mirror of
https://github.com/invoke-ai/InvokeAI.git
synced 2026-01-15 09:18:00 -05:00
Compare commits
667 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
aebcec28e0 | ||
|
|
db1c5a94f7 | ||
|
|
56222a8493 | ||
|
|
b7510ce709 | ||
|
|
5739799e2e | ||
|
|
813cf87920 | ||
|
|
c95b151daf | ||
|
|
a0f823a3cf | ||
|
|
64e0f6d688 | ||
|
|
ddd5b1087c | ||
|
|
008be9b846 | ||
|
|
8e7cabdc04 | ||
|
|
a4c4237f99 | ||
|
|
bda3740dcd | ||
|
|
5b4633baa9 | ||
|
|
96351181cb | ||
|
|
957d591d99 | ||
|
|
75f605ba1a | ||
|
|
ab898a7180 | ||
|
|
c9a4516ab1 | ||
|
|
fe97c0d5eb | ||
|
|
6056764840 | ||
|
|
8747c0dbb0 | ||
|
|
c5cdd5f9c6 | ||
|
|
abc5d53159 | ||
|
|
2f76019a89 | ||
|
|
3f45beb1ed | ||
|
|
bc1126a85b | ||
|
|
380017041e | ||
|
|
ab7cdbb7e0 | ||
|
|
e5b78d0221 | ||
|
|
1acaa6c486 | ||
|
|
b0381076b7 | ||
|
|
ffff2d6dbb | ||
|
|
afa9f07649 | ||
|
|
addb5c49ea | ||
|
|
a112d2d55b | ||
|
|
619a271c8a | ||
|
|
909f2ee36d | ||
|
|
b4cf3d9d03 | ||
|
|
e6ab6e0293 | ||
|
|
66d9c7c631 | ||
|
|
fec45f3eb6 | ||
|
|
7211d1a6fc | ||
|
|
f3069754a9 | ||
|
|
4f43152aeb | ||
|
|
7125055d02 | ||
|
|
c91a9ce390 | ||
|
|
3e7b73da2c | ||
|
|
61ac50c00d | ||
|
|
c1201f0bce | ||
|
|
acdffac5ad | ||
|
|
e420300fa4 | ||
|
|
260a5a4f9a | ||
|
|
ed0c2006fe | ||
|
|
9ffd888c86 | ||
|
|
175a9dc28d | ||
|
|
5764e4f7f2 | ||
|
|
4275a494b9 | ||
|
|
a3deb8d30d | ||
|
|
aafdb0a37b | ||
|
|
56a815719a | ||
|
|
4db26bfa3a | ||
|
|
8d84ccb12b | ||
|
|
3321d14997 | ||
|
|
43cc4684e1 | ||
|
|
afa5a4b17c | ||
|
|
33c433fe59 | ||
|
|
9cd47fa857 | ||
|
|
32d9abe802 | ||
|
|
3947d4a165 | ||
|
|
3583d03b70 | ||
|
|
bc954b9996 | ||
|
|
c08075946a | ||
|
|
df8df914e8 | ||
|
|
33924e8491 | ||
|
|
7e5ce1d69d | ||
|
|
6a24594140 | ||
|
|
61d26cffe6 | ||
|
|
fdbc244dbe | ||
|
|
0eea84c90d | ||
|
|
e079a91800 | ||
|
|
eb20173487 | ||
|
|
20dd0779b5 | ||
|
|
b384a92f5c | ||
|
|
116d32fbbe | ||
|
|
b044f31a61 | ||
|
|
6c3c24403b | ||
|
|
591f48bb95 | ||
|
|
dc6e45485c | ||
|
|
829820479d | ||
|
|
48a471bfb8 | ||
|
|
ff72315db2 | ||
|
|
790846297a | ||
|
|
230b455a13 | ||
|
|
71f0fff55b | ||
|
|
7f2c83b9e6 | ||
|
|
bc85bd4bd4 | ||
|
|
38b09d73e4 | ||
|
|
606c4ae88c | ||
|
|
f666bac77f | ||
|
|
c9bf7da23a | ||
|
|
dfc65b93e9 | ||
|
|
9ca40b4cf5 | ||
|
|
d571e71d5e | ||
|
|
ad1e6c3fe6 | ||
|
|
21d02911dd | ||
|
|
43afe0bd9a | ||
|
|
e7a68c446d | ||
|
|
b9c68a2e7e | ||
|
|
371a1b1af3 | ||
|
|
dae4591de6 | ||
|
|
8ccb2e30ce | ||
|
|
b8106a4613 | ||
|
|
ce51e9582a | ||
|
|
00848eb631 | ||
|
|
b48430a892 | ||
|
|
f94a218561 | ||
|
|
9b6ed40875 | ||
|
|
26553dbb0e | ||
|
|
9eb695d0b4 | ||
|
|
babab17e1d | ||
|
|
d0a80f3347 | ||
|
|
9b30363177 | ||
|
|
89bde36b0c | ||
|
|
86a8476d97 | ||
|
|
afa0661e55 | ||
|
|
ba09c1277f | ||
|
|
80bf9ddb71 | ||
|
|
1dbc98d747 | ||
|
|
0698188ea2 | ||
|
|
59d0ad4505 | ||
|
|
074a5692dd | ||
|
|
bb0741146a | ||
|
|
1845d9a87a | ||
|
|
748c393e71 | ||
|
|
9bd17ea02f | ||
|
|
24f9b46fbc | ||
|
|
54b3aa1d01 | ||
|
|
d85733f22b | ||
|
|
aff6ad0316 | ||
|
|
61496fdcbc | ||
|
|
ee8975401a | ||
|
|
bf3260446d | ||
|
|
f53823b45e | ||
|
|
5cbe89afdd | ||
|
|
c466d50c3d | ||
|
|
d20b894a61 | ||
|
|
20362448b9 | ||
|
|
5df10cc494 | ||
|
|
da171114ea | ||
|
|
62919a443c | ||
|
|
ffcec91d87 | ||
|
|
0a96466b60 | ||
|
|
e48cab0276 | ||
|
|
740f6eb19f | ||
|
|
d1bb4c2c70 | ||
|
|
e545f18a45 | ||
|
|
e8cd1bb3d8 | ||
|
|
90a906e203 | ||
|
|
5546110127 | ||
|
|
73bbb12f7a | ||
|
|
dde54740c5 | ||
|
|
f70a8e2c1a | ||
|
|
fdccdd52d5 | ||
|
|
31ffd73423 | ||
|
|
3fa1012879 | ||
|
|
c2a8fbd8d6 | ||
|
|
d6643d7263 | ||
|
|
412e79d8e6 | ||
|
|
f939dbdc33 | ||
|
|
24a0ca86f5 | ||
|
|
95c30f6a8b | ||
|
|
ac7441e606 | ||
|
|
9c9af312fe | ||
|
|
7bf5927c43 | ||
|
|
32c7cdd856 | ||
|
|
bbd89d54b4 | ||
|
|
ee61006a49 | ||
|
|
0b43f5fd64 | ||
|
|
6c61266990 | ||
|
|
2d5afe8094 | ||
|
|
2430137d19 | ||
|
|
6df4ee5fc8 | ||
|
|
371742d8f9 | ||
|
|
5440c03767 | ||
|
|
358dbdbf84 | ||
|
|
5ec2d71be0 | ||
|
|
8f28903c81 | ||
|
|
73d4c4d56d | ||
|
|
a071f2788a | ||
|
|
d9a257ef8a | ||
|
|
23fada3eea | ||
|
|
2917e59c38 | ||
|
|
c691855a67 | ||
|
|
a00347379b | ||
|
|
ad1a8fbb8d | ||
|
|
f03b77e882 | ||
|
|
2b000cb006 | ||
|
|
af636f08b8 | ||
|
|
f8150f46a5 | ||
|
|
b613be0f5d | ||
|
|
a833d74913 | ||
|
|
02df055e8a | ||
|
|
add31ce596 | ||
|
|
7d7ad3052e | ||
|
|
3b16dbffb2 | ||
|
|
d8b0648766 | ||
|
|
ae64ee224f | ||
|
|
1251dfd7f6 | ||
|
|
804ee3a7fb | ||
|
|
fc5f9047c2 | ||
|
|
0b208220e5 | ||
|
|
916b9f7741 | ||
|
|
0947a006cc | ||
|
|
2c2df6423e | ||
|
|
c3df9d38c0 | ||
|
|
3790c254f5 | ||
|
|
abf46eaacd | ||
|
|
166548246d | ||
|
|
985dcd9862 | ||
|
|
b1df592506 | ||
|
|
a09a0eff69 | ||
|
|
e73bd09d93 | ||
|
|
6f5477a3f0 | ||
|
|
f78a542401 | ||
|
|
8613efb03a | ||
|
|
d8347d856d | ||
|
|
336e6e0c19 | ||
|
|
5bd87ca89b | ||
|
|
fe87c198eb | ||
|
|
69a4a88925 | ||
|
|
6e7491b086 | ||
|
|
3da8076a2b | ||
|
|
80360a8abb | ||
|
|
acfeb4a276 | ||
|
|
b33dbfc95f | ||
|
|
f9bc29203b | ||
|
|
cbe7717409 | ||
|
|
d6add93901 | ||
|
|
ea45dce9dc | ||
|
|
8d44363d49 | ||
|
|
9933cdb6b7 | ||
|
|
e3e9d1f27c | ||
|
|
bb59ad438a | ||
|
|
e38f5b1576 | ||
|
|
1bb49b698f | ||
|
|
fa1fbd89fe | ||
|
|
190ef6732c | ||
|
|
947cd4694b | ||
|
|
ee32d0666d | ||
|
|
bc8ad9ccbf | ||
|
|
e96b290fa9 | ||
|
|
b9f83eae6a | ||
|
|
9868e23235 | ||
|
|
0060cae17c | ||
|
|
56f0845552 | ||
|
|
da3f85dd8b | ||
|
|
7185363f17 | ||
|
|
ac08c31fbc | ||
|
|
ea54a2655a | ||
|
|
cc83dede9f | ||
|
|
8464fd2ced | ||
|
|
c3316368d9 | ||
|
|
8b2d5ab28a | ||
|
|
3f6acdc2d3 | ||
|
|
4aa20a95b2 | ||
|
|
2d82e69a33 | ||
|
|
683f9a70e7 | ||
|
|
bb6d073828 | ||
|
|
7f7d8e5177 | ||
|
|
f37c5011f4 | ||
|
|
bb947c6162 | ||
|
|
a654dad20f | ||
|
|
2bd44662f3 | ||
|
|
e7f9086006 | ||
|
|
5141be8009 | ||
|
|
eacdfc660b | ||
|
|
5fd3c39431 | ||
|
|
7daf3b7d4a | ||
|
|
908f65698d | ||
|
|
63c4ac58e9 | ||
|
|
8c125681ea | ||
|
|
118f0ba3bf | ||
|
|
b3b7d084d0 | ||
|
|
812940eb95 | ||
|
|
0559480dd6 | ||
|
|
d99e7dd4e4 | ||
|
|
e854181417 | ||
|
|
de414c09fd | ||
|
|
ce4624f72b | ||
|
|
47c7df3476 | ||
|
|
4289b5e6c3 | ||
|
|
c8d1d14662 | ||
|
|
44c588d778 | ||
|
|
d75ac56d00 | ||
|
|
714dd5f0be | ||
|
|
2f4d3cb5e6 | ||
|
|
b76555bda9 | ||
|
|
1cdd501a0a | ||
|
|
1125218bc5 | ||
|
|
683504bfb5 | ||
|
|
03cf953398 | ||
|
|
24c115663d | ||
|
|
a9e7ecad49 | ||
|
|
76f4766324 | ||
|
|
3dfc242f77 | ||
|
|
1e43389cb4 | ||
|
|
cb33de34f7 | ||
|
|
7562ea48dc | ||
|
|
83f4700f5a | ||
|
|
704e7479b2 | ||
|
|
5f44559f30 | ||
|
|
7a22819100 | ||
|
|
70495665c5 | ||
|
|
ca30acc5b4 | ||
|
|
8121843d86 | ||
|
|
bc0ded0a23 | ||
|
|
30f6034f88 | ||
|
|
7d56a8ce54 | ||
|
|
e7dc439006 | ||
|
|
bce5a93eb1 | ||
|
|
93e98a1f63 | ||
|
|
0f93deab3b | ||
|
|
3f3aba8b10 | ||
|
|
0b84f567f1 | ||
|
|
69c0d7dcc9 | ||
|
|
5307248fcf | ||
|
|
2efaea8f79 | ||
|
|
c1dfd9b7d9 | ||
|
|
c594ef89d2 | ||
|
|
563db67b80 | ||
|
|
236c065edd | ||
|
|
1f5d744d01 | ||
|
|
b36c6af0ae | ||
|
|
4e431a9d5f | ||
|
|
48a8232285 | ||
|
|
94007fef5b | ||
|
|
9e6fb3bd3f | ||
|
|
8522129639 | ||
|
|
15033b1a9d | ||
|
|
743d78f82b | ||
|
|
06a434b0a2 | ||
|
|
7f2fdae870 | ||
|
|
00be03b5b9 | ||
|
|
0f98806a25 | ||
|
|
0f1541d091 | ||
|
|
c49bbb22e5 | ||
|
|
7bd4b586a6 | ||
|
|
754f049f54 | ||
|
|
883beb90eb | ||
|
|
ad76399702 | ||
|
|
69773a791d | ||
|
|
99e88e601d | ||
|
|
4050f7deae | ||
|
|
0399b04f29 | ||
|
|
3b349b2686 | ||
|
|
aa34dbe1e1 | ||
|
|
ac2476c63c | ||
|
|
f16489f1ce | ||
|
|
3b38b69192 | ||
|
|
2c601438eb | ||
|
|
5d6a2a3709 | ||
|
|
1d7a264050 | ||
|
|
c494e0642a | ||
|
|
849b9e8d86 | ||
|
|
4a66b7ac83 | ||
|
|
751eb59afa | ||
|
|
f537cf1916 | ||
|
|
0cc6f67bb1 | ||
|
|
b2bf03fd37 | ||
|
|
14bc06ab66 | ||
|
|
9c82cc7fcb | ||
|
|
c60cab97a7 | ||
|
|
eda979341a | ||
|
|
b6c7949bb7 | ||
|
|
d691f672a2 | ||
|
|
8deeac1372 | ||
|
|
4aace24f1f | ||
|
|
b1567fe0e4 | ||
|
|
3953e60a4f | ||
|
|
3c46522595 | ||
|
|
63a2e17f6b | ||
|
|
8b1ef4b902 | ||
|
|
5f2279c984 | ||
|
|
e82d67849c | ||
|
|
3977ffaa3e | ||
|
|
9a8a858fe4 | ||
|
|
859944f848 | ||
|
|
8d1a45863c | ||
|
|
6798bbab26 | ||
|
|
2c92e8a495 | ||
|
|
216b36c75d | ||
|
|
8bf8742984 | ||
|
|
c78eeb1645 | ||
|
|
cd88723a80 | ||
|
|
dea6cbd599 | ||
|
|
0dd9f1f772 | ||
|
|
5d11c30ce6 | ||
|
|
a783539cd2 | ||
|
|
2f8f30b497 | ||
|
|
f878e5e74e | ||
|
|
bfc460a5c6 | ||
|
|
a24581ede2 | ||
|
|
56731766ca | ||
|
|
80bc4ebee3 | ||
|
|
745b6dbd5d | ||
|
|
c7628945c4 | ||
|
|
728927ecff | ||
|
|
1a7eece695 | ||
|
|
2cd14dd066 | ||
|
|
5872f05342 | ||
|
|
4ad135c6ae | ||
|
|
c72c2770fe | ||
|
|
e733a1f30e | ||
|
|
4be3a33744 | ||
|
|
1751c380db | ||
|
|
16cda33025 | ||
|
|
8308e7d186 | ||
|
|
c0aab56d08 | ||
|
|
1795f4f8a2 | ||
|
|
5bfd2ec6b7 | ||
|
|
a35b229a9d | ||
|
|
e93da5d4b2 | ||
|
|
a17ea9bfad | ||
|
|
3578010ba4 | ||
|
|
459cf52043 | ||
|
|
9bcb93f575 | ||
|
|
d1a0e99701 | ||
|
|
92b1515d9d | ||
|
|
36515e1e2a | ||
|
|
c81bb761ed | ||
|
|
1d4a58e52b | ||
|
|
62d12e6468 | ||
|
|
9541156ce5 | ||
|
|
eb5b6625ea | ||
|
|
9758e5a622 | ||
|
|
58eba8bdbd | ||
|
|
2821ba8967 | ||
|
|
2cc72b19bc | ||
|
|
8544ba3798 | ||
|
|
65fe79fa0e | ||
|
|
c99852657e | ||
|
|
ed54b89e9e | ||
|
|
d56c80af8e | ||
|
|
0a65a01db8 | ||
|
|
5f416ee4fa | ||
|
|
115c82231b | ||
|
|
ccc1d4417e | ||
|
|
5806a4bc73 | ||
|
|
734631bfe4 | ||
|
|
8d6996cdf0 | ||
|
|
965d6be1f4 | ||
|
|
e31f253b90 | ||
|
|
5a94575603 | ||
|
|
1c3d06dc83 | ||
|
|
09b19e3640 | ||
|
|
1e0a4dfa3c | ||
|
|
5a1ab4aa9c | ||
|
|
d5c872292f | ||
|
|
0d7edbce25 | ||
|
|
e20d964b59 | ||
|
|
ee95321801 | ||
|
|
179c6d206c | ||
|
|
ffecd83815 | ||
|
|
f1c538fafc | ||
|
|
ed88b096f3 | ||
|
|
a28cabdf97 | ||
|
|
db25be3ba2 | ||
|
|
3b9d1e8218 | ||
|
|
05d9ba8fa0 | ||
|
|
3eee1ba113 | ||
|
|
7882e9beae | ||
|
|
7c9779b496 | ||
|
|
5832228fea | ||
|
|
1d32e70a75 | ||
|
|
9092280583 | ||
|
|
96dd1d5102 | ||
|
|
969f8b8e8d | ||
|
|
ccb5f90556 | ||
|
|
4770d9895d | ||
|
|
aeb2275bd8 | ||
|
|
aff5524457 | ||
|
|
825c564089 | ||
|
|
9b97c57f00 | ||
|
|
4b3a201790 | ||
|
|
7e1b9567c1 | ||
|
|
56ef754292 | ||
|
|
2de99ec32d | ||
|
|
889e63d585 | ||
|
|
56de2b3a51 | ||
|
|
eb40bdb810 | ||
|
|
0840e5fa65 | ||
|
|
b79f2a4e4f | ||
|
|
76a533e67e | ||
|
|
188974988c | ||
|
|
b47aae2165 | ||
|
|
7105a22e0f | ||
|
|
eee4175e4d | ||
|
|
e0b63559d0 | ||
|
|
aa54c1f969 | ||
|
|
87fdea4cc6 | ||
|
|
53443084c5 | ||
|
|
8d2e5bfd77 | ||
|
|
05e285c95a | ||
|
|
25f19a35d7 | ||
|
|
01bbd32598 | ||
|
|
0e2761d5c6 | ||
|
|
d5b51cca56 | ||
|
|
a303777777 | ||
|
|
e90b3de706 | ||
|
|
3ce94e5b84 | ||
|
|
42e5ec3916 | ||
|
|
ffa00d1d9a | ||
|
|
1648a2af6e | ||
|
|
852e9e280a | ||
|
|
af72412d3f | ||
|
|
72f715e688 | ||
|
|
3b567bef3d | ||
|
|
3d867db315 | ||
|
|
a8c7dd74d0 | ||
|
|
2dc069d759 | ||
|
|
2a90f4f59e | ||
|
|
af5f342347 | ||
|
|
6dd53b6a32 | ||
|
|
0ca8351911 | ||
|
|
b14cbfde13 | ||
|
|
46dc633df9 | ||
|
|
d4a981fc1c | ||
|
|
e0474ce822 | ||
|
|
9e5ce6b2d4 | ||
|
|
98fa946f77 | ||
|
|
ef80d40b63 | ||
|
|
7a9f923d35 | ||
|
|
fd982fa7c2 | ||
|
|
df86ed653a | ||
|
|
0be8aacee6 | ||
|
|
4f993a4f32 | ||
|
|
0158320940 | ||
|
|
bb2dc6c78b | ||
|
|
80d7d69c2f | ||
|
|
1010c9877c | ||
|
|
8fd8994ee8 | ||
|
|
262c2f1fc7 | ||
|
|
150d3239e3 | ||
|
|
e49e5e9782 | ||
|
|
2d1e745594 | ||
|
|
b793328edd | ||
|
|
e79b316645 | ||
|
|
8297e7964c | ||
|
|
26832c1a0e | ||
|
|
c29259ccdb | ||
|
|
3d4bd71098 | ||
|
|
814be44cd7 | ||
|
|
d328eaf743 | ||
|
|
b502c05009 | ||
|
|
0f333388bb | ||
|
|
bc63e2acc5 | ||
|
|
ec7e771942 | ||
|
|
fe84013392 | ||
|
|
710f81266b | ||
|
|
446e2884bc | ||
|
|
7d9f125232 | ||
|
|
66bbd62758 | ||
|
|
0875e861f5 | ||
|
|
0267d73dfc | ||
|
|
c9ab7c5233 | ||
|
|
f06765dfba | ||
|
|
f347b26999 | ||
|
|
c665cf3525 | ||
|
|
8cf19c4124 | ||
|
|
f7112ae57b | ||
|
|
2bfb0ddff5 | ||
|
|
950c9f5d0c | ||
|
|
db283d21f9 | ||
|
|
70cca7a431 | ||
|
|
3c3938cfc8 | ||
|
|
4455fc4092 | ||
|
|
4b7e920612 | ||
|
|
433146d08f | ||
|
|
324a46d0c8 | ||
|
|
c4421241f6 | ||
|
|
43b417be6b | ||
|
|
4a135c1017 | ||
|
|
dd591abc2b | ||
|
|
0e65f295ac | ||
|
|
ab7fbb7b30 | ||
|
|
92aed5e4fc | ||
|
|
d9b0697d1f | ||
|
|
34a9409bc1 | ||
|
|
319d82751a | ||
|
|
9b90834248 | ||
|
|
a8957aa50d | ||
|
|
807f458f13 | ||
|
|
68dbe45315 | ||
|
|
bd3d1dcdf9 | ||
|
|
386c01ede1 | ||
|
|
c224971cb4 | ||
|
|
ca55ef1da5 | ||
|
|
3072d80171 | ||
|
|
d5f2f4dc4e | ||
|
|
b2552323b8 | ||
|
|
61d217e377 | ||
|
|
57a80c456a | ||
|
|
211b2f84ed | ||
|
|
ea4104c7c4 | ||
|
|
8b46c2dc53 | ||
|
|
9812b9676b | ||
|
|
6efa1597eb | ||
|
|
cd6ef3edb3 | ||
|
|
fcdbb729d3 | ||
|
|
c0657072ec | ||
|
|
7167a5d3f4 | ||
|
|
8cf0d8c8d3 | ||
|
|
48311f38ba | ||
|
|
7631d55c2a | ||
|
|
ea0dc09c64 | ||
|
|
a424552c82 | ||
|
|
ba8ef6ff0f | ||
|
|
3463a968c7 | ||
|
|
c256826015 | ||
|
|
7d38a9b7fb | ||
|
|
249da858df | ||
|
|
d332d81866 | ||
|
|
21017edcde | ||
|
|
4a8d0f4671 | ||
|
|
4ee037a7c3 | ||
|
|
9a49374e12 | ||
|
|
81a4c5c23c | ||
|
|
5217d931ae | ||
|
|
75bedf6709 | ||
|
|
bdeec54886 | ||
|
|
8d50ecdfc3 | ||
|
|
ba07e255f5 | ||
|
|
8efa0668e0 | ||
|
|
fae96f3b9f | ||
|
|
154cd7dd17 | ||
|
|
65ed771f6d | ||
|
|
00dd5dbbce | ||
|
|
5a053b645e | ||
|
|
3ca6c35212 | ||
|
|
eb0f3c42d5 | ||
|
|
843f507e16 | ||
|
|
fa6e0583bc | ||
|
|
39585ccac0 | ||
|
|
0fccd9936c | ||
|
|
841178ceb7 | ||
|
|
70a35cc25a | ||
|
|
29bd5834c8 | ||
|
|
35685194f3 | ||
|
|
ffd088a693 | ||
|
|
3abc80b88e | ||
|
|
15020e615c | ||
|
|
bd0aabb064 | ||
|
|
97013e08ef | ||
|
|
cca807ed01 | ||
|
|
c8246b99d3 | ||
|
|
aad81a83a3 | ||
|
|
00bd4561fc | ||
|
|
a6062a4229 | ||
|
|
aa9594cb42 | ||
|
|
4f6b21c6d9 | ||
|
|
9c0d357817 | ||
|
|
8b9b64d21c | ||
|
|
417ef36eb0 | ||
|
|
7c53812d22 | ||
|
|
6bbaaed8cb |
@@ -105,7 +105,7 @@ Invoke features an organized gallery system for easily storing, accessing, and r
|
||||
### Other features
|
||||
|
||||
- Support for both ckpt and diffusers models
|
||||
- SD1.5, SD2.0, and SDXL support
|
||||
- SD1.5, SD2.0, SDXL, and FLUX support
|
||||
- Upscaling Tools
|
||||
- Embedding Manager & Support
|
||||
- Model Manager & Support
|
||||
|
||||
@@ -38,9 +38,9 @@ RUN --mount=type=cache,target=/root/.cache/pip \
|
||||
if [ "$TARGETPLATFORM" = "linux/arm64" ] || [ "$GPU_DRIVER" = "cpu" ]; then \
|
||||
extra_index_url_arg="--extra-index-url https://download.pytorch.org/whl/cpu"; \
|
||||
elif [ "$GPU_DRIVER" = "rocm" ]; then \
|
||||
extra_index_url_arg="--extra-index-url https://download.pytorch.org/whl/rocm5.6"; \
|
||||
extra_index_url_arg="--extra-index-url https://download.pytorch.org/whl/rocm6.1"; \
|
||||
else \
|
||||
extra_index_url_arg="--extra-index-url https://download.pytorch.org/whl/cu121"; \
|
||||
extra_index_url_arg="--extra-index-url https://download.pytorch.org/whl/cu124"; \
|
||||
fi &&\
|
||||
|
||||
# xformers + triton fails to install on arm64
|
||||
|
||||
@@ -1,7 +1,7 @@
|
||||
# Copyright (c) 2023 Eugene Brodsky https://github.com/ebr
|
||||
|
||||
x-invokeai: &invokeai
|
||||
image: "local/invokeai:latest"
|
||||
image: "ghcr.io/invoke-ai/invokeai:latest"
|
||||
build:
|
||||
context: ..
|
||||
dockerfile: docker/Dockerfile
|
||||
|
||||
@@ -144,7 +144,7 @@ As you might have noticed, we added two new arguments to the `InputField`
|
||||
definition for `width` and `height`, called `gt` and `le`. They stand for
|
||||
_greater than or equal to_ and _less than or equal to_.
|
||||
|
||||
These impose contraints on those fields, and will raise an exception if the
|
||||
These impose constraints on those fields, and will raise an exception if the
|
||||
values do not meet the constraints. Field constraints are provided by
|
||||
**pydantic**, so anything you see in the **pydantic docs** will work.
|
||||
|
||||
|
||||
@@ -239,7 +239,7 @@ Consult the
|
||||
get it set up.
|
||||
|
||||
Suggest using VSCode's included settings sync so that your remote dev host has
|
||||
all the same app settings and extensions automagically.
|
||||
all the same app settings and extensions automatically.
|
||||
|
||||
##### One remote dev gotcha
|
||||
|
||||
|
||||
@@ -2,7 +2,7 @@
|
||||
|
||||
## **What do I need to know to help?**
|
||||
|
||||
If you are looking to help to with a code contribution, InvokeAI uses several different technologies under the hood: Python (Pydantic, FastAPI, diffusers) and Typescript (React, Redux Toolkit, ChakraUI, Mantine, Konva). Familiarity with StableDiffusion and image generation concepts is helpful, but not essential.
|
||||
If you are looking to help with a code contribution, InvokeAI uses several different technologies under the hood: Python (Pydantic, FastAPI, diffusers) and Typescript (React, Redux Toolkit, ChakraUI, Mantine, Konva). Familiarity with StableDiffusion and image generation concepts is helpful, but not essential.
|
||||
|
||||
|
||||
## **Get Started**
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
# Tutorials
|
||||
|
||||
Tutorials help new & existing users expand their abilty to use InvokeAI to the full extent of our features and services.
|
||||
Tutorials help new & existing users expand their ability to use InvokeAI to the full extent of our features and services.
|
||||
|
||||
Currently, we have a set of tutorials available on our [YouTube channel](https://www.youtube.com/@invokeai), but as InvokeAI continues to evolve with new updates, we want to ensure that we are giving our users the resources they need to succeed.
|
||||
|
||||
@@ -8,4 +8,4 @@ Tutorials can be in the form of videos or article walkthroughs on a subject of y
|
||||
|
||||
## Contributing
|
||||
|
||||
Please reach out to @imic or @hipsterusername on [Discord](https://discord.gg/ZmtBAhwWhy) to help create tutorials for InvokeAI.
|
||||
Please reach out to @imic or @hipsterusername on [Discord](https://discord.gg/ZmtBAhwWhy) to help create tutorials for InvokeAI.
|
||||
|
||||
@@ -17,46 +17,49 @@ If you just want to use Invoke, you should use the [installer][installer link].
|
||||
## Setup
|
||||
|
||||
1. Run through the [requirements][requirements link].
|
||||
1. [Fork and clone][forking link] the [InvokeAI repo][repo link].
|
||||
1. Create an directory for user data (images, models, db, etc). This is typically at `~/invokeai`, but if you already have a non-dev install, you may want to create a separate directory for the dev install.
|
||||
1. Create a python virtual environment inside the directory you just created:
|
||||
2. [Fork and clone][forking link] the [InvokeAI repo][repo link].
|
||||
3. Create an directory for user data (images, models, db, etc). This is typically at `~/invokeai`, but if you already have a non-dev install, you may want to create a separate directory for the dev install.
|
||||
4. Create a python virtual environment inside the directory you just created:
|
||||
|
||||
```sh
|
||||
python3 -m venv .venv --prompt InvokeAI-Dev
|
||||
```
|
||||
```sh
|
||||
python3 -m venv .venv --prompt InvokeAI-Dev
|
||||
```
|
||||
|
||||
1. Activate the venv (you'll need to do this every time you want to run the app):
|
||||
5. Activate the venv (you'll need to do this every time you want to run the app):
|
||||
|
||||
```sh
|
||||
source .venv/bin/activate
|
||||
```
|
||||
```sh
|
||||
source .venv/bin/activate
|
||||
```
|
||||
|
||||
1. Install the repo as an [editable install][editable install link]:
|
||||
6. Install the repo as an [editable install][editable install link]:
|
||||
|
||||
```sh
|
||||
pip install -e ".[dev,test,xformers]" --use-pep517 --extra-index-url https://download.pytorch.org/whl/cu121
|
||||
```
|
||||
```sh
|
||||
pip install -e ".[dev,test,xformers]" --use-pep517 --extra-index-url https://download.pytorch.org/whl/cu121
|
||||
```
|
||||
|
||||
Refer to the [manual installation][manual install link]] instructions for more determining the correct install options. `xformers` is optional, but `dev` and `test` are not.
|
||||
Refer to the [manual installation][manual install link]] instructions for more determining the correct install options. `xformers` is optional, but `dev` and `test` are not.
|
||||
|
||||
1. Install the frontend dev toolchain:
|
||||
7. Install the frontend dev toolchain:
|
||||
|
||||
- [`nodejs`](https://nodejs.org/) (recommend v20 LTS)
|
||||
- [`pnpm`](https://pnpm.io/installation#installing-a-specific-version) (must be v8 - not v9!)
|
||||
- [`pnpm`](https://pnpm.io/8.x/installation) (must be v8 - not v9!)
|
||||
|
||||
1. Do a production build of the frontend:
|
||||
8. Do a production build of the frontend:
|
||||
|
||||
```sh
|
||||
pnpm build
|
||||
```
|
||||
```sh
|
||||
cd PATH_TO_INVOKEAI_REPO/invokeai/frontend/web
|
||||
pnpm i
|
||||
pnpm build
|
||||
```
|
||||
|
||||
1. Start the application:
|
||||
9. Start the application:
|
||||
|
||||
```sh
|
||||
python scripts/invokeai-web.py
|
||||
```
|
||||
```sh
|
||||
cd PATH_TO_INVOKEAI_REPO
|
||||
python scripts/invokeai-web.py
|
||||
```
|
||||
|
||||
1. Access the UI at `localhost:9090`.
|
||||
10. Access the UI at `localhost:9090`.
|
||||
|
||||
## Updating the UI
|
||||
|
||||
|
||||
@@ -21,6 +21,7 @@ To use a community workflow, download the `.json` node graph file and load it in
|
||||
+ [Clothing Mask](#clothing-mask)
|
||||
+ [Contrast Limited Adaptive Histogram Equalization](#contrast-limited-adaptive-histogram-equalization)
|
||||
+ [Depth Map from Wavefront OBJ](#depth-map-from-wavefront-obj)
|
||||
+ [Enhance Detail](#enhance-detail)
|
||||
+ [Film Grain](#film-grain)
|
||||
+ [Generative Grammar-Based Prompt Nodes](#generative-grammar-based-prompt-nodes)
|
||||
+ [GPT2RandomPromptMaker](#gpt2randompromptmaker)
|
||||
@@ -39,7 +40,9 @@ To use a community workflow, download the `.json` node graph file and load it in
|
||||
+ [Match Histogram](#match-histogram)
|
||||
+ [Metadata-Linked](#metadata-linked-nodes)
|
||||
+ [Negative Image](#negative-image)
|
||||
+ [Nightmare Promptgen](#nightmare-promptgen)
|
||||
+ [Nightmare Promptgen](#nightmare-promptgen)
|
||||
+ [Ollama](#ollama-node)
|
||||
+ [One Button Prompt](#one-button-prompt)
|
||||
+ [Oobabooga](#oobabooga)
|
||||
+ [Prompt Tools](#prompt-tools)
|
||||
+ [Remote Image](#remote-image)
|
||||
@@ -79,7 +82,7 @@ Note: These are inherited from the core nodes so any update to the core nodes sh
|
||||
|
||||
**Example Usage:**
|
||||
</br>
|
||||
<img src="https://github.com/skunkworxdark/autostereogram_nodes/blob/main/images/spider.png" width="200" /> -> <img src="https://github.com/skunkworxdark/autostereogram_nodes/blob/main/images/spider-depth.png" width="200" /> -> <img src="https://github.com/skunkworxdark/autostereogram_nodes/raw/main/images/spider-dots.png" width="200" /> <img src="https://github.com/skunkworxdark/autostereogram_nodes/raw/main/images/spider-pattern.png" width="200" />
|
||||
<img src="https://raw.githubusercontent.com/skunkworxdark/autostereogram_nodes/refs/heads/main/images/spider.png" width="200" /> -> <img src="https://raw.githubusercontent.com/skunkworxdark/autostereogram_nodes/refs/heads/main/images/spider-depth.png" width="200" /> -> <img src="https://raw.githubusercontent.com/skunkworxdark/autostereogram_nodes/refs/heads/main/images/spider-dots.png" width="200" /> <img src="https://raw.githubusercontent.com/skunkworxdark/autostereogram_nodes/refs/heads/main/images/spider-pattern.png" width="200" />
|
||||
|
||||
--------------------------------
|
||||
### Average Images
|
||||
@@ -140,6 +143,17 @@ To be imported, an .obj must use triangulated meshes, so make sure to enable tha
|
||||
**Example Usage:**
|
||||
</br><img src="https://raw.githubusercontent.com/dwringer/depth-from-obj-node/main/depth_from_obj_usage.jpg" width="500" />
|
||||
|
||||
--------------------------------
|
||||
### Enhance Detail
|
||||
|
||||
**Description:** A single node that can enhance the detail in an image. Increase or decrease details in an image using a guided filter (as opposed to the typical Gaussian blur used by most sharpening filters.) Based on the `Enhance Detail` ComfyUI node from https://github.com/spacepxl/ComfyUI-Image-Filters
|
||||
|
||||
**Node Link:** https://github.com/skunkworxdark/enhance-detail-node
|
||||
|
||||
**Example Usage:**
|
||||
</br>
|
||||
<img src="https://raw.githubusercontent.com/skunkworxdark/enhance-detail-node/refs/heads/main/images/Comparison.png" />
|
||||
|
||||
--------------------------------
|
||||
### Film Grain
|
||||
|
||||
@@ -306,7 +320,7 @@ View:
|
||||
**Node Link:** https://github.com/helix4u/load_video_frame
|
||||
|
||||
**Output Example:**
|
||||
<img src="https://raw.githubusercontent.com/helix4u/load_video_frame/main/_git_assets/testmp4_embed_converted.gif" width="500" />
|
||||
<img src="https://raw.githubusercontent.com/helix4u/load_video_frame/refs/heads/main/_git_assets/dance1736978273.gif" width="500" />
|
||||
|
||||
--------------------------------
|
||||
### Make 3D
|
||||
@@ -347,7 +361,7 @@ See full docs here: https://github.com/skunkworxdark/Prompt-tools-nodes/edit/mai
|
||||
|
||||
**Output Examples**
|
||||
|
||||
<img src="https://github.com/skunkworxdark/match_histogram/assets/21961335/ed12f329-a0ef-444a-9bae-129ed60d6097" width="300" />
|
||||
<img src="https://github.com/skunkworxdark/match_histogram/assets/21961335/ed12f329-a0ef-444a-9bae-129ed60d6097" />
|
||||
|
||||
--------------------------------
|
||||
### Metadata Linked Nodes
|
||||
@@ -389,6 +403,34 @@ View:
|
||||
|
||||
**Node Link:** [https://github.com/gogurtenjoyer/nightmare-promptgen](https://github.com/gogurtenjoyer/nightmare-promptgen)
|
||||
|
||||
--------------------------------
|
||||
### Ollama Node
|
||||
|
||||
**Description:** Uses Ollama API to expand text prompts for text-to-image generation using local LLMs. Works great for expanding basic prompts into detailed natural language prompts for Flux. Also provides a toggle to unload the LLM model immediately after expanding, to free up VRAM for Invoke to continue the image generation workflow.
|
||||
|
||||
**Node Link:** https://github.com/Jonseed/Ollama-Node
|
||||
|
||||
**Example Node Graph:** https://github.com/Jonseed/Ollama-Node/blob/main/Ollama-Node-Flux-example.json
|
||||
|
||||
**View:**
|
||||
|
||||
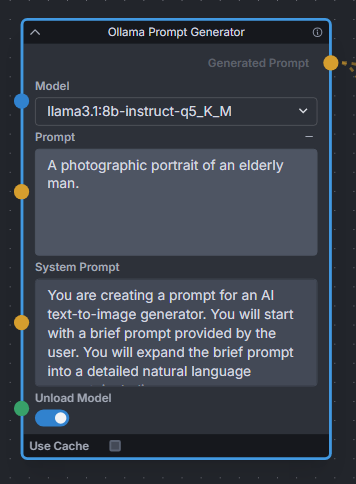
|
||||
|
||||
--------------------------------
|
||||
### One Button Prompt
|
||||
|
||||
<img src="https://raw.githubusercontent.com/AIrjen/OneButtonPrompt_X_InvokeAI/refs/heads/main/images/background.png" width="800" />
|
||||
|
||||
**Description:** an extensive suite of auto prompt generation and prompt helper nodes based on extensive logic. Get creative with the best prompt generator in the world.
|
||||
|
||||
The main node generates interesting prompts based on a set of parameters. There are also some additional nodes such as Auto Negative Prompt, One Button Artify, Create Prompt Variant and other cool prompt toys to play around with.
|
||||
|
||||
**Node Link:** [https://github.com/AIrjen/OneButtonPrompt_X_InvokeAI](https://github.com/AIrjen/OneButtonPrompt_X_InvokeAI)
|
||||
|
||||
**Nodes:**
|
||||
|
||||
<img src="https://raw.githubusercontent.com/AIrjen/OneButtonPrompt_X_InvokeAI/refs/heads/main/images/OBP_nodes_invokeai.png" width="800" />
|
||||
|
||||
--------------------------------
|
||||
### Oobabooga
|
||||
|
||||
@@ -440,7 +482,7 @@ See full docs here: https://github.com/skunkworxdark/Prompt-tools-nodes/edit/mai
|
||||
|
||||
**Workflow Examples**
|
||||
|
||||
<img src="https://github.com/skunkworxdark/prompt-tools/blob/main/images/CSVToIndexStringNode.png" width="300" />
|
||||
<img src="https://raw.githubusercontent.com/skunkworxdark/prompt-tools/refs/heads/main/images/CSVToIndexStringNode.png"/>
|
||||
|
||||
--------------------------------
|
||||
### Remote Image
|
||||
@@ -578,7 +620,7 @@ See full docs here: https://github.com/skunkworxdark/XYGrid_nodes/edit/main/READ
|
||||
|
||||
**Output Examples**
|
||||
|
||||
<img src="https://github.com/skunkworxdark/XYGrid_nodes/blob/main/images/collage.png" width="300" />
|
||||
<img src="https://raw.githubusercontent.com/skunkworxdark/XYGrid_nodes/refs/heads/main/images/collage.png" />
|
||||
|
||||
|
||||
--------------------------------
|
||||
|
||||
6
flake.lock
generated
6
flake.lock
generated
@@ -2,11 +2,11 @@
|
||||
"nodes": {
|
||||
"nixpkgs": {
|
||||
"locked": {
|
||||
"lastModified": 1690630721,
|
||||
"narHash": "sha256-Y04onHyBQT4Erfr2fc82dbJTfXGYrf4V0ysLUYnPOP8=",
|
||||
"lastModified": 1727955264,
|
||||
"narHash": "sha256-lrd+7mmb5NauRoMa8+J1jFKYVa+rc8aq2qc9+CxPDKc=",
|
||||
"owner": "NixOS",
|
||||
"repo": "nixpkgs",
|
||||
"rev": "d2b52322f35597c62abf56de91b0236746b2a03d",
|
||||
"rev": "71cd616696bd199ef18de62524f3df3ffe8b9333",
|
||||
"type": "github"
|
||||
},
|
||||
"original": {
|
||||
|
||||
@@ -34,7 +34,7 @@
|
||||
cudaPackages.cudnn
|
||||
cudaPackages.cuda_nvrtc
|
||||
cudatoolkit
|
||||
pkgconfig
|
||||
pkg-config
|
||||
libconfig
|
||||
cmake
|
||||
blas
|
||||
@@ -66,7 +66,7 @@
|
||||
black
|
||||
|
||||
# Frontend.
|
||||
yarn
|
||||
pnpm_8
|
||||
nodejs
|
||||
];
|
||||
LD_LIBRARY_PATH = pkgs.lib.makeLibraryPath buildInputs;
|
||||
|
||||
@@ -12,7 +12,7 @@ MINIMUM_PYTHON_VERSION=3.10.0
|
||||
MAXIMUM_PYTHON_VERSION=3.11.100
|
||||
PYTHON=""
|
||||
for candidate in python3.11 python3.10 python3 python ; do
|
||||
if ppath=`which $candidate`; then
|
||||
if ppath=`which $candidate 2>/dev/null`; then
|
||||
# when using `pyenv`, the executable for an inactive Python version will exist but will not be operational
|
||||
# we check that this found executable can actually run
|
||||
if [ $($candidate --version &>/dev/null; echo ${PIPESTATUS}) -gt 0 ]; then continue; fi
|
||||
@@ -30,10 +30,11 @@ done
|
||||
if [ -z "$PYTHON" ]; then
|
||||
echo "A suitable Python interpreter could not be found"
|
||||
echo "Please install Python $MINIMUM_PYTHON_VERSION or higher (maximum $MAXIMUM_PYTHON_VERSION) before running this script. See instructions at $INSTRUCTIONS for help."
|
||||
echo "For the best user experience we suggest enlarging or maximizing this window now."
|
||||
read -p "Press any key to exit"
|
||||
exit -1
|
||||
fi
|
||||
|
||||
echo "For the best user experience we suggest enlarging or maximizing this window now."
|
||||
|
||||
exec $PYTHON ./lib/main.py ${@}
|
||||
read -p "Press any key to exit"
|
||||
|
||||
@@ -245,6 +245,9 @@ class InvokeAiInstance:
|
||||
|
||||
pip = local[self.pip]
|
||||
|
||||
# Uninstall xformers if it is present; the correct version of it will be reinstalled if needed
|
||||
_ = pip["uninstall", "-yqq", "xformers"] & FG
|
||||
|
||||
pipeline = pip[
|
||||
"install",
|
||||
"--require-virtualenv",
|
||||
@@ -282,12 +285,6 @@ class InvokeAiInstance:
|
||||
shutil.copy(src, dest)
|
||||
os.chmod(dest, 0o0755)
|
||||
|
||||
def update(self):
|
||||
pass
|
||||
|
||||
def remove(self):
|
||||
pass
|
||||
|
||||
|
||||
### Utility functions ###
|
||||
|
||||
@@ -402,7 +399,7 @@ def get_torch_source() -> Tuple[str | None, str | None]:
|
||||
:rtype: list
|
||||
"""
|
||||
|
||||
from messages import select_gpu
|
||||
from messages import GpuType, select_gpu
|
||||
|
||||
# device can be one of: "cuda", "rocm", "cpu", "cuda_and_dml, autodetect"
|
||||
device = select_gpu()
|
||||
@@ -412,16 +409,22 @@ def get_torch_source() -> Tuple[str | None, str | None]:
|
||||
url = None
|
||||
optional_modules: str | None = None
|
||||
if OS == "Linux":
|
||||
if device.value == "rocm":
|
||||
url = "https://download.pytorch.org/whl/rocm5.6"
|
||||
elif device.value == "cpu":
|
||||
if device == GpuType.ROCM:
|
||||
url = "https://download.pytorch.org/whl/rocm6.1"
|
||||
elif device == GpuType.CPU:
|
||||
url = "https://download.pytorch.org/whl/cpu"
|
||||
elif device.value == "cuda":
|
||||
# CUDA uses the default PyPi index
|
||||
elif device == GpuType.CUDA:
|
||||
url = "https://download.pytorch.org/whl/cu124"
|
||||
optional_modules = "[onnx-cuda]"
|
||||
elif device == GpuType.CUDA_WITH_XFORMERS:
|
||||
url = "https://download.pytorch.org/whl/cu124"
|
||||
optional_modules = "[xformers,onnx-cuda]"
|
||||
elif OS == "Windows":
|
||||
if device.value == "cuda":
|
||||
url = "https://download.pytorch.org/whl/cu121"
|
||||
if device == GpuType.CUDA:
|
||||
url = "https://download.pytorch.org/whl/cu124"
|
||||
optional_modules = "[onnx-cuda]"
|
||||
elif device == GpuType.CUDA_WITH_XFORMERS:
|
||||
url = "https://download.pytorch.org/whl/cu124"
|
||||
optional_modules = "[xformers,onnx-cuda]"
|
||||
elif device.value == "cpu":
|
||||
# CPU uses the default PyPi index, no optional modules
|
||||
|
||||
@@ -206,6 +206,7 @@ def dest_path(dest: Optional[str | Path] = None) -> Path | None:
|
||||
|
||||
|
||||
class GpuType(Enum):
|
||||
CUDA_WITH_XFORMERS = "xformers"
|
||||
CUDA = "cuda"
|
||||
ROCM = "rocm"
|
||||
CPU = "cpu"
|
||||
@@ -221,11 +222,15 @@ def select_gpu() -> GpuType:
|
||||
return GpuType.CPU
|
||||
|
||||
nvidia = (
|
||||
"an [gold1 b]NVIDIA[/] GPU (using CUDA™)",
|
||||
"an [gold1 b]NVIDIA[/] RTX 3060 or newer GPU using CUDA",
|
||||
GpuType.CUDA,
|
||||
)
|
||||
vintage_nvidia = (
|
||||
"an [gold1 b]NVIDIA[/] RTX 20xx or older GPU using CUDA+xFormers",
|
||||
GpuType.CUDA_WITH_XFORMERS,
|
||||
)
|
||||
amd = (
|
||||
"an [gold1 b]AMD[/] GPU (using ROCm™)",
|
||||
"an [gold1 b]AMD[/] GPU using ROCm",
|
||||
GpuType.ROCM,
|
||||
)
|
||||
cpu = (
|
||||
@@ -235,14 +240,13 @@ def select_gpu() -> GpuType:
|
||||
|
||||
options = []
|
||||
if OS == "Windows":
|
||||
options = [nvidia, cpu]
|
||||
options = [nvidia, vintage_nvidia, cpu]
|
||||
if OS == "Linux":
|
||||
options = [nvidia, amd, cpu]
|
||||
options = [nvidia, vintage_nvidia, amd, cpu]
|
||||
elif OS == "Darwin":
|
||||
options = [cpu]
|
||||
|
||||
if len(options) == 1:
|
||||
print(f'Your platform [gold1]{OS}-{ARCH}[/] only supports the "{options[0][1]}" driver. Proceeding with that.')
|
||||
return options[0][1]
|
||||
|
||||
options = {str(i): opt for i, opt in enumerate(options, 1)}
|
||||
|
||||
@@ -5,9 +5,10 @@ from fastapi.routing import APIRouter
|
||||
from pydantic import BaseModel, Field
|
||||
|
||||
from invokeai.app.api.dependencies import ApiDependencies
|
||||
from invokeai.app.services.board_records.board_records_common import BoardChanges
|
||||
from invokeai.app.services.board_records.board_records_common import BoardChanges, BoardRecordOrderBy
|
||||
from invokeai.app.services.boards.boards_common import BoardDTO
|
||||
from invokeai.app.services.shared.pagination import OffsetPaginatedResults
|
||||
from invokeai.app.services.shared.sqlite.sqlite_common import SQLiteDirection
|
||||
|
||||
boards_router = APIRouter(prefix="/v1/boards", tags=["boards"])
|
||||
|
||||
@@ -115,6 +116,8 @@ async def delete_board(
|
||||
response_model=Union[OffsetPaginatedResults[BoardDTO], list[BoardDTO]],
|
||||
)
|
||||
async def list_boards(
|
||||
order_by: BoardRecordOrderBy = Query(default=BoardRecordOrderBy.CreatedAt, description="The attribute to order by"),
|
||||
direction: SQLiteDirection = Query(default=SQLiteDirection.Descending, description="The direction to order by"),
|
||||
all: Optional[bool] = Query(default=None, description="Whether to list all boards"),
|
||||
offset: Optional[int] = Query(default=None, description="The page offset"),
|
||||
limit: Optional[int] = Query(default=None, description="The number of boards per page"),
|
||||
@@ -122,9 +125,9 @@ async def list_boards(
|
||||
) -> Union[OffsetPaginatedResults[BoardDTO], list[BoardDTO]]:
|
||||
"""Gets a list of boards"""
|
||||
if all:
|
||||
return ApiDependencies.invoker.services.boards.get_all(include_archived)
|
||||
return ApiDependencies.invoker.services.boards.get_all(order_by, direction, include_archived)
|
||||
elif offset is not None and limit is not None:
|
||||
return ApiDependencies.invoker.services.boards.get_many(offset, limit, include_archived)
|
||||
return ApiDependencies.invoker.services.boards.get_many(order_by, direction, offset, limit, include_archived)
|
||||
else:
|
||||
raise HTTPException(
|
||||
status_code=400,
|
||||
|
||||
@@ -38,7 +38,12 @@ from invokeai.backend.model_manager.load.model_cache.model_cache_base import Cac
|
||||
from invokeai.backend.model_manager.metadata.fetch.huggingface import HuggingFaceMetadataFetch
|
||||
from invokeai.backend.model_manager.metadata.metadata_base import ModelMetadataWithFiles, UnknownMetadataException
|
||||
from invokeai.backend.model_manager.search import ModelSearch
|
||||
from invokeai.backend.model_manager.starter_models import STARTER_MODELS, StarterModel, StarterModelWithoutDependencies
|
||||
from invokeai.backend.model_manager.starter_models import (
|
||||
STARTER_BUNDLES,
|
||||
STARTER_MODELS,
|
||||
StarterModel,
|
||||
StarterModelWithoutDependencies,
|
||||
)
|
||||
|
||||
model_manager_router = APIRouter(prefix="/v2/models", tags=["model_manager"])
|
||||
|
||||
@@ -792,22 +797,52 @@ async def convert_model(
|
||||
return new_config
|
||||
|
||||
|
||||
@model_manager_router.get("/starter_models", operation_id="get_starter_models", response_model=list[StarterModel])
|
||||
async def get_starter_models() -> list[StarterModel]:
|
||||
class StarterModelResponse(BaseModel):
|
||||
starter_models: list[StarterModel]
|
||||
starter_bundles: dict[str, list[StarterModel]]
|
||||
|
||||
|
||||
def get_is_installed(
|
||||
starter_model: StarterModel | StarterModelWithoutDependencies, installed_models: list[AnyModelConfig]
|
||||
) -> bool:
|
||||
for model in installed_models:
|
||||
if model.source == starter_model.source:
|
||||
return True
|
||||
if (
|
||||
(model.name == starter_model.name or model.name in starter_model.previous_names)
|
||||
and model.base == starter_model.base
|
||||
and model.type == starter_model.type
|
||||
):
|
||||
return True
|
||||
return False
|
||||
|
||||
|
||||
@model_manager_router.get("/starter_models", operation_id="get_starter_models", response_model=StarterModelResponse)
|
||||
async def get_starter_models() -> StarterModelResponse:
|
||||
installed_models = ApiDependencies.invoker.services.model_manager.store.search_by_attr()
|
||||
installed_model_sources = {m.source for m in installed_models}
|
||||
starter_models = deepcopy(STARTER_MODELS)
|
||||
starter_bundles = deepcopy(STARTER_BUNDLES)
|
||||
for model in starter_models:
|
||||
if model.source in installed_model_sources:
|
||||
model.is_installed = True
|
||||
model.is_installed = get_is_installed(model, installed_models)
|
||||
# Remove already-installed dependencies
|
||||
missing_deps: list[StarterModelWithoutDependencies] = []
|
||||
|
||||
for dep in model.dependencies or []:
|
||||
if dep.source not in installed_model_sources:
|
||||
if not get_is_installed(dep, installed_models):
|
||||
missing_deps.append(dep)
|
||||
model.dependencies = missing_deps
|
||||
|
||||
return starter_models
|
||||
for bundle in starter_bundles.values():
|
||||
for model in bundle:
|
||||
model.is_installed = get_is_installed(model, installed_models)
|
||||
# Remove already-installed dependencies
|
||||
missing_deps: list[StarterModelWithoutDependencies] = []
|
||||
for dep in model.dependencies or []:
|
||||
if not get_is_installed(dep, installed_models):
|
||||
missing_deps.append(dep)
|
||||
model.dependencies = missing_deps
|
||||
|
||||
return StarterModelResponse(starter_models=starter_models, starter_bundles=starter_bundles)
|
||||
|
||||
|
||||
@model_manager_router.get(
|
||||
|
||||
@@ -83,7 +83,7 @@ async def create_workflow(
|
||||
)
|
||||
async def list_workflows(
|
||||
page: int = Query(default=0, description="The page to get"),
|
||||
per_page: int = Query(default=10, description="The number of workflows per page"),
|
||||
per_page: Optional[int] = Query(default=None, description="The number of workflows per page"),
|
||||
order_by: WorkflowRecordOrderBy = Query(
|
||||
default=WorkflowRecordOrderBy.Name, description="The attribute to order by"
|
||||
),
|
||||
@@ -93,5 +93,5 @@ async def list_workflows(
|
||||
) -> PaginatedResults[WorkflowRecordListItemDTO]:
|
||||
"""Gets a page of workflows"""
|
||||
return ApiDependencies.invoker.services.workflow_records.get_many(
|
||||
page=page, per_page=per_page, order_by=order_by, direction=direction, query=query, category=category
|
||||
order_by=order_by, direction=direction, page=page, per_page=per_page, query=query, category=category
|
||||
)
|
||||
|
||||
@@ -7,13 +7,14 @@ from pathlib import Path
|
||||
|
||||
import torch
|
||||
import uvicorn
|
||||
from fastapi import FastAPI
|
||||
from fastapi import FastAPI, Request
|
||||
from fastapi.middleware.cors import CORSMiddleware
|
||||
from fastapi.middleware.gzip import GZipMiddleware
|
||||
from fastapi.openapi.docs import get_redoc_html, get_swagger_ui_html
|
||||
from fastapi.responses import HTMLResponse
|
||||
from fastapi.responses import HTMLResponse, RedirectResponse
|
||||
from fastapi_events.handlers.local import local_handler
|
||||
from fastapi_events.middleware import EventHandlerASGIMiddleware
|
||||
from starlette.middleware.base import BaseHTTPMiddleware, RequestResponseEndpoint
|
||||
from torch.backends.mps import is_available as is_mps_available
|
||||
|
||||
# for PyCharm:
|
||||
@@ -78,6 +79,29 @@ app = FastAPI(
|
||||
lifespan=lifespan,
|
||||
)
|
||||
|
||||
|
||||
class RedirectRootWithQueryStringMiddleware(BaseHTTPMiddleware):
|
||||
"""When a request is made to the root path with a query string, redirect to the root path without the query string.
|
||||
|
||||
For example, to force a Gradio app to use dark mode, users may append `?__theme=dark` to the URL. Their browser may
|
||||
have this query string saved in history or a bookmark, so when the user navigates to `http://127.0.0.1:9090/`, the
|
||||
browser takes them to `http://127.0.0.1:9090/?__theme=dark`.
|
||||
|
||||
This breaks the static file serving in the UI, so we redirect the user to the root path without the query string.
|
||||
"""
|
||||
|
||||
async def dispatch(self, request: Request, call_next: RequestResponseEndpoint):
|
||||
if request.url.path == "/" and request.url.query:
|
||||
return RedirectResponse(url="/")
|
||||
|
||||
response = await call_next(request)
|
||||
return response
|
||||
|
||||
|
||||
# Add the middleware
|
||||
app.add_middleware(RedirectRootWithQueryStringMiddleware)
|
||||
|
||||
|
||||
# Add event handler
|
||||
event_handler_id: int = id(app)
|
||||
app.add_middleware(
|
||||
|
||||
@@ -547,7 +547,9 @@ class DenoiseLatentsInvocation(BaseInvocation):
|
||||
if not isinstance(single_ipa_image_fields, list):
|
||||
single_ipa_image_fields = [single_ipa_image_fields]
|
||||
|
||||
single_ipa_images = [context.images.get_pil(image.image_name) for image in single_ipa_image_fields]
|
||||
single_ipa_images = [
|
||||
context.images.get_pil(image.image_name, mode="RGB") for image in single_ipa_image_fields
|
||||
]
|
||||
with image_encoder_model_info as image_encoder_model:
|
||||
assert isinstance(image_encoder_model, CLIPVisionModelWithProjection)
|
||||
# Get image embeddings from CLIP and ImageProjModel.
|
||||
|
||||
@@ -192,6 +192,7 @@ class FieldDescriptions:
|
||||
freeu_s2 = 'Scaling factor for stage 2 to attenuate the contributions of the skip features. This is done to mitigate the "oversmoothing effect" in the enhanced denoising process.'
|
||||
freeu_b1 = "Scaling factor for stage 1 to amplify the contributions of backbone features."
|
||||
freeu_b2 = "Scaling factor for stage 2 to amplify the contributions of backbone features."
|
||||
instantx_control_mode = "The control mode for InstantX ControlNet union models. Ignored for other ControlNet models. The standard mapping is: canny (0), tile (1), depth (2), blur (3), pose (4), gray (5), low quality (6). Negative values will be treated as 'None'."
|
||||
|
||||
|
||||
class ImageField(BaseModel):
|
||||
|
||||
99
invokeai/app/invocations/flux_controlnet.py
Normal file
99
invokeai/app/invocations/flux_controlnet.py
Normal file
@@ -0,0 +1,99 @@
|
||||
from pydantic import BaseModel, Field, field_validator, model_validator
|
||||
|
||||
from invokeai.app.invocations.baseinvocation import (
|
||||
BaseInvocation,
|
||||
BaseInvocationOutput,
|
||||
Classification,
|
||||
invocation,
|
||||
invocation_output,
|
||||
)
|
||||
from invokeai.app.invocations.fields import FieldDescriptions, ImageField, InputField, OutputField, UIType
|
||||
from invokeai.app.invocations.model import ModelIdentifierField
|
||||
from invokeai.app.invocations.util import validate_begin_end_step, validate_weights
|
||||
from invokeai.app.services.shared.invocation_context import InvocationContext
|
||||
from invokeai.app.util.controlnet_utils import CONTROLNET_RESIZE_VALUES
|
||||
|
||||
|
||||
class FluxControlNetField(BaseModel):
|
||||
image: ImageField = Field(description="The control image")
|
||||
control_model: ModelIdentifierField = Field(description="The ControlNet model to use")
|
||||
control_weight: float | list[float] = Field(default=1, description="The weight given to the ControlNet")
|
||||
begin_step_percent: float = Field(
|
||||
default=0, ge=0, le=1, description="When the ControlNet is first applied (% of total steps)"
|
||||
)
|
||||
end_step_percent: float = Field(
|
||||
default=1, ge=0, le=1, description="When the ControlNet is last applied (% of total steps)"
|
||||
)
|
||||
resize_mode: CONTROLNET_RESIZE_VALUES = Field(default="just_resize", description="The resize mode to use")
|
||||
instantx_control_mode: int | None = Field(default=-1, description=FieldDescriptions.instantx_control_mode)
|
||||
|
||||
@field_validator("control_weight")
|
||||
@classmethod
|
||||
def validate_control_weight(cls, v: float | list[float]) -> float | list[float]:
|
||||
validate_weights(v)
|
||||
return v
|
||||
|
||||
@model_validator(mode="after")
|
||||
def validate_begin_end_step_percent(self):
|
||||
validate_begin_end_step(self.begin_step_percent, self.end_step_percent)
|
||||
return self
|
||||
|
||||
|
||||
@invocation_output("flux_controlnet_output")
|
||||
class FluxControlNetOutput(BaseInvocationOutput):
|
||||
"""FLUX ControlNet info"""
|
||||
|
||||
control: FluxControlNetField = OutputField(description=FieldDescriptions.control)
|
||||
|
||||
|
||||
@invocation(
|
||||
"flux_controlnet",
|
||||
title="FLUX ControlNet",
|
||||
tags=["controlnet", "flux"],
|
||||
category="controlnet",
|
||||
version="1.0.0",
|
||||
classification=Classification.Prototype,
|
||||
)
|
||||
class FluxControlNetInvocation(BaseInvocation):
|
||||
"""Collect FLUX ControlNet info to pass to other nodes."""
|
||||
|
||||
image: ImageField = InputField(description="The control image")
|
||||
control_model: ModelIdentifierField = InputField(
|
||||
description=FieldDescriptions.controlnet_model, ui_type=UIType.ControlNetModel
|
||||
)
|
||||
control_weight: float | list[float] = InputField(
|
||||
default=1.0, ge=-1, le=2, description="The weight given to the ControlNet"
|
||||
)
|
||||
begin_step_percent: float = InputField(
|
||||
default=0, ge=0, le=1, description="When the ControlNet is first applied (% of total steps)"
|
||||
)
|
||||
end_step_percent: float = InputField(
|
||||
default=1, ge=0, le=1, description="When the ControlNet is last applied (% of total steps)"
|
||||
)
|
||||
resize_mode: CONTROLNET_RESIZE_VALUES = InputField(default="just_resize", description="The resize mode used")
|
||||
# Note: We default to -1 instead of None, because in the workflow editor UI None is not currently supported.
|
||||
instantx_control_mode: int | None = InputField(default=-1, description=FieldDescriptions.instantx_control_mode)
|
||||
|
||||
@field_validator("control_weight")
|
||||
@classmethod
|
||||
def validate_control_weight(cls, v: float | list[float]) -> float | list[float]:
|
||||
validate_weights(v)
|
||||
return v
|
||||
|
||||
@model_validator(mode="after")
|
||||
def validate_begin_end_step_percent(self):
|
||||
validate_begin_end_step(self.begin_step_percent, self.end_step_percent)
|
||||
return self
|
||||
|
||||
def invoke(self, context: InvocationContext) -> FluxControlNetOutput:
|
||||
return FluxControlNetOutput(
|
||||
control=FluxControlNetField(
|
||||
image=self.image,
|
||||
control_model=self.control_model,
|
||||
control_weight=self.control_weight,
|
||||
begin_step_percent=self.begin_step_percent,
|
||||
end_step_percent=self.end_step_percent,
|
||||
resize_mode=self.resize_mode,
|
||||
instantx_control_mode=self.instantx_control_mode,
|
||||
),
|
||||
)
|
||||
@@ -1,35 +1,48 @@
|
||||
from contextlib import ExitStack
|
||||
from typing import Callable, Iterator, Optional, Tuple
|
||||
|
||||
import numpy as np
|
||||
import numpy.typing as npt
|
||||
import torch
|
||||
import torchvision.transforms as tv_transforms
|
||||
from torchvision.transforms.functional import resize as tv_resize
|
||||
from transformers import CLIPImageProcessor, CLIPVisionModelWithProjection
|
||||
|
||||
from invokeai.app.invocations.baseinvocation import BaseInvocation, Classification, invocation
|
||||
from invokeai.app.invocations.fields import (
|
||||
DenoiseMaskField,
|
||||
FieldDescriptions,
|
||||
FluxConditioningField,
|
||||
ImageField,
|
||||
Input,
|
||||
InputField,
|
||||
LatentsField,
|
||||
WithBoard,
|
||||
WithMetadata,
|
||||
)
|
||||
from invokeai.app.invocations.model import TransformerField
|
||||
from invokeai.app.invocations.flux_controlnet import FluxControlNetField
|
||||
from invokeai.app.invocations.ip_adapter import IPAdapterField
|
||||
from invokeai.app.invocations.model import TransformerField, VAEField
|
||||
from invokeai.app.invocations.primitives import LatentsOutput
|
||||
from invokeai.app.services.shared.invocation_context import InvocationContext
|
||||
from invokeai.backend.flux.controlnet.instantx_controlnet_flux import InstantXControlNetFlux
|
||||
from invokeai.backend.flux.controlnet.xlabs_controlnet_flux import XLabsControlNetFlux
|
||||
from invokeai.backend.flux.denoise import denoise
|
||||
from invokeai.backend.flux.extensions.inpaint_extension import InpaintExtension
|
||||
from invokeai.backend.flux.extensions.instantx_controlnet_extension import InstantXControlNetExtension
|
||||
from invokeai.backend.flux.extensions.xlabs_controlnet_extension import XLabsControlNetExtension
|
||||
from invokeai.backend.flux.extensions.xlabs_ip_adapter_extension import XLabsIPAdapterExtension
|
||||
from invokeai.backend.flux.ip_adapter.xlabs_ip_adapter_flux import XlabsIpAdapterFlux
|
||||
from invokeai.backend.flux.model import Flux
|
||||
from invokeai.backend.flux.sampling_utils import (
|
||||
clip_timestep_schedule,
|
||||
clip_timestep_schedule_fractional,
|
||||
generate_img_ids,
|
||||
get_noise,
|
||||
get_schedule,
|
||||
pack,
|
||||
unpack,
|
||||
)
|
||||
from invokeai.backend.flux.trajectory_guidance_extension import TrajectoryGuidanceExtension
|
||||
from invokeai.backend.lora.conversions.flux_lora_constants import FLUX_LORA_TRANSFORMER_PREFIX
|
||||
from invokeai.backend.lora.lora_model_raw import LoRAModelRaw
|
||||
from invokeai.backend.lora.lora_patcher import LoRAPatcher
|
||||
from invokeai.backend.model_manager.config import ModelFormat
|
||||
@@ -43,7 +56,7 @@ from invokeai.backend.util.devices import TorchDevice
|
||||
title="FLUX Denoise",
|
||||
tags=["image", "flux"],
|
||||
category="image",
|
||||
version="2.1.0",
|
||||
version="3.2.0",
|
||||
classification=Classification.Prototype,
|
||||
)
|
||||
class FluxDenoiseInvocation(BaseInvocation, WithMetadata, WithBoard):
|
||||
@@ -68,12 +81,6 @@ class FluxDenoiseInvocation(BaseInvocation, WithMetadata, WithBoard):
|
||||
description=FieldDescriptions.denoising_start,
|
||||
)
|
||||
denoising_end: float = InputField(default=1.0, ge=0, le=1, description=FieldDescriptions.denoising_end)
|
||||
trajectory_guidance_strength: float = InputField(
|
||||
default=0.0,
|
||||
ge=0.0,
|
||||
le=1.0,
|
||||
description="Value indicating how strongly to guide the denoising process towards the initial latents (during image-to-image). Range [0, 1]. A value of 0.0 is equivalent to vanilla image-to-image. A value of 1.0 will guide the denoising process very close to the original latents.",
|
||||
)
|
||||
transformer: TransformerField = InputField(
|
||||
description=FieldDescriptions.flux_model,
|
||||
input=Input.Connection,
|
||||
@@ -82,6 +89,24 @@ class FluxDenoiseInvocation(BaseInvocation, WithMetadata, WithBoard):
|
||||
positive_text_conditioning: FluxConditioningField = InputField(
|
||||
description=FieldDescriptions.positive_cond, input=Input.Connection
|
||||
)
|
||||
negative_text_conditioning: FluxConditioningField | None = InputField(
|
||||
default=None,
|
||||
description="Negative conditioning tensor. Can be None if cfg_scale is 1.0.",
|
||||
input=Input.Connection,
|
||||
)
|
||||
cfg_scale: float | list[float] = InputField(default=1.0, description=FieldDescriptions.cfg_scale, title="CFG Scale")
|
||||
cfg_scale_start_step: int = InputField(
|
||||
default=0,
|
||||
title="CFG Scale Start Step",
|
||||
description="Index of the first step to apply cfg_scale. Negative indices count backwards from the "
|
||||
+ "the last step (e.g. a value of -1 refers to the final step).",
|
||||
)
|
||||
cfg_scale_end_step: int = InputField(
|
||||
default=-1,
|
||||
title="CFG Scale End Step",
|
||||
description="Index of the last step to apply cfg_scale. Negative indices count backwards from the "
|
||||
+ "last step (e.g. a value of -1 refers to the final step).",
|
||||
)
|
||||
width: int = InputField(default=1024, multiple_of=16, description="Width of the generated image.")
|
||||
height: int = InputField(default=1024, multiple_of=16, description="Height of the generated image.")
|
||||
num_steps: int = InputField(
|
||||
@@ -92,6 +117,18 @@ class FluxDenoiseInvocation(BaseInvocation, WithMetadata, WithBoard):
|
||||
description="The guidance strength. Higher values adhere more strictly to the prompt, and will produce less diverse images. FLUX dev only, ignored for schnell.",
|
||||
)
|
||||
seed: int = InputField(default=0, description="Randomness seed for reproducibility.")
|
||||
control: FluxControlNetField | list[FluxControlNetField] | None = InputField(
|
||||
default=None, input=Input.Connection, description="ControlNet models."
|
||||
)
|
||||
controlnet_vae: VAEField | None = InputField(
|
||||
default=None,
|
||||
description=FieldDescriptions.vae,
|
||||
input=Input.Connection,
|
||||
)
|
||||
|
||||
ip_adapter: IPAdapterField | list[IPAdapterField] | None = InputField(
|
||||
description=FieldDescriptions.ip_adapter, title="IP-Adapter", default=None, input=Input.Connection
|
||||
)
|
||||
|
||||
@torch.no_grad()
|
||||
def invoke(self, context: InvocationContext) -> LatentsOutput:
|
||||
@@ -101,6 +138,19 @@ class FluxDenoiseInvocation(BaseInvocation, WithMetadata, WithBoard):
|
||||
name = context.tensors.save(tensor=latents)
|
||||
return LatentsOutput.build(latents_name=name, latents=latents, seed=None)
|
||||
|
||||
def _load_text_conditioning(
|
||||
self, context: InvocationContext, conditioning_name: str, dtype: torch.dtype
|
||||
) -> Tuple[torch.Tensor, torch.Tensor]:
|
||||
# Load the conditioning data.
|
||||
cond_data = context.conditioning.load(conditioning_name)
|
||||
assert len(cond_data.conditionings) == 1
|
||||
flux_conditioning = cond_data.conditionings[0]
|
||||
assert isinstance(flux_conditioning, FLUXConditioningInfo)
|
||||
flux_conditioning = flux_conditioning.to(dtype=dtype)
|
||||
t5_embeddings = flux_conditioning.t5_embeds
|
||||
clip_embeddings = flux_conditioning.clip_embeds
|
||||
return t5_embeddings, clip_embeddings
|
||||
|
||||
def _run_diffusion(
|
||||
self,
|
||||
context: InvocationContext,
|
||||
@@ -108,13 +158,15 @@ class FluxDenoiseInvocation(BaseInvocation, WithMetadata, WithBoard):
|
||||
inference_dtype = torch.bfloat16
|
||||
|
||||
# Load the conditioning data.
|
||||
cond_data = context.conditioning.load(self.positive_text_conditioning.conditioning_name)
|
||||
assert len(cond_data.conditionings) == 1
|
||||
flux_conditioning = cond_data.conditionings[0]
|
||||
assert isinstance(flux_conditioning, FLUXConditioningInfo)
|
||||
flux_conditioning = flux_conditioning.to(dtype=inference_dtype)
|
||||
t5_embeddings = flux_conditioning.t5_embeds
|
||||
clip_embeddings = flux_conditioning.clip_embeds
|
||||
pos_t5_embeddings, pos_clip_embeddings = self._load_text_conditioning(
|
||||
context, self.positive_text_conditioning.conditioning_name, inference_dtype
|
||||
)
|
||||
neg_t5_embeddings: torch.Tensor | None = None
|
||||
neg_clip_embeddings: torch.Tensor | None = None
|
||||
if self.negative_text_conditioning is not None:
|
||||
neg_t5_embeddings, neg_clip_embeddings = self._load_text_conditioning(
|
||||
context, self.negative_text_conditioning.conditioning_name, inference_dtype
|
||||
)
|
||||
|
||||
# Load the input latents, if provided.
|
||||
init_latents = context.tensors.load(self.latents.latents_name) if self.latents else None
|
||||
@@ -143,7 +195,7 @@ class FluxDenoiseInvocation(BaseInvocation, WithMetadata, WithBoard):
|
||||
)
|
||||
|
||||
# Clip the timesteps schedule based on denoising_start and denoising_end.
|
||||
timesteps = clip_timestep_schedule(timesteps, self.denoising_start, self.denoising_end)
|
||||
timesteps = clip_timestep_schedule_fractional(timesteps, self.denoising_start, self.denoising_end)
|
||||
|
||||
# Prepare input latent image.
|
||||
if init_latents is not None:
|
||||
@@ -172,11 +224,19 @@ class FluxDenoiseInvocation(BaseInvocation, WithMetadata, WithBoard):
|
||||
|
||||
inpaint_mask = self._prep_inpaint_mask(context, x)
|
||||
|
||||
b, _c, h, w = x.shape
|
||||
img_ids = generate_img_ids(h=h, w=w, batch_size=b, device=x.device, dtype=x.dtype)
|
||||
b, _c, latent_h, latent_w = x.shape
|
||||
img_ids = generate_img_ids(h=latent_h, w=latent_w, batch_size=b, device=x.device, dtype=x.dtype)
|
||||
|
||||
bs, t5_seq_len, _ = t5_embeddings.shape
|
||||
txt_ids = torch.zeros(bs, t5_seq_len, 3, dtype=inference_dtype, device=TorchDevice.choose_torch_device())
|
||||
pos_bs, pos_t5_seq_len, _ = pos_t5_embeddings.shape
|
||||
pos_txt_ids = torch.zeros(
|
||||
pos_bs, pos_t5_seq_len, 3, dtype=inference_dtype, device=TorchDevice.choose_torch_device()
|
||||
)
|
||||
neg_txt_ids: torch.Tensor | None = None
|
||||
if neg_t5_embeddings is not None:
|
||||
neg_bs, neg_t5_seq_len, _ = neg_t5_embeddings.shape
|
||||
neg_txt_ids = torch.zeros(
|
||||
neg_bs, neg_t5_seq_len, 3, dtype=inference_dtype, device=TorchDevice.choose_torch_device()
|
||||
)
|
||||
|
||||
# Pack all latent tensors.
|
||||
init_latents = pack(init_latents) if init_latents is not None else None
|
||||
@@ -187,21 +247,46 @@ class FluxDenoiseInvocation(BaseInvocation, WithMetadata, WithBoard):
|
||||
# Now that we have 'packed' the latent tensors, verify that we calculated the image_seq_len correctly.
|
||||
assert image_seq_len == x.shape[1]
|
||||
|
||||
# Prepare trajectory guidance extension.
|
||||
traj_guidance_extension: TrajectoryGuidanceExtension | None = None
|
||||
if init_latents is not None:
|
||||
traj_guidance_extension = TrajectoryGuidanceExtension(
|
||||
# Prepare inpaint extension.
|
||||
inpaint_extension: InpaintExtension | None = None
|
||||
if inpaint_mask is not None:
|
||||
assert init_latents is not None
|
||||
inpaint_extension = InpaintExtension(
|
||||
init_latents=init_latents,
|
||||
inpaint_mask=inpaint_mask,
|
||||
trajectory_guidance_strength=self.trajectory_guidance_strength,
|
||||
noise=noise,
|
||||
)
|
||||
|
||||
with (
|
||||
transformer_info.model_on_device() as (cached_weights, transformer),
|
||||
ExitStack() as exit_stack,
|
||||
):
|
||||
assert isinstance(transformer, Flux)
|
||||
# Compute the IP-Adapter image prompt clip embeddings.
|
||||
# We do this before loading other models to minimize peak memory.
|
||||
# TODO(ryand): We should really do this in a separate invocation to benefit from caching.
|
||||
ip_adapter_fields = self._normalize_ip_adapter_fields()
|
||||
pos_image_prompt_clip_embeds, neg_image_prompt_clip_embeds = self._prep_ip_adapter_image_prompt_clip_embeds(
|
||||
ip_adapter_fields, context
|
||||
)
|
||||
|
||||
cfg_scale = self.prep_cfg_scale(
|
||||
cfg_scale=self.cfg_scale,
|
||||
timesteps=timesteps,
|
||||
cfg_scale_start_step=self.cfg_scale_start_step,
|
||||
cfg_scale_end_step=self.cfg_scale_end_step,
|
||||
)
|
||||
|
||||
with ExitStack() as exit_stack:
|
||||
# Prepare ControlNet extensions.
|
||||
# Note: We do this before loading the transformer model to minimize peak memory (see implementation).
|
||||
controlnet_extensions = self._prep_controlnet_extensions(
|
||||
context=context,
|
||||
exit_stack=exit_stack,
|
||||
latent_height=latent_h,
|
||||
latent_width=latent_w,
|
||||
dtype=inference_dtype,
|
||||
device=x.device,
|
||||
)
|
||||
|
||||
# Load the transformer model.
|
||||
(cached_weights, transformer) = exit_stack.enter_context(transformer_info.model_on_device())
|
||||
assert isinstance(transformer, Flux)
|
||||
config = transformer_info.config
|
||||
assert config is not None
|
||||
|
||||
@@ -213,40 +298,110 @@ class FluxDenoiseInvocation(BaseInvocation, WithMetadata, WithBoard):
|
||||
LoRAPatcher.apply_lora_patches(
|
||||
model=transformer,
|
||||
patches=self._lora_iterator(context),
|
||||
prefix="",
|
||||
prefix=FLUX_LORA_TRANSFORMER_PREFIX,
|
||||
cached_weights=cached_weights,
|
||||
)
|
||||
)
|
||||
elif config.format in [ModelFormat.BnbQuantizedLlmInt8b, ModelFormat.BnbQuantizednf4b]:
|
||||
elif config.format in [
|
||||
ModelFormat.BnbQuantizedLlmInt8b,
|
||||
ModelFormat.BnbQuantizednf4b,
|
||||
ModelFormat.GGUFQuantized,
|
||||
]:
|
||||
# The model is quantized, so apply the LoRA weights as sidecar layers. This results in slower inference,
|
||||
# than directly patching the weights, but is agnostic to the quantization format.
|
||||
exit_stack.enter_context(
|
||||
LoRAPatcher.apply_lora_sidecar_patches(
|
||||
model=transformer,
|
||||
patches=self._lora_iterator(context),
|
||||
prefix="",
|
||||
prefix=FLUX_LORA_TRANSFORMER_PREFIX,
|
||||
dtype=inference_dtype,
|
||||
)
|
||||
)
|
||||
else:
|
||||
raise ValueError(f"Unsupported model format: {config.format}")
|
||||
|
||||
# Prepare IP-Adapter extensions.
|
||||
pos_ip_adapter_extensions, neg_ip_adapter_extensions = self._prep_ip_adapter_extensions(
|
||||
pos_image_prompt_clip_embeds=pos_image_prompt_clip_embeds,
|
||||
neg_image_prompt_clip_embeds=neg_image_prompt_clip_embeds,
|
||||
ip_adapter_fields=ip_adapter_fields,
|
||||
context=context,
|
||||
exit_stack=exit_stack,
|
||||
dtype=inference_dtype,
|
||||
)
|
||||
|
||||
x = denoise(
|
||||
model=transformer,
|
||||
img=x,
|
||||
img_ids=img_ids,
|
||||
txt=t5_embeddings,
|
||||
txt_ids=txt_ids,
|
||||
vec=clip_embeddings,
|
||||
txt=pos_t5_embeddings,
|
||||
txt_ids=pos_txt_ids,
|
||||
vec=pos_clip_embeddings,
|
||||
neg_txt=neg_t5_embeddings,
|
||||
neg_txt_ids=neg_txt_ids,
|
||||
neg_vec=neg_clip_embeddings,
|
||||
timesteps=timesteps,
|
||||
step_callback=self._build_step_callback(context),
|
||||
guidance=self.guidance,
|
||||
traj_guidance_extension=traj_guidance_extension,
|
||||
cfg_scale=cfg_scale,
|
||||
inpaint_extension=inpaint_extension,
|
||||
controlnet_extensions=controlnet_extensions,
|
||||
pos_ip_adapter_extensions=pos_ip_adapter_extensions,
|
||||
neg_ip_adapter_extensions=neg_ip_adapter_extensions,
|
||||
)
|
||||
|
||||
x = unpack(x.float(), self.height, self.width)
|
||||
return x
|
||||
|
||||
@classmethod
|
||||
def prep_cfg_scale(
|
||||
cls, cfg_scale: float | list[float], timesteps: list[float], cfg_scale_start_step: int, cfg_scale_end_step: int
|
||||
) -> list[float]:
|
||||
"""Prepare the cfg_scale schedule.
