redux-remember": "^5.1.0",
|
||||
@@ -102,56 +104,55 @@
|
||||
"rfdc": "^1.4.1",
|
||||
"roarr": "^7.21.1",
|
||||
"serialize-error": "^11.0.3",
|
||||
"socket.io-client": "^4.7.5",
|
||||
"socket.io-client": "^4.8.0",
|
||||
"stable-hash": "^0.0.4",
|
||||
"use-debounce": "^10.0.2",
|
||||
"use-debounce": "^10.0.3",
|
||||
"use-device-pixel-ratio": "^1.1.2",
|
||||
"uuid": "^10.0.0",
|
||||
"zod": "^3.23.8",
|
||||
"zod-validation-error": "^3.3.1"
|
||||
"zod-validation-error": "^3.4.0"
|
||||
},
|
||||
"peerDependencies": {
|
||||
"react": "^18.2.0",
|
||||
"react-dom": "^18.2.0",
|
||||
"ts-toolbelt": "^9.6.0"
|
||||
"react-dom": "^18.2.0"
|
||||
},
|
||||
"devDependencies": {
|
||||
"@invoke-ai/eslint-config-react": "^0.0.14",
|
||||
"@invoke-ai/prettier-config-react": "^0.0.7",
|
||||
"@storybook/addon-essentials": "^8.2.8",
|
||||
"@storybook/addon-interactions": "^8.2.8",
|
||||
"@storybook/addon-links": "^8.2.8",
|
||||
"@storybook/addon-storysource": "^8.2.8",
|
||||
"@storybook/manager-api": "^8.2.8",
|
||||
"@storybook/react": "^8.2.8",
|
||||
"@storybook/react-vite": "^8.2.8",
|
||||
"@storybook/theming": "^8.2.8",
|
||||
"@storybook/addon-essentials": "^8.3.4",
|
||||
"@storybook/addon-interactions": "^8.3.4",
|
||||
"@storybook/addon-links": "^8.3.4",
|
||||
"@storybook/addon-storysource": "^8.3.4",
|
||||
"@storybook/manager-api": "^8.3.4",
|
||||
"@storybook/react": "^8.3.4",
|
||||
"@storybook/react-vite": "^8.3.4",
|
||||
"@storybook/theming": "^8.3.4",
|
||||
"@types/dateformat": "^5.0.2",
|
||||
"@types/lodash-es": "^4.17.12",
|
||||
"@types/node": "^20.14.15",
|
||||
"@types/react": "^18.3.3",
|
||||
"@types/node": "^20.16.10",
|
||||
"@types/react": "^18.3.11",
|
||||
"@types/react-dom": "^18.3.0",
|
||||
"@types/uuid": "^10.0.0",
|
||||
"@vitejs/plugin-react-swc": "^3.7.0",
|
||||
"@vitest/coverage-v8": "^1.5.0",
|
||||
"@vitest/ui": "^1.5.0",
|
||||
"@vitejs/plugin-react-swc": "^3.7.1",
|
||||
"@vitest/coverage-v8": "^1.6.0",
|
||||
"@vitest/ui": "^1.6.0",
|
||||
"concurrently": "^8.2.2",
|
||||
"csstype": "^3.1.3",
|
||||
"dpdm": "^3.14.0",
|
||||
"eslint": "^8.57.0",
|
||||
"eslint-plugin-i18next": "^6.0.9",
|
||||
"eslint": "^8.57.1",
|
||||
"eslint-plugin-i18next": "^6.1.0",
|
||||
"eslint-plugin-path": "^1.3.0",
|
||||
"knip": "^5.27.2",
|
||||
"knip": "^5.31.0",
|
||||
"openapi-types": "^12.1.3",
|
||||
"openapi-typescript": "^7.3.0",
|
||||
"openapi-typescript": "^7.4.1",
|
||||
"prettier": "^3.3.3",
|
||||
"rollup-plugin-visualizer": "^5.12.0",
|
||||
"storybook": "^8.2.8",
|
||||
"ts-toolbelt": "^9.6.0",
|
||||
"tsafe": "^1.7.2",
|
||||
"typescript": "^5.5.4",
|
||||
"vite": "^5.4.0",
|
||||
"vite-plugin-css-injected-by-js": "^3.5.1",
|
||||
"storybook": "^8.3.4",
|
||||
"tsafe": "^1.7.5",
|
||||
"type-fest": "^4.26.1",
|
||||
"typescript": "^5.6.2",
|
||||
"vite": "^5.4.8",
|
||||
"vite-plugin-css-injected-by-js": "^3.5.2",
|
||||
"vite-plugin-dts": "^3.9.1",
|
||||
"vite-plugin-eslint": "^1.8.1",
|
||||
"vite-tsconfig-paths": "^4.3.2",
|
||||
|
||||
6059
invokeai/frontend/web/pnpm-lock.yaml
generated
6059
invokeai/frontend/web/pnpm-lock.yaml
generated
File diff suppressed because it is too large
Load Diff
@@ -4,7 +4,7 @@
|
||||
"reportBugLabel": "Fehler melden",
|
||||
"settingsLabel": "Einstellungen",
|
||||
"img2img": "Bild zu Bild",
|
||||
"nodes": "Workflows",
|
||||
"nodes": "Arbeitsabläufe",
|
||||
"upload": "Hochladen",
|
||||
"load": "Laden",
|
||||
"statusDisconnected": "Getrennt",
|
||||
@@ -93,7 +93,9 @@
|
||||
"placeholderSelectAModel": "Modell auswählen",
|
||||
"reset": "Zurücksetzen",
|
||||
"none": "Keine",
|
||||
"new": "Neu"
|
||||
"new": "Neu",
|
||||
"ok": "OK",
|
||||
"close": "Schließen"
|
||||
},
|
||||
"gallery": {
|
||||
"galleryImageSize": "Bildgröße",
|
||||
@@ -156,7 +158,11 @@
|
||||
"displayBoardSearch": "Board durchsuchen",
|
||||
"displaySearch": "Bild suchen",
|
||||
"go": "Los",
|
||||
"jump": "Springen"
|
||||
"jump": "Springen",
|
||||
"assetsTab": "Dateien, die Sie zur Verwendung in Ihren Projekten hochgeladen haben.",
|
||||
"imagesTab": "Bilder, die Sie in Invoke erstellt und gespeichert haben.",
|
||||
"boardsSettings": "Ordnereinstellungen",
|
||||
"imagesSettings": "Galeriebildereinstellungen"
|
||||
},
|
||||
"hotkeys": {
|
||||
"noHotkeysFound": "Kein Hotkey gefunden",
|
||||
@@ -263,6 +269,22 @@
|
||||
"quickSwitch": {
|
||||
"title": "Ebenen schnell umschalten",
|
||||
"desc": "Wechseln Sie zwischen den beiden zuletzt gewählten Ebenen. Wenn eine Ebene mit einem Lesezeichen versehen ist, wird zwischen ihr und der letzten nicht markierten Ebene gewechselt."
|
||||
},
|
||||
"applyFilter": {
|
||||
"title": "Filter anwenden",
|
||||
"desc": "Wende den ausstehenden Filter auf die ausgewählte Ebene an."
|
||||
},
|
||||
"cancelFilter": {
|
||||
"title": "Filter abbrechen",
|
||||
"desc": "Den ausstehenden Filter abbrechen."
|
||||
},
|
||||
"applyTransform": {
|
||||
"desc": "Die ausstehende Transformation auf die ausgewählte Ebene anwenden.",
|
||||
"title": "Transformation anwenden"
|
||||
},
|
||||
"cancelTransform": {
|
||||
"title": "Transformation abbrechen",
|
||||
"desc": "Die ausstehende Transformation abbrechen."
|
||||
}
|
||||
},
|
||||
"viewer": {
|
||||
@@ -559,7 +581,18 @@
|
||||
"scanResults": "Ergebnisse des Scans",
|
||||
"urlOrLocalPathHelper": "URLs sollten auf eine einzelne Datei deuten. Lokale Pfade können zusätzlich auch auf einen Ordner für ein einzelnes Diffusers-Modell hinweisen.",
|
||||
"inplaceInstallDesc": "Installieren Sie Modelle, ohne die Dateien zu kopieren. Wenn Sie das Modell verwenden, wird es direkt von seinem Speicherort geladen. Wenn deaktiviert, werden die Dateien während der Installation in das von Invoke verwaltete Modellverzeichnis kopiert.",
|
||||
"scanFolderHelper": "Der Ordner wird rekursiv nach Modellen durchsucht. Dies kann bei sehr großen Ordnern etwas dauern."
|
||||
"scanFolderHelper": "Der Ordner wird rekursiv nach Modellen durchsucht. Dies kann bei sehr großen Ordnern etwas dauern.",
|
||||
"includesNModels": "Enthält {{n}} Modelle und deren Abhängigkeiten",
|
||||
"starterBundles": "Starterpakete",
|
||||
"installingXModels_one": "{{count}} Modell wird installiert",
|
||||
"installingXModels_other": "{{count}} Modelle werden installiert",
|
||||
"skippingXDuplicates_one": ", überspringe {{count}} Duplikat",
|
||||
"skippingXDuplicates_other": ", überspringe {{count}} Duplikate",
|
||||
"installingModel": "Modell wird installiert",
|
||||
"loraTriggerPhrases": "LoRA-Auslösephrasen",
|
||||
"installingBundle": "Bündel wird installiert",
|
||||
"triggerPhrases": "Auslösephrasen",
|
||||
"mainModelTriggerPhrases": "Hauptmodell-Auslösephrasen"
|
||||
},
|
||||
"parameters": {
|
||||
"images": "Bilder",
|
||||
@@ -647,22 +680,24 @@
|
||||
"imageCopied": "Bild kopiert",
|
||||
"parametersNotSet": "Parameter nicht festgelegt",
|
||||
"addedToBoard": "Dem Board hinzugefügt",
|
||||
"loadedWithWarnings": "Workflow mit Warnungen geladen"
|
||||
"loadedWithWarnings": "Workflow mit Warnungen geladen",
|
||||
"imageSaved": "Bild gespeichert"
|
||||
},
|
||||
"accessibility": {
|
||||
"uploadImage": "Bild hochladen",
|
||||
"previousImage": "Vorheriges Bild",
|
||||
"showOptionsPanel": "Seitenpanel anzeigen",
|
||||
"reset": "Zurücksetzten",
|
||||
"nextImage": "Nächstes Bild",
|
||||
"showGalleryPanel": "Galerie-Panel anzeigen",
|
||||
"menu": "Menü",
|
||||
"invokeProgressBar": "Invoke Fortschrittsanzeige",
|
||||
"mode": "Modus",
|
||||
"resetUI": "$t(accessibility.reset) von UI",
|
||||
"createIssue": "Ticket erstellen",
|
||||
"about": "Über",
|
||||
"submitSupportTicket": "Support-Ticket senden"
|
||||
"submitSupportTicket": "Support-Ticket senden",
|
||||
"toggleRightPanel": "Rechtes Bedienfeld umschalten (G)",
|
||||
"toggleLeftPanel": "Linkes Bedienfeld umschalten (T)",
|
||||
"uploadImages": "Bild(er) hochladen"
|
||||
},
|
||||
"boards": {
|
||||
"autoAddBoard": "Board automatisch erstellen",
|
||||
@@ -697,12 +732,13 @@
|
||||
"shared": "Geteilte Ordner",
|
||||
"archiveBoard": "Ordner archivieren",
|
||||
"archived": "Archiviert",
|
||||
"noBoards": "Kein {boardType}} Ordner",
|
||||
"noBoards": "Kein {{boardType}} Ordner",
|
||||
"hideBoards": "Ordner verstecken",
|
||||
"viewBoards": "Ordner ansehen",
|
||||
"deletedPrivateBoardsCannotbeRestored": "Gelöschte Boards können nicht wiederhergestellt werden. Wenn Sie „Nur Board löschen“ wählen, werden die Bilder in einen privaten, nicht kategorisierten Status für den Ersteller des Bildes versetzt.",
|
||||
"assetsWithCount_one": "{{count}} in der Sammlung",
|
||||
"assetsWithCount_other": "{{count}} in der Sammlung"
|
||||
"assetsWithCount_other": "{{count}} in der Sammlung",
|
||||
"deletedBoardsCannotbeRestored": "Gelöschte Ordner können nicht wiederhergestellt werden. Die Auswahl von \"Nur Ordner löschen\" verschiebt Bilder in einen unkategorisierten Zustand."
|
||||
},
|
||||
"queue": {
|
||||
"status": "Status",
|
||||
@@ -805,7 +841,8 @@
|
||||
"parameterSet": "Parameter {{parameter}} setzen",
|
||||
"recallParameter": "{{label}} Abrufen",
|
||||
"parsingFailed": "Parsing Fehlgeschlagen",
|
||||
"canvasV2Metadata": "Leinwand"
|
||||
"canvasV2Metadata": "Leinwand",
|
||||
"guidance": "Führung"
|
||||
},
|
||||
"popovers": {
|
||||
"noiseUseCPU": {
|
||||
@@ -930,7 +967,8 @@
|
||||
},
|
||||
"paramScheduler": {
|
||||
"paragraphs": [
|
||||
"\"Planer\" definiert, wie iterativ Rauschen zu einem Bild hinzugefügt wird, oder wie ein Sample bei der Ausgabe eines Modells aktualisiert wird."
|
||||
"Verwendeter Planer währende des Generierungsprozesses.",
|
||||
"Jeder Planer definiert, wie einem Bild iterativ Rauschen hinzugefügt wird, oder wie ein Sample basierend auf der Ausgabe eines Modells aktualisiert wird."
|
||||
],
|
||||
"heading": "Planer"
|
||||
},
|
||||
@@ -956,6 +994,61 @@
|
||||
},
|
||||
"ipAdapterMethod": {
|
||||
"heading": "Methode"
|
||||
},
|
||||
"refinerScheduler": {
|
||||
"heading": "Planer",
|
||||
"paragraphs": [
|
||||
"Planer, der während der Veredelungsphase des Generierungsprozesses verwendet wird.",
|
||||
"Ähnlich wie der Generierungsplaner."
|
||||
]
|
||||
},
|
||||
"compositingCoherenceMode": {
|
||||
"paragraphs": [
|
||||
"Verwendete Methode zur Erstellung eines kohärenten Bildes mit dem neu generierten maskierten Bereich."
|
||||
],
|
||||
"heading": "Modus"
|
||||
},
|
||||
"compositingCoherencePass": {
|
||||
"heading": "Kohärenzdurchlauf"
|
||||
},
|
||||
"controlNet": {
|
||||
"heading": "ControlNet"
|
||||
},
|
||||
"compositingMaskAdjustments": {
|
||||
"paragraphs": [
|
||||
"Die Maske anpassen."
|
||||
],
|
||||
"heading": "Maskenanpassungen"
|
||||
},
|
||||
"compositingMaskBlur": {
|
||||
"paragraphs": [
|
||||
"Der Unschärferadius der Maske."
|
||||
],
|
||||
"heading": "Maskenunschärfe"
|
||||
},
|
||||
"compositingBlurMethod": {
|
||||
"paragraphs": [
|
||||
"Die auf den maskierten Bereich angewendete Unschärfemethode."
|
||||
],
|
||||
"heading": "Unschärfemethode"
|
||||
},
|
||||
"controlNetResizeMode": {
|
||||
"heading": "Größenänderungsmodus"
|
||||
},
|
||||
"paramWidth": {
|
||||
"heading": "Breite",
|
||||
"paragraphs": [
|
||||
"Breite des generierten Bildes. Muss ein Vielfaches von 8 sein."
|
||||
]
|
||||
},
|
||||
"controlNetControlMode": {
|
||||
"heading": "Kontrollmodus"
|
||||
},
|
||||
"controlNetProcessor": {
|
||||
"heading": "Prozessor"
|
||||
},
|
||||
"patchmatchDownScaleSize": {
|
||||
"heading": "Herunterskalieren"
|
||||
}
|
||||
},
|
||||
"invocationCache": {
|
||||
@@ -1059,7 +1152,25 @@
|
||||
"missingFieldTemplate": "Fehlende Feldvorlage",
|
||||
"missingNode": "Fehlender Aufrufknoten",
|
||||
"missingInvocationTemplate": "Fehlende Aufrufvorlage",
|
||||
"edit": "Bearbeiten"
|
||||
"edit": "Bearbeiten",
|
||||
"workflowAuthor": "Autor",
|
||||
"graph": "Graph",
|
||||
"workflowDescription": "Kurze Beschreibung",
|
||||
"versionUnknown": " Version unbekannt",
|
||||
"workflow": "Arbeitsablauf",
|
||||
"noGraph": "Kein Graph",
|
||||
"version": "Version",
|
||||
"zoomInNodes": "Hineinzoomen",
|
||||
"zoomOutNodes": "Herauszoomen",
|
||||
"workflowName": "Name",
|
||||
"unknownNode": "Unbekannter Knoten",
|
||||
"workflowContact": "Kontaktdaten",
|
||||
"workflowNotes": "Notizen",
|
||||
"workflowTags": "Tags",
|
||||
"workflowVersion": "Version",
|
||||
"saveToGallery": "In Galerie speichern",
|
||||
"noWorkflows": "Keine Arbeitsabläufe",
|
||||
"noMatchingWorkflows": "Keine passenden Arbeitsabläufe"
|
||||
},
|
||||
"hrf": {
|
||||
"enableHrf": "Korrektur für hohe Auflösungen",
|
||||
@@ -1127,7 +1238,17 @@
|
||||
"openWorkflow": "Arbeitsablauf öffnen",
|
||||
"saveWorkflowToProject": "Arbeitsablauf in Projekt speichern",
|
||||
"workflowCleared": "Arbeitsablauf gelöscht",
|
||||
"loading": "Lade Arbeitsabläufe"
|
||||
"loading": "Lade Arbeitsabläufe",
|
||||
"name": "Name",
|
||||
"ascending": "Aufsteigend",
|
||||
"defaultWorkflows": "Standard Arbeitsabläufe",
|
||||
"userWorkflows": "Benutzer Arbeitsabläufe",
|
||||
"projectWorkflows": "Projekt Arbeitsabläufe",
|
||||
"opened": "Geöffnet",
|
||||
"loadWorkflow": "Arbeitsablauf $t(common.load)",
|
||||
"updated": "Aktualisiert",
|
||||
"created": "Erstellt",
|
||||
"descending": "Absteigend"
|
||||
},
|
||||
"sdxl": {
|
||||
"concatPromptStyle": "Verknüpfen von Prompt & Stil",
|
||||
@@ -1219,7 +1340,16 @@
|
||||
"searchByName": "Nach Name suchen",
|
||||
"promptTemplateCleared": "Promptvorlage gelöscht",
|
||||
"preview": "Vorschau",
|
||||
"positivePrompt": "Positiv-Prompt"
|
||||
"positivePrompt": "Positiv-Prompt",
|
||||
"active": "Aktiv",
|
||||
"deleteTemplate2": "Sind Sie sicher, dass Sie diese Vorlage löschen möchten? Dies kann nicht rückgängig gemacht werden.",
|
||||
"deleteTemplate": "Vorlage löschen",
|
||||
"copyTemplate": "Vorlage kopieren",
|
||||
"editTemplate": "Vorlage bearbeiten",
|
||||
"deleteImage": "Bild löschen",
|
||||
"defaultTemplates": "Standardvorlagen",
|
||||
"nameColumn": "'name'",
|
||||
"exportDownloaded": "Export heruntergeladen"
|
||||
},
|
||||
"newUserExperience": {
|
||||
"gettingStartedSeries": "Wünschen Sie weitere Anleitungen? In unserer <LinkComponent>Einführungsserie</LinkComponent> finden Sie Tipps, wie Sie das Potenzial von Invoke Studio voll ausschöpfen können.",
|
||||
@@ -1232,13 +1362,22 @@
|
||||
"bbox": "Bbox"
|
||||
},
|
||||
"transform": {
|
||||
"fitToBbox": "An Bbox anpassen"
|
||||
"fitToBbox": "An Bbox anpassen",
|
||||
"reset": "Zurücksetzen",
|
||||
"apply": "Anwenden",
|
||||
"cancel": "Abbrechen"
|
||||
},
|
||||
"pullBboxIntoLayerError": "Problem, Bbox in die Ebene zu ziehen",
|
||||
"pullBboxIntoLayer": "Bbox in Ebene ziehen",
|
||||
"HUD": {
|
||||
"bbox": "Bbox",
|
||||
"scaledBbox": "Skalierte Bbox"
|
||||
"scaledBbox": "Skalierte Bbox",
|
||||
"entityStatus": {
|
||||
"isHidden": "{{title}} ist ausgeblendet",
|
||||
"isDisabled": "{{title}} ist deaktiviert",
|
||||
"isLocked": "{{title}} ist gesperrt",
|
||||
"isEmpty": "{{title}} ist leer"
|
||||
}
|
||||
},
|
||||
"fitBboxToLayers": "Bbox an Ebenen anpassen",
|
||||
"pullBboxIntoReferenceImage": "Bbox ins Referenzbild ziehen",
|
||||
@@ -1248,13 +1387,108 @@
|
||||
"clipToBbox": "Pinselstriche auf Bbox beschränken",
|
||||
"canvasContextMenu": {
|
||||
"saveBboxToGallery": "Bbox in Galerie speichern",
|
||||
"bboxGroup": "Aus Bbox erstellen"
|
||||
}
|
||||
"bboxGroup": "Aus Bbox erstellen",
|
||||
"canvasGroup": "Leinwand",
|
||||
"newGlobalReferenceImage": "Neues globales Referenzbild",
|
||||
"newRegionalReferenceImage": "Neues regionales Referenzbild",
|
||||
"newControlLayer": "Neue Kontroll-Ebene",
|
||||
"newRasterLayer": "Neue Raster-Ebene"
|
||||
},
|
||||
"rectangle": "Rechteck",
|
||||
"saveCanvasToGallery": "Leinwand in Galerie speichern",
|
||||
"newRasterLayerError": "Problem beim Erstellen einer Raster-Ebene",
|
||||
"saveLayerToAssets": "Ebene in Galerie speichern",
|
||||
"deleteReferenceImage": "Referenzbild löschen",
|
||||
"referenceImage": "Referenzbild",
|
||||
"opacity": "Opazität",
|
||||
"resetCanvas": "Leinwand zurücksetzen",
|
||||
"removeBookmark": "Lesezeichen entfernen",
|
||||
"rasterLayer": "Raster-Ebene",
|
||||
"rasterLayers_withCount_visible": "Raster-Ebenen ({{count}})",
|
||||
"controlLayers_withCount_visible": "Kontroll-Ebenen ({{count}})",
|
||||
"deleteSelected": "Ausgewählte löschen",
|
||||
"newRegionalReferenceImageError": "Problem beim Erstellen eines regionalen Referenzbilds",
|
||||
"newControlLayerOk": "Kontroll-Ebene erstellt",
|
||||
"newControlLayerError": "Problem beim Erstellen einer Kontroll-Ebene",
|
||||
"newRasterLayerOk": "Raster-Layer erstellt",
|
||||
"moveToFront": "Nach vorne bringen",
|
||||
"copyToClipboard": "In die Zwischenablage kopieren",
|
||||
"controlLayers_withCount_hidden": "Kontroll-Ebenen ({{count}} ausgeblendet)",
|
||||
"clearCaches": "Cache leeren",
|
||||
"controlLayer": "Kontroll-Ebene",
|
||||
"rasterLayers_withCount_hidden": "Raster-Ebenen ({{count}} ausgeblendet)",
|
||||
"transparency": "Transparenz",
|
||||
"canvas": "Leinwand",
|
||||
"global": "Global",
|
||||
"regional": "Regional",
|
||||
"newGlobalReferenceImageOk": "Globales Referenzbild erstellt",
|
||||
"savedToGalleryError": "Fehler beim Speichern in der Galerie",
|
||||
"savedToGalleryOk": "In Galerie gespeichert",
|
||||
"newGlobalReferenceImageError": "Problem beim Erstellen eines globalen Referenzbilds",
|
||||
"newRegionalReferenceImageOk": "Regionales Referenzbild erstellt",
|
||||
"duplicate": "Duplizieren",
|
||||
"regionalReferenceImage": "Regionales Referenzbild",
|
||||
"globalReferenceImage": "Globales Referenzbild",
|
||||
"regionIsEmpty": "Ausgewählte Region is leer",
|
||||
"mergeVisible": "Sichtbare vereinen",
|
||||
"mergeVisibleOk": "Sichtbare Ebenen vereinen",
|
||||
"mergeVisibleError": "Fehler beim Vereinen sichtbarer Ebenen",
|
||||
"clearHistory": "Verlauf leeren",
|
||||
"addLayer": "Ebene hinzufügen",
|
||||
"width": "Breite",
|
||||
"weight": "Gewichtung",
|
||||
"addReferenceImage": "$t(controlLayers.referenceImage) hinzufügen",
|
||||
"addInpaintMask": "$t(controlLayers.inpaintMask) hinzufügen",
|
||||
"addGlobalReferenceImage": "$t(controlLayers.globalReferenceImage) hinzufügen",
|
||||
"regionalGuidance": "Regionale Führung",
|
||||
"globalReferenceImages_withCount_visible": "Globale Referenzbilder ({{count}})",
|
||||
"addPositivePrompt": "$t(controlLayers.prompt) hinzufügen",
|
||||
"locked": "Gesperrt",
|
||||
"showHUD": "HUD anzeigen",
|
||||
"addNegativePrompt": "$t(controlLayers.negativePrompt) hinzufügen",
|
||||
"addRasterLayer": "$t(controlLayers.rasterLayer) hinzufügen",
|
||||
"addRegionalGuidance": "$t(controlLayers.regionalGuidance) hinzufügen",
|
||||
"addControlLayer": "$t(controlLayers.controlLayer) hinzufügen",
|
||||
"newCanvasSession": "Neue Leinwand-Sitzung",
|
||||
"replaceLayer": "Ebene ersetzen",
|
||||
"newGallerySession": "Neue Galerie-Sitzung",
|
||||
"unlocked": "Entsperrt",
|
||||
"showProgressOnCanvas": "Fortschritt auf Leinwand anzeigen",
|
||||
"controlMode": {
|
||||
"balanced": "Ausgewogen"
|
||||
},
|
||||
"globalReferenceImages_withCount_hidden": "Globale Referenzbilder ({{count}} ausgeblendet)",
|
||||
"sendToGallery": "An Galerie senden",
|
||||
"stagingArea": {
|
||||
"accept": "Annehmen",
|
||||
"next": "Nächste",
|
||||
"discardAll": "Alle verwerfen",
|
||||
"discard": "Verwerfen",
|
||||
"previous": "Vorherige"
|
||||
},
|
||||
"regionalGuidance_withCount_visible": "Regionale Führung ({{count}})",
|
||||
"regionalGuidance_withCount_hidden": "Regionale Führung ({{count}} ausgeblendet)",
|
||||
"settings": {
|
||||
"snapToGrid": {
|
||||
"on": "Ein",
|
||||
"off": "Aus",
|
||||
"label": "Am Raster ausrichten"
|
||||
}
|
||||
},
|
||||
"layer_one": "Ebene",
|
||||
"layer_other": "Ebenen",
|
||||
"layer_withCount_one": "Ebene ({{count}})",
|
||||
"layer_withCount_other": "Ebenen ({{count}})"
|
||||
},
|
||||
"upsell": {
|
||||
"shareAccess": "Zugang teilen",
|
||||
"professional": "Professionell",
|
||||
"inviteTeammates": "Teamkollegen einladen",
|
||||
"professionalUpsell": "Verfügbar in der Professional Edition von Invoke. Klicken Sie hier oder besuchen Sie invoke.com/pricing für weitere Details."
