mirror of
https://github.com/nod-ai/SHARK-Studio.git
synced 2026-01-12 23:38:12 -05:00
Compare commits
1 Commits
20230302.5
...
enable_cac
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
6d6a9dcae8 |
21
.github/workflows/nightly.yml
vendored
21
.github/workflows/nightly.yml
vendored
@@ -14,7 +14,7 @@ jobs:
|
||||
strategy:
|
||||
fail-fast: false
|
||||
matrix:
|
||||
python-version: ["3.11"]
|
||||
python-version: ["3.10"]
|
||||
|
||||
steps:
|
||||
- uses: actions/checkout@v2
|
||||
@@ -44,20 +44,18 @@ jobs:
|
||||
body: |
|
||||
Automatic snapshot release of nod.ai SHARK.
|
||||
draft: true
|
||||
prerelease: true
|
||||
prerelease: false
|
||||
|
||||
- name: Build Package
|
||||
shell: powershell
|
||||
run: |
|
||||
./setup_venv.ps1
|
||||
python process_skipfiles.py
|
||||
pyinstaller .\apps\stable_diffusion\shark_sd.spec
|
||||
mv ./dist/shark_sd.exe ./dist/shark_sd_${{ env.package_version_ }}.exe
|
||||
signtool sign /f c:\g\shark_02152023.cer /csp "eToken Base Cryptographic Provider" /k "${{ secrets.CI_CERT }}" ./dist/shark_sd_${{ env.package_version_ }}.exe
|
||||
signtool sign /f C:\shark_2023.cer /csp "eToken Base Cryptographic Provider" /k "${{ secrets.CI_CERT }}" ./dist/shark_sd_${{ env.package_version_ }}.exe
|
||||
pyinstaller .\apps\stable_diffusion\shark_sd_cli.spec
|
||||
python process_skipfiles.py
|
||||
mv ./dist/shark_sd_cli.exe ./dist/shark_sd_cli_${{ env.package_version_ }}.exe
|
||||
signtool sign /f c:\g\shark_02152023.cer /csp "eToken Base Cryptographic Provider" /k "${{ secrets.CI_CERT }}" ./dist/shark_sd_cli_${{ env.package_version_ }}.exe
|
||||
signtool sign /f C:\shark_2023.cer /csp "eToken Base Cryptographic Provider" /k "${{ secrets.CI_CERT }}" ./dist/shark_sd_cli_${{ env.package_version_ }}.exe
|
||||
|
||||
|
||||
# GHA windows VM OOMs so disable for now
|
||||
@@ -67,9 +65,9 @@ jobs:
|
||||
# $env:SHARK_PACKAGE_VERSION=${{ env.package_version }}
|
||||
# pip wheel -v -w dist . --pre -f https://download.pytorch.org/whl/nightly/torch -f https://llvm.github.io/torch-mlir/package-index/ -f https://nod-ai.github.io/SHARK-Runtime/pip-release-links.html
|
||||
|
||||
#- uses: actions/upload-artifact@v2
|
||||
# with:
|
||||
# path: dist/*
|
||||
- uses: actions/upload-artifact@v2
|
||||
with:
|
||||
path: dist/*
|
||||
|
||||
- name: Upload Release Assets
|
||||
id: upload-release-assets
|
||||
@@ -79,7 +77,6 @@ jobs:
|
||||
with:
|
||||
release_id: ${{ steps.create_release.outputs.id }}
|
||||
assets_path: ./dist/*
|
||||
#asset_content_type: application/vnd.microsoft.portable-executable
|
||||
|
||||
- name: Publish Release
|
||||
id: publish_release
|
||||
@@ -95,7 +92,7 @@ jobs:
|
||||
strategy:
|
||||
fail-fast: false
|
||||
matrix:
|
||||
python-version: ["3.11"]
|
||||
python-version: ["3.10"]
|
||||
backend: [IREE, SHARK]
|
||||
|
||||
steps:
|
||||
@@ -134,7 +131,7 @@ jobs:
|
||||
source iree.venv/bin/activate
|
||||
package_version="$(printf '%(%Y%m%d)T.${{ github.run_number }}')"
|
||||
SHARK_PACKAGE_VERSION=${package_version} \
|
||||
pip wheel -v -w wheelhouse . --pre -f https://download.pytorch.org/whl/nightly/torch -f https://llvm.github.io/torch-mlir/package-index/ -f https://openxla.github.io/iree/pip-release-links.html
|
||||
pip wheel -v -w wheelhouse . --pre -f https://download.pytorch.org/whl/nightly/torch -f https://llvm.github.io/torch-mlir/package-index/ -f https://iree-org.github.io/iree/pip-release-links.html
|
||||
# Install the built wheel
|
||||
pip install ./wheelhouse/nodai*
|
||||
# Validate the Models
|
||||
|
||||
6
.github/workflows/test-models.yml
vendored
6
.github/workflows/test-models.yml
vendored
@@ -31,7 +31,7 @@ jobs:
|
||||
matrix:
|
||||
os: [7950x, icelake, a100, MacStudio, ubuntu-latest]
|
||||
suite: [cpu,cuda,vulkan]
|
||||
python-version: ["3.11"]
|
||||
python-version: ["3.10"]
|
||||
include:
|
||||
- os: ubuntu-latest
|
||||
suite: lint
|
||||
@@ -151,10 +151,12 @@ jobs:
|
||||
if: matrix.suite == 'vulkan' && matrix.os == '7950x'
|
||||
run: |
|
||||
./setup_venv.ps1
|
||||
pytest -k vulkan -s
|
||||
pytest --benchmark -k vulkan -s
|
||||
type bench_results.csv
|
||||
|
||||
- name: Validate Stable Diffusion Models (Windows)
|
||||
if: matrix.suite == 'vulkan' && matrix.os == '7950x'
|
||||
run: |
|
||||
./setup_venv.ps1
|
||||
./shark.venv/Scripts/activate
|
||||
python build_tools/stable_diffusion_testing.py --device=vulkan
|
||||
|
||||
57
README.md
57
README.md
@@ -10,7 +10,7 @@ High Performance Machine Learning Distribution
|
||||
<summary>Prerequisites - Drivers </summary>
|
||||
|
||||
#### Install your Windows hardware drivers
|
||||
* [AMD RDNA Users] Download the latest driver [here](https://www.amd.com/en/support/kb/release-notes/rn-rad-win-23-2-1).
|
||||
* [AMD RDNA Users] Download this specific driver [here](https://www.amd.com/en/support/kb/release-notes/rn-rad-win-22-11-1-mril-iree). Latest drivers may not work.
|
||||
* [macOS Users] Download and install the 1.3.216 Vulkan SDK from [here](https://sdk.lunarg.com/sdk/download/1.3.216.0/mac/vulkansdk-macos-1.3.216.0.dmg). Newer versions of the SDK will not work.
|
||||
* [Nvidia Users] Download and install the latest CUDA / Vulkan drivers from [here](https://developer.nvidia.com/cuda-downloads)
|
||||
|
||||
@@ -25,32 +25,18 @@ Other users please ensure you have your latest vendor drivers and Vulkan SDK fro
|
||||
|
||||
### Quick Start for SHARK Stable Diffusion for Windows 10/11 Users
|
||||
|
||||
Install the Driver from [Prerequisites](https://github.com/nod-ai/SHARK#install-your-hardware-drivers) above
|
||||
Install Driver from [Prerequisites](https://github.com/nod-ai/SHARK#install-your-hardware-drivers) above
|
||||
|
||||
Download the [stable release](https://github.com/nod-ai/shark/releases/latest)
|
||||
Download the latest .exe https://github.com/nod-ai/SHARK/releases.
|
||||
|
||||
Double click the .exe and you should have the [UI](http://localhost:8080/) in the browser.
|
||||
Double click the .exe and you should have the [UI]( http://localhost:8080/?__theme=dark) in the browser.
|
||||
|
||||
If you have custom models put them in a `models/` directory where the .exe is.
|
||||
If you have custom models (ckpt, safetensors) put in a `models/` directory where the .exe is.
|
||||
|
||||
Enjoy.
|
||||
|
||||
<details>
|
||||
<summary>More installation notes</summary>
|
||||
* We recommend that you download EXE in a new folder, whenever you download a new EXE version. If you download it in the same folder as a previous install, you must delete the old `*.vmfb` files with `rm *.vmfb`. You can also use `--clear_all` flag once to clean all the old files.
|
||||
* If you recently updated the driver or this binary (EXE file), we recommend you clear all the local artifacts with `--clear_all`
|
||||
Some known AMD Driver quirks and fixes with cursors are documented [here](https://github.com/nod-ai/SHARK/blob/main/apps/stable_diffusion/stable_diffusion_amd.md ).
|
||||
|
||||
## Running
|
||||
|
||||
* Open a Command Prompt or Powershell terminal, change folder (`cd`) to the .exe folder. Then run the EXE from the command prompt. That way, if an error occurs, you'll be able to cut-and-paste it to ask for help. (if it always works for you without error, you may simply double-click the EXE)
|
||||
* The first run may take few minutes when the models are downloaded and compiled. Your patience is appreciated. The download could be about 5GB.
|
||||
* You will likely see a Windows Defender message asking you to give permission to open a web server port. Accept it.
|
||||
* Open a browser to access the Stable Diffusion web server. By default, the port is 8080, so you can go to http://localhost:8080/.
|
||||
|
||||
## Stopping
|
||||
|
||||
* Select the command prompt that's running the EXE. Press CTRL-C and wait a moment or close the terminal.
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>Advanced Installation (Only for developers)</summary>
|
||||
@@ -68,7 +54,7 @@ cd SHARK
|
||||
|
||||
### Windows 10/11 Users
|
||||
|
||||
* Install the latest Python 3.11.x version from [here](https://www.python.org/downloads/windows/)
|
||||
* Install the latest Python 3.10.x version from [here](https://www.python.org/downloads/windows/)
|
||||
|
||||
* Install Git for Windows from [here](https://git-scm.com/download/win)
|
||||
|
||||
@@ -119,15 +105,16 @@ source shark.venv/bin/activate
|
||||
|
||||
#### Linux / macOS Users
|
||||
```shell
|
||||
python3.11 apps/stable_diffusion/scripts/txt2img.py --precision=fp16 --device=vulkan --prompt="tajmahal, oil on canvas, sunflowers, 4k, uhd"
|
||||
python3.10 apps/stable_diffusion/scripts/txt2img.py --precision=fp16 --device=vulkan --prompt="tajmahal, oil on canvas, sunflowers, 4k, uhd"
|
||||
```
|
||||
|
||||
You can replace `vulkan` with `cpu` to run on your CPU or with `cuda` to run on CUDA devices. If you have multiple vulkan devices you can address them with `--device=vulkan://1` etc
|
||||
</details>
|
||||
|
||||
The output on a AMD 7900XTX would look something like:
|
||||
The output on a 7900XTX would like:
|
||||
|
||||
```shell
|
||||
```shell
|
||||
Stats for run 0:
|
||||
Average step time: 47.19188690185547ms/it
|
||||
Clip Inference time (ms) = 109.531
|
||||
VAE Inference time (ms): 78.590
|
||||
@@ -153,7 +140,7 @@ Find us on [SHARK Discord server](https://discord.gg/RUqY2h2s9u) if you have any
|
||||
This step sets up a new VirtualEnv for Python
|
||||
|
||||
```shell
|
||||
python --version #Check you have 3.11 on Linux, macOS or Windows Powershell
|
||||
python --version #Check you have 3.10 on Linux, macOS or Windows Powershell
|
||||
python -m venv shark_venv
|
||||
source shark_venv/bin/activate # Use shark_venv/Scripts/activate on Windows
|
||||
|
||||
@@ -167,7 +154,7 @@ python -m pip install --upgrade pip
|
||||
|
||||
### Install SHARK
|
||||
|
||||
This step pip installs SHARK and related packages on Linux Python 3.8, 3.10 and 3.11 and macOS / Windows Python 3.11
|
||||
This step pip installs SHARK and related packages on Linux Python 3.7, 3.8, 3.9, 3.10 and macOS Python 3.10
|
||||
|
||||
```shell
|
||||
pip install nodai-shark -f https://nod-ai.github.io/SHARK/package-index/ -f https://llvm.github.io/torch-mlir/package-index/ -f https://nod-ai.github.io/SHARK-Runtime/pip-release-links.html --extra-index-url https://download.pytorch.org/whl/nightly/cpu
|
||||
@@ -202,10 +189,10 @@ python ./minilm_jit.py --device="cpu" #use cuda or vulkan or metal
|
||||
<details>
|
||||
<summary>Development, Testing and Benchmarks</summary>
|
||||
|
||||
If you want to use Python3.11 and with TF Import tools you can use the environment variables like:
|
||||
If you want to use Python3.10 and with TF Import tools you can use the environment variables like:
|
||||
Set `USE_IREE=1` to use upstream IREE
|
||||
```
|
||||
# PYTHON=python3.11 VENV_DIR=0617_venv IMPORTER=1 ./setup_venv.sh
|
||||
# PYTHON=python3.10 VENV_DIR=0617_venv IMPORTER=1 ./setup_venv.sh
|
||||
```
|
||||
|
||||
### Run any of the hundreds of SHARK tank models via the test framework
|
||||
@@ -215,14 +202,14 @@ python -m shark.examples.shark_inference.resnet50_script --device="cpu" # Use g
|
||||
pytest tank/test_models.py -k "MiniLM"
|
||||
```
|
||||
|
||||
### How to use your locally built IREE / Torch-MLIR with SHARK
|
||||
|
||||
If you are a *Torch-mlir developer or an IREE developer* and want to test local changes you can uninstall
|
||||
the provided packages with `pip uninstall torch-mlir` and / or `pip uninstall iree-compiler iree-runtime` and build locally
|
||||
with Python bindings and set your PYTHONPATH as mentioned [here](https://github.com/iree-org/iree/tree/main/docs/api_docs/python#install-iree-binaries)
|
||||
for IREE and [here](https://github.com/llvm/torch-mlir/blob/main/development.md#setup-python-environment-to-export-the-built-python-packages)
|
||||
for Torch-MLIR.
|
||||
|
||||
How to use your locally built Torch-MLIR with SHARK:
|
||||
### How to use your locally built Torch-MLIR with SHARK
|
||||
```shell
|
||||
1.) Run `./setup_venv.sh in SHARK` and activate `shark.venv` virtual env.
|
||||
2.) Run `pip uninstall torch-mlir`.
|
||||
@@ -240,15 +227,9 @@ Now the SHARK will use your locally build Torch-MLIR repo.
|
||||
|
||||
## Benchmarking Dispatches
|
||||
|
||||
To produce benchmarks of individual dispatches, you can add `--dispatch_benchmarks=All --dispatch_benchmarks_dir=<output_dir>` to your pytest command line argument.
|
||||
To produce benchmarks of individual dispatches, you can add `--dispatch_benchmarks=All --dispatch_benchmarks_dir=<output_dir>` to your command line argument.
|
||||
If you only want to compile specific dispatches, you can specify them with a space seperated string instead of `"All"`. E.G. `--dispatch_benchmarks="0 1 2 10"`
|
||||
|
||||
For example, to generate and run dispatch benchmarks for MiniLM on CUDA:
|
||||
```
|
||||
pytest -k "MiniLM and torch and static and cuda" --benchmark_dispatches=All -s --dispatch_benchmarks_dir=./my_dispatch_benchmarks
|
||||
```
|
||||
The given command will populate `<dispatch_benchmarks_dir>/<model_name>/` with an `ordered_dispatches.txt` that lists and orders the dispatches and their latencies, as well as folders for each dispatch that contain .mlir, .vmfb, and results of the benchmark for that dispatch.
|
||||
|
||||
if you want to instead incorporate this into a python script, you can pass the `dispatch_benchmarks` and `dispatch_benchmarks_dir` commands when initializing `SharkInference`, and the benchmarks will be generated when compiled. E.G:
|
||||
|
||||
```
|
||||
@@ -272,7 +253,7 @@ Output will include:
|
||||
- A .txt file containing benchmark output
|
||||
|
||||
|
||||
See tank/README.md for further instructions on how to run model tests and benchmarks from the SHARK tank.
|
||||
See tank/README.md for instructions on how to run model tests and benchmarks from the SHARK tank.
|
||||
|
||||
</details>
|
||||
|
||||
|
||||
@@ -1,4 +1 @@
|
||||
from apps.stable_diffusion.scripts.txt2img import txt2img_inf
|
||||
from apps.stable_diffusion.scripts.img2img import img2img_inf
|
||||
from apps.stable_diffusion.scripts.inpaint import inpaint_inf
|
||||
from apps.stable_diffusion.scripts.outpaint import outpaint_inf
|
||||
|
||||
@@ -1,327 +0,0 @@
|
||||
import sys
|
||||
import torch
|
||||
import time
|
||||
from PIL import Image
|
||||
from dataclasses import dataclass
|
||||
from apps.stable_diffusion.src import (
|
||||
args,
|
||||
Image2ImagePipeline,
|
||||
StencilPipeline,
|
||||
get_schedulers,
|
||||
set_init_device_flags,
|
||||
utils,
|
||||
clear_all,
|
||||
save_output_img,
|
||||
)
|
||||
|
||||
|
||||
@dataclass
|
||||
class Config:
|
||||
model_id: str
|
||||
ckpt_loc: str
|
||||
precision: str
|
||||
batch_size: int
|
||||
max_length: int
|
||||
height: int
|
||||
width: int
|
||||
device: str
|
||||
use_stencil: str
|
||||
|
||||
|
||||
img2img_obj = None
|
||||
config_obj = None
|
||||
schedulers = None
|
||||
|
||||
|
||||
# Exposed to UI.
|
||||
def img2img_inf(
|
||||
prompt: str,
|
||||
negative_prompt: str,
|
||||
init_image: Image,
|
||||
height: int,
|
||||
width: int,
|
||||
steps: int,
|
||||
strength: float,
|
||||
guidance_scale: float,
|
||||
seed: int,
|
||||
batch_count: int,
|
||||
batch_size: int,
|
||||
scheduler: str,
|
||||
custom_model: str,
|
||||
hf_model_id: str,
|
||||
precision: str,
|
||||
device: str,
|
||||
max_length: int,
|
||||
use_stencil: str,
|
||||
save_metadata_to_json: bool,
|
||||
save_metadata_to_png: bool,
|
||||
):
|
||||
global img2img_obj
|
||||
global config_obj
|
||||
global schedulers
|
||||
|
||||
args.prompts = [prompt]
|
||||
args.negative_prompts = [negative_prompt]
|
||||
args.guidance_scale = guidance_scale
|
||||
args.seed = seed
|
||||
args.steps = steps
|
||||
args.strength = strength
|
||||
args.scheduler = scheduler
|
||||
args.img_path = "not none"
|
||||
|
||||
if init_image is None:
|
||||
return None, "An Initial Image is required"
|
||||
image = init_image.convert("RGB")
|
||||
|
||||
# set ckpt_loc and hf_model_id.
|
||||
types = (
|
||||
".ckpt",
|
||||
".safetensors",
|
||||
) # the tuple of file types
|
||||
args.ckpt_loc = ""
|
||||
args.hf_model_id = ""
|
||||
if custom_model == "None":
|
||||
if not hf_model_id:
|
||||
return (
|
||||
None,
|
||||
"Please provide either custom model or huggingface model ID, both must not be empty",
|
||||
)
|
||||
args.hf_model_id = hf_model_id
|
||||
elif ".ckpt" in custom_model or ".safetensors" in custom_model:
|
||||
args.ckpt_loc = custom_model
|
||||
else:
|
||||
args.hf_model_id = custom_model
|
||||
|
||||
args.save_metadata_to_json = save_metadata_to_json
|
||||
args.write_metadata_to_png = save_metadata_to_png
|
||||
|
||||
use_stencil = None if use_stencil == "None" else use_stencil
|
||||
args.use_stencil = use_stencil
|
||||
if use_stencil is not None:
|
||||
args.scheduler = "DDIM"
|
||||
args.hf_model_id = "runwayml/stable-diffusion-v1-5"
|
||||
elif args.scheduler != "PNDM":
|
||||
if "Shark" in args.scheduler:
|
||||
print(
|
||||
f"SharkEulerDiscrete scheduler not supported. Switching to PNDM scheduler"
|
||||
)
|
||||
args.scheduler = "PNDM"
|
||||
else:
|
||||
sys.exit(
|
||||
"Img2Img works best with PNDM scheduler. Other schedulers are not supported yet."
|
||||
)
|
||||
cpu_scheduling = not args.scheduler.startswith("Shark")
|
||||
args.precision = precision
|
||||
dtype = torch.float32 if precision == "fp32" else torch.half
|
||||
new_config_obj = Config(
|
||||
args.hf_model_id,
|
||||
args.ckpt_loc,
|
||||
precision,
|
||||
batch_size,
|
||||
max_length,
|
||||
height,
|
||||
width,
|
||||
device,
|
||||
use_stencil,
|
||||
)
|
||||
if not img2img_obj or config_obj != new_config_obj:
|
||||
config_obj = new_config_obj
|
||||
args.batch_size = batch_size
|
||||
args.max_length = max_length
|
||||
args.height = height
|
||||
args.width = width
|
||||
args.device = device.split("=>", 1)[1].strip()
|
||||
args.iree_vulkan_target_triple = ""
|
||||
args.use_tuned = True
|
||||
args.import_mlir = True
|
||||
set_init_device_flags()
|
||||
model_id = (
|
||||
args.hf_model_id
|
||||
if args.hf_model_id
|
||||
else "stabilityai/stable-diffusion-2-1-base"
|
||||
)
|
||||
schedulers = get_schedulers(model_id)
|
||||
scheduler_obj = schedulers[scheduler]
|
||||
if use_stencil is not None:
|
||||
args.use_tuned = False
|
||||
img2img_obj = StencilPipeline.from_pretrained(
|
||||
scheduler_obj,
|
||||
args.import_mlir,
|
||||
args.hf_model_id,
|
||||
args.ckpt_loc,
|
||||
args.custom_vae,
|
||||
args.precision,
|
||||
args.max_length,
|
||||
args.batch_size,
|
||||
args.height,
|
||||
args.width,
|
||||
args.use_base_vae,
|
||||
args.use_tuned,
|
||||
low_cpu_mem_usage=args.low_cpu_mem_usage,
|
||||
use_stencil=use_stencil,
|
||||
)
|
||||
else:
|
||||
img2img_obj = Image2ImagePipeline.from_pretrained(
|
||||
scheduler_obj,
|
||||
args.import_mlir,
|
||||
args.hf_model_id,
|
||||
args.ckpt_loc,
|
||||
args.custom_vae,
|
||||
args.precision,
|
||||
args.max_length,
|
||||
args.batch_size,
|
||||
args.height,
|
||||
args.width,
|
||||
args.use_base_vae,
|
||||
args.use_tuned,
|
||||
low_cpu_mem_usage=args.low_cpu_mem_usage,
|
||||
)
|
||||
|
||||
img2img_obj.scheduler = schedulers[scheduler]
|
||||
|
||||
start_time = time.time()
|
||||
img2img_obj.log = ""
|
||||
generated_imgs = []
|
||||
seeds = []
|
||||
img_seed = utils.sanitize_seed(seed)
|
||||
extra_info = {"STRENGTH": strength}
|
||||
for current_batch in range(batch_count):
|
||||
if current_batch > 0:
|
||||
img_seed = utils.sanitize_seed(-1)
|
||||
out_imgs = img2img_obj.generate_images(
|
||||
prompt,
|
||||
negative_prompt,
|
||||
image,
|
||||
batch_size,
|
||||
height,
|
||||
width,
|
||||
steps,
|
||||
strength,
|
||||
guidance_scale,
|
||||
img_seed,
|
||||
args.max_length,
|
||||
dtype,
|
||||
args.use_base_vae,
|
||||
cpu_scheduling,
|
||||
use_stencil=use_stencil,
|
||||
)
|
||||
save_output_img(out_imgs[0], img_seed, extra_info)
|
||||
generated_imgs.extend(out_imgs)
|
||||
seeds.append(img_seed)
|
||||
img2img_obj.log += "\n"
|
||||
|
||||
total_time = time.time() - start_time
|
||||
text_output = f"prompt={args.prompts}"
|
||||
text_output += f"\nnegative prompt={args.negative_prompts}"
|
||||
text_output += f"\nmodel_id={args.hf_model_id}, ckpt_loc={args.ckpt_loc}"
|
||||
text_output += f"\nscheduler={args.scheduler}, device={device}"
|
||||
text_output += f"\nsteps={steps}, strength={args.strength}, guidance_scale={guidance_scale}, seed={seeds}"
|
||||
text_output += f"\nsize={height}x{width}, batch_count={batch_count}, batch_size={batch_size}, max_length={args.max_length}"
|
||||
text_output += img2img_obj.log
|
||||
text_output += f"\nTotal image generation time: {total_time:.4f}sec"
|
||||
|
||||
return generated_imgs, text_output
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
if args.clear_all:
|
||||
clear_all()
|
||||
|
||||
if args.img_path is None:
|
||||
print("Flag --img_path is required.")
|
||||
exit()
|
||||
|
||||
# When the models get uploaded, it should be default to False.
|
||||
args.import_mlir = True
|
||||
|
||||
use_stencil = args.use_stencil
|
||||
if use_stencil:
|
||||
args.scheduler = "DDIM"
|
||||
args.hf_model_id = "runwayml/stable-diffusion-v1-5"
|
||||
elif args.scheduler != "PNDM":
|
||||
if "Shark" in args.scheduler:
|
||||
print(
|
||||
f"SharkEulerDiscrete scheduler not supported. Switching to PNDM scheduler"
|
||||
)
|
||||
args.scheduler = "PNDM"
|
||||
else:
|
||||
sys.exit(
|
||||
"Img2Img works best with PNDM scheduler. Other schedulers are not supported yet."
|
||||
)
|
||||
cpu_scheduling = not args.scheduler.startswith("Shark")
|
||||
dtype = torch.float32 if args.precision == "fp32" else torch.half
|
||||
set_init_device_flags()
|
||||
schedulers = get_schedulers(args.hf_model_id)
|
||||
|
||||
scheduler_obj = schedulers[args.scheduler]
|
||||
image = Image.open(args.img_path).convert("RGB")
|
||||
seed = utils.sanitize_seed(args.seed)
|
||||
# Adjust for height and width based on model
|
||||
|
||||
if use_stencil:
|
||||
img2img_obj = StencilPipeline.from_pretrained(
|
||||
scheduler_obj,
|
||||
args.import_mlir,
|
||||
args.hf_model_id,
|
||||
args.ckpt_loc,
|
||||
args.custom_vae,
|
||||
args.precision,
|
||||
args.max_length,
|
||||
args.batch_size,
|
||||
args.height,
|
||||
args.width,
|
||||
args.use_base_vae,
|
||||
args.use_tuned,
|
||||
low_cpu_mem_usage=args.low_cpu_mem_usage,
|
||||
use_stencil=use_stencil,
|
||||
)
|
||||
else:
|
||||
img2img_obj = Image2ImagePipeline.from_pretrained(
|
||||
scheduler_obj,
|
||||
args.import_mlir,
|
||||
args.hf_model_id,
|
||||
args.ckpt_loc,
|
||||
args.custom_vae,
|
||||
args.precision,
|
||||
args.max_length,
|
||||
args.batch_size,
|
||||
args.height,
|
||||
args.width,
|
||||
args.use_base_vae,
|
||||
args.use_tuned,
|
||||
low_cpu_mem_usage=args.low_cpu_mem_usage,
|
||||
)
|
||||
|
||||
start_time = time.time()
|
||||
generated_imgs = img2img_obj.generate_images(
|
||||
args.prompts,
|
||||
args.negative_prompts,
|
||||
image,
|
||||
args.batch_size,
|
||||
args.height,
|
||||
args.width,
|
||||
args.steps,
|
||||
args.strength,
|
||||
args.guidance_scale,
|
||||
seed,
|
||||
args.max_length,
|
||||
dtype,
|
||||
args.use_base_vae,
|
||||
cpu_scheduling,
|
||||
use_stencil=use_stencil,
|
||||
)
|
||||
total_time = time.time() - start_time
|
||||
text_output = f"prompt={args.prompts}"
|
||||
text_output += f"\nnegative prompt={args.negative_prompts}"
|
||||
text_output += f"\nmodel_id={args.hf_model_id}, ckpt_loc={args.ckpt_loc}"
|
||||
text_output += f"\nscheduler={args.scheduler}, device={args.device}"
|
||||
text_output += f"\nsteps={args.steps}, strength={args.strength}, guidance_scale={args.guidance_scale}, seed={seed}, size={args.height}x{args.width}"
|
||||
text_output += (
|
||||
f", batch size={args.batch_size}, max_length={args.max_length}"
|
||||
)
|
||||
text_output += img2img_obj.log
|
||||
text_output += f"\nTotal image generation time: {total_time:.4f}sec"
|
||||
|
||||
extra_info = {"STRENGTH": args.strength}
|
||||
save_output_img(generated_imgs[0], seed, extra_info)
|
||||
print(text_output)
|
||||
|
||||
@@ -1,258 +0,0 @@
|
||||
import sys
|
||||
import torch
|
||||
import time
|
||||
from PIL import Image
|
||||
from dataclasses import dataclass
|
||||
from apps.stable_diffusion.src import (
|
||||
args,
|
||||
InpaintPipeline,
|
||||
get_schedulers,
|
||||
set_init_device_flags,
|
||||
utils,
|
||||
clear_all,
|
||||
save_output_img,
|
||||
)
|
||||
|
||||
|
||||
@dataclass
|
||||
class Config:
|
||||
model_id: str
|
||||
ckpt_loc: str
|
||||
precision: str
|
||||
batch_size: int
|
||||
max_length: int
|
||||
height: int
|
||||
width: int
|
||||
device: str
|
||||
|
||||
|
||||
inpaint_obj = None
|
||||
config_obj = None
|
||||
schedulers = None
|
||||
|
||||
|
||||
# Exposed to UI.
|
||||
def inpaint_inf(
|
||||
prompt: str,
|
||||
negative_prompt: str,
|
||||
image_dict,
|
||||
height: int,
|
||||
width: int,
|
||||
steps: int,
|
||||
guidance_scale: float,
|
||||
seed: int,
|
||||
batch_count: int,
|
||||
batch_size: int,
|
||||
scheduler: str,
|
||||
custom_model: str,
|
||||
hf_model_id: str,
|
||||
precision: str,
|
||||
device: str,
|
||||
max_length: int,
|
||||
save_metadata_to_json: bool,
|
||||
save_metadata_to_png: bool,
|
||||
):
|
||||
global inpaint_obj
|
||||
global config_obj
|
||||
global schedulers
|
||||
|
||||
args.prompts = [prompt]
|
||||
args.negative_prompts = [negative_prompt]
|
||||
args.guidance_scale = guidance_scale
|
||||
args.steps = steps
|
||||
args.scheduler = scheduler
|
||||
args.img_path = "not none"
|
||||
args.mask_path = "not none"
|
||||
|
||||
# set ckpt_loc and hf_model_id.
|
||||
types = (
|
||||
".ckpt",
|
||||
".safetensors",
|
||||
) # the tuple of file types
|
||||
args.ckpt_loc = ""
|
||||
args.hf_model_id = ""
|
||||
if custom_model == "None":
|
||||
if not hf_model_id:
|
||||
return (
|
||||
None,
|
||||
"Please provide either custom model or huggingface model ID, both must not be empty",
|
||||
)
|
||||
args.hf_model_id = hf_model_id
|
||||
elif ".ckpt" in custom_model or ".safetensors" in custom_model:
|
||||
args.ckpt_loc = custom_model
|
||||
else:
|
||||
args.hf_model_id = custom_model
|
||||
|
||||
args.save_metadata_to_json = save_metadata_to_json
|
||||
args.write_metadata_to_png = save_metadata_to_png
|
||||
|
||||
dtype = torch.float32 if precision == "fp32" else torch.half
|
||||
cpu_scheduling = not scheduler.startswith("Shark")
|
||||
new_config_obj = Config(
|
||||
args.hf_model_id,
|
||||
args.ckpt_loc,
|
||||
precision,
|
||||
batch_size,
|
||||
max_length,
|
||||
height,
|
||||
width,
|
||||
device,
|
||||
)
|
||||
if not inpaint_obj or config_obj != new_config_obj:
|
||||
config_obj = new_config_obj
|
||||
args.precision = precision
|
||||
args.batch_size = batch_size
|
||||
args.max_length = max_length
|
||||
args.height = height
|
||||
args.width = width
|
||||
args.device = device.split("=>", 1)[1].strip()
|
||||
args.iree_vulkan_target_triple = ""
|
||||
args.use_tuned = True
|
||||
args.import_mlir = False
|
||||
set_init_device_flags()
|
||||
model_id = (
|
||||
args.hf_model_id
|
||||
if args.hf_model_id
|
||||
else "stabilityai/stable-diffusion-2-inpainting"
|
||||
)
|
||||
schedulers = get_schedulers(model_id)
|
||||
scheduler_obj = schedulers[scheduler]
|
||||
inpaint_obj = InpaintPipeline.from_pretrained(
|
||||
scheduler_obj,
|
||||
args.import_mlir,
|
||||
args.hf_model_id,
|
||||
args.ckpt_loc,
|
||||
args.custom_vae,
|
||||
args.precision,
|
||||
args.max_length,
|
||||
args.batch_size,
|
||||
args.height,
|
||||
args.width,
|
||||
args.use_base_vae,
|
||||
args.use_tuned,
|
||||
)
|
||||
|
||||
inpaint_obj.scheduler = schedulers[scheduler]
|
||||
|
||||
start_time = time.time()
|
||||
inpaint_obj.log = ""
|
||||
generated_imgs = []
|
||||
seeds = []
|
||||
img_seed = utils.sanitize_seed(seed)
|
||||
image = image_dict["image"]
|
||||
mask_image = image_dict["mask"]
|
||||
for i in range(batch_count):
|
||||
if i > 0:
|
||||
img_seed = utils.sanitize_seed(-1)
|
||||
out_imgs = inpaint_obj.generate_images(
|
||||
prompt,
|
||||
negative_prompt,
|
||||
image,
|
||||
mask_image,
|
||||
batch_size,
|
||||
height,
|
||||
width,
|
||||
steps,
|
||||
guidance_scale,
|
||||
img_seed,
|
||||
args.max_length,
|
||||
dtype,
|
||||
args.use_base_vae,
|
||||
cpu_scheduling,
|
||||
)
|
||||
save_output_img(out_imgs[0], img_seed)
|
||||
generated_imgs.extend(out_imgs)
|
||||
seeds.append(img_seed)
|
||||
inpaint_obj.log += "\n"
|
||||
|
||||
total_time = time.time() - start_time
|
||||
text_output = f"prompt={args.prompts}"
|
||||
text_output += f"\nnegative prompt={args.negative_prompts}"
|
||||
text_output += f"\nmodel_id={args.hf_model_id}, ckpt_loc={args.ckpt_loc}"
|
||||
text_output += f"\nscheduler={args.scheduler}, device={device}"
|
||||
text_output += f"\nsteps={args.steps}, guidance_scale={args.guidance_scale}, seed={seeds}"
|
||||
text_output += f"\nsize={args.height}x{args.width}, batch-count={batch_count}, batch-size={args.batch_size}, max_length={args.max_length}"
|
||||
text_output += inpaint_obj.log
|
||||
text_output += f"\nTotal image generation time: {total_time:.4f}sec"
|
||||
|
||||
return generated_imgs, text_output
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
if args.clear_all:
|
||||
clear_all()
|
||||
|
||||
if args.img_path is None:
|
||||
print("Flag --img_path is required.")
|
||||
exit()
|
||||
if args.mask_path is None:
|
||||
print("Flag --mask_path is required.")
|
||||
exit()
|
||||
|
||||
dtype = torch.float32 if args.precision == "fp32" else torch.half
|
||||
cpu_scheduling = not args.scheduler.startswith("Shark")
|
||||
set_init_device_flags()
|
||||
model_id = (
|
||||
args.hf_model_id
|
||||
if "inpaint" in args.hf_model_id
|
||||
else "stabilityai/stable-diffusion-2-inpainting"
|
||||
)
|
||||
schedulers = get_schedulers(model_id)
|
||||
scheduler_obj = schedulers[args.scheduler]
|
||||
seed = args.seed
|
||||
image = Image.open(args.img_path)
|
||||
mask_image = Image.open(args.mask_path)
|
||||
|
||||
inpaint_obj = InpaintPipeline.from_pretrained(
|
||||
scheduler_obj,
|
||||
args.import_mlir,
|
||||
args.hf_model_id,
|
||||
args.ckpt_loc,
|
||||
args.custom_vae,
|
||||
args.precision,
|
||||
args.max_length,
|
||||
args.batch_size,
|
||||
args.height,
|
||||
args.width,
|
||||
args.use_base_vae,
|
||||
args.use_tuned,
|
||||
)
|
||||
|
||||
for current_batch in range(args.batch_count):
|
||||
if current_batch > 0:
|
||||
seed = -1
|
||||
seed = utils.sanitize_seed(seed)
|
||||
|
||||
start_time = time.time()
|
||||
generated_imgs = inpaint_obj.generate_images(
|
||||
args.prompts,
|
||||
args.negative_prompts,
|
||||
image,
|
||||
mask_image,
|
||||
args.batch_size,
|
||||
args.height,
|
||||
args.width,
|
||||
args.steps,
|
||||
args.guidance_scale,
|
||||
seed,
|
||||
args.max_length,
|
||||
dtype,
|
||||
args.use_base_vae,
|
||||
cpu_scheduling,
|
||||
)
|
||||
total_time = time.time() - start_time
|
||||
text_output = f"prompt={args.prompts}"
|
||||
text_output += f"\nnegative prompt={args.negative_prompts}"
|
||||
text_output += (
|
||||
f"\nmodel_id={args.hf_model_id}, ckpt_loc={args.ckpt_loc}"
|
||||
)
|
||||
text_output += f"\nscheduler={args.scheduler}, device={args.device}"
|
||||
text_output += f"\nsteps={args.steps}, guidance_scale={args.guidance_scale}, seed={seed}, size={args.height}x{args.width}"
|
||||
text_output += (
|
||||
f", batch size={args.batch_size}, max_length={args.max_length}"
|
||||
)
|
||||
text_output += inpaint_obj.log
|
||||
text_output += f"\nTotal image generation time: {total_time:.4f}sec"
|
||||
|
||||
save_output_img(generated_imgs[0], seed)
|
||||
print(text_output)
|
||||
@@ -1,293 +0,0 @@
|
||||
import sys
|
||||
import torch
|
||||
import time
|
||||
from PIL import Image
|
||||
from dataclasses import dataclass
|
||||
from apps.stable_diffusion.src import (
|
||||
args,
|
||||
OutpaintPipeline,
|
||||
get_schedulers,
|
||||
set_init_device_flags,
|
||||
utils,
|
||||
clear_all,
|
||||
save_output_img,
|
||||
)
|
||||
|
||||
|
||||
@dataclass
|
||||
class Config:
|
||||
model_id: str
|
||||
ckpt_loc: str
|
||||
precision: str
|
||||
batch_size: int
|
||||
max_length: int
|
||||
height: int
|
||||
width: int
|
||||
device: str
|
||||
|
||||
|
||||
outpaint_obj = None
|
||||
config_obj = None
|
||||
schedulers = None
|
||||
|
||||
|
||||
# Exposed to UI.
|
||||
def outpaint_inf(
|
||||
prompt: str,
|
||||
negative_prompt: str,
|
||||
init_image: Image,
|
||||
pixels: int,
|
||||
mask_blur: int,
|
||||
directions: list,
|
||||
noise_q: float,
|
||||
color_variation: float,
|
||||
height: int,
|
||||
width: int,
|
||||
steps: int,
|
||||
guidance_scale: float,
|
||||
seed: int,
|
||||
batch_count: int,
|
||||
batch_size: int,
|
||||
scheduler: str,
|
||||
custom_model: str,
|
||||
hf_model_id: str,
|
||||
precision: str,
|
||||
device: str,
|
||||
max_length: int,
|
||||
save_metadata_to_json: bool,
|
||||
save_metadata_to_png: bool,
|
||||
):
|
||||
global outpaint_obj
|
||||
global config_obj
|
||||
global schedulers
|
||||
|
||||
args.prompts = [prompt]
|
||||
args.negative_prompts = [negative_prompt]
|
||||
args.guidance_scale = guidance_scale
|
||||
args.steps = steps
|
||||
args.scheduler = scheduler
|
||||
args.img_path = "not none"
|
||||
|
||||
# set ckpt_loc and hf_model_id.
|
||||
types = (
|
||||
".ckpt",
|
||||
".safetensors",
|
||||
) # the tuple of file types
|
||||
args.ckpt_loc = ""
|
||||
args.hf_model_id = ""
|
||||
if custom_model == "None":
|
||||
if not hf_model_id:
|
||||
return (
|
||||
None,
|
||||
"Please provide either custom model or huggingface model ID, both must not be empty",
|
||||
)
|
||||
args.hf_model_id = hf_model_id
|
||||
elif ".ckpt" in custom_model or ".safetensors" in custom_model:
|
||||
args.ckpt_loc = custom_model
|
||||
else:
|
||||
args.hf_model_id = custom_model
|
||||
|
||||
args.save_metadata_to_json = save_metadata_to_json
|
||||
args.write_metadata_to_png = save_metadata_to_png
|
||||
|
||||
dtype = torch.float32 if precision == "fp32" else torch.half
|
||||
cpu_scheduling = not scheduler.startswith("Shark")
|
||||
new_config_obj = Config(
|
||||
args.hf_model_id,
|
||||
args.ckpt_loc,
|
||||
precision,
|
||||
batch_size,
|
||||
max_length,
|
||||
height,
|
||||
width,
|
||||
device,
|
||||
)
|
||||
if not outpaint_obj or config_obj != new_config_obj:
|
||||
config_obj = new_config_obj
|
||||
args.precision = precision
|
||||
args.batch_size = batch_size
|
||||
args.max_length = max_length
|
||||
args.height = height
|
||||
args.width = width
|
||||
args.device = device.split("=>", 1)[1].strip()
|
||||
args.iree_vulkan_target_triple = ""
|
||||
args.use_tuned = True
|
||||
args.import_mlir = False
|
||||
set_init_device_flags()
|
||||
model_id = (
|
||||
args.hf_model_id
|
||||
if args.hf_model_id
|
||||
else "stabilityai/stable-diffusion-2-inpainting"
|
||||
)
|
||||
schedulers = get_schedulers(model_id)
|
||||
scheduler_obj = schedulers[scheduler]
|
||||
outpaint_obj = OutpaintPipeline.from_pretrained(
|
||||
scheduler_obj,
|
||||
args.import_mlir,
|
||||
args.hf_model_id,
|
||||
args.ckpt_loc,
|
||||
args.custom_vae,
|
||||
args.precision,
|
||||
args.max_length,
|
||||
args.batch_size,
|
||||
args.height,
|
||||
args.width,
|
||||
args.use_base_vae,
|
||||
args.use_tuned,
|
||||
)
|
||||
|
||||
outpaint_obj.scheduler = schedulers[scheduler]
|
||||
|
||||
start_time = time.time()
|
||||
outpaint_obj.log = ""
|
||||
generated_imgs = []
|
||||
seeds = []
|
||||
img_seed = utils.sanitize_seed(seed)
|
||||
|
||||
left = True if "left" in directions else False
|
||||
right = True if "right" in directions else False
|
||||
top = True if "up" in directions else False
|
||||
bottom = True if "down" in directions else False
|
||||
|
||||
for i in range(batch_count):
|
||||
if i > 0:
|
||||
img_seed = utils.sanitize_seed(-1)
|
||||
out_imgs = outpaint_obj.generate_images(
|
||||
prompt,
|
||||
negative_prompt,
|
||||
init_image,
|
||||
pixels,
|
||||
mask_blur,
|
||||
left,
|
||||
right,
|
||||
top,
|
||||
bottom,
|
||||
noise_q,
|
||||
color_variation,
|
||||
batch_size,
|
||||
height,
|
||||
width,
|
||||
steps,
|
||||
guidance_scale,
|
||||
img_seed,
|
||||
args.max_length,
|
||||
dtype,
|
||||
args.use_base_vae,
|
||||
cpu_scheduling,
|
||||
)
|
||||
save_output_img(out_imgs[0], img_seed)
|
||||
generated_imgs.extend(out_imgs)
|
||||
seeds.append(img_seed)
|
||||
outpaint_obj.log += "\n"
|
||||
|
||||
total_time = time.time() - start_time
|
||||
text_output = f"prompt={args.prompts}"
|
||||
text_output += f"\nnegative prompt={args.negative_prompts}"
|
||||
text_output += f"\nmodel_id={args.hf_model_id}, ckpt_loc={args.ckpt_loc}"
|
||||
text_output += f"\nscheduler={args.scheduler}, device={device}"
|
||||
text_output += f"\nsteps={args.steps}, guidance_scale={args.guidance_scale}, seed={seeds}"
|
||||
text_output += f"\nsize={args.height}x{args.width}, batch-count={batch_count}, batch-size={args.batch_size}, max_length={args.max_length}"
|
||||
text_output += outpaint_obj.log
|
||||
text_output += f"\nTotal image generation time: {total_time:.4f}sec"
|
||||
|
||||
return generated_imgs, text_output
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
if args.clear_all:
|
||||
clear_all()
|
||||
|
||||
if args.img_path is None:
|
||||
print("Flag --img_path is required.")