|
||||
|
||||
- Clips the cfg_scale schedule based on cfg_scale_start_step and cfg_scale_end_step.
|
||||
- If cfg_scale is a list, then it is assumed to be a schedule and is returned as-is.
|
||||
- If cfg_scale is a scalar, then a linear schedule is created from cfg_scale_start_step to cfg_scale_end_step.
|
||||
"""
|
||||
# num_steps is the number of denoising steps, which is one less than the number of timesteps.
|
||||
num_steps = len(timesteps) - 1
|
||||
|
||||
# Normalize cfg_scale to a list if it is a scalar.
|
||||
cfg_scale_list: list[float]
|
||||
if isinstance(cfg_scale, float):
|
||||
cfg_scale_list = [cfg_scale] * num_steps
|
||||
elif isinstance(cfg_scale, list):
|
||||
cfg_scale_list = cfg_scale
|
||||
else:
|
||||
raise ValueError(f"Unsupported cfg_scale type: {type(cfg_scale)}")
|
||||
assert len(cfg_scale_list) == num_steps
|
||||
|
||||
# Handle negative indices for cfg_scale_start_step and cfg_scale_end_step.
|
||||
start_step_index = cfg_scale_start_step
|
||||
if start_step_index < 0:
|
||||
start_step_index = num_steps + start_step_index
|
||||
end_step_index = cfg_scale_end_step
|
||||
if end_step_index < 0:
|
||||
end_step_index = num_steps + end_step_index
|
||||
|
||||
# Validate the start and end step indices.
|
||||
if not (0 <= start_step_index < num_steps):
|
||||
raise ValueError(f"Invalid cfg_scale_start_step. Out of range: {cfg_scale_start_step}.")
|
||||
if not (0 <= end_step_index < num_steps):
|
||||
raise ValueError(f"Invalid cfg_scale_end_step. Out of range: {cfg_scale_end_step}.")
|
||||
if start_step_index > end_step_index:
|
||||
raise ValueError(
|
||||
f"cfg_scale_start_step ({cfg_scale_start_step}) must be before cfg_scale_end_step "
|
||||
+ f"({cfg_scale_end_step})."
|
||||
)
|
||||
|
||||
# Set values outside the start and end step indices to 1.0. This is equivalent to disabling cfg_scale for those
|
||||
# steps.
|
||||
clipped_cfg_scale = [1.0] * num_steps
|
||||
clipped_cfg_scale[start_step_index : end_step_index + 1] = cfg_scale_list[start_step_index : end_step_index + 1]
|
||||
|
||||
return clipped_cfg_scale
|
||||
|
||||
def _prep_inpaint_mask(self, context: InvocationContext, latents: torch.Tensor) -> torch.Tensor | None:
|
||||
"""Prepare the inpaint mask.
|
||||
|
||||
@@ -288,6 +443,210 @@ class FluxDenoiseInvocation(BaseInvocation, WithMetadata, WithBoard):
|
||||
# `latents`.
|
||||
return mask.expand_as(latents)
|
||||
|
||||
def _prep_controlnet_extensions(
|
||||
self,
|
||||
context: InvocationContext,
|
||||
exit_stack: ExitStack,
|
||||
latent_height: int,
|
||||
latent_width: int,
|
||||
dtype: torch.dtype,
|
||||
device: torch.device,
|
||||
) -> list[XLabsControlNetExtension | InstantXControlNetExtension]:
|
||||
# Normalize the controlnet input to list[ControlField].
|
||||
controlnets: list[FluxControlNetField]
|
||||
if self.control is None:
|
||||
controlnets = []
|
||||
elif isinstance(self.control, FluxControlNetField):
|
||||
controlnets = [self.control]
|
||||
elif isinstance(self.control, list):
|
||||
controlnets = self.control
|
||||
else:
|
||||
raise ValueError(f"Unsupported controlnet type: {type(self.control)}")
|
||||
|
||||
# TODO(ryand): Add a field to the model config so that we can distinguish between XLabs and InstantX ControlNets
|
||||
# before loading the models. Then make sure that all VAE encoding is done before loading the ControlNets to
|
||||
# minimize peak memory.
|
||||
|
||||
# First, load the ControlNet models so that we can determine the ControlNet types.
|
||||
controlnet_models = [context.models.load(controlnet.control_model) for controlnet in controlnets]
|
||||
|
||||
# Calculate the controlnet conditioning tensors.
|
||||
# We do this before loading the ControlNet models because it may require running the VAE, and we are trying to
|
||||
# keep peak memory down.
|
||||
controlnet_conds: list[torch.Tensor] = []
|
||||
for controlnet, controlnet_model in zip(controlnets, controlnet_models, strict=True):
|
||||
image = context.images.get_pil(controlnet.image.image_name)
|
||||
if isinstance(controlnet_model.model, InstantXControlNetFlux):
|
||||
if self.controlnet_vae is None:
|
||||
raise ValueError("A ControlNet VAE is required when using an InstantX FLUX ControlNet.")
|
||||
vae_info = context.models.load(self.controlnet_vae.vae)
|
||||
controlnet_conds.append(
|
||||
InstantXControlNetExtension.prepare_controlnet_cond(
|
||||
controlnet_image=image,
|
||||
vae_info=vae_info,
|
||||
latent_height=latent_height,
|
||||
latent_width=latent_width,
|
||||
dtype=dtype,
|
||||
device=device,
|
||||
resize_mode=controlnet.resize_mode,
|
||||
)
|
||||
)
|
||||
elif isinstance(controlnet_model.model, XLabsControlNetFlux):
|
||||
controlnet_conds.append(
|
||||
XLabsControlNetExtension.prepare_controlnet_cond(
|
||||
controlnet_image=image,
|
||||
latent_height=latent_height,
|
||||
latent_width=latent_width,
|
||||
dtype=dtype,
|
||||
device=device,
|
||||
resize_mode=controlnet.resize_mode,
|
||||
)
|
||||
)
|
||||
|
||||
# Finally, load the ControlNet models and initialize the ControlNet extensions.
|
||||
controlnet_extensions: list[XLabsControlNetExtension | InstantXControlNetExtension] = []
|
||||
for controlnet, controlnet_cond, controlnet_model in zip(
|
||||
controlnets, controlnet_conds, controlnet_models, strict=True
|
||||
):
|
||||
model = exit_stack.enter_context(controlnet_model)
|
||||
|
||||
if isinstance(model, XLabsControlNetFlux):
|
||||
controlnet_extensions.append(
|
||||
XLabsControlNetExtension(
|
||||
model=model,
|
||||
controlnet_cond=controlnet_cond,
|
||||
weight=controlnet.control_weight,
|
||||
begin_step_percent=controlnet.begin_step_percent,
|
||||
end_step_percent=controlnet.end_step_percent,
|
||||
)
|
||||
)
|
||||
elif isinstance(model, InstantXControlNetFlux):
|
||||
instantx_control_mode: torch.Tensor | None = None
|
||||
if controlnet.instantx_control_mode is not None and controlnet.instantx_control_mode >= 0:
|
||||
instantx_control_mode = torch.tensor(controlnet.instantx_control_mode, dtype=torch.long)
|
||||
instantx_control_mode = instantx_control_mode.reshape([-1, 1])
|
||||
|
||||
controlnet_extensions.append(
|
||||
InstantXControlNetExtension(
|
||||
model=model,
|
||||
controlnet_cond=controlnet_cond,
|
||||
instantx_control_mode=instantx_control_mode,
|
||||
weight=controlnet.control_weight,
|
||||
begin_step_percent=controlnet.begin_step_percent,
|
||||
end_step_percent=controlnet.end_step_percent,
|
||||
)
|
||||
)
|
||||
else:
|
||||
raise ValueError(f"Unsupported ControlNet model type: {type(model)}")
|
||||
|
||||
return controlnet_extensions
|
||||
|
||||
def _normalize_ip_adapter_fields(self) -> list[IPAdapterField]:
|
||||
if self.ip_adapter is None:
|
||||
return []
|
||||
elif isinstance(self.ip_adapter, IPAdapterField):
|
||||
return [self.ip_adapter]
|
||||
elif isinstance(self.ip_adapter, list):
|
||||
return self.ip_adapter
|
||||
else:
|
||||
raise ValueError(f"Unsupported IP-Adapter type: {type(self.ip_adapter)}")
|
||||
|
||||
def _prep_ip_adapter_image_prompt_clip_embeds(
|
||||
self,
|
||||
ip_adapter_fields: list[IPAdapterField],
|
||||
context: InvocationContext,
|
||||
) -> tuple[list[torch.Tensor], list[torch.Tensor]]:
|
||||
"""Run the IPAdapter CLIPVisionModel, returning image prompt embeddings."""
|
||||
clip_image_processor = CLIPImageProcessor()
|
||||
|
||||
pos_image_prompt_clip_embeds: list[torch.Tensor] = []
|
||||
neg_image_prompt_clip_embeds: list[torch.Tensor] = []
|
||||
for ip_adapter_field in ip_adapter_fields:
|
||||
# `ip_adapter_field.image` could be a list or a single ImageField. Normalize to a list here.
|
||||
ipa_image_fields: list[ImageField]
|
||||
if isinstance(ip_adapter_field.image, ImageField):
|
||||
ipa_image_fields = [ip_adapter_field.image]
|
||||
elif isinstance(ip_adapter_field.image, list):
|
||||
ipa_image_fields = ip_adapter_field.image
|
||||
else:
|
||||
raise ValueError(f"Unsupported IP-Adapter image type: {type(ip_adapter_field.image)}")
|
||||
|
||||
if len(ipa_image_fields) != 1:
|
||||
raise ValueError(
|
||||
f"FLUX IP-Adapter only supports a single image prompt (received {len(ipa_image_fields)})."
|
||||
)
|
||||
|
||||
ipa_images = [context.images.get_pil(image.image_name, mode="RGB") for image in ipa_image_fields]
|
||||
|
||||
pos_images: list[npt.NDArray[np.uint8]] = []
|
||||
neg_images: list[npt.NDArray[np.uint8]] = []
|
||||
for ipa_image in ipa_images:
|
||||
assert ipa_image.mode == "RGB"
|
||||
pos_image = np.array(ipa_image)
|
||||
# We use a black image as the negative image prompt for parity with
|
||||
# https://github.com/XLabs-AI/x-flux-comfyui/blob/45c834727dd2141aebc505ae4b01f193a8414e38/nodes.py#L592-L593
|
||||
# An alternative scheme would be to apply zeros_like() after calling the clip_image_processor.
|
||||
neg_image = np.zeros_like(pos_image)
|
||||
pos_images.append(pos_image)
|
||||
neg_images.append(neg_image)
|
||||
|
||||
with context.models.load(ip_adapter_field.image_encoder_model) as image_encoder_model:
|
||||
assert isinstance(image_encoder_model, CLIPVisionModelWithProjection)
|
||||
|
||||
clip_image: torch.Tensor = clip_image_processor(images=pos_images, return_tensors="pt").pixel_values
|
||||
clip_image = clip_image.to(device=image_encoder_model.device, dtype=image_encoder_model.dtype)
|
||||
pos_clip_image_embeds = image_encoder_model(clip_image).image_embeds
|
||||
|
||||
clip_image = clip_image_processor(images=neg_images, return_tensors="pt").pixel_values
|
||||
clip_image = clip_image.to(device=image_encoder_model.device, dtype=image_encoder_model.dtype)
|
||||
neg_clip_image_embeds = image_encoder_model(clip_image).image_embeds
|
||||
|
||||
pos_image_prompt_clip_embeds.append(pos_clip_image_embeds)
|
||||
neg_image_prompt_clip_embeds.append(neg_clip_image_embeds)
|
||||
|
||||
return pos_image_prompt_clip_embeds, neg_image_prompt_clip_embeds
|
||||
|
||||
def _prep_ip_adapter_extensions(
|
||||
self,
|
||||
ip_adapter_fields: list[IPAdapterField],
|
||||
pos_image_prompt_clip_embeds: list[torch.Tensor],
|
||||
neg_image_prompt_clip_embeds: list[torch.Tensor],
|
||||
context: InvocationContext,
|
||||
exit_stack: ExitStack,
|
||||
dtype: torch.dtype,
|
||||
) -> tuple[list[XLabsIPAdapterExtension], list[XLabsIPAdapterExtension]]:
|
||||
pos_ip_adapter_extensions: list[XLabsIPAdapterExtension] = []
|
||||
neg_ip_adapter_extensions: list[XLabsIPAdapterExtension] = []
|
||||
for ip_adapter_field, pos_image_prompt_clip_embed, neg_image_prompt_clip_embed in zip(
|
||||
ip_adapter_fields, pos_image_prompt_clip_embeds, neg_image_prompt_clip_embeds, strict=True
|
||||
):
|
||||
ip_adapter_model = exit_stack.enter_context(context.models.load(ip_adapter_field.ip_adapter_model))
|
||||
assert isinstance(ip_adapter_model, XlabsIpAdapterFlux)
|
||||
ip_adapter_model = ip_adapter_model.to(dtype=dtype)
|
||||
if ip_adapter_field.mask is not None:
|
||||
raise ValueError("IP-Adapter masks are not yet supported in Flux.")
|
||||
ip_adapter_extension = XLabsIPAdapterExtension(
|
||||
model=ip_adapter_model,
|
||||
image_prompt_clip_embed=pos_image_prompt_clip_embed,
|
||||
weight=ip_adapter_field.weight,
|
||||
begin_step_percent=ip_adapter_field.begin_step_percent,
|
||||
end_step_percent=ip_adapter_field.end_step_percent,
|
||||
)
|
||||
ip_adapter_extension.run_image_proj(dtype=dtype)
|
||||
pos_ip_adapter_extensions.append(ip_adapter_extension)
|
||||
|
||||
ip_adapter_extension = XLabsIPAdapterExtension(
|
||||
model=ip_adapter_model,
|
||||
image_prompt_clip_embed=neg_image_prompt_clip_embed,
|
||||
weight=ip_adapter_field.weight,
|
||||
begin_step_percent=ip_adapter_field.begin_step_percent,
|
||||
end_step_percent=ip_adapter_field.end_step_percent,
|
||||
)
|
||||
ip_adapter_extension.run_image_proj(dtype=dtype)
|
||||
neg_ip_adapter_extensions.append(ip_adapter_extension)
|
||||
|
||||
return pos_ip_adapter_extensions, neg_ip_adapter_extensions
|
||||
|
||||
def _lora_iterator(self, context: InvocationContext) -> Iterator[Tuple[LoRAModelRaw, float]]:
|
||||
for lora in self.transformer.loras:
|
||||
lora_info = context.models.load(lora.lora)
|
||||
|
||||
89
invokeai/app/invocations/flux_ip_adapter.py
Normal file
89
invokeai/app/invocations/flux_ip_adapter.py
Normal file
@@ -0,0 +1,89 @@
|
||||
from builtins import float
|
||||
from typing import List, Literal, Union
|
||||
|
||||
from pydantic import field_validator, model_validator
|
||||
from typing_extensions import Self
|
||||
|
||||
from invokeai.app.invocations.baseinvocation import BaseInvocation, Classification, invocation
|
||||
from invokeai.app.invocations.fields import InputField, UIType
|
||||
from invokeai.app.invocations.ip_adapter import (
|
||||
CLIP_VISION_MODEL_MAP,
|
||||
IPAdapterField,
|
||||
IPAdapterInvocation,
|
||||
IPAdapterOutput,
|
||||
)
|
||||
from invokeai.app.invocations.model import ModelIdentifierField
|
||||
from invokeai.app.invocations.primitives import ImageField
|
||||
from invokeai.app.invocations.util import validate_begin_end_step, validate_weights
|
||||
from invokeai.app.services.shared.invocation_context import InvocationContext
|
||||
from invokeai.backend.model_manager.config import (
|
||||
IPAdapterCheckpointConfig,
|
||||
IPAdapterInvokeAIConfig,
|
||||
)
|
||||
|
||||
|
||||
@invocation(
|
||||
"flux_ip_adapter",
|
||||
title="FLUX IP-Adapter",
|
||||
tags=["ip_adapter", "control"],
|
||||
category="ip_adapter",
|
||||
version="1.0.0",
|
||||
classification=Classification.Prototype,
|
||||
)
|
||||
class FluxIPAdapterInvocation(BaseInvocation):
|
||||
"""Collects FLUX IP-Adapter info to pass to other nodes."""
|
||||
|
||||
# FLUXIPAdapterInvocation is based closely on IPAdapterInvocation, but with some unsupported features removed.
|
||||
|
||||
image: ImageField = InputField(description="The IP-Adapter image prompt(s).")
|
||||
ip_adapter_model: ModelIdentifierField = InputField(
|
||||
description="The IP-Adapter model.", title="IP-Adapter Model", ui_type=UIType.IPAdapterModel
|
||||
)
|
||||
# Currently, the only known ViT model used by FLUX IP-Adapters is ViT-L.
|
||||
clip_vision_model: Literal["ViT-L"] = InputField(description="CLIP Vision model to use.", default="ViT-L")
|
||||
weight: Union[float, List[float]] = InputField(
|
||||
default=1, description="The weight given to the IP-Adapter", title="Weight"
|
||||
)
|
||||
begin_step_percent: float = InputField(
|
||||
default=0, ge=0, le=1, description="When the IP-Adapter is first applied (% of total steps)"
|
||||
)
|
||||
end_step_percent: float = InputField(
|
||||
default=1, ge=0, le=1, description="When the IP-Adapter is last applied (% of total steps)"
|
||||
)
|
||||
|
||||
@field_validator("weight")
|
||||
@classmethod
|
||||
def validate_ip_adapter_weight(cls, v: float) -> float:
|
||||
validate_weights(v)
|
||||
return v
|
||||
|
||||
@model_validator(mode="after")
|
||||
def validate_begin_end_step_percent(self) -> Self:
|
||||
validate_begin_end_step(self.begin_step_percent, self.end_step_percent)
|
||||
return self
|
||||
|
||||
def invoke(self, context: InvocationContext) -> IPAdapterOutput:
|
||||
# Lookup the CLIP Vision encoder that is intended to be used with the IP-Adapter model.
|
||||
ip_adapter_info = context.models.get_config(self.ip_adapter_model.key)
|
||||
assert isinstance(ip_adapter_info, (IPAdapterInvokeAIConfig, IPAdapterCheckpointConfig))
|
||||
|
||||
# Note: There is a IPAdapterInvokeAIConfig.image_encoder_model_id field, but it isn't trustworthy.
|
||||
image_encoder_starter_model = CLIP_VISION_MODEL_MAP[self.clip_vision_model]
|
||||
image_encoder_model_id = image_encoder_starter_model.source
|
||||
image_encoder_model_name = image_encoder_starter_model.name
|
||||
image_encoder_model = IPAdapterInvocation.get_clip_image_encoder(
|
||||
context, image_encoder_model_id, image_encoder_model_name
|
||||
)
|
||||
|
||||
return IPAdapterOutput(
|
||||
ip_adapter=IPAdapterField(
|
||||
image=self.image,
|
||||
ip_adapter_model=self.ip_adapter_model,
|
||||
image_encoder_model=ModelIdentifierField.from_config(image_encoder_model),
|
||||
weight=self.weight,
|
||||
target_blocks=[], # target_blocks is currently unused for FLUX IP-Adapters.
|
||||
begin_step_percent=self.begin_step_percent,
|
||||
end_step_percent=self.end_step_percent,
|
||||
mask=None, # mask is currently unused for FLUX IP-Adapters.
|
||||
),
|
||||
)
|
||||
@@ -8,7 +8,7 @@ from invokeai.app.invocations.baseinvocation import (
|
||||
invocation_output,
|
||||
)
|
||||
from invokeai.app.invocations.fields import FieldDescriptions, Input, InputField, OutputField, UIType
|
||||
from invokeai.app.invocations.model import LoRAField, ModelIdentifierField, TransformerField
|
||||
from invokeai.app.invocations.model import CLIPField, LoRAField, ModelIdentifierField, TransformerField
|
||||
from invokeai.app.services.shared.invocation_context import InvocationContext
|
||||
from invokeai.backend.model_manager.config import BaseModelType
|
||||
|
||||
@@ -20,6 +20,7 @@ class FluxLoRALoaderOutput(BaseInvocationOutput):
|
||||
transformer: Optional[TransformerField] = OutputField(
|
||||
default=None, description=FieldDescriptions.transformer, title="FLUX Transformer"
|
||||
)
|
||||
clip: Optional[CLIPField] = OutputField(default=None, description=FieldDescriptions.clip, title="CLIP")
|
||||
|
||||
|
||||
@invocation(
|
||||
@@ -27,21 +28,28 @@ class FluxLoRALoaderOutput(BaseInvocationOutput):
|
||||
title="FLUX LoRA",
|
||||
tags=["lora", "model", "flux"],
|
||||
category="model",
|
||||
version="1.0.0",
|
||||
version="1.1.0",
|
||||
classification=Classification.Prototype,
|
||||
)
|
||||
class FluxLoRALoaderInvocation(BaseInvocation):
|
||||
"""Apply a LoRA model to a FLUX transformer."""
|
||||
"""Apply a LoRA model to a FLUX transformer and/or text encoder."""
|
||||
|
||||
lora: ModelIdentifierField = InputField(
|
||||
description=FieldDescriptions.lora_model, title="LoRA", ui_type=UIType.LoRAModel
|
||||
)
|
||||
weight: float = InputField(default=0.75, description=FieldDescriptions.lora_weight)
|
||||
transformer: TransformerField = InputField(
|
||||
transformer: TransformerField | None = InputField(
|
||||
default=None,
|
||||
description=FieldDescriptions.transformer,
|
||||
input=Input.Connection,
|
||||
title="FLUX Transformer",
|
||||
)
|
||||
clip: CLIPField | None = InputField(
|
||||
default=None,
|
||||
title="CLIP",
|
||||
description=FieldDescriptions.clip,
|
||||
input=Input.Connection,
|
||||
)
|
||||
|
||||
def invoke(self, context: InvocationContext) -> FluxLoRALoaderOutput:
|
||||
lora_key = self.lora.key
|
||||
@@ -49,18 +57,33 @@ class FluxLoRALoaderInvocation(BaseInvocation):
|
||||
if not context.models.exists(lora_key):
|
||||
raise ValueError(f"Unknown lora: {lora_key}!")
|
||||
|
||||
if any(lora.lora.key == lora_key for lora in self.transformer.loras):
|
||||
# Check for existing LoRAs with the same key.
|
||||
if self.transformer and any(lora.lora.key == lora_key for lora in self.transformer.loras):
|
||||
raise ValueError(f'LoRA "{lora_key}" already applied to transformer.')
|
||||
if self.clip and any(lora.lora.key == lora_key for lora in self.clip.loras):
|
||||
raise ValueError(f'LoRA "{lora_key}" already applied to CLIP encoder.')
|
||||
|
||||
transformer = self.transformer.model_copy(deep=True)
|
||||
transformer.loras.append(
|
||||
LoRAField(
|
||||
lora=self.lora,
|
||||
weight=self.weight,
|
||||
output = FluxLoRALoaderOutput()
|
||||
|
||||
# Attach LoRA layers to the models.
|
||||
if self.transformer is not None:
|
||||
output.transformer = self.transformer.model_copy(deep=True)
|
||||
output.transformer.loras.append(
|
||||
LoRAField(
|
||||
lora=self.lora,
|
||||
weight=self.weight,
|
||||
)
|
||||
)
|
||||
if self.clip is not None:
|
||||
output.clip = self.clip.model_copy(deep=True)
|
||||
output.clip.loras.append(
|
||||
LoRAField(
|
||||
lora=self.lora,
|
||||
weight=self.weight,
|
||||
)
|
||||
)
|
||||
)
|
||||
|
||||
return FluxLoRALoaderOutput(transformer=transformer)
|
||||
return output
|
||||
|
||||
|
||||
@invocation(
|
||||
@@ -68,7 +91,7 @@ class FluxLoRALoaderInvocation(BaseInvocation):
|
||||
title="FLUX LoRA Collection Loader",
|
||||
tags=["lora", "model", "flux"],
|
||||
category="model",
|
||||
version="1.0.0",
|
||||
version="1.1.0",
|
||||
classification=Classification.Prototype,
|
||||
)
|
||||
class FLUXLoRACollectionLoader(BaseInvocation):
|
||||
@@ -84,6 +107,12 @@ class FLUXLoRACollectionLoader(BaseInvocation):
|
||||
input=Input.Connection,
|
||||
title="Transformer",
|
||||
)
|
||||
clip: CLIPField | None = InputField(
|
||||
default=None,
|
||||
title="CLIP",
|
||||
description=FieldDescriptions.clip,
|
||||
input=Input.Connection,
|
||||
)
|
||||
|
||||
def invoke(self, context: InvocationContext) -> FluxLoRALoaderOutput:
|
||||
output = FluxLoRALoaderOutput()
|
||||
@@ -106,4 +135,9 @@ class FLUXLoRACollectionLoader(BaseInvocation):
|
||||
output.transformer = self.transformer.model_copy(deep=True)
|
||||
output.transformer.loras.append(lora)
|
||||
|
||||
if self.clip is not None:
|
||||
if output.clip is None:
|
||||
output.clip = self.clip.model_copy(deep=True)
|
||||
output.clip.loras.append(lora)
|
||||
|
||||
return output
|
||||
|
||||
@@ -1,4 +1,5 @@
|
||||
from typing import Literal
|
||||
from contextlib import ExitStack
|
||||
from typing import Iterator, Literal, Tuple
|
||||
|
||||
import torch
|
||||
from transformers import CLIPTextModel, CLIPTokenizer, T5EncoderModel, T5Tokenizer
|
||||
@@ -9,6 +10,10 @@ from invokeai.app.invocations.model import CLIPField, T5EncoderField
|
||||
from invokeai.app.invocations.primitives import FluxConditioningOutput
|
||||
from invokeai.app.services.shared.invocation_context import InvocationContext
|
||||
from invokeai.backend.flux.modules.conditioner import HFEncoder
|
||||
from invokeai.backend.lora.conversions.flux_lora_constants import FLUX_LORA_CLIP_PREFIX
|
||||
from invokeai.backend.lora.lora_model_raw import LoRAModelRaw
|
||||
from invokeai.backend.lora.lora_patcher import LoRAPatcher
|
||||
from invokeai.backend.model_manager.config import ModelFormat
|
||||
from invokeai.backend.stable_diffusion.diffusion.conditioning_data import ConditioningFieldData, FLUXConditioningInfo
|
||||
|
||||
|
||||
@@ -17,7 +22,7 @@ from invokeai.backend.stable_diffusion.diffusion.conditioning_data import Condit
|
||||
title="FLUX Text Encoding",
|
||||
tags=["prompt", "conditioning", "flux"],
|
||||
category="conditioning",
|
||||
version="1.0.0",
|
||||
version="1.1.0",
|
||||
classification=Classification.Prototype,
|
||||
)
|
||||
class FluxTextEncoderInvocation(BaseInvocation):
|
||||
@@ -78,15 +83,42 @@ class FluxTextEncoderInvocation(BaseInvocation):
|
||||
prompt = [self.prompt]
|
||||
|
||||
with (
|
||||
clip_text_encoder_info as clip_text_encoder,
|
||||
clip_text_encoder_info.model_on_device() as (cached_weights, clip_text_encoder),
|
||||
clip_tokenizer_info as clip_tokenizer,
|
||||
ExitStack() as exit_stack,
|
||||
):
|
||||
assert isinstance(clip_text_encoder, CLIPTextModel)
|
||||
assert isinstance(clip_tokenizer, CLIPTokenizer)
|
||||
|
||||
clip_text_encoder_config = clip_text_encoder_info.config
|
||||
assert clip_text_encoder_config is not None
|
||||
|
||||
# Apply LoRA models to the CLIP encoder.
|
||||
# Note: We apply the LoRA after the transformer has been moved to its target device for faster patching.
|
||||
if clip_text_encoder_config.format in [ModelFormat.Diffusers]:
|
||||
# The model is non-quantized, so we can apply the LoRA weights directly into the model.
|
||||
exit_stack.enter_context(
|
||||
LoRAPatcher.apply_lora_patches(
|
||||
model=clip_text_encoder,
|
||||
patches=self._clip_lora_iterator(context),
|
||||
prefix=FLUX_LORA_CLIP_PREFIX,
|
||||
cached_weights=cached_weights,
|
||||
)
|
||||
)
|
||||
else:
|
||||
# There are currently no supported CLIP quantized models. Add support here if needed.
|
||||
raise ValueError(f"Unsupported model format: {clip_text_encoder_config.format}")
|
||||
|
||||
clip_encoder = HFEncoder(clip_text_encoder, clip_tokenizer, True, 77)
|
||||
|
||||
pooled_prompt_embeds = clip_encoder(prompt)
|
||||
|
||||
assert isinstance(pooled_prompt_embeds, torch.Tensor)
|
||||
return pooled_prompt_embeds
|
||||
|
||||
def _clip_lora_iterator(self, context: InvocationContext) -> Iterator[Tuple[LoRAModelRaw, float]]:
|
||||
for lora in self.clip.loras:
|
||||
lora_info = context.models.load(lora.lora)
|
||||
assert isinstance(lora_info.model, LoRAModelRaw)
|
||||
yield (lora_info.model, lora.weight)
|
||||
del lora_info
|
||||
|
||||
@@ -9,6 +9,7 @@ from invokeai.app.invocations.fields import FieldDescriptions, InputField, Outpu
|
||||
from invokeai.app.invocations.model import ModelIdentifierField
|
||||
from invokeai.app.invocations.primitives import ImageField
|
||||
from invokeai.app.invocations.util import validate_begin_end_step, validate_weights
|
||||
from invokeai.app.services.model_records.model_records_base import ModelRecordChanges
|
||||
from invokeai.app.services.shared.invocation_context import InvocationContext
|
||||
from invokeai.backend.model_manager.config import (
|
||||
AnyModelConfig,
|
||||
@@ -17,6 +18,12 @@ from invokeai.backend.model_manager.config import (
|
||||
IPAdapterInvokeAIConfig,
|
||||
ModelType,
|
||||
)
|
||||
from invokeai.backend.model_manager.starter_models import (
|
||||
StarterModel,
|
||||
clip_vit_l_image_encoder,
|
||||
ip_adapter_sd_image_encoder,
|
||||
ip_adapter_sdxl_image_encoder,
|
||||
)
|
||||
|
||||
|
||||
class IPAdapterField(BaseModel):
|
||||
@@ -55,10 +62,14 @@ class IPAdapterOutput(BaseInvocationOutput):
|
||||
ip_adapter: IPAdapterField = OutputField(description=FieldDescriptions.ip_adapter, title="IP-Adapter")
|
||||
|
||||
|
||||
CLIP_VISION_MODEL_MAP = {"ViT-H": "ip_adapter_sd_image_encoder", "ViT-G": "ip_adapter_sdxl_image_encoder"}
|
||||
CLIP_VISION_MODEL_MAP: dict[Literal["ViT-L", "ViT-H", "ViT-G"], StarterModel] = {
|
||||
"ViT-L": clip_vit_l_image_encoder,
|
||||
"ViT-H": ip_adapter_sd_image_encoder,
|
||||
"ViT-G": ip_adapter_sdxl_image_encoder,
|
||||
}
|
||||
|
||||
|
||||
@invocation("ip_adapter", title="IP-Adapter", tags=["ip_adapter", "control"], category="ip_adapter", version="1.4.1")
|
||||
@invocation("ip_adapter", title="IP-Adapter", tags=["ip_adapter", "control"], category="ip_adapter", version="1.5.0")
|
||||
class IPAdapterInvocation(BaseInvocation):
|
||||
"""Collects IP-Adapter info to pass to other nodes."""
|
||||
|
||||
@@ -70,7 +81,7 @@ class IPAdapterInvocation(BaseInvocation):
|
||||
ui_order=-1,
|
||||
ui_type=UIType.IPAdapterModel,
|
||||
)
|
||||
clip_vision_model: Literal["ViT-H", "ViT-G"] = InputField(
|
||||
clip_vision_model: Literal["ViT-H", "ViT-G", "ViT-L"] = InputField(
|
||||
description="CLIP Vision model to use. Overrides model settings. Mandatory for checkpoint models.",
|
||||
default="ViT-H",
|
||||
ui_order=2,
|
||||
@@ -111,9 +122,11 @@ class IPAdapterInvocation(BaseInvocation):
|
||||
image_encoder_model_id = ip_adapter_info.image_encoder_model_id
|
||||
image_encoder_model_name = image_encoder_model_id.split("/")[-1].strip()
|
||||
else:
|
||||
image_encoder_model_name = CLIP_VISION_MODEL_MAP[self.clip_vision_model]
|
||||
image_encoder_starter_model = CLIP_VISION_MODEL_MAP[self.clip_vision_model]
|
||||
image_encoder_model_id = image_encoder_starter_model.source
|
||||
image_encoder_model_name = image_encoder_starter_model.name
|
||||
|
||||
image_encoder_model = self._get_image_encoder(context, image_encoder_model_name)
|
||||
image_encoder_model = self.get_clip_image_encoder(context, image_encoder_model_id, image_encoder_model_name)
|
||||
|
||||
if self.method == "style":
|
||||
if ip_adapter_info.base == "sd-1":
|
||||
@@ -147,7 +160,10 @@ class IPAdapterInvocation(BaseInvocation):
|
||||
),
|
||||
)
|
||||
|
||||
def _get_image_encoder(self, context: InvocationContext, image_encoder_model_name: str) -> AnyModelConfig:
|
||||
@classmethod
|
||||
def get_clip_image_encoder(
|
||||
cls, context: InvocationContext, image_encoder_model_id: str, image_encoder_model_name: str
|
||||
) -> AnyModelConfig:
|
||||
image_encoder_models = context.models.search_by_attrs(
|
||||
name=image_encoder_model_name, base=BaseModelType.Any, type=ModelType.CLIPVision
|
||||
)
|
||||
@@ -159,7 +175,11 @@ class IPAdapterInvocation(BaseInvocation):
|
||||
)
|
||||
|
||||
installer = context._services.model_manager.install
|
||||
job = installer.heuristic_import(f"InvokeAI/{image_encoder_model_name}")
|
||||
# Note: We hard-code the type to CLIPVision here because if the model contains both a CLIPVision and a
|
||||
# CLIPText model, the probe may treat it as a CLIPText model.
|
||||
job = installer.heuristic_import(
|
||||
image_encoder_model_id, ModelRecordChanges(name=image_encoder_model_name, type=ModelType.CLIPVision)
|
||||
)
|
||||
installer.wait_for_job(job, timeout=600) # Wait for up to 10 minutes
|
||||
image_encoder_models = context.models.search_by_attrs(
|
||||
name=image_encoder_model_name, base=BaseModelType.Any, type=ModelType.CLIPVision
|
||||
|
||||
@@ -5,6 +5,7 @@ from PIL import Image
|
||||
from invokeai.app.invocations.baseinvocation import BaseInvocation, Classification, InvocationContext, invocation
|
||||
from invokeai.app.invocations.fields import ImageField, InputField, TensorField, WithBoard, WithMetadata
|
||||
from invokeai.app.invocations.primitives import ImageOutput, MaskOutput
|
||||
from invokeai.backend.image_util.util import pil_to_np
|
||||
|
||||
|
||||
@invocation(
|
||||
@@ -148,3 +149,55 @@ class MaskTensorToImageInvocation(BaseInvocation, WithMetadata, WithBoard):
|
||||
mask_pil = Image.fromarray(mask_np, mode="L")
|
||||
image_dto = context.images.save(image=mask_pil)
|
||||
return ImageOutput.build(image_dto)
|
||||
|
||||
|
||||
@invocation(
|
||||
"apply_tensor_mask_to_image",
|
||||
title="Apply Tensor Mask to Image",
|
||||
tags=["mask"],
|
||||
category="mask",
|
||||
version="1.0.0",
|
||||
)
|
||||
class ApplyMaskTensorToImageInvocation(BaseInvocation, WithMetadata, WithBoard):
|
||||
"""Applies a tensor mask to an image.
|
||||
|
||||
The image is converted to RGBA and the mask is applied to the alpha channel."""
|
||||
|
||||
mask: TensorField = InputField(description="The mask tensor to apply.")
|
||||
image: ImageField = InputField(description="The image to apply the mask to.")
|
||||
invert: bool = InputField(default=False, description="Whether to invert the mask.")
|
||||
|
||||
def invoke(self, context: InvocationContext) -> ImageOutput:
|
||||
image = context.images.get_pil(self.image.image_name, mode="RGBA")
|
||||
mask = context.tensors.load(self.mask.tensor_name)
|
||||
|
||||
# Squeeze the channel dimension if it exists.
|
||||
if mask.dim() == 3:
|
||||
mask = mask.squeeze(0)
|
||||
|
||||
# Ensure that the mask is binary.
|
||||
if mask.dtype != torch.bool:
|
||||
mask = mask > 0.5
|
||||
mask_np = (mask.float() * 255).byte().cpu().numpy().astype(np.uint8)
|
||||
|
||||
if self.invert:
|
||||
mask_np = 255 - mask_np
|
||||
|
||||
# Apply the mask only to the alpha channel where the original alpha is non-zero. This preserves the original
|
||||
# image's transparency - else the transparent regions would end up as opaque black.
|
||||
|
||||
# Separate the image into R, G, B, and A channels
|
||||
image_np = pil_to_np(image)
|
||||
r, g, b, a = np.split(image_np, 4, axis=-1)
|
||||
|
||||
# Apply the mask to the alpha channel
|
||||
new_alpha = np.where(a.squeeze() > 0, mask_np, a.squeeze())
|
||||
|
||||
# Stack the RGB channels with the modified alpha
|
||||
masked_image_np = np.dstack([r.squeeze(), g.squeeze(), b.squeeze(), new_alpha])
|
||||
|
||||
# Convert back to an image (RGBA)
|
||||
masked_image = Image.fromarray(masked_image_np.astype(np.uint8), "RGBA")
|
||||
image_dto = context.images.save(image=masked_image)
|
||||
|
||||
return ImageOutput.build(image_dto)
|
||||
|
||||
@@ -40,7 +40,7 @@ class IPAdapterMetadataField(BaseModel):
|
||||
|
||||
image: ImageField = Field(description="The IP-Adapter image prompt.")
|
||||
ip_adapter_model: ModelIdentifierField = Field(description="The IP-Adapter model.")
|
||||
clip_vision_model: Literal["ViT-H", "ViT-G"] = Field(description="The CLIP Vision model")
|
||||
clip_vision_model: Literal["ViT-L", "ViT-H", "ViT-G"] = Field(description="The CLIP Vision model")
|
||||
method: Literal["full", "style", "composition"] = Field(description="Method to apply IP Weights with")
|
||||
weight: Union[float, list[float]] = Field(description="The weight given to the IP-Adapter")
|
||||
begin_step_percent: float = Field(description="When the IP-Adapter is first applied (% of total steps)")
|
||||
|
||||
@@ -1,9 +1,11 @@
|
||||
from enum import Enum
|
||||
from pathlib import Path
|
||||
from typing import Literal
|
||||
|
||||
import numpy as np
|
||||
import torch
|
||||
from PIL import Image
|
||||
from pydantic import BaseModel, Field, model_validator
|
||||
from transformers import AutoModelForMaskGeneration, AutoProcessor
|
||||
from transformers.models.sam import SamModel
|
||||
from transformers.models.sam.processing_sam import SamProcessor
|
||||
@@ -23,12 +25,31 @@ SEGMENT_ANYTHING_MODEL_IDS: dict[SegmentAnythingModelKey, str] = {
|
||||
}
|
||||
|
||||
|
||||
class SAMPointLabel(Enum):
|
||||
negative = -1
|
||||
neutral = 0
|
||||
positive = 1
|
||||
|
||||
|
||||
class SAMPoint(BaseModel):
|
||||
x: int = Field(..., description="The x-coordinate of the point")
|
||||
y: int = Field(..., description="The y-coordinate of the point")
|
||||
label: SAMPointLabel = Field(..., description="The label of the point")
|
||||
|
||||
|
||||
class SAMPointsField(BaseModel):
|
||||
points: list[SAMPoint] = Field(..., description="The points of the object")
|
||||
|
||||
def to_list(self) -> list[list[int]]:
|
||||
return [[point.x, point.y, point.label.value] for point in self.points]
|
||||
|
||||
|
||||
@invocation(
|
||||
"segment_anything",
|
||||
title="Segment Anything",
|
||||
tags=["prompt", "segmentation"],
|
||||
category="segmentation",
|
||||
version="1.0.0",
|
||||
version="1.1.0",
|
||||
)
|
||||
class SegmentAnythingInvocation(BaseInvocation):
|
||||
"""Runs a Segment Anything Model."""
|
||||
@@ -40,7 +61,13 @@ class SegmentAnythingInvocation(BaseInvocation):
|
||||
|
||||
model: SegmentAnythingModelKey = InputField(description="The Segment Anything model to use.")
|
||||
image: ImageField = InputField(description="The image to segment.")
|
||||
bounding_boxes: list[BoundingBoxField] = InputField(description="The bounding boxes to prompt the SAM model with.")
|
||||
bounding_boxes: list[BoundingBoxField] | None = InputField(
|
||||
default=None, description="The bounding boxes to prompt the SAM model with."
|
||||
)
|
||||
point_lists: list[SAMPointsField] | None = InputField(
|
||||
default=None,
|
||||
description="The list of point lists to prompt the SAM model with. Each list of points represents a single object.",
|
||||
)
|
||||
apply_polygon_refinement: bool = InputField(
|
||||
description="Whether to apply polygon refinement to the masks. This will smooth the edges of the masks slightly and ensure that each mask consists of a single closed polygon (before merging).",
|
||||
default=True,
|
||||
@@ -50,12 +77,22 @@ class SegmentAnythingInvocation(BaseInvocation):
|
||||
default="all",
|
||||
)
|
||||
|
||||
@model_validator(mode="after")
|
||||
def check_point_lists_or_bounding_box(self):
|
||||
if self.point_lists is None and self.bounding_boxes is None:
|
||||
raise ValueError("Either point_lists or bounding_box must be provided.")
|
||||
elif self.point_lists is not None and self.bounding_boxes is not None:
|
||||
raise ValueError("Only one of point_lists or bounding_box can be provided.")
|
||||
return self
|
||||
|
||||
@torch.no_grad()
|
||||
def invoke(self, context: InvocationContext) -> MaskOutput:
|
||||
# The models expect a 3-channel RGB image.
|
||||
image_pil = context.images.get_pil(self.image.image_name, mode="RGB")
|
||||
|
||||
if len(self.bounding_boxes) == 0:
|
||||
if (not self.bounding_boxes or len(self.bounding_boxes) == 0) and (
|
||||
not self.point_lists or len(self.point_lists) == 0
|
||||
):
|
||||
combined_mask = torch.zeros(image_pil.size[::-1], dtype=torch.bool)
|
||||
else:
|
||||
masks = self._segment(context=context, image=image_pil)
|
||||
@@ -83,14 +120,13 @@ class SegmentAnythingInvocation(BaseInvocation):
|
||||
assert isinstance(sam_processor, SamProcessor)
|
||||
return SegmentAnythingPipeline(sam_model=sam_model, sam_processor=sam_processor)
|
||||
|
||||
def _segment(
|
||||
self,
|
||||
context: InvocationContext,
|
||||
image: Image.Image,
|
||||
) -> list[torch.Tensor]:
|
||||
def _segment(self, context: InvocationContext, image: Image.Image) -> list[torch.Tensor]:
|
||||
"""Use Segment Anything (SAM) to generate masks given an image + a set of bounding boxes."""
|
||||
# Convert the bounding boxes to the SAM input format.
|
||||
sam_bounding_boxes = [[bb.x_min, bb.y_min, bb.x_max, bb.y_max] for bb in self.bounding_boxes]
|
||||
sam_bounding_boxes = (
|
||||
[[bb.x_min, bb.y_min, bb.x_max, bb.y_max] for bb in self.bounding_boxes] if self.bounding_boxes else None
|
||||
)
|
||||
sam_points = [p.to_list() for p in self.point_lists] if self.point_lists else None
|
||||
|
||||
with (
|
||||
context.models.load_remote_model(
|
||||
@@ -98,7 +134,7 @@ class SegmentAnythingInvocation(BaseInvocation):
|
||||
) as sam_pipeline,
|
||||
):
|
||||
assert isinstance(sam_pipeline, SegmentAnythingPipeline)
|
||||
masks = sam_pipeline.segment(image=image, bounding_boxes=sam_bounding_boxes)
|
||||
masks = sam_pipeline.segment(image=image, bounding_boxes=sam_bounding_boxes, point_lists=sam_points)
|
||||
|
||||
masks = self._process_masks(masks)
|
||||
if self.apply_polygon_refinement:
|
||||
@@ -141,9 +177,10 @@ class SegmentAnythingInvocation(BaseInvocation):
|
||||
|
||||
return masks
|
||||
|
||||
def _filter_masks(self, masks: list[torch.Tensor], bounding_boxes: list[BoundingBoxField]) -> list[torch.Tensor]:
|
||||
def _filter_masks(
|
||||
self, masks: list[torch.Tensor], bounding_boxes: list[BoundingBoxField] | None
|
||||
) -> list[torch.Tensor]:
|
||||
"""Filter the detected masks based on the specified mask filter."""
|
||||
assert len(masks) == len(bounding_boxes)
|
||||
|
||||
if self.mask_filter == "all":
|
||||
return masks
|
||||
@@ -151,6 +188,10 @@ class SegmentAnythingInvocation(BaseInvocation):
|
||||
# Find the largest mask.
|
||||
return [max(masks, key=lambda x: float(x.sum()))]
|
||||
elif self.mask_filter == "highest_box_score":
|
||||
assert (
|
||||
bounding_boxes is not None
|
||||
), "Bounding boxes must be provided to use the 'highest_box_score' mask filter."
|
||||
assert len(masks) == len(bounding_boxes)
|
||||
# Find the index of the bounding box with the highest score.
|
||||
# Note that we fallback to -1.0 if the score is None. This is mainly to satisfy the type checker. In most
|
||||
# cases the scores should all be non-None when using this filtering mode. That being said, -1.0 is a
|
||||
|
||||
@@ -1,7 +1,8 @@
|
||||
from abc import ABC, abstractmethod
|
||||
|
||||
from invokeai.app.services.board_records.board_records_common import BoardChanges, BoardRecord
|
||||
from invokeai.app.services.board_records.board_records_common import BoardChanges, BoardRecord, BoardRecordOrderBy
|
||||
from invokeai.app.services.shared.pagination import OffsetPaginatedResults
|
||||
from invokeai.app.services.shared.sqlite.sqlite_common import SQLiteDirection
|
||||
|
||||
|
||||
class BoardRecordStorageBase(ABC):
|
||||
@@ -39,12 +40,19 @@ class BoardRecordStorageBase(ABC):
|
||||
|
||||
@abstractmethod
|
||||
def get_many(
|
||||
self, offset: int = 0, limit: int = 10, include_archived: bool = False
|
||||
self,
|
||||
order_by: BoardRecordOrderBy,
|
||||
direction: SQLiteDirection,
|
||||
offset: int = 0,
|
||||
limit: int = 10,
|
||||
include_archived: bool = False,
|
||||
) -> OffsetPaginatedResults[BoardRecord]:
|
||||
"""Gets many board records."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def get_all(self, include_archived: bool = False) -> list[BoardRecord]:
|
||||
def get_all(
|
||||
self, order_by: BoardRecordOrderBy, direction: SQLiteDirection, include_archived: bool = False
|
||||
) -> list[BoardRecord]:
|
||||
"""Gets all board records."""
|
||||
pass
|
||||
|
||||
@@ -1,8 +1,10 @@
|
||||
from datetime import datetime
|
||||
from enum import Enum
|
||||
from typing import Optional, Union
|
||||
|
||||
from pydantic import BaseModel, Field
|
||||
|
||||
from invokeai.app.util.metaenum import MetaEnum
|
||||
from invokeai.app.util.misc import get_iso_timestamp
|
||||
from invokeai.app.util.model_exclude_null import BaseModelExcludeNull
|
||||
|
||||
@@ -60,6 +62,13 @@ class BoardChanges(BaseModel, extra="forbid"):
|
||||
archived: Optional[bool] = Field(default=None, description="Whether or not the board is archived")
|
||||
|
||||
|
||||
class BoardRecordOrderBy(str, Enum, metaclass=MetaEnum):
|
||||
"""The order by options for board records"""
|
||||
|
||||
CreatedAt = "created_at"
|
||||
Name = "board_name"
|
||||
|
||||
|
||||
class BoardRecordNotFoundException(Exception):
|
||||
"""Raised when an board record is not found."""
|
||||
|
||||
|
||||
@@ -8,10 +8,12 @@ from invokeai.app.services.board_records.board_records_common import (
|
||||
BoardRecord,
|
||||
BoardRecordDeleteException,
|
||||
BoardRecordNotFoundException,
|
||||
BoardRecordOrderBy,
|
||||
BoardRecordSaveException,
|
||||
deserialize_board_record,
|
||||
)
|
||||
from invokeai.app.services.shared.pagination import OffsetPaginatedResults
|
||||
from invokeai.app.services.shared.sqlite.sqlite_common import SQLiteDirection
|
||||
from invokeai.app.services.shared.sqlite.sqlite_database import SqliteDatabase
|
||||
from invokeai.app.util.misc import uuid_string
|
||||
|
||||
@@ -144,7 +146,12 @@ class SqliteBoardRecordStorage(BoardRecordStorageBase):
|
||||
return self.get(board_id)
|
||||
|
||||
def get_many(
|
||||
self, offset: int = 0, limit: int = 10, include_archived: bool = False
|
||||
self,
|
||||
order_by: BoardRecordOrderBy,
|
||||
direction: SQLiteDirection,
|
||||
offset: int = 0,
|
||||
limit: int = 10,
|
||||
include_archived: bool = False,
|
||||
) -> OffsetPaginatedResults[BoardRecord]:
|
||||
try:
|
||||
self._lock.acquire()
|
||||
@@ -154,17 +161,16 @@ class SqliteBoardRecordStorage(BoardRecordStorageBase):
|
||||
SELECT *
|
||||
FROM boards
|
||||
{archived_filter}
|
||||
ORDER BY created_at DESC
|
||||
ORDER BY {order_by} {direction}
|
||||
LIMIT ? OFFSET ?;
|
||||
"""
|
||||
|
||||
# Determine archived filter condition
|
||||
if include_archived:
|
||||
archived_filter = ""
|
||||
else:
|
||||
archived_filter = "WHERE archived = 0"
|
||||
archived_filter = "" if include_archived else "WHERE archived = 0"
|
||||
|
||||
final_query = base_query.format(archived_filter=archived_filter)
|
||||
final_query = base_query.format(
|
||||
archived_filter=archived_filter, order_by=order_by.value, direction=direction.value
|
||||
)
|
||||
|
||||
# Execute query to fetch boards
|
||||
self._cursor.execute(final_query, (limit, offset))
|
||||
@@ -198,23 +204,32 @@ class SqliteBoardRecordStorage(BoardRecordStorageBase):
|
||||
finally:
|
||||
self._lock.release()
|
||||
|
||||
def get_all(self, include_archived: bool = False) -> list[BoardRecord]:
|
||||
def get_all(
|
||||
self, order_by: BoardRecordOrderBy, direction: SQLiteDirection, include_archived: bool = False
|
||||
) -> list[BoardRecord]:
|
||||
try:
|
||||
self._lock.acquire()
|
||||
|
||||
base_query = """
|
||||
SELECT *
|
||||
FROM boards
|
||||
{archived_filter}
|
||||
ORDER BY created_at DESC
|
||||
"""
|
||||
|
||||
if include_archived:
|
||||
archived_filter = ""
|
||||
if order_by == BoardRecordOrderBy.Name:
|
||||
base_query = """
|
||||
SELECT *
|
||||
FROM boards
|
||||
{archived_filter}
|
||||
ORDER BY LOWER(board_name) {direction}
|
||||
"""
|
||||
else:
|
||||
archived_filter = "WHERE archived = 0"
|
||||
base_query = """
|
||||
SELECT *
|
||||
FROM boards
|
||||
{archived_filter}
|
||||
ORDER BY {order_by} {direction}
|
||||
"""
|
||||
|
||||
final_query = base_query.format(archived_filter=archived_filter)
|
||||
archived_filter = "" if include_archived else "WHERE archived = 0"
|
||||
|
||||
final_query = base_query.format(
|
||||
archived_filter=archived_filter, order_by=order_by.value, direction=direction.value
|
||||
)
|
||||
|
||||
self._cursor.execute(final_query)
|
||||
|
||||
|
||||
@@ -1,8 +1,9 @@
|
||||
from abc import ABC, abstractmethod
|
||||
|
||||
from invokeai.app.services.board_records.board_records_common import BoardChanges
|
||||
from invokeai.app.services.board_records.board_records_common import BoardChanges, BoardRecordOrderBy
|
||||
from invokeai.app.services.boards.boards_common import BoardDTO
|
||||
from invokeai.app.services.shared.pagination import OffsetPaginatedResults
|
||||
from invokeai.app.services.shared.sqlite.sqlite_common import SQLiteDirection
|
||||
|
||||
|
||||
class BoardServiceABC(ABC):
|
||||
@@ -43,12 +44,19 @@ class BoardServiceABC(ABC):
|
||||
|
||||
@abstractmethod
|
||||
def get_many(
|
||||
self, offset: int = 0, limit: int = 10, include_archived: bool = False
|
||||
self,
|
||||
order_by: BoardRecordOrderBy,
|
||||
direction: SQLiteDirection,
|
||||
offset: int = 0,
|
||||
limit: int = 10,
|
||||
include_archived: bool = False,
|
||||
) -> OffsetPaginatedResults[BoardDTO]:
|
||||
"""Gets many boards."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def get_all(self, include_archived: bool = False) -> list[BoardDTO]:
|
||||
def get_all(
|
||||
self, order_by: BoardRecordOrderBy, direction: SQLiteDirection, include_archived: bool = False
|
||||
) -> list[BoardDTO]:
|
||||
"""Gets all boards."""
|
||||
pass
|
||||
|
||||
@@ -1,8 +1,9 @@
|
||||
from invokeai.app.services.board_records.board_records_common import BoardChanges
|
||||
from invokeai.app.services.board_records.board_records_common import BoardChanges, BoardRecordOrderBy
|
||||
from invokeai.app.services.boards.boards_base import BoardServiceABC
|
||||
from invokeai.app.services.boards.boards_common import BoardDTO, board_record_to_dto
|
||||
from invokeai.app.services.invoker import Invoker
|
||||
from invokeai.app.services.shared.pagination import OffsetPaginatedResults
|
||||
from invokeai.app.services.shared.sqlite.sqlite_common import SQLiteDirection
|
||||
|
||||
|
||||
class BoardService(BoardServiceABC):
|
||||
@@ -47,9 +48,16 @@ class BoardService(BoardServiceABC):
|
||||
self.__invoker.services.board_records.delete(board_id)
|
||||
|
||||
def get_many(
|
||||
self, offset: int = 0, limit: int = 10, include_archived: bool = False
|
||||
self,
|
||||
order_by: BoardRecordOrderBy,
|
||||
direction: SQLiteDirection,
|
||||
offset: int = 0,
|
||||
limit: int = 10,
|
||||
include_archived: bool = False,
|
||||
) -> OffsetPaginatedResults[BoardDTO]:
|
||||
board_records = self.__invoker.services.board_records.get_many(offset, limit, include_archived)
|
||||
board_records = self.__invoker.services.board_records.get_many(
|
||||
order_by, direction, offset, limit, include_archived
|
||||
)
|
||||
board_dtos = []
|
||||
for r in board_records.items:
|
||||
cover_image = self.__invoker.services.image_records.get_most_recent_image_for_board(r.board_id)
|
||||
@@ -63,8 +71,10 @@ class BoardService(BoardServiceABC):
|
||||
|
||||
return OffsetPaginatedResults[BoardDTO](items=board_dtos, offset=offset, limit=limit, total=len(board_dtos))
|
||||
|
||||
def get_all(self, include_archived: bool = False) -> list[BoardDTO]:
|
||||
board_records = self.__invoker.services.board_records.get_all(include_archived)
|
||||
def get_all(
|
||||
self, order_by: BoardRecordOrderBy, direction: SQLiteDirection, include_archived: bool = False
|
||||
) -> list[BoardDTO]:
|
||||
board_records = self.__invoker.services.board_records.get_all(order_by, direction, include_archived)
|
||||
board_dtos = []
|
||||
for r in board_records:
|
||||
cover_image = self.__invoker.services.image_records.get_most_recent_image_for_board(r.board_id)
|
||||
|
||||
@@ -250,13 +250,13 @@ class InvokeAIAppConfig(BaseSettings):
|
||||
)
|
||||
|
||||
if as_example:
|
||||
file.write(
|
||||
"# This is an example file with default and example settings. Use the values here as a baseline.\n\n"
|
||||
)
|
||||
file.write("# This is an example file with default and example settings.\n")
|
||||
file.write("# You should not copy this whole file into your config.\n")
|
||||
file.write("# Only add the settings you need to change to your config file.\n\n")
|
||||
file.write("# Internal metadata - do not edit:\n")
|
||||
file.write(yaml.dump(meta_dict, sort_keys=False))
|
||||
file.write("\n")
|
||||
file.write("# Put user settings here - see https://invoke-ai.github.io/InvokeAI/features/CONFIGURATION/:\n")
|
||||
file.write("# Put user settings here - see https://invoke-ai.github.io/InvokeAI/configuration/:\n")
|
||||
if len(config_dict) > 0:
|
||||
file.write(yaml.dump(config_dict, sort_keys=False))
|
||||
|
||||
|
||||
@@ -110,15 +110,26 @@ class DiskImageFileStorage(ImageFileStorageBase):
|
||||
except Exception as e:
|
||||
raise ImageFileDeleteException from e
|
||||
|
||||
# TODO: make this a bit more flexible for e.g. cloud storage
|
||||
def get_path(self, image_name: str, thumbnail: bool = False) -> Path:
|
||||
path = self.__output_folder / image_name
|
||||
base_folder = self.__thumbnails_folder if thumbnail else self.__output_folder
|
||||
filename = get_thumbnail_name(image_name) if thumbnail else image_name
|
||||
|
||||
if thumbnail:
|
||||
thumbnail_name = get_thumbnail_name(image_name)
|
||||
path = self.__thumbnails_folder / thumbnail_name
|
||||
# Strip any path information from the filename
|
||||
basename = Path(filename).name
|
||||
|
||||
return path
|
||||
if basename != filename:
|
||||
raise ValueError("Invalid image name, potential directory traversal detected")
|
||||
|
||||
image_path = base_folder / basename
|
||||
|
||||
# Ensure the image path is within the base folder to prevent directory traversal
|
||||
resolved_base = base_folder.resolve()
|
||||
resolved_image_path = image_path.resolve()
|
||||
|
||||
if not resolved_image_path.is_relative_to(resolved_base):
|
||||
raise ValueError("Image path outside outputs folder, potential directory traversal detected")
|
||||
|
||||
return resolved_image_path
|
||||
|
||||
def validate_path(self, path: Union[str, Path]) -> bool:
|
||||
"""Validates the path given for an image or thumbnail."""
|
||||
|
||||
@@ -1,3 +1,4 @@
|
||||
from copy import deepcopy
|
||||
from dataclasses import dataclass
|
||||
from pathlib import Path
|
||||
from typing import TYPE_CHECKING, Callable, Optional, Union
|
||||
@@ -221,7 +222,7 @@ class ImagesInterface(InvocationContextInterface):
|
||||
)
|
||||
|
||||
def get_pil(self, image_name: str, mode: IMAGE_MODES | None = None) -> Image:
|
||||
"""Gets an image as a PIL Image object.
|
||||
"""Gets an image as a PIL Image object. This method returns a copy of the image.
|
||||
|
||||
Args:
|
||||
image_name: The name of the image to get.
|
||||
@@ -233,11 +234,15 @@ class ImagesInterface(InvocationContextInterface):
|
||||
image = self._services.images.get_pil_image(image_name)
|
||||
if mode and mode != image.mode:
|
||||
try:
|
||||
# convert makes a copy!
|
||||
image = image.convert(mode)
|
||||
except ValueError:
|
||||
self._services.logger.warning(
|
||||
f"Could not convert image from {image.mode} to {mode}. Using original mode instead."
|
||||
)
|
||||
else:
|
||||
# copy the image to prevent the user from modifying the original
|
||||
image = image.copy()
|
||||
return image
|
||||
|
||||
def get_metadata(self, image_name: str) -> Optional[MetadataField]:
|
||||
@@ -290,15 +295,15 @@ class TensorsInterface(InvocationContextInterface):
|
||||
return name
|
||||
|
||||
def load(self, name: str) -> Tensor:
|
||||
"""Loads a tensor by name.
|
||||
"""Loads a tensor by name. This method returns a copy of the tensor.
|
||||
|
||||
Args:
|
||||
name: The name of the tensor to load.
|
||||
|
||||
Returns:
|
||||
The loaded tensor.
|
||||
The tensor.
|
||||
"""
|
||||
return self._services.tensors.load(name)
|
||||
return self._services.tensors.load(name).clone()
|
||||
|
||||
|
||||
class ConditioningInterface(InvocationContextInterface):
|
||||
@@ -316,16 +321,16 @@ class ConditioningInterface(InvocationContextInterface):
|
||||
return name
|
||||
|
||||
def load(self, name: str) -> ConditioningFieldData:
|
||||
"""Loads conditioning data by name.
|
||||
"""Loads conditioning data by name. This method returns a copy of the conditioning data.
|
||||
|
||||
Args:
|
||||
name: The name of the conditioning data to load.
|
||||
|
||||
Returns:
|
||||
The loaded conditioning data.
|
||||
The conditioning data.
|
||||
"""
|
||||
|
||||
return self._services.conditioning.load(name)
|
||||
return deepcopy(self._services.conditioning.load(name))
|
||||
|
||||
|
||||
class ModelsInterface(InvocationContextInterface):
|
||||
|
||||
@@ -38,12 +38,12 @@
|
||||
},
|
||||
"nodes": [
|
||||
{
|
||||
"id": "eebd7252-0bd8-401a-bb26-2b8bc64892fa",
|
||||
"id": "cd367e62-2b45-4118-b4ba-7c33e2e0b370",
|
||||
"type": "invocation",
|
||||
"data": {
|
||||
"id": "eebd7252-0bd8-401a-bb26-2b8bc64892fa",
|
||||
"id": "cd367e62-2b45-4118-b4ba-7c33e2e0b370",
|
||||
"type": "flux_denoise",
|
||||
"version": "2.1.0",
|
||||
"version": "3.0.0",
|
||||
"label": "",
|
||||
"notes": "",
|
||||
"isOpen": true,
|
||||
@@ -77,11 +77,6 @@
|
||||
"label": "",
|
||||
"value": 1
|
||||
},
|
||||
"trajectory_guidance_strength": {
|
||||
"name": "trajectory_guidance_strength",
|
||||
"label": "",
|
||||
"value": 0.0
|
||||
},
|
||||
"transformer": {
|
||||
"name": "transformer",
|
||||
"label": ""
|
||||
@@ -118,8 +113,8 @@
|
||||
}
|
||||
},
|
||||
"position": {
|
||||
"x": 1159.584057771928,
|
||||
"y": -175.90561201366845
|
||||
"x": 1176.8139201354052,
|
||||
"y": -244.36724863022368
|
||||
}
|
||||
},
|
||||
{
|
||||
@@ -201,14 +196,7 @@
|
||||
"inputs": {
|
||||
"model": {
|
||||
"name": "model",
|
||||
"label": "Model (dev variant recommended for Image-to-Image)",
|
||||
"value": {
|
||||
"key": "b4990a6c-0899-48e9-969b-d6f3801acc6a",
|
||||
"hash": "random:aad8f7bc19ce76541dfb394b62a30f77722542b66e48064a9f25453263b45fba",
|
||||
"name": "FLUX Dev (Quantized)_2",
|
||||
"base": "flux",
|
||||
"type": "main"
|
||||
}
|
||||
"label": "Model (dev variant recommended for Image-to-Image)"
|
||||
},
|
||||
"t5_encoder_model": {
|
||||
"name": "t5_encoder_model",
|
||||
@@ -314,67 +302,67 @@
|
||||
}
|
||||
},
|
||||
"position": {
|
||||
"x": 725.834098928012,
|
||||
"y": 496.2710031089931
|
||||
"x": 750.4061458984118,
|
||||
"y": 279.2179215371294
|
||||
}
|
||||
}
|
||||
],
|
||||
"edges": [
|
||||
{
|
||||
"id": "reactflow__edge-eebd7252-0bd8-401a-bb26-2b8bc64892falatents-7e5172eb-48c1-44db-a770-8fd83e1435d1latents",
|
||||
"id": "reactflow__edge-cd367e62-2b45-4118-b4ba-7c33e2e0b370latents-7e5172eb-48c1-44db-a770-8fd83e1435d1latents",
|
||||
"type": "default",
|
||||
"source": "eebd7252-0bd8-401a-bb26-2b8bc64892fa",
|
||||
"source": "cd367e62-2b45-4118-b4ba-7c33e2e0b370",
|
||||
"target": "7e5172eb-48c1-44db-a770-8fd83e1435d1",
|
||||
"sourceHandle": "latents",
|
||||
"targetHandle": "latents"
|
||||
},
|
||||
{
|
||||
"id": "reactflow__edge-f8d9d7c8-9ed7-4bd7-9e42-ab0e89bfac90transformer-eebd7252-0bd8-401a-bb26-2b8bc64892fatransformer",
|
||||
"id": "reactflow__edge-4754c534-a5f3-4ad0-9382-7887985e668cvalue-cd367e62-2b45-4118-b4ba-7c33e2e0b370seed",
|
||||
"type": "default",
|
||||
"source": "f8d9d7c8-9ed7-4bd7-9e42-ab0e89bfac90",
|
||||
"target": "eebd7252-0bd8-401a-bb26-2b8bc64892fa",
|
||||
"sourceHandle": "transformer",
|
||||
"targetHandle": "transformer"
|
||||
"source": "4754c534-a5f3-4ad0-9382-7887985e668c",
|
||||
"target": "cd367e62-2b45-4118-b4ba-7c33e2e0b370",
|
||||
"sourceHandle": "value",
|
||||
"targetHandle": "seed"
|
||||
},
|
||||
{
|
||||
"id": "reactflow__edge-01f674f8-b3d1-4df1-acac-6cb8e0bfb63cconditioning-eebd7252-0bd8-401a-bb26-2b8bc64892fapositive_text_conditioning",
|
||||
"type": "default",
|
||||
"source": "01f674f8-b3d1-4df1-acac-6cb8e0bfb63c",
|
||||
"target": "eebd7252-0bd8-401a-bb26-2b8bc64892fa",
|
||||
"sourceHandle": "conditioning",
|
||||
"targetHandle": "positive_text_conditioning"
|
||||
},
|
||||
{
|
||||
"id": "reactflow__edge-2981a67c-480f-4237-9384-26b68dbf912blatents-eebd7252-0bd8-401a-bb26-2b8bc64892falatents",
|
||||
"id": "reactflow__edge-2981a67c-480f-4237-9384-26b68dbf912bheight-cd367e62-2b45-4118-b4ba-7c33e2e0b370height",
|
||||
"type": "default",
|
||||
"source": "2981a67c-480f-4237-9384-26b68dbf912b",
|
||||
"target": "eebd7252-0bd8-401a-bb26-2b8bc64892fa",
|
||||
"sourceHandle": "latents",
|
||||
"targetHandle": "latents"
|
||||
},
|
||||
{
|
||||
"id": "reactflow__edge-2981a67c-480f-4237-9384-26b68dbf912bwidth-eebd7252-0bd8-401a-bb26-2b8bc64892fawidth",
|
||||
"type": "default",
|
||||
"source": "2981a67c-480f-4237-9384-26b68dbf912b",
|
||||
"target": "eebd7252-0bd8-401a-bb26-2b8bc64892fa",
|
||||
"sourceHandle": "width",
|
||||
"targetHandle": "width"
|
||||
},
|
||||
{
|
||||
"id": "reactflow__edge-2981a67c-480f-4237-9384-26b68dbf912bheight-eebd7252-0bd8-401a-bb26-2b8bc64892faheight",
|
||||
"type": "default",
|
||||
"source": "2981a67c-480f-4237-9384-26b68dbf912b",
|
||||
"target": "eebd7252-0bd8-401a-bb26-2b8bc64892fa",
|
||||
"target": "cd367e62-2b45-4118-b4ba-7c33e2e0b370",
|
||||
"sourceHandle": "height",
|
||||
"targetHandle": "height"
|
||||
},
|
||||
{
|
||||
"id": "reactflow__edge-4754c534-a5f3-4ad0-9382-7887985e668cvalue-eebd7252-0bd8-401a-bb26-2b8bc64892faseed",
|
||||
"id": "reactflow__edge-2981a67c-480f-4237-9384-26b68dbf912bwidth-cd367e62-2b45-4118-b4ba-7c33e2e0b370width",
|
||||
"type": "default",
|
||||
"source": "4754c534-a5f3-4ad0-9382-7887985e668c",
|
||||
"target": "eebd7252-0bd8-401a-bb26-2b8bc64892fa",
|
||||
"sourceHandle": "value",
|
||||
"targetHandle": "seed"
|
||||
"source": "2981a67c-480f-4237-9384-26b68dbf912b",
|
||||
"target": "cd367e62-2b45-4118-b4ba-7c33e2e0b370",
|
||||
"sourceHandle": "width",
|
||||
"targetHandle": "width"
|
||||
},
|
||||
{
|
||||
"id": "reactflow__edge-01f674f8-b3d1-4df1-acac-6cb8e0bfb63cconditioning-cd367e62-2b45-4118-b4ba-7c33e2e0b370positive_text_conditioning",
|
||||
"type": "default",
|
||||
"source": "01f674f8-b3d1-4df1-acac-6cb8e0bfb63c",
|
||||
"target": "cd367e62-2b45-4118-b4ba-7c33e2e0b370",
|
||||
"sourceHandle": "conditioning",
|
||||
"targetHandle": "positive_text_conditioning"
|
||||
},
|
||||
{
|
||||
"id": "reactflow__edge-f8d9d7c8-9ed7-4bd7-9e42-ab0e89bfac90transformer-cd367e62-2b45-4118-b4ba-7c33e2e0b370transformer",
|
||||
"type": "default",
|
||||
"source": "f8d9d7c8-9ed7-4bd7-9e42-ab0e89bfac90",
|
||||
"target": "cd367e62-2b45-4118-b4ba-7c33e2e0b370",
|
||||
"sourceHandle": "transformer",
|
||||
"targetHandle": "transformer"
|
||||
},
|
||||
{
|
||||
"id": "reactflow__edge-2981a67c-480f-4237-9384-26b68dbf912blatents-cd367e62-2b45-4118-b4ba-7c33e2e0b370latents",
|
||||
"type": "default",
|
||||
"source": "2981a67c-480f-4237-9384-26b68dbf912b",
|
||||
"target": "cd367e62-2b45-4118-b4ba-7c33e2e0b370",
|
||||
"sourceHandle": "latents",
|
||||
"targetHandle": "latents"
|
||||
},
|
||||
{
|
||||
"id": "reactflow__edge-f8d9d7c8-9ed7-4bd7-9e42-ab0e89bfac90vae-2981a67c-480f-4237-9384-26b68dbf912bvae",
|
||||
|
||||
@@ -34,12 +34,12 @@
|
||||
},
|
||||
"nodes": [
|
||||
{
|
||||
"id": "4ecda92d-ee0e-45ca-aa35-6e9410ac39b9",
|
||||
"id": "0940bc54-21fb-4346-bc68-fca5724c2747",
|
||||
"type": "invocation",
|
||||
"data": {
|
||||
"id": "4ecda92d-ee0e-45ca-aa35-6e9410ac39b9",
|
||||
"id": "0940bc54-21fb-4346-bc68-fca5724c2747",
|
||||
"type": "flux_denoise",
|
||||
"version": "2.1.0",
|
||||
"version": "3.0.0",
|
||||
"label": "",
|
||||
"notes": "",
|
||||
"isOpen": true,
|
||||
@@ -61,7 +61,7 @@
|
||||
},
|
||||
"denoise_mask": {
|
||||
"name": "denoise_mask",
|
||||
"label": ""
|
||||
"label": "Denoise Mask"
|
||||
},
|
||||
"denoising_start": {
|
||||
"name": "denoising_start",
|
||||
@@ -73,11 +73,6 @@
|
||||
"label": "",
|
||||
"value": 1
|
||||
},
|
||||
"trajectory_guidance_strength": {
|
||||
"name": "trajectory_guidance_strength",
|
||||
"label": "",
|
||||
"value": 0
|
||||
},
|
||||
"transformer": {
|
||||
"name": "transformer",
|
||||
"label": ""
|
||||
@@ -114,8 +109,8 @@
|
||||
}
|
||||
},
|
||||
"position": {
|
||||
"x": 1161.0101524413685,
|
||||
"y": -223.33548695623742
|
||||
"x": 1180.8001377784371,
|
||||
"y": -219.96908055568326
|
||||
}
|
||||
},
|
||||
{
|
||||
@@ -169,14 +164,7 @@
|
||||
"inputs": {
|
||||
"model": {
|
||||
"name": "model",
|
||||
"label": "",
|
||||
"value": {
|
||||
"key": "b4990a6c-0899-48e9-969b-d6f3801acc6a",
|
||||
"hash": "random:aad8f7bc19ce76541dfb394b62a30f77722542b66e48064a9f25453263b45fba",
|
||||
"name": "FLUX Dev (Quantized)_2",
|
||||
"base": "flux",
|
||||
"type": "main"
|
||||
}
|
||||
"label": ""
|
||||
},
|
||||
"t5_encoder_model": {
|
||||
"name": "t5_encoder_model",
|
||||
@@ -289,36 +277,36 @@
|
||||
],
|
||||
"edges": [
|
||||
{
|
||||
"id": "reactflow__edge-f8d9d7c8-9ed7-4bd7-9e42-ab0e89bfac90transformer-4ecda92d-ee0e-45ca-aa35-6e9410ac39b9transformer",
|
||||
"id": "reactflow__edge-0940bc54-21fb-4346-bc68-fca5724c2747latents-7e5172eb-48c1-44db-a770-8fd83e1435d1latents",
|
||||
"type": "default",
|
||||
"source": "f8d9d7c8-9ed7-4bd7-9e42-ab0e89bfac90",
|
||||
"target": "4ecda92d-ee0e-45ca-aa35-6e9410ac39b9",
|
||||
"sourceHandle": "transformer",
|
||||
"targetHandle": "transformer"
|
||||
"source": "0940bc54-21fb-4346-bc68-fca5724c2747",
|
||||
"target": "7e5172eb-48c1-44db-a770-8fd83e1435d1",
|
||||
"sourceHandle": "latents",
|
||||
"targetHandle": "latents"
|
||||
},
|
||||
{
|
||||
"id": "reactflow__edge-01f674f8-b3d1-4df1-acac-6cb8e0bfb63cconditioning-4ecda92d-ee0e-45ca-aa35-6e9410ac39b9positive_text_conditioning",
|
||||
"type": "default",
|
||||
"source": "01f674f8-b3d1-4df1-acac-6cb8e0bfb63c",
|
||||
"target": "4ecda92d-ee0e-45ca-aa35-6e9410ac39b9",
|
||||
"sourceHandle": "conditioning",
|
||||
"targetHandle": "positive_text_conditioning"
|
||||
},
|
||||
{
|
||||
"id": "reactflow__edge-4754c534-a5f3-4ad0-9382-7887985e668cvalue-4ecda92d-ee0e-45ca-aa35-6e9410ac39b9seed",
|
||||
"id": "reactflow__edge-4754c534-a5f3-4ad0-9382-7887985e668cvalue-0940bc54-21fb-4346-bc68-fca5724c2747seed",
|
||||
"type": "default",
|
||||
"source": "4754c534-a5f3-4ad0-9382-7887985e668c",
|
||||
"target": "4ecda92d-ee0e-45ca-aa35-6e9410ac39b9",
|
||||
"target": "0940bc54-21fb-4346-bc68-fca5724c2747",
|
||||
"sourceHandle": "value",
|
||||
"targetHandle": "seed"
|
||||
},
|
||||
{
|
||||
"id": "reactflow__edge-4ecda92d-ee0e-45ca-aa35-6e9410ac39b9latents-7e5172eb-48c1-44db-a770-8fd83e1435d1latents",
|
||||
"id": "reactflow__edge-01f674f8-b3d1-4df1-acac-6cb8e0bfb63cconditioning-0940bc54-21fb-4346-bc68-fca5724c2747positive_text_conditioning",
|
||||
"type": "default",
|
||||
"source": "4ecda92d-ee0e-45ca-aa35-6e9410ac39b9",
|
||||
"target": "7e5172eb-48c1-44db-a770-8fd83e1435d1",
|
||||
"sourceHandle": "latents",
|
||||
"targetHandle": "latents"
|
||||
"source": "01f674f8-b3d1-4df1-acac-6cb8e0bfb63c",
|
||||
"target": "0940bc54-21fb-4346-bc68-fca5724c2747",
|
||||
"sourceHandle": "conditioning",
|
||||
"targetHandle": "positive_text_conditioning"
|
||||
},
|
||||
{
|
||||
"id": "reactflow__edge-f8d9d7c8-9ed7-4bd7-9e42-ab0e89bfac90transformer-0940bc54-21fb-4346-bc68-fca5724c2747transformer",
|
||||
"type": "default",
|
||||
"source": "f8d9d7c8-9ed7-4bd7-9e42-ab0e89bfac90",
|
||||
"target": "0940bc54-21fb-4346-bc68-fca5724c2747",
|
||||
"sourceHandle": "transformer",
|
||||
"targetHandle": "transformer"
|
||||
},
|
||||
{
|
||||
"id": "reactflow__edge-f8d9d7c8-9ed7-4bd7-9e42-ab0e89bfac90vae-7e5172eb-48c1-44db-a770-8fd83e1435d1vae",
|
||||
|
||||
@@ -39,11 +39,11 @@ class WorkflowRecordsStorageBase(ABC):
|
||||
@abstractmethod
|
||||
def get_many(
|
||||
self,
|
||||
page: int,
|
||||
per_page: int,
|
||||
order_by: WorkflowRecordOrderBy,
|
||||
direction: SQLiteDirection,
|
||||
category: WorkflowCategory,
|
||||
page: int,
|
||||
per_page: Optional[int],
|
||||
query: Optional[str],
|
||||
) -> PaginatedResults[WorkflowRecordListItemDTO]:
|
||||
"""Gets many workflows."""