|
||||
},
|
||||
"upscaling": {
|
||||
"creativity": "Kreativität",
|
||||
"structure": "Struktur",
|
||||
"scale": "Maßstab"
|
||||
}
|
||||
}
|
||||
|
||||
@@ -10,9 +10,10 @@
|
||||
"previousImage": "Previous Image",
|
||||
"reset": "Reset",
|
||||
"resetUI": "$t(accessibility.reset) UI",
|
||||
"showGalleryPanel": "Show Gallery Panel",
|
||||
"showOptionsPanel": "Show Side Panel",
|
||||
"uploadImage": "Upload Image"
|
||||
"toggleRightPanel": "Toggle Right Panel (G)",
|
||||
"toggleLeftPanel": "Toggle Left Panel (T)",
|
||||
"uploadImage": "Upload Image",
|
||||
"uploadImages": "Upload Image(s)"
|
||||
},
|
||||
"boards": {
|
||||
"addBoard": "Add Board",
|
||||
@@ -53,7 +54,8 @@
|
||||
"imagesWithCount_one": "{{count}} image",
|
||||
"imagesWithCount_other": "{{count}} images",
|
||||
"assetsWithCount_one": "{{count}} asset",
|
||||
"assetsWithCount_other": "{{count}} assets"
|
||||
"assetsWithCount_other": "{{count}} assets",
|
||||
"updateBoardError": "Error updating board"
|
||||
},
|
||||
"accordions": {
|
||||
"generation": {
|
||||
@@ -89,11 +91,14 @@
|
||||
"batch": "Batch Manager",
|
||||
"beta": "Beta",
|
||||
"cancel": "Cancel",
|
||||
"close": "Close",
|
||||
"copy": "Copy",
|
||||
"copyError": "$t(gallery.copy) Error",
|
||||
"clipboard": "Clipboard",
|
||||
"on": "On",
|
||||
"off": "Off",
|
||||
"or": "or",
|
||||
"ok": "Ok",
|
||||
"checkpoint": "Checkpoint",
|
||||
"communityLabel": "Community",
|
||||
"controlNet": "ControlNet",
|
||||
@@ -279,8 +284,10 @@
|
||||
"gallery": "Gallery",
|
||||
"alwaysShowImageSizeBadge": "Always Show Image Size Badge",
|
||||
"assets": "Assets",
|
||||
"assetsTab": "Files you’ve uploaded for use in your projects.",
|
||||
"autoAssignBoardOnClick": "Auto-Assign Board on Click",
|
||||
"autoSwitchNewImages": "Auto-Switch to New Images",
|
||||
"boardsSettings": "Boards Settings",
|
||||
"copy": "Copy",
|
||||
"currentlyInUse": "This image is currently in use in the following features:",
|
||||
"drop": "Drop",
|
||||
@@ -299,6 +306,8 @@
|
||||
"gallerySettings": "Gallery Settings",
|
||||
"go": "Go",
|
||||
"image": "image",
|
||||
"imagesTab": "Images you’ve created and saved within Invoke.",
|
||||
"imagesSettings": "Gallery Images Settings",
|
||||
"jump": "Jump",
|
||||
"loading": "Loading",
|
||||
"newestFirst": "Newest First",
|
||||
@@ -657,6 +666,7 @@
|
||||
"cfgRescaleMultiplier": "$t(parameters.cfgRescaleMultiplier)",
|
||||
"createdBy": "Created By",
|
||||
"generationMode": "Generation Mode",
|
||||
"guidance": "Guidance",
|
||||
"height": "Height",
|
||||
"imageDetails": "Image Details",
|
||||
"imageDimensions": "Image Dimensions",
|
||||
@@ -697,7 +707,7 @@
|
||||
"convert": "Convert",
|
||||
"convertingModelBegin": "Converting Model. Please wait.",
|
||||
"convertToDiffusers": "Convert To Diffusers",
|
||||
"convertToDiffusersHelpText1": "This model will be converted to the \ud83e\udde8 Diffusers format.",
|
||||
"convertToDiffusersHelpText1": "This model will be converted to the 🧨 Diffusers format.",
|
||||
"convertToDiffusersHelpText2": "This process will replace your Model Manager entry with the Diffusers version of the same model.",
|
||||
"convertToDiffusersHelpText3": "Your checkpoint file on disk WILL be deleted if it is in InvokeAI root folder. If it is in a custom location, then it WILL NOT be deleted.",
|
||||
"convertToDiffusersHelpText4": "This is a one time process only. It might take around 30s-60s depending on the specifications of your computer.",
|
||||
@@ -720,6 +730,7 @@
|
||||
"huggingFaceHelper": "If multiple models are found in this repo, you will be prompted to select one to install.",
|
||||
"hfToken": "HuggingFace Token",
|
||||
"imageEncoderModelId": "Image Encoder Model ID",
|
||||
"includesNModels": "Includes {{n}} models and their dependencies",
|
||||
"installQueue": "Install Queue",
|
||||
"inplaceInstall": "In-place install",
|
||||
"inplaceInstallDesc": "Install models without copying the files. When using the model, it will be loaded from its this location. If disabled, the model file(s) will be copied into the Invoke-managed models directory during installation.",
|
||||
@@ -773,6 +784,8 @@
|
||||
"simpleModelPlaceholder": "URL or path to a local file or diffusers folder",
|
||||
"source": "Source",
|
||||
"spandrelImageToImage": "Image to Image (Spandrel)",
|
||||
"starterBundles": "Starter Bundles",
|
||||
"starterBundleHelpText": "Easily install all models needed to get started with a base model, including a main model, controlnets, IP adapters, and more. Selecting a bundle will skip any models that you already have installed.",
|
||||
"starterModels": "Starter Models",
|
||||
"starterModelsInModelManager": "Starter Models can be found in Model Manager",
|
||||
"syncModels": "Sync Models",
|
||||
@@ -790,7 +803,13 @@
|
||||
"vae": "VAE",
|
||||
"vaePrecision": "VAE Precision",
|
||||
"variant": "Variant",
|
||||
"width": "Width"
|
||||
"width": "Width",
|
||||
"installingBundle": "Installing Bundle",
|
||||
"installingModel": "Installing Model",
|
||||
"installingXModels_one": "Installing {{count}} model",
|
||||
"installingXModels_other": "Installing {{count}} models",
|
||||
"skippingXDuplicates_one": ", skipping {{count}} duplicate",
|
||||
"skippingXDuplicates_other": ", skipping {{count}} duplicates"
|
||||
},
|
||||
"models": {
|
||||
"addLora": "Add LoRA",
|
||||
@@ -852,6 +871,8 @@
|
||||
"ipAdapter": "IP-Adapter",
|
||||
"loadingNodes": "Loading Nodes...",
|
||||
"loadWorkflow": "Load Workflow",
|
||||
"noWorkflows": "No Workflows",
|
||||
"noMatchingWorkflows": "No Matching Workflows",
|
||||
"noWorkflow": "No Workflow",
|
||||
"mismatchedVersion": "Invalid node: node {{node}} of type {{type}} has mismatched version (try updating?)",
|
||||
"missingTemplate": "Invalid node: node {{node}} of type {{type}} missing template (not installed?)",
|
||||
@@ -868,6 +889,7 @@
|
||||
"nodeType": "Node Type",
|
||||
"noFieldsLinearview": "No fields added to Linear View",
|
||||
"noFieldsViewMode": "This workflow has no selected fields to display. View the full workflow to configure values.",
|
||||
"workflowHelpText": "Need Help? Check out our guide to <LinkComponent>Getting Started with Workflows</LinkComponent>.",
|
||||
"noNodeSelected": "No node selected",
|
||||
"nodeOpacity": "Node Opacity",
|
||||
"nodeVersion": "Node Version",
|
||||
@@ -1081,6 +1103,7 @@
|
||||
"antialiasProgressImages": "Antialias Progress Images",
|
||||
"beta": "Beta",
|
||||
"confirmOnDelete": "Confirm On Delete",
|
||||
"confirmOnNewSession": "Confirm On New Session",
|
||||
"developer": "Developer",
|
||||
"displayInProgress": "Display Progress Images",
|
||||
"enableInformationalPopovers": "Enable Informational Popovers",
|
||||
@@ -1110,13 +1133,15 @@
|
||||
"reloadingIn": "Reloading in"
|
||||
},
|
||||
"toast": {
|
||||
"addedToBoard": "Added to board",
|
||||
"addedToBoard": "Added to board {{name}}'s assets",
|
||||
"addedToUncategorized": "Added to board $t(boards.uncategorized)'s assets",
|
||||
"baseModelChanged": "Base Model Changed",
|
||||
"baseModelChangedCleared_one": "Cleared or disabled {{count}} incompatible submodel",
|
||||
"baseModelChangedCleared_other": "Cleared or disabled {{count}} incompatible submodels",
|
||||
"canceled": "Processing Canceled",
|
||||
"connected": "Connected to Server",
|
||||
"imageCopied": "Image Copied",
|
||||
"linkCopied": "Link Copied",
|
||||
"unableToLoadImage": "Unable to Load Image",
|
||||
"unableToLoadImageMetadata": "Unable to Load Image Metadata",
|
||||
"unableToLoadStylePreset": "Unable to Load Style Preset",
|
||||
@@ -1158,7 +1183,10 @@
|
||||
"setNodeField": "Set as node field",
|
||||
"somethingWentWrong": "Something Went Wrong",
|
||||
"uploadFailed": "Upload failed",
|
||||
"uploadFailedInvalidUploadDesc": "Must be single PNG or JPEG image",
|
||||
"imagesWillBeAddedTo": "Uploaded images will be added to board {{boardName}}'s assets.",
|
||||
"uploadFailedInvalidUploadDesc_withCount_one": "Must be maximum of 1 PNG or JPEG image.",
|
||||
"uploadFailedInvalidUploadDesc_withCount_other": "Must be maximum of {{count}} PNG or JPEG images.",
|
||||
"uploadFailedInvalidUploadDesc": "Must be PNG or JPEG images.",
|
||||
"workflowLoaded": "Workflow Loaded",
|
||||
"problemRetrievingWorkflow": "Problem Retrieving Workflow",
|
||||
"workflowDeleted": "Workflow Deleted",
|
||||
@@ -1224,6 +1252,33 @@
|
||||
"heading": "Mask Adjustments",
|
||||
"paragraphs": ["Adjust the mask."]
|
||||
},
|
||||
"inpainting": {
|
||||
"heading": "Inpainting",
|
||||
"paragraphs": ["Controls which area is modified, guided by Denoising Strength."]
|
||||
},
|
||||
"rasterLayer": {
|
||||
"heading": "Raster Layer",
|
||||
"paragraphs": ["Pixel-based content of your canvas, used during image generation."]
|
||||
},
|
||||
"regionalGuidance": {
|
||||
"heading": "Regional Guidance",
|
||||
"paragraphs": ["Brush to guide where elements from global prompts should appear."]
|
||||
},
|
||||
"regionalGuidanceAndReferenceImage": {
|
||||
"heading": "Regional Guidance and Regional Reference Image",
|
||||
"paragraphs": [
|
||||
"For Regional Guidance, brush to guide where elements from global prompts should appear.",
|
||||
"For Regional Reference Image, brush to apply a reference image to specific areas."
|
||||
]
|
||||
},
|
||||
"globalReferenceImage": {
|
||||
"heading": "Global Reference Image",
|
||||
"paragraphs": ["Applies a reference image to influence the entire generation."]
|
||||
},
|
||||
"regionalReferenceImage": {
|
||||
"heading": "Regional Reference Image",
|
||||
"paragraphs": ["Brush to apply a reference image to specific areas."]