|
||||
exit()
|
||||
|
||||
dtype = torch.float32 if args.precision == "fp32" else torch.half
|
||||
cpu_scheduling = not args.scheduler.startswith("Shark")
|
||||
set_init_device_flags()
|
||||
model_id = (
|
||||
args.hf_model_id
|
||||
if "inpaint" in args.hf_model_id
|
||||
else "stabilityai/stable-diffusion-2-inpainting"
|
||||
)
|
||||
schedulers = get_schedulers(model_id)
|
||||
scheduler_obj = schedulers[args.scheduler]
|
||||
seed = args.seed
|
||||
image = Image.open(args.img_path)
|
||||
|
||||
outpaint_obj = OutpaintPipeline.from_pretrained(
|
||||
scheduler_obj,
|
||||
args.import_mlir,
|
||||
args.hf_model_id,
|
||||
args.ckpt_loc,
|
||||
args.custom_vae,
|
||||
args.precision,
|
||||
args.max_length,
|
||||
args.batch_size,
|
||||
args.height,
|
||||
args.width,
|
||||
args.use_base_vae,
|
||||
args.use_tuned,
|
||||
)
|
||||
|
||||
for current_batch in range(args.batch_count):
|
||||
if current_batch > 0:
|
||||
seed = -1
|
||||
seed = utils.sanitize_seed(seed)
|
||||
|
||||
start_time = time.time()
|
||||
generated_imgs = outpaint_obj.generate_images(
|
||||
args.prompts,
|
||||
args.negative_prompts,
|
||||
image,
|
||||
args.pixels,
|
||||
args.mask_blur,
|
||||
args.left,
|
||||
args.right,
|
||||
args.top,
|
||||
args.bottom,
|
||||
args.noise_q,
|
||||
args.color_variation,
|
||||
args.batch_size,
|
||||
args.height,
|
||||
args.width,
|
||||
args.steps,
|
||||
args.guidance_scale,
|
||||
seed,
|
||||
args.max_length,
|
||||
dtype,
|
||||
args.use_base_vae,
|
||||
cpu_scheduling,
|
||||
)
|
||||
total_time = time.time() - start_time
|
||||
text_output = f"prompt={args.prompts}"
|
||||
text_output += f"\nnegative prompt={args.negative_prompts}"
|
||||
text_output += (
|
||||
f"\nmodel_id={args.hf_model_id}, ckpt_loc={args.ckpt_loc}"
|
||||
)
|
||||
text_output += f"\nscheduler={args.scheduler}, device={args.device}"
|
||||
text_output += f"\nsteps={args.steps}, guidance_scale={args.guidance_scale}, seed={seed}, size={args.height}x{args.width}"
|
||||
text_output += (
|
||||
f", batch size={args.batch_size}, max_length={args.max_length}"
|
||||
)
|
||||
text_output += outpaint_obj.log
|
||||
text_output += f"\nTotal image generation time: {total_time:.4f}sec"
|
||||
|
||||
# save this information as metadata of output generated image.
|
||||
directions = []
|
||||
if args.left:
|
||||
directions.append("left")
|
||||
if args.right:
|
||||
directions.append("right")
|
||||
if args.top:
|
||||
directions.append("up")
|
||||
if args.bottom:
|
||||
directions.append("down")
|
||||
extra_info = {
|
||||
"PIXELS": args.pixels,
|
||||
"MASK_BLUR": args.mask_blur,
|
||||
"DIRECTIONS": directions,
|
||||
"NOISE_Q": args.noise_q,
|
||||
"COLOR_VARIATION": args.color_variation,
|
||||
}
|
||||
save_output_img(generated_imgs[0], seed, extra_info)
|
||||
print(text_output)
|
||||
@@ -1,15 +1,24 @@
|
||||
import os
|
||||
|
||||
if "AMD_ENABLE_LLPC" not in os.environ:
|
||||
os.environ["AMD_ENABLE_LLPC"] = "1"
|
||||
|
||||
import sys
|
||||
import json
|
||||
import torch
|
||||
import re
|
||||
import time
|
||||
from pathlib import Path
|
||||
from PIL import PngImagePlugin
|
||||
from datetime import datetime as dt
|
||||
from dataclasses import dataclass
|
||||
from csv import DictWriter
|
||||
from apps.stable_diffusion.src import (
|
||||
args,
|
||||
Text2ImagePipeline,
|
||||
get_schedulers,
|
||||
set_init_device_flags,
|
||||
utils,
|
||||
clear_all,
|
||||
save_output_img,
|
||||
)
|
||||
|
||||
|
||||
@@ -25,6 +34,96 @@ class Config:
|
||||
device: str
|
||||
|
||||
|
||||
# This has to come before importing cache objects
|
||||
if args.clear_all:
|
||||
print("CLEARING ALL, EXPECT SEVERAL MINUTES TO RECOMPILE")
|
||||
from glob import glob
|
||||
import shutil
|
||||
|
||||
vmfbs = glob(os.path.join(os.getcwd(), "*.vmfb"))
|
||||
for vmfb in vmfbs:
|
||||
if os.path.exists(vmfb):
|
||||
os.remove(vmfb)
|
||||
# Temporary workaround of deleting yaml files to incorporate diffusers' pipeline.
|
||||
# TODO: Remove this once we have better weight updation logic.
|
||||
inference_yaml = ["v2-inference-v.yaml", "v1-inference.yaml"]
|
||||
for yaml in inference_yaml:
|
||||
if os.path.exists(yaml):
|
||||
os.remove(yaml)
|
||||
home = os.path.expanduser("~")
|
||||
if os.name == "nt": # Windows
|
||||
appdata = os.getenv("LOCALAPPDATA")
|
||||
shutil.rmtree(os.path.join(appdata, "AMD/VkCache"), ignore_errors=True)
|
||||
shutil.rmtree(os.path.join(home, "shark_tank"), ignore_errors=True)
|
||||
elif os.name == "unix":
|
||||
shutil.rmtree(os.path.join(home, ".cache/AMD/VkCache"))
|
||||
shutil.rmtree(os.path.join(home, ".local/shark_tank"))
|
||||
|
||||
|
||||
# save output images and the inputs corresponding to it.
|
||||
def save_output_img(output_img, img_seed):
|
||||
output_path = args.output_dir if args.output_dir else Path.cwd()
|
||||
generated_imgs_path = Path(output_path, "generated_imgs")
|
||||
generated_imgs_path.mkdir(parents=True, exist_ok=True)
|
||||
csv_path = Path(generated_imgs_path, "imgs_details.csv")
|
||||
|
||||
prompt_slice = re.sub("[^a-zA-Z0-9]", "_", args.prompts[0][:15])
|
||||
out_img_name = (
|
||||
f"{prompt_slice}_{img_seed}_{dt.now().strftime('%y%m%d_%H%M%S')}"
|
||||
)
|
||||
|
||||
img_model = args.hf_model_id
|
||||
if args.ckpt_loc:
|
||||
img_model = os.path.basename(args.ckpt_loc)
|
||||
|
||||
if args.output_img_format == "jpg":
|
||||
out_img_path = Path(generated_imgs_path, f"{out_img_name}.jpg")
|
||||
output_img.save(out_img_path, quality=95, subsampling=0)
|
||||
else:
|
||||
out_img_path = Path(generated_imgs_path, f"{out_img_name}.png")
|
||||
pngInfo = PngImagePlugin.PngInfo()
|
||||
|
||||
if args.write_metadata_to_png:
|
||||
pngInfo.add_text(
|
||||
"parameters",
|
||||
f"{args.prompts[0]}\nNegative prompt: {args.negative_prompts[0]}\nSteps:{args.steps}, Sampler: {args.scheduler}, CFG scale: {args.guidance_scale}, Seed: {img_seed}, Size: {args.width}x{args.height}, Model: {img_model}",
|
||||
)
|
||||
|
||||
output_img.save(out_img_path, "PNG", pnginfo=pngInfo)
|
||||
|
||||
if args.output_img_format not in ["png", "jpg"]:
|
||||
print(
|
||||
f"[ERROR] Format {args.output_img_format} is not supported yet."
|
||||
"Image saved as png instead. Supported formats: png / jpg"
|
||||
)
|
||||
|
||||
new_entry = {
|
||||
"VARIANT": img_model,
|
||||
"SCHEDULER": args.scheduler,
|
||||
"PROMPT": args.prompts[0],
|
||||
"NEG_PROMPT": args.negative_prompts[0],
|
||||
"SEED": img_seed,
|
||||
"CFG_SCALE": args.guidance_scale,
|
||||
"PRECISION": args.precision,
|
||||
"STEPS": args.steps,
|
||||
"HEIGHT": args.height,
|
||||
"WIDTH": args.width,
|
||||
"MAX_LENGTH": args.max_length,
|
||||
"OUTPUT": out_img_path,
|
||||
}
|
||||
|
||||
with open(csv_path, "a") as csv_obj:
|
||||
dictwriter_obj = DictWriter(csv_obj, fieldnames=list(new_entry.keys()))
|
||||
dictwriter_obj.writerow(new_entry)
|
||||
csv_obj.close()
|
||||
|
||||
if args.save_metadata_to_json:
|
||||
del new_entry["OUTPUT"]
|
||||
json_path = Path(generated_imgs_path, f"{out_img_name}.json")
|
||||
with open(json_path, "w") as f:
|
||||
json.dump(new_entry, f, indent=4)
|
||||
|
||||
|
||||
txt2img_obj = None
|
||||
config_obj = None
|
||||
schedulers = None
|
||||
@@ -94,7 +193,7 @@ def txt2img_inf(
|
||||
width,
|
||||
device,
|
||||
)
|
||||
if not txt2img_obj or config_obj != new_config_obj:
|
||||
if config_obj != new_config_obj:
|
||||
config_obj = new_config_obj
|
||||
args.precision = precision
|
||||
args.batch_size = batch_size
|
||||
@@ -102,10 +201,8 @@ def txt2img_inf(
|
||||
args.height = height
|
||||
args.width = width
|
||||
args.device = device.split("=>", 1)[1].strip()
|
||||
args.iree_vulkan_target_triple = ""
|
||||
args.use_tuned = True
|
||||
args.import_mlir = False
|
||||
args.img_path = None
|
||||
set_init_device_flags()
|
||||
model_id = (
|
||||
args.hf_model_id
|
||||
@@ -119,7 +216,6 @@ def txt2img_inf(
|
||||
args.import_mlir,
|
||||
args.hf_model_id,
|
||||
args.ckpt_loc,
|
||||
args.custom_vae,
|
||||
args.precision,
|
||||
args.max_length,
|
||||
args.batch_size,
|
||||
@@ -127,9 +223,11 @@ def txt2img_inf(
|
||||
args.width,
|
||||
args.use_base_vae,
|
||||
args.use_tuned,
|
||||
low_cpu_mem_usage=args.low_cpu_mem_usage,
|
||||
)
|
||||
|
||||
if not txt2img_obj:
|
||||
sys.exit("text to image pipeline must not return a null value")
|
||||
|
||||
txt2img_obj.scheduler = schedulers[scheduler]
|
||||
|
||||
start_time = time.time()
|
||||
@@ -158,27 +256,21 @@ def txt2img_inf(
|
||||
generated_imgs.extend(out_imgs)
|
||||
seeds.append(img_seed)
|
||||
txt2img_obj.log += "\n"
|
||||
yield generated_imgs, generated_imgs[0], txt2img_obj.log
|
||||
|
||||
total_time = time.time() - start_time
|
||||
text_output = f"prompt={args.prompts}"
|
||||
text_output += f"\nnegative prompt={args.negative_prompts}"
|
||||
text_output += f"\nmodel_id={args.hf_model_id}, ckpt_loc={args.ckpt_loc}"
|
||||
text_output += f"\nscheduler={args.scheduler}, device={device}"
|
||||
text_output += (
|
||||
f"\nsteps={steps}, guidance_scale={guidance_scale}, seed={seeds}"
|
||||
)
|
||||
text_output += f"\nsize={height}x{width}, batch_count={batch_count}, batch_size={batch_size}, max_length={args.max_length}"
|
||||
# text_output += txt2img_obj.log
|
||||
text_output += f"\nsteps={args.steps}, guidance_scale={args.guidance_scale}, seed={seeds}"
|
||||
text_output += f"\nsize={args.height}x{args.width}, batch-count={batch_count}, batch-size={args.batch_size}, max_length={args.max_length}"
|
||||
text_output += txt2img_obj.log
|
||||
text_output += f"\nTotal image generation time: {total_time:.4f}sec"
|
||||
|
||||
yield generated_imgs, text_output
|
||||
return generated_imgs, text_output
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
if args.clear_all:
|
||||
clear_all()
|
||||
|
||||
dtype = torch.float32 if args.precision == "fp32" else torch.half
|
||||
cpu_scheduling = not args.scheduler.startswith("Shark")
|
||||
set_init_device_flags()
|
||||
@@ -191,7 +283,6 @@ if __name__ == "__main__":
|
||||
args.import_mlir,
|
||||
args.hf_model_id,
|
||||
args.ckpt_loc,
|
||||
args.custom_vae,
|
||||
args.precision,
|
||||
args.max_length,
|
||||
args.batch_size,
|
||||
@@ -199,11 +290,10 @@ if __name__ == "__main__":
|
||||
args.width,
|
||||
args.use_base_vae,
|
||||
args.use_tuned,
|
||||
low_cpu_mem_usage=args.low_cpu_mem_usage,
|
||||
)
|
||||
|
||||
for current_batch in range(args.batch_count):
|
||||
if current_batch > 0:
|
||||
for run in range(args.runs):
|
||||
if run > 0:
|
||||
seed = -1
|
||||
seed = utils.sanitize_seed(seed)
|
||||
|
||||
@@ -233,7 +323,7 @@ if __name__ == "__main__":
|
||||
text_output += (
|
||||
f", batch size={args.batch_size}, max_length={args.max_length}"
|
||||
)
|
||||
# TODO: if using --batch_count=x txt2img_obj.log will output on each display every iteration infos from the start
|
||||
# TODO: if using --runs=x txt2img_obj.log will output on each display every iteration infos from the start
|
||||
text_output += txt2img_obj.log
|
||||
text_output += f"\nTotal image generation time: {total_time:.4f}sec"
|
||||
|
||||
|
||||
@@ -15,12 +15,12 @@ datas += copy_metadata('filelock')
|
||||
datas += copy_metadata('numpy')
|
||||
datas += copy_metadata('tokenizers')
|
||||
datas += copy_metadata('importlib_metadata')
|
||||
datas += copy_metadata('torchvision')
|
||||
datas += copy_metadata('torch-mlir')
|
||||
datas += copy_metadata('diffusers')
|
||||
datas += copy_metadata('transformers')
|
||||
datas += copy_metadata('omegaconf')
|
||||
datas += copy_metadata('safetensors')
|
||||
datas += collect_data_files('diffusers')
|
||||
datas += collect_data_files('transformers')
|
||||
datas += collect_data_files('opencv-python')
|
||||
datas += collect_data_files('gradio')
|
||||
datas += collect_data_files('iree')
|
||||
datas += collect_data_files('google-cloud-storage')
|
||||
@@ -30,8 +30,8 @@ datas += [
|
||||
( 'src/utils/resources/model_db.json', 'resources' ),
|
||||
( 'src/utils/resources/opt_flags.json', 'resources' ),
|
||||
( 'src/utils/resources/base_model.json', 'resources' ),
|
||||
( 'web/ui/css/*', 'ui/css' ),
|
||||
( 'web/ui/logos/*', 'logos' )
|
||||
( 'web/css/*', 'css' ),
|
||||
( 'web/logos/*', 'logos' )
|
||||
]
|
||||
|
||||
binaries = []
|
||||
@@ -44,7 +44,7 @@ a = Analysis(
|
||||
pathex=['.'],
|
||||
binaries=binaries,
|
||||
datas=datas,
|
||||
hiddenimports=['shark', 'shark.shark_inference', 'apps'],
|
||||
hiddenimports=['shark', 'shark.*', 'shark.shark_inference', 'shark_inference', 'iree.tools.core', 'gradio', 'apps'],
|
||||
hookspath=[],
|
||||
hooksconfig={},
|
||||
runtime_hooks=[],
|
||||
|
||||
@@ -15,12 +15,12 @@ datas += copy_metadata('filelock')
|
||||
datas += copy_metadata('numpy')
|
||||
datas += copy_metadata('tokenizers')
|
||||
datas += copy_metadata('importlib_metadata')
|
||||
datas += copy_metadata('torchvision')
|
||||
datas += copy_metadata('torch-mlir')
|
||||
datas += copy_metadata('diffusers')
|
||||
datas += copy_metadata('transformers')
|
||||
datas += copy_metadata('omegaconf')
|
||||
datas += copy_metadata('safetensors')
|
||||
datas += collect_data_files('diffusers')
|
||||
datas += collect_data_files('transformers')
|
||||
datas += collect_data_files('opencv-python')
|
||||
datas += collect_data_files('gradio')
|
||||
datas += collect_data_files('iree')
|
||||
datas += collect_data_files('google-cloud-storage')
|
||||
@@ -42,7 +42,7 @@ a = Analysis(
|
||||
pathex=['.'],
|
||||
binaries=binaries,
|
||||
datas=datas,
|
||||
hiddenimports=['shark', 'shark.shark_inference', 'apps'],
|
||||
hiddenimports=['shark', 'shark.*', 'shark.shark_inference', 'shark_inference', 'iree.tools.core', 'gradio', 'apps'],
|
||||
hookspath=[],
|
||||
hooksconfig={},
|
||||
runtime_hooks=[],
|
||||
|
||||
@@ -3,14 +3,6 @@ from apps.stable_diffusion.src.utils import (
|
||||
set_init_device_flags,
|
||||
prompt_examples,
|
||||
get_available_devices,
|
||||
clear_all,
|
||||
save_output_img,
|
||||
)
|
||||
from apps.stable_diffusion.src.pipelines import (
|
||||
Text2ImagePipeline,
|
||||
Image2ImagePipeline,
|
||||
InpaintPipeline,
|
||||
OutpaintPipeline,
|
||||
StencilPipeline,
|
||||
)
|
||||
from apps.stable_diffusion.src.pipelines import Text2ImagePipeline
|
||||
from apps.stable_diffusion.src.schedulers import get_schedulers
|
||||
|
||||
@@ -2,7 +2,6 @@ from apps.stable_diffusion.src.models.model_wrappers import (
|
||||
SharkifyStableDiffusionModel,
|
||||
)
|
||||
from apps.stable_diffusion.src.models.opt_params import (
|
||||
get_vae_encode,
|
||||
get_vae,
|
||||
get_unet,
|
||||
get_clip,
|
||||
|
||||
@@ -1,9 +1,9 @@
|
||||
from diffusers import AutoencoderKL, UNet2DConditionModel, ControlNetModel
|
||||
from diffusers import AutoencoderKL, UNet2DConditionModel
|
||||
from transformers import CLIPTextModel
|
||||
from collections import defaultdict
|
||||
import torch
|
||||
import safetensors.torch
|
||||
import traceback
|
||||
import re
|
||||
import sys
|
||||
from apps.stable_diffusion.src.utils import (
|
||||
compile_through_fx,
|
||||
@@ -14,8 +14,6 @@ from apps.stable_diffusion.src.utils import (
|
||||
preprocessCKPT,
|
||||
get_path_to_diffusers_checkpoint,
|
||||
fetch_and_update_base_model_id,
|
||||
get_path_stem,
|
||||
get_extended_name,
|
||||
)
|
||||
|
||||
|
||||
@@ -30,19 +28,15 @@ def replace_shape_str(shape, max_len, width, height, batch_size):
|
||||
elif shape[i] == "width":
|
||||
new_shape.append(width)
|
||||
elif isinstance(shape[i], str):
|
||||
mul_val = int(shape[i].split("*")[0])
|
||||
if "batch_size" in shape[i]:
|
||||
mul_val = int(shape[i].split("*")[0])
|
||||
new_shape.append(batch_size * mul_val)
|
||||
elif "height" in shape[i]:
|
||||
new_shape.append(height * mul_val)
|
||||
elif "width" in shape[i]:
|
||||
new_shape.append(width * mul_val)
|
||||
else:
|
||||
new_shape.append(shape[i])
|
||||
return new_shape
|
||||
|
||||
|
||||
# Get the input info for various models i.e. "unet", "clip", "vae", "vae_encode".
|
||||
# Get the input info for various models i.e. "unet", "clip", "vae".
|
||||
def get_input_info(model_info, max_len, width, height, batch_size):
|
||||
dtype_config = {"f32": torch.float32, "i64": torch.int64}
|
||||
input_map = defaultdict(list)
|
||||
@@ -72,7 +66,6 @@ class SharkifyStableDiffusionModel:
|
||||
self,
|
||||
model_id: str,
|
||||
custom_weights: str,
|
||||
custom_vae: str,
|
||||
precision: str,
|
||||
max_len: int = 64,
|
||||
width: int = 512,
|
||||
@@ -80,8 +73,6 @@ class SharkifyStableDiffusionModel:
|
||||
batch_size: int = 1,
|
||||
use_base_vae: bool = False,
|
||||
use_tuned: bool = False,
|
||||
low_cpu_mem_usage: bool = False,
|
||||
is_inpaint: bool = False
|
||||
):
|
||||
self.check_params(max_len, width, height)
|
||||
self.max_len = max_len
|
||||
@@ -95,10 +86,6 @@ class SharkifyStableDiffusionModel:
|
||||
), "checkpoint files supported can be any of [.ckpt, .safetensors] type"
|
||||
custom_weights = get_path_to_diffusers_checkpoint(custom_weights)
|
||||
self.model_id = model_id if custom_weights == "" else custom_weights
|
||||
# TODO: remove the following line when stable-diffusion-2-1 works
|
||||
if self.model_id == "stabilityai/stable-diffusion-2-1":
|
||||
self.model_id = "stabilityai/stable-diffusion-2-1-base"
|
||||
self.custom_vae = custom_vae
|
||||
self.precision = precision
|
||||
self.base_vae = use_base_vae
|
||||
self.model_name = (
|
||||
@@ -115,28 +102,17 @@ class SharkifyStableDiffusionModel:
|
||||
self.use_tuned = use_tuned
|
||||
if use_tuned:
|
||||
self.model_name = self.model_name + "_tuned"
|
||||
self.model_name = self.model_name + "_" + get_path_stem(self.model_id)
|
||||
self.low_cpu_mem_usage = low_cpu_mem_usage
|
||||
self.is_inpaint = is_inpaint
|
||||
|
||||
def get_extended_name_for_all_model(self, mask_to_fetch):
|
||||
model_name = {}
|
||||
sub_model_list = ["clip", "unet", "stencil_unet", "vae", "vae_encode", "stencil_adaptor"]
|
||||
index = 0
|
||||
for model in sub_model_list:
|
||||
if mask_to_fetch[index] == False:
|
||||
index += 1
|
||||
continue
|
||||
sub_model = model
|
||||
model_config = self.model_name
|
||||
if "vae" == model:
|
||||
if self.custom_vae != "":
|
||||
model_config = model_config + get_path_stem(self.custom_vae)
|
||||
if self.base_vae:
|
||||
sub_model = "base_vae"
|
||||
model_name[model] = get_extended_name(sub_model + model_config)
|
||||
index += 1
|
||||
return model_name
|
||||
# We need a better naming convention for the .vmfbs because despite
|
||||
# using the custom model variant the .vmfb names remain the same and
|
||||
# it'll always pick up the compiled .vmfb instead of compiling the
|
||||
# custom model.
|
||||
# So, currently, we add `self.model_id` in the `self.model_name` of
|
||||
# .vmfb file.
|
||||
# TODO: Have a better way of naming the vmfbs using self.model_name.
|
||||
model_name = re.sub(r"\W+", "_", self.model_id)
|
||||
if model_name[0] == "_":
|
||||
model_name = model_name[1:]
|
||||
self.model_name = self.model_name + "_" + model_name
|
||||
|
||||
def check_params(self, max_len, width, height):
|
||||
if not (max_len >= 32 and max_len <= 77):
|
||||
@@ -146,57 +122,14 @@ class SharkifyStableDiffusionModel:
|
||||
if not (height % 8 == 0 and height >= 384):
|
||||
sys.exit("height should be greater than 384 and multiple of 8")
|
||||
|
||||
def get_vae_encode(self):
|
||||
class VaeEncodeModel(torch.nn.Module):
|
||||
def __init__(self, model_id=self.model_id, low_cpu_mem_usage=False):
|
||||
def get_vae(self):
|
||||
class VaeModel(torch.nn.Module):
|
||||
def __init__(self, model_id=self.model_id, base_vae=self.base_vae):
|
||||
super().__init__()
|
||||
self.vae = AutoencoderKL.from_pretrained(
|
||||
model_id,
|
||||
subfolder="vae",
|
||||
low_cpu_mem_usage=low_cpu_mem_usage,
|
||||
)
|
||||
|
||||
def forward(self, input):
|
||||
latents = self.vae.encode(input).latent_dist.sample()
|
||||
return 0.18215 * latents
|
||||
|
||||
vae_encode = VaeEncodeModel()
|
||||
inputs = tuple(self.inputs["vae_encode"])
|
||||
is_f16 = True if self.precision == "fp16" else False
|
||||
shark_vae_encode = compile_through_fx(
|
||||
vae_encode,
|
||||
inputs,
|
||||
is_f16=is_f16,
|
||||
use_tuned=self.use_tuned,
|
||||
model_name=self.model_name["vae_encode"],
|
||||
extra_args=get_opt_flags("vae", precision=self.precision),
|
||||
)
|
||||
return shark_vae_encode
|
||||
|
||||
def get_vae(self):
|
||||
class VaeModel(torch.nn.Module):
|
||||
def __init__(self, model_id=self.model_id, base_vae=self.base_vae, custom_vae=self.custom_vae, low_cpu_mem_usage=False):
|
||||
super().__init__()
|
||||
self.vae = None
|
||||
if custom_vae == "":
|
||||
self.vae = AutoencoderKL.from_pretrained(
|
||||
model_id,
|
||||
subfolder="vae",
|
||||
low_cpu_mem_usage=low_cpu_mem_usage,
|
||||
)
|
||||
elif not isinstance(custom_vae, dict):
|
||||
self.vae = AutoencoderKL.from_pretrained(
|
||||
custom_vae,
|
||||
subfolder="vae",
|
||||
low_cpu_mem_usage=low_cpu_mem_usage,
|
||||
)
|
||||
else:
|
||||
self.vae = AutoencoderKL.from_pretrained(
|
||||
model_id,
|
||||
subfolder="vae",
|
||||
low_cpu_mem_usage=low_cpu_mem_usage,
|
||||
)
|
||||
self.vae.load_state_dict(custom_vae)
|
||||
self.base_vae = base_vae
|
||||
|
||||
def forward(self, input):
|
||||
@@ -209,145 +142,33 @@ class SharkifyStableDiffusionModel:
|
||||
x = x * 255.0
|
||||
return x.round()
|
||||
|
||||
vae = VaeModel(low_cpu_mem_usage=self.low_cpu_mem_usage)
|
||||
vae = VaeModel()
|
||||
inputs = tuple(self.inputs["vae"])
|
||||
is_f16 = True if self.precision == "fp16" else False
|
||||
vae_name = "base_vae" if self.base_vae else "vae"
|
||||
shark_vae = compile_through_fx(
|
||||
vae,
|
||||
inputs,
|
||||
is_f16=is_f16,
|
||||
use_tuned=self.use_tuned,
|
||||
model_name=self.model_name["vae"],
|
||||
model_name=vae_name + self.model_name,
|
||||
extra_args=get_opt_flags("vae", precision=self.precision),
|
||||
)
|
||||
return shark_vae
|
||||
|
||||
def get_controlled_unet(self):
|
||||
class ControlledUnetModel(torch.nn.Module):
|
||||
def __init__(
|
||||
self, model_id=self.model_id, low_cpu_mem_usage=False
|
||||
):
|
||||
super().__init__()
|
||||
self.unet = UNet2DConditionModel.from_pretrained(
|
||||
"takuma104/control_sd15_canny", # TODO: ADD with model ID
|
||||
subfolder="unet",
|
||||
low_cpu_mem_usage=low_cpu_mem_usage,
|
||||
)
|
||||
self.in_channels = self.unet.in_channels
|
||||
self.train(False)
|
||||
|
||||
def forward( self, latent, timestep, text_embedding, guidance_scale, control1,
|
||||
control2, control3, control4, control5, control6, control7,
|
||||
control8, control9, control10, control11, control12, control13,
|
||||
):
|
||||
# expand the latents if we are doing classifier-free guidance to avoid doing two forward passes.
|
||||
db_res_samples = tuple([ control1, control2, control3, control4, control5, control6, control7, control8, control9, control10, control11, control12,])
|
||||
mb_res_samples = control13
|
||||
latents = torch.cat([latent] * 2)
|
||||
unet_out = self.unet.forward(
|
||||
latents,
|
||||
timestep,
|
||||
encoder_hidden_states=text_embedding,
|
||||
down_block_additional_residuals=db_res_samples,
|
||||
mid_block_additional_residual=mb_res_samples,
|
||||
return_dict=False,
|
||||
)[0]
|
||||
noise_pred_uncond, noise_pred_text = unet_out.chunk(2)
|
||||
noise_pred = noise_pred_uncond + guidance_scale * (
|
||||
noise_pred_text - noise_pred_uncond
|
||||
)
|
||||
return noise_pred
|
||||
|
||||
unet = ControlledUnetModel(low_cpu_mem_usage=self.low_cpu_mem_usage)
|
||||
is_f16 = True if self.precision == "fp16" else False
|
||||
|
||||
inputs = tuple(self.inputs["stencil_unet"])
|
||||
input_mask = [True, True, True, False, True, True, True, True, True, True, True, True, True, True, True, True, True,]
|
||||
shark_controlled_unet = compile_through_fx(
|
||||
unet,
|
||||
inputs,
|
||||
model_name=self.model_name["stencil_unet"],
|
||||
is_f16=is_f16,
|
||||
f16_input_mask=input_mask,
|
||||
use_tuned=self.use_tuned,
|
||||
extra_args=get_opt_flags("unet", precision=self.precision),
|
||||
)
|
||||
return shark_controlled_unet
|
||||
|
||||
def get_control_net(self):
|
||||
class StencilControlNetModel(torch.nn.Module):
|
||||
def __init__(
|
||||
self, model_id=self.model_id, low_cpu_mem_usage=False
|
||||
):
|
||||
super().__init__()
|
||||
self.cnet = ControlNetModel.from_pretrained(
|
||||
"takuma104/control_sd15_canny", # TODO: ADD with model ID
|
||||
subfolder="controlnet",
|
||||
low_cpu_mem_usage=low_cpu_mem_usage,
|
||||
)
|
||||
self.in_channels = self.cnet.in_channels
|
||||
self.train(False)
|
||||
|
||||
def forward(
|
||||
self,
|
||||
latent,
|
||||
timestep,
|
||||
text_embedding,
|
||||
stencil_image_input,
|
||||
):
|
||||
# expand the latents if we are doing classifier-free guidance to avoid doing two forward passes.
|
||||
# TODO: guidance NOT NEEDED change in `get_input_info` later
|
||||
latents = torch.cat(
|
||||
[latent] * 2
|
||||
) # needs to be same as controlledUNET latents
|
||||
stencil_image = torch.cat(
|
||||
[stencil_image_input] * 2
|
||||
) # needs to be same as controlledUNET latents
|
||||
down_block_res_samples, mid_block_res_sample = self.cnet.forward(
|
||||
latents,
|
||||
timestep,
|
||||
encoder_hidden_states=text_embedding,
|
||||
controlnet_cond=stencil_image,
|
||||
return_dict=False,
|
||||
)
|
||||
return tuple(list(down_block_res_samples) + [mid_block_res_sample])
|
||||
|
||||
scnet = StencilControlNetModel(low_cpu_mem_usage=self.low_cpu_mem_usage)
|
||||
is_f16 = True if self.precision == "fp16" else False
|
||||
|
||||
inputs = tuple(self.inputs["stencil_adaptor"])
|
||||
input_mask = [True, True, True, True]
|
||||
shark_cnet = compile_through_fx(
|
||||
scnet,
|
||||
inputs,
|
||||
model_name=self.model_name["stencil_adaptor"],
|
||||
is_f16=is_f16,
|
||||
f16_input_mask=input_mask,
|
||||
use_tuned=self.use_tuned,
|
||||
extra_args=get_opt_flags("unet", precision=self.precision),
|
||||
)
|
||||
return shark_cnet
|
||||
|
||||
def get_unet(self):
|
||||
class UnetModel(torch.nn.Module):
|
||||
def __init__(self, model_id=self.model_id, low_cpu_mem_usage=False):
|
||||
def __init__(self, model_id=self.model_id):
|
||||
super().__init__()
|
||||
self.unet = UNet2DConditionModel.from_pretrained(
|
||||
model_id,
|
||||
subfolder="unet",
|
||||
low_cpu_mem_usage=low_cpu_mem_usage,
|
||||
)
|
||||
self.in_channels = self.unet.in_channels
|
||||
self.train(False)
|
||||
if(args.attention_slicing is not None and args.attention_slicing != "none"):
|
||||
if(args.attention_slicing.isdigit()):
|
||||
self.unet.set_attention_slice(int(args.attention_slicing))
|
||||
else:
|
||||
self.unet.set_attention_slice(args.attention_slicing)
|
||||
|
||||
# TODO: Instead of flattening the `control` try to use the list.
|
||||
def forward(
|
||||
self, latent, timestep, text_embedding, guidance_scale,
|
||||
self, latent, timestep, text_embedding, guidance_scale
|
||||
):
|
||||
# expand the latents if we are doing classifier-free guidance to avoid doing two forward passes.
|
||||
latents = torch.cat([latent] * 2)
|
||||
@@ -360,14 +181,14 @@ class SharkifyStableDiffusionModel:
|
||||
)
|
||||
return noise_pred
|
||||
|
||||
unet = UnetModel(low_cpu_mem_usage=self.low_cpu_mem_usage)
|
||||
unet = UnetModel()
|
||||
is_f16 = True if self.precision == "fp16" else False
|
||||
inputs = tuple(self.inputs["unet"])
|
||||
input_mask = [True, True, True, False]
|
||||
shark_unet = compile_through_fx(
|
||||
unet,
|
||||
inputs,
|
||||
model_name=self.model_name["unet"],
|
||||
model_name="unet" + self.model_name,
|
||||
is_f16=is_f16,
|
||||
f16_input_mask=input_mask,
|
||||
use_tuned=self.use_tuned,
|
||||
@@ -377,50 +198,28 @@ class SharkifyStableDiffusionModel:
|
||||
|
||||
def get_clip(self):
|
||||
class CLIPText(torch.nn.Module):
|
||||
def __init__(self, model_id=self.model_id, low_cpu_mem_usage=False):
|
||||
def __init__(self, model_id=self.model_id):
|
||||
super().__init__()
|
||||
self.text_encoder = CLIPTextModel.from_pretrained(
|
||||
model_id,
|
||||
subfolder="text_encoder",
|
||||
low_cpu_mem_usage=low_cpu_mem_usage,
|
||||
)
|
||||
|
||||
def forward(self, input):
|
||||
return self.text_encoder(input)[0]
|
||||
|
||||
clip_model = CLIPText(low_cpu_mem_usage=self.low_cpu_mem_usage)
|
||||
clip_model = CLIPText()
|
||||
shark_clip = compile_through_fx(
|
||||
clip_model,
|
||||
tuple(self.inputs["clip"]),
|
||||
model_name=self.model_name["clip"],
|
||||
model_name="clip" + self.model_name,
|
||||
extra_args=get_opt_flags("clip", precision="fp32"),
|
||||
)
|
||||
return shark_clip
|
||||
|
||||
def process_custom_vae(self):
|
||||
custom_vae = self.custom_vae.lower()
|
||||
if not custom_vae.endswith((".ckpt", ".safetensors")):
|
||||
return self.custom_vae
|
||||
try:
|
||||
preprocessCKPT(self.custom_vae)
|
||||
return get_path_to_diffusers_checkpoint(self.custom_vae)
|
||||
except:
|
||||
print("Processing standalone Vae checkpoint")
|
||||
vae_checkpoint = None
|
||||
vae_ignore_keys = {"model_ema.decay", "model_ema.num_updates"}
|
||||
if custom_vae.endswith(".ckpt"):
|
||||
vae_checkpoint = torch.load(self.custom_vae, map_location="cpu")
|
||||
else:
|
||||
vae_checkpoint = safetensors.torch.load_file(self.custom_vae, device="cpu")
|
||||
if "state_dict" in vae_checkpoint:
|
||||
vae_checkpoint = vae_checkpoint["state_dict"]
|
||||
vae_dict = {k: v for k, v in vae_checkpoint.items() if k[0:4] != "loss" and k not in vae_ignore_keys}
|
||||
return vae_dict
|
||||
|
||||
|
||||
# Compiles Clip, Unet and Vae with `base_model_id` as defining their input
|
||||
# configiration.
|
||||
def compile_all(self, base_model_id, need_vae_encode, need_stencil):
|
||||
def compile_all(self, base_model_id):
|
||||
self.inputs = get_input_info(
|
||||
base_models[base_model_id],
|
||||
self.max_len,
|
||||
@@ -428,45 +227,18 @@ class SharkifyStableDiffusionModel:
|
||||
self.height,
|
||||
self.batch_size,
|
||||
)
|
||||
compiled_controlnet = None
|
||||
compiled_controlled_unet = None
|
||||
compiled_unet = None
|
||||
if need_stencil:
|
||||
compiled_controlnet = self.get_control_net()
|
||||
compiled_controlled_unet = self.get_controlled_unet()
|
||||
else:
|
||||
compiled_unet = self.get_unet()
|
||||
if self.custom_vae != "":
|
||||
print("Plugging in custom Vae")
|
||||
compiled_unet = self.get_unet()
|
||||
compiled_vae = self.get_vae()
|
||||
compiled_clip = self.get_clip()
|
||||
|
||||
if need_stencil:
|
||||
return compiled_clip, compiled_controlled_unet, compiled_vae, compiled_controlnet
|
||||
if need_vae_encode:
|
||||
compiled_vae_encode = self.get_vae_encode()
|
||||
return compiled_clip, compiled_unet, compiled_vae, compiled_vae_encode
|
||||
|
||||
|
||||
return compiled_clip, compiled_unet, compiled_vae
|
||||
|
||||
def __call__(self):
|
||||
# Step 1:
|
||||
# -- Fetch all vmfbs for the model, if present, else delete the lot.
|
||||
need_vae_encode, need_stencil = False, False
|
||||
if args.img_path is not None:
|
||||
if args.use_stencil is not None:
|
||||
need_stencil = True
|
||||
else:
|
||||
need_vae_encode = True
|
||||
# `mask_to_fetch` prepares a mask to pick a combination out of :-
|
||||
# ["clip", "unet", "stencil_unet", "vae", "vae_encode", "stencil_adaptor"]
|
||||
mask_to_fetch = [True, True, False, True, False, False]
|
||||
if need_vae_encode:
|
||||
mask_to_fetch = [True, True, False, True, True, False]
|
||||
elif need_stencil:
|
||||
mask_to_fetch = [True, False, True, True, False, True]
|
||||
self.model_name = self.get_extended_name_for_all_model(mask_to_fetch)
|
||||
vmfbs = fetch_or_delete_vmfbs(self.model_name, self.precision)
|
||||
vmfbs = fetch_or_delete_vmfbs(
|
||||
self.model_name, self.base_vae, self.precision
|
||||
)
|
||||
if vmfbs[0]:
|
||||
# -- If all vmfbs are indeed present, we also try and fetch the base
|
||||
# model configuration for running SD with custom checkpoints.
|
||||
@@ -486,18 +258,15 @@ class SharkifyStableDiffusionModel:
|
||||
assert self.custom_weights.lower().endswith(
|
||||
(".ckpt", ".safetensors")
|
||||
), "checkpoint files supported can be any of [.ckpt, .safetensors] type"
|
||||
preprocessCKPT(self.custom_weights, self.is_inpaint)
|
||||
preprocessCKPT(self.custom_weights)
|
||||
else:
|
||||
model_to_run = args.hf_model_id
|
||||
# For custom Vae user can provide either the repo-id or a checkpoint file,
|
||||
# and for a checkpoint file we'd need to process it via Diffusers' script.
|
||||
self.custom_vae = self.process_custom_vae()
|
||||
base_model_fetched = fetch_and_update_base_model_id(model_to_run)
|
||||
if base_model_fetched != "":
|
||||
print("Compiling all the models with the fetched base model configuration.")
|
||||
if args.ckpt_loc != "":
|
||||
args.hf_model_id = base_model_fetched
|
||||
return self.compile_all(base_model_fetched, need_vae_encode, need_stencil)
|
||||
return self.compile_all(base_model_fetched)
|
||||
|
||||
# Step 3:
|
||||
# -- This is the retry mechanism where the base model's configuration is not
|
||||
@@ -505,13 +274,10 @@ class SharkifyStableDiffusionModel:
|
||||
print("Inferring base model configuration.")