|
||||
|
||||
@@ -125,11 +125,11 @@ class SqliteWorkflowRecordsStorage(WorkflowRecordsStorageBase):
|
||||
|
||||
def get_many(
|
||||
self,
|
||||
page: int,
|
||||
per_page: int,
|
||||
order_by: WorkflowRecordOrderBy,
|
||||
direction: SQLiteDirection,
|
||||
category: WorkflowCategory,
|
||||
page: int = 0,
|
||||
per_page: Optional[int] = None,
|
||||
query: Optional[str] = None,
|
||||
) -> PaginatedResults[WorkflowRecordListItemDTO]:
|
||||
try:
|
||||
@@ -153,6 +153,7 @@ class SqliteWorkflowRecordsStorage(WorkflowRecordsStorageBase):
|
||||
"""
|
||||
main_params: list[int | str] = [category.value]
|
||||
count_params: list[int | str] = [category.value]
|
||||
|
||||
stripped_query = query.strip() if query else None
|
||||
if stripped_query:
|
||||
wildcard_query = "%" + stripped_query + "%"
|
||||
@@ -161,20 +162,28 @@ class SqliteWorkflowRecordsStorage(WorkflowRecordsStorageBase):
|
||||
main_params.extend([wildcard_query, wildcard_query])
|
||||
count_params.extend([wildcard_query, wildcard_query])
|
||||
|
||||
main_query += f" ORDER BY {order_by.value} {direction.value} LIMIT ? OFFSET ?;"
|
||||
main_params.extend([per_page, page * per_page])
|
||||
main_query += f" ORDER BY {order_by.value} {direction.value}"
|
||||
|
||||
if per_page:
|
||||
main_query += " LIMIT ? OFFSET ?"
|
||||
main_params.extend([per_page, page * per_page])
|
||||
|
||||
self._cursor.execute(main_query, main_params)
|
||||
rows = self._cursor.fetchall()
|
||||
workflows = [WorkflowRecordListItemDTOValidator.validate_python(dict(row)) for row in rows]
|
||||
|
||||
self._cursor.execute(count_query, count_params)
|
||||
total = self._cursor.fetchone()[0]
|
||||
pages = total // per_page + (total % per_page > 0)
|
||||
|
||||
if per_page:
|
||||
pages = total // per_page + (total % per_page > 0)
|
||||
else:
|
||||
pages = 1 # If no pagination, there is only one page
|
||||
|
||||
return PaginatedResults(
|
||||
items=workflows,
|
||||
page=page,
|
||||
per_page=per_page,
|
||||
per_page=per_page if per_page else total,
|
||||
pages=pages,
|
||||
total=total,
|
||||
)
|
||||
|
||||
0
invokeai/backend/flux/controlnet/__init__.py
Normal file
0
invokeai/backend/flux/controlnet/__init__.py
Normal file
58
invokeai/backend/flux/controlnet/controlnet_flux_output.py
Normal file
58
invokeai/backend/flux/controlnet/controlnet_flux_output.py
Normal file
@@ -0,0 +1,58 @@
|
||||
from dataclasses import dataclass
|
||||
|
||||
import torch
|
||||
|
||||
|
||||
@dataclass
|
||||
class ControlNetFluxOutput:
|
||||
single_block_residuals: list[torch.Tensor] | None
|
||||
double_block_residuals: list[torch.Tensor] | None
|
||||
|
||||
def apply_weight(self, weight: float):
|
||||
if self.single_block_residuals is not None:
|
||||
for i in range(len(self.single_block_residuals)):
|
||||
self.single_block_residuals[i] = self.single_block_residuals[i] * weight
|
||||
if self.double_block_residuals is not None:
|
||||
for i in range(len(self.double_block_residuals)):
|
||||
self.double_block_residuals[i] = self.double_block_residuals[i] * weight
|
||||
|
||||
|
||||
def add_tensor_lists_elementwise(
|
||||
list1: list[torch.Tensor] | None, list2: list[torch.Tensor] | None
|
||||
) -> list[torch.Tensor] | None:
|
||||
"""Add two tensor lists elementwise that could be None."""
|
||||
if list1 is None and list2 is None:
|
||||
return None
|
||||
if list1 is None:
|
||||
return list2
|
||||
if list2 is None:
|
||||
return list1
|
||||
|
||||
new_list: list[torch.Tensor] = []
|
||||
for list1_tensor, list2_tensor in zip(list1, list2, strict=True):
|
||||
new_list.append(list1_tensor + list2_tensor)
|
||||
return new_list
|
||||
|
||||
|
||||
def add_controlnet_flux_outputs(
|
||||
controlnet_output_1: ControlNetFluxOutput, controlnet_output_2: ControlNetFluxOutput
|
||||
) -> ControlNetFluxOutput:
|
||||
return ControlNetFluxOutput(
|
||||
single_block_residuals=add_tensor_lists_elementwise(
|
||||
controlnet_output_1.single_block_residuals, controlnet_output_2.single_block_residuals
|
||||
),
|
||||
double_block_residuals=add_tensor_lists_elementwise(
|
||||
controlnet_output_1.double_block_residuals, controlnet_output_2.double_block_residuals
|
||||
),
|
||||
)
|
||||
|
||||
|
||||
def sum_controlnet_flux_outputs(
|
||||
controlnet_outputs: list[ControlNetFluxOutput],
|
||||
) -> ControlNetFluxOutput:
|
||||
controlnet_output_sum = ControlNetFluxOutput(single_block_residuals=None, double_block_residuals=None)
|
||||
|
||||
for controlnet_output in controlnet_outputs:
|
||||
controlnet_output_sum = add_controlnet_flux_outputs(controlnet_output_sum, controlnet_output)
|
||||
|
||||
return controlnet_output_sum
|
||||
180
invokeai/backend/flux/controlnet/instantx_controlnet_flux.py
Normal file
180
invokeai/backend/flux/controlnet/instantx_controlnet_flux.py
Normal file
@@ -0,0 +1,180 @@
|
||||
# This file was initially copied from:
|
||||
# https://github.com/huggingface/diffusers/blob/99f608218caa069a2f16dcf9efab46959b15aec0/src/diffusers/models/controlnet_flux.py
|
||||
|
||||
|
||||
from dataclasses import dataclass
|
||||
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
|
||||
from invokeai.backend.flux.controlnet.zero_module import zero_module
|
||||
from invokeai.backend.flux.model import FluxParams
|
||||
from invokeai.backend.flux.modules.layers import (
|
||||
DoubleStreamBlock,
|
||||
EmbedND,
|
||||
MLPEmbedder,
|
||||
SingleStreamBlock,
|
||||
timestep_embedding,
|
||||
)
|
||||
|
||||
|
||||
@dataclass
|
||||
class InstantXControlNetFluxOutput:
|
||||
controlnet_block_samples: list[torch.Tensor] | None
|
||||
controlnet_single_block_samples: list[torch.Tensor] | None
|
||||
|
||||
|
||||
# NOTE(ryand): Mapping between diffusers FLUX transformer params and BFL FLUX transformer params:
|
||||
# - Diffusers: BFL
|
||||
# - in_channels: in_channels
|
||||
# - num_layers: depth
|
||||
# - num_single_layers: depth_single_blocks
|
||||
# - attention_head_dim: hidden_size // num_heads
|
||||
# - num_attention_heads: num_heads
|
||||
# - joint_attention_dim: context_in_dim
|
||||
# - pooled_projection_dim: vec_in_dim
|
||||
# - guidance_embeds: guidance_embed
|
||||
# - axes_dims_rope: axes_dim
|
||||
|
||||
|
||||
class InstantXControlNetFlux(torch.nn.Module):
|
||||
def __init__(self, params: FluxParams, num_control_modes: int | None = None):
|
||||
"""
|
||||
Args:
|
||||
params (FluxParams): The parameters for the FLUX model.
|
||||
num_control_modes (int | None, optional): The number of controlnet modes. If non-None, then the model is a
|
||||
'union controlnet' model and expects a mode conditioning input at runtime.
|
||||
"""
|
||||
super().__init__()
|
||||
|
||||
# The following modules mirror the base FLUX transformer model.
|
||||
# -------------------------------------------------------------
|
||||
self.params = params
|
||||
self.in_channels = params.in_channels
|
||||
self.out_channels = self.in_channels
|
||||
if params.hidden_size % params.num_heads != 0:
|
||||
raise ValueError(f"Hidden size {params.hidden_size} must be divisible by num_heads {params.num_heads}")
|
||||
pe_dim = params.hidden_size // params.num_heads
|
||||
if sum(params.axes_dim) != pe_dim:
|
||||
raise ValueError(f"Got {params.axes_dim} but expected positional dim {pe_dim}")
|
||||
self.hidden_size = params.hidden_size
|
||||
self.num_heads = params.num_heads
|
||||
self.pe_embedder = EmbedND(dim=pe_dim, theta=params.theta, axes_dim=params.axes_dim)
|
||||
self.img_in = nn.Linear(self.in_channels, self.hidden_size, bias=True)
|
||||
self.time_in = MLPEmbedder(in_dim=256, hidden_dim=self.hidden_size)
|
||||
self.vector_in = MLPEmbedder(params.vec_in_dim, self.hidden_size)
|
||||
self.guidance_in = (
|
||||
MLPEmbedder(in_dim=256, hidden_dim=self.hidden_size) if params.guidance_embed else nn.Identity()
|
||||
)
|
||||
self.txt_in = nn.Linear(params.context_in_dim, self.hidden_size)
|
||||
|
||||
self.double_blocks = nn.ModuleList(
|
||||
[
|
||||
DoubleStreamBlock(
|
||||
self.hidden_size,
|
||||
self.num_heads,
|
||||
mlp_ratio=params.mlp_ratio,
|
||||
qkv_bias=params.qkv_bias,
|
||||
)
|
||||
for _ in range(params.depth)
|
||||
]
|
||||
)
|
||||
|
||||
self.single_blocks = nn.ModuleList(
|
||||
[
|
||||
SingleStreamBlock(self.hidden_size, self.num_heads, mlp_ratio=params.mlp_ratio)
|
||||
for _ in range(params.depth_single_blocks)
|
||||
]
|
||||
)
|
||||
|
||||
# The following modules are specific to the ControlNet model.
|
||||
# -----------------------------------------------------------
|
||||
self.controlnet_blocks = nn.ModuleList([])
|
||||
for _ in range(len(self.double_blocks)):
|
||||
self.controlnet_blocks.append(zero_module(nn.Linear(self.hidden_size, self.hidden_size)))
|
||||
|
||||
self.controlnet_single_blocks = nn.ModuleList([])
|
||||
for _ in range(len(self.single_blocks)):
|
||||
self.controlnet_single_blocks.append(zero_module(nn.Linear(self.hidden_size, self.hidden_size)))
|
||||
|
||||
self.is_union = False
|
||||
if num_control_modes is not None:
|
||||
self.is_union = True
|
||||
self.controlnet_mode_embedder = nn.Embedding(num_control_modes, self.hidden_size)
|
||||
|
||||
self.controlnet_x_embedder = zero_module(torch.nn.Linear(self.in_channels, self.hidden_size))
|
||||
|
||||
def forward(
|
||||
self,
|
||||
controlnet_cond: torch.Tensor,
|
||||
controlnet_mode: torch.Tensor | None,
|
||||
img: torch.Tensor,
|
||||
img_ids: torch.Tensor,
|
||||
txt: torch.Tensor,
|
||||
txt_ids: torch.Tensor,
|
||||
timesteps: torch.Tensor,
|
||||
y: torch.Tensor,
|
||||
guidance: torch.Tensor | None = None,
|
||||
) -> InstantXControlNetFluxOutput:
|
||||
if img.ndim != 3 or txt.ndim != 3:
|
||||
raise ValueError("Input img and txt tensors must have 3 dimensions.")
|
||||
|
||||
img = self.img_in(img)
|
||||
|
||||
# Add controlnet_cond embedding.
|
||||
img = img + self.controlnet_x_embedder(controlnet_cond)
|
||||
|
||||
vec = self.time_in(timestep_embedding(timesteps, 256))
|
||||
if self.params.guidance_embed:
|
||||
if guidance is None:
|
||||
raise ValueError("Didn't get guidance strength for guidance distilled model.")
|
||||
vec = vec + self.guidance_in(timestep_embedding(guidance, 256))
|
||||
vec = vec + self.vector_in(y)
|
||||
txt = self.txt_in(txt)
|
||||
|
||||
# If this is a union ControlNet, then concat the control mode embedding to the T5 text embedding.
|
||||
if self.is_union:
|
||||
if controlnet_mode is None:
|
||||
# We allow users to enter 'None' as the controlnet_mode if they don't want to worry about this input.
|
||||
# We've chosen to use a zero-embedding in this case.
|
||||
zero_index = torch.zeros([1, 1], dtype=torch.long, device=txt.device)
|
||||
controlnet_mode_emb = torch.zeros_like(self.controlnet_mode_embedder(zero_index))
|
||||
else:
|
||||
controlnet_mode_emb = self.controlnet_mode_embedder(controlnet_mode)
|
||||
txt = torch.cat([controlnet_mode_emb, txt], dim=1)
|
||||
txt_ids = torch.cat([txt_ids[:, :1, :], txt_ids], dim=1)
|
||||
else:
|
||||
assert controlnet_mode is None
|
||||
|
||||
ids = torch.cat((txt_ids, img_ids), dim=1)
|
||||
pe = self.pe_embedder(ids)
|
||||
|
||||
double_block_samples: list[torch.Tensor] = []
|
||||
for block in self.double_blocks:
|
||||
img, txt = block(img=img, txt=txt, vec=vec, pe=pe)
|
||||
double_block_samples.append(img)
|
||||
|
||||
img = torch.cat((txt, img), 1)
|
||||
|
||||
single_block_samples: list[torch.Tensor] = []
|
||||
for block in self.single_blocks:
|
||||
img = block(img, vec=vec, pe=pe)
|
||||
single_block_samples.append(img[:, txt.shape[1] :])
|
||||
|
||||
# ControlNet Block
|
||||
controlnet_double_block_samples: list[torch.Tensor] = []
|
||||
for double_block_sample, controlnet_block in zip(double_block_samples, self.controlnet_blocks, strict=True):
|
||||
double_block_sample = controlnet_block(double_block_sample)
|
||||
controlnet_double_block_samples.append(double_block_sample)
|
||||
|
||||
controlnet_single_block_samples: list[torch.Tensor] = []
|
||||
for single_block_sample, controlnet_block in zip(
|
||||
single_block_samples, self.controlnet_single_blocks, strict=True
|
||||
):
|
||||
single_block_sample = controlnet_block(single_block_sample)
|
||||
controlnet_single_block_samples.append(single_block_sample)
|
||||
|
||||
return InstantXControlNetFluxOutput(
|
||||
controlnet_block_samples=controlnet_double_block_samples or None,
|
||||
controlnet_single_block_samples=controlnet_single_block_samples or None,
|
||||
)
|
||||
295
invokeai/backend/flux/controlnet/state_dict_utils.py
Normal file
295
invokeai/backend/flux/controlnet/state_dict_utils.py
Normal file
@@ -0,0 +1,295 @@
|
||||
from typing import Any, Dict
|
||||
|
||||
import torch
|
||||
|
||||
from invokeai.backend.flux.model import FluxParams
|
||||
|
||||
|
||||
def is_state_dict_xlabs_controlnet(sd: Dict[str, Any]) -> bool:
|
||||
"""Is the state dict for an XLabs ControlNet model?
|
||||
|
||||
This is intended to be a reasonably high-precision detector, but it is not guaranteed to have perfect precision.
|
||||
"""
|
||||
# If all of the expected keys are present, then this is very likely an XLabs ControlNet model.
|
||||
expected_keys = {
|
||||
"controlnet_blocks.0.bias",
|
||||
"controlnet_blocks.0.weight",
|
||||
"input_hint_block.0.bias",
|
||||
"input_hint_block.0.weight",
|
||||
"pos_embed_input.bias",
|
||||
"pos_embed_input.weight",
|
||||
}
|
||||
|
||||
if expected_keys.issubset(sd.keys()):
|
||||
return True
|
||||
return False
|
||||
|
||||
|
||||
def is_state_dict_instantx_controlnet(sd: Dict[str, Any]) -> bool:
|
||||
"""Is the state dict for an InstantX ControlNet model?
|
||||
|
||||
This is intended to be a reasonably high-precision detector, but it is not guaranteed to have perfect precision.
|
||||
"""
|
||||
# If all of the expected keys are present, then this is very likely an InstantX ControlNet model.
|
||||
expected_keys = {
|
||||
"controlnet_blocks.0.bias",
|
||||
"controlnet_blocks.0.weight",
|
||||
"controlnet_x_embedder.bias",
|
||||
"controlnet_x_embedder.weight",
|
||||
}
|
||||
|
||||
if expected_keys.issubset(sd.keys()):
|
||||
return True
|
||||
return False
|
||||
|
||||
|
||||
def _fuse_weights(*t: torch.Tensor) -> torch.Tensor:
|
||||
"""Fuse weights along dimension 0.
|
||||
|
||||
Used to fuse q, k, v attention weights into a single qkv tensor when converting from diffusers to BFL format.
|
||||
"""
|
||||
# TODO(ryand): Double check dim=0 is correct.
|
||||
return torch.cat(t, dim=0)
|
||||
|
||||
|
||||
def _convert_flux_double_block_sd_from_diffusers_to_bfl_format(
|
||||
sd: Dict[str, torch.Tensor], double_block_index: int
|
||||
) -> Dict[str, torch.Tensor]:
|
||||
"""Convert the state dict for a double block from diffusers format to BFL format."""
|
||||
to_prefix = f"double_blocks.{double_block_index}"
|
||||
from_prefix = f"transformer_blocks.{double_block_index}"
|
||||
|
||||
new_sd: dict[str, torch.Tensor] = {}
|
||||
|
||||
# Check one key to determine if this block exists.
|
||||
if f"{from_prefix}.attn.add_q_proj.bias" not in sd:
|
||||
return new_sd
|
||||
|
||||
# txt_attn.qkv
|
||||
new_sd[f"{to_prefix}.txt_attn.qkv.bias"] = _fuse_weights(
|
||||
sd.pop(f"{from_prefix}.attn.add_q_proj.bias"),
|
||||
sd.pop(f"{from_prefix}.attn.add_k_proj.bias"),
|
||||
sd.pop(f"{from_prefix}.attn.add_v_proj.bias"),
|
||||
)
|
||||
new_sd[f"{to_prefix}.txt_attn.qkv.weight"] = _fuse_weights(
|
||||
sd.pop(f"{from_prefix}.attn.add_q_proj.weight"),
|
||||
sd.pop(f"{from_prefix}.attn.add_k_proj.weight"),
|
||||
sd.pop(f"{from_prefix}.attn.add_v_proj.weight"),
|
||||
)
|
||||
|
||||
# img_attn.qkv
|
||||
new_sd[f"{to_prefix}.img_attn.qkv.bias"] = _fuse_weights(
|
||||
sd.pop(f"{from_prefix}.attn.to_q.bias"),
|
||||
sd.pop(f"{from_prefix}.attn.to_k.bias"),
|
||||
sd.pop(f"{from_prefix}.attn.to_v.bias"),
|
||||
)
|
||||
new_sd[f"{to_prefix}.img_attn.qkv.weight"] = _fuse_weights(
|
||||
sd.pop(f"{from_prefix}.attn.to_q.weight"),
|
||||
sd.pop(f"{from_prefix}.attn.to_k.weight"),
|
||||
sd.pop(f"{from_prefix}.attn.to_v.weight"),
|
||||
)
|
||||
|
||||
# Handle basic 1-to-1 key conversions.
|
||||
key_map = {
|
||||
# img_attn
|
||||
"attn.norm_k.weight": "img_attn.norm.key_norm.scale",
|
||||
"attn.norm_q.weight": "img_attn.norm.query_norm.scale",
|
||||
"attn.to_out.0.weight": "img_attn.proj.weight",
|
||||
"attn.to_out.0.bias": "img_attn.proj.bias",
|
||||
# img_mlp
|
||||
"ff.net.0.proj.weight": "img_mlp.0.weight",
|
||||
"ff.net.0.proj.bias": "img_mlp.0.bias",
|
||||
"ff.net.2.weight": "img_mlp.2.weight",
|
||||
"ff.net.2.bias": "img_mlp.2.bias",
|
||||
# img_mod
|
||||
"norm1.linear.weight": "img_mod.lin.weight",
|
||||
"norm1.linear.bias": "img_mod.lin.bias",
|
||||
# txt_attn
|
||||
"attn.norm_added_q.weight": "txt_attn.norm.query_norm.scale",
|
||||
"attn.norm_added_k.weight": "txt_attn.norm.key_norm.scale",
|
||||
"attn.to_add_out.weight": "txt_attn.proj.weight",
|
||||
"attn.to_add_out.bias": "txt_attn.proj.bias",
|
||||
# txt_mlp
|
||||
"ff_context.net.0.proj.weight": "txt_mlp.0.weight",
|
||||
"ff_context.net.0.proj.bias": "txt_mlp.0.bias",
|
||||
"ff_context.net.2.weight": "txt_mlp.2.weight",
|
||||
"ff_context.net.2.bias": "txt_mlp.2.bias",
|
||||
# txt_mod
|
||||
"norm1_context.linear.weight": "txt_mod.lin.weight",
|
||||
"norm1_context.linear.bias": "txt_mod.lin.bias",
|
||||
}
|
||||
for from_key, to_key in key_map.items():
|
||||
new_sd[f"{to_prefix}.{to_key}"] = sd.pop(f"{from_prefix}.{from_key}")
|
||||
|
||||
return new_sd
|
||||
|
||||
|
||||
def _convert_flux_single_block_sd_from_diffusers_to_bfl_format(
|
||||
sd: Dict[str, torch.Tensor], single_block_index: int
|
||||
) -> Dict[str, torch.Tensor]:
|
||||
"""Convert the state dict for a single block from diffusers format to BFL format."""
|
||||
to_prefix = f"single_blocks.{single_block_index}"
|
||||
from_prefix = f"single_transformer_blocks.{single_block_index}"
|
||||
|
||||
new_sd: dict[str, torch.Tensor] = {}
|
||||
|
||||
# Check one key to determine if this block exists.
|
||||
if f"{from_prefix}.attn.to_q.bias" not in sd:
|
||||
return new_sd
|
||||
|
||||
# linear1 (qkv)
|
||||
new_sd[f"{to_prefix}.linear1.bias"] = _fuse_weights(
|
||||
sd.pop(f"{from_prefix}.attn.to_q.bias"),
|
||||
sd.pop(f"{from_prefix}.attn.to_k.bias"),
|
||||
sd.pop(f"{from_prefix}.attn.to_v.bias"),
|
||||
sd.pop(f"{from_prefix}.proj_mlp.bias"),
|
||||
)
|
||||
new_sd[f"{to_prefix}.linear1.weight"] = _fuse_weights(
|
||||
sd.pop(f"{from_prefix}.attn.to_q.weight"),
|
||||
sd.pop(f"{from_prefix}.attn.to_k.weight"),
|
||||
sd.pop(f"{from_prefix}.attn.to_v.weight"),
|
||||
sd.pop(f"{from_prefix}.proj_mlp.weight"),
|
||||
)
|
||||
|
||||
# Handle basic 1-to-1 key conversions.
|
||||
key_map = {
|
||||
# linear2
|
||||
"proj_out.weight": "linear2.weight",
|
||||
"proj_out.bias": "linear2.bias",
|
||||
# modulation
|
||||
"norm.linear.weight": "modulation.lin.weight",
|
||||
"norm.linear.bias": "modulation.lin.bias",
|
||||
# norm
|
||||
"attn.norm_k.weight": "norm.key_norm.scale",
|
||||
"attn.norm_q.weight": "norm.query_norm.scale",
|
||||
}
|
||||
for from_key, to_key in key_map.items():
|
||||
new_sd[f"{to_prefix}.{to_key}"] = sd.pop(f"{from_prefix}.{from_key}")
|
||||
|
||||
return new_sd
|
||||
|
||||
|
||||
def convert_diffusers_instantx_state_dict_to_bfl_format(sd: Dict[str, torch.Tensor]) -> Dict[str, torch.Tensor]:
|
||||
"""Convert an InstantX ControlNet state dict to the format that can be loaded by our internal
|
||||
InstantXControlNetFlux model.
|
||||
|
||||
The original InstantX ControlNet model was developed to be used in diffusers. We have ported the original
|
||||
implementation to InstantXControlNetFlux to make it compatible with BFL-style models. This function converts the
|
||||
original state dict to the format expected by InstantXControlNetFlux.
|
||||
"""
|
||||
# Shallow copy sd so that we can pop keys from it without modifying the original.
|
||||
sd = sd.copy()
|
||||
|
||||
new_sd: dict[str, torch.Tensor] = {}
|
||||
|
||||
# Handle basic 1-to-1 key conversions.
|
||||
basic_key_map = {
|
||||
# Base model keys.
|
||||
# ----------------
|
||||
# txt_in keys.
|
||||
"context_embedder.bias": "txt_in.bias",
|
||||
"context_embedder.weight": "txt_in.weight",
|
||||
# guidance_in MLPEmbedder keys.
|
||||
"time_text_embed.guidance_embedder.linear_1.bias": "guidance_in.in_layer.bias",
|
||||
"time_text_embed.guidance_embedder.linear_1.weight": "guidance_in.in_layer.weight",
|
||||
"time_text_embed.guidance_embedder.linear_2.bias": "guidance_in.out_layer.bias",
|
||||
"time_text_embed.guidance_embedder.linear_2.weight": "guidance_in.out_layer.weight",
|
||||
# vector_in MLPEmbedder keys.
|
||||
"time_text_embed.text_embedder.linear_1.bias": "vector_in.in_layer.bias",
|
||||
"time_text_embed.text_embedder.linear_1.weight": "vector_in.in_layer.weight",
|
||||
"time_text_embed.text_embedder.linear_2.bias": "vector_in.out_layer.bias",
|
||||
"time_text_embed.text_embedder.linear_2.weight": "vector_in.out_layer.weight",
|
||||
# time_in MLPEmbedder keys.
|
||||
"time_text_embed.timestep_embedder.linear_1.bias": "time_in.in_layer.bias",
|
||||
"time_text_embed.timestep_embedder.linear_1.weight": "time_in.in_layer.weight",
|
||||
"time_text_embed.timestep_embedder.linear_2.bias": "time_in.out_layer.bias",
|
||||
"time_text_embed.timestep_embedder.linear_2.weight": "time_in.out_layer.weight",
|
||||
# img_in keys.
|
||||
"x_embedder.bias": "img_in.bias",
|
||||
"x_embedder.weight": "img_in.weight",
|
||||
}
|
||||
for old_key, new_key in basic_key_map.items():
|
||||
v = sd.pop(old_key, None)
|
||||
if v is not None:
|
||||
new_sd[new_key] = v
|
||||
|
||||
# Handle the double_blocks.
|
||||
block_index = 0
|
||||
while True:
|
||||
converted_double_block_sd = _convert_flux_double_block_sd_from_diffusers_to_bfl_format(sd, block_index)
|
||||
if len(converted_double_block_sd) == 0:
|
||||
break
|
||||
new_sd.update(converted_double_block_sd)
|
||||
block_index += 1
|
||||
|
||||
# Handle the single_blocks.
|
||||
block_index = 0
|
||||
while True:
|
||||
converted_singe_block_sd = _convert_flux_single_block_sd_from_diffusers_to_bfl_format(sd, block_index)
|
||||
if len(converted_singe_block_sd) == 0:
|
||||
break
|
||||
new_sd.update(converted_singe_block_sd)
|
||||
block_index += 1
|
||||
|
||||
# Transfer controlnet keys as-is.
|
||||
for k in list(sd.keys()):
|
||||
if k.startswith("controlnet_"):
|
||||
new_sd[k] = sd.pop(k)
|
||||
|
||||
# Assert that all keys have been handled.
|
||||
assert len(sd) == 0
|
||||
return new_sd
|
||||
|
||||
|
||||
def infer_flux_params_from_state_dict(sd: Dict[str, torch.Tensor]) -> FluxParams:
|
||||
"""Infer the FluxParams from the shape of a FLUX state dict. When a model is distributed in diffusers format, this
|
||||
information is all contained in the config.json file that accompanies the model. However, being apple to infer the
|
||||
params from the state dict enables us to load models (e.g. an InstantX ControlNet) from a single weight file.
|
||||
"""
|
||||
hidden_size = sd["img_in.weight"].shape[0]
|
||||
mlp_hidden_dim = sd["double_blocks.0.img_mlp.0.weight"].shape[0]
|
||||
# mlp_ratio is a float, but we treat it as an int here to avoid having to think about possible float precision
|
||||
# issues. In practice, mlp_ratio is usually 4.
|
||||
mlp_ratio = mlp_hidden_dim // hidden_size
|
||||
|
||||
head_dim = sd["double_blocks.0.img_attn.norm.query_norm.scale"].shape[0]
|
||||
num_heads = hidden_size // head_dim
|
||||
|
||||
# Count the number of double blocks.
|
||||
double_block_index = 0
|
||||
while f"double_blocks.{double_block_index}.img_attn.qkv.weight" in sd:
|
||||
double_block_index += 1
|
||||
|
||||
# Count the number of single blocks.
|
||||
single_block_index = 0
|
||||
while f"single_blocks.{single_block_index}.linear1.weight" in sd:
|
||||
single_block_index += 1
|
||||
|
||||
return FluxParams(
|
||||
in_channels=sd["img_in.weight"].shape[1],
|
||||
vec_in_dim=sd["vector_in.in_layer.weight"].shape[1],
|
||||
context_in_dim=sd["txt_in.weight"].shape[1],
|
||||
hidden_size=hidden_size,
|
||||
mlp_ratio=mlp_ratio,
|
||||
num_heads=num_heads,
|
||||
depth=double_block_index,
|
||||
depth_single_blocks=single_block_index,
|
||||
# axes_dim cannot be inferred from the state dict. The hard-coded value is correct for dev/schnell models.
|
||||
axes_dim=[16, 56, 56],
|
||||
# theta cannot be inferred from the state dict. The hard-coded value is correct for dev/schnell models.
|
||||
theta=10_000,
|
||||
qkv_bias="double_blocks.0.img_attn.qkv.bias" in sd,
|
||||
guidance_embed="guidance_in.in_layer.weight" in sd,
|
||||
)
|
||||
|
||||
|
||||
def infer_instantx_num_control_modes_from_state_dict(sd: Dict[str, torch.Tensor]) -> int | None:
|
||||
"""Infer the number of ControlNet Union modes from the shape of a InstantX ControlNet state dict.
|
||||
|
||||
Returns None if the model is not a ControlNet Union model. Otherwise returns the number of modes.
|
||||
"""
|
||||
mode_embedder_key = "controlnet_mode_embedder.weight"
|
||||
if mode_embedder_key not in sd:
|
||||
return None
|
||||
|
||||
return sd[mode_embedder_key].shape[0]
|
||||
130
invokeai/backend/flux/controlnet/xlabs_controlnet_flux.py
Normal file
130
invokeai/backend/flux/controlnet/xlabs_controlnet_flux.py
Normal file
@@ -0,0 +1,130 @@
|
||||
# This file was initially based on:
|
||||
# https://github.com/XLabs-AI/x-flux/blob/47495425dbed499be1e8e5a6e52628b07349cba2/src/flux/controlnet.py
|
||||
|
||||
|
||||
from dataclasses import dataclass
|
||||
|
||||
import torch
|
||||
from einops import rearrange
|
||||
|
||||
from invokeai.backend.flux.controlnet.zero_module import zero_module
|
||||
from invokeai.backend.flux.model import FluxParams
|
||||
from invokeai.backend.flux.modules.layers import DoubleStreamBlock, EmbedND, MLPEmbedder, timestep_embedding
|
||||
|
||||
|
||||
@dataclass
|
||||
class XLabsControlNetFluxOutput:
|
||||
controlnet_double_block_residuals: list[torch.Tensor] | None
|
||||
|
||||
|
||||
class XLabsControlNetFlux(torch.nn.Module):
|
||||
"""A ControlNet model for FLUX.
|
||||
|
||||
The architecture is very similar to the base FLUX model, with the following differences:
|
||||
- A `controlnet_depth` parameter is passed to control the number of double_blocks that the ControlNet is applied to.
|
||||
In order to keep the ControlNet small, this is typically much less than the depth of the base FLUX model.
|
||||
- There is a set of `controlnet_blocks` that are applied to the output of each double_block.
|
||||
"""
|
||||
|
||||
def __init__(self, params: FluxParams, controlnet_depth: int = 2):
|
||||
super().__init__()
|
||||
|
||||
self.params = params
|
||||
self.in_channels = params.in_channels
|
||||
self.out_channels = self.in_channels
|
||||
if params.hidden_size % params.num_heads != 0:
|
||||
raise ValueError(f"Hidden size {params.hidden_size} must be divisible by num_heads {params.num_heads}")
|
||||
pe_dim = params.hidden_size // params.num_heads
|
||||
if sum(params.axes_dim) != pe_dim:
|
||||
raise ValueError(f"Got {params.axes_dim} but expected positional dim {pe_dim}")
|
||||
self.hidden_size = params.hidden_size
|
||||
self.num_heads = params.num_heads
|
||||
self.pe_embedder = EmbedND(dim=pe_dim, theta=params.theta, axes_dim=params.axes_dim)
|
||||
self.img_in = torch.nn.Linear(self.in_channels, self.hidden_size, bias=True)
|
||||
self.time_in = MLPEmbedder(in_dim=256, hidden_dim=self.hidden_size)
|
||||
self.vector_in = MLPEmbedder(params.vec_in_dim, self.hidden_size)
|
||||
self.guidance_in = (
|
||||
MLPEmbedder(in_dim=256, hidden_dim=self.hidden_size) if params.guidance_embed else torch.nn.Identity()
|
||||
)
|
||||
self.txt_in = torch.nn.Linear(params.context_in_dim, self.hidden_size)
|
||||
|
||||
self.double_blocks = torch.nn.ModuleList(
|
||||
[
|
||||
DoubleStreamBlock(
|
||||
self.hidden_size,
|
||||
self.num_heads,
|
||||
mlp_ratio=params.mlp_ratio,
|
||||
qkv_bias=params.qkv_bias,
|
||||
)
|
||||
for _ in range(controlnet_depth)
|
||||
]
|
||||
)
|
||||
|
||||
# Add ControlNet blocks.
|
||||
self.controlnet_blocks = torch.nn.ModuleList([])
|
||||
for _ in range(controlnet_depth):
|
||||
controlnet_block = torch.nn.Linear(self.hidden_size, self.hidden_size)
|
||||
controlnet_block = zero_module(controlnet_block)
|
||||
self.controlnet_blocks.append(controlnet_block)
|
||||
self.pos_embed_input = torch.nn.Linear(self.in_channels, self.hidden_size, bias=True)
|
||||
self.input_hint_block = torch.nn.Sequential(
|
||||
torch.nn.Conv2d(3, 16, 3, padding=1),
|
||||
torch.nn.SiLU(),
|
||||
torch.nn.Conv2d(16, 16, 3, padding=1),
|
||||
torch.nn.SiLU(),
|
||||
torch.nn.Conv2d(16, 16, 3, padding=1, stride=2),
|
||||
torch.nn.SiLU(),
|
||||
torch.nn.Conv2d(16, 16, 3, padding=1),
|
||||
torch.nn.SiLU(),
|
||||
torch.nn.Conv2d(16, 16, 3, padding=1, stride=2),
|
||||
torch.nn.SiLU(),
|
||||
torch.nn.Conv2d(16, 16, 3, padding=1),
|
||||
torch.nn.SiLU(),
|
||||
torch.nn.Conv2d(16, 16, 3, padding=1, stride=2),
|
||||
torch.nn.SiLU(),
|
||||
zero_module(torch.nn.Conv2d(16, 16, 3, padding=1)),
|
||||
)
|
||||
|
||||
def forward(
|
||||
self,
|
||||
img: torch.Tensor,
|
||||
img_ids: torch.Tensor,
|
||||
controlnet_cond: torch.Tensor,
|
||||
txt: torch.Tensor,
|
||||
txt_ids: torch.Tensor,
|
||||
timesteps: torch.Tensor,
|
||||
y: torch.Tensor,
|
||||
guidance: torch.Tensor | None = None,
|
||||
) -> XLabsControlNetFluxOutput:
|
||||
if img.ndim != 3 or txt.ndim != 3:
|
||||
raise ValueError("Input img and txt tensors must have 3 dimensions.")
|
||||
|
||||
# running on sequences img
|
||||
img = self.img_in(img)
|
||||
controlnet_cond = self.input_hint_block(controlnet_cond)
|
||||
controlnet_cond = rearrange(controlnet_cond, "b c (h ph) (w pw) -> b (h w) (c ph pw)", ph=2, pw=2)
|
||||
controlnet_cond = self.pos_embed_input(controlnet_cond)
|
||||
img = img + controlnet_cond
|
||||
vec = self.time_in(timestep_embedding(timesteps, 256))
|
||||
if self.params.guidance_embed:
|
||||
if guidance is None:
|
||||
raise ValueError("Didn't get guidance strength for guidance distilled model.")
|
||||
vec = vec + self.guidance_in(timestep_embedding(guidance, 256))
|
||||
vec = vec + self.vector_in(y)
|
||||
txt = self.txt_in(txt)
|
||||
|
||||
ids = torch.cat((txt_ids, img_ids), dim=1)
|
||||
pe = self.pe_embedder(ids)
|
||||
|
||||
block_res_samples: list[torch.Tensor] = []
|
||||
|
||||
for block in self.double_blocks:
|
||||
img, txt = block(img=img, txt=txt, vec=vec, pe=pe)
|
||||
block_res_samples.append(img)
|
||||
|
||||
controlnet_block_res_samples: list[torch.Tensor] = []
|
||||
for block_res_sample, controlnet_block in zip(block_res_samples, self.controlnet_blocks, strict=True):
|
||||
block_res_sample = controlnet_block(block_res_sample)
|
||||
controlnet_block_res_samples.append(block_res_sample)
|
||||
|
||||
return XLabsControlNetFluxOutput(controlnet_double_block_residuals=controlnet_block_res_samples)
|
||||
12
invokeai/backend/flux/controlnet/zero_module.py
Normal file
12
invokeai/backend/flux/controlnet/zero_module.py
Normal file
@@ -0,0 +1,12 @@
|
||||
from typing import TypeVar
|
||||
|
||||
import torch
|
||||
|
||||
T = TypeVar("T", bound=torch.nn.Module)
|
||||
|
||||
|
||||
def zero_module(module: T) -> T:
|
||||
"""Initialize the parameters of a module to zero."""
|
||||
for p in module.parameters():
|
||||
torch.nn.init.zeros_(p)
|
||||
return module
|
||||
83
invokeai/backend/flux/custom_block_processor.py
Normal file
83
invokeai/backend/flux/custom_block_processor.py
Normal file
@@ -0,0 +1,83 @@
|
||||
import einops
|
||||
import torch
|
||||
|
||||
from invokeai.backend.flux.extensions.xlabs_ip_adapter_extension import XLabsIPAdapterExtension
|
||||
from invokeai.backend.flux.math import attention
|
||||
from invokeai.backend.flux.modules.layers import DoubleStreamBlock
|
||||
|
||||
|
||||
class CustomDoubleStreamBlockProcessor:
|
||||
"""A class containing a custom implementation of DoubleStreamBlock.forward() with additional features
|
||||
(IP-Adapter, etc.).
|
||||
"""
|
||||
|
||||
@staticmethod
|
||||
def _double_stream_block_forward(
|
||||
block: DoubleStreamBlock, img: torch.Tensor, txt: torch.Tensor, vec: torch.Tensor, pe: torch.Tensor
|
||||
) -> tuple[torch.Tensor, torch.Tensor, torch.Tensor]:
|
||||
"""This function is a direct copy of DoubleStreamBlock.forward(), but it returns some of the intermediate
|
||||
values.
|
||||
"""
|
||||
img_mod1, img_mod2 = block.img_mod(vec)
|
||||
txt_mod1, txt_mod2 = block.txt_mod(vec)
|
||||
|
||||
# prepare image for attention
|
||||
img_modulated = block.img_norm1(img)
|
||||
img_modulated = (1 + img_mod1.scale) * img_modulated + img_mod1.shift
|
||||
img_qkv = block.img_attn.qkv(img_modulated)
|
||||
img_q, img_k, img_v = einops.rearrange(img_qkv, "B L (K H D) -> K B H L D", K=3, H=block.num_heads)
|
||||
img_q, img_k = block.img_attn.norm(img_q, img_k, img_v)
|
||||
|
||||
# prepare txt for attention
|
||||
txt_modulated = block.txt_norm1(txt)
|
||||
txt_modulated = (1 + txt_mod1.scale) * txt_modulated + txt_mod1.shift
|
||||
txt_qkv = block.txt_attn.qkv(txt_modulated)
|
||||
txt_q, txt_k, txt_v = einops.rearrange(txt_qkv, "B L (K H D) -> K B H L D", K=3, H=block.num_heads)
|
||||
txt_q, txt_k = block.txt_attn.norm(txt_q, txt_k, txt_v)
|
||||
|
||||
# run actual attention
|
||||
q = torch.cat((txt_q, img_q), dim=2)
|
||||
k = torch.cat((txt_k, img_k), dim=2)
|
||||
v = torch.cat((txt_v, img_v), dim=2)
|
||||
|
||||
attn = attention(q, k, v, pe=pe)
|
||||
txt_attn, img_attn = attn[:, : txt.shape[1]], attn[:, txt.shape[1] :]
|
||||
|
||||
# calculate the img bloks
|
||||
img = img + img_mod1.gate * block.img_attn.proj(img_attn)
|
||||
img = img + img_mod2.gate * block.img_mlp((1 + img_mod2.scale) * block.img_norm2(img) + img_mod2.shift)
|
||||
|
||||
# calculate the txt bloks
|
||||
txt = txt + txt_mod1.gate * block.txt_attn.proj(txt_attn)
|
||||
txt = txt + txt_mod2.gate * block.txt_mlp((1 + txt_mod2.scale) * block.txt_norm2(txt) + txt_mod2.shift)
|
||||
return img, txt, img_q
|
||||
|
||||
@staticmethod
|
||||
def custom_double_block_forward(
|
||||
timestep_index: int,
|
||||
total_num_timesteps: int,
|
||||
block_index: int,
|
||||
block: DoubleStreamBlock,
|
||||
img: torch.Tensor,
|
||||
txt: torch.Tensor,
|
||||
vec: torch.Tensor,
|
||||
pe: torch.Tensor,
|
||||
ip_adapter_extensions: list[XLabsIPAdapterExtension],
|
||||
) -> tuple[torch.Tensor, torch.Tensor]:
|
||||
"""A custom implementation of DoubleStreamBlock.forward() with additional features:
|
||||
- IP-Adapter support
|
||||
"""
|
||||
img, txt, img_q = CustomDoubleStreamBlockProcessor._double_stream_block_forward(block, img, txt, vec, pe)
|
||||
|
||||
# Apply IP-Adapter conditioning.
|
||||
for ip_adapter_extension in ip_adapter_extensions:
|
||||
img = ip_adapter_extension.run_ip_adapter(
|
||||
timestep_index=timestep_index,
|
||||
total_num_timesteps=total_num_timesteps,
|
||||
block_index=block_index,
|
||||
block=block,
|
||||
img_q=img_q,
|
||||
img=img,
|
||||
)
|
||||
|
||||
return img, txt
|
||||
@@ -1,10 +1,15 @@
|
||||
import math
|
||||
from typing import Callable
|
||||
|
||||
import torch
|
||||
from tqdm import tqdm
|
||||
|
||||
from invokeai.backend.flux.controlnet.controlnet_flux_output import ControlNetFluxOutput, sum_controlnet_flux_outputs
|
||||
from invokeai.backend.flux.extensions.inpaint_extension import InpaintExtension
|
||||
from invokeai.backend.flux.extensions.instantx_controlnet_extension import InstantXControlNetExtension
|
||||
from invokeai.backend.flux.extensions.xlabs_controlnet_extension import XLabsControlNetExtension
|
||||
from invokeai.backend.flux.extensions.xlabs_ip_adapter_extension import XLabsIPAdapterExtension
|
||||
from invokeai.backend.flux.model import Flux
|
||||
from invokeai.backend.flux.trajectory_guidance_extension import TrajectoryGuidanceExtension
|
||||
from invokeai.backend.stable_diffusion.diffusers_pipeline import PipelineIntermediateState
|
||||
|
||||
|
||||
@@ -13,14 +18,23 @@ def denoise(
|
||||
# model input
|
||||
img: torch.Tensor,
|
||||
img_ids: torch.Tensor,
|
||||
# positive text conditioning
|
||||
txt: torch.Tensor,
|
||||
txt_ids: torch.Tensor,
|
||||
vec: torch.Tensor,
|
||||
# negative text conditioning
|
||||
neg_txt: torch.Tensor | None,
|
||||
neg_txt_ids: torch.Tensor | None,
|
||||
neg_vec: torch.Tensor | None,
|
||||
# sampling parameters
|
||||
timesteps: list[float],
|
||||
step_callback: Callable[[PipelineIntermediateState], None],
|
||||
guidance: float,
|
||||
traj_guidance_extension: TrajectoryGuidanceExtension | None, # noqa: F821
|
||||
cfg_scale: list[float],
|
||||
inpaint_extension: InpaintExtension | None,
|
||||
controlnet_extensions: list[XLabsControlNetExtension | InstantXControlNetExtension],
|
||||
pos_ip_adapter_extensions: list[XLabsIPAdapterExtension],
|
||||
neg_ip_adapter_extensions: list[XLabsIPAdapterExtension],
|
||||
):
|
||||
# step 0 is the initial state
|
||||
total_steps = len(timesteps) - 1
|
||||
@@ -33,11 +47,34 @@ def denoise(
|
||||
latents=img,
|
||||
),
|
||||
)
|
||||
step = 1
|
||||
# guidance_vec is ignored for schnell.
|
||||
guidance_vec = torch.full((img.shape[0],), guidance, device=img.device, dtype=img.dtype)
|
||||
for t_curr, t_prev in tqdm(list(zip(timesteps[:-1], timesteps[1:], strict=True))):
|
||||
for step_index, (t_curr, t_prev) in tqdm(list(enumerate(zip(timesteps[:-1], timesteps[1:], strict=True)))):
|
||||
t_vec = torch.full((img.shape[0],), t_curr, dtype=img.dtype, device=img.device)
|
||||
|
||||
# Run ControlNet models.
|
||||
controlnet_residuals: list[ControlNetFluxOutput] = []
|
||||
for controlnet_extension in controlnet_extensions:
|
||||
controlnet_residuals.append(
|
||||
controlnet_extension.run_controlnet(
|
||||
timestep_index=step_index,
|
||||
total_num_timesteps=total_steps,
|
||||
img=img,
|
||||
img_ids=img_ids,
|
||||
txt=txt,
|
||||
txt_ids=txt_ids,
|
||||
y=vec,
|
||||
timesteps=t_vec,
|
||||
guidance=guidance_vec,
|
||||
)
|
||||
)
|
||||
|
||||
# Merge the ControlNet residuals from multiple ControlNets.
|
||||
# TODO(ryand): We may want to calculate the sum just-in-time to keep peak memory low. Keep in mind, that the
|
||||
# controlnet_residuals datastructure is efficient in that it likely contains multiple references to the same
|
||||
# tensors. Calculating the sum materializes each tensor into its own instance.
|
||||
merged_controlnet_residuals = sum_controlnet_flux_outputs(controlnet_residuals)
|
||||
|
||||
pred = model(
|
||||
img=img,
|
||||
img_ids=img_ids,
|
||||
@@ -46,25 +83,54 @@ def denoise(
|
||||
y=vec,
|
||||
timesteps=t_vec,
|
||||
guidance=guidance_vec,
|
||||
timestep_index=step_index,
|
||||
total_num_timesteps=total_steps,
|
||||
controlnet_double_block_residuals=merged_controlnet_residuals.double_block_residuals,
|
||||
controlnet_single_block_residuals=merged_controlnet_residuals.single_block_residuals,
|
||||
ip_adapter_extensions=pos_ip_adapter_extensions,
|
||||
)
|
||||
|
||||
if traj_guidance_extension is not None:
|
||||
pred = traj_guidance_extension.update_noise(
|
||||
t_curr_latents=img, pred_noise=pred, t_curr=t_curr, t_prev=t_prev
|
||||
step_cfg_scale = cfg_scale[step_index]
|
||||
|
||||
# If step_cfg_scale, is 1.0, then we don't need to run the negative prediction.
|
||||
if not math.isclose(step_cfg_scale, 1.0):
|
||||
# TODO(ryand): Add option to run positive and negative predictions in a single batch for better performance
|
||||
# on systems with sufficient VRAM.
|
||||
|
||||
if neg_txt is None or neg_txt_ids is None or neg_vec is None:
|
||||
raise ValueError("Negative text conditioning is required when cfg_scale is not 1.0.")
|
||||
|
||||
neg_pred = model(
|
||||
img=img,
|
||||
img_ids=img_ids,
|
||||
txt=neg_txt,
|
||||
txt_ids=neg_txt_ids,
|
||||
y=neg_vec,
|
||||
timesteps=t_vec,
|
||||
guidance=guidance_vec,
|
||||
timestep_index=step_index,
|
||||
total_num_timesteps=total_steps,
|
||||
controlnet_double_block_residuals=None,
|
||||
controlnet_single_block_residuals=None,
|
||||
ip_adapter_extensions=neg_ip_adapter_extensions,
|
||||
)
|
||||
pred = neg_pred + step_cfg_scale * (pred - neg_pred)
|
||||
|
||||
preview_img = img - t_curr * pred
|
||||
img = img + (t_prev - t_curr) * pred
|
||||
|
||||
if inpaint_extension is not None:
|
||||
img = inpaint_extension.merge_intermediate_latents_with_init_latents(img, t_prev)
|
||||
preview_img = inpaint_extension.merge_intermediate_latents_with_init_latents(preview_img, 0.0)
|
||||
|
||||
step_callback(
|
||||
PipelineIntermediateState(
|
||||
step=step,
|
||||
step=step_index + 1,
|
||||
order=1,
|
||||
total_steps=total_steps,
|
||||
timestep=int(t_curr),
|
||||
latents=preview_img,
|
||||
),
|
||||
)
|
||||
step += 1
|
||||
|
||||
return img
|
||||
|
||||
0
invokeai/backend/flux/extensions/__init__.py
Normal file
0
invokeai/backend/flux/extensions/__init__.py
Normal file
@@ -0,0 +1,45 @@
|
||||
import math
|
||||
from abc import ABC, abstractmethod
|
||||
from typing import List, Union
|
||||
|
||||
import torch
|
||||
|
||||
from invokeai.backend.flux.controlnet.controlnet_flux_output import ControlNetFluxOutput
|
||||
|
||||
|
||||
class BaseControlNetExtension(ABC):
|
||||
def __init__(
|
||||
self,
|
||||
weight: Union[float, List[float]],
|
||||
begin_step_percent: float,
|
||||
end_step_percent: float,
|
||||
):
|
||||
self._weight = weight
|
||||
self._begin_step_percent = begin_step_percent
|
||||
self._end_step_percent = end_step_percent
|
||||
|
||||
def _get_weight(self, timestep_index: int, total_num_timesteps: int) -> float:
|
||||
first_step = math.floor(self._begin_step_percent * total_num_timesteps)
|
||||
last_step = math.ceil(self._end_step_percent * total_num_timesteps)
|
||||
|
||||
if timestep_index < first_step or timestep_index > last_step:
|
||||
return 0.0
|
||||
|
||||
if isinstance(self._weight, list):
|
||||
return self._weight[timestep_index]
|
||||
|
||||
return self._weight
|
||||
|
||||
@abstractmethod
|
||||
def run_controlnet(
|
||||
self,
|
||||
timestep_index: int,
|
||||
total_num_timesteps: int,
|
||||
img: torch.Tensor,
|
||||
img_ids: torch.Tensor,
|
||||
txt: torch.Tensor,
|
||||
txt_ids: torch.Tensor,
|
||||
y: torch.Tensor,
|
||||
timesteps: torch.Tensor,
|
||||
guidance: torch.Tensor | None,
|
||||
) -> ControlNetFluxOutput: ...
|
||||
@@ -19,8 +19,26 @@ class InpaintExtension:
|
||||
self._inpaint_mask = inpaint_mask
|
||||
self._noise = noise
|
||||
|
||||
def _apply_mask_gradient_adjustment(self, t_prev: float) -> torch.Tensor:
|
||||
"""Applies inpaint mask gradient adjustment and returns the inpaint mask to be used at the current timestep."""
|
||||
# As we progress through the denoising process, we promote gradient regions of the mask to have a full weight of
|
||||
# 1.0. This helps to produce more coherent seams around the inpainted region. We experimented with a (small)
|
||||
# number of promotion strategies (e.g. gradual promotion based on timestep), but found that a simple cutoff
|
||||
# threshold worked well.
|
||||
# We use a small epsilon to avoid any potential issues with floating point precision.
|
||||
eps = 1e-4
|
||||
mask_gradient_t_cutoff = 0.5
|
||||
if t_prev > mask_gradient_t_cutoff:
|
||||
# Early in the denoising process, use the inpaint mask as-is.
|
||||
return self._inpaint_mask
|
||||
else:
|
||||
# After the cut-off, promote all non-zero mask values to 1.0.
|
||||
mask = self._inpaint_mask.where(self._inpaint_mask <= (0.0 + eps), 1.0)
|
||||
|
||||
return mask
|
||||
|
||||
def merge_intermediate_latents_with_init_latents(
|
||||
self, intermediate_latents: torch.Tensor, timestep: float
|
||||
self, intermediate_latents: torch.Tensor, t_prev: float
|
||||
) -> torch.Tensor:
|
||||
"""Merge the intermediate latents with the initial latents for the current timestep using the inpaint mask. I.e.
|
||||
update the intermediate latents to keep the regions that are not being inpainted on the correct noise
|
||||
@@ -28,8 +46,10 @@ class InpaintExtension:
|
||||
|
||||
This function should be called after each denoising step.
|
||||
"""
|
||||
mask = self._apply_mask_gradient_adjustment(t_prev)
|
||||
|
||||
# Noise the init latents for the current timestep.
|
||||
noised_init_latents = self._noise * timestep + (1.0 - timestep) * self._init_latents
|
||||
noised_init_latents = self._noise * t_prev + (1.0 - t_prev) * self._init_latents
|
||||
|
||||
# Merge the intermediate latents with the noised_init_latents using the inpaint_mask.
|
||||
return intermediate_latents * self._inpaint_mask + noised_init_latents * (1.0 - self._inpaint_mask)
|
||||
return intermediate_latents * mask + noised_init_latents * (1.0 - mask)
|
||||
@@ -0,0 +1,194 @@
|
||||
import math
|
||||
from typing import List, Union
|
||||
|
||||
import torch
|
||||
from PIL.Image import Image
|
||||
|
||||
from invokeai.app.invocations.constants import LATENT_SCALE_FACTOR
|
||||
from invokeai.app.invocations.flux_vae_encode import FluxVaeEncodeInvocation
|
||||
from invokeai.app.util.controlnet_utils import CONTROLNET_RESIZE_VALUES, prepare_control_image
|
||||
from invokeai.backend.flux.controlnet.controlnet_flux_output import ControlNetFluxOutput
|
||||
from invokeai.backend.flux.controlnet.instantx_controlnet_flux import (
|
||||
InstantXControlNetFlux,
|
||||
InstantXControlNetFluxOutput,
|
||||
)
|
||||
from invokeai.backend.flux.extensions.base_controlnet_extension import BaseControlNetExtension
|
||||
from invokeai.backend.flux.sampling_utils import pack
|
||||
from invokeai.backend.model_manager.load.load_base import LoadedModel
|
||||
|
||||
|
||||
class InstantXControlNetExtension(BaseControlNetExtension):
|
||||
def __init__(
|
||||
self,
|
||||
model: InstantXControlNetFlux,
|
||||
controlnet_cond: torch.Tensor,
|
||||
instantx_control_mode: torch.Tensor | None,
|
||||
weight: Union[float, List[float]],
|
||||
begin_step_percent: float,
|
||||
end_step_percent: float,
|
||||
):
|
||||
super().__init__(
|
||||
weight=weight,
|
||||
begin_step_percent=begin_step_percent,
|
||||
end_step_percent=end_step_percent,
|
||||
)
|
||||
self._model = model
|
||||
# The VAE-encoded and 'packed' control image to pass to the ControlNet model.
|
||||
self._controlnet_cond = controlnet_cond
|
||||
# TODO(ryand): Should we define an enum for the instantx_control_mode? Is it likely to change for future models?
|
||||
# The control mode for InstantX ControlNet union models.
|
||||
# See the values defined here: https://huggingface.co/InstantX/FLUX.1-dev-Controlnet-Union#control-mode
|
||||
# Expected shape: (batch_size, 1), Expected dtype: torch.long
|
||||
# If None, a zero-embedding will be used.
|
||||
self._instantx_control_mode = instantx_control_mode
|
||||
|
||||
# TODO(ryand): Pass in these params if a new base transformer / InstantX ControlNet pair get released.
|
||||
self._flux_transformer_num_double_blocks = 19
|
||||
self._flux_transformer_num_single_blocks = 38
|
||||
|
||||
@classmethod
|
||||
def prepare_controlnet_cond(
|
||||
cls,
|
||||
controlnet_image: Image,
|
||||
vae_info: LoadedModel,
|
||||
latent_height: int,
|
||||
latent_width: int,
|
||||
dtype: torch.dtype,
|
||||
device: torch.device,
|
||||
resize_mode: CONTROLNET_RESIZE_VALUES,
|
||||
):
|
||||
image_height = latent_height * LATENT_SCALE_FACTOR
|
||||
image_width = latent_width * LATENT_SCALE_FACTOR
|
||||
|
||||
resized_controlnet_image = prepare_control_image(
|
||||
image=controlnet_image,
|
||||
do_classifier_free_guidance=False,
|
||||
width=image_width,
|
||||
height=image_height,
|
||||
device=device,
|
||||
dtype=dtype,
|
||||
control_mode="balanced",
|
||||
resize_mode=resize_mode,
|
||||
)
|
||||
|
||||
# Shift the image from [0, 1] to [-1, 1].
|
||||
resized_controlnet_image = resized_controlnet_image * 2 - 1
|
||||
|
||||
# Run VAE encoder.
|
||||
controlnet_cond = FluxVaeEncodeInvocation.vae_encode(vae_info=vae_info, image_tensor=resized_controlnet_image)
|
||||
controlnet_cond = pack(controlnet_cond)
|
||||
|
||||
return controlnet_cond
|
||||
|
||||
@classmethod
|
||||
def from_controlnet_image(
|
||||
cls,
|
||||
model: InstantXControlNetFlux,
|
||||
controlnet_image: Image,
|
||||
instantx_control_mode: torch.Tensor | None,
|
||||
vae_info: LoadedModel,
|
||||
latent_height: int,
|
||||
latent_width: int,
|
||||
dtype: torch.dtype,
|
||||
device: torch.device,
|
||||
resize_mode: CONTROLNET_RESIZE_VALUES,
|
||||
weight: Union[float, List[float]],
|
||||
begin_step_percent: float,
|
||||
end_step_percent: float,
|
||||
):
|
||||
image_height = latent_height * LATENT_SCALE_FACTOR
|
||||
image_width = latent_width * LATENT_SCALE_FACTOR
|
||||
|
||||
resized_controlnet_image = prepare_control_image(
|
||||
image=controlnet_image,
|
||||
do_classifier_free_guidance=False,
|
||||
width=image_width,
|
||||
height=image_height,
|
||||
device=device,
|
||||
dtype=dtype,
|
||||
control_mode="balanced",
|
||||
resize_mode=resize_mode,
|
||||
)
|
||||
|
||||
# Shift the image from [0, 1] to [-1, 1].
|
||||
resized_controlnet_image = resized_controlnet_image * 2 - 1
|
||||
|
||||
# Run VAE encoder.
|
||||
controlnet_cond = FluxVaeEncodeInvocation.vae_encode(vae_info=vae_info, image_tensor=resized_controlnet_image)
|
||||
controlnet_cond = pack(controlnet_cond)
|
||||
|
||||
return cls(
|
||||
model=model,
|
||||
controlnet_cond=controlnet_cond,
|
||||
instantx_control_mode=instantx_control_mode,
|
||||
weight=weight,
|
||||
begin_step_percent=begin_step_percent,
|
||||
end_step_percent=end_step_percent,
|
||||
)
|
||||
|
||||
def _instantx_output_to_controlnet_output(
|
||||
self, instantx_output: InstantXControlNetFluxOutput
|
||||
) -> ControlNetFluxOutput:
|
||||
# The `interval_control` logic here is based on
|
||||
# https://github.com/huggingface/diffusers/blob/31058cdaef63ca660a1a045281d156239fba8192/src/diffusers/models/transformers/transformer_flux.py#L507-L511
|
||||
|
||||
# Handle double block residuals.
|
||||
double_block_residuals: list[torch.Tensor] = []
|
||||
double_block_samples = instantx_output.controlnet_block_samples
|
||||
if double_block_samples:
|
||||
interval_control = self._flux_transformer_num_double_blocks / len(double_block_samples)
|
||||
interval_control = int(math.ceil(interval_control))
|
||||
for i in range(self._flux_transformer_num_double_blocks):
|
||||
double_block_residuals.append(double_block_samples[i // interval_control])
|
||||
|
||||
# Handle single block residuals.
|
||||
single_block_residuals: list[torch.Tensor] = []
|
||||
single_block_samples = instantx_output.controlnet_single_block_samples
|
||||
if single_block_samples:
|
||||
interval_control = self._flux_transformer_num_single_blocks / len(single_block_samples)
|
||||
interval_control = int(math.ceil(interval_control))
|
||||
for i in range(self._flux_transformer_num_single_blocks):
|
||||
single_block_residuals.append(single_block_samples[i // interval_control])
|
||||
|
||||
return ControlNetFluxOutput(
|
||||
double_block_residuals=double_block_residuals or None,
|
||||
single_block_residuals=single_block_residuals or None,
|
||||
)
|
||||
|
||||
def run_controlnet(
|
||||
self,
|
||||
timestep_index: int,
|
||||
total_num_timesteps: int,
|
||||
img: torch.Tensor,
|
||||
img_ids: torch.Tensor,
|
||||
txt: torch.Tensor,
|
||||
txt_ids: torch.Tensor,
|
||||
y: torch.Tensor,
|
||||
timesteps: torch.Tensor,
|
||||
guidance: torch.Tensor | None,
|
||||
) -> ControlNetFluxOutput:
|
||||
weight = self._get_weight(timestep_index=timestep_index, total_num_timesteps=total_num_timesteps)
|
||||
if weight < 1e-6:
|
||||
return ControlNetFluxOutput(single_block_residuals=None, double_block_residuals=None)
|
||||
|
||||
# Make sure inputs have correct device and dtype.
|
||||
self._controlnet_cond = self._controlnet_cond.to(device=img.device, dtype=img.dtype)
|
||||
self._instantx_control_mode = (
|
||||
self._instantx_control_mode.to(device=img.device) if self._instantx_control_mode is not None else None
|
||||
)
|
||||
|
||||
instantx_output: InstantXControlNetFluxOutput = self._model(
|
||||
controlnet_cond=self._controlnet_cond,
|
||||
controlnet_mode=self._instantx_control_mode,
|
||||
img=img,
|
||||
img_ids=img_ids,
|
||||
txt=txt,
|
||||
txt_ids=txt_ids,
|
||||
timesteps=timesteps,
|
||||
y=y,
|
||||
guidance=guidance,
|
||||
)
|
||||
|
||||
controlnet_output = self._instantx_output_to_controlnet_output(instantx_output)
|
||||
controlnet_output.apply_weight(weight)
|
||||
return controlnet_output
|
||||
150
invokeai/backend/flux/extensions/xlabs_controlnet_extension.py
Normal file
150
invokeai/backend/flux/extensions/xlabs_controlnet_extension.py
Normal file
@@ -0,0 +1,150 @@
|
||||
from typing import List, Union
|
||||
|
||||
import torch
|
||||
from PIL.Image import Image
|
||||
|
||||
from invokeai.app.invocations.constants import LATENT_SCALE_FACTOR
|
||||
from invokeai.app.util.controlnet_utils import CONTROLNET_RESIZE_VALUES, prepare_control_image
|
||||
from invokeai.backend.flux.controlnet.controlnet_flux_output import ControlNetFluxOutput
|
||||
from invokeai.backend.flux.controlnet.xlabs_controlnet_flux import XLabsControlNetFlux, XLabsControlNetFluxOutput
|
||||
from invokeai.backend.flux.extensions.base_controlnet_extension import BaseControlNetExtension
|
||||
|
||||
|
||||
class XLabsControlNetExtension(BaseControlNetExtension):
|
||||
def __init__(
|
||||
self,
|
||||
model: XLabsControlNetFlux,
|
||||
controlnet_cond: torch.Tensor,
|
||||
weight: Union[float, List[float]],
|
||||
begin_step_percent: float,
|
||||
end_step_percent: float,
|
||||
):
|
||||
super().__init__(
|
||||
weight=weight,
|
||||
begin_step_percent=begin_step_percent,
|
||||
end_step_percent=end_step_percent,
|
||||
)
|
||||
|
||||
self._model = model
|
||||
# _controlnet_cond is the control image passed to the ControlNet model.
|
||||
# Pixel values are in the range [-1, 1]. Shape: (batch_size, 3, height, width).
|
||||
self._controlnet_cond = controlnet_cond
|
||||
|
||||
# TODO(ryand): Pass in these params if a new base transformer / XLabs ControlNet pair get released.
|
||||
self._flux_transformer_num_double_blocks = 19
|
||||
self._flux_transformer_num_single_blocks = 38
|
||||
|
||||
@classmethod
|
||||
def prepare_controlnet_cond(
|
||||
cls,
|
||||
controlnet_image: Image,
|
||||
latent_height: int,
|
||||
latent_width: int,
|
||||
dtype: torch.dtype,
|
||||
device: torch.device,
|
||||
resize_mode: CONTROLNET_RESIZE_VALUES,
|
||||
):
|
||||
image_height = latent_height * LATENT_SCALE_FACTOR
|
||||
image_width = latent_width * LATENT_SCALE_FACTOR
|
||||
|
||||
controlnet_cond = prepare_control_image(
|
||||
image=controlnet_image,
|
||||
do_classifier_free_guidance=False,
|
||||
width=image_width,
|
||||
height=image_height,
|
||||
device=device,
|
||||
dtype=dtype,
|
||||
control_mode="balanced",
|
||||
resize_mode=resize_mode,
|
||||
)
|
||||
|
||||
# Map pixel values from [0, 1] to [-1, 1].
|
||||
controlnet_cond = controlnet_cond * 2 - 1
|
||||
|
||||
return controlnet_cond
|
||||
|
||||
@classmethod
|
||||
def from_controlnet_image(
|
||||
cls,
|
||||
model: XLabsControlNetFlux,
|
||||
controlnet_image: Image,
|
||||
latent_height: int,
|
||||
latent_width: int,
|
||||
dtype: torch.dtype,
|
||||
device: torch.device,
|
||||
resize_mode: CONTROLNET_RESIZE_VALUES,
|
||||
weight: Union[float, List[float]],
|
||||
begin_step_percent: float,
|
||||
end_step_percent: float,
|
||||
):
|
||||
image_height = latent_height * LATENT_SCALE_FACTOR
|
||||
image_width = latent_width * LATENT_SCALE_FACTOR
|
||||
|
||||
controlnet_cond = prepare_control_image(
|
||||
image=controlnet_image,
|
||||
do_classifier_free_guidance=False,
|
||||
width=image_width,
|
||||
height=image_height,
|
||||
device=device,
|
||||
dtype=dtype,
|
||||
control_mode="balanced",
|
||||
resize_mode=resize_mode,
|
||||
)
|
||||
|
||||
# Map pixel values from [0, 1] to [-1, 1].
|
||||
controlnet_cond = controlnet_cond * 2 - 1
|
||||
|
||||
return cls(
|
||||
model=model,
|
||||
controlnet_cond=controlnet_cond,
|
||||
weight=weight,
|
||||
begin_step_percent=begin_step_percent,
|
||||
end_step_percent=end_step_percent,
|
||||
)
|
||||
|
||||
def _xlabs_output_to_controlnet_output(self, xlabs_output: XLabsControlNetFluxOutput) -> ControlNetFluxOutput:
|
||||
# The modulo index logic used here is based on:
|
||||
# https://github.com/XLabs-AI/x-flux/blob/47495425dbed499be1e8e5a6e52628b07349cba2/src/flux/model.py#L198-L200
|
||||
|
||||
# Handle double block residuals.
|
||||
double_block_residuals: list[torch.Tensor] = []
|
||||
xlabs_double_block_residuals = xlabs_output.controlnet_double_block_residuals
|
||||
if xlabs_double_block_residuals is not None:
|
||||
for i in range(self._flux_transformer_num_double_blocks):
|
||||
double_block_residuals.append(xlabs_double_block_residuals[i % len(xlabs_double_block_residuals)])
|
||||
|
||||
return ControlNetFluxOutput(
|
||||
double_block_residuals=double_block_residuals,
|
||||
single_block_residuals=None,
|
||||
)
|
||||
|
||||
def run_controlnet(
|
||||
self,
|
||||
timestep_index: int,
|
||||
total_num_timesteps: int,
|
||||
img: torch.Tensor,
|
||||
img_ids: torch.Tensor,
|
||||
txt: torch.Tensor,
|
||||
txt_ids: torch.Tensor,
|
||||
y: torch.Tensor,
|
||||
timesteps: torch.Tensor,
|
||||
guidance: torch.Tensor | None,
|
||||
) -> ControlNetFluxOutput:
|
||||
weight = self._get_weight(timestep_index=timestep_index, total_num_timesteps=total_num_timesteps)
|
||||
if weight < 1e-6:
|
||||
return ControlNetFluxOutput(single_block_residuals=None, double_block_residuals=None)
|
||||
|
||||
xlabs_output: XLabsControlNetFluxOutput = self._model(
|
||||
img=img,
|
||||
img_ids=img_ids,
|
||||
controlnet_cond=self._controlnet_cond,
|
||||
txt=txt,
|
||||
txt_ids=txt_ids,
|
||||
timesteps=timesteps,
|
||||
y=y,
|
||||
guidance=guidance,
|
||||
)
|
||||
|
||||
controlnet_output = self._xlabs_output_to_controlnet_output(xlabs_output)
|
||||
controlnet_output.apply_weight(weight)
|
||||
return controlnet_output
|
||||
@@ -0,0 +1,89 @@
|
||||
import math
|
||||
from typing import List, Union
|
||||
|
||||
import einops
|
||||
import torch
|
||||
from PIL import Image
|
||||
from transformers import CLIPImageProcessor, CLIPVisionModelWithProjection
|
||||
|
||||
from invokeai.backend.flux.ip_adapter.xlabs_ip_adapter_flux import XlabsIpAdapterFlux
|
||||
from invokeai.backend.flux.modules.layers import DoubleStreamBlock
|
||||
|
||||
|
||||
class XLabsIPAdapterExtension:
|
||||
def __init__(
|
||||
self,
|
||||
model: XlabsIpAdapterFlux,
|
||||
image_prompt_clip_embed: torch.Tensor,
|
||||
weight: Union[float, List[float]],
|
||||
begin_step_percent: float,
|
||||
end_step_percent: float,
|
||||
):
|
||||
self._model = model
|
||||
self._image_prompt_clip_embed = image_prompt_clip_embed
|
||||
self._weight = weight
|
||||
self._begin_step_percent = begin_step_percent
|
||||
self._end_step_percent = end_step_percent
|
||||
|
||||
self._image_proj: torch.Tensor | None = None
|
||||
|
||||
def _get_weight(self, timestep_index: int, total_num_timesteps: int) -> float:
|
||||
first_step = math.floor(self._begin_step_percent * total_num_timesteps)
|
||||
last_step = math.ceil(self._end_step_percent * total_num_timesteps)
|
||||
|
||||
if timestep_index < first_step or timestep_index > last_step:
|
||||
return 0.0
|
||||
|
||||
if isinstance(self._weight, list):
|
||||
return self._weight[timestep_index]
|
||||
|
||||
return self._weight
|
||||
|
||||
@staticmethod
|
||||
def run_clip_image_encoder(
|
||||
pil_image: List[Image.Image], image_encoder: CLIPVisionModelWithProjection
|
||||
) -> torch.Tensor:
|
||||
clip_image_processor = CLIPImageProcessor()
|
||||
clip_image: torch.Tensor = clip_image_processor(images=pil_image, return_tensors="pt").pixel_values
|
||||
clip_image = clip_image.to(device=image_encoder.device, dtype=image_encoder.dtype)
|
||||
clip_image_embeds = image_encoder(clip_image).image_embeds
|
||||
return clip_image_embeds
|
||||
|
||||
def run_image_proj(self, dtype: torch.dtype):
|
||||
image_prompt_clip_embed = self._image_prompt_clip_embed.to(dtype=dtype)
|
||||
self._image_proj = self._model.image_proj(image_prompt_clip_embed)
|
||||
|
||||
def run_ip_adapter(
|
||||
self,
|
||||
timestep_index: int,
|
||||
total_num_timesteps: int,
|
||||
block_index: int,
|
||||
block: DoubleStreamBlock,
|
||||
img_q: torch.Tensor,
|
||||
img: torch.Tensor,
|
||||
) -> torch.Tensor:
|
||||
"""The logic in this function is based on:
|
||||
https://github.com/XLabs-AI/x-flux/blob/47495425dbed499be1e8e5a6e52628b07349cba2/src/flux/modules/layers.py#L245-L301
|
||||
"""
|
||||
weight = self._get_weight(timestep_index=timestep_index, total_num_timesteps=total_num_timesteps)
|
||||
if weight < 1e-6:
|
||||
return img
|
||||
|
||||
ip_adapter_block = self._model.ip_adapter_double_blocks.double_blocks[block_index]
|
||||
|
||||
ip_key = ip_adapter_block.ip_adapter_double_stream_k_proj(self._image_proj)
|
||||
ip_value = ip_adapter_block.ip_adapter_double_stream_v_proj(self._image_proj)
|
||||
|
||||
# Reshape projections for multi-head attention.
|
||||
ip_key = einops.rearrange(ip_key, "B L (H D) -> B H L D", H=block.num_heads)
|
||||
ip_value = einops.rearrange(ip_value, "B L (H D) -> B H L D", H=block.num_heads)
|
||||
|
||||
# Compute attention between IP projections and the latent query.
|
||||
ip_attn = torch.nn.functional.scaled_dot_product_attention(
|
||||
img_q, ip_key, ip_value, dropout_p=0.0, is_causal=False
|
||||
)
|
||||
ip_attn = einops.rearrange(ip_attn, "B H L D -> B L (H D)", H=block.num_heads)
|
||||
|
||||
img = img + weight * ip_attn
|
||||
|
||||
return img
|
||||
0
invokeai/backend/flux/ip_adapter/__init__.py
Normal file
0
invokeai/backend/flux/ip_adapter/__init__.py
Normal file
@@ -0,0 +1,93 @@
|
||||
# This file is based on:
|
||||
# https://github.com/XLabs-AI/x-flux/blob/47495425dbed499be1e8e5a6e52628b07349cba2/src/flux/modules/layers.py#L221
|
||||
import einops
|
||||
import torch
|
||||
|
||||
from invokeai.backend.flux.math import attention
|
||||
from invokeai.backend.flux.modules.layers import DoubleStreamBlock
|
||||
|
||||
|
||||
class IPDoubleStreamBlockProcessor(torch.nn.Module):
|
||||
"""Attention processor for handling IP-adapter with double stream block."""