|
||||
},
|
||||
"controlNet": {
|
||||
"heading": "ControlNet",
|
||||
"paragraphs": [
|
||||
@@ -1513,6 +1568,7 @@
|
||||
}
|
||||
},
|
||||
"workflows": {
|
||||
"chooseWorkflowFromLibrary": "Choose Workflow from Library",
|
||||
"defaultWorkflows": "Default Workflows",
|
||||
"userWorkflows": "User Workflows",
|
||||
"projectWorkflows": "Project Workflows",
|
||||
@@ -1525,7 +1581,9 @@
|
||||
"openWorkflow": "Open Workflow",
|
||||
"updated": "Updated",
|
||||
"uploadWorkflow": "Load from File",
|
||||
"uploadAndSaveWorkflow": "Upload to Library",
|
||||
"deleteWorkflow": "Delete Workflow",
|
||||
"deleteWorkflow2": "Are you sure you want to delete this workflow? This cannot be undone.",
|
||||
"unnamedWorkflow": "Unnamed Workflow",
|
||||
"downloadWorkflow": "Save to File",
|
||||
"saveWorkflow": "Save Workflow",
|
||||
@@ -1548,9 +1606,13 @@
|
||||
"loadFromGraph": "Load Workflow from Graph",
|
||||
"convertGraph": "Convert Graph",
|
||||
"loadWorkflow": "$t(common.load) Workflow",
|
||||
"autoLayout": "Auto Layout"
|
||||
"autoLayout": "Auto Layout",
|
||||
"edit": "Edit",
|
||||
"download": "Download",
|
||||
"copyShareLink": "Copy Share Link",
|
||||
"copyShareLinkForWorkflow": "Copy Share Link for Workflow",
|
||||
"delete": "Delete"
|
||||
},
|
||||
"app": {},
|
||||
"controlLayers": {
|
||||
"regional": "Regional",
|
||||
"global": "Global",
|
||||
@@ -1561,6 +1623,7 @@
|
||||
"saveCanvasToGallery": "Save Canvas to Gallery",
|
||||
"saveBboxToGallery": "Save Bbox to Gallery",
|
||||
"saveLayerToAssets": "Save Layer to Assets",
|
||||
"cropLayerToBbox": "Crop Layer to Bbox",
|
||||
"savedToGalleryOk": "Saved to Gallery",
|
||||
"savedToGalleryError": "Error saving to gallery",
|
||||
"newGlobalReferenceImageOk": "Created Global Reference Image",
|
||||
@@ -1623,19 +1686,20 @@
|
||||
"sendToCanvas": "Send To Canvas",
|
||||
"newLayerFromImage": "New Layer from Image",
|
||||
"newCanvasFromImage": "New Canvas from Image",
|
||||
"newImg2ImgCanvasFromImage": "New Img2Img from Image",
|
||||
"copyToClipboard": "Copy to Clipboard",
|
||||
"sendToCanvasDesc": "Pressing Invoke stages your work in progress on the canvas.",
|
||||
"viewProgressInViewer": "View progress and outputs in the <Btn>Image Viewer</Btn>.",
|
||||
"viewProgressOnCanvas": "View progress and stage outputs on the <Btn>Canvas</Btn>.",
|
||||
"rasterLayer_withCount_one": "$t(controlLayers.rasterLayer)",
|
||||
"controlLayer_withCount_one": "$t(controlLayers.controlLayer)",
|
||||
"inpaintMask_withCount_one": "$t(controlLayers.inpaintMask)",
|
||||
"regionalGuidance_withCount_one": "$t(controlLayers.regionalGuidance)",
|
||||
"globalReferenceImage_withCount_one": "$t(controlLayers.globalReferenceImage)",
|
||||
"rasterLayer_withCount_other": "Raster Layers",
|
||||
"controlLayer_withCount_one": "$t(controlLayers.controlLayer)",
|
||||
"controlLayer_withCount_other": "Control Layers",
|
||||
"inpaintMask_withCount_one": "$t(controlLayers.inpaintMask)",
|
||||
"inpaintMask_withCount_other": "Inpaint Masks",
|
||||
"regionalGuidance_withCount_one": "$t(controlLayers.regionalGuidance)",
|
||||
"regionalGuidance_withCount_other": "Regional Guidance",
|
||||
"globalReferenceImage_withCount_one": "$t(controlLayers.globalReferenceImage)",
|
||||
"globalReferenceImage_withCount_other": "Global Reference Images",
|
||||
"opacity": "Opacity",
|
||||
"regionalGuidance_withCount_hidden": "Regional Guidance ({{count}} hidden)",
|
||||
@@ -1648,13 +1712,22 @@
|
||||
"rasterLayers_withCount_visible": "Raster Layers ({{count}})",
|
||||
"globalReferenceImages_withCount_visible": "Global Reference Images ({{count}})",
|
||||
"inpaintMasks_withCount_visible": "Inpaint Masks ({{count}})",
|
||||
"layer": "Layer",
|
||||
"layer_one": "Layer",
|
||||
"layer_other": "Layers",
|
||||
"layer_withCount_one": "Layer ({{count}})",
|
||||
"layer_withCount_other": "Layers ({{count}})",
|
||||
"convertToControlLayer": "Convert to Control Layer",
|
||||
"convertToRasterLayer": "Convert to Raster Layer",
|
||||
"convertRasterLayerTo": "Convert $t(controlLayers.rasterLayer) To",
|
||||
"convertControlLayerTo": "Convert $t(controlLayers.controlLayer) To",
|
||||
"convertInpaintMaskTo": "Convert $t(controlLayers.inpaintMask) To",
|
||||
"convertRegionalGuidanceTo": "Convert $t(controlLayers.regionalGuidance) To",
|
||||
"copyRasterLayerTo": "Copy $t(controlLayers.rasterLayer) To",
|
||||
"copyControlLayerTo": "Copy $t(controlLayers.controlLayer) To",
|
||||
"copyInpaintMaskTo": "Copy $t(controlLayers.inpaintMask) To",
|
||||
"copyRegionalGuidanceTo": "Copy $t(controlLayers.regionalGuidance) To",
|
||||
"newRasterLayer": "New $t(controlLayers.rasterLayer)",
|
||||
"newControlLayer": "New $t(controlLayers.controlLayer)",
|
||||
"newInpaintMask": "New $t(controlLayers.inpaintMask)",
|
||||
"newRegionalGuidance": "New $t(controlLayers.regionalGuidance)",
|
||||
"transparency": "Transparency",
|
||||
"enableTransparencyEffect": "Enable Transparency Effect",
|
||||
"disableTransparencyEffect": "Disable Transparency Effect",
|
||||
@@ -1674,6 +1747,10 @@
|
||||
"negativePrompt": "Negative Prompt",
|
||||
"beginEndStepPercentShort": "Begin/End %",
|
||||
"weight": "Weight",
|
||||
"newGallerySession": "New Gallery Session",
|
||||
"newGallerySessionDesc": "This will clear the canvas and all settings except for your model selection. Generations will be sent to the gallery.",
|
||||
"newCanvasSession": "New Canvas Session",
|
||||
"newCanvasSessionDesc": "This will clear the canvas and all settings except for your model selection. Generations will be staged on the canvas.",
|
||||
"controlMode": {
|
||||
"controlMode": "Control Mode",
|
||||
"balanced": "Balanced",
|
||||
@@ -1727,7 +1804,7 @@
|
||||
"label": "Canny Edge Detection",
|
||||
"description": "Generates an edge map from the selected layer using the Canny edge detection algorithm.",
|
||||
"low_threshold": "Low Threshold",
|
||||
"high_threshold": "Hight Threshold"
|
||||
"high_threshold": "High Threshold"
|
||||
},
|
||||
"color_map": {
|
||||
"label": "Color Map",
|
||||
@@ -1795,10 +1872,25 @@
|
||||
"transform": {
|
||||
"transform": "Transform",
|
||||
"fitToBbox": "Fit to Bbox",
|
||||
"fitMode": "Fit Mode",
|
||||
"fitModeContain": "Contain",
|
||||
"fitModeCover": "Cover",
|
||||
"fitModeFill": "Fill",
|
||||
"reset": "Reset",
|
||||
"apply": "Apply",
|
||||
"cancel": "Cancel"
|
||||
},
|
||||
"segment": {
|
||||
"autoMask": "Auto Mask",
|
||||
"pointType": "Point Type",
|
||||
"include": "Include",
|
||||
"exclude": "Exclude",
|
||||
"neutral": "Neutral",
|
||||
"reset": "Reset",
|
||||
"saveAs": "Save As",
|
||||
"cancel": "Cancel",
|
||||
"process": "Process"
|
||||
},
|
||||
"settings": {
|
||||
"snapToGrid": {
|
||||
"label": "Snap to Grid",
|
||||
@@ -1809,11 +1901,12 @@
|
||||
"label": "Preserve Masked Region",
|
||||
"alert": "Preserving Masked Region"
|
||||
},
|
||||
"isolatedPreview": "Isolated Preview",
|
||||
"isolatedStagingPreview": "Isolated Staging Preview",
|
||||
"isolatedFilteringPreview": "Isolated Filtering Preview",
|
||||
"isolatedTransformingPreview": "Isolated Transforming Preview",
|
||||
"invertBrushSizeScrollDirection": "Invert Scroll for Brush Size"
|
||||
"isolatedPreview": "Isolated Preview",
|
||||
"isolatedLayerPreview": "Isolated Layer Preview",
|
||||
"isolatedLayerPreviewDesc": "Whether to show only this layer when performing operations like filtering or transforming.",
|
||||
"invertBrushSizeScrollDirection": "Invert Scroll for Brush Size",
|
||||
"pressureSensitivity": "Pressure Sensitivity"
|
||||
},
|
||||
"HUD": {
|
||||
"bbox": "Bbox",
|
||||
@@ -1828,6 +1921,7 @@
|
||||
}
|
||||
},
|
||||
"canvasContextMenu": {
|
||||
"canvasGroup": "Canvas",
|
||||
"saveToGalleryGroup": "Save To Gallery",
|
||||
"saveCanvasToGallery": "Save Canvas To Gallery",
|
||||
"saveBboxToGallery": "Save Bbox To Gallery",
|
||||
@@ -1835,7 +1929,8 @@
|
||||
"newGlobalReferenceImage": "New Global Reference Image",
|
||||
"newRegionalReferenceImage": "New Regional Reference Image",
|
||||
"newControlLayer": "New Control Layer",
|
||||
"newRasterLayer": "New Raster Layer"
|
||||
"newRasterLayer": "New Raster Layer",
|
||||
"cropCanvasToBbox": "Crop Canvas to Bbox"
|
||||
},
|
||||
"stagingArea": {
|
||||
"accept": "Accept",
|
||||
@@ -1958,8 +2053,12 @@
|
||||
}
|
||||
},
|
||||
"newUserExperience": {
|
||||
"toGetStarted": "To get started, enter a prompt in the box and click <StrongComponent>Invoke</StrongComponent> to generate your first image. You can choose to save your images directly to the <StrongComponent>Gallery</StrongComponent> or edit them to the <StrongComponent>Canvas</StrongComponent>.",
|
||||
"gettingStartedSeries": "Want more guidance? Check out our <LinkComponent>Getting Started Series</LinkComponent> for tips on unlocking the full potential of the Invoke Studio."
|
||||
"toGetStartedLocal": "To get started, make sure to download or import models needed to run Invoke. Then, enter a prompt in the box and click <StrongComponent>Invoke</StrongComponent> to generate your first image. Select a prompt template to improve results. You can choose to save your images directly to the <StrongComponent>Gallery</StrongComponent> or edit them to the <StrongComponent>Canvas</StrongComponent>.",
|
||||
"toGetStarted": "To get started, enter a prompt in the box and click <StrongComponent>Invoke</StrongComponent> to generate your first image. Select a prompt template to improve results. You can choose to save your images directly to the <StrongComponent>Gallery</StrongComponent> or edit them to the <StrongComponent>Canvas</StrongComponent>.",
|
||||
"gettingStartedSeries": "Want more guidance? Check out our <LinkComponent>Getting Started Series</LinkComponent> for tips on unlocking the full potential of the Invoke Studio.",
|
||||
"downloadStarterModels": "Download Starter Models",
|
||||
"importModels": "Import Models",
|
||||
"noModelsInstalled": "It looks like you don't have any models installed"
|
||||
},
|
||||
"whatsNew": {
|
||||
"whatsNewInInvoke": "What's New in Invoke",
|
||||
|
||||
@@ -219,14 +219,14 @@
|
||||
"uploadImage": "Cargar imagen",
|
||||
"previousImage": "Imagen anterior",
|
||||
"nextImage": "Siguiente imagen",
|
||||
"showOptionsPanel": "Mostrar el panel lateral",
|
||||
"menu": "Menú",
|
||||
"showGalleryPanel": "Mostrar panel de galería",
|
||||
"about": "Acerca de",
|
||||
"createIssue": "Crear un problema",
|
||||
"resetUI": "Interfaz de usuario $t(accessibility.reset)",
|
||||
"mode": "Modo",
|
||||
"submitSupportTicket": "Enviar Ticket de Soporte"
|
||||
"submitSupportTicket": "Enviar Ticket de Soporte",
|
||||
"toggleRightPanel": "Activar o desactivar el panel derecho (G)",
|
||||
"toggleLeftPanel": "Activar o desactivar el panel izquierdo (T)"
|
||||
},
|
||||
"nodes": {
|
||||
"zoomInNodes": "Acercar",
|
||||
@@ -275,7 +275,12 @@
|
||||
"addSharedBoard": "Agregar Panel Compartido",
|
||||
"boards": "Paneles",
|
||||
"archiveBoard": "Archivar Panel",
|
||||
"archived": "Archivado"
|
||||
"archived": "Archivado",
|
||||
"selectedForAutoAdd": "Seleccionado para agregar automáticamente",
|
||||
"unarchiveBoard": "Desarchivar el tablero",
|
||||
"noBoards": "No hay tableros {{boardType}}",
|
||||
"shared": "Carpetas compartidas",
|
||||
"deletedPrivateBoardsCannotbeRestored": "Los tableros eliminados no se pueden restaurar. Al elegir \"Eliminar solo tablero\", las imágenes se colocan en un estado privado y sin categoría para el creador de la imagen."
|
||||
},
|
||||
"accordions": {
|
||||
"compositing": {
|
||||
@@ -318,5 +323,13 @@
|
||||
"inviteTeammates": "Invitar compañeros de equipo",
|
||||
"shareAccess": "Compartir acceso",
|
||||
"professionalUpsell": "Disponible en la edición profesional de Invoke. Haz clic aquí o visita invoke.com/pricing para obtener más detalles."
|
||||
},
|
||||
"controlLayers": {
|
||||
"layer_one": "Capa",
|
||||
"layer_many": "Capas",
|
||||
"layer_other": "Capas",
|
||||
"layer_withCount_one": "({{count}}) capa",
|
||||
"layer_withCount_many": "({{count}}) capas",
|
||||
"layer_withCount_other": "({{count}}) capas"
|
||||
}
|
||||
}
|
||||
|
||||
@@ -4,8 +4,7 @@
|
||||
"uploadImage": "Lataa kuva",
|
||||
"invokeProgressBar": "Invoken edistymispalkki",
|
||||
"nextImage": "Seuraava kuva",
|
||||
"previousImage": "Edellinen kuva",
|
||||
"showOptionsPanel": "Näytä asetukset"
|
||||
"previousImage": "Edellinen kuva"
|
||||
},
|
||||
"common": {
|
||||
"languagePickerLabel": "Kielen valinta",
|
||||
|
||||
File diff suppressed because it is too large
Load Diff
@@ -65,7 +65,7 @@
|
||||
"blue": "Blu",
|
||||
"alpha": "Alfa",
|
||||
"copy": "Copia",
|
||||
"on": "Attivato",
|
||||
"on": "Acceso",
|
||||
"checkpoint": "Checkpoint",
|
||||
"safetensors": "Safetensors",
|
||||
"ai": "ia",
|
||||
@@ -85,13 +85,14 @@
|
||||
"openInViewer": "Apri nel visualizzatore",
|
||||
"apply": "Applica",
|
||||
"loadingImage": "Caricamento immagine",
|
||||
"off": "Disattivato",
|
||||
"off": "Spento",
|
||||
"edit": "Modifica",
|
||||
"placeholderSelectAModel": "Seleziona un modello",
|
||||
"reset": "Reimposta",
|
||||
"none": "Niente",
|
||||
"new": "Nuovo",
|
||||
"view": "Vista"
|
||||
"view": "Vista",
|
||||
"close": "Chiudi"
|
||||
},
|
||||
"gallery": {
|
||||
"galleryImageSize": "Dimensione dell'immagine",
|
||||
@@ -155,7 +156,11 @@
|
||||
"move": "Sposta",
|
||||
"gallery": "Galleria",
|
||||
"openViewer": "Apri visualizzatore",
|
||||
"closeViewer": "Chiudi visualizzatore"
|
||||
"closeViewer": "Chiudi visualizzatore",
|
||||
"imagesTab": "Immagini create e salvate in Invoke.",
|
||||
"assetsTab": "File che hai caricato per usarli nei tuoi progetti.",
|
||||
"boardsSettings": "Impostazioni Bacheche",
|
||||
"imagesSettings": "Impostazioni Immagini Galleria"
|
||||
},
|
||||
"hotkeys": {
|
||||
"searchHotkeys": "Cerca tasti di scelta rapida",
|
||||
@@ -321,6 +326,22 @@
|
||||
"selectViewTool": {
|
||||
"title": "Strumento Visualizza",
|
||||
"desc": "Seleziona lo strumento Visualizza."
|
||||
},
|
||||
"applyFilter": {
|
||||
"title": "Applica filtro",
|
||||
"desc": "Applica il filtro in sospeso al livello selezionato."
|
||||
},
|
||||
"cancelFilter": {
|
||||
"title": "Annulla filtro",
|
||||
"desc": "Annulla il filtro in sospeso."
|
||||
},
|
||||
"cancelTransform": {
|
||||
"desc": "Annulla la trasformazione in sospeso.",
|
||||
"title": "Annulla Trasforma"
|
||||
},
|
||||
"applyTransform": {
|
||||
"title": "Applica trasformazione",
|
||||
"desc": "Applica la trasformazione in sospeso al livello selezionato."
|
||||
}
|
||||
},
|
||||
"workflows": {
|
||||
@@ -556,7 +577,18 @@
|
||||
"noMatchingModels": "Nessun modello corrispondente",
|
||||
"starterModelsInModelManager": "I modelli iniziali possono essere trovati in Gestione Modelli",
|
||||
"spandrelImageToImage": "Immagine a immagine (Spandrel)",
|
||||
"learnMoreAboutSupportedModels": "Scopri di più sui modelli che supportiamo"
|
||||
"learnMoreAboutSupportedModels": "Scopri di più sui modelli che supportiamo",
|
||||
"starterBundles": "Pacchetti per iniziare",
|
||||
"installingBundle": "Installazione del pacchetto",
|
||||
"skippingXDuplicates_one": ", saltando {{count}} duplicato",
|
||||
"skippingXDuplicates_many": ", saltando {{count}} duplicati",
|
||||
"skippingXDuplicates_other": ", saltando {{count}} duplicati",
|
||||
"installingModel": "Installazione del modello",
|
||||
"installingXModels_one": "Installazione di {{count}} modello",
|
||||
"installingXModels_many": "Installazione di {{count}} modelli",
|
||||
"installingXModels_other": "Installazione di {{count}} modelli",
|
||||
"includesNModels": "Include {{n}} modelli e le loro dipendenze",
|
||||
"starterBundleHelpText": "Installa facilmente tutti i modelli necessari per iniziare con un modello base, tra cui un modello principale, controlnet, adattatori IP e altro. Selezionando un pacchetto salterai tutti i modelli che hai già installato."
|
||||
},
|
||||
"parameters": {
|
||||
"images": "Immagini",
|
||||
@@ -574,8 +606,8 @@
|
||||
"scale": "Scala",
|
||||
"imageFit": "Adatta l'immagine iniziale alle dimensioni di output",
|
||||
"scaleBeforeProcessing": "Scala prima dell'elaborazione",
|
||||
"scaledWidth": "Larghezza ridimensionata",
|
||||
"scaledHeight": "Altezza ridimensionata",
|
||||
"scaledWidth": "Larghezza scalata",
|
||||
"scaledHeight": "Altezza scalata",
|
||||
"infillMethod": "Metodo di riempimento",
|
||||
"tileSize": "Dimensione piastrella",
|
||||
"downloadImage": "Scarica l'immagine",
|
||||
@@ -617,7 +649,11 @@
|
||||
"ipAdapterIncompatibleBaseModel": "Il modello base dell'adattatore IP non è compatibile",
|
||||
"ipAdapterNoImageSelected": "Nessuna immagine dell'adattatore IP selezionata",
|
||||
"rgNoPromptsOrIPAdapters": "Nessun prompt o adattatore IP",
|
||||
"rgNoRegion": "Nessuna regione selezionata"
|
||||
"rgNoRegion": "Nessuna regione selezionata",
|
||||
"t2iAdapterIncompatibleBboxWidth": "$t(parameters.invoke.layer.t2iAdapterRequiresDimensionsToBeMultipleOf) {{multiple}}, larghezza riquadro è {{width}}",
|
||||
"t2iAdapterIncompatibleBboxHeight": "$t(parameters.invoke.layer.t2iAdapterRequiresDimensionsToBeMultipleOf) {{multiple}}, altezza riquadro è {{height}}",
|
||||
"t2iAdapterIncompatibleScaledBboxWidth": "$t(parameters.invoke.layer.t2iAdapterRequiresDimensionsToBeMultipleOf) {{multiple}}, larghezza del riquadro scalato {{width}}",
|
||||
"t2iAdapterIncompatibleScaledBboxHeight": "$t(parameters.invoke.layer.t2iAdapterRequiresDimensionsToBeMultipleOf) {{multiple}}, altezza del riquadro scalato {{height}}"
|
||||
},
|
||||
"fluxModelIncompatibleBboxHeight": "$t(parameters.invoke.fluxRequiresDimensionsToBeMultipleOf16), altezza riquadro è {{height}}",
|
||||
"fluxModelIncompatibleBboxWidth": "$t(parameters.invoke.fluxRequiresDimensionsToBeMultipleOf16), larghezza riquadro è {{width}}",
|
||||
@@ -625,7 +661,11 @@
|
||||
"fluxModelIncompatibleScaledBboxHeight": "$t(parameters.invoke.fluxRequiresDimensionsToBeMultipleOf16), altezza del riquadro scalato è {{height}}",
|
||||
"noT5EncoderModelSelected": "Nessun modello di encoder T5 selezionato per la generazione con FLUX",
|
||||
"noCLIPEmbedModelSelected": "Nessun modello CLIP Embed selezionato per la generazione con FLUX",
|
||||
"noFLUXVAEModelSelected": "Nessun modello VAE selezionato per la generazione con FLUX"
|
||||
"noFLUXVAEModelSelected": "Nessun modello VAE selezionato per la generazione con FLUX",
|
||||
"canvasIsTransforming": "La tela sta trasformando",
|
||||
"canvasIsRasterizing": "La tela sta rasterizzando",
|
||||
"canvasIsCompositing": "La tela è in fase di composizione",
|
||||
"canvasIsFiltering": "La tela sta filtrando"
|
||||
},
|
||||
"useCpuNoise": "Usa la CPU per generare rumore",
|
||||
"iterations": "Iterazioni",
|
||||
@@ -644,7 +684,12 @@
|
||||
"processImage": "Elabora Immagine",
|
||||
"sendToUpscale": "Invia a Amplia",
|
||||
"postProcessing": "Post-elaborazione (Shift + U)",
|
||||
"guidance": "Guida"
|
||||
"guidance": "Guida",
|
||||
"gaussianBlur": "Sfocatura Gaussiana",
|
||||
"boxBlur": "Sfocatura Box",
|
||||
"staged": "Maschera espansa",
|
||||
"optimizedImageToImage": "Immagine-a-immagine ottimizzata",
|
||||
"sendToCanvas": "Invia alla Tela"
|
||||
},
|
||||
"settings": {
|
||||
"models": "Modelli",
|
||||
@@ -678,7 +723,8 @@
|
||||
"enableInformationalPopovers": "Abilita testo informativo a comparsa",
|
||||
"reloadingIn": "Ricaricando in",
|
||||
"informationalPopoversDisabled": "Testo informativo a comparsa disabilitato",
|
||||
"informationalPopoversDisabledDesc": "I testi informativi a comparsa sono disabilitati. Attivali nelle impostazioni."