|
||||
for model_id in base_models:
|
||||
try:
|
||||
if need_vae_encode:
|
||||
compiled_clip, compiled_unet, compiled_vae, compiled_vae_encode = self.compile_all(model_id, need_vae_encode, need_stencil)
|
||||
elif need_stencil:
|
||||
compiled_clip, compiled_unet, compiled_vae, compiled_controlnet = self.compile_all(model_id, need_vae_encode, need_stencil)
|
||||
else:
|
||||
compiled_clip, compiled_unet, compiled_vae = self.compile_all(model_id, need_vae_encode, need_stencil)
|
||||
compiled_clip, compiled_unet, compiled_vae = self.compile_all(model_id)
|
||||
except Exception as e:
|
||||
if args.enable_stack_trace:
|
||||
traceback.print_exc()
|
||||
print("Retrying with a different base model configuration")
|
||||
continue
|
||||
# -- Once a successful compilation has taken place we'd want to store
|
||||
@@ -523,21 +289,7 @@ class SharkifyStableDiffusionModel:
|
||||
# the knowledge of base model id accordingly into `args.hf_model_id`.
|
||||
if args.ckpt_loc != "":
|
||||
args.hf_model_id = model_id
|
||||
if need_vae_encode:
|
||||
return (
|
||||
compiled_clip,
|
||||
compiled_unet,
|
||||
compiled_vae,
|
||||
compiled_vae_encode,
|
||||
)
|
||||
if need_stencil:
|
||||
return (
|
||||
compiled_clip,
|
||||
compiled_unet,
|
||||
compiled_vae,
|
||||
compiled_controlnet,
|
||||
)
|
||||
return compiled_clip, compiled_unet, compiled_vae
|
||||
sys.exit(
|
||||
"Cannot compile the model. Please create an issue with the detailed log at https://github.com/nod-ai/SHARK/issues"
|
||||
"Cannot compile the model. Please re-run the command with `--enable_stack_trace` flag and create an issue with detailed log at https://github.com/nod-ai/SHARK/issues"
|
||||
)
|
||||
|
||||
@@ -9,15 +9,13 @@ from apps.stable_diffusion.src.utils import (
|
||||
|
||||
|
||||
hf_model_variant_map = {
|
||||
"Linaqruf/anything-v3.0": ["anythingv3", "v1_4"],
|
||||
"dreamlike-art/dreamlike-diffusion-1.0": ["dreamlike", "v1_4"],
|
||||
"prompthero/openjourney": ["openjourney", "v1_4"],
|
||||
"wavymulder/Analog-Diffusion": ["analogdiffusion", "v1_4"],
|
||||
"Linaqruf/anything-v3.0": ["anythingv3", "v2_1base"],
|
||||
"dreamlike-art/dreamlike-diffusion-1.0": ["dreamlike", "v2_1base"],
|
||||
"prompthero/openjourney": ["openjourney", "v2_1base"],
|
||||
"wavymulder/Analog-Diffusion": ["analogdiffusion", "v2_1base"],
|
||||
"stabilityai/stable-diffusion-2-1": ["stablediffusion", "v2_1base"],
|
||||
"stabilityai/stable-diffusion-2-1-base": ["stablediffusion", "v2_1base"],
|
||||
"CompVis/stable-diffusion-v1-4": ["stablediffusion", "v1_4"],
|
||||
"runwayml/stable-diffusion-inpainting": ["stablediffusion", "inpaint_v1"],
|
||||
"stabilityai/stable-diffusion-2-inpainting": ["stablediffusion", "inpaint_v2"],
|
||||
}
|
||||
|
||||
|
||||
@@ -54,23 +52,6 @@ def get_unet():
|
||||
return get_shark_model(bucket, model_name, iree_flags)
|
||||
|
||||
|
||||
def get_vae_encode():
|
||||
variant, version = get_variant_version(args.hf_model_id)
|
||||
# Tuned model is present only for `fp16` precision.
|
||||
is_tuned = "tuned" if args.use_tuned else "untuned"
|
||||
if "vulkan" not in args.device and args.use_tuned:
|
||||
bucket_key = f"{variant}/{is_tuned}/{args.device}"
|
||||
model_key = f"{variant}/{version}/vae_encode/{args.precision}/length_77/{is_tuned}/{args.device}"
|
||||
else:
|
||||
bucket_key = f"{variant}/{is_tuned}"
|
||||
model_key = f"{variant}/{version}/vae_encode/{args.precision}/length_77/{is_tuned}"
|
||||
|
||||
bucket, model_name, iree_flags = get_params(
|
||||
bucket_key, model_key, "vae", is_tuned, args.precision
|
||||
)
|
||||
return get_shark_model(bucket, model_name, iree_flags)
|
||||
|
||||
|
||||
def get_vae():
|
||||
variant, version = get_variant_version(args.hf_model_id)
|
||||
# Tuned model is present only for `fp16` precision.
|
||||
|
||||
@@ -1,15 +1,3 @@
|
||||
from apps.stable_diffusion.src.pipelines.pipeline_shark_stable_diffusion_txt2img import (
|
||||
Text2ImagePipeline,
|
||||
)
|
||||
from apps.stable_diffusion.src.pipelines.pipeline_shark_stable_diffusion_img2img import (
|
||||
Image2ImagePipeline,
|
||||
)
|
||||
from apps.stable_diffusion.src.pipelines.pipeline_shark_stable_diffusion_inpaint import (
|
||||
InpaintPipeline,
|
||||
)
|
||||
from apps.stable_diffusion.src.pipelines.pipeline_shark_stable_diffusion_outpaint import (
|
||||
OutpaintPipeline,
|
||||
)
|
||||
from apps.stable_diffusion.src.pipelines.pipeline_shark_stable_diffusion_stencil import (
|
||||
StencilPipeline,
|
||||
)
|
||||
|
||||
@@ -1,172 +0,0 @@
|
||||
import torch
|
||||
import time
|
||||
import numpy as np
|
||||
from tqdm.auto import tqdm
|
||||
from random import randint
|
||||
from PIL import Image
|
||||
from transformers import CLIPTokenizer
|
||||
from typing import Union
|
||||
from shark.shark_inference import SharkInference
|
||||
from diffusers import (
|
||||
DDIMScheduler,
|
||||
PNDMScheduler,
|
||||
LMSDiscreteScheduler,
|
||||
EulerDiscreteScheduler,
|
||||
EulerAncestralDiscreteScheduler,
|
||||
DPMSolverMultistepScheduler,
|
||||
DEISMultistepScheduler,
|
||||
)
|
||||
from apps.stable_diffusion.src.schedulers import SharkEulerDiscreteScheduler
|
||||
from apps.stable_diffusion.src.pipelines.pipeline_shark_stable_diffusion_utils import (
|
||||
StableDiffusionPipeline,
|
||||
)
|
||||
|
||||
|
||||
class Image2ImagePipeline(StableDiffusionPipeline):
|
||||
def __init__(
|
||||
self,
|
||||
vae_encode: SharkInference,
|
||||
vae: SharkInference,
|
||||
text_encoder: SharkInference,
|
||||
tokenizer: CLIPTokenizer,
|
||||
unet: SharkInference,
|
||||
scheduler: Union[
|
||||
DDIMScheduler,
|
||||
PNDMScheduler,
|
||||
LMSDiscreteScheduler,
|
||||
EulerDiscreteScheduler,
|
||||
EulerAncestralDiscreteScheduler,
|
||||
DPMSolverMultistepScheduler,
|
||||
SharkEulerDiscreteScheduler,
|
||||
DEISMultistepScheduler,
|
||||
],
|
||||
):
|
||||
super().__init__(vae, text_encoder, tokenizer, unet, scheduler)
|
||||
self.vae_encode = vae_encode
|
||||
|
||||
def prepare_image_latents(
|
||||
self,
|
||||
image,
|
||||
batch_size,
|
||||
height,
|
||||
width,
|
||||
generator,
|
||||
num_inference_steps,
|
||||
strength,
|
||||
dtype,
|
||||
):
|
||||
# Pre process image -> get image encoded -> process latents
|
||||
|
||||
# TODO: process with variable HxW combos
|
||||
|
||||
# Pre process image
|
||||
image = image.resize((width, height))
|
||||
image_arr = np.stack([np.array(i) for i in (image,)], axis=0)
|
||||
image_arr = image_arr / 255.0
|
||||
image_arr = torch.from_numpy(image_arr).permute(0, 3, 1, 2).to(dtype)
|
||||
image_arr = 2 * (image_arr - 0.5)
|
||||
|
||||
# set scheduler steps
|
||||
self.scheduler.set_timesteps(num_inference_steps)
|
||||
init_timestep = min(
|
||||
int(num_inference_steps * strength), num_inference_steps
|
||||
)
|
||||
t_start = max(num_inference_steps - init_timestep, 0)
|
||||
# timesteps reduced as per strength
|
||||
timesteps = self.scheduler.timesteps[t_start:]
|
||||
# new number of steps to be used as per strength will be
|
||||
# num_inference_steps = num_inference_steps - t_start
|
||||
|
||||
# image encode
|
||||
latents = self.encode_image((image_arr,))
|
||||
latents = torch.from_numpy(latents).to(dtype)
|
||||
# add noise to data
|
||||
noise = torch.randn(latents.shape, generator=generator, dtype=dtype)
|
||||
latents = self.scheduler.add_noise(
|
||||
latents, noise, timesteps[0].repeat(1)
|
||||
)
|
||||
|
||||
return latents, timesteps
|
||||
|
||||
def encode_image(self, input_image):
|
||||
vae_encode_start = time.time()
|
||||
latents = self.vae_encode("forward", input_image)
|
||||
vae_inf_time = (time.time() - vae_encode_start) * 1000
|
||||
self.log += f"\nVAE Encode Inference time (ms): {vae_inf_time:.3f}"
|
||||
|
||||
return latents
|
||||
|
||||
def generate_images(
|
||||
self,
|
||||
prompts,
|
||||
neg_prompts,
|
||||
image,
|
||||
batch_size,
|
||||
height,
|
||||
width,
|
||||
num_inference_steps,
|
||||
strength,
|
||||
guidance_scale,
|
||||
seed,
|
||||
max_length,
|
||||
dtype,
|
||||
use_base_vae,
|
||||
cpu_scheduling,
|
||||
use_stencil,
|
||||
):
|
||||
# prompts and negative prompts must be a list.
|
||||
if isinstance(prompts, str):
|
||||
prompts = [prompts]
|
||||
|
||||
if isinstance(neg_prompts, str):
|
||||
neg_prompts = [neg_prompts]
|
||||
|
||||
prompts = prompts * batch_size
|
||||
neg_prompts = neg_prompts * batch_size
|
||||
|
||||
# seed generator to create the inital latent noise. Also handle out of range seeds.
|
||||
uint32_info = np.iinfo(np.uint32)
|
||||
uint32_min, uint32_max = uint32_info.min, uint32_info.max
|
||||
if seed < uint32_min or seed >= uint32_max:
|
||||
seed = randint(uint32_min, uint32_max)
|
||||
generator = torch.manual_seed(seed)
|
||||
|
||||
# Get text embeddings from prompts
|
||||
text_embeddings = self.encode_prompts(prompts, neg_prompts, max_length)
|
||||
|
||||
# guidance scale as a float32 tensor.
|
||||
guidance_scale = torch.tensor(guidance_scale).to(torch.float32)
|
||||
|
||||
# Prepare input image latent
|
||||
image_latents, final_timesteps = self.prepare_image_latents(
|
||||
image=image,
|
||||
batch_size=batch_size,
|
||||
height=height,
|
||||
width=width,
|
||||
generator=generator,
|
||||
num_inference_steps=num_inference_steps,
|
||||
strength=strength,
|
||||
dtype=dtype,
|
||||
)
|
||||
|
||||
# Get Image latents
|
||||
latents = self.produce_img_latents(
|
||||
latents=image_latents,
|
||||
text_embeddings=text_embeddings,
|
||||
guidance_scale=guidance_scale,
|
||||
total_timesteps=final_timesteps,
|
||||
dtype=dtype,
|
||||
cpu_scheduling=cpu_scheduling,
|
||||
)
|
||||
|
||||
# Img latents -> PIL images
|
||||
all_imgs = []
|
||||
for i in tqdm(range(0, latents.shape[0], batch_size)):
|
||||
imgs = self.decode_latents(
|
||||
latents=latents[i : i + batch_size],
|
||||
use_base_vae=use_base_vae,
|
||||
cpu_scheduling=cpu_scheduling,
|
||||
)
|
||||
all_imgs.extend(imgs)
|
||||
|
||||
return all_imgs
|
||||
|
||||
@@ -1,233 +0,0 @@
|
||||
import torch
|
||||
from tqdm.auto import tqdm
|
||||
import numpy as np
|
||||
from random import randint
|
||||
from PIL import Image
|
||||
from transformers import CLIPTokenizer
|
||||
from typing import Union
|
||||
from shark.shark_inference import SharkInference
|
||||
from diffusers import (
|
||||
DDIMScheduler,
|
||||
PNDMScheduler,
|
||||
LMSDiscreteScheduler,
|
||||
EulerDiscreteScheduler,
|
||||
EulerAncestralDiscreteScheduler,
|
||||
DPMSolverMultistepScheduler,
|
||||
DEISMultistepScheduler,
|
||||
)
|
||||
from apps.stable_diffusion.src.schedulers import SharkEulerDiscreteScheduler
|
||||
from apps.stable_diffusion.src.pipelines.pipeline_shark_stable_diffusion_utils import (
|
||||
StableDiffusionPipeline,
|
||||
)
|
||||
|
||||
|
||||
class InpaintPipeline(StableDiffusionPipeline):
|
||||
def __init__(
|
||||
self,
|
||||
vae_encode: SharkInference,
|
||||
vae: SharkInference,
|
||||
text_encoder: SharkInference,
|
||||
tokenizer: CLIPTokenizer,
|
||||
unet: SharkInference,
|
||||
scheduler: Union[
|
||||
DDIMScheduler,
|
||||
PNDMScheduler,
|
||||
LMSDiscreteScheduler,
|
||||
EulerDiscreteScheduler,
|
||||
EulerAncestralDiscreteScheduler,
|
||||
DPMSolverMultistepScheduler,
|
||||
SharkEulerDiscreteScheduler,
|
||||
DEISMultistepScheduler,
|
||||
],
|
||||
):
|
||||
super().__init__(vae, text_encoder, tokenizer, unet, scheduler)
|
||||
self.vae_encode = vae_encode
|
||||
|
||||
def prepare_mask_and_masked_image(self, image, mask, height, width):
|
||||
# preprocess image
|
||||
image = image.resize((width, height))
|
||||
mask = mask.resize((width, height))
|
||||
if isinstance(image, (Image.Image, np.ndarray)):
|
||||
image = [image]
|
||||
|
||||
if isinstance(image, list) and isinstance(image[0], Image.Image):
|
||||
image = [np.array(i.convert("RGB"))[None, :] for i in image]
|
||||
image = np.concatenate(image, axis=0)
|
||||
elif isinstance(image, list) and isinstance(image[0], np.ndarray):
|
||||
image = np.concatenate([i[None, :] for i in image], axis=0)
|
||||
|
||||
image = image.transpose(0, 3, 1, 2)
|
||||
image = torch.from_numpy(image).to(dtype=torch.float32) / 127.5 - 1.0
|
||||
|
||||
# preprocess mask
|
||||
if isinstance(mask, (Image.Image, np.ndarray)):
|
||||
mask = [mask]
|
||||
|
||||
if isinstance(mask, list) and isinstance(mask[0], Image.Image):
|
||||
mask = np.concatenate(
|
||||
[np.array(m.convert("L"))[None, None, :] for m in mask], axis=0
|
||||
)
|
||||
mask = mask.astype(np.float32) / 255.0
|
||||
elif isinstance(mask, list) and isinstance(mask[0], np.ndarray):
|
||||
mask = np.concatenate([m[None, None, :] for m in mask], axis=0)
|
||||
|
||||
mask[mask < 0.5] = 0
|
||||
mask[mask >= 0.5] = 1
|
||||
mask = torch.from_numpy(mask)
|
||||
|
||||
masked_image = image * (mask < 0.5)
|
||||
|
||||
return mask, masked_image
|
||||
|
||||
def prepare_latents(
|
||||
self,
|
||||
batch_size,
|
||||
height,
|
||||
width,
|
||||
generator,
|
||||
num_inference_steps,
|
||||
dtype,
|
||||
):
|
||||
latents = torch.randn(
|
||||
(
|
||||
batch_size,
|
||||
4,
|
||||
height // 8,
|
||||
width // 8,
|
||||
),
|
||||
generator=generator,
|
||||
dtype=torch.float32,
|
||||
).to(dtype)
|
||||
|
||||
self.scheduler.set_timesteps(num_inference_steps)
|
||||
self.scheduler.is_scale_input_called = True
|
||||
latents = latents * self.scheduler.init_noise_sigma
|
||||
return latents
|
||||
|
||||
def prepare_mask_latents(
|
||||
self,
|
||||
mask,
|
||||
masked_image,
|
||||
batch_size,
|
||||
height,
|
||||
width,
|
||||
dtype,
|
||||
):
|
||||
mask = torch.nn.functional.interpolate(
|
||||
mask, size=(height // 8, width // 8)
|
||||
)
|
||||
mask = mask.to(dtype)
|
||||
|
||||
masked_image = masked_image.to(dtype)
|
||||
masked_image_latents = self.vae_encode("forward", (masked_image,))
|
||||
masked_image_latents = torch.from_numpy(masked_image_latents)
|
||||
|
||||
# duplicate mask and masked_image_latents for each generation per prompt, using mps friendly method
|
||||
if mask.shape[0] < batch_size:
|
||||
if not batch_size % mask.shape[0] == 0:
|
||||
raise ValueError(
|
||||
"The passed mask and the required batch size don't match. Masks are supposed to be duplicated to"
|
||||
f" a total batch size of {batch_size}, but {mask.shape[0]} masks were passed. Make sure the number"
|
||||
" of masks that you pass is divisible by the total requested batch size."
|
||||
)
|
||||
mask = mask.repeat(batch_size // mask.shape[0], 1, 1, 1)
|
||||
if masked_image_latents.shape[0] < batch_size:
|
||||
if not batch_size % masked_image_latents.shape[0] == 0:
|
||||
raise ValueError(
|
||||
"The passed images and the required batch size don't match. Images are supposed to be duplicated"
|
||||
f" to a total batch size of {batch_size}, but {masked_image_latents.shape[0]} images were passed."
|
||||
" Make sure the number of images that you pass is divisible by the total requested batch size."
|
||||
)
|
||||
masked_image_latents = masked_image_latents.repeat(
|
||||
batch_size // masked_image_latents.shape[0], 1, 1, 1
|
||||
)
|
||||
return mask, masked_image_latents
|
||||
|
||||
def generate_images(
|
||||
self,
|
||||
prompts,
|
||||
neg_prompts,
|
||||
image,
|
||||
mask_image,
|
||||
batch_size,
|
||||
height,
|
||||
width,
|
||||
num_inference_steps,
|
||||
guidance_scale,
|
||||
seed,
|
||||
max_length,
|
||||
dtype,
|
||||
use_base_vae,
|
||||
cpu_scheduling,
|
||||
):
|
||||
# prompts and negative prompts must be a list.
|
||||
if isinstance(prompts, str):
|
||||
prompts = [prompts]
|
||||
|
||||
if isinstance(neg_prompts, str):
|
||||
neg_prompts = [neg_prompts]
|
||||
|
||||
prompts = prompts * batch_size
|
||||
neg_prompts = neg_prompts * batch_size
|
||||
|
||||
# seed generator to create the inital latent noise. Also handle out of range seeds.
|
||||
uint32_info = np.iinfo(np.uint32)
|
||||
uint32_min, uint32_max = uint32_info.min, uint32_info.max
|
||||
if seed < uint32_min or seed >= uint32_max:
|
||||
seed = randint(uint32_min, uint32_max)
|
||||
generator = torch.manual_seed(seed)
|
||||
|
||||
# Get initial latents
|
||||
init_latents = self.prepare_latents(
|
||||
batch_size=batch_size,
|
||||
height=height,
|
||||
width=width,
|
||||
generator=generator,
|
||||
num_inference_steps=num_inference_steps,
|
||||
dtype=dtype,
|
||||
)
|
||||
|
||||
# Get text embeddings from prompts
|
||||
text_embeddings = self.encode_prompts(prompts, neg_prompts, max_length)
|
||||
|
||||
# guidance scale as a float32 tensor.
|
||||
guidance_scale = torch.tensor(guidance_scale).to(torch.float32)
|
||||
|
||||
# Preprocess mask and image
|
||||
mask, masked_image = self.prepare_mask_and_masked_image(
|
||||
image, mask_image, height, width
|
||||
)
|
||||
|
||||
# Prepare mask latent variables
|
||||
mask, masked_image_latents = self.prepare_mask_latents(
|
||||
mask=mask,
|
||||
masked_image=masked_image,
|
||||
batch_size=batch_size,
|
||||
height=height,
|
||||
width=width,
|
||||
dtype=dtype,
|
||||
)
|
||||
|
||||
# Get Image latents
|
||||
latents = self.produce_img_latents(
|
||||
latents=init_latents,
|
||||
text_embeddings=text_embeddings,
|
||||
guidance_scale=guidance_scale,
|
||||
total_timesteps=self.scheduler.timesteps,
|
||||
dtype=dtype,
|
||||
cpu_scheduling=cpu_scheduling,
|
||||
mask=mask,
|
||||
masked_image_latents=masked_image_latents,
|
||||
)
|
||||
|
||||
# Img latents -> PIL images
|
||||
all_imgs = []
|
||||
for i in tqdm(range(0, latents.shape[0], batch_size)):
|
||||
imgs = self.decode_latents(
|
||||
latents=latents[i : i + batch_size],
|
||||
use_base_vae=use_base_vae,
|
||||
cpu_scheduling=cpu_scheduling,
|
||||
)
|
||||
all_imgs.extend(imgs)
|
||||
|
||||
return all_imgs
|
||||
@@ -1,542 +0,0 @@
|
||||
import torch
|
||||
from tqdm.auto import tqdm
|
||||
import numpy as np
|
||||
from random import randint
|
||||
from PIL import Image, ImageDraw, ImageFilter
|
||||
from transformers import CLIPTokenizer
|
||||
from typing import Union
|
||||
from shark.shark_inference import SharkInference
|
||||
from diffusers import (
|
||||
DDIMScheduler,
|
||||
PNDMScheduler,
|
||||
LMSDiscreteScheduler,
|
||||
EulerDiscreteScheduler,
|
||||
EulerAncestralDiscreteScheduler,
|
||||
DPMSolverMultistepScheduler,
|
||||
DEISMultistepScheduler,
|
||||
)
|
||||
from apps.stable_diffusion.src.schedulers import SharkEulerDiscreteScheduler
|
||||
from apps.stable_diffusion.src.pipelines.pipeline_shark_stable_diffusion_utils import (
|
||||
StableDiffusionPipeline,
|
||||
)
|
||||
import math
|
||||
|
||||
|
||||
class OutpaintPipeline(StableDiffusionPipeline):
|
||||
def __init__(
|
||||
self,
|
||||
vae_encode: SharkInference,
|
||||
vae: SharkInference,
|
||||
text_encoder: SharkInference,
|
||||
tokenizer: CLIPTokenizer,
|
||||
unet: SharkInference,
|
||||
scheduler: Union[
|
||||
DDIMScheduler,
|
||||
PNDMScheduler,
|
||||
LMSDiscreteScheduler,
|
||||
EulerDiscreteScheduler,
|
||||
EulerAncestralDiscreteScheduler,
|
||||
DPMSolverMultistepScheduler,
|
||||
SharkEulerDiscreteScheduler,
|
||||
DEISMultistepScheduler,
|
||||
],
|
||||
):
|
||||
super().__init__(vae, text_encoder, tokenizer, unet, scheduler)
|
||||
self.vae_encode = vae_encode
|
||||
|
||||
def prepare_latents(
|
||||
self,
|
||||
batch_size,
|
||||
height,
|
||||
width,
|
||||
generator,
|
||||
num_inference_steps,
|
||||
dtype,
|
||||
):
|
||||
latents = torch.randn(
|
||||
(
|
||||
batch_size,
|
||||
4,
|
||||
height // 8,
|
||||
width // 8,
|
||||
),
|
||||
generator=generator,
|
||||
dtype=torch.float32,
|
||||
).to(dtype)
|
||||
|
||||
self.scheduler.set_timesteps(num_inference_steps)
|
||||
self.scheduler.is_scale_input_called = True
|
||||
latents = latents * self.scheduler.init_noise_sigma
|
||||
return latents
|
||||
|
||||
def prepare_mask_and_masked_image(
|
||||
self, image, mask, mask_blur, width, height
|
||||
):
|
||||
if mask_blur > 0:
|
||||
mask = mask.filter(ImageFilter.GaussianBlur(mask_blur))
|
||||
image = image.resize((width, height))
|
||||
mask = mask.resize((width, height))
|
||||
|
||||
# preprocess image
|
||||
if isinstance(image, (Image.Image, np.ndarray)):
|
||||
image = [image]
|
||||
|
||||
if isinstance(image, list) and isinstance(image[0], Image.Image):
|
||||
image = [np.array(i.convert("RGB"))[None, :] for i in image]
|
||||
image = np.concatenate(image, axis=0)
|
||||
elif isinstance(image, list) and isinstance(image[0], np.ndarray):
|
||||
image = np.concatenate([i[None, :] for i in image], axis=0)
|
||||
|
||||
image = image.transpose(0, 3, 1, 2)
|
||||
image = torch.from_numpy(image).to(dtype=torch.float32) / 127.5 - 1.0
|
||||
|
||||
# preprocess mask
|
||||
if isinstance(mask, (Image.Image, np.ndarray)):
|
||||
mask = [mask]
|
||||
|
||||
if isinstance(mask, list) and isinstance(mask[0], Image.Image):
|
||||
mask = np.concatenate(
|
||||
[np.array(m.convert("L"))[None, None, :] for m in mask], axis=0
|
||||
)
|
||||
mask = mask.astype(np.float32) / 255.0
|
||||
elif isinstance(mask, list) and isinstance(mask[0], np.ndarray):
|
||||
mask = np.concatenate([m[None, None, :] for m in mask], axis=0)
|
||||
|
||||
mask[mask < 0.5] = 0
|
||||
mask[mask >= 0.5] = 1
|
||||
mask = torch.from_numpy(mask)
|
||||
|
||||
masked_image = image * (mask < 0.5)
|
||||
|
||||
return mask, masked_image
|
||||
|
||||
def prepare_mask_latents(
|
||||
self,
|
||||
mask,
|
||||
masked_image,
|
||||
batch_size,
|
||||
height,
|
||||
width,
|
||||
dtype,
|
||||
):
|
||||
mask = torch.nn.functional.interpolate(
|
||||
mask, size=(height // 8, width // 8)
|
||||
)
|
||||
mask = mask.to(dtype)
|
||||
|
||||
masked_image = masked_image.to(dtype)
|
||||
masked_image_latents = self.vae_encode("forward", (masked_image,))
|
||||
masked_image_latents = torch.from_numpy(masked_image_latents)
|
||||
|
||||
# duplicate mask and masked_image_latents for each generation per prompt, using mps friendly method
|
||||
if mask.shape[0] < batch_size:
|
||||
if not batch_size % mask.shape[0] == 0:
|
||||
raise ValueError(
|
||||
"The passed mask and the required batch size don't match. Masks are supposed to be duplicated to"
|
||||
f" a total batch size of {batch_size}, but {mask.shape[0]} masks were passed. Make sure the number"
|
||||
" of masks that you pass is divisible by the total requested batch size."
|
||||
)
|
||||
mask = mask.repeat(batch_size // mask.shape[0], 1, 1, 1)
|
||||
if masked_image_latents.shape[0] < batch_size:
|
||||
if not batch_size % masked_image_latents.shape[0] == 0:
|
||||
raise ValueError(
|
||||
"The passed images and the required batch size don't match. Images are supposed to be duplicated"
|
||||
f" to a total batch size of {batch_size}, but {masked_image_latents.shape[0]} images were passed."
|
||||
" Make sure the number of images that you pass is divisible by the total requested batch size."
|
||||
)
|
||||
masked_image_latents = masked_image_latents.repeat(
|
||||
batch_size // masked_image_latents.shape[0], 1, 1, 1
|
||||
)
|
||||
return mask, masked_image_latents
|
||||
|
||||
def get_matched_noise(
|
||||
self, _np_src_image, np_mask_rgb, noise_q=1, color_variation=0.05
|
||||
):
|
||||
# helper fft routines that keep ortho normalization and auto-shift before and after fft
|
||||
def _fft2(data):
|
||||
if data.ndim > 2: # has channels
|
||||
out_fft = np.zeros(
|
||||
(data.shape[0], data.shape[1], data.shape[2]),
|
||||
dtype=np.complex128,
|
||||
)
|
||||
for c in range(data.shape[2]):
|
||||
c_data = data[:, :, c]
|
||||
out_fft[:, :, c] = np.fft.fft2(
|
||||
np.fft.fftshift(c_data), norm="ortho"
|
||||
)
|
||||
out_fft[:, :, c] = np.fft.ifftshift(out_fft[:, :, c])
|
||||
else: # one channel
|
||||
out_fft = np.zeros(
|
||||
(data.shape[0], data.shape[1]), dtype=np.complex128
|
||||
)
|
||||
out_fft[:, :] = np.fft.fft2(
|
||||
np.fft.fftshift(data), norm="ortho"
|
||||
)
|
||||
out_fft[:, :] = np.fft.ifftshift(out_fft[:, :])
|
||||
|
||||
return out_fft
|
||||
|
||||
def _ifft2(data):
|
||||
if data.ndim > 2: # has channels
|
||||
out_ifft = np.zeros(
|
||||
(data.shape[0], data.shape[1], data.shape[2]),
|
||||
dtype=np.complex128,
|
||||
)
|
||||
for c in range(data.shape[2]):
|
||||
c_data = data[:, :, c]
|
||||
out_ifft[:, :, c] = np.fft.ifft2(
|
||||
np.fft.fftshift(c_data), norm="ortho"
|
||||
)
|
||||
out_ifft[:, :, c] = np.fft.ifftshift(out_ifft[:, :, c])
|
||||
else: # one channel
|
||||
out_ifft = np.zeros(
|
||||
(data.shape[0], data.shape[1]), dtype=np.complex128
|
||||
)
|
||||
out_ifft[:, :] = np.fft.ifft2(
|
||||
np.fft.fftshift(data), norm="ortho"
|
||||
)
|
||||
out_ifft[:, :] = np.fft.ifftshift(out_ifft[:, :])
|
||||
|
||||
return out_ifft
|
||||
|
||||
def _get_gaussian_window(width, height, std=3.14, mode=0):
|
||||
window_scale_x = float(width / min(width, height))
|
||||
window_scale_y = float(height / min(width, height))
|
||||
|
||||
window = np.zeros((width, height))
|
||||
x = (np.arange(width) / width * 2.0 - 1.0) * window_scale_x
|
||||
for y in range(height):
|
||||
fy = (y / height * 2.0 - 1.0) * window_scale_y
|
||||
if mode == 0:
|
||||
window[:, y] = np.exp(-(x**2 + fy**2) * std)
|
||||
else:
|
||||
window[:, y] = (
|
||||
1 / ((x**2 + 1.0) * (fy**2 + 1.0))
|
||||
) ** (std / 3.14)
|
||||
|
||||
return window
|
||||
|
||||
def _get_masked_window_rgb(np_mask_grey, hardness=1.0):
|
||||
np_mask_rgb = np.zeros(
|
||||
(np_mask_grey.shape[0], np_mask_grey.shape[1], 3)
|
||||
)
|
||||
if hardness != 1.0:
|
||||
hardened = np_mask_grey[:] ** hardness
|
||||
else:
|
||||
hardened = np_mask_grey[:]
|
||||
for c in range(3):
|
||||
np_mask_rgb[:, :, c] = hardened[:]
|
||||
return np_mask_rgb
|
||||
|
||||
def _match_cumulative_cdf(source, template):
|
||||
src_values, src_unique_indices, src_counts = np.unique(
|
||||
source.ravel(), return_inverse=True, return_counts=True
|
||||
)
|
||||
tmpl_values, tmpl_counts = np.unique(
|
||||
template.ravel(), return_counts=True
|
||||
)
|
||||
|
||||
# calculate normalized quantiles for each array
|
||||
src_quantiles = np.cumsum(src_counts) / source.size
|
||||
tmpl_quantiles = np.cumsum(tmpl_counts) / template.size
|
||||
|
||||
interp_a_values = np.interp(
|
||||
src_quantiles, tmpl_quantiles, tmpl_values
|
||||
)
|
||||
return interp_a_values[src_unique_indices].reshape(source.shape)
|
||||
|
||||
def _match_histograms(image, reference):
|
||||
if image.ndim != reference.ndim:
|
||||
raise ValueError(
|
||||
"Image and reference must have the same number of channels."
|
||||
)
|
||||
|
||||
if image.shape[-1] != reference.shape[-1]:
|
||||
raise ValueError(
|
||||
"Number of channels in the input image and reference image must match!"
|
||||
)
|
||||
|
||||
matched = np.empty(image.shape, dtype=image.dtype)
|
||||
for channel in range(image.shape[-1]):
|
||||
matched_channel = _match_cumulative_cdf(
|
||||
image[..., channel], reference[..., channel]
|
||||
)
|
||||
matched[..., channel] = matched_channel
|
||||
|
||||
matched = matched.astype(np.float64, copy=False)
|
||||
return matched
|
||||
|
||||
width = _np_src_image.shape[0]
|
||||
height = _np_src_image.shape[1]
|
||||
num_channels = _np_src_image.shape[2]
|
||||
|
||||
np_src_image = _np_src_image[:] * (1.0 - np_mask_rgb)
|
||||
np_mask_grey = np.sum(np_mask_rgb, axis=2) / 3.0
|
||||
img_mask = np_mask_grey > 1e-6
|
||||
ref_mask = np_mask_grey < 1e-3
|
||||
|
||||
# rather than leave the masked area black, we get better results from fft by filling the average unmasked color
|
||||
windowed_image = _np_src_image * (
|
||||
1.0 - _get_masked_window_rgb(np_mask_grey)
|
||||
)
|
||||
windowed_image /= np.max(windowed_image)
|
||||
windowed_image += np.average(_np_src_image) * np_mask_rgb
|
||||
|
||||
src_fft = _fft2(
|
||||
windowed_image
|
||||
) # get feature statistics from masked src img
|
||||
src_dist = np.absolute(src_fft)
|
||||
src_phase = src_fft / src_dist
|
||||
|
||||
# create a generator with a static seed to make outpainting deterministic / only follow global seed
|
||||
rng = np.random.default_rng(0)
|
||||
|
||||
noise_window = _get_gaussian_window(
|
||||
width, height, mode=1
|
||||
) # start with simple gaussian noise
|
||||
noise_rgb = rng.random((width, height, num_channels))
|
||||
noise_grey = np.sum(noise_rgb, axis=2) / 3.0
|
||||
# the colorfulness of the starting noise is blended to greyscale with a parameter
|
||||
noise_rgb *= color_variation
|
||||
for c in range(num_channels):
|
||||
noise_rgb[:, :, c] += (1.0 - color_variation) * noise_grey
|
||||
|
||||
noise_fft = _fft2(noise_rgb)
|
||||
for c in range(num_channels):
|
||||
noise_fft[:, :, c] *= noise_window
|
||||
noise_rgb = np.real(_ifft2(noise_fft))
|
||||
shaped_noise_fft = _fft2(noise_rgb)
|
||||
shaped_noise_fft[:, :, :] = (
|
||||
np.absolute(shaped_noise_fft[:, :, :]) ** 2
|
||||
* (src_dist**noise_q)
|
||||
* src_phase
|
||||
) # perform the actual shaping
|
||||
|
||||
# color_variation
|
||||
brightness_variation = 0.0
|
||||
contrast_adjusted_np_src = (
|
||||
_np_src_image[:] * (brightness_variation + 1.0)
|
||||
- brightness_variation * 2.0
|
||||
)
|
||||
|
||||
shaped_noise = np.real(_ifft2(shaped_noise_fft))
|
||||
shaped_noise -= np.min(shaped_noise)
|
||||
shaped_noise /= np.max(shaped_noise)
|
||||
shaped_noise[img_mask, :] = _match_histograms(
|
||||
shaped_noise[img_mask, :] ** 1.0,
|
||||
contrast_adjusted_np_src[ref_mask, :],
|
||||
)
|
||||
shaped_noise = (
|
||||
_np_src_image[:] * (1.0 - np_mask_rgb) + shaped_noise * np_mask_rgb
|
||||
)
|
||||
|
||||
matched_noise = shaped_noise[:]
|
||||
|
||||
return np.clip(matched_noise, 0.0, 1.0)
|
||||
|
||||
def generate_images(
|
||||
self,
|
||||
prompts,
|
||||
neg_prompts,
|
||||
image,
|
||||
pixels,
|
||||
mask_blur,
|
||||
is_left,
|
||||
is_right,
|
||||
is_top,
|
||||
is_bottom,
|
||||
noise_q,
|
||||
color_variation,
|
||||
batch_size,
|
||||
height,
|
||||
width,
|
||||
num_inference_steps,
|
||||
guidance_scale,
|
||||
seed,
|
||||
max_length,
|
||||
dtype,
|
||||
use_base_vae,
|
||||
cpu_scheduling,
|
||||
):
|
||||
# prompts and negative prompts must be a list.
|
||||
if isinstance(prompts, str):
|
||||
prompts = [prompts]
|
||||
|
||||
if isinstance(neg_prompts, str):
|
||||
neg_prompts = [neg_prompts]
|
||||
|
||||
prompts = prompts * batch_size
|
||||
neg_prompts = neg_prompts * batch_size
|
||||
|
||||
# seed generator to create the inital latent noise. Also handle out of range seeds.
|
||||
uint32_info = np.iinfo(np.uint32)
|
||||
uint32_min, uint32_max = uint32_info.min, uint32_info.max
|
||||
if seed < uint32_min or seed >= uint32_max:
|
||||
seed = randint(uint32_min, uint32_max)
|
||||
generator = torch.manual_seed(seed)
|
||||
|
||||
# Get initial latents
|
||||
init_latents = self.prepare_latents(
|
||||
batch_size=batch_size,
|
||||
height=height,
|
||||
width=width,
|
||||
generator=generator,
|
||||
num_inference_steps=num_inference_steps,
|
||||
dtype=dtype,
|
||||
)
|
||||
|
||||
# Get text embeddings from prompts
|
||||
text_embeddings = self.encode_prompts(prompts, neg_prompts, max_length)
|
||||
|
||||
# guidance scale as a float32 tensor.
|
||||
guidance_scale = torch.tensor(guidance_scale).to(torch.float32)
|
||||
|
||||
process_width = width
|
||||
process_height = height
|
||||
left = pixels if is_left else 0
|
||||
right = pixels if is_right else 0
|
||||
up = pixels if is_top else 0
|
||||
down = pixels if is_bottom else 0
|
||||
target_w = math.ceil((image.width + left + right) / 64) * 64
|
||||
target_h = math.ceil((image.height + up + down) / 64) * 64
|
||||
|
||||
if left > 0:
|
||||
left = left * (target_w - image.width) // (left + right)
|
||||
if right > 0:
|
||||
right = target_w - image.width - left
|
||||
if up > 0:
|
||||
up = up * (target_h - image.height) // (up + down)
|
||||
if down > 0:
|
||||
down = target_h - image.height - up
|
||||
|
||||
def expand(
|
||||
init_img,
|
||||
expand_pixels,
|
||||
is_left=False,
|
||||
is_right=False,
|
||||
is_top=False,
|
||||
is_bottom=False,
|
||||
):
|
||||
is_horiz = is_left or is_right
|
||||
is_vert = is_top or is_bottom
|
||||
pixels_horiz = expand_pixels if is_horiz else 0
|
||||
pixels_vert = expand_pixels if is_vert else 0
|
||||
|
||||
res_w = init_img.width + pixels_horiz
|
||||
res_h = init_img.height + pixels_vert
|
||||
process_res_w = math.ceil(res_w / 64) * 64
|
||||
process_res_h = math.ceil(res_h / 64) * 64
|
||||
|
||||
img = Image.new("RGB", (process_res_w, process_res_h))
|
||||
img.paste(
|
||||
init_img,
|
||||
(pixels_horiz if is_left else 0, pixels_vert if is_top else 0),
|
||||
)
|
||||
|
||||
msk = Image.new("RGB", (process_res_w, process_res_h), "white")
|
||||
draw = ImageDraw.Draw(msk)
|
||||
draw.rectangle(
|
||||
(
|
||||
expand_pixels + mask_blur if is_left else 0,
|
||||
expand_pixels + mask_blur if is_top else 0,
|
||||
msk.width - expand_pixels - mask_blur
|
||||
if is_right
|
||||
else res_w,
|
||||
msk.height - expand_pixels - mask_blur
|
||||
if is_bottom
|
||||
else res_h,
|
||||
),
|
||||
fill="black",
|
||||
)
|
||||
|
||||
np_image = (np.asarray(img) / 255.0).astype(np.float64)
|
||||
np_mask = (np.asarray(msk) / 255.0).astype(np.float64)
|
||||
noised = self.get_matched_noise(
|
||||
np_image, np_mask, noise_q, color_variation
|
||||
)
|
||||
output_image = Image.fromarray(
|
||||
np.clip(noised * 255.0, 0.0, 255.0).astype(np.uint8),
|
||||
mode="RGB",
|
||||
)
|
||||
|
||||
target_width = (
|
||||
min(width, init_img.width + pixels_horiz)
|
||||
if is_horiz
|
||||
else img.width
|
||||
)
|
||||
target_height = (
|
||||
min(height, init_img.height + pixels_vert)
|
||||
if is_vert
|
||||
else img.height
|
||||
)
|
||||
crop_region = (
|
||||
0 if is_left else output_image.width - target_width,
|
||||
0 if is_top else output_image.height - target_height,
|
||||
target_width if is_left else output_image.width,
|
||||
target_height if is_top else output_image.height,
|
||||
)
|
||||
mask_to_process = msk.crop(crop_region)
|
||||
image_to_process = output_image.crop(crop_region)
|
||||
|
||||
# Preprocess mask and image
|
||||
mask, masked_image = self.prepare_mask_and_masked_image(
|
||||
image_to_process, mask_to_process, mask_blur, width, height
|
||||
)
|
||||
|
||||
# Prepare mask latent variables
|
||||
mask, masked_image_latents = self.prepare_mask_latents(
|
||||
mask=mask,
|
||||
masked_image=masked_image,
|
||||
batch_size=batch_size,
|
||||
height=height,
|
||||
width=width,
|
||||
dtype=dtype,
|
||||
)
|
||||
|
||||
# Get Image latents
|
||||
latents = self.produce_img_latents(
|
||||
latents=init_latents,
|
||||
text_embeddings=text_embeddings,
|
||||
guidance_scale=guidance_scale,
|
||||
total_timesteps=self.scheduler.timesteps,
|
||||
dtype=dtype,
|
||||
cpu_scheduling=cpu_scheduling,
|
||||
mask=mask,
|
||||
masked_image_latents=masked_image_latents,
|
||||
)
|
||||
|
||||
# Img latents -> PIL images
|
||||
all_imgs = []
|
||||
for i in tqdm(range(0, latents.shape[0], batch_size)):
|
||||
imgs = self.decode_latents(
|
||||
latents=latents[i : i + batch_size],
|
||||
use_base_vae=use_base_vae,
|
||||
cpu_scheduling=cpu_scheduling,
|
||||
)
|
||||
all_imgs.extend(imgs)
|
||||
|
||||
res_img = all_imgs[0].resize(
|
||||
(image_to_process.width, image_to_process.height)
|
||||
)
|
||||
output_image.paste(
|
||||
res_img,
|
||||
(
|
||||
0 if is_left else output_image.width - res_img.width,
|
||||
0 if is_top else output_image.height - res_img.height,
|
||||
),
|
||||
)
|
||||
output_image = output_image.crop((0, 0, res_w, res_h))
|
||||
|
||||
return output_image
|
||||
|
||||
img = image.resize((width, height))
|
||||
if left > 0:
|
||||
img = expand(img, left, is_left=True)
|
||||
if right > 0:
|
||||
img = expand(img, right, is_right=True)
|
||||
if up > 0:
|
||||
img = expand(img, up, is_top=True)
|
||||
if down > 0:
|
||||
img = expand(img, down, is_bottom=True)
|
||||
|
||||
return [img]
|
||||
@@ -1,150 +0,0 @@
|
||||
import torch
|
||||
import time
|
||||
import numpy as np
|
||||
from tqdm.auto import tqdm
|
||||
from random import randint
|
||||
from PIL import Image
|
||||
from transformers import CLIPTokenizer
|
||||
from typing import Union
|
||||
from shark.shark_inference import SharkInference
|
||||
from diffusers import (
|
||||
DDIMScheduler,
|
||||
PNDMScheduler,
|
||||
LMSDiscreteScheduler,
|
||||
EulerDiscreteScheduler,
|
||||
EulerAncestralDiscreteScheduler,
|
||||
DPMSolverMultistepScheduler,
|
||||
)
|
||||
from apps.stable_diffusion.src.schedulers import SharkEulerDiscreteScheduler
|
||||
from apps.stable_diffusion.src.pipelines.pipeline_shark_stable_diffusion_utils import (
|
||||
StableDiffusionPipeline,
|
||||
)
|
||||
from apps.stable_diffusion.src.utils import controlnet_hint_conversion
|
||||
|
||||
|
||||
class StencilPipeline(StableDiffusionPipeline):
|
||||
def __init__(
|
||||
self,
|
||||
controlnet: SharkInference,
|
||||
vae: SharkInference,
|
||||
text_encoder: SharkInference,
|
||||
tokenizer: CLIPTokenizer,
|
||||
unet: SharkInference,
|
||||
scheduler: Union[
|
||||
DDIMScheduler,
|
||||
PNDMScheduler,
|
||||
LMSDiscreteScheduler,
|
||||
EulerDiscreteScheduler,
|
||||
EulerAncestralDiscreteScheduler,
|
||||
DPMSolverMultistepScheduler,
|
||||
SharkEulerDiscreteScheduler,
|
||||
],
|
||||
):
|
||||
super().__init__(vae, text_encoder, tokenizer, unet, scheduler)
|
||||
self.controlnet = controlnet
|
||||
|
||||
def prepare_latents(
|
||||
self,
|
||||
batch_size,
|
||||
height,
|
||||
width,
|
||||
generator,
|
||||
num_inference_steps,
|
||||
dtype,
|
||||
):
|
||||
latents = torch.randn(
|
||||
(
|
||||
batch_size,
|
||||
4,
|
||||
height // 8,
|
||||
width // 8,
|
||||
),
|
||||
generator=generator,
|
||||
dtype=torch.float32,
|
||||
).to(dtype)
|
||||
|
||||
self.scheduler.set_timesteps(num_inference_steps)
|
||||
self.scheduler.is_scale_input_called = True
|
||||
latents = latents * self.scheduler.init_noise_sigma
|
||||
return latents
|
||||
|
||||
def generate_images(
|
||||
self,
|
||||
prompts,
|
||||
neg_prompts,
|
||||
image,
|
||||
batch_size,
|
||||
height,
|
||||
width,
|
||||
num_inference_steps,
|
||||
strength,
|
||||
guidance_scale,
|
||||
seed,
|
||||
max_length,
|
||||
dtype,
|
||||
use_base_vae,
|
||||
cpu_scheduling,
|
||||
use_stencil,
|
||||
):