|
||||
|
||||
def __init__(self, context_dim: int, hidden_dim: int):
|
||||
super().__init__()
|
||||
|
||||
# Ensure context_dim matches the dimension of image_proj
|
||||
self.context_dim = context_dim
|
||||
self.hidden_dim = hidden_dim
|
||||
|
||||
# Initialize projections for IP-adapter
|
||||
self.ip_adapter_double_stream_k_proj = torch.nn.Linear(context_dim, hidden_dim, bias=True)
|
||||
self.ip_adapter_double_stream_v_proj = torch.nn.Linear(context_dim, hidden_dim, bias=True)
|
||||
|
||||
torch.nn.init.zeros_(self.ip_adapter_double_stream_k_proj.weight)
|
||||
torch.nn.init.zeros_(self.ip_adapter_double_stream_k_proj.bias)
|
||||
|
||||
torch.nn.init.zeros_(self.ip_adapter_double_stream_v_proj.weight)
|
||||
torch.nn.init.zeros_(self.ip_adapter_double_stream_v_proj.bias)
|
||||
|
||||
def __call__(
|
||||
self,
|
||||
attn: DoubleStreamBlock,
|
||||
img: torch.Tensor,
|
||||
txt: torch.Tensor,
|
||||
vec: torch.Tensor,
|
||||
pe: torch.Tensor,
|
||||
image_proj: torch.Tensor,
|
||||
ip_scale: float = 1.0,
|
||||
):
|
||||
# Prepare image for attention
|
||||
img_mod1, img_mod2 = attn.img_mod(vec)
|
||||
txt_mod1, txt_mod2 = attn.txt_mod(vec)
|
||||
|
||||
img_modulated = attn.img_norm1(img)
|
||||
img_modulated = (1 + img_mod1.scale) * img_modulated + img_mod1.shift
|
||||
img_qkv = attn.img_attn.qkv(img_modulated)
|
||||
img_q, img_k, img_v = einops.rearrange(
|
||||
img_qkv, "B L (K H D) -> K B H L D", K=3, H=attn.num_heads, D=attn.head_dim
|
||||
)
|
||||
img_q, img_k = attn.img_attn.norm(img_q, img_k, img_v)
|
||||
|
||||
txt_modulated = attn.txt_norm1(txt)
|
||||
txt_modulated = (1 + txt_mod1.scale) * txt_modulated + txt_mod1.shift
|
||||
txt_qkv = attn.txt_attn.qkv(txt_modulated)
|
||||
txt_q, txt_k, txt_v = einops.rearrange(
|
||||
txt_qkv, "B L (K H D) -> K B H L D", K=3, H=attn.num_heads, D=attn.head_dim
|
||||
)
|
||||
txt_q, txt_k = attn.txt_attn.norm(txt_q, txt_k, txt_v)
|
||||
|
||||
q = torch.cat((txt_q, img_q), dim=2)
|
||||
k = torch.cat((txt_k, img_k), dim=2)
|
||||
v = torch.cat((txt_v, img_v), dim=2)
|
||||
|
||||
attn1 = attention(q, k, v, pe=pe)
|
||||
txt_attn, img_attn = attn1[:, : txt.shape[1]], attn1[:, txt.shape[1] :]
|
||||
|
||||
# print(f"txt_attn shape: {txt_attn.size()}")
|
||||
# print(f"img_attn shape: {img_attn.size()}")
|
||||
|
||||
img = img + img_mod1.gate * attn.img_attn.proj(img_attn)
|
||||
img = img + img_mod2.gate * attn.img_mlp((1 + img_mod2.scale) * attn.img_norm2(img) + img_mod2.shift)
|
||||
|
||||
txt = txt + txt_mod1.gate * attn.txt_attn.proj(txt_attn)
|
||||
txt = txt + txt_mod2.gate * attn.txt_mlp((1 + txt_mod2.scale) * attn.txt_norm2(txt) + txt_mod2.shift)
|
||||
|
||||
# IP-adapter processing
|
||||
ip_query = img_q # latent sample query
|
||||
ip_key = self.ip_adapter_double_stream_k_proj(image_proj)
|
||||
ip_value = self.ip_adapter_double_stream_v_proj(image_proj)
|
||||
|
||||
# Reshape projections for multi-head attention
|
||||
ip_key = einops.rearrange(ip_key, "B L (H D) -> B H L D", H=attn.num_heads, D=attn.head_dim)
|
||||
ip_value = einops.rearrange(ip_value, "B L (H D) -> B H L D", H=attn.num_heads, D=attn.head_dim)
|
||||
|
||||
# Compute attention between IP projections and the latent query
|
||||
ip_attention = torch.nn.functional.scaled_dot_product_attention(
|
||||
ip_query, ip_key, ip_value, dropout_p=0.0, is_causal=False
|
||||
)
|
||||
ip_attention = einops.rearrange(ip_attention, "B H L D -> B L (H D)", H=attn.num_heads, D=attn.head_dim)
|
||||
|
||||
img = img + ip_scale * ip_attention
|
||||
|
||||
return img, txt
|
||||
50
invokeai/backend/flux/ip_adapter/state_dict_utils.py
Normal file
50
invokeai/backend/flux/ip_adapter/state_dict_utils.py
Normal file
@@ -0,0 +1,50 @@
|
||||
from typing import Any, Dict
|
||||
|
||||
import torch
|
||||
|
||||
from invokeai.backend.flux.ip_adapter.xlabs_ip_adapter_flux import XlabsIpAdapterParams
|
||||
|
||||
|
||||
def is_state_dict_xlabs_ip_adapter(sd: Dict[str, Any]) -> bool:
|
||||
"""Is the state dict for an XLabs FLUX IP-Adapter model?
|
||||
|
||||
This is intended to be a reasonably high-precision detector, but it is not guaranteed to have perfect precision.
|
||||
"""
|
||||
# If all of the expected keys are present, then this is very likely an XLabs IP-Adapter model.
|
||||
expected_keys = {
|
||||
"double_blocks.0.processor.ip_adapter_double_stream_k_proj.bias",
|
||||
"double_blocks.0.processor.ip_adapter_double_stream_k_proj.weight",
|
||||
"double_blocks.0.processor.ip_adapter_double_stream_v_proj.bias",
|
||||
"double_blocks.0.processor.ip_adapter_double_stream_v_proj.weight",
|
||||
"ip_adapter_proj_model.norm.bias",
|
||||
"ip_adapter_proj_model.norm.weight",
|
||||
"ip_adapter_proj_model.proj.bias",
|
||||
"ip_adapter_proj_model.proj.weight",
|
||||
}
|
||||
|
||||
if expected_keys.issubset(sd.keys()):
|
||||
return True
|
||||
return False
|
||||
|
||||
|
||||
def infer_xlabs_ip_adapter_params_from_state_dict(state_dict: dict[str, torch.Tensor]) -> XlabsIpAdapterParams:
|
||||
num_double_blocks = 0
|
||||
context_dim = 0
|
||||
hidden_dim = 0
|
||||
|
||||
# Count the number of double blocks.
|
||||
double_block_index = 0
|
||||
while f"double_blocks.{double_block_index}.processor.ip_adapter_double_stream_k_proj.weight" in state_dict:
|
||||
double_block_index += 1
|
||||
num_double_blocks = double_block_index
|
||||
|
||||
hidden_dim = state_dict["double_blocks.0.processor.ip_adapter_double_stream_k_proj.weight"].shape[0]
|
||||
context_dim = state_dict["double_blocks.0.processor.ip_adapter_double_stream_k_proj.weight"].shape[1]
|
||||
clip_embeddings_dim = state_dict["ip_adapter_proj_model.proj.weight"].shape[1]
|
||||
|
||||
return XlabsIpAdapterParams(
|
||||
num_double_blocks=num_double_blocks,
|
||||
context_dim=context_dim,
|
||||
hidden_dim=hidden_dim,
|
||||
clip_embeddings_dim=clip_embeddings_dim,
|
||||
)
|
||||
67
invokeai/backend/flux/ip_adapter/xlabs_ip_adapter_flux.py
Normal file
67
invokeai/backend/flux/ip_adapter/xlabs_ip_adapter_flux.py
Normal file
@@ -0,0 +1,67 @@
|
||||
from dataclasses import dataclass
|
||||
|
||||
import torch
|
||||
|
||||
from invokeai.backend.ip_adapter.ip_adapter import ImageProjModel
|
||||
|
||||
|
||||
class IPDoubleStreamBlock(torch.nn.Module):
|
||||
def __init__(self, context_dim: int, hidden_dim: int):
|
||||
super().__init__()
|
||||
|
||||
self.context_dim = context_dim
|
||||
self.hidden_dim = hidden_dim
|
||||
|
||||
self.ip_adapter_double_stream_k_proj = torch.nn.Linear(context_dim, hidden_dim, bias=True)
|
||||
self.ip_adapter_double_stream_v_proj = torch.nn.Linear(context_dim, hidden_dim, bias=True)
|
||||
|
||||
|
||||
class IPAdapterDoubleBlocks(torch.nn.Module):
|
||||
def __init__(self, num_double_blocks: int, context_dim: int, hidden_dim: int):
|
||||
super().__init__()
|
||||
self.double_blocks = torch.nn.ModuleList(
|
||||
[IPDoubleStreamBlock(context_dim, hidden_dim) for _ in range(num_double_blocks)]
|
||||
)
|
||||
|
||||
|
||||
@dataclass
|
||||
class XlabsIpAdapterParams:
|
||||
num_double_blocks: int
|
||||
context_dim: int
|
||||
hidden_dim: int
|
||||
|
||||
clip_embeddings_dim: int
|
||||
|
||||
|
||||
class XlabsIpAdapterFlux(torch.nn.Module):
|
||||
def __init__(self, params: XlabsIpAdapterParams):
|
||||
super().__init__()
|
||||
self.image_proj = ImageProjModel(
|
||||
cross_attention_dim=params.context_dim, clip_embeddings_dim=params.clip_embeddings_dim
|
||||
)
|
||||
self.ip_adapter_double_blocks = IPAdapterDoubleBlocks(
|
||||
num_double_blocks=params.num_double_blocks, context_dim=params.context_dim, hidden_dim=params.hidden_dim
|
||||
)
|
||||
|
||||
def load_xlabs_state_dict(self, state_dict: dict[str, torch.Tensor], assign: bool = False):
|
||||
"""We need this custom function to load state dicts rather than using .load_state_dict(...) because the model
|
||||
structure does not match the state_dict structure.
|
||||
"""
|
||||
# Split the state_dict into the image projection model and the double blocks.
|
||||
image_proj_sd: dict[str, torch.Tensor] = {}
|
||||
double_blocks_sd: dict[str, torch.Tensor] = {}
|
||||
for k, v in state_dict.items():
|
||||
if k.startswith("ip_adapter_proj_model."):
|
||||
image_proj_sd[k] = v
|
||||
elif k.startswith("double_blocks."):
|
||||
double_blocks_sd[k] = v
|
||||
else:
|
||||
raise ValueError(f"Unexpected key: {k}")
|
||||
|
||||
# Initialize the image projection model.
|
||||
image_proj_sd = {k.replace("ip_adapter_proj_model.", ""): v for k, v in image_proj_sd.items()}
|
||||
self.image_proj.load_state_dict(image_proj_sd, assign=assign)
|
||||
|
||||
# Initialize the double blocks.
|
||||
double_blocks_sd = {k.replace("processor.", ""): v for k, v in double_blocks_sd.items()}
|
||||
self.ip_adapter_double_blocks.load_state_dict(double_blocks_sd, assign=assign)
|
||||
@@ -16,7 +16,10 @@ def attention(q: Tensor, k: Tensor, v: Tensor, pe: Tensor) -> Tensor:
|
||||
|
||||
def rope(pos: Tensor, dim: int, theta: int) -> Tensor:
|
||||
assert dim % 2 == 0
|
||||
scale = torch.arange(0, dim, 2, dtype=torch.float64, device=pos.device) / dim
|
||||
scale = (
|
||||
torch.arange(0, dim, 2, dtype=torch.float32 if pos.device.type == "mps" else torch.float64, device=pos.device)
|
||||
/ dim
|
||||
)
|
||||
omega = 1.0 / (theta**scale)
|
||||
out = torch.einsum("...n,d->...nd", pos, omega)
|
||||
out = torch.stack([torch.cos(out), -torch.sin(out), torch.sin(out), torch.cos(out)], dim=-1)
|
||||
|
||||
@@ -5,6 +5,8 @@ from dataclasses import dataclass
|
||||
import torch
|
||||
from torch import Tensor, nn
|
||||
|
||||
from invokeai.backend.flux.custom_block_processor import CustomDoubleStreamBlockProcessor
|
||||
from invokeai.backend.flux.extensions.xlabs_ip_adapter_extension import XLabsIPAdapterExtension
|
||||
from invokeai.backend.flux.modules.layers import (
|
||||
DoubleStreamBlock,
|
||||
EmbedND,
|
||||
@@ -87,7 +89,12 @@ class Flux(nn.Module):
|
||||
txt_ids: Tensor,
|
||||
timesteps: Tensor,
|
||||
y: Tensor,
|
||||
guidance: Tensor | None = None,
|
||||
guidance: Tensor | None,
|
||||
timestep_index: int,
|
||||
total_num_timesteps: int,
|
||||
controlnet_double_block_residuals: list[Tensor] | None,
|
||||
controlnet_single_block_residuals: list[Tensor] | None,
|
||||
ip_adapter_extensions: list[XLabsIPAdapterExtension],
|
||||
) -> Tensor:
|
||||
if img.ndim != 3 or txt.ndim != 3:
|
||||
raise ValueError("Input img and txt tensors must have 3 dimensions.")
|
||||
@@ -105,12 +112,39 @@ class Flux(nn.Module):
|
||||
ids = torch.cat((txt_ids, img_ids), dim=1)
|
||||
pe = self.pe_embedder(ids)
|
||||
|
||||
for block in self.double_blocks:
|
||||
img, txt = block(img=img, txt=txt, vec=vec, pe=pe)
|
||||
# Validate double_block_residuals shape.
|
||||
if controlnet_double_block_residuals is not None:
|
||||
assert len(controlnet_double_block_residuals) == len(self.double_blocks)
|
||||
for block_index, block in enumerate(self.double_blocks):
|
||||
assert isinstance(block, DoubleStreamBlock)
|
||||
|
||||
img, txt = CustomDoubleStreamBlockProcessor.custom_double_block_forward(
|
||||
timestep_index=timestep_index,
|
||||
total_num_timesteps=total_num_timesteps,
|
||||
block_index=block_index,
|
||||
block=block,
|
||||
img=img,
|
||||
txt=txt,
|
||||
vec=vec,
|
||||
pe=pe,
|
||||
ip_adapter_extensions=ip_adapter_extensions,
|
||||
)
|
||||
|
||||
if controlnet_double_block_residuals is not None:
|
||||
img += controlnet_double_block_residuals[block_index]
|
||||
|
||||
img = torch.cat((txt, img), 1)
|
||||
for block in self.single_blocks:
|
||||
|
||||
# Validate single_block_residuals shape.
|
||||
if controlnet_single_block_residuals is not None:
|
||||
assert len(controlnet_single_block_residuals) == len(self.single_blocks)
|
||||
|
||||
for block_index, block in enumerate(self.single_blocks):
|
||||
img = block(img, vec=vec, pe=pe)
|
||||
|
||||
if controlnet_single_block_residuals is not None:
|
||||
img[:, txt.shape[1] :, ...] += controlnet_single_block_residuals[block_index]
|
||||
|
||||
img = img[:, txt.shape[1] :, ...]
|
||||
|
||||
img = self.final_layer(img, vec) # (N, T, patch_size ** 2 * out_channels)
|
||||
|
||||
@@ -97,6 +97,46 @@ def clip_timestep_schedule(timesteps: list[float], denoising_start: float, denoi
|
||||
return clipped_timesteps
|
||||
|
||||
|
||||
def clip_timestep_schedule_fractional(
|
||||
timesteps: list[float], denoising_start: float, denoising_end: float
|
||||
) -> list[float]:
|
||||
"""Clip the timestep schedule to the denoising range. Insert new timesteps to exactly match the desired denoising
|
||||
range. (A fractional version of clip_timestep_schedule().)
|
||||
|
||||
Args:
|
||||
timesteps (list[float]): The original timestep schedule: [1.0, ..., 0.0].
|
||||
denoising_start (float): A value in [0, 1] specifying the start of the denoising process. E.g. a value of 0.2
|
||||
would mean that the denoising process start at t=0.8.
|
||||
denoising_end (float): A value in [0, 1] specifying the end of the denoising process. E.g. a value of 0.8 would
|
||||
mean that the denoising process ends at t=0.2.
|
||||
|
||||
Returns:
|
||||
list[float]: The clipped timestep schedule.
|
||||
"""
|
||||
assert 0.0 <= denoising_start <= 1.0
|
||||
assert 0.0 <= denoising_end <= 1.0
|
||||
assert denoising_start <= denoising_end
|
||||
|
||||
t_start_val = 1.0 - denoising_start
|
||||
t_end_val = 1.0 - denoising_end
|
||||
|
||||
t_start_idx = _find_last_index_ge_val(timesteps, t_start_val)
|
||||
t_end_idx = _find_last_index_ge_val(timesteps, t_end_val)
|
||||
|
||||
clipped_timesteps = timesteps[t_start_idx : t_end_idx + 1]
|
||||
|
||||
# We know that clipped_timesteps[0] >= t_start_val. Replace clipped_timesteps[0] with t_start_val.
|
||||
clipped_timesteps[0] = t_start_val
|
||||
|
||||
# We know that clipped_timesteps[-1] >= t_end_val. If clipped_timesteps[-1] > t_end_val, add another step to
|
||||
# t_end_val.
|
||||
eps = 1e-6
|
||||
if clipped_timesteps[-1] > t_end_val + eps:
|
||||
clipped_timesteps.append(t_end_val)
|
||||
|
||||
return clipped_timesteps
|
||||
|
||||
|
||||
def unpack(x: torch.Tensor, height: int, width: int) -> torch.Tensor:
|
||||
"""Unpack flat array of patch embeddings to latent image."""
|
||||
return rearrange(
|
||||
@@ -128,8 +168,17 @@ def generate_img_ids(h: int, w: int, batch_size: int, device: torch.device, dtyp
|
||||
Returns:
|
||||
torch.Tensor: Image position ids.
|
||||
"""
|
||||
|
||||
if device.type == "mps":
|
||||
orig_dtype = dtype
|
||||
dtype = torch.float16
|
||||
|
||||
img_ids = torch.zeros(h // 2, w // 2, 3, device=device, dtype=dtype)
|
||||
img_ids[..., 1] = img_ids[..., 1] + torch.arange(h // 2, device=device, dtype=dtype)[:, None]
|
||||
img_ids[..., 2] = img_ids[..., 2] + torch.arange(w // 2, device=device, dtype=dtype)[None, :]
|
||||
img_ids = repeat(img_ids, "h w c -> b (h w) c", b=batch_size)
|
||||
|
||||
if device.type == "mps":
|
||||
img_ids.to(orig_dtype)
|
||||
|
||||
return img_ids
|
||||
|
||||
@@ -1,134 +0,0 @@
|
||||
import torch
|
||||
|
||||
from invokeai.backend.util.build_line import build_line
|
||||
|
||||
|
||||
class TrajectoryGuidanceExtension:
|
||||
"""An implementation of trajectory guidance for FLUX.
|
||||
|
||||
What is trajectory guidance?
|
||||
----------------------------
|
||||
With SD 1 and SDXL, the amount of change in image-to-image denoising is largely controlled by the denoising_start
|
||||
parameter. Doing the same thing with the FLUX model does not work as well, because the FLUX model converges very
|
||||
quickly (roughly time 1.0 to 0.9) to the structure of the final image. The result of this model characteristic is
|
||||
that you typically get one of two outcomes:
|
||||
1) a result that is very similar to the original image
|
||||
2) a result that is very different from the original image, as though it was generated from the text prompt with
|
||||
pure noise.
|
||||
|
||||
To address this issue with image-to-image workflows with FLUX, we employ the concept of trajectory guidance. The
|
||||
idea is that in addition to controlling the denoising_start parameter (i.e. the amount of noise added to the
|
||||
original image), we can also guide the denoising process to stay close to the trajectory that would reproduce the
|
||||
original. By controlling the strength of the trajectory guidance throughout the denoising process, we can achieve
|
||||
FLUX image-to-image behavior with the same level of control offered by SD1 and SDXL.
|
||||
|
||||
What is the trajectory_guidance_strength?
|
||||
-----------------------------------------
|
||||
In the limit, we could apply a different trajectory guidance 'strength' for every latent value in every timestep.
|
||||
This would be impractical for a user, so instead we have engineered a strength schedule that is more convenient to
|
||||
use. The `trajectory_guidance_strength` parameter is a single scalar value that maps to a schedule. The engineered
|
||||
schedule is defined as:
|
||||
1) An initial change_ratio at t=1.0.
|
||||
2) A linear ramp up to change_ratio=1.0 at t = t_cutoff.
|
||||
3) A constant change_ratio=1.0 after t = t_cutoff.
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self, init_latents: torch.Tensor, inpaint_mask: torch.Tensor | None, trajectory_guidance_strength: float
|
||||
):
|
||||
"""Initialize TrajectoryGuidanceExtension.
|
||||
|
||||
Args:
|
||||
init_latents (torch.Tensor): The initial latents (i.e. un-noised at timestep 0). In 'packed' format.
|
||||
inpaint_mask (torch.Tensor | None): A mask specifying which elements to inpaint. Range [0, 1]. Values of 1
|
||||
will be re-generated. Values of 0 will remain unchanged. Values between 0 and 1 can be used to blend the
|
||||
inpainted region with the background. In 'packed' format. If None, will be treated as a mask of all 1s.
|
||||
trajectory_guidance_strength (float): A value in [0, 1] specifying the strength of the trajectory guidance.
|
||||
A value of 0.0 is equivalent to vanilla image-to-image. A value of 1.0 will guide the denoising process
|
||||
very close to the original latents.
|
||||
"""
|
||||
assert 0.0 <= trajectory_guidance_strength <= 1.0
|
||||
self._init_latents = init_latents
|
||||
if inpaint_mask is None:
|
||||
# The inpaing mask is None, so we initialize a mask with a single value of 1.0.
|
||||
# This value will be broadcasted and treated as a mask of all 1s.
|
||||
self._inpaint_mask = torch.ones(1, device=init_latents.device, dtype=init_latents.dtype)
|
||||
else:
|
||||
self._inpaint_mask = inpaint_mask
|
||||
|
||||
# Calculate the params that define the trajectory guidance schedule.
|
||||
# These mappings from trajectory_guidance_strength have no theoretical basis - they were tuned manually.
|
||||
self._trajectory_guidance_strength = trajectory_guidance_strength
|
||||
self._change_ratio_at_t_1 = build_line(x1=0.0, y1=1.0, x2=1.0, y2=0.0)(self._trajectory_guidance_strength)
|
||||
self._change_ratio_at_cutoff = 1.0
|
||||
self._t_cutoff = build_line(x1=0.0, y1=1.0, x2=1.0, y2=0.5)(self._trajectory_guidance_strength)
|
||||
|
||||
def _apply_mask_gradient_adjustment(self, t_prev: float) -> torch.Tensor:
|
||||
"""Applies inpaint mask gradient adjustment and returns the inpaint mask to be used at the current timestep."""
|
||||
# As we progress through the denoising process, we promote gradient regions of the mask to have a full weight of
|
||||
# 1.0. This helps to produce more coherent seams around the inpainted region. We experimented with a (small)
|
||||
# number of promotion strategies (e.g. gradual promotion based on timestep), but found that a simple cutoff
|
||||
# threshold worked well.
|
||||
# We use a small epsilon to avoid any potential issues with floating point precision.
|
||||
eps = 1e-4
|
||||
mask_gradient_t_cutoff = 0.5
|
||||
if t_prev > mask_gradient_t_cutoff:
|
||||
# Early in the denoising process, use the inpaint mask as-is.
|
||||
return self._inpaint_mask
|
||||
else:
|
||||
# After the cut-off, promote all non-zero mask values to 1.0.
|
||||
mask = self._inpaint_mask.where(self._inpaint_mask <= (0.0 + eps), 1.0)
|
||||
|
||||
return mask
|
||||
|
||||
def _get_change_ratio(self, t_prev: float) -> float:
|
||||
"""Get the change_ratio for t_prev based on the change schedule."""
|
||||
change_ratio = 1.0
|
||||
if t_prev > self._t_cutoff:
|
||||
# If we are before the cutoff, linearly interpolate between the change_ratio at t=1.0 and the change_ratio
|
||||
# at the cutoff.
|
||||
change_ratio = build_line(
|
||||
x1=1.0, y1=self._change_ratio_at_t_1, x2=self._t_cutoff, y2=self._change_ratio_at_cutoff
|
||||
)(t_prev)
|
||||
|
||||
# The change_ratio should be in the range [0, 1]. Assert that we didn't make any mistakes.
|
||||
eps = 1e-5
|
||||
assert 0.0 - eps <= change_ratio <= 1.0 + eps
|
||||
return change_ratio
|
||||
|
||||
def update_noise(
|
||||
self, t_curr_latents: torch.Tensor, pred_noise: torch.Tensor, t_curr: float, t_prev: float
|
||||
) -> torch.Tensor:
|
||||
# Handle gradient cutoff.
|
||||
mask = self._apply_mask_gradient_adjustment(t_prev)
|
||||
|
||||
mask = mask * self._get_change_ratio(t_prev)
|
||||
|
||||
# NOTE(ryand): During inpainting, it is common to guide the denoising process by noising the initial latents for
|
||||
# the current timestep and then blending the predicted intermediate latents with the noised initial latents.
|
||||
# For example:
|
||||
# ```
|
||||
# noised_init_latents = self._noise * t_prev + (1.0 - t_prev) * self._init_latents
|
||||
# return t_prev_latents * self._inpaint_mask + noised_init_latents * (1.0 - self._inpaint_mask)
|
||||
# ```
|
||||
# Instead of guiding based on the noised initial latents, we have decided to guide based on the noise prediction
|
||||
# that points towards the initial latents. The difference between these guidance strategies is minor, but
|
||||
# qualitatively we found the latter to produce slightly better results. When change_ratio is 0.0 or 1.0 there is
|
||||
# no difference between the two strategies.
|
||||
#
|
||||
# We experimented with a number of related guidance strategies, but not exhaustively. It's entirely possible
|
||||
# that there's a much better way to do this.
|
||||
|
||||
# Calculate noise guidance
|
||||
# What noise should the model have predicted at this timestep to step towards self._init_latents?
|
||||
# Derivation:
|
||||
# > t_prev_latents = t_curr_latents + (t_prev - t_curr) * pred_noise
|
||||
# > t_0_latents = t_curr_latents + (0 - t_curr) * init_traj_noise
|
||||
# > t_0_latents = t_curr_latents - t_curr * init_traj_noise
|
||||
# > init_traj_noise = (t_curr_latents - t_0_latents) / t_curr)
|
||||
init_traj_noise = (t_curr_latents - self._init_latents) / t_curr
|
||||
|
||||
# Blend the init_traj_noise with the pred_noise according to the inpaint mask and the trajectory guidance.
|
||||
noise = pred_noise * mask + init_traj_noise * (1.0 - mask)
|
||||
|
||||
return noise
|
||||
@@ -1,4 +1,4 @@
|
||||
from typing import Optional
|
||||
from typing import Optional, TypeAlias
|
||||
|
||||
import torch
|
||||
from PIL import Image
|
||||
@@ -7,6 +7,14 @@ from transformers.models.sam.processing_sam import SamProcessor
|
||||
|
||||
from invokeai.backend.raw_model import RawModel
|
||||
|
||||
# Type aliases for the inputs to the SAM model.
|
||||
ListOfBoundingBoxes: TypeAlias = list[list[int]]
|
||||
"""A list of bounding boxes. Each bounding box is in the format [xmin, ymin, xmax, ymax]."""
|
||||
ListOfPoints: TypeAlias = list[list[int]]
|
||||
"""A list of points. Each point is in the format [x, y]."""
|
||||
ListOfPointLabels: TypeAlias = list[int]
|
||||
"""A list of SAM point labels. Each label is an integer where -1 is background, 0 is neutral, and 1 is foreground."""
|
||||
|
||||
|
||||
class SegmentAnythingPipeline(RawModel):
|
||||
"""A wrapper class for the transformers SAM model and processor that makes it compatible with the model manager."""
|
||||
@@ -27,20 +35,53 @@ class SegmentAnythingPipeline(RawModel):
|
||||
|
||||
return calc_module_size(self._sam_model)
|
||||
|
||||
def segment(self, image: Image.Image, bounding_boxes: list[list[int]]) -> torch.Tensor:
|
||||
def segment(
|
||||
self,
|
||||
image: Image.Image,
|
||||
bounding_boxes: list[list[int]] | None = None,
|
||||
point_lists: list[list[list[int]]] | None = None,
|
||||
) -> torch.Tensor:
|
||||
"""Run the SAM model.
|
||||
|
||||
Either bounding_boxes or point_lists must be provided. If both are provided, bounding_boxes will be used and
|
||||
point_lists will be ignored.
|
||||
|
||||
Args:
|
||||
image (Image.Image): The image to segment.
|
||||
bounding_boxes (list[list[int]]): The bounding box prompts. Each bounding box is in the format
|
||||
[xmin, ymin, xmax, ymax].
|
||||
point_lists (list[list[list[int]]]): The points prompts. Each point is in the format [x, y, label].
|
||||
`label` is an integer where -1 is background, 0 is neutral, and 1 is foreground.
|
||||
|
||||
Returns:
|
||||
torch.Tensor: The segmentation masks. dtype: torch.bool. shape: [num_masks, channels, height, width].
|
||||
"""
|
||||
# Add batch dimension of 1 to the bounding boxes.
|
||||
boxes = [bounding_boxes]
|
||||
inputs = self._sam_processor(images=image, input_boxes=boxes, return_tensors="pt").to(self._sam_model.device)
|
||||
|
||||
# Prep the inputs:
|
||||
# - Create a list of bounding boxes or points and labels.
|
||||
# - Add a batch dimension of 1 to the inputs.
|
||||
if bounding_boxes:
|
||||
input_boxes: list[ListOfBoundingBoxes] | None = [bounding_boxes]
|
||||
input_points: list[ListOfPoints] | None = None
|
||||
input_labels: list[ListOfPointLabels] | None = None
|
||||
elif point_lists:
|
||||
input_boxes: list[ListOfBoundingBoxes] | None = None
|
||||
input_points: list[ListOfPoints] | None = []
|
||||
input_labels: list[ListOfPointLabels] | None = []
|
||||
for point_list in point_lists:
|
||||
input_points.append([[p[0], p[1]] for p in point_list])
|
||||
input_labels.append([p[2] for p in point_list])
|
||||
|
||||
else:
|
||||
raise ValueError("Either bounding_boxes or points and labels must be provided.")
|
||||
|
||||
inputs = self._sam_processor(
|
||||
images=image,
|
||||
input_boxes=input_boxes,
|
||||
input_points=input_points,
|
||||
input_labels=input_labels,
|
||||
return_tensors="pt",
|
||||
).to(self._sam_model.device)
|
||||
outputs = self._sam_model(**inputs)
|
||||
masks = self._sam_processor.post_process_masks(
|
||||
masks=outputs.pred_masks,
|
||||
|
||||
@@ -2,6 +2,7 @@ from typing import Dict
|
||||
|
||||
import torch
|
||||
|
||||
from invokeai.backend.lora.conversions.flux_lora_constants import FLUX_LORA_TRANSFORMER_PREFIX
|
||||
from invokeai.backend.lora.layers.any_lora_layer import AnyLoRALayer
|
||||
from invokeai.backend.lora.layers.concatenated_lora_layer import ConcatenatedLoRALayer
|
||||
from invokeai.backend.lora.layers.lora_layer import LoRALayer
|
||||
@@ -189,7 +190,9 @@ def lora_model_from_flux_diffusers_state_dict(state_dict: Dict[str, torch.Tensor
|
||||
# Assert that all keys were processed.
|
||||
assert len(grouped_state_dict) == 0
|
||||
|
||||
return LoRAModelRaw(layers=layers)
|
||||
layers_with_prefix = {f"{FLUX_LORA_TRANSFORMER_PREFIX}{k}": v for k, v in layers.items()}
|
||||
|
||||
return LoRAModelRaw(layers=layers_with_prefix)
|
||||
|
||||
|
||||
def _group_by_layer(state_dict: Dict[str, torch.Tensor]) -> dict[str, dict[str, torch.Tensor]]:
|
||||
|
||||
@@ -3,18 +3,25 @@ from typing import Any, Dict, TypeVar
|
||||
|
||||
import torch
|
||||
|
||||
from invokeai.backend.lora.conversions.flux_lora_constants import FLUX_LORA_CLIP_PREFIX, FLUX_LORA_TRANSFORMER_PREFIX
|
||||
from invokeai.backend.lora.layers.any_lora_layer import AnyLoRALayer
|
||||
from invokeai.backend.lora.layers.utils import any_lora_layer_from_state_dict
|
||||
from invokeai.backend.lora.lora_model_raw import LoRAModelRaw
|
||||
|
||||
# A regex pattern that matches all of the keys in the Kohya FLUX LoRA format.
|
||||
# A regex pattern that matches all of the transformer keys in the Kohya FLUX LoRA format.
|
||||
# Example keys:
|
||||
# lora_unet_double_blocks_0_img_attn_proj.alpha
|
||||
# lora_unet_double_blocks_0_img_attn_proj.lora_down.weight
|
||||
# lora_unet_double_blocks_0_img_attn_proj.lora_up.weight
|
||||
FLUX_KOHYA_KEY_REGEX = (
|
||||
FLUX_KOHYA_TRANSFORMER_KEY_REGEX = (
|
||||
r"lora_unet_(\w+_blocks)_(\d+)_(img_attn|img_mlp|img_mod|txt_attn|txt_mlp|txt_mod|linear1|linear2|modulation)_?(.*)"
|
||||
)
|
||||
# A regex pattern that matches all of the CLIP keys in the Kohya FLUX LoRA format.
|
||||
# Example keys:
|
||||
# lora_te1_text_model_encoder_layers_0_mlp_fc1.alpha
|
||||
# lora_te1_text_model_encoder_layers_0_mlp_fc1.lora_down.weight
|
||||
# lora_te1_text_model_encoder_layers_0_mlp_fc1.lora_up.weight
|
||||
FLUX_KOHYA_CLIP_KEY_REGEX = r"lora_te1_text_model_encoder_layers_(\d+)_(mlp|self_attn)_(\w+)\.?.*"
|
||||
|
||||
|
||||
def is_state_dict_likely_in_flux_kohya_format(state_dict: Dict[str, Any]) -> bool:
|
||||
@@ -23,7 +30,10 @@ def is_state_dict_likely_in_flux_kohya_format(state_dict: Dict[str, Any]) -> boo
|
||||
This is intended to be a high-precision detector, but it is not guaranteed to have perfect precision. (A
|
||||
perfect-precision detector would require checking all keys against a whitelist and verifying tensor shapes.)
|
||||
"""
|
||||
return all(re.match(FLUX_KOHYA_KEY_REGEX, k) for k in state_dict.keys())
|
||||
return all(
|
||||
re.match(FLUX_KOHYA_TRANSFORMER_KEY_REGEX, k) or re.match(FLUX_KOHYA_CLIP_KEY_REGEX, k)
|
||||
for k in state_dict.keys()
|
||||
)
|
||||
|
||||
|
||||
def lora_model_from_flux_kohya_state_dict(state_dict: Dict[str, torch.Tensor]) -> LoRAModelRaw:
|
||||
@@ -35,13 +45,27 @@ def lora_model_from_flux_kohya_state_dict(state_dict: Dict[str, torch.Tensor]) -
|
||||
grouped_state_dict[layer_name] = {}
|
||||
grouped_state_dict[layer_name][param_name] = value
|
||||
|
||||
# Convert the state dict to the InvokeAI format.
|
||||
grouped_state_dict = convert_flux_kohya_state_dict_to_invoke_format(grouped_state_dict)
|
||||
# Split the grouped state dict into transformer and CLIP state dicts.
|
||||
transformer_grouped_sd: dict[str, dict[str, torch.Tensor]] = {}
|
||||
clip_grouped_sd: dict[str, dict[str, torch.Tensor]] = {}
|
||||
for layer_name, layer_state_dict in grouped_state_dict.items():
|
||||
if layer_name.startswith("lora_unet"):
|
||||
transformer_grouped_sd[layer_name] = layer_state_dict
|
||||
elif layer_name.startswith("lora_te1"):
|
||||
clip_grouped_sd[layer_name] = layer_state_dict
|
||||
else:
|
||||
raise ValueError(f"Layer '{layer_name}' does not match the expected pattern for FLUX LoRA weights.")
|
||||
|
||||
# Convert the state dicts to the InvokeAI format.
|
||||
transformer_grouped_sd = _convert_flux_transformer_kohya_state_dict_to_invoke_format(transformer_grouped_sd)
|
||||
clip_grouped_sd = _convert_flux_clip_kohya_state_dict_to_invoke_format(clip_grouped_sd)
|
||||
|
||||
# Create LoRA layers.
|
||||
layers: dict[str, AnyLoRALayer] = {}
|
||||
for layer_key, layer_state_dict in grouped_state_dict.items():
|
||||
layers[layer_key] = any_lora_layer_from_state_dict(layer_state_dict)
|
||||
for layer_key, layer_state_dict in transformer_grouped_sd.items():
|
||||
layers[FLUX_LORA_TRANSFORMER_PREFIX + layer_key] = any_lora_layer_from_state_dict(layer_state_dict)
|
||||
for layer_key, layer_state_dict in clip_grouped_sd.items():
|
||||
layers[FLUX_LORA_CLIP_PREFIX + layer_key] = any_lora_layer_from_state_dict(layer_state_dict)
|
||||
|
||||
# Create and return the LoRAModelRaw.
|
||||
return LoRAModelRaw(layers=layers)
|
||||
@@ -50,16 +74,34 @@ def lora_model_from_flux_kohya_state_dict(state_dict: Dict[str, torch.Tensor]) -
|
||||
T = TypeVar("T")
|
||||
|
||||
|
||||
def convert_flux_kohya_state_dict_to_invoke_format(state_dict: Dict[str, T]) -> Dict[str, T]:
|
||||
"""Converts a state dict from the Kohya FLUX LoRA format to LoRA weight format used internally by InvokeAI.
|
||||
def _convert_flux_clip_kohya_state_dict_to_invoke_format(state_dict: Dict[str, T]) -> Dict[str, T]:
|
||||
"""Converts a CLIP LoRA state dict from the Kohya FLUX LoRA format to LoRA weight format used internally by
|
||||
InvokeAI.
|
||||
|
||||
Example key conversions:
|
||||
|
||||
"lora_te1_text_model_encoder_layers_0_mlp_fc1" -> "text_model.encoder.layers.0.mlp.fc1",
|
||||
"lora_te1_text_model_encoder_layers_0_self_attn_k_proj" -> "text_model.encoder.layers.0.self_attn.k_proj"
|
||||
"""
|
||||
converted_sd: dict[str, T] = {}
|
||||
for k, v in state_dict.items():
|
||||
match = re.match(FLUX_KOHYA_CLIP_KEY_REGEX, k)
|
||||
if match:
|
||||
new_key = f"text_model.encoder.layers.{match.group(1)}.{match.group(2)}.{match.group(3)}"
|
||||
converted_sd[new_key] = v
|
||||
else:
|
||||
raise ValueError(f"Key '{k}' does not match the expected pattern for FLUX LoRA weights.")
|
||||
|
||||
return converted_sd
|
||||
|
||||
|
||||
def _convert_flux_transformer_kohya_state_dict_to_invoke_format(state_dict: Dict[str, T]) -> Dict[str, T]:
|
||||
"""Converts a FLUX tranformer LoRA state dict from the Kohya FLUX LoRA format to LoRA weight format used internally
|
||||
by InvokeAI.
|
||||
|
||||
Example key conversions:
|
||||
"lora_unet_double_blocks_0_img_attn_proj" -> "double_blocks.0.img_attn.proj"
|
||||
"lora_unet_double_blocks_0_img_attn_proj" -> "double_blocks.0.img_attn.proj"
|
||||
"lora_unet_double_blocks_0_img_attn_proj" -> "double_blocks.0.img_attn.proj"
|
||||
"lora_unet_double_blocks_0_img_attn_qkv" -> "double_blocks.0.img_attn.qkv"
|
||||
"lora_unet_double_blocks_0_img_attn_qkv" -> "double_blocks.0.img.attn.qkv"
|
||||
"lora_unet_double_blocks_0_img_attn_qkv" -> "double_blocks.0.img.attn.qkv"
|
||||
"""
|
||||
|
||||
def replace_func(match: re.Match[str]) -> str:
|
||||
@@ -70,9 +112,9 @@ def convert_flux_kohya_state_dict_to_invoke_format(state_dict: Dict[str, T]) ->
|
||||
|
||||
converted_dict: dict[str, T] = {}
|
||||
for k, v in state_dict.items():
|
||||
match = re.match(FLUX_KOHYA_KEY_REGEX, k)
|
||||
match = re.match(FLUX_KOHYA_TRANSFORMER_KEY_REGEX, k)
|
||||
if match:
|
||||
new_key = re.sub(FLUX_KOHYA_KEY_REGEX, replace_func, k)
|
||||
new_key = re.sub(FLUX_KOHYA_TRANSFORMER_KEY_REGEX, replace_func, k)
|
||||
converted_dict[new_key] = v
|
||||
else:
|
||||
raise ValueError(f"Key '{k}' does not match the expected pattern for FLUX LoRA weights.")
|
||||
|
||||
3
invokeai/backend/lora/conversions/flux_lora_constants.py
Normal file
3
invokeai/backend/lora/conversions/flux_lora_constants.py
Normal file
@@ -0,0 +1,3 @@
|
||||
# Prefixes used to distinguish between transformer and CLIP text encoder keys in the FLUX InvokeAI LoRA format.
|
||||
FLUX_LORA_TRANSFORMER_PREFIX = "lora_transformer-"
|
||||
FLUX_LORA_CLIP_PREFIX = "lora_clip-"
|
||||
@@ -114,6 +114,7 @@ class ModelFormat(str, Enum):
|
||||
T5Encoder = "t5_encoder"
|
||||
BnbQuantizedLlmInt8b = "bnb_quantized_int8b"
|
||||
BnbQuantizednf4b = "bnb_quantized_nf4b"
|
||||
GGUFQuantized = "gguf_quantized"
|
||||
|
||||
|
||||
class SchedulerPredictionType(str, Enum):
|
||||
@@ -157,6 +158,7 @@ class MainModelDefaultSettings(BaseModel):
|
||||
)
|
||||
width: int | None = Field(default=None, multiple_of=8, ge=64, description="Default width for this model")
|
||||
height: int | None = Field(default=None, multiple_of=8, ge=64, description="Default height for this model")
|
||||
guidance: float | None = Field(default=None, ge=1, description="Default Guidance for this model")
|
||||
|
||||
model_config = ConfigDict(extra="forbid")
|
||||
|
||||
@@ -196,7 +198,7 @@ class ModelConfigBase(BaseModel):
|
||||
class CheckpointConfigBase(ModelConfigBase):
|
||||
"""Model config for checkpoint-style models."""
|
||||
|
||||
format: Literal[ModelFormat.Checkpoint, ModelFormat.BnbQuantizednf4b] = Field(
|
||||
format: Literal[ModelFormat.Checkpoint, ModelFormat.BnbQuantizednf4b, ModelFormat.GGUFQuantized] = Field(
|
||||
description="Format of the provided checkpoint model", default=ModelFormat.Checkpoint
|
||||
)
|
||||
config_path: str = Field(description="path to the checkpoint model config file")
|
||||
@@ -362,6 +364,21 @@ class MainBnbQuantized4bCheckpointConfig(CheckpointConfigBase, MainConfigBase):
|
||||
return Tag(f"{ModelType.Main.value}.{ModelFormat.BnbQuantizednf4b.value}")
|
||||
|
||||
|
||||
class MainGGUFCheckpointConfig(CheckpointConfigBase, MainConfigBase):
|
||||
"""Model config for main checkpoint models."""
|
||||
|
||||
prediction_type: SchedulerPredictionType = SchedulerPredictionType.Epsilon
|
||||
upcast_attention: bool = False
|
||||
|
||||
def __init__(self, *args, **kwargs):
|
||||
super().__init__(*args, **kwargs)
|
||||
self.format = ModelFormat.GGUFQuantized
|
||||
|
||||
@staticmethod
|
||||
def get_tag() -> Tag:
|
||||
return Tag(f"{ModelType.Main.value}.{ModelFormat.GGUFQuantized.value}")
|
||||
|
||||
|
||||
class MainDiffusersConfig(DiffusersConfigBase, MainConfigBase):
|
||||
"""Model config for main diffusers models."""
|
||||
|
||||
@@ -377,6 +394,8 @@ class IPAdapterBaseConfig(ModelConfigBase):
|
||||
class IPAdapterInvokeAIConfig(IPAdapterBaseConfig):
|
||||
"""Model config for IP Adapter diffusers format models."""
|
||||
|
||||
# TODO(ryand): Should we deprecate this field? From what I can tell, it hasn't been probed correctly for a long
|
||||
# time. Need to go through the history to make sure I'm understanding this fully.
|
||||
image_encoder_model_id: str
|
||||
format: Literal[ModelFormat.InvokeAI]
|
||||
|
||||
@@ -465,6 +484,7 @@ AnyModelConfig = Annotated[
|
||||
Annotated[MainDiffusersConfig, MainDiffusersConfig.get_tag()],
|
||||
Annotated[MainCheckpointConfig, MainCheckpointConfig.get_tag()],
|
||||
Annotated[MainBnbQuantized4bCheckpointConfig, MainBnbQuantized4bCheckpointConfig.get_tag()],
|
||||
Annotated[MainGGUFCheckpointConfig, MainGGUFCheckpointConfig.get_tag()],
|
||||
Annotated[VAEDiffusersConfig, VAEDiffusersConfig.get_tag()],
|
||||
Annotated[VAECheckpointConfig, VAECheckpointConfig.get_tag()],
|
||||
Annotated[ControlNetDiffusersConfig, ControlNetDiffusersConfig.get_tag()],
|
||||
|
||||
@@ -0,0 +1,41 @@
|
||||
from pathlib import Path
|
||||
from typing import Optional
|
||||
|
||||
from transformers import CLIPVisionModelWithProjection
|
||||
|
||||
from invokeai.backend.model_manager.config import (
|
||||
AnyModel,
|
||||
AnyModelConfig,
|
||||
BaseModelType,
|
||||
DiffusersConfigBase,
|
||||
ModelFormat,
|
||||
ModelType,
|
||||
SubModelType,
|
||||
)
|
||||
from invokeai.backend.model_manager.load.load_default import ModelLoader
|
||||
from invokeai.backend.model_manager.load.model_loader_registry import ModelLoaderRegistry
|
||||
|
||||
|
||||
@ModelLoaderRegistry.register(base=BaseModelType.Any, type=ModelType.CLIPVision, format=ModelFormat.Diffusers)
|
||||
class ClipVisionLoader(ModelLoader):
|
||||
"""Class to load CLIPVision models."""
|
||||
|
||||
def _load_model(
|
||||
self,
|
||||
config: AnyModelConfig,
|
||||
submodel_type: Optional[SubModelType] = None,
|
||||
) -> AnyModel:
|
||||
if not isinstance(config, DiffusersConfigBase):
|
||||
raise ValueError("Only DiffusersConfigBase models are currently supported here.")
|
||||
|
||||
if submodel_type is not None:
|
||||
raise Exception("There are no submodels in CLIP Vision models.")
|
||||
|
||||
model_path = Path(config.path)
|
||||
|
||||
model = CLIPVisionModelWithProjection.from_pretrained(
|
||||
model_path, torch_dtype=self._torch_dtype, local_files_only=True
|
||||
)
|
||||
assert isinstance(model, CLIPVisionModelWithProjection)
|
||||
|
||||
return model
|
||||
@@ -8,17 +8,36 @@ from diffusers import ControlNetModel
|
||||
from invokeai.backend.model_manager import (
|
||||
AnyModel,
|
||||
AnyModelConfig,
|
||||
)
|
||||
from invokeai.backend.model_manager.config import (
|
||||
BaseModelType,
|
||||
ControlNetCheckpointConfig,
|
||||
ModelFormat,
|
||||
ModelType,
|
||||
SubModelType,
|
||||
)
|
||||
from invokeai.backend.model_manager.config import ControlNetCheckpointConfig, SubModelType
|
||||
from invokeai.backend.model_manager.load.model_loader_registry import ModelLoaderRegistry
|
||||
from invokeai.backend.model_manager.load.model_loaders.generic_diffusers import GenericDiffusersLoader
|
||||
|
||||
|
||||
@ModelLoaderRegistry.register(base=BaseModelType.Any, type=ModelType.ControlNet, format=ModelFormat.Diffusers)
|
||||
@ModelLoaderRegistry.register(base=BaseModelType.Any, type=ModelType.ControlNet, format=ModelFormat.Checkpoint)
|
||||
@ModelLoaderRegistry.register(
|
||||
base=BaseModelType.StableDiffusion1, type=ModelType.ControlNet, format=ModelFormat.Diffusers
|
||||
)
|
||||
@ModelLoaderRegistry.register(
|
||||
base=BaseModelType.StableDiffusion1, type=ModelType.ControlNet, format=ModelFormat.Checkpoint
|
||||
)
|
||||
@ModelLoaderRegistry.register(
|
||||
base=BaseModelType.StableDiffusion2, type=ModelType.ControlNet, format=ModelFormat.Diffusers
|
||||
)
|
||||
@ModelLoaderRegistry.register(
|
||||
base=BaseModelType.StableDiffusion2, type=ModelType.ControlNet, format=ModelFormat.Checkpoint
|
||||
)
|
||||
@ModelLoaderRegistry.register(
|
||||
base=BaseModelType.StableDiffusionXL, type=ModelType.ControlNet, format=ModelFormat.Diffusers
|
||||
)
|
||||
@ModelLoaderRegistry.register(
|
||||
base=BaseModelType.StableDiffusionXL, type=ModelType.ControlNet, format=ModelFormat.Checkpoint
|
||||
)
|
||||
class ControlNetLoader(GenericDiffusersLoader):
|
||||
"""Class to load ControlNet models."""
|
||||
|
||||
|
||||
@@ -10,6 +10,19 @@ from safetensors.torch import load_file
|
||||
from transformers import AutoConfig, AutoModelForTextEncoding, CLIPTextModel, CLIPTokenizer, T5EncoderModel, T5Tokenizer
|
||||
|
||||
from invokeai.app.services.config.config_default import get_config
|
||||
from invokeai.backend.flux.controlnet.instantx_controlnet_flux import InstantXControlNetFlux
|
||||
from invokeai.backend.flux.controlnet.state_dict_utils import (
|
||||
convert_diffusers_instantx_state_dict_to_bfl_format,
|
||||
infer_flux_params_from_state_dict,
|
||||
infer_instantx_num_control_modes_from_state_dict,
|
||||
is_state_dict_instantx_controlnet,
|
||||
is_state_dict_xlabs_controlnet,
|
||||
)
|
||||
from invokeai.backend.flux.controlnet.xlabs_controlnet_flux import XLabsControlNetFlux
|
||||
from invokeai.backend.flux.ip_adapter.state_dict_utils import infer_xlabs_ip_adapter_params_from_state_dict
|
||||
from invokeai.backend.flux.ip_adapter.xlabs_ip_adapter_flux import (
|
||||
XlabsIpAdapterFlux,
|
||||
)
|
||||
from invokeai.backend.flux.model import Flux
|
||||
from invokeai.backend.flux.modules.autoencoder import AutoEncoder
|
||||
from invokeai.backend.flux.util import ae_params, params
|
||||
@@ -24,8 +37,12 @@ from invokeai.backend.model_manager import (
|
||||
from invokeai.backend.model_manager.config import (
|
||||
CheckpointConfigBase,
|
||||
CLIPEmbedDiffusersConfig,
|
||||
ControlNetCheckpointConfig,
|
||||
ControlNetDiffusersConfig,
|
||||
IPAdapterCheckpointConfig,
|
||||
MainBnbQuantized4bCheckpointConfig,
|
||||
MainCheckpointConfig,
|
||||
MainGGUFCheckpointConfig,
|
||||
T5EncoderBnbQuantizedLlmInt8bConfig,
|
||||
T5EncoderConfig,
|
||||
VAECheckpointConfig,
|
||||
@@ -35,6 +52,8 @@ from invokeai.backend.model_manager.load.model_loader_registry import ModelLoade
|
||||
from invokeai.backend.model_manager.util.model_util import (
|
||||
convert_bundle_to_flux_transformer_checkpoint,
|
||||
)
|
||||
from invokeai.backend.quantization.gguf.loaders import gguf_sd_loader
|
||||
from invokeai.backend.quantization.gguf.utils import TORCH_COMPATIBLE_QTYPES
|
||||
from invokeai.backend.util.silence_warnings import SilenceWarnings
|
||||
|
||||
try:
|
||||
@@ -156,7 +175,7 @@ class T5EncoderCheckpointModel(ModelLoader):
|
||||
case SubModelType.Tokenizer2:
|
||||
return T5Tokenizer.from_pretrained(Path(config.path) / "tokenizer_2", max_length=512)
|
||||
case SubModelType.TextEncoder2:
|
||||
return T5EncoderModel.from_pretrained(Path(config.path) / "text_encoder_2")
|
||||
return T5EncoderModel.from_pretrained(Path(config.path) / "text_encoder_2", torch_dtype="auto")
|
||||
|
||||
raise ValueError(
|
||||
f"Only Tokenizer and TextEncoder submodels are currently supported. Received: {submodel_type.value if submodel_type else 'None'}"
|
||||
@@ -204,6 +223,52 @@ class FluxCheckpointModel(ModelLoader):
|
||||
return model
|
||||
|
||||
|
||||
@ModelLoaderRegistry.register(base=BaseModelType.Flux, type=ModelType.Main, format=ModelFormat.GGUFQuantized)
|
||||
class FluxGGUFCheckpointModel(ModelLoader):
|
||||
"""Class to load GGUF main models."""
|
||||
|
||||
def _load_model(
|
||||
self,
|
||||
config: AnyModelConfig,
|
||||
submodel_type: Optional[SubModelType] = None,
|
||||
) -> AnyModel:
|
||||
if not isinstance(config, CheckpointConfigBase):
|
||||
raise ValueError("Only CheckpointConfigBase models are currently supported here.")
|
||||
|
||||
match submodel_type:
|
||||
case SubModelType.Transformer:
|
||||
return self._load_from_singlefile(config)
|
||||
|
||||
raise ValueError(
|
||||
f"Only Transformer submodels are currently supported. Received: {submodel_type.value if submodel_type else 'None'}"
|
||||
)
|
||||
|
||||
def _load_from_singlefile(
|
||||
self,
|
||||
config: AnyModelConfig,
|
||||
) -> AnyModel:
|
||||
assert isinstance(config, MainGGUFCheckpointConfig)
|
||||
model_path = Path(config.path)
|
||||
|
||||
with SilenceWarnings():
|
||||
model = Flux(params[config.config_path])
|
||||
|
||||
# HACK(ryand): We shouldn't be hard-coding the compute_dtype here.
|
||||
sd = gguf_sd_loader(model_path, compute_dtype=torch.bfloat16)
|
||||
|
||||
# HACK(ryand): There are some broken GGUF models in circulation that have the wrong shape for img_in.weight.
|
||||
# We override the shape here to fix the issue.
|
||||
# Example model with this issue (Q4_K_M): https://civitai.com/models/705823/ggufk-flux-unchained-km-quants
|
||||
img_in_weight = sd.get("img_in.weight", None)
|
||||
if img_in_weight is not None and img_in_weight._ggml_quantization_type in TORCH_COMPATIBLE_QTYPES:
|
||||
expected_img_in_weight_shape = model.img_in.weight.shape
|
||||
img_in_weight.quantized_data = img_in_weight.quantized_data.view(expected_img_in_weight_shape)
|
||||
img_in_weight.tensor_shape = expected_img_in_weight_shape
|
||||
|
||||
model.load_state_dict(sd, assign=True)
|
||||
return model
|
||||
|
||||
|
||||
@ModelLoaderRegistry.register(base=BaseModelType.Flux, type=ModelType.Main, format=ModelFormat.BnbQuantizednf4b)
|
||||
class FluxBnbQuantizednf4bCheckpointModel(ModelLoader):
|
||||
"""Class to load main models."""
|
||||
@@ -244,3 +309,74 @@ class FluxBnbQuantizednf4bCheckpointModel(ModelLoader):
|
||||
sd = convert_bundle_to_flux_transformer_checkpoint(sd)
|
||||
model.load_state_dict(sd, assign=True)
|
||||
return model
|
||||
|
||||
|
||||
@ModelLoaderRegistry.register(base=BaseModelType.Flux, type=ModelType.ControlNet, format=ModelFormat.Checkpoint)
|
||||
@ModelLoaderRegistry.register(base=BaseModelType.Flux, type=ModelType.ControlNet, format=ModelFormat.Diffusers)
|
||||
class FluxControlnetModel(ModelLoader):
|
||||
"""Class to load FLUX ControlNet models."""
|
||||
|
||||
def _load_model(
|
||||
self,
|
||||
config: AnyModelConfig,
|
||||
submodel_type: Optional[SubModelType] = None,
|
||||
) -> AnyModel:
|
||||
if isinstance(config, ControlNetCheckpointConfig):
|
||||
model_path = Path(config.path)
|
||||
elif isinstance(config, ControlNetDiffusersConfig):
|
||||
# If this is a diffusers directory, we simply ignore the config file and load from the weight file.
|
||||
model_path = Path(config.path) / "diffusion_pytorch_model.safetensors"
|
||||
else:
|
||||
raise ValueError(f"Unexpected ControlNet model config type: {type(config)}")
|
||||
|
||||
sd = load_file(model_path)
|
||||
|
||||
# Detect the FLUX ControlNet model type from the state dict.
|
||||
if is_state_dict_xlabs_controlnet(sd):
|
||||
return self._load_xlabs_controlnet(sd)
|
||||
elif is_state_dict_instantx_controlnet(sd):
|
||||
return self._load_instantx_controlnet(sd)
|
||||
else:
|
||||
raise ValueError("Do not recognize the state dict as an XLabs or InstantX ControlNet model.")
|
||||
|
||||
def _load_xlabs_controlnet(self, sd: dict[str, torch.Tensor]) -> AnyModel:
|
||||
with accelerate.init_empty_weights():
|
||||
# HACK(ryand): Is it safe to assume dev here?
|
||||
model = XLabsControlNetFlux(params["flux-dev"])
|
||||
|
||||
model.load_state_dict(sd, assign=True)
|
||||
return model
|
||||
|
||||
def _load_instantx_controlnet(self, sd: dict[str, torch.Tensor]) -> AnyModel:
|
||||
sd = convert_diffusers_instantx_state_dict_to_bfl_format(sd)
|
||||
flux_params = infer_flux_params_from_state_dict(sd)
|
||||
num_control_modes = infer_instantx_num_control_modes_from_state_dict(sd)
|
||||
|
||||
with accelerate.init_empty_weights():
|
||||
model = InstantXControlNetFlux(flux_params, num_control_modes)
|
||||
|
||||
model.load_state_dict(sd, assign=True)
|
||||
return model
|
||||
|
||||
|
||||
@ModelLoaderRegistry.register(base=BaseModelType.Flux, type=ModelType.IPAdapter, format=ModelFormat.Checkpoint)
|
||||
class FluxIpAdapterModel(ModelLoader):
|
||||
"""Class to load FLUX IP-Adapter models."""
|
||||
|
||||
def _load_model(
|
||||
self,
|
||||
config: AnyModelConfig,
|
||||
submodel_type: Optional[SubModelType] = None,
|
||||
) -> AnyModel:
|
||||
if not isinstance(config, IPAdapterCheckpointConfig):
|
||||
raise ValueError(f"Unexpected model config type: {type(config)}.")
|
||||
|
||||
sd = load_file(Path(config.path))
|
||||
|
||||
params = infer_xlabs_ip_adapter_params_from_state_dict(sd)
|
||||
|
||||
with accelerate.init_empty_weights():
|
||||
model = XlabsIpAdapterFlux(params=params)
|
||||
|
||||
model.load_xlabs_state_dict(sd, assign=True)
|
||||
return model
|
||||
|
||||
@@ -22,7 +22,6 @@ from invokeai.backend.model_manager.load.load_default import ModelLoader
|
||||
from invokeai.backend.model_manager.load.model_loader_registry import ModelLoaderRegistry
|
||||
|
||||
|
||||
@ModelLoaderRegistry.register(base=BaseModelType.Any, type=ModelType.CLIPVision, format=ModelFormat.Diffusers)
|
||||
@ModelLoaderRegistry.register(base=BaseModelType.Any, type=ModelType.T2IAdapter, format=ModelFormat.Diffusers)
|
||||
class GenericDiffusersLoader(ModelLoader):
|
||||
"""Class to load simple diffusers models."""
|
||||
|
||||
@@ -10,6 +10,11 @@ from picklescan.scanner import scan_file_path
|
||||
|
||||
import invokeai.backend.util.logging as logger
|
||||
from invokeai.app.util.misc import uuid_string
|
||||
from invokeai.backend.flux.controlnet.state_dict_utils import (
|
||||
is_state_dict_instantx_controlnet,
|
||||
is_state_dict_xlabs_controlnet,
|
||||
)
|
||||
from invokeai.backend.flux.ip_adapter.state_dict_utils import is_state_dict_xlabs_ip_adapter
|
||||
from invokeai.backend.lora.conversions.flux_diffusers_lora_conversion_utils import (
|
||||
is_state_dict_likely_in_flux_diffusers_format,
|
||||
)
|
||||
@@ -30,6 +35,8 @@ from invokeai.backend.model_manager.config import (
|
||||
SchedulerPredictionType,
|
||||
)
|
||||
from invokeai.backend.model_manager.util.model_util import lora_token_vector_length, read_checkpoint_meta
|
||||
from invokeai.backend.quantization.gguf.ggml_tensor import GGMLTensor
|
||||
from invokeai.backend.quantization.gguf.loaders import gguf_sd_loader
|
||||
from invokeai.backend.spandrel_image_to_image_model import SpandrelImageToImageModel
|
||||
from invokeai.backend.util.silence_warnings import SilenceWarnings
|
||||
|
||||
@@ -114,6 +121,7 @@ class ModelProbe(object):
|
||||
"CLIPModel": ModelType.CLIPEmbed,
|
||||
"CLIPTextModel": ModelType.CLIPEmbed,
|
||||
"T5EncoderModel": ModelType.T5Encoder,
|
||||
"FluxControlNetModel": ModelType.ControlNet,
|
||||
}
|
||||
|
||||
@classmethod
|
||||
@@ -187,6 +195,7 @@ class ModelProbe(object):
|
||||
if fields["type"] in [ModelType.Main, ModelType.ControlNet, ModelType.VAE] and fields["format"] in [
|
||||
ModelFormat.Checkpoint,
|
||||
ModelFormat.BnbQuantizednf4b,
|
||||
ModelFormat.GGUFQuantized,
|
||||
]:
|
||||
ckpt_config_path = cls._get_checkpoint_config_path(
|
||||
model_path,
|
||||
@@ -220,7 +229,7 @@ class ModelProbe(object):
|
||||
|
||||
@classmethod
|
||||
def get_model_type_from_checkpoint(cls, model_path: Path, checkpoint: Optional[CkptType] = None) -> ModelType:
|
||||
if model_path.suffix not in (".bin", ".pt", ".ckpt", ".safetensors", ".pth"):
|
||||
if model_path.suffix not in (".bin", ".pt", ".ckpt", ".safetensors", ".pth", ".gguf"):
|
||||
raise InvalidModelConfigException(f"{model_path}: unrecognized suffix")
|
||||
|
||||
if model_path.name == "learned_embeds.bin":
|
||||
@@ -235,8 +244,6 @@ class ModelProbe(object):
|
||||
"cond_stage_model.",
|
||||
"first_stage_model.",
|
||||
"model.diffusion_model.",
|
||||
# FLUX models in the official BFL format contain keys with the "double_blocks." prefix.
|
||||
"double_blocks.",
|
||||
# Some FLUX checkpoint files contain transformer keys prefixed with "model.diffusion_model".
|
||||
# This prefix is typically used to distinguish between multiple models bundled in a single file.
|
||||
"model.diffusion_model.double_blocks.",
|
||||
@@ -244,6 +251,10 @@ class ModelProbe(object):
|
||||
):
|
||||
# Keys starting with double_blocks are associated with Flux models
|
||||
return ModelType.Main
|
||||
# FLUX models in the official BFL format contain keys with the "double_blocks." prefix, but we must be
|
||||
# careful to avoid false positives on XLabs FLUX IP-Adapter models.
|
||||
elif key.startswith("double_blocks.") and "ip_adapter" not in key:
|
||||
return ModelType.Main
|
||||
elif key.startswith(("encoder.conv_in", "decoder.conv_in")):
|
||||
return ModelType.VAE
|
||||
elif key.startswith(("lora_te_", "lora_unet_")):
|
||||
@@ -252,9 +263,28 @@ class ModelProbe(object):
|
||||
# LoRA models, but as of the time of writing, we support Diffusers FLUX PEFT LoRA models.
|
||||
elif key.endswith(("to_k_lora.up.weight", "to_q_lora.down.weight", "lora_A.weight", "lora_B.weight")):
|
||||
return ModelType.LoRA
|
||||
elif key.startswith(("controlnet", "control_model", "input_blocks")):
|
||||
elif key.startswith(
|
||||
(
|
||||
"controlnet",
|
||||
"control_model",
|
||||
"input_blocks",
|
||||
# XLabs FLUX ControlNet models have keys starting with "controlnet_blocks."
|
||||
# For example: https://huggingface.co/XLabs-AI/flux-controlnet-collections/blob/86ab1e915a389d5857135c00e0d350e9e38a9048/flux-canny-controlnet_v2.safetensors
|
||||
# TODO(ryand): This is very fragile. XLabs FLUX ControlNet models also contain keys starting with
|
||||
# "double_blocks.", which we check for above. But, I'm afraid to modify this logic because it is so
|
||||
# delicate.
|
||||
"controlnet_blocks",
|
||||
)
|
||||
):
|
||||
return ModelType.ControlNet
|
||||
elif key.startswith(("image_proj.", "ip_adapter.")):
|
||||
elif key.startswith(
|
||||
(
|
||||
"image_proj.",
|
||||
"ip_adapter.",
|
||||
# XLabs FLUX IP-Adapter models have keys startinh with "ip_adapter_proj_model.".
|
||||
"ip_adapter_proj_model.",
|
||||
)
|
||||
):
|
||||
return ModelType.IPAdapter
|
||||
elif key in {"emb_params", "string_to_param"}:
|
||||
return ModelType.TextualInversion
|
||||
@@ -278,12 +308,10 @@ class ModelProbe(object):
|
||||
return ModelType.SpandrelImageToImage
|
||||
except spandrel.UnsupportedModelError:
|
||||
pass
|
||||
except RuntimeError as e:
|
||||
if "No such file or directory" in str(e):
|
||||
# This error is expected if the model_path does not exist (which is the case in some unit tests).
|
||||
pass
|
||||
else:
|
||||
raise e
|
||||
except Exception as e:
|
||||
logger.warning(
|
||||
f"Encountered error while probing to determine if {model_path} is a Spandrel model. Ignoring. Error: {e}"
|
||||
)
|
||||
|
||||
raise InvalidModelConfigException(f"Unable to determine model type for {model_path}")
|
||||
|
||||
@@ -408,6 +436,8 @@ class ModelProbe(object):
|
||||
model = torch.load(model_path, map_location="cpu")
|
||||
assert isinstance(model, dict)
|
||||
return model
|
||||
elif model_path.suffix.endswith(".gguf"):
|
||||
return gguf_sd_loader(model_path, compute_dtype=torch.float32)
|
||||
else:
|
||||
return safetensors.torch.load_file(model_path)
|
||||
|
||||
@@ -432,9 +462,11 @@ MODEL_NAME_TO_PREPROCESSOR = {
|
||||
"normal": "normalbae_image_processor",
|
||||
"sketch": "pidi_image_processor",
|
||||
"scribble": "lineart_image_processor",
|
||||
"lineart": "lineart_image_processor",
|
||||
"lineart anime": "lineart_anime_image_processor",
|
||||
"lineart_anime": "lineart_anime_image_processor",
|
||||
"lineart": "lineart_image_processor",
|
||||
"softedge": "hed_image_processor",
|
||||
"hed": "hed_image_processor",
|
||||
"shuffle": "content_shuffle_image_processor",
|
||||
"pose": "dw_openpose_image_processor",
|
||||
"mediapipe": "mediapipe_face_processor",
|
||||
@@ -446,7 +478,8 @@ MODEL_NAME_TO_PREPROCESSOR = {
|
||||
|
||||
def get_default_settings_controlnet_t2i_adapter(model_name: str) -> Optional[ControlAdapterDefaultSettings]:
|
||||
for k, v in MODEL_NAME_TO_PREPROCESSOR.items():
|
||||
if k in model_name:
|
||||
model_name_lower = model_name.lower()
|
||||
if k in model_name_lower:
|
||||
return ControlAdapterDefaultSettings(preprocessor=v)
|
||||
return None
|
||||
|
||||
@@ -477,6 +510,8 @@ class CheckpointProbeBase(ProbeBase):
|
||||
or "model.diffusion_model.double_blocks.0.img_attn.proj.weight.quant_state.bitsandbytes__nf4" in state_dict
|
||||
):
|
||||
return ModelFormat.BnbQuantizednf4b
|
||||
elif any(isinstance(v, GGMLTensor) for v in state_dict.values()):
|
||||
return ModelFormat.GGUFQuantized
|
||||
return ModelFormat("checkpoint")
|
||||
|
||||
def get_variant_type(self) -> ModelVariantType:
|
||||
@@ -618,6 +653,11 @@ class ControlNetCheckpointProbe(CheckpointProbeBase):
|
||||
|
||||
def get_base_type(self) -> BaseModelType:
|
||||
checkpoint = self.checkpoint
|
||||
if is_state_dict_xlabs_controlnet(checkpoint) or is_state_dict_instantx_controlnet(checkpoint):
|
||||
# TODO(ryand): Should I distinguish between XLabs, InstantX and other ControlNet models by implementing
|
||||
# get_format()?
|
||||
return BaseModelType.Flux
|
||||
|
||||
for key_name in (
|
||||
"control_model.input_blocks.2.1.transformer_blocks.0.attn2.to_k.weight",
|
||||
"controlnet_mid_block.bias",
|
||||
@@ -643,6 +683,10 @@ class IPAdapterCheckpointProbe(CheckpointProbeBase):
|
||||
|
||||
def get_base_type(self) -> BaseModelType:
|
||||
checkpoint = self.checkpoint
|
||||
|
||||
if is_state_dict_xlabs_ip_adapter(checkpoint):
|
||||
return BaseModelType.Flux
|
||||
|
||||
for key in checkpoint.keys():
|
||||
if not key.startswith(("image_proj.", "ip_adapter.")):
|
||||
continue
|
||||
@@ -839,22 +883,19 @@ class ControlNetFolderProbe(FolderProbeBase):
|
||||
raise InvalidModelConfigException(f"Cannot determine base type for {self.model_path}")
|
||||
with open(config_file, "r") as file:
|
||||
config = json.load(file)
|
||||
|
||||
if config.get("_class_name", None) == "FluxControlNetModel":
|
||||
return BaseModelType.Flux
|
||||
|
||||
# no obvious way to distinguish between sd2-base and sd2-768
|
||||
dimension = config["cross_attention_dim"]
|
||||
base_model = (
|
||||
BaseModelType.StableDiffusion1
|
||||
if dimension == 768
|
||||
else (
|
||||
BaseModelType.StableDiffusion2
|
||||
if dimension == 1024
|
||||
else BaseModelType.StableDiffusionXL
|
||||
if dimension == 2048
|
||||
else None
|
||||
)
|
||||
)
|
||||
if not base_model:
|
||||
raise InvalidModelConfigException(f"Unable to determine model base for {self.model_path}")
|
||||
return base_model
|
||||
if dimension == 768:
|
||||
return BaseModelType.StableDiffusion1
|
||||
if dimension == 1024:
|
||||
return BaseModelType.StableDiffusion2
|
||||
if dimension == 2048:
|
||||
return BaseModelType.StableDiffusionXL
|
||||
raise InvalidModelConfigException(f"Unable to determine model base for {self.model_path}")
|
||||
|
||||
|
||||
class LoRAFolderProbe(FolderProbeBase):
|
||||
|
||||
@@ -130,7 +130,7 @@ class ModelSearch:
|
||||
return
|
||||
|
||||
for n in file_names:
|
||||
if n.endswith((".ckpt", ".bin", ".pth", ".safetensors", ".pt")):
|
||||
if n.endswith((".ckpt", ".bin", ".pth", ".safetensors", ".pt", ".gguf")):
|
||||
try:
|
||||
self.model_found(absolute_path / n)
|
||||
except KeyboardInterrupt:
|
||||
|
||||
File diff suppressed because it is too large
Load Diff
@@ -8,6 +8,8 @@ import safetensors
|
||||
import torch
|
||||
from picklescan.scanner import scan_file_path
|
||||
|
||||
from invokeai.backend.quantization.gguf.loaders import gguf_sd_loader
|
||||
|
||||
|
||||
def _fast_safetensors_reader(path: str) -> Dict[str, torch.Tensor]:
|
||||
checkpoint = {}
|
||||
@@ -54,7 +56,11 @@ def read_checkpoint_meta(path: Union[str, Path], scan: bool = False) -> Dict[str
|
||||
scan_result = scan_file_path(path)
|
||||
if scan_result.infected_files != 0:
|
||||
raise Exception(f'The model file "{path}" is potentially infected by malware. Aborting import.')
|
||||
checkpoint = torch.load(path, map_location=torch.device("meta"))
|
||||
if str(path).endswith(".gguf"):
|
||||
# The GGUF reader used here uses numpy memmap, so these tensors are not loaded into memory during this function
|
||||
checkpoint = gguf_sd_loader(Path(path), compute_dtype=torch.float32)
|
||||
else:
|
||||
checkpoint = torch.load(path, map_location=torch.device("meta"))
|
||||
return checkpoint
|
||||
|
||||
|
||||
|
||||
157
invokeai/backend/quantization/gguf/ggml_tensor.py
Normal file
157
invokeai/backend/quantization/gguf/ggml_tensor.py
Normal file
@@ -0,0 +1,157 @@
|
||||
from typing import overload
|
||||
|
||||
import gguf
|
||||
import torch
|
||||
|
||||
from invokeai.backend.quantization.gguf.utils import (
|
||||
DEQUANTIZE_FUNCTIONS,
|
||||
TORCH_COMPATIBLE_QTYPES,
|
||||
dequantize,
|
||||
)
|
||||
|
||||
|
||||
def dequantize_and_run(func, args, kwargs):
|
||||
"""A helper function for running math ops on GGMLTensor inputs.
|
||||
|
||||
Dequantizes the inputs, and runs the function.
|
||||
"""
|
||||
dequantized_args = [a.get_dequantized_tensor() if hasattr(a, "get_dequantized_tensor") else a for a in args]
|
||||
dequantized_kwargs = {
|
||||
k: v.get_dequantized_tensor() if hasattr(v, "get_dequantized_tensor") else v for k, v in kwargs.items()
|
||||
}
|
||||
return func(*dequantized_args, **dequantized_kwargs)
|
||||
|
||||
|
||||
def apply_to_quantized_tensor(func, args, kwargs):
|
||||
"""A helper function to apply a function to a quantized GGML tensor, and re-wrap the result in a GGMLTensor.
|
||||
|
||||
Assumes that the first argument is a GGMLTensor.
|
||||
"""
|
||||
# We expect the first argument to be a GGMLTensor, and all other arguments to be non-GGMLTensors.
|
||||
ggml_tensor = args[0]
|
||||
assert isinstance(ggml_tensor, GGMLTensor)
|
||||
assert all(not isinstance(a, GGMLTensor) for a in args[1:])
|
||||
assert all(not isinstance(v, GGMLTensor) for v in kwargs.values())
|
||||
|
||||
new_data = func(ggml_tensor.quantized_data, *args[1:], **kwargs)
|
||||
|
||||
if new_data.dtype != ggml_tensor.quantized_data.dtype:
|
||||
# This is intended to catch calls such as `.to(dtype-torch.float32)`, which are not supported on GGMLTensors.
|
||||
raise ValueError("Operation changed the dtype of GGMLTensor unexpectedly.")
|
||||
|
||||
return GGMLTensor(
|
||||
new_data, ggml_tensor._ggml_quantization_type, ggml_tensor.tensor_shape, ggml_tensor.compute_dtype
|
||||
)
|
||||
|
||||
|
||||
GGML_TENSOR_OP_TABLE = {
|
||||
# Ops to run on the quantized tensor.
|
||||
torch.ops.aten.detach.default: apply_to_quantized_tensor, # pyright: ignore
|
||||
torch.ops.aten._to_copy.default: apply_to_quantized_tensor, # pyright: ignore
|
||||
# Ops to run on dequantized tensors.
|
||||
torch.ops.aten.t.default: dequantize_and_run, # pyright: ignore
|
||||
torch.ops.aten.addmm.default: dequantize_and_run, # pyright: ignore
|
||||
torch.ops.aten.mul.Tensor: dequantize_and_run, # pyright: ignore
|
||||
}
|
||||
|
||||
if torch.backends.mps.is_available():
|
||||
GGML_TENSOR_OP_TABLE.update(
|
||||
{torch.ops.aten.linear.default: dequantize_and_run} # pyright: ignore
|
||||
)
|
||||
|
||||
|
||||
class GGMLTensor(torch.Tensor):
|
||||
"""A torch.Tensor sub-class holding a quantized GGML tensor.
|
||||
|
||||
The underlying tensor is quantized, but the GGMLTensor class provides a dequantized view of the tensor on-the-fly
|
||||
when it is used in operations.