|
||||
"informationalPopoversDisabledDesc": "I testi informativi a comparsa sono disabilitati. Attivali nelle impostazioni.",
|
||||
"confirmOnNewSession": "Conferma su nuova sessione"
|
||||
},
|
||||
"toast": {
|
||||
"uploadFailed": "Caricamento fallito",
|
||||
@@ -687,7 +733,7 @@
|
||||
"serverError": "Errore del Server",
|
||||
"connected": "Connesso al server",
|
||||
"canceled": "Elaborazione annullata",
|
||||
"uploadFailedInvalidUploadDesc": "Deve essere una singola immagine PNG o JPEG",
|
||||
"uploadFailedInvalidUploadDesc": "Devono essere immagini PNG o JPEG.",
|
||||
"parameterSet": "Parametro richiamato",
|
||||
"parameterNotSet": "Parametro non richiamato",
|
||||
"problemCopyingImage": "Impossibile copiare l'immagine",
|
||||
@@ -696,7 +742,7 @@
|
||||
"baseModelChangedCleared_other": "Cancellati o disabilitati {{count}} sottomodelli incompatibili",
|
||||
"loadedWithWarnings": "Flusso di lavoro caricato con avvisi",
|
||||
"imageUploaded": "Immagine caricata",
|
||||
"addedToBoard": "Aggiunto alla bacheca",
|
||||
"addedToBoard": "Aggiunto alle risorse della bacheca {{name}}",
|
||||
"modelAddedSimple": "Modello aggiunto alla Coda",
|
||||
"imageUploadFailed": "Caricamento immagine non riuscito",
|
||||
"setControlImage": "Imposta come immagine di controllo",
|
||||
@@ -721,7 +767,26 @@
|
||||
"somethingWentWrong": "Qualcosa è andato storto",
|
||||
"outOfMemoryErrorDesc": "Le impostazioni della generazione attuale superano la capacità del sistema. Modifica le impostazioni e riprova.",
|
||||
"importFailed": "Importazione non riuscita",
|
||||
"importSuccessful": "Importazione riuscita"
|
||||
"importSuccessful": "Importazione riuscita",
|
||||
"layerSavedToAssets": "Livello salvato nelle risorse",
|
||||
"problemSavingLayer": "Impossibile salvare il livello",
|
||||
"unableToLoadImage": "Impossibile caricare l'immagine",
|
||||
"problemCopyingLayer": "Impossibile copiare il livello",
|
||||
"sentToCanvas": "Inviato alla Tela",
|
||||
"sentToUpscale": "Inviato a Amplia",
|
||||
"unableToLoadStylePreset": "Impossibile caricare lo stile predefinito",
|
||||
"stylePresetLoaded": "Stile predefinito caricato",
|
||||
"unableToLoadImageMetadata": "Impossibile caricare i metadati dell'immagine",
|
||||
"imageSaved": "Immagine salvata",
|
||||
"imageSavingFailed": "Salvataggio dell'immagine non riuscito",
|
||||
"layerCopiedToClipboard": "Livello copiato negli appunti",
|
||||
"imageNotLoadedDesc": "Impossibile trovare l'immagine",
|
||||
"linkCopied": "Collegamento copiato",
|
||||
"addedToUncategorized": "Aggiunto alle risorse della bacheca $t(boards.uncategorized)",
|
||||
"imagesWillBeAddedTo": "Le immagini caricate verranno aggiunte alle risorse della bacheca {{boardName}}.",
|
||||
"uploadFailedInvalidUploadDesc_withCount_one": "Devi caricare al massimo 1 immagine PNG o JPEG.",
|
||||
"uploadFailedInvalidUploadDesc_withCount_many": "Devi caricare al massimo {{count}} immagini PNG o JPEG.",
|
||||
"uploadFailedInvalidUploadDesc_withCount_other": "Devi caricare al massimo {{count}} immagini PNG o JPEG."
|
||||
},
|
||||
"accessibility": {
|
||||
"invokeProgressBar": "Barra di avanzamento generazione",
|
||||
@@ -729,14 +794,15 @@
|
||||
"previousImage": "Immagine precedente",
|
||||
"nextImage": "Immagine successiva",
|
||||
"reset": "Reimposta",
|
||||
"showOptionsPanel": "Mostra il pannello laterale",
|
||||
"menu": "Menu",
|
||||
"showGalleryPanel": "Mostra il pannello Galleria",
|
||||
"mode": "Modalità",
|
||||
"resetUI": "$t(accessibility.reset) l'Interfaccia Utente",
|
||||
"createIssue": "Segnala un problema",
|
||||
"about": "Informazioni",
|
||||
"submitSupportTicket": "Invia ticket di supporto"
|
||||
"submitSupportTicket": "Invia ticket di supporto",
|
||||
"toggleLeftPanel": "Attiva/disattiva il pannello sinistro (T)",
|
||||
"toggleRightPanel": "Attiva/disattiva il pannello destro (G)",
|
||||
"uploadImages": "Carica immagine(i)"
|
||||
},
|
||||
"nodes": {
|
||||
"zoomOutNodes": "Rimpicciolire",
|
||||
@@ -856,7 +922,7 @@
|
||||
"clearWorkflowDesc": "Cancellare questo flusso di lavoro e avviarne uno nuovo?",
|
||||
"clearWorkflow": "Cancella il flusso di lavoro",
|
||||
"clearWorkflowDesc2": "Il tuo flusso di lavoro attuale presenta modifiche non salvate.",
|
||||
"viewMode": "Utilizzare nella vista lineare",
|
||||
"viewMode": "Usa la vista lineare",
|
||||
"reorderLinearView": "Riordina la vista lineare",
|
||||
"editMode": "Modifica nell'editor del flusso di lavoro",
|
||||
"resetToDefaultValue": "Ripristina il valore predefinito",
|
||||
@@ -874,7 +940,10 @@
|
||||
"imageAccessError": "Impossibile trovare l'immagine {{image_name}}, ripristino ai valori predefiniti",
|
||||
"boardAccessError": "Impossibile trovare la bacheca {{board_id}}, ripristino ai valori predefiniti",
|
||||
"modelAccessError": "Impossibile trovare il modello {{key}}, ripristino ai valori predefiniti",
|
||||
"saveToGallery": "Salva nella Galleria"
|
||||
"saveToGallery": "Salva nella Galleria",
|
||||
"noMatchingWorkflows": "Nessun flusso di lavoro corrispondente",
|
||||
"noWorkflows": "Nessun flusso di lavoro",
|
||||
"workflowHelpText": "Hai bisogno di aiuto? Consulta la nostra guida <LinkComponent>Introduzione ai flussi di lavoro</LinkComponent>."
|
||||
},
|
||||
"boards": {
|
||||
"autoAddBoard": "Aggiungi automaticamente bacheca",
|
||||
@@ -918,7 +987,8 @@
|
||||
"noBoards": "Nessuna bacheca {{boardType}}",
|
||||
"hideBoards": "Nascondi bacheche",
|
||||
"viewBoards": "Visualizza bacheche",
|
||||
"deletedPrivateBoardsCannotbeRestored": "Le bacheche cancellate non possono essere ripristinate. Selezionando 'Cancella solo bacheca', le immagini verranno spostate nella bacheca \"Non categorizzato\" privata dell'autore dell'immagine."
|
||||
"deletedPrivateBoardsCannotbeRestored": "Le bacheche cancellate non possono essere ripristinate. Selezionando 'Cancella solo bacheca', le immagini verranno spostate nella bacheca \"Non categorizzato\" privata dell'autore dell'immagine.",
|
||||
"updateBoardError": "Errore durante l'aggiornamento della bacheca"
|
||||
},
|
||||
"queue": {
|
||||
"queueFront": "Aggiungi all'inizio della coda",
|
||||
@@ -1403,6 +1473,25 @@
|
||||
"paragraphs": [
|
||||
"La struttura determina quanto l'immagine finale rispecchierà il layout dell'originale. Una struttura bassa permette cambiamenti significativi, mentre una struttura alta conserva la composizione e il layout originali."
|
||||
]
|
||||
},
|
||||
"fluxDevLicense": {
|
||||
"heading": "Licenza non commerciale",
|
||||
"paragraphs": [
|
||||
"I modelli FLUX.1 [dev] sono concessi in licenza con la licenza non commerciale FLUX [dev]. Per utilizzare questo tipo di modello per scopi commerciali in Invoke, visita il nostro sito Web per saperne di più."
|
||||
]
|
||||
},
|
||||
"optimizedDenoising": {
|
||||
"heading": "Immagine-a-immagine ottimizzata",
|
||||
"paragraphs": [
|
||||
"Abilita 'Immagine-a-immagine ottimizzata' per una scala di riduzione del rumore più graduale per le trasformazioni da immagine a immagine e di inpainting con modelli Flux. Questa impostazione migliora la capacità di controllare la quantità di modifica applicata a un'immagine, ma può essere disattivata se preferisci usare la scala di riduzione rumore standard. Questa impostazione è ancora in fase di messa a punto ed è in stato beta."
|
||||
]
|
||||
},
|
||||
"paramGuidance": {
|
||||
"heading": "Guida",
|
||||
"paragraphs": [
|
||||
"Controlla quanto il prompt influenza il processo di generazione.",
|
||||
"Valori di guida elevati possono causare sovrasaturazione e una guida elevata o bassa può causare risultati di generazione distorti. La guida si applica solo ai modelli FLUX DEV."
|
||||
]
|
||||
}
|
||||
},
|
||||
"sdxl": {
|
||||
@@ -1451,7 +1540,8 @@
|
||||
"parameterSet": "Parametro {{parameter}} impostato",
|
||||
"parsingFailed": "Analisi non riuscita",
|
||||
"recallParameter": "Richiama {{label}}",
|
||||
"canvasV2Metadata": "Tela"
|
||||
"canvasV2Metadata": "Tela",
|
||||
"guidance": "Guida"
|
||||
},
|
||||
"hrf": {
|
||||
"enableHrf": "Abilita Correzione Alta Risoluzione",
|
||||
@@ -1496,7 +1586,18 @@
|
||||
"convertGraph": "Converti grafico",
|
||||
"loadWorkflow": "$t(common.load) Flusso di lavoro",
|
||||
"autoLayout": "Disposizione automatica",
|
||||
"loadFromGraph": "Carica il flusso di lavoro dal grafico"
|
||||
"loadFromGraph": "Carica il flusso di lavoro dal grafico",
|
||||
"userWorkflows": "Flussi di lavoro utente",
|
||||
"projectWorkflows": "Flussi di lavoro del progetto",
|
||||
"defaultWorkflows": "Flussi di lavoro predefiniti",
|
||||
"uploadAndSaveWorkflow": "Carica nella libreria",
|
||||
"chooseWorkflowFromLibrary": "Scegli il flusso di lavoro dalla libreria",
|
||||
"deleteWorkflow2": "Vuoi davvero eliminare questo flusso di lavoro? Questa operazione non può essere annullata.",
|
||||
"edit": "Modifica",
|
||||
"download": "Scarica",
|
||||
"copyShareLink": "Copia Condividi Link",
|
||||
"copyShareLinkForWorkflow": "Copia Condividi Link del Flusso di lavoro",
|
||||
"delete": "Elimina"
|
||||
},
|
||||
"accordions": {
|
||||
"compositing": {
|
||||
@@ -1535,7 +1636,308 @@
|
||||
"addPositivePrompt": "Aggiungi $t(controlLayers.prompt)",
|
||||
"addNegativePrompt": "Aggiungi $t(controlLayers.negativePrompt)",
|
||||
"regionalGuidance": "Guida regionale",
|
||||
"opacity": "Opacità"
|
||||
"opacity": "Opacità",
|
||||
"mergeVisible": "Fondi il visibile",
|
||||
"mergeVisibleOk": "Livelli visibili uniti",
|
||||
"deleteReferenceImage": "Elimina l'immagine di riferimento",
|
||||
"referenceImage": "Immagine di riferimento",
|
||||
"fitBboxToLayers": "Adatta il riquadro di delimitazione ai livelli",
|
||||
"mergeVisibleError": "Errore durante l'unione dei livelli visibili",
|
||||
"regionalReferenceImage": "Immagine di riferimento Regionale",
|
||||
"newLayerFromImage": "Nuovo livello da immagine",
|
||||
"newCanvasFromImage": "Nuova tela da immagine",
|
||||
"globalReferenceImage": "Immagine di riferimento Globale",
|
||||
"copyToClipboard": "Copia negli appunti",
|
||||
"sendingToCanvas": "Effettua le generazioni nella Tela",
|
||||
"clearHistory": "Cancella la cronologia",
|
||||
"inpaintMask": "Maschera Inpaint",
|
||||
"sendToGallery": "Invia alla Galleria",
|
||||
"controlLayer": "Livello di Controllo",
|
||||
"rasterLayer_withCount_one": "$t(controlLayers.rasterLayer)",
|
||||
"rasterLayer_withCount_many": "Livelli Raster",
|
||||
"rasterLayer_withCount_other": "Livelli Raster",
|
||||
"controlLayer_withCount_one": "$t(controlLayers.controlLayer)",
|
||||
"controlLayer_withCount_many": "Livelli di controllo",
|
||||
"controlLayer_withCount_other": "Livelli di controllo",
|
||||
"clipToBbox": "Ritaglia i tratti al riquadro",
|
||||
"duplicate": "Duplica",
|
||||
"width": "Larghezza",
|
||||
"addControlLayer": "Aggiungi $t(controlLayers.controlLayer)",
|
||||
"addInpaintMask": "Aggiungi $t(controlLayers.inpaintMask)",
|
||||
"addRegionalGuidance": "Aggiungi $t(controlLayers.regionalGuidance)",
|
||||
"sendToCanvasDesc": "Premendo Invoke il lavoro in corso viene visualizzato sulla tela.",
|
||||
"addRasterLayer": "Aggiungi $t(controlLayers.rasterLayer)",
|
||||
"clearCaches": "Svuota le cache",
|
||||
"regionIsEmpty": "La regione selezionata è vuota",
|
||||
"recalculateRects": "Ricalcola rettangoli",
|
||||
"removeBookmark": "Rimuovi segnalibro",
|
||||
"saveCanvasToGallery": "Salva la tela nella Galleria",
|
||||
"regional": "Regionale",
|
||||
"global": "Globale",
|
||||
"canvas": "Tela",
|
||||
"bookmark": "Segnalibro per cambio rapido",
|
||||
"newRegionalReferenceImageOk": "Immagine di riferimento regionale creata",
|
||||
"newRegionalReferenceImageError": "Problema nella creazione dell'immagine di riferimento regionale",
|
||||
"newControlLayerOk": "Livello di controllo creato",
|
||||
"bboxOverlay": "Mostra sovrapposizione riquadro",
|
||||
"resetCanvas": "Reimposta la tela",
|
||||
"outputOnlyMaskedRegions": "Solo regioni mascherate in uscita",
|
||||
"enableAutoNegative": "Abilita Auto Negativo",
|
||||
"disableAutoNegative": "Disabilita Auto Negativo",
|
||||
"showHUD": "Mostra HUD",
|
||||
"maskFill": "Riempimento maschera",
|
||||
"addReferenceImage": "Aggiungi $t(controlLayers.referenceImage)",
|
||||
"addGlobalReferenceImage": "Aggiungi $t(controlLayers.globalReferenceImage)",
|
||||
"sendingToGallery": "Inviare generazioni alla Galleria",
|
||||
"sendToGalleryDesc": "Premendo Invoke viene generata e salvata un'immagine unica nella tua galleria.",
|
||||
"sendToCanvas": "Invia alla Tela",
|
||||
"viewProgressInViewer": "Visualizza i progressi e i risultati nel <Btn>Visualizzatore immagini</Btn>.",
|
||||
"viewProgressOnCanvas": "Visualizza i progressi e i risultati nella <Btn>Tela</Btn>.",
|
||||
"saveBboxToGallery": "Salva il riquadro di delimitazione nella Galleria",
|
||||
"cropLayerToBbox": "Ritaglia il livello al riquadro di delimitazione",
|
||||
"savedToGalleryError": "Errore durante il salvataggio nella galleria",
|
||||
"rasterLayer": "Livello Raster",
|
||||
"regionalGuidance_withCount_one": "$t(controlLayers.regionalGuidance)",
|
||||
"regionalGuidance_withCount_many": "Guide regionali",
|
||||
"regionalGuidance_withCount_other": "Guide regionali",
|
||||
"inpaintMask_withCount_one": "$t(controlLayers.inpaintMask)",
|
||||
"inpaintMask_withCount_many": "Maschere Inpaint",
|
||||
"inpaintMask_withCount_other": "Maschere Inpaint",
|
||||
"savedToGalleryOk": "Salvato nella Galleria",
|
||||
"newGlobalReferenceImageOk": "Immagine di riferimento globale creata",
|
||||
"newGlobalReferenceImageError": "Problema nella creazione dell'immagine di riferimento globale",
|
||||
"newControlLayerError": "Problema nella creazione del livello di controllo",
|
||||
"newRasterLayerOk": "Livello raster creato",
|
||||
"newRasterLayerError": "Problema nella creazione del livello raster",
|
||||
"saveLayerToAssets": "Salva il livello nelle Risorse",
|
||||
"pullBboxIntoLayerError": "Problema nel caricare il riquadro nel livello",
|
||||
"pullBboxIntoReferenceImageOk": "Contenuto del riquadro inserito nell'immagine di riferimento",
|
||||
"pullBboxIntoLayerOk": "Riquadro caricato nel livello",
|
||||
"pullBboxIntoReferenceImageError": "Problema nell'inserimento del contenuto del riquadro nell'immagine di riferimento",
|
||||
"globalReferenceImage_withCount_one": "$t(controlLayers.globalReferenceImage)",
|
||||
"globalReferenceImage_withCount_many": "Immagini di riferimento Globali",
|
||||
"globalReferenceImage_withCount_other": "Immagini di riferimento Globali",
|
||||
"controlMode": {
|
||||
"balanced": "Bilanciato",
|
||||
"controlMode": "Modalità di controllo",
|
||||
"prompt": "Prompt",
|
||||
"control": "Controllo",
|
||||
"megaControl": "Mega Controllo"
|
||||
},
|
||||
"negativePrompt": "Prompt Negativo",
|
||||
"prompt": "Prompt Positivo",
|
||||
"beginEndStepPercentShort": "Inizio/Fine %",
|
||||
"stagingOnCanvas": "Genera immagini nella",
|
||||
"ipAdapterMethod": {
|
||||
"full": "Completo",
|
||||
"style": "Solo Stile",
|
||||
"composition": "Solo Composizione",
|
||||
"ipAdapterMethod": "Metodo Adattatore IP"
|
||||
},
|
||||
"showingType": "Mostrare {{type}}",
|
||||
"dynamicGrid": "Griglia dinamica",
|
||||
"tool": {
|
||||
"view": "Muovi",
|
||||
"colorPicker": "Selettore Colore",
|
||||
"rectangle": "Rettangolo",
|
||||
"bbox": "Riquadro di delimitazione",
|
||||
"move": "Sposta",
|
||||
"brush": "Pennello",
|
||||
"eraser": "Cancellino"
|
||||
},
|
||||
"filter": {
|
||||
"apply": "Applica",
|
||||
"reset": "Reimposta",
|
||||
"process": "Elabora",
|
||||
"cancel": "Annulla",
|
||||
"autoProcess": "Processo automatico",
|
||||
"filterType": "Tipo Filtro",
|
||||
"filter": "Filtro",
|
||||
"filters": "Filtri",
|
||||
"mlsd_detection": {
|
||||
"score_threshold": "Soglia di punteggio",
|
||||
"distance_threshold": "Soglia di distanza",
|
||||
"description": "Genera una mappa dei segmenti di linea dal livello selezionato utilizzando il modello di rilevamento dei segmenti di linea MLSD.",
|
||||
"label": "Rilevamento segmenti di linea"
|
||||
},
|
||||
"content_shuffle": {
|
||||
"label": "Mescola contenuto",
|
||||
"scale_factor": "Fattore di scala",
|
||||
"description": "Mescola il contenuto del livello selezionato, in modo simile all'effetto \"liquefa\"."
|
||||
},
|
||||
"mediapipe_face_detection": {
|
||||
"min_confidence": "Confidenza minima",
|
||||
"label": "Rilevamento del volto MediaPipe",
|
||||
"max_faces": "Max volti",
|
||||
"description": "Rileva i volti nel livello selezionato utilizzando il modello di rilevamento dei volti MediaPipe."
|
||||
},
|
||||
"dw_openpose_detection": {
|
||||
"draw_face": "Disegna il volto",
|
||||
"description": "Rileva le pose umane nel livello selezionato utilizzando il modello DW Openpose.",
|
||||
"label": "Rilevamento DW Openpose",
|
||||
"draw_hands": "Disegna le mani",
|
||||
"draw_body": "Disegna il corpo"
|
||||
},
|
||||
"normal_map": {
|
||||
"description": "Genera una mappa delle normali dal livello selezionato.",
|
||||
"label": "Mappa delle normali"
|
||||
},
|
||||
"lineart_edge_detection": {
|
||||
"label": "Rilevamento bordi Lineart",
|
||||
"coarse": "Grossolano",
|
||||
"description": "Genera una mappa dei bordi dal livello selezionato utilizzando il modello di rilevamento dei bordi Lineart."
|
||||
},
|
||||
"depth_anything_depth_estimation": {
|
||||
"model_size_small": "Piccolo",
|
||||
"model_size_small_v2": "Piccolo v2",
|
||||
"model_size": "Dimensioni modello",
|
||||
"model_size_large": "Grande",
|
||||
"model_size_base": "Base",
|
||||
"description": "Genera una mappa di profondità dal livello selezionato utilizzando un modello Depth Anything."