|
||||
# Control Embedding check & conversion
|
||||
# TODO: 1. Change `num_images_per_prompt`.
|
||||
controlnet_hint = controlnet_hint_conversion(
|
||||
image, use_stencil, height, width, dtype, num_images_per_prompt=1
|
||||
)
|
||||
# prompts and negative prompts must be a list.
|
||||
if isinstance(prompts, str):
|
||||
prompts = [prompts]
|
||||
|
||||
if isinstance(neg_prompts, str):
|
||||
neg_prompts = [neg_prompts]
|
||||
|
||||
prompts = prompts * batch_size
|
||||
neg_prompts = neg_prompts * batch_size
|
||||
|
||||
# seed generator to create the inital latent noise. Also handle out of range seeds.
|
||||
uint32_info = np.iinfo(np.uint32)
|
||||
uint32_min, uint32_max = uint32_info.min, uint32_info.max
|
||||
if seed < uint32_min or seed >= uint32_max:
|
||||
seed = randint(uint32_min, uint32_max)
|
||||
generator = torch.manual_seed(seed)
|
||||
|
||||
# Get text embeddings from prompts
|
||||
text_embeddings = self.encode_prompts(prompts, neg_prompts, max_length)
|
||||
|
||||
# guidance scale as a float32 tensor.
|
||||
guidance_scale = torch.tensor(guidance_scale).to(torch.float32)
|
||||
|
||||
# Prepare initial latent.
|
||||
init_latents = self.prepare_latents(
|
||||
batch_size=batch_size,
|
||||
height=height,
|
||||
width=width,
|
||||
generator=generator,
|
||||
num_inference_steps=num_inference_steps,
|
||||
dtype=dtype,
|
||||
)
|
||||
final_timesteps = self.scheduler.timesteps
|
||||
|
||||
# Get Image latents
|
||||
latents = self.produce_stencil_latents(
|
||||
latents=init_latents,
|
||||
text_embeddings=text_embeddings,
|
||||
guidance_scale=guidance_scale,
|
||||
total_timesteps=final_timesteps,
|
||||
dtype=dtype,
|
||||
cpu_scheduling=cpu_scheduling,
|
||||
controlnet_hint=controlnet_hint,
|
||||
controlnet=self.controlnet,
|
||||
)
|
||||
|
||||
# Img latents -> PIL images
|
||||
all_imgs = []
|
||||
for i in tqdm(range(0, latents.shape[0], batch_size)):
|
||||
imgs = self.decode_latents(
|
||||
latents=latents[i : i + batch_size],
|
||||
use_base_vae=use_base_vae,
|
||||
cpu_scheduling=cpu_scheduling,
|
||||
)
|
||||
all_imgs.extend(imgs)
|
||||
|
||||
return all_imgs
|
||||
@@ -9,20 +9,15 @@ from diffusers import (
|
||||
DDIMScheduler,
|
||||
PNDMScheduler,
|
||||
LMSDiscreteScheduler,
|
||||
KDPM2DiscreteScheduler,
|
||||
EulerDiscreteScheduler,
|
||||
EulerAncestralDiscreteScheduler,
|
||||
DPMSolverMultistepScheduler,
|
||||
DEISMultistepScheduler,
|
||||
)
|
||||
from apps.stable_diffusion.src.schedulers import SharkEulerDiscreteScheduler
|
||||
from apps.stable_diffusion.src.pipelines.pipeline_shark_stable_diffusion_utils import (
|
||||
StableDiffusionPipeline,
|
||||
)
|
||||
|
||||
import cv2
|
||||
from PIL import Image
|
||||
|
||||
|
||||
class Text2ImagePipeline(StableDiffusionPipeline):
|
||||
def __init__(
|
||||
@@ -35,12 +30,10 @@ class Text2ImagePipeline(StableDiffusionPipeline):
|
||||
DDIMScheduler,
|
||||
PNDMScheduler,
|
||||
LMSDiscreteScheduler,
|
||||
KDPM2DiscreteScheduler,
|
||||
EulerDiscreteScheduler,
|
||||
EulerAncestralDiscreteScheduler,
|
||||
DPMSolverMultistepScheduler,
|
||||
SharkEulerDiscreteScheduler,
|
||||
DEISMultistepScheduler,
|
||||
],
|
||||
):
|
||||
super().__init__(vae, text_encoder, tokenizer, unet, scheduler)
|
||||
|
||||
@@ -1,5 +1,4 @@
|
||||
import torch
|
||||
import numpy as np
|
||||
from transformers import CLIPTokenizer
|
||||
from PIL import Image
|
||||
from tqdm.auto import tqdm
|
||||
@@ -9,17 +8,14 @@ from diffusers import (
|
||||
DDIMScheduler,
|
||||
PNDMScheduler,
|
||||
LMSDiscreteScheduler,
|
||||
KDPM2DiscreteScheduler,
|
||||
EulerDiscreteScheduler,
|
||||
EulerAncestralDiscreteScheduler,
|
||||
DPMSolverMultistepScheduler,
|
||||
DEISMultistepScheduler,
|
||||
)
|
||||
from shark.shark_inference import SharkInference
|
||||
from apps.stable_diffusion.src.schedulers import SharkEulerDiscreteScheduler
|
||||
from apps.stable_diffusion.src.models import (
|
||||
SharkifyStableDiffusionModel,
|
||||
get_vae_encode,
|
||||
get_vae,
|
||||
get_clip,
|
||||
get_unet,
|
||||
@@ -42,12 +38,10 @@ class StableDiffusionPipeline:
|
||||
DDIMScheduler,
|
||||
PNDMScheduler,
|
||||
LMSDiscreteScheduler,
|
||||
KDPM2DiscreteScheduler,
|
||||
EulerDiscreteScheduler,
|
||||
EulerAncestralDiscreteScheduler,
|
||||
DPMSolverMultistepScheduler,
|
||||
SharkEulerDiscreteScheduler,
|
||||
DEISMultistepScheduler,
|
||||
],
|
||||
):
|
||||
self.vae = vae
|
||||
@@ -110,118 +104,6 @@ class StableDiffusionPipeline:
|
||||
pil_images = [Image.fromarray(image) for image in images.numpy()]
|
||||
return pil_images
|
||||
|
||||
def produce_stencil_latents(
|
||||
self,
|
||||
latents,
|
||||
text_embeddings,
|
||||
guidance_scale,
|
||||
total_timesteps,
|
||||
dtype,
|
||||
cpu_scheduling,
|
||||
controlnet_hint=None,
|
||||
controlnet=None,
|
||||
controlnet_conditioning_scale: float = 1.0,
|
||||
mask=None,
|
||||
masked_image_latents=None,
|
||||
return_all_latents=False,
|
||||
):
|
||||
step_time_sum = 0
|
||||
latent_history = [latents]
|
||||
text_embeddings = torch.from_numpy(text_embeddings).to(dtype)
|
||||
text_embeddings_numpy = text_embeddings.detach().numpy()
|
||||
for i, t in tqdm(enumerate(total_timesteps)):
|
||||
step_start_time = time.time()
|
||||
timestep = torch.tensor([t]).to(dtype)
|
||||
latent_model_input = self.scheduler.scale_model_input(latents, t)
|
||||
if mask is not None and masked_image_latents is not None:
|
||||
latent_model_input = torch.cat(
|
||||
[
|
||||
torch.from_numpy(np.asarray(latent_model_input)),
|
||||
mask,
|
||||
masked_image_latents,
|
||||
],
|
||||
dim=1,
|
||||
).to(dtype)
|
||||
if cpu_scheduling:
|
||||
latent_model_input = latent_model_input.detach().numpy()
|
||||
|
||||
if not torch.is_tensor(latent_model_input):
|
||||
latent_model_input_1 = torch.from_numpy(
|
||||
np.asarray(latent_model_input)
|
||||
).to(dtype)
|
||||
else:
|
||||
latent_model_input_1 = latent_model_input
|
||||
control = controlnet(
|
||||
"forward",
|
||||
(
|
||||
latent_model_input_1,
|
||||
timestep,
|
||||
text_embeddings,
|
||||
controlnet_hint,
|
||||
),
|
||||
send_to_host=False,
|
||||
)
|
||||
down_block_res_samples = control[0:12]
|
||||
mid_block_res_sample = control[12:]
|
||||
down_block_res_samples = [
|
||||
down_block_res_sample * controlnet_conditioning_scale
|
||||
for down_block_res_sample in down_block_res_samples
|
||||
]
|
||||
mid_block_res_sample = (
|
||||
mid_block_res_sample[0] * controlnet_conditioning_scale
|
||||
)
|
||||
timestep = timestep.detach().numpy()
|
||||
# Profiling Unet.
|
||||
profile_device = start_profiling(file_path="unet.rdc")
|
||||
# TODO: Pass `control` as it is to Unet. Same as TODO mentioned in model_wrappers.py.
|
||||
noise_pred = self.unet(
|
||||
"forward",
|
||||
(
|
||||
latent_model_input,
|
||||
timestep,
|
||||
text_embeddings_numpy,
|
||||
guidance_scale,
|
||||
down_block_res_samples[0],
|
||||
down_block_res_samples[1],
|
||||
down_block_res_samples[2],
|
||||
down_block_res_samples[3],
|
||||
down_block_res_samples[4],
|
||||
down_block_res_samples[5],
|
||||
down_block_res_samples[6],
|
||||
down_block_res_samples[7],
|
||||
down_block_res_samples[8],
|
||||
down_block_res_samples[9],
|
||||
down_block_res_samples[10],
|
||||
down_block_res_samples[11],
|
||||
mid_block_res_sample,
|
||||
),
|
||||
send_to_host=False,
|
||||
)
|
||||
end_profiling(profile_device)
|
||||
|
||||
if cpu_scheduling:
|
||||
noise_pred = torch.from_numpy(noise_pred.to_host())
|
||||
latents = self.scheduler.step(
|
||||
noise_pred, t, latents
|
||||
).prev_sample
|
||||
else:
|
||||
latents = self.scheduler.step(noise_pred, t, latents)
|
||||
|
||||
latent_history.append(latents)
|
||||
step_time = (time.time() - step_start_time) * 1000
|
||||
# self.log += (
|
||||
# f"\nstep = {i} | timestep = {t} | time = {step_time:.2f}ms"
|
||||
# )
|
||||
step_time_sum += step_time
|
||||
|
||||
avg_step_time = step_time_sum / len(total_timesteps)
|
||||
self.log += f"\nAverage step time: {avg_step_time}ms/it"
|
||||
|
||||
if not return_all_latents:
|
||||
return latents
|
||||
all_latents = torch.cat(latent_history, dim=0)
|
||||
return all_latents
|
||||
|
||||
def produce_img_latents(
|
||||
self,
|
||||
latents,
|
||||
@@ -230,8 +112,6 @@ class StableDiffusionPipeline:
|
||||
total_timesteps,
|
||||
dtype,
|
||||
cpu_scheduling,
|
||||
mask=None,
|
||||
masked_image_latents=None,
|
||||
return_all_latents=False,
|
||||
):
|
||||
step_time_sum = 0
|
||||
@@ -242,15 +122,6 @@ class StableDiffusionPipeline:
|
||||
step_start_time = time.time()
|
||||
timestep = torch.tensor([t]).to(dtype).detach().numpy()
|
||||
latent_model_input = self.scheduler.scale_model_input(latents, t)
|
||||
if mask is not None and masked_image_latents is not None:
|
||||
latent_model_input = torch.cat(
|
||||
[
|
||||
torch.from_numpy(np.asarray(latent_model_input)),
|
||||
mask,
|
||||
masked_image_latents,
|
||||
],
|
||||
dim=1,
|
||||
).to(dtype)
|
||||
if cpu_scheduling:
|
||||
latent_model_input = latent_model_input.detach().numpy()
|
||||
|
||||
@@ -298,17 +169,14 @@ class StableDiffusionPipeline:
|
||||
DDIMScheduler,
|
||||
PNDMScheduler,
|
||||
LMSDiscreteScheduler,
|
||||
KDPM2DiscreteScheduler,
|
||||
EulerDiscreteScheduler,
|
||||
EulerAncestralDiscreteScheduler,
|
||||
DPMSolverMultistepScheduler,
|
||||
SharkEulerDiscreteScheduler,
|
||||
DEISMultistepScheduler,
|
||||
],
|
||||
import_mlir: bool,
|
||||
model_id: str,
|
||||
ckpt_loc: str,
|
||||
custom_vae: str,
|
||||
precision: str,
|
||||
max_length: int,
|
||||
batch_size: int,
|
||||
@@ -316,18 +184,13 @@ class StableDiffusionPipeline:
|
||||
width: int,
|
||||
use_base_vae: bool,
|
||||
use_tuned: bool,
|
||||
low_cpu_mem_usage: bool = False,
|
||||
use_stencil: bool = False,
|
||||
):
|
||||
is_inpaint = cls.__name__ in [
|
||||
"InpaintPipeline",
|
||||
"OutpaintPipeline",
|
||||
]
|
||||
if import_mlir:
|
||||
# TODO: Delet this when on-the-fly tuning of models work.
|
||||
use_tuned = False
|
||||
mlir_import = SharkifyStableDiffusionModel(
|
||||
model_id,
|
||||
ckpt_loc,
|
||||
custom_vae,
|
||||
precision,
|
||||
max_len=max_length,
|
||||
batch_size=batch_size,
|
||||
@@ -335,77 +198,9 @@ class StableDiffusionPipeline:
|
||||
width=width,
|
||||
use_base_vae=use_base_vae,
|
||||
use_tuned=use_tuned,
|
||||
low_cpu_mem_usage=low_cpu_mem_usage,
|
||||
is_inpaint=is_inpaint,
|
||||
)
|
||||
if cls.__name__ in [
|
||||
"Image2ImagePipeline",
|
||||
"InpaintPipeline",
|
||||
"OutpaintPipeline",
|
||||
]:
|
||||
clip, unet, vae, vae_encode = mlir_import()
|
||||
return cls(
|
||||
vae_encode, vae, clip, get_tokenizer(), unet, scheduler
|
||||
)
|
||||
if cls.__name__ in ["StencilPipeline"]:
|
||||
clip, unet, vae, controlnet = mlir_import()
|
||||
return cls(
|
||||
controlnet, vae, clip, get_tokenizer(), unet, scheduler
|
||||
)
|
||||
clip, unet, vae = mlir_import()
|
||||
return cls(vae, clip, get_tokenizer(), unet, scheduler)
|
||||
try:
|
||||
if cls.__name__ in [
|
||||
"Image2ImagePipeline",
|
||||
"InpaintPipeline",
|
||||
"OutpaintPipeline",
|
||||
]:
|
||||
return cls(
|
||||
get_vae_encode(),
|
||||
get_vae(),
|
||||
get_clip(),
|
||||
get_tokenizer(),
|
||||
get_unet(),
|
||||
scheduler,
|
||||
)
|
||||
if cls.__name__ == "StencilPipeline":
|
||||
import sys
|
||||
|
||||
sys.exit(
|
||||
"StencilPipeline not supported with SharkTank currently."
|
||||
)
|
||||
return cls(
|
||||
get_vae(), get_clip(), get_tokenizer(), get_unet(), scheduler
|
||||
)
|
||||
except:
|
||||
print("download pipeline failed, falling back to import_mlir")
|
||||
mlir_import = SharkifyStableDiffusionModel(
|
||||
model_id,
|
||||
ckpt_loc,
|
||||
custom_vae,
|
||||
precision,
|
||||
max_len=max_length,
|
||||
batch_size=batch_size,
|
||||
height=height,
|
||||
width=width,
|
||||
use_base_vae=use_base_vae,
|
||||
use_tuned=use_tuned,
|
||||
low_cpu_mem_usage=low_cpu_mem_usage,
|
||||
is_inpaint=is_inpaint,
|
||||
)
|
||||
if cls.__name__ in [
|
||||
"Image2ImagePipeline",
|
||||
"InpaintPipeline",
|
||||
"OutpaintPipeline",
|
||||
]:
|
||||
clip, unet, vae, vae_encode = mlir_import()
|
||||
return cls(
|
||||
vae_encode, vae, clip, get_tokenizer(), unet, scheduler
|
||||
)
|
||||
if cls.__name__ == "StencilPipeline":
|
||||
clip, unet, vae, controlnet = mlir_import()
|
||||
return cls(
|
||||
controlnet, vae, clip, get_tokenizer(), unet, scheduler
|
||||
)
|
||||
clip, unet, vae = mlir_import()
|
||||
return cls(vae, clip, get_tokenizer(), unet, scheduler)
|
||||
return cls(
|
||||
get_vae(), get_clip(), get_tokenizer(), get_unet(), scheduler
|
||||
)
|
||||
|
||||
@@ -3,10 +3,8 @@ from diffusers import (
|
||||
PNDMScheduler,
|
||||
DDIMScheduler,
|
||||
DPMSolverMultistepScheduler,
|
||||
KDPM2DiscreteScheduler,
|
||||
EulerDiscreteScheduler,
|
||||
EulerAncestralDiscreteScheduler,
|
||||
DEISMultistepScheduler,
|
||||
)
|
||||
from apps.stable_diffusion.src.schedulers.shark_eulerdiscrete import (
|
||||
SharkEulerDiscreteScheduler,
|
||||
@@ -19,10 +17,6 @@ def get_schedulers(model_id):
|
||||
model_id,
|
||||
subfolder="scheduler",
|
||||
)
|
||||
schedulers["KDPM2Discrete"] = KDPM2DiscreteScheduler.from_pretrained(
|
||||
model_id,
|
||||
subfolder="scheduler",
|
||||
)
|
||||
schedulers["LMSDiscrete"] = LMSDiscreteScheduler.from_pretrained(
|
||||
model_id,
|
||||
subfolder="scheduler",
|
||||
@@ -47,10 +41,6 @@ def get_schedulers(model_id):
|
||||
model_id,
|
||||
subfolder="scheduler",
|
||||
)
|
||||
schedulers["DEISMultistep"] = DEISMultistepScheduler.from_pretrained(
|
||||
model_id,
|
||||
subfolder="scheduler",
|
||||
)
|
||||
schedulers[
|
||||
"SharkEulerDiscrete"
|
||||
] = SharkEulerDiscreteScheduler.from_pretrained(
|
||||
|
||||
@@ -87,7 +87,7 @@ class SharkEulerDiscreteScheduler(EulerDiscreteScheduler):
|
||||
if sys.platform == "darwin":
|
||||
iree_flags.append("-iree-stream-fuse-binding=false")
|
||||
|
||||
def _import(self):
|
||||
if args.import_mlir:
|
||||
scaling_model = ScalingModel()
|
||||
self.scaling_model = compile_through_fx(
|
||||
scaling_model,
|
||||
@@ -105,28 +105,15 @@ class SharkEulerDiscreteScheduler(EulerDiscreteScheduler):
|
||||
+ args.precision,
|
||||
extra_args=iree_flags,
|
||||
)
|
||||
|
||||
if args.import_mlir:
|
||||
_import(self)
|
||||
|
||||
else:
|
||||
try:
|
||||
self.scaling_model = get_shark_model(
|
||||
SCHEDULER_BUCKET,
|
||||
"euler_scale_model_input_" + args.precision,
|
||||
iree_flags,
|
||||
)
|
||||
self.step_model = get_shark_model(
|
||||
SCHEDULER_BUCKET,
|
||||
"euler_step_" + args.precision,
|
||||
iree_flags,
|
||||
)
|
||||
except:
|
||||
print(
|
||||
"failed to download model, falling back and using import_mlir"
|
||||
)
|
||||
args.import_mlir = True
|
||||
_import(self)
|
||||
self.scaling_model = get_shark_model(
|
||||
SCHEDULER_BUCKET,
|
||||
"euler_scale_model_input_" + args.precision,
|
||||
iree_flags,
|
||||
)
|
||||
self.step_model = get_shark_model(
|
||||
SCHEDULER_BUCKET, "euler_step_" + args.precision, iree_flags
|
||||
)
|
||||
|
||||
def scale_model_input(self, sample, timestep):
|
||||
step_index = (self.timesteps == timestep).nonzero().item()
|
||||
|
||||
@@ -11,9 +11,6 @@ from apps.stable_diffusion.src.utils.resources import (
|
||||
)
|
||||
from apps.stable_diffusion.src.utils.sd_annotation import sd_model_annotation
|
||||
from apps.stable_diffusion.src.utils.stable_args import args
|
||||
from apps.stable_diffusion.src.utils.stencils.stencil_utils import (
|
||||
controlnet_hint_conversion,
|
||||
)
|
||||
from apps.stable_diffusion.src.utils.utils import (
|
||||
get_shark_model,
|
||||
compile_through_fx,
|
||||
@@ -27,8 +24,4 @@ from apps.stable_diffusion.src.utils.utils import (
|
||||
fetch_and_update_base_model_id,
|
||||
get_path_to_diffusers_checkpoint,
|
||||
sanitize_seed,
|
||||
get_path_stem,
|
||||
get_extended_name,
|
||||
clear_all,
|
||||
save_output_img,
|
||||
)
|
||||
|
||||
@@ -29,14 +29,6 @@
|
||||
"dtype": "f32"
|
||||
}
|
||||
},
|
||||
"vae_encode": {
|
||||
"image" : {
|
||||
"shape" : [
|
||||
"1*batch_size",3,"8*height","8*width"
|
||||
],
|
||||
"dtype":"f32"
|
||||
}
|
||||
},
|
||||
"vae": {
|
||||
"latents" : {
|
||||
"shape" : [
|
||||
@@ -85,236 +77,6 @@
|
||||
"dtype": "f32"
|
||||
}
|
||||
},
|
||||
"stencil_adaptor": {
|
||||
"latents": {
|
||||
"shape": [
|
||||
"1*batch_size",
|
||||
4,
|
||||
"height",
|
||||
"width"
|
||||
],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"timesteps": {
|
||||
"shape": [
|
||||
1
|
||||
],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"embedding": {
|
||||
"shape": [
|
||||
"2*batch_size",
|
||||
"max_len",
|
||||
768
|
||||
],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"controlnet_hint": {
|
||||
"shape": [1, 3, 512, 512],
|
||||
"dtype": "f32"
|
||||
}
|
||||
},
|
||||
"stencil_unet": {
|
||||
"latents": {
|
||||
"shape": [
|
||||
"1*batch_size",
|
||||
4,
|
||||
"height",
|
||||
"width"
|
||||
],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"timesteps": {
|
||||
"shape": [
|
||||
1
|
||||
],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"embedding": {
|
||||
"shape": [
|
||||
"2*batch_size",
|
||||
"max_len",
|
||||
768
|
||||
],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"guidance_scale": {
|
||||
"shape": 2,
|
||||
"dtype": "f32"
|
||||
},
|
||||
"control1": {
|
||||
"shape": [2, 320, 64, 64],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"control2": {
|
||||
"shape": [2, 320, 64, 64],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"control3": {
|
||||
"shape": [2, 320, 64, 64],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"control4": {
|
||||
"shape": [2, 320, 32, 32],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"control5": {
|
||||
"shape": [2, 640, 32, 32],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"control6": {
|
||||
"shape": [2, 640, 32, 32],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"control7": {
|
||||
"shape": [2, 640, 16, 16],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"control8": {
|
||||
"shape": [2, 1280, 16, 16],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"control9": {
|
||||
"shape": [2, 1280, 16, 16],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"control10": {
|
||||
"shape": [2, 1280, 8, 8],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"control11": {
|
||||
"shape": [2, 1280, 8, 8],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"control12": {
|
||||
"shape": [2, 1280, 8, 8],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"control13": {
|
||||
"shape": [2, 1280, 8, 8],
|
||||
"dtype": "f32"
|
||||
}
|
||||
},
|
||||
"vae_encode": {
|
||||
"image" : {
|
||||
"shape" : [
|
||||
"1*batch_size",3,"8*height","8*width"
|
||||
],
|
||||
"dtype":"f32"
|
||||
}
|
||||
},
|
||||
"vae": {
|
||||
"latents" : {
|
||||
"shape" : [
|
||||
"1*batch_size",4,"height","width"
|
||||
],
|
||||
"dtype":"f32"
|
||||
}
|
||||
},
|
||||
"clip": {
|
||||
"token" : {
|
||||
"shape" : [
|
||||
"2*batch_size",
|
||||
"max_len"
|
||||
],
|
||||
"dtype":"i64"
|
||||
}
|
||||
}
|
||||
},
|
||||
"stabilityai/stable-diffusion-2-inpainting": {
|
||||
"unet": {
|
||||
"latents": {
|
||||
"shape": [
|
||||
"1*batch_size",
|
||||
9,
|
||||
"height",
|
||||
"width"
|
||||
],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"timesteps": {
|
||||
"shape": [
|
||||
1
|
||||
],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"embedding": {
|
||||
"shape": [
|
||||
"2*batch_size",
|
||||
"max_len",
|
||||
1024
|
||||
],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"guidance_scale": {
|
||||
"shape": 2,
|
||||
"dtype": "f32"
|
||||
}
|
||||
},
|
||||
"vae_encode": {
|
||||
"image" : {
|
||||
"shape" : [
|
||||
"1*batch_size",3,"8*height","8*width"
|
||||
],
|
||||
"dtype":"f32"
|
||||
}
|
||||
},
|
||||
"vae": {
|
||||
"latents" : {
|
||||
"shape" : [
|
||||
"1*batch_size",4,"height","width"
|
||||
],
|
||||
"dtype":"f32"
|
||||
}
|
||||
},
|
||||
"clip": {
|
||||
"token" : {
|
||||
"shape" : [
|
||||
"2*batch_size",
|
||||
"max_len"
|
||||
],
|
||||
"dtype":"i64"
|
||||
}
|
||||
}
|
||||
},
|
||||
"runwayml/stable-diffusion-inpainting": {
|
||||
"unet": {
|
||||
"latents": {
|
||||
"shape": [
|
||||
"1*batch_size",
|
||||
9,
|
||||
"height",
|
||||
"width"
|
||||
],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"timesteps": {
|
||||
"shape": [
|
||||
1
|
||||
],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"embedding": {
|
||||
"shape": [
|
||||
"2*batch_size",
|
||||
"max_len",
|
||||
768
|
||||
],
|
||||
"dtype": "f32"
|
||||
},
|
||||
"guidance_scale": {
|
||||
"shape": 2,
|
||||
"dtype": "f32"
|
||||
}
|
||||
},
|
||||
"vae_encode": {
|
||||
"image" : {
|
||||
"shape" : [
|
||||
"1*batch_size",3,"8*height","8*width"
|
||||
],
|
||||
"dtype":"f32"
|
||||
}
|
||||
},
|
||||
"vae": {
|
||||
"latents" : {
|
||||
"shape" : [
|
||||
@@ -333,4 +95,4 @@
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
@@ -3,8 +3,6 @@
|
||||
"stablediffusion/v1_4":"CompVis/stable-diffusion-v1-4",
|
||||
"stablediffusion/v2_1base":"stabilityai/stable-diffusion-2-1-base",
|
||||
"stablediffusion/v2_1":"stabilityai/stable-diffusion-2-1",
|
||||
"stablediffusion/inpaint_v1":"runwayml/stable-diffusion-inpainting",
|
||||
"stablediffusion/inpaint_v2":"stabilityai/stable-diffusion-2-inpainting",
|
||||
"anythingv3/v1_4":"Linaqruf/anything-v3.0",
|
||||
"analogdiffusion/v1_4":"wavymulder/Analog-Diffusion",
|
||||
"openjourney/v1_4":"prompthero/openjourney",
|
||||
|
||||
@@ -22,6 +22,8 @@
|
||||
"stablediffusion/v1_4/vae/fp16/length_77/tuned":"vae_19dec_fp16_tuned",
|
||||
"stablediffusion/v1_4/vae/fp16/length_77/tuned/cuda":"vae_19dec_fp16_cuda_tuned",
|
||||
"stablediffusion/v1_4/vae/fp16/length_77/untuned/base":"vae_8dec_fp16",
|
||||
"stablediffusion/v1_4/vae/fp32/length_77/untuned":"vae_1dec_fp32",
|
||||
"stablediffusion/v1_4/clip/fp32/length_77/untuned":"clip_18dec_fp32",
|
||||
"stablediffusion/v2_1base/unet/fp16/length_77/untuned":"unet77_512_512_fp16_stabilityai_stable_diffusion_2_1_base",
|
||||
"stablediffusion/v2_1base/unet/fp16/length_77/tuned":"unet2base_8dec_fp16_tuned_v2",
|
||||
"stablediffusion/v2_1base/unet/fp16/length_77/tuned/cuda":"unet2base_8dec_fp16_cuda_tuned",
|
||||
@@ -40,41 +42,41 @@
|
||||
"stablediffusion/v2_1/vae/fp16/length_77/untuned":"vae77_512_512_fp16_stabilityai_stable_diffusion_2_1_base",
|
||||
"stablediffusion/v2_1/vae/fp16/length_77/untuned/base":"vae2_8dec_fp16",
|
||||
"stablediffusion/v2_1/clip/fp32/length_77/untuned":"clip77_512_512_fp16_stabilityai_stable_diffusion_2_1_base",
|
||||
"anythingv3/v1_4/unet/fp16/length_77/untuned":"av3_unet_19dec_fp16",
|
||||
"anythingv3/v1_4/unet/fp16/length_77/tuned":"av3_unet_19dec_fp16_tuned",
|
||||
"anythingv3/v1_4/unet/fp16/length_77/tuned/cuda":"av3_unet_19dec_fp16_cuda_tuned",
|
||||
"anythingv3/v1_4/unet/fp32/length_77/untuned":"av3_unet_19dec_fp32",
|
||||
"anythingv3/v1_4/vae/fp16/length_77/untuned":"av3_vae_19dec_fp16",
|
||||
"anythingv3/v1_4/vae/fp16/length_77/tuned":"av3_vae_19dec_fp16_tuned",
|
||||
"anythingv3/v1_4/vae/fp16/length_77/tuned/cuda":"av3_vae_19dec_fp16_cuda_tuned",
|
||||
"anythingv3/v1_4/vae/fp16/length_77/untuned/base":"av3_vaebase_22dec_fp16",
|
||||
"anythingv3/v1_4/vae/fp32/length_77/untuned":"av3_vae_19dec_fp32",
|
||||
"anythingv3/v1_4/vae/fp32/length_77/untuned/base":"av3_vaebase_22dec_fp32",
|
||||
"anythingv3/v1_4/clip/fp32/length_77/untuned":"av3_clip_19dec_fp32",
|
||||
"analogdiffusion/v1_4/unet/fp16/length_77/untuned":"ad_unet_19dec_fp16",
|
||||
"analogdiffusion/v1_4/unet/fp16/length_77/tuned":"ad_unet_19dec_fp16_tuned",
|
||||
"analogdiffusion/v1_4/unet/fp16/length_77/tuned/cuda":"ad_unet_19dec_fp16_cuda_tuned",
|
||||
"analogdiffusion/v1_4/unet/fp32/length_77/untuned":"ad_unet_19dec_fp32",
|
||||
"analogdiffusion/v1_4/vae/fp16/length_77/untuned":"ad_vae_19dec_fp16",
|
||||
"analogdiffusion/v1_4/vae/fp16/length_77/tuned":"ad_vae_19dec_fp16_tuned",
|
||||
"analogdiffusion/v1_4/vae/fp16/length_77/tuned/cuda":"ad_vae_19dec_fp16_cuda_tuned",
|
||||
"analogdiffusion/v1_4/vae/fp16/length_77/untuned/base":"ad_vaebase_22dec_fp16",
|
||||
"analogdiffusion/v1_4/vae/fp32/length_77/untuned":"ad_vae_19dec_fp32",
|
||||
"analogdiffusion/v1_4/vae/fp32/length_77/untuned/base":"ad_vaebase_22dec_fp32",
|
||||
"analogdiffusion/v1_4/clip/fp32/length_77/untuned":"ad_clip_19dec_fp32",
|
||||
"openjourney/v1_4/unet/fp16/length_64/untuned":"oj_unet_22dec_fp16_64",
|
||||
"openjourney/v1_4/unet/fp32/length_64/untuned":"oj_unet_22dec_fp32_64",
|
||||
"openjourney/v1_4/vae/fp16/length_77/untuned":"oj_vae_22dec_fp16",
|
||||
"openjourney/v1_4/vae/fp16/length_77/untuned/base":"oj_vaebase_22dec_fp16",
|
||||
"openjourney/v1_4/vae/fp32/length_77/untuned":"oj_vae_22dec_fp32",
|
||||
"openjourney/v1_4/vae/fp32/length_77/untuned/base":"oj_vaebase_22dec_fp32",
|
||||
"openjourney/v1_4/clip/fp32/length_64/untuned":"oj_clip_22dec_fp32_64",
|
||||
"dreamlike/v1_4/unet/fp16/length_77/untuned":"dl_unet_23dec_fp16_77",
|
||||
"dreamlike/v1_4/unet/fp32/length_77/untuned":"dl_unet_23dec_fp32_77",
|
||||
"dreamlike/v1_4/vae/fp16/length_77/untuned":"dl_vae_23dec_fp16",
|
||||
"dreamlike/v1_4/vae/fp16/length_77/untuned/base":"dl_vaebase_23dec_fp16",
|
||||
"dreamlike/v1_4/vae/fp32/length_77/untuned":"dl_vae_23dec_fp32",
|
||||
"dreamlike/v1_4/vae/fp32/length_77/untuned/base":"dl_vaebase_23dec_fp32",
|
||||
"dreamlike/v1_4/clip/fp32/length_77/untuned":"dl_clip_23dec_fp32_77"
|
||||
"anythingv3/v2_1base/unet/fp16/length_77/untuned":"av3_unet_19dec_fp16",
|
||||
"anythingv3/v2_1base/unet/fp16/length_77/tuned":"av3_unet_19dec_fp16_tuned",
|
||||
"anythingv3/v2_1base/unet/fp16/length_77/tuned/cuda":"av3_unet_19dec_fp16_cuda_tuned",
|
||||
"anythingv3/v2_1base/unet/fp32/length_77/untuned":"av3_unet_19dec_fp32",
|
||||
"anythingv3/v2_1base/vae/fp16/length_77/untuned":"av3_vae_19dec_fp16",
|
||||
"anythingv3/v2_1base/vae/fp16/length_77/tuned":"av3_vae_19dec_fp16_tuned",
|
||||
"anythingv3/v2_1base/vae/fp16/length_77/tuned/cuda":"av3_vae_19dec_fp16_cuda_tuned",
|
||||
"anythingv3/v2_1base/vae/fp16/length_77/untuned/base":"av3_vaebase_22dec_fp16",
|
||||
"anythingv3/v2_1base/vae/fp32/length_77/untuned":"av3_vae_19dec_fp32",
|
||||
"anythingv3/v2_1base/vae/fp32/length_77/untuned/base":"av3_vaebase_22dec_fp32",
|
||||
"anythingv3/v2_1base/clip/fp32/length_77/untuned":"av3_clip_19dec_fp32",
|
||||
"analogdiffusion/v2_1base/unet/fp16/length_77/untuned":"ad_unet_19dec_fp16",
|
||||
"analogdiffusion/v2_1base/unet/fp16/length_77/tuned":"ad_unet_19dec_fp16_tuned",
|
||||
"analogdiffusion/v2_1base/unet/fp16/length_77/tuned/cuda":"ad_unet_19dec_fp16_cuda_tuned",
|
||||
"analogdiffusion/v2_1base/unet/fp32/length_77/untuned":"ad_unet_19dec_fp32",
|
||||
"analogdiffusion/v2_1base/vae/fp16/length_77/untuned":"ad_vae_19dec_fp16",
|
||||
"analogdiffusion/v2_1base/vae/fp16/length_77/tuned":"ad_vae_19dec_fp16_tuned",
|
||||
"analogdiffusion/v2_1base/vae/fp16/length_77/tuned/cuda":"ad_vae_19dec_fp16_cuda_tuned",
|
||||
"analogdiffusion/v2_1base/vae/fp16/length_77/untuned/base":"ad_vaebase_22dec_fp16",
|
||||
"analogdiffusion/v2_1base/vae/fp32/length_77/untuned":"ad_vae_19dec_fp32",
|
||||
"analogdiffusion/v2_1base/vae/fp32/length_77/untuned/base":"ad_vaebase_22dec_fp32",
|
||||
"analogdiffusion/v2_1base/clip/fp32/length_77/untuned":"ad_clip_19dec_fp32",
|
||||
"openjourney/v2_1base/unet/fp16/length_64/untuned":"oj_unet_22dec_fp16_64",
|
||||
"openjourney/v2_1base/unet/fp32/length_64/untuned":"oj_unet_22dec_fp32_64",
|
||||
"openjourney/v2_1base/vae/fp16/length_77/untuned":"oj_vae_22dec_fp16",
|
||||
"openjourney/v2_1base/vae/fp16/length_77/untuned/base":"oj_vaebase_22dec_fp16",
|
||||
"openjourney/v2_1base/vae/fp32/length_77/untuned":"oj_vae_22dec_fp32",
|
||||
"openjourney/v2_1base/vae/fp32/length_77/untuned/base":"oj_vaebase_22dec_fp32",
|
||||
"openjourney/v2_1base/clip/fp32/length_64/untuned":"oj_clip_22dec_fp32_64",
|
||||
"dreamlike/v2_1base/unet/fp16/length_77/untuned":"dl_unet_23dec_fp16_77",
|
||||
"dreamlike/v2_1base/unet/fp32/length_77/untuned":"dl_unet_23dec_fp32_77",
|
||||
"dreamlike/v2_1base/vae/fp16/length_77/untuned":"dl_vae_23dec_fp16",
|
||||
"dreamlike/v2_1base/vae/fp16/length_77/untuned/base":"dl_vaebase_23dec_fp16",
|
||||
"dreamlike/v2_1base/vae/fp32/length_77/untuned":"dl_vae_23dec_fp32",
|
||||
"dreamlike/v2_1base/vae/fp32/length_77/untuned/base":"dl_vaebase_23dec_fp32",
|
||||
"dreamlike/v2_1base/clip/fp32/length_77/untuned":"dl_clip_23dec_fp32_77"
|
||||
}
|
||||
]
|
||||
|
||||
@@ -45,12 +45,12 @@
|
||||
"untuned": {
|
||||
"fp16": {
|
||||
"default_compilation_flags": [
|
||||
"--iree-preprocessing-pass-pipeline=builtin.module(func.func(iree-flow-detach-elementwise-from-named-ops,iree-preprocessing-pad-linalg-ops{pad-size=32}))"
|
||||
"--iree-preprocessing-pass-pipeline=builtin.module(func.func(iree-flow-detach-elementwise-from-named-ops,iree-flow-convert-1x1-filter-conv2d-to-matmul,iree-preprocessing-convert-conv2d-to-img2col,iree-preprocessing-pad-linalg-ops{pad-size=32}))"
|
||||
]
|
||||
},
|
||||
"fp32": {
|
||||
"default_compilation_flags": [
|
||||
"--iree-preprocessing-pass-pipeline=builtin.module(func.func(iree-flow-detach-elementwise-from-named-ops,iree-preprocessing-pad-linalg-ops{pad-size=16}))"
|
||||
"--iree-preprocessing-pass-pipeline=builtin.module(func.func(iree-flow-detach-elementwise-from-named-ops,iree-flow-convert-1x1-filter-conv2d-to-matmul,iree-preprocessing-convert-conv2d-to-img2col,iree-preprocessing-pad-linalg-ops{pad-size=16}))"
|
||||
]
|
||||
}
|
||||
}
|
||||
|
||||
@@ -20,22 +20,6 @@ def get_device():
|
||||
return device
|
||||
|
||||
|
||||
def get_device_args():
|
||||
device = get_device()
|
||||
device_spec_args = []
|
||||
if device == "cuda":
|
||||
from shark.iree_utils.gpu_utils import get_iree_gpu_args
|
||||
|
||||
gpu_flags = get_iree_gpu_args()
|
||||
for flag in gpu_flags:
|
||||
device_spec_args.append(flag)
|
||||
elif device == "vulkan":
|
||||
device_spec_args.append(
|
||||
f"--iree-vulkan-target-triple={args.iree_vulkan_target_triple} "
|
||||
)
|
||||
return device, device_spec_args
|
||||
|
||||
|
||||
# Download the model (Unet or VAE fp16) from shark_tank
|
||||
def load_model_from_tank():
|
||||
from apps.stable_diffusion.src.models import (
|
||||
@@ -70,7 +54,7 @@ def load_winograd_configs():
|
||||
config_bucket = "gs://shark_tank/sd_tuned/configs/"
|
||||
config_name = f"{args.annotation_model}_winograd_{device}.json"
|
||||
full_gs_url = config_bucket + config_name
|
||||
winograd_config_dir = os.path.join(WORKDIR, "configs", config_name)
|
||||
winograd_config_dir = f"{WORKDIR}configs/" + config_name
|
||||
print("Loading Winograd config file from ", winograd_config_dir)
|
||||
download_public_file(full_gs_url, winograd_config_dir, True)
|
||||
return winograd_config_dir
|
||||
@@ -78,48 +62,20 @@ def load_winograd_configs():
|
||||
|
||||
def load_lower_configs():
|
||||
from apps.stable_diffusion.src.models import get_variant_version
|
||||
from apps.stable_diffusion.src.utils.utils import (
|
||||
fetch_and_update_base_model_id,
|
||||
)
|
||||
|
||||
if args.ckpt_loc != "":
|
||||
base_model_id = fetch_and_update_base_model_id(args.ckpt_loc)
|
||||
else:
|
||||
base_model_id = fetch_and_update_base_model_id(args.hf_model_id)
|
||||
if base_model_id == "":
|
||||
base_model_id = args.hf_model_id
|
||||
|
||||
variant, version = get_variant_version(base_model_id)
|
||||
|
||||
if version == "inpaint_v1":
|
||||
version = "v1_4"
|
||||
elif version == "inpaint_v2":
|
||||
version = "v2_1base"
|
||||
|
||||
config_bucket = "gs://shark_tank/sd_tuned_configs/"
|
||||
|
||||
device, device_spec_args = get_device_args()
|
||||
spec = ""
|
||||
if device_spec_args:
|
||||
spec = device_spec_args[-1].split("=")[-1].strip()
|
||||
if device == "vulkan":
|
||||
spec = spec.split("-")[0]
|
||||
variant, version = get_variant_version(args.hf_model_id)
|
||||
|
||||
config_bucket = "gs://shark_tank/sd_tuned/configs/"
|
||||
config_version = version
|
||||
if variant in ["anythingv3", "analogdiffusion"]:
|
||||
args.max_length = 77
|
||||
config_version = "v1_4"
|
||||
if args.annotation_model == "vae":
|
||||
if not spec or spec in ["rdna3", "sm_80"]:
|
||||
config_name = (
|
||||
f"{args.annotation_model}_{args.precision}_{device}.json"
|
||||
)
|
||||
else:
|
||||
config_name = f"{args.annotation_model}_{args.precision}_{device}_{spec}.json"
|
||||
else:
|
||||
if not spec or spec in ["rdna3", "sm_80"]:
|
||||
config_name = f"{args.annotation_model}_{version}_{args.precision}_{device}.json"
|
||||
else:
|
||||
config_name = f"{args.annotation_model}_{version}_{args.precision}_{device}_{spec}.json"
|
||||
|
||||
args.max_length = 77
|
||||
device = get_device()
|
||||
config_name = f"{args.annotation_model}_{config_version}_{args.precision}_len{args.max_length}_{device}.json"
|
||||
full_gs_url = config_bucket + config_name
|
||||
lowering_config_dir = os.path.join(WORKDIR, "configs", config_name)
|
||||
lowering_config_dir = f"{WORKDIR}configs/" + config_name
|
||||
print("Loading lowering config file from ", lowering_config_dir)
|
||||
download_public_file(full_gs_url, lowering_config_dir, True)
|
||||
return lowering_config_dir
|
||||
@@ -127,6 +83,13 @@ def load_lower_configs():
|
||||
|
||||
# Annotate the model with Winograd attribute on selected conv ops
|
||||
def annotate_with_winograd(input_mlir, winograd_config_dir, model_name):
|
||||
if model_name.split("_")[-1] != "tuned":
|
||||
out_file_path = (
|
||||
f"{args.annotation_output}/{model_name}_tuned_torch.mlir"
|
||||
)
|
||||
else:
|
||||
out_file_path = f"{args.annotation_output}/{model_name}_torch.mlir"
|
||||
|
||||
with create_context() as ctx:
|
||||
winograd_model = model_annotation(
|
||||
ctx,
|
||||
@@ -140,41 +103,59 @@ def annotate_with_winograd(input_mlir, winograd_config_dir, model_name):
|
||||
winograd_model.operation.write_bytecode(bytecode_stream)
|
||||
bytecode = bytecode_stream.getvalue()
|
||||
|
||||
if args.save_annotation:
|
||||
if model_name.split("_")[-1] != "tuned":
|
||||
out_file_path = os.path.join(
|
||||
args.annotation_output, model_name + "_tuned_torch.mlir"
|
||||
)
|
||||
else:
|
||||
out_file_path = os.path.join(
|
||||
args.annotation_output, model_name + "_torch.mlir"
|
||||
)
|
||||
with open(out_file_path, "w") as f:
|
||||
f.write(str(winograd_model))
|
||||
f.close()
|
||||
|
||||
return bytecode
|
||||
with open(out_file_path, "w") as f:
|
||||
f.write(str(winograd_model))
|
||||
f.close()
|
||||
return bytecode, out_file_path
|
||||
|
||||
|
||||
def dump_after_mlir(input_mlir, use_winograd):
|
||||
import iree.compiler as ireec
|
||||
|
||||
device, device_spec_args = get_device_args()
|
||||
def dump_after_mlir(input_mlir, model_name, use_winograd):
|
||||
if use_winograd:
|
||||
preprocess_flag = "--iree-preprocessing-pass-pipeline=builtin.module(func.func(iree-flow-detach-elementwise-from-named-ops,iree-flow-convert-1x1-filter-conv2d-to-matmul,iree-preprocessing-convert-conv2d-to-img2col,iree-preprocessing-pad-linalg-ops{pad-size=32},iree-linalg-ext-convert-conv2d-to-winograd))"
|
||||
dump_after = "iree-linalg-ext-convert-conv2d-to-winograd"
|
||||
preprocess_flag = (
|
||||
"--iree-preprocessing-pass-pipeline='builtin.module"
|
||||
"(func.func(iree-flow-detach-elementwise-from-named-ops,"
|
||||
"iree-flow-convert-1x1-filter-conv2d-to-matmul,"
|
||||
"iree-preprocessing-convert-conv2d-to-img2col,"
|
||||
"iree-preprocessing-pad-linalg-ops{pad-size=32},"
|
||||
"iree-linalg-ext-convert-conv2d-to-winograd))' "
|
||||
)
|
||||
else:
|
||||
preprocess_flag = "--iree-preprocessing-pass-pipeline=builtin.module(func.func(iree-flow-detach-elementwise-from-named-ops,iree-flow-convert-1x1-filter-conv2d-to-matmul,iree-preprocessing-convert-conv2d-to-img2col,iree-preprocessing-pad-linalg-ops{pad-size=32}))"
|
||||
dump_after = "iree-preprocessing-pad-linalg-ops"
|
||||
preprocess_flag = (
|
||||
"--iree-preprocessing-pass-pipeline='builtin.module"
|
||||
"(func.func(iree-flow-detach-elementwise-from-named-ops,"
|
||||
"iree-flow-convert-1x1-filter-conv2d-to-matmul,"
|
||||
"iree-preprocessing-convert-conv2d-to-img2col,"
|
||||
"iree-preprocessing-pad-linalg-ops{pad-size=32}))' "
|
||||
)
|
||||
|
||||
dump_module = ireec.compile_str(
|
||||
input_mlir,
|
||||
target_backends=[iree_target_map(device)],
|
||||
extra_args=device_spec_args
|
||||
+ [
|
||||
preprocess_flag,
|
||||
"--compile-to=preprocessing",
|
||||
],
|
||||
device_spec_args = ""
|
||||
device = get_device()
|
||||
if device == "cuda":
|
||||
from shark.iree_utils.gpu_utils import get_iree_gpu_args
|
||||
|
||||
gpu_flags = get_iree_gpu_args()
|
||||
for flag in gpu_flags:
|
||||
device_spec_args += flag + " "
|
||||
elif device == "vulkan":
|
||||
device_spec_args = (
|
||||
f"--iree-vulkan-target-triple={args.iree_vulkan_target_triple} "
|
||||
)
|
||||
print("Applying tuned configs on", model_name)
|
||||
|
||||
run_cmd(
|
||||
f"iree-compile {input_mlir} "
|
||||
"--iree-input-type=tm_tensor "
|
||||
f"--iree-hal-target-backends={iree_target_map(device)} "
|
||||
f"{device_spec_args}"
|
||||
f"{preprocess_flag}"
|
||||
"--iree-stream-resource-index-bits=64 "
|
||||
"--iree-vm-target-index-bits=64 "
|
||||
f"--mlir-print-ir-after={dump_after} "
|
||||
"--compile-to=flow "
|
||||
f"2>{args.annotation_output}/dump_after_winograd.mlir "
|
||||
)
|
||||
return dump_module
|
||||
|
||||
|
||||
# For Unet annotate the model with tuned lowering configs
|
||||
@@ -182,63 +163,72 @@ def annotate_with_lower_configs(
|
||||
input_mlir, lowering_config_dir, model_name, use_winograd
|
||||
):
|
||||
# Dump IR after padding/img2col/winograd passes
|
||||
dump_module = dump_after_mlir(input_mlir, use_winograd)
|
||||
print("Applying tuned configs on", model_name)
|
||||
dump_after_mlir(input_mlir, model_name, use_winograd)
|
||||
|
||||
# Annotate the model with lowering configs in the config file
|
||||
with create_context() as ctx:
|
||||
tuned_model = model_annotation(
|
||||
ctx,
|
||||
input_contents=dump_module,
|
||||
input_contents=f"{args.annotation_output}/dump_after_winograd.mlir",
|
||||
config_path=lowering_config_dir,
|
||||
search_op="all",
|
||||
)
|
||||
|
||||
# Remove the intermediate mlir and save the final annotated model
|
||||
os.remove(f"{args.annotation_output}/dump_after_winograd.mlir")
|
||||
if model_name.split("_")[-1] != "tuned":
|
||||
out_file_path = (
|
||||
f"{args.annotation_output}/{model_name}_tuned_torch.mlir"
|
||||
)
|
||||
else:
|
||||
out_file_path = f"{args.annotation_output}/{model_name}_torch.mlir"
|
||||
|
||||
bytecode_stream = io.BytesIO()
|
||||
tuned_model.operation.write_bytecode(bytecode_stream)
|
||||
bytecode = bytecode_stream.getvalue()
|
||||
|
||||
if args.save_annotation:
|
||||
if model_name.split("_")[-1] != "tuned":
|
||||
out_file_path = (
|
||||
f"{args.annotation_output}/{model_name}_tuned_torch.mlir"
|
||||
)
|
||||
else:
|
||||
out_file_path = f"{args.annotation_output}/{model_name}_torch.mlir"
|
||||
with open(out_file_path, "w") as f:
|
||||
f.write(str(tuned_model))
|
||||
f.close()
|
||||
|
||||
return bytecode
|
||||
with open(out_file_path, "w") as f:
|
||||
f.write(str(tuned_model))
|
||||
f.close()
|
||||
return bytecode, out_file_path
|
||||
|
||||
|
||||
def sd_model_annotation(mlir_model, model_name):
|
||||
def sd_model_annotation(mlir_model, model_name, model_from_tank=False):
|
||||
device = get_device()
|
||||
if args.annotation_model == "unet" and device == "vulkan":
|
||||
use_winograd = True
|
||||
winograd_config_dir = load_winograd_configs()
|
||||
winograd_model = annotate_with_winograd(
|
||||
winograd_model, model_path = annotate_with_winograd(
|
||||
mlir_model, winograd_config_dir, model_name
|
||||
)
|
||||
lowering_config_dir = load_lower_configs()
|
||||
tuned_model = annotate_with_lower_configs(
|
||||
winograd_model, lowering_config_dir, model_name, use_winograd
|
||||
tuned_model, output_path = annotate_with_lower_configs(
|
||||
model_path, lowering_config_dir, model_name, use_winograd
|
||||
)
|
||||
elif args.annotation_model == "vae" and device == "vulkan":
|
||||
use_winograd = True
|
||||
winograd_config_dir = load_winograd_configs()
|
||||
tuned_model = annotate_with_winograd(
|
||||
tuned_model, output_path = annotate_with_winograd(
|
||||
mlir_model, winograd_config_dir, model_name
|
||||
)
|
||||
else:
|
||||
use_winograd = False
|
||||
if model_from_tank:
|
||||
mlir_model = f"{WORKDIR}{model_name}_torch/{model_name}_torch.mlir"
|
||||
else:
|
||||
# Just use this function to convert bytecode to string
|
||||
orig_model, model_path = annotate_with_winograd(
|
||||
mlir_model, "", model_name
|
||||
)
|
||||
mlir_model = model_path
|
||||
lowering_config_dir = load_lower_configs()
|
||||
tuned_model = annotate_with_lower_configs(
|
||||
tuned_model, output_path = annotate_with_lower_configs(
|
||||
mlir_model, lowering_config_dir, model_name, use_winograd
|
||||
)
|
||||
print(f"Saved the annotated mlir in {output_path}.")