|
||||
"""
|
||||
|
||||
@staticmethod
|
||||
def __new__(
|
||||
cls,
|
||||
data: torch.Tensor,
|
||||
ggml_quantization_type: gguf.GGMLQuantizationType,
|
||||
tensor_shape: torch.Size,
|
||||
compute_dtype: torch.dtype,
|
||||
):
|
||||
# Type hinting is not supported for torch.Tensor._make_wrapper_subclass, so we ignore the errors.
|
||||
return torch.Tensor._make_wrapper_subclass( # pyright: ignore
|
||||
cls,
|
||||
data.shape,
|
||||
dtype=data.dtype,
|
||||
layout=data.layout,
|
||||
device=data.device,
|
||||
strides=data.stride(),
|
||||
storage_offset=data.storage_offset(),
|
||||
)
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
data: torch.Tensor,
|
||||
ggml_quantization_type: gguf.GGMLQuantizationType,
|
||||
tensor_shape: torch.Size,
|
||||
compute_dtype: torch.dtype,
|
||||
):
|
||||
self.quantized_data = data
|
||||
self._ggml_quantization_type = ggml_quantization_type
|
||||
# The dequantized shape of the tensor.
|
||||
self.tensor_shape = tensor_shape
|
||||
self.compute_dtype = compute_dtype
|
||||
|
||||
def __repr__(self, *, tensor_contents=None):
|
||||
return f"GGMLTensor(type={self._ggml_quantization_type.name}, dequantized_shape=({self.tensor_shape})"
|
||||
|
||||
@overload
|
||||
def size(self, dim: None = None) -> torch.Size: ...
|
||||
|
||||
@overload
|
||||
def size(self, dim: int) -> int: ...
|
||||
|
||||
def size(self, dim: int | None = None):
|
||||
"""Return the size of the tensor after dequantization. I.e. the shape that will be used in any math ops."""
|
||||
if dim is not None:
|
||||
return self.tensor_shape[dim]
|
||||
return self.tensor_shape
|
||||
|
||||
@property
|
||||
def shape(self) -> torch.Size: # pyright: ignore[reportIncompatibleVariableOverride] pyright doesn't understand this for some reason.
|
||||
"""The shape of the tensor after dequantization. I.e. the shape that will be used in any math ops."""
|
||||
return self.size()
|
||||
|
||||
@property
|
||||
def quantized_shape(self) -> torch.Size:
|
||||
"""The shape of the quantized tensor."""
|
||||
return self.quantized_data.shape
|
||||
|
||||
def requires_grad_(self, mode: bool = True) -> torch.Tensor:
|
||||
"""The GGMLTensor class is currently only designed for inference (not training). Setting requires_grad to True
|
||||
is not supported. This method is a no-op.
|
||||
"""
|
||||
return self
|
||||
|
||||
def get_dequantized_tensor(self):
|
||||
"""Return the dequantized tensor.
|
||||
|
||||
Args:
|
||||
dtype: The dtype of the dequantized tensor.
|
||||
"""
|
||||
if self._ggml_quantization_type in TORCH_COMPATIBLE_QTYPES:
|
||||
return self.quantized_data.to(self.compute_dtype)
|
||||
elif self._ggml_quantization_type in DEQUANTIZE_FUNCTIONS:
|
||||
# TODO(ryand): Look into how the dtype param is intended to be used.
|
||||
return dequantize(
|
||||
data=self.quantized_data, qtype=self._ggml_quantization_type, oshape=self.tensor_shape, dtype=None
|
||||
).to(self.compute_dtype)
|
||||
else:
|
||||
# There is no GPU implementation for this quantization type, so fallback to the numpy implementation.
|
||||
new = gguf.quants.dequantize(self.quantized_data.cpu().numpy(), self._ggml_quantization_type)
|
||||
return torch.from_numpy(new).to(self.quantized_data.device, dtype=self.compute_dtype)
|
||||
|
||||
@classmethod
|
||||
def __torch_dispatch__(cls, func, types, args, kwargs):
|
||||
# We will likely hit cases here in the future where a new op is encountered that is not yet supported.
|
||||
# The new op simply needs to be added to the GGML_TENSOR_OP_TABLE.
|
||||
if func in GGML_TENSOR_OP_TABLE:
|
||||
return GGML_TENSOR_OP_TABLE[func](func, args, kwargs)
|
||||
return NotImplemented
|
||||
22
invokeai/backend/quantization/gguf/loaders.py
Normal file
22
invokeai/backend/quantization/gguf/loaders.py
Normal file
@@ -0,0 +1,22 @@
|
||||
from pathlib import Path
|
||||
|
||||
import gguf
|
||||
import torch
|
||||
|
||||
from invokeai.backend.quantization.gguf.ggml_tensor import GGMLTensor
|
||||
from invokeai.backend.quantization.gguf.utils import TORCH_COMPATIBLE_QTYPES
|
||||
|
||||
|
||||
def gguf_sd_loader(path: Path, compute_dtype: torch.dtype) -> dict[str, GGMLTensor]:
|
||||
reader = gguf.GGUFReader(path)
|
||||
|
||||
sd: dict[str, GGMLTensor] = {}
|
||||
for tensor in reader.tensors:
|
||||
torch_tensor = torch.from_numpy(tensor.data)
|
||||
shape = torch.Size(tuple(int(v) for v in reversed(tensor.shape)))
|
||||
if tensor.tensor_type in TORCH_COMPATIBLE_QTYPES:
|
||||
torch_tensor = torch_tensor.view(*shape)
|
||||
sd[tensor.name] = GGMLTensor(
|
||||
torch_tensor, ggml_quantization_type=tensor.tensor_type, tensor_shape=shape, compute_dtype=compute_dtype
|
||||
)
|
||||
return sd
|
||||
308
invokeai/backend/quantization/gguf/utils.py
Normal file
308
invokeai/backend/quantization/gguf/utils.py
Normal file
@@ -0,0 +1,308 @@
|
||||
# Largely based on https://github.com/city96/ComfyUI-GGUF
|
||||
|
||||
from typing import Callable, Optional, Union
|
||||
|
||||
import gguf
|
||||
import torch
|
||||
|
||||
TORCH_COMPATIBLE_QTYPES = {None, gguf.GGMLQuantizationType.F32, gguf.GGMLQuantizationType.F16}
|
||||
|
||||
# K Quants #
|
||||
QK_K = 256
|
||||
K_SCALE_SIZE = 12
|
||||
|
||||
|
||||
def get_scale_min(scales: torch.Tensor):
|
||||
n_blocks = scales.shape[0]
|
||||
scales = scales.view(torch.uint8)
|
||||
scales = scales.reshape((n_blocks, 3, 4))
|
||||
|
||||
d, m, m_d = torch.split(scales, scales.shape[-2] // 3, dim=-2)
|
||||
|
||||
sc = torch.cat([d & 0x3F, (m_d & 0x0F) | ((d >> 2) & 0x30)], dim=-1)
|
||||
min = torch.cat([m & 0x3F, (m_d >> 4) | ((m >> 2) & 0x30)], dim=-1)
|
||||
|
||||
return (sc.reshape((n_blocks, 8)), min.reshape((n_blocks, 8)))
|
||||
|
||||
|
||||
# Legacy Quants #
|
||||
def dequantize_blocks_Q8_0(
|
||||
blocks: torch.Tensor, block_size: int, type_size: int, dtype: Optional[torch.dtype] = None
|
||||
) -> torch.Tensor:
|
||||
d, x = split_block_dims(blocks, 2)
|
||||
d = d.view(torch.float16).to(dtype)
|
||||
x = x.view(torch.int8)
|
||||
return d * x
|
||||
|
||||
|
||||
def dequantize_blocks_Q5_1(
|
||||
blocks: torch.Tensor, block_size: int, type_size: int, dtype: Optional[torch.dtype] = None
|
||||
) -> torch.Tensor:
|
||||
n_blocks = blocks.shape[0]
|
||||
|
||||
d, m, qh, qs = split_block_dims(blocks, 2, 2, 4)
|
||||
d = d.view(torch.float16).to(dtype)
|
||||
m = m.view(torch.float16).to(dtype)
|
||||
qh = to_uint32(qh)
|
||||
|
||||
qh = qh.reshape((n_blocks, 1)) >> torch.arange(32, device=d.device, dtype=torch.int32).reshape(1, 32)
|
||||
ql = qs.reshape((n_blocks, -1, 1, block_size // 2)) >> torch.tensor(
|
||||
[0, 4], device=d.device, dtype=torch.uint8
|
||||
).reshape(1, 1, 2, 1)
|
||||
qh = (qh & 1).to(torch.uint8)
|
||||
ql = (ql & 0x0F).reshape((n_blocks, -1))
|
||||
|
||||
qs = ql | (qh << 4)
|
||||
return (d * qs) + m
|
||||
|
||||
|
||||
def dequantize_blocks_Q5_0(
|
||||
blocks: torch.Tensor, block_size: int, type_size: int, dtype: Optional[torch.dtype] = None
|
||||
) -> torch.Tensor:
|
||||
n_blocks = blocks.shape[0]
|
||||
|
||||
d, qh, qs = split_block_dims(blocks, 2, 4)
|
||||
d = d.view(torch.float16).to(dtype)
|
||||
qh = to_uint32(qh)
|
||||
|
||||
qh = qh.reshape(n_blocks, 1) >> torch.arange(32, device=d.device, dtype=torch.int32).reshape(1, 32)
|
||||
ql = qs.reshape(n_blocks, -1, 1, block_size // 2) >> torch.tensor(
|
||||
[0, 4], device=d.device, dtype=torch.uint8
|
||||
).reshape(1, 1, 2, 1)
|
||||
|
||||
qh = (qh & 1).to(torch.uint8)
|
||||
ql = (ql & 0x0F).reshape(n_blocks, -1)
|
||||
|
||||
qs = (ql | (qh << 4)).to(torch.int8) - 16
|
||||
return d * qs
|
||||
|
||||
|
||||
def dequantize_blocks_Q4_1(
|
||||
blocks: torch.Tensor, block_size: int, type_size: int, dtype: Optional[torch.dtype] = None
|
||||
) -> torch.Tensor:
|
||||
n_blocks = blocks.shape[0]
|
||||
|
||||
d, m, qs = split_block_dims(blocks, 2, 2)
|
||||
d = d.view(torch.float16).to(dtype)
|
||||
m = m.view(torch.float16).to(dtype)
|
||||
|
||||
qs = qs.reshape((n_blocks, -1, 1, block_size // 2)) >> torch.tensor(
|
||||
[0, 4], device=d.device, dtype=torch.uint8
|
||||
).reshape(1, 1, 2, 1)
|
||||
qs = (qs & 0x0F).reshape(n_blocks, -1)
|
||||
|
||||
return (d * qs) + m
|
||||
|
||||
|
||||
def dequantize_blocks_Q4_0(
|
||||
blocks: torch.Tensor, block_size: int, type_size: int, dtype: Optional[torch.dtype] = None
|
||||
) -> torch.Tensor:
|
||||
n_blocks = blocks.shape[0]
|
||||
|
||||
d, qs = split_block_dims(blocks, 2)
|
||||
d = d.view(torch.float16).to(dtype)
|
||||
|
||||
qs = qs.reshape((n_blocks, -1, 1, block_size // 2)) >> torch.tensor(
|
||||
[0, 4], device=d.device, dtype=torch.uint8
|
||||
).reshape((1, 1, 2, 1))
|
||||
qs = (qs & 0x0F).reshape((n_blocks, -1)).to(torch.int8) - 8
|
||||
return d * qs
|
||||
|
||||
|
||||
def dequantize_blocks_BF16(
|
||||
blocks: torch.Tensor, block_size: int, type_size: int, dtype: Optional[torch.dtype] = None
|
||||
) -> torch.Tensor:
|
||||
return (blocks.view(torch.int16).to(torch.int32) << 16).view(torch.float32)
|
||||
|
||||
|
||||
def dequantize_blocks_Q6_K(
|
||||
blocks: torch.Tensor, block_size: int, type_size: int, dtype: Optional[torch.dtype] = None
|
||||
) -> torch.Tensor:
|
||||
n_blocks = blocks.shape[0]
|
||||
|
||||
(
|
||||
ql,
|
||||
qh,
|
||||
scales,
|
||||
d,
|
||||
) = split_block_dims(blocks, QK_K // 2, QK_K // 4, QK_K // 16)
|
||||
|
||||
scales = scales.view(torch.int8).to(dtype)
|
||||
d = d.view(torch.float16).to(dtype)
|
||||
d = (d * scales).reshape((n_blocks, QK_K // 16, 1))
|
||||
|
||||
ql = ql.reshape((n_blocks, -1, 1, 64)) >> torch.tensor([0, 4], device=d.device, dtype=torch.uint8).reshape(
|
||||
(1, 1, 2, 1)
|
||||
)
|
||||
ql = (ql & 0x0F).reshape((n_blocks, -1, 32))
|
||||
qh = qh.reshape((n_blocks, -1, 1, 32)) >> torch.tensor([0, 2, 4, 6], device=d.device, dtype=torch.uint8).reshape(
|
||||
(1, 1, 4, 1)
|
||||
)
|
||||
qh = (qh & 0x03).reshape((n_blocks, -1, 32))
|
||||
q = (ql | (qh << 4)).to(torch.int8) - 32
|
||||
q = q.reshape((n_blocks, QK_K // 16, -1))
|
||||
|
||||
return (d * q).reshape((n_blocks, QK_K))
|
||||
|
||||
|
||||
def dequantize_blocks_Q5_K(
|
||||
blocks: torch.Tensor, block_size: int, type_size: int, dtype: Optional[torch.dtype] = None
|
||||
) -> torch.Tensor:
|
||||
n_blocks = blocks.shape[0]
|
||||
|
||||
d, dmin, scales, qh, qs = split_block_dims(blocks, 2, 2, K_SCALE_SIZE, QK_K // 8)
|
||||
|
||||
d = d.view(torch.float16).to(dtype)
|
||||
dmin = dmin.view(torch.float16).to(dtype)
|
||||
|
||||
sc, m = get_scale_min(scales)
|
||||
|
||||
d = (d * sc).reshape((n_blocks, -1, 1))
|
||||
dm = (dmin * m).reshape((n_blocks, -1, 1))
|
||||
|
||||
ql = qs.reshape((n_blocks, -1, 1, 32)) >> torch.tensor([0, 4], device=d.device, dtype=torch.uint8).reshape(
|
||||
(1, 1, 2, 1)
|
||||
)
|
||||
qh = qh.reshape((n_blocks, -1, 1, 32)) >> torch.tensor(list(range(8)), device=d.device, dtype=torch.uint8).reshape(
|
||||
(1, 1, 8, 1)
|
||||
)
|
||||
ql = (ql & 0x0F).reshape((n_blocks, -1, 32))
|
||||
qh = (qh & 0x01).reshape((n_blocks, -1, 32))
|
||||
q = ql | (qh << 4)
|
||||
|
||||
return (d * q - dm).reshape((n_blocks, QK_K))
|
||||
|
||||
|
||||
def dequantize_blocks_Q4_K(
|
||||
blocks: torch.Tensor, block_size: int, type_size: int, dtype: Optional[torch.dtype] = None
|
||||
) -> torch.Tensor:
|
||||
n_blocks = blocks.shape[0]
|
||||
|
||||
d, dmin, scales, qs = split_block_dims(blocks, 2, 2, K_SCALE_SIZE)
|
||||
d = d.view(torch.float16).to(dtype)
|
||||
dmin = dmin.view(torch.float16).to(dtype)
|
||||
|
||||
sc, m = get_scale_min(scales)
|
||||
|
||||
d = (d * sc).reshape((n_blocks, -1, 1))
|
||||
dm = (dmin * m).reshape((n_blocks, -1, 1))
|
||||
|
||||
qs = qs.reshape((n_blocks, -1, 1, 32)) >> torch.tensor([0, 4], device=d.device, dtype=torch.uint8).reshape(
|
||||
(1, 1, 2, 1)
|
||||
)
|
||||
qs = (qs & 0x0F).reshape((n_blocks, -1, 32))
|
||||
|
||||
return (d * qs - dm).reshape((n_blocks, QK_K))
|
||||
|
||||
|
||||
def dequantize_blocks_Q3_K(
|
||||
blocks: torch.Tensor, block_size: int, type_size: int, dtype: Optional[torch.dtype] = None
|
||||
) -> torch.Tensor:
|
||||
n_blocks = blocks.shape[0]
|
||||
|
||||
hmask, qs, scales, d = split_block_dims(blocks, QK_K // 8, QK_K // 4, 12)
|
||||
d = d.view(torch.float16).to(dtype)
|
||||
|
||||
lscales, hscales = scales[:, :8], scales[:, 8:]
|
||||
lscales = lscales.reshape((n_blocks, 1, 8)) >> torch.tensor([0, 4], device=d.device, dtype=torch.uint8).reshape(
|
||||
(1, 2, 1)
|
||||
)
|
||||
lscales = lscales.reshape((n_blocks, 16))
|
||||
hscales = hscales.reshape((n_blocks, 1, 4)) >> torch.tensor(
|
||||
[0, 2, 4, 6], device=d.device, dtype=torch.uint8
|
||||
).reshape((1, 4, 1))
|
||||
hscales = hscales.reshape((n_blocks, 16))
|
||||
scales = (lscales & 0x0F) | ((hscales & 0x03) << 4)
|
||||
scales = scales.to(torch.int8) - 32
|
||||
|
||||
dl = (d * scales).reshape((n_blocks, 16, 1))
|
||||
|
||||
ql = qs.reshape((n_blocks, -1, 1, 32)) >> torch.tensor([0, 2, 4, 6], device=d.device, dtype=torch.uint8).reshape(
|
||||
(1, 1, 4, 1)
|
||||
)
|
||||
qh = hmask.reshape(n_blocks, -1, 1, 32) >> torch.tensor(list(range(8)), device=d.device, dtype=torch.uint8).reshape(
|
||||
(1, 1, 8, 1)
|
||||
)
|
||||
ql = ql.reshape((n_blocks, 16, QK_K // 16)) & 3
|
||||
qh = (qh.reshape((n_blocks, 16, QK_K // 16)) & 1) ^ 1
|
||||
q = ql.to(torch.int8) - (qh << 2).to(torch.int8)
|
||||
|
||||
return (dl * q).reshape((n_blocks, QK_K))
|
||||
|
||||
|
||||
def dequantize_blocks_Q2_K(
|
||||
blocks: torch.Tensor, block_size: int, type_size: int, dtype: Optional[torch.dtype] = None
|
||||
) -> torch.Tensor:
|
||||
n_blocks = blocks.shape[0]
|
||||
|
||||
scales, qs, d, dmin = split_block_dims(blocks, QK_K // 16, QK_K // 4, 2)
|
||||
d = d.view(torch.float16).to(dtype)
|
||||
dmin = dmin.view(torch.float16).to(dtype)
|
||||
|
||||
# (n_blocks, 16, 1)
|
||||
dl = (d * (scales & 0xF)).reshape((n_blocks, QK_K // 16, 1))
|
||||
ml = (dmin * (scales >> 4)).reshape((n_blocks, QK_K // 16, 1))
|
||||
|
||||
shift = torch.tensor([0, 2, 4, 6], device=d.device, dtype=torch.uint8).reshape((1, 1, 4, 1))
|
||||
|
||||
qs = (qs.reshape((n_blocks, -1, 1, 32)) >> shift) & 3
|
||||
qs = qs.reshape((n_blocks, QK_K // 16, 16))
|
||||
qs = dl * qs - ml
|
||||
|
||||
return qs.reshape((n_blocks, -1))
|
||||
|
||||
|
||||
DEQUANTIZE_FUNCTIONS: dict[
|
||||
gguf.GGMLQuantizationType, Callable[[torch.Tensor, int, int, Optional[torch.dtype]], torch.Tensor]
|
||||
] = {
|
||||
gguf.GGMLQuantizationType.BF16: dequantize_blocks_BF16,
|
||||
gguf.GGMLQuantizationType.Q8_0: dequantize_blocks_Q8_0,
|
||||
gguf.GGMLQuantizationType.Q5_1: dequantize_blocks_Q5_1,
|
||||
gguf.GGMLQuantizationType.Q5_0: dequantize_blocks_Q5_0,
|
||||
gguf.GGMLQuantizationType.Q4_1: dequantize_blocks_Q4_1,
|
||||
gguf.GGMLQuantizationType.Q4_0: dequantize_blocks_Q4_0,
|
||||
gguf.GGMLQuantizationType.Q6_K: dequantize_blocks_Q6_K,
|
||||
gguf.GGMLQuantizationType.Q5_K: dequantize_blocks_Q5_K,
|
||||
gguf.GGMLQuantizationType.Q4_K: dequantize_blocks_Q4_K,
|
||||
gguf.GGMLQuantizationType.Q3_K: dequantize_blocks_Q3_K,
|
||||
gguf.GGMLQuantizationType.Q2_K: dequantize_blocks_Q2_K,
|
||||
}
|
||||
|
||||
|
||||
def is_torch_compatible(tensor: Optional[torch.Tensor]):
|
||||
return getattr(tensor, "tensor_type", None) in TORCH_COMPATIBLE_QTYPES
|
||||
|
||||
|
||||
def is_quantized(tensor: torch.Tensor):
|
||||
return not is_torch_compatible(tensor)
|
||||
|
||||
|
||||
def dequantize(
|
||||
data: torch.Tensor, qtype: gguf.GGMLQuantizationType, oshape: torch.Size, dtype: Optional[torch.dtype] = None
|
||||
):
|
||||
"""
|
||||
Dequantize tensor back to usable shape/dtype
|
||||
"""
|
||||
block_size, type_size = gguf.GGML_QUANT_SIZES[qtype]
|
||||
dequantize_blocks = DEQUANTIZE_FUNCTIONS[qtype]
|
||||
|
||||
rows = data.reshape((-1, data.shape[-1])).view(torch.uint8)
|
||||
|
||||
n_blocks = rows.numel() // type_size
|
||||
blocks = rows.reshape((n_blocks, type_size))
|
||||
blocks = dequantize_blocks(blocks, block_size, type_size, dtype)
|
||||
return blocks.reshape(oshape)
|
||||
|
||||
|
||||
def to_uint32(x: torch.Tensor) -> torch.Tensor:
|
||||
x = x.view(torch.uint8).to(torch.int32)
|
||||
return (x[:, 0] | x[:, 1] << 8 | x[:, 2] << 16 | x[:, 3] << 24).unsqueeze(1)
|
||||
|
||||
|
||||
def split_block_dims(blocks: torch.Tensor, *args):
|
||||
n_max = blocks.shape[1]
|
||||
dims = list(args) + [n_max - sum(args)]
|
||||
return torch.split(blocks, dims, dim=1)
|
||||
|
||||
|
||||
PATCH_TYPES = Union[torch.Tensor, list[torch.Tensor], tuple[torch.Tensor]]
|
||||
@@ -171,8 +171,19 @@ class StableDiffusionGeneratorPipeline(StableDiffusionPipeline):
|
||||
"""
|
||||
if xformers is available, use it, otherwise use sliced attention.
|
||||
"""
|
||||
|
||||
# On 30xx and 40xx series GPUs, `torch-sdp` is faster than `xformers`. This corresponds to a CUDA major
|
||||
# version of 8 or higher. So, for major version 7 or below, we prefer `xformers`.
|
||||
# See:
|
||||
# - https://developer.nvidia.com/cuda-gpus
|
||||
# - https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#compute-capabilities
|
||||
try:
|
||||
prefer_xformers = torch.cuda.is_available() and torch.cuda.get_device_properties("cuda").major <= 7 # type: ignore # Type of "get_device_properties" is partially unknown
|
||||
except Exception:
|
||||
prefer_xformers = False
|
||||
|
||||
config = get_config()
|
||||
if config.attention_type == "xformers":
|
||||
if config.attention_type == "xformers" and is_xformers_available() and prefer_xformers:
|
||||
self.enable_xformers_memory_efficient_attention()
|
||||
return
|
||||
elif config.attention_type == "sliced":
|
||||
@@ -187,20 +198,24 @@ class StableDiffusionGeneratorPipeline(StableDiffusionPipeline):
|
||||
self.disable_attention_slicing()
|
||||
return
|
||||
elif config.attention_type == "torch-sdp":
|
||||
if hasattr(torch.nn.functional, "scaled_dot_product_attention"):
|
||||
# diffusers enables sdp automatically
|
||||
return
|
||||
else:
|
||||
raise Exception("torch-sdp attention slicing not available")
|
||||
# torch-sdp is the default in diffusers.
|
||||
return
|
||||
|
||||
# the remainder if this code is called when attention_type=='auto'
|
||||
# See https://github.com/invoke-ai/InvokeAI/issues/7049 for context.
|
||||
# Bumping torch from 2.2.2 to 2.4.1 caused the sliced attention implementation to produce incorrect results.
|
||||
# For now, if a user is on an MPS device and has not explicitly set the attention_type, then we select the
|
||||
# non-sliced torch-sdp implementation. This keeps things working on MPS at the cost of increased peak memory
|
||||
# utilization.
|
||||
if torch.backends.mps.is_available():
|
||||
return
|
||||
|
||||
# The remainder if this code is called when attention_type=='auto'.
|
||||
if self.unet.device.type == "cuda":
|
||||
if is_xformers_available():
|
||||
if is_xformers_available() and prefer_xformers:
|
||||
self.enable_xformers_memory_efficient_attention()
|
||||
return
|
||||
elif hasattr(torch.nn.functional, "scaled_dot_product_attention"):
|
||||
# diffusers enables sdp automatically
|
||||
return
|
||||
# torch-sdp is the default in diffusers.
|
||||
return
|
||||
|
||||
if self.unet.device.type == "cpu" or self.unet.device.type == "mps":
|
||||
mem_free = psutil.virtual_memory().free
|
||||
|
||||
@@ -52,49 +52,51 @@
|
||||
}
|
||||
},
|
||||
"dependencies": {
|
||||
"@dagrejs/dagre": "^1.1.3",
|
||||
"@dagrejs/graphlib": "^2.2.3",
|
||||
"@dagrejs/dagre": "^1.1.4",
|
||||
"@dagrejs/graphlib": "^2.2.4",
|
||||
"@dnd-kit/core": "^6.1.0",
|
||||
"@dnd-kit/sortable": "^8.0.0",
|
||||
"@dnd-kit/utilities": "^3.2.2",
|
||||
"@fontsource-variable/inter": "^5.0.20",
|
||||
"@invoke-ai/ui-library": "^0.0.37",
|
||||
"@fontsource-variable/inter": "^5.1.0",
|
||||
"@invoke-ai/ui-library": "^0.0.43",
|
||||
"@nanostores/react": "^0.7.3",
|
||||
"@reduxjs/toolkit": "2.2.3",
|
||||
"@roarr/browser-log-writer": "^1.3.0",
|
||||
"async-mutex": "^0.5.0",
|
||||
"chakra-react-select": "^4.9.1",
|
||||
"chakra-react-select": "^4.9.2",
|
||||
"cmdk": "^1.0.0",
|
||||
"compare-versions": "^6.1.1",
|
||||
"dateformat": "^5.0.3",
|
||||
"fracturedjsonjs": "^4.0.2",
|
||||
"framer-motion": "^11.3.24",
|
||||
"i18next": "^23.12.2",
|
||||
"i18next-http-backend": "^2.5.2",
|
||||
"framer-motion": "^11.10.0",
|
||||
"i18next": "^23.15.1",
|
||||
"i18next-http-backend": "^2.6.1",
|
||||
"idb-keyval": "^6.2.1",
|
||||
"jsondiffpatch": "^0.6.0",
|
||||
"konva": "^9.3.14",
|
||||
"konva": "^9.3.15",
|
||||
"lodash-es": "^4.17.21",
|
||||
"lru-cache": "^11.0.0",
|
||||
"lru-cache": "^11.0.1",
|
||||
"nanoid": "^5.0.7",
|
||||
"nanostores": "^0.11.2",
|
||||
"nanostores": "^0.11.3",
|
||||
"new-github-issue-url": "^1.0.0",
|
||||
"overlayscrollbars": "^2.10.0",
|
||||
"overlayscrollbars-react": "^0.5.6",
|
||||
"perfect-freehand": "^1.2.2",
|
||||
"query-string": "^9.1.0",
|
||||
"raf-throttle": "^2.0.6",
|
||||
"react": "^18.3.1",
|
||||
"react-colorful": "^5.6.1",
|
||||
"react-dom": "^18.3.1",
|
||||
"react-dropzone": "^14.2.3",
|
||||
"react-dropzone": "^14.2.9",
|
||||
"react-error-boundary": "^4.0.13",
|
||||
"react-hook-form": "^7.52.2",
|
||||
"react-hook-form": "^7.53.0",
|
||||
"react-hotkeys-hook": "4.5.0",
|
||||
"react-i18next": "^14.1.3",
|
||||
"react-icons": "^5.2.1",
|
||||
"react-i18next": "^15.0.2",
|
||||
"react-icons": "^5.3.0",
|
||||
"react-redux": "9.1.2",
|
||||
"react-resizable-panels": "^2.1.2",
|
||||
"react-resizable-panels": "^2.1.4",
|
||||
"react-use": "^17.5.1",
|
||||
"react-virtuoso": "^4.9.0",
|
||||
"react-virtuoso": "^4.10.4",
|
||||
"reactflow": "^11.11.4",
|
||||
"redux-dynamic-middlewares": "^2.2.0",
|
||||
"redux-remember": "^5.1.0",
|
||||
@@ -102,56 +104,55 @@
|
||||
"rfdc": "^1.4.1",
|
||||
"roarr": "^7.21.1",
|
||||
"serialize-error": "^11.0.3",
|
||||
"socket.io-client": "^4.7.5",
|
||||
"socket.io-client": "^4.8.0",
|
||||
"stable-hash": "^0.0.4",
|
||||
"use-debounce": "^10.0.2",
|
||||
"use-debounce": "^10.0.3",
|
||||
"use-device-pixel-ratio": "^1.1.2",
|
||||
"uuid": "^10.0.0",
|
||||
"zod": "^3.23.8",
|
||||
"zod-validation-error": "^3.3.1"
|
||||
"zod-validation-error": "^3.4.0"
|
||||
},
|
||||
"peerDependencies": {
|
||||
"react": "^18.2.0",
|
||||
"react-dom": "^18.2.0",
|
||||
"ts-toolbelt": "^9.6.0"
|
||||
"react-dom": "^18.2.0"
|
||||
},
|
||||
"devDependencies": {
|
||||
"@invoke-ai/eslint-config-react": "^0.0.14",
|
||||
"@invoke-ai/prettier-config-react": "^0.0.7",
|
||||
"@storybook/addon-essentials": "^8.2.8",
|
||||
"@storybook/addon-interactions": "^8.2.8",
|
||||
"@storybook/addon-links": "^8.2.8",
|
||||
"@storybook/addon-storysource": "^8.2.8",
|
||||
"@storybook/manager-api": "^8.2.8",
|
||||
"@storybook/react": "^8.2.8",
|
||||
"@storybook/react-vite": "^8.2.8",
|
||||
"@storybook/theming": "^8.2.8",
|
||||
"@storybook/addon-essentials": "^8.3.4",
|
||||
"@storybook/addon-interactions": "^8.3.4",
|
||||
"@storybook/addon-links": "^8.3.4",
|
||||
"@storybook/addon-storysource": "^8.3.4",
|
||||
"@storybook/manager-api": "^8.3.4",
|
||||
"@storybook/react": "^8.3.4",
|
||||
"@storybook/react-vite": "^8.3.4",
|
||||
"@storybook/theming": "^8.3.4",
|
||||
"@types/dateformat": "^5.0.2",
|
||||
"@types/lodash-es": "^4.17.12",
|
||||
"@types/node": "^20.14.15",
|
||||
"@types/react": "^18.3.3",
|
||||
"@types/node": "^20.16.10",
|
||||
"@types/react": "^18.3.11",
|
||||
"@types/react-dom": "^18.3.0",
|
||||
"@types/uuid": "^10.0.0",
|
||||
"@vitejs/plugin-react-swc": "^3.7.0",
|
||||
"@vitest/coverage-v8": "^1.5.0",
|
||||
"@vitest/ui": "^1.5.0",
|
||||
"@vitejs/plugin-react-swc": "^3.7.1",
|
||||
"@vitest/coverage-v8": "^1.6.0",
|
||||
"@vitest/ui": "^1.6.0",
|
||||
"concurrently": "^8.2.2",
|
||||
"csstype": "^3.1.3",
|
||||
"dpdm": "^3.14.0",
|
||||
"eslint": "^8.57.0",
|
||||
"eslint-plugin-i18next": "^6.0.9",
|
||||
"eslint": "^8.57.1",
|
||||
"eslint-plugin-i18next": "^6.1.0",
|
||||
"eslint-plugin-path": "^1.3.0",
|
||||
"knip": "^5.27.2",
|
||||
"knip": "^5.31.0",
|
||||
"openapi-types": "^12.1.3",
|
||||
"openapi-typescript": "^7.3.0",
|
||||
"openapi-typescript": "^7.4.1",
|
||||
"prettier": "^3.3.3",
|
||||
"rollup-plugin-visualizer": "^5.12.0",
|
||||
"storybook": "^8.2.8",
|
||||
"ts-toolbelt": "^9.6.0",
|
||||
"tsafe": "^1.7.2",
|
||||
"typescript": "^5.5.4",
|
||||
"vite": "^5.4.0",
|
||||
"vite-plugin-css-injected-by-js": "^3.5.1",
|
||||
"storybook": "^8.3.4",
|
||||
"tsafe": "^1.7.5",
|
||||
"type-fest": "^4.26.1",
|
||||
"typescript": "^5.6.2",
|
||||
"vite": "^5.4.8",
|
||||
"vite-plugin-css-injected-by-js": "^3.5.2",
|
||||
"vite-plugin-dts": "^3.9.1",
|
||||
"vite-plugin-eslint": "^1.8.1",
|
||||
"vite-tsconfig-paths": "^4.3.2",
|
||||
|
||||
6059
invokeai/frontend/web/pnpm-lock.yaml
generated
6059
invokeai/frontend/web/pnpm-lock.yaml
generated
File diff suppressed because it is too large
Load Diff
@@ -5,7 +5,6 @@
|
||||
"reportBugLabel": "بلغ عن خطأ",
|
||||
"settingsLabel": "إعدادات",
|
||||
"img2img": "صورة إلى صورة",
|
||||
"unifiedCanvas": "لوحة موحدة",
|
||||
"nodes": "عقد",
|
||||
"upload": "رفع",
|
||||
"load": "تحميل",
|
||||
@@ -16,204 +15,8 @@
|
||||
"galleryImageSize": "حجم الصورة",
|
||||
"gallerySettings": "إعدادات المعرض",
|
||||
"autoSwitchNewImages": "التبديل التلقائي إلى الصور الجديدة",
|
||||
"loadMore": "تحميل المزيد",
|
||||
"noImagesInGallery": "لا توجد صور في المعرض"
|
||||
},
|
||||
"hotkeys": {
|
||||
"keyboardShortcuts": "مفاتيح الأزرار المختصرة",
|
||||
"appHotkeys": "مفاتيح التطبيق",
|
||||
"generalHotkeys": "مفاتيح عامة",
|
||||
"galleryHotkeys": "مفاتيح المعرض",
|
||||
"unifiedCanvasHotkeys": "مفاتيح اللوحةالموحدة ",
|
||||
"invoke": {
|
||||
"title": "أدعو",
|
||||
"desc": "إنشاء صورة"
|
||||
},
|
||||
"cancel": {
|
||||
"title": "إلغاء",
|
||||
"desc": "إلغاء إنشاء الصورة"
|
||||
},
|
||||
"focusPrompt": {
|
||||
"title": "تركيز الإشعار",
|
||||
"desc": "تركيز منطقة الإدخال الإشعار"
|
||||
},
|
||||
"toggleOptions": {
|
||||
"title": "تبديل الخيارات",
|
||||
"desc": "فتح وإغلاق لوحة الخيارات"
|
||||
},
|
||||
"pinOptions": {
|
||||
"title": "خيارات التثبيت",
|
||||
"desc": "ثبت لوحة الخيارات"
|
||||
},
|
||||
"toggleGallery": {
|
||||
"title": "تبديل المعرض",
|
||||
"desc": "فتح وإغلاق درابزين المعرض"
|
||||
},
|
||||
"maximizeWorkSpace": {
|
||||
"title": "تكبير مساحة العمل",
|
||||
"desc": "إغلاق اللوحات وتكبير مساحة العمل"
|
||||
},
|
||||
"changeTabs": {
|
||||
"title": "تغيير الألسنة",
|
||||
"desc": "التبديل إلى مساحة عمل أخرى"
|
||||
},
|
||||
"consoleToggle": {
|
||||
"title": "تبديل الطرفية",
|
||||
"desc": "فتح وإغلاق الطرفية"
|
||||
},
|
||||
"setPrompt": {
|
||||
"title": "ضبط التشعب",
|
||||
"desc": "استخدم تشعب الصورة الحالية"
|
||||
},
|
||||
"setSeed": {
|
||||
"title": "ضبط البذور",
|
||||
"desc": "استخدم بذور الصورة الحالية"
|
||||
},
|
||||
"setParameters": {
|
||||
"title": "ضبط المعلمات",
|
||||
"desc": "استخدم جميع المعلمات الخاصة بالصورة الحالية"
|
||||
},
|
||||
"restoreFaces": {
|
||||
"title": "استعادة الوجوه",
|
||||
"desc": "استعادة الصورة الحالية"
|
||||
},
|
||||
"showInfo": {
|
||||
"title": "عرض المعلومات",
|
||||
"desc": "عرض معلومات البيانات الخاصة بالصورة الحالية"
|
||||
},
|
||||
"sendToImageToImage": {
|
||||
"title": "أرسل إلى صورة إلى صورة",
|
||||
"desc": "أرسل الصورة الحالية إلى صورة إلى صورة"
|
||||
},
|
||||
"deleteImage": {
|
||||
"title": "حذف الصورة",
|
||||
"desc": "حذف الصورة الحالية"
|
||||
},
|
||||
"closePanels": {
|
||||
"title": "أغلق اللوحات",
|
||||
"desc": "يغلق اللوحات المفتوحة"
|
||||
},
|
||||
"previousImage": {
|
||||
"title": "الصورة السابقة",
|
||||
"desc": "عرض الصورة السابقة في الصالة"
|
||||
},
|
||||
"nextImage": {
|
||||
"title": "الصورة التالية",
|
||||
"desc": "عرض الصورة التالية في الصالة"
|
||||
},
|
||||
"increaseGalleryThumbSize": {
|
||||
"title": "زيادة حجم صورة الصالة",
|
||||
"desc": "يزيد حجم الصور المصغرة في الصالة"
|
||||
},
|
||||
"decreaseGalleryThumbSize": {
|
||||
"title": "انقاص حجم صورة الصالة",
|
||||
"desc": "ينقص حجم الصور المصغرة في الصالة"
|
||||
},
|
||||
"selectBrush": {
|
||||
"title": "تحديد الفرشاة",
|
||||
"desc": "يحدد الفرشاة على اللوحة"
|
||||
},
|
||||
"selectEraser": {
|
||||
"title": "تحديد الممحاة",
|
||||
"desc": "يحدد الممحاة على اللوحة"
|
||||
},
|
||||
"decreaseBrushSize": {
|
||||
"title": "تصغير حجم الفرشاة",
|
||||
"desc": "يصغر حجم الفرشاة/الممحاة على اللوحة"
|
||||
},
|
||||
"increaseBrushSize": {
|
||||
"title": "زيادة حجم الفرشاة",
|
||||
"desc": "يزيد حجم فرشة اللوحة / الممحاة"
|
||||
},
|
||||
"decreaseBrushOpacity": {
|
||||
"title": "تخفيض شفافية الفرشاة",
|
||||
"desc": "يخفض شفافية فرشة اللوحة"
|
||||
},
|
||||
"increaseBrushOpacity": {
|
||||
"title": "زيادة شفافية الفرشاة",
|
||||
"desc": "يزيد شفافية فرشة اللوحة"
|
||||
},
|
||||
"moveTool": {
|
||||
"title": "أداة التحريك",
|
||||
"desc": "يتيح التحرك في اللوحة"
|
||||
},
|
||||
"fillBoundingBox": {
|
||||
"title": "ملء الصندوق المحدد",
|
||||
"desc": "يملأ الصندوق المحدد بلون الفرشاة"
|
||||
},
|
||||
"eraseBoundingBox": {
|
||||
"title": "محو الصندوق المحدد",
|
||||
"desc": "يمحو منطقة الصندوق المحدد"
|
||||
},
|
||||
"colorPicker": {
|
||||
"title": "اختيار منتقي اللون",
|
||||
"desc": "يختار منتقي اللون الخاص باللوحة"
|
||||
},
|
||||
"toggleSnap": {
|
||||
"title": "تبديل التأكيد",
|
||||
"desc": "يبديل تأكيد الشبكة"
|
||||
},
|
||||
"quickToggleMove": {
|
||||
"title": "تبديل سريع للتحريك",
|
||||
"desc": "يبديل مؤقتا وضع التحريك"
|
||||
},
|
||||
"toggleLayer": {
|
||||
"title": "تبديل الطبقة",
|
||||
"desc": "يبديل إختيار الطبقة القناع / الأساسية"
|
||||
},
|
||||
"clearMask": {
|
||||
"title": "مسح القناع",
|
||||
"desc": "مسح القناع بأكمله"
|
||||
},
|
||||
"hideMask": {
|
||||
"title": "إخفاء الكمامة",
|
||||
"desc": "إخفاء وإظهار الكمامة"
|
||||
},
|
||||
"showHideBoundingBox": {
|
||||
"title": "إظهار / إخفاء علبة التحديد",
|
||||
"desc": "تبديل ظهور علبة التحديد"
|
||||
},
|
||||
"mergeVisible": {
|
||||
"title": "دمج الطبقات الظاهرة",
|
||||
"desc": "دمج جميع الطبقات الظاهرة في اللوحة"
|
||||
},
|
||||
"saveToGallery": {
|
||||
"title": "حفظ إلى صالة الأزياء",
|
||||
"desc": "حفظ اللوحة الحالية إلى صالة الأزياء"
|
||||
},
|
||||
"copyToClipboard": {
|
||||
"title": "نسخ إلى الحافظة",
|
||||
"desc": "نسخ اللوحة الحالية إلى الحافظة"
|
||||
},
|
||||
"downloadImage": {
|
||||
"title": "تنزيل الصورة",
|
||||
"desc": "تنزيل اللوحة الحالية"
|
||||
},
|
||||
"undoStroke": {
|
||||
"title": "تراجع عن الخط",
|
||||
"desc": "تراجع عن خط الفرشاة"
|
||||
},
|
||||
"redoStroke": {
|
||||
"title": "إعادة الخط",
|
||||
"desc": "إعادة خط الفرشاة"
|
||||
},
|
||||
"resetView": {
|
||||
"title": "إعادة تعيين العرض",
|
||||
"desc": "إعادة تعيين عرض اللوحة"
|
||||
},
|
||||
"previousStagingImage": {
|
||||
"title": "الصورة السابقة في المرحلة التجريبية",
|
||||
"desc": "الصورة السابقة في منطقة المرحلة التجريبية"
|
||||
},
|
||||
"nextStagingImage": {
|
||||
"title": "الصورة التالية في المرحلة التجريبية",
|
||||
"desc": "الصورة التالية في منطقة المرحلة التجريبية"
|
||||
},
|
||||
"acceptStagingImage": {
|
||||
"title": "قبول الصورة في المرحلة التجريبية",
|
||||
"desc": "قبول الصورة الحالية في منطقة المرحلة التجريبية"
|
||||
}
|
||||
},
|
||||
"modelManager": {
|
||||
"modelManager": "مدير النموذج",
|
||||
"model": "نموذج",
|
||||
@@ -258,8 +61,6 @@
|
||||
"scaledHeight": "الارتفاع المحجوب",
|
||||
"infillMethod": "طريقة التعبئة",
|
||||
"tileSize": "حجم البلاطة",
|
||||
"sendToImg2Img": "أرسل إلى صورة إلى صورة",
|
||||
"sendToUnifiedCanvas": "أرسل إلى الخطوط الموحدة",
|
||||
"copyImage": "نسخ الصورة",
|
||||
"downloadImage": "تحميل الصورة",
|
||||
"usePrompt": "استخدم المحث",
|
||||
@@ -272,7 +73,6 @@
|
||||
"models": "موديلات",
|
||||
"displayInProgress": "عرض الصور المؤرشفة",
|
||||
"confirmOnDelete": "تأكيد عند الحذف",
|
||||
"enableImageDebugging": "تمكين التصحيح عند التصوير",
|
||||
"resetWebUI": "إعادة تعيين واجهة الويب",
|
||||
"resetWebUIDesc1": "إعادة تعيين واجهة الويب يعيد فقط ذاكرة التخزين المؤقت للمتصفح لصورك وإعداداتك المذكورة. لا يحذف أي صور من القرص.",
|
||||
"resetWebUIDesc2": "إذا لم تظهر الصور في الصالة أو إذا كان شيء آخر غير ناجح، يرجى المحاولة إعادة تعيين قبل تقديم مشكلة على جيت هب.",
|
||||
@@ -281,71 +81,6 @@
|
||||
"toast": {
|
||||
"uploadFailed": "فشل التحميل",
|
||||
"imageCopied": "تم نسخ الصورة",
|
||||
"imageNotLoadedDesc": "لم يتم العثور على صورة لإرسالها إلى وحدة الصورة",
|
||||
"canvasMerged": "تم دمج الخط",
|
||||
"sentToImageToImage": "تم إرسال إلى صورة إلى صورة",
|
||||
"sentToUnifiedCanvas": "تم إرسال إلى لوحة موحدة",
|
||||
"parametersNotSet": "لم يتم تعيين المعلمات",
|
||||
"metadataLoadFailed": "فشل تحميل البيانات الوصفية"
|
||||
},
|
||||
"tooltip": {
|
||||
"feature": {
|
||||
"prompt": "هذا هو حقل التحذير. يشمل التحذير عناصر الإنتاج والمصطلحات الأسلوبية. يمكنك إضافة الأوزان (أهمية الرمز) في التحذير أيضًا، ولكن أوامر CLI والمعلمات لن تعمل.",
|
||||
"gallery": "تعرض Gallery منتجات من مجلد الإخراج عندما يتم إنشاؤها. تخزن الإعدادات داخل الملفات ويتم الوصول إليها عن طريق قائمة السياق.",
|
||||
"other": "ستمكن هذه الخيارات من وضع عمليات معالجة بديلة لـاستحضر الذكاء الصناعي. سيؤدي 'الزخرفة بلا جدران' إلى إنشاء أنماط تكرارية في الإخراج. 'دقة عالية' هي الإنتاج خلال خطوتين عبر صورة إلى صورة: استخدم هذا الإعداد عندما ترغب في توليد صورة أكبر وأكثر تجانبًا دون العيوب. ستستغرق الأشياء وقتًا أطول من نص إلى صورة المعتاد.",
|
||||
"seed": "يؤثر قيمة البذور على الضوضاء الأولي الذي يتم تكوين الصورة منه. يمكنك استخدام البذور الخاصة بالصور السابقة. 'عتبة الضوضاء' يتم استخدامها لتخفيف العناصر الخللية في قيم CFG العالية (جرب مدى 0-10), و Perlin لإضافة ضوضاء Perlin أثناء الإنتاج: كلا منهما يعملان على إضافة التنوع إلى النتائج الخاصة بك.",
|
||||
"upscale": "استخدم إي إس آر جان لتكبير الصورة على الفور بعد الإنتاج.",
|
||||
"boundingBox": "مربع الحدود هو نفس الإعدادات العرض والارتفاع لنص إلى صورة أو صورة إلى صورة. فقط المنطقة في المربع سيتم معالجتها."
|
||||
}
|
||||
},
|
||||
"unifiedCanvas": {
|
||||
"layer": "طبقة",
|
||||
"base": "قاعدة",
|
||||
"mask": "قناع",
|
||||
"maskingOptions": "خيارات القناع",
|
||||
"enableMask": "مكن القناع",
|
||||
"preserveMaskedArea": "الحفاظ على المنطقة المقنعة",
|
||||
"clearMask": "مسح القناع",
|
||||
"brush": "فرشاة",
|
||||
"eraser": "ممحاة",
|
||||
"fillBoundingBox": "ملئ إطار الحدود",
|
||||
"eraseBoundingBox": "مسح إطار الحدود",
|
||||
"colorPicker": "اختيار اللون",
|
||||
"brushOptions": "خيارات الفرشاة",
|
||||
"brushSize": "الحجم",
|
||||
"move": "تحريك",
|
||||
"resetView": "إعادة تعيين العرض",
|
||||
"mergeVisible": "دمج الظاهر",
|
||||
"saveToGallery": "حفظ إلى المعرض",
|
||||
"copyToClipboard": "نسخ إلى الحافظة",
|
||||
"downloadAsImage": "تنزيل على شكل صورة",
|
||||
"undo": "تراجع",
|
||||
"redo": "إعادة",
|
||||
"clearCanvas": "مسح سبيكة الكاملة",
|
||||
"canvasSettings": "إعدادات سبيكة الكاملة",
|
||||
"showIntermediates": "إظهار الوسطاء",
|
||||
"showGrid": "إظهار الشبكة",
|
||||
"snapToGrid": "الالتفاف إلى الشبكة",
|
||||
"darkenOutsideSelection": "تعمية خارج التحديد",
|
||||
"autoSaveToGallery": "حفظ تلقائي إلى المعرض",
|
||||
"saveBoxRegionOnly": "حفظ منطقة الصندوق فقط",
|
||||
"limitStrokesToBox": "تحديد عدد الخطوط إلى الصندوق",
|
||||
"showCanvasDebugInfo": "إظهار معلومات تصحيح سبيكة الكاملة",
|
||||
"clearCanvasHistory": "مسح تاريخ سبيكة الكاملة",
|
||||
"clearHistory": "مسح التاريخ",
|
||||
"clearCanvasHistoryMessage": "مسح تاريخ اللوحة تترك اللوحة الحالية عائمة، ولكن تمسح بشكل غير قابل للتراجع تاريخ التراجع والإعادة.",
|
||||
"clearCanvasHistoryConfirm": "هل أنت متأكد من رغبتك في مسح تاريخ اللوحة؟",
|
||||
"activeLayer": "الطبقة النشطة",
|
||||
"canvasScale": "مقياس اللوحة",
|
||||
"boundingBox": "صندوق الحدود",
|
||||
"scaledBoundingBox": "صندوق الحدود المكبر",
|
||||
"boundingBoxPosition": "موضع صندوق الحدود",
|
||||
"canvasDimensions": "أبعاد اللوحة",
|
||||
"canvasPosition": "موضع اللوحة",
|
||||
"cursorPosition": "موضع المؤشر",
|
||||
"previous": "السابق",
|
||||
"next": "التالي",
|
||||
"accept": "قبول",
|
||||
"discardAll": "تجاهل الكل"
|
||||
"parametersNotSet": "لم يتم تعيين المعلمات"
|
||||
}
|
||||
}
|
||||
|
||||
File diff suppressed because it is too large
Load Diff
@@ -10,10 +10,10 @@
|
||||
"previousImage": "Previous Image",
|
||||
"reset": "Reset",
|
||||
"resetUI": "$t(accessibility.reset) UI",
|
||||
"showGalleryPanel": "Show Gallery Panel",
|
||||
"showOptionsPanel": "Show Side Panel",
|
||||
"toggleRightPanel": "Toggle Right Panel (G)",
|
||||
"toggleLeftPanel": "Toggle Left Panel (T)",
|
||||
"uploadImage": "Upload Image",
|
||||
"loadMore": "Load More"
|
||||
"uploadImages": "Upload Image(s)"
|
||||
},
|
||||
"boards": {
|
||||
"addBoard": "Add Board",
|
||||
@@ -54,7 +54,8 @@
|
||||
"imagesWithCount_one": "{{count}} image",
|
||||
"imagesWithCount_other": "{{count}} images",
|
||||
"assetsWithCount_one": "{{count}} asset",
|
||||
"assetsWithCount_other": "{{count}} assets"
|
||||
"assetsWithCount_other": "{{count}} assets",
|
||||
"updateBoardError": "Error updating board"
|
||||
},
|
||||
"accordions": {
|
||||
"generation": {
|
||||
@@ -90,11 +91,14 @@
|
||||
"batch": "Batch Manager",
|
||||
"beta": "Beta",
|
||||
"cancel": "Cancel",
|
||||
"close": "Close",
|
||||
"copy": "Copy",
|
||||
"copyError": "$t(gallery.copy) Error",
|
||||
"clipboard": "Clipboard",
|
||||
"on": "On",
|
||||
"off": "Off",
|
||||
"or": "or",
|
||||
"ok": "Ok",
|
||||
"checkpoint": "Checkpoint",
|
||||
"communityLabel": "Community",
|
||||
"controlNet": "ControlNet",
|
||||
@@ -128,10 +132,8 @@
|
||||
"load": "Load",
|
||||
"loading": "Loading",
|
||||
"localSystem": "Local System",
|
||||
"loglevel": "Log Level",
|
||||
"learnMore": "Learn More",
|
||||
"modelManager": "Model Manager",
|
||||
"nodeEditor": "Node Editor",
|
||||
"nodes": "Workflows",
|
||||
"notInstalled": "Not $t(common.installed)",
|
||||
"openInNewTab": "Open in New Tab",
|
||||
@@ -152,7 +154,6 @@
|
||||
"template": "Template",
|
||||
"toResolve": "To resolve",
|
||||
"txt2img": "Text To Image",
|
||||
"unifiedCanvas": "Unified Canvas",
|
||||
"unknown": "Unknown",
|
||||
"upload": "Upload",
|
||||
"updated": "Updated",
|
||||
@@ -167,11 +168,7 @@
|
||||
"selected": "Selected",
|
||||
"tab": "Tab",
|
||||
"view": "View",
|
||||
"viewDesc": "Review images in a large gallery view",
|
||||
"edit": "Edit",
|
||||
"editDesc": "Edit on the Canvas",
|
||||
"comparing": "Comparing",
|
||||
"comparingDesc": "Comparing two images",
|
||||
"enabled": "Enabled",
|
||||
"disabled": "Disabled",
|
||||
"placeholderSelectAModel": "Select a model",
|
||||
@@ -287,8 +284,10 @@
|
||||
"gallery": "Gallery",
|
||||
"alwaysShowImageSizeBadge": "Always Show Image Size Badge",
|
||||
"assets": "Assets",
|
||||
"assetsTab": "Files you’ve uploaded for use in your projects.",
|
||||
"autoAssignBoardOnClick": "Auto-Assign Board on Click",
|
||||
"autoSwitchNewImages": "Auto-Switch to New Images",
|
||||
"boardsSettings": "Boards Settings",
|
||||
"copy": "Copy",
|
||||
"currentlyInUse": "This image is currently in use in the following features:",
|
||||
"drop": "Drop",
|
||||
@@ -307,16 +306,16 @@
|
||||
"gallerySettings": "Gallery Settings",
|
||||
"go": "Go",
|
||||
"image": "image",
|
||||
"imagesTab": "Images you’ve created and saved within Invoke.",
|
||||
"imagesSettings": "Gallery Images Settings",
|
||||
"jump": "Jump",
|
||||
"loading": "Loading",
|
||||
"loadMore": "Load More",
|
||||
"newestFirst": "Newest First",
|
||||
"oldestFirst": "Oldest First",
|
||||
"sortDirection": "Sort Direction",
|
||||
"showStarredImagesFirst": "Show Starred Images First",
|
||||
"noImageSelected": "No Image Selected",
|
||||
"noImagesInGallery": "No Images to Display",
|
||||
"setCurrentImage": "Set as Current Image",
|
||||
"starImage": "Star Image",
|
||||
"unstarImage": "Unstar Image",
|
||||
"unableToLoad": "Unable to load Gallery",
|
||||
@@ -326,14 +325,11 @@
|
||||
"bulkDownloadRequestedDesc": "Your download request is being prepared. This may take a few moments.",
|
||||
"bulkDownloadRequestFailed": "Problem Preparing Download",
|
||||
"bulkDownloadFailed": "Download Failed",
|
||||
"problemDeletingImages": "Problem Deleting Images",
|
||||
"problemDeletingImagesDesc": "One or more images could not be deleted",
|
||||
"viewerImage": "Viewer Image",
|
||||
"compareImage": "Compare Image",
|
||||
"openInViewer": "Open in Viewer",
|
||||
"searchImages": "Search by Metadata",
|
||||
"selectAllOnPage": "Select All On Page",
|
||||
"selectAllOnBoard": "Select All On Board",
|
||||
"showArchivedBoards": "Show Archived Boards",
|
||||
"selectForCompare": "Select for Compare",
|
||||
"selectAnImageToCompare": "Select an Image to Compare",
|
||||
@@ -341,16 +337,15 @@
|
||||
"sideBySide": "Side-by-Side",
|
||||
"hover": "Hover",
|
||||
"swapImages": "Swap Images",
|
||||
"compareOptions": "Comparison Options",
|
||||
"stretchToFit": "Stretch to Fit",
|
||||
"exitCompare": "Exit Compare",
|
||||
"compareHelp1": "Hold <Kbd>Alt</Kbd> while clicking a gallery image or using the arrow keys to change the compare image.",
|
||||
"compareHelp2": "Press <Kbd>M</Kbd> to cycle through comparison modes.",
|
||||
"compareHelp3": "Press <Kbd>C</Kbd> to swap the compared images.",
|
||||
"compareHelp4": "Press <Kbd>Z</Kbd> or <Kbd>Esc</Kbd> to exit.",
|
||||
"toggleMiniViewer": "Toggle Mini Viewer",
|
||||
"openViewer": "Open Viewer",
|
||||
"closeViewer": "Close Viewer"
|
||||
"closeViewer": "Close Viewer",
|
||||
"move": "Move"
|
||||
},
|
||||
"hotkeys": {
|
||||
"hotkeys": "Hotkeys",
|
||||
@@ -517,6 +512,22 @@
|
||||
"transformSelected": {
|
||||
"title": "Transform",
|
||||
"desc": "Transform the selected layer."
|
||||
},
|
||||
"applyFilter": {
|
||||
"title": "Apply Filter",
|
||||
"desc": "Apply the pending filter to the selected layer."
|
||||
},
|
||||
"cancelFilter": {
|
||||
"title": "Cancel Filter",
|
||||
"desc": "Cancel the pending filter."
|
||||
},
|
||||
"applyTransform": {
|
||||
"title": "Apply Transform",
|
||||
"desc": "Apply the pending transform to the selected layer."
|
||||
},
|
||||
"cancelTransform": {
|
||||
"title": "Cancel Transform",
|
||||
"desc": "Cancel the pending transform."
|
||||
}
|
||||
},
|
||||
"workflows": {
|
||||
@@ -654,12 +665,11 @@
|
||||
"cfgScale": "CFG scale",
|
||||
"cfgRescaleMultiplier": "$t(parameters.cfgRescaleMultiplier)",
|
||||
"createdBy": "Created By",
|
||||
"fit": "Image to image fit",
|
||||
"generationMode": "Generation Mode",
|
||||
"guidance": "Guidance",
|
||||
"height": "Height",
|
||||
"imageDetails": "Image Details",
|
||||
"imageDimensions": "Image Dimensions",
|
||||
"initImage": "Initial image",
|
||||
"metadata": "Metadata",
|
||||
"model": "Model",
|
||||
"negativePrompt": "Negative Prompt",
|
||||
@@ -679,7 +689,8 @@
|
||||
"Threshold": "Noise Threshold",
|
||||
"vae": "VAE",
|
||||
"width": "Width",
|
||||
"workflow": "Workflow"
|
||||
"workflow": "Workflow",
|
||||
"canvasV2Metadata": "Canvas"
|
||||
},
|
||||
"modelManager": {
|
||||
"active": "active",
|
||||
@@ -692,19 +703,22 @@
|
||||
"baseModel": "Base Model",
|
||||
"cancel": "Cancel",
|
||||
"clipEmbed": "CLIP Embed",
|
||||
"clipVision": "CLIP Vision",
|
||||
"config": "Config",
|
||||
"convert": "Convert",
|
||||
"convertingModelBegin": "Converting Model. Please wait.",
|
||||
"convertToDiffusers": "Convert To Diffusers",
|
||||
"convertToDiffusersHelpText1": "This model will be converted to the \ud83e\udde8 Diffusers format.",
|
||||
"convertToDiffusersHelpText1": "This model will be converted to the 🧨 Diffusers format.",
|
||||
"convertToDiffusersHelpText2": "This process will replace your Model Manager entry with the Diffusers version of the same model.",
|
||||
"convertToDiffusersHelpText3": "Your checkpoint file on disk WILL be deleted if it is in InvokeAI root folder. If it is in a custom location, then it WILL NOT be deleted.",
|
||||
"convertToDiffusersHelpText4": "This is a one time process only. It might take around 30s-60s depending on the specifications of your computer.",
|
||||
"convertToDiffusersHelpText5": "Please make sure you have enough disk space. Models generally vary between 2GB-7GB in size.",
|
||||
"convertToDiffusersHelpText6": "Do you wish to convert this model?",
|
||||
"noDefaultSettings": "No default settings configured for this model. Visit the Model Manager to add default settings.",
|
||||
"defaultSettings": "Default Settings",
|
||||
"defaultSettingsSaved": "Default Settings Saved",
|
||||
"defaultSettingsOutOfSync": "Some settings do not match the model's defaults:",
|
||||
"restoreDefaultSettings": "Click to use the model's default settings.",
|
||||
"usingDefaultSettings": "Using model's default settings",
|
||||
"delete": "Delete",
|
||||
"deleteConfig": "Delete Config",
|
||||
"deleteModel": "Delete Model",
|
||||
@@ -719,14 +733,8 @@
|
||||
"huggingFaceRepoID": "HuggingFace Repo ID",
|
||||
"huggingFaceHelper": "If multiple models are found in this repo, you will be prompted to select one to install.",
|
||||
"hfToken": "HuggingFace Token",
|
||||
"hfTokenHelperText": "A HF token is required to use checkpoint models. Click here to create or get your token.",
|
||||
"hfTokenInvalid": "Invalid or Missing HF Token",
|
||||
"hfTokenInvalidErrorMessage": "Invalid or missing HuggingFace token.",
|
||||
"hfTokenInvalidErrorMessage2": "Update it in the ",
|
||||
"hfTokenUnableToVerify": "Unable to Verify HF Token",
|
||||
"hfTokenUnableToVerifyErrorMessage": "Unable to verify HuggingFace token. This is likely due to a network error. Please try again later.",
|
||||
"hfTokenSaved": "HF Token Saved",
|
||||
"imageEncoderModelId": "Image Encoder Model ID",
|
||||
"includesNModels": "Includes {{n}} models and their dependencies",
|
||||
"installQueue": "Install Queue",
|
||||
"inplaceInstall": "In-place install",
|
||||
"inplaceInstallDesc": "Install models without copying the files. When using the model, it will be loaded from its this location. If disabled, the model file(s) will be copied into the Invoke-managed models directory during installation.",
|
||||
@@ -734,6 +742,7 @@
|
||||
"installAll": "Install All",
|
||||
"installRepo": "Install Repo",
|
||||
"ipAdapters": "IP Adapters",
|
||||
"learnMoreAboutSupportedModels": "Learn more about the models we support",
|
||||
"load": "Load",
|
||||
"localOnly": "local only",
|
||||
"manual": "Manual",
|
||||
@@ -752,8 +761,6 @@
|
||||
"modelManager": "Model Manager",
|
||||
"modelName": "Model Name",
|
||||
"modelSettings": "Model Settings",
|
||||
"modelsSynced": "Models Synced",
|
||||
"modelSyncFailed": "Model Sync Failed",
|
||||
"modelType": "Model Type",
|
||||
"modelUpdated": "Model Updated",
|
||||
"modelUpdateFailed": "Model Update Failed",
|
||||
@@ -781,6 +788,8 @@
|
||||
"simpleModelPlaceholder": "URL or path to a local file or diffusers folder",
|
||||
"source": "Source",
|
||||
"spandrelImageToImage": "Image to Image (Spandrel)",
|
||||
"starterBundles": "Starter Bundles",
|
||||
"starterBundleHelpText": "Easily install all models needed to get started with a base model, including a main model, controlnets, IP adapters, and more. Selecting a bundle will skip any models that you already have installed.",
|
||||
"starterModels": "Starter Models",
|
||||
"starterModelsInModelManager": "Starter Models can be found in Model Manager",
|
||||
"syncModels": "Sync Models",
|
||||
@@ -794,18 +803,20 @@
|
||||
"uploadImage": "Upload Image",
|
||||
"urlOrLocalPath": "URL or Local Path",
|
||||
"urlOrLocalPathHelper": "URLs should point to a single file. Local paths can point to a single file or folder for a single diffusers model.",
|
||||
"useDefaultSettings": "Use Default Settings",
|
||||
"v2_768": "v2 (768px)",
|
||||
"v2_base": "v2 (512px)",
|
||||
"vae": "VAE",
|
||||
"vaePrecision": "VAE Precision",
|
||||
"variant": "Variant",
|
||||
"width": "Width"
|
||||
"width": "Width",
|
||||
"installingBundle": "Installing Bundle",
|
||||
"installingModel": "Installing Model",
|
||||
"installingXModels_one": "Installing {{count}} model",
|
||||
"installingXModels_other": "Installing {{count}} models",
|
||||
"skippingXDuplicates_one": ", skipping {{count}} duplicate",
|
||||
"skippingXDuplicates_other": ", skipping {{count}} duplicates"
|
||||
},
|
||||
"models": {
|
||||
"addLora": "Add LoRA",
|
||||
"concepts": "Concepts",
|
||||
"esrganModel": "ESRGAN Model",
|
||||
"loading": "loading",
|
||||
"noMatchingLoRAs": "No matching LoRAs",
|
||||
"noMatchingModels": "No matching Models",
|
||||
@@ -863,6 +874,8 @@
|
||||
"ipAdapter": "IP-Adapter",
|
||||
"loadingNodes": "Loading Nodes...",
|
||||
"loadWorkflow": "Load Workflow",
|
||||
"noWorkflows": "No Workflows",
|
||||
"noMatchingWorkflows": "No Matching Workflows",
|
||||
"noWorkflow": "No Workflow",
|
||||
"mismatchedVersion": "Invalid node: node {{node}} of type {{type}} has mismatched version (try updating?)",
|
||||
"missingTemplate": "Invalid node: node {{node}} of type {{type}} missing template (not installed?)",
|
||||
@@ -871,7 +884,6 @@
|
||||
"sourceNodeFieldDoesNotExist": "Invalid edge: source/output field {{node}}.{{field}} does not exist",
|
||||
"targetNodeFieldDoesNotExist": "Invalid edge: target/input field {{node}}.{{field}} does not exist",
|
||||
"deletedInvalidEdge": "Deleted invalid edge {{source}} -> {{target}}",
|
||||
"noConnectionData": "No connection data",
|
||||
"noConnectionInProgress": "No connection in progress",
|
||||
"node": "Node",
|
||||
"nodeOutputs": "Node Outputs",
|
||||
@@ -880,8 +892,7 @@
|
||||
"nodeType": "Node Type",
|
||||
"noFieldsLinearview": "No fields added to Linear View",
|
||||
"noFieldsViewMode": "This workflow has no selected fields to display. View the full workflow to configure values.",
|
||||
"noFieldType": "No field type",
|
||||
"noMatchingNodes": "No matching nodes",
|
||||
"workflowHelpText": "Need Help? Check out our guide to <LinkComponent>Getting Started with Workflows</LinkComponent>.",
|
||||
"noNodeSelected": "No node selected",
|
||||
"nodeOpacity": "Node Opacity",
|
||||
"nodeVersion": "Node Version",
|
||||
@@ -951,7 +962,6 @@
|
||||
"zoomOutNodes": "Zoom Out",
|
||||
"betaDesc": "This invocation is in beta. Until it is stable, it may have breaking changes during app updates. We plan to support this invocation long-term.",
|
||||
"prototypeDesc": "This invocation is a prototype. It may have breaking changes during app updates and may be removed at any time.",
|
||||
"internalDesc": "This invocation is used internally by Invoke. It may have breaking changes during app updates and may be removed at any time.",
|
||||
"imageAccessError": "Unable to find image {{image_name}}, resetting to default",
|
||||
"boardAccessError": "Unable to find board {{board_id}}, resetting to default",
|
||||
"modelAccessError": "Unable to find model {{key}}, resetting to default",
|
||||
@@ -978,16 +988,11 @@
|
||||
"denoisingStrength": "Denoising Strength",
|
||||
"downloadImage": "Download Image",
|
||||
"general": "General",
|
||||
"globalSettings": "Global Settings",
|
||||
"guidance": "Guidance",
|
||||
"height": "Height",
|
||||
"imageFit": "Fit Initial Image To Output Size",
|
||||
"images": "Images",
|
||||
"infillMethod": "Infill Method",
|
||||
"infillMosaicTileWidth": "Tile Width",
|
||||
"infillMosaicTileHeight": "Tile Height",
|
||||
"infillMosaicMinColor": "Min Color",
|
||||
"infillMosaicMaxColor": "Max Color",
|
||||
"infillColorValue": "Fill Color",
|
||||
"info": "Info",
|
||||
"invoke": {
|
||||
@@ -996,21 +1001,14 @@
|
||||
"missingFieldTemplate": "Missing field template",
|
||||
"missingInputForField": "{{nodeLabel}} -> {{fieldLabel}} missing input",
|
||||
"missingNodeTemplate": "Missing node template",
|
||||
"noControlImageForControlAdapter": "Control Adapter #{{number}} has no control image",
|
||||
"imageNotProcessedForControlAdapter": "Control Adapter #{{number}}'s image is not processed",
|
||||
"noInitialImageSelected": "No initial image selected",
|
||||
"noModelForControlAdapter": "Control Adapter #{{number}} has no model selected.",
|
||||
"incompatibleBaseModelForControlAdapter": "Control Adapter #{{number}} model is incompatible with main model.",
|
||||
"noModelSelected": "No model selected",
|
||||
"noT5EncoderModelSelected": "No T5 Encoder model selected for FLUX generation",
|
||||
"noFLUXVAEModelSelected": "No VAE model selected for FLUX generation",
|
||||
"noCLIPEmbedModelSelected": "No CLIP Embed model selected for FLUX generation",
|
||||
"canvasManagerNotLoaded": "Canvas Manager not loaded",
|
||||
"fluxRequiresDimensionsToBeMultipleOf16": "FLUX requires width/height to be multiple of 16",
|
||||
"fluxModelIncompatibleBboxWidth": "$t(parameters.invoke.fluxRequiresDimensionsToBeMultipleOf16), bbox width is {{width}}",
|
||||
"fluxModelIncompatibleBboxHeight": "$t(parameters.invoke.fluxRequiresDimensionsToBeMultipleOf16), bbox height is {{height}}",
|
||||
"fluxModelIncompatibleScaledWidth": "$t(parameters.invoke.fluxRequiresDimensionsToBeMultipleOf16), scaled bbox width is {{width}}",
|
||||
"fluxModelIncompatibleScaledHeight": "$t(parameters.invoke.fluxRequiresDimensionsToBeMultipleOf16), scaled bbox height is {{height}}",
|
||||
"fluxModelIncompatibleScaledBboxWidth": "$t(parameters.invoke.fluxRequiresDimensionsToBeMultipleOf16), scaled bbox width is {{width}}",
|
||||
"fluxModelIncompatibleScaledBboxHeight": "$t(parameters.invoke.fluxRequiresDimensionsToBeMultipleOf16), scaled bbox height is {{height}}",
|
||||
"canvasIsFiltering": "Canvas is filtering",
|
||||
"canvasIsTransforming": "Canvas is transforming",
|
||||
"canvasIsRasterizing": "Canvas is rasterizing",
|
||||
@@ -1019,12 +1017,8 @@
|
||||
"noNodesInGraph": "No nodes in graph",
|
||||
"systemDisconnected": "System disconnected",
|
||||
"layer": {
|
||||
"initialImageNoImageSelected": "no initial image selected",
|
||||
"controlAdapterNoModelSelected": "no Control Adapter model selected",
|
||||
"controlAdapterIncompatibleBaseModel": "incompatible Control Adapter base model",
|
||||
"controlAdapterNoImageSelected": "no Control Adapter image selected",
|
||||
"controlAdapterImageNotProcessed": "Control Adapter image not processed",
|
||||
"t2iAdapterRequiresDimensionsToBeMultipleOf": "T2I Adapter requires width/height to be multiple of",
|
||||
"t2iAdapterIncompatibleBboxWidth": "$t(parameters.invoke.layer.t2iAdapterRequiresDimensionsToBeMultipleOf) {{multiple}}, bbox width is {{width}}",
|
||||
"t2iAdapterIncompatibleBboxHeight": "$t(parameters.invoke.layer.t2iAdapterRequiresDimensionsToBeMultipleOf) {{multiple}}, bbox height is {{height}}",
|
||||
"t2iAdapterIncompatibleScaledBboxWidth": "$t(parameters.invoke.layer.t2iAdapterRequiresDimensionsToBeMultipleOf) {{multiple}}, scaled bbox width is {{width}}",
|
||||
@@ -1038,12 +1032,10 @@
|
||||
},
|
||||
"maskBlur": "Mask Blur",
|
||||
"negativePromptPlaceholder": "Negative Prompt",
|
||||
"globalNegativePromptPlaceholder": "Global Negative Prompt",
|
||||
"noiseThreshold": "Noise Threshold",
|
||||
"patchmatchDownScaleSize": "Downscale",
|
||||
"perlinNoise": "Perlin Noise",
|
||||
"positivePromptPlaceholder": "Positive Prompt",
|
||||
"globalPositivePromptPlaceholder": "Global Positive Prompt",
|
||||
"iterations": "Iterations",
|
||||
"scale": "Scale",
|
||||
"scaleBeforeProcessing": "Scale Before Processing",
|
||||
@@ -1062,7 +1054,7 @@
|
||||
"strength": "Strength",
|
||||
"symmetry": "Symmetry",
|
||||
"tileSize": "Tile Size",
|
||||
"optimizedInpainting": "Optimized Inpainting",
|
||||
"optimizedImageToImage": "Optimized Image-to-Image",
|
||||
"type": "Type",
|
||||
"postProcessing": "Post-Processing (Shift + U)",
|
||||
"processImage": "Process Image",
|
||||
@@ -1073,15 +1065,16 @@
|
||||
"remixImage": "Remix Image",
|
||||
"usePrompt": "Use Prompt",
|
||||
"useSeed": "Use Seed",
|
||||
"width": "Width"
|
||||
"width": "Width",
|
||||
"gaussianBlur": "Gaussian Blur",
|
||||
"boxBlur": "Box Blur",
|
||||
"staged": "Staged"
|
||||
},
|
||||
"dynamicPrompts": {
|
||||
"showDynamicPrompts": "Show Dynamic Prompts",
|
||||
"dynamicPrompts": "Dynamic Prompts",
|
||||
"maxPrompts": "Max Prompts",
|
||||
"promptsPreview": "Prompts Preview",
|
||||
"promptsWithCount_one": "{{count}} Prompt",
|
||||
"promptsWithCount_other": "{{count}} Prompts",
|
||||
"seedBehaviour": {
|
||||
"label": "Seed Behaviour",
|
||||
"perIterationLabel": "Seed per Iteration",
|
||||
@@ -1113,11 +1106,15 @@
|
||||
"antialiasProgressImages": "Antialias Progress Images",
|
||||
"beta": "Beta",
|
||||
"confirmOnDelete": "Confirm On Delete",
|
||||
"confirmOnNewSession": "Confirm On New Session",
|
||||
"developer": "Developer",
|
||||
"displayInProgress": "Display Progress Images",
|
||||
"enableInformationalPopovers": "Enable Informational Popovers",
|
||||
"informationalPopoversDisabled": "Informational Popovers Disabled",
|
||||
"informationalPopoversDisabledDesc": "Informational popovers have been disabled. Enable them in Settings.",
|
||||
"enableModelDescriptions": "Enable Model Descriptions in Dropdowns",
|
||||
"modelDescriptionsDisabled": "Model Descriptions in Dropdowns Disabled",
|
||||
"modelDescriptionsDisabledDesc": "Model descriptions in dropdowns have been disabled. Enable them in Settings.",
|
||||
"enableInvisibleWatermark": "Enable Invisible Watermark",
|
||||
"enableNSFWChecker": "Enable NSFW Checker",
|
||||
"general": "General",
|
||||
@@ -1127,7 +1124,6 @@
|
||||
"resetWebUI": "Reset Web UI",
|
||||
"resetWebUIDesc1": "Resetting the web UI only resets the browser's local cache of your images and remembered settings. It does not delete any images from disk.",
|
||||
"resetWebUIDesc2": "If images aren't showing up in the gallery or something else isn't working, please try resetting before submitting an issue on GitHub.",
|
||||
"shouldLogToConsole": "Console Logging",
|
||||
"showProgressInViewer": "Show Progress Images in Viewer",
|
||||
"ui": "User Interface",
|
||||
"clearIntermediatesDisabled": "Queue must be empty to clear intermediates",
|
||||
@@ -1143,18 +1139,19 @@
|
||||
"reloadingIn": "Reloading in"
|
||||
},
|
||||
"toast": {
|
||||
"addedToBoard": "Added to board",
|
||||
"addedToBoard": "Added to board {{name}}'s assets",
|
||||
"addedToUncategorized": "Added to board $t(boards.uncategorized)'s assets",
|
||||
"baseModelChanged": "Base Model Changed",
|
||||
"baseModelChangedCleared_one": "Cleared or disabled {{count}} incompatible submodel",
|
||||
"baseModelChangedCleared_other": "Cleared or disabled {{count}} incompatible submodels",
|
||||
"canceled": "Processing Canceled",
|
||||
"canvasCopiedClipboard": "Canvas Copied to Clipboard",
|
||||
"canvasDownloaded": "Canvas Downloaded",
|
||||
"canvasMerged": "Canvas Merged",
|
||||
"canvasSavedGallery": "Canvas Saved to Gallery",
|
||||
"canvasSentControlnetAssets": "Canvas Sent to ControlNet & Assets",
|
||||
"connected": "Connected to Server",
|
||||
"imageCopied": "Image Copied",
|
||||
"linkCopied": "Link Copied",
|
||||
"unableToLoadImage": "Unable to Load Image",
|
||||
"unableToLoadImageMetadata": "Unable to Load Image Metadata",
|
||||
"unableToLoadStylePreset": "Unable to Load Style Preset",
|
||||
"stylePresetLoaded": "Style Preset Loaded",
|
||||
"imageNotLoadedDesc": "Could not find image",
|
||||
"imageSaved": "Image Saved",
|
||||
"imageSavingFailed": "Image Saving Failed",
|
||||
@@ -1166,9 +1163,6 @@
|
||||
"layerCopiedToClipboard": "Layer Copied to Clipboard",
|
||||
"layerSavedToAssets": "Layer Saved to Assets",
|
||||
"loadedWithWarnings": "Workflow Loaded with Warnings",
|
||||
"maskSavedAssets": "Mask Saved to Assets",
|
||||
"maskSentControlnetAssets": "Mask Sent to ControlNet & Assets",
|
||||
"metadataLoadFailed": "Failed to load metadata",
|
||||
"modelAddedSimple": "Model Added to Queue",
|
||||
"modelImportCanceled": "Model Import Canceled",
|
||||
"outOfMemoryError": "Out of Memory Error",
|
||||
@@ -1182,52 +1176,28 @@
|
||||
"parametersSet": "Parameters Recalled",
|
||||
"parametersNotSet": "Parameters Not Recalled",
|
||||
"errorCopied": "Error Copied",
|
||||
"problemCopyingCanvas": "Problem Copying Canvas",
|
||||
"problemCopyingCanvasDesc": "Unable to export base layer",
|
||||
"problemCopyingImage": "Unable to Copy Image",
|
||||
"problemCopyingLayer": "Unable to Copy Layer",
|
||||
"problemSavingLayer": "Unable to Save Layer",
|
||||
"problemDownloadingImage": "Unable to Download Image",
|
||||
"problemDownloadingCanvas": "Problem Downloading Canvas",
|
||||
"problemDownloadingCanvasDesc": "Unable to export base layer",
|
||||
"problemImportingMask": "Problem Importing Mask",
|
||||
"problemImportingMaskDesc": "Unable to export mask",
|
||||
"problemMergingCanvas": "Problem Merging Canvas",
|
||||
"problemMergingCanvasDesc": "Unable to export base layer",
|
||||
"problemSavingCanvas": "Problem Saving Canvas",
|
||||
"problemSavingCanvasDesc": "Unable to export base layer",
|
||||
"problemSavingMask": "Problem Saving Mask",
|
||||
"problemSavingMaskDesc": "Unable to export mask",
|
||||
"prunedQueue": "Pruned Queue",
|
||||
"resetInitialImage": "Reset Initial Image",
|
||||
"sentToCanvas": "Sent to Canvas",
|
||||
"sentToUpscale": "Sent to Upscale",
|
||||
"serverError": "Server Error",
|
||||
"sessionRef": "Session: {{sessionId}}",
|
||||
"setAsCanvasInitialImage": "Set as canvas initial image",
|
||||
"setCanvasInitialImage": "Set canvas initial image",
|
||||
"setControlImage": "Set as control image",
|
||||
"setInitialImage": "Set as initial image",
|
||||
"setNodeField": "Set as node field",
|
||||
"somethingWentWrong": "Something Went Wrong",
|
||||
"uploadFailed": "Upload failed",
|
||||
"uploadFailedInvalidUploadDesc": "Must be single PNG or JPEG image",
|
||||
"uploadInitialImage": "Upload Initial Image",
|
||||
"imagesWillBeAddedTo": "Uploaded images will be added to board {{boardName}}'s assets.",
|
||||
"uploadFailedInvalidUploadDesc_withCount_one": "Must be maximum of 1 PNG or JPEG image.",
|
||||
"uploadFailedInvalidUploadDesc_withCount_other": "Must be maximum of {{count}} PNG or JPEG images.",
|
||||
"uploadFailedInvalidUploadDesc": "Must be PNG or JPEG images.",
|
||||
"workflowLoaded": "Workflow Loaded",
|
||||
"problemRetrievingWorkflow": "Problem Retrieving Workflow",
|
||||
"workflowDeleted": "Workflow Deleted",
|
||||
"problemDeletingWorkflow": "Problem Deleting Workflow"
|
||||
},
|
||||
"tooltip": {
|
||||
"feature": {
|
||||
"boundingBox": "The bounding box is the same as the Width and Height settings for Text to Image or Image to Image. Only the area in the box will be processed.",
|
||||
"gallery": "Gallery displays generations from the outputs folder as they're created. Settings are stored within files and accesed by context menu.",
|
||||
"other": "These options will enable alternative processing modes for Invoke. 'Seamless tiling' will create repeating patterns in the output. 'High resolution' is generation in two steps with img2img: use this setting when you want a larger and more coherent image without artifacts. It will take longer than usual txt2img.",
|
||||
"prompt": "This is the prompt field. Prompt includes generation objects and stylistic terms. You can add weight (token importance) in the prompt as well, but CLI commands and parameters will not work.",
|
||||
"seed": "Seed value affects the initial noise from which the image is formed. You can use the already existing seeds from previous images. 'Noise Threshold' is used to mitigate artifacts at high CFG values (try the 0-10 range), and Perlin to add Perlin noise during generation: both serve to add variation to your outputs.",
|
||||
"upscale": "Use ESRGAN to enlarge the image immediately after generation."