|
||||
},
|
||||
"color_map": {
|
||||
"label": "Mappa colore",
|
||||
"description": "Crea una mappa dei colori dal livello selezionato.",
|
||||
"tile_size": "Dimens. Piastrella"
|
||||
},
|
||||
"canny_edge_detection": {
|
||||
"high_threshold": "Soglia superiore",
|
||||
"low_threshold": "Soglia inferiore",
|
||||
"description": "Genera una mappa dei bordi dal livello selezionato utilizzando l'algoritmo di rilevamento dei bordi Canny.",
|
||||
"label": "Rilevamento bordi Canny"
|
||||
},
|
||||
"spandrel_filter": {
|
||||
"scale": "Scala di destinazione",
|
||||
"autoScaleDesc": "Il modello selezionato verrà eseguito fino al raggiungimento della scala di destinazione.",
|
||||
"description": "Esegue un modello immagine-a-immagine sul livello selezionato.",
|
||||
"label": "Modello Immagine-a-Immagine",
|
||||
"model": "Modello",
|
||||
"autoScale": "Auto Scala"
|
||||
},
|
||||
"pidi_edge_detection": {
|
||||
"quantize_edges": "Quantizza i bordi",
|
||||
"scribble": "Scarabocchio",
|
||||
"description": "Genera una mappa dei bordi dal livello selezionato utilizzando il modello di rilevamento dei bordi PiDiNet.",
|
||||
"label": "Rilevamento bordi PiDiNet"
|
||||
},
|
||||
"hed_edge_detection": {
|
||||
"label": "Rilevamento bordi HED",
|
||||
"description": "Genera una mappa dei bordi dal livello selezionato utilizzando il modello di rilevamento dei bordi HED.",
|
||||
"scribble": "Scarabocchio"
|
||||
},
|
||||
"lineart_anime_edge_detection": {
|
||||
"description": "Genera una mappa dei bordi dal livello selezionato utilizzando il modello di rilevamento dei bordi Lineart Anime.",
|
||||
"label": "Rilevamento bordi Lineart Anime"
|
||||
}
|
||||
},
|
||||
"controlLayers_withCount_hidden": "Livelli di controllo ({{count}} nascosti)",
|
||||
"regionalGuidance_withCount_hidden": "Guida regionale ({{count}} nascosti)",
|
||||
"fill": {
|
||||
"grid": "Griglia",
|
||||
"crosshatch": "Tratteggio incrociato",
|
||||
"fillColor": "Colore di riempimento",
|
||||
"fillStyle": "Stile riempimento",
|
||||
"solid": "Solido",
|
||||
"vertical": "Verticale",
|
||||
"horizontal": "Orizzontale",
|
||||
"diagonal": "Diagonale"
|
||||
},
|
||||
"rasterLayers_withCount_hidden": "Livelli raster ({{count}} nascosti)",
|
||||
"inpaintMasks_withCount_hidden": "Maschere Inpaint ({{count}} nascoste)",
|
||||
"regionalGuidance_withCount_visible": "Guide regionali ({{count}})",
|
||||
"locked": "Bloccato",
|
||||
"hidingType": "Nascondere {{type}}",
|
||||
"logDebugInfo": "Registro Info Debug",
|
||||
"inpaintMasks_withCount_visible": "Maschere Inpaint ({{count}})",
|
||||
"layer_one": "Livello",
|
||||
"layer_many": "Livelli",
|
||||
"layer_other": "Livelli",
|
||||
"disableTransparencyEffect": "Disabilita l'effetto trasparenza",
|
||||
"controlLayers_withCount_visible": "Livelli di controllo ({{count}})",
|
||||
"transparency": "Trasparenza",
|
||||
"newCanvasSessionDesc": "Questo cancellerà la tela e tutte le impostazioni, eccetto la selezione del modello. Le generazioni saranno effettuate sulla tela.",
|
||||
"rasterLayers_withCount_visible": "Livelli raster ({{count}})",
|
||||
"globalReferenceImages_withCount_visible": "Immagini di riferimento Globali ({{count}})",
|
||||
"globalReferenceImages_withCount_hidden": "Immagini di riferimento globali ({{count}} nascoste)",
|
||||
"layer_withCount_one": "Livello ({{count}})",
|
||||
"layer_withCount_many": "Livelli ({{count}})",
|
||||
"layer_withCount_other": "Livelli ({{count}})",
|
||||
"convertToControlLayer": "Converti in livello di controllo",
|
||||
"convertToRasterLayer": "Converti in livello raster",
|
||||
"unlocked": "Sbloccato",
|
||||
"enableTransparencyEffect": "Abilita l'effetto trasparenza",
|
||||
"replaceLayer": "Sostituisci livello",
|
||||
"pullBboxIntoLayer": "Carica l'immagine delimitata nel riquadro",
|
||||
"pullBboxIntoReferenceImage": "Carica l'immagine delimitata nel riquadro",
|
||||
"showProgressOnCanvas": "Mostra i progressi sulla Tela",
|
||||
"weight": "Peso",
|
||||
"newGallerySession": "Nuova sessione Galleria",
|
||||
"newGallerySessionDesc": "Questo cancellerà la tela e tutte le impostazioni, eccetto la selezione del modello. Le generazioni saranno inviate alla galleria.",
|
||||
"newCanvasSession": "Nuova sessione Tela",
|
||||
"deleteSelected": "Elimina selezione",
|
||||
"settings": {
|
||||
"isolatedFilteringPreview": "Anteprima del filtraggio isolata",
|
||||
"isolatedStagingPreview": "Anteprima di generazione isolata",
|
||||
"isolatedTransformingPreview": "Anteprima di trasformazione isolata",
|
||||
"isolatedPreview": "Anteprima isolata",
|
||||
"invertBrushSizeScrollDirection": "Inverti scorrimento per dimensione pennello",
|
||||
"snapToGrid": {
|
||||
"label": "Aggancia alla griglia",
|
||||
"on": "Acceso",
|
||||
"off": "Spento"
|
||||
},
|
||||
"pressureSensitivity": "Sensibilità alla pressione",
|
||||
"preserveMask": {
|
||||
"alert": "Preservare la regione mascherata",
|
||||
"label": "Preserva la regione mascherata"
|
||||
}
|
||||
},
|
||||
"transform": {
|
||||
"reset": "Reimposta",
|
||||
"fitToBbox": "Adatta al Riquadro",
|
||||
"transform": "Trasforma",
|
||||
"apply": "Applica",
|
||||
"cancel": "Annulla",
|
||||
"fitMode": "Adattamento",
|
||||
"fitModeContain": "Contieni",
|
||||
"fitModeFill": "Riempi",
|
||||
"fitModeCover": "Copri"
|
||||
},
|
||||
"stagingArea": {
|
||||
"next": "Successiva",
|
||||
"discard": "Scarta",
|
||||
"discardAll": "Scarta tutto",
|
||||
"accept": "Accetta",
|
||||
"saveToGallery": "Salva nella Galleria",
|
||||
"previous": "Precedente",
|
||||
"showResultsOn": "Risultati visualizzati",
|
||||
"showResultsOff": "Risultati nascosti"
|
||||
},
|
||||
"HUD": {
|
||||
"bbox": "Riquadro di delimitazione",
|
||||
"entityStatus": {
|
||||
"isHidden": "{{title}} è nascosto",
|
||||
"isLocked": "{{title}} è bloccato",
|
||||
"isTransforming": "{{title}} sta trasformando",
|
||||
"isFiltering": "{{title}} sta filtrando",
|
||||
"isEmpty": "{{title}} è vuoto",
|
||||
"isDisabled": "{{title}} è disabilitato"
|
||||
},
|
||||
"scaledBbox": "Riquadro scalato"
|
||||
},
|
||||
"canvasContextMenu": {
|
||||
"newControlLayer": "Nuovo Livello di Controllo",
|
||||
"newRegionalReferenceImage": "Nuova immagine di riferimento Regionale",
|
||||
"newGlobalReferenceImage": "Nuova immagine di riferimento Globale",
|
||||
"bboxGroup": "Crea dal riquadro di delimitazione",
|
||||
"saveBboxToGallery": "Salva il riquadro nella Galleria",
|
||||
"cropCanvasToBbox": "Ritaglia la Tela al riquadro",
|
||||
"canvasGroup": "Tela",
|
||||
"newRasterLayer": "Nuovo Livello Raster",
|
||||
"saveCanvasToGallery": "Salva la Tela nella Galleria",
|
||||
"saveToGalleryGroup": "Salva nella Galleria"
|
||||
},
|
||||
"newImg2ImgCanvasFromImage": "Nuova Immagine da immagine"
|
||||
},
|
||||
"ui": {
|
||||
"tabs": {
|
||||
@@ -1547,7 +1949,8 @@
|
||||
"modelsTab": "$t(ui.tabs.models) $t(common.tab)",
|
||||
"queue": "Coda",
|
||||
"upscaling": "Amplia",
|
||||
"upscalingTab": "$t(ui.tabs.upscaling) $t(common.tab)"
|
||||
"upscalingTab": "$t(ui.tabs.upscaling) $t(common.tab)",
|
||||
"gallery": "Galleria"
|
||||
}
|
||||
},
|
||||
"upscaling": {
|
||||
@@ -1617,5 +2020,49 @@
|
||||
"noTemplates": "Nessun modello",
|
||||
"acceptedColumnsKeys": "Colonne/chiavi accettate:",
|
||||
"promptTemplateCleared": "Modello di prompt cancellato"
|
||||
},
|
||||
"newUserExperience": {
|
||||
"gettingStartedSeries": "Desideri maggiori informazioni? Consulta la nostra <LinkComponent>Getting Started Series</LinkComponent> per suggerimenti su come sfruttare appieno il potenziale di Invoke Studio.",
|
||||
"toGetStarted": "Per iniziare, inserisci un prompt nella casella e fai clic su <StrongComponent>Invoke</StrongComponent> per generare la tua prima immagine. Seleziona un modello di prompt per migliorare i risultati. Puoi scegliere di salvare le tue immagini direttamente nella <StrongComponent>Galleria</StrongComponent> o modificarle nella <StrongComponent>Tela</StrongComponent>.",
|
||||
"importModels": "Importa modelli",
|
||||
"downloadStarterModels": "Scarica i modelli per iniziare",
|
||||
"noModelsInstalled": "Sembra che tu non abbia installato alcun modello",
|
||||
"toGetStartedLocal": "Per iniziare, assicurati di scaricare o importare i modelli necessari per eseguire Invoke. Quindi, inserisci un prompt nella casella e fai clic su <StrongComponent>Invoke</StrongComponent> per generare la tua prima immagine. Seleziona un modello di prompt per migliorare i risultati. Puoi scegliere di salvare le tue immagini direttamente nella <StrongComponent>Galleria</StrongComponent> o modificarle nella <StrongComponent>Tela</StrongComponent>."
|
||||
},
|
||||
"whatsNew": {
|
||||
"canvasV2Announcement": {
|
||||
"readReleaseNotes": "Leggi le Note di Rilascio",
|
||||
"fluxSupport": "Supporto per la famiglia di modelli Flux",
|
||||
"newCanvas": "Una nuova potente tela di controllo",
|
||||
"watchReleaseVideo": "Guarda il video di rilascio",
|
||||
"watchUiUpdatesOverview": "Guarda le novità dell'interfaccia",
|
||||
"newLayerTypes": "Nuovi tipi di livello per un miglior controllo"
|
||||
},
|
||||
"whatsNewInInvoke": "Novità in Invoke"
|
||||
},
|
||||
"system": {
|
||||
"logLevel": {
|
||||
"info": "Info",
|
||||
"warn": "Avviso",
|
||||
"fatal": "Fatale",
|
||||
"error": "Errore",
|
||||
"debug": "Debug",
|
||||
"trace": "Traccia",
|
||||
"logLevel": "Livello di registro"
|
||||
},
|
||||
"logNamespaces": {
|
||||
"workflows": "Flussi di lavoro",
|
||||
"generation": "Generazione",
|
||||
"canvas": "Tela",
|
||||
"config": "Configurazione",
|
||||
"models": "Modelli",
|
||||
"gallery": "Galleria",
|
||||
"queue": "Coda",
|
||||
"events": "Eventi",
|
||||
"system": "Sistema",
|
||||
"metadata": "Metadati",
|
||||
"logNamespaces": "Elementi del registro"
|
||||
},
|
||||
"enableLogging": "Abilita la registrazione"
|
||||
}
|
||||
}
|
||||
|
||||
@@ -221,8 +221,6 @@
|
||||
"uploadImage": "画像をアップロード",
|
||||
"previousImage": "前の画像",
|
||||
"nextImage": "次の画像",
|
||||
"showOptionsPanel": "サイドパネルを表示",
|
||||
"showGalleryPanel": "ギャラリーパネルを表示",
|
||||
"menu": "メニュー",
|
||||
"createIssue": "問題を報告",
|
||||
"resetUI": "$t(accessibility.reset) UI",
|
||||
|
||||
@@ -92,9 +92,7 @@
|
||||
"mode": "모드",
|
||||
"menu": "메뉴",
|
||||
"uploadImage": "이미지 업로드",
|
||||
"showGalleryPanel": "갤러리 패널 표시",
|
||||
"reset": "리셋",
|
||||
"showOptionsPanel": "사이드 패널 표시"
|
||||
"reset": "리셋"
|
||||
},
|
||||
"modelManager": {
|
||||
"availableModels": "사용 가능한 모델",
|
||||
|
||||
@@ -326,9 +326,7 @@
|
||||
"uploadImage": "Upload afbeelding",
|
||||
"previousImage": "Vorige afbeelding",
|
||||
"nextImage": "Volgende afbeelding",
|
||||
"showOptionsPanel": "Toon zijscherm",
|
||||
"menu": "Menu",
|
||||
"showGalleryPanel": "Toon deelscherm Galerij",
|
||||
"about": "Over",
|
||||
"mode": "Modus",
|
||||
"resetUI": "$t(accessibility.reset) UI",
|
||||
|
||||
@@ -65,7 +65,6 @@
|
||||
"uploadImage": "Wgrywanie obrazu",
|
||||
"previousImage": "Poprzedni obraz",
|
||||
"nextImage": "Następny obraz",
|
||||
"showOptionsPanel": "Pokaż panel opcji",
|
||||
"menu": "Menu"
|
||||
}
|
||||
}
|
||||
|
||||
@@ -104,7 +104,6 @@
|
||||
"invokeProgressBar": "Invocar barra de progresso",
|
||||
"reset": "Reiniciar",
|
||||
"nextImage": "Próxima imagem",
|
||||
"showOptionsPanel": "Mostrar painel de opções",
|
||||
"uploadImage": "Enviar imagem",
|
||||
"previousImage": "Imagem Anterior",
|
||||
"menu": "Menu",
|
||||
@@ -112,8 +111,7 @@
|
||||
"resetUI": "$t(accessibility.reset)UI",
|
||||
"createIssue": "Reportar Problema",
|
||||
"submitSupportTicket": "Submeter um ticket de Suporte",
|
||||
"mode": "Modo",
|
||||
"showGalleryPanel": "Mostrar Painel de Galeria"
|
||||
"mode": "Modo"
|
||||
},
|
||||
"boards": {
|
||||
"selectedForAutoAdd": "Selecionado para Auto-Adicionar",
|
||||
|
||||
@@ -93,7 +93,9 @@
|
||||
"placeholderSelectAModel": "Выбрать модель",
|
||||
"reset": "Сброс",
|
||||
"none": "Ничего",
|
||||
"new": "Новый"
|
||||
"new": "Новый",
|
||||
"ok": "Ok",
|
||||
"close": "Закрыть"
|
||||
},
|
||||
"gallery": {
|
||||
"galleryImageSize": "Размер изображений",
|
||||
@@ -157,7 +159,11 @@
|
||||
"move": "Двигать",
|
||||
"gallery": "Галерея",
|
||||
"openViewer": "Открыть просмотрщик",
|
||||
"closeViewer": "Закрыть просмотрщик"
|
||||
"closeViewer": "Закрыть просмотрщик",
|
||||
"imagesTab": "Изображения, созданные и сохраненные в Invoke.",
|
||||
"assetsTab": "Файлы, которые вы загрузили для использования в своих проектах.",
|
||||
"boardsSettings": "Настройки доски",
|
||||
"imagesSettings": "Настройки галереи изображений"
|
||||
},
|
||||
"hotkeys": {
|
||||
"searchHotkeys": "Поиск горячих клавиш",
|
||||
@@ -227,6 +233,118 @@
|
||||
"selectBrushTool": {
|
||||
"title": "Инструмент кисть",
|
||||
"desc": "Выбирает кисть."
|
||||
},
|
||||
"selectBboxTool": {
|
||||
"title": "Инструмент рамка",
|
||||
"desc": "Выбрать инструмент «Ограничительная рамка»."
|
||||
},
|
||||
"incrementToolWidth": {
|
||||
"desc": "Increment the brush or eraser tool width, whichever is selected.",
|
||||
"title": "Increment Tool Width"
|
||||
},
|
||||
"selectColorPickerTool": {
|
||||
"title": "Color Picker Tool",
|
||||
"desc": "Select the color picker tool."
|
||||
},
|
||||
"prevEntity": {
|
||||
"title": "Prev Layer",
|
||||
"desc": "Select the previous layer in the list."
|
||||
},
|
||||
"filterSelected": {
|
||||
"title": "Filter",
|
||||
"desc": "Filter the selected layer. Only applies to Raster and Control layers."
|
||||
},
|
||||
"undo": {
|
||||
"desc": "Отменяет последнее действие на холсте.",
|
||||
"title": "Отменить"
|
||||
},
|
||||
"transformSelected": {
|
||||
"title": "Transform",
|
||||
"desc": "Transform the selected layer."
|
||||
},
|
||||
"setZoomTo400Percent": {
|
||||
"title": "Zoom to 400%",
|
||||
"desc": "Set the canvas zoom to 400%."
|
||||
},
|
||||
"setZoomTo200Percent": {
|
||||
"title": "Zoom to 200%",
|
||||
"desc": "Set the canvas zoom to 200%."
|
||||
},
|
||||
"deleteSelected": {
|
||||
"desc": "Delete the selected layer.",
|
||||
"title": "Delete Layer"
|
||||
},
|
||||
"resetSelected": {
|
||||
"title": "Reset Layer",
|
||||
"desc": "Reset the selected layer. Only applies to Inpaint Mask and Regional Guidance."
|
||||
},
|
||||
"redo": {
|
||||
"desc": "Возвращает последнее отмененное действие.",
|
||||
"title": "Вернуть"
|
||||
},
|
||||
"nextEntity": {
|
||||
"title": "Next Layer",
|
||||
"desc": "Select the next layer in the list."
|
||||
},
|
||||
"setFillToWhite": {
|
||||
"title": "Set Color to White",
|
||||
"desc": "Set the current tool color to white."
|
||||
},
|
||||
"applyFilter": {
|
||||
"title": "Apply Filter",
|
||||
"desc": "Apply the pending filter to the selected layer."
|
||||
},
|
||||
"cancelFilter": {
|
||||
"title": "Cancel Filter",
|
||||
"desc": "Cancel the pending filter."
|
||||
},
|
||||
"applyTransform": {
|
||||
"desc": "Apply the pending transform to the selected layer.",
|
||||
"title": "Apply Transform"
|
||||
},
|
||||
"cancelTransform": {
|
||||
"title": "Cancel Transform",
|
||||
"desc": "Cancel the pending transform."
|
||||
},
|
||||
"selectEraserTool": {
|
||||
"title": "Eraser Tool",
|
||||
"desc": "Select the eraser tool."
|
||||
},
|
||||
"fitLayersToCanvas": {
|
||||
"desc": "Scale and position the view to fit all visible layers.",
|
||||
"title": "Fit Layers to Canvas"
|
||||
},
|
||||
"decrementToolWidth": {
|
||||
"title": "Decrement Tool Width",
|
||||
"desc": "Decrement the brush or eraser tool width, whichever is selected."
|
||||
},
|
||||
"setZoomTo800Percent": {
|
||||
"title": "Zoom to 800%",
|
||||
"desc": "Set the canvas zoom to 800%."
|
||||
},
|
||||
"quickSwitch": {
|
||||
"title": "Layer Quick Switch",
|
||||
"desc": "Switch between the last two selected layers. If a layer is bookmarked, always switch between it and the last non-bookmarked layer."
|
||||
},
|
||||
"fitBboxToCanvas": {
|
||||
"title": "Fit Bbox to Canvas",
|
||||
"desc": "Scale and position the view to fit the bbox."
|
||||
},
|
||||
"setZoomTo100Percent": {
|
||||
"title": "Zoom to 100%",
|
||||
"desc": "Set the canvas zoom to 100%."
|
||||
},
|
||||
"selectMoveTool": {
|
||||
"desc": "Select the move tool.",
|
||||
"title": "Move Tool"
|
||||
},
|
||||
"selectRectTool": {
|
||||
"title": "Rect Tool",
|
||||
"desc": "Select the rect tool."
|
||||
},
|
||||
"selectViewTool": {
|
||||
"title": "View Tool",
|
||||
"desc": "Select the view tool."
|
||||
}
|
||||
},
|
||||
"hotkeys": "Горячие клавиши",
|
||||
@@ -236,11 +354,33 @@
|
||||
"desc": "Отменить последнее действие в рабочем процессе."
|
||||
},
|
||||
"deleteSelection": {
|
||||
"desc": "Удалить выделенные узлы и ребра."
|
||||
"desc": "Удалить выделенные узлы и ребра.",
|
||||
"title": "Delete"
|
||||
},
|
||||
"redo": {
|
||||
"title": "Вернуть",
|
||||
"desc": "Вернуть последнее действие в рабочем процессе."
|
||||
},
|
||||
"copySelection": {
|
||||
"title": "Copy",
|
||||
"desc": "Copy selected nodes and edges."
|
||||
},
|
||||
"pasteSelection": {
|
||||
"title": "Paste",
|
||||
"desc": "Paste copied nodes and edges."
|
||||
},
|
||||
"addNode": {
|
||||
"desc": "Open the add node menu.",
|
||||
"title": "Add Node"
|
||||
},
|
||||
"title": "Workflows",
|
||||
"pasteSelectionWithEdges": {
|
||||
"title": "Paste with Edges",
|
||||
"desc": "Paste copied nodes, edges, and all edges connected to copied nodes."
|
||||
},
|
||||
"selectAll": {
|
||||
"desc": "Select all nodes and edges.",
|
||||
"title": "Select All"
|
||||
}
|
||||
},
|
||||
"viewer": {
|
||||
@@ -257,12 +397,84 @@
|
||||
"title": "Восстановить все метаданные"
|
||||
},
|
||||
"swapImages": {
|
||||
"desc": "Поменять местами сравниваемые изображения."