|
||||
return tuned_model
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
mlir_model, model_name = load_model_from_tank()
|
||||
sd_model_annotation(mlir_model, model_name)
|
||||
sd_model_annotation(mlir_model, model_name, model_from_tank=True)
|
||||
|
||||
@@ -17,24 +17,18 @@ p = argparse.ArgumentParser(
|
||||
p.add_argument(
|
||||
"-p",
|
||||
"--prompts",
|
||||
nargs="+",
|
||||
default=["cyberpunk forest by Salvador Dali"],
|
||||
action="append",
|
||||
default=[],
|
||||
help="text of which images to be generated.",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--negative_prompts",
|
||||
nargs="+",
|
||||
default=["trees, green"],
|
||||
default=[""],
|
||||
help="text you don't want to see in the generated image.",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--img_path",
|
||||
type=str,
|
||||
help="Path to the image input for img2img/inpainting",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--steps",
|
||||
type=int,
|
||||
@@ -45,8 +39,8 @@ p.add_argument(
|
||||
p.add_argument(
|
||||
"--seed",
|
||||
type=int,
|
||||
default=-1,
|
||||
help="the seed to use. -1 for a random one.",
|
||||
default=42,
|
||||
help="the seed to use.",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
@@ -54,14 +48,13 @@ p.add_argument(
|
||||
type=int,
|
||||
default=1,
|
||||
choices=range(1, 4),
|
||||
help="the number of inferences to be made in a single `batch_count`.",
|
||||
help="the number of inferences to be made in a single `run`.",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--height",
|
||||
type=int,
|
||||
default=512,
|
||||
choices=range(384, 769, 8),
|
||||
help="the height of the output image.",
|
||||
)
|
||||
|
||||
@@ -69,7 +62,6 @@ p.add_argument(
|
||||
"--width",
|
||||
type=int,
|
||||
default=512,
|
||||
choices=range(384, 769, 8),
|
||||
help="the width of the output image.",
|
||||
)
|
||||
|
||||
@@ -87,81 +79,6 @@ p.add_argument(
|
||||
help="max length of the tokenizer output, options are 64 and 77.",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--strength",
|
||||
type=float,
|
||||
default=0.8,
|
||||
help="the strength of change applied on the given input image for img2img",
|
||||
)
|
||||
|
||||
##############################################################################
|
||||
### Inpainting and Outpainting Params
|
||||
##############################################################################
|
||||
|
||||
p.add_argument(
|
||||
"--mask_path",
|
||||
type=str,
|
||||
help="Path to the mask image input for inpainting",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--pixels",
|
||||
type=int,
|
||||
default=128,
|
||||
choices=range(8, 257, 8),
|
||||
help="Number of expended pixels for one direction for outpainting",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--mask_blur",
|
||||
type=int,
|
||||
default=8,
|
||||
choices=range(0, 65),
|
||||
help="Number of blur pixels for outpainting",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--left",
|
||||
default=False,
|
||||
action=argparse.BooleanOptionalAction,
|
||||
help="If expend left for outpainting",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--right",
|
||||
default=False,
|
||||
action=argparse.BooleanOptionalAction,
|
||||
help="If expend right for outpainting",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--top",
|
||||
default=False,
|
||||
action=argparse.BooleanOptionalAction,
|
||||
help="If expend top for outpainting",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--bottom",
|
||||
default=False,
|
||||
action=argparse.BooleanOptionalAction,
|
||||
help="If expend bottom for outpainting",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--noise_q",
|
||||
type=float,
|
||||
default=1.0,
|
||||
help="Fall-off exponent for outpainting (lower=higher detail) (min=0.0, max=4.0)",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--color_variation",
|
||||
type=float,
|
||||
default=0.05,
|
||||
help="Color variation for outpainting (min=0.0, max=1.0)",
|
||||
)
|
||||
|
||||
##############################################################################
|
||||
### Model Config and Usage Params
|
||||
##############################################################################
|
||||
@@ -231,10 +148,10 @@ p.add_argument(
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--batch_count",
|
||||
"--runs",
|
||||
type=int,
|
||||
default=1,
|
||||
help="number of batch to be generated with random seeds in single execution",
|
||||
help="number of images to be generated with random seeds in single execution",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
@@ -244,13 +161,6 @@ p.add_argument(
|
||||
help="Path to SD's .ckpt file.",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--custom_vae",
|
||||
type=str,
|
||||
default="",
|
||||
help="HuggingFace repo-id or path to SD model's checkpoint whose Vae needs to be plugged in.",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--hf_model_id",
|
||||
type=str,
|
||||
@@ -259,23 +169,10 @@ p.add_argument(
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--low_cpu_mem_usage",
|
||||
"--enable_stack_trace",
|
||||
default=False,
|
||||
action=argparse.BooleanOptionalAction,
|
||||
help="Use the accelerate package to reduce cpu memory consumption",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--attention_slicing",
|
||||
type=str,
|
||||
default="none",
|
||||
help="Amount of attention slicing to use (one of 'max', 'auto', 'none', or an integer)",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--use_stencil",
|
||||
choices=["canny"],
|
||||
help="Enable the stencil feature.",
|
||||
help="Enable showing the stack trace when retrying the base model configuration",
|
||||
)
|
||||
|
||||
##############################################################################
|
||||
@@ -283,7 +180,7 @@ p.add_argument(
|
||||
##############################################################################
|
||||
|
||||
p.add_argument(
|
||||
"--iree_vulkan_target_triple",
|
||||
"--iree-vulkan-target-triple",
|
||||
type=str,
|
||||
default="",
|
||||
help="Specify target triple for vulkan",
|
||||
@@ -382,7 +279,7 @@ p.add_argument(
|
||||
|
||||
p.add_argument(
|
||||
"--write_metadata_to_png",
|
||||
default=True,
|
||||
default=False,
|
||||
action=argparse.BooleanOptionalAction,
|
||||
help="flag for whether or not to save generation information in PNG chunk text to generated images.",
|
||||
)
|
||||
@@ -395,7 +292,7 @@ p.add_argument(
|
||||
"--progress_bar",
|
||||
default=True,
|
||||
action=argparse.BooleanOptionalAction,
|
||||
help="flag for removing the progress bar animation during image generation",
|
||||
help="flag for removing the pregress bar animation during image generation",
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
@@ -439,10 +336,10 @@ p.add_argument(
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
"--save_annotation",
|
||||
"--use_winograd",
|
||||
default=False,
|
||||
action=argparse.BooleanOptionalAction,
|
||||
help="Save annotated mlir file",
|
||||
help="Apply Winograd on selected conv ops.",
|
||||
)
|
||||
|
||||
args, unknown = p.parse_known_args()
|
||||
|
||||
@@ -1,6 +0,0 @@
|
||||
import cv2
|
||||
|
||||
|
||||
class CannyDetector:
|
||||
def __call__(self, img, low_threshold, high_threshold):
|
||||
return cv2.Canny(img, low_threshold, high_threshold)
|
||||
@@ -1,155 +0,0 @@
|
||||
import cv2
|
||||
import numpy as np
|
||||
from PIL import Image
|
||||
import torch
|
||||
from apps.stable_diffusion.src.utils.stencils.canny import CannyDetector
|
||||
|
||||
stencil = {}
|
||||
|
||||
|
||||
def HWC3(x):
|
||||
assert x.dtype == np.uint8
|
||||
if x.ndim == 2:
|
||||
x = x[:, :, None]
|
||||
assert x.ndim == 3
|
||||
H, W, C = x.shape
|
||||
assert C == 1 or C == 3 or C == 4
|
||||
if C == 3:
|
||||
return x
|
||||
if C == 1:
|
||||
return np.concatenate([x, x, x], axis=2)
|
||||
if C == 4:
|
||||
color = x[:, :, 0:3].astype(np.float32)
|
||||
alpha = x[:, :, 3:4].astype(np.float32) / 255.0
|
||||
y = color * alpha + 255.0 * (1.0 - alpha)
|
||||
y = y.clip(0, 255).astype(np.uint8)
|
||||
return y
|
||||
|
||||
|
||||
def resize_image(input_image, resolution):
|
||||
H, W, C = input_image.shape
|
||||
H = float(H)
|
||||
W = float(W)
|
||||
k = float(resolution) / min(H, W)
|
||||
H *= k
|
||||
W *= k
|
||||
H = int(np.round(H / 64.0)) * 64
|
||||
W = int(np.round(W / 64.0)) * 64
|
||||
img = cv2.resize(
|
||||
input_image,
|
||||
(W, H),
|
||||
interpolation=cv2.INTER_LANCZOS4 if k > 1 else cv2.INTER_AREA,
|
||||
)
|
||||
return img
|
||||
|
||||
|
||||
def controlnet_hint_shaping(
|
||||
controlnet_hint, height, width, dtype, num_images_per_prompt=1
|
||||
):
|
||||
channels = 3
|
||||
if isinstance(controlnet_hint, torch.Tensor):
|
||||
# torch.Tensor: acceptble shape are any of chw, bchw(b==1) or bchw(b==num_images_per_prompt)
|
||||
shape_chw = (channels, height, width)
|
||||
shape_bchw = (1, channels, height, width)
|
||||
shape_nchw = (num_images_per_prompt, channels, height, width)
|
||||
if controlnet_hint.shape in [shape_chw, shape_bchw, shape_nchw]:
|
||||
controlnet_hint = controlnet_hint.to(
|
||||
dtype=dtype, device=torch.device("cpu")
|
||||
)
|
||||
if controlnet_hint.shape != shape_nchw:
|
||||
controlnet_hint = controlnet_hint.repeat(
|
||||
num_images_per_prompt, 1, 1, 1
|
||||
)
|
||||
return controlnet_hint
|
||||
else:
|
||||
raise ValueError(
|
||||
f"Acceptble shape of `stencil` are any of ({channels}, {height}, {width}),"
|
||||
+ f" (1, {channels}, {height}, {width}) or ({num_images_per_prompt}, "
|
||||
+ f"{channels}, {height}, {width}) but is {controlnet_hint.shape}"
|
||||
)
|
||||
elif isinstance(controlnet_hint, np.ndarray):
|
||||
# np.ndarray: acceptable shape is any of hw, hwc, bhwc(b==1) or bhwc(b==num_images_per_promot)
|
||||
# hwc is opencv compatible image format. Color channel must be BGR Format.
|
||||
if controlnet_hint.shape == (height, width):
|
||||
controlnet_hint = np.repeat(
|
||||
controlnet_hint[:, :, np.newaxis], channels, axis=2
|
||||
) # hw -> hwc(c==3)
|
||||
shape_hwc = (height, width, channels)
|
||||
shape_bhwc = (1, height, width, channels)
|
||||
shape_nhwc = (num_images_per_prompt, height, width, channels)
|
||||
if controlnet_hint.shape in [shape_hwc, shape_bhwc, shape_nhwc]:
|
||||
controlnet_hint = torch.from_numpy(controlnet_hint.copy())
|
||||
controlnet_hint = controlnet_hint.to(
|
||||
dtype=dtype, device=torch.device("cpu")
|
||||
)
|
||||
controlnet_hint /= 255.0
|
||||
if controlnet_hint.shape != shape_nhwc:
|
||||
controlnet_hint = controlnet_hint.repeat(
|
||||
num_images_per_prompt, 1, 1, 1
|
||||
)
|
||||
controlnet_hint = controlnet_hint.permute(
|
||||
0, 3, 1, 2
|
||||
) # b h w c -> b c h w
|
||||
return controlnet_hint
|
||||
else:
|
||||
raise ValueError(
|
||||
f"Acceptble shape of `stencil` are any of ({width}, {channels}), "
|
||||
+ f"({height}, {width}, {channels}), "
|
||||
+ f"(1, {height}, {width}, {channels}) or "
|
||||
+ f"({num_images_per_prompt}, {channels}, {height}, {width}) but is {controlnet_hint.shape}"
|
||||
)
|
||||
elif isinstance(controlnet_hint, Image.Image):
|
||||
if controlnet_hint.size == (width, height):
|
||||
controlnet_hint = controlnet_hint.convert(
|
||||
"RGB"
|
||||
) # make sure 3 channel RGB format
|
||||
controlnet_hint = np.array(controlnet_hint) # to numpy
|
||||
controlnet_hint = controlnet_hint[:, :, ::-1] # RGB -> BGR
|
||||
return controlnet_hint_shaping(
|
||||
controlnet_hint, height, width, num_images_per_prompt
|
||||
)
|
||||
else:
|
||||
raise ValueError(
|
||||
f"Acceptable image size of `stencil` is ({width}, {height}) but is {controlnet_hint.size}"
|
||||
)
|
||||
else:
|
||||
raise ValueError(
|
||||
f"Acceptable type of `stencil` are any of torch.Tensor, np.ndarray, PIL.Image.Image but is {type(controlnet_hint)}"
|
||||
)
|
||||
|
||||
|
||||
def controlnet_hint_conversion(
|
||||
image, use_stencil, height, width, dtype, num_images_per_prompt=1
|
||||
):
|
||||
controlnet_hint = None
|
||||
match use_stencil:
|
||||
case "canny":
|
||||
print("Detecting edge with canny")
|
||||
controlnet_hint = hint_canny(image, width)
|
||||
case _:
|
||||
return None
|
||||
controlnet_hint = controlnet_hint_shaping(
|
||||
controlnet_hint, height, width, dtype, num_images_per_prompt
|
||||
)
|
||||
return controlnet_hint
|
||||
|
||||
|
||||
# Stencil 1. Canny
|
||||
def hint_canny(
|
||||
image: Image.Image,
|
||||
width=512,
|
||||
height=512,
|
||||
low_threshold=100,
|
||||
high_threshold=200,
|
||||
):
|
||||
with torch.no_grad():
|
||||
input_image = np.array(image)
|
||||
image_resolution = width
|
||||
|
||||
img = resize_image(HWC3(input_image), image_resolution)
|
||||
|
||||
if not "canny" in stencil:
|
||||
stencil["canny"] = CannyDetector()
|
||||
detected_map = stencil["canny"](img, low_threshold, high_threshold)
|
||||
detected_map = HWC3(detected_map)
|
||||
return detected_map
|
||||
@@ -1,10 +1,6 @@
|
||||
import os
|
||||
import gc
|
||||
import json
|
||||
import re
|
||||
from PIL import PngImagePlugin
|
||||
from datetime import datetime as dt
|
||||
from csv import DictWriter
|
||||
from pathlib import Path
|
||||
import numpy as np
|
||||
from random import randint
|
||||
@@ -18,30 +14,26 @@ from shark.iree_utils.gpu_utils import get_cuda_sm_cc
|
||||
from apps.stable_diffusion.src.utils.stable_args import args
|
||||
from apps.stable_diffusion.src.utils.resources import opt_flags
|
||||
from apps.stable_diffusion.src.utils.sd_annotation import sd_model_annotation
|
||||
import sys
|
||||
import sys, functools, operator
|
||||
from diffusers.pipelines.stable_diffusion.convert_from_ckpt import (
|
||||
load_pipeline_from_original_stable_diffusion_ckpt,
|
||||
)
|
||||
|
||||
|
||||
def get_extended_name(model_name):
|
||||
def get_vmfb_path_name(model_name):
|
||||
device = (
|
||||
args.device
|
||||
if "://" not in args.device
|
||||
else "-".join(args.device.split("://"))
|
||||
)
|
||||
extended_name = "{}_{}".format(model_name, device)
|
||||
return extended_name
|
||||
|
||||
|
||||
def get_vmfb_path_name(model_name):
|
||||
vmfb_path = os.path.join(os.getcwd(), model_name + ".vmfb")
|
||||
return vmfb_path
|
||||
vmfb_path = os.path.join(os.getcwd(), extended_name + ".vmfb")
|
||||
return [vmfb_path, extended_name]
|
||||
|
||||
|
||||
def _compile_module(shark_module, model_name, extra_args=[]):
|
||||
if args.load_vmfb or args.save_vmfb:
|
||||
vmfb_path = get_vmfb_path_name(model_name)
|
||||
[vmfb_path, extended_name] = get_vmfb_path_name(model_name)
|
||||
if args.load_vmfb and os.path.isfile(vmfb_path) and not args.save_vmfb:
|
||||
print(f"loading existing vmfb from: {vmfb_path}")
|
||||
shark_module.load_module(vmfb_path, extra_args=extra_args)
|
||||
@@ -55,7 +47,7 @@ def _compile_module(shark_module, model_name, extra_args=[]):
|
||||
)
|
||||
)
|
||||
path = shark_module.save_module(
|
||||
os.getcwd(), model_name, extra_args
|
||||
os.getcwd(), extended_name, extra_args
|
||||
)
|
||||
shark_module.load_module(path, extra_args=extra_args)
|
||||
else:
|
||||
@@ -125,6 +117,7 @@ def compile_through_fx(
|
||||
def set_iree_runtime_flags():
|
||||
vulkan_runtime_flags = [
|
||||
f"--vulkan_large_heap_block_size={args.vulkan_large_heap_block_size}",
|
||||
f"--device_allocator=caching",
|
||||
f"--vulkan_validation_layers={'true' if args.vulkan_validation_layers else 'false'}",
|
||||
]
|
||||
if args.enable_rgp:
|
||||
@@ -239,15 +232,10 @@ def set_init_device_flags():
|
||||
args.max_length = 64
|
||||
|
||||
# Use tuned models in the case of fp16, vulkan rdna3 or cuda sm devices.
|
||||
if args.ckpt_loc != "":
|
||||
base_model_id = fetch_and_update_base_model_id(args.ckpt_loc)
|
||||
else:
|
||||
base_model_id = fetch_and_update_base_model_id(args.hf_model_id)
|
||||
if base_model_id == "":
|
||||
base_model_id = args.hf_model_id
|
||||
|
||||
if (
|
||||
args.precision != "fp16"
|
||||
args.hf_model_id == "prompthero/openjourney"
|
||||
or args.ckpt_loc != ""
|
||||
or args.precision != "fp16"
|
||||
or args.height != 512
|
||||
or args.width != 512
|
||||
or args.batch_size != 1
|
||||
@@ -255,26 +243,13 @@ def set_init_device_flags():
|
||||
):
|
||||
args.use_tuned = False
|
||||
|
||||
elif base_model_id not in [
|
||||
"Linaqruf/anything-v3.0",
|
||||
"dreamlike-art/dreamlike-diffusion-1.0",
|
||||
"prompthero/openjourney",
|
||||
"wavymulder/Analog-Diffusion",
|
||||
"stabilityai/stable-diffusion-2-1",
|
||||
"stabilityai/stable-diffusion-2-1-base",
|
||||
"CompVis/stable-diffusion-v1-4",
|
||||
"runwayml/stable-diffusion-v1-5",
|
||||
"runwayml/stable-diffusion-inpainting",
|
||||
"stabilityai/stable-diffusion-2-inpainting",
|
||||
]:
|
||||
args.use_tuned = False
|
||||
|
||||
elif "vulkan" in args.device and not any(
|
||||
x in args.iree_vulkan_target_triple for x in ["rdna2", "rdna3"]
|
||||
elif (
|
||||
"vulkan" in args.device
|
||||
and "rdna3" not in args.iree_vulkan_target_triple
|
||||
):
|
||||
args.use_tuned = False
|
||||
|
||||
elif "cuda" in args.device and get_cuda_sm_cc() not in ["sm_80", "sm_89"]:
|
||||
elif "cuda" in args.device and get_cuda_sm_cc() not in ["sm_80"]:
|
||||
args.use_tuned = False
|
||||
|
||||
elif args.use_base_vae and args.hf_model_id not in [
|
||||
@@ -284,7 +259,7 @@ def set_init_device_flags():
|
||||
args.use_tuned = False
|
||||
|
||||
if args.use_tuned:
|
||||
print(f"Using tuned models for {base_model_id}/fp16/{args.device}.")
|
||||
print(f"Using tuned models for {args.hf_model_id}/fp16/{args.device}.")
|
||||
else:
|
||||
print("Tuned models are currently not supported for this setting.")
|
||||
|
||||
@@ -306,27 +281,6 @@ def set_init_device_flags():
|
||||
elif args.height != 512 or args.width != 512 or args.batch_size != 1:
|
||||
args.import_mlir = True
|
||||
|
||||
elif args.use_tuned and args.hf_model_id in [
|
||||
"dreamlike-art/dreamlike-diffusion-1.0",
|
||||
"prompthero/openjourney",
|
||||
"stabilityai/stable-diffusion-2-1",
|
||||
]:
|
||||
args.import_mlir = True
|
||||
|
||||
elif (
|
||||
args.use_tuned
|
||||
and "vulkan" in args.device
|
||||
and "rdna2" in args.iree_vulkan_target_triple
|
||||
):
|
||||
args.import_mlir = True
|
||||
|
||||
elif (
|
||||
args.use_tuned
|
||||
and "cuda" in args.device
|
||||
and get_cuda_sm_cc() == "sm_89"
|
||||
):
|
||||
args.import_mlir = True
|
||||
|
||||
|
||||
# Utility to get list of devices available.
|
||||
def get_available_devices():
|
||||
@@ -401,11 +355,6 @@ def get_opt_flags(model, precision="fp16"):
|
||||
return iree_flags
|
||||
|
||||
|
||||
def get_path_stem(path):
|
||||
path = Path(path)
|
||||
return path.stem
|
||||
|
||||
|
||||
def get_path_to_diffusers_checkpoint(custom_weights):
|
||||
path = Path(custom_weights)
|
||||
diffusers_path = path.parent.absolute()
|
||||
@@ -416,7 +365,7 @@ def get_path_to_diffusers_checkpoint(custom_weights):
|
||||
return path_to_diffusers
|
||||
|
||||
|
||||
def preprocessCKPT(custom_weights, is_inpaint=False):
|
||||
def preprocessCKPT(custom_weights):
|
||||
path_to_diffusers = get_path_to_diffusers_checkpoint(custom_weights)
|
||||
if next(Path(path_to_diffusers).iterdir(), None):
|
||||
print("Checkpoint already loaded at : ", path_to_diffusers)
|
||||
@@ -437,20 +386,17 @@ def preprocessCKPT(custom_weights, is_inpaint=False):
|
||||
print(
|
||||
"Loading diffusers' pipeline from original stable diffusion checkpoint"
|
||||
)
|
||||
num_in_channels = 9 if is_inpaint else 4
|
||||
pipe = load_pipeline_from_original_stable_diffusion_ckpt(
|
||||
checkpoint_path=custom_weights,
|
||||
extract_ema=extract_ema,
|
||||
from_safetensors=from_safetensors,
|
||||
num_in_channels=num_in_channels,
|
||||
)
|
||||
pipe.save_pretrained(path_to_diffusers)
|
||||
print("Loading complete")
|
||||
|
||||
|
||||
def load_vmfb(vmfb_path, model, precision):
|
||||
model = "vae" if "base_vae" in model or "vae_encode" in model else model
|
||||
model = "unet" if "stencil" in model else model
|
||||
model = "vae" if "base_vae" in model else model
|
||||
precision = "fp32" if "clip" in model else precision
|
||||
extra_args = get_opt_flags(model, precision)
|
||||
shark_module = SharkInference(mlir_module=None, device=args.device)
|
||||
@@ -458,30 +404,24 @@ def load_vmfb(vmfb_path, model, precision):
|
||||
return shark_module
|
||||
|
||||
|
||||
# This utility returns vmfbs of Clip, Unet, Vae and Vae_encode, in case all of them
|
||||
# This utility returns vmfbs of Clip, Unet and Vae, in case all three of them
|
||||
# are present; deletes them otherwise.
|
||||
def fetch_or_delete_vmfbs(extended_model_name, precision="fp32"):
|
||||
def fetch_or_delete_vmfbs(basic_model_name, use_base_vae, precision="fp32"):
|
||||
model_name = ["clip", "unet", "base_vae" if use_base_vae else "vae"]
|
||||
vmfb_path = [
|
||||
get_vmfb_path_name(extended_model_name[model])
|
||||
for model in extended_model_name
|
||||
get_vmfb_path_name(model + basic_model_name)[0] for model in model_name
|
||||
]
|
||||
number_of_vmfbs = len(vmfb_path)
|
||||
vmfb_present = [os.path.isfile(vmfb) for vmfb in vmfb_path]
|
||||
all_vmfb_present = True
|
||||
compiled_models = [None] * number_of_vmfbs
|
||||
|
||||
for i in range(number_of_vmfbs):
|
||||
all_vmfb_present = all_vmfb_present and vmfb_present[i]
|
||||
|
||||
all_vmfb_present = functools.reduce(operator.__and__, vmfb_present)
|
||||
compiled_models = [None] * 3
|
||||
# We need to delete vmfbs only if some of the models were compiled.
|
||||
if not all_vmfb_present:
|
||||
for i in range(number_of_vmfbs):
|
||||
for i in range(len(vmfb_path)):
|
||||
if vmfb_present[i]:
|
||||
os.remove(vmfb_path[i])
|
||||
print("Deleted: ", vmfb_path[i])
|
||||
else:
|
||||
model_name = [model for model in extended_model_name.keys()]
|
||||
for i in range(number_of_vmfbs):
|
||||
for i in range(len(vmfb_path)):
|
||||
compiled_models[i] = load_vmfb(
|
||||
vmfb_path[i], model_name[i], precision
|
||||
)
|
||||
@@ -519,97 +459,3 @@ def sanitize_seed(seed):
|
||||
if seed < uint32_min or seed >= uint32_max:
|
||||
seed = randint(uint32_min, uint32_max)
|
||||
return seed
|
||||
|
||||
|
||||
# clear all the cached objects to recompile cleanly.
|
||||
def clear_all():
|
||||
print("CLEARING ALL, EXPECT SEVERAL MINUTES TO RECOMPILE")
|
||||
from glob import glob
|
||||
import shutil
|
||||
|
||||
vmfbs = glob(os.path.join(os.getcwd(), "*.vmfb"))
|
||||
for vmfb in vmfbs:
|
||||
if os.path.exists(vmfb):
|
||||
os.remove(vmfb)
|
||||
# Temporary workaround of deleting yaml files to incorporate diffusers' pipeline.
|
||||
# TODO: Remove this once we have better weight updation logic.
|
||||
inference_yaml = ["v2-inference-v.yaml", "v1-inference.yaml"]
|
||||
for yaml in inference_yaml:
|
||||
if os.path.exists(yaml):
|
||||
os.remove(yaml)
|
||||
home = os.path.expanduser("~")
|
||||
if os.name == "nt": # Windows
|
||||
appdata = os.getenv("LOCALAPPDATA")
|
||||
shutil.rmtree(os.path.join(appdata, "AMD/VkCache"), ignore_errors=True)
|
||||
shutil.rmtree(os.path.join(home, "shark_tank"), ignore_errors=True)
|
||||
elif os.name == "unix":
|
||||
shutil.rmtree(os.path.join(home, ".cache/AMD/VkCache"))
|
||||
shutil.rmtree(os.path.join(home, ".local/shark_tank"))
|
||||
|
||||
|
||||
# save output images and the inputs corresponding to it.
|
||||
def save_output_img(output_img, img_seed, extra_info={}):
|
||||
output_path = args.output_dir if args.output_dir else Path.cwd()
|
||||
generated_imgs_path = Path(
|
||||
output_path, "generated_imgs", dt.now().strftime("%Y%m%d")
|
||||
)
|
||||
generated_imgs_path.mkdir(parents=True, exist_ok=True)
|
||||
csv_path = Path(generated_imgs_path, "imgs_details.csv")
|
||||
|
||||
prompt_slice = re.sub("[^a-zA-Z0-9]", "_", args.prompts[0][:15])
|
||||
out_img_name = (
|
||||
f"{prompt_slice}_{img_seed}_{dt.now().strftime('%y%m%d_%H%M%S')}"
|
||||
)
|
||||
|
||||
img_model = args.hf_model_id
|
||||
if args.ckpt_loc:
|
||||
img_model = os.path.basename(args.ckpt_loc)
|
||||
|
||||
if args.output_img_format == "jpg":
|
||||
out_img_path = Path(generated_imgs_path, f"{out_img_name}.jpg")
|
||||
output_img.save(out_img_path, quality=95, subsampling=0)
|
||||
else:
|
||||
out_img_path = Path(generated_imgs_path, f"{out_img_name}.png")
|
||||
pngInfo = PngImagePlugin.PngInfo()
|
||||
|
||||
if args.write_metadata_to_png:
|
||||
pngInfo.add_text(
|
||||
"parameters",
|
||||
f"{args.prompts[0]}\nNegative prompt: {args.negative_prompts[0]}\nSteps:{args.steps}, Sampler: {args.scheduler}, CFG scale: {args.guidance_scale}, Seed: {img_seed}, Size: {args.width}x{args.height}, Model: {img_model}",
|
||||
)
|
||||
|
||||
output_img.save(out_img_path, "PNG", pnginfo=pngInfo)
|
||||
|
||||
if args.output_img_format not in ["png", "jpg"]:
|
||||
print(
|
||||
f"[ERROR] Format {args.output_img_format} is not supported yet."
|
||||
"Image saved as png instead. Supported formats: png / jpg"
|
||||
)
|
||||
|
||||
new_entry = {
|
||||
"VARIANT": img_model,
|
||||
"SCHEDULER": args.scheduler,
|
||||
"PROMPT": args.prompts[0],
|
||||
"NEG_PROMPT": args.negative_prompts[0],
|
||||
"SEED": img_seed,
|
||||
"CFG_SCALE": args.guidance_scale,
|
||||
"PRECISION": args.precision,
|
||||
"STEPS": args.steps,
|
||||
"HEIGHT": args.height,
|
||||
"WIDTH": args.width,
|
||||
"MAX_LENGTH": args.max_length,
|
||||
"OUTPUT": out_img_path,
|
||||
}
|
||||
|
||||
new_entry.update(extra_info)
|
||||
|
||||
with open(csv_path, "a") as csv_obj:
|
||||
dictwriter_obj = DictWriter(csv_obj, fieldnames=list(new_entry.keys()))
|
||||
dictwriter_obj.writerow(new_entry)
|
||||
csv_obj.close()
|
||||
|
||||
if args.save_metadata_to_json:
|
||||
del new_entry["OUTPUT"]
|
||||
json_path = Path(generated_imgs_path, f"{out_img_name}.json")
|
||||
with open(json_path, "w") as f:
|
||||
json.dump(new_entry, f, indent=4)
|
||||
|
||||
70
apps/stable_diffusion/stable_diffusion_amd.md
Normal file
70
apps/stable_diffusion/stable_diffusion_amd.md
Normal file
@@ -0,0 +1,70 @@
|
||||
# Stable Diffusion optimized for AMD RDNA2/RDNA3 GPUs
|
||||
|
||||
Before you start, please be aware that this is beta software that relies on a special AMD driver. Like all StableDiffusion GUIs published so far, you need some technical expertise to set it up. We apologize in advance if you bump into issues. If that happens, please don't hesitate to ask our Discord community for help! Please be assured that we (Nod and AMD) are working hard to improve the user experience in coming months.
|
||||
If it works well for you, please "star" the following GitHub projects... this is one of the best ways to help and spread the word!
|
||||
|
||||
* https://github.com/nod-ai/SHARK
|
||||
* https://github.com/iree-org/iree
|
||||
|
||||
## Install this specific AMD Drivers (AMD latest may not have all the fixes).
|
||||
|
||||
### AMD KB Drivers for RDNA2 and RDNA3:
|
||||
|
||||
*AMD Software: Adrenalin Edition 22.11.1 for MLIR/IREE Driver Version 22.20.29.09 for Windows® 10 and Windows® 11 (Windows Driver Store Version 31.0.12029.9003)*
|
||||
|
||||
First, for RDNA2 users, download this special driver in a folder of your choice. We recommend you keep the installation files around, since you may need to re-install it later, if Windows Update decides to overwrite it:
|
||||
https://www.amd.com/en/support/kb/release-notes/rn-rad-win-22-11-1-mlir-iree
|
||||
|
||||
For RDNA3, the latest driver 23.1.2 supports MLIR/IREE as well: https://www.amd.com/en/support/kb/release-notes/rn-rad-win-23-1-2-kb
|
||||
|
||||
KNOWN ISSUES with this special AMD driver:
|
||||
* `Windows Update` may (depending how it's configured) automatically install a new official AMD driver that overwrites this IREE-specific driver. If Stable Diffusion used to work, then a few days later, it slows down a lot or produces incorrect results (e.g. black images), this may be the cause. To fix this problem, please check the installed driver version, and re-install the special driver if needed. (TODO: document how to prevent this `Windows Update` behavior!)
|
||||
* Some people using this special driver experience mouse pointer accuracy issues, especially if using a larger-than-default mouse pointer. The clicked point isn't centered properly. One possible work-around is to reset the pointer size to "1" in "Change pointer size and color".
|
||||
|
||||
## Installation
|
||||
|
||||
Download the latest Windows SHARK SD binary [492 here](https://github.com/nod-ai/SHARK/releases/download/20230203.492/shark_sd_20230203_492.exe) in a folder of your choice. If you want nighly builds, you can look for them on the GitHub releases page.
|
||||
|
||||
Notes:
|
||||
* We recommend that you download this EXE in a new folder, whenever you download a new EXE version. If you download it in the same folder as a previous install, you must delete the old `*.vmfb` files. Those contain Vulkan dispatches compiled from MLIR which can be outdated if you run a new EXE from the same folder. You can use `--clear_all` flag once to clean all the old files.
|
||||
* If you recently updated the driver or this binary (EXE file), we recommend you:
|
||||
* clear all the local artifacts with `--clear_all` OR
|
||||
* clear the Vulkan shader cache: For Windows users this can be done by clearing the contents of `C:\Users\%username%\AppData\Local\AMD\VkCache\`. On Linux the same cache is typically located at `~/.cache/AMD/VkCache/`.
|
||||
* clear the `huggingface` cache. In Windows, this is `C:\Users\%username%\.cache\huggingface`.
|
||||
|
||||
## Running
|
||||
|
||||
* Open a Command Prompt or Powershell terminal, change folder (`cd`) to the .exe folder. Then run the EXE from the command prompt. That way, if an error occurs, you'll be able to cut-and-paste it to ask for help. (if it always works for you without error, you may simply double-click the EXE to start the web browser)
|
||||
* The first run may take about 10-15 minutes when the models are downloaded and compiled. Your patience is appreciated. The download could be about 5GB.
|
||||
* If successful, you will likely see a Windows Defender message asking you to give permission to open a web server port. Accept it.
|
||||
* Open a browser to access the Stable Diffusion web server. By default, the port is 8080, so you can go to http://localhost:8080/?__theme=dark.
|
||||
|
||||
## Stopping
|
||||
|
||||
* Select the command prompt that's running the EXE. Press CTRL-C and wait a moment. The application should stop.
|
||||
* Please make sure to do the above step before you attempt to update the EXE to a new version.
|
||||
|
||||
# Results
|
||||
|
||||
<img width="1607" alt="webui" src="https://user-images.githubusercontent.com/74956/204939260-b8308bc2-8dc4-47f6-9ac0-f60b66edab99.png">
|
||||
|
||||
|
||||
Here are some samples generated:
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
|
||||
The output on a 7900XTX would like:
|
||||
|
||||
```shell
|
||||
Stats for run 0:
|
||||
Average step time: 47.19188690185547ms/it
|
||||
Clip Inference time (ms) = 109.531
|
||||
VAE Inference time (ms): 78.590
|
||||
|
||||
Total image generation time: 2.5788655281066895sec
|
||||
```
|
||||
|
||||
Find us on [SHARK Discord server](https://discord.gg/RUqY2h2s9u) if you have any trouble with running it on your hardware.