|
||||
}
|
||||
},
|
||||
"popovers": {
|
||||
"clipSkip": {
|
||||
"heading": "CLIP Skip",
|
||||
@@ -1288,6 +1258,33 @@
|
||||
"heading": "Mask Adjustments",
|
||||
"paragraphs": ["Adjust the mask."]
|
||||
},
|
||||
"inpainting": {
|
||||
"heading": "Inpainting",
|
||||
"paragraphs": ["Controls which area is modified, guided by Denoising Strength."]
|
||||
},
|
||||
"rasterLayer": {
|
||||
"heading": "Raster Layer",
|
||||
"paragraphs": ["Pixel-based content of your canvas, used during image generation."]
|
||||
},
|
||||
"regionalGuidance": {
|
||||
"heading": "Regional Guidance",
|
||||
"paragraphs": ["Brush to guide where elements from global prompts should appear."]
|
||||
},
|
||||
"regionalGuidanceAndReferenceImage": {
|
||||
"heading": "Regional Guidance and Regional Reference Image",
|
||||
"paragraphs": [
|
||||
"For Regional Guidance, brush to guide where elements from global prompts should appear.",
|
||||
"For Regional Reference Image, brush to apply a reference image to specific areas."
|
||||
]
|
||||
},
|
||||
"globalReferenceImage": {
|
||||
"heading": "Global Reference Image",
|
||||
"paragraphs": ["Applies a reference image to influence the entire generation."]
|
||||
},
|
||||
"regionalReferenceImage": {
|
||||
"heading": "Regional Reference Image",
|
||||
"paragraphs": ["Brush to apply a reference image to specific areas."]
|
||||
},
|
||||
"controlNet": {
|
||||
"heading": "ControlNet",
|
||||
"paragraphs": [
|
||||
@@ -1570,88 +1567,29 @@
|
||||
]
|
||||
},
|
||||
"optimizedDenoising": {
|
||||
"heading": "Optimized Inpainting",
|
||||
"heading": "Optimized Image-to-Image",
|
||||
"paragraphs": [
|
||||
"Enable optimized denoising for enhanced inpainting transformations with Flux models. This setting improves detail and clarity during generation, but may be turned off to preserve more of your original image. This setting is still being tuned and is in beta status."
|
||||
"Enable 'Optimized Image-to-Image' for a more gradual Denoise Strength scale for image-to-image and inpainting transformations with Flux models. This setting improves the ability to control the amount of change applied to an image, but may be turned off if you prefer to use the standard Denoise Strength scale. This setting is still being tuned and is in beta status."
|
||||
]
|
||||
}
|
||||
},
|
||||
"unifiedCanvas": {
|
||||
"accept": "Accept",
|
||||
"activeLayer": "Active Layer",
|
||||
"antialiasing": "Antialiasing",
|
||||
"autoSaveToGallery": "Auto Save to Gallery",
|
||||
"base": "Base",
|
||||
"boundingBox": "Bounding Box",
|
||||
"boundingBoxPosition": "Bounding Box Position",
|
||||
"brush": "Brush",
|
||||
"brushOptions": "Brush Options",
|
||||
"brushSize": "Size",
|
||||
"canvasDimensions": "Canvas Dimensions",
|
||||
"canvasPosition": "Canvas Position",
|
||||
"canvasScale": "Canvas Scale",
|
||||
"canvasSettings": "Canvas Settings",
|
||||
"clearCanvas": "Clear Canvas",
|
||||
"clearCanvasHistory": "Clear Canvas History",
|
||||
"clearCanvasHistoryConfirm": "Are you sure you want to clear the canvas history?",
|
||||
"clearCanvasHistoryMessage": "Clearing the canvas history leaves your current canvas intact, but irreversibly clears the undo and redo history.",
|
||||
"clearHistory": "Clear History",
|
||||
"clearMask": "Clear Mask (Shift+C)",
|
||||
"coherenceModeGaussianBlur": "Gaussian Blur",
|
||||
"coherenceModeBoxBlur": "Box Blur",
|
||||
"coherenceModeStaged": "Staged",
|
||||
"colorPicker": "Color Picker",
|
||||
"copyToClipboard": "Copy to Clipboard",
|
||||
"cursorPosition": "Cursor Position",
|
||||
"darkenOutsideSelection": "Darken Outside Selection",
|
||||
"discardAll": "Discard All & Cancel Pending Generations",
|
||||
"discardCurrent": "Discard Current",
|
||||
"downloadAsImage": "Download As Image",
|
||||
"enableMask": "Enable Mask",
|
||||
"eraseBoundingBox": "Erase Bounding Box",
|
||||
"eraser": "Eraser",
|
||||
"fillBoundingBox": "Fill Bounding Box",
|
||||
"hideBoundingBox": "Hide Bounding Box",
|
||||
"initialFitImageSize": "Fit Image Size on Drop",
|
||||
"invertBrushSizeScrollDirection": "Invert Scroll for Brush Size",
|
||||
"layer": "Layer",
|
||||
"limitStrokesToBox": "Limit Strokes to Box",
|
||||
"mask": "Mask",
|
||||
"maskingOptions": "Masking Options",
|
||||
"mergeVisible": "Merge Visible",
|
||||
"move": "Move",
|
||||
"next": "Next",
|
||||
"preserveMaskedArea": "Preserve Masked Area",
|
||||
"previous": "Previous",
|
||||
"redo": "Redo",
|
||||
"resetView": "Reset View",
|
||||
"saveBoxRegionOnly": "Save Box Region Only",
|
||||
"saveMask": "Save $t(unifiedCanvas.mask)",
|
||||
"saveToGallery": "Save To Gallery",
|
||||
"scaledBoundingBox": "Scaled Bounding Box",
|
||||
"showBoundingBox": "Show Bounding Box",
|
||||
"showCanvasDebugInfo": "Show Additional Canvas Info",
|
||||
"showGrid": "Show Grid",
|
||||
"showResultsOn": "Show Results (On)",
|
||||
"showResultsOff": "Show Results (Off)",
|
||||
"showIntermediates": "Show Intermediates",
|
||||
"snapToGrid": "Snap to Grid",
|
||||
"undo": "Undo"
|
||||
},
|
||||
"workflows": {
|
||||
"chooseWorkflowFromLibrary": "Choose Workflow from Library",
|
||||
"defaultWorkflows": "Default Workflows",
|
||||
"userWorkflows": "User Workflows",
|
||||
"projectWorkflows": "Project Workflows",
|
||||
"ascending": "Ascending",
|
||||
"created": "Created",
|
||||
"descending": "Descending",
|
||||
"workflows": "Workflows",
|
||||
"workflowLibrary": "Library",
|
||||
"userWorkflows": "My Workflows",
|
||||
"defaultWorkflows": "Default Workflows",
|
||||
"projectWorkflows": "Project Workflows",
|
||||
"opened": "Opened",
|
||||
"openWorkflow": "Open Workflow",
|
||||
"updated": "Updated",
|
||||
"uploadWorkflow": "Load from File",
|
||||
"uploadAndSaveWorkflow": "Upload to Library",
|
||||
"deleteWorkflow": "Delete Workflow",
|
||||
"deleteWorkflow2": "Are you sure you want to delete this workflow? This cannot be undone.",
|
||||
"unnamedWorkflow": "Unnamed Workflow",
|
||||
"downloadWorkflow": "Save to File",
|
||||
"saveWorkflow": "Save Workflow",
|
||||
@@ -1661,8 +1599,6 @@
|
||||
"problemSavingWorkflow": "Problem Saving Workflow",
|
||||
"workflowSaved": "Workflow Saved",
|
||||
"name": "Name",
|
||||
"noRecentWorkflows": "No Recent Workflows",
|
||||
"noUserWorkflows": "No User Workflows",
|
||||
"noWorkflows": "No Workflows",
|
||||
"problemLoading": "Problem Loading Workflows",
|
||||
"loading": "Loading Workflows",
|
||||
@@ -1676,10 +1612,12 @@
|
||||
"loadFromGraph": "Load Workflow from Graph",
|
||||
"convertGraph": "Convert Graph",
|
||||
"loadWorkflow": "$t(common.load) Workflow",
|
||||
"autoLayout": "Auto Layout"
|
||||
},
|
||||
"app": {
|
||||
"storeNotInitialized": "Store is not initialized"
|
||||
"autoLayout": "Auto Layout",
|
||||
"edit": "Edit",
|
||||
"download": "Download",
|
||||
"copyShareLink": "Copy Share Link",
|
||||
"copyShareLinkForWorkflow": "Copy Share Link for Workflow",
|
||||
"delete": "Delete"
|
||||
},
|
||||
"controlLayers": {
|
||||
"regional": "Regional",
|
||||
@@ -1691,8 +1629,7 @@
|
||||
"saveCanvasToGallery": "Save Canvas to Gallery",
|
||||
"saveBboxToGallery": "Save Bbox to Gallery",
|
||||
"saveLayerToAssets": "Save Layer to Assets",
|
||||
"newControlLayerFromBbox": "New Control Layer from Bbox",
|
||||
"newRasterLayerFromBbox": "New Raster Layer from Bbox",
|
||||
"cropLayerToBbox": "Crop Layer to Bbox",
|
||||
"savedToGalleryOk": "Saved to Gallery",
|
||||
"savedToGalleryError": "Error saving to gallery",
|
||||
"newGlobalReferenceImageOk": "Created Global Reference Image",
|
||||
@@ -1713,13 +1650,7 @@
|
||||
"mergeVisibleError": "Error merging visible layers",
|
||||
"clearHistory": "Clear History",
|
||||
"bboxOverlay": "Show Bbox Overlay",
|
||||
"generateMode": "Generate",
|
||||
"generateModeDesc": "Create individual images. Generated images are added directly to the gallery.",
|
||||
"composeMode": "Compose",
|
||||
"composeModeDesc": "Compose your work iterative. Generated images are added back to the canvas.",
|
||||
"autoSave": "Auto-save to Gallery",
|
||||
"resetCanvas": "Reset Canvas",
|
||||
"resetAll": "Reset All",
|
||||
"clearCaches": "Clear Caches",
|
||||
"recalculateRects": "Recalculate Rects",
|
||||
"clipToBbox": "Clip Strokes to Bbox",
|
||||
@@ -1730,19 +1661,12 @@
|
||||
"moveToBack": "Move to Back",
|
||||
"moveForward": "Move Forward",
|
||||
"moveBackward": "Move Backward",
|
||||
"brushSize": "Brush Size",
|
||||
"width": "Width",
|
||||
"zoom": "Zoom",
|
||||
"resetView": "Reset View",
|
||||
"controlLayers": "Control Layers",
|
||||
"globalMaskOpacity": "Global Mask Opacity",
|
||||
"autoNegative": "Auto Negative",
|
||||
"enableAutoNegative": "Enable Auto Negative",
|
||||
"disableAutoNegative": "Disable Auto Negative",
|
||||
"deletePrompt": "Delete Prompt",
|
||||
"deleteReferenceImage": "Delete Reference Image",
|
||||
"resetRegion": "Reset Region",
|
||||
"debugLayers": "Debug Layers",
|
||||
"showHUD": "Show HUD",
|
||||
"rectangle": "Rectangle",
|
||||
"maskFill": "Mask Fill",
|
||||
@@ -1754,12 +1678,12 @@
|
||||
"addInpaintMask": "Add $t(controlLayers.inpaintMask)",
|
||||
"addRegionalGuidance": "Add $t(controlLayers.regionalGuidance)",
|
||||
"addGlobalReferenceImage": "Add $t(controlLayers.globalReferenceImage)",
|
||||
"regionalGuidanceLayer": "$t(controlLayers.regionalGuidance) $t(unifiedCanvas.layer)",
|
||||
"raster": "Raster",
|
||||
"rasterLayer": "Raster Layer",
|
||||
"controlLayer": "Control Layer",
|
||||
"inpaintMask": "Inpaint Mask",
|
||||
"regionalGuidance": "Regional Guidance",
|
||||
"canvasAsRasterLayer": "$t(controlLayers.canvas) as $t(controlLayers.rasterLayer)",
|
||||
"canvasAsControlLayer": "$t(controlLayers.canvas) as $t(controlLayers.controlLayer)",
|
||||
"referenceImage": "Reference Image",
|
||||
"regionalReferenceImage": "Regional Reference Image",
|
||||
"globalReferenceImage": "Global Reference Image",
|
||||
@@ -1770,19 +1694,20 @@
|
||||
"sendToCanvas": "Send To Canvas",
|
||||
"newLayerFromImage": "New Layer from Image",
|
||||
"newCanvasFromImage": "New Canvas from Image",
|
||||
"newImg2ImgCanvasFromImage": "New Img2Img from Image",
|
||||
"copyToClipboard": "Copy to Clipboard",
|
||||
"sendToCanvasDesc": "Pressing Invoke stages your work in progress on the canvas.",
|
||||
"viewProgressInViewer": "View progress and outputs in the <Btn>Image Viewer</Btn>.",
|
||||
"viewProgressOnCanvas": "View progress and stage outputs on the <Btn>Canvas</Btn>.",
|
||||
"rasterLayer_withCount_one": "$t(controlLayers.rasterLayer)",
|
||||
"controlLayer_withCount_one": "$t(controlLayers.controlLayer)",
|
||||
"inpaintMask_withCount_one": "$t(controlLayers.inpaintMask)",
|
||||
"regionalGuidance_withCount_one": "$t(controlLayers.regionalGuidance)",
|
||||
"globalReferenceImage_withCount_one": "$t(controlLayers.globalReferenceImage)",
|
||||
"rasterLayer_withCount_other": "Raster Layers",
|
||||
"controlLayer_withCount_one": "$t(controlLayers.controlLayer)",
|
||||
"controlLayer_withCount_other": "Control Layers",
|
||||
"inpaintMask_withCount_one": "$t(controlLayers.inpaintMask)",
|
||||
"inpaintMask_withCount_other": "Inpaint Masks",
|
||||
"regionalGuidance_withCount_one": "$t(controlLayers.regionalGuidance)",
|
||||
"regionalGuidance_withCount_other": "Regional Guidance",
|
||||
"globalReferenceImage_withCount_one": "$t(controlLayers.globalReferenceImage)",
|
||||
"globalReferenceImage_withCount_other": "Global Reference Images",
|
||||
"opacity": "Opacity",
|
||||
"regionalGuidance_withCount_hidden": "Regional Guidance ({{count}} hidden)",
|
||||
@@ -1795,20 +1720,22 @@
|
||||
"rasterLayers_withCount_visible": "Raster Layers ({{count}})",
|
||||
"globalReferenceImages_withCount_visible": "Global Reference Images ({{count}})",
|
||||
"inpaintMasks_withCount_visible": "Inpaint Masks ({{count}})",
|
||||
"layer": "Layer",
|
||||
"opacityFilter": "Opacity Filter",
|
||||
"clearProcessor": "Clear Processor",
|
||||
"resetProcessor": "Reset Processor to Defaults",
|
||||
"noLayersAdded": "No Layers Added",
|
||||
"layer_one": "Layer",
|
||||
"layer_other": "Layers",
|
||||
"layer_withCount_one": "Layer ({{count}})",
|
||||
"layer_withCount_other": "Layers ({{count}})",
|
||||
"objects_zero": "empty",
|
||||
"objects_one": "{{count}} object",
|
||||
"objects_other": "{{count}} objects",
|
||||
"convertToControlLayer": "Convert to Control Layer",
|
||||
"convertToRasterLayer": "Convert to Raster Layer",
|
||||
"convertRasterLayerTo": "Convert $t(controlLayers.rasterLayer) To",
|
||||
"convertControlLayerTo": "Convert $t(controlLayers.controlLayer) To",
|
||||
"convertInpaintMaskTo": "Convert $t(controlLayers.inpaintMask) To",
|
||||
"convertRegionalGuidanceTo": "Convert $t(controlLayers.regionalGuidance) To",
|
||||
"copyRasterLayerTo": "Copy $t(controlLayers.rasterLayer) To",
|
||||
"copyControlLayerTo": "Copy $t(controlLayers.controlLayer) To",
|
||||
"copyInpaintMaskTo": "Copy $t(controlLayers.inpaintMask) To",
|
||||
"copyRegionalGuidanceTo": "Copy $t(controlLayers.regionalGuidance) To",
|
||||
"newRasterLayer": "New $t(controlLayers.rasterLayer)",
|
||||
"newControlLayer": "New $t(controlLayers.controlLayer)",
|
||||
"newInpaintMask": "New $t(controlLayers.inpaintMask)",
|
||||
"newRegionalGuidance": "New $t(controlLayers.regionalGuidance)",
|
||||
"transparency": "Transparency",
|
||||
"enableTransparencyEffect": "Enable Transparency Effect",
|
||||
"disableTransparencyEffect": "Disable Transparency Effect",
|
||||
@@ -1819,9 +1746,6 @@
|
||||
"locked": "Locked",
|
||||
"unlocked": "Unlocked",
|
||||
"deleteSelected": "Delete Selected",
|
||||
"deleteAll": "Delete All",
|
||||
"flipHorizontal": "Flip Horizontal",
|
||||
"flipVertical": "Flip Vertical",
|
||||
"stagingOnCanvas": "Staging images on",
|
||||
"replaceLayer": "Replace Layer",
|
||||
"pullBboxIntoLayer": "Pull Bbox into Layer",
|
||||
@@ -1831,6 +1755,11 @@
|
||||
"negativePrompt": "Negative Prompt",
|
||||
"beginEndStepPercentShort": "Begin/End %",
|
||||
"weight": "Weight",
|
||||
"newGallerySession": "New Gallery Session",
|
||||
"newGallerySessionDesc": "This will clear the canvas and all settings except for your model selection. Generations will be sent to the gallery.",
|
||||
"newCanvasSession": "New Canvas Session",
|
||||
"newCanvasSessionDesc": "This will clear the canvas and all settings except for your model selection. Generations will be staged on the canvas.",
|
||||
"replaceCurrent": "Replace Current",
|
||||
"controlMode": {
|
||||
"controlMode": "Control Mode",
|
||||
"balanced": "Balanced",
|
||||
@@ -1844,8 +1773,6 @@
|
||||
"style": "Style Only",
|
||||
"composition": "Composition Only"
|
||||
},
|
||||
"useSizeOptimizeForModel": "Copy size to W/H (optimize for model)",
|
||||
"useSizeIgnoreModel": "Copy size to W/H (ignore model)",
|
||||
"fill": {
|
||||
"fillColor": "Fill Color",
|
||||
"fillStyle": "Fill Style",
|
||||
@@ -1886,7 +1813,7 @@
|
||||
"label": "Canny Edge Detection",
|
||||
"description": "Generates an edge map from the selected layer using the Canny edge detection algorithm.",
|
||||
"low_threshold": "Low Threshold",
|
||||
"high_threshold": "Hight Threshold"
|
||||
"high_threshold": "High Threshold"
|
||||
},
|
||||
"color_map": {
|
||||
"label": "Color Map",
|
||||
@@ -1954,10 +1881,33 @@
|
||||
"transform": {
|
||||
"transform": "Transform",
|
||||
"fitToBbox": "Fit to Bbox",
|
||||
"fitMode": "Fit Mode",
|
||||
"fitModeContain": "Contain",
|
||||
"fitModeCover": "Cover",
|
||||
"fitModeFill": "Fill",
|
||||
"reset": "Reset",
|
||||
"apply": "Apply",
|
||||
"cancel": "Cancel"
|
||||
},
|
||||
"selectObject": {
|
||||
"selectObject": "Select Object",
|
||||
"pointType": "Point Type",
|
||||
"invertSelection": "Invert Selection",
|
||||
"include": "Include",
|
||||
"exclude": "Exclude",
|
||||
"neutral": "Neutral",
|
||||
"apply": "Apply",
|
||||
"reset": "Reset",
|
||||
"saveAs": "Save As",
|
||||
"cancel": "Cancel",
|
||||
"process": "Process",
|
||||
"help1": "Select a single target object. Add <Bold>Include</Bold> and <Bold>Exclude</Bold> points to indicate which parts of the layer are part of the target object.",
|
||||
"help2": "Start with one <Bold>Include</Bold> point within the target object. Add more points to refine the selection. Fewer points typically produce better results.",
|
||||
"help3": "Invert the selection to select everything except the target object.",
|
||||
"clickToAdd": "Click on the layer to add a point",
|
||||
"dragToMove": "Drag a point to move it",
|
||||
"clickToRemove": "Click on a point to remove it"
|
||||
},
|
||||
"settings": {
|
||||
"snapToGrid": {
|
||||
"label": "Snap to Grid",
|
||||
@@ -1968,15 +1918,16 @@
|
||||
"label": "Preserve Masked Region",
|
||||
"alert": "Preserving Masked Region"
|
||||
},
|
||||
"isolatedPreview": "Isolated Preview",
|
||||
"isolatedStagingPreview": "Isolated Staging Preview",
|
||||
"isolatedFilteringPreview": "Isolated Filtering Preview",
|
||||
"isolatedTransformingPreview": "Isolated Transforming Preview"
|
||||
"isolatedPreview": "Isolated Preview",
|
||||
"isolatedLayerPreview": "Isolated Layer Preview",
|
||||
"isolatedLayerPreviewDesc": "Whether to show only this layer when performing operations like filtering or transforming.",
|
||||
"invertBrushSizeScrollDirection": "Invert Scroll for Brush Size",
|
||||
"pressureSensitivity": "Pressure Sensitivity"
|
||||
},
|
||||
"HUD": {
|
||||
"bbox": "Bbox",
|
||||
"scaledBbox": "Scaled Bbox",
|
||||
"autoSave": "Auto Save",
|
||||
"entityStatus": {
|
||||
"isFiltering": "{{title}} is filtering",
|
||||
"isTransforming": "{{title}} is transforming",
|
||||
@@ -1987,6 +1938,7 @@
|
||||
}
|
||||
},
|
||||
"canvasContextMenu": {
|
||||
"canvasGroup": "Canvas",
|
||||
"saveToGalleryGroup": "Save To Gallery",
|
||||
"saveCanvasToGallery": "Save Canvas To Gallery",
|
||||
"saveBboxToGallery": "Save Bbox To Gallery",
|
||||
@@ -1994,7 +1946,20 @@
|
||||
"newGlobalReferenceImage": "New Global Reference Image",
|
||||
"newRegionalReferenceImage": "New Regional Reference Image",
|
||||
"newControlLayer": "New Control Layer",
|
||||
"newRasterLayer": "New Raster Layer"
|
||||
"newRasterLayer": "New Raster Layer",
|
||||
"newInpaintMask": "New Inpaint Mask",
|
||||
"newRegionalGuidance": "New Regional Guidance",
|
||||
"cropCanvasToBbox": "Crop Canvas to Bbox"
|
||||
},
|
||||
"stagingArea": {
|
||||
"accept": "Accept",
|
||||
"discardAll": "Discard All",
|
||||
"discard": "Discard",
|
||||
"previous": "Previous",
|
||||
"next": "Next",
|
||||
"saveToGallery": "Save To Gallery",
|
||||
"showResultsOn": "Showing Results",
|
||||
"showResultsOff": "Hiding Results"
|
||||
}
|
||||
},
|
||||
"upscaling": {
|
||||
@@ -2051,7 +2016,6 @@
|
||||
"searchByName": "Search by name",
|
||||
"shared": "Shared",
|
||||
"sharedTemplates": "Shared Templates",
|
||||
"templateActions": "Template Actions",
|
||||
"templateDeleted": "Prompt template deleted",
|
||||
"toggleViewMode": "Toggle View Mode",
|
||||
"type": "Type",
|
||||
@@ -2065,25 +2029,21 @@
|
||||
"upsell": {
|
||||
"inviteTeammates": "Invite Teammates",
|
||||
"professional": "Professional",
|
||||
"professionalUpsell": "Available in Invoke’s Professional Edition. Click here or visit invoke.com/pricing for more details.",
|
||||
"professionalUpsell": "Available in Invoke's Professional Edition. Click here or visit invoke.com/pricing for more details.",
|
||||
"shareAccess": "Share Access"
|
||||
},
|
||||
"ui": {
|
||||
"tabs": {
|
||||
"generation": "Generation",
|
||||
"generationTab": "$t(ui.tabs.generation) $t(common.tab)",
|
||||
"canvas": "Canvas",
|
||||
"canvasTab": "$t(ui.tabs.canvas) $t(common.tab)",
|
||||
"workflows": "Workflows",
|
||||
"workflowsTab": "$t(ui.tabs.workflows) $t(common.tab)",
|
||||
"models": "Models",
|
||||
"modelsTab": "$t(ui.tabs.models) $t(common.tab)",
|
||||
"queue": "Queue",
|
||||
"queueTab": "$t(ui.tabs.queue) $t(common.tab)",
|
||||
"upscaling": "Upscaling",
|
||||
"upscalingTab": "$t(ui.tabs.upscaling) $t(common.tab)",
|
||||
"gallery": "Gallery",
|
||||
"galleryTab": "$t(ui.tabs.gallery) $t(common.tab)"
|
||||
"gallery": "Gallery"
|
||||
}
|
||||
},
|
||||
"system": {
|
||||
@@ -2109,12 +2069,15 @@
|
||||
"events": "Events",
|
||||
"queue": "Queue",
|
||||
"metadata": "Metadata"
|
||||
},
|
||||
"showSendingToAlerts": "Alert When Sending to Different View"
|
||||
}
|
||||
},
|
||||
"newUserExperience": {
|
||||
"toGetStarted": "To get started, enter a prompt in the box and click <StrongComponent>Invoke</StrongComponent> to generate your first image. You can choose to save your images directly to the <StrongComponent>Gallery</StrongComponent> or edit them to the <StrongComponent>Canvas</StrongComponent>.",
|
||||
"gettingStartedSeries": "Want more guidance? Check out our <LinkComponent>Getting Started Series</LinkComponent> for tips on unlocking the full potential of the Invoke Studio."
|
||||
"toGetStartedLocal": "To get started, make sure to download or import models needed to run Invoke. Then, enter a prompt in the box and click <StrongComponent>Invoke</StrongComponent> to generate your first image. Select a prompt template to improve results. You can choose to save your images directly to the <StrongComponent>Gallery</StrongComponent> or edit them to the <StrongComponent>Canvas</StrongComponent>.",
|
||||
"toGetStarted": "To get started, enter a prompt in the box and click <StrongComponent>Invoke</StrongComponent> to generate your first image. Select a prompt template to improve results. You can choose to save your images directly to the <StrongComponent>Gallery</StrongComponent> or edit them to the <StrongComponent>Canvas</StrongComponent>.",
|
||||
"gettingStartedSeries": "Want more guidance? Check out our <LinkComponent>Getting Started Series</LinkComponent> for tips on unlocking the full potential of the Invoke Studio.",
|
||||
"downloadStarterModels": "Download Starter Models",
|
||||
"importModels": "Import Models",
|
||||
"noModelsInstalled": "It looks like you don't have any models installed"
|
||||
},
|
||||
"whatsNew": {
|
||||
"whatsNewInInvoke": "What's New in Invoke",
|
||||
|
||||
@@ -5,7 +5,6 @@
|
||||
"reportBugLabel": "Reportar errores",
|
||||
"settingsLabel": "Ajustes",
|
||||
"img2img": "Imagen a Imagen",
|
||||
"unifiedCanvas": "Lienzo Unificado",
|
||||
"nodes": "Flujos de trabajo",
|
||||
"upload": "Subir imagen",
|
||||
"load": "Cargar",
|
||||
@@ -61,13 +60,11 @@
|
||||
"format": "formato",
|
||||
"unknown": "Desconocido",
|
||||
"input": "Entrada",
|
||||
"nodeEditor": "Editor de nodos",
|
||||
"template": "Plantilla",
|
||||
"prevPage": "Página Anterior",
|
||||
"red": "Rojo",
|
||||
"alpha": "Transparencia",
|
||||
"outputs": "Salidas",
|
||||
"editing": "Editando",
|
||||
"learnMore": "Aprende más",
|
||||
"enabled": "Activado",
|
||||
"disabled": "Desactivado",
|
||||
@@ -76,14 +73,12 @@
|
||||
"created": "Creado",
|
||||
"save": "Guardar",
|
||||
"unknownError": "Error Desconocido",
|
||||
"blue": "Azul",
|
||||
"viewingDesc": "Revisar imágenes en una vista de galería grande"
|
||||
"blue": "Azul"
|
||||
},
|
||||
"gallery": {
|
||||
"galleryImageSize": "Tamaño de la imagen",
|
||||
"gallerySettings": "Ajustes de la galería",
|
||||
"autoSwitchNewImages": "Auto seleccionar Imágenes nuevas",
|
||||
"loadMore": "Cargar más",
|
||||
"noImagesInGallery": "No hay imágenes para mostrar",
|
||||
"deleteImage_one": "Eliminar Imagen",
|
||||
"deleteImage_many": "Eliminar {{count}} Imágenes",
|
||||
@@ -92,206 +87,6 @@
|
||||
"assets": "Activos",
|
||||
"autoAssignBoardOnClick": "Asignación automática de tableros al hacer clic"
|
||||
},
|
||||
"hotkeys": {
|
||||
"keyboardShortcuts": "Atajos de teclado",
|
||||
"appHotkeys": "Atajos de aplicación",
|
||||
"generalHotkeys": "Atajos generales",
|
||||
"galleryHotkeys": "Atajos de galería",
|
||||
"unifiedCanvasHotkeys": "Atajos de lienzo unificado",
|
||||
"invoke": {
|
||||
"title": "Invocar",
|
||||
"desc": "Generar una imagen"
|
||||
},
|
||||
"cancel": {
|
||||
"title": "Cancelar",
|
||||
"desc": "Cancelar el proceso de generación de imagen"
|
||||
},
|
||||
"focusPrompt": {
|
||||
"title": "Mover foco a Entrada de texto",
|
||||
"desc": "Mover foco hacia el campo de texto de la Entrada"
|
||||
},
|
||||
"toggleOptions": {
|
||||
"title": "Alternar opciones",
|
||||
"desc": "Mostar y ocultar el panel de opciones"
|
||||
},
|
||||
"pinOptions": {
|
||||
"title": "Fijar opciones",
|
||||
"desc": "Fijar el panel de opciones"
|
||||
},
|
||||
"toggleGallery": {
|
||||
"title": "Alternar galería",
|
||||
"desc": "Mostar y ocultar la galería de imágenes"
|
||||
},
|
||||
"maximizeWorkSpace": {
|
||||
"title": "Maximizar espacio de trabajo",
|
||||
"desc": "Cerrar otros páneles y maximizar el espacio de trabajo"
|
||||
},
|
||||
"changeTabs": {
|
||||
"title": "Cambiar",
|
||||
"desc": "Cambiar entre áreas de trabajo"
|
||||
},
|
||||
"consoleToggle": {
|
||||
"title": "Alternar consola",
|
||||
"desc": "Mostar y ocultar la consola"
|
||||
},
|
||||
"setPrompt": {
|
||||
"title": "Establecer Entrada",
|
||||
"desc": "Usar el texto de entrada de la imagen actual"
|
||||
},
|
||||
"setSeed": {
|
||||
"title": "Establecer semilla",
|
||||
"desc": "Usar la semilla de la imagen actual"
|
||||
},
|
||||
"setParameters": {
|
||||
"title": "Establecer parámetros",
|
||||
"desc": "Usar todos los parámetros de la imagen actual"
|
||||
},
|
||||
"restoreFaces": {
|
||||
"title": "Restaurar rostros",
|
||||
"desc": "Restaurar rostros en la imagen actual"
|
||||
},
|
||||
"showInfo": {
|
||||
"title": "Mostrar información",
|
||||
"desc": "Mostar metadatos de la imagen actual"
|
||||
},
|
||||
"sendToImageToImage": {
|
||||
"title": "Enviar hacia Imagen a Imagen",
|
||||
"desc": "Enviar imagen actual hacia Imagen a Imagen"
|
||||
},
|
||||
"deleteImage": {
|
||||
"title": "Eliminar imagen",
|
||||
"desc": "Eliminar imagen actual"
|
||||
},
|
||||
"closePanels": {
|
||||
"title": "Cerrar páneles",
|
||||
"desc": "Cerrar los páneles abiertos"
|
||||
},
|
||||
"previousImage": {
|
||||
"title": "Imagen anterior",
|
||||
"desc": "Muetra la imagen anterior en la galería"
|
||||
},
|
||||
"nextImage": {
|
||||
"title": "Imagen siguiente",
|
||||
"desc": "Muetra la imagen siguiente en la galería"
|
||||
},
|
||||
"increaseGalleryThumbSize": {
|
||||
"title": "Aumentar imagen en galería",
|
||||
"desc": "Aumenta el tamaño de las miniaturas de la galería"
|
||||
},
|
||||
"decreaseGalleryThumbSize": {
|
||||
"title": "Reducir imagen en galería",
|
||||
"desc": "Reduce el tamaño de las miniaturas de la galería"
|
||||
},
|
||||
"selectBrush": {
|
||||
"title": "Seleccionar pincel",
|
||||
"desc": "Selecciona el pincel en el lienzo"
|
||||
},
|
||||
"selectEraser": {
|
||||
"title": "Seleccionar borrador",
|
||||
"desc": "Selecciona el borrador en el lienzo"
|
||||
},
|
||||
"decreaseBrushSize": {
|
||||
"title": "Disminuir tamaño de herramienta",
|
||||
"desc": "Disminuye el tamaño del pincel/borrador en el lienzo"
|
||||
},
|
||||
"increaseBrushSize": {
|
||||
"title": "Aumentar tamaño del pincel",
|
||||
"desc": "Aumenta el tamaño del pincel en el lienzo"
|
||||
},
|
||||
"decreaseBrushOpacity": {
|
||||
"title": "Disminuir opacidad del pincel",
|
||||
"desc": "Disminuye la opacidad del pincel en el lienzo"
|
||||
},
|
||||
"increaseBrushOpacity": {
|
||||
"title": "Aumentar opacidad del pincel",
|
||||
"desc": "Aumenta la opacidad del pincel en el lienzo"
|
||||
},
|
||||
"moveTool": {
|
||||
"title": "Herramienta de movimiento",
|
||||
"desc": "Permite navegar por el lienzo"
|
||||
},
|
||||
"fillBoundingBox": {
|
||||
"title": "Rellenar Caja contenedora",
|
||||
"desc": "Rellena la caja contenedora con el color seleccionado"
|
||||
},
|
||||
"eraseBoundingBox": {
|
||||
"title": "Borrar Caja contenedora",
|
||||
"desc": "Borra el contenido dentro de la caja contenedora"
|
||||
},
|
||||
"colorPicker": {
|
||||
"title": "Selector de color",
|
||||
"desc": "Selecciona un color del lienzo"
|
||||
},
|
||||
"toggleSnap": {
|
||||
"title": "Alternar ajuste de cuadrícula",
|
||||
"desc": "Activa o desactiva el ajuste automático a la cuadrícula"
|
||||
},
|
||||
"quickToggleMove": {
|
||||
"title": "Alternar movimiento rápido",
|
||||
"desc": "Activa momentáneamente la herramienta de movimiento"
|
||||
},
|
||||
"toggleLayer": {
|
||||
"title": "Alternar capa",
|
||||
"desc": "Alterna entre las capas de máscara y base"
|
||||
},
|
||||
"clearMask": {
|
||||
"title": "Limpiar máscara",
|
||||
"desc": "Limpia toda la máscara actual"
|
||||
},
|
||||
"hideMask": {
|
||||
"title": "Ocultar máscara",
|
||||
"desc": "Oculta o muetre la máscara actual"
|
||||
},
|
||||
"showHideBoundingBox": {
|
||||
"title": "Alternar caja contenedora",
|
||||
"desc": "Muestra u oculta la caja contenedora"
|
||||
},
|
||||
"mergeVisible": {
|
||||
"title": "Consolida capas visibles",
|
||||
"desc": "Consolida todas las capas visibles en una sola"
|
||||
},
|
||||
"saveToGallery": {
|
||||
"title": "Guardar en galería",
|
||||
"desc": "Guardar la imagen actual del lienzo en la galería"
|
||||
},
|
||||
"copyToClipboard": {
|
||||
"title": "Copiar al portapapeles",
|
||||
"desc": "Copiar el lienzo actual al portapapeles"
|
||||
},
|
||||
"downloadImage": {
|
||||
"title": "Descargar imagen",
|
||||
"desc": "Descargar la imagen actual del lienzo"
|
||||
},
|
||||
"undoStroke": {
|
||||
"title": "Deshar trazo",
|
||||
"desc": "Desahacer el último trazo del pincel"
|
||||
},
|
||||
"redoStroke": {
|
||||
"title": "Rehacer trazo",
|
||||
"desc": "Rehacer el último trazo del pincel"
|
||||
},
|
||||
"resetView": {
|
||||
"title": "Restablecer vista",
|
||||
"desc": "Restablecer la vista del lienzo"
|
||||
},
|
||||
"previousStagingImage": {
|
||||
"title": "Imagen anterior",
|
||||
"desc": "Imagen anterior en el área de preparación"
|
||||
},
|
||||
"nextStagingImage": {
|
||||
"title": "Imagen siguiente",
|
||||
"desc": "Siguiente imagen en el área de preparación"
|
||||
},
|
||||
"acceptStagingImage": {
|
||||
"title": "Aceptar imagen",
|
||||
"desc": "Aceptar la imagen actual en el área de preparación"
|
||||
},
|
||||
"addNodes": {
|
||||
"title": "Añadir Nodos",
|
||||
"desc": "Abre el menú para añadir nodos"
|
||||
},
|
||||
"nodesHotkeys": "Teclas de acceso rápido a los nodos"
|
||||
},
|
||||
"modelManager": {
|
||||
"modelManager": "Gestor de Modelos",
|
||||
"model": "Modelo",
|
||||
@@ -325,9 +120,7 @@
|
||||
"alpha": "Alfa",
|
||||
"allModels": "Todos los modelos",
|
||||
"repo_id": "Identificador del repositorio",
|
||||
"v2_base": "v2 (512px)",
|
||||
"none": "ninguno",
|
||||
"v2_768": "v2 (768px)",
|
||||
"vae": "VAE",
|
||||
"variant": "Variante",
|
||||
"baseModel": "Modelo básico",
|
||||
@@ -338,9 +131,7 @@
|
||||
"modelDeleted": "Modelo eliminado",
|
||||
"modelDeleteFailed": "Error al borrar el modelo",
|
||||
"settings": "Ajustes",
|
||||
"syncModels": "Sincronizar las plantillas",
|
||||
"modelsSynced": "Plantillas sincronizadas",
|
||||
"modelSyncFailed": "La sincronización de la plantilla falló"
|
||||
"syncModels": "Sincronizar las plantillas"
|
||||
},
|
||||
"parameters": {
|
||||
"images": "Imágenes",
|
||||
@@ -362,8 +153,6 @@
|
||||
"scaledHeight": "Alto escalado",
|
||||
"infillMethod": "Método de relleno",
|
||||
"tileSize": "Tamaño del mosaico",
|
||||
"sendToImg2Img": "Enviar a Imagen a Imagen",
|
||||
"sendToUnifiedCanvas": "Enviar a Lienzo Unificado",
|
||||
"downloadImage": "Descargar imagen",
|
||||
"usePrompt": "Usar Entrada",
|
||||
"useSeed": "Usar Semilla",
|
||||
@@ -389,13 +178,11 @@
|
||||
"models": "Modelos",
|
||||
"displayInProgress": "Mostrar las imágenes del progreso",
|
||||
"confirmOnDelete": "Confirmar antes de eliminar",
|
||||
"enableImageDebugging": "Habilitar depuración de imágenes",
|
||||
"resetWebUI": "Restablecer interfaz web",
|
||||
"resetWebUIDesc1": "Al restablecer la interfaz web, solo se restablece la caché local del navegador de sus imágenes y la configuración guardada. No se elimina ninguna imagen de su disco duro.",
|
||||
"resetWebUIDesc2": "Si las imágenes no se muestran en la galería o algo más no funciona, intente restablecer antes de reportar un incidente en GitHub.",
|
||||
"resetComplete": "Se ha restablecido la interfaz web.",
|
||||
"general": "General",
|
||||
"shouldLogToConsole": "Registro de la consola",
|
||||
"developer": "Desarrollador",
|
||||
"antialiasProgressImages": "Imágenes del progreso de Antialias",
|
||||
"showProgressInViewer": "Mostrar las imágenes del progreso en el visor",
|
||||
@@ -411,12 +198,7 @@
|
||||
"toast": {
|
||||
"uploadFailed": "Error al subir archivo",
|
||||
"imageCopied": "Imágen copiada",
|
||||
"imageNotLoadedDesc": "No se pudo encontrar la imagen",
|
||||
"canvasMerged": "Lienzo consolidado",
|
||||
"sentToImageToImage": "Enviar hacia Imagen a Imagen",
|
||||
"sentToUnifiedCanvas": "Enviar hacia Lienzo Consolidado",
|
||||
"parametersNotSet": "Parámetros no recuperados",
|
||||
"metadataLoadFailed": "Error al cargar metadatos",
|
||||
"serverError": "Error en el servidor",
|
||||
"canceled": "Procesando la cancelación",
|
||||
"connected": "Conectado al servidor",
|
||||
@@ -431,82 +213,20 @@
|
||||
"baseModelChangedCleared_many": "Borrados o desactivados {{count}} submodelos incompatibles",
|
||||
"baseModelChangedCleared_other": "Borrados o desactivados {{count}} submodelos incompatibles"
|
||||
},
|
||||
"tooltip": {
|
||||
"feature": {
|
||||
"prompt": "Este campo tomará todo el texto de entrada, incluidos tanto los términos de contenido como los estilísticos. Si bien se pueden incluir pesos en la solicitud, los comandos/parámetros estándar de línea de comandos no funcionarán.",
|
||||
"gallery": "Conforme se generan nuevas invocaciones, los archivos del directorio de salida se mostrarán aquí. Las generaciones tienen opciones adicionales para configurar nuevas generaciones.",
|
||||
"other": "Estas opciones habilitarán modos de procesamiento alternativos para Invoke. 'Seamless mosaico' creará patrones repetitivos en la salida. 'Alta resolución' es la generación en dos pasos con img2img: use esta configuración cuando desee una imagen más grande y más coherente sin artefactos. tomar más tiempo de lo habitual txt2img.",
|
||||
"seed": "Los valores de semilla proporcionan un conjunto inicial de ruido que guían el proceso de eliminación de ruido y se pueden aleatorizar o rellenar con una semilla de una invocación anterior. La función Umbral se puede usar para mitigar resultados indeseables a valores CFG más altos (intente entre 0-10), y Perlin se puede usar para agregar ruido Perlin al proceso de eliminación de ruido. Ambos sirven para agregar variación a sus salidas.",
|
||||
"upscale": "Usando ESRGAN, puede aumentar la resolución de salida sin requerir un ancho/alto más alto en la generación inicial.",
|
||||
"boundingBox": "La caja delimitadora es análoga a las configuraciones de Ancho y Alto para Texto a Imagen o Imagen a Imagen. Solo se procesará el área en la caja."
|
||||
}
|
||||
},
|
||||
"unifiedCanvas": {
|
||||
"layer": "Capa",
|
||||
"base": "Base",
|
||||
"mask": "Máscara",
|
||||
"maskingOptions": "Opciones de máscara",
|
||||
"enableMask": "Habilitar Máscara",
|
||||
"preserveMaskedArea": "Preservar área enmascarada",
|
||||
"clearMask": "Limpiar máscara",
|
||||
"brush": "Pincel",
|
||||
"eraser": "Borrador",
|
||||
"fillBoundingBox": "Rellenar Caja Contenedora",
|
||||
"eraseBoundingBox": "Eliminar Caja Contenedora",
|
||||
"colorPicker": "Selector de color",
|
||||
"brushOptions": "Opciones de pincel",
|
||||
"brushSize": "Tamaño",
|
||||
"move": "Mover",
|
||||
"resetView": "Restablecer vista",
|
||||
"mergeVisible": "Consolidar vista",
|
||||
"saveToGallery": "Guardar en galería",
|
||||
"copyToClipboard": "Copiar al portapapeles",
|
||||
"downloadAsImage": "Descargar como imagen",
|
||||
"undo": "Deshacer",
|
||||
"redo": "Rehacer",
|
||||
"clearCanvas": "Limpiar lienzo",
|
||||
"canvasSettings": "Ajustes de lienzo",
|
||||
"showIntermediates": "Mostrar intermedios",
|
||||
"showGrid": "Mostrar cuadrícula",
|
||||
"snapToGrid": "Ajustar a cuadrícula",
|
||||
"darkenOutsideSelection": "Oscurecer fuera de la selección",
|
||||
"autoSaveToGallery": "Guardar automáticamente en galería",
|
||||
"saveBoxRegionOnly": "Guardar solo región dentro de la caja",
|
||||
"limitStrokesToBox": "Limitar trazos a la caja",
|
||||
"showCanvasDebugInfo": "Mostrar la información adicional del lienzo",
|
||||
"clearCanvasHistory": "Limpiar historial de lienzo",
|
||||
"clearHistory": "Limpiar historial",
|
||||
"clearCanvasHistoryMessage": "Limpiar el historial de lienzo también restablece completamente el lienzo unificado. Esto incluye todo el historial de deshacer/rehacer, las imágenes en el área de preparación y la capa base del lienzo.",
|
||||
"clearCanvasHistoryConfirm": "¿Está seguro de que desea limpiar el historial del lienzo?",
|
||||
"activeLayer": "Capa activa",
|
||||
"canvasScale": "Escala de lienzo",
|
||||
"boundingBox": "Caja contenedora",
|
||||
"scaledBoundingBox": "Caja contenedora escalada",
|
||||
"boundingBoxPosition": "Posición de caja contenedora",
|
||||
"canvasDimensions": "Dimensiones de lienzo",
|
||||
"canvasPosition": "Posición de lienzo",
|
||||
"cursorPosition": "Posición del cursor",
|
||||
"previous": "Anterior",
|
||||
"next": "Siguiente",
|
||||
"accept": "Aceptar",
|
||||
"discardAll": "Descartar todo",
|
||||
"antialiasing": "Suavizado"
|
||||
},
|
||||
"accessibility": {
|
||||
"invokeProgressBar": "Activar la barra de progreso",
|
||||
"reset": "Reiniciar",
|
||||
"uploadImage": "Cargar imagen",
|
||||
"previousImage": "Imagen anterior",
|
||||
"nextImage": "Siguiente imagen",
|
||||
"showOptionsPanel": "Mostrar el panel lateral",
|
||||
"menu": "Menú",
|
||||
"showGalleryPanel": "Mostrar panel de galería",
|
||||
"loadMore": "Cargar más",
|
||||
"about": "Acerca de",
|
||||
"createIssue": "Crear un problema",
|
||||
"resetUI": "Interfaz de usuario $t(accessibility.reset)",
|
||||
"mode": "Modo",
|
||||
"submitSupportTicket": "Enviar Ticket de Soporte"
|
||||
"submitSupportTicket": "Enviar Ticket de Soporte",
|
||||
"toggleRightPanel": "Activar o desactivar el panel derecho (G)",
|
||||
"toggleLeftPanel": "Activar o desactivar el panel izquierdo (T)"
|
||||
},
|
||||
"nodes": {
|
||||
"zoomInNodes": "Acercar",
|
||||
@@ -555,7 +275,12 @@
|
||||
"addSharedBoard": "Agregar Panel Compartido",
|
||||
"boards": "Paneles",
|
||||
"archiveBoard": "Archivar Panel",
|
||||
"archived": "Archivado"
|
||||
"archived": "Archivado",
|
||||
"selectedForAutoAdd": "Seleccionado para agregar automáticamente",
|
||||
"unarchiveBoard": "Desarchivar el tablero",
|
||||
"noBoards": "No hay tableros {{boardType}}",
|
||||
"shared": "Carpetas compartidas",
|
||||
"deletedPrivateBoardsCannotbeRestored": "Los tableros eliminados no se pueden restaurar. Al elegir \"Eliminar solo tablero\", las imágenes se colocan en un estado privado y sin categoría para el creador de la imagen."
|
||||
},
|
||||
"accordions": {
|
||||
"compositing": {
|
||||
@@ -578,44 +303,15 @@
|
||||
},
|
||||
"ui": {
|
||||
"tabs": {
|
||||
"generationTab": "$t(ui.tabs.generation) $t(common.tab)",
|
||||
"canvas": "Lienzo",
|
||||
"generation": "Generación",
|
||||
"queue": "Cola",
|
||||
"queueTab": "$t(ui.tabs.queue) $t(common.tab)",
|
||||
"workflows": "Flujos de trabajo",
|
||||
"models": "Modelos",
|
||||
"modelsTab": "$t(ui.tabs.models) $t(common.tab)",
|
||||
"canvasTab": "$t(ui.tabs.canvas) $t(common.tab)",
|
||||
"workflowsTab": "$t(ui.tabs.workflows) $t(common.tab)"
|
||||
}
|
||||
},
|
||||
"controlLayers": {
|
||||
"layers_one": "Capa",
|
||||
"layers_many": "Capas",
|
||||
"layers_other": "Capas"
|
||||
},
|
||||
"controlnet": {
|
||||
"crop": "Cortar",
|
||||
"delete": "Eliminar",
|
||||
"depthAnythingDescription": "Generación de mapa de profundidad usando la técnica de Depth Anything",
|
||||
"duplicate": "Duplicar",
|
||||
"colorMapDescription": "Genera un mapa de color desde la imagen",
|
||||
"depthMidasDescription": "Crea un mapa de profundidad con Midas",
|
||||
"balanced": "Equilibrado",
|
||||
"beginEndStepPercent": "Inicio / Final Porcentaje de pasos",
|
||||
"detectResolution": "Detectar resolución",
|
||||
"beginEndStepPercentShort": "Inicio / Final %",
|
||||
"t2i_adapter": "$t(controlnet.controlAdapter_one) #{{number}} ($t(common.t2iAdapter))",
|
||||
"controlnet": "$t(controlnet.controlAdapter_one) #{{number}} ($t(common.controlNet))",
|
||||
"ip_adapter": "$t(controlnet.controlAdapter_one) #{{number}} ($t(common.ipAdapter))",
|
||||
"addControlNet": "Añadir $t(common.controlNet)",
|
||||
"addIPAdapter": "Añadir $t(common.ipAdapter)",
|
||||
"controlAdapter_one": "Adaptador de control",
|
||||
"controlAdapter_many": "Adaptadores de control",
|
||||
"controlAdapter_other": "Adaptadores de control",
|
||||
"addT2IAdapter": "Añadir $t(common.t2iAdapter)"
|
||||
},
|
||||
"queue": {
|
||||
"back": "Atrás",
|
||||
"front": "Delante",
|
||||
@@ -627,5 +323,13 @@
|
||||
"inviteTeammates": "Invitar compañeros de equipo",
|
||||
"shareAccess": "Compartir acceso",
|
||||
"professionalUpsell": "Disponible en la edición profesional de Invoke. Haz clic aquí o visita invoke.com/pricing para obtener más detalles."
|
||||
},
|
||||
"controlLayers": {
|
||||
"layer_one": "Capa",
|
||||
"layer_many": "Capas",
|
||||
"layer_other": "Capas",
|
||||
"layer_withCount_one": "({{count}}) capa",
|
||||
"layer_withCount_many": "({{count}}) capas",
|
||||
"layer_withCount_other": "({{count}}) capas"
|
||||
}
|
||||
}
|
||||
|
||||
@@ -4,8 +4,7 @@
|
||||
"uploadImage": "Lataa kuva",
|
||||
"invokeProgressBar": "Invoken edistymispalkki",
|
||||
"nextImage": "Seuraava kuva",
|
||||
"previousImage": "Edellinen kuva",
|
||||
"showOptionsPanel": "Näytä asetukset"
|
||||
"previousImage": "Edellinen kuva"
|
||||
},
|
||||
"common": {
|
||||
"languagePickerLabel": "Kielen valinta",
|
||||
@@ -24,28 +23,12 @@
|
||||
"back": "Takaisin",
|
||||
"statusDisconnected": "Yhteys katkaistu",
|
||||
"loading": "Ladataan",
|
||||
"txt2img": "Teksti kuvaksi",
|
||||
"unifiedCanvas": "Yhdistetty kanvas"
|
||||
"txt2img": "Teksti kuvaksi"
|
||||
},
|
||||
"gallery": {
|
||||
"galleryImageSize": "Kuvan koko",
|
||||
"gallerySettings": "Gallerian asetukset",
|
||||
"autoSwitchNewImages": "Vaihda uusiin kuviin automaattisesti",
|
||||
"noImagesInGallery": "Ei kuvia galleriassa",
|
||||
"loadMore": "Lataa lisää"
|
||||
},
|
||||
"hotkeys": {
|
||||
"keyboardShortcuts": "näppäimistön pikavalinnat",
|
||||
"appHotkeys": "Sovelluksen pikanäppäimet",
|
||||
"generalHotkeys": "Yleiset pikanäppäimet",
|
||||
"galleryHotkeys": "Gallerian pikanäppäimet",
|
||||
"unifiedCanvasHotkeys": "Yhdistetyn kanvaan pikanäppäimet",
|
||||
"cancel": {
|
||||
"desc": "Peruuta kuvan luominen",
|
||||
"title": "Peruuta"
|
||||
},
|
||||
"invoke": {
|
||||
"desc": "Luo kuva"
|
||||
}
|
||||
"noImagesInGallery": "Ei kuvia galleriassa"
|
||||
}
|
||||
}
|
||||
|
||||
File diff suppressed because it is too large
Load Diff
@@ -39,7 +39,6 @@
|
||||
"discordLabel": "דיסקורד",
|
||||
"settingsLabel": "הגדרות",
|
||||
"img2img": "תמונה לתמונה",
|
||||
"unifiedCanvas": "קנבס מאוחד",
|
||||
"nodes": "צמתים",
|
||||
"statusDisconnected": "מנותק",
|
||||
"hotkeysLabel": "מקשים חמים",
|
||||
@@ -48,206 +47,10 @@
|
||||
"load": "טעינה",
|
||||
"back": "אחורה"
|
||||
},
|
||||
"hotkeys": {
|
||||
"toggleGallery": {
|
||||
"desc": "פתח וסגור את מגירת הגלריה",
|
||||
"title": "הצג את הגלריה"
|
||||
},
|
||||
"keyboardShortcuts": "קיצורי מקלדת",
|
||||
"appHotkeys": "קיצורי אפליקציה",
|
||||
"generalHotkeys": "קיצורי דרך כלליים",
|
||||
"galleryHotkeys": "קיצורי דרך של הגלריה",
|
||||
"unifiedCanvasHotkeys": "קיצורי דרך לקנבס המאוחד",
|
||||
"invoke": {
|
||||
"title": "הפעל",
|
||||
"desc": "צור תמונה"
|
||||
},
|
||||
"focusPrompt": {
|
||||
"title": "התמקדות על הבקשה",
|
||||
"desc": "התמקדות על איזור הקלדת הבקשה"
|
||||
},
|
||||
"toggleOptions": {
|
||||
"desc": "פתח וסגור את פאנל ההגדרות",
|
||||
"title": "הצג הגדרות"
|
||||
},
|
||||
"pinOptions": {
|
||||
"title": "הצמד הגדרות",
|
||||
"desc": "הצמד את פאנל ההגדרות"
|
||||
},
|
||||
"changeTabs": {
|
||||
"title": "החלף לשוניות",
|
||||
"desc": "החלף לאיזור עבודה אחר"
|
||||
},
|
||||
"consoleToggle": {
|
||||
"desc": "פתח וסגור את הקונסול",
|
||||
"title": "הצג קונסול"
|
||||
},
|
||||
"setPrompt": {
|
||||
"title": "הגדרת בקשה",
|
||||
"desc": "שימוש בבקשה של התמונה הנוכחית"
|
||||
},
|
||||
"restoreFaces": {
|
||||
"desc": "שחזור התמונה הנוכחית",
|
||||
"title": "שחזור פרצופים"
|
||||
},
|
||||
"showInfo": {
|
||||
"title": "הצג מידע",
|
||||
"desc": "הצגת פרטי מטא-נתונים של התמונה הנוכחית"
|
||||
},
|
||||
"sendToImageToImage": {
|
||||
"title": "שלח לתמונה לתמונה",
|
||||
"desc": "שלח תמונה נוכחית לתמונה לתמונה"
|
||||
},
|
||||
"deleteImage": {
|
||||
"title": "מחק תמונה",
|
||||
"desc": "מחק את התמונה הנוכחית"
|
||||
},
|
||||
"closePanels": {
|
||||
"title": "סגור לוחות",
|
||||
"desc": "סוגר לוחות פתוחים"
|
||||
},
|
||||
"previousImage": {
|
||||
"title": "תמונה קודמת",
|
||||
"desc": "הצג את התמונה הקודמת בגלריה"
|
||||
},
|
||||
"decreaseGalleryThumbSize": {
|
||||
"title": "הקטנת גודל תמונת גלריה",
|
||||
"desc": "מקטין את גודל התמונות הממוזערות של הגלריה"
|
||||
},
|
||||
"selectBrush": {
|
||||
"desc": "בוחר את מברשת הקנבס",
|
||||
"title": "בחר מברשת"
|
||||
},
|
||||
"selectEraser": {
|
||||
"title": "בחר מחק",
|
||||
"desc": "בוחר את מחק הקנבס"
|
||||
},
|
||||
"decreaseBrushSize": {
|
||||
"title": "הקטנת גודל המברשת",
|
||||
"desc": "מקטין את גודל מברשת הקנבס/מחק"
|
||||
},
|
||||
"increaseBrushSize": {
|
||||
"desc": "מגדיל את גודל מברשת הקנבס/מחק",
|
||||
"title": "הגדלת גודל המברשת"
|
||||
},
|
||||
"decreaseBrushOpacity": {
|
||||
"title": "הפחת את אטימות המברשת",
|
||||
"desc": "מקטין את האטימות של מברשת הקנבס"
|
||||
},
|
||||
"increaseBrushOpacity": {
|
||||
"title": "הגדל את אטימות המברשת",
|
||||
"desc": "מגביר את האטימות של מברשת הקנבס"
|
||||
},
|
||||
"moveTool": {
|
||||
"title": "כלי הזזה",
|
||||
"desc": "מאפשר ניווט על קנבס"
|
||||
},
|
||||
"fillBoundingBox": {
|
||||
"desc": "ממלא את התיבה התוחמת בצבע מברשת",
|
||||
"title": "מילוי תיבה תוחמת"
|
||||
},
|
||||
"eraseBoundingBox": {
|
||||
"desc": "מוחק את אזור התיבה התוחמת",
|
||||
"title": "מחק תיבה תוחמת"
|
||||
},
|
||||
"colorPicker": {
|
||||
"title": "בחר בבורר צבעים",
|
||||
"desc": "בוחר את בורר צבעי הקנבס"
|
||||
},
|
||||
"toggleSnap": {
|
||||
"title": "הפעל הצמדה",
|
||||
"desc": "מפעיל הצמדה לרשת"
|
||||
},
|
||||
"quickToggleMove": {
|
||||
"title": "הפעלה מהירה להזזה",
|
||||
"desc": "מפעיל זמנית את מצב ההזזה"
|
||||
},
|
||||
"toggleLayer": {
|
||||
"title": "הפעל שכבה",
|
||||
"desc": "הפעל בחירת שכבת בסיס/מסיכה"
|
||||
},
|
||||
"clearMask": {
|
||||
"title": "נקה מסיכה",
|
||||
"desc": "נקה את כל המסכה"
|
||||
},
|
||||
"hideMask": {
|
||||
"desc": "הסתרה והצגה של מסיכה",
|
||||
"title": "הסתר מסיכה"
|
||||
},
|
||||
"showHideBoundingBox": {
|
||||
"title": "הצגה/הסתרה של תיבה תוחמת",
|
||||
"desc": "הפעל תצוגה של התיבה התוחמת"
|
||||
},
|
||||
"mergeVisible": {
|
||||
"title": "מיזוג תוכן גלוי",
|
||||
"desc": "מיזוג כל השכבות הגלויות של הקנבס"
|
||||
},
|
||||
"saveToGallery": {
|
||||
"title": "שמור לגלריה",
|
||||
"desc": "שמור את הקנבס הנוכחי בגלריה"
|
||||
},
|
||||
"copyToClipboard": {
|
||||
"title": "העתק ללוח ההדבקה",
|
||||
"desc": "העתק את הקנבס הנוכחי ללוח ההדבקה"
|
||||
},
|
||||
"downloadImage": {
|
||||
"title": "הורד תמונה",
|
||||
"desc": "הורד את הקנבס הנוכחי"
|
||||
},
|
||||
"undoStroke": {
|
||||
"title": "בטל משיכה",
|
||||
"desc": "בטל משיכת מברשת"
|
||||
},
|
||||
"redoStroke": {
|
||||
"title": "בצע שוב משיכה",
|
||||
"desc": "ביצוע מחדש של משיכת מברשת"
|
||||
},
|
||||
"resetView": {
|
||||
"title": "איפוס תצוגה",
|
||||
"desc": "אפס תצוגת קנבס"
|
||||
},
|
||||
"previousStagingImage": {
|
||||
"desc": "תמונת אזור ההערכות הקודמת",
|
||||
"title": "תמונת הערכות קודמת"
|
||||
},
|
||||
"nextStagingImage": {
|
||||
"title": "תמנות הערכות הבאה",
|
||||
"desc": "תמונת אזור ההערכות הבאה"
|
||||
},
|
||||
"acceptStagingImage": {
|
||||
"desc": "אשר את תמונת איזור ההערכות הנוכחית",
|
||||
"title": "אשר תמונת הערכות"
|
||||
},
|
||||
"cancel": {
|
||||
"desc": "ביטול יצירת תמונה",
|
||||
"title": "ביטול"
|
||||
},
|
||||
"maximizeWorkSpace": {
|
||||
"title": "מקסם את איזור העבודה",
|
||||
"desc": "סגור פאנלים ומקסם את איזור העבודה"
|
||||
},
|
||||
"setSeed": {
|
||||
"title": "הגדר זרע",
|
||||
"desc": "השתמש בזרע התמונה הנוכחית"
|
||||
},
|
||||
"setParameters": {
|
||||
"title": "הגדרת פרמטרים",
|
||||
"desc": "שימוש בכל הפרמטרים של התמונה הנוכחית"
|
||||
},
|
||||
"increaseGalleryThumbSize": {
|
||||
"title": "הגדל את גודל תמונת הגלריה",
|
||||
"desc": "מגדיל את התמונות הממוזערות של הגלריה"
|
||||
},
|
||||
"nextImage": {
|
||||
"title": "תמונה הבאה",
|
||||
"desc": "הצג את התמונה הבאה בגלריה"
|
||||
}
|
||||
},
|
||||
"gallery": {
|
||||
"galleryImageSize": "גודל תמונה",
|
||||
"gallerySettings": "הגדרות גלריה",
|
||||
"autoSwitchNewImages": "החלף אוטומטית לתמונות חדשות",
|
||||
"loadMore": "טען עוד",
|
||||
"noImagesInGallery": "אין תמונות בגלריה"
|
||||
},
|
||||
"parameters": {
|
||||
@@ -268,8 +71,6 @@
|
||||
"symmetry": "סימטריה",
|
||||
"copyImage": "העתקת תמונה",
|
||||
"downloadImage": "הורדת תמונה",
|
||||
"sendToImg2Img": "שליחה לתמונה לתמונה",
|
||||
"sendToUnifiedCanvas": "שליחה אל קנבס מאוחד",
|
||||
"usePrompt": "שימוש בבקשה",
|
||||
"useSeed": "שימוש בזרע",
|
||||
"useAll": "שימוש בהכל",
|
||||
@@ -290,77 +91,11 @@
|
||||
"resetWebUI": "איפוס ממשק משתמש",
|
||||
"resetWebUIDesc1": "איפוס ממשק המשתמש האינטרנטי מאפס רק את המטמון המקומי של הדפדפן של התמונות וההגדרות שנשמרו. זה לא מוחק תמונות מהדיסק.",
|
||||
"resetComplete": "ממשק המשתמש אופס. יש לבצע רענון דף בכדי לטעון אותו מחדש.",
|
||||
"enableImageDebugging": "הפעלת איתור באגים בתמונה",
|
||||
"resetWebUIDesc2": "אם תמונות לא מופיעות בגלריה או שמשהו אחר לא עובד, נא לנסות איפוס /או אתחול לפני שליחת תקלה ב-GitHub."
|
||||
},
|
||||
"toast": {
|
||||
"uploadFailed": "העלאה נכשלה",
|
||||
"imageCopied": "התמונה הועתקה",
|
||||
"imageNotLoadedDesc": "לא נמצאה תמונה לשליחה למודול תמונה לתמונה",
|
||||
"canvasMerged": "קנבס מוזג",
|
||||
"sentToImageToImage": "נשלח לתמונה לתמונה",
|
||||
"sentToUnifiedCanvas": "נשלח אל קנבס מאוחד",
|
||||
"parametersNotSet": "פרמטרים לא הוגדרו",
|
||||
"metadataLoadFailed": "טעינת מטא-נתונים נכשלה"
|
||||
},
|
||||
"tooltip": {
|
||||
"feature": {
|
||||
"gallery": "הגלריה מציגה יצירות מתיקיית הפלטים בעת יצירתם. ההגדרות מאוחסנות בתוך קבצים ונגישות באמצעות תפריט הקשר.",
|
||||
"upscale": "השתמש ב-ESRGAN כדי להגדיל את התמונה מיד לאחר היצירה.",
|
||||
"prompt": "זהו שדה הבקשה. הבקשה כוללת אובייקטי יצירה ומונחים סגנוניים. באפשרותך להוסיף משקל (חשיבות אסימון) גם בשורת הפקודה, אך פקודות ופרמטרים של CLI לא יפעלו.",
|
||||
"other": "אפשרויות אלה יאפשרו מצבי עיבוד חלופיים עבור ההרצה. 'ריצוף חלק' ייצור תבניות חוזרות בפלט. 'רזולוציה גבוהה' נוצר בשני שלבים עם img2img: השתמש בהגדרה זו כאשר אתה רוצה תמונה גדולה וקוהרנטית יותר ללא חפצים. פעולה זאת תקח יותר זמן מפעולת טקסט לתמונה רגילה.",
|
||||
"seed": "ערך הזרע משפיע על הרעש הראשוני שממנו נוצרת התמונה. אתה יכול להשתמש בזרעים שכבר קיימים מתמונות קודמות. 'סף רעש' משמש להפחתת חפצים בערכי CFG גבוהים (נסה את טווח 0-10), ופרלין כדי להוסיף רעשי פרלין במהלך היצירה: שניהם משמשים להוספת וריאציה לתפוקות שלך.",
|
||||
"boundingBox": "התיבה התוחמת זהה להגדרות 'רוחב' ו'גובה' עבור 'טקסט לתמונה' או 'תמונה לתמונה'. רק האזור בתיבה יעובד."