|
||||
"desc": "Поменять местами сравниваемые изображения.",
|
||||
"title": "Swap Comparison Images"
|
||||
},
|
||||
"title": "Просмотрщик изображений",
|
||||
"toggleViewer": {
|
||||
"title": "Открыть/закрыть просмотрщик",
|
||||
"desc": "Показать или скрыть просмотрщик изображений. Доступно только на вкладке «Холст»."
|
||||
},
|
||||
"recallSeed": {
|
||||
"title": "Recall Seed",
|
||||
"desc": "Recall the seed for the current image."
|
||||
},
|
||||
"recallPrompts": {
|
||||
"desc": "Recall the positive and negative prompts for the current image.",
|
||||
"title": "Recall Prompts"
|
||||
},
|
||||
"remix": {
|
||||
"title": "Remix",
|
||||
"desc": "Recall all metadata except for the seed for the current image."
|
||||
},
|
||||
"useSize": {
|
||||
"desc": "Use the current image's size as the bbox size.",
|
||||
"title": "Use Size"
|
||||
},
|
||||
"runPostprocessing": {
|
||||
"title": "Run Postprocessing",
|
||||
"desc": "Run the selected postprocessing on the current image."
|
||||
},
|
||||
"toggleMetadata": {
|
||||
"title": "Show/Hide Metadata",
|
||||
"desc": "Show or hide the current image's metadata overlay."
|
||||
}
|
||||
},
|
||||
"gallery": {
|
||||
"galleryNavRightAlt": {
|
||||
"desc": "Same as Navigate Right, but selects the compare image, opening compare mode if it isn't already open.",
|
||||
"title": "Navigate Right (Compare Image)"
|
||||
},
|
||||
"galleryNavRight": {
|
||||
"desc": "Navigate right in the gallery grid, selecting that image. If at the last image of the row, go to the next row. If at the last image of the page, go to the next page.",
|
||||
"title": "Navigate Right"
|
||||
},
|
||||
"galleryNavUp": {
|
||||
"desc": "Navigate up in the gallery grid, selecting that image. If at the top of the page, go to the previous page.",
|
||||
"title": "Navigate Up"
|
||||
},
|
||||
"galleryNavDown": {
|
||||
"title": "Navigate Down",
|
||||
"desc": "Navigate down in the gallery grid, selecting that image. If at the bottom of the page, go to the next page."
|
||||
},
|
||||
"galleryNavLeft": {
|
||||
"title": "Navigate Left",
|
||||
"desc": "Navigate left in the gallery grid, selecting that image. If at the first image of the row, go to the previous row. If at the first image of the page, go to the previous page."
|
||||
},
|
||||
"galleryNavDownAlt": {
|
||||
"title": "Navigate Down (Compare Image)",
|
||||
"desc": "Same as Navigate Down, but selects the compare image, opening compare mode if it isn't already open."
|
||||
},
|
||||
"galleryNavLeftAlt": {
|
||||
"desc": "Same as Navigate Left, but selects the compare image, opening compare mode if it isn't already open.",
|
||||
"title": "Navigate Left (Compare Image)"
|
||||
},
|
||||
"clearSelection": {
|
||||
"desc": "Clear the current selection, if any.",
|
||||
"title": "Clear Selection"
|
||||
},
|
||||
"deleteSelection": {
|
||||
"title": "Delete",
|
||||
"desc": "Delete all selected images. By default, you will be prompted to confirm deletion. If the images are currently in use in the app, you will be warned."
|
||||
},
|
||||
"galleryNavUpAlt": {
|
||||
"title": "Navigate Up (Compare Image)",
|
||||
"desc": "Same as Navigate Up, but selects the compare image, opening compare mode if it isn't already open."
|
||||
},
|
||||
"title": "Gallery",
|
||||
"selectAllOnPage": {
|
||||
"title": "Select All On Page",
|
||||
"desc": "Select all images on the current page."
|
||||
}
|
||||
}
|
||||
},
|
||||
@@ -372,7 +584,20 @@
|
||||
"ipAdapters": "IP адаптеры",
|
||||
"starterModelsInModelManager": "Стартовые модели можно найти в Менеджере моделей",
|
||||
"learnMoreAboutSupportedModels": "Подробнее о поддерживаемых моделях",
|
||||
"t5Encoder": "T5 энкодер"
|
||||
"t5Encoder": "T5 энкодер",
|
||||
"spandrelImageToImage": "Image to Image (Spandrel)",
|
||||
"clipEmbed": "CLIP Embed",
|
||||
"installingXModels_one": "Установка {{count}} модели",
|
||||
"installingXModels_few": "Установка {{count}} моделей",
|
||||
"installingXModels_many": "Установка {{count}} моделей",
|
||||
"installingBundle": "Установка пакета",
|
||||
"installingModel": "Установка модели",
|
||||
"starterBundles": "Стартовые пакеты",
|
||||
"skippingXDuplicates_one": ", пропуская {{count}} дубликат",
|
||||
"skippingXDuplicates_few": ", пропуская {{count}} дубликата",
|
||||
"skippingXDuplicates_many": ", пропуская {{count}} дубликатов",
|
||||
"includesNModels": "Включает в себя {{n}} моделей и их зависимостей",
|
||||
"starterBundleHelpText": "Легко установите все модели, необходимые для начала работы с базовой моделью, включая основную модель, сети управления, IP-адаптеры и многое другое. При выборе комплекта все уже установленные модели будут пропущены."
|
||||
},
|
||||
"parameters": {
|
||||
"images": "Изображения",
|
||||
@@ -432,12 +657,16 @@
|
||||
"rgNoRegion": "регион не выбран",
|
||||
"rgNoPromptsOrIPAdapters": "нет текстовых запросов или IP-адаптеров",
|
||||
"ipAdapterIncompatibleBaseModel": "несовместимая базовая модель IP-адаптера",
|
||||
"ipAdapterNoImageSelected": "изображение IP-адаптера не выбрано"
|
||||
"ipAdapterNoImageSelected": "изображение IP-адаптера не выбрано",
|
||||
"t2iAdapterIncompatibleScaledBboxWidth": "$t(parameters.invoke.layer.t2iAdapterRequiresDimensionsToBeMultipleOf) {{multiple}}, масштабированная ширина рамки {{width}}",
|
||||
"t2iAdapterIncompatibleBboxHeight": "$t(parameters.invoke.layer.t2iAdapterRequiresDimensionsToBeMultipleOf) {{multiple}}, высота рамки {{height}}",
|
||||
"t2iAdapterIncompatibleBboxWidth": "$t(parameters.invoke.layer.t2iAdapterRequiresDimensionsToBeMultipleOf) {{multiple}}, ширина рамки {{width}}",
|
||||
"t2iAdapterIncompatibleScaledBboxHeight": "$t(parameters.invoke.layer.t2iAdapterRequiresDimensionsToBeMultipleOf) {{multiple}}, масштабированная высота рамки {{height}}"
|
||||
},
|
||||
"fluxModelIncompatibleBboxWidth": "$t(parameters.invoke.fluxRequiresDimensionsToBeMultipleOf16), ширина bbox {{width}}",
|
||||
"fluxModelIncompatibleBboxHeight": "$t(parameters.invoke.fluxRequiresDimensionsToBeMultipleOf16), высота bbox {{height}}",
|
||||
"fluxModelIncompatibleScaledBboxHeight": "$t(parameters.invoke.fluxRequiresDimensionsToBeMultipleOf16), масштабированная высота bbox {{height}}",
|
||||
"fluxModelIncompatibleScaledBboxWidth": "$t(parameters.invoke.fluxRequiresDimensionsToBeMultipleOf16) масштабированная ширина bbox {{width}}",
|
||||
"fluxModelIncompatibleBboxWidth": "$t(parameters.invoke.fluxRequiresDimensionsToBeMultipleOf16), ширина рамки {{width}}",
|
||||
"fluxModelIncompatibleBboxHeight": "$t(parameters.invoke.fluxRequiresDimensionsToBeMultipleOf16), высота рамки {{height}}",
|
||||
"fluxModelIncompatibleScaledBboxHeight": "$t(parameters.invoke.fluxRequiresDimensionsToBeMultipleOf16), масштабированная высота рамки {{height}}",
|
||||
"fluxModelIncompatibleScaledBboxWidth": "$t(parameters.invoke.fluxRequiresDimensionsToBeMultipleOf16) масштабированная ширина рамки {{width}}",
|
||||
"noFLUXVAEModelSelected": "Для генерации FLUX не выбрана модель VAE",
|
||||
"noT5EncoderModelSelected": "Для генерации FLUX не выбрана модель T5 энкодера",
|
||||
"canvasIsFiltering": "Холст фильтруется",
|
||||
@@ -470,7 +699,8 @@
|
||||
"staged": "Инсценировка",
|
||||
"optimizedImageToImage": "Оптимизированное img2img",
|
||||
"sendToCanvas": "Отправить на холст",
|
||||
"guidance": "Точность"
|
||||
"guidance": "Точность",
|
||||
"boxBlur": "Box Blur"
|
||||
},
|
||||
"settings": {
|
||||
"models": "Модели",
|
||||
@@ -504,7 +734,8 @@
|
||||
"intermediatesClearedFailed": "Проблема очистки промежуточных",
|
||||
"reloadingIn": "Перезагрузка через",
|
||||
"informationalPopoversDisabled": "Информационные всплывающие окна отключены",
|
||||
"informationalPopoversDisabledDesc": "Информационные всплывающие окна были отключены. Включите их в Настройках."
|
||||
"informationalPopoversDisabledDesc": "Информационные всплывающие окна были отключены. Включите их в Настройках.",
|
||||
"confirmOnNewSession": "Подтверждение нового сеанса"
|
||||
},
|
||||
"toast": {
|
||||
"uploadFailed": "Загрузка не удалась",
|
||||
@@ -513,19 +744,19 @@
|
||||
"serverError": "Ошибка сервера",
|
||||
"connected": "Подключено к серверу",
|
||||
"canceled": "Обработка отменена",
|
||||
"uploadFailedInvalidUploadDesc": "Должно быть одно изображение в формате PNG или JPEG",
|
||||
"uploadFailedInvalidUploadDesc": "Это должны быть изображения PNG или JPEG.",
|
||||
"parameterNotSet": "Параметр не задан",
|
||||
"parameterSet": "Параметр задан",
|
||||
"problemCopyingImage": "Не удается скопировать изображение",
|
||||
"baseModelChangedCleared_one": "Очищена или отключена {{count}} несовместимая подмодель",
|
||||
"baseModelChangedCleared_few": "Очищены или отключены {{count}} несовместимые подмодели",
|
||||
"baseModelChangedCleared_many": "Очищены или отключены {{count}} несовместимых подмоделей",
|
||||
"baseModelChangedCleared_few": "Очищено или отключено {{count}} несовместимых подмодели",
|
||||
"baseModelChangedCleared_many": "Очищено или отключено {{count}} несовместимых подмоделей",
|
||||
"loadedWithWarnings": "Рабочий процесс загружен с предупреждениями",
|
||||
"setControlImage": "Установить как контрольное изображение",
|
||||
"setNodeField": "Установить как поле узла",
|
||||
"invalidUpload": "Неверная загрузка",
|
||||
"imageUploaded": "Изображение загружено",
|
||||
"addedToBoard": "Добавлено на доску",
|
||||
"addedToBoard": "Добавлено в активы доски {{name}}",
|
||||
"workflowLoaded": "Рабочий процесс загружен",
|
||||
"problemDeletingWorkflow": "Проблема с удалением рабочего процесса",
|
||||
"modelAddedSimple": "Модель добавлена в очередь",
|
||||
@@ -560,22 +791,29 @@
|
||||
"unableToLoadStylePreset": "Невозможно загрузить предустановку стиля",
|
||||
"layerCopiedToClipboard": "Слой скопирован в буфер обмена",
|
||||
"sentToUpscale": "Отправить на увеличение",
|
||||
"layerSavedToAssets": "Слой сохранен в активах"
|
||||
"layerSavedToAssets": "Слой сохранен в активах",
|
||||
"linkCopied": "Ссылка скопирована",
|
||||
"addedToUncategorized": "Добавлено в активы доски $t(boards.uncategorized)",
|
||||
"imagesWillBeAddedTo": "Загруженные изображения будут добавлены в активы доски {{boardName}}.",
|
||||
"uploadFailedInvalidUploadDesc_withCount_one": "Должно быть не более {{count}} изображения в формате PNG или JPEG.",
|
||||
"uploadFailedInvalidUploadDesc_withCount_few": "Должно быть не более {{count}} изображений в формате PNG или JPEG.",
|
||||
"uploadFailedInvalidUploadDesc_withCount_many": "Должно быть не более {{count}} изображений в формате PNG или JPEG."
|
||||
},
|
||||
"accessibility": {
|
||||
"uploadImage": "Загрузить изображение",
|
||||
"nextImage": "Следующее изображение",
|
||||
"previousImage": "Предыдущее изображение",
|
||||
"showOptionsPanel": "Показать боковую панель",
|
||||
"invokeProgressBar": "Индикатор выполнения",
|
||||
"reset": "Сброс",
|
||||
"menu": "Меню",
|
||||
"showGalleryPanel": "Показать панель галереи",
|
||||
"mode": "Режим",
|
||||
"resetUI": "$t(accessibility.reset) интерфейс",
|
||||
"createIssue": "Сообщить о проблеме",
|
||||
"about": "Об этом",
|
||||
"submitSupportTicket": "Отправить тикет в службу поддержки"
|
||||
"submitSupportTicket": "Отправить тикет в службу поддержки",
|
||||
"toggleRightPanel": "Переключить правую панель (G)",
|
||||
"toggleLeftPanel": "Переключить левую панель (T)",
|
||||
"uploadImages": "Загрузить изображения"
|
||||
},
|
||||
"nodes": {
|
||||
"zoomInNodes": "Увеличьте масштаб",
|
||||
@@ -713,7 +951,10 @@
|
||||
"imageAccessError": "Невозможно найти изображение {{image_name}}, сбрасываем на значение по умолчанию",
|
||||
"boardAccessError": "Невозможно найти доску {{board_id}}, сбрасываем на значение по умолчанию",
|
||||
"modelAccessError": "Невозможно найти модель {{key}}, сброс на модель по умолчанию",
|
||||
"saveToGallery": "Сохранить в галерею"
|
||||
"saveToGallery": "Сохранить в галерею",
|
||||
"noWorkflows": "Нет рабочих процессов",
|
||||
"noMatchingWorkflows": "Нет совпадающих рабочих процессов",
|
||||
"workflowHelpText": "Нужна помощь? Ознакомьтесь с нашим руководством <LinkComponent>Getting Started with Workflows</LinkComponent>."
|
||||
},
|
||||
"boards": {
|
||||
"autoAddBoard": "Авто добавление Доски",
|
||||
@@ -732,16 +973,16 @@
|
||||
"loading": "Загрузка...",
|
||||
"clearSearch": "Очистить поиск",
|
||||
"deleteBoardOnly": "Удалить только доску",
|
||||
"movingImagesToBoard_one": "Перемещаем {{count}} изображение на доску:",
|
||||
"movingImagesToBoard_few": "Перемещаем {{count}} изображения на доску:",
|
||||
"movingImagesToBoard_many": "Перемещаем {{count}} изображений на доску:",
|
||||
"movingImagesToBoard_one": "Перемещение {{count}} изображения на доску:",
|
||||
"movingImagesToBoard_few": "Перемещение {{count}} изображений на доску:",
|
||||
"movingImagesToBoard_many": "Перемещение {{count}} изображений на доску:",
|
||||
"downloadBoard": "Скачать доску",
|
||||
"deleteBoard": "Удалить доску",
|
||||
"deleteBoardAndImages": "Удалить доску и изображения",
|
||||
"deletedBoardsCannotbeRestored": "Удаленные доски не могут быть восстановлены. Выбор «Удалить только доску» переведет изображения в состояние без категории.",
|
||||
"assetsWithCount_one": "{{count}} ассет",
|
||||
"assetsWithCount_few": "{{count}} ассета",
|
||||
"assetsWithCount_many": "{{count}} ассетов",
|
||||
"assetsWithCount_one": "{{count}} актив",
|
||||
"assetsWithCount_few": "{{count}} актива",
|
||||
"assetsWithCount_many": "{{count}} активов",
|
||||
"imagesWithCount_one": "{{count}} изображение",
|
||||
"imagesWithCount_few": "{{count}} изображения",
|
||||
"imagesWithCount_many": "{{count}} изображений",
|
||||
@@ -757,7 +998,8 @@
|
||||
"hideBoards": "Скрыть доски",
|
||||
"viewBoards": "Просмотреть доски",
|
||||
"noBoards": "Нет досок {{boardType}}",
|
||||
"deletedPrivateBoardsCannotbeRestored": "Удаленные доски не могут быть восстановлены. Выбор «Удалить только доску» переведет изображения в приватное состояние без категории для создателя изображения."
|
||||
"deletedPrivateBoardsCannotbeRestored": "Удаленные доски не могут быть восстановлены. Выбор «Удалить только доску» переведет изображения в приватное состояние без категории для создателя изображения.",
|
||||
"updateBoardError": "Ошибка обновления доски"
|
||||
},
|
||||
"dynamicPrompts": {
|
||||
"seedBehaviour": {
|
||||
@@ -1188,7 +1430,8 @@
|
||||
"recallParameter": "Отозвать {{label}}",
|
||||
"allPrompts": "Все запросы",
|
||||
"imageDimensions": "Размеры изображения",
|
||||
"canvasV2Metadata": "Холст"
|
||||
"canvasV2Metadata": "Холст",
|
||||
"guidance": "Точность"
|
||||
},
|
||||
"queue": {
|
||||
"status": "Статус",
|
||||
@@ -1337,7 +1580,15 @@
|
||||
"autoLayout": "Автоматическое расположение",
|
||||
"userWorkflows": "Пользовательские рабочие процессы",
|
||||
"projectWorkflows": "Рабочие процессы проекта",
|
||||
"defaultWorkflows": "Стандартные рабочие процессы"
|
||||
"defaultWorkflows": "Стандартные рабочие процессы",
|
||||
"deleteWorkflow2": "Вы уверены, что хотите удалить этот рабочий процесс? Это нельзя отменить.",
|
||||
"chooseWorkflowFromLibrary": "Выбрать рабочий процесс из библиотеки",
|
||||
"uploadAndSaveWorkflow": "Загрузить в библиотеку",
|
||||
"edit": "Редактировать",
|
||||
"download": "Скачать",
|
||||
"copyShareLink": "Скопировать ссылку на общий доступ",
|
||||
"copyShareLinkForWorkflow": "Скопировать ссылку на общий доступ для рабочего процесса",
|
||||
"delete": "Удалить"
|
||||
},
|
||||
"hrf": {
|
||||
"enableHrf": "Включить исправление высокого разрешения",
|
||||
@@ -1394,15 +1645,15 @@
|
||||
"autoNegative": "Авто негатив",
|
||||
"deletePrompt": "Удалить запрос",
|
||||
"rectangle": "Прямоугольник",
|
||||
"addNegativePrompt": "Добавить $t(common.negativePrompt)",
|
||||
"addNegativePrompt": "Добавить $t(controlLayers.negativePrompt)",
|
||||
"regionalGuidance": "Региональная точность",
|
||||
"opacity": "Непрозрачность",
|
||||
"addLayer": "Добавить слой",
|
||||
"moveToFront": "На передний план",
|
||||
"addPositivePrompt": "Добавить $t(common.positivePrompt)",
|
||||
"addPositivePrompt": "Добавить $t(controlLayers.prompt)",
|
||||
"regional": "Региональный",
|
||||
"bookmark": "Закладка для быстрого переключения",
|
||||
"fitBboxToLayers": "Подогнать Bbox к слоям",
|
||||
"fitBboxToLayers": "Подогнать рамку к слоям",
|
||||
"mergeVisibleOk": "Объединенные видимые слои",
|
||||
"mergeVisibleError": "Ошибка объединения видимых слоев",
|
||||
"clearHistory": "Очистить историю",
|
||||
@@ -1411,7 +1662,7 @@
|
||||
"saveLayerToAssets": "Сохранить слой в активы",
|
||||
"clearCaches": "Очистить кэши",
|
||||
"recalculateRects": "Пересчитать прямоугольники",
|
||||
"saveBboxToGallery": "Сохранить Bbox в галерею",
|
||||
"saveBboxToGallery": "Сохранить рамку в галерею",
|
||||
"resetCanvas": "Сбросить холст",
|
||||
"canvas": "Холст",
|
||||
"global": "Глобальный",
|
||||
@@ -1423,15 +1674,284 @@
|
||||
"newRasterLayerOk": "Создан растровый слой",
|
||||
"newRasterLayerError": "Ошибка создания растрового слоя",
|
||||
"newGlobalReferenceImageOk": "Создано глобальное эталонное изображение",
|
||||
"bboxOverlay": "Показать наложение Bbox",
|
||||
"bboxOverlay": "Показать наложение ограничительной рамки",
|
||||
"saveCanvasToGallery": "Сохранить холст в галерею",
|
||||
"pullBboxIntoReferenceImageOk": "Bbox перенесен в эталонное изображение",
|
||||
"pullBboxIntoReferenceImageError": "Ошибка переноса BBox в эталонное изображение",
|
||||
"pullBboxIntoReferenceImageOk": "рамка перенесена в эталонное изображение",
|
||||
"pullBboxIntoReferenceImageError": "Ошибка переноса рамки в эталонное изображение",
|
||||
"regionIsEmpty": "Выбранный регион пуст",
|
||||
"savedToGalleryOk": "Сохранено в галерею",
|
||||
"savedToGalleryError": "Ошибка сохранения в галерею",
|
||||
"pullBboxIntoLayerOk": "Bbox перенесен в слой",
|
||||
"pullBboxIntoLayerError": "Проблема с переносом BBox в слой"
|
||||
"pullBboxIntoLayerOk": "Рамка перенесена в слой",
|
||||
"pullBboxIntoLayerError": "Проблема с переносом рамки в слой",
|
||||
"newLayerFromImage": "Новый слой из изображения",
|
||||
"filter": {
|
||||
"lineart_anime_edge_detection": {
|
||||
"label": "Обнаружение краев Lineart Anime",
|
||||
"description": "Создает карту краев выбранного слоя с помощью модели обнаружения краев Lineart Anime."