|
||||
@@ -144,30 +144,19 @@
|
||||
--dataset-table-border-hover: var(--color-grey-800);
|
||||
}
|
||||
|
||||
/* SHARK theme */
|
||||
body {
|
||||
/* SHARK theme customization */
|
||||
|
||||
.gradio-container {
|
||||
background-color: var(--color-background-primary);
|
||||
}
|
||||
|
||||
/* display in full width for desktop devices */
|
||||
@media (min-width: 1536px)
|
||||
{
|
||||
.gradio-container {
|
||||
max-width: var(--size-full) !important;
|
||||
}
|
||||
}
|
||||
|
||||
.gradio-container .contain {
|
||||
padding: 0 var(--size-4) !important;
|
||||
}
|
||||
|
||||
.container {
|
||||
background-color: black !important;
|
||||
padding-top: var(--size-5) !important;
|
||||
padding-top: 20px !important;
|
||||
}
|
||||
|
||||
#ui_title {
|
||||
padding: var(--size-2) 0 0 var(--size-1);
|
||||
padding: 10px !important;
|
||||
}
|
||||
|
||||
#top_logo {
|
||||
@@ -176,6 +165,15 @@ body {
|
||||
border: 0;
|
||||
}
|
||||
|
||||
#demo_title {
|
||||
background-color: var(--color-background-primary);
|
||||
border-radius: 0 !important;
|
||||
border: 0;
|
||||
padding-top: 15px;
|
||||
padding-bottom: 0px;
|
||||
width: 350px !important;
|
||||
}
|
||||
|
||||
#demo_title_outer {
|
||||
border-radius: 0;
|
||||
}
|
||||
@@ -184,7 +182,7 @@ body {
|
||||
border-radius: 0 !important
|
||||
}
|
||||
|
||||
#prompt_box textarea, #negative_prompt_box textarea {
|
||||
#prompt_box textarea {
|
||||
background-color: var(--color-background-primary) !important;
|
||||
}
|
||||
|
||||
@@ -198,7 +196,7 @@ body {
|
||||
|
||||
#ui_body {
|
||||
background-color: var(--color-background-secondary) !important;
|
||||
padding: var(--size-2) !important;
|
||||
padding: 10px !important;
|
||||
border-radius: 0.5em !important;
|
||||
}
|
||||
|
||||
@@ -209,13 +207,3 @@ body {
|
||||
footer {
|
||||
display: none !important;
|
||||
}
|
||||
|
||||
#gallery + div {
|
||||
border-radius: 0 !important;
|
||||
}
|
||||
|
||||
/* Prevent progress bar to block gallery navigation while building images (Gradio V3.19.0) */
|
||||
#gallery .wrap.default {
|
||||
pointer-events: none;
|
||||
}
|
||||
|
||||
0
apps/stable_diffusion/web/gradio/img2img_ui.py
Normal file
0
apps/stable_diffusion/web/gradio/img2img_ui.py
Normal file
0
apps/stable_diffusion/web/gradio/txt2img_ui.py
Normal file
0
apps/stable_diffusion/web/gradio/txt2img_ui.py
Normal file
@@ -1,21 +1,14 @@
|
||||
import os
|
||||
import sys
|
||||
from pathlib import Path
|
||||
import glob
|
||||
|
||||
if "AMD_ENABLE_LLPC" not in os.environ:
|
||||
os.environ["AMD_ENABLE_LLPC"] = "1"
|
||||
|
||||
if sys.platform == "darwin":
|
||||
os.environ["DYLD_LIBRARY_PATH"] = "/usr/local/lib"
|
||||
|
||||
import gradio as gr
|
||||
from apps.stable_diffusion.src import args, clear_all
|
||||
from apps.stable_diffusion.web.utils.gradio_configs import (
|
||||
clear_gradio_tmp_imgs_folder,
|
||||
)
|
||||
|
||||
# clear all gradio tmp images from the last session
|
||||
clear_gradio_tmp_imgs_folder()
|
||||
|
||||
if args.clear_all:
|
||||
clear_all()
|
||||
|
||||
|
||||
def resource_path(relative_path):
|
||||
"""Get absolute path to resource, works for dev and for PyInstaller"""
|
||||
@@ -25,114 +18,245 @@ def resource_path(relative_path):
|
||||
return os.path.join(base_path, relative_path)
|
||||
|
||||
|
||||
dark_theme = resource_path("ui/css/sd_dark_theme.css")
|
||||
|
||||
from apps.stable_diffusion.web.ui import (
|
||||
txt2img_web,
|
||||
txt2img_gallery,
|
||||
txt2img_sendto_img2img,
|
||||
txt2img_sendto_inpaint,
|
||||
txt2img_sendto_outpaint,
|
||||
img2img_web,
|
||||
img2img_gallery,
|
||||
img2img_init_image,
|
||||
img2img_sendto_inpaint,
|
||||
img2img_sendto_outpaint,
|
||||
inpaint_web,
|
||||
inpaint_gallery,
|
||||
inpaint_init_image,
|
||||
inpaint_sendto_img2img,
|
||||
inpaint_sendto_outpaint,
|
||||
outpaint_web,
|
||||
outpaint_gallery,
|
||||
outpaint_init_image,
|
||||
outpaint_sendto_img2img,
|
||||
outpaint_sendto_inpaint,
|
||||
import gradio as gr
|
||||
from PIL import Image
|
||||
from apps.stable_diffusion.src import (
|
||||
prompt_examples,
|
||||
args,
|
||||
get_available_devices,
|
||||
)
|
||||
from apps.stable_diffusion.scripts import txt2img_inf
|
||||
|
||||
nodlogo_loc = resource_path("logos/nod-logo.png")
|
||||
sdlogo_loc = resource_path("logos/sd-demo-logo.png")
|
||||
|
||||
|
||||
def register_button_click(button, selectedid, inputs, outputs):
|
||||
button.click(
|
||||
lambda x: (
|
||||
x[0]["name"] if len(x) != 0 else None,
|
||||
gr.Tabs.update(selected=selectedid),
|
||||
),
|
||||
inputs,
|
||||
outputs,
|
||||
)
|
||||
demo_css = resource_path("css/sd_dark_theme.css")
|
||||
|
||||
|
||||
with gr.Blocks(
|
||||
css=dark_theme, analytics_enabled=False, title="Stable Diffusion"
|
||||
) as sd_web:
|
||||
with gr.Tabs() as tabs:
|
||||
with gr.TabItem(label="Text-to-Image", id=0):
|
||||
txt2img_web.render()
|
||||
with gr.TabItem(label="Image-to-Image", id=1):
|
||||
img2img_web.render()
|
||||
with gr.TabItem(label="Inpainting", id=2):
|
||||
inpaint_web.render()
|
||||
with gr.TabItem(label="Outpainting", id=3):
|
||||
outpaint_web.render()
|
||||
with gr.Blocks(title="Stable Diffusion", css=demo_css) as shark_web:
|
||||
with gr.Row(elem_id="ui_title"):
|
||||
nod_logo = Image.open(nodlogo_loc)
|
||||
logo2 = Image.open(sdlogo_loc)
|
||||
with gr.Row():
|
||||
with gr.Column(scale=1, elem_id="demo_title_outer"):
|
||||
gr.Image(
|
||||
value=nod_logo,
|
||||
show_label=False,
|
||||
interactive=False,
|
||||
elem_id="top_logo",
|
||||
).style(width=150, height=100)
|
||||
with gr.Column(scale=5, elem_id="demo_title_outer"):
|
||||
gr.Image(
|
||||
value=logo2,
|
||||
show_label=False,
|
||||
interactive=False,
|
||||
elem_id="demo_title",
|
||||
).style(width=150, height=100)
|
||||
|
||||
register_button_click(
|
||||
txt2img_sendto_img2img,
|
||||
1,
|
||||
[txt2img_gallery],
|
||||
[img2img_init_image, tabs],
|
||||
)
|
||||
register_button_click(
|
||||
txt2img_sendto_inpaint,
|
||||
2,
|
||||
[txt2img_gallery],
|
||||
[inpaint_init_image, tabs],
|
||||
)
|
||||
register_button_click(
|
||||
txt2img_sendto_outpaint,
|
||||
3,
|
||||
[txt2img_gallery],
|
||||
[outpaint_init_image, tabs],
|
||||
)
|
||||
register_button_click(
|
||||
img2img_sendto_inpaint,
|
||||
2,
|
||||
[img2img_gallery],
|
||||
[inpaint_init_image, tabs],
|
||||
)
|
||||
register_button_click(
|
||||
img2img_sendto_outpaint,
|
||||
3,
|
||||
[img2img_gallery],
|
||||
[outpaint_init_image, tabs],
|
||||
)
|
||||
register_button_click(
|
||||
inpaint_sendto_img2img,
|
||||
1,
|
||||
[inpaint_gallery],
|
||||
[img2img_init_image, tabs],
|
||||
)
|
||||
register_button_click(
|
||||
inpaint_sendto_outpaint,
|
||||
3,
|
||||
[inpaint_gallery],
|
||||
[outpaint_init_image, tabs],
|
||||
)
|
||||
register_button_click(
|
||||
outpaint_sendto_img2img,
|
||||
1,
|
||||
[outpaint_gallery],
|
||||
[img2img_init_image, tabs],
|
||||
)
|
||||
register_button_click(
|
||||
outpaint_sendto_inpaint,
|
||||
2,
|
||||
[outpaint_gallery],
|
||||
[inpaint_init_image, tabs],
|
||||
)
|
||||
with gr.Row(elem_id="ui_body"):
|
||||
with gr.Row():
|
||||
with gr.Column(scale=1, min_width=600):
|
||||
with gr.Row():
|
||||
ckpt_path = (
|
||||
Path(args.ckpt_dir)
|
||||
if args.ckpt_dir
|
||||
else Path(Path.cwd(), "models")
|
||||
)
|
||||
ckpt_path.mkdir(parents=True, exist_ok=True)
|
||||
types = (
|
||||
"*.ckpt",
|
||||
"*.safetensors",
|
||||
) # the tuple of file types
|
||||
ckpt_files = ["None"]
|
||||
for extn in types:
|
||||
files = glob.glob(os.path.join(ckpt_path, extn))
|
||||
ckpt_files.extend(files)
|
||||
custom_model = gr.Dropdown(
|
||||
label=f"Models (Custom Model path: {ckpt_path})",
|
||||
value="None",
|
||||
choices=ckpt_files
|
||||
+ [
|
||||
"Linaqruf/anything-v3.0",
|
||||
"prompthero/openjourney",
|
||||
"wavymulder/Analog-Diffusion",
|
||||
"stabilityai/stable-diffusion-2-1",
|
||||
"stabilityai/stable-diffusion-2-1-base",
|
||||
"CompVis/stable-diffusion-v1-4",
|
||||
],
|
||||
)
|
||||
hf_model_id = gr.Textbox(
|
||||
placeholder="Select 'None' in the Models dropdown on the left and enter model ID here e.g: SG161222/Realistic_Vision_V1.3",
|
||||
value="",
|
||||
label="HuggingFace Model ID",
|
||||
)
|
||||
|
||||
with gr.Group(elem_id="prompt_box_outer"):
|
||||
prompt = gr.Textbox(
|
||||
label="Prompt",
|
||||
value="cyberpunk forest by Salvador Dali",
|
||||
lines=1,
|
||||
elem_id="prompt_box",
|
||||
)
|
||||
negative_prompt = gr.Textbox(
|
||||
label="Negative Prompt",
|
||||
value="trees, green",
|
||||
lines=1,
|
||||
elem_id="prompt_box",
|
||||
)
|
||||
with gr.Accordion(label="Advanced Options", open=False):
|
||||
with gr.Row():
|
||||
scheduler = gr.Dropdown(
|
||||
label="Scheduler",
|
||||
value="SharkEulerDiscrete",
|
||||
choices=[
|
||||
"DDIM",
|
||||
"PNDM",
|
||||
"LMSDiscrete",
|
||||
"DPMSolverMultistep",
|
||||
"EulerDiscrete",
|
||||
"EulerAncestralDiscrete",
|
||||
"SharkEulerDiscrete",
|
||||
],
|
||||
)
|
||||
with gr.Group():
|
||||
save_metadata_to_png = gr.Checkbox(
|
||||
label="Save prompt information to PNG",
|
||||
value=True,
|
||||
interactive=True,
|
||||
)
|
||||
save_metadata_to_json = gr.Checkbox(
|
||||
label="Save prompt information to JSON file",
|
||||
value=False,
|
||||
interactive=True,
|
||||
)
|
||||
with gr.Row():
|
||||
height = gr.Slider(
|
||||
384, 786, value=512, step=8, label="Height"
|
||||
)
|
||||
width = gr.Slider(
|
||||
384, 786, value=512, step=8, label="Width"
|
||||
)
|
||||
precision = gr.Radio(
|
||||
label="Precision",
|
||||
value="fp16",
|
||||
choices=[
|
||||
"fp16",
|
||||
"fp32",
|
||||
],
|
||||
visible=False,
|
||||
)
|
||||
max_length = gr.Radio(
|
||||
label="Max Length",
|
||||
value=64,
|
||||
choices=[
|
||||
64,
|
||||
77,
|
||||
],
|
||||
visible=False,
|
||||
)
|
||||
with gr.Row():
|
||||
steps = gr.Slider(
|
||||
1, 100, value=50, step=1, label="Steps"
|
||||
)
|
||||
guidance_scale = gr.Slider(
|
||||
0,
|
||||
50,
|
||||
value=7.5,
|
||||
step=0.1,
|
||||
label="CFG Scale",
|
||||
)
|
||||
with gr.Row():
|
||||
batch_count = gr.Slider(
|
||||
1,
|
||||
10,
|
||||
value=1,
|
||||
step=1,
|
||||
label="Batch Count",
|
||||
interactive=True,
|
||||
)
|
||||
batch_size = gr.Slider(
|
||||
1,
|
||||
4,
|
||||
value=1,
|
||||
step=1,
|
||||
label="Batch Size",
|
||||
interactive=True,
|
||||
)
|
||||
with gr.Row():
|
||||
seed = gr.Number(value=-1, precision=0, label="Seed")
|
||||
available_devices = get_available_devices()
|
||||
device = gr.Dropdown(
|
||||
label="Device",
|
||||
value=available_devices[0],
|
||||
choices=available_devices,
|
||||
)
|
||||
with gr.Row():
|
||||
random_seed = gr.Button("Randomize Seed")
|
||||
random_seed.click(
|
||||
None,
|
||||
inputs=[],
|
||||
outputs=[seed],
|
||||
_js="() => Math.floor(Math.random() * 4294967295)",
|
||||
)
|
||||
stable_diffusion = gr.Button("Generate Image")
|
||||
with gr.Accordion(label="Prompt Examples!", open=False):
|
||||
ex = gr.Examples(
|
||||
examples=prompt_examples,
|
||||
inputs=prompt,
|
||||
cache_examples=False,
|
||||
elem_id="prompt_examples",
|
||||
)
|
||||
|
||||
sd_web.queue()
|
||||
sd_web.launch(
|
||||
with gr.Column(scale=1, min_width=600):
|
||||
with gr.Group():
|
||||
gallery = gr.Gallery(
|
||||
label="Generated images",
|
||||
show_label=False,
|
||||
elem_id="gallery",
|
||||
).style(grid=[2], height="auto")
|
||||
std_output = gr.Textbox(
|
||||
value="Nothing to show.",
|
||||
lines=4,
|
||||
show_label=False,
|
||||
)
|
||||
output_dir = args.output_dir if args.output_dir else Path.cwd()
|
||||
output_dir = Path(output_dir, "generated_imgs")
|
||||
output_loc = gr.Textbox(
|
||||
label="Saving Images at",
|
||||
value=output_dir,
|
||||
interactive=False,
|
||||
)
|
||||
kwargs = dict(
|
||||
fn=txt2img_inf,
|
||||
inputs=[
|
||||
prompt,
|
||||
negative_prompt,
|
||||
height,
|
||||
width,
|
||||
steps,
|
||||
guidance_scale,
|
||||
seed,
|
||||
batch_count,
|
||||
batch_size,
|
||||
scheduler,
|
||||
custom_model,
|
||||
hf_model_id,
|
||||
precision,
|
||||
device,
|
||||
max_length,
|
||||
save_metadata_to_json,
|
||||
save_metadata_to_png,
|
||||
],
|
||||
outputs=[gallery, std_output],
|
||||
show_progress=args.progress_bar,
|
||||
)
|
||||
|
||||
prompt.submit(**kwargs)
|
||||
stable_diffusion.click(**kwargs)
|
||||
|
||||
shark_web.queue()
|
||||
shark_web.launch(
|
||||
share=args.share,
|
||||
inbrowser=True,
|
||||
server_name="0.0.0.0",
|
||||
|
||||
BIN
apps/stable_diffusion/web/logos/Nod_logo.png
Normal file
BIN
apps/stable_diffusion/web/logos/Nod_logo.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 33 KiB |
{kind=link}
|
Before Width: | Height: | Size: 10 KiB After Width: | Height: | Size: 10 KiB |
BIN
apps/stable_diffusion/web/logos/sd-demo-logo.png
Normal file
BIN
apps/stable_diffusion/web/logos/sd-demo-logo.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 5.0 KiB |
@@ -1,28 +0,0 @@
|
||||
from apps.stable_diffusion.web.ui.txt2img_ui import (
|
||||
txt2img_web,
|
||||
txt2img_gallery,
|
||||
txt2img_sendto_img2img,
|
||||
txt2img_sendto_inpaint,
|
||||
txt2img_sendto_outpaint,
|
||||
)
|
||||
from apps.stable_diffusion.web.ui.img2img_ui import (
|
||||
img2img_web,
|
||||
img2img_gallery,
|
||||
img2img_init_image,
|
||||
img2img_sendto_inpaint,
|
||||
img2img_sendto_outpaint,
|
||||
)
|
||||
from apps.stable_diffusion.web.ui.inpaint_ui import (
|
||||
inpaint_web,
|
||||
inpaint_gallery,
|
||||
inpaint_init_image,
|
||||
inpaint_sendto_img2img,
|
||||
inpaint_sendto_outpaint,
|
||||
)
|
||||
from apps.stable_diffusion.web.ui.outpaint_ui import (
|
||||
outpaint_web,
|
||||
outpaint_gallery,
|
||||
outpaint_init_image,
|
||||
outpaint_sendto_img2img,
|
||||
outpaint_sendto_inpaint,
|
||||
)
|
||||
@@ -1,247 +0,0 @@
|
||||
import os
|
||||
import sys
|
||||
import glob
|
||||
from pathlib import Path
|
||||
import gradio as gr
|
||||
from PIL import Image
|
||||
from apps.stable_diffusion.scripts import img2img_inf
|
||||
from apps.stable_diffusion.src import args
|
||||
from apps.stable_diffusion.web.ui.utils import (
|
||||
available_devices,
|
||||
nodlogo_loc,
|
||||
)
|
||||
|
||||
|
||||
with gr.Blocks(title="Image-to-Image") as img2img_web:
|
||||
with gr.Row(elem_id="ui_title"):
|
||||
nod_logo = Image.open(nodlogo_loc)
|
||||
with gr.Row():
|
||||
with gr.Column(scale=1, elem_id="demo_title_outer"):
|
||||
gr.Image(
|
||||
value=nod_logo,
|
||||
show_label=False,
|
||||
interactive=False,
|
||||
elem_id="top_logo",
|
||||
).style(width=150, height=50)
|
||||
with gr.Row(elem_id="ui_body"):
|
||||
with gr.Row():
|
||||
with gr.Column(scale=1, min_width=600):
|
||||
with gr.Row():
|
||||
ckpt_path = (
|
||||
Path(args.ckpt_dir)
|
||||
if args.ckpt_dir
|
||||
else Path(Path.cwd(), "models")
|
||||
)
|
||||
ckpt_path.mkdir(parents=True, exist_ok=True)
|
||||
types = (
|
||||
"*.ckpt",
|
||||
"*.safetensors",
|
||||
) # the tuple of file types
|
||||
ckpt_files = ["None"]
|
||||
for extn in types:
|
||||
files = glob.glob(os.path.join(ckpt_path, extn))
|
||||
ckpt_files.extend(files)
|
||||
custom_model = gr.Dropdown(
|
||||
label=f"Models (Custom Model path: {ckpt_path})",
|
||||
value=args.ckpt_loc if args.ckpt_loc else "None",
|
||||
choices=ckpt_files
|
||||
+ [
|
||||
"Linaqruf/anything-v3.0",
|
||||
"prompthero/openjourney",
|
||||
"wavymulder/Analog-Diffusion",
|
||||
"stabilityai/stable-diffusion-2-1",
|
||||
"stabilityai/stable-diffusion-2-1-base",
|
||||
"CompVis/stable-diffusion-v1-4",
|
||||
],
|
||||
)
|
||||
hf_model_id = gr.Textbox(
|
||||
placeholder="Select 'None' in the Models dropdown on the left and enter model ID here e.g: SG161222/Realistic_Vision_V1.3",
|
||||
value="",
|
||||
label="HuggingFace Model ID",
|
||||
lines=3,
|
||||
)
|
||||
|
||||
with gr.Group(elem_id="prompt_box_outer"):
|
||||
prompt = gr.Textbox(
|
||||
label="Prompt",
|
||||
value=args.prompts[0],
|
||||
lines=1,
|
||||
elem_id="prompt_box",
|
||||
)
|
||||
negative_prompt = gr.Textbox(
|
||||
label="Negative Prompt",
|
||||
value=args.negative_prompts[0],
|
||||
lines=1,
|
||||
elem_id="negative_prompt_box",
|
||||
)
|
||||
|
||||
img2img_init_image = gr.Image(
|
||||
label="Input Image", type="pil"
|
||||
).style(height=300)
|
||||
|
||||
with gr.Accordion(label="Stencil Options", open=False):
|
||||
with gr.Row():
|
||||
use_stencil = gr.Dropdown(
|
||||
label="Stencil model",
|
||||
value="None",
|
||||
choices=["None", "canny"],
|
||||
)
|
||||
with gr.Accordion(label="Advanced Options", open=False):
|
||||
with gr.Row():
|
||||
scheduler = gr.Dropdown(
|
||||
label="Scheduler",
|
||||
value="PNDM",
|
||||
choices=[
|
||||
"DDIM",
|
||||
"PNDM",
|
||||
"DPMSolverMultistep",
|
||||
"EulerAncestralDiscrete",
|
||||
],
|
||||
)
|
||||
with gr.Group():
|
||||
save_metadata_to_png = gr.Checkbox(
|
||||
label="Save prompt information to PNG",
|
||||
value=args.write_metadata_to_png,
|
||||
interactive=True,
|
||||
)
|
||||
save_metadata_to_json = gr.Checkbox(
|
||||
label="Save prompt information to JSON file",
|
||||
value=args.save_metadata_to_json,
|
||||
interactive=True,
|
||||
)
|
||||
with gr.Row():
|
||||
height = gr.Slider(
|
||||
384, 768, value=args.height, step=8, label="Height"
|
||||
)
|
||||
width = gr.Slider(
|
||||
384, 768, value=args.width, step=8, label="Width"
|
||||
)
|
||||
precision = gr.Radio(
|
||||
label="Precision",
|
||||
value=args.precision,
|
||||
choices=[
|
||||
"fp16",
|
||||
"fp32",
|
||||
],
|
||||
visible=True,
|
||||
)
|
||||
max_length = gr.Radio(
|
||||
label="Max Length",
|
||||
value=args.max_length,
|
||||
choices=[
|
||||
64,
|
||||
77,
|
||||
],
|
||||
visible=False,
|
||||
)
|
||||
with gr.Row():
|
||||
steps = gr.Slider(
|
||||
1, 100, value=args.steps, step=1, label="Steps"
|
||||
)
|
||||
strength = gr.Slider(
|
||||
0,
|
||||
1,
|
||||
value=args.strength,
|
||||
step=0.01,
|
||||
label="Strength",
|
||||
)
|
||||
with gr.Row():
|
||||
guidance_scale = gr.Slider(
|
||||
0,
|
||||
50,
|
||||
value=args.guidance_scale,
|
||||
step=0.1,
|
||||
label="CFG Scale",
|
||||
)
|
||||
batch_count = gr.Slider(
|
||||
1,
|
||||
100,
|
||||
value=args.batch_count,
|
||||
step=1,
|
||||
label="Batch Count",
|
||||
interactive=True,
|
||||
)
|
||||
batch_size = gr.Slider(
|
||||
1,
|
||||
4,
|
||||
value=args.batch_size,
|
||||
step=1,
|
||||
label="Batch Size",
|
||||
interactive=False,
|
||||
visible=False,
|
||||
)
|
||||
with gr.Row():
|
||||
seed = gr.Number(
|
||||
value=args.seed, precision=0, label="Seed"
|
||||
)
|
||||
device = gr.Dropdown(
|
||||
label="Device",
|
||||
value=available_devices[0],
|
||||
choices=available_devices,
|
||||
)
|
||||
with gr.Row():
|
||||
random_seed = gr.Button("Randomize Seed")
|
||||
random_seed.click(
|
||||
None,
|
||||
inputs=[],
|
||||
outputs=[seed],
|
||||
_js="() => Math.floor(Math.random() * 4294967295)",
|
||||
)
|
||||
stable_diffusion = gr.Button("Generate Image(s)")
|
||||
|
||||
with gr.Column(scale=1, min_width=600):
|
||||
with gr.Group():
|
||||
img2img_gallery = gr.Gallery(
|
||||
label="Generated images",
|
||||
show_label=False,
|
||||
elem_id="gallery",
|
||||
).style(grid=[2])
|
||||
std_output = gr.Textbox(
|
||||
value="Nothing to show.",
|
||||
lines=1,
|
||||
show_label=False,
|
||||
)
|
||||
output_dir = args.output_dir if args.output_dir else Path.cwd()
|
||||
output_dir = Path(output_dir, "generated_imgs")
|
||||
output_loc = gr.Textbox(
|
||||
label="Saving Images at",
|
||||
value=output_dir,
|
||||
interactive=False,
|
||||
)
|
||||
with gr.Row():
|
||||
img2img_sendto_inpaint = gr.Button(value="SendTo Inpaint")
|
||||
img2img_sendto_outpaint = gr.Button(
|
||||
value="SendTo Outpaint"
|
||||
)
|
||||
|
||||
kwargs = dict(
|
||||
fn=img2img_inf,
|
||||
inputs=[
|
||||
prompt,
|
||||
negative_prompt,
|
||||
img2img_init_image,
|
||||
height,
|
||||
width,
|
||||
steps,
|
||||
strength,
|
||||
guidance_scale,
|
||||
seed,
|
||||
batch_count,
|
||||
batch_size,
|
||||
scheduler,
|
||||
custom_model,
|
||||
hf_model_id,
|
||||
precision,
|
||||
device,
|
||||
max_length,
|
||||
use_stencil,
|
||||
save_metadata_to_json,
|
||||
save_metadata_to_png,
|
||||
],
|
||||
outputs=[img2img_gallery, std_output],
|
||||
show_progress=args.progress_bar,
|
||||
)
|
||||
|
||||
prompt.submit(**kwargs)
|
||||
negative_prompt.submit(**kwargs)
|
||||
stable_diffusion.click(**kwargs)
|
||||
@@ -1,230 +0,0 @@
|
||||
import os
|
||||
import sys
|
||||
import glob
|
||||
from pathlib import Path
|
||||
import gradio as gr
|
||||
from PIL import Image
|
||||
from apps.stable_diffusion.scripts import inpaint_inf
|
||||
from apps.stable_diffusion.src import args
|
||||
from apps.stable_diffusion.web.ui.utils import (
|
||||
available_devices,
|
||||
nodlogo_loc,
|
||||
)
|
||||
|
||||
|
||||
with gr.Blocks(title="Inpainting") as inpaint_web:
|
||||
with gr.Row(elem_id="ui_title"):
|
||||
nod_logo = Image.open(nodlogo_loc)
|
||||
with gr.Row():
|
||||
with gr.Column(scale=1, elem_id="demo_title_outer"):
|
||||
gr.Image(
|
||||
value=nod_logo,
|
||||
show_label=False,
|
||||
interactive=False,
|
||||
elem_id="top_logo",
|
||||
).style(width=150, height=50)
|
||||
with gr.Row(elem_id="ui_body"):
|
||||
with gr.Row():
|
||||
with gr.Column(scale=1, min_width=600):
|
||||
with gr.Row():
|
||||
ckpt_path = (
|
||||
Path(args.ckpt_dir)
|
||||
if args.ckpt_dir
|
||||
else Path(Path.cwd(), "models")
|
||||
)
|
||||
ckpt_path.mkdir(parents=True, exist_ok=True)
|
||||
types = (
|
||||
"*.ckpt",
|
||||
"*.safetensors",
|
||||
) # the tuple of file types
|
||||
ckpt_files = ["None"]
|
||||
for extn in types:
|
||||
files = glob.glob(os.path.join(ckpt_path, extn))
|
||||
ckpt_files.extend(files)
|
||||
custom_model = gr.Dropdown(
|
||||
label=f"Models (Custom Model path: {ckpt_path})",
|
||||
value=args.ckpt_loc if args.ckpt_loc else "None",
|
||||
choices=ckpt_files
|
||||
+ [
|
||||
"runwayml/stable-diffusion-inpainting",
|
||||
"stabilityai/stable-diffusion-2-inpainting",
|
||||
],
|
||||
)
|
||||
hf_model_id = gr.Textbox(
|
||||
placeholder="Select 'None' in the Models dropdown on the left and enter model ID here e.g: ghunkins/stable-diffusion-liberty-inpainting",
|
||||
value="",
|
||||
label="HuggingFace Model ID",
|
||||
lines=3,
|
||||
)
|
||||
|
||||
with gr.Group(elem_id="prompt_box_outer"):
|
||||
prompt = gr.Textbox(
|
||||
label="Prompt",
|
||||
value=args.prompts[0],
|
||||
lines=1,
|
||||
elem_id="prompt_box",
|
||||
)
|
||||
negative_prompt = gr.Textbox(
|
||||
label="Negative Prompt",
|
||||
value=args.negative_prompts[0],
|
||||
lines=1,
|
||||
elem_id="negative_prompt_box",
|
||||
)
|
||||
|
||||
inpaint_init_image = gr.Image(
|
||||
label="Masked Image",
|
||||
source="upload",
|
||||
tool="sketch",
|
||||
type="pil",
|
||||
).style(height=350)
|
||||
|
||||
with gr.Accordion(label="Advanced Options", open=False):
|
||||
with gr.Row():
|
||||
scheduler = gr.Dropdown(
|
||||
label="Scheduler",
|
||||
value="PNDM",
|
||||
choices=[
|
||||
"DDIM",
|
||||
"PNDM",
|
||||
"DPMSolverMultistep",
|
||||
"EulerAncestralDiscrete",
|
||||
],
|
||||
)
|
||||
with gr.Group():
|
||||
save_metadata_to_png = gr.Checkbox(
|
||||
label="Save prompt information to PNG",
|
||||
value=args.write_metadata_to_png,
|
||||
interactive=True,
|
||||
)
|
||||
save_metadata_to_json = gr.Checkbox(
|
||||
label="Save prompt information to JSON file",
|
||||
value=args.save_metadata_to_json,
|
||||
interactive=True,
|
||||
)
|
||||
with gr.Row():
|
||||
height = gr.Slider(
|
||||
384, 768, value=args.height, step=8, label="Height"
|
||||
)
|
||||
width = gr.Slider(
|
||||
384, 768, value=args.width, step=8, label="Width"
|
||||
)
|
||||
precision = gr.Radio(
|
||||
label="Precision",
|
||||
value=args.precision,
|
||||
choices=[
|
||||
"fp16",
|
||||
"fp32",
|
||||
],
|
||||
visible=False,
|
||||
)
|
||||
max_length = gr.Radio(
|
||||
label="Max Length",
|
||||
value=args.max_length,
|
||||
choices=[
|
||||
64,
|
||||
77,
|
||||
],
|
||||
visible=False,
|
||||
)
|
||||
with gr.Row():
|
||||
steps = gr.Slider(
|
||||
1, 100, value=args.steps, step=1, label="Steps"
|
||||
)
|
||||
with gr.Row():
|
||||
guidance_scale = gr.Slider(
|
||||
0,
|
||||
50,
|
||||
value=args.guidance_scale,
|
||||
step=0.1,
|
||||
label="CFG Scale",
|
||||
)
|
||||
batch_count = gr.Slider(
|
||||
1,
|
||||
100,
|
||||
value=args.batch_count,
|
||||
step=1,
|
||||
label="Batch Count",
|
||||
interactive=True,
|
||||
)
|
||||
batch_size = gr.Slider(
|
||||
1,
|
||||
4,
|
||||
value=args.batch_size,
|
||||
step=1,
|
||||
label="Batch Size",
|
||||
interactive=False,
|
||||
visible=False,
|
||||
)
|
||||
with gr.Row():
|
||||
seed = gr.Number(
|
||||
value=args.seed, precision=0, label="Seed"
|
||||
)
|
||||
device = gr.Dropdown(
|
||||
label="Device",
|
||||
value=available_devices[0],
|
||||
choices=available_devices,
|
||||
)
|
||||
with gr.Row():
|
||||
random_seed = gr.Button("Randomize Seed")
|
||||
random_seed.click(
|
||||
None,
|
||||
inputs=[],
|
||||
outputs=[seed],
|
||||
_js="() => Math.floor(Math.random() * 4294967295)",
|
||||
)
|
||||
stable_diffusion = gr.Button("Generate Image(s)")
|
||||
|
||||
with gr.Column(scale=1, min_width=600):
|
||||
with gr.Group():
|
||||
inpaint_gallery = gr.Gallery(
|
||||
label="Generated images",
|
||||
show_label=False,
|
||||
elem_id="gallery",
|
||||
).style(grid=[2])
|
||||
std_output = gr.Textbox(
|
||||
value="Nothing to show.",
|
||||
lines=1,
|
||||
show_label=False,
|
||||
)
|
||||
output_dir = args.output_dir if args.output_dir else Path.cwd()
|
||||
output_dir = Path(output_dir, "generated_imgs")
|
||||
output_loc = gr.Textbox(
|
||||
label="Saving Images at",
|
||||
value=output_dir,
|
||||
interactive=False,
|
||||
)
|
||||
with gr.Row():
|
||||
inpaint_sendto_img2img = gr.Button(value="SendTo Img2Img")
|
||||
inpaint_sendto_outpaint = gr.Button(
|
||||
value="SendTo Outpaint"
|
||||
)
|
||||
|
||||
kwargs = dict(
|
||||
fn=inpaint_inf,
|
||||
inputs=[
|
||||
prompt,
|
||||
negative_prompt,
|
||||
inpaint_init_image,
|
||||
height,
|
||||
width,
|
||||
steps,
|
||||
guidance_scale,
|
||||
seed,
|
||||
batch_count,
|
||||
batch_size,
|
||||
scheduler,
|
||||
custom_model,
|
||||
hf_model_id,
|
||||
precision,
|
||||
device,
|
||||
max_length,
|
||||
save_metadata_to_json,
|
||||
save_metadata_to_png,
|
||||
],
|
||||
outputs=[inpaint_gallery, std_output],
|
||||
show_progress=args.progress_bar,
|
||||
)
|
||||
|
||||
prompt.submit(**kwargs)
|
||||
negative_prompt.submit(**kwargs)
|
||||
stable_diffusion.click(**kwargs)
|
||||
@@ -1,266 +0,0 @@
|
||||
import os
|
||||
import sys
|
||||
import glob
|
||||
from pathlib import Path
|
||||
import gradio as gr
|
||||
from PIL import Image
|
||||
from apps.stable_diffusion.scripts import outpaint_inf
|
||||
from apps.stable_diffusion.src import args
|
||||
from apps.stable_diffusion.web.ui.utils import (
|
||||
available_devices,
|
||||
nodlogo_loc,
|
||||
)
|
||||
|
||||
|
||||
with gr.Blocks(title="Outpainting") as outpaint_web:
|
||||
with gr.Row(elem_id="ui_title"):
|
||||
nod_logo = Image.open(nodlogo_loc)
|
||||
with gr.Row():
|
||||
with gr.Column(scale=1, elem_id="demo_title_outer"):
|
||||
gr.Image(
|
||||
value=nod_logo,
|
||||
show_label=False,
|
||||
interactive=False,
|
||||
elem_id="top_logo",
|
||||
).style(width=150, height=50)
|
||||
with gr.Row(elem_id="ui_body"):
|
||||
with gr.Row():
|
||||
with gr.Column(scale=1, min_width=600):
|
||||
with gr.Row():
|
||||
ckpt_path = (
|
||||
Path(args.ckpt_dir)
|
||||
if args.ckpt_dir
|
||||
else Path(Path.cwd(), "models")
|
||||
)
|
||||
ckpt_path.mkdir(parents=True, exist_ok=True)
|
||||
types = (
|
||||
"*.ckpt",
|
||||
"*.safetensors",
|
||||
) # the tuple of file types
|
||||
ckpt_files = ["None"]
|
||||
for extn in types:
|
||||
files = glob.glob(os.path.join(ckpt_path, extn))
|
||||
ckpt_files.extend(files)
|
||||
custom_model = gr.Dropdown(
|
||||
label=f"Models (Custom Model path: {ckpt_path})",
|
||||
value=args.ckpt_loc if args.ckpt_loc else "None",
|
||||
choices=ckpt_files
|
||||
+ [
|
||||
"runwayml/stable-diffusion-inpainting",
|
||||
"stabilityai/stable-diffusion-2-inpainting",
|
||||
],
|
||||
)
|
||||
hf_model_id = gr.Textbox(
|
||||
placeholder="Select 'None' in the Models dropdown on the left and enter model ID here e.g: ghunkins/stable-diffusion-liberty-inpainting",
|
||||
value="",
|
||||
label="HuggingFace Model ID",
|
||||
lines=3,
|
||||
)
|
||||
|
||||
with gr.Group(elem_id="prompt_box_outer"):
|
||||
prompt = gr.Textbox(
|
||||
label="Prompt",
|
||||
value=args.prompts[0],
|
||||
lines=1,
|
||||
elem_id="prompt_box",
|
||||
)
|
||||
negative_prompt = gr.Textbox(
|
||||
label="Negative Prompt",
|
||||
value=args.negative_prompts[0],
|
||||
lines=1,
|
||||
elem_id="negative_prompt_box",
|
||||
)
|
||||
|
||||
outpaint_init_image = gr.Image(
|
||||
label="Input Image", type="pil"
|
||||
).style(height=300)
|
||||
|
||||
with gr.Accordion(label="Advanced Options", open=False):
|
||||
with gr.Row():
|
||||
scheduler = gr.Dropdown(
|
||||
label="Scheduler",
|
||||
value="PNDM",
|
||||
choices=[
|
||||
"DDIM",
|
||||
"PNDM",
|
||||
"DPMSolverMultistep",
|
||||
"EulerAncestralDiscrete",
|
||||
],
|
||||
)
|
||||
with gr.Group():
|
||||
save_metadata_to_png = gr.Checkbox(
|
||||
label="Save prompt information to PNG",
|
||||
value=args.write_metadata_to_png,
|
||||
interactive=True,
|
||||
)
|
||||
save_metadata_to_json = gr.Checkbox(
|
||||
label="Save prompt information to JSON file",
|
||||
value=args.save_metadata_to_json,
|
||||
interactive=True,
|
||||
)
|
||||
with gr.Row():
|
||||
pixels = gr.Slider(
|
||||
8,
|
||||
256,
|
||||
value=args.pixels,
|
||||
step=8,
|
||||
label="Pixels to expand",
|
||||
)
|
||||
mask_blur = gr.Slider(
|
||||
0,
|
||||
64,
|
||||
value=args.mask_blur,
|
||||
step=1,
|
||||
label="Mask blur",
|
||||
)
|
||||
with gr.Row():
|
||||
directions = gr.CheckboxGroup(
|
||||
label="Outpainting direction",
|
||||
choices=["left", "right", "up", "down"],
|
||||
value=["left", "right", "up", "down"],
|
||||
)
|
||||
with gr.Row():
|
||||
noise_q = gr.Slider(
|
||||
0.0,
|
||||
4.0,
|
||||
value=1.0,
|
||||
step=0.01,
|
||||
label="Fall-off exponent (lower=higher detail)",
|
||||
)
|
||||
color_variation = gr.Slider(
|
||||
0.0,
|
||||
1.0,
|
||||
value=0.05,
|
||||
step=0.01,
|
||||
label="Color variation",
|
||||
)
|
||||
with gr.Row():
|
||||
height = gr.Slider(
|
||||
384, 768, value=args.height, step=8, label="Height"
|
||||
)
|
||||
width = gr.Slider(
|
||||
384, 768, value=args.width, step=8, label="Width"
|
||||
)
|
||||
precision = gr.Radio(
|
||||
label="Precision",
|
||||
value=args.precision,
|
||||
choices=[
|
||||
"fp16",
|
||||
"fp32",
|
||||
],
|
||||
visible=False,
|
||||
)
|
||||
max_length = gr.Radio(
|
||||
label="Max Length",
|
||||
value=args.max_length,
|
||||
choices=[
|
||||
64,
|
||||
77,
|
||||
],
|
||||
visible=False,
|
||||
)
|
||||
with gr.Row():
|
||||
steps = gr.Slider(
|
||||
1, 100, value=20, step=1, label="Steps"
|
||||
)
|
||||
with gr.Row():
|
||||
guidance_scale = gr.Slider(
|
||||
0,
|
||||
50,
|
||||
value=args.guidance_scale,
|
||||
step=0.1,
|
||||
label="CFG Scale",
|
||||
)
|
||||
batch_count = gr.Slider(
|
||||
1,
|
||||
100,
|
||||
value=args.batch_count,
|
||||
step=1,
|
||||
label="Batch Count",
|
||||
interactive=True,
|
||||
)
|
||||
batch_size = gr.Slider(
|
||||
1,
|
||||
4,
|
||||
value=args.batch_size,
|
||||
step=1,
|
||||
label="Batch Size",
|
||||
interactive=False,
|
||||
visible=False,
|
||||
)
|
||||
with gr.Row():
|
||||
seed = gr.Number(
|
||||
value=args.seed, precision=0, label="Seed"
|
||||
)
|
||||
device = gr.Dropdown(
|
||||
label="Device",
|
||||
value=available_devices[0],
|
||||
choices=available_devices,
|
||||
)
|
||||
with gr.Row():
|
||||
random_seed = gr.Button("Randomize Seed")
|
||||
random_seed.click(
|
||||
None,
|
||||
inputs=[],
|
||||
outputs=[seed],
|
||||
_js="() => Math.floor(Math.random() * 4294967295)",
|
||||
)
|
||||
stable_diffusion = gr.Button("Generate Image(s)")
|
||||
|
||||
with gr.Column(scale=1, min_width=600):
|
||||
with gr.Group():
|
||||
outpaint_gallery = gr.Gallery(
|
||||
label="Generated images",
|
||||
show_label=False,
|
||||
elem_id="gallery",
|
||||
).style(grid=[2])
|
||||
std_output = gr.Textbox(
|
||||
value="Nothing to show.",
|
||||
lines=1,
|
||||
show_label=False,
|
||||
)
|
||||
output_dir = args.output_dir if args.output_dir else Path.cwd()
|
||||
output_dir = Path(output_dir, "generated_imgs")
|
||||
output_loc = gr.Textbox(
|
||||
label="Saving Images at",
|
||||
value=output_dir,
|
||||
interactive=False,
|
||||
)
|
||||
with gr.Row():
|
||||
outpaint_sendto_img2img = gr.Button(value="SendTo Img2Img")
|
||||
outpaint_sendto_inpaint = gr.Button(value="SendTo Inpaint")
|
||||
|
||||
kwargs = dict(
|
||||
fn=outpaint_inf,
|
||||
inputs=[
|
||||
prompt,
|
||||
negative_prompt,
|
||||
outpaint_init_image,
|
||||
pixels,
|
||||
mask_blur,
|
||||
directions,
|
||||
noise_q,
|
||||
color_variation,
|
||||
height,
|
||||
width,
|
||||
steps,
|
||||
guidance_scale,
|
||||
seed,
|
||||
batch_count,
|
||||
batch_size,
|
||||
scheduler,
|
||||
custom_model,
|
||||
hf_model_id,
|
||||
precision,
|
||||
device,
|
||||
max_length,
|
||||
save_metadata_to_json,
|
||||
save_metadata_to_png,
|
||||
],
|
||||
outputs=[outpaint_gallery, std_output],
|
||||
show_progress=args.progress_bar,
|
||||
)
|
||||
|
||||
prompt.submit(**kwargs)
|
||||
negative_prompt.submit(**kwargs)
|
||||
stable_diffusion.click(**kwargs)
|
||||
@@ -1,236 +0,0 @@
|
||||
import os
|
||||
import sys
|
||||
import glob
|
||||
from pathlib import Path
|
||||
import gradio as gr
|
||||
from PIL import Image
|
||||
from apps.stable_diffusion.scripts import txt2img_inf
|
||||
from apps.stable_diffusion.src import prompt_examples, args
|
||||
from apps.stable_diffusion.web.ui.utils import (
|
||||
available_devices,
|
||||