|
||||
}
|
||||
},
|
||||
"unifiedCanvas": {
|
||||
"layer": "שכבה",
|
||||
"base": "בסיס",
|
||||
"maskingOptions": "אפשרויות מסכות",
|
||||
"enableMask": "הפעלת מסיכה",
|
||||
"colorPicker": "בוחר הצבעים",
|
||||
"preserveMaskedArea": "שימור איזור ממוסך",
|
||||
"clearMask": "ניקוי מסיכה",
|
||||
"brush": "מברשת",
|
||||
"eraser": "מחק",
|
||||
"fillBoundingBox": "מילוי תיבה תוחמת",
|
||||
"eraseBoundingBox": "מחק תיבה תוחמת",
|
||||
"copyToClipboard": "העתק ללוח ההדבקה",
|
||||
"downloadAsImage": "הורדה כתמונה",
|
||||
"undo": "ביטול",
|
||||
"redo": "ביצוע מחדש",
|
||||
"clearCanvas": "ניקוי קנבס",
|
||||
"showGrid": "הצגת רשת",
|
||||
"snapToGrid": "הצמדה לרשת",
|
||||
"darkenOutsideSelection": "הכהיית בחירה חיצונית",
|
||||
"saveBoxRegionOnly": "שמירת איזור תיבה בלבד",
|
||||
"limitStrokesToBox": "הגבלת משיכות לקופסא",
|
||||
"showCanvasDebugInfo": "הצגת מידע איתור באגים בקנבס",
|
||||
"clearCanvasHistory": "ניקוי הסטוריית קנבס",
|
||||
"clearHistory": "ניקוי היסטוריה",
|
||||
"clearCanvasHistoryConfirm": "האם את/ה בטוח/ה שברצונך לנקות את היסטוריית הקנבס?",
|
||||
"activeLayer": "שכבה פעילה",
|
||||
"canvasScale": "קנה מידה של קנבס",
|
||||
"canvasDimensions": "מידות קנבס",
|
||||
"previous": "הקודם",
|
||||
"next": "הבא",
|
||||
"accept": "אישור",
|
||||
"discardAll": "בטל הכל",
|
||||
"boundingBox": "תיבה תוחמת",
|
||||
"scaledBoundingBox": "תיבה תוחמת לאחר שינוי קנה מידה",
|
||||
"brushOptions": "אפשרויות מברשת",
|
||||
"brushSize": "גודל",
|
||||
"mergeVisible": "מיזוג תוכן גלוי",
|
||||
"move": "הזזה",
|
||||
"resetView": "איפוס תצוגה",
|
||||
"saveToGallery": "שמור לגלריה",
|
||||
"canvasSettings": "הגדרות קנבס",
|
||||
"showIntermediates": "הצגת מתווכים",
|
||||
"autoSaveToGallery": "שמירה אוטומטית בגלריה",
|
||||
"clearCanvasHistoryMessage": "ניקוי היסטוריית הקנבס משאיר את הקנבס הנוכחי ללא שינוי, אך מנקה באופן בלתי הפיך את היסטוריית הביטול והביצוע מחדש.",
|
||||
"boundingBoxPosition": "מיקום תיבה תוחמת",
|
||||
"canvasPosition": "מיקום קנבס",
|
||||
"cursorPosition": "מיקום הסמן",
|
||||
"mask": "מסכה"
|
||||
"parametersNotSet": "פרמטרים לא הוגדרו"
|
||||
}
|
||||
}
|
||||
|
||||
@@ -4,8 +4,7 @@
|
||||
"uploadImage": "Fénykép feltöltése",
|
||||
"nextImage": "Következő kép",
|
||||
"previousImage": "Előző kép",
|
||||
"menu": "Menü",
|
||||
"loadMore": "Több betöltése"
|
||||
"menu": "Menü"
|
||||
},
|
||||
"boards": {
|
||||
"cancel": "Mégsem",
|
||||
|
||||
File diff suppressed because it is too large
Load Diff
@@ -10,7 +10,6 @@
|
||||
"cancel": "キャンセル",
|
||||
"accept": "同意",
|
||||
"img2img": "img2img",
|
||||
"unifiedCanvas": "Unified Canvas",
|
||||
"loading": "ロード中",
|
||||
"githubLabel": "Github",
|
||||
"hotkeysLabel": "ホットキー",
|
||||
@@ -23,7 +22,6 @@
|
||||
"dontAskMeAgain": "次回から確認しない",
|
||||
"areYouSure": "本当によろしいですか?",
|
||||
"on": "オン",
|
||||
"nodeEditor": "ノードエディター",
|
||||
"ipAdapter": "IPアダプター",
|
||||
"auto": "自動",
|
||||
"openInNewTab": "新しいタブで開く",
|
||||
@@ -71,8 +69,6 @@
|
||||
"prevPage": "前のページ",
|
||||
"unknownError": "未知のエラー",
|
||||
"orderBy": "並び順:",
|
||||
"comparing": "比較中",
|
||||
"comparingDesc": "2 つの画像の比較する",
|
||||
"enabled": "有効",
|
||||
"notInstalled": "未インストール",
|
||||
"positivePrompt": "プロンプト",
|
||||
@@ -81,31 +77,24 @@
|
||||
"aboutDesc": "Invokeを業務で利用する場合はマークしてください:",
|
||||
"beta": "ベータ",
|
||||
"disabled": "無効",
|
||||
"loglevel": "ログラベル",
|
||||
"editor": "エディタ",
|
||||
"safetensors": "Safetensors",
|
||||
"tab": "タブ",
|
||||
"viewingDesc": "画像を大きなギャラリービューで開く",
|
||||
"editing": "編集",
|
||||
"editingDesc": "コントロールレイヤキャンバスで編集",
|
||||
"toResolve": "解決方法"
|
||||
},
|
||||
"gallery": {
|
||||
"galleryImageSize": "画像のサイズ",
|
||||
"gallerySettings": "ギャラリーの設定",
|
||||
"loadMore": "さらに読み込む",
|
||||
"noImagesInGallery": "表示する画像がありません",
|
||||
"autoSwitchNewImages": "新しい画像に自動切替",
|
||||
"copy": "コピー",
|
||||
"image": "画像",
|
||||
"setCurrentImage": "現在の画像としてセット",
|
||||
"autoAssignBoardOnClick": "クリックしたボードに自動追加",
|
||||
"featuresWillReset": "この画像を削除すると、これらの機能は即座にリセットされます。",
|
||||
"unstarImage": "スターを外す",
|
||||
"loading": "ロード中",
|
||||
"assets": "アセット",
|
||||
"currentlyInUse": "この画像は現在下記の機能を使用しています:",
|
||||
"problemDeletingImages": "画像の削除中に問題が発生",
|
||||
"drop": "ドロップ",
|
||||
"dropOrUpload": "$t(gallery.drop) またはアップロード",
|
||||
"deleteImage_other": "画像を削除",
|
||||
@@ -116,7 +105,6 @@
|
||||
"bulkDownloadRequestedDesc": "ダウンロードの準備中です。しばらくお待ちください。",
|
||||
"bulkDownloadRequestFailed": "ダウンロード準備中に問題が発生",
|
||||
"bulkDownloadFailed": "ダウンロード失敗",
|
||||
"problemDeletingImagesDesc": "1つ以上の画像を削除できませんでした",
|
||||
"alwaysShowImageSizeBadge": "画像サイズバッジを常に表示",
|
||||
"dropToUpload": "$t(gallery.drop) してアップロード",
|
||||
"noImageSelected": "画像が選択されていません",
|
||||
@@ -132,7 +120,6 @@
|
||||
"sideBySide": "横並び",
|
||||
"hover": "ホバー",
|
||||
"swapImages": "画像を入れ替える",
|
||||
"compareOptions": "比較オプション",
|
||||
"stretchToFit": "画面に合わせる",
|
||||
"exitCompare": "比較を終了する",
|
||||
"compareHelp1": "<Kbd>Alt</Kbd> キーを押しながらギャラリー画像をクリックするか、矢印キーを使用して比較画像を変更します。",
|
||||
@@ -141,227 +128,9 @@
|
||||
"compareHelp2": "<Kbd>M</Kbd> キーを押して比較モードを切り替えます。"
|
||||
},
|
||||
"hotkeys": {
|
||||
"keyboardShortcuts": "ホットキー",
|
||||
"appHotkeys": "アプリケーション",
|
||||
"generalHotkeys": "一般",
|
||||
"galleryHotkeys": "ギャラリー",
|
||||
"unifiedCanvasHotkeys": "Unified Canvasのホットキー",
|
||||
"invoke": {
|
||||
"desc": "画像を生成",
|
||||
"title": "Invoke"
|
||||
},
|
||||
"cancel": {
|
||||
"title": "キャンセル",
|
||||
"desc": "現在のキューをキャンセル"
|
||||
},
|
||||
"focusPrompt": {
|
||||
"desc": "プロンプトテキストボックスにフォーカス",
|
||||
"title": "プロンプトにフォーカス"
|
||||
},
|
||||
"toggleOptions": {
|
||||
"title": "オプションパネルのトグル",
|
||||
"desc": "オプションパネルの開閉"
|
||||
},
|
||||
"pinOptions": {
|
||||
"title": "ピン",
|
||||
"desc": "オプションパネルを固定"
|
||||
},
|
||||
"toggleGallery": {
|
||||
"title": "ギャラリーのトグル",
|
||||
"desc": "ギャラリードロワーの開閉"
|
||||
},
|
||||
"maximizeWorkSpace": {
|
||||
"title": "作業領域の最大化",
|
||||
"desc": "パネルを閉じて、作業領域を最大に"
|
||||
},
|
||||
"changeTabs": {
|
||||
"title": "タブの切替",
|
||||
"desc": "他の作業領域と切替"
|
||||
},
|
||||
"consoleToggle": {
|
||||
"title": "コンソールのトグル",
|
||||
"desc": "コンソールの開閉"
|
||||
},
|
||||
"setPrompt": {
|
||||
"title": "プロンプトをセット",
|
||||
"desc": "現在の画像のプロンプトを使用"
|
||||
},
|
||||
"setSeed": {
|
||||
"title": "シード値をセット",
|
||||
"desc": "現在の画像のシード値を使用"
|
||||
},
|
||||
"setParameters": {
|
||||
"title": "パラメータをセット",
|
||||
"desc": "現在の画像のすべてのパラメータを使用"
|
||||
},
|
||||
"restoreFaces": {
|
||||
"title": "顔の修復",
|
||||
"desc": "現在の画像を修復"
|
||||
},
|
||||
"showInfo": {
|
||||
"title": "情報を見る",
|
||||
"desc": "現在の画像のメタデータ情報を表示"
|
||||
},
|
||||
"sendToImageToImage": {
|
||||
"title": "Image To Imageに転送",
|
||||
"desc": "現在の画像をImage to Imageに転送"
|
||||
},
|
||||
"deleteImage": {
|
||||
"title": "画像を削除",
|
||||
"desc": "現在の画像を削除"
|
||||
},
|
||||
"closePanels": {
|
||||
"title": "パネルを閉じる",
|
||||
"desc": "開いているパネルを閉じる"
|
||||
},
|
||||
"previousImage": {
|
||||
"title": "前の画像",
|
||||
"desc": "ギャラリー内の1つ前の画像を表示"
|
||||
},
|
||||
"nextImage": {
|
||||
"title": "次の画像",
|
||||
"desc": "ギャラリー内の1つ後の画像を表示"
|
||||
},
|
||||
"increaseGalleryThumbSize": {
|
||||
"title": "ギャラリーの画像を拡大",
|
||||
"desc": "ギャラリーのサムネイル画像を拡大"
|
||||
},
|
||||
"decreaseGalleryThumbSize": {
|
||||
"title": "ギャラリーの画像サイズを縮小",
|
||||
"desc": "ギャラリーのサムネイル画像を縮小"
|
||||
},
|
||||
"selectBrush": {
|
||||
"title": "ブラシを選択",
|
||||
"desc": "ブラシを選択"
|
||||
},
|
||||
"selectEraser": {
|
||||
"title": "消しゴムを選択",
|
||||
"desc": "消しゴムを選択"
|
||||
},
|
||||
"decreaseBrushSize": {
|
||||
"title": "ブラシサイズを縮小",
|
||||
"desc": "ブラシ/消しゴムのサイズを縮小"
|
||||
},
|
||||
"increaseBrushSize": {
|
||||
"title": "ブラシサイズを拡大",
|
||||
"desc": "ブラシ/消しゴムのサイズを拡大"
|
||||
},
|
||||
"decreaseBrushOpacity": {
|
||||
"title": "ブラシの不透明度を下げる",
|
||||
"desc": "キャンバスブラシの不透明度を下げる"
|
||||
},
|
||||
"increaseBrushOpacity": {
|
||||
"title": "ブラシの不透明度を上げる",
|
||||
"desc": "キャンバスブラシの不透明度を上げる"
|
||||
},
|
||||
"fillBoundingBox": {
|
||||
"title": "バウンディングボックスを塗りつぶす",
|
||||
"desc": "ブラシの色でバウンディングボックス領域を塗りつぶす"
|
||||
},
|
||||
"eraseBoundingBox": {
|
||||
"title": "バウンディングボックスを消す",
|
||||
"desc": "バウンディングボックス領域を消す"
|
||||
},
|
||||
"colorPicker": {
|
||||
"title": "カラーピッカーを選択",
|
||||
"desc": "カラーピッカーを選択"
|
||||
},
|
||||
"toggleLayer": {
|
||||
"title": "レイヤーを切替",
|
||||
"desc": "マスク/ベースレイヤの選択を切替"
|
||||
},
|
||||
"clearMask": {
|
||||
"title": "マスクを消す",
|
||||
"desc": "マスク全体を消す"
|
||||
},
|
||||
"hideMask": {
|
||||
"title": "マスクを非表示",
|
||||
"desc": "マスクを表示/非表示"
|
||||
},
|
||||
"showHideBoundingBox": {
|
||||
"title": "バウンディングボックスを表示/非表示",
|
||||
"desc": "バウンディングボックスの表示/非表示を切替"
|
||||
},
|
||||
"saveToGallery": {
|
||||
"title": "ギャラリーに保存",
|
||||
"desc": "現在のキャンバスをギャラリーに保存"
|
||||
},
|
||||
"copyToClipboard": {
|
||||
"title": "クリップボードにコピー",
|
||||
"desc": "現在のキャンバスをクリップボードにコピー"
|
||||
},
|
||||
"downloadImage": {
|
||||
"title": "画像をダウンロード",
|
||||
"desc": "現在の画像をダウンロード"
|
||||
},
|
||||
"resetView": {
|
||||
"title": "キャンバスをリセット",
|
||||
"desc": "キャンバスをリセット"
|
||||
},
|
||||
"acceptStagingImage": {
|
||||
"title": "プレビュー画像の採用",
|
||||
"desc": "現在のプレビュー画像を採用する"
|
||||
},
|
||||
"addNodes": {
|
||||
"desc": "ノード追加メニューを開く",
|
||||
"title": "ノードを追加"
|
||||
},
|
||||
"moveTool": {
|
||||
"desc": "キャンバスを移動する",
|
||||
"title": "手のひらツール"
|
||||
},
|
||||
"nextStagingImage": {
|
||||
"desc": "次のプレビュー画像",
|
||||
"title": "次のステージング画像"
|
||||
},
|
||||
"cancelAndClear": {
|
||||
"desc": "生成をキャンセルしキューもクリアします",
|
||||
"title": "キャンセルとクリア"
|
||||
},
|
||||
"mergeVisible": {
|
||||
"title": "表示レイヤーを統合",
|
||||
"desc": "全ての表示レイヤーを統合"
|
||||
},
|
||||
"searchHotkeys": "ホットキーを検索",
|
||||
"clearSearch": "検索をクリア",
|
||||
"noHotkeysFound": "ホットキーが見つかりません",
|
||||
"remixImage": {
|
||||
"title": "画像をリミックス",
|
||||
"desc": "現在の画像のシード値を除く全パラメータを使用"
|
||||
},
|
||||
"redoStroke": {
|
||||
"title": "ストロークをやり直す",
|
||||
"desc": "ブラシストロークのやり直し"
|
||||
},
|
||||
"resetOptionsAndGallery": {
|
||||
"title": "オプションとギャラリーをリセット",
|
||||
"desc": "オプションとギャラリーパネルをリセット"
|
||||
},
|
||||
"quickToggleMove": {
|
||||
"title": "高速トグル切り替え",
|
||||
"desc": "一時的に移動モードを切り替える"
|
||||
},
|
||||
"toggleSnap": {
|
||||
"title": "スナップの切り替え",
|
||||
"desc": "グリッドへのスナップの切り替え"
|
||||
},
|
||||
"previousStagingImage": {
|
||||
"desc": "ステージング領域の前の画像",
|
||||
"title": "前のステージング画像"
|
||||
},
|
||||
"nodesHotkeys": "ノード",
|
||||
"toggleOptionsAndGallery": {
|
||||
"desc": "オプションとギャラリーパネルのオンオフを切り替える",
|
||||
"title": "オプションとギャラリーを切り替える"
|
||||
},
|
||||
"undoStroke": {
|
||||
"desc": "ブラシストロークの取り消し",
|
||||
"title": "ストロークの取り消し"
|
||||
},
|
||||
"toggleViewer": {
|
||||
"desc": "イメージ ビューアーと現在のタブのワークスペースを切り替えます。",
|
||||
"title": "画像ビューアの切り替え"
|
||||
}
|
||||
"noHotkeysFound": "ホットキーが見つかりません"
|
||||
},
|
||||
"modelManager": {
|
||||
"modelManager": "モデルマネージャ",
|
||||
@@ -398,7 +167,6 @@
|
||||
"modelConverted": "モデル変換が完了しました",
|
||||
"predictionType": "予測タイプ(安定したディフュージョン 2.x モデルおよび一部の安定したディフュージョン 1.x モデル用)",
|
||||
"selectModel": "モデルを選択",
|
||||
"modelSyncFailed": "モデルの同期に失敗しました",
|
||||
"advanced": "高度な設定",
|
||||
"modelDeleted": "モデルが削除されました",
|
||||
"convertToDiffusersHelpText2": "このプロセスでは、モデルマネージャーのエントリーを同じモデルのディフューザーバージョンに置き換えます。",
|
||||
@@ -408,7 +176,6 @@
|
||||
"syncModels": "モデルを同期",
|
||||
"modelType": "モデルタイプ",
|
||||
"convertToDiffusersHelpText1": "このモデルは 🧨 Diffusers フォーマットに変換されます。",
|
||||
"modelsSynced": "モデルが同期されました",
|
||||
"convertToDiffusersHelpText3": "チェックポイントファイルは、InvokeAIルートフォルダ内にある場合、ディスクから削除されます。カスタムロケーションにある場合は、削除されません。",
|
||||
"convertToDiffusersHelpText4": "これは一回限りのプロセスです。コンピュータの仕様によっては、約30秒から60秒かかる可能性があります。",
|
||||
"cancel": "キャンセル"
|
||||
@@ -426,18 +193,12 @@
|
||||
"scaleBeforeProcessing": "処理前のスケール",
|
||||
"scaledWidth": "幅のスケール",
|
||||
"scaledHeight": "高さのスケール",
|
||||
"sendToImg2Img": "Image to Imageに転送",
|
||||
"sendToUnifiedCanvas": "Unified Canvasに転送",
|
||||
"downloadImage": "画像をダウンロード",
|
||||
"usePrompt": "プロンプトを使用",
|
||||
"useSeed": "シード値を使用",
|
||||
"useAll": "すべてを使用",
|
||||
"info": "情報",
|
||||
"showOptionsPanel": "オプションパネルを表示",
|
||||
"invoke": {
|
||||
"noControlImageForControlAdapter": "コントロールアダプター #{{number}} に画像がありません",
|
||||
"noModelForControlAdapter": "コントロールアダプター #{{number}} のモデルが選択されていません。"
|
||||
},
|
||||
"iterations": "生成回数",
|
||||
"general": "基本設定"
|
||||
},
|
||||
@@ -445,7 +206,6 @@
|
||||
"models": "モデル",
|
||||
"displayInProgress": "生成中の画像を表示する",
|
||||
"confirmOnDelete": "削除時に確認",
|
||||
"enableImageDebugging": "画像のデバッグを有効化",
|
||||
"resetWebUI": "WebUIをリセット",
|
||||
"resetWebUIDesc1": "WebUIのリセットは、画像と保存された設定のキャッシュをリセットするだけです。画像を削除するわけではありません。",
|
||||
"resetWebUIDesc2": "もしギャラリーに画像が表示されないなど、何か問題が発生した場合はGitHubにissueを提出する前にリセットを試してください。",
|
||||
@@ -453,63 +213,7 @@
|
||||
},
|
||||
"toast": {
|
||||
"uploadFailed": "アップロード失敗",
|
||||
"imageCopied": "画像をコピー",
|
||||
"imageNotLoadedDesc": "Image To Imageに転送する画像が見つかりません。",
|
||||
"canvasMerged": "Canvas Merged",
|
||||
"sentToImageToImage": "Image To Imageに転送",
|
||||
"sentToUnifiedCanvas": "Unified Canvasに転送",
|
||||
"metadataLoadFailed": "メタデータの読み込みに失敗。"
|
||||
},
|
||||
"tooltip": {
|
||||
"feature": {
|
||||
"prompt": "これはプロンプトフィールドです。プロンプトには生成オブジェクトや文法用語が含まれます。プロンプトにも重み(Tokenの重要度)を付けることができますが、CLIコマンドやパラメータは機能しません。",
|
||||
"gallery": "ギャラリーは、出力先フォルダから生成物を表示します。設定はファイル内に保存され、コンテキストメニューからアクセスできます。.",
|
||||
"seed": "シード値は、画像が形成される際の初期ノイズに影響します。以前の画像から既に存在するシードを使用することができます。ノイズしきい値は高いCFG値でのアーティファクトを軽減するために使用され、Perlinは生成中にPerlinノイズを追加します(0-10の範囲を試してみてください): どちらも出力にバリエーションを追加するのに役立ちます。",
|
||||
"upscale": "生成直後の画像をアップスケールするには、ESRGANを使用します。",
|
||||
"boundingBox": "バウンディングボックスは、Text To ImageまたはImage To Imageの幅/高さの設定と同じです。ボックス内の領域のみが処理されます。"
|
||||
}
|
||||
},
|
||||
"unifiedCanvas": {
|
||||
"mask": "マスク",
|
||||
"maskingOptions": "マスクのオプション",
|
||||
"enableMask": "マスクを有効化",
|
||||
"preserveMaskedArea": "マスク領域の保存",
|
||||
"clearMask": "マスクを解除",
|
||||
"brush": "ブラシ",
|
||||
"eraser": "消しゴム",
|
||||
"fillBoundingBox": "バウンディングボックスの塗りつぶし",
|
||||
"eraseBoundingBox": "バウンディングボックスの消去",
|
||||
"colorPicker": "カラーピッカー",
|
||||
"brushOptions": "ブラシオプション",
|
||||
"brushSize": "サイズ",
|
||||
"saveToGallery": "ギャラリーに保存",
|
||||
"copyToClipboard": "クリップボードにコピー",
|
||||
"downloadAsImage": "画像としてダウンロード",
|
||||
"undo": "取り消し",
|
||||
"redo": "やり直し",
|
||||
"clearCanvas": "キャンバスを片付ける",
|
||||
"canvasSettings": "キャンバスの設定",
|
||||
"showGrid": "グリッドを表示",
|
||||
"darkenOutsideSelection": "外周を暗くする",
|
||||
"autoSaveToGallery": "ギャラリーに自動保存",
|
||||
"saveBoxRegionOnly": "ボックス領域のみ保存",
|
||||
"showCanvasDebugInfo": "キャンバスのデバッグ情報を表示",
|
||||
"clearCanvasHistory": "キャンバスの履歴を削除",
|
||||
"clearHistory": "履歴を削除",
|
||||
"clearCanvasHistoryMessage": "履歴を消去すると現在のキャンバスは残りますが、取り消しややり直しの履歴は不可逆的に消去されます。",
|
||||
"clearCanvasHistoryConfirm": "履歴を削除しますか?",
|
||||
"activeLayer": "Active Layer",
|
||||
"canvasScale": "Canvas Scale",
|
||||
"boundingBox": "バウンディングボックス",
|
||||
"boundingBoxPosition": "バウンディングボックスの位置",
|
||||
"canvasDimensions": "キャンバスの大きさ",
|
||||
"canvasPosition": "キャンバスの位置",
|
||||
"cursorPosition": "カーソルの位置",
|
||||
"previous": "前",
|
||||
"next": "次",
|
||||
"accept": "同意",
|
||||
"discardAll": "すべて破棄",
|
||||
"snapToGrid": "グリッドにスナップ"
|
||||
"imageCopied": "画像をコピー"
|
||||
},
|
||||
"accessibility": {
|
||||
"invokeProgressBar": "進捗バー",
|
||||
@@ -517,106 +221,13 @@
|
||||
"uploadImage": "画像をアップロード",
|
||||
"previousImage": "前の画像",
|
||||
"nextImage": "次の画像",
|
||||
"showOptionsPanel": "サイドパネルを表示",
|
||||
"showGalleryPanel": "ギャラリーパネルを表示",
|
||||
"menu": "メニュー",
|
||||
"loadMore": "さらに読み込む",
|
||||
"createIssue": "問題を報告",
|
||||
"resetUI": "$t(accessibility.reset) UI",
|
||||
"mode": "モード:",
|
||||
"about": "Invoke について",
|
||||
"submitSupportTicket": "サポート依頼を送信する"
|
||||
},
|
||||
"controlnet": {
|
||||
"resize": "リサイズ",
|
||||
"showAdvanced": "高度な設定を表示",
|
||||
"addT2IAdapter": "$t(common.t2iAdapter)を追加",
|
||||
"importImageFromCanvas": "キャンバスから画像をインポート",
|
||||
"lineartDescription": "画像を線画に変換",
|
||||
"importMaskFromCanvas": "キャンバスからマスクをインポート",
|
||||
"hideAdvanced": "高度な設定を非表示",
|
||||
"resetControlImage": "コントロール画像をリセット",
|
||||
"beginEndStepPercent": "開始 / 終了ステップパーセンテージ",
|
||||
"duplicate": "複製",
|
||||
"balanced": "バランス",
|
||||
"prompt": "プロンプト",
|
||||
"depthMidasDescription": "Midasを使用して深度マップを生成",
|
||||
"control": "コントロール",
|
||||
"resizeMode": "リサイズモード",
|
||||
"weight": "重み",
|
||||
"selectModel": "モデルを選択",
|
||||
"crop": "切り抜き",
|
||||
"w": "幅",
|
||||
"processor": "プロセッサー",
|
||||
"addControlNet": "$t(common.controlNet)を追加",
|
||||
"none": "なし",
|
||||
"detectResolution": "検出解像度",
|
||||
"pidiDescription": "PIDI画像処理",
|
||||
"controlMode": "コントロールモード",
|
||||
"fill": "塗りつぶし",
|
||||
"cannyDescription": "Canny 境界検出",
|
||||
"addIPAdapter": "$t(common.ipAdapter)を追加",
|
||||
"colorMapDescription": "画像からカラーマップを生成",
|
||||
"lineartAnimeDescription": "アニメスタイルの線画処理",
|
||||
"imageResolution": "画像解像度",
|
||||
"megaControl": "メガコントロール",
|
||||
"lowThreshold": "最低閾値",
|
||||
"autoConfigure": "プロセッサーを自動設定",
|
||||
"highThreshold": "最大閾値",
|
||||
"saveControlImage": "コントロール画像を保存",
|
||||
"toggleControlNet": "このコントロールネットを切り替え",
|
||||
"delete": "削除",
|
||||
"controlAdapter_other": "コントロールアダプター",
|
||||
"colorMapTileSize": "タイルサイズ",
|
||||
"mediapipeFaceDescription": "Mediapipeを使用して顔を検出",
|
||||
"depthZoeDescription": "Zoeを使用して深度マップを生成",
|
||||
"setControlImageDimensions": "コントロール画像のサイズを幅と高さにセット",
|
||||
"amult": "a_mult",
|
||||
"contentShuffleDescription": "画像の内容をシャッフルします",
|
||||
"bgth": "bg_th",
|
||||
"controlnet": "$t(controlnet.controlAdapter_one) #{{number}} ($t(common.controlNet))",
|
||||
"ip_adapter": "$t(controlnet.controlAdapter_one) #{{number}} ($t(common.ipAdapter))",
|
||||
"t2i_adapter": "$t(controlnet.controlAdapter_one) #{{number}} ($t(common.t2iAdapter))",
|
||||
"minConfidence": "最小確信度",
|
||||
"colorMap": "Color",
|
||||
"noneDescription": "処理は行われていません",
|
||||
"canny": "Canny",
|
||||
"hedDescription": "階層的エッジ検出",
|
||||
"maxFaces": "顔の最大数",
|
||||
"depthMidas": "深度 (Midas)",
|
||||
"f": "F",
|
||||
"h": "H",
|
||||
"lineart": "線画",
|
||||
"depthAnythingDescription": "Depth Anything 技術を使って深度マップを生成します",
|
||||
"hed": "HED",
|
||||
"normalBaeDescription": "法線 BAE 処理中",
|
||||
"pidi": "PIDI",
|
||||
"resizeSimple": "リサイズ(シンプル)",
|
||||
"scribble": "らくがき",
|
||||
"small": "小型",
|
||||
"mediapipeFace": "Mediapipe 顔",
|
||||
"mlsd": "M-LSD",
|
||||
"normalBae": "法線 BAE",
|
||||
"base": "ベース",
|
||||
"contentShuffle": "シャッフル",
|
||||
"modelSize": "モデルサイズ",
|
||||
"safe": "セーフモード",
|
||||
"depthZoe": "深度 (Zoe)",
|
||||
"face": "顔",
|
||||
"body": "体",
|
||||
"hands": "手",
|
||||
"large": "大型",
|
||||
"lineartAnime": "アニメ線画",
|
||||
"mlsdDescription": "最小線分検知",
|
||||
"dwOpenpose": "DW オープンポーズ",
|
||||
"dwOpenposeDescription": "DW オープンポーズによる人体ポーズの推定",
|
||||
"ipAdapterMethod": "方式",
|
||||
"setControlImageDimensionsForce": "モデルを無視してサイズを W/H にコピー",
|
||||
"style": "スタイルのみ",
|
||||
"selectCLIPVisionModel": "CLIP Visionのモデルを選択",
|
||||
"composition": "構図のみ",
|
||||
"beginEndStepPercentShort": "開始 / 終了 %"
|
||||
},
|
||||
"metadata": {
|
||||
"seamless": "シームレス",
|
||||
"Threshold": "ノイズ閾値",
|
||||
|
||||
@@ -4,7 +4,6 @@
|
||||
"reportBugLabel": "버그 리포트",
|
||||
"githubLabel": "Github",
|
||||
"settingsLabel": "설정",
|
||||
"unifiedCanvas": "통합 캔버스",
|
||||
"nodes": "Workflow Editor",
|
||||
"upload": "업로드",
|
||||
"load": "불러오기",
|
||||
@@ -27,7 +26,6 @@
|
||||
"on": "켜기",
|
||||
"save": "저장",
|
||||
"created": "생성됨",
|
||||
"nodeEditor": "Node Editor",
|
||||
"error": "에러",
|
||||
"prevPage": "이전 페이지",
|
||||
"ipAdapter": "IP 어댑터",
|
||||
@@ -71,15 +69,12 @@
|
||||
"deleteSelection": "선택 항목 삭제",
|
||||
"featuresWillReset": "이 이미지를 삭제하면 해당 기능이 즉시 재설정됩니다.",
|
||||
"assets": "자산",
|
||||
"problemDeletingImagesDesc": "하나 이상의 이미지를 삭제할 수 없습니다",
|
||||
"noImagesInGallery": "보여줄 이미지가 없음",
|
||||
"autoSwitchNewImages": "새로운 이미지로 자동 전환",
|
||||
"loading": "불러오는 중",
|
||||
"unableToLoad": "갤러리를 로드할 수 없음",
|
||||
"image": "이미지",
|
||||
"loadMore": "더 불러오기",
|
||||
"drop": "드랍",
|
||||
"problemDeletingImages": "이미지 삭제 중 발생한 문제",
|
||||
"downloadSelection": "선택 항목 다운로드",
|
||||
"deleteImage_other": "이미지 삭제",
|
||||
"currentlyInUse": "이 이미지는 현재 다음 기능에서 사용되고 있습니다:",
|
||||
@@ -89,7 +84,6 @@
|
||||
"deleteImagePermanent": "삭제된 이미지는 복원할 수 없습니다.",
|
||||
"noImageSelected": "선택된 이미지 없음",
|
||||
"autoAssignBoardOnClick": "클릭 시 Board로 자동 할당",
|
||||
"setCurrentImage": "현재 이미지로 설정",
|
||||
"dropToUpload": "업로드를 위해 $t(gallery.drop)"
|
||||
},
|
||||
"accessibility": {
|
||||
@@ -98,10 +92,7 @@
|
||||
"mode": "모드",
|
||||
"menu": "메뉴",
|
||||
"uploadImage": "이미지 업로드",
|
||||
"showGalleryPanel": "갤러리 패널 표시",
|
||||
"reset": "리셋",
|
||||
"loadMore": "더 불러오기",
|
||||
"showOptionsPanel": "사이드 패널 표시"
|
||||
"reset": "리셋"
|
||||
},
|
||||
"modelManager": {
|
||||
"availableModels": "사용 가능한 모델",
|
||||
@@ -117,7 +108,6 @@
|
||||
"predictionType": "예측 유형(안정 확산 2.x 모델 및 간혹 안정 확산 1.x 모델의 경우)",
|
||||
"selectModel": "모델 선택",
|
||||
"repo_id": "Repo ID",
|
||||
"modelSyncFailed": "모델 동기화 실패",
|
||||
"convertToDiffusersHelpText6": "이 모델을 변환하시겠습니까?",
|
||||
"config": "구성",
|
||||
"selected": "선택된",
|
||||
@@ -136,10 +126,8 @@
|
||||
"syncModels": "동기화 모델",
|
||||
"modelType": "모델 유형",
|
||||
"convertingModelBegin": "모델 변환 중입니다. 잠시만 기다려 주십시오.",
|
||||
"v2_base": "v2 (512px)",
|
||||
"name": "이름",
|
||||
"convertToDiffusersHelpText1": "이 모델은 🧨 Diffusers 형식으로 변환됩니다.",
|
||||
"modelsSynced": "동기화된 모델",
|
||||
"vaePrecision": "VAE 정밀도",
|
||||
"deleteMsg2": "모델이 InvokeAI root 폴더에 있으면 디스크에서 모델이 삭제됩니다. 사용자 지정 위치를 사용하는 경우 모델이 디스크에서 삭제되지 않습니다.",
|
||||
"baseModel": "기본 모델",
|
||||
@@ -152,279 +140,10 @@
|
||||
"allModels": "모든 모델",
|
||||
"alpha": "Alpha",
|
||||
"noModelSelected": "선택한 모델 없음",
|
||||
"v2_768": "v2 (768px)",
|
||||
"convertToDiffusersHelpText4": "이것은 한 번의 과정일 뿐입니다. 컴퓨터 사양에 따라 30-60초 정도 소요될 수 있습니다.",
|
||||
"model": "모델",
|
||||
"delete": "삭제"
|
||||
},
|
||||
"controlnet": {
|
||||
"amult": "a_mult",
|
||||
"resize": "크기 조정",
|
||||
"showAdvanced": "고급 표시",
|
||||
"contentShuffleDescription": "이미지에서 content 섞기",
|
||||
"bgth": "bg_th",
|
||||
"addT2IAdapter": "$t(common.t2iAdapter) 추가",
|
||||
"pidi": "PIDI",
|
||||
"importImageFromCanvas": "캔버스에서 이미지 가져오기",
|
||||
"lineartDescription": "이미지->lineart 변환",
|
||||
"normalBae": "Normal BAE",
|
||||
"importMaskFromCanvas": "캔버스에서 Mask 가져오기",
|
||||
"hed": "HED",
|
||||
"contentShuffle": "Content Shuffle",
|
||||
"resetControlImage": "Control Image 재설정",
|
||||
"beginEndStepPercent": "Begin / End Step Percentage",
|
||||
"mlsdDescription": "Minimalist Line Segment Detector",
|
||||
"duplicate": "복제",
|
||||
"balanced": "Balanced",
|
||||
"f": "F",
|
||||
"h": "H",
|
||||
"prompt": "프롬프트",
|
||||
"depthMidasDescription": "Midas를 사용하여 Depth map 생성하기",
|
||||
"control": "Control",
|
||||
"resizeMode": "크기 조정 모드",
|
||||
"coarse": "Coarse",
|
||||
"weight": "Weight",
|
||||
"selectModel": "모델 선택",
|
||||
"crop": "Crop",
|
||||
"depthMidas": "Depth (Midas)",
|
||||
"w": "W",
|
||||
"processor": "프로세서",
|
||||
"addControlNet": "$t(common.controlNet) 추가",
|
||||
"none": "해당없음",
|
||||
"detectResolution": "해상도 탐지",
|
||||
"pidiDescription": "PIDI image 처리",
|
||||
"mediapipeFace": "Mediapipe Face",
|
||||
"mlsd": "M-LSD",
|
||||
"controlMode": "Control Mode",
|
||||
"fill": "채우기",
|
||||
"cannyDescription": "Canny 모서리 삭제",
|
||||
"addIPAdapter": "$t(common.ipAdapter) 추가",
|
||||
"lineart": "Lineart",
|
||||
"colorMapDescription": "이미지에서 color map을 생성합니다",
|
||||
"lineartAnimeDescription": "Anime-style lineart 처리",
|
||||
"minConfidence": "Min Confidence",
|
||||
"imageResolution": "이미지 해상도",
|
||||
"megaControl": "Mega Control",
|
||||
"depthZoe": "Depth (Zoe)",
|
||||
"colorMap": "색",
|
||||
"lowThreshold": "Low Threshold",
|
||||
"autoConfigure": "프로세서 자동 구성",
|
||||
"highThreshold": "High Threshold",
|
||||
"normalBaeDescription": "Normal BAE 처리",
|
||||
"noneDescription": "처리되지 않음",
|
||||
"saveControlImage": "Control Image 저장",
|
||||
"toggleControlNet": "해당 ControlNet으로 전환",
|
||||
"delete": "삭제",
|
||||
"controlAdapter_other": "Control Adapter(s)",
|
||||
"safe": "Safe",
|
||||
"colorMapTileSize": "타일 크기",
|
||||
"lineartAnime": "Lineart Anime",
|
||||
"mediapipeFaceDescription": "Mediapipe를 사용하여 Face 탐지",
|
||||
"canny": "Canny",
|
||||
"depthZoeDescription": "Zoe를 사용하여 Depth map 생성하기",
|
||||
"hedDescription": "Holistically-Nested 모서리 탐지",
|
||||
"setControlImageDimensions": "Control Image Dimensions를 W/H로 설정",
|
||||
"scribble": "scribble",
|
||||
"maxFaces": "Max Faces"
|
||||
},
|
||||
"hotkeys": {
|
||||
"toggleSnap": {
|
||||
"desc": "Snap을 Grid로 전환",
|
||||
"title": "Snap 전환"
|
||||
},
|
||||
"setSeed": {
|
||||
"title": "시드 설정",
|
||||
"desc": "현재 이미지의 시드 사용"
|
||||
},
|
||||
"keyboardShortcuts": "키보드 바로 가기",
|
||||
"decreaseGalleryThumbSize": {
|
||||
"desc": "갤러리 미리 보기 크기 축소",
|
||||
"title": "갤러리 이미지 크기 축소"
|
||||
},
|
||||
"previousStagingImage": {
|
||||
"title": "이전 스테이징 이미지",
|
||||
"desc": "이전 스테이징 영역 이미지"
|
||||
},
|
||||
"decreaseBrushSize": {
|
||||
"title": "브러시 크기 줄이기",
|
||||
"desc": "캔버스 브러시/지우개 크기 감소"
|
||||
},
|
||||
"consoleToggle": {
|
||||
"desc": "콘솔 열고 닫기",
|
||||
"title": "콘솔 전환"
|
||||
},
|
||||
"selectBrush": {
|
||||
"desc": "캔버스 브러시를 선택",
|
||||
"title": "브러시 선택"
|
||||
},
|
||||
"previousImage": {
|
||||
"title": "이전 이미지",
|
||||
"desc": "갤러리에 이전 이미지 표시"
|
||||
},
|
||||
"unifiedCanvasHotkeys": "Unified Canvas Hotkeys",
|
||||
"toggleOptions": {
|
||||
"desc": "옵션 패널을 열고 닫기",
|
||||
"title": "옵션 전환"
|
||||
},
|
||||
"selectEraser": {
|
||||
"title": "지우개 선택",
|
||||
"desc": "캔버스 지우개를 선택"
|
||||
},
|
||||
"setPrompt": {
|
||||
"title": "프롬프트 설정",
|
||||
"desc": "현재 이미지의 프롬프트 사용"
|
||||
},
|
||||
"acceptStagingImage": {
|
||||
"desc": "현재 준비 영역 이미지 허용",
|
||||
"title": "준비 이미지 허용"
|
||||
},
|
||||
"resetView": {
|
||||
"desc": "Canvas View 초기화",
|
||||
"title": "View 초기화"
|
||||
},
|
||||
"hideMask": {
|
||||
"title": "Mask 숨김",
|
||||
"desc": "mask 숨김/숨김 해제"
|
||||
},
|
||||
"pinOptions": {
|
||||
"title": "옵션 고정",
|
||||
"desc": "옵션 패널을 고정"
|
||||
},
|
||||
"toggleGallery": {
|
||||
"desc": "gallery drawer 열기 및 닫기",
|
||||
"title": "Gallery 전환"
|
||||
},
|
||||
"quickToggleMove": {
|
||||
"title": "빠른 토글 이동",
|
||||
"desc": "일시적으로 이동 모드 전환"
|
||||
},
|
||||
"generalHotkeys": "General Hotkeys",
|
||||
"showHideBoundingBox": {
|
||||
"desc": "bounding box 표시 전환",
|
||||
"title": "Bounding box 표시/숨김"
|
||||
},
|
||||
"showInfo": {
|
||||
"desc": "현재 이미지의 metadata 정보 표시",
|
||||
"title": "정보 표시"
|
||||
},
|
||||
"copyToClipboard": {
|
||||
"title": "클립보드로 복사",
|
||||
"desc": "현재 캔버스를 클립보드로 복사"
|
||||
},
|
||||
"restoreFaces": {
|
||||
"title": "Faces 복원",
|
||||
"desc": "현재 이미지 복원"
|
||||
},
|
||||
"fillBoundingBox": {
|
||||
"title": "Bounding Box 채우기",
|
||||
"desc": "bounding box를 브러시 색으로 채웁니다"
|
||||
},
|
||||
"closePanels": {
|
||||
"desc": "열린 panels 닫기",
|
||||
"title": "panels 닫기"
|
||||
},
|
||||
"downloadImage": {
|
||||
"desc": "현재 캔버스 다운로드",
|
||||
"title": "이미지 다운로드"
|
||||
},
|
||||
"setParameters": {
|
||||
"title": "매개 변수 설정",
|
||||
"desc": "현재 이미지의 모든 매개 변수 사용"
|
||||
},
|
||||
"maximizeWorkSpace": {
|
||||
"desc": "패널을 닫고 작업 면적을 극대화",
|
||||
"title": "작업 공간 극대화"
|
||||
},
|
||||
"galleryHotkeys": "Gallery Hotkeys",
|
||||
"cancel": {
|
||||
"desc": "이미지 생성 취소",
|
||||
"title": "취소"
|
||||
},
|
||||
"saveToGallery": {
|
||||
"title": "갤러리에 저장",
|
||||
"desc": "현재 캔버스를 갤러리에 저장"
|
||||
},
|
||||
"eraseBoundingBox": {
|
||||
"desc": "bounding box 영역을 지웁니다",
|
||||
"title": "Bounding Box 지우기"
|
||||
},
|
||||
"nextImage": {
|
||||
"title": "다음 이미지",
|
||||
"desc": "갤러리에 다음 이미지 표시"
|
||||
},
|
||||
"colorPicker": {
|
||||
"desc": "canvas color picker 선택",
|
||||
"title": "Color Picker 선택"
|
||||
},
|
||||
"invoke": {
|
||||
"desc": "이미지 생성",
|
||||
"title": "불러오기"
|
||||
},
|
||||
"sendToImageToImage": {
|
||||
"desc": "현재 이미지를 이미지로 보내기"
|
||||
},
|
||||
"toggleLayer": {
|
||||
"desc": "mask/base layer 선택 전환",
|
||||
"title": "Layer 전환"
|
||||
},
|
||||
"increaseBrushSize": {
|
||||
"title": "브러시 크기 증가",
|
||||
"desc": "캔버스 브러시/지우개 크기 증가"
|
||||
},
|
||||
"appHotkeys": "App Hotkeys",
|
||||
"deleteImage": {
|
||||
"title": "이미지 삭제",
|
||||
"desc": "현재 이미지 삭제"
|
||||
},
|
||||
"moveTool": {
|
||||
"desc": "캔버스 탐색 허용",
|
||||
"title": "툴 옮기기"
|
||||
},
|
||||
"clearMask": {
|
||||
"desc": "전체 mask 제거",
|
||||
"title": "Mask 제거"
|
||||
},
|
||||
"increaseGalleryThumbSize": {
|
||||
"title": "갤러리 이미지 크기 증가",
|
||||
"desc": "갤러리 미리 보기 크기를 늘립니다"
|
||||
},
|
||||
"increaseBrushOpacity": {
|
||||
"desc": "캔버스 브러시의 불투명도를 높입니다",
|
||||
"title": "브러시 불투명도 증가"
|
||||
},
|
||||
"focusPrompt": {
|
||||
"desc": "프롬프트 입력 영역에 초점을 맞춥니다",
|
||||
"title": "프롬프트에 초점 맞추기"
|
||||
},
|
||||
"decreaseBrushOpacity": {
|
||||
"desc": "캔버스 브러시의 불투명도를 줄입니다",
|
||||
"title": "브러시 불투명도 감소"
|
||||
},
|
||||
"nextStagingImage": {
|
||||
"desc": "다음 스테이징 영역 이미지",
|
||||
"title": "다음 스테이징 이미지"
|
||||
},
|
||||
"redoStroke": {
|
||||
"title": "Stroke 다시 실행",
|
||||
"desc": "brush stroke 다시 실행"
|
||||
},
|
||||
"nodesHotkeys": "Nodes Hotkeys",
|
||||
"addNodes": {
|
||||
"desc": "노드 추가 메뉴 열기",
|
||||
"title": "노드 추가"
|
||||
},
|
||||
"undoStroke": {
|
||||
"title": "Stroke 실행 취소",
|
||||
"desc": "brush stroke 실행 취소"
|
||||
},
|
||||
"changeTabs": {
|
||||
"desc": "다른 workspace으로 전환",
|
||||
"title": "탭 바꾸기"
|
||||
},
|
||||
"mergeVisible": {
|
||||
"desc": "캔버스의 보이는 모든 레이어 병합"
|
||||
}
|
||||
},
|
||||
"nodes": {
|
||||
"missingTemplate": "잘못된 노드: {{type}} 유형의 {{node}} 템플릿 누락(설치되지 않으셨나요?)",
|
||||
"noNodeSelected": "선택한 노드 없음",
|
||||
@@ -451,7 +170,6 @@
|
||||
"downloadWorkflow": "Workflow JSON 다운로드",
|
||||
"ipAdapter": "IP-Adapter",
|
||||
"noConnectionInProgress": "진행중인 연결이 없습니다",
|
||||
"noConnectionData": "연결 데이터 없음",
|
||||
"fieldTypesMustMatch": "필드 유형은 일치해야 합니다",
|
||||
"edge": "Edge",
|
||||
"sourceNodeFieldDoesNotExist": "잘못된 모서리: 소스/출력 필드 {{node}}. {{field}}이(가) 없습니다",
|
||||
@@ -461,10 +179,8 @@
|
||||
"fullyContainNodesHelp": "선택하려면 노드가 선택 상자 안에 완전히 있어야 합니다",
|
||||
"nodePack": "Node pack",
|
||||
"nodeType": "노드 유형",
|
||||
"noMatchingNodes": "일치하는 노드 없음",
|
||||
"fullyContainNodes": "선택할 노드 전체 포함",
|
||||
"executionStateInProgress": "진행중",
|
||||
"noFieldType": "필드 유형 없음",
|
||||
"executionStateError": "에러",
|
||||
"boolean": "Booleans",
|
||||
"hideMinimapnodes": "미니맵 숨기기",
|
||||
@@ -551,7 +267,6 @@
|
||||
"model": "모델",
|
||||
"noImageDetails": "이미지 세부 정보를 찾을 수 없습니다",
|
||||
"cfgScale": "CFG scale",
|
||||
"initImage": "초기이미지",
|
||||
"recallParameters": "매개변수 호출",
|
||||
"height": "Height",
|
||||
"noMetaData": "metadata를 찾을 수 없습니다",
|
||||
@@ -593,7 +308,6 @@
|
||||
},
|
||||
"models": {
|
||||
"noMatchingModels": "일치하는 모델 없음",
|
||||
"esrganModel": "ESRGAN 모델",
|
||||
"loading": "로딩중",
|
||||
"noMatchingLoRAs": "일치하는 LoRA 없음",
|
||||
"noModelsAvailable": "사용 가능한 모델이 없음",
|
||||
|
||||
@@ -5,7 +5,6 @@
|
||||
"reportBugLabel": "Meld bug",
|
||||
"settingsLabel": "Instellingen",
|
||||
"img2img": "Afbeelding naar afbeelding",
|
||||
"unifiedCanvas": "Centraal canvas",
|
||||
"nodes": "Werkstromen",
|
||||
"upload": "Upload",
|
||||
"load": "Laad",
|
||||
@@ -28,7 +27,6 @@
|
||||
"communityLabel": "Gemeenschap",
|
||||
"t2iAdapter": "T2I-adapter",
|
||||
"on": "Aan",
|
||||
"nodeEditor": "Knooppunteditor",
|
||||
"ipAdapter": "IP-adapter",
|
||||
"auto": "Autom.",
|
||||
"controlNet": "ControlNet",
|
||||
@@ -55,7 +53,6 @@
|
||||
"goTo": "Ga naar",
|
||||
"template": "Sjabloon",
|
||||
"input": "Invoer",
|
||||
"loglevel": "Logboekniveau",
|
||||
"safetensors": "Safetensors",
|
||||
"saveAs": "Bewaar als",
|
||||
"created": "Gemaakt",
|
||||
@@ -76,10 +73,6 @@
|
||||
"or": "of",
|
||||
"updated": "Bijgewerkt",
|
||||
"outpaint": "outpainten",
|
||||
"viewing": "Bekijken",
|
||||
"viewingDesc": "Beoordeel afbeelding in een grote galerijweergave",
|
||||
"editing": "Bewerken",
|
||||
"editingDesc": "Bewerk op het canvas Stuurlagen",
|
||||
"ai": "ai",
|
||||
"inpaint": "inpainten",
|
||||
"unknown": "Onbekend",
|
||||
@@ -93,7 +86,6 @@
|
||||
"galleryImageSize": "Afbeeldingsgrootte",
|
||||
"gallerySettings": "Instellingen galerij",
|
||||
"autoSwitchNewImages": "Wissel autom. naar nieuwe afbeeldingen",
|
||||
"loadMore": "Laad meer",
|
||||
"noImagesInGallery": "Geen afbeeldingen om te tonen",
|
||||
"deleteImage_one": "Verwijder afbeelding",
|
||||
"deleteImage_other": "",
|
||||
@@ -106,208 +98,7 @@
|
||||
"downloadSelection": "Download selectie",
|
||||
"currentlyInUse": "Deze afbeelding is momenteel in gebruik door de volgende functies:",
|
||||
"copy": "Kopieer",
|
||||
"download": "Download",
|
||||
"setCurrentImage": "Stel in als huidige afbeelding"
|
||||
},
|
||||
"hotkeys": {
|
||||
"keyboardShortcuts": "Sneltoetsen",
|
||||
"appHotkeys": "Appsneltoetsen",
|
||||
"generalHotkeys": "Algemene sneltoetsen",
|
||||
"galleryHotkeys": "Sneltoetsen galerij",
|
||||
"unifiedCanvasHotkeys": "Sneltoetsen centraal canvas",
|
||||
"invoke": {
|
||||
"title": "Genereer",
|
||||
"desc": "Genereert een afbeelding"
|
||||
},
|
||||
"cancel": {
|
||||
"title": "Annuleer",
|
||||
"desc": "Annuleert het genereren van een afbeelding"
|
||||
},
|
||||
"focusPrompt": {
|
||||
"title": "Focus op invoer",
|
||||
"desc": "Legt de focus op het invoertekstvak"
|
||||
},
|
||||
"toggleOptions": {
|
||||
"title": "Open/sluit Opties",
|
||||
"desc": "Opent of sluit het deelscherm Opties"
|
||||
},
|
||||
"pinOptions": {
|
||||
"title": "Zet Opties vast",
|
||||
"desc": "Zet het deelscherm Opties vast"
|
||||
},
|
||||
"toggleGallery": {
|
||||
"title": "Zet Galerij vast",
|
||||
"desc": "Opent of sluit het deelscherm Galerij"
|
||||
},
|
||||
"maximizeWorkSpace": {
|
||||
"title": "Maximaliseer werkgebied",
|
||||
"desc": "Sluit deelschermen en maximaliseer het werkgebied"
|
||||
},
|
||||
"changeTabs": {
|
||||
"title": "Wissel van tabblad",
|
||||
"desc": "Wissel naar een ander werkgebied"
|
||||
},
|
||||
"consoleToggle": {
|
||||
"title": "Open/sluit console",
|
||||
"desc": "Opent of sluit de console"
|
||||
},
|
||||
"setPrompt": {
|
||||
"title": "Stel invoertekst in",
|
||||
"desc": "Gebruikt de invoertekst van de huidige afbeelding"
|
||||
},
|
||||
"setSeed": {
|
||||
"title": "Stel seed in",
|
||||
"desc": "Gebruikt de seed van de huidige afbeelding"
|
||||
},
|
||||
"setParameters": {
|
||||
"title": "Stel parameters in",
|
||||
"desc": "Gebruikt alle parameters van de huidige afbeelding"
|
||||
},
|
||||
"restoreFaces": {
|
||||
"title": "Herstel gezichten",
|
||||
"desc": "Herstelt de huidige afbeelding"
|
||||
},
|
||||
"showInfo": {
|
||||
"title": "Toon info",
|
||||
"desc": "Toont de metagegevens van de huidige afbeelding"
|
||||
},
|
||||
"sendToImageToImage": {
|
||||
"title": "Stuur naar Afbeelding naar afbeelding",
|
||||
"desc": "Stuurt de huidige afbeelding naar Afbeelding naar afbeelding"
|
||||
},
|
||||
"deleteImage": {
|
||||
"title": "Verwijder afbeelding",
|
||||
"desc": "Verwijdert de huidige afbeelding"
|
||||
},
|
||||
"closePanels": {
|
||||
"title": "Sluit deelschermen",
|
||||
"desc": "Sluit geopende deelschermen"
|
||||
},
|
||||
"previousImage": {
|
||||
"title": "Vorige afbeelding",
|
||||
"desc": "Toont de vorige afbeelding in de galerij"
|
||||
},
|
||||
"nextImage": {
|
||||
"title": "Volgende afbeelding",
|
||||
"desc": "Toont de volgende afbeelding in de galerij"
|
||||
},
|
||||
"increaseGalleryThumbSize": {
|
||||
"title": "Vergroot afbeeldingsgrootte galerij",
|
||||
"desc": "Vergroot de grootte van de galerijminiaturen"
|
||||
},
|
||||
"decreaseGalleryThumbSize": {
|
||||
"title": "Verklein afbeeldingsgrootte galerij",
|
||||
"desc": "Verkleint de grootte van de galerijminiaturen"
|
||||
},
|
||||
"selectBrush": {
|
||||
"title": "Kies penseel",
|
||||
"desc": "Kiest de penseel op het canvas"
|
||||
},
|
||||
"selectEraser": {
|
||||
"title": "Kies gum",
|
||||
"desc": "Kiest de gum op het canvas"
|
||||
},
|
||||
"decreaseBrushSize": {
|
||||
"title": "Verklein penseelgrootte",
|
||||
"desc": "Verkleint de grootte van het penseel/gum op het canvas"
|
||||
},
|
||||
"increaseBrushSize": {
|
||||
"title": "Vergroot penseelgrootte",
|
||||
"desc": "Vergroot de grootte van het penseel/gum op het canvas"
|
||||
},
|
||||
"decreaseBrushOpacity": {
|
||||
"title": "Verlaag ondoorzichtigheid penseel",
|
||||
"desc": "Verlaagt de ondoorzichtigheid van de penseel op het canvas"
|
||||
},
|
||||
"increaseBrushOpacity": {
|
||||
"title": "Verhoog ondoorzichtigheid penseel",
|
||||
"desc": "Verhoogt de ondoorzichtigheid van de penseel op het canvas"
|
||||
},
|
||||
"moveTool": {
|
||||
"title": "Verplaats canvas",
|
||||
"desc": "Maakt canvasnavigatie mogelijk"
|
||||
},
|
||||
"fillBoundingBox": {
|
||||
"title": "Vul tekenvak",
|
||||
"desc": "Vult het tekenvak met de penseelkleur"
|
||||
},
|
||||
"eraseBoundingBox": {
|
||||
"title": "Wis tekenvak",
|
||||
"desc": "Wist het gebied van het tekenvak"
|
||||
},
|
||||
"colorPicker": {
|
||||
"title": "Kleurkiezer",
|
||||
"desc": "Opent de kleurkiezer op het canvas"
|
||||
},
|
||||
"toggleSnap": {
|
||||
"title": "Zet uitlijnen aan/uit",
|
||||
"desc": "Zet uitlijnen op raster aan/uit"
|
||||
},
|
||||
"quickToggleMove": {
|
||||
"title": "Verplaats canvas even",
|
||||
"desc": "Verplaats kortstondig het canvas"
|
||||
},
|
||||
"toggleLayer": {
|
||||
"title": "Zet laag aan/uit",
|
||||
"desc": "Wisselt tussen de masker- en basislaag"
|
||||
},
|
||||
"clearMask": {
|
||||
"title": "Wis masker",
|
||||
"desc": "Wist het volledig masker"
|
||||
},
|
||||
"hideMask": {
|
||||
"title": "Toon/verberg masker",
|
||||
"desc": "Toont of verbegt het masker"
|
||||
},
|
||||
"showHideBoundingBox": {
|
||||
"title": "Toon/verberg tekenvak",
|
||||
"desc": "Wisselt de zichtbaarheid van het tekenvak"
|
||||
},
|
||||
"mergeVisible": {
|
||||
"title": "Voeg lagen samen",
|
||||
"desc": "Voegt alle zichtbare lagen op het canvas samen"
|
||||
},
|
||||
"saveToGallery": {
|
||||
"title": "Bewaar in galerij",
|
||||
"desc": "Bewaart het huidige canvas in de galerij"
|
||||
},
|
||||
"copyToClipboard": {
|
||||
"title": "Kopieer naar klembord",
|
||||
"desc": "Kopieert het huidige canvas op het klembord"
|
||||
},
|
||||
"downloadImage": {
|
||||
"title": "Download afbeelding",
|
||||
"desc": "Downloadt het huidige canvas"
|
||||
},
|
||||
"undoStroke": {
|
||||
"title": "Maak streek ongedaan",
|
||||
"desc": "Maakt een penseelstreek ongedaan"
|
||||
},
|
||||
"redoStroke": {
|
||||
"title": "Herhaal streek",
|
||||
"desc": "Voert een ongedaan gemaakte penseelstreek opnieuw uit"
|
||||
},
|
||||
"resetView": {
|
||||
"title": "Herstel weergave",
|
||||
"desc": "Herstelt de canvasweergave"
|
||||
},
|
||||
"previousStagingImage": {
|
||||
"title": "Vorige sessie-afbeelding",
|
||||
"desc": "Bladert terug naar de vorige afbeelding in het sessiegebied"
|
||||
},
|
||||
"nextStagingImage": {
|
||||
"title": "Volgende sessie-afbeelding",
|
||||
"desc": "Bladert vooruit naar de volgende afbeelding in het sessiegebied"
|
||||
},
|
||||
"acceptStagingImage": {
|
||||
"title": "Accepteer sessie-afbeelding",
|
||||
"desc": "Accepteert de huidige sessie-afbeelding"
|
||||
},
|
||||
"addNodes": {
|
||||
"title": "Voeg knooppunten toe",
|
||||
"desc": "Opent het menu Voeg knooppunt toe"
|
||||
},
|
||||
"nodesHotkeys": "Sneltoetsen knooppunten"
|
||||
"download": "Download"
|
||||
},
|
||||
"modelManager": {
|
||||
"modelManager": "Modelonderhoud",
|
||||
@@ -342,8 +133,6 @@
|
||||
"convertToDiffusersHelpText5": "Zorg ervoor dat je genoeg schijfruimte hebt. Modellen nemen gewoonlijk ongeveer 2 tot 7 GB ruimte in beslag.",
|
||||
"modelConverted": "Model omgezet",
|
||||
"alpha": "Alfa",
|
||||
"v2_base": "v2 (512px)",
|
||||
"v2_768": "v2 (768px)",
|
||||
"none": "geen",
|
||||
"baseModel": "Basismodel",
|
||||
"vae": "VAE",
|
||||
@@ -354,8 +143,6 @@
|
||||
"settings": "Instellingen",
|
||||
"modelDeleted": "Model verwijderd",
|
||||
"syncModels": "Synchroniseer Modellen",
|
||||
"modelsSynced": "Modellen Gesynchroniseerd",
|
||||
"modelSyncFailed": "Synchronisatie modellen mislukt",
|
||||
"modelDeleteFailed": "Model kon niet verwijderd worden",
|
||||
"convertingModelBegin": "Model aan het converteren. Even geduld.",
|
||||
"predictionType": "Soort voorspelling",
|
||||
@@ -414,8 +201,6 @@
|
||||
"scaledHeight": "Geschaalde H",
|
||||
"infillMethod": "Infill-methode",
|
||||
"tileSize": "Grootte tegel",
|
||||
"sendToImg2Img": "Stuur naar Afbeelding naar afbeelding",
|
||||
"sendToUnifiedCanvas": "Stuur naar Centraal canvas",
|
||||
"downloadImage": "Download afbeelding",
|
||||
"usePrompt": "Hergebruik invoertekst",
|
||||
"useSeed": "Hergebruik seed",
|
||||
@@ -442,29 +227,20 @@
|
||||
"noModelSelected": "Geen model ingesteld",
|
||||
"invoke": "Start",
|
||||
"noPrompts": "Geen prompts gegenereerd",
|
||||
"noInitialImageSelected": "Geen initiële afbeelding gekozen",
|
||||
"missingInputForField": "{{nodeLabel}} -> {{fieldLabel}} invoer ontbreekt",
|
||||
"noControlImageForControlAdapter": "Controle-adapter #{{number}} heeft geen controle-afbeelding",
|
||||
"noModelForControlAdapter": "Control-adapter #{{number}} heeft geen model ingesteld staan.",
|
||||
"incompatibleBaseModelForControlAdapter": "Model van controle-adapter #{{number}} is niet compatibel met het hoofdmodel.",
|
||||
"systemDisconnected": "Systeem is niet verbonden",
|
||||
"missingNodeTemplate": "Knooppuntsjabloon ontbreekt",
|
||||
"missingFieldTemplate": "Veldsjabloon ontbreekt",
|
||||
"addingImagesTo": "Bezig met toevoegen van afbeeldingen aan",
|
||||
"layer": {
|
||||
"initialImageNoImageSelected": "geen initiële afbeelding geselecteerd",
|
||||
"controlAdapterNoModelSelected": "geen controle-adaptermodel geselecteerd",
|
||||
"controlAdapterIncompatibleBaseModel": "niet-compatibele basismodel voor controle-adapter",
|
||||
"controlAdapterNoImageSelected": "geen afbeelding voor controle-adapter geselecteerd",
|
||||
"controlAdapterImageNotProcessed": "Afbeelding voor controle-adapter niet verwerkt",
|
||||
"ipAdapterIncompatibleBaseModel": "niet-compatibele basismodel voor IP-adapter",
|
||||
"ipAdapterNoImageSelected": "geen afbeelding voor IP-adapter geselecteerd",
|
||||
"rgNoRegion": "geen gebied geselecteerd",
|
||||
"rgNoPromptsOrIPAdapters": "geen tekstprompts of IP-adapters",
|
||||
"t2iAdapterIncompatibleDimensions": "T2I-adapter vereist een afbeelding met afmetingen met een veelvoud van 64",
|
||||
"ipAdapterNoModelSelected": "geen IP-adapter geselecteerd"
|
||||
},
|
||||
"imageNotProcessedForControlAdapter": "De afbeelding van controle-adapter #{{number}} is niet verwerkt"
|
||||
}
|
||||
},
|
||||
"patchmatchDownScaleSize": "Verklein",
|
||||
"useCpuNoise": "Gebruik CPU-ruis",
|
||||
@@ -476,31 +252,22 @@
|
||||
"setToOptimalSize": "Optimaliseer grootte voor het model",
|
||||
"setToOptimalSizeTooSmall": "$t(parameters.setToOptimalSize) (is mogelijk te klein)",
|
||||
"aspect": "Beeldverhouding",
|
||||
"infillMosaicTileWidth": "Breedte tegel",
|
||||
"setToOptimalSizeTooLarge": "$t(parameters.setToOptimalSize) (is mogelijk te groot)",
|
||||
"lockAspectRatio": "Zet beeldverhouding vast",
|
||||
"infillMosaicTileHeight": "Hoogte tegel",
|
||||
"globalNegativePromptPlaceholder": "Globale negatieve prompt",
|
||||
"globalPositivePromptPlaceholder": "Globale positieve prompt",
|
||||
"useSize": "Gebruik grootte",
|
||||
"swapDimensions": "Wissel afmetingen om",
|
||||
"globalSettings": "Globale instellingen",
|
||||
"coherenceEdgeSize": "Randgrootte",
|
||||
"coherenceMinDenoise": "Min. ontruising",
|
||||
"infillMosaicMinColor": "Min. kleur",
|
||||
"infillMosaicMaxColor": "Max. kleur",
|
||||
"cfgRescaleMultiplier": "Vermenigvuldiger voor CFG-herschaling"
|
||||
},
|
||||
"settings": {
|
||||
"models": "Modellen",
|
||||
"displayInProgress": "Toon voortgangsafbeeldingen",
|
||||
"confirmOnDelete": "Bevestig bij verwijderen",
|
||||
"enableImageDebugging": "Schakel foutopsporing afbeelding in",
|
||||
"resetWebUI": "Herstel web-UI",
|
||||
"resetWebUIDesc1": "Herstel web-UI herstelt alleen de lokale afbeeldingscache en de onthouden instellingen van je browser. Het verwijdert geen afbeeldingen van schijf.",
|
||||
"resetWebUIDesc2": "Als afbeeldingen niet getoond worden in de galerij of iets anders werkt niet, probeer dan eerst deze herstelfunctie voordat je een fout aanmeldt op GitHub.",
|
||||
"resetComplete": "Webinterface is hersteld.",
|
||||
"shouldLogToConsole": "Schrijf logboek naar console",
|
||||
"developer": "Ontwikkelaar",
|
||||
"general": "Algemeen",
|
||||
"showProgressInViewer": "Toon voortgangsafbeeldingen in viewer",
|
||||
@@ -526,12 +293,7 @@
|
||||
"toast": {
|
||||
"uploadFailed": "Upload mislukt",
|
||||
"imageCopied": "Afbeelding gekopieerd",
|
||||
"imageNotLoadedDesc": "Geen afbeeldingen gevonden",
|
||||
"canvasMerged": "Canvas samengevoegd",
|
||||
"sentToImageToImage": "Gestuurd naar Afbeelding naar afbeelding",
|
||||
"sentToUnifiedCanvas": "Gestuurd naar Centraal canvas",
|
||||
"parametersNotSet": "Parameters niet ingesteld",
|
||||
"metadataLoadFailed": "Fout bij laden metagegevens",
|
||||
"serverError": "Serverfout",
|
||||
"connected": "Verbonden met server",
|
||||
"canceled": "Verwerking geannuleerd",
|
||||
@@ -541,110 +303,22 @@
|
||||
"problemCopyingImage": "Kan Afbeelding Niet Kopiëren",
|
||||
"baseModelChangedCleared_one": "Basismodel is gewijzigd: {{count}} niet-compatibel submodel weggehaald of uitgeschakeld",
|
||||
"baseModelChangedCleared_other": "Basismodel is gewijzigd: {{count}} niet-compatibele submodellen weggehaald of uitgeschakeld",
|
||||
"imageSavingFailed": "Fout bij bewaren afbeelding",
|
||||
"canvasSentControlnetAssets": "Canvas gestuurd naar ControlNet en Assets",
|
||||
"problemCopyingCanvasDesc": "Kan basislaag niet exporteren",
|
||||
"loadedWithWarnings": "Werkstroom geladen met waarschuwingen",
|
||||
"setInitialImage": "Ingesteld als initiële afbeelding",
|
||||
"canvasCopiedClipboard": "Canvas gekopieerd naar klembord",
|
||||
"setControlImage": "Ingesteld als controle-afbeelding",
|
||||
"setNodeField": "Ingesteld als knooppuntveld",
|
||||
"problemSavingMask": "Fout bij bewaren masker",
|
||||
"problemSavingCanvasDesc": "Kan basislaag niet exporteren",
|
||||
"maskSavedAssets": "Masker bewaard in Assets",
|
||||
"problemDownloadingCanvas": "Fout bij downloaden van canvas",
|
||||
"problemMergingCanvas": "Fout bij samenvoegen canvas",
|
||||
"setCanvasInitialImage": "Initiële canvasafbeelding ingesteld",
|
||||
"imageUploaded": "Afbeelding geüpload",
|
||||
"addedToBoard": "Toegevoegd aan bord",
|
||||
"workflowLoaded": "Werkstroom geladen",
|
||||
"modelAddedSimple": "Model toegevoegd aan wachtrij",
|
||||
"problemImportingMaskDesc": "Kan masker niet exporteren",
|
||||
"problemCopyingCanvas": "Fout bij kopiëren canvas",
|
||||
"problemSavingCanvas": "Fout bij bewaren canvas",
|
||||
"canvasDownloaded": "Canvas gedownload",
|
||||
"problemMergingCanvasDesc": "Kan basislaag niet exporteren",
|
||||
"problemDownloadingCanvasDesc": "Kan basislaag niet exporteren",
|
||||
"problemSavingMaskDesc": "Kan masker niet exporteren",
|
||||
"imageSaved": "Afbeelding bewaard",
|
||||
"maskSentControlnetAssets": "Masker gestuurd naar ControlNet en Assets",
|
||||
"canvasSavedGallery": "Canvas bewaard in galerij",
|
||||
"imageUploadFailed": "Fout bij uploaden afbeelding",
|
||||
"problemImportingMask": "Fout bij importeren masker",
|
||||
"workflowDeleted": "Werkstroom verwijderd",
|
||||
"invalidUpload": "Ongeldige upload",
|
||||
"uploadInitialImage": "Initiële afbeelding uploaden",
|
||||
"setAsCanvasInitialImage": "Ingesteld als initiële afbeelding voor canvas",
|
||||
"problemRetrievingWorkflow": "Fout bij ophalen van werkstroom",
|
||||
"parameters": "Parameters",
|
||||
"modelImportCanceled": "Importeren model geannuleerd",
|
||||
"problemDeletingWorkflow": "Fout bij verwijderen van werkstroom",
|
||||
"prunedQueue": "Wachtrij gesnoeid",
|
||||
"problemDownloadingImage": "Fout bij downloaden afbeelding",
|
||||
"resetInitialImage": "Initiële afbeelding hersteld"
|
||||
},
|
||||
"tooltip": {
|
||||
"feature": {
|
||||
"prompt": "Dit is het invoertekstvak. De invoertekst bevat de te genereren voorwerpen en stylistische termen. Je kunt hiernaast in de invoertekst ook het gewicht (het belang van een trefwoord) toekennen. Opdrachten en parameters voor op de opdrachtregelinterface werken hier niet.",
|
||||
"gallery": "De galerij toont gegenereerde afbeeldingen uit de uitvoermap nadat ze gegenereerd zijn. Instellingen worden opgeslagen binnen de bestanden zelf en zijn toegankelijk via het contextmenu.",
|
||||
"other": "Deze opties maken alternative werkingsstanden voor Invoke mogelijk. De optie 'Naadloze tegels' maakt herhalende patronen in de uitvoer. 'Hoge resolutie' genereert in twee stappen via Afbeelding naar afbeelding: gebruik dit als je een grotere en coherentere afbeelding wilt zonder artifacten. Dit zal meer tijd in beslag nemen t.o.v. Tekst naar afbeelding.",
|
||||
"seed": "Seedwaarden hebben invloed op de initiële ruis op basis waarvan de afbeelding wordt gevormd. Je kunt de al bestaande seeds van eerdere afbeeldingen gebruiken. De waarde 'Drempelwaarde ruis' wordt gebruikt om de hoeveelheid artifacten te verkleinen bij hoge CFG-waarden (beperk je tot 0 - 10). De Perlinruiswaarde wordt gebruikt om Perlinruis toe te voegen bij het genereren: beide dienen als variatie op de uitvoer.",
|
||||
"upscale": "Gebruik ESRGAN om de afbeelding direct na het genereren te vergroten.",
|
||||
"boundingBox": "Het tekenvak is gelijk aan de instellingen Breedte en Hoogte voor de functies Tekst naar afbeelding en Afbeelding naar afbeelding. Alleen het gebied in het tekenvak wordt verwerkt."
|
||||
}
|
||||
},
|
||||
"unifiedCanvas": {
|
||||
"layer": "Laag",
|
||||
"base": "Basis",
|
||||
"mask": "Masker",
|
||||
"maskingOptions": "Maskeropties",
|
||||
"enableMask": "Schakel masker in",
|
||||
"preserveMaskedArea": "Behoud gemaskeerd gebied",
|
||||
"clearMask": "Wis masker",
|
||||
"brush": "Penseel",
|
||||
"eraser": "Gum",
|
||||
"fillBoundingBox": "Vul tekenvak",
|
||||
"eraseBoundingBox": "Wis tekenvak",
|
||||
"colorPicker": "Kleurenkiezer",
|
||||
"brushOptions": "Penseelopties",
|
||||
"brushSize": "Grootte",
|
||||
"move": "Verplaats",
|
||||
"resetView": "Herstel weergave",
|
||||
"mergeVisible": "Voeg lagen samen",
|
||||
"saveToGallery": "Bewaar in galerij",
|
||||
"copyToClipboard": "Kopieer naar klembord",
|
||||
"downloadAsImage": "Download als afbeelding",
|
||||
"undo": "Maak ongedaan",
|
||||
"redo": "Herhaal",
|
||||
"clearCanvas": "Wis canvas",
|
||||
"canvasSettings": "Canvasinstellingen",
|
||||
"showIntermediates": "Toon tussenafbeeldingen",
|
||||
"showGrid": "Toon raster",
|
||||
"snapToGrid": "Lijn uit op raster",
|
||||
"darkenOutsideSelection": "Verduister buiten selectie",
|
||||
"autoSaveToGallery": "Bewaar automatisch naar galerij",
|
||||
"saveBoxRegionOnly": "Bewaar alleen tekengebied",
|
||||
"limitStrokesToBox": "Beperk streken tot tekenvak",
|
||||
"showCanvasDebugInfo": "Toon aanvullende canvasgegevens",
|
||||
"clearCanvasHistory": "Wis canvasgeschiedenis",
|
||||
"clearHistory": "Wis geschiedenis",
|
||||
"clearCanvasHistoryMessage": "Het wissen van de canvasgeschiedenis laat het huidige canvas ongemoeid, maar wist onherstelbaar de geschiedenis voor het ongedaan maken en herhalen.",
|
||||
"clearCanvasHistoryConfirm": "Weet je zeker dat je de canvasgeschiedenis wilt wissen?",
|
||||
"activeLayer": "Actieve laag",
|
||||
"canvasScale": "Schaal canvas",
|
||||
"boundingBox": "Tekenvak",
|
||||
"scaledBoundingBox": "Geschaalde tekenvak",
|
||||
"boundingBoxPosition": "Positie tekenvak",
|
||||
"canvasDimensions": "Afmetingen canvas",
|
||||
"canvasPosition": "Positie canvas",
|
||||
"cursorPosition": "Positie cursor",
|
||||
"previous": "Vorige",
|
||||
"next": "Volgende",
|
||||
"accept": "Accepteer",
|
||||
"discardAll": "Gooi alles weg",
|
||||
"antialiasing": "Anti-aliasing",
|
||||
"showResultsOn": "Toon resultaten (aan)",
|
||||
"showResultsOff": "Toon resultaten (uit)"
|
||||
"problemDownloadingImage": "Fout bij downloaden afbeelding"
|
||||
},
|
||||
"accessibility": {
|
||||
"invokeProgressBar": "Voortgangsbalk Invoke",
|
||||
@@ -652,10 +326,7 @@
|
||||
"uploadImage": "Upload afbeelding",
|
||||
"previousImage": "Vorige afbeelding",
|
||||
"nextImage": "Volgende afbeelding",
|
||||
"showOptionsPanel": "Toon zijscherm",
|
||||
"menu": "Menu",
|
||||
"showGalleryPanel": "Toon deelscherm Galerij",
|
||||
"loadMore": "Laad meer",
|
||||
"about": "Over",
|
||||
"mode": "Modus",
|
||||
"resetUI": "$t(accessibility.reset) UI",
|
||||
@@ -705,7 +376,6 @@
|
||||
"ipAdapter": "IP-adapter",
|
||||
"noConnectionInProgress": "Geen verbinding bezig te maken",
|
||||
"workflowVersion": "Versie",
|
||||
"noConnectionData": "Geen verbindingsgegevens",
|
||||
"fieldTypesMustMatch": "Veldsoorten moeten overeenkomen",
|
||||
"workflow": "Werkstroom",
|
||||
"edge": "Rand",
|
||||
@@ -718,10 +388,8 @@
|
||||
"fullyContainNodesHelp": "Knooppunten moeten zich volledig binnen het keuzevak bevinden om te worden gekozen",
|
||||
"workflowValidation": "Validatiefout werkstroom",
|
||||
"nodeType": "Soort knooppunt",
|
||||
"noMatchingNodes": "Geen overeenkomende knooppunten",
|
||||
"fullyContainNodes": "Omvat knooppunten volledig om ze te kiezen",
|
||||
"executionStateInProgress": "Bezig",
|
||||
"noFieldType": "Geen soort veld",
|
||||
"executionStateError": "Fout",
|
||||
"boolean": "Booleaanse waarden",
|
||||
"executionStateCompleted": "Voltooid",
|
||||
@@ -791,100 +459,6 @@
|
||||
"unableToUpdateNodes_one": "Fout bij bijwerken van {{count}} knooppunt",
|
||||
"unableToUpdateNodes_other": "Fout bij bijwerken van {{count}} knooppunten"
|
||||
},
|
||||
"controlnet": {
|
||||
"amult": "a_mult",
|
||||
"resize": "Schaal",
|
||||
"showAdvanced": "Toon uitgebreide opties",
|
||||
"contentShuffleDescription": "Verschuift het materiaal in de afbeelding",
|
||||
"bgth": "bg_th",
|
||||
"addT2IAdapter": "Voeg $t(common.t2iAdapter) toe",
|
||||
"pidi": "PIDI",
|
||||
"importImageFromCanvas": "Importeer afbeelding uit canvas",
|
||||
"lineartDescription": "Zet afbeelding om naar line-art",
|
||||
"normalBae": "Normale BAE",
|
||||
"importMaskFromCanvas": "Importeer masker uit canvas",
|
||||
"hed": "HED",
|
||||
"hideAdvanced": "Verberg uitgebreid",
|
||||
"contentShuffle": "Verschuif materiaal",
|
||||
"resetControlImage": "Herstel controle-afbeelding",
|
||||
"beginEndStepPercent": "Percentage begin-/eindstap",
|
||||
"mlsdDescription": "Minimalistische herkenning lijnsegmenten",
|
||||
"duplicate": "Maak kopie",
|
||||
"balanced": "Gebalanceerd",
|
||||
"f": "F",
|
||||
"h": "H",
|
||||
"prompt": "Prompt",
|
||||
"depthMidasDescription": "Genereer diepteblad via Midas",
|
||||
"controlnet": "$t(controlnet.controlAdapter_one) #{{number}} ($t(common.controlNet))",
|
||||
"control": "Controle",
|
||||
"resizeMode": "Modus schaling",
|
||||
"coarse": "Grof",
|
||||
"weight": "Gewicht",
|
||||
"selectModel": "Kies een model",
|
||||
"crop": "Snij bij",
|
||||
"depthMidas": "Diepte (Midas)",
|
||||
"w": "B",
|
||||
"processor": "Verwerker",
|
||||
"addControlNet": "Voeg $t(common.controlNet) toe",
|
||||
"none": "Geen",
|
||||
"detectResolution": "Herken resolutie",
|
||||
"ip_adapter": "$t(controlnet.controlAdapter_one) #{{number}} ($t(common.ipAdapter))",
|
||||
"pidiDescription": "PIDI-afbeeldingsverwerking",
|
||||
"mediapipeFace": "Mediapipe - Gezicht",
|
||||
"mlsd": "M-LSD",
|
||||
"controlMode": "Controlemodus",
|
||||
"fill": "Vul",
|
||||
"cannyDescription": "Herkenning Canny-rand",
|
||||
"addIPAdapter": "Voeg $t(common.ipAdapter) toe",
|
||||
"lineart": "Line-art",
|
||||
"colorMapDescription": "Genereert een kleurenblad van de afbeelding",
|
||||
"lineartAnimeDescription": "Lineartverwerking in anime-stijl",
|
||||
"t2i_adapter": "$t(controlnet.controlAdapter_one) #{{number}} ($t(common.t2iAdapter))",
|
||||
"minConfidence": "Min. vertrouwensniveau",
|
||||
"imageResolution": "Resolutie afbeelding",
|
||||
"megaControl": "Zeer veel controle",
|
||||
"depthZoe": "Diepte (Zoe)",
|
||||
"colorMap": "Kleur",
|
||||
"lowThreshold": "Lage drempelwaarde",
|
||||
"autoConfigure": "Configureer verwerker automatisch",
|
||||
"highThreshold": "Hoge drempelwaarde",
|
||||
"normalBaeDescription": "Normale BAE-verwerking",
|
||||
"noneDescription": "Geen verwerking toegepast",
|
||||
"saveControlImage": "Bewaar controle-afbeelding",
|
||||
"toggleControlNet": "Zet deze ControlNet aan/uit",
|
||||
"delete": "Verwijder",
|
||||
"controlAdapter_one": "Control-adapter",
|
||||
"controlAdapter_other": "Control-adapters",
|
||||
"safe": "Veilig",
|
||||
"colorMapTileSize": "Grootte tegel",
|
||||
"lineartAnime": "Line-art voor anime",
|
||||
"mediapipeFaceDescription": "Gezichtsherkenning met Mediapipe",
|
||||
"canny": "Canny",
|
||||
"depthZoeDescription": "Genereer diepteblad via Zoe",
|
||||
"hedDescription": "Herkenning van holistisch-geneste randen",
|
||||
"setControlImageDimensions": "Kopieer grootte naar B/H (optimaliseer voor model)",
|
||||
"scribble": "Krabbel",
|
||||
"maxFaces": "Max. gezichten",
|
||||
"dwOpenpose": "DW Openpose",
|
||||
"depthAnything": "Depth Anything",
|
||||
"base": "Basis",
|
||||
"hands": "Handen",
|
||||
"selectCLIPVisionModel": "Selecteer een CLIP Vision-model",
|
||||
"modelSize": "Modelgrootte",
|
||||
"small": "Klein",
|
||||
"large": "Groot",
|
||||
"resizeSimple": "Wijzig grootte (eenvoudig)",
|
||||
"beginEndStepPercentShort": "Begin-/eind-%",
|
||||
"depthAnythingDescription": "Genereren dieptekaart d.m.v. de techniek Depth Anything",
|
||||
"face": "Gezicht",
|
||||
"body": "Lichaam",
|
||||
"dwOpenposeDescription": "Schatting menselijke pose d.m.v. DW Openpose",
|
||||
"ipAdapterMethod": "Methode",
|
||||
"full": "Volledig",
|
||||
"style": "Alleen stijl",
|
||||
"composition": "Alleen samenstelling",
|
||||
"setControlImageDimensionsForce": "Kopieer grootte naar B/H (negeer model)"
|
||||
},
|
||||
"dynamicPrompts": {
|
||||
"seedBehaviour": {
|
||||
"perPromptDesc": "Gebruik een verschillende seedwaarde per afbeelding",
|
||||
@@ -894,8 +468,6 @@
|
||||
"label": "Gedrag seedwaarde"
|
||||
},
|
||||
"maxPrompts": "Max. prompts",
|
||||
"promptsWithCount_one": "{{count}} prompt",
|
||||
"promptsWithCount_other": "{{count}} prompts",
|
||||
"dynamicPrompts": "Dynamische prompts",
|
||||
"showDynamicPrompts": "Toon dynamische prompts",
|
||||
"loading": "Genereren van dynamische prompts...",
|
||||
@@ -1106,8 +678,6 @@
|
||||
"model": "Model",
|
||||
"noImageDetails": "Geen afbeeldingsdetails gevonden",
|
||||
"cfgScale": "CFG-schaal",
|
||||
"fit": "Schaal aanpassen in Afbeelding naar afbeelding",
|
||||
"initImage": "Initiële afbeelding",
|
||||
"recallParameters": "Opnieuw aan te roepen parameters",
|
||||
"height": "Hoogte",
|
||||
"noMetaData": "Geen metagegevens gevonden",
|
||||
@@ -1201,7 +771,6 @@
|
||||
"noRefinerModelsInstalled": "Geen SDXL-verfijningsmodellen geïnstalleerd",
|
||||
"defaultVAE": "Standaard-VAE",
|
||||
"lora": "LoRA",
|
||||
"esrganModel": "ESRGAN-model",
|
||||
"addLora": "Voeg LoRA toe",
|
||||
"concepts": "Concepten"
|
||||
},
|
||||
|
||||
@@ -5,7 +5,6 @@
|
||||
"reportBugLabel": "Zgłoś błąd",
|
||||
"settingsLabel": "Ustawienia",
|
||||
"img2img": "Obraz na obraz",
|
||||
"unifiedCanvas": "Tryb uniwersalny",
|
||||
"nodes": "Węzły",
|
||||
"upload": "Prześlij",
|
||||
"load": "Załaduj",
|
||||
@@ -17,204 +16,8 @@
|
||||
"galleryImageSize": "Rozmiar obrazów",
|
||||
"gallerySettings": "Ustawienia galerii",
|
||||
"autoSwitchNewImages": "Przełączaj na nowe obrazy",
|
||||
"loadMore": "Wczytaj więcej",
|
||||
"noImagesInGallery": "Brak obrazów w galerii"
|
||||
},
|
||||
"hotkeys": {
|
||||
"keyboardShortcuts": "Skróty klawiszowe",
|
||||
"appHotkeys": "Podstawowe",
|
||||
"generalHotkeys": "Pomocnicze",
|
||||
"galleryHotkeys": "Galeria",
|
||||
"unifiedCanvasHotkeys": "Tryb uniwersalny",
|
||||
"invoke": {
|
||||
"title": "Wywołaj",
|
||||
"desc": "Generuje nowy obraz"
|
||||
},
|
||||
"cancel": {
|
||||
"title": "Anuluj",
|
||||
"desc": "Zatrzymuje generowanie obrazu"
|
||||
},
|
||||
"focusPrompt": {
|
||||
"title": "Aktywuj pole tekstowe",
|
||||
"desc": "Aktywuje pole wprowadzania sugestii"
|
||||
},
|
||||
"toggleOptions": {
|
||||
"title": "Przełącz panel opcji",
|
||||
"desc": "Wysuwa lub chowa panel opcji"
|
||||
},
|
||||
"pinOptions": {
|
||||
"title": "Przypnij opcje",
|
||||
"desc": "Przypina panel opcji"
|
||||
},
|
||||
"toggleGallery": {
|
||||
"title": "Przełącz galerię",
|
||||
"desc": "Wysuwa lub chowa galerię"
|
||||
},
|
||||
"maximizeWorkSpace": {
|
||||
"title": "Powiększ obraz roboczy",
|
||||
"desc": "Chowa wszystkie panele, zostawia tylko podgląd obrazu"
|
||||
},
|
||||
"changeTabs": {
|
||||
"title": "Przełącznie trybu",
|
||||
"desc": "Przełącza na n-ty tryb pracy"
|
||||
},
|
||||
"consoleToggle": {
|
||||
"title": "Przełącz konsolę",
|
||||
"desc": "Otwiera lub chowa widok konsoli"
|
||||
},
|
||||
"setPrompt": {
|
||||
"title": "Skopiuj sugestie",
|
||||
"desc": "Kopiuje sugestie z aktywnego obrazu"
|
||||
},
|
||||
"setSeed": {
|
||||
"title": "Skopiuj inicjator",
|
||||
"desc": "Kopiuje inicjator z aktywnego obrazu"
|
||||
},
|
||||
"setParameters": {
|
||||
"title": "Skopiuj wszystko",
|
||||
"desc": "Kopiuje wszystkie parametry z aktualnie aktywnego obrazu"
|
||||
},
|
||||
"restoreFaces": {
|
||||
"title": "Popraw twarze",
|
||||
"desc": "Uruchamia proces poprawiania twarzy dla aktywnego obrazu"
|
||||
},
|
||||
"showInfo": {
|
||||
"title": "Pokaż informacje",
|
||||
"desc": "Pokazuje metadane zapisane w aktywnym obrazie"
|
||||
},
|
||||
"sendToImageToImage": {
|
||||
"title": "Użyj w trybie \"Obraz na obraz\"",
|
||||
"desc": "Ustawia aktywny obraz jako źródło w trybie \"Obraz na obraz\""
|
||||
},
|
||||
"deleteImage": {
|
||||
"title": "Usuń obraz",
|
||||
"desc": "Usuwa aktywny obraz"
|
||||
},
|
||||
"closePanels": {
|
||||
"title": "Zamknij panele",
|
||||
"desc": "Zamyka wszystkie otwarte panele"
|
||||
},
|
||||
"previousImage": {
|
||||
"title": "Poprzedni obraz",
|
||||
"desc": "Aktywuje poprzedni obraz z galerii"
|
||||
},
|
||||
"nextImage": {
|
||||
"title": "Następny obraz",
|
||||
"desc": "Aktywuje następny obraz z galerii"
|
||||
},
|
||||
"increaseGalleryThumbSize": {
|
||||
"title": "Powiększ obrazy",
|
||||
"desc": "Powiększa rozmiar obrazów w galerii"
|
||||
},
|
||||
"decreaseGalleryThumbSize": {
|
||||
"title": "Pomniejsz obrazy",
|
||||
"desc": "Pomniejsza rozmiar obrazów w galerii"
|
||||
},
|
||||
"selectBrush": {
|
||||
"title": "Aktywuj pędzel",
|
||||
"desc": "Aktywuje narzędzie malowania"
|
||||
},
|
||||
"selectEraser": {
|
||||
"title": "Aktywuj gumkę",
|
||||
"desc": "Aktywuje narzędzie usuwania"
|
||||
},
|
||||
"decreaseBrushSize": {
|
||||
"title": "Zmniejsz rozmiar narzędzia",
|
||||
"desc": "Zmniejsza rozmiar aktywnego narzędzia"
|
||||
},
|
||||
"increaseBrushSize": {
|
||||
"title": "Zwiększ rozmiar narzędzia",
|
||||
"desc": "Zwiększa rozmiar aktywnego narzędzia"
|
||||
},
|
||||
"decreaseBrushOpacity": {
|
||||
"title": "Zmniejsz krycie",
|
||||
"desc": "Zmniejsza poziom krycia pędzla"
|
||||
},
|
||||
"increaseBrushOpacity": {
|
||||
"title": "Zwiększ",
|
||||
"desc": "Zwiększa poziom krycia pędzla"
|
||||
},
|
||||
"moveTool": {
|
||||
"title": "Aktywuj przesunięcie",
|
||||
"desc": "Włącza narzędzie przesuwania"
|
||||
},
|
||||
"fillBoundingBox": {
|
||||
"title": "Wypełnij zaznaczenie",
|
||||
"desc": "Wypełnia zaznaczony obszar aktualnym kolorem pędzla"
|
||||
},
|
||||
"eraseBoundingBox": {
|
||||
"title": "Wyczyść zaznaczenia",
|
||||
"desc": "Usuwa całą zawartość zaznaczonego obszaru"
|
||||
},
|
||||
"colorPicker": {
|
||||
"title": "Aktywuj pipetę",
|
||||
"desc": "Włącza narzędzie kopiowania koloru"
|
||||
},
|
||||
"toggleSnap": {
|
||||
"title": "Przyciąganie do siatki",
|
||||
"desc": "Włącza lub wyłącza opcje przyciągania do siatki"
|
||||
},
|
||||
"quickToggleMove": {
|
||||
"title": "Szybkie przesunięcie",
|
||||
"desc": "Tymczasowo włącza tryb przesuwania obszaru roboczego"
|
||||
},
|
||||
"toggleLayer": {
|
||||
"title": "Przełącz wartwę",
|
||||
"desc": "Przełącza pomiędzy warstwą bazową i maskowania"
|
||||
},
|
||||
"clearMask": {
|
||||
"title": "Wyczyść maskę",
|
||||
"desc": "Usuwa całą zawartość warstwy maskowania"
|
||||
},
|
||||
"hideMask": {
|
||||
"title": "Przełącz maskę",
|
||||
"desc": "Pokazuje lub ukrywa podgląd maski"
|
||||
},
|
||||
"showHideBoundingBox": {
|
||||
"title": "Przełącz zaznaczenie",
|
||||
"desc": "Pokazuje lub ukrywa podgląd zaznaczenia"
|
||||
},
|
||||
"mergeVisible": {
|
||||
"title": "Połącz widoczne",
|
||||
"desc": "Łączy wszystkie widoczne maski w jeden obraz"
|
||||
},
|
||||
"saveToGallery": {
|
||||
"title": "Zapisz w galerii",
|
||||
"desc": "Zapisuje całą zawartość płótna w galerii"
|
||||
},
|
||||
"copyToClipboard": {
|
||||
"title": "Skopiuj do schowka",
|
||||
"desc": "Zapisuje zawartość płótna w schowku systemowym"
|
||||
},
|
||||
"downloadImage": {
|
||||
"title": "Pobierz obraz",
|
||||
"desc": "Zapisuje zawartość płótna do pliku obrazu"
|
||||
},
|
||||
"undoStroke": {
|
||||
"title": "Cofnij",
|
||||
"desc": "Cofa ostatnie pociągnięcie pędzlem"
|
||||
},
|
||||
"redoStroke": {
|
||||
"title": "Ponawia",
|
||||
"desc": "Ponawia cofnięte pociągnięcie pędzlem"
|
||||
},
|
||||
"resetView": {
|
||||
"title": "Resetuj widok",
|
||||
"desc": "Centruje widok płótna"
|
||||
},
|
||||
"previousStagingImage": {
|
||||
"title": "Poprzedni obraz tymczasowy",
|
||||
"desc": "Pokazuje poprzedni obraz tymczasowy"
|
||||
},
|
||||
"nextStagingImage": {
|
||||
"title": "Następny obraz tymczasowy",
|
||||
"desc": "Pokazuje następny obraz tymczasowy"
|
||||
},
|
||||
"acceptStagingImage": {
|
||||
"title": "Akceptuj obraz tymczasowy",
|
||||
"desc": "Akceptuje aktualnie wybrany obraz tymczasowy"
|
||||
}
|
||||
},
|
||||
"parameters": {
|
||||
"images": "L. obrazów",
|
||||
"steps": "L. kroków",
|
||||
@@ -235,8 +38,6 @@
|
||||
"scaledHeight": "Sk. do wys.",
|
||||
"infillMethod": "Metoda wypełniania",
|
||||
"tileSize": "Rozmiar kafelka",
|
||||
"sendToImg2Img": "Użyj w trybie \"Obraz na obraz\"",
|
||||
"sendToUnifiedCanvas": "Użyj w trybie uniwersalnym",
|
||||
"downloadImage": "Pobierz obraz",
|
||||
"usePrompt": "Skopiuj sugestie",
|
||||
"useSeed": "Skopiuj inicjator",
|
||||
@@ -248,7 +49,6 @@
|
||||
"models": "Modele",
|
||||
"displayInProgress": "Podgląd generowanego obrazu",
|
||||
"confirmOnDelete": "Potwierdzaj usuwanie",
|
||||
"enableImageDebugging": "Włącz debugowanie obrazu",
|
||||
"resetWebUI": "Zresetuj interfejs",
|
||||
"resetWebUIDesc1": "Resetowanie interfejsu wyczyści jedynie dane i ustawienia zapisane w pamięci przeglądarki. Nie usunie żadnych obrazów z dysku.",
|
||||
"resetWebUIDesc2": "Jeśli obrazy nie są poprawnie wyświetlane w galerii lub doświadczasz innych problemów, przed zgłoszeniem błędu spróbuj zresetować interfejs.",
|
||||
@@ -257,72 +57,7 @@
|
||||
"toast": {
|
||||
"uploadFailed": "Błąd przesyłania obrazu",
|
||||
"imageCopied": "Skopiowano obraz",
|
||||
"imageNotLoadedDesc": "Nie znaleziono obrazu, który można użyć w Obraz na obraz",
|
||||
"canvasMerged": "Scalono widoczne warstwy",
|
||||
"sentToImageToImage": "Wysłano do Obraz na obraz",
|
||||
"sentToUnifiedCanvas": "Wysłano do trybu uniwersalnego",
|
||||
"parametersNotSet": "Nie ustawiono parametrów",
|
||||
"metadataLoadFailed": "Błąd wczytywania metadanych"
|
||||
},
|
||||
"tooltip": {
|
||||
"feature": {
|
||||
"prompt": "To pole musi zawierać cały tekst sugestii, w tym zarówno opis oczekiwanej zawartości, jak i terminy stylistyczne. Chociaż wagi mogą być zawarte w sugestiach, inne parametry znane z linii poleceń nie będą działać.",
|
||||
"gallery": "W miarę generowania nowych wywołań w tym miejscu będą wyświetlane pliki z katalogu wyjściowego. Obrazy mają dodatkowo opcje konfiguracji nowych wywołań.",
|
||||
"other": "Opcje umożliwią alternatywne tryby przetwarzania. Płynne scalanie będzie pomocne przy generowaniu powtarzających się wzorów. Optymalizacja wysokiej rozdzielczości wykonuje dwuetapowy cykl generowania i powinna być używana przy wyższych rozdzielczościach, gdy potrzebny jest bardziej spójny obraz/kompozycja.",
|
||||
"seed": "Inicjator określa początkowy zestaw szumów, który kieruje procesem odszumiania i może być losowy lub pobrany z poprzedniego wywołania. Funkcja \"Poziom szumu\" może być użyta do złagodzenia saturacji przy wyższych wartościach CFG (spróbuj między 0-10), a Perlin może być użyty w celu dodania wariacji do twoich wyników.",
|
||||
"upscale": "Korzystając z ESRGAN, możesz zwiększyć rozdzielczość obrazu wyjściowego bez konieczności zwiększania szerokości/wysokości w ustawieniach początkowych.",
|
||||
"boundingBox": "Zaznaczony obszar odpowiada ustawieniom wysokości i szerokości w trybach Tekst na obraz i Obraz na obraz. Jedynie piksele znajdujące się w obszarze zaznaczenia zostaną uwzględnione podczas wywoływania nowego obrazu."