|
||||
},
|
||||
"hed_edge_detection": {
|
||||
"scribble": "Штрих",
|
||||
"label": "обнаружение границ HED",
|
||||
"description": "Создает карту границ из выбранного слоя с использованием модели обнаружения границ HED."
|
||||
},
|
||||
"mlsd_detection": {
|
||||
"description": "Генерирует карту сегментов линий из выбранного слоя с помощью модели обнаружения сегментов линий MLSD.",
|
||||
"score_threshold": "Пороговый балл",
|
||||
"distance_threshold": "Порог расстояния",
|
||||
"label": "Обнаружение сегментов линии"
|
||||
},
|
||||
"canny_edge_detection": {
|
||||
"low_threshold": "Низкий порог",
|
||||
"high_threshold": "Высокий порог",
|
||||
"label": "Обнаружение краев",
|
||||
"description": "Создает карту краев выбранного слоя с помощью алгоритма обнаружения краев Canny."
|
||||
},
|
||||
"color_map": {
|
||||
"description": "Создайте цветовую карту из выбранного слоя.",
|
||||
"label": "Цветная карта",
|
||||
"tile_size": "Размер плитки"
|
||||
},
|
||||
"depth_anything_depth_estimation": {
|
||||
"model_size_base": "Базовая",
|
||||
"model_size_large": "Большая",
|
||||
"label": "Анализ глубины",
|
||||
"model_size_small": "Маленькая",
|
||||
"model_size_small_v2": "Маленькая v2",
|
||||
"description": "Создает карту глубины из выбранного слоя с использованием модели Depth Anything.",
|
||||
"model_size": "Размер модели"
|
||||
},
|
||||
"mediapipe_face_detection": {
|
||||
"min_confidence": "Минимальная уверенность",
|
||||
"label": "Распознавание лиц MediaPipe",
|
||||
"description": "Обнаруживает лица в выбранном слое с помощью модели обнаружения лиц MediaPipe.",
|
||||
"max_faces": "Максимум лиц"
|
||||
},
|
||||
"lineart_edge_detection": {
|
||||
"label": "Обнаружение краев Lineart",
|
||||
"description": "Создает карту краев выбранного слоя с помощью модели обнаружения краев Lineart.",
|
||||
"coarse": "Грубый"
|
||||
},
|
||||
"filterType": "Тип фильтра",
|
||||
"autoProcess": "Автообработка",
|
||||
"reset": "Сбросить",
|
||||
"content_shuffle": {
|
||||
"scale_factor": "Коэффициент",
|
||||
"label": "Перетасовка контента",
|
||||
"description": "Перемешивает содержимое выбранного слоя, аналогично эффекту «сжижения»."
|
||||
},
|
||||
"dw_openpose_detection": {
|
||||
"label": "Обнаружение DW Openpose",
|
||||
"draw_hands": "Рисовать руки",
|
||||
"description": "Обнаруживает позы человека в выбранном слое с помощью модели DW Openpose.",
|
||||
"draw_face": "Рисовать лицо",
|
||||
"draw_body": "Рисовать тело"
|
||||
},
|
||||
"normal_map": {
|
||||
"label": "Карта нормалей",
|
||||
"description": "Создает карту нормалей для выбранного слоя."
|
||||
},
|
||||
"spandrel_filter": {
|
||||
"model": "Модель",
|
||||
"label": "Модель img2img",
|
||||
"autoScale": "Авто масштабирование",
|
||||
"scale": "Целевой масштаб",
|
||||
"description": "Запустить модель изображения к изображению на выбранном слое.",
|
||||
"autoScaleDesc": "Выбранная модель будет работать до тех пор, пока не будет достигнут целевой масштаб."
|
||||
},
|
||||
"pidi_edge_detection": {
|
||||
"scribble": "Штрих",
|
||||
"description": "Генерирует карту краев из выбранного слоя с помощью модели обнаружения краев PiDiNet.",
|
||||
"label": "Обнаружение краев PiDiNet",
|
||||
"quantize_edges": "Квантизация краев"
|
||||
},
|
||||
"process": "Обработать",
|
||||
"apply": "Применить",
|
||||
"cancel": "Отменить",
|
||||
"filter": "Фильтр",
|
||||
"filters": "Фильтры"
|
||||
},
|
||||
"HUD": {
|
||||
"entityStatus": {
|
||||
"isHidden": "{{title}} скрыт",
|
||||
"isLocked": "{{title}} заблокирован",
|
||||
"isDisabled": "{{title}} отключен",
|
||||
"isEmpty": "{{title}} пуст",
|
||||
"isFiltering": "{{title}} фильтруется",
|
||||
"isTransforming": "{{title}} трансформируется"
|
||||
},
|
||||
"scaledBbox": "Масштабированная рамка",
|
||||
"bbox": "Ограничительная рамка"
|
||||
},
|
||||
"canvasContextMenu": {
|
||||
"saveBboxToGallery": "Сохранить рамку в галерею",
|
||||
"newGlobalReferenceImage": "Новое глобальное эталонное изображение",
|
||||
"bboxGroup": "Сохдать из рамки",
|
||||
"canvasGroup": "Холст",
|
||||
"newControlLayer": "Новый контрольный слой",
|
||||
"newRasterLayer": "Новый растровый слой",
|
||||
"saveToGalleryGroup": "Сохранить в галерею",
|
||||
"saveCanvasToGallery": "Сохранить холст в галерею",
|
||||
"cropCanvasToBbox": "Обрезать холст по рамке",
|
||||
"newRegionalReferenceImage": "Новое региональное эталонное изображение"
|
||||
},
|
||||
"fill": {
|
||||
"solid": "Сплошной",
|
||||
"fillStyle": "Стиль заполнения",
|
||||
"fillColor": "Цвет заполнения",
|
||||
"grid": "Сетка",
|
||||
"horizontal": "Горизонтальная",
|
||||
"diagonal": "Диагональная",
|
||||
"crosshatch": "Штриховка",
|
||||
"vertical": "Вертикальная"
|
||||
},
|
||||
"showHUD": "Показать HUD",
|
||||
"copyToClipboard": "Копировать в буфер обмена",
|
||||
"ipAdapterMethod": {
|
||||
"composition": "Только композиция",
|
||||
"style": "Только стиль",
|
||||
"ipAdapterMethod": "Метод IP адаптера",
|
||||
"full": "Полный"
|
||||
},
|
||||
"addReferenceImage": "Добавить $t(controlLayers.referenceImage)",
|
||||
"inpaintMask": "Маска перерисовки",
|
||||
"sendToGalleryDesc": "При нажатии кнопки Invoke создается изображение и сохраняется в вашей галерее.",
|
||||
"sendToCanvas": "Отправить на холст",
|
||||
"regionalGuidance_withCount_one": "$t(controlLayers.regionalGuidance)",
|
||||
"regionalGuidance_withCount_few": "Региональных точности",
|
||||
"regionalGuidance_withCount_many": "Региональных точностей",
|
||||
"controlLayer_withCount_one": "$t(controlLayers.controlLayer)",
|
||||
"controlLayer_withCount_few": "Контрольных слоя",
|
||||
"controlLayer_withCount_many": "Контрольных слоев",
|
||||
"newCanvasFromImage": "Новый холст из изображения",
|
||||
"inpaintMask_withCount_one": "$t(controlLayers.inpaintMask)",
|
||||
"inpaintMask_withCount_few": "Маски перерисовки",
|
||||
"inpaintMask_withCount_many": "Масок перерисовки",
|
||||
"globalReferenceImages_withCount_visible": "Глобальные эталонные изображения ({{count}})",
|
||||
"controlMode": {
|
||||
"prompt": "Запрос",
|
||||
"controlMode": "Режим контроля",
|
||||
"megaControl": "Мега контроль",
|
||||
"balanced": "Сбалансированный",
|
||||
"control": "Контроль"
|
||||
},
|
||||
"settings": {
|
||||
"isolatedPreview": "Изолированный предпросмотр",
|
||||
"isolatedTransformingPreview": "Изолированный предпросмотр преобразования",
|
||||
"invertBrushSizeScrollDirection": "Инвертировать прокрутку для размера кисти",
|
||||
"snapToGrid": {
|
||||
"label": "Привязка к сетке",
|
||||
"on": "Вкл",
|
||||
"off": "Выкл"
|
||||
},
|
||||
"isolatedFilteringPreview": "Изолированный предпросмотр фильтрации",
|
||||
"pressureSensitivity": "Чувствительность к давлению",
|
||||
"isolatedStagingPreview": "Изолированный предпросмотр на промежуточной стадии",
|
||||
"preserveMask": {
|
||||
"label": "Сохранить замаскированную область",
|
||||
"alert": "Сохранение замаскированной области"
|
||||
}
|
||||
},
|
||||
"stagingArea": {
|
||||
"discardAll": "Отбросить все",
|
||||
"discard": "Отбросить",
|
||||
"accept": "Принять",
|
||||
"previous": "Предыдущий",
|
||||
"next": "Следующий",
|
||||
"saveToGallery": "Сохранить в галерею",
|
||||
"showResultsOn": "Показать результаты",
|
||||
"showResultsOff": "Скрыть результаты"
|
||||
},
|
||||
"pullBboxIntoReferenceImage": "Поместить рамку в эталонное изображение",
|
||||
"enableAutoNegative": "Включить авто негатив",
|
||||
"maskFill": "Заполнение маски",
|
||||
"viewProgressInViewer": "Просматривайте прогресс и результаты в <Btn>Просмотрщике изображений</Btn>.",
|
||||
"convertToRasterLayer": "Конвертировать в растровый слой",
|
||||
"tool": {
|
||||
"move": "Двигать",
|
||||
"bbox": "Ограничительная рамка",
|
||||
"view": "Смотреть",
|
||||
"brush": "Кисть",
|
||||
"eraser": "Ластик",
|
||||
"rectangle": "Прямоугольник",
|
||||
"colorPicker": "Подборщик цветов"
|
||||
},
|
||||
"rasterLayer": "Растровый слой",
|
||||
"sendingToCanvas": "Постановка генераций на холст",
|
||||
"rasterLayers_withCount_visible": "Растровые слои ({{count}})",
|
||||
"regionalGuidance_withCount_hidden": "Региональная точность ({{count}} скрыто)",
|
||||
"enableTransparencyEffect": "Включить эффект прозрачности",
|
||||
"hidingType": "Скрыть {{type}}",
|
||||
"addRegionalGuidance": "Добавить $t(controlLayers.regionalGuidance)",
|
||||
"sendingToGallery": "Отправка генераций в галерею",
|
||||
"viewProgressOnCanvas": "Просматривайте прогресс и результаты этапов на <Btn>Холсте</Btn>.",
|
||||
"controlLayers_withCount_hidden": "Контрольные слои ({{count}} скрыто)",
|
||||
"rasterLayers_withCount_hidden": "Растровые слои ({{count}} скрыто)",
|
||||
"deleteSelected": "Удалить выбранное",
|
||||
"stagingOnCanvas": "Постановка изображений на",
|
||||
"pullBboxIntoLayer": "Поместить рамку в слой",
|
||||
"locked": "Заблокировано",
|
||||
"replaceLayer": "Заменить слой",
|
||||
"width": "Ширина",
|
||||
"controlLayer": "Слой управления",
|
||||
"addRasterLayer": "Добавить $t(controlLayers.rasterLayer)",
|
||||
"addControlLayer": "Добавить $t(controlLayers.controlLayer)",
|
||||
"addInpaintMask": "Добавить $t(controlLayers.inpaintMask)",
|
||||
"inpaintMasks_withCount_hidden": "Маски перерисовки ({{count}} скрыто)",
|
||||
"regionalGuidance_withCount_visible": "Региональная точность ({{count}})",
|
||||
"newGallerySessionDesc": "Это очистит холст и все настройки, кроме выбранной модели. Генерации будут отправлены в галерею.",
|
||||
"newCanvasSession": "Новая сессия холста",
|
||||
"newCanvasSessionDesc": "Это очистит холст и все настройки, кроме выбора модели. Генерации будут размещены на холсте.",
|
||||
"cropLayerToBbox": "Обрезать слой по ограничительной рамке",
|
||||
"clipToBbox": "Обрезка штрихов в рамке",
|
||||
"outputOnlyMaskedRegions": "Вывод только маскированных областей",
|
||||
"duplicate": "Дублировать",
|
||||
"inpaintMasks_withCount_visible": "Маски перерисовки ({{count}})",
|
||||
"layer_one": "Слой",
|
||||
"layer_few": "Слоя",
|
||||
"layer_many": "Слоев",
|
||||
"prompt": "Запрос",
|
||||
"negativePrompt": "Исключающий запрос",
|
||||
"beginEndStepPercentShort": "Начало/конец %",
|
||||
"transform": {
|
||||
"transform": "Трансформировать",
|
||||
"fitToBbox": "Вместить в рамку",
|
||||
"reset": "Сбросить",
|
||||
"apply": "Применить",
|
||||
"cancel": "Отменить",
|
||||
"fitModeContain": "Уместить",
|
||||
"fitMode": "Режим подгонки",
|
||||
"fitModeFill": "Заполнить"
|
||||
},
|
||||
"disableAutoNegative": "Отключить авто негатив",
|
||||
"deleteReferenceImage": "Удалить эталонное изображение",
|
||||
"controlLayers_withCount_visible": "Контрольные слои ({{count}})",
|
||||
"rasterLayer_withCount_one": "$t(controlLayers.rasterLayer)",
|
||||
"rasterLayer_withCount_few": "Растровых слоя",
|
||||
"rasterLayer_withCount_many": "Растровых слоев",
|
||||
"transparency": "Прозрачность",
|
||||
"weight": "Вес",
|
||||
"newGallerySession": "Новая сессия галереи",
|
||||
"sendToCanvasDesc": "Нажатие кнопки Invoke отображает вашу текущую работу на холсте.",
|
||||
"globalReferenceImages_withCount_hidden": "Глобальные эталонные изображения ({{count}} скрыто)",
|
||||
"convertToControlLayer": "Конвертировать в контрольный слой",
|
||||
"layer_withCount_one": "Слой ({{count}})",
|
||||
"layer_withCount_few": "Слои ({{count}})",
|
||||
"layer_withCount_many": "Слои ({{count}})",
|
||||
"disableTransparencyEffect": "Отключить эффект прозрачности",
|
||||
"showingType": "Показать {{type}}",
|
||||
"dynamicGrid": "Динамическая сетка",
|
||||
"logDebugInfo": "Писать отладочную информацию",
|
||||
"unlocked": "Разблокировано",
|
||||
"showProgressOnCanvas": "Показать прогресс на холсте",
|
||||
"globalReferenceImage_withCount_one": "$t(controlLayers.globalReferenceImage)",
|
||||
"globalReferenceImage_withCount_few": "Глобальных эталонных изображения",
|
||||
"globalReferenceImage_withCount_many": "Глобальных эталонных изображений",
|
||||
"regionalReferenceImage": "Региональное эталонное изображение",
|
||||
"globalReferenceImage": "Глобальное эталонное изображение",
|
||||
"sendToGallery": "Отправить в галерею",
|
||||
"referenceImage": "Эталонное изображение",
|
||||
"addGlobalReferenceImage": "Добавить $t(controlLayers.globalReferenceImage)",
|
||||
"newImg2ImgCanvasFromImage": "Новое img2img из изображения"
|
||||
},
|
||||
"ui": {
|
||||
"tabs": {
|
||||
@@ -1443,7 +1963,8 @@
|
||||
"modelsTab": "$t(ui.tabs.models) $t(common.tab)",
|
||||
"queue": "Очередь",
|
||||
"upscaling": "Увеличение",
|
||||
"upscalingTab": "$t(ui.tabs.upscaling) $t(common.tab)"
|
||||
"upscalingTab": "$t(ui.tabs.upscaling) $t(common.tab)",
|
||||
"gallery": "Галерея"
|
||||
}
|
||||
},
|
||||
"upscaling": {
|
||||
@@ -1515,5 +2036,45 @@
|
||||
"professional": "Профессионал",
|
||||
"professionalUpsell": "Доступно в профессиональной версии Invoke. Нажмите здесь или посетите invoke.com/pricing для получения более подробной информации.",
|
||||
"shareAccess": "Поделиться доступом"
|
||||
},
|
||||
"system": {
|
||||
"logNamespaces": {
|
||||
"canvas": "Холст",
|
||||
"config": "Конфигурация",
|
||||
"generation": "Генерация",
|
||||
"workflows": "Рабочие процессы",
|
||||
"gallery": "Галерея",
|
||||
"models": "Модели",
|
||||
"logNamespaces": "Пространства имен логов",
|
||||
"events": "События",
|
||||
"system": "Система",
|
||||
"queue": "Очередь",
|
||||
"metadata": "Метаданные"
|
||||
},
|
||||
"enableLogging": "Включить логи",
|
||||
"logLevel": {
|
||||
"logLevel": "Уровень логов",
|
||||
"fatal": "Фатальное",
|
||||
"debug": "Отладка",
|
||||
"info": "Инфо",
|
||||
"warn": "Предупреждение",
|
||||
"error": "Ошибки",
|
||||
"trace": "Трассировка"
|
||||
}
|
||||
},
|
||||
"whatsNew": {
|
||||
"canvasV2Announcement": {
|
||||
"newLayerTypes": "Новые типы слоев для еще большего контроля",
|
||||
"readReleaseNotes": "Прочитать информацию о выпуске",
|
||||
"watchReleaseVideo": "Смотреть видео о выпуске",
|
||||
"fluxSupport": "Поддержка семейства моделей Flux",
|
||||
"newCanvas": "Новый мощный холст управления",
|
||||
"watchUiUpdatesOverview": "Обзор обновлений пользовательского интерфейса"
|
||||
},
|
||||
"whatsNewInInvoke": "Что нового в Invoke"
|
||||
},
|
||||
"newUserExperience": {
|
||||
"toGetStarted": "Чтобы начать работу, введите в поле запрос и нажмите <StrongComponent>Invoke</StrongComponent>, чтобы сгенерировать первое изображение. Выберите шаблон запроса, чтобы улучшить результаты. Вы можете сохранить изображения непосредственно в <StrongComponent>Галерею</StrongComponent> или отредактировать их на <StrongComponent>Холсте</StrongComponent>.",
|
||||
"gettingStartedSeries": "Хотите получить больше рекомендаций? Ознакомьтесь с нашей серией <LinkComponent>Getting Started Series</LinkComponent> для получения советов по раскрытию всего потенциала Invoke Studio."