nodlogo_loc,
|
||||
)
|
||||
|
||||
|
||||
with gr.Blocks(title="Text-to-Image") as txt2img_web:
|
||||
with gr.Row(elem_id="ui_title"):
|
||||
nod_logo = Image.open(nodlogo_loc)
|
||||
with gr.Row():
|
||||
with gr.Column(scale=1, elem_id="demo_title_outer"):
|
||||
gr.Image(
|
||||
value=nod_logo,
|
||||
show_label=False,
|
||||
interactive=False,
|
||||
elem_id="top_logo",
|
||||
).style(width=150, height=50)
|
||||
with gr.Row(elem_id="ui_body"):
|
||||
with gr.Row():
|
||||
with gr.Column(scale=1, min_width=600):
|
||||
with gr.Row():
|
||||
ckpt_path = (
|
||||
Path(args.ckpt_dir)
|
||||
if args.ckpt_dir
|
||||
else Path(Path.cwd(), "models")
|
||||
)
|
||||
ckpt_path.mkdir(parents=True, exist_ok=True)
|
||||
types = (
|
||||
"*.ckpt",
|
||||
"*.safetensors",
|
||||
) # the tuple of file types
|
||||
ckpt_files = ["None"]
|
||||
for extn in types:
|
||||
files = glob.glob(os.path.join(ckpt_path, extn))
|
||||
ckpt_files.extend(files)
|
||||
custom_model = gr.Dropdown(
|
||||
label=f"Models (Custom Model path: {ckpt_path})",
|
||||
value=args.ckpt_loc if args.ckpt_loc else "None",
|
||||
choices=ckpt_files
|
||||
+ [
|
||||
"Linaqruf/anything-v3.0",
|
||||
"prompthero/openjourney",
|
||||
"wavymulder/Analog-Diffusion",
|
||||
"stabilityai/stable-diffusion-2-1",
|
||||
"stabilityai/stable-diffusion-2-1-base",
|
||||
"CompVis/stable-diffusion-v1-4",
|
||||
],
|
||||
)
|
||||
hf_model_id = gr.Textbox(
|
||||
placeholder="Select 'None' in the Models dropdown on the left and enter model ID here e.g: SG161222/Realistic_Vision_V1.3",
|
||||
value="",
|
||||
label="HuggingFace Model ID",
|
||||
lines=3,
|
||||
)
|
||||
|
||||
with gr.Group(elem_id="prompt_box_outer"):
|
||||
prompt = gr.Textbox(
|
||||
label="Prompt",
|
||||
value=args.prompts[0],
|
||||
lines=1,
|
||||
elem_id="prompt_box",
|
||||
)
|
||||
negative_prompt = gr.Textbox(
|
||||
label="Negative Prompt",
|
||||
value=args.negative_prompts[0],
|
||||
lines=1,
|
||||
elem_id="negative_prompt_box",
|
||||
)
|
||||
with gr.Accordion(label="Advanced Options", open=False):
|
||||
with gr.Row():
|
||||
scheduler = gr.Dropdown(
|
||||
label="Scheduler",
|
||||
value=args.scheduler,
|
||||
choices=[
|
||||
"DDIM",
|
||||
"PNDM",
|
||||
"LMSDiscrete",
|
||||
"KDPM2Discrete",
|
||||
"DPMSolverMultistep",
|
||||
"EulerDiscrete",
|
||||
"EulerAncestralDiscrete",
|
||||
"SharkEulerDiscrete",
|
||||
],
|
||||
)
|
||||
with gr.Group():
|
||||
save_metadata_to_png = gr.Checkbox(
|
||||
label="Save prompt information to PNG",
|
||||
value=args.write_metadata_to_png,
|
||||
interactive=True,
|
||||
)
|
||||
save_metadata_to_json = gr.Checkbox(
|
||||
label="Save prompt information to JSON file",
|
||||
value=args.save_metadata_to_json,
|
||||
interactive=True,
|
||||
)
|
||||
with gr.Row():
|
||||
height = gr.Slider(
|
||||
384, 768, value=args.height, step=8, label="Height"
|
||||
)
|
||||
width = gr.Slider(
|
||||
384, 768, value=args.width, step=8, label="Width"
|
||||
)
|
||||
precision = gr.Radio(
|
||||
label="Precision",
|
||||
value=args.precision,
|
||||
choices=[
|
||||
"fp16",
|
||||
"fp32",
|
||||
],
|
||||
visible=False,
|
||||
)
|
||||
max_length = gr.Radio(
|
||||
label="Max Length",
|
||||
value=args.max_length,
|
||||
choices=[
|
||||
64,
|
||||
77,
|
||||
],
|
||||
visible=False,
|
||||
)
|
||||
with gr.Row():
|
||||
steps = gr.Slider(
|
||||
1, 100, value=args.steps, step=1, label="Steps"
|
||||
)
|
||||
guidance_scale = gr.Slider(
|
||||
0,
|
||||
50,
|
||||
value=args.guidance_scale,
|
||||
step=0.1,
|
||||
label="CFG Scale",
|
||||
)
|
||||
with gr.Row():
|
||||
batch_count = gr.Slider(
|
||||
1,
|
||||
100,
|
||||
value=args.batch_count,
|
||||
step=1,
|
||||
label="Batch Count",
|
||||
interactive=True,
|
||||
)
|
||||
batch_size = gr.Slider(
|
||||
1,
|
||||
4,
|
||||
value=args.batch_size,
|
||||
step=1,
|
||||
label="Batch Size",
|
||||
interactive=True,
|
||||
)
|
||||
with gr.Row():
|
||||
seed = gr.Number(
|
||||
value=args.seed, precision=0, label="Seed"
|
||||
)
|
||||
device = gr.Dropdown(
|
||||
label="Device",
|
||||
value=available_devices[0],
|
||||
choices=available_devices,
|
||||
)
|
||||
with gr.Row():
|
||||
random_seed = gr.Button("Randomize Seed")
|
||||
random_seed.click(
|
||||
None,
|
||||
inputs=[],
|
||||
outputs=[seed],
|
||||
_js="() => Math.floor(Math.random() * 4294967295)",
|
||||
)
|
||||
stable_diffusion = gr.Button("Generate Image(s)")
|
||||
with gr.Accordion(label="Prompt Examples!", open=False):
|
||||
ex = gr.Examples(
|
||||
examples=prompt_examples,
|
||||
inputs=prompt,
|
||||
cache_examples=False,
|
||||
elem_id="prompt_examples",
|
||||
)
|
||||
|
||||
with gr.Column(scale=1, min_width=600):
|
||||
with gr.Group():
|
||||
txt2img_gallery = gr.Gallery(
|
||||
label="Generated images",
|
||||
show_label=False,
|
||||
elem_id="gallery",
|
||||
).style(grid=[2])
|
||||
std_output = gr.Textbox(
|
||||
value="Nothing to show.",
|
||||
lines=1,
|
||||
show_label=False,
|
||||
)
|
||||
output_dir = args.output_dir if args.output_dir else Path.cwd()
|
||||
output_dir = Path(output_dir, "generated_imgs")
|
||||
output_loc = gr.Textbox(
|
||||
label="Saving Images at",
|
||||
value=output_dir,
|
||||
interactive=False,
|
||||
)
|
||||
with gr.Row():
|
||||
txt2img_sendto_img2img = gr.Button(value="SendTo Img2Img")
|
||||
txt2img_sendto_inpaint = gr.Button(value="SendTo Inpaint")
|
||||
txt2img_sendto_outpaint = gr.Button(
|
||||
value="SendTo Outpaint"
|
||||
)
|
||||
|
||||
kwargs = dict(
|
||||
fn=txt2img_inf,
|
||||
inputs=[
|
||||
prompt,
|
||||
negative_prompt,
|
||||
height,
|
||||
width,
|
||||
steps,
|
||||
guidance_scale,
|
||||
seed,
|
||||
batch_count,
|
||||
batch_size,
|
||||
scheduler,
|
||||
custom_model,
|
||||
hf_model_id,
|
||||
precision,
|
||||
device,
|
||||
max_length,
|
||||
save_metadata_to_json,
|
||||
save_metadata_to_png,
|
||||
],
|
||||
outputs=[txt2img_gallery, std_output],
|
||||
show_progress=args.progress_bar,
|
||||
)
|
||||
|
||||
prompt.submit(**kwargs)
|
||||
negative_prompt.submit(**kwargs)
|
||||
stable_diffusion.click(**kwargs)
|
||||
@@ -1,15 +0,0 @@
|
||||
import os
|
||||
import sys
|
||||
from apps.stable_diffusion.src import get_available_devices
|
||||
|
||||
|
||||
def resource_path(relative_path):
|
||||
"""Get absolute path to resource, works for dev and for PyInstaller"""
|
||||
base_path = getattr(
|
||||
sys, "_MEIPASS", os.path.dirname(os.path.abspath(__file__))
|
||||
)
|
||||
return os.path.join(base_path, relative_path)
|
||||
|
||||
|
||||
nodlogo_loc = resource_path("logos/nod-logo.png")
|
||||
available_devices = get_available_devices()
|
||||
@@ -1,31 +0,0 @@
|
||||
import os
|
||||
import tempfile
|
||||
import gradio
|
||||
from os import listdir
|
||||
|
||||
gradio_tmp_imgs_folder = os.path.join(os.getcwd(), "shark_tmp/")
|
||||
|
||||
|
||||
# Clear all gradio tmp images
|
||||
def clear_gradio_tmp_imgs_folder():
|
||||
if not os.path.exists(gradio_tmp_imgs_folder):
|
||||
return
|
||||
for fileName in listdir(gradio_tmp_imgs_folder):
|
||||
# Delete tmp png files
|
||||
if fileName.startswith("tmp") and fileName.endswith(".png"):
|
||||
os.remove(gradio_tmp_imgs_folder + fileName)
|
||||
|
||||
|
||||
# Overwrite save_pil_to_file from gradio to save tmp images generated by gradio into our own tmp folder
|
||||
def save_pil_to_file(pil_image, dir=None):
|
||||
if not os.path.exists(gradio_tmp_imgs_folder):
|
||||
os.mkdir(gradio_tmp_imgs_folder)
|
||||
file_obj = tempfile.NamedTemporaryFile(
|
||||
delete=False, suffix=".png", dir=gradio_tmp_imgs_folder
|
||||
)
|
||||
pil_image.save(file_obj)
|
||||
return file_obj
|
||||
|
||||
|
||||
# Register save_pil_to_file override
|
||||
gradio.processing_utils.save_pil_to_file = save_pil_to_file
|
||||
@@ -30,15 +30,9 @@ def compare_images(new_filename, golden_filename):
|
||||
diff = np.abs(new - golden)
|
||||
mean = np.mean(diff)
|
||||
if mean > 0.1:
|
||||
if os.name != "nt":
|
||||
subprocess.run(
|
||||
[
|
||||
"gsutil",
|
||||
"cp",
|
||||
new_filename,
|
||||
"gs://shark_tank/testdata/builder/",
|
||||
]
|
||||
)
|
||||
subprocess.run(
|
||||
["gsutil", "cp", new_filename, "gs://shark_tank/testdata/builder/"]
|
||||
)
|
||||
raise SystemExit("new and golden not close")
|
||||
else:
|
||||
print("SUCCESS")
|
||||
|
||||
@@ -1,16 +1,13 @@
|
||||
import os
|
||||
from sys import executable
|
||||
import subprocess
|
||||
from apps.stable_diffusion.src.utils.resources import (
|
||||
get_json_file,
|
||||
)
|
||||
from datetime import datetime as dt
|
||||
from shark.shark_downloader import download_public_file
|
||||
from image_comparison import compare_images
|
||||
import argparse
|
||||
from glob import glob
|
||||
import shutil
|
||||
import requests
|
||||
|
||||
model_config_dicts = get_json_file(
|
||||
os.path.join(
|
||||
@@ -20,179 +17,51 @@ model_config_dicts = get_json_file(
|
||||
)
|
||||
|
||||
|
||||
def parse_sd_out(filename, command, device, use_tune, model_name, import_mlir):
|
||||
with open(filename, "r+") as f:
|
||||
lines = f.readlines()
|
||||
metrics = {}
|
||||
vals_to_read = [
|
||||
"Clip Inference time",
|
||||
"Average step",
|
||||
"VAE Inference time",
|
||||
"Total image generation",
|
||||
]
|
||||
for line in lines:
|
||||
for val in vals_to_read:
|
||||
if val in line:
|
||||
metrics[val] = line.split(" ")[-1].strip("\n")
|
||||
|
||||
metrics["Average step"] = metrics["Average step"].strip("ms/it")
|
||||
metrics["Total image generation"] = metrics[
|
||||
"Total image generation"
|
||||
].strip("sec")
|
||||
metrics["device"] = device
|
||||
metrics["use_tune"] = use_tune
|
||||
metrics["model_name"] = model_name
|
||||
metrics["import_mlir"] = import_mlir
|
||||
metrics["command"] = command
|
||||
return metrics
|
||||
|
||||
|
||||
def get_inpaint_inputs():
|
||||
os.mkdir("./test_images/inputs")
|
||||
img_url = (
|
||||
"https://huggingface.co/datasets/diffusers/test-arrays/resolve"
|
||||
"/main/stable_diffusion_inpaint/input_bench_image.png"
|
||||
)
|
||||
mask_url = (
|
||||
"https://huggingface.co/datasets/diffusers/test-arrays/resolve"
|
||||
"/main/stable_diffusion_inpaint/input_bench_mask.png"
|
||||
)
|
||||
img = requests.get(img_url)
|
||||
mask = requests.get(mask_url)
|
||||
open("./test_images/inputs/image.png", "wb").write(img.content)
|
||||
open("./test_images/inputs/mask.png", "wb").write(mask.content)
|
||||
|
||||
|
||||
def test_loop(device="vulkan", beta=False, extra_flags=[]):
|
||||
# Get golden values from tank
|
||||
shutil.rmtree("./test_images", ignore_errors=True)
|
||||
model_metrics = []
|
||||
os.mkdir("./test_images")
|
||||
os.mkdir("./test_images/golden")
|
||||
get_inpaint_inputs()
|
||||
hf_model_names = model_config_dicts[0].values()
|
||||
tuned_options = ["--no-use_tuned", "--use_tuned"]
|
||||
import_options = ["--import_mlir", "--no-import_mlir"]
|
||||
prompt_text = "--prompt=cyberpunk forest by Salvador Dali"
|
||||
inpaint_prompt_text = "--prompt=Face of a yellow cat, high resolution, sitting on a park bench"
|
||||
if os.name == "nt":
|
||||
prompt_text = '--prompt="cyberpunk forest by Salvador Dali"'
|
||||
inpaint_prompt_text = '--prompt="Face of a yellow cat, high resolution, sitting on a park bench"'
|
||||
tuned_options = ["--no-use_tuned", "use_tuned"]
|
||||
if beta:
|
||||
extra_flags.append("--beta_models=True")
|
||||
extra_flags.append("--no-progress_bar")
|
||||
to_skip = [
|
||||
"Linaqruf/anything-v3.0",
|
||||
"prompthero/openjourney",
|
||||
"wavymulder/Analog-Diffusion",
|
||||
"dreamlike-art/dreamlike-diffusion-1.0",
|
||||
]
|
||||
for import_opt in import_options:
|
||||
for model_name in hf_model_names:
|
||||
if model_name in to_skip:
|
||||
continue
|
||||
for use_tune in tuned_options:
|
||||
command = (
|
||||
[
|
||||
executable, # executable is the python from the venv used to run this
|
||||
"apps/stable_diffusion/scripts/txt2img.py",
|
||||
"--device=" + device,
|
||||
prompt_text,
|
||||
"--negative_prompts=" + '""',
|
||||
"--seed=42",
|
||||
import_opt,
|
||||
"--output_dir="
|
||||
+ os.path.join(os.getcwd(), "test_images", model_name),
|
||||
"--hf_model_id=" + model_name,
|
||||
use_tune,
|
||||
]
|
||||
if "inpainting" not in model_name
|
||||
else [
|
||||
executable,
|
||||
"apps/stable_diffusion/scripts/inpaint.py",
|
||||
"--device=" + device,
|
||||
inpaint_prompt_text,
|
||||
"--negative_prompts=" + '""',
|
||||
"--img_path=./test_images/inputs/image.png",
|
||||
"--mask_path=./test_images/inputs/mask.png",
|
||||
"--seed=42",
|
||||
"--import_mlir",
|
||||
"--output_dir="
|
||||
+ os.path.join(os.getcwd(), "test_images", model_name),
|
||||
"--hf_model_id=" + model_name,
|
||||
use_tune,
|
||||
]
|
||||
)
|
||||
command += extra_flags
|
||||
if os.name == "nt":
|
||||
command = " ".join(command)
|
||||
dumpfile_name = "_".join(model_name.split("/")) + ".txt"
|
||||
dumpfile_name = os.path.join(os.getcwd(), dumpfile_name)
|
||||
with open(dumpfile_name, "w+") as f:
|
||||
generated_image = not subprocess.call(
|
||||
command,
|
||||
stdout=f,
|
||||
stderr=f,
|
||||
)
|
||||
if os.name != "nt":
|
||||
command = " ".join(command)
|
||||
if generated_image:
|
||||
model_metrics.append(
|
||||
parse_sd_out(
|
||||
dumpfile_name,
|
||||
command,
|
||||
device,
|
||||
use_tune,
|
||||
model_name,
|
||||
import_opt,
|
||||
)
|
||||
)
|
||||
print(command)
|
||||
print("Successfully generated image")
|
||||
os.makedirs(
|
||||
"./test_images/golden/" + model_name, exist_ok=True
|
||||
)
|
||||
download_public_file(
|
||||
"gs://shark_tank/testdata/golden/" + model_name,
|
||||
"./test_images/golden/" + model_name,
|
||||
)
|
||||
test_file_path = os.path.join(
|
||||
os.getcwd(),
|
||||
"test_images",
|
||||
model_name,
|
||||
"generated_imgs",
|
||||
dt.now().strftime("%Y%m%d"),
|
||||
"*.png",
|
||||
)
|
||||
test_file = glob(test_file_path)[0]
|
||||
|
||||
golden_path = (
|
||||
"./test_images/golden/" + model_name + "/*.png"
|
||||
)
|
||||
golden_file = glob(golden_path)[0]
|
||||
compare_images(test_file, golden_file)
|
||||
else:
|
||||
print(command)
|
||||
print("failed to generate image for this configuration")
|
||||
if "2_1_base" in model_name:
|
||||
print("failed a known successful model.")
|
||||
exit(1)
|
||||
with open(os.path.join(os.getcwd(), "sd_testing_metrics.csv"), "w+") as f:
|
||||
header = "model_name;device;use_tune;import_opt;Clip Inference time(ms);Average Step (ms/it);VAE Inference time(ms);total image generation(s);command\n"
|
||||
f.write(header)
|
||||
for metric in model_metrics:
|
||||
output = [
|
||||
metric["model_name"],
|
||||
metric["device"],
|
||||
metric["use_tune"],
|
||||
metric["import_mlir"],
|
||||
metric["Clip Inference time"],
|
||||
metric["Average step"],
|
||||
metric["VAE Inference time"],
|
||||
metric["Total image generation"],
|
||||
metric["command"],
|
||||
for model_name in hf_model_names:
|
||||
for use_tune in tuned_options:
|
||||
command = [
|
||||
"python",
|
||||
"apps/stable_diffusion/scripts/txt2img.py",
|
||||
"--device=" + device,
|
||||
"--prompt=cyberpunk forest by Salvador Dali",
|
||||
"--output_dir="
|
||||
+ os.path.join(os.getcwd(), "test_images", model_name),
|
||||
"--hf_model_id=" + model_name,
|
||||
use_tune,
|
||||
]
|
||||
f.write(";".join(output) + "\n")
|
||||
command += extra_flags
|
||||
generated_image = not subprocess.call(
|
||||
command, stdout=subprocess.DEVNULL
|
||||
)
|
||||
if generated_image:
|
||||
print(" ".join(command))
|
||||
print("Successfully generated image")
|
||||
os.makedirs(
|
||||
"./test_images/golden/" + model_name, exist_ok=True
|
||||
)
|
||||
download_public_file(
|
||||
"gs://shark_tank/testdata/golden/" + model_name,
|
||||
"./test_images/golden/" + model_name,
|
||||
)
|
||||
test_file_path = os.path.join(
|
||||
os.getcwd(), "test_images", model_name, "generated_imgs"
|
||||
)
|
||||
test_file = glob(test_file_path + "/*.png")[0]
|
||||
golden_path = "./test_images/golden/" + model_name + "/*.png"
|
||||
golden_file = glob(golden_path)[0]
|
||||
compare_images(test_file, golden_file)
|
||||
else:
|
||||
print(" ".join(command))
|
||||
print("failed to generate image for this configuration")
|
||||
|
||||
|
||||
parser = argparse.ArgumentParser()
|
||||
|
||||
10
conftest.py
10
conftest.py
@@ -60,13 +60,3 @@ def pytest_addoption(parser):
|
||||
default="gs://shark_tank/latest",
|
||||
help="URL to bucket from which to download SHARK tank artifacts. Default is gs://shark_tank/latest",
|
||||
)
|
||||
parser.addoption(
|
||||
"--benchmark_dispatches",
|
||||
default=None,
|
||||
help="Benchmark individual dispatch kernels produced by IREE compiler. Use 'All' for all, or specific dispatches e.g. '0 1 2 10'",
|
||||
)
|
||||
parser.addoption(
|
||||
"--dispatch_benchmarks_dir",
|
||||
default="./temp_dispatch_benchmarks",
|
||||
help="Directory in which dispatch benchmarks are saved.",
|
||||
)
|
||||
|
||||
@@ -1,118 +0,0 @@
|
||||
# Overview
|
||||
|
||||
This document is intended to provide a starting point for profiling with SHARK/IREE. At it's core
|
||||
[SHARK](https://github.com/nod-ai/SHARK/tree/main/tank) is a python API that links the MLIR lowerings from various
|
||||
frameworks + frontends (e.g. PyTorch -> Torch-MLIR) with the compiler + runtime offered by IREE. More information
|
||||
on model coverage and framework support can be found [here](https://github.com/nod-ai/SHARK/tree/main/tank). The intended
|
||||
use case for SHARK is for compilation and deployment of performant state of the art AI models.
|
||||
|
||||
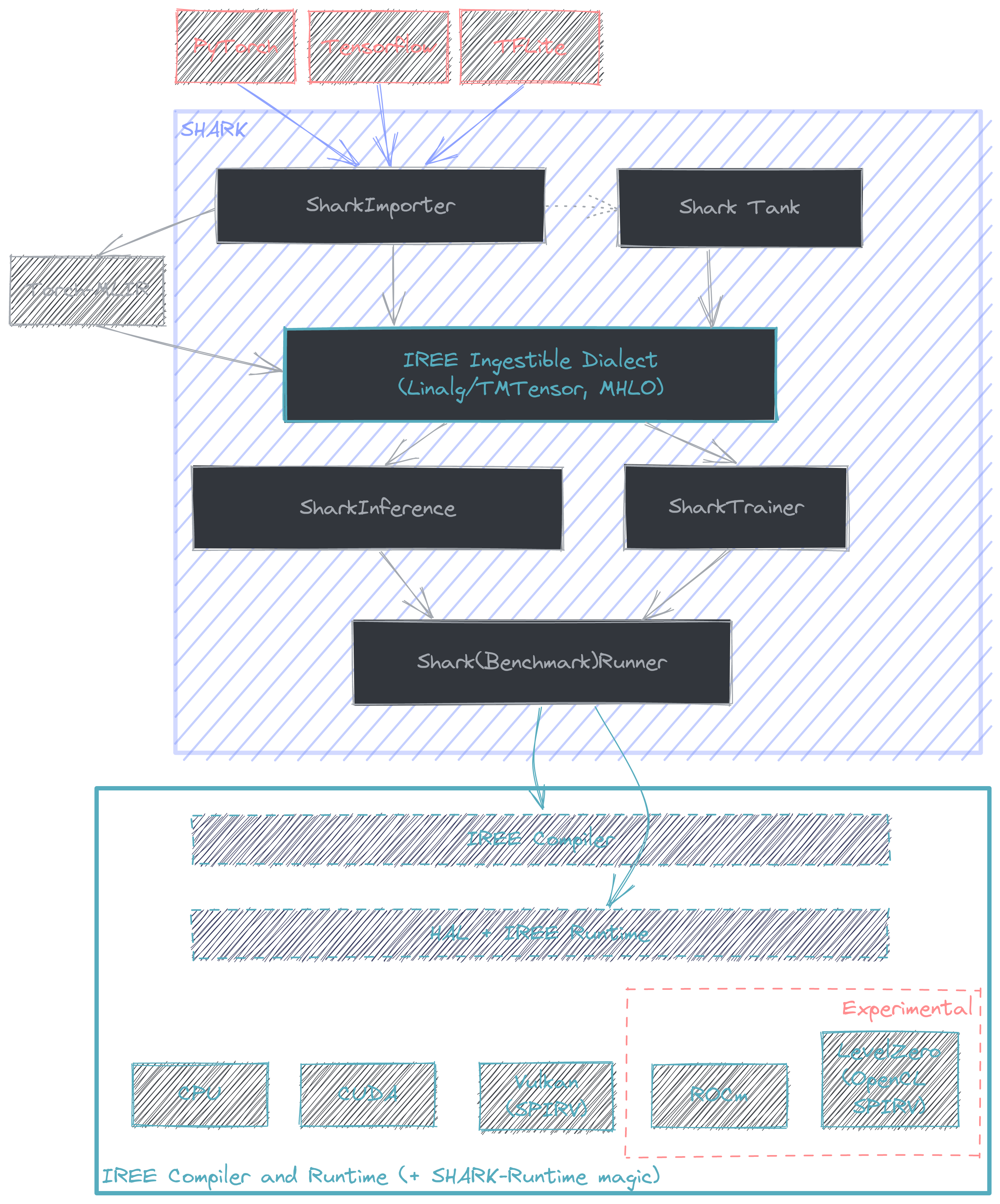
|
||||
|
||||
## Benchmarking with SHARK
|
||||
|
||||
TODO: Expand this section.
|
||||
|
||||
SHARK offers native benchmarking support, although because it is model focused, fine grain profiling is
|
||||
hidden when compared against the common "model benchmarking suite" use case SHARK is good at.
|
||||
|
||||
### SharkBenchmarkRunner
|
||||
|
||||
SharkBenchmarkRunner is a class designed for benchmarking models against other runtimes.
|
||||
TODO: List supported runtimes for comparison + example on how to benchmark with it.
|
||||
|
||||
## Directly profiling IREE
|
||||
|
||||
A number of excellent developer resources on profiling with IREE can be
|
||||
found [here](https://github.com/iree-org/iree/tree/main/docs/developers/developing_iree). As a result this section will
|
||||
focus on the bridging the gap between the two.
|
||||
- https://github.com/iree-org/iree/blob/main/docs/developers/developing_iree/profiling.md
|
||||
- https://github.com/iree-org/iree/blob/main/docs/developers/developing_iree/profiling_with_tracy.md
|
||||
- https://github.com/iree-org/iree/blob/main/docs/developers/developing_iree/profiling_vulkan_gpu.md
|
||||
- https://github.com/iree-org/iree/blob/main/docs/developers/developing_iree/profiling_cpu_events.md
|
||||
|
||||
Internally, SHARK builds a pair of IREE commands to compile + run a model. At a high level the flow starts with the
|
||||
model represented with a high level dialect (commonly Linalg) and is compiled to a flatbuffer (.vmfb) that
|
||||
the runtime is capable of ingesting. At this point (with potentially a few runtime flags) the compiled model is then run
|
||||
through the IREE runtime. This is all facilitated with the IREE python bindings, which offers a convenient method
|
||||
to capture the compile command SHARK comes up with. This is done by setting the environment variable
|
||||
`IREE_SAVE_TEMPS` to point to a directory of choice, e.g. for stable diffusion
|
||||
```
|
||||
# Linux
|
||||
$ export IREE_SAVE_TEMPS=/path/to/some/directory
|
||||
# Windows
|
||||
$ $env:IREE_SAVE_TEMPS="C:\path\to\some\directory"
|
||||
$ python apps/stable_diffusion/scripts/txt2img.py -p "a photograph of an astronaut riding a horse" --save_vmfb
|
||||
```
|
||||
NOTE: Currently this will only save the compile command + input MLIR for a single model if run in a pipeline.
|
||||
In the case of stable diffusion this (should) be UNet so to get examples for other models in the pipeline they
|
||||
need to be extracted and tested individually.
|
||||
|
||||
The save temps directory should contain three files: `core-command-line.txt`, `core-input.mlir`, and `core-output.bin`.
|
||||
The command line for compilation will start something like this, where the `-` needs to be replaced with the path to `core-input.mlir`.
|
||||
```
|
||||
/home/quinn/nod/iree-build/compiler/bindings/python/iree/compiler/tools/../_mlir_libs/iree-compile - --iree-input-type=none ...
|
||||
```
|
||||
The `-o output_filename.vmfb` flag can be used to specify the location to save the compiled vmfb. Note that a dump of the
|
||||
dispatches that can be compiled + run in isolation can be generated by adding `--iree-hal-dump-executable-benchmarks-to=/some/directory`. Say, if they are in the `benchmarks` directory, the following compile/run commands would work for Vulkan on RDNA3.
|
||||
```
|
||||
iree-compile --iree-input-type=none --iree-hal-target-backends=vulkan --iree-vulkan-target-triple=rdna3-unknown-linux --iree-stream-resource-index-bits=64 --iree-vm-target-index-bits=64 benchmarks/module_forward_dispatch_${NUM}_vulkan_spirv_fb.mlir -o benchmarks/module_forward_dispatch_${NUM}_vulkan_spirv_fb.vmfb
|
||||
|
||||
iree-benchmark-module --module=benchmarks/module_forward_dispatch_${NUM}_vulkan_spirv_fb.vmfb --function=forward --device=vulkan
|
||||
```
|
||||
Where `${NUM}` is the dispatch number that you want to benchmark/profile in isolation.
|
||||
|
||||
### Enabling Tracy for Vulkan profiling
|
||||
|
||||
To begin profiling with Tracy, a build of IREE runtime with tracing enabled is needed. SHARK-Runtime builds an
|
||||
instrumented version alongside the normal version nightly (.whls typically found [here](https://github.com/nod-ai/SHARK-Runtime/releases)), however this is only available for Linux. For Windows, tracing can be enabled by enabling a CMake flag.
|
||||
```
|
||||
$env:IREE_ENABLE_RUNTIME_TRACING="ON"
|
||||
```
|
||||
Getting a trace can then be done by setting environment variable `TRACY_NO_EXIT=1` and running the program that is to be
|
||||
traced. Then, to actually capture the trace, use the `iree-tracy-capture` tool in a different terminal. Note that to get
|
||||
the capture and profiler tools the `IREE_BUILD_TRACY=ON` CMake flag needs to be set.
|
||||
```
|
||||
TRACY_NO_EXIT=1 python apps/stable_diffusion/scripts/txt2img.py -p "a photograph of an astronaut riding a horse"
|
||||
|
||||
# (in another terminal, either on the same machine or through ssh with a tunnel through port 8086)
|
||||
iree-tracy-capture -o trace_filename.tracy
|
||||
```
|
||||
To do it over ssh, the flow looks like this
|
||||
```
|
||||
# From terminal 1 on local machine
|
||||
ssh -L 8086:localhost:8086 <remote_server_name>
|
||||
TRACY_NO_EXIT=1 python apps/stable_diffusion/scripts/txt2img.py -p "a photograph of an astronaut riding a horse"
|
||||
|
||||
# From terminal 2 on local machine. Requires having built IREE with the CMake flag `IREE_BUILD_TRACY=ON` to build the required tooling.
|
||||
iree-tracy-capture -o /path/to/trace.tracy
|
||||
```
|
||||
|
||||
The trace can then be viewed with
|
||||
```
|
||||
iree-tracy-profiler /path/to/trace.tracy
|
||||
```
|
||||
Capturing a runtime trace will work with any IREE tooling that uses the runtime. For example, `iree-benchmark-module`
|
||||
can be used for benchmarking an individual module. Importantly this means that any SHARK script can be profiled with tracy.
|
||||
|
||||
NOTE: Not all backends have the same tracy support. This writeup is focused on CPU/Vulkan backends but there is recently added support for tracing on CUDA (requires the `--cuda_tracing` flag).
|
||||
|
||||
## Experimental RGP support
|
||||
|
||||
TODO: This section is temporary until proper RGP support is added.
|
||||
|
||||
Currently, for stable diffusion there is a flag for enabling UNet to be visible to RGP with `--enable_rgp`. To get a proper capture though, the `DevModeSqttPrepareFrameCount=1` flag needs to be set for the driver (done with `VkPanel` on Windows).
|
||||
With these two settings, a single iteration of UNet can be captured.
|
||||
|
||||
(AMD only) To get a dump of the pipelines (result of compiled SPIR-V) the `EnablePipelineDump=1` driver flag can be set. The
|
||||
files will typically be dumped to a directory called `spvPipeline` (on Linux `/var/tmp/spvPipeline`. The dumped files will
|
||||
include header information that can be used to map back to the source dispatch/SPIR-V, e.g.
|
||||
```
|
||||
[Version]
|
||||
version = 57
|
||||
|
||||
[CsSpvFile]
|
||||
fileName = Shader_0x946C08DFD0C10D9A.spv
|
||||
|
||||
[CsInfo]
|
||||
entryPoint = forward_dispatch_193_matmul_256x65536x2304
|
||||
```
|
||||
@@ -162,13 +162,13 @@ def save_tf_model(tf_model_list):
|
||||
tf_model_name = tf_model_name.replace("/", "_")
|
||||
tf_model_dir = os.path.join(WORKDIR, str(tf_model_name) + "_tf")
|
||||
os.makedirs(tf_model_dir, exist_ok=True)
|
||||
|
||||
mlir_importer = SharkImporter(
|
||||
model,
|
||||
inputs=input,
|
||||
input,
|
||||
frontend="tf",
|
||||
)
|
||||
mlir_importer.import_debug(
|
||||
is_dynamic=False,
|
||||
dir=tf_model_dir,
|
||||
model_name=tf_model_name,
|
||||
)
|
||||
|
||||
@@ -1,44 +0,0 @@
|
||||
# This script will toggle the comment/uncommenting aspect for dealing
|
||||
# with __file__ AttributeError arising in case of a few modules in
|
||||
# `torch/_dynamo/skipfiles.py` (within shark.venv)
|
||||
|
||||
from distutils.sysconfig import get_python_lib
|
||||
import fileinput
|
||||
from pathlib import Path
|
||||
|
||||
# Diffusers 0.13.1 fails with transformers __init.py errros in BLIP. So remove it for now until we fork it
|
||||
pix2pix_file = Path(
|
||||
get_python_lib()
|
||||
+ "/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_pix2pix_zero.py"
|
||||
)
|
||||
if pix2pix_file.exists():
|
||||
print("Removing..%s", pix2pix_file)
|
||||
pix2pix_file.unlink()
|
||||
|
||||
|
||||
path_to_skipfiles = Path(get_python_lib() + "/torch/_dynamo/skipfiles.py")
|
||||
|
||||
modules_to_comment = ["abc,", "os,", "posixpath,", "_collections_abc,"]
|
||||
startMonitoring = 0
|
||||
for line in fileinput.input(path_to_skipfiles, inplace=True):
|
||||
if "SKIP_DIRS = " in line:
|
||||
startMonitoring = 1
|
||||
print(line, end="")
|
||||
elif startMonitoring in [1, 2]:
|
||||
if "]" in line:
|
||||
startMonitoring += 1
|
||||
print(line, end="")
|
||||
else:
|
||||
flag = True
|
||||
for module in modules_to_comment:
|
||||
if module in line:
|
||||
if not line.startswith("#"):
|
||||
print(f"#{line}", end="")
|
||||
else:
|
||||
print(f"{line[1:]}", end="")
|
||||
flag = False
|
||||
break
|
||||
if flag:
|
||||
print(line, end="")
|
||||
else:
|
||||
print(line, end="")
|
||||
@@ -1,7 +1,7 @@
|
||||
-f https://download.pytorch.org/whl/nightly/cpu/torch_nightly.html
|
||||
--pre
|
||||
|
||||
numpy>1.22.4
|
||||
numpy==1.22.4
|
||||
torchvision
|
||||
pytorch-triton
|
||||
tabulate
|
||||
@@ -15,8 +15,8 @@ iree-tools-tf
|
||||
|
||||
# TensorFlow and JAX.
|
||||
gin-config
|
||||
tf-nightly
|
||||
keras>=2.10
|
||||
tensorflow==2.10.1
|
||||
keras==2.10
|
||||
#tf-models-nightly
|
||||
#tensorflow-text-nightly
|
||||
transformers
|
||||
|
||||
@@ -16,14 +16,13 @@ parameterized
|
||||
|
||||
# Add transformers, diffusers and scipy since it most commonly used
|
||||
transformers
|
||||
diffusers @ git+https://github.com/nod-ai/diffusers@stable_stencil
|
||||
diffusers
|
||||
scipy
|
||||
ftfy
|
||||
gradio
|
||||
altair
|
||||
omegaconf
|
||||
safetensors
|
||||
opencv-python
|
||||
|
||||
# Keep PyInstaller at the end. Sometimes Windows Defender flags it but most folks can continue even if it errors
|
||||
pefile
|
||||
|
||||
@@ -1,54 +1,19 @@
|
||||
<#
|
||||
.SYNOPSIS
|
||||
A script to update and install the SHARK runtime and its dependencies.
|
||||
|
||||
.DESCRIPTION
|
||||
This script updates and installs the SHARK runtime and its dependencies.
|
||||
It checks the Python version installed and installs any required build
|
||||
dependencies into a Python virtual environment.
|
||||
If that environment does not exist, it creates it.
|
||||
|
||||
.PARAMETER update-src
|
||||
git pulls latest version
|
||||
|
||||
.PARAMETER force
|
||||
removes and recreates venv to force update of all dependencies
|
||||
|
||||
.EXAMPLE
|
||||
.\setup_venv.ps1 --force
|
||||
|
||||
.EXAMPLE
|
||||
.\setup_venv.ps1 --update-src
|
||||
|
||||
.INPUTS
|
||||
None
|
||||
|
||||
.OUTPUTS
|
||||
None
|
||||
|
||||
#>
|
||||
|
||||
param([string]$arguments)
|
||||
|
||||
if ($arguments -eq "--update-src"){
|
||||
git pull
|
||||
}
|
||||
|
||||
if ($arguments -eq "--force"){
|
||||
if (Test-Path env:VIRTUAL_ENV) {
|
||||
Write-Host "deactivating..."
|
||||
Deactivate
|
||||
}
|
||||
|
||||
if (Test-Path .\shark.venv\) {
|
||||
Write-Host "removing and recreating venv..."
|
||||
Remove-Item .\shark.venv -Force -Recurse
|
||||
if (Test-Path .\shark.venv\) {
|
||||
Write-Host 'could not remove .\shark-venv - please try running ".\setup_venv.ps1 --force" again!'
|
||||
break
|
||||
}
|
||||
}
|
||||
}
|
||||
#Write-Host "Installing python"
|
||||
|
||||
#Start-Process winget install Python.Python.3.10 '/quiet InstallAllUsers=1 PrependPath=1' -wait -NoNewWindow
|
||||
|
||||
#Write-Host "python installation completed successfully"
|
||||
|
||||
#Write-Host "Reload environment variables"
|
||||
#$env:Path = [System.Environment]::GetEnvironmentVariable("Path","Machine") + ";" + [System.Environment]::GetEnvironmentVariable("Path","User")
|
||||
#Write-Host "Reloaded environment variables"
|
||||
|
||||
|
||||
# redirect stderr into stdout
|
||||
$p = &{python -V} 2>&1
|
||||
@@ -60,36 +25,19 @@ $version = if($p -is [System.Management.Automation.ErrorRecord])
|
||||
}
|
||||
else
|
||||
{
|
||||
# otherwise return complete Python list
|
||||
$ErrorActionPreference = 'SilentlyContinue'
|
||||
$PyVer = py --list
|
||||
# otherwise return as is
|
||||
$p
|
||||
}
|
||||
|
||||
# deactivate any activated venvs
|
||||
if ($PyVer -like "*venv*")
|
||||
{
|
||||
deactivate # make sure we don't update the wrong venv
|
||||
$PyVer = py --list # update list
|
||||
}
|
||||
Write-Host "Python version found is"
|
||||
Write-Host $p
|
||||
|
||||
Write-Host "Python versions found are"
|
||||
Write-Host ($PyVer | Out-String) # formatted output with line breaks
|
||||
if (!($PyVer.length -ne 0)) {$p} # return Python --version String if py.exe is unavailable
|
||||
if (!($PyVer -like "*3.11*") -and !($p -like "*3.11*")) # if 3.11 is not in any list
|
||||
{
|
||||
Write-Host "Please install Python 3.11 and try again"
|
||||
break
|
||||
}
|
||||
|
||||
Write-Host "Installing Build Dependencies"
|
||||
# make sure we really use 3.11 from list, even if it's not the default.
|
||||
if (!($PyVer.length -ne 0)) {py -3.11 -m venv .\shark.venv\}
|
||||
else {python -m venv .\shark.venv\}
|
||||
python -m venv .\shark.venv\
|
||||
.\shark.venv\Scripts\activate
|
||||
python -m pip install --upgrade pip
|
||||
pip install wheel
|
||||
pip install -r requirements.txt
|
||||
pip install --pre torch-mlir torch --extra-index-url https://download.pytorch.org/whl/nightly/cpu -f https://llvm.github.io/torch-mlir/package-index/
|
||||
pip install --pre torch-mlir torch torchvision --extra-index-url https://download.pytorch.org/whl/nightly/cpu -f https://llvm.github.io/torch-mlir/package-index/
|
||||
pip install --upgrade -f https://nod-ai.github.io/SHARK-Runtime/pip-release-links.html iree-compiler iree-runtime
|
||||
Write-Host "Building SHARK..."
|
||||
pip install -e . -f https://llvm.github.io/torch-mlir/package-index/ -f https://nod-ai.github.io/SHARK-Runtime/pip-release-links.html
|
||||
|
||||
@@ -42,7 +42,7 @@ Green=`tput setaf 2`
|
||||
Yellow=`tput setaf 3`
|
||||
|
||||
# Assume no binary torch-mlir.
|
||||
# Currently available for macOS m1&intel (3.11) and Linux(3.8,3.10,3.11)
|
||||
# Currently available for macOS m1&intel (3.10) and Linux(3.7,3.8,3.9,3.10)
|
||||
torch_mlir_bin=false
|
||||
if [[ $(uname -s) = 'Darwin' ]]; then
|
||||
echo "${Yellow}Apple macOS detected"
|
||||
@@ -60,12 +60,12 @@ if [[ $(uname -s) = 'Darwin' ]]; then
|
||||
fi
|
||||
echo "${Yellow}Run the following commands to setup your SSL certs for your Python version if you see SSL errors with tests"
|
||||
echo "${Yellow}/Applications/Python\ 3.XX/Install\ Certificates.command"
|
||||
if [ "$PYTHON_VERSION_X_Y" == "3.11" ]; then
|
||||
if [ "$PYTHON_VERSION_X_Y" == "3.10" ]; then
|
||||
torch_mlir_bin=true
|
||||
fi
|
||||
elif [[ $(uname -s) = 'Linux' ]]; then
|
||||
echo "${Yellow}Linux detected"
|
||||
if [ "$PYTHON_VERSION_X_Y" == "3.8" ] || [ "$PYTHON_VERSION_X_Y" == "3.10" ] || [ "$PYTHON_VERSION_X_Y" == "3.11" ] ; then
|
||||
if [ "$PYTHON_VERSION_X_Y" == "3.7" ] || [ "$PYTHON_VERSION_X_Y" == "3.8" ] || [ "$PYTHON_VERSION_X_Y" == "3.9" ] || [ "$PYTHON_VERSION_X_Y" == "3.10" ] ; then
|
||||
torch_mlir_bin=true
|
||||
fi
|
||||
else
|
||||
@@ -89,7 +89,7 @@ if [ "$torch_mlir_bin" = true ]; then
|
||||
fi
|
||||
else
|
||||
echo "${Red}No binaries found for Python $PYTHON_VERSION_X_Y on $(uname -s)"
|
||||
echo "${Yello}Python 3.11 supported on macOS and 3.8,3.10 and 3.11 on Linux"
|
||||
echo "${Yello}Python 3.10 supported on macOS and 3.7,3.8,3.9 and 3.10 on Linux"
|
||||
echo "${Red}Please build torch-mlir from source in your environment"
|
||||
exit 1
|
||||
fi
|
||||
@@ -98,7 +98,7 @@ if [[ -z "${USE_IREE}" ]]; then
|
||||
RUNTIME="https://nod-ai.github.io/SHARK-Runtime/pip-release-links.html"
|
||||
else
|
||||
touch ./.use-iree
|
||||
RUNTIME="https://openxla.github.io/iree/pip-release-links.html"
|
||||
RUNTIME="https://iree-org.github.io/iree/pip-release-links.html"
|
||||
fi
|
||||
if [[ -z "${NO_BACKEND}" ]]; then
|
||||
echo "Installing ${RUNTIME}..."