|
||||
}
|
||||
},
|
||||
"unifiedCanvas": {
|
||||
"layer": "Warstwa",
|
||||
"base": "Główna",
|
||||
"mask": "Maska",
|
||||
"maskingOptions": "Opcje maski",
|
||||
"enableMask": "Włącz maskę",
|
||||
"preserveMaskedArea": "Zachowaj obszar",
|
||||
"clearMask": "Wyczyść maskę",
|
||||
"brush": "Pędzel",
|
||||
"eraser": "Gumka",
|
||||
"fillBoundingBox": "Wypełnij zaznaczenie",
|
||||
"eraseBoundingBox": "Wyczyść zaznaczenie",
|
||||
"colorPicker": "Pipeta",
|
||||
"brushOptions": "Ustawienia pędzla",
|
||||
"brushSize": "Rozmiar",
|
||||
"move": "Przesunięcie",
|
||||
"resetView": "Resetuj widok",
|
||||
"mergeVisible": "Scal warstwy",
|
||||
"saveToGallery": "Zapisz w galerii",
|
||||
"copyToClipboard": "Skopiuj do schowka",
|
||||
"downloadAsImage": "Zapisz do pliku",
|
||||
"undo": "Cofnij",
|
||||
"redo": "Ponów",
|
||||
"clearCanvas": "Wyczyść obraz",
|
||||
"canvasSettings": "Ustawienia obrazu",
|
||||
"showIntermediates": "Pokazuj stany pośrednie",
|
||||
"showGrid": "Pokazuj siatkę",
|
||||
"snapToGrid": "Przyciągaj do siatki",
|
||||
"darkenOutsideSelection": "Przyciemnij poza zaznaczeniem",
|
||||
"autoSaveToGallery": "Zapisuj automatycznie do galerii",
|
||||
"saveBoxRegionOnly": "Zapisuj tylko zaznaczony obszar",
|
||||
"limitStrokesToBox": "Rysuj tylko wewnątrz zaznaczenia",
|
||||
"showCanvasDebugInfo": "Informacje dla developera",
|
||||
"clearCanvasHistory": "Wyczyść historię operacji",
|
||||
"clearHistory": "Wyczyść historię",
|
||||
"clearCanvasHistoryMessage": "Wyczyszczenie historii nie będzie miało wpływu na sam obraz, ale niemożliwe będzie cofnięcie i otworzenie wszystkich wykonanych do tej pory operacji.",
|
||||
"clearCanvasHistoryConfirm": "Czy na pewno chcesz wyczyścić historię operacji?",
|
||||
"activeLayer": "Warstwa aktywna",
|
||||
"canvasScale": "Poziom powiększenia",
|
||||
"boundingBox": "Rozmiar zaznaczenia",
|
||||
"scaledBoundingBox": "Rozmiar po skalowaniu",
|
||||
"boundingBoxPosition": "Pozycja zaznaczenia",
|
||||
"canvasDimensions": "Rozmiar płótna",
|
||||
"canvasPosition": "Pozycja płótna",
|
||||
"cursorPosition": "Pozycja kursora",
|
||||
"previous": "Poprzedni",
|
||||
"next": "Następny",
|
||||
"accept": "Zaakceptuj",
|
||||
"discardAll": "Odrzuć wszystkie"
|
||||
"parametersNotSet": "Nie ustawiono parametrów"
|
||||
},
|
||||
"accessibility": {
|
||||
"invokeProgressBar": "Pasek postępu",
|
||||
@@ -330,7 +65,6 @@
|
||||
"uploadImage": "Wgrywanie obrazu",
|
||||
"previousImage": "Poprzedni obraz",
|
||||
"nextImage": "Następny obraz",
|
||||
"showOptionsPanel": "Pokaż panel opcji",
|
||||
"menu": "Menu"
|
||||
}
|
||||
}
|
||||
|
||||
@@ -5,7 +5,6 @@
|
||||
"languagePickerLabel": "Seletor de Idioma",
|
||||
"hotkeysLabel": "Hotkeys",
|
||||
"img2img": "Imagem para Imagem",
|
||||
"unifiedCanvas": "Tela Unificada",
|
||||
"nodes": "Nós",
|
||||
"upload": "Upload",
|
||||
"load": "Abrir",
|
||||
@@ -18,205 +17,9 @@
|
||||
"gallery": {
|
||||
"gallerySettings": "Configurações de Galeria",
|
||||
"autoSwitchNewImages": "Trocar para Novas Imagens Automaticamente",
|
||||
"loadMore": "Carregar Mais",
|
||||
"noImagesInGallery": "Sem Imagens na Galeria",
|
||||
"galleryImageSize": "Tamanho da Imagem"
|
||||
},
|
||||
"hotkeys": {
|
||||
"generalHotkeys": "Atalhos Gerais",
|
||||
"galleryHotkeys": "Atalhos da Galeria",
|
||||
"maximizeWorkSpace": {
|
||||
"desc": "Fechar painéis e maximixar área de trabalho",
|
||||
"title": "Maximizar a Área de Trabalho"
|
||||
},
|
||||
"changeTabs": {
|
||||
"title": "Mudar Guias",
|
||||
"desc": "Trocar para outra área de trabalho"
|
||||
},
|
||||
"consoleToggle": {
|
||||
"desc": "Abrir e fechar console",
|
||||
"title": "Ativar Console"
|
||||
},
|
||||
"setPrompt": {
|
||||
"title": "Definir Prompt",
|
||||
"desc": "Usar o prompt da imagem atual"
|
||||
},
|
||||
"sendToImageToImage": {
|
||||
"desc": "Manda a imagem atual para Imagem Para Imagem",
|
||||
"title": "Mandar para Imagem Para Imagem"
|
||||
},
|
||||
"previousImage": {
|
||||
"desc": "Mostra a imagem anterior na galeria",
|
||||
"title": "Imagem Anterior"
|
||||
},
|
||||
"nextImage": {
|
||||
"title": "Próxima Imagem",
|
||||
"desc": "Mostra a próxima imagem na galeria"
|
||||
},
|
||||
"decreaseGalleryThumbSize": {
|
||||
"desc": "Diminui o tamanho das thumbs na galeria",
|
||||
"title": "Diminuir Tamanho da Galeria de Imagem"
|
||||
},
|
||||
"selectBrush": {
|
||||
"title": "Selecionar Pincel",
|
||||
"desc": "Seleciona o pincel"
|
||||
},
|
||||
"selectEraser": {
|
||||
"title": "Selecionar Apagador",
|
||||
"desc": "Seleciona o apagador"
|
||||
},
|
||||
"decreaseBrushSize": {
|
||||
"title": "Diminuir Tamanho do Pincel",
|
||||
"desc": "Diminui o tamanho do pincel/apagador"
|
||||
},
|
||||
"increaseBrushOpacity": {
|
||||
"desc": "Aumenta a opacidade do pincel",
|
||||
"title": "Aumentar Opacidade do Pincel"
|
||||
},
|
||||
"moveTool": {
|
||||
"title": "Ferramenta Mover",
|
||||
"desc": "Permite navegar pela tela"
|
||||
},
|
||||
"decreaseBrushOpacity": {
|
||||
"desc": "Diminui a opacidade do pincel",
|
||||
"title": "Diminuir Opacidade do Pincel"
|
||||
},
|
||||
"toggleSnap": {
|
||||
"title": "Ativar Encaixe",
|
||||
"desc": "Ativa Encaixar na Grade"
|
||||
},
|
||||
"quickToggleMove": {
|
||||
"title": "Ativar Mover Rapidamente",
|
||||
"desc": "Temporariamente ativa o modo Mover"
|
||||
},
|
||||
"toggleLayer": {
|
||||
"title": "Ativar Camada",
|
||||
"desc": "Ativa a seleção de camada de máscara/base"
|
||||
},
|
||||
"clearMask": {
|
||||
"title": "Limpar Máscara",
|
||||
"desc": "Limpa toda a máscara"
|
||||
},
|
||||
"hideMask": {
|
||||
"title": "Esconder Máscara",
|
||||
"desc": "Esconde e Revela a máscara"
|
||||
},
|
||||
"mergeVisible": {
|
||||
"title": "Fundir Visível",
|
||||
"desc": "Fundir todas as camadas visíveis das telas"
|
||||
},
|
||||
"downloadImage": {
|
||||
"desc": "Descarregar a tela atual",
|
||||
"title": "Descarregar Imagem"
|
||||
},
|
||||
"undoStroke": {
|
||||
"title": "Desfazer Traço",
|
||||
"desc": "Desfaz um traço de pincel"
|
||||
},
|
||||
"redoStroke": {
|
||||
"title": "Refazer Traço",
|
||||
"desc": "Refaz o traço de pincel"
|
||||
},
|
||||
"keyboardShortcuts": "Atalhos de Teclado",
|
||||
"appHotkeys": "Atalhos do app",
|
||||
"invoke": {
|
||||
"title": "Invocar",
|
||||
"desc": "Gerar uma imagem"
|
||||
},
|
||||
"cancel": {
|
||||
"title": "Cancelar",
|
||||
"desc": "Cancelar geração de imagem"
|
||||
},
|
||||
"focusPrompt": {
|
||||
"title": "Foco do Prompt",
|
||||
"desc": "Foco da área de texto do prompt"
|
||||
},
|
||||
"toggleOptions": {
|
||||
"title": "Ativar Opções",
|
||||
"desc": "Abrir e fechar o painel de opções"
|
||||
},
|
||||
"pinOptions": {
|
||||
"title": "Fixar Opções",
|
||||
"desc": "Fixar o painel de opções"
|
||||
},
|
||||
"closePanels": {
|
||||
"title": "Fechar Painéis",
|
||||
"desc": "Fecha os painéis abertos"
|
||||
},
|
||||
"unifiedCanvasHotkeys": "Atalhos da Tela Unificada",
|
||||
"toggleGallery": {
|
||||
"title": "Ativar Galeria",
|
||||
"desc": "Abrir e fechar a gaveta da galeria"
|
||||
},
|
||||
"setSeed": {
|
||||
"title": "Definir Seed",
|
||||
"desc": "Usar seed da imagem atual"
|
||||
},
|
||||
"setParameters": {
|
||||
"title": "Definir Parâmetros",
|
||||
"desc": "Usar todos os parâmetros da imagem atual"
|
||||
},
|
||||
"restoreFaces": {
|
||||
"title": "Restaurar Rostos",
|
||||
"desc": "Restaurar a imagem atual"
|
||||
},
|
||||
"showInfo": {
|
||||
"title": "Mostrar Informações",
|
||||
"desc": "Mostrar metadados de informações da imagem atual"
|
||||
},
|
||||
"deleteImage": {
|
||||
"title": "Apagar Imagem",
|
||||
"desc": "Apaga a imagem atual"
|
||||
},
|
||||
"increaseGalleryThumbSize": {
|
||||
"title": "Aumentar Tamanho da Galeria de Imagem",
|
||||
"desc": "Aumenta o tamanho das thumbs na galeria"
|
||||
},
|
||||
"increaseBrushSize": {
|
||||
"title": "Aumentar Tamanho do Pincel",
|
||||
"desc": "Aumenta o tamanho do pincel/apagador"
|
||||
},
|
||||
"fillBoundingBox": {
|
||||
"title": "Preencher Caixa Delimitadora",
|
||||
"desc": "Preenche a caixa delimitadora com a cor do pincel"
|
||||
},
|
||||
"eraseBoundingBox": {
|
||||
"title": "Apagar Caixa Delimitadora",
|
||||
"desc": "Apaga a área da caixa delimitadora"
|
||||
},
|
||||
"colorPicker": {
|
||||
"title": "Selecionar Seletor de Cor",
|
||||
"desc": "Seleciona o seletor de cores"
|
||||
},
|
||||
"showHideBoundingBox": {
|
||||
"title": "Mostrar/Esconder Caixa Delimitadora",
|
||||
"desc": "Ativa a visibilidade da caixa delimitadora"
|
||||
},
|
||||
"saveToGallery": {
|
||||
"title": "Gravara Na Galeria",
|
||||
"desc": "Grava a tela atual na galeria"
|
||||
},
|
||||
"copyToClipboard": {
|
||||
"title": "Copiar para a Área de Transferência",
|
||||
"desc": "Copia a tela atual para a área de transferência"
|
||||
},
|
||||
"resetView": {
|
||||
"title": "Resetar Visualização",
|
||||
"desc": "Reseta Visualização da Tela"
|
||||
},
|
||||
"previousStagingImage": {
|
||||
"title": "Imagem de Preparação Anterior",
|
||||
"desc": "Área de Imagem de Preparação Anterior"
|
||||
},
|
||||
"nextStagingImage": {
|
||||
"title": "Próxima Imagem de Preparação Anterior",
|
||||
"desc": "Próxima Área de Imagem de Preparação Anterior"
|
||||
},
|
||||
"acceptStagingImage": {
|
||||
"title": "Aceitar Imagem de Preparação Anterior",
|
||||
"desc": "Aceitar Área de Imagem de Preparação Anterior"
|
||||
}
|
||||
},
|
||||
"modelManager": {
|
||||
"modelUpdated": "Modelo Atualizado",
|
||||
"description": "Descrição",
|
||||
@@ -227,7 +30,6 @@
|
||||
"convertToDiffusersHelpText6": "Deseja converter este modelo?",
|
||||
"alpha": "Alpha",
|
||||
"config": "Configuração",
|
||||
"v2_768": "v2 (768px)",
|
||||
"modelConverted": "Modelo Convertido",
|
||||
"manual": "Manual",
|
||||
"name": "Nome",
|
||||
@@ -241,7 +43,6 @@
|
||||
"convertToDiffusersHelpText1": "Este modelo será convertido ao formato 🧨 Diffusers.",
|
||||
"convertToDiffusersHelpText2": "Este processo irá substituir a sua entrada de Gestor de Modelos por uma versão Diffusers do mesmo modelo.",
|
||||
"convertToDiffusersHelpText3": "O seu ficheiro de ponto de verificação no disco NÃO será excluído ou modificado de forma alguma. Pode adicionar o seu ponto de verificação ao Gestor de modelos novamente, se desejar.",
|
||||
"v2_base": "v2 (512px)",
|
||||
"none": "nenhum",
|
||||
"modelManager": "Gerente de Modelo",
|
||||
"model": "Modelo",
|
||||
@@ -279,8 +80,6 @@
|
||||
"scaledWidth": "L Escalada",
|
||||
"scaledHeight": "A Escalada",
|
||||
"infillMethod": "Método de Preenchimento",
|
||||
"sendToImg2Img": "Mandar para Imagem Para Imagem",
|
||||
"sendToUnifiedCanvas": "Mandar para Tela Unificada",
|
||||
"copyImage": "Copiar imagem",
|
||||
"downloadImage": "Descarregar Imagem",
|
||||
"useSeed": "Usar Seed",
|
||||
@@ -289,7 +88,6 @@
|
||||
},
|
||||
"settings": {
|
||||
"confirmOnDelete": "Confirmar Antes de Apagar",
|
||||
"enableImageDebugging": "Ativar Depuração de Imagem",
|
||||
"resetWebUIDesc1": "Reiniciar a interface apenas reinicia o cache local do broswer para imagens e configurações lembradas. Não apaga nenhuma imagem do disco.",
|
||||
"models": "Modelos",
|
||||
"displayInProgress": "Mostrar Progresso de Imagens Em Andamento",
|
||||
@@ -299,80 +97,30 @@
|
||||
},
|
||||
"toast": {
|
||||
"uploadFailed": "Envio Falhou",
|
||||
"imageNotLoadedDesc": "Nenhuma imagem encontrada a enviar para o módulo de imagem para imagem",
|
||||
"imageCopied": "Imagem Copiada",
|
||||
"canvasMerged": "Tela Fundida",
|
||||
"sentToImageToImage": "Mandar Para Imagem Para Imagem",
|
||||
"sentToUnifiedCanvas": "Enviada para a Tela Unificada",
|
||||
"parametersNotSet": "Parâmetros Não Definidos",
|
||||
"metadataLoadFailed": "Falha ao tentar carregar metadados"
|
||||
},
|
||||
"tooltip": {
|
||||
"feature": {
|
||||
"prompt": "Este é o campo de prompt. O prompt inclui objetos de geração e termos estilísticos. Também pode adicionar peso (importância do token) no prompt, mas comandos e parâmetros de CLI não funcionarão.",
|
||||
"other": "Essas opções ativam modos alternativos de processamento para o Invoke. 'Seamless tiling' criará padrões repetidos na saída. 'High resolution' é uma geração em duas etapas com img2img: use essa configuração quando desejar uma imagem maior e mais coerente sem artefatos. Levará mais tempo do que o txt2img usual.",
|
||||
"seed": "O valor da semente afeta o ruído inicial a partir do qual a imagem é formada. Pode usar as sementes já existentes de imagens anteriores. 'Limiar de ruído' é usado para mitigar artefatos em valores CFG altos (experimente a faixa de 0-10) e o Perlin para adicionar ruído Perlin durante a geração: ambos servem para adicionar variação às suas saídas.",
|
||||
"gallery": "A galeria exibe as gerações da pasta de saída conforme elas são criadas. As configurações são armazenadas em ficheiros e acessadas pelo menu de contexto.",
|
||||
"upscale": "Use o ESRGAN para ampliar a imagem imediatamente após a geração.",
|
||||
"boundingBox": "A caixa delimitadora é a mesma que as configurações de largura e altura para Texto para Imagem ou Imagem para Imagem. Apenas a área na caixa será processada."
|
||||
}
|
||||
},
|
||||
"unifiedCanvas": {
|
||||
"scaledBoundingBox": "Caixa Delimitadora Escalada",
|
||||
"boundingBoxPosition": "Posição da Caixa Delimitadora",
|
||||
"next": "Próximo",
|
||||
"accept": "Aceitar",
|
||||
"discardAll": "Descartar Todos",
|
||||
"base": "Base",
|
||||
"brush": "Pincel",
|
||||
"showIntermediates": "Mostrar Intermediários",
|
||||
"showGrid": "Mostrar Grade",
|
||||
"clearCanvasHistoryConfirm": "Tem certeza que quer limpar o histórico de tela?",
|
||||
"boundingBox": "Caixa Delimitadora",
|
||||
"canvasDimensions": "Dimensões da Tela",
|
||||
"canvasPosition": "Posição da Tela",
|
||||
"cursorPosition": "Posição do cursor",
|
||||
"previous": "Anterior",
|
||||
"layer": "Camada",
|
||||
"mask": "Máscara",
|
||||
"maskingOptions": "Opções de Mascaramento",
|
||||
"enableMask": "Ativar Máscara",
|
||||
"preserveMaskedArea": "Preservar Área da Máscara",
|
||||
"clearMask": "Limpar Máscara",
|
||||
"eraser": "Apagador",
|
||||
"fillBoundingBox": "Preencher Caixa Delimitadora",
|
||||
"eraseBoundingBox": "Apagar Caixa Delimitadora",
|
||||
"colorPicker": "Seletor de Cor",
|
||||
"brushOptions": "Opções de Pincel",
|
||||
"brushSize": "Tamanho",
|
||||
"move": "Mover",
|
||||
"resetView": "Resetar Visualização",
|
||||
"mergeVisible": "Fundir Visível",
|
||||
"saveToGallery": "Gravar na Galeria",
|
||||
"copyToClipboard": "Copiar para a Área de Transferência",
|
||||
"downloadAsImage": "Descarregar Como Imagem",
|
||||
"undo": "Desfazer",
|
||||
"redo": "Refazer",
|
||||
"clearCanvas": "Limpar Tela",
|
||||
"canvasSettings": "Configurações de Tela",
|
||||
"snapToGrid": "Encaixar na Grade",
|
||||
"darkenOutsideSelection": "Escurecer Seleção Externa",
|
||||
"autoSaveToGallery": "Gravar Automaticamente na Galeria",
|
||||
"saveBoxRegionOnly": "Gravar Apenas a Região da Caixa",
|
||||
"limitStrokesToBox": "Limitar Traços à Caixa",
|
||||
"showCanvasDebugInfo": "Mostrar Informações de Depuração daTela",
|
||||
"clearCanvasHistory": "Limpar o Histórico da Tela",
|
||||
"clearHistory": "Limpar Históprico",
|
||||
"clearCanvasHistoryMessage": "Limpar o histórico de tela deixa a sua tela atual intacta, mas limpa de forma irreversível o histórico de desfazer e refazer.",
|
||||
"activeLayer": "Camada Ativa",
|
||||
"canvasScale": "Escala da Tela"
|
||||
"parametersNotSet": "Parâmetros Não Definidos"
|
||||
},
|
||||
"accessibility": {
|
||||
"invokeProgressBar": "Invocar barra de progresso",
|
||||
"reset": "Repôr",
|
||||
"reset": "Reiniciar",
|
||||
"nextImage": "Próxima imagem",
|
||||
"showOptionsPanel": "Mostrar painel de opções",
|
||||
"uploadImage": "Enviar imagem",
|
||||
"previousImage": "Imagem anterior"
|
||||
"previousImage": "Imagem Anterior",
|
||||
"menu": "Menu",
|
||||
"about": "Sobre",
|
||||
"resetUI": "$t(accessibility.reset)UI",
|
||||
"createIssue": "Reportar Problema",
|
||||
"submitSupportTicket": "Submeter um ticket de Suporte",
|
||||
"mode": "Modo"
|
||||
},
|
||||
"boards": {
|
||||
"selectedForAutoAdd": "Selecionado para Auto-Adicionar",
|
||||
"addBoard": "Adicionar Quadro",
|
||||
"addPrivateBoard": "Adicionar Quadro privado",
|
||||
"addSharedBoard": "Adicionar quadro Compartilhado",
|
||||
"boards": "Quadros",
|
||||
"autoAddBoard": "Auto-adicao de Quadro",
|
||||
"archiveBoard": "Arquivar Quadro",
|
||||
"archived": "Arquivado"
|
||||
}
|
||||
}
|
||||
|
||||
@@ -5,7 +5,6 @@
|
||||
"reportBugLabel": "Relatar Bug",
|
||||
"settingsLabel": "Configurações",
|
||||
"img2img": "Imagem Para Imagem",
|
||||
"unifiedCanvas": "Tela Unificada",
|
||||
"nodes": "Nódulos",
|
||||
"upload": "Enviar",
|
||||
"load": "Carregar",
|
||||
@@ -19,204 +18,8 @@
|
||||
"galleryImageSize": "Tamanho da Imagem",
|
||||
"gallerySettings": "Configurações de Galeria",
|
||||
"autoSwitchNewImages": "Trocar para Novas Imagens Automaticamente",
|
||||
"loadMore": "Carregar Mais",
|
||||
"noImagesInGallery": "Sem Imagens na Galeria"
|
||||
},
|
||||
"hotkeys": {
|
||||
"keyboardShortcuts": "Atalhos de Teclado",
|
||||
"appHotkeys": "Atalhos do app",
|
||||
"generalHotkeys": "Atalhos Gerais",
|
||||
"galleryHotkeys": "Atalhos da Galeria",
|
||||
"unifiedCanvasHotkeys": "Atalhos da Tela Unificada",
|
||||
"invoke": {
|
||||
"title": "Invoke",
|
||||
"desc": "Gerar uma imagem"
|
||||
},
|
||||
"cancel": {
|
||||
"title": "Cancelar",
|
||||
"desc": "Cancelar geração de imagem"
|
||||
},
|
||||
"focusPrompt": {
|
||||
"title": "Foco do Prompt",
|
||||
"desc": "Foco da área de texto do prompt"
|
||||
},
|
||||
"toggleOptions": {
|
||||
"title": "Ativar Opções",
|
||||
"desc": "Abrir e fechar o painel de opções"
|
||||
},
|
||||
"pinOptions": {
|
||||
"title": "Fixar Opções",
|
||||
"desc": "Fixar o painel de opções"
|
||||
},
|
||||
"toggleGallery": {
|
||||
"title": "Ativar Galeria",
|
||||
"desc": "Abrir e fechar a gaveta da galeria"
|
||||
},
|
||||
"maximizeWorkSpace": {
|
||||
"title": "Maximizar a Área de Trabalho",
|
||||
"desc": "Fechar painéis e maximixar área de trabalho"
|
||||
},
|
||||
"changeTabs": {
|
||||
"title": "Mudar Abas",
|
||||
"desc": "Trocar para outra área de trabalho"
|
||||
},
|
||||
"consoleToggle": {
|
||||
"title": "Ativar Console",
|
||||
"desc": "Abrir e fechar console"
|
||||
},
|
||||
"setPrompt": {
|
||||
"title": "Definir Prompt",
|
||||
"desc": "Usar o prompt da imagem atual"
|
||||
},
|
||||
"setSeed": {
|
||||
"title": "Definir Seed",
|
||||
"desc": "Usar seed da imagem atual"
|
||||
},
|
||||
"setParameters": {
|
||||
"title": "Definir Parâmetros",
|
||||
"desc": "Usar todos os parâmetros da imagem atual"
|
||||
},
|
||||
"restoreFaces": {
|
||||
"title": "Restaurar Rostos",
|
||||
"desc": "Restaurar a imagem atual"
|
||||
},
|
||||
"showInfo": {
|
||||
"title": "Mostrar Informações",
|
||||
"desc": "Mostrar metadados de informações da imagem atual"
|
||||
},
|
||||
"sendToImageToImage": {
|
||||
"title": "Mandar para Imagem Para Imagem",
|
||||
"desc": "Manda a imagem atual para Imagem Para Imagem"
|
||||
},
|
||||
"deleteImage": {
|
||||
"title": "Apagar Imagem",
|
||||
"desc": "Apaga a imagem atual"
|
||||
},
|
||||
"closePanels": {
|
||||
"title": "Fechar Painéis",
|
||||
"desc": "Fecha os painéis abertos"
|
||||
},
|
||||
"previousImage": {
|
||||
"title": "Imagem Anterior",
|
||||
"desc": "Mostra a imagem anterior na galeria"
|
||||
},
|
||||
"nextImage": {
|
||||
"title": "Próxima Imagem",
|
||||
"desc": "Mostra a próxima imagem na galeria"
|
||||
},
|
||||
"increaseGalleryThumbSize": {
|
||||
"title": "Aumentar Tamanho da Galeria de Imagem",
|
||||
"desc": "Aumenta o tamanho das thumbs na galeria"
|
||||
},
|
||||
"decreaseGalleryThumbSize": {
|
||||
"title": "Diminuir Tamanho da Galeria de Imagem",
|
||||
"desc": "Diminui o tamanho das thumbs na galeria"
|
||||
},
|
||||
"selectBrush": {
|
||||
"title": "Selecionar Pincel",
|
||||
"desc": "Seleciona o pincel"
|
||||
},
|
||||
"selectEraser": {
|
||||
"title": "Selecionar Apagador",
|
||||
"desc": "Seleciona o apagador"
|
||||
},
|
||||
"decreaseBrushSize": {
|
||||
"title": "Diminuir Tamanho do Pincel",
|
||||
"desc": "Diminui o tamanho do pincel/apagador"
|
||||
},
|
||||
"increaseBrushSize": {
|
||||
"title": "Aumentar Tamanho do Pincel",
|
||||
"desc": "Aumenta o tamanho do pincel/apagador"
|
||||
},
|
||||
"decreaseBrushOpacity": {
|
||||
"title": "Diminuir Opacidade do Pincel",
|
||||
"desc": "Diminui a opacidade do pincel"
|
||||
},
|
||||
"increaseBrushOpacity": {
|
||||
"title": "Aumentar Opacidade do Pincel",
|
||||
"desc": "Aumenta a opacidade do pincel"
|
||||
},
|
||||
"moveTool": {
|
||||
"title": "Ferramenta Mover",
|
||||
"desc": "Permite navegar pela tela"
|
||||
},
|
||||
"fillBoundingBox": {
|
||||
"title": "Preencher Caixa Delimitadora",
|
||||
"desc": "Preenche a caixa delimitadora com a cor do pincel"
|
||||
},
|
||||
"eraseBoundingBox": {
|
||||
"title": "Apagar Caixa Delimitadora",
|
||||
"desc": "Apaga a área da caixa delimitadora"
|
||||
},
|
||||
"colorPicker": {
|
||||
"title": "Selecionar Seletor de Cor",
|
||||
"desc": "Seleciona o seletor de cores"
|
||||
},
|
||||
"toggleSnap": {
|
||||
"title": "Ativar Encaixe",
|
||||
"desc": "Ativa Encaixar na Grade"
|
||||
},
|
||||
"quickToggleMove": {
|
||||
"title": "Ativar Mover Rapidamente",
|
||||
"desc": "Temporariamente ativa o modo Mover"
|
||||
},
|
||||
"toggleLayer": {
|
||||
"title": "Ativar Camada",
|
||||
"desc": "Ativa a seleção de camada de máscara/base"
|
||||
},
|
||||
"clearMask": {
|
||||
"title": "Limpar Máscara",
|
||||
"desc": "Limpa toda a máscara"
|
||||
},
|
||||
"hideMask": {
|
||||
"title": "Esconder Máscara",
|
||||
"desc": "Esconde e Revela a máscara"
|
||||
},
|
||||
"showHideBoundingBox": {
|
||||
"title": "Mostrar/Esconder Caixa Delimitadora",
|
||||
"desc": "Ativa a visibilidade da caixa delimitadora"
|
||||
},
|
||||
"mergeVisible": {
|
||||
"title": "Fundir Visível",
|
||||
"desc": "Fundir todas as camadas visíveis em tela"
|
||||
},
|
||||
"saveToGallery": {
|
||||
"title": "Salvara Na Galeria",
|
||||
"desc": "Salva a tela atual na galeria"
|
||||
},
|
||||
"copyToClipboard": {
|
||||
"title": "Copiar para a Área de Transferência",
|
||||
"desc": "Copia a tela atual para a área de transferência"
|
||||
},
|
||||
"downloadImage": {
|
||||
"title": "Baixar Imagem",
|
||||
"desc": "Baixa a tela atual"
|
||||
},
|
||||
"undoStroke": {
|
||||
"title": "Desfazer Traço",
|
||||
"desc": "Desfaz um traço de pincel"
|
||||
},
|
||||
"redoStroke": {
|
||||
"title": "Refazer Traço",
|
||||
"desc": "Refaz o traço de pincel"
|
||||
},
|
||||
"resetView": {
|
||||
"title": "Resetar Visualização",
|
||||
"desc": "Reseta Visualização da Tela"
|
||||
},
|
||||
"previousStagingImage": {
|
||||
"title": "Imagem de Preparação Anterior",
|
||||
"desc": "Área de Imagem de Preparação Anterior"
|
||||
},
|
||||
"nextStagingImage": {
|
||||
"title": "Próxima Imagem de Preparação Anterior",
|
||||
"desc": "Próxima Área de Imagem de Preparação Anterior"
|
||||
},
|
||||
"acceptStagingImage": {
|
||||
"title": "Aceitar Imagem de Preparação Anterior",
|
||||
"desc": "Aceitar Área de Imagem de Preparação Anterior"
|
||||
}
|
||||
},
|
||||
"modelManager": {
|
||||
"modelManager": "Gerente de Modelo",
|
||||
"model": "Modelo",
|
||||
@@ -271,8 +74,6 @@
|
||||
"scaledHeight": "A Escalada",
|
||||
"infillMethod": "Método de Preenchimento",
|
||||
"tileSize": "Tamanho do Ladrilho",
|
||||
"sendToImg2Img": "Mandar para Imagem Para Imagem",
|
||||
"sendToUnifiedCanvas": "Mandar para Tela Unificada",
|
||||
"downloadImage": "Baixar Imagem",
|
||||
"usePrompt": "Usar Prompt",
|
||||
"useSeed": "Usar Seed",
|
||||
@@ -288,7 +89,6 @@
|
||||
"models": "Modelos",
|
||||
"displayInProgress": "Mostrar Progresso de Imagens Em Andamento",
|
||||
"confirmOnDelete": "Confirmar Antes de Apagar",
|
||||
"enableImageDebugging": "Ativar Depuração de Imagem",
|
||||
"resetWebUI": "Reiniciar Interface",
|
||||
"resetWebUIDesc1": "Reiniciar a interface apenas reinicia o cache local do broswer para imagens e configurações lembradas. Não apaga nenhuma imagem do disco.",
|
||||
"resetWebUIDesc2": "Se as imagens não estão aparecendo na galeria ou algo mais não está funcionando, favor tentar reiniciar antes de postar um problema no GitHub.",
|
||||
@@ -297,71 +97,6 @@
|
||||
"toast": {
|
||||
"uploadFailed": "Envio Falhou",
|
||||
"imageCopied": "Imagem Copiada",
|
||||
"imageNotLoadedDesc": "Nenhuma imagem encontrar para mandar para o módulo de imagem para imagem",
|
||||
"canvasMerged": "Tela Fundida",
|
||||
"sentToImageToImage": "Mandar Para Imagem Para Imagem",
|
||||
"sentToUnifiedCanvas": "Enviada para a Tela Unificada",
|
||||
"parametersNotSet": "Parâmetros Não Definidos",
|
||||
"metadataLoadFailed": "Falha ao tentar carregar metadados"
|
||||
},
|
||||
"unifiedCanvas": {
|
||||
"layer": "Camada",
|
||||
"base": "Base",
|
||||
"mask": "Máscara",
|
||||
"maskingOptions": "Opções de Mascaramento",
|
||||
"enableMask": "Ativar Máscara",
|
||||
"preserveMaskedArea": "Preservar Área da Máscara",
|
||||
"clearMask": "Limpar Máscara",
|
||||
"brush": "Pincel",
|
||||
"eraser": "Apagador",
|
||||
"fillBoundingBox": "Preencher Caixa Delimitadora",
|
||||
"eraseBoundingBox": "Apagar Caixa Delimitadora",
|
||||
"colorPicker": "Seletor de Cor",
|
||||
"brushOptions": "Opções de Pincel",
|
||||
"brushSize": "Tamanho",
|
||||
"move": "Mover",
|
||||
"resetView": "Resetar Visualização",
|
||||
"mergeVisible": "Fundir Visível",
|
||||
"saveToGallery": "Salvar na Galeria",
|
||||
"copyToClipboard": "Copiar para a Área de Transferência",
|
||||
"downloadAsImage": "Baixar Como Imagem",
|
||||
"undo": "Desfazer",
|
||||
"redo": "Refazer",
|
||||
"clearCanvas": "Limpar Tela",
|
||||
"canvasSettings": "Configurações de Tela",
|
||||
"showIntermediates": "Mostrar Intermediários",
|
||||
"showGrid": "Mostrar Grade",
|
||||
"snapToGrid": "Encaixar na Grade",
|
||||
"darkenOutsideSelection": "Escurecer Seleção Externa",
|
||||
"autoSaveToGallery": "Salvar Automaticamente na Galeria",
|
||||
"saveBoxRegionOnly": "Salvar Apenas a Região da Caixa",
|
||||
"limitStrokesToBox": "Limitar Traços para a Caixa",
|
||||
"showCanvasDebugInfo": "Mostrar Informações de Depuração daTela",
|
||||
"clearCanvasHistory": "Limpar o Histórico da Tela",
|
||||
"clearHistory": "Limpar Históprico",
|
||||
"clearCanvasHistoryMessage": "Limpar o histórico de tela deixa sua tela atual intacta, mas limpa de forma irreversível o histórico de desfazer e refazer.",
|
||||
"clearCanvasHistoryConfirm": "Tem certeza que quer limpar o histórico de tela?",
|
||||
"activeLayer": "Camada Ativa",
|
||||
"canvasScale": "Escala da Tela",
|
||||
"boundingBox": "Caixa Delimitadora",
|
||||
"scaledBoundingBox": "Caixa Delimitadora Escalada",
|
||||
"boundingBoxPosition": "Posição da Caixa Delimitadora",
|
||||
"canvasDimensions": "Dimensões da Tela",
|
||||
"canvasPosition": "Posição da Tela",
|
||||
"cursorPosition": "Posição do cursor",
|
||||
"previous": "Anterior",
|
||||
"next": "Próximo",
|
||||
"accept": "Aceitar",
|
||||
"discardAll": "Descartar Todos"
|
||||
},
|
||||
"tooltip": {
|
||||
"feature": {
|
||||
"seed": "O valor da semente afeta o ruído inicial a partir do qual a imagem é formada. Você pode usar as sementes já existentes de imagens anteriores. 'Limiar de ruído' é usado para mitigar artefatos em valores CFG altos (experimente a faixa de 0-10), e o Perlin para adicionar ruído Perlin durante a geração: ambos servem para adicionar variação às suas saídas.",
|
||||
"gallery": "A galeria exibe as gerações da pasta de saída conforme elas são criadas. As configurações são armazenadas em arquivos e acessadas pelo menu de contexto.",
|
||||
"other": "Essas opções ativam modos alternativos de processamento para o Invoke. 'Seamless tiling' criará padrões repetidos na saída. 'High resolution' é uma geração em duas etapas com img2img: use essa configuração quando desejar uma imagem maior e mais coerente sem artefatos. Levará mais tempo do que o txt2img usual.",
|
||||
"boundingBox": "A caixa delimitadora é a mesma que as configurações de largura e altura para Texto para Imagem ou Imagem para Imagem. Apenas a área na caixa será processada.",
|
||||
"upscale": "Use o ESRGAN para ampliar a imagem imediatamente após a geração.",
|
||||
"prompt": "Este é o campo de prompt. O prompt inclui objetos de geração e termos estilísticos. Você também pode adicionar peso (importância do token) no prompt, mas comandos e parâmetros de CLI não funcionarão."
|
||||
}
|
||||
"parametersNotSet": "Parâmetros Não Definidos"
|
||||
}
|
||||
}
|
||||
|
||||
File diff suppressed because it is too large
Load Diff
@@ -4,8 +4,7 @@
|
||||
"invokeProgressBar": "Invoke förloppsmätare",
|
||||
"nextImage": "Nästa bild",
|
||||
"reset": "Starta om",
|
||||
"previousImage": "Föregående bild",
|
||||
"showOptionsPanel": "Visa inställningspanelen"
|
||||
"previousImage": "Föregående bild"
|
||||
},
|
||||
"common": {
|
||||
"hotkeysLabel": "Snabbtangenter",
|
||||
@@ -13,7 +12,6 @@
|
||||
"githubLabel": "Github",
|
||||
"discordLabel": "Discord",
|
||||
"settingsLabel": "Inställningar",
|
||||
"unifiedCanvas": "Förenad kanvas",
|
||||
"upload": "Ladda upp",
|
||||
"cancel": "Avbryt",
|
||||
"accept": "Acceptera",
|
||||
@@ -29,135 +27,8 @@
|
||||
},
|
||||
"gallery": {
|
||||
"galleryImageSize": "Bildstorlek",
|
||||
"loadMore": "Ladda mer",
|
||||
"gallerySettings": "Galleriinställningar",
|
||||
"noImagesInGallery": "Inga bilder i galleriet",
|
||||
"autoSwitchNewImages": "Ändra automatiskt till nya bilder"
|
||||
},
|
||||
"hotkeys": {
|
||||
"generalHotkeys": "Allmänna snabbtangenter",
|
||||
"galleryHotkeys": "Gallerisnabbtangenter",
|
||||
"unifiedCanvasHotkeys": "Snabbtangenter för sammanslagskanvas",
|
||||
"invoke": {
|
||||
"title": "Anropa",
|
||||
"desc": "Genererar en bild"
|
||||
},
|
||||
"cancel": {
|
||||
"title": "Avbryt",
|
||||
"desc": "Avbryt bildgenerering"
|
||||
},
|
||||
"focusPrompt": {
|
||||
"desc": "Fokusera området för promptinmatning",
|
||||
"title": "Fokusprompt"
|
||||
},
|
||||
"pinOptions": {
|
||||
"desc": "Nåla fast alternativpanelen",
|
||||
"title": "Nåla fast alternativ"
|
||||
},
|
||||
"toggleOptions": {
|
||||
"title": "Växla inställningar",
|
||||
"desc": "Öppna och stäng alternativpanelen"
|
||||
},
|
||||
"toggleGallery": {
|
||||
"title": "Växla galleri",
|
||||
"desc": "Öppna eller stäng galleribyrån"
|
||||
},
|
||||
"maximizeWorkSpace": {
|
||||
"title": "Maximera arbetsyta",
|
||||
"desc": "Stäng paneler och maximera arbetsyta"
|
||||
},
|
||||
"changeTabs": {
|
||||
"title": "Växla flik",
|
||||
"desc": "Byt till en annan arbetsyta"
|
||||
},
|
||||
"consoleToggle": {
|
||||
"title": "Växla konsol",
|
||||
"desc": "Öppna och stäng konsol"
|
||||
},
|
||||
"setSeed": {
|
||||
"desc": "Använd seed för nuvarande bild",
|
||||
"title": "välj seed"
|
||||
},
|
||||
"setParameters": {
|
||||
"title": "Välj parametrar",
|
||||
"desc": "Använd alla parametrar från nuvarande bild"
|
||||
},
|
||||
"setPrompt": {
|
||||
"desc": "Använd prompt för nuvarande bild",
|
||||
"title": "Välj prompt"
|
||||
},
|
||||
"restoreFaces": {
|
||||
"title": "Återskapa ansikten",
|
||||
"desc": "Återskapa nuvarande bild"
|
||||
},
|
||||
"showInfo": {
|
||||
"title": "Visa info",
|
||||
"desc": "Visa metadata för nuvarande bild"
|
||||
},
|
||||
"sendToImageToImage": {
|
||||
"title": "Skicka till Bild till bild",
|
||||
"desc": "Skicka nuvarande bild till Bild till bild"
|
||||
},
|
||||
"deleteImage": {
|
||||
"title": "Radera bild",
|
||||
"desc": "Radera nuvarande bild"
|
||||
},
|
||||
"closePanels": {
|
||||
"title": "Stäng paneler",
|
||||
"desc": "Stäng öppna paneler"
|
||||
},
|
||||
"previousImage": {
|
||||
"title": "Föregående bild",
|
||||
"desc": "Visa föregående bild"
|
||||
},
|
||||
"nextImage": {
|
||||
"title": "Nästa bild",
|
||||
"desc": "Visa nästa bild"
|
||||
},
|
||||
"increaseGalleryThumbSize": {
|
||||
"title": "Förstora galleriets bildstorlek",
|
||||
"desc": "Förstora miniatyrbildernas storlek"
|
||||
},
|
||||
"decreaseGalleryThumbSize": {
|
||||
"title": "Minska gelleriets bildstorlek",
|
||||
"desc": "Minska miniatyrbildernas storlek i galleriet"
|
||||
},
|
||||
"decreaseBrushSize": {
|
||||
"desc": "Förminska storleken på kanvas- pensel eller suddgummi",
|
||||
"title": "Minska penselstorlek"
|
||||
},
|
||||
"increaseBrushSize": {
|
||||
"title": "Öka penselstorlek",
|
||||
"desc": "Öka stoleken på kanvas- pensel eller suddgummi"
|
||||
},
|
||||
"increaseBrushOpacity": {
|
||||
"title": "Öka penselns opacitet",
|
||||
"desc": "Öka opaciteten för kanvaspensel"
|
||||
},
|
||||
"decreaseBrushOpacity": {
|
||||
"desc": "Minska kanvaspenselns opacitet",
|
||||
"title": "Minska penselns opacitet"
|
||||
},
|
||||
"moveTool": {
|
||||
"title": "Flytta",
|
||||
"desc": "Tillåt kanvasnavigation"
|
||||
},
|
||||
"fillBoundingBox": {
|
||||
"title": "Fyll ram",
|
||||
"desc": "Fyller ramen med pensels färg"
|
||||
},
|
||||
"keyboardShortcuts": "Snabbtangenter",
|
||||
"appHotkeys": "Appsnabbtangenter",
|
||||
"selectBrush": {
|
||||
"desc": "Välj kanvaspensel",
|
||||
"title": "Välj pensel"
|
||||
},
|
||||
"selectEraser": {
|
||||
"desc": "Välj kanvassuddgummi",
|
||||
"title": "Välj suddgummi"
|
||||
},
|
||||
"eraseBoundingBox": {
|
||||
"title": "Ta bort ram"
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
@@ -2,7 +2,6 @@
|
||||
"accessibility": {
|
||||
"invokeProgressBar": "Invoke durum çubuğu",
|
||||
"nextImage": "Sonraki Görsel",
|
||||
"showOptionsPanel": "Yan Paneli Göster",
|
||||
"reset": "Resetle",
|
||||
"uploadImage": "Görsel Yükle",
|
||||
"previousImage": "Önceki Görsel",
|
||||
@@ -10,8 +9,6 @@
|
||||
"about": "Hakkında",
|
||||
"mode": "Kip",
|
||||
"resetUI": "$t(accessibility.reset)Arayüz",
|
||||
"showGalleryPanel": "Galeri Panelini Göster",
|
||||
"loadMore": "Daha Getir",
|
||||
"createIssue": "Sorun Bildir"
|
||||
},
|
||||
"common": {
|
||||
@@ -26,7 +23,6 @@
|
||||
"linear": "Doğrusal",
|
||||
"nodes": "İş Akışı Düzenleyici",
|
||||
"postprocessing": "Rötuş",
|
||||
"unifiedCanvas": "Tuval",
|
||||
"batch": "Toplu İş Yöneticisi",
|
||||
"accept": "Onayla",
|
||||
"cancel": "Vazgeç",
|
||||
@@ -52,7 +48,6 @@
|
||||
"outpaint": "dışboyama",
|
||||
"outputs": "Çıktılar",
|
||||
"learnMore": "Bilgi Edin",
|
||||
"nodeEditor": "Çizge Düzenleyici",
|
||||
"save": "Kaydet",
|
||||
"random": "Rastgele",
|
||||
"simple": "Basit",
|
||||
@@ -132,85 +127,6 @@
|
||||
"changeBoard": "Panoyu Değiştir",
|
||||
"bottomMessage": "Bu panoyu ve görselleri silmek, bunları kullanan özelliklerin resetlemesine neden olacaktır."
|
||||
},
|
||||
"controlnet": {
|
||||
"balanced": "Dengeli",
|
||||
"contentShuffle": "İçerik Karıştırma",
|
||||
"contentShuffleDescription": "Görselin içeriğini karıştırır",
|
||||
"depthZoe": "Derinlik (Zoe)",
|
||||
"depthZoeDescription": "Zoe kullanarak derinlik haritası oluşturma",
|
||||
"resizeMode": "Boyutlandırma Kipi",
|
||||
"addControlNet": "$t(common.controlNet) Ekle",
|
||||
"addIPAdapter": "$t(common.ipAdapter) Ekle",
|
||||
"addT2IAdapter": "$t(common.t2iAdapter) Ekle",
|
||||
"colorMap": "Renk",
|
||||
"crop": "Kırpma",
|
||||
"delete": "Kaldır",
|
||||
"depthMidas": "Derinlik (Midas)",
|
||||
"depthMidasDescription": "Midas kullanarak derinlik haritası oluşturma",
|
||||
"detectResolution": "Çözünürlüğü Bul",
|
||||
"none": "Hiçbiri",
|
||||
"noneDescription": "Hiçbir işlem uygulanmamış",
|
||||
"selectModel": "Model seçin",
|
||||
"showAdvanced": "Gelişmiş Seçenekleri Göster",
|
||||
"canny": "Canny",
|
||||
"colorMapDescription": "Görselden renk haritası oluşturur",
|
||||
"processor": "İşlemci",
|
||||
"prompt": "İstem",
|
||||
"duplicate": "Kopyala",
|
||||
"large": "Büyük",
|
||||
"modelSize": "Model Boyutu",
|
||||
"resize": "Boyutlandır",
|
||||
"resizeSimple": "Boyutlandır (Basit)",
|
||||
"safe": "Güvenli",
|
||||
"small": "Küçük",
|
||||
"weight": "Etki",
|
||||
"cannyDescription": "Canny kenar algılama",
|
||||
"fill": "Doldur",
|
||||
"highThreshold": "Üst Eşik",
|
||||
"imageResolution": "Görsel Çözünürlüğü",
|
||||
"colorMapTileSize": "Döşeme Boyutu",
|
||||
"importImageFromCanvas": "Tuvaldeki Görseli Al",
|
||||
"importMaskFromCanvas": "Tuvalden Maskeyi İçe Aktar",
|
||||
"lowThreshold": "Alt Eşik",
|
||||
"base": "Taban",
|
||||
"depthAnythingDescription": "Depth Anything yöntemi ile derinlik haritası oluşturma",
|
||||
"controlAdapter_one": "Yönetim Aracı",
|
||||
"controlAdapter_other": "Yönetim Aracı",
|
||||
"beginEndStepPercent": "Başlangıç / Bitiş Yüzdesi",
|
||||
"control": "Yönetim",
|
||||
"controlnet": "{{number}}. $t(controlnet.controlAdapter_one) ($t(common.controlNet))",
|
||||
"amult": "a_mult",
|
||||
"hideAdvanced": "Gelişmiş Seçenekleri Gizle",
|
||||
"hed": "HED",
|
||||
"ip_adapter": "{{number}}. $t(controlnet.controlAdapter_one) ($t(common.ipAdapter))",
|
||||
"t2i_adapter": "{{number}}. $t(controlnet.controlAdapter_one) ($t(common.t2iAdapter))",
|
||||
"autoConfigure": "Aracı otomatik yapılandır",
|
||||
"bgth": "bg_th",
|
||||
"coarse": "İri",
|
||||
"controlMode": "Yönetim Kipi",
|
||||
"depthAnything": "Depth Anything",
|
||||
"hedDescription": "Holistically-Nested Edge Detection (Bütünsel Yuvalanmış Kenar Tespiti)",
|
||||
"lineartAnime": "Çizim (Anime)",
|
||||
"lineartAnimeDescription": "Anime stili çizim işleme",
|
||||
"minConfidence": "Özgüven Alt Limiti",
|
||||
"pidiDescription": "PIDI görsel işleme",
|
||||
"mediapipeFace": "Mediapipe Yüz",
|
||||
"megaControl": "Aşırı Yönetim",
|
||||
"mlsd": "M-LSD",
|
||||
"setControlImageDimensions": "Yönetim Görseli Boyutlarını En/Boydan Al",
|
||||
"pidi": "PIDI",
|
||||
"scribble": "çiziktirme",
|
||||
"mediapipeFaceDescription": "Mediapipe kullanarak yüz algılama",
|
||||
"saveControlImage": "Yönetim Görselini Kaydet",
|
||||
"w": "En",
|
||||
"lineartDescription": "Görseli çizime dönüştürür",
|
||||
"maxFaces": "Yüz Üst Limiti",
|
||||
"mlsdDescription": "Minimalist Line Segment Detector (Kolay Çizgi Parçası Algılama)",
|
||||
"normalBae": "Normal BAE",
|
||||
"normalBaeDescription": "Normal BAE işleme",
|
||||
"resetControlImage": "Yönetim Görselini Kaldır",
|
||||
"lineart": "Çizim"
|
||||
},
|
||||
"queue": {
|
||||
"resumeSucceeded": "İşlem Sürdürüldü",
|
||||
"openQueue": "Sırayı Göster",
|
||||
@@ -285,11 +201,9 @@
|
||||
"starImage": "Yıldız Koy",
|
||||
"download": "İndir",
|
||||
"deleteSelection": "Seçileni Sil",
|
||||
"problemDeletingImages": "Görsel Silmede Sorun",
|
||||
"featuresWillReset": "Bu görseli silerseniz, o özellikler resetlenecektir.",
|
||||
"noImageSelected": "Görsel Seçilmedi",
|
||||
"unstarImage": "Yıldızı Kaldır",
|
||||
"problemDeletingImagesDesc": "Bir ya da daha çok görsel silinemedi",
|
||||
"gallerySettings": "Galeri Düzeni",
|
||||
"image": "görsel",
|
||||
"galleryImageSize": "Görsel Boyutu",
|
||||
@@ -299,8 +213,6 @@
|
||||
"currentlyInUse": "Bu görsel şurada kullanımda:",
|
||||
"deleteImage_one": "Görseli Sil",
|
||||
"deleteImage_other": "",
|
||||
"loadMore": "Daha Getir",
|
||||
"setCurrentImage": "Çalışma Görseli Yap",
|
||||
"unableToLoad": "Galeri Yüklenemedi",
|
||||
"downloadSelection": "Seçileni İndir",
|
||||
"dropOrUpload": "$t(gallery.drop) ya da Yükle",
|
||||
@@ -320,225 +232,7 @@
|
||||
"hotkeys": {
|
||||
"noHotkeysFound": "Kısayol Tuşu Bulanamadı",
|
||||
"searchHotkeys": "Kısayol Tuşlarında Ara",
|
||||
"clearSearch": "Aramayı Sil",
|
||||
"colorPicker": {
|
||||
"title": "Renk Seçici",
|
||||
"desc": "Tuvalde renk seçiciye geçer"
|
||||
},
|
||||
"consoleToggle": {
|
||||
"title": "Konsolu Aç-Kapat",
|
||||
"desc": "Konsolu aç-kapat"
|
||||
},
|
||||
"hideMask": {
|
||||
"desc": "Maskeyi gizle-göster",
|
||||
"title": "Maskeyi Gizle"
|
||||
},
|
||||
"focusPrompt": {
|
||||
"title": "İsteme Odaklan",
|
||||
"desc": "Görsel istemi alanına odaklanır"
|
||||
},
|
||||
"keyboardShortcuts": "Kısayol Tuşları",
|
||||
"nextImage": {
|
||||
"title": "Sonraki Görsel",
|
||||
"desc": "Galerideki sonraki görseli göster"
|
||||
},
|
||||
"maximizeWorkSpace": {
|
||||
"desc": "Panelleri kapatıp çalışma alanını genişlet",
|
||||
"title": "Çalışma Alanını Genişlet"
|
||||
},
|
||||
"pinOptions": {
|
||||
"desc": "Seçenekler panelini iğnele",
|
||||
"title": "Seçenekleri İğnele"
|
||||
},
|
||||
"nodesHotkeys": "Çizgeler",
|
||||
"quickToggleMove": {
|
||||
"desc": "Geçici olarak Kayma Aracına geçer",
|
||||
"title": "Geçici Kayma"
|
||||
},
|
||||
"showHideBoundingBox": {
|
||||
"title": "Sınırlayıcı Kutuyu Gizle/Göster",
|
||||
"desc": "Sınırlayıcı kutunun görünürlüğünü değiştir"
|
||||
},
|
||||
"showInfo": {
|
||||
"desc": "Seçili görselin üstverisini göster",
|
||||
"title": "Bilgileri Göster"
|
||||
},
|
||||
"nextStagingImage": {
|
||||
"desc": "Sonraki Görsel Parçayı Göster",
|
||||
"title": "Sonraki Görsel Parça"
|
||||
},
|
||||
"acceptStagingImage": {
|
||||
"desc": "Geçiçi Görsel Parçasını Onayla",
|
||||
"title": "Geçiçi Görsel Parçasını Onayla"
|
||||
},
|
||||
"changeTabs": {
|
||||
"desc": "Çalışma alanını değiştir",
|
||||
"title": "Sekmeyi değiştir"
|
||||
},
|
||||
"closePanels": {
|
||||
"title": "Panelleri Kapat",
|
||||
"desc": "Açık panelleri kapat"
|
||||
},
|
||||
"decreaseBrushOpacity": {
|
||||
"title": "Fırça Saydamlığını Artır",
|
||||
"desc": "Tuval fırçasının saydamlığını artırır"
|
||||
},
|
||||
"clearMask": {
|
||||
"title": "Maskeyi Sil",
|
||||
"desc": "Tüm maskeyi sil"
|
||||
},
|
||||
"decreaseGalleryThumbSize": {
|
||||
"desc": "Galerideki küçük görsel boyutunu düşürür",
|
||||
"title": "Küçük Görsel Boyutunu Düşür"
|
||||
},
|
||||
"deleteImage": {
|
||||
"desc": "Seçili görseli sil",
|
||||
"title": "Görseli Sil"
|
||||
},
|
||||
"invoke": {
|
||||
"desc": "Görsel Oluştur",
|
||||
"title": "Invoke"
|
||||
},
|
||||
"increaseGalleryThumbSize": {
|
||||
"title": "Küçük Görsel Boyutunu Artır",
|
||||
"desc": "Galerideki küçük görsel boyutunu artırır"
|
||||
},
|
||||
"setParameters": {
|
||||
"title": "Değişkenleri Kullan",
|
||||
"desc": "Seçili görselin tüm değişkenlerini kullan"
|
||||
},
|
||||
"setPrompt": {
|
||||
"desc": "Seçili görselin istemini kullan",
|
||||
"title": "İstemi Kullan"
|
||||
},
|
||||
"toggleLayer": {
|
||||
"desc": "Maske/Taban katmanları arasında geçiş yapar",
|
||||
"title": "Katmanı Gizle-Göster"
|
||||
},
|
||||
"setSeed": {
|
||||
"title": "Tohumu Kullan",
|
||||
"desc": "Seçili görselin tohumunu kullan"
|
||||
},
|
||||
"appHotkeys": "Uygulama",
|
||||
"cancel": {
|
||||
"desc": "Geçerli İşi Sil",
|
||||
"title": "Vazgeç"
|
||||
},
|
||||
"sendToImageToImage": {
|
||||
"title": "Görselden Görsel'e Gönder",
|
||||
"desc": "Seçili görseli Görselden Görsel'e gönder"
|
||||
},
|
||||
"fillBoundingBox": {
|
||||
"title": "Sınırlayıcı Kutuyu Doldur",
|
||||
"desc": "Sınırlayıcı kutuyu fırçadaki renkle doldurur"
|
||||
},
|
||||
"moveTool": {
|
||||
"desc": "Tuvalde kaymayı sağlar",
|
||||
"title": "Kayma Aracı"
|
||||
},
|
||||
"redoStroke": {
|
||||
"desc": "Fırça vuruşunu yinele",
|
||||
"title": "Vuruşu Yinele"
|
||||
},
|
||||
"increaseBrushOpacity": {
|
||||
"title": "Fırçanın Saydamlığını Düşür",
|
||||
"desc": "Tuval fırçasının saydamlığını düşürür"
|
||||
},
|
||||
"selectEraser": {
|
||||
"desc": "Tuval silgisini kullan",
|
||||
"title": "Silgiyi Kullan"
|
||||
},
|
||||
"toggleOptions": {
|
||||
"desc": "Seçenekler panelini aç-kapat",
|
||||
"title": "Seçenekleri Aç-Kapat"
|
||||
},
|
||||
"copyToClipboard": {
|
||||
"desc": "Tuval içeriğini kopyala",
|
||||
"title": "Kopyala"
|
||||
},
|
||||
"galleryHotkeys": "Galeri",
|
||||
"generalHotkeys": "Genel",
|
||||
"mergeVisible": {
|
||||
"desc": "Tuvalin görünür tüm katmanlarını birleştir",
|
||||
"title": "Katmanları Birleştir"
|
||||
},
|
||||
"toggleGallery": {
|
||||
"title": "Galeriyi Aç-Kapat",
|
||||
"desc": "Galeri panelini aç-kapat"
|
||||
},
|
||||
"downloadImage": {
|
||||
"title": "Görseli İndir",
|
||||
"desc": "Tuval içeriğini indir"
|
||||
},
|
||||
"previousStagingImage": {
|
||||
"title": "Önceki Görsel Parça",
|
||||
"desc": "Önceki Görsel Parçayı Göster"
|
||||
},
|
||||
"increaseBrushSize": {
|
||||
"title": "Fırça Boyutunu Artır",
|
||||
"desc": "Tuval fırçasının/silgisinin boyutunu artırır"
|
||||
},
|
||||
"previousImage": {
|
||||
"desc": "Galerideki önceki görseli göster",
|
||||
"title": "Önceki Görsel"
|
||||
},
|
||||
"toggleOptionsAndGallery": {
|
||||
"title": "Seçenekleri ve Galeriyi Aç-Kapat",
|
||||
"desc": "Seçenekler ve galeri panellerini aç-kapat"
|
||||
},
|
||||
"toggleSnap": {
|
||||
"desc": "Kılavuza Uydur",
|
||||
"title": "Kılavuza Uydur"
|
||||
},
|
||||
"resetView": {
|
||||
"desc": "Tuval Görüşünü Resetle",
|
||||
"title": "Görüşü Resetle"
|
||||
},
|
||||
"cancelAndClear": {
|
||||
"desc": "Geçerli işi geri çek ve sıradaki tüm işleri sil",
|
||||
"title": "Vazgeç ve Sil"
|
||||
},
|
||||
"decreaseBrushSize": {
|
||||
"title": "Fırça Boyutunu Düşür",
|
||||
"desc": "Tuval fırçasının/silgisinin boyutunu düşürür"
|
||||
},
|
||||
"resetOptionsAndGallery": {
|
||||
"desc": "Seçenekler ve galeri panellerini resetler",
|
||||
"title": "Seçenekleri ve Galeriyi Resetle"
|
||||
},
|
||||
"remixImage": {
|
||||
"desc": "Seçili görselin tohumu hariç tüm değişkenlerini kullan",
|
||||
"title": "Benzerini Türet"
|
||||
},
|
||||
"undoStroke": {
|
||||
"title": "Vuruşu Geri Al",
|
||||
"desc": "Fırça vuruşunu geri al"
|
||||
},
|
||||
"saveToGallery": {
|
||||
"title": "Galeriye Gönder",
|
||||
"desc": "Tuval içeriğini galeriye gönder"
|
||||
},
|
||||
"unifiedCanvasHotkeys": "Tuval",
|
||||
"addNodes": {
|
||||
"desc": "Çizge ekleme menüsünü açar",
|
||||
"title": "Çizge Ekle"
|
||||
},
|
||||
"eraseBoundingBox": {
|
||||
"desc": "Sınırlayıcı kutunun içini boşaltır",
|
||||
"title": "Sınırlayıcı Kutuyu Boşalt"
|
||||
},
|
||||
"selectBrush": {
|
||||
"desc": "Tuval fırçasını kullan",
|
||||
"title": "Fırçayı Kullan"
|
||||
},
|
||||
"restoreFaces": {
|
||||
"title": "Yüzleri Onar",
|
||||
"desc": "Geçerli görseli onar"
|
||||
}
|
||||
},
|
||||
"unifiedCanvas": {
|
||||
"accept": "Onayla",
|
||||
"clearCanvasHistoryMessage": "Tuval geçmişini silmek tuvale dokunmaz, ancak yineleme ve geri alma geçmişini geri dönülemez bir biçimde siler."
|
||||
"clearSearch": "Aramayı Sil"
|
||||
},
|
||||
"nodes": {
|
||||
"unableToValidateWorkflow": "İş Akışı Doğrulanamadı",
|
||||
@@ -596,15 +290,9 @@
|
||||
"workflowSaved": "İş Akışı Kaydedildi"
|
||||
},
|
||||
"toast": {
|
||||
"problemDownloadingCanvasDesc": "Taban katman indirilemedi",
|
||||
"problemSavingMaskDesc": "Maske kaydedilemedi",
|
||||
"problemSavingCanvasDesc": "Taban katman kaydedilemedi",
|
||||
"problemRetrievingWorkflow": "İş Akışını Getirmede Sorun",
|
||||
"workflowDeleted": "İş Akışı Silindi",
|
||||
"loadedWithWarnings": "İş Akışı Yüklendi Ancak Uyarılar Var",
|
||||
"problemImportingMaskDesc": "Maske aktarılamadı",
|
||||
"problemMergingCanvasDesc": "Taban katman aktarılamadı",
|
||||
"problemCopyingCanvasDesc": "Taban katman aktarılamadı",
|
||||
"workflowLoaded": "İş Akışı Yüklendi",
|
||||
"problemDeletingWorkflow": "İş Akışını Silmede Sorun"
|
||||
},
|
||||
@@ -612,7 +300,6 @@
|
||||
"invoke": {
|
||||
"noPrompts": "İstem oluşturulmadı",
|
||||
"noModelSelected": "Model seçilmedi",
|
||||
"incompatibleBaseModelForControlAdapter": "{{number}}. yönetim aracı, ana model ile uyumlu değil.",
|
||||
"systemDisconnected": "Sistem bağlantısı kesildi",
|
||||
"invoke": "Invoke"
|
||||
},
|
||||
@@ -642,8 +329,6 @@
|
||||
"noiseThreshold": "Gürültü Eşiği",
|
||||
"seed": "Tohum",
|
||||
"imageActions": "Görsel İşlemleri",
|
||||
"sendToImg2Img": "Görselden Görsele Aktar",
|
||||
"sendToUnifiedCanvas": "Tuvale Aktar",
|
||||
"showOptionsPanel": "Yan Paneli Göster (O ya da T)",
|
||||
"shuffle": "Kar",
|
||||
"usePrompt": "İstemi Kullan",
|
||||
@@ -680,9 +365,7 @@
|
||||
"vaePrecision": "VAE Kesinliği",
|
||||
"convertToDiffusersHelpText6": "Bu modeli dönüştürmek istiyor musunuz?",
|
||||
"deleteMsg1": "Bu modeli InvokeAI'dan silmek istediğinize emin misiniz?",
|
||||
"modelSyncFailed": "Modeller Senkronize Edilemedi",
|
||||
"settings": "Seçenekler",
|
||||
"v2_768": "v2 (768pks)",
|
||||
"vae": "VAE",
|
||||
"width": "En",
|
||||
"delete": "Sil",
|
||||
@@ -705,22 +388,15 @@
|
||||
"deleteMsg2": "Model InvokeAI ana klasöründeyse bilgisayarınızdan silinir, bu klasör dışındaysa bilgisayarınızdan silinmeyecektir.",
|
||||
"load": "Yükle",
|
||||
"modelDeleteFailed": "Model kaldırılamadı",
|
||||
"modelsSynced": "Modeller Senkronize Edildi",
|
||||
"noModelSelected": "Model Seçilmedi",
|
||||
"predictionType": "Saptama Türü",
|
||||
"selectModel": "Model Seç",
|
||||
"v2_base": "v2 (512pks)",
|
||||
"modelConversionFailed": "Model Dönüşümü Başarısız",
|
||||
"modelConverted": "Model Dönüştürüldü",
|
||||
"description": "Tanım"
|
||||
},
|
||||
"dynamicPrompts": {
|
||||
"promptsWithCount_one": "{{count}} İstem",
|
||||
"promptsWithCount_other": "{{count}} İstem"
|
||||
},
|
||||
"models": {
|
||||
"addLora": "LoRA Ekle",
|
||||
"esrganModel": "ESRGAN Modeli",
|
||||
"defaultVAE": "Varsayılan VAE",
|
||||
"lora": "LoRA",
|
||||
"noModelsAvailable": "Model yok",
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user