|
||||
}
|
||||
}
|
||||
|
||||
@@ -4,8 +4,7 @@
|
||||
"invokeProgressBar": "Invoke förloppsmätare",
|
||||
"nextImage": "Nästa bild",
|
||||
"reset": "Starta om",
|
||||
"previousImage": "Föregående bild",
|
||||
"showOptionsPanel": "Visa inställningspanelen"
|
||||
"previousImage": "Föregående bild"
|
||||
},
|
||||
"common": {
|
||||
"hotkeysLabel": "Snabbtangenter",
|
||||
|
||||
@@ -2,7 +2,6 @@
|
||||
"accessibility": {
|
||||
"invokeProgressBar": "Invoke durum çubuğu",
|
||||
"nextImage": "Sonraki Görsel",
|
||||
"showOptionsPanel": "Yan Paneli Göster",
|
||||
"reset": "Resetle",
|
||||
"uploadImage": "Görsel Yükle",
|
||||
"previousImage": "Önceki Görsel",
|
||||
@@ -10,7 +9,6 @@
|
||||
"about": "Hakkında",
|
||||
"mode": "Kip",
|
||||
"resetUI": "$t(accessibility.reset)Arayüz",
|
||||
"showGalleryPanel": "Galeri Panelini Göster",
|
||||
"createIssue": "Sorun Bildir"
|
||||
},
|
||||
"common": {
|
||||
|
||||
@@ -114,7 +114,6 @@
|
||||
"reset": "Скинути",
|
||||
"uploadImage": "Завантажити зображення",
|
||||
"previousImage": "Попереднє зображення",
|
||||
"showOptionsPanel": "Показати опції",
|
||||
"menu": "Меню"
|
||||
}
|
||||
}
|
||||
|
||||
@@ -410,14 +410,13 @@
|
||||
"nextImage": "下一张图片",
|
||||
"uploadImage": "上传图片",
|
||||
"previousImage": "上一张图片",
|
||||
"showOptionsPanel": "显示侧栏浮窗",
|
||||
"menu": "菜单",
|
||||
"showGalleryPanel": "显示图库浮窗",
|
||||
"mode": "模式",
|
||||
"resetUI": "$t(accessibility.reset) UI",
|
||||
"createIssue": "创建问题",
|
||||
"about": "关于",
|
||||
"submitSupportTicket": "提交支持工单"
|
||||
"submitSupportTicket": "提交支持工单",
|
||||
"toggleRightPanel": "切换右侧面板(G)"
|
||||
},
|
||||
"nodes": {
|
||||
"zoomInNodes": "放大",
|
||||
|
||||
@@ -4,6 +4,7 @@ import type { StudioInitAction } from 'app/hooks/useStudioInitAction';
|
||||
import { useStudioInitAction } from 'app/hooks/useStudioInitAction';
|
||||
import { useSyncQueueStatus } from 'app/hooks/useSyncQueueStatus';
|
||||
import { useLogger } from 'app/logging/useLogger';
|
||||
import { useSyncLoggingConfig } from 'app/logging/useSyncLoggingConfig';
|
||||
import { appStarted } from 'app/store/middleware/listenerMiddleware/listeners/appStarted';
|
||||
import { useAppDispatch, useAppSelector } from 'app/store/storeHooks';
|
||||
import type { PartialAppConfig } from 'app/types/invokeai';
|
||||
@@ -13,17 +14,25 @@ import { useClearStorage } from 'common/hooks/useClearStorage';
|
||||
import { useFullscreenDropzone } from 'common/hooks/useFullscreenDropzone';
|
||||
import { useGlobalHotkeys } from 'common/hooks/useGlobalHotkeys';
|
||||
import ChangeBoardModal from 'features/changeBoardModal/components/ChangeBoardModal';
|
||||
import {
|
||||
NewCanvasSessionDialog,
|
||||
NewGallerySessionDialog,
|
||||
} from 'features/controlLayers/components/NewSessionConfirmationAlertDialog';
|
||||
import DeleteImageModal from 'features/deleteImageModal/components/DeleteImageModal';
|
||||
import { DynamicPromptsModal } from 'features/dynamicPrompts/components/DynamicPromptsPreviewModal';
|
||||
import DeleteBoardModal from 'features/gallery/components/Boards/DeleteBoardModal';
|
||||
import { ImageContextMenu } from 'features/gallery/components/ImageContextMenu/ImageContextMenu';
|
||||
import { useStarterModelsToast } from 'features/modelManagerV2/hooks/useStarterModelsToast';
|
||||
import { ShareWorkflowModal } from 'features/nodes/components/sidePanel/WorkflowListMenu/ShareWorkflowModal';
|
||||
import { ClearQueueConfirmationsAlertDialog } from 'features/queue/components/ClearQueueConfirmationAlertDialog';
|
||||
import { DeleteStylePresetDialog } from 'features/stylePresets/components/DeleteStylePresetDialog';
|
||||
import { StylePresetModal } from 'features/stylePresets/components/StylePresetForm/StylePresetModal';
|
||||
import RefreshAfterResetModal from 'features/system/components/SettingsModal/RefreshAfterResetModal';
|
||||
import { configChanged } from 'features/system/store/configSlice';
|
||||
import { selectLanguage } from 'features/system/store/systemSelectors';
|
||||
import { AppContent } from 'features/ui/components/AppContent';
|
||||
import { AnimatePresence } from 'framer-motion';
|
||||
import { DeleteWorkflowDialog } from 'features/workflowLibrary/components/DeleteLibraryWorkflowConfirmationAlertDialog';
|
||||
import { NewWorkflowConfirmationAlertDialog } from 'features/workflowLibrary/components/NewWorkflowConfirmationAlertDialog';
|
||||
import i18n from 'i18n';
|
||||
import { size } from 'lodash-es';
|
||||
import { memo, useCallback, useEffect } from 'react';
|
||||
@@ -51,6 +60,7 @@ const App = ({ config = DEFAULT_CONFIG, studioInitAction }: Props) => {
|
||||
useGlobalModifiersInit();
|
||||
useGlobalHotkeys();
|
||||
useGetOpenAPISchemaQuery();
|
||||
useSyncLoggingConfig();
|
||||
|
||||
const { dropzone, isHandlingUpload, setIsHandlingUpload } = useFullscreenDropzone();
|
||||
|
||||
@@ -84,28 +94,33 @@ const App = ({ config = DEFAULT_CONFIG, studioInitAction }: Props) => {
|
||||
<ErrorBoundary onReset={handleReset} FallbackComponent={AppErrorBoundaryFallback}>
|
||||
<Box
|
||||
id="invoke-app-wrapper"
|
||||
w="100vw"
|
||||
h="100vh"
|
||||
w="100dvw"
|
||||
h="100dvh"
|
||||
position="relative"
|
||||
overflow="hidden"
|
||||
{...dropzone.getRootProps()}
|
||||
>
|
||||
<input {...dropzone.getInputProps()} />
|
||||
<AppContent />
|
||||
<AnimatePresence>
|
||||
{dropzone.isDragActive && isHandlingUpload && (
|
||||
<ImageUploadOverlay dropzone={dropzone} setIsHandlingUpload={setIsHandlingUpload} />
|
||||
)}
|
||||
</AnimatePresence>
|
||||
{dropzone.isDragActive && isHandlingUpload && (
|
||||
<ImageUploadOverlay dropzone={dropzone} setIsHandlingUpload={setIsHandlingUpload} />
|
||||
)}
|
||||
</Box>
|
||||
<DeleteImageModal />
|
||||
<ChangeBoardModal />
|
||||
<DynamicPromptsModal />
|
||||
<StylePresetModal />
|
||||
<ClearQueueConfirmationsAlertDialog />
|
||||
<NewWorkflowConfirmationAlertDialog />
|
||||
<DeleteStylePresetDialog />
|
||||
<DeleteWorkflowDialog />
|
||||
<ShareWorkflowModal />
|
||||
<RefreshAfterResetModal />
|
||||
<DeleteBoardModal />
|
||||
<GlobalImageHotkeys />
|
||||
<NewGallerySessionDialog />
|
||||
<NewCanvasSessionDialog />
|
||||
<ImageContextMenu />
|
||||
</ErrorBoundary>
|
||||
);
|
||||
};
|
||||
|
||||
@@ -44,7 +44,7 @@ const AppErrorBoundaryFallback = ({ error, resetErrorBoundary }: Props) => {
|
||||
}, [error.message, error.name, isLocal]);
|
||||
|
||||
return (
|
||||
<Flex layerStyle="body" w="100vw" h="100vh" alignItems="center" justifyContent="center" p={4}>
|
||||
<Flex layerStyle="body" w="100dvw" h="100dvh" alignItems="center" justifyContent="center" p={4}>
|
||||
<Flex layerStyle="first" flexDir="column" borderRadius="base" justifyContent="center" gap={8} p={16}>
|
||||
<Flex alignItems="center" gap="2">
|
||||
<Image src={InvokeLogoYellow} alt="invoke-logo" w="24px" h="24px" minW="24px" minH="24px" userSelect="none" />
|
||||
|
||||
@@ -1,6 +1,7 @@
|
||||
import { skipToken } from '@reduxjs/toolkit/query';
|
||||
import { useAppSelector } from 'app/store/storeHooks';
|
||||
import { useIsRegionFocused } from 'common/hooks/focus';
|
||||
import { useAssertSingleton } from 'common/hooks/useAssertSingleton';
|
||||
import { selectIsStaging } from 'features/controlLayers/store/canvasStagingAreaSlice';
|
||||
import { useImageActions } from 'features/gallery/hooks/useImageActions';
|
||||
import { selectLastSelectedImage } from 'features/gallery/store/gallerySelectors';
|
||||
@@ -11,6 +12,7 @@ import { useGetImageDTOQuery } from 'services/api/endpoints/images';
|
||||
import type { ImageDTO } from 'services/api/types';
|
||||
|
||||
export const GlobalImageHotkeys = memo(() => {
|
||||
useAssertSingleton('GlobalImageHotkeys');
|
||||
const lastSelectedImage = useAppSelector(selectLastSelectedImage);
|
||||
const { currentData: imageDTO } = useGetImageDTOQuery(lastSelectedImage?.image_name ?? skipToken);
|
||||
|
||||
|
||||
@@ -2,6 +2,8 @@ import 'i18n';
|
||||
|
||||
import type { Middleware } from '@reduxjs/toolkit';
|
||||
import type { StudioInitAction } from 'app/hooks/useStudioInitAction';
|
||||
import type { LoggingOverrides } from 'app/logging/logger';
|
||||
import { $loggingOverrides, configureLogging } from 'app/logging/logger';
|
||||
import { $authToken } from 'app/store/nanostores/authToken';
|
||||
import { $baseUrl } from 'app/store/nanostores/baseUrl';
|
||||
import { $customNavComponent } from 'app/store/nanostores/customNavComponent';
|
||||
@@ -20,7 +22,7 @@ import Loading from 'common/components/Loading/Loading';
|
||||
import AppDndContext from 'features/dnd/components/AppDndContext';
|
||||
import type { WorkflowCategory } from 'features/nodes/types/workflow';
|
||||
import type { PropsWithChildren, ReactNode } from 'react';
|
||||
import React, { lazy, memo, useEffect, useMemo } from 'react';
|
||||
import React, { lazy, memo, useEffect, useLayoutEffect, useMemo } from 'react';
|
||||
import { Provider } from 'react-redux';
|
||||
import { addMiddleware, resetMiddlewares } from 'redux-dynamic-middlewares';
|
||||
import { $socketOptions } from 'services/events/stores';
|
||||
@@ -46,6 +48,7 @@ interface Props extends PropsWithChildren {
|
||||
isDebugging?: boolean;
|
||||
logo?: ReactNode;
|
||||
workflowCategories?: WorkflowCategory[];
|
||||
loggingOverrides?: LoggingOverrides;
|
||||
}
|
||||
|
||||
const InvokeAIUI = ({
|
||||
@@ -65,7 +68,26 @@ const InvokeAIUI = ({
|
||||
isDebugging = false,
|
||||
logo,
|
||||
workflowCategories,
|
||||
loggingOverrides,
|
||||
}: Props) => {
|
||||
useLayoutEffect(() => {
|
||||
/*
|
||||
* We need to configure logging before anything else happens - useLayoutEffect ensures we set this at the first
|
||||
* possible opportunity.
|
||||
*
|
||||
* Once redux initializes, we will check the user's settings and update the logging config accordingly. See
|
||||
* `useSyncLoggingConfig`.
|
||||
*/
|
||||
$loggingOverrides.set(loggingOverrides);
|
||||
|
||||
// Until we get the user's settings, we will use the overrides OR default values.
|
||||
configureLogging(
|
||||
loggingOverrides?.logIsEnabled ?? true,
|
||||
loggingOverrides?.logLevel ?? 'debug',
|
||||
loggingOverrides?.logNamespaces ?? '*'
|
||||
);
|
||||
}, [loggingOverrides]);
|
||||
|
||||
useEffect(() => {
|
||||
// configure API client token
|
||||
if (token) {
|
||||
|
||||
@@ -9,11 +9,11 @@ import { imageDTOToImageObject } from 'features/controlLayers/store/util';
|
||||
import { $imageViewer } from 'features/gallery/components/ImageViewer/useImageViewer';
|
||||
import { sentImageToCanvas } from 'features/gallery/store/actions';
|
||||
import { parseAndRecallAllMetadata } from 'features/metadata/util/handlers';
|
||||
import { $isWorkflowListMenuIsOpen } from 'features/nodes/store/workflowListMenu';
|
||||
import { $isStylePresetsMenuOpen, activeStylePresetIdChanged } from 'features/stylePresets/store/stylePresetSlice';
|
||||
import { toast } from 'features/toast/toast';
|
||||
import { setActiveTab } from 'features/ui/store/uiSlice';
|
||||
import { activeTabCanvasRightPanelChanged, setActiveTab } from 'features/ui/store/uiSlice';
|
||||
import { useGetAndLoadLibraryWorkflow } from 'features/workflowLibrary/hooks/useGetAndLoadLibraryWorkflow';
|
||||
import { $workflowLibraryModal } from 'features/workflowLibrary/store/isWorkflowLibraryModalOpen';
|
||||
import { useCallback, useEffect, useRef } from 'react';
|
||||
import { useTranslation } from 'react-i18next';
|
||||
import { getImageDTO, getImageMetadata } from 'services/api/endpoints/images';
|
||||
@@ -140,6 +140,7 @@ export const useStudioInitAction = (action?: StudioInitAction) => {
|
||||
case 'generation':
|
||||
// Go to the canvas tab, open the image viewer, and enable send-to-gallery mode
|
||||
store.dispatch(setActiveTab('canvas'));
|
||||
store.dispatch(activeTabCanvasRightPanelChanged('gallery'));
|
||||
store.dispatch(settingsSendToCanvasChanged(false));
|
||||
$imageViewer.set(true);
|
||||
break;
|
||||
@@ -160,7 +161,7 @@ export const useStudioInitAction = (action?: StudioInitAction) => {
|
||||
case 'viewAllWorkflows':
|
||||
// Go to the workflows tab and open the workflow library modal
|
||||
store.dispatch(setActiveTab('workflows'));
|
||||
$workflowLibraryModal.set(true);
|
||||
$isWorkflowListMenuIsOpen.set(true);
|
||||
break;
|
||||
case 'viewAllStylePresets':
|
||||
// Go to the canvas tab and open the style presets menu
|
||||
|
||||
@@ -9,11 +9,10 @@ const serializeMessage: MessageSerializer = (message) => {
|
||||
};
|
||||
|
||||
ROARR.serializeMessage = serializeMessage;
|
||||
ROARR.write = createLogWriter();
|
||||
|
||||
export const BASE_CONTEXT = {};
|
||||
const BASE_CONTEXT = {};
|
||||
|
||||
export const $logger = atom<Logger>(Roarr.child(BASE_CONTEXT));
|
||||
const $logger = atom<Logger>(Roarr.child(BASE_CONTEXT));
|
||||
|
||||
export const zLogNamespace = z.enum([
|
||||
'canvas',
|
||||
@@ -35,8 +34,22 @@ export const zLogLevel = z.enum(['trace', 'debug', 'info', 'warn', 'error', 'fat
|
||||
export type LogLevel = z.infer<typeof zLogLevel>;
|
||||
export const isLogLevel = (v: unknown): v is LogLevel => zLogLevel.safeParse(v).success;
|
||||
|
||||
/**
|
||||
* Override logging settings.
|
||||
* @property logIsEnabled Override the enabled log state. Omit to use the user's settings.
|
||||
* @property logNamespaces Override the enabled log namespaces. Use `"*"` for all namespaces. Omit to use the user's settings.
|
||||
* @property logLevel Override the log level. Omit to use the user's settings.
|
||||
*/
|
||||
export type LoggingOverrides = {
|
||||
logIsEnabled?: boolean;
|
||||
logNamespaces?: LogNamespace[] | '*';
|
||||
logLevel?: LogLevel;
|
||||
};
|
||||
|
||||
export const $loggingOverrides = atom<LoggingOverrides | undefined>();
|
||||
|
||||
// Translate human-readable log levels to numbers, used for log filtering
|
||||
export const LOG_LEVEL_MAP: Record<LogLevel, number> = {
|
||||
const LOG_LEVEL_MAP: Record<LogLevel, number> = {
|
||||
trace: 10,
|
||||
debug: 20,
|
||||
info: 30,
|
||||
@@ -44,3 +57,40 @@ export const LOG_LEVEL_MAP: Record<LogLevel, number> = {
|
||||
error: 50,
|
||||
fatal: 60,
|
||||
};
|
||||
|
||||
/**
|
||||
* Configure logging, pushing settings to local storage.
|
||||
*
|
||||
* @param logIsEnabled Whether logging is enabled
|
||||
* @param logLevel The log level
|
||||
* @param logNamespaces A list of log namespaces to enable, or '*' to enable all
|
||||
*/
|
||||
export const configureLogging = (
|
||||
logIsEnabled: boolean = true,
|
||||
logLevel: LogLevel = 'warn',
|
||||
logNamespaces: LogNamespace[] | '*'
|
||||
): void => {
|
||||
if (!logIsEnabled) {
|
||||
// Disable console log output
|
||||
localStorage.setItem('ROARR_LOG', 'false');
|
||||
} else {
|
||||
// Enable console log output
|
||||
localStorage.setItem('ROARR_LOG', 'true');
|
||||
|
||||
// Use a filter to show only logs of the given level
|
||||
let filter = `context.logLevel:>=${LOG_LEVEL_MAP[logLevel]}`;
|
||||
|
||||
const namespaces = logNamespaces === '*' ? zLogNamespace.options : logNamespaces;
|
||||
|
||||
if (namespaces.length > 0) {
|
||||
filter += ` AND (${namespaces.map((ns) => `context.namespace:${ns}`).join(' OR ')})`;
|
||||
} else {
|
||||
// This effectively hides all logs because we use namespaces for all logs
|
||||
filter += ' AND context.namespace:undefined';
|
||||
}
|
||||
|
||||
localStorage.setItem('ROARR_FILTER', filter);
|
||||
}
|
||||
|
||||
ROARR.write = createLogWriter();
|
||||
};
|
||||
|
||||
@@ -1,53 +1,9 @@
|
||||
import { createLogWriter } from '@roarr/browser-log-writer';
|
||||
import { useAppSelector } from 'app/store/storeHooks';
|
||||
import {
|
||||
selectSystemLogIsEnabled,
|
||||
selectSystemLogLevel,
|
||||
selectSystemLogNamespaces,
|
||||
} from 'features/system/store/systemSlice';
|
||||
import { useEffect, useMemo } from 'react';
|
||||
import { ROARR, Roarr } from 'roarr';
|
||||
import { useMemo } from 'react';
|
||||
|
||||
import type { LogNamespace } from './logger';
|
||||
import { $logger, BASE_CONTEXT, LOG_LEVEL_MAP, logger } from './logger';
|
||||
import { logger } from './logger';
|
||||
|
||||
export const useLogger = (namespace: LogNamespace) => {
|
||||
const logLevel = useAppSelector(selectSystemLogLevel);
|
||||
const logNamespaces = useAppSelector(selectSystemLogNamespaces);
|
||||
const logIsEnabled = useAppSelector(selectSystemLogIsEnabled);
|
||||
|
||||
// The provided Roarr browser log writer uses localStorage to config logging to console
|
||||
useEffect(() => {
|
||||
if (logIsEnabled) {
|
||||
// Enable console log output
|
||||
localStorage.setItem('ROARR_LOG', 'true');
|
||||
|
||||
// Use a filter to show only logs of the given level
|
||||
let filter = `context.logLevel:>=${LOG_LEVEL_MAP[logLevel]}`;
|
||||
if (logNamespaces.length > 0) {
|
||||
filter += ` AND (${logNamespaces.map((ns) => `context.namespace:${ns}`).join(' OR ')})`;
|
||||
} else {
|
||||
filter += ' AND context.namespace:undefined';
|
||||
}
|
||||
localStorage.setItem('ROARR_FILTER', filter);
|
||||
} else {
|
||||
// Disable console log output
|
||||
localStorage.setItem('ROARR_LOG', 'false');
|
||||
}
|
||||
ROARR.write = createLogWriter();
|
||||
}, [logLevel, logIsEnabled, logNamespaces]);
|
||||
|
||||
// Update the module-scoped logger context as needed
|
||||
useEffect(() => {
|
||||
// TODO: type this properly
|
||||
//eslint-disable-next-line @typescript-eslint/no-explicit-any
|
||||
const newContext: Record<string, any> = {
|
||||
...BASE_CONTEXT,
|
||||
};
|
||||
|
||||
$logger.set(Roarr.child(newContext));
|
||||
}, []);
|
||||
|
||||
const log = useMemo(() => logger(namespace), [namespace]);
|
||||
|
||||
return log;
|
||||
|
||||
@@ -0,0 +1,43 @@
|
||||
import { useStore } from '@nanostores/react';
|
||||
import { $loggingOverrides, configureLogging } from 'app/logging/logger';
|
||||
import { useAppSelector } from 'app/store/storeHooks';
|
||||
import { useAssertSingleton } from 'common/hooks/useAssertSingleton';
|
||||
import {
|
||||
selectSystemLogIsEnabled,
|
||||
selectSystemLogLevel,
|
||||
selectSystemLogNamespaces,
|
||||
} from 'features/system/store/systemSlice';
|
||||
import { useLayoutEffect } from 'react';
|
||||
|
||||
/**
|
||||
* This hook synchronizes the logging configuration stored in Redux with the logging system, which uses localstorage.
|
||||
*
|
||||
* The sync is one-way: from Redux to localstorage. This means that changes made in the UI will be reflected in the
|
||||
* logging system, but changes made directly to localstorage will not be reflected in the UI.
|
||||
*
|
||||
* See {@link configureLogging}
|
||||
*/
|
||||
export const useSyncLoggingConfig = () => {
|
||||
useAssertSingleton('useSyncLoggingConfig');
|
||||
|
||||
const loggingOverrides = useStore($loggingOverrides);
|
||||
|
||||
const logLevel = useAppSelector(selectSystemLogLevel);
|
||||
const logNamespaces = useAppSelector(selectSystemLogNamespaces);
|
||||
const logIsEnabled = useAppSelector(selectSystemLogIsEnabled);
|
||||
|
||||
useLayoutEffect(() => {
|
||||
configureLogging(
|
||||
loggingOverrides?.logIsEnabled ?? logIsEnabled,
|
||||
loggingOverrides?.logLevel ?? logLevel,
|
||||
loggingOverrides?.logNamespaces ?? logNamespaces
|
||||
);
|
||||
}, [
|
||||
logIsEnabled,
|
||||
logLevel,
|
||||
logNamespaces,
|
||||
loggingOverrides?.logIsEnabled,
|
||||
loggingOverrides?.logLevel,
|
||||
loggingOverrides?.logNamespaces,
|
||||
]);
|
||||
};
|
||||
@@ -1,3 +1,4 @@
|
||||
export const STORAGE_PREFIX = '@@invokeai-';
|
||||
export const EMPTY_ARRAY = [];
|
||||
/** @knipignore */
|
||||
export const EMPTY_OBJECT = {};
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user