|
||||
@@ -112,7 +112,7 @@ if [[ ! -z "${IMPORTER}" ]]; then
|
||||
if [[ $(uname -s) = 'Linux' ]]; then
|
||||
echo "${Yellow}Linux detected.. installing Linux importer tools"
|
||||
#Always get the importer tools from upstream IREE
|
||||
$PYTHON -m pip install --no-warn-conflicts --upgrade -r "$TD/requirements-importer.txt" -f https://openxla.github.io/iree/pip-release-links.html --extra-index-url https://download.pytorch.org/whl/nightly/cpu
|
||||
$PYTHON -m pip install --no-warn-conflicts --upgrade -r "$TD/requirements-importer.txt" -f https://iree-org.github.io/iree/pip-release-links.html --extra-index-url https://download.pytorch.org/whl/nightly/cpu
|
||||
elif [[ $(uname -s) = 'Darwin' ]]; then
|
||||
echo "${Yellow}macOS detected.. installing macOS importer tools"
|
||||
#Conda seems to have some problems installing these packages and hope they get resolved upstream.
|
||||
@@ -129,7 +129,7 @@ if [[ $(uname -s) = 'Linux' && ! -z "${BENCHMARK}" ]]; then
|
||||
TV_VERSION=${TV_VER:9:18}
|
||||
$PYTHON -m pip uninstall -y torch torchvision
|
||||
$PYTHON -m pip install -U --pre --no-warn-conflicts triton
|
||||
$PYTHON -m pip install --no-deps https://download.pytorch.org/whl/nightly/cu117/torch-${TORCH_VERSION}%2Bcu117-cp311-cp311-linux_x86_64.whl https://download.pytorch.org/whl/nightly/cu117/torchvision-${TV_VERSION}%2Bcu117-cp311-cp311-linux_x86_64.whl
|
||||
$PYTHON -m pip install --no-deps https://download.pytorch.org/whl/nightly/cu117/torch-${TORCH_VERSION}%2Bcu117-cp310-cp310-linux_x86_64.whl https://download.pytorch.org/whl/nightly/cu117/torchvision-${TV_VERSION}%2Bcu117-cp310-cp310-linux_x86_64.whl
|
||||
if [ $? -eq 0 ];then
|
||||
echo "Successfully Installed torch + cu117."
|
||||
else
|
||||
|
||||
@@ -1,698 +0,0 @@
|
||||
####################################################################################
|
||||
# Please make sure you have transformers 4.21.2 installed before running this demo
|
||||
#
|
||||
# -p --model_path: the directory in which you want to store the bloom files.
|
||||
# -dl --device_list: the list of device indices you want to use. if you want to only use the first device, or you are running on cpu leave this blank.
|
||||
# Otherwise, please give this argument in this format: "[0, 1, 2]"
|
||||
# -de --device: the device you want to run bloom on. E.G. cpu, cuda
|
||||
# -c, --recompile: set to true if you want to recompile to vmfb.
|
||||
# -d, --download: set to true if you want to redownload the mlir files
|
||||
# -t --token_count: the number of tokens you want to generate
|
||||
# -pr --prompt: the prompt you want to feed to the model
|
||||
# -m --model_namme: the name of the model, e.g. bloom-560m
|
||||
#####################################################################################
|
||||
|
||||
import os
|
||||
import io
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
from collections import OrderedDict
|
||||
import torch_mlir
|
||||
from torch_mlir import TensorPlaceholder
|
||||
import re
|
||||
from transformers.models.bloom.configuration_bloom import BloomConfig
|
||||
import json
|
||||
import sys
|
||||
import argparse
|
||||
import json
|
||||
import urllib.request
|
||||
|
||||
from torch.fx.experimental.proxy_tensor import make_fx
|
||||
from torch._decomp import get_decompositions
|
||||
from shark.shark_inference import SharkInference
|
||||
from shark.shark_downloader import download_public_file
|
||||
from transformers import (
|
||||
BloomTokenizerFast,
|
||||
BloomForSequenceClassification,
|
||||
BloomForCausalLM,
|
||||
)
|
||||
from transformers.models.bloom.modeling_bloom import (
|
||||
BloomBlock,
|
||||
build_alibi_tensor,
|
||||
)
|
||||
|
||||
IS_CUDA = False
|
||||
|
||||
|
||||
class ShardedBloom:
|
||||
def __init__(self, src_folder):
|
||||
f = open(f"{src_folder}/config.json")
|
||||
config = json.load(f)
|
||||
f.close()
|
||||
|
||||
self.layers_initialized = False
|
||||
|
||||
self.src_folder = src_folder
|
||||
try:
|
||||
self.n_embed = config["n_embed"]
|
||||
except KeyError:
|
||||
self.n_embed = config["hidden_size"]
|
||||
self.vocab_size = config["vocab_size"]
|
||||
self.n_layer = config["n_layer"]
|
||||
try:
|
||||
self.n_head = config["num_attention_heads"]
|
||||
except KeyError:
|
||||
self.n_head = config["n_head"]
|
||||
|
||||
def _init_layer(self, layer_name, device, replace, device_idx):
|
||||
if replace or not os.path.exists(
|
||||
f"{self.src_folder}/{layer_name}.vmfb"
|
||||
):
|
||||
f_ = open(f"{self.src_folder}/{layer_name}.mlir", encoding="utf-8")
|
||||
module = f_.read()
|
||||
f_.close()
|
||||
module = bytes(module, "utf-8")
|
||||
shark_module = SharkInference(
|
||||
module,
|
||||
device=device,
|
||||
mlir_dialect="tm_tensor",
|
||||
device_idx=device_idx,
|
||||
)
|
||||
shark_module.save_module(
|
||||
module_name=f"{self.src_folder}/{layer_name}",
|
||||
extra_args=[
|
||||
"--iree-vm-bytecode-module-output-format=flatbuffer-binary",
|
||||
"--iree-stream-resource-max-allocation-size=1000000000",
|
||||
"--iree-codegen-check-ir-before-llvm-conversion=false",
|
||||
],
|
||||
)
|
||||
else:
|
||||
shark_module = SharkInference(
|
||||
"",
|
||||
device=device,
|
||||
mlir_dialect="tm_tensor",
|
||||
device_idx=device_idx,
|
||||
)
|
||||
|
||||
return shark_module
|
||||
|
||||
def init_layers(self, device, replace=False, device_idx=[0]):
|
||||
if device_idx is not None:
|
||||
n_devices = len(device_idx)
|
||||
|
||||
self.word_embeddings_module = self._init_layer(
|
||||
"word_embeddings",
|
||||
device,
|
||||
replace,
|
||||
device_idx if device_idx is None else device_idx[0 % n_devices],
|
||||
)
|
||||
self.word_embeddings_layernorm_module = self._init_layer(
|
||||
"word_embeddings_layernorm",
|
||||
device,
|
||||
replace,
|
||||
device_idx if device_idx is None else device_idx[1 % n_devices],
|
||||
)
|
||||
self.ln_f_module = self._init_layer(
|
||||
"ln_f",
|
||||
device,
|
||||
replace,
|
||||
device_idx if device_idx is None else device_idx[2 % n_devices],
|
||||
)
|
||||
self.lm_head_module = self._init_layer(
|
||||
"lm_head",
|
||||
device,
|
||||
replace,
|
||||
device_idx if device_idx is None else device_idx[3 % n_devices],
|
||||
)
|
||||
self.block_modules = [
|
||||
self._init_layer(
|
||||
f"bloom_block_{i}",
|
||||
device,
|
||||
replace,
|
||||
device_idx
|
||||
if device_idx is None
|
||||
else device_idx[(i + 4) % n_devices],
|
||||
)
|
||||
for i in range(self.n_layer)
|
||||
]
|
||||
|
||||
self.layers_initialized = True
|
||||
|
||||
def load_layers(self):
|
||||
assert self.layers_initialized
|
||||
|
||||
self.word_embeddings_module.load_module(
|
||||
f"{self.src_folder}/word_embeddings.vmfb"
|
||||
)
|
||||
self.word_embeddings_layernorm_module.load_module(
|
||||
f"{self.src_folder}/word_embeddings_layernorm.vmfb"
|
||||
)
|
||||
for block_module, i in zip(self.block_modules, range(self.n_layer)):
|
||||
block_module.load_module(f"{self.src_folder}/bloom_block_{i}.vmfb")
|
||||
self.ln_f_module.load_module(f"{self.src_folder}/ln_f.vmfb")
|
||||
self.lm_head_module.load_module(f"{self.src_folder}/lm_head.vmfb")
|
||||
|
||||
def forward_pass(self, input_ids, device):
|
||||
if IS_CUDA:
|
||||
cudaSetDevice(self.word_embeddings_module.device_idx)
|
||||
|
||||
input_embeds = self.word_embeddings_module(
|
||||
inputs=(input_ids,), function_name="forward"
|
||||
)
|
||||
|
||||
input_embeds = torch.tensor(input_embeds).float()
|
||||
if IS_CUDA:
|
||||
cudaSetDevice(self.word_embeddings_layernorm_module.device_idx)
|
||||
hidden_states = self.word_embeddings_layernorm_module(
|
||||
inputs=(input_embeds,), function_name="forward"
|
||||
)
|
||||
|
||||
hidden_states = torch.tensor(hidden_states).float()
|
||||
|
||||
attention_mask = torch.ones(
|
||||
[hidden_states.shape[0], len(input_ids[0])]
|
||||
)
|
||||
alibi = build_alibi_tensor(
|
||||
attention_mask,
|
||||
self.n_head,
|
||||
hidden_states.dtype,
|
||||
hidden_states.device,
|
||||
)
|
||||
|
||||
causal_mask = _prepare_attn_mask(
|
||||
attention_mask, input_ids.size(), input_embeds, 0
|
||||
)
|
||||
causal_mask = torch.tensor(causal_mask).float()
|
||||
|
||||
presents = ()
|
||||
all_hidden_states = tuple(hidden_states)
|
||||
|
||||
for block_module, i in zip(self.block_modules, range(self.n_layer)):
|
||||
if IS_CUDA:
|
||||
cudaSetDevice(block_module.device_idx)
|
||||
|
||||
output = block_module(
|
||||
inputs=(
|
||||
hidden_states.detach().numpy(),
|
||||
alibi.detach().numpy(),
|
||||
causal_mask.detach().numpy(),
|
||||
),
|
||||
function_name="forward",
|
||||
)
|
||||
hidden_states = torch.tensor(output[0]).float()
|
||||
all_hidden_states = all_hidden_states + (hidden_states,)
|
||||
presents = presents + (
|
||||
tuple(
|
||||
(
|
||||
output[1],
|
||||
output[2],
|
||||
)
|
||||
),
|
||||
)
|
||||
if IS_CUDA:
|
||||
cudaSetDevice(self.ln_f_module.device_idx)
|
||||
|
||||
hidden_states = self.ln_f_module(
|
||||
inputs=(hidden_states,), function_name="forward"
|
||||
)
|
||||
if IS_CUDA:
|
||||
cudaSetDevice(self.lm_head_module.device_idx)
|
||||
|
||||
logits = self.lm_head_module(
|
||||
inputs=(hidden_states,), function_name="forward"
|
||||
)
|
||||
logits = torch.tensor(logits).float()
|
||||
|
||||
return torch.argmax(logits[:, -1, :], dim=-1)
|
||||
|
||||
|
||||
def _make_causal_mask(
|
||||
input_ids_shape: torch.Size,
|
||||
dtype: torch.dtype,
|
||||
past_key_values_length: int = 0,
|
||||
):
|
||||
"""
|
||||
Make causal mask used for bi-directional self-attention.
|
||||
"""
|
||||
batch_size, target_length = input_ids_shape
|
||||
mask = torch.full((target_length, target_length), torch.finfo(dtype).min)
|
||||
mask_cond = torch.arange(mask.size(-1))
|
||||
intermediate_mask = mask_cond < (mask_cond + 1).view(mask.size(-1), 1)
|
||||
mask.masked_fill_(intermediate_mask, 0)
|
||||
mask = mask.to(dtype)
|
||||
|
||||
if past_key_values_length > 0:
|
||||
mask = torch.cat(
|
||||
[
|
||||
torch.zeros(
|
||||
target_length, past_key_values_length, dtype=dtype
|
||||
),
|
||||
mask,
|
||||
],
|
||||
dim=-1,
|
||||
)
|
||||
expanded_mask = mask[None, None, :, :].expand(
|
||||
batch_size, 1, target_length, target_length + past_key_values_length
|
||||
)
|
||||
return expanded_mask
|
||||
|
||||
|
||||
def _expand_mask(mask: torch.Tensor, dtype: torch.dtype, tgt_len: int = None):
|
||||
"""
|
||||
Expands attention_mask from `[bsz, seq_len]` to `[bsz, 1, tgt_seq_len, src_seq_len]`.
|
||||
"""
|
||||
batch_size, source_length = mask.size()
|
||||
tgt_len = tgt_len if tgt_len is not None else source_length
|
||||
|
||||
expanded_mask = (
|
||||
mask[:, None, None, :]
|
||||
.expand(batch_size, 1, tgt_len, source_length)
|
||||
.to(dtype)
|
||||
)
|
||||
|
||||
inverted_mask = 1.0 - expanded_mask
|
||||
|
||||
return inverted_mask.masked_fill(
|
||||
inverted_mask.to(torch.bool), torch.finfo(dtype).min
|
||||
)
|
||||
|
||||
|
||||
def _prepare_attn_mask(
|
||||
attention_mask, input_shape, inputs_embeds, past_key_values_length
|
||||
):
|
||||
# create causal mask
|
||||
# [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
|
||||
combined_attention_mask = None
|
||||
if input_shape[-1] > 1:
|
||||
combined_attention_mask = _make_causal_mask(
|
||||
input_shape,
|
||||
inputs_embeds.dtype,
|
||||
past_key_values_length=past_key_values_length,
|
||||
).to(attention_mask.device)
|
||||
|
||||
if attention_mask is not None:
|
||||
# [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
|
||||
expanded_attn_mask = _expand_mask(
|
||||
attention_mask, inputs_embeds.dtype, tgt_len=input_shape[-1]
|
||||
)
|
||||
combined_attention_mask = (
|
||||
expanded_attn_mask
|
||||
if combined_attention_mask is None
|
||||
else expanded_attn_mask + combined_attention_mask
|
||||
)
|
||||
|
||||
return combined_attention_mask
|
||||
|
||||
|
||||
def download_model(destination_folder, model_name):
|
||||
download_public_file(
|
||||
f"https://{model_name}/config.json", destination_folder
|
||||
)
|
||||
f = open(f"{destination_folder}/config.json")
|
||||
config = json.load(f)
|
||||
f.close()
|
||||
n_blocks = config["n_layer"]
|
||||
download_public_file(
|
||||
f"https://{model_name}/lm_head.mlir", destination_folder
|
||||
)
|
||||
download_public_file(f"https://{model_name}/ln_f.mlir", destination_folder)
|
||||
download_public_file(
|
||||
f"https://{model_name}/word_embeddings.mlir", destination_folder
|
||||
)
|
||||
download_public_file(
|
||||
f"https://{model_name}/word_embeddings_layernorm.mlir",
|
||||
destination_folder,
|
||||
)
|
||||
download_public_file(
|
||||
f"https://{model_name}/tokenizer.json", destination_folder
|
||||
)
|
||||
|
||||
for i in range(n_blocks):
|
||||
download_public_file(
|
||||
f"https://{model_name}/bloom_block_{i}.mlir", destination_folder
|
||||
)
|
||||
|
||||
|
||||
def compile_embeddings(embeddings_layer, input_ids, path):
|
||||
input_ids_placeholder = torch_mlir.TensorPlaceholder.like(
|
||||
input_ids, dynamic_axes=[1]
|
||||
)
|
||||
module = torch_mlir.compile(
|
||||
embeddings_layer,
|
||||
(input_ids_placeholder),
|
||||
torch_mlir.OutputType.LINALG_ON_TENSORS,
|
||||
use_tracing=False,
|
||||
verbose=False,
|
||||
)
|
||||
|
||||
bytecode_stream = io.BytesIO()
|
||||
module.operation.write_bytecode(bytecode_stream)
|
||||
bytecode = bytecode_stream.getvalue()
|
||||
|
||||
f_ = open(path, "w+")
|
||||
f_.write(str(module))
|
||||
f_.close()
|
||||
return
|
||||
|
||||
|
||||
def compile_word_embeddings_layernorm(
|
||||
embeddings_layer_layernorm, embeds, path
|
||||
):
|
||||
embeds_placeholder = torch_mlir.TensorPlaceholder.like(
|
||||
embeds, dynamic_axes=[1]
|
||||
)
|
||||
module = torch_mlir.compile(
|
||||
embeddings_layer_layernorm,
|
||||
(embeds_placeholder),
|
||||
torch_mlir.OutputType.LINALG_ON_TENSORS,
|
||||
use_tracing=False,
|
||||
verbose=False,
|
||||
)
|
||||
|
||||
bytecode_stream = io.BytesIO()
|
||||
module.operation.write_bytecode(bytecode_stream)
|
||||
bytecode = bytecode_stream.getvalue()
|
||||
|
||||
f_ = open(path, "w+")
|
||||
f_.write(str(module))
|
||||
f_.close()
|
||||
return
|
||||
|
||||
|
||||
def strip_overloads(gm):
|
||||
"""
|
||||
Modifies the target of graph nodes in :attr:`gm` to strip overloads.
|
||||
Args:
|
||||
gm(fx.GraphModule): The input Fx graph module to be modified
|
||||
"""
|
||||
for node in gm.graph.nodes:
|
||||
if isinstance(node.target, torch._ops.OpOverload):
|
||||
node.target = node.target.overloadpacket
|
||||
gm.recompile()
|
||||
|
||||
|
||||
def compile_to_mlir(
|
||||
bblock,
|
||||
hidden_states,
|
||||
layer_past=None,
|
||||
attention_mask=None,
|
||||
head_mask=None,
|
||||
use_cache=None,
|
||||
output_attentions=False,
|
||||
alibi=None,
|
||||
block_index=0,
|
||||
path=".",
|
||||
):
|
||||
fx_g = make_fx(
|
||||
bblock,
|
||||
decomposition_table=get_decompositions(
|
||||
[
|
||||
torch.ops.aten.split.Tensor,
|
||||
torch.ops.aten.split_with_sizes,
|
||||
]
|
||||
),
|
||||
tracing_mode="real",
|
||||
_allow_non_fake_inputs=False,
|
||||
)(hidden_states, alibi, attention_mask)
|
||||
|
||||
fx_g.graph.set_codegen(torch.fx.graph.CodeGen())
|
||||
fx_g.recompile()
|
||||
|
||||
strip_overloads(fx_g)
|
||||
|
||||
hidden_states_placeholder = TensorPlaceholder.like(
|
||||
hidden_states, dynamic_axes=[1]
|
||||
)
|
||||
attention_mask_placeholder = TensorPlaceholder.like(
|
||||
attention_mask, dynamic_axes=[2, 3]
|
||||
)
|
||||
alibi_placeholder = TensorPlaceholder.like(alibi, dynamic_axes=[2])
|
||||
|
||||
ts_g = torch.jit.script(fx_g)
|
||||
|
||||
module = torch_mlir.compile(
|
||||
ts_g,
|
||||
(
|
||||
hidden_states_placeholder,
|
||||
alibi_placeholder,
|
||||
attention_mask_placeholder,
|
||||
),
|
||||
torch_mlir.OutputType.LINALG_ON_TENSORS,
|
||||
use_tracing=False,
|
||||
verbose=False,
|
||||
)
|
||||
|
||||
module_placeholder = module
|
||||
module_context = module_placeholder.context
|
||||
|
||||
def check_valid_line(line, line_n, mlir_file_len):
|
||||
if "private" in line:
|
||||
return False
|
||||
if "attributes" in line:
|
||||
return False
|
||||
if mlir_file_len - line_n == 2:
|
||||
return False
|
||||
|
||||
return True
|
||||
|
||||
mlir_file_len = len(str(module).split("\n"))
|
||||
|
||||
def remove_constant_dim(line):
|
||||
if "17x" in line:
|
||||
line = re.sub("17x", "?x", line)
|
||||
line = re.sub("tensor.empty\(\)", "tensor.empty(%dim)", line)
|
||||
if "tensor.empty" in line and "?x?" in line:
|
||||
line = re.sub(
|
||||
"tensor.empty\(%dim\)", "tensor.empty(%dim, %dim)", line
|
||||
)
|
||||
if "arith.cmpi eq" in line:
|
||||
line = re.sub("c17", "dim", line)
|
||||
if " 17," in line:
|
||||
line = re.sub(" 17,", " %dim,", line)
|
||||
return line
|
||||
|
||||
module = "\n".join(
|
||||
[
|
||||
remove_constant_dim(line)
|
||||
for line, line_n in zip(
|
||||
str(module).split("\n"), range(mlir_file_len)
|
||||
)
|
||||
if check_valid_line(line, line_n, mlir_file_len)
|
||||
]
|
||||
)
|
||||
|
||||
module = module_placeholder.parse(module, context=module_context)
|
||||
bytecode_stream = io.BytesIO()
|
||||
module.operation.write_bytecode(bytecode_stream)
|
||||
bytecode = bytecode_stream.getvalue()
|
||||
|
||||
f_ = open(path, "w+")
|
||||
f_.write(str(module))
|
||||
f_.close()
|
||||
return
|
||||
|
||||
|
||||
def compile_ln_f(ln_f, hidden_layers, path):
|
||||
hidden_layers_placeholder = torch_mlir.TensorPlaceholder.like(
|
||||
hidden_layers, dynamic_axes=[1]
|
||||
)
|
||||
module = torch_mlir.compile(
|
||||
ln_f,
|
||||
(hidden_layers_placeholder),
|
||||
torch_mlir.OutputType.LINALG_ON_TENSORS,
|
||||
use_tracing=False,
|
||||
verbose=False,
|
||||
)
|
||||
|
||||
bytecode_stream = io.BytesIO()
|
||||
module.operation.write_bytecode(bytecode_stream)
|
||||
bytecode = bytecode_stream.getvalue()
|
||||
|
||||
f_ = open(path, "w+")
|
||||
f_.write(str(module))
|
||||
f_.close()
|
||||
return
|
||||
|
||||
|
||||
def compile_lm_head(lm_head, hidden_layers, path):
|
||||
hidden_layers_placeholder = torch_mlir.TensorPlaceholder.like(
|
||||
hidden_layers, dynamic_axes=[1]
|
||||
)
|
||||
module = torch_mlir.compile(
|
||||
lm_head,
|
||||
(hidden_layers_placeholder),
|
||||
torch_mlir.OutputType.LINALG_ON_TENSORS,
|
||||
use_tracing=False,
|
||||
verbose=False,
|
||||
)
|
||||
|
||||
bytecode_stream = io.BytesIO()
|
||||
module.operation.write_bytecode(bytecode_stream)
|
||||
bytecode = bytecode_stream.getvalue()
|
||||
|
||||
f_ = open(path, "w+")
|
||||
f_.write(str(module))
|
||||
f_.close()
|
||||
return
|
||||
|
||||
|
||||
def create_mlirs(destination_folder, model_name):
|
||||
model_config = "bigscience/" + model_name
|
||||
sample_input_ids = torch.ones([1, 17], dtype=torch.int64)
|
||||
|
||||
urllib.request.urlretrieve(
|
||||
f"https://huggingface.co/bigscience/{model_name}/resolve/main/config.json",
|
||||
filename=f"{destination_folder}/config.json",
|
||||
)
|
||||
urllib.request.urlretrieve(
|
||||
f"https://huggingface.co/bigscience/bloom/resolve/main/tokenizer.json",
|
||||
filename=f"{destination_folder}/tokenizer.json",
|
||||
)
|
||||
|
||||
class HuggingFaceLanguage(torch.nn.Module):
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
self.model = BloomForCausalLM.from_pretrained(model_config)
|
||||
|
||||
def forward(self, tokens):
|
||||
return self.model.forward(tokens)[0]
|
||||
|
||||
class HuggingFaceBlock(torch.nn.Module):
|
||||
def __init__(self, block):
|
||||
super().__init__()
|
||||
self.model = block
|
||||
|
||||
def forward(self, tokens, alibi, attention_mask):
|
||||
output = self.model(
|
||||
hidden_states=tokens,
|
||||
alibi=alibi,
|
||||
attention_mask=attention_mask,
|
||||
use_cache=True,
|
||||
output_attentions=False,
|
||||
)
|
||||
return (output[0], output[1][0], output[1][1])
|
||||
|
||||
model = HuggingFaceLanguage()
|
||||
|
||||
compile_embeddings(
|
||||
model.model.transformer.word_embeddings,
|
||||
sample_input_ids,
|
||||
f"{destination_folder}/word_embeddings.mlir",
|
||||
)
|
||||
|
||||
inputs_embeds = model.model.transformer.word_embeddings(sample_input_ids)
|
||||
|
||||
compile_word_embeddings_layernorm(
|
||||
model.model.transformer.word_embeddings_layernorm,
|
||||
inputs_embeds,
|
||||
f"{destination_folder}/word_embeddings_layernorm.mlir",
|
||||
)
|
||||
|
||||
hidden_states = model.model.transformer.word_embeddings_layernorm(
|
||||
inputs_embeds
|
||||
)
|
||||
|
||||
input_shape = sample_input_ids.size()
|
||||
|
||||
current_sequence_length = hidden_states.shape[1]
|
||||
past_key_values_length = 0
|
||||
past_key_values = tuple([None] * len(model.model.transformer.h))
|
||||
|
||||
attention_mask = torch.ones(
|
||||
(hidden_states.shape[0], current_sequence_length), device="cpu"
|
||||
)
|
||||
|
||||
alibi = build_alibi_tensor(
|
||||
attention_mask,
|
||||
model.model.transformer.n_head,
|
||||
hidden_states.dtype,
|
||||
"cpu",
|
||||
)
|
||||
|
||||
causal_mask = _prepare_attn_mask(
|
||||
attention_mask, input_shape, inputs_embeds, past_key_values_length
|
||||
)
|
||||
|
||||
head_mask = model.model.transformer.get_head_mask(
|
||||
None, model.model.transformer.config.n_layer
|
||||
)
|
||||
output_attentions = model.model.transformer.config.output_attentions
|
||||
|
||||
all_hidden_states = ()
|
||||
|
||||
for i, (block, layer_past) in enumerate(
|
||||
zip(model.model.transformer.h, past_key_values)
|
||||
):
|
||||
all_hidden_states = all_hidden_states + (hidden_states,)
|
||||
|
||||
proxy_model = HuggingFaceBlock(block)
|
||||
|
||||
compile_to_mlir(
|
||||
proxy_model,
|
||||
hidden_states,
|
||||
layer_past=layer_past,
|
||||
attention_mask=causal_mask,
|
||||
head_mask=head_mask[i],
|
||||
use_cache=True,
|
||||
output_attentions=output_attentions,
|
||||
alibi=alibi,
|
||||
block_index=i,
|
||||
path=f"{destination_folder}/bloom_block_{i}.mlir",
|
||||
)
|
||||
|
||||
compile_ln_f(
|
||||
model.model.transformer.ln_f,
|
||||
hidden_states,
|
||||
f"{destination_folder}/ln_f.mlir",
|
||||
)
|
||||
hidden_states = model.model.transformer.ln_f(hidden_states)
|
||||
compile_lm_head(
|
||||
model.model.lm_head,
|
||||
hidden_states,
|
||||
f"{destination_folder}/lm_head.mlir",
|
||||
)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = argparse.ArgumentParser(prog="Bloom-560m")
|
||||
parser.add_argument("-p", "--model_path")
|
||||
parser.add_argument("-dl", "--device_list", default=None)
|
||||
parser.add_argument("-de", "--device", default="cpu")
|
||||
parser.add_argument("-c", "--recompile", default=False, type=bool)
|
||||
parser.add_argument("-d", "--download", default=False, type=bool)
|
||||
parser.add_argument("-t", "--token_count", default=10, type=int)
|
||||
parser.add_argument("-m", "--model_name", default="bloom-560m")
|
||||
parser.add_argument(
|
||||
"-pr",
|
||||
"--prompt",
|
||||
default="The SQL command to extract all the users whose name starts with A is: ",
|
||||
)
|
||||
args = parser.parse_args()
|
||||
|
||||
if args.device_list is not None:
|
||||
args.device_list = json.loads(args.device_list)
|
||||
|
||||
if args.device == "cuda" and args.device_list is not None:
|
||||
IS_CUDA = True
|
||||
from cuda.cudart import cudaSetDevice
|
||||
if args.download:
|
||||
# download_model(args.model_path, args.model_name)
|
||||
create_mlirs(args.model_path, args.model_name)
|
||||
from transformers import AutoTokenizer, AutoModelForCausalLM, BloomConfig
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained(args.model_path)
|
||||
input_ids = tokenizer.encode(args.prompt, return_tensors="pt")
|
||||
|
||||
shardedbloom = ShardedBloom(args.model_path)
|
||||
shardedbloom.init_layers(
|
||||
device=args.device, replace=args.recompile, device_idx=args.device_list
|
||||
)
|
||||
shardedbloom.load_layers()
|
||||
|
||||
for _ in range(args.token_count):
|
||||
next_token = shardedbloom.forward_pass(
|
||||
torch.tensor(input_ids), device=args.device
|
||||
)
|
||||
input_ids = torch.cat([input_ids, next_token.unsqueeze(-1)], dim=-1)
|
||||
|
||||
print(tokenizer.decode(input_ids.squeeze()))
|
||||
@@ -139,14 +139,9 @@ def run_benchmark_module(benchmark_cl):
|
||||
benchmark_path
|
||||
), "Cannot find benchmark_module, Please contact SHARK maintainer on discord."
|
||||
bench_result = run_cmd(" ".join(benchmark_cl))
|
||||
try:
|
||||
regex_split = re.compile("(\d+[.]*\d*)( *)([a-zA-Z]+)")
|
||||
match = regex_split.search(bench_result)
|
||||
time = float(match.group(1))
|
||||
unit = match.group(3)
|
||||
except AttributeError:
|
||||
regex_split = re.compile("(\d+[.]*\d*)([a-zA-Z]+)")
|
||||
match = regex_split.search(bench_result)
|
||||
time = float(match.group(1))
|
||||
unit = match.group(2)
|
||||
print(bench_result)
|
||||
regex_split = re.compile("(\d+[.]*\d*)( *)([a-zA-Z]+)")
|
||||
match = regex_split.search(bench_result)
|
||||
time = float(match.group(1))
|
||||
unit = match.group(3)
|
||||
return 1.0 / (time * 0.001)
|
||||
|
||||
@@ -70,6 +70,7 @@ def get_iree_common_args():
|
||||
return [
|
||||
"--iree-stream-resource-index-bits=64",
|
||||
"--iree-vm-target-index-bits=64",
|
||||
"--iree-vm-bytecode-module-strip-source-map=true",
|
||||
"--iree-util-zero-fill-elided-attrs",
|
||||
]
|
||||
|
||||
|
||||
@@ -22,7 +22,7 @@ from shark.parser import shark_args
|
||||
# Get the default gpu args given the architecture.
|
||||
def get_iree_gpu_args():
|
||||
ireert.flags.FUNCTION_INPUT_VALIDATION = False
|
||||
ireert.flags.parse_flags("--cuda_allow_inline_execution")
|
||||
ireert.flags.parse_flags("--cuda_allow_inline_execution", "--device_allocator=caching")
|
||||
# TODO: Give the user_interface to pass the sm_arch.
|
||||
sm_arch = get_cuda_sm_cc()
|
||||
if (
|
||||
|
||||
@@ -139,9 +139,8 @@ def get_vulkan_triple_flag(device_name="", extra_args=[]):
|
||||
|
||||
|
||||
def get_iree_vulkan_args(extra_args=[]):
|
||||
# vulkan_flag = ["--iree-flow-demote-i64-to-i32"]
|
||||
res_vulkan_flag = ["--device_allocator=caching"]
|
||||
|
||||
res_vulkan_flag = []
|
||||
vulkan_triple_flag = None
|
||||
for arg in extra_args:
|
||||
if "-iree-vulkan-target-triple=" in arg:
|
||||
|
||||
@@ -118,11 +118,10 @@ class SharkBenchmarkRunner(SharkRunner):
|
||||
)
|
||||
HFmodel, input = get_torch_model(modelname)[:2]
|
||||
frontend_model = HFmodel.model
|
||||
# frontend_model = dynamo.optimize("inductor")(frontend_model)
|
||||
frontend_model.to(torch_device)
|
||||
input.to(torch_device)
|
||||
|
||||
# frontend_model = torch.compile(frontend_model, mode="max-autotune", backend="inductor")
|
||||
|
||||
for i in range(shark_args.num_warmup_iterations):
|
||||
frontend_model.forward(input)
|
||||
|
||||
|
||||
@@ -99,7 +99,6 @@ else:
|
||||
print(
|
||||
f"shark_tank local cache is located at {WORKDIR} . You may change this by setting the --local_tank_cache= flag"
|
||||
)
|
||||
os.makedirs(WORKDIR, exist_ok=True)
|
||||
|
||||
|
||||
# Checks whether the directory and files exists.
|
||||
|
||||
@@ -1,8 +1,8 @@
|
||||
resnet50,mhlo,tf,1e-2,1e-3,default,nhcw-nhwc,False,False,False,"","macos"
|
||||
albert-base-v2,mhlo,tf,1e-2,1e-2,default,None,False,False,False,"",""
|
||||
roberta-base,mhlo,tf,1e-02,1e-3,default,nhcw-nhwc,True,True,True,"","macos"
|
||||
bert-base-uncased,mhlo,tf,1e-2,1e-3,default,None,False,False,False,"","enabled_windows"
|
||||
camembert-base,mhlo,tf,1e-2,1e-3,default,None,True,True,True,"",""
|
||||
roberta-base,mhlo,tf,1e-02,1e-3,default,nhcw-nhwc,False,False,False,"","macos"
|
||||
bert-base-uncased,mhlo,tf,1e-2,1e-3,default,None,False,False,False,"",""
|
||||
camembert-base,mhlo,tf,1e-2,1e-3,default,None,False,False,False,"",""
|
||||
dbmdz/convbert-base-turkish-cased,mhlo,tf,1e-2,1e-3,default,nhcw-nhwc,True,True,False,"https://github.com/iree-org/iree/issues/9971",""
|
||||
distilbert-base-uncased,mhlo,tf,1e-2,1e-3,default,None,False,False,False,"",""
|
||||
facebook/convnext-tiny-224,mhlo,tf,1e-2,1e-3,tf_vit,nhcw-nhwc,True,True,False,"https://github.com/nod-ai/SHARK/issues/311 & https://github.com/nod-ai/SHARK/issues/342",""
|
||||
@@ -12,18 +12,17 @@ google/mobilebert-uncased,mhlo,tf,1e-2,1e-3,default,None,True,False,False,"Fails
|
||||
google/vit-base-patch16-224,mhlo,tf,1e-2,1e-3,tf_vit,nhcw-nhwc,False,False,False,"",""
|
||||
microsoft/MiniLM-L12-H384-uncased,mhlo,tf,1e-2,1e-3,tf_hf,None,True,False,False,"Fails during iree-compile.",""
|
||||
microsoft/layoutlm-base-uncased,mhlo,tf,1e-2,1e-3,default,None,False,False,False,"",""
|
||||
microsoft/mpnet-base,mhlo,tf,1e-2,1e-2,default,None,True,True,True,"",""
|
||||
microsoft/mpnet-base,mhlo,tf,1e-2,1e-2,default,None,False,False,False,"",""
|
||||
albert-base-v2,linalg,torch,1e-2,1e-3,default,None,True,True,True,"issue with aten.tanh in torch-mlir",""
|
||||
alexnet,linalg,torch,1e-2,1e-3,default,None,True,True,False,"https://github.com/nod-ai/SHARK/issues/879",""
|
||||
bert-base-cased,linalg,torch,1e-2,1e-3,default,None,False,False,False,"",""
|
||||
bert-base-uncased,linalg,torch,1e-2,1e-3,default,None,False,False,False,"",""
|
||||
bert-base-uncased_fp16,linalg,torch,1e-1,1e-1,default,None,True,False,True,"",""
|
||||
bert-large-uncased,linalg,torch,1e-2,1e-3,default,None,True,True,True,"disabled until generateable",""
|
||||
bert-large-uncased,mhlo,tf,1e-2,1e-3,default,None,True,True,True,"disabled until generatedable",""
|
||||
facebook/deit-small-distilled-patch16-224,linalg,torch,1e-2,1e-3,default,nhcw-nhwc,False,True,False,"Fails during iree-compile.",""
|
||||
google/vit-base-patch16-224,linalg,torch,1e-2,1e-3,default,nhcw-nhwc,False,True,False,"https://github.com/nod-ai/SHARK/issues/311",""
|
||||
microsoft/beit-base-patch16-224-pt22k-ft22k,linalg,torch,1e-2,1e-3,default,nhcw-nhwc,False,True,False,"https://github.com/nod-ai/SHARK/issues/390",""
|
||||
microsoft/MiniLM-L12-H384-uncased,linalg,torch,1e-2,1e-3,default,None,False,False,False,"",""
|
||||
microsoft/resnet-50,linalg,torch,1e-2,1e-3,default,nhcw-nhwc/img2col,False,False,False,"","macos"
|
||||
google/mobilebert-uncased,linalg,torch,1e-2,1e-3,default,None,False,False,False,"https://github.com/nod-ai/SHARK/issues/344",""
|
||||
mobilenet_v3_small,linalg,torch,1e-1,1e-2,default,nhcw-nhwc,False,True,False,"https://github.com/nod-ai/SHARK/issues/388","macos"
|
||||
nvidia/mit-b0,linalg,torch,1e-2,1e-3,default,None,True,True,False,"https://github.com/nod-ai/SHARK/issues/343","macos"
|
||||
@@ -34,4 +33,4 @@ resnet50_fp16,linalg,torch,1e-2,1e-2,default,nhcw-nhwc/img2col,True,False,True,"
|
||||
squeezenet1_0,linalg,torch,1e-2,1e-3,default,nhcw-nhwc,False,False,False,"","macos"
|
||||
wide_resnet50_2,linalg,torch,1e-2,1e-3,default,nhcw-nhwc/img2col,False,False,False,"","macos"
|
||||
efficientnet-v2-s,mhlo,tf,1e-02,1e-3,default,nhcw-nhwc,False,False,False,"","macos"
|
||||
mnasnet1_0,linalg,torch,1e-2,1e-3,default,nhcw-nhwc,True,True,True,"","macos"
|
||||
mnasnet1_0,linalg,torch,1e-2,1e-3,default,nhcw-nhwc,False,False,False,"","macos"
|
||||
|
||||
|
@@ -31,4 +31,3 @@ xlm-roberta-base,False,False,-,-,-
|
||||
facebook/convnext-tiny-224,False,False,-,-,-
|
||||
efficientnet-v2-s,False,False,22M,"image-classification,cnn","Includes MBConv and Fused-MBConv"
|
||||
mnasnet1_0,False,True,-,"cnn, torchvision, mobile, architecture-search","Outperforms other mobile CNNs on Accuracy vs. Latency"
|
||||
bert-large-uncased,True,hf,True,330M,"nlp;bert-variant;transformer-encoder","24 layers, 1024 hidden units, 16 attention heads"
|
||||
|
||||
|
@@ -15,7 +15,6 @@ keras_models = ["resnet50", "efficientnet-v2-s"]
|
||||
maskedlm_models = [
|
||||
"albert-base-v2",
|
||||
"bert-base-uncased",
|
||||
"bert-large-uncased",
|
||||
"camembert-base",
|
||||
"dbmdz/convbert-base-turkish-cased",
|
||||
"deberta-base",
|
||||
|
||||
@@ -137,19 +137,6 @@ class SharkModuleTester:
|
||||
def create_and_check_module(self, dynamic, device):
|
||||
shark_args.local_tank_cache = self.local_tank_cache
|
||||
shark_args.force_update_tank = self.update_tank
|
||||
shark_args.dispatch_benchmarks = self.benchmark_dispatches
|
||||
if self.benchmark_dispatches is not None:
|
||||
_m = self.config["model_name"].split("/")
|
||||
_m.extend([self.config["framework"], str(dynamic), device])
|
||||
_m = "_".join(_m)
|
||||
shark_args.dispatch_benchmarks_dir = os.path.join(
|
||||
self.dispatch_benchmarks_dir,
|
||||
_m,
|
||||
)
|
||||
if not os.path.exists(self.dispatch_benchmarks_dir):
|
||||
os.mkdir(self.dispatch_benchmarks_dir)
|
||||
if not os.path.exists(shark_args.dispatch_benchmarks_dir):
|
||||
os.mkdir(shark_args.dispatch_benchmarks_dir)
|
||||
if "nhcw-nhwc" in self.config["flags"] and not os.path.isfile(
|
||||
".use-iree"
|
||||
):
|
||||
@@ -291,12 +278,6 @@ class SharkModuleTest(unittest.TestCase):
|
||||
"update_tank"
|
||||
)
|
||||
self.module_tester.tank_url = self.pytestconfig.getoption("tank_url")
|
||||
self.module_tester.benchmark_dispatches = self.pytestconfig.getoption(
|
||||
"benchmark_dispatches"
|
||||
)
|
||||
self.module_tester.dispatch_benchmarks_dir = (
|
||||
self.pytestconfig.getoption("dispatch_benchmarks_dir")
|
||||
)
|
||||
|
||||
if config["xfail_cpu"] == "True" and device == "cpu":
|
||||
pytest.xfail(reason=config["xfail_reason"])
|
||||
@@ -307,9 +288,6 @@ class SharkModuleTest(unittest.TestCase):
|
||||
if config["xfail_vkm"] == "True" and device in ["metal", "vulkan"]:
|
||||
pytest.xfail(reason=config["xfail_reason"])
|
||||
|
||||
if os.name == "nt" and "enabled_windows" not in config["xfail_other"]:
|
||||
pytest.xfail(reason="this model skipped on windows")
|
||||
|
||||
# Special cases that need to be marked.
|
||||
if "macos" in config["xfail_other"] and device in [
|
||||
"metal",
|
||||
|
||||
@@ -18,4 +18,3 @@ microsoft/mpnet-base,hf
|
||||
facebook/convnext-tiny-224,img
|
||||
google/vit-base-patch16-224,img
|
||||
efficientnet-v2-s,keras
|
||||
bert-large-uncased,hf
|
||||
|
||||
|
@@ -18,4 +18,3 @@ nvidia/mit-b0,True,hf_img_cls,False,3.7M,"image-classification,transformer-encod
|
||||
mnasnet1_0,False,vision,True,-,"cnn, torchvision, mobile, architecture-search","Outperforms other mobile CNNs on Accuracy vs. Latency"
|
||||
resnet50_fp16,False,vision,True,23M,"cnn,image-classification,residuals,resnet-variant","Bottlenecks with only conv2d (1x1 conv -> 3x3 conv -> 1x1 conv blocks)"
|
||||
bert-base-uncased_fp16,True,fp16,False,109M,"nlp;bert-variant;transformer-encoder","12 layers; 768 hidden; 12 attention heads"
|
||||
bert-large-uncased,True,hf,True,330M,"nlp;bert-variant;transformer-encoder","24 layers, 1024 hidden units, 16 attention heads"
|
||||
|
Reference in New Issue
Block a user